Zephyr: Direct Distillation of LM Alignment
Lewis Tunstall, Edward Beeching,$^{*}$* Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf The H4 (Helpful, Honest, Harmless, Huggy) Team https://huggingface.co/HuggingFaceH4
* Equal contribution.
Abstract
We aim to produce a smaller language model that is aligned to user intent. Previous research has shown that applying distilled supervised fine-tuning (dSFT) on larger models significantly improves task accuracy; however, these models are unaligned, i.e. they do not respond well to natural prompts. To distill this property, we experiment with the use of preference data from AI Feedback (AIF). Starting from a dataset of outputs ranked by a teacher model, we apply distilled direct preference optimization (dDPO) to learn a chat model with significantly improved intent alignment. The approach requires only a few hours of training without any additional sampling during fine-tuning. The final result, $\textsc{Zephyr-7B}$, sets a new state-of-the-art on chat benchmarks for 7B parameter models, and requires no human annotation. In particular, results on MT-Bench show that $\textsc{Zephyr-7B}$ surpasses $\textsc{Llama2-Chat-70B}$, the best open-access RLHF-based model. Code, models, data, and tutorials for the system are available at https://github.com/huggingface/alignment-handbook.
Executive Summary: Large language models (LLMs) have advanced rapidly, enabling powerful chat systems, but smaller open-source versions often fail to align with user intent, producing unhelpful or off-topic responses. This gap limits their practical use in applications like customer support or education, where proprietary models from companies like OpenAI dominate due to costly human feedback training. With growing demand for accessible AI tools, there is an urgent need for efficient methods to align smaller models without expensive human annotation, making high-quality chat AI more democratic and cost-effective.
This document evaluates a new approach to align a 7-billion-parameter open-source LLM, starting from Mistral-7B, to better follow user instructions and preferences. It demonstrates that distillation from larger teacher models can produce a chat model rivaling much bigger systems, all in a few hours of training.
The team applied a two-step process. First, they performed distilled supervised fine-tuning using a cleaned dataset of 200,000 multi-turn dialogues generated by a larger model (UltraChat), teaching the base model to respond to instructions. Second, they created preference data by having several models generate responses to 64,000 prompts, scoring them with a teacher model (like GPT-4) for qualities such as helpfulness and honesty (UltraFeedback), then used distilled direct preference optimization to train the model to favor better responses over worse ones. This avoided complex reinforcement learning methods or human labeling, relying on synthetic data from public models, and ran on standard hardware like 16 high-end GPUs over 2-4 hours total.
Key findings highlight the method's effectiveness. The resulting Zephyr-7B model achieved a top score of 7.00 on the MT-Bench multi-turn chat benchmark, surpassing other 7B open models by 5-15% and even outperforming the much larger Llama2-Chat-70B (a 70-billion-parameter model trained with human feedback). On AlpacaEval, a single-turn helpfulness test, Zephyr-7B won 86% of comparisons against a baseline, competitive with proprietary models like GPT-3.5-turbo and ahead of most open rivals. Ablations showed that skipping the preference step dropped scores by 10-20%, confirming its necessity, while the full process maintained strong performance on academic tasks like reasoning and knowledge questions, matching or exceeding the base model's results. Overfitting during training did not harm evaluation scores, allowing quick iterations.
These results mean smaller open models can now deliver intent-aligned chat performance comparable to giants, slashing development costs and timelines from weeks to hours while avoiding human data expenses. This shifts risks from proprietary dependencies to open ecosystems, boosting innovation in performance-critical areas like real-time assistance, though Zephyr focuses solely on helpfulness, not safety—unlike human-feedback methods that often include harm reduction. It challenges prior work by simplifying alignment without reinforcement learning, proving synthetic preferences suffice for gains beyond basic fine-tuning.
Leaders should deploy Zephyr-7B for cost-sensitive chat applications, integrating it via the open-source code and models provided. For broader use, prioritize adding safety fine-tuning using similar distillation to curb harmful outputs, as this remains unaddressed. Test scaling the method to larger models like 70B parameters, where gains could be even bigger, and run pilots on domain-specific tasks to validate real-world fit.
Confidence in the chat benchmark results is high for 7B-scale models, backed by multiple evaluators like GPT-4, but caution is needed due to potential biases in those scorers favoring verbose outputs and the lack of safety testing, which could expose risks in production. Data from public models limits edge-case coverage, so further validation with diverse prompts is essential before high-stakes decisions.
1. Introduction
Section Summary: Open large language models have become much more capable and compact in recent years, but they often fail to align with users' intentions, producing responses that don't fully match human preferences, as shown by benchmarks where proprietary models outperform open ones trained through distillation or human feedback. In this work, researchers align a small open model called Zephyr-7B, based on Mistral-7B, entirely through distillation techniques that use AI feedback from stronger teacher models as preference data, via a method called distilled direct preference optimization (dDPO), which avoids the need for costly human annotations and trains quickly on modest hardware. The resulting model matches the performance of much larger 70B-parameter models on academic and conversational benchmarks, though the focus is on helpfulness rather than safety, which remains a challenge for future efforts.
Smaller, open large language models (LLMs) have greatly increased in ability in recent years, from early GPT-2-like models ([1]) to accurate and compact models ([2, 3, 4]) that are trained on significantly more tokens than the "compute-optimal" amount suggested by the Chincilla scaling laws ([5]). In addition, researchers have shown that these models can be further trained through distilled supervised fine-tuning (dSFT) based on proprietary models to increase their accuracy ([6]). In this approach, the output of a more capable teacher model is used as supervised data for the student model.
Distillation has proven to be an effective tool for improving open models on a range of different tasks ([7]); however, it does not reach the performance of the teacher models ([8]). Users have noted that these models are not "intent aligned", i.e. they do not behave in a manner that aligns with human users' preferences. This property often leads to outputs that do not provide correct responses to queries.
Intention alignment has been difficult to quantify, but recent work has led to the development of benchmarks like MT-Bench ([9]) and AlpacaEval ([10]) that specifically target this behavior. These benchmarks yield scores that correlate closely with human ratings of model outputs and confirm the qualitative intuition that proprietary models perform better than open models trained with human feedback, which in turn perform better than open models trained with distillation. This motivates careful collection of human feedback for alignment, often at enormous cost at scale, such as in $\textsc{Llama2-Chat}$ ([2]).
In this work, we consider the problem of aligning a small open LLM entirely through distillation. The main step is to utilize AI Feedback (AIF) from an ensemble of teacher models as preference data, and apply distilled direct preference optimization as the learning objective ([11]). We refer to this approach as dDPO. Notably, it requires no human annotation and no sampling compared to using other approaches like proximal preference optimization (PPO) ([12]). Moreover, by utilizing a small base LM, the resulting chat model can be trained in a matter of hours on 16 A100s (80GB).
