Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, Sitan Chen
Harvard University
University of Texas Austin
Equal contribution
Correspondence to: Kulin Shah [email protected]
Keywords: Machine Learning, ICML
Abstract
In recent years, masked diffusion models (MDMs) have emerged as a promising alternative approach for generative modeling over discrete domains. Compared to autoregressive models (ARMs), MDMs trade off complexity at training time with flexibility at inference time. At training time, they must learn to solve an exponentially large number of infilling problems, but at inference time, they can decode tokens in essentially arbitrary order. In this work, we closely examine these two competing effects. On the training front, we theoretically and empirically demonstrate that MDMs indeed train on computationally intractable subproblems compared to their autoregressive counterparts. On the inference front, we show that a suitable strategy for adaptively choosing the token decoding order significantly enhances the capabilities of MDMs, allowing them to sidestep hard subproblems. On logic puzzles like Sudoku, we show that adaptive inference can boost solving accuracy in pretrained MDMs from % to %, even outperforming ARMs with as many parameters and that were explicitly trained via teacher forcing to learn the right order of decoding. This shows that MDMs without knowledge of the correct token generation order during training and inference can outperform ARMs trained with knowledge of the correct token generation order. We also show the effectiveness of adaptive MDM inference on reasoning tasks such as coding and math on the 8B large language diffusion model (LLaDa 8B).
1. Introduction
While diffusion models [1,2] are now the dominant approach for generative modeling in continuous domains like image, video, and audio, efforts to extend this methodology to discrete domains like text and proteins [3,4,5] remain nascent. Among numerous proposals, masked diffusion models (MDMs) [4,6,7] have emerged as a leading variant, distinguished by a simple and principled objective: to generate samples, learn to reverse a noise process which independently and randomly masks tokens.
In many applications, such as language modeling, masked diffusion models (MDMs) still underperform compared to autoregressive models (ARMs) [8,9], which instead learn to reverse a noise process that unmasks tokens sequentially from left to right. However, recent studies suggest that MDMs may offer advantages in areas where ARMs fall short, including reasoning [8,10], planning [11], and infilling [12]. This raises a key question: what are the strengths and limitations of MDMs compared to ARMs, and on what type of tasks can MDMs be scaled to challenge the dominance of ARMs in discrete generative modeling?
To understand these questions, we turn a microscope to two key competing factors when weighing the merits of MDMs over ARMs:
- Complexity at training time: MDMs face a more challenging training task by design. While ARMs predict the next token given an unmasked prefix, MDMs predict a token conditioned on a set of unmasked tokens in arbitrary positions. This inherently increases their training complexity.
- Flexibility at inference time: On the other hand, the sampling paths taken by an MDM are less rigid. Unlike the fixed left-to-right decoding of ARMs, MDMs decode tokens in random order at inference. Even more is possible: MDMs can be used to decode in any order (including left-to-right).
Therefore, we ask:
Are the benefits of inference flexibility for MDMs enough to outweigh the drawbacks of training complexity?
In this work, we provide dual perspectives on this question.
(1) Training for the worst. \enspace First, we provide theoretical and empirical evidence that the overhead imposed by training complexity quantifiably impacts MDMs' performance.
Theoretically, we show examples of simple data distributions with a natural left-to-right order, where ARMs can provably generate samples efficiently. In contrast, there are noise levels at which a large fraction of the corresponding subproblems solved by MDMs for these distributions are provably computationally intractable. Empirically, we validate this claim on real-world text data, known to have left-to-right order and show that the imbalance in training complexity across subproblems persists even in real-world text data (Figure 2, left).
(2) Planning for the best.
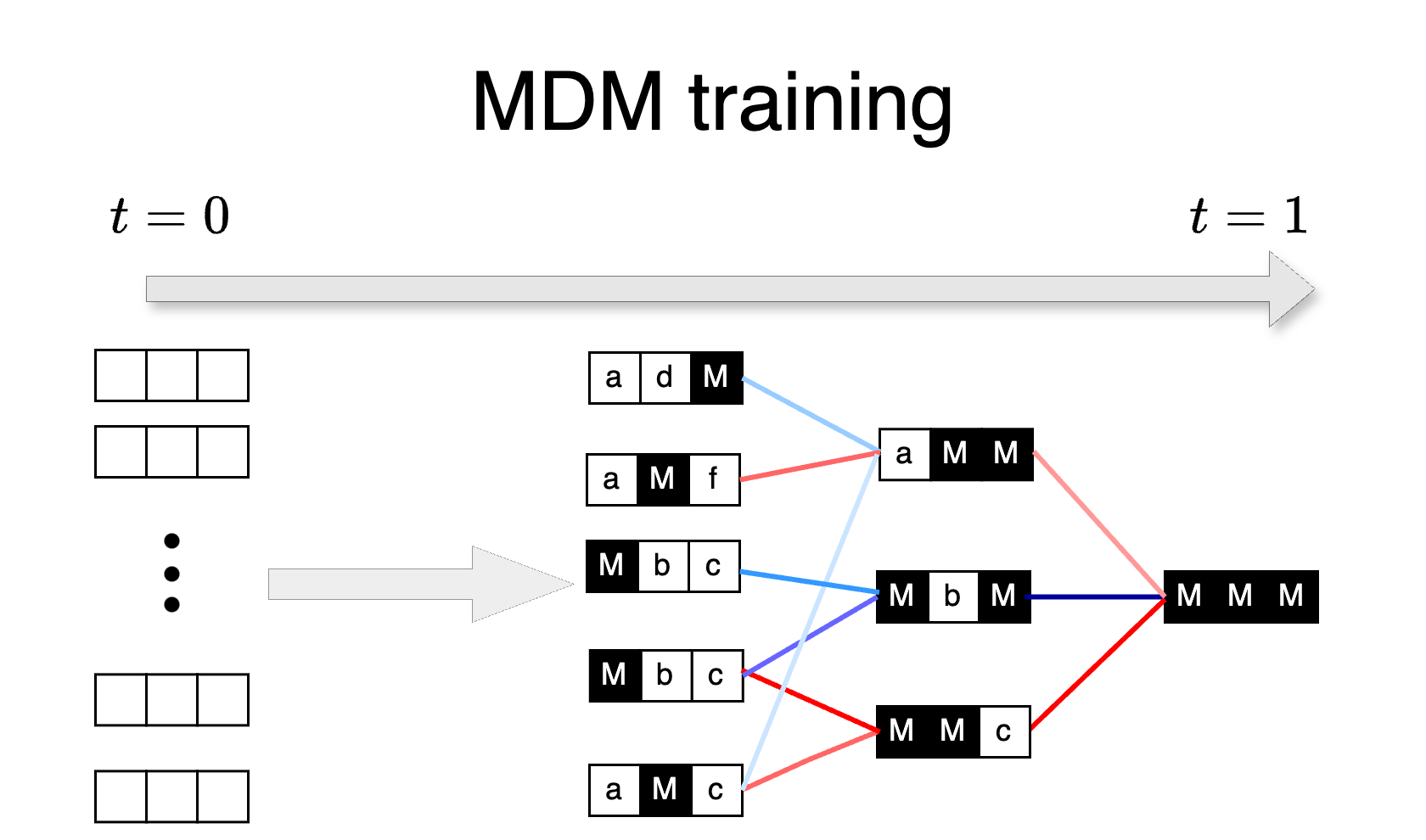
While the above might appear to be bad news for MDMs, in the second part of this paper, we answer our guiding question in the affirmative by building upon the observation [13,14] that MDMs which can perfectly solve all masking subproblems can be used to decode in any order.
In first part of the paper, we show that the imbalance in complexity across subproblems during the training of MDMs results in some of the subproblems being poorly trained and the vanilla MDM inference that unmasks tokens in random order results in evaluating the poorly trained marginals. Therefore, in place of vanilla MDM inference, we consider adaptive strategies that carefully select which token to unmask next. Our key insight is that the adaptive strategies makes it possible to sidestep the hard subproblems from training (Figure 1). In particular, we find that even without modifying how MDMs are trained, the resulting models' logits contain enough information to determine the right order in which to unmask. We show the effectiveness of the adaptive inference in solving logic puzzles, coding, math and infilling tasks. For example, on Sudoku puzzles, a simple adaptive strategy (Section 4.1) improves the accuracy of MDMs from % to almost 90%.
Advantage of MDMs over ARMs.
We show that the main effectiveness of MDMs lies in tasks that do not have the same natural token generation order across all sequences (e.g., logic puzzles and reasoning tasks like coding and math). By carefully designing experiments on logic puzzles, we show that MDMs without the knowledge of the correct token generation order during training and inference can outperform ARMs trained with the knowledge of the correct token generation order. In particular, we show that MDMs that decide the correct token generation order during inference via adaptive strategies can outperform ARMs that are trained to learn the right token generation order via supervised teacher forcing [15,16].
Organization.
In Section 2, we provide preliminaries on MDMs and set notation. In Section 3, we examine MDM training and demonstrate the imbalance in computational intractability across subproblems. In Section 4, we consider adaptive inference in MDMs and investigate its impact on likelihood modeling across various tasks.
2. Masked Diffusion Models (MDM)
In this section, we explain the framework of Masked Diffusion Models [7,6] and highlight its interpretation as an order-agnostic learner. MDMs gradually add masking noise to the true discrete data and learn the marginal distribution of the induced reverse process. We formally define both the forward and reverse processes for MDMs below.
