SPECTRAL LENS: ACTIVATION AND GRADIENT SPECTRA AS DIAGNOSTICS OF LLM OPTIMIZATION
ANDY ZEYI LIU
Department of Applied Physics, Yale University, New Haven, CT 06511, United States
ELLIOT PAQUETTE
Department of Mathematics and Statistics, McGill University
JOHN SOUS
Department of Applied Physics, Yale University, New Haven, Connecticut 06511, USA
Energy Sciences Institute, Yale University, West Haven, Connecticut 06516, USA
Abstract
Training loss and throughput can hide distinct internal representation in language-model training. To examine these hidden mechanics, we use spectral measurements as practical and operational diagnostics. Using a controlled family of decoder-only models adapted from the modded NanoGPT codebase, we introduce an empirical protocol based on activation covariance and per-sample gradient SVD spectra. This dual-view reveals three empirical findings and one mechanistic explanation. First, batch size acts as a latent determinant of representation geometry: runs that reach equal loss settle into systematically distinct activation spectra. Second, the activation covariance tail measured early in training reliably forecasts downstream token efficiency. Third, movement of the activation spectrum head (leading modes), together with gradient spectra, characterizes underlying learning-dynamics changes, separating learning-side architectural improvements from primarily execution-side gains. These predictive and diagnostic signals persist across the 12-, 36-, and 48-layer model tiers. Finally, a mechanistic model proves the main observations and explains how activation covariance spectra correlate with task-aligned feature learning. Our code is available here.
E-mail addresses: [email protected], [email protected], [email protected].
Date: May 8, 2026.
Executive Summary: Training large language models is typically guided by aggregate metrics such as loss curves and tokens processed. These scalars often mask substantial differences in how models internally organize information, leaving practitioners without reliable ways to diagnose why one training run outperforms another or to choose among competing optimizations. The authors therefore developed spectral diagnostics—measurements of the shape of activation covariances and per-sample gradient singular values—to expose hidden structure in representation geometry and update dynamics.
The work set out to determine whether these spectra could serve as practical, transferable diagnostics: specifically, whether they could distinguish internal states that loss alone cannot, forecast which batch sizes will be most token-efficient, and classify whether a given architectural change primarily accelerates learning or merely speeds execution.
The study combined controlled experiments on decoder-only transformers (12- to 48-layer models up to 3.57 billion parameters, trained on FineWeb subsets) with a mechanistic toy model based on modular arithmetic. Activation spectra were obtained from centered covariance matrices of hidden states at selected layers; gradient spectra came from singular-value decompositions of per-sample gradients at the final attention output projection. All comparisons were performed at matched loss, and an early-training tail exponent was tested for predictive power. A simplified Fourier-feature model then supplied closed-form explanations for the observed patterns.
Three central findings emerged. First, models that reach identical validation loss under different effective batch sizes settle into systematically different activation spectra; the separation is reproducible, larger under the Muon optimizer than under Adam, and preserved when depth and context length increase. Second, the shape of the activation-spectrum tail measured at roughly 20 % of training progress ranks batch tiers by final token efficiency with high within-family correlation (Spearman ρ ≈ 0.95–0.97) and remains reliable at 36- and 48-layer scale. Third, activation-head movement and gradient concentration cleanly separate interventions that reshape learned representations from those that primarily improve throughput, yielding a practical four-category taxonomy of architectural gains.
These results matter because they give training teams an early, inexpensive signal that can guide batch-size selection, flag whether an optimization is truly advancing capability or merely accelerating execution, and reduce reliance on expensive full-scale ablations. If adopted, the diagnostics could shorten the iteration cycle for both research and production runs while improving the chance that reported gains reflect genuine representational progress rather than hidden differences in geometry or schedule.
The most immediate next steps are to close the loop by feeding spectral feedback into online batch-size or learning-rate controllers, to test whether the same early-tail signal predicts downstream zero-shot or few-shot performance, and to extend the taxonomy to mixture-of-experts architectures. Practitioners should also verify the protocol on their own data mixtures and loss targets before relying on it for critical decisions.
The evidence rests on decoder-only models, pre-training loss targets, and cumulative intervention chains; the toy model is an abstraction rather than a faithful replica of language. Within these bounds the empirical patterns are consistent across scales and ablations, but extrapolation beyond the tested regime should be treated as provisional until further data are collected.
1. Introduction
Section Summary: Large language models are typically trained by following scaling rules that link more computing power, data, and model size to steady drops in training error and better overall performance. Yet simply tracking those error reductions gives an incomplete picture, since the model's internal organization can shift in complex and uneven ways that error measurements overlook. This work explores internal patterns of how information spreads across dimensions as a more reliable guide for forecasting training efficiency and comparing different design choices as models grow larger.
The optimization of large language models is largely guided by neural scaling laws, which predict that training loss evolves predictably with compute, data, and model size ([1, 2]). Downstream capabilities then appear to be unlocked largely as a function of improving loss ([3, 4, 5]). Yet, training loss alone often creates an optimization mirage: while training loss decreases smoothly and monotonically, it offers an incomplete account of internal learning, masking profound, non-monotonic transformations in the model's internal structure ([6, 7]). This disconnect exposes a critical blind spot: if loss fails to capture how these internal geometries change, how can we reliably diagnose and tune the training process? Choosing training regimes proactively rather than merely summarizing them post hoc requires a deeper understanding of how internal representations are affected by practitioner choices.
Spectral probes offer a natural lens here. We focus on the heavy-tail exponent ($\alpha$), which summarizes how variance is distributed across internal dimensions and connects naturally to scaling-law efficiency ([8, 9]). Crucially, these spectral signatures scale: diagnostic patterns observed in small-scale models transfer predictably to larger tiers, providing a stable protocol for forecasting dynamics as models grow in depth and parameter count.
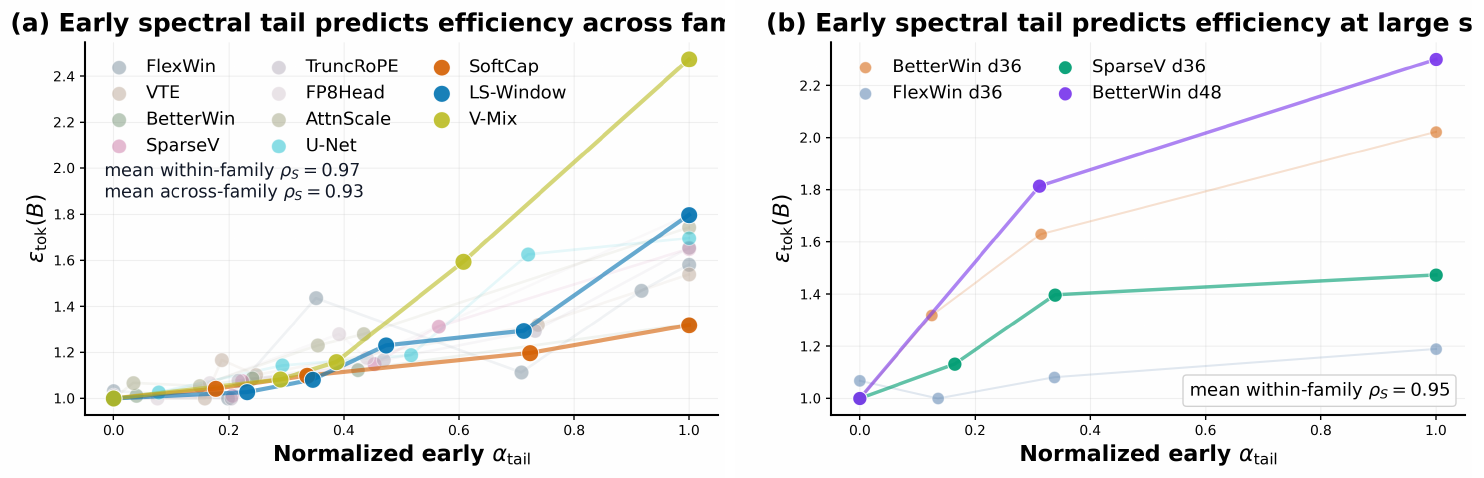
Our empirical study proceeds in two stages: a systematic scan of decoder-only models to identify transferable spectral signatures, followed by a toy-model analysis for mechanistic grounding. Using the modded-NanoGPT codebase ([10]), we generate a controlled intervention chain and evaluate diagnostics across layer tiers. Figure 1 previews these results: we identify internal geometries that diverge despite matched loss (Figure 1 a), demonstrate that early-training signatures identified in 12-layer runs reliably predict the token-efficiency of 36- and 48-layer models up to 3.57B parameters (Figure 1 b), and categorize architectural optimizations along a learning-versus-throughput axis (Figure 1 c). Finally, we ground these empirical observations in a modular-arithmetic toy model where Fourier structure makes task-relevant feature learning directly observable.
Main Results & Contributions

Related work.
Spectral measurements have been used as descriptive windows into representation and optimization geometry, including eigendecay and effective-rank summaries of activation covariance ([6, 11, 12]), gradient-subspace concentration and Hessian outliers ([13, 14, 15]), and heavy-tailed exponents connecting spectral decay to batch-size effects and scaling-law efficiency ([16, 8, 17]). The role of batch size in shaping internal geometry and efficiency has been studied via sharp versus flat minima ([18]) and gradient noise scale ([19]). In contrast, we use activation and gradient spectra as operational diagnostics for hidden batch-induced geometry, early token-efficiency prediction, and intervention-level mechanism differences. Additional related work is in Appendix A.
2. Preliminaries
Section Summary: The preliminaries explain how the authors analyze transformer models by examining the internal hidden states and optimization behavior through spectral methods rather than final outputs alone. They form covariance matrices from collections of activation vectors at chosen layers, extract and normalize the eigenvalues to reveal power-law decay patterns, and fit exponents over rank windows that shift with model size to focus on the unresolved tail of the spectrum. The same approach is applied to matrices of per-sample gradients for specific weight matrices, allowing comparisons of representation structure and update concentration at matched loss levels, while training efficiency is quantified by the tokens needed to reach target performance under different batch sizes within each architecture family.
A standard decoder-only transformer ([20]) maps token embeddings through $L$ residual blocks. Rather than evaluating only the final output, our spectral diagnostics probe intermediate representations within these blocks. For a chosen layer $\ell$, let $h_i^{(\ell)} \in \mathbb{R}^d$ denote a hidden state from a fixed held-out pool of validation sequences, reused across checkpoints and runs. Flattening all token positions from this pool yields an activation matrix $H_\ell \in \mathbb{R}^{N \times d}$, where $N$ counts token positions, and we estimate the centered covariance:
$ H_\ell = \begin{bmatrix} (h_1^{(\ell)})\dots (h_N^{(\ell)}) \end{bmatrix}^\top \in \mathbb{R}^{N \times d}, \quad \hat\Sigma_h = \frac{1}{N-1}\sum_{i=1}^N (h_i^{(\ell)}-\bar{h})(h_i^{(\ell)}-\bar{h})^\top. $
We compute the sorted eigenvalues $\lambda_1 \ge \lambda_2 \ge \dots \ge \lambda_d \ge 0$ of $\hat\Sigma_h$ and trace-normalize them as $\tilde\lambda_j = \frac{\lambda_j}{\sum_k \lambda_k}$. This keeps comparisons focused on spectral shape rather than raw scale. Following theoretical work linking spectral decay to neural scaling laws and kernel learning curves ([8, 21, 22, 23, 24]), we characterize the representation's power-law structure $\tilde{\lambda}_j \propto j^{-\alpha}$ by defining the band-restricted exponent $\alpha(I)$:
$ \alpha(I) := -slope\Big({(\log j, \log \tilde{\lambda}_j)}, {j \in I}\Big) $
where the slope is the least-squares fit in log-log coordinates. We evaluate $\alpha(I)$ over a pre-registered bank of expanding rank windows:
$ \mathcal{I}_{bank} = {[100, 200], [200, 400], [400, 800]} $
We define the scale-dependent diagnostic $\alpha_{\mathrm{tail}}$ as $\alpha(I^{(s)})$, where $s$ indexes the model scale—specifically $d12$, $d36$, and $d48$ for the 12-, 36-, and 48-layer models studied in this paper. Rather than fixing a single universal window across all scales, we select $I^{(s)}$ from $\mathcal{I}{\mathrm{bank}}$ according to model capacity. The motivation is that larger models possess more hidden dimensions and learn a larger number of resolved feature directions, so the boundary between the learned head and the unresolved tail of the activation spectrum sits at a higher rank. Measuring $\alpha$ over a window that is too low-rank for a large model would therefore probe already-learned features rather than the tail of interest. Concretely, we calibrate the informative window on the smallest scale ($I^{(d12)}=[100, 200]$) and shift it outward at larger scales ($I^{(d36)}=[200, 400]$, $I^{(d48)}=[400, 800]$). For even larger models, the same rule suggests continuing to the next window in the bank. This protocol allows $\alpha{\mathrm{tail}}$ to serve as a prospective diagnostic that remains comparable across scales.
Complementing the activation representations, we also probe the model's optimization dynamics. For a selected weight matrix $W \in \mathbb{R}^{d_{\mathrm{out}} \times d_{\mathrm{in}}}$ with $P = d_{\mathrm{out}} \cdot d_{\mathrm{in}}$ parameters, we compute per-sample gradients on a fixed held-out pool of validation sequences, where one sample means one validation sequence rather than one token. Let $g_m = \mathrm{vec}!\left(\nabla_W L_m(\theta)\right) \in \mathbb{R}^{P}$ denote the gradient of the mean autoregressive loss on sample $m$. Stacking $M$ such rows gives
$ G = \begin{bmatrix} g_1 \dots g_M \end{bmatrix}^\top \in \mathbb{R}^{M \times P}, $
and we analyze the singular value spectrum of $G$. Since $G$ is matrix-specific, gradient spectra are probe-dependent; we default to the final-block attention output projection $W_O$ and audit alternatives in Figure 6, which shows that matrix choice changes the detailed concentration and tail shape but not the qualitative diagnostic conclusions. The two spectra play complementary roles: activation spectra answer "where representation variance lives, "while gradient spectra answer "how concentrated the update is." To rigorously compare runs across these two views, we compare spectra under matched loss, matched tokens, and matched schedule fraction, focusing mainly on matched loss as it most sharply isolates differences in internal states despite identical performance.
Finally, for early prediction, each architecture family defines its own relative efficiency. We use effective batch size $B$ because, from the FixedWin modded-NanoGPT variant onward, the 65,536-token context forces local batch size 1 on a single GPU; $B$ therefore denotes the global batch induced by gradient accumulation.[^1] Let $T(B)$ be the total tokens required for a training run at effective batch size $B$ to reach a target validation loss. We evaluate efficiency via the within-family token ratio:
[^1]: Tokens per optimizer step scale as effective batch size times sequence length. The short-context prefix uses 1,024-token sequences, while the FixedWin-and-later long-context trunk uses 65,536-token sequences; see Table 1 and Appendix B.
$ \epsilon_{tok}(B) = \frac{T(B)}{\min_{B'}T(B')}, $
where the minimum is taken over the set of effective batch sizes $B'$ swept within the same architectural family.
2.1 Model architectures and training setup
Our experiments evaluate architectural variants and optimization techniques adopted from the modded-nanogpt codebase [10], as summarized in Table 1. These modifications form an incremental refinement path: each subsequent variant is cumulative, incorporating the optimizations of its predecessors. Full architectural dimensions, the sequence of concatenated code modifications, per-variant attributions, and validation of the spectral equivalence between the 100B-token and 10B-token FineWeb splits are detailed in Appendix B.
: Table 1: Experimental blocks and named model families. We summarize the core configurations here; exact architectural dimensions and cumulative code changes are detailed in Appendix B.
| Experimental block | Model families | Core setting |
|---|---|---|
| Variants 1–4 | Baseline, RoPE, Muon, Untied | d12 GPT-2-small scale models (1k context), trained on the 100B-token split of FineWeb. |
| Variants 5–16 | ValueMix, U-Net, FixedWin, FlexWin, VTE, BetterWin, SparseV, TruncRoPE, SoftCap, FP8Head, LSWA, AttnScale | d12 models trained on the 10B-token split of FineWeb. ValueMix and U-Net remain in the short-context regime; the 1k $\rightarrow$ 65k context shift occurs at U-Net $\rightarrow$ FixedWin. All regimes match a total batch budget of $\approx$ 0.5M tokens/step (bs8-equivalent). |
| Larger-scale robustness follow-up | FlexWin d36, BetterWin d36, SparseV d36; BetterWin d48 |
Scale-up runs testing generalization, scaling up to 48 layers and 32k context across multiple batch tiers. |
Throughout our language-model experiments, the main d12 comparisons target a validation loss of 3.2 on a fixed held-out validation set taken from the FineWeb-10B validation split. We use the 100B-token split of FineWeb ([25]) for earlier, less data-efficient variants, transitioning to the 10B-token split from the ValueMix variant onward. Unless noted otherwise, efficiency is measured strictly in training tokens consumed to reach this first target checkpoint, which we treat as a proxy for compute given the fixed model architecture and hardware setup within each comparison.
To ensure our spectral comparisons isolate batch-dependent geometry rather than under-tuned optimization, we perform ASHA-filtered learning-rate sweeps ([26]) for each batch tier prior to analysis (see Appendix B for the full sweep procedure). Thus, our matched-loss figures compare each tier under its own optimal schedule. We evaluate batch tiers $B \in {1, 2, 4, 8, 16, 32}$ for the 12-layer models, and $B \in {2, 4, 8, 16}$ for the d36 robustness follow-up described in Table 1.
2.2 Transition outcome coordinates
Our subsequent analysis studies consecutive transitions along the matched-total-batch intervention chain. For each architectural transition $a\rightarrow b$ on effective batch size 8 (see Table 1), we define the relative token and throughput gains:
$ TokGain(a!\rightarrow! b)=\frac{T(a)}{T(b)}-1, \qquad ThrGain(a!\rightarrow! b)=\frac{Q(b)}{Q(a)}-1, $
where $T(\cdot)$ is the number of training tokens required to reach the target loss, and $Q(\cdot)$ is the throughput in tokens per second. For visualization, we also use the log-gain coordinates:
$ g_{tok}=\log!\big(T(a)/T(b)\big), \qquad g_{thr}=\log!\big(Q(b)/Q(a)\big). $
3. Batch Size Leaves Distinct, Predictive, and Robust Spectral Signatures
Section Summary: The size of the training batch creates distinct patterns in a model's internal activation statistics, even among runs that reach identical loss values. These early patterns, particularly in the tail of the activation spectrum, can already forecast which batch size will prove most token-efficient for the remainder of training. The same spectral signatures remain reliable predictors when the approach is scaled to substantially larger and deeper networks.
With our spectral metrics established, we first apply them to reexamine a fundamental training variable: the effective batch size, and show that it is a fundamental driver of representational state. This section establishes three batch-size-specific findings. We find that batch size induces disparate activation covariance spectra. We then demonstrate that these spectral signatures are predictive, allowing us to identify the compute-optimal batch size early in the training process. Finally, we validate that these findings are scale-stable, showing that the signatures identified in 12-layer models generalize to 36- and 48-layer architectures.
- Matched loss does not imply matched geometry. Empirically, matched-loss runs within a given architecture settle into systematically different activation-covariance spectra, as demonstrated in Figure 1(a). We justify the universality of this observation in Appendix G, providing spectra across all tested model families and scales. Besides, since our architectural optimizations are cumulative, with most built upon the Muon optimizer, we perform a separate ablation study in Appendix D comparing Adam and Muon. We find that batch size remains a meaningful latent determinant under Adam, though Muon is more batch-sensitive, producing sharper head concentration and greater spectral separation. We provide a mechanistic analogue of this phenomenon in Section 5. This same toy model is used to mathematically demonstrate that equal loss does not guarantee an equivalent spectrum.
- Early spectra predict efficient tiers. As initially demonstrated in Figure 1 b, the early activation covariance tail exponent ($\alpha_{\mathrm{tail}}$) exhibits a strong positive correlation with the total training tokens required to reach a target loss. We expand this analysis in Figure 2 a by aggregating all depth-12 model variants across their respective batch-size tiers. To enable cross-variant comparisons, we apply a per-variant min-max normalization to the early $\alpha_{\mathrm{tail}}$ statistic, scaling each variant's raw values linearly so that its smallest exponent maps to 0 and its largest to 1.
This normalized view yields strong evidence that early spectra accurately diagnose proximity to the token-optimal batch size. We quantify this predictive power using the Spearman rank correlation ($\rho_S$) to measure monotonic alignment, where $\rho_S = 1$ indicates a perfectly monotonic relationship between the early diagnostic and final token efficiency. The high mean within-family correlation ($\rho_S = 0.97$) demonstrates that early $\alpha_{\mathrm{tail}}$ correctly orders the eventual token efficiency of batch tiers inside any given architecture. Furthermore, the across-family correlation ($\rho_S = 0.93$) on the pooled normalized data confirms that this transformation successfully aligns distinct architectures onto a shared efficiency axis. To track how this predictive signal develops, Appendix E provides an ablation study mapping the evolution of the correlation coefficient across training progress percentages. Finally, Section 5 provides a mechanistic interpretation of this empirical signal, where we demonstrate that flatter informative tails mathematically correspond to shorter remaining time-to-target when learning is bottlenecked by the recruitment of task-relevant tail features. 3. The predictive signal survives scale. Our larger-tier experiments confirm that both facets of this phenomenon generalize to the 36- and 48-layer architectures, including the 3.57B-parameter BetterWin d48 run. The d36 hidden-state panel in Figure 2 demonstrates that matched-loss spectral separation persists across batch tiers despite increased depth and context length. Crucially, the early predictive signal remains highly reliable; correlation analysis on the scaled d36/d48 models (Figure 2 b) yields a strong mean within-family correlation of $\rho_S=0.95$. In deeper models, the informative tail windows shifts to higher ranks, consistent with deeper models having a quantitatively higher rank of learned features.
