SimCSE: Simple Contrastive Learning of Sentence Embeddings
Tianyu Gao $^{\dagger*}$ Xingcheng Yao $^{\ddagger*}$ Danqi Chen $^{\dagger}$
$^{\dagger}$ Department of Computer Science, Princeton University
$^{\ddagger}$ Institute for Interdisciplinary Information Sciences, Tsinghua University
[email protected], [email protected]
[email protected]
$^{*}$The first two authors contributed equally (listed in alphabetical order). This work was done when Xingcheng visited the Princeton NLP group remotely.
Abstract
This paper presents SimCSE, a simple contrastive learning framework that greatly advances state-of-the-art sentence embeddings. We first describe an unsupervised approach, which takes an input sentence and predicts itself in a contrastive objective, with only standard dropout used as noise. This simple method works surprisingly well, performing on par with previous supervised counterparts. We find that dropout acts as minimal data augmentation, and removing it leads to a representation collapse. Then, we propose a supervised approach, which incorporates annotated pairs from natural language inference datasets into our contrastive learning framework by using entailment'' pairs as positives and contradiction'' pairs as hard negatives. We evaluate SimCSE on standard semantic textual similarity (STS) tasks, and our unsupervised and supervised models using BERT $_base$ achieve an average of 76.3% and 81.6% Spearman’s correlation respectively, a 4.2% and 2.2% improvement compared to the previous best results. We also show---both theoretically and empirically---that the contrastive learning objective regularizes pre-trained embeddings' anisotropic space to be more uniform, and it better aligns positive pairs when supervised signals are available.
Executive Summary: In natural language processing, a key challenge is creating effective vector representations of entire sentences—known as sentence embeddings—that capture semantic meaning for tasks like measuring text similarity, powering search engines, or enabling chatbots. These embeddings are vital now because pre-trained models like BERT have revolutionized language understanding, but their sentence-level representations often suffer from uneven distribution in vector space, limiting performance in real-world applications such as recommendation systems or automated translation quality checks. Improving them without complex data manipulations could democratize better NLP tools across industries.
This paper introduces SimCSE, a straightforward contrastive learning framework aimed at enhancing sentence embeddings from pre-trained models like BERT or RoBERTa. It evaluates two variants: an unsupervised one that learns from unlabeled text by treating variants of the same sentence as similar, and a supervised one that uses labeled pairs from natural language inference datasets to refine similarities and differences.
The approach starts with pre-trained encoders and applies contrastive learning, which pulls similar sentence representations closer while pushing dissimilar ones apart. For the unsupervised version, researchers fed the same sentence through the model twice, using standard dropout—a noise technique in neural networks—to create slight variations as positive pairs, while treating other sentences in a batch as negatives. They trained on one million sentences sampled from English Wikipedia over one epoch. The supervised version built on this by incorporating 314,000 pairs from SNLI and MNLI datasets, treating entailment pairs as positives and contradictions as hard negatives, trained over three epochs. Evaluations focused on seven standard semantic textual similarity tasks, using Spearman's correlation as the metric without additional training on test data, ensuring unsupervised assessment.
Key findings highlight SimCSE's effectiveness. First, the unsupervised model achieved an average 76.3% Spearman's correlation across tasks using BERT base, a 4.2% gain over the prior best unsupervised method. Second, the supervised model reached 81.6%, improving 2.2% on the previous supervised state-of-the-art. Third, dropout alone outperformed more elaborate techniques like word deletion or synonym replacement by 5-15% on benchmark tests, as it provided subtle augmentation without distorting meaning. Fourth, analysis showed SimCSE improved embedding uniformity—spreading representations evenly across space—by about 20-30% compared to raw BERT, while maintaining alignment between similar pairs, addressing a known anisotropy issue where embeddings cluster narrowly. Fifth, on transfer tasks like sentiment analysis, SimCSE matched or slightly exceeded baselines, with an optional masked language modeling add-on boosting averages by 0.4%.
These results mean SimCSE delivers more accurate semantic matching, potentially reducing errors in applications like plagiarism detection or content recommendation by capturing nuances better than prior methods. Unlike expectations of needing heavy data augmentation, its simplicity—relying on built-in model noise—cuts computational costs and risks of introducing errors, while supervised fine-tuning with NLI data yields outsized gains due to high-quality labels. This challenges previous work emphasizing complex operators, showing pre-trained models already hold strong priors that contrastive objectives can unlock efficiently.
Organizations should adopt SimCSE for embedding needs, starting with the unsupervised version for broad unlabeled data and adding supervision where labeled pairs are available, as it outperforms alternatives like SBERT by 2-4% on similarity tasks with minimal extra effort. For broader impact, integrate it into custom NLP pipelines or pre-training workflows. Pilot tests on domain-specific data, such as legal or medical text, could validate extensions. If scaling to non-English languages, combine with multilingual models like mBERT.
Limitations include reliance on English-centric datasets and pre-trained encoders, potentially limiting generalizability; transfer task results were competitive but not always superior, suggesting sentence-level focus suits similarity over classification best. Confidence is high for STS benchmarks, backed by replicated baselines and ablation tests, but caution applies to low-resource scenarios where more data might be needed.
1. Introduction
Section Summary: Learning universal sentence embeddings is a key challenge in natural language processing, and this work introduces SimCSE, a straightforward framework that uses contrastive learning with pre-trained models like BERT to create high-quality embeddings from either unlabeled or labeled data. The unsupervised version treats the same sentence passed twice through the model—with slight variations from dropout noise—as positive pairs, while using other sentences in the batch as negatives, proving surprisingly effective and outperforming more complex methods. The supervised approach draws on natural language inference datasets, pairing similar sentences as positives and opposites as hard negatives, leading to top results on semantic similarity tasks and transfer learning benchmarks, with analysis showing improved embedding quality through better alignment and uniformity.
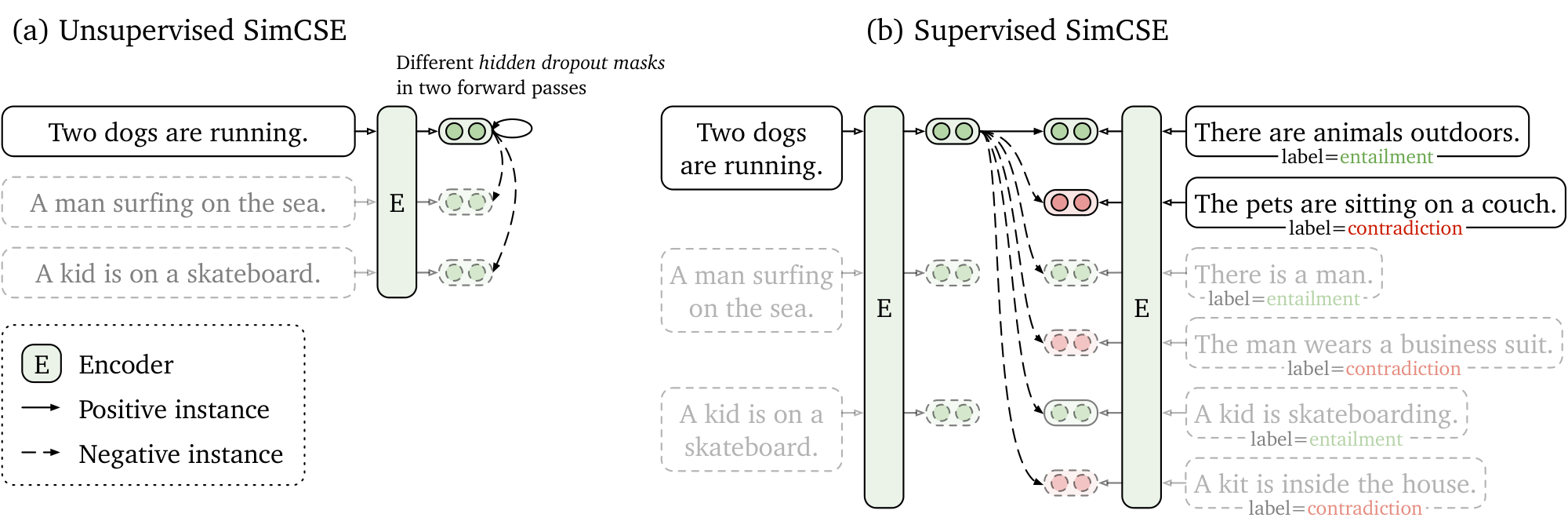
Learning universal sentence embeddings is a fundamental problem in natural language processing and has been studied extensively in the literature [1, 2, 3, 4, 5, ?]. In this work, we advance state-of-the-art sentence embedding methods and demonstrate that a contrastive objective can be extremely effective when coupled with pre-trained language models such as BERT [6] or RoBERTa [7]. We present SimCSE, a $\underline{sim}$ ple $\underline{c}$ ontrastive $\underline{s}$ entence $\underline{e}$ mbedding framework, which can produce superior sentence embeddings, from either unlabeled or labeled data.
Our unsupervised SimCSE simply predicts the input sentence itself with only dropout [8] used as noise (Figure 1(a)). In other words, we pass the same sentence to the pre-trained encoder twice: by applying the standard dropout twice, we can obtain two different embeddings as "positive pairs". Then we take other sentences in the same mini-batch as "negatives", and the model predicts the positive one among the negatives. Although it may appear strikingly simple, this approach outperforms training objectives such as predicting next sentences [4] and discrete data augmentation (e.g., word deletion and replacement) by a large margin, and even matches previous supervised methods. Through careful analysis, we find that dropout acts as minimal "data augmentation" of hidden representations while removing it leads to a representation collapse.
Our supervised SimCSE builds upon the recent success of using natural language inference (NLI) datasets for sentence embeddings [3, 9] and incorporates annotated sentence pairs in contrastive learning (Figure 1(b)). Unlike previous work that casts it as a 3-way classification task (entailment, neutral, and contradiction), we leverage the fact that entailment pairs can be naturally used as positive instances. We also find that adding corresponding contradiction pairs as hard negatives further improves performance. This simple use of NLI datasets achieves a substantial improvement compared to prior methods using the same datasets. We also compare to other labeled sentence-pair datasets and find that NLI datasets are especially effective for learning sentence embeddings.
To better understand the strong performance of SimCSE, we borrow the analysis tool from [10], which takes alignment between semantically-related positive pairs and uniformity of the whole representation space to measure the quality of learned embeddings. Through empirical analysis, we find that our unsupervised SimCSE essentially improves uniformity while avoiding degenerated alignment via dropout noise, thus improving the expressiveness of the representations. The same analysis shows that the NLI training signal can further improve alignment between positive pairs and produce better sentence embeddings. We also draw a connection to the recent findings that pre-trained word embeddings suffer from anisotropy [11, 12] and prove that—through a spectrum perspective—the contrastive learning objective "flattens" the singular value distribution of the sentence embedding space, hence improving uniformity.
We conduct a comprehensive evaluation of SimCSE on seven standard semantic textual similarity (STS) tasks [13, 14, 15, 16, 17, 18, 19] and seven transfer tasks [20]. On the STS tasks, our unsupervised and supervised models achieve a 76.3% and 81.6% averaged Spearman’s correlation respectively using BERT $_\texttt{base}$, a 4.2% and 2.2% improvement compared to previous best results. We also achieve competitive performance on the transfer tasks. Finally, we identify an incoherent evaluation issue in the literature and consolidate the results of different settings for future work in evaluation of sentence embeddings.
2. Background: Contrastive Learning
Section Summary: Contrastive learning is a technique for training AI models to create useful data representations by bringing similar examples closer together in a mathematical space while pushing unrelated ones farther apart. It works by pairing related items, such as augmented versions of the same text or supervised matches like question-answer sets, and uses a formula based on similarity scores to fine-tune models like BERT on batches of these pairs. In natural language processing, creating these pairs is tricky due to text's discrete nature, so simpler methods like dropout often work better, and the approach is evaluated using metrics for alignment (how close pairs are) and uniformity (how evenly unrelated items are spread).
Contrastive learning aims to learn effective representation by pulling semantically close neighbors together and pushing apart non-neighbors [21]. It assumes a set of paired examples $\mathcal{D} = {(x_i, x^{+}i) }{i=1}^m$, where $x_i$ and $x_i^+$ are semantically related. We follow the contrastive framework in [22] and take a cross-entropy objective with in-batch negatives [23, 24]: let $\mathbf{h}_i$ and $\mathbf{h}_i^+$ denote the representations of $x_i$ and $x_i^+$, the training objective for $(x_i, x^{+}_i)$ with a mini-batch of $N$ pairs is:
$ \begin{aligned} \ell_i = -\log \frac{e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}^+i)/\tau}}{\sum{j=1}^N e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}_j^+)/\tau}}, \end{aligned}\tag{1} $
where $\tau$ is a temperature hyperparameter and $\mathrm{sim}(\mathbf{h}_1, \mathbf{h}_2)$ is the cosine similarity $ \frac{\mathbf{h}_1^\top \mathbf{h}_2}{\Vert \mathbf{h}_1\Vert \cdot \Vert \mathbf{h}2\Vert}$. In this work, we encode input sentences using a pre-trained language model such as BERT [6] or RoBERTa [7]: $\mathbf{h} = f{\theta}(x)$, and then fine-tune all the parameters using the contrastive learning objective Equation (1).
Positive instances.
One critical question in contrastive learning is how to construct $(x_i, x_i^+)$ pairs. In visual representations, an effective solution is to take two random transformations of the same image (e.g., cropping, flipping, distortion and rotation) as $x_i$ and $x_i^+$ [25]. A similar approach has been recently adopted in language representations [26, 27] by applying augmentation techniques such as word deletion, reordering, and substitution. However, data augmentation in NLP is inherently difficult because of its discrete nature. As we will see in § 3, simply using standard dropout on intermediate representations outperforms these discrete operators.