Let the distribution on be the data distribution over sequences of length and with vocabulary . We use to denote the "mask" token.
Forward process.
For a given and a noise level , the forward process is a coordinate-independent masking process via , where
Here, is a predefined noise schedule satisfying and is a one-hot vector corresponding to the value of token . denotes the categorical distribution given by . In other words, for each -th coordinate, is masked to the mask token with probability and remains unchanged otherwise.
💭 Click to ask about this figure
Reverse process.
The reverse process of the above forward process is denoted by and is given by for any , where
The reverse transition probability is approximated using where is a denoising network trained to predict the marginal distribution on via an ELBO-based loss for all masked tokens at noise scale (i.e., for all such that ). To be precise, indicates the conditional probability where is placed in the position of within . The denoising network is trained to minimize the following loss derived from the score-entropy [4,6,7,17]:
where and the summation is computed over masked tokens (i.e., all such that ). In practice, a time-embedding-free architecture for the denoising network, i.e., is generally used as implicitly contains information about via the number of masked tokens.
The reverse sampling process starts from the fully masked sentence . Suppose we have a partially \fully masked sequence at a given noise level . Then, to obtain for a predetermined noise level , we sample for all . This process is repeated recursively from to .
2.1 Reformulating the training and inference of MDMs
In this section, we first discuss training of MDMs and compare it with ``left-to-right" order training of autoregressive models in Section 2.1.1. Then, we reformulate vanilla MDM inference in Section 2.1.2 to set the stage for the upcoming discussion.
2.1.1 Order-agnostic training of MDMs
Recent works [9,17] have observed that the learning problem of MDM is equivalent to a masked language model. Building upon their analysis, we reformulate the loss to show that is a linear combination of the loss for all possible infilling masks. We first define as a masked sequence, obtained from original sequence where indices in the mask set (a subset of ) are replaced with mask token .
Proposition 1
Assume , and denoising network is time-embedding free.
Then and
where is the size of the set and indicates the conditional probability of the -th coordinate from .
The proof of the above proposition is given in Appendix E. As the MDM loss is a linear combination of the loss for all possible infilling mask , the minimizer of the loss learns to solve every masking problem. In other words, the optimal predictor is the posterior marginal of the -th token, conditioned on for all masks .
On the other hand, Autoregressive Models (ARMs) learn to predict token based on all preceding tokens, from to . This is equivalent to predicting by masking positions from to . Therefore, the training objective for ARMs can be expressed as:
Typically, ARMs are trained to predict tokens sequentially from left to right. We refer to this as left-to-right training. However, it's also possible to train these models to predict tokens sequentially based on a fixed, known permutation of the sequence. We refer to this general approach as order-aware training.
To understand the comparison between the training objective of MDMs and ARMs, we want to highlight the equivalence between any-order autoregressive loss and MDM loss [18,17]. In particular, under conditions of Proposition 1, MDM loss is equal to
where is a uniform distribution over all the permutations of length (See Appendix E.1 for the proof). Observe that if the expectation is only with respect to the identity permutation, then the loss becomes an autoregressive loss. This shows that MDM loss solves exponentially more subproblems than ARM loss. In contrast to ARM loss, MDM does not prefer any particular (e.g., left-to-right) order during the training; therefore, we call its training order-agnostic training.
2.1.2 Order-agnostic inference of MDMs
The MDM inference can be decomposed into two steps: (a) randomly selecting a set of positions to unmask and (b) assigning token values to each position via the denoising network . More precisely, we can reformulate the reverse process as follows.
Algorithm 1: Vanilla MDM inference
- (a) Sample a set of masked tokens , .
- (b) For each , sample .
Therefore, the inference in MDM is implemented by randomly selecting and then filling each token value according to the posterior probability .
On the other hand, ARMs are trained to predict tokens sequentially from left to right and therefore, generate tokens also in left-to-right order. In contrast, vanilla MDM inference generates the tokens in a random order.
3. MDMs train on hard problems
💭 Click to ask about this figure
In this section, we provide theoretical and empirical evidence that when the data distribution has left-to-right order (or any fixed known order) then autoregressive training in left-to-right order (or in the known order) is more tractable than MDMs. In particular, for such distributions with fixed order, we show that ARMs can efficiently sample from the distributions but for MDMs, we theoretically and empirically demonstrate that a large portion of masking subproblems can be difficult to learn.
In Section 3.1, we show several examples of simple, non-pathological distributions for which: (1) the masking problems encountered during order-aware training (such as in ARMs) are computationally tractable, yet (2) many of the ones encountered during order-agnostic training (such as in MDMs) are computationally intractable. In Section 3.2, we empirically show that text data also exhibits this gap between the computational complexity of order-aware and order-agnostic training and therefore, MDMs train on subproblems of wide variety of complexity (depending on the order/masks). In Section 3.3, we empirically show that the variety in training complexity results in : MDMs trained on data from such distributions exhibits small errors on easy subproblems but suffers from large errors on harder ones.
3.1 Benign distributions with hard masking problems
We now describe a simple model of data under which we explore the computational complexity of masking problems and show the contrast between masking problems encountered by MDMs and ARMs.
Definition 2
A latents-and-observations (L&O) distribution is a data distribution over sequence of length with alphabet size (precisely, is over ) is specified by a permutation over indices , number of latent tokens , number of observation tokens such that , prior distribution of latent variables over and efficiently learnable observation functions , 1
Here efficiently learnable is in the standard PAC sense: given polynomially many examples of the form where and , there is an efficient algorithm that can w.h.p. learn to approximate in expectation over .
- (Latent tokens) For , sample independently from the prior distribution of the latents.
- (Observation tokens) For , sample independently from .
L&O distributions contain two types of tokens: (1) latent tokens and (2) observation tokens. Intuitively, latent tokens are tokens in the sequence, indexed by that serve as ``seeds" that provide randomness in the sequence; the remaining tokens, called observation tokens (indexed by ), are determined as (possibly randomized) functions of the latent tokens via . Observe that L&O distributions specified by a permutation have a natural generation order by permutation .
Order-aware training
Order-aware training, i.e. by permuting the sequence so that becomes the identity permutation and then performing autoregressive training, is computationally tractable: predicting given is trivial when as the tokens are independent, and computationally tractable when because only depends on and is efficiently learnable by assumption. In contrast, below we will show examples where if one performs order-agnostic training à la MDMs, one will run into hard masking problems with high probability.
Order-agnostic training
We first note that if the observations are given by a cryptographic hash function, then the masking problem of predicting given is computationally intractable by design because it requires inverting the hash function. While this is a well-known folklore observation regarding the role of token ordering in language modeling, it is not entirely satisfying because this construction is worst-case in nature --- in real-world data, one rarely trains on sequences given by cryptographic hash functions. Furthermore, it only establishes hardness for a specific masking pattern which need not be encountered in the course of running the reverse process.
We provide several simple instances of L&O distributions that address these issues: instead of leveraging delicate cryptographic constructions, they are average-case in nature and furthermore we can establish hardness for typical masking problems encountered along the reverse process.
In all these examples, the hardness results we establish hold even if the algorithm knows all of the parameters of as well as the observation functions . Due to space constraints, here we focus on the following example, deferring two others to Apps. Appendix B.1 and Appendix B.2.
Example 3: Sparse predicate observations
Consider the following class of L&O distributions. Given arity , fix a predicate function . Consider
the set of all ordered subsets of of size and set the total number of observation latents equal to the size of this set (hence ). To sample a new sequence, we first sample latent tokens from the prior distribution and an observation latent corresponding to a -sized subset is given by . In other words, each observation latent corresponds to a -sized subset of and the corresponding observation function is given by .
Proposition 4
Let be a sample from an L&O distribution with sparse predicate observations as defined in Example 3, with arity and predicate satisfying Assumption 14, and let be the probability that is satisfied by a random assignment from . Let and be some constants associated with the predicate function (see Definition 15). Suppose each token in is independently masked with probability , and is the set of indices for the masked tokens. If , then under the 1RSB cavity prediction (see Conjecture 16), with probability over the randomness of the masking, no polynomial-time algorithm can solve the resulting subproblem of predicting any of the masked tokens among given .
The complete proof of the proposition is given in Appendix B.4. We also provide a proof outline in Appendix B.3 for a comprehensive understanding.
3.2 Empirical evidence of hardness via likelihoods
In the previous section, we provided theoretical evidence that order-aware training is tractable when data has a natural order but the order-agnostic training is not. In this section, we provide empirical evidence to support this claim, using natural text data. Additionally, recent studies [8,9] have shown that masked diffusion models (MDMs) underperform compared to autoregressive models (ARMs) on natural text data. In this section, we provide evidence that this performance gap is primarily due to the order-agnostic training of MDMs. Natural text inherently follows a left-to-right token order, and we show that as training deviates from this order, model performance progressively declines.
To understand the importance of the order during the training, we use the following setting: Given a permutation of indices , define a * -learner* to be a likelihood model given as follows:
In other words, the -learner predicts the token at position given the clean tokens and masked tokens . If is the identity permutation, this reduces to the standard (left-to-right) autoregressive training. Note that the MDM loss encodes a -learner for every permutation because the MDM loss Equation 1 is equivalent to the average loss of those -learners over sampled from :
where denotes the set of all permutations over . The proof of the above equivalence is given in Appendix E. Therefore, by measuring the 'hardness' of each -learner, we can probe differences in hardness between arbitrary masking problems and left-to-right masking problems.