Appendix E provides two controls for the early-prediction result. First, a random-seed control shows that FlexWin tier-16 runs initialized with different seeds cluster much closer to one another than to different batch tiers, supporting that the observed separation is driven by effective batch size. Second, a d36 layerwise ablation shows that the predictive signal is depth-sensitive: early and middle layers are weak or sign-inconsistent, while the deepest stored probe layer gives the strongest positive correlation across the available d36 families. This supports our convention of using the deepest available activation layer, while leaving full layer-selection rules to future work.
4. Spectral Taxonomy of Architectural Acceleration
Section Summary: Researchers analyzed a sequence of architectural changes to language models by measuring how each one boosted learning (token efficiency) versus speed (throughput), then used the spectra of activations and gradients to identify the underlying cause. This produced four clear categories of improvements: some primarily reshape what the model represents, others alter information flow and updates without changing the final representations much, a third group mainly speeds up computation, and a few create direct trade-offs between gains and costs. The approach shows that different kinds of design tweaks leave distinct geometric fingerprints in training dynamics rather than improving performance through a single mechanism.
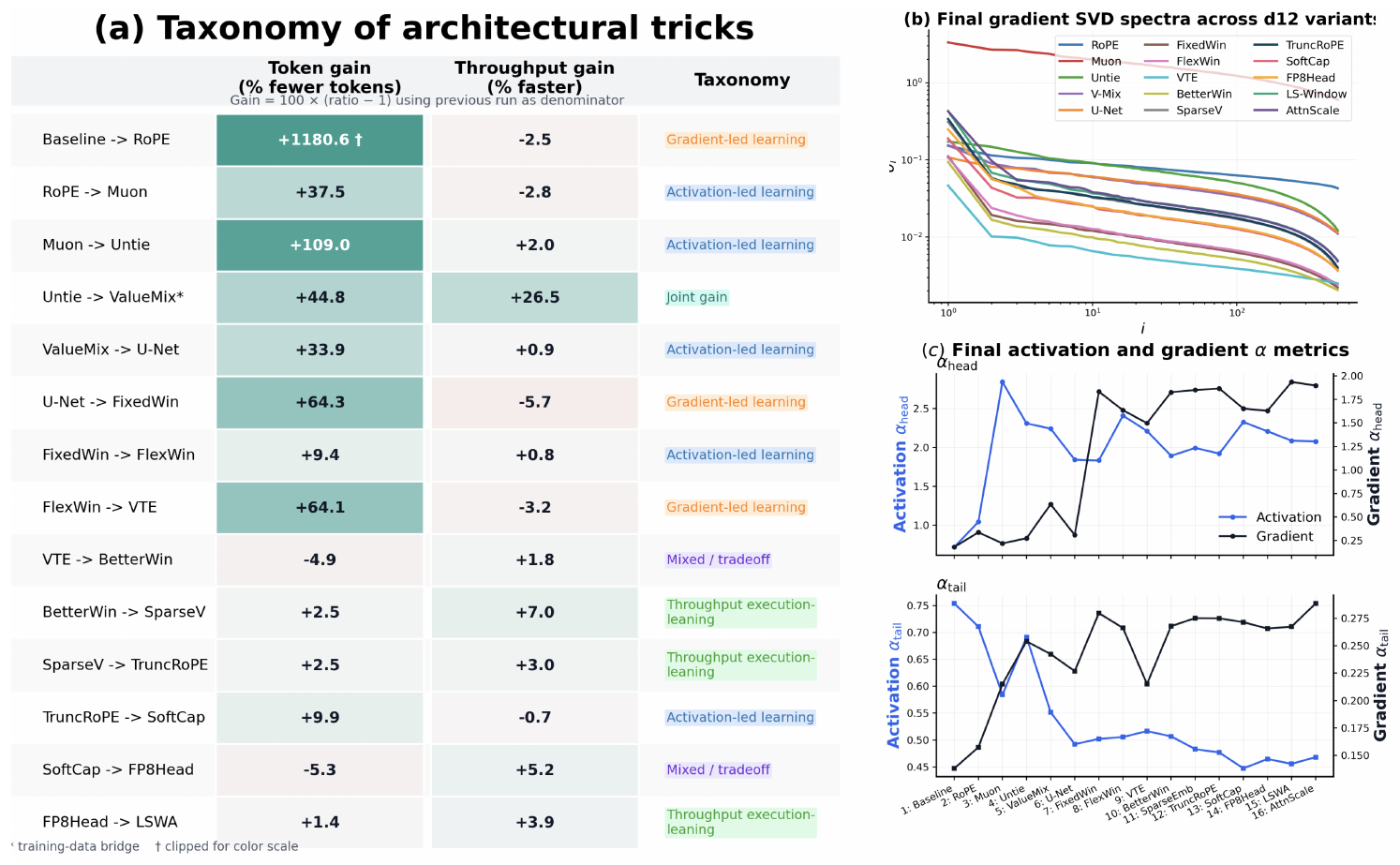
Our second main result turns the spectral framework into an optimization-level diagnostic. Moving beyond the batch-size analysis, we ask a different operational question: once an architectural intervention improves performance, how did it help?
We address this by placing each consecutive transition along our incremental refinement path onto two observable outcome axes: token gain and throughput gain (defined in Section 2.2). Since these architectural tricks are cumulative, the reported percentage changes represent the incremental improvement relative to the immediately preceding variant. As validated in Appendix B, the 100B-token and 10B-token splits of FineWeb produce nearly identical spectral signatures. Because of this baseline equivalence, we link the optimization tricks together regardless of the dataset split, evaluating the entire progression (variants 1–18) as a single, continuous chain in Figure 3 a.
While the outcome coordinates categorize performance, they lack a mechanistic explanation. To bridge this gap, we use activation covariance and gradient SVD spectra as in Figure 3(b–c) to diagnose the underlying geometric driver, classifying transitions into four explicit categories:
- Activation-led learning: The token gain corresponds to a clear displacement in final activation covariance spectrum, in particular $\alpha_{\text{head}}$. These are interventions that directly alter representational degrees of freedom or readout geometry (e.g., RoPE, untied heads, FlexWin, SoftCap).
- Gradient-led learning: The dominant geometric shift appears in the gradient spectra or checkpoint-wise path separation, even if the final activation endpoint remains relatively static. These typically involve modifications to routing or attention horizons (e.g., FixedWin, VTE).
- Throughput execution-leaning: These interventions primarily recondition execution cost or trade off learning dynamics for throughput. They encompass masking, kernel refinements, and optimizer tunings (e.g., SparseV, TruncRoPE, FP8Head).
- Mixed / tradeoff: The intervention improves one training objective while weakening the other comparably (e.g., positive token gain with negative throughput gain), thus failing to land cleanly in a single mechanistic bucket.
This diagnostic split aligns systematically with the underlying architectural mechanisms detailed in Appendix B. By examining the operational definition of each intervention, we can trace why specific tricks map to specific spectral outcomes:
Representational shifts manifest as activation-led learning. The clearest cases are transitions that directly expand or reshape the model's representational degrees of freedom. In Muon $\rightarrow$ Untied, removing the weight-tying constraint between token embedding and LM head expands the output-layer parameterization. In TruncRoPE $\rightarrow$ SoftCap, the bounded $\tanh$ reshapes the output geometry seen by the loss. In both cases, the dominant signature is a clear displacement in the final activation covariance spectrum.
Routing and horizon changes manifest as gradient-led learning. These transitions modify how information moves through the network without comparably large changes to the final readout space, leaving the activation endpoint relatively stable while changing the update path. U-Net $\rightarrow$ FixedWin replaces full causal attention with a sliding FlexAttention mask, altering which tokens interact rather than the feature space itself. FlexWin $\rightarrow$ VTE injects a layer-by-layer value-token embedding pathway, changing value routing. Both are evidenced empirically by sharper changes in gradient concentration and checkpoint-wise path separation than in the final activation endpoint.
Systems-motivated constraints manifest as throughput execution-leaning. These are late-trunk transitions whose main effect is to improve execution efficiency while producing comparatively smaller activation-side movement. BetterWin $\rightarrow$ SparseV trades dense value embeddings for sparse reusable tables, SparseV $\rightarrow$ TruncRoPE simplifies positional application, and FP8Head $\rightarrow$ LSWA primarily improves the execution side relative to the preceding row. Their common signature is clearer throughput gain than learning-side geometric displacement.
Crucially, this taxonomy relies on different spectral features than our earlier batch-size analysis. While early prediction (Section 3) depends on the activation tail—reflecting the distribution of unresolved mass—this architectural taxonomy is governed by activation head movement and gradient concentration. As mathematically grounded by our toy model (Section 5), head and gradient dynamics capture the shifting balance between learned and residual energy, rather than unresolved structural capacity.[^2]
[^2]: Phase-like geometry dynamics (collapse–expansion–compression) are also observable in our low-batch runs. However, because their visibility depends heavily on measurement alignment, we treat them as secondary qualitative evidence and defer the full analysis to Appendix G.
5. Mechanistic Model: From Spectral Signatures to Feature Learning
Section Summary: This section uses a simplified toy model of next-token prediction on cyclic sequences to explain why activation spectra can forecast and diagnose training progress. In the model the true task structure is known and directly expressed through a small set of Fourier characters, so changes in the spectrum can be compared with actual feature acquisition. Theoretical analysis of linearized and two-layer variants shows that flatter spectral tails predict faster later learning, concentration of mass on task-relevant Fourier modes tracks genuine feature emergence, and the tested tricks improve results by restoring cyclic symmetry, altering optimization geometry, or removing output bottlenecks; small-scale transformer simulations confirm these spectral signatures appear in practice.
Section 3–Section 4 show that spectra predict and diagnose training regimes empirically. This section explains why by studying toy tasks whose Fourier features are known, so activation spectra can be compared directly to task-aligned feature learning. Inspired by mechanistic interpretability and grokking studies on algorithmic and modular-arithmetic tasks (e.g., [27, 28, 29]), we introduce a controlled Fourier random feature model for next-token prediction where the latent task structure is analytically visible. Fix an integer cycle length $c \ge 2$, a step size $d \in {0, 1, \dots, c-1}$, an offset $o$, and a context length $L \ge 1$. For a latent phase $a \in \mathbb{Z}_c$, we define the clean single-component sequence and its target as:
$ x(a)=\bigl(o+(a+jd)\bmod c\bigr)_{j=0}^{L-1}, \qquad y(a)=o+(a+Ld)\bmod c. $
As the essential latent state is the phase $a$ on the finite cyclic group $\mathbb{Z}_c$, the natural representation coordinates are the Fourier characters $\chi_r(a)=e^{2\pi i r a/c}$ for $r \in {0, 1, \dots, c-1}$. These characters form an orthonormal basis on $\mathbb{Z}_c$, serving as a dictionary of fundamental Fourier random features.
To bridge these observables with our empirical taxonomy, we incrementally apply selected optimization tricks RoPE, Muon, and untied embeddings, to a baseline, allowing us to empirically track how each accelerates task-aligned feature learning (full protocol in Appendix F). To formally ground these observations, our theoretical analysis proceeds through models of increasing complexity. We begin with a linearized gradient-flow model, progress to a two-layer diagonal Fourier factor model, and finally analyze a full two-layer Transformer. The main results for each setting are outlined below with proofs detailed in Appendix F.4.
- Informal result 1: Tail shape predicts family-local token efficiency. Using a linearized gradient-flow model, we first prove that distinct batch regimes can achieve identical loss while possessing fundamentally different activation spectra. In the cyclic-shift core where Fourier modes diagonalize the dynamics, the activation spectrum under specialization develops a learned head and an unresolved tail with exponent $\alpha_{\mathrm{tail}}(B) = p + 2q_B$. The appendix proves a sharper "efficiency theorem" (Corollary 8): given two runs with the same matched early progress at an anchor rank, the run with the smaller (flatter) tail exponent $\alpha_{\mathrm{tail}}$ is guaranteed to reach any deeper task-relevant cutoff in fewer tokens. This establishes early spectral tails as a reliable mechanistic forecast for later efficiency, provided the comparison remains within an architectural family and a task-relevant fit window.
- Informal result 2: Task-band concentration tracks feature learning. The two-layer diagonal Fourier factor model makes feature learning visible as concentration of learned mass on the teacher-supported Fourier band. In this model, each learned Fourier coefficient $m_r(t)=u_r(t)v_r(t)$ follows a nonlinear gradient-flow equation: modes with teacher coefficient $\beta_r>0$ grow toward their target value, while modes with $\beta_r=0$ decay. Consequently, if the teacher signal lies in a task-relevant band $S$, the band-concentration statistic
$ H_S(t)=\frac{\sum_{r\in S} m_r(t)}{\sum_r m_r(t)} $
increases monotonically as long as both the in-band mass $\sum_{r\in S} m_r(t)$ and the off-band mass $\sum_{r\notin S} m_r(t)$ are nonzero (Appendix F.4, especially Corollary 12). This gives the theoretical reason to interpret increasing task-band concentration as feature learning in the toy model. 3. Informal result 3: RoPE, Muon, and untied readouts act through distinct geometric mechanisms. The appendix proves an intervention-aligned mechanism results for the three toy-model tricks. RoPE restores the task's cyclic symmetry at the attention-score level: scores are shift-equivariant and depend on position only through relative offsets, while nontrivial absolute positional tables generically break this equivariance (Theorem 13 and Proposition 14). Muon changes the optimization geometry, not the model class: replacing a matrix gradient by its polar factor is steepest descent for an operator-norm trust region, equalizing singular directions and acting as spectral preconditioning (Theorem 17). Untying the readout changes the model class: tied token-to-logit maps are confined to the embedding output subspace, while untied heads strictly enlarge the realizable class and remove this bottleneck (Theorem 15 and Corollary 16). Thus faster concentration of task-relevant Fourier mass can arise from three sources: symmetry bias, matrix-update geometry, or output-factorization freedom.
To connect the informal theory to an observable training process, we instantiate the cyclic task above with a small modular-arithmetic Transformer. The simulation uses a two-layer, four-head model and replays the cumulative prefix Baseline $\rightarrow$ RoPE $\rightarrow$ Muon $\rightarrow$ Untied while sweeping batch size. Because the latent phase and Fourier coordinates are known by construction, this setting lets us measure activation spectra, Fourier-mode energy, and feature concentration directly rather than treating spectra only as black-box diagnostics. Full training, replay, and probe details are given in Appendix F.
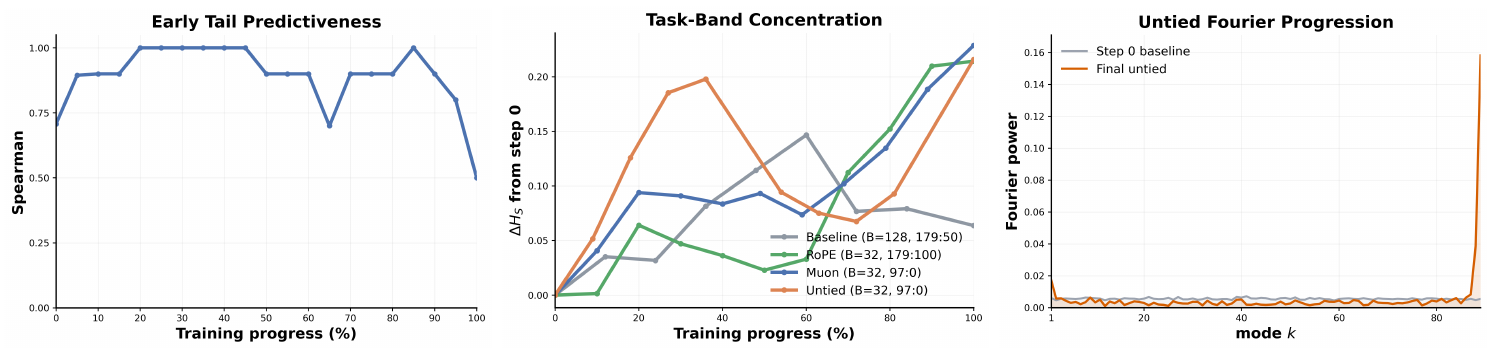
The simulation mirrors the larger-model phenomenon and then explains it in feature space. As in the main experiments, different batch sizes can reach comparable objectives while retaining distinct spectra; the matched-loss batch-spectrum control in Figure 11 in Appendix shows this directly. Figure 4 then asks whether those spectral differences correspond to feature recruitment. In Figure 4(a), the Muon local tail statistic reaches $\rho_S=1$ at roughly $20%$ of training progress, showing that early spectral shape can already rank later token efficiency. Figure 4(b) tracks the same task-band concentration statistic used in Informal Result 2, $H_S(t)=\sum_{r\in S}m_r(t)/\sum_r m_r(t)$: larger values mean that a greater share of hidden-state Fourier energy lies in the task-relevant band, so its growth indicates increasingly selective Fourier feature learning. Figure 4(c) makes the same transition explicit, with the step-0 grey curve spread broadly across modes and the final untied curve developing sharp spikes on a small number of Fourier modes. Together, these panels turn the spectral diagnostics from correlates of training into measurable signatures of task-aligned feature recruitment in the toy setting.
6. Conclusion
Section Summary: This research demonstrates that tracking patterns in model activations and gradients during training can reveal important details about large language models, such as optimal batch sizes and efficiency gains that standard loss metrics overlook. A simplified math example helps explain how these patterns connect to effective feature learning. The authors note limitations like a focus on training performance rather than real-world tasks, along with ideas for future refinements such as real-time adjustments based on these signals.
In this work we treat activation and gradient spectra as practical diagnostics for LLM training. Across batch sweeps and an architectural intervention chain, the same two measurements expose hidden batch-size regimes that scalar loss cannot distinguish, predict token efficiency from early activation-tail shape, and separate learning-side architectural gains from execution-side speedups. A modular-arithmetic toy model grounds these signals in task-aligned feature learning.
Limitations.
The current efficiency target is pretraining validation loss rather than downstream capability, so extending the same early-tail diagnostic to zero-shot or few-shot behavior remains an open question. Likewise, the present taxonomy is established on decoder-only cumulative intervention families and may require adaptation for MoE settings. Within this scope, the current analysis still compresses some detail: compact spectral summaries do not fully disentangle representation and systems changes in every variant, some early-prediction correlations are informative but still noisy, the informative tail window is selected by a stable empirical protocol rather than a fully automatic estimator, and the toy models are best viewed as mechanistic abstractions rather than faithful models of language. Natural next steps are online batch-size or learning-rate control from spectral feedback, layer-resolved diagnostics of how spectral signatures propagate through depth, and automatic rules for locating the resolved-head / unresolved-tail boundary.
Acknowledgements
Section Summary: The authors thank Atish Agarwala for useful discussions about the project. Funding for the work came in part from the Yale Office of the Provost, and the experiments were carried out on Yale’s Bouchet computing cluster. Researcher E.P. received further support through several grants from Canadian and U.S. agencies as well as a donation from Google Canada.
We acknowledge helpful discussions with Atish Agarwala. This research was supported in part by the Yale Office of the Provost and experiments were run on the Yale Bouchet Cluster. E. P was supported by an NSERC Discovery Grant RGPIN-2025-04643, an FRQNT–NSERC NOVA Grant, a CIFAR Catalyst Grant, an AFOSR grant and a gift from Google Canada.
Appendix
Section Summary: The appendix expands on related research connecting representation spectra, optimization dynamics, spectral learning theory, and Fourier-based analyses in tasks like modular arithmetic and grokking, showing how these ideas inform the study's use of activation spectra to track feature learning. It also details the experimental setup for the language-model tests, describing a sequence of cumulative architectural and optimizer changes applied to a GPT-2-style baseline along with the datasets and training choices used. These sections provide the broader context and implementation specifics supporting the main paper's spectral diagnostics.
A. Additional Related Work
The main paper uses spectra as operational diagnostics, so the closest prior work spans representation geometry, optimization spectra, spectral learning theory, and simplified models of algorithmic feature learning.
Representation spectra and effective-rank summaries.
RankMe ([12]) motivates the entropy effective rank as a compact unsupervised summary of representation spread, while $\alpha$-ReQ ([30]) uses eigenspectrum decay as a representation-quality signal in self-supervised learning. Covariance and dimensionality summaries also appear implicitly in redundancy-reduction objectives such as Barlow Twins and VICReg ([31, 32]), where representation collapse or excessive concentration is treated as a training pathology. In language models, anisotropy and low-dimensional dominant directions have long been observed in contextual embeddings ([33, 34]); these results motivate reporting the whole spectrum, or at least several spectral summaries, rather than relying only on raw cosine geometry. More recent work uses covariance eigendecay and geometry phases to study representation changes during pretraining and post-training ([6, 11]). The most directly related activation-spectrum precursor is Evolution of the Spectral Dimension of Transformer Activations ([35]), which studies heavy-tailed activation spectra and spectral-exponent evolution across layers and training. Our use is complementary: we test whether early and matched-loss spectra predict batch efficiency and distinguish architectural interventions.
