COGVIDEOX: TEXT-TO-VIDEO DIFFUSION MODELS WITH AN EXPERT TRANSFORMER
Zhuoyi Yang$^{}$ $^{\ddagger}$ Jiayan Teng$^{}$ $^{\ddagger}$ Wendi Zheng$^{\ddagger}$ Ming Ding$^{\dagger}$ Shiyu Huang$^{\dagger}$ Jiazheng Xu$^{\ddagger}$ Yuanming Yang$^{\ddagger}$ Wenyi Hong$^{\ddagger}$ Xiaohan Zhang$^{\dagger}$ Guanyu Feng$^{\dagger}$ Da Yin$^{\dagger}$ Yuxuan Zhang$^{\dagger}$ Weihan Wang$^{\dagger}$ Yean Cheng$^{\dagger}$ Bin Xu$^{\ddagger}$ Xiaotao Gu$^{\dagger}$ Yuxiao Dong$^{\ddagger}$ Jie Tang$^{\ddagger}$
$^{\ddagger}$ Tsinghua University
$^{\dagger}$ Zhipu AI
Abstract
We present CogVideoX, a large-scale text-to-video generation model based on diffusion transformer, which can generate 10-second continuous videos that align seamlessly with text prompts, with a frame rate of 16 fps and resolution of 768 $\times$ 1360 pixels. Previous video generation models often struggled with limited motion and short durations. It is especially difficult to generate videos with coherent narratives based on text. We propose several designs to address these issues. First, we introduce a 3D Variational Autoencoder (VAE) to compress videos across spatial and temporal dimensions, enhancing both the compression rate and video fidelity. Second, to improve text-video alignment, we propose an expert transformer with expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. Third, by employing progressive training and multi-resolution frame packing, CogVideoX excels at generating coherent, long-duration videos with diverse shapes and dynamic movements. In addition, we develop an effective pipeline that includes various pre-processing strategies for text and video data. Our innovative video captioning model significantly improves generation quality and semantic alignment. Results show that CogVideoX achieves state-of-the-art performance in both automated benchmarks and human evaluation. We publish the code and model checkpoints
*Equal contributions. Core contributors: Zhuoyi, Jiayan, Wendi, Ming, Shiyu and Xiaotao.
{yangzy22,tengjy24}@mails.tsinghua.edu.cn, corresponding author: [email protected]
Visiting our demo website https://yzy-thu.github.io/CogVideoX-demo/ to watch more videos!
Executive Summary: The rapid rise of AI-generated content has created a pressing need for tools that can produce high-quality videos from simple text descriptions, such as turning "a lightning bolt splits a rock and a person emerges" into a smooth, realistic 10-second clip. Current models often fall short, generating short clips with choppy motion, flickering frames, or mismatched details, which limits their use in entertainment, education, and marketing where dynamic, narrative-driven videos are essential. With AI technologies advancing quickly, addressing these gaps is timely to enable broader applications like automated video production and creative storytelling.
This paper introduces CogVideoX, a new text-to-video model designed to create long, coherent videos that closely follow text prompts with rich actions and semantics. The team aimed to demonstrate its ability to generate videos up to 10 seconds long at high resolution while outperforming existing open-source models.
The researchers built CogVideoX using a diffusion transformer architecture, a type of AI system that refines random noise into structured outputs through iterative steps. Key innovations include a 3D video compressor (called a variational autoencoder) to shrink video data both in space and time for efficiency and smoothness; an expert transformer module to better blend text and visual elements; and progressive training techniques that start with lower resolutions and shorter clips before scaling up. They trained two versions—a 5-billion-parameter model and a 2-billion one—on about 35 million filtered video clips averaging 6 seconds each, plus 2 billion high-quality images, over several months. Data preparation involved custom pipelines to remove low-quality videos (like shaky footage or static lectures) and generate detailed captions using AI models, ensuring the training data supported dynamic, realistic motion.
CogVideoX's top results include generating videos at 768x1360 pixel resolution and 16 frames per second with minimal flickering—about 8% smoother than prior methods. In automated benchmarks across 500 test videos, the 5-billion model scored highest in five of seven categories, such as human actions (96.8% vs. competitors' 85-96%) and dynamic degree (71% vs. 40-65%), while the 2-billion version was highly competitive. Human evaluators preferred CogVideoX over a leading closed-source model (Kling) in all areas, including sensory quality (0.72 vs. 0.64 on a 0-1 scale) and instruction following (0.50 vs. 0.37), based on 100 diverse prompts. The model also supports image-to-video extensions, maintaining consistency across styles. These findings show scalability: larger models with more data yield better performance, up to 20-30% gains in motion coherence.
These outcomes mean AI can now produce professional-grade videos with natural movements and precise text alignment, reducing the need for manual editing and lowering costs in video creation by potentially 50-70% for short-form content. Unlike earlier models that prioritized short, static scenes, CogVideoX handles complex narratives and large motions, which could enhance safety in simulations (e.g., realistic physics) or boost creative industries. The open-source release marks a shift, providing commercial-level tools without proprietary barriers, though it may amplify risks like deepfakes if not regulated.
Next, deploy the released 5-billion and 2-billion models for pilots in applications like ad generation or educational tools, starting with the smaller version for faster inference on standard hardware. Scale training to even larger sizes (e.g., 10+ billion parameters) for longer videos (20+ seconds) and higher resolutions, while refining the video captioning pipeline for diverse languages. Conduct user studies on real-world biases before widespread adoption.
While robust, the work relies on filtered internet data, which may overlook rare cultural contexts or introduce subtle biases toward common scenes; aggressive compression could limit extreme motions in future scales. Confidence is high in benchmark and human results, supported by ablations showing design choices reduce errors by 10-20%, but caution is advised for niche prompts where more diverse training data would help.
1. Introduction
Section Summary: Recent breakthroughs in text-to-video technology, powered by Transformer and diffusion models, have led to impressive tools like CogVideo, Phenaki, and Sora, but they still struggle with creating long, consistent videos featuring complex, dynamic scenes. To tackle this, researchers developed CogVideoX, a family of large-scale models that use a 3D Variational Autoencoder for efficient video compression, an advanced Transformer for better text-video alignment and motion capture, improved data captioning, and progressive training methods to generate smooth, high-quality videos up to 10 seconds long. Evaluations show the 5-billion and 2-billion parameter versions outperforming leading models, and they've been released openly to push the field forward.
The rapid development of text-to-video models has been phenomenal, driven by both the Transformer architecture ([1]) and diffusion model ([2]). Early attempts to pretrain and scale Transformers to generate videos from text have shown great promise, such as CogVideo ([3]) and Phenaki ([4]). Meanwhile, diffusion models have recently made exciting advancements in video generation([5, 6]). By using Transformers as the backbone of diffusion models, i.e., Diffusion Transformers (DiT) ([7]), text-to-video generation has reached a new milestone, as evidenced by the impressive Sora showcases ([8]).
Despite these rapid advancements in DiTs, it remains technically unclear how to achieve long-term consistent video generation with dynamic plots. For example, previous models had difficulty generating a video based on a prompt like "a bolt of lightning splits a rock, and a person jumps out from inside the rock".
In this work, we train and introduce CogVideoX, a set of large-scale diffusion transformer models designed for generating long-term, temporally consistent videos with rich motion semantics. We address the challenges mentioned above by developing a 3D Variational Autoencoder, an expert Transformer, a progressive training pipeline, and a video data filtering and captioning pipeline, respectively.
First, to efficiently consume high-dimension video data, we design and train a 3D causal VAE that compresses the video along both spatial and temporal dimensions. Compared to previous method([9]) of fine-tuning 2D VAE, this strategy helps significantly reduce the sequence length and associated training compute and also helps prevent flicker in the generated videos, that is, ensuring continuity among frames.
Second, to improve the alignment between videos and texts, we propose an expert Transformer with expert adaptive LayerNorm to facilitate the fusion between the two modalities. To ensure the temporal consistency in video generation and capture large-scale motions, we propose to use 3D full attention to comprehensively model the video along both temporal and spatial dimensions.
Third, as most video data available online lacks accurate textual descriptions, we develop a video captioning pipeline capable of accurately describing video content. This pipeline is used to generate new textual descriptions for all video training data, which significantly enhances CogVideoX's ability to grasp precise semantic understanding.
In addition, we adopt and design progressive training techniques, including multi-resolution frame pack and resolution progressive training, to further enhance the generation performance and stability of CogVideoX. Furthermore, we propose Explicit Uniform Sampling, which stablizes the training loss curve and accelerates convergence by setting different timestep sampling intervals on each data parallel rank.
To date, we have completed the CogVideoX training with two sizes: 5 billion and 2 billion, respectively. Both machine and human evaluations suggest that CogVideoX-5B outperforms well-known video models and CogVideoX-2B is very competitive across most dimensions.
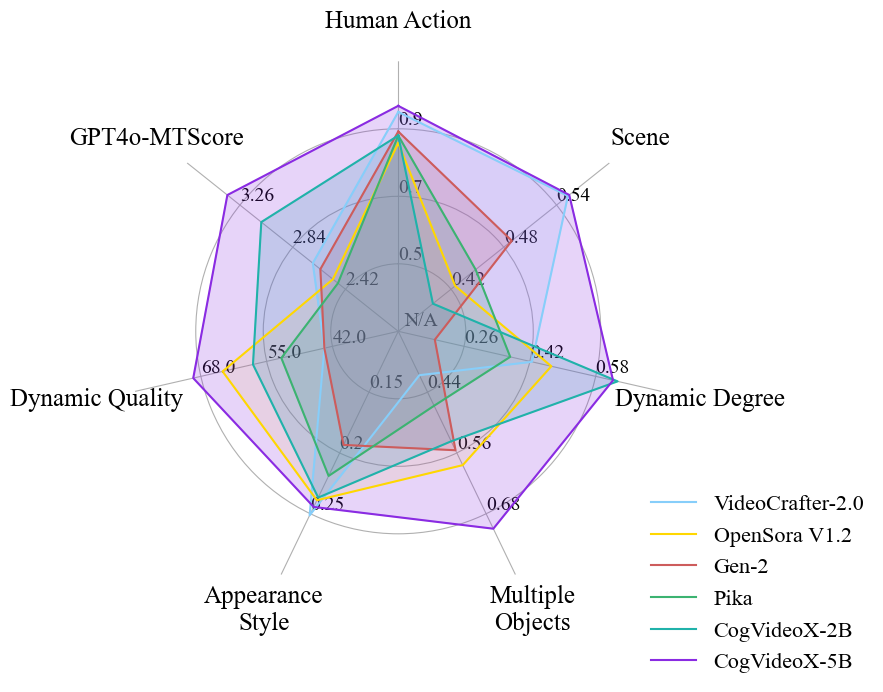
Figure 2 shows the performance of CogVideoX-5B and CogVideoX-2B in different aspects. It shows that CogVideoX has the property of being scalable. As the size of model parameters, data volume, and training volume increase, the performance will get better in the future.
Our contributions can be summarized as follows:
- We propose CogVideoX, a simple and scalable structure with a 3D causal VAE and an expert transformer, designed for generating coherent, long-duration, high-action videos. It can generate long videos with multiple aspect ratios, up to 768 $\times$ 1360 resolution, 10 seconds in length, at 16fps.
- We evaluate CogVideoX through automated metric evaluation and human assessment, compared with openly-accessible top-performing text-to-video models. CogVideoX achieves state-of-the-art performance.
- We publicly release our 5B and 2B models, including text-to-video and image-to-video versions, the first commercial-grade open-source video generation models. We hope it can advance the filed of video generation.
2. The CogVideoX Architecture
Section Summary: CogVideoX is an AI model that generates videos from text descriptions by first compressing the input video into a compact latent representation using a 3D causal variational autoencoder, which handles both spatial and temporal details efficiently to reduce data size while preserving quality. This compressed video data is then broken into patches and combined with text embeddings created from the input prompt using a language model like T5. The combined sequence passes through a series of specialized transformer blocks, which process it to produce a refined output that gets decoded back into a full video.
