Classical Planning in Deep Latent Space
Masataro Asai [email protected]
MIT-IBM Watson AI Lab, IBM Research, Cambridge USA
Hiroshi Kajino [email protected]
IBM Research - Tokyo, Tokyo Japan
Alex Fukunaga [email protected]
Graduate School of Arts and Sciences, University of Tokyo, Tokyo Japan
Christian Muise [email protected]
School of Computing, Queen's University, Kingston Canada
Abstract
Current domain-independent, classical planners require symbolic models of the problem domain and instance as input, resulting in a knowledge acquisition bottleneck. Meanwhile, although deep learning has achieved significant success in many fields, the knowledge is encoded in a subsymbolic representation which is incompatible with symbolic systems such as planners. We propose Latplan, an unsupervised architecture combining deep learning and classical planning. Given only an unlabeled set of image pairs showing a subset of transitions allowed in the environment (training inputs), Latplan learns a complete propositional PDDL action model of the environment. Later, when a pair of images representing the initial and the goal states (planning inputs) is given, Latplan finds a plan to the goal state in a symbolic latent space and returns a visualized plan execution. We evaluate Latplan using image-based versions of 6 planning domains: 8-puzzle, 15-Puzzle, Blocksworld, Sokoban and Two variations of LightsOut.
Executive Summary: Latplan is an architecture that automatically learns a complete propositional PDDL action model from raw, unlabeled image pairs showing valid environment transitions, then solves planning problems given only initial- and goal-state images. It was developed to overcome the knowledge-acquisition bottleneck that prevents classical planners from being applied in new or unforeseen settings where no human is available to hand-craft or compile symbolic models.
The system was trained unsupervised on image-transition datasets drawn from six image-based planning domains (MNIST 8-puzzle, Mandrill 15-puzzle, two LightsOut variants, photo-realistic Blocksworld, and Sokoban). Four successively more sophisticated action-model learners (AMA₁–AMA₄⁺) were compared; the final bidirectional Cube-Space Autoencoder (AMA₄⁺) jointly learns a stable propositional state encoding and a STRIPS-compatible action model that can be exported directly as PDDL. Off-the-shelf planners (Fast Downward) then solve the resulting instances, and the resulting plans are decoded back into image sequences for human inspection. Performance was measured by reconstruction accuracy (ELBO), latent-state stability under noise, successor-prediction error, and end-to-end planning success (coverage, validity of visualized plans, and optimality).
AMA₄⁺ with a Bernoulli(0.1) latent prior produced the strongest results. It achieved 30–40 valid solutions per domain (versus far fewer for the unidirectional AMA₃⁺ baseline), solved 254 of 280 test instances across all domains and heuristics, and returned optimal visualized plans in roughly 60 % of the solvable cases where optimality could be verified. The non-standard prior measurably improved symbol stability, reduced disconnected regions in the latent space, and increased the fraction of plans that remained optimal under noisy image inputs. Standard domain-independent heuristics (LM-cut, Merge-and-Shrink, LAMA) continued to reduce node expansions by roughly an order of magnitude relative to blind search, demonstrating that the learned representations retain useful structure even though they are not human-designed.
These findings show that it is possible to obtain sound, compact, and planner-compatible PDDL models from raw perceptual data without manual symbol engineering or task-specific supervision. The approach therefore removes a major obstacle to deploying classical planning in autonomous, sensor-rich environments such as spacecraft or robotics. At the same time, the current implementation still assumes fully observable (if noisy) domains, propositional rather than first-order representations, a single goal image, and uniform sampling of transitions—limitations that must be relaxed before the technology can be used on physical robots or in partially observable settings.
The immediate next steps are therefore (1) to collect and learn from non-uniform, real-robot transition data, (2) to extend the architecture to handle multiple or partially specified goals and first-order generalizations so that new objects do not require retraining, and (3) to integrate the learned models with existing perception and control stacks for closed-loop execution. A modest pilot on a physical manipulation platform would quickly reveal whether the remaining accuracy and stability gaps are acceptable for practical use.
1. Introduction
Section Summary: Recent advances in automated planning require human-created symbolic models in languages like PDDL, creating a bottleneck that prevents their use in new situations without experts, such as autonomous exploration from raw sensor data. Neural networks excel at processing images and other perceptual inputs but lack the completeness and optimality guarantees of symbolic planners. Latplan addresses this gap by using unsupervised neural autoencoders to automatically learn compact symbolic state and action representations from unlabeled images, enabling a classical planner to solve problems like an image-based 8-puzzle and produce visual plan executions.
Recent advances in domain-independent planning have greatly enhanced their capabilities. However, planning problems need to be provided to the planner in a structured, symbolic representation such as Planning Domain Definition Language (PDDL) [1], and in general, such symbolic models need to be provided by a human, either directly in a modeling language such as PDDL, or via a compiler which transforms some other symbolic problem representation into PDDL. This results in the knowledge-acquisition bottleneck, where the modeling step is sometimes the bottleneck in the problem-solving cycle. The requirement for symbolic input poses a significant obstacle to applying planning in new, unforeseen situations where no human is available to create such a model or a generator, e.g., autonomous spacecraft exploration. In particular, this first requires generating symbols from raw sensor input, i.e., the symbol grounding problem [2].
Recently, significant advances have been made in neural network (NN) deep learning approaches for perceptually-based cognitive tasks including image classification [3], object recognition [4], speech recognition [5], machine translation as well as NN-based problem-solving systems [6, 7]. However, the current state-of-the-art, pure NN-based systems do not yet provide guarantees provided by symbolic planning systems, such as deterministic completeness and solution optimality.
Using a NN-based perceptual system to automatically provide input models for domain-independent planners could greatly expand the applicability of planning technology and offer the benefits of both paradigms. We consider the problem of robustly, automatically bridging the gap between such subsymbolic representations and the symbolic representations required by domain-independent planners.
Figure 1 (left) shows a scrambled, 3x3 tiled version of the photograph on the right, i.e., an image-based instance of the 8-puzzle. Even for humans, this photograph-based task is arguably more difficult to solve than the standard 8-puzzle because of the distracting visual aspects. We seek a domain-independent system which, given only a set of unlabeled images showing the valid moves for this image-based puzzle, finds an optimal solution to the puzzle (Figure 2). Although the 8-puzzle is trivial for symbolic planners, solving this image-based problem with a domain-independent system which (1) has no prior assumptions/knowledge (e.g., "sliding objects", "tile arrangement"), and (2) must acquire all knowledge from the images, is nontrivial. Such a system should not make assumptions about the image (e.g., "a grid-like structure"). The only assumption allowed about the nature of the task is that it can be modeled as a classical planning problem (deterministic and fully observable).

We propose Latent-space Planner (Latplan), an architecture that automatically generates a symbolic problem representation from the subsymbolic input, that can be used as the input for a classical planner. The current implementation of Latplan contains four neural components in addition to the classical planner:
- A discrete autoencoder with multinomial binary latent variables, named State Autoencoder (SAE), which learns a bidirectional mapping between the raw observations of the environment and its propositional representation.
- A discrete autoencoder with a single categorical latent variable and a skip connection, named Action Autoencoder (AAE), which performs an unsupervised clustering over the latent transitions and generates action symbols.
- A specific decoder implementation of the AAE, named Back-To-Logit (BTL), which models the state progression / forward dynamics that directly compiles into STRIPS action effects.
- An identical BTL structure to model the state regression / time-inverse dynamics which directly compiles into STRIPS action preconditions.
Given only a set of unlabeled images of the environment, and in an unsupervised manner, we train Latplan to generate a symbolic representation. Then, given a planning problem instance as a pair of initial and goal images such as Figure 1, Latplan uses the SAE to map the problem to a symbolic planning instance, invokes a planner, then visualizes the plan execution by a sequence of images.
A system that generates symbols from the scratch has an advantage of being able to work on multiple domains more easily. In planning, symbolic manipulation enables the encoding of powerful domain-independent knowledge that can be easily applied to multiple tasks without training data. For example, given a problem instance from a previously unseen STRIPS planning domain $D$, a planning algorithm can often solve an instance of $D$ much faster than blind search by using domain-independent heuristic functions that exploit $D$ based purely on the symbolic structure of the action model of $D$ [8, 9]. The advantage of exploiting symbolic structures is a predicament of the Physical Symbol Systems Hypothesis [10, 11, 12], which states that "[a] physical symbol system has the necessary and sufficient means for general intelligent action." In contrast, while current learning-based approaches to planning such as AlphaZero [13] or MuZero [14] achieve impressive performance, they require using or generating massive amounts of data in order to learn task-dependent evaluation functions and policies that result in high performance on a given task. Transferring domain-independent strategies across tasks remains a challenge for learning-based approaches, as they currently lack a convenient representation for expressing and exchanging task-independent knowledge between different systems. It is trivial in classical planning, where domain-independent heuristics are available.
The paper is organized as follows. We first begin with a review of preliminaries and background (Section 2). We next provide our high-level problem statement (Section 3). We next give an overview of the Latplan architecture (Section 4). In Section 5, we describe the SAE implemented as a Binary-Concrete Variational Auto-Encoder, which generates propositional symbols from images. We identify and define the Symbol Stability Problem which arises when grounding propositional symbols, and propose countermeasures to address it.
Next, in Section 6-Section 9, we explain our approach to action model learning. Since the action model learning is a complex problem, we introduce four increasingly sophisticated versions (AMA$1$-AMA${4}^+$), where each version inherits the entire model of its previous version as a component. We chose this presentation to help illustrate which aspect of the learning problem is addressed by each component. AMA$1$-AMA${4}^+$ can be summarized as follows: (Section 6) AMA$1$, a direct translation of image transitions to grounded actions, (Section 7) AMA$2$, which uses the AAE as a general, black-box successor function, (Section 8) AMA${3}^+$, an approach which trains a Cube-Space AE network which jointly trains an SAE and a Back-to-Logit AAE for STRIPS domains and extracts a PDDL model compatible with off-the-shelf State-of-the-Art planners, and (Section 9) AMA${4}^+$, an approach which trains a Bidirectional Cube-Space AE network which improves upon AMA$_{3}^+$ by using complete state regression semantics to learn accurate action preconditions.
We then evaluate Latplan using image-based versions of the 8-puzzle, 15-puzzle, LightsOut (two versions), Blocksworld, and Sokoban domains. Section 10 presents empirical evaluations of the accuracy and stability of the SAE, as well as the action model accuracy of AMA${3}^+$ and AMA${4}^+$. Section 11 presents empirical evaluation of end-to-end planning with Latplan, including the effectiveness of standard planning heuristics. Section 12 surveys related work, and we conclude with a discussion of our contributions and directions for future work (Section 13). Some additional technical details, background, and data are presented in the Appendix.
Latplan is a first step in bridging the gap between symbolic and subsymbolic reasoning, therefore it currently has various limitations. For example, Latplan is evaluated in a fully-observable environment (although it is noisy). Also, Latplan's state representation is entirely propositional and lack first-order logic generalization, thus requires a retraining when new objects are added. Latplan is limited to tasks where a single goal state is specified. Finally, Latplan requires uniform sampling from the environment, which is nontrivial in many scenarios. We discuss these limitations in detail in the discussion (Section 13).
This paper summarizes and extends the work that has appeared in [15, 16, 17]. The major new technical contributions in this journal version are: (1) the improved precondition learning enabled by the regressive action modeling (Section 9), (2) theoretical justifications of the training objectives throughout the paper, and (3) thorough empirical evaluations (Section 10-Section 11).
2. Preliminaries and Important Background Concepts
Section Summary: This section first outlines the mathematical notations for arrays, subarrays, concatenations, and related concepts used throughout the paper. It then defines propositional classical planning as a STRIPS problem over propositions and actions, where each action has preconditions and effects that transform an initial state into one satisfying a goal condition, with optimality defined by minimal plan length. Finally, it reviews autoencoders as neural networks that learn compressed latent representations of inputs via reconstruction loss, along with their variational extensions that regularize the latent space using a prior distribution and KL divergence.
2.1 Notations
We denote a multi-dimensional array in bold and its elements with a subscript (e.g., ${\bm{x}}\in \mathbb{R}^{N\times M}$, ${\bm{x}}2 \in \mathbb{R}^M$). An integer range $n\leq i<m$ is represented by $n..m$. By analogy, we use dotted subscripts to denote a subarray, e.g. ${\bm{x}}{2..5}=({\bm{x}}_2, {\bm{x}}_3, {\bm{x}}_4)$. $\bm{1}^D$ and $\bm{0}^D$ denote constant matrices of shape $D$ with all elements being 1/0, respectively. ${\bm{a}}; {\bm{b}}$ denotes a concatenation of tensors ${\bm{a}}$ and ${\bm{b}}$ in the first axis where the rest of the dimensions are same between ${\bm{a}}$ and ${\bm{b}}$. The $i$-th data point of a dataset is denoted by a superscript $^{i}$ which we may omit for clarity. These superscripts are also sometimes abbreviated by $..$ to improve the readability, e.g., ${\bm{x}}^{0..2}=({\bm{x}}^0, {\bm{x}}^1, {\bm{x}}^2)$. Functions (e.g., $\log, \exp$) are applied to arrays element-wise. Finally, we denote $\mathbb{B} = [0, 1]$.
2.2 Propositional Classical Planning
We define a grounded (propositional) STRIPS Planning problem with negative preconditions and unit costs as a 4-tuple ${\left<P, A, I, G\right>}$ where $P$ is a set of propositions, $A$ is a set of actions, $I\subseteq P$ is the initial state, and $G\subseteq P$ is a goal condition. Each action $a\in A$ is a 4-tuple $a={\left< \textsc{pos}(a), \allowbreak \textsc{neg}(a), \allowbreak \textsc{add}(a), \allowbreak \textsc{del}(a)\right>}$ where $\textsc{pos}(a)$, $\textsc{neg}(a)$ are the positive and negative preconditions, $\textsc{add}(a)$, $\textsc{del}(a)$ are the add-effects and delete-effects, $\textsc{pos}(a), \textsc{neg}(a), \textsc{add}(a), \textsc{del}(a) \subseteq P$, $\textsc{pos}(a) \cap \textsc{neg}(a) = \emptyset$, and $\textsc{add}(a) \cap \textsc{del}(a) = \emptyset$. A complete state (or just state) $s\subseteq P$ is a set of true propositions where those in $P \setminus s$ are presumed to be false. A partial state is similarly represented (i.e. a subset of $P$), but those propositions not mentioned may be either true or false. The initial state ($I$) is a complete state while the goal condition ($G$) and effect sets ($\textsc{pos}(a)$, $\textsc{neg}(a)$, $\textsc{add}(a)$, and $\textsc{del}(a)$) are partial states. We say that a state $s$ entails a partial state $ps$ when $ps \subseteq s$ – intuitively, every proposition that must be true in $ps$ is true in the state $s$. An action $a$ is applicable when $s\supseteq \textsc{pos}(a)$ and $s\cap \textsc{neg}(a)=\emptyset$, and applying an action $a$ to $s$ yields a new successor state $a(s) = (s \setminus \textsc{del}(a)) \cup \textsc{add}(a)$. The task of classical planning is to find a plan $(a_1, \cdot s, a_n)$ which satisfies $G$ by the repeated application of applicable actions, i.e., $G \subseteq a_n \circ \cdot s \circ a_1(I)$. A plan $\pi$ is optimal when there are no other plans whose length is shorter than $\pi$.
2.3 Autoencoders and Variational Autoencoders
We review relevant probability theory in the appendix (Appendix A).
An Autoencoder (AE) is a type of neural network that learns an identity function whose output matches the input [18]. Autoencoders consist of an input ${\bm{x}}$, a latent vector ${\bm{z}}$, an output $\hat{{\bm{x}}}$, an encoder $f$, and a decoder $g$, where ${\bm{z}}=f({\bm{x}})$ and $\hat{{\bm{x}}}=g({\bm{z}})=g(f({\bm{x}}))$. The output is also called a reconstruction. The dimension of ${\bm{z}}$ is typically smaller than the input; thus ${\bm{z}}$ is considered a compressed representation of ${\bm{x}}$.
The networks $f, g$ are optimized by minimizing a reconstruction loss $| {\bm{x}}-\hat{{\bm{x}}}|$ under some norm, which is typically a Square Error / L2-norm. Which norm to use is semi-arbitrarily decided by a model designer — More explanation on the choice of the loss is given in the appendix (Appendix B). Assuming a 1-dimensional case, let $x$ be a data point in the dataset, $z$ be a certain latent value, and a probability distribution $p(x|z)$ be what the neural network (and the model designer) believes is the distribution of $x$ given $z$. Typical AEs for images assume that $x$ follows a Gaussian distribution centered around the predicted value $\hat{x}=g(z)$, i.e., $p(x|z)=\mathcal{N}(x|\hat{x}, \sigma) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\hat{x})^2}{2\sigma^2}}$ for an arbitrary fixed constant $\sigma$. This leads to a negative log likelihood (NLL) [^1] $-\log p(x|z)=\frac{(x-\hat{x})^2}{2\sigma^2}+\log \sqrt{2\pi\sigma^2}$ which is a scaled/shifted square error / L2-norm reconstruction loss. In images, they are summed across dimensions (pixels).
[^1]: Likelihood is a synonym of probability. "Log likelihood of ${\bm{x}}$ " means a logarithm of a probability of observing the data ${\bm{x}}$. Negative log likelihood is its negation.
A Variational Autoencoder (VAE) is an autoencoder that additionally assumes that the latent variable ${\bm{z}}$ by default follows a certain distribution $p({\bm{z}})$, typically called a prior distribution. A prior distribution is chosen arbitrarily by a model designer, such as a unit Normal distribution $\mathcal{N}(\bm{0}, \bm{1})$. More precisely, ${\bm{z}}$ follows $p({\bm{z}})$ unless the observation ${\bm{x}}$ forces it otherwise — ${\bm{z}}$ is meant to diverge from it based on the data through the training.
A VAE is trained by minimizing a sum of a reconstruction loss $-\log p({\bm{x}}| {\bm{z}})$ and a KL divergence $D_{\mathrm{KL}}(q({\bm{z}}| {\bm{x}})\mathrel{|} p({\bm{z}}))$ between $q({\bm{z}}| {\bm{x}})$ and $p({\bm{z}})$, where $q({\bm{z}}| {\bm{x}})$ is a distribution of the latent vector ${\bm{z}}$ obtained by the encoder at hand. $q({\bm{z}}| {\bm{x}})$ must be in the same family of distributions as $p({\bm{z}})$, e.g., if $p({\bm{z}})$ is Gaussian, $q({\bm{z}}| {\bm{x}})$ should also be a Gaussian, in order to obtain an analytical form of the KL divergence that can be processed by automatic differentiation frameworks. When $p({\bm{z}})=\mathcal{N}(\bm{0}, \bm{1})$, a model engineer can then design an encoder that returns two vectors ${\bm{\mu}}, {\bm{\sigma}}=f({\bm{x}})$ and sample ${\bm{z}}$ as ${\bm{z}}\sim \mathcal{N}({\bm{\mu}}, {\bm{\sigma}}) = q({\bm{z}}| {\bm{x}})$, using ${\bm{z}}= {\bm{\mu}} + {\bm{\sigma}} {\bm{\epsilon}}$ where ${\bm{\epsilon}}$ is a noise that follows $\mathcal{N}(\bm{0}, \bm{1})$ (reparameterization trick). Then the analytical form of the KL divergence is obtained from the closed form of Gaussian distribution as follows:
$ \begin{aligned} D_{KL}(\mathcal{N}({\bm{\mu}}, {\bm{\sigma}})||\mathcal{N}(\bm{0}, \bm{1})) &= \sum_{i} \frac{1}{2} {\left({\bm{\sigma}}_i + {\bm{\mu}}_i^2 - 1 - \log {\bm{\sigma}}_i^2\right)}. \end{aligned}\tag{1} $
A negative sum of the reconstruction loss and the KL divergence is called an Evidence Lower Bound (ELBO), a lower bound of the log likelihood $\log p({\bm{x}})$ of observing ${\bm{x}}$ ([19]). Under maximum likelihood estimation framework, this lower bound characteristics make VAEs theoretically more appealing than AEs because maximizing $\log p({\bm{x}})$ is the true goal of unsupervised learning: To maximize $\log p({\bm{x}})$, we maximize its lower bound $\text{ELBO}({\bm{x}})$, and thus we minimize the loss function $-\text{ELBO}({\bm{x}})$. To derive a lower bound, ELBO uses the variational method which sees $q({\bm{z}}| {\bm{x}})$ as an approximation of $p({\bm{z}}| {\bm{x}})$. [^2] The lower bound matches $\log p({\bm{x}})$ when $q=p$. The proof is shown by using Jensen's inequality about exchanging an expectation and a convex function (in this case, $\log$) as follows:
[^2]: We say $q({\bm{z}}| {\bm{x}})$ is a variational distribution. In addition, both $q({\bm{z}}| {\bm{x}})$ and $p({\bm{z}}| {\bm{x}})$ are called posterior distribution because they are distributions of latent variables given observed variables. When combined, we say $q({\bm{z}}| {\bm{x}})$ is a variational posterior distribution, which is a variational approximation of the true posterior distribution $p({\bm{z}}| {\bm{x}})$.
$ \begin{aligned} \log p({\bm{x}}) &=\log \sum_{{\bm{z}}} p({\bm{x}}, {\bm{z}}) =\log \sum_{{\bm{z}}} p({\bm{x}}| {\bm{z}}) p({\bm{z}}) =\log \sum_{{\bm{z}}} p({\bm{x}}| {\bm{z}}) \frac{p({\bm{z}})}{q({\bm{z}}| {\bm{x}})} q({\bm{z}}| {\bm{x}}) \nonumber\ &=\log {\left(\mathbb{E}{q({\bm{z}}| {\bm{x}})} {\left<p({\bm{x}}| {\bm{z}}) \frac{p({\bm{z}})}{q({\bm{z}}| {\bm{x}})}\right>}\right)}\quad\text{(definition of an expectation.)}\nonumber\ &\geq \mathbb{E}{q({\bm{z}}| {\bm{x}})} {\left<\log {\left(p({\bm{x}}| {\bm{z}}) \frac{p({\bm{z}})}{q({\bm{z}}| {\bm{x}})}\right)}\right>} \quad\text{(Jensen's inequality.)} \nonumber\ & = \mathbb{E}{q({\bm{z}}\mid {\bm{x}})} {\left<\log p({\bm{x}}\mid {\bm{z}})\right>} -\mathbb{E}{q({\bm{z}}| {\bm{x}})}{\left<\log\frac{q({\bm{z}}\mid {\bm{x}})}{p({\bm{z}})}\right>} \nonumber\ &= \mathbb{E}_{q({\bm{z}}\mid {\bm{x}})}{\left<\log p({\bm{x}}\mid {\bm{z}})\right>}
- D_{KL} (q({\bm{z}}\mid {\bm{x}})\mathrel{|} p({\bm{z}})) \quad\text{(definition of KL.)}\nonumber\ &=\text{ELBO}({\bm{x}}). \end{aligned}\tag{2} $
In contrast to VAEs, the loss function of an AE (= reconstruction loss $\log p({\bm{x}}| {\bm{z}})$) does not have this lower bound property. Maximizing $\log p({\bm{x}}| {\bm{z}})$ does not guarantee that it maximizes $\log p({\bm{x}})$.
Finally, among popular extensions of VAEs, $\beta$-VAE [20] uses a loss function that scales the KL divergence term with a hyperparameter $\beta\geq 1$.
$ \text{ELBO}\beta({\bm{x}})= \mathbb{E}{q({\bm{z}}| {\bm{x}})}{\left<\log p({\bm{x}}\mid {\bm{z}})\right>} - \beta D_{\mathrm{KL}} (q({\bm{z}}\mid {\bm{x}})||p({\bm{z}})). $
$\text{ELBO}({\bm{x}}) \geq \text{ELBO}\beta({\bm{x}})$ because $D{\mathrm{KL}}$ is always positive, thus $\text{ELBO}_\beta({\bm{x}})$ is also a lower bound of $\log p({\bm{x}})$. However, some literature uses $\beta<1$ which is tuned manually by a visual inspection of the reconstructed image, which violates ELBO. In this paper, we always use $\beta\geq 1$ so that it does not violate ELBO. We will discuss the effect of different $\beta$ during the empirical evaluation.
2.4 Discrete Variational Autoencoders
While typically $p(z)$ is a Normal distribution ${\mathcal{N}}(0, 1)$ for continuous latent variables, there are multiple VAE methods for discrete latent distributions. A notable example is a method we use in this paper: Gumbel-Softmax (GS) VAE ([21]). Gumbel-Softmax VAE is independently discovered by [22] as Concrete VAE; therefore it may be called as such in some literature. The binary special case of Gumbel Softmax VAE is called Binary-Concrete (BC) VAE ([22]). These VAEs use a discrete, uniform categorical/Bernoulli(0.5) distribution as the prior $p(z)$, and further approximate it with a continuous relaxation by introducing a temperature parameter $\tau$ that is annealed down to 0. In this section, we briefly summarize the information necessary for implementing GS and BC.
For Gumbel Softmax and Binary Concrete, we denote corresponding stochastic activation functions in the latent space as $\textsc{GS}{\tau}({\bm{l}})$ and $\textsc{BC}{\tau}(l)$, where ${\bm{l}}\in \mathbb{R}^C$, $l\in \mathbb{R}$, and $C$ denotes the number of classes represented by Gumbel Softmax. ${\bm{l}}$ and $l$ can be an arbitrary vector/scalar produced by the encoder neural network $f$. Both functions use a temperature parameter $\tau$ which is annealed during the training in a fixed schedule such as an exponential schedule $\tau(t)=Ar^{-(t-t_0)}$, where $t$ is a training epoch. Each output, ${\bm{z}}= \textsc{GS}{\tau}({\bm{l}})$ or $z= \textsc{BC}{\tau}(l)$, follows Gumbel-Softmax distribution $\mathbf{GS}({\bm{l}}, \tau)$ and Binary-Concrete distribution $\mathbf{BC}(l, \tau)$. In other words, the stochastic activation is equivalent to a sampling process from these distribution, and the output is a sample from these distributions. It can also be seen as a reparameterization trick for this distribution.
GS is defined as
$ {\bm{z}}= \textsc{GS}_{\tau}({\bm{l}})= \textsc{softmax}{\left(\frac{{\bm{l}}+\textsc{Gumbel}^C(0, 1)}{\tau}\right)}\tag{3} $
where $\textsc{Gumbel}^C(0, 1)=-\log(-\log {\bm{u}})$ and ${\bm{u}}\sim\textsc{Uniform}^C(0, 1)\in \mathbb{B}^C$.
BC is a binary special case (i.e. $C=2$) of GS. It is defined as
$ z= \textsc{BC}_{\tau}(l)=\textsc{Sigmoid}{\left(\frac{l+\textsc{Logistic}(0, 1)}{\tau}\right)}\tag{4} $
where $\textsc{Logistic}(0, 1)=\log u-\log(1-u)$ and $u\sim\textsc{Uniform}(0, 1)\in \mathbb{B}$.
Both functions converge to discrete functions at the limit $\tau\rightarrow 0$: $\textsc{GS}{\tau}({\bm{l}})\rightarrow \operatorname{arg, max}({\bm{l}})$ and $\textsc{BC}{\tau}(l)\rightarrow\textsc{step}(l)=(l<0), ?, 0:1$. Note that we assume $\operatorname{arg, max}$ returns a one-hot representation rather than the index of the maximum value in order to maintain dimensional compatibility with $\textsc{softmax}$ function.
In practice, GS-VAEs and BC-VAEs contain multiple latent vectors / latent scalars to model complex inputs, which we call $n$-way Gumbel-Softmax / Binary-Concrete. The latent space is denoted as ${\bm{z}}\in \mathbb{B}^{n\times C}$ for Gumbel-Softmax, and ${\bm{z}}\in \mathbb{B}^{n}$ for Binary Concrete.
For the derivation of the KL divergence of Gumbel-Softmax, refer to Appendix D in the Appendix.
To see how Gumbel-Softmax and Binary-Concrete relate to other discrete methods, refer to Appendix C in the Appendix.
2.5 Notational Convention for Neural Networks
In this paper, we define each sub-network of the entire neural network so that it does not contain the last activation. This is because each network does not produce a sample of the probability distribution such as ${\bm{z}}$; the output of each network is instead a parameter of the probability distribution, such as ${\bm{l}}$ of a Gumbel-Softmax distribution $\mathbf{GS}({\bm{l}}, \tau)$ or ${\bm{\mu}}, {\bm{\sigma}}$ of a Gaussian distribution $\mathcal{N}({\bm{\mu}}, {\bm{\sigma}})$. The sampling process for ${\bm{z}}\sim \mathbf{GS}({\bm{l}}, \tau)$ is placed outside each subnetwork, although it is still part of the entire network.
3. The Problem: Unsupervised Acquisition of a Classical Planning Model From Low-Level Inputs
Section Summary: The section outlines the core challenge of building an AI system that can automatically learn a full classical planning model, including symbols for objects, predicates, and actions, directly from raw noisy inputs like images in a physical setting and without any human help. Achieving this unsupervised process requires solving symbol grounding, which assigns meaningful referents to discrete symbolic names inside a knowledge base, along with action model acquisition to capture preconditions and effects. The authors stress that symbols must be generated entirely by the system itself, rather than supplied by people, to avoid reintroducing the knowledge acquisition bottleneck.
Our goal is to build a system that acquires a classical planning model from low-level inputs (e.g., images) in a real-world (e.g., physical) environment without human involvement. In order to fully automatically acquire symbolic models for Classical Planning, we need Symbol Grounding [23, 2, 24] and Action Model Acquisition ([25, 26], AMA), which are one of the key challenges in achieving autonomous symbolic systems for real-world environments and in Artificial Intelligence.
Symbol Grounding is an unsupervised process of establishing a mapping between symbols and noisy, continuous and/or unstructured inputs. Action Model Acquisition (also known as Planning Operator Acquisition [27], or Action Model Learning [28]) is indeed a grounding process for actions, typically with a focus on descriptive action schema (preconditions and effects in the STRIPS subset of PDDL) as the referents. To clarify these high-level goals, we formalize symbol grounding and discuss its relation to PDDL construction. Following a traditional definition seen in the LISP family of programming languages, formally:
########## {caption="Definition"}
A symbol is a tuple of a name and a referent, which can be uniquely looked up in a knowledge base using the name as a key. Symbol grounding is a process of assigning referents to symbols.
For example, a name can be an ASCII string or an integer. A referent is an arbitrary representation of a meaning of the symbol, e.g., a referent of a predicate symbol is a boolean function, while a referent of an action symbol is an action schema. We do not distinguish whether referents are hand-coded or learned; thus a predicate can be a binary classifier learned by a machine learning system. A symbol designates a referent [10]. A knowledge base is a namespace (e.g., a hash table) that defines a type of a symbol.
Symbols with the same name may exist in different namespaces and designate different referents. For example, many English words, such as "move", "cut", or "train", can be seen as an action symbol (a verb), a predicate symbol (an adjective), or an object symbol (a noun) simultaneously. Our view is in line with historic literature, e.g., [29] mentions propositional/constant(=object)/predicate/function symbols, and [30] wrote "The 'wash' ... is a symbol denoting the action required" (an action symbol).
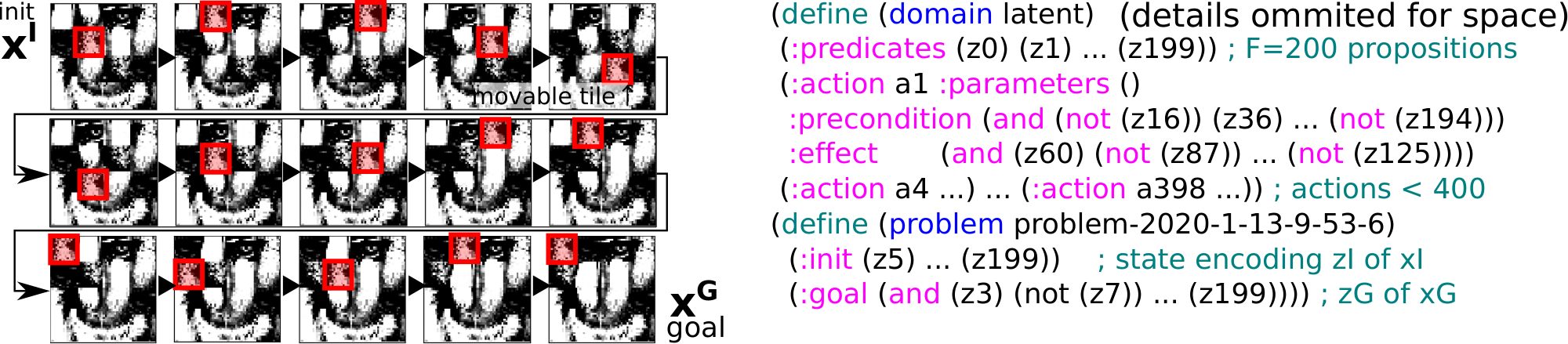
PDDL has at least six kinds (i.e., knowledge bases) of symbols: Propositions, actions, objects, predicates, problems, and domains (Table 1). Each type of symbol requires its own mechanism for grounding. For example, the large body of work on recognizing objects (e.g., individual faces) and their attributes (male, female) in images, or scenes in videos (e.g., cooking), can be viewed as grounding object, predicate and action symbols, respectively. Extensions of PDDL may require more types of symbols, such as numeric fluents in numeric planning [31]. Symbol grounding does not target purely syntactic constructs such as and, or or :requirement that do not need referents. Of six types, we aim to develop mechanisms for propositions and actions because our goal is to generate a propositional classical planning model in a single environment.
Finally, in order to fully avoid the knowledge acquisition bottleneck, a system must generate symbols without human input. The generation of symbols has long been recognized as an imporant aspect of symbol grounding [23]. In contrast to systems which can autonomously generate symbols, systems which does not generate symbols but only grounds symbols given by humans are characterized as parasitic by [24], as such human-provided symbols already impose discrete categorization of the observations.
::: {caption="Table 1: Six types of symbols in a PDDL definition."}
:::
4. Latplan: Overview of the System Architecture
Section Summary: Latplan is a two-phase system that performs classical AI planning directly from raw image data rather than hand-written symbolic models. In the training phase a neural network learns to translate images into compact bit-vector state descriptions and to extract transition rules, after which a PDDL domain file is generated automatically. During planning the same network converts start- and goal-images into symbolic states, an off-the-shelf planner finds a sequence of actions, and the resulting state trace is converted back into a human-readable image animation.
Latplan is a framework for domain-independent classical planning in environments where symbolic input (PDDL models) are unavailable and only subsymbolic sensor input (e.g., images) are accessible. Latplan operates in two phases: The training phase and the planning phase. Its abstract pipeline is described in Algorithm 1. The rest of the section describe the role of each abstract procedure, although the details may vary depending on the implementation.
Training Phase:
**Require:** Dataset X, untrained machine learning model M
Trained model M' ← TRAIN(M, X)
M' provides functions ENCODE and DECODE.
PDDL domain file D ← GENERATEDOMAIN(M')
**return** M', D
Planning Phase:
**Require:** M', D, initial state observation {xᴵ, goal state observation {xᴳ
Encode {xᴵ, {xᴳ into propositional states {zᴵ, {zᴳ
PDDL problem file P ← GENERATEPROBLEM({zᴵ, {zᴳ)
Plan π=(a₀, a₁, …, ) ← SOLVE(P, D) using a planner (e.g., Fast Downward)
State trace ({zᴵ= z⁰, z¹⁼a₀(z⁰), z²⁼a₁(z¹), …, {zᴳ) ← SIMULATE(π, {zᴵ, D)
using a plan validator for PDDL, e.g., VAL ([32]).
**return** Decode an observation trace ({xᴵ= x⁰, x¹, x², …, {xᴳ).
4.1 Training Phase
In the training phase, it first trains a model $M$ which learns state representations and transition rules of the environment entirely from subsymbolic state transition data $\mathcal{X}$ (e.g., image-based observations) using deep neural networks (2). This is done by an abstract procedure $\textsc{train}$ which obtains a trained model $M'$. $M'$ provides a function $\textsc{encode}$ that maps subsymbolic observations into symbolic states, and a function $\textsc{decode}$ that maps symbolic states back to subsymbolic visualization (3). Then we produce a PDDL domain file $D$ using an abstract procedure $\textsc{generateDomain}$ (4).
$\mathcal{X}$ is a set of pairs of observations (e.g., raw image data) sampled from the environment. The $i$-th pair in the dataset ${\bm{x}}^{i}=({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1}) \in \mathcal{X}$ is a transition from an observation ${\bm{x}}^{i, 0}$ to another observation ${\bm{x}}^{i, 1}$ caused by an unknown high-level action. As discussed in Section 3, there are mainly three key challenges in training Latplan: (1) generating and grounding propositional symbols, (2) generating and grounding action symbols, and (3) acquiring a descriptive action model. The first challenge arises because we have no access to the state representation. The second challenge arises because we have no access to the action labels that caused the transitions. The third challenge arises because no symbolic representation of the action is available.
Challenge (1) is addressed by a State AutoEncoder (SAE) (Figure 3) neural network that learns a bidirectional mapping between subsymbolic raw data ${\bm{x}}$ (e.g., images) and propositional states ${\bm{z}}\in{\left{0, 1\right}}^F$, i.e., $F$-dimensional bit vectors. This generates and grounds propositional symbols to feature extractors encoding complex patterns found in the image. The network consists of two functions $\textsc{encode}$ and $\textsc{decode}$, where $\textsc{encode}$ encodes an image ${\bm{x}}$ to a bit vector ${\bm{z}}$, and $\textsc{decode}$ decodes ${\bm{z}}$ back to an image $\tilde{{\bm{x}}}$. These are trained so that $\tilde{{\bm{x}}}\approx {\bm{x}}$ holds.
Challenge (2) and (3) are more intricate, and we propose four variants of action model acquisition methods. The mapping $\textsc{encode}$ from ${\left{\ldots {\bm{x}}^{i, 0}, {\bm{x}}^{i, 1}\ldots\right}}$ to ${\left{\ldots {\bm{z}}^{i, 0}, {\bm{z}}^{i, 1}\ldots\right}}$ provides a set of propositional transitions ${\bm{z}}^{i}=({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})\in \mathcal{Z}$. Using $\mathcal{Z}$, action model acquisition methods have to learn not only action symbols but also their transition rules. The four variants, in increasing order of sophistication, are as follows.
- $\textsc{generateDomain}$ of AMA$_1$ applies the SAE to pairs of image transitions to obtain propositional transition ${\bm{z}}^{i}$ and directly converts each ${\bm{z}}^{i}$ to a ground STRIPS action. For example, in a state space represented by 2 latent space propositions ${\bm{z}}=({\bm{z}}_1, {\bm{z}}_2)$, a transition from ${\bm{z}}^{i, 0}=(0, 1)$ to ${\bm{z}}^{i, 1}=(1, 0)$ is translated into an action with $\textsc{pos}(a)= {\left{{\bm{z}}_2\right}}, \textsc{neg}(a)= {\left{{\bm{z}}_1\right}}, \textsc{add}(a) = {\left{{\bm{z}}_1\right}}, \textsc{del}(a) = {\left{{\bm{z}}_2\right}}$. AMA$_1$ is developed to demonstrate the feasibility of using SAE-generated propositional symbols directly with existing planners. While it successfully demonstrates the feasibility, AMA$_1$ is impractical in that it does not generalize $\mathcal{X}$: AMA$_1$ only encodes the transitions (ground actions) in the training data $\mathcal{X}$. Thus, generating an AMA$_1$ model which can be used to find a path between an arbitrary start and goal state (assuming such a path exists in the domain) requires that $\mathcal{X}$ contains the transitions necessary to form such a path – in the worst case, this may require the entire state space (i.e., all possible valid image transitions) as input. Furthermore, the size of the PDDL model is proportional to the number of transitions in the state space, slowing down the planning preprocessing and heuristic calculation at each search node. In other words, AMA$_1$ only addresses the challenge (1) (using SAE).
- AMA$_2$ is a neural architecture that jointly learns action symbols and action models from a small subset of transitions in an unsupervised manner. It learns a black-box successor generation function, which, given a latent space symbolic state, returns its successors. Unlike existing methods, AMA$_2$ does not require high-level action symbols as part of the input. While AMA$_2$ is a general approach to learning a successor function which does not make strong assumptions about the domain (e.g., STRIPS assumptions), this limits its applicability to classical planning because it does not produce PDDL-compatible action descriptions and it cannot implement $\textsc{generateDomain}$; it is incompatible with PDDL-based solvers and cannot leverage existing implementations of domain-independent heuristics. It requires a search algorithm implementation which does not require descriptive action models, such as novelty-based planners [33], or a best-first search algorithm with trivial heuristics which work with AMA$_2#39;s black-box limitation, such as Goal Count heuristics [34]. In other words, AMA$_2$ addresses the challenge (1) and (2).
- AMA$_3^+$ is a neural architecture that improves AMA$_2$ so that the resulting neural network can be directly compiled into a descriptive action model (PDDL). AMA$_3^+$ builds on the previously published AMA$_3$ to provide an architecture and an optimization objective that are theoretically motivated by the Evidence Lower BOund (ELBO). AMA$_3^+$ has a neural network component that exclusively models the STRIPS/PDDL-compatible action effects and can implement $\textsc{generateDomain}$, but it requires a separate, ad-hoc process for generating preconditions. In other words, it addresses the challenge (3), but only partially.
- AMA$_4^+$, which we propose in this paper, is an enhancement of AMA$_3^+$ with a new ability to learn and emit STRIPS/PDDL-compatible preconditions. Unlike AMA$_3^+$, it does not require a separate, ad-hoc process which results in less accurate preconditions. AMA$_4^+$ models the state space with complete state regression semantics, which is inspired by SAS+ formalism [35]. This finally addresses all of challenges (1), (2), and (3).
We reemphasize that each new model inherits the entire components of its predecessor: SAE in AMA$1$ is included in AMA$2$ and later, AAE in AMA$2$ is included in AMA${3}^+$ and later as a subnetwork, and finally, AMA${4}^+$ contains AMA${3}^+$ as a subnetwork. Therefore, understanding each earlier variant is important for understanding the full potential and mechanics of our most sophisticated model AMA$_{4}^+$.
4.2 Planning Phase
In the planning phase, Latplan takes as input a planning input $({{\bm{x}}^{I}}, {{\bm{x}}^{G}})$, a pair of subsymbolic observations (raw data, images) corresponding to an initial and goal state of the environment. We first apply $\textsc{encode}$ to each observation and obtain their symbolic representations (2). An abstract procedure $\textsc{generateProblem}$ then generates a PDDL problem file containing these symbolic initial and goal states (3). An abstract procedure $\textsc{solve}$ then solves the problem in the learned symbolic state space and returns a symbolic plan, using an off-the-shelf planner such as Fast Downward [36] (4). It then obtains a propositional intermediate state trace $({{\bm{z}}^{I}}, \ \ldots, \ {{\bm{z}}^{G}})$ of the plan by applying a plan simulator ($\textsc{simulate}$) to the symbolic initial state and the symbolic plan (6).
While we have a symbolic state trace at this point, they are not interpretable for a human observer, which is an issue. This is primarily because the states in the state trace are generated by SAE neural network which was trained unsupervised — each bit of the state has a "meaning" in the latent space determined by the neural network, which does not necessarily directly correspond to human-interpretable notions. Furthermore, the "actions" in the plan trace are transitions according to the AMA, but are not necessarily directly interpretable by a human. In order to make the plan generated by Latplan understandable to a human (or other agents outside Latplan), Latplan outputs a step-by-step visualization of the plan execution, $({{\bm{x}}^{I}}, \ \ldots, \ {{\bm{x}}^{G}})$ (e.g. Figure 2), by decoding the latent bit vectors for each intermediate state in $({{\bm{z}}^{I}}, \ \ldots, \ {{\bm{z}}^{G}})$ (7).
While we present an image-based implementation ("data" = raw images), the architecture itself does not make such assumptions and could be applied to other types of data such as audio/text.
