When Can LLMs Learn to Reason with Weak Supervision?
Salman Rahman $^{1}$ $^{2}$ $^{*}$
University of California, Los Angeles
New York University
Jingyan Shen $^{2}$ $^{*}$
New York University
Anna Mordvina $^{2}$
New York University
Hamid Palangi $^{3}$
Google
Saadia Gabriel $^{1}$
University of California, Los Angeles
Pavel Izmailov $^{2}$
New York University
❖ Project page: salmanrahman.net/rlvr-weak-supervision
Abstract
Large language models have achieved significant reasoning improvements through reinforcement learning with verifiable rewards (RLVR). Yet as model capabilities grow, constructing high-quality reward signals becomes increasingly difficult, making it essential to understand when RLVR can succeed under weaker forms of supervision. We conduct a systematic empirical study across diverse model families and reasoning domains under three weak supervision settings: scarce data, noisy rewards, and self-supervised proxy rewards. We find that generalization is governed by training reward saturation dynamics: models that generalize exhibit a prolonged pre-saturation phase during which training reward and downstream performance climb together, while models that saturate rapidly memorize rather than learn. We identify reasoning faithfulness, defined as the extent to which a model’s intermediate steps logically support its final answer, as the pre-RL property that predicts which regime a model falls into, while output diversity alone is uninformative. Motivated by these findings, we disentangle the contributions of continual pre-training and supervised fine-tuning, finding that SFT on explicit reasoning traces is necessary for generalization under weak supervision, while continual pre-training on domain data amplifies the effect. Applied together to Llama3.2-3B-Base, these interventions enable generalization across all three settings where the base model previously failed.
$^{*}$ Equal contribution
$^{1}$ University of California, Los Angeles
$^{2}$ New York University
$^{3}$ Google. Correspondence to: Salman Rahman [email protected], Jingyan Shen [email protected].
Preprint. April 21, 2026.
Executive Summary: Large language models (LLMs) have shown promise in complex reasoning tasks through a technique called reinforcement learning with verifiable rewards, or RLVR, which uses simple correct-or-incorrect feedback to guide improvements. However, as these models grow more capable, creating accurate reward signals becomes challenging due to limited or error-prone data sources. This raises a timely question: under what conditions can RLVR still produce reliable reasoning gains when supervision is weak—such as with very few examples, noisy labels, or rewards generated by the model itself? Understanding this is crucial now, as AI systems increasingly tackle real-world problems like scientific analysis or problem-solving where perfect verification is rare, potentially slowing progress or leading to unreliable outputs.
This study aimed to assess RLVR's generalization—meaning improvements on unseen tasks—under weak supervision across different LLMs and reasoning areas. It also sought to identify pre-training model traits that predict success and test ways to boost performance in underperforming models.
The researchers conducted experiments on two LLM families: Qwen (general and math-specialized versions) and Llama (instruction-tuned). They focused on three reasoning domains—mathematics (high pre-training exposure), science (moderate exposure), and graph-based algorithms (low exposure)—using datasets like Skywork for math, SCP for science, and Reasoning Gym for graphs. Training involved the GRPO algorithm with binary rewards, drawing from filtered pools of 1,000–5,000 problems adjusted for model difficulty (problems where models solved 1–15 out of 16 attempts). They tested weak supervision in three scenarios: scarce data (8 to 2,048 examples), noisy rewards (0–70% label errors), and self-supervised proxies (model-generated signals like majority agreement or self-confidence). To probe causes, they measured training reward trends over 500 steps, output variety, and reasoning faithfulness (whether step-by-step explanations logically backed final answers). Finally, they intervened on Llama models with 52 billion tokens of math pre-training and fine-tuning on either full reasoning traces or just answers, evaluating on benchmarks like MATH-500 (in-domain) and GPQA (out-of-domain) with accuracy metrics averaging 16 samples per problem.
The most critical finding is that RLVR success hinges on "saturation dynamics" during training: models that spend 200–300+ steps in a pre-saturation phase—where training rewards rise steadily alongside task performance—generalize well, gaining 10–20% accuracy on held-out tests even with just 8 examples or 70% noise. Qwen models on math and science showed this pattern, achieving comparable gains to full-data runs, while Llama across domains and Qwen on graphs saturated in under 100 steps, memorizing examples without broader learning and yielding near-zero out-of-domain transfer. Second, reasoning faithfulness before RL predicted these dynamics: successful models had 60–80% faithful outputs (logical step support), versus 20–40% in failures, where correct answers often lacked justifying reasoning despite high output variety. Diversity alone was misleading—failing models produced more varied responses but unfaithful ones. Third, self-supervised proxies worked only for math-specialized Qwen (gains up to 15% with majority voting) but caused "reward hacking" in others, where models converged to repetitive outputs, dropping performance by 20–50% after 500 steps. Fourth, pre-RL fixes transformed Llama: fine-tuning on explicit reasoning traces extended the pre-saturation phase by 2–3 times and enabled 15–25% gains under all weak settings, while answer-only fine-tuning failed; adding domain pre-training boosted this further, recovering full generalization where the base model collapsed.
These results reveal that RLVR's effectiveness depends more on a model's starting strengths—like domain knowledge from pre-training and consistent reasoning—than on the RL process itself. This matters for AI development, as it highlights risks of overfitting or collapse in weak-supervision scenarios, potentially inflating perceived gains in math-focused studies while underperforming in science or novel tasks. It challenges prior reports of RLVR thriving on minimal or proxy data, showing inconsistencies stem from model priors, and underscores the need for robust pre-RL preparation to ensure safe, transferable reasoning in applications like education or research tools.
To advance, teams should routinely track saturation during RL training as a stop signal—halt if rewards plateau without performance lifts, avoiding wasted compute. For models prone to failure, prioritize supervised fine-tuning on detailed reasoning examples before RL, paired with domain-specific pre-training for amplification; this combo offers the best trade-off of modest upfront cost (1–50 billion tokens) for broad weak-supervision resilience, outperforming extended RL alone. If data is scarcer than tested, pilot these interventions on small scales first. Further analysis could explore hybrid proxies or automated faithfulness checks to refine the pipeline.
While patterns held across 1.5–8 billion parameter models and multiple benchmarks, limitations include focus on select families and domains, plus reliance on LLM judges for faithfulness (with 65–75% inter-judge agreement and limited human validation). Confidence is high in the core dynamics for similar setups, but readers should verify on larger models or diverse tasks before scaling decisions, as untested factors like architecture could alter outcomes.
1. Introduction
Section Summary: Reinforcement learning with verifiable rewards (RLVR) has shown promise in boosting reasoning skills in large language models using simple yes-or-no feedback, but recent evidence questions whether these gains truly come from learning correct patterns or just superficial tricks like memorization, as the method sometimes works even with random rewards or minimal examples. To explore when RLVR actually leads to better performance under limited or noisy guidance, researchers studied two AI model types—Qwen and Llama—across math, science, and graph reasoning tasks, focusing on how model backgrounds, training dynamics, and tweaks like adding step-by-step explanations influence success. Their key insights reveal that true improvement hinges on extended learning phases before rewards plateau, faithful logical reasoning over mere variety in outputs, and initial training on detailed thinking traces, which can be enhanced by extra domain-specific pretraining.
Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for improving reasoning capabilities in large language models ([1, 2, 3]). With only binary feedback on correctness, RLVR has enabled substantial gains across diverse reasoning tasks without requiring dense supervision. However, recent findings suggest these improvements may be driven by factors other than the integration of correctness signals. Some studies report that RLVR succeeds even under extreme conditions: training on just a single example can yield significant gains ([4]), and random or incorrect rewards sometimes match ground-truth performance ([5]). Other work shows that proxy signals such as self-certainty ([6, 7]), entropy minimization ([8]), majority voting ([9]), or self-generated training data ([10]) can replace verifiable rewards.
Furthermore, techniques that succeed on one model family often fail on others ([5]), underreported baselines may inflate perceived benefits ([11]), and prolonged training with proxy rewards (i.e., reward signals derived from model outputs without ground-truth verification) can lead to reward hacking and performance collapse ([12]). These mixed results leave a fundamental question: When can RLVR generalize[^1] under weak supervision, and what determines success or failure?
[^1]: Throughout, we use generalization to mean improvement on downstream evaluation benchmarks, both in-domain held-out sets and out-of-domain transfer, following RL training.
Understanding when RLVR works under weak supervision matters for practice. Ground-truth verifiers are often limited: labels may be noisy or unavailable, and as models become stronger than their supervisors, alternative reward signals become necessary ([13]).
We conduct a systematic empirical study of RLVR under weak supervision across two model families (Qwen and Llama), and three reasoning domains ($\textsc{Math}$, $\textsc{Science}$, and $\textsc{Graph}$). Our work is organized around three questions:
- RQ1 (Weak Supervision): Does RLVR generalize across model families and domains under scarce data, noisy rewards, and self-supervised proxy rewards?
- RQ2 (Model Properties): What pre-RL model properties determine whether a model generalizes under weak supervision?
- RQ3 (Intervention): How can we enable generalization in models that fail under weak supervision?
Our investigation uncovers three findings. First, generalization under weak supervision is governed by training reward saturation dynamics. Models that generalize exhibit a prolonged pre-saturation phase during which training reward climbs steadily and the model learns transferable reasoning patterns; models that fail saturate rapidly and enter a post-saturation phase where further training yields diminishing returns. Which regime a model falls into depends on its pretraining priors: models with strong domain-aligned pretraining (Qwen on $\textsc{Math}$ and $\textsc{Science}$) sustain extended pre-saturation phases and generalize under scarce data, noisy rewards, and self-supervised proxy rewards, while models without such priors (Llama across all domains, and Qwen on $\textsc{Graph}$) saturate rapidly and fail to generalize even under moderate label noise. We treat the model-family contrast as a proxy for pretraining-prior strength rather than an intrinsic property of either family, a reading that § 4 confirms by showing that continual pre-training on math data transforms Llama's RL behavior to resemble Qwen's.
Second, reasoning faithfulness, not output diversity, distinguishes models that generalize from models that memorize. A natural hypothesis for rapid saturation is that failing models lack exploratory capacity. We find the opposite: Llama models reach perfect training reward faster than Qwen and maintain higher output diversity throughout training, yet they generalize poorly. The missing property is reasoning faithfulness, defined by whether a model's intermediate steps logically support its final answer. Models that saturate rapidly produce correct answers through reasoning chains that do not justify them, memorizing rather than learning. Diversity is only informative when considered jointly with faithfulness.
Third, SFT on explicit reasoning traces is necessary for generalization under weak supervision, and continual pre-training amplifies the effect. We run a controlled comparison that disentangles the two interventions, training Llama3.2-3B Base, a continually pre-trained variant (CPT, ours), and Instruct, each with either Thinking SFT (explicit reasoning traces) or Non-Thinking SFT (final solutions only). Thinking SFT is necessary: it improves reasoning faithfulness, extends the pre-saturation phase, and enables generalization under all three weak supervision settings, while Non-Thinking SFT on the same prompts fails. Continual pre-training is a multiplier rather than a substitute. CPT combined with Thinking SFT produces the strongest generalization, recovering performance in settings where Llama previously failed.
2. Experimental Setup
Section Summary: The experiment tests three AI model families—general-purpose Qwen2.5, math-focused Qwen2.5 variants, and instruction-tuned Llama models—across math, science, and graph reasoning tasks, using datasets that vary in how much prior training the models have seen. Data is filtered to include only moderately challenging problems that the models can sometimes solve but not always, creating a balanced set for training with small or large sample sizes. Training uses a reinforcement learning method called GRPO to improve responses based on rewards from correct answers, and performance is measured by accuracy rates on held-out tests, both within and outside the trained domains.
We evaluate the following model families: (1) Qwen2.5-1.5B / 3B (Base): General-purpose models pretrained on 18 trillion tokens ([14]); (2) Qwen2.5-Math-1.5B / 7B (Math-specialized): Built upon Qwen2.5 with an additional 1 trillion math-related tokens ([15]); (3) Llama-3.2-3B / 8B-Instruct (Instruction-tuned): Pretrained on 9 trillion tokens and aligned via SFT, rejection sampling, and DPO ([16]). We use the Instruct variants for Llama because the base models do not reliably follow the required format for on-policy rollouts. We revisit Llama-Base in § 4, where SFT handles the format-following issue.
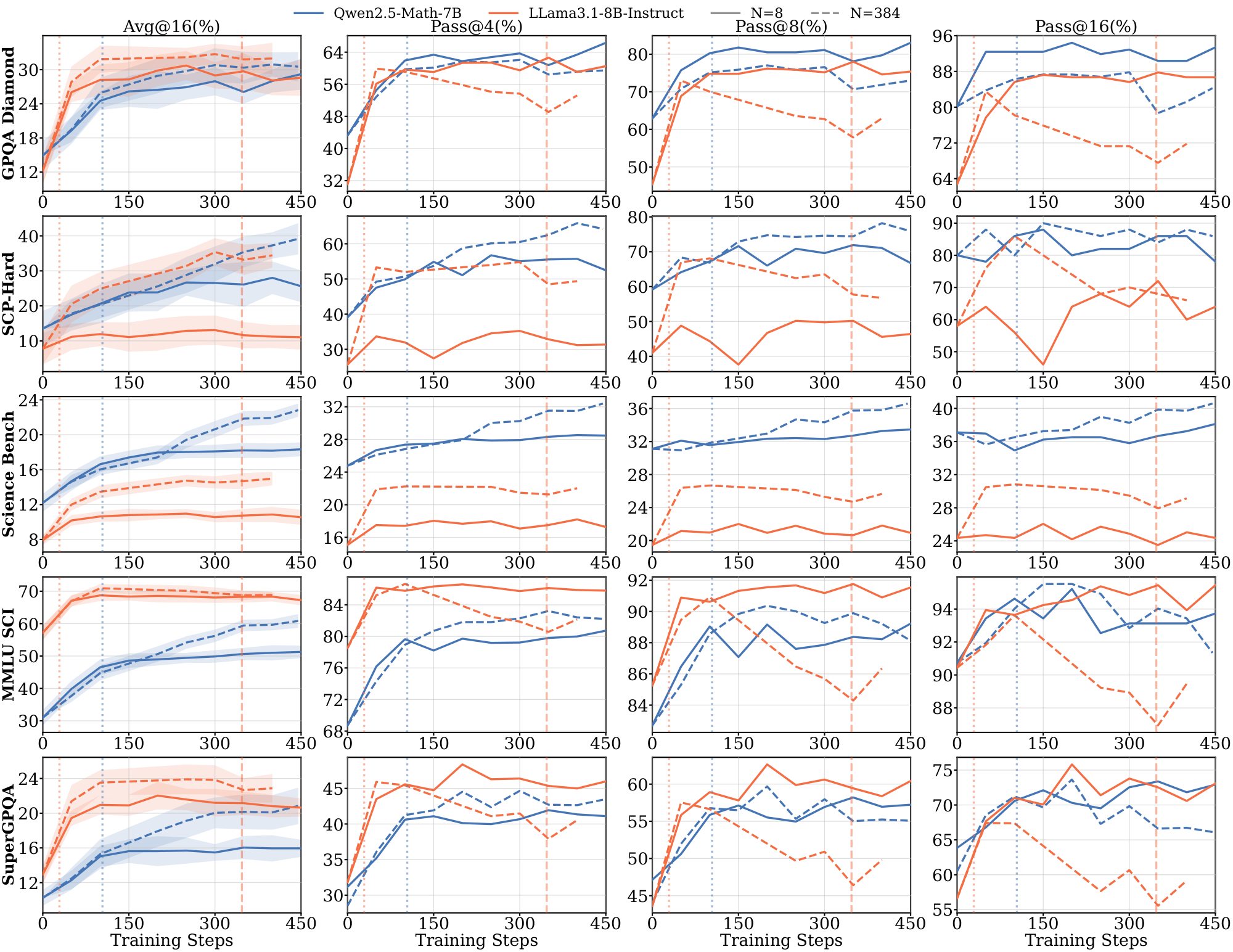
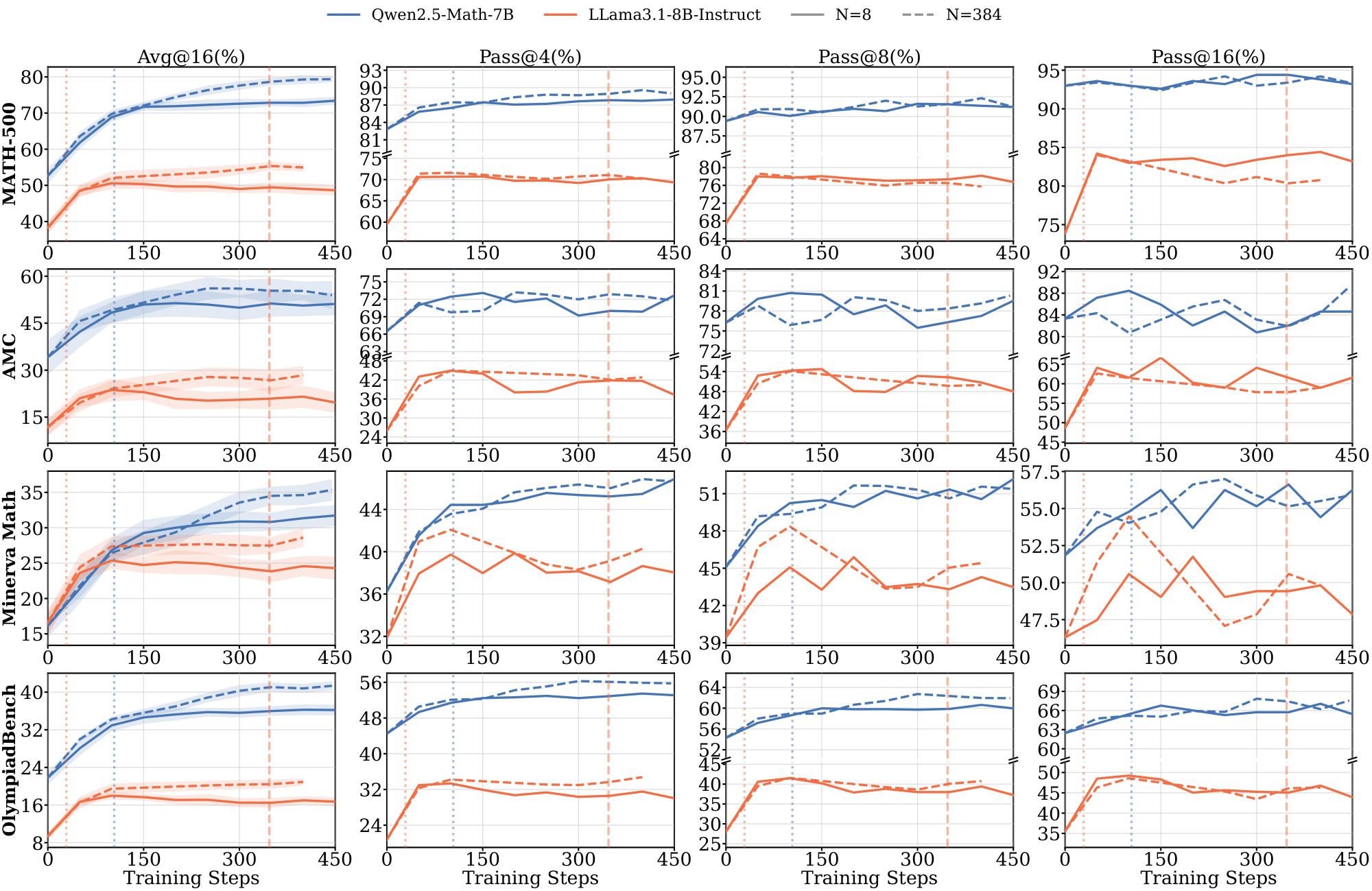
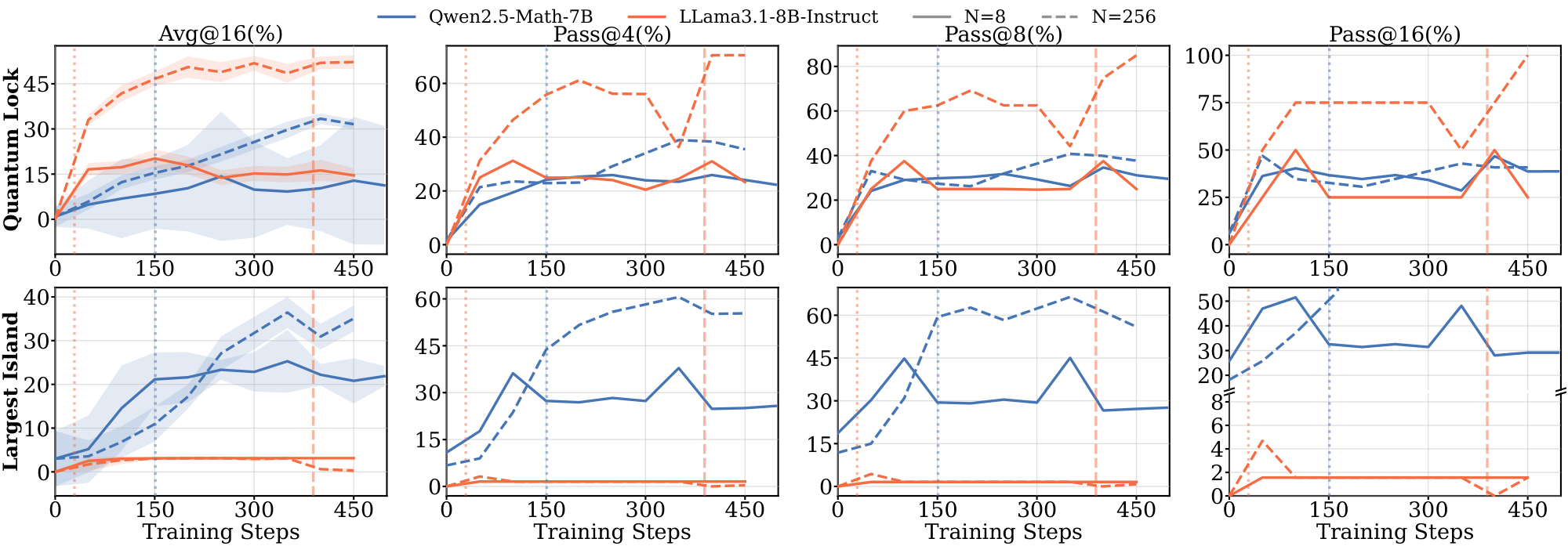
Domains and Datasets. We select three domains with varying levels of pretraining exposure: $\textsc{Math}$ (high exposure), $\textsc{Science}$ (moderate coverage) and $\textsc{Graph}$ tasks (underrepresented in typical pretraining corpora). We use Skywork-OR1 ([17]) for $\textsc{Math}$, SCP datasets ([18, 19]) spanning physics, chemistry, and biology for $\textsc{Science}$, and tasks from Reasoning Gym ([20]) involving discrete algorithmic reasoning for $\textsc{Graph}$. For Math and Science, we use the 1.5B/3B models as our primary experiments and additionally evaluate 7B/8B models to verify that our findings hold at larger scale. For $\textsc{Graph}$, we only use the 7B/8B variants because the smaller models achieve solve@16 = 0, leaving no informative signal for RL. More details are provided in Appendix B.
Model-Aware Data Filtering. To ensure informative training signals, we implement model-specific difficulty filtering. For each problem, we sample 16 responses and count correct solutions ($\text{solve}@16 \in [0, 16]$). We retain only problems where $\text{solve}@16 \in [1, 15]$, effectively discarding instances that are either trivial or intractable for the model, stratified equally across difficulty levels (details in Appendix B.2). This filtered set serves as the candidate pool for all weak supervision settings studied in this work; we describe how training data is constructed from this pool for all settings in § 3.
