An Embarrassingly Simple Graph Heuristic Reveals Shortcut-Solvable Benchmarks for Sequential Recommendation
Haoyu Han$^{1}$, Li Ma$^{1}$, Hanbing Wang$^{1}$, Bingheng Li$^{1}$, Daochen Zha$^{2}$, Chun How Tan$^{2}$,
Huiji Gao$^{2}$, Xin Liu$^{2}$, Stephanie Moyerman$^{2}$, Sanjeev Katariya$^{2}$, Hui Liu$^{1}$, Jiliang Tang$^{1}$
$^{1}$Michigan State University, $^{2}$Airbnb, Inc.
{hanhaoy1, mali13, wangh137, libinghe, liuhui7, tangjili}@msu.edu
{daochen.zha, chunhow.tan, huiji.gao, xin.liu}@airbnb.com
{stephanie.moyerman, sanjeev.katariya}@airbnb.com
Abstract
Sequential recommendation is a central task in recommender systems, and recent research has increasingly shifted toward generative recommenders that leverage both sequential patterns and semantic item information. However, these methods are often evaluated on a small set of widely used benchmarks. This raises a natural question: do these benchmarks actually require the advanced modeling capabilities of modern generative recommenders? We conduct a benchmark audit using an intentionally simple graph heuristic: starting from only the last one or two interacted items, it retrieves candidates from a few-hop item-transition graph and ranks them with item-feature similarity. Surprisingly, despite its simplicity, this heuristic matches or outperforms a broad set of modern baselines on a variety of popular sequential recommendation benchmarks. For example, it achieves relative NDCG@10 improvements of 38.10% and 44.18% over the best competing baseline on the widely used Amazon Review Sports and CDs datasets, respectively.
We further show that this phenomenon is not merely an artifact of a particular heuristic, but reflects shortcut solvability in existing benchmarks. Specifically, we identify three shortcut structures that could make next-item prediction easier than expected: low-branching local transition structure, feature-smooth transitions, and limited dependence on long user histories. These shortcuts need not appear simultaneously. Depending on the dataset, even one or two strong shortcut signals can make simple local retrieval highly competitive, while weakening the relevant signals allows more sophisticated models to show clearer benefits. Our broader evaluation across 14 diverse datasets further shows that model rankings change substantially with dataset properties, while the simple graph heuristic remains competitive on 10 out of 14 datasets. These findings suggest that strong performance on several standard sequential recommendation benchmarks may not faithfully reflect whether recent methods achieve the advanced modeling capabilities they aim to demonstrate. Rather than treating datasets as interchangeable leaderboards, we argue for more careful dataset selection and dataset-level diagnostic analysis when using benchmarks to support claims about the benefits of new recommendation models.
Preprint.
Executive Summary: Sequential recommendation systems predict a user's next item interaction based on their past behavior, powering personalized suggestions in e-commerce, music, and entertainment platforms. As the field advances toward complex generative models that incorporate semantic item details like text descriptions, evaluations increasingly rely on a handful of popular benchmarks, such as Amazon Review datasets. This concentration raises a key question: do these benchmarks truly demand the sophisticated capabilities of modern methods, or can they be solved through simpler signals? The issue matters now because overstated performance on shortcut-friendly benchmarks can mislead research progress, waste resources on unnecessary complexity, and delay improvements in real-world recommendation accuracy and user satisfaction.
This document sets out to audit these benchmarks by testing whether a deliberately simple approach can match advanced models, and to identify underlying data patterns that enable such simplicity.
The authors developed a basic graph heuristic, called TGH, that builds a simple network of item-to-item transitions from user interaction histories in training data. At prediction time, it focuses only on a user's most recent one or two items, pulls a small set of candidate items from nearby connections in this network (up to three steps away), and ranks them using similarity in item features like titles or categories, with a slight boost for direct connections. No training, deep learning, or full user history analysis is involved. They compared TGH against a range of baselines—including traditional collaborative filtering, graph neural networks, transformer-based sequential models, and recent generative recommenders—across 14 diverse datasets from domains like reviews, movies, news, and fashion. Datasets spanned 700 to over a million users, with sequences from a few to dozens of interactions, using standard ranking metrics like NDCG@10 (a measure of how well the true next item ranks high in suggestions).
The core findings reveal that TGH performs surprisingly well despite its simplicity. First, it outperforms or matches the strongest baselines on the four dominant Amazon Review datasets, achieving about 38% and 44% relative gains in NDCG@10 on Sports and CDs categories compared to the best competitors. Second, across the full 14 datasets, TGH ranks first or second on 10 of them, succeeding where local patterns dominate. Third, the authors pinpoint three common data shortcuts explaining this: low-branching transition networks, where recent items connect to just 8-13 likely next options out of thousands (covering 5-9% of true targets directly and up to 60% within three steps); feature-smooth transitions, where connected items share similar attributes like genres or brands, making similarity-based ranking effective; and limited reliance on long histories, where the last one or two interactions alone capture most predictive signal, as shown by baselines using full sequences dropping only slightly (under 10% in many cases) when restricted to recent items. Fourth, TGH struggles on the remaining four datasets, like MovieLens and news feeds, where branches are denser (over 70 options per item) or long histories matter more, allowing advanced models to shine by 10-20% in ranking scores.
These results imply that many benchmarks reward basic local and similarity signals over the advanced sequential dynamics, semantic reasoning, or long-context modeling that generative recommenders claim to advance. High scores on these datasets may signal exploitability rather than true innovation, potentially inflating claims about model superiority and skewing investment toward overengineered solutions. This contrasts with expectations that benchmarks test complex user preferences, highlighting a risk of stalled progress in handling diverse, real-world scenarios like evolving tastes or sparse data. For stakeholders, it underscores efficiency gains: simple heuristics run faster and cheaper, reducing costs for deployment without sacrificing much performance on common cases.
To move forward, researchers should prioritize datasets that minimize these shortcuts—such as those with dense transitions, weak feature overlaps, or strong long-history needs—for claims about generative or sequential advances. Benchmark creators ought to include upfront diagnostics on transition branching, feature similarity, and history dependence to guide usage. Options include sticking with Amazon-style data for quick tests of basic signals or shifting to harder sets like MovieLens for validating complexity; the trade-off is that easier benchmarks speed iteration but risk false positives, while tougher ones demand more robust models at higher computational cost. Before firm decisions on adopting new recommenders, conduct pilots on custom data to verify gains beyond shortcuts.
While confident in the patterns across these 14 datasets—supported by consistent outperformance and statistical diagnostics—readers should note limitations: the analysis covers common but not all possible datasets, overlooks other potential shortcuts like popularity biases, and uses fixed settings for TGH that might underperform if tuned per dataset. Further validation on emerging benchmarks would strengthen these insights.
1. Introduction
Section Summary: Sequential recommendation systems aim to predict what users will interact with next based on their past behavior, evolving from simple filtering and chain models to advanced neural and generative approaches that heavily rely on item details like text and metadata. However, evaluations have become overly focused on Amazon Review datasets, raising doubts about whether high performance truly reflects sophisticated modeling or just exploits simple patterns in the data. Researchers developed a basic graph-based shortcut method that surprisingly beats many complex models on these benchmarks, revealing widespread easy-to-exploit structures like local item connections and feature similarities across various datasets, and urging better alignment between tests and claimed abilities.
Sequential recommendation has long been a fundamental problem in recommender systems, where the goal is to infer a user's next interaction from past behaviors [1, 2, 3]. Early studies mainly relied on collaborative filtering [4, 5] and Markov-chain models [6, 7], while later neural methods introduced recurrent networks [8, 9], graph-based recommenders [10, 11], and attention-based sequence encoders [12, 13]. Recently, however, the field has seen a rapid rise of generative recommendation methods [14, 15, 16]. These generative methods reformulate recommendation as generation or retrieval over discrete item identifiers, semantic IDs, or textual item representations [17, 18]. As a result, item-side information has become increasingly central: many recent models rely on item text, metadata, semantic embeddings, or LLM-generated representations to construct item codes, prompts, or prediction targets [19, 16, 20].
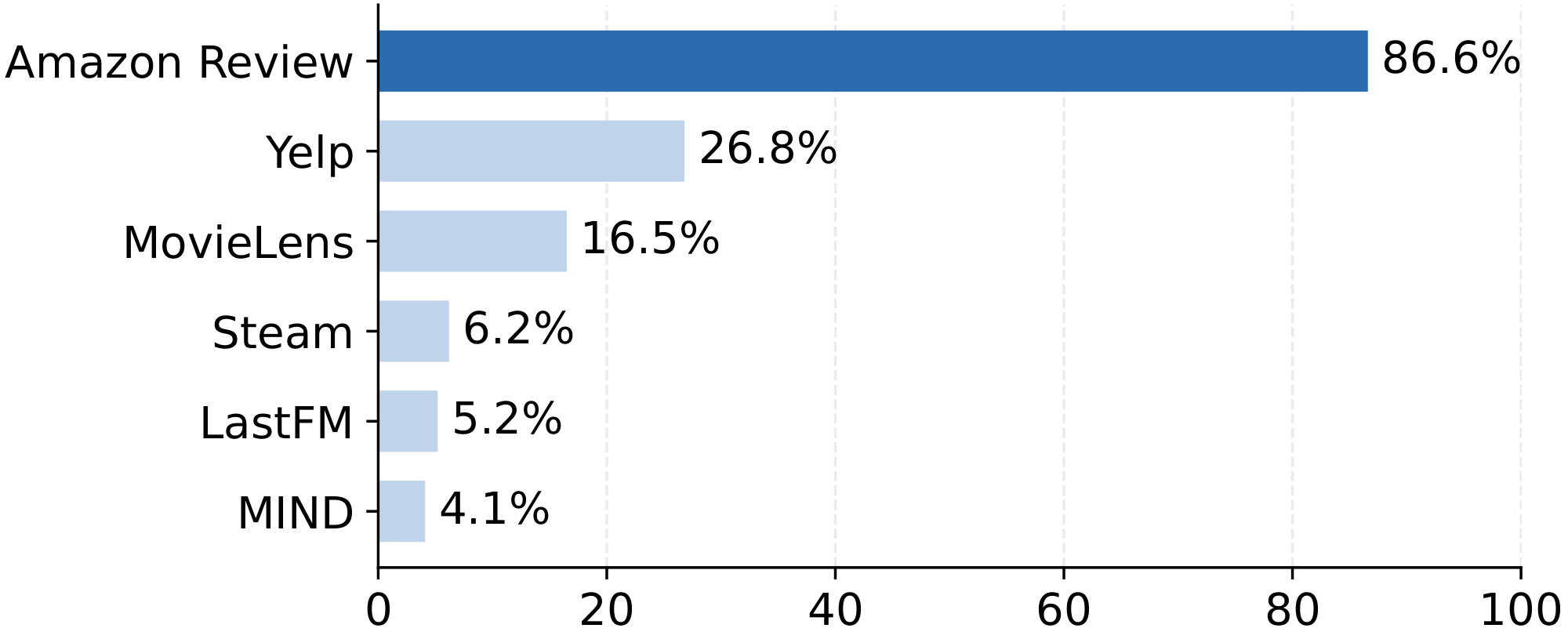
Along with this methodological shift, evaluation practice has also become strikingly concentrated. We analyze dataset usage across 94 recent generative-recommendation papers, detailed in Appendix A. As shown in Figure 1, Amazon Review datasets [21] dominate recent evaluations, while other datasets are used much less frequently. This dominance is understandable: Amazon Review datasets provide rich item-side metadata, such as titles, categories, brands, prices, reviews, and other textual fields, which can be naturally processed by text encoders or LLM-based generators [22, 23] for semantic and generative recommendation.
However, this concentration creates a critical question: what do these dominant benchmarks actually measure? High performance on these datasets is often taken as evidence that a model better captures user preferences, sequential dynamics, semantic structure, long-range dependencies, or generative reasoning. But this interpretation relies on an implicit assumption: the benchmark truly requires these advanced capabilities. If the same benchmark can be solved by a much simpler signal, then the comparison may be less informative than it appears. Strong performance may reflect dataset-specific shortcuts rather than genuinely advanced sequential modeling.
In this work, we uncover such shortcuts. We revisit widely used sequential recommendation benchmarks through an intentionally simple graph heuristic. Given only the training sequences, we construct an item-transition graph from observed item-to-item transitions. At test time, the heuristic looks only at the user's last one or two interacted items, retrieves candidates from their few-hop neighborhoods in the transition graph, and ranks them by item-feature similarity with a small direct-edge bonus. It has no deep sequence encoder, no generative objective, no learned user representations, and no training, making it simple and computationally efficient.
Despite its simplicity, this heuristic outperforms a broad set of strong baselines on the Amazon Review benchmarks, including traditional sequential models, graph-based recommenders, transformer-based recommenders, and recent generative recommenders. This result suggests that strong performance on these datasets may be achievable through much simpler signals than expected. Therefore, relying only on these datasets may not faithfully reflect the advanced modeling capabilities that recent methods aim to demonstrate. To understand why this happens, we identify three shortcut structures that potentially help explain this phenomenon: low-branching local transition structure, where recent items have small but useful transition neighborhoods; feature-smooth transitions, where transition-connected items are close in feature space; and limited dependence on long user histories, where the last one or two interactions already provide enough signal for next-item prediction.
We then ask whether this phenomenon is unique to Amazon Review benchmarks or reflects a broader issue in sequential recommendation evaluation. To answer this question, we evaluate the same baselines across 14 datasets with diverse transition structures, feature signals, and history dependencies. The simple heuristic remains competitive on 10 of them, suggesting that shortcut-solvable structures are widespread in existing benchmarks. At the same time, the heuristic is not universally superior: when the relevant shortcut signals are weakened, more sophisticated models can show clearer benefits. These results suggest two cautions for the community. For model designers, we encourage benchmark choices to be aligned with the capabilities being claimed. Methods that claim improved semantic understanding, generative modeling, or long-context reasoning should ideally be evaluated on datasets where simple local-transition, feature-similarity, or short-history shortcuts are insufficient. For dataset and benchmark creators, dataset releases would benefit from accompanying diagnostic analyses of transition structure, feature smoothness, history dependence, and other relevant properties. Such diagnostics can help clarify what a dataset actually measures and reduce the risk that future evaluations mistake shortcut-solvable performance for genuine modeling progress.
2. Related Work
Section Summary: Sequential recommendation systems predict the next item a user might like based on their past interactions, starting with simple methods like collaborative filtering and Markov chains, and evolving to advanced neural networks such as recurrent models, convolutions, self-attention, and graph-based approaches that map user-item connections. Recent developments incorporate semantic understanding from item details like descriptions and reviews, using generative models and large language models to create more sophisticated predictions. However, evaluations of these systems can be unreliable due to factors like data handling and baseline choices, prompting the authors to audit benchmarks and reveal that simple graph shortcuts can solve many popular datasets without needing complex techniques.
Sequential recommendation.
Sequential recommendation aims to predict the next item a user will interact with given a historical interaction sequence. Early approaches often combine collaborative filtering with sequential transition modeling ([6]). For example, matrix factorization ([24]) learns user and item representations from historical interactions, while Markov-chain-based methods model short-term item-to-item transitions [25]. Later neural methods introduce more expressive sequence encoders to capture user dynamics. GRU4Rec [8] uses recurrent neural networks to model session-level behavior, Caser [26] applies convolutional filters over recent interactions, SASRec [27] uses self-attention to capture item dependencies in user histories, and BERT4Rec [28] adopts bidirectional Transformer-style representation learning with masked item prediction. Beyond sequence encoders, graph-based recommendation methods exploit the structure of user-item or item-item interactions. LightGCN [10] performs simplified graph propagation on the user-item interaction graph and serves as a strong collaborative filtering baseline. For sequential and session-based recommendation, SR-GNN [11] represents each session as an item-transition graph, while GCE-GNN [29] further combines local session graphs with global item-transition information. These methods show that collaborative structure and item-transition patterns are highly informative for next-item prediction.
