The Curious Case of Neural Text Degeneration
Ari Holtzman$^{\dagger\ddagger}$ Jan Buys$^{\S\dagger}$ Li Du$^{\dagger}$ Maxwell Forbes$^{\dagger\ddagger}$ Yejin Choi$^{\dagger\ddagger}$
$^{\dagger}$Paul G. Allen School of Computer Science & Engineering, University of Washington
$^{\ddagger}$Allen Institute for Artificial Intelligence
$^{\S}$Department of Computer Science, University of Cape Town
{ahai,dul2,mbforbes,yejin}@cs.washington.edu, [email protected]
Abstract
Despite considerable advances in neural language modeling, it remains an open question what the best decoding strategy is for text generation from a language model (e.g. to generate a story). The counter-intuitive empirical observation is that even though the use of likelihood as training objective leads to high quality models for a broad range of language understanding tasks, maximization-based decoding methods such as beam search lead to degeneration — output text that is bland, incoherent, or gets stuck in repetitive loops.
To address this we propose Nucleus Sampling, a simple but effective method to draw considerably higher quality text out of neural language models than previous decoding strategies. Our approach avoids text degeneration by truncating the unreliable tail of the probability distribution, sampling from the dynamic nucleus of tokens containing the vast majority of the probability mass.
To properly examine current maximization-based and stochastic decoding methods, we compare generations from each of these methods to the distribution of human text along several axes such as likelihood, diversity, and repetition. Our results show that (1) maximization is an inappropriate decoding objective for open-ended text generation, (2) the probability distributions of the best current language models have an unreliable tail which needs to be truncated during generation and (3) Nucleus Sampling is currently the best available decoding strategy for generating long-form text that is both high-quality — as measured by human evaluation — and as diverse as human-written text.

Executive Summary: Neural language models have advanced rapidly, enabling machines to generate human-like text for applications like story writing or content continuation. However, a key challenge persists: standard methods for producing text from these models often yield bland, repetitive, or incoherent outputs. This problem is especially acute for open-ended tasks, where the model must create free-form continuations rather than tightly constrained responses, such as in translation. With models like GPT-2 gaining prominence in 2019, understanding and fixing these generation flaws became urgent to unlock reliable AI-driven writing tools that could impact creative industries, education, and automation.
This document sets out to diagnose why common text generation strategies fail and to propose a better alternative. It evaluates various decoding methods—techniques for selecting the next word based on the model's predictions—and introduces Nucleus Sampling as a way to balance quality and variety in outputs.
The authors analyzed generations from GPT-2 Large, a state-of-the-art model trained on 40 gigabytes of web text, using a held-out portion of that dataset. They generated 5,000 text passages, each starting from a short prompt and continuing up to 200 words or an end marker. Key strategies compared included beam search (a maximization approach that picks the most probable sequences), pure sampling (drawing randomly from all predictions), top-k sampling (limiting choices to the top k most likely words), temperature-adjusted sampling (which flattens or sharpens probabilities), and the new Nucleus Sampling (which dynamically selects a minimal set of words capturing most of the probability mass). Evaluations drew on statistical measures like perplexity (how surprised the model is by the text), diversity metrics, and repetition rates, plus human judgments of typicality from 20 annotators per sample across 200 examples per method. This setup ensured credible comparisons to human-written text without relying on overly technical details.
The analysis revealed five core findings. First, maximization methods like beam search produce text with unnaturally high predictability—about 8 to 10 times lower perplexity than human writing—leading to generic, repetitive loops in over 70% of cases for simple greedy decoding and 29% for wider beams. Second, pure sampling generates diverse but incoherent text, with perplexity roughly 80% worse than human levels, as it often picks rare, low-confidence words from the model's "unreliable tail." Third, top-k sampling improves coherence over pure sampling but needs a large k (around 640) to match human diversity, which still introduces occasional incoherence and high variability in quality. Fourth, temperature adjustments help control repetition but sacrifice either diversity (at low temperatures) or coherence (at high ones), failing to align closely with human statistics. Finally, Nucleus Sampling outperforms others, achieving perplexity within 6% of human text, diversity scores matching human levels (Self-BLEU of 0.32 versus 0.31), low repetition (0.36%), and the highest human-statistical score (0.97 on a 0-1 scale).
These results challenge the assumption that selecting the most probable text yields the best outputs; human writing favors informative, varied language over predictable blandness, an intrinsic trait models struggle to capture. For practical impacts, Nucleus Sampling reduces risks of repetitive or off-topic AI text, improving performance in open-ended applications like chatbots or creative tools, where bland outputs could erode user trust or limit utility. Unlike prior work, it avoids fixed limits that either stifle creativity or invite nonsense, offering more reliable generations without added training costs. This matters now as AI text tools scale up, potentially affecting content creation efficiency, policy on AI ethics (e.g., avoiding generic propaganda), and compliance in automated reporting.
Leaders should adopt Nucleus Sampling as the default for open-ended text generation from similar models, tuning the parameter p around 0.95 for optimal results. For directed tasks like summarization, stick with beam search but consider hybrids. If integrating into products, pilot Nucleus Sampling on real user prompts to confirm gains in engagement. Future work could combine it with model retraining to penalize repetition or add semantic guides for topic control, though decisions on full deployment should await such enhancements.
While robust for GPT-2 on web-like text, the study relies on one model and dataset, so results may vary for specialized domains like legal writing. Assumptions about human-like quality hold mainly for open-ended English prose. Confidence is high in Nucleus Sampling's superiority here—backed by aligned metrics and human agreement—but users should validate in their contexts to address potential gaps in cultural or stylistic nuances.
1. Introduction
Section Summary: In 2019, OpenAI's GPT-2 model produced surprisingly high-quality text like an article on Ovid's Unicorn by using random sampling from the top k most likely words, rather than trying to pick the single most probable sequence, which often results in dull, repetitive output from methods like beam search. Pure random sampling from the model's full predictions, however, generates incoherent text because of an "unreliable tail" of low-probability words that skew the results. To fix this, the authors propose Nucleus Sampling, which dynamically selects a small group of the most promising words that together hold a set portion of the total probability, leading to more diverse and human-like text as shown through various quality and diversity tests.
