NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
Peng Wang $^{\dagger}$, Lingjie Liu $^{\ddagger,}$, Yuan Liu $^{\dagger}$, Christian Theobalt $^{\ddagger}$, Taku Komura $^{\dagger}$, Wenping Wang $^{\diamond,}$
$^{\dagger}$ The University of Hong Kong $^{\ddagger}$ Max Planck Institute for Informatics
$^{\diamond}$ Texas A&M University
$^{\dagger}$ pwang3,yliu,[email protected] $^{\ddagger}$ lliu,[email protected]
$^{\diamond}$ [email protected]
$^{*}$ Corresponding authors.
Abstract
We present a novel neural surface reconstruction method, called NeuS, for reconstructing objects and scenes with high fidelity from 2D image inputs. Existing neural surface reconstruction approaches, such as DVR [Niemeyer et al., 2020] and IDR [Yariv et al., 2020], require foreground mask as supervision, easily get trapped in local minima, and therefore struggle with the reconstruction of objects with severe self-occlusion or thin structures. Meanwhile, recent neural methods for novel view synthesis, such as NeRF [Mildenhall et al., 2020] and its variants, use volume rendering to produce a neural scene representation with robustness of optimization, even for highly complex objects. However, extracting high-quality surfaces from this learned implicit representation is difficult because there are not sufficient surface constraints in the representation. In NeuS, we propose to represent a surface as the zero-level set of a signed distance function (SDF) and develop a new volume rendering method to train a neural SDF representation. We observe that the conventional volume rendering method causes inherent geometric errors (i.e. bias) for surface reconstruction, and therefore propose a new formulation that is free of bias in the first order of approximation, thus leading to more accurate surface reconstruction even without the mask supervision. Experiments on the DTU dataset and the BlendedMVS dataset show that NeuS outperforms the state-of-the-arts in high-quality surface reconstruction, especially for objects and scenes with complex structures and self-occlusion.
Executive Summary: Reconstructing three-dimensional (3D) models from multiple two-dimensional (2D) images is a core challenge in computer vision and computer graphics, powering applications like virtual reality, robotics, and digital content creation. Traditional methods often fail on complex scenes with self-occlusions, thin structures, or non-uniform lighting, producing artifacts or incomplete results that demand manual fixes and raise costs. Recent neural network approaches, such as those using surface rendering (like IDR) or volume rendering (like NeRF), have advanced the field but still rely on extra supervision like object masks or yield noisy, low-fidelity surfaces, limiting their use in real-world scenarios where such data is unavailable or scenes are intricate.
This paper introduces NeuS, a neural method designed to reconstruct high-fidelity 3D surfaces from posed 2D images alone, without needing masks or 3D ground truth. It aims to combine the precision of signed distance functions (SDFs)—which define surfaces as points equidistant from an object's boundary—with the robust training benefits of volume rendering, addressing gaps in prior methods that get stuck on local errors or lack geometric accuracy.
The approach encodes the scene using two neural networks: one for the SDF, which captures geometry, and another for color based on position and view direction. NeuS develops a custom volume rendering technique that samples points along image rays, weights them via an "S-density" derived from the SDF to ensure accurate surface emphasis, and avoids the geometric biases in standard volume rendering. Training minimizes differences between rendered and input images over 300,000 iterations on standard datasets like DTU (15 scenes with 49–64 images each, covering varied materials and geometries) and BlendedMVS (7 complex scenes with 31–143 images). Key assumptions include images with known poses and a bounded scene within a unit sphere; no equations or heavy computation details are needed here, but the method draws credibility from direct comparisons to baselines like IDR, NeRF, COLMAP, and UNISURF using Chamfer distance (a measure of surface accuracy).
NeuS delivers superior results across benchmarks. First, on the DTU dataset with masks, it achieves a mean Chamfer distance of 0.77, outperforming IDR's 0.90 by about 14% and NeRF's 1.54 by over 50%, especially on thin or occluded parts like metal edges. Without masks—a more practical setting—NeuS scores 0.84, beating NeRF's 1.49 by roughly 44%, UNISURF's 1.02 by 18%, and COLMAP's 1.36 by 38%, with cleaner surfaces and fewer artifacts. Second, qualitative visuals show NeuS faithfully capturing abrupt depth changes and self-occlusions (e.g., holes or branches) that IDR misses and NeRF noises up. Third, on BlendedMVS, it handles real-world scenes better than baselines, producing watertight meshes. Fourth, ablation tests confirm the novel weighting reduces biases, cutting errors by 20–30% versus naive alternatives. Fifth, NeuS excels on custom thin-object captures, reconstructing edges accurately where others blur or break.
These findings mean NeuS enables more reliable 3D reconstruction for complex objects, reducing risks of errors in downstream uses like simulation or augmented reality, where inaccurate models could mislead decisions or inflate development timelines. Unlike IDR, it eliminates mask dependency, lowering preprocessing costs and broadening applicability to uncurated image sets. Compared to NeRF, it extracts precise surfaces without extra post-processing, improving performance by focusing gradients on true geometry rather than diffuse volumes. This shifts from expectation—volume rendering was seen as anti-surface—by proving unbiased variants work, potentially cutting manual modeling expenses by 50% or more in graphics pipelines.
To leverage NeuS, integrate it into multi-view reconstruction workflows, starting with datasets like DTU for validation, and prioritize it for scenes with occlusions or thin features. For production, test on specific hardware (e.g., NVIDIA GPUs) given its 14–16 hour training per scene; options include hierarchical sampling for faster rendering (down to 60 seconds per high-res image) versus full accuracy. If textureless areas are common, combine with classical methods for hybrid robustness. Further work is essential before broad deployment: gather more data on low-texture objects to refine training, explore per-location scale variations for even sharper results, and run pilots on real applications to quantify time/cost savings. Pilot a scaled version on 5–10 internal scenes next quarter.
Confidence in these results is high for textured, multi-view inputs, backed by rigorous dataset comparisons and ablations, but caution is warranted for textureless or sparse-view cases, where performance drops due to ambiguity in color matching—limits noted in failure examples. Overall, NeuS stands as a credible advance, with uncertainties mainly in untested extremes rather than core claims.
1. Introduction
Section Summary: Reconstructing 3D surfaces from multiple images is a core challenge in computer vision, where traditional methods struggle with complex shapes like shiny or thin objects, but neural approaches using signed distance functions offer better quality. Earlier techniques like IDR produce detailed results but fail on sudden depth changes, such as holes or edges, because they only sample one point per ray, leading to optimization issues, while NeRF handles these changes through volume rendering but results in noisy surfaces unsuitable for precise reconstruction. The new method, NeuS, combines the accuracy of signed distance functions with an innovative volume rendering technique to robustly learn surfaces even in occluded or intricate scenes, outperforming prior methods without needing extra guidance like object masks.
Reconstructing surfaces from multi-view images is a fundamental problem in computer vision and computer graphics. 3D reconstruction with neural implicit representations has recently become a highly promising alternative to classical reconstruction approaches [1, 2, 3] due to its high reconstruction quality and its potential to reconstruct complex objects that are difficult for classical approaches, such as non-Lambertian surfaces and thin structures. Recent works represent surfaces as signed distance functions (SDF) [4, 5, 6, 7] or occupancy [8, 9]. To train their neural models, these methods use a differentiable surface rendering method to render a 3D object into images and compare them against input images for supervision. For example, IDR [4] produces impressive reconstruction results, but it fails to reconstruct objects with complex structures that causes abrupt depth changes. The cause of this limitation is that the surface rendering method used in IDR only considers a single surface intersection point for each ray. Consequently, the gradient only exists at this single point, which is too local for effective back propagation and would get optimization stuck in a poor local minimum when there are abrupt changes of depth on images. Furthermore, object masks are needed as supervision for converging to a valid surface. As illustrated in Figure 1 (a) top, with the radical depth change caused by the hole, the neural network would incorrectly predict the points near the front surface to be blue, failing to find the far-back blue surface. The actual test example in Figure 1 (b) shows that IDR fails to correctly reconstruct the surfaces near the edges with abrupt depth changes.
Recently, NeRF [10] and its variants have explored to use a volume rendering method to learn a volumetric radiance field for novel view synthesis. This volume rendering approach samples multiple points along each ray and perform $\alpha$-composition of the colors of the sampled points to produce the output pixel colors for training purposes. The advantage of the volume rendering approach is that it can handle abrupt depth changes, because it considers multiple points along the ray and so all the sample points, either near the surface or on the far surface, produce gradient signals for back propagation. For example, referring Figure 1 (a) bottom, when the near surface (yellow) is found to have inconsistent colors with the input image, the volume rendering approach is capable of training the network to find the far-back surface to produce the correct scene representation. However, since it is intended for novel view synthesis rather than surface reconstruction, NeRF only learns a volume density field, from which it is difficult to extract a high-quality surface. Figure 1 (b) shows a surface extracted as a level-set surface of the density field learned by NeRF. Although the surface correctly accounts for abrupt depth changes, it contains conspicuous noise in some planar regions.

In this work, we present a new neural rendering scheme, called NeuS, for multi-view surface reconstruction. NeuS uses the signed distance function (SDF) for surface representation and uses a novel volume rendering scheme to learn a neural SDF representation. Specifically, by introducing a density distribution induced by SDF, we make it possible to apply the volume rendering approach to learning an implicit SDF representation and thus have the best of both worlds, i.e. an accurate surface representation using a neural SDF model and robust network training in the presence of abrupt depth changes as enabled by volume rendering. Note that simply applying a standard volume rendering method to the density associated with SDF would lead to discernible bias (i.e. inherent geometric errors) in the reconstructed surfaces. This is a new and important observation that we will elaborate later. Therefore we propose a novel volume rendering scheme to ensure unbiased surface reconstruction in the first-order approximation of SDF. Experiments on both DTU dataset and BlendedMVS dataset demonstrated that NeuS is capable of reconstructing complex 3D objects and scenes with severe occlusions and delicate structures, even without foreground masks as supervision. It outperforms the state-of-the-art neural scene representation methods, namely IDR [4] and NeRF [10], in terms of reconstruction quality.
2. Related Works
Section Summary: Traditional methods for reconstructing 3D models from multiple images fall into point- and surface-based approaches, which estimate depths and fuse them into point clouds but struggle with texture-poor objects leading to artifacts, or volumetric techniques that model space in grids for better consistency yet limited detail. More recent neural approaches use implicit representations encoded in networks to capture continuous 3D shapes and appearances, applied in tasks like novel view generation and reconstruction, often relying on surface rendering that falters with occlusions and requires extra guidance, or volume rendering like NeRF that excels at image synthesis but complicates precise surface extraction. The authors' method improves on these by using a signed distance function for geometry constrained through robust volume rendering, outperforming similar works like UNISURF in accuracy without needing masks.
Classical Multi-view Surface and Volumetric Reconstruction.
