Authors: Aidan Clark$^*$, Diego de las Casas$^*$, Aurelia Guy$^*$, Arthur Mensch$^*$
Michela Paganini, Jordan Hoffmann, Bogdan Damoc, Blake Hechtman$^‡$, Trevor Cai, Sebastian Borgeaud, George van den Driessche, Eliza Rutherford, Tom Hennigan, Matthew Johnson$^‡$, Katie Millican, Albin Cassirer, Chris Jones, Elena Buchatskaya, David Budden, Laurent Sifre, Simon Osindero, Oriol Vinyals, Jack Rae, Erich Elsen, Koray Kavukcuoglu, Karen Simonyan
DeepMind
Google Research$^‡$
$^*$Shared first authorship.
Correspondence to [email protected], [email protected]. All affiliation to DeepMind unless noted.
Abstract
Section Summary: Researchers have found that the performance of language models improves predictably with their size, following a power-law pattern based on the number of parameters they use. This study examines "Routing Networks," which are advanced AI architectures that activate only a portion of their parameters depending on the input, treating both total parameters and computational demands as separate factors that boost performance. By deriving new scaling laws that extend known patterns, the researchers analyze various routing designs trained in three ways, and apply these laws to create an "Effective Parameter Count" for fair comparisons and to quantitatively evaluate the training techniques, based on tests across models ranging from small to hundreds of billions of parameters.
The performance of a language model has been shown to be effectively modeled as a power-law in its parameter count. Here we study the scaling behaviors of Routing Networks: architectures that conditionally use only a subset of their parameters while processing an input. For these models, parameter count and computational requirement form two independent axes along which an increase leads to better performance. In this work we derive and justify scaling laws defined on these two variables which generalize those known for standard language models and describe the performance of a wide range of routing architectures trained via three different techniques. Afterwards we provide two applications of these laws: first deriving an Effective Parameter Count along which all models scale at the same rate, and then using the scaling coefficients to give a quantitative comparison of the three routing techniques considered. Our analysis derives from an extensive evaluation of Routing Networks across five orders of magnitude of size, including models with hundreds of experts and hundreds of billions of parameters.
Executive Summary: ### Scaling Behaviors of Routing Networks for Language Models
In the quest to build more powerful AI language models, a key challenge is balancing performance gains from larger models against skyrocketing computational demands. Traditional neural networks scale parameters and compute together, driving up training and inference costs as models grow to billions of parameters. Routing Networks address this by dynamically selecting only a subset of parameters for each input, decoupling total capacity from per-input compute needs. This matters now as organizations push toward trillion-parameter models amid rising energy and hardware constraints, seeking ways to achieve better results without proportional resource hikes.
This document evaluates how Routing Networks—transformer-based language models that route inputs to specialized "expert" subnetworks—perform when scaled along two axes: dense model size (parameters active per input) and expert count (total specialized subnetworks). It derives predictive scaling laws to forecast performance and compares three training techniques for these networks.
Researchers trained 168 models, ranging from 15 million to 1.3 billion dense parameters and 2 to 512 experts, on a vast English text dataset of trillions of tokens. All models saw a fixed 130 billion tokens during training to isolate scaling effects, using standard optimization on specialized hardware. They measured performance via validation loss (a metric of prediction accuracy on held-out text) and focused on decoder-only transformers, a top architecture for language tasks. Key assumptions included treating the dataset as effectively infinite (no overfitting observed) and evaluating at training end, approximating convergence.
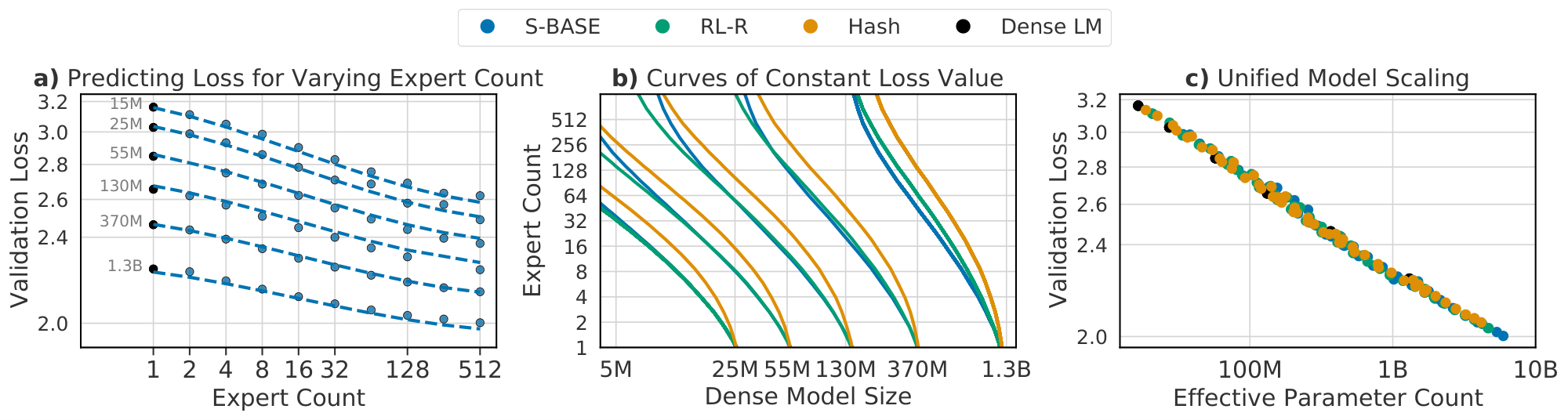
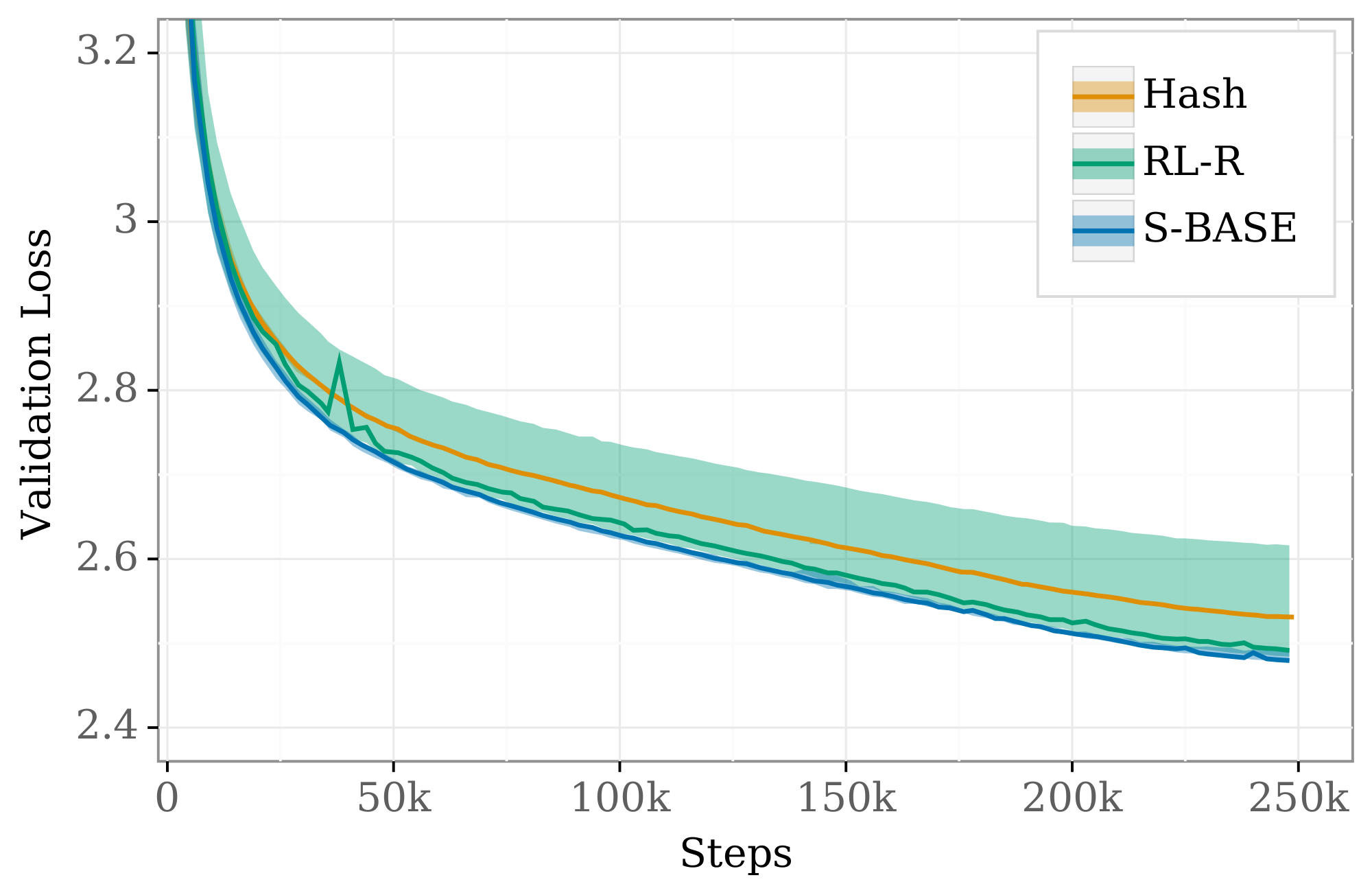
The analysis reveals four core findings. First, routing consistently boosts performance: for instance, a 5-million-parameter model with 128 experts matches the loss of a 55-million-parameter dense model, achieving similar accuracy with far less active compute per input. Second, performance follows a bilinear power-law scaling in dense size N and a saturated transformation of expert count E, generalizing prior laws for dense models; loss drops roughly as N^{-0.08} and E^{-0.1} at small scales, with interaction making expert gains diminish logarithmically (about 40-50% less benefit per doubling of N). Third, the three techniques—Sinkhorn-based sparse mixtures of experts (s-base), reinforcement learning routing (RL-R), and deterministic hash routing—obey the same laws, but s-base outperforms by 5-10% in loss reduction across sizes, followed closely by RL-R, then hash. Fourth, an "effective parameter count" metric equates routed and dense models, predicting all scale identically along this unified axis, while benefits cap at a "cutoff" dense size of 80-900 billion parameters per method, beyond which routing adds no edge.
These results imply routing enhances efficiency for current model scales, enabling 10-20x more capacity without extra inference compute, which cuts costs and emissions while sustaining performance. Unlike prior work assuming constant scaling, the diminishing expert returns highlight routing's role as a temporary accelerator, not a replacement for broader scaling in N or data. For policy and deployment, it reduces risks of compute bottlenecks in safety-critical AI, though downstream tasks like question answering show varying gains (e.g., 10-30% better on some, neutral on others), urging task-specific tuning. Overall, routing aligns with dense models in predictability but shines in resource-constrained settings.
Leaders should adopt routing for models up to 1.3 billion parameters, starting with s-base and 64-128 experts for optimal balance of gains and stability; RL-R suits smaller scales but risks instability, while hash is simplest yet least effective. Use one expert per input (K=1) and route every other layer for efficiency. Next, conduct pilots on larger dense sizes (toward 10 billion) and more experts (up to 1,000) to pinpoint cutoffs and refine laws, especially under varied token counts. Develop techniques lowering the interaction coefficient (c ≈ 0.01 here) to extend benefits, and validate innovations across multiple sizes before scaling.
While fits are precise (errors under 0.006 in log scale), limitations include fixed training tokens precluding full convergence and focus on English text, potentially overestimating gains for multilingual or specialized data. Confidence is high for scales studied, but extrapolate cautiously to trillion-parameter regimes or non-language tasks, where untested factors like expert interference could weaken predictions.
1. Introduction
Section Summary: Many people believe that making neural networks larger improves their performance, especially on real-world data, and recent studies confirm this through scaling laws where bigger models reduce errors predictably. Routing Networks offer a twist by letting each input use only a small, selected portion of the model's parameters, decoupling the total size from the effort needed per input and complicating traditional scaling ideas. This paper examines three ways to build these networks with models up to 200 billion parameters, finding that routing boosts performance across sizes, follows new scaling laws based on experts and compute, and allows an "effective parameter count" to compare them to standard dense models.
It is a commonly held belief that increasing the size of a neural network leads to better performance, especially when training on large and diverse real-world datasets. This vague and debated notion has become increasingly justified as large empirical studies have shown that the performance of models on many interesting classes of problems are well understood as power-laws; where a multiplicative increase in model size leads to an additive reduction in the model's loss ([1, 2, 3, 4]). These relationships are not well understood, but a key implication is that a sequence of small[^1] models can be used both to infer the performance of models many times more powerful, but also to provide global information about the scalability of an architecture.
[^1]: Measured as training or inference floating point operations, devices or time required, financial cost, carbon emissions, etc.
Enter Routing Networks: models with the unusual property that each input interacts with only a subset of the network's parameters — chosen independently for each datapoint ([5, 6, 7]). For a Routing Network, the number of parameters is nearly independent from the computational cost of processing a datapoint. This bifurcates the definition of size and prevents a scaling law in parameters alone from fully describing the model class. Specific Routing Networks have been trained successfully at large scales ([8, 9, 10]), but the general scaling behavior is not well understood. In this work we analyze the behavior of routed language models so that we might infer the scaling laws that describe their performance.
Key contributions.
We analyze three different techniques for training Routing Networks, detailed in Section 3: Sinkhorn- $\textsc{base}$ , a sparse mixture-of-experts ($\textsc{smoe}$ ) approach modifying $\textsc{base}$ ([11]); non-parametric $\textsc{hash}$ Layers ([12]); and routing via Reinforcement Learning ($\textsc{rl-r}$ ). With models up to 200 billion parameters, we observe the following:
- Routing improves the performance of language models across all sizes and variants attempted (see Figure 1).
- Training a Routing Network with RL (Section 3.3), a technique used in early routing work ([6]), is of comparable effectiveness to state-of-the-art techniques.
- The performance of all Routing Networks is accurately described by scaling laws in the number of experts and in the underlying dense model size (Section 4) which generalize those from [1].
- These laws can be restated in terms of parameter count and inference compute, capturing an even wider set of routing architectures under a shared fit (Section 4.4).
- They further imply an Effective Parameter Count: a mapping equating the performance and scaling for both dense and routed networks (Section 5).
2. Background
Section Summary: Language modeling involves training neural networks to predict the next word in a sequence of text, with performance improving predictably as models grow larger, following power-law scaling based on the number of parameters, when trained on massive datasets. To make bigger models without proportionally increasing training costs, routing networks use a technique called sparse mixtures of experts, where a router dynamically selects a subset of the model's parameters—called experts—for each input, activating only what's needed. These are applied to Transformer architectures by routing specific layers, keeping the total active parameters similar to standard models while allowing for more overall parameters to boost performance.
We first review the language modelling problem and existing scaling laws before discussing the process of routing a neural network and how it is applied to language models.
Language modelling.
We consider the problem of autoregressively predicting natural language, a task with consistent and predictable scaling characteristics across many orders of magnitude ([3, 1]). The objective is to maximize the likelihood of a sequence of tokens $P(x_1, \dotsc, x_T)$ factored auto-regressively as $p \left (x_1, \dotsc, x_T \right) = \prod_i^T p \left (x_i | x_{j < i} \right)$. Our primary metric of performance is the negative log-likelihood of a validation dataset whose statistics match the training distribution. We focus on this validation loss, but briefly consider zero-shot transfer to other tasks in Appendix E.
Scaling laws for large-scale data.
We train on a multi-trillion-token compendium of English language text comprising documents from the internet alongside open-source text datasets, details of which are given in [13]. In this setting [1] argue that the converged performance of a model trained on a dataset of infinite size is a power-law in the model's parameter count $N$. Our dataset is not infinite, but its size – and the lack of any observed overfitting – make this a reasonable approximation. We consider the final (and best) evaluation value as the converged value, though this is also an approximation which is discussed further in Appendix F.
2.1 Routing Networks
Power-law scaling implies the performance of a language model increases with size, but so too does the compute needed to train the model. This undesirable connection between size and computation motivates a search for architectures wherein the two are disentangled. Routing Networks are one such class of model: a type of neural network that incorporates a specific flavor of conditional computation. In a Routing Network, each input (e.g., a token of text) is transformed into an output while only interacting with a fixed subset of the network's parameters – dynamically selected based on the input itself. Many sparsely-activated networks have this property, but here we exclusively study the layout based on Sparse Mixtures of Experts ([14]) where multiple sub-components of a deep neural network (i.e., several layers) are independently converted to routed equivalents and jointly trained with the rest of the network.
Routing a single layer.
The core idea of a routed layer is that multiple versions of the parameters are kept, and a per-input decision on which version to use is made. To route a layer $f_\theta$ in $E$ ways, we start by creating $E$ separate versions of the parameters $\theta$ (${\theta_1, ... \theta_E}$) where $f$ using the $i$-th version of the parameters ($f_i\triangleq f_{\theta_i}$) is termed the i-th Expert. To determine which expert to pick given the input, we introduce an additional router function $\rho: \mathbb{R}^M \to \left[1, E\right]$ associated to the layer, typically a small network itself, with parameters $\varphi$. The routed form $h$ of $f$ is then given by $h(x) \triangleq f_{\rho(x)}(x)$. When performance increases with $E$, routing gives a method by which to improve a neural network with minimal computational increase (corresponding only to the compute needed by $\rho(x)$).
We also consider the $K$-way routed generalization, where the router outputs a set of integers as $\rho(\cdot): \mathbb{R}^M \to \left[1, E\right]^K$, and we set the output of the layer to be the sum of the outputs of each expert, namely $h(x) \triangleq \sum_{i \in \rho(x)} f_i(x)$. We default to $K=1$, but revisit this in Section 4.4.
Routed Transformers
We apply routing to a decoder-only Transformer ([15]) to measure the scaling properties that result: an architecture chosen due to its state-of-the-art performance. Details of the baseline architecture we use are in Appendix A. We will refer to non-routed Transformers as dense models, in opposition to Routed Transformers which sparsely activate some of their parameters. Our conversion to a Routed Transformer is the same as is used in prior work ([16, 8]). Namely, we apply routing to every other set of feedforward components (FFWs) of the Transformer, sub-components that act on each timestep independently. Though different layers can have different numbers of experts, here all routed layers share the same number of experts $E$, and we will refer to the network as being routed $E$ ways.
Model size and inference cost.
We use $N$ to indicate a network's dense model size: the number of parameters any one input interacts with. This is in opposition to $P$: the total number of parameters. For a dense model, $P = N$, whereas for a Routing Network $P$ is roughly proportional to $N\cdot E$, with factors that depend on details of the routing architecture (Section 4.4). Except for a small overhead due to running the routers, the cost $F$ (in TeraFLOPs) of executing a Routed Transformer is the same as its dense equivalent.
Training Details.
All models are trained on TPUs with JAX ([17]) using a combination of data, expert (see Appendix C) and sharding parallelism ([18]). Models were trained with a sequence length of $2048$ and batch size of $256$ for 250, 000 steps, i.e. 130 billion tokens, regardless of $N$. This is an important detail, and we discuss some of the implications in Appendix F. All were optimized with AdamW ([19]) and ZeRO Stage 1 was used to shard the optimizer state ([20]). Appendix A contains further details.
3. Routing Techniques
Section Summary: Routing networks separate a model's computational power from its overall cost, but training the router that directs inputs to different experts is tricky because its decisions aren't easily adjustable through standard learning methods. Researchers have developed three main approaches to overcome this: sparse mixture-of-experts weighting, which multiplies expert outputs by selection probabilities to enable gradient-based learning and includes balancing tricks for even expert use; hash-based routing, which picks experts using a simple fixed hash of the input without extra parameters; and reinforcement learning, which treats routing as a decision-making policy optimized to improve predictions, though it requires handling high variability in updates. Surprisingly, these diverse techniques all follow similar patterns in how their performance scales with model size.