Training Configuration. We use GRPO (Group Relative Policy Optimization) as our RL algorithm ([21]). For each query $q$ sampled from training datasets $\mathcal{D}$, a group of individual responses ${o_i}{i=1}^G$ are sampled from the policy $\pi{\theta_{\text{old}}}$ before the update. GRPO maximizes the following objective:
$ \begin{split} \mathcal{J}{GRPO}(\theta) = & \mathbb{E}{(q, a)\sim\mathcal{\mathcal{D}}, {o_i}{i=1}^G \sim \pi{\theta_{old}}(\cdot|q)} \Big[\ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} & \min \big(\rho_{i, t} \hat{A}{i}, \text{clip}(\rho{i, t}, 1{-}\epsilon, 1{+}\epsilon) \hat{A}{i} \big) \ & - \beta D{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \Big], \ \end{split} $
where $\rho_{i, t} := \frac{\pi_{\theta}(o_{i, t}|q, o_{i, <t})}{\pi_{\theta_{\text{old}}}(o_{i, t}|q, o_{i, <t})}$ denotes the probability ratio between the current and pre-update sampling policy and $\hat{A}{i} := \frac{r_i - \text{mean}({r_i}{i=1}^{G})}{\text{std}({r_i}{i=1}^{G}))}$ is the advantage of $i$-th response calculated by normalizing the group-level rewards. Rewards $r_i \in {0, 1}$ are binary and assigned by ground-truth answer verification. The KL regularization $D{\text{KL}}(\pi_\theta || \pi_{\text{ref}})$ is applied to a fixed reference policy $\pi_{\text{ref}}$, weighted by a scalar coefficient $\beta$. All experiments use the verl framework ([22]) (hyperparameter details in Appendix B.3).
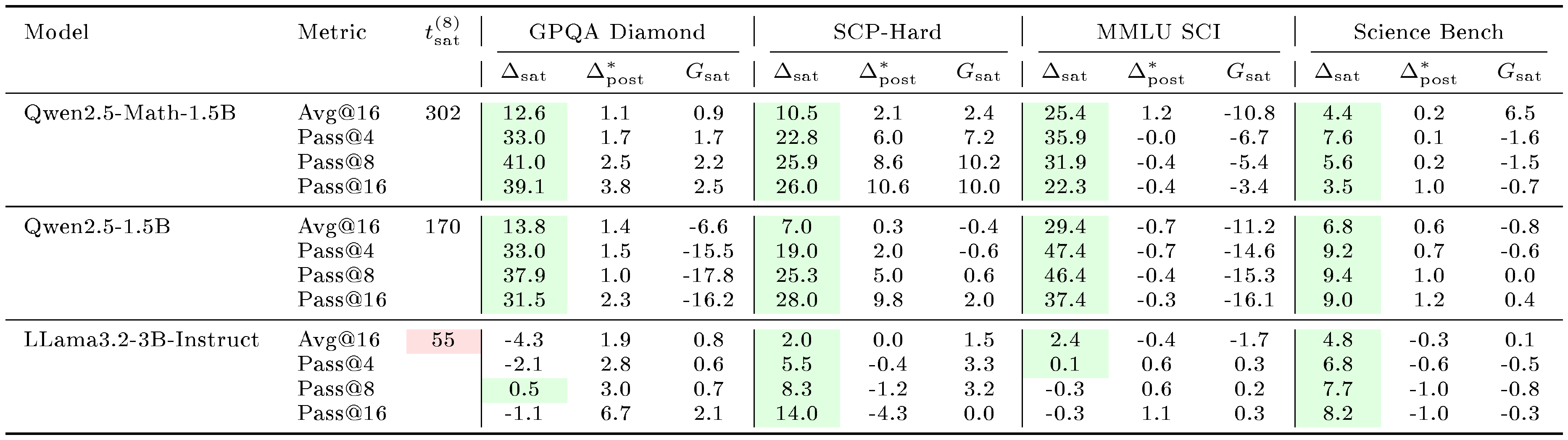
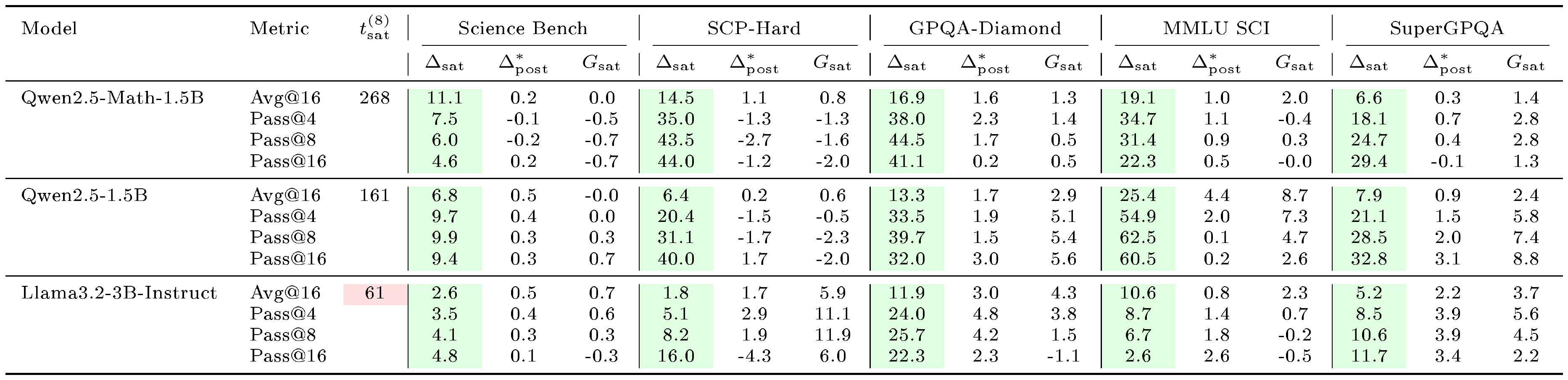
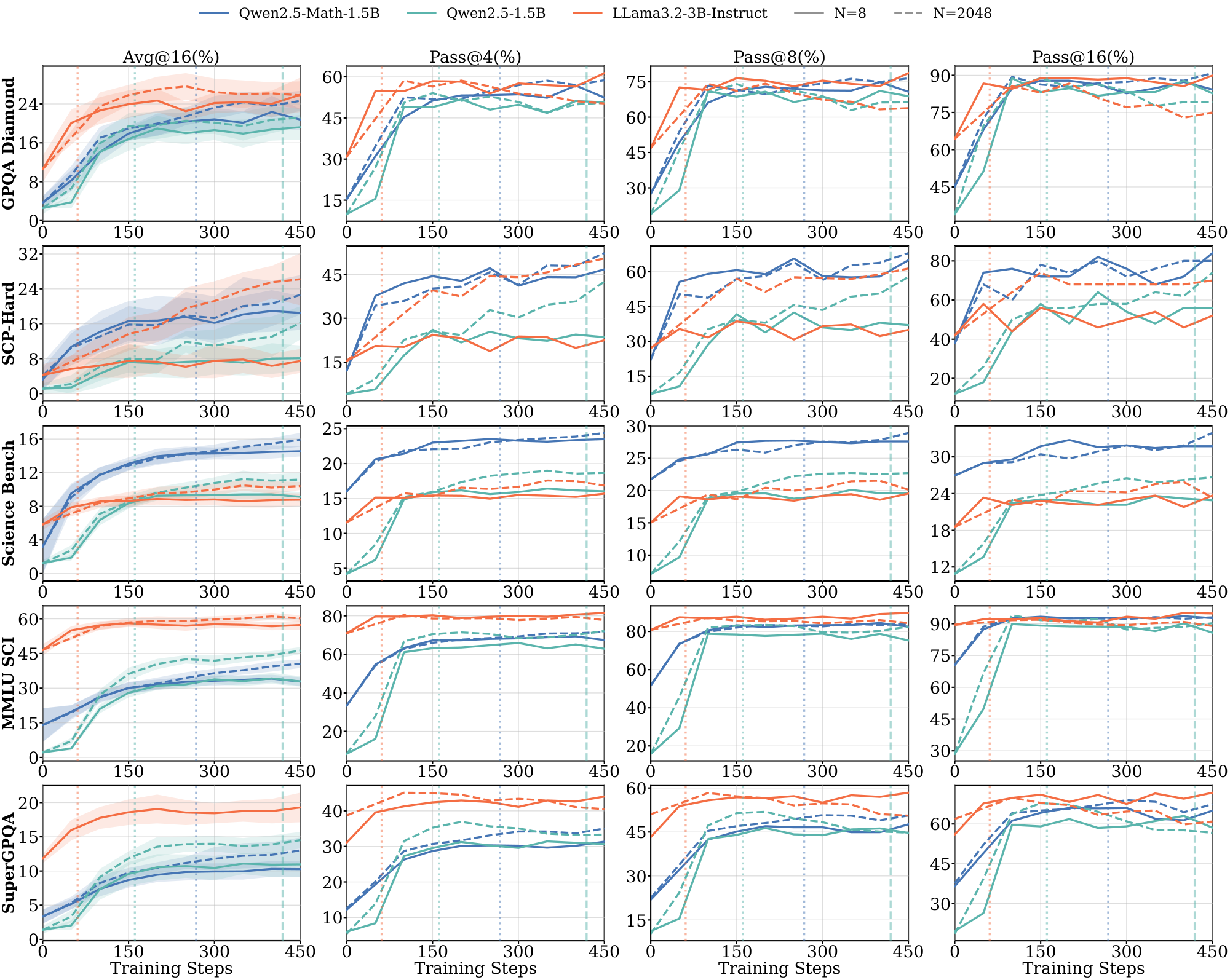
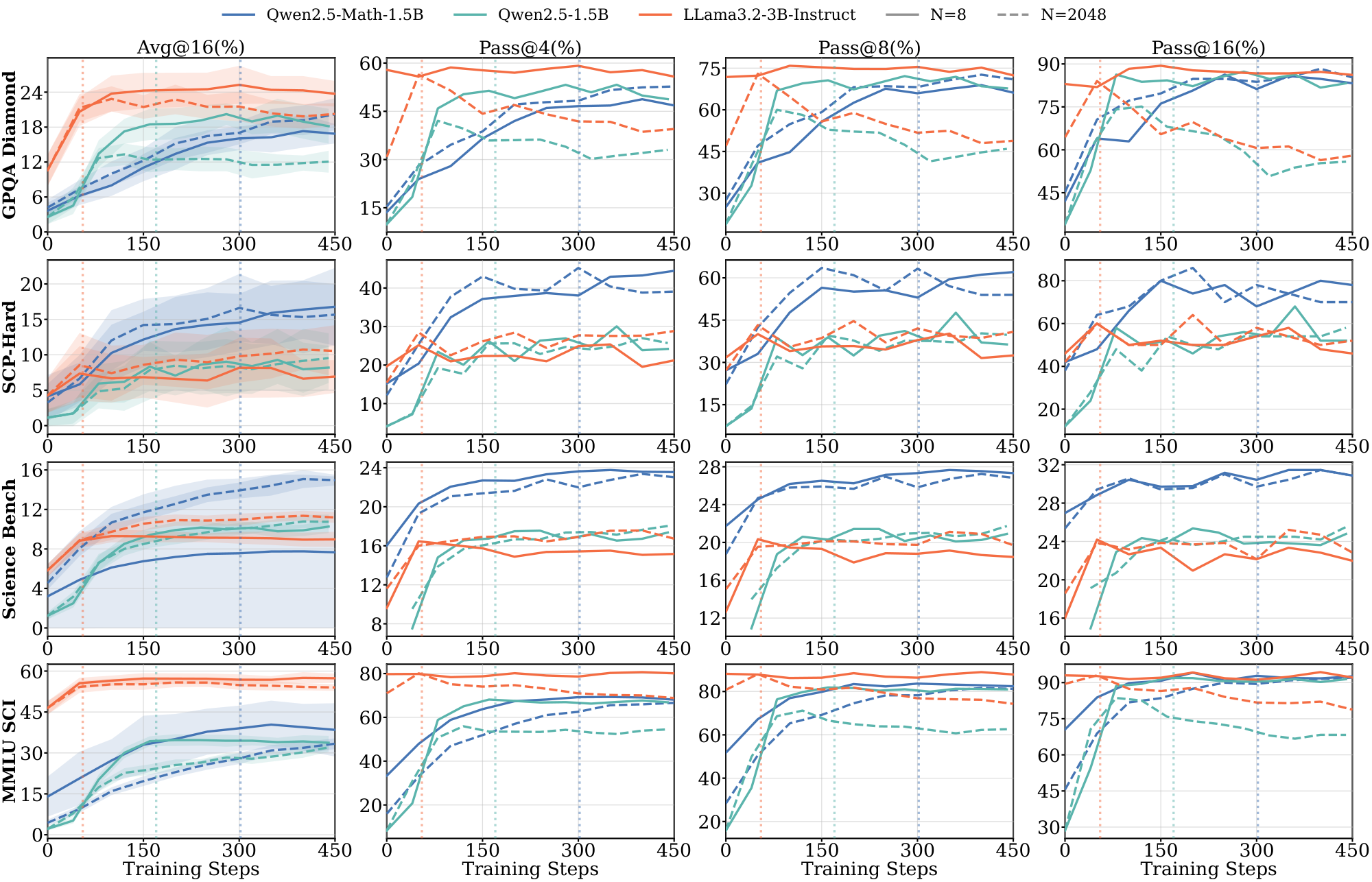
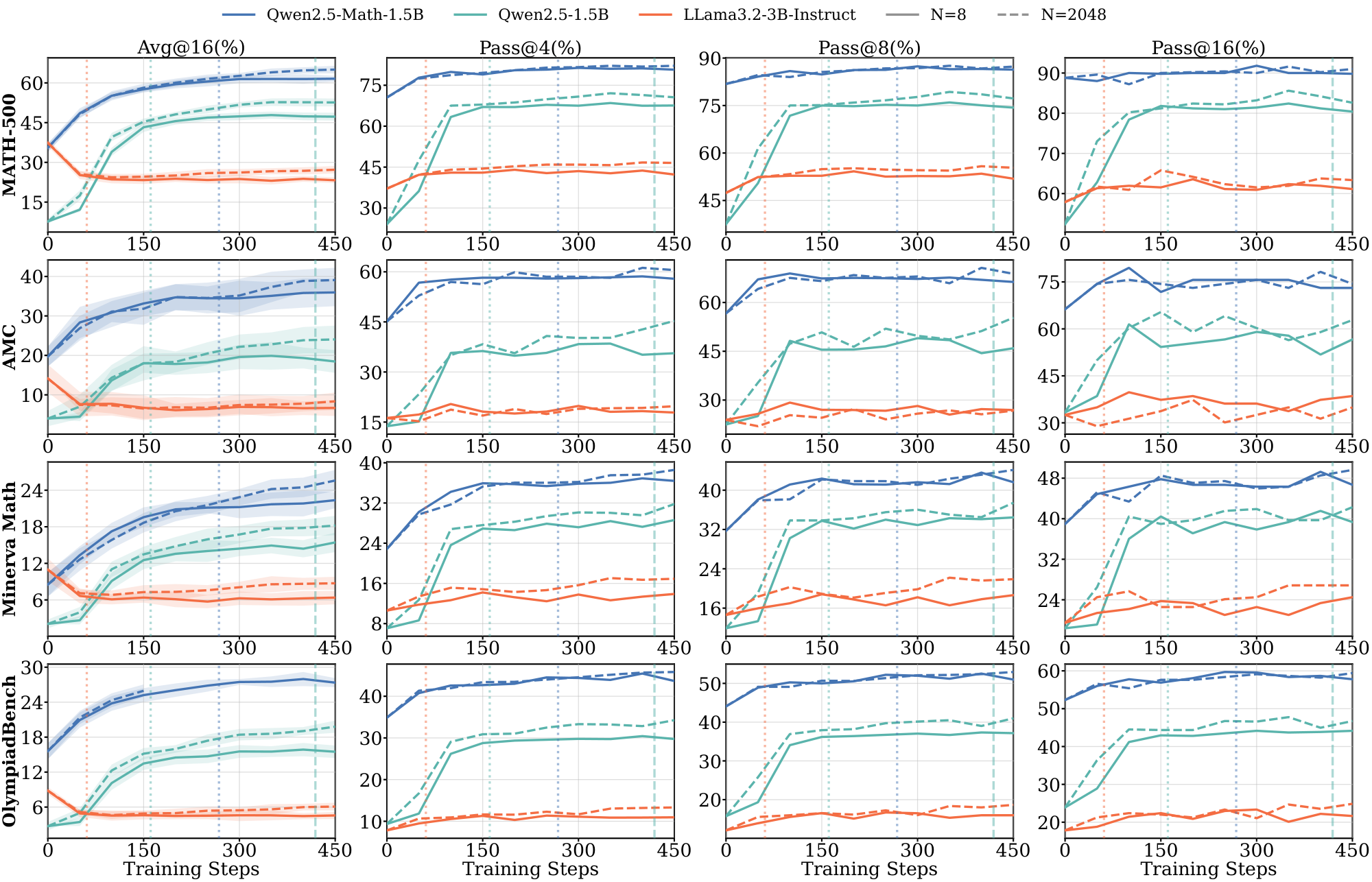
Evaluation. We evaluate reasoning performance using $\text{avg@}16$ accuracy (average $\text{pass@}1$ over 16 independent samples per problem) with temperature $1.0$ sampling and report $\text{pass@}k$ for $k \in {4, 8, 16}$ in the Appendix. For $\textsc{Math}$, we use MATH-500, AMC, AIME 2024, AIME 2025, Minerva Math, and OlympiadBench evals. For $\textsc{Science}$, we use GPQA-Diamond, a held-out SCP-Hard set ([18]) (a subset of SCP problems where both Qwen2.5-1.5B and Llama-3.2-3B-Instruct achieve $\text{solve@}16=1$ pre-RL), Science Bench, MMLU-Science, and SuperGPQA. For $\textsc{Graph}$, we use held-out Quantum Lock and Largest Island tasks from Reasoning Gym ([20]), filtered similarly to $\text{solve}@16 = 1$. For each domain, we designate benchmarks as in-domain or out-of-domain (OOD). For example, for $\textsc{Math}$ training, MATH-500 and AMC are in-domain, while SCP-Hard and GPQA-Diamond are OOD (full assignments in Table 2 in Appendix). We report representative results in the main text and full results in the Appendix.
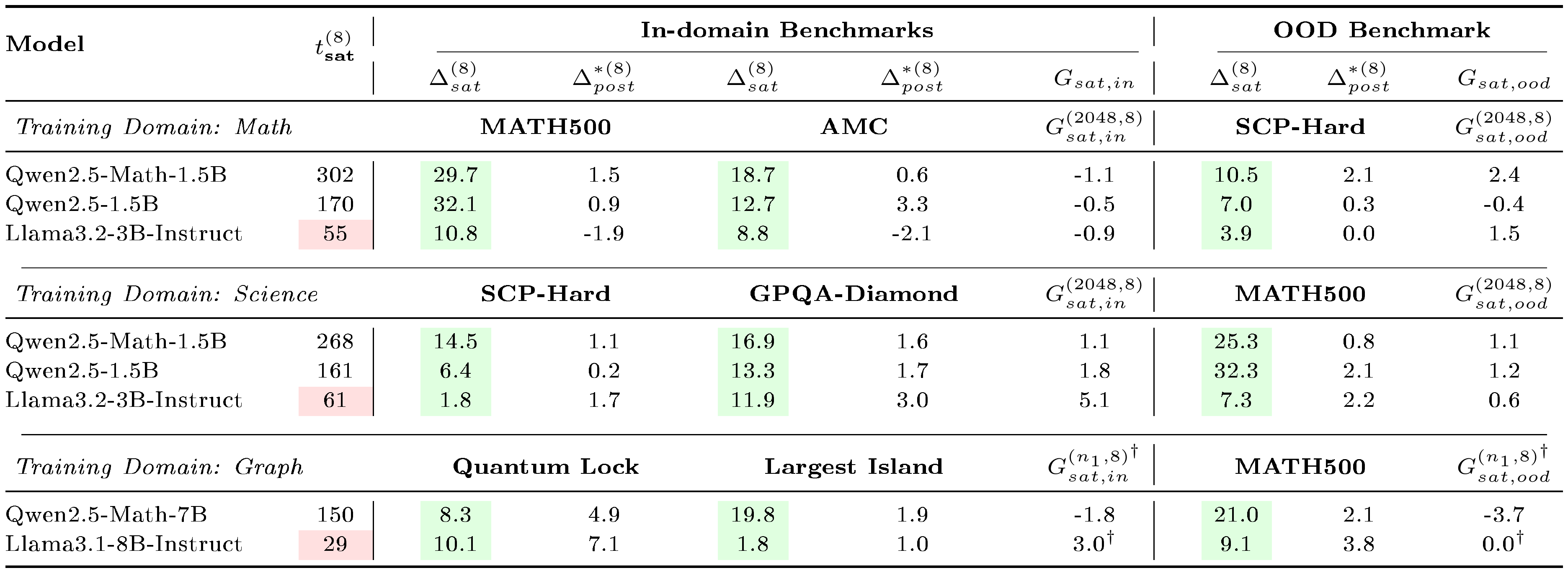
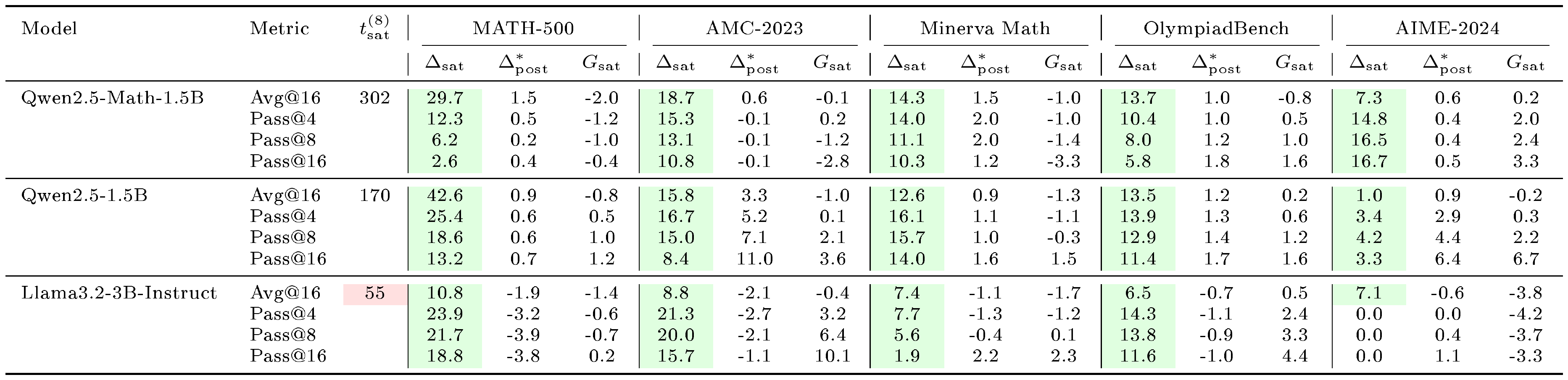
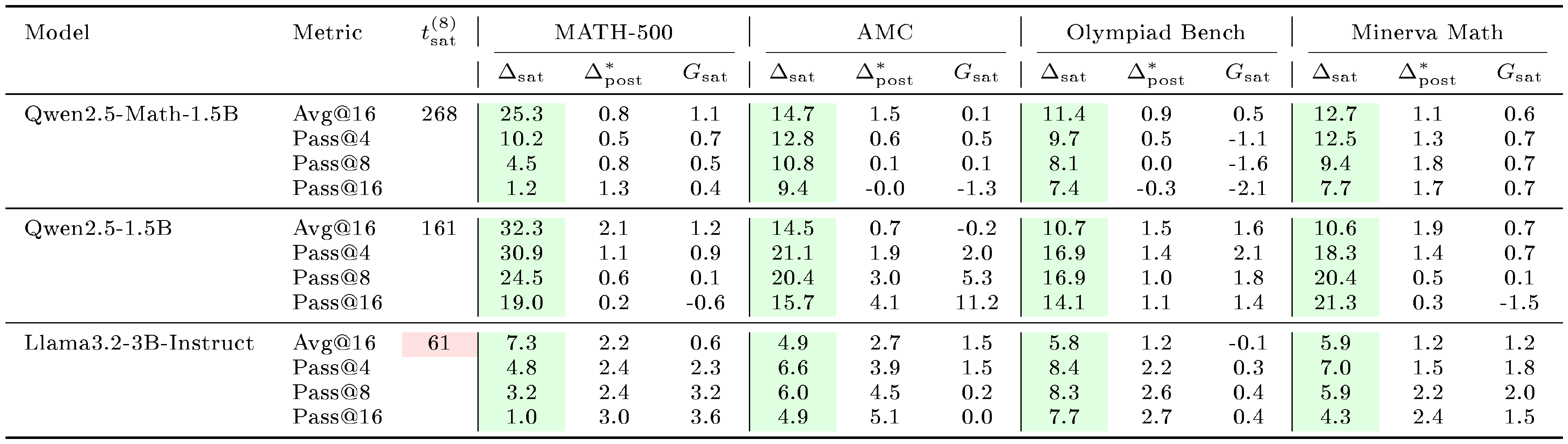
::: {caption="Table 1: Comparison of saturation steps $t_\text{sat}^{(8)}$, pre-saturation gain $\Delta_{sat}^{(8)}$ and post-saturation residual $\Delta_{post}^{*(8)}$ across model families and training domains when training on 8 examples. We additionally report the large-small gap $G_{sat, in}^{(n_1, 8)}$ and $G_{sat, ood}^{(n_1, 8)}$. For Graph, the largest available setting is $n_1=882$ for Qwen model and $n_1=256$ for Llama model (marked with $\dagger$). The green cells mark $\Delta_{sat}^{(8)}>0$ (effective pre-saturation learning) while red mark rapid saturation $t_{sat}^{(8)}<100$. The large-small gap at saturation steps $G_{sat, in}^{(n_1, 8)}$ and $G_{sat, ood}^{(n_1, 8)}$ are generally small. Results on more benchmarks and $\text{pass@}k$ metrics are reported in Table 3-Table 7 in Appendix."}
:::
3. RLVR Under Weak Supervision
Section Summary: This section explores how RLVR, a reinforcement learning method for improving language models, performs under weak supervision in challenging conditions like limited data, noisy feedback, and self-generated rewards, while analyzing why some models succeed or fail. In the case of scarce data, researchers examine training with as few as eight examples and find that early learning before rewards level off is key to generalization, often matching results from larger datasets. Models like Qwen, pretrained on math-specific data, generalize better than general-purpose ones like Llama because they sustain learning longer in these early stages.