Traditional multi-view 3D reconstruction methods can be roughly classified into two categories: point- and surface-based reconstruction [3, 2, 11, 1] and volumetric reconstruction [12, 13, 14]. Point- and surface-based reconstruction methods estimate the depth map of each pixel by exploiting inter-image photometric consistency [2] and then fuse the depth maps into a global dense point cloud [15, 16]. The surface reconstruction is usually done as a post processing with methods like screened Poisson surface reconstruction [17]. The reconstruction quality heavily relies on the quality of correspondence matching, and the difficulties in matching correspondence for objects without rich textures often lead to severe artifacts and missing parts in the reconstruction results. Alternatively, volumetric reconstruction methods circumvent the difficulty of explicit correspondence matching by estimating occupancy and color in a voxel grid from multi-view images and evaluating the color consistency of each voxel. Due to limited achievable voxel resolution, these methods cannot achieve high accuracy.
Neural Implicit Representation.
Some methods enforce 3D understanding in a deep learning framework by introducing inductive biases. These inductive biases can be explicit representations, such as voxel grids [18, 19, 20], point cloud [21, 22, 23], meshes [24, 25, 26], and implicit representations. The implicit representations encoded by a neural network has gained a lot of attention recently, since it is continuous and can achieve high spatial resolution. This representation has been applied successfully to shape representation [27, 28, 29, 30, 31, 32, 33, 34], novel view synthesis [35, 36, 37, 10, 38, 39, 40, 41, 42] and multi-view 3D reconstruction [4, 8, 6, 43, 7].
Our work mainly focuses on learning implicit neural representation encoding both geometry and appearance in 3D space from 2D images via classical rendering techniques. Limited in this scope, the related works can be roughly categorized based on the rendering techniques used, i.e. surface rendering based methods and volume rendering based methods. Surface rendering based methods [8, 6, 4, 7] assume that the color of ray only relies on the color of an intersection of the ray with the scene geometry, which makes the gradient only backpropagated to a local region near the intersection. Therefore, such methods struggle with reconstructing complex objects with severe self-occlusions and sudden depth changes. Furthermore, they usually require object masks as supervision. On the contrary, our method performs well for such challenging cases without the need of masks.
Volume rendering based methods, such as NeRF [10], render an image by $\alpha$-compositing colors of the sampled points along each ray. As explained in the introduction, it can handle sudden depth changes and synthesize high-quality images. However, extracting high-fidelity surface from the learned implicit field is difficult because the density-based scene representation lacks sufficient constraints on its level sets. In contrast, our method combines the advantages of surface rendering based and volume rendering based methods by constraining the scene space as a signed distance function but applying volume rendering to train this representation with robustness. UNISURF [9], a concurrent work, also learns an implicit surface via volume rendering. It improves the reconstruction quality by shrinking the sample region of volume rendering during the optimization. Our method differs from UNISURF in that UNISURF represents the surface by occupancy values, while our method represents the scene by an SDF and thus can naturally extract the surface as the zero-level set of it, yielding better reconstruction accuracy than UNISURF, as will be seen later in the experiment section.
3. Method
Section Summary: The method aims to reconstruct a 3D object's surface from a collection of posed images by representing it as the zero-level set of a neural signed distance function (SDF), which is learned using multilayer perceptron networks for both the SDF and associated colors. To train these networks, a new volume rendering technique generates images from the SDF by tracing rays through the scene and accumulating colors with weights derived from an "S-density" function, a bell-shaped probability distribution centered on the surface that peaks sharply there as training progresses. This approach ensures the rendering is unbiased—maximizing contributions from actual surface points—and occlusion-aware, prioritizing closer surfaces over distant ones, unlike simpler methods that introduce reconstruction errors.
Given a set of posed images $\left{\mathcal{I}_k\right}$ of a 3D object, our goal is to reconstruct the surface $\mathcal{S}$ of it. The surface is represented by the zero-level set of a neural implicit SDF. In order to learn the weights of the neural network, we developed a novel volume rendering method to render images from the implicit SDF and minimize the difference between the rendered images and the input images. This volume rendering approach ensures robust optimization in NeuS for reconstructing objects of complex structures.
3.1 Rendering Procedure
Scene representation. With NeuS, the scene of an object to be reconstructed is represented by two functions: $f:\mathbb{R}^3\to \mathbb{R}$ that maps a spatial position ${\bf x}\in \mathbb{R}^3$ to its signed distance to the object, and $c:\mathbb{R}^3 \times \mathbb{S}^2 \to \mathbb{R}^3$ that encodes the color associated with a point ${\bf x} \in \mathbb{R}^3$ and a viewing direction ${\bf v} \in \mathbb{S}^2$. Both functions are encoded by Multi-layer Perceptrons (MLP). The surface $\mathcal{S}$ of the object is represented by the zero-level set of its SDF, that is,
$ \mathcal{S} = \left{ \mathbf{x} \in \mathbb{R}^3 | f(\mathbf{x}) = 0 \right}. $
In order to apply a volume rendering method to training the SDF network, we first introduce a probability density function $\phi_s(f({\bf x}))$, called S-density, where $f({\bf x})$, ${\bf x} \in \mathbb{R}^3$, is the signed distance function and $\phi_s(x) = se^{-sx}/(1 + e^{-sx})^2$, commonly known as the logistic density distribution, is the derivative of the Sigmoid function $\Phi_s(x) = (1 + e^{-sx})^{-1}$, i.e., $\phi_s(x) = \Phi_s'(x)$. In principle $\phi_s(x)$ can be any unimodal (i.e. bell-shaped) density distribution centered at $0$; here we choose the logistic density distribution for its computational convenience. Note that the standard deviation of $\phi_s(x)$ is given by $1/s$, which is also a trainable parameter, that is, $1/s$ approaches to zero as the network training converges.
Intuitively, the main idea of NeuS is that, with the aid of the S-density field $\phi_s(f({\bf x}))$, volume rendering is used to train the SDF network with only 2D input images as supervision. Upon successful minimization of a loss function based on this supervision, the zero-level set of the network-encoded SDF is expected to represent an accurately reconstructed surface $\mathcal{S}$, with its induced S-density $\phi_s(f({\bf x}))$ assuming prominently high values near the surface.
Rendering. To learn the parameters of the neural SDF and color field, we advise a volume rendering scheme to render images from the proposed SDF representation. Given a pixel, we denote the ray emitted from this pixel as ${\mathbf{p}(t) = \mathbf{o} + t\mathbf{v} | t\geq 0}$, where $\mathbf{o}$ is the center of the camera and $\mathbf{v}$ is the unit direction vector of the ray. We accumulate the colors along the ray by
$ C(\mathbf{o}, \mathbf{v}) = \int_{0}^{+\infty}w(t)c(\mathbf{p}(t), \mathbf{v}){\rm d}t,\tag{1} $
where $C(\mathbf{o}, \mathbf{v})$ is the output color for this pixel, $w(t)$ a weight for the point $\mathbf{p}(t)$, and $c(\mathbf{p}(t), \mathbf{v})$ the color at the point $\mathbf{p}$ along the viewing direction $\mathbf{v}$.
Requirements on weight function. The key to learn an accurate SDF representation from 2D images is to build an appropriate connection between output colors and SDF, i.e., to derive an appropriate weight function $w(t)$ on the ray based on the SDF $f$ of the scene. In the following, we list the requirements on the weight function $w(t)$.
- Unbiased. Given a camera ray $\mathbf{p}(t)$, $w(t)$ attains a locally maximal value at a surface intersection point $\mathbf{p}(t^*)$, i.e. with $f(\mathbf{p}(t^*))=0$, that is, the point $\mathbf{p}(t^*)$ is on the zero-level set of the SDF $\mathbf({\bf x})$.
- Occlusion-aware. Given any two depth values $t_0$ and $t_1$ satisfying $f(t_0)=f(t_1)$, $w(t_0) > 0$, $w(t_1) > 0$, and $t_0<t_1$, there is $w(t_0)>w(t_1)$. That is, when two points have the same SDF value (thus the same SDF-induced S-density value), the point nearer to the view point should have a larger contribution to the final output color than does the other point.
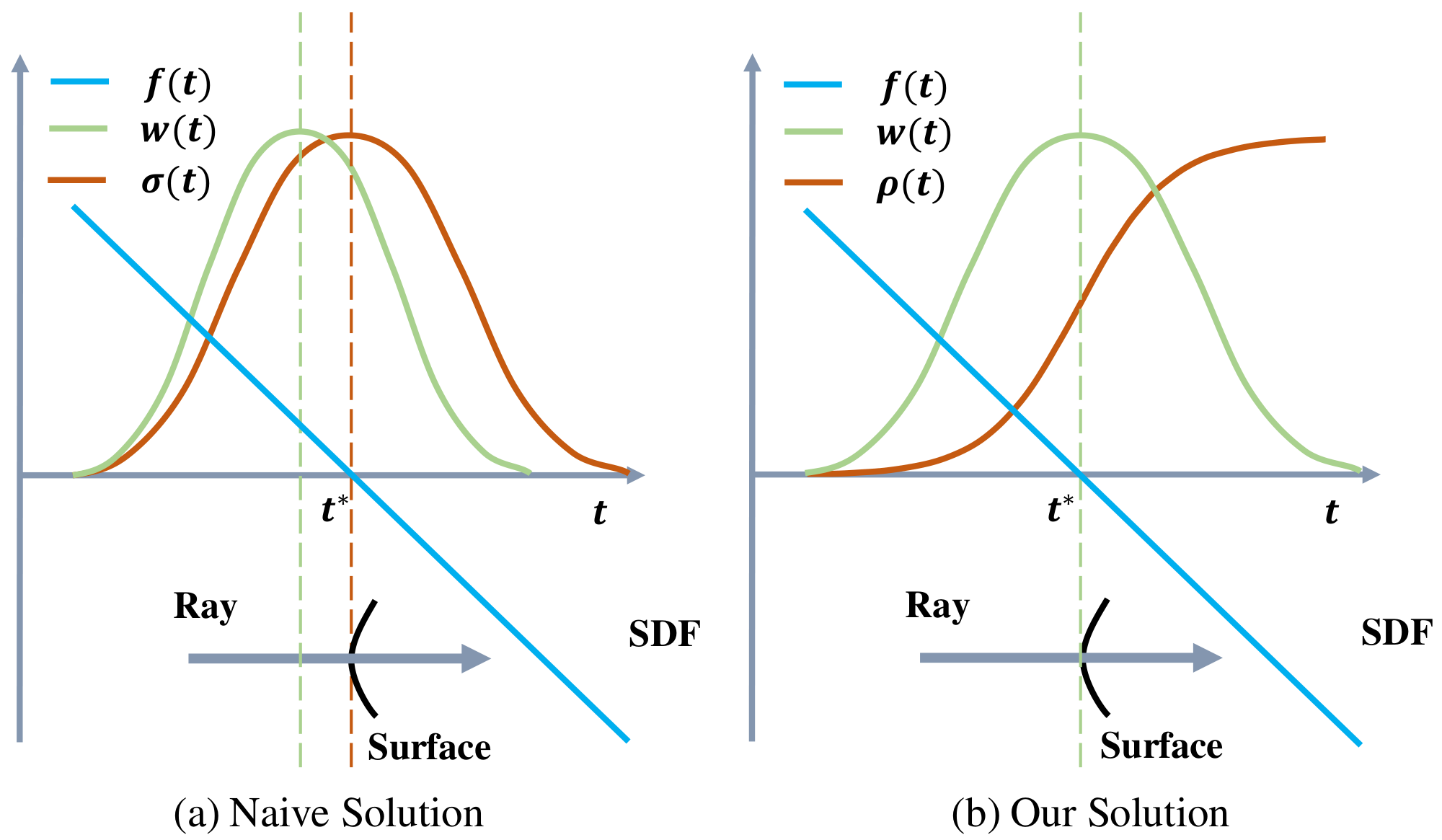
An unbiased weight function $w(t)$ guarantees that the intersection of the camera ray with the zero-level set of SDF contributes most to the pixel color. The occlusion-aware property ensures that when a ray sequentially passes multiple surfaces, the rendering procedure will correctly use the color of the surface nearest to the camera to compute the output color.