More recently, sequential recommendation has moved toward increasingly sophisticated semantic, generative, and LLM-based models [30, 31, 32]. This trend is partly driven by datasets with rich item-side information [21, 33], where item titles, descriptions, categories, and reviews can be used to construct semantic representations or natural-language prompts. Generative recommenders [34, 35] reformulate recommendation as item generation or generative retrieval, often by assigning items discrete semantic identifiers or token sequences. HSTU [36] studies large-scale sequential transduction for recommendation, TIGER [14] formulates recommendation as generative retrieval over semantic item IDs, LETTER [15] integrates semantic information and collaborative signals to learn item tokenizations, and CoFiRec [19] learns a coarse-to-fine tokenizer for generative recommendation. LLM-based recommenders [17, 37] further leverage language models to encode item content, user histories, or recommendation prompts. Although these models are motivated by advanced modeling capabilities such as semantic understanding, generative retrieval, and long-context sequence modeling, many of them are evaluated on a relatively small set of widely used sequential recommendation benchmarks. In contrast to proposing another sophisticated recommender, our work asks whether these benchmarks actually require such advanced modeling capacity.
Evaluation and benchmark auditing.
Offline evaluation is central to recommender system research, but prior work [38, 39, 40] has shown that empirical conclusions can be highly sensitive to preprocessing choices, data splitting, candidate sampling, hyperparameter tuning, and baseline selection. Several studies [41, 42, 43] further question whether complex neural recommenders always provide genuine progress over strong and well-tuned simpler baselines. Our work follows this benchmark-auditing perspective, but studies a different failure mode: shortcut solvability in sequential recommendation benchmarks. Prior critiques mainly examine whether evaluation protocols are fair and whether proposed models are compared against sufficiently strong baselines. In contrast, we ask what signals the benchmarks themselves reward. We show that several widely used sequential recommendation datasets can be largely solved by an embarrassingly simple graph heuristic.
3. Problem Setup and Diagnostic Heuristic
Section Summary: This section outlines the challenge of sequential recommendation, where systems predict a user's next item interaction based on their chronological history of past engagements with items like movies or products. To diagnose the predictive strength of basic signals in this task, the authors propose a straightforward tool called the Transition-Graph Heuristic (TGH), which builds a graph tracking common item transitions from user histories and scores potential next items using their similarity to recent ones plus a small boost for frequent direct follow-ups, all without complex training. Experiments evaluate TGH's two simple variants against established recommendation methods on standard benchmarks, using metrics like recall and ranking quality to measure performance.
In this section, we introduce the sequential recommendation and our graph-based diagnostic heuristic.
3.1 Problem Formulation
Let $\mathcal{U}$ and $\mathcal{I}$ denote the user and item sets, respectively. Each user $u \in \mathcal{U}$ has a chronological interaction sequence
$ S_u = (i^u_1, i^u_2, \ldots, i^u_{T_u}), $
where $i^u_t \in \mathcal{I}$ is the item interacted with at time $t$. Given a prefix sequence
$ S^u_{1:t} = (i^u_1, \ldots, i^u_t), $
the goal of sequential recommendation is to rank candidate items so that the next item $i^u_{t+1}$ appears near the top.
3.2 A Simple Graph-Heuristic Probe
We use an intentionally simple graph heuristic as a diagnostic probe. The heuristic is motivated by two basic sources of recommendation signals: collaborative structure from user-item interaction sequences, and semantic similarity from item-side features. Rather than proposing a new recommendation architecture, we use this heuristic to assess how much predictive power these simple signals provide on widely used benchmarks.
Given the training sequences, we construct a directed item transition graph $G=(\mathcal{I}, \mathcal{E})$, where each node is an item $i\in \mathcal{I}$. A directed edge $(i, j) \in \mathcal{E}$ is added if item $j$ appears immediately after item $i$ in a training sequence. Let $N_{i, j}$ denote the number of observed transitions from item $i$ to $j$. We assign each edge a normalized weight
$ w_{i, j}
\frac{\log(1+N_{i, j})} {\max_{j': N_{i, j'}>0} \log(1+N_{i, j'})}, $
so that outgoing normalized edge weights from each item are scaled to $[0, 1]$.
At inference time, given a prefix sequence $S^u_{1:t}$, the heuristic uses either the last item $i^u_t$ or the last two items $(i^u_{t-1}, i^u_t)$ as anchors. For each anchor item $s$, it retrieves candidates from a few-hop neighborhood of $s$ in the transition graph. Within each hop, candidates are ranked mainly by feature similarity to the anchor, with a small edge-weight bonus for direct $1$-hop neighbors. This bonus reflects the intuition that larger edge weights correspond to more frequent transitions and thus higher transition likelihood.
Specifically, each item $i$ has an L2-normalized feature embedding $\hat{\mathbf{e}}_i$. For a candidate item $c$ retrieved from the $\ell$-hop neighborhood of anchor $s$, we compute
$ \begin{align} \mathrm{score}_s(c)
\hat{\mathbf{e}}_s^\top \hat{\mathbf{e}}c + \alpha \cdot \mathbf{1}[\ell=1] \cdot w{s, c}, \end{align}\tag{1} $
where $\alpha$ is a small edge-weight bonus weight. The first term is the cosine similarity between the anchor and the candidate. The second term is a direct-transition bonus based on the normalized edge weight, and is applied only to $1$-hop candidates. For candidates from hops larger than one, the score reduces to feature similarity.
For each anchor and each hop, we keep only a small number of top-scoring candidates. If the same item is retrieved from multiple anchors or hops, we keep its highest score. The final recommendation list is obtained by sorting all retained candidates by their scores.
We refer to this heuristic as $\textsc{TGH}$, short for Transition-Graph Heuristic. It is deliberately simple: it uses only recent anchor items, local transition-graph neighborhoods, and item-feature similarity, without a sequence encoder, generative objective, representation learning, or training. As a result, it is substantially more efficient than existing learnable sequential recommenders, which typically require extensive training.
3.3 Experimental Setting
Evaluation protocol.
We follow the standard next-item recommendation protocol [27, 14]. For each user, interactions are ordered chronologically, and models are evaluated by ranking the held-out next item given a prefix sequence. We report top- $K$ ranking metrics, including Recall@K and NDCG@K, where $K \in [1, 5, 10]$.
Text representation.
To ensure a fair comparison among methods that use item-side textual information, we use a shared text encoder for all of them. Specifically, we encode item text with google/flan-t5-xl [22], following [44]. The input text is constructed from the available metadata in each dataset, such as item title, category, description, or other textual fields.
Graph-heuristic variants.
We evaluate two short-context variants of $\textsc{TGH}$. Although the retrieval budgets and hyperparameters could be tuned on the validation set, we fix them across all datasets to keep the heuristic deliberately simple and ensure that its performance is not driven by dataset-specific configuration choices.
In the $\textsc{TGH-1}$ setting, $\textsc{TGH}$ uses only the last interacted item $i_t^u$ as the anchor. It considers the anchor's $1$-, $2$-, and $3$-hop neighborhoods in the transition graph, and selects the top $(7, 2, 1)$ candidates from these hops according to the scoring function in Equation 1, respectively.
In the $\textsc{TGH-2}$ setting, $\textsc{TGH}$ uses both the last item $i_t^u$ and the second-last item $i_{t-1}^u$ as anchors. For the last item, it selects the top $(5, 1)$ candidates from its $1$- and $2$-hop neighborhoods. For the second-to-last item, it selects the top $(3, 1)$ candidates from its $1$- and $2$-hop neighborhoods.
We also set the edge-bonus weight to $\alpha=0.5$ for all datasets.[^1]
[^1]: The code is available at https://github.com/haoyuhan1/GraphRec/.
Compared methods.
We compare the heuristic with representative methods from multiple recommendation families, including graph-based recommendation methods such as LightGCN [10] and SR-GNN [11], conventional sequential recommenders such as SASRec [27], and recent generative recommendation methods such as HSTU [36], TIGER [14], LETTER [15], and CoFiRec [19].
4. Experiments
Section Summary: The experiments evaluate a simple graph-based recommendation method called TGH on popular Amazon product review datasets for categories like beauty, sports, toys, and CDs, where it surprisingly outperforms more complex models in retrieving and ranking relevant next items, achieving up to 44% better scores on some benchmarks. This success highlights that these datasets rely on straightforward patterns in user interactions, raising doubts about whether advanced AI techniques are truly needed for good performance here. To uncover why, the study analyzes data statistics showing that recent purchases often connect to a small, local set of likely next items, and tests basic baselines that confirm item similarities and transitions alone can capture much of the predictive signal.
4.1 The Graph Heuristic is Surprisingly Strong on Amazon Review Benchmarks
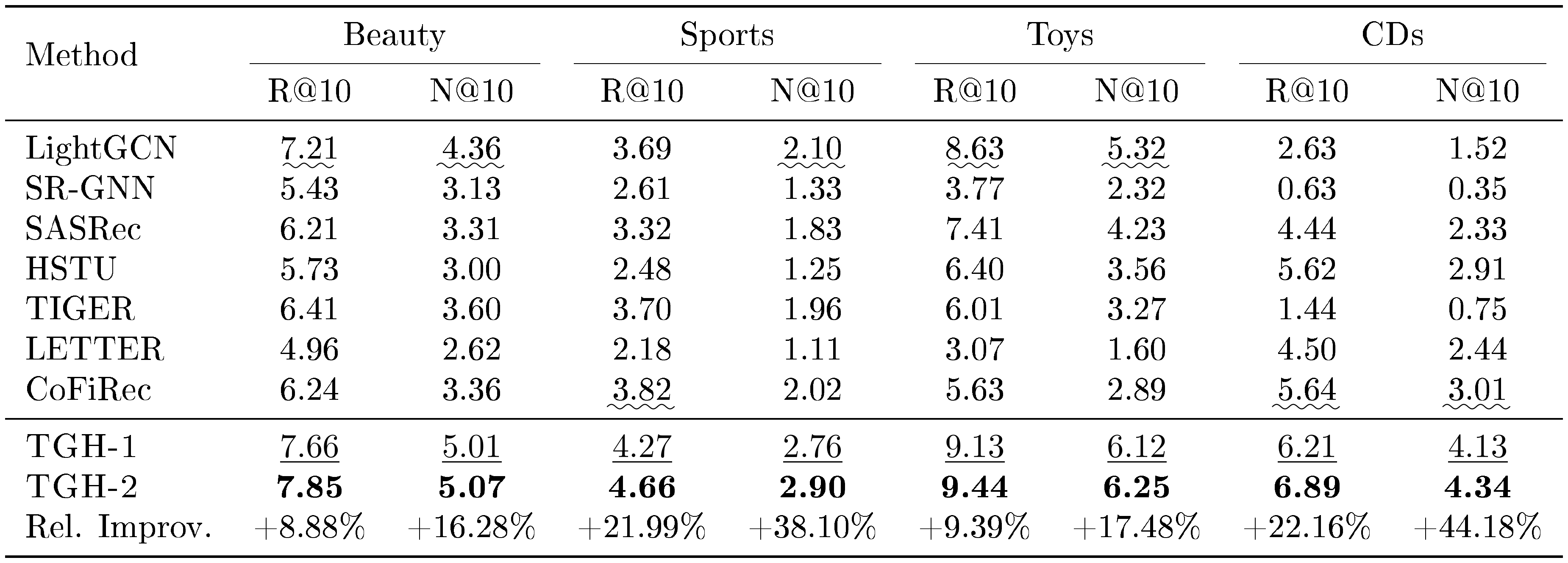
::: {caption="Table 1: Main results on Amazon Review benchmarks. We report Recall@10 and NDCG@10. All results are percentages. Best results are in bold, second-best results are $\underline{underlined}$, and the best baseline is denoted by $\underline{wavy underline}$."}
:::
We first evaluate on the most widely used Amazon Review benchmarks [21], including Beauty, Sports, Toys and CDs. Table 1 reports Recall@10 (R@10) and NDCG@10 (N@10); full results with additional metrics are provided in Appendix E. Despite its simplicity, $\textsc{TGH}$ is highly competitive across all four Amazon datasets. In particular, it achieves relative NDCG@10 improvements of 38.10% and 44.18% over the best competing baselines on Sports and CDs, respectively.
These results are surprising because $\textsc{TGH}$ retrieves only a small number of candidates from local transition-graph neighborhoods and ranks them with item-feature similarity, yet still achieves strong performance. This suggests that the Amazon Review benchmarks contain simple predictive signals that can be exploited without advanced sequential or generative modeling. Considering that Amazon Review datasets are used in 86.6% of the surveyed generative recommendation papers, as shown in Figure 1, this finding raises concerns about whether relying heavily on performance on these benchmarks provides sufficient evidence for the claimed benefits of modern recommendation models.
4.2 What Signals Make the Heuristic Work?
Although $\textsc{TGH}$ achieves surprisingly strong performance on Amazon Review benchmarks, it remains unclear why such a simple heuristic can outperform much more sophisticated models. To understand the underlying signals, we analyze dataset statistics and introduce a set of diagnostic baselines.
Dataset statistics.
We consider both general dataset statistics and item-transition graph statistics. The general statistics include the number of users, the number of items, and the average sequence length (Avg. Seq. Len.). For the item-transition graph constructed from the training sequences, we report the average out-degree (Avg. Out-Deg.), the average edge weight (Avg. Edge W.), and the coverage of the ground-truth item within the 1-, 2-, and 3-hop neighborhoods of the last interacted item (Cov@1, Cov@2, and Cov@3).
Diagnostic baselines.
We introduce three controlled baselines to isolate simple signals in the data. First, $\textsc{ID-Last}$ learns a trainable embedding for each item ID and uses only the last interacted item to predict the next item. This baseline measures how much signal can be captured from the ID-based transitions. Second, $\textsc{Sem-NN}$ is a training-free semantic nearest-neighbor baseline. Given the last interacted item, $\textsc{Sem-NN}$ ranks all candidate items by cosine similarity between their text embeddings and the text embedding of the last item. This baseline tests whether item-feature similarity alone is predictive for next-item retrieval. Finally, $\textsc{ID+Sem}$ combines the scores of $\textsc{ID-Last}$ and $\textsc{Sem-NN}$ through late fusion, where the final score is the sum of the ID-based score and the semantic-similarity score. This baseline tests whether ID-based transition signals and item-feature similarity provide complementary information. We further conduct a history-window ablation on SASRec and HSTU. Instead of using the full interaction sequence, we restrict the maximum history window to $1$, so that each prediction can only condition on the immediately previous item. We refer to these variants as $\textsc{Last-1}$.
