$\delta$-mem: Efficient Online Memory for Large Language Models
Jingdi Lei$^{\dagger, 1, 3}$, Di Zhang$^{\dagger, 2, 3}$, Junxian Li$^{4}$, Weida Wang$^{2}$, Kaixuan Fan$^{5, 3}$, Xiang Liu$^{6, 3}$, Qihan Liu$^{3}$, Xiaoteng Ma$^{3}$, Baian Chen$^{3}$, Soujanya Poria$^{1}$
$^{1}$Nanyang Technological University, $^{2}$Fudan University, $^{3}$Mind Lab, $^{4}$Shanghai Jiao Tong University, $^{5}$The Chinese University of Hong Kong, $^{6}$The Hong Kong University of Science and Technology (Guangzhou)
$^{\dagger}$ These authors contributed equally.
Abstract
Large language models increasingly need to accumulate and reuse historical information in long-term assistants and agent systems. Simply expanding the context window is costly and often fails to ensure effective context utilization. We propose $\delta$-mem, a lightweight memory mechanism that augments a frozen full-attention backbone with a compact online state of associative memory. $\delta$-mem compresses past information into a fixed-size state matrix updated by delta-rule learning, and uses its readout to generate low-rank corrections to the backbone's attention computation during generation. With only an $8 \times 8$ online memory state, $\delta$-mem improves the average score to $1.10\times$ that of the frozen backbone and $1.15\times$ that of the strongest non-$\delta$-mem memory baseline. It achieves larger gains on memory-heavy benchmarks, reaching $1.31\times$ on MEMORYAGENTBENCH and $1.20\times$ on LoCoMo, while largely preserving general capabilities. These results show that effective memory can be realized through a compact online state directly coupled with attention computation, without full fine-tuning, backbone replacement, or explicit context extension.
Executive Summary: Large language models (LLMs) power tools like personal assistants and autonomous agents, but they struggle to retain and use information from long past interactions. Simply feeding more history into the model increases computing costs quadratically and often leads to poor performance due to "context rot," where key details get lost in lengthy inputs. This problem is urgent as these models expand into real-world applications requiring ongoing memory, such as multi-turn conversations or task planning over days or weeks, demanding solutions that are efficient and effective without overhauling the core model.
This document introduces and tests δ-mem, a simple add-on mechanism designed to give frozen LLMs—models whose main parameters stay unchanged—a compact way to store and apply historical knowledge. It aims to show that δ-mem can boost memory use in long interactions while keeping general abilities intact and adding minimal extra work.
The approach builds δ-mem around existing LLMs like Qwen3-4B and SmolLM3-3B, using a tiny 8-by-8 matrix to compress past data into an evolving "online state" updated token by token or by message segments. This state influences the model's attention—the part that weighs input relevance—through small adjustments, without retraining the full model. Researchers trained δ-mem on a dataset of question-answering examples up to 8,000 tokens long, then evaluated it on benchmarks for memory-intensive tasks (like LoCoMo for conversation history and MemoryAgentBench for agent planning) and general ones (like HotpotQA for multi-step reasoning and IFEval for following instructions). They compared it to baselines like text compression methods, external memory modules, and parameter tweaks, focusing on setups with similar low added parameters for fair credibility.
Key results highlight δ-mem's edge. First, it lifts overall performance across tasks by 10%, scoring 51.7% on average versus 46.8% for the plain model, and beats the top competing memory add-on by 15%. Second, gains are biggest where memory matters most: scores on MemoryAgentBench rise 31% to 38.9%, on LoCoMo 20% to 49.1%, and one subtask nearly doubles from 26% to 51%. Third, even without feeding any past context, δ-mem recovers useful history—HotpotQA accuracy jumps from near zero to 6.5%—proving the small state holds relevant signals. Fourth, it works across model sizes, boosting small ones like SmolLM3-3B by 42% while adding just 0.12% more parameters and negligible runtime cost. Finally, variants like segment-wise updates or multiple sub-states fine-tune it for different needs, with full-layer use yielding the best results.
These findings mean δ-mem addresses LLM memory bottlenecks practically, cutting costs from bloated contexts or heavy retraining while enhancing reliability in extended use cases. It outperforms rivals that either lose details in text summaries, add complex retrieval steps, or fail to adapt dynamically, revealing that a tight link to the model's attention core drives better results than expected from such a minimal setup. This shifts focus from hardware fixes to smarter internal aids, potentially speeding up deployments in cost-sensitive areas like mobile apps or enterprise agents, though it shines more on memory tasks than pure reasoning.
Leaders should integrate δ-mem into LLM pipelines for memory-needy apps, starting with the query-output correction variant for efficiency. It offers a low-risk upgrade: test on your specific tasks via plug-in to frozen models. For broader rollout, pilot multi-state versions to handle diverse info types, weighing slight speed trade-offs against memory gains. More work is needed, like scaling to billion-parameter models or real-time user studies, to confirm edge cases.
Confidence is high in the core gains, backed by consistent wins across three models and five benchmarks, but caution applies to very niche domains untested here—assumptions like stable input formats might falter in noisy real data, and the fixed small state could saturate in ultra-long histories beyond 30,000 tokens without tweaks.
1. Introduction
Section Summary: Large language models are increasingly used in tasks requiring long-term memory, like personalized assistants, but simply adding more conversation history to inputs becomes inefficient due to high computational costs and the models' difficulty in using very long contexts effectively. Existing memory approaches, such as storing history as text, using external modules, or embedding it in model parameters, each have drawbacks like limited flexibility or poor adaptability to changing information. To address this, the authors introduce δ-mem, a compact system that maintains a small, evolving memory state updated in real-time and integrates it directly into the model's attention process without altering the core model, leading to significant performance gains on memory-intensive benchmarks while using just an 8x8 matrix for storage.
As large language models (LLMs) are increasingly deployed in memory-heavy scenarios requiring continuous interaction, such as long-term personalized assistants ([1, 2]) and long-horizon agent systems ([3, 4, 5]), their life-cycle must go beyond responding to isolated prompts and instead accumulate, update, and reuse historical information over extended memory-heavy tasks ([3, 6, 1, 7, 8]). In these settings, model performance depends not only on understanding the current input, but also on effectively leveraging relevant past context during test-time ([9, 10]). An intuitive way is to simply expand the input context and retain more interaction history. However, this strategy only reduces the memory problem to a long-context processing problem, which is both computationally expensive and increasingly difficult to harness. On the one hand, standard attention incurs quadratic cost with respect to context length ([11, 12, 13]). On the other hand, simply increasing the context window does not guarantee effective use of the additional information, as models often suffer from context degradation or context rot when the context becomes very long ([14, 15]), which suggests that even million-token context windows ([16, 17]) do not fundamentally solve the memory problem. These limitations call for more advanced memory mechanisms (MMs) that can represent historical information more compactly within a given context window, maintain it dynamically across interactions, and make it effectively usable by the backbone model during test-time ([10, 1, 18, 7, 19, 20, 8]).
From a unified perspective, existing memory mechanisms can be characterized along two dimensions under a given context window: memory state, which defines how historical information is stored, and memory steering, which determines how stored information influences backbone reasoning. Under this framework, prior methods fall into three paradigms. Textual memory mechanisms (TMMs) ([1, 10, 21, 22, 23]) store memory as text and inject it through the input context, offering flexibility without architectural changes but suffering from context-window limits, retrieval noise, and inevitable compaction loss. Outside-channel memory mechanisms (OMMs) ([24, 18, 25]) keep memory in external modules and interact with the backbone via retrieval or encoding on outside pathways, enabling modularity but introducing overhead, integration complexity, and potential misalignments with the backbone. Parametric memory mechanisms (PMMs) ([26, 27, 28, 29]) encode memory into parameters of prefixes or adapters, making them efficient and compatible with frozen backbones, but their static nature limits adaptation to dynamically evolving information. Taken together, these limitations point to a need for a memory mechanism that can maintain a compact and dynamically evolving memory state while steering the backbone through a pathway tightly aligned with its internal attention computation.
Following this motivation, we propose $\delta\text{-mem}$, a memory mechanism that keeps a compact and dynamically updated memory alongside a frozen full-attention backbone. Instead of storing all historical tokens in the input context, $\delta\text{-mem}$ compresses past information into an online state of associative memory (OSAM). This state is continuously updated via delta-rule learning as new tokens arrive, allowing the model to maintain useful historical information in a fixed-size matrix representation of associative memories. During generation, $\delta\text{-mem}$ does not simply retrieve text from memory. Instead, the current input queries the online state to extract context-relevant associative memory signals, which are then transformed into a low-rank correction to the backbone’s attention components. In this way, associative memory directly participates in the backbone’s forward computation while leaving the backbone frozen. The online state is further updated after each interaction, enabling $\delta\text{-mem}$ to evolve its associative memory over time.