In NLP, a similar contrastive learning objective has been explored in different contexts [24, 28, 29]. In these cases, $(x_i, x_i^+)$ are collected from supervised datasets such as question-passage pairs. Because of the distinct nature of $x_i$ and $x_i^+$, these approaches always use a dual-encoder framework, i.e., using two independent encoders $f_{\theta_1}$ and $f_{\theta_2}$ for $x_i$ and $x_i^+$. For sentence embeddings, [4] also use contrastive learning with a dual-encoder approach, by forming current sentence and next sentence as $(x_i, x^+_i)$.
Alignment and uniformity.
Recently, [10] identify two key properties related to contrastive learning—alignment and uniformity—and propose to use them to measure the quality of representations. Given a distribution of positive pairs $p_{\mathrm{pos}}$, alignment calculates expected distance between embeddings of the paired instances (assuming representations are already normalized):
$ \ell_{\mathrm{align}}\triangleq \underset{(x, x^+)\sim p_{\mathrm{pos}}}{\mathbb{E}} \Vert f(x) - f(x^+) \Vert^2.\tag{2} $
On the other hand, uniformity measures how well the embeddings are uniformly distributed:
$ \ell_{\mathrm{uniform}}\triangleq\log \underset{\quad x, y\stackrel{i.i.d.}{\sim} p_{\mathrm{data}}}{\mathbb{E}} e^{-2\Vert f(x)-f(y) \Vert^2},\tag{3} $
where $p_{\mathrm{data}}$ denotes the data distribution. These two metrics are well aligned with the objective of contrastive learning: positive instances should stay close and embeddings for random instances should scatter on the hypersphere. In the following sections, we will also use the two metrics to justify the inner workings of our approaches.
3. Unsupervised SimCSE
Section Summary: Unsupervised SimCSE is a simple method for training sentence embeddings without labeled data, where the same sentence serves as both itself and its positive pair, but it gets encoded twice with different random dropout masks to create subtle variations. This approach uses a contrastive loss to make embeddings of identical sentences similar while pushing apart those from different sentences in a batch, outperforming traditional techniques like word deletion, synonym replacement, or next-sentence prediction on tasks measuring semantic similarity. Experiments show that the default dropout rate in Transformer models maintains good alignment of similar embeddings and improves their even distribution, explaining why this minimal augmentation works better than more aggressive changes.
The idea of unsupervised SimCSE is extremely simple: we take a collection of sentences ${x_i}_{i=1}^{m}$ and use $x^+_i = x_i$. The key ingredient to get this to work with identical positive pairs is through the use of independently sampled dropout masks for $x_i$ and $x^+_i$. In standard training of Transformers [30], there are dropout masks placed on fully-connected layers as well as attention probabilities (default $p = 0.1$). We denote $\mathbf{h}i^z = f{\theta}(x_i, z)$ where $z$ is a random mask for dropout. We simply feed the same input to the encoder twice and get two embeddings with different dropout masks $z, z'$, and the training objective of SimCSE becomes:
$ \begin{aligned} \ell_i = - \log \frac{e^{\mathrm{sim}(\mathbf{h}_i^{z_i}, \mathbf{h}_i^{z'i}) / \tau }}{\sum{j=1}^Ne^{\mathrm{sim}(\mathbf{h}_i^{z_i}, \mathbf{h}_j^{z_j'}) /\tau}}, \end{aligned}\tag{4} $
for a mini-batch of $N$ sentences. Note that $z$ is just the standard dropout mask in Transformers and we do not add any additional dropout.
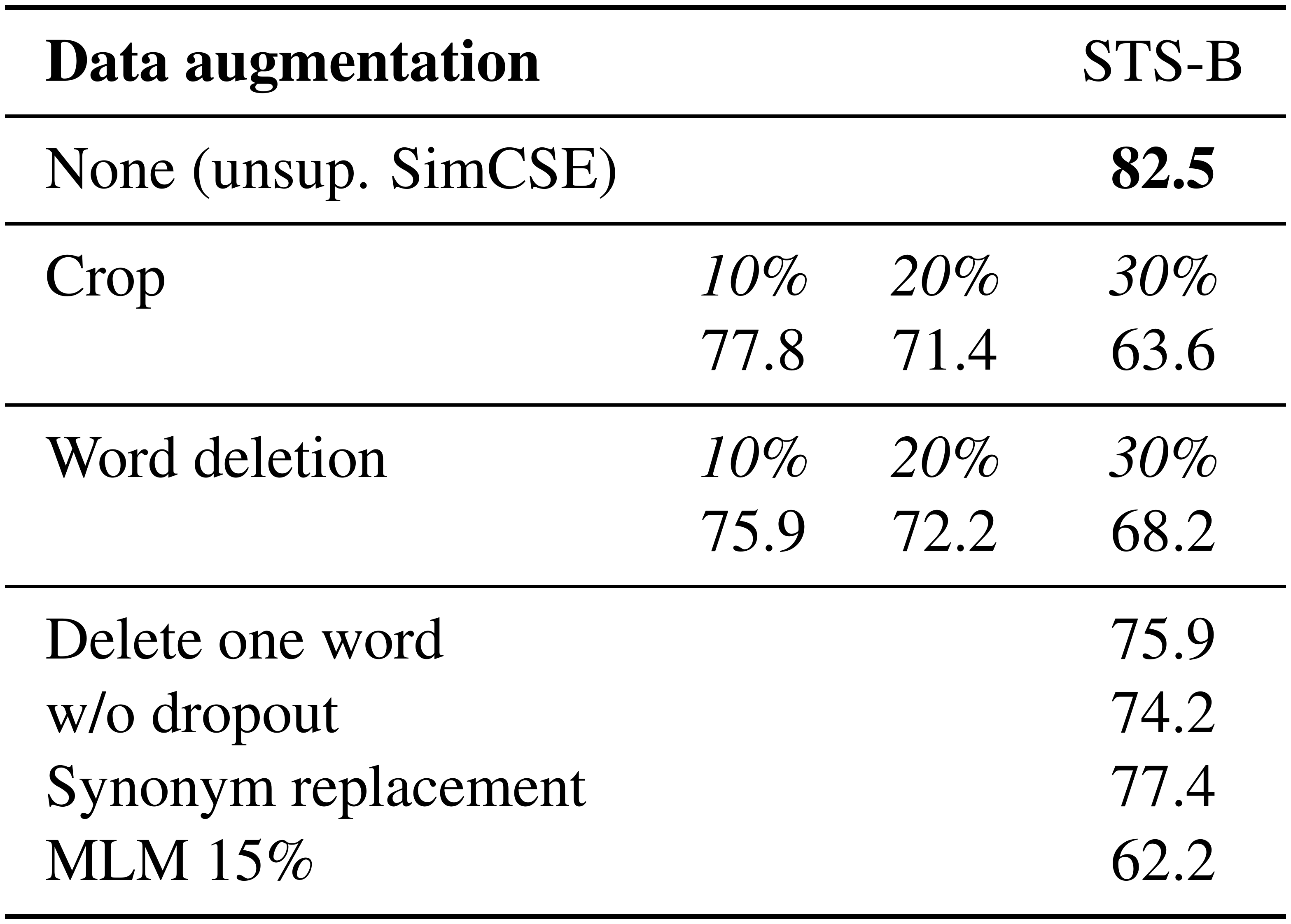
::: {caption="Table 1: Comparison of data augmentations on STS-B development set (Spearman's correlation). Crop $k$ %: keep 100- $k$ % of the length; word deletion $k$ %: delete $k$ % words; Synonym replacement: use nlpaug [31] to randomly replace one word with its synonym; MLM $k$ %: use BERT $_\texttt{base}$ to replace $k$ % of words."}
:::
: Table 2: Comparison of different unsupervised objectives (STS-B development set, Spearman's correlation). The two columns denote whether we use one encoder or two independent encoders. Next 3 sentences: randomly sample one from the next 3 sentences. Delete one word: delete one word randomly (see Table 1).
| Training objective | $f_{\theta}$ | $(f_{\theta_1}, f_{\theta_2})$ |
|---|---|---|
| Next sentence | 67.1 | 68.9 |
| Next 3 sentences | 67.4 | 68.8 |
| Delete one word | 75.9 | 73.1 |
| Unsupervised SimCSE | 82.5 | 80.7 |
Dropout noise as data augmentation.
We view it as a minimal form of data augmentation: the positive pair takes exactly the same sentence, and their embeddings only differ in dropout masks. We compare this approach to other training objectives on the STS-B development set [18][^4]. Table 1 compares our approach to common data augmentation techniques such as crop, word deletion and replacement, which can be viewed as $\mathbf{h} = f_{\theta}(g(x), z)$ and $g$ is a (random) discrete operator on $x$. We note that even deleting one word would hurt performance and none of the discrete augmentations outperforms dropout noise.
[^4]: We randomly sample $10^6$ sentences from English Wikipedia and fine-tune BERT $_\texttt{base}$ with learning rate = 3e-5, $N$ = 64. In all our experiments, no STS training sets are used.
We also compare this self-prediction training objective to the next-sentence objective used in [4], taking either one encoder or two independent encoders. As shown in Table 2, we find that SimCSE performs much better than the next-sentence objectives (82.5 vs 67.4 on STS-B) and using one encoder instead of two makes a significant difference in our approach.
Why does it work?
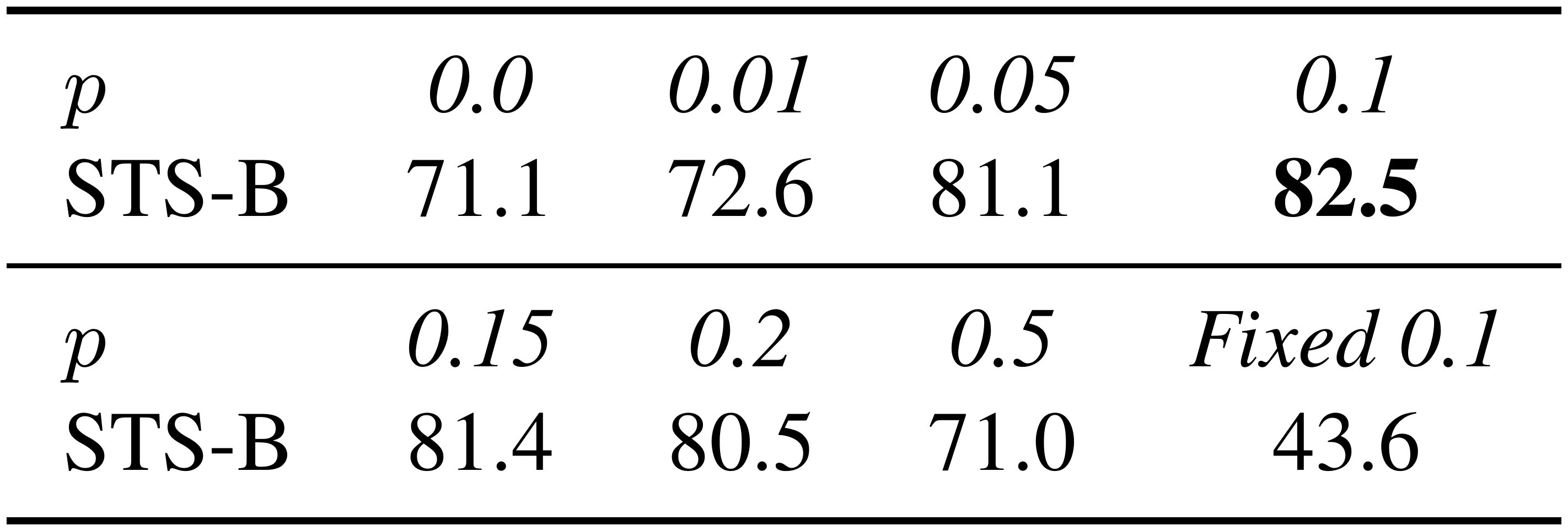
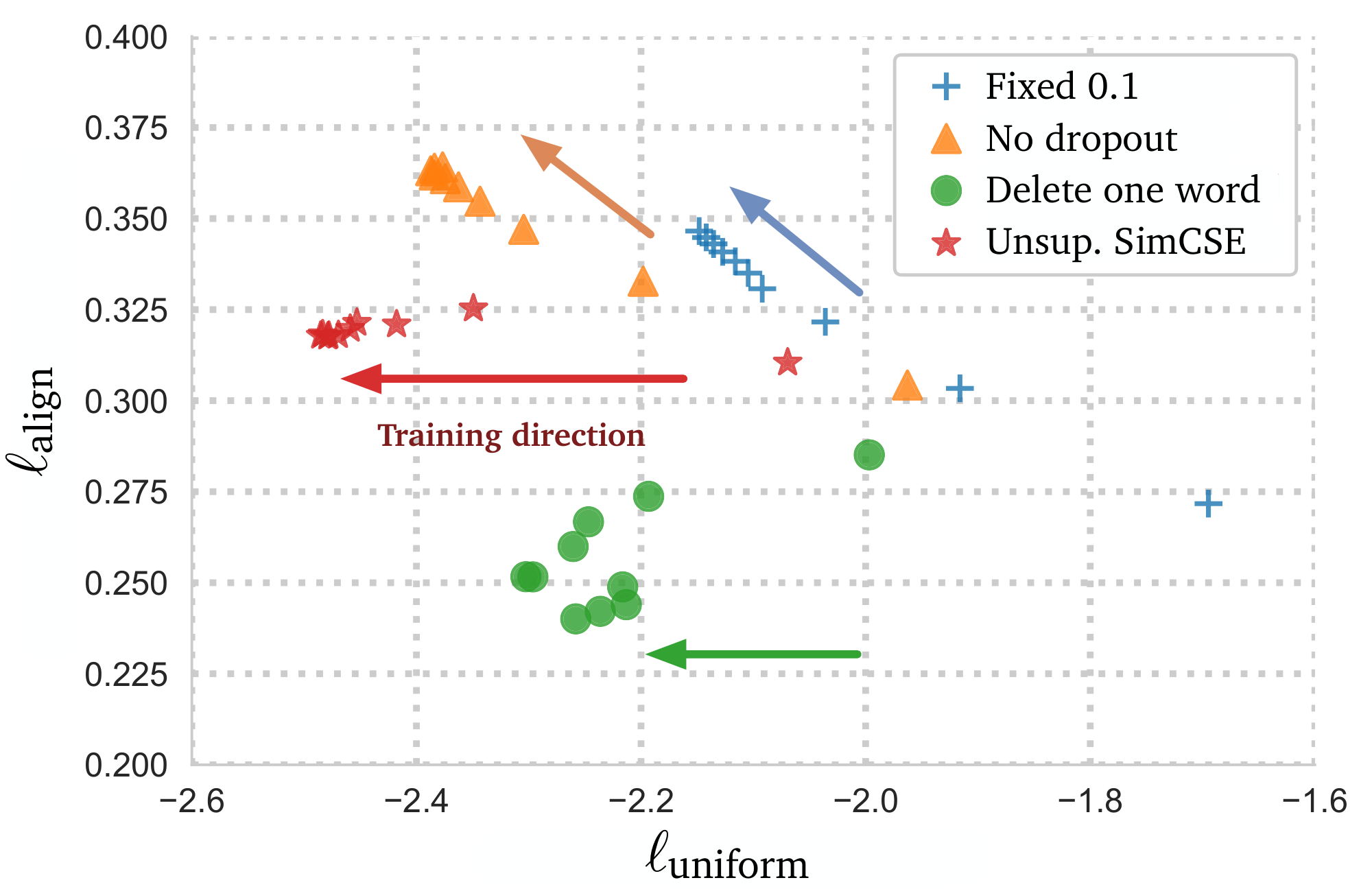
To further understand the role of dropout noise in unsupervised SimCSE, we try out different dropout rates in Table 3 and observe that all the variants underperform the default dropout probability $p=0.1$ from Transformers. We find two extreme cases particularly interesting: "no dropout" ($p=0$) and "fixed 0. $1'' ($ using default dropout $p=0.1$ but the same dropout masks for the pair). In both cases, the resulting embeddings for the pair are exactly the same, and it leads to a dramatic performance degradation. We take the checkpoints of these models every 10 steps during training and visualize the alignment and uniformity metrics[^5] in Figure 2, along with a simple data augmentation model "delete one word". As clearly shown, starting from pre-trained checkpoints, all models greatly improve uniformity. However, the alignment of the two special variants also degrades drastically, while our unsupervised SimCSE keeps a steady alignment, thanks to the use of dropout noise. It also demonstrates that starting from a pre-trained checkpoint is crucial, for it provides good initial alignment. At last, "delete one word" improves the alignment yet achieves a smaller gain on the uniformity metric, and eventually underperforms unsupervised SimCSE.
