Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Jihan Yang$^{1}$ $^{*}$
New York University
Shusheng Yang$^{1}$ $^{*}$
New York University
Anjali W. Gupta$^{1}$ $^{*}$
New York University
Rilyn Han$^{2}$ $^{*}$
Yale University
Li Fei-Fei$^{3}$
Stanford University
Saining Xie$^{1}$
New York University
$^{*}$ Equal contribution.
Abstract
Humans possess the visual-spatial intelligence to remember spaces from sequential visual observations. However, can Multimodal Large Language Models (MLLMs) trained on million-scale video datasets also "think in space" from videos? We present a novel video-based visual-spatial intelligence benchmark (VSI-Bench) of over 5,000 question-answer pairs, and find that MLLMs exhibit competitive—though subhuman—visual-spatial intelligence. We probe models to express how they think in space both linguistically and visually and find that while spatial reasoning capabilities remain the primary bottleneck for MLLMs to reach higher benchmark performance, local world models and spatial awareness do emerge within these models. Notably, prevailing linguistic reasoning techniques (e.g., chain-of-thought, self-consistency, tree-of-thoughts) fail to improve performance, whereas explicitly generating cognitive maps during question-answering enhances MLLMs' spatial distance ability.
Executive Summary: The document addresses a practical gap: current multimodal large language models (MLLMs) already handle conversation and basic video tasks, but their ability to perceive, remember, and reason about three-dimensional spaces from video remains poorly measured. This capability matters for real-world uses such as robotics, autonomous navigation, and immersive AR/VR systems, where agents must estimate distances, track object layouts, and plan routes after limited observation.
The work introduces VSI-Bench, a video-based test set of more than 5,000 questions drawn from 288 real indoor scenes. The authors evaluate 15 open- and closed-source MLLMs under zero-shot conditions, compare them with human baselines, and conduct targeted probes of model reasoning. They also test whether standard language prompting methods or explicit map generation improve results.
Humans reach roughly 79 percent average accuracy, exceeding the strongest model, Gemini-1.5 Pro, by 33 percentage points. Proprietary models outperform most open-source ones, yet even the best models stay well above chance on only a few tasks. Spatial reasoning errors account for about 71 percent of model mistakes, while common techniques such as chain-of-thought or tree-of-thoughts either leave performance unchanged or reduce it by up to 21 percent on certain tasks. When prompted to generate simple grid-based cognitive maps, however, the same leading model improves relative-distance accuracy by 10 percent.
These findings indicate that current MLLMs already form useful local spatial representations but struggle to maintain consistent global layouts. The gap limits their reliability in embodied settings where precise spatial recall and perspective-taking are required. Linguistic prompting alone is unlikely to close the gap, whereas methods that encourage explicit mental maps show promise.
Developers should therefore prioritize task-specific fine-tuning, self-supervised objectives that reward consistent spatial maps, and prompting strategies that incorporate explicit layout generation. Additional human evaluation on more diverse environments and longer video sequences would strengthen before large-scale deployment. The study rests on indoor scenes from three public datasets and zero-shot protocols; results may shift with different video lengths, outdoor data, or model updates.
1. Introduction
Section Summary: Humans naturally build mental maps of rooms and spaces after just a quick look, allowing them to judge sizes, positions, and how objects relate to each other in everyday situations like shopping for furniture. The paper points out that current AI systems have made big strides in language but still lag in this kind of visual-spatial reasoning, which matters for robots, self-driving cars, and virtual reality. To measure and improve progress, the authors created VSI-Bench, a large video-based test showing that leading models fall well short of human performance mainly because they struggle with true spatial understanding rather than just seeing or describing scenes.
When shopping for furniture, we often try to recall our living room to imagine if a desired cabinet will fit. Estimating distances is difficult, yet after even a single viewing, humans can mentally reconstruct spaces, recalling objects in a room, their positions, and sizes. We live in a sensory-rich 3D world where visual signals surround and ground us, allowing us to perceive, understand, and interact with it.
Visual-spatial intelligence entails perceiving and mentally manipulating spatial relationships [1]; it requires myriad capabilities, including relational reasoning and the ability to transform between egocentric and allocentric perspectives (Section 2). While Large Language Models (LLMs) [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13] have advanced linguistic intelligence, visual-spatial intelligence remains under-explored, despite its relevance to robotics [14, 15, 16, 17], autonomous driving [18], and AR/VR [19, 20, 21].
Multimodal Large Language Models (MLLMs) [22, 23, 24, 25, 26, 24, 27, 28], which integrate language and vision, exhibit strong capacities to think and reason in open-ended dialog and practical tasks like web agents [29, 30, 31, 14]. To advance this intelligence in the visual-spatial realm, we introduce VSI-Bench, a video-based benchmark featuring over 5, 000 question-answer pairs across nearly 290 real indoor-scene videos (Section 3). Video data, by capturing continuous, temporal input, both parallels how we observe the world and enables richer spatial understanding and reasoning than static images. Evaluating open- and closed-source models on VSI-Bench reveals that even though a large performance gap exists between models and humans, MLLMs exhibit emerging visual-spatial intelligence despite the challenges of video understanding, textual understanding, and spatial reasoning (Section 4).
To analyze model behavior and inspired by dual-coding theory [32], which posits that linguistic and visual processing are distinct yet complementary, we prompt selected models for self-explanations (linguistic) and cognitive maps (visual). Analyzing the self-explanations reveals that spatial reasoning, as compared to visual perception, linguistic intelligence, or temporal processing, is the main factor behind weak performance on VSI-Bench (Section 5). "Cognitive maps", which represent internal layouts of environments [33, 34], allow us to evaluate MLLMs' implicit spatial world models and find that MLLMs build strong local models but weak global ones (Section 6). Furthermore, standard linguistic reasoning techniques fail to enhance performance on our benchmark. However, explicitly generating and using cognitive maps improves spatial distance question-answering.
Expressing visual-spatial intelligence is difficult (and often piecemeal), even for humans [1]. With this work, we aim to encourage the community to explore grounding frontier models with visual-spatial intelligence and to pave and illuminate this direction.
2. Visual-Spatial Intelligence
Section Summary: The section defines visual-spatial intelligence as the broader capacity to perceive and reason about space using visual input from real-world environments, rather than limiting it to abstract pen-and-paper tests or non-visual senses. It outlines a taxonomy of required abilities that include visual perception, language understanding, temporal processing, and spatial reasoning, with the last of these further divided into relational reasoning about object distances and sizes plus the mental shift between self-centered and environment-centered perspectives. These combined skills, supported by visuospatial working memory, underpin the benchmark tasks that follow.
We discuss preliminaries and scope visual-spatial intelligence to provide context and a framework for later analysis.
Term Use. We use "intelligence"rather than "cognition"as it is broader, and "spatial cognition"is a branch of cognitive psychology [35]. We prefix spatial intelligence in our work with "visual", as spatial intelligence exists irrespective of sensory modality (e.g., a blind person can perceive space through other senses) [1]. Given our focus on video input, we discuss visual-spatial intelligence.
Investigation Scope. While classic spatial intelligence tests also include pen-paper tasks like the Mental Rotation Test [36], our focus is on visual-spatial intelligence as it applies to real-world environments, particularly in common spaces like homes, offices, and factories.
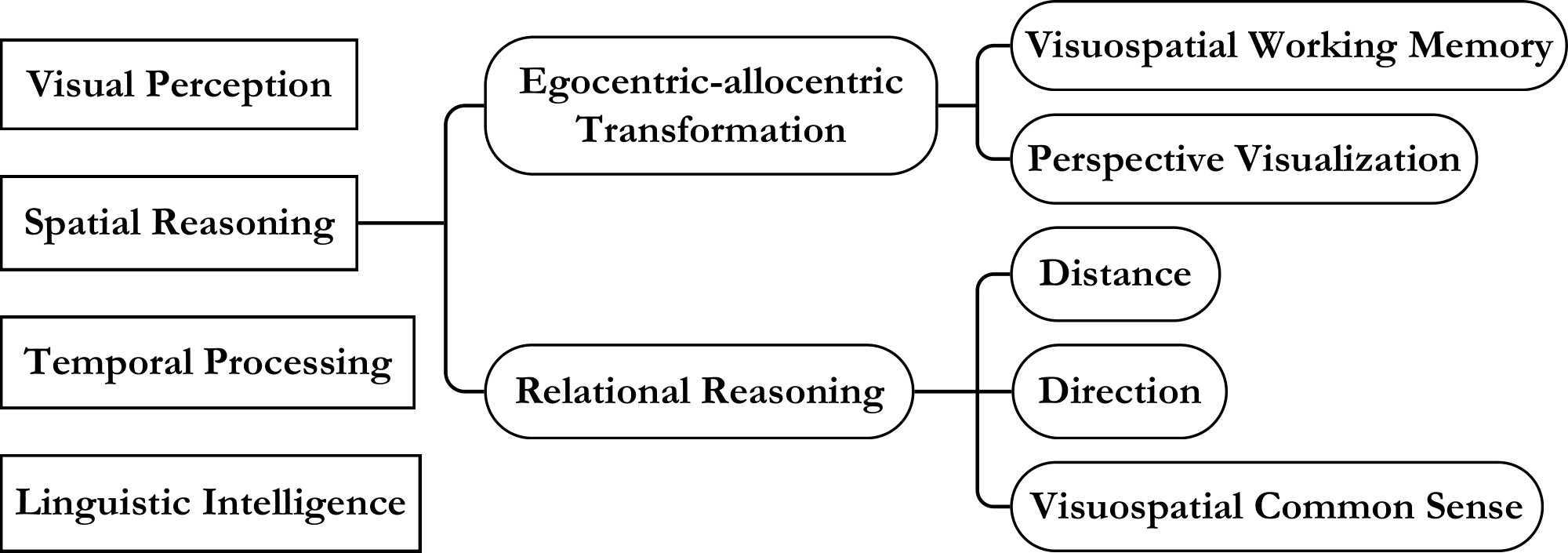
Taxonomy. We provide a taxonomy of capabilities potentially required for visual-spatial intelligence (Figure 1), based on cognitive psychology [1, 37, 34, 38] and human experience with our benchmark tasks in Section 3. Visual perception, linguistic intelligence, temporal processing, and spatial reasoning are the four areas needed in VSI-Bench. For example, [38] shows that visual object and spatial processing are neurally distinct, which motivates "visual perception"and "spatial reasoning" as separate areas. We break spatial reasoning into two broad capabilities: relational reasoning and egocentric-allocentric transformation.

Relational reasoning is the ability to identify, via distance and direction, relationships between objects. It also encompasses reasoning about distance between objects by relying on visuospatial common sense about the sizes of other objects. For example, knowing a standard beverage can is approximately 12 cm tall, humans can estimate other object sizes by comparing visual proportions.
Egocentric-allocentric transformation involves shifting between a self-centered (egocentric) view and an environment-centered (allocentric) one. In our setting, each egocentric video frame maps to allocentric object positions and camera trajectory. When humans observe a space, they convert egocentric perceptions into an allocentric mental map, enabling perspective-taking from various viewpoints— essential for tasks like relative direction or route planning. This transformation relies on visualizing new perspectives and on visuospatial working memory [39], the ability to hold and manipulate spatial information, say by updating object positions from new egocentric input [40, 41].
Every task in VSI-Bench requires perceptual, linguistic, and temporal abilities and varying degrees of spatial reasoning. For example, egocentric-allocentric transformation is much more important for a task like route planning than object size estimation. These factors provide some context for the complexity of visual-spatial intelligence.
3. VSI-Bench
Section Summary: VSI-Bench is a new test designed to measure how well AI models understand spatial relationships, sizes, and layouts from first-person videos of indoor spaces. It includes over 5,000 question-answer pairs drawn from 288 real videos across homes, offices, labs, and factories, covering eight tasks that range from counting objects and judging distances to estimating room sizes and recalling the order in which things appeared. The benchmark was built by combining existing 3D scene datasets, using templates and some human input to create questions, and applying repeated human reviews to remove ambiguities and errors.
3.1 Overview
We introduce VSI-Bench to quantitatively evaluate the visual-spatial intelligence of MLLMs from egocentric video. VSI-Bench comprises over 5, 000 question-answer pairs derived from 288 real videos. These videos are sourced from the validation sets of the public indoor 3D scene reconstruction datasets ScanNet [42], ScanNet++ [43], and ARKitScenes [44] and represent diverse environments— including residential spaces, professional settings (e.g., offices, labs), and industrial spaces (e.g., factories)— and multiple geographic regions. Repurposing these existing 3D reconstruction and understanding datasets offers accurate object-level annotations which we use in question generation and could enable future study into the connection between MLLMs and 3D reconstruction. VSI-Bench is high-quality, having been iteratively reviewed to minimize question ambiguity and to remove incorrect annotations propagated from the source datasets.
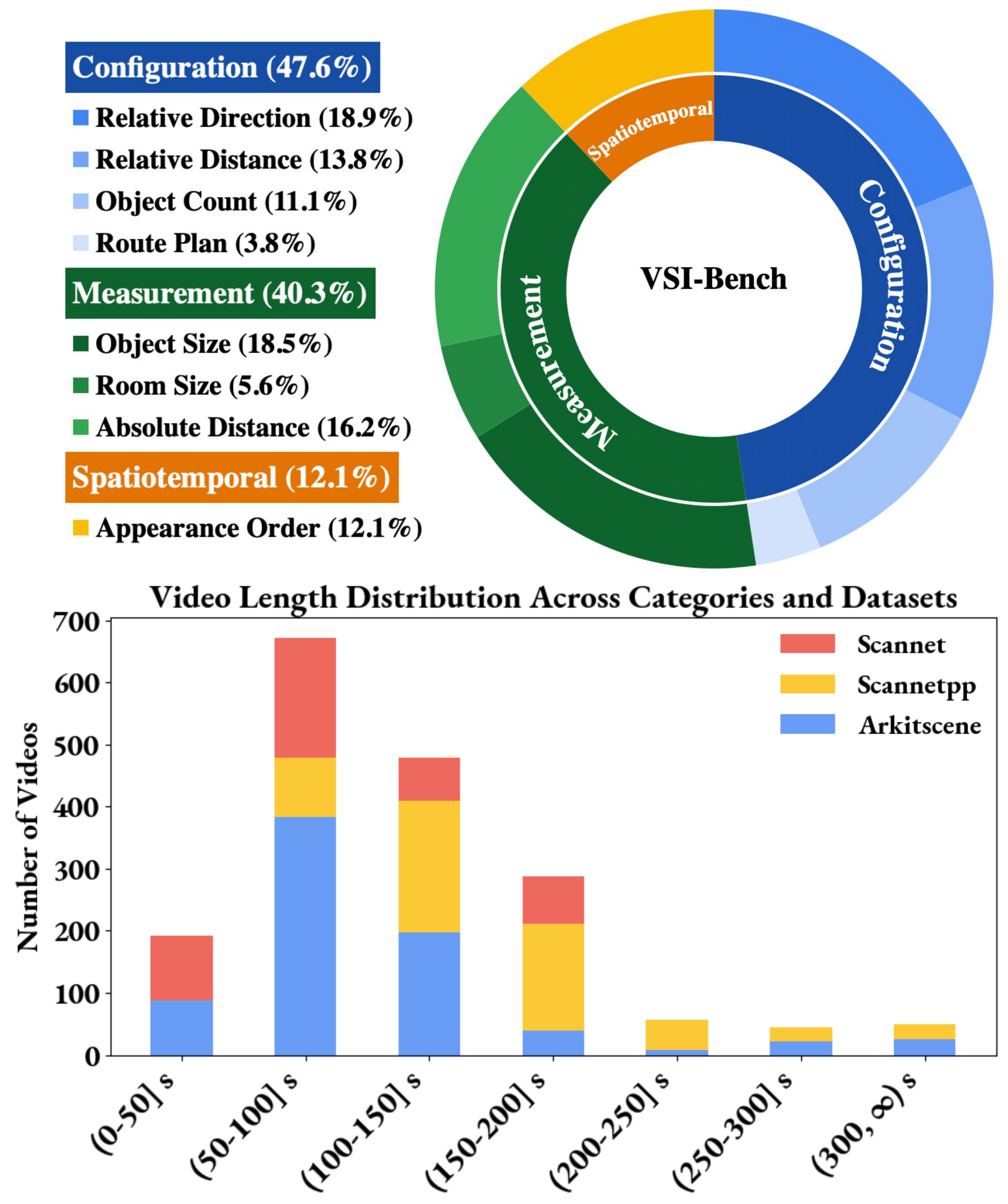
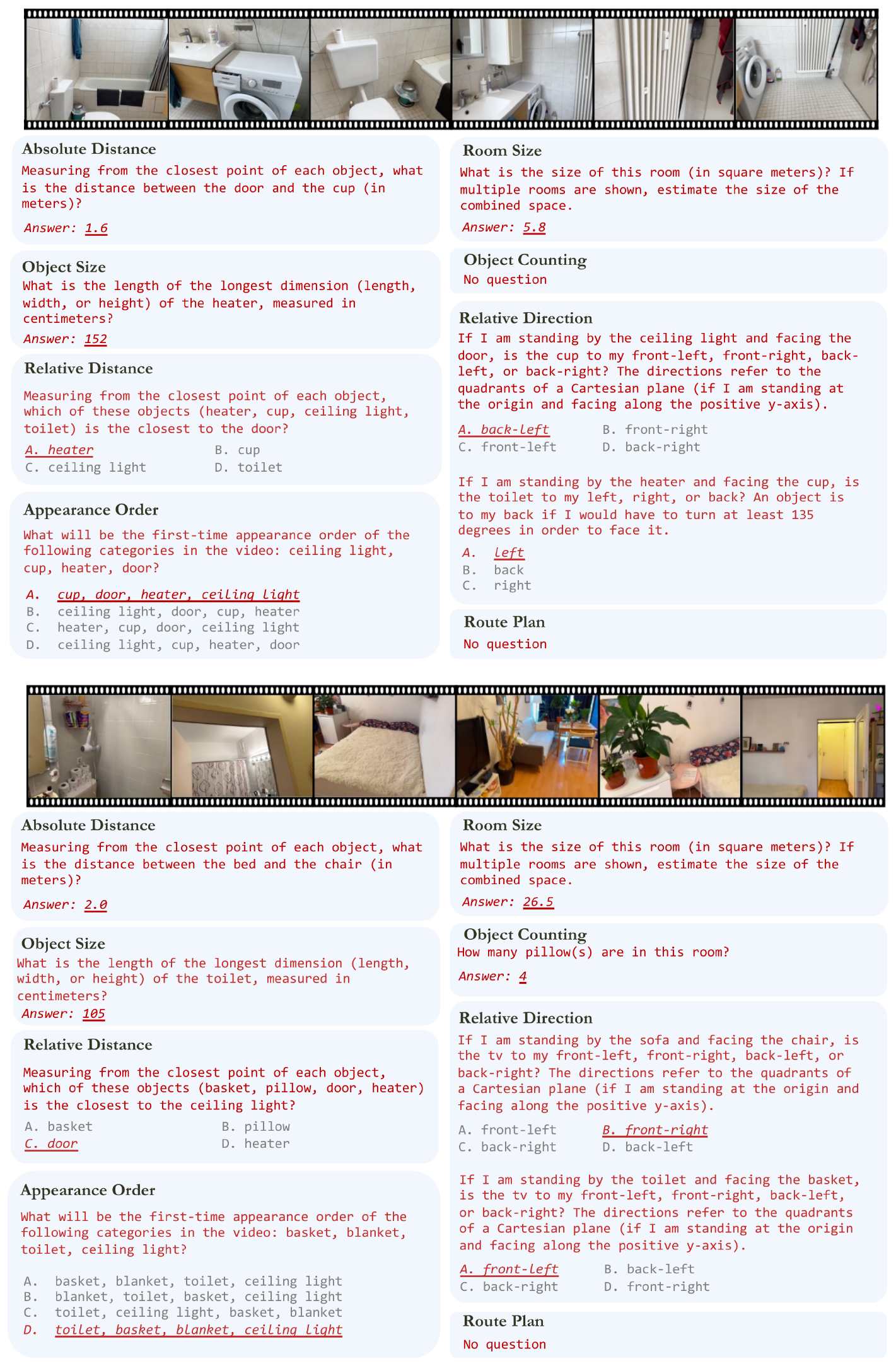
VSI-Bench includes eight tasks of three types: configurational, measurement estimation, and spatiotemporal. The configurational tasks (object count, relative distance, relative direction, route plan) test a model’s understanding of the configuration of a space and are more intuitive for humans (see Section 4 for comparison between MLLM and human performance). Measurement estimation (of object size, room size, and absolute distance) is of value to any embodied agent. While predicting a measurement exactly is very difficult, for both humans and models, a better sense of distance and other measurements is intuitively correlated with better visual-spatial intelligence and underpins a wide range of tasks that require spatial awareness, like interaction with objects and navigation. Spatiotemporal tasks like appearance order test a model's memory of a space as seen in video. See Figure 2 for an overview of VSI-Bench tasks and Figure 4 for dataset statistics.
