End-to-End Test-Time Training for Long Context
Show me an executive summary.
Purpose and Context
Large language models like GPT rely on self-attention mechanisms that examine every previous token when processing new input. This approach excels at recalling details but becomes prohibitively expensive for long contexts—computational cost grows quadratically with context length. Alternative architectures like RNNs (Mamba 2, Gated DeltaNet) run faster but lose effectiveness as context grows longer. The goal of this work was to develop a method that maintains the performance benefits of full attention at long context while achieving the constant-per-token cost of RNNs.
Approach
The research reframes long-context modeling as a continual learning problem rather than purely an architecture challenge. The core idea: instead of trying to recall every detail perfectly, compress the context into the model's weights through test-time training (TTT). Specifically, when processing a test sequence, the model continues learning via next-token prediction on the given context, storing compressed information in its parameters rather than in an explicit memory cache.
The method uses a standard Transformer architecture with sliding-window attention (8K window) as the baseline. During inference, after processing each mini-batch of tokens (typically 1K tokens), the model takes gradient steps to update a subset of its weights (the MLP layers in the final quarter of the network). Critically, the model's initialization is optimized at training time through meta-learning—training explicitly prepares the model to learn effectively during test-time deployment, not just to perform well out-of-the-box.
Key Findings
Testing focused on 3B parameter models trained on 164B tokens, evaluated up to 128K context length on the Books dataset:
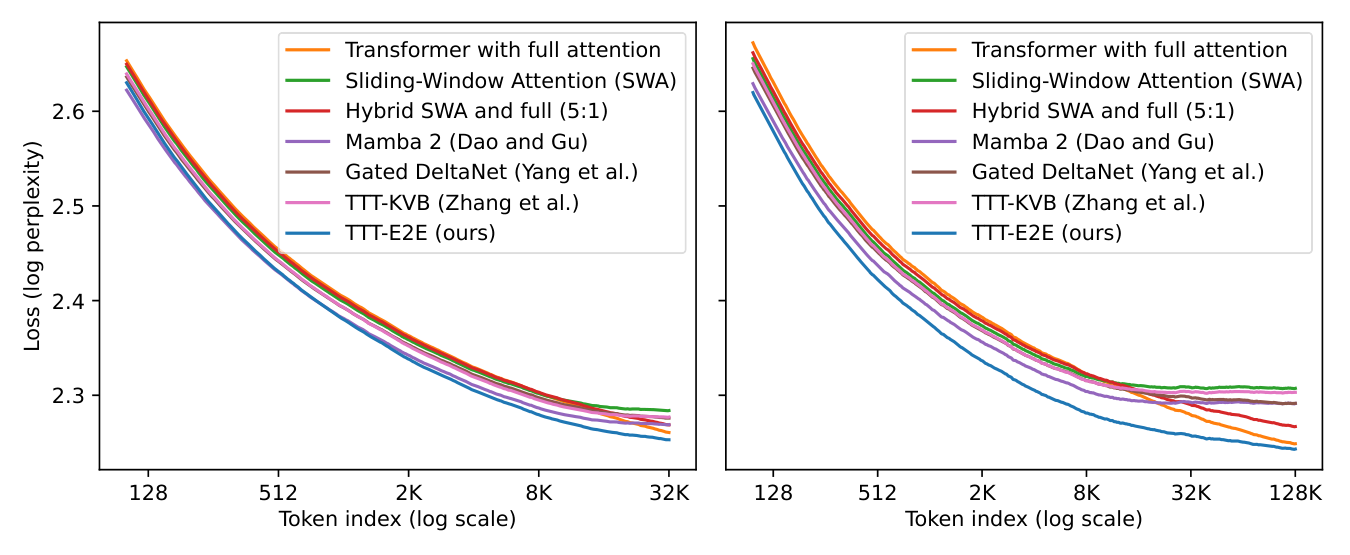
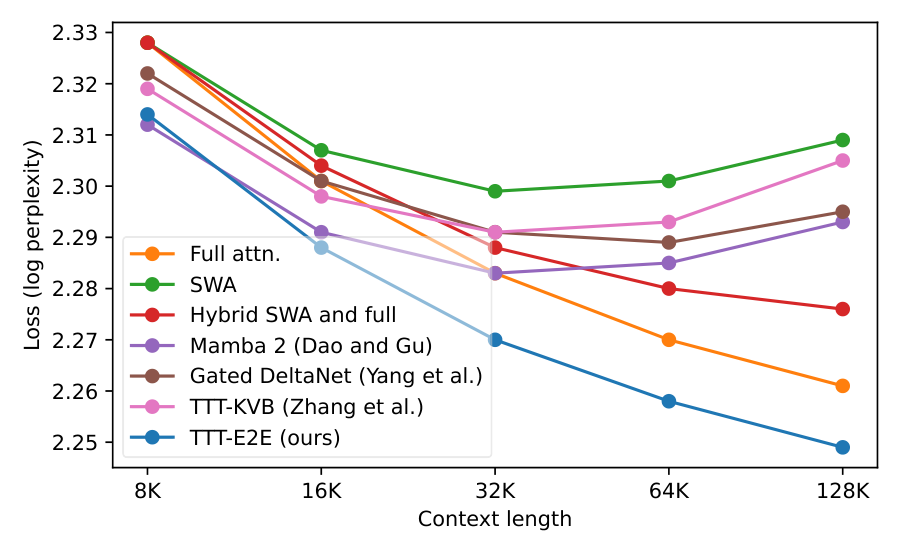
- Performance scales with context: TTT-E2E maintains the same advantage over full attention across all context lengths tested (8K to 128K). Other methods (Mamba 2, Gated DeltaNet, TTT-KVB) show degrading performance relative to full attention as context grows.
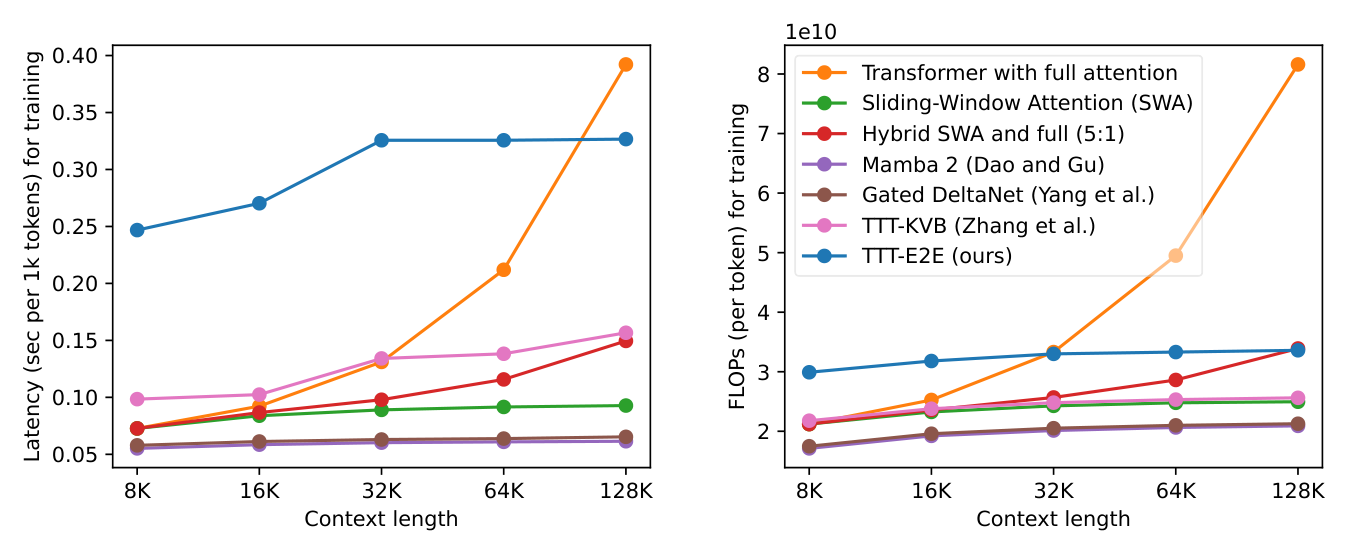
- Speed advantage: Inference latency remains constant regardless of context length, making TTT-E2E 2.7× faster than full attention at 128K context on an H100 GPU. This matches RNN-style methods in speed while exceeding them in performance.
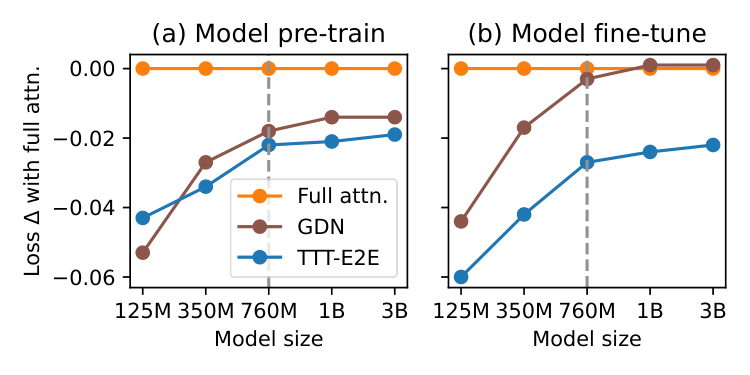
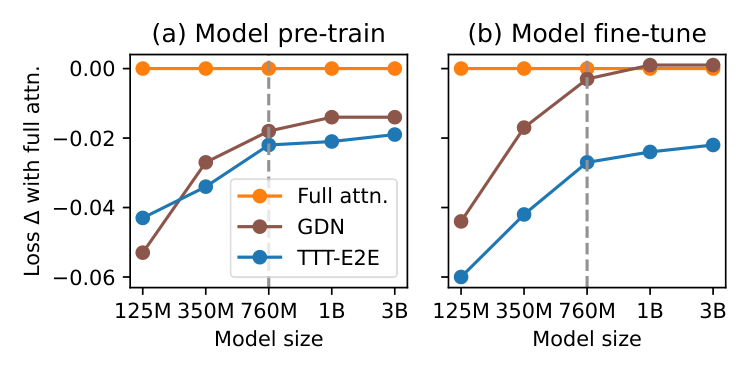
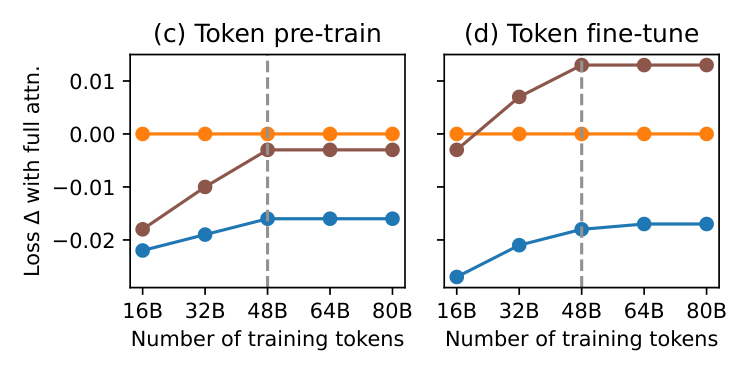
- Training compute scaling: Under large training budgets (models above 760M parameters or more than 48B training tokens), TTT-E2E follows similar scaling trends to full attention. With smaller budgets, the gap between TTT-E2E and full attention narrows, but this appears to reflect full attention's known tendency to underperform with limited training rather than a fundamental limitation of the method.
- Trade-off with recall: On Needle-in-Haystack tasks requiring precise retrieval of specific details from long context, full attention dramatically outperforms TTT-E2E and all other methods. This reflects the fundamental design choice: TTT-E2E compresses information and discards seemingly irrelevant details, while full attention preserves nearly everything.
What the Results Mean
The findings demonstrate that test-time learning can be a viable path to efficient long-context modeling. By treating context processing as an online learning problem, the method achieves a different performance-cost trade-off than existing approaches. For applications where understanding broad patterns matters more than perfect recall of every detail (similar to human memory), this approach offers substantial efficiency gains with minimal performance loss.
The results also validate that architecture design plays a supporting rather than primary role—the method achieves its gains mainly through the learning algorithm, not architectural novelty. This suggests the approach could potentially be applied to other baseline architectures beyond Transformers.
Recommendations and Next Steps
For production deployment:
- Consider TTT-E2E for long-context applications where compression of information is acceptable and inference cost is a primary concern (e.g., document summarization, long-form content generation).
- Avoid TTT-E2E for tasks requiring precise retrieval of specific facts from long context; use full attention instead.
- For hybrid systems, explore combining TTT-E2E with sparse full attention layers for critical retrieval needs.
Before broader adoption:
- Address training latency limitations. Current implementation is 3.4× slower than full attention during pre-training at short context. Two directions show promise: developing custom attention kernels that support gradients-of-gradients, or initializing TTT-E2E training from pre-trained standard Transformers.
- Test at larger scale (10B+ parameters) and longer contexts (1M+ tokens) to confirm scaling properties hold.