If the benefit of Routing Networks is the decoupling of parameter capacity from network cost, the fundamental difficulty is in effectively learning the parameters $\varphi$ of the router given the non-differentiability of its output. Much research in Routing Networks has therefore focused on techniques for learning $\varphi$. A major finding of this work is that three notably different techniques of training Routing Networks are effectively described by the same scaling laws. We now introduce and contextualize these three methods.
3.1 Sparse Mixture-of-Experts via Weighting
Sparse Mixture-of-Experts ($\textsc{smoe}$ ) methods ([14]) solve the problem of non-differentiability by reusing the probability of expert selection as a scalar multiplier on that expert's output, guaranteeing a gradient passed to the logits of selected experts despite the the non-differentiability of sampling from those logits. Formally, the router is given as $\rho(x) = \operatorname{topk}(Wx + b)$, where $Wx + b$ is an unnormalized distribution over $\left[1, E\right]$ from which the experts corresponding to the top $K$ values are selected. In the final output of the routed layer, the normalized logits are reused as gating weights, i.e. the final output of the routed layer is $h(x) = \sum_{i \in \rho(x)} g_i(x) f_i(x)$ where $g(x) = \operatorname{softmax}(Wx + b)$.
Though this formulation supplies a gradient to $\varphi = (W, b)$, it represents changes to the scalar multiplier and does not directly correspond to optimizing expert selection. This method is nevertheless effective, and can be seen as a sparse approximation to dense mixture of experts models ([21, 22]) where the likelihood of skipping an expert is inversely proportional to the value of its scalar gate $g_i$.
It was conjectured that $\textsc{smoe}$ s require $(K \geqslant 2)$-way routing to produce effective gradients in the routers ([14]), and many attempts at incorporating routing into large Transformers use $K = 2$ ([16, 9]). However recently this has been challenged, and stable modifications have been proposed for $K = 1$; namely the Switch Transformer ([8]). Most $\textsc{smoe}$ s, including Switch, are reliant on auxiliary balancing losses which encourage the router output $\rho(x)$ to be more uniform across minibatches of inputs. To improve on this, $\textsc{base}$ ([11]) post-processes the router output with a Hungarian Matching algorithm that re-assigns expert selections to ensure that all experts are selected evenly.
Our implementation of $\textsc{base}$ replaces the Hungarian Matching with a regularized Optimal Transport formulation ([23]) using the Sinkhorn algorithm as an approximate matching step during expert selection. This substantially improves routing efficiency on accelerated hardware (details in Appendix B.2.1). We call the resulting method Sinkhorn- $\textsc{base}$ ($\textsc{s-base}$ ), and use it as the representative of $\textsc{smoe}$ methods, as early tests showed the benefit of its balancing mechanism.
3.2 Input-based Deterministic Hash Routing
An alternative approach eschews extra parameters completely and represents $\rho$ as a fixed function of the input. This is the concept pioneered by $\textsc{hash}$ Layers ([12]) which circumvents the need to simultaneously learn $\varphi$ and $\theta$. Our implementation takes the token ID assigned to the input by the SentencePiece tokenizer ([24]) and uses the remainder of it divided by $E$ as the expert selection. See Appendix B.4 for details.
3.3 Routing via Reinforcement Learning
Finally, we re-analyze a technique that optimizes the router via Reinforcement Learning (a class of methods we call $\textsc{rl-r}$ ), which was proposed in early work on neural conditional computation ([6, 5, 25, 7]). In this approach each router is seen as a policy whose actions are the selection of an expert in each routed layer and whose observations are the activations passed to that router. After completing the forward pass, the probability the Routed Transformer assigns to the correct output token can be used as a reward, maximization of which is equivalent to minimization of NLL. To jointly train the experts and the router, we minimize a composite loss formed with the language modelling loss and a policy-gradient term ([26]) using the selected set of experts as actions. We highlight that the optimal expert selection is dependent not only on the input activations but on the parameters of the rest of the network. This disrupts the theoretical underpinning, crucial to RL, that this is a Markov Decision Process. Nevertheless, it has been observed that this theoretical issue does not affect the practicality of the method ([27]).
Relative to $\textsc{smoe}$ , $\textsc{rl-r}$ benefits from directly optimizing actions to improve the language modelling loss. However this absence of bias comes with complications, especially the high variance of the gradient ([27, 7]). We use $\textsc{reinforce}$ with a learned baseline ([28, 29]) to address this issue, so that improving the policy means increasing the likelihood of selecting experts which lead to a better than average next token prediction. As with $\textsc{smoe}$ , we find it useful to add a balancing term. To our knowledge, we are the first to experiment routing with Reinforcement Learning on large Transformer-based language models—we therefore explore key ablations in Appendix B.3.
4. Scaling Behavior at Convergence
Section Summary: Researchers propose that the final error rate in their routing-based AI models follows a predictable pattern based on model size and the number of specialized "experts," described by a mathematical formula that combines these factors in a balanced, interactive way, with adjustments for when adding more experts yields diminishing returns. They tested this on 168 different models using three routing techniques, finding that the formula fits the data well and shows that increasing experts generally improves performance, though the benefits lessen in larger models. Their analysis starts with simple independent scaling rules and builds to more complex ones, confirming that a combined interactive model with saturation effects provides the best predictions, as evidenced by low error rates in comparisons to basic approaches.
Our main hypothesis is that the converged log-loss of a Routing Network is bilinear in the terms $\log N$ and $\log \widehat{E}$, where $\hat E$ is a saturating transformation of $E$. Specifically, we fit the 6-parameter scaling law:
$ \begin{align} &!!!\log L (N, E) \triangleq a \log N {+} b \log \widehat{E} {+} c \log N \log \widehat{E} {+} d \ &\text{where}\quad \frac{1}{\widehat{E}} \triangleq \frac{1}{E - 1 + \left(\frac{1}{E_\text{start}} - \frac{1}{E_{\max}}\right)^{-1}} + \frac{1}{E_{\max}}.\notag \end{align}\tag{1} $
We can generalize this law across a wider range of routing architectures by a change of variables, using the model inference cost $F$ and the total number of parameters $P$, as:
$ \begin{align} \log L (F, B) \triangleq a \log F {+} b \log \widehat{B} {+} c \log F \log \widehat{B} {+} d, \end{align}\tag{2} $
\begin{tabular}{ c c | c c c}
\toprule
$L$ log-log prediction & Eq. & \textsc{s-base} & \mbox{\textsc{rl-r}} & \textsc{hash} \\
\midrule
Separably linear in $N$, $E$ & Equation 5 & 80e-4 & 90e-4 & 90e-4 \\
Bilinear in $(N, E)$ & Equation 7 & 60e-4 & 57e-4 & 60e-4 \\
Bilin. + saturat. in $(N, E)$ & Equation 1 & 58e-4 & 56e-4 & 56e-4 \\
\midrule
Per- $N$ fits in $(E)$ & Equation 4 & \textbf{46e-4} & \textbf{29e-4} & \textbf{19e-4} \\
\bottomrule
\end{tabular}
\begin{tabular}{ c | c c}
& $\alpha_N$ & $N_c$ \\
\midrule
\textbf{Ours} & $0.078$ & $3.568e13$ \\
\textbf{[1]} & $0.076$ & $8.8e13$ \\
\bottomrule
\end{tabular}
where $B \triangleq \frac{P}{F}$ and $B \to \hat B$ is the same saturating transform as $E \to \hat E$. Before justifying Equation 1, we validate its candidacy by fitting it to empirical data obtained on a large sweep of models. This sweep consists of a Routing Network trained for each of the three techniques described in Section 3: across six model sizes (described in Table 4) while varying $E$ across $[2, 4, 8, 16, 32, 64, 128, 256, 512]$. This totals 168 different models, including dense baselines.
The observed losses for each model are shown in Figure 2(a-c). We fit Equation 1 to each routing method and plot predictions for fixed values of $N$ as dotted lines. The goodness-of-fit across all methods is apparent, as is the clear behavior that increasing $E$ leads to a reduction in validation loss. Figure 2(d) plots the relative predictions for all three techniques, clearly showing that $\textsc{s-base}$ performs best across all model sizes, followed by $\textsc{rl-r}$ , followed by $\textsc{hash}$ (see Section 5.3). The remainder of this section justifies the chosen functional forms Equation 1 and 2; first supposing independent power laws in $N$ and $E$ (Section 4.1), then introducing a multiplicative interaction (Section 4.2) and saturation in the second term (Section 4.3), followed by a change of variables (Section 4.4). The benefit gained by this progression of fits can be seen in Table 1. Notations are recalled in Figure 3.
4.1 Separable Scaling Laws in Model Size and Experts
[1] argue that the converged performance of a dense model with $N$ parameters can be modelled accurately as the two-parameter power law
$ \log L(N) \triangleq a \log N + d, \quad\text{i.e.}\quad L(N) = {\left(\frac{N_c}{N}\right)}^{\alpha_N}\tag{3} $
where $\alpha_N \triangleq -a$ and $N_c \triangleq 10^{d/-a}$. We can re-estimate these coefficients from the performance of our own dense models, leading to estimations in Table 2. The similarity of $\alpha_N$ is a reassuring sanity check (there are differences in dataset, vocabulary, tokenization and model which effect $N_c$).
An immediate hypothesis is that for all values of $N$, scaling in $E$ obeys a similar power law:
$ \log L_N(E) \triangleq b \log E + d'\tag{4} $
Because $L_N(1) = L(N)$ (a fact we will call dense equivalence), Equation 3 and 4 can be combined into:
$ \log L_N(E) \triangleq a \log N + b \log E + d,\tag{5} $
corresponding to the multiplicative separated power law:
$ L_N(E) = \left(\frac{10^{d/a}}{N}\right)^{a} \left(\frac{1}{E} \right)^{b}\tag{6} $
If Equation 4 fits observed data for any $N$ we can proceed with an assumption that scaling in $E$ obeys a power-law for fixed $N$. Observing a constant $b$ across $N$ would allow to fit Equation 5 to models ranging across $N$ and $E$ simultaneously.
Fitting.
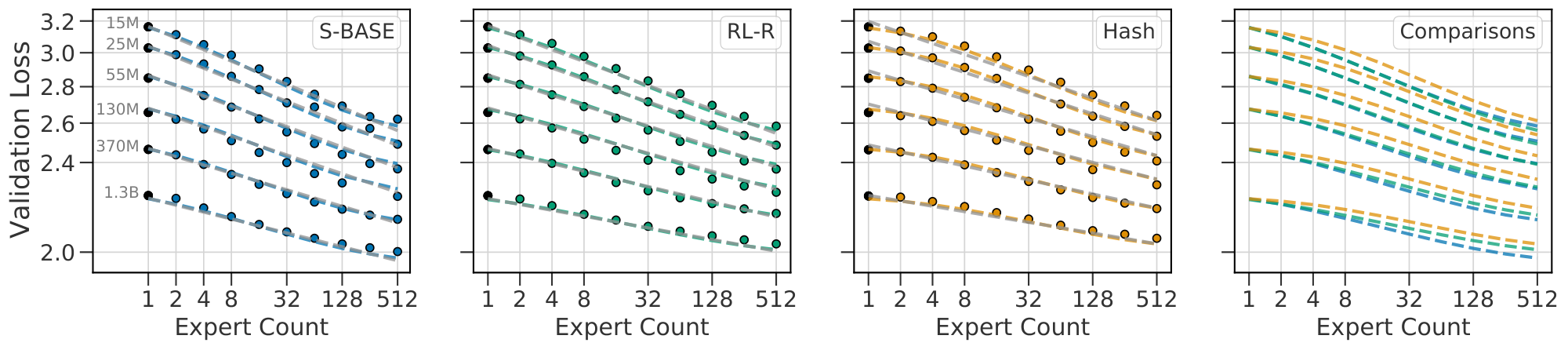
The first hypothesis is easily tested and confirmed to a reasonable degree. We fit Equation 4 for each technique and value of $N$ separately, plotted as colored lines in Figure 4. The values of $b$ are shown in Figure 3.

We observe that $b(N)$ is increasing with $N$ (values listed in Table 6), corresponding to a reduction in benefit from routing as size increases, with a slope that is approximately linear in $\log N$ (Figure 3). Equation 5 requires that $b$ remains fixed across $N$; therefore we expect it to poorly predict model performance. We can attempt a fit nevertheless: plotted in grey in Figure 4. Qualitatively, this mis-predicts some validation losses by over 0.2, particularly overestimating the performance at large $N$ and $E$. As reported in Table 1, the fit has held-out RMSLE values greater than 80e-4.
4.2 Quadratic Interaction in $N$ and $E$
This motivates us to introduce a simple extension: that of a multiplicative interaction between $\log N$ and $\log E$. This is conveniently the exact function which leads to $b$ scaling with $\log N$ and takes the following form:
$ \begin{gather} !!!\log L(N, E) {\triangleq} {+} a \log N {+} b \log E {+} c \log N \log E {+} d \end{gather}\tag{7} $
This function has the property that the log-log slope in both $N$ and $E$ are affine in the logarithm of the other variable. In other words, with $E$ or $N$ fixed, the performance $L$ scales with $N$ or $E$ following Equation 3 and 4 with slopes given by:
$ \begin{gather} a(E) \triangleq - \frac{\partial \log L}{\partial \log N} = a + c \log(E)\ b(N) \triangleq - \frac{\partial \log L}{\partial \log E} = b + c \log (N), \notag \end{gather}\tag{8} $
$b(N)$ matches the behavior reported in Table 6. A transposed table, fitting sets of models with fixed $E$ and changing $N$, can be found to match the behavior predicted by $a(E)$ (see Table 8). There are two symmetric non-logarithmic representations of Equation 7, useful for comparison to 6:
$ \begin{align} \stepcounter{equation} L(N, E) &= \left(\frac{10^{d/a}}{N}\right)^a\left(\frac{1}{E}\right)^{b + c \log (N)}\tag{\arabic{equation}a}\tag{a}, \ &= \left(\frac{10^{d/b}}{E}\right)^b\left(\frac{1}{N}\right)^{a + c\log(E)}.\tag{\arabic{equation}b}\tag{b} \end{align}\tag{9} $
::::
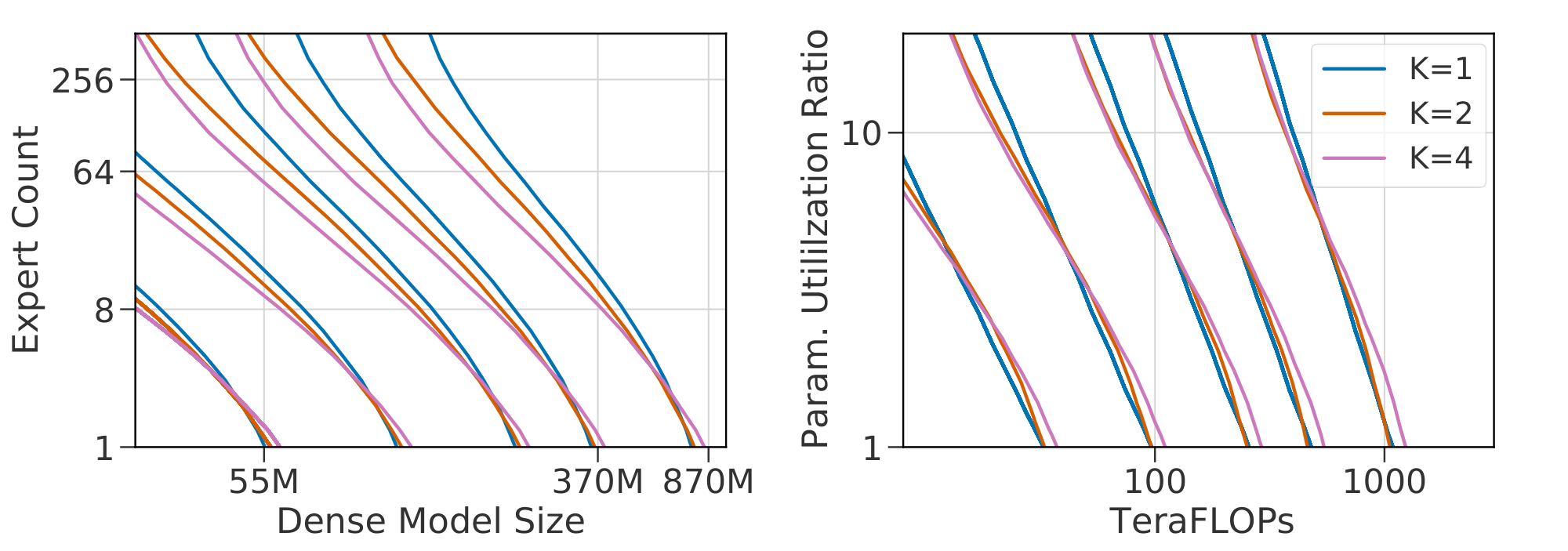
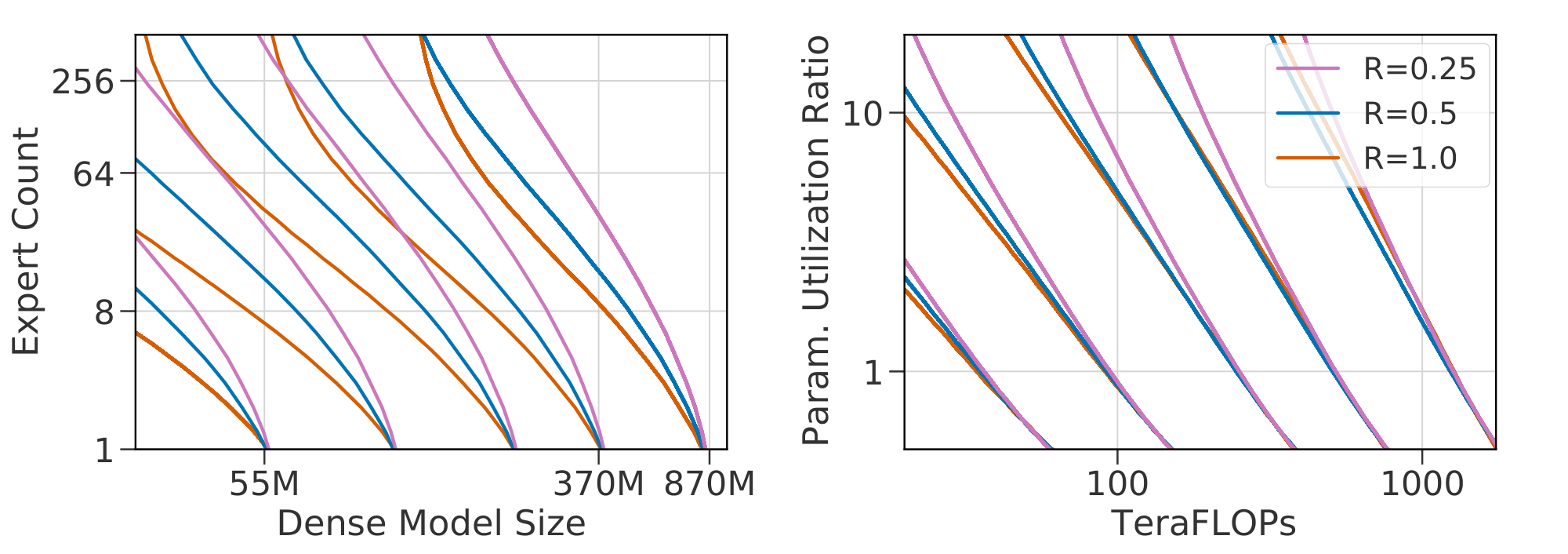
Figure 5: Level curves for Equation 1 and 2 on $\textsc{s-base}$ for $K \in {1, 2, 4}$ (left two), $R \in {1.0, 0.5, 0.25}$ (right two). Scaling laws in $(N, E)$ differ for models with different values of $(K, R)$: indicated by non-overlapping level-curves. A change of variables to $(F, P)$ leads to almost-overlapping functions: allowing the same fits to be reused across changes in the routing architecture. ::::
Fitting.