Finally, we evaluate $\delta\text{-mem}$ on memory-heavy benchmarks, including $\textsc{HotpotQA}$ ([30]), $\textsc{LoCoMo}$ ([31]), and $\textsc{MemoryAgentBench}$ ([32]), together with general capability benchmarks $\textsc{IFEval}$ ([33]) and $\textsc{GPQA-Diamond}$ ([34]). With only a fixed $8\times8$ online state of associative memory, $\delta\text{-mem}$ improves the final average score by $1.10\times$ over the frozen backbone and outperforms the strongest non- $\delta\text{-mem}$ memory baseline by $1.15\times$. On memory-heavy tasks, the improvement is larger: MemoryAgentBench increases over $1.31\times$, LoCoMo over $1.20\times$, and the TTL subtask nearly doubles from $26.14$ to $50.50$. These results show that a compact online state, when directly coupled with attention computation, can provide effective associative memory without relying on extending explicit context or heavy external retrieval modules.
Our contributions can be summarized as follows:
- We propose $\delta\text{-mem}$, a memory mechanism that augments a frozen full-attention backbone with a compact online state of associative memory, enabling historical information to be dynamically maintained and directly coupled with the backbone's attention computation.
- We show that an extremely small memory state, implemented as an $8 \times 8$ matrix, can retain useful historical signals through OSAM and help the model recover context-relevant information even after explicit history is removed.
- We evaluate $\delta\text{-mem}$ on multiple memory-heavy and general capability benchmarks with significant gains on memory-heavy tasks such as $\textsc{MemoryAgentBench}$ and $\textsc{LoCoMo}$, without full fine-tuning or replacing the backbone architecture.
2. Preliminaries
Section Summary: In Transformer models for handling sequences, the preliminaries introduce δ-mem, a compact associative memory that tracks key-value pairs from past data by maintaining and updating a matrix called S as new information arrives. This memory predicts a value for a new key by multiplying the prior S with that key, then refines itself by adding only the necessary corrections along the key's direction, ensuring efficient updates without overwriting everything. To manage long-term retention, a forget gate is added, which scales down the old memory while blending in the new correction, controlled by parameters that balance forgetting and learning for stable performance.
In terms of a Transformer for sequence modeling, let $\mathbf x\in\mathbb{R}^{N\times d}$ denote the input hidden sequence of a selected Transformer layer, where $N$ is the sequence length and $d$ is the hidden dimension. The hidden state at a single position is denoted as $\mathbf x_t\in\mathbb{R}^{d}$. For concise notation, each single-position vector is treated as a column vector. The sequence form can be understood as stacking these vectors along the position dimension. We use $\mathbf Q, \mathbf K, \mathbf V$ to denote the query, key, and value in attention, and use $\mathbf S_t$ to denote the online state after processing position $t$. Unless otherwise specified, we omit the layer index in the following.
Concretely, $\delta\text{-mem}$ maintains a matrix $\mathbf{S}$ as the online state of associative memory. As tokens are processed, this state is updated sequentially to compactly encode key–value associations from the historical context. Given a memory key $\mathbf k_t\in\mathbb{R}^{r}$ and value $\mathbf v_t\in\mathbb{R}^{r}$ at position $t$, the state is expected to store the association $\mathbf k_t\mapsto \mathbf v_t$. The prediction made by the previous state is
$ \hat{\mathbf v}_t
\mathbf S_{t-1}\mathbf k_t . $
This memory update can then be regarded as optimizing an online regression loss using SGD:
$ \mathcal{L}t(\mathbf{S}) = \frac{1}{2}\left|\mathbf{S}\mathbf{k}t - \mathbf{v}t\right|^2, \quad \mathbf{S}t = \mathbf{S}{t-1} - \beta_t \nabla{\mathbf{S}{t-1}} \mathcal{L}t(\mathbf{S}{t-1}) = \mathbf{S}{t-1} + \beta_t \left(\mathbf{v}t-\mathbf{S}{t-1}\mathbf{k}_t\right)\mathbf{k}_t^{\top}, $
This formulation writes only the residual information along the key direction. Consequently, well-learned associations induce negligible updates, whereas predictive discrepancies dynamically correct the memory state. Inspired by gated retention design in Qwen-Next ([35]), we further introduce a forget gate to control long-range state evolution:
$ \mathbf S_t
\lambda_t\mathbf S_{t-1} + \beta_t (\mathbf v_t-\mathbf S_{t-1}\mathbf k_t) \mathbf k_t^\top . $
Here $\lambda_t$ controls how much previous memory is retained, while $\beta_t$ controls the strength of the residual write. This gated delta update forms the basis of the stable online memory dynamics in $\delta\text{-mem}$.
3. $\delta\text{-mem}$
Section Summary: δ-mem is a lightweight addition to transformer models that helps them remember and use past information without changing the model's core parameters. It works by projecting the current input into a compact memory space, pulling relevant signals from a previous "online state" to subtly adjust the attention mechanism through small corrections, and then updating that state with new details using a simple delta-rule update. This allows the model to compress and evolve its understanding of long sequences over time, making reasoning more efficient without storing everything explicitly.
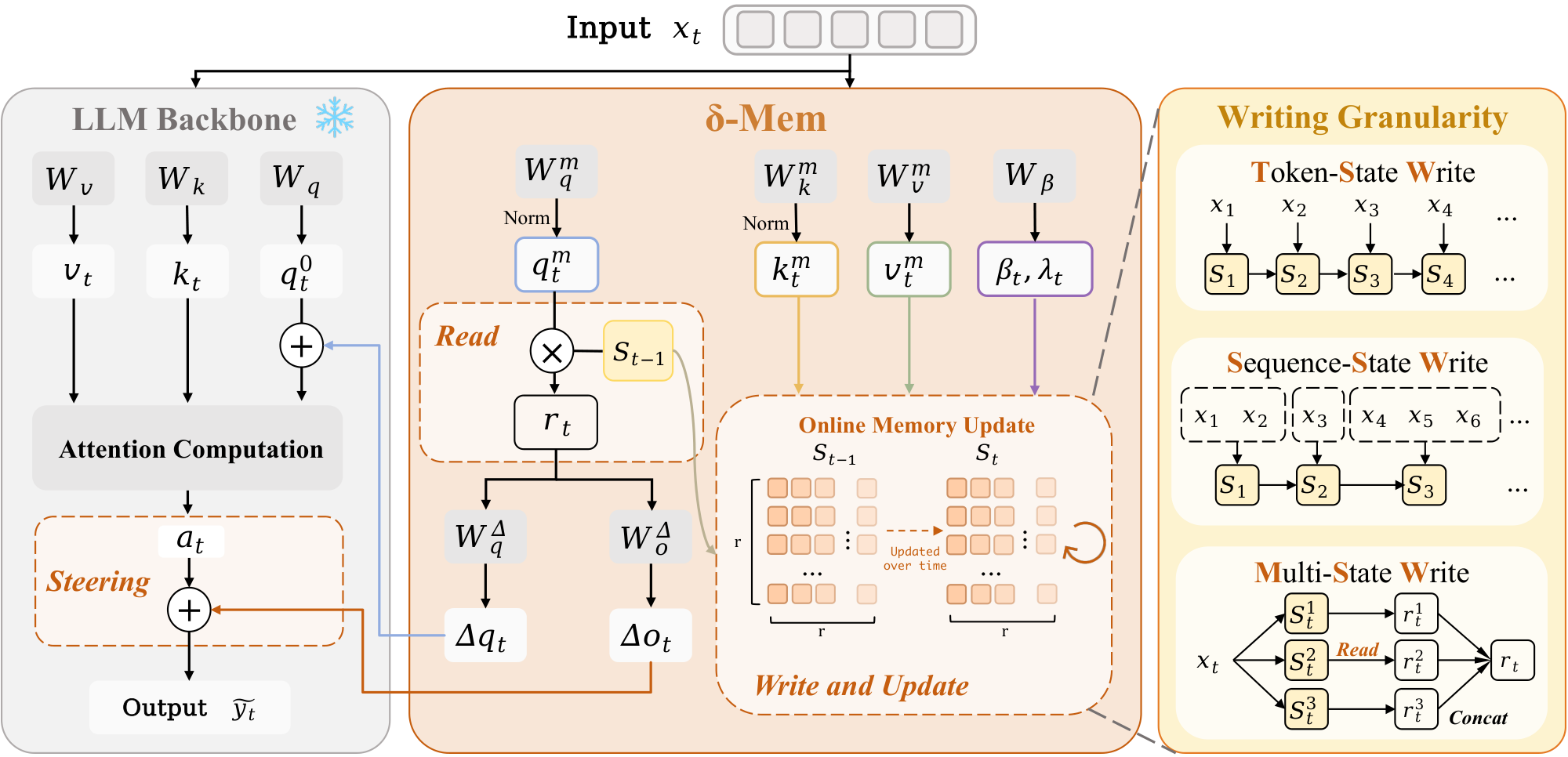
At each position, $\delta\text{-mem}$ follows the same computation order: read associative memory signals from the old state, use the signals to steer attention, and then write the current information into the state. In this way, the model can compress history into a state that evolves with the sequence and use it in later reasoning, without updating the backbone parameters. Figure 1 provides an overview of this design. The frozen backbone performs the standard attention computation, while $\delta\text{-mem}$ reads from the previous state, generates query-side and output-side attention corrections, and updates the online state with the current memory key-value information. The figure also summarizes the three writing strategies studied in this work, corresponding to token-level updates, segment-level updates, and multi-state memory organization.