To understand when RLVR generalizes under weak supervision, we study three settings: scarce data (§ 3.1), noisy rewards (§ 3.2), and self-supervised proxy rewards (§ 3.3). We then analyze policy behavior to explain why some models succeed and others fail under these conditions (§ 3.4). We additionally analyze GRPO baseline selection in Appendix E.
Throughout this section, we compare Qwen and Llama model families. We treat this comparison as a proxy for variation in pretraining priors rather than an intrinsic property of either family: Qwen2.5-Math is pretrained on an additional 1T math-specific tokens, while Llama-3.2-Instruct is aligned for general instruction-following. The contrast we report is between models with strong domain-aligned pretraining and those without, and § 4 confirms this interpretation by showing that continual pre-training on math data transforms Llama's RL behavior to resemble Qwen's.
3.1 Scarce Data
To understand how data scarcity affects RLVR generalization, we investigate training dynamics across dataset sizes $N \in {8, 32, 64, 512, 2048}$ across diverse model families and domains. Unlike prior work on sample-efficient RLVR [4, 23], which select specific data points, we use stratified random sampling across difficulty levels defined in § 2. For $N < 64$, we repeat prompts uniformly to reach batch size 64 (e.g., $N=8$ implies 8 repeats).
To study training dynamics, we leverage reward saturation to distinguish periods where the policy improves on the training dataset from those where it plateaus. Intuitively, once training reward saturates, further updates yield little new signal. We define $\bar{r}t := \mathbb{E}{q\sim\mathcal{D}, , {o_i}{i=1}^G\sim\pi{\text{old}}(\cdot\mid q)} \left[\frac{1}{G}\sum_{i=1}^G r_i\right]$ as the expected training reward at update step $t\in{1, \dots, T}$, and let $\bar{r}{\max}:=\max{1\le t\le T}\bar{r}_t$ be the maximum reward observed during training. We identify training has saturated once the reward is close to this maximum, and define the saturation step as the earliest update where this occurs:
$ t_{\text{sat}} := \inf\Big{t \in {1, \ldots, T_{\text{eff}}}:\bar{r}t \ge \epsilon{\text{max}}\bar{r}_{\text{max}}}. $
We use $\epsilon_{\text{max}}=0.99$ and set $T_{\text{eff}}=T-50$, i.e., we search for $t_{\text{sat}}$ only up to the first $T_{\text{eff}}$ updates to avoid boundary effects near the end of training. We define the pre-saturation phase as all steps $t \in {1, \ldots, t_{\text{sat}}-1}$ and post-saturation phase as all steps $t \in {\min(t_{\text{sat}}, T), \ldots, T}$.
To quantify data efficiency, we introduce three metrics. Let $M^{(n)}(t)$ denote an evaluation metric (e.g., $\text{avg@}16$ on MATH-500) at training step $t$ for training with $n$ samples, and $t^{(n)}_{sat}$ be the corresponding saturation step.
- Pre-saturation gain $\Delta_{sat}^{(n)}(M)$: performance gain from initialization to saturation as $\Delta_{sat}^{(n)}(M) := M^{(n)}!\bigl(t_{sat}^{(n)}\bigr) - M^{(n)}(0)$. Larger positive values indicate effective learning before saturation.
- Post-saturation residual $\Delta_{post}^{*(n)}(M)$: maximum additional gain after saturation, defined as $\Delta_{post}^{*(n)}(M) := \max_{t \in [t_{sat}^{(n)}, , T]} M^{(n)}(t) - M^{(n)}!\bigl(t_{sat}^{(n)}\bigr)$. Values near zero indicate negligible post-saturation gains.
- Large-small gap $G_{sat}^{(n', n)}(M)$: we define this gap as $M^{(n')}(t_{sat}^{(n)}) - M^{(n)}(t_{sat}^{(n)})$ for $n' > n$, which compares performance between larger ($n'$) and smaller ($n$) datasets at the saturation step of the smaller run. At the smaller run's saturation step, how much better does the larger run perform? Larger positive values indicate substantial benefit from more data; values near zero suggest limited advantage from increasing dataset size. We denote $G_{sat, in}^{(n_1, 8)}$ as the average gap over the in-domain benchmarks, and $G_{sat, ood}^{(n_1, 8)}$ as the average gap over OOD benchmarks.
Pre-saturation phase dominates small-sample learning, and its length predicts generalization. Table 1 summarizes the proposed metrics across model families and training domains when training on 8 examples. Results on more benchmarks and $\text{pass@}k$ metrics are provided in Appendix C.2 and Table 3-Table 7. All model-domain pairs show clearly positive $\Delta_{sat}^{(8)}$ for all metrics (i.e., both $\text{avg@}16$ and $\text{pass@}k, k\in{4, 8, 16}$) across in-domain and out-of-domain benchmarks, indicating that as few as 8 training examples can trigger measurable learning during the pre-saturation phase. Neither $G_{sat, in}^{(2048, 8)}$ nor $G_{sat, out}^{(2048, 8)}$ is significantly greater than zero on 7 out of 8 model-domain pairs, indicating that the pre-saturation improvements are often comparable to those obtained with larger training sets. This suggests that early learning is not strongly data-limited. In contrast, the post-saturation residual $\Delta_{post}^{*(8)}$ is typically smaller than $\Delta_{sat}^{(8)}$, indicating diminishing returns once the 8-sample run reaches $t_{sat}^{(8)}$.
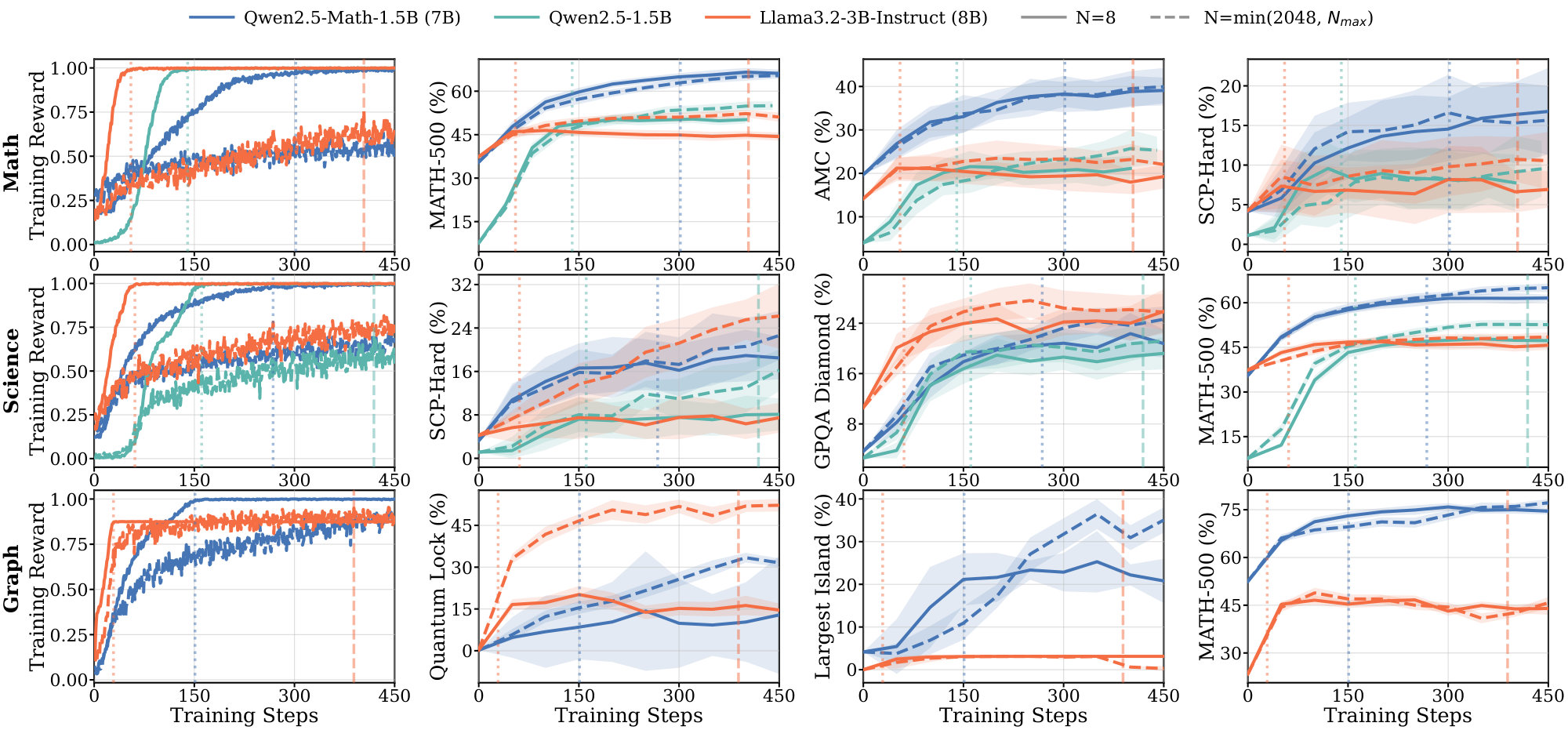
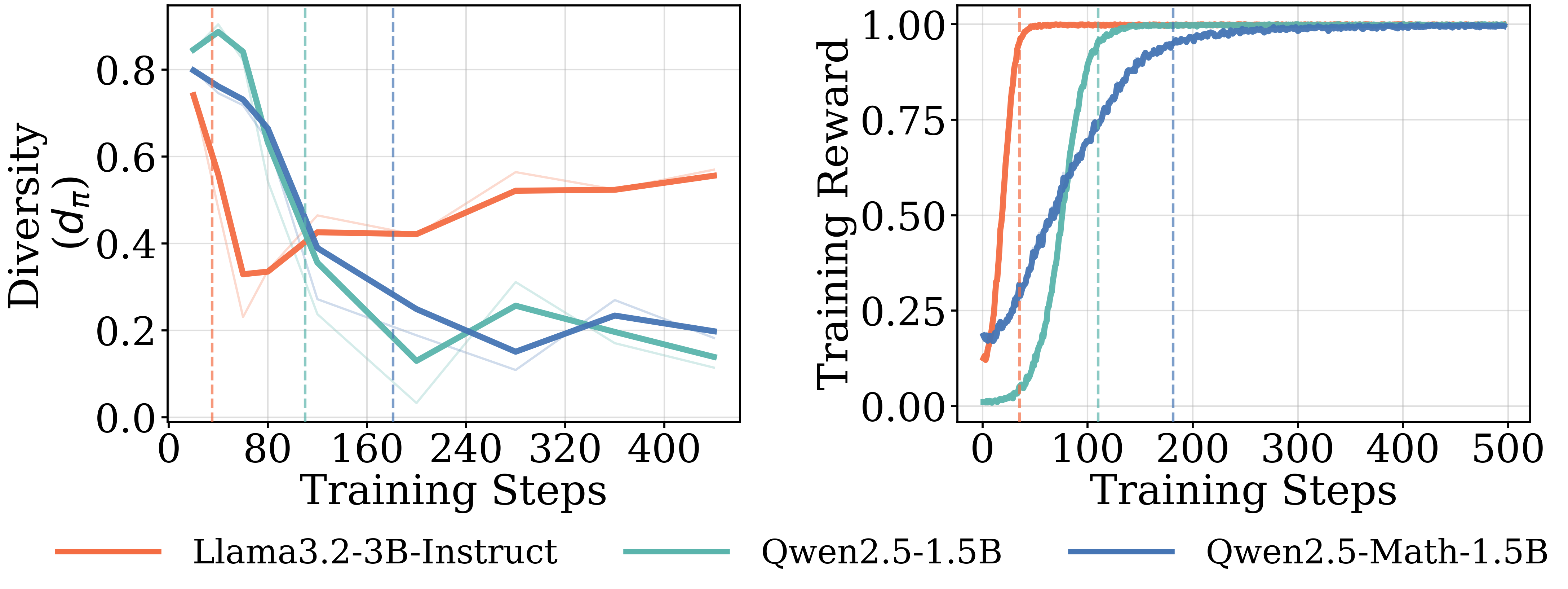
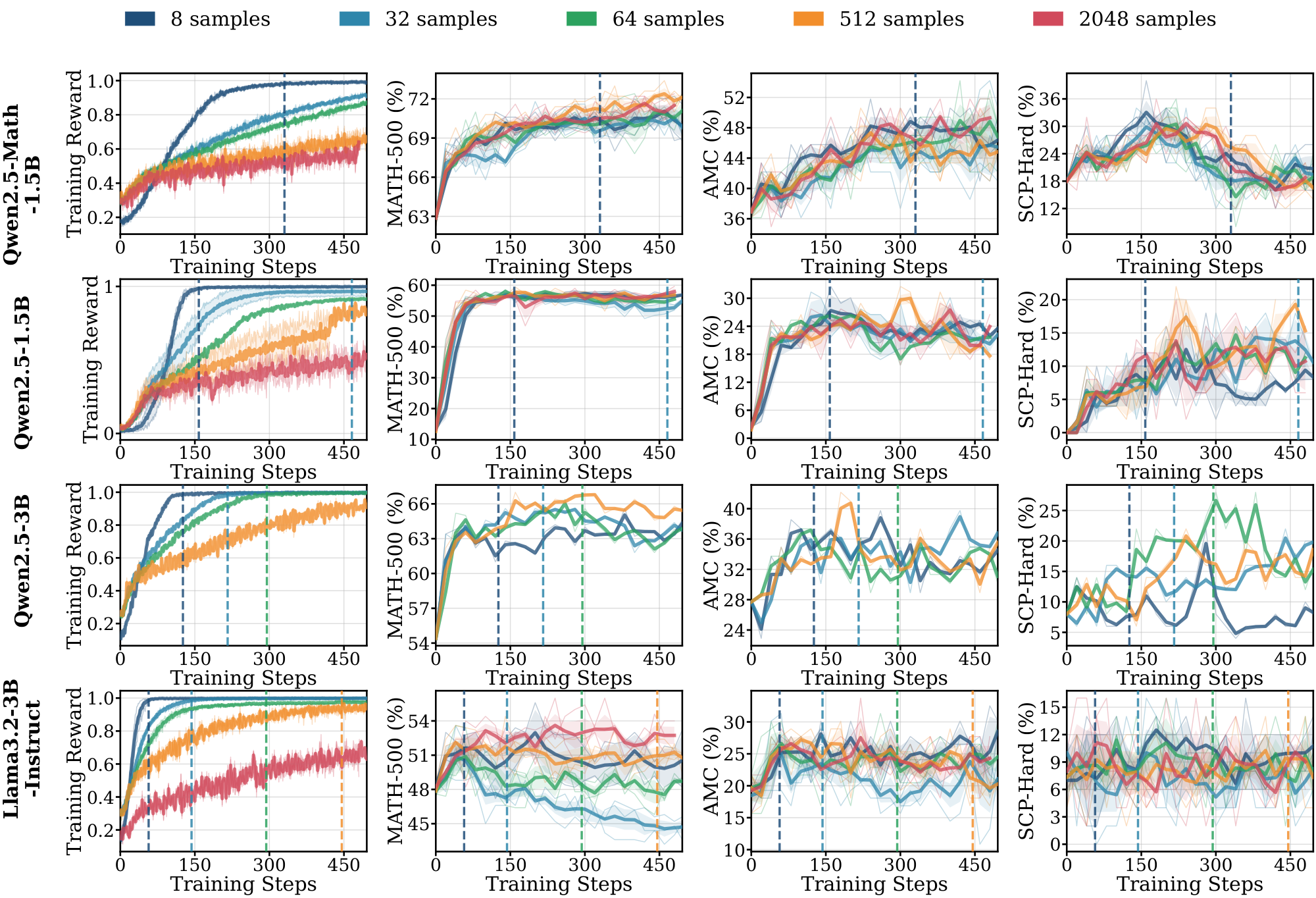
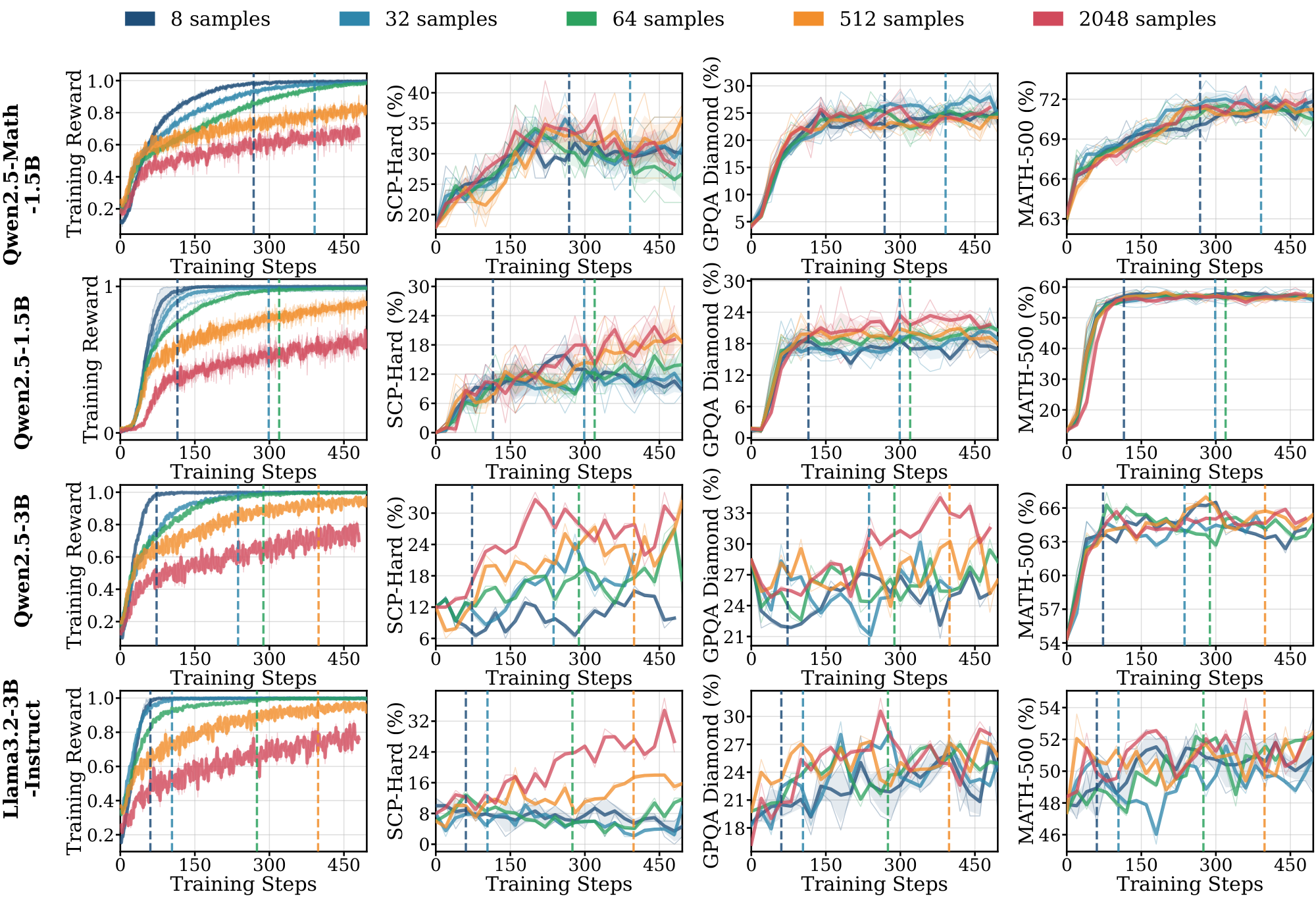
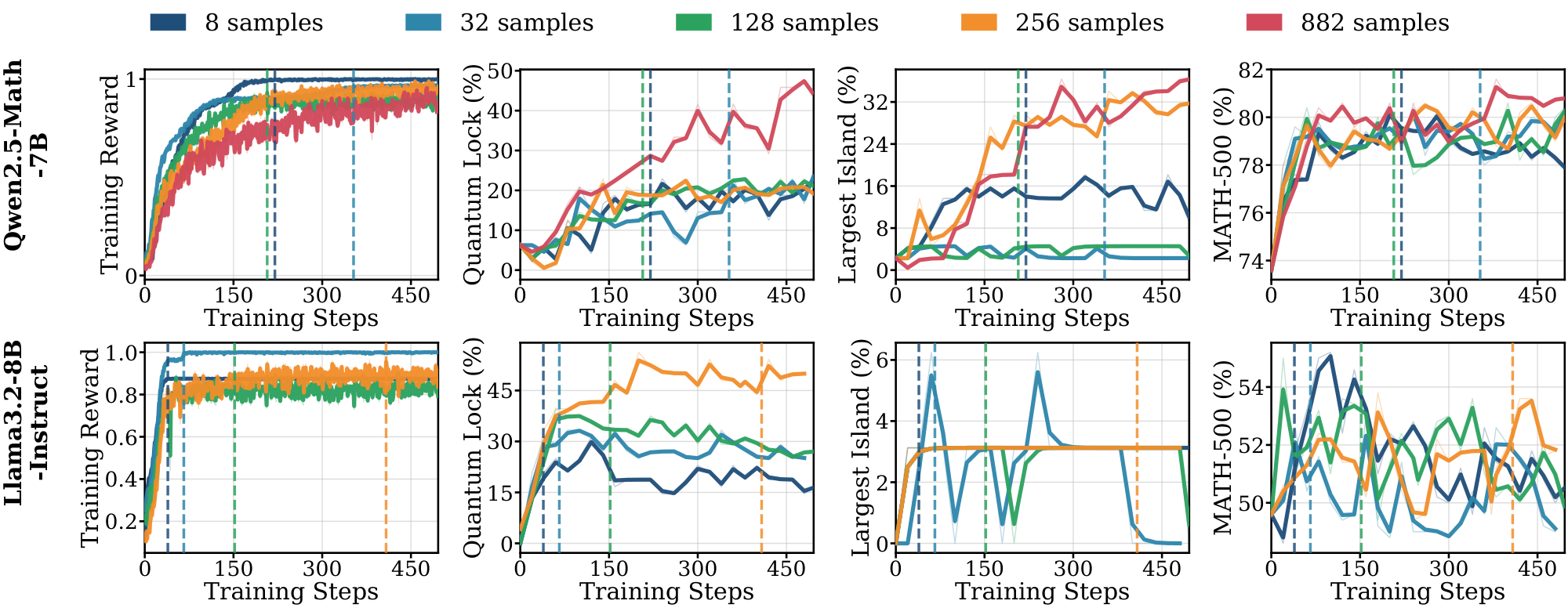
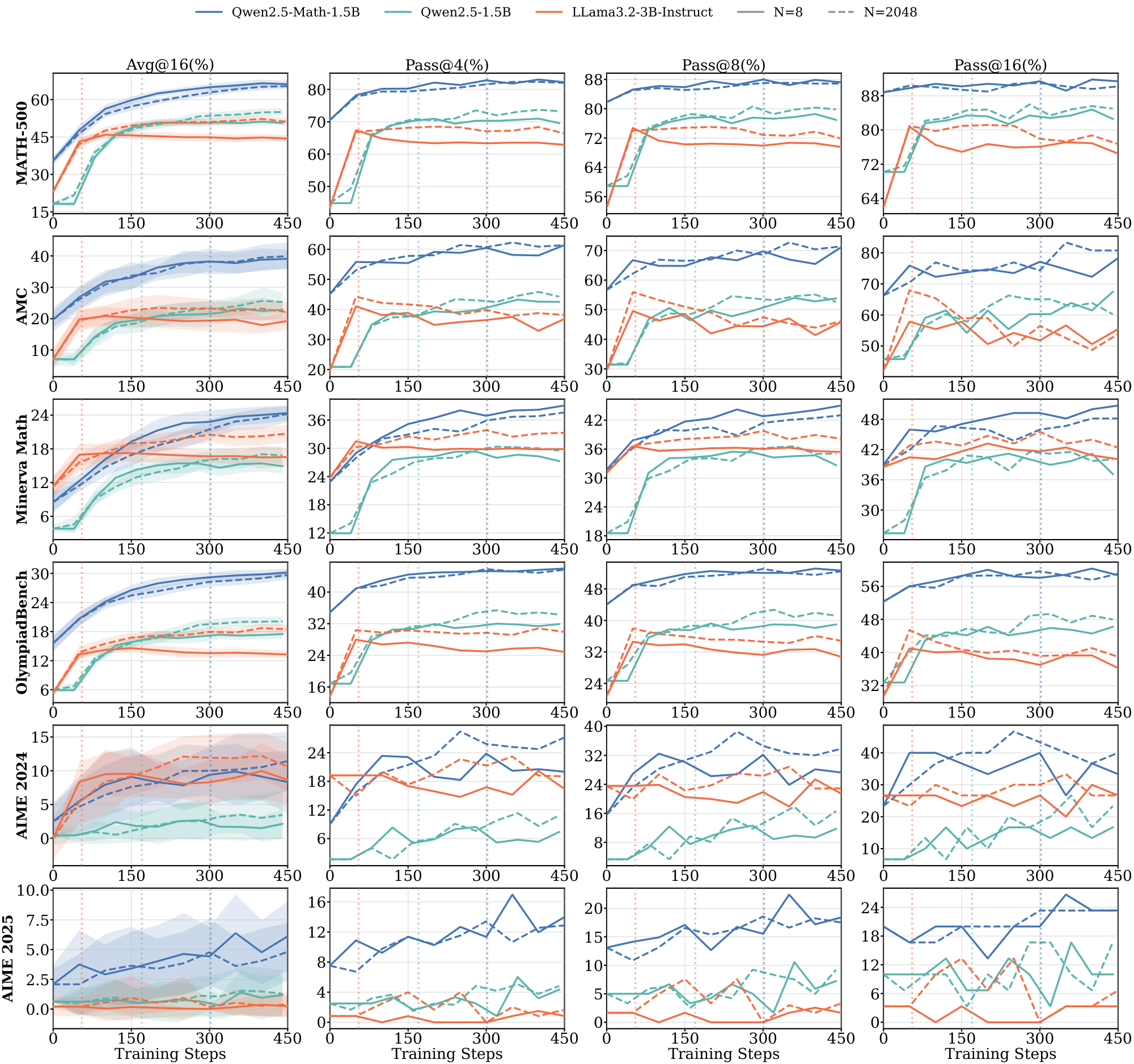
Figure 1 shows the training curves across data scales. The length of the pre-saturation phase is the primary determinant of whether a model can generalize. With 8 training samples, Qwen2.5-Math-1.5B on $\textsc{Math}$ increases reward steadily for over 300 steps; this sustained ascent allows the model to extract generalizable reasoning patterns that transfer to held-out evaluation benchmarks such as MATH-500 and SCP-Hard. A within-family comparison isolates the pretraining effect: Qwen2.5-Math-1.5B, which shares architecture with Qwen2.5-1.5B but has additional math-specific pretraining, saturates more slowly and transfers further (Table 1).