: Table 2: Statistics of the item-transition graphs on Amazon Review benchmarks. Coverage@k denotes the percentage of test targets reachable within $k$ hops from the last interacted item.
| Dataset | #Users | #Items | #Edges | Avg. Seq. Len. | Avg. Out-Deg. | Avg. Edge W. | Cov@1 | Cov@2 | Cov@3 |
|---|---|---|---|---|---|---|---|---|---|
| Beauty | 22, 363 | 12, 101 | 114, 582 | 8.15 | 9.47 | 1.15 | 8.61% | 24.85% | 56.64% |
| Sports | 35, 598 | 18, 357 | 180, 610 | 7.96 | 9.84 | 1.05 | 5.13% | 20.26% | 58.16% |
| Toys | 19, 412 | 11, 924 | 102, 268 | 7.97 | 8.58 | 1.07 | 8.06% | 20.16% | 47.16% |
| CDs | 75, 258 | 64, 443 | 810, 347 | 14.58 | 12.57 | 1.08 | 9.07% | 28.06% | 61.44% |
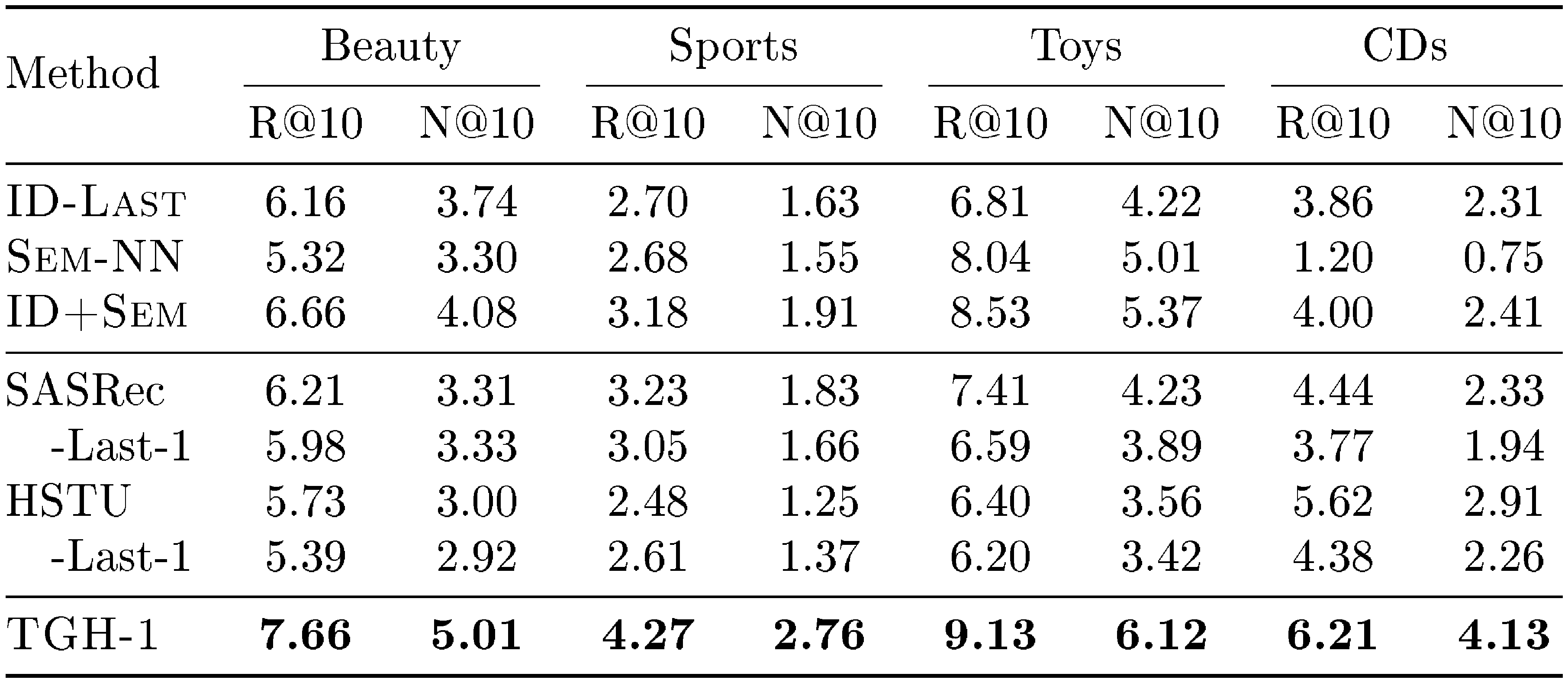
::: {caption="Table 3: Results of diagnostic baselines on Amazon review benchmarks."}
:::
The item-transition graph statistics are shown in Table 2, and the performance of the diagnostic baselines is shown in Table 3. These results lead to the following key findings.
Finding 1: many targets are reachable through low-branching local transitions.
As shown in Table 2, the Amazon Review transition graphs have relatively small average out-degrees compared with the total number of items. For example, the average out-degree is only $9.47$ for Beauty and $12.57$ for CDs, while the datasets contain thousands to tens of thousands of items. Meanwhile, the direct $1$-hop neighbors already cover a non-trivial fraction of test targets, with Cov@1 of $8.61%$ and $9.07%$ on Beauty and CDs, respectively. This indicates that recent items provide a small but informative local candidate space. After expanding to a few hops, the target coverage increases substantially while the search remains restricted to local transition neighborhoods. We refer to this shortcut structure as low-branching local transition structure: the transition graph narrows next-item prediction from ranking over the full item universe to selecting among a small set of locally plausible candidates.
Finding 2: item features provide a useful ranking signal.
As shown in Table 3, $\textsc{Sem-NN}$ retrieves from the full item set using only feature similarity, yet already achieves strong performance on Beauty, Sports, and Toys datasets. This suggests that items adjacent in user sequences often have similar item features on these datasets, making feature similarity a useful signal for next-item prediction. We refer to this shortcut structure as feature-smooth transitions. However, this property does not hold equally across all Amazon Review datasets. On CDs, $\textsc{Sem-NN}$ performs much worse, indicating that global feature similarity alone may be insufficient.
Finding 3: many Amazon Review benchmarks require little long-context information.
The strong performance of $\textsc{TGH-1}$ suggests that the most recent interaction already contains much of the useful signal. This observation is also supported by $\textsc{ID-Last}$, which uses only the last item ID to predict the next item and still achieves strong performance on several Amazon Review datasets. To further examine whether long-range history is necessary, we conduct a history-window ablation on SASRec and HSTU. Specifically, we compare the full-history models with their $\textsc{Last-1}$ variants, where each prediction only conditions on the immediately previous item. As shown in Table 3, using only a history window of size $1$ achieves performance close to the full-history setting on Beauty, Sports, and Toys. This suggests that long-range sequential information may not be essential for strong performance on these benchmarks. We refer to this shortcut structure as limited dependence on long user histories: the benchmark can be largely solved using very recent interactions, without requiring models to capture long-range user preference or complex sequential dynamics.
Overall, these analyses suggest that the three shortcut structures could serve as useful diagnostic axes for interpreting the strong performance of $\textsc{TGH}$ on Amazon Review datasets. While they are not meant to be an exhaustive explanation of benchmark behavior, they help characterize several simple signals that can make a dataset shortcut-solvable. The heuristic can benefit from low-branching local transition structure, feature-smooth transitions, and limited dependence on long user histories, but these shortcuts need not appear simultaneously. For example, CDs shows a weak global feature-similarity signal, as $\textsc{Sem-NN}$ performs poorly when retrieving from the full item set. Yet $\textsc{TGH}$ remains effective, suggesting that the transition graph first restricts retrieval to a local candidate set, where feature similarity becomes more useful for ranking. This example illustrates that shortcut-solvability may arise from the interaction of multiple simple signals, rather than requiring all identified shortcut structures to be present at once.
4.3 Beyond Amazon Review: Shortcut Solvability Across Diverse Benchmarks
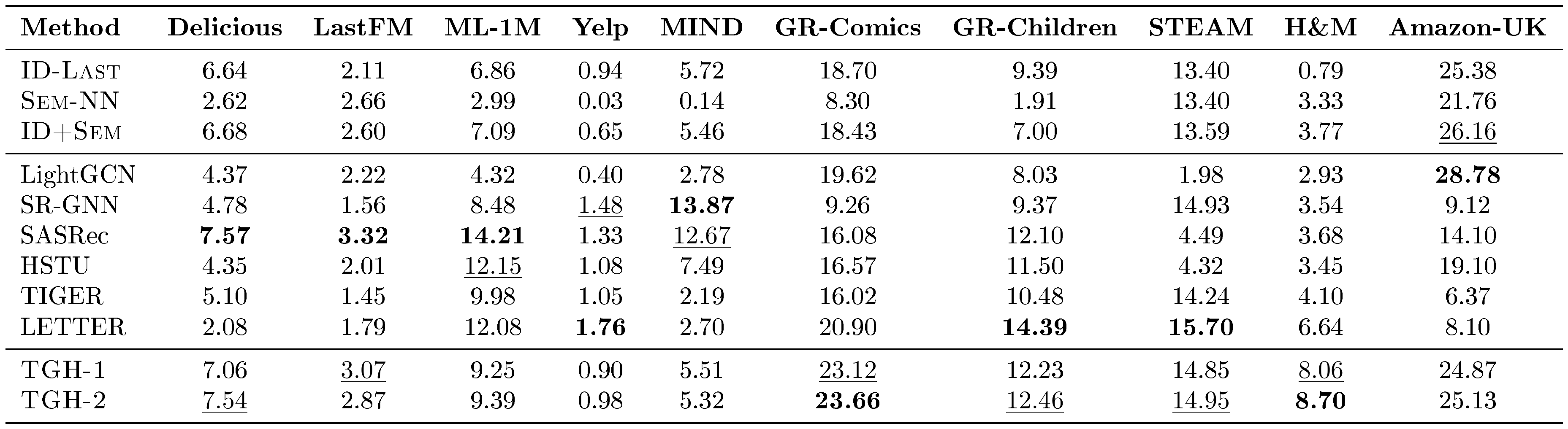
The previous subsection shows that $\textsc{TGH}$ performs surprisingly well on Amazon Review benchmarks and identifies three potential dataset shortcuts that could help explain this behavior. We next ask whether this phenomenon is specific to Amazon Review datasets, or whether similar shortcut-solvable patterns also appear in other sequential recommendation benchmarks with item-side information. To this end, we evaluate on a broader collection of datasets, including Delicious [45], LastFM [45], MovieLens-1M (ML-1M) [46], Yelp [47], MIND [48], Goodreads-Comics (GR-Comics) [49], Goodreads-Children (GR-Children) [49], STEAM [27], H&M [50], and Amazon-M2-UK (Amazon-UK) [33]. The dataset statistics are shown in Table 4. Compared with the Amazon Review datasets, these benchmarks cover more diverse data regimes, with substantially different sequence lengths, transition-graph densities, and average out-degrees. For example, some datasets have much longer user histories, while others have much larger local transition neighborhoods. This diversity allows us to examine whether the proposed shortcuts help interpret model behavior beyond the Amazon Review setting. We use the same baseline suite as in the Amazon Review experiments, except for CoFiRec, which is specifically designed for Amazon Review datasets.
Table 5 reports NDCG@10 on the broader set of datasets; additional metrics are provided in Appendix F. Overall, $\textsc{TGH}$ remains competitive beyond Amazon Review benchmarks, achieving the best or second-best performance on 6 out of 10 datasets and comparable performance on Amazon-M2-UK. However, $\textsc{TGH}$ is not universally superior. On MovieLens-1M, Yelp, and MIND, it underperforms traditional and generative sequential recommenders. We next use the shortcut structures identified from the Amazon Review analysis to interpret both the success and failure cases of $\textsc{TGH}$ across these broader datasets.
Shortcut 1: low-branching local transition structure.
As shown in Table 4, Delicious, LastFM, and Amazon-M2-UK have average out-degrees below $10$, indicating low-branching local transition graphs. On these datasets, the local neighborhoods of recent items provide compact candidate spaces, and $\textsc{TGH}$ achieves strong performance. In contrast, MovieLens-1M has a much larger average out-degree of $78.71$. Although many targets may still be reachable within a few hops, the local candidate space is much larger, making fixed-budget local retrieval less effective. This helps explain why $\textsc{TGH}$ underperforms stronger sequential recommenders on MovieLens-1M.
Shortcut 2: feature-smooth transitions.
Some datasets remain favorable to $\textsc{TGH}$ even when their transition graphs are not low-branching. For example, Steam and H&M have large average out-degrees of $186.54$ and $116.81$, respectively, yet $\textsc{TGH}$ still performs well. We attribute this to feature-smooth transitions: adjacent items in user sequences tend to have similar item features. This is supported by the strong performance of $\textsc{Sem-NN}$, which retrieves items using only semantic similarity. In contrast, Yelp has a much smaller average out-degree of $10.96$, but $\textsc{TGH}$ still underperforms the baselines. This suggests that low branching alone is not sufficient. On Yelp, adjacent items are less feature-smooth, as indicated by the weak performance of $\textsc{Sem-NN}$. Therefore, even though the local candidate space is relatively small, feature similarity cannot reliably rank the correct next item.
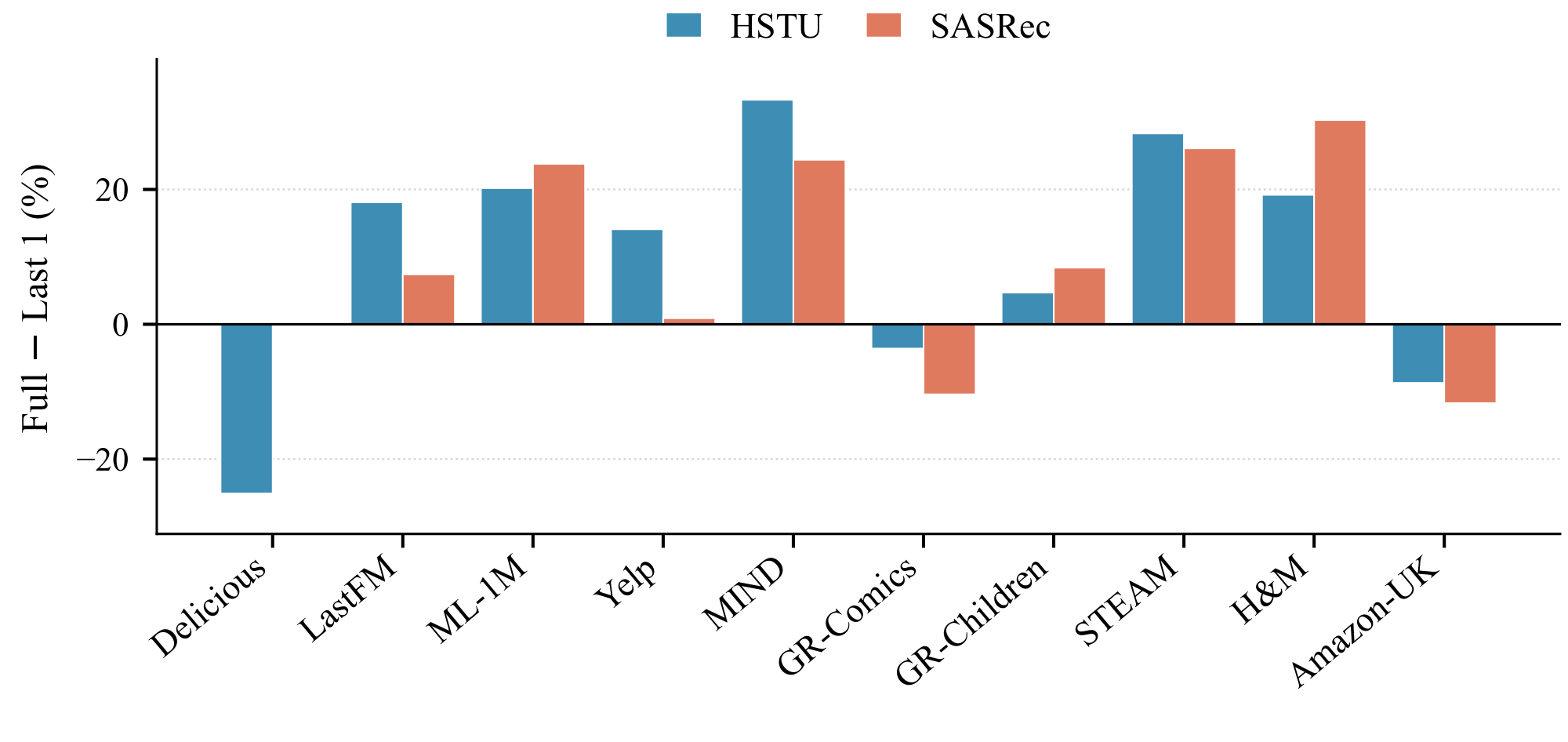
Shortcut 3: limited dependence on long user histories.
To test whether each dataset requires long-range user-history information, we compare SASRec and HSTU under two settings: the full-sequence setting and the $\textsc{Last-1}$ setting, where each prediction only uses the immediately previous item. Figure 2 reports the relative performance gap between these two settings. On MovieLens-1M and MIND, the full-sequence models achieve much stronger performance than their $\textsc{Last-1}$ variants, suggesting that these datasets rely more heavily on long-range user histories. Since $\textsc{TGH}$ only uses the last one or two items as anchors, it cannot capture this long-context signal, which helps explain its weaker performance on these datasets.