5. State AutoEncoder (SAE) for Propositional Symbol Grounding
Section Summary: The section introduces a State AutoEncoder, implemented as a discrete variational autoencoder, that learns to translate raw images of an environment into binary propositional symbols usable by logical planners and to reconstruct images from those symbols. This satisfies practical needs such as generalizing to unseen states, producing consistent outputs for similar inputs, and supporting bidirectional mapping between pixels and logic. The authors observe that a basic version yields unstable symbols that flip unpredictably and therefore outline two targeted improvements to make the representations reliable for planning.
This section presents a method to a propositional representation of a real-world environment on which a planning solver can perform logical reasoning. We believe such a representation must satisfy the following three properties to be practical:
- The ability to describe unseen world states using the same symbols,
- Similar images for "the same world state" should map to the same representation,
- The ability to map symbolic states back to images.
For example, one may come up with a trivial method to simply discretize the pixel values of an image array or to compute an image hash function. Such a trivial representation lacks robustness and the ability to generalize.
In the following, Section 5.1 presents a State AutoEncoder (SAE) as a framework to address propositional symbol grounding by a discrete VAE. As elaborated in Section 5.2, we find that its naive implementation is unfavorable to a planning system because of unstable symbols caused by two sources of uncertainty. Section 5.3-Section 5.4 present two methods to address them.
5.1 Naive State AutoEncoder
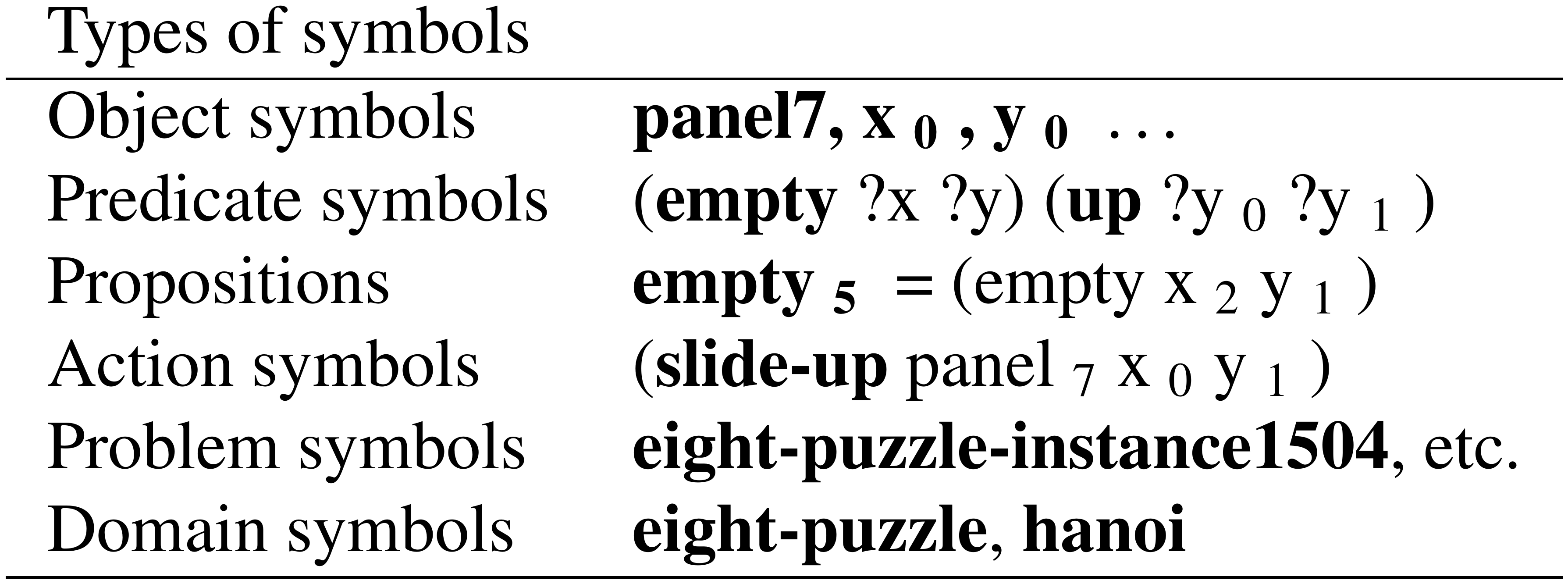
Our first technical contribution is a State AutoEncoder (SAE) implemented by a discrete VAE (Figure 3), which allows us to obtain a propositional representation satisfying the three requirements described above. Our key observation is that the categorical variables modeled by discrete VAEs are compatible with symbolic reasoning systems. For example, binary latent variables of Binary-Concrete VAE can be used as propositional symbols in STRIPS language, providing a solution to the propositional symbol grounding, i.e., generation and grounding of propositional symbols.
The trained SAE provides an approximation of a bidirectional mapping $f, f^{-1}$ between the raw inputs (subsymbolic representation) and their symbolic representations:
- ${\bm{z}}=f({\bm{x}})$ maps an image ${\bm{x}}\in \mathbb{R}^{H \times W \times C}$ to a boolean vector ${\bm{z}}\in \mathbb{B}^F$.
- $\tilde{{\bm{x}}}\approx f^{-1}({\bm{z}})$ maps a boolean vector ${\bm{z}}$ to an image $\tilde{{\bm{x}}}$.
Here, $H, W, C$ represents the height, the width, and the number of color channels of the image. $f({\bm{x}})$ maps a raw input ${\bm{x}}$ to a symbolic representation by feeding the raw input to the encoder network which ends with a Binary Concrete activation, resulting in a binary vector of length $F$. $f^{-1}({\bm{z}})$ maps a binary vector ${\bm{z}}$ back to an image. These are lossy compression/decompression functions, so in general, $\tilde{{\bm{x}}}$ may have an acceptable amount of errors from ${\bm{x}}$ for visualization.
In order to map an image to a latent state with sufficient accuracy, the latent layer requires a certain capacity. The lower bound of the number of propositional variables $F$ is the encoding length of the states, i.e., $F \geq \log_2 {\left|S\right|}$ for a state space $S$. In practice, however, obtaining the most compact representation is not only difficult but also unnecessary, and we use a hyperparameter $F$ which could be significantly larger than $\log_2 {\left|S\right|}$.
It is not sufficient to simply use traditional activation functions such as sigmoid or softmax and round the continuous activation values in the latent layer to obtain discrete 0/1 values. In order to map the propositional states back to images, we need a decoding network trained for 0/1 values. A rounding-based scheme would be unable to restore the images because the decoder is not trained with inputs near 0/1 values. Also, simply using the rounding operation as a layer of the network is infeasible because rounding is non-differentiable, precluding backpropagation-based training of the network. Furthermore, as we discuss in Appendix C, AEs with Straight-Through step function is known to be outperformed by VAEs in terms of accuracy, and its optimization objective lacks theoretical justification as a lower bound of the likelihood.
The SAE implementation can easily and significantly benefit from progress made by the image processing community. We augmented the VAE implementation with a GaussianNoise layer to add noise robustness [37], as well as Batch Normalization [38] and Dropout [39], which helps faster training under high learning rates (see experimental details in Section 10.2).
5.2 The Symbol Stability Problem: Issues Caused by Unstable Propositional Symbols
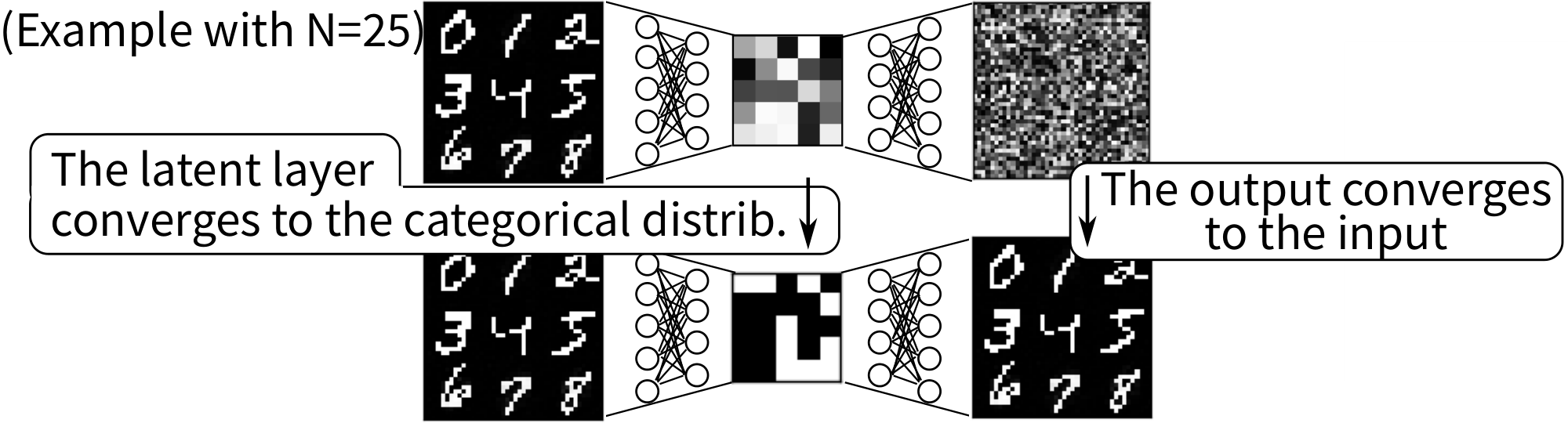
Propositional representations learned by Binary Concrete VAEs in the original form proposed and evaluated by ([21, 22]) have a problematic behavior that makes them less suitable for propositional reasoning. While the SAE can reconstruct the input with high accuracy, the learned latent representations are not "stable, " i.e., some propositions may flip the value (true/false) randomly given identical or nearly identical image inputs (Figure 4).
The core issue with the vanilla Binary Concrete VAEs is that the class probability for the class "true" and the class "false" could be neutral (e.g., around 0.5) at some neuron, causing the value of the neuron to change frequently due to the stochasticity of the system. The source of stochasticity is twofold:
- Systemic/epistemic uncertainty: The first source is the random sampling in the network, which introduces stochasticity and causes the propositions to change values even for the exact same inputs.
- Statistical/aleatoric uncertainty: The second source is the stochastic observation of the environment, which corrupts the input image. When the class probabilities are almost neutral, a tiny variation in the input image may cause the activation to cross the decision boundary for each neuron, causing bit flips. In contrast, humans still regard the corrupted image as the "same" image.
These unstable symbols are harmful to symbolic reasoning because they break the identity assumption built into the recipient symbolic reasoning algorithms such as classical planners. It causes several issues: Firstly, the performance of search algorithms (e.g., $A^*$) that run on the state space generated by the propositional vectors are degraded by multiple propositional states which correspond to the same real-world state. As standard symbolic duplicate detection techniques would treat such spurious representations of the same state as different states, the search algorithm can unnecessarily re-expand the "same" real-world state several times, slowing down the search.

Secondly, the state space could be disconnected due to such random variations (Figure 5). Some states may be reachable only via a single variation of the real-world state and are not connected to another propositional variation of the same real-world state. One way to circumvent this phenomenon is state augmentation, which samples the propositional states at every node by decoding and encoding the current state several times. This is inefficient, and is also infeasible in the standard PDDL-based classical planners that operate completely in the propositional space.
Thirdly, in order to reduce the stochasticity of the propositions, we encounter a hyperparameter tuning problem which is costly when we train a large NN. The neurons that behave randomly for the same or perturbed input do not affect the output, i.e., they are unused and uninformative. Unused neurons appear because the network has an excessive capacity to model the entire state space, i.e., they are surplus neurons. Therefore, a straightforward solution to address this issue is to reduce the size of the latent space $F$. On the other hand, if $F$ is too small, it lacks the capacity to represent the state space, and the SAE no longer learns to reconstruct the real-world image. Thus we need to find an ideal value of $F$, a costly and difficult hyperparameter tuning problem.
These unstable propositional symbols indicate that the Binary Concrete VAE learns the mapping between images and binary representations as a many-to-many relationship. While this property has not been considered as a major issue in the machine learning community where accuracy is the primary consideration, its unstable latent representation poses a significant impediment to the reasoning ability of the planners. Unlike machine learning tasks, symbolic planning requires a mapping that abstracts many images into a single symbolic state, i.e., many-to-one mapping. To this end, it is necessary to develop an autoencoder that learns a many-to-one relationship between images and binary representations.
Fundamentally, the first two harmful effects are caused by the fact that the representation learned by a standard Binary Concrete VAE lacks a critical feature of symbols, designation [10], that each symbol uniquely designates a referent, e.g., the referents of the symbols grounded by SAEs are the truth assignments based on visual features. If the grounding (meaning) of a symbol changes frequently and unexpectedly, the entire symbolic manipulation is fruitless because the underlying symbols are not tied to any particular concept and do not represent the real-world.
Thus, for a symbol grounding procedure to produce a set of symbols for symbolic reasoning, it is not sufficient to find a set of symbols that can be mapped to real states in the environment; It should find a stable symbolic representation that uniquely represents the environment.
########## {caption="Definition"}
A symbol is stable when its referents are identical for the same observation, under some equivalence relation (e.g., invariance or noise threshold on the observation).
########## {caption="Example 1"}
A propositional symbol points to a boolean value. The value should not change under the same real-world state and its noisy observations.
########## {caption="Example"}
A symbolic state ID points to a set of propositions whose values are true. The content of the set should be the same under the same real-world state and its observations.
########## {caption="Example"}
A symbolic action label points to a tuple containing an action definition (e.g., preconditions). It should point to the same action definition each time it observes the same state transition.
########## {caption="Example 2"}
Say that a real-world state $s_1$ transitions to another state $s_2$ by performing a certain symbolic action $a$. The representation obtained by applying the symbolic action definition of $a$ to the symbolic representation of $s_1$ should be equivalent to the symbolic representation directly observed from $s_2$.
The stability of the representation obtained by a NN depends on its inherent (systemic, epistemic) stochasticity of the system during the runtime (as opposed to the training time) as well as the stochasticity of the environment (statistical, aleatoric). Thus, any symbol grounding system potentially suffers from the symbol stability problem. As for the stochasticity of the environment, in many real-world tasks, it is common to obtain stochastic observations due to external interference, e.g., vibrations of the camera caused by the wind. As for the stochasticity of the network, both VAEs [19, 21, 20] used in Latplan and GANs (Generative Adversarial Networks) [40] used in Causal InfoGAN [41] rely on sampling processes.
The stability of the learned representation is orthogonal to the robustness of the autoencoder because unstable latent variables do not always cause bad reconstruction accuracy. The reason that random latent variables do not harm the reconstruction accuracy is that the decoder pipeline of the network learns to ignore the random neurons by assigning a negligible weight. This indicates that unstable propositions are also "unused" and "uninformative."
While this issue is similar to posterior collapse [42, 43], which is also caused by ignored latent variables, an important difference is that the latter degrades the reconstruction (makes it blurry) because there are too many ignored variables. In contrast, the symbol stability issue is significant even if the reconstruction is successful.
5.3 Addressing the Systemic Uncertainty: Removing the Run-Time Stochasticity
The first improvement we made from the original GS-VAE/BC-VAE is that we can disable the stochasticity of the network in the test time. After the training, we replace the Gumbel-softmax activation with a pure argmax of class probabilities, which makes the network fully deterministic.
$ \textsc{GS}_{\tau}({\bm{l}}) \rightarrow \operatorname{arg, max}({\bm{l}}). \quad({\bm{l}} \in \mathbb{R}^{F\times C}) $
Again note that we assume $\operatorname{arg, max}$ returns a one-hot representation rather than the index of the maximum value. In this form, there is no systemic uncertainty due to the Gumbel noise. In Binary Concrete, this is equivalent to using Heaviside step function:
$ \textsc{BC}_{\tau}({\bm{l}}) \rightarrow \textsc{step}({\bm{l}}). \quad({\bm{l}} \in \mathbb{R}^{F}) $
Similarly, there is no systemic uncertainty due to the Logistic noise in this form.
5.4 Addressing the Statistical Uncertainty: Selecting the Appropriate Prior
The prior distribution of the original Gumbel-Softmax VAE is a uniform random categorical distribution $\mathbf{Cat}(\bm{1}/C)$, and the prior distribution of the original Binary-Concrete VAE is a uniform random Bernoulli distribution $\text{Bernoulli}(0.5)$. By optimizing the ELBO with stochastic gradient descent algorithms, the KL divergence $D_{\mathrm{KL}}(q({\bm{z}}| {\bm{x}})\mathrel{|} p({\bm{z}}))$ in the ELBO moves the encoder distribution $q({\bm{z}}| {\bm{x}})$ closer to the target distribution (prior distribution) $p({\bm{z}})= \text{Bernoulli}(0.5)$. Observe that this objective encourages the latent representation to be more random, as $\text{Bernoulli}(0.5)$ is the most random distribution among $\text{Bernoulli}(p)$ for all $p$.
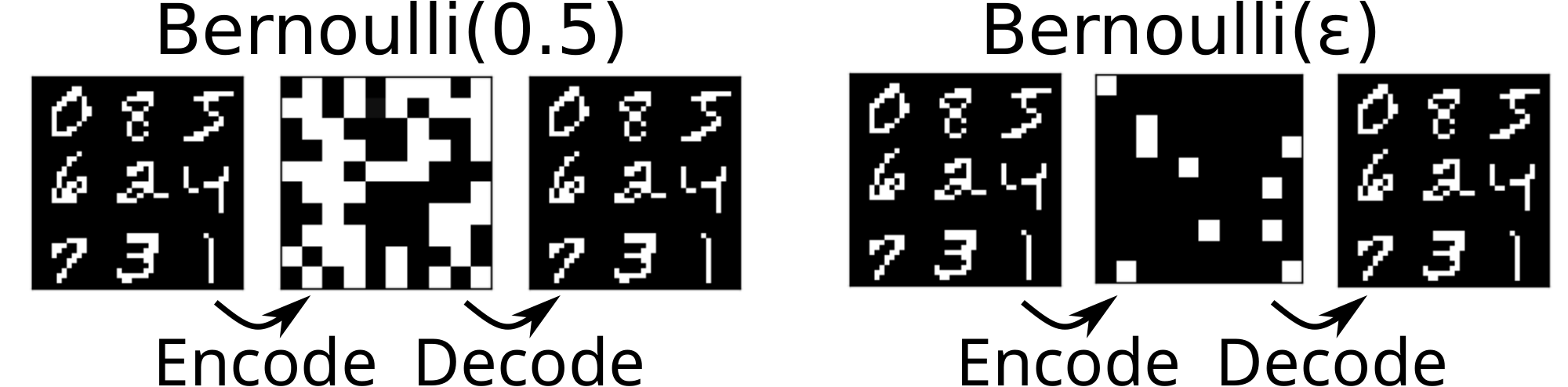
To tackle the instability of the propositional representation, we propose a different prior distribution $p({\bm{z}})$ for the latent random variables: $p({\bm{z}})= \text{Bernoulli}(0)$ (Figure 6). Its key insight is to penalize the latent propositions for unnecessarily becoming true while preserving the propositions that are absolutely necessary for maintaining the reconstruction accuracy. In practice, however, since computing the KL divergence with $p({\bm{z}})= \text{Bernoulli}(0)$ causes a division-by-zero error in the logarithm, we instead use $p({\bm{z}})= \text{Bernoulli}(\epsilon)$ for a small $\epsilon$ (e.g., 0.1, 0.01).
We formalize the notions above as follows. Consider a case where ${\bm{z}}$ is a 1-dimensional scalar $z$. The KL divergence $D_{\mathrm{KL}}(q(z| {\bm{x}})\mathrel{|} p(z))$ with $p(z)= \text{Bernoulli}(0.5)$ and $q=q(z=1| {\bm{x}})= \textsc{sigmoid}(\textsc{encode}({\bm{x}}))$ is as follows (Section 2.4):
$ \begin{aligned} \sum_{k\in{0, 1}} q(z=k| {\bm{x}}) \log\frac{q(z=k| {\bm{x}})}{p(z=k)} = q\log\frac{q}{0.5}+(1-q)\log\frac{(1-q)}{(1-0.5)} &=-H(q) + \log 2. \end{aligned} $
$H(q)$ is an entropy of the probability $q$, which models the randomness of $q$. Therefore, minimizing the KL divergence is equivalent to maximizing the entropy, which encourages the latent vector $z\sim q(z| {\bm{x}})$ to be more random. The KL divergence with $p(z)= \text{Bernoulli}(\epsilon)$ results in a form
$ \begin{aligned} q\log\frac{q}{\epsilon}+(1-q)\log\frac{(1-q)}{(1-\epsilon)} &=-H(q) + \alpha \cdot q - \log (1-\epsilon) \end{aligned}\tag{5} $
for $\alpha=\log (1-\epsilon)-\log \epsilon$. When $\alpha > 0 \ (\epsilon<\frac{1}{2})$, this form shows that minimizing the KL divergence has an additional regularization pressure to move $q$ toward 0.
Intuitively, this optimization objective assumes a variable to be false when there is not enough "evidence" from the input image to flip a variable to true. The evidence in the data detected as a combination of complex patterns by the neural network declares some variables to be true if the evidence is strong enough. This resembles closed-world assumption [44] where propositional variables (generated by grounding a set of first order logic formulae with terms) are assumed to be false unless it is explicitly declared or proven to be true. The difference is whether the declaration is implicit (performed by the encoder using the input data) or explicit (encoded manually by human, or proved by a proof system).
In contrast, the optimization objective made by the original prior distribution $p(z)= \text{Bernoulli}(0.5)$ makes a latent proposition highly random when there is neither the evidence for it to be true nor the evidence for it to be false. Since a uniform binary distribution $\text{Bernoulli}(0.5)$ carries no information about either the truthfullness or the falsifiability of the proposition, thus a variable having this distribution can be seen as in an "unknown" state. Again, this resembles an open-world assumption where a propositional variable that is neither declared true or false are put in an unknown state.
We discuss the difference from an ad-hoc method presented in the conference version ([16])
in Appendix E.
6. AMA1: An SAE-based Translation from Image Transitions to Ground Actions
Section Summary: The section describes AMA1, a basic method that uses a sparse autoencoder to convert pairs of images showing valid state changes into a grounded PDDL planning model. Each image pair is encoded into binary propositions that become an action's preconditions and effects based on their differences, allowing a standard planner to chain observed transitions from a start image to a goal image. This works only for transitions already seen in the data and offers no way to generalize or invent reusable action templates, so the approach is mainly of theoretical interest.
An SAE by itself is sufficient for a minimal approach to generating a PDDL definition for a grounded STRIPS planning problem from image data. Given a pair of images ${\bm{x}}^{i}=({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ which represents a valid transition in the domain, we can apply the SAE to ${\mathbf{x}}^{0}$ and ${\mathbf{x}}^{1}$ to obtain ${\bm{z}}^{i, 0}$ and ${\bm{z}}^{i, 1}$, the latent-space propositional representations of these states.
The transition $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1}) \in \mathcal{Z}$ can be directly translated to an action ${\bm{a}}^{i}$ as follows: each bit ${\bm{z}}^{i, j}_f$ ($f\in 1..F, j\in 0..1$) in a boolean vector ${\bm{z}}^{i, j}$ is mapped to a proposition (z$_f$) when the value is 1, or to its negation (not (z$_f$)) when the value is 0. The elements of a bitvector ${\bm{z}}^{i, 0}$ are directly used as the preconditions of action ${\bm{a}}^{i}$ using negative precondition extension of STRIPS. The add/delete effects of the action are obtained from the bitwise differences between ${\bm{z}}^{i, 0}$ and ${\bm{z}}^{i, 1}$. For example, when $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})=(0011, 0101)$, the action definition would look like
(:action action-0011-0101
:preconditions (and (not (z0)) (not (z1)) (z2) (z3))
:effects (and (z1) (not (z2))))
Given a set of image pairs $\mathcal{X}$, AMA$_1$ directly maps each image transition to a STRIPS action as described above. The initial and the goal states are similarly created by applying the SAE to the initial and goal images and encoding them into a PDDL file, which can be input to an off-the shelf planner. If $\mathcal{X}$ contains images for a sufficient portion of the state space containing a path from the initial and goal states, then a planner can find a satisficing solution. If $\mathcal{X}$ includes image pairs for all valid transitions, then an optimal solution can be found using an admissible search algorithm. However, collecting such a sufficient of transitions $\mathcal{X}$ is impractical in most domains. Thus, AMA$_1$ is of limited practical utility, as it only provides the planner with a grounded model of state transitions which have already been observed – this lacks the key ability to generalize from grounded observations and predict/project previously unseen transitions, i.e., AMA$_1$ lacks the ability to generate more general action schemas.
7. AMA2: Action Symbol Grounding with an Action Auto-Encoder (AAE)
Section Summary: The AMA2 approach uses an unsupervised Action Autoencoder neural network to learn a set of discrete action symbols directly from limited examples of image pairs that show state transitions. The encoder assigns an action label to each transition while the decoder learns to predict the resulting successor image, allowing the model to act as a black-box generator of possible next states for forward search algorithms in visual planning tasks. Although this enables solving problems in image-based domains, the resulting non-symbolic model resists conversion into explicit formats such as PDDL and cannot easily support standard goal-directed heuristics.
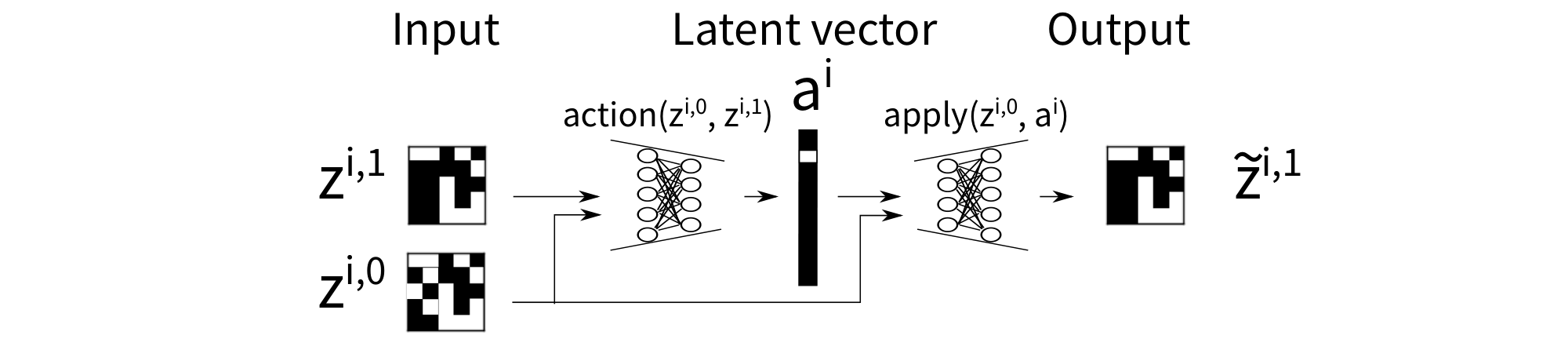
Next, we propose an unsupervised approach to acquiring an action model from a limited set of examples (image transition pairs). AMA$_2$ contains a neural network named Action Autoencoder (AAE, Figure 7). The AAE jointly learns action symbols and the corresponding effects and provides an ability to enumerate the successors of a given state, i.e., it can be used as a black-box successor function for a forward state space search algorithm. The key idea is that the successor predictor can be trained along with the action predictor by a variant of Gumbel-Softmax VAE.
- The encoder $\textsc{action}({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})$ samples an action label ${\bm{a}}^{i}$ for a state transition $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})$.
- The decoder $\textsc{apply}({\bm{a}}^{i}, {\bm{z}}^{i, 0})$ applies ${\bm{a}}^{i}$ to ${\bm{z}}^{i, 0}$ and samples a successor $\tilde{{\bm{z}}}^{i, 1}$. Thus the decoder network can be seen as modeling the effect of each action, which represents what change should be made to ${\bm{z}}^{i, 0}$ due to the application of the action.
- It takes a concatenated vector ${\bm{z}}^{i, 0}; {\bm{z}}^{i, 1}$ of a state transition pair $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})$ and returns a reconstruction $\tilde{{\bm{z}}}^{i, 1}$. The output layer is activated by a sigmoid function. The training is performed by minimizing the loss $\mathcal{L}({\bm{z}}^{i, 1}, \tilde{{\bm{z}}}^{i, 1}) + D_{\mathrm{KL}}$. The reconstruction loss $\mathcal{L}$ is a Binary Cross Entropy loss because predicting a binary successor state is equivalent to multinomial classification. The KL divergence is a standard one for Gumbel-Softmax.
- Unlike typical Gumbel-Softmax VAEs, which contain multiple ($n$-way) one-hot vectors in the latent space, AAE has a single (1-way) one-hot vector of $A$ classes, representing an action label ${\bm{a}}^{i}\in \mathbb{B}^A$. $A$ is a hyperparameter for the maximum number of action labels to be learned.
The number of labels $A$ serves as an upper bound on the number of action symbols learned by the network. We tend to use a large value for $A$ because (1) too few labels make AAE reconstruction loss fail to converge to zero, and (2) even if a large $A$ is given, AAE tends to use the available set of labels $1..A$ frugally and leave the excess labels unused. We remove those unused labels after the training by iterating through the dataset and checking which labels were used.
Our earlier conference paper showed that AMA$_2$ could be used to successfully learn an action model for several image-based planning domains, and that a forward search algorithm using AMA$_2$ as the successor function could be used to solve planning instances in those domains [15].
AMA$_2$ provides a non-descriptive, black-box neural model as the successor generator, instead of a descriptive, symbolic model (e.g., PDDL model). A black-box action model can be useful for exploration-based search algorithms such as Iterated Width [33]. On the other hand, the non-descriptive, black-box nature of AMA$_2$ has a drawback: The lack of a descriptive model prevents the use of existing, goal-directed heuristic search techniques, which are known to further improve the performance when combined with exploration-based search [45].
To overcome this problem, we could try to translate/compile such a black-box model into a descriptive model usable by a standard symbolic problem solver. However, this is not trivial. Converting an AAE learned for a standard STRIPS domain to PDDL can result in a PDDL file which is several orders of magnitude larger than typical PDDL benchmarks. This is because the AAE has the ability to learn an arbitrarily complex state transition model. The traditional STRIPS progression $\textsc{apply}(s, a)= (s \setminus \textsc{del}(a)) \cup \textsc{add}(a)$ disentangles the effects from the current state $s$, i.e., the effect $\textsc{add}(a)$ and $\textsc{del}(a)$ are defined entirely based on action $a$. In contrast, the AAE's black-box progression $\textsc{apply}({\bm{a}}^{i}, {\bm{z}}^{i, 0})$ does not offer such a separation, allowing the model to learn arbitrarily complex conditional effects. For example, we found that a straightforward logical translation of the AAE with a rule-based learner (e.g., Random Forest [46]) results in a PDDL that cannot be processed by modern classical planners due to the huge file size and exponential compilation of disjunctive formula [47].
8. AMA3/AMA3+: Descriptive Action Model Acquisition with Cube-Space AutoEncoder
Section Summary: The section introduces the Cube-Space AutoEncoder architecture, which learns a compact state representation and a STRIPS-compliant action model together from small numbers of raw image pairs, then exports a ready-to-use PDDL file for classical planners. It improves on AMA2 by performing joint rather than staged training and by embedding the discrete, add/delete semantics of STRIPS directly into the network, so that valid preconditions and effects can be read out without further post-processing. The authors first present a simpler “vanilla” autoencoder whose training objective is a theoretically justified lower bound on the likelihood of the observed transitions, then insert the structural prior that yields the final AMA3/AMA3+ model.
We now propose the Cube-Space AutoEncoder architecture (CSAE), which can generate a standard PDDL model file from a limited set of observed image transitions for domains which conform to STRIPS semantics. There are two major technical advances from AMA$_2$. First, CSAE jointly learns a state representation and an action model, whereas AMA$_2$ learns a state representation first and learns the action model on the fixed state representation. As often pointed out in the machine learning literature, the joint learning is expected to improve the performance. Second, CSAE constrains the action model to the STRIPS semantics. Thus we can trivially extract STRIPS/PDDL-compatible action effects from the trained CSAE, providing a grounded PDDL that is immediately usable by off-the-shelf planners. We implement the restriction as a structural prior that replaces the MLP decoder $\textsc{apply}$ in the AAE. Due to the joint training, the state space shapes itself to satisfy the constraints of the action model.
We will refer to the previously published version of Cube-Space AE [17] as AMA$_3$, and the updated version presented here as AMA$_3^+$. The architecture and the objective function of AMA$_3$ were neither theoretically analyzed in [17], nor were designed with theoretical justification in mind. AMA$_3^+$ revises AMA$_3$ by providing a theoretically sound optimization objective and architecture.
This section proceeds as follows: In Section 8.1, we introduce Vanilla Space AutoEncoder, which performs a joint training of the state and action models in AMA$_2$, but without the novel structure in CSAE that restricts the action model. We define its training objective which is theoretically justified as a lower bound of the log likelihood of observing the data. In Section 8.3, we formally introduce CSAE by inserting a structural prior to Vanilla Space AE. Section 8.3 shows that the CSAE generates a STRIPS model. Section 8.3 briefly discuss how to extract the action effects and preconditions from CSAE. In the following, we always omit the dataset index $^i$.
8.1 Vanilla Space AutoEncoder
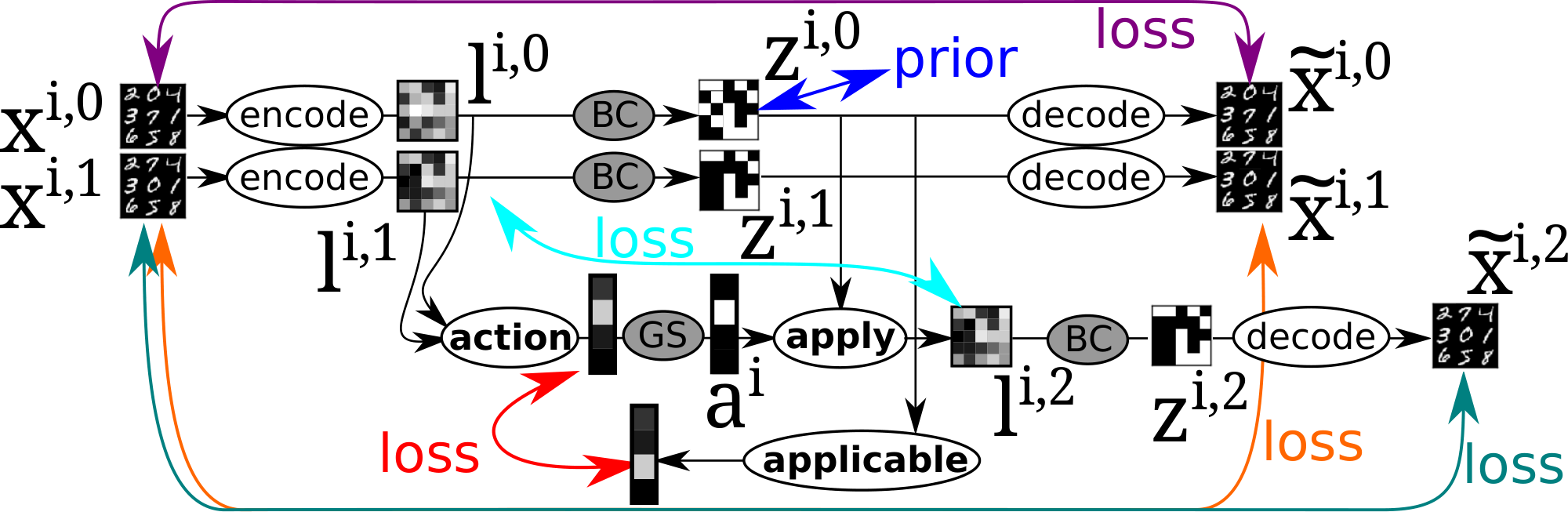

Vanilla Space AE (Figure 8) is a network representing a function of two inputs ${\bm{x}}^{i, 0}, {\bm{x}}^{i, 1}$ and three outputs ${\tilde{{\bm{x}}}}^{i, 0}, {\tilde{{\bm{x}}}}^{i, 1}, {\tilde{{\bm{x}}}}^{i, 2}$. It consists of several subnetworks: $\textsc{encode}, \textsc{decode}, \textsc{action}, \textsc{apply}, \textsc{applicable}$. $\textsc{applicable}$ is a new subnetwork that was missing AMA$_3$ and is necessary for using a theoretically justifiable optimization objective (ELBO). The data pipeline from the input to the output is defined in Figure 9. $\textsc{applicable}$ is not used in this main pipeline because it is used only for regularizing the network during the training, and is not used in the test time where we generate a PDDL output. The network is trained by maximizing $\text{ELBO}({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ defined in Equation 7, where each probability is obtained from the corresponding neural network as defined in the generative model Equation (8) and the variational model Equation (9).
Theoretical Property
Unlike AMA$_3$, the loss function $\text{ELBO}({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ is theoretically justified as the lower bound of the log likelihood $\log p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ of observing a pair of images $({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$, following Maximum Likelihood Estimation (MLE) and variational inference framework (Section 2.3). An important implication of this theoretical property is that, in theory, when $p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ converges to the ground-truth distribution, Latplan never generates visualizations containing invalid states and invalid transitions. In the ground-truth distribution, $p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})=0$ if $({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ is an invalid transition, or if either ${\bm{x}}^{i, 0}$ or ${\bm{x}}^{i, 1}$ are invalid states. MLE achieves this by maximizing $p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ for real data, which reduces $p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ for invalid data because a probability distribution sums/integrates into 1 ($\int p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})d({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})=1$). Thus, following the MLE framework, which is the current dominant theoretical foundation of machine learning models, converging a lower bound (ELBO) of the log likelihood $\log p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ to the ground-truth distribution guarantees the correctness of the learned results as well as the planning results (due to the soundness of the planner being used).
In practice, this convergence is not achieved and visualized plans do not have a correctness guarantee in a traditional sense. However, note that this is not necessarily a disadvantage of our paradigm, since the use case of this system is where human supervision and manual modeling are not available. Moreover, even human could write a PDDL model with a bug that results in an incorrect modeling.
Interpretation
Equation 7 is not only theoretically justified, but also has a clear interpretation. The first three terms represent reconstruction losses for ${\bm{z}}^{i, 0}, {\bm{z}}^{i, 1}$. The remaining KL divergence terms, which regularizes the training, have the following interpretations: $D_{\mathrm{KL}}(q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0}) \mathrel{|} p({\mathbf{z}}^{0}))$ addresses the stability of propositional symbols learned by SAE due to noise, as discussed in Section 5.2, Example 1. $D_{\mathrm{KL}}(q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{a}}\mid {\mathbf{z}}^{0}))$ addresses applicability of actions (precondition learning). $D_{\mathrm{KL}}(q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}))$ addresses effects of actions and the stability of propositional symbols due to effects, as discussed in Section 5.2, Example 2.
$D_{\mathrm{KL}}(q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{a}}\mid {\mathbf{z}}^{0}))$ compares $q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ and $p({\mathbf{a}}\mid {\mathbf{z}}^{0})$, which are outputs of $\textsc{action}$ and $\textsc{applicable}$, respectively. $q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ is a distribution of an action predicted by observing the states both before and after the transition. In contrast, $p({\mathbf{a}}\mid {\mathbf{z}}^{0})$ is a distribution predicted without observing the result (successor state) of the action. The latter is thus intrinsically ambiguous, and returns a distribution of applicable actions (hence the name of the network). The former, in contrast, can be seen as a distribution of the actual action that happened, having access to the consequence of the action.
By minimizing the KL divergence on the training data, two things happen: First, the distribution of the actual action ($q(\ldots)$) gets closer to applicable actions ($p(\ldots)$) in each transition. Second, the distribution of applicable actions ($p(\ldots)$) is stretched toward various actual actions ($q(\ldots)$) by multiple transitions with the same ${\mathbf{z}}^{0}$ and different ${\mathbf{z}}^{1}$. For example, $p(\ldots)$ could be $1/3$ for each of three applicable actions, while $q(\ldots)$ is one-hot. As a result, informally speaking, the KL divergence is forcing each actual action to be in a set of applicable actions.
$D_{\mathrm{KL}}(q({\mathbf{z}}^{1}= {\bm{z}}^{i, 1}\mid {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{z}}^{1}= {\bm{z}}^{i, 2}\mid {\mathbf{z}}^{0}, {\mathbf{a}}))$ compares $q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})$ and $p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})$, which are both distributions of a latent successor state ${\mathbf{z}}^{1}$. $p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})$ is a distribution of the result of symbolically applying an action to a latent current state (thus is an output of $\textsc{apply}$), and $q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})$ is a distribution of the latent successor state obtained from an observation. By matching them, we maintain the stability of the latent propositions and the correctness of the effects at the same time.
To reduce the length of the paper, more in-depth discussion on the design decision and the derivation of this loss function was moved to the appendix (Appendix F). Readers who are not familiar with machine learning may find the section useful because we describe not only our mathematical derivation, but also the general strategy of statistical modelling which allows one to derive a machine learning model with a principled theoretical justification.
8.2 Cube-Like Graph
The state space modeled by AMA$_2$, and Vanilla Space AE as its end-to-end version, are not specifically designed for generating a compact STRIPS action model, therefore its STRIPS compilation may be exponentially large [47]. To illustrate this issue, we consider the problem of assigning action labels to each edge in the latent space based on node embedding differences caused by action effects. This yields a graph class called Cube-Like Graph, which inspired the name of our new architecture:
########## {caption="Definition 3"}
A cube-like graph ([48]) is a simple[^3] undirected graph $G(S, D)=(V, E)$ defined by sets $S$ and $D$. Each node $v\in V$ is a finite subset of $S$, i.e., $v\subseteq S$. The set $D$ is a family of subsets of $S$, and for every edge $e = (v, w) \in E$, the symmetric difference between the connected nodes belongs to $D$, i.e., $d = v\oplus w = (v\setminus w) \cup (w\setminus v) \in D$.
[^3]: No duplicated edges between the same pair of nodes
For example, a unit cube becomes a cube-like graph if we assign a set to each vertex appropriately as in Figure 10, i.e.,
$ \begin{aligned} S&={\left{x, y, z\right}}, & V&={\left{\emptyset, {\left{x\right}}, \ldots {\left{x, y, z\right}}\right}}, \ E&={\left{(\emptyset, {\left{x\right}}), \ldots ({\left{y, z\right}}, {\left{x, y, z\right}})\right}}, & D&={\left{{\left{x\right}}, {\left{y\right}}, {\left{z\right}}\right}}. \end{aligned} $
The set-based representations can alternatively be represented as bit-vectors, e.g.,
$ V={\left{(0, 0, 0), (0, 0, 1), \ldots (1, 1, 1)\right}}. $
We observed a similarity between STRIPS action models and cube-like graphs, with the difference being that STRIPS action models consider a directed version, i.e., for every edge $e = (v, w) \in E$, their asymmetric differences $(d^+, d^-)=(w \setminus v, v \setminus w)$ satisfy $w=(v \setminus d^-) \cup d^+$, which is typically denoted as $w=(v \setminus \textsc{del}(a)) \cup \textsc{add}(a)$.
Consider the number of actions required in two node embeddings in Figure 10. The first embedding (left and center) requires 3 labels (6 labels if directed), where each label is assigned to 4 parallel edges which share the same node embedding differences. The set of node embedding differences corresponds to the set $D$, and each element of $D$ represents an action, such as $a$ whose difference is $(1, 0, 0)$ in the figure.
In contrast, the graph on the right has node embeddings that are randomly shuffled. Despite having the same topology and the same embedding size, this graph lacks the patterns we saw on the left, thus it needs more action labels, i.e., it lacks a compact STRIPS action model. For example, action $a_1$ represents a difference $(1, 1, 0)-(0, 0, 1)=(1, 1, -1)$ and action $a_2$ represents $(1, 0, 0)$, requiring different effects. While some edges may share the effects, such as the action $b$ with difference $(-1, 0, 0)$, there are 9 differences in this graph, thus it needs 9 actions (18 if directed).
8.3 Cube-Space AE (CSAE)
Based on this intuition, we named our new architecture Cube-Space AE. Cube-Space AE modifies the $\textsc{apply}$ network so that it directly predicts the effects without taking the current state as the input and logically computes the successor state based on the predicted effect and the current state.