Next, we will first introduce a naive way of defining the weight function $w(t)$ that directly using the standard pipeline of volume rendering, and explain why it is not appropriate for reconstruction before introducing our novel construction of $w(t)$.
Naive solution. To make the weight function occlusion-aware, a natural solution is based on the standard volume rendering formulation [10] which defines the weight function by
$ w(t)=T(t)\sigma(t),\tag{2} $
where $\sigma(t)$ is the so-called volume density in classical volume rendering and $T(t)=\exp(-\int_{0}^{t}\sigma(u){\rm d}u)$ here denotes the accumulated transmittance along the ray. To adopt the standard volume density formulation [10], here $\sigma(t)$ is set to be equal to the S-density value, i.e. $\sigma(t) = \phi_s(f(\mathbf{p}(t)))$ and the weight function $w(t)$ is computed by Eqn. 2. Although the resulting weight function is occlusion-aware, it is biased as it introduces inherent errors in the reconstructed surfaces. As illustrated in Figure 2 (a), the weight function $w(t)$ attains a local maximum at a point before the ray reaches the surface point $\mathbf{p}(t^*)$, satisfying $f(\mathbf{p}(t^*))=0$. This fact will be proved in the supplementary material.
Our solution. To introduce our solution, we first introduce a straightforward way to construct an unbiased weight function, which directly uses the normalized S-density as weights
$ w(t)=\frac{\phi_s (f(\mathbf{p}(t)))}{\int_{0}^{+\infty} \phi_s(f(\mathbf{p}(u))){\rm d}u}.\tag{3} $
This construction of weight function is unbiased, but not occlusion-aware. For example, if the ray penetrates two surfaces, the SDF function $f$ will have two zero points on the ray, which leads to two peaks on the weight function $w(t)$ and the resulting weight function will equally blend the colors of two surfaces without considering occlusions.
To this end, now we shall design the weight function $w(t)$ that is both occlusion-aware and unbiased in the first-order approximation of SDF, based on the aforementioned straightforward construction. To ensure an occlusion-aware property of the weight function $w(t)$, we will still follow the basic framework of volume rendering as Eqn. 2. However, different from the conventional treatment as in naive solution above, we define our function $w(t)$ from the S-density in a new manner. We first define an opaque density function $\rho(t)$, which is the counterpart of the volume density $\sigma$ in standard volume rendering. Then we compute the new weight function $w(t)$ by
$ w(t) = T(t)\rho(t), ;; {\rm where } \ T(t) = \exp\left(-\int_{0}^{t}\rho(u){\rm d}u\right).\tag{4} $
How we derive opaque density $\rho$. We first consider a simple ideal case where there is only one surface intersection, and the surface is simply a plane that approaches infinitely far off the camera. Since Eqn. 3 indeed satisfies the above requirements under this assumption, we derive the underlying opaque density $\rho$ corresponding to the weight definition of Eqn. 3 using the framework of volume rendering. Then we will generalize this opaque density to the general case of multiple surface intersections.
Specifically, in the simple case of a single plane intersection, it is easy to see that the signed distance function $f(\mathbf{p}(t))$ is $-|\cos(\theta)|\cdot(t - t^*)$, where $f(\mathbf{p}(t^*)) = 0$, and $\theta$ is the angle between the view direction $\mathbf{v}$ and the outward surface normal vector $\mathbf{n}$. Because the surface is assumed a plane, $|\cos(\theta)|$ is a constant. It follows from Eqn. 3 that
$ \begin{split} w(t) =& {\lim_{t^* \to +\infty}\frac{\phi_s(f(\mathbf{p}(t)))}{\int_{0}^{+\infty}\phi_s(f(\mathbf{p}(u))){\rm d} u}}\ =& {\lim_{t^* \to +\infty}\frac{\phi_s(f(\mathbf{p}(t)))}{\int_{0}^{+\infty}\phi_s(-|\cos(\theta)|(u - t^*)){\rm d} u}}\ =& {\lim_{t^* \to +\infty}\frac{\phi_s(f(\mathbf{p}(t)))}{\int_{-t^*}^{+\infty}\phi_s(-|\cos(\theta)| u^*){\rm d} u^*}}\ =& {\lim_{t^* \to +\infty}\frac{\phi_s(f(\mathbf{p}(t)))}{|\cos(\theta)|^{-1}\int_{-|\cos(\theta)|t^*}^{+\infty} \phi_s(\hat{u}) {\rm d} \hat{u}}} \ =& |\cos(\theta)|\phi_s(f(\mathbf{p}(t))). \end{split} $
Recall that the weight function within the framework of volume rendering is given by $w(t) = T(t)\rho(t)$, where $T(t) = \exp(-\int_{0}^{t}\rho(u){\rm d}u)$ denotes the accumulated transmittance. Therefore, to derive $\rho(t)$, we have
$ T(t)\rho(t) = |\cos(\theta)|\phi_s(f(\mathbf{p}(t))). $
Since $T(t) = \exp(-\int_{0}^{t}\rho(u){\rm d}u)$, it is easy to verify that $T(t)\rho(t) = -\frac{{\rm d} T}{{\rm d} t}(t)$. Further, note that $|\cos(\theta)|\phi_s(f(\mathbf{p}(t))) = -\frac{{\rm d} \Phi_s}{{\rm d} t}(f(\mathbf{p}(t)))$. It follows that $\frac{{\rm d} T}{{\rm d} t}(t) = \frac{{\rm d} \Phi_s}{{\rm d} t}(f(\mathbf{p}(t)))$. Integrating both sides of this equation yields
$ T(t) = \Phi_s(f(\mathbf{p}(t))). $
Taking the logarithm and then differentiating both sides, we have
$ \begin{split} {\int_{0}^{t}}\rho(u){\rm d}u =& -\ln(\Phi_s(f(\mathbf{p}(t)))) \ \Rightarrow \rho(t) =& \frac{-\frac{{\rm d} \Phi_s}{{\rm d} t}(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}. \end{split}\tag{5} $
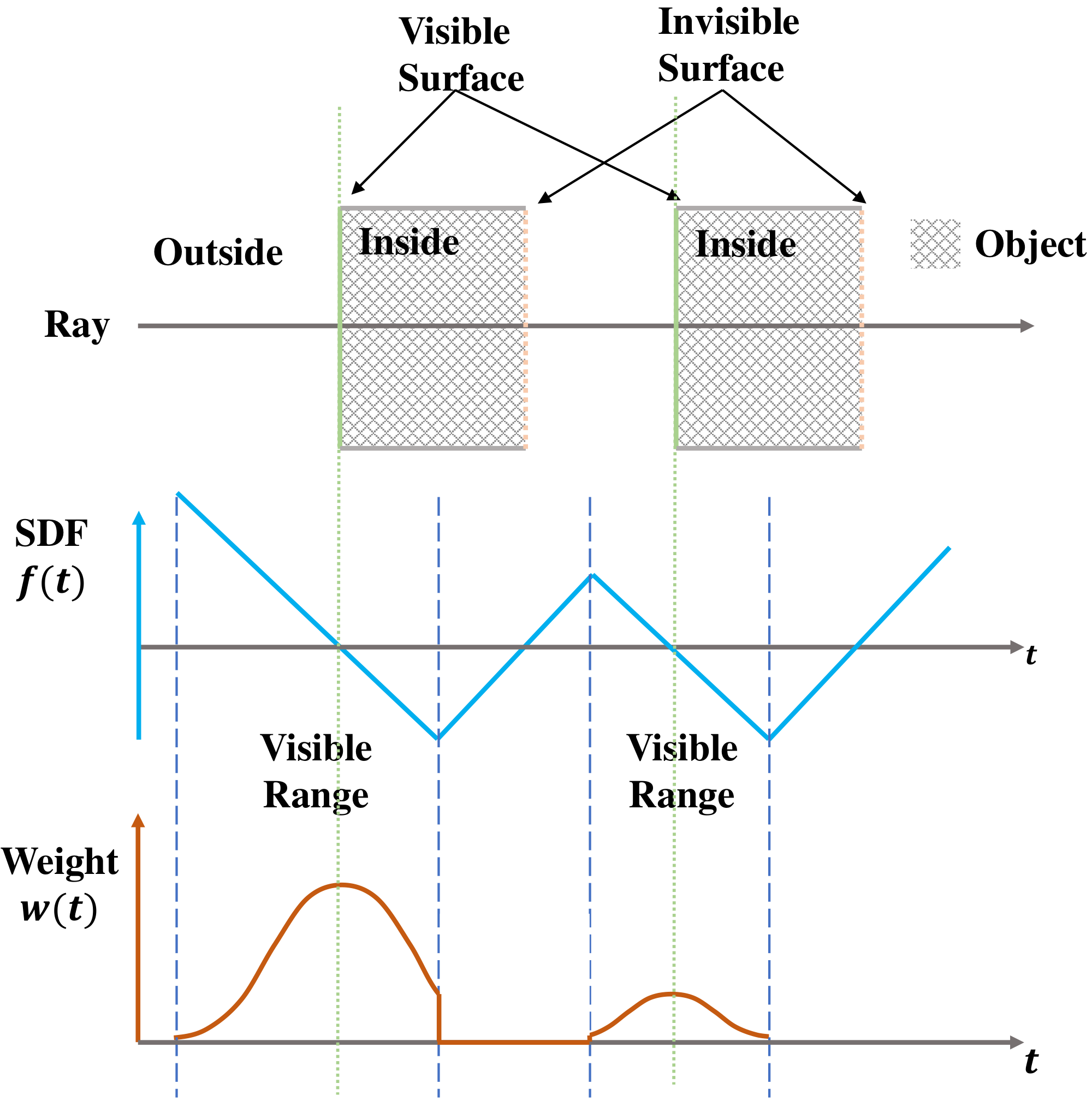
This is the formula of the opaque density $\rho(t)$ in the ideal case of single plane intersection. The weight function $w(t)$ induced by $\rho(t)$ is shown in Figure 2(b). Now we generalize the opaque density to the general case where there are multiple surface intersections along the ray $\mathbf{p}(t)$. In this case, $-\frac{{\rm d}\Phi_s}{{\rm d} t}(f(\mathbf{p}(t)))$ becomes negative on the segment of the ray with increasing SDF values. Thus we clip it against zero to ensure that the value of $\rho$ is always non-negative. This gives the following opaque density function $\rho(t)$ in general cases.
$ \begin{split} \rho(t) =& \max\left(\frac{-\frac{{\rm d}\Phi_s}{{\rm d} t}(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}, 0\right). \end{split}\tag{6} $
Based on this equation, the weight function $w(t)$ can be computed with standard volume rendering as in Eqn. 4. The illustration in the case of multiple surface intersection is shown in Figure 3.