[^5]: We take STS-B pairs with a score higher than 4 as $p_{\mathrm{pos}}$ and all STS-B sentences as $p_{\mathrm{data}}$.
::: {caption="Table 3: Effects of different dropout probabilities $p$ on the STS-B development set (Spearman's correlation, BERT $_\texttt{base}$). Fixed 0.1: default 0.1 dropout rate but apply the same dropout mask on both $x_i$ and $x^+_i$."}
:::
4. Supervised SimCSE
Section Summary: Researchers in this section explore using supervised datasets to enhance the alignment of positive sentence pairs in their SimCSE model, aiming for stronger training signals. They test various datasets like Quora question pairs, image captions, paraphrases, and natural language inference sets, finding that high-quality entailment pairs from SNLI and MNLI perform best due to their crowdsourced nature and lower word overlap. By also incorporating contradiction pairs as challenging negatives, they boost performance even more, achieving their final supervised SimCSE results.
We have demonstrated that adding dropout noise is able to keep a good alignment for positive pairs $(x, x^+) \sim p_{\text{pos}}$. In this section, we study whether we can leverage supervised datasets to provide better training signals for improving alignment of our approach. Prior work [3, 9] has demonstrated that supervised natural language inference (NLI) datasets [32, 33] are effective for learning sentence embeddings, by predicting whether the relationship between two sentences is entailment, neutral or contradiction. In our contrastive learning framework, we instead directly take $(x_i, x_i^+)$ pairs from supervised datasets and use them to optimize Equation 1.
Choices of labeled data.
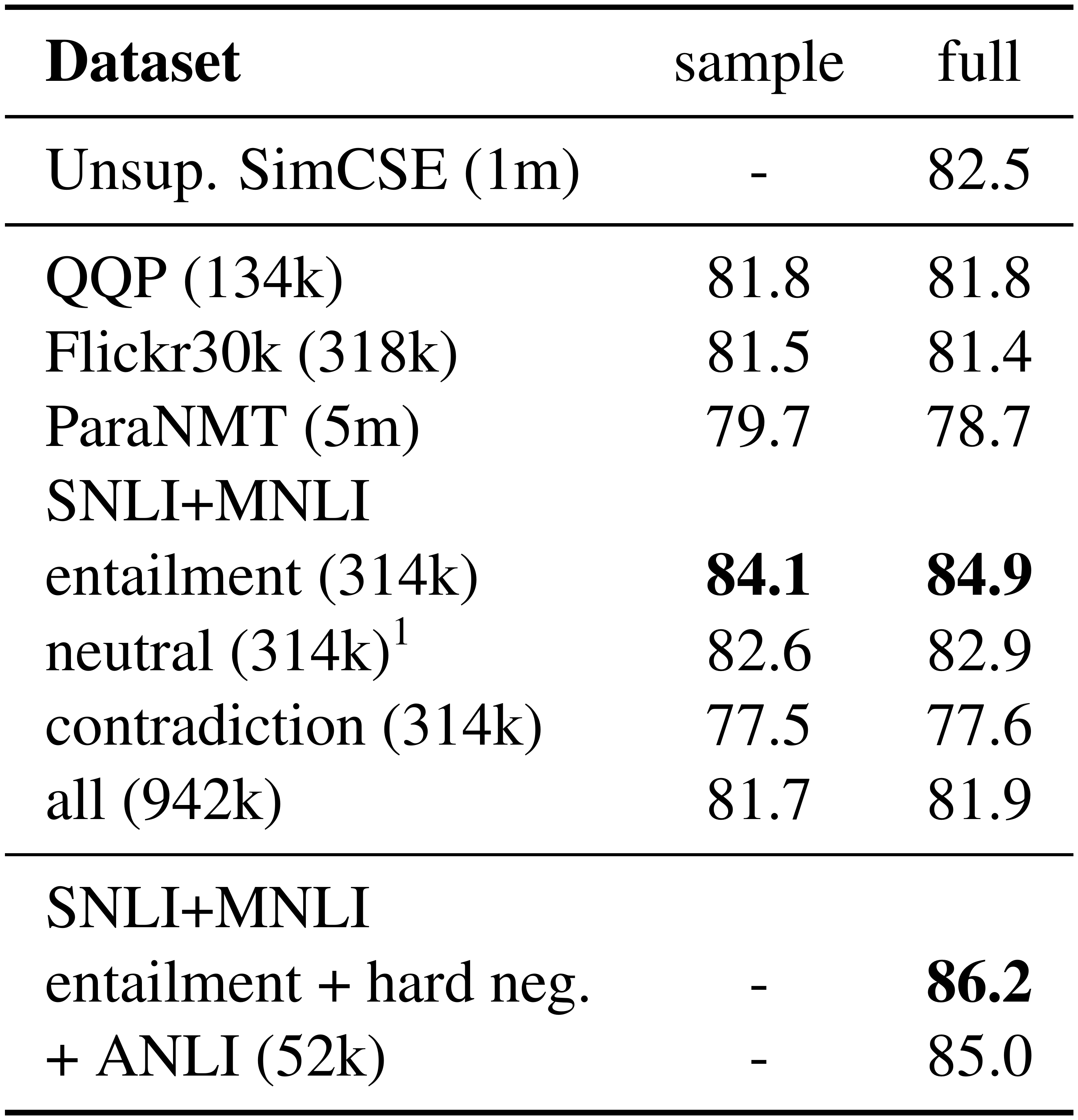
We first explore which supervised datasets are especially suitable for constructing positive pairs $(x_i, x^+_i)$. We experiment with a number of datasets with sentence-pair examples, including 1) QQP^6: Quora question pairs; 2) Flickr30k [34]: each image is annotated with 5 human-written captions and we consider any two captions of the same image as a positive pair; 3) ParaNMT [35]: a large-scale back-translation paraphrase dataset[^7]; and finally 4) NLI datasets: SNLI [32] and MNLI [33].
[^7]: ParaNMT is automatically constructed by machine translation systems. Strictly speaking, we should not call it "supervised". It underperforms our unsupervised SimCSE though.
We train the contrastive learning model Equation (1) with different datasets and compare the results in Table 4. For a fair comparison, we also run experiments with the same # of training pairs. Among all the options, using entailment pairs from the NLI (SNLI + MNLI) datasets performs the best. We think this is reasonable, as the NLI datasets consist of high-quality and crowd-sourced pairs. Also, human annotators are expected to write the hypotheses manually based on the premises and two sentences tend to have less lexical overlap. For instance, we find that the lexical overlap (F1 measured between two bags of words) for the entailment pairs (SNLI + MNLI) is 39%, while they are 60% and 55% for QQP and ParaNMT.
Contradiction as hard negatives.
Finally, we further take the advantage of the NLI datasets by using its contradiction pairs as hard negatives[^8]. In NLI datasets, given one premise, annotators are required to manually write one sentence that is absolutely true (entailment), one that might be true (neutral), and one that is definitely false (contradiction). Therefore, for each premise and its entailment hypothesis, there is an accompanying contradiction hypothesis[^9] (see Figure 1 for an example).
[^8]: We also experimented with adding neutral hypotheses as hard negatives. See Section 6.3 for more discussion.
[^9]: In fact, one premise can have multiple contradiction hypotheses. In our implementation, we only sample one as the hard negative and we did not find a difference by using more.
Formally, we extend $(x_i, x_i^+)$ to $(x_i, x_i^+, x_i^-)$, where $x_i$ is the premise, $x_i^+$ and $x_i^-$ are entailment and contradiction hypotheses. The training objective $\ell_i$ is then defined by ($N$ is mini-batch size):
$ \begin{aligned}
- \log \frac{e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}i^+)/ \tau }}{\sum{j=1}^N\left(e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}_j^+)/\tau}+e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}_j^-)/ \tau}\right)}. \end{aligned}\tag{5} $
As shown in Table 4, adding hard negatives can further improve performance (84.9 $\rightarrow$ 86.2) and this is our final supervised SimCSE. We also tried to add the ANLI dataset [36] or combine it with our unsupervised SimCSE approach, but didn't find a meaningful improvement. We also considered a dual encoder framework in supervised SimCSE and it hurt performance (86.2 $\rightarrow$ 84.2).
::: {caption="Table 4: Comparisons of different supervised datasets as positive pairs. Results are Spearman's correlations on the STS-B development set using BERT $_\texttt{base}$ (we use the same hyperparameters as the final SimCSE model). Numbers in brackets denote the # of pairs. Sample: subsampling 134k positive pairs for a fair comparison among datasets; full: using the full dataset. In the last block, we use entailment pairs as positives and contradiction pairs as hard negatives (our final model)."}
:::
5. Connection to Anisotropy
Section Summary: In language models, an anisotropy problem occurs when word and sentence embeddings cluster tightly in a narrow cone within the vector space, reducing their ability to capture diverse meanings effectively. Researchers have addressed this through post-processing techniques that redistribute embeddings more evenly or by adding regularization during training, but this study shows that contrastive learning objectives can also mitigate the issue by pushing unrelated examples apart and promoting a more uniform, balanced distribution. By analyzing the mathematical structure of these objectives, the approach flattens the spectrum of embedding values, improving overall representation quality while simultaneously aligning similar pairs, unlike methods that only focus on isotropy.
Recent work identifies an anisotropy problem in language representations [11, 12], i.e., the learned embeddings occupy a narrow cone in the vector space, which severely limits their expressiveness. [37] demonstrate that language models trained with tied input/output embeddings lead to anisotropic word embeddings, and this is further observed by [11] in pre-trained contextual representations. [38] show that singular values of the word embedding matrix in a language model decay drastically: except for a few dominating singular values, all others are close to zero.
A simple way to alleviate the problem is post-processing, either to eliminate the dominant principal components [39, 40], or to map embeddings to an isotropic distribution [12, 41]. Another common solution is to add regularization during training [37, 38]. In this work, we show that—both theoretically and empirically—the contrastive objective can also alleviate the anisotropy problem.
The anisotropy problem is naturally connected to uniformity [10], both highlighting that embeddings should be evenly distributed in the space. Intuitively, optimizing the contrastive learning objective can improve uniformity (or ease the anisotropy problem), as the objective pushes negative instances apart. Here, we take a singular spectrum perspective—which is a common practice in analyzing word embeddings [40, 37, 38], and show that the contrastive objective can "flatten" the singular value distribution of sentence embeddings and make the representations more isotropic.