Experimental setup.
We use the Slimpajama dataset [19] to evaluate the performance of training in different orders. To train a -learner, we employ a transformer with causal attention and use permuted data as input. By varying while maintaining all other training configurations (e.g., model, optimization), we can use the resulting likelihood (computed using Equation 3) as a metric to capture the hardness of subproblems solved by the -learner.
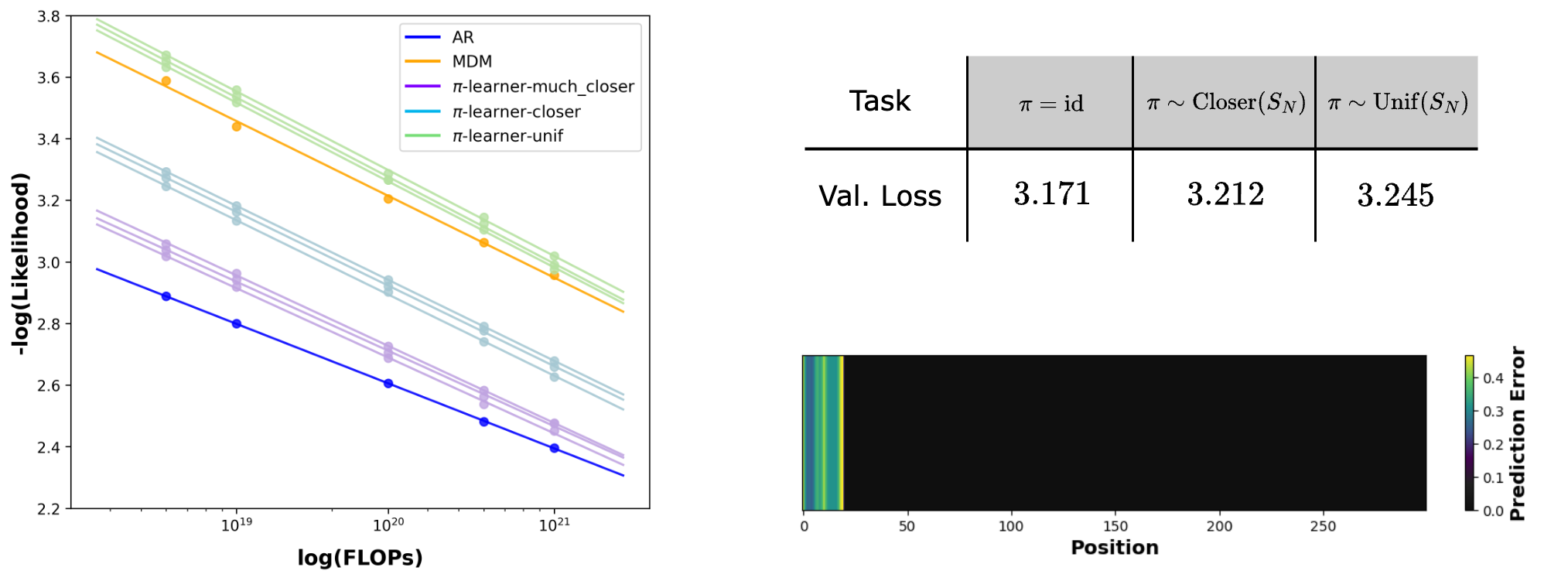
In our experiments, the sequence length is , so repeating the scaling laws for each is infeasible. Instead, we sample and examine the scaling law of the -learner's likelihood. We leverage the codebase from [8], where the baseline scaling laws of MDM and ARM were introduced. Moreover, given that RoPE has an inductive bias towards left-to-right ordering, we employ a learnable positional embedding layer for all experiments to correct this. Consequently, we also re-run the baseline results, where RoPE was employed. To investigate how the distance between and the identity permutation affects the scaling law, we consider two interpolating distributions over permutations between (i.e, MDM training) and the point mass at the identical permutation (i.e, ARM training). We sample three permutations from the interpolating distribution and and plot the scaling law for each of the permutation. Due to space constraints, we provide further experimental details in Appendix C.1.
Results.
As shown in Figure 2, the scaling law for a -learner with uniformly random is worse than that of an ARM. This elucidates the inherent hardness of masking problems beyond left-to-right prediction and also explains why MDM, which is trained simultaneously on all , is worse than ARM in likelihood modeling. Additionally, as gets closer to the identity permutation, the scaling laws also get closer to ARM (-learner-closer and -learner-much-closer in Figure 2). This also supports the common belief that ARM is a good fit for text data as it inherently follows a left-to-right ordering.
That said, it should also be noted that even though MDMs are trained on exponentially more masking problems than ARM ( versus ), its performance is not significantly worse than -learners. We attribute this to the blessing of task diversity; multi-task training can benefit both the optimization dynamics [20] and validation performance [21,22,23] due to positive transfers across tasks.
3.3 Error is imbalanced across masking problems
In previous sections, we have demonstrated that the hardness of different masking problems can vary significantly, potentially hindering the MDM's learning. In this section, we provide empirical evidence that the MDM's final performance exhibits a similar imbalance across subproblems. Details are provided in App. Appendix C.2.
L&O-NAE-SAT.
Consider an L&O distribution with given by the identity permutation and where each observation is deterministically given by for some randomly chosen (prefixed) triples . For an MDM trained on this distribution, we measure the error it achieves on each task via , where denotes the Bayes-optimal predictor. Technically, we do not have access to this, so instead we train another MDM for a much larger number of iterations and use this as a proxy. Figure 2 reveals that prediction tasks for latent positions (light region) exhibit larger errors compared to those for observation positions (dark region).
Text.
Here we revisit the text experiment from Section 3.2. Since we do not have access to the Bayes-optimal predictor, we use the metric . This captures the accumulation of error across subproblems , since minimizes this metric. Figure 2 shows a clear gap between different subproblems.
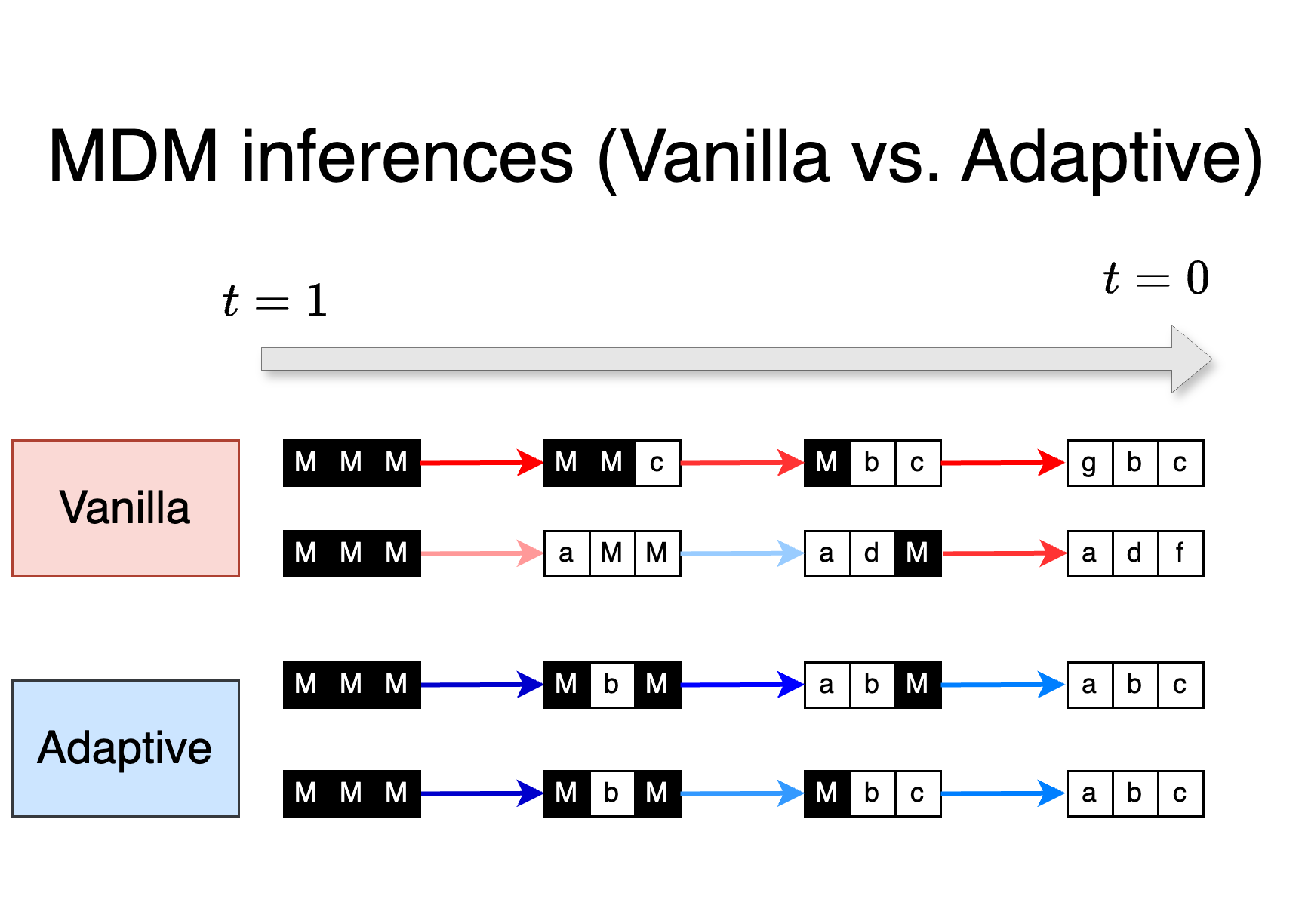
The theoretical and empirical evidence demonstrates that MDMs perform better in estimating for some subproblems than for others. We therefore want to avoid encountering hard subproblems at inference time. In the next section, we show that while vanilla MDM inference can run into such subproblems, simple modifications at the inference stage can effectively circumvent these issues, resulting in dramatic, training-free performance improvements.