3.1 Memory Projections
To form the online state of associative memory, given a hidden state $\mathbf x_t\in\mathbb{R}^{d}$ at the current position, $\delta\text{-mem}$ projects it into a low-dimensional associative memory space:
$ \mathbf q_t^m
L_2 \operatorname{norm} \left(\tanh(\mathbf W_q^m \mathbf x_t) \right), \quad \mathbf k_t^m
L_2 \operatorname{norm} \left(\tanh(\mathbf W_k^m \mathbf x_t) \right), \quad \mathbf v_t^m
\mathbf W_v^m \mathbf x_t, $
where $\mathbf q_t^m, \mathbf k_t^m, \mathbf v_t^m\in\mathbb{R}^{r}$. These three vectors correspond to reading and writing in memory. $\mathbf q_t^m$ queries the old state, while $\mathbf k_t^m$ and $\mathbf v_t^m$ describe how the current information should be written into the state. Normalizing the query and key can reduce state instability caused by scale drift during long-sequence recurrence.
The write gate and retention gate are also determined by the current hidden state:
$ \boldsymbol\beta_t=\sigma(\mathbf W_\beta \mathbf x_t+\mathbf b), \quad \boldsymbol\lambda_t=\mathbf 1-\boldsymbol\beta_t. $
where $\boldsymbol\beta_t, \boldsymbol\lambda_t\in\mathbb{R}^{r}$, $\mathbf b$ is the bias, and $\sigma$ is the sigmoid function. This allows the state update to be adjusted dimension by dimension: some dimensions retain old memory, while others write the current information more actively.
3.2 Reading from Online State of Associative Memory
Before writing the current information, $\delta\text{-mem}$ first reads from the old state:
$ \mathbf r_t
\mathbf S_{t-1}\mathbf q_t^m. $
The read vector $\mathbf r_t\in\mathbb{R}^{r}$ is the result of querying the online memory state with the current input. Since the size of $\mathbf S_{t-1}$ is fixed, the cost of this step is independent of the history length.
This reading form is complementary to standard attention. Attention compares the query with all keys within the explicit context, while $\delta\text{-mem}$ directly obtains continuous associative memory signals from the compressed state. It does not return text segments or add context tokens. Instead, it provides history-dependent steering signals before the attention computation.
3.3 Steering Attention through Low-Rank Corrections
The associative memory signals steer the attention computation through two lightweight linear mappings. First, the read signal $\mathbf r_t$ is projected into a query-side correction and an output-side correction:
$ \Delta \mathbf q_t = \mathbf W_q^\Delta \mathbf r_t, \qquad \Delta \mathbf o_t = \mathbf W_o^\Delta \mathbf r_t . $
The query-side correction is then added to the original query of the frozen backbone:
$ \mathbf q_t^0 = \mathbf W_Q \mathbf x_t, \qquad \tilde{\mathbf q}_t = \mathbf q_t^0+\frac{\alpha}{r}\Delta \mathbf q_t . $
The attention output $\mathbf a_t$ is then computed using the corrected query and the frozen backbone keys and values, while the output-side correction is added after attention:
$ \mathbf a_t = \operatorname{Attn}(\tilde{\mathbf q}t, \mathbf K{\leq t}, \mathbf V_{\leq t}), \qquad \tilde{\mathbf y}_t = \mathbf a_t+\frac{\alpha}{r}\Delta \mathbf o_t . $
The main implementation only uses the two correction terms on the query and output sides, and we detail these choices in Section 5. The low-rank correction here is different from a static adapter. Although $\mathbf W_q^\Delta$ and $\mathbf W_o^\Delta$ are fixed after training, their input $\mathbf r_t$ comes from the dynamic state $\mathbf S_{t-1}$. Therefore, the same set of parameters can produce different steering effects under different histories.
3.4 Writing into Online State of Associative Memory
After the current attention computation is completed, $\delta\text{-mem}$ writes the information at the current position into the online state. Given the current memory key-value pair $(\mathbf k_t^m, \mathbf v_t^m)$, the previous state first predicts the value associated with the current key as $\mathbf S_{t-1}\mathbf k_t^m$. The difference between the target value and this prediction defines the residual information to be written. As described in Section 2 $\delta\text{-mem}$ updates the state with a dimension-wise gated delta-rule:
$ \mathbf S_t
Diag(\boldsymbol\lambda_t)\mathbf S_{t-1} + Diag(\boldsymbol\beta_t) \left(\mathbf v_t^m-\mathbf S_{t-1}\mathbf k_t^m \right) (\mathbf k_t^m)^\top . $
Expanding the update gives:
$ \mathbf S_t
Diag(\boldsymbol\lambda_t)\mathbf S_{t-1}
Diag(\boldsymbol\beta_t) \mathbf S_{t-1} \mathbf k_t^m(\mathbf k_t^m)^\top + Diag(\boldsymbol\beta_t) \mathbf v_t^m(\mathbf k_t^m)^\top . $
The three terms have clear roles: the first term retains the previous state, the second term removes the old prediction component along the current key direction, and the third term writes the new value into the same direction. Thus, the memory state is updated by error correction with controlled forgetting, rather than by unselectively accumulating new outer products.
The dimension-wise nature of the gates can be seen by expanding the update row by row. Let $\mathbf s_t^{(i)}$ denote the $i$-th row of $\mathbf S_t$. Then,
$ \mathbf s_t^{(i)}
\lambda_{t, i}\mathbf s_{t-1}^{(i)} + \beta_{t, i} \left(v_{t, i}^m-\mathbf s_{t-1}^{(i)}\mathbf k_t^m \right) (\mathbf k_t^m)^\top . $
This shows that each memory dimension can independently control how much old information is retained and how strongly the current residual is written. Such dimension-wise gating is useful for continuous interactions, where the state must preserve stable historical information while still adapting to new inputs.
3.5 Writing Granularity of Online State
The above formulas explain how a single write operation is performed, but the memory mechanism also depends on the definition of writing granularity. A token is the finest granularity, but it is not always the most suitable one. In conversations and agent trajectories, messages, semantic segments, or stage-level events are often more stable. We therefore examine three writing strategies. As illustrated in Figure 1, TSW writes at every token, SSW averages the hidden states within each segment and writes per segment, and MSW writes into multiple parallel sub-states and then aggregates their readouts.
Token-State Write (TSW).
Token-State Write updates the online state at each token position:
$ \mathbf S_t
\operatorname{Update}(\mathbf S_{t-1}, \mathbf x_t). $
It preserves the finest-grained information and is suitable for scenarios that need to capture local changes. However, since every token triggers a write operation, the state is also more easily affected by format symbols, repeated expressions, and short-term noise.
Sequence-State Write (SSW).
Sequence-State Write raises the writing granularity from unit tokens to a message segment. Let $\mathcal{M}^{(j)}$ denote the set of token indices in the $j$-th message. We first obtain the segment representation by averaging the hidden states of all tokens within this message:
$ \bar{\mathbf x}^{(j)} = \frac{1}{|\mathcal{M}^{(j)}|} \sum_{t \in \mathcal{M}^{(j)}} \mathbf x_t. $
Then, each message updates the online state once. Let $\mathbf S_{(j)}$ denote the state after incorporating the $j$-th message:
$ \mathbf S_{(j)} = \operatorname{Update}(\mathbf S_{(j-1)}, \bar{\mathbf x}^{(j)}). $
SSW reduces redundant writes and smooths the state evolution. The cost is that some fine-grained token-level details are absorbed by the averaged segment representation.
Multi-State Write (MSW).
The first two strategies adjust the writing granularity, while MSW adjusts the state organization. A single state needs to contain facts, preferences, task progress, and local events at the same time, which may easily lead to overwriting and interference. MSW decomposes memory into multiple parallel sub-states:
$ \mathcal S_t={\mathbf S_t^{(1)}, \ldots, \mathbf S_t^{(N)}}, \qquad \mathbf S_t^{(i)}= \operatorname{Update}^{(i)}(\mathbf S_{t-1}^{(i)}, \mathbf x_t), \qquad \mathbf r_t=Concat(\mathbf r_t^{(1)}, \ldots, \mathbf r_t^{(N)}). $
where $N$ is the number of state, $\mathbf S_t^{(i)}\in\mathbb{R}^{r\times r}$, and $\mathbf r_t^{(i)}=\mathbf S_{t-1}^{(i)}\mathbf q_t^{m, (i)}$ for $i=1, \ldots, N$. This organization allows different sub-states to accumulate different types of information, thereby reducing mutual interference within a single state.