Fitting the bilinear Equation 7 instead of Equation 5 substantially reduces the prediction error for large $N$ (Table 1, Equation 5 vs Equation 7), as displayed in Figure 4 (dotted lines match the dashed ones, where the grey separable fit doesn't). We verify dense equivalence: $\alpha_N \approx a$, while $N_c\approx \exp(d/a)$, and thus the law Equation 7 gives similar prediction to the reference law Equation 3 for dense models. Predictions for fixed $N$ are visualized as grey lines in Figure 2.
Interpretation.
In Equation 7, when $c$ is positive, the expert improvement slope $b(N)$ reduces with model size $N$. All three routing techniques considered therefore predict diminishing improvements from routing when increasing scale. However, the scaling of $\textsc{s-base}$ is predicted (and seen) to be substantially better. When designing a new technique, we can fit Equation 7 and predict a better scaling behavior if the fitted $c$ is lower than with other techniques. A clear goal for future work in routing techniques should be to find a method with scaling coefficient $c \approx 0$.
4.3 Bounded Scaling in $E$
Equation 5 models scaling in $E$ as a power law. For both small and large values of $E$, there are reasons to expect some deviation. If a routing technique degrades with $E$ (for instance, the variance of gradients in $\textsc{rl-r}$ will increase), performance for large $E$ might be worse than predicted. On the other hand, fixed overhead (e.g., interference from auxiliary losses) might worsen scaling for low values of $E$, counter-intuitively leading to better than expected performance. Both phenomena appear clearly in Figure 2. We seek to model this saturation such that the limit behavior in $E$ is bounded on both sides. We choose the following transformation, but discuss in Section 5.1 a number of implications which are independent of the specific saturating form used:
$ \begin{align} \frac{1}{\widehat{E}} \triangleq \frac{1}{E - E_{\min} + \left(\frac{1}{E_\text{start}} - \frac{1}{E_{\max}}\right)^{-1}} + \frac{1}{E_{\max}}. \end{align}\tag{10} $
This is constructed so that we have $\hat E(E_{\min}) = E_{\text{start}}$, while $\hat{E} \to E_{\max}$ as $E \to \infty$. We fix $E_{\min} = 1$, indicating the lower bound of meaningful expert counts. $\hat E$ can be seen as a thresholded version of $E$: increasing past $E_{\max}$ will give improvement, but not following a power law. Similarly, when $E_{\operatorname{start}} > 1$, $\hat{E} > E$ for small values of $E$. Practically, the fit is the same over a wide range of different thresholding functions.
Fitting.
Solving Equation 1, equal to 7 with $E \to \hat{E}$, is complicated by its non-convexity. We find the coefficients $(a, b, c, d, E_{\operatorname{start}}, E_{\max})$ as the best of repeated solutions provided by the L-BFGS-B algorithm ([30]). Figure 2 shows fitted curves from these equations; coefficients are reported in Table 3.
Interpretation.
Relative to using the simple bilinear law Equation 7, fitting Equation 1 improves prediction for the lowest and highest values of $E$ considered. Crucially, while the deviation from a power-law (and therefore improvement in RMSLE) is relatively minor for the values of $E$ considered, the deviation is nonetheless clear (seen best looking at the raw losses in Figure 21). We believe it is important to model this saturation because (as argued in Section 5.2) the limit behavior of model performance as $N$ increases is substantially different when bounded, with important properties that are independent of $E_{\max}$. We further hypothesize that future work, able to test still larger values of $E$, will see a more quantitative benefit from including these terms. This can be already observed in Figure 20 when noting that the law Equation 7 does not over and under estimate the performance for $E = {2, 4, 256, 512}$ as it does in Figure 4. Level curves of Equation 1 enumerate the ${(N, E)}$ which are predicted to achieve fixed performance, as visualized in Figure 1(b). This demonstrates of the power of routing: a model with $N=5M$ and $E=128$ equals the performance of a model with $N=55M$ and $E=1$, which requires over ten times more compute per inference.
4.4 Generalizing Across Architecture Variants
The models trained so far use fixed choices for two key details of routing: the number of experts executed per-datapoint $K$ and the frequency of routed layers across depth $R$ (previously set at 1 and $0.5$, respectively). For any selected value of $K$ and $R$ we may fit Equation 1 to observed performance, but since these variables are independent of $N$ and $E$, we do not expect the same coefficients to remain valid across values of $K$ and $R$. To allow for a unified scaling law, we modify Equation 1 to use terms in $F$, the TeraFLOPs required per forward pass, and in the ratio $B \triangleq \frac{P}{F}$ where $P$ is the total number of parameters. Specifically, $F$ is motivated by the approximation from [1] that $F = 2N$. $B$, the parameter utilization ratio, is an affine function of $E$, close to linear when most parameters lie in the routed components of the model.
Using $(F, B)$ instead of $(N, E)$ (and setting $E_{\min}$ to $\frac{1}{2}$) results in Equation 2. To show the advantage of this change of variables we conduct two experiments: varying $K$ across ${1, 2, 4}$ and $R$ across ${0.25, 0.5, 1.0}$. In both cases, we vary $E \in {8, 64, 256}$ and $N \in {15M, 370M, 870M}$.
Fitting.
Equation 2 predicts the scaling behavior of models as well as Equation 1 for a given routing architecture, as indicated in Figure 24. The benefit of the change of variables is seen most clearly in Figure 5, which plots contours of fixed loss value as functions of $(N, E)$ and of $(F, B)$. For varying $(K, R)$, the loss surface as a function of $N$ and $E$ changes: meaning a joint fit would be inaccurate. Plotted as functions of $(F, B)$, the loss surface is almost the same, suggesting a shared fit between all three methods (see Figure 25 and Figure 26 for joint fits for $K$ and $R$ respectively). We highlight that $R = 0.25$ deviates slightly. Plausible explanations are discussed in Appendix D.4. The possibility to use a shared fit indicates a singular takeaway: the architectural details $K$ and $R$ little affect the scaling behavior of a Routing Network. The loss of the network can thus be predicted based only on inference flops $F$ and total number of parameters $P$.
5. Scaling Law Applications
Section Summary: This section explores practical uses of scaling laws for AI models trained on 130 billion tokens, introducing the concept of "effective parameter count" to compare the performance of routing networks—where tasks are distributed across specialized sub-models—with traditional dense models, revealing a unified power-law pattern that holds across different approaches. It also examines how routing benefits diminish as models grow larger, defining a cutoff point beyond which routing no longer boosts efficiency, with this threshold varying by method and potentially rising with more training data. Finally, it compares three routing techniques, noting that a baseline method performs best overall while all face scaling limits, and offers advice for users to apply routing in smaller models with specific expert counts and frequencies for optimal results.
Next we provide two applications of the scaling laws presented. We re-emphasize that all values are only valid at the specific token count all models were trained at: 130B. Appendix F provides evidence that our analysis, if not the numerical values, are nevertheless robust to token count.
5.1 Effective Parameter Equivalence
We leverage Equation 1 to compute the size $\bar N$ of a dense model giving the same performance as a Routing Network. Specifically, we solve for $L(\bar{N}, 1) = L(N, E)$, yielding
$ \bar{N} \triangleq {\left(N\right)}^{\alpha(\hat E) / \alpha(E_{\operatorname{start}})} {\left(\hat{E} / E_{\operatorname{start}}\right)}^{b / \alpha(E_{\operatorname{start}})}\tag{11} $
Here $\alpha(E) = a + c \log E$. Given a model with $N$ and $E$, we call $\bar{N}$ that model's Effective Parameter Count (or $\textsc{epc}$ ). Equation 1 predicts that the performance of all models increases as a power law in this variable
$ \log L(N, E) = a \log \bar{N}(N, E) + d. $
The result of plotting all models as a function of $\bar N$ is shown in Figure 1(c): a good fit across four orders of magnitude. Scaling in terms of $\bar{N}$ results in a unifying power law: valid for dense and routed language models alike.
5.2 Routing Behavior for Large $N$
:Table 3: Solutions to 1.
| a | b | c | d | $E_\text{start}$ | $E_{\max}$ | |
|---|---|---|---|---|---|---|
| $\textsc{s-base}$ | -0.082 | -0.108 | 0.009 | 1.104 | 1.847 | 314.478 |
| $\textsc{rl-r}$ | -0.083 | -0.126 | 0.012 | 1.111 | 1.880 | 469.982 |
| $\textsc{hash}$ | -0.087 | -0.136 | 0.012 | 1.157 | 4.175 | 477.741 |
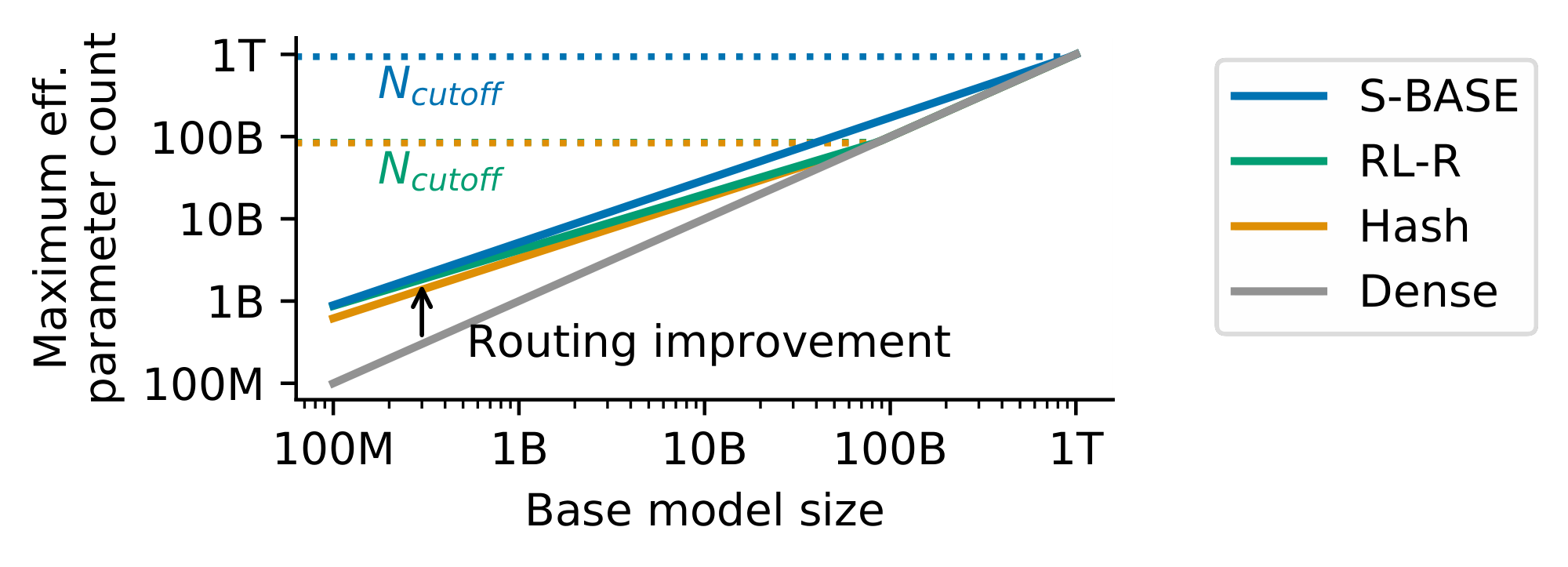
$\textsc{epc}$ leads to a better grasp of the behavior of routing as $N$ increases. Of immediate interest is $N_{\textrm{cutoff}}$: the value of $N$ where $\bar{N}(N, E) \leqslant N$. For larger $N$, routing will not improve performance. This is easily found to obey $\log N_{\textrm{cutoff}} = \frac{b}{c}$. $N_{\textrm{cutoff}}$ equals $937\textrm{B}$, $85\textrm{B}$ and $83\textrm{B}$ for $\textsc{s-base}$ , $\textsc{rl-r}$ and $\textsc{hash}$ respectively. These values are highly dependent on the number of tokens seen, and $N_{\textrm{cutoff}}$ is expected to increase with increased numbers of tokens.
Next we consider $\bar N_{\max}(N) \triangleq \max_E \bar N(N, E)$, i.e. the maximal effective parameter count that a routing network can reach. Equation 11 predicts that $\log \bar N$ is an affine function of $\log N$ for any fixed $E$, and $\bar N_{\max}(N) = N$ for $N > N_{\textrm{cutoff}}$. Therefore $\log {\bar N}_{\max}$ is piecewise-affine in $\log N$, as displayed in Figure 6:
$ \begin{align} \forall , N \leqslant N_{\textrm{cutoff}} = 10^{-\frac{b}{c}}, \quad \bar N_{\max}(N) &= \bar N(N, E_{\max}), \notag \ \forall N \geqslant N_{\textrm{cutoff}}, \bar N_{\max}(N) &= N. \end{align} $
Note that $\bar{N}{\max}$ is continuous near $N{\textrm{cutoff}}$, since for all $E$, $\bar N(N_{\textrm{cutoff}}, E) = N_{\textrm{cutoff}}$. Moreover, the slope of $\bar N_{\max}(\cdot)$ for $N \leqslant N_{\textrm{cutoff}}$ is positive whenever $E_{\max} \leqslant E_{\operatorname{start}} 10^{-a/c}$, which is true for our coefficients. In this setting $\bar N_{\max}(\cdot)$ is a non-decreasing function of $N$. Therefore for any routing network where $N < N_{\textrm{cutoff}}$, $N \leqslant \bar N_{\max}(N) \leqslant N_{\textrm{cutoff}}$, meaning routing will never let you train a model more powerful than $N_{\textrm{cutoff}}$. Note that despite this value not depending on $E_{\max}$, its existence crucially depends on the saturating transformation: without it ${\bar N}_{\max}$ is unbounded.
5.3 Comparative Analysis
[1] use scaling laws to encapsulate and contrast the behavior of entire model classes. Here we mirror this analysis by using the scaling laws we have proposed to summarize the relative behavior of the three routing techniques considered. We make four concrete observations:
- $\textsc{s-base}$ consistently outperforms $\textsc{rl-r}$ and $\textsc{hash}$, though $\textsc{rl-r}$ is very competitive at smaller $N$.
- All routing techniques suffer from reducing efficacy as $N$ increases. Amongst the three techniques, $\textsc{s-base}$ scales best: the fitted parameter $c$ is lowest.
- For small $N$, $\textsc{rl-r}$ and $\textsc{s-base}$ scale similarly with expert count and better than $\textsc{hash}$ (as indicated by computing the effective expert slope $b(N) = b + c \log N$).
- $\textsc{hash}$ and $\textsc{rl-r}$ maintain power-law behavior for longer than $\textsc{s-base}$ (larger $E_{\max}$). However they suffer from more interference ($c$); leading to worse performance for most model sizes.
- $\textsc{hash}$ has large initial overhead (bigger $E_\text{start}$), clearly visible as a more obvious curvature at small $E$.
For a practitioner interested in applying routing techniques, we conclude with some recommendations:
- Use routing when training any model with $N \leqslant \text{1.3B}$.
- $\textsc{s-base}$ is a good default routing algorithm. $\textsc{rl-r}$ will sometimes match $\textsc{s-base}$ in performance but is less robust and scalable (Appendix D.1).
- Target using $E \in {64, 128}$ experts. Larger values will continue to improve, but with diminishing returns.
- Use $K{=}1$ experts. Route layers at frequency $0.5 \leqslant R \leqslant 1$; lower frequency reduces performance.
- Future routing research should focus on the terms $c$ and $E_{\max}$; indicative of limits to arbitrary scaling.
- New routing techniques must be validated at multiple values of $N$ and $E$ when comparing with prior work. Results on single sizes cannot be extrapolated.
6. Related Work
Section Summary: This section reviews prior research on scaling AI models, building on empirical studies like those in reference [1] that inspired further work, while noting that the underlying theory remains underexplored with limited explorations in sources like [32] and [33]. It highlights foundational advances in making Transformer models more scalable, including influential systems such as GPT-2, GPT-3, and Gopher, along with techniques for efficient parallel computing across devices. Additionally, it discusses the parallel development of Routing Networks, evolving from concepts like Conditional Computation and Mixture of Experts, with key large-scale implementations like Switch Transformer and ongoing refinements to routing mechanisms for better performance.
In studying the empirical aspects of scaling, this work follows [1]; which triggered much research including [3], [2] and [31]. The underlying theory is less understood, but there is some exploration of this space including [32] and [33].
These studies, and ours, are mutually reliant on a large corpus of work improving the scalability of Transformers. This includes models like GPT-2 ([34]), GPT-3 ([35]), Jurassic-1 ([36]) and Gopher ([13]), as well as work improving the ability of these models to be efficiently parallelized across multiple devices, including [18], [37], [38] and [39].
Parallel to all this has been a long study of Routing Networks; a term introduced by [40] but developed extensively in the literature as Conditional Computation ([6, 5, 25, 7]) and Mixture of Experts ([22, 41, 21]). The framework is sometimes further generalized, seen as per-example architecture search in [42] or as a graph problem in [7]. Routing was popularized for large scale training by [14], and furthered by work including GShard ([16]), Switch Transformer ([8]) and GLaM ([9]). In this vein, [10] undertake a comparative analysis of dense networks and $\textsc{smoe}$ s with $E = 512$ that aligns with our results. Finally, the core routing architecture is still being improved. [43] adapt $K$ through training where [44] learn it via a differentiable loss. [42] increase $K$ through depth and encourage architectural diversity across experts. [45] grows $E$ throughout training and [46] propose networks where $E$ changes with depth.
7. Conclusion
Section Summary: Researchers have long aimed to scale neural networks using conditional computation, and routing networks have gained traction for this purpose. In this conclusion, the authors present a scaling law that shows adding routing to language models boosts performance, with improvements following a power-law pattern based on the number of experts, though this benefit decreases as models grow larger. This framework not only compares different routing methods but also encourages wider adoption of routing as a tool that complements traditional scaling techniques and remains effective for massive models exceeding 900 billion parameters.
Using conditional computation to scale neural networks has long been a research goal, and methods based on Routing Networks have been increasing in popularity. Here we have introduced a scaling law Equation (1) that models the behavior of these networks. This scaling law predicts that, for all models considered, introducing routing into a language model improves performance. That improvement follows a power-law in the number of experts $E$ that diminishes with model size $N$, and can be further generalized across routing architectures with Equation 2. These scaling laws quantify the differences between three different routing techniques and lead to a single scalar Equation (11) that simultaneously describes the performance of routed and dense models alike.
This work provides an empirical framework with which to analyze future innovations in routing. We hope the overwhelming evidence we provide towards the benefits of routing encourage it to be more rapidly adopted as a powerful tool for model improvement, whose scaling characteristics align with traditional methods of scaling (in depth and width) and which will remain beneficial up to models with base model size greater than 900 billion parameters.
Acknowledgments
Section Summary: The authors express gratitude to Marc'Aurelio Ranzato, Nando de Freitas, Jacob Menick, and Andy Brock for their helpful comments and feedback on early versions of the paper. They also credit the JAX and XLA teams, particularly Peter Hawkins, Roy Frostig, and James Bradbury, for their essential contributions to the infrastructure and routing software that enabled training the models.
We would like to thank Marc'Aurelio Ranzato, Nando de Freitas, Jacob Menick and Andy Brock for useful comments and feedback on early drafts of this paper. The infrastructure needed to train these models wouldn't have been possible without the dedicated work of the JAX and XLA teams, especially Peter Hawkins, Roy Frostig and James Bradbury who all were crucial in the development of the routing software.
Appendix
Section Summary: The appendix outlines the technical architecture of the Transformer-based language models used in the study, including details on tokenization with SentencePiece, parameter storage in bfloat16 for efficiency, and a learning rate schedule that warms up and then decays over 250,000 training steps. It lists seven model sizes ranging from 15 million to 1.3 billion parameters, with a table specifying dimensions like hidden layers and heads, and includes training curves showing that different random seeds cause only minimal variation in performance after an initial period. Additionally, it explains routing techniques for mixture-of-experts models, such as balancing losses to ensure even expert usage and a Sinkhorn-based method for redistributing expert assignments more efficiently than traditional algorithms.