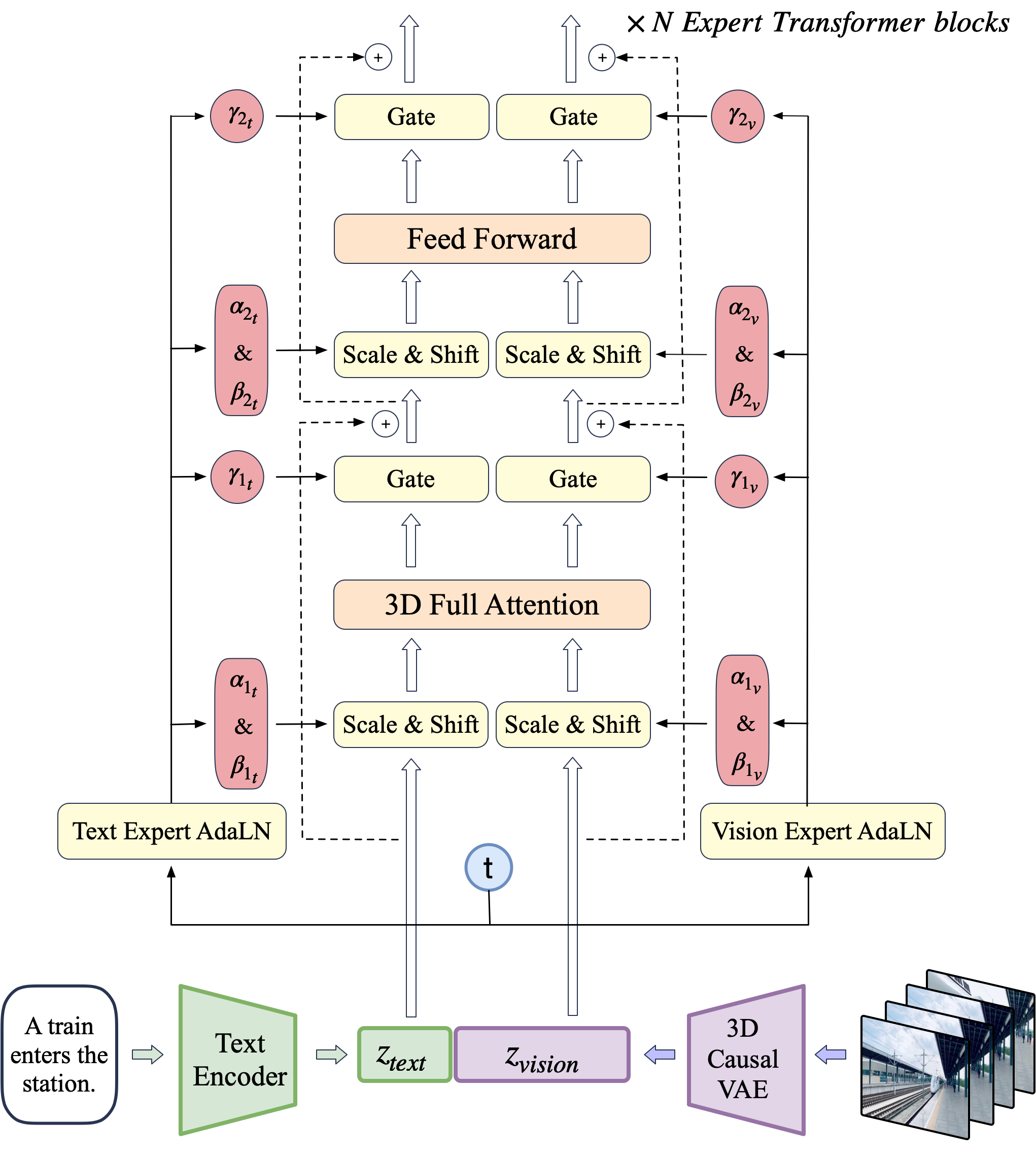
In the section, we present the CogVideoX model. Figure 3 illustrates the overall architecture. Given a pair of video and text input, we design a 3D causal VAE to compress the video into the latent space, and the latents are then patchified and unfolded into a long sequence denoted as $z_{\text{vision}}$. Simultaneously, we encode the textual input into text embeddings $z_{\text{text}}$ using T5 ([10]). Subsequently, $z_{\text{text}}$ and $z_{\text{vision}}$ are concatenated along the sequence dimension. The concatenated embeddings are then fed into a stack of expert transformer blocks. Finally, the model output are unpatchified to restore the original latent shape, which is then decoded using a 3D causal VAE decoder to reconstruct the video. We illustrate the technical design of the 3D causal VAE and expert transfomer in detail.
2.1 3D Causal VAE
Videos contain both spatial and temporal information, typically resulting in much larger data volumes than images. To tackle the computational challenge of modeling video data, we propose to implement a video compression module based on 3D Variational Autoencoders ([11]). The idea is to incorporate three-dimentional convolutions to compress videos both spatially and temporally. This can help achieve a higher compression ratio with largely improved quality and continuity of video reconstruction.
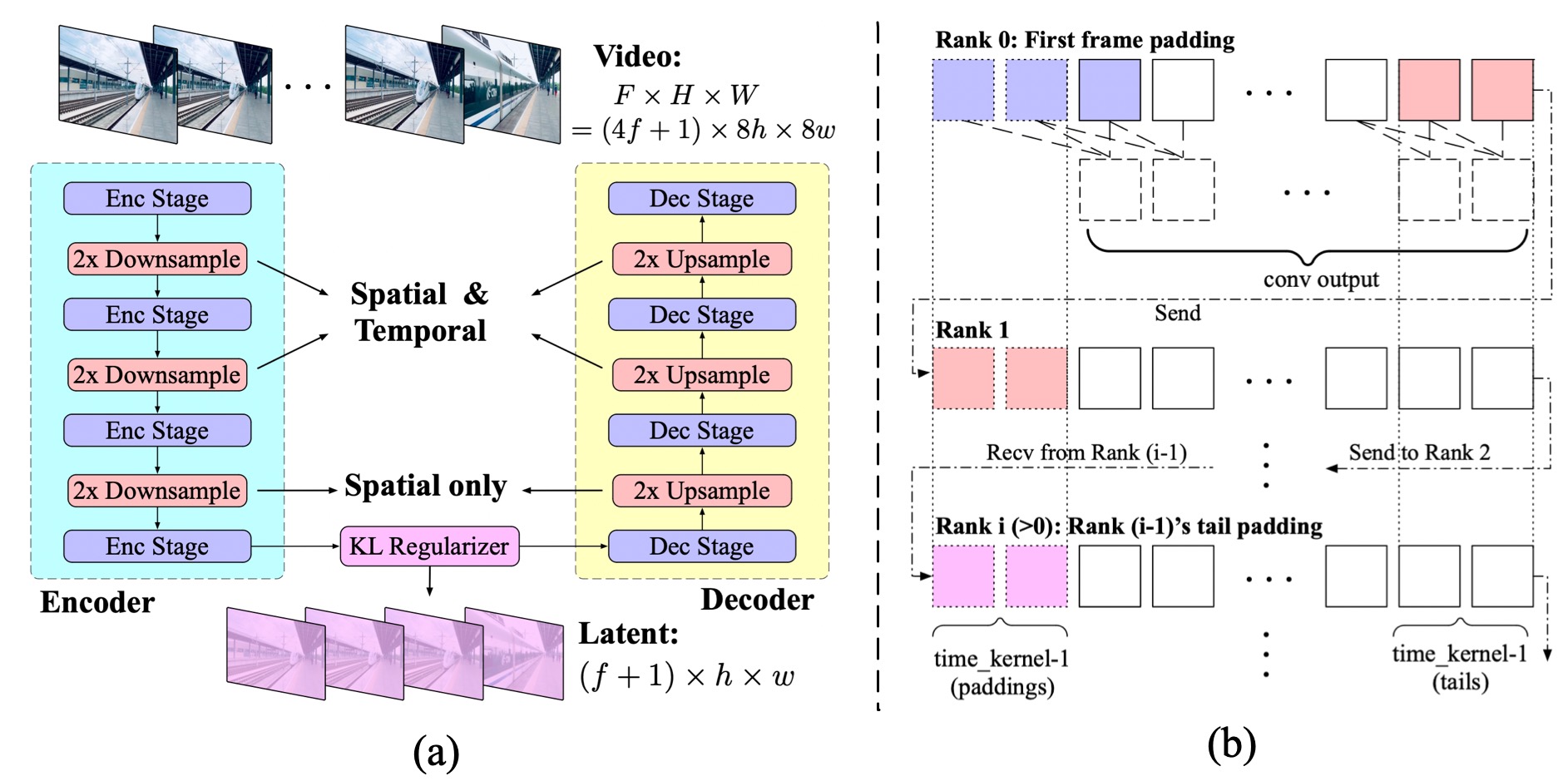
Figure 4 (a) shows the structure of the proposed 3D VAE. It comprises an encoder, a decoder and a Kullback-Leibler (KL) regularizer. The encoder and decoder consist of symmetrically arranged stages, respectively performing 2 $\times$ downsampling and upsampling by the interleaving of ResNet block stacked stages. Some blocks perform 3D downsampling (upsampling), while others only perform 2D downsampling (upsampling).
We adopt the temporally causal convolution ([11]), which places all the paddings at the beginning of the convolution space, as shown in Figure 4 (b). This ensures that future information does not influence the present or past predictions.
We also conducted ablation studies comparing different compression ratios and latent channels in Table 1. After using 3D structures, the reconstructed video shows almost no more jitter, and as the latent channels increase, the restoration quality improves. However, when spatial-temporal compression is too aggressive (16 $\times$ 16 $\times$ 8), even if the channel dimensions are correspondingly increased, the convergence of the model also becomes extremely difficult. Exploring VAE with larger compression ratios is our future work.
: Table 1: Ablation with different variants of 3D VAE. The baseline is SDXL([12]) 2D VAE. Flickering calculates the L1 difference between each pair of adjacent frames to evaluate the degree of flickering in the video. We use variant B for pretraining.
| Variants | Baseline | A | B | C | D | E |
|---|---|---|---|---|---|---|
| Compression | 8 $\times$ 8 $\times$ 1 | 8 $\times$ 8 $\times$ 4 | 8 $\times$ 8 $\times$ 4 | 8 $\times$ 8 $\times$ 4 | 8 $\times$ 8 $\times$ 8 | 16 $\times$ 16 $\times$ 8 |
| Latent channel | 4 | 8 | 16 | 32 | 32 | 128 |
| Flickering $\downarrow$ | 93.2 | 87.6 | 86.3 | 87.7 | 87.8 | 87.3 |
| PSNR $\uparrow$ | 28.4 | 27.2 | 28.7 | 30.5 | 29 | 27.9 |
Given that processing long-duration videos introduces excessive GPU memory usage, we apply context parallel at the temporal dimension for 3D convolution to distribute computation among multiple devices. As illustrated by Figure 4 (b), due to the causal nature of the convolution, each rank simply sends a segment of length $k-1$ to the next rank, where $k$ indicates the temporal kernel size. This results in relatively low communication overhead.
During training, we first train a 3D VAE at $256\times256$ resolution and $17$ frames to save computation. Randomly select 8 or 16 fps to enhance the model's robustness. We observe that the model can encode larger resolution videos well without additional training as it has no attention modules, but this isn't effective when encoding videos with more frames.
Therefore, we conduct a two-stage training by first training on 17-frame videos and finetuning by context parallel on 161-frame videos. Both stages utilize a weighted combination of the L1 reconstruction loss, LPIPS ([13]) perceptual loss, and KL loss. After a few thousand training steps, we additionally introduce the GAN loss from a 3D discriminator.
2.2 Expert Transformer
We introduce the design choices in Transformer for CogVideoX, including the patching, positional embedding, and attention strategies.
Patchify.
The 3D causal VAE encodes a video latent of shape $T \times H \times W \times C$, where $T$ represents the number of frames, $H$ and $W$ represent the height and width of each frame, $C$ represents the channel number, respectively. The video latents are then patchified, generating sequence $z_{\text{vision}}$ of length $\frac{T}{q}\cdot \frac{H}{p} \cdot \frac{W}{p}$. When $q > 1$, we repeat the first frame of videos and images at the beginning of the sequence to enable joint training of images and videos.
3D-RoPE.
Rotary Position Embedding (RoPE) ([14]) is a relative positional encoding that has been demonstrated to capture inter-token relationships effectively in LLMs, particularly excelling in modeling long sequences. To adapt to video data, we extend the original RoPE to 3D-RoPE. Each latent in the video tensor can be represented by a 3D coordinate $(x, y, t)$. We independently apply 1D-RoPE to each dimension of the coordinates, each occupying $3/8$, $3/8$, and $2/8$ of the hidden states' channel. The resulting encoding is then concatenated along the channel dimension to obtain the final 3D-RoPE encoding.
Expert Adaptive Layernorm.
We concatenate the embeddings of both text and video at the input stage to better align visual and semantic information. However, the feature spaces of these two modalities differ significantly, and their embeddings may even have different numerical scales. To better process them within the same sequence, we employ the Expert Adaptive Layernorm to handle each modality independently. As shown in Figure 3, following DiT ([7]), we use the timestep $t$ of the diffusion process as the input to the modulation module. Then, the Vision Expert Adaptive Layernorm (Vison Expert AdaLN) and Text Expert Adaptive Layernorm (Text Expert AdaLN) apply this modulation to the vision hidden states and text hidden states, respectively. This strategy promotes the alignment of feature spaces across two modalities while minimizing additional parameters.
3D Full Attention.
