Exploration by Random Network Distillation
Yuri Burda$^\ast$
OpenAI
Harrison Edwards$^{*}$
OpenAI
Amos Storkey
Univ. of Edinburgh
Oleg Klimov
OpenAI
$^{*}$ Alphabetical ordering; the first two authors contributed equally.
Abstract
We introduce an exploration bonus for deep reinforcement learning methods that is easy to implement and adds minimal overhead to the computation performed. The bonus is the error of a neural network predicting features of the observations given by a fixed randomly initialized neural network. We also introduce a method to flexibly combine intrinsic and extrinsic rewards. We find that the random network distillation (RND) bonus combined with this increased flexibility enables significant progress on several hard exploration Atari games. In particular we establish state of the art performance on Montezuma's Revenge, a game famously difficult for deep reinforcement learning methods. To the best of our knowledge, this is the first method that achieves better than average human performance on this game without using demonstrations or having access to the underlying state of the game, and occasionally completes the first level.
 for videos.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/nsjuq656/complex_fig_f61ff830c79f.png)
Executive Summary: Reinforcement learning (RL) agents excel at tasks with frequent rewards but falter in environments with sparse rewards, where positive outcomes are rare and distant. This poses a real-world challenge for applications like robotics, autonomous driving, or game AI, where designing dense reward signals is often impractical. Games such as Atari's Montezuma's Revenge exemplify this: agents must navigate deadly obstacles over hundreds of steps to find keys or treasures, and standard RL methods rarely progress beyond the first room without special aids like expert demonstrations or hidden game states. With growing computational resources enabling massive parallel simulations, there is an urgent need for scalable exploration techniques that guide agents toward novelty without excessive complexity.
This document introduces and evaluates Random Network Distillation (RND), a simple exploration method to address sparse-reward challenges in deep RL. It aims to boost agent performance on hard-exploration Atari games by adding an intrinsic reward bonus that encourages visiting novel states, while combining it flexibly with the game's extrinsic rewards.
The approach builds on Proximal Policy Optimization (PPO), a policy gradient RL algorithm, enhanced with RND. At its core, RND uses two neural networks: a fixed, randomly initialized target network that processes observations (like game screens) into embeddings, and a predictor network trained on the agent's experience to mimic those embeddings. The exploration bonus is the prediction error, which is high for unfamiliar states, rewarding novelty without relying on stochastic predictions that can trap agents in unproductive loops. Experiments ran on six Atari games with sparse rewards, using up to 1,024 parallel environments over billions of frames, collected from 2023-style no-op starts and sticky actions to prevent memorization. Key assumptions include normalized observations and rewards for consistency across games, with separate value functions for intrinsic and extrinsic rewards to handle different time horizons.
The most critical findings center on Montezuma's Revenge. First, RND achieved state-of-the-art results, with a mean score of 8,152—more than double the prior best of 3,700 without aids—and explored up to 22 of 24 rooms, occasionally completing the first level. Second, even using only the intrinsic RND bonus, agents found over half the rooms and earned returns up to 6,700 by pursuing novelty alone. Third, combining non-episodic intrinsic rewards (to encourage long-term curiosity) with a high discount factor for extrinsic rewards (0.999) outperformed episodic setups, boosting scores by 40-50% in ablations. Fourth, scaling to more parallel environments (from 32 to 1,024) raised final scores by about 30%, with recurrent neural network policies edging out convolutional ones by 10-20% on average. Fifth, across other games like Venture and Gravitar, RND surpassed baselines: it scored 1,859 on Venture (60% above prior state-of-the-art) and 3,906 on Gravitar (75% over previous), often exceeding average human levels, while dynamics-prediction bonuses—prone to exploiting noise—lagged by 50-80% on games like Private Eye.
These results mean RND provides a robust, low-overhead way to tackle exploration bottlenecks, enabling RL agents to discover rewards in sparse settings without custom engineering. It reduces reliance on demonstrations or privileged information, cutting development costs and risks in real applications like training robots for unseen terrains. Unlike prior methods that scale poorly, RND's efficiency supports massive data regimes, potentially shortening timelines for RL deployment in games or simulations. It aligns with human-like curiosity, where agents interact boldly with hazards (e.g., jumping over moving skulls) after exhausting easy rewards, but falls short of expectations in global planning—agents rarely sacrifice immediate gains for distant ones, unlike humans or aided systems.
Next steps should integrate RND into broader RL pipelines for sparse-reward tasks, starting with pilots on robotics benchmarks to validate scalability. For Montezuma's Revenge, enhance global exploration by tuning intrinsic rewards to balance short-term novelty against long-term extrinsic trade-offs, or combine with hierarchical RL for multi-step planning. If pursuing full-level mastery, test hybrid approaches with minimal demonstrations, weighing their simplicity against RND's zero-aid purity.
While experiments used standardized Atari setups with billions of frames, limitations include sensitivity to hyperparameters like discount rates and struggles with ultra-long horizons (e.g., consistent level completion occurred in under 10% of runs). Partial observability from pixel inputs may undervalue memory aids like recurrence. Confidence is high for Atari hard-exploration games, based on reproducible code and multiple seeds, but readers should be cautious extrapolating to non-game domains without further validation.
1. Introduction
Section Summary: Reinforcement learning helps agents learn by maximizing rewards, but it struggles in environments with sparse rewards that are hard to discover through random actions, making it tough to design helpful reward signals manually. This paper proposes a simple exploration bonus that encourages agents to seek novel experiences by measuring how poorly a neural network—trained on past data or fixed and random—predicts new observations, avoiding pitfalls like chasing unpredictable randomness. On challenging Atari games like Montezuma's Revenge, where rewards are rare and distant, the method enables agents to explore over half the levels even without main rewards and achieves top performance when combined with policy optimization tweaks.
Reinforcement learning (RL) methods work by maximizing the expected return of a policy. This works well when the environment has dense rewards that are easy to find by taking random sequences of actions, but tends to fail when the rewards are sparse and hard to find. In reality it is often impractical to engineer dense reward functions for every task one wants an RL agent to solve. In these situations methods that explore the environment in a directed way are necessary.
Recent developments in RL seem to suggest that solving the most challenging tasks ([1, 2, 3, 4, 5, 6]) requires processing large numbers of samples obtained from running many copies of the environment in parallel. In light of this it is desirable to have exploration methods that scale well with large amounts of experience. However many of the recently introduced exploration methods based on counts, pseudo-counts, information gain or prediction gain are difficult to scale up to large numbers of parallel environments.
This paper introduces an exploration bonus that is particularly simple to implement, works well with high-dimensional observations, can be used with any policy optimization algorithm, and is efficient to compute as it requires only a single forward pass of a neural network on a batch of experience. Our exploration bonus is based on the observation that neural networks tend to have significantly lower prediction errors on examples similar to those on which they have been trained. This motivates the use of prediction errors of networks trained on the agent's past experience to quantify the novelty of new experience.
As pointed out by many authors, agents that maximize such prediction errors tend to get attracted to transitions where the answer to the prediction problem is a stochastic function of the inputs. For example if the prediction problem is that of predicting the next observation given the current observation and agent's action (forward dynamics), an agent trying to maximize this prediction error will tend to seek out stochastic transitions, like those involving randomly changing static noise on a TV, or outcomes of random events such as coin tosses. This observation motivated the use of methods that quantify the relative improvement of the prediction, rather than its absolute error. Unfortunately, as previously mentioned, such methods are hard to implement efficiently.
We propose an alternative solution to this undesirable stochasticity by defining an exploration bonus using a prediction problem where the answer is a deterministic function of its inputs. Namely we predict the output of a fixed randomly initialized neural network on the current observation.
Atari games have been a standard benchmark for deep reinforcement learning algorithms since the pioneering work by [7]. [8] identified among these games the hard exploration games with sparse rewards: Freeway, Gravitar, Montezuma's Revenge, Pitfall!, Private Eye, Solaris, and Venture. RL algorithms tend to struggle on these games, often not finding even a single positive reward.
In particular, Montezuma's Revenge is considered to be a difficult problem for RL agents, requiring a combination of mastery of multiple in-game skills to avoid deadly obstacles, and finding rewards that are hundreds of steps apart from each other even under optimal play. Significant progress has been achieved by methods with access to either expert demonstrations ([9, 10, 11]), special access to the underlying emulator state ([12, 13]), or both ([14]). However without such aids, progress on the exploration problem in Montezuma's Revenge has been slow, with the best methods finding about half the rooms ([8]). For these reasons we provide extensive ablations of our method on this environment.
We find that even when disregarding the extrinsic reward altogether, an agent maximizing the RND exploration bonus consistently finds more than half of the rooms in Montezuma's Revenge. To combine the exploration bonus with the extrinsic rewards we introduce a modification of Proximal Policy Optimization (PPO, [15]) that uses two value heads for the two reward streams. This allows the use of different discount rates for the different rewards, and combining episodic and non-episodic returns. With this additional flexibility, our best agent often finds 22 out of the 24 rooms on the first level in Montezuma's Revenge, and occasionally (though not frequently) passes the first level. The same method gets state of the art performance on Venture and Gravitar.
2. Method
Section Summary: Exploration bonuses help AI agents explore environments with rare rewards by adding an extra incentive, called i_t, to the usual reward, making it more likely for the agent to visit new or unusual places. Traditional approaches use visit counts or prediction errors from things like guessing the next state, but this paper proposes Random Network Distillation (RND), where a fixed random neural network creates a prediction target, and another network learns to mimic it, with errors acting as bonuses that are higher for unfamiliar states. RND focuses on genuine novelty detection while avoiding issues like getting stuck on random noise, as shown in simple tests and game examples.
2.1 Exploration bonuses
Exploration bonuses are a class of methods that encourage an agent to explore even when the environment's reward $e_t$ is sparse. They do so by replacing $e_t$ with a new reward $r_t=e_t+i_t$, where $i_t$ is the exploration bonus associated with the transition at time $t$.