A. Architecture
Our Transformer ([15]) is based on the architecture in ([34]) with relative positional encodings ([47]). Text is tokenized via SentencePiece ([24]) with $32, 000$ tokens and a byte-level backoff. We use Megatron-style FFW sharding ([18]) where useful. Parameters are stored in bfloat16 but all optimizer statistics are kept in float32. As a result, the activations of the language models are calculated in bfloat16 (though we explicitly upcast to perform all operations involving a softmax, including the Attention Block and Router, in full float32 precision). This is crucial to maintain stability on larger models ([8, 13]). The learning rate starts at 1e-7 and decays to 2e-5 with a cosine decay rate over the entire $250, 000$ steps, after an initial warmup phase ramping up to 2e-4 in the first $1500$ steps.
We use seven different model sizes, with names and architectures specified in the following table. The width of the hidden layer $d_{\mathit{ffw}}$ is fixed at four times the width of the activations $d_{\mathit{model}}$, and we use the same dimension for keys and values.
:Table 4: Model definitions used throughout this work.
| Name | $d_{\textit{model}}$ | $n_\mathit{layers}$ | $n_\mathit{heads}$ | K/V size | Actual # Params |
|---|---|---|---|---|---|
| 15M | 512 | 6 | 8 | 32 | $16, 527, 360$ |
| 25M | 512 | 8 | 8 | 64 | $27, 279, 360$ |
| 55M | 640 | 10 | 12 | 64 | $57, 369, 600$ |
| 130M | 896 | 12 | 16 | 64 | $132, 163, 584$ |
| 370M | 1536 | 12 | 12 | 128 | $368, 123, 904$ |
| 870M | 2048 | 16 | 16 | 128 | $872, 546, 304$ |
| 1.3B | 2048 | 24 | 16 | 128 | $1, 308, 819, 456$ |
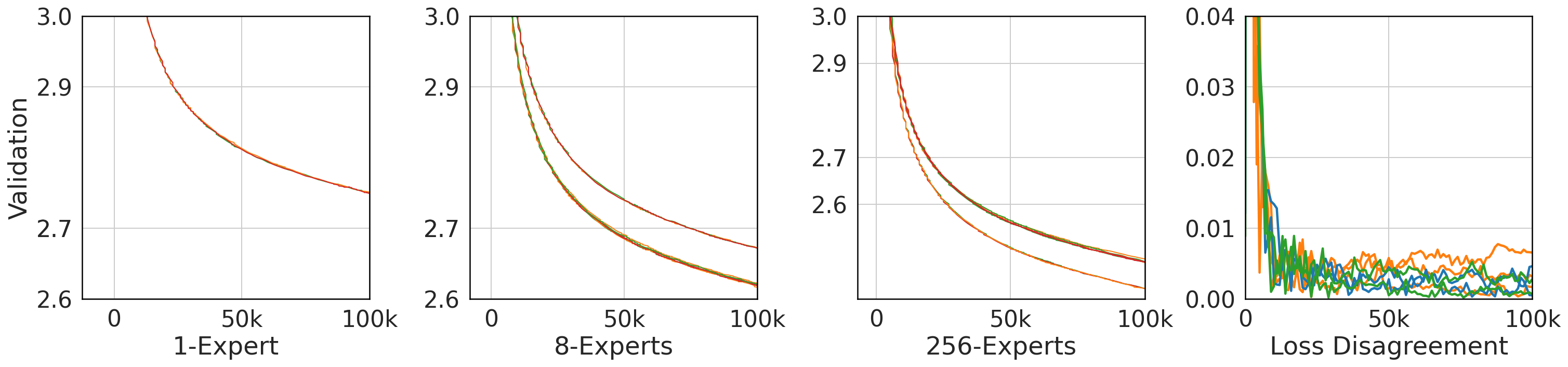
The number of models we trained was too large to practically include multiple runs of each model with different seeds. To give an idea of the potential error introduced by random chance, we trained all three routing techniques with 3 different seeds on a 130M model for $100, 000$ steps with $8$ and $256$ experts (along with a dense baseline). Results are shown in Figure 7. Different seeds (which influence not only parameter initialization but Expert Parallelism – see Appendix C) lead to extremely minimal model divergence after an initial transitory period, with different seeds diverging by no more than $0.01$ before $100, 000$ steps. This is a close match to the $0.02$ error mentioned in ([1])[^2].
[^2]: Anecdotally, throughout the development of this work we used $0.02$ as the cutoff to denote statistical significance.
B. Detailed Routing Techniques
Here we detail aspects of the routing techniques crucial to their implementation and provide comparisons to key alternatives.
B.1 Balancing Losses
We encourage uniform routing in both our SMoE and RL-R methods with the differentiable load balancing loss adapted from the mean square auxiliary loss in [14] and introduced in [16, 8].
$ L_B = {E} \cdot \sum_{e=1}^{E} m_e \cdot \frac{g_e}{N}\tag{12} $
Where $m_e$ is the mean gate per expert:
$ m_e = \frac{1}{N} \sum_{x \in B} p_e(x) $
And $g_e$ is the gating decision per expert:
$ g_e = \sum_{x \in B} 1 {\operatorname{argmax} p(x), e} $
For $x$ in batch $B$ of size $N$ and policy $p(x) = \operatorname{softmax}(W_p x + b_p)$. There are two cases where the selected experts may not be the ones used: in $\textsc{s-base}$ after the Sinkhorn redistribution step (see Appendix B.2.1) and when experts are skipped due to load-balancing (see Appendix C.2). In both cases, the balancing loss is applied to the original gating decisions made by the policy. We found that the auxiliary loss is less effective if post-balancing experts were considered.
B.2 SMoE with Sinkhorn redistribution ($\textsc{s-base}$ )
Our implementation of $\textsc{s-base}$ differs from that proposed in [11] in two ways. First, we replace the auction algorithm for re-assigning expect selections with a continuous rebalancing process implemented via a Sinkhorn algorithm ([23, 48]). Second, we add a shuffling step, similar to [11], before computing the optimal assignment via Sinkhorn per-device (as opposed to across all devices as done in [11]). In addition, we did not use any input jitter on the activations sent to $\rho$ as we did not see a noticeable effect. This is in line with $\textsc{base}$ but differs from recommendations in other $\textsc{smoe}$ papers ([16, 8]).
B.2.1 Sinkhorn Redistribution
We rebalance expert selections using a Sinkhorn layer applied on top of the router logits, an idea that was explored independently in parallel by [49]. This is substantially more efficient on our accelerator cluster than a hard matching algorithm. We consider $H \in \mathbb{R}^{T \times d}$ the intermediary embeddings of the networks before the application of a routed layer (folded on the batch and time axes of respective sizes $b$ and $t$, with $T \triangleq b t$). Those are fed to the linear router, which output a logits matrix $L_i = H_i W + b \in \mathbb{R}^{T \times e}$. Here $E$ is the number of experts, and $W \in \mathbb{R}^{d \times E}$ and $b \in \mathbb{R}^{E}$ are the router parameters. From these logits, $\textsc{smoe}$ and $\textsc{rl-r}$ computes expert selection probabilities $\Pi$ by applying a softmax operation along the expert axis. In doing this, we compute selection probabilities for each input separately, without taking into consideration any capacity constraints on expert, forcing us to introduce load-balancing later (Appendix C.2). We seek a proper way to integrate constraints in a mathematically grounded framework.
Mathematically, $\Pi$ is obtained by solving a simple problem with constraints: each input must, on average, prefer exactly one expert. This is made clear by the variational formulation of the softmax:
$ \Pi \in \mathbb{R}^{T \times E} \triangleq [\operatorname{softmax}(L_i)] {i \in [1, T]} \ = \operatorname{argmax}{\substack{ \Pi \geqslant 0, \ \forall , i \in [T], \sum_{j \in [E]} p_{ij} = 1, }} \langle \Pi, , L\rangle - H(\Pi) $
where $H$ is the Shannon entropy of the matrix $\Pi$, i.e. $H(\Pi) \triangleq \sum_{i =1}^T \sum_{j=1}^E p_{ij} \log p_{ij}$, and $[\cdot]$ denotes horizontal stacking. This variational formulation offers a natural alternative to incorporate extra constraints. For ideal performance, each expert should be assigned the same number of tokens on average $B = \frac{T}{E}$. We therefore add $E$ additional constraints:
$ \Big{ \forall, j \in [E], , \sum_{i = 1}^T p_{ij} = B \Big}, $
which yields the doubly constrained regularized linear problem
$ \begin{align} & \Pi \in \mathbb{R}^{T \times E} \triangleq \operatorname{argmax} \langle \Pi, , L\rangle - H(\Pi), \ & \text{under the constraints}\qquad \left{ \begin{array}{l} \Pi \geqslant 0, \ \forall , i \in [T], \sum_{j=1}^E p_{ij} = \frac{1}{T}, \ \forall , j \in [E], \sum_{i=1}^T p_{ij} = \frac{1}{E} \end{array} \right. \notag \end{align}\tag{13} $
that we recognize as the regularized Kantorovich problem of optimal transport ([50, 23]).
We solve this problem using the Sinkhorn algorithm ([51]), that takes the logit matrix $L \in \mathbb{R}^{T \times E}$ and returns a soft-assignment matrix $\Pi \in \mathbb{R}^{T \times E}$. The Sinkhorn algorithm solves Equation 13 by alternated ascent in the dual (see [48] for details). Starting from $f_0 = 0 \in \mathbb{R}^T$ and $g_0 = 0 \in \mathbb{R}^E$, we set
$ \begin{align} \forall , i \in [T], \qquad {(f_{t+1})}i &= - \log \frac{1}{E} \sum{j=1}^E \exp(L_{ij} - {(g_t)}j), \ \forall , j \in [E], \qquad {(g{t+1})}j &= - \log \frac{1}{T} \sum{i=1}^T \exp(L_{ij} - {(f_{t+1})}_i).\notag \end{align}\tag{14} $
These updates converge towards an optimal couple $(f, g)$, such that
$ \Pi = \frac{1}{T E} \exp(L + f \oplus g) $
is the solution to 13, where $(f \oplus g)_{ij} \triangleq f_i + g_j$ for all $i, j \in [T] \times [E]$. As detailed below, we early stop the iterations Equation 14 by measuring the primal violation of constraints in $L_1$ norm, i.e. when
$ \sum_{j=1}^E \left\vert \sum_{i=1}^T {(\Pi_t)}_{ij} - \frac{1}{E} \right\vert
- \sum_{i=1}^T \left|\sum_{j=1}^E {(\Pi_t)}{ij} - \frac{1}{T}\right| \leqslant e{\textrm{tol}}\tag{15} $
Once the plan is computed, we greedily select, for each token, the device with highest device-selection probability, effectively applying an $\operatorname{argmax}$ operation on top of the Sinkhorn logits to form a transportation plan projection.
Comparison to $\textsc{s-base}$ and performance.
Compared to using an exact (early-stopped) auction algorithm as [11], the complexity of the Sinkhorn algorithm is in $\mathcal{O}(N \times E)$ versus $\mathcal{O}((N \times E)^{3/2})$, and its update are well adapted to batch computations on TPU/GPU. In contrast, the auction algorithm must be run on CPU as it is a greedy per-coordinate algorithm; it becomes a computational bottleneck applied to models with many routed layers. Replacing the softmax output by an regularized optimal transport plan is very naturally interpreted as adding a balancing distribution constraint to the softmax operator. Using an auction algorithm on top of the softmax assignment does not have this property.
Moreover, the Sinkhorn algorithm can be halted before it has fully converged with a proper tolerance parameter Equation 15 where [11] uses a hard number of iterations. We find an error tolerance of $e_{\textrm{tol}}=10^{-2}$ gives consistently good performance. In practice we observe an end-to-end model overhead of $1%$ to $3%$ compared to Switch (the same routing technique without this reassignment). This computational offset is negligible compared to the per-step performance gain. Without the rebalancing step, Switch is very sensitive to balancing loss hyperparameters (as noted in [11]) whereas $\textsc{s-base}$ maintains uniform routing decisions with improved performance and robustness while varying $E$ and $N$.
B.2.2 Shuffling Tokens
Similar to [11], we shuffle router inputs across workers by first computing a random permutation of the inputs and sending the $t$ th row of the batch to the $\lfloor \frac{tE}{T} \rfloor$ th worker. We found that this shuffling stage was necessary to prevent training from becoming unstable at larger scales. Our hypothesis is that the re-assignment provides a subtle side channel through which information can be propagated backwards in time, and this can be abused by larger models resulting in the validation loss diverging during training. Adding a shuffling stage ameliorates this issue by introducing a large number of irrelevant elements to the rebalancing process, making it harder to infer behavior of future inputs. Further work is needed to confirm this theory, but the introduction of the shuffling step does eliminate this performance degradation.
B.3 Routing with Reinforcement Learning ($\textsc{rl-r}$ )
We will first describe a naive REINFORCE ([28]) implementation of routing, then describe possible extensions and improvements which lead to the form used in the main text as $\textsc{rl-r}$ .
Our implementation of REINFORCE uses the balancing loss in Equation 12 and a policy gradient loss:
$ L = \frac{1}{N} \sum_{i=1}^{N} \log \pi_i \cdot R_i\tag{16} $
Where $R_i$ is the reward for each sequence in the batch of size N and $\pi$ is the normalized expert preferences output by a linear transformation as in $\textsc{smoe}$ . The proper thing is for $\rho$, the selected experts, to be samples from the distribution $\pi$, but we found that this substantially degraded performance at larger scales. This phenomenon can be attributed towards unwanted interference, where exploratory steps for $\rho$ which turn out to be unnecessary lead to bad gradient updates to the rest of the network ([27]). We therefore consider a greedy selection method, where router outputs are selected as $\rho(x) = \textrm{TopK}(\textrm{softmax}(W_px + b_p))$.
While sampling (even when tuning softmax temperature) decreased the performance of the model, we would nevertheless like to regain some of its exploratory power. To ameliorate this, we can use Nucleus Sampling ([52]), which samples from the top- $p$ set of experts $E^{(p)}$.
$ P'(e) = \begin{cases} P(e) / p' \quad &\text{if} , e \in E^{(p)}, \ 0 \quad &\text{otherwise.} \ \end{cases} $
Where $E^{(p)}$ is the smallest set of experts such that:
$ \sum_{e \in E^{(p)}} P(e) \geqslant p $
This eliminates the possibility of selecting experts with very low likelihood, while still introducing some randomness. It is important to emphasize that this introduces a distributional shift to the samples, which can be corrected with off-policy correction methods such as Importance Sampling.
An alternative improvement is to learn an additional baseline function for each router. This method has an additional entropy regularization loss and computes advantages $A_i=R_i-b_i$ for the learned baseline $b_i$:
$ L = \frac{1}{N} \sum_{i=1}^{N} \log p_i \cdot A_i - \frac{1}{N} \sum_{i=1}^{N} \log p_i \cdot p_i + \frac{1}{N} \sum_{i=1}^{N} v_i\tag{17} $
Where we use the Huber Loss to calculate the value loss $v_i$.
$ v_i = \begin{cases} \frac{1}{2} (R_i - b_i)^2 \quad &\text{if} , \left\lvertR_i - b_i\right\rvert \leqslant \delta, \ \delta (\left\lvertR_i - b_i\right\rvert - \frac{1}{2} \delta) \quad &\text{otherwise.} \ \end{cases} $
We numerate three $\textsc{rl-r}$ variants below:
- Greedy REINFORCE (RLR-G). REINFORCE selecting the top- $k$ experts and no additional auxiliary losses.
- Nucleus-sampled REINFORCE (RLR-S). REINFORCE using nucleus sampling to eliminate less reliable expert selections and reduce noise in the policy gradient update. In this method we sample from the top- $p$ truncated distribution. Nucleus sampling at a fixed top- $p$ scales well with increasing the number of experts.
- REINFORCE with baseline (RLR-B). Our RL method which stabilizes training with a learned baseline and a policy entropy regularization loss. We learn a baseline with a value function that has a single hidden layer of size $\frac{d_{\textit{model}}}{8}$.
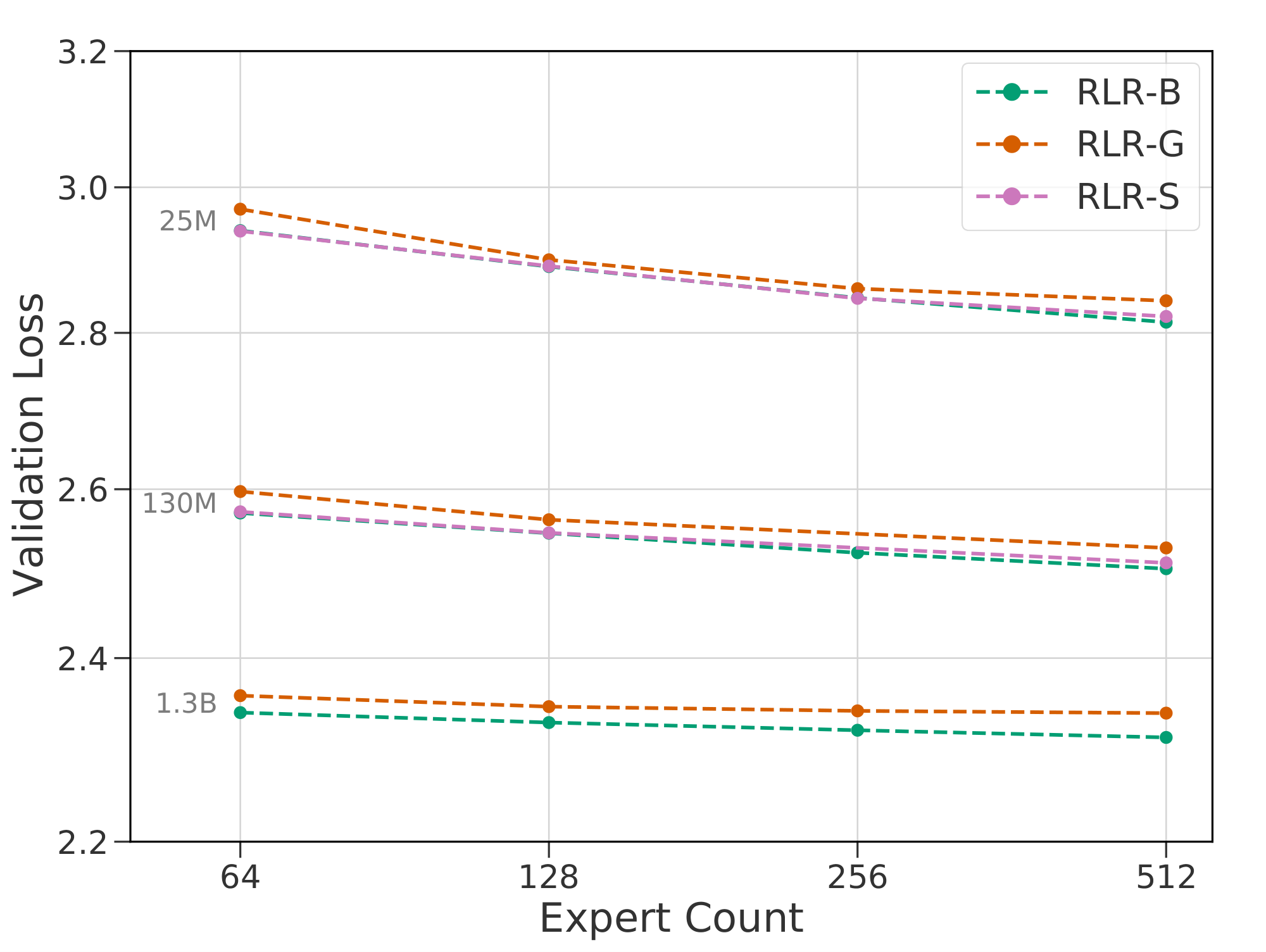
Table 5 details the hyperparameters chosen for each $\textsc{rl-r}$ variant and Figure 8 contains validation losses across a number of models. Note that the entropy loss is negative to encourage a more concentrated policy, and the weight must be tuned jointly with the load balancing loss to keep routing balanced. This is in line with [5], who also use two loss terms to both encourage early specialization and expert diversity. Additionally, since the policy entropy loss has a similar effect to nucleus sampling, we did not see an improvement from including both regularization methods. RLR-B consistently performed the best, especially with regards to scalability in $E$ and $N$. For that reason we selected it as our prime example, and refer to it as $\textsc{rl-r}$ elsewhere.