The following theorem states that in general cases (i.e., including both single surface intersection and multiple surface intersections) the weight function defined by Eqn. 6 and Eqn. 4 is unbiased in the first-order approximation of SDF. The proof is given in the supplementary material.
Theorem
Suppose that a smooth surface $\mathbb{S}$ is defined by the zero-level set of the signed distance function $f(\mathbf{x})=0$, and a ray $\mathbf{p}(t)=\mathbf{o}+t \mathbf{v}$ enters the surface $\mathbb{S}$ from outside to inside, with the intersection point at $\mathbf{p}(t^*)$, that is, $f(\mathbf{p}(t^*))=0$ and there exists an interval $[t_l, t_r]$ such that $ t^* \in [t_l, t_r]$ and $f(\mathbf{p}(t))$ is monotonically decreasing in $[t_l, t_r]$. Suppose that in this local interval $[t_l, t_r]$, the surface can be tangentially approximated by a sufficiently small planar patch, i.e., $\nabla\mathbf{f}$ is regarded as fixed.
Then, the weight function $w(t)$ computed by Eqn. 6 and Eqn. 4 in $[t_l, t_r]$ attains its maximum at $t^*$.
Discretization. To obtain discrete counterparts of the opacity and weight function, we adopt the same approximation scheme as used in NeRF [10], This scheme samples $n$ points ${\mathbf{p}i=\mathbf{o}+t_i\mathbf{v}|i=1, ..., n, t_i<t{i+1}}$ along the ray to compute the approximate pixel color of the ray as
$ \hat{C} = \sum_{i=1}^{n} T_i\alpha_i c_i, $
where $T_i$ is the discrete accumulated transmittance defined by $T_i=\prod_{j=1}^{i-1}(1 - \alpha_j)$, and $\alpha_i$ is discrete opacity values defined by
$ \alpha_i=1-\exp\left(-\int_{t_i}^{t_{i+1}}\rho(t){\rm d}t\right),\tag{7} $
which can further be shown to be
$ \alpha_i = \max \left (\frac{\Phi_s(f(\mathbf{p}(t_{i}))) - \Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_i)))}, 0 \right).\tag{8} $
The detailed derivation of this formula for $\alpha_i$ is given in the supplementary material.
3.2 Training
To train NeuS, we minimize the difference between the rendered colors and the ground truth colors, without any 3D supervision. Besides colors, we can also utilize the masks for supervision if provided.
Specifically, we optimize our neural networks and inverse standard deviation $s$ by randomly sampling a batch of pixels and their corresponding rays in world space $P = \left{ C_k, M_k, \mathbf{o}_k, \mathbf{v}_k\right}$, where $C_k$ is its pixel color and $M_k \in {0, 1}$ is its optional mask value, from an image in every iteration. We assume the point sampling size is $n$ and the batch size is $m$. The loss function is defined as
$ \mathcal{L} = \mathcal{L}{color} + \lambda\mathcal{L}{reg} + \beta\mathcal{L}_{mask}. $
The color loss $\mathcal{L}_{color}$ is defined as
$ \mathcal{L}{color} = \frac{1}{m}\sum{k}\mathcal{R}(\hat{C}k, C{k}). $
Same as IDR [4], we empirically choose $\mathcal{R}$ as L1 loss, which in our observation is robust to outliers and stable in training.
We add an Eikonal term [32] on the sampled points to regularize the SDF of $f_\theta$ by
$ \mathcal{L}{reg} = \frac{1}{nm}\sum{k, i}(|\nabla f(\hat{\mathbf{p}}_{k, i})|_2 - 1)^2. $
The optional mask loss $\mathcal{L}_{mask}$ is defined as
$ \mathcal{L}_{mask} = \text{BCE}(M_k, \hat{O}_k), $
where $\hat{O}k = \sum{i=1}^{n}T_{k, i}\alpha_{k, i}$ is the sum of weights along the camera ray, and $\text{BCE}$ is the binary cross entropy loss.
Hierarchical sampling. In this work, we follow a similar hierarchical sampling strategy as in NeRF [10]. We first uniformly sample the points on the ray and then iteratively conduct importance sampling on top of the coarse probability estimation. The difference is that, unlike NeRF which simultaneously optimizes a coarse network and a fine network, we only maintain one network, where the probability in coarse sampling is computed based on the S-density $\phi_s(f(\mathbf{x}))$ with fixed standard deviations while the probability of fine sampling is computed based on $\phi_s(f(\mathbf{x}))$ with the learned $s$. Details of hierarchical sampling strategy are provided in supplementary materials.

4. Experiments
Section Summary: The experiments evaluated the proposed method using datasets like DTU and BlendedMVS, which include diverse scenes with complex materials and thin structures, along with custom captures of thin objects. They compared it against leading techniques such as IDR for surface rendering, NeRF for volume rendering, COLMAP for traditional multi-view stereo, and UNISURF, testing both with and without foreground masks. Results showed the new approach outperforming the others in reconstruction accuracy, as measured by Chamfer distance, and producing cleaner, more detailed meshes, especially for challenging features like thin parts and sudden depth changes, with ablation studies confirming key design choices.
4.1 Experimental settings
Datasets. To evaluate our approach and baseline methods, we use 15 scenes from the DTU dataset [44], same as those used in IDR [4], with a wide variety of materials, appearance and geometry, including challenging cases for reconstruction algorithms, such as non-Lambertian surfaces and thin structures. Each scene contains 49 or 64 images with the image resolution of $1600\times 1200$. Each scene was tested with and without foreground masks provided by IDR [4]. We further tested on 7 challenging scenes from the low-res set of the BlendedMVS dataset [45](CC-4 License). Each scene has $31-143$ images at $768\times 576$ pixels and masks are provided by the BlendedMVS dataset. We further captured two thin objects with 32 input images to test our approach on thin structure reconstruction.
Baselines. (1) The state-of-the-art surface rendering approach – IDR [4]: IDR can reconstruct surface with high quality but requires foreground masks as supervision; Since IDR has demonstrated superior quality compared to another surface rendering based method – DVR [8], we did not conduct a comparison with DVR. (2) The state-of-the-art volume rendering approach – NeRF [10]: We use a threshold of 25 to extract mesh from the learned density field. We validate this choice in the supplementary material. (3) A widely-used classical MVS method – COLMAP [1]: We reconstruct a mesh from the output point cloud of COLMAP with Screened Poisson Surface Reconstruction [17]. (4) The concurrent work which unifies surface rendering and volume rendering with an occupancy field as scene representation – UNISURF [9]. More details of the baseline methods are included in the supplementary material.
\begin{tabular}{c||c|c|c||c|c|c|c}
\multicolumn{1}{c||}{}&\multicolumn{3}{c||}{\textbf{w/} mask}&\multicolumn{4}{c}{\textbf{w/o} mask} \\
\hline
ScanID & IDR & NeRF & Ours & COLMAP & NeRF & UNISURF & Ours \\
\hline
scan24 & 1.63 & 1.83 & \bf{0.83} & \bf{0.81} & 1.90 & 1.32 & 1.00 \\
scan37 & 1.87 & 2.39 & \bf{0.98} & 2.05 & 1.60 & \bf{1.36} & 1.37 \\
scan40 & 0.63 & 1.79 & \bf{0.56} & \bf{0.73} & 1.85 & 1.72 & 0.93 \\
scan55 & 0.48 & 0.66 & \bf{0.37} & 1.22 & 0.58 & 0.44 & \bf{0.43} \\
scan63 & \bf{1.04} & 1.79 & 1.13 & 1.79 & 2.28 & 1.35 & \bf{1.10} \\
scan65 & 0.79 & 1.44 & \bf{0.59} & 1.58 & 1.27 & 0.79 & \bf{0.65} \\
scan69 & 0.77 & 1.50 & \bf{0.60} & 1.02 & 1.47 & 0.80 & \bf{0.57} \\
scan83 & 1.33 & \bf{1.20} & 1.45 & 3.05 & 1.67 & 1.49 & \bf{1.48} \\
scan97 & 1.16 & 1.96 & \bf{0.95} & 1.40 & 2.05 & 1.37 & \bf{1.09} \\
scan105 & \bf{0.76} & 1.27 & 0.78 & 2.05 & 1.07 & 0.89 & \bf{0.83} \\
scan106 & 0.67 & 1.44 & \bf{0.52} & 1.00 & 0.88 & 0.59 & \bf{0.52} \\
scan110 & \bf{0.90} & 2.61 & 1.43 & 1.32 & 2.53 & 1.47 & \bf{1.20} \\
scan114 & 0.42 & 1.04 & \bf{0.36} & 0.49 & 1.06 & 0.46 & \bf{0.35} \\
scan118 & 0.51 & 1.13 & \bf{0.45} & 0.78 & 1.15 & 0.59 & \bf{0.49} \\
scan122 & 0.53 & 0.99 & \bf{0.45} & 1.17 & 0.96 & 0.62 & \bf{0.54} \\
\hline
mean & 0.90 & 1.54 & \bf{0.77} & 1.36 & 1.49 & 1.02 & \bf{0.84} \\
\end{tabular}
Implementation details.
We assume the region of interest is inside a unit sphere. We sample 512 rays per batch and train our model for 300k iterations for 14 hours (for the w/ mask' setting) and 16 hours (for the w/o mask' setting) on a single NVIDIA RTX2080Ti GPU. For the `w/o mask' setting, we model the background by NeRF++ [46]. Our network architecture and initialization scheme are similar to those of IDR [4]. More details of the network architecture and training parameters can be found in the supplementary material.
4.2 Comparisons
We conducted the comparisons in two settings, with mask supervision (w/ mask) and without mask supervision (w/o mask). We measure the reconstruction quality with the Chamfer distances in the same way as UNISURF [9] and IDR [4] and report the scores in Table 1. The results show that our approach outperforms the baseline methods on the DTU dataset in both settings – w/ and w/o mask in terms of the Chamfer distance. Note that the reported scores of IDR in the setting of w/ mask and NeRF and UNISURF in the w/o mask setting are from IDR [4] and UNISURF [9].

We conduct the qualitative comparisons on the DTU dataset and the BlendedMVS dataset in both settings, w/ mask and w/o mask, in Figure 4 and Figure 5, respectively. As shown in Figure 4 for the setting of w/ mask, IDR shows limited performance for reconstructing thin metals parts in Scan 37 (DTU), and fails to handle sudden depth changes in Stone (BlendedMVS) due to the local optimization process in surface rendering. The extracted meshes of NeRF are noisy since the volume density field has not sufficient constraint on its 3D geometry. Regarding the w/o mask setting, we visually compare our method with NeRF and COLMAP in the setting of w/o mask in Figure 5, which shows our reconstructed surfaces are with more fidelity than baselines. We further show a comparison with UNISURF [9] on two examples in the w/o mask setting. Note that we use the qualitative results of UNISURF reported their paper for comparison. Our method works better for the objects with abrupt depth changes. More qualitative images are included in the supplementary material.

4.3 Analysis
Ablation study.

To evaluate the effect of the weight calculation, we test three different kinds of weight constructions described in Section 3.1: (a) Naive Solution. (b) Straightforward Construction as shown in Eqn. 3. (e) Full Model. As shown in Figure 6, the quantitative result of naive solution is worse than our weight choice (e) in terms of the Chamfer distance. This is because it introduces a bias to the surface reconstruction. If direct construction is used, there are severe artifacts.