To encourage the agent to visit novel states, it is desirable for $i_t$ to be higher in novel states than in frequently visited ones. Count-based exploration methods provide an example of such bonuses. In a tabular setting with a finite number of states one can define $i_t$ to be a decreasing function of the visitation count $n_t({\bm{s}})$ of the state ${\bm{s}}$. In particular $i_t = 1/n_t({\bm{s}})$ and $i_t = 1/\sqrt{n_t({\bm{s}})}$ have been used in prior work ([8, 16]). In non-tabular cases it is not straightforward to produce counts, as most states will be visited at most once. One possible generalization of counts to non-tabular settings is pseudo-counts ([8]) which uses changes in state density estimates as an exploration bonus. In this way the counts derived from the density model can be positive even for states that have not been visited in the past, provided they are similar to previously visited states.
An alternative is to define $i_t$ as the prediction error for a problem related to the agent's transitions. Generic examples of such problems include forward dynamics ([17, 18, 19, 20, 21]) and inverse dynamics ([22]). Non-generic prediction problems can also be used if specialized information about the environment is available, like predicting physical properties of objects the agent interacts with ([23]). Such prediction errors tend to decrease as the agent collects more experience similar to the current one. For this reason even trivial prediction problems like predicting a constant zero function can work as exploration bonuses ([24]).
2.2 Random Network Distillation
This paper introduces a different approach where the prediction problem is randomly generated. This involves two neural networks: a fixed and randomly initialized target network which sets the prediction problem, and a predictor network trained on data collected by the agent. The target network takes an observation to an embedding $f: \mathcal{O} \to \mathbb{R}^k$ and the predictor neural network $\hat{f}: \mathcal{O} \to \mathbb{R}^k$ is trained by gradient descent to minimize the expected MSE $\Vert \hat{f}({\textnormal{x}}; \theta) - f({\textnormal{x}}) \Vert^2$ with respect to its parameters $\theta_{\hat{f}}$. This process distills a randomly initialized neural network into a trained one. The prediction error is expected to be higher for novel states dissimilar to the ones the predictor has been trained on.
To build intuition we consider a toy model of this process on MNIST. We train a predictor neural network to mimic a randomly initialized target network on training data consisting of a mixture of images with the label 0 and of a target class, varying the proportion of the classes, but not the total number of training examples. We then test the predictor network on the unseen test examples of the target class and report the MSE. In this model the zeros are playing the role of states that have been seen many times before, and the target class is playing the role of states that have been visited infrequently. The results are shown in Figure 2. The figure shows that test error decreases as a function of the number of training examples in the target class, suggesting that this method can be used to detect novelty. Figure 1 shows that the intrinsic reward is high in novel states in an episode of Montezuma's Revenge.
One objection to this method is that a sufficiently powerful optimization algorithm might find a predictor that mimics the target random network perfectly on any input (for example the target network itself would be such a predictor). However the above experiment on MNIST shows that standard gradient-based methods don't overgeneralize in this undesirable way.
2.2.1 Sources of prediction errors
In general, prediction errors can be attributed to a number of factors:
- Amount of training data. Prediction error is high where few similar examples were seen by the predictor (epistemic uncertainty).
- Stochasticity. Prediction error is high because the target function is stochastic (aleatoric uncertainty). Stochastic transitions are a source of such error for forward dynamics prediction.
- Model misspecification. Prediction error is high because necessary information is missing, or the model class is too limited to fit the complexity of the target function.
- Learning dynamics. Prediction error is high because the optimization process fails to find a predictor in the model class that best approximates the target function.
Factor 1 is what allows one to use prediction error as an exploration bonus. In practice the prediction error is caused by a combination of all of these factors, not all of them desirable.
For instance if the prediction problem is forward dynamics, then factor 2 results in the 'noisy-TV' problem. This is the thought experiment where an agent that is rewarded for errors in the prediction of its forward dynamics model gets attracted to local sources of entropy in the environment. A TV showing white noise would be such an attractor, as would a coin flip.
To avoid the undesirable factors 2 and 3, methods such as those by [25, 26, 27, 19] instead use a measurement of how much the prediction model improves upon seeing a new datapoint. However these approaches tend to be computationally expensive and hence difficult to scale.
RND obviates factors 2 and 3 since the target network can be chosen to be deterministic and inside the model-class of the predictor network.
2.2.2 Relation to uncertainty quantification
RND prediction error is related to an uncertainty quantification method introduced by [28]. Namely, consider a regression problem with data distribution $D = {x_i, y_i }i$. In the Bayesian setting we would consider a prior $p(\theta^*)$ over the parameters of a mapping $f{\theta^*}$ and calculate the posterior after updating on the evidence.
Let $\mathcal{F}$ be the distribution over functions $g_\theta=f_\theta+f_{\theta^*}$, where $\theta^*$ is drawn from $p(\theta^*)$ and $\theta$ is given by minimizing the expected prediction error
$ \theta = \operatorname{arg, min}{\theta} \mathbb{E}{(x_i, y_i)\sim D}\Vert f_{\theta}(x_i)+f_{\theta^*}(x_i)-y_i\Vert ^2 + \mathcal{R}(\theta), $
where $\mathcal{R}(\theta)$ is a regularization term coming from the prior (see Lemma 3, [28]). [28] argue (by analogy to the case of Bayesian linear regression) that the ensemble $\mathcal{F}$ is an approximation of the posterior.
If we specialize the regression targets $y_i$ to be zero, then the optimization problem $\operatorname{arg, min}{\theta} \mathbb{E}{(x_i, y_i)\sim D}\Vert f_{\theta}(x_i)+f_{\theta^*}(x_i)\Vert ^2$ is equivalent to distilling a randomly drawn function from the prior. Seen from this perspective, each coordinate of the output of the predictor and target networks would correspond to a member of an ensemble (with parameter sharing amongst the ensemble), and the MSE would be an estimate of the predictive variance of the ensemble (assuming the ensemble is unbiased). In other words the distillation error could be seen as a quantification of uncertainty in predicting the constant zero function.
2.3 Combining intrinsic and extrinsic returns
In preliminary experiments that used only intrinsic rewards, treating the problem as non-episodic resulted in better exploration. In that setting the return is not truncated at "game over". We argue that this is a natural way to do exploration in simulated environments, since the agent's intrinsic return should be related to all the novel states that it could find in the future, regardless of whether they all occur in one episode or are spread over several. It is also argued in ([21]) that using episodic intrinsic rewards can leak information about the task to the agent.
We also argue that this is closer to how humans explore games. For example let's say Alice is playing a videogame and is attempting a tricky maneuver to reach a suspected secret room. Because the maneuver is tricky the chance of a game over is high, but the payoff to Alice's curiosity will be high if she succeeds. If Alice is modelled as an episodic reinforcement learning agent, then her future return will be exactly zero if she gets a game over, which might make her overly risk averse. The real cost of a game over to Alice is the opportunity cost incurred by having to play through the game from the beginning (which is presumably less interesting to Alice having played the game for some time).
However using non-episodic returns for extrinsic rewards could be exploited by a strategy that finds a reward close to the beginning of the game, deliberately restarts the game by getting a game over, and repeats this in an endless cycle.
It is not obvious how to estimate the combined value of the non-episodic stream of intrinsic rewards $i_t$ and the episodic stream of extrinsic rewards $e_t$. Our solution is to observe that the return is linear in the rewards and so can be decomposed as a sum $R = R_E + R_I$ of the extrinsic and intrinsic returns respectively. Hence we can fit two value heads $V_E$ and $V_I$ separately using their respective returns, and combine them to give the value function $V = V_E + V_I$. This same idea can also be used to combine reward streams with different discount factors.
Note that even where one is not trying to combine episodic and non-episodic reward streams, or reward streams with different discount factors, there may still be a benefit to having separate value functions since there is an additional supervisory signal to the value function. This may be especially important for exploration bonuses since the extrinsic reward function is stationary whereas the intrinsic reward function is non-stationary.
2.4 Reward and Observation Normalization
One issue with using prediction error as an exploration bonus is that the scale of the reward can vary greatly between different environments and at different points in time, making it difficult to choose hyperparameters that work in all settings. In order to keep the rewards on a consistent scale we normalized the intrinsic reward by dividing it by a running estimate of the standard deviations of the intrinsic returns.
Observation normalization is often important in deep learning but it is crucial when using a random neural network as a target, since the parameters are frozen and hence cannot adjust to the scale of different datasets. Lack of normalization can result in the variance of the embedding being extremely low and carrying little information about the inputs. To address this issue we use an observation normalization scheme often used in continuous control problems whereby we whiten each dimension by subtracting the running mean and then dividing by the running standard deviation. We then clip the normalized observations to be between -5 and 5. We initialize the normalization parameters by stepping a random agent in the environment for a small number of steps before beginning optimization. We use the same observation normalization for both predictor and target networks but not the policy network.
3. Experiments
Section Summary: The experiments section tests the Random Network Distillation (RND) method for exploration in the challenging Atari game Montezuma's Revenge, starting with pure intrinsic rewards to see how well agents discover new areas without external goals, and finding that a continuous, non-episodic setup leads to more rooms explored than resetting after episodes. When mixing intrinsic rewards with standard game rewards, the non-episodic approach still boosts exploration, though game rewards help maintain useful behaviors, and using separate value estimates for each reward type is essential but doesn't always outperform a single one. Adjusting discount factors shows that planning farther ahead improves results for game rewards but can hinder the novelty-seeking intrinsic rewards, with overall tests running millions of game frames across setups.
We begin with an intrinsic reward only experiment on Montezuma's Revenge in Section 3.1 to isolate the inductive bias of the RND bonus, follow by extensive ablations of RND on Montezuma's Revenge in Section 3.2-Section 3.4 to understand the factors that contribute to RND's performance, and conclude with a comparison to baseline methods on 6 hard exploration Atari games in Section 3.6. For details of hyperparameters and architectures we refer the reader to Appendix A.3 and Appendix A.4. Most experiments are run for 30K rollouts of length $128$ per environment with $128$ parallel environments, for a total of $1.97$ billion frames of experience.