:Table 5: Selected hyperparameters for $\textsc{rl-r}$ variants.
| Hyperparameter | RLR-G | RLR-S | RLR-B |
|---|---|---|---|
| Policy entropy weight | 0. | 0. | -5e-4 |
| Load balancing weight | 1. | 1. | 1. |
| Policy gradient weight | 1e-1 | 1e-1 | 1e-2 |
| Nucleus top- $p$ | - | 0.9 | 1. |
| Value weight | - | - | 1e-2 |
| Value hidden layers | - | - | 1 |
| Value loss type | - | - | Huber |
B.4 Hash layers ($\textsc{hash}$ )
$\textsc{hash}$ is simple compared to $\textsc{rl-r}$ or $\textsc{s-base}$ , but is highly reliant on the particular choice of hashing function. Many functions rely on knowing the integer ID which the tokenizer assigns to each unique token (characters, bytes, subwords, etc.). [12] describe multiple alternative functions, including pre-computing expert assignments for each token using a greedy assignment based on the frequency counts of the token on the training set. They do not observe any improvement in terms of perplexity relative to simpler random assignments of token to expert, but argue that balanced hashing has better properties for distributed training.
Our implementation uses a simple modular hashing function, namely the token index modulo the number of experts. Tokens are indexed by our tokenizer in an order that is roughly ordered by their underlying frequencies in the training dataset, which means this strategy will be more balanced than an arbitrarily random assignment, while simpler to implement than fully balanced hashing. We note that poor balancing with increasing expert count is to some extent inevitable for any routing technique that defines one-to-one mappings between tokens and experts, assuming a bounded Expert Capacity (see Appendix C.2), as it becomes progressively harder to assign high frequency tokens into a bigger number of smaller buckets due to the tokens' heavy-tailed distribution. This can be seen in Figure 9.
![**Figure 9:** $\textsc{hash}$ becomes less balanced as $E$ increases. Here we compare three hash routing strategies using the token frequency in our validation set. The lines represent the amount of tokens sent to each expert, ordered from most subscribed to least subscribed. The dotted line represents the point where tokens are likely to overflow under our bounded Expert Capacity setup ($C=2$). `greedy` implements Balanced assignment as described in [12], where the per-token frequency tables are pre-computed and tokens are assigned to the most empty expert ordered by frequency; `random` assigns each token to a random expert; and `modulo` uses the technique described in this paper. Note that (a) the token distribution is different from the one used by the tokenizer and (b) this simulation is based on marginal token frequencies, not batches of sequences. The `greedy` strategy does improve the workload for the mid range ($E=64)$, but not significantly for low ($E=8$) or high ($E=512$) numbers of experts. `modulo` provides a modest improvement over `random`.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/vp8c7dsu/hash-balancing.png)
C. Distributed Routing Details
Here we describe the key aspects of Routing relevant to training on large clusters. We note there are several libraries available for supporting large-scale Routing, including DeepSpeed ([38, 46]) and GSPMD ([39]). Unfortunately these were incompatible with our preexisting infrastructure.
C.1 Expert Parallelism
We briefly review parallelism techniques, building up to Expert Parallelism, a technique for efficiently distributing parameters over an accelerator cluster. For a more in-depth exposition we recommend [11], [16] or [46]. In a fully data-parallel world, every device has an identical copy of all parameters $\Theta$ and a different input batch $X$. Each device executes a forward and backward pass on $X$ and (usually) does a synchronous all-reduce across all devices on the gradients to $\Theta$. This is effective, but requires one copy of $\Theta$ for each device, wasteful when $|\Theta|$ is large.
The general class of techniques known as Model Parallelism reduce this duplication by having any individual device store only a subset of the entire model parameters. This reduction in memory comes with a cost: no longer can a single device take an input and produce the model's output; that device no longer contains all of $\Theta$. Most techniques therefore require some additional synchronization or data exchange.
Sharding Parallelism ([18]) takes advantage of a mathematical property present both in 2-layer-MLPs and a Transformer's attention blocks: namely, that the output can be represented as the sum of $N$ components, where each component applies the same functional form with independent weights on the same input. [18] contains more details, but a simplified example can be given for a matrix multiplication where we observe the effect of splitting a matrix into columnwise sub-matrices: $Wx = [W_1, ..., W_N] x = \sum_i^NW_ix$. The effect of applying this technique such that each device has a separate subcolumn is to prevent the duplication of the weight matrices (which consist of the vast majority of $\Theta$). The disadvantage is that all devices must see the same input, meaning the total throughput of data on the cluster has been reduced $N$-fold. In addition, the sum described above is actually now a sum across devices, which introduces additional communication overhead.
Expert Parallelism takes further advantage of the structure of a routed layer to similarly reduce the necessity of parameter duplication while avoiding the need to duplicate data between devices. In particular, rather than duplicating experts across all devices, each device contains only a subset of the experts which are not replicated anywhere else. Different devices still see different inputs. The key motivation is that a given input $x$ never needs to interact with the parameters corresponding to experts which the router did not send $x$ to. Therefore, a single input $x$ need only be present on a single device (the one which contains the experts which the router selected for $x$) to produce the correct output. In order to produce an output, the router selects an expert for all inputs and an additional data-exchange is introduced which sends all inputs to the device which contains the requested experts. Each device then processes the inputs it was sent, then returns all inputs to their original devices. Crucially, a roughly uniform router distribution leads to an evenly balanced computation across devices. This allows routed layers to be stored across a cluster with no duplicated data and without a reduction in data throughput. The downside is that this data exchange required across devices is generally more costly than the cross-device-sum required by sharding. More details are given in [11]. Previous work ([8]) suggests using one expert per device. We believe this to be an implementation detail dependent on many aspects of the infrastructure in use. For us, typically using $4$ or $8$ local experts per device gave good performance.
All of Data, Sharding and Expert parallelism can be applied simultaneously. We use all three methods at will, selecting the combination which works fastest for a given cluster structure and model size. There are still more variations of model parallelism, notably Pipeline Parallelism ([37, 53]), which we do not use.
C.2 Load Balancing
This at-will changing of parallelism techniques is dependent on the parallelism not affecting the output of the model. This is generally true, but expert parallelism brings in one complicating factor: load balancing. In the description above, we emphasized that a roughly-uniform router (averaged over a minibatch) will send the same number of inputs to each device (we will call the expected value $BS_\text{avg}$). However, in the worst case all inputs on all devices might select the same expert, and therefore need to be sent to a single device. If memory is pre-allocated to accommodate this worse case, then each device must have enough free memory to potentially store the entire global batch size: prohibitive for large clusters.
The most common solution is to specify a capacity factor $C$, and only allocate space for $BS_\text{avg} \times C$ tokens. When an expert is oversubscribed tokens are dropped at random until no experts are exceeding capacity. Having $C > 1$ is useful during training to prevent unnecessarily large numbers of tokens from being dropped. We set $C = 2$ for all experiments (though during evaluation we always allow all tokens to be routed to the desired expert). This strategy works well for the Transformer architecture due to its residual connections – dropping a token means skipping that transformer block. As long as the amount of dropped tokens is kept at a reasonable bound, it does not impact learning.
An optimization we support is allowing an oversubscribed expert to use the memory allocated by an undersubscribed expert on the same device. This reduces the average number of tokens which are skipped, but does so at the minor cost of introducing an interaction between tokens being skipped and the specific co-habitation of experts on devices. In practice we do not find this to have a large effect. We note that the rebalancing used in $\textsc{s-base}$ substantially ameliorates the load balancing problem by attempting to force all experts to be assigned the same number of tokens. However because we use the approximate Sinkhorn algorithm, not a hard matching algorithm, over-subscription still happens (though at a much reduced rate) and so these steps are still taken.
D. Architectural Variations
Throughout this work we have focused on a narrow subset of possible Routing Net architectures, which we believe are representative of recent work on large scale Routing Nets ([12, 8, 11, 14, 10, 16]). However, we also experimented with many variations of these architectures, some of which we highlight now in more depth.
D.1 Robustness to hyper-parameter changes
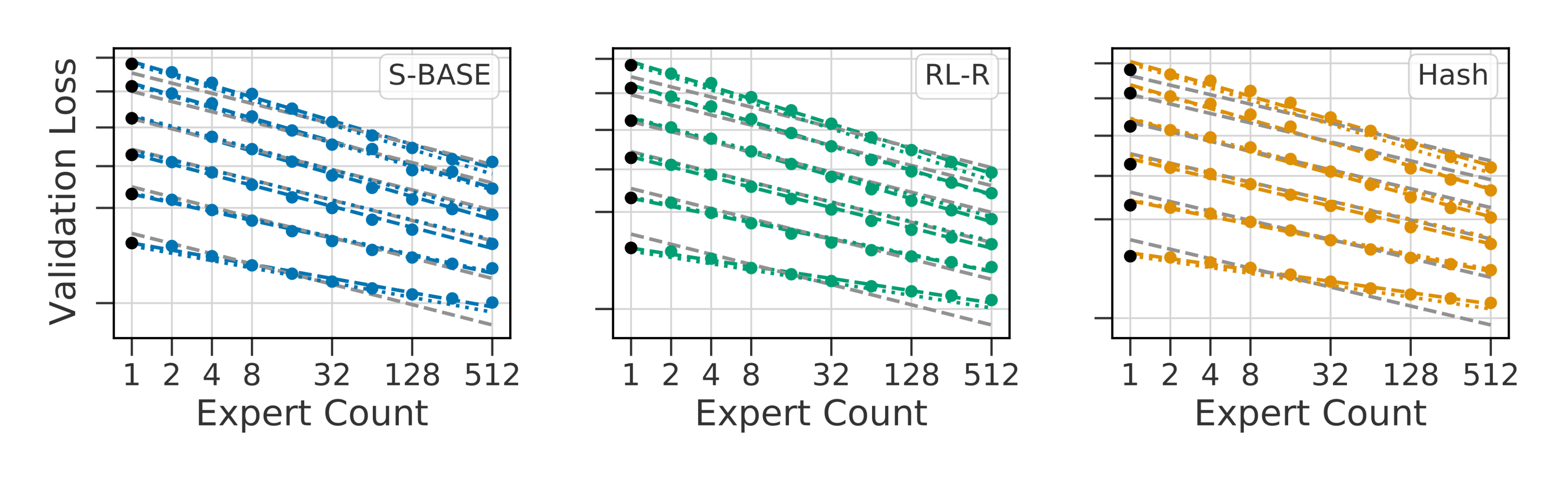
We evaluated the robustness of $\textsc{s-base}$ and $\textsc{rl-r}$ to changes in hyperparameters in Figure 10. We focus on $E = 512$ due to anecdotal experience that the largest performance variance occurred at this scale. $\textsc{rl-r}$ is found to be highly sensitive to the hyperparameters in Table 5, especially the choice of balancing weight. In addition, changes to the policy entropy weight can lead to unbalanced routers when the balancing weight is not tuned jointly.
Unlike Switch which has been shown to be sensitive to the choice of balancing loss ([12]), $\textsc{s-base}$ is robust to changes in balancing weight for values of $1e-3$ to 1. $\textsc{s-base}$ also has competitive performance without a balancing loss, but training is less stable. Additionally, Switch has higher expert oversubscription rates even when tuning the balancing weight.
D.2 Varying Routing Frequencies
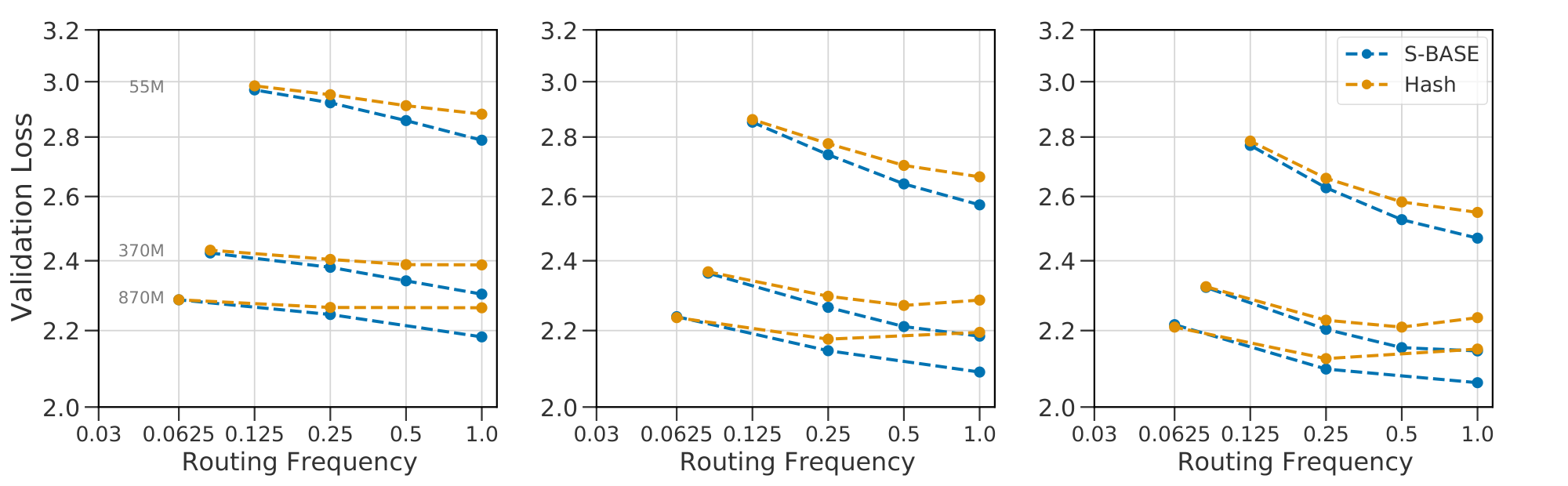
All of our models thus far have been routed every other layer with experts which are single FFWs ([16, 8]). However, [11, 12] explored stacking FFWs in the experts and placing $N$ routed layers at $\frac{L}{N+1}...\frac{NL}{N+1}$. We consider the performance impact of alternative routing frequencies, varying the frequency $R=\frac{N}{L}$ and placing routed layers at $\frac{L}{N}...\frac{NL}{N}$.
We compare routing every layer to routing at frequencies $R \in {\frac{1}{2}, \frac{1}{4}, \frac{1}{L}}$. For routing a single layer we chose the second to last layer ([12]), but consider routing at $\frac{L}{2}$ in subsection Appendix D.4. $\textsc{s-base}$ scales well with routing frequency, but $\textsc{hash}$ degrades in performance as shown in Figure 11. At a single routed layer, $\textsc{hash}$ has the lowest validation loss across model sizes.
D.3 Varying the Routing Policy
Motivated by the improved scaling results for $\textsc{s-base}$ , we investigate whether learning a routing policy becomes more beneficial as the frequency of routers increases.
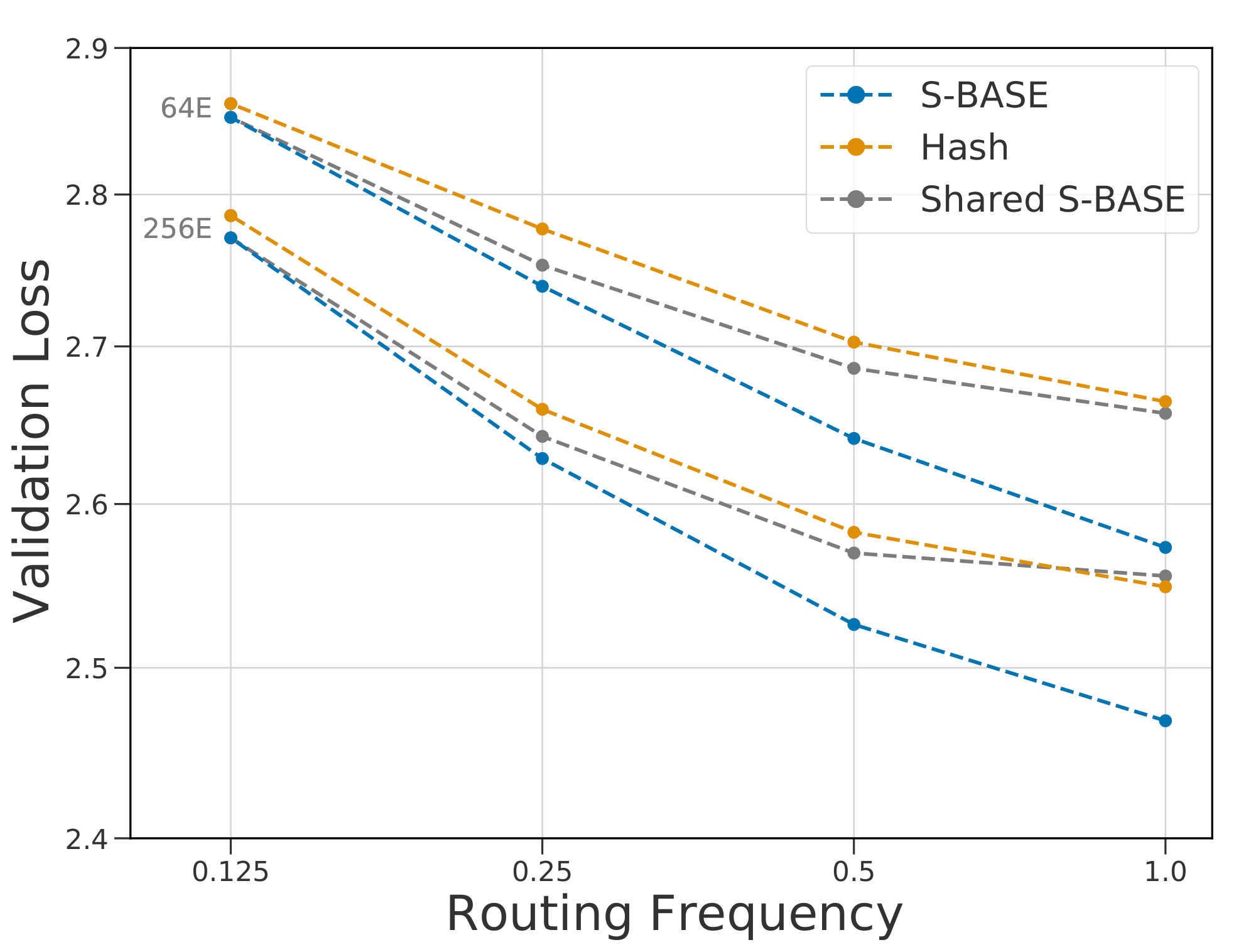
Shared routing decisions.
In Figure 12, the routing decisions are made at the first routed layer and shared across layers, which keeps the number of routers constant as $R$ increases. As $\textsc{hash}$ selects experts based on the token index at the input layer, its routing function is unchanged for this variant. $\textsc{s-base}$ and $\textsc{hash}$ have similar losses for shared routing decisions, whereas $\textsc{s-base}$ improves when learning to route at each expert layer.
Permuting the hash function.
Conversely, we tested a variant of $\textsc{hash}$ where the hash function at each router uses a static permutation of the input tokens to select the experts. This allows tokens to be routed to the same expert at some layers without having the same hash. We found that performance was unchanged for this variant, suggesting that increasing the number of possible routing paths does not necessarily impact performance for static policies.
These router variants suggest that methods which can adapt to each expert layer will outperform static policies. Further work is needed in analyzing how policies can more effectively learn to route across layers.
D.4 Routing a Single Layer

We analyzed the scaling behavior of $\textsc{hash}$ and $\textsc{s-base}$ when only routing a single layer. We observed that the routing gains for $R=\frac{1}{L}$ deviated from higher frequencies, which also impacted $R=\frac{1}{4}$ to a lesser degree. We attribute this performance regression to the suboptimal behavior of the first routed layer. In both cases the total number of routers is low, and the first layer has a larger impact on overall performance than at higher routing frequencies. For $R=\frac{1}{L}$ the complexity of routing is reduced and a simpler routing method can reach competitive performance. $\textsc{hash}$ and $\textsc{s-base}$ have similar performance across expert counts in this case, as shown in Figure 13.