3.6 Training Objective
$\delta\text{-mem}$ is trained with the standard SFT loss. For each example, the context tokens are first written into the online state, producing $\mathbf S_C$, while they are not replayed as explicit backbone input during prediction. The frozen backbone only receives the query $Q$ and response $Y$, and the stored state steers attention through $\delta\text{-mem}$. The loss is the autoregressive cross-entropy over response tokens:
$ \mathcal L_{SFT}
-\sum_{j=1}^{|Y|} \log p_{\phi, \theta}(y_j \mid Q, y_{<j}, \mathbf S_C), $
where $\theta$ denotes the trainable $\delta\text{-mem}$ parameters and $\phi$ denotes the frozen backbone parameters.
4. Experiments
Section Summary: The experiments test a new memory method called δ-mem on various AI benchmarks for reasoning, question-answering, instruction-following, and long-term memory retention, comparing it to other memory techniques using the same base language models. δ-mem outperforms the baselines across all tasks, especially in memory-intensive ones, achieving up to 4.87 percentage points higher average scores by maintaining memory as an evolving state rather than compressing or encoding it statically. When applied to different model sizes, δ-mem consistently boosts performance, with tailored strategies working best for larger models to reduce noise and for smaller ones to handle interference through multiple memory states.
4.1 Experimental Setup
Evaluation and Benchmarks.
To independently measure general reasoning and memory effectiveness, we evaluate our method on general tasks and memory-heavy benchmarks. General multi-hop reasoning, knowledge-intensive QA, and instruction-following are assessed using HotpotQA ([30]), GPQA-Diamond ([34]), and IFEval ([33]). For the memory-heavy side, we utilize LoCoMo ([31]) (following ([23]), the adversarial question category is excluded), alongside MemoryAgentBench ([32]) to evaluate the retention, retrieval, and utilization of memory information across extended interaction histories.
Baselines.
We compare $\delta\text{-mem}$ against representative memory mechanisms. All methods are built on the same Qwen3-4B-Instruct backbone. For textual memory mechanisms, we consider BM25 RAG ([36]), which retrieves relevant historical text and prepends it to the context; LLMLingua-2 ([21]), which compresses long histories into a shorter textual context; and MemoryBank ([10]), which maintains continuous interaction history through textual memory entries. For parametric memory mechanisms, we compare with Context2LoRA ([26, 37]) and MemGen ([38]), which encode memory or context-dependent adaptation into additional trainable parameters. For outside-channel memory, we include an MLP Memory ([25]) baseline that retrieves information in a separate module and then fuses back into the model. We additionally report trainable parameter counts for rank-8 configurations to compare memory effectiveness under similar or smaller adaptation budgets in Appendix C.
Implementation Details
We select LLM backbones of varying sizes, including Qwen3-8B ([35]), Qwen3-4B-Instruct ([35]), and SmolLM3-3B ([39]). More training setup and evaluation configurations are listed in Appendix A.
4.2 Main Results across Memory Mechanisms
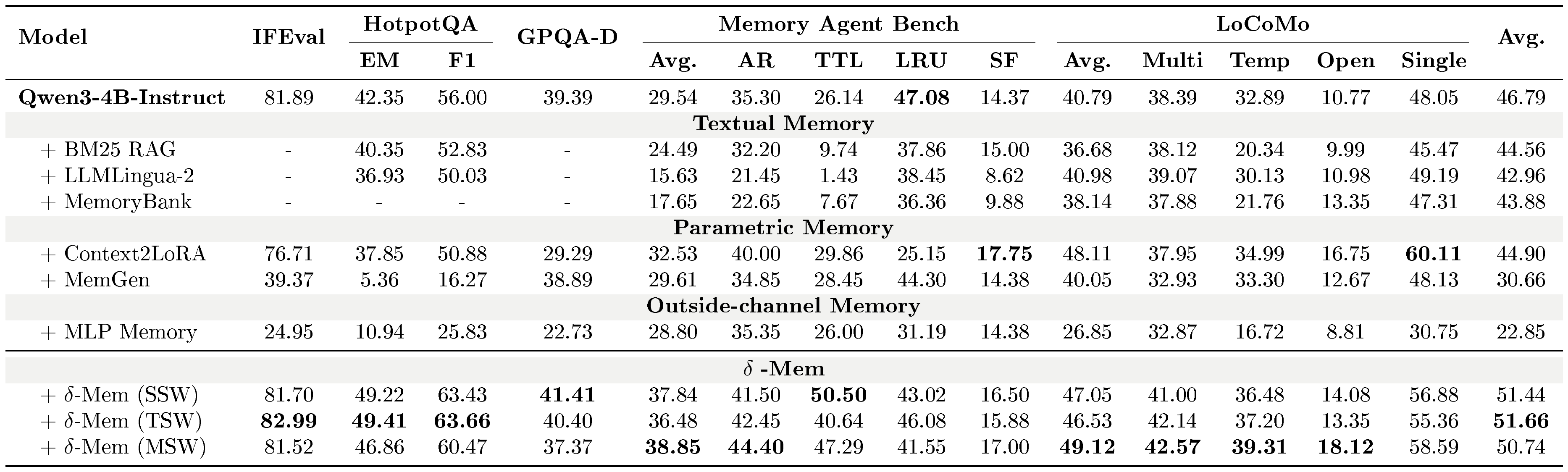
::: {caption="Table 1: Main benchmark results comparing different memory mechanisms on Qwen3-4B-Instruct. All values report the task-specific metrics detailed in Appendix A. For the final average score, HotpotQA is counted using Exact Match (EM)."}
:::
Table 1 compares $\delta\text{-mem}$ with representative memory-augmented baselines on general reasoning, instruction following, and memory-heavy benchmarks. $\delta\text{-mem}$ achieves the strongest performance across all methods. The TSW variant reaches the best average score of 51.66%, improving over the Qwen3-4B-Instruct backbone (46.79%) by +4.87 points and over Context2LoRA (44.90%) by +6.76 points. SSW and MSW also perform strongly, achieving 51.44% and 50.74%, respectively. The gains are most pronounced on memory-heavy benchmarks. On MemoryAgentBench, $\delta\text{-mem}$ improves the average score from 29.54% to 38.85%, with MSW performing best. On LoCoMo, MSW achieves the highest average of 49.12% and performs best on Multi, Temporal, and Open subsets. On HotpotQA, TSW improves EM/F1 from 42.35%/56.00% to 49.41%/63.66%.
Across baselines, different memory mechanisms exhibit distinct limitations. Textual memory methods show inconsistent gains, likely due to retrieval noise and information loss introduced by compressing memory into token space. Parametric memory methods such as Context2LoRA tend to generalize less robustly across tasks, as their memory is statically encoded in parameters and can overfit to training distributions. The MLP Memory baseline performs relatively limited, indicating it lacks sequential state accumulation and cannot explicitly model long-range dependencies, while also introducing information loss by approximating instance-level retrieval. In contrast, $\delta\text{-mem}$ consistently improves performance across both general and memory-heavy evaluations, suggesting that maintaining memory as an online state provides a more robust memory mechanism.