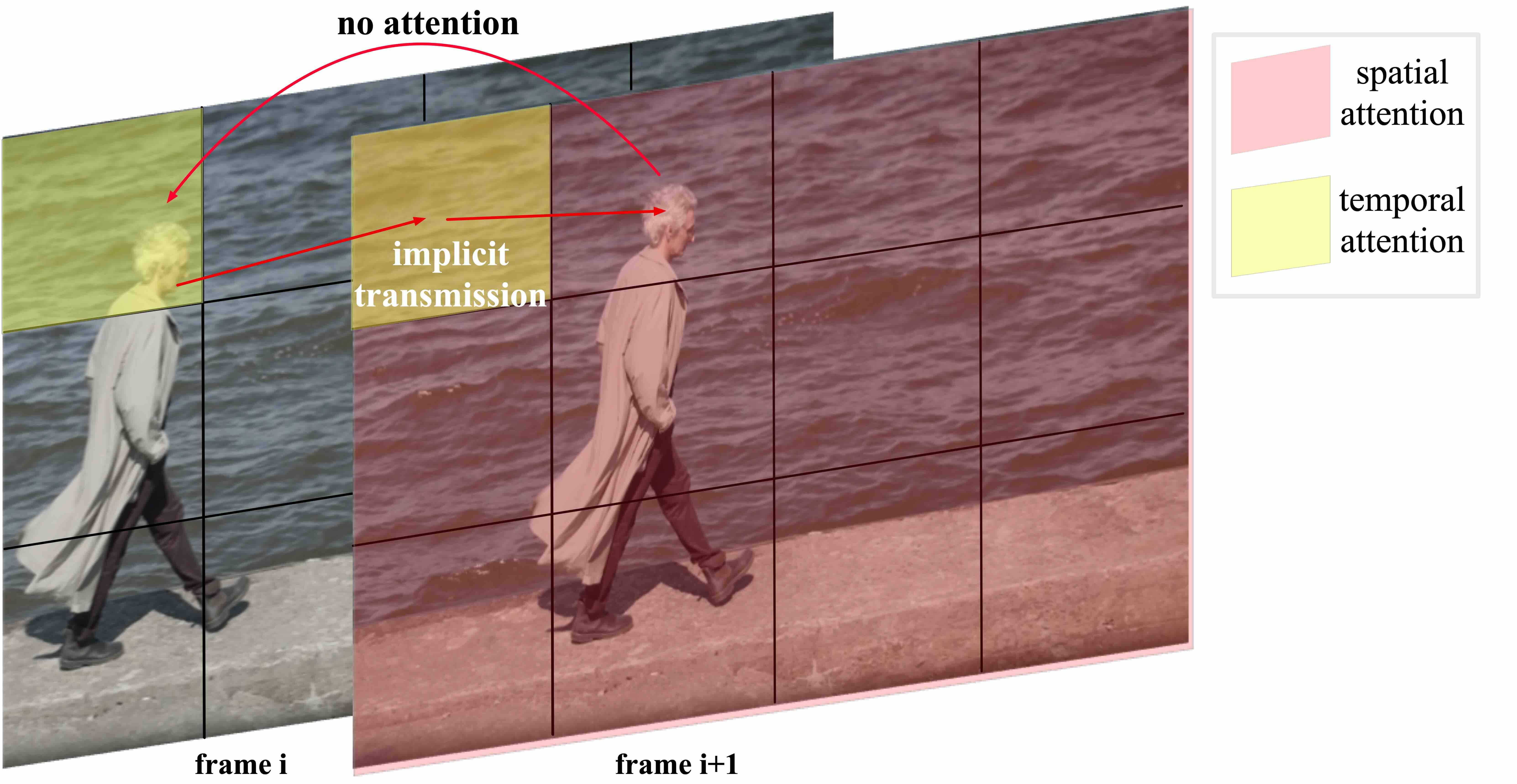
Previous works ([5, 15]) often employ separated spatial and temporal attention to reduce computational complexity and facilitate fine-tuning from text-to-image models. However, as illustrated in Figure 5, this separated attention approach requires extensive implicit transmission of visual information, significantly increasing the learning complexity and making it challenging to maintain the consistency of large-movement objects. Considering the great success of long-context training in LLMs ([16]) and the efficiency of FlashAttention ([17]), we propose a 3D text-video hybrid attention mechanism. This mechanism not only achieves better results but can also be easily adapted to various parallel acceleration methods.
3. Training CogVideoX
Section Summary: The training of CogVideoX involves blending images and videos by treating images as single-frame videos, while using progressive training that starts with lower resolutions like 256 pixels to build basic understanding before advancing to higher ones up to 768 pixels, ensuring cost efficiency and adaptability to different video lengths and aspect ratios through a technique called Multi-Resolution Frame Pack and stable diffusion sampling methods. This approach addresses challenges like inconsistent batch sizes by packing varied video durations and resolutions uniformly, and employs relative position encoding to maintain detail clarity. The process relies on a curated dataset of about 35 million high-quality, single-shot video clips averaging six seconds each, supplemented by two billion filtered images, with rigorous filtering to exclude low-motion, edited, or poor-quality videos that could hinder learning real-world dynamics.
We mix images and videos during training, treating each image as a single-frame video. Additionally, we employ progressive training from the resolution perspective. For the diffusion setting, we adopt v-prediction ([18]) and zero SNR ([19]), following the noise schedule used in LDM ([20]).
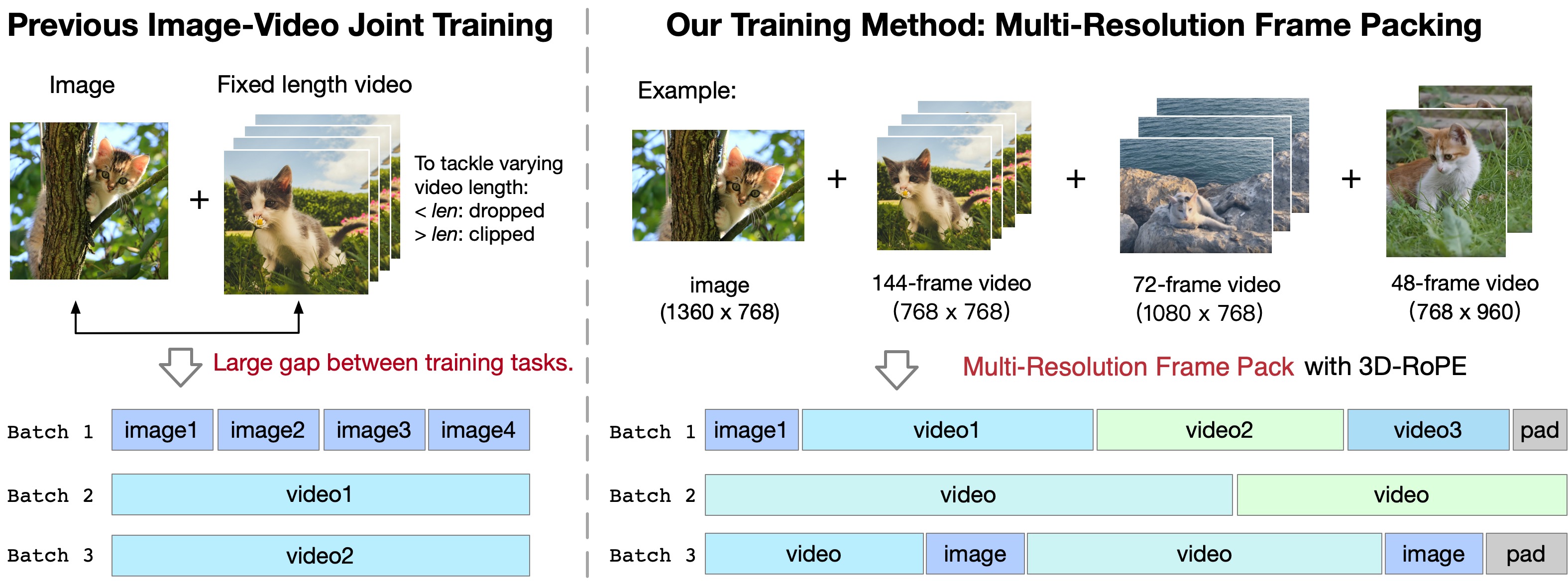
3.1 Multi-Resolution Frame Pack
Previous video training methods often involve joint training of images and videos with a fixed number of frames ([5, 9]). However, this approach usually leads to two issues: First, there is a significant gap between the two input types using bidirectional attention, with images having one frame while videos having dozens of frames. We observe that models trained this way tend to diverge into two generative modes based on the token count and not to have good generalizations. Second, to train with a fixed duration, we have to discard short videos and truncate long videos, which prevents full utilization of the videos of varying number of frames. For different resolutions, SDXL([12]) uses a bucketed approach to address the issue of generating cropped images, but it makes the data and training pipeline more complex.
To address these issues, we chose mixed-duration training, which means training videos of different lengths together. However, inconsistent data shapes within the batch make training difficult. Inspired by Patch'n Pack ([21]), we place videos of different duration (also different resolutions) into the same batch to ensure consistent shapes within each batch, a method we refer to as Multi-Resolution Frame Pack, illustrated in Figure 6.
We use 3D RoPE to model the position relationship of various video shape. There are two ways to adapt RoPE to different resolutions and durations. One approach is to expand the position encoding table and, for each video, select the front portion of the table according to the resolution (extrapolation). The other is to scale a fixed-length position encoding table to match the resolution of the video (interpolation). Considering that RoPE is a relative position encoding, we chose the first approach to keep the clarity of model details.
3.2 Progressive Training
Videos from the Internet usually include a significant amount of low-resolution ones. And directly training on high-resolution videos is extremely expensive. To fully utilize data and save costs, the model is first trained on 256px videos to learn semantic and low-frequency knowledge. Then it is trained on gradually increased resolutions, from 256px to 512px, 768px, to learn high-frequency knowledge. To maintain the ability of generating videos with different aspect ratios, we keep the aspect ratio unchanged and resize the short side to above resolutions. Finally, we do a high-quality fine-tuning, See Appendix A Moreover, we trained an image-to-video model based on above model. See Appendix D for details.
3.3 Explicit Uniform Sampling
[2] defines the training objective of diffusion as
$ ~ L_simple(\theta) := \mathbf{E}{t, x_0, \epsilon}{ \left| \epsilon - \epsilon\theta(\sqrt{\bar\alpha_t} x_0 + \sqrt{1-\bar\alpha_t}\epsilon, t) \right|^2},\tag{1} $
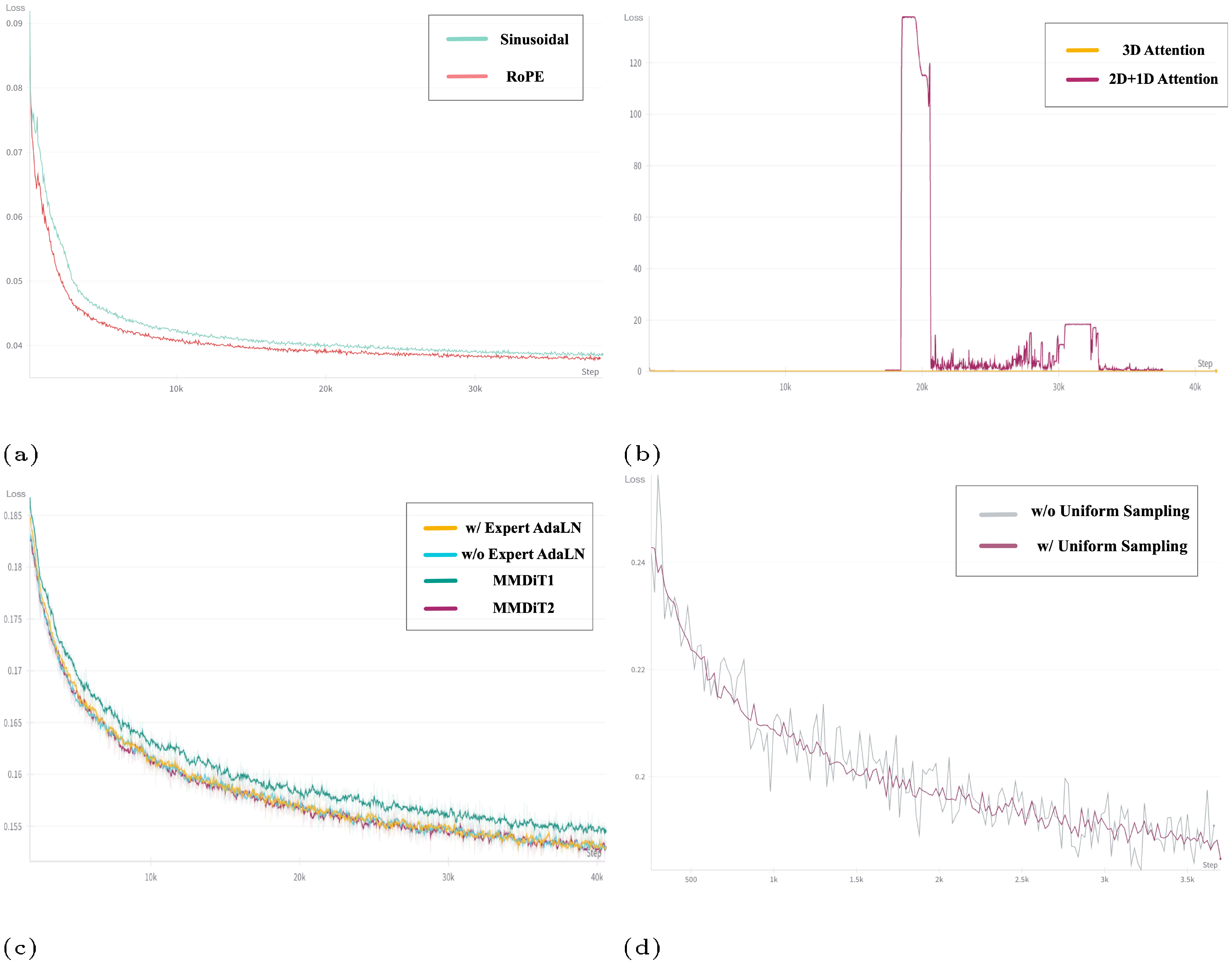
where $t$ is uniformly distributed between 1 and T. The common practice is for each rank in the data parallel group to uniformly sample a value between 1 and $T$, which is in theory equivalent to 1. However, in practice, the results obtained from such random sampling are often not sufficiently uniform, and since the magnitude of the diffusion loss is related to the timesteps, this can lead to significant fluctuations in the loss. Thus, we propose to use Explicit Uniform Sampling to divide the range from 1 to $T$ into $n$ intervals, where $n$ is the number of ranks. Each rank then uniformly samples within its respective interval. This method ensures a more uniform distribution of timesteps. As shown in Figure 10 (d), the loss curve from training with Explicit Uniform Sampling is noticeably more stable.