Following [10], the asymptotics of the contrastive learning objective Equation (1) can be expressed by the following equation when the number of negative instances approaches infinity (assuming $f(x)$ is normalized):
$ \begin{aligned} &-\frac{1}{\tau}\underset{(x, x^+)\sim p_{\mathrm{pos}}}{\mathbb{E}}\left[f(x)^\top f(x^+)\right] \ &+\underset{x\sim p_{\mathrm{data}}}{\mathbb{E}}\left[\log\underset{x^-\sim p_{\mathrm{data}}}{\mathbb{E}}\left[e^{f(x)^\top f(x^-)/\tau}\right]\right], \end{aligned}\tag{6} $
where the first term keeps positive instances similar and the second pushes negative pairs apart. When $p_{\mathrm{data}}$ is uniform over finite samples ${x_i}_{i=1}^m$, with $\mathbf{h}_i = f(x_i)$, we can derive the following formula from the second term with Jensen's inequality:
$ \begin{aligned} &\underset{x\sim p_{\mathrm{data}}}{\mathbb{E}}\left[\log\underset{x^-\sim p_{\mathrm{data}}}{\mathbb{E}}\left[e^{f(x)^\top f(x^-)/\tau}\right]\right]\ =&\frac{1}{m}\sum_{i=1}^m\log\left(\frac{1}{m}\sum_{j=1}^me^{\mathbf{h}i^\top \mathbf{h}j/\tau}\right) \ \geq & \frac{1}{\tau m^2}\sum{i=1}^m\sum{j=1}^m \mathbf{h}_i^\top \mathbf{h}_j. \end{aligned}\tag{7} $
Let $\mathbf{W}$ be the sentence embedding matrix corresponding to ${x_i}{i=1}^m$, i.e., the $i$-th row of $\mathbf{W}$ is $\mathbf{h}i$. Optimizing the second term in Equation 6 essentially minimizes an upper bound of the summation of all elements in $\mathbf{W}\mathbf{W}^\top$, i.e., $\mathrm{Sum}(\mathbf{W}\mathbf{W}^\top) = \sum{i=1}^m \sum{j=1}^m\mathbf{h}_i^\top\mathbf{h}_j$.
Since we normalize $\mathbf{h}_i$, all elements on the diagonal of $\mathbf{W}\mathbf{W}^\top$ are $1$ and then $\mathrm{tr}(\mathbf{W}\mathbf{W}^\top)$ (the sum of all eigenvalues) is a constant. According to [42], if all elements in $\mathbf{W}\mathbf{W}^\top$ are positive, which is the case in most times according to Figure 5, then $\mathrm{Sum}(\mathbf{W}\mathbf{W}^\top)$ is an upper bound for the largest eigenvalue of $\mathbf{W} \mathbf{W}^\top$. When minimizing the second term in Equation 6, we reduce the top eigenvalue of $\mathbf{W} \mathbf{W}^\top$ and inherently "flatten" the singular spectrum of the embedding space. Therefore, contrastive learning is expected to alleviate the representation degeneration problem and improve uniformity of sentence embeddings.
Compared to post-processing methods in [12, 41], which only aim to encourage isotropic representations, contrastive learning also optimizes for aligning positive pairs by the first term in Equation 6, which is the key to the success of SimCSE. A quantitative analysis is given in § 7.
6. Experiment
Section Summary: The researchers tested their SimCSE method on seven tasks measuring how well sentences capture similar meanings, using no specialized training data for these tests to keep things fair and unsupervised, though the supervised version drew from other labeled datasets like those for natural language inference. They compared SimCSE to earlier approaches and found it significantly better, raising average performance scores from about 72% to 76% without supervision and up to 84% with it, especially when using advanced language models like RoBERTa. Additional checks showed that the best way to extract sentence representations involved a specific processing step during training, with similar or superior results on other language tasks.
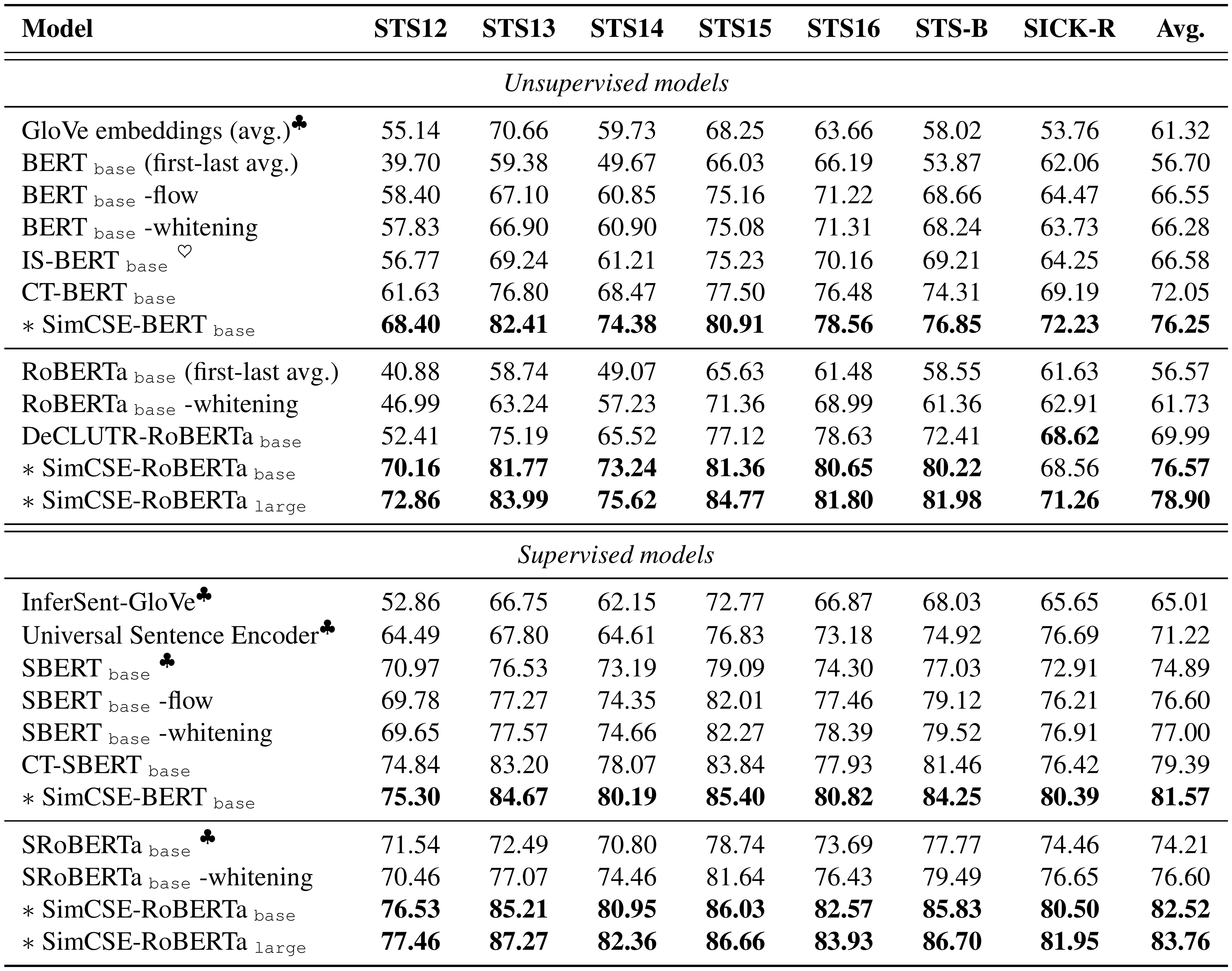
::: {caption="Table 5: Sentence embedding performance on STS tasks (Spearman's correlation, "all" setting). We highlight the highest numbers among models with the same pre-trained encoder. $\clubsuit$ : results from [9]; $\heartsuit$ : results from [43]; all other results are reproduced or reevaluated by ourselves. For BERT-flow [12] and whitening [41], we only report the "NLI" setting (see Table 13)."}
:::
6.1 Evaluation Setup
We conduct our experiments on 7 semantic textual similarity (STS) tasks. Note that all our STS experiments are fully unsupervised and no STS training sets are used. Even for supervised SimCSE, we simply mean that we take extra labeled datasets for training, following previous work [3]. We also evaluate 7 transfer learning tasks and provide detailed results in Appendix E. We share a similar sentiment with [9] that the main goal of sentence embeddings is to cluster semantically similar sentences and hence take STS as the main result.
Semantic textual similarity tasks.
We evaluate on 7 STS tasks: STS 2012–2016 [13, 14, 15, 16, 17], STS Benchmark [18] and SICK-Relatedness [19]. When comparing to previous work, we identify invalid comparison patterns in published papers in the evaluation settings, including (a) whether to use an additional regressor, (b) Spearman's vs Pearson's correlation, and (c) how the results are aggregated (Table 10). We discuss the detailed differences in Appendix B and choose to follow the setting of [9] in our evaluation (no additional regressor, Spearman's correlation, and "all" aggregation). We also report our replicated study of previous work as well as our results evaluated in a different setting in Table 11 and Table 12. We call for unifying the setting in evaluating sentence embeddings for future research.
Training details.
We start from pre-trained checkpoints of BERT [6] (uncased) or RoBERTa [7] (cased) and take the [CLS] representation as the sentence embedding[^10] (see §Table 15 for comparison between different pooling methods). We train unsupervised SimCSE on $10^6$ randomly sampled sentences from English Wikipedia, and train supervised SimCSE on the combination of MNLI and SNLI datasets (314k). More training details can be found in Appendix A.
[^10]: There is an MLP layer over [CLS] in BERT's original implementation and we keep it with random initialization.
6.2 Main Results
We compare unsupervised and supervised SimCSE to previous state-of-the-art sentence embedding methods on STS tasks. Unsupervised baselines include average GloVe embeddings [44], average BERT or RoBERTa embeddings[^11], and post-processing methods such as BERT-flow [12] and BERT-whitening [41]. We also compare to several recent methods using a contrastive objective, including 1) IS-BERT [43], which maximizes the agreement between global and local features; 2) DeCLUTR [45], which takes different spans from the same document as positive pairs; 3) CT [46], which aligns embeddings of the same sentence from two different encoders.[^12] Other supervised methods include InferSent [3], Universal Sentence Encoder [5], and SBERT/SRoBERTa [9] with post-processing methods (BERT-flow, whitening, and CT). We provide more details of these baselines in Appendix C.
[^11]: Following [41], we take the average of the first and the last layers, which is better than only taking the last.
[^12]: We do not compare to CLEAR [26], because they use their own version of pre-trained models, and the numbers appear to be much lower. Also note that CT is a concurrent work to ours.
Table 5 shows the evaluation results on 7 STS tasks. SimCSE can substantially improve results on all the datasets with or without extra NLI supervision, greatly outperforming the previous state-of-the-art models. Specifically, our unsupervised SimCSE-BERT $\texttt{base}$ improves the previous best averaged Spearman's correlation from 72.05% to 76.25%, even comparable to supervised baselines. When using NLI datasets, SimCSE-BERT $\texttt{base}$ further pushes the state-of-the-art results to 81.57%. The gains are more pronounced on RoBERTa encoders, and our supervised SimCSE achieves 83.76% with RoBERTa $_\texttt{large}$ .
In Appendix E, we show that SimCSE also achieves on par or better transfer task performance compared to existing work, and an auxiliary MLM objective can further boost performance.
6.3 Ablation Studies
We investigate the impact of different pooling methods and hard negatives. All reported results in this section are based on the STS-B development set. We provide more ablation studies (normalization, temperature, and MLM objectives) in Appendix D.
: Table 6: Ablation studies of different pooling methods in unsupervised and supervised SimCSE. [CLS] w/ MLP (train): using MLP on [CLS] during training but removing it during testing. The results are based on the development set of STS-B using BERT $_\texttt{base}$ .
| Pooler | Unsup. | Sup. |
|---|---|---|
[CLS] |
||
| w/ MLP | 81.7 | 86.2 |
| w/ MLP (train) | 82.5 | 85.8 |
| w/o MLP | 80.9 | 86.2 |
| First-last avg. | 81.2 | 86.1 |
Pooling methods.
[9, 12] show that taking the average embeddings of pre-trained models (especially from both the first and last layers) leads to better performance than [CLS]. Table 6 shows the comparison between different pooling methods in both unsupervised and supervised SimCSE. For [CLS] representation, the original BERT implementation takes an extra MLP layer on top of it. Here, we consider three different settings for [CLS]: 1) keeping the MLP layer; 2) no MLP layer; 3) keeping MLP during training but removing it at testing time. We find that for unsupervised SimCSE, taking [CLS] representation with MLP only during training works the best; for supervised SimCSE, different pooling methods do not matter much. By default, we take [CLS] with MLP (train) for unsupervised SimCSE and [CLS] with MLP for supervised SimCSE.