4. MDMs can plan around hard problems
We previously argued that due to the complex nature of masking subproblems, MDM must perform poorly on certain ones . Therefore, during vanilla MDM inference, MDM inevitably encounters such difficult subproblems at Step (b). While this might suggest that we need to fundamentally revisit how MDMs are trained, in this section we show that, surprisingly, simple modifications at the inference stage—without any further training—can sidestep these issues and lead to significant performance improvements.
MDM offers multiple sampling paths.
The vanilla MDM inference (Algorithm 1) aim to align the intermediate distributions with the forward process, as used in continuous diffusion. However, unlike continuous diffusion, the reverse process of MDM allows multiple valid sampling paths (different orders of unmasking the tokens) that match the starting distribution of the forward process of MDM.
We first show that when we have an ideal MDM that perfectly solves all masking problems, i.e., , then using any sampling path (unmasking the tokens in any order) results in the same distribution. Consider the following sampler: For every step, is a set with one index selected agnostically (without following any distribution). For any clean sample generated by this sampler, note that by chain rule, and this is equal to . Therefore, other choices of , not necessarily following Algorithm 1, still capture the true likelihood.
![**Figure 3:** **Generative Perplexity.** We compare the resulting generative perplexity (GenPPL) of adaptive vs. vanilla MDM inference. We employ a pretrained $170$ M MDM and LLaMA- $7$ B [24] as inference and evaluation, respectively. Adaptive MDM inference {(Blue)} leads to a substantial reduction in generative perplexity, while maintaining the entropy.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/e93f548a/perplexity_vs_sampling_steps_with_entropy_1.1B.png)
💭 Click to ask about this figure
In practice, unlike this ideal case, MDM does not perform equally well on all subproblems, as shown in Section 3.3. Consequently, different sampling paths result in varying likelihood modeling abilities. Motivated by this observation, we consider adaptive inference for MDMs:
Algorithm 2: Adaptive MDM inference
- (a) Sample a set of masked tokens .
- (b) For each , sample .
Instead of selecting randomly, adaptive MDM inference leverages an oracle to select strategically to avoid hard masking problems. This naturally raises the question of how to design an effective oracle .
In the following sections, we demonstrate that adaptive MDM inference with careful choices of enhance MDM's likelihood matching ability. In other words, a pretrained MDM, even if it performs poorly on certain hard subproblems, still contains sufficient information to avoid them when paired with an effective oracle .
4.1 Effective design of ordering oracle
We introduce two different oracles, Top probability and Top probability margin. Intuitively, both strategies are based on the idea that should be selected based on how "certain" the model is about each position. We caution that these strategies should not be confused with notions like nucleus sampling in ARMs [25]; the oracles we describe are for selecting the position of the next token to decode, rather than the value, and thus are only meaningful in the context of MDMs.
Top probability [14].
Suppose we want to unmask positions at time step , i.e., select . In the top probability, the uncertainty of a position is estimated by the maximum probability assigned to any value in the vocabulary. More precisely, the certainty at position is and .
Top probability strategy is a good proxy for many tasks and works well in practice [14,11,26]. However, this approach can often provide misleading estimates of uncertainty. Consider when an MDM is confused between two token values, thus assigning them almost equal but high probabilities. In this case, unmasking according to top probability may still choose to unmask this position, despite its uncertainty. To mitigate this issue, we propose the following alternative strategy.
Top probability margin.
In this strategy, the uncertainty of a position is instead estimated using the absolute difference between the two most probable values at position . More precisely, if and are the two most probable values in vocabulary according to in position , the certainty in the position is given by and . When multiple values have similar probabilities at a position, top probability margin strategy will provide a better estimate of the uncertainty of a position, and when there is a single best choice of value then top probability and top probability margin work similarly.
4.2 Adaptive MDM inference
In this section, we experimentally validate that adaptive MDM inference helps MDMs avoid hard subproblems, leading to better likelihood matching. We first show our results on L&O-NAE-SAT and text data, before turning to our primary application to logic puzzles.
L&O-NAE-SAT and text data. For the L&O-NAE-SAT distribution defined in Section 3.3, we evaluate the effectiveness of adaptive inference by measuring the accuracy in predicting the observation tokens. Table 1 in the appendix reveals a clear improvement over vanilla inference. For the text dataset, we evaluate using the standard metric of generative perplexity, by which likelihood is measured by a large language model. We also compute the entropy of the generated samples to ensure both inference strategies exhibit similar levels of diversity. As shown in Figure 3, we observe a substantial decrease in generative perplexity using adaptive inference. We defer further experimental details to Appendix D.1.
Logic puzzles. We consider two different types of logic puzzles: Sudoku and Zebra (Einstein) puzzles. Intuitively, for Sudoku, some empty (masked) cells are significantly easier to predict than others and we want to choose the cells that are easier to predict during the inference. We evaluate the effectiveness of adaptive MDM inference over vanilla MDM inference in selecting such cells.2
A prior work [11] reported that a M MDM with Top- inference achieves 100% accuracy on Sudoku. Given that a 6M MDM with Top- only achieves 18.51% on our dataset (Table 2), this suggests that the Sudoku dataset in [11] is significantly easier than ours.
To measure the performance of an inference method, we use the percentage of correctly solved puzzles. For both puzzles, we use train and test datasets from [15]. For the Sudoku puzzle (Table 2) we observe that adaptive MDM inference, in particular, Top probability margin strategy, obtains substantially higher accuracy (89.49%) compared to vanilla MDM inference (6.88%). Additionally, Top probability margin obtains higher accuracy (89.49%) than Top probability strategy (18.51%). As mentioned in Section 4.1, this is because Top probability margin strategy more reliably estimates uncertainty when multiple competing values are close in probability at a given position, as is often the case in Sudoku. For the Zebra puzzle, as shown in Table 3, we observe a consistent result: Top probability (98.5%) and Top probability margin (98.3%) outperform vanilla MDM inference (76.9%).
4.3 Eliciting sequence-dependent reasoning paths using adaptive MDM inference in logic puzzles
In this section, we study the effectiveness of adaptive MDM inference in finding the right reasoning/generation order for tasks where every sequence has a different "natural" order. To do so, we will compare the performance of adaptive MDM inference to that of ARM on Sudoku and Zebra puzzles. For these puzzles, the natural order of generation is not only different from left-to-right, but it is also sequence-dependent. For such tasks, prior works have shown that ARMs struggle if the information about the order is not provided during the training [15,16]. Therefore, to obtain a strong baseline, we not only consider an ARM trained without the order information but also consider an ARM trained with the order information for each sequence in the training data. Note that the latter is a much stronger baseline than the former as one can hope to teach the model to figure out the correct order by some form of supervised teacher forcing (as performed in [15,16]), eliminating the issue of finding the right order in an unsupervised manner.
We compare ARMs and MDMs for Sudoku in Table 2 and Zebra puzzles in Table 3. We observe that for both, Top probability margin-based adaptive MDM inference not only outperforms the ARM trained without ordering information, but it even outperforms the ARM trained with ordering information! This shows that the unsupervised way of finding the correct order and solving such logic puzzles using adaptive MDM inference outperforms the supervised way of finding the correct order and solving such puzzles using an ARM, and is significantly less computationally intensive.
4.4 Adaptive MDM inference on natural language tasks
To examine the effect of different inference strategies on text benchmarks, we adapted LLaDA, the 8B MDM model from [27]. We compare three inference strategies: vanilla, top probability, and top probability margin. The results are presented in Table 4.
We see that both adaptive MDM inference strategies, top probability and top probability margin, consistently outperform vanilla MDM inference. Notably, top probability margin demonstrates a clear advantage over top probability in challenging tasks like HumanEval-Multiline (infill), HumanEval-Split Line (infill), and Math. This is because Top probability margin provides a more reliable estimate of uncertainty when multiple tokens have similar probabilities, a frequent occurrence in these difficult tasks. These results further underscore the potential for developing new, sophisticated adaptive inference strategies for various tasks. We provide experimental details in Appendix D.3.
4.5 Easy to hard generalization
In the previous section we showed that when the training and inference sequences come from the same distribution, order-agnostic training of MDMs combined with adaptive inference can perform very well on logic puzzles. To evaluate if the model has learned the correct way of solving the puzzles and test the robustness of adaptive inference, we also test the MDMs on harder puzzles than the ones from training, for Sudoku.
We keep the training dataset the same as proposed in [15]. [15] created this dataset from [28] by selecting the puzzles that can be solved using 7 fixed strategies and do not require backtracking-based search. We use the remaining puzzles in [28] as our hard dataset. Hence, these puzzles all use a strategy not seen during training and/or backtracking to obtain the correct solution.