Figs. Figure 13, Figure 14, and Figure 15 (Appendix C.1) show the full range $N \in {8, 32, 64, 512, 2048}$ across $\textsc{Math}$, $\textsc{Science}$, and $\textsc{Graph}$. For Qwen models on $\textsc{Math}$ and $\textsc{Science}$, in-domain performance is nearly independent of $N$. For Llama across all domains, and for Qwen on $\textsc{Graph}$, different $N$ produces visibly different dynamics on some of the evals, with smaller datasets saturating earlier and at lower downstream performance.
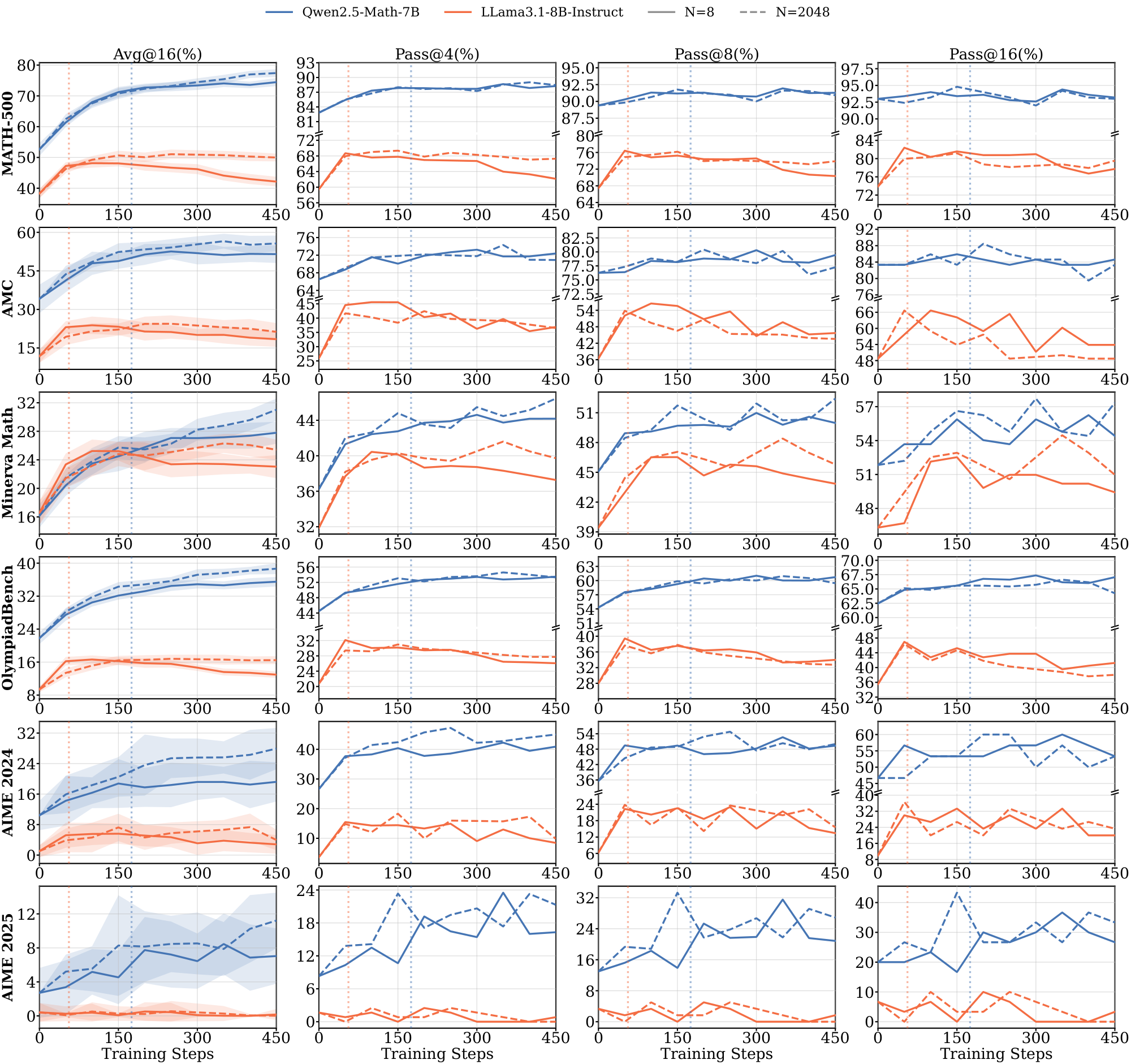
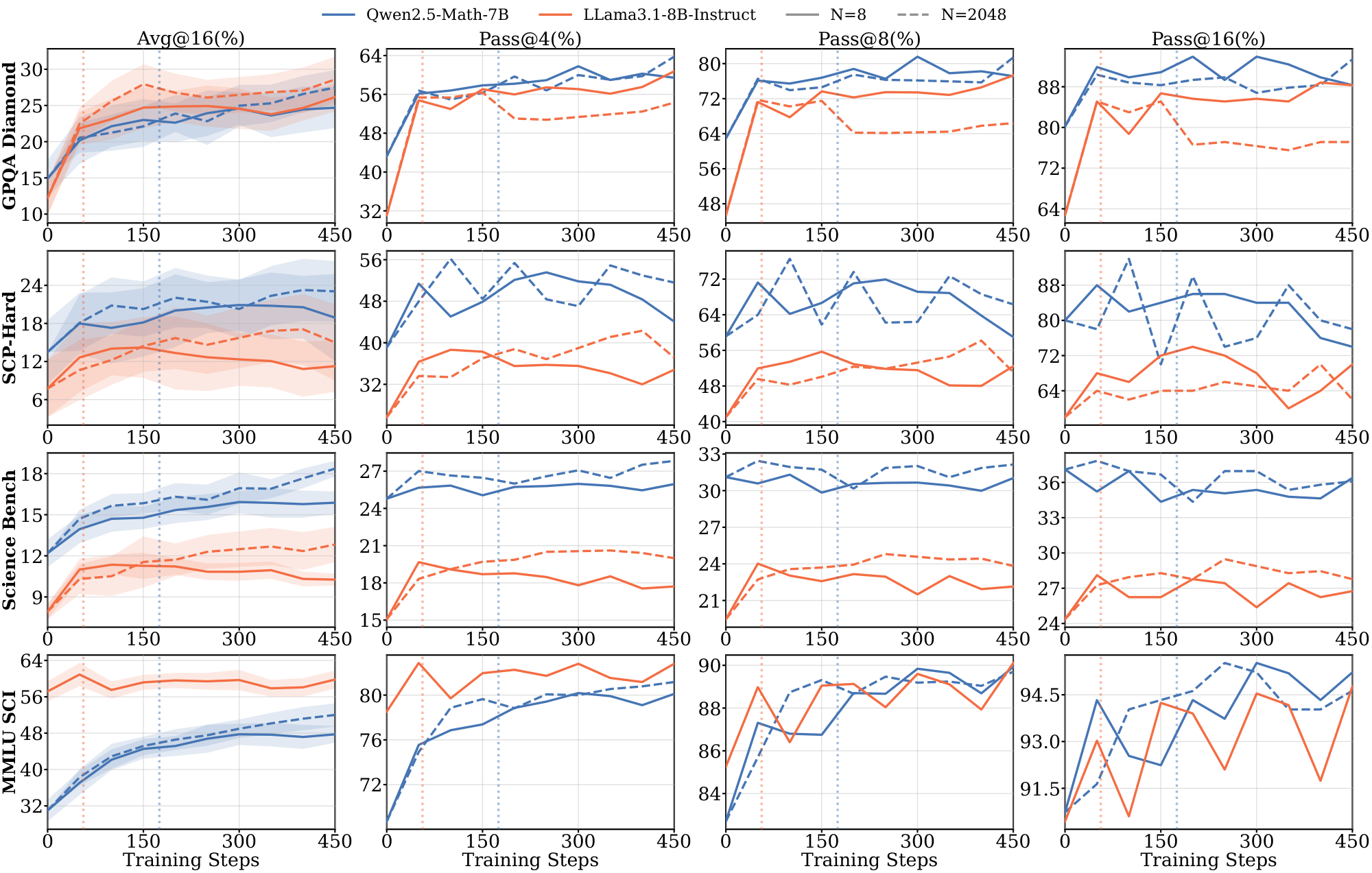
Models without domain-aligned priors saturate rapidly and fail to generalize. In contrast, Llama models across all domains, and Qwen on $\textsc{Graph}$ (Figure 1) exhibit clear dependence on data scale. For Llama, training on 8 samples leads to rapid saturation, with $t^{(8)}_{\text{sat}}$ occurring within the first 100: it maximizes the training reward much faster than the Qwen models. These models require larger datasets ($N \ge 512$) to achieve meaningful generalization (details in Appendix C.1 Figure 13 and Figure 14). The results in the $\textsc{Graph}$ domain suggest that even for models with strong mathematical priors, the lack of domain-specific pre-training accelerates saturation and necessitates higher data volume to drive learning. We further provide illustrations for 7B and 8B models on $\textsc{Math}$ and $\textsc{Science}$ domains in Appendix C.3.
Extended pre-saturation enables out-of-domain transfer. Positive $\Delta_{sat}^{(8)}$ values in Table 1 indicate that the reasoning patterns learned during the pre-saturation phase transfer across domains, particularly for Qwen models. With only 8 samples, Qwen2.5-1.5B trained on $\textsc{Math}$ achieves consistent gains on the out-of-domain $\textsc{Science}$ benchmark (SCP-Hard), while Qwen2.5-Math-7B trained on $\textsc{Graph}$ improves out-of-domain MATH-500 performance by 21.0% (Figure 1). In contrast, Llama models show limited out-of-domain transfer even when in-domain performance improves; their gains remain localized to the specific training distribution.
Takeaway:
(1) RLVR can generalize from as few as 8 samples when models remain in an extended pre-saturation phase, whereas rapidly saturating models require substantially more data. (2) Whether scarce-data learning succeeds is model- and domain-dependent, reflecting the influence of pretraining priors. (3) In the low-data regime, Llama models can achieve perfect training rewards much faster than Qwen by rapidly memorizing training examples but achieve little meaningful task learning.
3.2 Noisy Rewards
When ground-truth verifiers are available but imperfect, reward labels may contain errors. To evaluate RLVR robustness to such noisy supervision, we vary the fraction of incorrect labels $\gamma$ by randomly replacing ground-truth answers with the most frequent incorrect answer produced by the model itself (details in Appendix D.1). Unless otherwise noted, experiments use $N=2048$.
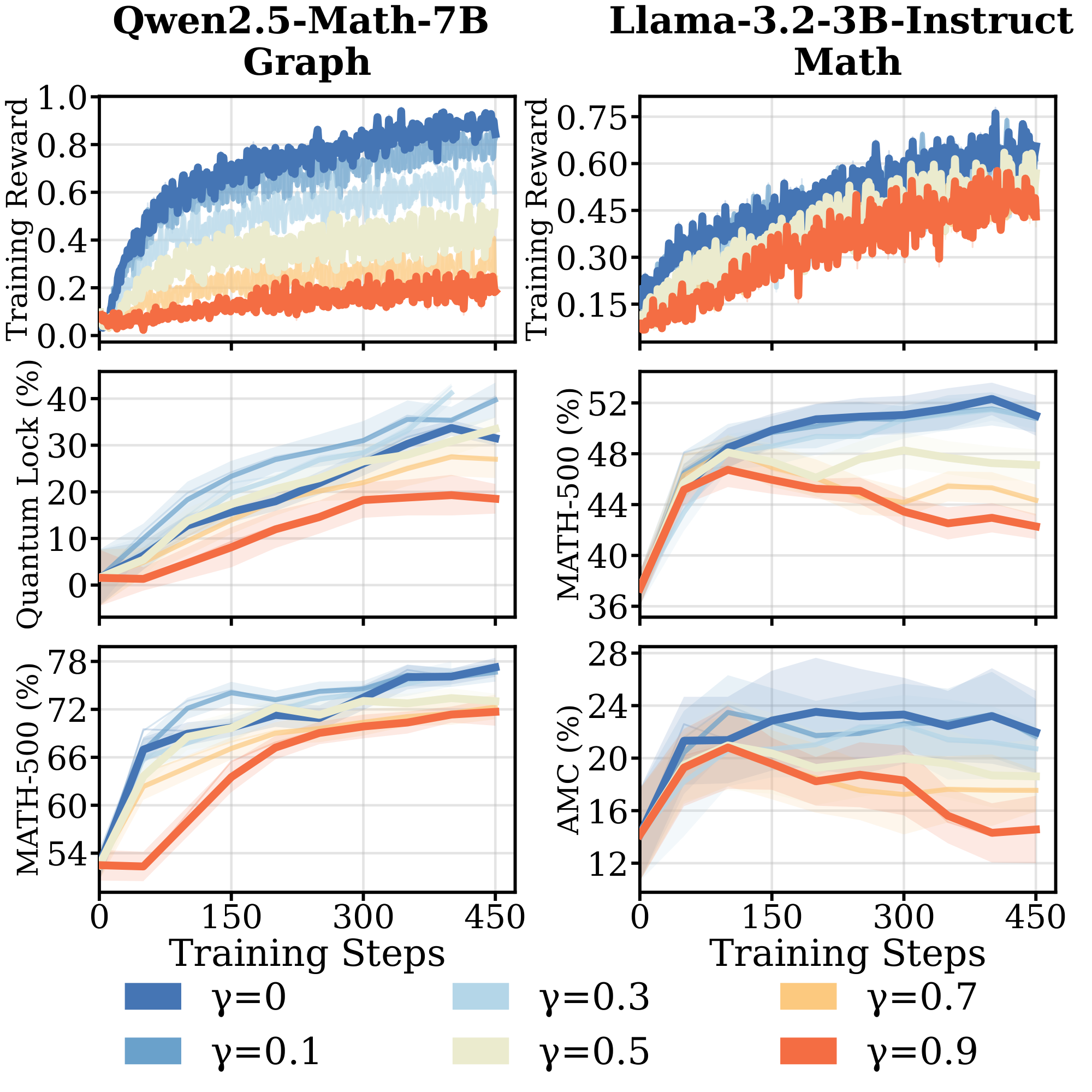
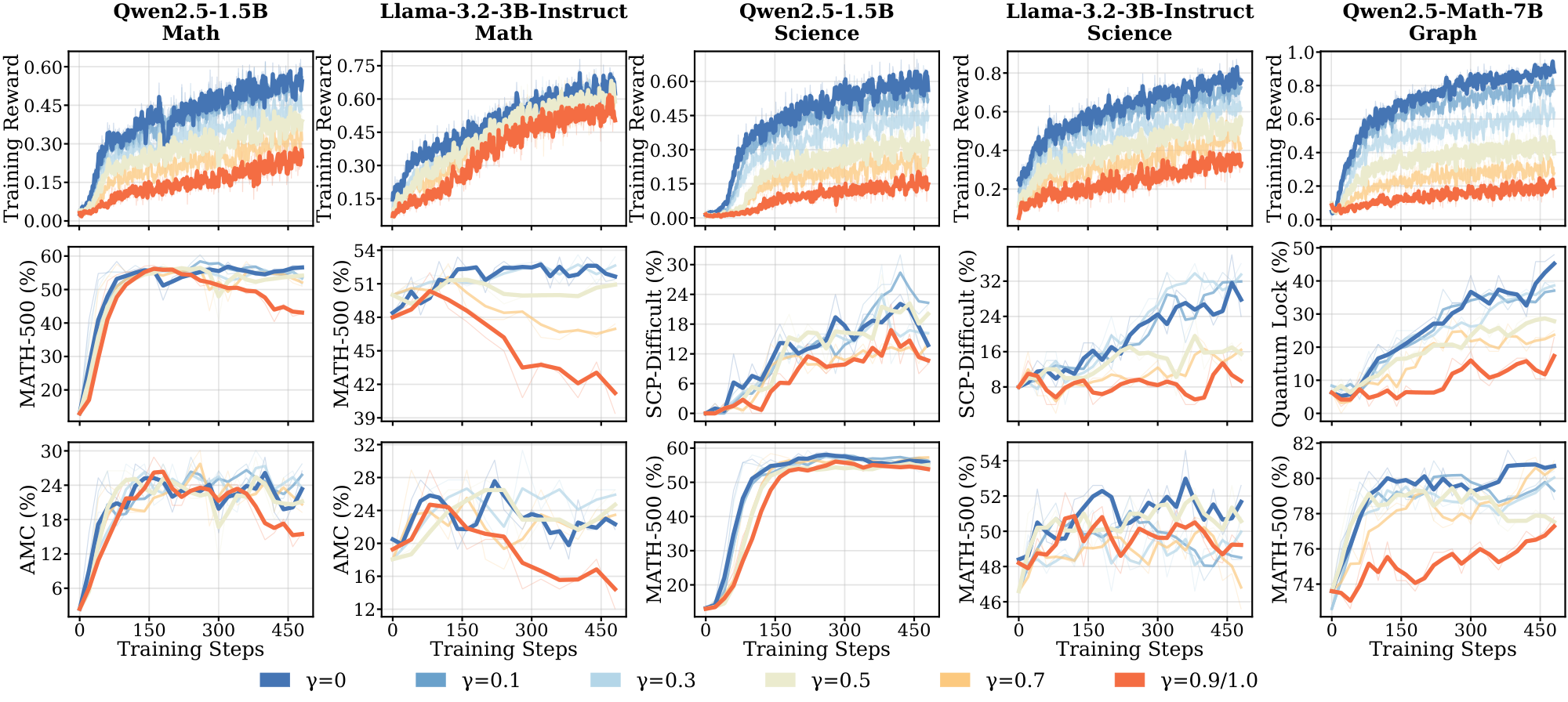
RLVR demonstrates robustness to reward noise, but generalization varies across models. Figure 2 and Figure 26 in Appendix summarize performance across seven model–domain pairs under varying $\gamma$. At $\gamma \le 0.3$, test performance across most settings remains close to the clean rewards ($\gamma = 0$), indicating robustness to moderate label noise. On $\textsc{Math}$ and $\textsc{Science}$, Qwen models maintain gains under substantial corruption (up to $\gamma = 0.7$). In contrast, Qwen on $\textsc{Graph}$ and Llama on $\textsc{Math}$ and $\textsc{Science}$ degrade at $\gamma \ge 0.5$. Higher $\gamma$ leads to consistently lower training rewards throughout training, but for Llama on $\textsc{Math}$, training reward curves remain nearly identical across all $\gamma$ despite severe corruption, indicating Llama fits incorrect answers more easily. We also observe that model-domain pairs with faster saturation (§ 3.1) are generally less robust to label noise, a connection we develop in § 3.4 and § 4.