3.1 Pure exploration
:::: {cols="4"}
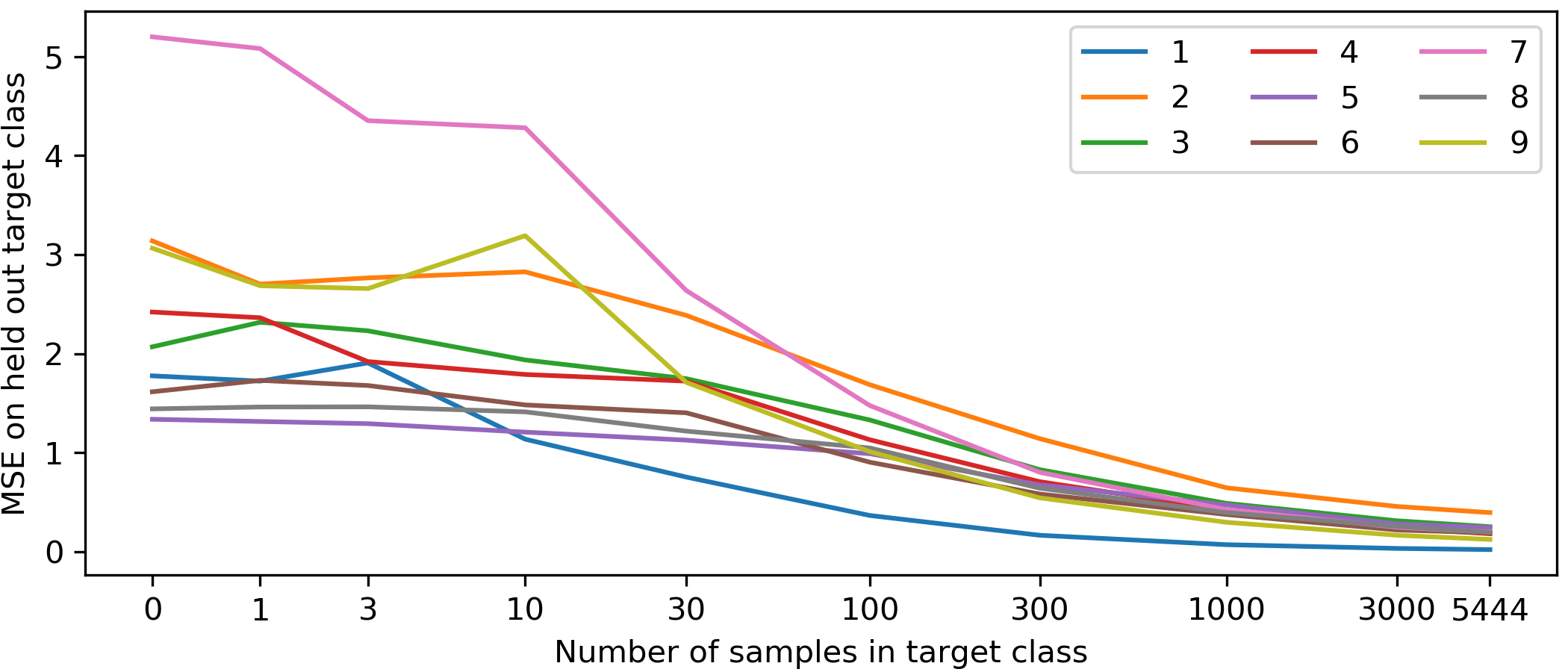
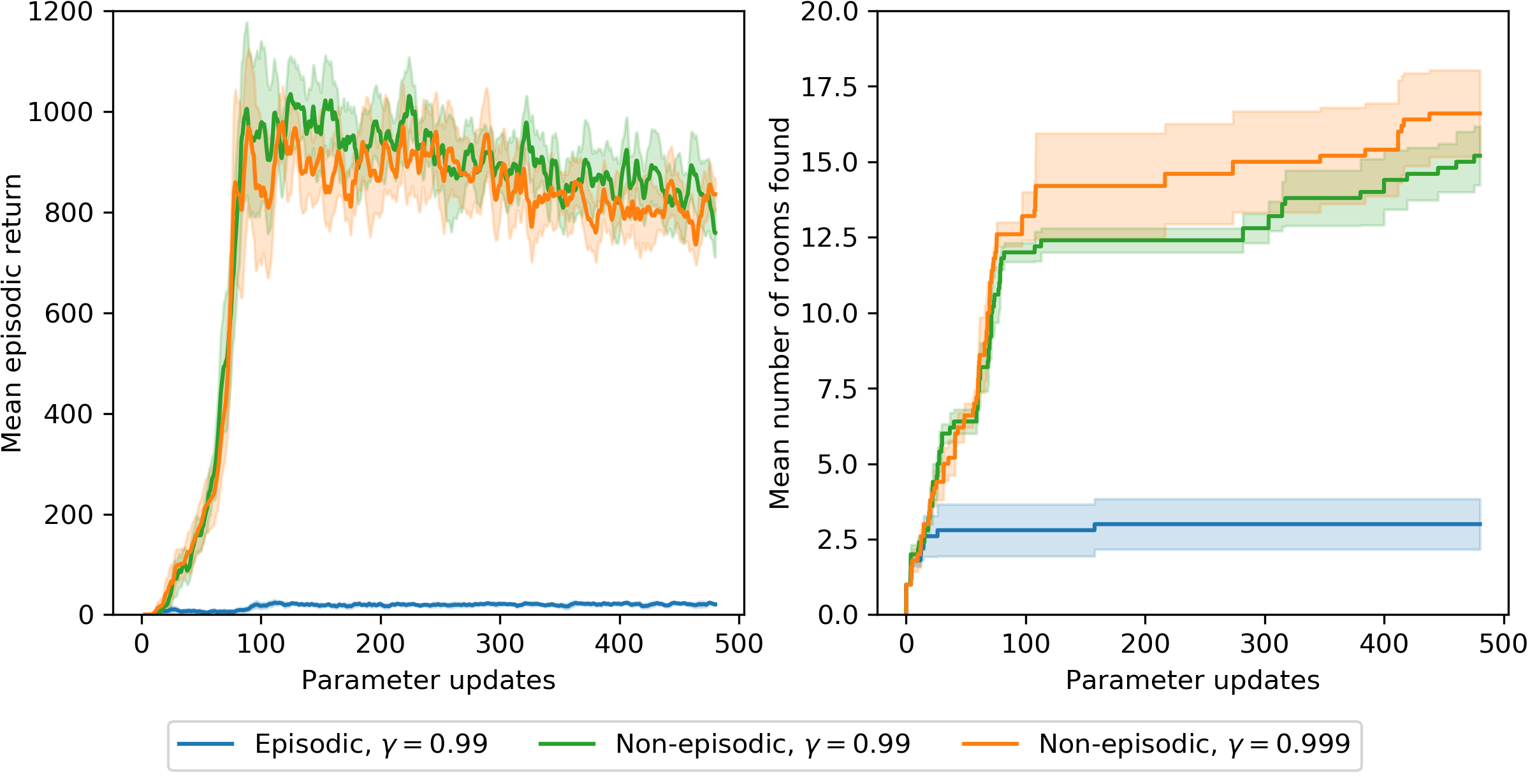
Figure 2: Novelty detection on MNIST: a predictor network mimics a randomly initialized target network. The training data consists of varying proportions of images from class `` $0''$ and a target class. Each curve shows the test MSE on held out target class examples plotted against the number of training examples of the target class (log scale).
::::
In this section we explore the performance of RND in the absence of any extrinsic reward. In Section 2.3 we argued that exploration with RND might be more natural in the non-episodic setting. By comparing the performance of the pure exploration agent in episodic and non-episodic settings we can see if this observation translates to improved exploration performance.
We report two measures of exploration performance in Figure 2: mean episodic return, and the number of rooms the agent finds over the training run. Since the pure exploration agent is not aware of the extrinsic rewards or number of rooms, it is not directly optimizing for any of these measures. However obtaining some rewards in Montezuma's Revenge (like getting the key to open a door) is required for accessing more interesting states in new rooms, and hence we observe the extrinsic reward increasing over time up to some point. The best return is achieved when the agent interacts with some of the objects, but the agent has no incentive to keep doing the same once such interactions become repetitive, hence returns are not consistently high.
We clearly see in Figure 2 that on both measures of exploration the non-episodic agent performs best, consistent with the discussion in Section 2.3. The non-episodic setting with $\gamma_I = 0.999$ explores more rooms than $\gamma_I = 0.99$, with one of the runs exploring 21 rooms. The best return achieved by 4 out 5 runs of this setting was 6, 700.
3.2 Combining episodic and non-episodic returns
In Section 3.1 we saw that the non-episodic setting resulted in more exploration than the episodic setting when exploring without any extrinsic rewards. Next we consider whether this holds in the case where we combine intrinsic and extrinsic rewards. As discussed in Section 2.3 in order to combine episodic and non-episodic reward streams we require two value heads. This also raises the question of whether it is better to have two value heads even when both reward streams are episodic. In Figure 6 we compare episodic intrinsic rewards to non-episodic intrinsic rewards combined with episodic extrinsic rewards, and additionally two value heads versus one for the episodic case. The discount factors are $\gamma_I = \gamma_E = 0.99$.