Optimization-side spectra and heavy-tail views.
Optimization spectra provide a complementary lens on the update path. Prior work shows that gradient descent can concentrate in a low-dimensional subspace ([13]), stochastic-gradient covariance can exhibit power-law structure ([17]), and Hessian spectra contain informative outliers tied to data and class structure ([14, 15]). Heavy-tailed random-matrix analyses likewise connect spectral decay exponents to optimization regimes and batch-size effects ([16]), while scaling-law theory connects spectral structure to learning curves and generalization ([8, 36]). We therefore treat activation and gradient spectra as related but non-interchangeable measurements: one describes represented variance, the other describes update concentration.
Spectral learning theory and random-feature models.
The toy analysis starts from linearized gradient flow because, in kernel and random-feature regimes, eigenvalues of the feature covariance or kernel operator directly control learning rates across target components. Random Fourier features provide a controlled finite-dimensional approximation to shift-invariant kernels ([37]), and later learning-curve analyses make the dependence on kernel spectra and task alignment explicit ([22, 23, 24]). Recent nonlinear spiked-covariance theory studies related signal-propagation and feature-selection questions ([38]). This line of work motivates the appendix's first toy step: before studying transformers, isolate how a spectrum over Fourier modes shapes which task components are learned early, late, or not at all.
Fourier mechanisms in grokking and modular arithmetic.
Modular arithmetic is a natural second toy setting because the cyclic group has an explicit Fourier basis. The original grokking experiments showed delayed generalization on small algorithmic datasets, including modular tasks ([39]). Subsequent work connected these dynamics to structured representation learning and phase diagrams ([28]), reverse-engineered modular-addition transformers into Fourier-space circuits with continuous progress measures ([27]), and studied interpretable two-layer solutions for modular arithmetic ([29]). Recent analyses of two-layer modular-addition networks further emphasize single-frequency Fourier features, phase alignment, and gradient-flow competition among frequencies ([40]). Other grokking studies frame delayed generalization through competing subnetworks or early spectral signatures of the learning curve ([41, 42]). Our toy-model sequence follows this literature but uses it for a narrower purpose: to check whether the spectral diagnostics used in language-model experiments track task-aligned feature recruitment, rather than only measuring black-box covariance concentration.
B. Model Training Setup
This section elaborates on the architectural tricks, model cards, dataset choices, and learning-rate selection protocol used by the language-model experiments. The suite follows a cumulative intervention path: each later label inherits the implementation choices of the previous label unless the row states a new change.
B.1 Architectural tricks and variants
Table 2 integrates the intervention descriptions, external provenance, and mechanism-level grouping used throughout the paper. The table is intentionally descriptive rather than code-level: it names what changes in the model or optimizer and how that change should be interpreted in the spectral analysis.
: Table 2: Cumulative intervention catalog with mechanism groupings. The 16 named variants form a single incremental chain: each row inherits every prior row's changes and describes only its own delta. The Group column encodes the mechanism-level axis used in the spectral taxonomy of Section 4: positional control, optimizer, parameterization, value pathway, depth routing, attention geometry, and output/system path; allowing each transition's spectral signature to be read back against its architectural role. Provenance and contributor attributions follow the modded-NanoGPT record chain.
| Stage | Group | Incremental change | ** Provenance / reference** |
|---|---|---|---|
| Baseline | Reference trunk | GPT-2-small-style decoder with learned absolute positions, tied token embedding and LM head, dense causal attention, RMS normalization, and squared-ReLU MLPs. | GPT-2 ([43]); modded-NanoGPT record ([44]). |
| RoPE | Positional control | Replaces learned positions with rotary embeddings and explicit query/key/value projections; normalizes query/key states before rotation. | RoFormer ([45]); record ([46]). |
| Muon | Optimizer | Keeps the RoPE trunk but changes hidden-layer matrix updates to Muon; embeddings, LM head, and scalar/control parameters remain being trained with Adam. | Muon ([47]); record ([48]). |
| Untied | Parameterization | Unties the token embedding and LM head and assigns them separate optimizer groups. | Record ([49]). |
| ValueMix | Value pathway | Adds cross-layer value mixing through learned interpolation between the current value tensor and previous-layer value state. | Record ([50]). |
| U-Net | Depth routing | Adds encoder–decoder-style skip connections across the 12-layer stack. | U-Net ([51]); record ([52]). |
| FixedWin | Attention geometry | Replaces dense causal attention with document-aware local FlexAttention over a fixed horizon. | Record ([53]). |
| FlexWin | Attention geometry | Warms the local attention horizon during training instead of using one fixed window throughout. | Record ([54]). |
| VTE | Value pathway | Adds a dedicated value-token embedding pathway injected into the value stream. | Record ([55]). |
| BetterWin | Attention/value geometry | Refines the VTE/windowed trunk with split value embeddings, block sliding windows, and separate block masks. | Record ([56]). |
| SparseV | Value sparsity | Replaces dense per-layer value-token embeddings with a sparse reusable embedding pattern. | Record ([57]). |
| TruncRoPE | Positional shaping | Applies rotary phase information to only a subset of each head dimension. | Record ([57]). |
| SoftCap | Output shaping | Applies bounded logit soft-capping before the loss. | Gemma 2 ([58]); record ([59]). |
| FP8Head | Output/system path | Moves LM-head computation to an FP8 matrix-multiply path with explicit scaling. | FP8 formats ([60]); record ([61]). |
| LSWA | Attention geometry | Uses paired long and short attention masks assigned across layers. | Gemma 2 ([58]); record ([62]). |
| AttnScale/SubLR | Schedule controls | Rescales attention scores or selected parameter learning rates while keeping the late trunk fixed. | Record family ([62]). |
B.2 Model card and parameter counts
Table 3 gives the canonical tier notation used throughout the paper: d12, d36, and d48 refer to 12-, 36-, and 48-layer Transformer profiles, respectively. Table 4 then summarizes the model families and parameter counts used in the paper. Counts include registered trainable parameters and exclude buffers, masks, cached rotary tables, and other runtime state. All counts use the padded training vocabulary size of 50,304 tokens. Optimizer-only controls, such as the LSWA Adam comparison, therefore share the same parameter count as the corresponding architectural family.
: Table 3: Canonical model-tier notation. The paper names scale primarily by layer count: d12, d36, and d48 denote the 12-, 36-, and 48-layer profiles. Parameter ranges vary because architectural families differ in value-token embeddings, sparse value pathways, and output parameterization.
| Tier | Layers | Heads / width | Parameter range | Context length | Dataset split | Representative runs |
|---|---|---|---|---|---|---|
| d12 prefix | 12 | 6 / 768 | 123.57M–162.20M | 1, 024 | FineWeb-100B | Baseline, RoPE, Muon, Untied. |
| d12 trunk | 12 | 6 / 768 | 162.20M–625.80M | 65, 536 | FineWeb-10B | ValueMix through AttnScale. |
| d36 support | 36 | 20 / 1280 | 836.57M–2.00B | 32, 768 | FineWeb-10B | FlexWin, BetterWin, SparseV, AttnScale. |
| d48 support | 48 | 25 / 1600 | 1.87B–3.57B | 32, 768 | FineWeb-10B | BetterWin and SparseV scale follow-ups. |
: Table 4: Model-card summary with parameter counts. The 12-layer experiments use GPT-2-small-scale width unless otherwise noted. The d36 and d48 follow-ups use the larger long-context profiles. Scaled sparse-family counts use the runtime-resolved sparse attention pattern used in training. The largest completed robustness run reported in the paper is BetterWin d48 at 3.57B parameters.
| Family | Representative variants | Shape | Parameters | Training role |
|---|---|---|---|---|
| Baseline learned-position tied | Baseline | 12 layers / 6 heads / width 768 | 124.35M | Short-context reference. |
| RoPE tied | RoPE, Muon | 12 / 6 / 768 | 123.57M | Positional and optimizer prefix. |
| Untied RoPE | Untied | 12 / 6 / 768 | 162.20M | Output-parameterization control. |
| ValueMix | ValueMix | 12 / 6 / 768 | 162.20M | Cross-layer value mixing. |
| U-Net/fixed/flex | U-Net, FixedWin, FlexWin | 12 / 6 / 768 | 162.20M | Main local-attention trunk before VTE. |
| Full VTE | VTE | 12 / 6 / 768 | 625.80M | Dense value-token embedding pathway. |
| Half VTE / BetterWin | BetterWin | 12 / 6 / 768 | 394.00M | Split/reused value-token embedding pathway. |
| Sparse family | SparseV, TruncRoPE, SoftCap, FP8Head, LSWA, LSWA-Adam, SubLR | 12 / 6 / 768 | 275.74M | Late sparse value and output-shaping trunk. |
| Scaled U-Net/flex | FlexWin d36 | 36 / 20 / 1280 | 836.57M | Scale robustness for the local-attention trunk. |
| Scaled BetterWin | BetterWin d36 / d48 | 36 / 20 / 1280 or 48 / 25 / 1600 | 2.00B / 3.57B | Largest half-VTE robustness runs. |
| Scaled sparse family | SparseV d36 / d48, AttnScale d36 | 36 / 20 / 1280 or 48 / 25 / 1600 | 1.02B / 1.87B | Larger sparse-trunk support. |
The scaled full-VTE profile is larger than the half-VTE BetterWin profile, but the completed scale-robustness analysis reported here uses BetterWin and sparse-family follow-ups. We therefore reserve the "largest run" statement for the completed BetterWin d48 experiment rather than for every model profile that can be instantiated by the architecture.
B.3 Training specifics
The short-context prefix variants use sequence length $1{,}024$ and the 100B-token FineWeb sample for training; the long-context variants uses sequence length $65{,}536$ for the 12-layer runs and the 10B-token split for training. The d36 and d48 robustness runs use the long-context family with sequence length $32{,}768$. All 12-layer runs are trained on a single H200; the d36/d48 follow-up uses a single B200. Unless stated otherwise, the main d12 comparisons target validation loss 3.2 on a fixed held-out validation set drawn from the FineWeb-10B validation split, which is reused across the 100B/10B training-data bridge. Token efficiency is measured by the number of training tokens consumed before the first checkpoint meeting that target.
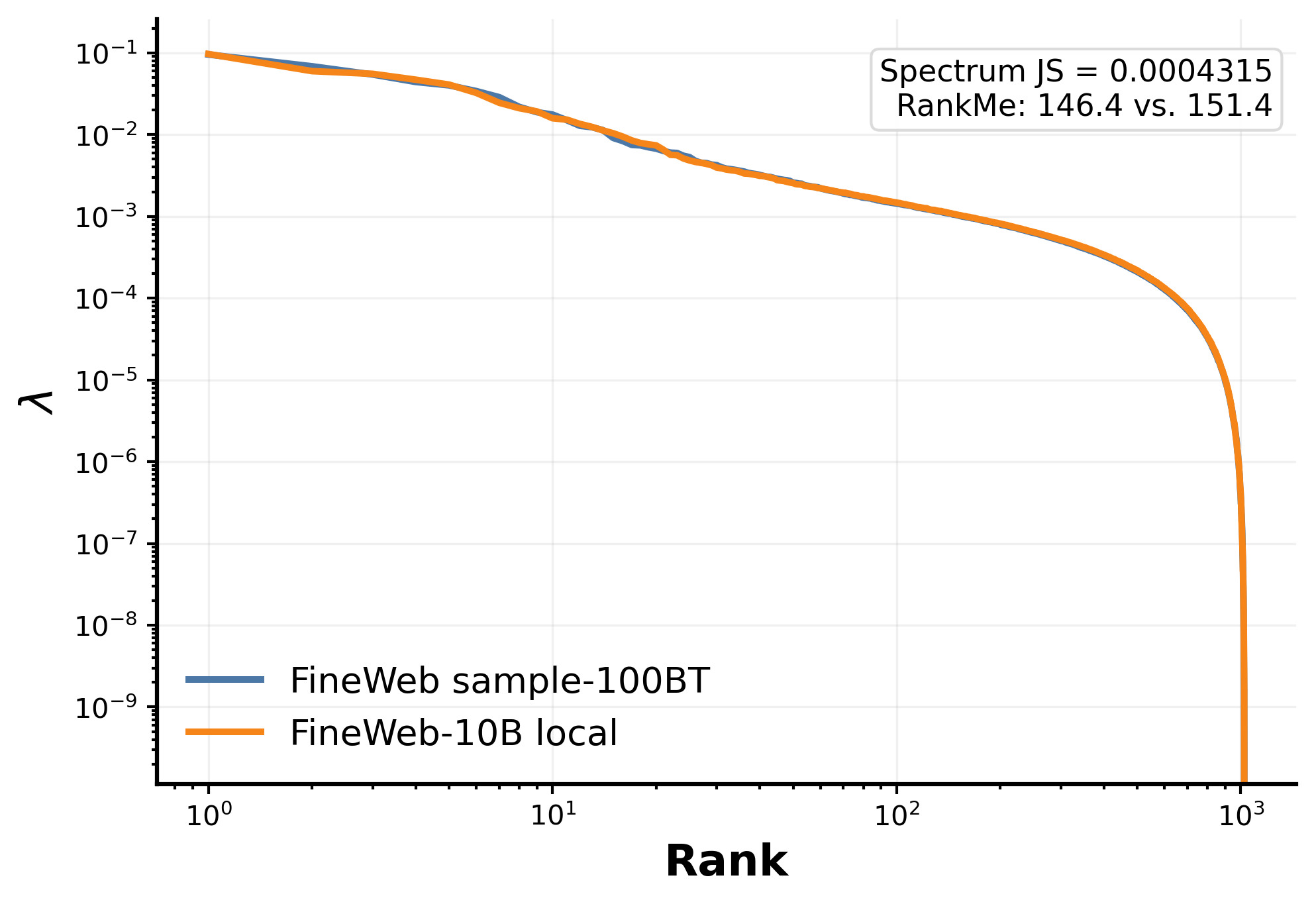
FineWeb is a cleaned English CommonCrawl corpus drawn from 96 dumps spanning 2013 through April 2024 and containing approximately 15 trillion GPT-2 tokens ([25]). The two sampled splits are used for practical reasons: less token-efficient early variants are run on the 100B-token sample, while later variants use the 10B-token split. To verify that this switch does not introduce a spectral confound, we compare $1{,}024$ windows of $1{,}024$ tokens from the local FineWeb-10B shard against the Hugging Face FineWeb sample-100BT split. As shown in Figure 5, the covariance spectra nearly overlap: the Jensen–Shannon divergence between the two splits is $4.31 \times 10^{-4}$, well below the run-to-run variability observed in the same spectral diagnostic. This supports treating the two data samples on a common spectral scale while explicitly noting the protocol difference.
Spectral measurement protocol.
Spectra are extracted from deterministic prefixes of a held-out validation shard and reused across checkpoints and runs within each family. From FixedWin onward in the main d12 trunk, we use $T=65{,}536$, 512 validation sequences for activation covariance, and 512 validation sequences for per-sample gradient SVD, with covariance batch size=2 and gradient batch size=2; activation covariance therefore uses $N = 512 \times 65{,}536$ token-position rows. Before FixedWin, the short-context prefix uses the equivalent activation budget $32{,}768 \times 1{,}024$ and 512 gradient samples. Short-context targets are formed by shifting within a sequence and masking the last position, whereas the long-context trunk reads length- $(T+1)$ chunks so that each input token has a true next-token target.
Learning-rate selection.
Learning rates are selected separately for each model family and effective batch tier. The reference tier matches the tier-8 modded-NanoGPT token batch: 8 sequences for 65,536-token runs and 512 sequences for the 1,024-token prefix runs, with reference rates taken from the corresponding modded-NanoGPT configuration. Concretely, the tied AdamW prefix uses $6\times10^{-4}$; the Muon prefix uses embedding and hidden-matrix rates $(3.$ 6 $\times 10^{-3}, , 3.$ 6 $\times 10^{-4})$; the untied prefix uses $(0.3, , 0.002, , 0.02)$ for embedding, LM-head, and Muon; the long-context trunk uses $(0.6, , 0.008, , 0.04, , 0.04)$ for embedding, LM-head, hidden-matrix, and scalar/control parameters. The LSWA Adam control keeps the same embedding, head, and scalar rates but sets the Adam matrix rate to $0.004$.
To scale to a target tier $B$ from reference $B_0$, we form scaling centers $\sqrt{B/B_0}$ and $B/B_0$ and evaluate each at local multipliers ${0.5, , 1/!\sqrt{2}, , 1, , \sqrt{2}, , 2}$, deduplicating coincident candidates. Each multiplier is applied uniformly across all optimizer groups, preserving relative rates between parameter classes while varying the global step size.
All d12 variants sweep over ${1, 2, 4, 8, 16, 32}$; d36 uses ${2, 4, 8, 16}$ and d48 uses ${1, 2, 4, 8}$, subject to hardware constraints. Candidates are filtered by a synchronized successive-halving procedure ([26]): all candidates train to 50M tokens, survivors extend to 150M, and remaining candidates extend to 500M, with validation loss evaluated every 20M tokens. Promotion retains the top half at each rung, always keeping at least one survivor per family/tier pair. Power-law extrapolations to 1B tokens are recorded as diagnostics but do not drive promotion, which is based on observed validation loss at each rung. Final candidates were selected under the top-half rule throughout; a top-third rule used in early pilots was abandoned before the main sweep. The surviving configuration for each family and batch tier is then used for the final constant-loss spectral runs—a necessary step, since matched-loss spectral comparisons are only meaningful when each tier trains under its own well-tuned schedule.
C. Per-Sample Gradient Computation
For a hidden activation matrix $H\in\mathbb{R}^{N\times d}$ collected from a fixed measurement pool, we compute the centered covariance $C=N^{-1}(H-\bar{H})^\top(H-\bar{H})$ and analyze its eigenvalue spectrum after trace normalization. RankMe is the entropy effective rank,
$ \operatorname{RankMe}(C)=\exp\left(-\sum_j p_j\log p_j\right), \qquad p_j=\lambda_j/\sum_k\lambda_k, $
where $\lambda_j$ are the covariance eigenvalues. We also fit band-restricted power-law slopes $\lambda_j\propto j^{-\alpha}$ over head or tail rank windows; these exponents summarize whether variance is concentrated in leading modes or spread through a heavy tail.
For gradient spectra, choose a trainable weight matrix $W\in\mathbb{R}^{d_{\rm out}\times d_{\rm in}}$ and compute one loss gradient per sample from a fixed held-out pool of validation sequences, where one sample means one validation sequence. Writing $g_m=\operatorname{vec}(\nabla_W \ell_m)$ for the gradient of the sample-mean autoregressive loss on sample $m$, we stack the rows into
$ G=\begin{bmatrix} g_1^\top\ \cdots\ g_M^\top \end{bmatrix}\in\mathbb{R}^{M\times d_{\rm out}d_{\rm in}}, $
and analyze the singular values of $G$. This matrix is a tensor-specific view of update concentration, not a global invariant of the architecture. In the main text we standardize on the deepest saved attention-output projection because it is broadly available and directly measures attention writeback into the residual stream.