3.2 Benchmark Construction
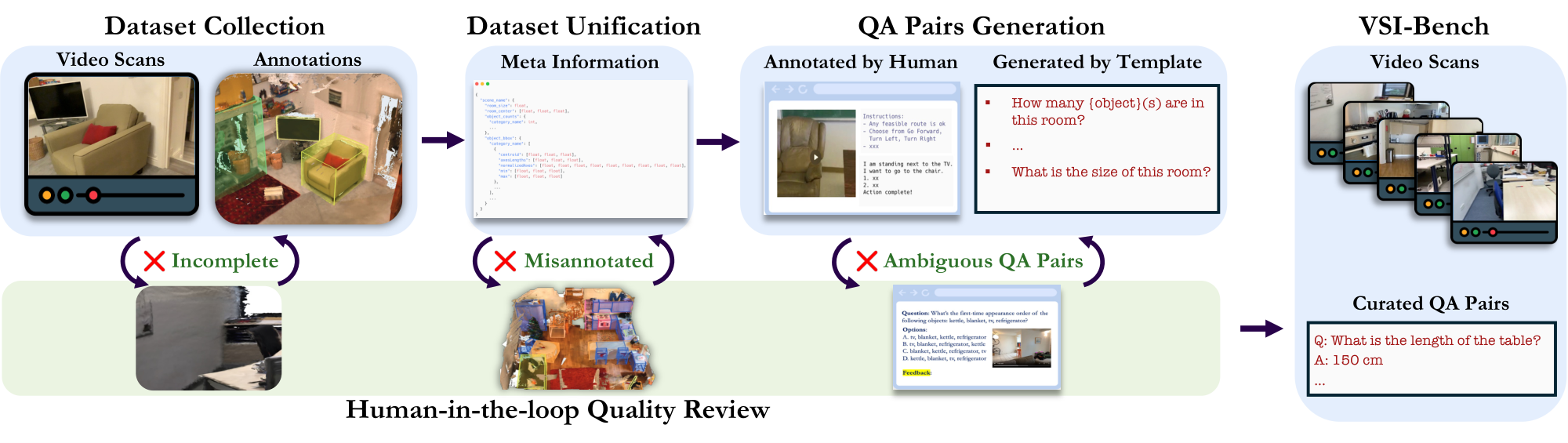
We develop a sophisticated benchmark construction pipeline to effectively generate high-quality question-answer (QA) pairs at scale, as shown in Figure 3.
Data Collection and Unification. We begin our dataset construction by standardizing various datasets into a unified meta-information structure, ensuring dataset-agnostic QA pair generation. Our benchmark aggregates existing 3D indoor scene understanding and reconstruction datasets: ScanNet [42], ScanNet++ [43], and ARKitScenes [44]. These datasets provide high-fidelity video scans capable of space reconstruction, ensuring MLLMs can answer space-level questions with only video input. Additionally, their object-level 3D annotations facilitated our question generation. We parse the datasets into a unified meta-information format including object categories, bounding boxes, video specifications (resolution and frame rate), and more.
Question-Answer Generation. QA pairs are primarily auto-annotated using the meta-information and question templates; the route plan task was human-annotated. We sophisticatedly design and refine the question template for each task and provide guidelines for human annotators. For more detailed design, see Appendix B.1.
Human-in-the-loop Quality Review. Despite human-annotated data sources and a meticulously designed QA generation methodology, certain ambiguities and errors inevitably persist, primarily due to inherent annotation errors in the source datasets. We implement a human-in-the-loop verification protocol spanning benchmark construction. This iterative quality assurance is bidirectional: when evaluators flag ambiguous or erroneous questions, we trace the error source and remove the problematic data sample or modify the meta-information, question template, or QA generation rule accordingly to rectify other erroneous questions stemming from the same source. Following each human review cycle, we update and iterate the benchmark until it satisfies our quality standards.
4. Evaluation on VSI-Bench
Section Summary: The evaluation tested 15 different video-capable multimodal AI models, both proprietary systems like Gemini-1.5 and GPT-4o and various open-source ones, using zero-shot prompts and new accuracy metrics suited to multiple-choice and numerical answers. Humans achieved 79% average accuracy on the benchmark, well ahead of the best model by a wide margin, although the leading proprietary model Gemini-1.5 Pro came close to human levels on tasks involving distance or size estimation. Several top open-source models performed competitively with the closed-source leaders, but most open-source systems fell below simple chance-level baselines, highlighting current limitations in visual-spatial understanding.
4.1 Evaluation Setup
Benchmark Models. We comprehensively evaluate 15 video-supporting MLLMs across diverse model families, encompassing various parameter scales and training recipes. For proprietary models, we consider Gemini-1.5 [23] and GPT-4o [22]. For open-source models, we evaluate models from InternVL2 [45], ViLA [46], LongViLA [47], LongVA [48], LLaVA-OneVision [49], and LLaVA-Video [50]. All evaluations are conducted under zero-shot settings and using each model's default prompts. To ensure reproducibility, we use greedy decoding for all models.
Metric Design. Based on whether the ground-truth answer is verbal or numerical, our tasks are suited to either a Multiple-Choice Answer (MCA) or Numerical Answer (NA) format (see Figure 2). For MCA tasks, we follow standard practice [51, 52, 53] by using Accuracy ($\mathcal{ACC}$), based on exact matching (with possible fuzzy matching), as the primary metric. For NA tasks, where models predict continuous values, accuracy via exact matching fails to capture the degree of proximity between model predictions and ground-truth answers. Therefore, we introduce a new metric, Mean Relative Accuracy ($\mathcal{MRA}$), inspired by previous works [54, 55, 56]. Specifically, for a NA question, given a model's prediction $\hat{y}$, ground truth $y$, and a confidence threshold $\theta$, relative accuracy is calculated by considering $\hat{y}$ correct if the relative error rate, defined as $|\hat{y}-y|/y$, is less than $1-\theta$. As single-confidence-threshold accuracy only considers relative error in a narrow scope, $\mathcal{MRA}$ averages the relative accuracy across a range of confidence thresholds $\mathcal{C}={0.5, 0.55, \dots, 0.95}$:
$ \mathcal{MRA} = \frac{1}{10}\sum_{\theta \in \mathcal{C}}\mathbb{1} \left(\frac{|\hat{y} - y|}{y} < 1-\theta \right). $
$\mathcal{MRA}$ offers a more reliable and discriminative measurement for calculating the similarity between numerical predictions and ground truth values.
Chance Level Baselines. We provide two baselines:
- Chance Level (Random) is the random selection accuracy for MCA tasks (and is inapplicable for NA tasks).
- Chance Level (Frequency) represents the highest performance MLLMs would achieve by always selecting the most frequent answer for each task. This identifies performance gains that may result from inherently long-tailed answers or imbalanced multiple-choice distributions.
Human Level Performance. We sample a subset of 400 questions (50 per task), which we will refer to as VSI-Bench (tiny). Human evaluators independently answer each question, and their performance is evaluated using the above-mentioned metrics. For comparison, we also report Gemini-1.5 Pro's performance on VSI-Bench (tiny). See Appendix C for details on evaluation setups.

4.2 Main Results
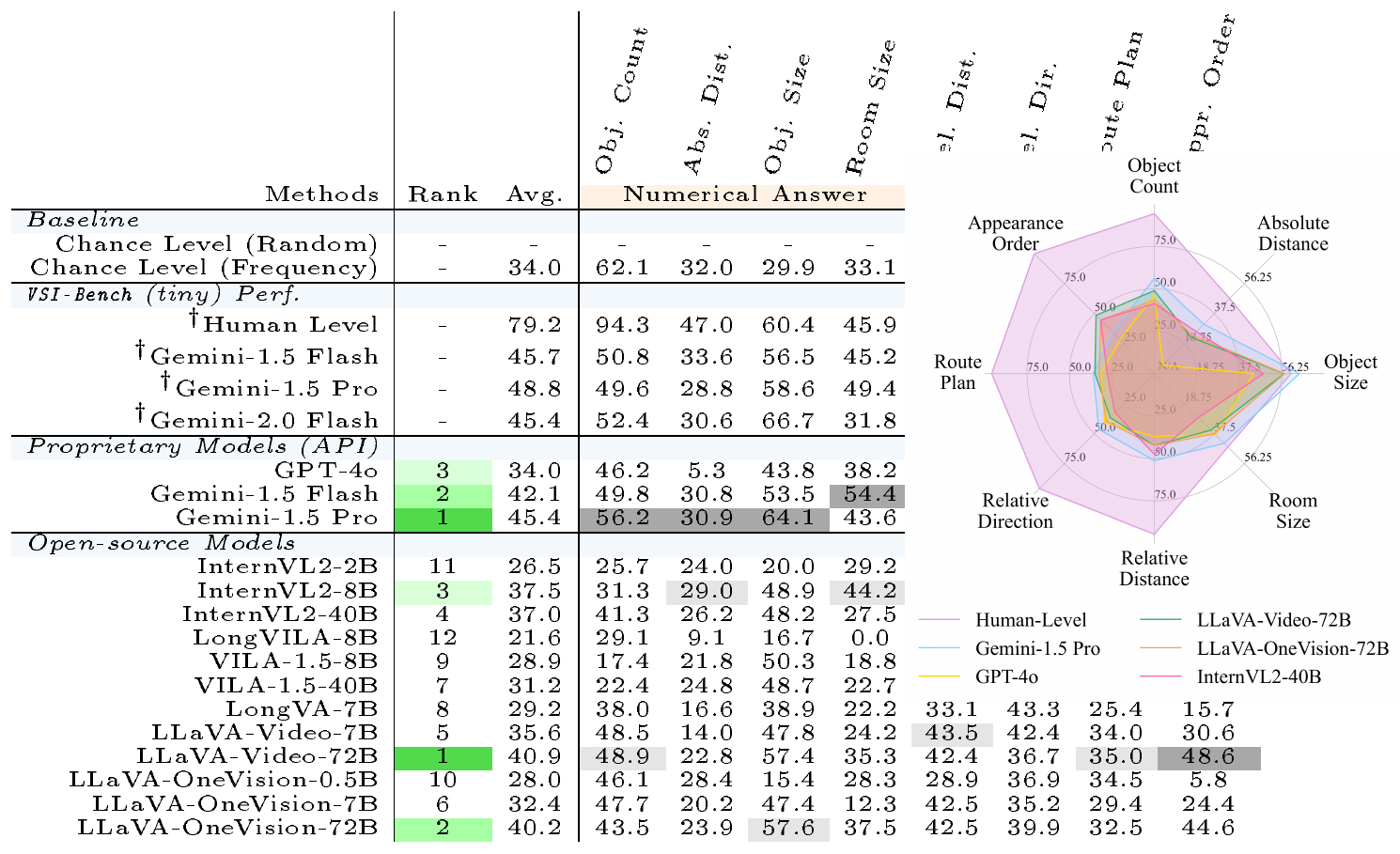
Figure 5 shows overall model performance on VSI-Bench. Our key observations are as follows:
Human Level Performance. Not surprisingly, human evaluators achieve 79% average accuracy on our benchmark, outperforming the best model by 33%. Notably, human performance on configuration and spatiotemporal tasks is remarkably high, ranging from 94% to 100%, indicating human intuitiveness. In contrast, the performance gap between humans and the best MLLM is much narrower on the three measurement tasks that require precise estimation of absolute distance or size, suggesting that MLLMs may have a relative strength in tasks requiring quantitative estimation.
Proprietary MLLMs. Despite a significant performance gap with humans, the leading proprietary model, Gemini-1.5 Pro, delivers competitive results. It surpasses the chance level baselines by a substantial margin and manages to approach human level performance in tasks such as absolute distance and room size estimation. It's worth noting that while human evaluators have years of experience in understanding the physical world spatially, MLLMs are only trained on 2D digital data like internet videos.
Open-source MLLMs. Top-tier open-source models like LLaVA-Video-72B and LLaVA-OneVision-72B demonstrate highly competitive performance to closed-source models, trailing the leading Gemini-1.5 Pro by only 4% to 5%. However, the majority of open-source models (7 $/$ 12) perform below the chance level baseline, indicating significant limitations in their visual-spatial intelligence.
5. How MLLMs Think in Space Linguistically
Section Summary: Researchers analyze how the strongest multimodal model reasons about space by asking it to explain its answers in language on a set of video-based spatial tasks. The explanations show that the model often produces accurate step-by-step descriptions and appears to maintain an implicit 3-D layout, yet the great majority of its mistakes arise from failures in core spatial operations such as perspective shifts and relational judgments rather than from misperceiving objects or misunderstanding language. Common prompting methods that improve ordinary language reasoning, including chain-of-thought and tree-of-thoughts, actually lower accuracy on these tasks, revealing that spatial intelligence remains a distinct bottleneck.
To better understand when and why models succeed or fail and to elucidate the facets of visual-spatial intelligence they possess, we examine how MLLMs think in space linguistically here and visually in Section 6. We begin by prompting the best-performing MLLM in VSI-Bench, Gemini-1.5 Pro [23], to articulate its internal reasoning in language.
5.1 Probing via Self-Explanations
Self-explanations are a prevailing approach on par with traditional model explanations like LIME saliency maps [57] for understanding LLM-generated responses [58, 59, 60] and are widely used in analyzing language model behavior [51, 61]. We randomly sample a subset of 163 incorrect answers, prompt the MLLM to provide explanations for the predicted answers, and carefully review them by hand.