- Evaluate on instruction-following and reinforcement learning scenarios, where test-time learning on self-generated tokens may offer additional benefits.
Limitations and Confidence
Main limitations:
- Training cost remains higher than standard Transformers at short context lengths due to gradients-of-gradients computation and gradient checkpointing overhead.
- Evaluation of long-sequence generation uses a proxy (external model scoring) rather than downstream task performance after instruction tuning.
- Sensitivity to data quality and tokenizer choice observed but not comprehensively characterized—newer, higher-quality data improved results.
Confidence level: High for the core finding that TTT-E2E matches full attention's scaling with context while maintaining constant inference cost. Medium for production readiness due to training efficiency concerns. The method works as designed, but operational deployment would benefit from the optimizations listed above.
Arnuv Tandon∗1,3^{*1,3}∗1,3, Karan Dalal∗1,4^{*1,4}∗1,4, Xinhao Li∗5^{*5}∗5, Daniel Koceja∗3^{*3}∗3, Marcel Rød∗3^{*3}∗3, Sam Buchanan4^44
Xiaolong Wang5^55, Jure Leskovec3^33, Sanmi Koyejo3^33, Tatsunori Hashimoto3^33, Carlos Guestrin3^33
Jed McCaleb1^11, Yejin Choi2^22, Yu Sun∗2,3^{*2,3}∗2,3
1^11 Astera Institute 2^22 NVIDIA 3^33 Stanford University 4^44 UC Berkeley 5^55 UC San Diego
Abstract
We formulate long-context language modeling as a problem in continual learning rather than architecture design.
Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention.
However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights.
In addition, we improve the model's initialization for learning at test time via meta-learning at training time.
Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms.
We conduct extensive experiments with a focus on scaling properties.
In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not.
However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it
2.7×2.7\times2.7× faster than full attention for 128K context.
Our
code is publicly available.
1 Introduction
In this section, the authors reframe long-context language modeling as a continual learning problem rather than an architectural challenge, drawing an analogy to how humans compress experience into intuition without perfect recall. While Transformers with full attention achieve lossless recall but scale poorly with context length, and modern RNNs like Mamba 2 maintain constant cost per token but degrade in longer contexts, the proposed TTT-E2E method achieves both efficiency and effectiveness through compression. The key insight is to continue training the language model at test time via next-token prediction on the given context, effectively compressing context into the model's weights. To address the mismatch between training and test-time objectives, the method employs meta-learning to optimize the model's initialization specifically for test-time training through gradients of gradients. This end-to-end approach enables the method to match full attention's scaling properties while maintaining constant inference latency, achieving 2.7× speedup at 128K context length.
Humans are able to improve themselves with more experience throughout their lives, despite their imperfect recall of the exact details. Consider your first lecture in machine learning: You might not recall the instructor's first word during the lecture, but the intuition you learned is probably helping you understand this paper, even if that lecture happened years ago.
On the other hand, Transformers with self-attention still struggle to efficiently process long context equivalent to years of human experience, in part because they are designed for nearly lossless recall. Self-attention over the full context, also known as full attention, must scan through the keys and values of all previous tokens for every new token. As a consequence, it readily attends to every detail, but its cost per token grows linearly with context length and quickly becomes prohibitive.
As an alternative to Transformers, RNNs such as Mamba 2 [1] and Gated DeltaNet [2] have constant cost per token, but become less effective in longer context, as shown in Figure 1. Some modern architectures approximate full attention with a sliding window [3, 4], or stack attention and RNN layers together [5, 6]. However, these techniques are still less effective than full attention in using longer context to achieve better performance in language modeling.
How can we design an effective method for language modeling with only constant cost per token? Specifically, how can we achieve better performance in longer context without recalling every detail, as in the opening example? The key mechanism is compression. For example, humans compress a massive amount of experience into their brains, which preserve the important information while leaving out many details. For language models, training with next-token prediction also compresses a massive amount of data into their weights. So what if we just continue training the language model at test time via next-token prediction on the given context?
This form of Test-Time Training (TTT), similar to an old idea known as dynamic evaluation [7, 8], still has a missing piece: At training time, we were optimizing the model for its loss out of the box, not for its loss after TTT. To resolve this mismatch, we prepare the model's initialization for TTT via meta-learning [9, 10, 11] instead of standard pre-training. Specifically, each training sequence is first treated as if it were a test sequence, so we perform TTT on it in the inner loop. Then we average the loss after TTT over many independent training sequences, and optimize this average w.r.t. the model's initialization for TTT through gradients of gradients in the outer loop [12, 13, 14].
In summary, our method is end-to-end in two ways. Our inner loop directly optimizes the next-token prediction loss at the end of the network, in contrast to prior work on long-context TTT [15, 16]; Subsection 2.4 explains this difference through an alternative derivation of our method. Moreover, our outer loop directly optimizes the final loss after TTT, in contrast to dynamic evaluation [7, 8], as discussed. Our key results are highlighted in Figure 1, with the rest presented in Section 3.
The conceptual framework of TTT has a long history with many applications beyond long context, and many forms without meta-learning [17, 18, 19, 20]. Our work is also inspired by the literature on fast weights [9, 10, 21, 22], especially [23] by Clark et al., which shares our high-level approach. Section 4 discusses related work in detail.
2 Method
In this section, the authors address the challenge of efficient long-context language modeling by formulating it as a continual learning problem rather than an architectural one. They propose Test-Time Training End-to-End (TTT-E2E), which uses a standard Transformer with sliding-window attention but continues learning at test time via next-token prediction on the given context, effectively compressing context into the model's weights. Unlike prior approaches that optimize layer-wise reconstruction losses or use naive training objectives mismatched with test-time behavior, TTT-E2E employs meta-learning to optimize the model's initialization for post-training performance through gradients of gradients. The method incorporates mini-batch gradient descent for stability and parallelism, updates only the MLP layers in the last quarter of blocks to balance computational cost with context compression capacity, and adds duplicate MLP layers to preserve pre-trained knowledge. This approach can be alternatively derived from prior Key-Value Binding methods by replacing their reconstruction loss with end-to-end next-token prediction, ultimately achieving superior language modeling performance with constant per-token inference cost.
Consider the standard task of next-token prediction, which consists of two phases at test time:
- Prefill: conditioning on T+1T+1T+1 given tokens x0,x1,…,xTx_0, x_1, \dots, x_Tx0,x1,…,xT, where x0x_0x0 is the Beginning of Sequence (
<BOS>) token.
- Decode: predicting a distribution p^T+1\hat{p}_{T+1}p^T+1 over all possible instantiations of the next token.
The test loss is then CE(p^T+1,xT+1)\mathsf{CE}\left(\hat{p}_{T+1}, x_{T+1}\right)CE(p^T+1,xT+1), where CE\mathsf{CE}CE is the cross entropy and xT+1x_{T+1}xT+1 is generated by nature.
For ease of exposition, we first focus on the task of prefilling T+1T+1T+1 tokens and then decoding a single token. In this setting, self-attention over the full context, also known as full attention, has computational complexity O(T2)O(T^2)O(T2) for prefill and O(T)O(T)O(T) for decode. We now discuss our method using Test-Time Training (TTT), which has O(T)O(T)O(T) for prefill and O(1)O(1)O(1) for decode.
2.1 TTT via Next-Token Prediction
To motivate our main method, we introduce a toy example that we will develop all the way up to the middle of Subsection 2.3. This toy example is based on a rather silly architecture: a Transformer with all of its self-attention layers removed, leaving only the MLP layers. Our toy baseline – blithely applying this architecture to language modeling – is effectively a bigram since it has no memory of previous tokens. Our goal is to understand the effect of TTT in isolation, without the confounding of other sequence modeling components.
One way to give our baseline architecture some memory is to train it on the context. Similar to standard pre-training, we can predict p^t\hat{p}_tp^t and compare it to xtx_txt at every t=1,…,Tt = 1, \dots, Tt=1,…,T as an exercise. Specifically, denote the baseline architecture as fff with weights WWW, then the standard next-token prediction loss at time ttt can be written as:
We update WWW at test time for every t=1,…,Tt=1, \dots, Tt=1,…,T, in sequential order, with gradient descent:
where η\etaη is a learning rate, and W0W_0W0 is the initial weights at test time. In the end, we simply output p^T+1=f(xT;WT)\hat{p}_{T+1} = f(x_T; W_T)p^T+1=f(xT;WT). We illustrate this form of TTT in the left panel of Figure 2: Our toy baseline only uses the upward arrows, while TTT adds the backward and horizontal arrows.
2.2 Learning to (Learn at Test Time)
We now consider how W0W_0W0 – the initial weights after (training-time) training but before test-time training – is obtained, within the scope of the same toy example. By definition, our test-time training loss ℓt(Wt−1)\ell_t(W_{t-1})ℓt(Wt−1) is also the test loss for the next-token prediction task that conditions on x0,…,xt−1x_0, \dots, x_{t-1}x0,…,xt−1 and tries to predict xtx_txt. Therefore, the test loss over a sequence X=(x1,…,xT)X = (x_1, \dots, x_T)X=(x1,…,xT) is:
To obtain a W0W_0W0 that will produce low L(W0;X)\mathcal{L}(W_0; X)L(W0;X) at test time, the most direct approach is to optimize the same loss at training time over a large training set of sequences on average. This direct approach is an example of End-to-End (E2E) training, where the training loss matches the test loss. When TTT uses a W0W_0W0 trained in this fashion, we call it TTT-E2E.
As a contrasting example, consider another approach that naively imitates the training loss of a static model without taking into account that W0W_0W0 will be updated at test time:
This approach is not E2E, since there is a mismatch between the model's behavior at training and test time. As a consequence, we can provide little guarantee that a minimizer of Lnaive\mathcal{L}_{\text{naive}}Lnaive will also produce low test loss L\mathcal{L}L. We call this approach TTT-naive. It has been the mainstream approach in the literature of dynamic evaluation [7, 8].
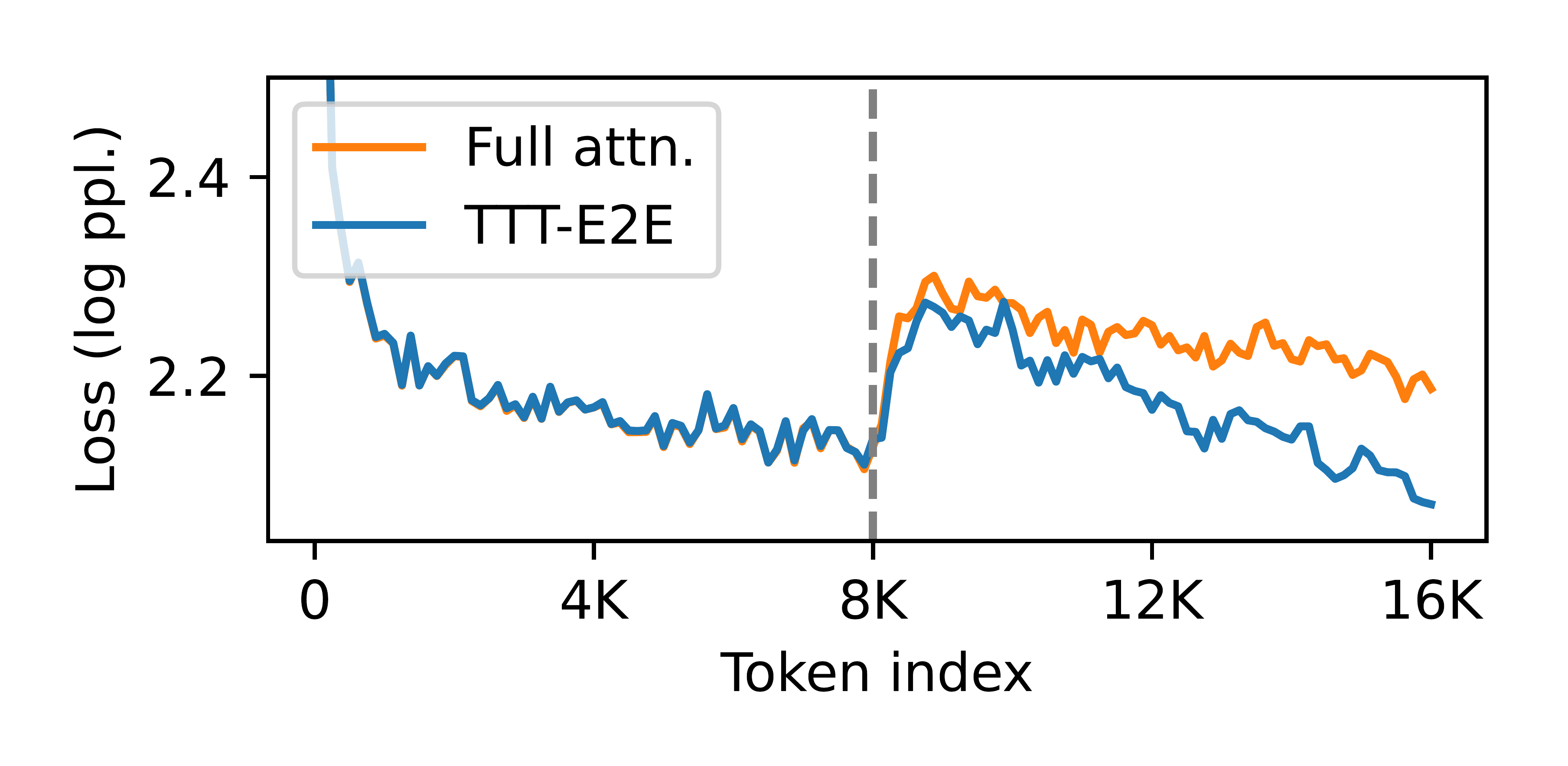
The right panel of Figure 2 plots the token-level test loss ℓt\ell_tℓt, averaged over many test sequences, for t=1,…,128t=1, \dots, 128t=1,…,128. So far, we have discussed four methods: Transformer with full attention (orange), our toy baseline without attention (green), TTT-naive (gray), and TTT-E2E (blue for b=1b=1b=1; we will cover the variant with b=16b=16b=16 in Subsection 2.3); see details of the experimental setup in Appendix A. While TTT-naive performs only slightly better than the toy baseline, TTT-E2E performs almost as well as full attention. In particular, TTT-E2E can effectively use more context to better predict the next token, as demonstrated by the test loss decreasing over time.