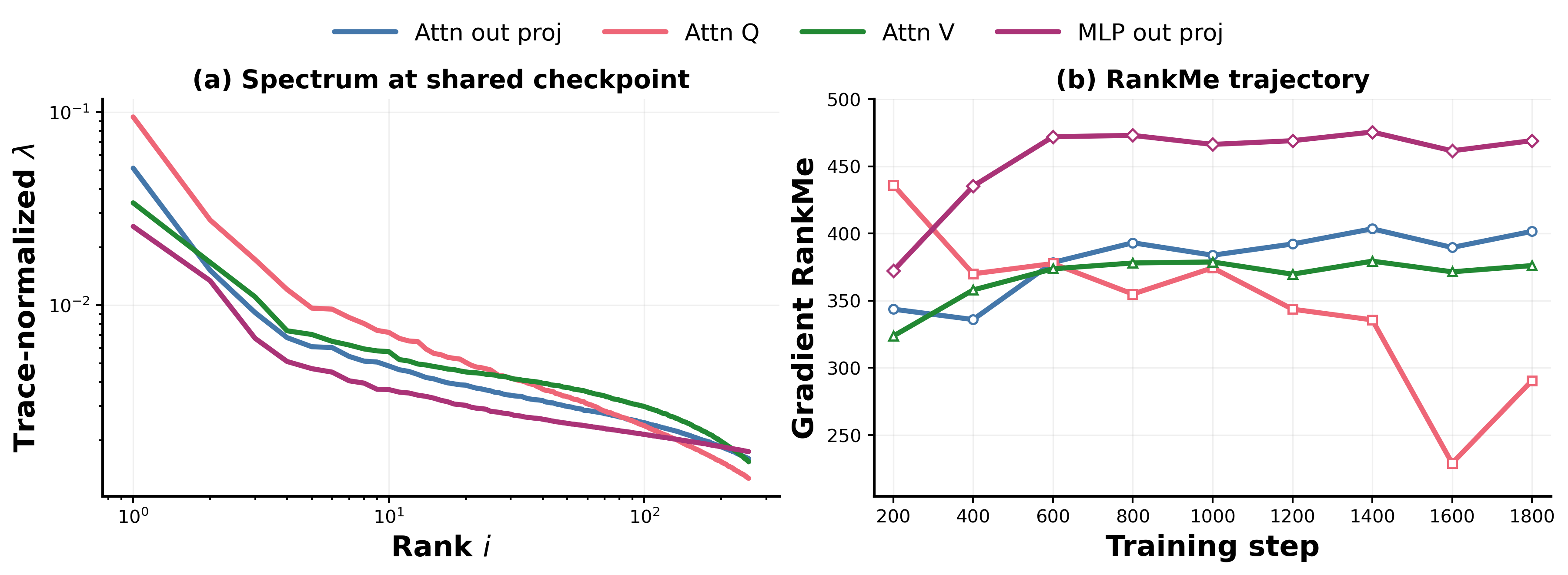
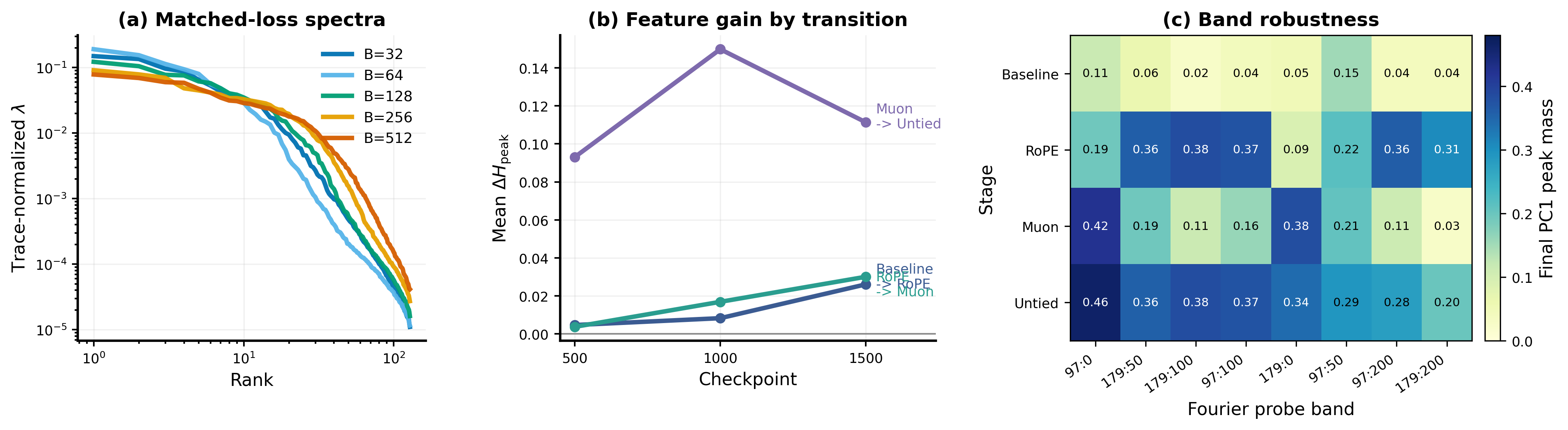
Figure 6 shows the matrix-choice dependence. Each weight matrix exposes a different stage of the attention computation. Query and key gradients reflect how the model is revising its attention routing, which positions or feature directions a token should attend to or be attended by, upstream of any content movement. Value gradients reflect how the model adjusts what content gets aggregated once routing is fixed: a large gradient here means the read-out per attended position is changing, not the selection pattern itself. Attention-output gradients capture something distinct from both: $W_O$ is the matrix that projects the concatenated multi-head outputs back into the residual stream, making it the unique write gate through which all attended content must pass before influencing downstream computation. Its gradient therefore summarizes the attention layer's net contribution to the residual stream after routing and content selection have both been applied. MLP-output gradients play the analogous role for the feed-forward pathway.
We use $W_O$ of the final attention block as our primary gradient probe for two reasons. First, it is the natural complement to the activation covariance spectrum: activation spectra answer what has been learned (the state of the residual stream), while $W_O$ gradients answer how the attention layer is currently updating that stream, giving the dual-view its interpretive coherence. Second, $W_O$ is the most stable probe across the intervention chain. Unlike $W_V$, whose shape and semantics shift when value pathways are restructured (ValueMix, VTE, BetterWin), and unlike $W_Q$ / $W_K$, whose routing role changes with attention geometry (FixedWin, FlexWin, LSWA), $W_O$ retains the same architectural role, attention writeback to the residual stream, across all 16 variants. This invariance is what allows gradient spectra to serve as a consistent comparative diagnostic along the full intervention chain. As Figure 6 confirms, the qualitative diagnostic conclusions are robust to this choice; the different probes differ in concentration level and tail shape but not in their implied taxonomic groupings.
D. Muon/Adam Comparison
Most later variants use a mixed optimizer: Adam-style updates for embeddings, the LM head, and scalar/control parameters, and Muon updates for hidden-layer matrix parameters. The batch-size phenomenon studied in Section 3, point 1 is therefore not automatically a property of Muon alone. To isolate this, we train the LSWA variant under both the standard mixed-Muon setup and an Adam matrix-update variant, keeping all other hyperparameters fixed.
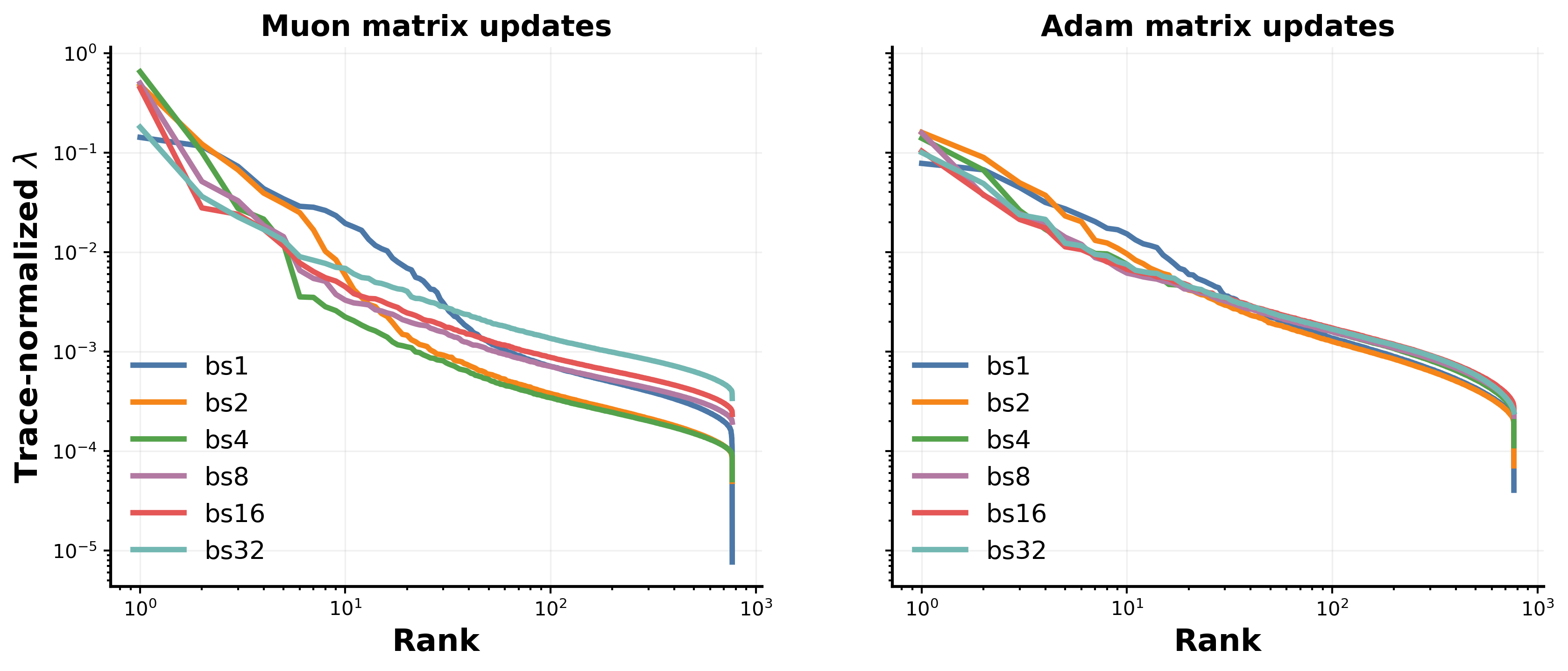
Figure 7 shows that the Adam control preserves the key qualitative result: equal architecture and different batch tiers still produce measurably different activation spectra. Muon amplifies this separation, particularly in the leading modes, but its existence under Adam confirms that effective batch size is a latent determinant of representation geometry, not merely an artifact of the matrix optimizer choice.
The amplified separation under Muon admits a natural mechanistic explanation from Theorem 17. Muon's update is the polar factor $Q(G)=UV^\top$ of the gradient matrix, which equalizes every nonzero singular direction to unit magnitude. This scale-balancing is exactly what gives Muon its preconditioning advantage, but it also makes the direction of each update sensitive to the singular structure of the empirical gradient $G$ itself. At small effective batch size, $G$ contains substantial mass in noise singular directions whose magnitudes scale as $\mathcal{O}(1/\sqrt{B})$, and orthogonalization treats these directions as equivalent to signal directions rather than down-weighting them by their amplitude. As $B$ grows, the noise singular values shrink relative to signal, and $Q(G)$ converges toward the polar factor of the population gradient. Adam's per-coordinate normalization, by contrast, rescales magnitudes coordinatewise but does not redistribute mass between singular directions at all, so its update direction depends less sharply on $B$. Concurrent work corroborates this picture by showing that Muon admits a substantially larger critical batch size than Adam under matched recipes, so the tiers swept here span more of Muon's rising compute-time curve and produce correspondingly larger trajectory differences.
Two practical implications follow. First, batch-tier selection is more consequential under Muon than under Adam: an Adam-tuned batch regime does not transfer cleanly, and the apparent within-architecture variance attributable to batch choice is larger when the matrix optimizer is Muon. Second, the spectral diagnostics introduced in this paper have higher discrimination value under Muon, which is consistent with the sharper batch separation visible throughout the main figures. The amplified batch dependence is not a pathology of Muon but a direct geometric consequence of replacing magnitude-aware updates with direction-equalizing ones.
E. Predictive Ablations
This section tests how robust the early-prediction story is to training progress, random seed, and probe layer. These ablations are intentionally narrower than the main result: they ask whether the diagnostic survives plausible measurement choices rather than claiming that one scalar is universally optimal.
E.1 Spearman correlation over training percentage
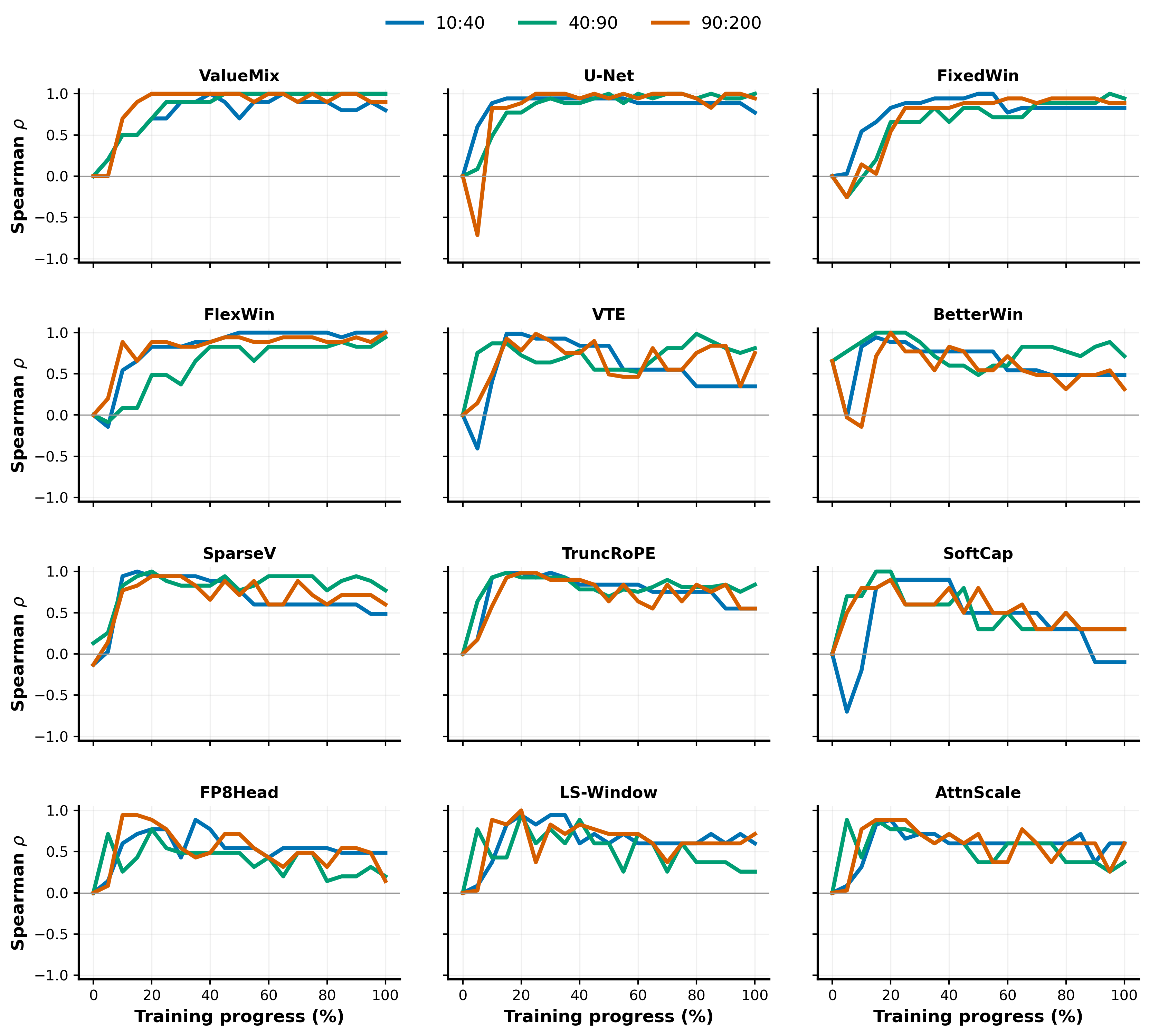
Figure 8 asks when the early-prediction signal becomes visible across the d12 variant chain. Each panel fixes one d12 model family and plots the Spearman correlation between a local activation-spectrum exponent and the final token-efficiency ranking of that family's batch tiers. The three curves correspond to power-law fits over progressively deeper rank windows of the trace-normalized activation covariance spectrum: ranks $10$ – $40$ probe the upper modes just past the leading head, ranks $40$ – $90$ probe an intermediate band, and ranks $100$ – $200$ correspond to the informative tail window used by our main early-prediction analysis (Eq. 3).
A unifying observation across all panels is that the deepest-window correlation peaks near roughly $20%$ of training progress, regardless of variant. This holds even for the variants where the signal is otherwise weak or noisy: FP8Head, LSWA, and AttnScale all attain their highest $\rho_S$ near the same early window before drifting downward over the rest of training. The $20%$ checkpoint is therefore not a feature of "easy" variants—it is a property of the diagnostic itself, and a practical one: once a variant has produced its peak early-tail signal, additional training does not improve and may erode the diagnostic. This is consistent with the mechanistic picture in Section 5, where early tail shape reflects which slow modes are still being recruited; once recruitment completes, that informative window closes. Beyond this shared peak time, the panels separate into three regimes that map cleanly onto the architectural groups in Table 2 and the taxonomy of Section 4.
Clean monotone signal in single-mechanism variants.
In ValueMix, U-Net, FixedWin, FlexWin, SparseV, and TruncRoPE, the deepest-window correlation rises smoothly, reaches its maximum around $20%$ progress, and holds near that maximum for the remainder of training. These variants share a structural property: each introduces a single, uniformly-applied change—one new value-mixing rule, one skip pattern, one window size, one sparsity pattern, or one rotary truncation—so the activation tail develops along a single timescale and the early shape stably ranks batch tiers throughout training.
Delayed-onset inversion in multi-component or amplitude-dependent variants.
In VTE, BetterWin, and SoftCap, the deepest-window correlation begins strongly negative and climbs to positive values during training, again peaking near $20%$ progress. Each of these variants introduces a structural mechanism whose effect on the tail emerges with delay rather than from initialization. VTE injects a dedicated value-token embedding pathway that must itself be learned before its spectral signature stabilizes; BetterWin simultaneously layers split value embeddings, block sliding windows, and separate block masks, requiring the three components to differentiate across blocks; and SoftCap's bounded $\tanh$ on logits is amplitude-dependent, behaving nearly linearly until logits enter the saturation regime later in training. In all three cases the early tail does not yet reflect the intervention's eventual geometry, producing transient anti-correlation that resolves as the new component specializes. This is consistent with the two-component dynamics analyzed in Theorem 11 (two-layer Fourier factor model), where mode growth is nonlinear and informative tail structure emerges only after a feature pathway has begun to recruit. Notably, in several of these panels the shallow $10$ – $40$ window reaches a high correlation before the deeper window does, mirroring the head-then-tail learning order predicted by Theorem 6.
Peak-then-decay in throughput-leaning variants.
FP8Head, LSWA, and AttnScale also peak around $20%$ progress, but their correlations decay back toward $\rho_S $ $\approx 0$ $.5$ over the rest of training rather than holding. These are precisely the variants classified as throughput-leaning in Section 4: FP8Head changes the LM-head's numerical precision rather than its geometry; LSWA assigns different mask types to different layers, so a single-layer probe sees only one mask regime; and AttnScale rescales attention scores or selected learning rates while keeping the late-trunk geometry fixed. None of these interventions reshape the late-trunk feature geometry that the layer-11 probe measures, so the small early-tail signal that does exist is gradually overwritten by execution-side noise as training progresses. Under this view the decay is consistent with, rather than contrary to, our framework: the diagnostic correctly reports low stable discrimination when the underlying token-efficiency gap is small, while still recovering the canonical $20%$-peak behavior shared with the rest of the chain.
Together, the three regimes turn Figure 8 from a robustness check into structural validation of the Section 4 taxonomy: every variant shares the same early-prediction time horizon, but only those whose architectural change reshapes late-trunk feature geometry retain a stable diagnostic afterward. The $20%$-checkpoint rule for measuring $\alpha_{\mathrm{tail}}$ is therefore well-founded across the entire intervention chain, while persistence of the signal beyond that point is itself a useful secondary indicator of whether the intervention is learning-side or execution-side.
E.2 Random seed experiments
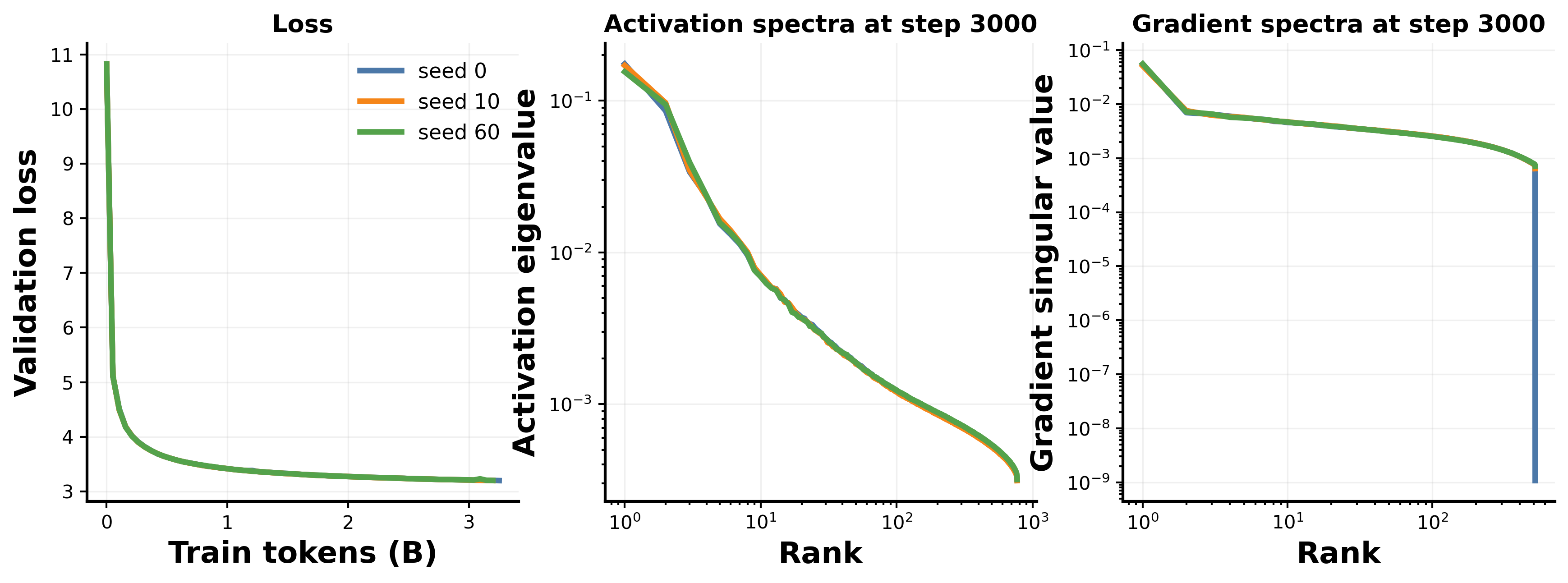
Figure 9 provides a focused robustness check for FlexWin tier-16 configuration, comparing the original seed against two additional seeds. All three panels support the same conclusion. The validation-loss curves are essentially indistinguishable throughout training, confirming that the three runs reach the same loss trajectory rather than merely converging at a shared late checkpoint. At the common step-3000 checkpoint, both the activation covariance spectra and the gradient SVD spectra stack so tightly across seeds that the curves are nearly coincident—seed-to-seed variation is negligible relative to the scale of cross-tier separation visible in the main figures. This is the relevant comparison: the batch-tier differences reported throughout the paper are not an artifact of a single lucky or unlucky initialization, but reflect a structural property of the training regime that is stable across independent runs.