On February 14th 2019, OpenAI surprised the scientific community with an impressively high-quality article about Ovid's Unicorn, written by GPT-2.^1 Notably, the top-quality generations obtained from the model rely on randomness in the decoding method, in particular through top- $k$ sampling that samples the next word from the top $k$ most probable choices ([1, 2, 3]), instead of aiming to decode text that maximizes likelihood.
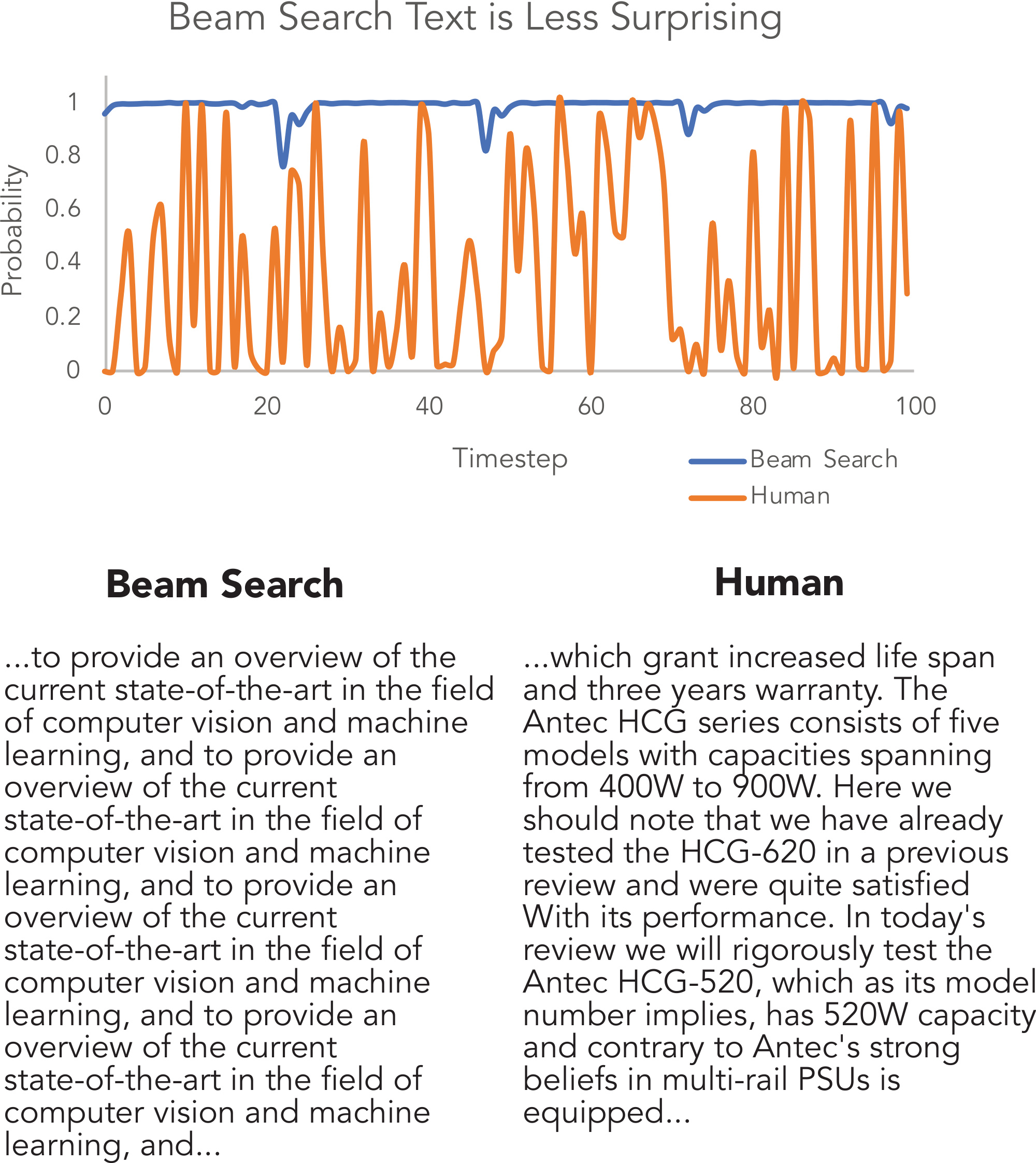
In fact, decoding strategies that optimize for output with high probability, such as beam search, lead to text that is incredibly degenerate, even when using state-of-the-art models such as GPT-2 Large, as shown in Figure 1. This may seem counter-intuitive, as one would expect that good models would assign higher probability to more human-like, grammatical text. Indeed, language models do generally assign high scores to well-formed text, yet the highest scores for longer texts are often generic, repetitive, and awkward. Figure 2 exposes how different the distribution of probabilities assigned to beam search decoded text and naturally occurring text really are.
Perhaps equally surprising is the right side of Figure 1, which shows that pure sampling — sampling directly from the probabilities predicted by the model — results in text that is incoherent and almost unrelated to the context. Why is text produced by pure sampling so degenerate? In this work we show that the "unreliable tail" is to blame. This unreliable tail is composed of tens of thousands of candidate tokens with relatively low probability that are over-represented in the aggregate.
To overcome these issues we introduce Nucleus Sampling (§ 3.1). The key intuition of Nucleus Sampling is that the vast majority of probability mass at each time step is concentrated in the nucleus, a small subset of the vocabulary that tends to range between one and a thousand candidates. Instead of relying on a fixed top- $k$, or using a temperature parameter to control the shape of the distribution without sufficiently suppressing the unreliable tail, we propose sampling from the top- $p$ portion of the probability mass, expanding and contracting the candidate pool dynamically.
In order to compare current methods to Nucleus Sampling, we compare various distributional properties of generated text to the reference distribution, such as the likelihood of veering into repetition and the perplexity of generated text.