: Table 4: Statistics of the item-transition graphs on the ten additional benchmarks. Coverage@k denotes the percentage of test targets reachable within $k$ hops from the last interacted item.
| Dataset | #Users | #Items | #Edges | Avg. Seq. Len. | Avg. Out-Deg. | Avg. Edge W. | Cov@1 | Cov@2 | Cov@3 |
|---|---|---|---|---|---|---|---|---|---|
| Delicious | 718 | 1, 200 | 4, 016 | 9.13 | 3.35 | 1.1 | 9.33 | 11.98 | 18.38 |
| LastFM | 1, 090 | 3, 646 | 30, 372 | 34.02 | 8.33 | 1.11 | 5.69 | 21.93 | 53.58 |
| MovieLens-1M | 6, 040 | 3, 416 | 268, 867 | 74.06 | 78.71 | 1.6 | 48.11 | 96.59 | 99.93 |
| Yelp | 30, 431 | 20, 033 | 219, 632 | 10.4 | 10.96 | 1.02 | 5.75 | 27.86 | 73.57 |
| MIND | 48, 577 | 39, 757 | 824, 397 | 28.16 | 20.74 | 1.48 | 40.13 | 89.19 | 96.73 |
| Goodreads-Comics | 89, 186 | 48, 623 | 1, 282, 693 | 33.78 | 26.38 | 2.14 | 49.67 | 84.36 | 97.25 |
| Goodreads-Children | 163, 143 | 55, 221 | 1, 622, 817 | 24.26 | 29.39 | 2.14 | 57.04 | 88.57 | 98.13 |
| STEAM | 334, 728 | 13, 047 | 1, 524, 022 | 12.59 | 116.81 | 2.11 | 59.44 | 97.97 | 99.8 |
| H&M | 1, 077, 045 | 104, 468 | 19, 487, 762 | 26.01 | 186.54 | 1.27 | 34.32 | 95.28 | 99.72 |
| Amazon-M2-UK | 1, 182, 181 | 494, 409 | 1, 500, 196 | 5.12 | 3.03 | 1.67 | 30.35 | 43.69 | 52.94 |
::: {caption="Table 5: NDCG@10 (%) across datasets. Bold: best per dataset; $\underline{underlined}$ : second-best."}
:::
Overall, across the four Amazon Review benchmarks and ten additional datasets, $\textsc{TGH}$ achieves competitive performance, ranking best or second-best on 10 out of 14 datasets. Its successes and failures can be potentially interpreted through the three shortcut structures identified above. Importantly, this does not imply that modern sequential or generative recommenders are ineffective. Rather, it shows that some benchmarks allow simple shortcuts to dominate evaluation, while other datasets expose prediction behaviors that $\textsc{TGH}$ cannot capture. We therefore next examine prediction-level differences between $\textsc{TGH}$ and learned recommenders to better understand what advanced models may capture beyond the heuristic.
4.4 Prediction-Level Differences Between the Heuristic and Learned Models
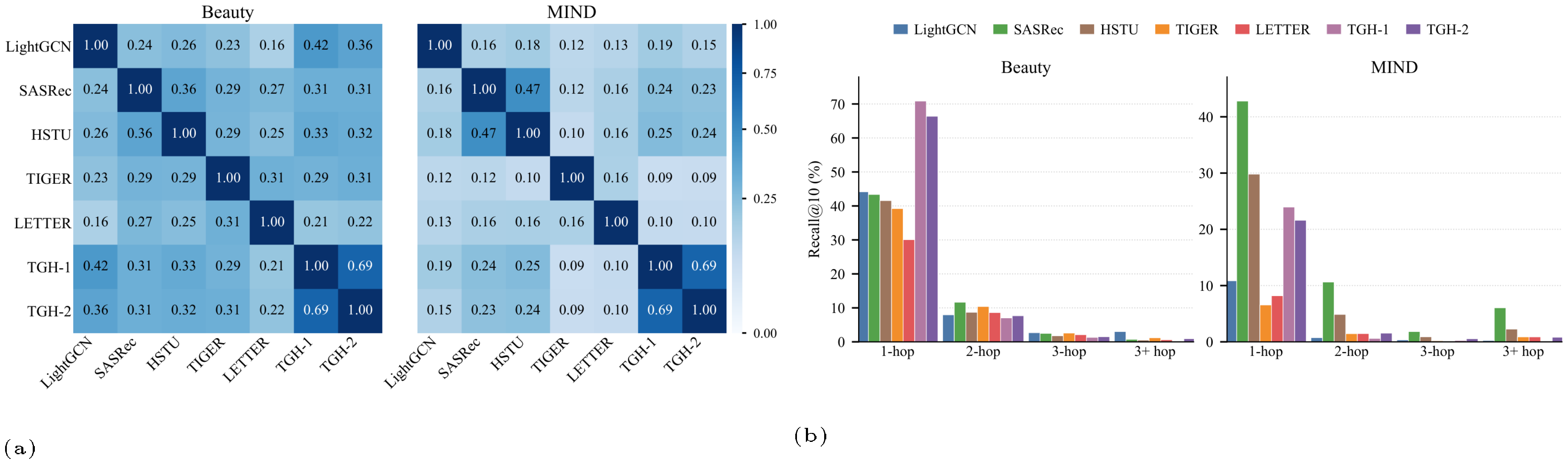
The previous results show that $\textsc{TGH}$ can be highly competitive, but this does not imply that learned sequential or generative recommenders are ineffective. To better understand the difference between $\textsc{TGH}$ and learned models, we further analyze their prediction patterns.
We first measure the Jaccard similarity between the correct-prediction sets of different methods. Figure 3(a) shows the overlap analysis on Beauty and MIND. The overlap between $\textsc{TGH}$ and learned sequential recommenders is relatively low, indicating that they often succeed on different test instances. This suggests that, although $\textsc{TGH}$ can achieve competitive overall performance by exploiting benchmark shortcuts, learned models capture additional signals that are not fully covered by the heuristic.
We further evaluate Recall@10 grouped by the hop distance between the last interacted item and the ground-truth item in the transition graph. As shown in Figure 3(b), $\textsc{TGH}$ performs best when the ground-truth item is within a small number of hops, which is expected given its local retrieval mechanism. In contrast, learned sequential recommenders achieve stronger performance on harder cases, especially when the ground-truth item is beyond $3$ hops. This indicates that learned models can capture prediction patterns beyond simple local retrieval, such as longer-range sequential dependencies or more complex user-behavior signals.
Overall, this analysis shows that the issue is not that current baselines are weak. Rather, many widely used benchmarks contain shortcuts that can be solved by simple heuristics, so aggregating the overall performance on these datasets alone may be unreliable evidence for the advantages of new methods. For model designers, this calls for evaluation on datasets that truly test the claimed capability, such as settings where local-transition retrieval, feature similarity, or short-history prediction is insufficient. For benchmark designers, this calls for reporting dataset-level diagnostics, such as transition branching, feature-smoothness, and history dependence, to make clear what signals the benchmark rewards.
5. Conclusion
Section Summary: Researchers have found that a straightforward method using transition graphs can match the performance of advanced generative recommendation systems on many popular benchmarks, including Amazon review datasets, suggesting that success often stems from simple patterns rather than sophisticated modeling. By analyzing datasets, they pinpoint three key shortcuts—limited branching in local patterns, smooth feature changes, and reliance on short user histories—that explain this, with the simple approach working well on 10 out of 14 datasets, though advanced models shine when these shortcuts are reduced. The study urges creators to pick datasets that truly test their models' intended strengths and for benchmark developers to include detailed checks to reveal what easy signals are being rewarded, treating tests as tools for deeper understanding rather than just rankings.
In this work, we revisit the evaluation practice of sequential recommendation, especially in the context of recent generative recommenders. We show that an intentionally simple transition-graph heuristic can achieve competitive performance on many widely used benchmarks, including several Amazon Review datasets that dominate recent evaluations. This result suggests that strong benchmark performance may sometimes be driven by simple shortcut signals rather than advanced sequential or generative modeling ability.
Through dataset statistics, diagnostic baselines, and cross-dataset evaluation, we identify three shortcut structures that help explain this behavior: low-branching local transition structure, feature-smooth transitions, and limited dependence on long user histories. Across 14 datasets, the heuristic is competitive on 10, but it is not universally superior; when these shortcut signals are weakened, learned sequential and generative models can show clearer benefits.
Our findings highlight the need for more capability-aware evaluation. We encourage model designers to select datasets that directly test the capabilities their methods aim to improve, and benchmark designers to report dataset-level diagnostics that clarify what signals a benchmark rewards. Rather than treating benchmarks as interchangeable leaderboards, future work can use them as tools for understanding when and why different recommendation models succeed.
Appendix
Section Summary: This appendix details a collection of 94 research papers from 2022 to 2026 on generative recommendation methods, mostly from academic conferences and online archives like arXiv, with a notable surge in publications starting in 2024. It describes 14 common datasets used for testing, spanning areas like e-commerce, music, movies, news, and games, all preprocessed similarly to past studies by filtering low-activity users and keeping key text details such as titles and descriptions. Finally, it outlines several baseline methods for comparison, including simple item-matching techniques, graph-based models, and transformer systems that predict user preferences from interaction histories.
A. Details of Surveyed Papers
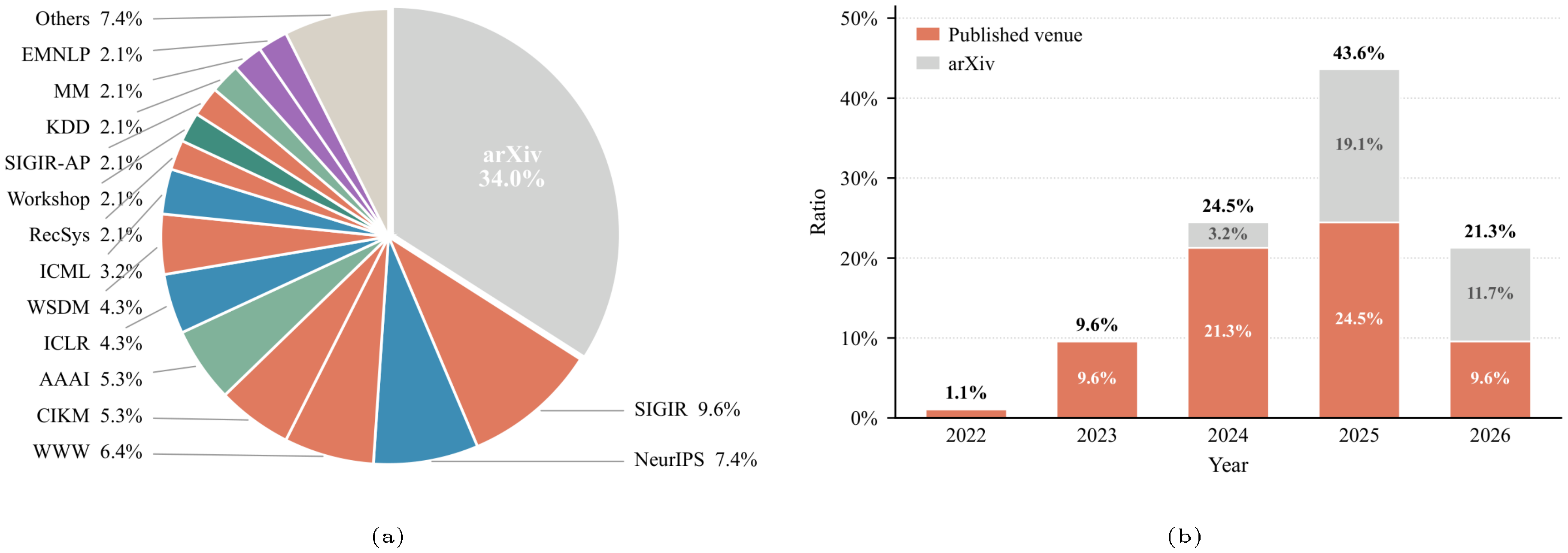
We collect 94 papers published between 2022 and 2026 that propose or evaluate generative recommendation methods; the full list of paper titles is provided in our code repository. The corpus statistics are summarized in Figure 4. These papers are gathered from major recommendation, information retrieval, machine learning, and data mining venues, as well as from arXiv. As shown in Figure 4a, arXiv preprints account for approximately $34.0%$ of the corpus, while the remaining papers are published in venues such as SIGIR, NeurIPS, WWW, CIKM, AAAI, ICLR, WSDM, ICML, and RecSys. Figure 4b further shows the rapid growth of generative recommendation research in recent years. The field expanded sharply after 2023: papers from 2024 account for $24.5%$ of the corpus, papers from 2025 account for $43.6%$, and papers from 2026 already account for $21.3%$, including preprints and accepted-but-not-yet-published works.
B. Datasets
We conduct experiments on 14 widely used recommendation datasets covering e-commerce, review, news, music, movie, and game recommendation scenarios. To ensure fair comparisons with prior work, each dataset is preprocessed following the protocols used in previous studies. In general, we construct user interaction sequences according to interaction timestamps.
Amazon Review benchmarks [21]. The Amazon Review benchmarks are category-specific product recommendation datasets constructed from user reviews and interaction histories. We use four subsets: Beauty, Sports, Toys, and CDs. Following TIGER [14], GRID [44], and ActionPiece [16], we filter out users with fewer than 5 interactions. For item textual information, we retain the title, price, brand, and categories fields.
Delicious [45]. Delicious is a social bookmarking dataset that captures user interactions with web resources and their associated tags. We filter out users and items with fewer than 5 interactions and retain the title and tags as textual fields.
LastFM [45] and MovieLens-1M (ML-1M) [46]. LastFM is a music recommendation dataset based on user–artist interactions, while ML-1M is a movie recommendation dataset based on user ratings. We follow the preprocessing settings used in TokenRec [51]. Specifically, we filter out users with fewer than 5 interactions and truncate the maximum sequence length to 100. We keep artist and tags for LastFM, and title and genres for ML-1M.
Yelp [47]. Yelp is a business review dataset that reflects users' preferences over local businesses such as restaurants and services. Following LETTER [15], we filter out users with fewer than 5 interactions and retain the title and description fields as item textual information.
MIND [48]. MIND is a news recommendation dataset built from user click histories over online news articles. We use the validation split of the MIND-small dataset as our experimental dataset, which contains approximately 50K users and six weeks of click histories. Following [48], we retain the news title as the item textual feature and filter out users with fewer than 3 interactions.
GoodReads [49]. GoodReads is a book recommendation dataset constructed from users' reading and review histories. We use two subsets [52]: GoodReads-Children and GoodReads-Comics. We filter out users with fewer than 3 interactions and retain the title, authors, publisher, year, and description fields as textual information.
Steam [27]. Steam is a video game recommendation dataset based on user interactions with games on the Steam platform. We follow the commonly used preprocessing strategy in [27] and filter out users with fewer than 3 interactions. We retain the title, developer, publisher, and tags fields as textual information.
Amazon-M2-UK [33]. Amazon-M2 is a multi-market e-commerce dataset designed for recommendation across different regional Amazon marketplaces. We use the UK locale from the Amazon-M2 dataset and filter out users with fewer than 3 interactions. We retain the title, brand, categories, and description fields as textual information.
C. Baselines
We compare our method with the following representative baselines:
- $\textsc{ID-Last}$ is a pure item-to-item collaborative filtering method trained with the BPR loss. It predicts the next item based on the last interacted item.
- $\textsc{Sem-NN}$ ranks candidate items according to their pretrained language-model embedding similarity to the anchor item, serving as a content-based lower bound.
- $\textsc{ID+Sem}$ combines $\textsc{ID-Last}$ and $\textsc{Sem-NN}$ by integrating collaborative item-transition signals with semantic item similarity.
- LightGCN [10] simplifies GCN-based collaborative filtering by retaining only linear neighborhood aggregation and using layer-averaged embeddings as the final representation. For fair comparison with sequential baselines, we apply the same propagation rule on a global item-item transition graph constructed from training sequences. We also leverage the item text embeddings as the node features.
- SR-GNN [11] models each session as a directed graph and uses a gated graph neural network to capture complex item transitions. It then combines global session preference and current interest with attention for next-item recommendation.
- SASRec [27] is a Transformer-based sequential recommender that models user interaction histories with causal self-attention and predicts the next item by matching the sequence representation with item embeddings.
- HSTU [36] is a generative sequential recommender that reformulates ranking and retrieval as sequential transduction tasks. It encodes user actions into a unified sequence and uses efficient hierarchical sequential transduction units for long-sequence recommendation modeling.
- TIGER [14] is a generative retrieval framework for sequential recommendation. It represents each item with a short discrete semantic ID produced by an RQ-VAE [53] tokenizer trained on item content embeddings, and trains an encoder–decoder Transformer to autoregressively generate the semantic ID of the next item.
- LETTER [15] improves the RQ-VAE tokenizer by introducing collaborative-filtering alignment with SASRec [27] embeddings and a codebook-diversity loss to alleviate codebook collapse and semantic ID collisions.
- CoFiRec [19] extends the RQ-VAE tokenizer with a hierarchical design that separately quantizes textual views and collaborative signals into semantic IDs, which are then used by a TIGER-style encoder–decoder generator.
D. Implementation Details
Following the standard leave-one-out evaluation protocol [27, 14], we use the last interacted item of each user for testing, the second-to-last item for validation, and the remaining interactions for training. For all baselines, we carefully follow the implementation details and hyperparameter settings suggested in their original papers. We truncate each user history to the most recent $50$ items [16] for ID-based methods and $20$ items [15, 36] for generative methods. We set the latent dimension to $64$ for all methods, except for LETTER, where we use a latent dimension of $32$ following its original setting.