We also compared routing a single layer at $\frac{L}{2}$ with three FFWs per expert to three evenly spaced routed layers in Figure 13. Similar to the results shown in ([12]), three evenly spaced routed layers has slightly better performance than three stacked FFWs for a 32E 1.3B model. We also found that $\textsc{s-base}$ benefits more from interleaving the routed and dense layers, which is consistent with our routing frequency results.
D.5 Varying number of experts per datapoint
In this work we have focused on routing each datapoint to a single expert at all routing layers, i.e. for the case where $K=1$. However, SMoE models have historically routed datapoints to more than one expert ([14, 16, 42]). Increasing $K$ incurs in extra computation on the experts, but this additional computation may be helpful for the end result, reflecting in better loss. Moreover, routing a datapoint through more experts means each expert gets to see more data for each forward pass, which may speed up training. For these reasons, it is not obvious that $K=1$ is the best setup. Section 4.4 investigated this and argued both that the generalized formula Equation 2 can accommodate such cases and also that the resulting fits show no substantial difference in performance for $K$. However we explore this variance more in Figure 14: plotting both scaling curves for varying values of $K$ as well as plotting the loss in terms of $F$. Higher values of $K$ invariably yield better performance per step, but they are not necessarily more flop efficient. In fact, $K=1$ is always in the pareto front. We can verify that this holds for varying numbers of experts.
Note that this difference in flop-efficiency is not only theoretical, and is also followed by increased communication costs when using expert parallelism. We observed in practice that reducing K by half amounted to close to 2x speedup in inference and training.
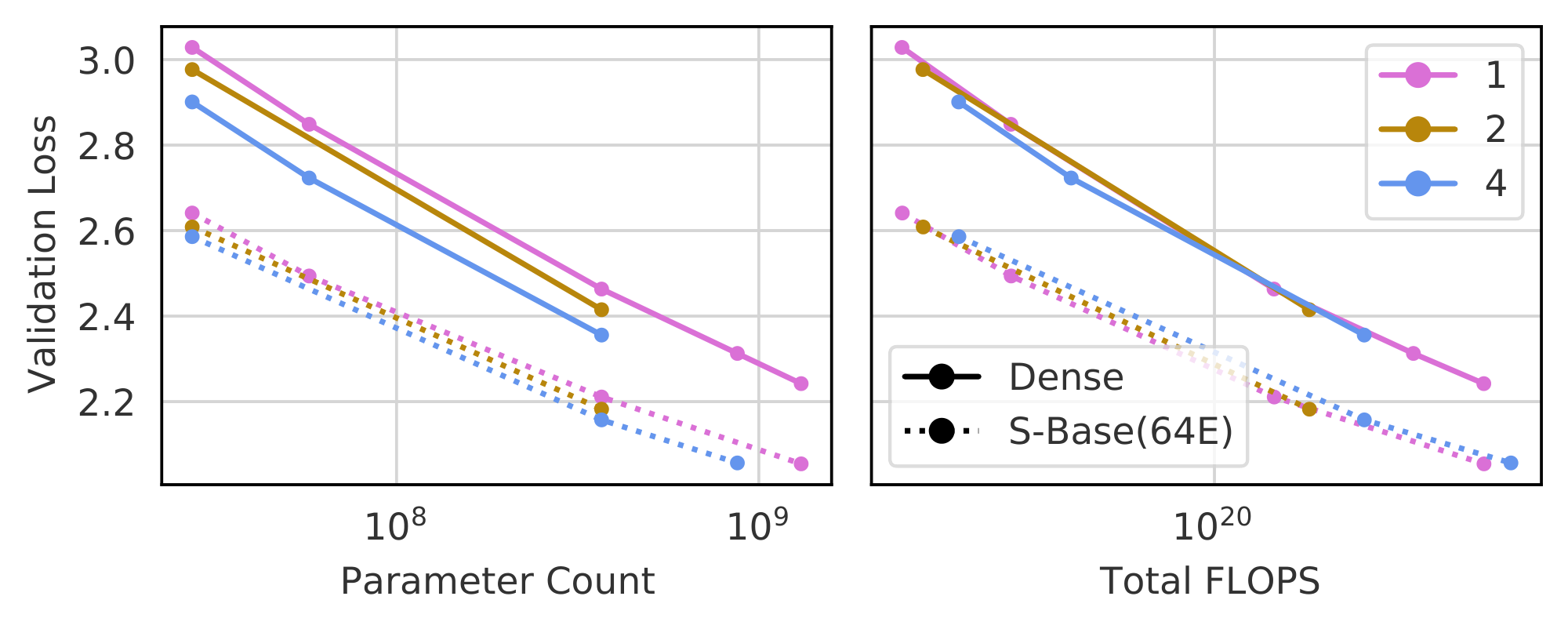
E. Effects of scaling strategy on Zero-shot Transfer
There is a strong relationship between the validation loss we have been discussing and the downstream performance of models and specific tasks ([1]). However, recent work has shown that this relationship is not as straightforward for large Routing Networks, and individual tasks can benefit more or less from expert scaling. For example, [10] show a narrowing performance gap between a $\textsc{smoe}$ Routing Network with $E=512$ and its dense equivalent, with more marked improvement from routing in some tasks like HellaSwag and PIQA than in in tasks like Winogrande and ReCoRD. Likewise, [8] shows that Switch benefits more from scale better in TrivaQA than in SuperGlue.
A detailed analysis of the scaling properties of Routing Networks and how that transfers to downstream tasks merits dedicated work. Here we start the conversation by looking at zero-shot transfer on a set of well known downstream tasks: LAMBADA ([54]), The Pile ([55]), Curation Corpus ([56]), WikiText-103 ([57]) and C4 ([58]).
We estimate the scaling coefficients individually for each task and routing technique. For simplicity of interpretation we ignore the bounded scaling term and focus on the bilinear fit on Equation 7. The coefficients can be seen in Table 9. We expect that scaling in both $N$ and $E$ will improve the downstream performance. The key question revolves around understanding changes in the relative magnitude of $a$, $b$ and $c$ as we move from task to task.

Viewing Table 9 it is immediately clear that the individual scaling coefficients vary greatly across tasks, i.e. different tasks have different relative gains at Zero-Shot performance as we move to larger scales. This can be better shown in Figure 15, where all coefficients are displayed in a single plot. The variation across tasks are not the same for $a$ and $b$. e.g. WikiText-103 has higher values for $b$ and lower for $a$ when compared to the validation set. This means that even though tasks see monotonic improvement in performance by scaling through either adding more experts or increasing the base model size, some tasks benefit more and some less from which method is used.
For a more complete picture, we can account for the $N$ and $E$ interaction coefficient $c$ by incorporating it into one of the scaling coefficients – by holding the other quantity fixed – which leads to $a(E)$ and $b(N)$ (see Section 4.2). This can be seen in Figure 16 for varying values of $N$ and $E$.
We see that $\textsc{s-base}$ tends to dominate with lower coefficients at higher values of $E$ and $N$ (due to its smaller interaction term relative to scaling terms), but this varies across tasks. For example, $\textsc{rl-r}$ shows better $b(N)$ for most values of $N$ in LAMBADA, until it is overtaken by $\textsc{s-base}$ at $N=410M$, but $\textsc{s-base}$ is always superior in C4. Moreover, the ordering is not consistent between $\textsc{hash}$ and $\textsc{rl-r}$ across tasks, even though they often do not cross. This all means it is difficult to establish superior performance of a routing technique without looking at a variety of tasks and scales.
We often want to compare Routing Networks with a dense baseline with the same performance on the validation set, and see how this changes on downstream tasks. We can use these parameters in a simplified version of the Effective Parameter Count (EPC, Equation 11), by assuming $E_{start}=1$ and $E_{max}=\infty$, such that $\hat{E}=E$. First, we note that since the coefficients vary greatly across tasks, each task will have a different EPC for the same network configuration. Moreover, the effects of scaling by varying $E$ and $N$ will vary across tasks. Say we have a routing net of size $N$ with $E$ experts and we want to increase its base model size by a factor of $x$ while keeping the same number of experts. The effect on $\bar{N}$ in this case will be a multiplication by $x^{a(E)/a(1)} = x^{1 + c \log E}$. Since $c$ varies per task, the improvement achieved by increasing the base model size will also be task dependent.
Say we have a routing net of size $N$ with $E$ experts and we want to increase its base model size by a factor of $x$ while keeping the same number of experts. The effect on $\bar{N}$ in this case will be a multiplication by $x^{a(E)/a(1)} = x^{1 + \frac{c}{a} \log E}$. Since $\frac{c}{a}$ varies per task, the improvement achieved by increasing the base model size will also be task dependent.
For example, the $\textsc{epc}$ ${validation}$ for N=110M, E=32 is 370M, but $\textsc{epc}$ ${lambada}$ for the same model is 284M, while $\textsc{epc}$ $_{pile}$ is 535M. The key implication here is not only do the values change, but their slopes are different. This means that downstream tasks must be analyzed carefully: a practitioner could scale a model via routing expecting some overarching improvement, but get a much diminished (or enhanced!) improvement on specific downstream tasks, depending on their specific values of $b$ and $c$.
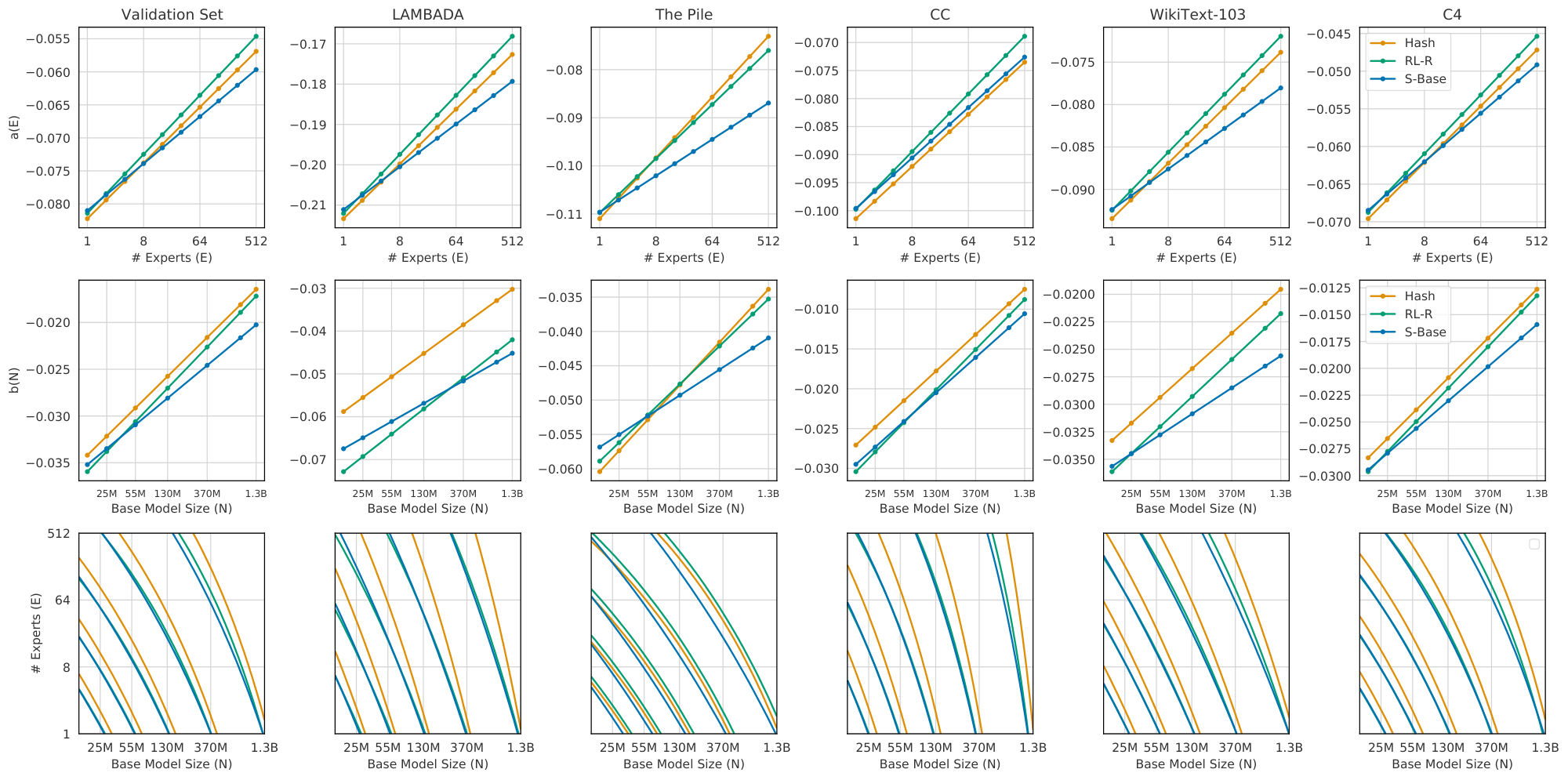
F. On Convergence, or Lack Thereof
Here we digress on two important details, both focusing on token count. First we argue that discussing converged performance of large transformers on modern and massive text datasets is probably a misnomer; scaling analyses should focus on optimal performance at a fixed number of tokens. Second, we provide evidence arguing against a proposed equation in [1] (Eq. (1.6)).
F.1 Convergence on Large Datasets
There are two cases where the converged performance of a model can be clearly defined. The first is when continued training of the model produces no improved results (even analyzed at logarithmic scale in the number of tokens), the second is when continued training leads to reduced validation performance: overfitting.
Our models exhibit neither behavior. No overfitting is seen even for our largest models, likely due to the complexity and size of the dataset used. Furthermore, despite being trained for 130 billion tokens, not even our smallest models have saturated. We push this envelope even further: training two additional sets of 15M models with $1$, $64$, $128$ and $512$ experts. The first set is trained for just $75, 000$ steps, and the second for $1, 000, 000$ steps: four times more data (half a trillion tokens). We highlight that this involves corresponding changes to the cosine cycle decay. We exclusively train $\textsc{hash}$ models, both due to limits in the number of extra models we were able to train and also because it has the largest value of $E_{\max}$.
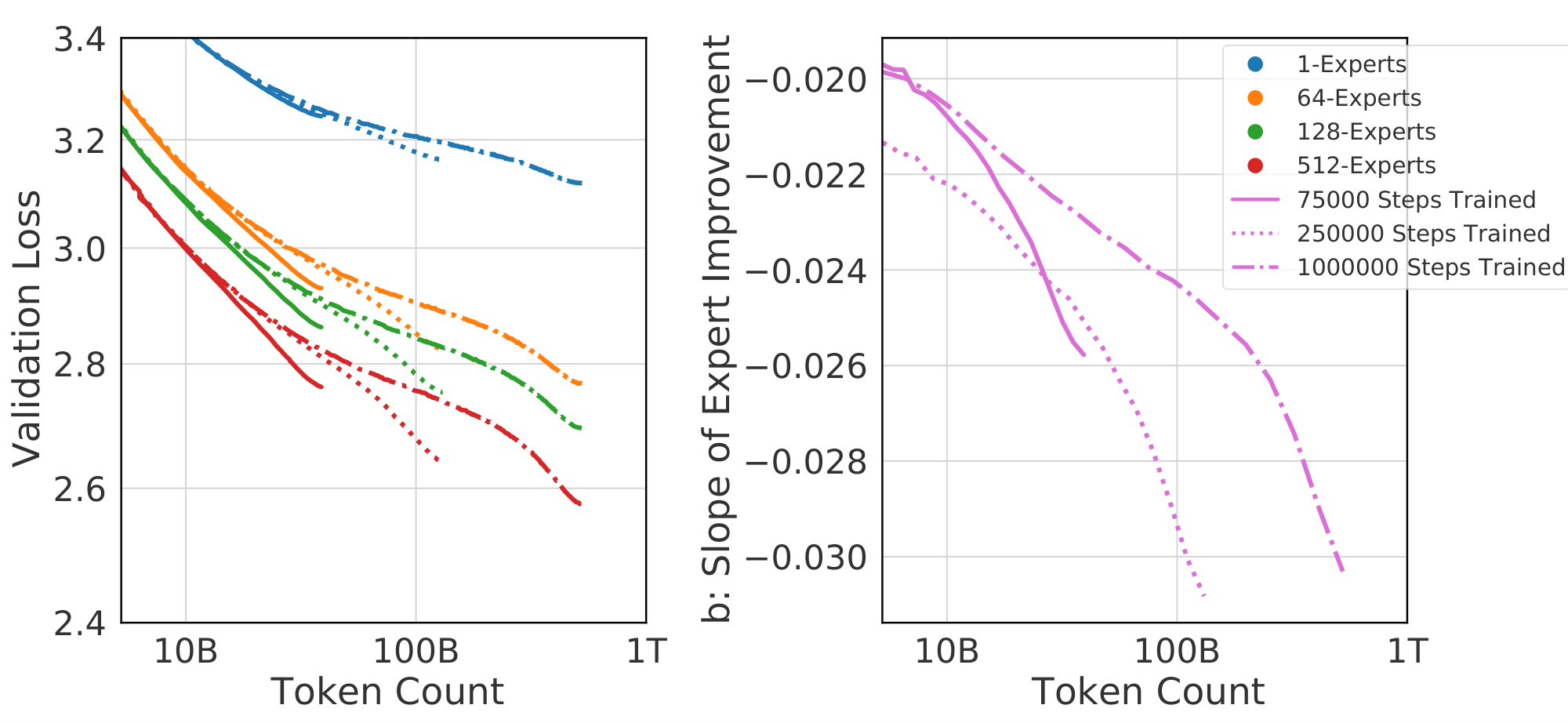
Results from these models are plotted in Figure 17 (left). 15M with no routing, the smallest model we train as part of this work, is still far from having saturated its performance capability. Indeed, training for 4x longer further reduces the validation loss by $0.05$. This pattern continues, and is exacerbated, when increasing the expert count: the same model with $E = 512$ gets a $0.07$ reduction in loss from 4x more tokens.
It is clear then that the very smallest models considered have yet to converge. The same is certainly true for larger ones, and probably more so. If 500 billion tokens is a lower bound to the convergence point of 15M, the analysis in [1] would predict needing trillions of tokens to converge 1.3B: much more than what was used to train some of the largest language models yet created ([35]). For large, complex text datasets of the scale used to train large language models, convergence is not a proper criteria.
F.2 Performance Qualified on Token Count
Rather than claiming analysis at a non-observed point of convergence, we emphasize that the scaling behavior we have described in this work is valid only as a function of a particular number of steps (or tokens). At each point, we can define instantaneous values of scaling coefficients, with the values from all models taken at $S$ steps[^3].
[^3]: This sidesteps the issue of critical batch size ([59, 1]), consideration of which requires a substantially larger sweep of models. Future work estimating the critical batch size will likely lead to better model fits.
In fact, the situation is more complicated that simply conditioning our scaling coefficients on token count. We can see this by plotting $b$, the scaling coefficient for changes in expert-count in Figure 17(right). An immediate observation is that the values of $b$ are non-constant, supporting the need to qualify scaling on token count. A second, more substantial point, is that these values are not uniquely defined by token count. For a given number of tokens, the scaling behavior of three different sets of models is completely different, dependent on how far into the learning rate schedule those sets of models were. We note that this behavior is suggested by experiments in [1] (App. D.6).
Attempting to find the full set of parameters on which these scaling terms depend is beyond the scope of this work. We highlight just the importance of insuring that all variables possible are matched when comparing values to calculate scaling coefficients.
F.3 Performance Modeled as L(N, S)
We conclude by highlighting one implication of the fact that scaling coefficients are dependent on token count. We analyze only the dense models trained as part of this work, and calculate values of $a$ in Equation 3 for all dense models trained as part of the primary sweep across all step counts; plotted in @fig:bad_fits with RMSE values plotted in @fig:bad_fits. First, it is important to emphasize that the fits remain good throughout $S$ (after an initial period of transience). Namely, though the slope is different, the validation losses for a given intermediate $S$ follow a power law about as well as they do later in training (if anything, more so). Second, the estimated coefficients $a$ are clearly monotonically increasing with $S$.