The latter reveals that text generated by maximization or top- $k$ sampling is too probable, indicating a lack of diversity and divergence in vocabulary usage from the human distribution. On the other hand, pure sampling produces text that is significantly less likely than the gold, corresponding to lower generation quality.
Vocabulary usage and Self-BLEU ([4]) statistics reveal that high values of $k$ are needed to make top- $k$ sampling match human statistics. Yet, generations based on high values of $k$ often have high variance in likelihood, hinting at qualitatively observable incoherency issues. Nucleus Sampling can easily match reference perplexity through tuning the value of $p$, avoiding the incoherence caused by setting $k$ high enough to match distributional statistics.
Finally, we perform Human Unified with Statistical Evaluation (HUSE; [5]) to jointly assess the overall quality and diversity of the decoding strategies, which cannot be captured using either human or automatic evaluation alone. The HUSE evaluation demonstrates that Nucleus Sampling is the best overall decoding strategy. We include generated examples for qualitative analysis – see Figure 3 for a representative example, and further examples in the appendix.[^2]
[^2]: Code and all generations are available at https://github.com/ari-holtzman/degen
2. Background
Section Summary: Recent research highlights problems with common text generation methods, like maximizing probability, which produce grammatically correct but repetitive and unvaried outputs, while alternatives like GANs fail to improve diversity without sacrificing quality. Techniques such as diverse beam search and unlikelihood training help, but the proposed Nucleus Sampling offers a flexible decoding approach to avoid repetition and incoherence during generation. The background distinguishes directed tasks, like translation or summarization, where outputs closely follow inputs and repetition is less of an issue, from open-ended ones like story continuation, which allow more creative freedom but amplify these generation challenges.
2.1 Text Generation Decoding Strategies
A number of recent works have alluded to the disadvantages of generation by maximization, which tend to generate output with high grammaticality but low diversity ([6, 2, 1]). Generative Adversarial Networks (GANs) have been a prominent research direction ([7, 8]), but recent work has shown that when quality and diversity are considered jointly, GAN-generated text fails to outperform generations from language models ([9, 10, 11]). Work on neural dialog systems have proposed methods for diverse beam search, using a task-specific diversity scoring function or constraining beam hypotheses to be sufficiently different ([12, 13, 6, 14]). While such utility functions encourage desirable properties in generations, they do not remove the need to choose an appropriate decoding strategy, and we believe that Nucleus Sampling will have complementary advantages in such approaches. Finally, [15] begin to address the problem of neural text degeneration through an "unlikelihood loss", which decreases training loss on repeated tokens and thus implicitly reduces gradients on frequent tokens as well. Our focus is on exposing neural text degeneration and providing a decoding solution that can be used with arbitrary models, but future work will likely combine training-time and inference-time solutions.

2.2 Open-Ended vs Directed Generation
Many text generation tasks are defined through (input, output) pairs, such that the output is a constrained transformation of the input. Example applications include machine translation ([16]), data-to-text generation ([17]), and summarization ([18]). We refer to these tasks as directed generation. Typically encoder-decoder architectures are used, often with an attention mechanism ([16, 19]) or using attention-based architectures such as the Transformer ([20]). Generation is usually performed using beam search; since output is tightly scoped by the input, repetition and genericness are not as problematic. Still, similar issues have been reported when using large beam sizes ([21]) and more recently with exact inference ([22]), a counter-intuitive observation since more comprehensive search helps maximize probability.
Open-ended generation, which includes conditional story generation and contextual text continuation (as in Figure 1), has recently become a promising research direction due to significant advances in neural language models ([23, 2, 1, 24, 3]). While the input context restricts the space of acceptable output generations, there is a considerable degree of freedom in what can plausibly come next, unlike in directed generation settings. Our work addresses the challenges faced by neural text generation with this increased level of freedom, but we note that some tasks, such as goal-oriented dialog, may fall somewhere in between open-ended and directed generation.
3. Language Model Decoding
Section Summary: Language models generate continuing text from a given context by predicting the next word based on probabilities, using strategies to select from possible options. Traditional approaches like beam search try to maximize likelihood but often produce repetitive or bland results, prompting alternatives like top-k sampling, which picks from a fixed number of top probable words, though it struggles with varying confidence levels in predictions. The proposed nucleus sampling improves this by dynamically choosing the smallest set of words whose combined probability meets a threshold, adapting to the model's uncertainty, while temperature adjustments can sharpen or broaden these probabilities for better control.
Given an input text passage as context, the task of open-ended generation is to generate text that forms a coherent continuation from the given context. More formally, given a sequence of $m$ tokens $x_1 \ldots x_m$ as context, the task is to generate the next $n$ continuation tokens to obtain the completed sequence $x_1 \ldots x_{m+n}$. We assume that models compute $P(x_{1:m+n})$ using the common left-to-right decomposition of the text probability,
$ P(x_{1:m+n}) = \prod_{i=1}^{m+n} P(x_i | x_1 \ldots x_{i-1}), \tag{1} $
which is used to generate the generation token-by-token using a particular decoding strategy.
Maximization-based decoding
The most commonly used decoding objective, in particular for directed generation, is maximization-based decoding. Assuming that the model assigns higher probability to higher quality text, these decoding strategies search for the continuation with the highest likelihood. Since finding the optimum argmax sequence from recurrent neural language models or Transformers is not tractable ([25]), common practice is to use beam search ([26, 27, 17]). However, several recent studies on open-ended generation have reported that maximization-based decoding does not lead to high quality text ([1, 2]).