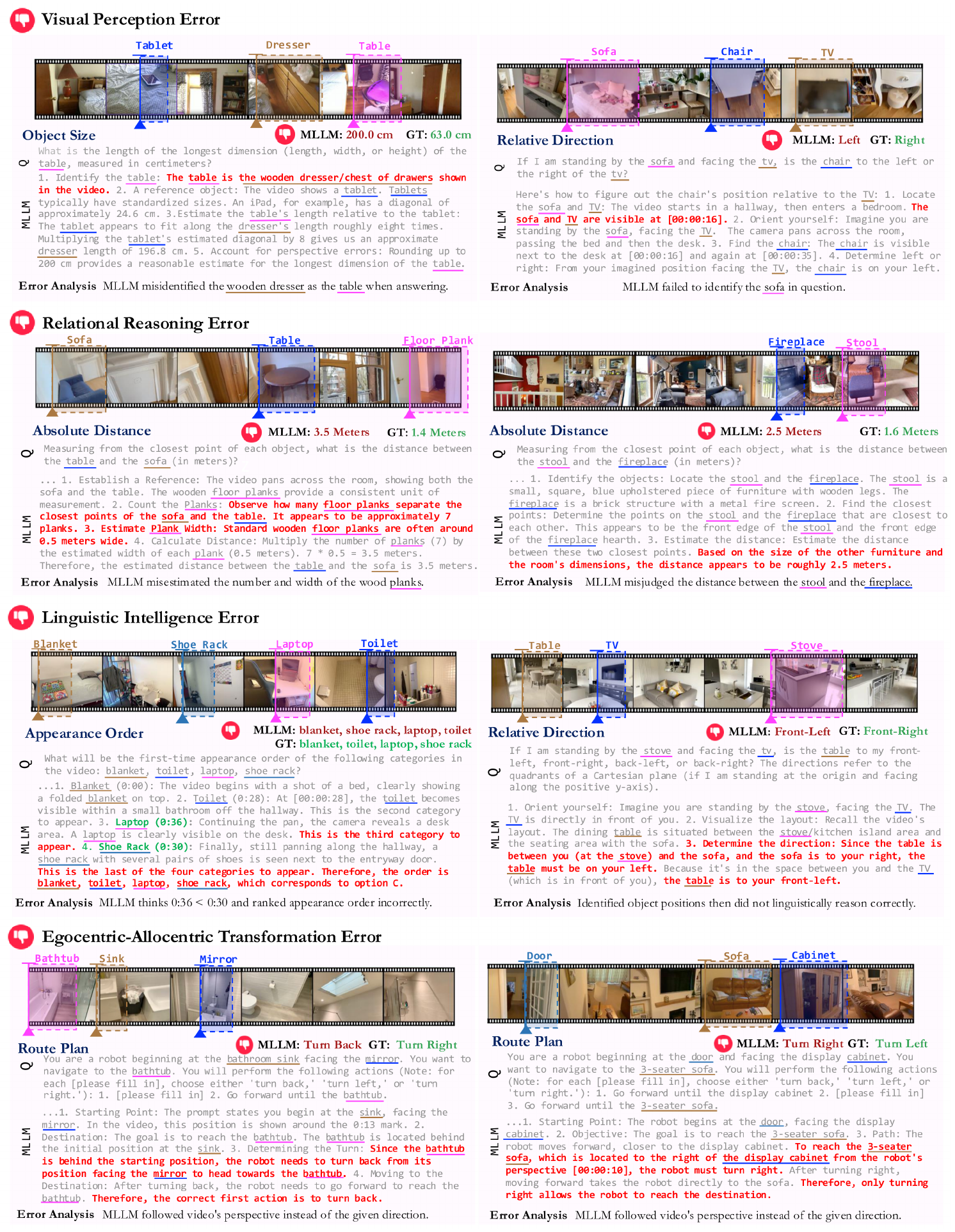
Case Studies. Figure 6 presents self-explanations in both a success and an error case. In both examples, when thinking in space, the MLLM exhibits advanced video understanding, demonstrated by the impressive accuracy of its timestamped descriptions. The model also forms correct step-by-step reasoning processes, outlining steps such as "orient yourself", "locate the dishwasher"and "visualize the quadrants" for the relative direction task. Furthermore, the construction of a global coordinate system (Figure 6, left) suggests that MLLMs may possess or build an implicit world model. Rather than using isolated frames, short clips, or random guesses, the MLLM used global spatial context and reasoning to infer correctly.
In the incorrect example (Figure 6, right), we can identify faulty visual-spatial capabilities like egocentric-allocentric transformation and relational reasoning, as introduced in Figure 1. In the video, the camera pans right to shift the view from the edge of the bed to the wall and window. The model obeys this egocentric view, responding that "to face the wall where the window is located, you must turn right" instead of creating an allocentric view reflecting the reality that the route from door to bed means turning left.
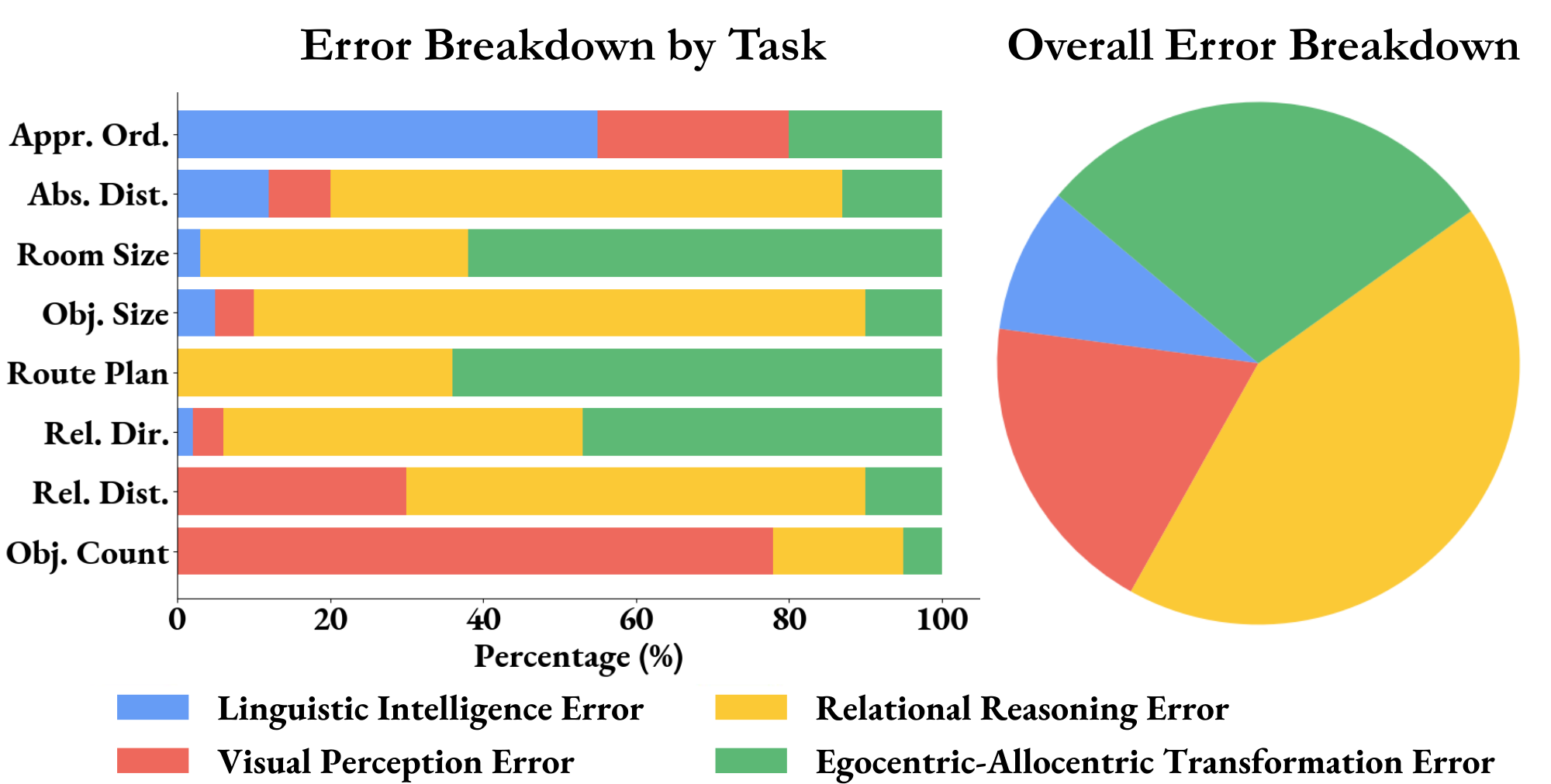
Error Analysis. To quantify and identify the main bottleneck for the best-performing MLLM on our benchmark, we analyze its errors on VSI-Bench (tiny), categorizing them into four distinct types which arose from both our outlined visual-spatial capabilities (Figure 1) and a clear four-way categorization of errors upon examination:
- Visual perception error, stemming from unrecognized objects or misclassified object categories;
- Linguistic intelligence error, caused by logical, mathematical reasoning, or language understanding defects;
- Relational reasoning error includes errors in spatial relationship reasoning, i.e., distance, direction, and size;
- Egocentric-allocentric transformation error, resulting from an incorrect allocentric spatial layout or improper perspective-taking.
As shown in Figure 7, around 71% of errors are attributed to spatial reasoning (as ontologically conceived in Figure 1), which suggests that:
Spatial reasoning is the primary bottleneck for MLLM performance on VSI-Bench.
Further analysis and case studies are in Appendix E.2.
5.2 Limits of CoT Methods in Visuospatial Tasks
Prompting techniques improve the reasoning and problem-solving abilities for large models across diverse tasks [29, 62, 31, 63]. Their successes motivate us to investigate whether these linguistic prompting methods could also improve the visual-spatial capabilities of MLLMs in VSI-Bench. We investigate three prevailing prompting techniques (see Appendix B.3 for more details):
- Zero-Shot Chain-of-Thought (CoT). Following [64, 65], we add "Let's think step by step" to the prompts.
- Self-Consistency w/ CoT. We follow [66] and set the MLLM's temperature to 1.0 to encourage diverse reasoning and then take the majority consensus from five runs (employed w/ Zero-Shot CoT) as the final prediction.
- Tree-of-Thoughts (ToT). Following the "Creative Writting" practice in [67], we divide reasoning into plan generation and answer prediction. The MLLM first drafts and selects a plan, then generates three candidate answers and selects the most confident one as prediction.
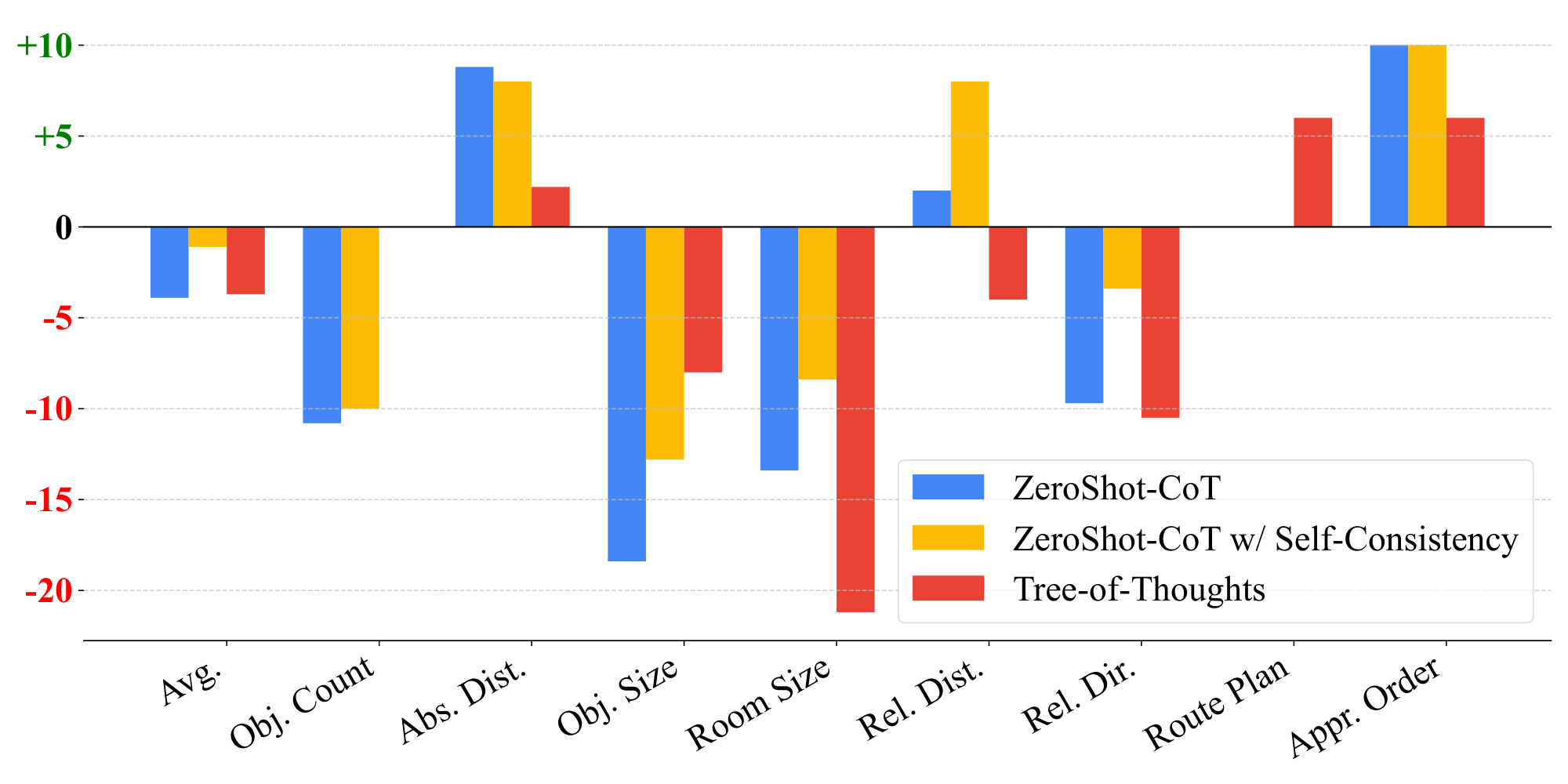
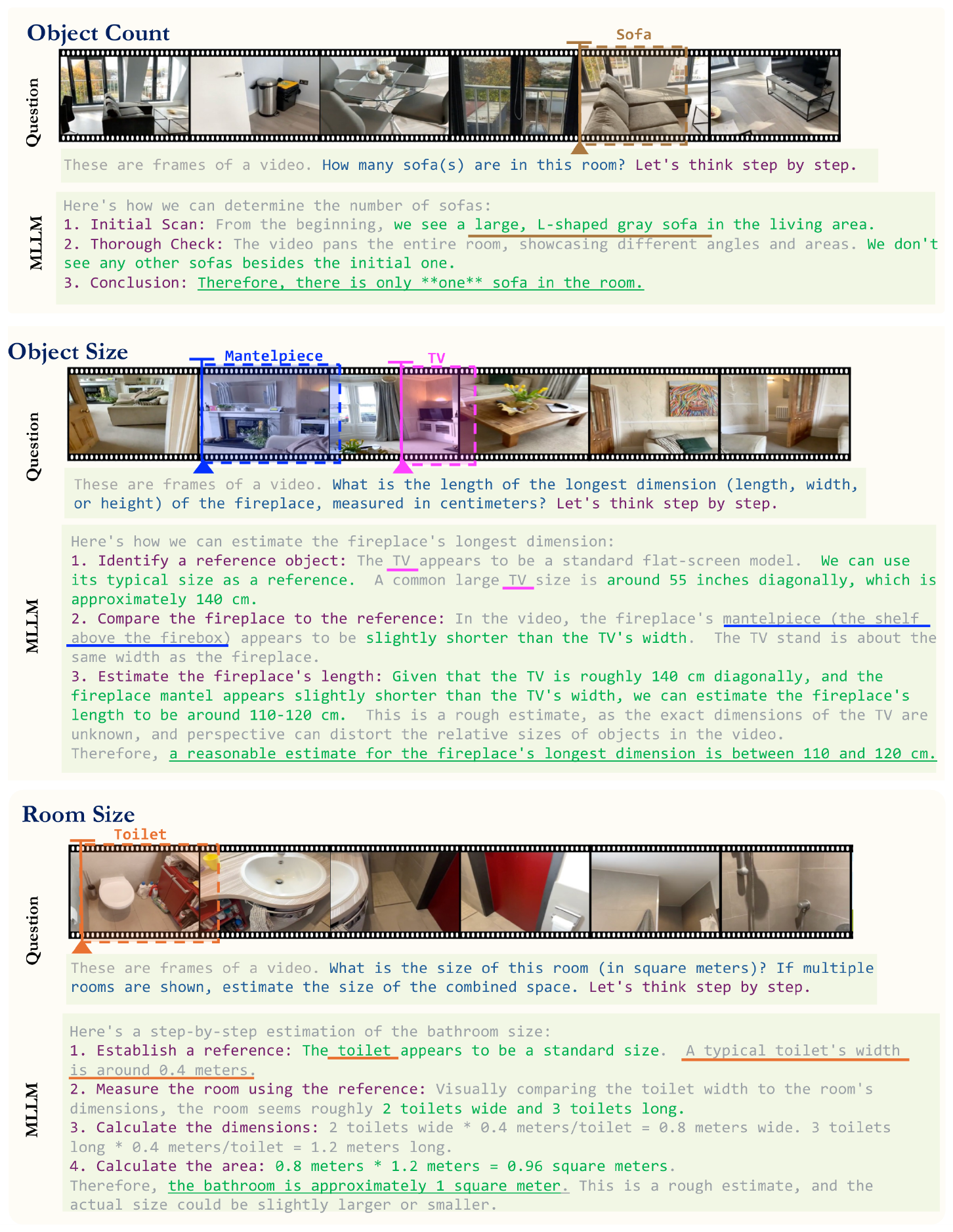
As shown in Figure 8, surprisingly, all three linguistic reasoning techniques lead to performance degradation on VSI-Bench. Zero-Shot CoT and ToT reduce average performance by about 4%, and self-consistency, though slightly better, still falls 1.1% below the no-prompting baseline. The unilateral improvement in the appearance order and absolute distance estimation tasks is easily explained by their significant percentage of linguistic intelligence errors (see Figure 7). In contrast, the room size and object size tasks suffer a large 8% to 21% decrease, showing that encouraging a model to think more can be not just unreliable but downright harmful. Meanwhile, as shown in Table 1, ZeroShot CoT achieves a 1.6% improvement on the general video understanding benchmark VideoMME [52]. Therefore, our results suggest that:
Linguistic prompting techniques, although effective in language reasoning and general visual tasks, are harmful for spatial reasoning.