To validate this approach, we construct $\textsc{Zephyr-7B}$, an aligned version of Mistral-7B ([4]). We first use dSFT, based on the UltraChat ([13]) dataset. Next we use the AI feedback data collected in the UltraFeedback dataset ([14]). Finally, we apply dDPO based on this feedback data. Experiments show that this 7B parameter model can achieve performance comparable to 70B-parameter chat models aligned with human feedback. Results show improvements both in terms of standard academic benchmarks as well as benchmarks that take into account conversational capabilities. Analysis shows that the use of preference learning is critical in achieving these results. Models, code, and instructions are available at https://github.com/huggingface/alignment-handbook.
We note an important caveat for these results. We are primarily concerned with intent alignment of models for helpfulness. The work does not consider safety considerations of the models, such as whether they produce harmful outputs or provide illegal advice ([15]). As distillation only works with the output of publicly available models this is technically more challenging to do because of added challenges in curating that type of synthetic data, and is an important subject for future work.
2. Related Work
Section Summary: The section discusses the rapid rise of open large language models like LLaMA, Mistral, and others since ChatGPT's launch, which have fueled research into improving efficiency, context handling, and applications, with the Zephyr model building on the high-performing Mistral 7B. It also covers techniques for enhancing smaller models by distilling knowledge from larger ones, starting with methods like self-instruct and Alpaca, and extending to preference optimization, comparing Zephyr to approaches in models such as WizardLM and Xwin-LM. Finally, it reviews advanced tools for evaluating these models, including crowd-sourced battles in the LMSYS arena, AI-judged rankings like AlpacaEval and MTBench, and leaderboards like HuggingFace's, which the authors use to assess their work.
There has been significant growth in the number of open large language models (LLMs) that have served as artifacts for the research community to study and use as a starting model for building chatbots and other applications. After the release of ChatGPT, the LLaMA model ([2]) opened the doors to a wide range of research on efficient fine-tuning, longer prompt context, retrieval augmented generation (RAG), and quantization. After LLaMA, there has been a continuous stream of open access text based LLMs including MosaicML's MPT ([16]), the Together AI's RedPajama-INCITE ([17]), the TII's Falcon ([3]), Meta's Llama 2 ([2]), and the Mistral 7B ([4]). Zephyr uses Mistral 7B as the starting point due to its strong performance.
With the development of open models, researchers have worked on approaches to improve small model performance by distillation from larger models. This trend started with self-instruct method ([18]) and the Alpaca model ([6]), which was followed by Vicuna ([7])and other distilled models. These works primarily focused on distilling the SFT stage of alignment, whereas we focus on both SFT and preference optimization. Some models such as WizardLM ([19]) have explored methods beyond dSFT. Contemporaneously with this work, Xwin-LM ([20]) introduced an approach that distilled preference optimization through PPO ([12]). We compare to these approaches in our experiments.
Tools for benchmarking and evaluating LLMs have greatly evolved to keep up with the pace of innovation in generative AI. Powerful LLMs such as GPT-4 and Claude are used as evaluators to judge model responses by scoring model outputs or ranking responses in a pairwise setting. The LMSYS chatbot arena benchmarks LLMs in anonymous, randomized battles using crowdsourcing ([9]). The models are ranked based on their Elo ratings on the leaderboard. AlpacaEval is an example of another such leaderboard that compares models in a pairwise setting but instead uses bigger LLMs such as GPT-4 and Claude in place of humans ([21]). In a similar spirit, MTBench uses GPT-4 to score model responses on a scale of 1-10 for multi-turn instructions across task categories such as reasoning, roleplay, math, coding, writing, humanities, STEM and extraction ([9]). The HuggingFace Open LLM leaderbaord ([22]), the Chain-of-Thought Hub ([23]), ChatEval ([24]), and FastEval ([25]) are examples of other tools for evaluating chatty models. We present results by evaluating on MTBench, AlpacaEval, and the HuggingFace OpenLLM Leaderboard.
3. Method
Section Summary: The method aims to train an open-source large language model to better match user intentions by leveraging a larger "teacher" model, following three main steps. First, it creates a high-quality dataset of instructions and responses by having the teacher generate and refine them, then fine-tunes the student model on this data through a process called distilled supervised fine-tuning. Next, it collects AI feedback by generating responses from various models, scoring them with the teacher to form pairs of preferred (better) and non-preferred (worse) outputs, and finally refines the model using distilled direct preference optimization to favor the better responses without complex reinforcement learning.
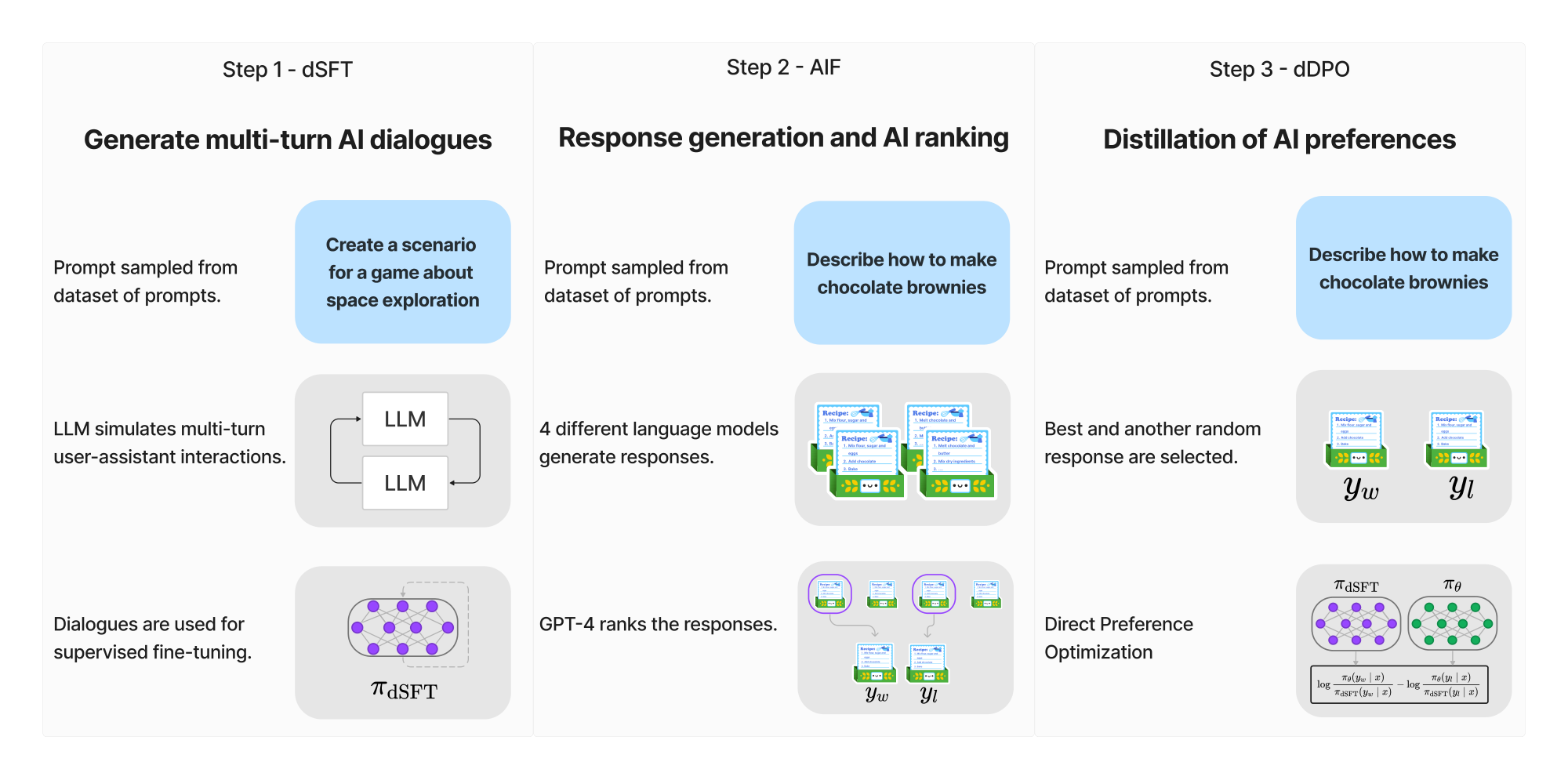
The goal of this work is to align an open-source large-language model to the intent of the user. Throughout the work we assume access to a larger teacher model $\pi_{\text{T}}$ which can be queried by prompted generation. Our goal is be to produce a student model $\pi_{\theta}$ and our approach follows similar stages as InstructGPT ([26]) as shown in Figure 2.