For gradient-based optimization, computing ∇L(W0)\nabla \mathcal{L}(W_0)∇L(W0) for the E2E L\mathcal{L}L entails computing gradients of gradients, since the update rule in Equation 2 itself contains a gradient operation. Fortunately, modern frameworks for automatic differentiation can efficiently compute gradients of gradients with minimal overhead [24, 25]. Once ∇L(W0)\nabla \mathcal{L}(W_0)∇L(W0) is computed, we can plug it into standard optimizers. In the field of meta-learning, gradient steps on L\mathcal{L}L are called the outer loop, and on ℓ\ellℓ the inner loop.
The current version of TTT-E2E still has two problems for large models in long context. The first is efficiency, because our inner loop has many steps that cannot be parallelized. The second is stability, because each gradient step in the inner loop depends on only a single token, which can easily lead to gradient explosion by chance. The next subsection addresses these two problems.
2.3 Mini-Batch TTT and Sliding Window
The two problems above share a common cause: Equation 2 performs online instead of mini-batch gradient descent. Given a training set of size TTT, the standard practice is to partition it into T/bT/bT/b batches, each of size bbb (assuming divisible), and take one gradient step per batch. Compared to online gradient descent, where b=1b=1b=1, a larger bbb is known to improve both parallelism and stability. We can apply the mini-batch idea to TTT for the same benefits. Given the (test-time) training set that contains x1,…,xTx_1, \dots, x_Tx1,…,xT, we generalize Equation 2 to:
for i=1,…,T/bi=1, \dots, T/bi=1,…,T/b (assuming divisible), then output p^T+1=f(xT;WT/b)\hat{p}_{T+1} = f(x_T; W_{T/b})p^T+1=f(xT;WT/b). In addition, for (training-time) training to reflect the change in test-time training, we also generalize Equation 3 to:
Note that b=1b=1b=1 recovers Equation 2 and 3.
However, our model with mini-batch TTT is now a bigram again within each batch, as illustrated by the red line in Figure 2 with b=16b=16b=16. For example, consider the first mini-batch that contains x1,…,xbx_1, \dots, x_bx1,…,xb. Since every prediction p^t=f(xt−1;W0)\hat{p}_t = f(x_{t-1}; W_0)p^t=f(xt−1;W0) is made with W0W_0W0 instead of Wt−1W_{t-1}Wt−1, we observe that ℓt(W0)\ell_t(W_0)ℓt(W0) increases with ttt as p^t\hat{p}_tp^t misses more context, namely all the tokens up to t−1t-1t−1. This observation holds within every mini-batch, where the only predictions without missing context are the first and second ones inside the mini-batch. These increasing losses produce worse gradient steps for TTT, which ultimately translate into worse performance of the purple line compared to the blue line.
To address this problem, we finally advance beyond the toy example and augment our architecture with sliding-window attention layers. While our toy example removes the self-attention layers entirely, our main method only restricts them to a fixed window size kkk. For our main results with T=128T=128T=128K, we set the window size kkk to 8K and the TTT mini-batch size bbb to 1K. It is important to set k≥bk\geq bk≥b so our model can remember the context within each mini-batch before TTT has a chance to update its weights.
This modification of the baseline architecture completes our main method. Next, we introduce three implementation details, and then consider the task of decoding multiple tokens. Our main method, complete with the implementation details, is illustrated in the left panel of Figure 3.
2.3.1 Implementation Details
Three implementation details are necessary for achieving our reported results. We will justify these details with ablations in Section 3. However, it is still possible that they are merely artifacts of our experimental setup, and different design choices could be better suited in other setups.
TTT only the MLP layers. Modern Transformers are built in repeated blocks, each consisting of a full attention layer (which we have replaced with sliding window attention), an MLP layer, and a few normalization layers. We freeze the embedding layers, normalization layers, and attention layers during TTT, since updating them in the inner loop causes instability in the outer loop. Therefore, the MLP layers are the only ones updated during TTT.
TTT only 1/4 of the blocks. In general, less information is lost during compression when we have a larger amount of storage. In our case, the information is the context, and the storage is the updated MLP layers. However, updating more layers also implies more computation to back-propagate the gradients. Therefore, we have an intuitive trade-off between computational cost and the ability to scale with context length, as we will illustrate with ablations in Section 3. We choose to TTT only the last 1/4 of the blocks according to the ablations, but other experimental setups, especially those with even longer contexts, might require a different choice.
Two MLP layers per block. One of the concerns of TTT is forgetting the knowledge learned during pre-training. We adopt the simplest way to address this concern. In the blocks updated during TTT, we add a static, second MLP layer as a "safe" storage for pre-trained knowledge. For fair comparison with the baselines, we reduce the hidden dimension of the MLPs throughout the entire network (including those frozen during TTT), so the total number of parameters remains the same.
2.3.2 Decoding Multiple Tokens
Up to this point, we have focused on the task of prefilling T+1T+1T+1 tokens (including <BOS> as x0x_0x0) and then decoding a single token. We now consider decoding multiple tokens, for which our method admits a natural extension: It only takes a gradient step once the decoded tokens have completely filled a TTT mini-batch. For example, assuming that TTT is divisible by bbb, so TTT depletes the prefilled tokens in exactly T/bT/bT/b mini-batches. Then our method does not need to do anything special when decoding the next bbb tokens. After that, it performs TTT on this batch of decoded tokens, and then continues to decode using the updated weights.
2.4 Alternative Derivation
This subsection discusses an alternative derivation of our main method, starting from prior work on long-context TTT based on Key-Value Binding (KVB) [26, 16]. The key step is to replace their layer-wise reconstruction loss with the standard next-token prediction loss, so TTT becomes E2E at test time. This derivation is not needed to understand the results in Section 3, but it provides additional insight into how our method is connected to the literature on RNNs.
2.4.1 Starting Point: Key-Value Binding
Building on the same idea of compressing context into the weights of a model, prior work [26] uses TTT to construct a sequence modeling layer that serves as a drop-in replacement for self-attention. While self-attention associates the key and value of every previous token by storing them explicitly in a cache, prior work proposes storing these associations implicitly in a model, by learning at test time to predict each value from its key. This learning objective, later known as KV Binding, has been the core component in many popular variants of TTT, such as MesaNet [27], Titans [28], and Nested Learning [29]; linear attention [10, 30] and many of its variants, such as Gated DeltaNet [2], can also be derived from this perspective.
Concretely, given the input embeddings xt(l)x_t^{(l)}xt(l) at layer lll, the basic form of TTT-KVB takes a gradient step at each t=1,…,Tt=1, \dots, Tt=1,…,T on the following loss [26]:
where ggg is usually an MLP, Wt−1(l)W_{t-1}^{(l)}Wt−1(l) is the weights of ggg after the previous timestep, and θK(l)\theta_K^{(l)}θK(l) and θV(l)\theta_V^{(l)}θV(l) are outer-loop parameters, similar to the key-value projection matrices in Transformers. After the gradient step, ggg uses the updated weights to produce the output embedding:
where θQ(l)\theta_Q^{(l)}θQ(l) is also a set of outer-loop parameters. The mechanism above is known as a TTT layer. When used inside a network, every TTT layer is an independent unit with its own loss and weights. At training time, the outer loop of TTT-KVB is identical to that of TTT-E2E in Equation 6, and all the outer-loop parameters, including θK\theta_KθK, θV\theta_VθV, and θQ\theta_QθQ of all the TTT layers, are optimized together. Similar to TTT-E2E in Subsection 2.3, TTT(-KVB) layers can effectively use (inner-loop) mini-batch gradient descent when preceded by sliding-window attention layers [16]. This hybrid architecture serves as the starting point of our derivation.
2.4.2 First Step: Simplified Output Rule
First, we observe that the output rule in Equation 8 can be simplified into:
with practically no harm, as shown in Table 1. This new output rule is a simplification because it reuses the prediction of ggg in Equation 7 as the output embedding instead of calling ggg again with the updated weights and the separate input θQxt\theta_Qx_tθQxt. Intuitively, calling ggg with the updated weights can be unnecessary if sliding-window attention already provides enough local context, and prior work has argued that the separation between θK\theta_KθK and θQ\theta_QθQ can also be unnecessary [32, 33, 34].
In the right panel of Figure 3, we illustrate TTT-KVB after this simplification. Compared to TTT-E2E in the left panel, there are four differences, with the latter two considered implementation details:
- Each Transformer block in TTT-KVB has a reconstruction loss ℓ(l)\ell^{(l)}ℓ(l), whereas TTT-E2E has a single next-token prediction loss ℓ\ellℓ at the end of the entire network.
- Each Transformer block in TTT-KVB has additional outer-loop parameters θK\theta_KθK and θV\theta_VθV.
- TTT-KVB updates an MLP layer in every Transformer block, whereas TTT-E2E only updates an MLP layer in the last 1/4 of the blocks.
- Not shown in the figure, the updated MLPs in TTT-KVB are split into multiple heads in the same way as self-attention, so these MLPs are much smaller than the regular ones in TTT-E2E. Moreover, these MLPs are updated with LoRA [35], so their effective capacity is even smaller.
However, Figure 3 also highlights the similarity between these two forms of TTT: Similar to TTT-E2E, TTT-KVB can be understood from the perspective of training the entire network. First, there is a forward pass through the entire network, as illustrated by all the upward arrows. Then there is a backward pass, with contributions from many losses in the fashion of Deeply Supervised Nets [36]. However, the gradients are stopped after reaching only one MLP layer, as illustrated by the single downward arrow in each block.
2.4.3 Key Step: E2E at Test Time
The key step in this derivation is to replace the KVB loss with the next-token prediction loss, which implies removing differences 1 and 2 together, since without the layer-wise reconstruction losses, there is also no use for θK\theta_KθK or θV\theta_VθV. This step brings us to an intermediate method called TTT-E2E all layers MH, where MH stands for multi-head. As shown in Table 1, replacing the loss significantly improves performance in language modeling, essentially reaching the level of our final method.
This intermediate method is now E2E at test time, because its (test-time) training loss is exactly the token-level test loss ℓt\ell_tℓt. At this point, it is especially interesting to recognize the duality between our two derivations. Our primary derivation starts from TTT via next-token prediction, which is E2E at test time, and focused on making it E2E at training time via meta-learning in Subsection 2.2. Our alternative derivation, on the other hand, starts from TTT-KVB, which is E2E at training time, and focused on making it E2E at test time via next-token prediction.
2.4.4 Final Step: Larger State with Less Compute
TTT(-KVB) layers are often viewed as a class of RNN layers [26], and TTT-KVB is often viewed as an RNN. Similarly, TTT-E2E can also be viewed as an RNN, except that it only has one RNN layer, since the entire network is updated in one backward pass. Among the three components of an RNN, we have modified the output rule in the first step of this derivation, and the update rule in the second (the key) step. Now we modify the hidden state.
A critical factor that often improves the long-context performance of an RNN is a larger hidden state, which, in turn, often requires more compute to be updated. Consider our intermediate method, TTT-E2E all layers MH. If we remove difference 3 by updating only the last 1/4 of the blocks, then we save compute at test time but end up with a smaller state. And if we remove difference 4 by reverting to regular MLPs (instead of multi-head MLPs with LoRA), then we have a larger effective state at the cost of more compute (and memory).
