Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Lee Xiong, Chenyan Xiong$^{*}$, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, Arnold Overwijk Microsoft lexion, chenyan.xiong, yeli1, kwokfung.tang, jialliu,
paul.n.bennett, jahmed, [email protected]
* Lee and Chenyan contributed equally.
Abstract
Conducting text retrieval in a dense representation space has many intriguing advantages. Yet the end-to-end learned dense retrieval (DR) often underperforms word-based sparse retrieval. In this paper, we first theoretically show the learning bottleneck of dense retrieval is due to the domination of uninformative negatives sampled locally in batch, which yield diminishing gradient norms, large stochastic gradient variances, and slow learning convergence. We then propose Approximate nearest neighbor Negative Contrastive Learning (ANCE), a learning mechanism that selects hard training negatives globally from the entire corpus, using an asynchronously updated ANN index. Our experiments demonstrate the effectiveness of ANCE on web search, question answering, and in a commercial search environment, showing ANCE dot-product retrieval nearly matches the accuracy of BERT-based cascade IR pipeline, while being 100x more efficient.
Executive Summary: Text retrieval forms the foundation of many language systems, such as search engines, question answering, and fact verification. Traditional methods rely on matching exact words, like the BM25 algorithm, which often misses relevant information due to vocabulary mismatches or lack of semantic understanding. This creates a bottleneck, limiting the performance of advanced downstream models powered by deep learning. Dense retrieval offers a promising alternative by representing texts as continuous embeddings in a high-dimensional space, enabling more nuanced semantic matching and faster searches via approximate nearest neighbor techniques. However, current dense approaches underperform sparse methods because of poor training practices, particularly the use of uninformative negative examples, making this an urgent issue as AI systems increasingly depend on efficient, accurate retrieval.
This paper analyzes the reasons behind dense retrieval's training challenges and introduces Approximate Nearest Neighbor Negative Contrastive Learning (ANCE) to address them. It demonstrates how ANCE can train effective dense retrievers that rival or exceed traditional sparse methods in accuracy while being far more efficient.
The authors first conducted a theoretical analysis of dense retrieval training convergence, showing that common negative sampling from small batches leads to weak gradients and slow learning. They then developed ANCE, which selects challenging negative examples globally from the entire document corpus using an asynchronously updated index of embeddings. This draws hard negatives that closely resemble relevant documents but are irrelevant, aligning training better with real-world retrieval needs. Experiments tested ANCE on standard benchmarks, including the TREC 2019 Deep Learning Track for web search (using millions of passages and documents from the MS MARCO dataset over 2019 queries), Natural Questions and TriviaQA for open-domain question answering (covering thousands of queries), and a commercial search engine's production system. Models were fine-tuned from RoBERTa-base (a transformer like BERT), with assumptions that one negative per positive improves learning without overwhelming computation. Training spanned about 10 epochs on four GPUs, sampling from the top 200 index matches.
Key findings highlight ANCE's superiority. First, on the TREC benchmark, ANCE achieved an NDCG@10 score of 0.67 for document retrieval, about 20-30% higher than baselines like BM25 (0.51-0.55) or other dense methods (0.50-0.60), making it the only dense approach to robustly outperform sparse retrieval. Second, in question answering, ANCE improved answer coverage in the top 20-100 results by 5-10% over prior dense systems like DPR, leading to 2-5% gains in final answer accuracy when paired with existing readers. Third, in production search, ANCE delivered around 15% relative improvements in retrieval quality across various corpus sizes and embedding dimensions, with online query latency under 10 milliseconds—100 times faster than BERT-based reranking pipelines. Fourth, empirical validation confirmed the theory: ANCE negatives produced gradient norms orders of magnitude larger than batch negatives, reducing training variance and speeding convergence by maintaining higher losses on hard examples. Finally, ANCE narrowed the performance gap between retrieval and reranking to near zero, showing dense models can capture relevance without complex interactions.
These results mean dense retrieval, powered by ANCE, can transform information systems by providing high-accuracy results at low cost and risk, without the inefficiencies of multi-stage pipelines. It reduces reliance on sparse methods, improves handling of semantic nuances (like synonyms or context), and cuts computational demands—potentially shortening response times in search by orders of magnitude while boosting user satisfaction through better relevance. This challenges prior views that term-level matching is essential, opening doors to simpler, scalable AI architectures. In production, it lowers operational costs without sacrificing performance, though it differs markedly from sparse results (only 15-25% overlap), which could affect integration with legacy systems.
Leaders should prioritize adopting ANCE for training dense retrievers in search and QA pipelines, starting with warm-up on sparse negatives to accelerate initial gains. For full deployment, integrate it into hybrid systems combining dense and sparse for robustness, weighing the trade-off of slightly higher training compute (due to corpus indexing) against 100x inference speedups. Further work is needed, such as pilots in diverse domains, deeper analysis of embedding behaviors, and expanded benchmarks to address low label coverage in evaluations. Overall confidence is high, backed by consistent gains across academic and real-world tests, but caution is advised on hyperparameter tuning (like index refresh rates) and async update gaps, which could cause instability if resources are limited; data gaps in sparse-heavy labels also slightly temper recall metrics.
1. Introduction
Section Summary: Many language systems start by retrieving relevant documents using simple word-matching methods like BM25, but this creates a bottleneck because later deep learning stages cannot fully compensate for its limitations. Dense retrieval addresses the issue by learning continuous representations with neural networks, yet it struggles to train effectively because it needs high-quality negative examples drawn from the entire collection rather than easy or local ones. This paper shows that common negative sampling strategies converge slowly due to high gradient variance and introduces ANCE, which uses an asynchronously updated approximate nearest neighbor index to select harder, globally relevant negatives and thereby improves both training speed and final accuracy.