4.3 Main Results Across Different Backbone Models
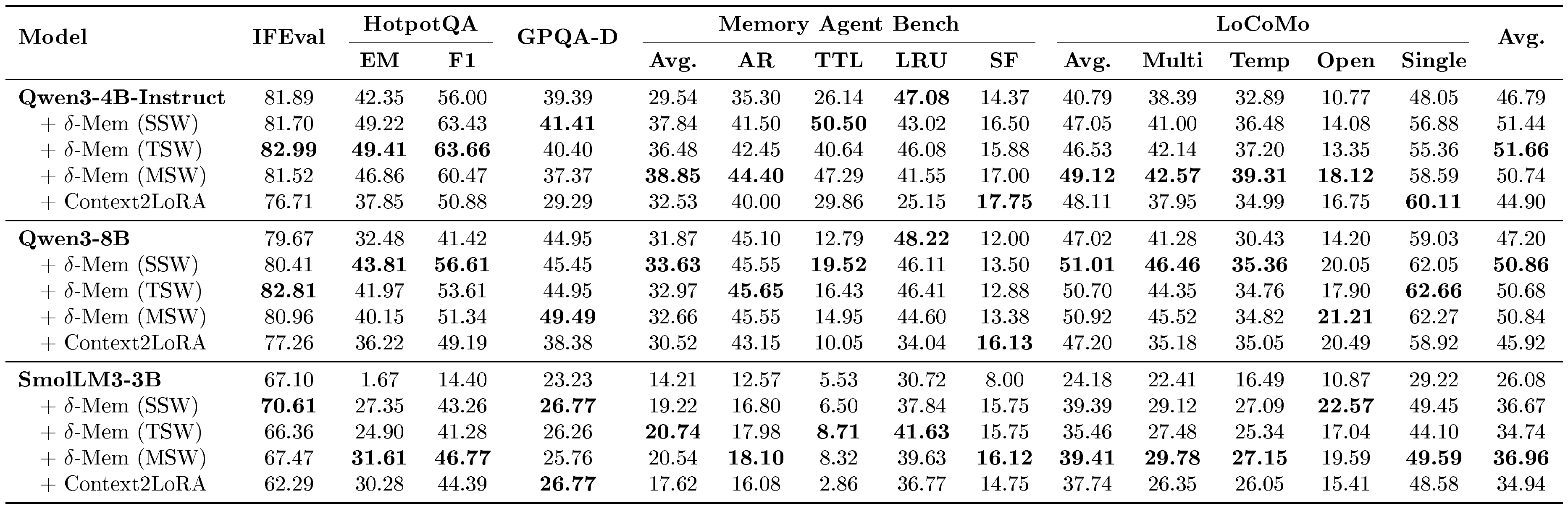
::: {caption="Table 2: General benchmark and long-context evaluation results across backbone models. All values report the task-specific metrics detailed in Appendix A. For the final average score, HotpotQA is counted using Exact Match (EM)."}
:::
Table 2 evaluates $\delta\text{-mem}$ across three backbone models, demonstrating consistent improvements in average scores across the board. $\delta\text{-mem}$ improves the average score on all backbones. Specifically, it boosts Qwen3-4B-Instruct from 46.79% to 51.66%, Qwen3-8B from 47.20% to 50.86%, and SmolLM3-3B from 26.08% to 36.96%. Notably, the effectiveness of the writing strategies varies by model capacity. On the more capable Qwen3-8B, the improvements are more modest but steady, with SSW securing the top average score of 50.86%. This suggests that for backbones with stronger inherent reasoning, segment-level writing (SSW) smooths state updates and effectively mitigates token-level noise. In contrast, the smaller SmolLM3-3B exhibits a substantial performance leap (from 26.08% to 36.96%) driven by MSW, indicating that smaller backbones benefit significantly from separating memory into multiple states to minimize interference.
5. Ablative Study
Section Summary: Researchers tested whether a method called δ-mem could retain useful past information in an AI model's memory without needing the original context, finding that it boosted performance on reasoning tasks like HotpotQA and LoCoMo, especially for questions requiring multiple steps or evidence links. They also examined where in the model's attention system to apply this memory correction, discovering that targeting both the query and output parts worked well for efficiency, though using all attention components gave the top results overall. Finally, applying the correction across all layers of the model yielded the best outcomes, with middle layers proving particularly effective for balancing general understanding and specific task handling.
5.1 Context Recovery
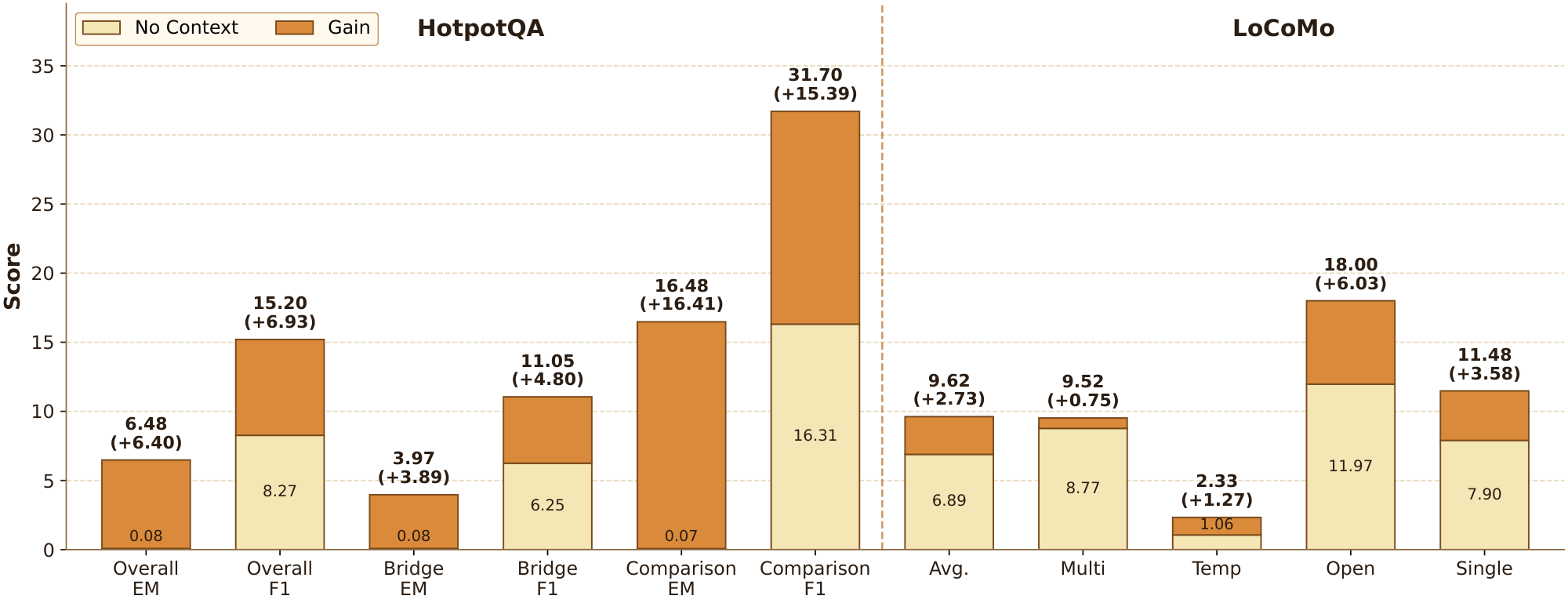
To examine whether the online state of associative memory can preserve useful historical information without explicit context replay, we evaluate $\delta\text{-mem}$ under a no-context setting, where the original historical context is removed and only the compressed memory state is injected. As shown in Figure 2, $\delta\text{-mem}$ consistently improves over the no-context baseline on both HotpotQA and LoCoMo. On HotpotQA, the overall EM increases from 0.08% to 6.48%, and the overall F1 improves from 8.27% to 15.20%. The gains are especially large on the Bridge subset, where EM rises from 0.08% to 3.97% and F1 increases from 6.25% to 11.05%, indicating that the online state can recover part of the missing multi-hop evidence. On LoCoMo, $\delta\text{-mem}$ also improves the overall average from 3.49% to 8.05%, with clear gains across multi-hop, temporal, open-domain, and single-hop questions. These results suggest that the online state of associative memory stores context-relevant historical signals that can be reused when explicit context is unavailable.
5.2 Heads Ablation
::: {caption="Table 3: Head Ablation Results on HotpotQA and LoCoMo with Qwen3-4B-Instruct as the backbone."}
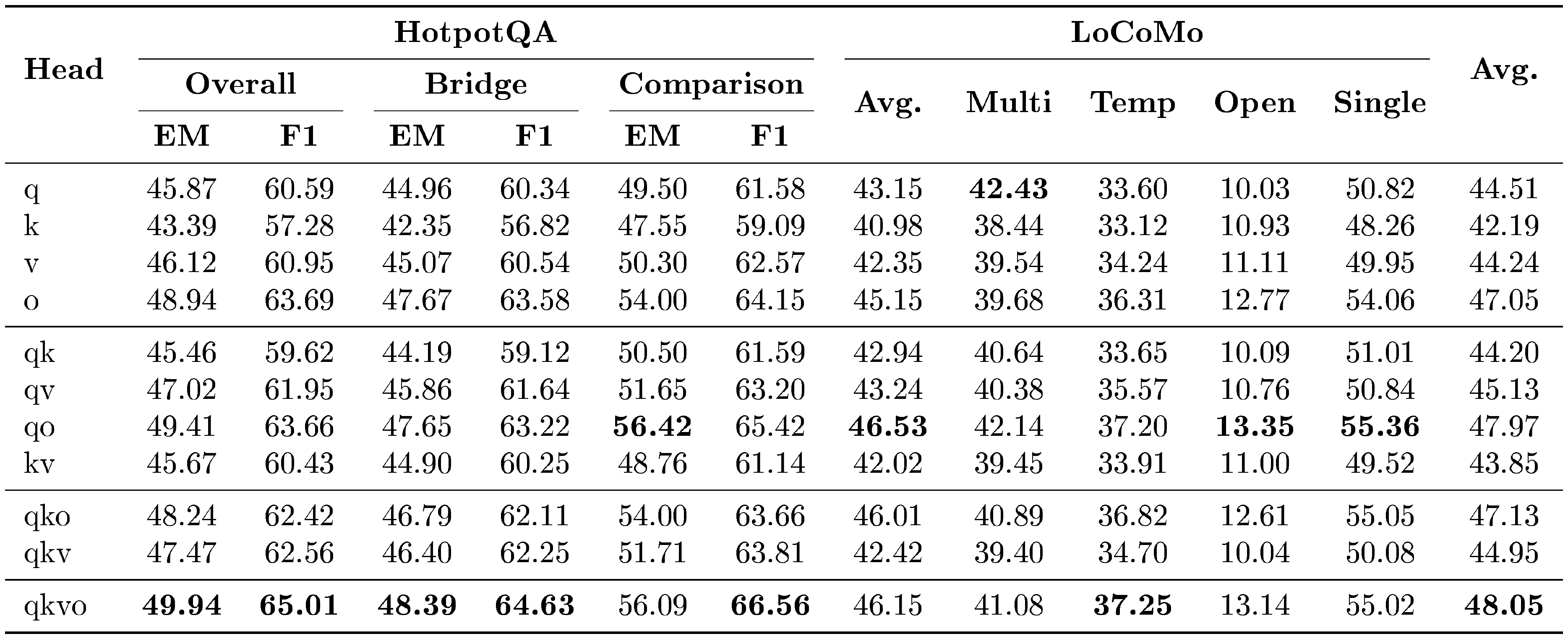
:::
We first study where the memory-induced correction should be injected within the attention block. As shown in Table 3, applying $\delta\text{-mem}$ to both query and output branches already yields strong performance, suggesting that query-side and output-side corrections provide an effective interface for memory injection. Among single-branch variants, the output branch performs best, achieving an average score of 47.05%, while the key branch is less effective. Combining multiple branches further improves performance. The full qkvo configuration achieves the best average score of 48.05%. These results suggest that associative memory signals are most effective when they can jointly influence query formation, key-value interaction, and output representation. While qkvo yields the highest average score, its marginal gain over qo does not justify the extra parameter overhead. Thus, we default to qo for an optimal performance-efficiency trade-off.