3.4 Data
We construct a collection of relatively high-quality video clips with text descriptions with video filters and recaption models. After filtering, approximately 35M single-shot clips remain, with each clip averaging about 6 seconds. We additionally use 2B images filtered with aesthetics score from LAION-5B ([22]) and COYO-700M ([23]) datasets to assist training.
Video Filtering.
Video generation models should capture the dynamic nature of the world. However, raw video data often contains significant noise for two intrinsic reasons: First, the artificial editing during video creation can distort the true dynamic information; Second, video quality may suffer due to filming issues such as camera shakes or using subpar equipment. In addition to the intrinsic quality of the videos, we also consider how well the video data supports model training. Videos with minimal dynamic information or lacking connectivity in dynamic aspects are considered detrimental. Consequently, we have developed a set of negative labels, which include:
- Editing: Videos that have undergone noticeable artificial processing, such as re-editing and special effects, which compromise the visual integrity.
- Lack of Motion Connectivity: Video segments with transitions that lack coherent motion, often found in artificially spliced videos or those edited from static images.
- Low Quality: Poorly shot videos with unclear visuals or excessive camera shake.
- Lecture Type: Videos focusing primarily on a person continuously talking with minimal effective motion, such as lectures, and live-streamed discussions.
- Text Dominated: Videos containing a large amount of visible text or primarily focusing on textual content.
- Noisy Screenshots: Videos captured directly from phone or computer screens, often characterized by poor quality.
We first sample 20, 000 videos and label each video as positive or negative by their quality. Using these annotations, we train 6 filters based on Video-LLaMA ([24]) to screen out low-quality video data. Examples of negative labels and the classifier's performance on the test set can be found in Appendix K. In addition, we calculate the optical flow scores and image aesthetic scores of all training videos, and dynamically adjust their threshold during training to ensure the dynamic and aesthetic quality of generated videos.
Video Captioning.
Video-text pairs are essential for the training of text-to-video generation models. However, most video data does not come with corresponding descriptive text. Therefore, it is necessary to label the video data with comprehensive textual descriptions. There are some video caption datasets available now, such as Panda70M ([25]), COCO Caption ([26]), and WebVid [27]. However, the captions in these datasets are usually very short and fail to describe the video comprehensively.
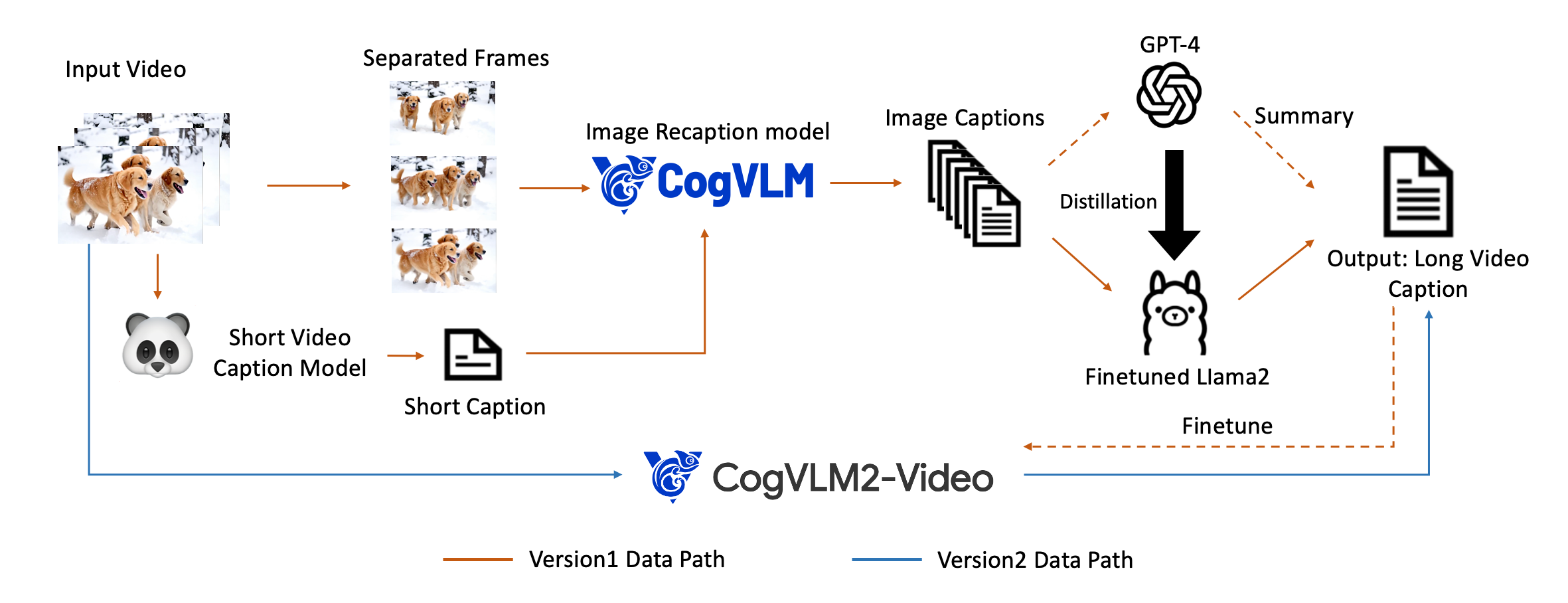
To generate high-quality video caption data, we establish a Dense Video Caption Data Generation pipeline, as detailed in Figure 7. The main idea is to generate video captions with the help of image captions.
First, we use the video caption model from [25] to generate short captions for the videos. Then, we employ the image recaptioning model CogVLM ([28]) used in CogView3 ([29]) to create dense image captions for each frame. Subsequently, we use GPT-4 to summarize all the image captions to produce the final video caption. To accelerate the generation from image captions to video captions, we fine-tune a LLaMA2 ([30]) using the summary data generated by GPT-4 ([31]), enabling large-scale video caption data generation. Additional details regarding the video caption data generation process can be found in Appendix G.
To further accelerate video recaptioning, we also fine-tune an end-to-end video understanding model CogVLM2-Caption , based on the CogVLM2-Video ([32]) and Llama3 ([16]), by using the dense caption data generated from the aforementioned pipeline. Examples of video captions generated by this end-to-end CogVLM2-Caption model are shown in Figure 15 and Appendix H. CogVLM2-Caption can provide detailed descriptions of video content and changes. Interestingly, we find that we can perform video-to-video generation by connecting CogVideoX and CogVLM2-Caption, as detailed in Appendix I.
4. Experiments
Section Summary: The experiments section tests key design choices for the CogVideoX model through ablation studies, showing that features like 3D rotary position embedding, expert adaptive layer normalization, full 3D attention, and explicit uniform sampling improve training stability, performance metrics, and convergence speed compared to alternatives. Automated evaluations on video quality and dynamics reveal that CogVideoX-5B outperforms other models in most benchmarks, including action recognition, scene consistency, and dynamic content, while its 3D variational autoencoder achieves superior reconstruction with less flickering. Human assessments further confirm CogVideoX-5B's strengths, as it surpasses a leading closed-source model like Kling in sensory quality, instruction adherence, physics simulation, and overall appeal.
4.1 Ablation Study
We conducted ablation studies on some of the designs mentioned in Section 2 to verify their effectiveness.
Position Embedding.
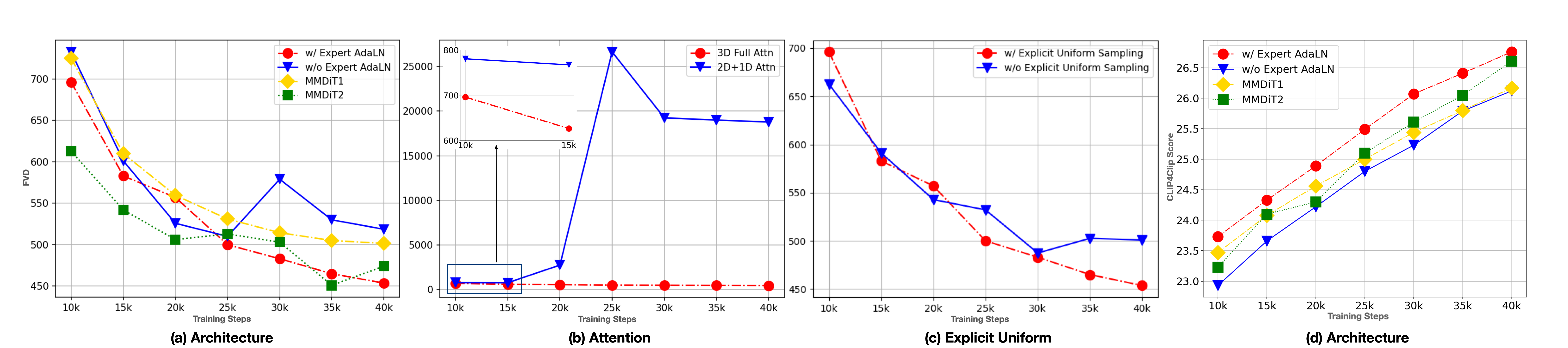
We compared 3D RoPE with sinusoidal absolute position embedding. As shown in Figure 10a indicates the loss curve of RoPE converges significantly faster than absolute one. This is consistent with the common choice in LLMs.
Expert Adaptive Layernorm.
We compare three architectures in Figure 8 a, Figure 8 d and Figure 10c: MMDiT [33], Expert AdaLN(CogVideoX), without Expert AdaLN. Cross-attention DiT has been shown to be inferior to MMDiT in ([33]), so we don't repeat. According to FVD, CLIP4Clip([34]) Score and loss, expert AdaLN significantly outperforms the model without expert AdaLN and MMDiT with the same number of parameters. We infer that expert adaptive layernorm is enough to alleviate the difference in feature space between the two modalities. So two independent transformers in MMDiT are not necessary, which greatly increases the number of parameters. Moreover, the design of Expert AdaLN is more simplified than MMDiT and is closer to current LLMs, making it easier to scale up further.
3D Full Attention.
In Figure 8 b and Figure 10b, when we replace 3D full attention with 2D + 1D attention, the FVD will become much higher than 3D attention in early steps. We also observe that 2D+1D is unstable and prone to collapse. We suppose that as the model size increases, such as 5B, training becomes more prone to instability, placing higher demands on the structural design. The 2D+1D structure, as discussed in Section 2.2, is not suitable for video generation tasks, which could lead to instability during training.
Explicit Uniform Sampling.
From Figure 8 c and Figure 10d, we find that using Explicit Uniform Sampling can make a more stable decrease in loss and get a better performance. In addition, in Table 9 we compare the loss at each diffusion timestep alone between two choices for a more precise comparison. We find that the loss at all timesteps is lower with explicit uniform sampling, indicating that this method can also accelerate loss convergence. We suppose that this is because the loss of different timesteps varies greatly. When the timesteps sampled for training are not uniform enough, the loss fluctuates greatly due to the above randomness. Explicit uniformity can reduce randomness, thereby bringing a common decrease in all timesteps.
4.2 Evaluation
4.2.1 Automated Metric Evaluation
VAE Reconstruction Effect
We compared our 3DVAE with other open-source 3DVAE on $256\times256$ resolution 17-frame videos, using the validation set of the WebVid ([35]). On Table 2, our VAE achieved the best PSNR and exhibited the least jitter. Notably, other VAE methods use fewer latent channels than ours.
: Table 2: Comparison with the performance of other spatiotemporal compression VAEs.
| Flickering $\downarrow$ | PSNR $\uparrow$ | |
|---|---|---|
| Open-Sora | 92.4 | 28.5 |
| Open-Sora-Plan | 90.2 | 27.6 |
| Ours | 85.5 | 29.1 |
Evaluation Metrics.
To evaluate the text-to-video generation, we employ several metrics in Vbench ([36]) that are consistent with human perception: Human Action, Scene, Dynamic Degree, Multiple Objects, and Appearance Style. Other metrics, such as color, tend to give higher scores to simple, static videos, so we do not use them.