For generative methods, we reproduce TIGER [14] under the GRID [44] architecture, and implement LETTER [15] and CoFiRec [19] following their original papers. These methods generally follow a two-stage training recipe. In Stage 1, an RQ-VAE tokenizer compresses each item's pretrained text embedding into a 4-tuple of discrete codes, using $L{=}4$ residual codebooks with codebook size $K{=}256$. In Stage 2, a lightweight T5 encoder–decoder model is trained from scratch on user histories of up to $H{=}20$ items, where each item is represented as a flattened sequence of discrete codes. During inference, top- $K$ recommendations are generated by beam search with beam size $10$. Unless otherwise specified, all hyperparameters are kept consistent with those reported in the original papers. We use a single H200 GPU to train and inference all baselines.
E. Detailed Results on Amazon Review Datasets
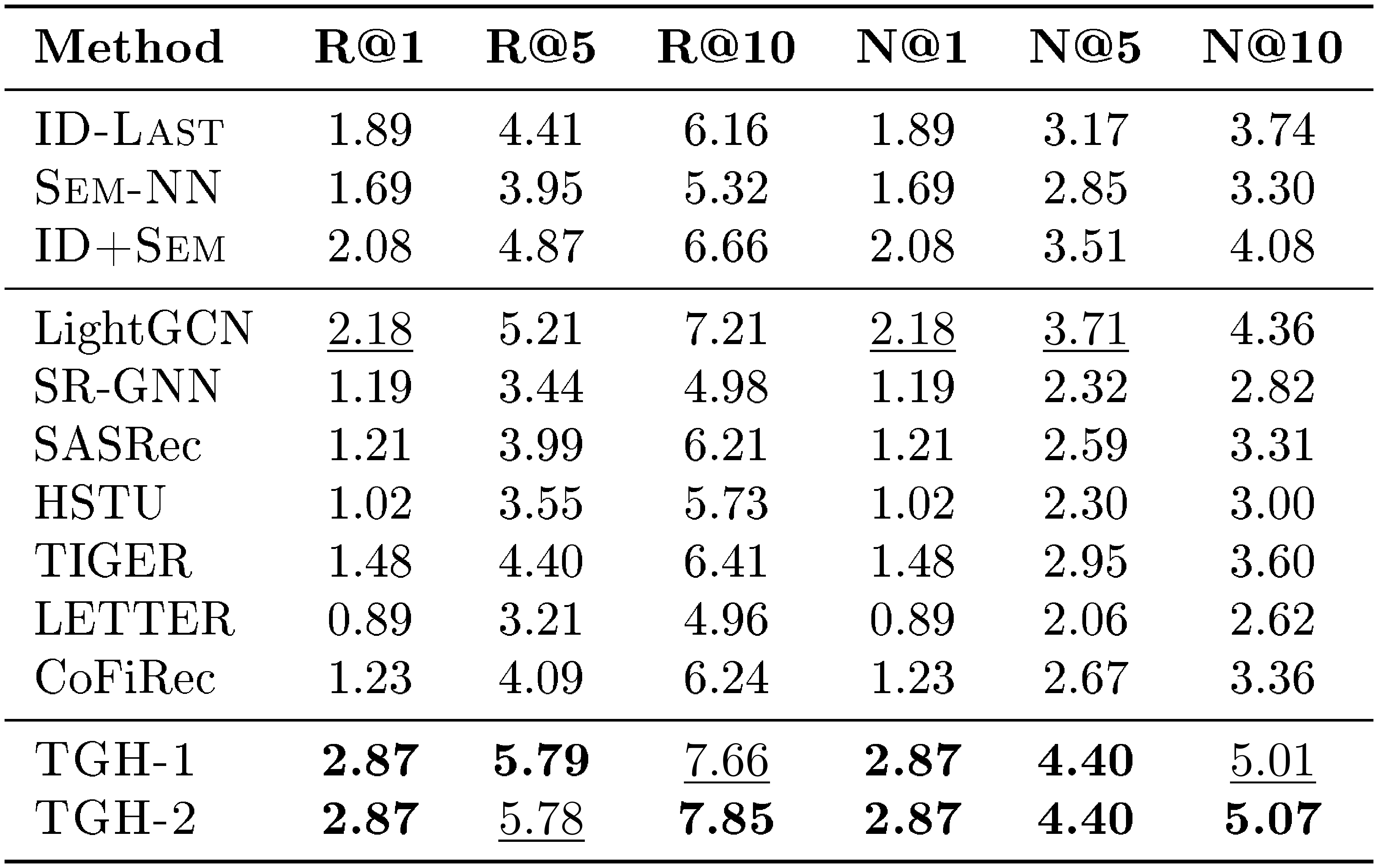
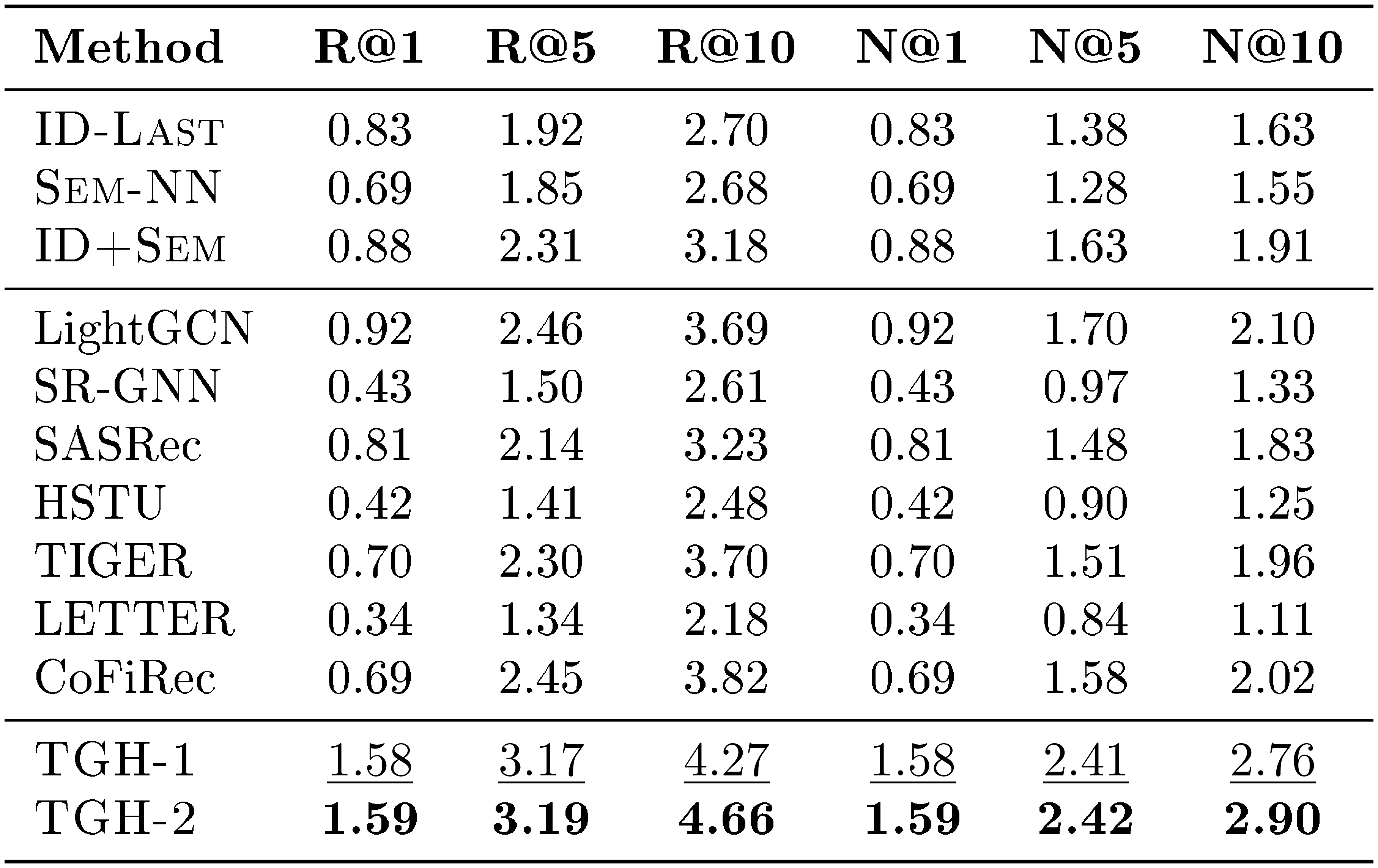
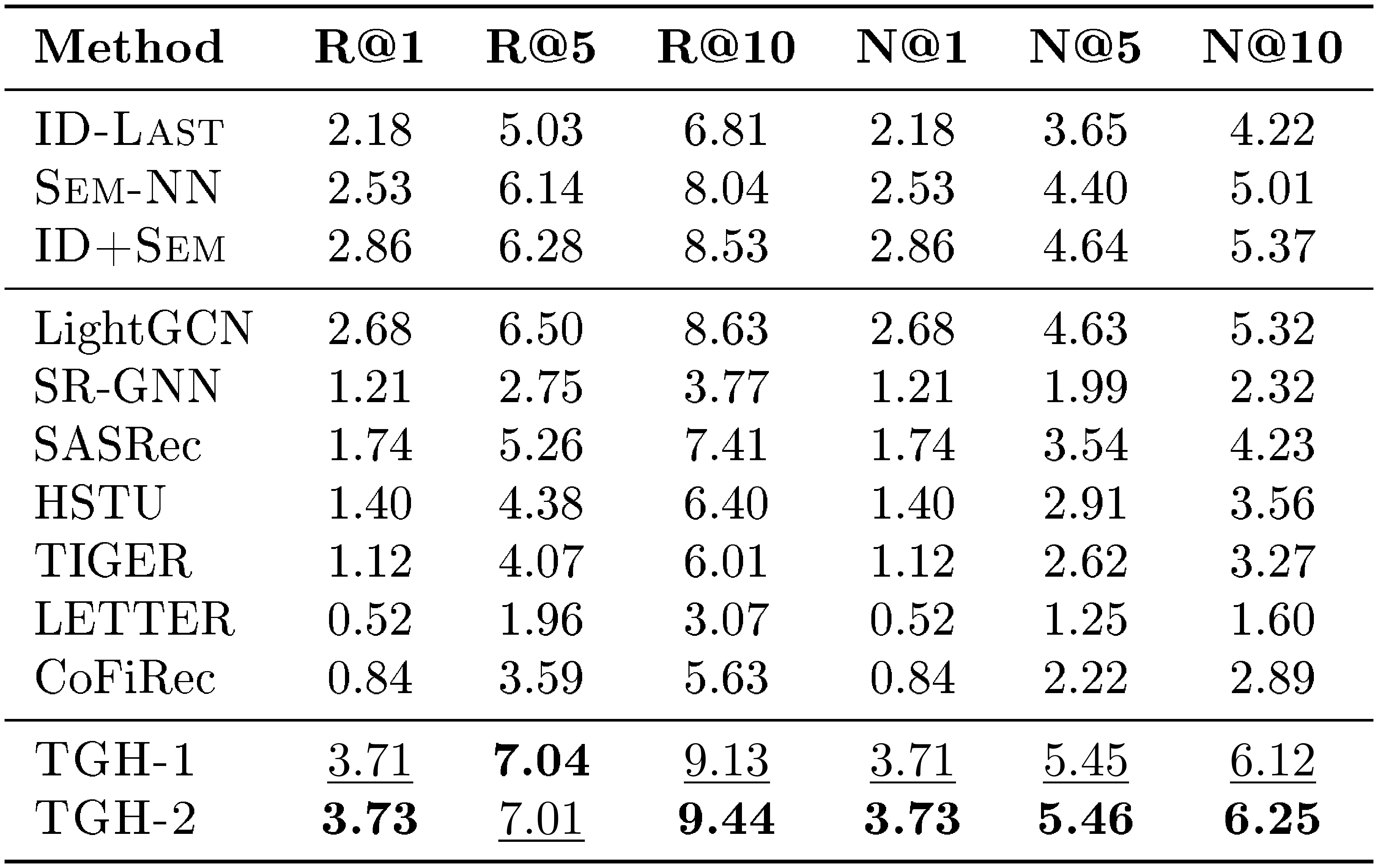
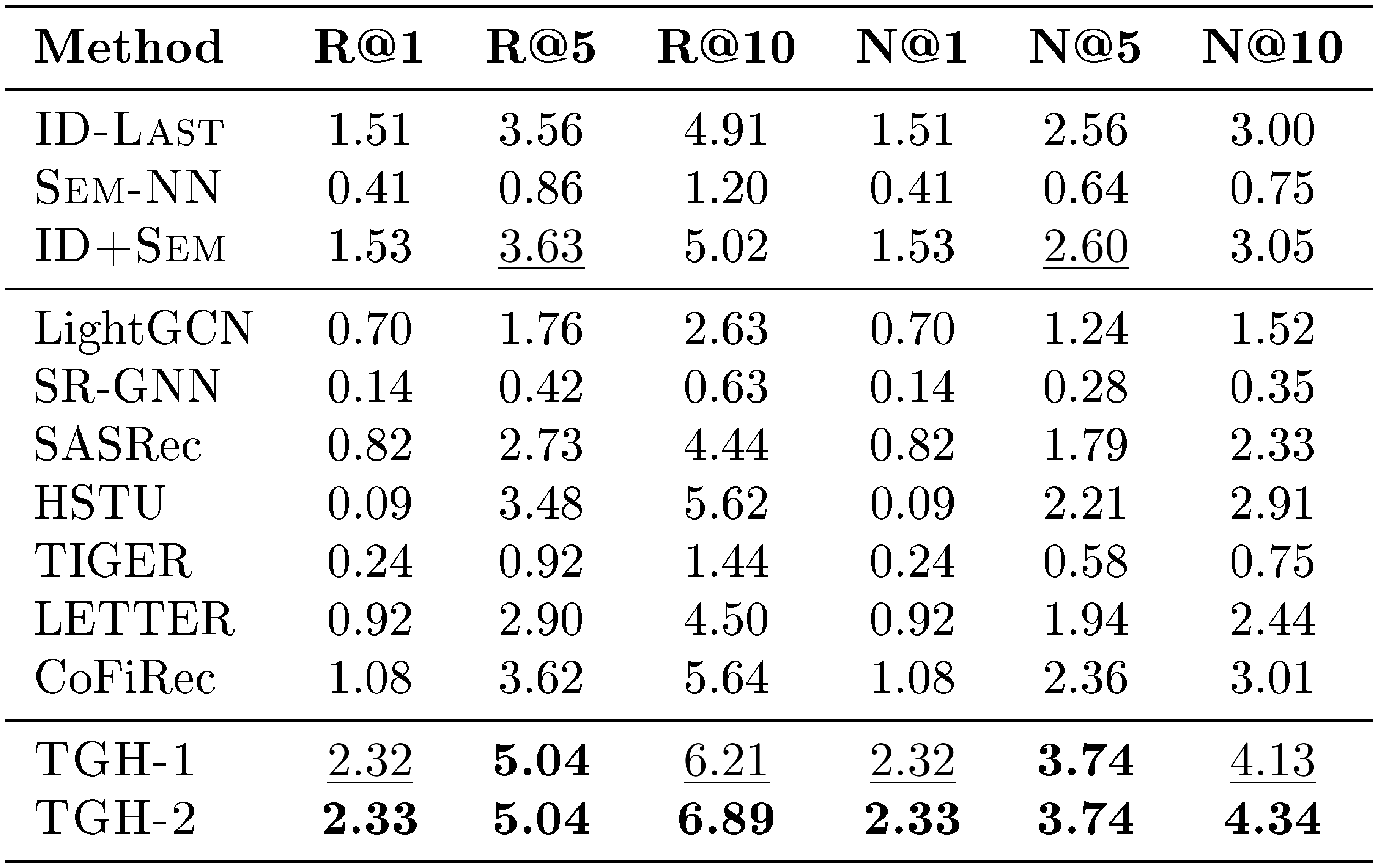
In Section 4, we report only Recall@10 (R@10) and NDCG@10 (N@10) on the four Amazon Review datasets. In this section, we provide the full results for Recall@1, Recall@5, Recall@10, NDCG@1, NDCG@5, and NDCG@10 on Beauty, Sports, Toys, and CDs. The detailed results are shown in Table 6, Table 7, Table 8, and Table 9, respectively. From the results, we observe that the proposed $\textsc{TGH}$ consistently outperforms all baselines across all datasets and evaluation metrics, further demonstrating its effectiveness on the Amazon Review benchmarks.