Many language systems rely on text retrieval as their first step to find relevant information. For example, search ranking ([1]), open domain question answering (OpenQA) ([2]), and fact verification ([3]) all first retrieve relevant documents for their later stage reranking, machine reading, and reasoning models. All these later-stage models enjoy the advancements of deep learning techniques ([4, 5]), while, the first stage retrieval still mainly relies on matching discrete bag-of-words, e.g., BM25, which has become the bottleneck of many systems ([1, 6, 7]).
Dense Retrieval (DR) aims to overcome the sparse retrieval bottleneck by matching texts in a continuous representation space learned via deep neural networks ([8, 9, 6]). It has many desired properties: fully learnable representation, easy integration with pretraining, and efficiency support from approximate nearest neighbor (ANN) search ([10]). These make dense retrieval an intriguing potential choice to fundamentally overcome some intrinsic limitations of sparse retrieval, for example, vocabulary mismatch ([11]).
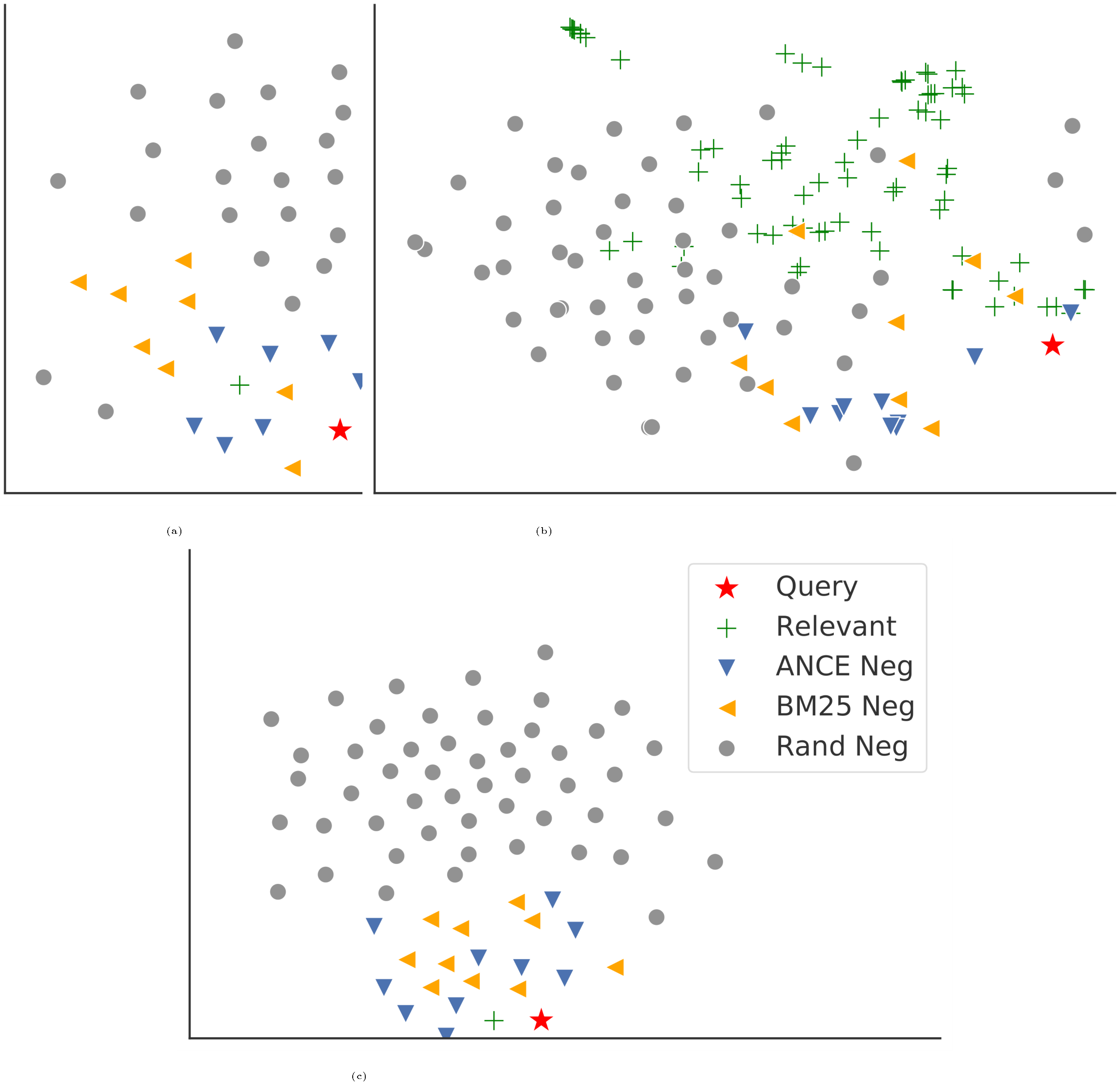
A key challenge in DR is to construct proper negative instances during its representation learning ([9]). Unlike in reranking where negatives are naturally the irrelevant documents from previous retrieval stages, in first stage retrieval, DR models have to distinguish relevant documents from all irrelevant ones in the entire corpus. As illustrated in Figure 1, these global negatives are quite different from negatives retrieved by sparse models.
Recent research explored various ways to construct negative training instances for dense retrieval ([12, 9])., e.g., using contrastive learning ([13, 14, 15, 16]) to select hard negatives in current or recent mini-batches. However, as observed in recent research ([9]), the in-batch local negatives, though effective in learning word or visual representations, are not significantly better than spare-retrieved negatives in representation learning for dense retrieval. In addition, the accuracy of dense retrieval models often underperform BM25, especially on documents ([8, 17, 6]).
