Horovod: fast and easy distributed deep learning in TensorFlow
Alexander Sergeev
Uber Technologies, Inc.[email protected]
Mike Del Balso
Uber Technologies, Inc.[email protected]
Abstract
Training modern deep learning models requires large amounts of computation, often provided by GPUs. Scaling computation from one GPU to many can enable much faster training and research progress but entails two complications. First, the training library must support inter-GPU communication. Depending on the particular methods employed, this communication may entail anywhere from negligible to significant overhead. Second, the user must modify his or her training code to take advantage of inter-GPU communication. Depending on the training library's API, the modification required may be either significant or minimal.
Existing methods for enabling multi-GPU training under the TensorFlow library entail non-negligible communication overhead and require users to heavily modify their model-building code, leading many researchers to avoid the whole mess and stick with slower single-GPU training. In this paper we introduce Horovod, an open source library that improves on both obstructions to scaling: it employs efficient inter-GPU communication via ring reduction and requires only a few lines of modification to user code, enabling faster, easier distributed training in TensorFlow. Horovod is available under the Apache 2.0 license at https://github.com/uber/horovod.
Executive Summary: Training deep learning models has become essential for applications like image recognition, forecasting, and fraud detection, powering advancements in businesses such as ride-sharing services. However, as models and datasets grow larger, single-GPU training often takes days or weeks, delaying innovation and increasing costs. At the same time, scaling to multiple GPUs across servers has been hindered by inefficient communication between devices and the need for extensive code changes in popular frameworks like TensorFlow, leading many teams to avoid distributed training altogether.
This paper introduces Horovod, an open-source library designed to simplify and accelerate distributed deep learning in TensorFlow. The goal was to enable users to scale training across many GPUs with minimal code modifications—typically just a few lines—while reducing communication overhead to make full use of hardware resources.
The authors developed Horovod by building on existing research, including Baidu's ring-allreduce algorithm for efficient gradient averaging among GPUs and NVIDIA's optimized communication library. They created a standalone Python package that works with various TensorFlow versions, supports models spanning multiple GPUs on a single server, and integrates with standard tools like the Message Passing Interface for launching jobs across machines. Key enhancements include a simple application programming interface and a profiling tool called Horovod Timeline to visualize training across nodes. They tested Horovod using official TensorFlow benchmarks on up to 128 NVIDIA Pascal GPUs over a 25-gigabit Ethernet network, focusing on popular models like Inception V3 and ResNet-101.
The core findings highlight Horovod's strong performance. First, it achieved 88 percent scaling efficiency across 128 GPUs, processing images about twice as fast as standard distributed TensorFlow, which wasted nearly half of resources due to communication bottlenecks. Second, for models with many small tensors, a feature called Tensor Fusion combined them before communication, yielding up to 65 percent faster training on standard networks. Third, using advanced networking like remote direct memory access provided modest gains (3-4 percent) for most models but up to 30 percent speedup for parameter-heavy ones like VGG-16, pushing efficiency over 90 percent. Overall, Horovod eliminated the need for complex setups like parameter servers, making distributed training accessible without deep expertise.
These results mean teams can train models much faster—potentially cutting week-long jobs to hours—freeing engineers to focus on model design rather than infrastructure. This boosts productivity in high-stakes areas like autonomous vehicles or demand prediction, reduces compute costs by better utilizing existing GPUs, and aligns with the shift toward large-scale machine learning platforms. Unlike prior methods, Horovod's simplicity avoids subtle bugs and steep learning curves, marking a practical advance over standard TensorFlow's limitations.
To leverage Horovod, organizations should integrate it into their TensorFlow workflows for new projects, starting with small-scale tests on multi-GPU servers to verify gains. For clusters, pair it with optimized networks if using communication-intensive models. Future work includes simplifying installation on large systems and developing guidelines for tuning model parameters in distributed settings to maintain accuracy at scale. Teams could also extend it to very large models spanning multiple servers, with community contributions encouraged via the open-source repository.
While benchmarks show reliable results on standard hardware and networks, limitations include the effort to set up communication tools on clusters and its focus on models fitting within one server. Confidence in the efficiency claims is high based on repeated tests, but users should validate on their specific setups, especially for custom models or non-GPU hardware, where adaptations may be needed.
1. Introduction
Section Summary: Deep learning has made huge strides in areas like image processing, speech recognition, and forecasting, and at Uber, it's used to improve everything from self-driving cars to predicting trips and preventing fraud for better user experiences. Uber favors TensorFlow as its main deep learning tool because it's popular and user-friendly for newcomers, offers high performance with flexibility for custom tweaks, and supports the full process from research to deploying models on servers, phones, or vehicles. In 2017, Uber launched Michelangelo, a platform to make machine learning easier and scalable for everyone, and this paper spotlights Horovod, its open-source feature that simplifies and accelerates distributed deep learning projects using TensorFlow.
Over the past few years, advances in deep learning have driven tremendous progress in image processing, speech recognition, and forecasting. At Uber, we apply deep learning across our business; from self-driving research to trip forecasting and fraud prevention, deep learning enables our engineers and data scientists to create better experiences for our users.