We measure the accuracy of MDMs and ARMs on the hard test set and present the results in Table 5. We see that the Top probability margin-based adaptive MDM inference strategy (49.88%) again significantly outperforms ARMs trained with order information (32.57%). In particular, although the accuracy drops for both methods due to the more challenging test set, MDMs with adaptive inference appear to be more robust to this distribution shift than ARMs. We believe this is due to the fact that MDMs try to solve a significantly higher number of infilling problems than ARMs ( compared to ) and therefore are able to extract knowledge about the problem more efficiently than ARMs.
5. Conclusion
In this work, we examined the impact of token generation order on training and inference in MDMs. We provided theoretical and experimental evidence that MDMs train on hard masking problems. We also demonstrated that adaptive inference strategies can be used to sidestep these hard problems. For logic puzzles, we find that this leads to dramatic improvements in performance not just over vanilla MDMs, but even over ARMs trained with teacher forcing to learn the right order of decoding. An important direction for future work is to go beyond the relatively simple adaptive strategies to find a better generation order like top probability and top probability margin considered here.
Acknowledgements.
JK thanks Kiwhan Song for discussions about MDM training. KS and VK are supported by the NSF AI Institute for Foundations of Machine Learning (IFML). KS and VK thank the computing support on the Vista GPU Cluster through the Center for Generative AI (CGAI) and the Texas Advanced Computing Center (TACC) at UT Austin. KS thanks Nishanth Dikkala for the initial discussions about the project. SK acknowledges: this work has been made possible in part by a gift from the Chan Zuckerberg Initiative Foundation to establish the Kempner Institute for the Study of Natural and Artificial Intelligence and support from the Office of Naval Research under award N00014-22-1-2377. SC is supported by the Harvard Dean's Competitive Fund for Promising Scholarship and thanks Brice Huang and Sidhanth Mohanty for enlightening discussions about computational-statistical tradeoffs for planted CSPs.
Impact statement
This paper advances the understanding of discrete diffusion models, contributing to the broader field of Machine Learning. There are many potential societal consequences of our work, none of which we feel must be specifically highlighted here.
Appendix
A. Related works
Discrete diffusion models.
(Continuous) diffusion models were originally built on continuous-space Markov chains with Gaussian transition kernels [29,1]. This was later extended to continuous time through the theory of stochastic differential equations [2]. In a similar vein, discrete diffusion models have emerged from discrete-space Markov chains [5]. Specifically, [3] introduced D3PM with various types of transition matrices. Later, [4] proposed SEDD, incorporating a theoretically and practically robust score-entropy objective. Additionally, [30,31] introduced novel modeling strategies that classify tokens in a noisy sequence as either signal (coming from clean data) or noise (arising from the forward process). In particular, [31] uses this to give a planner that adaptively determines which tokens to denoise. While this is similar in spirit to our general discussion about devising adaptive inference strategies, we emphasize that their approach is specific to discrete diffusions for which the forward process scrambles the token values, rather than masking them.
Masked diffusion models.
Meanwhile, the absorbing transition kernel has gained popularity as a common choice due to its better performance than other kernels. Building on this, [6,7] aligned its framework with continuous diffusion, resulting in a simple and principled training recipe, referring to it as Masked Diffusion Model. Subsequent studies have explored various aspects of MDM. [12] efficiently trained MDM via adaptation from autoregressive models, scaling MDM up to 7B parameters. [9] interpreted MDMs as order-agnostic learners and proposed a first-hitting sampler based on this insight. [11,12] demonstrated that MDM outperforms autoregressive models in reasoning and planning tasks, emphasizing its impact on downstream applications. [8] examined the scaling laws of MDM, while [32,33] identified limitations in capturing coordinate dependencies when the number of sampling steps is small and proposed additional modeling strategies to address this issue. [34] studied conditional generation using MDM and [35] tackled the challenge of controlling generated data distributions through steering methodologies. [36] provided a theoretical analysis showing that sampling error is small given accurate score function estimation.
Any-order reasoning.
Even though language tasks generally have a natural order of
left-to-right" token generation, in many tasks like planning, reasoning, and combinatorial optimization, the natural order of token generation can be quite different from left-to-right". Even though prominent autoregressive-based language models achieve impressive performance on various tasks, many works [37,38,10] have shown that this performance is tied to the training order of the tasks and therefore can cause brittleness from it. For example, [38] showed that simply permuting the premise order on math tasks causes a performance drop of 30%. The reason behind such brittleness regarding the ordering is the inherent ``left-to-right" nature of the autoregressive models. Several works [39] have tried to address this issue in the autoregressive framework. In particular, [40] highlighted the significance of left-to-right ordering in natural language by comparing its likelihood to that of the reverse (right-to-left) ordering.Recently, discrete diffusion models have emerged as a promising approach for discrete data apart from autoregressive models. Additionally, the order-agnostic training of discrete diffusion models opens up the multiple sampling paths during the inference but it also faces some challenges during the training therefore, they seem a promising approach to elicit any order reasoning. [14] proposed different ways of implementing an adaptive inference strategy for MDM but a concrete understanding of why such an adaptive inference strategy is needed is still lacking. In this work, we explore various aspects of vanilla MDM training and how adaptive MDM inference can mitigate the issues raised by vanilla MDM training and elicit any order reasoning.
We also want to mention the concurrent work by [41] that proposes an alternative adaptive inference strategy by selecting based on the BERT model or the denoiser itself. In particular, [41] uses the BERT model or the denoiser to obtain the uncertainty of a token and then uses Top- to decide the positions to unmask it. In contrast to their work, we disentangle the impact of token ordering on MDM training vs. MDM inference and provide a more complete understanding of the motivations for and benefits of adaptive inference. Additionally, our results indicate drawbacks to using Top- strategy as opposed to Top- margin in deciding which tokens to unmask when there are multiple values with high probabilities.
Beyond autoregressive models.
Efforts to learn the natural language using non-autoregressive modeling began with BERT [42]. Non-causal approaches can take advantage of the understanding the text data representation. [13] adopted a similar approach for learning image representations. Building on these intuitions, [43,18] proposed any-order modeling, which allows a model to generate in any desired order. [43] made the same observation that any-order models by default have to solve exponentially more masking problems than autoregressive models. However, whereas our work shows that learning in the face of this challenging task diversity can benefit the model at inference time, their work sought to alleviate complexity at training time by reducing the number of masking problems that need to be solved.
B. Technical details from Section 3
Notations.
Throughout this section, we use to denote the -th coordinate of the vector and to denote the -th example. The -th coordinate of the vector is denoted by .
B.1 Additional example: sparse parity observations
Example 5: Noisy sparse parity observations
Let , , and . Fix noise rate as well as strings sampled independently and uniformly at random from the set of -sparse strings in . For each , define to be the distribution which places mass on (resp. ) and mass on (resp. ) if is odd (resp. even). Note that for , each of these observations is efficiently learnable by brute-force.
Below we show that for a certain range of masking fractions, a constant fraction of the masking problems for the corresponding L&O distributions are computationally hard under the Sparse Learning Parity with Noise assumption [44]. Formally we have:
Proposition 6
Let be an arbitrary absolute constant, and let be sufficiently large. Let be a sample from a L&O distribution with noisy parity observations as defined in Example 5. Suppose each token is independently masked with probability , and is the set of indices for the masked tokens. If , then under the Sparse Learning Parity with Noise (SLPN) assumption (see Definition 7), with constant probability over , no polynomial-time algorithm can solve the resulting masking problem of predicting any of the masked tokens among given .
We note that it is important for us to take the observations to be sparse parities and to leverage the Sparse Learning Parity with Noise assumption. If instead we used dense parities and invoked the standard Learning Parity with Noise (LPN) assumption, we would still get the hardness of masking problems, but the observations themselves would be hard to learn, assuming LPN. This result is based on the following standard hardness assumption:
Definition 7: Sparse Learning Parity with Noise
Given input dimension , noise parameter , and sample size , an instance of the Sparse Learning Parity with Noise (SLPN) problem is generated as follows:
- Nature samples a random bitstring from
- We observe examples of the form where is sampled independently and uniformly at random from -sparse bitstrings in , and is given by , where is with probability and otherwise.
Given the examples , the goal is to recover .
The SLPN assumption is that for any for constant , and any sufficiently large inverse polynomial noise rate , no -time algorithm can recover with high probability.
Proof of Proposition 6: With probability at least , all of the variable tokens for are masked. Independently, the number of unmasked tokens among the observation tokens is distributed as , so by a Chernoff bound, with probability at least we have that at least observation tokens are unmasked. The masking problem in this case amounts to an instance of SLPN with input dimension and sample size in . Because of the lower bound on the sample size, prediction of is information-theoretically possible. Because of the upper bound on the sample size, the SLPN assumption makes it computationally hard. As a result, estimating the posterior mean on any entry of given the unmasked tokens is computationally hard as claimed.
B.2 Additional example: random slab observations
Example 8: Random slab observations
Let and for constant . Fix slab width and vectors sampled independently from . For each , define the corresponding observation to be deterministically if , and deterministically otherwise.