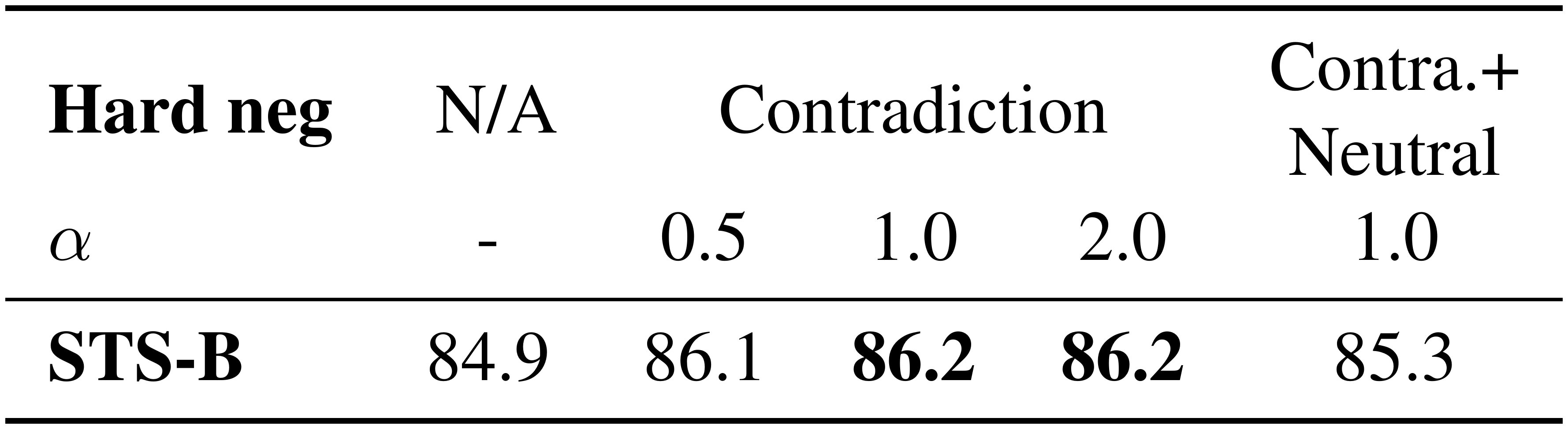
::: {caption="Table 7: STS-B development results with different hard negative policies. "N/A": no hard negative."}
:::
Hard negatives.
Intuitively, it may be beneficial to differentiate hard negatives (contradiction examples) from other in-batch negatives. Therefore, we extend our training objective defined in Equation 5 to incorporate weighting of different negatives:
$ \begin{aligned}
- \log \frac{e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}i^+)/ \tau }}{\sum{j=1}^N\left(e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}_j^+)/\tau}+\alpha^{\mathbb{1}^j_i}e^{\mathrm{sim}(\mathbf{h}_i, \mathbf{h}_j^-)/ \tau}\right)}, \end{aligned}\tag{8} $
where $\mathbb{1}^j_i\in{0, 1}$ is an indicator that equals 1 if and only if $i = j$. We train SimCSE with different values of $\alpha$ and evaluate the trained models on the development set of STS-B. We also consider taking neutral hypotheses as hard negatives. As shown in Table 7, $\alpha = 1$ performs the best, and neutral hypotheses do not bring further gains.
7. Analysis
Section Summary: The analysis examines how well sentence embedding models balance uniformity (even spread of representations) and alignment (consistent directional accuracy), finding that top performers excel in both, which boosts their overall results on similarity tasks. Pre-trained models like BERT start with strong alignment but poor uniformity, while methods like BERT-flow fix uniformity at the cost of alignment; in contrast, unsupervised SimCSE enhances uniformity without sacrificing alignment, and its supervised version further refines alignment, leading to more balanced embeddings. A retrieval test on image captions shows SimCSE pulling more relevant matches than SBERT, highlighting its practical edge in finding similar sentences.
In this section, we conduct further analyses to understand the inner workings of SimCSE.
Uniformity and alignment.
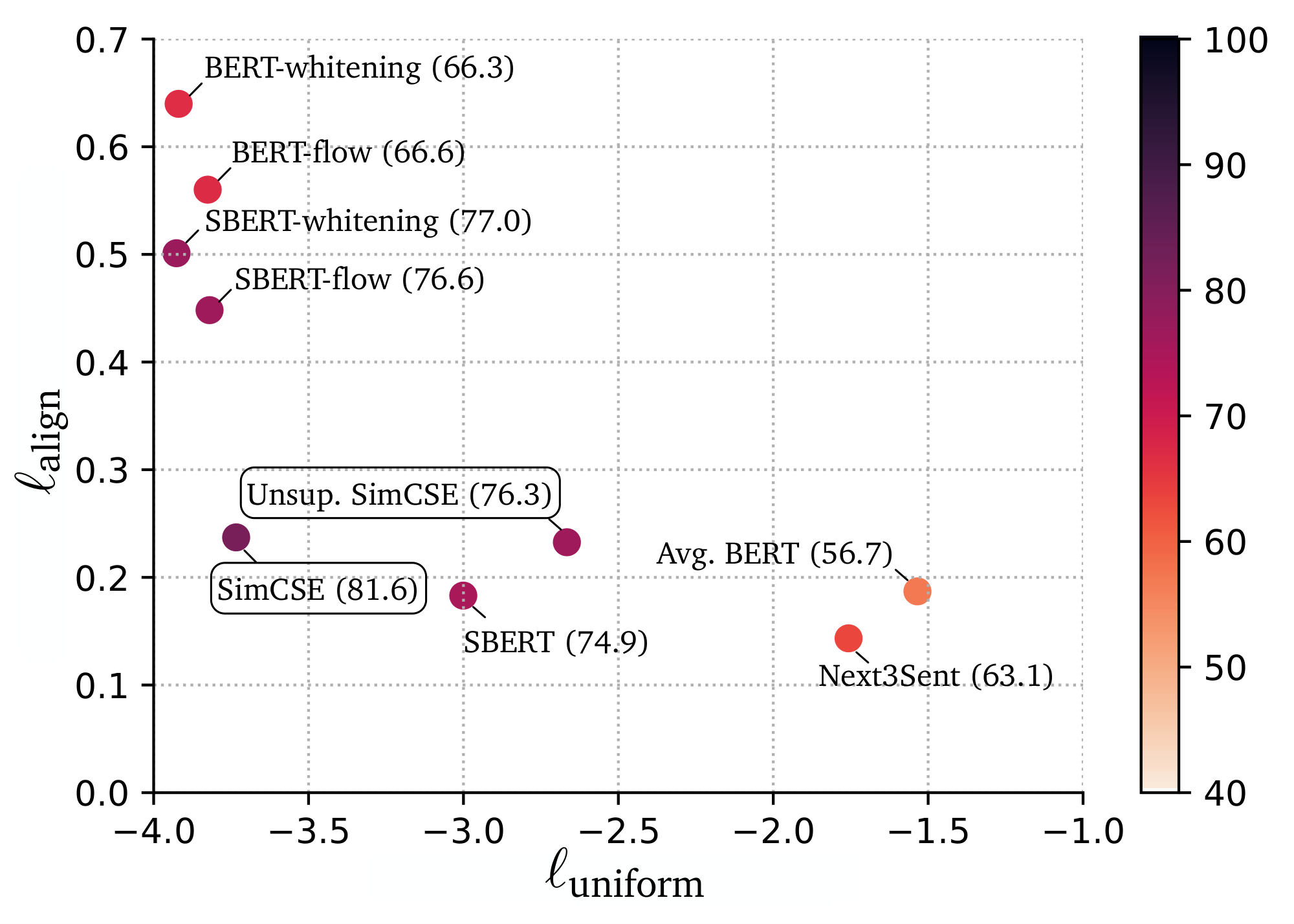
Figure 3 shows uniformity and alignment of different sentence embedding models along with their averaged STS results. In general, models which have both better alignment and uniformity achieve better performance, confirming the findings in [10]. We also observe that (1) though pre-trained embeddings have good alignment, their uniformity is poor (i.e., the embeddings are highly anisotropic); (2) post-processing methods like BERT-flow and BERT-whitening greatly improve uniformity but also suffer a degeneration in alignment; (3) unsupervised SimCSE effectively improves uniformity of pre-trained embeddings whereas keeping a good alignment; (4) incorporating supervised data in SimCSE further amends alignment. In Appendix F, we further show that SimCSE can effectively flatten singular value distribution of pre-trained embeddings. In Appendix G, we demonstrate that SimCSE provides more distinguishable cosine similarities between different sentence pairs.
Qualitative comparison.
We conduct a small-scale retrieval experiment using SBERT $\texttt{base}$ and SimCSE-BERT $\texttt{base}$ . We use 150k captions from Flickr30k dataset and take any random sentence as query to retrieve similar sentences (based on cosine similarity). As several examples shown in Table 8, the retrieved sentences by SimCSE have a higher quality compared to those retrieved by SBERT.
::: {caption="Table 8: Retrieved top-3 examples by SBERT and supervised SimCSE from Flickr30k (150k sentences)."}
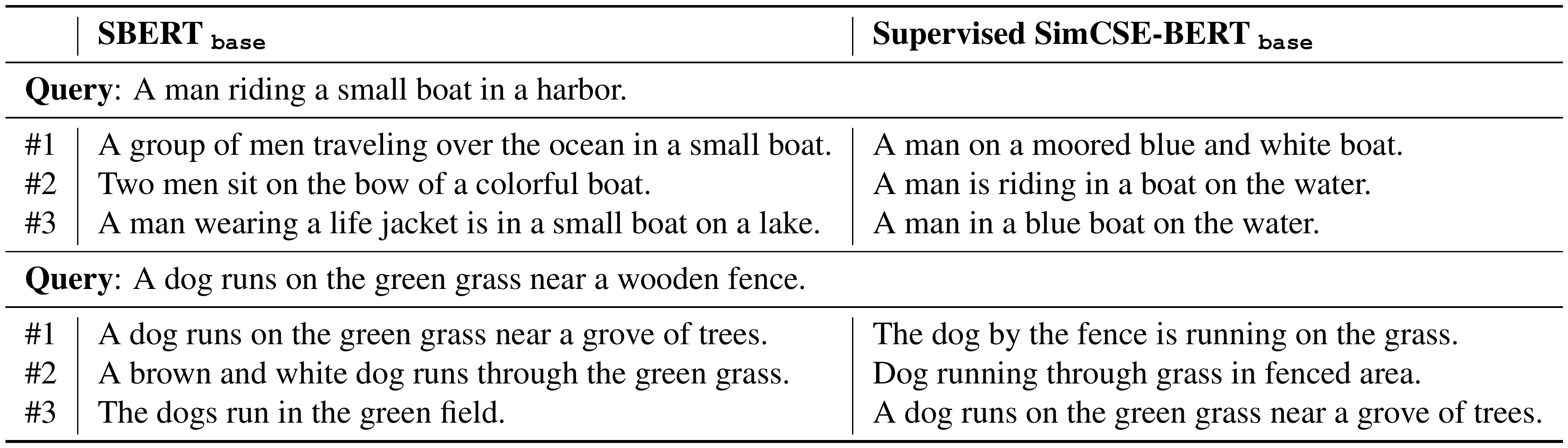
:::
8. Related Work
Section Summary: Early research on sentence embeddings relied on the idea that words in similar contexts have similar meanings, often by predicting nearby sentences or enhancing word-level models like word2vec with n-grams for better results. More recent methods use contrastive learning, where models compare different versions of the same sentence—created through data tweaks or model variations—to capture similarities, and SimCSE stands out by simply using a model's own random variations via dropout, achieving top performance on semantic tasks. Supervised approaches, which train on labeled data like natural language inference or bilingual translations, generally outperform unsupervised ones, while additional efforts focus on refining embeddings to prevent common issues like overly simplistic representations, leading to notable gains over basic language models.
Early work in sentence embeddings builds upon the distributional hypothesis by predicting surrounding sentences of a given one [1, 2, 4]. [47] show that simply augmenting the idea of word2vec [48] with n-gram embeddings leads to strong results. Several recent (and concurrent) approaches adopt contrastive objectives [43, 45, 26, 27, 46, 49, 50] by taking different views—from data augmentation or different copies of models—of the same sentence or document. Compared to these work, SimCSE uses the simplest idea by taking different outputs of the same sentence from standard dropout, and performs the best on STS tasks.
Supervised sentence embeddings are promised to have stronger performance compared to unsupervised counterparts. [3] propose to fine-tune a Siamese model on NLI datasets, which is further extended to other encoders or pre-trained models [5, 9]. Furthermore, [35, 51] demonstrate that bilingual and back-translation corpora provide useful supervision for learning semantic similarity. Another line of work focuses on regularizing embeddings [12, 41, 52] to alleviate the representation degeneration problem (as discussed in § 5), and yields substantial improvement over pre-trained language models.
9. Conclusion
Section Summary: This paper introduces SimCSE, a straightforward contrastive learning method that significantly enhances sentence embeddings for tasks like measuring how similar two pieces of text are in meaning. It includes an unsupervised version that uses dropout noise to predict the original sentence and a supervised one that draws on natural language inference datasets, with analysis showing how it aligns and distributes representations better than other models. The authors suggest this approach, particularly the unsupervised part, could apply more widely in natural language processing, offering fresh ways to augment data from text and integrate into training large language models.
In this work, we propose SimCSE, a simple contrastive learning framework, which greatly improves state-of-the-art sentence embeddings on semantic textual similarity tasks. We present an unsupervised approach which predicts input sentence itself with dropout noise and a supervised approach utilizing NLI datasets. We further justify the inner workings of our approach by analyzing alignment and uniformity of SimCSE along with other baseline models. We believe that our contrastive objective, especially the unsupervised one, may have a broader application in NLP. It provides a new perspective on data augmentation with text input, and can be extended to other continuous representations and integrated in language model pre-training.
Acknowledgements
Section Summary: The authors express gratitude to Tao Lei, Jason Lee, Zhengyan Zhang, Jinhyuk Lee, Alexander Wettig, Zexuan Zhong, and the Princeton NLP group for their insightful discussions and helpful feedback. Their research received support from a Graduate Fellowship at Princeton University. Additionally, funding came in the form of a generous gift award from Apple.
We thank Tao Lei, Jason Lee, Zhengyan Zhang, Jinhyuk Lee, Alexander Wettig, Zexuan Zhong, and the members of the Princeton NLP group for helpful discussion and valuable feedback. This research is supported by a Graduate Fellowship at Princeton University and a gift award from Apple.