Distilled Supervised Fine-Tuning (dSFT)
Starting with a raw LLM, we first need to train it to respond to user prompts. This step is traditionally done through supervised fine tuning (SFT) on a dataset of high-quality instructions and responses ([27, 28]). Given access to a teacher language models, we can instead have the model generate instructions and responses ([6]), and train the model directly on these. We refer to this as distilled SFT (dSFT).
Approaches to dSFT follow the self-instruct protocol ([18]). Let $x^0_1, \ldots, x^0_J$ be a set of seed prompts, constructed to represent a diverse set of topical domains. A dataset is constructed through iterative self-prompting where the teacher is used to both respond to an instruction and refine the instruction based on the response. For each $x^0$, we first sample response $y^0 \sim \pi_{\text{T}}(\cdot | x^0)$, and then refine by sampling a new instruction (using a prompt for refinement), $x^1 \sim \pi_{\text{T}}(\cdot | x^0, y^0)$. The end point is a final dataset, ${\cal C} ={(x_1, y_1), \ldots, (x_J, y_J)}$. Distillation is performed by SFT,
$ \pi_{\text{dSFT}} = \max_{\pi} \mathop{\mathbb{E}}_{(x, y) \sim \mathcal{C}} \log \pi(y | x) $
AI Feedback through Preferences (AIF)
Human feedback (HF) can provide additional signal to align LLMs. Human feedback is typically given through preferences on the quality of LLM responses ([26]). For distillation, we instead use AI preferences from the teacher model on generated outputs from other models.
We follow the approach of UltraFeedback ([14]) which uses the teacher to provide preferences on model outputs. As with SFT, the system starts with a set of prompts $x_1, \ldots, x_J$. Each prompt $x$ is fed to a collection of four models $\pi_1, \ldots, \pi_4$, e.g. Claude, Falcon, Llama, etc, each of which yield a response $y^1 \sim \pi_1(\cdot | x), \ldots, y^4 \sim \pi_4(\cdot | x)$. These responses are then fed to the teacher model, e.g. GPT-4, which gives a score for the response $s^1 \sim \pi_T(\cdot | x, y^1), \ldots, s^4 \sim \pi_T(\cdot | x, y^4)$. After collecting the scores for a prompt $x$, we save the highest scoring response as $y_w$ and a random lower scoring prompt as $y_l$. The final feedback dataset $\mathcal{D}$ consists of a set of these triples $(x, y_w, y_l)$.
Distilled Direct Preference Optimization (dDPO)
The goal of the final step is to refine the $\pi_{\text{dSFT}}$ by maximizing the likelihood of ranking the preferred $y_w$ over $y_l$ in a preference model. The preference model is determined by a reward function $r_{\theta}(x, y)$ which utilizes the student language model $\pi_{\theta}$. Past work using AI feedback has primarily focused on using RL methods such as proximal policy optimization (PPO) to optimize $\theta$ with respect to this reward. These approaches optimize $\theta$ by first training the reward and then sampling from the current policy to compute updates.
Direct preference optimization (DPO) uses a simpler approach to directly optimize the preference model from the static data ([11]). The key observation is to derive the optimal reward function in terms of the optimal LLM policy $\pi_{*}$ and the original LLM policy $\pi_{\text{dSFT}}$. Under an appropriate choice of preference model they show, for constant $\beta$ and partition function $Z$ that,
$ r^*(x, y) = \beta \frac{\pi_{\text{*}}(y | x)} {\pi_{\text{dSFT}}(y | x)} + \beta\log Z(x) $
By plugging this function of the reward into the preference model, the authors show that the objective can be written as,
$ \pi_\theta = \max_{\pi} \mathop{\mathbb{E}}{\left(x, y_w, y_l\right)\ \sim \mathcal{D}}\log \sigma\left(\beta \log \frac{\pi(y_w | x)}{\pi{\mathrm{dSFT}}(y_w | x)}-\beta \log \frac{\pi (y_l | x)}{\pi_{\mathrm{dSFT}}(y_l | x)}\right) .\tag{1} $
While this term looks complex, we note that it implies a simple training procedure. Starting with the dSFT version of the model, we iterate through each AIF triple $(x, y_w, y_l)$.
- Compute the probability for $(x, y_w)$ and $(x, y_l)$ from the dSFT model (forward-only).
- Compute the probability for $(x, y_w)$ and $(x, y_l)$ from the dDPO model.
- Compute Eq Equation 1 and backpropagate to update. Repeat.
4. Experimental Details
Section Summary: The researchers fine-tuned the Mistral 7B language model, a top-performing open-source option, using specialized tools like the Transformer Reinforcement Learning library along with memory-saving techniques, running experiments on 16 powerful A100 GPUs that typically lasted 2-4 hours. They drew from two key datasets: UltraChat, a collection of about 200,000 cleaned-up multi-turn conversations to teach helpful responses, and UltraFeedback, 64,000 prompts turned into preference pairs for improving alignment without bias. Training involved supervised fine-tuning for 1-3 epochs with larger batches and then direct preference optimization for further refinement, evaluated on benchmarks like MT-Bench for multi-turn chats, AlpacaEval for single-turn helpfulness, and the Open LLM Leaderboard for general reasoning, comparing results to models like Llama2 and GPT-4.
We conduct all of our fine-tuning experiments using Mistral 7B ([4]), which is the current state-of-the-art base LM at the 7B parameter scale, and matches the performance of much larger models like LLaMa 34B on many NLP benchmarks. We use the Transformer Reinforcement Learning (TRL) library for fine-tuning ([29]), in conjunction with DeepSpeed ZeRO-3 ([30]) and FlashAttention-2 ([31]) to optimize memory and improve training speed. All models are trained with the AdamW optimizer and no weight decay. We did not experiment with parameter-efficient techniques such as LoRA ([32]), but expect similar results to hold with these methods. All experiments were run on 16 A100s using bfloat16 precision and typically took 2-4 hours to complete. For the full set of hyperparameters and instructions on how to train the models, see: https://github.com/huggingface/alignment-handbook.