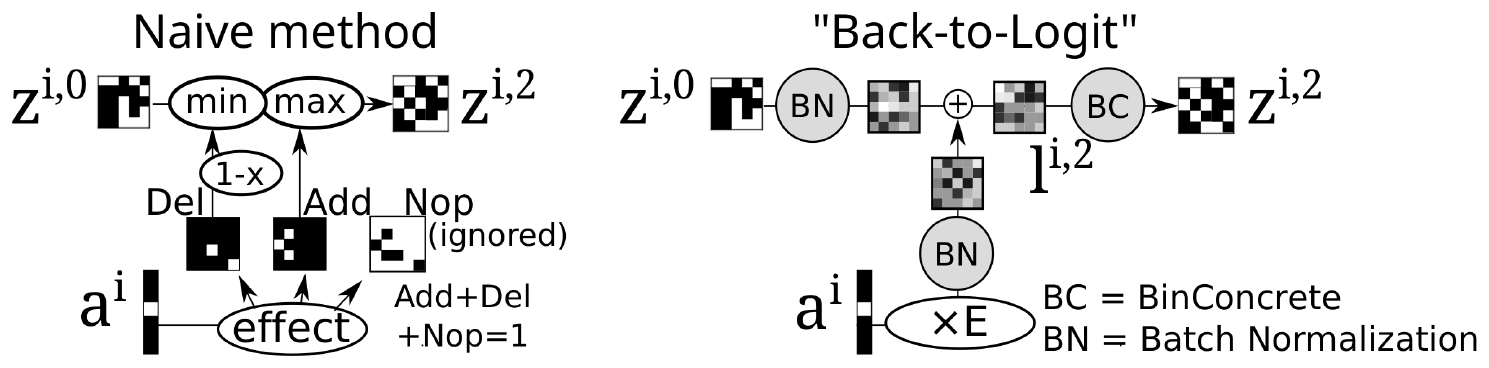
Naive implementation:
To illustrate the idea, we first present an ad-hoc, naive and impractical implementation of such a network in Figure 11 (left), which directly simulates STRIPS action application with vector operations. The $\textsc{effect}$ network predicts a binary tensor of shape $F\times 3$ using $F$-way Gumbel-Softmax of 3 categories. Each Gumbel Softmax corresponds to one bit in the $F$-bit latent space and 3 classes correspond to the add effect, delete effect, and NOP, only one of which is selected by the one-hot vector. The effects are applied to the current state by max/min operations. Formally, the naive CSAE is formulated as follows:
$ \begin{aligned} \mathbb{B}^F\ni {\bm{z}}^{i, 2}=&\max (\min ({\bm{z}}^{i, 0}, 1-\textsc{del}({\bm{a}}^{i})), \textsc{add}({\bm{a}}^{i})), \quad\text{where} \end{aligned} $
$ \begin{aligned} \textsc{effect}({\bm{a}}^{i}) &= \textsc{GS}_{\tau}(\text{MLP}({\bm{a}}^{i})) \in \mathbb{B}^{F\times 3}, & \textsc{add}({\bm{a}}^{i}) &= \textsc{effect}({\bm{a}}^{i})_0, \nonumber\ \textsc{del}({\bm{a}}^{i}) &= \textsc{effect}({\bm{a}}^{i})_1, & \textsc{nop}({\bm{a}}^{i}) &= \textsc{effect}({\bm{a}}^{i})_2. \end{aligned} $
While intuitive, we found these naive implementations extremely difficult to train in AMA$3$. Moreover, ${\bm{z}}^{i, 2}$ in these models is not produced by Binary Concrete using a logit ${\bm{l}}^{i, 2}$, making it impossible to compute the KL divergence $D{\mathrm{KL}}(q({\bm{z}}^{i, 1}\mid {\bm{x}}^{i, 1}) \mathrel{|} p({\bm{z}}^{i, 2}\mid {\bm{z}}^{i, 0}, {\bm{a}}^{i}))$ where $q({\bm{z}}^{i, 1}\mid {\bm{x}}^{i, 1})= \textsc{sigmoid}({\bm{l}}^{i, 1})$ and $p({\bm{z}}^{i, 2}\mid {\bm{z}}^{i, 0}, {\bm{a}}^{i})= \textsc{sigmoid}({\bm{l}}^{i, 2})$, which is required by the theoretically motivated ELBO objective of AMA$_3^+$. We thus abandoned this idea in favor of a theoretically justifiable alternative.
Back-to-Logit:
Our contribution to the architecture is Back-to-Logit (BTL, Figure 11, right), a generic approach that computes a logical operation in the continuous logit space. We re-encode a logical, binary vector back to a continuous, logit representation by an element-wise monotonic function $m$. This monotonicity preserves the order between true (1) and false (0) even after transformed into real numbers. We then apply the given action by adding a continuous effect vector to the continuous current state. The effect vector is produced by applying an MLP named $\textsc{effect}$ to the action vector ${\bm{a}}^{i}$. After adding the continuous vectors, we re-discretize the result with Binary Concrete. Formally,
$ {\bm{z}}^{i, 2}= \textsc{BC}{\tau}(\textsc{apply}({\bm{z}}^{i, 0}, {\bm{a}}^{i})) = \textsc{BC}{\tau}(m({\bm{z}}^{i, 0})+\textsc{effect}({\bm{a}}^{i})).\tag{10} $
Batch Normalization as $m$:
We found that an easy and successful way to implement $m$ is Batch Normalization [38], a method that was originally developed for addressing covariate shift in deep neural networks. For simplicity, we consider a scalar operation, which can be applied to vectors element-wise. During the batched training of the neural network, Batch Normalization layer $\textsc{BN}(x)$ takes a minibatch input $B={\left{x^{1}\ldots x^{|B|}\right}}$, computes the mean $\mu_B$ and the variance $\sigma_B^2$ of $B$, then shifts and scales each $x^i$ so that the resulting batch has a mean of 0 and a variance of 1. It then shifts and scales the results by two trainable scalars $\gamma$ and $\beta$, which are shared across different batches. Formally,
$ \forall x^i\in B;\ \textsc{BN}(x^i) = \frac{x^i-\mu_B}{\sigma_B} \gamma + \beta.\tag{11} $
After the training, $\textsc{BN}$ behaves deterministically. At the end of the training, $\mu_B$ and $\sigma_B$ are set to the statistics of the entire training dataset $\mathcal{X}$, i.e., $\mu_\mathcal{X}$, $\sigma_\mathcal{X}$.
Final definition:
Furthermore, since ${\bm{a}}^{i}$ is a probability vector over $A$ action ids and ${\bm{a}}^{i}$ eventually converges to a one-hot vector due to Gumbel-Softmax annealing, the additional MLP can be merely a linear embedding, i.e., $\textsc{effect}({\bm{a}}^{i})= {\bm{E}} {\bm{a}}^{i}$, where ${\bm{E}} \in \mathbb{R}^{F\times A}$. It also helps the training if we apply batch normalization on the effect vector. Therefore, a recommended implementation is:
$ {\bm{z}}^{i, 2}= \textsc{BC}{\tau}(\textsc{apply}({\bm{z}}^{i, 0}, {\bm{a}}^{i})) = \textsc{BC}{\tau}(\textsc{BN}({\bm{z}}^{i, 0})+\textsc{BN}({\bm{E}} {\bm{a}}^{i})).\tag{12} $
Similar to the original Vanilla Space AE, we can interpret it from a Bayesian generative modeling perspective as well. We discuss the interpretation in Appendix G.
Equivalence to STRIPS:
Consider an ideal training result where $\forall i; {\bm{z}}^{i, 1}\equiv {\bm{z}}^{i, 2}$, i.e.,
$ D_{\mathrm{KL}}(q({\mathbf{z}}^{1}= {\bm{z}}^{i, 1}\mid {\bm{x}}^{i, 1}) \mathrel{|} p({\mathbf{z}}^{1}= {\bm{z}}^{i, 2}\mid {\bm{z}}^{i, 0}, {\bm{a}}^{i}))=0. $
States learned by BTL have the following property:
########## {caption="Theorem 4"}
For state transitions ${\bm{z}}^{i, 0}, {\bm{z}}^{i, 1}$ whose action is ${\bm{a}}$, the transitions satisfy the following conditions. For each bit $j$, it is either:
$ \begin{aligned} (\text{add:})\ & \forall i; ({\bm{z}}^{i, 0}_j, {\bm{z}}^{i, 1}_j)\in {\left{(0, 1), (1, 1)\right}}, \ \text{or}\ (\text{del:})\ & \forall i; ({\bm{z}}^{i, 0}_j, {\bm{z}}^{i, 1}_j)\in {\left{(1, 0), (0, 0)\right}}, \ \text{or}\ (\text{nop:})\ & \forall i; ({\bm{z}}^{i, 0}_j, {\bm{z}}^{i, 1}_j)\in {\left{(0, 0), (1, 1)\right}}. \end{aligned} $
In other words, they are bitwise monotonic (${\bm{z}}^{i, 0}_j\leq {\bm{z}}^{i, 1}_j$, ${\bm{z}}^{i, 0}_j= {\bm{z}}^{i, 1}_j$, or ${\bm{z}}^{i, 0}_j\geq {\bm{z}}^{i, 1}_j$), deterministic (${\bm{z}}^{i, 0}_j \mapsto {\bm{z}}^{i, 1}_j$ is a function), and these three modes never mix up for the same action. The proof is straightforward from the monotonicity of $m$ and Binary Concrete (See Appendix H).
This theorem guarantees that each action deterministically sets a certain bit on and off in the binary latent space. Therefore, the actions and the transitions satisfy the STRIPS state transition rule $s' = (s \setminus \textsc{del}(a)) \cup \textsc{add}(a)$, thus enabling a direct translation from neural network weights to PDDL modeling language, as depicted in Figure 2.
Effect extraction:
To extract the effects of an action ${\bm{a}}$ from CSAE, we compute $\textsc{add}({\bm{a}})= \textsc{apply}({\bm{a}}, \bm{0})$ and $\textsc{del}({\bm{a}})=1-\textsc{apply}({\bm{a}}, \bm{1})$ for each action ${\bm{a}}$, where $\bm{0}, \bm{1} \in \mathbb{B}^F$ are vectors filled by zeros/ones and has the same size as the binary embedding. Since $\textsc{apply}$ deterministically sets values to 0 or 1, feeding these vectors is sufficient to see which bit it turns on and off. For each $j$-th bit that is 1 in each result, a corresponding proposition is added to the add/delete-effect, respectively.
There is one difference between theory and practice. As mentioned in Equation 11, batch normalization has a trainable parameter $\gamma$ for each dimension. This $\gamma$ must be positive in order for a batch normalization layer to be monotonic. The value of $\gamma$ is typically initialized by a positive constant (e.g., 1 in Keras) and typically stays positive during the training. However, in rare cases, it is possible that $\gamma$ turns negative in some bits, which requires special handling.
We call this monotonicity violation as XOR semantics, as the resulting bitwise value follows a pattern ${\left{(0, 1), (1, 0)\right}}$ that is not allowed under STRIPS. Detecting XOR semantics from the extracted effects is easy because these problematic bits have both add- and delete-effects in the same action. We compile them away by splitting the action into two versions, appending appropriate preconditions. While the compilation is exponential to the number of violations, violations are usually rare. We will report the number of violations in the empirical evaluation.
Precondition extraction:
To extract the preconditions of an action ${\bm{a}}$, we propose a simple ad-hoc method that is similar to [49] and [50]. It looks for bits that always have the same value when ${\bm{a}}$ is used. Let $\mathcal{Z}^0({\bm{a}})$ be the set of states that we can observe the usage of an action ${\bm{a}}$ in the dataset, i.e., ${\left{{\bm{z}}^{i, 0}\mid ({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})\in \mathcal{Z}; \operatorname{arg, max}(\textsc{action}({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1}))= {\bm{a}}\right}}$. Then the positive and the negative preconditions of an action ${\bm{a}}$ are defined as follows:
$ \textsc{pos}({\bm{a}})={f\mid\forall {\bm{z}}^{i, 0}\in \mathcal{Z}^0({\bm{a}}); {\bm{z}}^{i, 0}_f=1}, \textsc{neg}({\bm{a}}) = {f\mid\forall {\bm{z}}^{i, 0}\in \mathcal{Z}^0({\bm{a}}); {\bm{z}}^{i, 0}_f=0}. $
This ad-hoc method suffers from a serious lack of accuracy because the propositions whose values differ between different samples in $\mathcal{Z}^0({\bm{a}})$ are always treated as "don't care" even if they could consist of several patterns. Suppose the ground-truth generator of $\mathcal{Z}^0({\bm{a}})$ is a random vector ${\mathbf{z}} = [0, {\textnormal{a}}, \lnot {\textnormal{b}}, \lnot {\textnormal{b}}, {\textnormal{b}}, 1, {\textnormal{c}}]$ of independent Bernoulli(0.5) random variables ${\textnormal{a}}, {\textnormal{b}}, {\textnormal{c}}$ and constants 0, 1. The random vector can be alternatively represented by a logical formula $\lnot {\mathbf{z}}_0 \land {\mathbf{z}}_5 \land ((\lnot {\mathbf{z}}_2 \land \lnot {\mathbf{z}}_3 \land {\mathbf{z}}_4) \lor ({\mathbf{z}}_2 \land {\mathbf{z}}_3 \land \lnot {\mathbf{z}}_4))$. The ad-hoc method will only recognize $\lnot {\mathbf{z}}_0 \land {\mathbf{z}}_5$, failing to detect the disjunctions.
While we could develop a divide-and-conquer method which recursively extracts disjunctive conditions, DSAMA [47] showed that it is impractical. It learned them with decision trees applied to $\mathcal{Z}^0({\bm{a}})$ obtained from AMA2, then compiled the tree into a disjunctive precondition in PDDL. Disjunctive conditions are typically compiled away in modern planners at the cost of exponential blowup in the number of ground actions, which a deeper and more accurate tree suffers from. On the other hand, if we stop the recursion at a certain depth to suppress the explosion, such a shallow decision tree suffers from the limited accuracy.
These issues are naturally caused by the fact that the network and the state representation are not conditioned to learn a compact action model with conjunctive preconditions. To address these issues, we propose AMA$_{4}^+$, an improved architecture which also restricts the actions to have fully conjunctive preconditions.
9. AMA4+: Learning Preconditions as Effects Backward in Time
Section Summary: The section introduces AMA4+, which improves on prior models by learning action preconditions explicitly rather than through ad-hoc extraction. It does so by framing precondition inference as effect prediction in reverse via a Bidirectional Cube-Space Autoencoder that performs complete-state regression, using prevail conditions to keep regressed states fully determined and deterministic. This produces a symmetric network architecture that jointly trains forward effects and backward preconditions with the same Back-to-Logit mechanism.
While AMA$_3^+$ managed to model the STRIPS action effects, it requires an ad-hoc precondition extraction with limited accuracy because the CSAE lacks an explicit mechanism for action preconditions. We address this problem in a Bidirectional Cube-Space AE (BiCSAE): a neural network that casts precondition learning as effect learning for regression planning. To our knowledge, no existing work has addressed precondition learning in this manner. Modeling the precondition learning as a type of effect learning requires us to treat the problem in a time-symmetric manner. However, it causes a unique issue in that we have an expectation that regressed states are complete.
9.1 Complete State Regression Semantics
Regression planning is a group of search methods that solve a classical planning problem by looking for the initial state backward from the goal [51, 52]. It typically operates on a partial state / condition as a search node, which specifies values only for a subset of state variables. For a classical planning problem ${\left<P, A, I, G\right>}$, it starts from a node that contains the goal condition $G$, unlike usual forward search planners, which starts from the initial state $I$. State transitions on partial states are performed by regression, which infers the properties of a state prior to applying an action.
In general, regression produces partial states. This is so, even if we regress a complete state. Because of the nature of our learned latent representation, we must maintain this complete state property. Consider Table 2: a list of possible transitions of a propositional variable $p\in{\left{0, 1\right}}$ when a predecessor state $s$ transitioned to a successor state $t$ using a STRIPS action. In the precondition / effect columns, + indicates a positive precondition and an add-effect,
- indicates a negative precondition and a delete effect,
0 indicates that the action does not contain either effects,
- indicates that the action does not contain either preconditions.
When the precondition is not specified (*) for a bit that is modified by an effect, there is ambiguity in the source state, indicated by "?" (line 3, 6 in Table 2) — the previous value could be either 0 or 1. In other words, regressing such an action is non-deterministic, and the default STRIPS semantics for unspecified precondition is disjunctive (true or false).
::: {caption="Table 2: (Left) Possible transitions of a propositional value with a STRIPS action. (Right) Possible transitions of a propositional value with a STRIPS action, modeled by a prevail condition (precondition=0)."}
:::
One way to address this uncertainty / non-determinism / disjunctiveness in complete state is to reformulate the action model using prevail condition introduced in SAS+ formalism [35], a condition that is satisfied when the value is unchanged. In this form, a precondition for a propositional variable is either +, -, or 0 (unchanged), instead of +, -, * (don't-care). This modification rules out the ambiguous columns as seen in Table 2 (right), making regression deterministic, and making preconditions conjunctive. Note that certain combinations of preconditions and effects are equivalent. For example, lines 0, 1, 3, as well as lines 6, 8, 9 in Table 2 are redundant. We refer to this restricted form of regression as complete state regression.
The semantics of preconditions with positive, negative, and prevail conditions exactly mirrors the semantics of effects (add, delete, NOP), with the only difference being the direction of application. For example, BTL is able to model NOP, which does not change the value of a propositional variable. In complete state regression, this corresponds to a prevail condition.
9.2 Learning with Complete State Regression in Bidirectional Cube-Space AE (BiCSAE)
Complete state regression semantics provides a theoretical background for modeling a precondition learning problem as an effect learning problem. Based on this underlying semantics, we now propose Bidirectional Cube-Space AE (BiCSAE), a neural network that can learn the effects and the preconditions at the same time. Since the semantics of complete state regression and STRIPS effects are equivalent, we can apply the same Back-to-Logit technique to learn a complete state regression model. As a result, the resulting network contains a symmetric copy of Cube-Space AE (AMA$_3^+$).
We build BiCSAE by augmenting CSAE with a network $\textsc{regress}({\bm{z}}^{i, 1}, {\bm{a}}^{i})$ that uses the same BTL mechanism for predicting the outcome of action regression, i.e., predict the current state ${\bm{z}}^{i, 3}$ from a successor state ${\bm{z}}^{i, 1}$ and a one-hot action vector ${\bm{a}}^{i}$. A BiCSAE also has $\textsc{regressable}({\bm{z}}^{i, 1})$, a symmetric counterpart of $\textsc{applicable}({\bm{z}}^{i, 0})$ which returns a probability over actions and is used for regularizing ${\bm{a}}^{i}$ via KL divergence. The generative model is also a symmetric copy of AMA$_3^+$. The main data pipeline excluding the networks for regularization ($\textsc{regressable}$, $\textsc{applicable}$) is formalized in Figure 12. The full network is depicted in Figure 13.

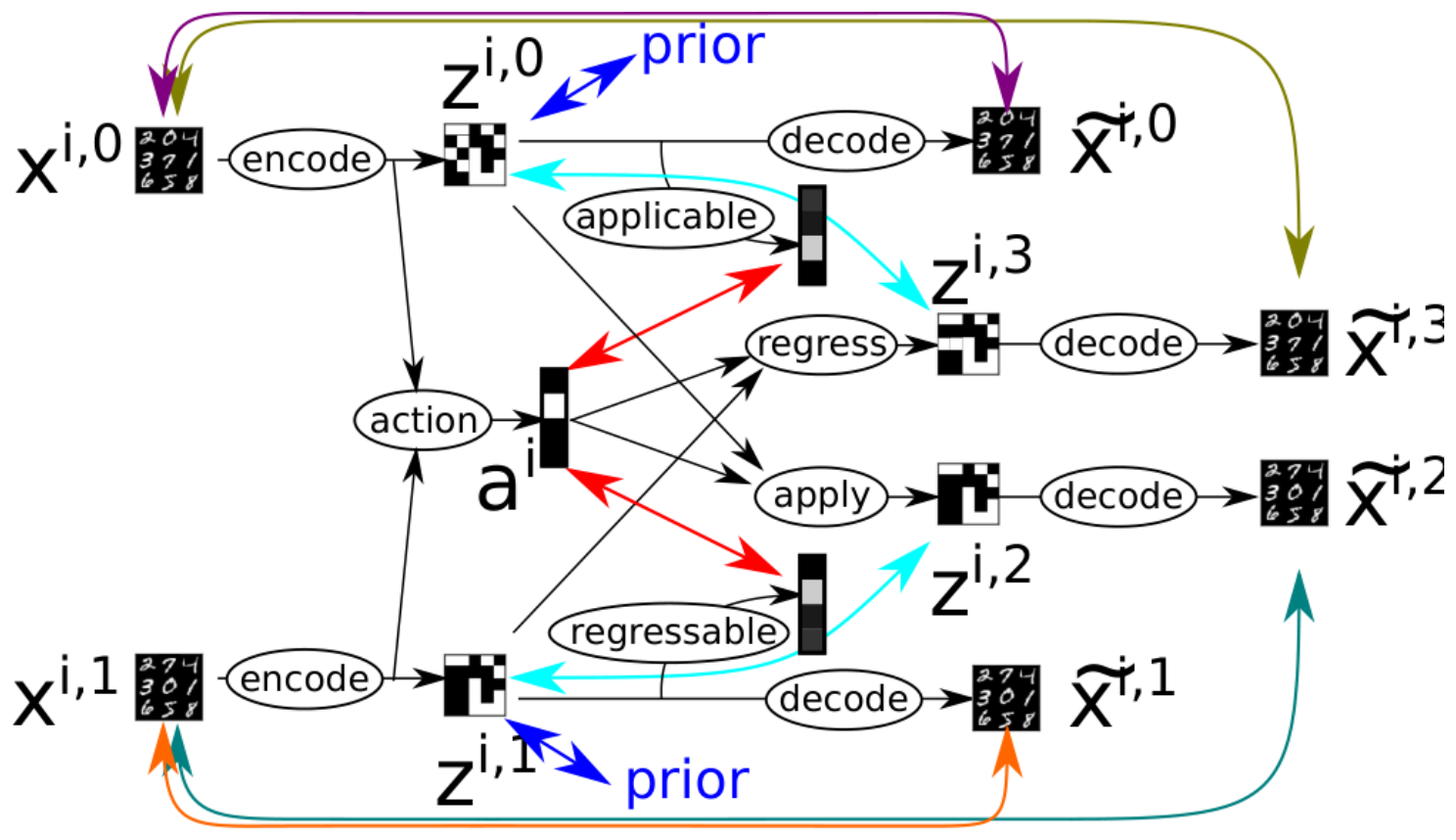
Since ${\bm{a}}^{i}$ is learned unsupervised, action replication happens automatically during the training. $\textsc{regress}$ is formalized with a trainable matrix ${\bm{P}}$ (for preconditions) as:
$ \begin{aligned} {\bm{z}}^{i, 3}= \textsc{BC}{\tau}(\textsc{regress}({\bm{z}}^{i, 1}, {\bm{a}}^{i})) &= \textsc{BC}{\tau}(\textsc{BN}({\bm{z}}^{i, 1})+\textsc{BN}({\bm{P}} {\bm{a}}^{i})). \end{aligned} $
In $\textsc{regress}$, add-effects and delete-effects now correspond to positive preconditions and negative preconditions. While negative preconditions are (strictly speaking) out of STRIPS formalism, it is commonly supported by modern classical planners that participate in the recent competitions.
BiCSAE restricts the preconditions to be strictly conjunctive. Note that STRIPS planning assumes deterministic environments, thus its effects are conjunctive: For example, if an action contained a disjunctive effect such as "flipping a coin makes it tail or head", then the state transition is non-deterministic. As seen in Theorem 4, this does not happen in CSAE. By using the same mechanism for learning the regression (preconditions), preconditions learned by BiCSAE do not contain disjunctions, its regression is deterministic, and it achieve complete regression semantics, as promised.
To extract the preconditions from the network, we apply the same method used for extracting the effects from the progressive/forward dynamics with two modifications. First, when an action contains a prevail condition for a bit $j$ and either an add-effect or a delete-effect for $j$, we must convert a prevail condition for $j$ into a positive / negative precondition for $j$, respectively. Otherwise, it underspecifies a set of transitions. Second, when both the effect and the precondition of a bit $j$ have the XOR semantics, we should duplicate the action only once (resulting in 2 copies of actions), not separately (resulting in 4 copies of actions).
Given a BiCSAE network as shown in Figure 13, we must define its optimization objective as a variational lower bound similar to that of CSAE/AMA$_3^+$. This is straightforward given the ELBO of CSAE, because the backward network is a symmetric copy of CSAE. We obtain an identical loss function for the forward and the backward network, then optimize the average of these objectives.
As seen in AMA$_{3}^+$, each uni-directional model already individually captures both the preconditions and the effects by itself. We therefore have duplicate components in the forward and the backward model: Preconditions are learned by both $\textsc{applicable}$ and $\textsc{regress}$, effects are learned by both $\textsc{apply}$ and $\textsc{regressable}$. Two models are individually theoretically justified and we merely trained them at once. Due to this decoupling, the training objectives in the forward and the backward direction do not need any special term designed for bidirectionality. Note that, while two models are trained at once, they share $\textsc{encode}$, $\textsc{decode}$ and $\textsc{action}$, therefore they use the same state encoding and the same set of actions. In other words, this weight sharing ties two uni-directional models together.
Having duplicate components does not affect the theoretical validity of the model. This is because, at the limit of convergence where the lower-bound (ELBO) matches the ground truth ($\log p({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$) in both forward/backward models, the variational distributions (distributions using $q$) matches the ground-truth generative distributions (distributions using $p$), as explained in Section 2.3. Therefore the forward model eventually matches the backward model and vice versa.
10. Training Performance
Section Summary: This section empirically evaluates the proposed networks by comparing metrics such as overall accuracy, latent state stability, and prediction quality across different model variants, priors, and hyperparameter settings. The goal is to assess the impact of tuning choices, nonstandard probability distributions, successor prediction methods, and any violations of expected ordering properties. It begins by outlining the experimental setup, including how datasets were generated for six image-based puzzle domains ranging from simple tile puzzles to more complex problems like Sokoban and photo-realistic block stacking.
In this section, we empirically and thoroughly analyze the networks proposed in this paper. We compare several metrics (overall accuracy, latent state stability, successor prediction accuracy, monotonicity violation, precondition accuracy) between different latent space priors, AMA${3}^+$ and AMA${4}^+$, and various hyperparameters. The primary objective of the comparisons made in this section is to verify the following factors:
- The effect of hyperparameter tuning on the overall accuracy, especially the impact of tuning $\beta_{1..3}$.
- The effect of non-standard prior $\text{Bernoulli}(\epsilon), \epsilon=0.1$ proposed in Section 5.4, compared to the standard uniform Bernoulli prior $\epsilon=0.5$.
- The successor prediction accuracy of Back-to-Logit proposed in Section 5.4.
- The number of monotonicity violations described in Section 8.3 in the learned results.
In addition, we provide a training curve plot in Appendix I in the appendix to facilitate the readers' replication of our result.
We first describe the experimental setup including dataset generation Section 10.1 and training/architecture details Section 10.2.
10.1 Experimental Domains

We evaluate Latplan on 6 domains. Example visualizations are shown in Figure 14.
- MNIST 8-Puzzle ([15]) is a 42x42 pixel, monochrome image-based version of the 8-Puzzle. Tiles contain hand-written digits (0-9) from the MNIST database ([53]), which are shrunk to 14x14 pixels so that each state of the puzzle is a 42x42 image. Valid moves swap the "0" tile with a neighboring tile, i.e., the "0" serves as the "blank" tile in the classic 8-Puzzle. 8-Puzzle has 362880($=9!$) states and 967680 transitions, while half of the states are unreachable. The longest shortest path in 8-puzzle contains 31 moves [54]. From any specific goal state, the reachable number of states is 181440 ($9!/2$). Note that the same image is used for each digit in all states, e.g., the tile for the "1" digit is the same image in all states.
- The Scrambled Photograph (Mandrill) 15-puzzle cuts and scrambles a real photograph, similar to the puzzles sold in stores. We used a "Mandrill" image taken from the USC-SIPI benchmark set [55]. These differ from the MNIST 8-puzzle in that "tiles" are not cleanly separated by black regions (we re-emphasize that Latplan has no built-in notion of square or movable region). Unlike 8-puzzle, this domain can increase the state space easily by dissecting the image 4x4 instead of 3x3, generating 15-puzzle instances whose state space is significantly larger than that of 8-puzzle. The image consists of 56x56 pixels. It was converted to greyscale, and then histogram-normalization and contrast enhancement was applied.
- A recreation of LightsOut ([56]) by Tiger Electronics in 1995, or sometimes also known as "Magic Square" game mode of Merlin The Electronic Wizard. It is an electronic puzzle game where a grid of lights is in some on/off configuration ($+$: On), and pressing a light toggles its state as well as the states of its neighbors. The goal is to turn all lights Off. Unlike previous puzzles, a single operator can flip 5 locations at once and removes some "objects" (lights). This demonstrates that Latplan is not limited to domains with highly local effects and static objects. $n \times n$ LightsOut has $2^{n^2}$ states and $n^22^{n^2}$ transitions. In this paper, we used 5x5 configuration (33554432 states) whose images consist of 45x45 pixels.
- Twisted LightsOut distorts images in LightsOut by a swirl effect available in scikit-image package, showing that Latplan is not limited to handling rectangular "objects"/regions. It has the same image dimensions as the original LightsOut. The effect is applied to the center, with strength=3, linear interpolation, and radius equal to 0.75 times the dimension of the image.
- Photo-realistic Blocksworld ([57]) is a dataset that consists of 100x150 RGB images rendered by Blender 3D engine. The image contains complex visual elements such as reflections from neighboring blocks. We modified the rendering parameter to simplify the dataset: We limited the object shapes to be cylinders and removed the jitters (small noise) in the object placements. The final images are resized to 30x45 pixels. As shown in the figures, Blocksworld contains 4 objects and maximum 5 towers, which results in $4! \times 5^4 = 15000$ logical states and each state has a branching factor from 4 (where all blocks are stacked in a single tower) to 20 (where all blocks are on the table). For each logical state, there are infinite number of images due to different random jitter and raytracing rendering noise.
- Sokoban ([58, 59]) is a PSPACE-hard puzzle domain whose 112x112 pixel visualizations are obtained from the PDDLGym library ([60]) and are resized into 28x28 pixels. Unlike other domains, this domain is irreversible and dead-ends exist. We used p006-microban-sequential instance as the visualization source. p006-microban-sequential has 23363 states reachable from the initial state. States have varying branching factors from 1 to 4. The dataset is generated by generating all reachable states with an exhaustive Dijkstra search and their corresponding transitions, then sampling 20000 valid transitions.
In 8-Puzzle and two Lightsout domains, we sampled 5000 transitions / 10000 states. In 15-Puzzle, Blocksworld, and Sokoban, we sampled 20000 transitions / 40000 states because they are visually challenging domains that contain more objects, more noise, and more complex modes of state transitions. All datasets are generated by domain-specific generators. Except sokoban, the generators generate a pair of states at a time: One uniformly sampled configuration of the environment and its uniformly sampled successor state. In Sokoban, the dataset is uniformly sampled from the whole state space enumerated by an exhaustive search. These datasets are divided into 90%, 5%, 5% for the training set, validation/tuning set, and testing set, respectively. During the development of the network models, we look at the validation set to tune the network while only in the final report we evaluate the network on the test set and report the results. While the number of states (images) used for visually challenging domains may appear to be reaching the interpolation rather than generalization, note that there are much more transitions (multiplied by the branching factor) in the environment that the system must generalize to.
The pixel values in the image datasets are normalized to mean 0, variance 1 for each pixel and channel, i.e., for an image pair $({\bm{x}}^{i, 0}, {\bm{x}}^{i, 1})$ where ${\bm{x}}^{i, j}\in \mathbb{R}^{H, W, C}$ (with $H, W, C$ being height, width, and color channel respectively), $\forall k, l, m; \mathbb{E}{i, j} [{\bm{x}}^{i, j}{klm}] = 0$ and $\mathrm{Var}{i, j} [{\bm{x}}^{i, j}{klm}] = 1$.
All experiments are performed on a distributed compute cluster equipped with nVidia Tesla K80 / V100 / A100 GPUs and Xeon E5-2600 v4. With V100 (a Volta generation GPU), training a single instance of AMA${3}^+$ model on 8-Puzzle takes 2 hours, and AMA${4}^+$ model takes 3 hours due to additional networks. 15-Puzzle, Blocksworld, and Sokoban take more runtime varying from 5 hours to 15 hours due to more data points and larger images. The system is implemented on top of Keras library [61].
10.2 Network Specifications
We trained the AMA${3}^+$ and the AMA${4}^+$ models as discussed in Section 8-Section 9. We do not include training results of previous models AMA${1..3}$ due to the lack of STRIPS export capability and their ad-hoc natures. The ad-hoc nature indeed prevents us from defining an effective metric that is independent from the implementation of the neural network. For example, while we can directly compare the loss values of the AMA${3}^+$ and the AMA${4}^+$ because both values are lower bounds of the likelihood $p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$, we cannot derive a meaningful conclusion by comparing the loss values of AMA${1..3}$.
Detailed specifications of each network component of AMA${3}^+$ and AMA${4}^+$ are listed in Table 3. The encoder and the decoders consist of three convolutional layers [62, 63] each, while action-related networks primarily consist of fully connected networks. We use Rectified Linear Unit ($\textsc{Relu}(x)=\max(0, x)$) as the activation function of each layer, which performs better in deep networks because it avoids gradient vanishing compared to a $\textsc{sigmoid}$ function. Each activation is typically followed by Batch Normalization ($\textsc{BN}$) [38] and Dropout [39] layers, both of which are generally known to improve the performance and allow for training the network with a higher learning rate. A layer that is immediately followed by a $\textsc{BN}$ layer does not need the bias weights because $\textsc{BN}$ has its own bias weights. Following the theoretical and empirical finding by [64], all layers that are immediately followed by a ReLU activation are initialized by Kaimin He's uniform weight initialization [64], as opposed to other layers that are initialized by the Glorot Xavier's uniform weight initialization [65], which is the default in Keras library. In addition, the input is augmented by a GaussianNoise layer which adds a fixed amount of Gaussian noise, making the network an instance of Denoising AutoEncoder [37].
For each dataset, we evaluated 30 hyperparameter configurations using grid search, varying the latent space size $F$ and the $\beta_1$, $\beta_3$ coefficients of KL divergence terms ($\beta_2$ was kept at 1). Parameter ranges are listed in Table 4. We tested numerous hyperparameters during the development (using validation set) to narrow down the range of hyperparameters to those listed in this table. Naturally, a single hyperparameter does not work for all domains because, for example, a more complex domain (e.g., 15 Puzzle) requires a larger latent space than a simpler domain (e.g., 8 Puzzle). The values in this table have a sufficient range for covering all domains we tested.
\begin{tabular}{|cc|}\hline
\emph{Subnetworks} & \emph{Layers} \\\hline
\multirow{4}{*}{$\textsc{encode}$}
& GaussianNoise(0.2), $\textsc{BN}$, \\
& Conv(5, 32), ReLU, $\textsc{BN}$, Dropout(0.2), \\
& Conv(5, 32), ReLU, $\textsc{BN}$, Dropout(0.2), \\
& Conv(5, 32) \\\hline
\multirow{4}{*}{$\textsc{decode}$} & $\textsc{BN}$, \\
& Conv(5, 32), ReLU, $\textsc{BN}$, Dropout(0.2), \\
& Conv(5, 32), ReLU, $\textsc{BN}$, Dropout(0.2), \\
& Conv(5, 32) \\\hline
$\textsc{action}$ & $\textsc{sigmoid}$, fc(1000), ReLU, $\textsc{BN}$, Dropout(0.2), fc(6000) \\\hline
$\textsc{apply}, \textsc{regress}$ & Equation 12 \\\hline
$\textsc{applicable}, \textsc{regressable}$ & fc(6000) \\\hline
\end{tabular}
::: {caption="Table 4: List of hyperparameters."}
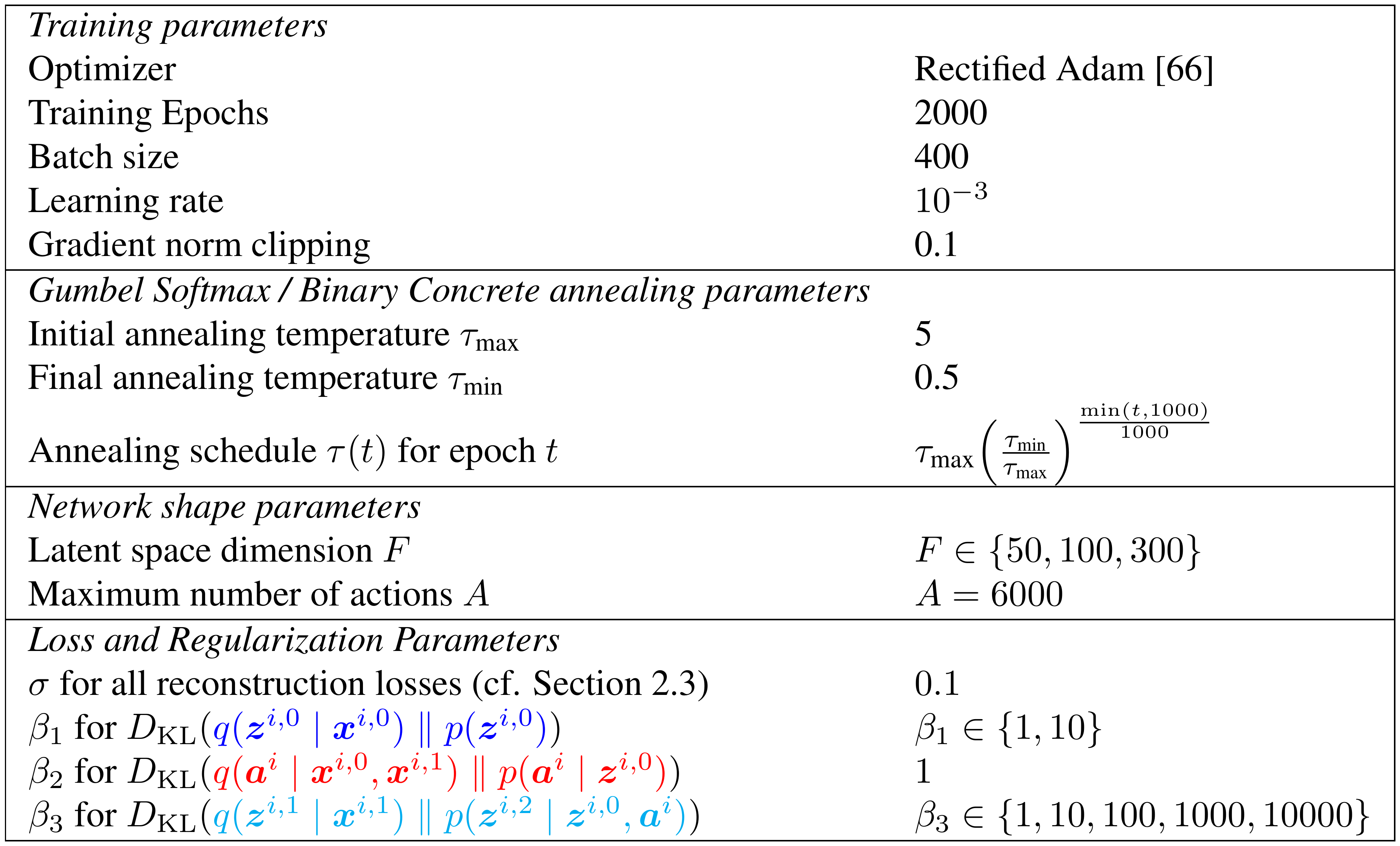
:::
10.3 Accuracy Measured as a Lower Bound of Likelihood
We first evaluate the ELBO, the lower bound of the likelihood $\log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ of observing the entire dataset (the higher, the better). The summary of the results is shown in Table 5. We report the ELBO values obtained by setting $\beta_{1..3}$ to 1 after the training. The original maximization objectives with $\beta_{1..3}\geq 1$ used for training are lower bounds of the ELBO with $\beta_{1..3}=1$ because all KL divergences have a negative sign Equation (25) and KL divergences themselves are always positive (Section 2.3). Resetting $\beta_{1..3}$ to 1 improves / increases the lower bound while still being the lower bound of the likelihood. Since ELBO is a model-agnostic metric, we can directly compare the values of different models.
The actual numbers we report are loss values -ELBO (negative value of ELBO) that are minimized (lower the better). In addition, the numbers do not include a constant term $C_2 = \log \sqrt{2\pi\sigma^2}$ with $\sigma=0.1$ multiplied by the number of pixels (cf. Section 2.3). While the constant should be added to obtain the true value of -ELBO, and -ELBO+Constant has an intuitive interpretation as a sum of scaled squared errors and KL divergences. The constant does not affect the training either. The drawback is that the -ELBO we report should not be compared between different domains because different datasets have different numbers of pixels, resulting in a different amount of constant offsets.
Note that the best accuracy/ELBO alone
is *not* the sole factor that improves the likelihood of success in solving visual planning problems.
It is affected by multiple factors, including all metrics we evaluate in the following sections.
For example, even if the overall accuracy (-ELBO, which is a sum of reconstruction and KL losses) is good,
the planning is not likely to succeed
if its action model does not predict the latent successor state accurately
because it overly focuses on improving the reconstruction accuracy
and sacrifices successor prediction accuracy modeled by
$\beta_3 D_{\mathrm{KL}}(q({\bm{z}}^{i, 1}\mid {\bm{x}}^{i, 1}) \mathrel{\|} p({\bm{z}}^{i, 2}\mid {\bm{z}}^{i, 0}, {\bm{a}}^{i}))$.
\begin{tabular}{|r|rrrr|rrrr|rrrr|}
\hline
& \multicolumn{ 4}{c|}{\textbf{kltune}} & \multicolumn{ 4}{c|}{notune} & \multicolumn{ 4}{c|}{default} \\
& \multicolumn{ 4}{c|}{$\epsilon=0.1$} & \multicolumn{ 4}{c|}{$\epsilon=0.1, \beta_{1..3}=1$} & \multicolumn{ 4}{c|}{$\epsilon=0.5$} \\
domain & -ELBO & $\beta_1$ & $\beta_3$ & $F$ & -ELBO & $\beta_1$ & $\beta_3$ & $F$ & -ELBO & $\beta_1$ & $\beta_3$ & $F$ \\
\hline
\multicolumn{ 13}{|c|}{AMA$_{3}^+$} \\
\hline
Blocks & \textbf{\textit{6.26E+03}} & 10 & 1 & 300 & 6.55E+03 & 1 & 1 & 300 & \textit{6.32E+03} & 1 & 100 & 300 \\
LOut & 1.97E+03 & 1 & 1000 & 50 & 2.07E+03 & 1 & 1 & 100 & \textbf{1.90E+03} & 1 & 1000 & 300 \\
Twisted & 1.95E+03 & 10 & 1000 & 50 & 2.03E+03 & 1 & 1 & 50 & \textbf{1.93E+03} & 10 & 1000 & 300 \\
Mandrill & \textbf{2.65E+03} & 10 & 10 & 300 & 3.39E+03 & 1 & 1 & 100 & \textit{3.09E+03} & 10 & 10 & 300 \\
MNIST & \textbf{1.21E+03} & 10 & 10 & 300 & 1.41E+03 & 1 & 1 & 100 & \textit{1.21E+03} & 1 & 10 & 300 \\
Sokoban & \textbf{\textit{1.45E+03}} & 10 & 1 & 50 & 1.60E+03 & 1 & 1 & 50 & 1.50E+03 & 1 & 1 & 50 \\
\hline
\multicolumn{ 13}{|c|}{AMA$_{4}^+$} \\
\hline
Blocks & 7.43E+03 & 1 & 1 & 100 & 7.61E+03 & 1 & 1 & 100 & \textbf{7.25E+03} & 10 & 10 & 100 \\
LOut & \textbf{\textit{1.82E+03}} & 10 & 10 & 300 & 1.89E+03 & 1 & 1 & 300 & \textit{1.85E+03} & 10 & 1 & 300 \\
Twisted & \textbf{\textit{1.82E+03}} & 10 & 1 & 300 & 1.93E+03 & 1 & 1 & 300 & \textit{1.85E+03} & 10 & 1 & 300 \\
Mandrill & \textbf{\textit{2.58E+03}} & 10 & 100 & 300 & 3.26E+03 & 1 & 1 & 100 & 3.18E+03 & 10 & 100 & 100 \\
MNIST & \textbf{1.31E+03} & 10 & 1 & 300 & 1.50E+03 & 1 & 1 & 300 & 1.34E+03 & 10 & 1 & 300 \\
Sokoban & 1.53E+03 & 10 & 10 & 300 & 1.55E+03 & 1 & 1 & 100 & \textbf{\textit{1.12E+03}} & 10 & 10 & 300 \\
\hline
\end{tabular}
In Table 5, we first assess the effectiveness of $\beta$-VAE objective with tuned $\beta_{1..3}$. Comparing the best hyperparameters ("kltune") and the baseline that uses $\beta_{1..3}=1$ during the training ("notune"), we observed that tuning these parameters is important for obtaining accurate models. Note that the latent space size $F$ is still tuned in both cases.