::: {caption="Table 6: Detailed results on Beauty. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 7: Detailed results on Sports. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 8: Detailed results on Toys. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 9: Detailed results on CDs. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
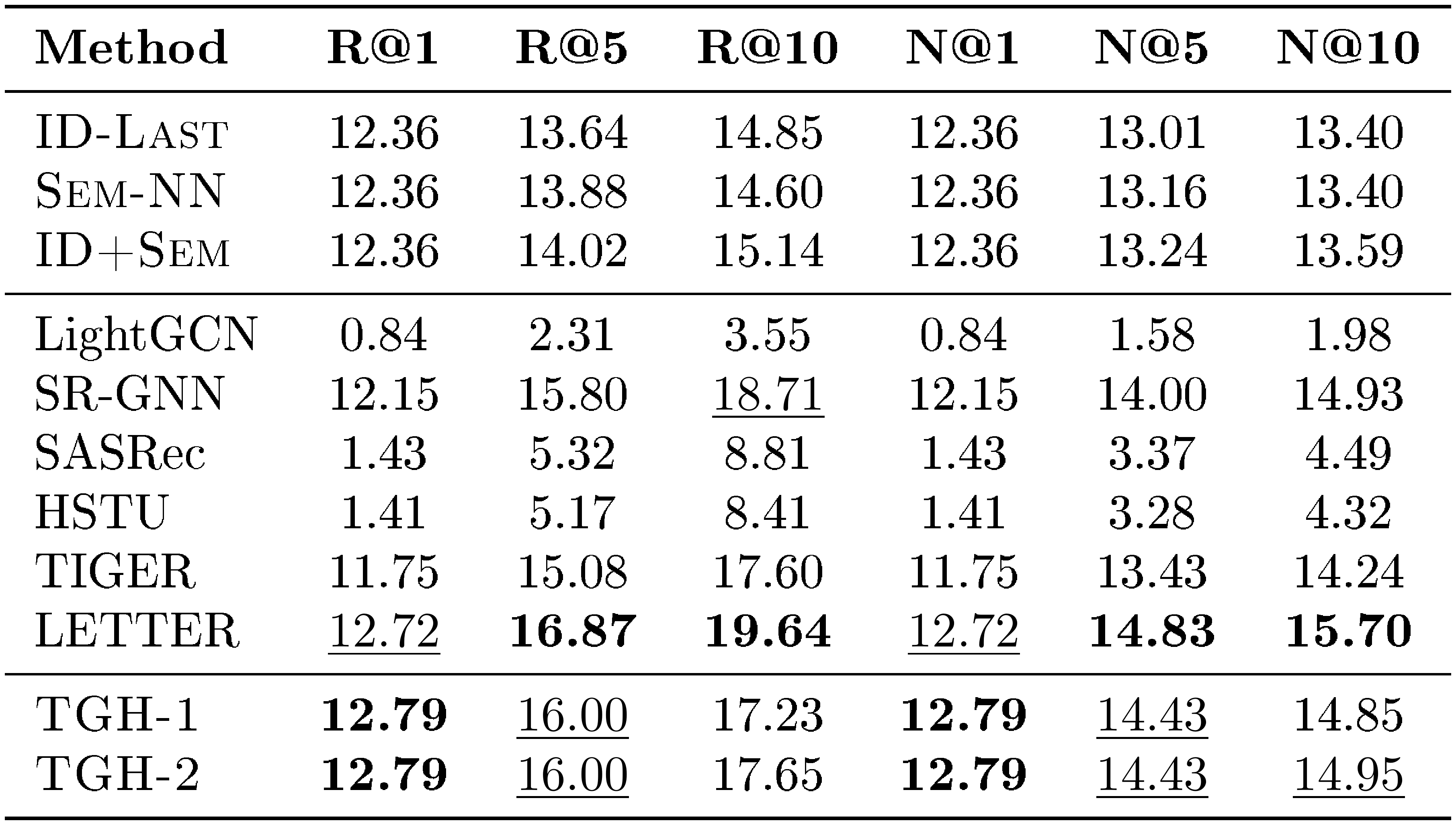
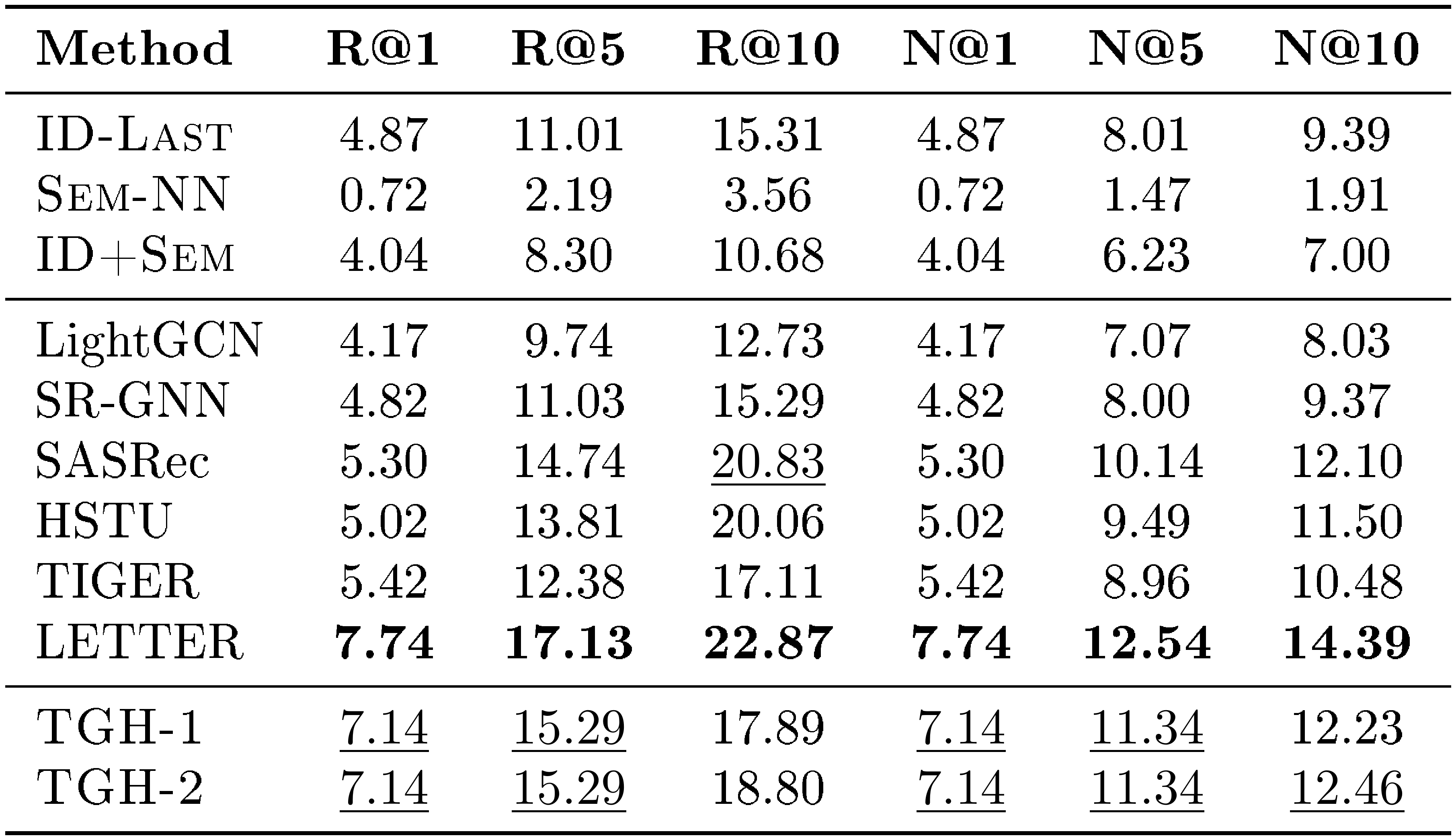
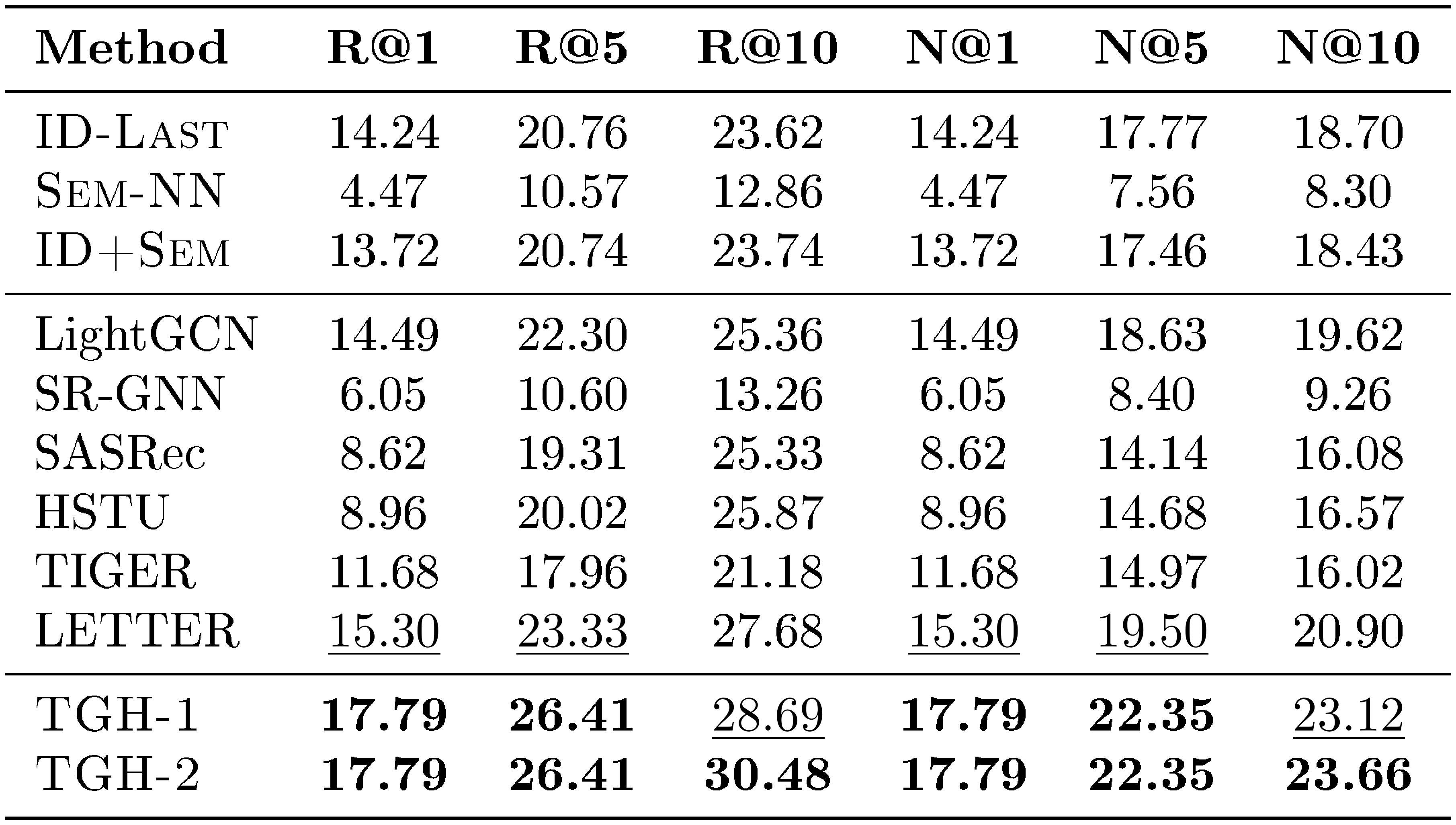
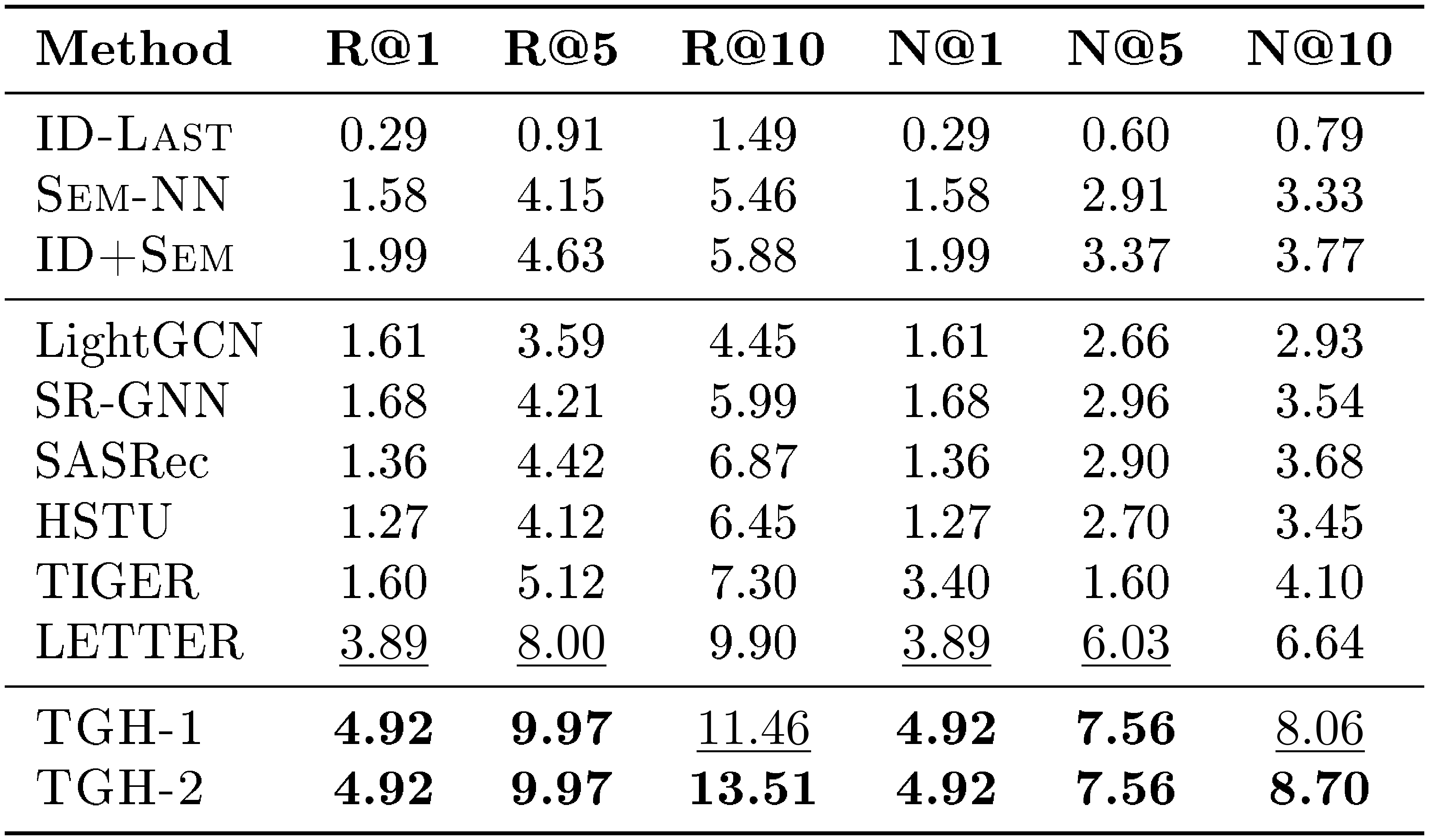
F. Detailed Results on More Datasets
For completeness, we further report the full per-metric results on the remaining ten benchmarks beyond the four Amazon Review datasets. These datasets cover diverse domains, including LastFM, Delicious, ML-1M, Yelp, MIND, Steam, GR-Children and GR-Comics, H&M, and Amazon-M2-UK. We report Recall@1, Recall@5, Recall@10, NDCG@1, NDCG@5, and NDCG@10 in Table 10, Table 11, Table 12, Table 13, Table 14, Table 15, Table 16, Table 17, Table 18, and Table 19, respectively.