4.1 Datasets
We focus on two dialogue datasets that have been distilled from a mix of open and proprietary models, and have previously been shown to produce strong chat models like the UltraLM ([13]):
- UltraChat ([13]) is a self-refinement dataset consisting of 1.47M multi-turn dialogues generated by $\textsc{gpt-3.5-turbo}$ over 30 topics and 20 different types of text material. We initially ran dSFT over the whole corpus, but found the resulting chat model had a tendency to respond with incorrect capitalization and would preface its answers with phrases such as "I don't have personal experiences", even for straightforward questions like "How do I clean my car?". To handle these issues in the training data, we applied truecasing heuristics to fix the grammatical errors (approximately 5% of the dataset), as well as several filters to focus on helpfulness and remove the undesired model responses. The resulting dataset contains approximately 200k examples.
- UltraFeedback ([14]) consists of 64k prompts, each of which have four LLM responses that are rated by GPT-4 according to criteria like instruction-following, honesty, and helpfulness. We construct binary preferences from UltraFeedback by selecting the highest mean score as the "chosen" response and one of the remaining three at random as "rejected". We opted for random selection instead of selecting the lowest-scored response to encourage diversity and make the DPO objective more challenging. As noted above, this step is computed offline and does not involve any sampling from the reference model.
We make the pre-processed datasets available on the Hugging Face Hub.^1
4.2 Evaluation
Our main evaluations are on single-turn and multi-turn chat benchmarks that measure a model's ability to follow instructions and respond to challenging prompts across a diverse range of domains:
- MT-Bench ([9]) is a multi-turn benchmark that consists of 160 questions across eight different areas of knowledge. In this benchmark, the model must answer an initial question, and then provide a second response to a predefined followup question. Each model response is then rated by GPT-4 on a scale from 1-10, with the final score given by the mean over the two turns.
- AlpacaEval ([10]) is a single-turn benchmark where a model must generate a response to 805 questions on different topics, mostly focused on helpfulness. Models are also scored by GPT-4, but the final metric is the pairwise win-rate against a baseline model (text-davinci-003).
We also evaluate $\textsc{Zephyr-7B}$ on the Open LLM Leaderboard ([22]), which measures the performance of LMs across four multiclass classification tasks: ARC ([33]), HellaSwag ([34]), MMLU ([35]), and Truthful QA([36]). Although this leaderboard does not directly measure the conversational quality of chat models, it does provide a useful signal to validate whether fine-tuning has introduced regressions on the base model's reasoning and truthfulness capabilities.
Across all benchmarks, we compare $\textsc{Zephyr-7b}$ against a variety of open and proprietary models, each with different alignment procedures. To facilitate comparison across open model sizes, we group our comparisons in terms of 7B models ($\textsc{Xwin-LM}$ ([20]), $\textsc{Mistral-Instruct}$ ([4]), $\textsc{MPT-Chat}$ ([16]), and StableLM- $\alpha$), as well as larger models up to 70B parameters ($\textsc{Llama2-Chat}$ ([2]), $\textsc{Vicuña}$ ([7]), WizardLM ([19]), and $\textsc{Guanaco}$ ([37])). For the chat benchmarks, we also compare against proprietary models, including $\textsc{Claude 2}$, $\textsc{GPT-3.5-turbo}$ and $\textsc{GPT-4}$ ([38]).
4.3 Details of SFT training
We train our SFT models for one to three epochs. We use a cosine learning rate scheduler with a peak learning rate of 2e-5 and 10% warmup steps. We train all models with a global batch size of 512 and use packing with a sequence length of 2048 tokens.
4.4 Details of DPO training
Similar to SFT, we train our DPO models for one to three epochs. We use a linear learning rate scheduler with a peak learning rate of 5e-7 and 10% warmup steps. We train all models with a global batch size of 32 and use $\beta=0.1$ from Eq. (1) to control the deviation from the reference model. The final $\textsc{Zephyr-7B}$ model was initialized from the SFT model that was trained for one epoch and further optimized for three DPO epochs (see Figure 3 for an epoch ablation on MT-Bench).
5. Results and Ablations
Section Summary: The Zephyr-7B model, trained using a method called dDPO, outperforms other open-source models of similar size on chat benchmarks like MT-Bench and AlpacaEval, achieving results competitive with much larger models and even some proprietary ones like GPT-3.5, though it lags in areas like math and coding. On academic tasks, it leads among 7B models and matches the performance of 40B-scale ones in some knowledge-heavy areas. Experiments show that combining supervised fine-tuning with dDPO is essential for strong results, and surprisingly, the model can overfit during training without hurting its real-world performance.
In this section we collect our main results; see Section 7 for sample model completions.
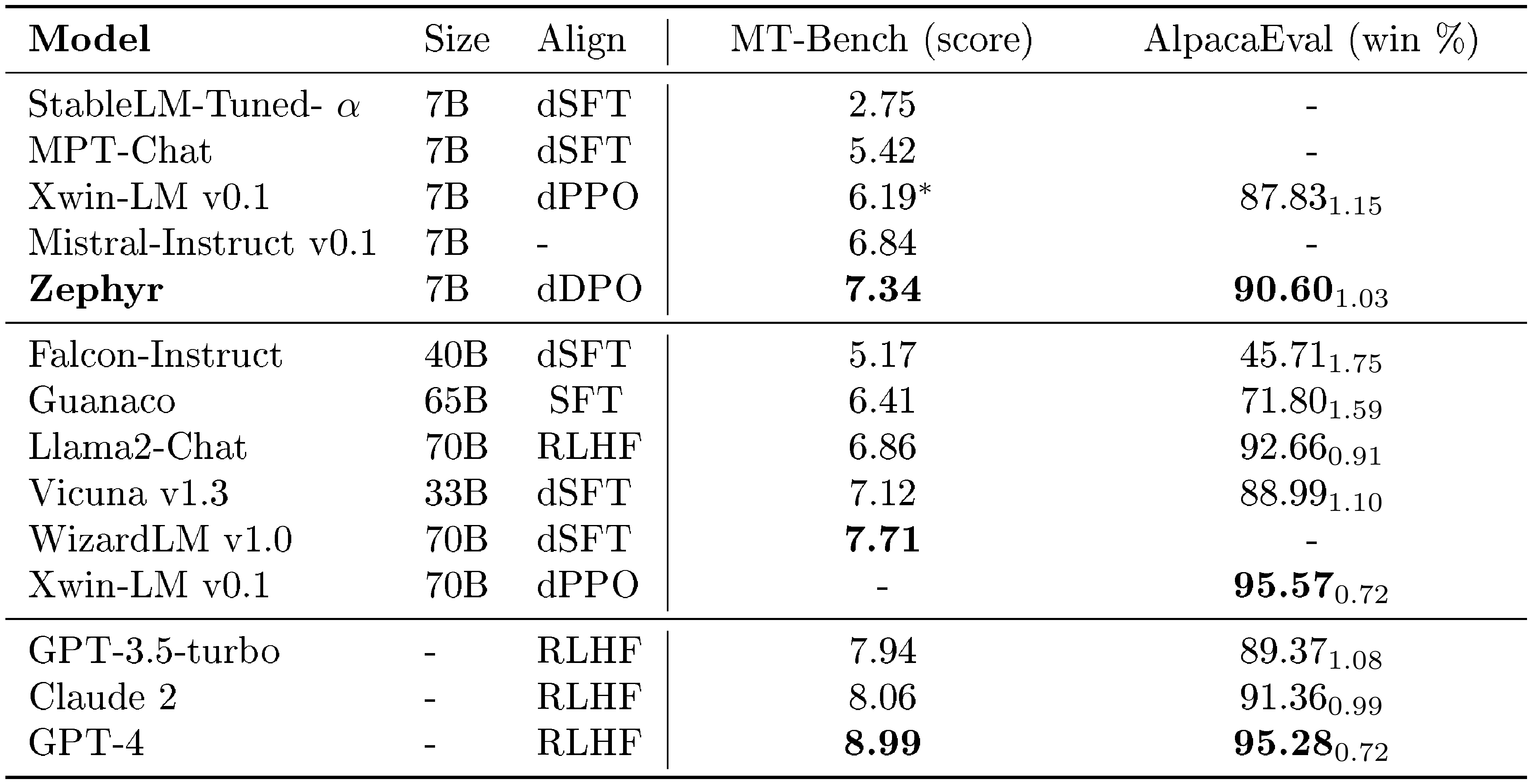
::: {caption="Table 1: Chat benchmark results for open-access and proprietary models on MT-Bench and AlpacaEval. A dash $(-)$ indicates model or alignment information that is not publicly available, or an evaluation that is absent on the public leaderboards. Scores marked with an asterisk $(*)$ denote evaluations done by ourselves."}
:::
dDPO Improves Chat Capabilities.