However, when using the E2E loss, the trade-offs of these two differences are rather disproportionate: In order to update the small multi-head MLP in a block, gradients need to back-propagate through the large MLP above it, let alone the attention layer below for the backward pass to proceed further. Given the heavy cost of preparing the upstream gradients, it should be more cost-effective to update fewer blocks, each containing a larger hidden state. Indeed, our final method (TTT-E2E), which removes both differences together, has 5×5\times5× larger hidden state (88M vs. 18M for the 760M model) and half the inference latency (0.0086 vs. 0.017 sec per 1K tokens for prefill on H100) compared to TTT-E2E all layers MH.
Does this larger state actually improve performance? It is difficult to see the difference in Table 1 because these experiments are only at 8K context length. In Subsection 3.2, we will investigate the effect of state size in terms of scaling with context length, by ablating the number of layers updated. This ablation will clearly show that a smaller state leads to worse context scaling.
3 Main Results
In this section, the authors evaluate TTT-E2E through systematic experiments on language modeling, beginning with ablations on three key hyperparameters: sliding window size (set to 8K), TTT mini-batch size (set to 1K), and the fraction of layers updated during test-time training (set to 1/4 of all layers), where updating fewer layers degrades context scaling. They then investigate scaling behavior along two axes of training compute—model size (up to 3B parameters) and number of training tokens (up to 5× the Chinchilla baseline)—finding that TTT-E2E initially underperforms full attention with small training budgets but converges to similar scaling trends beyond approximately 760M parameters or 48B tokens, mirroring the behavior of other RNN baselines like Gated DeltaNet. For context length scaling up to 128K tokens, TTT-E2E consistently outperforms full attention in aggregate loss, with its advantage concentrated in earlier token positions rather than the final tokens, suggesting that test-time weight updates allow the model to focus on immediate predictions rather than preparing for all possible future contexts.
In this section, the authors provide implementation details and experimental recipes that enable reproducibility of their TTT-E2E method. The toy example uses a simplified two-block Transformer architecture trained on DCLM with 128-token contexts, where removing attention layers creates the baseline for all TTT variants, with learning rates optimized through systematic sweeps. The basic recipe scales from 125M to 2.7B parameters following GPT-3 configurations but with Mamba 2's higher learning rates and smaller batch sizes, using RoPE with theta equals 500K for pretraining and adjusted theta values for extension fine-tuning at longer contexts. Baseline improvements include upgrading to FlashAttention 3 kernels and adding QK normalization for training stability. For decoding evaluation, the authors use standard sampling with temperature 1, top-p threshold 0.95, and repetition penalty 1.1 to prevent degenerate outputs. Additional analysis reveals that while longer contexts consistently improve full attention and hybrid models, pure RNN-based methods like Mamba 2 and Gated DeltaNet suffer performance degradation beyond 32K context due to higher gradient variance from fewer sequences per batch.
3.1 Setup
Given the research nature of this paper, our goal is to experiment in the simplest setups at small and medium scales that can inform production-level training runs at large scale. In general, today's large-scale runs usually consist of two or more stages [37, 38, 39, 40]:
- Pre-training at short context length on a general dataset containing diverse knowledge.
- Extending the context length by fine-tuning on a dataset of long sequences. To gradually reach very long context, e.g., 1M, extension is usually broken down further into multiple stages.
For simplicity, our training runs consist of only two stages: pre-training at 8K context length, and extension fine-tuning at the final context length, at most 128K, depending on the experiment.
Datasets. For pre-training, we use DCLM, specifically DCLM-Baseline, a heavily filtered subset of Common Crawl [41]. Given the 3.8T tokens in DCLM-Baseline, we first discard all documents shorter than 8K, our pre-training context length, and then randomly sample from the remaining ones to construct training sets of various sizes. However, most of the sequences in DCLM that are longer than 128K, our maximum context length for extension, are of low quality. So for fine-tuning, we use Books [42], a standard academic dataset for long-context extension [43, 44]. We also use a held-out partition of Books for language modeling evaluation.
Basic recipe. We experiment with models of five sizes, ranging from 125M to 3B parameters. Our configurations and training hyper-parameters in various experiments are all derived from a single basic recipe detailed in Appendix B. In summary, the basic recipe for model configurations and pre-training is taken from GPT-3 [45] and Mamba [1]; to produce the basic recipe for fine-tuning, we performed grid search for the Transformer baseline with full attention.
Baselines. We compare our method with six baselines that represent the state-of-the-art approaches in architecture design. All the baselines with sliding window use the same window size k=8k=8k=8K.
- Transformer with full attention [46]: with the model configurations discussed above.
- Transformer with Sliding-Window Attention (SWA) [47]: with every full attention layer replaced by a SWA layer. Our main method in Subsection 2.3, without the implementation details, is also based on this architecture. The window size kkk is set to 8K in all our experiments, except for the window size ablations. Since the pre-training context length is also 8K, the full attention and SWA baselines are identical until extension fine-tuning.
- Hybrid SWA and full attention (5:1) [48]: repeating the pattern of five SWA layers followed by one full attention layer, in the style of Gemma [48].
- Mamba 2 [49]: a popular RNN that uses a hybrid of Mamba 2 layers and SWA layers; tested at large scale in Nemotron-H [6].
- Gated DeltaNet [2]: a popular RNN that extends Mamba 2 and DeltaNet [50], and uses a hybrid of Gated DeltaNet layers and SWA layers; tested at large scale in Kimi Linear [5].
- TTT-KVB [16]: a popular RNN that uses a hybrid of TTT-MLP layers with Key-Value Binding (KVB) [26] and SWA layers; also our starting point in Subsection 2.4 (without the simplified output rule). Titans [28] and Nested Learning [29] follow a similar construction.
We implement baselines 1–3 in JAX, together with our own method. For baselines 4–6, we use the official code and configurations provided by the authors and have consulted them to improve the baselines when possible. Our improvements to the baselines are discussed in Appendix C.
3.2 Ablations on Hyper-Parameters
To help readers gradually build an empirical intuition for our method, we start with the simplest experiments – ablations on the hyper-parameters introduced in Subsection 2.3. For all the ablations, we use the 760M model with the basic recipe.
Sliding window size kkk. This hyper-parameter is present in all the methods, except for full attention. Therefore, we also conduct this ablation for two representative baselines: SWA and Gated DeltaNet. Not surprisingly, a larger kkk improves performance for all three methods, as shown in the leftmost panel of Figure 4, and TTT-E2E has similar sensitivity to changes in kkk compared to the baselines. We choose k=8k=8k=8 K as the default since a smaller kkk does not significantly improve runtime.
TTT-E2E with full attention. The window size ablation is conducted with only pre-training on DCLM without fine-tuning on Books, so the results above are evaluated on DCLM as well. Since the pre-training context length is also 8K, SWA with k=8k=8k=8K is exactly full attention, and TTT-E2E with k=8k=8k=8K becomes the same as TTT-E2E on top of full attention. It is especially interesting to observe that TTT-E2E can improve the test loss (by 0.018) even on top of full attention, and the difference between TTT-E2E and SWA does not change significantly as kkk increases. This observation suggests that TTT-E2E is not merely compensating for the difference between full attention and SWA; instead, it produces an orthogonal improvement when other factors, such as context length, are fixed.
TTT mini-batch size bbb. The middle panel of Figure 4 experiments with the TTT mini-batch size bbb, ranging from 1K to 8K. This hyper-parameter is unique to methods derived from the TTT perspective, so the only other baseline that allows for a meaningful comparison here is TTT-KVB. Similar to the window size ablation, the models are evaluated on DCLM after pre-training. For both TTT-E2E and TTT-KVB, we observe that a larger choice of bbb significantly hurts performance. However, a choice of bbb smaller than 1K also significantly hurts our hardware utilization and stability, to the point that it becomes difficult to experiment with. Therefore, we choose b=1b=1b=1K as the default.
Modified architectures without TTT. The choice of b=8b=8b=8K is equivalent to not doing TTT at all, because our pre-training context length is also 8K. However, both TTT-E2E and TTT-KVB without TTT are slightly different from Transformer with full attention, because both of these methods have slightly modified the Transformer architecture, as previously illustrated in Figure 3. So do these modifications still matter without TTT? Figure 4 suggests that the answer is no. Without TTT, the loss for either TTT-E2E (2.825) or TTT-KVB (2.826) is almost no different from full attention (2.827). This observation suggests that architecture design plays a minor, supporting role in our method.
3.2.1 Number of Layers Updated
We now turn to the most important ablation. As discussed in Subsection 2.3, the number of layers updated during TTT controls the amount of storage in which we can compress the information in the context window. Therefore, we investigate its effect in terms of context scaling, and present this ablation in the format of Figure 1 (left). Specifically, for each number of layers, we pre-train a single checkpoint on DCLM and then fine-tune five versions on Books, one for each context length, so the final results are evaluated on Books.
We experiment with updating the last 1/2, 1/4, and 1/8 of the layers. For our 760M model with a total of 24 layers, these ratios translate to the last 12, 6, and 3 layers. We also experiment with updating only the final layer. From the rightmost panel of Figure 4, we observe that when updating only 1 or 3 layers, our method does not scale with context length in the same way as full attention. When updating 6 or 12 layers, our method does scale. However, updating 12 layers only performs at roughly the same level as 6. Therefore, we always update the last 1/4 regardless of model size.
3.3 Scaling with Training Compute
In general, there are two axes of training compute: the model size and the number of training tokens. We investigate the behavior of our method along these axes when compared to full attention and Gated DeltaNet, and present the results in Figure 5. We choose Gated DeltaNet as the representative among the RNN baselines because it is the most recent work with highly optimized training time.
One popular practice for measuring the effect of training compute is to evaluate on the pre-training dataset immediately after pre-training, as in many scaling law papers [52, 53]. In the left panels of Figure 5, we follow this practice and evaluate on DCLM after pre-training. But as discussed in Subsection 3.2, our window size is the same as the pre-training context length, making SWA, our baseline architecture, equivalent to full attention. This equivalence raises the concern that the practice discussed above might not reveal the true behavior of our method without full attention. So we also evaluate on Books at 32K context length after fine-tuning, as shown in the right panels.
Figure 5: Scaling with training compute in two axes: model size (left) and number of training tokens (right); see details in Subsection 3.3. Overall, TTT-E2E exhibits a similar trend to full attention under a large training budget (right of the dotted line). We report results both on DCLM at 8K context length after pre-training (a, c) and on Books at 32K after fine-tuning with the same context length (b, d). Loss Δ\DeltaΔ (↓\downarrow↓), the yyy-value, is the same as in Figure 1 and 4. The legend in the leftmost panel is shared across all panels.
Figure 5: Scaling with training compute in two axes: model size (left) and number of training tokens (right); see details in Subsection 3.3. Overall, TTT-E2E exhibits a similar trend to full attention under a large training budget (right of the dotted line). We report results both on DCLM at 8K context length after pre-training (a, c) and on Books at 32K after fine-tuning with the same context length (b, d). Loss Δ\DeltaΔ (↓\downarrow↓), the yyy-value, is the same as in Figure 1 and 4. The legend in the leftmost panel is shared across all panels.
::::
For scaling with model size, we simply vary across the five sizes in our basic recipe. For scaling with the number of training tokens, we keep the model size fixed at 760M, and vary the number of training tokens for pre-training and fine-tuning. Specifically, our basic number of tokens for pre-training is taken from the Chinchilla recipe [53], and our basic number for fine-tuning is 5% of that for pre-training, as discussed in Appendix B. We experiment with up to 5×5\times5× the basic number for pre-training and fine-tuning, keeping the 5% ratio fixed.
Similar trend to full attention under large budget. We observe a similar trend across the panels:
- The advantage of TTT-E2E over full attention visibly decreases with more training compute in the regime of small compute budget.
- However, in the regime of medium compute budget, TTT-E2E follows a similar scaling trend to full attention, as indicated by the blue line staying relatively flat. Although there is still a small uptick for scaling with model size, we expect this uptick to disappear for even larger models given the overall trend.
For scaling with model size, the boundary for the change of regime is roughly 760M. For scaling with number of training tokens, this boundary is roughly 48B. We mark these boundaries in Figure 5 with dotted vertical lines. It is especially interesting to observe that Gated DeltaNet follows the same trend as TTT-E2E. We offer two potential explanations for this observation:
- Our method can also be interpreted as a hybrid RNN, similar to Gated DeltaNet, as explained in Subsection Section 2.4. We expect RNNs (sequence models with hidden states of fixed size) to share a similar trend for scaling with training compute.
- Transformers are widely known to under-perform with insufficient training compute compared to RNNs [52, 53]. Our observations can be interpreted as a deficiency of the full attention baseline with small compute, rather than a deficiency of RNNs with large compute.
Overall, our empirical observations strongly indicate that TTT-E2E should produce the same trend as full attention for scaling with training compute in large-budget production runs.