![**Figure 1:** T-SNE ([18]) representations of query, relevant documents, negative training instances from BM25 (BM25 Neg) or randomly sampled (Rand Neg), and testing negatives (DR Neg) in dense retrieval.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/7gt8uu54/complex_fig_a8ec3041ce7d.png)
In this paper, we first theoretically analyze the convergence of dense retrieval training with negative sampling. Using the variance reduction framework ([19, 20]), we show that, under conditions commonly met in dense retrieval, local in-batch negatives lead to diminishing gradient norms, resulted in high stochastic gradient variances and slow training convergence — the local negative sampling is the bottleneck of dense retrieval's effectiveness.
Based on our analysis, we propose Approximate nearest neighbor Negative Contrastive Estimation (ANCE), a new contrastive representation learning mechanism for dense retrieval. Instead of random or in-batch local negatives, ANCE constructs global negatives using the being-optimized DR model to retrieve from the entire corpus. This fundamentally aligns the distribution of negative samples in training and of irrelevant documents to separate in testing. From the variance reduction point of view, these ANCE negatives lift the upper bound of per instance gradient norm, reduce the variance of the stochastic gradient estimation, and lead to faster learning convergence.
We implement ANCE using an asynchronously updated ANN index of the corpus representation. Similar to [21], we maintain an Inferencer that parallelly computes the document encodings with a recent checkpoint from the being optimized DR model, and refresh the ANN index used for negative sampling once it finishes, to keep up with the model training. Our experiments demonstrate the advantage of ANCE in three text retrieval scenarios: standard web search ([22]), OpenQA ([4, 23]), and in a commercial search engine's retrieval system. We also empirically validate our theory that the gradient norms on ANCE sampled negatives are much bigger than local negatives and thus improve the convergence of dense retrieval models. Our code and trained models are available at https://aka.ms/ance.
2. Preliminaries
Section Summary: Dense retrieval finds relevant documents for a given query by encoding both into dense vector representations with a model such as BERT, then ranking them according to simple similarity measures like cosine or dot product in that learned space. Training optimizes the encoder so that relevant query-document pairs lie close together while irrelevant ones are pushed apart, using a ranking loss over positive and negative examples. Because the full set of possible negatives is enormous, training instead relies on sampled negatives, most often drawn from an initial BM25 ranking or from other items in the same mini-batch.
In this section, we discuss the preliminaries of dense retrieval and its representation learning.
Task Definition: Given a query $q$ and a corpus $C$, the first stage retrieval is to find a set of documents relevant to the query $D^+={d_1, ..., d_i, ..., d_n}$ from $C$ ($|D^+| \ll |C|$), which then serve as input to later more complex models ([11]). Instead of using sparse term matches and inverted index, Dense Retrieval calculates the retrieval score $f()$ using similarities in a learned embedding space ([8, 6, 9]):
$ \begin{align} f(q, d) &= \text{sim}(g(q; \theta), g(d; \theta)), \end{align}\tag{1} $
where $g()$ is the representation model that encodes the query or document to dense embeddings. The encoder parameter $\theta$ provides the main capacity, often fine-tuned from pretrained transformers, e.g., BERT ([8]). The similarity function (sim()) is often simply cosine or dot product, to leverage efficient ANN retrieval ([10, 24]).
Learning with Negative Sampling: The effectiveness of DR resides in learning a good representation space that maps query and relevant documents together, while separating irrelevant ones. The learning of this representation often follows standard learning to rank ([25]): Given a query $q$, a set of relevant document $D^+$ and irrelevant ones $D^-$, find the best $\theta^*$ that:
$ \begin{align} \theta^* &= \text{argmin}{\theta} \sum{q} \sum_{d^+\in D^+} \sum_{d^- \in D^-} l(f(q, d^+), f(q, d^-)). \end{align}\tag{2} $
The loss $l()$ can be binary cross entropy (BCE), hinge loss, or negative log likelihood (NLL).
A unique challenge in dense retrieval, targeting first stage retrieval, is that the irrelevant documents to separate are from the entire corpus $(D^- = C \setminus D^+)$. This often leads to millions of negative instances, which have to be sampled in training:
$ \begin{align} \theta^* &= \text{argmin}{\theta} \sum_q \sum{d^+\in D^+} \sum_{d^- \in \hat{D}^-} l(f(q, d^+), f(q, d^-)). \end{align}\tag{3} $
A natural choice is to sample negatives $\hat{D}^-$ from top documents retrieved by BM25. However, they may bias the DR model to merely learn sparse retrieval and do not elevate DR models much beyond BM25 ([6]). Another way is to sample negatives in local mini-batches, e.g., as in contrastive learning ([14, 16]), however, these local negatives do not significantly outperform BM25 negatives ([9, 6]).
3. Analyses on The Convergence of Dense Retrieval Training
Section Summary: The section analyzes how dense retrieval models converge during training by linking progress to the size of gradient updates from negative examples. It shows that uninformative negatives produce near-zero gradients and therefore contribute little to learning, while an optimal sampling distribution would prioritize negatives with large gradient norms. Common in-batch negatives rarely satisfy this need, because random small batches almost never contain the few truly informative “hard” negatives amid a much larger corpus.
In this section, we provide theoretical analyses on the convergence of representation training in dense retrieval. We first show the connections between learning convergence and gradient norms, then the bounded gradient norms by uninformative negatives, and finally, how in-batch local negatives are ineffective under common conditions in dense retrieval.