We also plotted the results with all matching hyperparameters (same $F$) in Figure 15. The scatter plot provides richer information on how these hyperparameters affect the ELBO. It emphasizes the importance of hyperparameter tuning: Bad hyperparameter of $\beta_{1..3}$ could quite negatively affect the result while tuning the value appropriately yields a better result.
:::: {cols="2"}
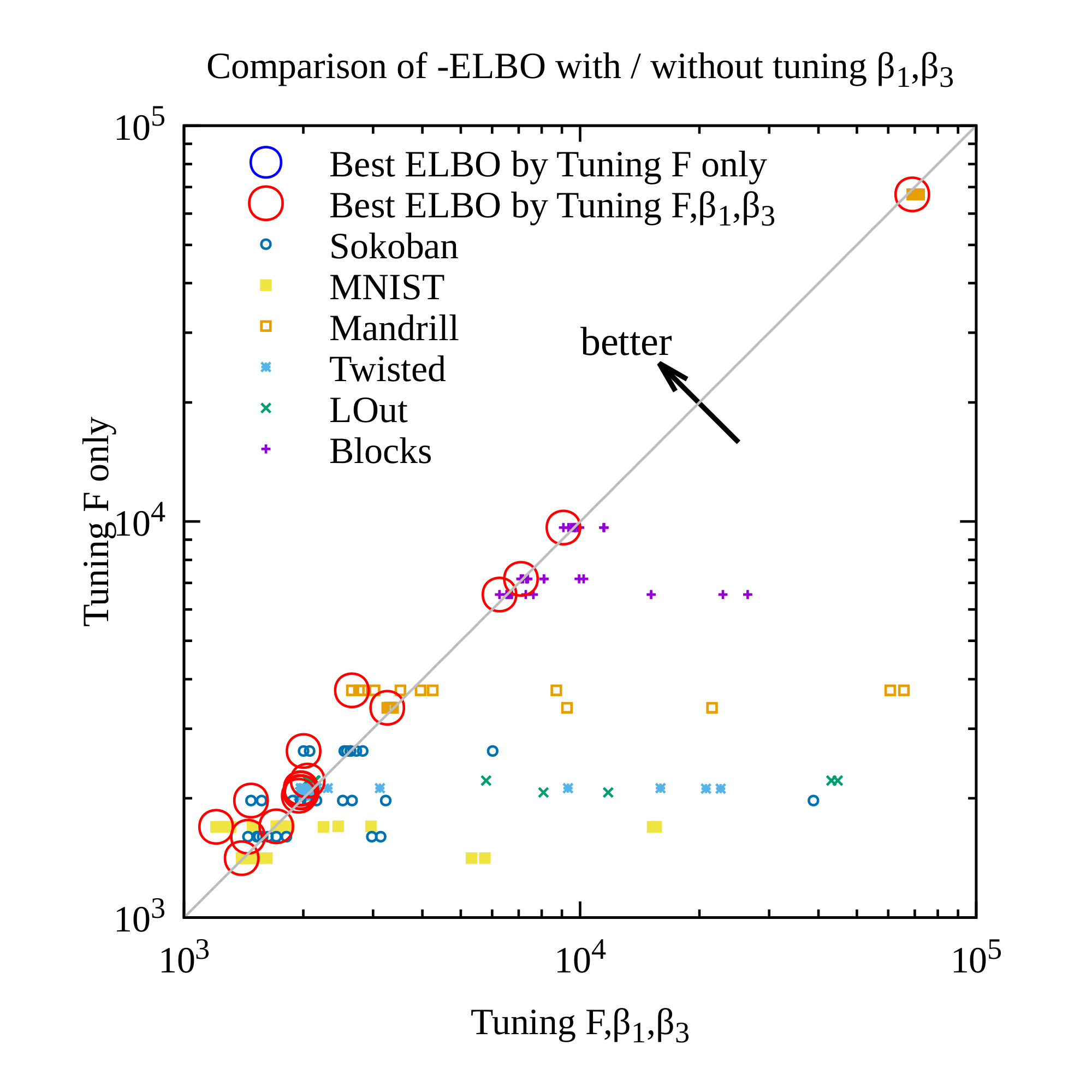
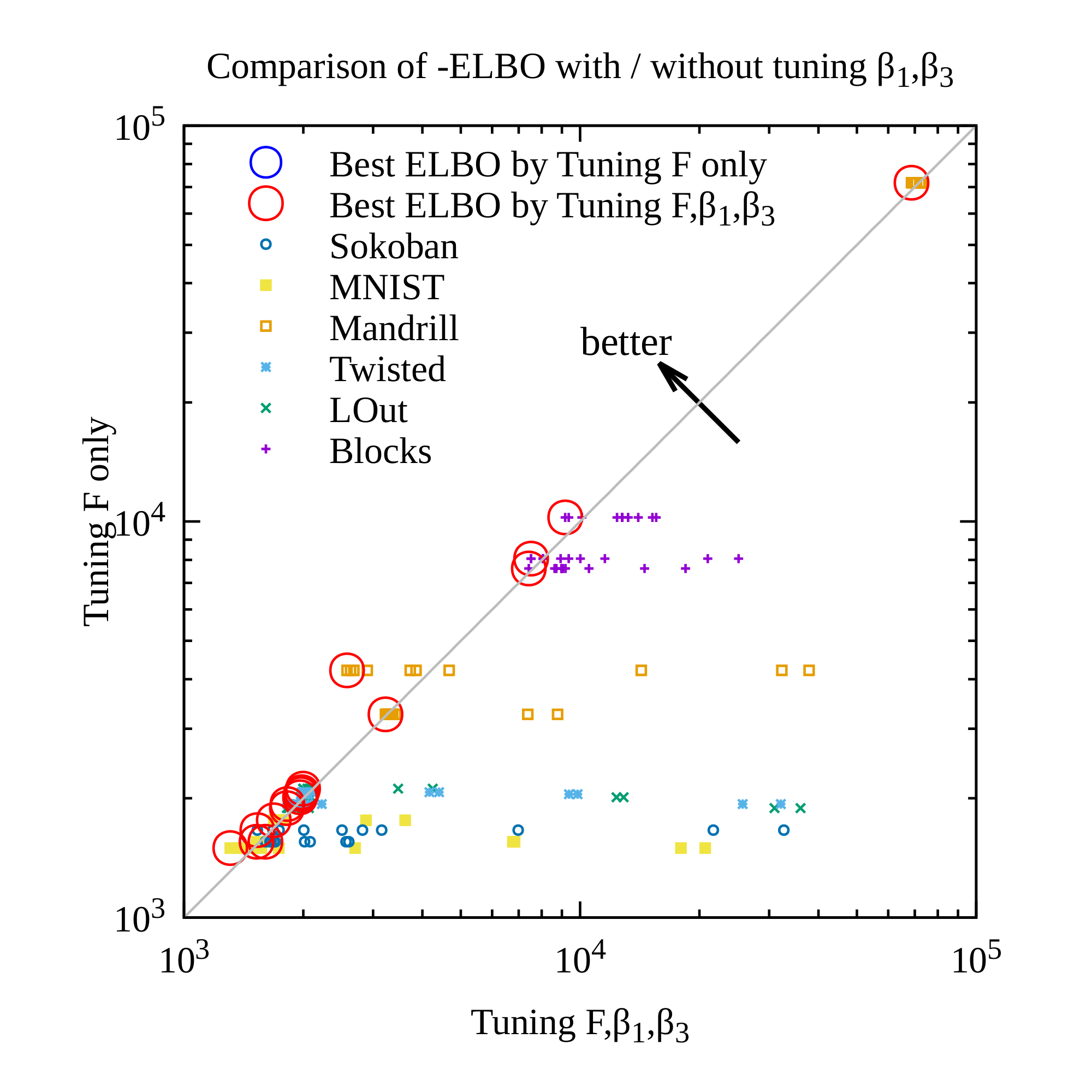
Figure 15: (Left: AMA${3}^+$, Right: AMA${4}^+$.) Comparing the effect of tuning $\beta_{1..3}$ on -ELBO. Each point represents a pair of configurations with the same $F$, where the $y$-axis always represents the result from $\beta_1=\beta_3=1$, while the $x$-axis represents the results from various $\beta_1, \beta_3$. For each $F$, we highlighted the best configuration of $\beta_1, \beta_3$ with blue circles. While bad parameters will significantly degrade the accuracy (below the diagonal), tuning the value appropriately will improve the accuracy (above the diagonal). ::::
We next compare the results obtained by training the networks with a standard $\text{Bernoulli}(\epsilon=0.5)$ prior and with a proposed $\text{Bernoulli}(\epsilon=0.1)$ prior for the latent vector ${\bm{z}}$. As we already discussed in Section 5.2, we observed comparable results; therefore it does not affect the accuracy. For the scatter plot, please refer to Figure 16. This is not surprising, as we are merely training the network with two different underlying assumptions: $\text{Bernoulli}(\epsilon=0.5)$ assumes an open-world assumption, while $\lim_{\epsilon \rightarrow 0}\text{Bernoulli}(\epsilon)$ assumes a closed-world assumption (Section 5.4).
:::: {cols="2"}
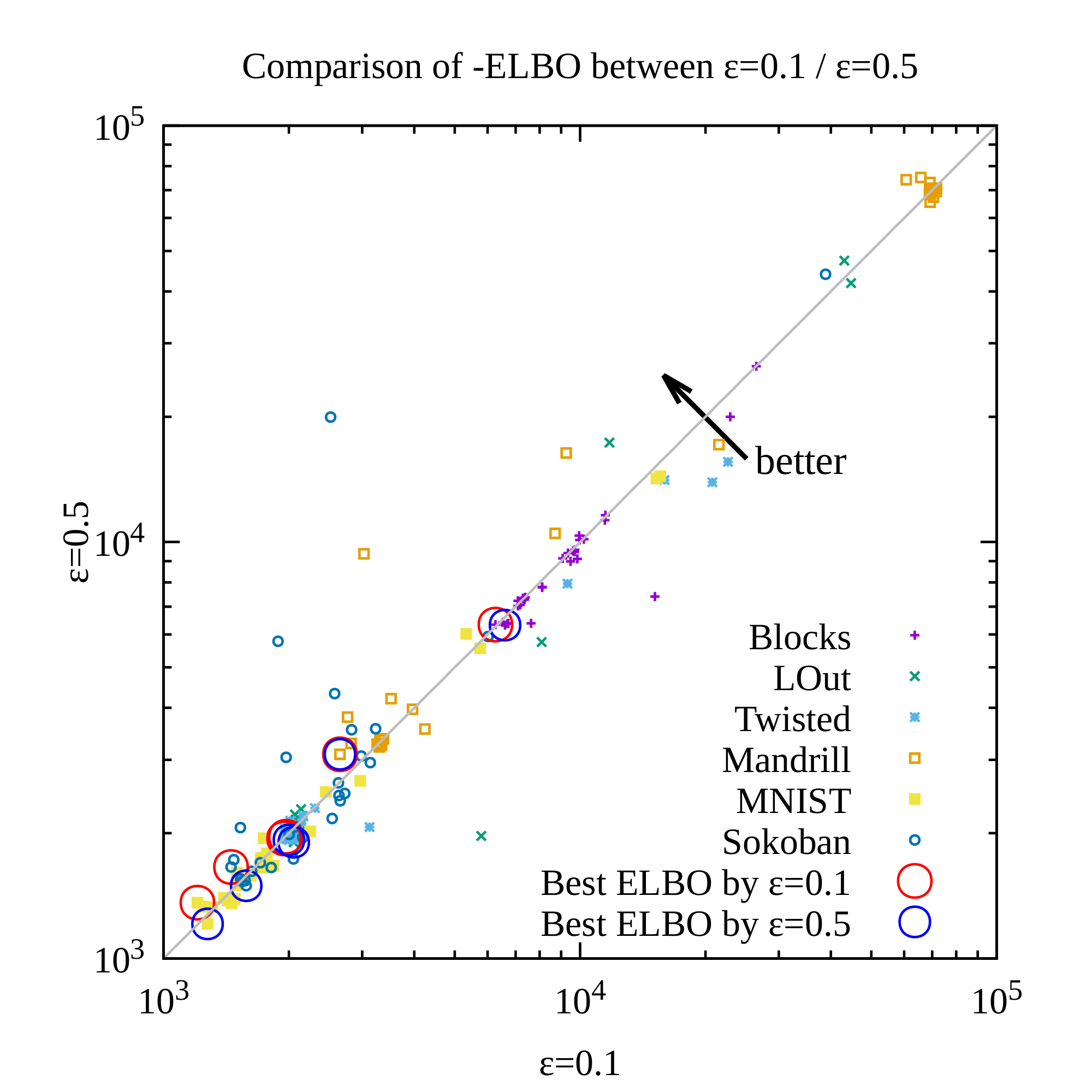
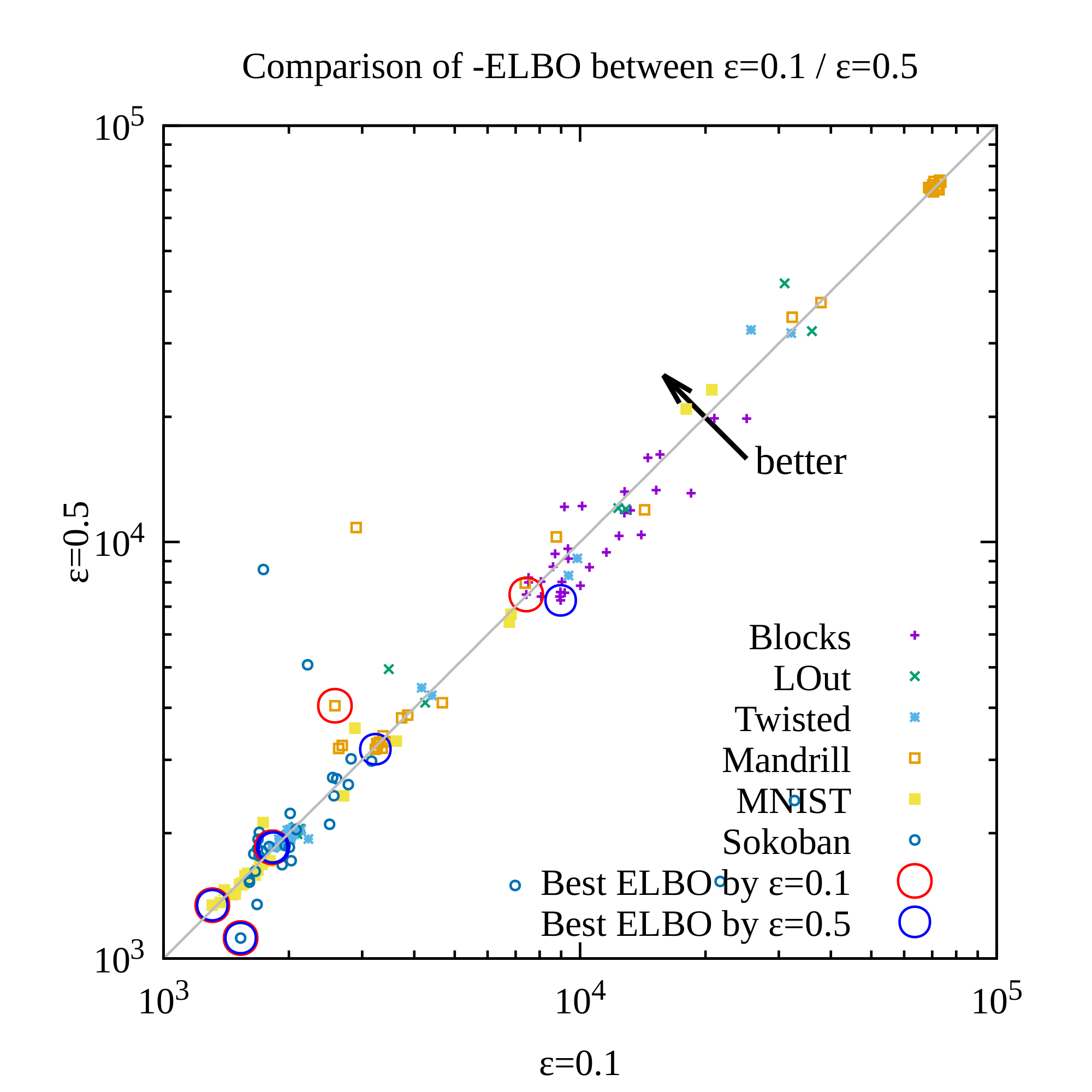
Figure 16: (Left: AMA${3}^+$, Right: AMA${4}^+$.) Comparing the effect of the prior distribution on -ELBO. Each point represents a pair of configurations with the same $F, \beta_1, \beta_3$, where the $x$-axis represents a result from $\epsilon=0.1$, while the $y$-axis represents a result from $\epsilon=0.5$. As expected, we do not see a significant difference of ELBO between these two configurations. ::::
We next compare AMA${3}^+$ and AMA${4}^+$ models by their ELBO. Table 5 and Figure 17 show that the accuracy of AMA${3}^+$ and AMA${4}^+$ are comparable.
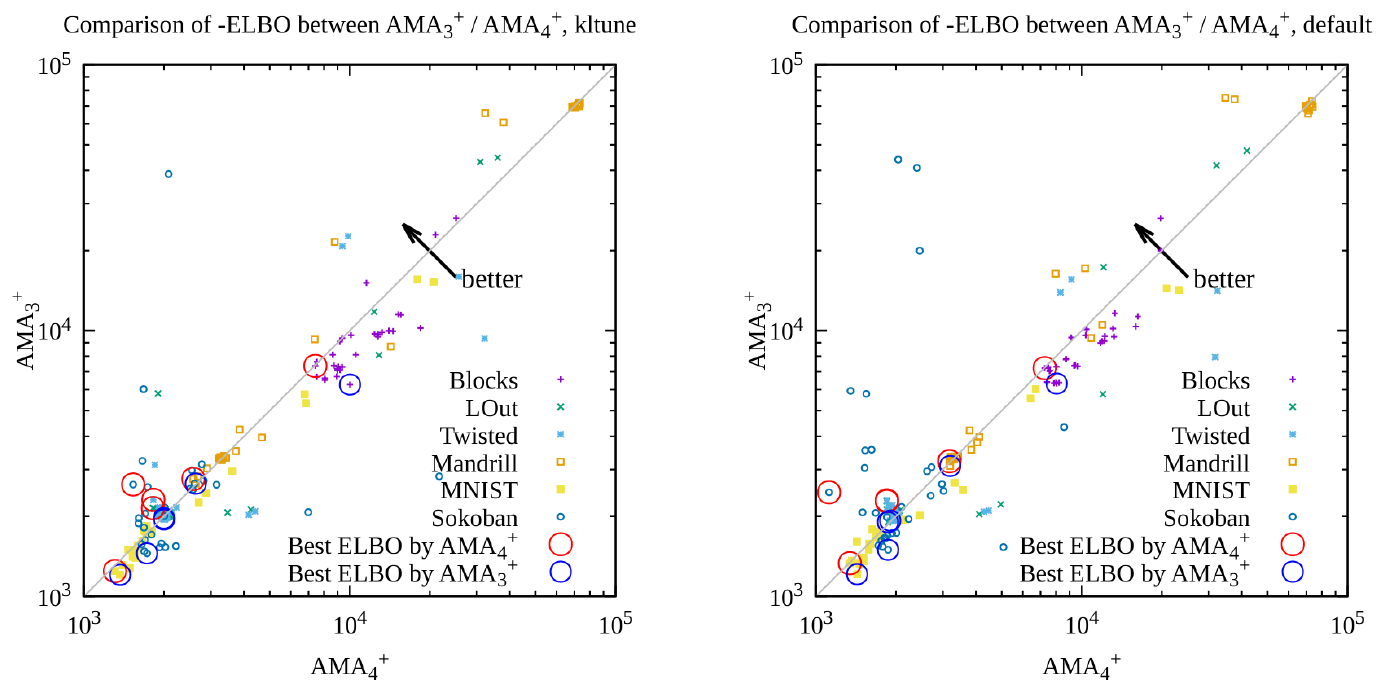
10.4 Stability of Propositional Symbols Measured as a State Variance
For each hyperparameter which resulted in the best ELBO in each domain and configuration, we next measured other effects of using $p({\mathbf{z}}^{0})= \text{Bernoulli}(\epsilon=0.1)$ ("kltune") against the default $p({\mathbf{z}}^{0})= \text{Bernoulli}(\epsilon=0.5)$ configuration ("default"). We focus on the stability of a latent vector ${\bm{z}}^{i, 0}$ on perturbed inputs, whose role in a symbol grounding process was discussed in Section 5.2.
The stability is measured by the state variance for the noisy input, i.e., the variance of the latent vectors ${\bm{z}}^{i, 0}= \textsc{BC}_{\tau}(\textsc{encode}({\bm{x}}^{i, 0}+{\bm{n}}))$ where ${\bm{n}}$ is a noise following a Gaussian distribution $\mathcal{N}(\mu=0, \sigma=0.3)$. We compute the variance by iterating over 10 random vectors, then average the results over $F$ bits in the latent space and the dataset index $i$. Formally,
$ \text{State Variance} = \mathbb{E}{f\in 0..F}\mathbb{E}{i} \mathrm{Var}{j\in 0..10}[\textsc{BC}{\tau}(\textsc{encode}({\bm{x}}^{i, 0}+{\bm{n}}^j)_f)]. $
As we discussed in Section 5.2 about the potential cause of unstable symbols, this value is likely to increase when the latent space has an excessive capacity (larger $F$) and could also be affected by other hyperparameters. Therefore, we made a scatter plot where each point represents a result of evaluating $\epsilon=0.1$ and $\epsilon=0.5$ configurations with the same hyperparameter. In Figure 18, we observed that the network trained with $\text{Bernoulli}(\epsilon=0.1)$ has a lower state variance, confirming that the proposed prior makes the resulting symbolic propositional states more stable against aleatoric uncertainty.
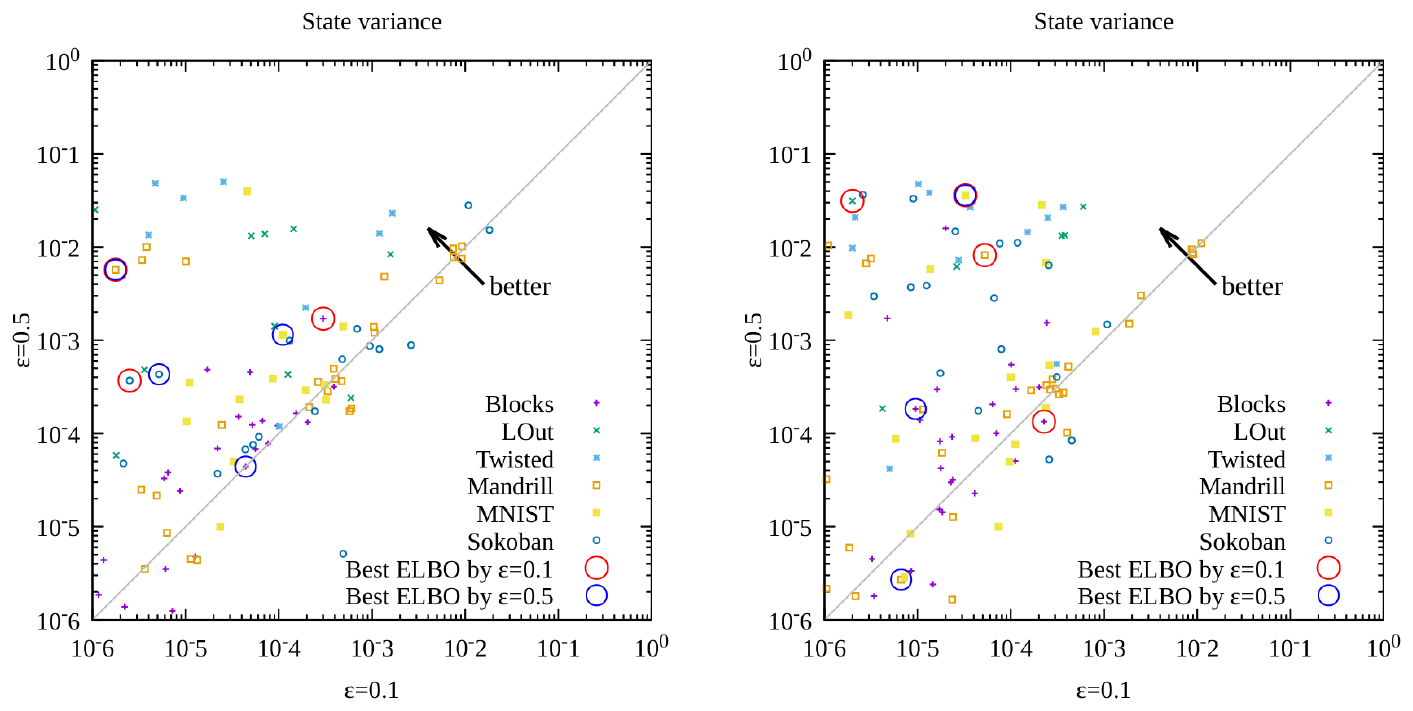
Another related metric we can evaluate is how many "effective bits" each model uses in the latent space. An effective bit is defined as follows: For each bit $f$ in the latent vector ${\bm{z}}^{i, 0}= \textsc{BC}_{\tau}(\textsc{encode}({\bm{x}}^{i, 0}))$ where ${\bm{x}}^{i, 0}$ is from a test dataset, we check if ${\bm{z}}^{i, 0}_f$ ever changes its value when we iterated across different $i$ in the dataset. If it changes, it is an "effective bit." Otherwise, the bit is a constant and is not used for encoding the information in an image. In Figure 19, we observed that our proposed configuration ("kltune") tends to have fewer effective bits; thus each bit of the latent vectors changes its value less frequently across the dataset.
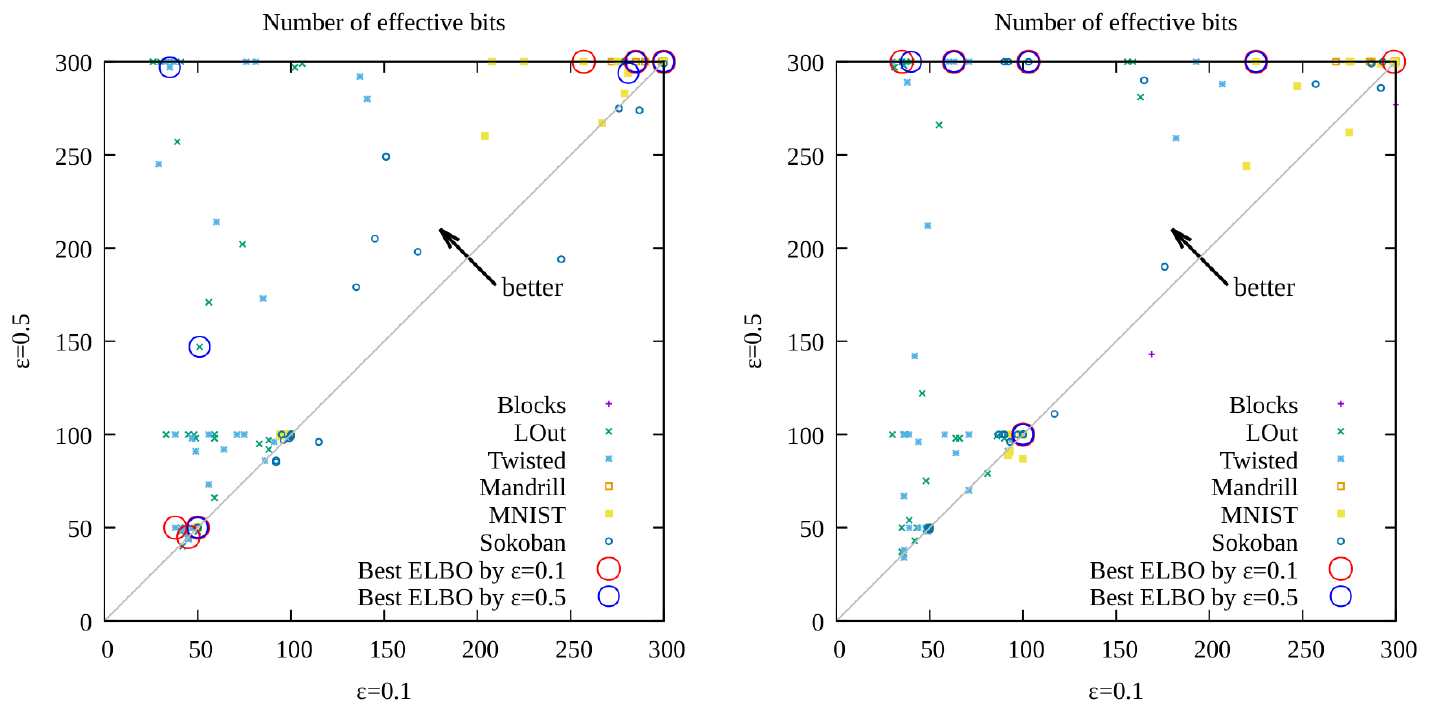
Furthermore, we confirmed that those static bits tend to be 0 rather than 1. We extracted the bits whose values are always 0 regardless of the input by iterating over the test dataset. Figure 20 shows that the modified prior induces more constant 0 bits in the latent space.
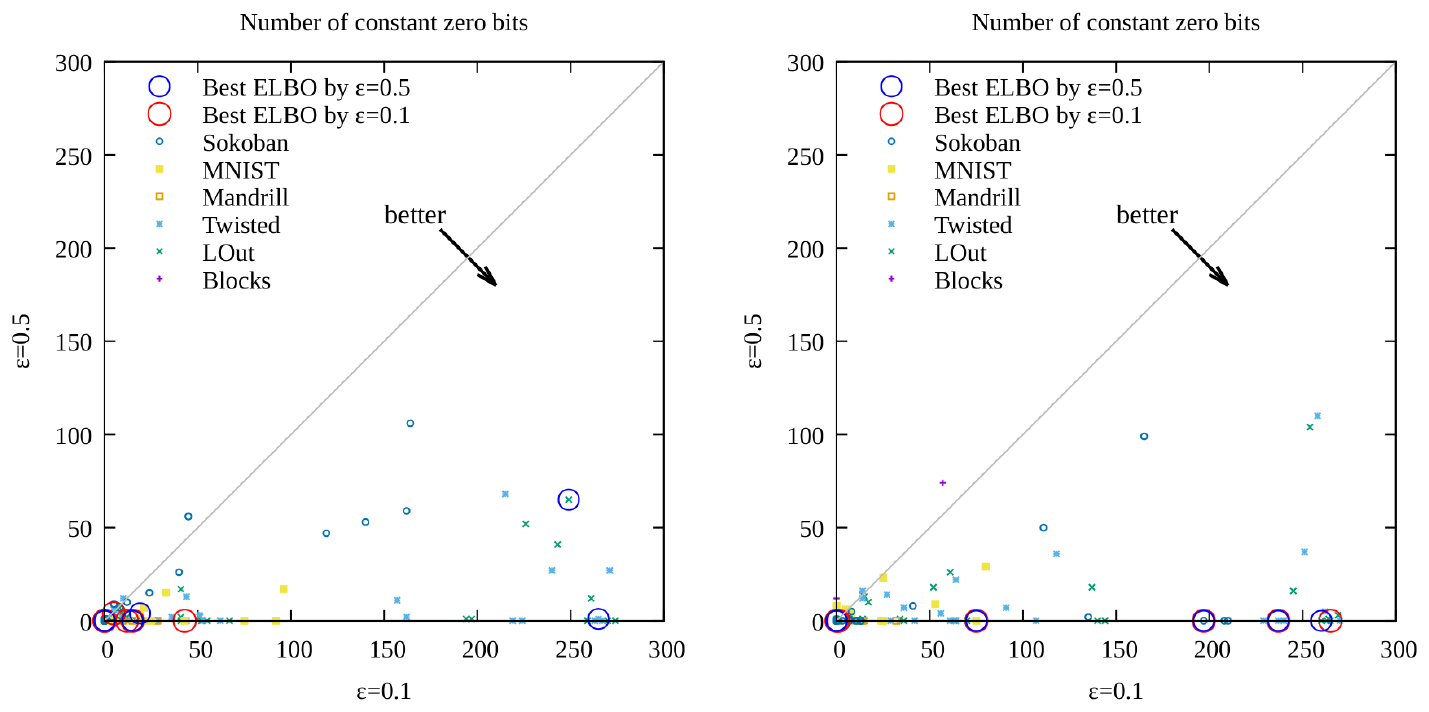
Note that better stability does not by itself imply the overall "quality" of the resulting network and should always be considered in conjunction with other metrics. For example, a failed training result that exhibits posterior collapse may have a latent space where all bits are always 0, and may fail to reconstruct an input image at all. While such a latent space shows a perfect "stability, " the network is not useful for planning because it does not map the input image to an informative latent vector.
10.5 Evaluating the Accuracy of Action Models: Successor State Prediction
We next measured the accuracy of the progression prediction (effect). In this experiment, we measured $\mathbb{E}_{i, f} | {\bm{z}}^{i, 1}_f-{\bm{z}}^{i, 2}f|$, i.e., the absolute error between ${\bm{z}}^{i, 1}$ (encoded directly from the image) and ${\bm{z}}^{i, 2}$ (predicted by the BTL mechanism) averaged over latent bits and the test dataset. We show the absolute error instead of the corresponding KL divergence loss $D{\mathrm{KL}}(q({\bm{z}}^{i, 1}\mid {\bm{x}}^{i, 1}) \mathrel{|} p({\bm{z}}^{i, 2}\mid {\bm{z}}^{i, 0}, {\bm{a}}^{i}))$ which was used for training because the average absolute error gives an intuitive understanding of "how often it predicts a wrong bit."
Figure 21 shows these metrics for the best hyperparameter configuration that achieved the best ELBO. For those configurations, AMA${3}^+$ and AMA${4}^+$ models obtained comparable accuracy. If we compare AMA${3}^+$ and AMA${4}^+$ having the same hyperparameter, the result seems slightly in favor of AMA$_{4}^+$.
Comparing the results of different priors, $\epsilon=0.1$ configurations (Figure 21, left) tend to have better successor prediction accuracy than $\epsilon=0.5$ (Figure 21, right). This is presumably because the state instability causes a non-deterministic state transition that cannot be captured well by the BTL mechanism because BTL assumes STRIPS-compatible state transitions.
Again, note that neither the best ELBO or the best successor prediction accuracy alone determine the likelihood of success in solving visual planning problems. For example, in a collapsed latent space, successor prediction is quite easy because not a single latent space bit will change its value. Also, even if the overall accuracy (ELBO) is good, the planning is not likely to succeed if the network sacrifices successor prediction accuracy for reconstruction accuracy.
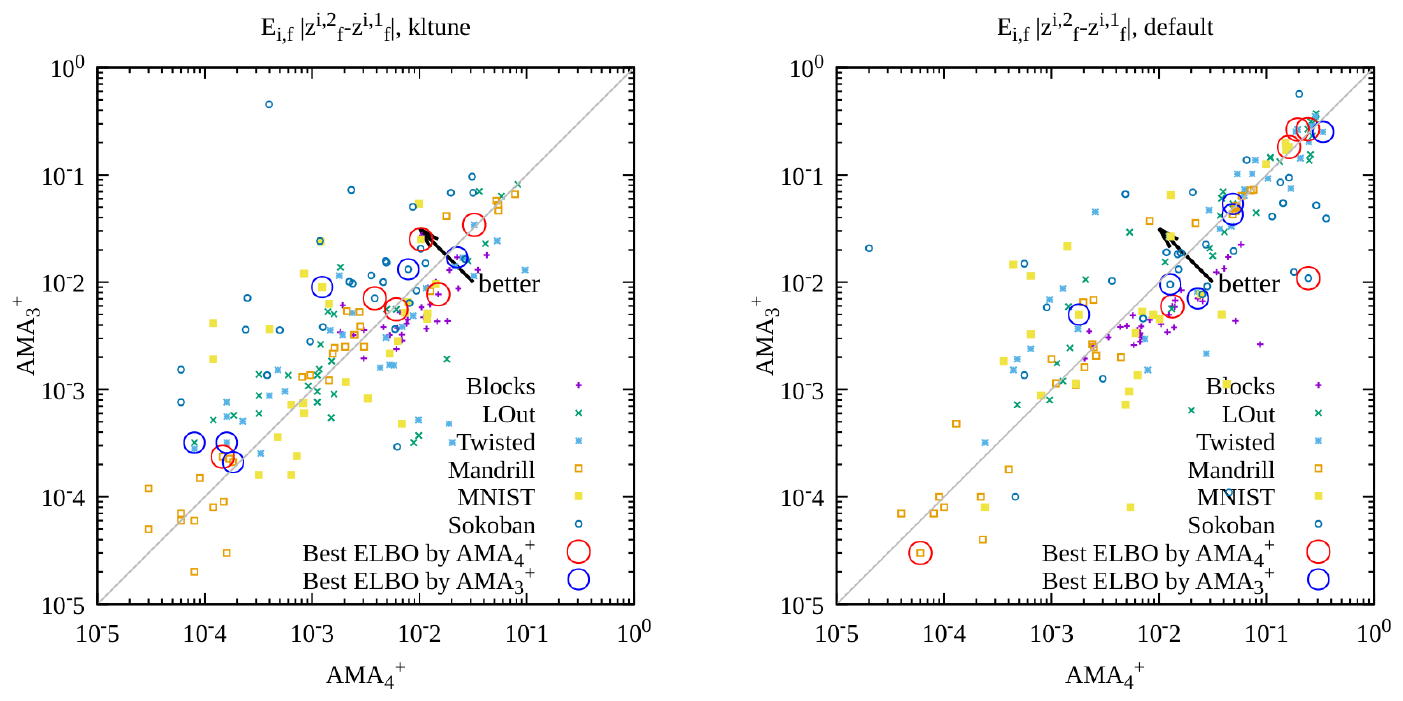
10.6 Violation of Monotonicity in BTL
As discussed in Section 8.3, Batch Normalization used as a "continualizer" $m$ in BTL may violate the monotonicity of $m$. This causes an action with XOR semantics which always flips the value, which is not directly expressible in the STRIPS semantics.
To quantify the harmful effect of these bits with XOR semantics, we first counted the number of such violations averaged over all actions. As we see in Table 6, the number of such bits is small compared to the entire representation size. We also compared the number of actions before and after compiling these XOR semantics away. While the increase of STRIPS action is exponential to the number of violations in the worst case, the empirical increase tends to be marginal because the number of violations was small for each action, except for one instance of Sokoban in AMA$_{4}^+$.
While the Sokoban result from the best ELBO hyperparameter of AMA$_{4}^+$ resulted in a relatively large number of monotonicity violations, this is not always the case across hyperparameters. Table 6 (Right) plots ELBO and the compiled number of actions, $A_2$, which varies significantly between hyperparameters despite having a similar ELBO. This is another case demonstrating that the ELBO alone does not necessarily characterize the detrimental effect on search performance.
Note that the increase depends on whether the violations are concentrated in one action. For example, if 5 violations are found in one action, the action is compiled into $2^5=32$ variants. However, if 1 violation is found in 5 separate actions, it only adds 5 more actions.
::: {caption="Table 6: The XOR columns show the number of bits with XOR semantics averaged across actions for a hyperparameter configuration that achieved the best ELBO in each domain. A_1 column shows the number of actions before compiling XOR bits away, and A_2 shows the number after the compilation. Note that A_1 <= A = 6000, where A is the hyperparameter that specifies the length of one-hot vector a^i, thus serves as the maximum number of action labels that can be learned by the neural network. In AMA_3^+, we observed that the number of monotonicity violations is small, and thus the empirical increase of the number of actions due to the compilation is marginal. In AMA_4^+, this is also the case except for the Sokoban domain that resulted in a larger number of XOR bits. However, note that this is not always the case in all hyperparameters; In the figure on the right, we plotted the number of compiled actions in the y-axis against the ELBO in the x-axis. The number of compiled actions varies significantly for a similar ELBO."}
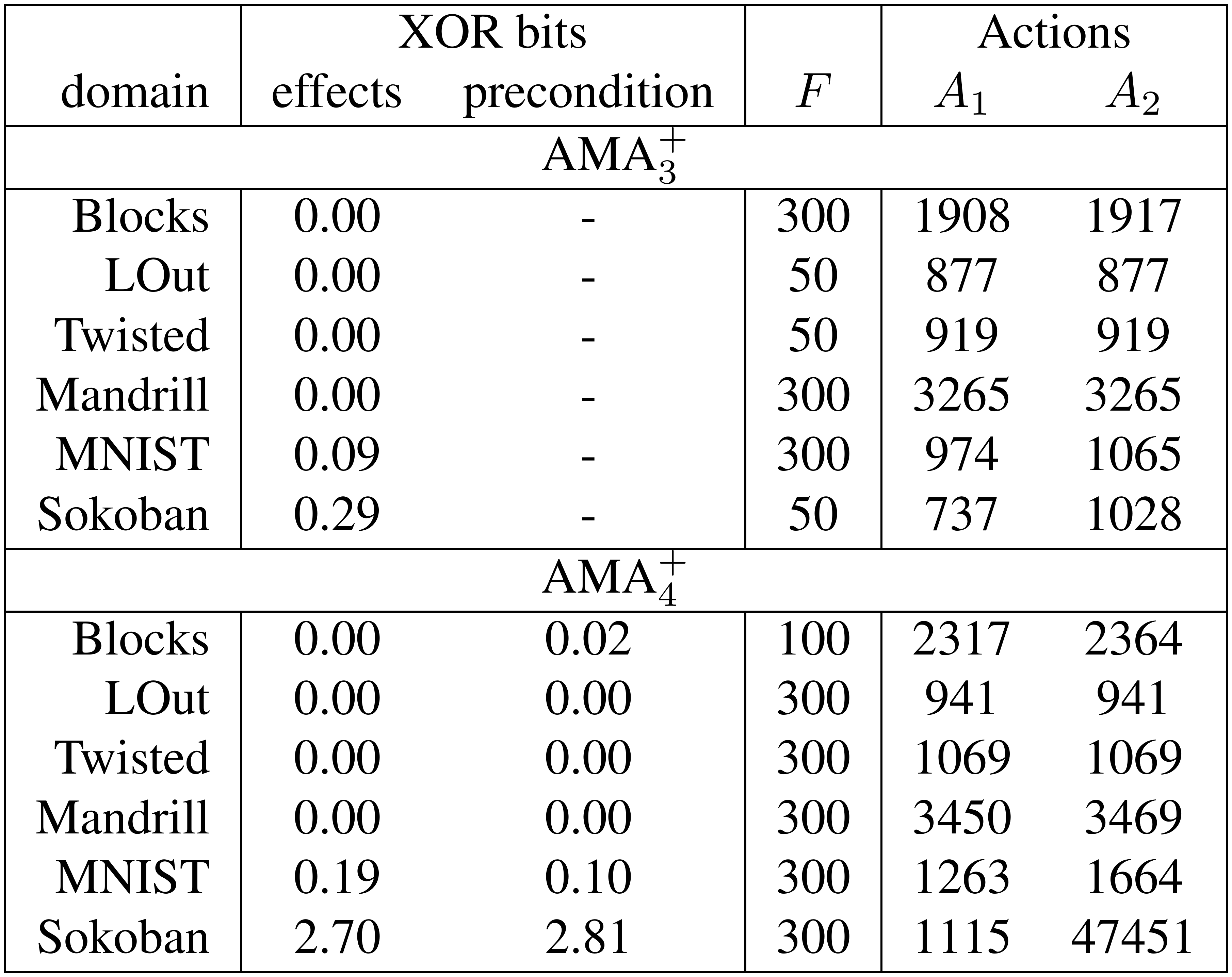
:::
10.7 Summary Statistics of the Learned PDDL Representation
Finally, Table 7 summarizes the statistics of the PDDL obtained from our final model, AMA$_4^+$, with $\text{Bernoulli}(\epsilon=0.1)$ prior. This table shows the number of effective bits (Section 10.4), the number of compiled actions (Section 10.6), average state differences between current and successor states, and the average number of delete/add effects, positive/negative preconditions.