Sensitivity to tokenizer and data quality. During our scaling investigation, we collected anecdotal observations on the effect of tokenizer and data quality, as indicated by recency. Specifically:
- Switching to the Llama 3 tokenizer (2024) from the Llama 2 tokenizer (2023) improved our advantage over full attention by about 0.01 for 3B models.
- Switching to DCLM (2024) from SlimPajama (2023) [54] enabled our method to produce the same trend as full attention for scaling with number of training tokens after 48B; our trend with FineWebEdu (2024) [55] is also the same as full attention. With SlimPajama, our lines in the right panels of Figure 5 exhibited a small uptick, similar to those in the left panels for scaling with model size.
A comprehensive investigation of these effects would entail reproducing Figure 5 for a wide variety of tokenizers and datasets, which is beyond the scope of our paper. Nevertheless, our anecdotal observations might still offer a starting point for future work. An especially interesting direction is TTT on self-generated tokens, which can be a filtered or rephrased version of the current mini-batch of tokens or a review of the previous mini-batches. It is widely known that the gating mechanisms in RNNs can guard the hidden states against spurious inputs and better retain the information in valuable ones [56, 57]. We believe that self-generation during TTT can play a similar role.
3.4 Scaling with Context Length
We presented the key results for scaling with context length in Figure 1 on the first page. Here, we discuss the setup of these experiments and present a breakdown of some of these results in Figure 6. In addition, Figure 9 in the appendix directly plots the loss values in Figure 1 instead of the loss Δ\DeltaΔ s.
For the experiments in Figure 1, we use the largest model (3B) in our basic recipe. We also use 3×3\times3× the basic number of tokens for both pre-training and fine-tuning. As discussed, the basic number for pre-training is taken from the Chinchilla recipe, and that for fine-tuning is 5% of pre-training. As in our previous experiments, we pre-train a single checkpoint on DCLM and then fine-tune five versions on Books, one for each context length, so the final results are evaluated on Books.
3.4.1 Loss Breakdown by Token Index
Figure 6 focuses on two context lengths, 32K and 128K, and breaks down the corresponding results in Figure 1 by token index; we have followed the same process in Subsection 2.1 to produce the right panel of Figure 2. Specifically, given a context length TTT, for each t=1,…,Tt=1, \dots, Tt=1,…,T, we plot the test loss of the next-token prediction task that conditions on x0,…,xt−1x_0, \dots, x_{t-1}x0,…,xt−1 and tries to predict xtx_txt. Therefore, for each method with context length TTT, its test loss in Figure 1 is the average of all the losses on its corresponding curve in Figure 6. It is important to note that the breakdown for 32K is not a subset of that for 128K, since they are produced from two different models.
We make the following observations from both panels of Figure 6:
- TTT-E2E is the only method that always achieves lower losses than full attention throughout the entire context length.
- The difference in test loss between TTT-E2E and full attention is small around the end of the context window. The aggregated advantage of TTT-E2E over full attention mostly comes from the earlier tokens.
The fact that both observations hold simultaneously for both panels is especially interesting in a somewhat paradoxical way. As part of the second observation, the difference between TTT-E2E and full attention in the left panel is small around t=t=t= 32K, the end of the context window. Without other information, one might even speculate that the curves would cross for larger context lengths, such as 128K. But this speculation is false, as asserted by the first observation from the right panel. The breakdown plot for 128K better resembles a stretched out version of that for 32K rather than a speculated continuation. Given that TTT-E2E maintains the same advantage over full attention across context lengths in Figure 1, this stretching effect should not be surprising.
What gives TTT-E2E an advantage over full attention for the earlier tokens? Note that this advantage exists even before t=1t=1t=1 K, when TTT takes the first gradient step on the first (inner-loop) mini-batch. In other words, before t=1t=1t=1 K, TTT-E2E and full attention have exactly the same computation graph and only differ in their weights. So why do the weights of TTT-E2E produce much lower losses?
Here is an intuitive explanation: The weights of full attention must prepare to be good at all future tokens in the context window. Such a task can be very hard, because being good at all possible futures limits the model’s capacity to be good at any particular one. But the weights of TTT-E2E only need to be good at the present mini-batch of tokens, since TTT will produce future weights for the future tokens. This more focused task should be much easier. In fact, a key intuition of TTT in general, as we will discuss in Subsection Section 4.2, is to focus on the present.
3.5 Needle in a Haystack
The motivation for our method, as discussed in Section 1, was to use longer context to achieve better performance in language modeling without having to recall every detail. Up to this point, we have focused on evaluations that do not require detailed recall. Here, we consider a popular evaluation explicitly designed for recall known as Needle in a Haystack (NIAH): The model needs to retrieve a target string (needle) in a passage (haystack), where the target string is distinguished by its clear irrelevance to the rest of the passage. Specifically, we evaluate all the 3B models fine-tuned at 128K context length, on the three NIAH tasks in RULER [58].
From Table 2, we observe that Transformer with full attention dramatically outperforms the other methods, including ours, especially in long context. This observation, combined with findings from our previous subsections, supports the intuition that the strength of full attention lies in its nearly lossless recall. This strength is inherent to the design of self-attention, which attends to the keys and values of all previous tokens in its cache. In contrast, the key mechanism in our method is compression, which leaves out seemingly irrelevant details, such as the target string.
3.6 Decoding Long Sequences
Up to this point, all our evaluations have required the model to decode no more than a dozen tokens. As discussed in the end of Subsection 2.3, when the decoded tokens have filled a TTT mini-batch, TTT-E2E takes a gradient step on this batch of decoded tokens. Does this method of "self-training" at test time work for decoding long sequences?
In practice, scenarios that require decoding long sequences typically arise either after instruction fine-tuning or during reinforcement learning, e.g., when the model generates long chains of thought. Therefore, it is inherently challenging to evaluate base models, without the two stages above, in a realistic way. Since these two stages are beyond the scope of our paper, we make our best effort to evaluate the 3B base models we have trained in Subsection 3.4.
For the evaluation in Figure 7, we use Qwen-3-8B-Base [59] as the evaluator. Since our models were trained on Books, we prefill their context windows with 8K tokens from Books, decode another 8K tokens as continuation, and then plot the loss (log likelihood) of Qwen-8B on the concatenated 16K sequence by token index. While Figure 6 uses log scale for the xxx-axis, Figure 7 here uses linear scale, allowing us to easily compare the trends for prefill and decode. Additional details of this evaluation are provided in Appendix D.
Similar to our previous observations, TTT-E2E achieves lower Qwen loss than full attention in this limited evaluation. In addition, we have carefully inspected ≈20\approx 20≈20 samples of the generated text and found them reasonable. For both methods, the Qwen loss increases sharply at the boundary between prefill and decode, and then gradually decreases again. This behavior likely arises because Qwen is initially unfamiliar with the generation style of the evaluated method, but then gradually adapts as more generated content accumulates within its context window.
3.7 Computational Efficiency
In Figure 1, we have presented our inference latency, specifically prefill latency, compared to that of the baselines. Here, we discuss our setup for measuring prefill latency, and consider two additional axes where computational efficiency is important: decode and training. In particular, we highlight training latency as a significant limitation of our current implementation and discuss two potential directions for improving it.
Setup for prefill latency. For each method in the right panel of Figure 1, we took its corresponding 3B model in the left panel and measured its prefill latency on one H100. We also took additional steps to optimize the inference latency of the PyTorch baselines, as discussed in Appendix C. Following Gated DeltaNet [2], the latency experiments are performed with a constant number of tokens (128K) per (outer-loop) batch. For example, at 128K context length, each batch contains one sequence, and at 8K each batch contains 16 sequences.
TTT-E2E only uses standard infrastructure. At test time, TTT-E2E can simply use the standard infrastructure optimized for training a regular Transformer. Specifically, since our hidden state takes the form of regular MLP layers, it can be sharded across GPUs using standard tools with no custom kernel. In contrast, prior work must fit their hidden states onto the individual chips inside a GPU, which significantly limits their hidden state size. For example, TTT-KVB [16] must reduce its state size with LoRA, while other prior work, such as Mamba 2 [49] and Gated DeltaNet [2], must use a linear hidden state and write custom kernels for efficient memory I/O.
Decode latency. As discussed in the end of Subsection 2.3, our method does not perform TTT until the decoded tokens have completely filled a TTT mini-batch. So before reaching a full batch, our decode latency is the same as that of a regular Transformer with SWA. Once we have a full batch, we need a step of TTT before decoding the next batch of tokens, and our latency for this TTT step is the same as that for prefill. Altogether, our latency for decoding a long sequence of multiple batches is simply the sum of the two latencies above: that of SWA decode and that of our prefill. Since both are readily available, we do not report separate measurements for the decode latency of TTT-E2E.
Setup for training latency. Most of our training was performed on GB200s. Since many of our baselines do not have custom kernels written for GB200s (Blackwell), we benchmark training latency on an H200 (Hopper) for fairness to the baselines. Following our protocol for prefill, we use a constant number of tokens (128K) per batch regardless of context length.
Training latency is a limitation. At training time, TTT-E2E takes gradients of gradients, which is a much less optimized procedure compared to training a regular Transformer. As shown in the left panel Figure 8, our training latency is 1.2×1.2\times1.2× faster than full attention at 128K context length, but 3.4×3.4\times3.4× slower at 8K. Since most of the training compute is typically spent on pre-training with short context, the training latency of our current implementation remains a significant limitation. Note that even though our number of FLOPs per token remains constant, as shown in the right panel, our latency grows between 8K and 32K. This trend arises because we have to increase the amount of gradient checkpointing through time by a factor of log(T)\log(T)log(T), where TTT is the context length.
Directions for faster training. There are two directions for improving our overall training time:
- Our current implementation cannot use cuDNN FlashAttention [61] at training time because it does not support gradients of gradients. A custom attention kernel would significantly improve our hardware utilization, and potentially eliminate the undesirable trend caused by gradient checkpointing through time.
- We believe that the training of TTT-E2E can be initialized from a pre-trained Transformer without TTT – a technique often adopted by prior work on RNNs [62, 63, 64]. This practical technique allows TTT-E2E to only take up a small portion of the overall training compute, so the negative effect of its training latency is minimal.
We leave these directions for future work.
4 Related Work
In this section, the authors position TTT-E2E within the broader landscape of continual learning, test-time training, fast weights, and meta-learning. Continual learning traditionally focuses on updating models as distributions shift over time while avoiding catastrophic forgetting, whereas test-time training emphasizes personalized, instance-specific learning that blurs the train-test boundary—mirroring how humans learn continuously from their unique experiences. Three forms of TTT are discussed: training on nearest neighbors to increase effective capacity, generating auxiliary data for better generalization to novel instances, and updating on sequences to extend memory, with TTT-KVB as the most relevant prior work for long-context modeling. Fast weight programmers update "fast" weights at test time using "slow" meta-learned parameters, a framework encompassing both modern RNN layers and the current method, which uses MLPs as fast weights interleaved with attention layers. Finally, the connection to meta-learning is drawn through MAML's bi-level optimization, though TTT-E2E differs by formulating language modeling itself as a learning-to-learn problem rather than requiring multiple separate datasets.
4.1 Continual Learning
Most of today's AI systems remain static after deployment, even though the world keeps changing. The high-level goal of continual learning is to enable AI systems to keep changing with the world, similar to how humans improve throughout their lives [65, 66].
Conventionally, continual learning as a research field has focused on learning from a distribution that gradually changes over time [67, 68, 69]. For example, one could update a chatbot model every hour using new knowledge from the Internet, while typical use cases of the model may require knowledge from both the past and the present [70, 71, 72]. More formally, at each timestep, we sample new training and test data from the current distribution, update our model using the new training data, and then evaluate it on all the test data up to the current timestep. Under this setting, most algorithms focus on not forgetting the past when learning from the present [73, 74, 75, 76].
4.2 Test-Time Training
The algorithmic framework of test-time training has the same high-level goal as continual learning, but it focuses on two aspects where human learning stands out from the forms of continual learning in the conventional literature.
First, each person has a unique brain that learns within the context of their individual life. This personalized form of continual learning is quite different from, for example, the chatbot model that is fine-tuned hourly using the latest information available worldwide. While such a model does change over time, it is still the same at any given moment for every user and every problem instance.
Second, most human learning happens without a boundary between training and testing. Consider your commute to work this morning. It is both "testing" because you did care about getting to work this very morning, and "training" because you were also gaining experience for future commutes. But in machine learning, the train-test split has always been a fundamental concept.
The concept of test-time training is introduced to realize these two special aspects of human learning. Training typically involves formulating a learning problem (such as empirical risk minimization) and then solving it. Following [15], test-time training is defined as any kind of training that formulates a potentially different learning problem based on each individual test instance.