3.1 Nucleus Sampling
We propose a new stochastic decoding method: Nucleus Sampling. The key idea is to use the shape of the probability distribution to determine the set of tokens to be sampled from. Given a distribution $P(x | x_{1:i-1})$, we define its top- $p$ vocabulary $V^{(p)} \subset V$ as the smallest set such that
$ \sum_{x \in V^{(p)}} P(x | x_{1:i-1}) \geq p. \tag{2} $
Let $p' = \sum_{x \in V^{(p)}} P(x | x_{1:i-1})$. The original distribution is re-scaled to a new distribution, from which the next word is sampled:
$ P'(x | x_{1:i-1}) = \left{ \begin{array}{ll} P(x | x_{1:i-1})/p' & \text{if } x \in V^{(p)} \ 0 & \text{otherwise.} \end{array} \right.\tag{3} $
In practice this means selecting the highest probability tokens whose cumulative probability mass exceeds the pre-chosen threshold $p$. The size of the sampling set will adjust dynamically based on the shape of the probability distribution at each time step. For high values of $p$, this is a small subset of vocabulary that takes up vast majority of the probability mass — the nucleus.
3.2 Top-k Sampling
Top- $k$ sampling has recently become a popular alternative sampling procedure ([1, 2, 3]). Nucleus Sampling and top- $k$ both sample from truncated Neural LM distributions, differing only in the strategy of where to truncate. Choosing where to truncate can be interpreted as determining the generative model's trustworthy prediction zone.
At each time step, the top $k$ possible next tokens are sampled from according to their relative probabilities. Formally, given a distribution $P(x | x_{1:i-1})$, we define its top- $k$ vocabulary $V^{(k)} \subset V$ as the set of size $k$ which maximizes $\sum_{x \in V^{(k)}} P(x | x_{1:i-1})$. Let $p' = \sum_{x \in V^{(k)}} P(x | x_{1:i-1})$. The distribution is then re-scaled as in equation 3, and sampling is performed based on that distribution. Note that the scaling factor $p'$ can vary wildly at each time-step, in contrast to Nucleus Sampling.
Difficulty in choosing a suitable value of $k$
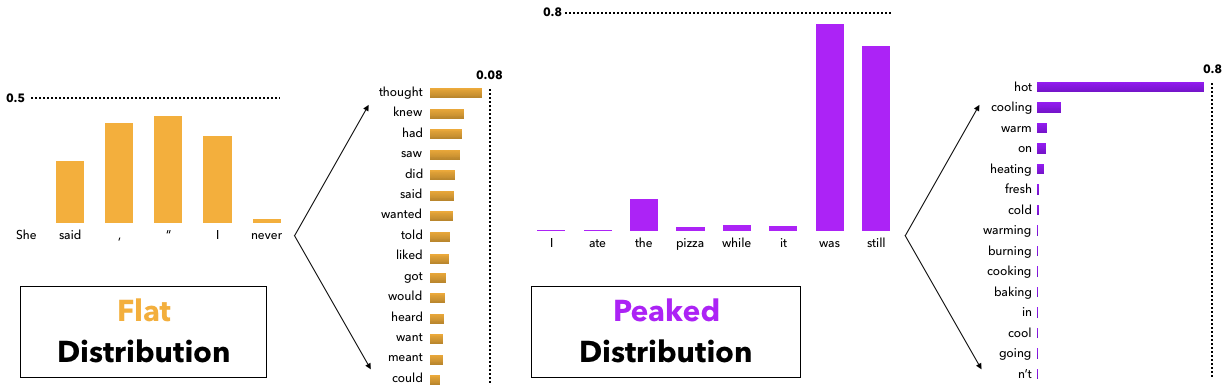
While top- $k$ sampling leads to considerably higher quality text than either beam search or sampling from the full distribution, the use of a constant $k$ is sub-optimal across varying contexts. As illustrated on the left of Figure 5, in some contexts the head of the next word distribution can be flat across tens or hundreds of reasonable options (e.g. nouns or verbs in generic contexts), while in other contexts most of the probability mass is concentrated in one or a small number of tokens, as on the right of the figure. Therefore if $k$ is small, in some contexts there is a risk of generating bland or generic text, while if $k$ is large the top- $k$ vocabulary will include inappropriate candidates which will have their probability of being sampled increased by the renormalization. Under Nucleus Sampling, the number of candidates considered rises and falls dynamically, corresponding to the changes in the model's confidence region over the vocabulary which top- $k$ sampling fails to capture for any one choice of $k$.
3.3 Sampling with Temperature
Another common approach to sampling-based generation is to shape a probability distribution through temperature ([28]). Temperature sampling has been applied widely to text generation ([29, 1, 9]). Given the logits $u_{1:|V|}$ and temperature $t$, the softmax is re-estimated as
$ p(x = V_l | x_{1:i-1}) = \frac {\exp(u_l/ t)} {\sum_{l'} \exp(u_l'/ t)}. \tag{4} $
Setting $t \in [0, 1)$ skews the distribution towards high probability events, which implicitly lowers the mass in the tail distribution. Low temperature sampling has also been used to partially alleviate the issues of top- $k$ sampling discussed above, by shaping the distribution before top- $k$ sampling ([30, 1]). However, recent analysis has shown that, while lowering the temperature improves generation quality, it comes at the cost of decreasing diversity ([9, 5]).
4. Likelihood Evaluation
Section Summary: Researchers used the GPT-2 language model to generate thousands of text passages based on real web documents, comparing different generation techniques like greedy decoding, beam search, and sampling methods against human-written text. They evaluated these outputs using metrics such as perplexity, which measures how surprised the model is by the text, finding that nucleus sampling came closest to matching the unpredictability of human writing, while methods like beam search produced overly predictable and repetitive results. Human language avoids maximum probability because it favors informative and varied words over obvious ones, a trait that current models struggle to replicate due to how they learn word by word.
4.1 Experimental Setup
While many neural network architectures have been proposed for language modeling, including LSTMs ([31]) and convolutional networks ([32]), the Transformer architecture ([20]) has been the most successful in the extremely large-scale training setups in recent literature ([30, 3]). In this study we use the Generatively Pre-trained Transformer, version 2 (GPT2; [3]), which was trained on WebText, a 40GB collection of text scraped from the web.[^3] We perform experiments using the Large model (762M parameters). Our analysis is based on generating 5, 000 text passages, which end upon reaching an end-of-document token or a maximum length of 200 tokens. Texts are generated conditionally, conditioned on the initial paragraph (restricted to 1-40 tokens) of documents in the held-out portion of WebText, except where otherwise mentioned.