Convergence Rate and Gradient Norms: Let $l(d^+, d^-)=l(f(q, d^+), f(q, d^-)$ be the loss function on the training triple $(q, d^+, d^-)$, $P_{D^-}$ the negative sampling distribution for the given $(q, d^+)$, and $p_{d^-}$ the sampling probability of negative instance $d^-$, a stochastic gradient decent (SGD) step with importance sampling ([19]) is:
$ \begin{align} \theta_{t+1} &= \theta_t - \eta \frac{1}{Np_{d^-}} \nabla_{\theta_t} l(d^+, d^-), \end{align}\tag{4} $
with $\theta_t$ the parameter at $t$-th step, $\theta_{t+1}$ the one after, and $N$ the total number of negatives. The scaling factor $\frac{1}{Np_{d^-}}$ is to make sure Eqn. 4 is an unbiased estimator of the full gradient.
Then we can characterize the converge rate of this SGD step as the movement to optimal $\theta^*$. Following derivations in variance reduction ([20, 26]), let $g_{d^-}= \frac{1}{Np_{d^-}} \nabla_{\theta_t} l(d^+, d^-)$ the weighted gradient, the convergence rate is:
$ \begin{align} \mathbb{E}\Delta^t &= ||\theta_t - \theta^*||^2 - \mathbb{E}{P{D^-}}(||\theta_{t+1} - \theta^* ||^2) \ &= ||\theta_t||^2 - 2\theta_t^T\theta^* - \mathbb{E}{P{D^-}}(||\theta_{t}-\eta g_{d^-}||^2) + 2 \theta^{T}\mathbb{E}{P{D^-}}(\theta_{t}-\eta g_{d^-}) \ &= -\eta^2 \mathbb{E}{P{D^-}}(||g_{d^-}||^2) + 2 \eta \theta_t^T \mathbb{E}{P{D^-}}(g_{d^-}) - 2\eta \theta^{T}\mathbb{E}{P{D^-}}(g_{d^-}) \ &= 2\eta \mathbb{E}{P{D^-}}(g_{d^-})^T (\theta_t - \theta^) -\eta^2 \mathbb{E}{P{D^-}}(||g_{d^-}||^2) \ &= 2\eta \mathbb{E}{P{D^-}}(g_{d^-})^T (\theta_t - \theta^) -\eta^2 \mathbb{E}{P{D^-}}(g_{d^-})^T \mathbb{E}{P{D^-}}(g_{d^-}) - \eta^2 \text{Tr}(\mathcal{V}{P{D^-}}(g_{d^-})). \end{align}\tag{5} $
This shows we can obtain better convergence rate by sampling from a distribution $P_{D^-}$ that minimizes the variance of the gradient estimator, $\mathbb{E}{P{D^-}}(||g_{d^-}||^2)$, or $\text{Tr}(\mathcal{V}{P{D^-}}(g_{d^-}))$ as the estimator is unbiased. There exists an optimal distribution that:
$ \begin{align} p^*_{d^-} = \text{argmin}{p{d^-}} \text{Tr}(\mathcal{V}{P{D^-}}(g_{d^-})) \propto ||\nabla_{\theta_t} l(d^+, d^-)||_2, \end{align}\tag{6} $
which is to sample proportionally to per instance gradient norm. This is a well known result in importance sampling ([19, 26]). It can be proved by applying Jensen's inequality on the gradient variance and then verifying that Eqn. 6 achieves the minimum. We do not repeat this proof and refer to [26] for exact derivations.
Intuitively, an negative instance with larger gradient norm is more likely to reduce the training loss more, while those with diminishing gradients are not informative. Empirically, the correlation of gradient norm and training convergence is also observed in BERT fine-tuning ([27]).
Diminishing Gradients of Uninformative Negatives: The oracle distribution in Eqn. 6 is too expensive to compute and the closed form of gradient norms can be complicated in deep neural networks. Nevertheless, for MLP networks, [20] derives an upper bound of the per sample gradient norm:
$ \begin{align} ||\nabla_{\theta_t} l(d^+, d^-)||2 \leq L \rho || \nabla{\phi_L} l(d^+, d^-) ||_2, \end{align} $
where L is the number of layers, $\rho$ is composed by pre-activation weights and gradients in intermediate layers, and $|| \nabla_{\phi_L} l(d^+, d^-) ||2$ is the gradient w.r.t. the last layer. Intuitively, the intermediate layers are more regulated by various normalization techniques; the main moving piece is $|| \nabla{\phi_L} l(d^+, d^-) ||_2$ ([20]).
For common learning to rank loss functions, for example, BCE loss and pairwise hinge loss, we can verified that ([20]):
$ \begin{align} l(d^+, d^-) \rightarrow 0 \Rightarrow || \nabla_{\phi_L} l(d^+, d^-) ||2 \rightarrow 0 \Rightarrow ||\nabla{\theta_t} l(d^+, d^-)||_2 \rightarrow 0. \end{align}\tag{7} $
Intuitively, negative samples with near zero loss have near zero gradients and contribute little to model convergence. The convergence of dense retrieval model training relies on the informativeness of constructed negatives.
Inefficacy of Local In-Batch Negatives: We argue that the in-batch local negatives are unlikely to provide informative samples due to two common properties of text retrieval.
Let $D^{-}$ be the set of informative negatives that are hard to distinguish from $D^{+}$, and $b$ be the batch size, we have (1) $b \ll |C|$, the batch size is far smaller than the corpus size; (2) $|D^{-}| \ll |C|$, that only a few negatives are informative and the majority of corpus is trivially unrelated.
Both conditions are easy to verify empirically in dense retrieval benchmarks. The two together make the probability that a random mini-batch includes meaningful negatives $p=\frac{b |D^{-*}|}{|C|^2}$ close to zero. Selecting negatives from local training batches is unlikely to provide optimal training signals for dense retrieval.