([1]) propose (Eq. 1.6) a unified prediction of the loss achieved by a model with size $N$ training for $S$ steps:
$ L(N, S) = \left(\frac{N_c}{N}\right)^{\alpha_N} + \left(\frac{S_c}{S}\right)^{\alpha_S} $
This comes with the subtlety that $S$ must be defined as the number of steps when training at the averaged critical batch size, where our models are trained with a fixed batch size. This means a proper analysis must use $S_\mathit{min}$ with $S = S(1 + \frac{B_c}{B L^{-\alpha_B}})^{-1}$ for constants $B_c$ and $\alpha_B$. It is important to highlight however that $S_\mathit{min}$, as described in [1], should be independent of $N$. This implies that $\frac{\partial}{\partial N}\left(L(N, S)\right)$ is independent of S, or in log-log space:
$ \left. \frac{\partial \log(L(N^*, S))}{\partial N^*} \right|_{N^* = 10^{N}} = -\alpha_N\tag{18} $
This prediction of constant scale is in concrete opposition to the increasing value seen in @fig:bad_fits. We can furthermore check that this functional form cannot be obviously fit to our learning curves, with examples show in @fig:bad_fits.
There are subtle differences between training setups, and we do not want to claim our experiments wholly disprove the conjecture in ([1]). However, the results in [@fig:bad_fits] motivate us to assume that [@eq:claimed_step] cannot be used to model our specific training curves. A consequence of this is that we can also no longer conclude Equation B.5 from ([1]), that:
$ L(N_{eff}(C), C) = (1 + \frac{\alpha_N}{\alpha_S})L(N_{eff}, \infty) $
With this equation, we might be able to lower-bound true converged performance (which we have not seen in our models) by inference from compute-efficient performance, which has been achieved by the majority of our models.
G. Large Scale Routing Behavior, Coefficient Sensitivity, and Future Work
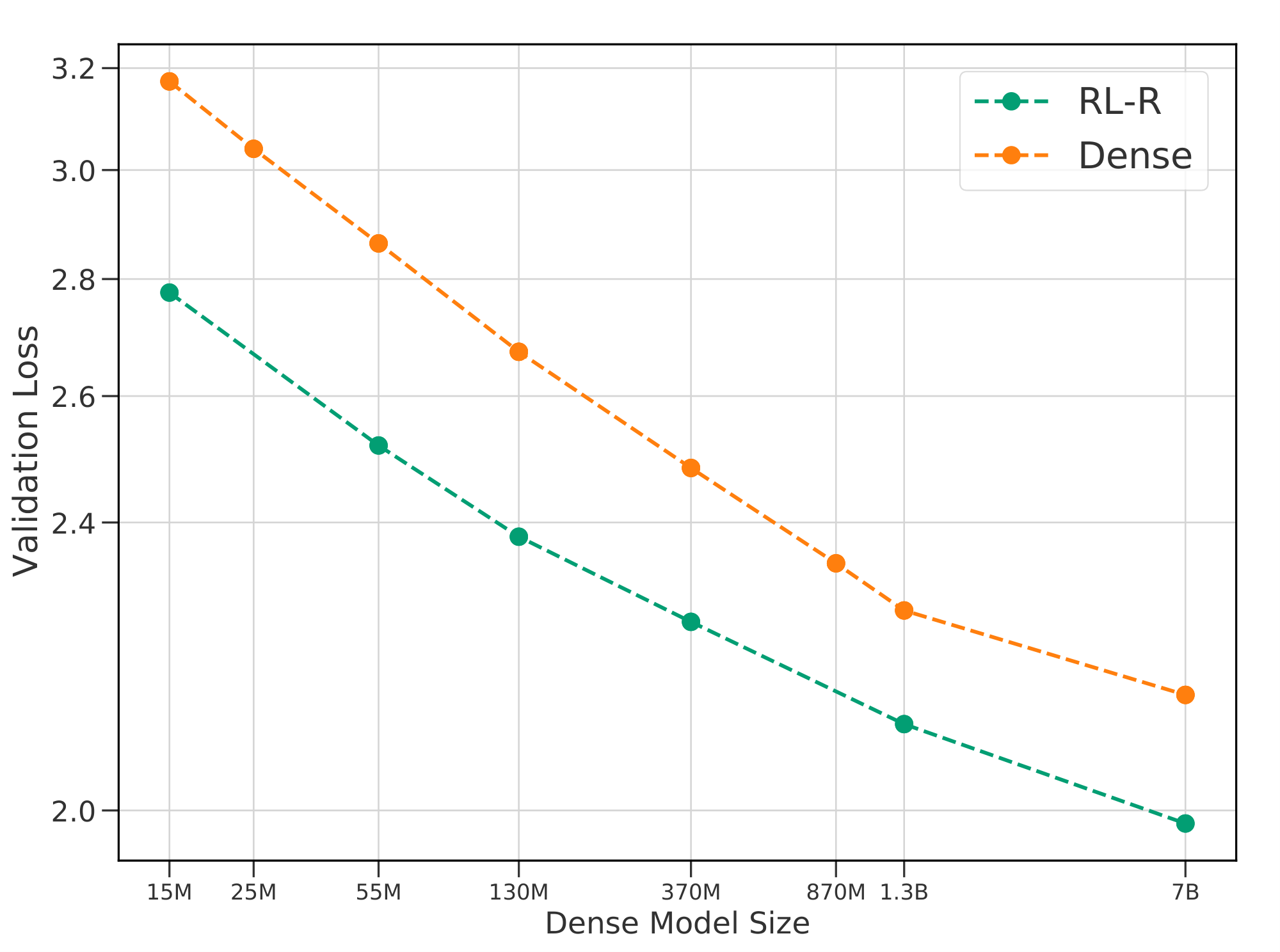
Our analysis predicts that larger values of $E$ will continue to improve performance, especially for small models, at a diminishing rate. Section 5.2 also predicts that routing will continue to help with increasing $N$ for at least one, if not two orders of magnitude larger base model size. Practical compute limitations prevented our sweep from exploring these regimes, and there are interesting unanswered questions in the limit of these two variables. In particular, exact predictions of $N_{\textrm{cutoff}}$ are highly dependent on the precise value of $b$, where error in the second decimal place shifts predicted values by orders of magnitude (not surprising, as it is the slope of a line in log-log space).
We believe exploring the limit behavior of $N$ and $E$, especially arriving at a more precise value of $b$, is crucial. Anecdotally, we can report the results of one experiment: a large $\textsc{rl-r}$ model with $N > 7, 000, 000$, providing a rough upper bound for error in $b$ for $\textsc{rl-r}$ . In particular, we trained a model with $d_{model}=4096$, $n_{layers}=32$, $n_{heads}=32, E=64$ and K/V size of 128. There are some important eccentricities of this model which affect its match to the fits described in this work: it was trained with a batch size of 1024 for 100k steps with a policy gradient weight of 1e-1 and balancing weight of 1e-1. Other training details are consistent with Section 2.1.
The performance of this model, relative to a dense model of the same size and also to a number of smaller models, is plotted in Figure 19 evaluated at 100B tokens. The changes described above prevent the analysis in this work from accurately predicting this model's performance, but one key feature remains: the routed 7B model substantially outperforms the baseline. This is of particular interest since just a $0.01$ decrease in $b$ would predict an $N_{\textrm{cutoff}}$ at $9B$, meaning we would already be close to the regime where routing would cease to work. Nevertheless, at this value routing is clearly still a major improvement, and our estimate of $b$ is unlikely to be a substantial overshoot.
While the differences between this model and those analyzed in the paper make concrete extrapolation impossible, it shows that routing techniques still maintain competitive improvements at almost an order of magnitude larger value of $N$ than analyzed and it is unlikely the scaling coefficients measured in this work substantially overestimate the routing technique's scalability. We encourage future work probing the limits of routing networks, both in $N$ and $E$, to better understand their properties and provide more accurate predictions of their scaling coefficients.
H. Extra Plots and Tables
This section contains some helpful visualizations and data which are not included in the main text.
:Table 6: Values of $b(N)$ with hold-out RMSEs in parentheses.
| 15M | 25M | 130M | 370M | 1.3B | |
|---|---|---|---|---|---|
| $\textsc{s-base}$ | -0.035 | -0.031 | -0.029 | -0.024 | -0.019 |
| (0.035) | (0.019) | (0.017) | (0.014) | (0.012) | |
| $\textsc{rl-r}$ | -0.033 | -0.031 | -0.027 | -0.022 | -0.016 |
| (0.016) | (0.013) | (0.013) | (0.014) | (0.009) | |
| $\textsc{hash}$ | -0.031 | -0.029 | -0.025 | -0.021 | -0.015 |
| (0.039) | (0.029) | (0.023) | (0.016) | (0.011) |
:Table 7: Fits to 7.
| a | b | c | d | |
|---|---|---|---|---|
| $\textsc{s-base}$ | 0.079 | 0.088 | 0.007 | 1.072 |
| $\textsc{rl-r}$ | 0.080 | 0.105 | 0.010 | 1.076 |
| $\textsc{hash}$ | 0.081 | 0.097 | 0.009 | 1.086 |
:Table 8: Values of $a(E)$ for different values of $E$
| $\textsc{s-base}$ | RL-R | HashLayers | |
|---|---|---|---|
| 4 | 0.077 | 0.075 | 0.077 |
| 8 | 0.073 | 0.073 | 0.075 |
| 32 | 0.070 | 0.067 | 0.069 |
| 64 | 0.066 | 0.063 | 0.066 |
| 128 | 0.064 | 0.060 | 0.063 |
| 256 | 0.058 | 0.056 | 0.059 |
| 512 | 0.060 | 0.053 | 0.056 |
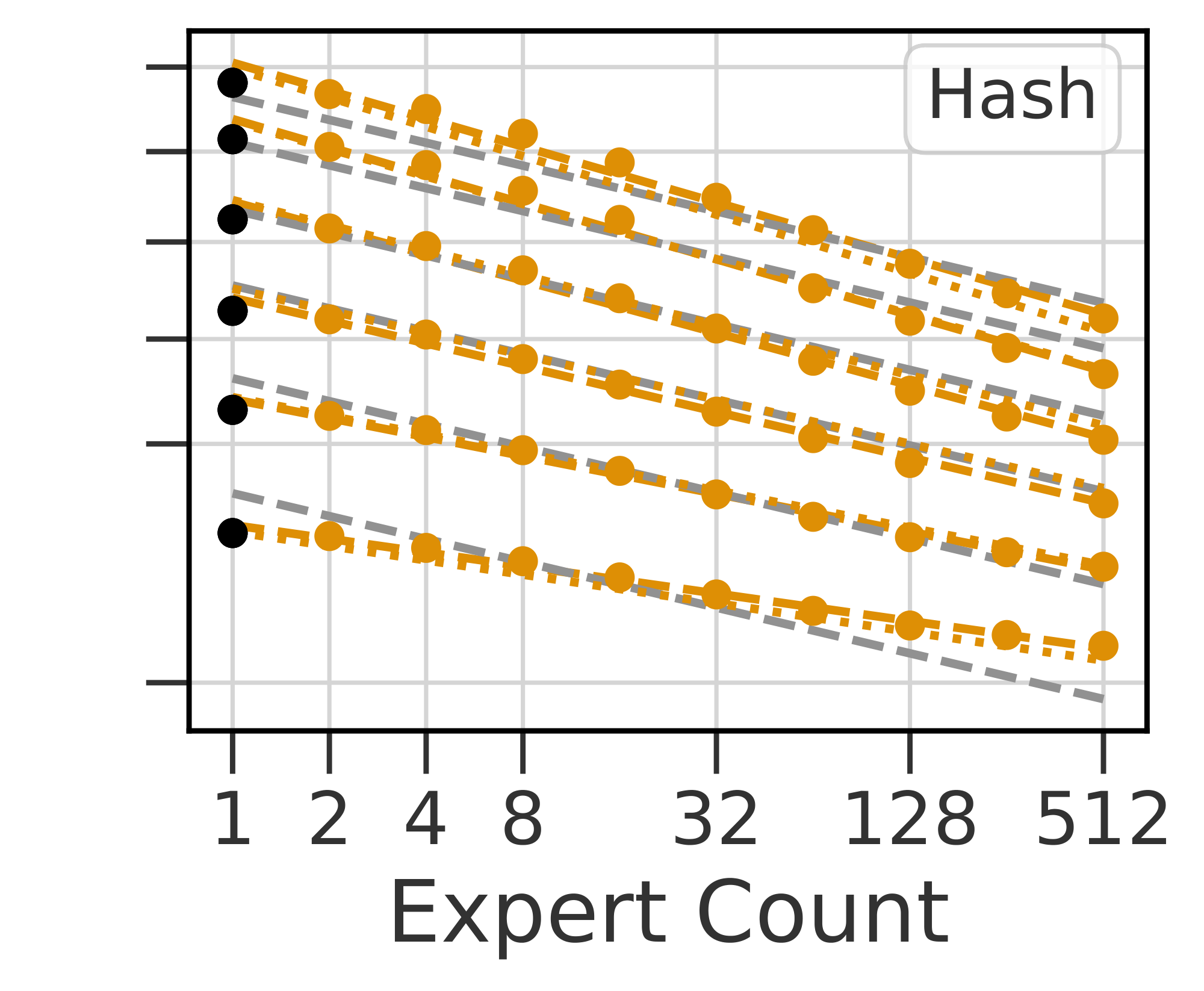
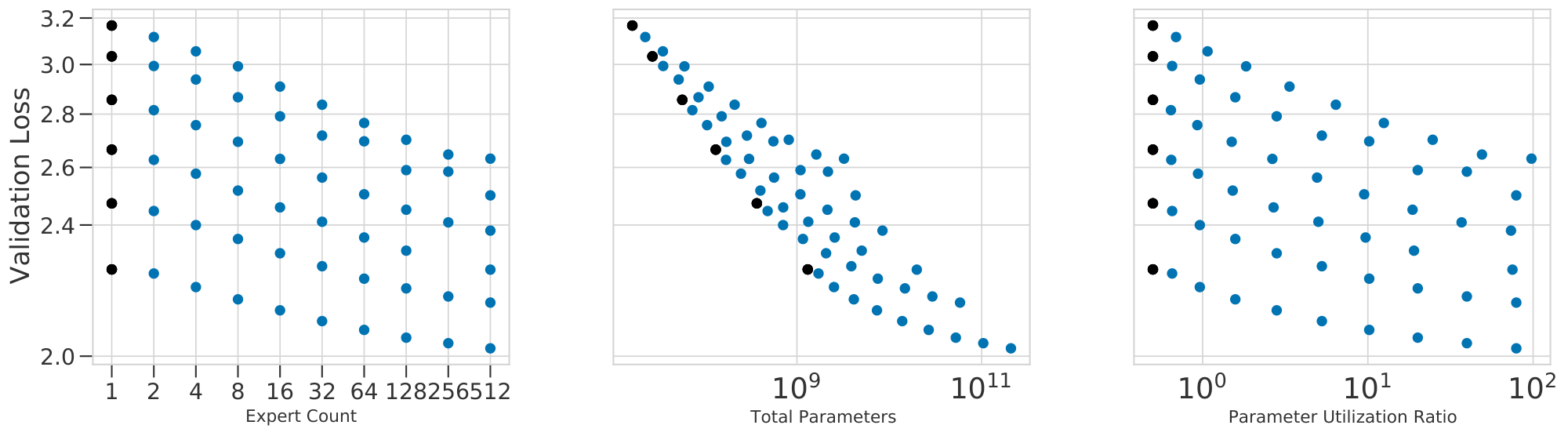
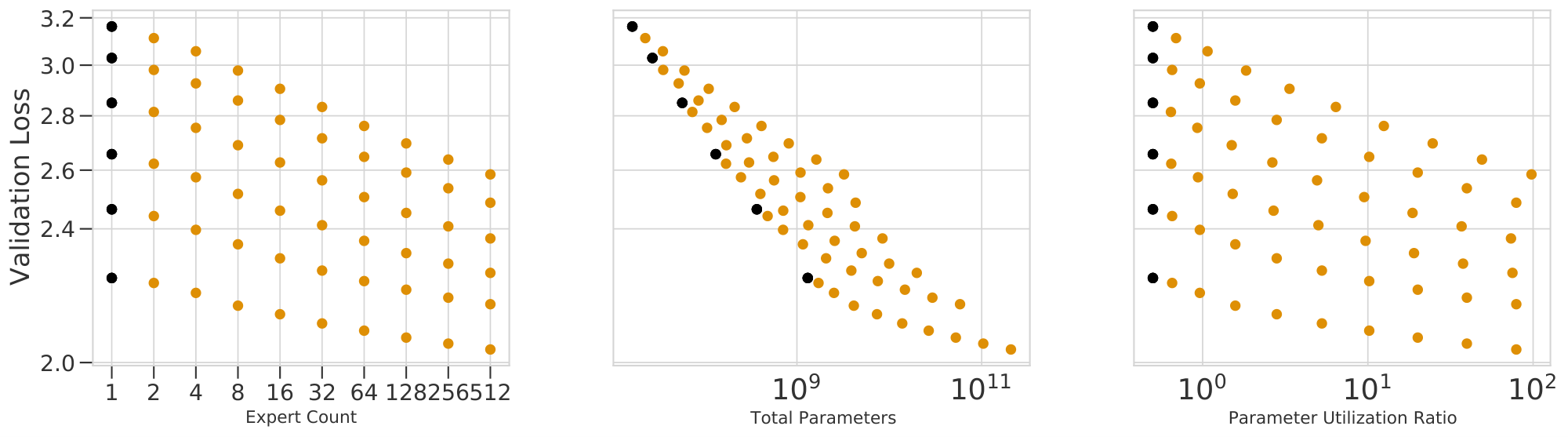
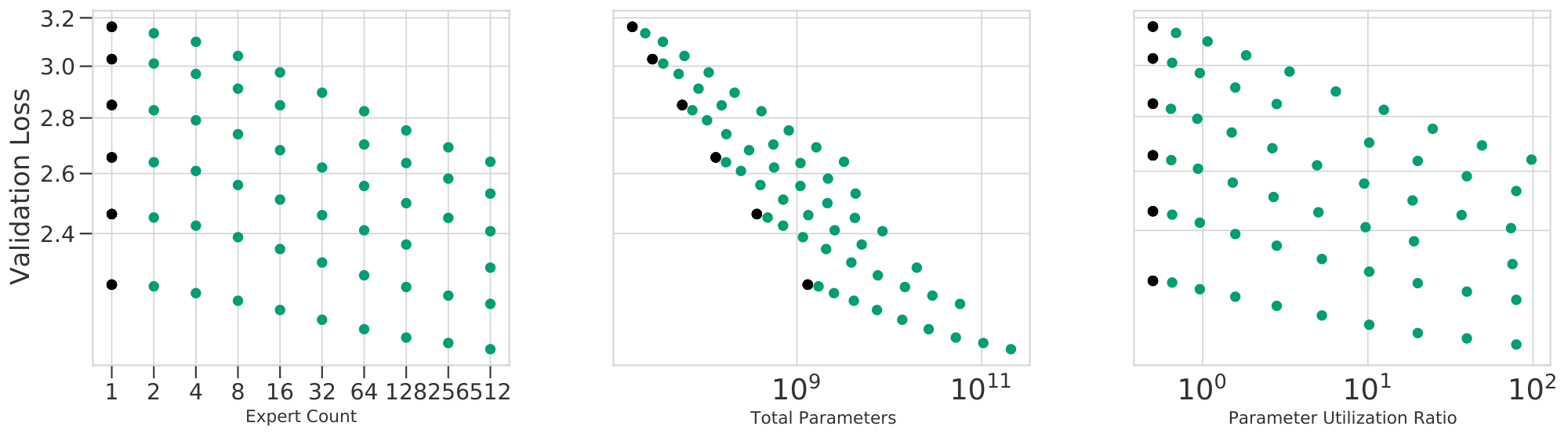
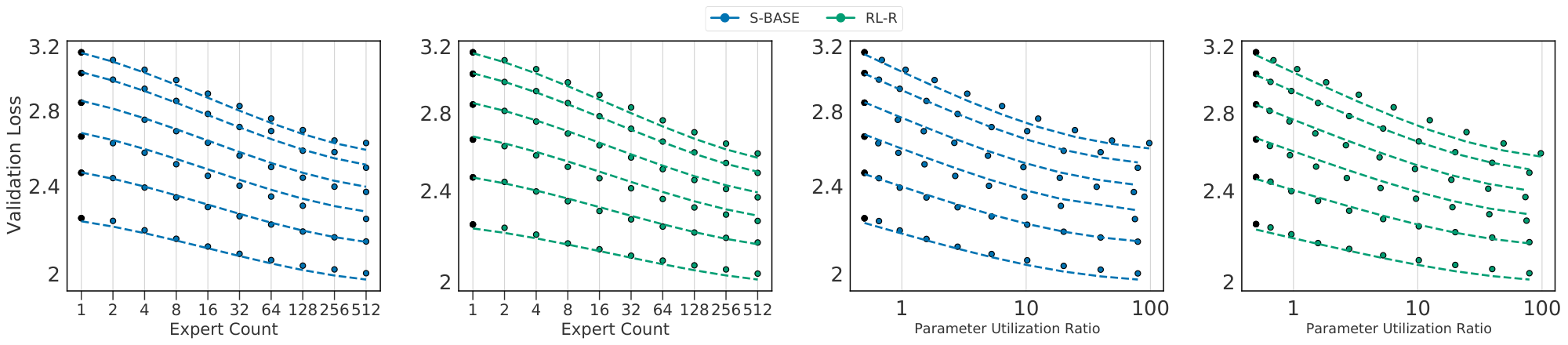
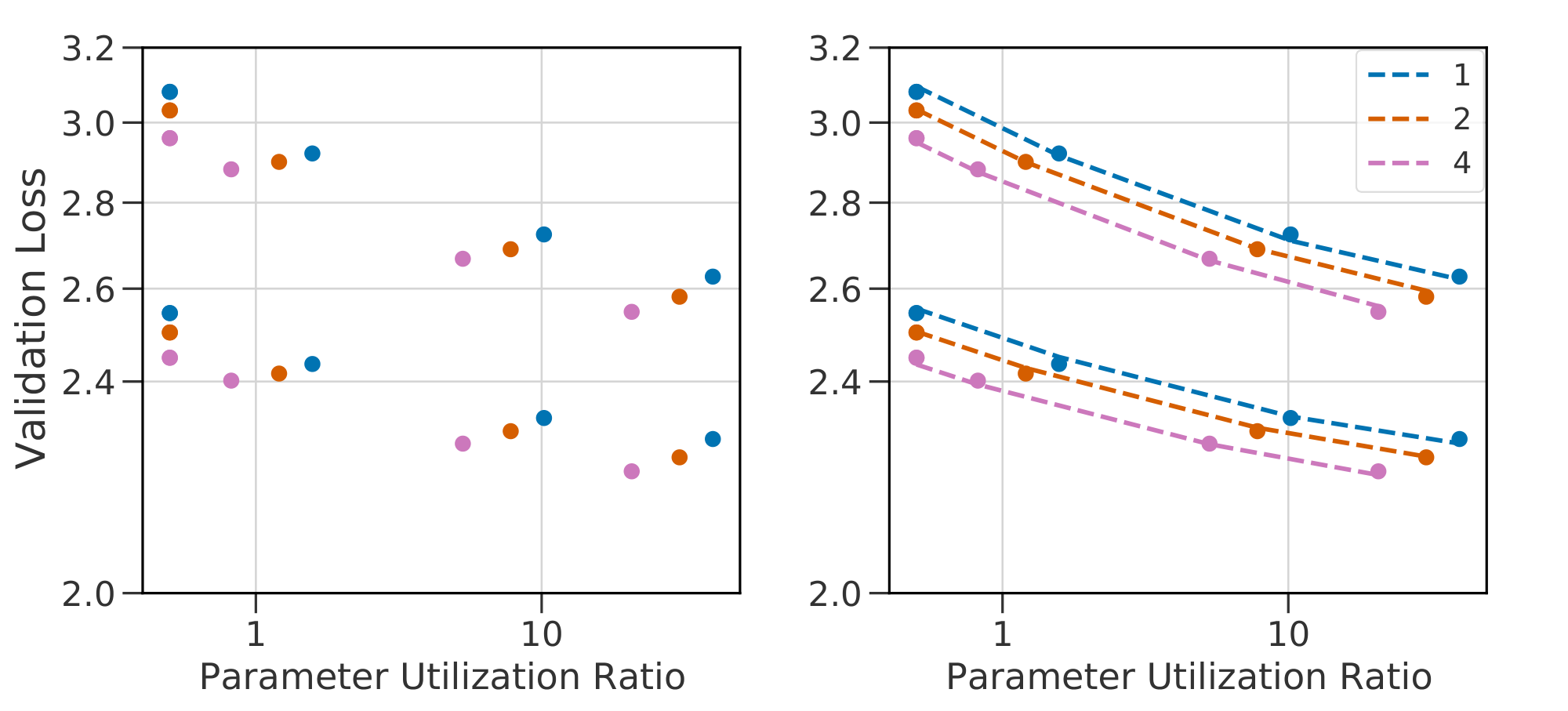
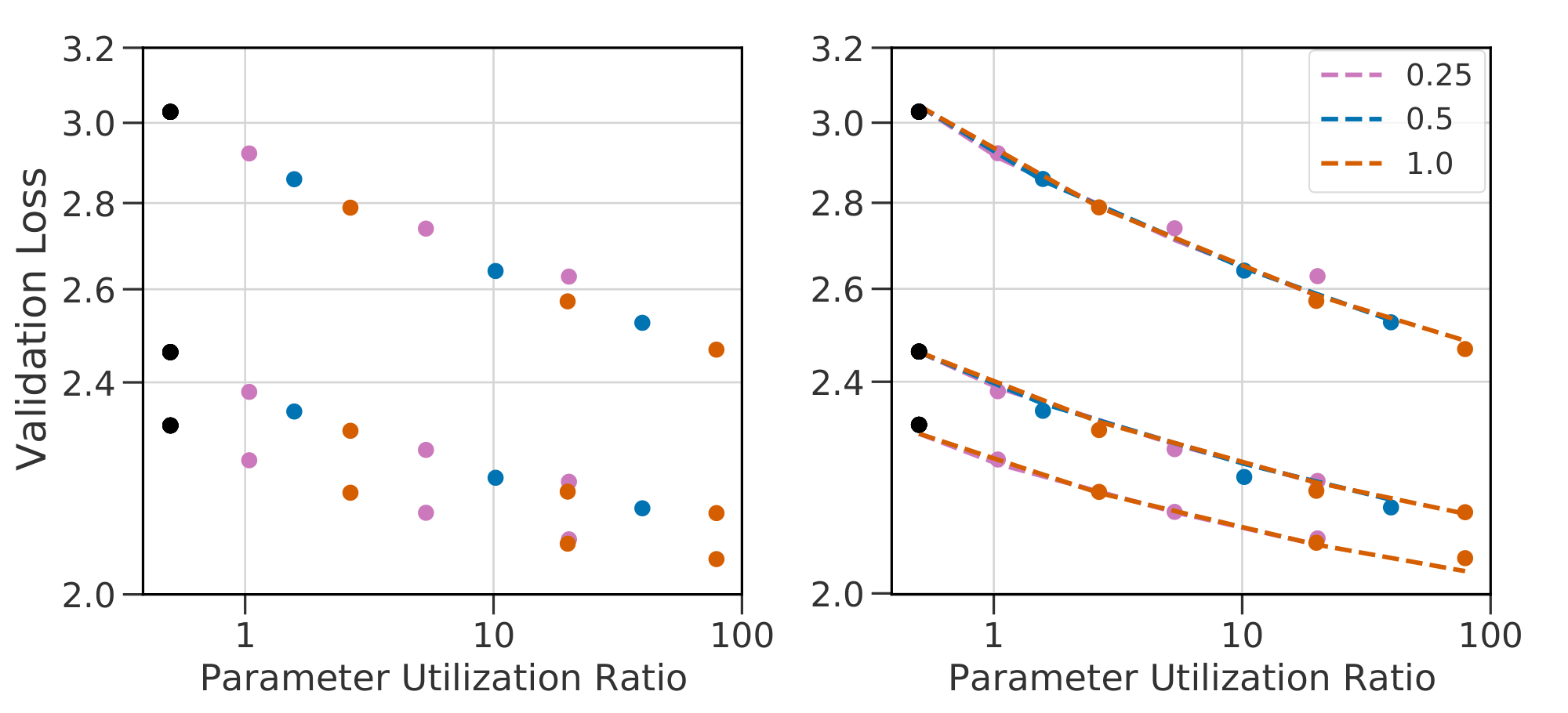
\begin{tabular}{llrrrrr}
\toprule
& & a & b & c & d & RMSE \\
policy & dataset & & & & & \\
\midrule
Dense & Validation Set & -0.078 & & & 1.063 & 0.014 \\
& LAMBADA & -0.203 & & & 1.952 & 0.039 \\
& The Pile & -0.102 & & & 1.239 & 0.020 \\
& CC & -0.097 & & & 1.133 & 0.041 \\
& WikiText-103 & -0.090 & & & 1.172 & 0.015 \\
& C4 & -0.066 & & & 1.009 & 0.014 \\
Hash & Validation Set & -0.082 & -0.102 & 0.009 & 1.102 & 0.022 \\
& LAMBADA & -0.213 & -0.167 & 0.015 & 2.049 & 0.051 \\
& The Pile & -0.111 & -0.161 & 0.014 & 1.325 & 0.023 \\
& CC & -0.101 & -0.101 & 0.010 & 1.177 & 0.045 \\
& WikiText-103 & -0.093 & -0.086 & 0.007 & 1.208 & 0.027 \\
& C4 & -0.070 & -0.088 & 0.008 & 1.045 & 0.021 \\
S-Base & Validation Set & -0.081 & -0.092 & 0.008 & 1.086 & 0.025 \\
& LAMBADA & -0.211 & -0.152 & 0.012 & 2.020 & 0.048 \\
& The Pile & -0.110 & -0.117 & 0.008 & 1.309 & 0.028 \\
& CC & -0.100 & -0.101 & 0.010 & 1.154 & 0.050 \\
& WikiText-103 & -0.092 & -0.074 & 0.005 & 1.194 & 0.025 \\
& C4 & -0.068 & -0.081 & 0.007 & 1.031 & 0.024 \\
RL-R & Validation Set & -0.081 & -0.107 & 0.010 & 1.090 & 0.022 \\
& LAMBADA & -0.212 & -0.190 & 0.016 & 2.030 & 0.051 \\
& The Pile & -0.110 & -0.149 & 0.012 & 1.320 & 0.030 \\
& CC & -0.100 & -0.113 & 0.011 & 1.156 & 0.045 \\
& WikiText-103 & -0.092 & -0.091 & 0.008 & 1.195 & 0.023 \\
& C4 & -0.069 & -0.092 & 0.009 & 1.033 & 0.022 \\
\bottomrule
\end{tabular}
References
[1] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv:2001.08361, 2020.
[2] Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer. arXiv:2102.01293, 2021.
[3] Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B Brown, Prafulla Dhariwal, Scott Gray, et al. Scaling laws for autoregressive generative modeling. arXiv:2010.14701, 2020.
[4] Jonathan S Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit. A constructive prediction of the generalization error across scales. In International Conference on Learning Representations, 2019.
[5] Emmanuel Bengio, Pierre-Luc Bacon, Joelle Pineau, and Doina Precup. Conditional computation in neural networks for faster models. In International Conference on Learning Representations, 2016.
[6] Yoshua Bengio, Nicholas Léonard, and Aaron C. Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. CoRR, abs/1308.3432, 2013.
[7] Ludovic Denoyer and Patrick Gallinari. Deep sequential neural networks. In NIPS Deep Learning Workshop, 2014.