[^3]: Available at https://github.com/openai/gpt-2-output-dataset
: Table 1: Main results for comparing all decoding methods with selected parameters of each method. The numbers closest to human scores are in bold except for HUSE ([5]), a combined human and statistical evaluation, where the highest (best) value is bolded. For Top- $k$ and Nucleus Sampling, HUSE is computed with interpolation rather than truncation (see § 6.1).
| Method | Perplexity | Self-BLEU4 | Zipf Coefficient | Repetition % | HUSE |
|---|---|---|---|---|---|
| Human | 12.38 | 0.31 | 0.93 | 0.28 | - |
| Greedy | 1.50 | 0.50 | 1.00 | 73.66 | - |
| Beam, b=16 | 1.48 | 0.44 | 0.94 | 28.94 | - |
| Stochastic Beam, b=16 | 19.20 | 0.28 | 0.91 | 0.32 | - |
| Pure Sampling | 22.73 | 0.28 | 0.93 | 0.22 | 0.67 |
| Sampling, $t$ =0.9 | 10.25 | 0.35 | 0.96 | 0.66 | 0.79 |
| Top- $k$ =40 | 6.88 | 0.39 | 0.96 | 0.78 | 0.19 |
| Top- $k$ =640 | 13.82 | 0.32 | 0.96 | 0.28 | 0.94 |
| Top- $k$ =40, $t$ =0.7 | 3.48 | 0.44 | 1.00 | 8.86 | 0.08 |
| Nucleus $p$ =0.95 | 13.13 | 0.32 | 0.95 | 0.36 | 0.97 |
4.2 Perplexity
Our first evaluation is to compute the perplexity of generated text using various decoding strategies, according to the model that is being generated from. We compare these perplexities against that of the gold text (Figure 6). Importantly, we argue that the optimal generation strategy should produce text which has a perplexity close to that of the gold text: Even though the model has the ability to generate text that has lower perplexity (higher probability), such text tends to have low diversity and get stuck in repetition loops, as shown in § 5 and illustrated in Figure 4.
We see that perplexity of text obtained from pure sampling is worse than the perplexity of the gold. This indicates that the model is confusing itself: sampling too many unlikely tokens and creating context that makes it difficult to recover the human distribution of text, as in Figure 1. Yet, setting the temperature lower creates diversity and repetition issues, as we shall see in § 5. Even with our relatively fine-grained parameter sweep, Nucleus Sampling obtains closest perplexity to human text, as shown in Table 1.
![**Figure 6:** Perplexities of generations from various decoding methods. Note that beam search has unnaturally low perplexities. A similar effect is seen using a temperature of $0.7$ with top- $k$ as in both [3] and [1]. Sampling, Top- $k$, and Nucleus can all be calibrated to human perplexities, but the first two face coherency issues when their parameters are set this high.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/xqsjvup4/cond_ppl.png)
4.3 Natural Language Does Not Maximize Probability
One might wonder if the issue with maximization is a search error, i.e., there are higher quality sentences to which the model assigns higher probability than to the decoded ones, beam search has just failed to find them. Yet Figures 2 & 6 show that the per-token probability of natural text is, on average, much lower than text generated by beam search. Natural language rarely remains in a high probability zone for multiple consecutive time steps, instead veering into lower-probability but more informative tokens. Nor does natural language tend to fall into repetition loops, even though the model tends to assign high probability to this, as seen in Figure 4.
Why is human-written text not the most probable text? We conjecture that this is an intrinsic property of human language. Language models that assign probabilities one word at a time without a global model of the text will have trouble capturing this effect. Grice's Maxims of Communication ([33]) show that people optimize against stating the obvious. Thus, making every word as predictable as possible will be disfavored. This makes solving the problem simply by training larger models or improving neural architectures using standard per-word learning objectives unlikely: such models are forced to favor the lowest common denominator, rather than informative language.
5. Distributional Statistical Evaluation
Section Summary: This section evaluates how well AI-generated text matches human writing by analyzing word frequency patterns, diversity, and repetition. It finds that pure sampling produces vocabulary distributions closest to human text, followed by Nucleus sampling, while lower temperature settings reduce rare words but increase repetition and perplexity. Overall, Nucleus sampling performs best in balancing these qualities for practical use, avoiding excessive similarity or loops in generated content.