For longer-generated videos, some models might produce videos with minimal changes between frames to get higher scores, but these videos lack rich content. Therefore, metrics for evaluating the dynamism become important. To address this, we use two video evaluation tools: Dynamic Quality ([37]) and GPT4o-MTScore ([38]).
Dynamic Quality is defined by the integration of various quality metrics with dynamic scores, mitigating biases arising from negative correlations between video dynamics and video quality. GPT4o-MTScore is a metric designed to measure the metamorphic amplitude of time-lapse videos using GPT-4o, such as those depicting physical, biological, and meteorological changes.
Results.
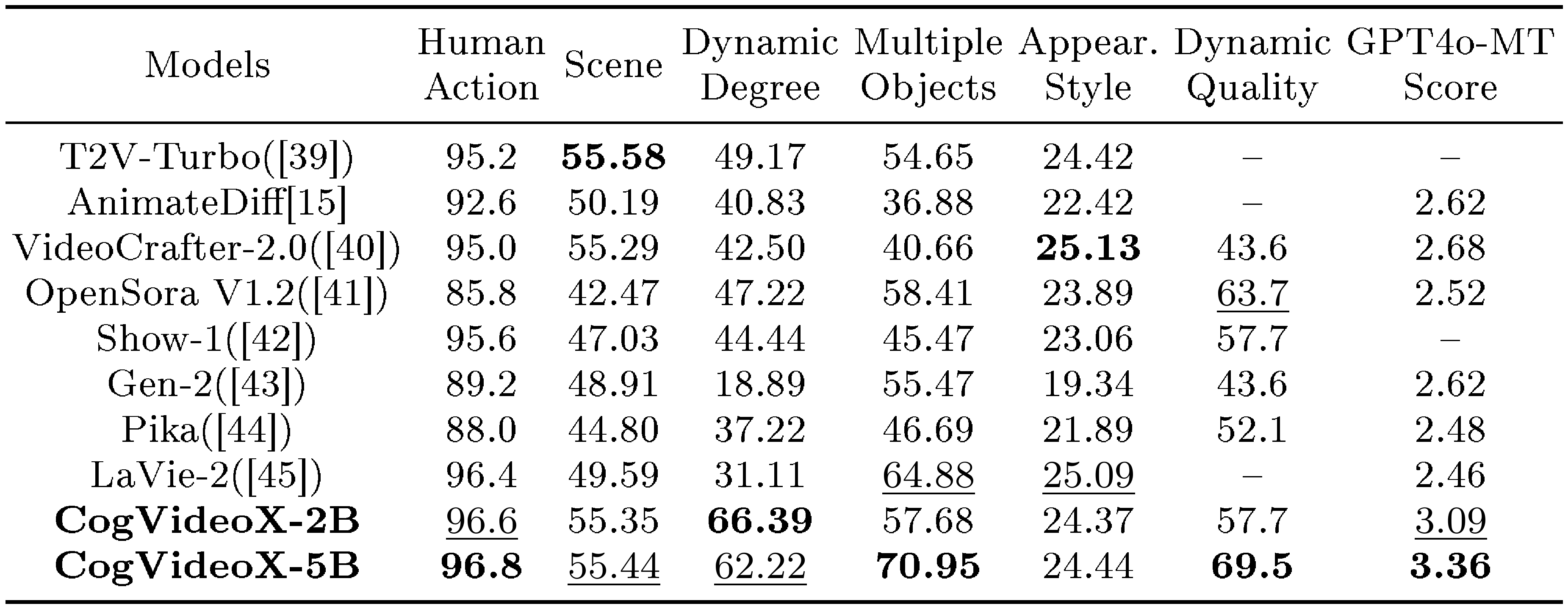
Table 3 provides the performance comparison of CogVideoX and other models. CogVideoX-5B achieves the best performance in five out of the seven metrics and shows competitive results in the remaining two metrics. These results demonstrate that the model not only excels in video generation quality but also outperforms previous models in handling various complex dynamic scenes. In addition, Figure 2 presents a radar chart that visually illustrates the performance advantages of CogVideoX. We present the time and space consumption during inference at different resolutions in Appendix A.
::: {caption="Table 3: Evaluation results of CogVideoX-5B and CogVideoX-2B."}
:::
4.2.2 Human Evaluation
In addition to automated scoring mechanisms, we also establish a comprehensive human evaluation framework to assess the general capabilities of video generation models. Evaluators will score the generated videos on four aspects: Sensory Quality, Instruction Following, Physics Simulation, and Cover Quality, using three levels: 0, 0.5, or 1. Each level is defined by detailed guidelines. The specific details are provided in the Appendix J.
We compare Kling (2024.7), one of the best closed-source models, with CogVideoX-5B under this framework. The results shown in Table 4 indicate that CogVideoX-5B wins the human preference over Kling across all aspects.
::: {caption="Table 4: Human evaluation between CogVideoX and Kling."}

:::
5. Conclusion
Section Summary: This paper introduces CogVideoX, an advanced AI system that turns text descriptions into videos using a special technique called diffusion modeling. It employs a 3D video encoder and a smart transformer design to create smooth, lengthy videos full of realistic movement. The researchers are studying how to scale up these models further, with plans to build even more powerful versions that produce longer and higher-quality videos, expanding the possibilities in AI-generated video creation.
In this paper, we present CogVideoX, a state-of-the-art text-to-video diffusion model. It leverages a 3D VAE and an Expert Transformer architecture to generate coherent long duration videos with significant motion. We are also exploring the scaling laws of video generation models and aim to train larger and more powerful models to generate longer and higher-quality videos, pushing the boundaries of what is achievable in text-to-video generation.
Acknowledgments
This work is supported by NSFC 62425601 and 62495063, Tsinghua University Initiative Scientific Research Program 20233080067, New Cornerstone Science Foundation through the XPLORER PRIZE. We would like to thank all the data annotators, infrastructure operators, collaborators, and partners. We also extend our gratitude to everyone at Zhipu AI and Tsinghua University who have provided support, feedback, or contributed to the CogVideoX, even if not explicitly mentioned in this report. We would also like to greatly thank BiliBili for technical discussions.
Appendix
Section Summary: The appendix provides detailed insights into the development of the CogVideoX model, including training specifics like fine-tuning on high-quality video subsets to remove artifacts, comparisons of position encoding methods for resolution adaptation, and tables outlining hyperparameters, batch sizes, and inference performance across different model versions. It also features loss curves showing training progress, additional text-to-video and image-to-video generation examples that demonstrate the model's capabilities in motion and style, and explanations of data filtering and captioning techniques. Finally, it surveys related research on video generation methods, from GANs and autoregressive approaches to recent diffusion models.
Appendix Contents
- Appendix A: Training Details
- Appendix B: Loss Curve
- Appendix C: More Examples
- Appendix D: Image To Video Model
- Appendix E: Related Works
- Appendix F: Caption Upsampler
- Appendix G: Dense Video Caption Data Generation
- Appendix H: Video Caption Example
- Appendix I: Video to Video via CogVideoX and CogVLM2-Caption
- Appendix J: Human Evaluation Details
- Appendix K: Data Filtering Details
A. Training Details
High-Quality Fine-Tuning.
Since the filtered pre-training data still contains a certain proportion of dirty data, such as subtitles, watermarks, and low-bitrate videos, we selected a subset of higher quality video data, accounting for 20% of the total dataset, for fine-tuning in the final stage. This step effectively removed generated subtitles and watermarks and slightly improved the visual quality. However, we also observed a slight degradation in the model's semantic ability.
Visualizing different rope interpolation methods
When adapting low-resolution position encoding to high-resolution, we consider two different methods: interpolation and extrapolation. We show the effects of two methods in Figure 9. Interpolation tends to preserve global information more effectively, whereas the extrapolation better retains local details. Given that RoPE is a relative position encoding, We chose the extrapolation to maintain the relative position between pixels.

Model & Training Hyperparameters
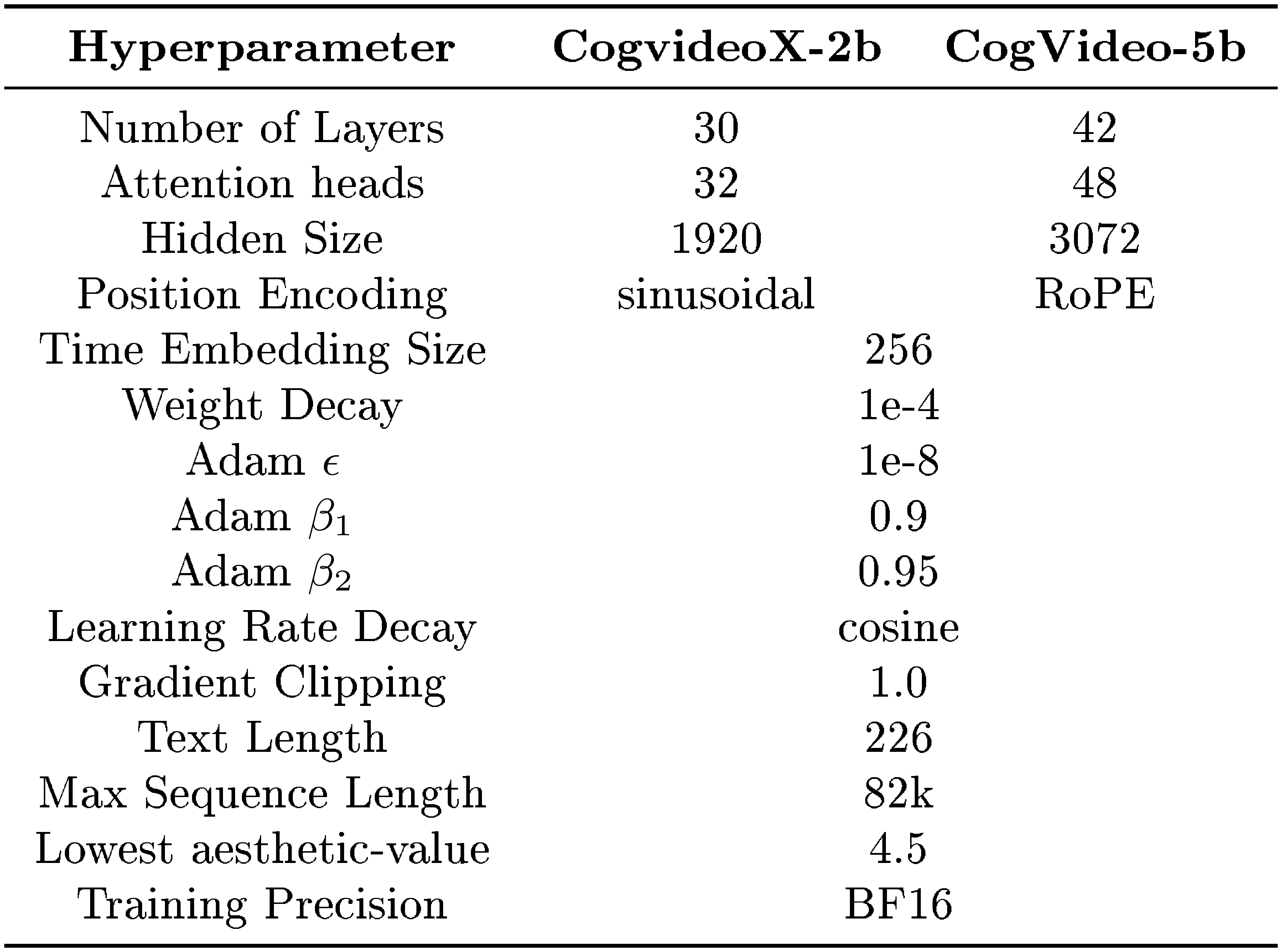
We present the model and training hyperparameters in Table 5 and Table 6.