: Table 1: Gemini-1.5 Pro CoT performance on a 500-questions subset in VideoMME.
| Case | Performance |
|---|---|
| Gemini-1.5 Pro (w/o CoT) | 77.2 |
| Gemini-1.5 Pro (w/ CoT) | 79.8 |
6. How MLLMs Think in Space Visually
Section Summary: Researchers examined how multimodal large language models build internal mental representations of space from video, much like the subconscious spatial maps humans create. When prompted to generate grid-based cognitive maps of object positions, the models proved quite accurate at capturing relationships between nearby items but struggled to form consistent representations of objects farther apart, suggesting they rely on fragmented local snapshots rather than a single unified view of a scene. Encouraging the models to produce and consult these maps improved their performance on distance-reasoning tasks by roughly 10 percent, indicating that explicitly building such mental imagery could support stronger spatial understanding.
Since humans subconsciously build mental representations [33, 68] of space when reasoning spatially, we explore how MLLMs remember spaces.
6.1 Probing via Cognitive Maps
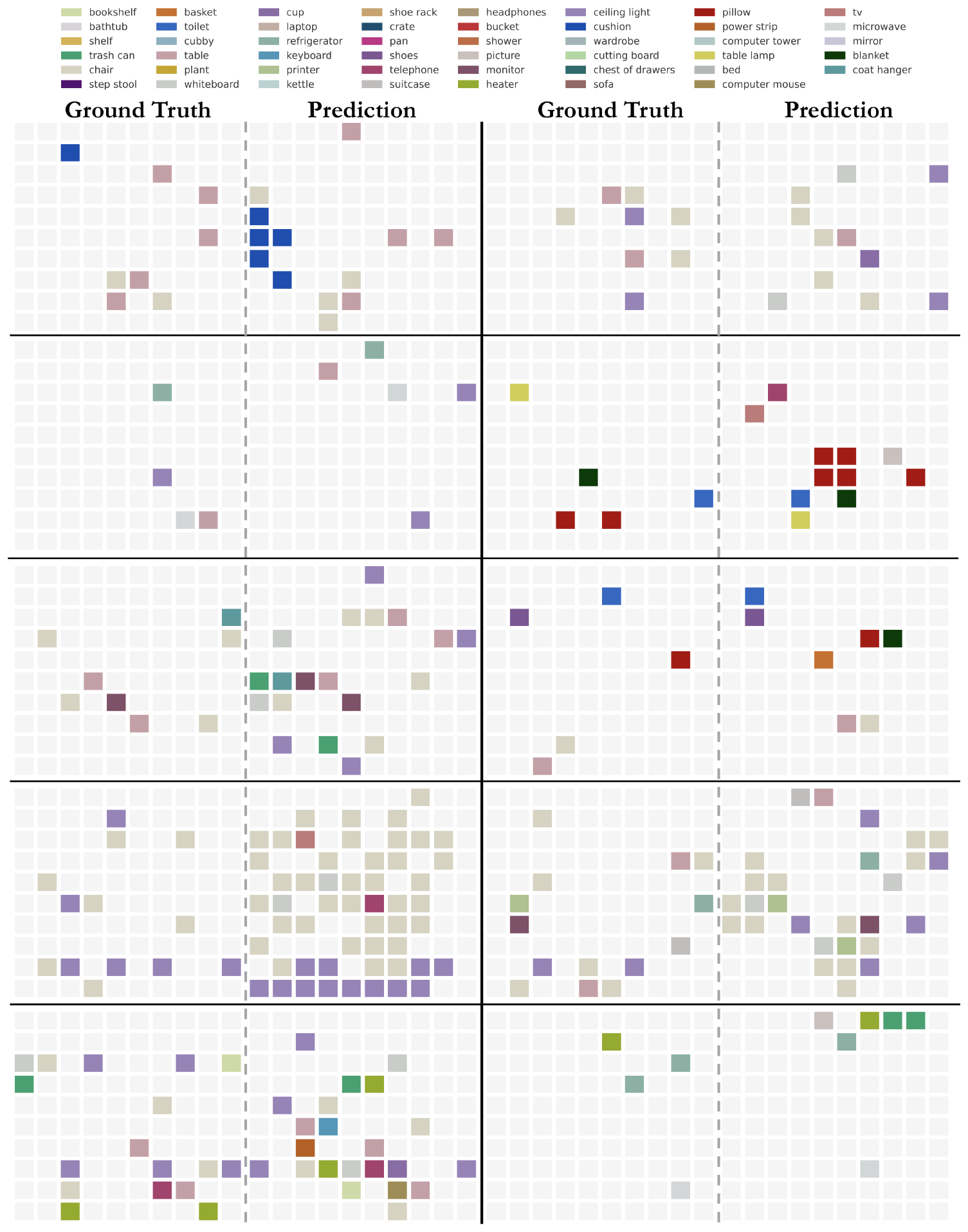
We prompt MLLMs to express their internal representations of the spaces they see using cognitive maps, a well-established framework for remembering objects in a set environment [34, 33]. We prompt the best-performing MLLM, Gemini-1.5 Pro, to predict object center positions within a 10 $\times$ 10 grid based on video input (see Figure 10b for grid size ablation and Appendix B.4 for prompt). We present examples of the resulting cognitive maps in Figure 9.

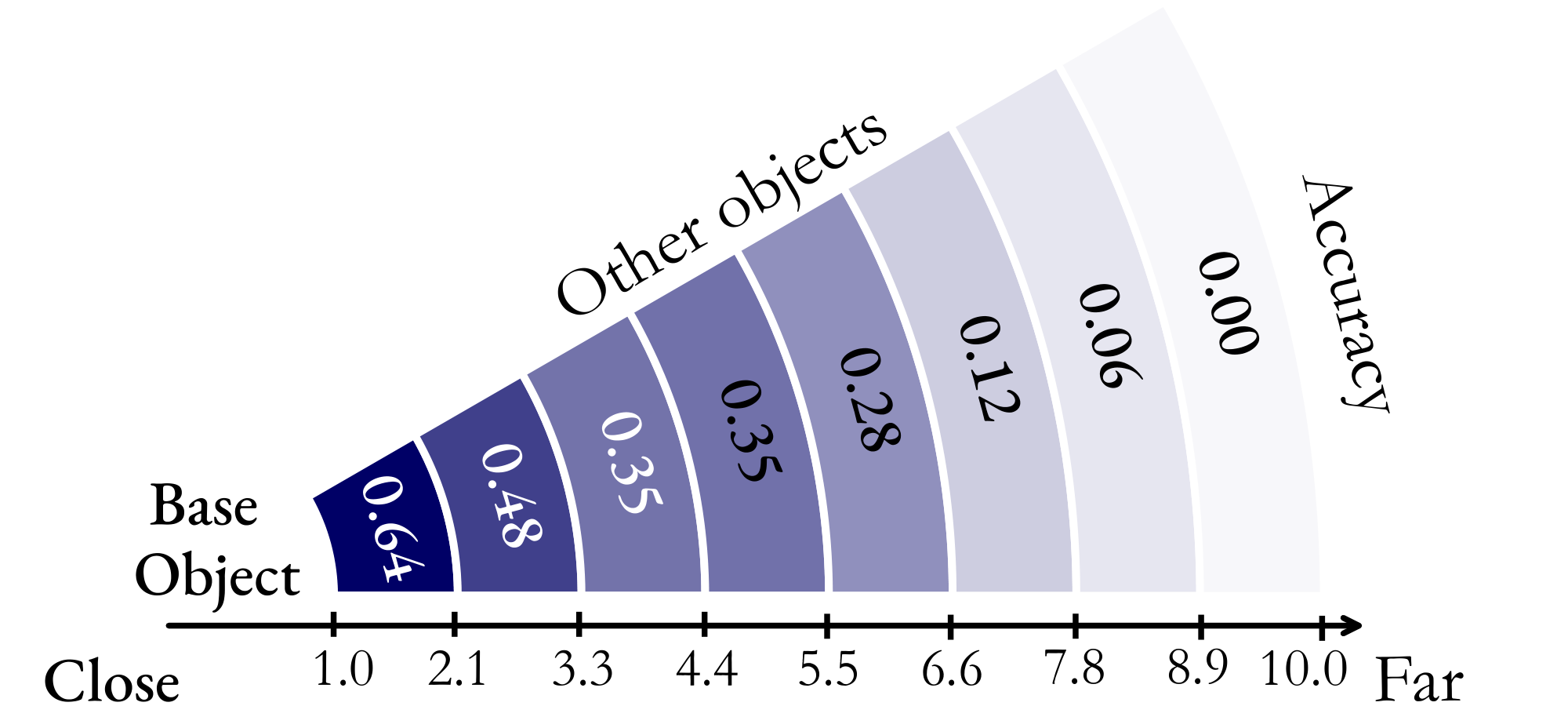
To quantitatively assess these cognitive maps, we evaluate the Euclidean distance between all pairs of objects within each map. We consider the distance (on the grid) between two objects to be correct if it deviates by no more than one grid unit from the distance in the ground truth cognitive map. As shown in Figure 10, we divide the map-distances into eight distinct bins for analysis. Interestingly, we find that the MLLM achieves a remarkable 64% accuracy in positioning adjacent objects within its cognitive map, indicating robust local spatial awareness. However, this accuracy significantly deteriorates as the distance between two objects increases, which suggests that:
When remembering spaces, a MLLM forms a series of local world models in its mind from a given video, rather than a unified global model.
This observation aligns with the challenge of forming a global space representation from discrete video frames, which is inherently difficult for MLLMs. While this task may not be trivial for humans either, it is likely that they can build such global space representations more accurately.
6.2 Better Distance Reasoning via Cognitive Maps
Given the local awareness of MLLMs in remembering spaces (see Figure 9 and Figure 10) and the importance of mental imagery to how humans think in space, we investigate whether generating and using cognitive maps can help MLLMs'spatial reasoning in terms of VSI-Bench's relative distance task. This tests if the local distance awareness emerged through cognitive maps transfers to improved distance recall and reasoning.
::: {caption="Table 2: Cognitive map prompting."}
:::
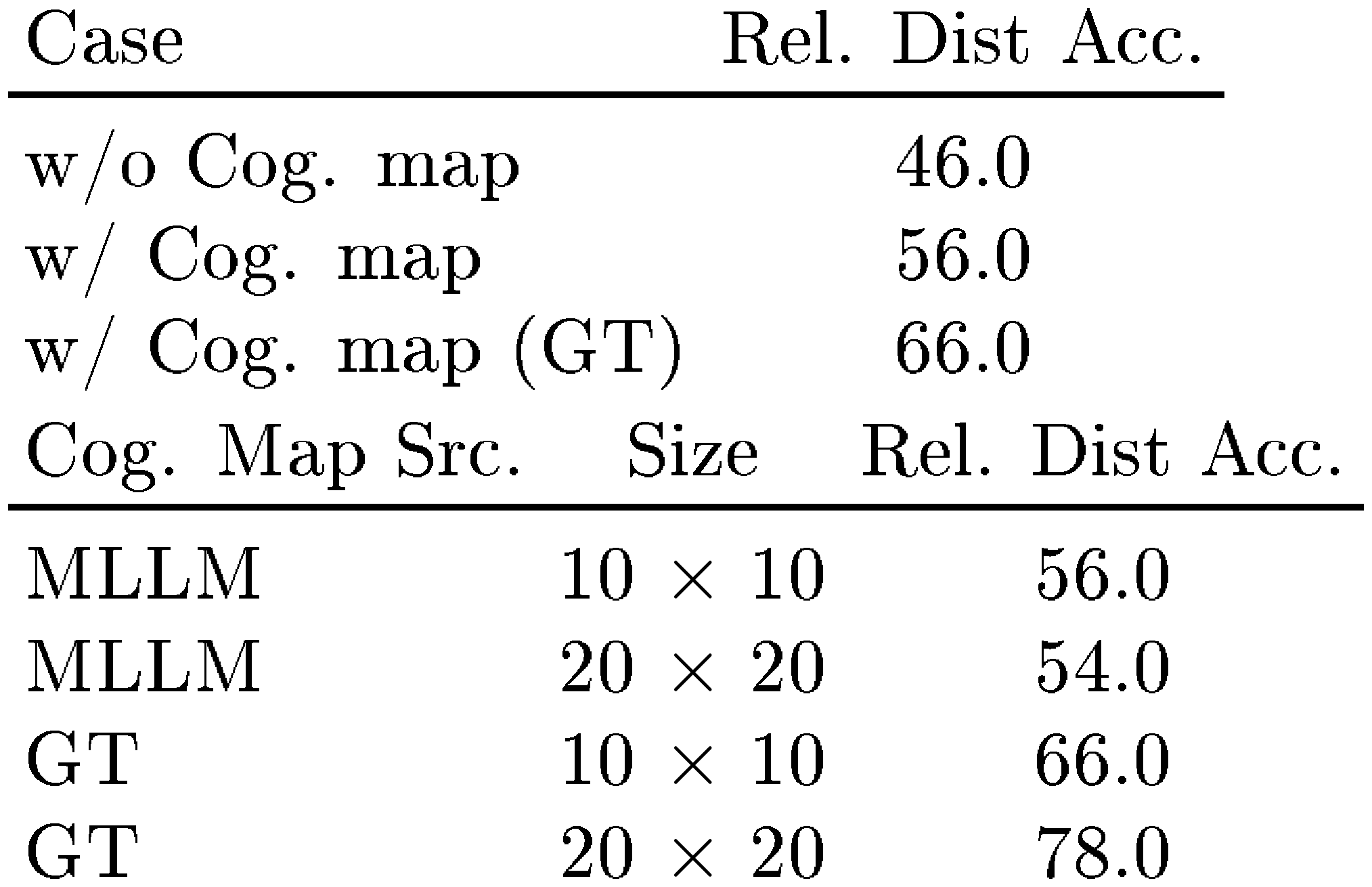
We prompt Gemini-1.5 Pro to first generate a cognitive map based on the given video and question, and then to use the predicted map to answer the question. As shown in Table 2a, we find that using mental imagery improves a MLLM's relative distance accuracy by 10%. The 20% to 32% gain over baseline with the ground truth cognitive map underscores the importance of building accurate mental maps of a scene, which enforce a globally consistent topology, but indicates that such mental imagery is only one part of the puzzle, albeit a crucial one. These results point to building a mental spatial world model or cognitive map as a valuable pretext task or a promising solution for MLLMs to tackle visual-spatial reasoning.
7. Related Works
Section Summary: This section situates the current research within two main strands of prior work on multimodal large language models. One line of studies has explored how these models can understand spatial relationships from images or text, yet most stop short of testing them on realistic video scenarios that would support real-world uses like robotics. The other line has developed video benchmarks to probe perception and reasoning over time, but these efforts have largely overlooked deeper spatial skills such as mentally reconstructing scenes or maintaining visual memory across frames.
Apart from visual-spatial intelligence in Section 2, we further ground our work in the following two related areas:
MLLMs with Visual-Spatial Awareness. Building on the powerful language and reasoning abilities of LLMs [7, 8, 9, 10, 11, 12, 13] and the feature extraction abilities of modern vision encoders [69, 70, 71], MLLMs, especially visual MLLMs, exhibit unprecedented visual understanding capabilities [22, 23, 49, 72, 73, 47, 74], a promising direction toward developing world models [75] and embodied agents [14, 76, 77, 78]. However, grounding MLLMs in the real world presents significant challenges for models' visual-spatial intelligence, motivating recent efforts [79, 80, 81, 82, 83, 84, 85, 86]. Unlike prior works, which primarily focus on understanding spatial information through 2D images [87, 88, 89] or solely language [90, 91, 92, 93, 90], our work assesses models' visual spatial intelligence using real-world videos, which more closely mirrors human understanding of the world and application scenarios for embodied agents.