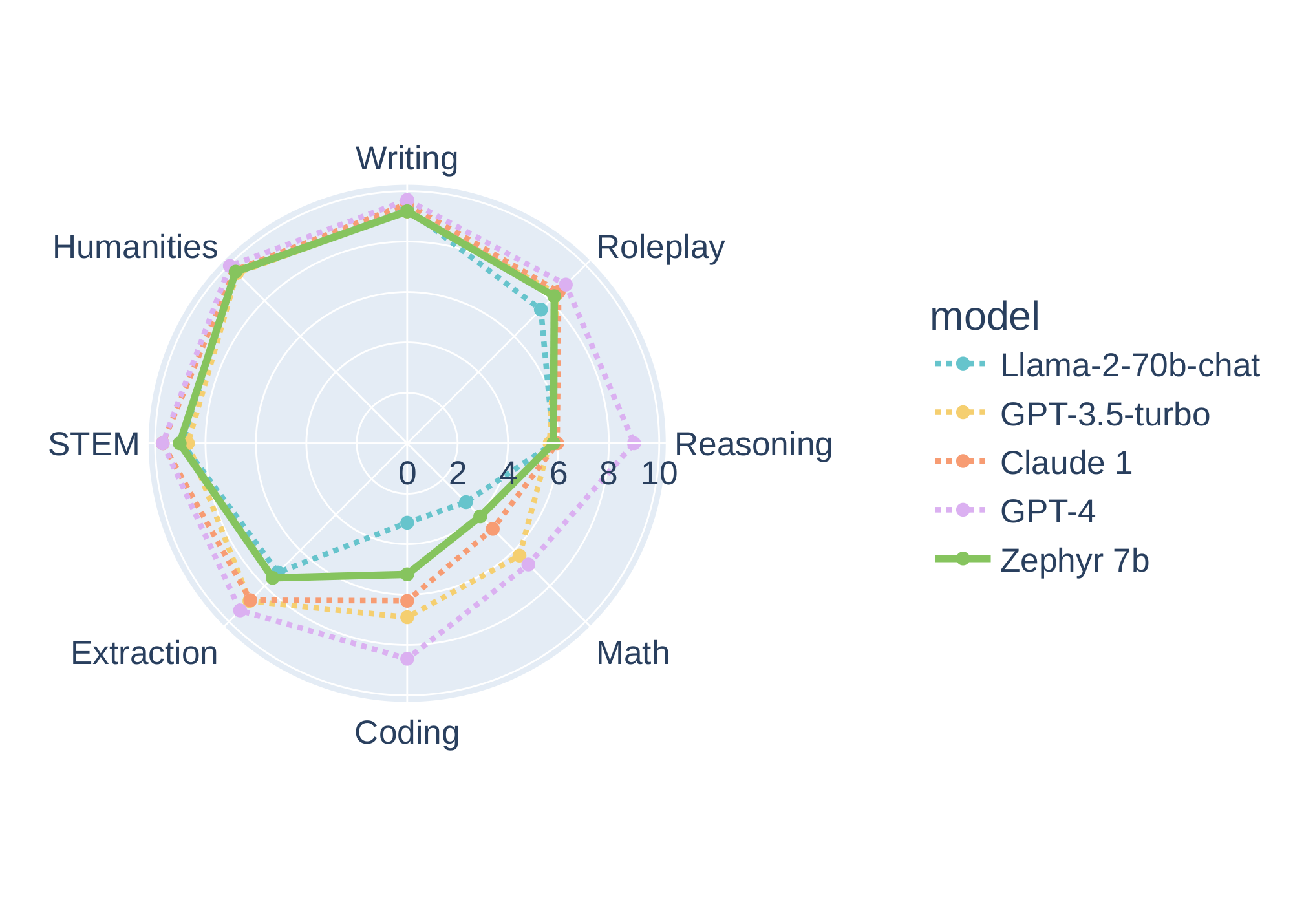
In Table 1 we compare the performance of $\textsc{Zephyr-7B}$ on the MT-Bench and AlpacaEval benchmarks. Compared to other open 7B models, $\textsc{Zephyr-7B}$ sets a new state-of-the-art and performs significantly better than dSFT models across both benchmarks. In particular, $\textsc{Zephyr-7B}$ outperforms $\textsc{Xwin-LM-7B}$, which is one of the few open models to be trained with distilled PPO (dPPO). When compared to larger open models, $\textsc{Zephyr-7B}$ achieves competitive performance with $\textsc{Llama2-Chat 70B}$, scoring better on MT-Bench and within two standard deviations on AlpacaEval. However, $\textsc{zephyr-7b}$ performs worse than $\textsc{WizardLM-70B}$ and $\textsc{Xwin-LM-70B}$, which suggests that applying dDPO to larger model sizes may be needed to match performance at these scales. When compared to proprietary models, $\textsc{zephyr-7B}$ is competitive with $\textsc{gpt-3.5-turbo}$ and $\textsc{Claude 2}$ on AlpacaEval, however these results should be interpreted with care since the prompts in AlpacaEval may not be representative of real-usage and advanced applications. This is partly visible in Figure 1, which shows the breakdown of model performance on MT-Bench across each domain. We can see that although $\textsc{Zephyr-7b}$ is competitive with proprietary models on several categories, is much worse in math and coding.