E.3 Layerwise ablation
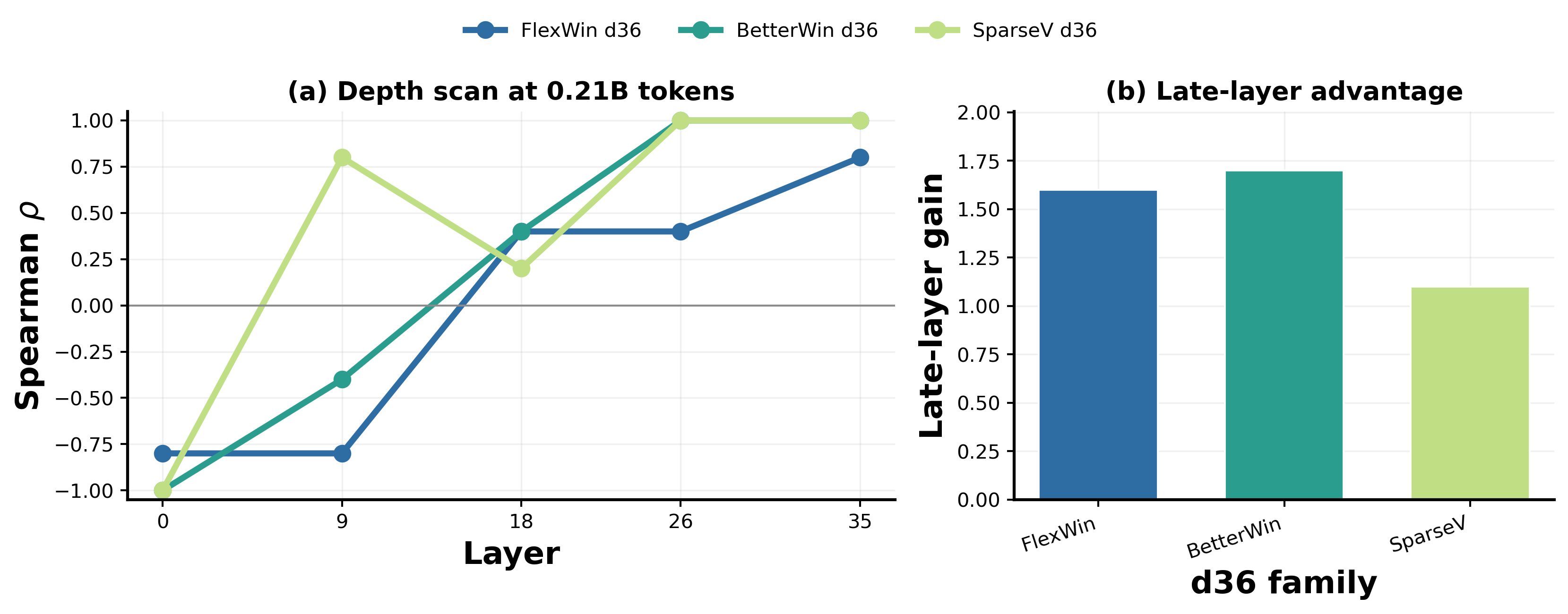
In this ablation we ask whether the final-layer activation probe used in the main early-prediction analysis is a principled measurement choice, or whether an earlier probe layer would serve equally well. For each d36 run, we select the saved checkpoint at 0.21B training tokens and refit the tail exponent over ranks $[200, 400]$, matching the predictive window used in the main figures.
Figure 10 shows the Spearman correlation between this early tail exponent and tokens-to-target as a function of probe layer, for the three available d36 families. The pattern is consistent: early and middle layers carry weak or sign-inconsistent signal, while the final stored probe layer (L35) shows the strongest positive correlation in all three families. This late-layer advantage is visible directly in the heatmap, correlations tend to become more positive moving from L00 toward L35, and supports the convention of probing the deepest available activation layer in the main experiments. We treat this as supporting evidence rather than a universal layer-selection rule: the evidence is limited to three d36 families and does not cover every d12 variant or every architectural regime in the chain.
F. Toy Model
The spectral measurements in the main paper are empirical: they track covariance eigenvalues and gradient singular values, but do not by themselves reveal why those quantities predict training efficiency or distinguish architectural interventions. The toy experiments address this gap through two controlled settings in which the same measurements can be traced back to explicit task structure. The analytic Fourier controls show how loss, feature spectra, and gradient spectra can decouple even when the target basis is fully known. The modular-arithmetic Transformer then provides an empirical bridge: because the task is defined on a finite cyclic group, Fourier modes are explicit task-aligned coordinates, allowing feature learning to be measured directly rather than inferred from black-box covariance statistics.
F.1 Linearized and diagonal Fourier models
In the following we show that one-layer gradient-flow model shows that loss alone does not identify the hidden spectrum: different learning rates or noise levels can reach the same objective while retaining different activation covariance spectra, because Fourier modes approach their teacher coefficients at different rates. The two-layer diagonal Fourier model strengthens this by allowing each learned coefficient to factor through two trainable components, making mode growth nonlinear. Early spectral tails then become informative precisely because they reveal which unresolved modes still carry energy even after the scalar objective has moved substantially.
F.2 Optimization and parameterization interventions
The modular-arithmetic setting provides interpretable analogues of RoPE, Muon, and untied readouts. RoPE aligns the model with shift-equivariant Fourier coordinates, making the cyclic task structure natural. Muon changes the update geometry for matrix parameters, producing optimization efficiency gains without necessarily inducing an equally large change in feature concentration—a distinction visible in Figure 11(b). Untying the readout expands the accessible output subspace and removes constraints that force unrelated Fourier modes to share parameters. Together these distinctions mirror the main paper's taxonomy: some interventions primarily improve optimization efficiency, while others more directly reshape the learned representation.
F.3 Two-layer Transformer and feature probes
Our empirical Transformer toy uses a two-layer, four-head modular-arithmetic language model with context length $64$, vocabulary size $1{,}024$, dataset size $32{,}000$, and last-token pooling. We sweep $B \in {32, 64, 128, 256, 512}$ for the matched-loss spectra and use the cumulative chain Baseline $\rightarrow$ RoPE $\rightarrow$ Muon $\rightarrow$ Untied for the intervention analyses. Learning rates are selected by the same successive-halving logic used in the language-model experiments, and constant-loss comparisons use a validation-loss target of $2.0$.
Feature-learning probes are computed from saved checkpoints by Fourier-transforming hidden states along task-aligned bands. We report the task-band concentration statistic $H_S$, a peak statistic $H_{\mathrm{peak}}$, a smoother Gini-style whole-profile statistic, and PCA-based localization metrics. The main paper uses $H_S$ because it matches the theoretical quantity in Informal Result 2; the appendix uses $H_{\mathrm{peak}}$ and PC1 peak mass to expose where feature-learning signal enters the intervention chain.
Figure 11 complements the main-text toy figure with three views. Panel (a) confirms that even in this controlled modular task, matched validation loss does not imply matched spectra: smaller batches produce visibly steeper tails than larger ones. Panel (b) decomposes the chain into consecutive $\Delta H_{\mathrm{peak}}$ gains. The Muon $\rightarrow$ Untied step (purple) yields a jump roughly five times larger than either preceding transition, which remain small and tightly clustered. This supports a clean distinction between gains from optimization geometry (RoPE, Muon) and gains from expanding the realizable output class (Untied).
Panel (c) checks robustness across eight Fourier probe bands of varying width and offset. Baseline is uniformly low; Untied is consistently the strongest stage across every band; RoPE is broadly elevated with mild dips on the narrowest bands; and Muon peaks precisely on those narrow bands while remaining low on wider ones. We interpret this complementarity as a spectral signature of the optimization-side versus representation-side distinction: Muon's preconditioning concentrates on a narrow subset of Fourier directions, while Untied's enlarged readout class produces a broadband effect consistent with Theorem 15. The toy model thus supports a bounded but coherent interpretation: the controlled setting links spectral diagnostics to task-aligned feature recruitment, used qualitatively rather than as a claim about universal transformer dynamics.
F.4 Formal toy-model theory and proofs
The main text states a small number of theorem-level claims in informal form. This subsection gives full formal statements and complete proofs for the claims we use. These are statements about the toy model and its measurements, not about full nonlinear transformer training. We begin by formalizing the task itself: modular arithmetic reduces to tracking a phase on a finite cyclic group, and the Fourier characters on that group are the natural basis. We then introduce a tractable shift-equivariant kernel-gradient-flow toy model and show that it decouples the learning problem into independent one-dimensional dynamics, one per Fourier mode. Those dynamics can then be read back into the measurements used in the paper: activation covariance spectra weight learned mode energy, while gradient covariance spectra weight residual mode energy. With that identification in place, the toy claims used in the main text—that loss-matched runs occupy different spectral states, that early spectra predict later efficiency, that a smooth power-law specialization yields a learned head plus unresolved tail, and that activation and gradient spectra are complementary—follow from the same modewise dynamics.
F.4.1 One-layer Fourier model
Fix an integer $c \ge 2$, a step size $d \in {0, 1, \dots, c-1}$, an offset $o$, and a context length $L \ge 1$. For each phase $a \in \mathbb{Z}_c$, define the clean single-component sequence
$ x(a)=\bigl(o+(a+jd)\bmod c\bigr)_{j=0}^{L-1}, $
with next-token target
$ y(a)=o+(a+Ld)\bmod c. $
The essential latent state is therefore the phase $a$ on the finite cyclic group $\mathbb{Z}_c$. Let
$ \omega=e^{2\pi i/c}, \qquad \chi_r(a)=\omega^{ra}, \qquad r=0, 1, \dots, c-1, $
be the Fourier characters on $\mathbb{Z}_c$. They form an orthonormal basis of functions $f: \mathbb{Z}_c\to \mathbb{C}$ under the inner product
$ \left\langle f, g \right\rangle = \frac{1}{c}\sum_{a\in \mathbb{Z}_c} f(a)\overline{g(a)}. $
########## {caption="Lemma 1: The clean toy target is a cyclic shift"}
Let $S_q$ be the shift operator on functions $f: \mathbb{Z}_c\to \mathbb{C}$ defined by
$ (S_q f)(a)=f(a+q \bmod c). $
Then the clean modular-arithmetic prediction map is the shift $S_{Ld}$, and each Fourier character is an eigenfunction:
$ S_{Ld}\chi_r=\omega^{rLd}\chi_r. $
Lemma 1 characterizes the ideal solution but says nothing about the path to it. To make the training dynamics tractable, we introduce the linearized kernel-gradient-flow model
$ \partial_t f_t = K(f^\star-f_t),\tag{1} $
where $f^\star$ is the target function and $K$ is a positive semidefinite linear operator on functions on $\mathbb{Z}_c$. The key modeling assumption is that $K$ is shift-equivariant---it respects the cyclic symmetry of the task:
$ K(a+s, a'+s)=K(a, a') \qquad for all a, a', s \in \mathbb{Z}_c. $
Equivalently, there exists a kernel $k: \mathbb{Z}_c\to \mathbb{C}$ such that
$ (Kf)(a)= \sum_{a'\in \mathbb{Z}_c} k(a-a')f(a'). $
This symmetry is what makes the analysis simple. Because $K$ commutes with cyclic shifts, the Fourier characters $\chi_r$ are simultaneously eigenfunctions of $K$ and of the task target, which means the learning problem decomposes into $c$ entirely independent one-dimensional dynamics. Parts (a)--(c) of the following theorem make this decoupling precise; part (d) then connects the resulting abstract Fourier dynamics to the activation and gradient second moments measured in the toy analysis, after which Proposition 3 converts them to the centered covariances used in the experiments.
########## {caption="Theorem 2: Modewise Fourier dynamics for a one-layer linearized model"}
Assume Equation 1 with the shift-equivariant positive semidefinite operator $K$ defined above. Expand the target and predictor in the Fourier basis:
$ f^\star=\sum_{r=0}^{c-1}\beta_r\chi_r, \qquad f_t=\sum_{r=0}^{c-1} a_r(t)\chi_r. $
Then:

Proof: For part (a), compute directly:
$ \begin{aligned} (K \chi_r)(a) &= \sum_{a'\in \mathbb{Z}c} k(a-a')\chi_r(a') = \sum{\delta\in \mathbb{Z}c} k(\delta)\chi_r(a-\delta) \ &= \chi_r(a)\sum{\delta\in \mathbb{Z}_c} k(\delta)\omega^{-r\delta} = \kappa_r\chi_r(a). \end{aligned} $
So each character is an eigenfunction.
For part (b), substitute the Fourier expansions into Equation 1:
$ \sum_r \dot{a}_r(t)\chi_r = K \Big(\sum_r \bigl(\beta_r-a_r(t)\bigr)\chi_r\Big) = \sum_r \kappa_r\bigl(\beta_r-a_r(t)\bigr)\chi_r. $
since $K$ is a linear operator. Orthogonality of the $\chi_r$ gives
$ \dot{a}_r(t) = -\kappa_r(a_r(t)-\beta_r), $
whose solution is the stated exponential formula.
Part (c) is Parseval in the orthonormal Fourier basis:
$ \left \lVert f_t-f^\star \right\rVert_{L^2(\mathbb{Z}_c)}^2 = \sum_r |a_r(t)-\beta_r|^2. $
For part (d), use orthogonality of the hidden directions and Fourier characters. For $M_h$,
$ \begin{aligned} M_h(t) &= \mathbb{E}\left[\sum_{r, s} a_r(t)\overline{a_s(t)}, u_r u_s^\ast, \chi_r(a)\overline{\chi_s(a)}\right] \ &= \sum_{r, s} a_r(t)\overline{a_s(t)}u_r u_s^\ast\mathbb{E}\bigl[\chi_r(a)\overline{\chi_s(a)}\bigr] \ &= \sum_r |a_r(t)|^2 u_r u_r^\ast. \end{aligned} $
The formula for $M_g$ is identical after replacing $a_r(t)$ by $\kappa_r(\beta_r-a_r(t))$.
########## {caption="Proposition 3: Second moments and centered covariances"}
In the setting of Theorem 2(d), define
$ M_h(t)= \mathbb{E}[h_t(a)h_t(a)^\ast], \qquad M_g(t)= \mathbb{E}[g_t(a)g_t(a)^\ast]. $
Then the means are
$ \mu_h(t)= \mathbb{E}[h_t(a)] = a_0(t)u_0, \qquad \mu_g(t)= \mathbb{E}[g_t(a)] = \kappa_0\bigl(\beta_0-a_0(t)\bigr)u_0, $
and the centered covariances are
$ \begin{aligned} Cov(h_t(a)) &= M_h(t)-\mu_h(t)\mu_h(t)^\ast = \sum_{r=1}^{c-1} |a_r(t)|^2 u_r u_r^\ast, \ Cov(g_t(a)) &= M_g(t)-\mu_g(t)\mu_g(t)^\ast = \sum_{r=1}^{c-1}\kappa_r^2 |\beta_r-a_r(t)|^2 u_r u_r^\ast. \end{aligned} $
Thus the DC mode contributes to the mean and uncentered second moment, but it drops out of the centered covariance used by the experiments.
Proof: Since $\mathbb{E}a[\chi_r(a)]=\frac{1}{c}\sum{a\in \mathbb{Z}c}\omega^{ra}=\delta{r, 0}$, only the DC mode has nonzero mean:
$ \begin{aligned} \mu_h(t) &= \sum_{r=0}^{c-1} a_r(t)u_r \mathbb{E}[\chi_r(a)] = a_0(t)u_0, \ \mu_g(t) &= \sum_{r=0}^{c-1} \kappa_r(\beta_r-a_r(t))u_r \mathbb{E}[\chi_r(a)] = \kappa_0(\beta_0-a_0(t))u_0. \end{aligned} $
Subtracting $\mu_h(t)\mu_h(t)^\ast$ and $\mu_g(t)\mu_g(t)^\ast$ from the second moments in Theorem 2(d) removes exactly the $r=0$ term, which yields the stated covariance formulas.
Theorem 2 together with Proposition 3 is the analytical foundation for all three empirical claims about the toy model. Part (d) gives the second-moment dictionary, and Proposition 3 converts it into the centered covariance form used in the experiments: activation spectra weight the energies $|a_r(t)|^2$ of modes that have already been learned, while gradient spectra weight the residual energies $\kappa_r^2|\beta_r - a_r(t)|^2$ of modes still being learned. Since different training regimes induce different rates ${\kappa_r}$, the mode energies diverge across regimes even at equal total loss---and those divergences are directly visible in the observable covariances. The three results below make this precise.
########## {caption="Proposition 4: Matched loss does not identify spectral state"}
Consider $m\ge 2$ modes with zero initialization and equal target coefficients $\beta_r=1$ for $r=1, \dots, m$. Suppose regime $\mathrm{A}$ has isotropic rates $\kappa_r^{\mathrm{A}}=\kappa>0$ for all $r$, and regime $\mathrm{B}$ has strictly ordered anisotropic rates
$ \kappa_1^{B}>\kappa_2^{B}>\cdots>\kappa_m^{B}>0. $
Define the normalized activation mass on mode $1$ by
$ P_j(t)=\frac{|a_1^{(j)}(t)|^2}{\sum_{r=1}^m |a_r^{(j)}(t)|^2}, \qquad j \in A, B. $
Then for every loss level $\ell\in(0, m/2)$ there exist unique times $t_{\mathrm{A}}, t_{\mathrm{B}}>0$ such that $\mathcal{L}{\mathrm{A}}(t{\mathrm{A}})=\mathcal{L}{\mathrm{B}}(t{\mathrm{B}})=\ell$, but
$ P_{A}(t_{A})=\frac{1}{m}, \qquad P_{B}(t_{B})>\frac{1}{m}. $
So equal scalar loss does not determine equal internal spectral state.
Proof: Under zero initialization, Theorem 2 gives $a_r^{(j)}(t)=1-e^{-\kappa_r^{(j)}t}$. In regime $\mathrm{A}$ all modes evolve identically, so $P_{\mathrm{A}}(t)=1/m$ for every $t>0$ and $\mathcal{L}_{\mathrm{A}}(t)=\frac{m}{2}e^{-2\kappa t}$, which decreases strictly and continuously from $m/2$ to $0$. In regime $\mathrm{B}$,
$ \mathcal{L}{B}(t) = \frac{1}{2}\sum{r=1}^{m} e^{-2\kappa_r^{(B)}t}, $
which also decreases strictly and continuously from $m/2$ to $0$, so for each $\ell\in(0, m/2)$ there are unique matched-loss times. Since $\kappa_1^{(\mathrm{B})}>\kappa_r^{(\mathrm{B})}$ for all $r>1$, we have $1-e^{-\kappa_1^{(\mathrm{B})}t}>1-e^{-\kappa_r^{(\mathrm{B})}t}$ for every $t>0$, hence $P_{\mathrm{B}}(t)>1/m$ for every $t>0$. Therefore the matched-loss spectral states differ.
Proposition 4 shows that different regimes leave different spectral fingerprints even at equal loss. The next result shows that these fingerprints are visible early: a run's spectral concentration at any fixed early time $t_0$ already determines its time-to-target, within a family of problems that share the same fast-mode rate but vary in how quickly the slow mode is learned.
########## {caption="Proposition 5: Early band concentration predicts time-to-target"}
Consider $m$ modes partitioned into a fast band $F={1, \dots, k}$ with shared rate $\bar\kappa>0$ and a slow band $S={k+1, \dots, m}$ with shared rate $\kappa_s\in(0, \bar\kappa)$, with zero initialization and $\beta_r=1$ for all $r$. At an early time $t_0>0$, define the band concentration on the fast modes by
$ C^{(k)}(t_0;\kappa_s) = \frac{k, (1-e^{-\bar\kappa t_0})^2}{k, (1-e^{-\bar\kappa t_0})^2+(m-k)(1-e^{-\kappa_s t_0})^2}. $
For a target loss $\varepsilon\in(0, m/2)$, let $T_\varepsilon(\kappa_s)$ be the unique time satisfying
$ \frac{1}{2}\Bigl(ke^{-2\bar\kappa T_\varepsilon}+(m-k)e^{-2\kappa_s T_\varepsilon}\Bigr)=\varepsilon. $
Then
$ \frac{\partial C^{(k)}}{\partial\kappa_s}(t_0;\kappa_s)<0, \qquad \frac{dT_\varepsilon}{d\kappa_s}(\kappa_s)<0. $
Hence larger early band concentration $C^{(k)}$ implies larger time-to-target $T_\varepsilon$.