Benchmarking MLLMs on Video. With MLLMs displaying impressive performance on still-images across perception, reasoning, and multi-disciplinary tasks [51, 94, 95, 96], there is increasing interest in evaluating MLLMs' video understanding capabilities [52, 21, 97, 98, 99, 100, 101, 102, 103, 104, 105]. For example, Video-MME [52] comprehensively evaluates MLLMs across various video-related tasks, including recognition and perception. EgoSchema [21] and OpenEQA [17] evaluate MLLMs' understanding abilities using egocentric videos. Despite their significance, most prior works focus on content-level understanding [52, 97, 21, 98], which primarily serves as a temporal extension of 2D image understanding without 3D spatial consideration. Extending beyond prior benchmarks, our work focuses on spatial intelligence and requires core spatial capabilities like visual working memory and implicit scene reconstruction.
8. Discussion and Future Work
Section Summary: The researchers created a new benchmark called VSI-Bench to explore how multimodal AI models perceive, remember, and reason about physical spaces, revealing that these systems show solid abilities in perception and language but struggle with tasks like shifting between different viewpoints and understanding relationships between objects. They found that standard language-based prompting techniques offered little help for spatial thinking, whereas methods that helped models build explicit internal maps of spaces improved their performance on distance-related questions. Looking ahead, the authors suggest that targeted model training, new self-training approaches focused on space, and specialized prompting strategies could help overcome these limitations.
We study how models see, remember, and recall spaces by building VSI-Bench and investigating the performance and behavior of MLLMs on it. Our analysis of how MLLMs think in space linguistically and visually identifies existing strengths (e.g., prominent perceptual, temporal, and linguistic abilities) and bottlenecks for visual-spatial intelligence (e.g., egocentric-allocentric transformation and relational reasoning). While prevailing linguistic prompting methods fail to improve spatial reasoning, building explicit cognitive maps does enhance the spatial distance reasoning of MLLMs. Future avenues of improvement include task-specific fine-tuning, developing self-supervised learning objectives for spatial reasoning, or visuospatial-tailored prompting techniques for MLLMs.
Acknowledgments. We thank Ellis Brown, Ryan Inkook Chun, Youming Deng, Oscar Michel, Srivats Poddar, Xichen Pan, Austin Wang, Gavin Yang, and Boyang Zheng for their contributions as human annotators and evaluators. We also thank Fred Lu for proofreading our manuscript. We also thank Chen Feng, Richard Tucker, Noah Snavely, Leo Guibas, and Rob Fergus for their helpful discussions and feedback. This work was mainly supported by the Open Path AI Foundation, Google TPU Research Cloud (TRC) program, and the Google Cloud Research Credits program (GCP19980904). SX also acknowledges support from Intel AI SRS, IITP grant funded by the Korean Government (MSIT) (No. RS-2024-00457882, National AI Research Lab Project), Amazon Research Award, and NSF Award IIS-2443404.
Appendix
Section Summary: This appendix supplies extra technical materials that support the main paper on evaluating visual-spatial intelligence in multimodal AI models. It begins with an outline of five sections covering benchmark construction, experiments, sequencing studies, and visualizations. The core content then details the VSI-Bench pipeline, including how videos and 3D scene data are collected from ARKitScenes, ScanNet++, and ScanNet, standardized into unified formats for rooms and objects, and used to generate consistent multiple-choice questions that test skills such as counting, distance estimation, and route planning.
A. Appendix Outline
In these supplementary materials, we provide:
- Technical details about
VSI-Benchconstruction and our linguistic and visual analysis (Appendix B); - Evaluation setup and full evaluation results for
VSI-Benchsub-experiments (Appendix C); - Analysis on input sequencing and repetition (Appendix D);
- Additional visualization results (Appendix E).
B. Technical Details for VSI-Bench Construction and Analysis
In this section, we provide more technical details on the construction of VSI-Bench and analyzing MLLM thinking via self-explanations, Chain-of-Thought-based methods, and cognitive maps.
B.1 VSI-Bench Construction Pipeline
Here, we discuss the concrete setup for each stage in the benchmark construction pipeline.
Dataset Collection and Unification. We curate our evaluation dataset by collecting 150 samples from ARKitScenes [44], 50 samples from ScanNet++ [43], and 88 samples from ScanNet [42]. For video processing, we convert ScanNet's individual frames into continuous videos at 24 FPS, while subsampling ScanNet++ and ARKitScenes videos to 30 FPS. All videos are standardized to a resolution of 640 $\times$ 480 pixels. Given that ARKitScenes contains videos with varying orientations, we normalize their rotation to maintain a consistent upward orientation across all samples.
Due to varying annotation structures across the three datasets, we unify them into a standardized meta-information format for each scene with the following attributes: dataset, video path, room size, room center, object counts, and object bounding boxes. The room size is calculated by the Alpha shape algorithm^1 with the scene's point cloud. The room center is calculated as the geometric center of the minimal bounding box of the scene's point cloud. Object counts record the number of instances for each category. As for the object bounding boxes, we unify different annotation formats to the format of OrientedBoundingBox in Open3D [106].
For the categories included in the meta-information, we carefully curate a subset of categories from the three source datasets. Since our benchmark aims to evaluate the visual-spatial intelligence of MLLMs, we exclude both rare categories and those with extremely small object sizes to reduce perceptual challenges. Additionally, we implement category remapping to ensure vocabulary consistency and intuitive understanding across the benchmark. This category remapping is also iteratively refined during human review.
```latextable {caption="Table 3: Question Templates for tasks in VSI-Bench. We replace the highlighted part in the question template from scene to scene to construct our benchmark. Note that a complete example question is provided for Route Plan."}
\begin{tabular}{r|p{13.5cm}}
\textbf{Task} & \textbf{Question Template} \
\hline
Object Counting &
\textit{How many \textcolor{red}{{category}}(s) are in this room?} \
\hline
Relative Distance &
\textit{Measuring from the closest point of each object, which of these objects (\textcolor{red}{{choice a}}, \textcolor{red}{{choice b}}, \textcolor{red}{{choice c}}, \textcolor{red}{{choice d}}) is the closest to the \textcolor{red}{{category}}?} \
\hline
Relative Direction &
To create a comprehensive test of relative direction, three difficulty levels were created:
\begin{itemize}
\item \textbf{Easy:} \textit{If I am standing by the \textcolor{red}{{positioning object}} and facing the \textcolor{red}{{orienting object}}, is the \textcolor{red}{{querying object}} to the left or the right of the \textcolor{red}{{orienting object}}?}
\item \textbf{Medium:} \textit{If I am standing by the \textcolor{red}{{positioning object}} and facing the \textcolor{red}{{orienting object}}, is the \textcolor{red}{{querying object}} to my left, right, or back? An object is to my back if I would have to turn at least 135 degrees in order to face it.}
\item \textbf{Hard:} \textit{If I am standing by the \textcolor{red}{{positioning object}} and facing the \textcolor{red}{{orienting object}}, is the \textcolor{red}{{querying object}} to my front-left, front-right, back-left, or back-right? Directions refer to the quadrants of a Cartesian plane (assuming I am at the origin and facing the positive y-axis).}
\end{itemize} \
\hline
Appearance Order &
\textit{What will be the first-time appearance order of the following categories in the video: \textcolor{red}{{choice a}}, \textcolor{red}{{choice b}}, \textcolor{red}{{choice c}}, \textcolor{red}{{choice d}}?}
\
\hline
Object Size &
\textit{What is the length of the longest dimension (length, width, or height) of the \textcolor{red}{{category}}, measured in centimeters?}
\
\hline
Absolute Distance &
\textit{Measuring from the closest point of each object, what is the direct distance between the \textcolor{red}{{object 1}} and the \textcolor{red}{{object 2}} (in meters)?}
\
\hline
Room Size &
\textit{What is the size of this room (in square meters)?
If multiple rooms are shown, estimate the size of the combined space.}
\
\hline
Route Plan &
\textit{You are a robot beginning at \textcolor{red}{{the bed facing the tv}}. You want to navigate to \textcolor{red}{{the toilet}}. You will perform the following actions (Note: for each [please fill in], choose either turn back, ' turn left, ' or `turn right.'): \textcolor{red}{{1. Go forward until the TV 2. [please fill in] 3. Go forward until the shower 4. [please fill in] 5. Go forward until the toilet.}} You have reached the final destination.}
\
\end{tabular}
**QA-Pair Generation.** Each QA-pair contains the following attributes: *question ID*, *source dataset*, *task type*, *video path*, *question*, *multiple-choice options w/ letter answer*, and *verbal or numerical ground truth*. Of the eight tasks in `VSI-Bench`, the QA-pairs for seven tasks are derived from the unified meta-information and the Route Plan QA-pairs from human-annotated routes.
We evaluate the multiple-choice answer (MCA) tasks via accuracy and the numerical-answer (NA) tasks via mean relative accuracy ($\mathcal{MRA}$), but our VQA dataset also includes generated multiple-choice options and letter answers for the NA tasks. The generated multiple-choice options are sampled between a lower and upper bound factor of the ground truth numerical answer and are re-sampled if any two options are within a given threshold of each other. We sub-sample the number of questions for each scene for each task to prevent over-representation of any scene or task and to create a more balanced dataset. For MCA tasks, the letter answers are distributed as uniformly as possible.
For the *object counting* task, objects with counts of one are not included. For the *relative distance* task, only unique-instance objects are used for the primary category; multiple-instance objects are allowed for the object choices. If there are multiple instances of an object category, the minimum absolute distance to the primary object is used. If any of the four option distances are within a threshold (30 cm for rooms with size greater than 40 sq m, 15 cm otherwise) of each other, the question is considered ambiguous. For the *relative direction* task, to make sure the direction is clear, questions are considered ambiguous if they violate lower and upper bounds on the distance between any two objects or a threshold for proximity to angle boundaries. For the *appearance order* task, first appearance is considered to be the timestamp where the number of object pixels cross a set threshold, and timestamps too close together are considered ambiguous. For the *object size* task, the ground truth is taken as the longest dimension of the unique object's bounding box. For the *room size* task, room size is calculated by the alpha shape algorithm, as specified earlier. For the *absolute distance* task, we first uniformly sample points within the bounding boxes of the two objects. The distance is the minimum Euclidean distance among pairwise points. For the *route planning* task, humans construct routes given a template and instructions to choose any two unique objects as the start and end position, respectively, such that the route between them can be described in approximately two to five movements. Routes are comprised of two actions: "Go forward until [unique object]"and "Turn [left / right / back]". After collection, filtering and standardization are done. In the question, the "turn" directions are replaced with "[please fill in]".
The question templates for the generation of each task are listed in Table 3.
**Human-in-the-loop Quality Review.** The quality review process occurs throughout two stages of our pipeline. During dataset collection, we manually filter the validation set by removing scenes with a high ratio of incomplete 3D mesh reconstruction that could misalign 3D annotations with visible video content. After generating scene meta-information, we manually verify its correctness, with a specific focus on ensuring the correctness of *object counts*.
In the QA pairs generation stage, we customize a web interface for human quality review. Human evaluators are asked to answer the benchmark questions without prior knowledge of the correct answers. They flag QA pairs where they believe the answers are incorrect. When evaluators identify ambiguous or erroneous questions, we trace the source of the errors and take corrective actions, such as removing problematic data samples or adjusting the meta-information, question templates, or modifying QA generation rules to prevent similar issues in the future. We iterate this procedure multiple times to ensure the quality.
#### B.2 Probing MLLM via Self-Explanations
Here, we provide more concrete implementations for the self-explanations and error analysis.
**Self-Explanations.** To conduct error analysis on a model's reasoning chains behind its predictions, we explicitly extract the reasoning chains that support the model's questionanswering process. Specifically, after the model predicts an answer to a given question, it is further prompted with *"Please explain your answer step by step."* to generate the internal rationale leading to its prediction. It is important to note that this process is fundamentally different from *Chain-of-Thought* reasoning, where the model is asked to generate reasoning chains first and then predict the answer.
**Error Analysis.** For error analysis, we manually review within `VSI-Bench` (tiny) all error cases for tasks in multiple-choice answers and the bottom half of the worst-performing cases for tasks in numerical answers, which totals 163 samples. For each error case, human examiners are required to classify its primary error into one of four primary categories: *visual perception error*, *linguistic intelligence error*, *relational reasoning error*, and *egocentric-allocentric transformation error*. If an incorrect prediction is attributed to multiple reasons, it is proportionally assigned as $\frac{1}{n}$ to each applicable category, where $n$ is the number of error categories.
#### B.3 Implementation Details of CoT Methods
As detailed in our paper, we evaluate several advanced linguistic prompting methods on our benchmark, including *Chain-of-Thought*, *Self-Consistency*, and *Tree-of-Thoughts*. In this section, we elaborate on the implementation details of these three methods.
- *Chain-of-Thought* prompting. Following Zero-shot-CoT [64, 65], we append the phrase "Let's think step by step." to each question to elicit step-by-step reasoning from the large language model. The temperature, top-p, and top-k parameters are set to 0, 1, and 1, respectively. After the model generates its prediction, we initiate an additional turn of dialogue to prompt the model to extract its answer explicitly (*e.g.*, the letter corresponding to the correct option for multiple-choice questions or a numerical value for numerical questions). This approach mitigates errors arising from fuzzy matching.
- *Self-Consistency w/ CoT*. In line with Self-Consistency [66], we prompt MLLMs to generate multiple answers for a given question under Zero-shot-CoT [65] prompting. To encourage diversity among runs, we set the temperature to 0.7, top-p to 1, and top-k to 40. Initially, the model is prompted to provide an answer with step-by-step reasoning (using Zero-shot-CoT). As with Zero-shot-CoT, an additional dialogue turn is added to explicitly extract the prediction from the model's response. For each question, we perform 5 independent runs and take the majority prediction as the final answer.
- *Tree-of-Thoughts*. Inspired by the "Creative Writing" practice in [67], we divide the problem-solving process into two steps: plan generation and answer prediction. The temperature, top-p, and top-k parameters remain consistent with the Self-Consistency setup. For the plan generation step, we ask the model to generate 3 distinct plans to answer the given question. We then start a new dialogue and prompt the model to select the most promising plan based on the video, the question and the generated plans. This voting process is repeated 3 times, with the majority-selected plan chosen for the next step. In the answer prediction step, based on the video and the selected plan, the model is asked to predict the answer. Similar to the previous step, 3 independent predictions are generated, and the model votes 3 times to determine the most confident answer. A majority vote determines the final prediction.
Figure 16. Figure 17, and Figure 18 illustrate these three prompting techniques and model outputs under the different strategies.
#### B.4 Cognitive Map
**Generation.** To generate the cognitive map for each video, we specify the target categories of interest and prompt the MLLM to predict the central position for each of these categories. The following prompt is used:
~~~ {caption="Cognitive Map Prompt"}
[Task]
This video captures an indoor scene. Your objective is to identify specific objects within the video, understand the spatial arrangement of the scene, and estimate the center point of each object, assuming the entire scene is represented by a 10x10 grid.
1. We provide the categories to care about in this scene: categories_of_interest. Focus ONLY on these categories.
2. Estimate the center location of each instance within the provided categories, assuming the entire scene is represented by a 10x10 grid.
3. If a category contains multiple instances, include all of them.
4. Each object's estimated location should accurately reflect its real position in the scene, preserving the relative spatial relationships among all objects.
Present the estimated center locations for each object as a list within a dictionary.
STRICTLY follow this JSON format:
"category name": [($x_1, y_1)$, ...], ...
~~~
For the categories of interest, we include all potential categories as shown in Figure 9 and Figure 10. Such setup facilitates our focus on assessing the spatial awareness of the MLLM rather than its perceptual capabilities. In contrast, for benchmark tasks such as evaluating relative distance (as shown in Table 2), we restrict the provided categories to those explicitly mentioned in each question. This ensures that no additional information apart from the question is included.
**Distance Locality Calculation.** To quantitatively evaluate the cognitive maps, we measure inter-category distances as illustrated in Figure 10. Specifically, for each category, we compute its Euclidean distance to all other categories. When a category contains multiple objects, we define the inter-category distance as the shortest distance between any two objects from the respective categories. We perform these distance calculations on both MLLM-predicted and ground truth cognitive maps and consider an MLLM's predicted distance between two categories to be correct if it differs from the ground truth distance by no more than one grid unit. We apply this evaluation process across all cognitive maps and group the distances into eight bins to calculate the average accuracy on different bins.
#### B.5 Cognitive Map on More MLLMs
We evaluate two more MLLMs, LLaVA-Video-7B and LLaVA-Video-72B. Table 4 validates our Section 6.1 finding of significantly stronger local than global accuracy. Regarding Section 6.2, as shown in Table 5, LLaVA-Video-72B achieves an 8% performance gain. In contrast, LLaVA-Video-7B performance decreases, likely due to its limited model capacity, which impairs cog. map prediction (Table 4 shows its suboptimal acc. on cog. map compared to Gemini-1.5 Pro and LLaVA-Video-72B).