This concept has a rich history in AI. A well-known example in NLP is dynamic evaluation, pioneered by Mikolov et al. [7] and extended by Krause et al. [8], which our Subsection 2.1 builds upon. In computer vision, early examples have also emerged in applications such as face detection [77], video segmentation [78], super-resolution [79], and 3D reconstruction [80]. Next, we discuss three popular forms of test-time training today, with an emphasis on their connections to each other and to historical examples.
4.2.1 TTT on Nearest Neighbors: Larger Effective Capacity
One simple form of test-time training was called locally weighted regression in the 1970s [17, 81], local learning in the 1990s [18], and KNN-SVM in the 2000s [82]: Given a test instance, find its nearest neighbors in the training set, and then train (or fine-tune) the model on these neighbors before making a prediction. This procedure can significantly increase the effective capacity of the model; for example, it allows a linear model to fit a highly nonlinear ground truth [17].
This simple form captures one of the key intuitions of test-time training. In the conventional view of machine learning, a model, once trained, no longer changes at test time. As a consequence, it must prepare to be good at all possible inputs in the future. This task can be very hard, because being good at all possible futures limits the model’s capacity to be good at any particular one. But only one future is actually going to happen. So why not train our model once this future happens?
Recently, [83] extended this idea to modern language models and observed a similar benefit of larger effective model capacity after test-time training, and [19] further improved these results through better strategies for neighbor selection. In addition, [84] showed that test-time training on neighbors from the training set is also effective with RL for reasoning tasks, and [85] developed the same idea for visual-motor tasks.
4.2.2 TTT for Novel Instances: Better Generalization
As models become larger today, their competence is often limited not by their capacity, but by the amount of available training data, especially when they need to generalize to novel test instances that are "out-of-distribution". In this case, it is even harder to prepare for all possible test instances in the future, especially the novel ones, with a static model. But once a specific test instance is given, we can use it to generate relevant data, which we can then use for training [86]. In other words, the "neighbors" for TTT do not have to come from the training set; they can also be generated on-the-fly.
Since the test instance is unlabeled, one way to make it useful for training is through self-supervision, which generates new pairs of inputs and labels for an auxiliary task such as masked reconstruction (e.g., BERT [87] and MAE [88]). While the auxiliary task is different from the main prediction task, improving performance in one can help the other through their shared representations. This form of TTT can significantly improve generalization under distribution shifts [86, 89].
Recently, TTT has been an important part of AlphaProof [90], which achieved IMO silver-medal standard in 2024. Given each test problem, their system first generates a targeted curriculum of easier problems by prompting a language model, and then performs reinforcement learning on the generated data. Another recent work, Akyurek et al. [20], found TTT effective for few-shot reasoning tasks such as ARC-AGI. Their system generates augmentations of the few-shot demonstrations in the test problem then performs supervised learning.
4.2.3 TTT on Sequences: Longer Memory
In all the forms of TTT discussed so far, the model is reset after each prediction because the test instances are independent. However, humans do not constantly reset their minds. Our memory of how to solve the previous learning problem often helps with the current one, because our experience in the world is much closer to a correlated sequence of data than independent ones.
Sequential applications, such as videos and robotics, offer a playground that bridges this difference. For example, [91] extended TTT with self-supervision to a manipulation policy whose input is a video stream of the robot's workstation, and found that no reset leads to a much larger improvement. Recently, [92] extended the same idea to video segmentation using a model trained with only images. In this case, TTT can be viewed as compressing the context from previous frames into the weights of the model without learning to learn, similar to the naive version of our method in Subsection 2.1.
TTT-KVB. Text, like videos, is a form of sequence. In Subsection 2.4, we have discussed TTT-KVB as the most relevant line of prior work [26, 16, 93], which includes variants such as MesaNet [27], Titans [28], and Nested Learning [29]. The popularity of TTT-KVB has two side effects:
- Because the KVB objective is inspired by self-attention, which stores the keys and values, many think that long-context TTT is about memorization instead of generalization.
- Because TTT(-KVB) layers are drop-in replacements for self-attention layers, many also think of long-context TTT as an approach to architecture design.
Our work shows that long-context TTT does not need to memorize the association between the keys and values. In addition, our method is derived purely under the formulation of a continual learning problem, with minimal changes to the architecture.
4.3 Fast Weights and Fast Weight Programmers
The general idea of fast weights is to update the parameters of a "fast" model on only the most relevant data, as opposed to the conventional practice of updating a "slow" model on all data [94]. This idea has existed since the 1980s [95, 9, 96]. Because the most relevant data can often include the test instance itself, test-time training can be viewed as a special case of fast weights, with a heavier emphasis on the formulation of an explicit learning problem.
The general idea of fast weight programmers (FWPs) is to update the fast weights at test time with a "slow" model (as a programmer) that, in turn, is updated less frequently, if at all [10]. In our method, the inner-loop weights WWW can be viewed as "fast" and the outer-loop weights θ\thetaθ as "slow". Therefore, our method can be viewed as a special case of FWPs [11]. Next, we briefly review some of the literature on FWPs in the order of relevance.
Clark et al. [23]. This work is the most relevant to ours in methodology. Given a Transformer baseline with full attention, they add an MLP layer as fast weights, whose initialization is trained as slow weights along with the rest of the model. Similar to ours, their method updates the fast weights by taking a gradient step on the next-token prediction loss computed over each chunk (mini-batch) of tokens. Their method significantly improves perplexity compared to the baseline but does not improve efficiency, since their combined architecture does not have linear complexity. In addition, their design adds the fast weights only to the end of the model instead of interleaving them with attention layers. In our experiments, interleaving proves to be critical for maintaining the performance gain on top of larger baselines. Nevertheless, we find Clark et al. to be a valuable inspiration. An earlier work [97] also contains sketches of a similar idea with limited experiments.
FWPs for long context. Many methods addressing the problem of long context have roots in the literature of FWPs. In particular, [10] (Schmidhuber, 1992) has been a major source of inspiration for modern RNN layers, such as linear attention [30, 21], DeltaNet [31, 50], and Gated DeltaNet [51], one of our baselines. In addition, some of the work on TTT for long context [26, 16] (discussed in Subsection 4.2) can also be viewed as FWPs, due to the connection between TTT and fast weights. Notably, one instantiation in Irie et al. [22] uses MLPs as layer-wise fast weights for long context, preceding the similar instantiation in [26].
Other FWPs. While the FWPs above can be interpreted through TTT, many other varieties cannot. For example, [98] designs the fast weights to be programmed by themselves, [99] builds an image generator using the images as fast weights, [100] applies continuous-time extensions of FWPs to time-series classification, while [101] and [102] demonstrate how the choice of update rules affects the expressiveness of FWPs on formal language recognition tasks. In fact, all networks with some gating mechanism, such as Transformers with SwiGLU blocks [103], can also be viewed as FWPs [1].
4.4 Learning to Learn
For decades, researchers have been arguing that learning to learn, also known as meta-learning or bi-level optimization, should be an important component of intelligence [104, 105, 106, 107]. Perhaps the most relevant work in this field is MAML [14]. Similar to our work, MAML also has an outer loop that learns the initialization of the inner loop through gradients of gradients. The main difference between MAML and our work lies in the problem setting. Specifically, their inner loop learns from an entire dataset at a time, so the outer loop requires a large collection of datasets. In contrast, our work addresses the problem of language modeling by casting it as learning to learn. In principle, any supervised learning problem can be cast into our problem formulation.
5 Conclusion
In this section, the authors present TTT-E2E as a general method for addressing long-context language modeling by enabling models to update their weights at test time. The approach can be applied to any baseline architecture, though the experiments focus on Transformers with sliding-window attention. When integrated with such a baseline, TTT-E2E creates a biologically-inspired memory hierarchy where test-time updated weights serve as long-term memory while the sliding window functions as short-term memory. This dual-memory system mirrors patterns observed in biological cognition. The authors emphasize that TTT-E2E is architecture-agnostic in principle, suggesting broad applicability across different model designs. Looking forward, they express confidence that these two complementary memory mechanisms will continue to work synergistically, with anticipated improvements as more sophisticated short-term memory techniques emerge to further enhance the combined system's performance on long-context tasks.
We have introduced TTT-E2E, a general method for long-context language modeling. In principle, TTT can be applied to any baseline architecture. For our experiments, this baseline is a Transformer with sliding-window attention. Adding our method to this baseline induces a hierarchy often found in biological memory, where the weights updated at test time can be interpreted as long-term memory and the sliding window as short-term memory. We believe that these two classes of memory will continue to complement each other, and stronger forms of short-term memory will further improve the combined method.
Author Contributions
In this section, the TTT-E2E research project represents a collaborative effort where six core contributors played distinct but complementary roles in developing a method for long-context language modeling. Arnuv Tandon and Karan Dalal led the scaling investigations and final experiments while managing infrastructure, Xinhao Li developed early experiments and codebase foundations, Daniel Koceja clarified scaling compute investigations through mid-project experiments, and Marcel Rød built the initial codebase with latency optimization expertise. Yu Sun served as project lead, conceived the TTT-E2E idea, designed experimental protocols, and authored the paper. The project evolved over approximately one year from October 2024, with team members joining at different stages and some departing at various points, ultimately demonstrating how distributed expertise in experimental design, infrastructure development, and theoretical direction converged to produce a novel approach combining test-time training with end-to-end learning for language models.
We state the contributions of each of the six core contributors.
Arnuv Tandon and Karan Dalal led the investigations into scaling with training compute and scaling with context length, developed the codebase, conducted the final experiments, managed our cluster, and played a central role in every aspect of this research, including its overall direction.
Xinhao Li developed and conducted most of the early experiments, including the toy experiments, co-developed our early codebase with Marcel, and contributed features for large-scale training.
Daniel Koceja led a set of mid-project experiments that brought clarity to the team's investigation into scaling with training compute.
Marcel Rød developed most of the early codebase and provided expertise to improve latency.
Yu Sun served as the project lead, making decisions on most day-to-day matters and on the project's overall direction. He developed the idea of TTT-E2E, designed most of the early experiments, and established the experimental protocols for the team. He also wrote the paper.
Yu Sun started the project in October 2024 together with Xinhao Li, Karan Dalal, and Daniel Koceja. Arnuv Tandon and Marcel Rød joined the project in November 2024. Karan Dalal and Daniel Koceja left from November 2024 through March 2025, and rejoined the project in April 2025. Marcel Rød left the project in May 2025. Xinhao Li and Daniel Koceja left in September 2025.
Acknowledgements
In this section, the authors acknowledge the extensive support that made their research possible, spanning computational resources, technical expertise, and intellectual guidance. Hyperbolic Labs and SF Compute provided GPU cloud services, while Matt Behrens and the Voltage Park team assisted with cluster management. Regular discussions with Zacharie Bugaud and Alan Zheng at Astera, along with general research support from Jan Kautz at NVIDIA, contributed to the project's development. Zhuang Liu offered valuable input during early stages, and Arjun Vikram, Gashon Hussein, and Aaditya Prasad made short-term contributions. Arnuv and Karan received compute credits through Harj Taggar at Y-Combinator. Yu Sun especially thanks Songlin Yang and Tianyuan Zhang for feedback on drafts and results, Mert Yuksekgonul and Chloe Hsu for continuous support throughout the project, and his PhD advisors Alexei A. Efros and Moritz Hardt, whose insights from years prior ultimately shaped key aspects of this work.
XW was supported, in part, by NSF CAREER Award IIS-2240014. TH was supported by the Tianqiao and Chrissy Chen Foundation and a grant under the NSF CAREER IIS-2338866, ONR N00014-24-1-2609, and DARPA Cooperative Agreement HR00112520013. This work does not necessarily reflect the position or policy of the government, and no official endorsement should be inferred.
The authors would like to thank Hyperbolic Labs and SF Compute for their GPU cloud services, Matt Behrens and the service team at Voltage Park for their help with our cluster, Zacharie Bugaud and Alan Zheng at Astera for discussions during the weekly meetings, Jan Kautz at NVIDIA for general research support, Zhuang Liu for discussions during the early phase of the project, and Arjun Vikram, Gashon Hussein, and Aaditya Prasad for their short-term contributions. Arnuv and Karan would like to thank Harj Taggar at Y-Combinator for his support with compute credits. Yu would like to thank Songlin Yang and Tianyuan Zhang for their feedback on drafts and results, Mert Yuksekgonul and Chloe Hsu for their support at every phase of the project, as well as his PhD advisors, Alexei A. Efros and Moritz Hardt, for their many insights from years ago that eventually became part of this paper.
Appendix
A Recipe for the Toy Example
There are two architectures in our toy example: Transformer with full attention, and Transformer without attention. Their only difference is that the latter has every attention layer removed, therefore fewer parameters. All the TTT methods are based on the latter architecture. Both architectures consist of two Transformer blocks. These blocks are constructed based on those in the 125M model in the basic recipe, with half the embedding dimension (384) and number of attention heads (6).