Appendix
Section Summary: The appendix details the training process for SimCSE models, which uses the transformers library to fine-tune pre-trained language models over a few epochs with specific batch sizes and learning rates tuned on a development dataset, incorporating techniques like dropout and an optional masked language modeling task to preserve token knowledge. It also explains variations in evaluating semantic textual similarity (STS) tasks across research papers, such as whether to add extra regressors, use Pearson or Spearman correlations, and how to combine results from different subsets, with the authors opting for a standardized approach of direct cosine similarities, Spearman metrics, and full aggregation to ensure fair comparisons. Finally, it compares SimCSE against baseline models under these protocols and calls for unified evaluation standards in future studies.
A. Training Details
We implement SimCSE with transformers package [53]. For supervised SimCSE, we train our models for $3$ epochs, evaluate the model every $250$ training steps on the development set of STS-B and keep the best checkpoint for the final evaluation on test sets. We do the same for the unsupervised SimCSE, except that we train the model for one epoch. We carry out grid-search of batch size $\in {64, 128, 256, 512}$ and learning rate $\in {$ 1e-5, 3e-5, 5e-5 $}$ on STS-B development set and adopt the hyperparameter settings in Table 9. We find that SimCSE is not sensitive to batch sizes as long as tuning the learning rates accordingly, which contradicts the finding that contrastive learning requires large batch sizes [22]. It is probably due to that all SimCSE models start from pre-trained checkpoints, which already provide us a good set of initial parameters.
::: {caption="Table 9: Batch sizes and learning rates for SimCSE."}
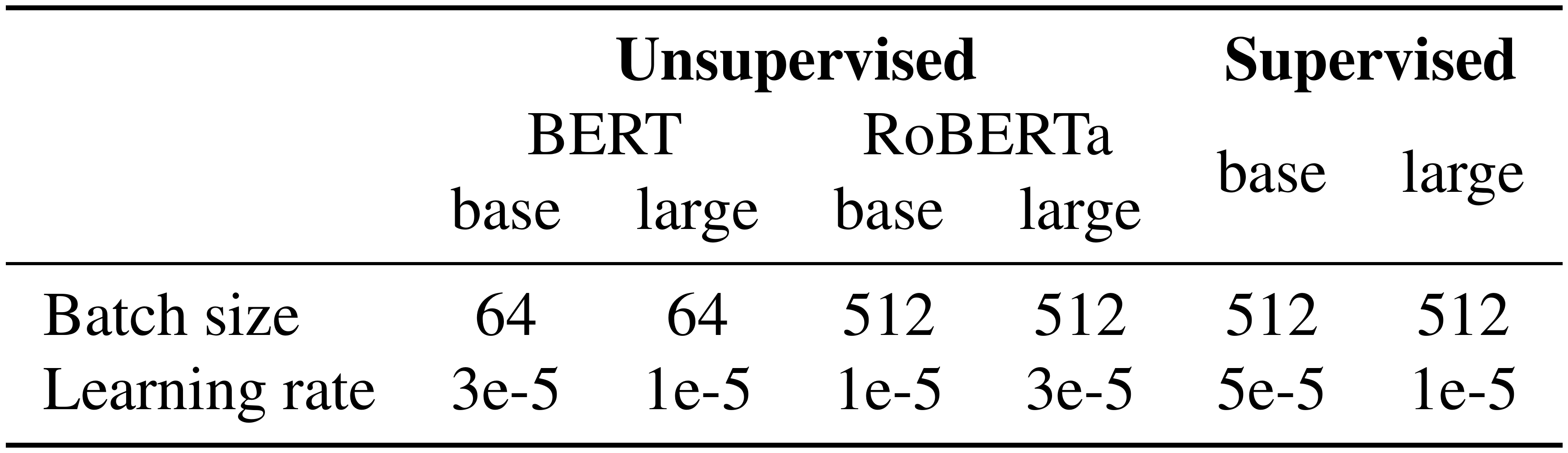
:::
For both unsupervised and supervised SimCSE, we take the [CLS] representation with an MLP layer on top of it as the sentence representation. Specially, for unsupervised SimCSE, we discard the MLP layer and only use the [CLS] output during test, since we find that it leads to better performance (ablation study in §Table 15).
Finally, we introduce one more optional variant which adds a masked language modeling (MLM) objective [6] as an auxiliary loss to 1: $\ell + \lambda \cdot \ell^{\mathrm{mlm}}$ ($\lambda$ is a hyperparameter). This helps SimCSE avoid catastrophic forgetting of token-level knowledge. As we will show in Table 15, we find that adding this term can help improve performance on transfer tasks (not on sentence-level STS tasks).
B. Different Settings for STS Evaluation
: Table 10: STS evaluation protocols used in different papers. "Reg.": whether an additional regressor is used; "aggr.": methods to aggregate different subset results.
| Paper | Reg. | Metric | Aggr. |
|---|---|---|---|
| Both | all | ||
| ✓ | Pearson | mean | |
| ✓ | Pearson | mean | |
| Spearman | all | ||
| Spearman | all | ||
| Spearman | wmean | ||
| Spearman | wmean | ||
| Pearson | mean | ||
| Spearman | mean | ||
| Ours | Spearman | all |
We elaborate the differences in STS evaluation settings in previous work in terms of (a) whether to use additional regressors; (b) reported metrics; (c) different ways to aggregate results.
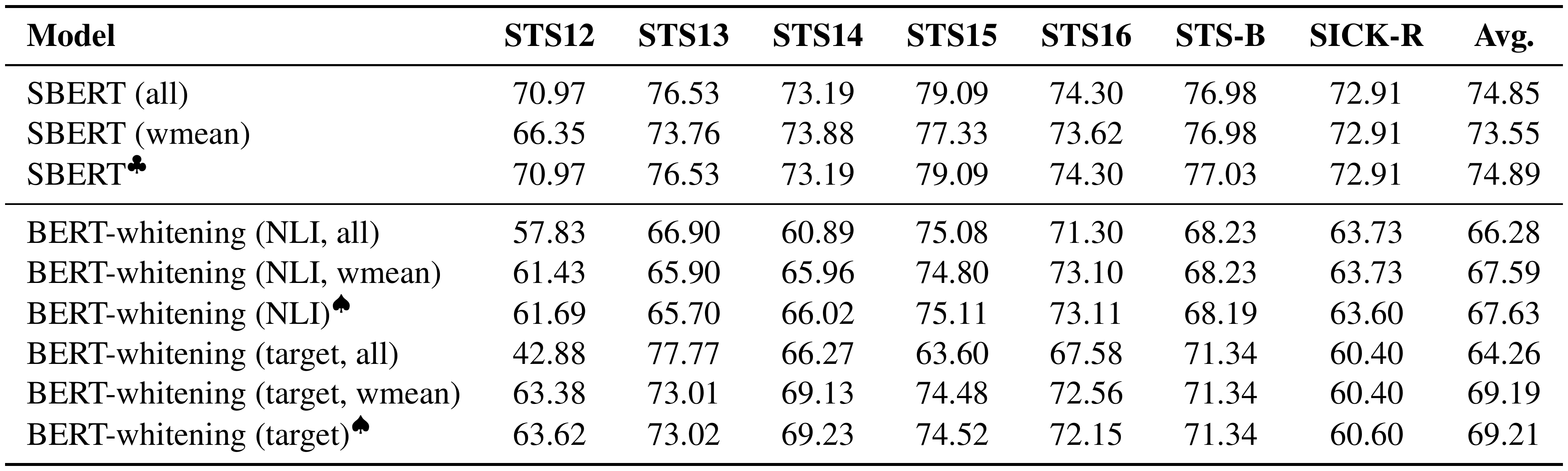
::: {caption="Table 11: Comparisons of our reproduced results using different evaluation protocols and the original numbers. $\clubsuit$ : results from [9]; $\spadesuit$ : results from [41]; Other results are reproduced by us. From the table we see that SBERT takes the "all" evaluation and BERT-whitening takes the "wmean" evaluation."}
:::
::: {caption="Table 12: STS results with "wmean" setting (Spearman). $\spadesuit$ : from [12, 41]."}
:::
Additional regressors. The default SentEval implementation applies a linear regressor on top of frozen sentence embeddings for STS-B and SICK-R, and train the regressor on the training sets of the two tasks, while most sentence representation papers take the raw embeddings and evaluate in an unsupervised way. In our experiments, we do not apply any additional regressors and directly take cosine similarities for all STS tasks.
Metrics. Both Pearson's and Spearman's correlation coefficients are used in the literature. [54] argue that Spearman correlation, which measures the rankings instead of the actual scores, better suits the need of evaluating sentence embeddings. For all of our experiments, we report Spearman's rank correlation.
Aggregation methods. Given that each year's STS challenge contains several subsets, there are different choices to gather results from them: one way is to concatenate all the topics and report the overall Spearman's correlation (denoted as "all"), and the other is to calculate results for different subsets separately and average them (denoted as "mean" if it is simple average or "wmean" if weighted by the subset sizes). However, most papers do not claim the method they take, making it challenging for a fair comparison. We take some of the most recent work: SBERT [9], BERT-flow [12] and BERT-whitening [41][^13] as an example: In Table 11, we compare our reproduced results to reported results of SBERT and BERT-whitening, and find that [9] take the "all" setting but [12, 41] take the "wmean" setting, even though [12] claim that they take the same setting as [9]. Since the "all" setting fuses data from different topics together, it makes the evaluation closer to real-world scenarios, and unless specified, we take the "all" setting.
[^13]: [12] and [41] have consistent results, so we assume that they take the same evaluation and just take BERT-whitening in experiments here.
We list evaluation settings for a number of previous work in Table 10. Some of the settings are reported by the paper and some of them are inferred by comparing the results and checking their code. As we can see, the evaluation protocols are very incoherent across different papers. We call for unifying the setting in evaluating sentence embeddings for future research. We will also release our evaluation code for better reproducibility. Since previous work uses different evaluation protocols from ours, we further evaluate our models in these settings to make a direct comparison to the published numbers. We evaluate SimCSE with "wmean" and Spearman's correlation to directly compare to [12] and [41] in Table 12.
C. Baseline Models
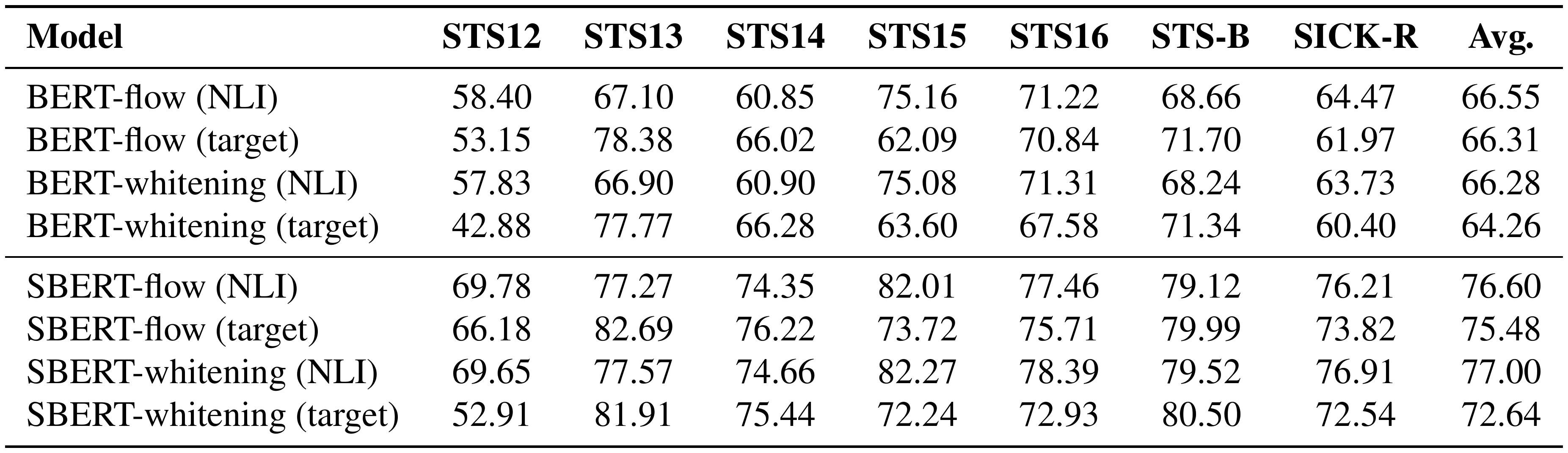
::: {caption="Table 13: Comparison of using NLI or target data for postprocessing methods ("all", Spearman's correlation)."}
:::
We elaborate on how we obtain different baselines for comparison in our experiments:
- For average GloVe embedding [44], InferSent [3] and Universal Sentence Encoder [5], we directly report the results from [9], since our evaluation setting is the same as theirs.
- For BERT [6] and RoBERTa [7], we download the pre-trained model weights from HuggingFace's
Transformers^1, and evaluate the models with our own scripts. - For SBERT and SRoBERTa [9], we reuse the results from the original paper. For results not reported by [9], such as the performance of SRoBERTa on transfer tasks, we download the model weights from SentenceTransformers^2 and evaluate them.
- For DeCLUTR [45] and contrastive tension [46], we reevaluate their checkpoints in our setting.
- For BERT-flow [12], since their original numbers take a different setting, we retrain their models using their code^3, and evaluate the models using our own script.
- For BERT-whitening [41], we implemented our own version of whitening script following the same pooling method in [41], i.e. first-last average pooling. Our implementation can reproduce the results from the original paper (see Table 11).