: Table 5: Hyperparameters of CogvideoX-2b and CogVideo-5b.
| Training Stage | stage1 | stage2 | stage3 | stage4 (FT) |
|---|---|---|---|---|
| Max Resolution | 256 $\times$ 384 | 480 $\times$ 720 | 768 $\times$ 1360 | 768 $\times$ 1360 |
| Max duration | 6s | 6s | 10s | 10s |
| Batch Size | 2000 | 1000 | 250 | 100 |
| Sequence Length | 25k | 75k | 700k | 700k |
| Training Steps | 400k | 220k | 120k | 10k |
::: {caption="Table 6: Hyperparameters of CogvideoX-2b and CogVideo-5b."}
:::
: Table 7: Inference time and memory consumption of CogVideoX. We evaluate the model on bf, H800 with 50 inference steps.
| 5b-480x720-6s | 5b-768x1360-5s | 2b-480x720-6s | 2b-768x1360-5s | |
|---|---|---|---|---|
| Time | 113s | 500s | 49s | 220s |
| Memory | 26GB | 76GB | 18GB | 53GB |
: Table 8: Inference time comparison between 3D Full attention and 2D+1D attention. We evaluate the model on bf, H800 with one dit forward step. Thanks to the optimization by Flash Attention, the increase in sequence length does not make the inference time unacceptable.
| 2563846s | 4807206s | 76813605s | |
|---|---|---|---|
| 2D+1D | 0.38s | 1.26s | 4.17s |
| 3D | 0.41s | 2.11s | 9.60s |
B. Loss
: Table 9: Validation loss at different diffusion timesteps when the training steps is 40k.
| Timestep | 100 | 300 | 500 | 700 | 900 |
|---|---|---|---|---|---|
| w/o explicit uniform sampling | 0.222 | 0.130 | 0.119 | 0.133 | 0.161 |
| w/ explicit uniform sampling | 0.216 | 0.126 | 0.116 | 0.129 | 0.157 |
C. More Examples
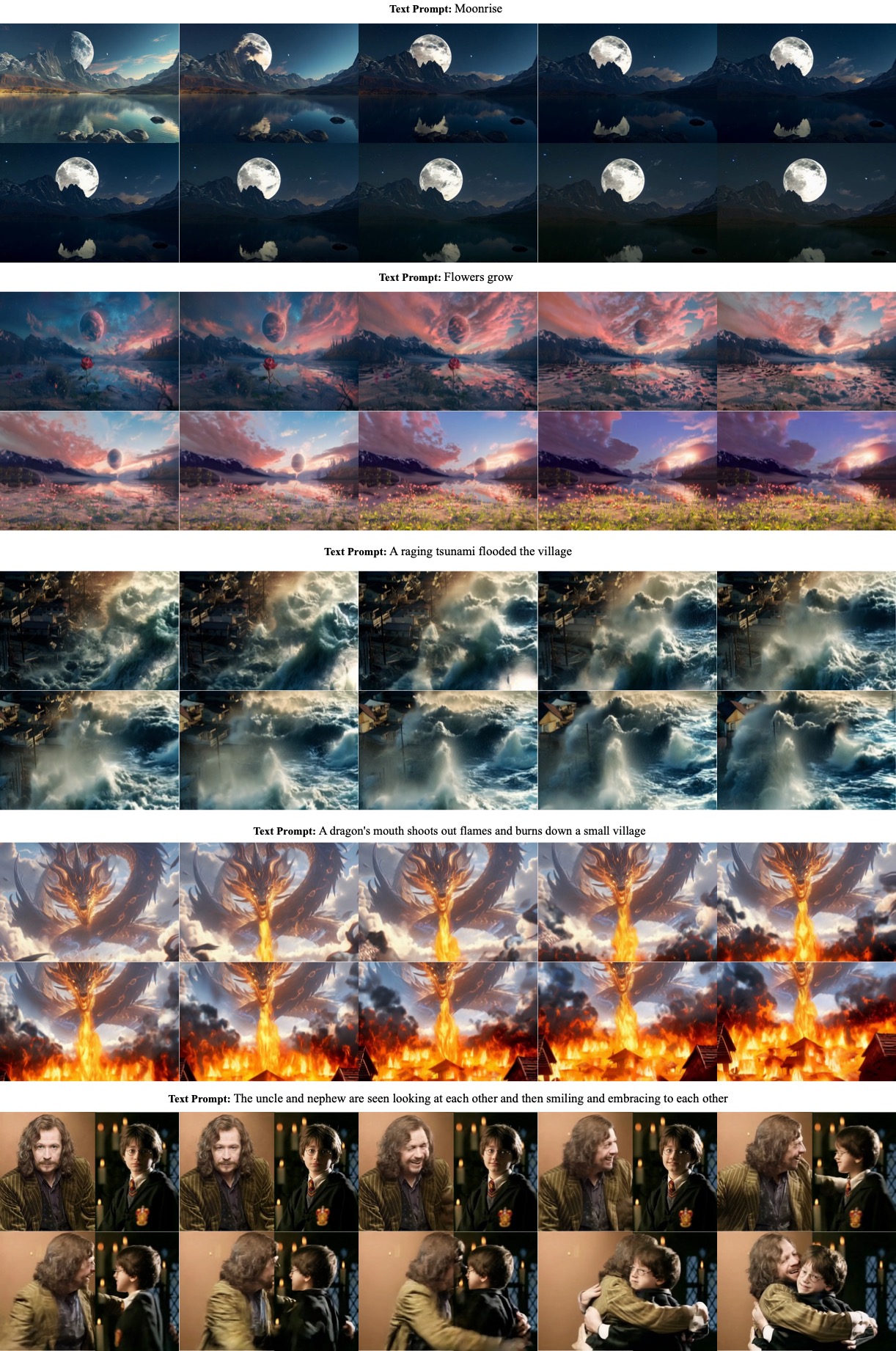
More text-to-video examples are shown in Figure 11 and Figure 12.


D. Image To Video Model
We finetune an image-to-video model from the text-to-video model. Drawing from the ([9]), we add an image as an additional condition alongside the text. The image is passed through 3D VAE and concatenated with the noised input in the channel dimension. Similar to super-resolution tasks, there is a significant distribution gap between training and inference (the first frame of videos vs. real-world images). To enhance the model's robustness, we add large noise to the image condition during training. Some examples are shown in Figure 13, Figure 14. CogVideoX can handle different styles of image input.

E. Related works
Video diffusion models
Generating videos has been explored through various types of generative models, such as Generative Adversarial Networks (GANs) ([46, 47]), autoregressive methods ([3, 48]), and non-autoregressive methods ([4, 49]). Diffusion models have recently gained significant attention, achieving remarkable results in both image generation([20, 33]) and video generation([5, 9, 15]). However, the limited compression ratio and simple training strategy often restrict the generation to low-resolution short-duration videos (2-3 seconds), requiring multiple super-resolution and frame interpolation models to be cascaded([5, 6]) for a generation. This leads to generated videos with limited semantic information and minimal motion.
Video VAEs
To increase the compression ratio of videos and reduce computation costs, a common approach is to encode the video into a latent space using a Variational Autoencoder(VAE), which is also widely used in image generation. Early video models usually directly use image VAE for generation. However, modeling only the space dimension can result in jittery videos. SVD([9]) tries to finetune the image VAE decoder to solve the jittering issue. However, this approach cannot take advantage of the temporal redundancy in videos and still cannot achieve an optimal compression rate. Recently, some video models([41, 50]) try to use 3D VAE for temporal compression, but small latent channels still result in blurry and jittery videos.
F. Caption Upsampler
To ensure that text input distribution during inference is as close as possible to the distribution during training, similar to ([51]), we use a large language model to upsample the user's input during inference, making it more detailed and precise. Finetuned LLM can generate better prompts than zero/few-shot.
For image-to-video, we use the vision language model to upsample the prompt, such as GPT4V, CogVLM([28]).
```
You are part of a team of bots that create videos. You work
with an assistant bot that will draw anything you say in
square brackets. For example, outputting \" a beautiful
morning in the woods with the sun peaking through the
trees \" will trigger your partner bot to output a video
of a forest morning, as described. You will be prompted
by people looking to create detailed, amazing videos.
The way to accomplish this is to take their short prompts
and make them extremely detailed and descriptive.
There are a few rules to follow :
You will only ever output a single video description
per user request.
When modifications are requested, you should not simply
make the description longer. You should refactor the
entire description to integrate the suggestions.
```
G. Dense Video Caption Data Generation
In the pipeline for generating video captions, we extract one frame every two seconds for image captioning. Ultimately, we collected 50, 000 data points to fine-tune the summary model. Below is the prompt we used for summarization with GPT-4:
```
We extracted several frames from this video and described
each frame using an image understanding model, stored
in the dictionary variable `image_captions: Dict[str: str]`.
In `image_captions`, the key is the second at which the image
appears in the video, and the value is a detailed description
of the image at that moment. Please describe the content of
this video in as much detail as possible, based on the
information provided by `image_captions`, including
the objects, scenery, animals, characters, and camera
movements within the video. \n image_captions={new_captions}\n
You should output your summary directly, and not mention
variables like `image_captions` in your response.
Do not include `\\n' and the word 'video' in your response.
Do not use introductory phrases such as: \"The video
presents\", \"The video depicts\", \"This video showcases\",
\"The video captures\" and so on.\n Please start the
description with the video content directly, such as \"A man
first sits in a chair, then stands up and walks to the
kitchen....\"\n Do not use phrases like: \"as the video
progressed\" and \"Throughout the video\".\n Please describe
the content of the video and the changes that occur, in
chronological order.\n Please keep the description of this
video within 100 English words.
```
H. Video Caption Example
Below we present more examples to compare the performance of the Panda-70M video captioning model and our CogVLM2-Caption model:
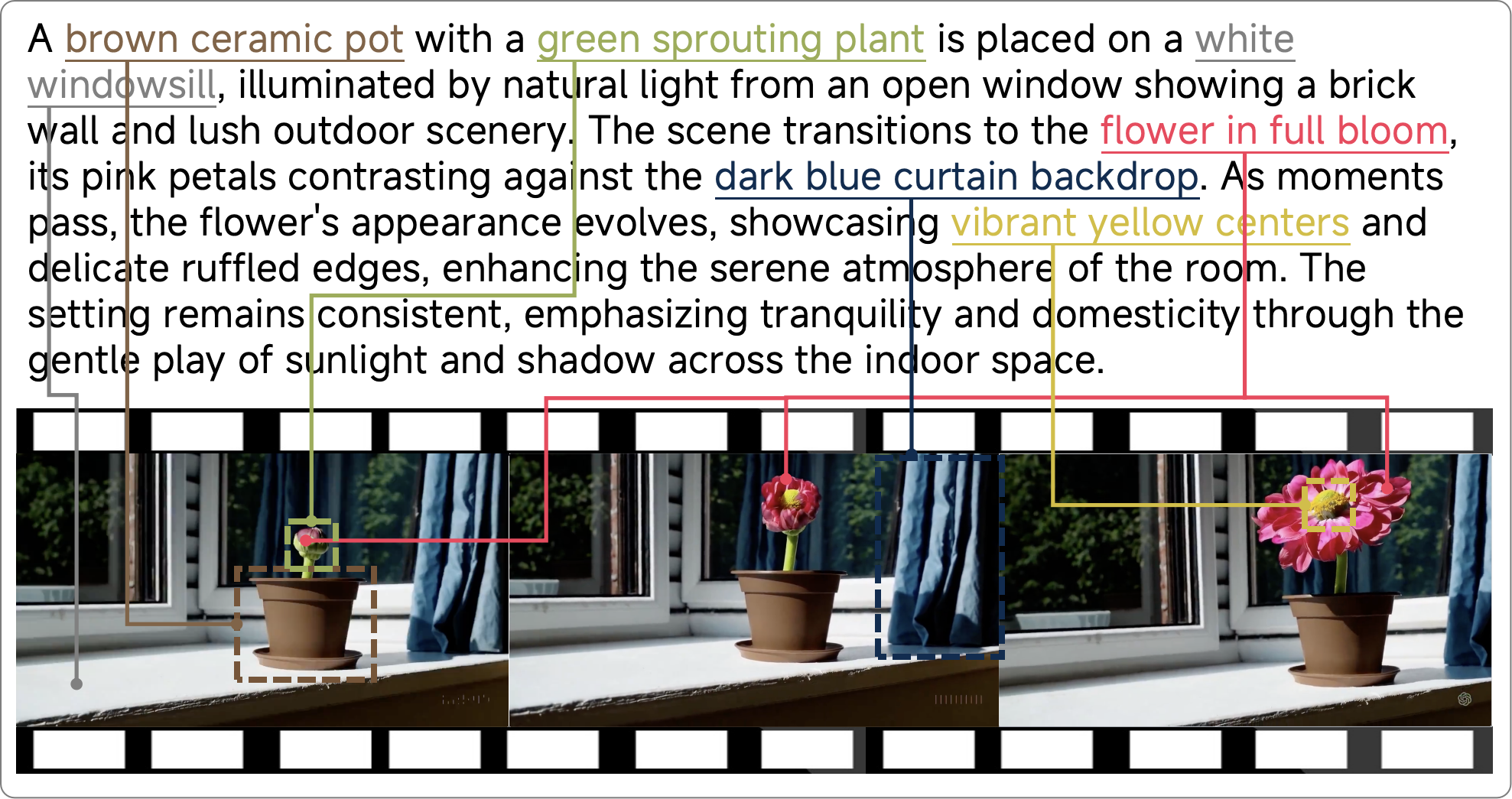

```
A close up of a white dragon with blue eyes.
```
```
A meticulously crafted white dragon with a serene expression
and piercing blue eyes is showcased in various close-ups, its
scales detailed with golden highlights. Initially, the dragon's
horns are curved back, but as time passes, they change to
spiraling gold, adding elegance. The creature's demeanor shifts
from tranquil majesty to a more formidable presence, with its
mouth agape revealing sharp teeth at times. Its expressions
alternate between calmness and fierce determination,
maintaining an air of mythical serenity throughout. The
consistent neutral background focuses attention on the dragon's
textured features and expressive eyes.
```

```
A crab is walking on the beach with a light bulb on its back.