We train all the methods on DCLM at context length 128. The number of training tokens follows the Chinchilla recipe, and the (outer-loop) batch size is 125K tokens. We evaluate on the same held-out partition of DCLM as in Section 3. For each method, we sweep for its optimal learning rate in the range of [2e−3, 6e−3][2\mathrm{e}{-3}, \, 6\mathrm{e}{-3}][2e−3,6e−3] in increments of 0.5e−30.5\mathrm{e}{-3}0.5e−3. The optimal learning rate is 3e−33\mathrm{e}{-3}3e−3 for Transformer with full attention, and 5e−35\mathrm{e}{-3}5e−3 for Transformer without attention and all the TTT variants.
B Basic Recipe
We use the standard Transformer architecture with QK norm [40], and the Llama, 3 tokenizer [37]. Our basic recipe is shown in Table 3. It uses the model configurations and pre-training recipe in GPT-3 [45], with two changes following the Mamba, 2 paper [49]: We use 5×5\times5× the peak learning rate in GPT-3, and half the batch size for the 1B model. These two changes have been shown to improve the full attention baseline. Our learning rate schedule, also following Mamba 2, is the same for every model size: For the first 10% of training, our learning rate increases from 0 to the peak in a linear schedule. For the rest of training, it decays to 1e-5 in a cosine schedule.
For extension fine-tuning, we always use 5% of the number of pre-training tokens. We also double the batch size so there can be a reasonable number of sequences per batch. To reduce the cost of hyper-parameter search, we only sweep the peak learning rate for the full attention baseline. Specifically, for each model size in [760M, 1B, 3B], and each context length in [32K, 128K], we sweep the following learning rates: [8e−5, 1e−4, 2e−4, 4e−4, 8e−48\mathrm{e}{-5}, \, 1\mathrm{e}{-4}, \, 2\mathrm{e}{-4}, \, 4\mathrm{e}{-4}, \, 8\mathrm{e}{-4}8e−5,1e−4,2e−4,4e−4,8e−4]. We find that a single choice, 4e−44\mathrm{e}{-4}4e−4, happens to perform the best across all the model sizes and context lengths above. Therefore, we use this learning rate for every context length and model size in the basic recipe. Following [44], we restart the cosine schedule at the beginning of fine-tuning.
We use RoPE [32] with θ=500\theta=500θ=500K for pre-training at 8K context length, following Llama 3 [37]. For extension fine-tuning, we change the RoPE θ\thetaθ for full attention, following standard practice [37, 38]. Unfortunately, we could not find the values of θ\thetaθ in most of the papers on long context. Following [108], we use θ=10\theta=10θ=10M at 128K, and choose the other values of θ\thetaθ by assuming a log-linear relationship with context length: θ=1\theta=1θ=1M for 16K, 222M for 32K, and 555M for 64K.
C Improvements to the Baselines
We made two improvements to the baselines.
Latency. Our method, implemented in JAX, uses the latest cuDNN kernel for attention. However, all the RNN baselines, implemented in PyTorch, originally used the FlashAttention 2 kernel [61], which was much less efficient. To improve the baselines, we upgraded their attention layers to use the latest version of FlashAttention 3 [109].
QK norm. We find that normalizing the queries and keys in the attention layers (QK norm) makes training more stable for TTT-E2E, and also improves the Transformer baselines, as suggested by prior work [40]. Therefore, we apply it to the other baselines with sliding-window attention layers. At the scale of 760M, applying QK norm to Gated DeltaNet improves its loss from 2.814 to 2.809 for pre-training at 8K context length, and from 2.691 to 2.683 for extension fine-tuning at 32K.
D Additional Details for Decoding Evaluation
For sampling, we set the softmax temperature to 1, and the threshold ppp for top- ppp vocabulary to 0.95, following [110].
In addition, it is widely known that base models without instruction fine-tuning tend to decode patterns of repetition. To address this problem, we use the standard API for repetition penalty in the HuggingFace toolkit for generation, and set its value to 1.1. This value is recommended by many HuggingFace users, and makes the full attention baseline generate reasonable text, as we have found through manual inspection.
References
In this section, the references collectively trace the intellectual lineage and contextual foundations of TTT-E2E, spanning decades of research in neural architectures, meta-learning, and memory systems. Early work on recurrent networks, fast weights, and learning-to-learn paradigms from the late 1980s and 1990s established the conceptual basis for adaptive, self-modifying systems. These ideas evolved through advances in attention mechanisms, state-space models, and efficient transformers, addressing scalability and long-context challenges in modern language modeling. Recent developments in test-time training, continual learning, and hybrid architectures demonstrate growing recognition that models should adapt dynamically to new data during inference. The references also cover practical innovations like Flash Attention kernels, RoPE positional encodings, and large-scale pretraining recipes that enable efficient implementation. Together, these works converge on a central insight: combining slow outer-loop learning with fast inner-loop adaptation creates biologically-inspired memory hierarchies that enhance both efficiency and performance in sequence modeling tasks.
[1] Gu, Albert and Dao, Tri (2023). Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752.
[2] Yang et al. (2024). Gated Delta Networks: Improving Mamba2 with Delta Rule. arXiv preprint arXiv:2412.06464.
[3] Agarwal et al. (2025). gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925.
[4] Yuan et al. (2025). Native sparse attention: Hardware-aligned and natively trainable sparse attention. arXiv preprint arXiv:2502.11089.
[5] Kimi Team et al. (2025). Kimi linear: An expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692.
[6] Blakeman et al. (2025). Nemotron-h: A family of accurate and efficient hybrid mamba-transformer models. arXiv preprint arXiv:2504.03624.
[7] Mikolov et al. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[8] Krause et al. (2018). Dynamic evaluation of neural sequence models. In International Conference on Machine Learning. pp. 2766–2775.
[9] Hinton, Geoffrey E and Plaut, David C (1987). Using fast weights to deblur old memories. In Proceedings of the ninth annual conference of the Cognitive Science Society. pp. 177–186.
[10] Schmidhuber, Jürgen (1992). Learning to control fast-weight memories: An alternative to dynamic recurrent networks. Neural Computation. 4(1). pp. 131–139.
[11] Kirsch, Louis and Schmidhuber, Jürgen (2021). Meta learning backpropagation and improving it. Advances in Neural Information Processing Systems. 34. pp. 14122–14134.
[12] Maclaurin et al. (2015). Gradient-based hyperparameter optimization through reversible learning. In International conference on machine learning. pp. 2113–2122.
[13] Andrychowicz et al. (2016). Learning to learn by gradient descent by gradient descent. Advances in neural information processing systems. 29.
[14] Finn et al. (2017). Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning. pp. 1126–1135.
[15] Sun et al. (2023). Learning to (Learn at Test Time). arXiv preprint arXiv:2310.13807.
[16] Zhang et al. (2025). Test-time training done right. arXiv preprint arXiv:2505.23884.
[17] Stone, Charles J (1977). Consistent nonparametric regression. The annals of statistics. pp. 595–620.
[18] Bottou, Léon and Vapnik, Vladimir (1992). Local learning algorithms. Neural computation. 4(6). pp. 888–900.
[19] Hübotter et al. (2024). Efficiently learning at test-time: Active fine-tuning of llms. arXiv preprint arXiv:2410.08020.
[20] Akyürek et al. (2024). The surprising effectiveness of test-time training for abstract reasoning. arXiv e-prints. pp. arXiv–2411.
[21] Schlag et al. (2020). Learning associative inference using fast weight memory. arXiv preprint arXiv:2011.07831.
[22] Irie et al. (2021). Going beyond linear transformers with recurrent fast weight programmers. Advances in Neural Information Processing Systems.
[23] Clark et al. (2022). Meta-Learning Fast Weight Language Models. arXiv preprint arXiv:2212.02475.
[25] Engstrom et al. (2025). Optimizing ml training with metagradient descent. arXiv preprint arXiv:2503.13751.
[26] Sun et al. (2024). Learning to (learn at test time): Rnns with expressive hidden states. arXiv preprint arXiv:2407.04620.
[27] von Oswald et al. (2025). MesaNet: Sequence Modeling by Locally Optimal Test-Time Training. arXiv preprint arXiv:2506.05233.
[28] Behrouz et al. (2024). Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663.
[29] Behrouz et al. (2025). Nested learning: The illusion of deep learning architectures. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.
[30] Katharopoulos et al. (2020). Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning. pp. 5156–5165.
[31] Schlag et al. (2021). Linear transformers are secretly fast weight programmers. In International Conference on Machine Learning. pp. 9355–9366.
[32] Kitaev et al. (2020). Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451.
[33] Tay et al. (2021). Synthesizer: Rethinking self-attention for transformer models. In International conference on machine learning. pp. 10183–10192.
[34] Zhai et al. (2021). An attention free transformer. arXiv preprint arXiv:2105.14103.
[35] Hu et al. (2022). Lora: Low-rank adaptation of large language models. ICLR. 1(2). pp. 3.
[36] Lee et al. (2015). Deeply-supervised nets. In Artificial intelligence and statistics. pp. 562–570.
[37] Dubey et al. (2024). The llama 3 herd of models. arXiv e-prints. pp. arXiv–2407.
[38] Wenhan Xiong et al. (2023). Effective Long-Context Scaling of Foundation Models.
[39] Liu et al. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.
[41] Li et al. (2024). Datacomp-lm: In search of the next generation of training sets for language models. Advances in Neural Information Processing Systems. 37. pp. 14200–14282.
[42] Leo Gao et al. (2020). The Pile: An 800GB Dataset of Diverse Text for Language Modeling.
[43] Authors Guild (2023). You Just Found Out Your Book Was Used to Train AI. Now What?. Accessed: 2024-06-24.
[44] Liu et al. (2024). World model on million-length video and language with blockwise ringattention. arXiv preprint arXiv:2402.08268.
[45] Brown et al. (2020). Language models are few-shot learners. Advances in neural information processing systems. 33. pp. 1877–1901.
[46] Hugo Touvron et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models.
[47] Beltagy et al. (2020). Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
[48] Gemma Team et al. (2024). Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118.
[49] Dao, Tri and Gu, Albert (2024). Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. arXiv preprint arXiv:2405.21060.
[50] Yang et al. (2024). Parallelizing Linear Transformers with the Delta Rule over Sequence Length. arXiv preprint arXiv:2406.06484.
[51] Yang et al. (2023). Gated linear attention transformers with hardware-efficient training. arXiv preprint arXiv:2312.06635.
[52] Kaplan et al. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
[53] Jordan Hoffmann et al. (2022). Training Compute-Optimal Large Language Models.
[56] Hochreiter, Sepp and Schmidhuber, Jürgen (1997). Long short-term memory. Neural computation. 9(8). pp. 1735–1780.
[57] Chung et al. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555.
[58] Hsieh et al. (2024). RULER: What's the Real Context Size of Your Long-Context Language Models?. arXiv preprint arXiv:2404.06654.
[60] Tianqi Chen et al. (2016). Training Deep Nets with Sublinear Memory Cost.
[61] Dao, Tri (2023). Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691.
[63] Bick et al. (2024).
Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models. arXiv preprint arXiv:2408.10189.
https://arxiv.org/abs/2408.10189.
[65] Hassabis et al. (2017). Neuroscience-inspired artificial intelligence. Neuron. 95(2). pp. 245–258.
[66] De Lange et al. (2021). A continual learning survey: Defying forgetting in classification tasks. IEEE transactions on pattern analysis and machine intelligence. 44(7). pp. 3366–3385.
[67] Lopez-Paz, David and Ranzato, Marc'Aurelio (2017). Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems. pp. 6467–6476.
[68] Van de Ven, Gido M and Tolias, Andreas S (2019). Three scenarios for continual learning. arXiv preprint arXiv:1904.07734.
[69] Hadsell et al. (2020). Embracing change: Continual learning in deep neural networks. Trends in cognitive sciences. 24(12). pp. 1028–1040.
[70] Scialom et al. (2022). Fine-tuned language models are continual learners. arXiv preprint arXiv:2205.12393.
[71] Ke et al. (2023). Continual pre-training of language models. arXiv preprint arXiv:2302.03241.
[72] Wang et al. (2024). A comprehensive survey of continual learning: Theory, method and application. IEEE transactions on pattern analysis and machine intelligence. 46(8). pp. 5362–5383.
[73] Santoro et al. (2016). Meta-learning with memory-augmented neural networks. In International conference on machine learning. pp. 1842–1850.
[74] Li, Zhizhong and Hoiem, Derek (2017). Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence. 40(12). pp. 2935–2947.
[75] Kirkpatrick et al. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences. 114(13). pp. 3521–3526.
[76] Gidaris, Spyros and Komodakis, Nikos (2018). Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4367–4375.
[77] Jain, Vidit and Learned-Miller, Erik (2011). Online domain adaptation of a pre-trained cascade of classifiers. In CVPR 2011. pp. 577–584.
[78] Mullapudi et al. (2018). Online Model Distillation for Efficient Video Inference. arXiv preprint arXiv:1812.02699.