TensorFlow [1] has become a preferred deep learning library at Uber for a variety of reasons. To start, the framework is one of the most widely used open source frameworks for deep learning, which makes it easy to onboard new users. It also combines high performance with an ability to tinker with low-level model details—for instance, we can use both high-level APIs, such as Keras [2], and implement our own custom operators using NVIDIA's CUDA toolkit. Additionally, TensorFlow has end-to-end support for a wide variety of deep learning use cases, from conducting exploratory research to deploying models in production on cloud servers, mobile apps, and even self-driving vehicles.
In September 2017, Uber Engineering introduced Michelangelo [3], an internal ML-as-a-service platform that democratizes machine learning and makes it easy to build and deploy these systems at scale. In this paper, we introduce Horovod, an open-source component of Michelangelo's deep learning toolkit which makes it easier to start—and speed up—distributed deep learning projects with TensorFlow. Horovod is available under the Apache 2.0 license at https://github.com/uber/horovod.
2. Going distributed
Section Summary: As Uber's machine learning models grew larger and required more data, training times stretched to a week or longer, prompting the team to explore distributed training to speed things up without sacrificing data volume. They tested the standard TensorFlow approach but ran into complications: its complex setup introduced confusing new concepts that often led to tricky bugs, and it didn't scale well at Uber's level, wasting nearly half of their GPU resources on large setups like 128 machines. This experience was invigorated by a Facebook study showing it was possible to train a major model in just one hour across 256 GPUs using smart data-sharing techniques, underscoring the huge productivity gains from effective distributed training.
As we began training more and more machine learning models at Uber, their size and data consumption grew significantly. In a large portion of cases, the models were still small enough to fit on one or multiple GPUs within a server, but as datasets grew, so did the training times, which sometimes took a week or longer to complete. We found ourselves in need of a way to train using a lot of data while maintaining short training times. To achieve this, our team turned to distributed training.
We began by testing the standard distributed TensorFlow [4] technique. After trying it out on a few models, it became apparent that we needed to make two adjustments.
First, after following the documentation and code examples, it was not always clear which code modifications needed to be made to distribute their model training code. The standard distributed TensorFlow package introduces many new concepts: workers, parameter servers, tf.Server(), tf.ClusterSpec(), tf.train.SyncReplicasOptimizer(), and tf.train.replicas_device_setter() to name a few.
While this API may be well-suited to certain scenarios, in many cases it introduced subtle, hard-to-diagnose bugs. Identifying and fixing these bugs unfortunately required users to climb a steep learning curve of concepts they almost never care about—they just want to take an existing model and make it faster, not become an expert along the way in syncronization primtivies.
The second issue dealt with the challenge of computing at Uber's scale. After running a few benchmarks, we found that we could not get the standard distributed TensorFlow to scale as well as our services required. For example, we lost about half of our resources due to communication overhead when training on 128 GPUs.
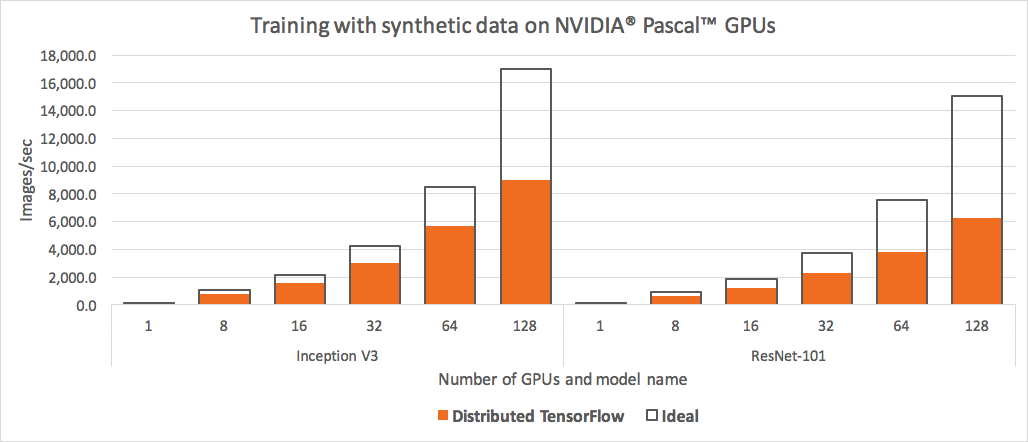
When we ran the standard TensorFlow benchmarking suite [5] on 128 NVIDIA Pascal GPUs, showcased in Figure 1, we observed that both the Inception V3 and ResNet-101 models were were unable to leverage nearly half of our GPU resources.
Motivated to make the most of our GPU capacity, we became even more excited about distributed training after Facebook published a paper [6], demonstrating training of a ResNet-50 network in one hour on 256 GPUs by combining principles of data parallelism [7] with an innovative learning rate adjustment technique. This milestone made it abundantly clear that large-scale distributed training can have an enormous impact on model developer productivity.