```
```
A hermit crab with a dark, glossy shell and reddish-brown legs
is seen carrying an illuminated light bulb on its back across
the sandy terrain of a beach at night. The scene transitions
from a soft glow to a more pronounced illumination as the crab
moves, highlighting its delicate limbs against the smooth sand
and tranquil sea backdrop. This surreal tableau blends natural
beauty with human ingenuity, creating a serene yet whimsical
atmosphere that emphasizes the crab's unique adaptation and the
contrast between nature and technology in this quiet nocturnal
setting.
```

```
A young black man is sitting on a cloud and reading a book
with a blue sky in the background.
```
```
A young Black man with an afro hairstyle and a neatly trimmed
beard is seen sitting cross-legged on fluffy white clouds,
deeply engrossed in reading a book with a red cover. He wears
a plain white T-shirt and dark pants against a vivid blue sky
dotted with cumulus clouds. Throughout the scenes, his
expression remains one of deep concentration and peaceful
contemplation, highlighting a moment of intellectual pursuit
amidst nature's grandeur. The imagery suggests a serene
atmosphere that emphasizes solitude and introspection, with no
other people or objects around him.
```
I. Video to Video via CogVideoX and CogVLM2-Caption
In this section, we present several examples of video-to-video generation using CogVideoX and CogVLM2-Caption. Specifically, we first input the original video into CogVLM2-Caption to obtain the video's caption, and then feed this caption into the CogVideoX model to generate a new video. From the examples below, it can be seen that our pipeline achieves a high degree of fidelity to the original video, showing that CogVLM2-Caption can capture almost all the details in the video.
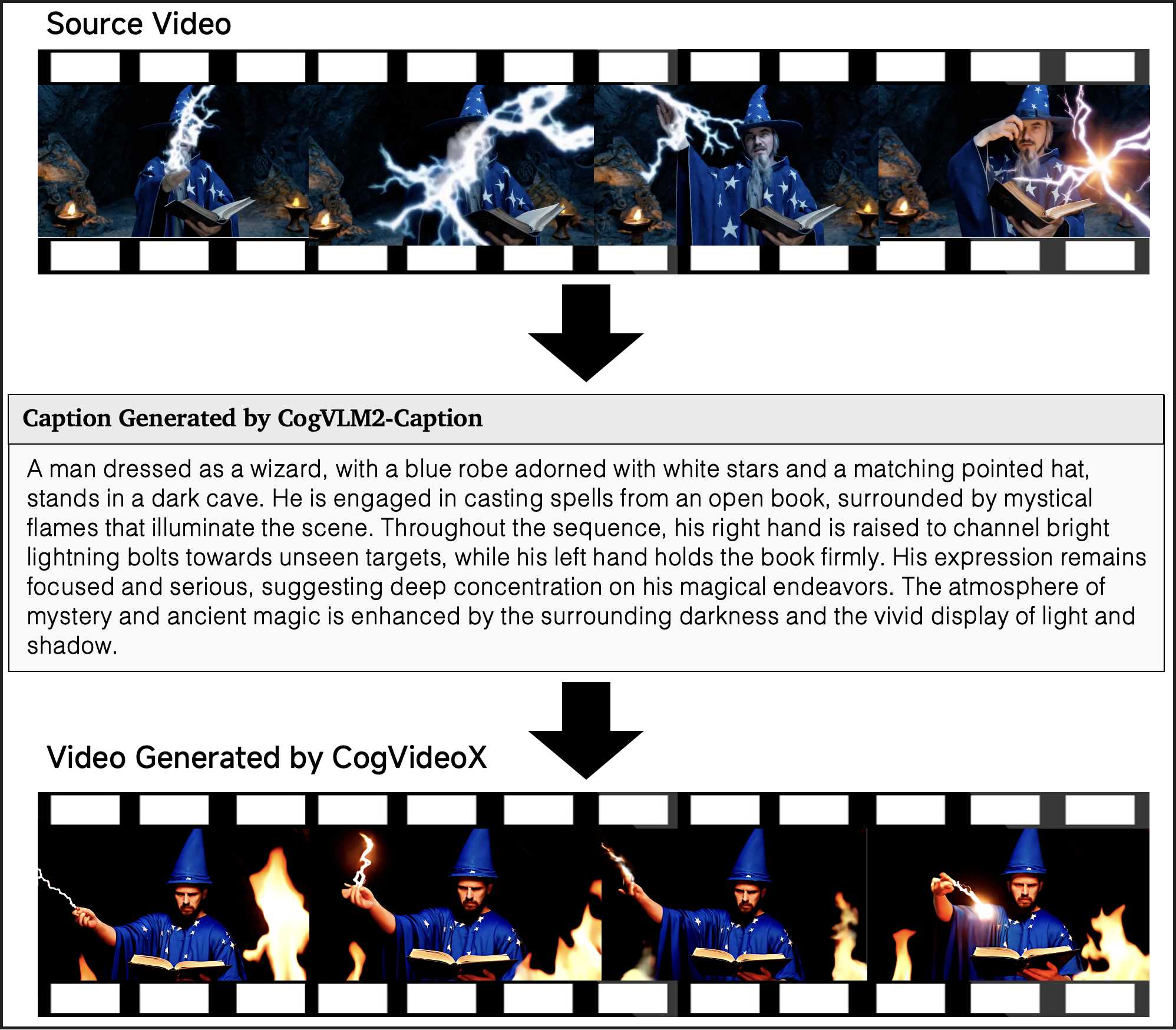
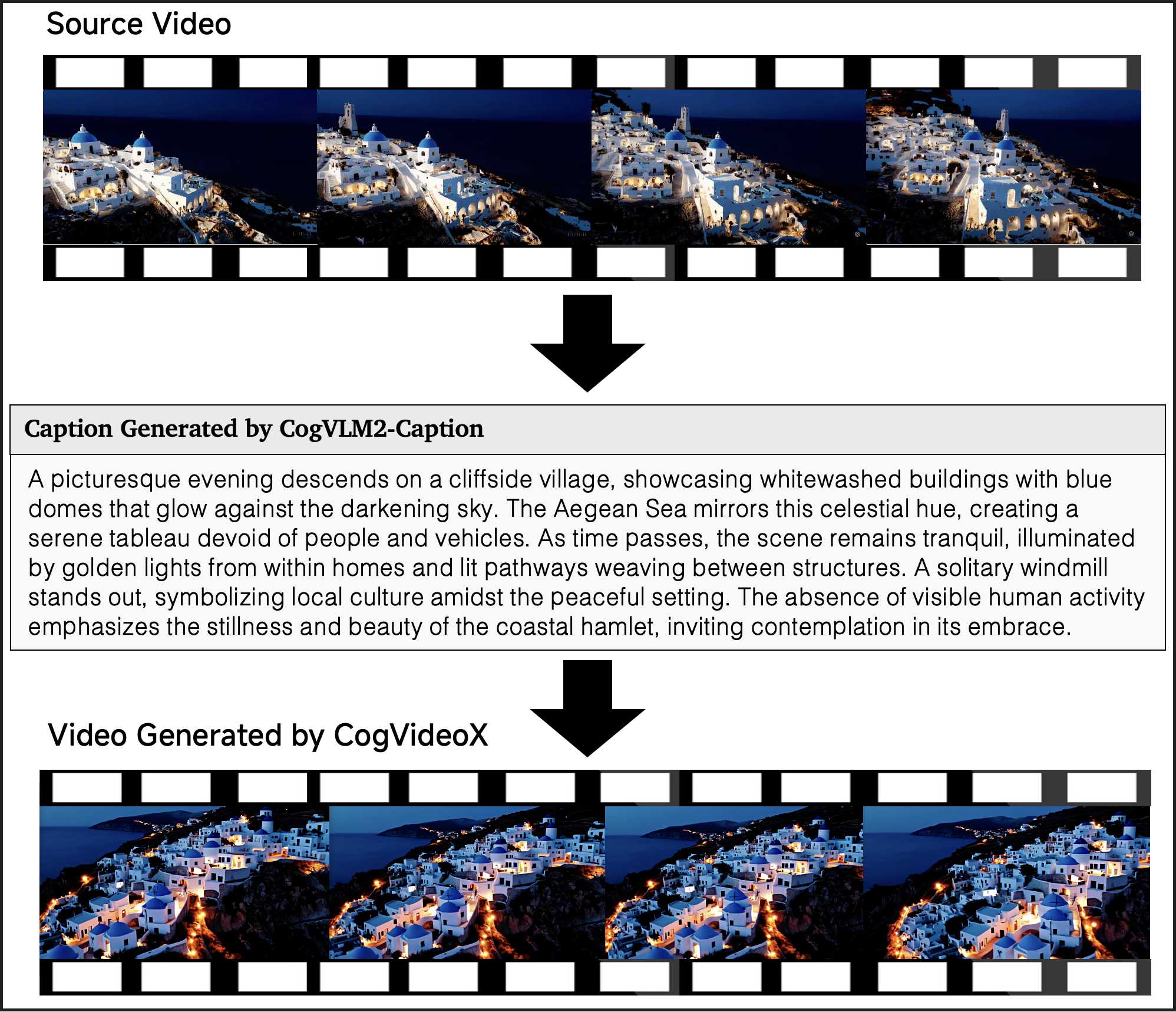
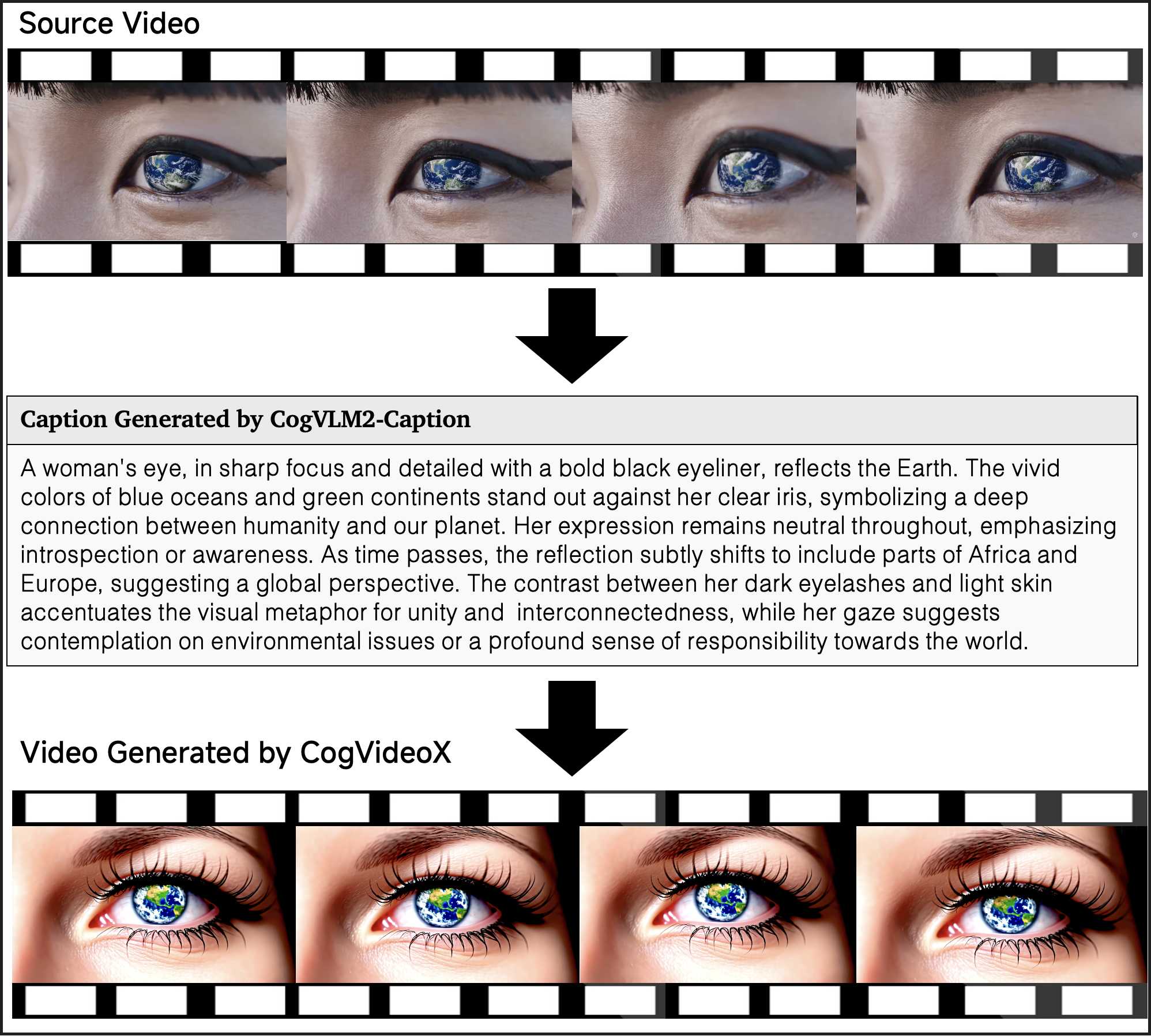
J. Human Evaluation Details
One hundred meticulously crafted prompts are used for human evaluators, characterized by their broad distribution, clear articulation, and well-defined conceptual scope.