5.1 Zipf Distribution Analysis
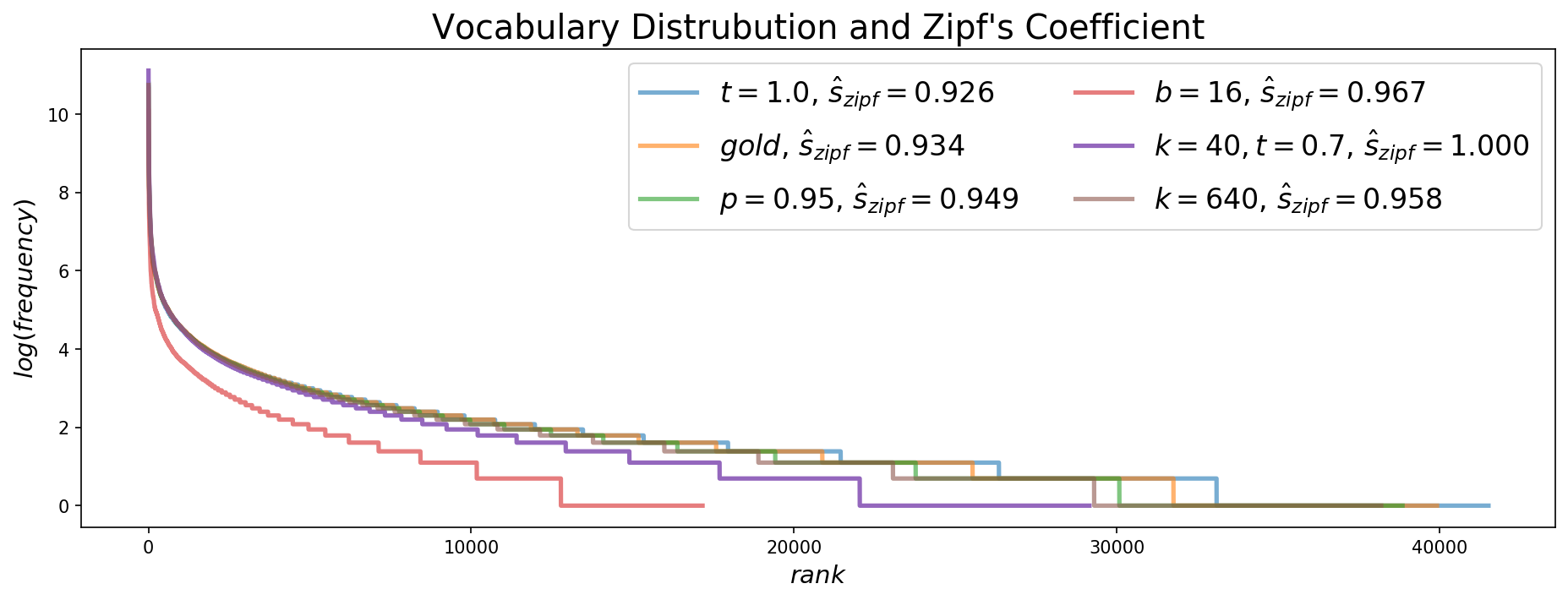
In order to compare generations to the reference text, we begin by analyzing their use of vocabulary. Zipf's law suggests that there is an exponential relationship between the rank of a word and its frequency in text. The Zipfian coefficient $s$ can be used to compare the distribution in a given text to a theoretically perfect exponential curve, where $s=1$ ([34]). Figure 7 shows the vocabulary distributions along with estimated Zipf coefficients for selected parameters of different decoding methods. As expected, pure sampling is the closest to the human distribution, followed by Nucleus Sampling. The visualization of the distribution shows that pure sampling slightly overestimates the use of rare words, likely one reason why pure sampling also has higher perplexity than human text. Furthermore, lower temperature sampling avoids sampling these rare words from the tail, which is why it has been used in some recent work ([1, 3]).
![Figure 8: Self-BLEU calculated on the unconditional generations produced by stochastic decoding methods; lower Self-BLEU scores imply higher diversity. Horizontal blue and orange lines represent human self-BLEU scores. Note how common values of $t \in [0.5, 1]$ and $k \in [1, 100]$ result in high self-similarity, whereas "normal" values of $p \in 0.9, 1)$ closely match the human distribution of text.
{kind=link}
5.2 Self-BLEU
We follow previous work and compute Self-BLEU ([4]) as a metric of diversity. Self-BLEU is calculated by computing the BLEU score of each generated document using all other generations in the evaluation set as references. Due to the expense of computing such an operation, we sample 1000 generations, each of which is compared with all 4999 other generations as references. A lower Self-BLEU score implies higher diversity. Figure 8 shows that Self-BLEU results largely follow that of the Zipfian distribution analysis as a diversity measure. It is worth noting that very high values of $k$ and $t$ are needed to get close to the reference distribution, though these result in unnaturally high perplexity (§ 4).
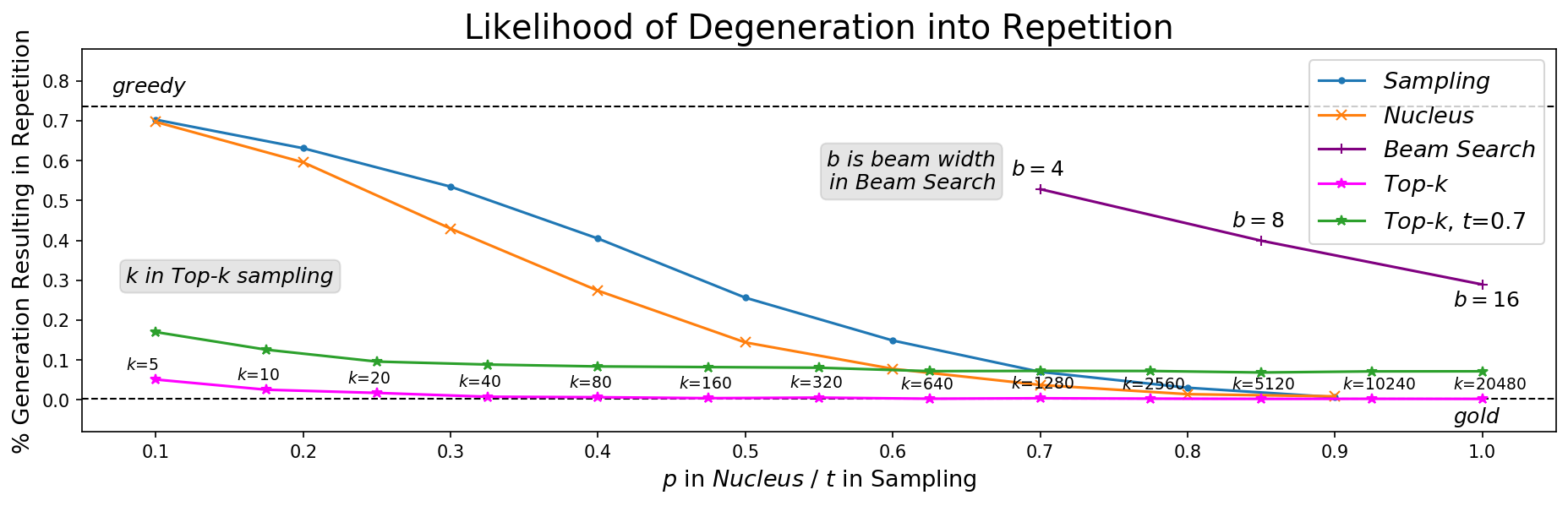
![Figure 9: We visualize how often different decoding methods get "stuck" in loops within the first 200 tokens. A phrase (minimum length 2) is considered a repetition when it repeats at least three times at the end of the generation. We label points with their parameter values except for $t$ and $p$ which follow the x-axis. Values of $k$ greater than 100 are rarely used in practice and values of $p$ are usually in $0.9, 1)$; therefore Nucleus Sampling is far closer to the human distribution in its usual parameter range. Sampling with temperatures lower than 0.9 severely increase repetition. Finally, although beam search becomes less repetitive according to this metric as beam width increases, this is largely because average length gets shorter as $b$ increases (see Appendix A).