In [45], it was shown that stable algorithms (Definition 10), which encompass many powerful methods for statistical inference like low-degree polynomial estimators, MCMC, and algorithmic stochastic localization [46], are unable to sample from the posterior distribution over a random bitstring conditioned on it satisfying for any number of constraints , provided is not too large that the support of the posterior is empty. This ensemble is the well-studied symmetric perceptron [47]. The following is a direct reinterpretation of the result of [45]:
Proposition 9
Let be a L&O distribution with random slab observations as defined in Example 8, with parameter and slab width . There exists a constant such that for any absolute constant ,
if and , the following holds. Let denote the distribution given by independently masking every coordinate in with probability . Then any -stable algorithm, even one not based on masked diffusion, which takes as input a sample from and, with probability outputs a Wasserstein-approximate3 sample from conditioned on the unmasked tokens in , must run in super-polynomial time.
Here the notion of approximation is -closeness in Wasserstein-2 distance.
The upshot of this is that any stable, polynomial-time masked diffusion sampler will, with non-negligible probability, encounter a computationally hard masking problem at some point during the reverse process.
For the proof, we first formally define the (planted) symmetric Ising perceptron model:
Definition.
Let . The planted symmetric Ising perceptron model is defined as follows:
- Nature samples uniformly at random from
- For each , we sample independently from conditioned on satisfying .
The goal is to sample from the posterior on conditioned on these observations .
Next, we formalize the notion of stable algorithms.
Definition 10
Given a matrix , define for independent .
A randomized algorithm which takes as input and outputs an element of is said to be * -stable* if .
As discussed at depth in [46], many algorithms like low-degree polynomial estimators and Langevin dynamics are stable.
Theorem 11: Theorem 2.1 in [45][^4]
Note that while the theorem statement in [45] refers to the non-planted version of the symmetric binary perceptron, the first step in their proof is to argue that these two models are mutually contiguous in the regime of interest.
For any constant , there exists such that the following holds for all constants . For , any -stable randomized algorithm which takes as input and outputs an element of will fail to sample from the posterior on conditioned on in the symmetric Ising perceptron model to Wasserstein error .
Proof of Proposition 9: By a union bound, with probability at least over a draw , all of the tokens are masked. The number of unmasked tokens in among the observations is distributed as . By a Chernoff bound, this is in with at least constant probability. The claim then follows immediately from Theorem 11 above.
B.3 Proof outline of Proposition 4
To understand the proof idea, we consider the case where all the latent tokens are masked and some of the observation tokens are unmasked. In this case, the prediction task reduces to learning to recover the latent tokens that are consistent with the observations. Intuitively, each observation provides some constraints and the task is to recover an assignment that satisfies the constraints. This is reminiscent of Constraint Satisfaction Problems (CSPs). Indeed, to show the hardness result, we use the rich theory developed for planted CSPs at the intersection of statistical physics and average-case complexity.
In a planted CSP, there is an unknown randomly sampled vector of length and, one is given randomly chosen Boolean constraints which is promised to satisfy, and the goal is to recover as best as possible (see Definition 12). Prior works have shown the hardness of efficiently learning to solve the planted CSP problem [48,45]. We show the hardness of masking problems in L&O distributions based on these results. Consider the ground truth latent tokens as the random vector and each observation as a constraint. In this case, the problem of learning to recover the latent tokens from the observation tokens reduces to recovery for the planted CSP.
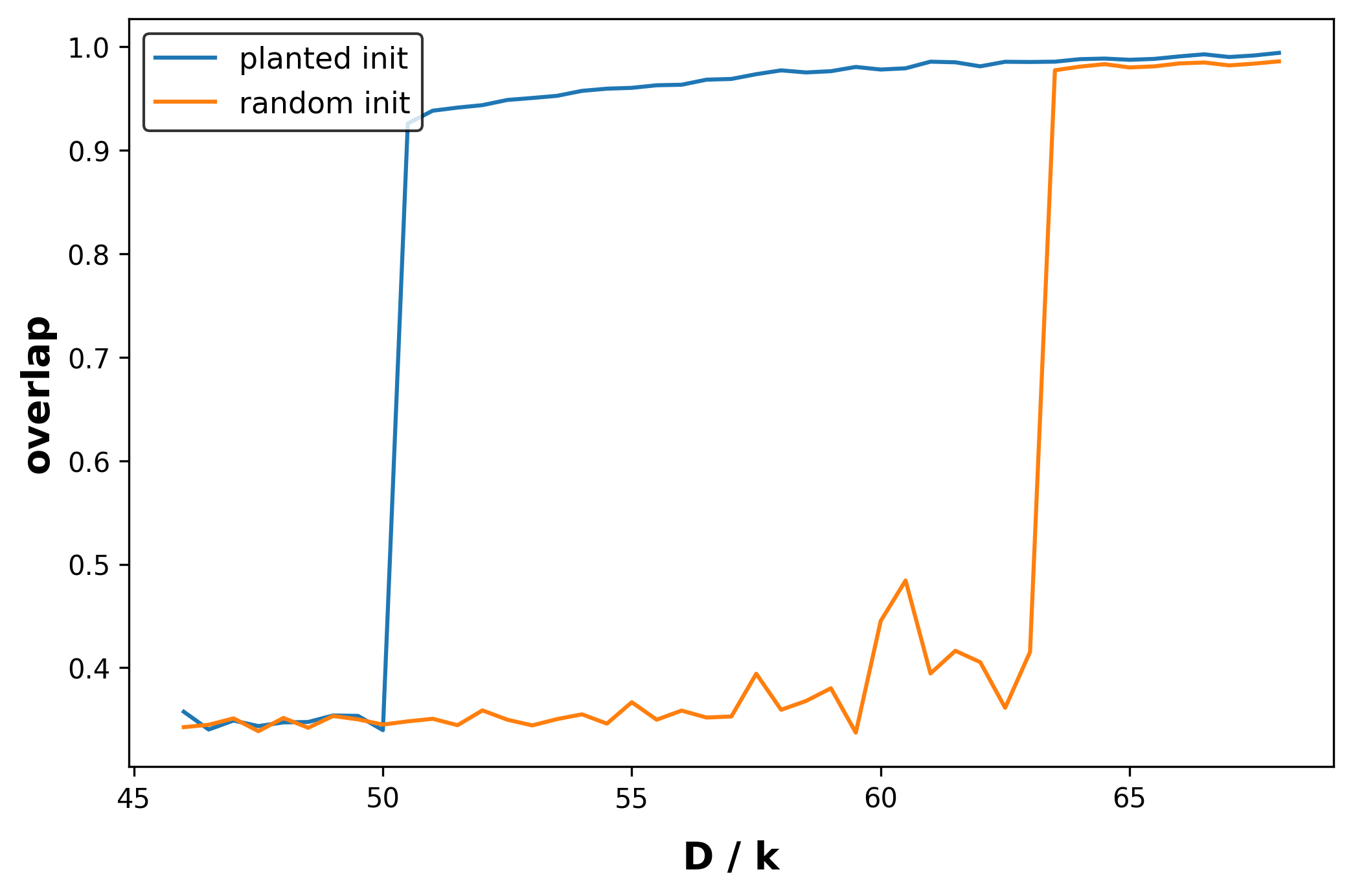
There are precise predictions for the values of vocabulary size and the number of observations for which the information-theoretically best possible overlap and the best overlap achievable by any computationally efficient algorithm are different. We show that these predictions directly translate to predictions about when masking problems become computationally intractable:
💭 Click to ask about this figure
As a simple example, let us consider sparse predicate observations with and . These can be formally related to the well-studied problem of planted -coloring. In the planted -coloring, a random graph of average degree is sampled consistent with an unknown vertex coloring and the goal is to estimate the coloring as well as possible [48], as measured by the overlap of the output of the algorithm to the ground-truth coloring (see Definition 12). As a corollary of our main result, we show that when all the latent tokens are masked and a few unmasked observation tokens provide the information of the form for , then solving the masking problem can be reduced to solving planted coloring.
For planted -coloring, when the thresholds in Proposition 4 are given by and [48] (the factor of here is simply because the observations correspond to ordered subsets of size ). For general predicates and arities, there is an established recipe for numerically computing and based on the behavior of the belief propagation algorithm (see the discussion in Appendix B.4). As an example, in Figure 4, we execute this recipe for , , and given by the Not-All-Equal predicate to obtain thresholds that can be plugged into Proposition 4.
Additional examples of the hardness.
The above setup can also be generalized to capture Bayesian constraint satisfaction problems [49,50], one notable example of which is the stochastic block model [51]. There are analogous predictions for the onset of hardness of inference, which can likewise be translated to hardness of masking problems for seemingly benign L&O distributions. In Appendix B.1 and Appendix B.2, we give two more examples of L&O distributions for which order-aware training is tractable yet order-agnostic training of the MDM is computationally hard.
First, we consider L&O distributions whose observations are sparse, noisy parities in the latents and deduce hardness for order-agnostic training from the Sparse Learning Parity with Noise assumption [44]. We then consider L&O distributions whose observations are generalized linear models in the latents, and deduce hardness for a large class of efficient algorithms from existing results on Lipschitz hardness [45] for the symmetric binary perceptron [47].
B.4 Proof of Proposition 4: sparse predicate observations
Here we formally define the relevant notions needed to formalize our claim about hardness in Proposition 4.
Definition 12: Planted CSPs
Given arity , vocabulary/alphabet size , predicate , latent dimension , and clause density , the corresponding planted constraint satisfaction problem is defined as follows: Nature samples an unknown assignment uniformly at random from , and then for each ordered -tuple of distinct elements from , we observe the clause independently with probability if .
To measure the quality of an algorithm for recovering given the observations, define the overlap between an estimate and the ground truth by where denotes the set of all permutations of . Define the average degree to be , i.e. the expected number of variables that share at least one clause with a given variable.