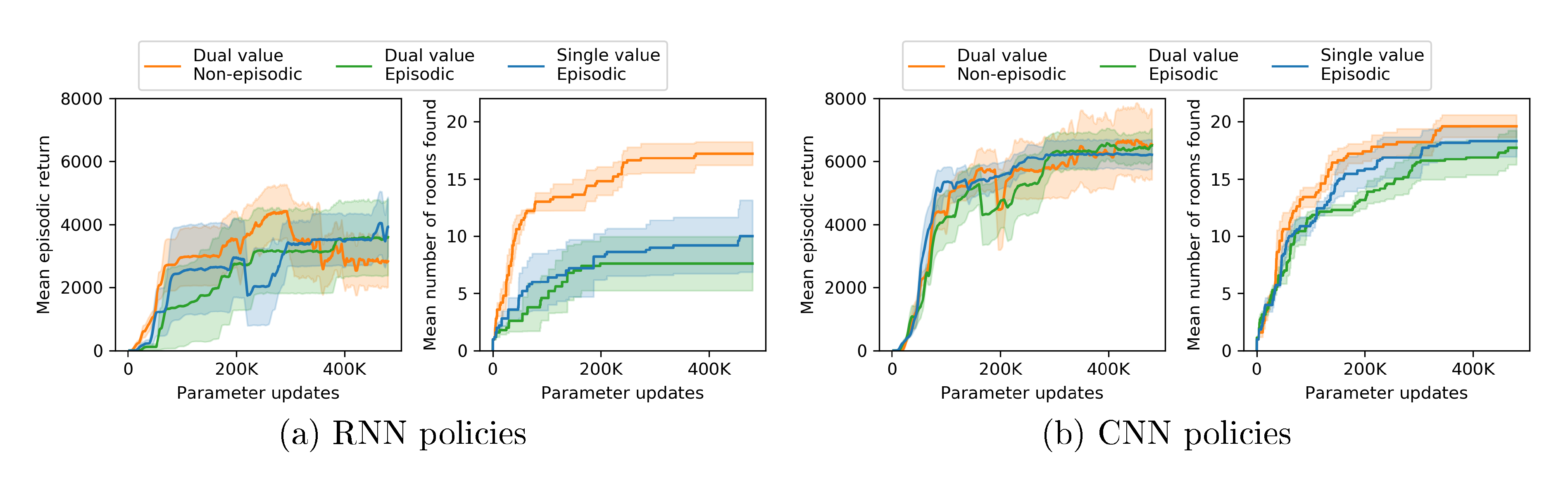
In Figure 6 we see that using a non-episodic intrinsic reward stream increases the number of rooms explored for both CNN and RNN policies, consistent with the experiments in Section 3.1, but that the difference is less dramatic, likely because the extrinsic reward is able to preserve useful behaviors. We also see that the difference is less pronounced for the CNN experiments, and that the RNN results tend to be less stable and perform worse for $\gamma_E=0.99$.
Contrary to our expectations (Section 2.3) using two value heads did not show any benefit over a single head in the episodic setting. Nevertheless having two value heads is necessary for combining reward streams with different characteristics, and so all further experiments use two value heads.
3.3 Discount factors
Previous experiments ([14, 9, 11]) solving Montezuma's Revenge using expert demonstrations used a high discount factor to achieve the best performance, enabling the agent to anticipate rewards far into the future. We compare the performance of the RND agent with $\gamma_E \in {0.99, 0.999 }$ and $\gamma_I = 0.99$. We also investigate the effect of increasing $\gamma_I$ to 0.999. The results are shown in Figure 7.
In Figure 7 we see that increasing $\gamma_E$ to 0.999 while holding $\gamma_I$ at 0.99 greatly improves performance. We also see that further increasing $\gamma_I$ to 0.999 hurts performance. This is at odds with the results in Figure 2 where increasing $\gamma_I$ did not significantly impact performance.
3.4 Scaling up training
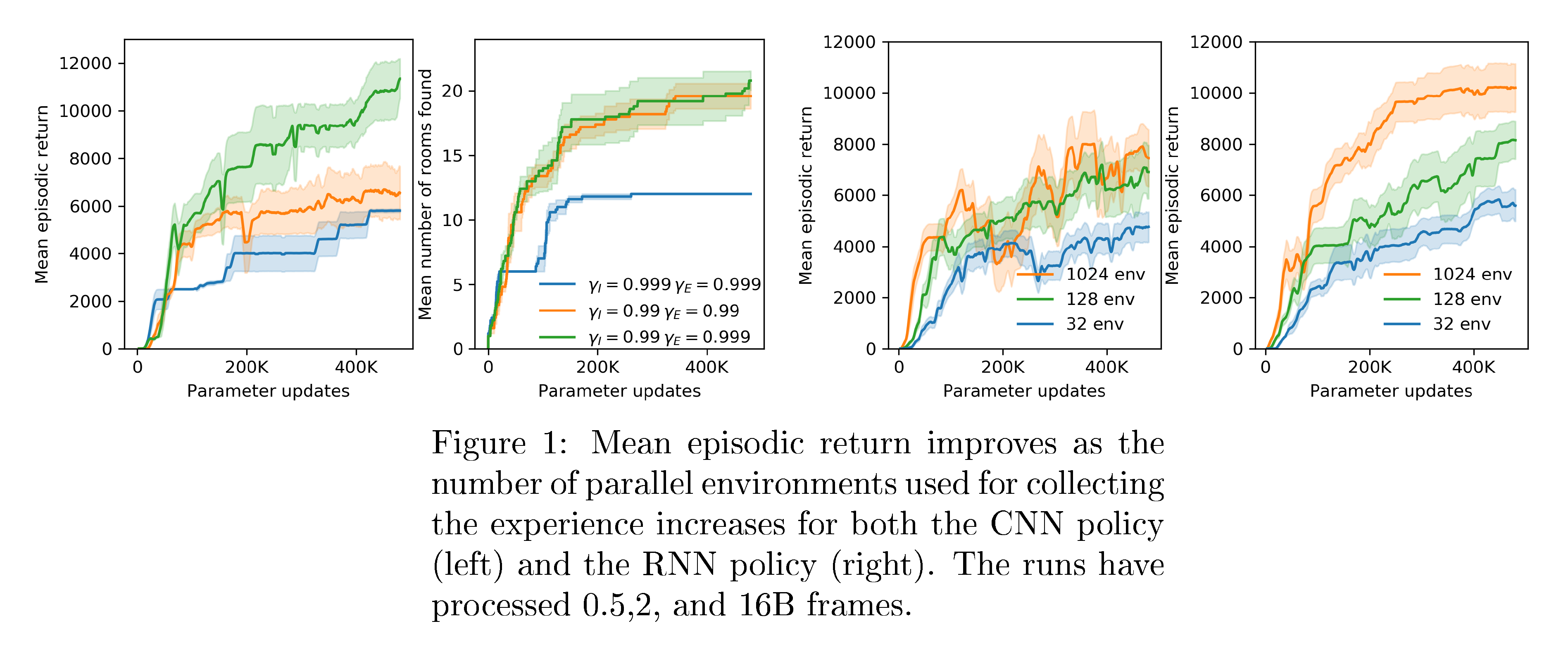
In this section we report experiments showing the effect of increased scale on training. The intrinsic rewards are non-episodic with $\gamma_I =0.99$, and $\gamma_E = 0.999$.
To hold the rate at which the intrinsic reward decreases over time constant across experiments with different numbers of parallel environments, we downsample the batch size when training the predictor to match the batch size with 32 parallel environments (for full details see Appendix A.4). Larger numbers of environments results in larger batch sizes per update for training the policy, whereas the predictor network batch size remains constant. Since the intrinsic reward disappears over time it is important for the policy to learn to find and exploit these transitory rewards, since they act as stepping-stones to nearby novel states.
Figure 7 shows that agents trained with larger batches of experience collected from more parallel environments obtain higher mean returns after similar numbers of updates. They also achieve better final performance. This effect seems to saturate earlier for the CNN policy than for the RNN policy.
We allowed the RNN experiment with 32 parallel environments to run for more time, eventually reaching a mean return of 7, 570 after processing 1.6 billion frames over 1.6 million parameter updates. One of these runs visited all 24 rooms, and passed the first level once, achieving a best return of 17, 500. The RNN experiment with 1024 parallel environments had mean return of 10, 070 at the end of training, and yielded one run with mean return of 14, 415.
3.5 Recurrence
Montezuma's Revenge is a partially observable environment even though large parts of the game state can be inferred from the screen. For example the number of keys the agent has appears on the screen, but not where they come from, how many keys have been used in the past, or what doors have been opened. To deal with this partial observability, an agent should maintain a state summarizing the past, for example the state of a recurrent policy. Hence it would be natural to hope for better performance from agents with recurrent policies. Contrary to expectations in Figure 6 recurrent policies performed worse than non-recurrent counterparts with $\gamma_E=0.99$. However in Figure 7 the RNN policy with $\gamma_E=0.999$ outperformed the CNN counterpart at each scale[^1]. Comparison of Figure 8 and Figure 10 shows that across multiple games the RNN policy outperforms the CNN more frequently than the other way around.
[^1]: The results in Figure 7 for the CNN policy were obtained as an average of 5 random seeds. When we ran 10 different seeds for the best performing setting for Figure 7 we found a large discrepancy in performance. This discrepancy is likely explained by the fact that the distribution of results on Montezuma's Revenge dominated by effects of discrete choices (such as going left or right from the first room), and hence contains a preponderance of outliers. In addition, the results in Figure 7 were run with an earlier version of our code base and it is possible that subtle differences between that version and the publicly released one have contributed to the discrepancy. The results in Figure 7 were reproduced with the publicly released code and so we suggest that future work compares against these results.