dDPO Improves Academic Task Performance
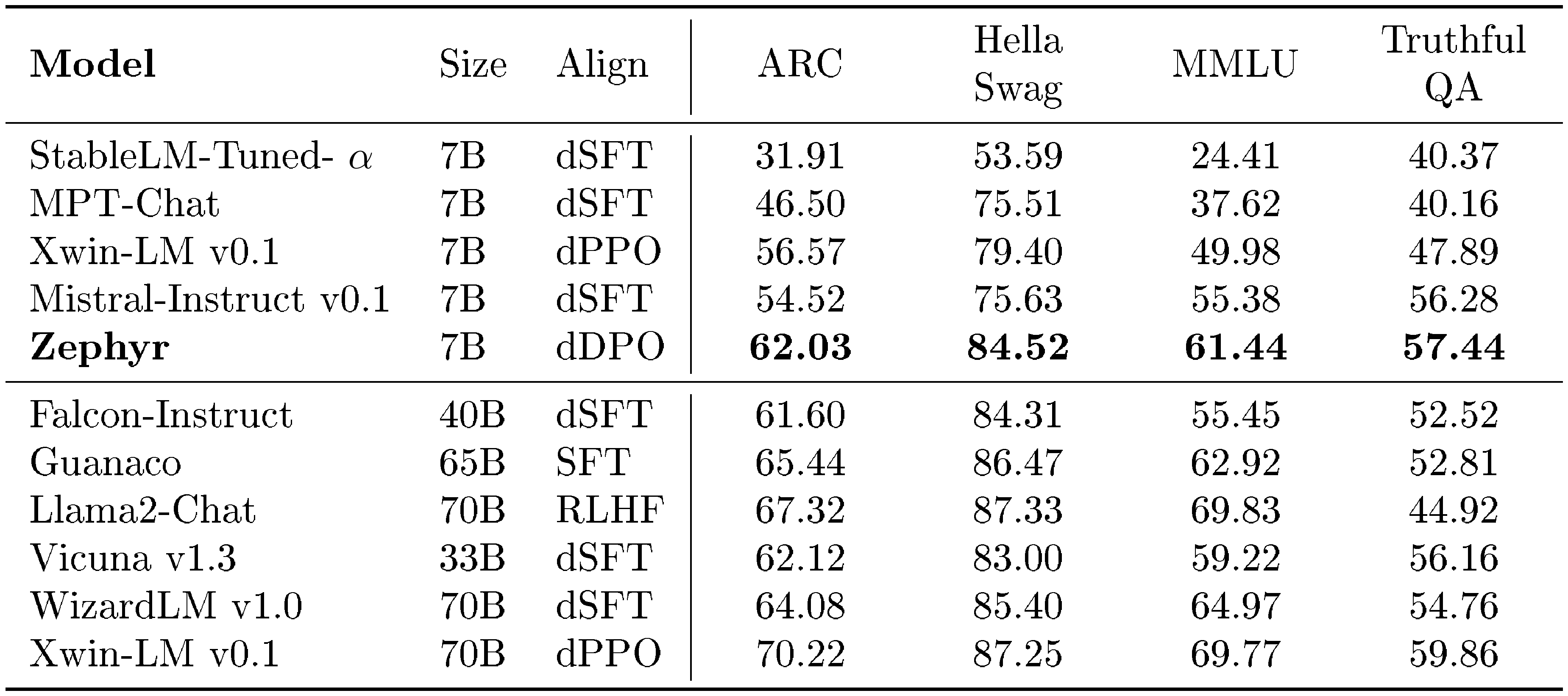
Table 2 shows the main chat results comparing the performance of the proposed model with a variety of other closed source and open-source LLMs. Results show that the dDPO model performs the best among all 7B models, with a large gap over the best dSFT models as well as Xwin-LM dPPO model. Model scale does matter more for these results and the larger models perform better than Zephyr on some of the knowledge intensive tasks. However, Zephyr does reach the performance of the 40B scale models.
::: {caption="Table 2: Academic benchmark results for open-access models on the Open LLM Leaderboard."}
:::
Is Preference Optimization Necessary?
In Table 3 we examine the impact from different steps of the alignment process by fine-tuning Mistral 7B in four different ways:
- dDPO - dSFT fine-tunes the base model directly with DPO for one epoch on UltraFeedback.
- dSFT-1 fine-tunes the base model with SFT for one epoch on UltraChat.
- dSFT-2 applies dSFT-1 first, followed by one more epoch of SFT on the top-ranked completions of UltraFeedback.
- dDPO + dSFT applies dSFT-1 first, followed by one epoch of DPO on UltraFeedback.
First, we replicate past results ([26]) and show that without an initial SFT step (-dSFT), models are not able to learn at all from feedback and perform terribly. Using dSFT improves model score significantly on both chat benchmarks. We also consider running dSFT directly on the feedback data by training on the most preferred output (dSFT- $2$); however we find that this does not make an impact in performance. Finally, we see that the full Zephyr models (dDPO+dDSFT) gives a large increase in both benchmarks.
: Table 3: Ablation of different alignment methods on the base Mistral 7B model.
| Align | MT-Bench (score) | AlpacaEval (win %) |
|---|---|---|
| dDPO - dSFT | 4.76 | 30.76$_{1.63}$ |
| dSFT-1 | 6.64 | 85.65$_{1.23}$ |
| dSFT-2 | 6.19 | 78.54$_{1.44}$ |
| dDPO + dSFT | 7.00 | 86.07$_{1.22}$ |
Does Overfitting Harm Downstream Performance?
In the process of training $\textsc{Zephyr-7b}$ we observed that after one epoch of DPO training, the model would strongly overfit, as indicated by perfect training set accuracies in Figure 3. Surprisingly, this did not harm downstream performance on MT-Bench and AlpacaEval; as shown in Figure 3, the strongest model was obtained with one epoch of SFT followed by three epochs of DPO. However, we do observe that if the SFT model is trained for more than one epoch, the DPO step actually induces a performance regression with longer training.