5.3 Insertion Depth Ablation
Table 4 studies the insertion depth of $\delta\text{-mem}$ across model's layers. Applying memory correction to all layers achieves the best overall performance, with an average score of 47.97%. It also obtains the strongest HotpotQA result, improving the overall EM/F1 to 49.41%/63.66%, and reaches the best LoCoMo average of 46.53%. These results suggest that associative memory signals are most effective when they can influence the representation hierarchy across the full depth of the backbone. Among partial-layer variants, the middle-layer configuration performs best, reaching an average score of 46.66%. It clearly outperforms both the front-layer and back-layer configurations on the final average score. This indicates that intermediate layers provide a particularly effective interface for memory injection, balancing semantic abstraction and task-specific computation. In contrast, front-layer injections act on overly local representations, while back-layer injections leave insufficient depth for associative memory signals to propagate through subsequent computations.
::: {caption="Table 4: Insertion depth results on HotpotQA and LoCoMo with Qwen3-4B-Instruct as the backbone."}
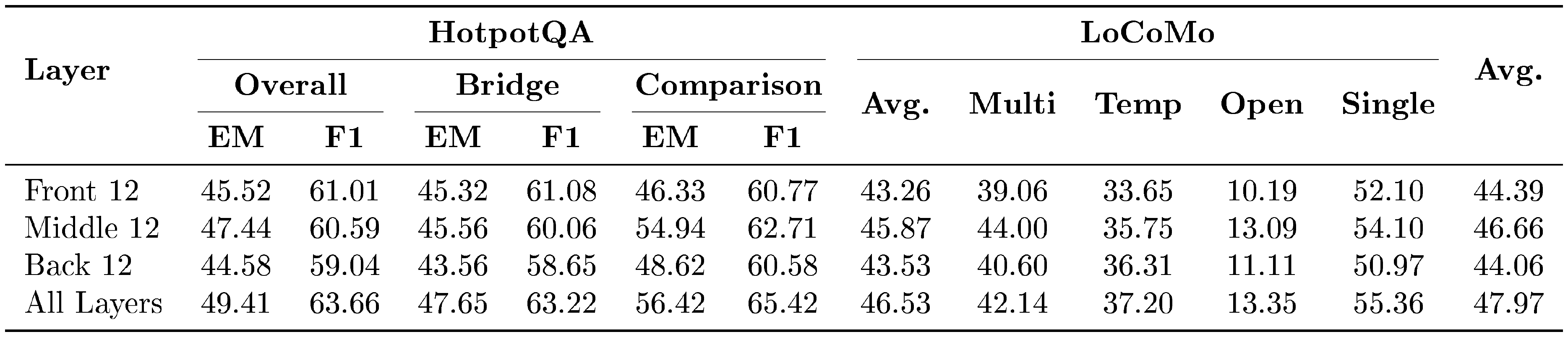
:::
6. Related Work
Section Summary: This section reviews existing approaches to memory in AI systems, starting with textual methods that store and retrieve information as text summaries or documents to enhance model responses, though they struggle with data compression and processing limits. It then covers outside-channel techniques that keep memory in a hidden, non-text form outside the main model for richer storage, but these add extra retrieval steps and potential mismatches. Finally, it discusses parametric methods that embed memory directly into model parameters via small updates, which work well for fixed changes but less so for ongoing, dynamic interactions, contrasting with the δ-mem system's use of real-time, low-rank adjustments to attention without these drawbacks.
Textual Memory Mechanisms.
Textual memory mechanisms externalize memory as text entries, summaries, or retrievable documents, and re-inject selected evidence into the input context or retrieval-augmented generation process. Early retrieval-augmented systems ([36, 22]) demonstrate the effectiveness of scalable textual stores for knowledge-intensive generation, while later agent-oriented methods ([1, 40, 10, 23]) extend this paradigm to continuous interaction by organizing past history and experience through logging, summarization, and reflection. Despite their flexibility, textual memory remains constrained by its tokenized form: memory use is sensitive to compression fidelity, retrieval noise, and context budget ([9, 14]). $\delta\text{-mem}$ does not route compressed history back through token space. Instead, it maintains a compact online state and uses its readout to steer the frozen Transformer through low-rank attention corrections, separating memory maintenance from prompt-level reinsertion.
Outside-Channel Memory Mechanisms.
A related line of work stores memory outside the backbone while preserving it in latent rather than textual form ([24, 18, 25]). Memorizing Transformers ([24]) store past internal representations as non-differentiable key-value memories and retrieve them with approximate kNN, while LongMem ([18]) uses a frozen backbone as a memory encoder and an adaptive residual side network to read from an external memory bank. Compared with textual memory, latent memory can avoid part of the information loss introduced by natural-language summarization and preserve richer internal representations. However, memory still interacts with the backbone through a separate retrieval or reader pathway, introducing retrieval overhead, fusion complexity, and possible mismatch between stored and current representations. $\delta\text{-mem}$ differs in that its memory is not retrieved as an auxiliary external source; instead, its compact online state directly produces low-rank corrections to the attention computation, allowing memory to participate in the current forward pass.
Parametric Memory Mechanisms.
Parametric memory mechanisms encode memory into additional parameters or localized weight edits. Prefix-Tuning ([27]) learns continuous virtual tokens for a frozen model, while LoRA ([26]) injects low-rank trainable updates into selected layers, showing that small parameter additions can effectively steer model behavior. Model-editing methods such as ROME ([28]) and MEMIT ([29]) further treat parameters as a writable memory substrate by inserting factual associations through localized or low-rank weight updates. However, these methods are less suited to online memory: their memory is usually fixed after training or updated through discrete editing steps, rather than evolving continuously with the sequence. Their write granularity is also less aligned with interaction history, which often unfolds at token-, message-, or segment-level resolution. As a result, parametric memory often acts as a persistent modification to model behavior, rather than a state-conditioned memory mechanism whose influence changes with the current history. $\delta\text{-mem}$ is close to LoRA in its low-rank interface, but differs fundamentally in that LoRA's low-rank update is static, whereas $\delta\text{-mem}$ generates low-rank attention corrections from a compact online state at runtime.
7. Conclusion
Section Summary: This paper introduces δ-mem, a simple memory system that adds a small, constantly updating storage of past information to a fixed AI model without changing its core structure or requiring extensive retraining. It works by squeezing old data into a tiny online record and using it to subtly adjust the model's attention to key details, allowing the memory to influence real-time decisions efficiently. Tests show it boosts performance on tasks needing good recall while keeping the model's overall abilities intact, proving that even a very small memory area can retrieve useful history without bloating the input or adding complex add-ons, making it a practical way to enhance frozen AI backbones.
In this work, we introduced $\delta\text{-mem}$, a lightweight memory mechanism that equips a frozen full-attention backbone with a compact and dynamically updated online state of associative memory. $\delta\text{-mem}$ compresses past information into a fixed-size online state and uses its readout to generate low-rank corrections to the backbone's attention components. This design allows memory to be maintained online and to directly participate in forward computation without full fine-tuning or replacing the backbone architecture. Empirically, $\delta\text{-mem}$ improves performance on memory-heavy benchmarks while largely preserving the general capabilities of the frozen backbone. Notably, even with an extremely small $8\times8$ online state, the model can recover useful historical information after explicit context is removed, showing that effective memory does not require extending explicit context or heavy external retrieval modules. These results suggest that compact online states can serve as a scalable and efficient interface for test-time memory in frozen Transformer backbones.