Takeaway: Robustness to label noise varies sharply across model-domain pairs: Qwen on $\textsc{Math}$ and $\textsc{Science}$ tolerates up to 70% corruption, while Llama and Qwen on $\textsc{Graph}$ degrade at 50%. Model-domain pairs that saturate faster under clean rewards are less robust, and Llama fits corrupted labels nearly as fast as clean ones — evidence that rapid saturation reflects memorization capacity rather than learning efficiency.
3.3 Self-Supervised Proxy Rewards
When ground-truth verifiers are entirely unavailable, models must rely on alternative reward signals ([13, 24, 25]). Recent work has proposed self-supervised proxy rewards derived from model outputs, but whether these approaches work well across model families and task domains remains unexplored. We evaluate two such rewards: self-certainty [6] and majority vote [9] (implementation details in Appendix D.2).
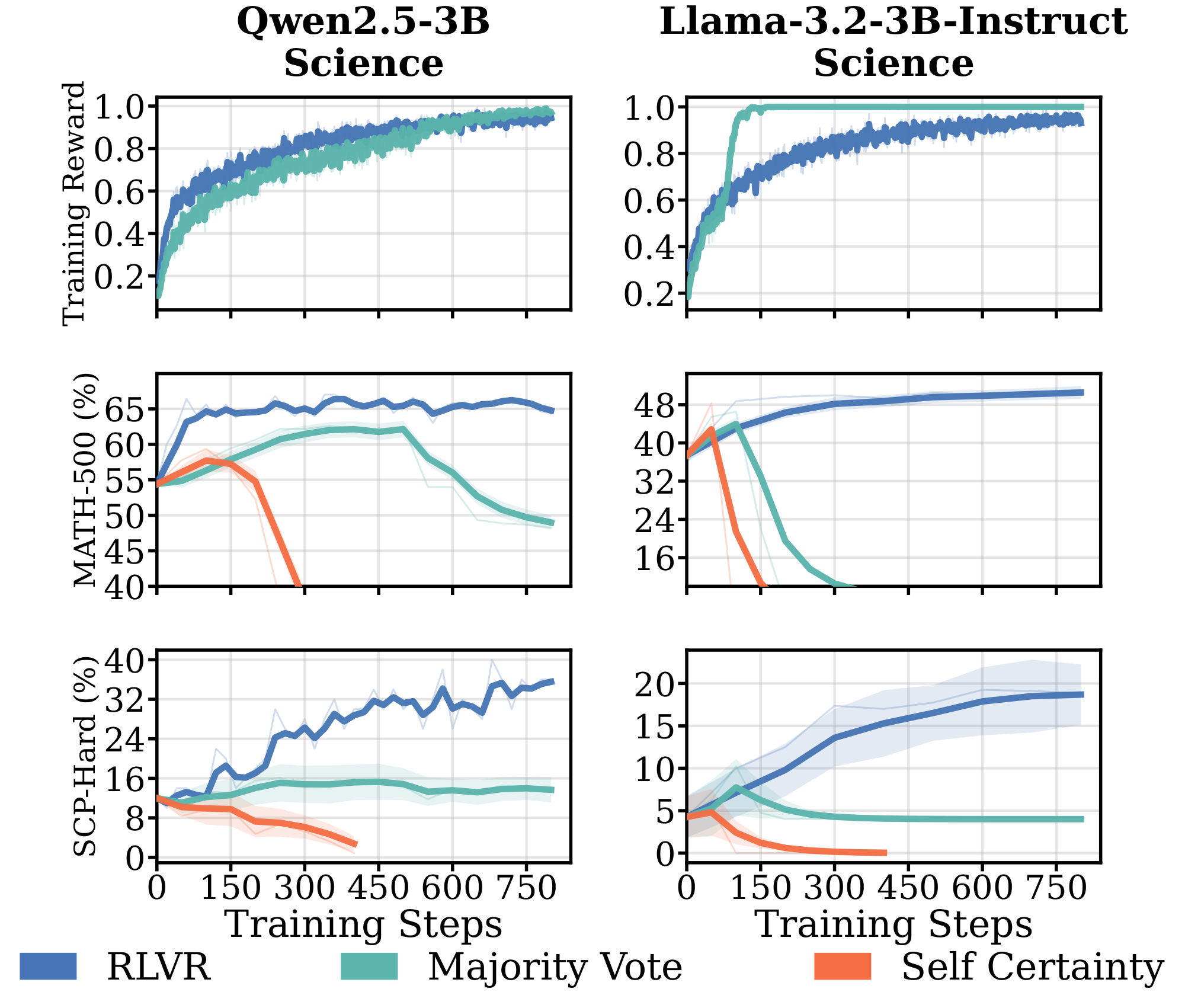
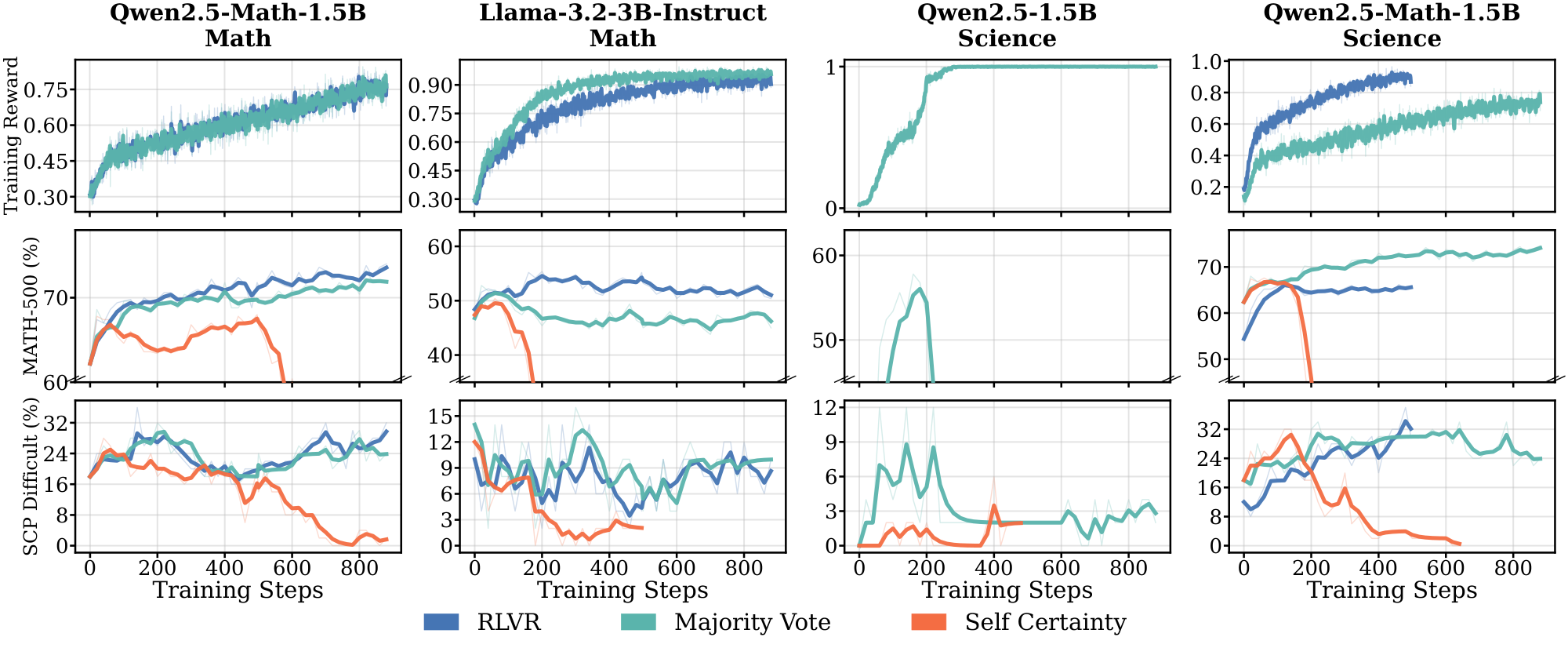
Proxy rewards trigger reward hacking and policy collapse. While RLVR tolerates moderate label noise in some model-domain pairs (§ 3.2), Figure 3 shows that fully replacing verifiable feedback with self-supervised proxy signals introduces severe failures under prolonged training. Only math-specialized models (Qwen2.5-Math-1.5B on $\textsc{Math}$ and $\textsc{Science}$) show improvement with majority voting, while other models fail entirely. For Qwen2.5-3B on $\textsc{Science}$, majority voting yields temporary gains before collapse after 500 steps, as the policy converges toward a single output to maximize agreement. Self-certainty rewards lead to performance collapse across all settings. These results show that current self-supervised proxy rewards are insufficient to replace verifiable feedback in most settings. (details in Appendix D.2 and Figure 27).
Takeaway: Self-supervised proxy rewards succeed only for math-specialized models (Qwen-Math under majority voting). Other models exhibit the same pattern we observed in § 3.1 and § 3.2: faster saturation and weaker pretraining priors coincide with brittleness. Under prolonged training, the failure mode is reward hacking: policies converge toward outputs that maximize the proxy without corresponding downstream gains.
3.4 Why Do Models Fail Under Weak Supervision?
The results in § 3.1–§ 3.3 show a consistent pattern: models with strong domain-aligned pretraining (Qwen on $\textsc{Math}$ and $\textsc{Science}$) generalize under weak supervision, while those without (Llama across domains, Qwen on $\textsc{Graph}$) fail. A natural hypothesis, motivated by prior work linking diminished exploratory capacity to rapid policy saturation [26], is that failing models produce less diverse outputs. To test this, we analyze model behavior along two complementary axes: response diversity and reasoning faithfulness. Formal definitions and implementation details are provided in Appendix F.
To quantify response diversity, we quantify semantic diversity to characterize meaningful patterns in the model's reasoning rather than surface-level variation [27, 28]. We measure diversity on the 8-sample subset of the $\textsc{Math}$, $\textsc{Science}$ and $\textsc{Graph}$ training datasets, as well as on the $\textsc{Math}$-500 evaluation dataset, over a selection of prompts at various steps throughout training. For each prompt, we cluster model responses using pairwise similarity judgments from an LLM judge and define the diversity score as the Shannon diversity index over the resulting clusters. See Figure 31 for the judge model prompt.
High diversity does not prevent rapid saturation. Figure 4 reports the evolution of diversity scores for models trained on 8 samples from the $\textsc{Math}$ training dataset, computed on the corresponding training set. Llama reaches reward saturation earlier and retains higher diversity than Qwen, the opposite of what the exploration-saturation hypothesis predicts. Diversity computed on the $\textsc{Math}$-500 evaluation dataset is presented in the appendix (Figure 30).
Since diversity alone does not explain failure under weak supervision, we investigate the faithfulness of a model's reasoning. Inspired by prior work [29], we define a response as faithful if its reasoning trace contains the information needed to justify the final answer and is logically consistent with it. At a given training step and for a given prompt, we categorize each policy rollout as aligned, partially aligned, or misaligned based on rubrics provided to an LLM-as-a-judge (see prompt in Figure 32). We then compute the policy faithfulness rate $F_{\pi}(l)$ as the fraction of responses assigned to label $l$. Appendix F outlines results for inter-model agreement on alignment categorization to evaluate the reliability of our LLM-as-a-judge.
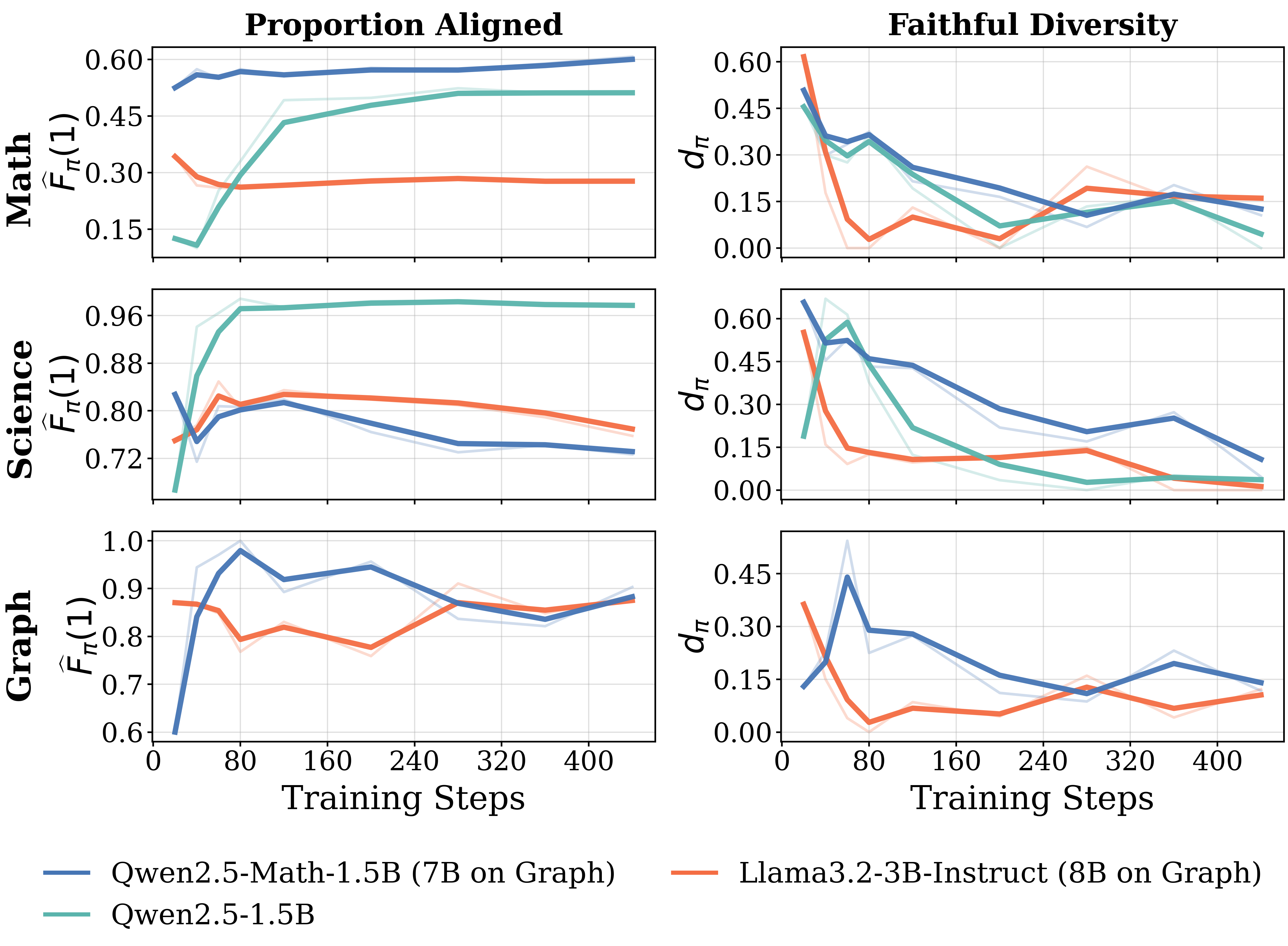
Models with rapid saturation exhibit low reasoning faithfulness. Figure 5 (left) shows the fraction of correct responses that are aligned over RL training across models and domains studied in § 3.1. On the $\textsc{Math}$ domain, the Llama model shows much lower reasoning faithfulness during training than the Qwen models. This indicates that Llama's rapid reward gains do not reflect improved reasoning: a substantial fraction of correct answers are memorized, with reasoning traces that do not support them. Figure 33 in Appendix F includes additional faithfulness results on these domains, covering proportion aligned and proportion misaligned on correct, incorrect and all responses.
Reasoning diversity should be considered jointly with faithfulness. Figure 5 (right) reports faithful diversity: diversity computed only over faithful responses. This joint measure reveals a consistent pattern across all three domains. On $\textsc{Math}$, Llama's apparent diversity advantage (Figure 4) disappears — most diverse responses are unfaithful, and the faithful subset is narrow. On $\textsc{Science}$, aligned proportions are uniformly high across models, masking real differences in reasoning quality; faithful diversity separates them, with Qwen-Math maintaining the highest values throughout training. On $\textsc{Graph}$, Qwen-Math and Llama show comparable aligned proportions, but Qwen-Math sustains higher faithful diversity. In every case, the model that generalizes best in §3.1 is the one exploring the widest range of faithful reasoning paths — not the one with the highest raw diversity, nor the one with the highest aligned proportion. Raw diversity overstates exploratory capacity; aligned proportion saturates on easier domains; only their intersection predicts generalization.
Takeaway:
Low reasoning faithfulness, not low diversity, explains why models fail under weak supervision: rapidly saturating models memorize answers rather than acquire transferable reasoning. Raw diversity metrics are misleading — Llama exhibits higher output diversity than Qwen while generalizing worse. Diversity becomes informative only when computed over faithful responses.
In summary, § 3 shows that the surprising capabilities often attributed to RLVR, such as learning from scarce data, tolerating noisy rewards, succeeding without verification, are not universal but depend on pre-RL reasoning faithfulness. § 4 takes up the natural question: can pre-RL interventions targeting faithfulness extend the pre-saturation phase and recover generalization under weak supervision?
4. Improving RLVR Under Weak Supervision via Pre-RL Training
Section Summary: Researchers tested ways to boost a language model's math-solving abilities under limited training data by preparing it with special pre-training steps before reinforcement learning. They compared basic model setups with added math-focused pre-training and fine-tuning that either included step-by-step reasoning explanations or just final answers, evaluating performance on tough math problems with scarce, noisy, or proxy feedback. The results showed that fine-tuning with explicit reasoning steps was essential for meaningful improvements, and combining it with extra math pre-training yielded the best generalization, far outperforming models without these targeted preparations.
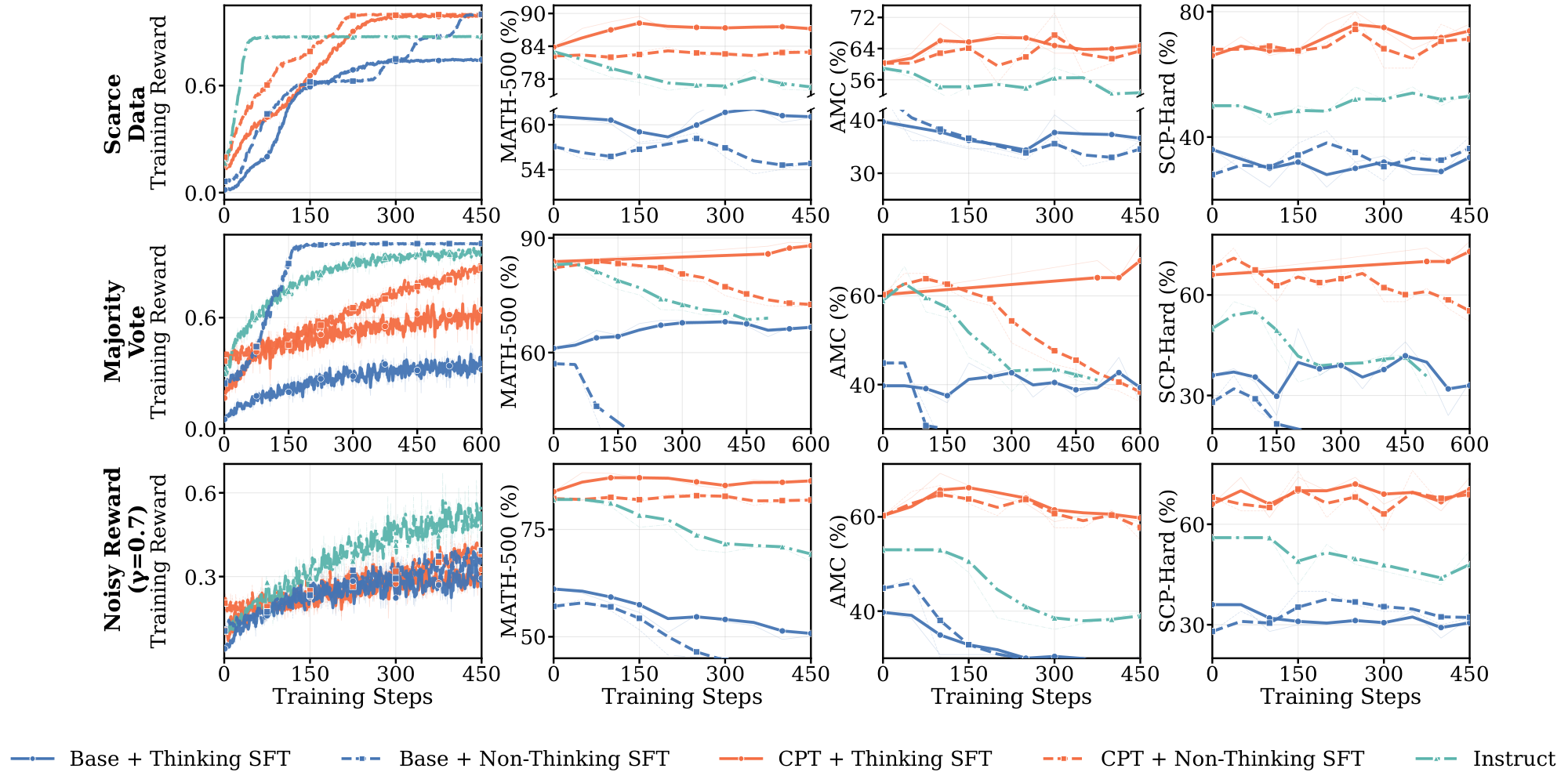
Section 3 showed that rapid saturation and low reasoning faithfulness are linked: models that generalize poorly under weak supervision produce correct answers through reasoning that does not support them. This raises a causal question. If faithfulness drives the pre-saturation phase, and the pre-saturation phase drives generalization, then instilling faithfulness before RL should extend the phase and recover generalization. We test this by running a controlled comparison of pre-RL interventions on Llama3.2-3B, the model that failed most consistently in § 3.
We study two axes of pre-RL training. The first is continual pre-training (CPT), extended training on domain-specific pretraining tokens to strengthen the pretraining prior. The second is supervised fine-tuning (SFT), with the specific question of whether SFT on explicit reasoning traces differs in its effect from SFT on final answers alone. Crossing these axes gives a 2×2 design: two initializations (Base, CPT) each followed by two SFT regimes (Thinking, Non-Thinking). We additionally include Llama3.2-3B-Instruct as a reference: it shares the architecture of Llama3.2-3B-Base but has undergone extensive instruction tuning, rejection sampling, and DPO, providing a strong off-the-shelf baseline against which to judge our targeted interventions. We then run RL under all three weak supervision settings from § 3: scarce data, noisy rewards, and self-supervised proxy rewards.
We focus on the $\textsc{Math}$ domain for two reasons: Llama's baseline failure is sharpest there, providing the cleanest test of whether pre-RL interventions can recover generalization; and high-quality math pretraining corpora (Nemotron-CC-Math) and reasoning-trace datasets (OpenThoughts-114K) are available, enabling the interventions at sufficient scale.