3. Leveraging a different type of algorithm
Section Summary: To improve distributed training for their small TensorFlow models that fit on single or multiple GPUs, the team adopted a data-parallel approach, where multiple copies of the training script process data chunks separately, compute gradients, average them across nodes, and update the model together. The standard TensorFlow method using parameter servers helped but introduced problems like finding the optimal worker-to-server ratio to avoid bottlenecks and dealing with complex code for setup and multi-GPU support. They then turned to Baidu's ring-allreduce algorithm, a peer-to-peer method that efficiently averages gradients without servers by having nodes communicate in a ring, making it bandwidth-optimal and simpler to implement using tools like MPI.
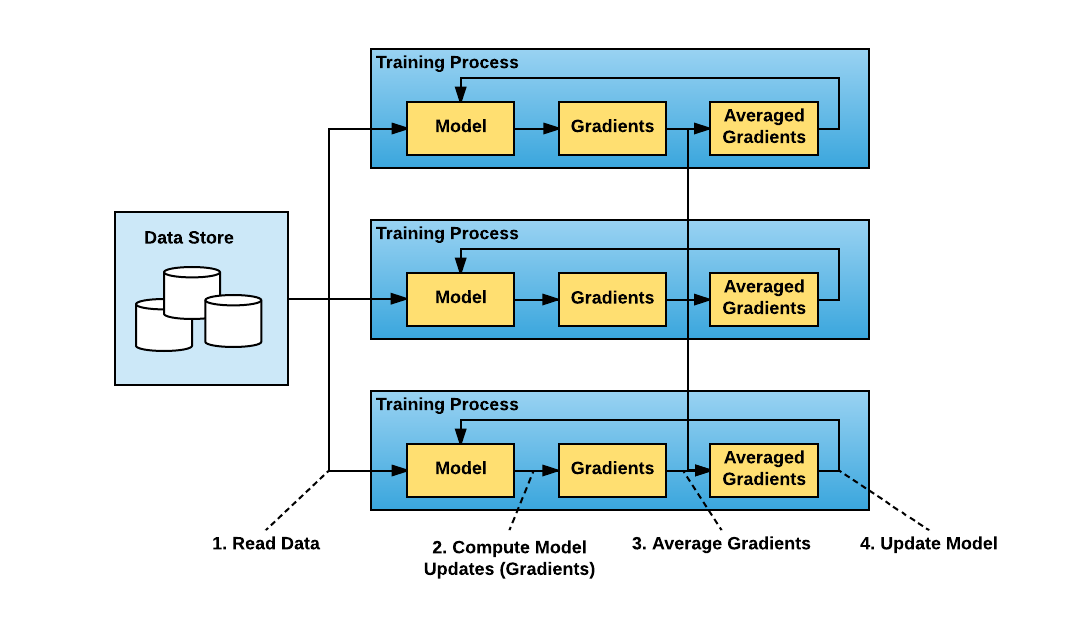
After this realization, we started looking for a better way to train our distributed TensorFlow models. Since our models were small enough to fit on a single GPU, or multiple GPUs in a single server, we tried using Facebook's data parallel approach to distributed training, shown on Figure 2.
Conceptually, the data-parallel distributed training paradigm is straightforward:
Run multiple copies of the training script and each copy: {#itm_repeat}
reads a chunk of the data
runs it through the model
computes model updates (gradients)
Average gradients among those multiple copies {#itm_average}
Update the model {#itm_update}
Repeat (from Step Section 3)
The standard distributed TensorFlow package runs with a parameter server approach to averaging gradients, shown on Figure 3. In this approach, each process has one of two potential roles: a worker or a parameter server. Workers process the training data, compute gradients, and send them to parameter servers to be averaged.
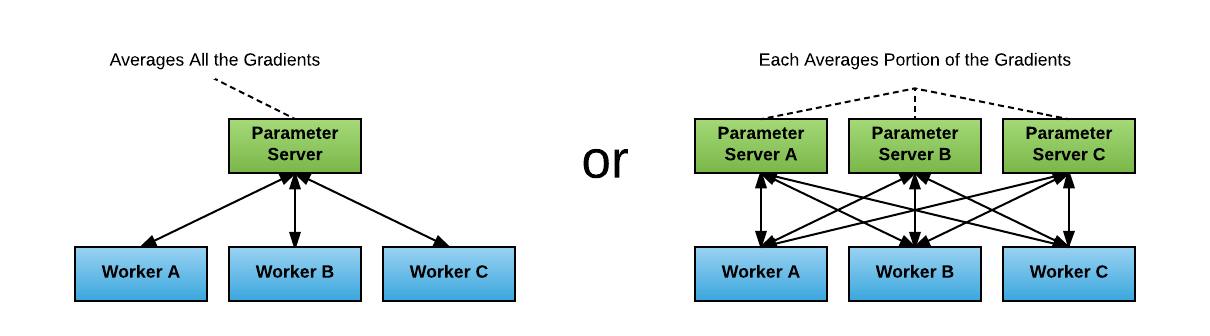
While this approach improved our performance, we encountered two challenges:
- Identifying the right ratio of worker to parameter servers: If one parameter server is used, it will likely become a networking or computational bottleneck. If multiple parameter servers are used, the communication pattern becomes “all-to-all” which may saturate network interconnects.