: Table 4: Locality of cognitive maps.
| Distance | [1.0, 2.1] | (2.1, 3.3] | (3.3, 4.4] | (4.4, 5.5] | (5.5, 6.6] | (6.6, 7.8] | (7.8, 8.9] | (8.9, 10.0] |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Gemini-1.5 Pro | 0.64 | 0.48 | 0.35 | 0.35 | 0.28 | 0.12 | 0.06 | 0.00 |
| LLaVA-Video-72B | 0.59 | 0.45 | 0.42 | 0.30 | 0.15 | 0.23 | 0.16 | 0.00 |
| LLaVA-Video-7B | 0.50 | 0.43 | 0.34 | 0.29 | 0.19 | 0.18 | 0.14 | 0.00 |
: Table 5: Rel. dist. task with cognitive maps.
| Models | LLaVA-Video-72B | LLaVA-Video-7B |
| :--- | :---: | :---: |
| *w/o.* Cog. Map | 36.0 | 40.0 |
| *w/.* Cog. Map | 42.0 | 32.0 |
### C. Evaluation Details
#### C.1 General Evaluation Setup
Our evaluation processes are primarily conducted using the `LMMs-Eval` project [107]. To ensure reproducibility, unless otherwise specified, we adopt a greedy decoding strategy for all models (*i.e.*, the temperature is set to 0, and both top-p and top-k are set to 1). The input for the models is formatted as follows: `[Video Frames][Pre-prompt][Question][Post-prompt]`, where `Question` includes the question and any available options. The specific `Pre-prompt` and `Post-prompt` for different models and question types are detailed in Table 9.
#### C.2 Human Evaluation Setup
During the evaluation of human-level performance on `VSI-Bench` (tiny), human evaluators are allowed unlimited time to answer questions to the best of their ability. They receive both the questions and corresponding videos simultaneously and can review the videos multiple times to gather comprehensive information. We do not restrict the number of times evaluators can review videos for two key reasons. First, MLLMs auto-regressively generate answers, enabling them to analyze videos repeatedly during the response generation process. Second, MLLMs are designed to achieve and exceed typical human-level performance for practical real-world applications.
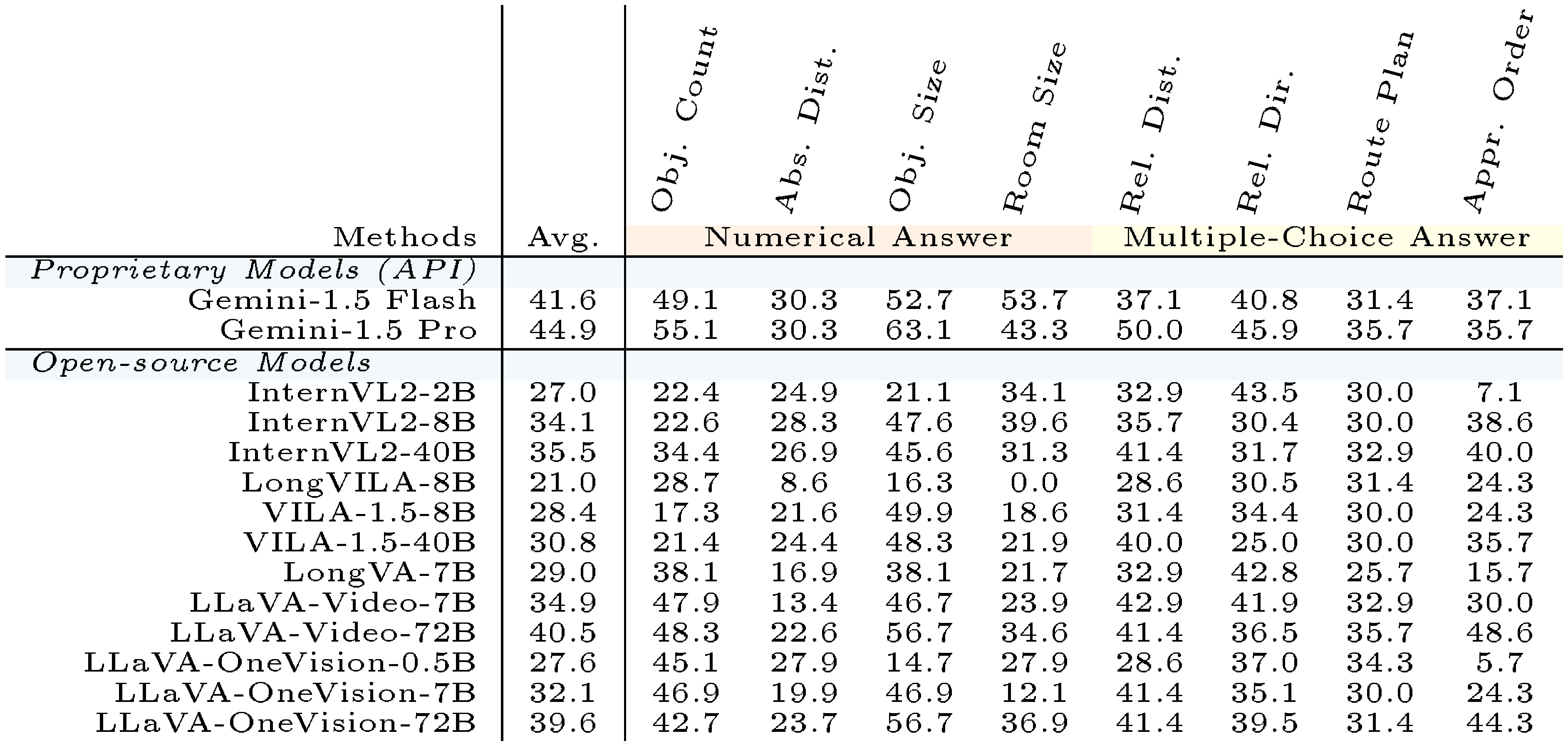
In addition, we provide the human evaluation on another `VSI-Bench` subset with 560 samples optimized to minimize the average performance gap between this subset and full set for all MLLMs. As shown in Table 10, this subset has an average performance discrepancy compared to full set (see Figure 5) just 0.5% and a maximum of 2.9%.
#### C.3 Number of Frames Setup
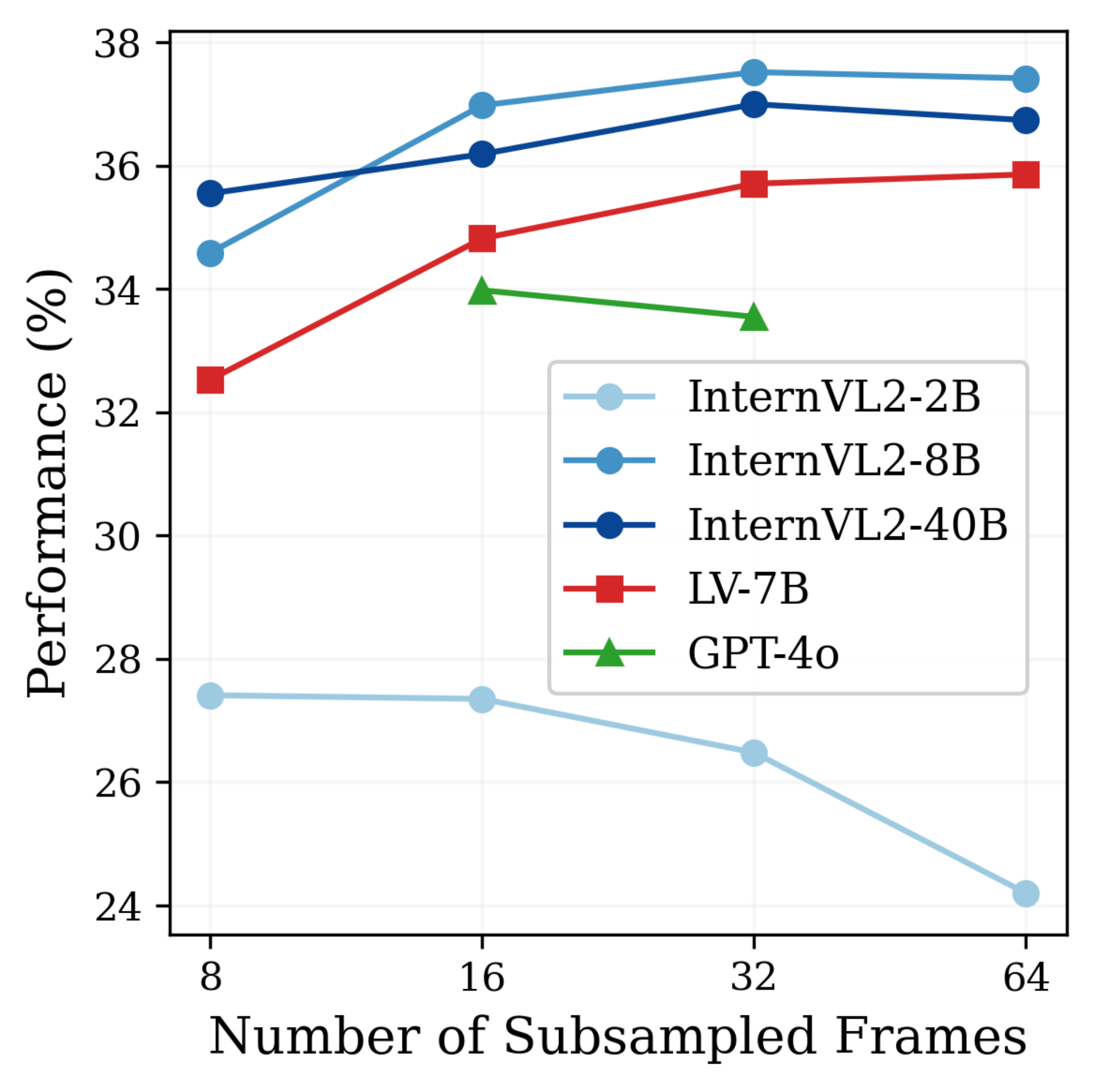
Typically, MLLMs subsample a fixed number of frames for evaluation. For all open-source models and the GPT-4 API, following [107], we manually sample video frames from the entire video at evenly spaced time intervals. For the Gemini API, we follow its instructions, uploading and feeding the entire video to the model. The number of frames used for each model are provided in Table 8. We believe that frame sampling strategies are a model design choice separate from the benchmark design. Established benchmarks (*e.g.*, VideoMME [52] and EgoSchema [21]) also employ default sampling, reinforcing this perspective. In addition, as shown in the Figure 11, the # of sampled frames only marginally affects performance—it is not the primary bottleneck.
#### C.4 More Evaluation Results
Here, we provide more evaluation results on our benchmark, including blind evaluation results, the Socratic LLMs, the full evaluation results of `VSI-Bench` (tiny), and vision-enabled $-$ vision-disabled results.
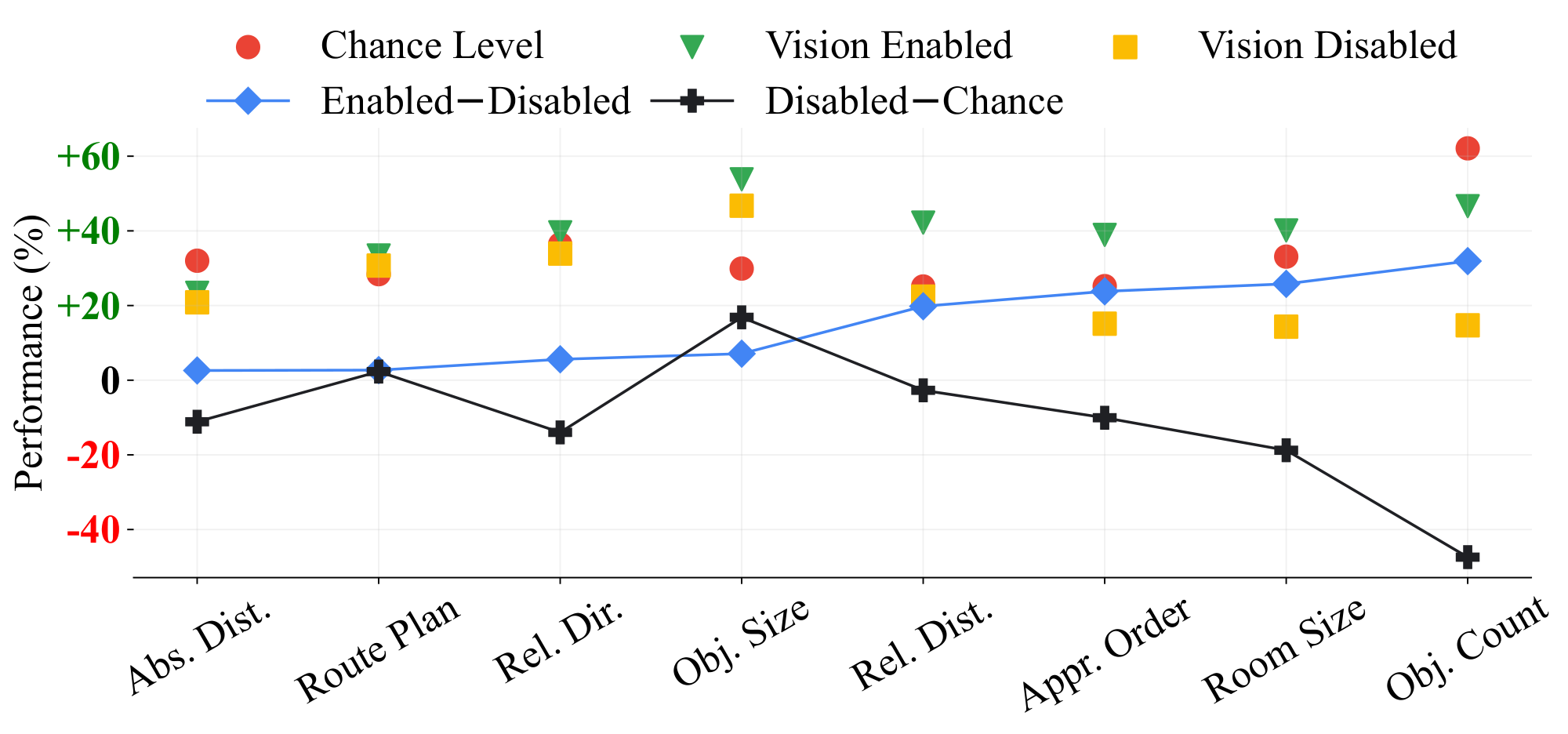
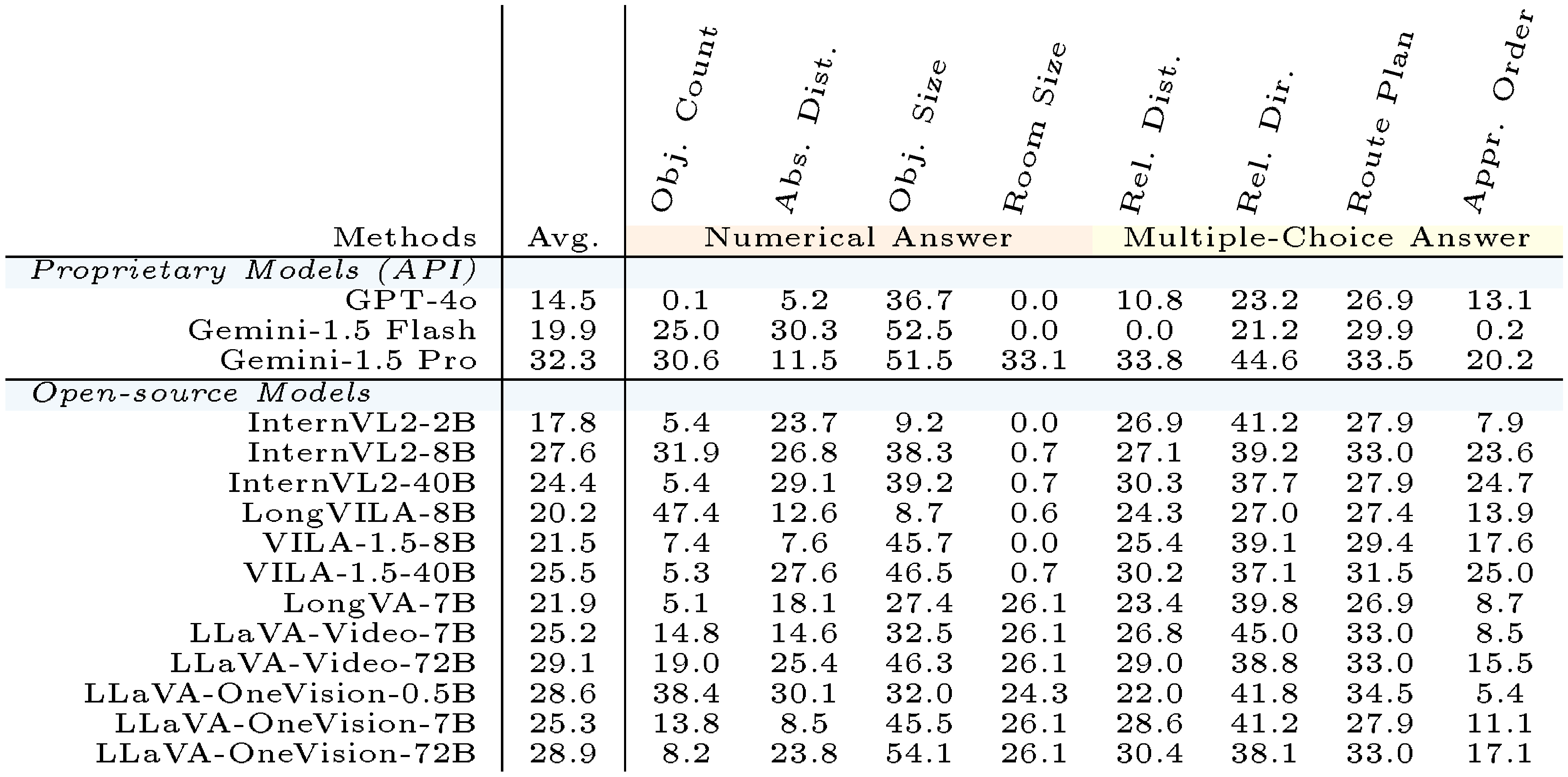
**Blind Evaluation.** We compare MLLMs'performance against "Chance Level (frequency)"and "Vision Disabled" (blind) results, using averages across six of the strongest models (3 open-source and 3 closed-source). As shown in Figure 12, the consistent improvements in "Enabled $-$ Disabled"and general degradation in "Disabled $-$ Chance" demonstrates that video is essential and beneficial for our `VSI-Bench`, with blind models performing below chance level. Meanwhile, MLLMs struggle to improve beyond chance level in the absolute distance estimation, route plan, and relative direction tasks, whether vision is enabled or not, underscoring the difficulty of these tasks. Note that on object size, "Vision Disabled" models already significantly outperform chance level, likely due to common-sense knowledge learned during language model training.