Appendix
Section Summary: The appendix provides details on training and evaluating memory-augmented language models, including a single training run on a dataset of over 2,000 short samples using specific hardware, sequence limits, and optimization techniques, along with standardized metrics for benchmarks like accuracy and F1 scores across various tasks. It compares the efficiency of the proposed δ-mem method, showing it uses minimal extra GPU memory and maintains decent speed during inference, even with long prompts, outperforming bulkier alternatives like MemGen. Additionally, δ-mem adds only a tiny fraction of new parameters—less than 0.5% of the base model—making it lightweight, followed by a list of references to related research.
A. Implementation Details
Training Setup.
All models are trained for one epoch on the shortest 2, 219-sample split of QASPER ([41]), whose maximum sequence length is 8, 269 tokens. The maximum backbone training sequence length is set to 512, while the memory write budget is set to 8, 192 tokens. Unless otherwise specified, $\delta\text{-mem}$ uses $r=8$ and $\alpha=16$, and is applied only to the query and output branches. The number of states in MSW is set to 4. Training is conducted on 8 $\times$ A800 GPUs with bfloat16 precision, DeepSpeed ZeRO-2 ([42]), and fused AdamW. We use a peak learning rate of $2\times10^{-4}$ with cosine decay and a warmup ratio of 0.1. The per-device batch size is 1, with 4 gradient accumulation steps, resulting in an effective global batch size of 32. The random seed is fixed to 42.
Evaluation Details.
We follow the official evaluation prompts and decoding settings for all benchmarks. Specifically, we report prompt-level strict accuracy for IFEval, Exact Match (EM) and F1 for HotpotQA, accuracy for GPQA, and F1 for LoCoMo. For MemoryAgentBench, Table 5 summarizes the evaluation categories, datasets, and metrics. Each dataset is evaluated using its corresponding metric, and the final MemoryAgentBench score is computed as the sample-weighted average.
::: {caption="Table 5: Evaluation categories, datasets, and metrics in MemoryAgentBench."}
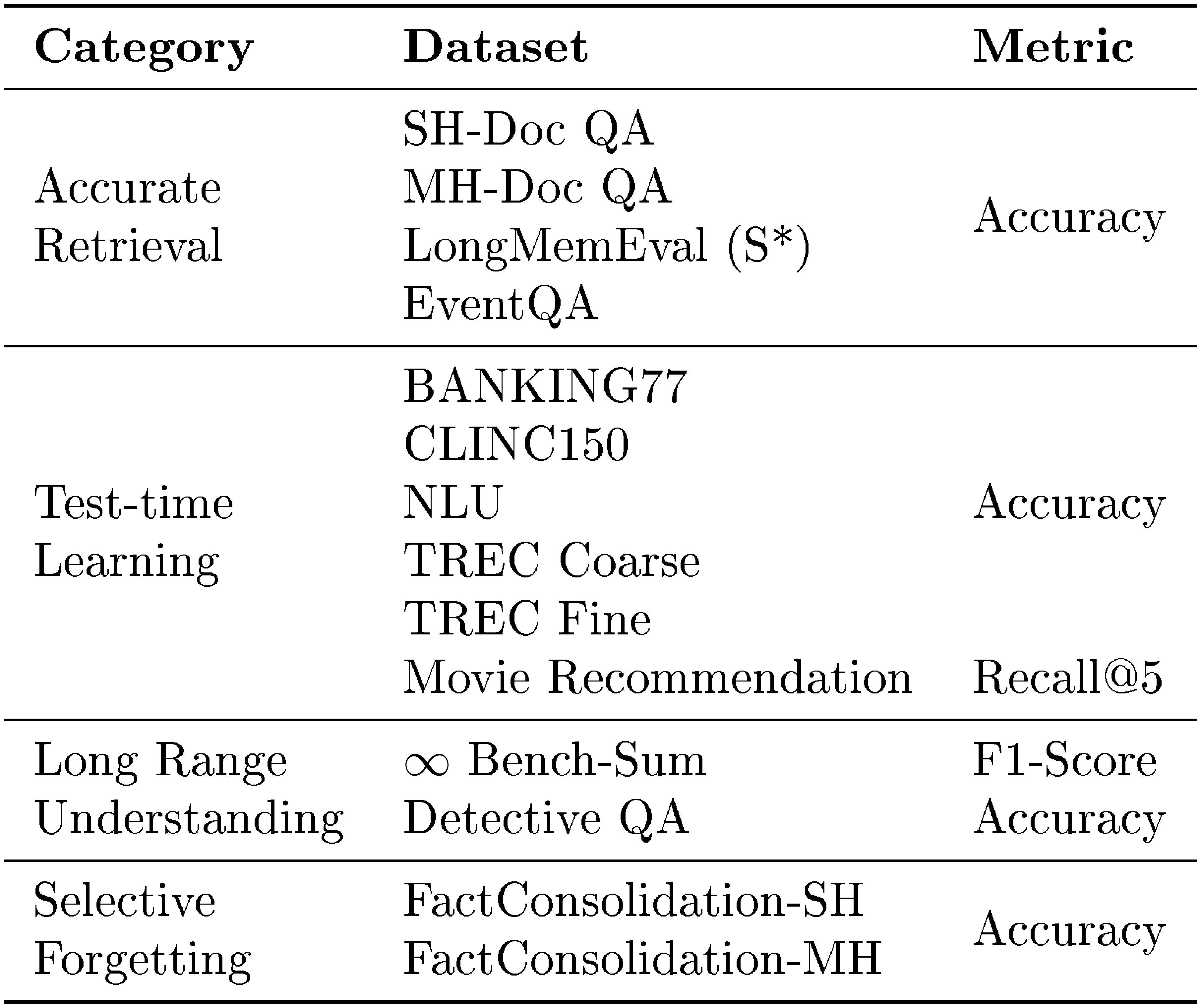
:::
B. Inference Efficiency and Memory Use
We further compare the inference efficiency of different memory-augmented methods under varying prompt and decoding lengths, as shown in Figure 3b and Figure 3a. $\delta\text{-mem}$ achieves nearly the same GPU memory usage as Vanilla and Context2LoRA, indicating that its compact recurrent state introduces negligible memory overhead even when the prompt length increases to 32K. By contrast, MLP Memory and MemGen require substantially more memory, reflecting the cost of maintaining or generating larger auxiliary memory representations. In terms of decoding throughput, $\delta\text{-mem}$ is slower than Vanilla and Context2LoRA because each step involves reading from and updating the online state, but it remains considerably faster and more stable than MemGen across all tested settings. These results demonstrate that $\delta\text{-mem}$ improves long-context memory with a lightweight computational footprint, offering a practical balance between memory capability and inference efficiency.