3.6 Comparison to baselines
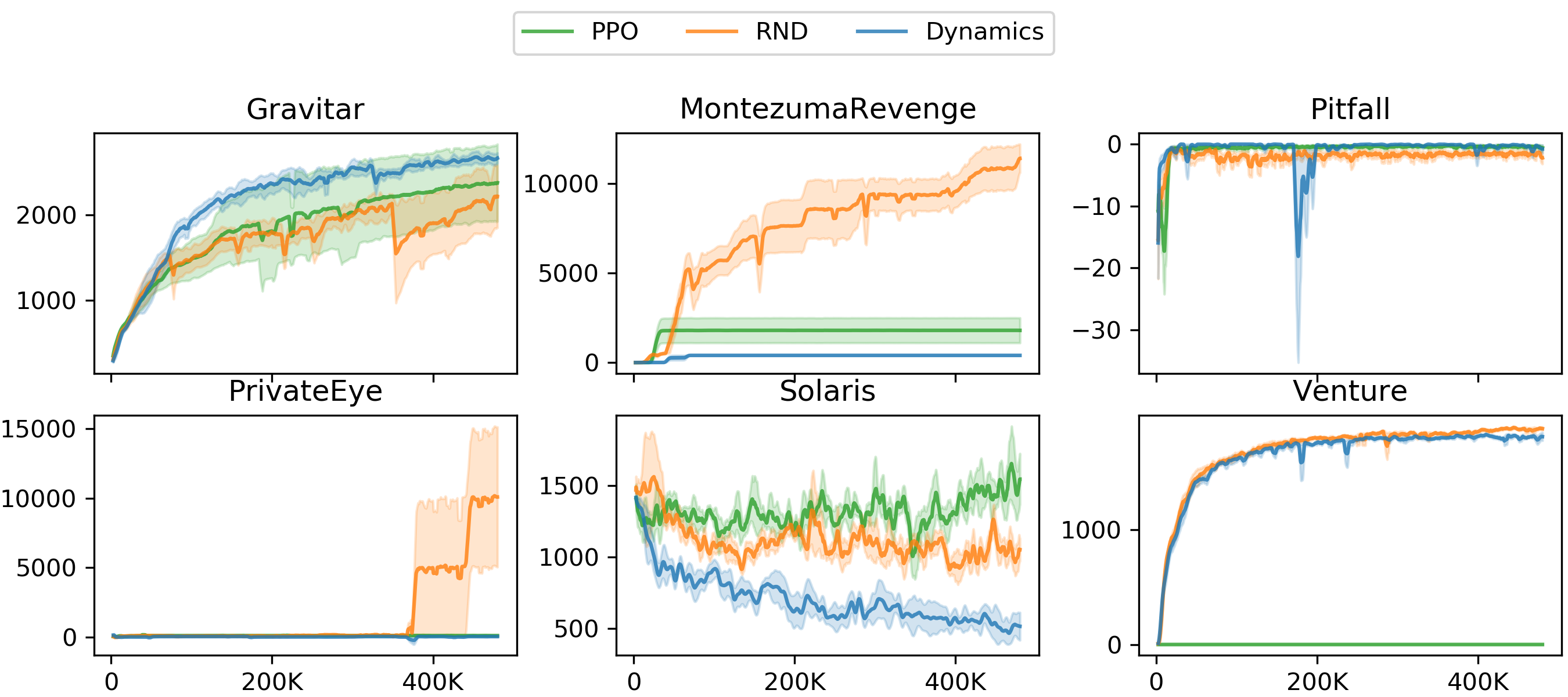
In this section we compare RND to two baselines: PPO without an exploration bonus and an alternative exploration bonus based on forward dynamics error. We evaluate RND's performance on six hard exploration Atari games: Gravitar, Montezuma's Revenge, Pitfall!, Private Eye, Solaris, and Venture. We first compare to the performance of a baseline PPO implementation without intrinsic reward. For RND the intrinsic rewards are non-episodic with $\gamma_I=0.99$, while $\gamma_E =0.999$ for both PPO and RND. The results are shown in Figure 8 for the RNN policy and summarized in Table 1 (see also Figure 10 for the CNN policy).
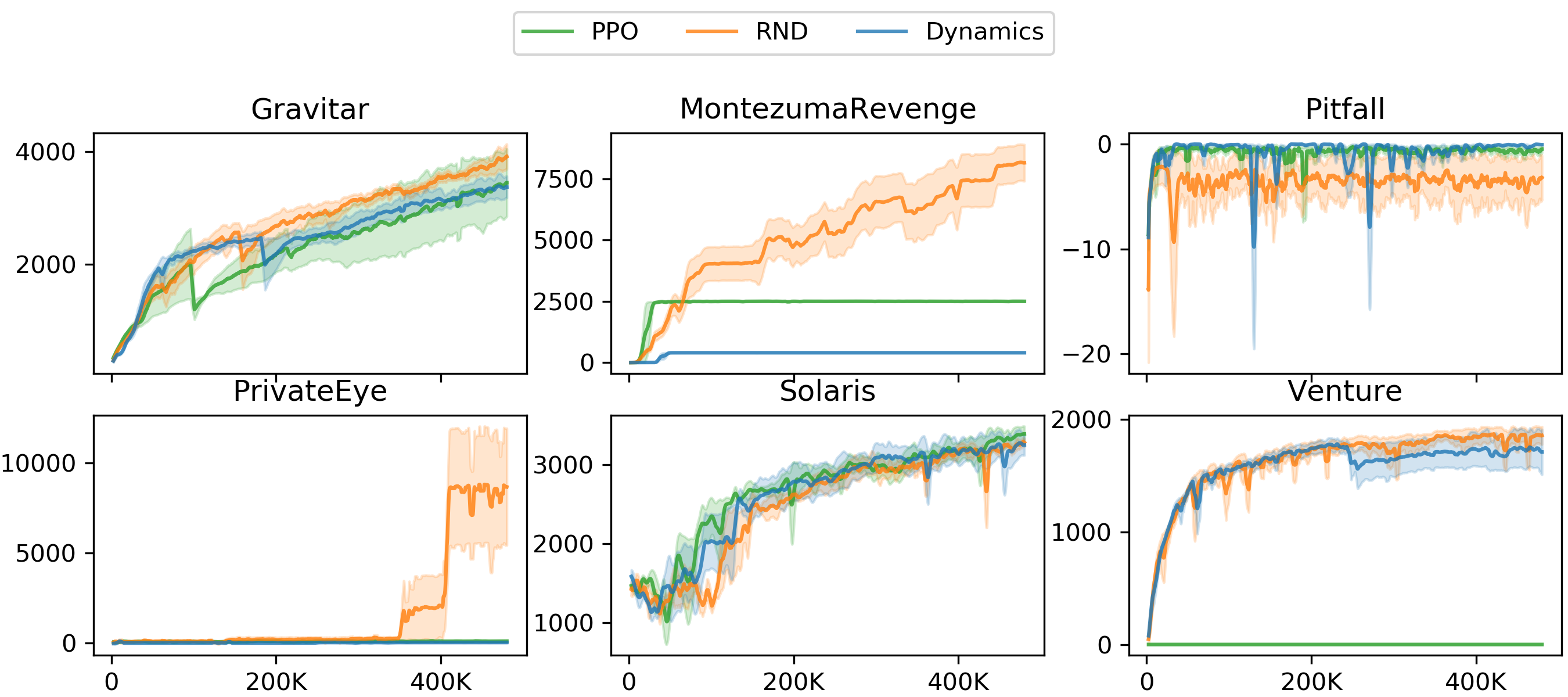
In Gravitar we see that RND does not consistently exceed the performance of PPO. However both exceed average human performance with an RNN policy, as well as the previous state of the art. On Montezuma's Revenge and Venture RND significantly outperforms PPO, and exceeds state of the art performance and average human performance. On Pitfall! both algorithms fail to find any positive rewards. This is a typical result for this game, as the extrinsic positive reward is very sparse. On Private Eye RND's performance exceeds that of PPO. On Solaris RND's performance is comparable to that of PPO.
Next we consider an alternative exploration bonus based on forward dynamics error. There are numerous previous works using such a bonus ([17, 18, 19, 20, 21]). Fortuitously [21] show that training a forward dynamics model in a random feature space typically works as well as any other feature space when used to create an exploration bonus. This means that we can easily implement an apples to apples comparison and change the loss in RND so the predictor network predicts the random features of the next observation given the current observation and action, while holding fixed all other parts of our method such as dual value heads, non-episodic intrinsic returns, normalization schemes etc. This provides an ablation of the prediction problem defining the exploration bonus, while also being representative of a class of prior work using forward dynamics error. Our expectation was that these methods should be fairly similar except where the dynamics-based agent is able to exploit non-determinism in the environment to get intrinsic reward.
Figure 8 shows that dynamics-based exploration performs significantly worse than RND with the same CNN policy on Montezuma's Revenge, PrivateEye, and Solaris, and performs similarly on Venture, Pitfall, and Gravitar. By analyzing agent's behavior at convergence we notice that in Montezuma's Revenge the agent oscillates between two rooms. This leads to an irreducibly high prediction error, as the non-determinism of sticky actions makes it impossible to know whether, once the agent is close to crossing a room boundary, making one extra step will result in it staying in the same room, or crossing to the next one. This is a manifestation of the `noisy TV' problem, or aleatoric uncertainty discussed in Section 2.2.1. Similar behavior emerges in PrivateEye and Pitfall!. In Table 1 the final training performance for each algorithm is listed, alongside the state of the art from previous work and average human performance.
::: {caption="Table 1: Comparison to baselines results. Final mean performance for various methods. State of the art results taken from: [1] ([29]) [2] ([8]) [3] ([3])"}

:::
3.7 Qualitative Analysis: Dancing with skulls
By observing the RND agent, we notice that frequently once it obtains all the extrinsic rewards that it knows how to obtain reliably (as judged by the extrinsic value function), the agent settles into a pattern of behavior where it keeps interacting with potentially dangerous objects. For instance in Montezuma's Revenge the agent jumps back and forth over a moving skull, moves in between laser gates, and gets on and off disappearing bridges. We also observe similar behavior in Pitfall!. It might be related to the very fact that such dangerous states are difficult to achieve, and hence are rarely represented in agent's past experience compared to safer states.
4. Related Work
Section Summary: The section reviews various exploration techniques in reinforcement learning, such as count-based bonuses that reward visiting new states, methods that use prediction errors or uncertainty measures to encourage discovery, and other approaches like adversarial training or parameter noise. It highlights challenges in the game Montezuma's Revenge, where standard algorithms struggle to explore beyond the first room, but improvements come from pseudo-count bonuses, expert demonstrations, or special access to game states, with the current work incorporating sticky actions to avoid relying on the game's predictability. Additionally, it discusses random features from neural networks for better exploration and vectorized value functions that break down rewards into components for more effective learning.
Exploration. Count-based exploration bonuses are a natural and effective way to do exploration ([30]) and a lot of work has studied how to tractably generalize count bonuses to large state spaces ([8, 31, 32, 12, 33, 24]).
Another class of exploration methods rely on errors in predicting dynamics ([17, 18, 19, 20, 21]). As discussed in Section 2.2, these methods are subject to the `noisy TV' problem in stochastic or partially-observable environments. This has motivated work on exploration via quantification of uncertainty ([34, 35]) or prediction improvement measures ([25, 26, 27, 19]).
Other methods of exploration include adversarial self-play ([36]), maximizing empowerment ([37]), parameter noise ([38, 29]), identifying diverse policies ([39, 40]), and using ensembles of value functions ([28, 41, 42]).
Montezuma's Revenge. Early neural-network based reinforcement learning algorithms that were successful on a significant portion of Atari games ([43, 44, 45]) failed to make meaningful progress on Montezuma's Revenge, not finding a way out of the first room reliably. This is not necessarily a failure of exploration, as even a random agent finds the key in the first room once every few hundred thousand steps, and escapes the first room every few million steps. Indeed, a mean return of about 2, 500 can be reliably achieved without special exploration methods ([3, 4, 46]).