For both BERT-flow and BERT-whitening, they have two variants of postprocessing: one takes the NLI data ("NLI") and one directly learns the embedding distribution on the target sets ("target"). We find that in our evaluation setting, "target" is generally worse than "NLI" (Table 13), so we only report the NLI variant in the main results.
D. Ablation Studies
: Table 14: STS-B development results (Spearman's correlation) with different temperatures. "N/A": Dot product instead of cosine similarity.
| $\tau$ | N/A | 0.001 | 0.01 | 0.05 | 0.1 | 1 |
|---|---|---|---|---|---|---|
| STS-B | 85.9 | 84.9 | 85.4 | 86.2 | 82.0 | 64.0 |
Normalization and temperature.
We train SimCSE using both dot product and cosine similarity with different temperatures and evaluate them on the STS-B development set. As shown in Table 14, with a carefully tuned temperature $\tau = 0.05$, cosine similarity is better than dot product.
MLM auxiliary task.
Finally, we study the impact of the MLM auxiliary objective with different $\lambda$. As shown in Table 15, the token-level MLM objective improves the averaged performance on transfer tasks modestly, yet it brings a consistent drop in semantic textual similarity tasks.
: Table 15: Ablation studies of the MLM objective based on the development sets using BERT $_\texttt{base}$ .
| Model | STS-B | Avg. transfer |
|---|---|---|
| w/o MLM | 86.2 | 85.8 |
| w/ MLM | ||
| $\lambda=0.01$ | 85.7 | 86.1 |
| $\lambda=0.1$ | 85.7 | 86.2 |
| $\lambda=1$ | 85.1 | 85.8 |
E. Transfer Tasks
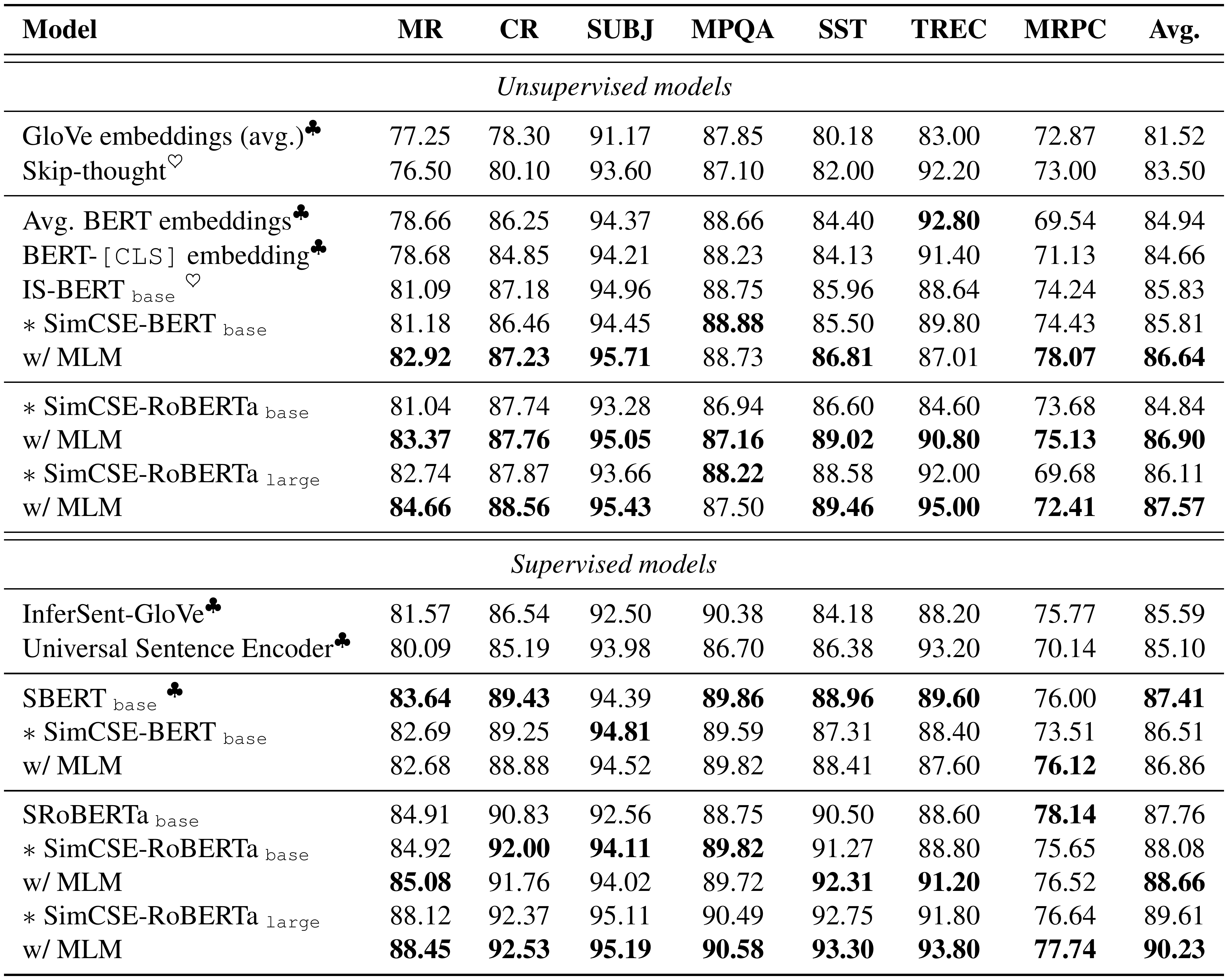
::: {caption="Table 16: Transfer task results of different sentence embedding models (measured as accuracy). $\clubsuit$ : results from [9]; $\heartsuit$ : results from [43]. We highlight the highest numbers among models with the same pre-trained encoder. MLM: adding MLM as an auxiliary task with $\lambda = 0.1$."}
:::
We evaluate our models on the following transfer tasks: MR [55], CR [56], SUBJ [57], MPQA [58], SST-2 [59], TREC [60] and MRPC [61]. A logistic regression classifier is trained on top of (frozen) sentence embeddings produced by different methods. We follow default configurations from SentEval^14.
Table 16 shows the evaluation results on transfer tasks. We find that supervised SimCSE performs on par or better than previous approaches, although the trend of unsupervised models remains unclear. We find that adding this MLM term consistently improves performance on transfer tasks, confirming our intuition that sentence-level objective may not directly benefit transfer tasks. We also experiment with post-processing methods (BERT-flow/whitening) and find that they both hurt performance compared to their base models, showing that good uniformity of representations does not lead to better embeddings for transfer learning. As we argued earlier, we think that transfer tasks are not a major goal for sentence embeddings, and thus we take the STS results for main comparison.
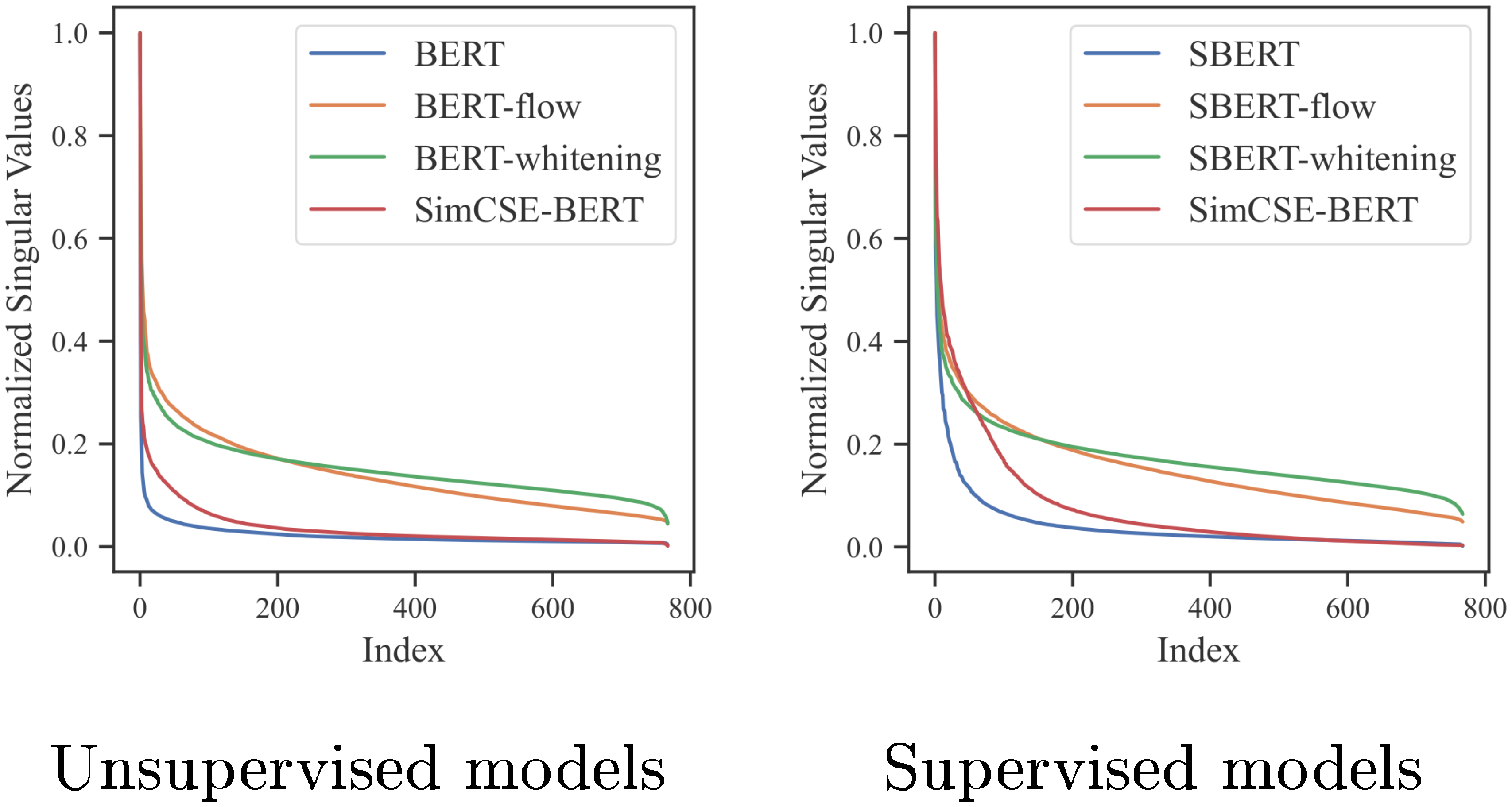
F. Distribution of Singular Values
Figure 4 shows the singular value distribution of SimCSE together with other baselines. For both unsupervised and supervised cases, singular value drops the fastest for vanilla BERT or SBERT embeddings, while SimCSE helps flatten the spectrum distribution. Postprocessing-based methods such as BERT-flow or BERT-whitening flatten the curve even more since they directly aim for the goal of mapping embeddings to an isotropic distribution.
G. Cosine-similarity Distribution
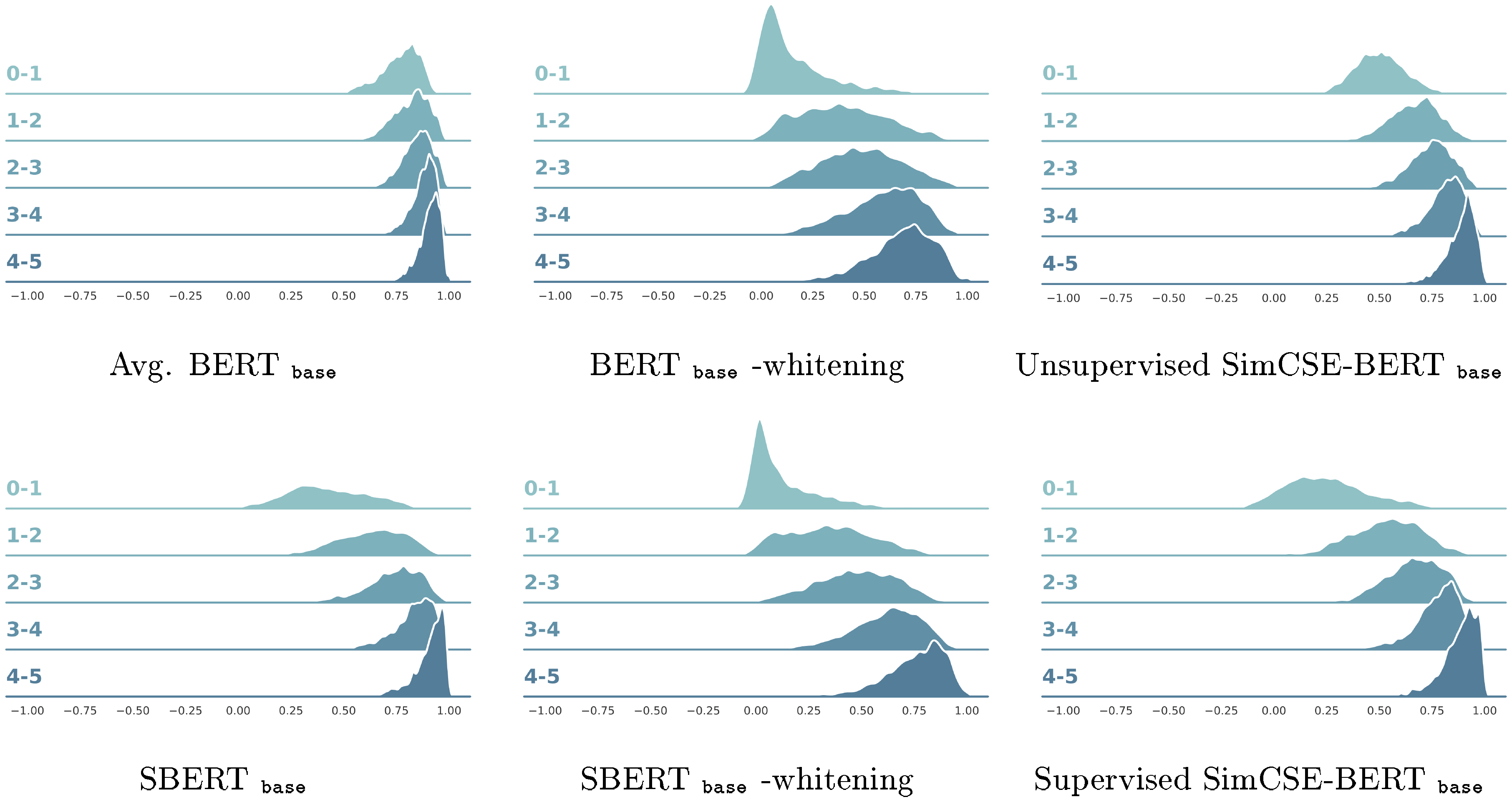
To directly show the strengths of our approaches on STS tasks, we illustrate the cosine similarity distributions of STS-B pairs with different groups of human ratings in Figure 5. Compared to all the baseline models, both unsupervised and supervised SimCSE better distinguish sentence pairs with different levels of similarities, thus leading to a better performance on STS tasks. In addition, we observe that SimCSE generally shows a more scattered distribution than BERT or SBERT, but also preserves a lower variance on semantically similar sentence pairs compared to whitened distribution. This observation further validates that SimCSE can achieve a better alignment-uniformity balance.