5.3 Repetition
One attribute of text quality that we can quantify is repetition. Figure 9 shows that Nucleus Sampling and top- $k$ sampling have the least repetition for reasonable parameter ranges. Generations from temperature sampling have more repetition unless very high temperatures are used, which we have shown negatively affects coherence (as measured by high perplexity). Further, all stochastic methods face repetition issues when their tuning parameters are set too low, which tends to over-truncate, mimicking greedy search. Therefore we conclude that only Nucleus Sampling satisfies all the distributional criteria for desirable generations.
6. Human Evaluation
Section Summary: To better assess the quality and diversity of text generated by different decoding methods, researchers combined human judgments with statistical measures using a method called HUSE, which trains a system to differentiate human-like text from machine-generated ones based on probability scores and annotator ratings of typicality. They evaluated 200 text samples per method, gathering 4,000 annotations from 20 different people each, and found that Nucleus Sampling performed best overall, followed by Top-k sampling, after adjusting for issues like probability truncation in the models. In examining specific examples, beam search often repeated phrases endlessly, full sampling produced confusing or invented words, while Nucleus Sampling made minor errors like mixing up animals but stayed more coherent than Top-k, which tended to wander off-topic or repeat at lower temperatures.
6.1 Human Unified with Statistical Evaluation (HUSE)
Statistical evaluations are unable to measure the coherence of generated text properly. While the metrics in previous sections gave us vital insights into the different decoding methods we compare, human evaluation is still required to get a full measure of the quality of the generated text. However, pure human evaluation does not take into account the diversity of the generated text; therefore we use HUSE ([5]) to combine human and statistical evaluation. HUSE is computed by training a discriminator to distinguish between text drawn from the human and model distributions, based on only two features: The probability assigned by the language model, and human judgements of typicality of generations. Text that is close to the human distribution in terms of quality and diversity should perform well on both likelihood evaluation and human judgements.
As explored in the previous sections, the current best-performing decoding methods rely on truncation of the probability distribution, which yields a probability of 0 for the vast majority of potential tokens. Initial exploration of applying HUSE directly led to top- $k$ and Nucleus Sampling receiving scores of nearly 0 due to truncation, despite humans favoring these methods. As a proxy, when generating the text used to compute HUSE, we interpolate (with mass $0.1$) the original probability distribution with the top- $k$ and Nucleus Sampling distribution, smoothing the truncated distribution.
For each decoding algorithm we annotate 200 generations for typicality, with each generation receiving 20 annotations from 20 different annotators. This results in a total of 4000 annotations per a decoding scheme. We use a KNN classifier to compute HUSE, as in the original paper, with $k=13$ neighbors, which we found led to the higher accuracy in discrimination. The results in Table 1 shows that Nucleus Sampling obtains the highest HUSE score, with Top- $k$ sampling performing second best.
6.2 Qualitative Analysis
Figure 3 shows representative example generations. Unsurprisingly, beam search gets stuck in a repetition loop it cannot escape. Of the stochastic decoding schemes, the output of full sampling is clearly the hardest to understand, even inventing a new word "umidauda", apparently a species of bird. The generation produced by Nucleus Sampling isn't perfect – the model appears to confuse whales with birds, and begins writing about those instead. Yet, top- $k$ sampling immediately veers off into an unrelated event. When top- $k$ sampling is combined with a temperature of 0.7, as is commonly done ([3, 1]), the output devolves into repetition, exhibiting the classic issues of low-temperature decoding. More generations are available in Appendix B.
7. Conclusion
Section Summary: This paper examined the main ways AI language models generate open-ended text, revealing that the most reliable method often leads to repetitive and bland outputs, while random sampling can pick unlikely or poor-quality words. To fix this, the authors introduced Nucleus Sampling, a technique that focuses on the model's most confident predictions to produce more natural and varied results. Looking ahead, they plan to refine this by better tracking confidence levels and incorporating meaning-based guidance for even stronger text generation.
This paper provided a deep analysis into the properties of the most common decoding methods for open-ended language generation. We have shown that likelihood maximizing decoding causes repetition and overly generic language usage, while sampling methods without truncation risk sampling from the low-confidence tail of a model's predicted distribution. Further, we proposed Nucleus Sampling as a solution that captures the region of confidence of language models effectively. In future work, we wish to dynamically characterize this region of confidence and include a more semantic utility function to guide the decoding process.
Acknowledgments
Section Summary: The research was partly funded by the National Science Foundation through grants like IIS-1524371 and a Graduate Research Fellowship. It also received support from DARPA programs administered via the Army Research Office and NIWC Pacific, along with contributions from the South African Centre for Artificial Intelligence Research and the Allen Institute for AI.
This research was supported in part by NSF (IIS-1524371), the National Science Foundation Graduate Research Fellowship under Grant No. DGE1256082, DARPA CwC through ARO (W911NF15-1- 0543), DARPA MCS program through NIWC Pacific (N66001-19-2-4031), the South African Centre for Artificial Intelligence Research, and the Allen Institute for AI.
A Beam Width Effect

B Example Generations
Section Summary: This section offers more examples of AI-generated text starting from a basic tag line, presented in Figures 11, 12, and 13 for easy visual comparison. These show how various generation methods handle the task, with full versions available on GitHub. In particular, Figure 12 highlights that only Pure Sampling and Nucleus Sampling break free from repetitive loops, with Nucleus Sampling producing outputs that most closely match the original style.
We include a set of examples for further qualitative comparison.