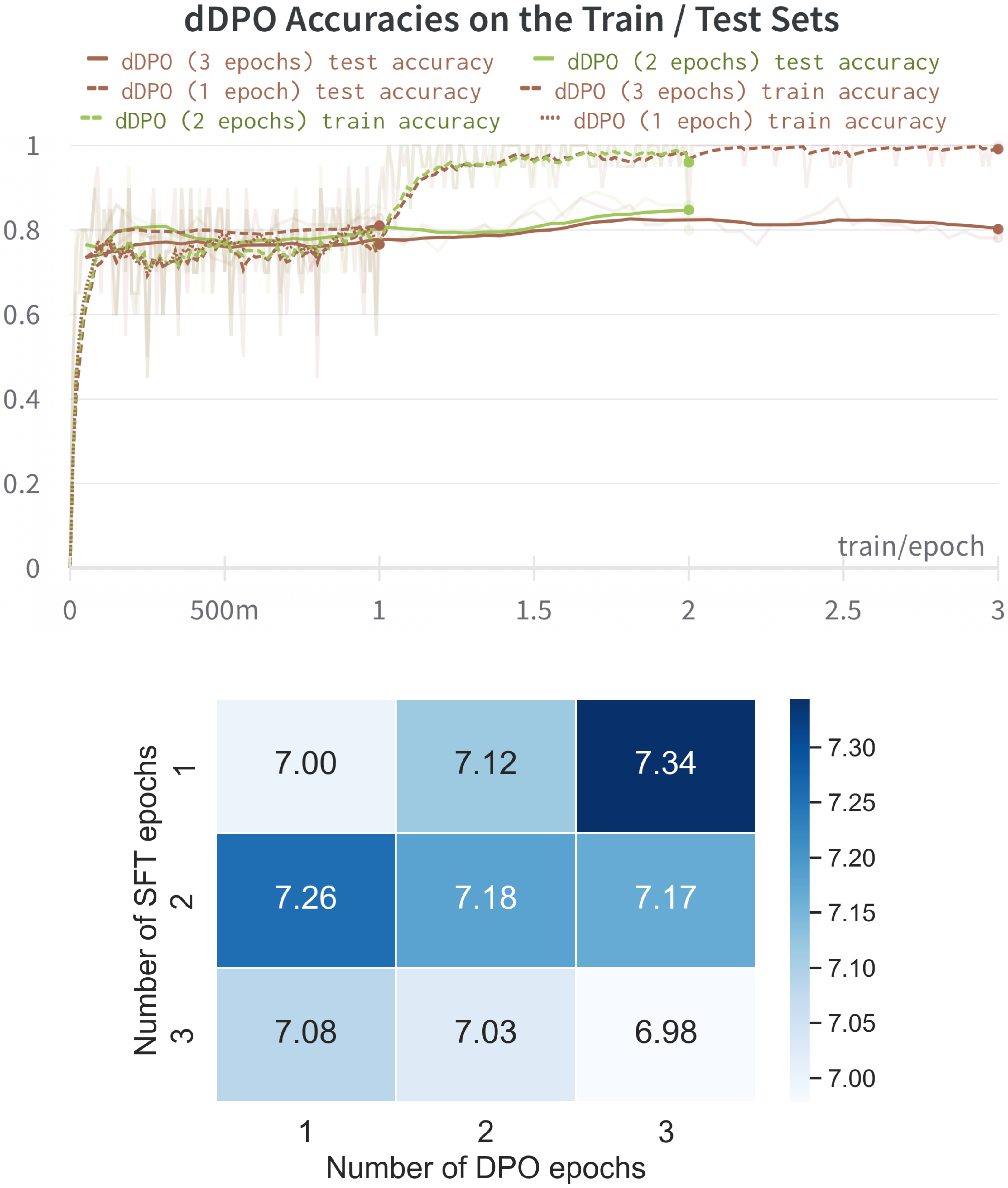
6. Conclusions and Limitations
Section Summary: The study introduces a method to transfer conversational skills from a large language model to a smaller one using direct preference optimization based on AI feedback, skipping complex sampling techniques. This results in Zephyr-7B, a 7-billion-parameter model derived from Mistral-7B, which achieves top performance among similar-sized chat models and even surpasses the much larger Llama2-Chat-70B on key benchmarks, encouraging more focus on efficient open-source models. However, limitations include reliance on GPT-4 for evaluation, which may favor models trained like it or those giving lengthy but inaccurate answers, and a lack of testing on scaling to bigger models where benefits could be greater.
We consider the problem of alignment distillation from an LLM onto a smaller pretrained model. The method avoids the use of sampling-based approaches like rejection sampling or PPO, and distills conversational capabilities with direct preference optimization (DPO) from a dataset of AI feedback. The resulting model $\textsc{Zephyr-7B}$, based on $\textsc{Mistral-7B}$, sets a new state=of-the-art for 7B parameter chat models, and even outperforms $\textsc{Llama2-Chat-70B}$ on MT-Bench. We hope this approach motivates further exploration of the capacity of smaller, open-models by demonstrating their ability to align to the intent of user interactions.
There are several limitations associated with our study. The main one is the use of GPT-4 as an evaluator for the AlpacaEval and MT-Bench benchmarks, which is known to be biased towards models distilled from it, or those that produce verbose, but potentially incorrect responses. Another limitation is examining whether our method scales to much larger models like $\textsc{Llama2-70B}$, where the performance gains are potentially larger.
7. Acknowledgements
Section Summary: The authors express gratitude to several colleagues, including Philipp Schmid for discussions on fine-tuning language models, Olivier Dehaene and Nicolas Patry for help with deploying them, Yacine Jernite for guidance on ethical releases, and Pedro Cuenca for report feedback, as well as Eric Mitchell, Rafael Rafailov, Archit Sharma for expertise on a training technique called DPO, and Teven Le Scao for early experiments. They also thank open-source projects like Mistral, UltraChat, UltraFeedback, Alpaca, and LMSys for their supportive resources and models. Finally, the work relied on the Hugging Face Training Cluster, with special thanks to Guillaume Salou and Guillaume Legendre for ensuring the computing power ran smoothly.
We thank Philipp Schmid for many helpful discussions on aligning LLMs, Olivier Dehaene and Nicolas Patry for their assistance with model deployments, Yacine Jernite for his valuable advice on preparing responsible model releases, and Pedro Cuenca for providing feedback on the report. We are grateful to Eric Mitchell, Rafael Rafailov, and Archit Sharma for sharing their insights on DPO. Teven Le Scao for helping with initial experiments. The Mistral, UltraChat, UltraFeedback, Alpaca, and LMSys projects for their support and for releasing great open models. This work would not have been possible without the Hugging Face Training Cluster, and we thank Guillaume Salou and Guillaume Legendre for their help with making the GPUs go brrrr.
Appendix
Section Summary: This appendix presents qualitative examples comparing responses from two AI model variants—dSFT and dDPO—using prompts from the MT-Bench dataset and tougher adversarial ones that test instruction-following, misleading premises, and harmful requests, with figures illustrating how dDPO often performs better, such as in math tasks or polite refusals, though safety could improve with more targeted training. It includes an ablation study showing that skipping the initial supervised fine-tuning (SFT) step before direct preference optimization (DPO) significantly drops performance on benchmarks like MT-Bench and AlpacaEval, as the pure DPO model fails to properly apply chat formats. The section ends with a detailed list of references to foundational papers and tools in language model research.
A.1 Qualitative Examples
To qualitatively compare the responses from our dSFT and dDPO models, we choose prompts from a few domains of MT-Bench, as well as some adversarial prompts to test each model's capability to follow instructions with false premises or harmful intent. Completions for the adversarial prompts were generated with nucleus sampling(top- $p=0.95$) and $T=0.7$.