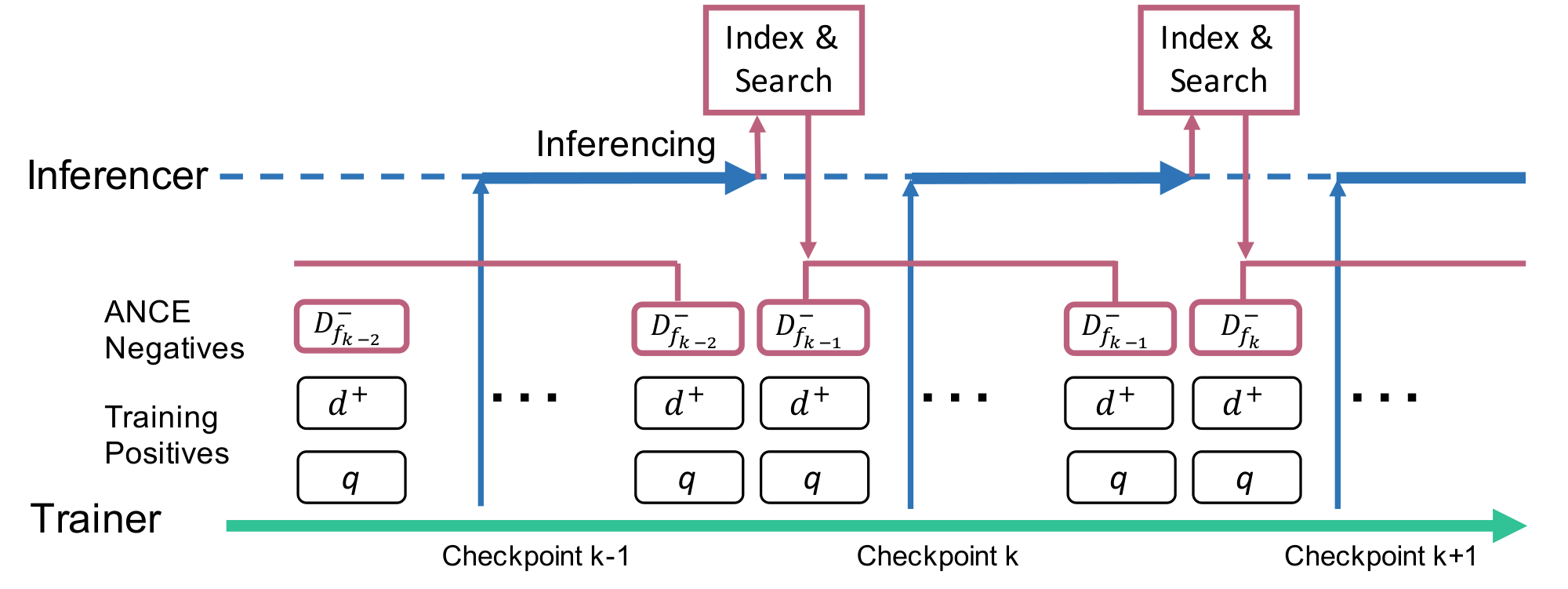
4. Approximate Nearest Neighbor Noise Contrastive Estimation
Section Summary: The ANCE method improves dense retrieval training by constructing hard negative examples globally from the full corpus rather than from limited local batches. It does so by using an approximate nearest-neighbor index to retrieve the top-ranked documents for each query and treating all but the known positives as negatives, which supply stronger training gradients because they closely resemble the positives under the current model. To keep the index reasonably fresh without prohibitive cost, a separate process recomputes document encodings and rebuilds the index only every few training batches while the main learner continues with the previous negatives.
Our analyses show the importance, if not necessity, to construct negatives globally from the corpus. In this section, we propose Approximate nearest neighbor Negative Contrastive Estimation, (ANCE), which selects negatives from the entire corpus using an asynchronously updated ANN index.
ANCE samples negatives from the top retrieved documents via the DR model from the ANN index:
$ \begin{align} & \theta^* = \text{argmin}{\theta} \sum_q \sum{d^+\in D^+} \sum_{d^- \in D^-_\text{ANCE}} l(f(q, d^+), f(q, d^-)), \end{align}\tag{8} $
with $D^-\text{ANCE} = \text{ANN}{f(q, d)} \setminus D^+$ and $\text{ANN}{f(q, d)}$ the top retrieved documents by $f()$ from the ANN index. By definition, $D^-\text{ANCE}$ are the hardest negatives for the current DR model: $D^-_\text{ANCE} \approx D^{-*}$. In theory, these more informative negatives have higher training loss, higher upper bound on the gradient norms, and will improve training convergence.
ANCE can be used to train any dense retrieval model. For simplicity, we use a simple set up in recent research ([6]) with BERT Siamese/Dual Encoder (shared between $q$ and $d$), dot product similarity, and negative log likelihood (NLL) loss.
Asynchronous Index Refresh: During stochastic training, the DR model $f()$ is updated each mini-batch. Maintaining an update-to-date ANN index to select fresh ANCE negatives is challenging, as the index update requires two operations: 1) Inference: refresh the representations of all documents in the corpus with an updated DR model; 2) Index: rebuild the ANN index using updated representations. Although Index is efficient ([10]), Inference is too expensive to compute per batch as it requires a forward pass on the entire corpus which is much bigger than the training batch.
Thus we implement an asynchronous index refresh similar to [21], and update the ANN index once every $m$ batches, i.e., with checkpoint $f_k$. As illustrated in Figure 2, besides the Trainer, we run an Inferencer that takes the latest checkpoint (e.g., $f_{k}$) and recomputes the encodings of the entire corpus. In parallel, the Trainer continues its stochastic learning using $D^-{f{k-1}}$ from $\text{ANN}{f{{k-1}}}$. Once the corpus is re-encoded, Inferencer updates the ANN index ($\text{ANN}{f{k}}$) and feed it to the Trainer.