- Handling increased TensorFlow program complexity: During our testing, every user of distributed TensorFlow had to explicitly start each worker and parameter server, pass around service discovery information such as hosts and ports of all the workers and parameter servers, and modify the training program to construct
tf.Server()with an appropriatetf.ClusterSpec(). Additionally, users had to ensure that all the operations were placed appropriately usingtf.train.device_replica_setter()and code is modified to use towers to leverage multiple GPUs within the server. This often led to a steep learning curve and a significant amount of code restructuring, taking time away from the actual modeling.
In early 2017 Baidu published an article [8] evangelizing a different algorithm for averaging gradients and communicating those gradients to all nodes (Steps Section 3 and Section 3 above), called ring-allreduce, as well as a fork of TensorFlow through which they demonstrated a draft implementation of this algorithm. The algorithm was based on the approach introduced in the 2009 paper by Patarasuk and Yuan [9].
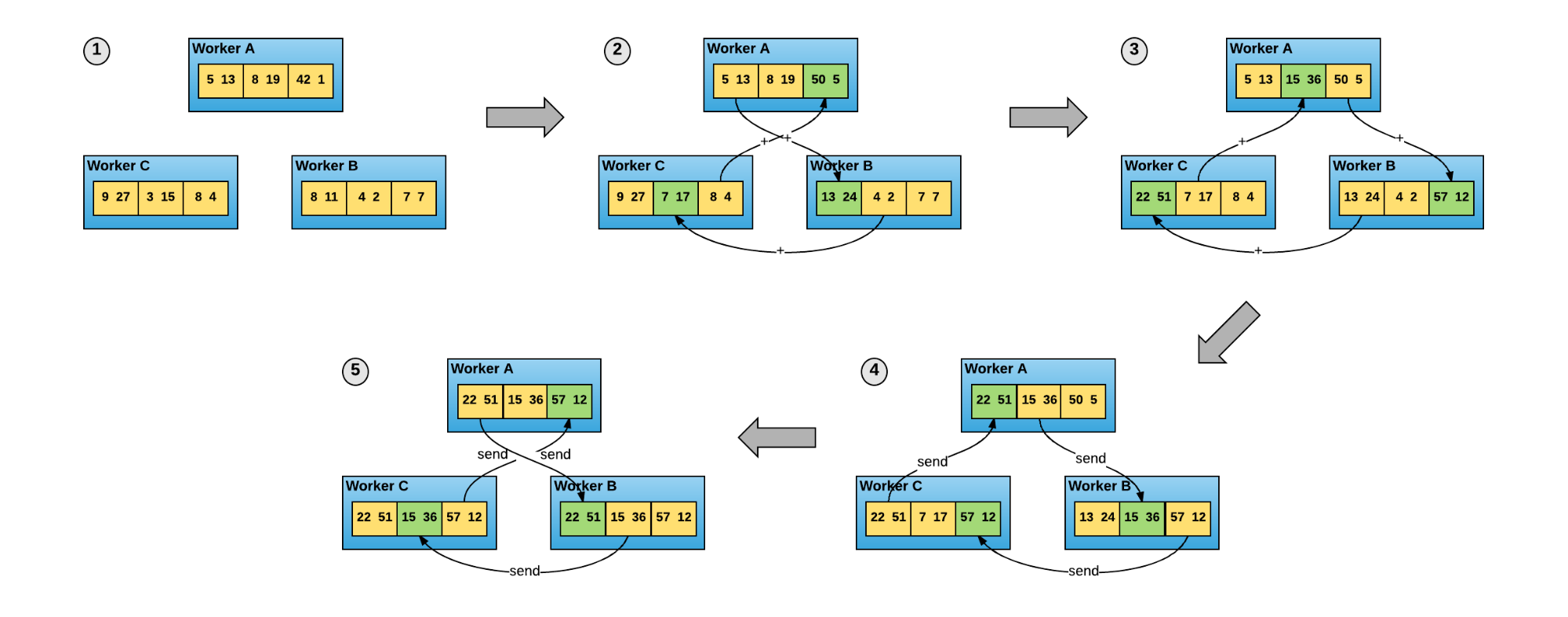
In the ring-allreduce algorithm, shown on Figure 4, each of $N$ nodes communicates with two of its peers $2*(N-1)$ times. During this communication, a node sends and receives chunks of the data buffer. In the first $N-1$ iterations, received values are added to the values in the node's buffer. In the second $N-1$ iterations, received values replace the values held in the node's buffer. Patarasuk and Yuan in [9] suggest that this algorithm is bandwidth-optimal, meaning that if the buffer is large enough, it will optimally utilize the available network.
In addition to being network-optimal, the allreduce approach is much easier to understand and adopt. Users utilize a Message Passing Interface (MPI) [10] implementation such as Open MPI [11] to launch all copies of the TensorFlow program. MPI then transparently sets up the distributed infrastructure necessary for workers to communicate with each other. All the user needs to do is modify their program to average gradients using an allreduce() operation.