Proof: Set $A=k(1-e^{-\bar\kappa t_0})^2$ and $B(\kappa_s)=(m-k)(1-e^{-\kappa_s t_0})^2$. Since
$ \frac{dB}{d\kappa_s}=2(m-k)t_0 e^{-\kappa_s t_0}(1-e^{-\kappa_s t_0})>0, $
we get $\partial C^{(k)}/\partial\kappa_s = -AB'(\kappa_s)/(A+B(\kappa_s))^2<0$.
For $T_\varepsilon$, define $F(T, \kappa_s)=\frac{1}{2}(k, e^{-2\bar\kappa T}+(m-k)e^{-2\kappa_s T})-\varepsilon$. By construction $F(T_\varepsilon(\kappa_s), \kappa_s)=0$. Implicit differentiation gives
$ \frac{dT_\varepsilon}{d\kappa_s} = - \frac{\partial_{\kappa_s}F}{\partial_T F} = - \frac{-(m-k), T_\varepsilon, e^{-2\kappa_s T_\varepsilon}}{-k\bar\kappa, e^{-2\bar\kappa T_\varepsilon}-(m-k)\kappa_s, e^{-2\kappa_s T_\varepsilon}}<0. $
Since both $C^{(k)}$ and $T_\varepsilon$ decrease in $\kappa_s$, higher early band concentration implies longer time-to-target.
Proposition 5 is the minimal two-band version of the batch-selection story. It is intentionally family-local: runs are compared only after fixing the progress of the fast band and varying the recruitment speed of the slower band. The next stylized specialization sharpens that same idea into the line-shape language used in the main text: learned head, crossover rank, unresolved tail, exact band-recruitment time, and the outward shift of the useful tail-fit window.
F.4.2 Smooth-spectrum extension for family-local batch selection
Assume the teacher energy follows a power law
$ \beta_r^2 = C r^{-p}, \qquad C>0, \quad p>0,\tag{2} $
and the batch-dependent learning rates take the form
$ \kappa_r(B)=\eta_B r^{-q_B}, \qquad \eta_B>0, \quad q_B\ge 0.\tag{3} $
Under zero initialization, Theorem 2 gives
$ a_r(B, t)=\beta_r\bigl(1-e^{-\eta_B t r^{-q_B}}\bigr), $
so the activation-side covariance eigenvalues are
$ \lambda_r^{act}(B, t)
|a_r(B, t)|^2
C r^{-p}\Bigl(1-e^{-\eta_B t r^{-q_B}}\Bigr)^2.\tag{4} $
########## {caption="Theorem 6: Three-zone activation spectrum"}
Assume Equation 2–Equation 4 with $q_B>0$, and define the crossover rank
$ r_*(B, t):=(\eta_B t)^{1/q_B}.\tag{5} $
Then the activation spectrum has three asymptotic zones:

Proof: Set
$ x_{r, B}(t)=\eta_B t r^{-q_B}. $
Then Equation 4 becomes
$ \lambda_r^{act}(B, t)=C r^{-p}(1-e^{-x_{r, B}(t)})^2. $
If $r \ll r_*(B, t)$, then $x_{r, B}(t)\to\infty$, so $1-e^{-x_{r, B}(t)}\to 1$, which gives the head asymptotic. If $r \gg r_*(B, t)$, then $x_{r, B}(t)\to 0$, and the Taylor expansion $1-e^{-x}=x+O(x^2)$ yields
$ (1- e^{-x_{r, B}(t)})^2
\eta_B^2 t^2 r^{-2q_B}\bigl(1+o(1)\bigr), $
which proves the tail formula and 6. The crossover statement is exactly the regime $x_{r, B}(t)\asymp 1$.
########## {caption="Theorem 7: Band-recruitment law"}
Assume Equation 2--Equation 4, zero initialization, and monotone rates in rank. Fix a cutoff $R$ and a tolerance $\delta\in(0, 1)$, and define
$ T_{R, \delta}(B) := \inf \Bigl{ t\ge 0: a_r(B, t)\ge (1- \delta)\beta_r for all 1\le r\le R \Bigr}. $
Then
$ T_{R, \delta}(B)
\frac{\log(1/\delta)}{\eta_B}R^{q_B}
\frac{\log(1/\delta)}{\eta_B}R^{(\alpha_{tail}(B)-p)/2}.\tag{7} $
Consequently, the exact family-local objective is to maximize the tail-band rate $\eta_B R^{-q_B}$.
Proof: Because the rates are monotone decreasing in $r$, the slowest mode among ${1, \dots, R}$ is mode $R$. Under zero initialization,
$ a_R(B, t)=\beta_R\bigl(1-e^{-\eta_B t R^{-q_B}}\bigr). $
The condition $a_R(B, t)\ge (1-\delta)\beta_R$ is equivalent to
$ e^{-\eta_B t R^{-q_B}}\le \delta, $
or
$ t\ge \frac{\log(1/\delta)}{\eta_B}R^{q_B}. $
This is necessary and sufficient for all $1\le r\le R$ because every earlier mode has rate at least as large as mode $R$. The second expression in Equation 7 follows from Equation 6.
########## {caption="Corollary 8: Head-matched early measurement gives an exact tail criterion"}
Assume the setting of Theorem 7. Suppose batches are compared at an early time $t_0$ after matching the progress of a head-anchor mode $r_h$, in the sense that
$ a_{r_h}(B, t_0)=\xi\beta_{r_h} \qquad \text{for the same } \xi\in(0, 1) \text{ and every } B. $
Assume also that $R>r_h$, so the target band extends beyond the matched head. Then
$ T_{R, \delta}(B)
\frac{\log(1/\delta)}{-\log(1-\xi)}t_0\Bigl(\frac{R}{r_h}\Bigr)^{q_B}
C_{\delta, \xi, t_0}\Bigl(\frac{R}{r_h}\Bigr)^{(\alpha_{tail}(B)-p)/2},\tag{8} $
for a constant $C_{\delta, \xi, t_0}$ independent of $B$. Therefore the family-local token-optimal batch is exactly the batch with the smallest informative tail exponent.
Proof: The head-anchor condition gives
$ 1-e^{-\eta_B t_0 r_h^{-q_B}}=\xi, $
so
$ \eta_B=-t_0^{-1}r_h^{q_B}\log(1-\xi). $
Substituting this identity into Equation 7 yields Equation 8.
########## {caption="Proposition 9: Crossover-rank explanation of the tail-window shift"}
In the setting of Theorem 6, a fixed fit window $[R_1, R_2]$ recovers the true tail exponent $p+2q_B$ only when it lies in the unresolved-tail regime, that is, when $R_1 \gg r_*(B, t)$. If scale, probe depth, or early-time dynamics change in such a way that $r_*(B, t)$ increases, then any previously informative fixed window eventually enters the bend region, and the useful tail-fit window must move outward.
Proof: By Theorem 6, the unresolved-tail asymptotic with slope $p+2q_B$ is valid only for ranks satisfying $r \gg r_*(B, t)$. If $R_1/r_*(B, t)$ ceases to be large, then the lower end of the fit window enters the crossover region, where the local slope is shallower than the true tail slope. So the same fixed window no longer estimates $\alpha_{\mathrm{tail}}(B)$ reliably, and moving the fit window outward restores the unresolved-tail condition.
Theorem 6, Theorem 7, and Corollary 8 are the formal version of the family-local line-shape claim used in the main text. They show that the useful early spectrum is not summarized by one universal scalar. Within a matched family, the informative signal is the combination of a sufficiently progressed head, a crossover rank $r_*(B, t)$ pushed outward, and an unresolved tail that remains comparatively flat.
The smooth-spectrum extension explains when a run will reach its target and which early tail shape is informative after normalizing for head progress; the final result explains why the activation and gradient views of that trajectory are complementary rather than redundant. Intuitively, the activation spectrum captures what has already been learned (high- $\kappa_r$ modes consolidate first), while the gradient spectrum captures what is still being actively updated (slow modes dominate residual energy at late times). The following proposition formalizes this crossover.
########## {caption="Proposition 10: Activation–gradient complementarity via mode crossovers"}
Consider $m$ modes with zero initialization, equal target coefficients $\beta_r=1$, and strictly ordered rates $\kappa_1>\kappa_2>\cdots>\kappa_m>0$. Define activation energies $A_r(t)=(1-e^{-\kappa_r t})^2$ and update-side energies $G_r(t)=\kappa_r^2 e^{-2\kappa_r t}$. Then:
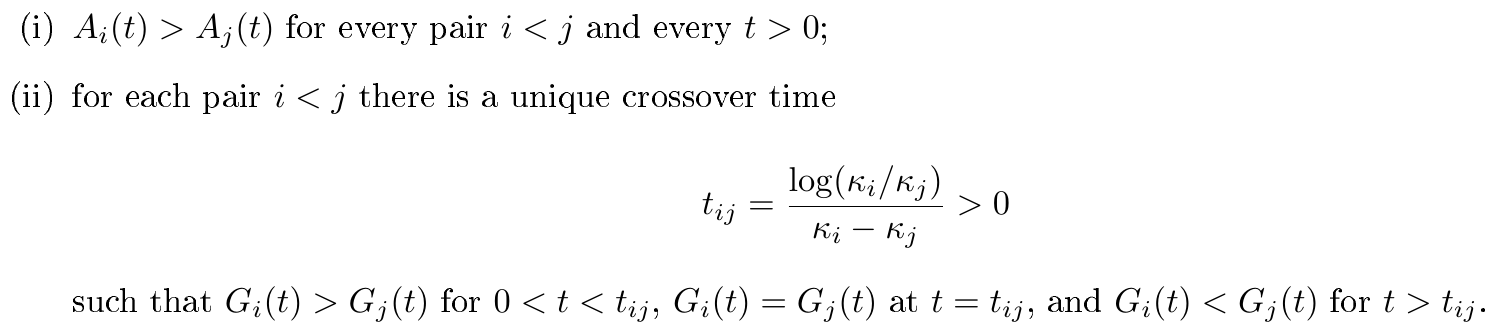
Setting $T^\ast=\max_{i<j}t_{ij}$, for all $t>T^\ast$ the activation ranking satisfies $A_1(t)>\cdots>A_m(t)$ while the update-side ranking is fully reversed: $G_m(t)>\cdots>G_1(t)$.
Proof: Part (i): $\kappa_i>\kappa_j$ implies $1-e^{-\kappa_i t}>1-e^{-\kappa_j t}$ for all $t>0$; squaring gives $A_i(t)>A_j(t)$.
For part (ii), compare the update-side energies of modes $i$ and $j$:
$ G_i(t)<G_j(t) \iff \kappa_i^2 e^{-2\kappa_i t}<\kappa_j^2 e^{-2\kappa_j t} \iff e^{(\kappa_i-\kappa_j)t}>\frac{\kappa_i}{\kappa_j}. $
Since $\kappa_i>\kappa_j$, this holds iff $t>t_{ij}$, and uniqueness follows from strict monotonicity of the exponential. After $T^\ast$, every pair $(i, j)$ with $i<j$ satisfies $G_i(t)<G_j(t)$, giving the stated full reversal of the gradient ranking.
In the smooth-spectrum specialization above, this same crossover logic is what separates the learned head from the unresolved tail and makes the tail-window proposition natural. The point of Proposition 10 is the complementary one: even when activation and gradient are generated by the same modewise dynamics, they need not rank modes the same way at the same time.
F.4.3 Two-layer Fourier factor model
Let ${\phi_r}_{r=1}^m$ be any orthonormal real Fourier-derived basis. Consider the two-layer factor model
$ f_t(a)=\sum_{r=1}^m u_r(t)v_r(t)\phi_r(a), $
with target
$ f^\star(a)=\sum_{r=1}^m \beta_r \phi_r(a), \qquad \beta_r\ge 0, $
trained by gradient flow on the squared loss
$ \mathcal J(u, v)=\frac12\sum_{r=1}^m (u_r v_r-\beta_r)^2. $
########## {caption="Theorem 11: Balanced two-layer Fourier factor dynamics"}
Assume gradient flow on $\mathcal J$ with balanced positive initialization
$ u_r(0)=v_r(0)>0 \qquad for all r. $
Let
$ m_r(t)=u_r(t)v_r(t). $
Then:

Proof: Gradient flow on $\mathcal J$ gives, for each $r$,
$ \dot{u}_r=-(u_rv_r-\beta_r)v_r, \qquad \dot{v}_r=-(u_rv_r-\beta_r)u_r. $
Then
$ \frac{d}{dt}(u_r^2-v_r^2)=2u_r\dot{u}_r-2v_r\dot{v}_r=0. $
Since $u_r(0)=v_r(0)$, we have $u_r(t)^2=v_r(t)^2$ for all $t$. It is cleaner to track the difference directly:
$ \frac{d}{dt}(u_r-v_r)=\dot{u}_r-\dot{v}_r=-(u_rv_r-\beta_r)(v_r-u_r)=(u_rv_r-\beta_r)(u_r-v_r). $
Because $u_r(0)-v_r(0)=0$, uniqueness of solutions implies $u_r(t)-v_r(t)\equiv 0$, so $u_r(t)=v_r(t)$ for all $t$. Write this common value as $s_r(t)$. Then
$ \dot{s}_r=s_r(\beta_r-s_r^2). $
Since the vector field is locally Lipschitz and $s_r=0$ is an equilibrium, a solution starting from $s_r(0)>0$ cannot cross zero without violating uniqueness. Hence $s_r(t)>0$ for all $t$, so the balanced positive branch is preserved. This proves part (a).
For part (b), differentiate $m_r=u_rv_r$:
$ \begin{aligned} \dot{m}_r &= \dot{u}_r v_r + u_r \dot{v}_r \ &= -(u_rv_r-\beta_r)(v_r^2+u_r^2) \ &= -2m_r(m_r-\beta_r) = 2m_r(\beta_r-m_r). \end{aligned} $
For part (c), if $\beta_r>0$, separate variables:
$ \frac{dm_r}{m_r(\beta_r-m_r)} = 2dt. $
Using the partial-fraction identity
$ \frac{1}{m_r(\beta_r-m_r)}
\frac{1}{\beta_r}\left(\frac{1}{m_r}+\frac{1}{\beta_r-m_r}\right), $
we obtain
$ \frac{1}{\beta_r}\log!\left|\frac{m_r(t)}{\beta_r-m_r(t)}\right|=2t+C_r. $
Evaluating at $t=0$ gives
$ C_r=\frac{1}{\beta_r}\log!\left|\frac{m_r(0)}{\beta_r-m_r(0)}\right|, $
Exponentiating absorbs the sign into the integration constant, so the final closed-form solution is unchanged:
$ \frac{m_r(t)}{\beta_r-m_r(t)}
\frac{m_r(0)}{\beta_r-m_r(0)}e^{2\beta_r t}. $
Solving for $m_r(t)$ yields
$ m_r(t)=\frac{\beta_r}{1+\left(\frac{\beta_r}{m_r(0)}-1\right)e^{-2\beta_r t}}. $
If $\beta_r=0$, the equation becomes $\dot{m}_r=-2m_r^2$, whose solution is
$ m_r(t)=\frac{m_r(0)}{1+2m_r(0)t}. $
########## {caption="Corollary 12: Monotone task-band concentration"}
Let $S\subseteq{1, \dots, m}$ be a task-relevant Fourier band. Assume
$ \beta_r>0 for r\in S, \qquad \beta_r=0 for r\notin S, $
and $0<m_r(0)<\beta_r$ for every $r\in S$. Define the band-concentration statistic
$ H_S(t)=\frac{\sum_{r\in S} m_r(t)}{\sum_{r=1}^m m_r(t)}. $
Then $H_S(t)$ is strictly increasing for every $t$ as long as both on-band and off-band mass are nonzero.
Proof: Set
$ A(t)=\sum_{r\in S} m_r(t), \qquad B(t)=\sum_{r\notin S} m_r(t), \qquad H_S(t)=\frac{A(t)}{A(t)+B(t)}. $
By Theorem 11, for $r\in S$ we have
$ \dot{m}_r = 2m_r(\beta_r-m_r)>0, $
because $0<m_r(t)<\beta_r$ is preserved by the logistic flow. Thus $A'(t)>0$ whenever $A(t)>0$.
For $r\notin S$, $\beta_r=0$, so Theorem 11 gives
$ \dot{m}_r = -2m_r^2<0 $
whenever $m_r(t)>0$. Thus $B'(t)<0$ whenever $B(t)>0$.
Differentiate $H_S$:
$ H_S'(t) = \frac{A'(t)(A(t)+B(t)) - A(t)(A'(t)+B'(t))}{(A(t)+B(t))^2} = \frac{A'(t)B(t)-A(t)B'(t)}{(A(t)+B(t))^2}. $
If $A(t), B(t)>0$, then $A'(t)>0$ and $-B'(t)>0$, so both terms in the numerator are positive. Hence $H_S'(t)>0$.
F.4.4 Variant-aligned mechanism theorems
RoPE as symmetry restoration.
Let $x=(x_t)_{t\in \mathbb{Z}}$ be a bi-infinite sequence with $x_t\in \mathbb{R}^m$, and for a shift $\tau\in \mathbb{Z}$ define
$ (S_\tau x)t = x{t-\tau}. $
Let $W_q, W_k\in \mathbb{R}^{d\times m}$ be fixed matrices and define
$ q_t(x)=W_qx_t, \qquad k_t(x)=W_kx_t. $
Assume a family of orthogonal matrices $(R_t)_{t\in \mathbb{Z}}\subset O(d)$ satisfying
$ R_{s+t}=R_sR_t, \qquad R_0=I. $
Define the RoPE attention score
$ a_{ij}(x)=\langle R_i q_i(x), R_j k_j(x)\rangle. $
########## {caption="Theorem 13: RoPE score equivariance under sequence shifts"}
For every sequence $x$, all indices $i, j\in \mathbb{Z}$, and every shift $\tau\in \mathbb{Z}$,
$ a_{i+\tau, j+\tau}(S_\tau x)=a_{ij}(x). $
Equivalently, the positional part of the score depends on sequence position only through the relative offset $j-i$.
Proof: By definition of the shifted sequence,
$ q_{i+\tau}(S_\tau x)=W_q(S_\tau x)_{i+\tau}=W_qx_i=q_i(x), $
and similarly $k_{j+\tau}(S_\tau x)=k_j(x)$. Therefore
$ \begin{aligned} a_{i+\tau, j+\tau}(S_\tau x) &= \left\langle R_{i+\tau}q_i(x), R_{j+\tau}k_j(x)\right\rangle \ &= q_i(x)^\top R_{i+\tau}^\top R_{j+\tau}k_j(x). \end{aligned} $
Because the $R_t$ are orthogonal and form a representation of $\mathbb{Z}$,
$ R_{i+\tau}^\top R_{j+\tau} = R_{-(i+\tau)}R_{j+\tau} = R_{j-i}. $
Hence
$ a_{i+\tau, j+\tau}(S_\tau x) = q_i(x)^\top R_{j-i}k_j(x) = \langle R_i q_i(x), R_j k_j(x)\rangle = a_{ij}(x). $
########## {caption="Proposition 14: Absolute positional tables generically break shift equivariance"}
Let $(p_t)_{t\in \mathbb{Z}}\subset \mathbb{R}^m$ be a positional table and define
$ \tilde{q}_t(x)=W_q(x_t+p_t), \qquad \tilde{k}_t(x)=W_k(x_t+p_t), $
with score
$ b_{ij}(x)=\langle \tilde{q}_i(x), \tilde{k}_j(x)\rangle. $
Assume $W_q, W_k\in \mathbb{R}^{d\times m}$ have full row rank $d$. Assume that for every sequence $x$ and every $i, j, \tau\in \mathbb{Z}$,
$ b_{i+\tau, j+\tau}(S_\tau x)=b_{ij}(x). $
Then
$ W_q p_t \equiv constant in t, \qquad W_k p_t \equiv constant in t. $
In particular, any nontrivial absolute positional signal that survives the $W_q$ or $W_k$ projection breaks translation equivariance.
Proof: Fix $i, j, \tau$. Using $(S_\tau x){i+\tau}=x_i$ and $(S\tau x)_{j+\tau}=x_j$, the assumed equivariance becomes
$ \big\langle W_q(x_i+p_{i+\tau}), W_k(x_j+p_{j+\tau})\big\rangle
\big\langle W_q(x_i+p_i), W_k(x_j+p_j)\big\rangle $
for all $x_i, x_j\in \mathbb{R}^m$. Expanding both sides and subtracting gives
$ \begin{aligned} 0 &= \langle W_qx_i, W_k(p_{j+\tau}-p_j)\rangle
- \langle W_q(p_{i+\tau}-p_i), W_kx_j\rangle \ &\qquad
- \langle W_qp_{i+\tau}, W_kp_{j+\tau}\rangle
- \langle W_qp_i, W_kp_j\rangle \end{aligned} $
for all $x_i, x_j$. Now set $x_j=0$ and vary $x_i$ arbitrarily. The first term must vanish for all $x_i$, so
$ \langle W_qx_i, W_k(p_{j+\tau}-p_j)\rangle = 0 \qquad for all x_i\in \mathbb{R}^m. $
Because $W_q$ has full row rank, its row space is all of $\mathbb{R}^d$, so the vectors $W_qx_i$ span $\mathbb{R}^d$. Hence the only vector orthogonal to every $W_qx_i$ is the zero vector, and therefore
$ W_k(p_{j+\tau}-p_j)=0. $
Because $j, \tau$ were arbitrary, $W_kp_t$ is independent of $t$. By symmetry, setting $x_i=0$ and varying $x_j$ yields
$ \langle W_q(p_{i+\tau}-p_i), W_kx_j\rangle = 0 \qquad for all x_j\in \mathbb{R}^m. $
Because $W_k$ has full row rank, the vectors $W_kx_j$ span $\mathbb{R}^d$, so
$ W_q(p_{i+\tau}-p_i)=0 $
for all $i, \tau$, so $W_qp_t$ is also independent of $t$.