References
[1] Kiros et al. (2015). Skip-thought vectors. In nips. pp. 3294–3302. https://papers.nips.cc/paper/2015/hash/f442d33fa06832082290ad8544a8da27-Abstract.html.
[2] Hill et al. (2016). Learning Distributed Representations of Sentences from Unlabelled Data. In naacl_hlt. pp. 1367–1377. doi:10.18653/v1/N16-1162. https://www.aclweb.org/anthology/N16-1162.
[3] Conneau et al. (2017). Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In emnlp. pp. 670–680. doi:10.18653/v1/D17-1070. https://www.aclweb.org/anthology/D17-1070.
[4] Lajanugen Logeswaran and Honglak Lee (2018). An efficient framework for learning sentence representations. In iclr. https://openreview.net/forum?id=rJvJXZb0W.
[5] Cer et al. (2018). Universal Sentence Encoder for English. In emnlp_demo. pp. 169–174. doi:10.18653/v1/D18-2029. https://www.aclweb.org/anthology/D18-2029.
[6] Devlin et al. (2019). *BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding*. In naacl_hlt. pp. 4171–4186. doi:10.18653/v1/N19-1423. https://www.aclweb.org/anthology/N19-1423.
[7] Liu et al. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692. https://arxiv.org/abs/1907.11692.
[8] Srivastava et al. (2014). Dropout: a simple way to prevent neural networks from overfitting. jmlr. 15(1). pp. 1929–1958. https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf.
[9] Reimers, Nils and Gurevych, Iryna (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In emnlp_ijcnlp. pp. 3982–3992. doi:10.18653/v1/D19-1410. https://www.aclweb.org/anthology/D19-1410.
[10] Wang, Tongzhou and Isola, Phillip (2020). Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In icml. pp. 9929–9939. http://proceedings.mlr.press/v119/wang20k/wang20k.pdf.
[11] Ethayarajh, Kawin (2019). How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. In emnlp_ijcnlp. pp. 55–65. doi:10.18653/v1/D19-1006. https://www.aclweb.org/anthology/D19-1006.
[12] Li et al. (2020). On the Sentence Embeddings from Pre-trained Language Models. In emnlp. pp. 9119–9130. https://www.aclweb.org/anthology/2020.emnlp-main.733.
[13] Agirre et al. (2012). SemEval-2012 Task 6: A Pilot on Semantic Textual Similarity. In *SEM 2012: The First Joint Conference on Lexical and Computational Semantics – Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012). pp. 385–393. https://www.aclweb.org/anthology/S12-1051.
[14] Agirre et al. (2013). *SEM 2013 shared task: Semantic Textual Similarity. In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity. pp. 32–43. https://www.aclweb.org/anthology/S13-1004.
[15] Agirre et al. (2014). SemEval-2014 Task 10: Multilingual Semantic Textual Similarity. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014). pp. 81–91. doi:10.3115/v1/S14-2010. https://www.aclweb.org/anthology/S14-2010.
[16] Agirre et al. (2015). SemEval-2015 Task 2: Semantic Textual Similarity, English, Spanish and Pilot on Interpretability. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015). pp. 252–263. doi:10.18653/v1/S15-2045. https://www.aclweb.org/anthology/S15-2045.
[17] Agirre et al. (2016). SemEval-2016 Task 1: Semantic Textual Similarity, Monolingual and Cross-Lingual Evaluation. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). pp. 497–511. doi:10.18653/v1/S16-1081. https://www.aclweb.org/anthology/S16-1081.
[18] Cer et al. (2017). SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). pp. 1–14. doi:10.18653/v1/S17-2001. https://www.aclweb.org/anthology/S17-2001.
[19] Marelli et al. (2014). A SICK cure for the evaluation of compositional distributional semantic models. In lrec. pp. 216–223. http://www.lrec-conf.org/proceedings/lrec2014/pdf/363_Paper.pdf.
[20] Conneau, Alexis and Kiela, Douwe (2018). SentEval: An Evaluation Toolkit for Universal Sentence Representations. In lrec. https://www.aclweb.org/anthology/L18-1269.
[21] Hadsell et al. (2006). Dimensionality reduction by learning an invariant mapping. In cvpr. pp. 1735–1742. https://ieeexplore.ieee.org/abstract/document/1640964/.
[22] Chen et al. (2020). A simple framework for contrastive learning of visual representations. In icml. pp. 1597–1607. http://proceedings.mlr.press/v119/chen20j.html.
[23] Chen et al. (2017). On sampling strategies for neural network-based collaborative filtering. In ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 767–776. https://dl.acm.org/doi/abs/10.1145/3097983.3098202.
[24] Henderson et al. (2017). Efficient natural language response suggestion for smart reply. arXiv preprint arXiv:1705.00652. https://arxiv.org/pdf/1705.00652.pdf.
[25] Dosovitskiy et al. (2014). Discriminative Unsupervised Feature Learning with Convolutional Neural Networks. In nips. https://proceedings.neurips.cc/paper/2014/file/07563a3fe3bbe7e3ba84431ad9d055af-Paper.pdf.
[26] Wu et al. (2020). CLEAR: Contrastive Learning for Sentence Representation. arXiv preprint arXiv:2012.15466. https://arxiv.org/abs/2012.15466.
[27] Meng et al. (2021). *COCO-LM: Correcting and contrasting text sequences for language model pretraining*. arXiv preprint arXiv:2102.08473. https://arxiv.org/abs/2102.08473.
[28] Gillick et al. (2019). Learning Dense Representations for Entity Retrieval. In conll. pp. 528–537. https://www.aclweb.org/anthology/K19-1049.
[29] Karpukhin et al. (2020). Dense Passage Retrieval for Open-Domain Question Answering. In emnlp. pp. 6769–6781. doi:10.18653/v1/2020.emnlp-main.550. https://www.aclweb.org/anthology/2020.emnlp-main.550.
[30] Vaswani et al. (2017). Attention is all you need. In nips. pp. 6000–6010. https://arxiv.org/pdf/1706.03762.pdf.
[31] Edward Ma (2019). NLP Augmentation. https://github.com/makcedward/nlpaug. https://github.com/makcedward/nlpaug.
[32] Bowman et al. (2015). A large annotated corpus for learning natural language inference. In emnlp. pp. 632–642. doi:10.18653/v1/D15-1075. https://www.aclweb.org/anthology/D15-1075.
[33] Williams et al. (2018). A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. In naacl_hlt. pp. 1112–1122. doi:10.18653/v1/N18-1101. https://www.aclweb.org/anthology/N18-1101.
[34] Young et al. (2014). From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics. 2. pp. 67–78. doi:10.1162/tacl_a_00166. https://www.aclweb.org/anthology/Q14-1006.
[35] Wieting, John and Gimpel, Kevin (2018). ParaNMT-50M: Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations. In acl. pp. 451–462. doi:10.18653/v1/P18-1042. https://www.aclweb.org/anthology/P18-1042.
[36] Nie et al. (2020). Adversarial NLI: A New Benchmark for Natural Language Understanding. In acl. pp. 4885–4901. doi:10.18653/v1/2020.acl-main.441. https://www.aclweb.org/anthology/2020.acl-main.441.
[37] Jun Gao et al. (2019). Representation Degeneration Problem in Training Natural Language Generation Models. In iclr. https://openreview.net/forum?id=SkEYojRqtm.
[38] Lingxiao Wang et al. (2020). Improving Neural Language Generation with Spectrum Control. In iclr. https://openreview.net/forum?id=ByxY8CNtvr.
[39] Arora et al. (2017). A simple but tough-to-beat baseline for sentence embeddings. In iclr. https://openreview.net/forum?id=SyK00v5xx.
[40] Jiaqi Mu and Pramod Viswanath (2018). All-but-the-Top: Simple and Effective Postprocessing for Word Representations. In iclr. https://openreview.net/forum?id=HkuGJ3kCb.
[41] Su et al. (2021). Whitening sentence representations for better semantics and faster retrieval. arXiv preprint arXiv:2103.15316. https://arxiv.org/pdf/2103.15316.pdf.
[42] Jorma Kaarlo Merikoski (1984). On the trace and the sum of elements of a matrix. Linear Algebra and its Applications. 60. pp. 177-185. doi:https://doi.org/10.1016/0024-3795(84)90078-8. https://www.sciencedirect.com/science/article/pii/0024379584900788.
[43] Zhang et al. (2020). An Unsupervised Sentence Embedding Method by Mutual Information Maximization. In emnlp. pp. 1601–1610. doi:10.18653/v1/2020.emnlp-main.124. https://www.aclweb.org/anthology/2020.emnlp-main.124.
[44] Pennington et al. (2014). GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 1532–1543. doi:10.3115/v1/D14-1162. https://www.aclweb.org/anthology/D14-1162.
[45] Giorgi et al. (2021). DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations. In acl_ijcnlp. pp. 879–895. doi:10.18653/v1/2021.acl-long.72. https://aclanthology.org/2021.acl-long.72.
[46] Fredrik Carlsson et al. (2021). Semantic Re-tuning with Contrastive Tension. In iclr. https://openreview.net/forum?id=Ov_sMNau-PF.
[47] Pagliardini et al. (2018). Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In naacl_hlt. pp. 528–540. doi:10.18653/v1/N18-1049. https://www.aclweb.org/anthology/N18-1049.
[48] Tomas Mikolov et al. (2013). Distributed Representations of Words and Phrases and their Compositionality. In nips. https://arxiv.org/pdf/1310.4546.pdf.
[49] Kim et al. (2021). Self-Guided Contrastive Learning for BERT Sentence Representations. In acl_ijcnlp. pp. 2528–2540. doi:10.18653/v1/2021.acl-long.197. https://aclanthology.org/2021.acl-long.197.
[50] Yan et al. (2021). ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer. In acl_ijcnlp. pp. 5065–5075. doi:10.18653/v1/2021.acl-long.393. https://aclanthology.org/2021.acl-long.393.
[51] Wieting et al. (2020). A Bilingual Generative Transformer for Semantic Sentence Embedding. In emnlp. pp. 1581–1594. doi:10.18653/v1/2020.emnlp-main.122. https://www.aclweb.org/anthology/2020.emnlp-main.122.
[52] Huang et al. (2021). WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach. arXiv preprint arXiv:2104.01767. https://arxiv.org/abs/2104.01767.
[53] Wolf et al. (2020). Transformers: State-of-the-Art Natural Language Processing. In emnlp_demo. pp. 38–45. doi:10.18653/v1/2020.emnlp-demos.6. https://www.aclweb.org/anthology/2020.emnlp-demos.6.
[54] Reimers et al. (2016). Task-Oriented Intrinsic Evaluation of Semantic Textual Similarity. In coling. pp. 87–96. https://www.aclweb.org/anthology/C16-1009.
[55] Pang, Bo and Lee, Lillian (2005). Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In acl. pp. 115–124. https://www.aclweb.org/anthology/P05-1015.pdf.
[56] Hu, Minqing and Liu, Bing (2004). Mining and summarizing customer reviews. In ACM SIGKDD international conference on Knowledge discovery and data mining. https://www.cs.uic.edu/~liub/publications/kdd04-revSummary.pdf.
[57] Pang, Bo and Lee, Lillian (2004). A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. In acl. pp. 271–278. https://www.aclweb.org/anthology/P04-1035.pdf.
[58] Wiebe et al. (2005). Annotating expressions of opinions and emotions in language. Language resources and evaluation. 39(2-3). pp. 165–210. https://www.cs.cornell.edu/home/cardie/papers/lre05withappendix.pdf.
[59] Socher et al. (2013). Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In emnlp. pp. 1631–1642. https://www.aclweb.org/anthology/D13-1170.pdf.
[60] Voorhees, Ellen M and Tice, Dawn M (2000). Building a question answering test collection. In the 23rd annual international ACM SIGIR conference on Research and development in information retrieval. pp. 200–207. https://www.egr.msu.edu/~jchai/QAPapers/qa-testcollection.pdf.
[61] Dolan, William B. and Brockett, Chris (2005). Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005). https://www.aclweb.org/anthology/I05-5002.