In this process, the ANCE negatives ($D^-_\text{ANCE}$) are asynchronously updated to "catch up" with the stochastic training. The gap between the ANN index and the DR model optimization depends on the allocation of computing resources between Trainer and Inferencer. Appendix A.3 shows an 1:1 GPU split is sufficient to minimize the influence of this gap.
5. Experimental Methodologies
Section Summary: The experimental section evaluates the ANCE dense retrieval method on web search using the TREC 2019 Deep Learning benchmark and on open-domain question answering with the Natural Questions and TriviaQA datasets, following prior work and measuring both retrieval quality and downstream answer accuracy. It also tests ANCE by retraining a production model from a commercial search engine and measuring offline gains across different corpus sizes and search settings. Baselines include standard dense retrieval approaches that rely on random or BM25-sampled negatives, while implementation details cover training warm-up procedures, document handling strategies such as first-paragraph or max-pooling, and Faiss-based approximate nearest-neighbor search with periodic index refreshes.
This section describes our experimental setups. More details can be found in Appendix A.1 and Appendix A.2.
Benchmarks: The web search experiments use the TREC 2019 Deep Learning (DL) Track benchmark ([22]), a large scale ad hoc retrieval dataset. We follow the official guideline and evaluate mainly in the retrieval setting, but also results when reranking top 100 BM25 candidates.
The OpenQA experiments use the Natural Questions (NQ) ([23]) and TriviaQA (TQA) ([28]), following the exact settings from [9]. The metrics are Coverage@20/100, which evaluate whether the Top-20/100 retrieved passages include the answer. We also evaluate whether ANCE's better retrieval can propagate to better answer accuracy, by running the state-of-the-art systems' readers on top of ANCE instead of DPR retrieval. The readers are RAG-Token ([29]) on NQ and DPR Reader on TQA, in their suggested settings.
We also study the effectiveness of ANCE in the first stage retrieval of a commercial search engine's production system. We change the training of a production-quality DR model to ANCE, and evaluate the offline gains in various corpus sizes, encoding dimensions, and exact/approximate search.
Baselines: In TREC DL, we include best runs in relevant categories and refer to [22] for more baseline scores. We implement recent DR baselines that use the same BERT-Siamese, but vary in negative construction: random sampling in batch (Rand Neg), random sampling from BM25 top 100 (BM25 Neg) ([8, 17]) and the 1:1 combination of BM25 and Random negatives (BM25 + Rand Neg) ([9, 6]). We also compare with contrastive learning/Noise Contrastive Estimation, which uses hardest negatives in batch (NCE Neg) ([30, 14, 16]). In OpenQA, we compare with DPR, BM25, and their combinations ([9]).
Implementation Details: In TREC DL, recent research found MARCO passage training labels cleaner ([31]) and BM25 negatives can help train dense retrieval ([9, 6]). Thus, we include a "BM25 Warm Up" setting (BM25 $\rightarrow *$), where the DR models are first trained using MARCO official BM25 Negatives. ANCE is also warmed up by BM25 negatives. All DR models in TREC DL are fine-tuned from RoBERTa base ([32]). In OpenQA, we warm up ANCE using the released DPR checkpoints ([9]).