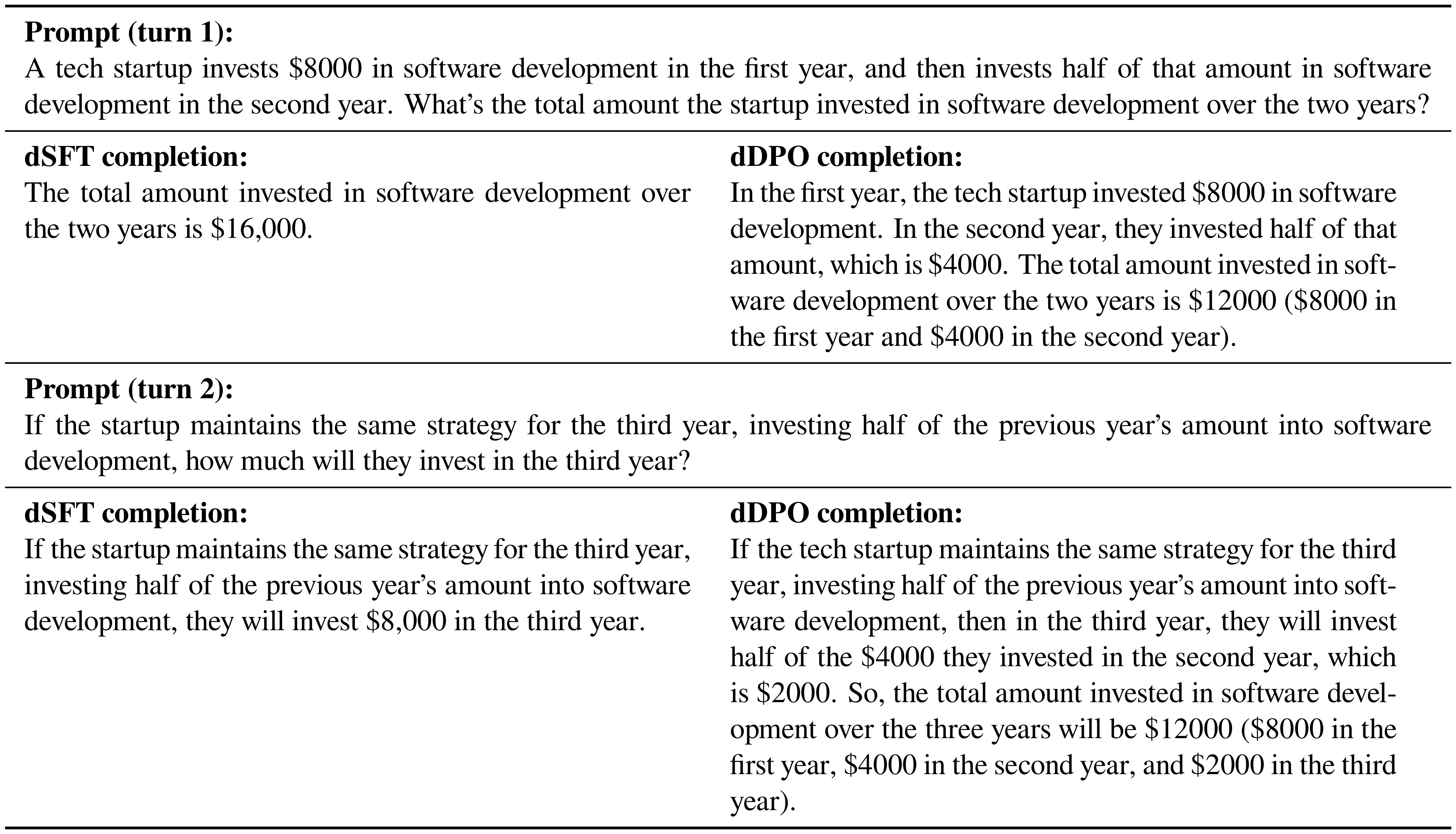


A.2 SFT is a required step before DPO
In Table 3 we ran an ablation to see whether SFT is necessary prior to the DPO step. We observed a significant reduction in performance in both the MT-Bench and AlpacaEval scores when the SFT step is skipped. After a qualitative evaluation of the MT-Bench generations, we observe that the pure DPO model struggles to learn the chat template:

References
[1] Wang, Ben and Komatsuzaki, Aran (2021). GPT-J-6B: A 6 billion parameter autoregressive language model.
[2] Touvron et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288.
[3] Guilherme Penedo et al. (2023). The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only. arXiv:2306.01116.
[4] Jiang et al. (2023). Mistral 7B. arXiv:2310.06825.
[5] De Vries, Harm (2023). Go smol or go home. https://www.harmdevries.com/post/model-size-vs-compute-overhead/.
[6] Taori et al. (2023). Alpaca: A strong, replicable instruction-following model. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html. 3(6). pp. 7.
[7] Chiang et al. (2023). Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality*.
[8] Gudibande et al. (2023). The False Promise of Imitating Proprietary LLMs. arXiv:2305.15717.
[9] Zheng et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685.
[10] Li et al. (2023). AlpacaEval: An Automatic Evaluator of Instruction-following Models.
[11] Rafailov et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv:2305.18290.
[12] Schulman et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
[13] Ding et al. (2023). Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. arXiv:2305.14233.
[14] Cui et al. (2023). UltraFeedback: Boosting Language Models with High-quality Feedback. arXiv:2310.01377.
[15] Yuntao Bai et al. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv:2204.05862.
[16] Mosaic ML (2023). Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs. https://www.mosaicml.com/blog/mpt-7b.
[17] Together AI (2023). Releasing 3B and 7B RedPajama-INCITE family of models including base, instruction-tuned and chat models. https://together.ai/blog/redpajama-models-v1.
[18] Wang et al. (2023). Self-Instruct: Aligning Language Models with Self-Generated Instructions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13484–13508.
[19] Xu et al.. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304. 12244.
[20] Team, Xwin-Lm (2023). Xwin-LM.
[21] Yann Dubois et al. (2023). AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback. arXiv:2305.14387.
[22] Edward Beeching et al. (2023). Open LLM Leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
[23] Yao Fu et al. (2023). Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models' Reasoning Performance. arXiv:2305.17306.
[24] Sedoc et al. (2019). ChatEval: A Tool for Chatbot Evaluation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). pp. 60–65. http://aclweb.org/anthology/N19-4011.
[25] (2023). FastEval. https://github.com/FastEval/FastEval.
[26] Ouyang et al. (2022). Training language models to follow instructions with human feedback. pp. 27730–27744. arXiv:2203.02155.
[27] Chung et al. (2022). Scaling Instruction-Finetuned Language Models. arXiv:2210.11416.
[28] Sanh et al. (2021). Multitask Prompted Training Enables Zero-Shot Task Generalization. arXiv:2110.08207.
[29] von Werra et al. (2020). TRL: Transformer Reinforcement Learning.
[30] Samyam Rajbhandari et al. (2020). ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. arXiv:1910.02054.
[31] Dao, Tri (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.
[32] Edward J. Hu et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
[33] Clark et al. (2018). Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge.
[34] Zellers et al. (2019). HellaSwag: Can a Machine Really Finish Your Sentence?.
[35] Hendrycks et al. (2021). Measuring Massive Multitask Language Understanding.
[36] Lin et al. (2022). TruthfulQA: Measuring How Models Mimic Human Falsehoods.
[37] Tim Dettmers et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314.
[38] OpenAI (2023). GPT-4 Technical Report. arXiv:2303.08774.