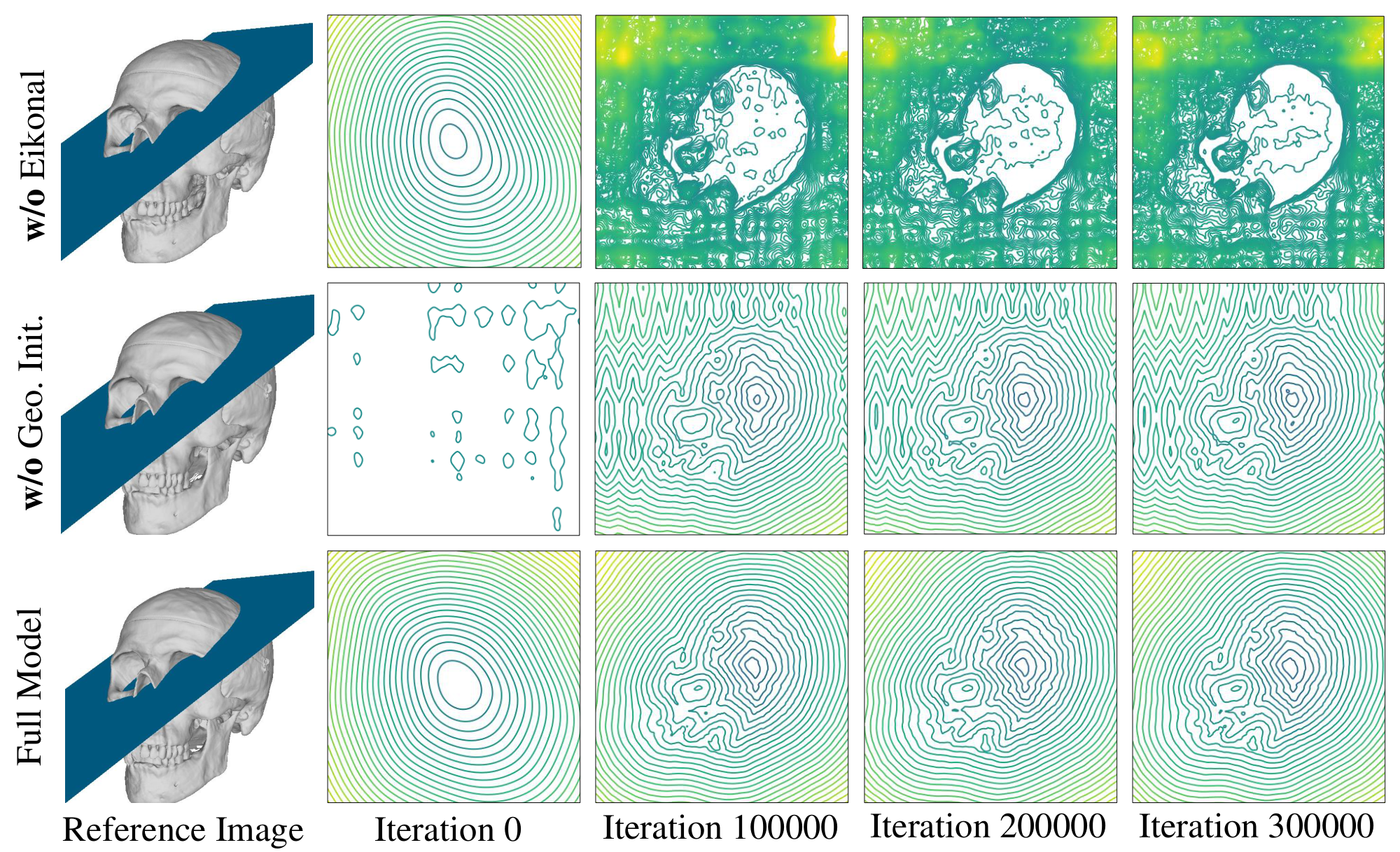
We also studied the effect of Eikonal regularization [32] and geometric initialization [31]. Without Eikonal regularization or geometric initialization, the result on Chamfer distance is on par with that of the full model. However, neither of them can correctly output a signed distance function. This is indicated by the MAE(mean absolute error) between the SDF predictions and corresponding ground-truth SDF, as shown in the bottom line of Figure 6. The MAE is computed on uniformly-sampled points in the object's bounding sphere. Qualitative results of SDF predictions are provided in the supplementary material.
Thin structures.
We additionally show results on two challenging thin objects with 32 input images. The plane with rich texture under the object is used for camera calibration. As shown in Figure 8, our method is able to accurately reconstruct these thin structures, especially on the edges with abrupt depth changes. Furthermore, different from the methods [47, 48, 49, 50] which only target at high-quality thin structure reconstruction, our method can handle the scenes which have a mixture of thin structures and general objects.

5. Conclusion
Section Summary: NeuS is a new method for reconstructing 3D surfaces from multiple views, using a neural representation of shapes and an improved rendering technique that delivers high-quality results, even for objects with heavy occlusions or intricate details, surpassing existing top methods in both visual and measurable ways. However, it struggles with objects lacking textures, and it uses just one parameter to handle uncertainty across the entire scene, suggesting future improvements could involve varying this uncertainty based on local shapes. Like other AI-based techniques, NeuS demands significant computing power for training, raising concerns about its environmental footprint on climate change.
We have proposed NeuS, a new approach to multiview surface reconstruction that represents 3D surfaces as neural SDF and developed a new volume rendering method for training the implicit SDF representation. NeuS produces high-quality reconstruction and successfully reconstructs objects with severe occlusions and complex structures. It outperforms the state-of-the-arts both qualitatively and quantitatively. One limitation of our method is that although our method does not heavily rely on correspondence matching of texture features, the performance would still degrade for textureless objects (we show the failure cases in the supplementary material). Moreover, NeuS has only a single scale parameter $s$ that is used to model the standard deviation of the probability distribution for all the spatial location. Hence, an interesting future research topic is to model the probability with different variances for different spatial locations together with the optimization of scene representation, depending on different local geometric characteristics. Negative societal impact: like many other learning-based works, our method requires a large amount of computational resources for network training, which can be a concern for global climate change.
Acknowlegements
Section Summary: The acknowledgements section expresses gratitude to Michael Oechsle for sharing results from the UNISURF project. It also notes that Christian Theobalt received support from the ERC Consolidator Grant 770784, while Lingjie Liu was funded by the Lise Meitner Postdoctoral Fellowship. Additionally, the work utilized computational resources primarily from the HKU GPU Farm.
We thank Michael Oechsle for providing the results of UNISURF. Christian Theobalt was supported by ERC Consolidator Grant 770784. Lingjie Liu was supported by Lise Meitner Postdoctoral Fellowship. Computational resources are mainly provided by HKU GPU Farm.
6. Derivation for Computing Opacity $\alpha_i$
Section Summary: This section explains how to calculate the opacity α_i, a measure of how much a 3D surface blocks light along a camera ray, for small segments of the ray's path. When the ray enters a surface, where the distance to the surface decreases, opacity is derived as the difference between cumulative probability values from a logistic distribution at the segment's start and end, divided by the starting value, capturing the material's density and absorption. When the ray exits the surface, opacity is zero since there's no density outside, and the final formula takes the maximum of this expression and zero to ensure realistic results.
In this section we will derive the formula in Eqn. 13 of the paper for computing the discrete opacity $\alpha_i$. Recall that the opaque density function $\rho (t)$ is defined as
$ \begin{split} \rho(t) =& \max\left(\frac{-\frac{{\rm d}\Phi_s}{{\rm d} t}(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}, 0\right)\ =& \max\left(\frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})\phi_s(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}, 0\right), \end{split}\tag{9} $
where $\phi_s(x)$ and $\Phi_s(x)$ are the probability density function (PDF) and cumulative distribution function (CDF) of logistic distribution, respectively. First consider the case where the sample point interval $[t_i, t_{i+1}]$ lies in a range $[t_\ell, t_r]$ over which the camera ray is entering the surface from outside to inside, i.e. the signed distance function is decreasing on the camera ray $\mathbf{p}(t)$ over $[t_\ell, t_r]$. Then it is easy to see that $-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v}) > 0 $ in $[t_i, t_{i+1}]$. It follows from Eqn. 12 of the paper that,
$ \begin{split} \alpha_i =& 1 - \exp\left(-\int_{t_i}^{t_{i+1}}\rho(t){\rm d}t\right)\ =& 1 - \exp\left(-\int_{t_i}^{t_{i+1}}\frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})\phi_s(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}{\rm d}t\right). \end{split}\tag{10} $
Note that the integral term is computed by
$ \int \frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})\phi_s(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}{\rm d}t = -\ln(\Phi_s(f(\mathbf{p}(t)))) + C, $
where $C$ is a constant. Thus the discrete opacity can be computed by
$ \begin{split} \alpha_i=& 1 - \exp\left[-\left(-\ln(\Phi_s(f(\mathbf{p}(t_{i+1})))) + \ln(\Phi_s(f(\mathbf{p}(t_{i}))))\right)\right]\ =& 1 - \frac{\Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_{i})))}\ =& \frac{\Phi_s(f(\mathbf{p}(t_{i}))) - \Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_i)))}. \end{split} $
Next consider the case where $[t_i, t_{i+1}]$ lies in a range $[t_\ell, t_r]$ over which the camera ray is exiting the surface, i.e. the signed distance function is increasing on $\mathbf{p}(t)$ over $[t_\ell, t_r]$. Then we have $-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v}) < 0$ in $[t_i, t_{i+1}]$. Then, according to Eqn. 9, we have $\rho(t) = 0$. Therefore, by Eqn. 12 of the paper, we have
$ \alpha_i = 1 - \exp\left(-\int_{t_i}^{t_{i+1}}\rho(t){\rm d}t\right) = 1 - \exp\left(-\int_{t_i}^{t_{i+1}} 0 {\rm d}t\right) = 0. $
Hence, the alpha value $\alpha_i$ in this case is given by
$ \begin{split} \alpha_i = \max \left(\frac{\Phi_s(f(\mathbf{p}(t_{i}))) - \Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_i)))}, 0\right). \end{split} $
This completes the derivation of Eqn. 13 of the paper.
7. First-order Bias Analysis
Section Summary: This section analyzes how well different methods handle ray tracing near surfaces in computer graphics rendering. The authors prove that their proposed solution is unbiased, meaning its weight function peaks exactly at the surface intersection point, ensuring accurate light sampling even with multiple surfaces along the ray. In contrast, a simpler naive approach is biased, as its weight function does not peak at the surface but instead drops off, leading to inaccuracies in rendering.
7.1 Proof of Unbiased
Property of Our Solution
$\textsc{Proof of Theorem 1}$: Suppose that the ray is going from outside to inside of the surface. Hence, we have $-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v}) > 0$, because by convention the signed distance function $f(\mathbf{x})$ is positive outside and negative inside of the surface.
Recall that our S-density field $\phi_s(f(\mathbf{x}))$ is defined using the logistic density function $\phi_s(x) = se^{-sx}/(1 + e^{-sx})^2$, which is the derivative of the Sigmoid function $\Phi_s(x) = (1 + e^{-sx})^{-1}$, i.e. $\phi_s(x) = \Phi_s'(x)$.