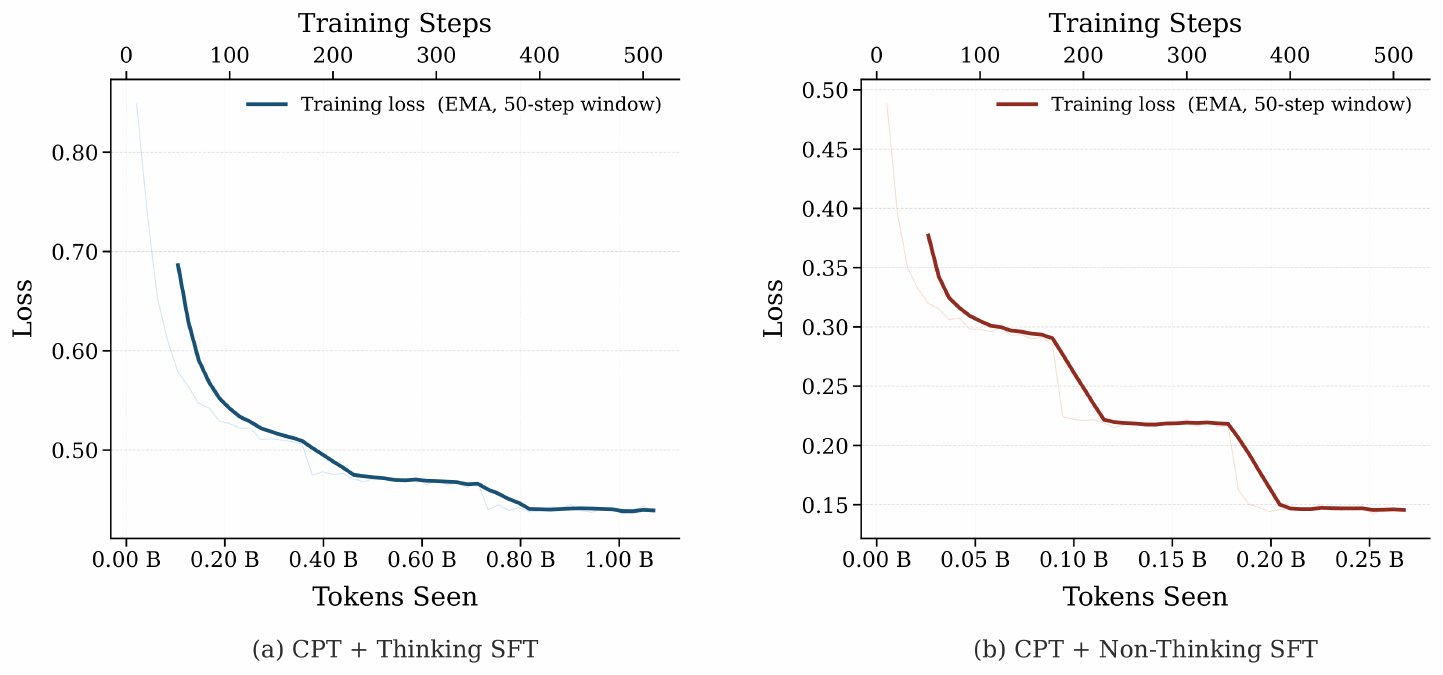
Continual Pre-Training (CPT). We continually pre-train Llama3.2-3B-Base for one epoch on approximately 52B math tokens from the Nemotron-CC-Math dataset ([30])^2. Training details are provided in Appendix B.5.
SFT Training Regimes. Following CPT or Base initialization, we apply supervised fine-tuning to determine whether explicit reasoning traces influence subsequent RL dynamics. We compare two SFT regimes that differ only in whether the supervision includes explicit reasoning. Both regimes use the same 43.5K math prompts and differ only in the target output. Specifically, we sample these prompts from OpenThoughts-114K ([31]), retaining only those whose reasoning traces have correct final answers and total length below 8192 tokens.
- Non-thinking SFT: The model is supervised to output the final solution without generating intermediate reasoning traces.
- Thinking SFT: The model is trained on explicit, verified long-form reasoning traces.
A training example is shown in Figure 12 in the Appendix. The SFT regimes are near-iso-compute: Thinking SFT trains on roughly 1B tokens, Non-Thinking SFT on roughly 0.27B, both negligible relative to the 52B-token CPT stage. Differences between Thinking and Non-Thinking SFT therefore reflect the content of the supervision rather than its cost. We report the CPT loss curve in Figure 10 in Appendix and the SFT loss curves in Figure 11.
Implementation and training details of SFT are provided in Appendix B.6. For the subsequent RL phase, we evaluate across all three weak supervision settings: scarce data ($N=8$), noisy rewards ($\gamma = 0.7$), and self-supervised proxy rewards (majority vote). All other hyperparameters follow the configurations in § 2, with the maximum response length during RL extended to 8192 tokens to accommodate long-form reasoning traces.
4.1 Results
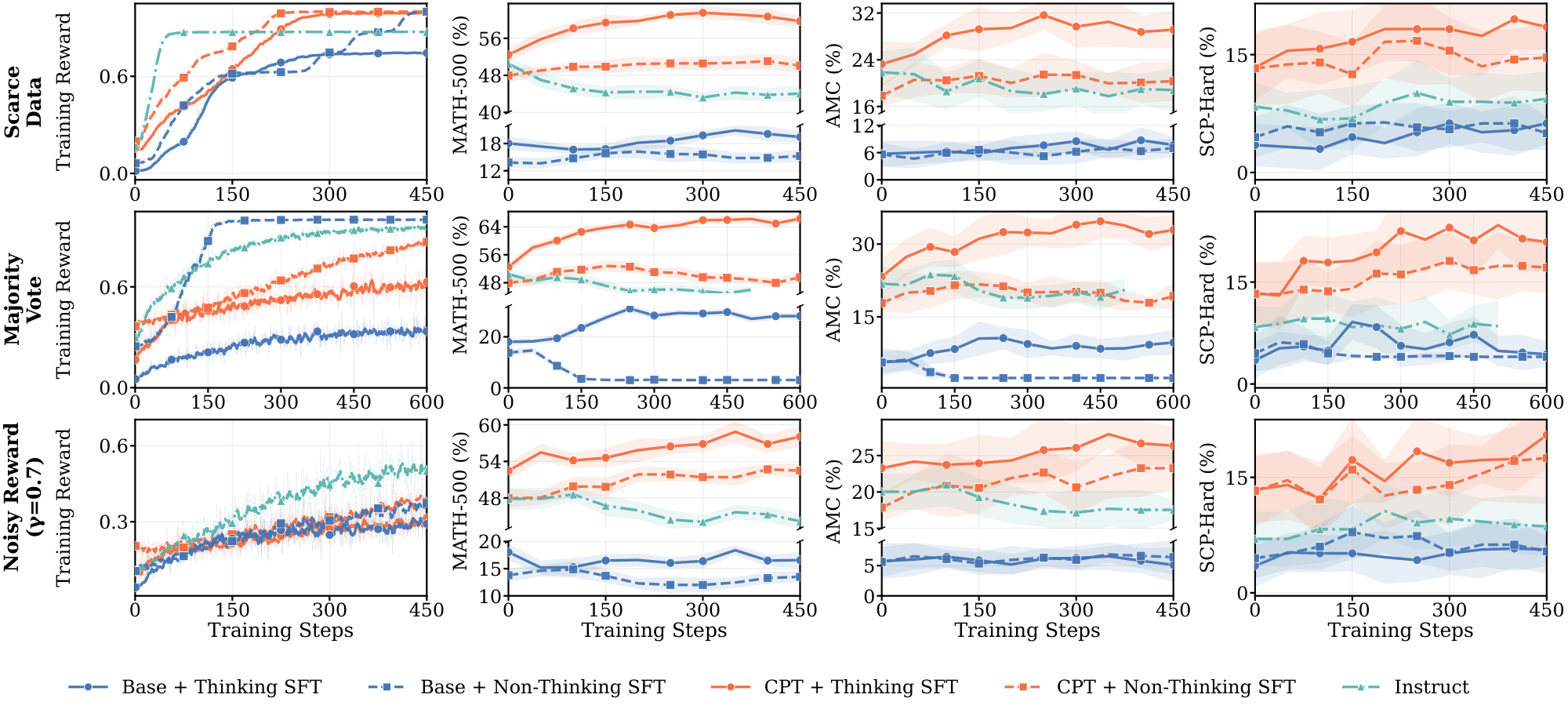
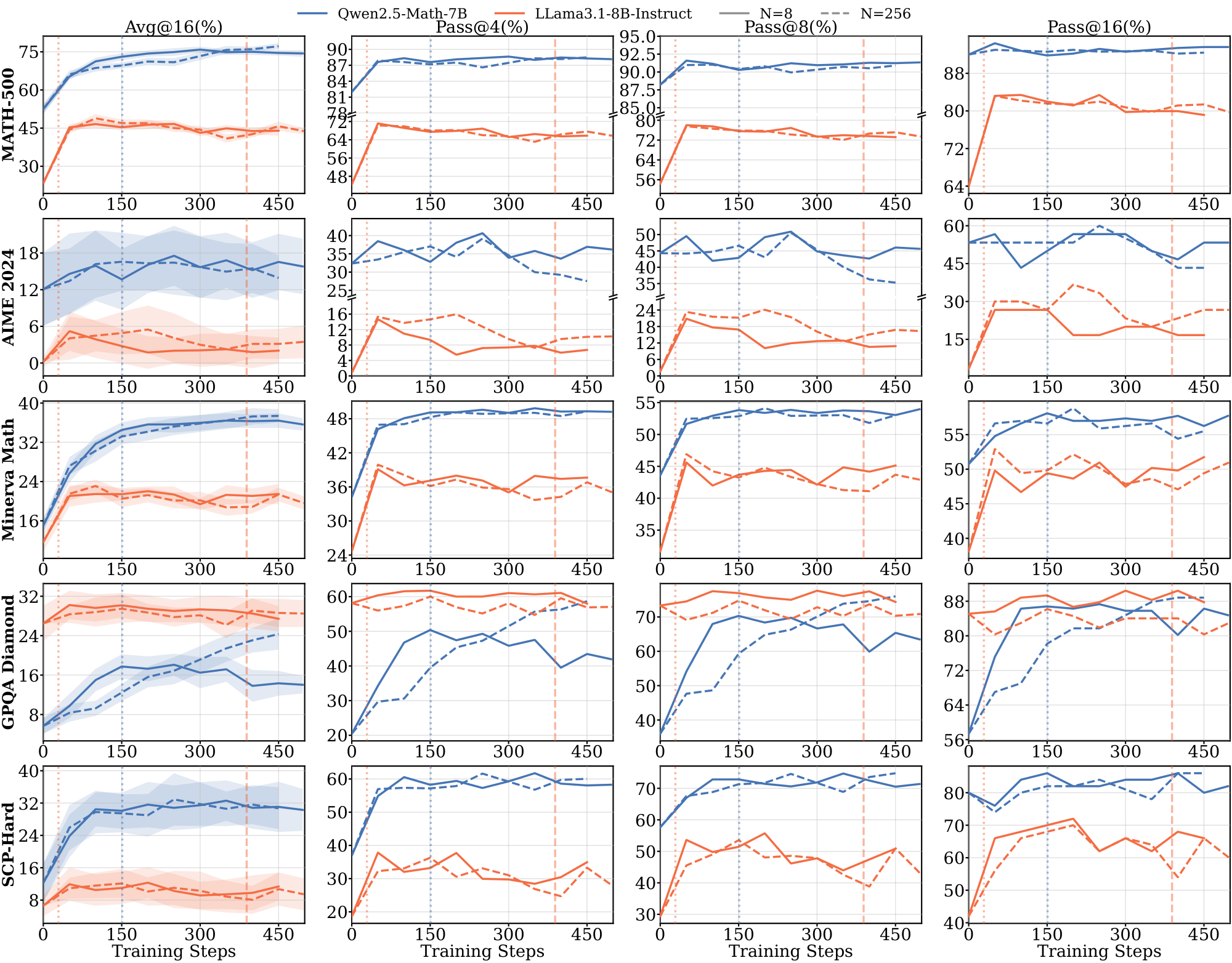
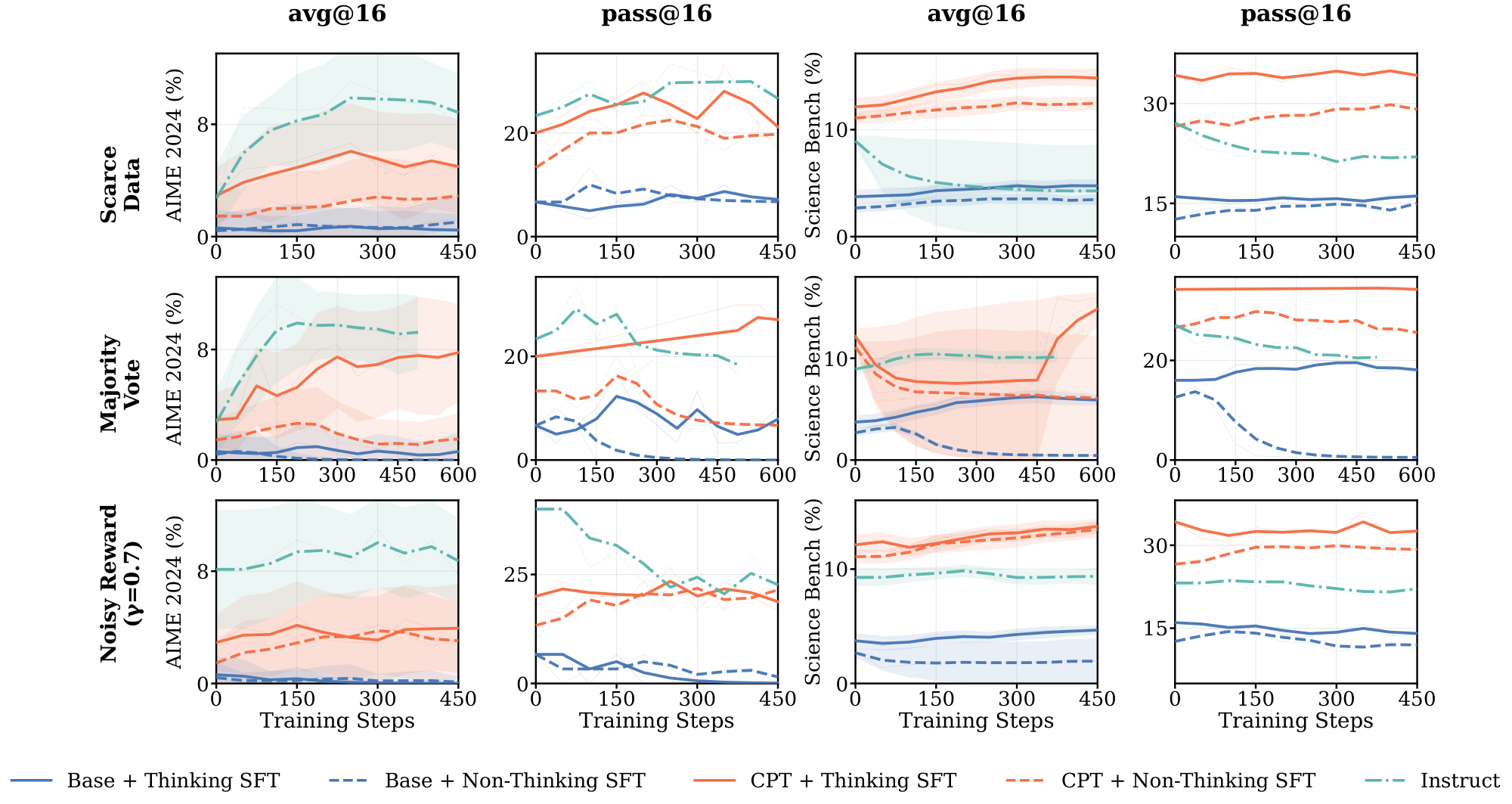
Figure 6 reports RL training dynamics for the five pre-RL configurations (Base, CPT, and Instruct, with Thinking SFT or Non-Thinking SFT applied to Base and CPT) across the three weak supervision settings. For each setting, we plot training reward alongside three downstream metrics: two in-domain (MATH-500, AMC) and one out-of-domain (SCP-Hard); additional benchmarks and pass@k results are Figure 34 and Figure 35 in Appendix G. We draw three findings from this figure, developed in the paragraphs below.
Thinking SFT is necessary for substantial learning under weak supervision. The Instruct baseline is flat or decreasing across all three settings on all downstream evaluations — RL produces no meaningful improvement from this starting point. Thinking SFT is the only intervention that enables substantial downstream gains on scarce data and majority vote, and it does so for both Base and CPT initializations (solid blue and solid red). Non-Thinking SFT shows modest gains only when paired with CPT, and only under noisy rewards; Non-Thinking SFT on Base is flat or degrades across all three settings.
CPT amplifies the Thinking SFT effect. Thinking SFT on Base alone produces modest gains. Combined with CPT, it produces substantially larger gains on every evaluation: CPT + Thinking SFT is the top-performing curve across all three weak supervision settings and all three evals. The CPT + Non-Thinking SFT comparison rules out a compute-based explanation: the same 52B CPT tokens, paired with SFT targets that strip reasoning traces, fail to enable generalization on scarce data and majority vote. The amplification is specific to the combination: extra pre-training compute alone is insufficient; Thinking SFT alone helps but is limited, only the combination recovers full generalization.
Base initialization fails under most weak supervision settings regardless of SFT. The Base model shows meaningful improvement only in two combinations: Base + Thinking SFT under scarce data and majority vote, and even there gains are modest. Under noisy rewards, neither Base + Thinking SFT nor Base + Non-Thinking SFT produces meaningful downstream improvement. This isolates CPT's contribution: Thinking SFT is necessary but not sufficient — domain-aligned pretraining is required for the intervention to generalize across all three weak supervision settings.
Thinking SFT improves reasoning faithfulness. In § 3.4, we identified low reasoning faithfulness as the pre-RL property that distinguished failing from succeeding models. Figure 7 shows that Thinking SFT raises aligned-response rate throughout the pre-saturation phase, relative to the Non-Thinking SFT baseline. CPT + Thinking SFT achieves the highest faithfulness among all configurations, consistent with its strongest generalization across all weak supervision settings. Together with the extended pre-saturation dynamics visible in Figure 6 (leftmost column), this result supports our hypothesis in § 3.4: pre-RL interventions that instill faithfulness produce longer pre-saturation phases and recovered generalization, in models that previously failed.
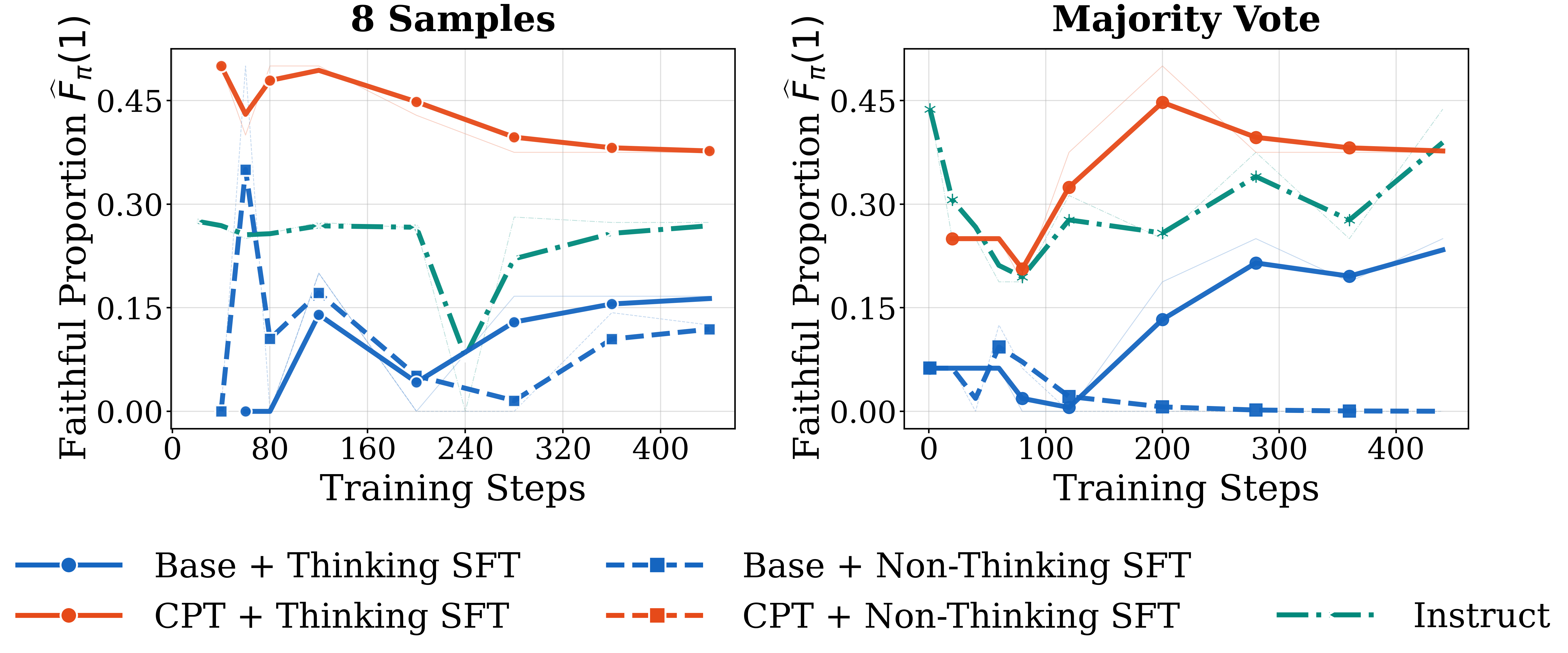
Takeaway: SFT on explicit reasoning traces, not on final answers, is necessary for Llama to learn substantially from RL under weak supervision.
It raises reasoning faithfulness, extends the pre-saturation phase, and recovers generalization under scarce data, noisy rewards, and self-supervised proxy rewards. Continual pre-training amplifies the effect but does not substitute for it: CPT + Non-Thinking SFT fails despite matched compute. The strongest configuration, CPT + Thinking SFT, recovers performance in settings where Llama had previously collapsed entirely.
5. Related Work
Section Summary: Researchers have developed reinforcement learning with verifiable rewards, known as RLVR, to boost reasoning abilities in large language models, but results vary across different models and often fail to generalize beyond specific areas like math. While pre-training and fine-tuning influence how well these models generalize during reinforcement learning, past studies have not deeply explored how initial model knowledge from ongoing training enables success under imperfect guidance. This work builds on efforts to maintain output variety and ensure logical thought processes by identifying why simple diversity isn't enough for broad improvement and proposing ways to enhance faithful reasoning before reinforcement to achieve better generalization.
RLVR for Reasoning. Reinforcement learning with verifiable rewards has emerged as an effective post-training method for improving reasoning in large language models ([1, 32, 33, 34]). Recent work has explored when RLVR yields improvements ([35, 18, 36]). [4] demonstrate that training on a single example can provide meaningful learning signals. Other work explores alternative rewards, including self-certainty ([6]), majority voting ([9]), negative signals ([37]), self-generated training data [10], and spurious rewards ([5]). However, these findings often do not transfer across model families, with studies reporting inconsistent results between Qwen and Llama ([34, 38, 5]). Moreover, most prior work focuses on improving performance on narrow domains (primarily math) without examining generalization. Recent work [39, 40, 41] has concurrently studied when and how RLVR can learn under self-supervision or noisy supervision. Our work extends this literature in two ways. First, we characterize the conditions under which RLVR generalizes across model families and domains, focusing on saturation dynamics and reasoning faithfulness. Second, we identify a concrete intervention that restores generalization in models where weak supervision would otherwise fail.
Role of Pre-Training and Fine-Tuning in RL. Recent work emphasizes that pre-training and mid-training shape RL generalization ([42, 43, 44, 45]), but focuses on compute allocation and distribution alignment to improve performance. Our work specifically focuses on understanding how base model priors shaped from continual pretraining and reasoning SFT can enable generalization across different weak supervision settings.