](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/xqsjvup4/examples2.png)
](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/xqsjvup4/examples3.png)
](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/xqsjvup4/examples4.png)
References
Section Summary: This section provides a bibliography of academic papers and preprints on artificial intelligence topics, mainly focused on generating human-like text and stories using neural networks. It covers early works on story generation techniques, generative adversarial networks for creating diverse text, and methods to evaluate how well these models perform. Additional references explore neural translation tools, attention mechanisms in AI, and challenges in producing coherent, varied language outputs from 2015 to 2020.
[1] Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pp.\ 889–898, 2018.
[2] Ari Holtzman, Jan Buys, Maxwell Forbes, Antoine Bosselut, David Golub, and Yejin Choi. Learning to write with cooperative discriminators. In Proceedings of the Association for Computational Linguistics, 2018.
[3] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, February 2019. URL https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf. Unpublished manuscript.
[4] Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, and Yong Yu. Texygen: A benchmarking platform for text generation models. SIGIR, 2018.
[5] Tatsunori B. Hashimoto, Hugh Zhang, and Percy Liang. Unifying human and statistical evaluation for natural language generation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019.
[6] Ilya Kulikov, Alexander H Miller, Kyunghyun Cho, and Jason Weston. Importance of search and evaluation strategies in neural dialogue modeling. International Conference on Natural Language Generation, 2019.
[7] Lantao Yu, Weinan Zhang, Jun Wang, and Yong Yu. Seqgan: Sequence generative adversarial nets with policy gradient. In AAAI, 2017.
[8] Jingjing Xu, Xuancheng Ren, Junyang Lin, and Xu Sun. Diversity-promoting gan: A cross-entropy based generative adversarial network for diversified text generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp.\ 3940–3949, Brussels, Belgium, oct 2018.
[9] Massimo Caccia, Lucas Caccia, William Fedus, Hugo Larochelle, Joelle Pineau, and Laurent Charlin. Language gans falling short. In Critiquing and Correcting Trends in Machine Learning: NeurIPS 2018 Workshop, 2018. URL http://arxiv.org/abs/1811.02549.
[10] Guy Tevet, Gavriel Habib, Vered Shwartz, and Jonathan Berant. Evaluating text gans as language models. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp.\ 2241–2247, 2019.
[11] Stanislau Semeniuta, Aliaksei Severyn, and Sylvain Gelly. On accurate evaluation of gans for language generation. arXiv preprint arXiv:1806.04936, 2018.
[12] Jiwei Li, Will Monroe, and Dan Jurafsky. A simple, fast diverse decoding algorithm for neural generation. arXiv preprint arXiv:1611.08562, 2016a.
[13] Ashwin K. Vijayakumar, Michael Cogswell, Ramprasaath R. Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search for improved description of complex scenes. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[14] Chris Pal, Charles Sutton, and Andrew McCallum. Sparse forward-backward using minimum divergence beams for fast training of conditional random fields. In 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, volume 5, May 2006.
[15] Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. Neural text generation with unlikelihood training. In Proceedings of the International Conference on Learning Representations (ICLR), 2020.
[16] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. Proceedings of the 2015 International Conference on Learning Representations, 2015.
[17] Sam Wiseman, Stuart Shieber, and Alexander Rush. Challenges in data-to-document generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp.\ 2253–2263, Copenhagen, Denmark, September 2017.
[18] Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, Caglar Gulcehre, and Bing Xiang. Abstractive text summarization using sequence-to-sequence rnns and beyond. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning, pp.\ 280–290, 2016.
[19] Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pp.\ 1412–1421, 2015.
[20] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, pp.\ 5998–6008, 2017.
[21] Philipp Koehn and Rebecca Knowles. Six challenges for neural machine translation. In Proceedings of the First Workshop on Neural Machine Translation, pp.\ 28–39, 2017.
[22] Felix Stahlberg and Bill Byrne. On nmt search errors and model errors: Cat got your tongue? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 3347–3353, 2019.
[23] Elizabeth Clark, Yangfeng Ji, and Noah A. Smith. Neural text generation in stories using entity representations as context. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp.\ 2250–2260, New Orleans, Louisiana, June 2018.
[24] Nanyun Peng, Marjan Ghazvininejad, Jonathan May, and Kevin Knight. Towards controllable story generation. In Proceedings of the First Workshop on Storytelling, pp.\ 43–49, New Orleans, Louisiana, June 2018. doi:10.18653/v1/W18-1505.
[25] Yining Chen, Sorcha Gilroy, Andreas Maletti, Jonathan May, and Kevin Knight. Recurrent neural networks as weighted language recognizers. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp.\ 2261–2271, New Orleans, Louisiana, June 2018.
[26] Jiwei Li, Will Monroe, Alan Ritter, Dan Jurafsky, Michel Galley, and Jianfeng Gao. Deep reinforcement learning for dialogue generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp.\ 1192–1202, 2016b.
[27] Tianxiao Shen, Tao Lei, Regina Barzilay, and Tommi Jaakkola. Style transfer from non-parallel text by cross-alignment. In Advances in neural information processing systems, pp.\ 6830–6841, 2017.
[28] David H Ackley, Geoffrey E Hinton, and Terrence J Sejnowski. A learning algorithm for boltzmann machines. Cognitive science, 9(1):147–169, 1985.
[29] Jessica Ficler and Yoav Goldberg. Controlling linguistic style aspects in neural language generation. In Proceedings of the Workshop on Stylistic Variation, pp.\ 94–104, 2017.
[30] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training, 2018. URL https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf. Unpublished manuscript.
[31] Martin Sundermeyer, Ralf Schlüter, and Hermann Ney. Lstm neural networks for language modeling. In Thirteenth annual conference of the international speech communication association, 2012.
[32] Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning, pp.\ 933–941, 2017.
[33] H Paul Grice. Logic and conversation. In P Cole and J L Morgan (eds.), Speech Acts, volume 3 of Syntax and Semantics, pp.\ 41–58. Academic Press, 1975.
[34] Steven T Piantadosi. Zipf’s word frequency law in natural language: A critical review and future directions. Psychonomic bulletin & review, 21(5):1112–1130, 2014.