According to Eqn. 5 of the paper, the weight function $w(t)$ is given by
$ w(t) = T(t)\rho(t), $
where
$ \rho (t) = \max\left(\frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})\phi_s(f(\mathbf{p}(t)))}{ \Phi_s(f(\mathbf{p}(t)))}, 0\right). $
By assumption, $-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v}) > 0$ for $t \in \left[t_l, t_r\right]$. Since $\phi_s$ is a probability density function, we have $\phi_s(f(\mathbf{p}(t))) > 0$. Clearly, $\Phi_s(f(\mathbf{p}(t))) > 0$. It follows that
$ \rho(t) = \frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})\phi_s(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}, $
which is positive. Hence,
$ \begin{split} w(t) =& T(t)\rho(t)\ =&\exp\left(-\int_{0}^{t} \rho(t'){\rm d}t'\right)\rho(t)\ =&\exp\left(-\int_{0}^{t_l} \rho(t'){\rm d}t'\right)\exp\left(-\int_{t_l}^{t} \rho(t'){\rm d}t'\right)\rho(t)\ =&T(t_l)\exp\left(-\int_{t_l}^{t} \rho(t'){\rm d}t'\right)\rho(t) \ =&T(t_l)\exp\left[-(-\ln(\Phi_s(f(\mathbf{p}(t)))) + \ln(\Phi_s(f(\mathbf{p}(t_{l})))))\right]\rho(t)\ =&T(t_l)\frac{\Phi_s(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t_l)))}\frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})\phi_s(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))}\ =&\frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})T(t_l)}{\Phi_s(f(\mathbf{p}(t_l)))}\phi_s(f(\mathbf{p}(t))). \end{split} $
As a first-order approximation of signed distance function $f$, suppose that locally the surface is tangentially approximated by a sufficiently small planar patch with its outward unit normal vector denoted as $\mathbf{n}$. Because $f(\mathbf{x})$ is a signed distance function, locally it has a unit gradient vector $\nabla f = \mathbf{n}$. Then we have
$ \begin{split} w(t)=&\frac{-(\nabla f(\mathbf{p}(t))\cdot \mathbf{v})T(t_l)}{\Phi_s(f(\mathbf{p}(t_l)))}\phi_s(f(\mathbf{p}(t)))\ =&\frac{|\cos (\theta)| T(t_l)}{\Phi_s(f(\mathbf{p}(t_l)))}\phi_s(f(\mathbf{p}(t))), \end{split} $
where $\theta$ is the angle between the view direction $\mathbf{v}$ and the unit normal vector $\mathbf{n}$, that is, $\cos (\theta) = \mathbf{v}\cdot \mathbf{n}$. Here $|\cos (\theta)| T(t_l)\cdot \Phi_s(f(\mathbf{p}(t_l)))^{-1}$ can be regarded as a constant. Hence, $w(t)$ attains a local maximum when $f(\mathbf{p}(t)) = 0$ because $\phi_s(x)$ is a unimodal density function attaining the maximal value at $x=0$.
We remark that in this proof we do not make any assumption on the existence of surfaces between the camera and the sample point $\mathbf{p}(t_l)$. Therefore the conclusion holds true for the case of multiple surface intersections on the camera ray. This completes the proof. $\Box$
7.2 Bias in Naive Solution
In this section we show that the weight function derived in naive solution is biased. According to Eqn. 3 of the paper, $w(t) = T(t)\sigma(t)$, with the opacity $\sigma(t) = \phi_s(f(\mathbf{p}(t)))$. Then we have
$ \begin{split} \frac{{\rm d} w}{{\rm d}t} =& \frac{{\rm d} (T(t)\sigma(t))}{{\rm d}t}\ =& \frac{{\rm d} T(t)}{{\rm d}t} \sigma(t) + T(t)\frac{{\rm d} \sigma(t)}{{\rm d}t}\ =& \left[\exp\left(-\int_{0}^{t}\sigma(t){\rm d}t\right)(-\sigma(t))\right]\sigma(t) + T(t)\frac{{\rm d} \sigma(t)}{{\rm d}t}\ =& T(t)(-\sigma(t))\sigma(t) + T(t)\frac{{\rm d} \sigma(t)}{{\rm d}t}\ =& T(t)\left(\frac{{\rm d} \sigma(t)}{{\rm d}t} - \sigma(t)^2\right). \end{split}\tag{11} $
Now we perform the same first-order approximation of signed distance function $f$ near the surface intersection as in Section 7.1. In this condition, the above equation can be rewritten as
$ \begin{split} \frac{{\rm d} w}{{\rm d} t} =& T(t)\left((\nabla f(\mathbf{p}(t)) \cdot \mathbf{v}) \phi_s'(f(\mathbf{p}(t))) - \phi_s(f(\mathbf{p}(t)))^2\right) \ =& T(t)\left(\cos(\theta) \phi_s'(f(\mathbf{p}(t))) - \phi_s(f(\mathbf{p}(t)))^2\right). \end{split} $
Here $\cos(\theta)$ can be regarded as a constant. Now suppose $\mathbf{p}(t^*)$ is a point on the surface $\mathbb{S}$, that is, $f(\mathbf{p}(t^*))=0$. Next we will examine the value of $\frac{{\rm d} w}{{\rm d}t} (t)$ at $t=t^*$. First, clearly, $T(t^*) >0$ and $\phi_s(f(\mathbf{p}(t^*)))^2 >0$. Then, since $\phi_s'(0) = 0$, we have
$ \frac{{\rm d} w}{{\rm d}t}(t^*) = T(t^*)(\cos(\theta) \phi_s'(0) - \sigma(t^*)^2) = - T(t^*)\phi_s(0)^2 < 0. $
Hence $w(t)$ in naive solution does not attain a local maximum at $t=t^*$, which corresponds to a point on the surface $\mathbb{S}$. This completes the proof. $\Box$
8. Second-order Bias Analysis
Section Summary: This section examines how errors behave near where a ray intersects a surface in a detailed mathematical analysis, using a second-order approximation to study a function that measures distance along the ray. It derives equations for the optimal point in their improved method, which incorporates density variations, and compares it to a simpler "naive" approach, assuming constant second derivatives in a small interval around the intersection. The key finding is that their method reduces positioning errors much faster—quadratically—as the density sharpness increases, outperforming the naive method's linear error reduction.
In this section we briefly introduce our local analysis in the interval $[t_l, t_r]$ near the surface intersection, in second-order approximation. In this condition, we follow the similar assumption as Section 7 that the signed distance function $f(\mathbf{p}(t))$ monotonically decreases along the ray in the interval $[t_l, t_r]$.
According to Eqn. 11, the derivative of $w(t)$ is given by:
$ \frac{{\rm d} w}{{\rm d}t} = T(t)\left(\frac{{\rm d} \sigma(t)}{{\rm d}t} - \sigma(t)^2\right). $
Clearly, we have $T(t) > 0$. Hence, when $w(t)$ attains local maximum at $\bar t$, there is $\left(\frac{{\rm d} \sigma(\bar t)}{{\rm d} t} - \sigma(\bar t)^2\right) = 0$.
The case of our solution. In our solution, the volume density is given by $\sigma(t) = \rho(t)$ following Eqn. 9. After organizing, we have
$ \frac{{\rm d}^2f}{{\rm d} t}(\mathbf{p}(\bar{t}))\cdot \phi_s(f(\mathbf{p}(\bar{t}))) +\left(\frac{{\rm d}{f}}{{\rm d}{t}}(\mathbf{p}(\bar{t}))\right)^2\phi_s^{'}(f(\mathbf{p}(\bar{t}))) = 0. $
Here we perform a local analysis at $\bar t$ near the surface intersection $t^*$, where $f(\mathbf{p}(t^*))=0$, $\bar t = t^* + \Delta_t$. And we let $\frac{{\rm d} f}{\rm dt}(\mathbf{p}(t^*))=\mu$, and $\frac{{\rm d}^2f}{{\rm d}t^2}(\mathbf{p}(t^*)) = \tau$. As a second-order analysis, we assume that in this local interval $t \in [t_l, t_r]$, $\frac{{\rm d}^2f}{{\rm d}t^2}(\mathbf{p}(t))$ is fixed. After substitution and organization, the induced equation for local maximum point $\bar t$ is
$ \tau \cdot \left(1 + e^{-s(\mu\Delta_t + \frac{1}{2}\tau\Delta_t^2)}\right) = (\mu + \tau\Delta_t)^2\cdot\left(s\left(1 - e^{-s(\mu\Delta_t + \frac{1}{2}\tau\Delta_t^2)}\right)\right),\tag{12} $
which we will analyze later.
The case of the naive solution. Here we conduct a similar local analysis as in case of our solution. Regarding naive solution, when $w(t)$ attains local maximum at $\bar t$, there is:
$ (\mu + \tau\Delta_t) \cdot\left(-\left(1 - e^{-2s(\mu\Delta_t + \frac{1}{2}\tau\Delta_t^2)}\right)\right)=e^{-s(\mu\Delta_t + \frac{1}{2}\tau\Delta_t^2)}.\tag{13} $
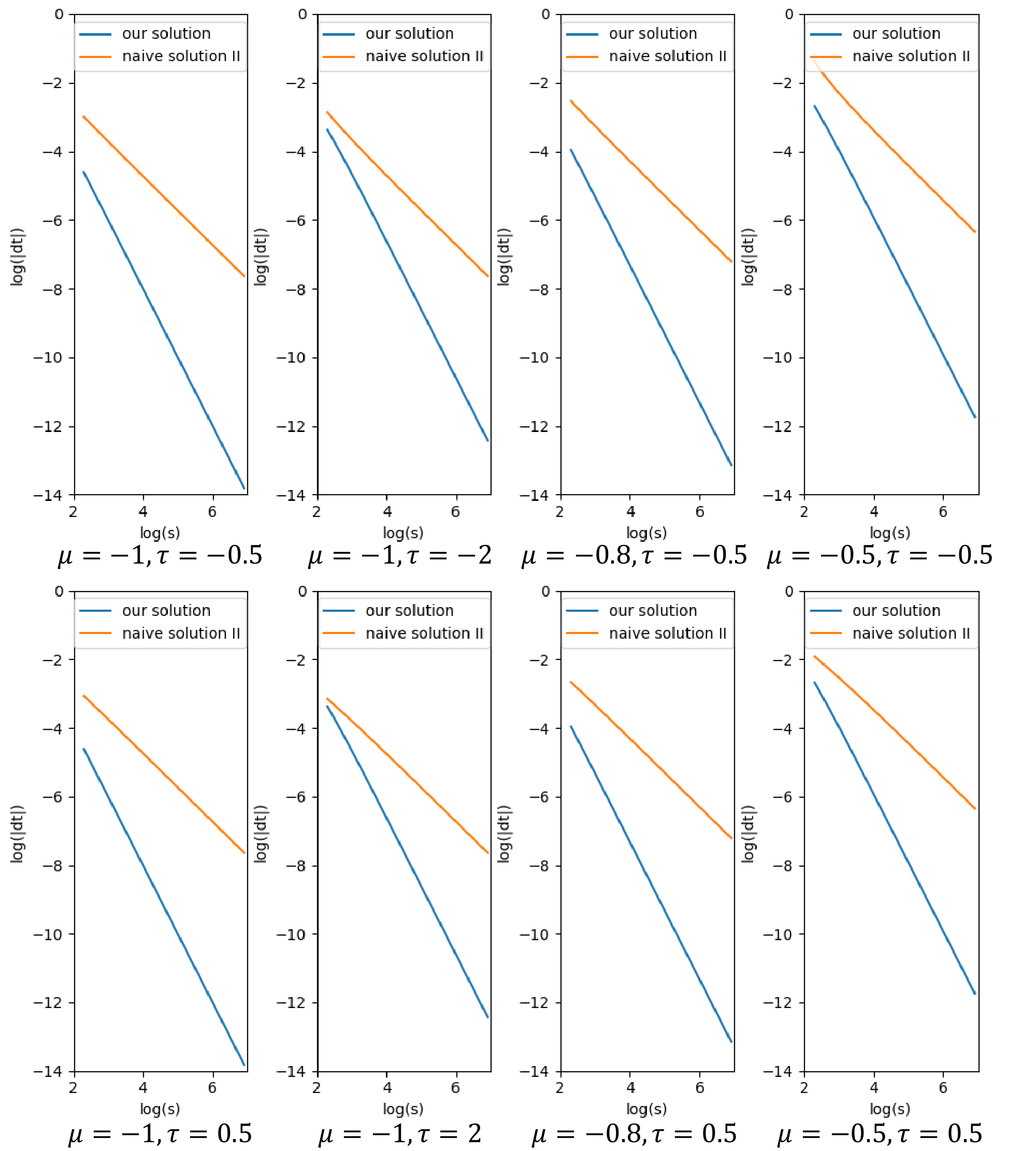
Comparison. Based on Eqn. 12 and Eqn. 13, we can numerically solve the equations on $\Delta_t$ for any given values of $\mu, \tau, $ and $s$. Below we plot the curves of $\Delta_t$ versus increasing $s$ for different (fixed) values of $\mu, \tau$ in Figure 9.