Combining DQN with a pseudo-count exploration bonus [8] set a new state of the art performance, exploring 15 rooms and getting best return of 6, 600. Since then a number of other works have achieved similar performance ([47, 16, 33, 28]), without exceeding it.
Special access to the underlying RAM state can also be used to improve exploration by using it to hand-craft exploration bonuses ([48, 12, 13]). Even with such access previous work achieves performance inferior to average human performance.
Expert demonstrations can be used effectively to simplify the exploration problem in Montezuma's Revenge, and a number of works ([14, 9, 10, 11]) have achieved performance comparable to or better than that of human experts. Learning from expert demonstrations benefits from the game's determinism. The suggested training method ([49]) to prevent an agent from simply memorizing the correct sequence of actions is to use sticky actions (i.e. randomly repeating previous action) has not been used in these works. In this work we use sticky actions and thus don't rely on determinism.
Random features. Features of randomly initialized neural networks have been extensively studied in the context of supervised learning ([50, 51, 52, 53]). More recently they have been used in the context of exploration ([28, 21]). The work [28] provides motivation for random network distillation as discussed in Section 2.2.
Vectorized value functions. [54] find that a vectorized value function (with coordinates corresponding to additive factors of the reward) improves their method. [55] parametrize the value as a linear combination of value heads that estimate probabilities of discretized returns. However the Bellman backup equation used there is not itself vectorized.
5. Discussion
Section Summary: This paper's exploration method, based on random network distillation, successfully enables directed exploration in Atari games with sparse rewards, showing that simple techniques can make progress on challenging tasks when scaled up, particularly by separating intrinsic rewards from external ones. However, while it handles short-term local exploration effectively, such as deciding to interact with nearby objects, it struggles with long-term global strategies requiring coordinated actions over time. In the game Montezuma's Revenge, for instance, the agent rarely saves keys for later doors because the intrinsic rewards aren't strong enough to offset immediate gains, highlighting a key area for future research in advanced exploration.
This paper introduced an exploration method based on random network distillation and experimentally showed that the method is capable of performing directed exploration on several Atari games with very sparse rewards. These experiments suggest that progress on hard exploration games is possible with relatively simple generic methods, especially when applied at scale. They also suggest that methods that are able to treat the stream of intrinsic rewards separately from the stream of extrinsic rewards (for instance by having separate value heads) can benefit from such flexibility.
We find that the RND exploration bonus is sufficient to deal with local exploration, i.e. exploring the consequences of short-term decisions, like whether to interact with a particular object, or avoid it. However global exploration that involves coordinated decisions over long time horizons is beyond the reach of our method.
To solve the first level of Montezuma's Revenge, the agent must enter a room locked behind two doors. There are four keys and six doors spread throughout the level. Any of the four keys can open any of the six doors, but are consumed in the process. To open the final two doors the agent must therefore forego opening two of the doors that are easier to find and that would immediately reward it for opening them.
To incentivize this behavior the agent should receive enough intrinsic reward for saving the keys to balance the loss of extrinsic reward from using them early on. From our analysis of the RND agent's behavior, it does not get a large enough incentive to try this strategy, and only stumbles upon it rarely.
Solving this and similar problems that require high level exploration is an important direction for future work.
Appendix
Section Summary: The appendix provides in-depth technical details on the Random Network Distillation (RND) method for improving exploration in reinforcement learning, explaining how it pairs with the PPO algorithm by adding an exploration bonus to rewards. It includes pseudo-code for the RND process, along with specifics on preprocessing environments and networks, hyperparameters for PPO and RND, and architectures like RNN and CNN policies, all with links to the project's code for exact implementation. It also shares additional experiment results, such as comparisons showing RND outperforming autoencoder-based exploration while both beat plain PPO.
A.1 Reinforcement Learning Algorithm
An exploration bonus can be used with any RL algorithm by modifying the rewards used to train the model (i.e., $r_t = i_t + e_t$). We combine our proposed exploration bonus with a baseline reinforcement learning algorithm PPO ([15]). PPO is a policy gradient method that we have found to require little tuning for good performance. For algorithmic details see Algorithm 1.
A.2 RND Pseudo-code Algorithm 1 gives an overall picture of the RND method. Exact details of the method can be found in the code accompanying this paper.
$N \gets$ number of rollouts
$N_{\text{opt}} \gets$ number of optimization steps
$K \gets$ length of rollout
$M \gets$ number of initial steps for initializing observation normalization
$t=0$
Sample state $s_0\sim p_0(s_0)$
**for** $m=1$ **to** $M$ **do**
sample $a_t \sim \text{Uniform}(a_t)$
sample $s_{t+1} \sim p(s_{t+1} | s_t, a_t)$
Update observation normalization parameters using $s_{t+1}$
t += 1
**end for**
**for** $i=1$ **to** $N$ **do**
**for** $j=1$ **to** $K$ **do**
sample $a_t \sim \pi(a_t|s_t)$
sample $s_{t+1}, e_t \sim p(s_{t+1}, e_t | s_t, a_t)$
calculate intrinsic reward $i_t = \lVert \hat{f}(s_{t+1}) - f(s_{t+1}) \rVert^2$
add $s_t, s_{t+1}, a_t, e_t, i_t$ to optimization batch $B_i$
Update reward normalization parameters using $i_t$
t += 1
**end for**
Normalize the intrinsic rewards contained in $B_i$
Calculate returns $R_I,i$ and advantages $A_I,i$ for intrinsic reward
Calculate returns $R_E,i$ and advantages $A_E,i$ for extrinsic reward
Calculate combined advantages $A_i = A_I, i + A_E,i$
Update observation normalization parameters using $B_i$
**for** $j=1$ **to** $N_{\text{opt}}$ **do**
optimize $\theta_{\pi}$ wrt PPO loss on batch $B_i, R_i, A_i$ using Adam
optimize $\theta_{\hat{f}}$ wrt distillation loss on $B_i$ using Adam
**end for**
**end for**
A.3 Preprocessing details
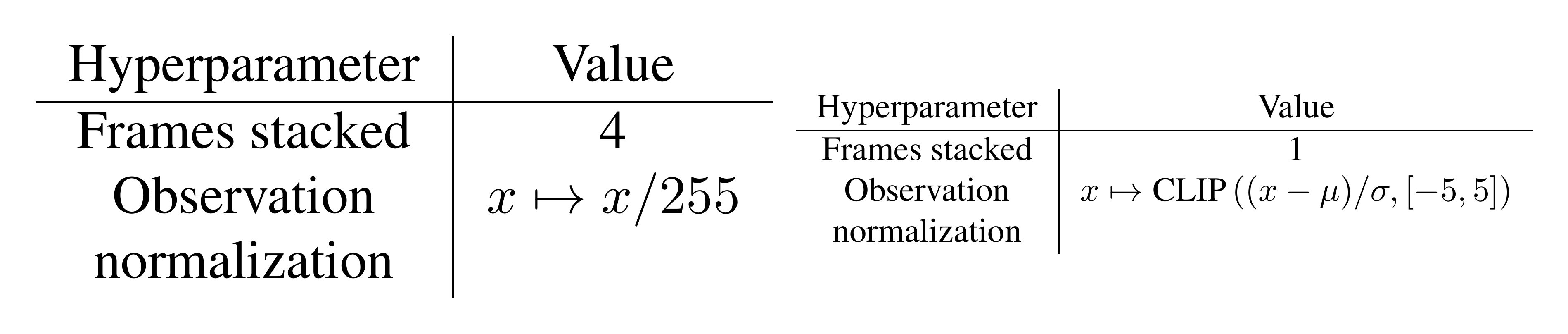
Table 2 contains details of how we preprocessed the environment for our experiments. We followed the recommendations in [49] in using sticky actions in order to make the environments non-deterministic so that memorization of action sequences is not possible. In Table 3 we show additional preprocessing details for the policy and value networks. In Table 3 we show additional preprocessing details for the predictor and target networks.
::: {caption="Table 2: Preprocessing details for the environments for all experiments."}

:::
::: {caption="Table 3: Preprocessing details for policy and value network for all experiments."}
:::
A.4 PPO and RND hyperparameters
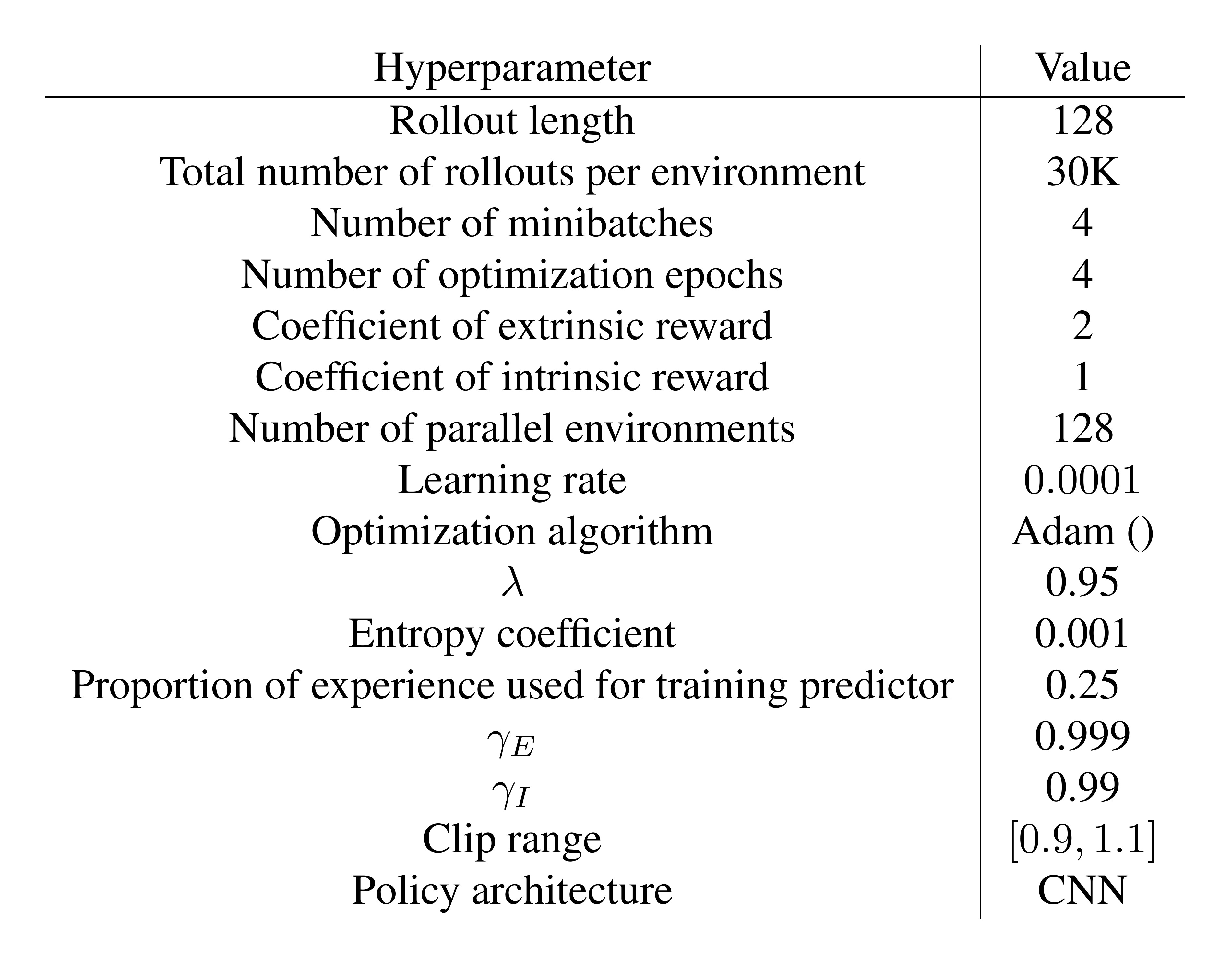
In Table 4 the hyperparameters for the PPO RL algorithm along with any additional hyperparameters used for RND are shown. Complete details for how these hyperparameters are used can be found in the code accompanying this paper.