[8] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv:2101.03961, 2021.
[9] Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, Kathy Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc V Le, Yonghui Wu, Zhifeng Chen, and Claire Cui. Glam: Efficient scaling of language models with mixture-of-experts. arXiv 2112.06905, 2021.
[10] Mikel Artetxe, Shruti Bhosale, Naman Goyal, Todor Mihaylov, Myle Ott, Sam Shleifer, Xi Victoria Lin, Jingfei Du, Srinivasan Iyer, Ramakanth Pasunuru, Giri Anantharaman, Xian Li, Shuohui Chen, Halil Akin, Mandeep Baines, Louis Martin, Xing Zhou, Punit Singh Koura, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Mona Diab, Zornitsa Kozareva, and Ves Stoyanov. Efficient Large Scale Language Modeling with Mixtures of Experts. arXiv:2112.10684, 2021.
[11] Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. BASE layers: Simplifying training of large, sparse models. In International Conference on Machine Learning, 2021.
[12] Stephen Roller, Sainbayar Sukhbaatar, Arthur Szlam, and Jason Weston. Hash layers for large sparse models. arXiv:2106.04426, 2021.
[13] Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Maribeth Rauh, Po-Sen Huang, Amelia Glaese, Johannes Welbl, Sumanth Dathathri, Saffron Huang, Jonathan Uesato, John Mellor, Irina Higgins, Antonia Creswell, Nat McAleese, Amy Wu, Erich Elsen, Siddhant Jayakumar, Elena Buchatskaya, David Budden, Esme Sutherland, Karen Simonyan, Michela Paganini, Laurent Sifre, Lena Martens, Xiang Lorraine Li, Adhiguna Kuncoro, Aida Nematzadeh, Elena Gribovskaya, Domenic Donato, Angeliki Lazaridou, Arthur Mensch, Jean-Baptiste Lespiau, Maria Tsimpoukelli, Nikolai Grigorev, Doug Fritz, Thibault Sottiaux, Mantas Pajarskas, Toby Pohlen, Zhitao Gong, Daniel Toyama, Cyprien de Masson d'Autume, Yujia Li, Tayfun Terzi, Vladimir Mikulik, Igor Babuschkin, Aidan Clark, Diego de Las Casas, Aurelia Guy, Chris Jones, James Bradbury, Matthew Johnson, Blake Hechtman, Laura Weidinger, Iason Gabriel, William Isaac, Ed Lockhart, Simon Osindero, Laura Rimell, Chris Dyer, Oriol Vinyals, Kareem Ayoub, Jeff Stanway, Lorrayne Bennett, Demis Hassabis, Koray Kavukcuoglu, and Geoffrey Irving. Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv:2112.11446, 2021.
[14] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In International Conference on Learning Representations, 2017.
[15] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 2017.
[16] Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. In International Conference on Learning Representations, 2020.
[17] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, and Skye Wanderman-Milne. Jax: composable transformations of Python + NumPy programs, 2018.
[18] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv:1909.08053, 2019.
[19] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2018.
[20] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16, 2020.
[21] David Eigen, Marc'Aurelio Ranzato, and Ilya Sutskever. Learning factored representations in a deep mixture of experts. ICLR Workshop, 2014.
[22] Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991.
[23] Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. In Advances in Neural Information Processing Systems, 2013.
[24] Taku Kudo and John Richardson. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2018.
[25] Emmanuel Bengio. On Reinforcement Learning for Deep Neural Architectures: Conditional Computation with Stochastic Computation Policies. McGill University (Canada), 2017.
[26] Richard S Sutton, David A McAllester, Satinder P Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In Advances in neural information processing systems, 2000.
[27] Clemens Rosenbaum, Ignacio Cases, Matthew Riemer, and Tim Klinger. Routing networks and the challenges of modular and compositional computation. arXiv:1904.12774, 2019.
[28] Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3):229–256, 1992.
[29] Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018.
[30] Richard H Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu. A limited memory algorithm for bound constrained optimization. SIAM Journal on scientific computing, 16(5):1190–1208, 1995.
[31] Behrooz Ghorbani, Orhan Firat, Markus Freitag, Ankur Bapna, Maxim Krikun, Xavier Garcia, Ciprian Chelba, and Colin Cherry. Scaling laws for neural machine translation. arXiv:2109.07740, 2021.
[32] Marcus Hutter. Learning curve theory. arXiv:2102.04074, 2021.
[33] Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws. arXiv:2102.06701, 2021.
[34] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 2019.
[35] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. arXiv:2005.14165, 2020.
[36] Opher Lieber, Or Sharir, Barak Lenz, and Yoav Shoham. Jurassic-1: Technical details and evaluation. White Paper. AI21 Labs, 2021.
[37] Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. Pipedream: Generalized pipeline parallelism for dnn training. In Proceedings of the ACM Symposium on Operating Systems Principles, 2019.
[38] Young Jin Kim, Ammar Ahmad Awan, Alexandre Muzio, Andres Felipe Cruz Salinas, Liyang Lu, Amr Hendy, Samyam Rajbhandari, Yuxiong He, and Hany Hassan Awadalla. Scalable and efficient MoE training for multitask multilingual models. CoRR, abs/2109.10465, 2021.
[39] Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake Hechtman, Yanping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy Ly, Marcello Maggioni, et al. Gspmd: General and scalable parallelization for ml computation graphs. arXiv:2105.04663, 2021.
[40] Clemens Rosenbaum, Tim Klinger, and Matthew Riemer. Routing networks: Adaptive selection of non-linear functions for multi-task learning. In International Conference on Learning Representations, 2018.
[41] Ronan Collobert, Yoshua Bengio, and Samy Bengio. Scaling large learning problems with hard parallel mixtures. International Journal of Pattern Recognition and Artificial Intelligence, 17(03):349–365, 2003.
[42] Prajit Ramachandran and Quoc V Le. Diversity and depth in per-example routing models. In International Conference on Learning Representations, 2018.
[43] Xiaonan Nie, Shijie Cao, Xupeng Miao, Lingxiao Ma, Jilong Xue, Youshan Miao, Zichao Yang, Zhi Yang, and Bin Cui. Dense-to-sparse gate for mixture-of-experts. arXiv:2112.14397, 2021.
[44] Hussein Hazimeh, Zhe Zhao, Aakanksha Chowdhery, Maheswaran Sathiamoorthy, Yihua Chen, Rahul Mazumder, Lichan Hong, and Ed H Chi. Dselect-k: Differentiable selection in the mixture of experts with applications to multi-task learning. Advances in Neural Information Processing Systems, 2021.
[45] Lucas Caccia, Jing Xu, Myle Ott, Marc'Aurelio Ranzato, and Ludovic Denoyer. On anytime learning at macroscale. arXiv:2106.09563, 2021.
[46] Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation AI scale. arXiv 2201.05596, 2022.
[47] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell, Quoc Le, and Ruslan Salakhutdinov. Transformer-XL: Attentive language models beyond a fixed-length context. In Annual Meeting of the Association for Computational Linguistics, pages 2978–2988, 2019.
[48] Gabriel Peyré and Marco Cuturi. Computational Optimal Transport. Foundations and Trends in Machine Learning, 2019.
[49] Wouter Kool, Chris J. Maddison, and Andriy Mnih. Unbiased gradient estimation with balanced assignments for mixtures of experts. CoRR, abs/2109.11817, 2021.
[50] L. Kantorovitch. On the Translocation of Masses. Management Science, 5(1):1–4, 1958.
[51] Paul Knopp and Richard Sinkhorn. Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21(2):343–348, 1967.
[52] Ari Holtzman, Jan Buys, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. CoRR, 2019.
[53] Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in Neural Information Processing Systems, 2019.
[54] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc-Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016.
[55] Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800GB dataset of diverse text for language modeling. arXiv:2101.00027, 2020.
[56] Curation. Curation corpus base, 2020.
[57] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. International Conference on Learning Representations, 2016.
[58] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21:1–67, 2020.
[59] Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training. arXiv:1812.06162, 2018.