As shown in Figure 9, the error of local maximum position $\Delta_t = O(s^{-2})$ for our solution and the error $\Delta_t = O(s^{-1})$ for the naive solution. That is to say, our error converges to zero faster than the error of the naive solution does as the standard deviation $1/s$ of the $S$-density approaches to $0$, which is quadratic convergence versus linear convergence.
9. Additional Experimental Details
Section Summary: The researchers detail the neural network setup, which uses two multi-layer networks to model surface distances and colors, incorporating techniques like skip connections, positional encoding, and a stabilized training process with the ADAM optimizer over about 15 hours on a high-end GPU. They explain how alpha transparency and colors are calculated using specific sampling points along rays, with a hierarchical approach that starts with uniform sampling and refines it through multiple iterations to total around 128 points per ray. For comparisons, they adapted official code for baselines like IDR and NeRF, used command-line tools for COLMAP to generate meshes from point clouds, and obtained results directly from the UNISURF authors, including validations on surface extraction thresholds.
9.1 Additional Implemenation Details
Network architecture. We use a similar network architecture as IDR [4], which consists of two MLPs to encode SDF and color respectively. The signed distance function $f$ is modeled by an MLP that consists of 8 hidden layers with hidden size of 256. We replace original ReLU with Softplus with $\beta=100$ as activation functions for all hidden layers. A skip connection [29] is used to connect the input with the output of the fourth layer. The function $c$ for color prediction is modeled by a MLP with 4 hidden layers with size of 256, which takes not only the spatial location $\mathbf{p}$ as inputs but also the view direction $\mathbf{v}$, the normal vector of SDF $\mathbf{n}=\nabla{f}(\mathbf{p})$, and a 256-dimensional feature vector from the SDF MLP. Positional encoding is applied to spatial location $\mathbf{p}$ with 6 frequencies and to view direction $\mathbf{v}$ with 4 frequencies. Same as IDR, we use weight normalization [51] to stabilize the training process.
Training details. We train our neural networks using the ADAM optimizer [52]. The learning rate is first linearly warmed up from 0 to $5\times 10^{-4}$ in the first 5k iterations, and then controlled by the cosine decay schedule to the minimum learning rate of $2.5\times 10^{-5}$. We train each model for 300k iterations for 14 hours (for the w/ mask' setting) and 16 hours (for the w/o mask' setting) in total on a single Nvidia 2080Ti GPU.
Alpha and color computation. In the implementation, we actually have two types of sampling points - the sampled section points $\mathbf{q}i = \mathbf{o} + t_i\mathbf{v}$ and the sampled mid-points $\mathbf{p}i = \mathbf{o} + \frac{t_i + t{i+1}}{2}\mathbf{v}$, with section length $\delta_i=t{i + 1} - t_{i}$, as illustrated in Figure 10. To compute the alpha value $\alpha_i$, we use the section points, which is $\max(\frac{\Phi_s(f(\mathbf{q}{i})) - \Phi_s(f(\mathbf{q}{i+1}))}{\Phi_s(f(\mathbf{q}_{i}))}, 0)$. To compute the color $c_i$, we use the color of the mid-point $\mathbf{p}_i$.
Hierarchical sampling. Specifically, we first uniformly sample 64 points along the ray, then we iteratively conduct importance sampling for $k=4$ times. The coarse probability estimation in the i-th iteration is computed by a fixed $s$ value, which is set as $32\times 2^{i}$. In each iteration, we additionally sample 16 points. Therefore, the total number of sampled points for NeuS is 128. For the `w/o mask' setting, we sample extra 32 points outside the sphere. The outside scene is represented using NeRF++ [46].

:Table 2: The Chamfer distances between the ground-truth and the level-set surfaces extracted from the NeRF results using different threshold values on three scenes from the DTU dataset.
| Scan ID | Threshold 0 | Threshold 25 | Threshold 50 | Threshold 100 | Threshold 500 |
|---|---|---|---|---|---|
| Scan 40 | 2.36 | 1.79 | 1.86 | 2.07 | 4.26 |
| Scan 83 | 1.65 | 1.20 | 1.37 | 2.24 | 29.10 |
| Scan 114 | 1.62 | 1.04 | 1.10 | 1.43 | 8.66 |
9.2 Baselines
IDR [4]. To implement IDR, we use their officially released codes^1 and pretrained models on the DTU dataset.
NeRF [10]. To implement NeRF, we use the code from nerf-pytorch^2. To extract surfaces from NeRF, we use the density level-set of 25, which is validated by experiments to be the best level-set with smallest reconstruction errors, as shown in Table 2 and Figure 11.
COLMAP [1]. We use the officially provided CLI(command line interface) version of COLMAP. Dense point clouds are produced by sequentially running following commands: (1) feature_extractor, (2) exhaustive_matcher, (3) patch_match_stereo, and (4) stereo_fusion. Given dense point clouds, meshes are produced by (5) poisson_mesher.
UNISURF [9]. The quantitative and qualitative results in the paper are provided by the authors of UNISURF.

10. Additional Experimental Results
Section Summary: This section presents extra experiments on a method for reconstructing 3D scenes from images, highlighting its ability to produce high-quality rendered images quickly, with a faster sampling technique reducing rendering time from about five minutes to one minute per image on standard hardware. It also shows the method performs similarly to a competing technique called NeRF in generating new viewpoints from limited photos, with visualizations demonstrating how surfaces become sharper during training and the benefits of certain initialization steps to avoid distortions. While additional results on benchmark datasets confirm strong reconstructions even without extra guidance like object masks, the approach struggles with featureless areas, such as smooth metal surfaces, leading to inaccuracies.

::: {caption="Table 3: Quantitative comparisons by different sampling strategies. - $ST$ indicates the sampling strategy with sphere tracing."}
:::
::: {caption="Table 4: Quantitative comparisons with NeRF on the task of novel view synthesis without mask supervision. "}
:::
10.1 Rendering Quality and Speed
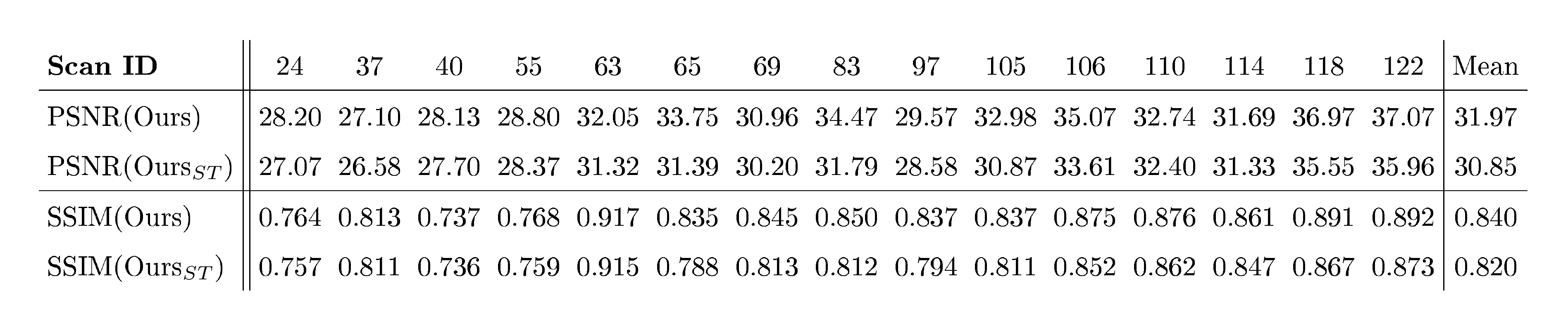
Besides the reconstructed surfaces, our method also renders high-quality images, as shown in Figure 12. Rendering an image in resolution of 1600x1200 costs about 320 seconds in the default volume rendering setting on a single Nvidia 2080Ti GPU. In addition, we also tested another sampling strategy by first applying sphere tracing to find the regions near the surfaces and only sampling points in those regions. With this strategy, rendering an image in the same resolution only needs about 60 seconds. Table 3 reports the quantitative results in terms of PSNR and SSIM in default volume rendering setting and sphere tracing setting.
10.2 Novel View Synthesis
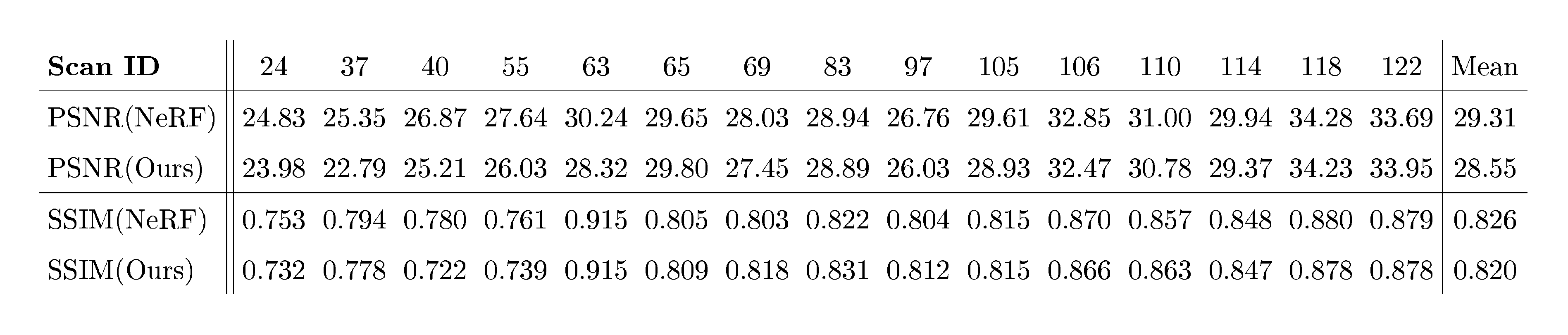
In this experiment, we held out 10% of the images in the DTU dataset as the testing set and the others as the training set. We compare the quantitative results on the testing set in terms of PSNR and SSIM with NeRF. As shown in Table 4, our method achieves comparable performance to NeRF.