We begin by defining the central algorithm driving statistical physics predictions about hardness for random constraint satisfaction problems: belief propagation (BP).
Definition 13: BP update rules
Belief propagation is an algorithm that iteratively updates a set of messages , where range over all pairs of variable indices and observations . At time , the messages are computed via
where assigns to entry and to the remaining entries.
A set of messages can be used to estimate the marginals of the posterior on conditioned on the observations as follows. The marginal on the -th variable has probability mass function over proportional to . Given a set of marginals, a natural way to extract an estimate for is to round to the color in at which the probability mass function is largest.
Throughout we will make the following assumption that ensures that the trivial messages and are a fixed point, sometimes called the paramagnetic fixed point, for the iteration above:
Assumption 14
The quantity is constant across all and .
Definition 15
Given , the Kesten-Stigum threshold is defined to be the largest average degree for which BP is locally stable around the paramagnetic fixed point, that is, starting from a small perturbation of the paramagnetic fixed point, it converges to the paramagnetic fixed point. More formally, is the largest average degree at which the Jacobian of the BP operator has spectral radius less than .
The condensation threshold is defined to be the largest average degree at which the planted CSP ensemble and the following simple null model become mutually contiguous and thus statistically indistinguishable as . The null model is defined as follows: there is no single unknown assignment, but instead for every ordered subset of variables, Nature independently samples an unknown local assignment , and the observation is included with probability if .
For , there exists some other fixed point of the BP operator whose marginals, once rounded to an assignment, achieves strictly higher overlap than does BP with messages initialized randomly. The prediction is that in this regime, no efficient algorithm can achieve optimal recovery [48].
Conjecture 16: 1RSB cavity prediction
Suppose satisfy Assumption 14, and let and denote the associated Kesten-Stigum and condensation thresholds for the average degree. Then for all for which , the best overlap achieved by a computationally efficient algorithm for recovering is strictly less than the best overlap achievable.
Proof of Proposition 4: At masking fraction satisfying the bounds in the Proposition, with probability at least we have that all tokens corresponding to latents get masked. Independently of this, the number of unmasked tokens among the observation tokens is distributed as , so by standard binomial tail bounds, with constant probability (depending on the gap between and ) this lies between and . Furthermore, of these unmasked tokens in expectation fraction of them correspond to observations for which the associated predicate evaluates to . Conditioned on the above events, the masking problem thus reduces exactly to inference for a planted constraint satisfaction problem at average degree , from which the Proposition follows.
C. Experimental details in Section 3
C.1 Experimental details in Section 3.2
-learner configurations.
We consider two distributions of that interpolate between where denote the uniform distribution over all permutations of indices and the point mass at the identical distribution: (Closer) and (Much-closer). To construct those distributions, we start from the identity permutation and perform a certain number of random swapping operations. Since number of swaps results in a distribution that is very close to [52], we use and swaps to construct the (Closer) and (Much-closer) distributions, respectively. For consistency, we repeat this sampling process three times.
Model and training configurations.
As explained in Section 3.2, to evaluate the scaling law of the -learner, we can simply adapt the autoregressive training setup (a transformer with causal attention) by modifying the input to and using a learnable positional embedding layer instead of RoPE. We borrow the training configurations from [8], which are also consistent with the TinyLlama [53] configurations. In particular, we use AdamW optimizer [54], setting , , and a weight decay of and . A cosine learning rate schedule is applied, with a maximum learning rate of and a minimum learning rate of . We also note that unless otherwise specified, we maintain the same training configuration throughout the paper.
Examining scaling laws.
We conduct IsoFLOP analysis [55]. For a given number of FLOPs , by varying the number of non-embedding parameters of transformers, we set the iteration numbers so that the total number of tokens observed by the model during training equals , following prior studies [55,56]. We then select the smallest validation loss and set it as a data point.
C.2 Experimental details in Section 3.3
C.2.1 Experiment on L&O-NAE-SAT distribution
We consider the L&O-NAE-SAT distribution with . For each example sequence from L&O-NAE-SAT, we pad the last tokens with an additional token value of . We employ a M MDM with RoPE and a maximum sequence length of . Then, this MDM is trained for iterations. To attain a proxy MDM for the Bayes optimal predictor, we further train it for iterations.
To measure the error across different tasks, we consider the following setup. For each , we randomly mask tokens in the latent positions and tokens in the observed positions. Across all masked prediction positions, , we measure the error for each position. For certainty, we repeat this process times. The result in Figure 2 corresponds to the case when , and we observe the same tendency for other values of .
C.2.2 Experiment on text data
We take a M MDM pretrained with text data for a baseline model. To measure the performance imbalance between likelihood modeling tasks
As done in the experiments in Section 3.2, we sample s from three different distributions: , (Closer), the point mass of identical distribution. For each case, we calculate the expectation over samples of .
D. Experimental details in Section 4
D.1 Experimental details in Section 4.2
D.1.1 Experiment on L&O-NAE-SAT distribution
We consider five instances of L&O-NAE-SAT: . For each distribution, we train a 19M MDM and measure the accuracy difference between vanilla inference and adaptive inference using top probability margin.
D.1.2 Experiment on text data
Top probability margin sampler with temperature.
To modify our inference for text data modeling, which does not have a determined answer, we found that adding a certain level of temperature to the oracle is useful. This is because the top probability margin or the top probability often leads to greedy sampling, which harms the diversity (entropy) of the generated samples. Therefore, we consider a variant of the oracle as follows, incorporating a Gaussian noise term .
Note that this approach has also been employed for unconditional sampling [26,14].
Generative perplexity and entropy.
We employ a 1.1B MDM pretrained on text data as a baseline. For each sampling step, we unconditionally generate samples using both vanilla and adaptive inference. Next, we calculate the likelihood using LLama2-7B as a baseline large language model. Moreover, we denote the entropy of a generated sample as , where .
Choice of number of tokens to unmask.
We set the number of tokens to unmask so that the number of unmasked tokens matches that of vanilla MDM inference in expectation. For an inference transition from step to , vanilla MDM expects unmasked. Accordingly, we choose . This choice keeps the number of revealed tokens balanced throughout inference. Alternatively, one can sample stochastically from . We found that both the deterministic and stochastic choices of result in comparable generative perplexity.
This choice of can be potentially helpful when the network is time-conditioned, since this keeps where is the max sequence length--matching the marginal that the model saw during training.
D.2 Experimental details on Sudoku and Zebra puzzles
Dataset.
For both Sudoku and Zebra puzzles, we use the dataset provided in [15] to train our model. To evaluate our model on the same difficulty tasks, we use the test dataset proposed in [15]. This dataset is created by filtering the puzzles from [28] that can be solved using a fixed list of 7 strategies. To create a hard dataset to evaluate easy-to-hard generalization, we use the remaining puzzles from [28] as they either require a new strategy unseen during the training and/or require backtracking. The hard dataset contains around 1M Sudoku puzzles.
Model, training, and inference.
For the training and inference, we use the codebase of [11] with keeping most of the hyperparameters default given in the codebase. For the Sudoku dataset, we use M GPT-2 model, and for the Zebra dataset, we use M model. We set the learning rate to 0.001 with a batch size of 128 to train the model for 300 epochs. For the inference, we use 50 reverse sampling steps using the appropriate strategy. Additionally, we add Gumbel noise with a coefficient of 0.5 to the MDM inference oracle .
D.3 Experimental details on LLaDA-8B
Our evaluation covers two task categories: (i) infilling(HumanEval-Infill and ROCStories) and (ii) instruction–answering (Math). For instruction–answering tasks, we employ a semi-autoregressive sampling strategy, whereas for infilling tasks we retain the non-autoregressive approach. For infilling tasks, the output length is predetermined—matching the size of the masked span—whereas instruction–answering tasks require an explicit length specification. For the latter, we follow the sampling configuration of [27].
For HumanEval-Infill, we adopt the problem set introduced by [57]. Each instance is grouped by the span of the masked code—the region the model must infill—into three categories: single-line, multi-line, and split. The task difficulty rises as the length of the masked span increases.
E. Omitted proofs
Proof of Proposition 1: We build on Proposition 3.1 from [9] to obtain the result of Proposition 1. We first re-state the result from [9] for the case when the denoising network does not depend on the noise-scale explicitly. Let be a sequence with tokens being masked from , and denotes the token value of the sequence . Let be the probability distribution corresponding to randomly and uniformly masking tokens of .
Proposition (Proposition 3.1 of [9]).
For clean data , let be the discrete forward process that randomly and uniformly masks tokens of .
Suppose the noise schedules satisfies and . Then, the MDM training loss Equation 1 can be reformulated as
To obtain an alternative formulation of Equation 4, we expand the expectation . Since there are total positions of , we have the probability assigned for each equals . Therefore, expanding the above equation with the expectation and treating as for some set of size , we obtain the result.
E.1 Equivalence between the MDM loss and any-order autoregressive loss
In this section, we will demonstrate the equivalence for MDM loss and any-order autoregressive loss. In particular, for all , we show
We now consider and and count the number of that induces a specific term . To induce the term, for a given and , must satisfy
The number of that satisfies above is . Using this and the number of total permutations is , we obtain the result.
References
[1] Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
[2] Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. ICLR, 2021.
[3] Austin, J., Johnson, D. D., Ho, J., Tarlow, D., and van den Berg, R. Structured denoising diffusion models in discrete state-spaces. NeruIPS, 2021.