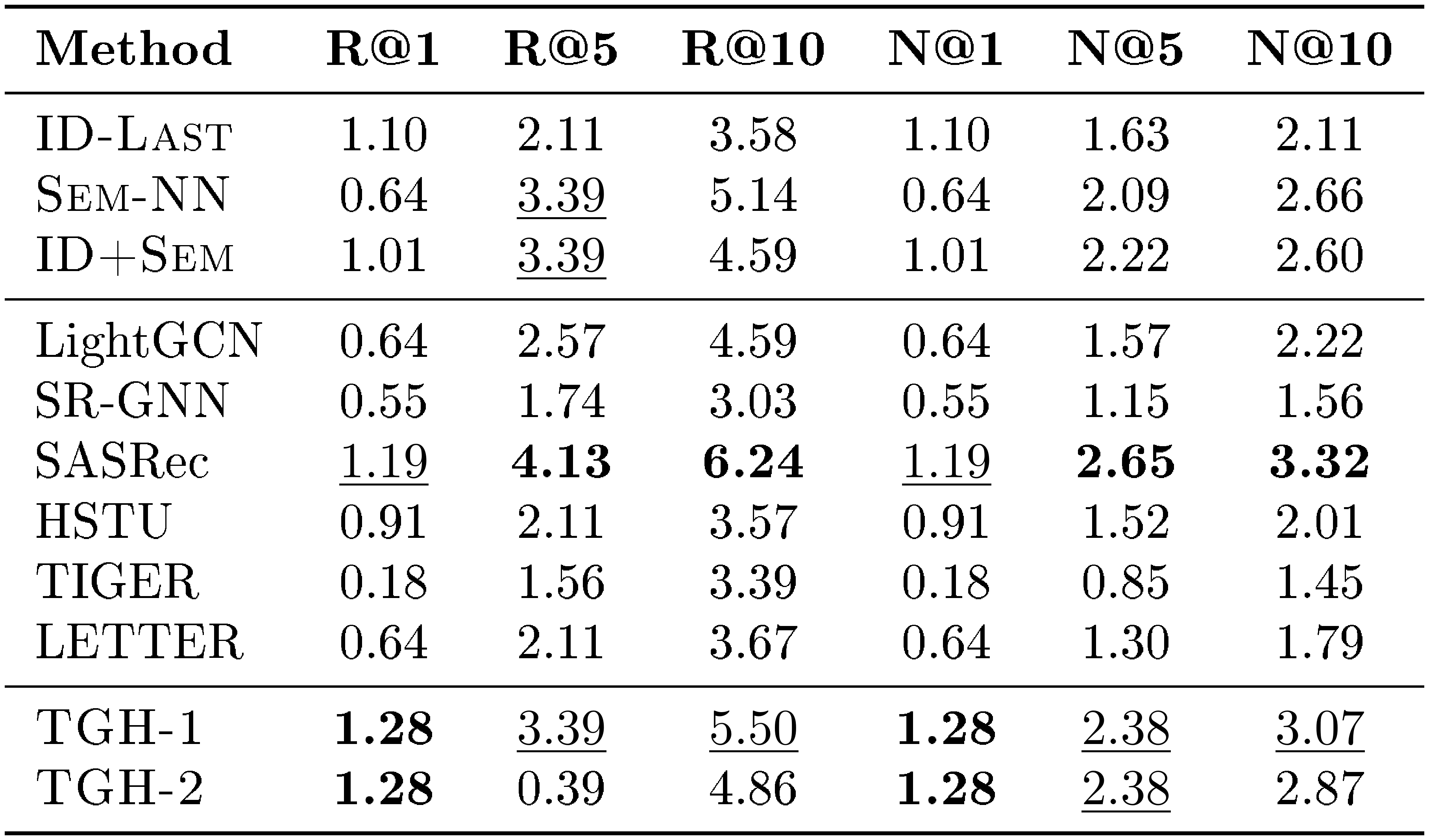
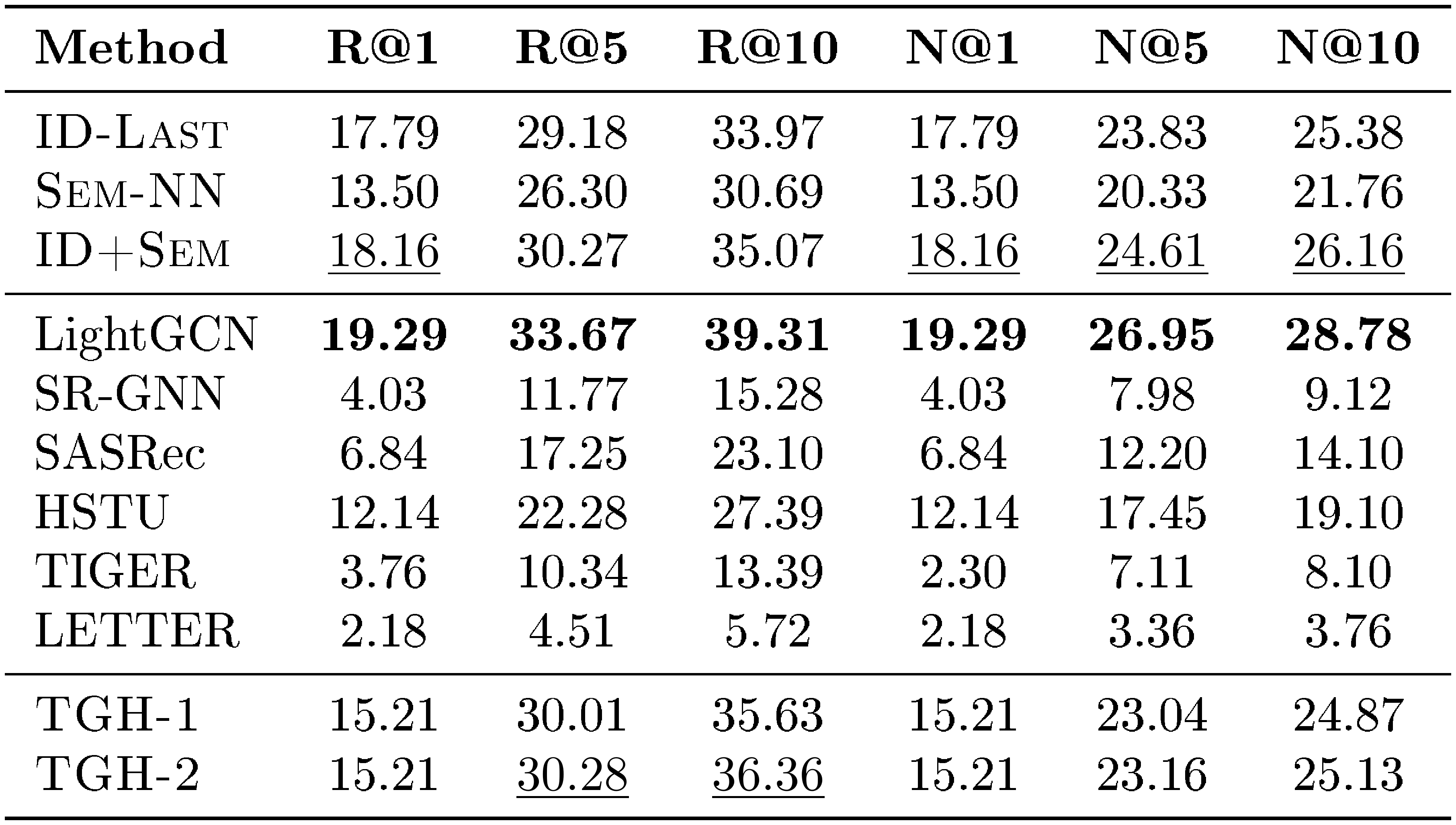
Across these ten datasets, $\textsc{TGH}$ achieves the best or second-best performance on a large fraction of metrics. These results show that the proposed heuristic remains competitive beyond the Amazon Review benchmarks and can generalize to a wide range of domains and dataset scales. At the same time, the results also reveal that $\textsc{TGH}$ is not universally superior, suggesting that different datasets exhibit different degrees of shortcut solvability.
::: {caption="Table 10: Detailed results on LastFM. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 11: Detailed results on Delicious. Bold: best per metric; $\underline{underlined}$ : second-best."}
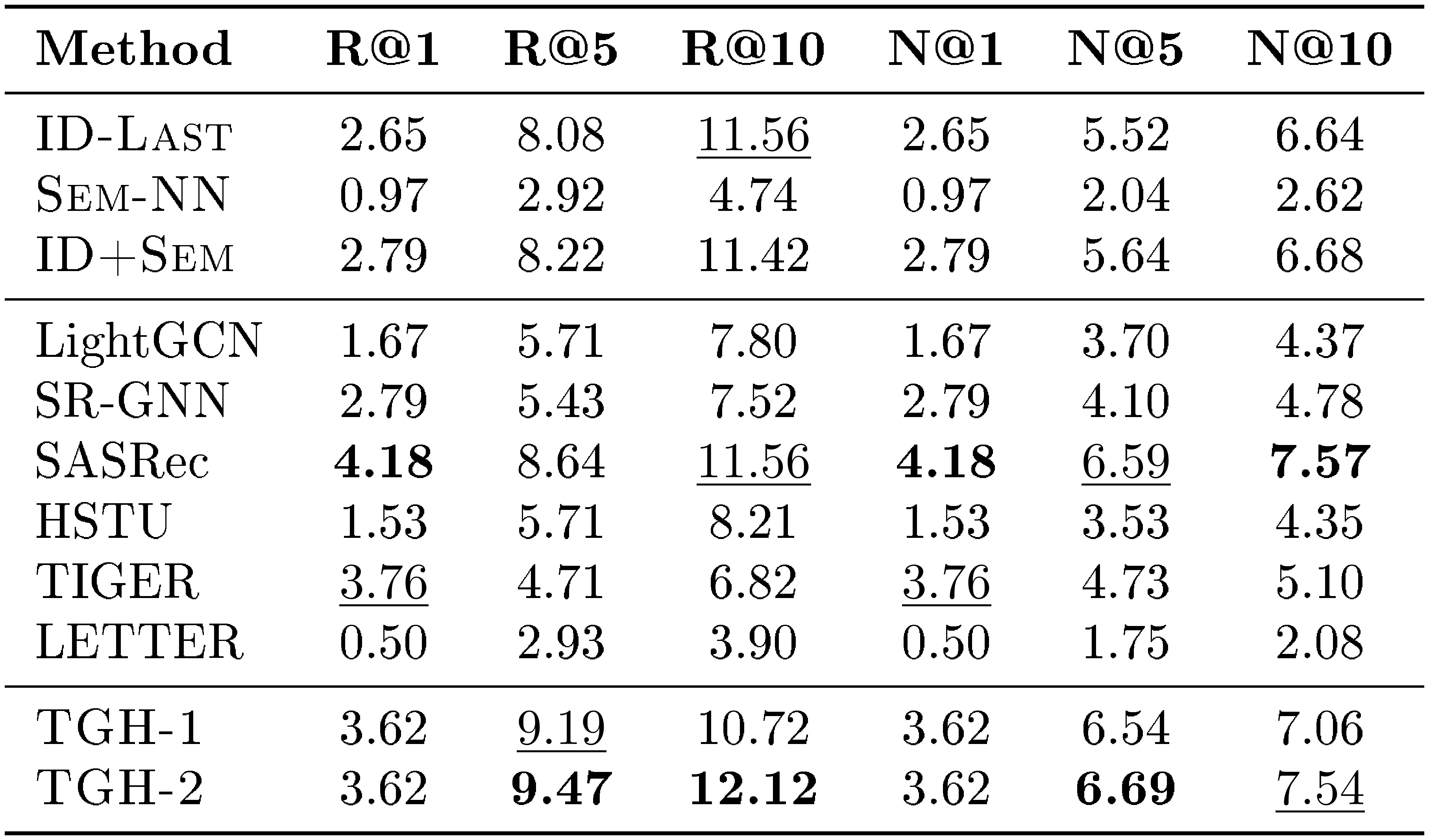
:::
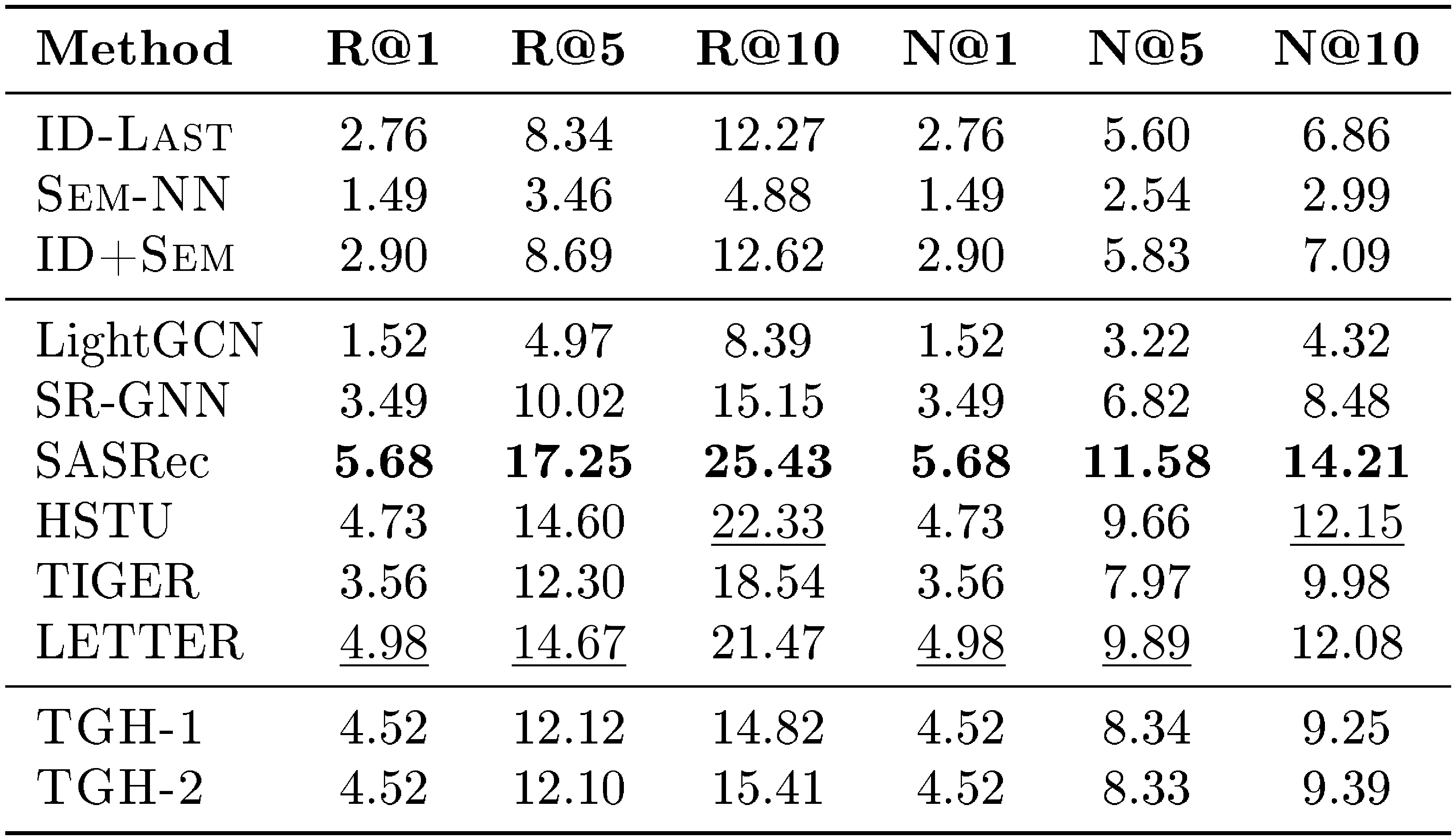
::: {caption="Table 12: Detailed results on ML-1M. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
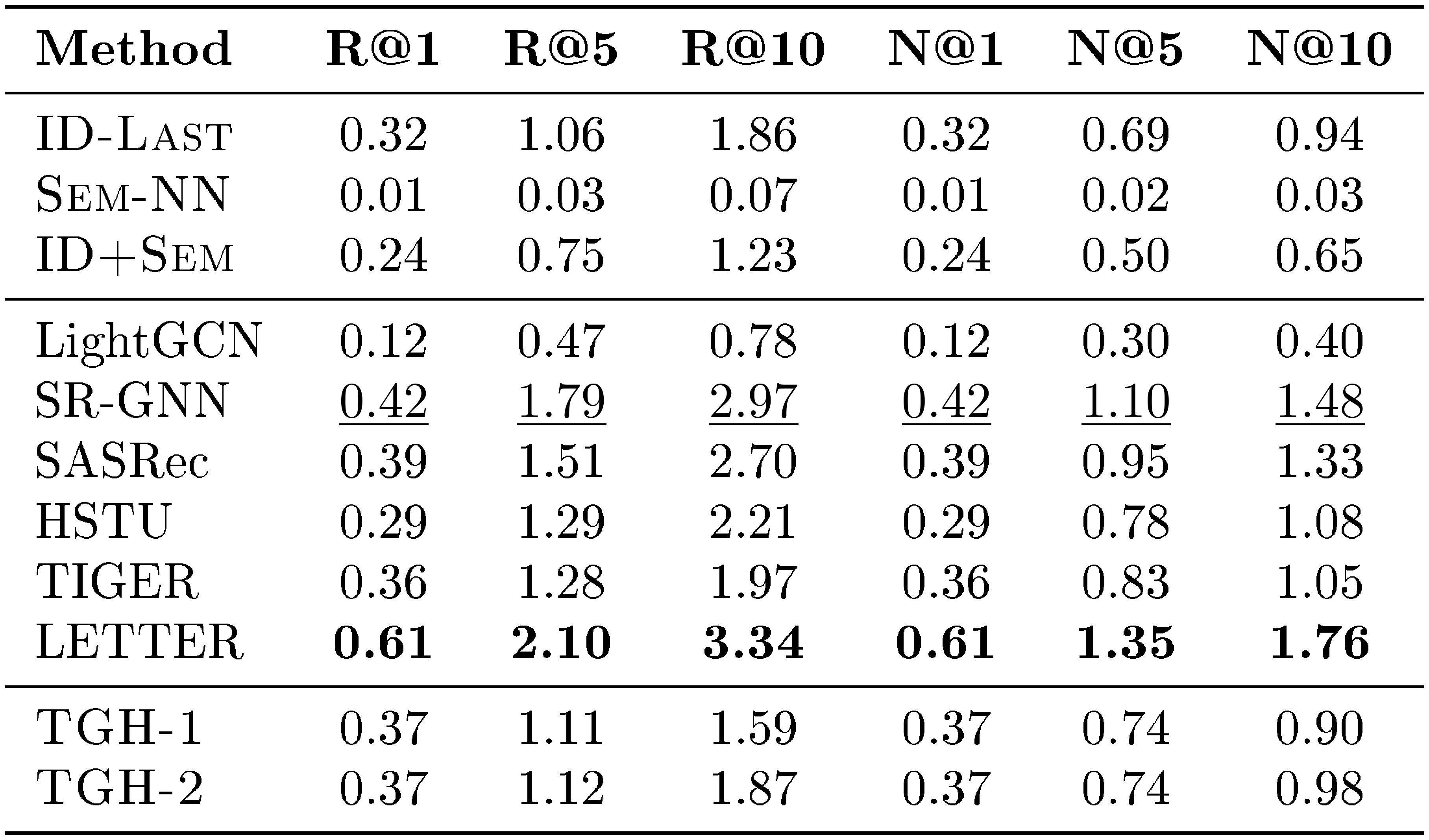
::: {caption="Table 13: Detailed results on Yelp. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
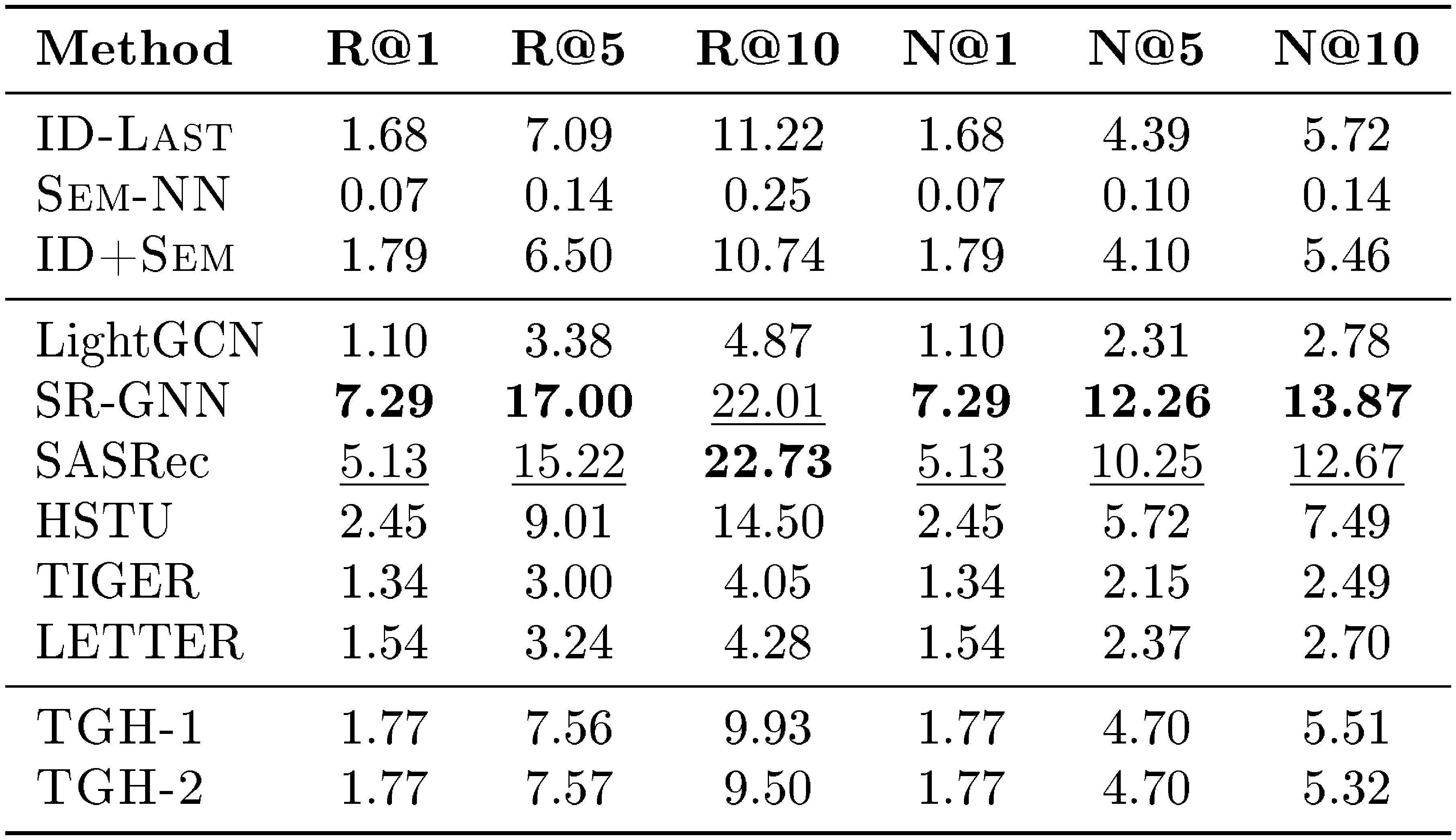
::: {caption="Table 14: Detailed results on MIND. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 15: Detailed results on STEAM. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 16: Detailed results on GR-Children. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 17: Detailed results on GR-Comics. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 18: Detailed results on H&M. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
::: {caption="Table 19: Detailed results on Amazon-UK. Bold: best per metric; $\underline{underlined}$ : second-best."}
:::
G. Limitations
Our study has several limitations. First, the three shortcut structures we identify are not intended to be an exhaustive explanation of benchmark behavior. Sequential recommendation datasets may contain other shortcut signals, such as popularity effects, temporal regularities, repeated consumption patterns, or preprocessing artifacts. Our diagnostics provide a useful lens for interpreting the behavior of $\textsc{TGH}$, but they do not fully characterize all factors that influence model performance. Second, our analysis is based on a finite set of datasets and baselines. Although we evaluate on 14 datasets covering different domains, sequence lengths, graph structures, and feature signals, they still cannot represent all sequential recommendation scenarios. Similarly, while we include representative traditional, graph-based, sequential, and generative recommenders, new architectures or stronger implementations may behave differently. Third, our heuristic uses fixed hyperparameters and fixed retrieval budgets across datasets. This design keeps the heuristic simple and avoids dataset-specific configurations, but it may not be optimal for every dataset. Finally, our goal is not to argue that advanced sequential or generative recommenders are unnecessary. Instead, we show that some widely used benchmarks may not be sufficient to demonstrate their benefits. Future work can extend our diagnostics to more datasets, richer evaluation protocols, and more settings to better understand when advanced recommendation models provide genuine advantages.
H. Broader Impacts
This work studies evaluation practice in sequential recommendation. Its main positive impact is to encourage more reliable and capability-aware benchmarking. By showing that some widely used datasets can be solved by simple shortcut signals, our analysis may help researchers avoid overclaiming model capabilities based on narrow benchmark results. It may also help benchmark creators release more transparent datasets by reporting diagnostic properties such as transition branching, feature-smoothness, and history dependence.
More careful benchmark selection can benefit both the research community and downstream users of recommender systems. If models are evaluated on datasets that better match their claimed capabilities, progress in semantic modeling, generative retrieval, and long-context recommendation can be measured more accurately. This may reduce wasted effort on optimizing for shortcut-solvable benchmarks and encourage the development of models that address harder and more realistic recommendation challenges.
Overall, we hope this work promotes more transparent evaluation practice in sequential recommendation, where both model designers and benchmark creators analyze dataset properties before drawing broad conclusions about model capability.
References
[1] Boka et al. (2024). A survey of sequential recommendation systems: Techniques, evaluation, and future directions. Information Systems. 125. pp. 102427.
[2] Pan et al. (2026). A survey on sequential recommendation. Frontiers of Computer Science. 20(3). pp. 2003606.
[3] Fang et al. (2020). Deep learning for sequential recommendation: Algorithms, influential factors, and evaluations. ACM Transactions on Information Systems (TOIS). 39(1). pp. 1–42.
[4] Hu et al. (2008). Collaborative filtering for implicit feedback datasets. In 2008 Eighth IEEE international conference on data mining. pp. 263–272.
[5] Ekstrand et al. (2011). Collaborative filtering recommender systems. Foundations and Trends® in Human–Computer Interaction. 4(2). pp. 81–173.
[6] Hu et al. (2008). Collaborative filtering for implicit feedback datasets. In 2008 Eighth IEEE international conference on data mining. pp. 263–272.
[7] He et al. (2017). Translation-based recommendation. In Proceedings of the eleventh ACM conference on recommender systems. pp. 161–169.
[8] Hidasi et al. (2015). Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939.
[9] Tan et al. (2016). Improved recurrent neural networks for session-based recommendations. In Proceedings of the 1st workshop on deep learning for recommender systems. pp. 17–22.
[10] He et al. (2020). Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. pp. 639–648.
[11] Wu et al. (2019). Session-based recommendation with graph neural networks. In Proceedings of the AAAI conference on artificial intelligence. pp. 346–353.
[12] Zhou et al. (2018). Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. pp. 1059–1068.