::: {caption="Table 4: Default hyperparameters for PPO and RND algorithms for experiments where applicable. Any differences to these defaults are detailed in the main text."}
:::
Initial preliminary experiments with RND were run with only 32 parallel environments. We expected that increasing the number of parallel environments would improve performance by allowing the policy to adapt more quickly to transient intrinsic rewards. This effect could have been mitigated however if the predictor network also learned more quickly. To avoid this situation when scaling up from 32 to 128 environments we kept the effective batch size for the predictor network the same by randomly dropping out elements of the batch with keep probability $0.25$. Similarly in our experiments with 256 and 1, 024 environments we dropped experience for the predictor with respective probabilities $0.125$ and $0.03125$.
A.5 Architectures
In this paper we use two policy architectures: an RNN and a CNN. Both contain convolutional encoders identical of those in the standard architecture from ([43]). The RNN architecture additionally contains GRU ([56]) cells to capture longer contexts. The layer sizes of the policies were chosen so that the number of parameters matches closely. The architectures of the target and predictor networks also have convolutional encoders identical to the ones in ([43]) followed by dense layers. Exact details are given in the code accompanying this paper.
A.6 Additional experimental results
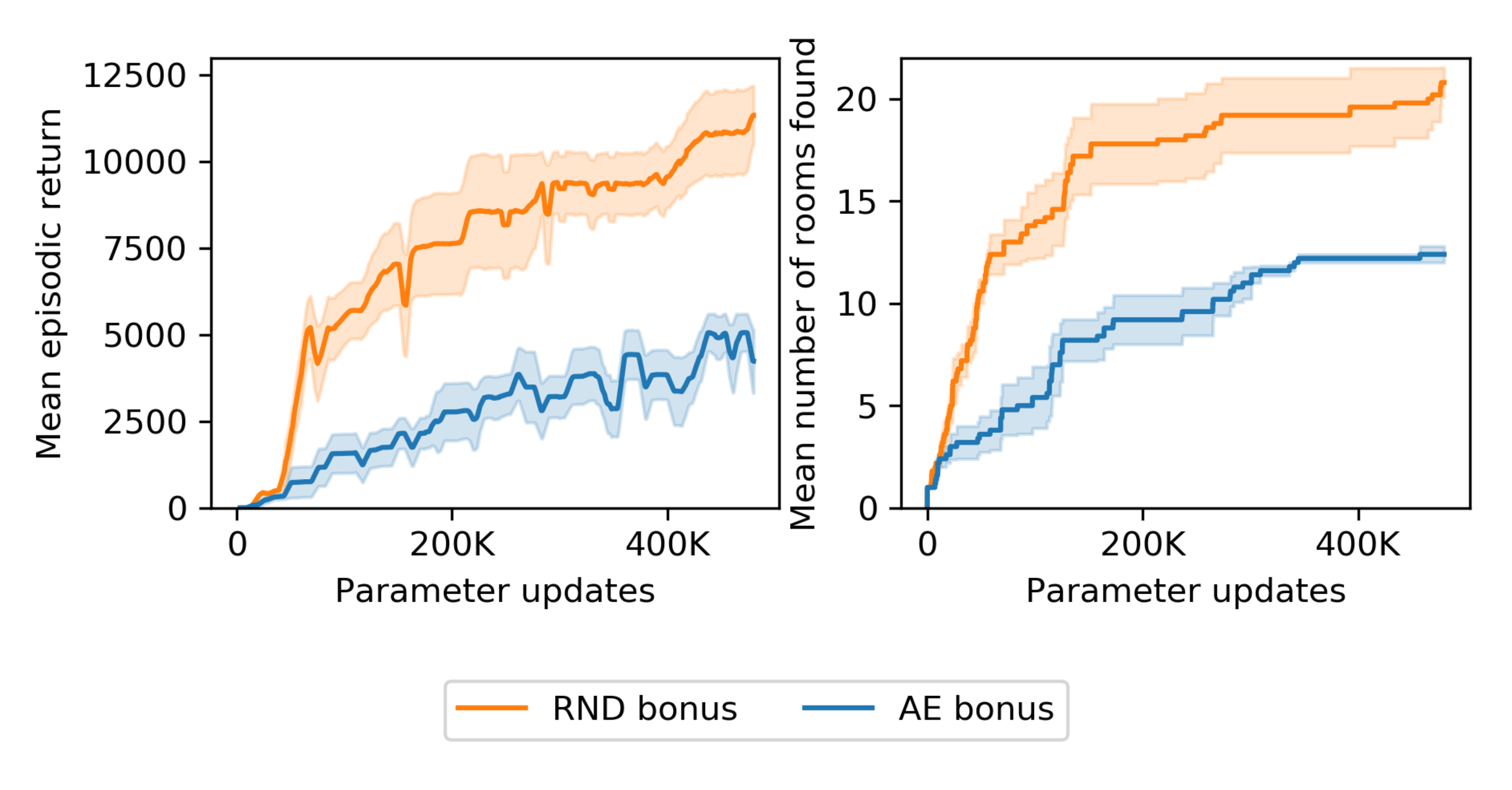
Figure 9 compares the performance of RND with an identical algorithm, but with the exploration bonus defined as the reconstruction error of an autoencoder. The autoencoding task is similar in nature to the random network distillation, as it also obviates the second (though not necessarily the third) sources of prediction error from Section 2.2.1. The experiment shows that the autoencoding task can also be successfully used for exploration.
Figure 10 compares the performance of RND to PPO and dynamics prediction-based baselines for CNN policies.
A.7 Additional Experimental Details
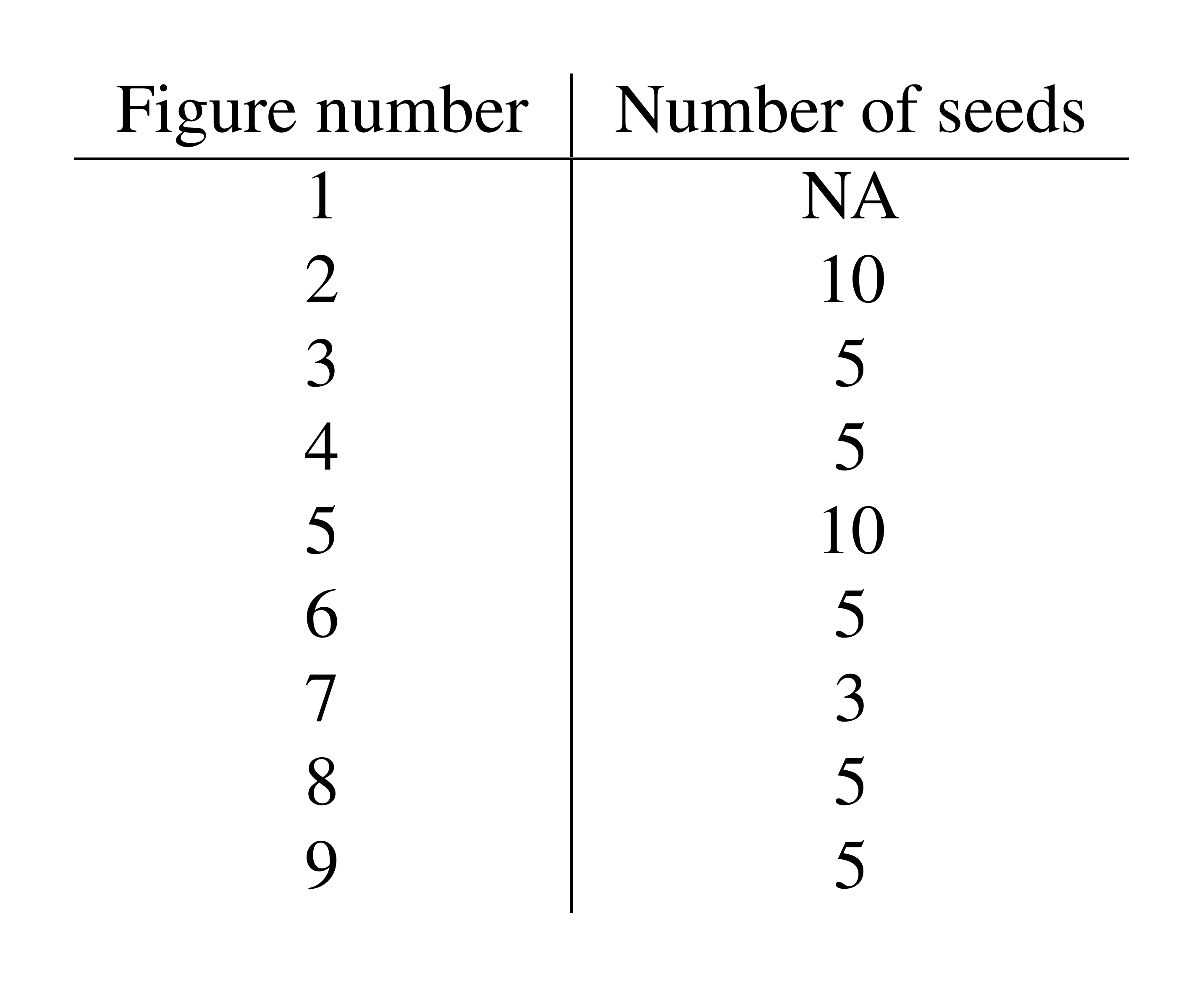
In Table 5 we show the number of seeds used for each experiment, indexed by figure.