4. Introducing Horovod
Section Summary: Uber engineers developed Horovod, a standalone Python package inspired by a Russian folk dance, to simplify and speed up distributed training in TensorFlow using a ring-allreduce communication method originally from Baidu. They enhanced it by integrating NVIDIA's optimized NCCL library for better performance across multiple machines and GPUs, and expanded support to handle larger models that span several GPUs on one server. User feedback led to API improvements that make it easy to adapt existing single-GPU programs with just four simple operations, including one to ensure consistent model setup across workers.
The realization that a ring-allreduce approach can improve both usability and performance motivated us to work on our own implementation to address Uber's TensorFlow needs. We adopted Baidu's draft implementation [12] of the TensorFlow ring-allreduce algorithm and built upon it. We outline our process below:
- We converted the code into a stand-alone Python package called Horovod, named after a traditional Russian folk dance in which performers dance with linked arms in a circle, much like how distributed TensorFlow processes use Horovod to communicate with each other. At any point in time, various teams at Uber may be using different releases of TensorFlow. We wanted all teams to be able to leverage the ring-allreduce algorithm without needing to upgrade to the latest version of TensorFlow, apply patches to their versions, or even spend time building out the framework. Having a stand-alone package allowed us to cut the time required to install Horovod from about an hour to a few minutes, depending on the hardware.
- We replaced the Baidu ring-allreduce implementation with NCCL [13]. NCCL is NVIDIA's library for collective communication that provides a highly optimized version of ring-allreduce. NCCL 2 introduced the ability to run ring-allreduce across multiple machines, enabling us to take advantage of its many performance boosting optimizations.
- We added support for models that fit inside a single server, potentially on multiple GPUs, whereas the original version only supported models that fit on a single GPU.
- Finally, we made several API improvements inspired by feedback we received from a number of initial users. In particular, we implemented a broadcast operation that enforces consistent initialization of the model on all workers. The new API allowed us to cut down the number of operations a user had to introduce to their single GPU program to four.
Next, we discuss how you can use Horovod for your team's machine learning use cases, too!
5. Distributing your training job with Horovod
Section Summary: Horovod makes it easy to scale up TensorFlow training programs from a single GPU to multiple machines with just a few simple code changes, like initializing the library, assigning GPUs to processes, wrapping the optimizer for gradient sharing, and ensuring variables are synced across nodes. For instance, you can add these tweaks to your existing program and then launch it across servers using a command like mpirun to run copies on multiple GPUs simultaneously. This approach also works seamlessly with Keras programs, helping engineers and data scientists distribute their work efficiently without much hassle.
Whereas the parameter server paradigm for distributed TensorFlow training often requires careful implementation of significant boilerplate code [14], Horovod needs just a few new lines. In Listing Algorithm 1, we offer an example of a TensorFlow program distributed using Horovod.
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01)
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes
# during initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing
# when done or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir="/tmp/train_logs",
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
As this example shows, there are only a few changes necessary to make single-GPU programs distributed:
hvd.init()initializes Horovod.config.gpu_options.visible_device_list = str(hvd.local_rank())assigns a GPU to each of the TensorFlow processes.opt=hvd.DistributedOptimizer(opt)wraps any regular TensorFlow optimizer with Horovod optimizer which takes care of averaging gradients using ring-allreduce.hvd.BroadcastGlobalVariablesHook(0)broadcasts variables from the first process to all other processes to ensure consistent initialization. If the program does not useMonitoredTrainingSession, users can run thehvd.broadcast_global_variables(0)operations instead.
User can then run several copies of the program across multiple servers using the mpirun command:
$ mpirun -np 16 -H server1:4, server2:4, server3:4, server4:4 python train.py
The mpirun command distributes train.py to four nodes and runs it on four GPUs per node.
Horovod can also distribute Keras programs by following the same steps. (You can find examples of scripts for both TensorFlow and Keras on the Horovod GitHub page [15].)
Horovod's ease of use, debugging efficiency, and speed makes it a highly effective sidekick for engineers and data scientists interested in distributing a single-GPU or single-server program. Next, we introduce Horovod Timeline, a means of providing a high level of understanding of the states of worker nodes during a distributed training job.
6. Horovod Timeline
Section Summary: When developers onboarded users to Horovod, a tool for distributed machine learning, they noticed it was hard to spot bugs in code across multiple servers using standard profilers like TensorFlow's timelines or CUDA Profiler, which required manually combining data from each machine. To solve this, they created Horovod Timeline, a simple profiling tool that gives a clear, high-level view of what operations are happening on each node over time during training jobs. Users can activate it with just one environment variable and review the results easily in a web browser using Chrome's tracing viewer, making it simpler to find errors and optimize performance.