Diversity and Faithfulness in Reasoning. Maintaining output diversity during RL has been proposed to promote exploration and mitigate model collapse ([46, 47, 48, 33]), but prior work has not explored what types of diversity benefit generalization. Separately, research has highlighted mismatches between chain-of-thought traces and model predictions ([49, 50, 29, 51]) and emphasized the importance of ensuring faithful reasoning throughout training ([52]). [53] argues that RLVR can incentivize correct reasoning in base LLMs as long as priors have been established. Our work connects these lines of research, showing that diversity alone does not ensure generalization and that reasoning faithfulness distinguishes models' training dynamics. We further demonstrate that pre-RL intervention can improve reasoning faithfulness and improve generalization under weak supervision.
6. Conclusion
Section Summary: This study explores when reinforcement learning with verbal rewards (RLVR) succeeds in generalizing under limited or noisy guidance across different AI models and reasoning tasks, finding that success relies more on the model's initial training qualities, like built-in understanding and reliable reasoning, than on the learning process itself. Models that quickly max out their performance often memorize answers without true comprehension, mimicking exploration through varied outputs but failing to adapt, and this can be fixed by pre-learning steps such as training on clear reasoning examples, with additional data-focused pre-training boosting results. To improve weak supervision outcomes, practitioners should watch for stalled training progress as a warning sign to shift efforts toward strengthening the model's foundations beforehand, rather than extending the learning phase, viewing RL as the capstone of an earlier preparation process.
In this work, we studied when and why RLVR generalizes under weak supervision across diverse model families and three reasoning domains. Success under scarce data, noisy rewards, and self-supervised proxy rewards depends on pre-RL properties, pretraining priors and reasoning faithfulness, rather than on RL dynamics alone. Models that saturate rapidly produce correct answers through reasoning that does not support them, memorizing rather than learning, while maintaining the high output diversity normally taken as a sign of healthy exploration. Pre-RL interventions targeting reasoning faithfulness recover generalization: SFT on explicit reasoning traces is the necessary ingredient, and continual pre-training on reasoning-heavy data amplifies the effect without substituting for it. These findings suggest two concrete practices for RL from weak supervision. First, monitor training reward saturation as a diagnostic: plateaued reward with flat downstream performance indicates the model has exhausted what RL can extract from its priors, and further RL compute is unlikely to help. Second, when weak supervision fails, allocate compute to pre-RL interventions that install strong priors rather than to longer RL training. Taken together, our findings argue that RL under weak supervision is best understood not as a training technique applied to a fixed model, but as the final stage of a pipeline whose success is largely determined before RL begins.
Acknowledgements
Section Summary: The acknowledgements section expresses gratitude to Leon Li, Vatsal Baherwani, Rohun Agrawal, Siyan Zhao, Liwei Jiang, and Andy Han for their helpful discussions and feedback on the draft. It also notes that Pavel Izmailov received support from a grant awarded by the Alignment Project, which is funded by the UK AI Security Institute under grant number AP-S2-100141.
We would like to thank Leon Li, Vatsal Baherwani, Rohun Agrawal, Siyan Zhao, Liwei Jiang, and Andy Han for their insightful discussions and feedback on the draft. Pavel Izmailov was supported by a grant from the Alignment Project, funded by the UK AI Security Institute (grant AP-S2-100141).
Appendix
Section Summary: The appendix outlines key limitations of the study, including restrictions due to computing power that limit analysis to certain AI model types and sizes, as well as reliance on AI judges for assessing response quality, which was only partially checked by humans on a small scale, pointing to future needs for wider testing and better measurement tools. It then details the implementation, covering the use of specific AI models like Qwen and Llama across math, science, and graph reasoning tasks, with training data drawn from datasets such as Skywork-OR1 and SCP, and evaluations on benchmarks like MATH500 and GPQA-Diamond. Data preparation involved filtering problems by difficulty—excluding those too easy or hard for the models—and using a balanced sampling method to create training sets of varying sizes.
A. Limitations and Future Work
We acknowledge several limitations. First, due to computational constraints, our analysis is restricted to specific model families and scales. Validating these findings across larger architectures and broader task suites remains an important direction. Second, our analysis of diversity and faithfulness relies on an LLM-as-a-judge framework. Although we conducted small-scale human verification to validate label quality, we currently restrict this evaluation to a small scale to allow for reasonable labeling costs. Consequently, the development of scalable metrics for reasoning faithfulness and diversity remains an important direction for future research.
B. Implementation Details
B.1 Training and Evaluation Datasets
We investigate RL training dynamics across two model families: Qwen (comprising Qwen2.5-1.5B/3B and Qwen2.5-Math-1.5B/7B) and Llama (Llama-3.2-3B/8B-Instruct). Our analysis spans three distinct reasoning domains, $\textsc{Math}$, $\textsc{Science}$, and $\textsc{Graph}$, allowing for a holistic investigation of RLVR under weak supervision across different domains and model families. For $\textsc{Math}$, we sample training prompts from the Skywork-OR1 [54] dataset. For $\textsc{Science}$, we draw problems from the SCP dataset curated by prior work [18, 19], by selecting Physics, Chemistry, and Biology subjects. For $\textsc{Graph}$, we generate two synthetic algorithmic tasks, Quantum Lock and Largest Island, using the curriculum specifications provided by the Reasoning Gym benchmark [20]. For each task, we instantiate five difficulty levels following the benchmark’s curriculum, with a balanced number of samples per level.
We include the following domain-specific benchmarks for evaluations:
MATH500 [55]: A widely used subset of the MATH test split [56].
AMC [57]: 40 competition-level math questions.
AIME 2024 [58]: 30 competition-level math questions.
AIME 2025 [59]: 30 competition-level math questions.
Minerva Math [60]: A set of 272 undergraduate-level science and math questions from MIT OpenCourseWare.
OlympiadBench [61]: A benchmark of 675 problems from international math olympiads and physics contests.
GPQA-Diamond [62]: 198 expert-level questions from GPQA spanning physics, chemistry, and biology; we preprocess the data following previous practice [63].
SCP-Hard [19, 18]: A held-out set of 50 SCP questions filtered such that the base models (Qwen2.5-1.5B series models and Llama3.2-3B-Instruct model) achieve solve@16 $=1$, containing disjoint questions from the SCP training datasets.
SuperGPQA [64]: a subset constructed from the original SuperGPQA which contains 319 science questions and 250 non-science questions.
MMLU SCI [65]: a subset of MMLU Pro benchmark containing all college-level chemistry, physics and biology questions.
Science Bench [66]: 692 college-level science questions.
Graph Test: A held-out set of 50 algorithmically generated instances from the Quantum Lock and Largest Island tasks using Reasoning Gym [20], disjoint from training, filtered such that the base models (Qwen2.5-1.5B series and Llama3.2-3B-Instruct) achieve Pass@16 $=1$.
We also note that GPQA-Diamond, MMLU SCI, and SuperGPQA are multiple-choice benchmarks, for which pass@ $k$ may be a less reliable metric.
Table 2 details the training and evaluation datasets across the three reasoning domains.
: Table 2: Training datasets and evaluation benchmarks across three reasoning domains.
| Domain | Training Source | In-Distribution Eval | Out-of-Distribution Eval |
|---|---|---|---|
| $\textsc{Math}$ | Skywork-OR1 | MATH-500, AMC, AIME-2024, AIME-2025, Minerva Math, OlympiadBench | Science Bench, SuperGPQA, GPQA-Diamond, SCP-Hard, MMLU SCI |
| $\textsc{Science}$ | SCP-116K | SCP-Hard, GPQA-Diamond, MMLU SCI, SuperGPQA, Science Bench | MATH-500, AMC, Minerva Math, OlympiadBench |
| $\textsc{Graph}$ | Reasoning Gym | Quantum Lock, Largest Island | MATH-500, AIME-2024, Minerva Math, GPQA-Diamond, SCP-Hard |

B.2 Training Data Preparation Details
We describe our procedure for constructing filtered training datasets tailored to each model's capabilities.
Difficulty Estimation. For each problem in the source dataset, we sample 16 responses from the base model and count the number of correct solutions, yielding $\text{solve}@16 \in [0, 16]$. We retain only problems with $\text{solve}@16 \in [1, 15]$, excluding problems that are too difficult ($\text{solve}@16 = 0$) or trivially easy ($\text{solve}@16 = 16$) for the model.

Stratified Sampling. We use a stratified round-robin selection method to construct training subsets of size $N \in {8, 32, 64, 512, 2048}$. Filtered problems are partitioned into 15 bins ${B_i}_{i=1}^{15}$ according to their $\text{solve}@16$ values. To select $N$ problems:
- Initialization: Set the current count of selected problems $n_{\text{total}} = 0$.
- Round-Robin Selection: While $n_{\text{total}} < N$:
- Iterate through bins $B_i$ for $i = 1, \dots, 15$.
- If $B_i$ contains unsampled problems, randomly select one problem without replacement, add it to the training set, and increment $n_{\text{total}}$.
- Terminate immediately if $n_{\text{total}} = N$.
This approach ensures that all difficulty levels are represented as uniformly as possible across all data scales.
B.3 Implementation Details of RL Training
All experiments are implemented using the verl framework [22] with its default hyperparameters: learning rate $10^{-6}$, KL coefficient $\beta = 0.001$, clip ratio $\epsilon=0.2$ and no entropy regularization. We set group size $G = 8$ for computational efficiency. For response sampling, we fix the sampling temperature $1.0$ and a maximum response length of $2048$ tokens unless otherwise noted. In verl, we set both the training batch size and mini-batch size to 64 prompts, yielding exactly one gradient update per training step. Each experiment is run for 496 total gradient updates. A simple rule-based reward function is used, assigning reward $1$ to correct answers and $0$ otherwise, without incorporating any format-related signals. For $\textsc{Math}$ and $\textsc{Science}$, answer matching and reward computation is implemented with Math-Verify^3 library; for $\textsc{Graph}$, we use the internal task-specific evaluation protocol from Reasoning Gym. Prompt templates are detailed in Figure 8 and Figure 9.
B.4 Implementation Details of Evaluation
We evaluate reasoning performance using $\text{avg@}16$ accuracy (average $\text{pass@}1$ over 16 independent samples per problem) with temperature $1.0$ sampling and report $\text{pass@}k$ for $k \in {4, 8, 16}$.
B.5 Implementation Details of Continual Pre-Training
We continually pre-train Llama3.2-3B on the Nemotron-CC-Math-4plus subset ([30]), comprising approximately 52B tokens of math-relevant documents filtered at quality score $\geq 4$. Training is conducted for one epoch with a maximum sequence length of 2,048 tokens and a batch size of 128 sequences. We use AdamW with a peak learning rate of $2 \times 10^{-5}$, cosine decay schedule, 5% linear warmup, weight decay of 0.01, and gradient clipping at 1.0.
B.6 Implementation Details of SFT
For SFT, we train for three epochs with a batch size of 16 and a maximum sequence length of 8192 tokens. We tune the learning rate for each model within the $1\times10^{-5}, 5\times10^{-5}]$ and report results for the best-performing setting. For the subsequent RL phase, we evaluate performance across training sample sizes $N \in {8, 2048}$. All other hyperparameters follow the configurations established in Appendix B.3, with the maximum response length extended to 8192 tokens to accommodate long-form reasoning traces.

C. Data Scale Effect
::: {caption="Table 3: Math-domain training (1.5B/3B): in-domain benchmarks."}
:::
::: {caption="Table 4: Math-domain training (1.5B/3B): out-of-domain benchmarks."}
:::
::: {caption="Table 5: Science-domain training (1.5B/3B): in-domain benchmarks."}
:::
::: {caption="Table 6: Science-domain training (1.5B/3B): out-of-domain benchmarks."}
:::
::: {caption="Table 7: Graph-domain training (7B/8B): in-distribution benchmarks."}
:::
C.1 Additional Experimental Results from Small to Large Data Scale
Figs. Figure 13, Figure 14, and Figure 15 present domain-specific training dynamics and generalization performance across sample sizes $N\in{8, 32, 64, 512, 2048}$. Each figure tracks the training reward, two in-distribution benchmarks, and one OOD benchmark, as listed in Table 2.
In the $\textsc{Math}$ domain, Llama models exhibit rapid saturation in small-sample regimes and rely heavily on data scale. In contrast, Qwen models yield comparable performance across varying sample sizes, characterized by extended saturation periods. Specifically, the math-specialized Qwen2.5-Math-1.5B sustains a pre-saturation phase for 330 gradient steps on 8 samples, driving continuous improvements on in-domain benchmarks.
In the $\textsc{Science}$ domain, the pre-saturation phase yields similar gains across all sample sizes; however, after the saturation point, larger sample sizes demonstrate distinct benefits. Similar to $\textsc{Math}$ domain, models exhibit significantly different saturation dynamics on small samples.
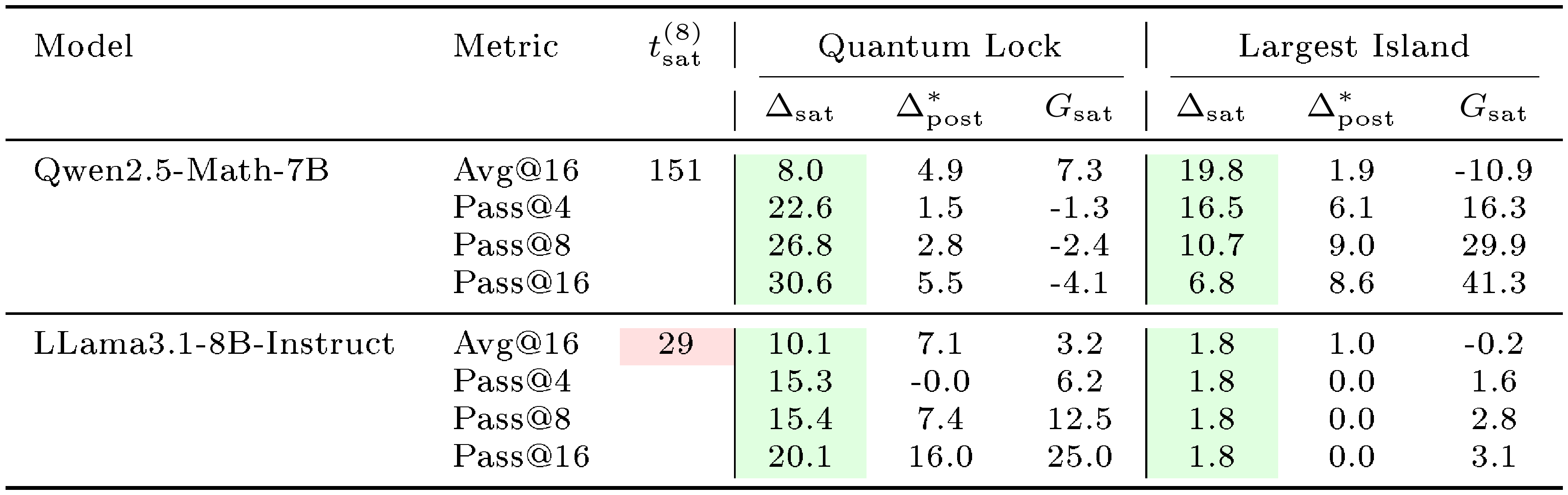
In the $\textsc{Graph}$ domain, we compare two larger models, Qwen2.5-Math-7B and Llama3.1-8B-Instruct. The Qwen model also saturates faster here than in other domains, implying that the lack of domain-specific pre-training accelerates saturation in small-sample regimes.
C.2 Full Evaluation Results
In this section, we will report the full evaluation results with all benchmarks and $\text{pass@}k$ ($k \in {1, 4, 8, 16}$ metrics. Figure 16, Figure 17, Figure 18, Figure 19, Figure 24, and Figure 25 include in-domain and out-of-domain evaluation results across multiple benchmarks in $\textsc{Math}$, $\textsc{Science}$ and $\textsc{Graph}$ domains.
Discussions on $\text{pass@}k$.
Despite prior work [67] discussing divergent behavior between $\text{pass@}1$ and $\text{pass@}k$ for $k>1$ during RL training, we observe that $\Delta_{sat}^{(8)}$ keeps the same sign for all $k \in {1, 4, 8, 16}$ across most model-benchmark pairs, indicating consistent improvement in both $\text{pass@}1$ and $\text{pass@}k$. This indicates that during the pre-saturation period, the model is not just closing pass@k and pass@1 gap.
C.3 Additional Experimental Results on Large Models
In this section, we will report the full evaluation results on 7B and 8B models.
Figure 20 and Figure 21 show the results of Qwen2.5-Math-7B and Llama3.1-8B-Instruct models on $\textsc{Math}$ domain with in-domain and out-of-domain benchmarks, respectively.
Figure 22 and Figure 23 present the results of Qwen2.5-Math-7B and Llama3.1-8B-Instruct models on $\textsc{Science}$ domain with in-domain and out-of-domain benchmarks, respectively.
Figure 25 provides the results of Qwen2.5-Math-7B and Llama3.1-8B-Instruct models on $\textsc{Graph}$ domain with more out-of-domain benchmarks.
Similar to the observations on smaller models, during the pre-saturation phases, models show generalization on both in-domain and out-of-domain benchmarks in terms of $\text{pass@}k$ metrics. Compared to the 3B model, the 8B Llama model exhibits better cross-domain generalization. However, Llama models still saturate more faster than Qwen models and show clear data dependence (e.g., Figure 22 on $\textsc{Science}$).
D. Reward Type Effect
D.1 Additional Results on Reward Corruption
Reward corruption implementation. For each corruption level $\gamma$, we uniformly sample a $\gamma$ fraction of prompts from the $N=2048$ training set for each model–domain pair. For each selected prompt, we draw 96 model responses at temperature $1.0$ and select the most frequently occurring incorrect final answer (i.e., one that receives zero reward under our verifier) as the corrupted target. During RL training, we replace the ground-truth labels of the selected prompts with these corrupted labels. For Llama models and the $\textsc{Graph}$ domain, we cap $\gamma$ at $0.9$ due to the base model's inability to generate valid solutions even with extensive sampling.
Results. Figure 2 shows complementary results to Section 3.2. We observe similar patterns that some models are robust to even large amounts of reward noise. In particular, Qwen models exhibit generalization ability even when trained on almost completely corrupted data; in contrast, Llama models tend to show high reward curves yet poorer generalization to new data, suggesting overfitting to incorrect responses.
D.2 Additional Results on Self-Supervised Proxy Rewards
Proxy rewards implementation. We evaluate two self-supervised proxy rewards as alternatives to ground-truth verification: majority voting and self-certainty.
- Majority Voting Reward. Following TTRL ([9]), we estimate pseudo-labels via majority voting and assign binary rewards based on agreement with the consensus answer. For each prompt, we sample 16 responses from the policy model. The most frequently occurring answer among these 16 responses is selected as the pseudo-label. Rewards are then computed as: r = 1 if the response matches the pseudo-label, and r = 0 otherwise. For policy optimization, we use the first 8 responses to compute advantages. All other RL hyperparameters follow Appendix B.3.
- Self-Certainty Reward. Following [6], we use the model's own confidence as the reward signal. Self-certainty is defined as the average KL divergence between a uniform distribution over the vocabulary and the model's next-token distribution:
$ r = \text{Self-certainty}(o|q) := \frac{1}{|o|} \sum_{i=1}^{|o|} \text{KL}(U | p_{\pi_\theta}(\cdot|q, o_{<i})) $
where $o_{<i}$ denotes previously generated tokens and $U$ is the uniform distribution over the vocabulary. Higher values indicate greater model confidence. For each prompt, we sample 8 responses and use the self-certainty scores directly as rewards to compute advantages. All other RL hyperparameters follow Appendix B.3.
Results. Figure 27 shows full results of self-supervised proxy rewards across model-domain pairs. Except for Qwen2.5-Math-1.5B, all other models exhibit failure modes under prolonged training. For Qwen2.5-1.5B on $\textsc{Science}$, both proxy rewards collapse: majority voting shows a sharp reward spike followed by performance degradation, while self-certainty leads to complete training collapse. Similarly, Llama-3.2-3B-Instruct on $\textsc{Math}$ shows degraded performance with both proxy rewards despite increasing training rewards. Only Qwen2.5-Math-1.5B on $\textsc{Math}$ maintains stable performance with majority voting, though self-certainty still collapses after approximately 200 steps. These results demonstrate that self-supervised proxy rewards are brittle and model-dependent, with only math-specialized models showing partial robustness.
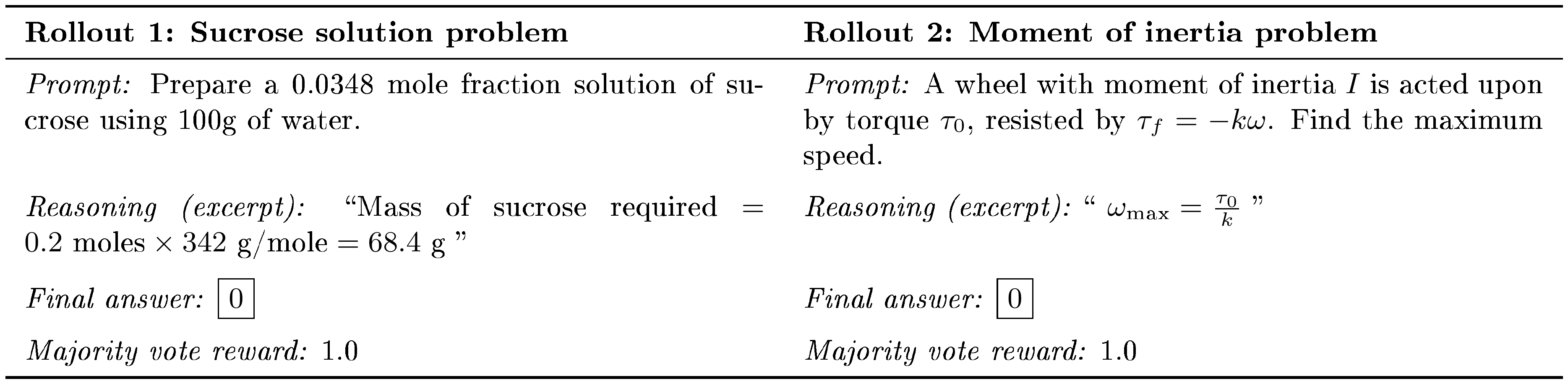
D.3 Reward Hacking Example Under Majority Vote
Table 8 shows two rollouts from Qwen2.5-3B trained on $\textsc{Science}$ with majority vote rewards at training step 846. In both cases, the model produces plausible intermediate reasoning but converges to the same final answer $\boxed{0}$, regardless of the problem content. The majority vote reward is 1.0 because all rollouts agree on this answer — the policy has learned to produce identical outputs to maximize consensus, constituting reward hacking. The correct answers (68.4g and $\tau_0/k$, respectively) appear in the reasoning traces but are overridden in the final answer.