In addition, as shown in Table 12, we present the evaluation results for all MLLMs on `VSI-Bench`. Generally, larger variants within the same model family often demonstrate better performance in blind evaluations, as seen in comparisons such as Gemini-1.5 Flash *vs.* Gemini-1.5 Pro and VILA-1.5-8B *vs.* VILA-1.5-40B. The blind evaluation also highlights LLM biases across tasks. For instance, LongVILA-8B achieves 47.5% accuracy on the object count task, benefiting from a bias that frequently leads it to predict 2 as the answer.
**Socratic LLMs with Frame Captions.** Following OpenEQA [103] and HourVideo [19], we implement a Socratic variant of GPT-4o using LLaVA-Video-72B as the captioner and GPT-4o as the answering LLM. As shown in Table 6, Socratic lags behind the standard GPT-4o by 4.7%.
: Table 6: Socratic LLMs with Frame Captions.
| GPT-4o | Standard | Socratic | Blind |
| :--- | :---: | :---: | :---: |
| Avg. | 34.0 | 29.3 | 14.5 |
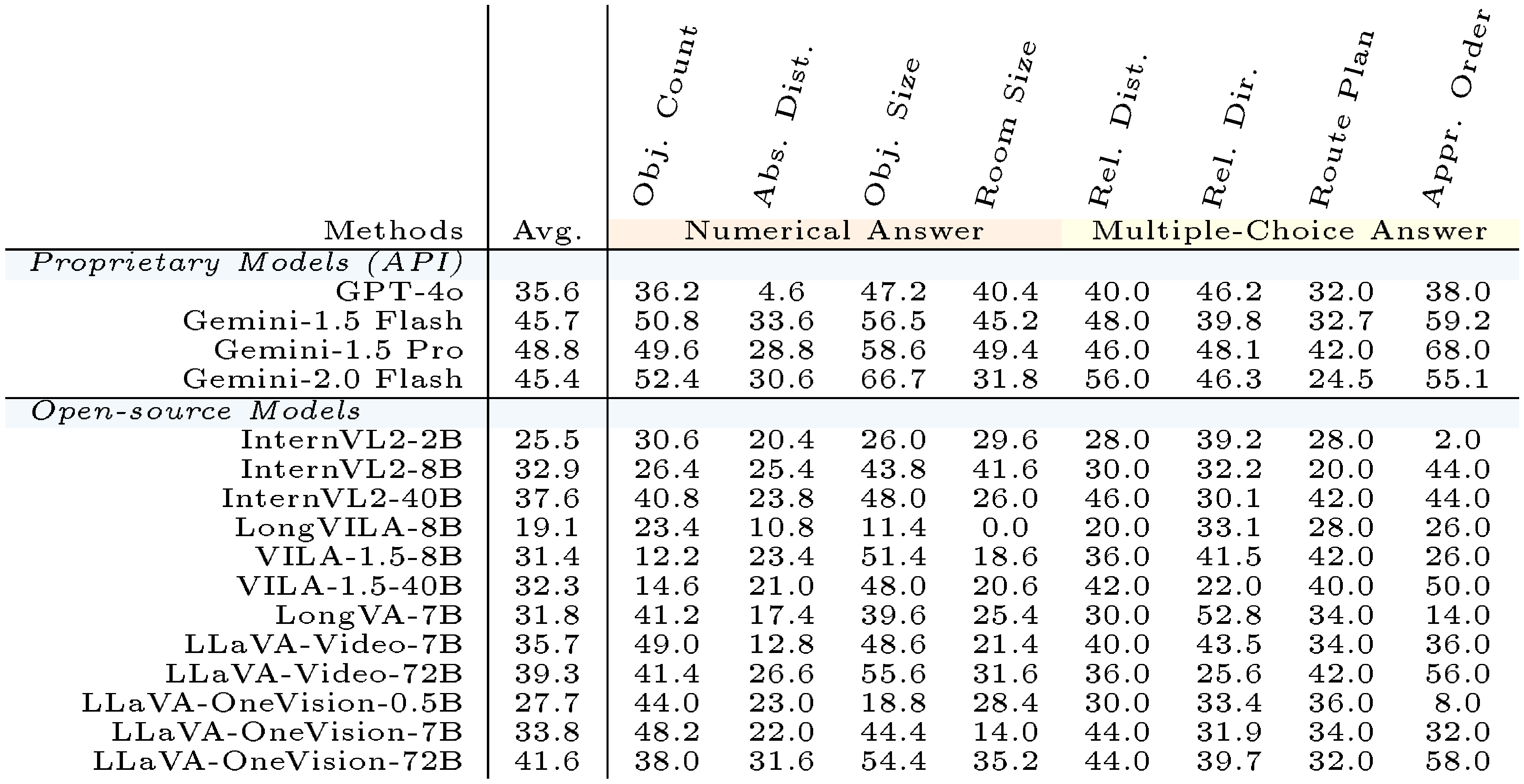
**`VSI-Bench` (tiny) Results.** As shown in Table 11, we provide the evaluation results of all models on `VSI-Bench` (tiny). The rankings and average accuracy of MLLMs on `VSI-Bench` (tiny) remain consistent to the results reported in Figure 5. This consistency suggests that the human evaluation and analysis results conducted on `VSI-Bench` (tiny) are reliable.
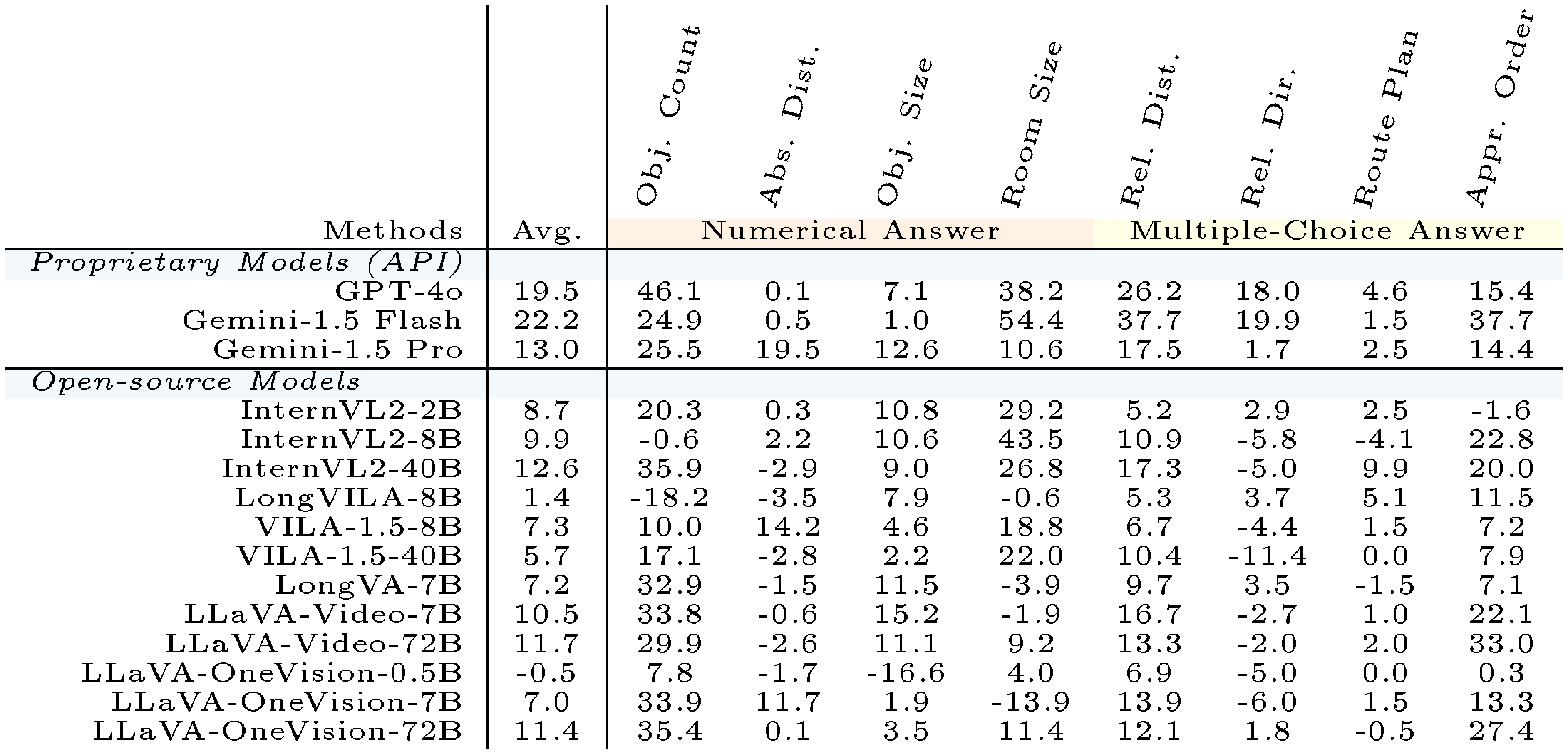
**Vision Enabled $-$ Vision Disabled.** Table 13 presents the improvement of MLLMs from using visual signals to answer `VSI-Bench`. Almost all MLLMs obtain improvements from visual signals, with notable improvements in tasks such as object count, room size, relative distance and appearance order.
### D. Input Sequencing and Repetition Analysis
Human performance in visual problem-solving improves when they know the question before viewing the visual content, as it helps direct their attention to relevant visual cues. However, current MLLMs typically rely on a visual-first paradigm [23, 24], leading us to examine how the presentation order of video-question pairs impacts model performance. To investigate, we conduct experiments using Gemini-1.5 Pro on `VSI-Bench` (tiny).
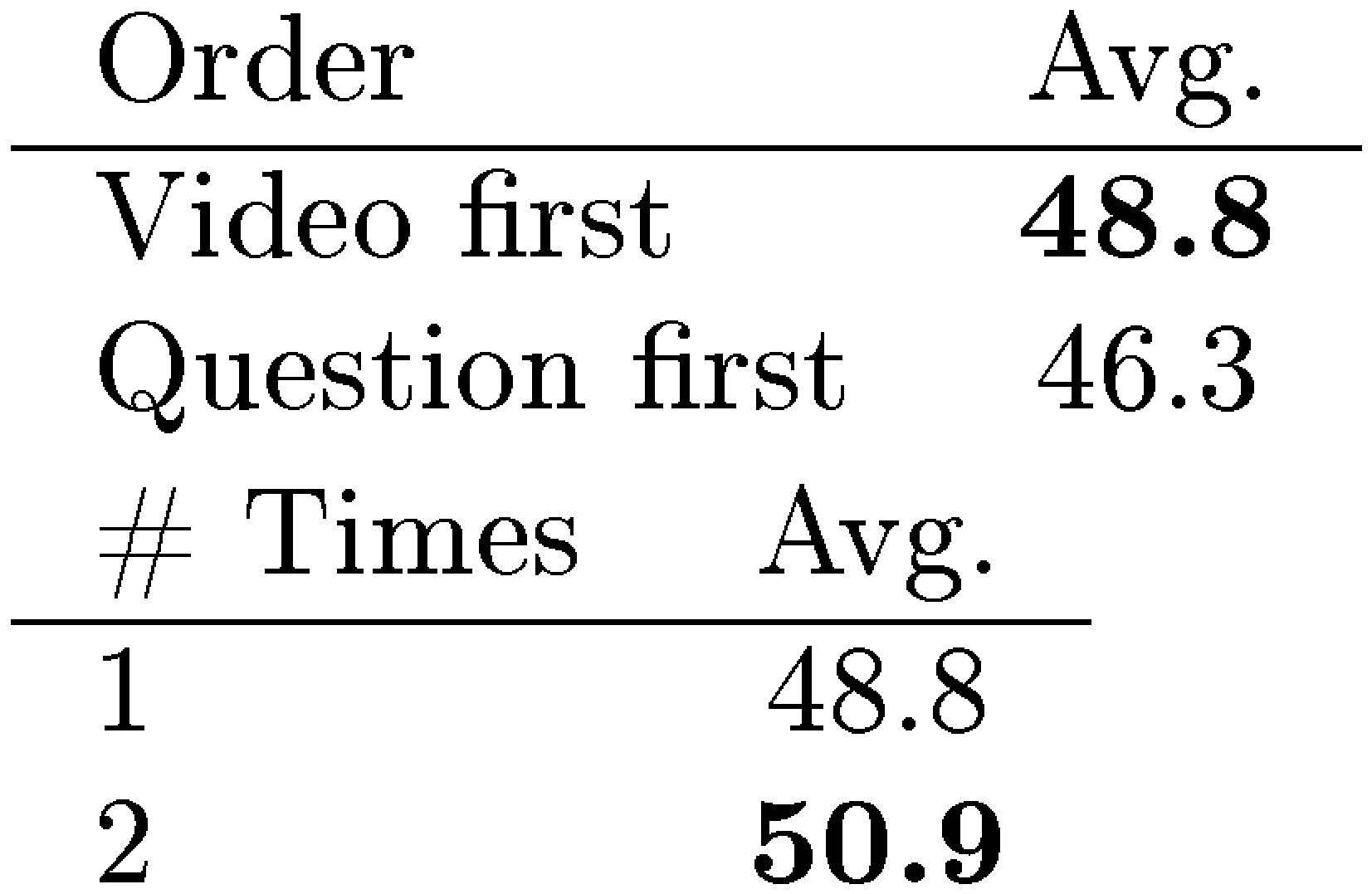
**MLLM's performance degrades with question-first paradigm.** As shown in Table 7 (a), switching to a video-first approach results in a 2.5% decrease in overall performance for Gemini compared to the question-first approach.
::: {caption="Table 7: Input Sequence"}
:::
**MLLM benefits from multiple video views.** In addition, humans often improve their VQA performance by reviewing visual content multiple times, inspiring us to implement a similar setup for MLLMs. Specifically, input is formatted as: `[Video] [Context] [Video]` with identical video, where the system prompt explicitly informs the model of the redundancy of input video. As shown in Table 7 (b), Gemini achieves a notable 2.1% performance gain with two repeated videos as input. This is surprising, as autoregressive MLLMs theoretically have the capability to revisit the video multiple times during answer generation, even if the video is only presented once. This finding suggests that, despite its remarkable capabilities, a powerful MLLM like Gemini still has suboptimal reasoning processes for Video QA.
### E. Visualization Results
In this section, we present more qualitative results, including more examples of `VSI-Bench`, further error analysis case studies, examples of Chain-of-Thought promptings, and additional cognitive maps.