A panel of evaluators is instructed to assign scores for each detail on a scale from zero to one, with the overall total score rated on a scale from $0$ to $5$, where higher scores reflect better video quality.
To better complement automated evaluation, human evaluation emphasizes the instruction-following capability: the total score cannot exceed $2$ if the generated video fails to follow the instructions.
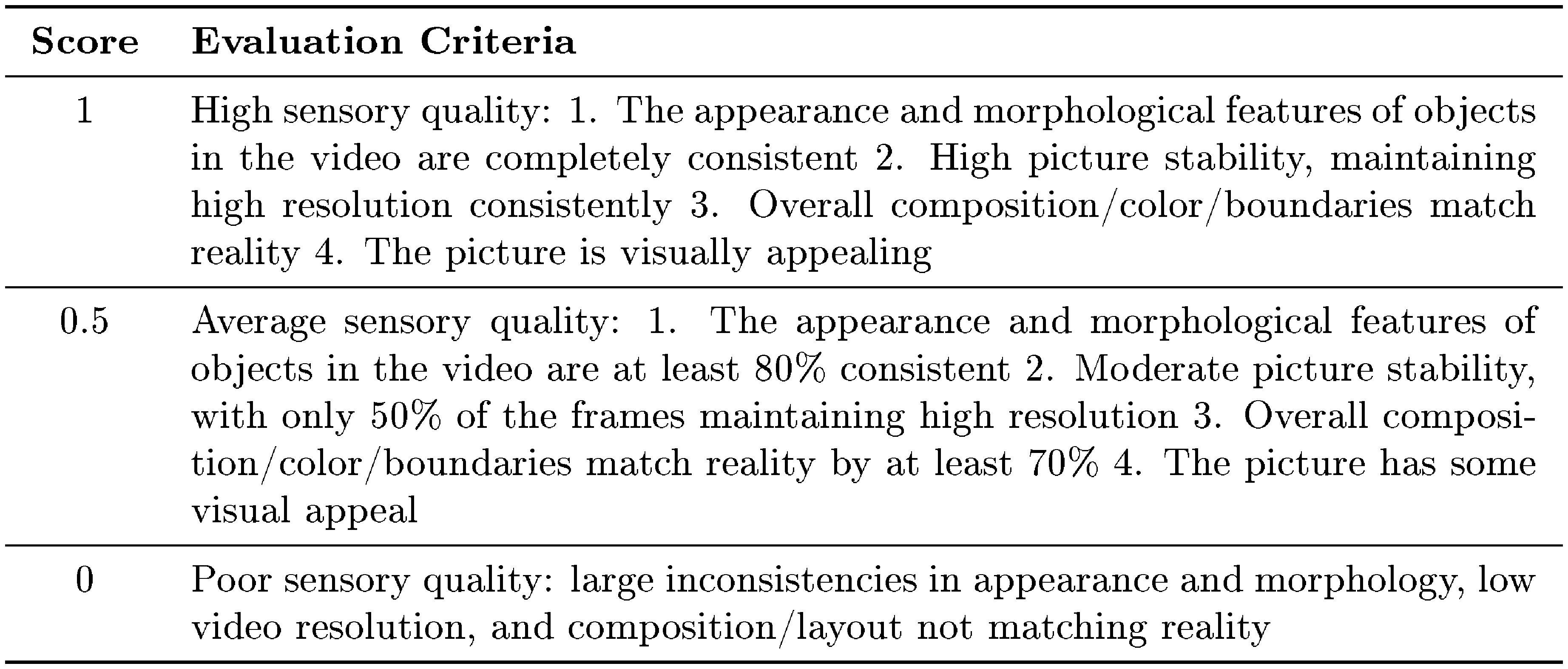
Sensory Quality: This part focuses mainly on the perceptual quality of videos, including subject consistency, frame continuity, and stability.
::: {caption="Table 10: Sensory Quality Evaluation Criteria."}
:::
Instruction Following: This part focuses on whether the generated video aligns with the prompt, including the accuracy of the subject, quantity, elements, and details.
::: {caption="Table 11: Instruction Following Evaluation Criteria."}

:::
Physics Simulation: This part focuses on whether the model can adhere to the objective law of the physical world, such as the lighting effect, interactions between different objects, and the realism of fluid dynamics.
::: {caption="Table 12: Physics Simulation Evaluation Criteria."}
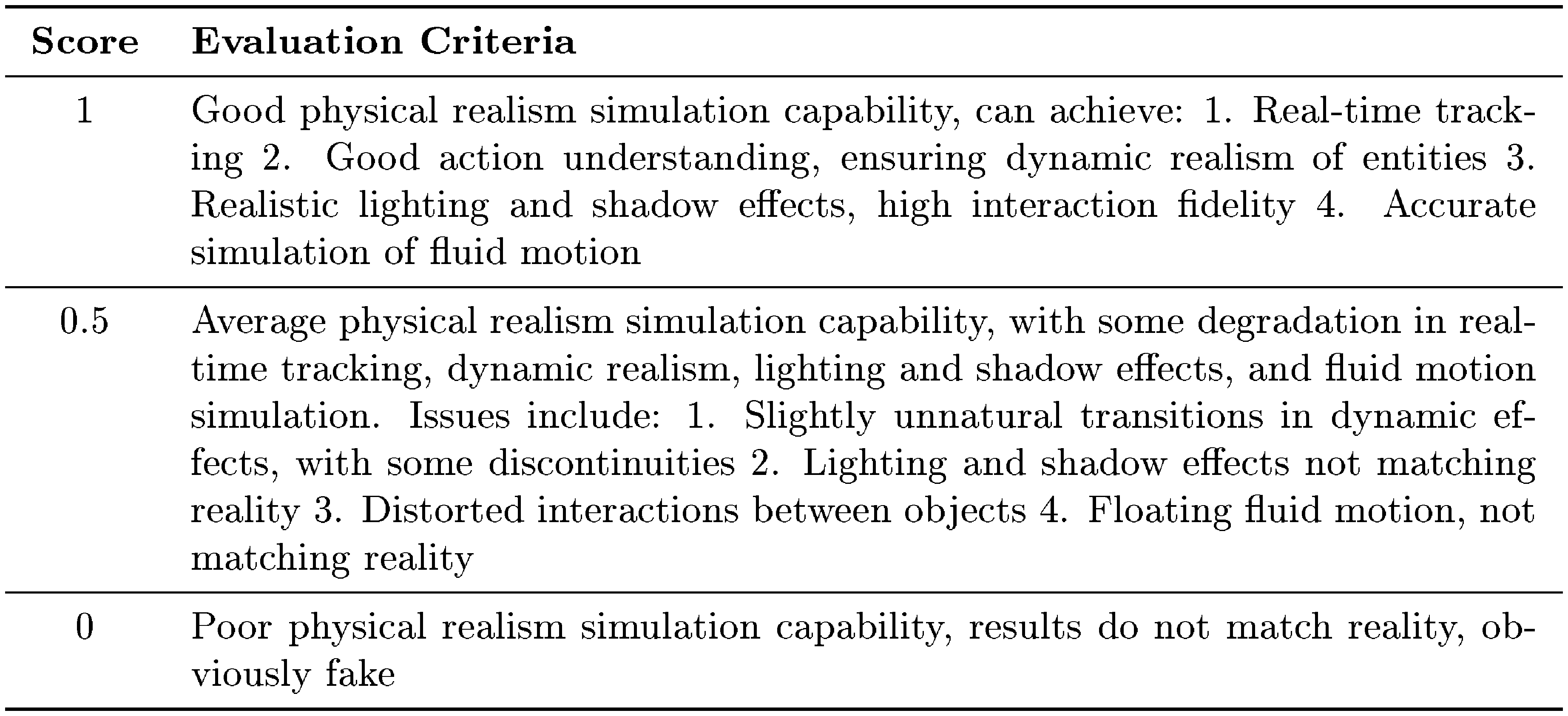
:::
Cover Quality: This part mainly focuses on metrics that can be assessed from single-frame images, including aesthetic quality, clarity, and fidelity.
::: {caption="Table 13: Cover Quality Evaluation Criteria."}

:::
K. Data Filtering Details
In order to obtain high-quality training data, we designed a set of negative labels to filter out low-quality data. Figure 16 presents our negative labels along with sample videos for each label.In Table 14, we present the accuracy and recall of our classifier, trained based on video-llama, on the test set (10% randomly labeled data).
: Table 14: Summary of Classifiers Performance on the Test Set. TP: True Positive, FP: False Positive, TN: True Negative, FN: False Negative.
| Classifier | TP | FP | TN | FN | Test Acc |
|---|---|---|---|---|---|
| Classifier - Editing | 0.81 | 0.02 | 0.09 | 0.08 | 0.91 |
| Classifier - Static | 0.48 | 0.04 | 0.44 | 0.04 | 0.92 |
| Classifier - Lecture | 0.52 | 0.00 | 0.47 | 0.01 | 0.99 |
| Classifier - Text | 0.60 | 0.03 | 0.36 | 0.02 | 0.96 |
| Classifier - Screenshot | 0.61 | 0.01 | 0.37 | 0.01 | 0.98 |
| Classifier - Low Quality | 0.80 | 0.02 | 0.09 | 0.09 | 0.89 |
References
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[2] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
[3] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868, 2022.
[4] Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual descriptions. In International Conference on Learning Representations, 2022.
[5] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792, 2022.
[6] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022.
[7] William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4195–4205, 2023.
[8] OpenAI. Sora. 2024. URL https://openai.com/index/sora/.
[9] Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023.
[10] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
[11] Lijun Yu, José Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, et al. Language model beats diffusion–tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737, 2023b.
[12] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023.
[13] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 586–595, 2018.
[14] Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024.
[15] Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023.
[16] AI@Meta. Llama 3 model card. 2024. URL https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md.
[17] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
[18] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022.
[19] Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 5404–5411, 2024.
[20] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022.
[21] Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim M Alabdulmohsin, et al. Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution. Advances in Neural Information Processing Systems, 36, 2024.
[22] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
[23] Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: Image-text pair dataset. https://github.com/kakaobrain/coyo-dataset, 2022.
[24] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023b.
[25] Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13320–13331, 2024b.
[26] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, 2014.
[27] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 1728–1738, 2021b.
[28] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023a.
[29] Wendi Zheng, Jiayan Teng, Zhuoyi Yang, Weihan Wang, Jidong Chen, Xiaotao Gu, Yuxiao Dong, Ming Ding, and Jie Tang. Cogview3: Finer and faster text-to-image generation via relay diffusion. arXiv preprint arXiv:2403.05121, 2024a.
[30] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
[31] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[32] Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Junhui Ji, et al. Cogvlm2: Visual language models for image and video understanding. arXiv preprint arXiv:2408.16500, 2024.
[33] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024.
[34] Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 508:293–304, 2022.
[35] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In IEEE International Conference on Computer Vision, 2021a.
[36] Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
[37] Mingxiang Liao, Hannan Lu, Xinyu Zhang, Fang Wan, Tianyu Wang, Yuzhong Zhao, Wangmeng Zuo, Qixiang Ye, and Jingdong Wang. Evaluation of text-to-video generation models: A dynamics perspective, 2024. URL https://arxiv.org/abs/2407.01094.
[38] Shenghai Yuan, Jinfa Huang, Yongqi Xu, Yaoyang Liu, Shaofeng Zhang, Yujun Shi, Ruijie Zhu, Xinhua Cheng, Jiebo Luo, and Li Yuan. Chronomagic-bench: A benchmark for metamorphic evaluation of text-to-time-lapse video generation. arXiv preprint arXiv:2406.18522, 2024.
[39] Jiachen Li, Weixi Feng, Tsu-Jui Fu, Xinyi Wang, Sugato Basu, Wenhu Chen, and William Yang Wang. T2v-turbo: Breaking the quality bottleneck of video consistency model with mixed reward feedback. arXiv preprint arXiv:2405.18750, 2024.
[40] Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7310–7320, 2024a.
[41] Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all, March 2024b. URL https://github.com/hpcaitech/Open-Sora.
[42] David Junhao Zhang, Jay Zhangjie Wu, Jia-Wei Liu, Rui Zhao, Lingmin Ran, Yuchao Gu, Difei Gao, and Mike Zheng Shou. Show-1: Marrying pixel and latent diffusion models for text-to-video generation. arXiv preprint arXiv:2309.15818, 2023a.
[43] runway. Gen-2. 2023. URL https://runwayml.com/ai-tools/gen-2-text-to-video.
[44] Pika beta. 2023. URL https://pika.art/home.
[45] Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, et al. Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:2309.15103, 2023b.
[46] Sihyun Yu, Jihoon Tack, Sangwoo Mo, Hyunsu Kim, Junho Kim, Jung-Woo Ha, and Jinwoo Shin. Generating videos with dynamics-aware implicit generative adversarial networks. arXiv preprint arXiv:2202.10571, 2022.
[47] Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1526–1535, 2018.
[48] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
[49] Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, et al. Magvit: Masked generative video transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10459–10469, 2023a.
[50] PKU-Yuan Lab and Tuzhan AI etc. Open-sora-plan, April 2024. URL https://doi.org/10.5281/zenodo.10948109.
[51] James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023.