State differences are the average number of different bits between the current and the successor states over the dataset, i.e., $\mathbb{E}_{i, f} | {\bm{z}}^{i, 0}_f-{\bm{z}}^{i, 1}_f|$. It explains why the PDDL files generally contain larger numbers of delete effects and negative preconditions: The system recognized static predicates that take false values and added it to the preconditions/effects.
::: {caption="Table 7: A summary of the statistics of the PDDL files obtained from the AMA_4^+ model for each domain (hyperparameter with the best ELBO and with Bernoulli(epsilon=0.1) prior)."}
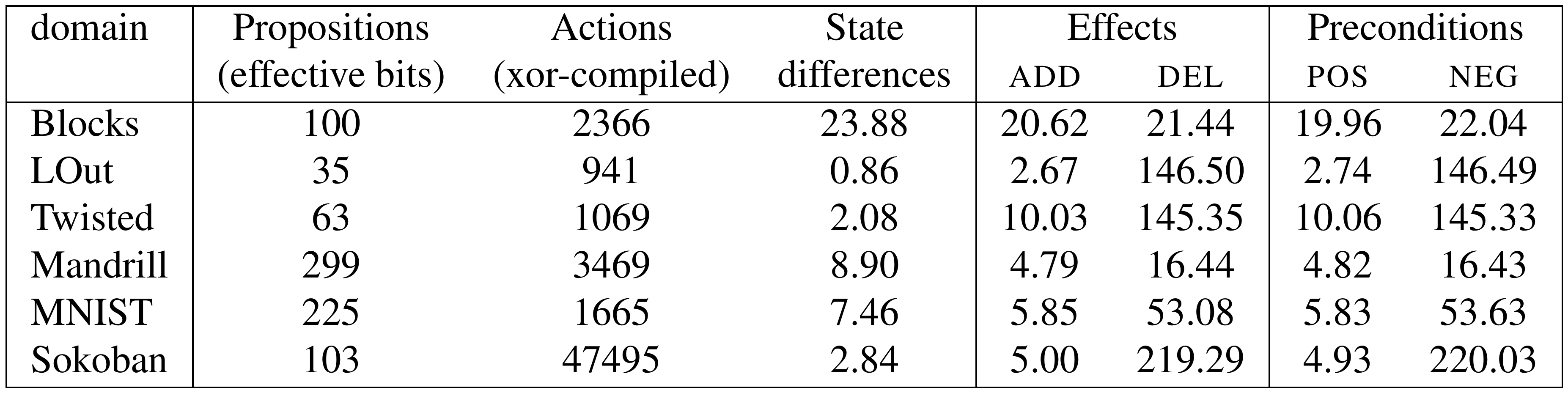
:::
11. Planning Performance
Section Summary: This section assesses how effectively the PDDL models learned by the neural networks support actual planning across several visual domains. It describes an experimental setup that encodes randomly generated start and goal images into PDDL, runs the Fast Downward planner with different heuristics under time and memory limits, and counts how many solutions are found, empirically valid when visualized, and optimal. Results indicate that bidirectional models produce more reliable preconditions than earlier unidirectional versions, yielding higher coverage and more optimal plans especially on challenging domains such as Sokoban and Blocksworld.
We next evaluate the PDDL models produced by the networks using randomly generated problem instances for each domain. The objectives of the comparisons made in this section are threefold:
- Verifying the effectiveness of the preconditions generated by Bidirectional Cube-Space AE (AMA${4}^+$) over the ad-hoc preconditions generated by Cube-Space AE (AMA${3}^+$).
- Verifying the effect of state-of-the-art heuristics on the search performance in the latent space generated by AMA${3}^+$/AMA${4}^+$.
- Verifying the effect of improved symbol stability on the planning performance,
11.1 Experimental Setup
We ran the off-the-shelf planner Fast Downward on the PDDL generated by our system. To evaluate the quality of the domains, we similarly generate multiple problems by encoding an initial and a goal state image $({{\bm{x}}^{I}}, {{\bm{x}}^{G}})$ which are randomly generated using domain-specific code. The images are normalized to mean-0, variance-1 using the statistics of the training dataset, i.e., they are shifted and scaled by the mean and the variance of the training dataset. Each normalized image is encoded by the encoder, then is converted into a PDDL encoding of the initial state and the goal state. Formally, when ${{\bm{x}}^{I}}\in [0, 255]^{H, W, C}$ is an initial state image of width $H$, width $W$ and color channel $C\in{\left{1, 3\right}}$, and ${\bm{\mu}}= \mathbb{E}{i, j} [{\bm{x}}^{i, j}]$ and ${\bm{\sigma}}^2= \mathrm{Var}{i, j} [{\bm{x}}^{i, j}]$ are the mean and the variance of the training dataset, the latent propositional initial state vector is ${{\bm{z}}^{I}}= \textsc{BC}_{\tau}(\textsc{encode}(\frac{{{\bm{x}}^{I}}-{\bm{\mu}}}{{\bm{\sigma}}}))$, just as all training is performed on the normalized dataset.
In 8-Puzzle, 15-Puzzle, LightsOut and Twisted, we used a randomly sampled initial state image ${{\bm{x}}^{I}}$ and a fixed complete goal state ${{\bm{x}}^{G}}$. The goal states are those states that are normally considered to solve the puzzles, e.g., for a Mandrill 15-Puzzle, the goal state is a state where all tiles are ordered correctly so that the whole configuration recovers the original photograph of a Mandrill. Initial states ${{\bm{x}}^{I}}$ are sampled from the frontier of a Dijkstra search, which was run backward from the goal. The search stops when it exhausts the plateau at a specific $g$-value, at which point the shortest path length from the goal state is obtained for each of those states. We then randomly select a state from this plateau. In each domain, we generated 20 instances for $g=7$ and $g=14$, resulting in 40 instances per domain.[^4]
[^4]: $g$ is the measure of distance from the initial state to a node is the search graph.
In 8-Puzzle, we also added instances whose goal states are randomly generated using domain-specific code, and the initial states are sampled with $g=7$ and $g=14$ thresholds. The purpose of evaluating them is to see whether the system is generalized over the goals.
In Sokoban, the goal-based sampling approach described above does not work because the problem is not reversible. We instead sampled goal states from the initial state of p006-microban-sequential instance with $g=7$ and $g=14$ thresholds. These goal states do not correspond to the goal states of p006-microban-sequential which solve the puzzle.
In Blocksworld, we randomly generated an initial state and performed a 7-step or 14-step random walk to generate a goal state. The number of steps does not correspond to the optimal plan length.
We tested $A^*$ with blind heuristics, Landmark-Cut ([9], LMcut), Merge-and-Shrink (M&S) [67], and the first iteration of the satisficing planner LAMA [68]. Experiments are run with the 10 minutes time limit and 8GB memory limit. We tested the PDDL generated by AMA${3}^+$ and AMA${4}^+$ models, each trained with different latent space priors $\text{Bernoulli}(\epsilon=0.5)$ and $\text{Bernoulli}(\epsilon=0.1)$.
We counted the number of instances in which a solution was found. However, the solution found by our system is not always correct because the correctness of the plan is guaranteed only with respect to the PDDL model — if the symbolic mapping produced by the neural network is incorrect, the resulting visualization of the symbolic plan does not correspond to a realistically correct visual plan. To address this issue, we wrote a domain-specific plan validator for each domain which heuristically examines the visualized results and we counted the number of plans which are empirically valid. Finally, we are also interested in how often the solution is optimal out of the valid plans. In domains where we generated the instances with Dijkstra-based sampling method, we compared the solution length with the $g$ threshold which was used to generate the instance.
In the comparisons made in the following sections, we select the hyperparameter configuration which maximizes the metric of interest (e.g., the number of valid solutions or the number of optimal solutions). This selection is performed on a per domain basis.
11.2 Bidirectional Models Outperform Unidirectional Models
We evaluated each hyperparameter configuration of AMA${3}^+$ and AMA${4}^+$ on the problem instances we generated. We verified the solutions and Table 8 shows the numbers obtained from configurations that achieved the highest number of valid solutions. The result shows that AMA${4}^+$ outperforms AMA${3}^+$, indicating that the precondition generated by the complete state regression in AMA${4}^+$ is more effective than those generated by an ad-hoc method in AMA${3}^+$. All results are based on $\text{Bernoulli}(\epsilon=0.1)$ prior for the latent representation (i.e., $\epsilon$ is not considered as a hyperparameter).
In particular, we note the significant jump in (1) coverage on arguably the most visually challenging domains (Blocks and Sokoban); and (2) the ratio of valid plans that are also optimal (AMA$_{4}^+$ struggled with only MNIST in this regard).
\begin{tabular}{|r|ccc|ccc|ccc|ccc|}
\hline
& \multicolumn{ 3}{c|}{Blind} & \multicolumn{ 3}{c|}{LAMA} & \multicolumn{ 3}{c|}{LMCut} & \multicolumn{ 3}{c|}{M\&S} \\
\hline
& \textbf{found} & \textbf{valid} & {\textbf{optimal}} & {\textbf{found}} & {\textbf{valid}} & {\textbf{optimal}} & {\textbf{found}} & {\textbf{valid}} & {\textbf{optimal}} & {\textbf{found}} & {\textbf{valid}} & {\textbf{optimal}} \\
\hline
\multicolumn{ 13}{|c|}{AMA$_{3}^+$} \\
\hline
Blocks & 1 & 1 & - & 1 & 1 & - & 1 & 1 & - & 1 & 1 & - \\
LOut & 40 & 40 & 35 & 40 & 39 & 0 & 20 & 20 & 18 & 40 & 40 & 35 \\
Twisted & 40 & 40 & 36 & 40 & 40 & 0 & \textbf{23} & 20 & 18 & 40 & 40 & 16 \\
Mandrill & \textbf{38} & \textbf{38} & 20 & \textbf{38} & \textbf{38} & 9 & 38 & \textbf{38} & 18 & 40 & \textbf{40} & 26 \\
MNIST & 39 & 39 & 5 & \textbf{39} & \textbf{39} & 4 & 39 & 39 & 5 & 39 & 39 & 5 \\
Random MNIST & \textbf{39} & \textbf{39} & 4 & \textbf{39} & \textbf{36} & 4 & \textbf{39} & \textbf{39} & 4 & \textbf{39} & \textbf{39} & 4 \\
Sokoban & 14 & 14 & 12 & 14 & 14 & 12 & 14 & 14 & 12 & 14 & 14 & 12 \\
\hline
\textbf{Total} & 211 & 211 & 112 & 211 & 207 & 29 & 174 & 171 & 75 & 213 & 213 & 98 \\
\hline
\multicolumn{ 13}{|c|}{\textbf{AMA$_{4}^+$}} \\
\hline
Blocks & \textbf{33} & \textbf{32} & - & \textbf{19} & \textbf{19} & - & \textbf{34} & \textbf{34} & - & \textbf{34} & \textbf{33} & - \\
LOut & 40 & 40 & \textbf{40} & 40 & \textbf{40} & \textbf{1} & 20 & 20 & \textbf{20} & 40 & 40 & \textbf{40} \\
Twisted & 40 & 40 & \textbf{40} & 40 & 40 & \textbf{1} & 20 & 20 & \textbf{20} & 40 & 40 & \textbf{40} \\
Mandrill & 25 & 23 & \textbf{23} & 20 & 15 & \textbf{11} & 38 & 30 & \textbf{30} & 40 & 32 & \textbf{32} \\
MNIST & \textbf{40} & 39 & \textbf{6} & 35 & 35 & \textbf{16} & \textbf{40} & 39 & \textbf{6} & \textbf{40} & 39 & \textbf{6} \\
Random MNIST & 36 & 34 & \textbf{11} & 32 & 32 & \textbf{5} & 35 & 32 & \textbf{11} & 36 & 33 & \textbf{11} \\
Sokoban & \textbf{40} & \textbf{39} & \textbf{38} & \textbf{40} & \textbf{31} & \textbf{21} & \textbf{40} & \textbf{38} & \textbf{37} & \textbf{40} & \textbf{39} & \textbf{38} \\
\hline
\textbf{Total} & \textbf{254} & \textbf{247} & \textbf{158} & \textbf{226} & \textbf{212} & \textbf{55} & \textbf{227} & \textbf{213} & \textbf{124} & \textbf{270} & \textbf{256} & \textbf{167} \\
\hline
\end{tabular}
11.3 Classical Planning Heuristics Reduce the Search Effort in the Latent Space
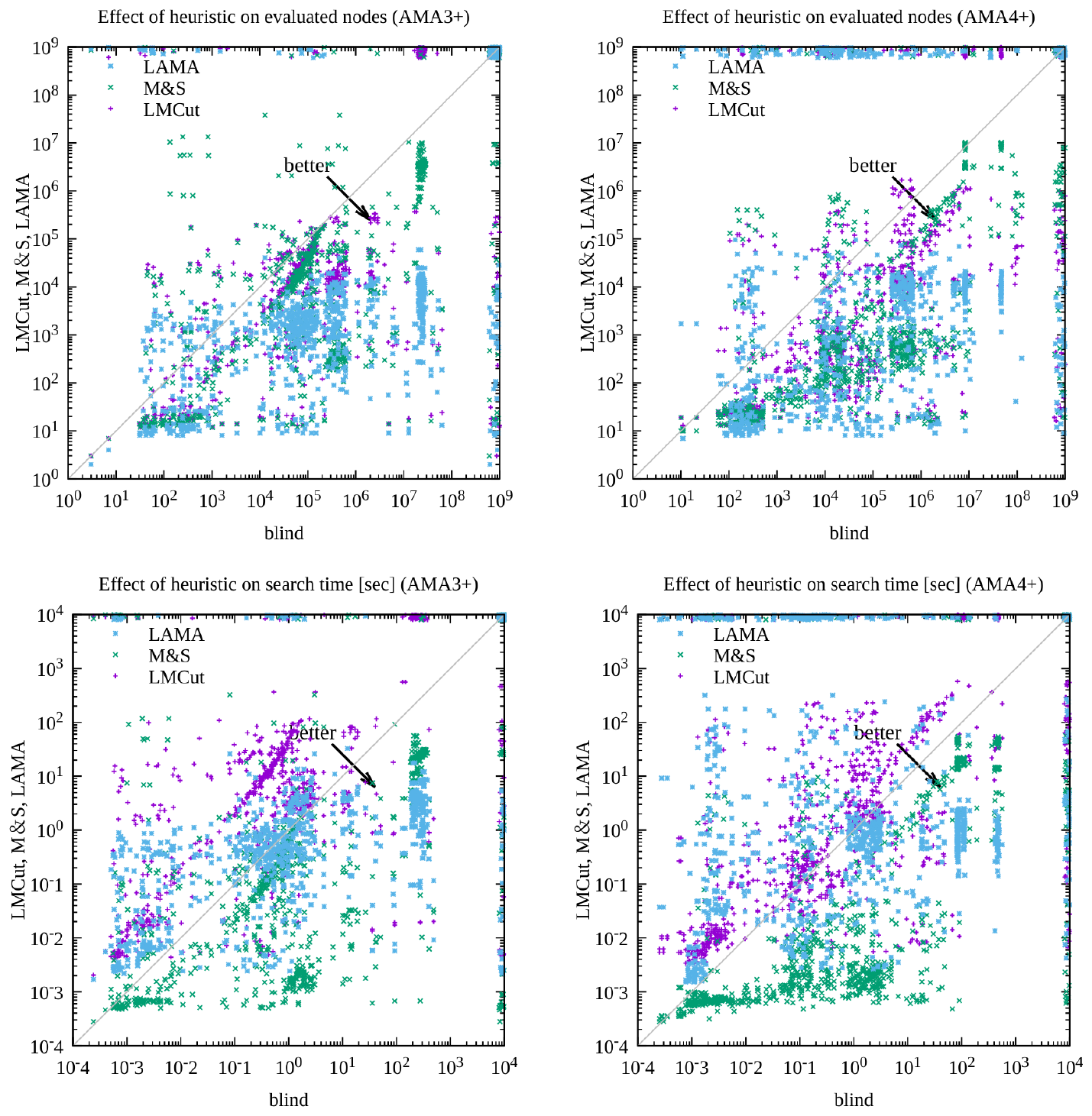
Domain-in-dep-endent heuristics in the planning literature are traditionally evaluated on hand-coded benchmarks, e.g., International Planning Competition instances [1], which contain a wide variety of domains and are regarded as a representative subset of the real-world tasks. As a result, they assume a certain general class of structures that are commonly found in domains made by humans, such as serializable subgoals and abstraction [69]. However, the latent space domains derived from raw pixels and neural networks may have completely different characteristics that could render them useless. In fact, blind heuristic can sometimes outperform well-known heuristics on some IPC domains (e.g., floortile) specifically designed to defeat their efficacy [70]. Also, even though the image-based 8-puzzle domains we evaluate correspond to the 8-puzzle domain used in the combinatorial search and classical planning literature, the latent representations of the 8-puzzle states may be unlike any standard PDDL encoding of the 8-puzzle written by humans. While the symbolic representation acquired by Latplan captures the state space graph of the domain, the propositions in the latent space do not necessarily correspond to conceptual propositions in a natural, hand-coded PDDL model. Thus, there is little a priori reason to believe that the standard heuristics will be effective until we evaluate them.
We evaluated the effect of state-of-the-art heuristic functions in the latent space generated by our neural networks. Figure 22 compares node evaluations and search time between blind search and LMcut, M&S heuristics as well as LAMA. For each domain, we select the hyperparameter configuration with the largest number of valid solutions. Results are based on $\text{Bernoulli}(\epsilon=0.1)$.
Node evaluation plots confirm the overall reduction in the search effort. In contrast, the results on search time are mixed. M&S reduces the search time by an order of magnitude, while LMcut tends to be slow due to the high evaluation cost per node. LAMA tends to be faster than a blind search in more difficult instances, though a blind search is faster in easier instances that require less search (
lt;10$ seconds).Despite the increased runtime, the reduced node evaluation strongly indicates that either the models we are inferring contain similar properties as the human-designed PDDL models, or that powerful, domain-independent planning heuristics can induce effective search guidance even in less human-like PDDL models.
11.4 Stable Symbols Contributes to the Better Performance
Section 5.2 discussed three harmful effects of unstable symbols: (1) disconnected search space, (2) having many variations of latent states for a single real-world state, (3) hyperparameter tuning for improving symbol stability. We already evaluated the issue (3) in the previous sections, where we verified that $\text{Bernoulli}(\epsilon=0.1)$ automatically finds a latent space with smaller effective bits when a large $F$ is given. In this section, we proceed to verify the effect of $\text{Bernoulli}(\epsilon=0.1)$ on the first and the second issue.
Issue (1) (disconnected search space) would result in more exhausted instances, i.e., the number of instances where Fast Downward exhausted the state space without finding a solution. It would also result in a lower success ratio, given that we set a certain time limit on the planner and not all unsolvable instances are detected.
Issue (2) (many variations of latent states) would result in more suboptimal visualized plans that are optimal in the latent space / PDDL encoding. There are several possible reasons that a visualized solution becomes suboptimal.
The first and most obvious one is that satisficing planner configuration (LAMA) could return a suboptimal latent space solution, which results in a suboptimal visual solution. Since this is trivial, we do not include LAMA during optimality evaluation.
Second, if a certain action is not correctly learned by the neural network (e.g., missing or having unnecessary preconditions and effects), the optimal solution with regard to the PDDL model may not be in fact optimal when visualized: The planner may not be able to take certain otherwise valid transitions, thus resulting in a longer solution; Or an action effect may alter the values of some bits that do not affect the image reconstruction, and the planner tries to fix it with additional actions. As discussed in Example 2, accurate successor prediction is a form of symbol stability. In Section 10.5, we already observed that $\epsilon=0.1$ tend to predict successors better than $\epsilon=0.5$ due to its stable state representation.
The third case is unstable init/goal states: When symbol instability is significant, a noisy goal state image ${{\bm{x}}^{G}}$ may map to multiple different latent states ${{\bm{z}}^{G}}, {\bm{z}}'^{G}$ depending on the input noise. The encoded initial state ${{\bm{z}}^{I}}$ may be closer to ${\bm{z}}'^{G}$ than to ${{\bm{z}}^{G}}$ specified in PDDL, thus reaching ${{\bm{z}}^{G}}$ may require an extra number of steps, resulting in a suboptimal visual solution. The same mechanism applies to the initial state too.
To investigate the effect of symbol stability, we additionally evaluated our system on a set of initial/goal state images that are corrupted by a Gaussian noise $\mathcal{N}(0, 1)$. We added the noise to the images that are already normalized to mean-0, variance-1 using the statistics from the training dataset (see Section 11.1). As a result, when de-normalized for visualization in Figure 23, the noise appears missing in the static regions, which have little variations across the dataset.

:::: {cols="2"}
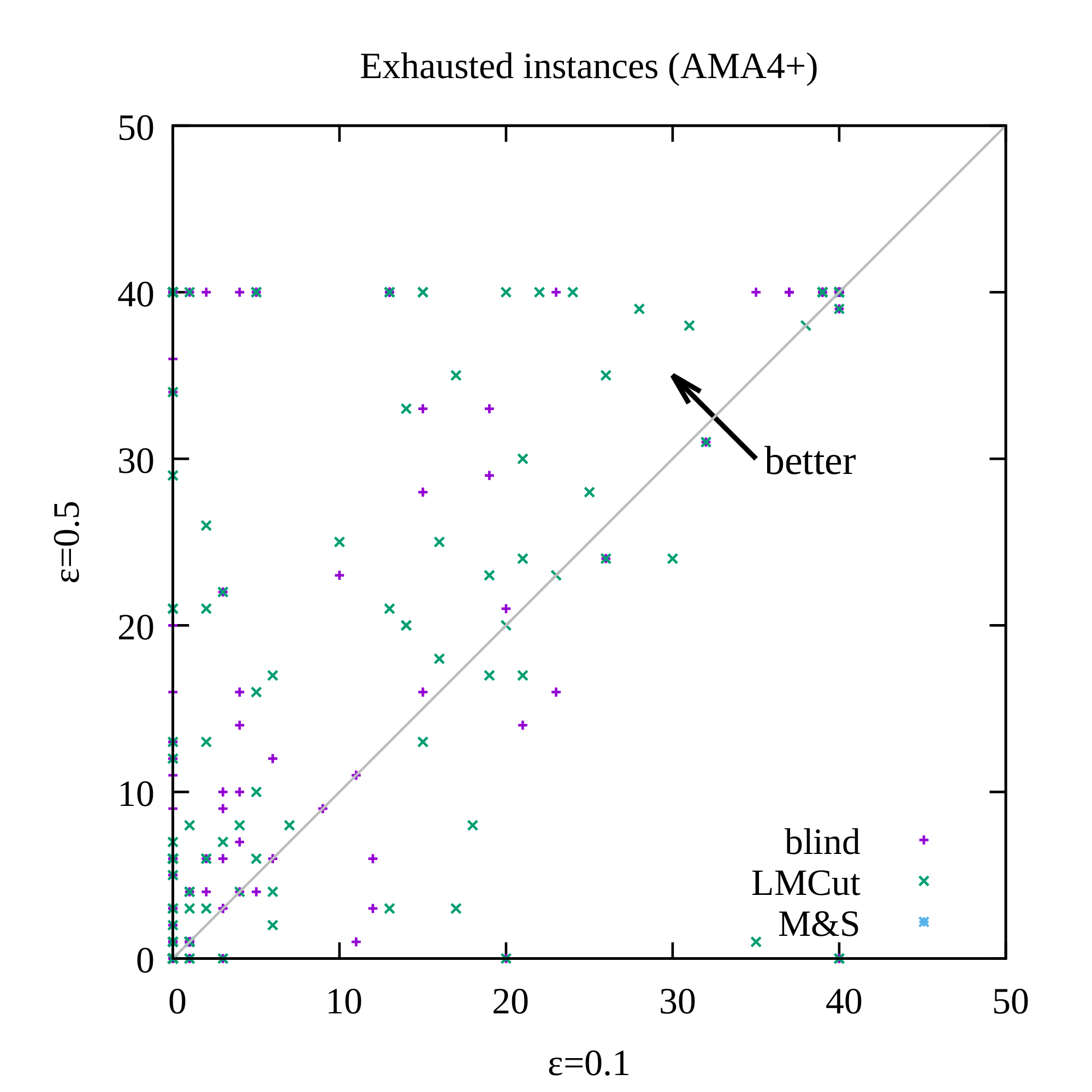
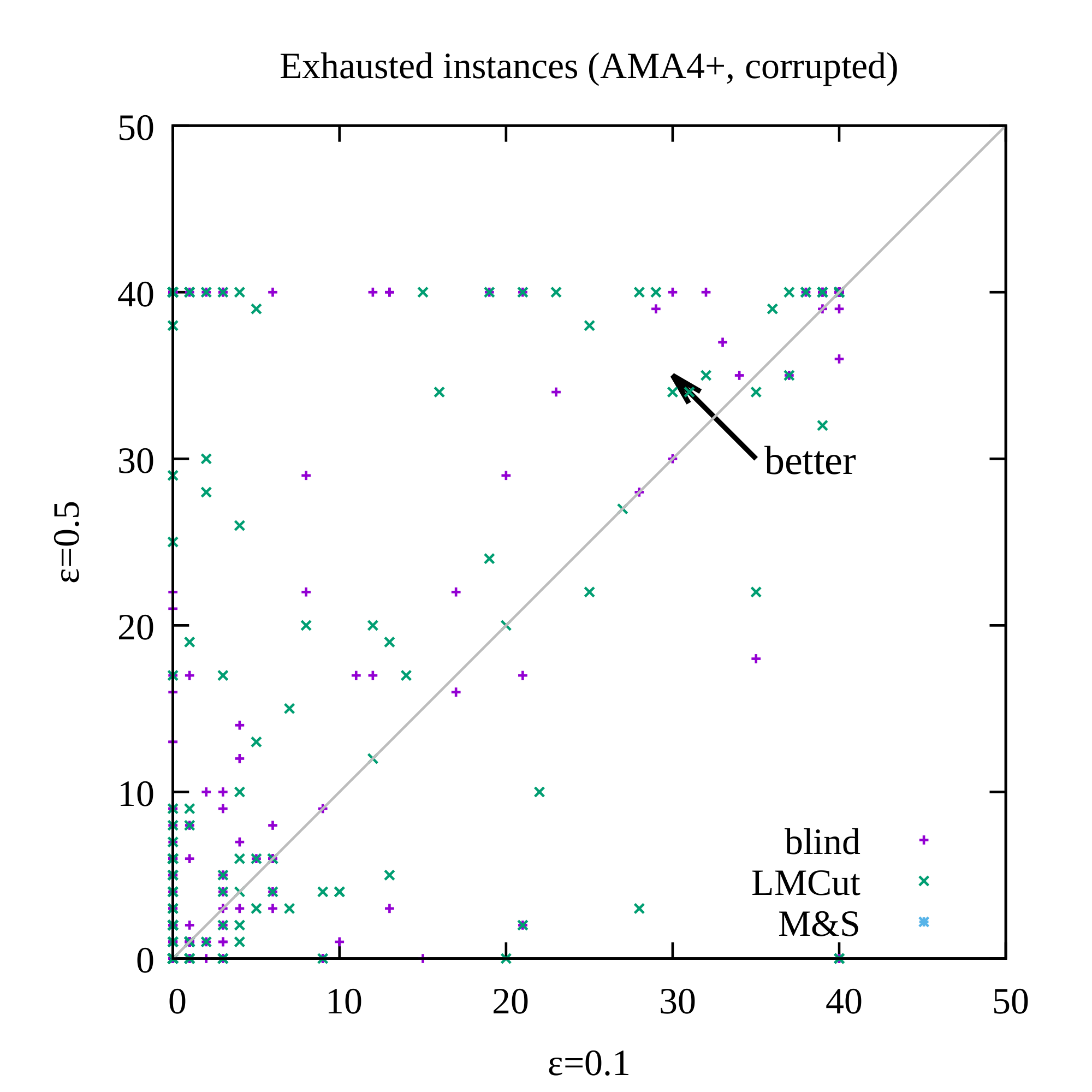
Figure 24: The left figure shows the noiseless instances, and the right figure shows the result from corrupted input images. Each point represents a tuple $(\text{domain}, \text{heuristic}, F, \beta_1, \beta_3)$. We evaluated different heuristics because they have different performances in terms of exhaustively searching the space within the time limit. For each point, each axis represents the number of unsolvable instances among the 40 instances in the domain, which are discovered by Fast Downward by exhaustively searching the state space. $x$-axis represents AMA$_{4}^+$ networks with $\epsilon=0.1$ prior, and $y$-axis the $\epsilon=0.5$ prior. $\epsilon=0.1$ resulted in significantly fewer unsolvable instances. For a plot colored by domains rather than heuristics, see appendix (Appendix K). ::::
::: {caption="Table 9: The number of instances where a valid solution is found. Each number is the largest number among different hyperparameter configurations (F, beta_1, beta_3) in a single domain. Networks trained with Bernoulli(epsilon=0.1) latent space prior outperformed the networks trained with Bernoulli(epsilon=0.5). Numbers are highlighted in bold for the better latent space prior, except ties."}
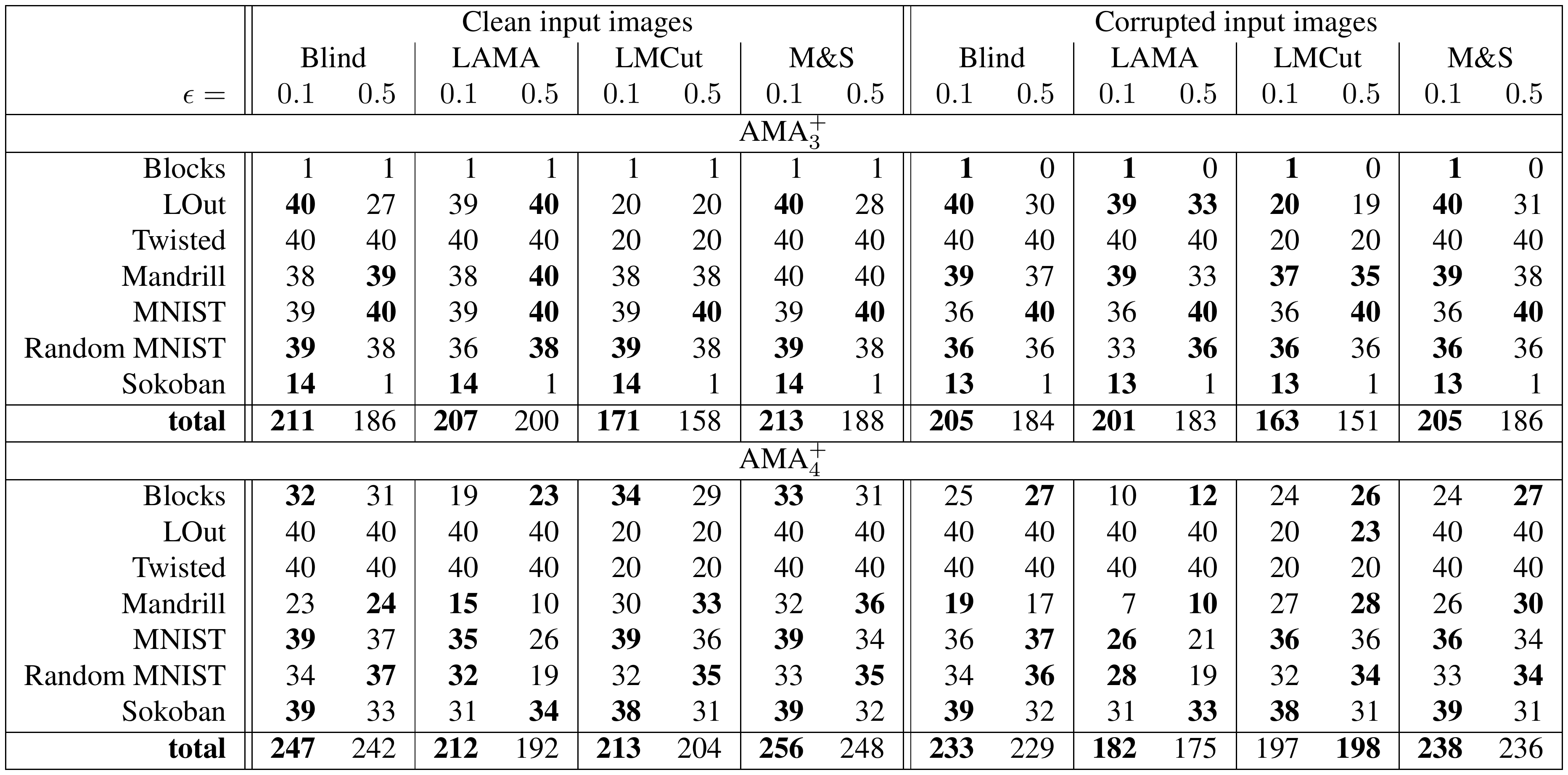
:::
\begin{tabular}{|r|*3{|*3{rr|}}}
\hline
& \multicolumn{ 6}{c||}{Clean input images} & \multicolumn{ 6}{c||}{Corrupted input images} & \multicolumn{ 6}{c|}{Difference due to noise} \\
& \multicolumn{ 2}{c|}{Blind} & \multicolumn{ 2}{c|}{LMCut} & \multicolumn{ 2}{c||}{M\&S}
& \multicolumn{ 2}{c|}{Blind} & \multicolumn{ 2}{c|}{LMCut} & \multicolumn{ 2}{c||}{M\&S}
& \multicolumn{ 2}{c|}{Blind} & \multicolumn{ 2}{c|}{LMCut} & \multicolumn{ 2}{c|}{M\&S} \\
$\epsilon=$
& $0.1$ & $0.5$ & $0.1$ & $0.5$ & $0.1$ & $0.5$
& $0.1$ & $0.5$ & $0.1$ & $0.5$ & $0.1$ & $0.5$
& $0.1$ & $0.5$ & $0.1$ & $0.5$ & $0.1$ & $0.5$ \\
\hline
\multicolumn{19}{|c|}{AMA$_{3}^+$} \\
\hline
LOut & .88 & .93 & .95 & 1.00 & .88 & .93 & .88 & .90 & .95 & 1.00 & .88 & .90 & \textbf{.000} & -.026 & .000 & .000 & \textbf{.000} & -.025 \\
Twisted & .90 & .88 & .90 & .85 & .90 & .88 & .90 & .88 & .90 & .84 & .90 & .88 & .000 & .000 & \textbf{.000} & -.008 & .000 & .000 \\
Mandrill & .81 & .77 & .83 & .79 & .79 & .75 & .79 & .70 & .84 & .74 & .79 & .68 & \textbf{-.016} & -.067 & \textbf{.005} & -.047 & \textbf{.005} & -.066 \\
MNIST & .43 & .20 & .48 & .20 & .43 & .20 & .43 & .21 & .48 & .21 & .43 & .21 & .000 & \textbf{.007} & .000 & \textbf{.007} & .000 & \textbf{.007} \\
Random MNIST & .24 & .28 & .24 & .28 & .24 & .28 & .29 & .28 & .28 & .28 & .28 & .28 & \textbf{.056} & .002 & \textbf{.045} & .002 & \textbf{.045} & .002 \\
Sokoban & .86 & 1.00 & .86 & 1.00 & .86 & 1.00 & .85 & 1.00 & .85 & 1.00 & .85 & 1.00 & -.011 & \textbf{.000} & -.011 & \textbf{.000} & -.011 & \textbf{.000} \\
\hline
\multicolumn{19}{|c|}{\textbf{AMA$_{4}^+$}} \\
\hline
LOut & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & .000 & .000 & .000 & .000 & .000 & .000 \\
Twisted & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & .000 & .000 & .000 & .000 & .000 & .000 \\
Mandrill & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & 1.00 & .96 & 1.00 & 1.00 & 1.00 & .000 & .000 & -.037 & \textbf{.000} & .000 & .000 \\
MNIST & 1.00 & .78 & 1.00 & .81 & 1.00 & .79 & 1.00 & .78 & 1.00 & .81 & 1.00 & .79 & .000 & .000 & .000 & .000 & .000 & .000 \\
Random MNIST & .91 & .92 & .94 & .91 & .94 & .91 & .95 & .92 & 1.00 & .91 & .95 & .91 & \textbf{.041} & -.002 & \textbf{.065} & -.003 & \textbf{.017} & -.003 \\
Sokoban & .97 & .79 & .97 & .80 & .97 & .78 & .97 & .78 & .97 & .77 & .97 & .77 & \textbf{.000} & -.007 & \textbf{.000} & -.026 & \textbf{.000} & -.007 \\
\hline
\end{tabular}
We first investigated the effect of (1). We evaluated AMA${3}^+$ and AMA${4}^+$ trained with different $\text{Bernoulli}(\epsilon)$ priors. Figure 24 plots the number of instances where Fast Downward exhaustively searched the state space and failed to find a solution. The PDDL is generated by AMA${4}^+$, and we compare the numbers between $\text{Bernoulli}(\epsilon=0.1)$ prior and the $\text{Bernoulli}(\epsilon=0.5)$ prior. We do not show AMA${3}^+$ results because its preconditions are less accurate and ad-hoc, and the precondition accuracy is crucial in this evaluation. The figure clearly shows that more instances have disconnected search spaces when encoded by $\epsilon=0.5$ prior.
Next, to address the issue of insufficient runtime to prove the unsolvability, Figure 16 shows the number of valid solutions found. For each domain, heuristic, and $\epsilon\in{\left{0.1, 0.5\right}}$, we selected the hyperparameter which resulted in the largest number of valid solutions. $\epsilon=0.1$ configuration outperforms $\epsilon=0.5$ on both clean and corrupted input images.
Recall that networks trained with different $\text{Bernoulli}(\epsilon)$ priors had comparable results in terms of ELBO — thus, ELBO (accuracy) alone is not the sole factor that determines the likelihood of success in finding a solution. In fact, $\epsilon=0.1$ configuration solves more instances than $\epsilon=0.5$ configuration does in LightsOut (AMA${3}^+$), Blocks, and Sokoban (AMA${4}^+$) where $\epsilon=0.5$ had the better ELBO (Table 5).
We next evaluate the effect of (2), predicted to result in more suboptimal plans. For each domain, heuristics, and prior distribution ($\epsilon\in{\left{0.1, 0.5\right}}$), we selected the hyperparameter configuration which found the most valid optimal solutions. Note that the absolute number of optimal plans is not a proper metric for evaluating the effect of (1) because if a configuration finds fewer valid plans, the number of optimal plans found is also expected to decrease. Instead, we measure the ratio between the number of optimal plans over the number of valid plans. The results are shown in Table 10. AMA${4}^+$ results show that $\epsilon=0.1$ is less affected by the noise than $\epsilon=0.5$ is. While AMA${3}^+$ results are mixed, we attribute the mixed results to the lower optimality ratio of $\epsilon=0.5$ in MNIST (around 0.2, compared to around 0.43-0.48 in AMA${4}^+$) as well as the fact that AMA${3}^+$ finds only a single valid instance of Sokoban, which was optimal (thus the optimality rate is 1).
11.5 The Effect of Planner Preprocessing
One may be interested in whether the planners are by themselves able to prune more propositions/actions in the translation phase. We compared the number of "relevant propositions/actions" as measured by Fast Downward translator (translator variables / translator operators) against total number of propositions and actions. For each domain, we selected an AMA$_{4}^+$ model that returned the largest number of valid solutions with M&S (we selected M&S because it achieved the best overall performance).
As the total number of propositions, we used the number of effective bits discussed in Figure 19, rather than the number of propositions in a PDDL file, because we do not filter propositions based on their effectiveness when writing them into a PDDL file. As the total number of actions, we directly used the number of actions in a PDDL file because we already filter actions that is never mapped to by $\textsc{action}$ in the tranining dataset (see AMA$_2$ section). The number of actions in a PDDL file corresponds to $A_2$ after XOR compilation (Section 8.3, Section 10.6).
Results showed that Fast Downward did not reduce propositions/actions significantly. For actions, over 95% of original actions are retained. The ratio $\frac{[\text{translator operators}]}{[\text{actions}]}$ was blocks:99.8%, lightsout:98.6%, twisted:98.8%, mandrill:96.2%, mnist:95.4%, sokoban:99.7%.
The number of effective bits and the number of translator variables also closely matched: The ratio $\frac{[\text{translator variables}]}{[\text{effective bits}]}$ was blocks:100.0%, lightsout:103.2%, twisted:103.4%, mandrill:100.0%, mnist:100.0%, sokoban:100.0%. The numbers can exceed 100% because effective bits can be underestimated: It is measured by encoding a dataset, which contains only a subset of samples in the entire state space.
There were no variations in the translator variables / operators across problem instances except instances where no solution was found. This is unlike normal PDDL instances where these numbers differ due to different goal conditions. In instances where no solution was found, typically all actions and variables are detected as irrelevant and then removed.
12. Related Work
Section Summary: The section surveys prior research on acquiring action models and grounding symbols, ranging from purely symbolic methods that rely on pre-existing structured inputs like predicates or state IDs, to more recent neuro-symbolic hybrids. It compares many existing systems along axes such as the type of human-provided inputs required, which symbols they can generate or ground, and the optimization methods employed (for instance, MAXSAT, finite-state machines, or answer-set programming), noting that nearly all depend on some form of symbolic domain knowledge rather than starting from raw unstructured data. Latplan is positioned as distinct in learning propositional and action symbols from noisy images alone via deep generative models and likelihood maximization, without needing initial symbolic inputs.
In this section, we cover a wide range of related work from purely connectionist approaches to purely symbolic approaches. In between, there is a recent body of work which are collectively called Neural/Neuro-Symbolic hybrid approaches.