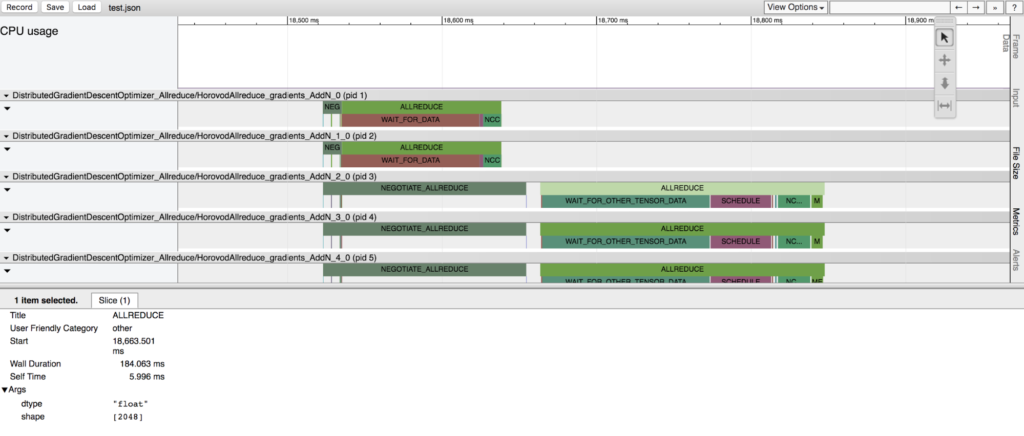
As we onboarded users to Horovod, we realized that we needed a way for them to easily identify bugs in their code, an issue commonly faced when dealing with complex distributed systems. In particular, it was difficult to use native TensorFlow timelines or the CUDA Profiler because users are required to collect and cross-reference profiles from the various servers.
With Horovod, we wanted to created a way to provide a high-level understanding of operation timelines across nodes. To do so, we built Horovod Timeline, a Horovod-focused profiling tool compatible with Chrome's about:tracing [16] trace event profiling viewer. Users can use Horovod Timelines to view exactly what each node was doing at each time step throughout a training job. This helps identify bugs and debug performance issues. Users can enable timelines by setting a single environment variable and can view the profiling results in the browser through chrome://tracing. Figure 5 shows an example of Horovod Timeline.
7. Tensor Fusion
Section Summary: Researchers found that models like ResNet-101 generate many small data packets that slow down the efficient ring-allreduce process used in distributed machine learning. To fix this, they developed Tensor Fusion, an algorithm that combines these small packets into larger ones before processing, leading to up to 65 percent faster performance on complex models over slower network connections. The process involves selecting compatible packets, copying them into a temporary buffer, reducing the combined data, and then distributing the results, making overall machine learning systems quicker and easier to use with tools like Horovod.
After we analyzed the timelines of a few models, we noticed that those with a large amount of tensors, such as ResNet-101, tended to have many tiny allreduce operations. As noted earlier, ring-allreduce utilizes the network in an optimal way if the tensors are large enough, but does not work as efficiently or quickly if they are very small. We asked ourselves: what if multiple tiny tensors could be fused together before performing ring-allreduce on them?
Our answer: Tensor Fusion, an algorithm that fuses tensors together before we call Horovod's ring-allreduce. As we experimented with this approach, we observed up to 65 percent improvement in performance on models with a large number of layers running on an unoptimized transmission control protocol (TCP) network. We outline how to use Tensor Fusion, below:
- Determine which tensors are ready to be reduced. Select the first few tensors that fit in the buffer and have the same data type.
- Allocate a fusion buffer if it was not previously allocated. Default fusion buffer size is 64 MB.
- Copy data of selected tensors into the fusion buffer.
- Execute the allreduce operation on the fusion buffer.
- Copy data from the fusion buffer into the output tensors.
- Repeat until there are no more tensors to reduce in the cycle.
With Horovod, Tensor Fusion, and other features built on top of Michelangelo, we can increase the efficiency, speed, and ease-of-use across our machine learning systems. In our next section, we share real world benchmarks that showcase Horovod's performance.
8. Horovod Benchmarks
Section Summary: Researchers tested Horovod, a tool for distributed deep learning training, against standard TensorFlow on NVIDIA GPUs using models like Inception V3 and ResNet-101, finding that Horovod doubled the training speed and achieved 88 percent efficiency by better utilizing GPU resources. They also compared Horovod over regular high-speed Ethernet (TCP) with advanced direct memory access networking (RDMA), which offered only slight improvements of three to four percent for the first two models but boosted efficiency above 90 percent. However, for the parameter-heavy VGG-16 model, RDMA provided a significant 30 percent speedup by easing communication bottlenecks, showing Horovod's strong scalability on both network types with extra benefits for complex models.