::: {caption="Table 5: The numbers of seeds run for each experiment is shown in the table. The results of each seed are then averaged to provide a mean curve in each figure, and the standard error is used make the shaded region surrounding each curve."}
:::
References
[1] David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587):484–489, Jan 2016. ISSN 0028-0836. doi:10.1038/nature16961.
[2] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, 2016.
[3] Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado Van Hasselt, and David Silver. Distributed prioritized experience replay. arXiv preprint arXiv:1803.00933, 2018.
[4] Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Volodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. IMPALA: Scalable distributed Deep-RL with importance weighted actor-learner architectures. arXiv preprint arXiv:1802.01561, 2018.
[5] OpenAI. OpenAI Five. https://blog.openai.com/openai-five/, 2018.
[6] OpenAI, :, M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba. Learning Dexterous In-Hand Manipulation. ArXiv e-prints, August 2018.
[7] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing Atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
[8] Marc Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. Unifying count-based exploration and intrinsic motivation. In NIPS, 2016.
[9] Tobias Pohlen, Bilal Piot, Todd Hester, Mohammad Gheshlaghi Azar, Dan Horgan, David Budden, Gabriel Barth-Maron, Hado van Hasselt, John Quan, Mel Večer'ık, et al. Observe and look further: Achieving consistent performance on Atari. arXiv preprint arXiv:1805.11593, 2018.
[10] Yusuf Aytar, Tobias Pfaff, David Budden, Tom Le Paine, Ziyu Wang, and Nando de Freitas. Playing hard exploration games by watching YouTube. arXiv preprint arXiv:1805.11592, 2018.
[11] Michał Garmulewicz, Henryk Michalewski, and Piotr Miłoś. Expert-augmented actor-critic for vizdoom and montezumas revenge. arXiv preprint arXiv:1809.03447, 2018.
[12] Haoran Tang, Rein Houthooft, Davis Foote, Adam Stooke, Xi Chen, Yan Duan, John Schulman, Filip DeTurck, and Pieter Abbeel. # exploration: A study of count-based exploration for deep reinforcement learning. In NIPS, 2017.
[13] Christopher Stanton and Jeff Clune. Deep curiosity search: Intra-life exploration improves performance on challenging deep reinforcement learning problems. arXiv preprint arXiv:1806.00553, 2018.
[14] Tim Salimans and Richard Chen. Learning Montezuma's Revenge from a single demonstration. https://blog.openai.com/learning-montezumas-revenge-from-a-single-demonstration/, 2018.
[15] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[16] Georg Ostrovski, Marc G Bellemare, Aaron van den Oord, and Rémi Munos. Count-based exploration with neural density models. International Conference for Machine Learning, 2018.
[17] Jürgen Schmidhuber. A possibility for implementing curiosity and boredom in model-building neural controllers. In Proceedings of the First International Conference on Simulation of Adaptive Behavior, 1991b.
[18] Bradly C Stadie, Sergey Levine, and Pieter Abbeel. Incentivizing exploration in reinforcement learning with deep predictive models. NIPS Workshop, 2015.
[19] Joshua Achiam and Shankar Sastry. Surprise-based intrinsic motivation for deep reinforcement learning. arXiv:1703.01732, 2017.
[20] Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. In ICML, 2017.
[21] Yuri Burda, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, and Alexei A. Efros. Large-scale study of curiosity-driven learning. In arXiv:1808.04355, 2018.
[22] Nick Haber, Damian Mrowca, Li Fei-Fei, and Daniel LK Yamins. Learning to play with intrinsically-motivated self-aware agents. arXiv preprint arXiv:1802.07442, 2018.
[23] Misha Denil, Pulkit Agrawal, Tejas D Kulkarni, Tom Erez, Peter Battaglia, and Nando de Freitas. Learning to perform physics experiments via deep reinforcement learning. arXiv preprint arXiv:1611.01843, 2016.
[24] Lior Fox, Leshem Choshen, and Yonatan Loewenstein. Dora the explorer: Directed outreaching reinforcement action-selection. International Conference on Learning Representations, 2018.
[25] Jürgen Schmidhuber. Curious model-building control systems. In Neural Networks, 1991. 1991 IEEE International Joint Conference on, pp.\ 1458–1463. IEEE, 1991a.
[26] Pierre-Yves Oudeyer, Frdric Kaplan, and Verena V Hafner. Intrinsic motivation systems for autonomous mental development. Evolutionary Computation, 2007.
[27] Manuel Lopes, Tobias Lang, Marc Toussaint, and Pierre-Yves Oudeyer. Exploration in model-based reinforcement learning by empirically estimating learning progress. In NIPS, 2012.
[28] Ian Osband, John Aslanides, and Albin Cassirer. Randomized prior functions for deep reinforcement learning. arXiv preprint arXiv:1806.03335, 2018.
[29] Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, and Shane Legg. Noisy networks for exploration. arXiv:1706.10295, 2017.
[30] Alexander L Strehl and Michael L Littman. An analysis of model-based interval estimation for markov decision processes. Journal of Computer and System Sciences, 74(8):1309–1331, 2008.
[31] Justin Fu, John D Co-Reyes, and Sergey Levine. EX2: Exploration with exemplar models for deep reinforcement learning. NIPS, 2017.
[32] Georg Ostrovski, Marc G Bellemare, Aaron van den Oord, and Rémi Munos. Count-based exploration with neural density models. arXiv:1703.01310, 2017.
[33] Marlos C Machado, Marc G Bellemare, and Michael Bowling. Count-based exploration with the successor representation. arXiv preprint arXiv:1807.11622, 2018.
[34] Susanne Still and Doina Precup. An information-theoretic approach to curiosity-driven reinforcement learning. Theory in Biosciences, 2012.
[35] Rein Houthooft, Xi Chen, Yan Duan, John Schulman, Filip De Turck, and Pieter Abbeel. VIME: Variational information maximizing exploration. In NIPS, 2016.
[36] Sainbayar Sukhbaatar, Ilya Kostrikov, Arthur Szlam, and Rob Fergus. Intrinsic motivation and automatic curricula via asymmetric self-play. In ICLR, 2018.
[37] Karol Gregor, Danilo Jimenez Rezende, and Daan Wierstra. Variational intrinsic control. ICLR Workshop, 2017.
[38] Matthias Plappert, Rein Houthooft, Prafulla Dhariwal, Szymon Sidor, Richard Y Chen, Xi Chen, Tamim Asfour, Pieter Abbeel, and Marcin Andrychowicz. Parameter space noise for exploration. arXiv:1706.01905, 2017.
[39] Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. arXiv preprint, 2018.
[40] Joshua Achiam, Harrison Edwards, Dario Amodei, and Pieter Abbeel. Variational option discovery algorithms. arXiv preprint arXiv:1807.10299, 2018.
[41] Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. Deep exploration via bootstrapped DQN. In NIPS, 2016.
[42] Richard Y Chen, John Schulman, Pieter Abbeel, and Szymon Sidor. UCB and infogain exploration via $q$-ensembles. arXiv:1706.01502, 2017.
[43] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, February 2015.
[44] Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In ICML, 2016.
[45] Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improvements in deep reinforcement learning. arXiv preprint arXiv:1710.02298, 2017.
[46] Junhyuk Oh, Yijie Guo, Satinder Singh, and Honglak Lee. Self-imitation learning. arXiv preprint arXiv:1806.05635, 2018.
[47] Brendan O'Donoghue, Ian Osband, Remi Munos, and Volodymyr Mnih. The uncertainty Bellman equation and exploration. arXiv preprint arXiv:1709.05380, 2017.
[48] Tejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh Tenenbaum. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. In Advances in neural information processing systems, pp.\ 3675–3683, 2016.
[49] Marlos C Machado, Marc G Bellemare, Erik Talvitie, Joel Veness, Matthew Hausknecht, and Michael Bowling. Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents. arXiv preprint arXiv:1709.06009, 2017.
[50] Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Advances in neural information processing systems, pp.\ 1177–1184, 2008.
[51] Andrew M Saxe, Pang Wei Koh, Zhenghao Chen, Maneesh Bhand, Bipin Suresh, and Andrew Y Ng. On random weights and unsupervised feature learning. In ICML, pp.\ 1089–1096, 2011.
[52] Kevin Jarrett, Koray Kavukcuoglu, Yann LeCun, et al. What is the best multi-stage architecture for object recognition? In Computer Vision, 2009 IEEE 12th International Conference on, pp.\ 2146–2153. IEEE, 2009.
[53] Zichao Yang, Marcin Moczulski, Misha Denil, Nando de Freitas, Alex Smola, Le Song, and Ziyu Wang. Deep fried convnets. In Proceedings of the IEEE International Conference on Computer Vision, pp.\ 1476–1483, 2015.
[54] Vitchyr Pong, Shixiang Gu, Murtaza Dalal, and Sergey Levine. Temporal difference models: Model-free deep RL for model-based control. arXiv preprint arXiv:1802.09081, 2018.
[55] Marc G Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforcement learning. arXiv preprint arXiv:1707.06887, 2017.
[56] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.