12.1 Previous Work on Action Model Acquisition and Symbol Grounding
\begin{tabular}{r|llllll|lll|lll|l|l}
\toprule
& \multicolumn{ 6}{c|}{Required Input} & \multicolumn{ 3}{c|}{Symbol Generation} & \multicolumn{ 3}{c|}{Symbol Grounding} & \multicolumn{1}{c|}{Optimization Method for} & Target \\
& state ID & prop. & pred. & act. & obs. & noise & prop. & pred. & act. & prop. & pred. & act. & Likelihood Maximization & language \\
\midrule
[28] & Y & Y & Y & Y & full & N & N & N & N & N & N & Y & MAXSAT & PDDL \\
[71] & Y & Y & Y & Y & \textbf{partial} & \textbf{Y} & N & N & N & N & N & Y & SVM & PDDL \\
[72] & Y & Y & Y & Y & full & \textbf{Y} & N & N & N & N & N & Y & MAXSAT & PDDL \\
[73] & Y & Y & Y & Y & \textbf{dis.} & \textbf{Y} & N & N & N & N & N & Y & MAXSAT & PDDL \\
\midrule
[74] & Y & Y & Y & Y & full & N & N & N & N & N & N & Y & FSM & PDDL \\
[75] & Y & Y & Y & Y & full & N & N & N & N & N & N & Y & FSM & PDDL \\
[76] & Y & Y & Y & Y & full & N & N & N & N & N & N & Y & FSM & PDDL \\
[77] & Y & Y & Y & Y & full & N & N & N & N & N & N & Y & FSM & PDDL \\
\midrule
[78] & Y & Y & Y & \textbf{N} & \textbf{partial} & N & N & N & \textbf{Y} & N & N & Y & Classical Planning & PDDL \\
\midrule
[79] & Y & \textbf{N} & \textbf{N} & Y & N/A & N & \textbf{Y} & \textbf{Y} & N & \textbf{Y} & \textbf{Y} & Y & MAXSAT & PDDL \\
[80] & Y & \textbf{N} & \textbf{N} & Y & N/A & \textbf{Y} & \textbf{Y} & \textbf{Y} & N & \textbf{Y} & \textbf{Y} & Y & ASP & PDDL \\
\midrule
[81] & \textbf{N} & \textbf{N} & \textbf{N} & Y & full & N & \textbf{Y} & N & N & Y & N & Y & C4.5 & PDDL \\
[82] & \textbf{N} & \textbf{N} & \textbf{N} & Y & full & \textbf{Y} & \textbf{Y} & N & N & Y & N & Y & mixed & PPDDL \\
[83] & \textbf{N} & \textbf{N} & \textbf{N} & Y & full & \textbf{Y} & \textbf{Y} & N & N & Y & N & Y & mixed & PPDDL \\
[84] & \textbf{N} & \textbf{N} & \textbf{N} & Y & full & \textbf{Y} & \textbf{Y} & N & N & Y & N & Y & mixed & PPDDL \\
\midrule
[85] & N & Y & Y & Y & N/A & Y & N & N & N & N & N & Y & ILP & Prolog \\
[86] & N & Y & Y & Y & N/A & Y & N & N & N & N & N & Y & ILP & GGP \\
[87] & \textbf{N} & \textbf{N} & \textbf{N} & Y & full & Y & \textbf{Y} & \textbf{Y*} & N & N & N & Y & mixed & PDDL \\
[88] & \textbf{N} & \textbf{N} & \textbf{N} & Y & full & Y & \textbf{Y} & \textbf{Y*} & N & N & N & Y & mixed & PPDDL \\
\midrule
[89] & \multicolumn{ 6}{c}{\textbf{natural language}} & N & N & N & N & N & Y & k-medoid clustering & PDDL \\
[90] & \multicolumn{ 6}{c}{\textbf{natural language}} & N & N & N & N & N & Y & RL+LOCM2 & PDDL \\
\midrule
\textbf{Latplan} & \textbf{N} & \textbf{N} & \textbf{N} & \textbf{N} & full & \textbf{Y} & \textbf{Y} & N & \textbf{Y} & \textbf{Y} & N & Y & Deep Generative Model & PDDL \\
\bottomrule
\end{tabular}
Table 11 summarizes a variety of action model acquisition approaches that have been proposed already [91, 92]. They can be understood from three major axes:
Input:
Traditionally, symbolic action learners tend to require a certain type of human domain knowledge and have been situating itself merely as an additional assistance tool for humans, rather than a system that builds knowledge from the scratch, e.g., from unstructured images. Existing systems [28, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84] require some type of symbolic inputs as defined in Section 3 and exploit the categorical information and/or the structures provided by the input, as shown in the Table 11. The input format could vary, e.g., sequence of ground actions [28, 72, 73, 74, 75, 76, 77], sequence of actions and intermediate states [71, 81, 82, 84, 83], initial/goal states (and optionally plans and partial action models) [78], or a graph of atomic states (state IDs) and actions [79, 80]. Some systems accept varying amount of noise and partial observability [71, 72, 73, 78, 80]. Approaches such as Framer [89] and cEASDRL [90] obtain action models from natural language corpus. They reuse the symbols found in the corpus, thus are grounding but not generating symbols, though it contains a type of noise specific to natural language, e.g., case inflection and ambiguity.
Output:
While existing systems do not generate all types of symbols, some systems generate some symbols. For example, [79, 80] generates predicate symbols from state IDs and action symbols, [78] generates action symbols from predicate symbols, and [81, 82, 84, 83] generates propositional symbols from action symbols.
Optimization Method for Likelihood Maximization:
Although it is not explicitly acknowledged in some of the previous work, machine learning problems can be cast as optimization problems through Maximum-Likelihood Estimation framework (Section 2.3), thus they are implicitly operating under the same framework as our paper, with the difference being the implementation, differentiability, and joint training of the optimizer.
Each system tackles a learning problem using different optimization approaches. The learning problem is encoded into Maximum Satisfiability ([93], MAX-SAT) in [28, 72, 73, 79], classical planning in [78], or Answer Set Programming ([94], ASP) in [80]. Approaches based on Finite State Machines (FSM) [74, 75, 76, 77] tackle the learning problem by generating a large number of candidate FSMs and pruning those which contradict data, effectively maximizing the number of data points that follow the set of FSMs, i.e., $\operatorname{arg, max}_{\text{FSMs}} p(x)$.
Many approaches [81, 82, 84, 83, 87, 88, 89, 90] combine several machine learning subprocedures, where each module individually optimize conditional likelihood, which is similar to how AMA$_2$ learns a state representation and an action model separately. Examples include C4.5 Decision Tree in [81, 87], Support Vector Machine, DBSCAN, and Kernel density estimation in [82], Bayesian sparse Dirichlet-categorical model and Bayesian Hierarchical Clustering in [83], sparse Principal Component Analysis in the robotic task using point clouds in [84], Binary-Concrete VAE (also used in our paper in AMA$1$ and AMA$2$) [88], CoreNLP language model [89], or Reinforcement Learning and LOCM in [90]. While they maximize individual conditional likelihoods (e.g., $q({\bm{z}}\mid {\bm{x}})$) separately, they are not formally motivated as such, nor are they guaranteed to maximize the likelihood of observation. In contrast, Latplan AMA${3}^+$ and AMA${4}^+$ jointly maximize the likelihood of observation through differentiable neural network.
12.2 Neural Networks as Search Guidance, World Models
Existing work [95, 96, 97, 98, 99, 100, 101, 102, 103] has combined symbolic search and machine learning by learning a function that provides search control knowledge, e.g., domain-specific heuristic functions for the sliding-tile puzzle and Rubik's Cube [96], classical planning [98], or the game of Go [104]. Some approaches use supervised learning from the precomputed target values (e.g., optimal solution cost) or expert traces, while others use Reinforcement Learning ([105], RL).
Model-free reinforcement learning has solved complex problems, including video games in Arcade Learning Environment ([106], ALE) where the agent communicates with a simulator through images ([6], DQN). The system avoids symbol grounding by using the subsymbolic states directly and assuming a set of action symbols that are given apriori by a simulator. For example, the ALE provides agents its discrete action labels such as 8-directional joysticks and buttons. Another limitation of RL approaches is that they require a carefully designed dense reward function to perform efficient exploration. When the available reward function is sparse, RL approaches suffer from sample efficiency issues where the agents require millions or billions of interactions with the simulator to learn meaningful behavior.
Latplan does not learn domain-control knowledge / search heuristics from data, but instead offloads the derivation of heuristic functions to the underlying off-the-shelf classical planner such as Fast Downward by passing a learned PDDL model. This framework enables the direct application of the large body of work on symbolically derived heuristics, e.g., delete-relaxation heuristics including $\text{LMcut}$ [8, 9] and abstraction heuristics including $\text{M&S}$ [67]. It has an advantage over policy-learning approaches because our system maintains all of the theoretical characteristics (optimality, completeness, etc.) of the underlying off-the-shelf planner, with respect to the learned state space. In contrast, learned policies typically do not guarantee admissibility, and only guarantees the convergence to the optimal policy in the limit. Greedy algorithms typically used by RL agents during the evaluation also contribute to the lack of reliability. Such a lack of the completeness/optimality guarantee is problematic for critical real-world applications. Moreover, while systems that learn search control knowledge require supervised signals, reward signals, or simulators that provides action symbols, Latplan only requires a set of unlabeled image pairs (transitions), and does not require a reward function, expert solution traces, simulators, or predetermined action symbols.
Model-based RL [14, 107] additionally learns a transition function in the state space to facilitate efficient exploration. World-model literature [108] learns latent representations of states and their black-box transition functions, i.e., a representation learning portion of model-based RL. The learned transition function is typically a black-box function that is not compatible with symbolic model analysis that are necessary for deriving heuristic functions. AMA$_2$ (Section 7) and Vanilla Space AE (Section 8.1) can be seen as an instance of such a black-box world model. As another example, Causal InfoGAN [41], which was published after the conference version of this paper [15], learns binary latent representations and transition functions similar to Latplan but with Generative Adversarial Networks ([40], GANs) augmented with Mutual Information maximization ([109], InfoGAN). A significant limitation of this approach is that their transition function lacks the concept of actions: The successor generation relies on sampling from a transition function which is expected to be multi-modal. Unlike symbolic transition models, this does not guarantee that all logically plausible successors are enumerated by a finite number of samples from a successor function, making the search process potentially incomplete.
More recently, several papers proposed ideas that resembles Cube-Space AE, although outside the context of STRIPS model learning. Alchemy [110] is a benchmark environment and an analysis toolkit for meta-reinforcement learning, where the environment contains multiple stones which change shapes, colors, and sizes etc. due to actions. Environment observations are provided either in a form of 3D rendering or in a symbolic encoding. Its underlying dynamics assumes that each action has a consistent effect that resembles STRIPS actions. Bisimulation metrics [111] proposed to improve the quality of the latent space learned by model-based RL. The metric also resembles the assumptions in STRIPS, although the additional loss function as well as the entire loss for representation learning are not justified as a lower bound of the likelihood.
12.3 Neural Networks that Directly Models the Problems
There is a large body of work using NNs to directly solve combinatorial tasks by modeling the problem as the network itself, starting with the well-known TSP solver by Hopfield and Tank [112]. Neurosolver represented a search state as a node in NN and solved Tower of Hanoi [113]. However, they assume a symbolic input that is converted to the nodes in a network. The neural network is merely used as a vehicle that carries out optimization.
12.4 Novelty-Based Planning without Action Description
While there are recent efforts in handling a complex state space without having its action description [33], action models could be used for other purposes such as Goal Recognition [114], macro-actions [115, 116], or plan optimization [117]. Moreover, goal-directed heuristics based on descriptive action models are complementary to novelty-based search techniques, and has their combination has been shown to achieve state-of-the-art results on IPC domains [45].
13. Discussion and Conclusion
Section Summary: Latplan is a system that takes unlabeled pairs of images showing the start and end of actions, automatically builds a logical planning problem from them, solves it with standard AI search algorithms, and turns the solution back into an understandable series of pictures. It works across several different puzzle-like tasks without any task-specific code or prior knowledge, relying only on the assumption that the underlying environment is fully visible and predictable. The work demonstrates a first bridge between neural networks and symbolic planning but notes important limits, such as the need for complete data sampling and the restriction to high-level, deterministic, single-goal problems, which future research must address.
We proposed Latplan, an integrated architecture for learning and planning which, given only a set of unlabeled image pairs and no prior knowledge, generates a classical planning problem, solves it with a symbolic planner, and presents the plan as a human-comprehensible sequence of images. We empirically demonstrated its feasibility using image-based versions of planning/state-space-search problems (Blocksworld, 8-puzzle, 15-puzzle, Lights Out, Sokoban), provided a theoretical justification for the training objectives from the maximum-likelihood standpoint, and analyzed the model complexity of STRIPS action models from the perspective of graph coloring and Cube-Like Graphs.
Our technical contributions are (1) State Auto-Encoder, which leverages the Binary-Concrete technique to learn a bidirectional mapping between raw images and propositional symbols compatible with symbolic planners. For example, on the 8-puzzle, the SAE can robustly compress the "gist" of a training image into a propositional vector representing the essential information (puzzle configuration) presented in the images. (2) Non-standard prior distribution $\text{Bernoulli}(\epsilon=0.1)$ for Binary Concrete, which improves the stability of propositional symbols and helps symbolic search algorithms operate on latent representations. The non-standard prior encodes a closed-world assumption, which assumes that propositions are False by default, unlike the standard prior $\text{Bernoulli}(\epsilon=0.5)$ which assigns random, stochastic bits to unused dimensions in the latent space, i.e., "unknown, " much like in open-world assumption. (3) Action Auto-Encoder, which grounds action symbols, i.e., identifies which transitions are "same" with regard to the state changes. By having a finite set of action symbols, agents can enumerate successor states efficiently during planning, instead of exhaustively enumerating the entire state space or sampling successor states. (4) Back-to-Logit, which enables learning and extracting descriptive, STRIPS-compatible action effects using a neural network. It restricts the hypothesis space of the action model with its structural prior, and bounds the complexity of the action model through graph coloring on cube-like graphs. (5) Complete State Regression Semantics, in which preconditions can be modeled as effects backward in time. – preconditions are now modeled with prevail-conditions. The network enables efficient and accurate extraction of preconditions from the trained network weights, which resulted in better planning performance. (6) Formalization of the training process under a sound likelihood maximization / variational inference framework. This results in a training objective that is less susceptible to overfitting due to various regularization terms and the lower bounding characteristics.
The only key assumption we make about the input domain is that it is fully observable and deterministic, i.e., that it is in fact a classical plannning domain. We have shown that different domains can all be solved by the same system without modifying any code or the NN architecture. In other words, Latplan is a domain-independent, image-based classical planner. To our knowledge, this is the first system that completely automatically constructs a logical representation directly usable by a symbolic planner from a set of unlabeled image pairs for a diverse set of problems.
We demonstrated the feasibility of leveraging deep learning in order to enable symbolic planning using classical search algorithms such as $A^*$, when only image pairs representing action start/end states are available, and there is no simulator, no expert solution traces, and no reward function. Although much work is required to determine the applicability and scalability of this approach, we believe this is an important first step in bridging the gap between symbolic and subsymbolic reasoning and opens many avenues for future research. In the following, we discuss several key limitations that Latplan must address in the future.
Latplan requires uniform sampling from the environment, which is nontrivial in many scenarios. Automatic data collection via exploration and active learning [118] is a major component of future work.
Next, in this paper, we evaluate Latplan as a high-level planner using puzzle domains such as the 8-puzzle. Mapping a high-level action to low-level actuation sequences via a motion planner is beyond the scope of this paper. Physically "executing" the plan is not necessary, as finding the solution to the puzzles is the objective, so a "mental image" of the solution (i.e., the image sequence visualization) is sufficient. However, in domains where actions have effects in the world, it will be necessary to consider how actions found by Latplan (transitions between latent bit vector pairs) can be mapped to actuations. One direction of future work could be learning a continuous-discrete hybrid representation that is more suitable for physical dynamical systems such as robotic tasks.
Latplan was evaluated in a noisy but fully observable and deterministic environment. Representing states and state transitions with probabilistic belief states for partial observations and stochastic state transitions would enable probabilistic planners to reason in such environments.
Latplan is also currently limited to tasks where a single goal state is specified. Developing a method for specifying a set of goal states with a partial goal specification as in IPC domains is an interesting topic for future work. For example, one may want to tell the planner "the goal states must have tiles 0, 1, 2 in the correct places" in a MNIST 8-puzzle instance.
Although we have shown that the Latplan architecture can be successfully applied to image-based versions of several relatively large standard puzzle domains (15-puzzle, Sokoban), some seemingly simple image-based domains may pose challenges for the current implementation of Latplan. For example, in Appendix M we discuss the result of applying Latplan to 4-disk, 4-tower Towers of Hanoi domain where the success ratio is quite low despite the fact that the domain has only 256 valid states, and thus is much "simpler" than domains such as the 15-puzzle. We listed several potential reasons for failure in this domain, one of which is that some features are "rare", e.g., the smallest disk rarely appears in the top region of the image, resulting in an imbalanced dataset. Such features are hard for the current SAE implementations to learn and generalize correctly, leading to incorrect plans. Thus, methods for training a SAE on similar domains where images containing key features are very rare is a direction for future work.
Latplan's state representation is entirely propositional and lacks first-order logic concepts such as predicates and parameters. Historically, action model acquisition literature focused on such representations, which provides generalization to environments with different numbers of objects. As a result, adding an object to a Blocksworld environment currently requires training the model from the scratch. One promising direction is using object-based representation, such as an ad-hoc approach pursued in ([119]), in a more principled probabilistic manner.
Also, although we demonstrated that the SAE is somewhat robust to variations/noise, it is not able to, for example, solve an instance (initial state image) of a sliding-tile puzzle instance scrawled on a napkin by an arbitrary person. Latplan will fail if, for example, some of the numbers in the initial state image for the 8-puzzle were rotated or translated, or the appearance of the digits differed significantly from the those in the training data. An ideal system would be robust enough to solve an instance (initial state image) of a sliding-tile puzzle instance scrawled on a napkin by an arbitrary person. Achieving this level of robustness will require improving the state encoder to the point that it is robust to styles, rotation, translation, etc.
Another direction for modifying the SAE is to combine the techniques in the autoencoders for the other types of inputs: e.g., unstructured text [120] and audio data [121]. Applying Gumbel-Softmax to these techniques, it may be possible for Latplan to perform language-based or voice-based reasoning.
In addition to the technical contributions, this paper provides several conceptual contributions. First and foremost, we provide the first demonstration that it is possible to leverage deep learning quite effectively for classical planning, which "has been central to AI research since its inception." ([29], p396) We bridged the gap between connectionist and symbolic approaches by using the former as a perception system generating the symbols for the latter resulting in a neuro-symbolic system.
Second, based on our observations of the problematic behavior of unstable propositions, we defined the general Symbol Stability Problem (SSP), a subproblem of symbol grounding. We identified two sources of stochasticity which can introduce the instability: (1) the inherent stochasticity of the network, and (2) the external stochasticity from the observations. This suggests that SSP is an important problem that applies to any modern NN-based symbol grounding process that operates on the noisy real-world inputs and performs a sampling-based, stochastic process (e.g. VAEs, GANs) that are gaining popularity in the literature. Thus, characterizing the aspect of SSP would help the process of designing a planning system operating on real-world input. We demonstrated the importance of addressing the instability by a thorough empirical analysis of the impact of instability on the planning performance. An interesting avenue for future work is to extend our approach to InfoGAN-based discrete representation of the environment [41].
Finally, we demonstrated that state-of-the-art domain-independent search heuristics provide effective search guidance in the automatically learned state spaces. These domain-independent functions, which have been a central focus of the planning community in the last two decades, provide search guidance without learning. This is in contrast to popular reinforcement learning approaches that suffer from poor sample efficiency, domain-dependence, and the lack of formal guarantees on admissibility. We believe this finding stimulates further research into heuristic search as well as reinforcement learning.
Appendix
Section Summary: The appendix first reviews core probability concepts including distributions, joint and conditional probabilities, and Kullback-Leibler divergence between two distributions over the same variable. It then shows that choosing a Gaussian model for reconstruction error in an autoencoder turns negative log-likelihood into a scaled squared-error loss, with the mean-square version arising from a specific choice of variance; other distributions produce different losses such as absolute error. This approach frames training as maximum-likelihood estimation, where the loss function is selected according to an assumed output distribution.
A. Probability Theory
A probability distribution $P({\textnormal{x}})$ of a random variable ${\textnormal{x}}$ defined on a certain domain $X$ is a function from a value $x\in X$ to some non-negative real $P({\textnormal{x}}=x)$. The sum / integral over $X$ (when $X$ is discrete / continuous) is equal to 1, i.e., $\sum_{x\in X} P({\textnormal{x}}=x) = 1$ (discrete domain) or $\int_{x\in X} P({\textnormal{x}}=x) dx = 1$ (continuous domain), respectively. The function is also called a probability mass function (PMF) or a probability density function (PDF), respectively. Typically, each random variable is given a certain meaning, thus two notations $P({\textnormal{x}})$ and $P({\textnormal{y}})$ denote different PMFs/PDFs and the letter $P$ does not designate a function by itself, unlike normal mathematical functions where $f(x)$ and $f(y)$ are equivalent under variable substitution. For example, if ${\textnormal{x}}$ is a boolean variable for getting a cancer and ${\textnormal{y}}$ is a boolean variable for smoking cigarettes, then $P({\textnormal{x}})$ and $P({\textnormal{y}})$ denote completely different PMFs, and we could write $P({\textnormal{x}})=f({\textnormal{x}})$, $P({\textnormal{y}})=g({\textnormal{y}})$, and $f\not=g$ to make it explicit. When a value $x\in X$ is given, we obtain an actual value $P({\textnormal{x}}=x)=f(x)$, which is sometimes abbreviated as $P(x)$. To denote two different distributions for the same random variable, an alternative letter such as $Q({\textnormal{x}})$ is used.
A joint probability $P({\textnormal{x}}=x, {\textnormal{y}}=y)$ is a function of two arguments which returns a probability of observing $x, y$ at once. Conditional probability $P({\textnormal{x}}=x| {\textnormal{y}}=y)$ represents a probability of observing $x$ when $y$ was already observed, and is defined as $P({\textnormal{x}}| {\textnormal{y}}) = \frac{P({\textnormal{x}}, {\textnormal{y}})}{P({\textnormal{y}})}$. Therefore $P({\textnormal{x}}=x) = \sum_{y\in Y} P({\textnormal{x}}=x | {\textnormal{y}}=y) P({\textnormal{y}}=y)$ holds.
For two probability distributions $Q({\textnormal{x}})$ and $P({\textnormal{x}})$ for a random variable ${\textnormal{x}}$, a Kullback-Leibler (KL) divergence $D_{\mathrm{KL}}(Q({\textnormal{x}})||P({\textnormal{x}}))$ is an expectation of their log ratio over $Q({\textnormal{x}}=x\in X)$:
$ D_{\mathrm{KL}}(Q({\textnormal{x}})||P({\textnormal{x}}))= \mathbb{E}_{Q({\textnormal{x}}=x)}{\left<\log \frac{Q({\textnormal{x}}=x)}{P({\textnormal{x}}=x)}\right>}. $
This is $\sum_{x\in X} Q(x)\log \frac{Q(x)}{P(x)}$ for discrete distributions and $\int_{x\in X} Q(x)\log \frac{Q(x)}{P(x)}dx$ for continuous distributions. KL divergence is always non-negative, and equals to 0 when $P=Q$. Conceptually it resembles a distance between distributions, but it is not a distance because it does not satisfy the triangular inequality.
B. Why do we Minimize L2-Norm / Square Errors ? Why not the Mean Square Errors?
While ad hoc approaches have been successful in many machine learning systems, a more principled approach to implementing machine learning algorithms is facilitated by a probabilistic interpretation [122].
The networks $f, g$ of an AE are optimized by minimizing a reconstruction loss $|| {\bm{x}}-\hat{{\bm{x}}}||$ under some norm, which is typically a (Mean) Square Error / L2-norm. Which norm to use is determined by the distribution of ${\bm{x}}$ assumed by the model designer. Assuming a 1-dimensional case, let $x$ be a data point in the dataset, $z$ be a certain latent value, and a probability distribution $p(x|z)$ be what the neural network (and the model designer) believes is the distribution of $x$ given $z$. Typical AEs for images assume that $x$ follows a Gaussian distribution centered around the predicted value $\hat{x}=g(z)$, i.e., $p(x|z)=\mathcal{N}(x|\hat{x}, \sigma) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\hat{x})^2}{2\sigma^2}}$ for an arbitrary fixed constant $\sigma$. This leads to an analytical form of the negative log likelihood (NLL) $-\log p(x|z)$:
$ -\log \mathcal{N}(x|\hat{x}, \sigma) = -\log \Big[\frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\hat{x})^2}{2\sigma^2}}\Big] = \frac{(x-\hat{x})^2}{2\sigma^2} +\log \sqrt{2\pi\sigma^2} = C_1 (x-\hat{x})^2 + C_2\tag{13} $
for some constant $C_1>0$ and $C_2$, which is a scaled/shifted square error / L2-norm reconstruction loss.
For a multi-dimensional case, by assuming that individual outputs (e.g., pixels) ${\bm{x}}_i$, ${\bm{x}}_j$ are independent for $i\not=j$, we sum up Equation 13 across output dimensions $i$, because $-\log p({\bm{x}}| {\bm{z}})=-\log \prod_i p({\bm{x}}_i| {\bm{z}}) = \sum_i -\log p({\bm{x}}_i| {\bm{z}})$. Finally, a mean square loss ($C_1=1/D$, where $D$ is the number of output dimensions, e.g., pixels) is obtained by arbitrarily setting $\sigma=\sqrt{D/2}$.
By minimizing the reconstruction loss $-\log p({\bm{x}}| {\bm{z}})$, the training maximizes $p({\bm{x}}| {\bm{z}})$, the likelihood of observing ${\bm{x}}$ — the higher the probability, the more likely we get an output $\hat{{\bm{x}}}$ closer to the real data ${\bm{x}}$. The general framework that casts a machine learning task as a likelihood maximization task is called maximum likelihood estimation.
By assuming a different distribution on ${\bm{x}}$, we obtain a different loss function. For example, a Laplace distribution $\frac{1}{2b}\exp (-\frac{| {\bm{x}}-\hat{{\bm{x}}}|}{b})$ results in an absolute error loss $| {\bm{x}}-\hat{{\bm{x}}}|$. Further, in many cases, a metric $d(x, \hat{x})$ automatically maps to a probability distribution through $-\log p(x|\hat{x}) \propto d(x, \hat{x}) \Leftrightarrow p(x|\hat{x}) = C_1\exp (-C_2d(x, \hat{x}))$, where $C_1, C_2$ are constants for maintaining $\int_x p(x|\hat{x})=1$. While the choice of the loss function (thus the distribution of ${\bm{x}}$) is arbitrary, we typically choose Gaussian distribution because it is the maximum entropy distribution among continuous distributions on $\mathbb{R}$ with the same variance and the mean, i.e., the Gaussian distribution has the highest entropy $\int -p(x)\log p(x)dx$, thus is most random, therefore assumes the least about the distribution.
In many AE/VAE implementations, $C_2$ is ignored, and $C_1 = 1/D$ by assuming $\sigma=\sqrt{D/2}$. Since this is an arbitrary value, it is sometimes necessary to tune $\sigma$ manually. Alternatively, Bayesian NN methods [123] learn to predict both $\sigma$ and the mean $\hat{x}$ of the Gaussian distribution by doubling the size of the output of the network. It trains the network by optimizing Equation 13 without omitting (now non-constant) $C_2$.
C. Other Discrete Variational Methods
Other discrete VAE methods include VQVAE ([124]), DVAE++ ([125]), and DVAE# ([126]). The difference between them is the training stability and accuracy. They may contribute to stable performance, but we leave the task of faster / easier training for future work.
A variant called Straight-Through Gumbel-Softmax (ST-GS) [21] combines a so-called Straight-Through estimator with Gumbel Softmax. ST-GS is outperformed by standard GS ([21], Figure 3(b)), thus we do not use it in this paper. However, we explain it in an attempt to cover as many methods as possible, and also because this ST-estimator frequently appears in other discrete representation learning literature, including ST-estimator for Heaviside $\textsc{step}$ function [127, 128] and VQVAE [124].
A Straight-Through estimator is implemented by a primitive operation called stop gradient $\textsc{sg}$, which is available in major deep learning / automatic differentiation frameworks. $\textsc{sg}$ acts as an identity in the forward computation but acts as a zero during the weight update / backpropagation step of automatic differentiation in neural network training. To understand how it works, it is best to see how ST-GS is implemented:
$ \begin{aligned} \textsc{ST-GS}({\bm{l}})=\textsc{sg}(\operatorname{arg, max}({\bm{l}})-\textsc{GS}{\tau}({\bm{l}}))+\textsc{GS}{\tau}({\bm{l}}) = \left{ \begin{array}{ll} \operatorname{arg, max}({\bm{l}}) & \text{(forward)}\ 0+\textsc{GS}_{\tau} ({\bm{l}}) & \text{(backward)} \end{array} \right. \end{aligned} $
Notice that this function acts exactly as $\operatorname{arg, max}({\bm{l}})$ in the forward computation, but uses only the differentiable $\textsc{GS}_{\tau}({\bm{l}})$ for backpropagation, thus eliminating the need for a gradient of a non-differentiable function $\operatorname{arg, max}$. Several applications of ST-estimator exist. ST estimator that combines Heaviside step function $\textsc{step}$ and a linear function $x$ was used in [127, 128] but was outperformed by Binary Concrete ([21], Figure 3(a)). Similarly, an ST-estimator can combine $\textsc{step}$ and Binary Concrete, but this was also outperformed by the standard Binary Concrete ([21], Figure 3(a)).
D. ELBO Computation of Gumbel Softmax / Binary Concrete VAE
Having provided the overview, we explain the details of ELBO computation of Gumbel Softmax VAE and then Binary Concrete VAE, following [21, 22]. Those who are not interested in these theoretical aspects can safely skip this section, but it becomes relevant in later sections where we analyze our contributions. This section also discusses several ad-hoc variations of the implementations shared by the original authors (and their issues) to sort out the information available in the field.
To compute ELBO, we need an analytical form of the reconstruction loss and the KL divergence. We focus on the latter because the choice of reconstruction loss $\mathbb{E}{q({\bm{z}}\mid {\bm{x}})} [\log p({\bm{x}}\mid {\bm{z}})]$ is independent from the computation of the KL divergence $D{\mathrm{KL}}(q({\bm{z}}\mid {\bm{x}})||p({\bm{z}}))$.
We denote a categorical distribution of $C$ classes as $\mathbf{Cat}({\bm{p}})$ with parameters ${\bm{p}}\in \mathbb{B}^C$. Here, ${\bm{p}}$ is a probability vector for $C$ classes, thus it sums up to 1, i.e., $\sum_{k=1}^C {\bm{p}}_k = 1$. For example, when ${\bm{p}}_k=1/6$ for all $k$ and $C=6$, it models a fair cube dice.
Gumbel-Softmax is a continuous relaxation of Gumbel-Max technique ([129, 130]), a method for drawing samples of categorical distribution $\mathbf{Cat}({\bm{p}})$ from a log-unnormalized probability or a logit ${\bm{l}}$. "Log-unnormalized" imply that ${\bm{l}}=\log {\bm{p}}'$, where ${\bm{p}}'$ is an unnormalized probability. Since it is not normalized, ${\bm{p}}'$ does not sum up to 1, but normalization is trivial (${\bm{p}}= {\bm{p}}'_k/\sum_k {\bm{p}}'_k$). Combining these facts derives a following relation:
$ {\bm{p}}_k = {\bm{p}}'_k/\sum_k {\bm{p}}'_k = \exp {\bm{l}}_k/\sum_k\exp {\bm{l}}_k = \textsc{softmax}({\bm{l}})_k. $
Log-unnormalized probabilities ${\bm{l}}$ are convenient for neural networks because it can take an arbitrary value in $\mathbb{R}^C$. Gumbel-Max draws samples from $\mathbf{Cat}({\bm{p}})$ using ${\bm{l}}$ without computing ${\bm{p}}$ explicitly:
$ {\left{0, 1\right}}^C\ni\textsc{GumbelMax}({\bm{l}})= \operatorname{arg, max}({\bm{l}} + \textsc{Gumbel}^C(0, 1)) \sim \mathbf{Cat}({\bm{p}}). $
Again, note that we assume $\operatorname{arg, max}$ returns a one-hot representation rather than the index of the maximum value.
Unlike samples generated by Gumbel-Max technique, samples from Gumbel-Softmax function follows its own $\mathbf{GS}({\bm{l}}, \tau)$ distribution, not the original $\mathbf{Cat}({\bm{p}})$ distribution:
$ \mathbb{B}^C\ni {\bm{z}}= \textsc{GS}_{\tau}({\bm{l}})= \textsc{softmax}{\left(\frac{{\bm{l}}+\textsc{Gumbel}^C(0, 1)}{\tau}\right)} \sim \mathbf{GS}({\bm{l}}, \tau). $
An obscure closed-form probability density function (PDF) of this distribution is available [21, 22] as follows:
$ \mathbf{GS}({\bm{z}}\mid {\bm{l}}, \tau) =\ (C-1)! \tau^{C-1} \prod_{k=1}^{C} \frac{\exp {\bm{l}}_k {\bm{z}}k^{-(\tau+1)}}{\sum{i=1}^C \exp {\bm{l}}_i {\bm{z}}_i^{-\tau}}. $
The factorial $(C-1)!$ is sometimes denoted by a Gamma function $\Gamma(C)$ depending on the literature.
D.1 A Simple Add-Hoc Implementation
In practice, an actual VAE implementation may avoid using this complicated PDF of $\mathbf{GS}({\bm{l}}, \tau)$ by computing the KL divergence based on $\mathbf{Cat}({\bm{p}})$ instead. While it could potentially violate the true lower bound (ELBO), in practice, it does not seem to cause a significant problem. This issue is discussed by [22], Eq.21, 22. The following derivation is based on the actual implementation shared by an author on his website ^5, which corresponds to Eq.22 in [22]. It made two modifications to the faithful formulation based on the complicated PDF of $\mathbf{GS}({\bm{l}}, \tau)$ in order to simplify the optimization objective. In this implementation, it computes the KL divergence as if the annealing is completed ($\tau=0$), treating the variable ${\bm{z}}$ as a discrete random variable. The implementation also uses $p({\bm{z}})= \mathbf{Cat}(\bm{1}/C)$ (i.e., a uniform categorical distribution) as a prior distribution. The KL divergence in the VAE is thus as follows:
$ \begin{aligned} \int q({\bm{z}}\mid {\bm{x}}) \log \frac{q({\bm{z}}\mid {\bm{x}})}{p({\bm{z}})} d {\bm{z}} &\approx \sum_{k\in{\left{1..C\right}}} q({\mathbf{z}}_k=1\mid {\bm{x}}) \log \frac{q({\mathbf{z}}_k=1\mid {\bm{x}})}{p({\mathbf{z}}k=1)} \quad \because {\bm{z}}\text{ is treated as discrete.} \nonumber\ &= \sum{k\in{\left{1..C\right}}} q({\mathbf{z}}_k=1\mid {\bm{x}}) \log \frac{q({\mathbf{z}}k=1\mid {\bm{x}})}{\frac{1}{C}} \nonumber\ &= \sum{k\in{\left{1..C\right}}} q({\mathbf{z}}_k=1\mid {\bm{x}}) \log q({\mathbf{z}}k=1\mid {\bm{x}}) + \sum{k\in{\left{1..C\right}}} q({\mathbf{z}}k=1\mid {\bm{x}})(\log C) \nonumber\ &= \sum{k\in{\left{1..C\right}}} q({\mathbf{z}}_k=1\mid {\bm{x}}) \log q({\mathbf{z}}_k=1\mid {\bm{x}}) + \log C \quad \because q\text{ sums up to 1.} \end{aligned} $
Since it assumes that the annealing is completed, the distribution is also treated as if it is equivalent to $\mathbf{Cat}({\bm{q}})$ where ${\bm{q}}= \textsc{softmax}({\bm{l}})$. Therefore, this formula can be computed using $q({\mathbf{z}}_k=1\mid {\bm{x}})= {\bm{q}}_k= \textsc{softmax}({\bm{l}})_k$.
E. Difference of the Non-Standard Bernoulli Prior (Section 5.4) from the Zero-Suppress SAE [16]
Our conference paper ([16]) proposed ZSAE (Zero-suppress SAE), a method which uses an additional ad-hoc loss term called Zero-suppress loss defined as follows:
$ -H(q) + \alpha\cdot \textsc{BC}_{\tau}(l)\tag{14} $
where $l$ is an output of the encoder network, which is a logit of $q$ (i.e., $q= \textsc{sigmoid}(l)$). Compare this with the KL divergence we defined in Equation 5 (repost):
$ \begin{aligned} q\log\frac{q}{\epsilon}+(1-q)\log\frac{(1-q)}{(1-\epsilon)} &=-H(q) + \alpha \cdot q - \log (1-\epsilon) \end{aligned}\tag{15} $
Two losses are similar up to the constant difference $-\log (1-\epsilon)$ because $\textsc{BC}{\tau}$ is a modified form of $\textsc{sigmoid}$ Equation (4), therefore $\textsc{BC}{\tau}(l)$ in Equation 14 and $q$ in Equation 5 behave similarly.
Although Zero-suppress loss was shown to work, it is an ad-hoc loss that is not theoretically justified as an ELBO. Moreover, ZSAE used the values after the Binary Concrete activation $\textsc{BC}{\tau}(l)$: This introduces unnecessary noise in the loss due to the logistic noise in $\textsc{BC}{\tau}$, which makes the training slower and less stable than the theoretically justified formulation presented in this paper.
F. Loss derivation for AMA3+
We define the statistical model of this network as a probability distribution $p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ of observed random variables ${\mathbf{x}}^{0}$ and ${\mathbf{x}}^{1}$, also known as a generative model of ${\mathbf{x}}^{0}$ and ${\mathbf{x}}^{1}$. Specifically, we model the probability distribution $p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ by introducing latent variables corresponding to an action label ${\mathbf{a}}$ (one-hot vector) and the current and successor propositional states, ${\mathbf{z}}^{0}$ and ${\mathbf{z}}^{1}$ (binary vectors). The model is trained by maximizing the log-likelihood $\log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ observing a tuple $({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$. Since it is difficult to compute the log-likelihood function of such a latent variable model, we resort to a variational method to approximately maximize the likelihood, which leads to the autoencoder architecture depicted in Figure 8.
We start to model $p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ by assuming a set of dependencies between variables and a set of distributional assumptions for the variables. This process is often called statistical modeling. Following this process often helps to define a sound probabilistic model.
Equation 16a-Equation 16c below define dependencies between variables, where all summations are over the respective domains. In Equation 16c, we assumed ${\mathbf{x}}^{0}$ and ${\mathbf{x}}^{1}$ depend only on ${\mathbf{z}}^{0}$ and ${\mathbf{z}}^{1}$, respectively, because ${\mathbf{x}}^{0}$ and ${\mathbf{x}}^{1}$ are visualizations of ${\mathbf{z}}^{0}$ and ${\mathbf{z}}^{1}$, respectively.
$ \begin{aligned} p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}) & = \sum_{{\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}} p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}, {\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}) \nonumber\ & = \sum_{{\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}} p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}) p({\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}). \quad\text{(a)}\ p({\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}) & = p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})p({\mathbf{a}}\mid {\mathbf{z}}^{0}) p({\mathbf{z}}^{0}). \quad\text{(b)}\ p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}) & = p({\mathbf{x}}^{0}\mid {\mathbf{z}}^{0}) p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1}). \quad\text{(c)} \end{aligned}\tag{16} $
The dependencies also define the I/O interfaces of the subnetworks (e.g., $p({\mathbf{x}}^{0}\mid {\mathbf{z}}^{0})$ is modeled by a network that takes ${\bm{z}}^{i, 0}$ and returns ${\tilde{{\bm{x}}}}^{i, 0}$), and which ones are prior distributions that take no inputs (e.g., $p({\mathbf{z}}^{0})$). In general, when defining a generative model, it is better to avoid making unnecessary/unjustified independence assumptions. For example, although it is possible, we generally avoid assuming $p({\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}})= p({\mathbf{z}}^{0}) p({\mathbf{z}}^{1}) p({\mathbf{a}})$, i.e., ${\mathbf{z}}^{0}, {\mathbf{z}}^{1}$ and ${\mathbf{a}}$ to be all independent, unless there is a domain knowledge that justifies the independence.
This process is also called graphical modeling ([29], Chapter 14). It visualizes the statistical model using a directed acyclic graph (DAG) notation whose nodes are variables and edges are conditional dependencies. For example, our model Equation (16a-Equation 16c) can be visualized as Figure 25.
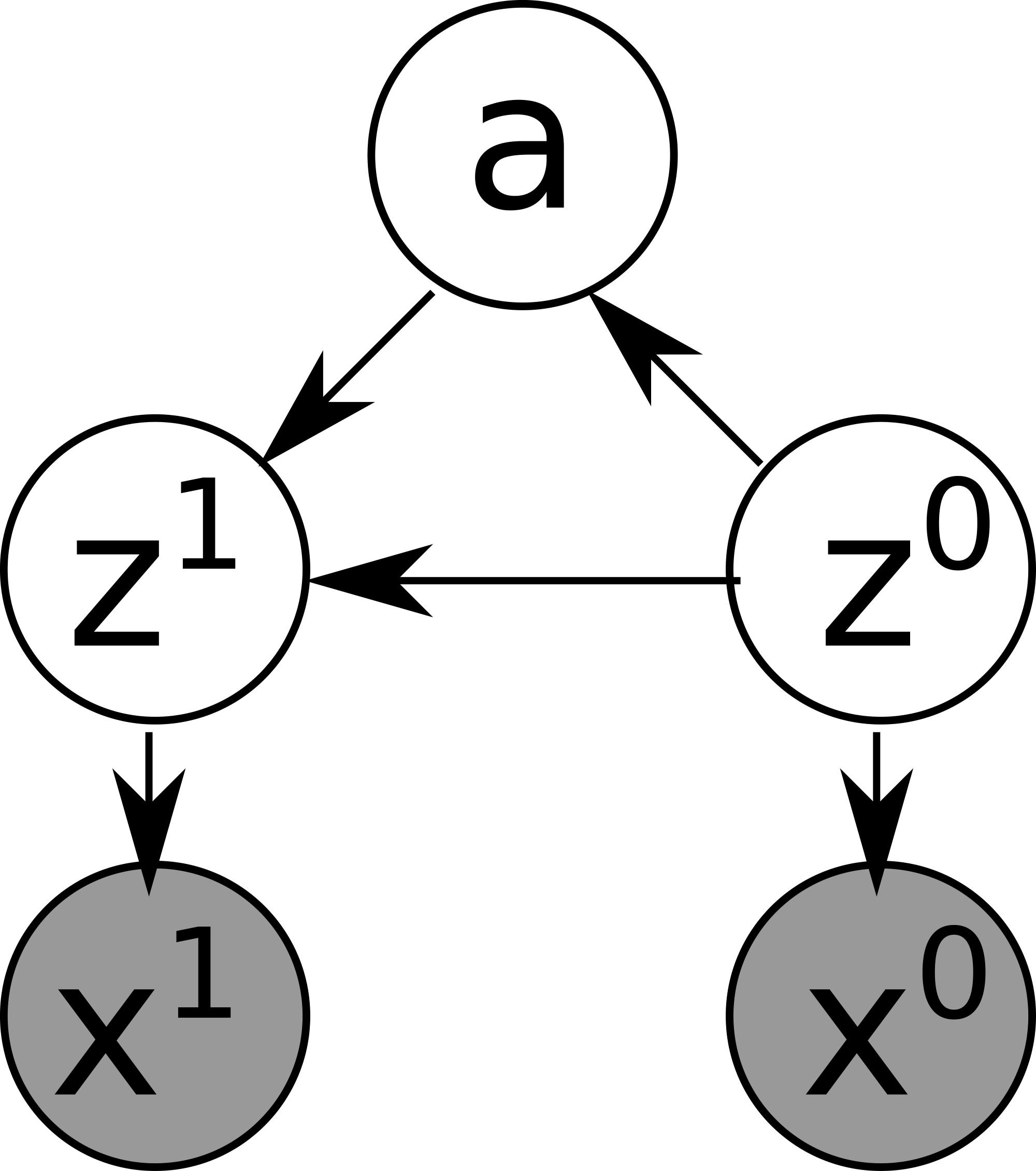
After defining the dependencies, we assign an assumption to each distribution, as shown below. Thanks to the process of defining our generative model, we now realize that $p({\mathbf{a}}\mid {\mathbf{z}}^{0})$ requires an additional subnetwork $\textsc{applicable}({\bm{z}})$ that is missing in both the AMA$_2$ and the AMA$_3$ models. This network models $p({\mathbf{a}}\mid {\mathbf{z}}^{0})$ by taking a latent vector ${\bm{z}}$ and returns a probability vector over actions. Note that some distributional assumptions apply to multiple vectors in Figure 8. For example, Equation 17c applies to both ${\bm{z}}= {\bm{z}}^{i, 1}$ and ${\bm{z}}= {\bm{z}}^{i, 2}$.