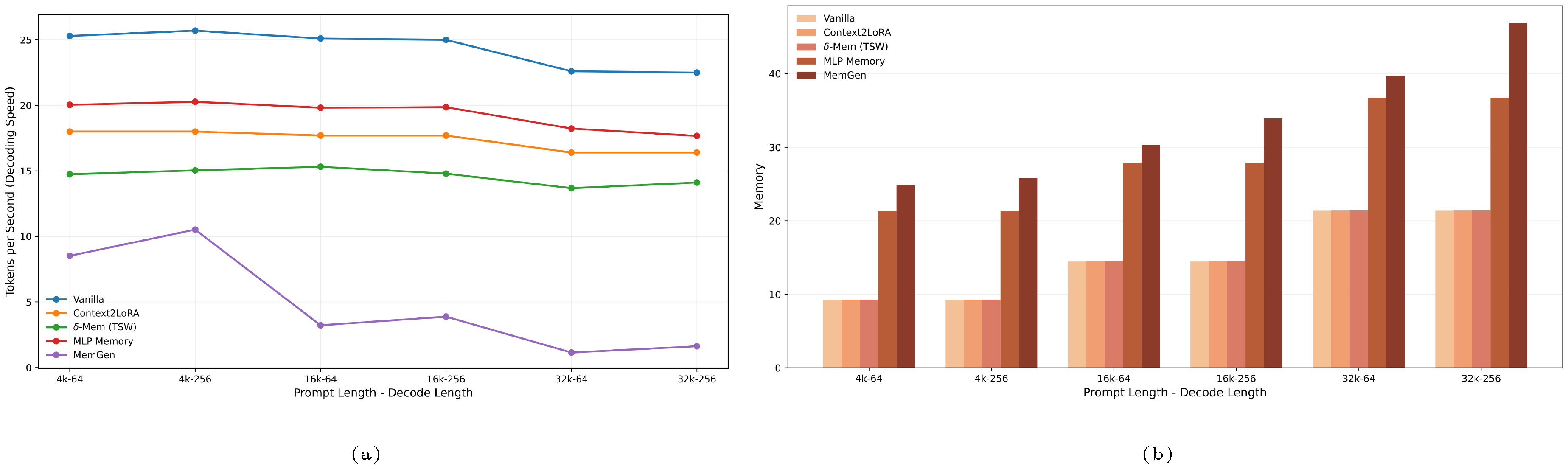
C. Parameter Overhead
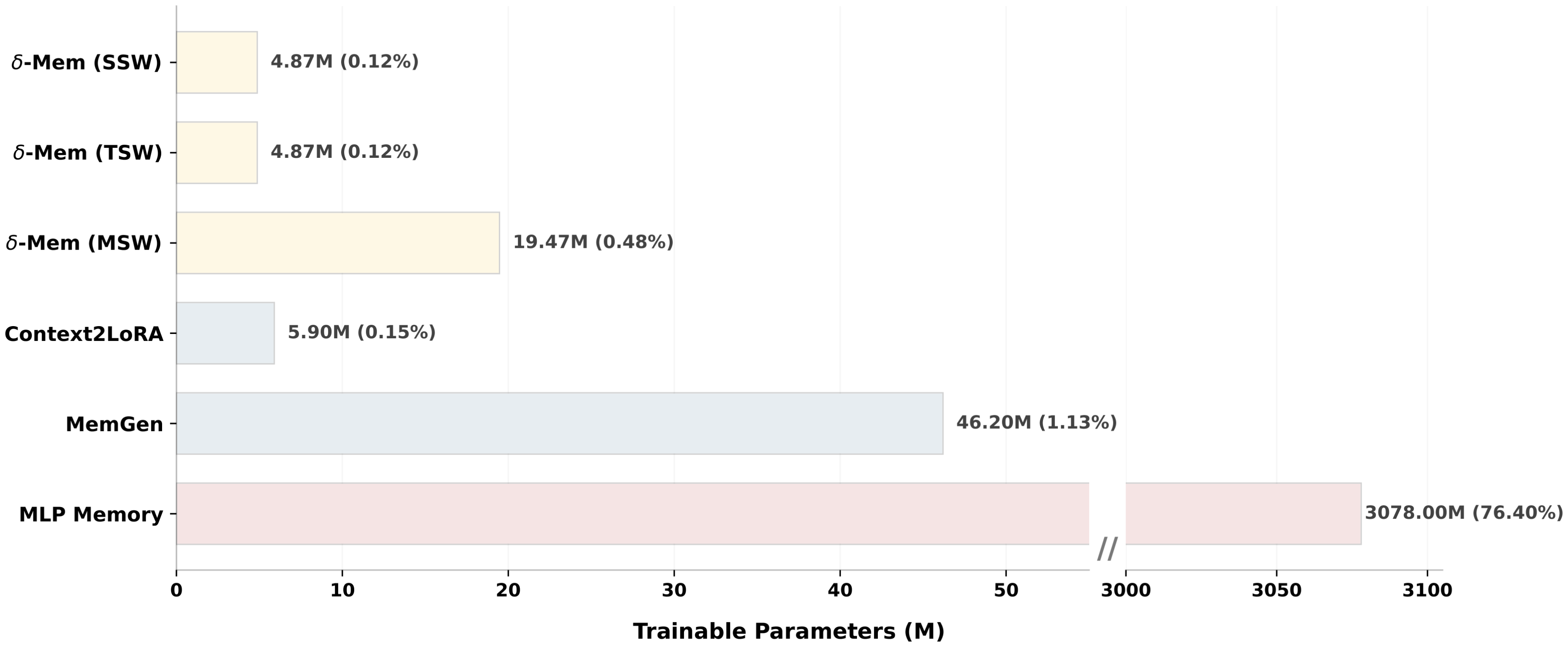
We compare the trainable parameter overhead of $\delta\text{-mem}$ with representative memory-augmented baselines, as shown in Figure 4. $\delta\text{-mem}$ introduces only 4.87M trainable parameters for both SSW and TSW variants, accounting for merely 0.12% of the backbone parameters. Even the MSW variant, which maintains multiple memory states, requires only 19.47M trainable parameters, corresponding to 0.48% of the backbone. In contrast, MemGen uses 46.20M trainable parameters, while MLP Memory requires 3078.00M parameters, reaching 76.40% of the backbone scale. These results show that $\delta\text{-mem}$ achieves online memory augmentation with substantially lower parameter overhead, making it a lightweight alternative to larger auxiliary-memory modules.
References
[1] Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. Memgpt: towards llms as operating systems. 2023.
[2] Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, et al. Personamem-v2: Towards personalized intelligence via learning implicit user personas and agentic memory. arXiv preprint arXiv:2512.06688, 2025.
[3] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations, 2022.
[4] OpenAI. Codex. https://developers.openai.com/codex, 2026. OpenAI Developers documentation, accessed April 14, 2026.
[5] Anthropic. Claude code overview. https://code.claude.com/docs/en/overview, 2026. Claude Code Docs, accessed April 14, 2026.
[6] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems, 36:8634–8652, 2023.
[7] Yu Wang and Xi Chen. Mirix: Multi-agent memory system for llm-based agents. arXiv preprint arXiv:2507.07957, 2025.
[8] Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, et al. Agent learning via early experience. arXiv preprint arXiv:2510.08558, 2025b.
[9] Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. Llms get lost in multi-turn conversation. arXiv preprint arXiv:2505.06120, 2025.
[10] Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024.
[11] Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, et al. Native sparse attention: Hardware-aligned and natively trainable sparse attention. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23078–23097, 2025.
[12] Jingdi Lei, Di Zhang, and Soujanya Poria. Error-free linear attention is a free lunch: Exact solution from continuous-time dynamics. arXiv preprint arXiv:2512.12602, 2025.
[13] Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692, 2025.
[14] Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts llm performance. Technical report, Chroma, July 2025. https://research.trychroma.com/context-rot.
[15] Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Bodapati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A Huerta, and Hao Peng. Context length alone hurts llm performance despite perfect retrieval. arXiv preprint arXiv:2510.05381, 2025.
[16] OpenAI. Introducing gpt-5.5. https://openai.com/index/introducing-gpt-5-5/.
[17] Google. A new era of intelligence with gemini 3. https://blog.google/products-and-platforms/products/gemini/gemini-3/.
[18] Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory. Advances in Neural Information Processing Systems, 36:74530–74543, 2023.
[19] Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024.
[20] Yu Wang, Dmitry Krotov, Yuanzhe Hu, Yifan Gao, Wangchunshu Zhou, Julian McAuley, Dan Gutfreund, Rogerio Feris, and Zexue He. M+: Extending memoryllm with scalable long-term memory. arXiv preprint arXiv:2502.00592, 2025.
[21] Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, et al. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Linguistics: ACL 2024, pages 963–981, 2024.
[22] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR, 2022.
[23] Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413, 2025.
[24] Yuhuai Wu, Markus N Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing transformers. arXiv preprint arXiv:2203.08913, 2022.
[25] Rubin Wei, Jiaqi Cao, Jiarui Wang, Jushi Kai, Qipeng Guo, Bowen Zhou, and Zhouhan Lin. Mlp memory: A retriever-pretrained memory for large language models, 2026. https://arxiv.org/abs/2508.01832.
[26] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022.
[27] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021.
[28] Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. Advances in neural information processing systems, 35:17359–17372, 2022a.
[29] Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer. arXiv preprint arXiv:2210.07229, 2022b.
[30] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018.
[31] Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. arXiv preprint arXiv:2402.17753, 2024.
[32] Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions. arXiv preprint arXiv:2507.05257, 2025.
[33] Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023. https://arxiv.org/abs/2311.07911.
[34] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023.
[35] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Lianghao Deng, Mei Li, Mingfeng Xue, Mingze Li, Pei Zhang, Peng Wang, Qin Zhu, Rui Men, Ruize Gao, Shixuan Liu, Shuang Luo, Tianhao Li, Tianyi Tang, Wenbiao Yin, Xingzhang Ren, Xinyu Wang, Xinyu Zhang, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yinger Zhang, Yu Wan, Yuqiong Liu, Zekun Wang, Zeyu Cui, Zhenru Zhang, Zhipeng Zhou, and Zihan Qiu. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
[36] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459–9474, 2020.
[37] Seungju Back, Dongwoo Lee, Naun Kang, Taehee Lee, SK Hong, Youngjune Gwon, and Sungjin Ahn. Understanding lora as knowledge memory: An empirical analysis. arXiv preprint arXiv:2603.01097, 2026.
[38] Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self-evolving agents. arXiv preprint arXiv:2509.24704, 2025a.
[39] Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Carlos Miguel Patiño, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gallouédec, Kashif Rasul, Nathan Habib, Clémentine Fourrier, Hynek Kydlicek, Guilherme Penedo, Hugo Larcher, Mathieu Morlon, Vaibhav Srivastav, Joshua Lochner, Xuan-Son Nguyen, Colin Raffel, Leandro von Werra, and Thomas Wolf. SmolLM3: smol, multilingual, long-context reasoner. https://huggingface.co/blog/smollm3, 2025.
[40] Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023.
[41] Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. 2021.
[42] Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506, 2020.