[13] Zhou et al. (2019). Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence. pp. 5941–5948.
[14] Rajput et al. (2023). Recommender systems with generative retrieval. Advances in Neural Information Processing Systems. 36. pp. 10299–10315.
[15] Wang et al. (2024). Learnable item tokenization for generative recommendation. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. pp. 2400–2409.
[16] Hou et al. (2025). Actionpiece: Contextually tokenizing action sequences for generative recommendation. arXiv preprint arXiv:2502.13581.
[17] Geng et al. (2022). Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In Proceedings of the 16th ACM conference on recommender systems. pp. 299–315.
[18] Hua et al. (2023). How to index item ids for recommendation foundation models. In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. pp. 195–204.
[19] Wei et al. (2025). CoFiRec: Coarse-to-Fine Tokenization for Generative Recommendation. arXiv preprint arXiv:2511.22707.
[20] Ji et al. (2024). Genrec: Large language model for generative recommendation. In European Conference on Information Retrieval. pp. 494–502.
[21] McAuley et al. (2015). Image-based recommendations on styles and substitutes. In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. pp. 43–52.
[22] Chung et al. (2024). Scaling instruction-finetuned language models. Journal of Machine Learning Research. 25(70). pp. 1–53.
[23] Touvron et al. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
[24] Koren et al. (2009). Matrix factorization techniques for recommender systems. Computer. 42(8). pp. 30–37.
[25] Rendle et al. (2010). Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th international conference on World wide web. pp. 811–820.
[26] Tang, Jiaxi and Wang, Ke (2018). Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the eleventh ACM international conference on web search and data mining. pp. 565–573.
[27] Kang, Wang-Cheng and McAuley, Julian (2018). Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). pp. 197–206.
[28] Sun et al. (2019). BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. pp. 1441–1450.
[29] Wang et al. (2020). Global context enhanced graph neural networks for session-based recommendation. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. pp. 169–178.
[30] Zhou et al. (2020). S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM international conference on information & knowledge management. pp. 1893–1902.
[31] Hou et al. (2022). Towards universal sequence representation learning for recommender systems. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. pp. 585–593.
[32] Li et al. (2023). Text is all you need: Learning language representations for sequential recommendation. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 1258–1267.
[33] Jin et al. (2023). Amazon-m2: A multilingual multi-locale shopping session dataset for recommendation and text generation. Advances in Neural Information Processing Systems. 36. pp. 8006–8026.
[34] Deldjoo et al. (2024). A review of modern recommender systems using generative models (gen-recsys). In Proceedings of the 30th ACM SIGKDD conference on Knowledge Discovery and Data Mining. pp. 6448–6458.
[35] Ayemowa et al. (2024). Analysis of recommender system using generative artificial intelligence: A systematic literature review. Ieee Access. 12. pp. 87742–87766.
[36] Zhai et al. (2024). Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations. arXiv preprint arXiv:2402.17152.
[37] Li et al. (2024). Large language models for generative recommendation: A survey and visionary discussions. In Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024). pp. 10146–10159.
[38] Krichene, Walid and Rendle, Steffen (2020). On sampled metrics for item recommendation. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. pp. 1748–1757.
[39] Meng et al. (2020). Exploring data splitting strategies for the evaluation of recommendation models. In Proceedings of the 14th acm conference on recommender systems. pp. 681–686.
[40] Zhao et al. (2022). A revisiting study of appropriate offline evaluation for top-N recommendation algorithms. ACM Transactions on Information Systems. 41(2). pp. 1–41.
[41] Ferrari Dacrema et al. (2019). Are we really making much progress? A worrying analysis of recent neural recommendation approaches. In Proceedings of the 13th ACM conference on recommender systems. pp. 101–109.
[42] Ferrari Dacrema et al. (2021). A troubling analysis of reproducibility and progress in recommender systems research. ACM Transactions on Information Systems (TOIS). 39(2). pp. 1–49.
[43] Rendle et al. (2020). Neural collaborative filtering vs. matrix factorization revisited. In Proceedings of the 14th ACM conference on recommender systems. pp. 240–248.
[44] Ju et al. (2025). Generative Recommendation with Semantic IDs: A Practitioner's Handbook. In Proceedings of the 34th ACM International Conference on Information and Knowledge Management. pp. 6420–6425.
[45] Cantador et al. (2011). Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In Proceedings of the fifth ACM conference on Recommender systems. pp. 387–388.
[46] Harper, F Maxwell and Konstan, Joseph A (2015). The movielens datasets: History and context. Acm transactions on interactive intelligent systems (tiis). 5(4). pp. 1–19.
[47] https://www.yelp.com/dataset (2023). Yelp open dataset. In **.
[48] Wu et al. (2020). Mind: A large-scale dataset for news recommendation. In Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 3597–3606.
[49] Wan, Mengting and McAuley, Julian (2018). Item recommendation on monotonic behavior chains. In Proceedings of the 12th ACM conference on recommender systems. pp. 86–94.
[50] https://www.kaggle.com/c/h-and-m-personalized-fashion-recommendations/overview (2022). H&M Personalized Fashion Recommendations. In **.
[51] Qu et al. (2025). Tokenrec: Learning to tokenize id for llm-based generative recommendations. IEEE Transactions on Knowledge and Data Engineering.
[52] Ma et al. (2020). Memory augmented graph neural networks for sequential recommendation. In Proceedings of the AAAI conference on artificial intelligence. pp. 5045–5052.
[53] Lee et al. (2022). Autoregressive image generation using residual quantization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11523–11532.