$ \begin{aligned} & p({\mathbf{z}}^{0}) = \text{Bernoulli}(\epsilon). & & \text{Section 5.4.} \nonumber\ & p({\mathbf{a}}| {\mathbf{z}}^{0}= {\bm{z}}) = \mathbf{Cat}(\textsc{applicable}({\bm{z}}))& & \quad\text{(a)}\ & p({\mathbf{x}}^{0}| {\mathbf{z}}^{0}= {\bm{z}}) = \mathcal{N}({\tilde{{\bm{x}}}}, \sigma), \text{where}\ {\tilde{{\bm{x}}}} = \textsc{decode}({\bm{z}}). \quad\text{(b)} \ & p({\mathbf{x}}^{1}| {\mathbf{z}}^{1}= {\bm{z}}) = \mathcal{N}({\tilde{{\bm{x}}}}, \sigma), \text{where}\ {\tilde{{\bm{x}}}} = \textsc{decode}({\bm{z}}). \quad\text{(c)} \ & p({\mathbf{z}}^{1}| {\mathbf{z}}^{0}= {\bm{z}}, {\mathbf{a}}= {\bm{a}}) = \text{Bernoulli}({\bm{q}}), \text{where}\ {\bm{q}} = \textsc{sigmoid}({\bm{l}}), {\bm{l}}= \textsc{apply}({\bm{z}}, {\bm{a}}^{i})\text{.} \quad\text{(d)} \end{aligned}\tag{17} $
Next, to compute and maximize $p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$, we should compute the integral/summation over latent variables ${\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}$ Equation (16a). Such an integration is known to be intractable; in fact, the complexity class of computing the likelihood of observations (e.g., $p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$) is shown to be #P-hard [131, 132, 133] through reduction to #3SAT. Therefore, we have to resort to maximizing $p({\mathbf{x}}^{0}, {\mathbf{x}}^{1})$ approximately.
Variational modeling techniques, including VAEs, tackle this complexity by approximating the likelihood from below. This approximated objective is called ELBO (Evidence Lower BOund) and is defined by introducing a variational model $q$, an arbitrary distribution that a model designer can choose. To derive an autoencoding architecture, we model the variational distribution with encoders. Equation 18a-Equation 18c define dependencies and assumptions in $q$, e.g., ${\mathbf{z}}^{1}$ depends only on ${\mathbf{x}}^{1}$.
$ \begin{aligned} & q({\mathbf{z}}^{0}| {\mathbf{x}}^{0}= {\bm{x}}) = \text{Bernoulli}({\bm{q}}), \text{where}\ {\bm{q}} = \textsc{sigmoid}({\bm{l}}), {\bm{l}}= \textsc{encode}({\bm{x}}). \quad\text{(a)} \ & q({\mathbf{z}}^{1}| {\mathbf{x}}^{1}= {\bm{x}}) = \text{Bernoulli}({\bm{q}}), \text{where}\ {\bm{q}} = \textsc{sigmoid}({\bm{l}}), {\bm{l}} = \textsc{encode}({\bm{x}}). \quad\text{(b)} \ & q({\mathbf{a}}| {\mathbf{x}}^{0}= {\bm{x}}, {\mathbf{x}}^{1}= {\bm{x}}') = \mathbf{Cat} ({\bm{q}}), \text{where}\ {\bm{q}} = \textsc{softmax}({\bm{l}}), {\bm{l}}= \textsc{action}({\bm{x}}, {\bm{x}}'). \quad\text{(c)} \end{aligned}\tag{18} $
Using this model, we derive a lower bound by introducing variables one by one. The first variable to introduce is ${\mathbf{z}}^{0}$ and the bound is derived using the same proof used for obtaining VAE's ELBO Equation (2).
$ \begin{aligned} \log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}) & = \log {\left(\sum_{{\mathbf{z}}^{0}} p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}) p({\mathbf{z}}^{0})\right)} \nonumber\ & = \log {\left(\sum_{{\mathbf{z}}^{0}} p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}) \frac{p({\mathbf{z}}^{0})}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})} q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})\right)} \nonumber\ & = \log {\left(\mathbb{E}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})} {\left< p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}) \frac{p({\mathbf{z}}^{0})}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})}\right>}\right)} \quad \text{(Definition of expectations)} \nonumber\ & \geq \mathbb{E}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})} {\left<\log {\left(p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}) \frac{p({\mathbf{z}}^{0})}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})}\right)}\right>} \quad \text{(Jensen's inequality)}\nonumber\ & = \mathbb{E}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})} {\left< \log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0})\right>} \nonumber\ & \quad - D{KL}(q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0}) \mathrel{|} p({\mathbf{z}}^{0})). \quad \text{(Definition of KL divergence)} \end{aligned}\tag{19} $
Next, we decompose $\log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0})$ by introducing ${\mathbf{a}}$ and deriving the lower bound. We are merely reapplying the same proof with a different set of variables and distributions:
$ \begin{aligned} \log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}) & \geq \mathbb{E}{q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1})} {\left< \log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})\right>} - D{KL}(q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{a}}\mid {\mathbf{z}}^{0})). \end{aligned}\tag{20} $
Since ${\mathbf{x}}^{0}$ does not depend on ${\mathbf{x}}^{1}$ and ${\mathbf{a}}$ Equation (16c),
$ \begin{aligned} \log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}) &= \log p({\mathbf{x}}^{0}\mid {\mathbf{z}}^{0}) p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})\nonumber\ & = \log p({\mathbf{x}}^{0}\mid {\mathbf{z}}^{0}) + \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}). \end{aligned}\tag{21} $
We further decompose $\log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})$ by deriving its variational lower bound:
$ \begin{aligned} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}) &= \log \sum_{{\mathbf{z}}^{1}} p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}) \frac{p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})}{q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})} q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})\nonumber\ &\geq \mathbb{E}{q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}) - D{KL}(q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}))\nonumber\ &= \mathbb{E}{q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1}) - D{KL}(q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})). \end{aligned}\tag{22} $
However, we can also decompose it by applying Jensen's inequality directly. The reconstruction loss obtained from this formula corresponds to the reconstruction from the latent vector ${\bm{z}}^{i, 2}$ (Figure 8) generated/sampled by the AAE, as the value is an expectation over $p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})$.
$ \begin{aligned} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}) &= \log \sum_{{\mathbf{z}}^{1}} p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}}) p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})\nonumber\ &\geq \mathbb{E}{p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{z}}^{1}, {\mathbf{a}})\nonumber\ &= \mathbb{E}{p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1}) \quad\text{Equation 16c}. \end{aligned}\tag{23} $
We wish to optimize both of these objectives Equation (22-Equation 23). To understand the motivation, it is crucial to see the interpretation of these objectives. First, $D_{\mathrm{KL}}(q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}))$ maintains the symbol stability we discussed in Section 5.2 by making two distributions ($q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})$ and $p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})$) identical. Without this KL term, latent vectors encoded by the encoder (i.e., $q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})$) and by the AAE (i.e., $p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})$) may diverge, despite them being the symbolic representation for the same raw observation ${\mathbf{x}}^{1}$. Second, $\mathbb{E}_{p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1})$ ensures that the latent vectors generated by the action model are reconstructable. If we optimize Equation 22 alone, the stability is maintained, but the resulting vector ${\mathbf{z}}^{1}$ is not guaranteed to be reconstructable. If we optimize Equation 23 alone, the stability is not maintained. Therefore, it is crucial to optimize both objectives at once.
To optimize both objectives at once, we combine them into a single objective. There is some flexibility in how to achieve this: For example, one could consider alternating two loss functions in each epoch, or consider optimizing the maximum of two objectives. Optimizing their Pareto front may also be an option. However, since they both give a lower bound of $\log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})$, a simple approach to optimizing them at once while maintaining the ELBO is to take a weighted sum between them, with equal weights 0.5.
Now that the log likelihood is decomposed into either reconstruction losses from a decoder or KL divergences, we can finally discuss the total optimization objective. Similar to $\beta$-VAE discussed in Section 2.3, we can apply coefficients $\beta_1, \beta_2, \beta_3 \geq 1$ to each of the KL terms. This does not overestimate the ELBO because KL divergence is always positive, and larger $\beta$ results in a lower bound of the original ELBO. Combining Equation 19-Equation 23, we obtain the following total maximization objective:
$ \begin{aligned} \log p({\mathbf{x}}^{0}, {\mathbf{x}}^{1}) \geq & - \beta_1 D_{KL}(q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0}) \mathrel{|} p({\mathbf{z}}^{0}))\nonumber\ &+\mathbb{E}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})} \left[\begin{array}{ll} - \beta_2 D{KL}(q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{a}}\mid {\mathbf{z}}^{0}))\nonumber\ + \mathbb{E}{q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1})} \left[\begin{array}{ll} \log p({\mathbf{x}}^{0}\mid {\mathbf{z}}^{0}) \nonumber\ + \frac{1}{2}\mathbb{E}{q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1})\nonumber\ - \frac{1}{2}\beta_3 D_{KL}(q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}}))\nonumber\ + \frac{1}{2}\mathbb{E}_{p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1}) \end{array} \right]\nonumber\ \end{array} \right]\nonumber\
& - \beta_1 D_{KL}(q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0}) \mathrel{|} p({\mathbf{z}}^{0}))\nonumber\ & +\mathbb{E}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})} \left[- \beta_2 D{KL}(q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{a}}\mid {\mathbf{z}}^{0}))\right]\nonumber\ & +\mathbb{E}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})} \log p({\mathbf{x}}^{0}\mid {\mathbf{z}}^{0})\nonumber\ & +\frac{1}{2}\mathbb{E}{q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1})\nonumber\ &+\frac{1}{2}\mathbb{E}{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1})} \left[- \beta_3 D{KL}(q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1}) \mathrel{|} p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})) \right]\nonumber\ & +\frac{1}{2}\mathbb{E}_{q({\mathbf{z}}^{0}\mid {\mathbf{x}}^{0})q({\mathbf{a}}\mid {\mathbf{x}}^{0}, {\mathbf{x}}^{1})p({\mathbf{z}}^{1}\mid {\mathbf{z}}^{0}, {\mathbf{a}})} \log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1}). \nonumber\ \end{aligned}\tag{24} $
Compared to 7 we showed in the main.text, this formula appears much more complex. In particular, it contains a large number of complex expectations ($\mathbb{E}\ldots$). We now explain what these expectations imply.
Practical VAE implementations typically compute the expectations of quantities that depend on stochastic variables (e.g., reconstruction loss $\mathbb{E}{q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})}\log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1})$ in Equation 22, which depends on stochastic ${\mathbf{z}}^{1}$ sampled from $q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})$) by merely taking a single sample of the variables rather than taking multiple samples and computing the mean of the quantities. Recall that ${\bm{z}}^{i, 1}= \textsc{BC}{\tau}({\bm{l}}^{i, 1})$ is a noisy function, thus computing the value of ${\bm{z}}^{i, 1}$ from ${\bm{l}}^{i, 1}$ is equivalent to sampling the value once.
The reason VAE implementations, including ours, follow this approach is that it reduces the runtime, simplifies the code, and empirically works well. If we want to compute an expectation $\mathbb{E}{q({\mathbf{z}}^{1}\mid {\mathbf{x}}^{1})}\log p({\mathbf{x}}^{1}\mid {\mathbf{z}}^{1})$ from multiple samples instead, we could do as follows: First, we compute ${\bm{l}}^{i, 1}= \textsc{encode}({\bm{x}}^{i, 1})$, which is deterministic. Next, we compute a noisy function $\textsc{BC}{\tau}({\bm{l}}^{i, 1})$ for $K$ times, i.e., take $K$ samples ${\bm{z}}^{1, 1}, \ldots, {\bm{z}}^{1, K}$ from a single ${\bm{l}}^{i, 1}$. We then run the decoder $K$ times to obtain $K$ samples of ${\tilde{{\bm{x}}}}^{1, k}= \textsc{decode}({\bm{z}}^{1, k})$, compute $K$ reconstruction losses $\log p({\bm{x}}^{1, k} \mid {\bm{z}}^{1, k})$ (e.g., scaled squared error in Equation 13), then obtain the mean $\frac{1}{k}\sum_{k=1}^{K} \log p({\bm{x}}^{1, k} \mid {\bm{z}}^{1, k})$. Limiting $K=1$ avoids these complications.
As a result, practically, Equation 24 for each data sample ${\bm{x}}^{i, 0}, {\bm{x}}^{i, 1}$ is implemented as follows. Reordering the formula for readability,
$ \begin{aligned} & \log p({\bm{x}}^{i, 0}\mid {\bm{z}}^{i, 0}) + \frac{1}{2}\log p({\bm{x}}^{i, 1}\mid {\bm{z}}^{i, 1}) + \frac{1}{2}\log p({\bm{x}}^{i, 1}\mid {\bm{z}}^{i, 2}) &\text{(Reconstruction losses)} \nonumber\ & - \beta_1 D_{KL}(q({\bm{z}}^{i, 0}\mid {\bm{x}}^{i, 0}) \mathrel{|} p({\bm{z}}^{i, 0})) &\text{(Prior for }{\bm{z}}^{i, 0}\text{)} \nonumber\ & - \beta_2 D_{KL}(q({\bm{a}}^{i}\mid {\bm{x}}^{i, 0}, {\bm{x}}^{i, 1}) \mathrel{|} p({\bm{a}}^{i}\mid {\bm{z}}^{i, 0})) &\text{(Prior for }{\bm{a}}^{i}\text{)} \nonumber\ & - \frac{1}{2}\beta_3 D_{KL}(q({\mathbf{z}}^{1}= {\bm{z}}^{i, 1}\mid {\bm{x}}^{i, 1}) \mathrel{|} p({\mathbf{z}}^{1}= {\bm{z}}^{i, 2}\mid {\bm{z}}^{i, 0}, {\bm{a}}^{i})). & \end{aligned}\tag{25} $
Reconstruction losses are square errors due to Gaussian assumptions. For KL terms, for example, $D_{\mathrm{KL}}(q({\bm{z}}^{i, 1}\mid {\bm{x}}^{i, 1}) \mathrel{|} p({\bm{z}}^{i, 2}\mid {\bm{z}}^{i, 0}, {\bm{a}}^{i}))$ is obtained by converting the logits ${\bm{l}}^{i, 1}, {\bm{l}}^{i, 2}\in \mathbb{R}$ to probabilities ${\bm{q}}^{i, 1}= \textsc{sigmoid}({\bm{l}}^{i, 1}), {\bm{q}}^{i, 2}= \textsc{sigmoid}({\bm{l}}^{i, 2})$, then computing the KL divergence as follows.
$ D_{\mathrm{KL}}({\bm{q}}^{i, 1}\mathrel{|}{\bm{q}}^{i, 2})= {\bm{q}}^{i, 1}\frac{\log {\bm{q}}^{i, 1}}{\log {\bm{q}}^{i, 2}}+(1-{\bm{q}}^{i, 1})\frac{\log (1-{\bm{q}}^{i, 1})}{\log (1-{\bm{q}}^{i, 2})}. $
**Comparison to AMA$_3$:**
AMA$_3$ contains a number of ad-hoc differences from AMA$_3^+$.
For example, AMA$_3$ uses an *absolute error loss* between two latent vectors ${\bm{z}}^{i, 1}$ and ${\bm{z}}^{i, 2}$,
instead of using the KL divergence $D_{\mathrm{KL}}({\bm{q}}^{i, 1}\mathrel{\|}{\bm{q}}^{i, 2})$.
This is not theoretically justified, and is inefficient because losses using the sampled values ${\bm{z}}^{i, 1}$ introduce noise in the loss function.
G. Bayesian Interpretation of Back-to-Logit
We can view BTL as a mechanism that injects a new assumption into $p({\mathbf{z}}^{1}| {\mathbf{z}}^{0}, {\mathbf{a}})$ by introducing a random variable ${\mathbf{e}}$ and removing the dependency from ${\mathbf{e}}$ to ${\mathbf{z}}^{0}$ as follows:
$ \begin{aligned} p({\mathbf{z}}^{1}| {\mathbf{z}}^{0}, {\mathbf{a}}) &=\sum_{{\mathbf{e}}} p({\mathbf{z}}^{1}| {\mathbf{z}}^{0}, {\mathbf{a}}, {\mathbf{e}}) p({\mathbf{e}}| {\mathbf{z}}^{0}, {\mathbf{a}})\nonumber\ &=\sum_{{\mathbf{e}}} p({\mathbf{z}}^{1}| {\mathbf{z}}^{0}, {\mathbf{e}}) p({\mathbf{e}}| {\mathbf{a}}) \end{aligned} $
where $p({\mathbf{e}}| {\mathbf{a}})$ is modeled by $\textsc{effect}$, and $p({\mathbf{z}}^{1}| {\mathbf{z}}^{0}, {\mathbf{e}})$ is modeled by $m$ and an addition. This approach is supported by the Bayesian theoretical analysis of batch normalization [134]. Obtaining a value of (i.e., sampling the value of) ${\mathbf{e}}$ from ${\mathbf{a}}$ with $p({\mathbf{e}}| {\mathbf{a}})$ is a stochastic process because it is affected by other data points in the same batch, which are randomly sampled in each training iteration.
This model can be visualized as a graphical model in Figure 26.
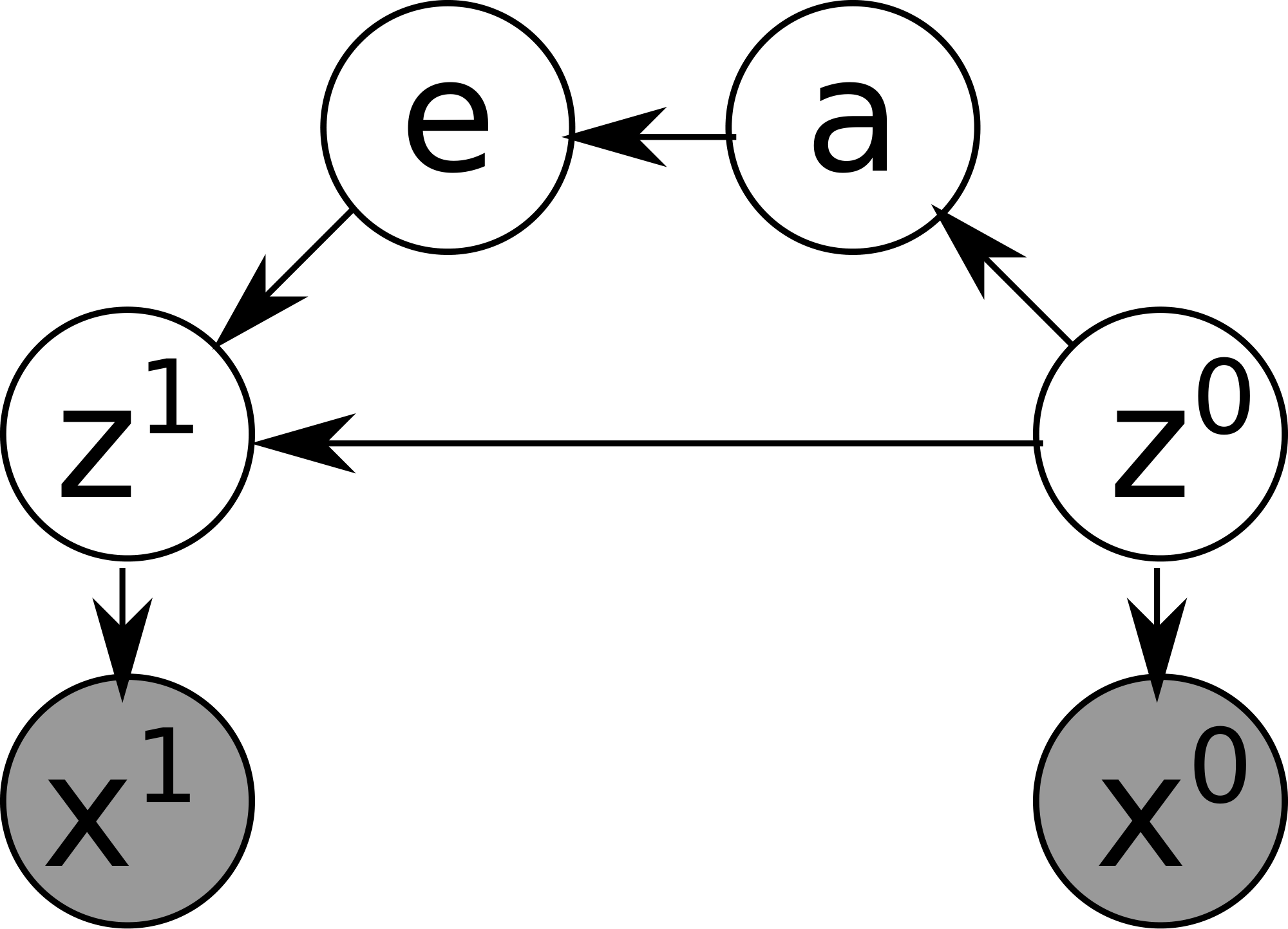
H. Proof of Monotonicity
Proof of Theorem 4:
Proof: For readability, we omit $j$ and assume a 1-dimensional case. Let $e= \textsc{effect}({\bm{a}})\in \mathbb{R}$, which is a constant for a fixed action ${\bm{a}}$. In the test time, Binary Concrete is replaced by a step function (Section 5.3). The BTL is then simplified to
$ {\bm{z}}^{i, 1}=\textsc{step}(m({\bm{z}}^{i, 0})+e). $
The possible values of a pair $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})$ is $(0, 0), (0, 1), (1, 0), (1, 1)$. Since both $\textsc{step}$ and $m= \textsc{BN}$ are deterministic at the testing time ([38]), we consider only the deterministic mapping from ${\bm{z}}^{i, 0}$ to ${\bm{z}}^{i, 1}$. There are only 4 deterministic mappings from ${\left{0, 1\right}}$ to ${\left{0, 1\right}}$: ${\left{(0, 1), (1, 1)\right}}$, ${\left{(1, 0), (0, 0)\right}}$, ${\left{(0, 0), (1, 1)\right}}$, ${\left{(0, 1), (1, 0)\right}}$. Thus our goal is to show that the last mapping ${\left{(0, 1), (1, 0)\right}}$ is impossible in the latent space produced by an ideally trained BTL.
To prove this, first, assume that there is $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})=(0, 1)$ for some index $i$. Then
$ 1=\textsc{step}(m(0)+e) \Rightarrow m(0)+e>0 \Rightarrow m(1)+e>0 \Rightarrow \forall i; m({\bm{z}}^{i, 0})+e > 0. $
The second step is due to the monotonicity $m(0)<m(1)$. This shows ${\bm{z}}^{i, 1}$ is constantly $1$ regardless of ${\bm{z}}^{i, 0}$, therefore it proves that $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})=(1, 0)$ cannot happen in any $i$.
Likewise, if $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})=(1, 0)$ for some index $i$,
$ 0=\textsc{step}(m(1)+e) \Rightarrow m(1)+e<0 \Rightarrow m(0)+e<0 \Rightarrow \forall i; m({\bm{z}}^{i, 0})+e < 0. $
Therefore, ${\bm{z}}^{i, 1}=0$ regardless of ${\bm{z}}^{i, 0}$, and thus $({\bm{z}}^{i, 0}, {\bm{z}}^{i, 1})=(0, 1)$ cannot happen in any $i$.
Finally, if the data points do not contain $(0, 1)$ or $(1, 0)$, then by assumption they do not coexist. Therefore, the embedding learned by BTL cannot contain $(0, 1)$ and $(1, 0)$ at the same time.
I. Training Curve
To facilitate reproducibility, we show the training and validation loss curves and what to expect. Figure 27 shows the results of training AMA${4}^+$ networks on 8-Puzzle. Similar behaviors were observed in other domains and AMA${3}^+$ networks. We see multiple curves in each subfigure due to multiple hyperparameters. The figure includes three metrics as well as the annealing parameter $\tau$. We could make several observations from these plots.
ELBO: In the successful training curves with lower final ELBO, we do not observe overfitting behavior. ELBO curves show that annealing $\tau$ and training the network with higher $\tau$ is essential, as the networks stop improving the ELBO after the annealing phase is finished at epoch 1000. Indeed, we performed the same experiments with a lower initial value $\tau_{\text{min}}=1.0$, and they exhibited significantly less accuracy. This is because lower $\tau$ in $\textsc{BC}_{\tau}$ makes the latent $\textsc{sigmoid}$ function closer to a step function (steeper around 0, flatter away from 0) and produce smaller gradients, as discussed by [21].
KL divergence against the prior distribution: The group with the lower initial,
$ D_{\mathrm{KL}}(q({\bm{z}}^{i, 0}| {\mathbf{x}}^{0})||p({\bm{z}}^{i, 0})), $
consists of those with hyperparameter $F=50$. This is because the KL divergence is the sum across latent dimensions and the KL divergence in each dimension tends to have a similar value initially.
KL divergence for successor prediction: While the overall ELBO loss monotonically decreases, the $D_{\mathrm{KL}}(\allowbreak q({\bm{z}}^{i, 1}| {\bm{x}}^{i, 1})\allowbreak ||\allowbreak p({\bm{z}}^{i, 2}| {\bm{z}}^{i, 0}, {\bm{a}}^{i}))$ loss representing successor prediction accuracy initially goes up, then goes down. This indicates that the network initially focuses on learning the reconstructions, then moves on to adjust the state representation and the action model in the later stage of the training. The KL divergence continues to improve after the annealing is finished at epoch 1000. The curves seem to indicate that we could train the network even longer in order to achieve better successor prediction loss.
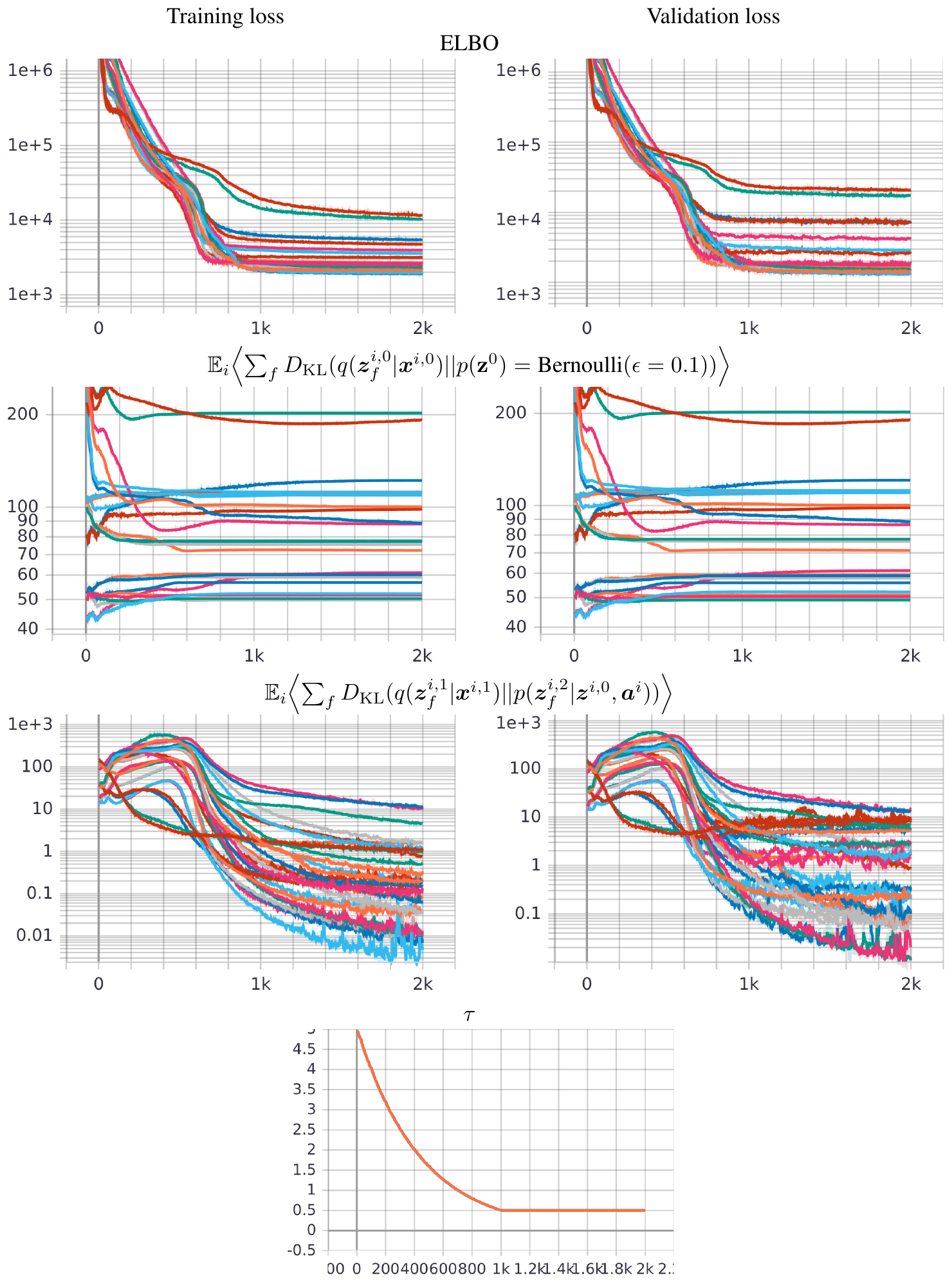
J. Domain-wise colorization of heuristics figure
Cf. Figure 22.
:::: {cols="2"}
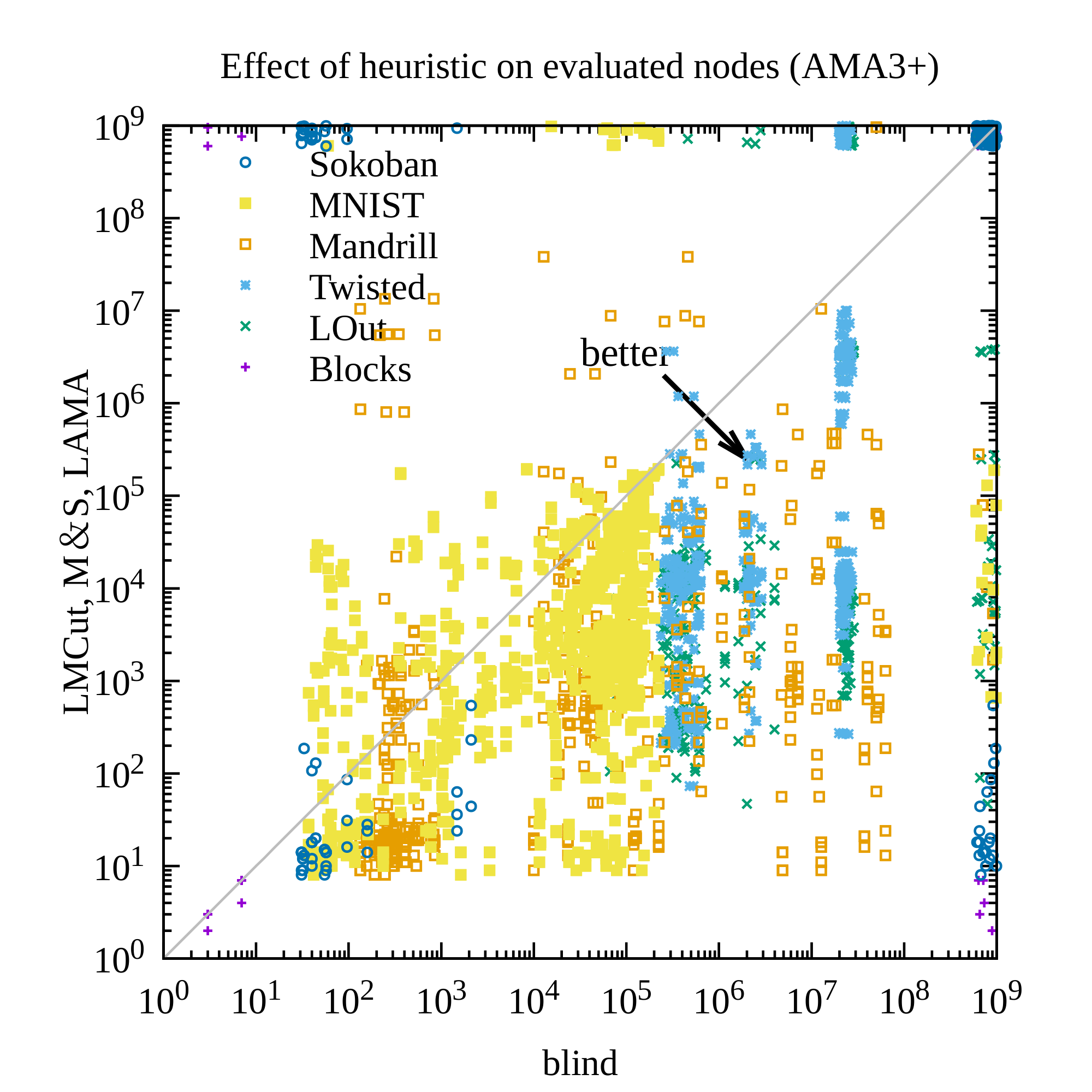
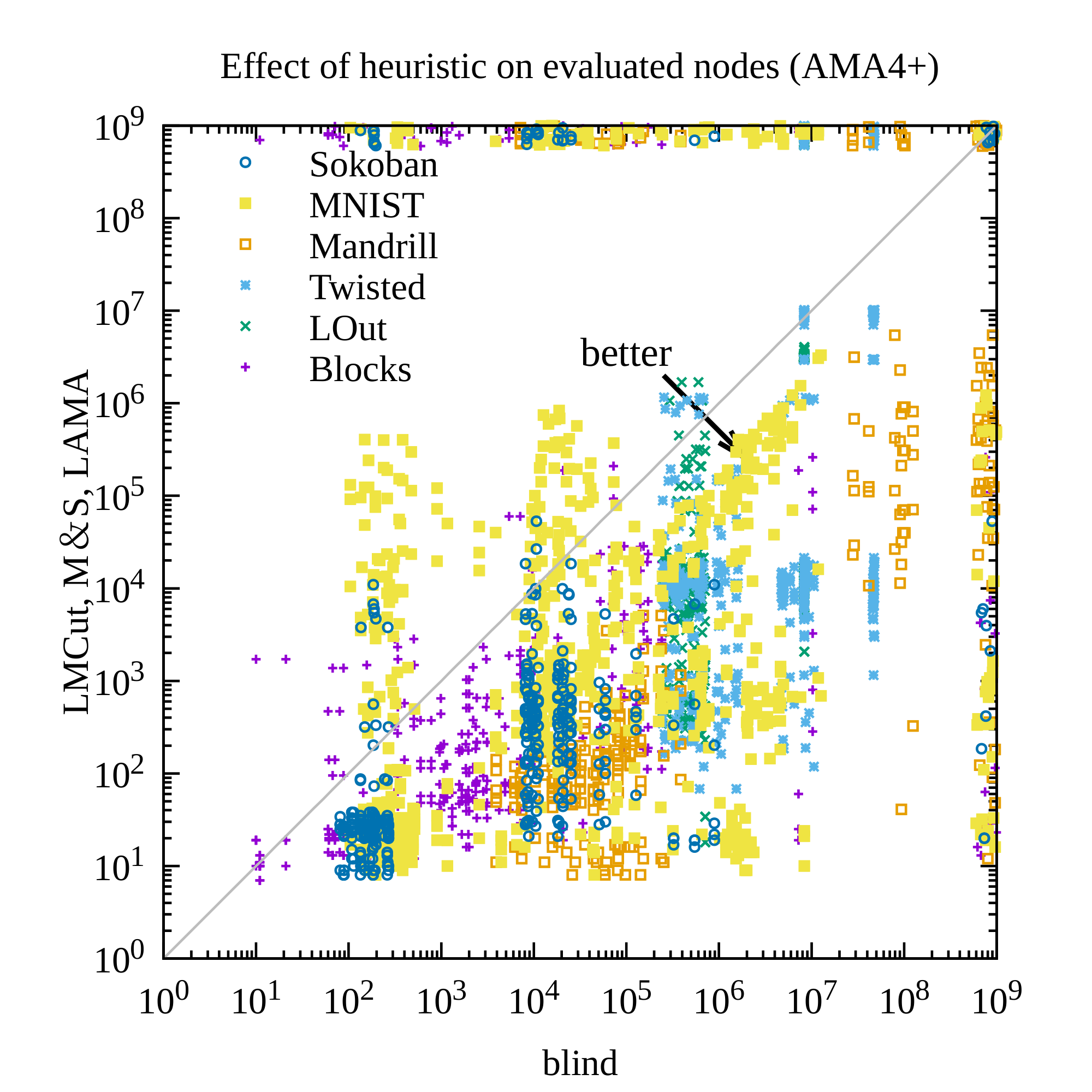
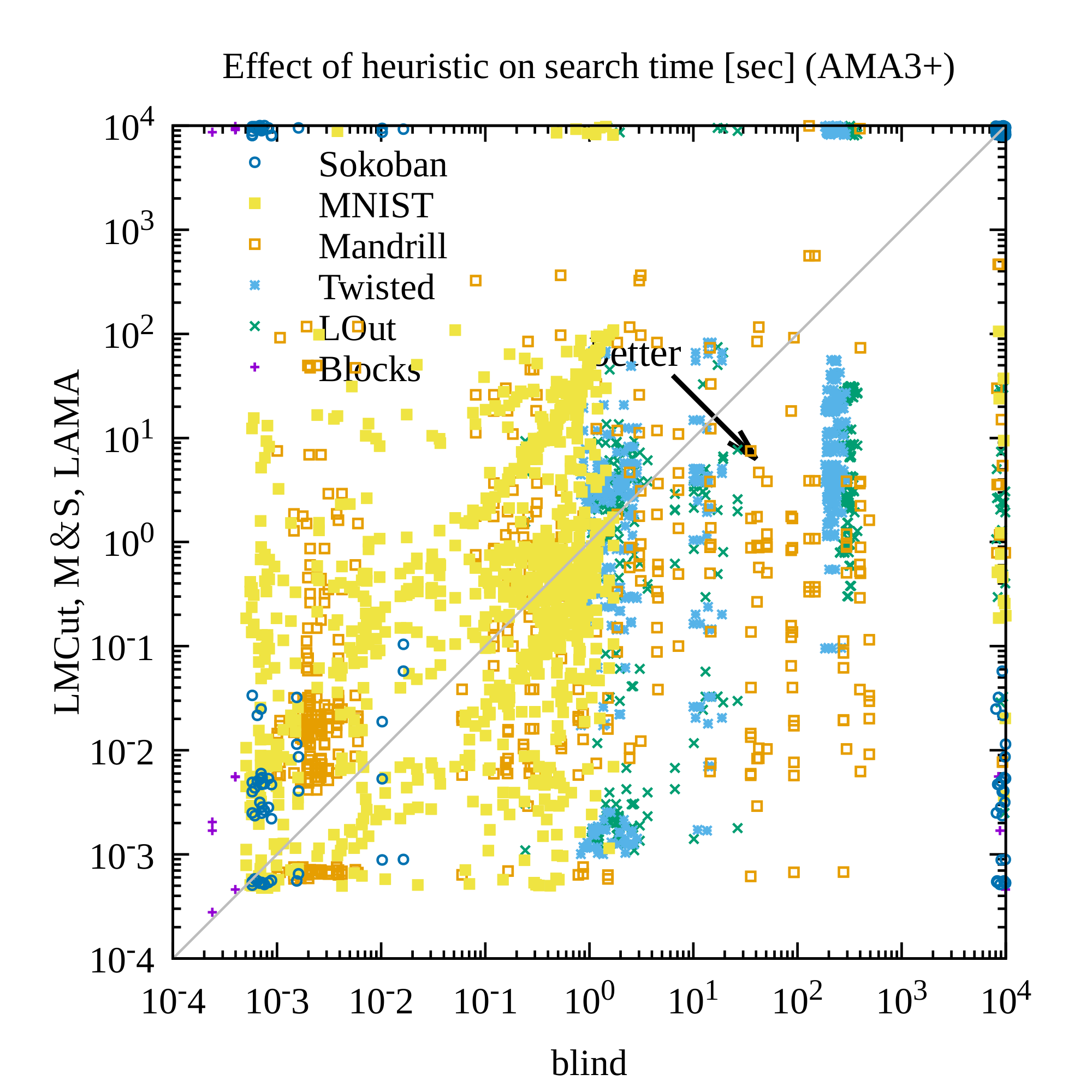
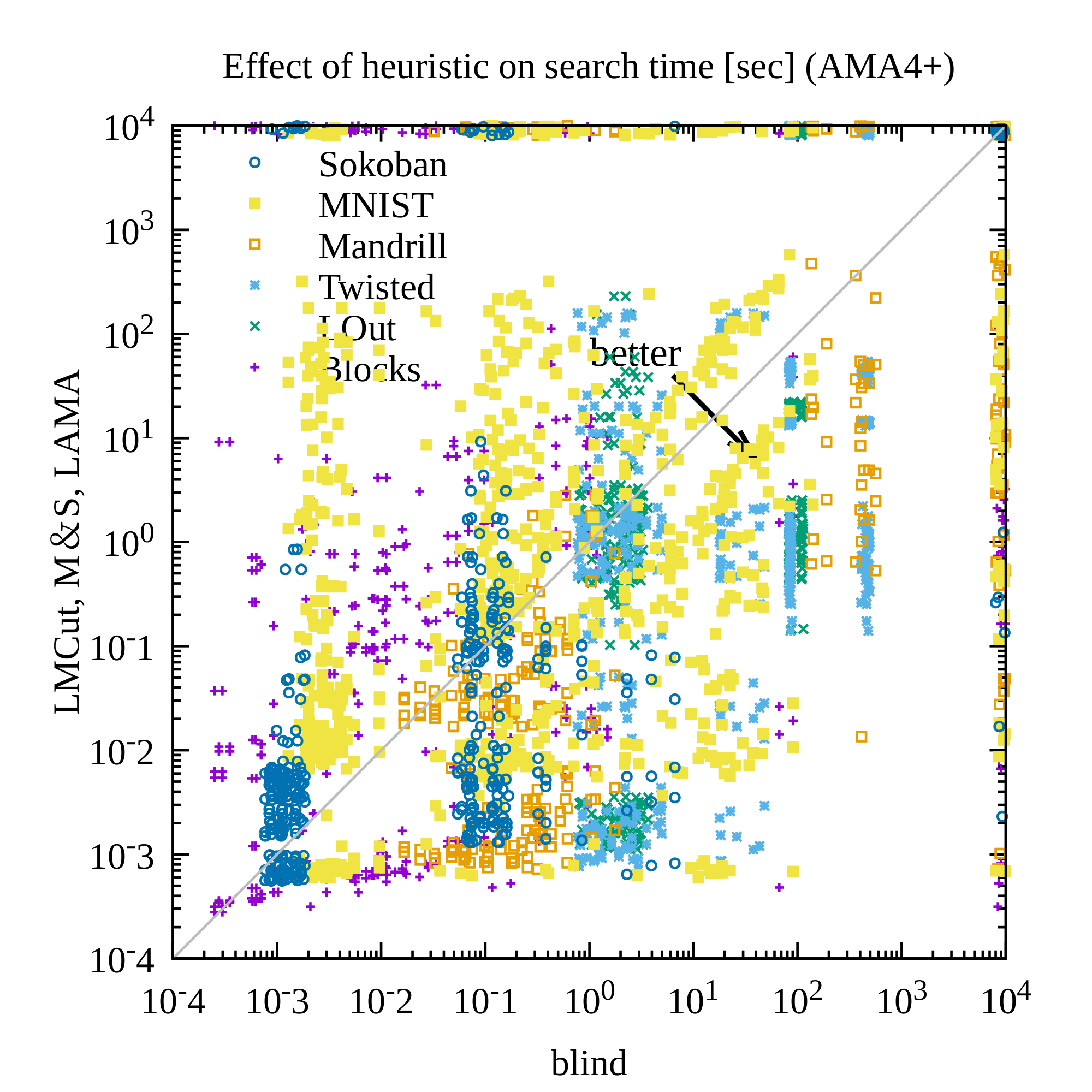 ::::
::::
K. Domain-wise colorization of solvability experiments
:::: {cols="2"}
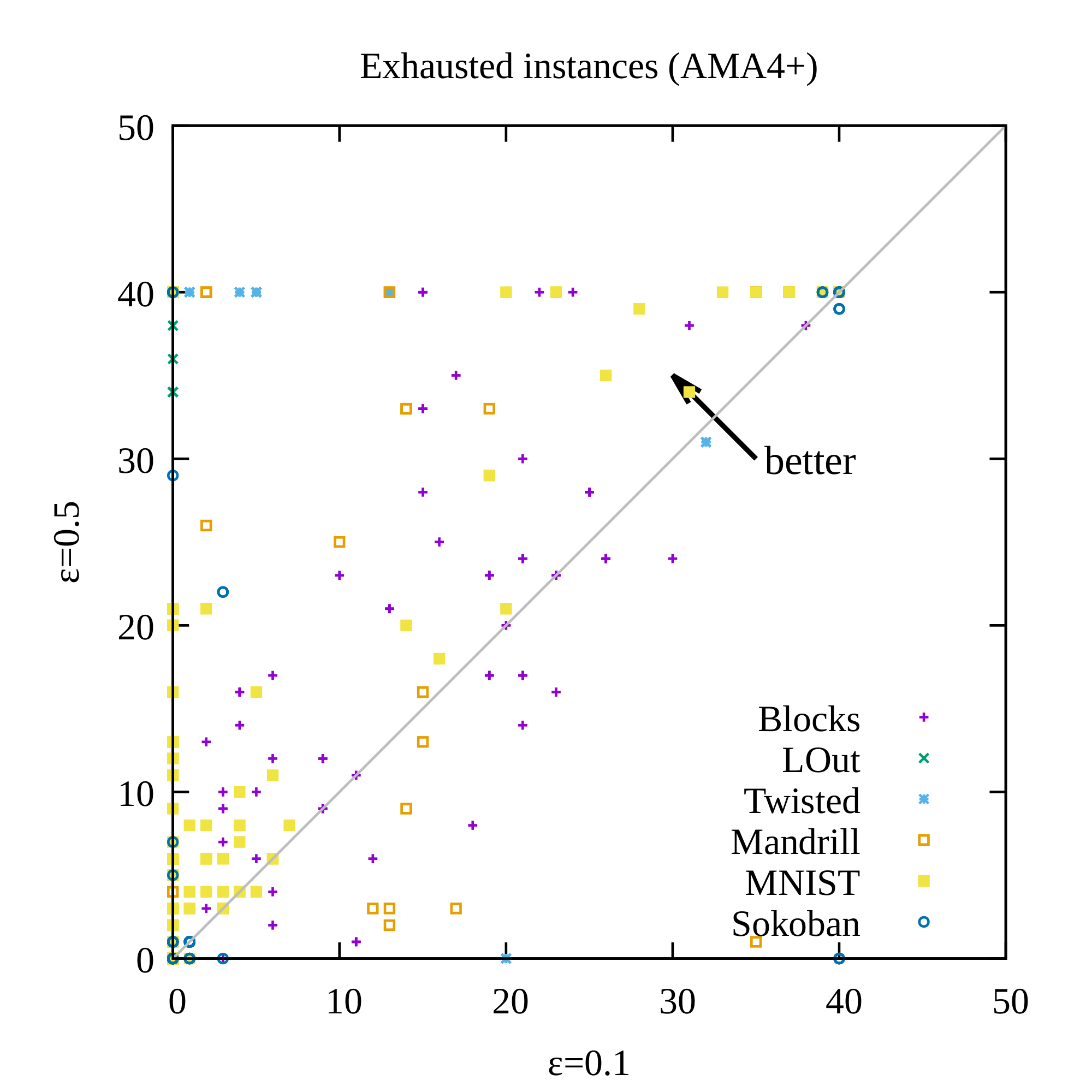
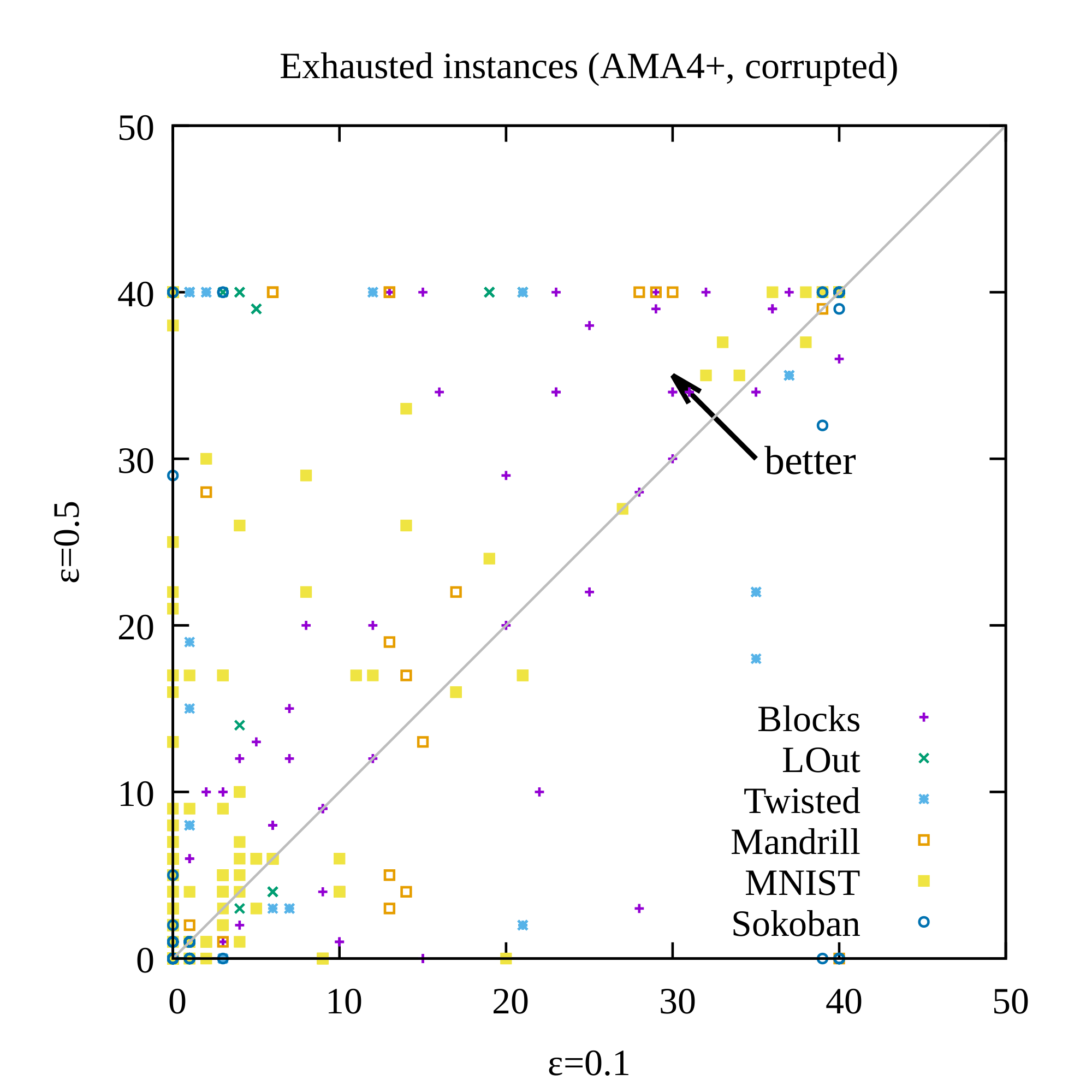
Figure 28: Domain-wise colorization of Figure 24. ::::
L. Plan Validators
We developed a plan validator for each visual planning domain to evaluated the accuracy of the learned representation and the performance of the planner. This section describe the details of these validators.