Untied readout as reduced factorization constraint.
Let $E\in \mathbb{R}^{d\times V}$ be the token embedding matrix with full row rank $d<V$. Consider the two classes of effective token-to-logit maps
$ \mathcal F_{tied}={E^\top A E : A\in \mathbb{R}^{d\times d}}, \qquad \mathcal F_{untied}={W^\top A E : A\in \mathbb{R}^{d\times d}, W\in \mathbb{R}^{d\times V}}. $
########## {caption="Theorem 15: Strict expressivity inclusion for untied heads"}
Assume $E\in \mathbb{R}^{d\times V}$ has full row rank $d<V$. Then:

Proof: For (1), if $T=W^\top A E\in\mathcal F_{\mathrm{untied}}$, set $B=W^\top A\in \mathbb{R}^{V\times d}$, so $T=BE$. Conversely, for any $B\in \mathbb{R}^{V\times d}$, choosing $A=I_d$ and $W=B^\top$ gives $T=W^\top A E=BE$. Hence
$ \mathcal F_{untied}={BE:B\in \mathbb{R}^{V\times d}}. $
For (2), every tied map is untied by taking $B=E^\top A$, so
$ \mathcal F_{tied}\subseteq\mathcal F_{untied}. $
To show strictness, choose a nonzero vector $u\in \mathbb{R}^V$ with
$ u\notin \operatorname{col}(E^\top). $
Such a vector exists because $\dim\operatorname{col}(E^\top)=d<V$. Choose any nonzero $\alpha\in \mathbb{R}^d$ and set
$ B=u\alpha^\top. $
Then
$ T:=BE=u(\alpha^\top E)\in \mathcal F_{untied}. $
Because $E$ has full row rank and $\alpha\neq 0$, we have $\alpha^\top E\neq 0$, so $T\neq 0$. Moreover,
$ \operatorname{im}(T)=\operatorname{span}{u}. $
Since $u\notin\operatorname{col}(E^\top)$, we have
$ \operatorname{im}(T)\not\subseteq \operatorname{col}(E^\top), $
so $T\notin \mathcal F_{\mathrm{tied}}$.
For (3), if $T=E^\top A E$, then for every $x\in \mathbb{R}^V$,
$ Tx = E^\top(A(Ex)), $
so $Tx\in\operatorname{col}(E^\top)$. Thus $\operatorname{im}(T)\subseteq \operatorname{col}(E^\top)$. Also if $x\in\operatorname{ker}(E)$, then $Tx=E^\top A E x=0$, so $\operatorname{ker}(E)\subseteq\operatorname{ker}(T)$.
For (4), every untied map has the form $T=BE$, so again $x\in\operatorname{ker}(E)$ implies $Tx=0$. On the output side, however, $B$ is arbitrary. Because $E$ has full row rank, it admits a right inverse $R\in \mathbb{R}^{V\times d}$ with $ER=I_d$. Hence for every $B$,
$ B=(BE)R, $
so $\operatorname{col}(B)\subseteq\operatorname{col}(BE)$, while trivially $\operatorname{col}(BE)\subseteq\operatorname{col}(B)$. Therefore $\operatorname{col}(BE)=\operatorname{col}(B)$. Since $B$ is arbitrary, any output subspace of dimension at most $d$ can occur.
########## {caption="Corollary 16: Irreducible tied-head error outside the tied output subspace"}
Let $P_{\mathrm{out}}$ be the orthogonal projector onto $\operatorname{col}(E^\top)$. Then for every target map $T_\star\in \mathbb{R}^{V\times V}$,
$ \inf_{T\in\mathcal F_{tied}}\left\lVert T-T_\star \right\rVert_F \ge \left\lVert (I-P_{out})T_\star \right\rVert_F. $
If in addition $T_\star=BE$ for some $B\in \mathbb{R}^{V\times d}$, then $T_\star\in\mathcal F_{\mathrm{untied}}$.
Proof: For any $T\in\mathcal F_{\mathrm{tied}}$, Theorem 15(3) gives $T=P_{\mathrm{out}}T$. Hence
$ T-T_\star = P_{out}T - P_{out}T_\star - (I-P_{out})T_\star. $
The first term has every column in $\operatorname{col}(E^\top)$, while the second has every column in its orthogonal complement, so these components are orthogonal in Frobenius inner product. Therefore
$ \left\lVert T-T_\star \right\rVert_F^2
\left\lVert P_{out}(T-T_\star) \right\rVert_F^2 + \left\lVert (I-P_{out})T_\star \right\rVert_F^2 \ge \left\lVert (I-P_{out})T_\star \right\rVert_F^2. $
Taking the infimum over $T\in\mathcal F_{\mathrm{tied}}$ proves the bound. If $T_\star=BE$, then Theorem 15(1) implies $T_\star\in\mathcal F_{\mathrm{untied}}$.
Idealized Muon as spectral preconditioning.
For a nonzero matrix $G\in \mathbb{R}^{m\times n}$ with compact SVD
$ G=U\Sigma V^\top, \qquad \Sigma=\operatorname{diag}(\sigma_1, \dots, \sigma_r), \quad \sigma_i>0, $
define its exact polar factor
$ Q(G)=UV^\top. $
########## {caption="Theorem 17: Idealized Muon is steepest descent under an operator-norm trust region"}
Let $G\in \mathbb{R}^{m\times n}$ be nonzero with rank $r$. Then:

Proof: For (1), if $G=U\Sigma V^\top$, then $cG=U(c\Sigma)V^\top$ has the same singular vectors, so
$ Q(cG)=UV^\top=Q(G). $
For (2), the dual norm of the operator norm is the nuclear norm, so
$ \max_{\left\lVert M \right\rVert_{op}\le 1}\langle G, M\rangle = \left\lVert G \right\rVert_*. $
We verify that $M=Q(G)$ attains the maximum:
$ \langle G, Q(G)\rangle
\operatorname{tr}\bigl((U\Sigma V^\top)^\top UV^\top\bigr)
\operatorname{tr}(V\Sigma V^\top)
\operatorname{tr}(\Sigma)
\left\lVert G \right\rVert_*. $
Hence $Q(G)$ is a maximizer. Replacing $M$ by $-\Delta/\eta$ shows that $-\eta Q(G)$ is a minimizer of the operator-norm-constrained linearized objective.
For (3), by $L$-smoothness,
$ f(W+\Delta)\le f(W)+\langle G, \Delta\rangle + \frac{L}{2}\left\lVert \Delta \right\rVert_F^2. $
Substitute $\Delta=-\eta Q(G)$:
$ f(W^+)\le f(W)-\eta\langle G, Q(G)\rangle + \frac{L\eta^2}{2}\left\lVert Q(G) \right\rVert_F^2. $
By part (2),
$ \langle G, Q(G)\rangle = \left\lVert G \right\rVert_*. $
Also $Q(G)=UV^\top$ has $r$ singular values equal to $1$, so
$ \left\lVert Q(G) \right\rVert_F^2 = r. $
Therefore
$ f(W^+) \le f(W)-\eta\left\lVert G \right\rVert_*+\frac{L\eta^2}{2}r. $
The strict-descent condition follows immediately.
G. Additional Plots
This section collects supporting plots that audit the claims of the main paper but were too large to include there. RankMe is the entropy effective rank defined in Appendix C, used here as a compact trajectory summary alongside tail exponents and raw spectra.
G.1 Loss atlases
Figure 12 shows the loss-curve evidence behind every matched-loss comparison in the main paper. Panel (a) collects validation-loss trajectories for families with stored validation checkpoints; panel (b) collects train-loss trajectories for the late-trunk and d36 support runs where validation checkpoints were unavailable. Two features matter. First, every batch tier within every family reaches the target loss, confirming that matched-loss comparisons are not selecting only the easiest tiers. Second, the spread between tiers in tokens-to-target is visible directly: smaller batches sit on shallower learning curves and require substantially more tokens than the family-local efficient regime, which sits near the modal $B=8$ tier in most variants.
G.2 Spectral atlases for individual models
Figs. Figure 13–Figure 15 provide the per-variant raw evidence underlying the transition-level taxonomy of Section 4. Each row shows one variant in three views: trace-normalized activation covariance spectra, gradient SVD spectra, and summary trajectories of RankMe and $\alpha_{\mathrm{tail}}$ over training. The legacy prefix atlas (Figure 13) contains the largest geometric shifts in the chain, spanning both the early gradient-led and activation-led transitions seen in the main taxonomy figure. The matched-trunk atlases (Figs. Figure 14–Figure 15) show the smaller incremental changes from ValueMix through AttnScale, where the transition labels are best inferred from the joint activation–gradient summaries rather than from any single raw spectrum alone. The tier-2 atlas (Figure 16) applies the same format to the larger-scale support runs and shows that the qualitative spectral signatures persist at scale.
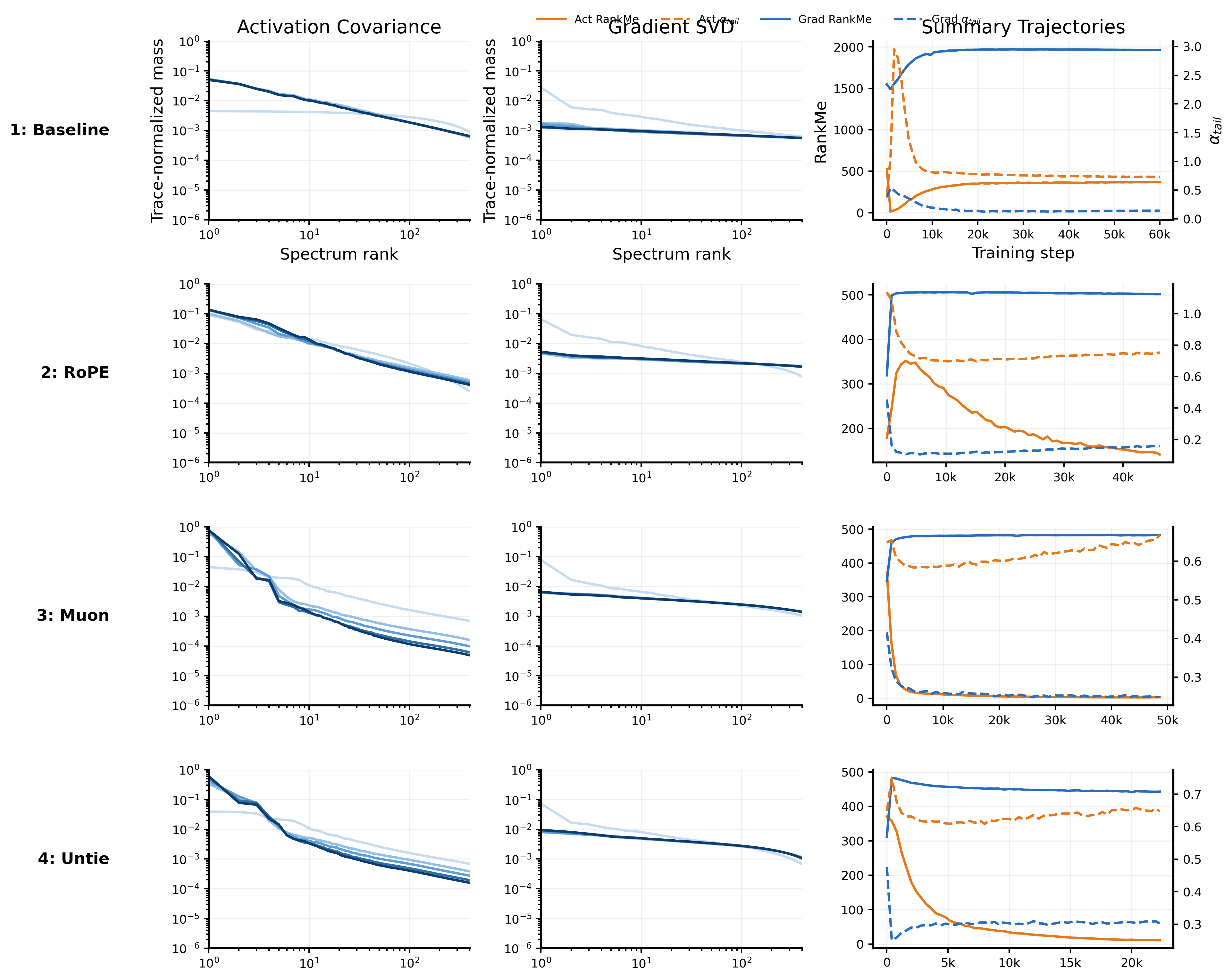
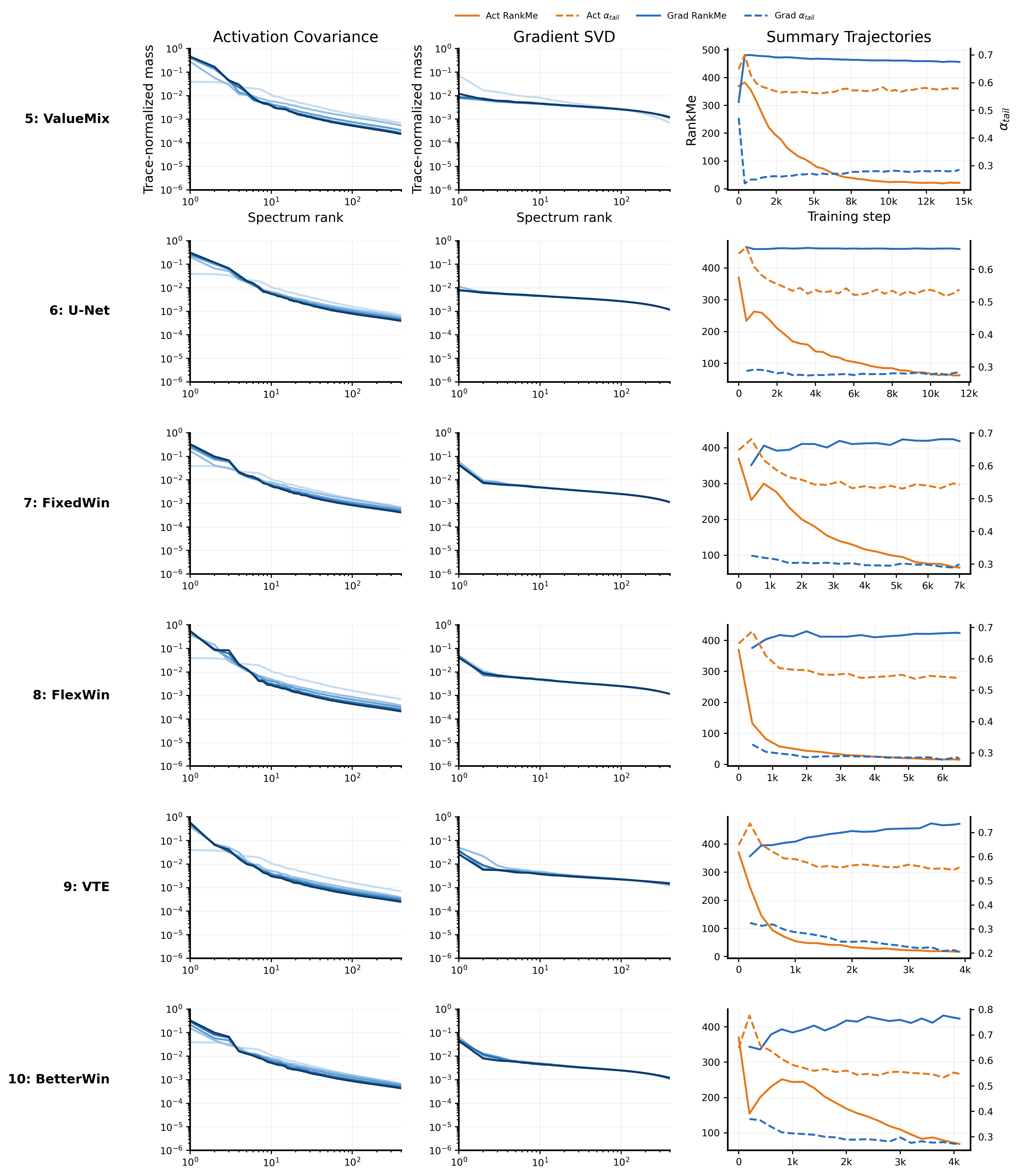
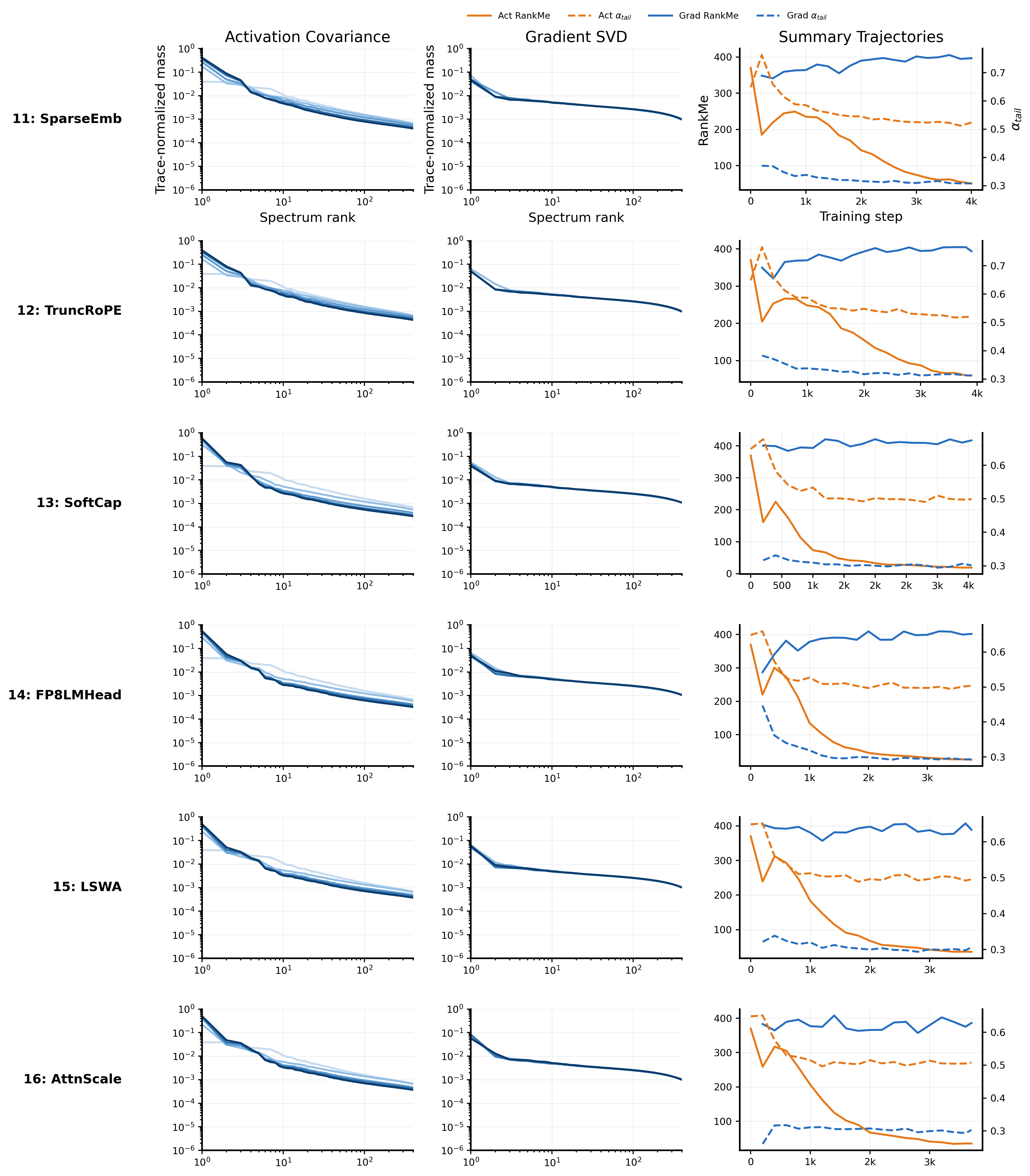
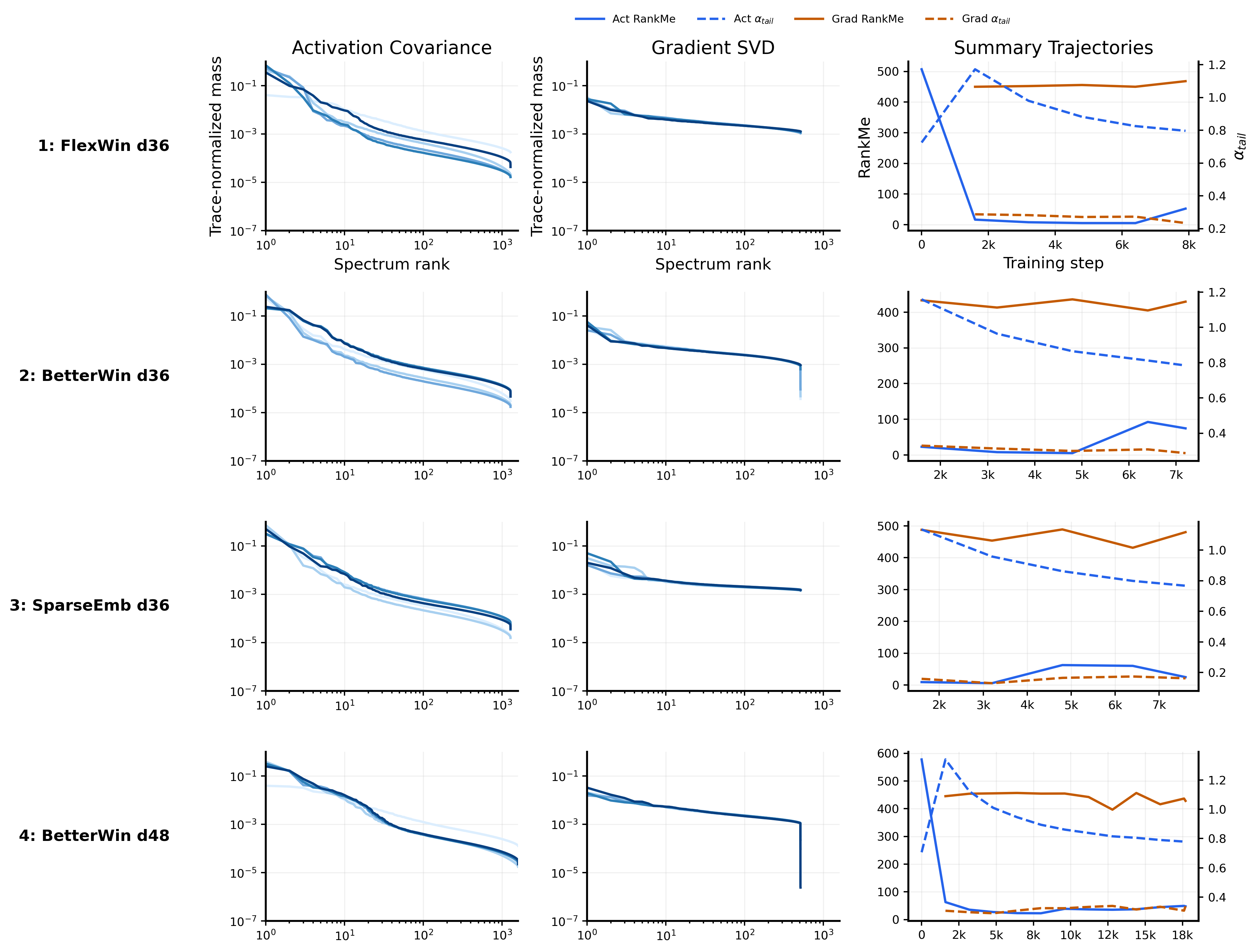
G.3 Weight-matrix spectra
Activation and gradient spectra describe the data-side and update-side of training. Figure 17 adds a third view: the spectra of the trained weight matrices themselves, comparing the layer-11 attention-output projection $W_O$ against the layer-11 MLP-output projection at the final checkpoint, with head exponents shown at step 1600 and at the end of training. The MLP-output projection shows clearer cross-variant divergence than $W_O$ in both raw spectrum shape and head-exponent trajectories. The asymmetry is consistent with the gradient-probe stability argument in Appendix C: $W_O$ retains the same architectural role across the full chain, while the feed-forward writeback path is touched by several trunk-side interventions (ValueMix, U-Net, BetterWin, SparseV). Either probe is informative, but they answer different questions and should not be expected to coincide.