To fit long documents in BERT-Siamese, ANCE uses the two settings from [33], FirstP which uses the first 512 tokens of the document, and MaxP, where the document is split to 512-token passages (maximum 4) and the passage level scores are max-pooled. The max-pooling operation is natively supported in ANN. The ANN search uses the Faiss IndexFlatIP Index ([10]). We use 1:1 Trainer:Inference GPU allocation, index refreshing per 10k training batches, batch size 8, and gradient accumulation step 2 on 4 GPUs. For each positive, we uniformly sample one negative from ANN top 200. We measured ANCE efficiency using a single 32GB V100 GPU, on a cloud VM with Intel(R) Xeon(R) Platinum 8168 CPU and 650GB of RAM memory.
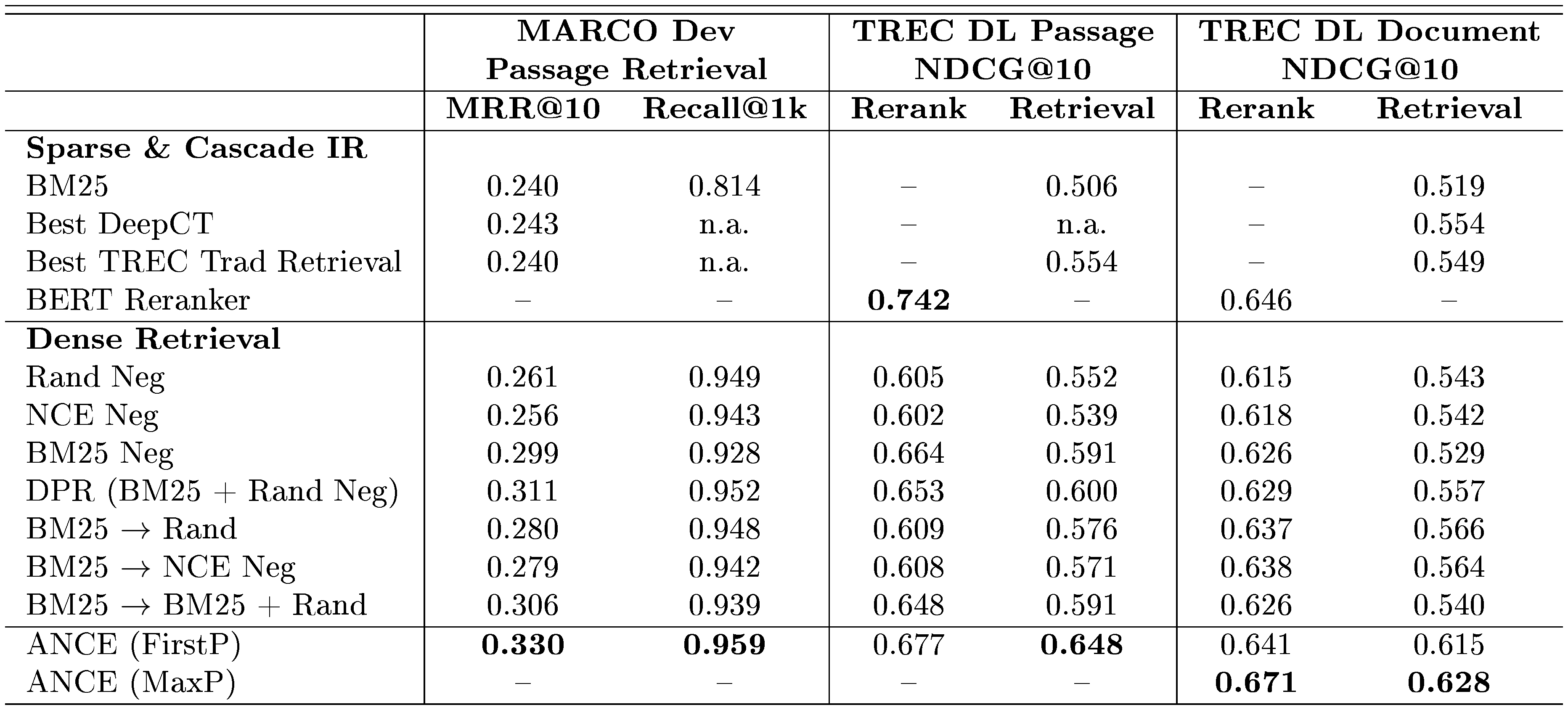
::: {caption="Table 1: Results in TREC 2019 Deep Learning Track. Results not available are marked as "n.a.", not applicable are marked as "–". Best results in each category are marked bold. "}
:::
\begin{tabular}{l|cc|cc} \hline \hline
& \multicolumn{2}{c|}{\textbf{Single Task}}
& \multicolumn{2}{c}{\textbf{Multi Task}} \\ \hline
& \multicolumn{1}{c}{\textbf{NQ}}
& \multicolumn{1}{c|}{\textbf{TQA}}
& \multicolumn{1}{c}{\textbf{NQ}}
& \multicolumn{1}{c}{\textbf{TQA}} \\ \hline
\textbf{Retriever}
& Top-20/100
& Top-20/100
& Top-20/100
& Top-20/100 \\ \hline
BM25 & 59.1/73.7 & 66.9/76.7 & --/-- & --/--
\\
DPR & 78.4/85.4 & 79.4/85.0 & 79.4/86.0 & 78.8/84.7
\\
BM25+DPR & 76.6/83.8 & 79.8/84.5 & 78.0/83.9 & 79.9/84.4
\\ \hline
ANCE & \textbf{81.9}/\textbf{87.5} & \textbf{80.3}/\textbf{85.3} & \textbf{82.1}/\textbf{87.9} & \textbf{80.3}/\textbf{85.2} \\
\hline
\end{tabular}
\begin{tabular}{rrr|r} \hline \hline
\textbf{Corpus Size} & \textbf{Dim} & \textbf{Search} &
\textbf{Gain}
\\ \hline
250 Million & 768 & KNN & +18.4\% \\
8 Billion & 64 & KNN & +14.2\% \\
8 Billion & 64 & ANN & +15.5\% \\ \hline
\end{tabular}
6. Evaluation Results
Section Summary: The evaluation shows that ANCE substantially improves retrieval accuracy over sparse keyword methods and prior dense approaches across standard benchmarks and real-world production data, with gains that also boost final answer quality in question-answering systems. It delivers these results far more efficiently, cutting online search latency by roughly 100 times compared with traditional reranking pipelines because document representations can be precomputed. Separate analyses of the training process confirm that ANCE’s use of globally informative negatives sustains higher loss values and stronger gradient signals, enabling faster and more stable convergence than training with uninformative local negatives.
In this section, we first evaluate the effectiveness and efficiency of ANCE. Then we empirically study the convergence of ANCE training following our theoretical analyses.
6.1 Effectiveness and Efficiency
The results on TREC 2019 DL benchmark are in Table 1. ANCE significantly outperforms all sparse retrieval, including DeepCT, which uses BERT to learn term weights ([34]). Among all different negative construction mechanisms, ANCE is the only one that elevates BERT-Siamese to robustly exceed the sparse methods in document retrieval. It also outperforms DPR in passage retrieval in OpenQA (Table 2). ANCE's effectiveness is even more observed in real production (Table 3) with about 15% relative gains all around. Its better retrieval does indeed lead to better answer accuracy with the same readers used in RAG ([29]) and DPR (Table 4).