All validators consist of two stages: State-wise validation (validate_states) and transition validation (validate_transitions). State-wise validation typically checks for inaccurate reconstructions and violation of domain-specific constraints in the image. Transition validation checks for the correctness of the transitions.
The source code of these validators are available in the source code of Latplan repository ^6.
L.1 Sliding Tile Puzzle Validators (MNIST, Mandrill)
Since we know the number of rectangular grids in each domain, we first segment each image in the plan into tile patches. For each patch, we compare the mean absolute errors against a fixed set of ground-truth tile patterns which are used to generate the dataset.
After computing the distance, we do not simply pick the nearest tile — it would result in selecting the same ground-truth tile pattern for several patches. Instead, the algorithm searches for the best threshold value $\theta$ for the absolute error by a binary search under $0.0\leq\theta\leq 0.5$. A patch is considered a "match" when the absolute error is below $\theta$. The reason we search for the threshold is because MNIST and Mandrill images have different pixel value ranges. Manually searching for the threshold is not only cumbersome but would also result in an arbitrary decision (for example, we could set a very forgiving / strict value and claim that it works well / does not work well). Another reason is that Sliding Tile Puzzle assumes that there are no duplicate tiles, which can be used to detect invalid states.
The threshold $\theta$ is increased/decreased so that it balances the number $n_1$ of ambiguous patches that matches more than one ground-truth tiles and the number $n_2$ of patches that fail to match any ground truth. $\theta$ is increased when $n_1<n_2$ and decreased when $n_1>n_2$. The search is stopped when $|n_1-n_2|\leq 1$. We consider an image is invalid when $n_1\not=0$ and $n_2\not=0$.
To validate a transition, we map an image into a compact state configuration representing each tile as an integer id using the threshold value discovered in the previous step. We then check if only two tiles are changed, if the tiles are adjacent, and if one of them is the empty tile (tile id 0).
L.2 LightsOut and Twisted LightsOut Validator
We reuse some of the code from Sliding Tile Puzzle validators with two ground-truth tiles being the "On" tile (indicated by a + sign) and the "Off" tile (a blank black tile).
Unlike MNIST and Mandrill, LightsOut images consist of complete black-and-white pixels, and also multiple patches can match the same groud-truth tile (either "on" or "off"). We therefore set the threshold to 0.01, a value small enough that any noticeable + marks will be detected as an "On" state of each button. We map each state into a 0/1 configuration representing a puzzle state and validate the transitions.
To handle Twisted LightsOut images, we undo this swirl effect and apply the same validator. The threshold is increased to 0.04 to account for the numerical errors (e.g., anti-aliasing effects) caused by the swirl effect.
L.3 Blocksworld Validator
We use the ground-truth knowledge of the image generator that the image consists of 4 blocks with four different colors (red, green, blue, black).
The first step of the validator parses the image into a compact representation. To do so, it quantifies the image into 3-bit colors, then counts the number of pixels for each color to detect the objects. The most frequent color (gray) is ignored as the background. Also, colors which occur less than 0.1% of the entire image are ignored as a noise.
For each color, we compute the centroid and the width/height to obtain the estimate of the object location. While doing so, we ignore the outliers by first computing the 25% and 75% quantiles, and ignoring the coordinates outside 1.5 times the width of the quantiles. Assume ${\bm{x}}$ is a vector of $x$-axis or $y$-axis coordinates for each pixel in the image with the target color of interest. Formally, we perform the following operation for each coordinate axis and each color:
$ \begin{aligned} Q_1 & \leftarrow \text{Quantile}({\bm{x}}, 1/4)\ Q_3 & \leftarrow \text{Quantile}({\bm{x}}, 3/4)\ w & \leftarrow Q_3 - Q_1\ l & \leftarrow Q_1 - 1.5 \cdot w\ u & \leftarrow Q_3 + 1.5 \cdot w\ \text{Return:} &\quad {\left{x\in {\bm{x}} \mid l<x<u\right}}. \end{aligned} $
After parsing the image into a set of objects, we check the validity of the state as follows. For each object $o$, it first searches for objects below it using the half-width $o.w$ (half the width of the bounding box, i.e., dimension from the center), the half-height $o.h$ and the centroid coordinates $o.x, o.y$. An object $o_1$ is below another object $o_2$ when $o_1.y > o_2.y$ and in the same tower, i.e., $|o_1.x - o_2.x| < \frac{o_1.w + o_2.w}{2}$. (Note that the pixel coordinates are measured with the top-left being the origin.)
If an object $o$ is a "bottom" object (nothing is directly below it), it compares the bottom edge of the bounding box $o.y+o.h$ with other bottom objects and check if they have the similar $y$-coordinates, ensuring that none of them are in the mid air. The $y$-coordinates are considered "similar" when the differences are within half the average height of two objects, i.e., $|o_1.y-o_2.y| < \frac{o_1.h + o_2.h}{2}$.
Otherwise, there are other objects below the object $o_1$. It collects all objects below it, and extracts the object $o_2$ with the smallest $y$-coordinate. It checks if $o_1$ and $o_2$ are in direct contact by checking if $y$-coordinate difference is around the sum of both heights, i.e., $(o_1.h + o_2.h) \cdot 0.5 < |o_1.y - o_2.y| < (o_1.h + o_2.h) \cdot 1.5$.
To check the validity of the transitions, it first looks for unaffected objects, and check if exactly one object is moved. If this is satisfied, it further checks if the moved object is a "top" object both before and after the transition.
L.4 Sokoban Validator
The sokoban validator partially shares code with LightsOut, therefore it does not use the binary search to find the threshold. Moreover, it does not use the threshold and it assigns each patch to the closest ground-truth panel (wall, stone, player, goal, clear, stone-at-goal) available in PDDLGym.
To validate the state, we use the fact that the environment was generated from a single PDDL instance (p006-microban-sequential). We enumerate the entire state space with Dijkstra search and store the ground-truth configurations of the states into an archive. A state is valid when the same configuration is found in an archive.
To validate the transition, we can't use the same approach used for states because the archive contains all states but not all transitions — Since the enumeration uses a Dijkstra search to enumerate states, there is only one transition for each state as a destination. We reimplemented the precondition and the effects of each PDDL action (move, push-to-goal, push-to-nongoal) for our representation.
M. Additional Experiments for Towers of Hanoi Domain (Negative Results)
As a failure case of Latplan, we describe Towers of Hanoi (ToH) domain and the experiments we performed. A $(d, t)$-ToH domain with $t$ towers and $d$ disks has $t^d$ states and $t^{d+1}-2$ transitions in total. The optimal solution for moving a complete tower takes $2^d-1$ steps if $t=3$, but we parameterized our image generator so that it can generate images with more than 3 towers. Each input image has a dimension of $(H, W, C)=(hd, wt, 3)$ (height, width, color channel), where each disk is presented as a $h$ x $w$ pixel rectangle ($h=1, w=4$) with distinct colors. The validator of ToH images is identical to that of the Sliding Tile Puzzles except for the fixed patterns that are matched against each image patch.
We generated several datasets with increasing generator parameters, namely $(d, t)=(4, 4), \allowbreak (3, 9), \allowbreak (4, 9), \allowbreak (5, 9)$. The number of states in each configurations is 256, 729, 6561, 59049. We generated 20 problem instances for each configuration, where the number of optimal solution length is 5 for $(3, 9)$ because it lacks 7-step optimal plans[^7], and is 7 for $(4, 4)$, $(4, 9)$, and $(5, 9)$ because they lack 14-step optimal plans. While several 3-disk instances were solved successfully, no valid plans were produced with larger number of disks, as seen in Figure 33. Visualizations of successful and failure cases are shown in Figure 33-Figure 34.
[^7]: The diameter of the state space graph is less than 7.
The apparent failure of Latplan in ToH is surprising because its state space tends to be smaller and thus is "simpler" than the other domains we tested. It could be because the size of the dataset is too small for deep-learning based approaches, or that the images are horizontally long and the 5x5 convolutions are not adequate. It could also be due to the lack of visual cues – however, alternative image renderers did not change the results (e.g., black/white tiles with varying disk size, thicker disks, disks painted with hand-crafted patterns.) Lastly, there may be imbalance in the visual features because the smallest disk rarely appears in the top region of the image. For $d$-disk, $t$-tower ToH domain, the smallest disk can appear only $t$ times in the top row among $t^d$ states, which is exponentially rare in a uniformly randomly sampled dataset. As a result, pixel data in the top rows are biased toward being gray (the background color). We suspect deep-learning may have an assumption that all of the factors (i.e., fluents that distinguish the states) are seen often enough, which is not satisfied in this dataset.
\begin{tabular}{|r|*4{ccc|ccc|}}
\hline
& \multicolumn{6}{c|}{Blind} & \multicolumn{6}{c|}{LAMA} & \multicolumn{6}{c|}{LMCut} & \multicolumn{6}{c|}{M\&S} \\ \hline
& \multicolumn{3}{c|}{kltune} & \multicolumn{3}{c|}{default}
& \multicolumn{3}{c|}{kltune} & \multicolumn{3}{c|}{default}
& \multicolumn{3}{c|}{kltune} & \multicolumn{3}{c|}{default}
& \multicolumn{3}{c|}{kltune} & \multicolumn{3}{c|}{default} \\ \hline
domain
& f & v & o & f & v & o
& f & v & o & f & v & o
& f & v & o & f & v & o
& f & v & o & f & v & o \\ \hline
\multicolumn{25}{|c|}{AMA$_{3}^+$}\\\hline
$(d, t)=(4, 4)$ & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
$(d, t)=(3, 9)$ & 3 & 2 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 3 & 2 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
$(d, t)=(4, 9)$ & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
$(d, t)=(5, 9)$ & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \hline
\multicolumn{25}{|c|}{AMA$_{4}^+$}\\\hline
$(d, t)=(4, 4)$ & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
$(d, t)=(3, 9)$ & 20 & 12 & 8 & 13 & 5 & 0 & 17 & 1 & 0 & 0 & 0 & 0 & 20 & 12 & 7 & 13 & 5 & 0 & 20 & 12 & 8 & 13 & 5 & 0 \\
$(d, t)=(4, 9)$ & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
$(d, t)=(5, 9)$ & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \hline
\end{tabular}
N. Examples of Planning Results
Finally, Figure 29-Figure 34 show several examples of successful plans (optimal and suboptimal) as well as invalid plans in order to illustrate how Latplan could behave or fail.
We did not see any qualitative differences between the visualized results obtained by various configurations, conditioned by the same validity status of the plan (invalid/suboptimal/optimal). For example, we did not find any particular differences between the sets of invalid results regardless of the choice of AMA${3}^+$, AMA${4}^+$, $\epsilon=0.1$ (kltune), $\epsilon=0.5$ (default), or other hyperparameter differences. All invalid results look similarly invalid (albeit individual variations), except the statistical differences observed in the overall number of invalid plans as discussed in Section 11. Similarly, suboptimal results look similarly suboptimal and no configuration particularly / visually / qualitatively stands out. Optimal results also looks similarly optimal. One exception is the case of using LAMA, in which case plans tend to be much longer than in the other configurations.
Due to this and the obvious space reasons, we do not attempt to exhaustively enumerate the results of all configurations. We instead hand-picked several examples without much consideration on the configuration.
Thus, although we describe each configuration in the description, it is not our intention to compare these results and make any claims based on them.

:::: {cols="1"}


Examples of invalid plans in Blocksworld for a 7-steps problem and a 14-steps problem. In the first instance, floating objects can be observed. In the second instance, the colors of some blocks change and some objects are duplicated. (The first instance was generated by AMA${4}^+$, default prior, LAMA. The second instance was produced by AMA${4}^+$, $\epsilon=0.1$ prior, M&S.) ::::
:::: {cols="1"}


Examples from MNIST 8-puzzle. The first plan is optimal (14 steps). The second plan is invalid due to the duplicated "6" tiles in the second step. (The first instance was generated by AMA${3}^+$, default prior, blind. The second instance was produced by AMA${4}^+$, $\epsilon=0.1$ prior, blind.) ::::
:::: {cols="1"}


Examples from Mandrill 15-puzzle. The first plan is optimal (7 steps). The second plan is invalid because it is hard to distinguish different tiles. (Both instances were generated by AMA$_{3}^+$, $\epsilon=0.1$ prior, blind but with different hyperparameters $(F, \beta_1, \beta_3)$.) ::::


:::: {cols="2"}

Suboptimal plans generated for 7-steps instances of MNIST 8-Puzzle and Twisted LightsOut by LAMA. Plans generated by LAMA tends to be hugely suboptimal compared to the suboptimal visual plans generated by $A^*$ and admissible heuristics (e.g., blind, LMcut, M&S). See also: Section 11.4 discusses why $A^*$ + admissible heuristics can generate suboptimal visual plans. (The first instance was generated by AMA${4}^+$, default prior, LAMA. The second instance was generated by AMA${3}^+$, $\epsilon=0.1$ prior, LAMA.) ::::


References
Section Summary: This section consists of a numbered bibliography listing 33 academic papers, books, and conference proceedings focused on artificial intelligence. The works span topics such as AI planning systems, neural networks for image and speech processing, reinforcement learning successes in games, and foundational debates on symbol grounding and knowledge representation. Many entries come from venues like NeurIPS, ICAPS, AAAI, and journals including Nature and AI Magazine, highlighting both classic and recent research in symbolic and subsymbolic AI.
[1] McDermott, D. V. (2000). The 1998 AI Planning Systems Competition. AI Magazine, 21(2), 35–55.
[2] Steels, L. (2008). The Symbol Grounding Problem has been Solved. So What's Next?. In de Vega, M., Glenberg, A., & Graesser, A. (Eds.), Symbols and Embodiment. Oxford University Press.
[3] Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). ImageNet: A Large-Scale Hierarchical Image Database. In Proc. of IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE.
[4] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems, pp. 91–99.
[5] Deng, L., Hinton, G. E., & Kingsbury, B. (2013). New Types of Deep Neural Network Learning for Speech Recognition and Related Applications: An Overview. In Proc. of IEEE Conference on Acoustics, Speech and Signal Processing, pp. 8599–8603. IEEE.
[6] Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., et al. (2015). Human-Level Control through Deep Reinforcement Learning. Nature, 518(7540), 529–533.
[7] Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwińska, A., Colmenarejo, S. G., Grefenstette, E., Ramalho, T., Agapiou, J., et al. (2016). Hybrid Computing using a Neural Network with Dynamic External Memory. Nature, 538(7626), 471–476.
[8] Hoffmann, J., & Nebel, B. (2001). The FF Planning System: Fast Plan Generation through Heuristic Search. J. Artif. Intell. Res.(JAIR), 14, 253–302.
[9] Helmert, M., & Domshlak, C. (2009). Landmarks, Critical Paths and Abstractions: What's the Difference Anyway?. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS).
[10] Newell, A., & Simon, H. A. (1976). Computer Science as Empirical Inquiry: Symbols and Search. Commun. ACM, 19(3), 113–126.
[11] Newell, A. (1980). Physical Symbol Systems. Cognitive science, 4(2), 135–183.
[12] Nilsson, N. J. (2007). The Physical Symbol System Hypothesis: Status and Prospects. In 50 Years of Artificial Intelligence, pp. 9–17. Springer.
[13] Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T. P., Simonyan, K., & Hassabis, D. (2017). Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. CoRR, abs/1712.01815.
[14] Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., Lillicrap, T. P., & Silver, D. (2019). Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. CoRR, abs/1911.08265.
[15] Asai, M., & Fukunaga, A. (2018). Classical planning in deep latent space: Bridging the subsymbolic-symbolic boundary. In McIlraith, S. A., & Weinberger, K. Q. (Eds.), Proc. of AAAI Conference on Artificial Intelligence, pp. 6094–6101. AAAI Press.
[16] Asai, M., & Kajino, H. (2019). Towards Stable Symbol Grounding with Zero-Suppressed State AutoEncoder. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS).
[17] Asai, M., & Muise, C. (2020). Learning Neural-Symbolic Descriptive Planning Models via Cube-Space Priors: The Voyage Home (to STRIPS). In Proc. of International Joint Conference on Artificial Intelligence (IJCAI).
[18] Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the Dimensionality of Data with Neural Networks. Science, 313(5786), 504–507.
[19] Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. In Proc. of the International Conference on Learning Representations.
[20] Higgins, I., Matthey, L., Pal, A., et al. (2017). $\beta$-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proc. of the International Conference on Learning Representations.
[21] Jang, E., Gu, S., & Poole, B. (2017). Categorical Reparameterization with Gumbel-Softmax. In Proc. of the International Conference on Learning Representations.
[22] Maddison, C. J., Mnih, A., & Teh, Y. W. (2017). The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables. In Proc. of the International Conference on Learning Representations.
[23] Harnad, S. (1990). The Symbol Grounding Problem. Physica D: Nonlinear Phenomena, 42(1-3), 335–346.
[24] Taddeo, M., & Floridi, L. (2005). Solving the Symbol Grounding Problem: A Critical Review of Fifteen Years of Research. Journal of Experimental & Theoretical Artificial Intelligence, 17(4), 419–445.
[25] Zhuo, H. H., & Yang, Q. (2014). Action-Model Acquisition for Planning via Transfer Learning. Artificial Intelligence, 212, 80–103.
[26] Zhuo, H. H. (2015). Crowdsourced Action-Model Acquisition for Planning. In Proc. of AAAI Conference on Artificial Intelligence, Vol. 29.
[27] Wang, X. (1995). Learning by Observation and Practice: An Incremental Approach for Planning Operator Acquisition. In Proc. of the International Conference on Machine Learning, pp. 549–557. Elsevier.
[28] Yang, Q., Wu, K., & Jiang, Y. (2007). Learning Action Models from Plan Examples using Weighted MAX-SAT. Artificial Intelligence, 171(2-3), 107–143.
[29] Russell, S. J., Norvig, P., Canny, J. F., Malik, J. M., & Edwards, D. D. (1995). Artificial Intelligence: A Modern Approach, Vol. 2. Prentice hall Englewood Cliffs.
[30] Vera, A. H., & Simon, H. A. (1993). Situated Action: A Symbolic Interpretation. Cognitive science, 17(1), 7–48.
[31] Fox, M., & Long, D. (2003). PDDL2.1: An Extension to PDDL for Expressing Temporal Planning Domains. J. Artif. Intell. Res.(JAIR), 20, 61–124.
[32] Howey, R., & Long, D. (2003). VAL’s Progress: The Automatic Validation Tool for PDDL2.1 used in the International Planning Competition. In Proceedings of ICAPS Workshop on the IPC, pp. 28–37. Citeseer.
[33] Frances, G., Ram'ırez, M., Lipovetzky, N., & Geffner, H. (2017). Purely Declarative Action Representations are Overrated: Classical Planning with Simulators. In Proc. of International Joint Conference on Artificial Intelligence (IJCAI), pp. 4294–4301.
[34] Fikes, R. E., & Nilsson, N. J. (1972). STRIPS: A New Approach to the Application of Theorem Proving to Problem Solving. Artificial Intelligence, 2(3), 189–208.
[35] Bäckström, C., & Nebel, B. (1995). Complexity Results for SAS+ Planning. Computational Intelligence, 11(4), 625–655.
[36] Helmert, M. (2006). The Fast Downward Planning System. J. Artif. Intell. Res.(JAIR), 26, 191–246.
[37] Vincent, P., Larochelle, H., Bengio, Y., & Manzagol, P.-A. (2008). Extracting and Composing Robust Features with Denoising Autoencoders. In Proc. of the International Conference on Machine Learning, pp. 1096–1103. ACM.
[38] Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Bach, F. R., & Blei, D. M. (Eds.), Proc. of the International Conference on Machine Learning, Vol. 37 of JMLR Workshop and Conference Proceedings, pp. 448–456. JMLR.org.
[39] Hinton, G. E., Nitish, S., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. R. (2012). Improving Neural Networks by Preventing Co-adaptation of Feature Detectors. CoRR, abs/1207.0580.
[40] Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. C., & Bengio, Y. (2014). Generative Adversarial Nets. In Advances in Neural Information Processing Systems, pp. 2672–2680.
[41] Kurutach, T., Tamar, A., Yang, G., Russell, S. J., & Abbeel, P. (2018). Learning Plannable Representations with Causal InfoGAN. In Advances in Neural Information Processing Systems.
[42] Dinh, L., & Dumoulin, V. (2014). Training Neural Bayesian Nets..
[43] Bowman, S., Vilnis, L., Vinyals, O., Dai, A., Jozefowicz, R., & Bengio, S. (2016). Generating Sentences from a Continuous Space. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning, pp. 10–21.
[44] Reiter, R. (1981). On Closed World Data Bases. In Readings in Artificial Intelligence, pp. 119–140. Elsevier.
[45] Lipovetzky, N. (2017). Best-First Width Search: Exploration and Exploitation in Classical Planning . In Proc. of AAAI Conference on Artificial Intelligence.
[46] Ho, T. K. (1998). The Random Subspace Method for Constructing Decision Forests. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(8).
[47] Asai, M. (2020). Unsuccessful Neural-Symbolic Descriptive Action Model from Images: The Search for STRIPS. In Proc. of the ICAPS Workshop on Knowledge Engineering for Planning and Scheduling(KEPS).
[48] Payan, C. (1992). On the Chromatic Number of Cube-Like Graphs. Discrete mathematics, 103(3).
[49] Wang, X. (1994). Learning planning operators by observation and practice. In Hammond, K. J. (Ed.), Proceedings of the Second International Conference on Artificial Intelligence Planning Systems, pp. 335–340. AAAI.
[50] Amado, L., Pereira, R. F., Aires, J. P., Magnaguagno, M. C., Granada, R., & Meneguzzi, F. (2018). Goal Recognition in Latent Space. In Proc. of International Joint Conference on Neural Networks (IJCNN).
[51] Bonet, B., & Geffner, H. (2001). Planning as Heuristic Search. Artificial Intelligence, 129(1), 5–33.
[52] Alcázar, V., Borrajo, D., Fernández, S., & Fuentetaja, R. (2013). Revisiting Regression in Planning. In Proc. of International Joint Conference on Artificial Intelligence (IJCAI).
[53] LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-Based Learning Applied to Document Recognition. Proc. of the IEEE, 86(11), 2278–2324.
[54] Reinefeld, A. (1993). Complete Solution of the Eight-Puzzle and the Benefit of Node Ordering in IDA*. In Proc. of International Joint Conference on Artificial Intelligence (IJCAI), pp. 248–253.
[55] Weber, A. G. (1997). The USC-SIPI image database version 5. USC-SIPI Report, 315(1).
[56] Anderson, M., & Feil, T. (1998). Turning lights out with linear algebra. Mathematics Magazine, 71(4), 300–303.
[57] Asai, M. (2018). Photo-realistic blocksworld dataset. CoRR, abs/1812.01818.
[58] Culberson, J. (1998). Sokoban is PSPACE-complete. In Proceedings in Informatics 4, International Conference on Fun with Algorithms, pp. 65–76. Carleton Scientific.
[59] Junghanns, A., & Schaeffer, J. (2001). Sokoban: Enhancing General Single-Agent Search Methods using Domain Knowledge. Artificial Intelligence, 129(1), 219–251.
[60] Silver, T., & Chitnis, R. (2020). PDDLGym: Gym Environments from PDDL Problems..
[61] Chollet, F., et al. (2015). Keras. https://keras.io.
[62] Fukushima, K. (1980). Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. Biological Cybernetics, 36(4).
[63] LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D. (1989). Backpropagation Applied to Handwritten Zip Code Recognition. Neural Computation, 1(4).
[64] He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proc. of the IEEE International Conference on Computer Vision, pp. 1026–1034.
[65] Glorot, X., & Bengio, Y. (2010). Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proc. of International Conference on Artificial Intelligence and Statistics, pp. 249–256. JMLR Workshop and Conference Proceedings.
[66] Liu, L., et al. (2019). On the Variance of the Adaptive Learning Rate and Beyond. CoRR, abs/1908.03265.
[67] Helmert, M., Haslum, P., Hoffmann, J., & Nissim, R. (2014). Merge-and-Shrink Abstraction: A Method for Generating Lower Bounds in Factored State Spaces. Journal of ACM, 61(3), 16:1–16:63.
[68] Richter, S., & Westphal, M. (2010). The LAMA Planner: Guiding Cost-Based Anytime Planning with Landmarks. J. Artif. Intell. Res.(JAIR), 39(1), 127–177.
[69] Korf, R. E. (1985). Macro-Operators: A Weak Method for Learning. J. Artif. Intell. Res.(JAIR), 26(1), 35–77.
[70] Edelkamp, S. (2012). PDB or not PDB? - that's the Question. A Tribute to Blind Search Planning. In Festivus in the 22nd International Conference on Automated Planning and Scheduling(ICAPS).
[71] Mourão, K., Zettlemoyer, L. S., Petrick, R. P. A., & Steedman, M. (2012). Learning STRIPS Operators from Noisy and Incomplete Observations. In Proc. of the International Conference on Uncertainty in Artificial Intelligence, pp. 614–623.
[72] Zhuo, H. H., & Kambhampati, S. (2013). Action-Model Acquisition from Noisy Plan Traces. In Proc. of International Joint Conference on Artificial Intelligence (IJCAI).
[73] Zhuo, H. H., Peng, J., & Kambhampati, S. (2019). Learning Action Models from Disordered and Noisy Plan Traces. CoRR, abs/1908.09800.
[74] Cresswell, S., McCluskey, T. L., & West, M. (2009). Acquisition of object-centred domain models from planning examples. In Nineteenth International Conference on Automated Planning and Scheduling.
[75] Cresswell, S., & Gregory, P. J. (2011). Generalised Domain Model Acquisition from Action Traces. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS).
[76] Cresswell, S., McCluskey, T. L., & West, M. M. (2013). Acquiring planning domain models using LOCM. Knowledge Engineering Review, 28(2), 195–213.
[77] Gregory, P. J., & Cresswell, S. (2015). Domain Model Acquisition in the Presence of Static Relations in the LOP System. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS), pp. 97–105.
[78] Aineto, D., Jiménez, S., & Onaindia, E. (2018). Learning STRIPS Action Models with Classical Planning. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS).
[79] Bonet, B., & Geffner, H. (2020). Learning First-Order Symbolic Representations for Planning from the Structure of the State Space. In Proc. of European Conference on Artificial Intelligence.
[80] Rodriguez, I. D., Bonet, B., Romero, J., & Geffner, H. (2021). Learning First-Order Representations for Planning from Black-Box States: New Results. In Proc. of the International Conference on Principles of Knowledge Representation and Reasoning.
[81] Konidaris, G., Kaelbling, L. P., & Lozano-Pérez, T. (2014). Constructing Symbolic Representations for High-Level Planning. In Proc. of AAAI Conference on Artificial Intelligence, pp. 1932–1938.
[82] Konidaris, G., Kaelbling, L. P., & Lozano-Pérez, T. (2015). Symbol Acquisition for Probabilistic High-Level Planning. In Proc. of International Joint Conference on Artificial Intelligence (IJCAI), pp. 3619–3627.
[83] Andersen, G., & Konidaris, G. (2017). Active Exploration for Learning Symbolic Representations. In Advances in Neural Information Processing Systems, pp. 5009–5019.
[84] Konidaris, G., Kaelbling, L. P., & Lozano-Pérez, T. (2018). From Skills to Symbols: Learning Symbolic Representations for Abstract High-Level Planning. J. Artif. Intell. Res.(JAIR), 61, 215–289.
[85] Barbu, A., Narayanaswamy, S., & Siskind, J. M. (2010). Learning Physically-Instantiated Game Play through Visual Observation. In Proc. of IEEE International Conference on Robotics and Automaton (ICRA), pp. 1879–1886.
[86] Kaiser, L. (2012). Learning Games from Videos Guided by Descriptive Complexity. In Proc. of AAAI Conference on Artificial Intelligence.
[87] Ugur, E., & Piater, J. H. (2015). Bottom-up Learning of Object Categories, Action Effects and Logical Rules: From Continuous Manipulative Exploration to Symbolic Planning. In Proc. of IEEE International Conference on Robotics and Automaton (ICRA), pp. 2627–2633. IEEE.
[88] Ahmetoglu, A., Seker, M. Y., Sayin, A., Bugur, S., Piater, J. H., Öztop, E., & Ugur, E. (2020). DeepSym: Deep Symbol Generation and Rule Learning from Unsupervised Continuous Robot Interaction for Planning. CoRR, abs/2012.02532.
[89] Lindsay, A., Read, J., Ferreira, J. F., Hayton, T., Porteous, J., & Gregory, P. J. (2017). Framer: Planning Models from Natural Language Action Descriptions. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS).
[90] Miglani, S., & Yorke-Smith, N. (2020). NLtoPDDL: One-Shot Learning of PDDL Models from Natural Language Process Manuals. In Proc. of the ICAPS Workshop on Knowledge Engineering for Planning and Scheduling(KEPS). ICAPS.
[91] Jiménez, S., de la Rosa, T., Fernández, S., Fernández, F., & Borrajo, D. (2012). A Review of Machine Learning for Automated Planning. Knowledge Engineering Review, 27(4), 433.
[92] Arora, A., Fiorino, H., Pellier, D., Etivier, M., & Pesty, S. (2018). A Review of Learning Planning Action Models. Knowledge Engineering Review, 33.
[93] Vazirani, V. V. (2013). Approximation Algorithms. Springer Science & Business Media.
[94] Gebser, M., Kaufmann, B., Kaminski, R., Ostrowski, M., Schaub, T., & Schneider, M. (2011). Potassco: The Potsdam Answer Set Solving Collection. AI Communications, 24(2), 107–124.
[95] Arfaee, S. J., Zilles, S., & Holte, R. C. (2010). Bootstrap learning of heuristic functions. In Felner, A., & Sturtevant, N. R. (Eds.), Proc. of Annual Symposium on Combinatorial Search. AAAI Press.
[96] Arfaee, S. J., Zilles, S., & Holte, R. C. (2011). Learning Heuristic Functions for Large State Spaces. Artificial Intelligence, 175(16-17), 2075–2098.
[97] Thayer, J. T., Dionne, A., & Ruml, W. (2011). Learning Inadmissible Heuristics during Search. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS), Vol. 21.
[98] Satzger, B., & Kramer, O. (2013). Goal Distance Estimation for Automated Planning using Neural Networks and Support Vector Machines. Natural Computing, 12(1), 87–100.
[99] Yoon, S. W., Fern, A., & Givan, R. (2006). Learning Heuristic Functions from Relaxed Plans.. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS), Vol. 2, p. 3.
[100] Yoon, S. W., Fern, A., & Givan, R. (2008). Learning Control Knowledge for Forward Search Planning.. Journal of Machine Learning Research, 9(4).
[101] Ferber, P., Helmert, M., & Hoffmann, J. (2020). Neural Network Heuristics for Classical Planning: A Study of Hyperparameter Space. In Proc. of European Conference on Artificial Intelligence, pp. 2346–2353.
[102] Toyer, S., Trevizan, F., Thiébaux, S., & Xie, L. (2018). Action Schema Networks: Generalised Policies with Deep Learning. In Proc. of AAAI Conference on Artificial Intelligence, Vol. 32.
[103] Shen, W., Trevizan, F., & Thiébaux, S. (2020). Learning Domain-Independent Planning Heuristics with Hypergraph Networks. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS), Vol. 30, pp. 574–584.
[104] Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. (2016). Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature, 529(7587), 484–489.
[105] Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT press.
[106] Bellemare, M. G., Naddaf, Y., Veness, J., & Bowling, M. (2013). The Arcade Learning Environment: An Evaluation Platform for General Agents. J. Artif. Intell. Res.(JAIR), 47, 253–279.
[107] Kaiser, L., Babaeizadeh, M., Milos, P., Osinski, B., Campbell, R. H., Czechowski, K., Erhan, D., Finn, C., Kozakowski, P., Levine, S., Mohiuddin, A., Sepassi, R., Tucker, G., & Michalewski, H. (2020). Model Based Reinforcement Learning for Atari. In Proc. of the International Conference on Learning Representations.
[108] Ha, D., & Schmidhuber, J. (2018). World Models. CoRR, abs/1803.10122.
[109] Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Advances in Neural Information Processing Systems, pp. 2172–2180.
[110] Wang, J. X., King, M., Porcel, N. P. M., Kurth-Nelson, Z., Zhu, T., Deck, C., Choy, P., Cassin, M., Reynolds, M., Song, H. F., Buttimore, G., Reichert, D. P., Rabinowitz, N. C., Matthey, L., Hassabis, D., Lerchner, A., & Botvinick, M. (2021). Alchemy: A Benchmark and Analysis Toolkit for Meta-Reinforcement Learning Agents. In NIPS, Datasets and Benchmarks Track (Round 2).
[111] Zhang, A., McAllister, R. T., Calandra, R., Gal, Y., & Levine, S. (2021). Learning Invariant Representations for Reinforcement Learning without Reconstruction. In Proc. of the International Conference on Learning Representations.
[112] Hopfield, J. J., & Tank, D. W. (1985). "Neural" Computation of Decisions in Optimization Problems. Biological Cybernetics, 52(3), 141–152.
[113] Bieszczad, A., & Kuchar, S. (2015). Neurosolver Learning to Solve Towers of Hanoi Puzzles. In Proc. of International Joint Conference on Computational Intelligence (IJCCI), Vol. 3, pp. 28–38. IEEE.
[114] Ram'ırez, M., & Geffner, H. (2009). Plan Recognition as Planning. In Proc. of AAAI Conference on Artificial Intelligence.
[115] Botea, A., & Braghin, S. (2015). Contingent versus Deterministic Plans in Multi-Modal Journey Planning. In Proc. of the International Conference on Automated Planning and Scheduling(ICAPS), pp. 268–272.
[116] Chrpa, L., Vallati, M., & McCluskey, T. L. (2015). On the Online Generation of Effective Macro-Operators. In Proc. of International Joint Conference on Artificial Intelligence (IJCAI).
[117] Chrpa, L., & Siddiqui, F. H. (2015). Exploiting Block Deordering for Improving Planners Efficiency. In Proc. of International Joint Conference on Artificial Intelligence (IJCAI).
[118] Settles, B. (2012). Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers.
[119] Harman, H., & Simoens, P. (2020). Learning Symbolic Action Definitions from Unlabelled Image Pairs. In 2020 The 4th International Conference on Advances in Artificial Intelligence, pp. 72–78.
[120] Li, J., Luong, M.-T., & Jurafsky, D. (2015). A Hierarchical Neural Autoencoder for Paragraphs and Documents. In Proc. of the Annual Meeting of the Association for Computational Linguistics.
[121] Deng, L., Seltzer, M. L., Yu, D., Acero, A., Mohamed, A.-r., & Hinton, G. E. (2010). Binary Coding of Speech Spectrograms using a Deep Auto-Encoder. In Interspeech, pp. 1692–1695. Citeseer.
[122] Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT press.
[123] Nix, D. A., & Weigend, A. S. (1994). Estimating the Mean and Variance of the Target Probability Distribution. In Proceedings of the IEEE International Conference on Neural Networks (ICNN'94), Vol. 1, pp. 55–60. IEEE.
[124] van den Oord, A., Vinyals, O., et al. (2017). Neural Discrete Representation Learning. In Advances in Neural Information Processing Systems.
[125] Vahdat, A., Macready, W. G., Bian, Z., & Khoshaman, A. (2018b). DVAE++: Discrete Variational Autoencoders with Overlapping Transformations. CoRR, abs/1802.04920.
[126] Vahdat, A., Andriyash, E., & Macready, W. G. (2018a). DVAE#: Discrete variational autoencoders with relaxed Boltzmann priors. In Advances in Neural Information Processing Systems.
[127] Koul, A., Fern, A., & Greydanus, S. (2019). Learning Finite State Representations of Recurrent Policy Networks. In Proc. of the International Conference on Learning Representations.
[128] Bengio, Y., Léonard, N., & Courville, A. C. (2013). Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. CoRR, abs/1308.3432.
[129] Gumbel, E. J., & Lieblein, J. (1954). Statistical Theory of Extreme Values and Some Practical Applications: A Series of Lectures, Vol. 33. US Government Printing Office.
[130] Maddison, C. J., Tarlow, D., & Minka, T. (2014). A* sampling. In Advances in Neural Information Processing Systems, pp. 3086–3094.
[131] Dagum, P., & Chavez, R. M. (1993). Approximating Probabilistic Inference in Bayesian Belief Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 15(3), 246–255.
[132] Roth, D. (1996). On the Hardness of Approximate Reasoning. Artificial Intelligence, 82(1-2), 273–302.
[133] Dagum, P., & Luby, M. (1997). An Optimal Approximation Algorithm for Bayesian Inference. Artificial Intelligence, 93(1), 1–28.
[134] Teye, M., Azizpour, H., & Smith, K. (2018). Bayesian Uncertainty Estimation for Batch Normalized Deep Networks. In Proc. of the International Conference on Machine Learning, pp. 4907–4916. PMLR.