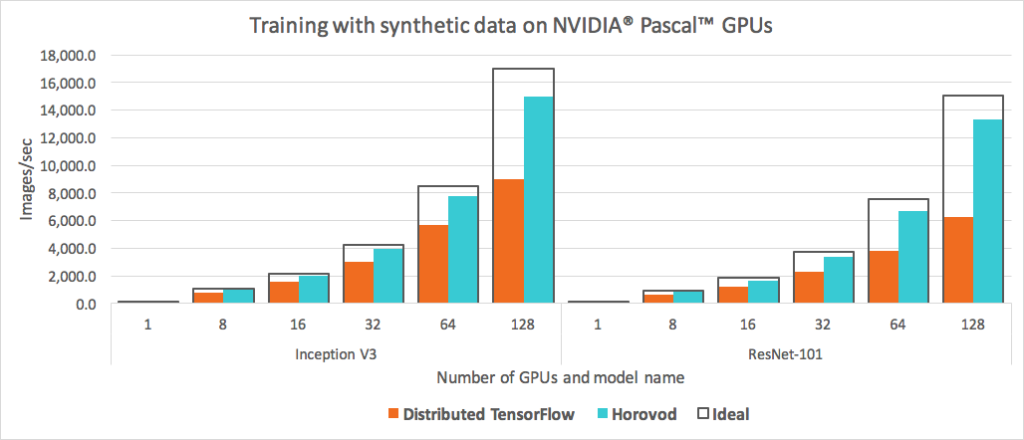
We re-ran the official TensorFlow benchmarks modified to use Horovod [17] and compared the performance with regular distributed TensorFlow. As depicted in Figure 6, we observed large improvements in our ability to scale; we were no longer wasting half of the GPU resources—in fact, scaling using both Inception V3 and ResNet-101 models achieved an 88 percent efficiency mark. In other words, the training was about twice as fast as standard distributed TensorFlow.
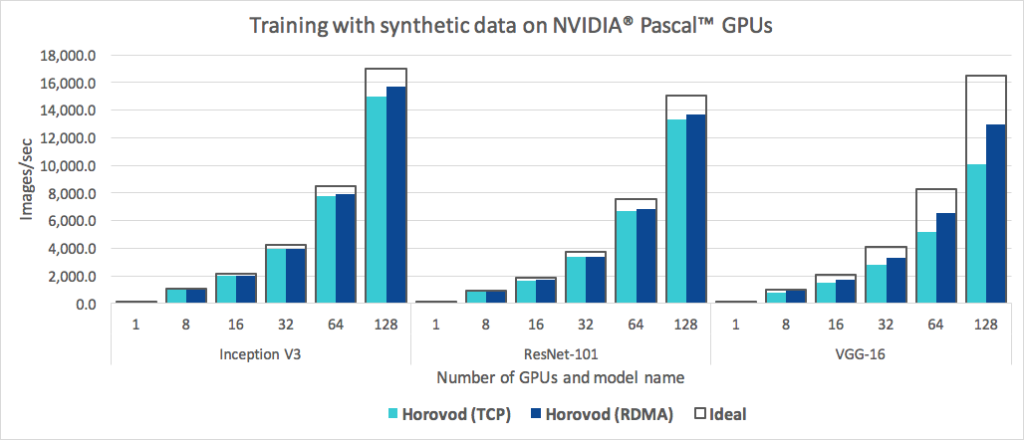
Since both MPI and NCCL support remote direct memory access (RDMA) [18] capable networking (e.g., via InfiniBand [19] or RDMA over Converged Ethernet [20]), we ran additional sets of benchmarking tests using RDMA network cards to determine if they helped us enhance efficiency compared to TCP networking. Figure 7 shows the results of this benchmark.
For the Inception V3 and ResNet-101 models, we found that RDMA did not significantly improve our performance and only achieved a three to four percent increase over TCP networking. RDMA, however, did help Horovod exceed 90 percent scaling efficiency on both models.
Meanwhile, the VGG-16 model experienced a significant 30 percent speedup when we leveraged RDMA networking. This can be explained by VGG-16's high number of model parameters, caused by the use of fully connected layers combined with its small number of layers. These characteristics shifted the critical path from GPU computation to communication and created a networking bottleneck.
These benchmarks demonstrate that Horovod scales well on both plain TCP and RDMA-capable networks, although users with RDMA networking will be able to squeeze out optimal performance and experience a significant efficiency gain when using models with a high number of model parameters, such as the VGG-16.
With Horovod, we have only scratched the surface when it comes to exploring performance optimizations in deep learning; in the future, we intend to continue leveraging the open source community to extract additional performance gains with our machine learning systems and frameworks.
9. Next steps
Section Summary: The developers of Horovod are focusing on several improvements, such as simplifying the installation of MPI software on clusters by creating guides in collaboration with experts and hardware makers, gathering insights on tweaking model settings to maintain accuracy in distributed training across many GPUs, and providing more examples for handling very large models that spread across multiple machines. They reference research showing successful scaling, like training on 256 GPUs, and aim to partner with others to advance this field. Overall, they encourage users to adopt Horovod for better resource use in deep learning, and invite feedback, issue reports, performance shares, and contributions.
There are a few areas that we are actively working on to improve Horovod, including:
- Making it easier to install MPI: While it is relatively easy to install MPI on a workstation, installation of MPI on a cluster typically requires some effort; for instance, there are number of workload managers available and different tweaks should be made depending on network hardware. We are developing reference designs for running Horovod on a cluster; to do so, we hope to work with the MPI community and network hardware vendors to develop instructions for installing MPI and relevant drivers.