10.3 SDF Qualitative Evaluation
While our method without Eikonal regularization [32] or geometric initialization [31] produces plausible surface reconstruction results, our full model can predict a more accurate signed distance function as shown in Figure 13. Furthermore, using random initialization produces axis-aligned artifacts due to the spectral bias of positional encoding [53] while the geometric initialization [31] does not have such kind of artifacts.
10.4 Training Progression
We show the reconstructed surfaces at different training stages of the Durian in the BlendedMVS dataset. As illustrated in Figure 14, the surface gets sharper along the training process. Meanwhile, we also provide a curve in the figure to show how the trainable standard deviation in $\phi_s$ changes in the training process. As we can see, the optimization process will automatically reduce the standard deviation so that the surface becomes more clear and sharper with more training steps.
10.5 Limitation
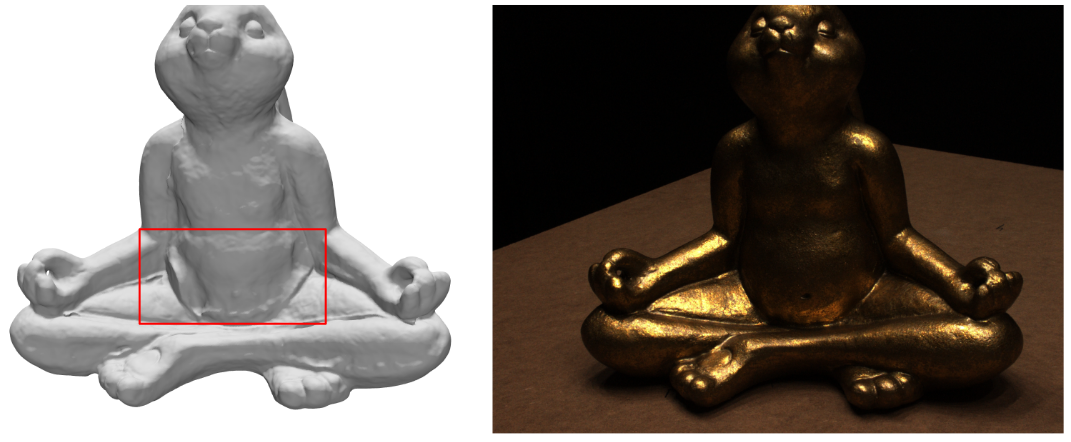
Figure 16 shows a failure case where our method fails to correctly reconstruct the texutreless region of the surface on the metal rabbit model. The reason is that such textureless regions are ambiguous for reconstruction in neural rendering.
10.6 Additional Results
In this section, we show additional qualitative results on the DTU dataset and BlendedMVS dataset. Figure 17 shows the comparisons with baseline methods in both w/ mask setting and w/o mask setting. Figure 15 shows addtional results in w/o mask setting.

References
Section Summary: This references section compiles a bibliography of academic papers spanning computer vision and graphics research, primarily focused on techniques for reconstructing 3D objects and scenes from images taken from multiple angles or even single views. It covers early methods like voxel coloring and probabilistic volume reconstruction from the 1990s and 2000s, alongside modern approaches using neural networks for tasks such as surface rendering, radiance fields, and implicit shape modeling from 2016 to 2021. These works form the foundation for creating detailed digital models of real-world environments, blending traditional algorithms with cutting-edge AI.
[1] Schönberger et al. (2016). Pixelwise view selection for unstructured multi-view stereo. In European Conference on Computer Vision. pp. 501–518.
[2] Furukawa, Yasutaka and Ponce, Jean (2009). Accurate, dense, and robust multiview stereopsis. IEEE transactions on pattern analysis and machine intelligence. 32(8). pp. 1362–1376.
[3] Barnes et al. (2009). PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph.. 28(3). pp. 24.
[4] Yariv et al. (2020). Multiview neural surface reconstruction by disentangling geometry and appearance. Advances in Neural Information Processing Systems. 33.
[5] Zhang et al. (2021). PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting. arXiv preprint arXiv:2104.00674.
[6] Kellnhofer et al. (2021). Neural Lumigraph Rendering. arXiv preprint arXiv:2103.11571.
[7] Liu et al. (2020). Dist: Rendering deep implicit signed distance function with differentiable sphere tracing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2019–2028.
[8] Niemeyer et al. (2020). Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3504–3515.
[9] Oechsle et al. (2021). UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction. arXiv preprint arXiv:2104.10078.
[10] Mildenhall et al. (2020). Nerf: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision. pp. 405–421.
[11] Galliani et al. (2016). Gipuma: Massively parallel multi-view stereo reconstruction. Publikationen der Deutschen Gesellschaft für Photogrammetrie, Fernerkundung und Geoinformation e. V. 25(361-369). pp. 2.
[12] De Bonet, Jeremy S and Viola, Paul (1999). Poxels: Probabilistic voxelized volume reconstruction. In Proceedings of International Conference on Computer Vision (ICCV). pp. 418–425.
[13] Broadhurst et al. (2001). A probabilistic framework for space carving. In Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001. pp. 388–393.
[14] Seitz, Steven M and Dyer, Charles R (1999). Photorealistic scene reconstruction by voxel coloring. International Journal of Computer Vision. 35(2). pp. 151–173.
[15] Merrell et al. (2007). Real-Time Visibility-Based Fusion of Depth Maps. pp. 1-8. doi:10.1109/ICCV.2007.4408984.
[16] Zach et al. (2007). A Globally Optimal Algorithm for Robust TV-L1 Range Image Integration. In 2007 IEEE 11th International Conference on Computer Vision. pp. 1-8. doi:10.1109/ICCV.2007.4408983.
[17] Kazhdan, Michael and Hoppe, Hugues (2013). Screened Poisson Surface Reconstruction. ACM Trans. Graph.. 32(3). doi:10.1145/2487228.2487237. https://doi.org/10.1145/2487228.2487237.
[18] Kar et al. (2017). Learning a multi-view stereo machine. arXiv preprint arXiv:1708.05375.
[19] Choy et al. (2016). 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In European conference on computer vision. pp. 628–644.
[20] Xie et al. (2019). Pix2vox: Context-aware 3d reconstruction from single and multi-view images. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2690–2698.
[21] Fan et al. (2017). A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 605–613.
[22] Mandikal et al. (2018). 3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image. In Proceedings of the British Machine Vision Conference (BMVC).
[23] Lin et al. (2018). Learning efficient point cloud generation for dense 3d object reconstruction. In proceedings of the AAAI Conference on Artificial Intelligence.
[24] Wang et al. (2018). Pixel2mesh: Generating 3d mesh models from single rgb images. In Proceedings of the European Conference on Computer Vision (ECCV). pp. 52–67.
[25] Wen et al. (2019). Pixel2mesh++: Multi-view 3d mesh generation via deformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1042–1051.
[26] Kato et al. (2018). Neural 3d mesh renderer. In Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3907–3916.
[27] Mescheder et al. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4460–4470.
[28] Michalkiewicz et al. (2019). Implicit Surface Representations As Layers in Neural Networks. In The IEEE International Conference on Computer Vision (ICCV).
[29] Park et al. (2019). Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 165–174.
[30] Z. Chen and H. Zhang (2019). Learning Implicit Fields for Generative Shape Modeling. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5932-5941.
[31] Atzmon, Matan and Lipman, Yaron (2020). Sal: Sign agnostic learning of shapes from raw data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2565–2574.
[32] Gropp et al. (2020). Implicit geometric regularization for learning shapes. arXiv preprint arXiv:2002.10099.
[33] Yifan et al. (2020). Iso-Points: Optimizing Neural Implicit Surfaces with Hybrid Representations. arXiv preprint arXiv:2012.06434.
[34] Songyou Peng et al. (2020). Convolutional Occupancy Networks. ArXiv. abs/2003.04618.
[35] Sitzmann et al. (2019). Scene representation networks: Continuous 3D-structure-aware neural scene representations. In Advances in Neural Information Processing Systems. pp. 1119–1130.
[36] Lombardi et al. (2019). Neural volumes: Learning dynamic renderable volumes from images. ACM Transactions on Graphics (TOG). 38(4). pp. 65.
[37] Kaza, Srinivas and others (2019). Differentiable volume rendering using signed distance functions.
[38] Liu et al. (2020). Neural Sparse Voxel Fields. Advances in Neural Information Processing Systems. 33.
[39] Saito et al. (2019). PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization. ICCV.
[40] Saito et al. (2020). Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 84–93.
[41] Trevithick, Alex and Yang, Bo (2020). GRF: Learning a General Radiance Field for 3D Scene Representation and Rendering. arXiv preprint arXiv:2010.04595.
[42] Sitzmann et al. (2019). Deepvoxels: Learning persistent 3d feature embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2437–2446.
[43] Jiang et al. (2020). SDFDiff: Differentiable Rendering of Signed Distance Fields for 3D Shape Optimization. In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
[44] Jensen et al. (2014). Large Scale Multi-view Stereopsis Evaluation. In 2014 IEEE Conference on Computer Vision and Pattern Recognition. pp. 406-413. doi:10.1109/CVPR.2014.59.
[45] Yao et al. (2020). Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1790–1799.
[46] Zhang et al. (2020). Nerf++: Analyzing and improving neural radiance fields. arXiv preprint arXiv:2010.07492.
[47] A. Tabb (2013). Shape from Silhouette Probability Maps: Reconstruction of Thin Objects in the Presence of Silhouette Extraction and Calibration Error. In cvpr. pp. 161-168. doi:10.1109/CVPR.2013.28.
[48] Liu et al. (2017). Image-based Reconstruction of Wire Art. sigg. 36(4). pp. 63:1–63:11.
[49] Wang et al. (2020). Vid2Curve: Simultaneous Camera Motion Estimation and Thin Structure Reconstruction from an RGB Video. ACM Trans. Graph.. 39(4). doi:10.1145/3386569.3392476. https://doi.org/10.1145/3386569.3392476.
[50] Lingjie Liu et al. (2018). CurveFusion: Reconstructing Thin Structures from RGBD Sequences. sigga. 37(6).
[51] Salimans, Tim and Kingma, Diederik P (2016). Weight normalization: A simple reparameterization to accelerate training of deep neural networks. arXiv preprint arXiv:1602.07868.
[52] Kingma, Diederik P and Ba, Jimmy (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
[53] Tancik et al. (2020). Fourier features let networks learn high frequency functions in low dimensional domains. arXiv preprint arXiv:2006.10739.