[4] Lou, A., Meng, C., and Ermon, S. Discrete diffusion modeling by estimating the ratios of the data distribution. ICML, 2024.
[5] Hoogeboom, E., Nielsen, D., Jaini, P., Forré, P., and Welling, M. Argmax flows and multinomial diffusion: Learning categorical distributions. NeurIPS, 2021b.
[6] Sahoo, S., Arriola, M., Schiff, Y., Gokaslan, A., Marroquin, E., Chiu, J., Rush, A., and Kuleshov, V. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37:130136–130184, 2025.
[7] Shi, J., Han, K., Wang, Z., Doucet, A., and Titsias, M. K. Simplified and generalized masked diffusion for discrete data. NeurIPS, 2024.
[8] Nie, S., Zhu, F., Du, C., Pang, T., Liu, Q., Zeng, G., Lin, M., and Li, C. Scaling up masked diffusion models on text. arXiv preprint arXiv:2410.18514, 2024.
[9] Zheng, K., Chen, Y., Mao, H., Liu, M.-Y., Zhu, J., and Zhang, Q. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. arXiv preprint arXiv:2409.02908, 2024.
[10] Kitouni, O., Nolte, N. S., Williams, A., Rabbat, M., Bouchacourt, D., and Ibrahim, M. The factorization curse: Which tokens you predict underlie the reversal curse and more. Advances in Neural Information Processing Systems, 37:112329–112355, 2025.
[11] Ye, J., Gao, J., Gong, S., Zheng, L., Jiang, X., Li, Z., and Kong, L. Beyond autoregression: Discrete diffusion for complex reasoning and planning. arXiv preprint arXiv: 2410.14157, 2024.
[12] Gong, S., Agarwal, S., Zhang, Y., Ye, J., Zheng, L., Li, M., An, C., Zhao, P., Bi, W., Han, J., et al. Scaling diffusion language models via adaptation from autoregressive models. arXiv preprint arXiv:2410.17891, 2024.
[13] Chang, H., Zhang, H., Jiang, L., Liu, C., and Freeman, W. T. Maskgit: Masked generative image transformer. CVPR, 2022.
[14] Zheng, L., Yuan, J., Yu, L., and Kong, L. A reparameterized discrete diffusion model for text generation. arXiv preprint arXiv:2302.05737, 2023.
[15] Shah, K., Dikkala, N., Wang, X., and Panigrahy, R. Causal language modeling can elicit search and reasoning capabilities on logic puzzles. arXiv preprint arXiv:2409.10502, 2024.
[16] Lehnert, L., Sukhbaatar, S., Su, D., Zheng, Q., McVay, P., Rabbat, M., and Tian, Y. Beyond a*: Better planning with transformers via search dynamics bootstrapping. 2024.
[17] Ou, J., Nie, S., Xue, K., Zhu, F., Sun, J., Li, Z., and Li, C. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv preprint arXiv:2406.03736, 2024.
[18] Hoogeboom, E., Gritsenko, A. A., Bastings, J., Poole, B., Berg, R. v. d., and Salimans, T. Autoregressive diffusion models. arXiv preprint arXiv:2110.02037, 2021a.
[19] Soboleva, D., Al-Khateeb, F., Myers, R., Steeves, J. R., Hestness, J., and Dey, N. Slimpajama: A 627b token cleaned and deduplicated version of redpajama, June 2023.
[20] Kim, J., Kwon, S., Choi, J. Y., Park, J., Cho, J., Lee, J. D., and Ryu, E. K. Task diversity shortens the icl plateau. arXiv preprint arXiv:2410.05448, 2024.
[21] Tripuraneni, N., Jin, C., and Jordan, M. I. Provable meta-learning of linear representations. ICML, 2021.
[22] Maurer, A., Pontil, M., and Romera-Paredes, B. The benefit of multitask representation learning. JMLR, 17(81):1–32, 2016.
[23] Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 1706.05098, 2017.
[24] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S., and Scialom, T. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv: 2307.09288, 2023.
[25] Holtzman, A., Buys, J., Du, L., Forbes, M., and Choi, Y. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751, 2019.
[26] Wang, X., Zheng, Z., Ye, F., Xue, D., Huang, S., and Gu, Q. Diffusion language models are versatile protein learners. ICML, 2024.
[27] Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y., Wen, J.-R., and Li, C. Large language diffusion models. arXiv preprint arXiv:2502.09992, 2025.
[28] Radcliffe, D. G. 3 million sudoku puzzles with ratings, 2020. URL https://www.kaggle.com/dsv/1495975
[29] Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. ICML, 2015.
[30] Varma, H., Nagaraj, D., and Shanmugam, K. Glauber generative model: Discrete diffusion models via binary classification. arXiv preprint arXiv: 2405.17035, 2024.
[31] Liu, S., Nam, J., Campbell, A., Stärk, H., Xu, Y., Jaakkola, T., and Gómez-Bombarelli, R. Think while you generate: Discrete diffusion with planned denoising. arXiv preprint arXiv:2410.06264, 2024b.
[32] Xu, M., Geffner, T., Kreis, K., Nie, W., Xu, Y., Leskovec, J., Ermon, S., and Vahdat, A. Energy-based diffusion language models for text generation. arxiv preprint arXiv: 2410.21357, 2024.
[33] Liu, A., Broadrick, O., Niepert, M., and Broeck, G. V. d. Discrete copula diffusion. arXiv preprint arXiv:2410.01949, 2024a.
[34] Schiff, Y., Sahoo, S. S., Phung, H., Wang, G., Boshar, S., Dalla-torre, H., de Almeida, B. P., Rush, A., Pierrot, T., and Kuleshov, V. Simple guidance mechanisms for discrete diffusion models. arXiv preprint arXiv:2412.10193, 2024.
[35] Rector-Brooks, J., Hasan, M., Peng, Z., Quinn, Z., Liu, C., Mittal, S., Dziri, N., Bronstein, M., Bengio, Y., Chatterjee, P., et al. Steering masked discrete diffusion models via discrete denoising posterior prediction. arXiv preprint arXiv:2410.08134, 2024.
[36] Chen, H. and Ying, L. Convergence analysis of discrete diffusion model: Exact implementation through uniformization. arXiv preprint arXiv: 2402.08095, 2024.
[37] Golovneva, O., Allen-Zhu, Z., Weston, J., and Sukhbaatar, S. Reverse training to nurse the reversal curse. arXiv preprint arXiv:2403.13799, 2024.
[38] Chen, X., Chi, R. A., Wang, X., and Zhou, D. Premise order matters in reasoning with large language models. arXiv preprint arXiv:2402.08939, 2024.
[39] Liao, Y., Jiang, X., and Liu, Q. Probabilistically masked language model capable of autoregressive generation in arbitrary word order. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 263–274. Association for Computational Linguistics, 2020.
[40] Papadopoulos, V., Wenger, J., and Hongler, C. Arrows of time for large language models. arXiv preprint arXiv:2401.17505, 2024.
[41] Peng, F. Z., Bezemek, Z., Patel, S., Yao, S., Rector-Brooks, J., Tong, A., and Chatterjee, P. Path planning for masked diffusion model sampling. arXiv preprint arXiv:2502.03540, 2025.
[42] Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp.\ 4171–4186, 2019.
[43] Shih, A., Sadigh, D., and Ermon, S. Training and inference on any-order autoregressive models the right way. NeurIPS, 2022.
[44] Alekhnovich, M. More on average case vs approximation complexity. In 44th Annual IEEE Symposium on Foundations of Computer Science, 2003. Proceedings., pp.\ 298–307. IEEE, 2003.
[45] Alaoui, A. E. and Gamarnik, D. Hardness of sampling solutions from the symmetric binary perceptron. arXiv preprint arXiv:2407.16627, 2024.
[46] Gamarnik, D. The overlap gap property: A topological barrier to optimizing over random structures. Proceedings of the National Academy of Sciences, 118(41):e2108492118, 2021.
[47] Aubin, B., Perkins, W., and Zdeborová, L. Storage capacity in symmetric binary perceptrons. Journal of Physics A: Mathematical and Theoretical, 52(29):294003, 2019.
[48] Krzakala, F. and Zdeborová, L. Hiding quiet solutions in random constraint satisfaction problems. Physical review letters, 102(23):238701, 2009.
[49] Montanari, A. Estimating random variables from random sparse observations. European Transactions on Telecommunications, 19(4):385–403, 2008.
[50] Liu, S., Mohanty, S., and Raghavendra, P. On statistical inference when fixed points of belief propagation are unstable . In 2021 IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS), pp.\ 395–405. IEEE Computer Society, 2022.
[51] Decelle, A., Krzakala, F., Moore, C., and Zdeborová, L. Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications. Phys. Rev. E, 84:066106, Dec 2011.
[52] Bormashenko, O. A coupling argument for the random transposition walk. arXiv preprint arXiv: 1109.3915, 2011.
[53] Zhang, P., Zeng, G., Wang, T., and Lu, W. Tinyllama: An open-source small language model. arXiv preprint arXiv: 2401.02385, 2024.
[54] Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
[55] Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
[56] Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[57] Bavarian, M., Jun, H., Tezak, N., Schulman, J., McLeavey, C., Tworek, J., and Chen, M. Efficient training of language models to fill in the middle, 2022. URL https://arxiv.org/abs/2207.14255