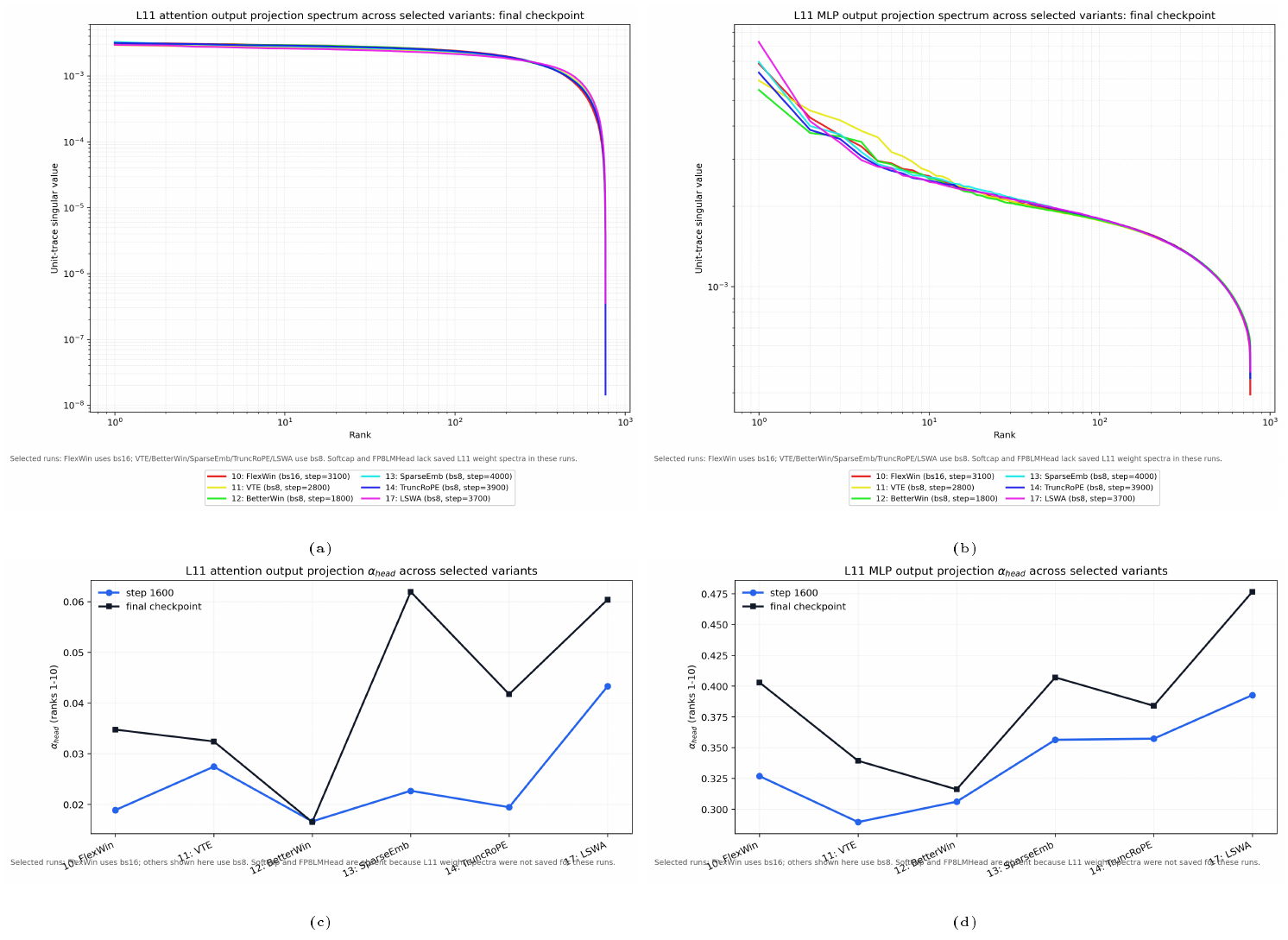
G.4 Training dynamics and phase visibility
Prior geometry work has reported a collapse–expansion–compression phase sequence in representation rank during training. Figure 18 plots RankMe trajectories on normalized training progress for FixedWin, SparseV, and LSWA across all batch tiers. The classical phase shape is most clearly visible in intermediate tiers; very small and very large batches often produce monotone or muted trajectories without a sharply localized expansion peak. We therefore treat phase-like dynamics as secondary qualitative evidence rather than a universal training signature, since their visibility depends on both batch tier and variant.
References
Section Summary: This references section compiles a list of academic papers, preprints, and conference proceedings that examine the training, scaling, and internal behavior of large neural networks and language models. The cited works explore topics such as optimal compute allocation during training, representation geometry, optimization dynamics, and mathematical analyses drawn from random matrix theory and spectral methods. Together they trace the development of empirical scaling laws and theoretical insights into how these models improve with size and data.
[1] Kaplan et al. (2020). Scaling Laws for Neural Language Models. doi:10.48550/arXiv.2001.08361. https://arxiv.org/abs/2001.08361. arXiv:2001.08361.
[2] Hoffmann et al. (2022). Training compute-optimal large language models. arXiv preprint arXiv:2203.15556. doi:10.48550/arXiv.2203.15556. https://arxiv.org/abs/2203.15556.
[3] Brown et al. (2020). Language models are few-shot learners. Advances in neural information processing systems. 33. pp. 1877–1901. https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
[4] Rae et al. (2021). Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446. doi:10.48550/arXiv.2112.11446. https://arxiv.org/abs/2112.11446.
[5] Ganguli et al. (2022). Predictability and surprise in large generative models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. pp. 1747–1764. doi:10.1145/3531146.3533229. https://doi.org/10.1145/3531146.3533229.
[6] Li et al. (2025). Tracing the Representation Geometry of Language Models from Pretraining to Post-training. doi:10.48550/arXiv.2509.23024. https://arxiv.org/abs/2509.23024. arXiv:2509.23024.
[7] Liu et al. (2025). Superposition Yields Robust Neural Scaling. arXiv preprint arXiv:2505.10465. doi:10.48550/arXiv.2505.10465. https://arxiv.org/abs/2505.10465.
[8] Bahri et al. (2024). Explaining Neural Scaling Laws. Proceedings of the National Academy of Sciences. 121(27). pp. e2311878121. doi:10.1073/pnas.2311878121. https://doi.org/10.1073/pnas.2311878121.
[9] Martin, Charles H. and Mahoney, Michael W. (2021). Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning. Journal of Machine Learning Research. 22(165). pp. 1–73. https://www.jmlr.org/papers/v22/20-410.html.
[10] Jordan et al. (2024). modded-nanogpt: Speedrunning the NanoGPT baseline. https://github.com/KellerJordan/modded-nanogpt.
[11] Chang et al. (2022). The Geometry of Multilingual Language Model Representations. In Proceedings of EMNLP. doi:10.18653/v1/2022.emnlp-main.9. https://aclanthology.org/2022.emnlp-main.9/.
[12] Garrido et al. (2023). RankMe: Assessing the Downstream Performance of Pretrained Self-Supervised Representations by Their Rank. In Proceedings of the 40th International Conference on Machine Learning. pp. 10929–10974. https://proceedings.mlr.press/v202/garrido23a.html.
[13] Gur-Ari et al. (2018). Gradient Descent Happens in a Tiny Subspace. doi:10.48550/arXiv.1812.04754. https://arxiv.org/abs/1812.04754. arXiv:1812.04754.
[14] Ghorbani et al. (2019). An Investigation into Neural Net Optimization via Hessian Eigenvalue Density. In Proceedings of ICML. https://proceedings.mlr.press/v97/ghorbani19b.html.
[15] Papyan, Vardan (2019). Measurements of Three-Level Hierarchical Structure in the Outliers in the Spectrum of Deepnet Hessians. In Proceedings of ICML. https://proceedings.mlr.press/v97/papyan19a.html.
[16] Mahoney, Michael W. and Martin, Charles H. (2019). Traditional and Heavy Tailed Self Regularization in Neural Network Models. In Proceedings of the 36th International Conference on Machine Learning. pp. 4284–4293. https://proceedings.mlr.press/v97/mahoney19a.html.
[17] Xie et al. (2023). On the Overlooked Structure of Stochastic Gradients. In Proceedings of NeurIPS. https://proceedings.neurips.cc/paper_files/paper/2023/hash/d0b2eda0386f477ab14d7e181e16c899-Abstract-Conference.html.
[18] Keskar et al. (2017). On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. In International Conference on Learning Representations. https://arxiv.org/abs/1609.04836.
[19] McCandlish et al. (2018). An Empirical Model of Large-Batch Training. arXiv preprint arXiv:1812.06162. https://arxiv.org/abs/1812.06162.
[20] Vaswani et al. (2017). Attention Is All You Need. In Advances in Neural Information Processing Systems. https://papers.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html.
[21] Maloney et al. (2022). A Solvable Model of Neural Scaling Laws. doi:10.48550/arXiv.2210.16859. https://arxiv.org/abs/2210.16859. arXiv:2210.16859.
[22] Bordelon et al. (2020). Spectrum Dependent Learning Curves in Kernel Regression and Wide Neural Networks. In Proceedings of the 37th International Conference on Machine Learning. pp. 1024–1034.
[23] Canatar et al. (2021). Spectral Bias and Task-Model Alignment Explain Generalization in Kernel Regression and Infinitely Wide Neural Networks. Nature Communications. 12(2914).
[24] Spigler et al. (2019). Asymptotic Learning Curves of Kernel Methods: Empirical Data Versus Teacher–Student Paradigm. arXiv:1905.10843.
[25] Penedo et al. (2024). The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. arXiv preprint arXiv:2406.17557. doi:10.48550/arXiv.2406.17557. https://arxiv.org/abs/2406.17557.
[26] Li et al. (2020). A System for Massively Parallel Hyperparameter Tuning. In Proceedings of Machine Learning and Systems. pp. 230–246. https://proceedings.mlsys.org/paper_files/paper/2020/hash/a06f20b349c6cf09a6b171c71b88bbfc-Abstract.html.
[27] Nanda et al. (2023). Progress Measures for Grokking via Mechanistic Interpretability. In International Conference on Learning Representations. doi:10.48550/arXiv.2301.05217. https://arxiv.org/abs/2301.05217.
[28] Liu et al. (2022). Towards Understanding Grokking: An Effective Theory of Representation Learning. In Advances in Neural Information Processing Systems. pp. 34651–34663. https://proceedings.neurips.cc/paper_files/paper/2022/hash/dfc310e81992d2e4cedc09ac47eff13e-Abstract-Conference.html.
[29] Gromov, Andrey (2023). Grokking Modular Arithmetic. doi:10.48550/arXiv.2301.02679. https://arxiv.org/abs/2301.02679. arXiv:2301.02679.
[30] Agrawal et al. (2022). $\alpha$-ReQ: Assessing Representation Quality in Self-Supervised Learning by Measuring Eigenspectrum Decay. In Advances in Neural Information Processing Systems. https://proceedings.neurips.cc/paper_files/paper/2022/hash/70596d70542c51c8d9b4e423f4bf2736-Abstract-Conference.html.
[31] Zbontar et al. (2021). Barlow Twins: Self-Supervised Learning via Redundancy Reduction. In Proceedings of ICML. https://proceedings.mlr.press/v139/zbontar21a.html.
[32] Bardes et al. (2022). VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning. In Proceedings of ICLR. https://openreview.net/forum?id=xm6YD62D1Ub.
[33] Ethayarajh, Kawin (2019). How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. pp. 55–65. doi:10.18653/v1/D19-1006. https://aclanthology.org/D19-1006/.
[34] Timkey, William and van Schijndel, Marten (2021). All Bark and No Bite: Rogue Dimensions in Transformer Language Models Obscure Representational Quality. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 4527–4546. doi:10.18653/v1/2021.emnlp-main.372. https://aclanthology.org/2021.emnlp-main.372/.
[35] Liu et al. (2025). Evolution of the Spectral Dimension of Transformer Activations. In OPT 2025: Optimization for Machine Learning. https://openreview.net/forum?id=Va5is76bTP.
[36] Sharma, Utkarsh and Kaplan, Jared (2022). Scaling Laws from the Data Manifold Dimension. Journal of Machine Learning Research. 23(9). pp. 1–34. https://www.jmlr.org/papers/v23/20-1111.html.
[37] Rahimi, Ali and Recht, Benjamin (2007). Random Features for Large-Scale Kernel Machines. In Advances in Neural Information Processing Systems. https://papers.nips.cc/paper_files/paper/2007/hash/013a006f03dbc5392effeb8f18fda755-Abstract.html.
[38] Wang et al. (2024). Nonlinear Spiked Covariance Matrices and Signal Propagation in Deep Neural Networks. In Proceedings of COLT. https://proceedings.mlr.press/v247/wang24b.html.
[39] Power et al. (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. doi:10.48550/arXiv.2201.02177. https://arxiv.org/abs/2201.02177. arXiv:2201.02177.
[40] He et al. (2026). On the Mechanism and Dynamics of Modular Addition: Fourier Features, Lottery Ticket, and Grokking. doi:10.48550/arXiv.2602.16849. https://arxiv.org/abs/2602.16849. arXiv:2602.16849.
[41] Merrill et al. (2023). A Tale of Two Circuits: Grokking as Competition of Sparse and Dense Subnetworks. doi:10.48550/arXiv.2303.11873. https://arxiv.org/abs/2303.11873. arXiv:2303.11873.
[42] Notsawo et al. (2023). Predicting Grokking Long Before it Happens: A Look into the Loss Landscape of Models which Grok. doi:10.48550/arXiv.2306.13253. https://arxiv.org/abs/2306.13253. arXiv:2306.13253.
[43] Radford et al. (2019). Language Models are Unsupervised Multitask Learners. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf.
[44] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 1: llm.c baseline. Replacement link for the repository's record-1 log; the originally uploaded 2024-05-2 $8_l$ lmc path did not resolve.. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-10-1 $3_l$ lmc/main.log.
[45] Su et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. doi:10.48550/arXiv.2104.09864. https://arxiv.org/abs/2104.09864. arXiv:2104.09864.
[46] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 2: Tuned learning rate and rotary embeddings. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-06-0 $6_A$ damW/f66d43d7-e449-4029-8adf-e8537bab49ea.log.
[47] Jordan, Keller (2024). Muon: An Optimizer for Hidden Layers in Neural Networks. https://kellerjordan.github.io/posts/muon/.
[48] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 3: Introduced the Muon optimizer. The repository's world-record table lists record 3, but says no log is available; the originally uploaded 2024-10-0 $4_M$ uon path did not resolve.. https://github.com/KellerJordan/modded-nanogpt#world-record-history.
[49] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 8: Untied embedding and head. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-11-0 $3_U$ ntieEmbed/d6b50d71-f419-4d26-bb39-a60d55ae7a04.txt.
[50] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 9: Value and embedding skip connections, momentum warmup, logit softcap. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-11-0 $6_S$ hortcutsTweaks/dd7304a6-cc43-4d5e-adb8-c070111464a1.txt.
[51] Ronneberger et al. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention. doi:10.1007/978-3-319-24574- $4_28. [$ https://doi.org/10.1007/978-3-319-24574- $4_28]($ https://doi.org/10.1007/978-3-319-24574-$4_28)$.
[52] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 11: U-net pattern skip connections and double lr. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-11-1 $0_U$ NetDoubleLr/c87bb826-797b-4f37-98c7-d3a5dad2de74.txt.
[53] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 12: 1024-ctx dense causal attention to 64K-ctx FlexAttention. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-11-1 $9_F$ lexAttention/8384493d-dba9-4991-b16b-8696953f5e6d.txt.
[54] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 13: Attention window warmup. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-11-2 $4_W$ indowWarmup/cf9e4571-c5fc-4323-abf3-a98d862ec6c8.txt.
[55] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 14: Value Embeddings. https://github.com/KellerJordan/modded-nanogpt/tree/master/records/track_1_short/2024-12-0 $4_V$ alueEmbed.
[56] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 16: Split value embeddings, block sliding window, separate block mask. https://github.com/KellerJordan/modded-nanogpt/tree/master/records/track_1_short/2024-12-1 $0_M$ FUTweaks.
[57] KellerJordan/modded-nanogpt contributors (2024). modded-nanogpt Record 17: Sparsify value embeddings, improve rotary embeddings, drop an attn layer. https://github.com/KellerJordan/modded-nanogpt/tree/master/records/track_1_short/2024-12-1 $7_S$ parsifyEmbeds.
[58] Gemma Team (2024). Gemma 2: Improving Open Language Models at a Practical Size. doi:10.48550/arXiv.2408.00118. https://arxiv.org/abs/2408.00118. arXiv:2408.00118.
[59] KellerJordan/modded-nanogpt contributors (2025). modded-nanogpt Record 18: Lower logit softcap from 30 to 15. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2025-01-0 $4_S$ oftCap/31d6c427-f1f7-4d8a-91be-a67b5dcd13fd.txt.
[60] Micikevicius et al. (2022). FP8 Formats for Deep Learning. https://arxiv.org/abs/2209.05433. arXiv:2209.05433.
[61] KellerJordan/modded-nanogpt contributors (2025). modded-nanogpt Record 19: FP8 head, offset logits, lr decay to 0.1 instead of 0.0. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2025-01-1 $3_Fp8$ LmHead/c51969c2-d04c-40a7-bcea-c092c3c2d11a.txt.
[62] KellerJordan/modded-nanogpt contributors (2025). modded-nanogpt Record 20: Merged QKV weights, long-short attention, attention scale, lower Adam epsilon, batched Muon. https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2025-01-1 $6_S$ ub3Min/1d3bd93b-a69e-4118-aeb8-8184239d7566.txt.