[79] Shocher et al. (2018). “Zero-Shot” Super-Resolution using Deep Internal Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3118–3126.
[80] Luo et al. (2020). Consistent video depth estimation. ACM Transactions on Graphics (ToG). 39(4). pp. 71–1.
[81] Cleveland, William S (1979). Robust locally weighted regression and smoothing scatterplots. Journal of the American statistical association. 74(368). pp. 829–836.
[82] Zhang et al. (2006). SVM-KNN: Discriminative nearest neighbor classification for visual category recognition. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). pp. 2126–2136.
[83] Hardt, Moritz and Sun, Yu (2023). Test-Time Training on Nearest Neighbors for Large Language Models. arXiv preprint arXiv:2305.18466.
[84] Hübotter et al. (2025). Learning on the Job: Test-Time Curricula for Targeted Reinforcement Learning. arXiv preprint arXiv:2510.04786.
[85] Bagatella et al. (2025). Test-time offline reinforcement learning on goal-related experience. arXiv preprint arXiv:2507.18809.
[86] Sun et al. (2020). Test-time training with self-supervision for generalization under distribution shifts. In International Conference on Machine Learning. pp. 9229–9248.
[87] Devlin et al. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[88] He et al. (2021). Masked Autoencoders Are Scalable Vision Learners. CoRR. abs/2111.06377.
[89] Gandelsman et al. (2022). Test-Time Training with Masked Autoencoders. Advances in Neural Information Processing Systems.
[90] Hubert et al. (2025). Olympiad-level formal mathematical reasoning with reinforcement learning. Nature.
[91] Hansen et al. (2020). Self-supervised policy adaptation during deployment. arXiv preprint arXiv:2007.04309.
[92] Wang et al. (2023). Test-time training on video streams. arXiv preprint arXiv:2307.05014.
[93] Dalal et al. (2025). One-minute video generation with test-time training. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17702–17711.
[94] Tieleman, Tijmen and Hinton, Geoffrey (2009). Using fast weights to improve persistent contrastive divergence. In Proceedings of the 26th annual international conference on machine learning. pp. 1033–1040.
[95] Feldman, Jerome A (1982). Dynamic connections in neural networks. Biological cybernetics. 46(1). pp. 27–39.
[96] Von Der Malsburg, Christoph (1994). The correlation theory of brain function.
[97] Wolf et al. (2018). Meta-learning a dynamical language model. arXiv preprint arXiv:1803.10631.
[98] Irie et al. (2022). A modern self-referential weight matrix that learns to modify itself. In International Conference on Machine Learning. pp. 9660–9677.
[99] Irie, Kazuki and Schmidhuber, Jürgen (2022). Images as weight matrices: Sequential image generation through synaptic learning rules. International Conference on Learning Representations (ICLR).
[100] Irie et al. (2022). Neural differential equations for learning to program neural nets through continuous learning rules. Advances in Neural Information Processing Systems.
[101] Irie et al. (2023). Practical computational power of linear transformers and their recurrent and self-referential extensions. Conference on Empirical Methods in Natural Language Processing (EMNLP).
[102] Grazzi et al. (2024). Unlocking state-tracking in linear rnns through negative eigenvalues. International Conference on Learning Representations (ICLR).
[103] Noam Shazeer (2020). GLU Variants Improve Transformer.
[104] Schmidhuber, Jürgen (1987). Evolutionary principles in self-referential learning, or on learning how to learn: the meta-meta-... hook.
[105] Bengio et al. (1990). Learning a synaptic learning rule. Citeseer.
[106] Thrun, Sebastian and Pratt, Lorien (1998). Learning to learn: Introduction and overview.
[107] Lake et al. (2017). Building machines that learn and think like people. Behavioral and brain sciences. 40. pp. e253.
[110] Holtzman et al. (2019). The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751.
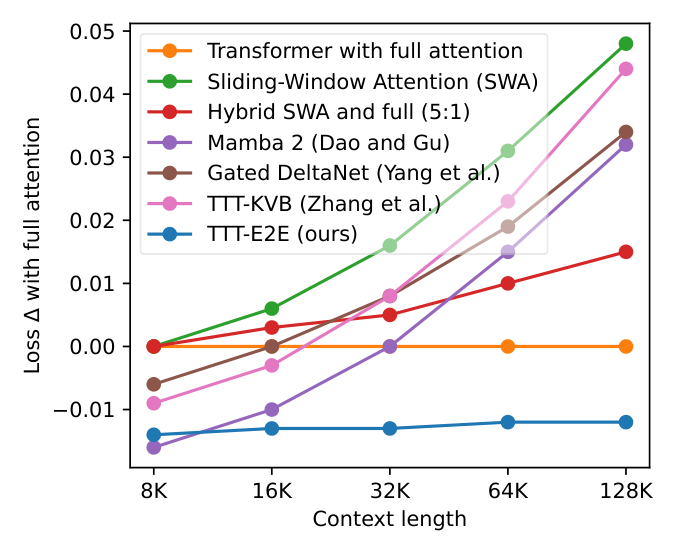
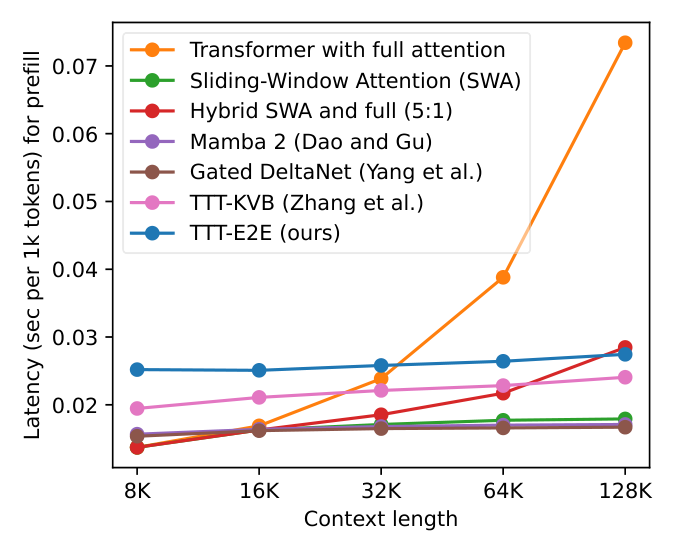
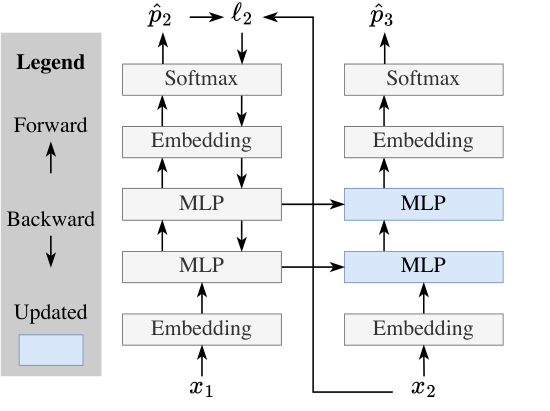
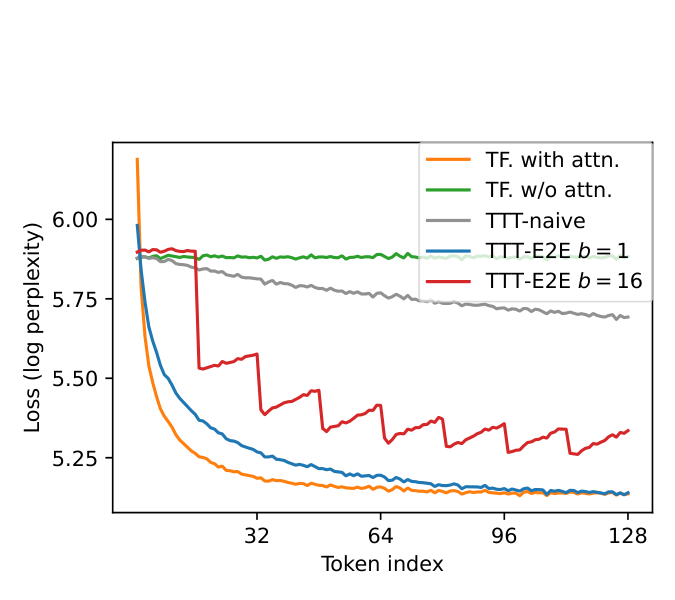
![**Figure 3:** Computation graphs following the setup in Figure 2: Given $x_1$ and $x_2$ as context, we want to predict the unknown $x_3$. **Left:** Our main method with the sliding-window attention layers and the implementation details discussed in Subsection 2.3. For ease of notation, our illustration uses online gradient descent ($b=1$). The lowest downward arrow is disconnected to the MLP below, since gradients pass through the last $L/4$ blocks but not further down. **Right:** The first step of our alternative derivation in Subsection 2.4: a simplified version of TTT-KVB in prior work [16, 26].](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/zk7duzw3/main.png)
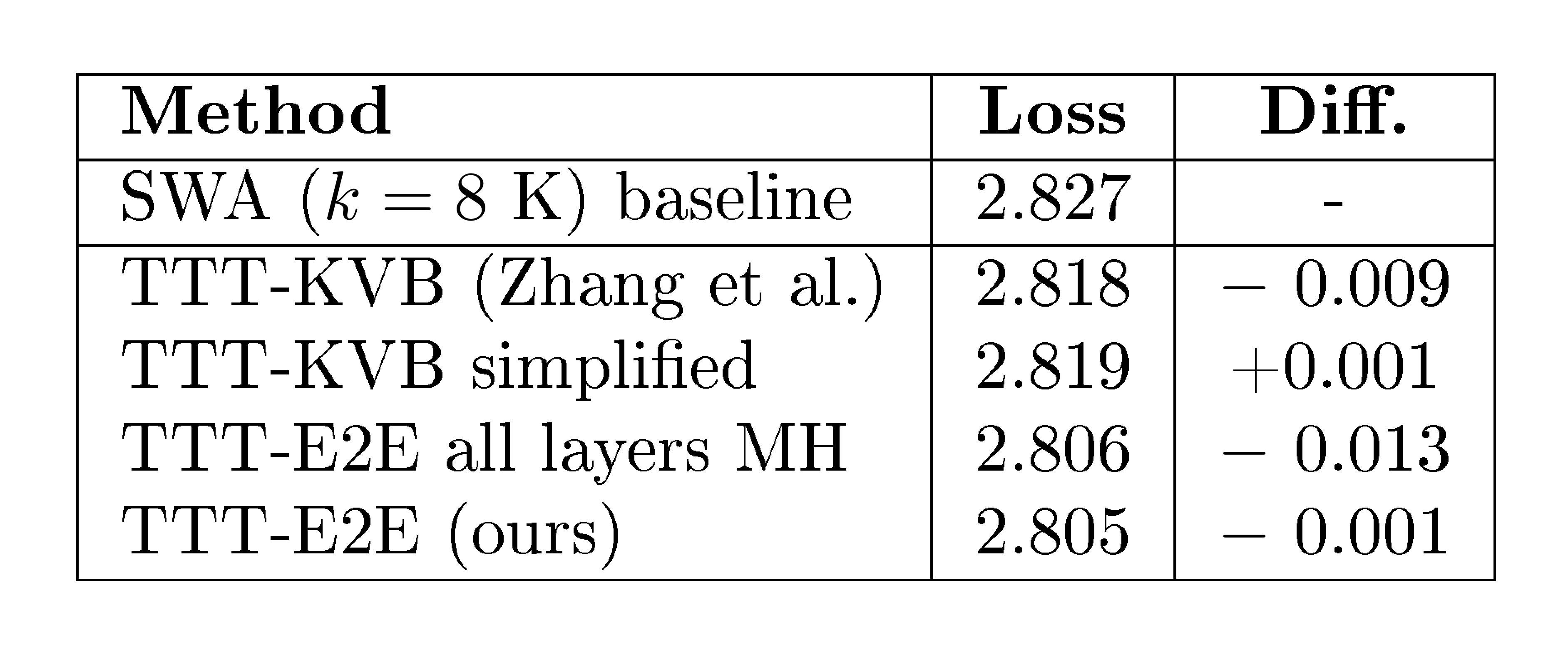
![**Figure 4:** Ablations on three hyper-parameters: sliding window size $k$, mini-batch size $b$, and the number of layers updated during TTT; see details in Subsection 3.2. Given the trends in these ablations, we set $k=8$ K, $b=1$ K, and we update 1/4 the total number of layers. Loss $\Delta$ ($\downarrow$), the $y$-value in the rightmost panel, is the same as in Figure 1. It is computed as (loss of the reported method) $-$ (loss of Transformer with full attention), so loss $\Delta$ of full attention itself (orange) is the flat line at $y=0$. GDN stands for Gated DeltaNet [51].](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/zk7duzw3/ablations.png)