- Collecting and sharing learnings about adjusting model parameters for distributed deep learning: Facebook’s paper [6] describes the adjustments needed to model hyperparameters to achieve the same or greater accuracy in a distributed training job compared to training the same model on a single GPU, demonstrating the feasibility of training a TensorFlow model on 256 GPUs. We believe this area of deep learning research is still in its early stages and hope to collaborate with other teams about approaches to further scale deep learning training.
- Adding examples of very large models: Horovod currently supports models that fit into one server but may span multiple GPUs. We are eager to develop more examples for large models spanning multiple GPUs, and encourage others to test Horovod on these types of models as well.
We hope the simplicity of Horovod enables others to adopt distributed training and better leverage their compute resources for deep learning. We welcome feedback and contributions: please report any issues you encounter, share speed-ups, and send pull requests.
Acknowledgements
The authors would like to thank Molly Vorwerck and Jason Yosinski for the help in preparing this paper.
References
Section Summary: This references section provides a bibliography of key sources on machine learning frameworks and distributed computing tools. It highlights foundational papers and documentation for TensorFlow, a widely used system for training AI models on large datasets across multiple computers, along with related libraries like Keras and Horovod, and platforms such as Uber's Michelangelo. The list also includes resources on parallel processing techniques, communication standards like MPI, and high-speed networking methods including InfiniBand and RDMA, which enable faster collaboration between computing devices in complex AI tasks.
[1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viegas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. Tensorflow: Large-scale machine learning on heterogeneous distributed systems, 2016a, arXiv:1603.04467.
[2] François Chollet et al. Keras. https://github.com/fchollet/keras, 2015. [Online; accessed 6-December-2017].
[3] Jeremy Hermann and Mike Del Balso. Meet Michelangelo: Uber’s machine learning platform. https://eng.uber.com/michelangelo/, 2017. [Online; accessed 6-December-2017].
[4] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. Tensorflow: A system for large-scale machine learning, 2016b, arXiv:1605.08695.
[5] TensorFlow Authors. Tensorflow benchmarks. https://github.com/tensorflow/benchmarks, 2017a. [Online; accessed 6-December-2017].
[6] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: Training ImageNet in 1 hour, 2017, arXiv:1706.02677.
[7] Wikipedia. Data parallelism — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Data_parallelism&oldid=807618997, 2017a. [Online; accessed 6-December-2017].
[8] Andrew Gibiansky. Bringing HPC techniques to deep learning. http://research.baidu.com/bringing-hpc-techniques-deep-learning, 2017. [Online; accessed 6-December-2017].
[9] Pitch Patarasuk and Xin Yuan. Bandwidth optimal all-reduce algorithms for clusters of workstations. J. Parallel Distrib. Comput., 69:117–124, 2009.
[10] MPI Forum. Message Passing Interface (MPI) Forum Home Page. http://www.mpi-forum.org, 2017. [Online; accessed 6-December-2017].
[11] Edgar Gabriel, Graham E. Fagg, George Bosilca, Thara Angskun, Jack J. Dongarra, Jeffrey M. Squyres, Vishal Sahay, Prabhanjan Kambadur, Brian Barrett, Andrew Lumsdaine, Ralph H. Castain, David J. Daniel, Richard L. Graham, and Timothy S. Woodall. Open MPI: Goals, concept, and design of a next generation MPI implementation. In Proceedings, 11th European PVM/MPI Users' Group Meeting, pages 97–104, Budapest, Hungary, September 2004.
[12] Andrew Gibiansky and Joel Hestness. baidu-research/tensorflow-allreduce. https://github.com/baidu-research/tensorflow-allreduce, 2017. [Online; accessed 6-December-2017].
[13] NVIDIA. NVIDIA collective communications library (NCCL). https://developer.nvidia.com/nccl, 2017. [Online; accessed 6-December-2017].
[14] TensorFlow Authors. Distributed TensorFlow. https://www.tensorflow.org/deploy/distributed#putting_it_all_together_example_trainer_program, 2017b. [Online; accessed 6-December-2017].
[15] Alexander Sergeev et al. uber/horovod: Distributed training framework for TensorFlow. https://github.com/uber/horovod, 2017. [Online; accessed 6-December-2017].
[16] Chromium Authors. The Trace Event Profiling Tool (about:tracing). https://www.chromium.org/developers/how-tos/trace-event-profiling-tool, 2017c. [Online; accessed 6-December-2017].
[17] Alexander Sergeev. TensorFlow Benchmarks. https://github.com/alsrgv/benchmark/tree/horovod_v2, 2017. [Online; accessed 6-December-2017].
[18] Wikipedia. Remote direct memory access — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Remote_direct_memory_access&oldid=812842097, 2017b. [Online; accessed 6-December-2017].
[19] Wikipedia. InfiniBand — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=InfiniBand&oldid=810171440, 2017c. [Online; accessed 6-December-2017].
[20] Wikipedia. RDMA over Converged Ethernet — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=RDMA_over_Converged_Ethernet&oldid=782744462, 2017d. [Online; accessed 6-December-2017].