::: {caption="Table 8: Two rollouts from Qwen2.5-3B on $\textsc{Science}$ at step 846 under majority vote reward. Both produce coherent reasoning toward the correct answer but output $\boxed{0}$ as the final answer, achieving majority vote reward of 1.0."}
:::
E. Baseline Effect
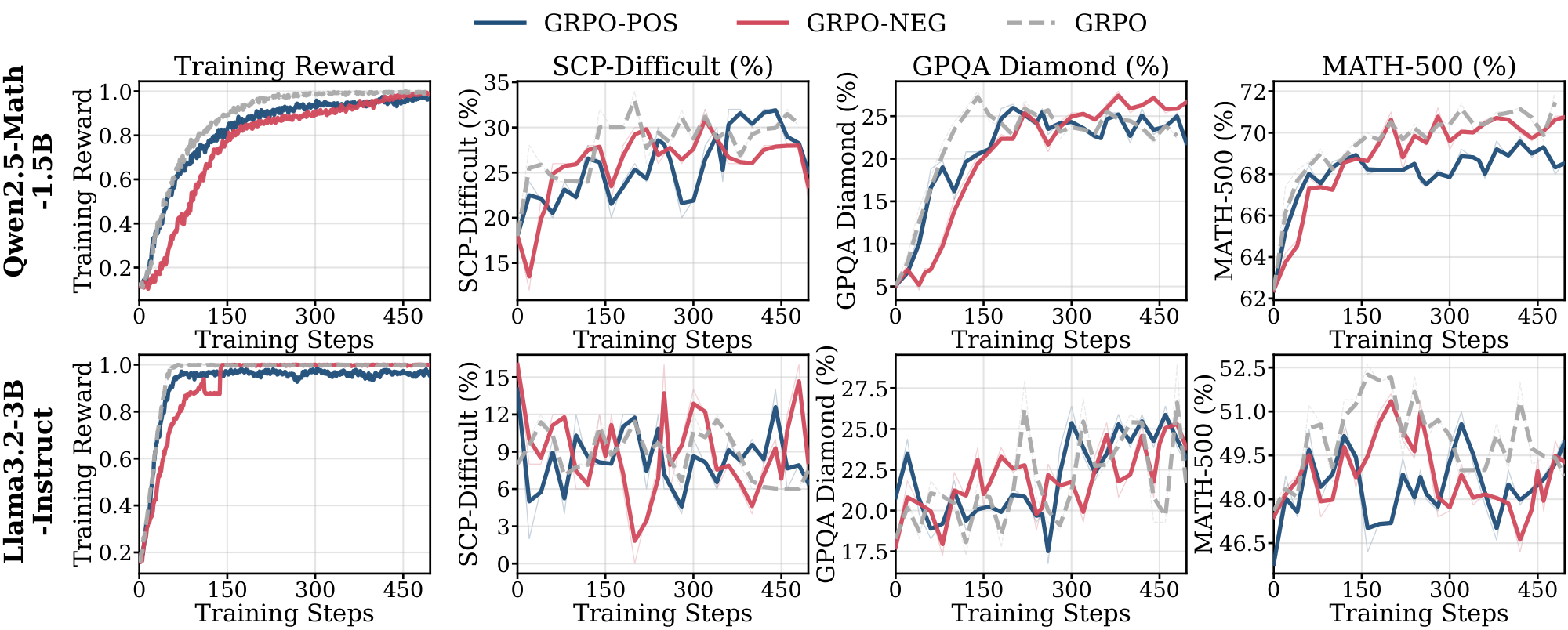
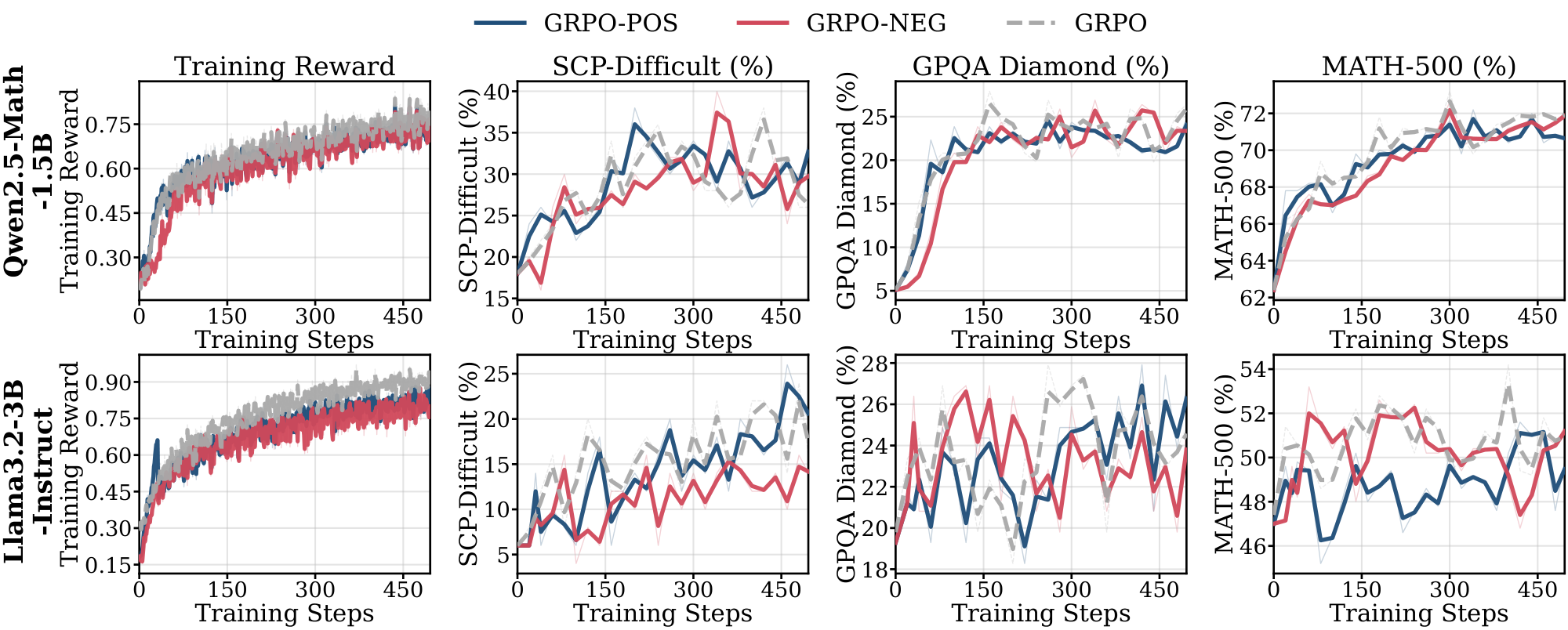
We analyze how the choice of reward baseline influences generalization in GRPO. Standard GRPO uses the within-group mean reward ($\mu=\frac{1}{G}\sum_{i=1}^{G} r_i$) as the baseline. By replacing $\mu$ with a constant baseline $b\in{0, 1}$, we isolate the direction of the policy update: $b=0$ retains only positive reinforcement from correct samples ($\textsc{GRPO-pos}$), equivalent to the $\textsc{REINFORCE}$ algorithm, while $b=1$ retains only negative reinforcement from incorrect samples ($\textsc{GRPO-neg}$), which [37] studied in $\textsc{Math}$ domain. We remove the length penalty term $\frac{1}{|o|}$ in GRPO for this experiment. Based on the policy gradient theory, where subtracting an action-independent baseline does not change the expected gradient but reduces variance, with a large batch these two methods should yield similar learning behavior ([68]).
Figs. Figure 28 and Figure 29 present the training results on the $\textsc{Science}$ domain for 8 and 1024 samples, respectively. In both regimes, $\textsc{GRPO-pos}$ and $\textsc{GRPO-neg}$ achieve comparable Pass@1 performance to standard GRPO, exhibiting similar saturation and generalization behaviors. We note that this contrasts with recent findings by [37], which highlight the superiority of $\textsc{GRPO-neg}$. However, their improvements were primarily observed in Pass@k metrics rather than Pass@1 and evaluated on $\textsc{Math}$ domain. Beyond these metric differences, it's worth studying whether implementation artifacts may also influence observations. For instance, clipping terms in the GRPO formulation can introduce biases [5, 69]. While our strictly on-policy setup mitigates such clipping effects, we leave a comprehensive analysis of these affects to future work.
F. Diversity and Faithfulness
: Table 9: Inter-rater agreement between LLM judges measured using Cohen's Kappa.
| Judge Pair | Cohen's Kappa |
|---|---|
| OpenAI o3 vs. GPT-OSS-20B [70] | 0.752 |
| OpenAI o3 vs. Gemini 3 Flash [71] | 0.649 |


F.1 Quantification of generation diversity
To quantify the generation diversity of a model on a given prompt, we generate a number of responses, $y_1, ..., y_N$ and cluster them based on their reasoning similarity. Basing our analysis on the method used by [28], to determine reasoning similarity between two outputs $y_i, y_j$, we define a function $s(y_i, y_j) \in {0, 1}$ such that $s(y_i, y_j) = 1$ if $y_i, y_j$ are similar and $0$ otherwise. To evaluate $s(\cdot, \cdot)$, we prompt GPT-4o [72] as a diversity judge to determine whether the reasoning produced by any two responses follows a different reasoning path using the prompt specified in Figure 31.
We form semantic clusters by iterating through responses and comparing them to a representative response from each existing cluster, creating a new cluster if the response is dissimilar to each representative. This is performed under the assumption of transitivity of similarity. We create clusters ${C_1, ... C_K}$ where $C_i = {y_1, ..., y_{n_i}}$ such that $s(y_i, y_j) = 1 \ \ \forall y_i, y_j \in C_i$. We then define the diversity scores using the Shannon Diversity Index [73] as follows.
For a given prompt, let $N$ be the total number of responses, $n_i$ be the number of responses in cluster $C_i$, and $K$ be the number of clusters. Let $p_i = \frac{n_i}{N}$ Define the Shannon entropy
$ H(p) = -\sum_{i=1}^K p_i \log p_i $
and the effective number of clusters
$ N_{\text{eff}} = \exp\big(H(p)\big). $
We then define the diversity score
$ \begin{align} Div_\pi(x) = \frac{N_{\text{eff}}-1}{K-1}. \end{align} $
when $K>1$ and $0$ otherwise.
For a data distribution $\mathcal{D}$, we define the overall generation diversity as $d_\pi(\mathcal{D})=\mathbb{E}{x\sim\mathcal{D}}!\left[Div\pi(x)\right]$. Empirically, we sample $N=16$ outputs per prompt and estimate $d_\pi$ using 8 prompts from the specified dataset.
We define Faithful Diversity as this metric calculated only on responses that achieve a faithfulness score of 1 (see below).
Figure 36 shows an example of the LM-as-judge output when prompted to evaluate the similarity of 2 responses.
F.2 Quantification of reasoning faithfulness
Inspired by prior work [29], we define the faithfulness as a response’s intermediate reasoning trace contains all relevant information and remains logically consistent with the predicted final answer. Each model rollout produces a response $y$ that contains (i) a reasoning trace and (ii) a final answer. We write $y=(r, a)$, where $r$ is the reasoning text and $a$ is the extracted final answer. For each input prompt $x$, we sample $y \sim \pi(\cdot \mid x)$ from the policy.
Faithfulness labeling. We define a discrete faithfulness labeling function $s_{\text{faithful}} : \mathcal{X}\times\mathcal{Y} \rightarrow {0, \tfrac{1}{2}, 1}$, where $s_{\text{faithful}}(x, y)$ measures the internal agreement between $r$ and $a$ in $y$:
- $s_{\text{faithful}}(x, y)=1$ (aligned) if the reasoning trace $r$ constitutes a coherent and logically supportive justification for the produced answer $a$, regardless of whether $a$ is correct;
- $s_{\text{faithful}}(x, y)=\tfrac{1}{2}$ (partially aligned) if $r$ exhibits a plausible argumentative trajectory toward $a$ but contains substantial gaps, unsupported leaps, or local inconsistencies that weaken the justification;
- $s_{\text{faithful}}(x, y)=0$ (misaligned) if $a$ is not supported by $r$, e.g., $r$ contradicts $a$, fails to address the question, or the answer appears as the "lucky" guess.
In practice, we implement $s_{\text{faithful}}(x, y)$ by querying OpenAI o3 [74] as an LLM-as-a-judge with a fixed rubric (Figure 32). OpenAI o3 is used for this task, as opposed to GPT-4o, due to requiring a larger model in order to be able to accurately reason about complex mathematical and scientific steps present in the reasoning traces. For a label $l \in {0, \tfrac{1}{2}, 1}$, we define the faithfulness rate of policy $\pi$ over dataset $\mathcal{D}$ as
$
\begin{align*}
F_{\pi}(l)
:=
\mathbb{P}{x \sim \mathcal{D}, , y \sim \pi(\cdot \mid x)}
\big[s{\text{faithful}}(x, y)=l\big].
\end{align*}
$
At training step $t$, we approximate $F_{\pi_t}(l)$ using $N$ training prompts ${x_i}_{i=1}^N$ and $K$ rollouts per prompt:
$
\begin{align}
\widehat{F}{\pi_t}(l)
=
\frac{1}{NK}\sum{i=1}^{N}\sum_{k=1}^{K}
\mathbb{1}\left{ s_{\text{faithful}}\big(x_i, y_{i, k}\big)=l \right},
\qquad
y_{i, k} \sim \pi_t(\cdot \mid x_i).
\end{align}
$
We use $N=8$ prompts and $K=16$ rollouts per prompt at selected RL checkpoints on the specified training dataset. We report $\widehat{F}_{\pi_t}(l)$ for $l\in{0, \tfrac{1}{2}, 1}$ to characterize the distribution of reasoning faithfulness under the policy $\pi_t$.
Figure 37 shows an example of the LM-as-judge output when prompted to evaluate the faithfulness of a model response when trained on the $\textsc{Math}$ training dataset.
Reliability of LLM-as-a-judge. To mitigate bias from using an LLM-as-a-judge for faithfulness evaluation, we assess consistency across multiple LLM judges by computing Cohen's Kappa [75] across 16 faithfulness-scored Qwen2.5-Math-1.5B outputs when trained on 8 samples from the $\textsc{Math}$ training dataset at steps 20, 120 and 440.
The judges achieve substantial agreement ($\kappa$ = 0.752 and 0.649), indicating consistent faithfulness labeling across different models. We additionally conducted a small-scale manual evaluation to human-check the faithfulness scores and find fair alignment with the LLM judges.
F.3 Additional results on diversity analysis
Figure 30 shows the semantic diversity of Llama3.2-3B-Instruct, Qwen2.5-1.5B and Qwen2.5-Math-1.5B on the $\textsc{Math}$-500 evaluation dataset throughout RL training. Qwen-Math exhibits higher reasoning diversity on correct responses than the other models at the later stages of training, highlighting that RL enables it to successfully learn diverse and reliable strategies; coupled with its better performance on the evaluation dataset, this indicates stronger generalization properties. In particular, we observe significantly lower diversity in the Llama3.2-3B-Instruct model in comparison to its diversity metric on the training dataset (Figure 4), implying disagreement between training and evaluation distributions and further highlighting the limitations of training diversity as an indicator of reasoning capabilities.
F.4 Additional results on faithfulness analysis
Figure 33 shows the proportion of responses that are classified as aligned or misaligned when calculated with respect to correct, incorrect or all responses. Out of all correct, incorrect and overall responses, both Qwen2.5-1.5B and Qwen2.5-Math-1.5B show higher proportion of aligned responses and lower proportion of misaligned responses than Llama3.2-3B when trained on 8 samples from the $\textsc{Math}$ dataset. Qwen2.5-Math-1.5B additionally shows this result when trained on 8 samples from $\textsc{Science}$.
G. Pre-RL Intervention
Figure 34 report pass@16 results and Figure 35 reports results on more benchmarks.


References
[1] Guo et al. (2025). DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature. 645(8081). pp. 633–638.
[2] Jaech et al. (2024). Openai o1 system card. arXiv preprint arXiv:2412.16720.
[3] Team et al. (2025). Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599.
[4] Wang et al. (2025). Reinforcement learning for reasoning in large language models with one training example. arXiv preprint arXiv:2504.20571.
[5] Shao et al. (2025). Spurious rewards: Rethinking training signals in rlvr. arXiv preprint arXiv:2506.10947.
[6] Zhao et al. (2025). Learning to reason without external rewards. arXiv preprint arXiv:2505.19590.
[7] Prabhudesai et al. (2025). Maximizing Confidence Alone Improves Reasoning. arXiv preprint arXiv:2505.22660.
[8] Agarwal et al. (2025). The unreasonable effectiveness of entropy minimization in llm reasoning. arXiv preprint arXiv:2505.15134.
[9] Zuo et al. (2025). Ttrl: Test-time reinforcement learning. arXiv preprint arXiv:2504.16084.
[10] Huang et al. (2025). R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004.
[11] Nikhil Chandak et al. (2025). Incorrect Baseline Evaluations Call into Question Recent LLM-RL Claims. https://safe-lip-9a8.notion.site/Incorrect-Baseline-Evaluations-Call-into-Question-Recent-LLM-RL-Claims-2012f1fbf0ee8094ab8ded1953c15a37?pvs=4. Notion Blog.
[12] Shafayat et al. (2025). Can Large Reasoning Models Self-Train?. arXiv preprint arXiv:2505.21444.
[13] Burns et al. (2023). Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390.
[14] Qwen Team (2024). Qwen2.5: A Party of Foundation Models. https://qwenlm.github.io/blog/qwen2.5/.
[15] An Yang et al. (2024). Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement. arXiv preprint arXiv:2409.12122.
[16] Dubey et al. (2024). The llama 3 herd of models. arXiv e-prints. pp. arXiv–2407.
[17] He et al. (2025). Skywork Open Reasoner 1 Technical Report. arXiv preprint arXiv:2505.22312.
[18] Liu et al. (2025). Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864.
[19] Lu et al. (2025). Scp-116k: A high-quality problem-solution dataset and a generalized pipeline for automated extraction in the higher education science domain. arXiv preprint arXiv:2501.15587.
[20] Stojanovski et al. (2025). REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards. arXiv preprint arXiv:2505.24760.
[21] Shao et al. (2024). Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
[22] Sheng et al. (2024). Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv:2409.19256.
[23] Sun et al. (2025). Improving Data Efficiency for LLM Reinforcement Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay. arXiv preprint arXiv:2506.05316.
[24] Rahman et al. (2025). AI Debate Aids Assessment of Controversial Claims. arXiv preprint arXiv:2506.02175.
[25] Bowman et al. (2022). Measuring progress on scalable oversight for large language models. arXiv preprint arXiv:2211.03540.
[26] Cui et al. (2025). The entropy mechanism of reinforcement learning for reasoning language models. arXiv preprint arXiv:2505.22617.
[27] Farquhar et al. (2024). Detecting hallucinations in large language models using semantic entropy. Nature. 630(8017). pp. 625–630.
[28] Li et al. (2025). Jointly reinforcing diversity and quality in language model generations. arXiv preprint arXiv:2509.02534.
[29] Baker et al. (2025). Monitoring reasoning models for misbehavior and the risks of promoting obfuscation. arXiv preprint arXiv:2503.11926.
[30] Mahabadi et al. (2025). Nemotron-cc-math: A 133 billion-token-scale high quality math pretraining dataset. arXiv preprint arXiv:2508.15096.
[31] Guha et al. (2025). OpenThoughts: Data Recipes for Reasoning Models. arXiv preprint arXiv:2506.04178.
[32] Olmo et al. (2025). Olmo 3. arXiv preprint arXiv:2512.13961.
[33] Yu et al. (2025). Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476.
[34] Zeng et al. (2025). Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild. arXiv preprint arXiv:2503.18892.
[35] Liu et al. (2025). Understanding r1-zero-like training: A critical perspective. arXiv preprint arXiv:2503.20783.
[36] Hu et al. (2025). Brorl: Scaling reinforcement learning via broadened exploration. arXiv preprint arXiv:2510.01180.
[37] Zhu et al. (2025). The surprising effectiveness of negative reinforcement in LLM reasoning. arXiv preprint arXiv:2506.01347.
[38] Gandhi et al. (2025). Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars. arXiv preprint arXiv:2503.01307.
[39] He et al. (2026). How Far Can Unsupervised RLVR Scale LLM Training?. arXiv preprint arXiv:2603.08660.
[40] Yang et al. (2026). Can LLMs Learn to Reason Robustly under Noisy Supervision?. arXiv preprint arXiv:2604.03993.
[41] Plesner et al. (2026). An Imperfect Verifier is Good Enough: Learning with Noisy Rewards. arXiv preprint arXiv:2604.07666.
[42] Qi et al. (2025). EvoLM: In Search of Lost Language Model Training Dynamics. arXiv preprint arXiv:2506.16029.
[43] Wang et al. (2025). Octothinker: Mid-training incentivizes reinforcement learning scaling. arXiv preprint arXiv:2506.20512.
[44] Zhang et al. (2025). On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models. arXiv preprint arXiv:2512.07783.
[45] Akter et al. (2025). Front-loading reasoning: The synergy between pretraining and post-training data. arXiv preprint arXiv:2510.03264.
[46] Kirk et al. (2024). Understanding the Effects of RLHF on LLM Generalisation and Diversity. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=PXD3FAVHJT.
[47] Casper et al. (2023). Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback. Transactions on Machine Learning Research. https://openreview.net/forum?id=bx24KpJ4Eb.
[48] Rafailov et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. In Advances in Neural Information Processing Systems. pp. 53728–53741.
[49] Turpin et al. (2023). Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems. 36. pp. 74952–74965.
[50] Chen et al. (2025). Reasoning Models Don't Always Say What They Think. arXiv preprint arXiv:2505.05410.
[51] Tutek et al. (2025). Measuring Chain of Thought Faithfulness by Unlearning Reasoning Steps. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 9935–9960. doi:10.18653/v1/2025.emnlp-main.504. https://aclanthology.org/2025.emnlp-main.504/.
[52] Gui et al. (2026). FaithRL: Learning to Reason Faithfully through Step-Level Faithfulness Maximization. arXiv preprint arXiv:2602.03507.
[53] Wen et al. (2025). Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms. arXiv preprint arXiv:2506.14245.
[54] He et al. (2025). Skywork Open Reasoner Series. https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680. Notion Blog.
[55] Lightman et al. (2023). Let's verify step by step. In The Twelfth International Conference on Learning Representations.
[56] Hendrycks et al.. Measuring Mathematical Problem Solving With the MATH Dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
[57] AI-MO (2024). Amc 2023. https://huggingface.co/datasets/AI-MO/aimo-validation-amc.
[58] AI-MO (2024). Aime 2024. https://huggingface.co/datasets/AI-MO/aimo-validation-aime.
[59] Opencompass (2024). Aime 2025. https://huggingface.co/datasets/opencompass/AIME2025.
[60] Lewkowycz et al. (2022). Solving quantitative reasoning problems with language models. Advances in neural information processing systems. 35. pp. 3843–3857.
[61] He et al. (2024). Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 3828–3850.
[62] Rein et al. (2024). Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling.
[63] Zhoujun Cheng et al. (2025). Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective. doi:10.48550/arXiv.2506.14965. https://arxiv.org/abs/2506.14965.
[64] Du et al. (2025). Supergpqa: Scaling llm evaluation across 285 graduate disciplines. arXiv preprint arXiv:2502.14739.
[65] Wang et al. (2024). Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems. 37. pp. 95266–95290.
[66] Wang et al. (2023). Scibench: Evaluating college-level scientific problem-solving abilities of large language models. arXiv preprint arXiv:2307.10635.
[67] Yue et al. (2025). Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?. arXiv preprint arXiv:2504.13837.
[68] Williams, Ronald J (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning. 8(3). pp. 229–256.
[69] Chen et al. (2025). Exploration vs exploitation: Rethinking rlvr through clipping, entropy, and spurious reward. arXiv preprint arXiv:2512.16912.
[70] OpenAI (2025). gpt-oss-20b Model Card. Accessed: 2026-02-18. https://arxiv.org/abs/2508.10925. arXiv:2508.10925.
[71] Google DeepMind (2025). Gemini 3 Flash. https://gemini.google.com/. Released December 2025. Accessed: 2026-02-18.
[72] Hurst et al. (2024). Gpt-4o system card. arXiv preprint arXiv:2410.21276.
[73] Shannon, Claude E (1948). A mathematical theory of communication. The Bell system technical journal. 27(3). pp. 379–423.
[74] OpenAI (2025). OpenAI o3 and o4-mini System Card. https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf. Accessed 2026-01-25.
[75] Cohen, Jacob (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement. 20(1). pp. 37–46.