#### E.1 `VSI-Bench` Examples
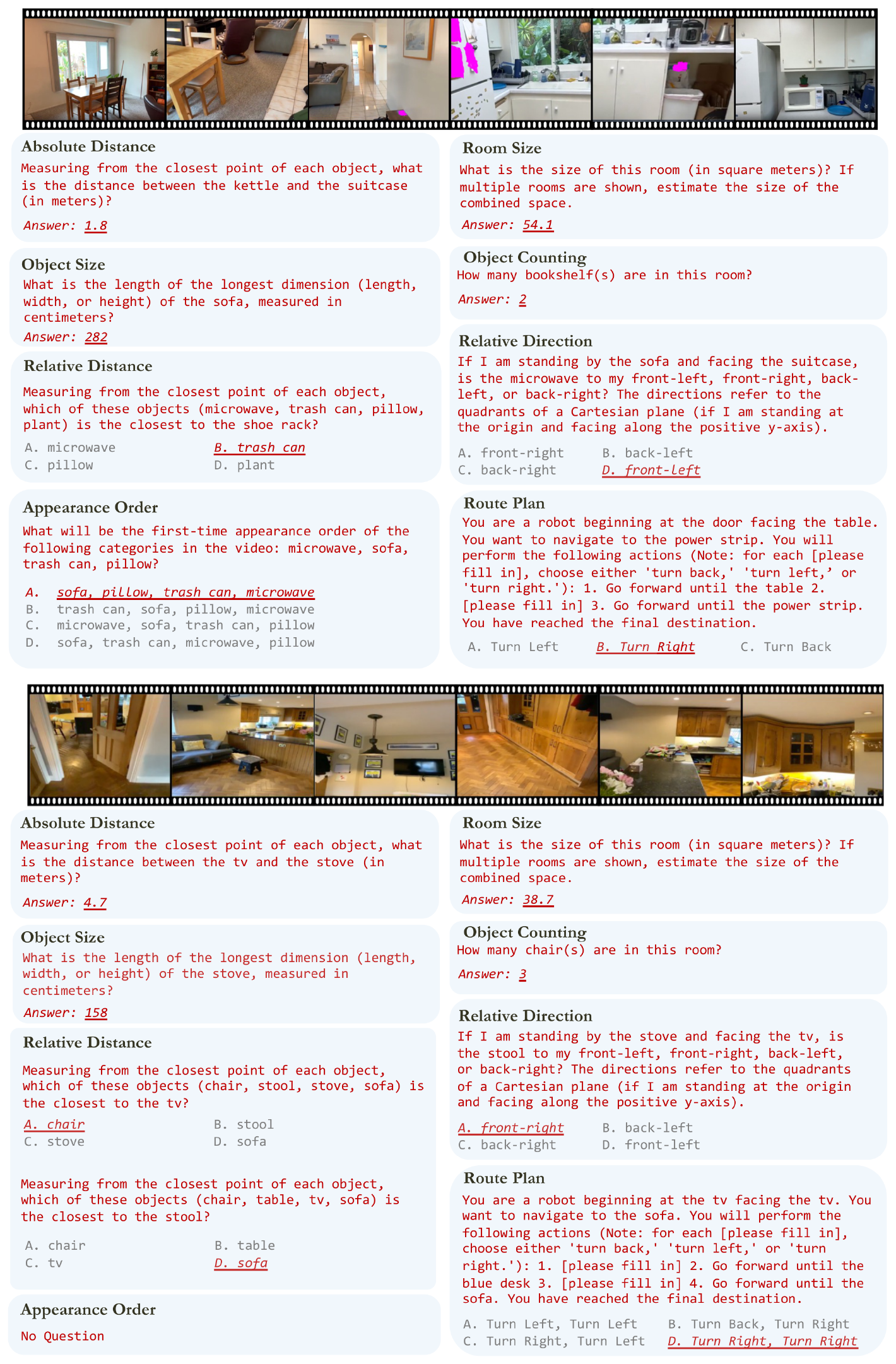
In Figure 13 and Figure 14, we provide more examples from `VSI-Bench` to illustrate the structure and format of tasks, questions, and answers.
#### E.2 Error Analysis Examples
In Figure 15, we present more case studies for our human-conducted error analysis on `VSI-Bench`. In the error analysis, we identify the categorized error types and highlight the relevant parts of the explanation.
```latextable {caption="Table 8: Number of frames used in evaluation."}
\begin{tabular}{r|c}
Methods & # of Frames \\
\hline
\rowcolor{navyblue!5}
\multicolumn{1}{l|}{\textcolor{black}{\textit{Proprietary Models (API)}}} & \\
GPT-4o & 16 \\
Gemini-1.5 Flash & - \\
Gemini-1.5 Pro & - \\
\hline
\rowcolor{navyblue!5}
\multicolumn{1}{l|}{\textcolor{black}{\textit{Open-source Models}}} & \\
InternVL2-2B & 32 \\
InternVL2-8B & 32 \\
InternVL2-40B & 32 \\
LongVILA-8B & 32 \\
VILA-1.5-8B & 32 \\
VILA-1.5-40B & 32 \\
LongVA-7B & 32 \\
LLaVA-Video-7B & 32 \\
LLaVA-Video-72B & 32 \\
LLaVA-OneVision-0.5B & 32 \\
LLaVA-OneVision-7B & 32 \\
LLaVA-OneVision-72B & 32 \\
\end{tabular}
E.3 Linguistic Prompting Examples
We provide examples for the three CoT prompting methods discussed in Section 5.2 to illustrate their concrete reasoning procedure in detail. We include examples of three selected tasks: object count, object size, and room size. For Zero-Shot Chain of Thought, as shown in Figure 16, we highlight each step of the MLLM's reasoning process to offer insights into how it arrives at its final decision. For Self-Consistency w/ CoT, as illustrated in Figure 17, each example is paired with five independent responses. The final answer is then determined by a majority vote. For Tree-of-Thought, Figure 18 details how each depth of the decision tree is reached. At the first depth, the MLLM generates three potential plans and conducts a choice analysis to select the optimal plan. At the second and final depth, the selected plan is used to generate three potential answers, with the final output determined through a majority vote.
E.4 Cognitive Map Examples
In Figure 19, we include 10 additional cognitive maps and pair each prediction with its corresponding ground truth map to provide insight into the alignment between predicted and ground truth layouts.
\begin{tabular}{c|c|c|l}
& Models & QA. Type & Prompt \\
\hline
{\small\texttt{Pre-Prompt}} & - & - & \textit{These are frames of a video.} \\
\hline
\multirow{4}{*}{{\small\texttt{Post-Prompt}}} & \multirow{2}{*}{Open-source Models} & NA & \textit{Please answer the question using a single word or phrase.} \\
& & MCA & \textit{Answer with the option's letter from the given choices directly.} \\
& \multirow{2}{*}{Proprietary Models} & NA & \textit{Do not respond with anything other than a single number!} \\
& & MCA & \textit{Answer with the option's letter from the given choices directly.} \\
\end{tabular}
::: {caption="Table 10: Evaluation results on VSI-Bench 560 samples subset."}
:::
::: {caption="Table 11: Complete VSI-Bench (tiny) evaluation results."}
:::
::: {caption="Table 12: Complete blind evaluation results."}
:::
::: {caption="Table 13: Results of Vision Enabled $-$ Vision Disabled."}
:::


References
Section Summary: This section lists dozens of academic sources cited throughout the document, starting with Howard Gardner's foundational 1983 book on multiple intelligences and then shifting to an extensive collection of recent papers on large language models such as Llama, GPT, and Gemini. Subsequent entries focus on multimodal systems that combine language with vision or action, including models like Flamingo and BLIP-2, as well as robotics platforms and long-video understanding benchmarks. Together the references trace the progression from core AI theory to contemporary research in language, vision, and embodied systems.
[1] Howard Gardner. Frames of Mind: The Theory of Multiple Intelligences. Basic Books, tenth-anniversary edition, second paperback edition edition, 1983.
[2] Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435, 2023.
[3] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. TMLR, 2022a.
[4] Gašper Beguš, Maksymilian Dąbkowski, and Ryan Rhodes. Large linguistic models: Analyzing theoretical linguistic abilities of llms. arXiv preprint arXiv:2305.00948, 2023.
[5] Zhihao Zhang, Jun Zhao, Qi Zhang, Tao Gui, and Xuanjing Huang. Unveiling linguistic regions in large language models. In ACL, 2024f.
[6] Nora Kassner, Oyvind Tafjord, Ashish Sabharwal, Kyle Richardson, Hinrich Schütze, and Peter Clark. Language models with rationality. In EMNLP, 2023.
[7] Alec Radford. Improving language understanding by generative pre-training. OpenAI Blog, 2018.
[8] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[9] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. NeurIPS, 2020.
[10] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
[11] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
[12] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023a.
[13] Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
[14] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. In ICML, 2023.
[15] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. In RSS, 2023b.
[16] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In CoRL, 2023a.
[17] Abby O'Neill, Abdul Rehman, Abhinav Gupta, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, et al. Open x-embodiment: Robotic learning datasets and rt-x models. arXiv preprint arXiv:2310.08864, 2023.
[18] Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. In CoRL, 2024.
[19] Keshigeyan Chandrasegaran, Agrim Gupta, Lea M. Hadzic, Taran Kota, Jimming He, Cristobal Eyzaguirre, Zane Durante, Manling Li, Jiajun Wu, and Fei-Fei Li. Hourvideo: 1-hour video-language understanding. In NeurIPS, 2024.
[20] Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In CVPR, 2022.
[21] Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. NeurIPS, 2023.
[22] Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024.
[23] Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
[24] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. NeurIPS, 2024b.
[25] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. NeurIPS, 2022.
[26] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023a.
[27] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023b.
[28] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR, 2024c.
[29] Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In ICLR, 2024.
[30] Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis. In ICLR, 2024.
[31] Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In ICML, 2022.
[32] James M. Clark and Allan Paivio. Dual coding theory and education. Educational Psychology Review, 3(3):149–210, 1991.
[33] E. C. Tolman. Cognitive maps in rats and men. Psychological Review, 55(4):189–208, 1948.
[34] Nora S. Newcombe. Spatial Cognition. MIT Press, 2024. https://oecs.mit.edu/pub/or750iar.
[35] David Ed Waller and Lynn Ed Nadel. *Handbook of spatial cognition.*American Psychological Association, 2013.
[36] Shenna Shepard and Douglas Metzler. Mental rotation: effects of dimensionality of objects and type of task. Journal of experimental psychology: Human perception and performance, 14(1):3, 1988.
[37] Chiara Meneghetti, Laura Miola, Tommaso Feraco, Veronica Muffato, and Tommaso Feraco Miola. Individual differences in navigation: an introductory overview. Prime archives in psychology, 2022.
[38] Christopher F Chabris, Thomas E Jerde, Anita W Woolley, Margaret E Gerbasi, Jonathon P Schuldt, Sean L Bennett, J Richard Hackman, and Stephen M Kosslyn. Spatial and object visualization cognitive styles: Validation studies in 3800 individuals. Group brain technical report, 2:1–20, 2006.
[39] Alan Baddeley. Working memory. Science, 255(5044):556–559, 1992.
[40] Julia McAfoose and Bernhard T. Baune. Exploring visual–spatial working memory: A critical review of concepts and models. Neuropsychology Review, 2009.
[41] Milton J. Dehn. Working Memory and Academic Learning: Assessment and Intervention. John Wiley & Sons, 2011.
[42] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In CVPR, 2017.
[43] Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes. In ICCV, 2023.
[44] Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. ARKitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile RGB-d data. In NeurIPS, 2021.
[45] Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821, 2024b.
[46] Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. In CVPR, 2024.
[47] Fuzhao Xue, Yukang Chen, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context visual language models for long videos. arXiv preprint arXiv:2408.10188, 2024.
[48] Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024b.
[49] Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024b.
[50] Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713, 2024e.
[51] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In CVPR, 2024.
[52] Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024.
[53] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In ICLR, 2021.
[54] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. IJCV, 2010.
[55] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
[56] Gerard Salton and Michael J. McGill. Introduction to Modern Information Retrieval. McGraw-Hill, Inc., USA, 1986.
[57] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " why should i trust you?" explaining the predictions of any classifier. In KDD, 2016.
[58] Shiyuan Huang, Siddarth Mamidanna, Shreedhar Jangam, Yilun Zhou, and Leilani H Gilpin. Can large language models explain themselves? a study of llm-generated self-explanations. arXiv preprint arXiv:2310.11207, 2023.
[59] Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. In ACL, 2023.
[60] Haoyu Gao, Ting-En Lin, Hangyu Li, Min Yang, Yuchuan Wu, Wentao Ma, Fei Huang, and Yongbin Li. Self-explanation prompting improves dialogue understanding in large language models. In COLING, 2024.
[61] Letitia Parcalabescu and Anette Frank. On measuring faithfulness or self-consistency of natural language explanations. In ACL, 2024.
[62] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. TMLR, 2023a.
[63] D'ıdac Sur'ıs, Sachit Menon, and Carl Vondrick. Vipergpt: Visual inference via python execution for reasoning. In ICCV, 2023.
[64] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 2022b.
[65] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In NeurIPS, 2022.
[66] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In ICLR, 2023b.
[67] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In NeurIPS, 2024.
[68] Lynn Nadel. The Hippocampus and Context Revisited. Oxford University Press, 2008.
[69] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In CVPR, 2022.
[70] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
[71] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. DINOv2: Learning robust visual features without supervision. TMLR, 2024.
[72] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024b.
[73] Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, 2024d.
[74] Xiaofeng Zhang, Yihao Quan, Chen Shen, Xiaosong Yuan, Shaotian Yan, Liang Xie, Wenxiao Wang, Chaochen Gu, Hao Tang, and Jieping Ye. From redundancy to relevance: Information flow in lvlms across reasoning tasks, 2024c.
[75] Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with ringattention. arXiv preprint arXiv:2402.08268, 2024c.
[76] Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought. NeurIPS, 2024.
[77] Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. In CoRL, 2024.
[78] Junmo Cho, Jaesik Yoon, and Sungjin Ahn. Spatially-aware transformers for embodied agents. In ICLR, 2023.
[79] Jihan Yang, Runyu Ding, Ellis Brown, Xiaojuan Qi, and Saining Xie. V-irl: Grounding virtual intelligence in real life. In ECCV, 2024.
[80] Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In CVPR, 2024a.
[81] An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. In NeurIPS, 2024.
[82] Wenxiao Cai, Yaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. arXiv preprint arXiv:2406.13642, 2024.
[83] Benlin Liu, Yuhao Dong, Yiqin Wang, Yongming Rao, Yansong Tang, Wei-Chiu Ma, and Ranjay Krishna. Coarse correspondence elicit 3d spacetime understanding in multimodal language model. arXiv preprint arXiv:2408.00754, 2024a.
[84] Chengzu Li, Caiqi Zhang, Han Zhou, Nigel Collier, Anna Korhonen, and Ivan Vulić. Topviewrs: Vision-language models as top-view spatial reasoners. arXiv preprint arXiv:2406.02537, 2024c.
[85] Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness. arXiv preprint arXiv:2409.18125, 2024.
[86] Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, and Si Liu. Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection. arXiv preprint arXiv:2411.14794, 2024.
[87] Yihong Tang, Ao Qu, Zhaokai Wang, Dingyi Zhuang, Zhaofeng Wu, Wei Ma, Shenhao Wang, Yunhan Zheng, Zhan Zhao, and Jinhua Zhao. Sparkle: Mastering basic spatial capabilities in vision language models elicits generalization to composite spatial reasoning. arXiv preprint arXiv:2410.16162, 2024.
[88] Santhosh Kumar Ramakrishnan, Erik Wijmans, Philipp Kraehenbuehl, and Vladlen Koltun. Does spatial cognition emerge in frontier models? arXiv preprint arXiv:2410.06468, 2024.
[89] Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023.
[90] Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, and Furu Wei. Visualization-of-thought elicits spatial reasoning in large language models. NeurIPS, 2024.
[91] Julia Rozanova, Deborah Ferreira, Krishna Dubba, Weiwei Cheng, Dell Zhang, and Andre Freitas. Grounding natural language instructions: Can large language models capture spatial information? arXiv preprint arXiv:2109.08634, 2021.
[92] Yutaro Yamada, Yihan Bao, Andrew Kyle Lampinen, Jungo Kasai, and Ilker Yildirim. Evaluating spatial understanding of large language models. TMLR, 2024.
[93] Ida Momennejad, Hosein Hasanbeig, Felipe Vieira Frujeri, Hiteshi Sharma, Nebojsa Jojic, Hamid Palangi, Robert Ness, and Jonathan Larson. Evaluating cognitive maps and planning in large language models with cogeval. NeurIPS, 2024.
[94] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In ECCV, 2025.
[95] Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. In CVPR, 2024a.
[96] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. ICML, 2024.
[97] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. In CVPR, 2024d.
[98] Munan Ning, Bin Zhu, Yujia Xie, Bin Lin, Jiaxi Cui, Lu Yuan, Dongdong Chen, and Li Yuan. Video-bench: A comprehensive benchmark and toolkit for evaluating video-based large language models. arXiv preprint arXiv:2311.16103, 2023.
[99] Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. TempCompass: Do video LLMs really understand videos? In Findings of ACL, 2024d.
[100] Shicheng Li, Lei Li, Shuhuai Ren, Yuanxin Liu, Yi Liu, Rundong Gao, Xu Sun, and Lu Hou. Vitatecs: A diagnostic dataset for temporal concept understanding of video-language models. arXiv preprint arXiv:2311.17404, 2023b.
[101] Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. Mmbench-video: A long-form multi-shot benchmark for holistic video understanding. In NeurIPS, 2024.
[102] Hanrong Ye, Haotian Zhang, Erik Daxberger, Lin Chen, Zongyu Lin, Yanghao Li, Bowen Zhang, Haoxuan You, Dan Xu, Zhe Gan, et al. Mm-ego: Towards building egocentric multimodal llms. arXiv preprint arXiv:2410.07177, 2024.
[103] Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. In CVPR, 2024.
[104] Xiongkun Linghu, Jiangyong Huang, Xuesong Niu, Xiaojian Shawn Ma, Baoxiong Jia, and Siyuan Huang. Multi-modal situated reasoning in 3d scenes. Advances in Neural Information Processing Systems, 37:140903–140936, 2024.
[105] Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Sharon Li, and Neel Joshi. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. Advances in Neural Information Processing Systems, 37:75392–75421, 2024a.
[106] Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3D: A modern library for 3D data processing. arXiv:1801.09847, 2018.
[107] Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. arXiv preprint arXiv:2407.12772, 2024a.