\begin{tabular}{l|cc} \hline \hline
\small
\textbf{Model}
& \multicolumn{1}{c}{\textbf{NQ}}
& \multicolumn{1}{c}{\textbf{TQA}} \\ \hline
T5-11B ([35]) & 34.5 & -
\\
T5-11B + SSM ([35]) & 36.6 & -
\\
REALM ([21]) & 40.4 & -
\\ \hline
DPR ([9]) & 41.5 & 56.8
\\
DPR + BM25 ([9]) & 39.0 & 57.0
\\
RAG-Token ([29]) & 44.1 & 55.2
\\
RAG-Sequence ([29]) & 44.5 & 56.1
\\ \hline
ANCE + Reader & \textbf{46.0} & \textbf{57.5}
\\
\hline
\end{tabular}
\begin{tabular}{l|r|r} \hline \hline
\textbf{Operation} & \textbf{Offline} & \textbf{Online } \\ \hline
BM25 Index Build & 3h & -- \\
BM25 Retrieval & -- & 37ms \\
BERT Rerank &-- & 1.15s \\
Sparse IR Total (BM25 + BERT) &-- & \textbf{1.42s} \\
\hline
{\textbf{ANCE Inference}} & \\
Encoding of Corpus/Per doc & 10h/4.5ms & -- \\
Query Encoding & --& 2.6ms \\
ANN Retrieval (batched q) &-- & 9ms \\
Dense Retrieval Total &-- & \textbf{11.6ms}
\\\hline
{\textbf{ANCE Training}} & \\
Encoding of Corpus/Per doc & 10h/4.5ms & -- \\
ANN Index Build & 10s & -- \\
Neg Construction Per Batch & 72ms & -- \\
Back Propagation Per Batch & 19ms & -- \\
\hline
\end{tabular}
Among all DR models, ANCE has the smallest gap between its retrieval and reranking accuracy, showing the importance of global negatives in training retrieval models. ANCE retrieval nearly matches the accuracy of the cascade IR with interaction-based BERT Reranker. This overthrows a previously-held belief that modeling term-level interactions is necessary in search ([36, 37]). With ANCE, we can learn a representation space that effectively captures the finesse of search relevance.
Table 5 measures the efficiency ANCE (FirstP) in TREC DL document retrieval. The online latency is on one query and 100 retrieved documents. DR with standard batching provides a 100x speed up compared to BERT Rerank, a natural benefit from the Siamese network and pre-computable document encoding. In ANCE training, the bulk of computing is to update the encodings of the training corpus using new checkpoints. Assuming the model used to sample negatives and to be learned is the same, this is inevitable but can be mitigated by asynchronous index refresh.
6.2 Empirical Analyses on Training Convergence
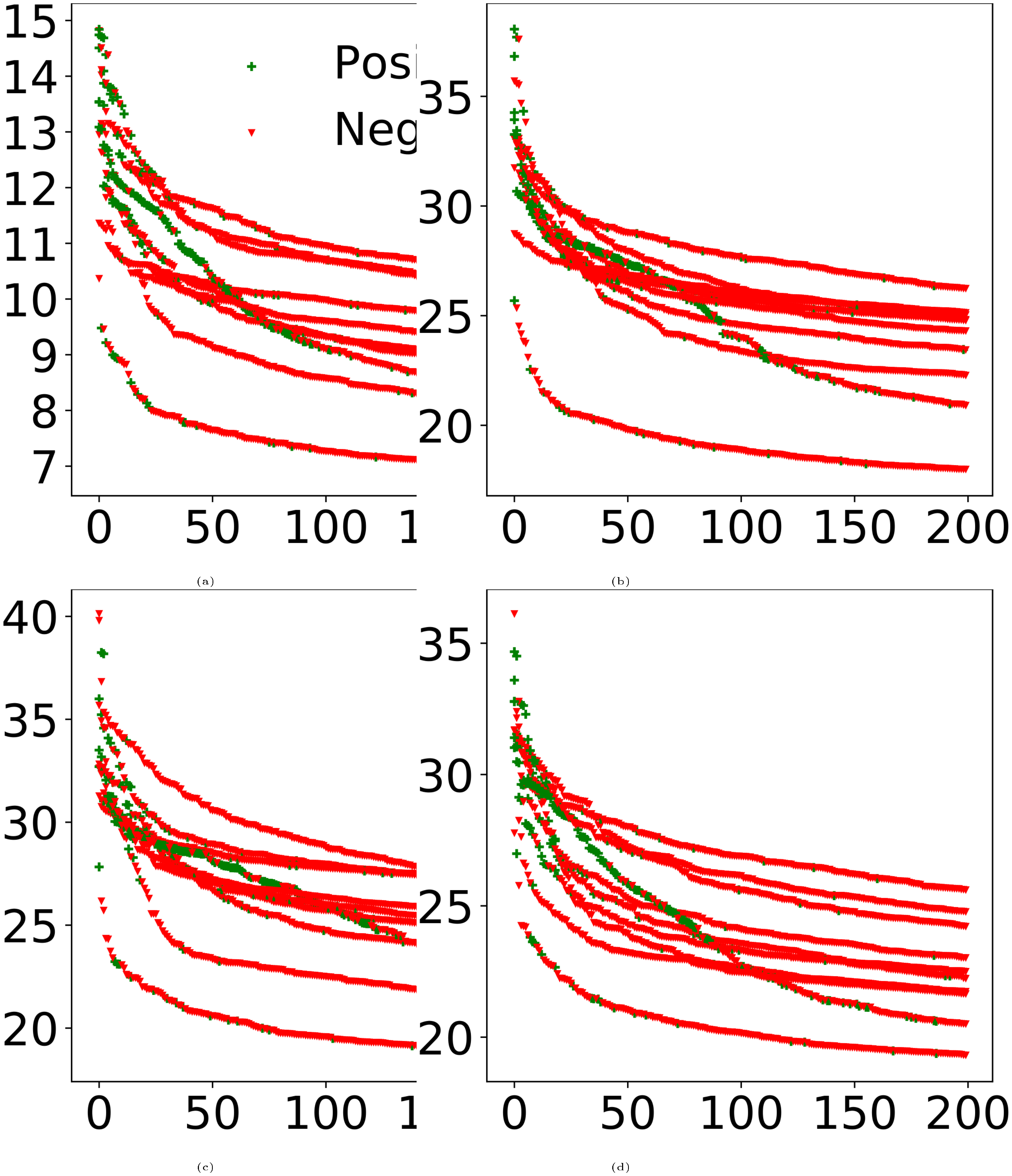
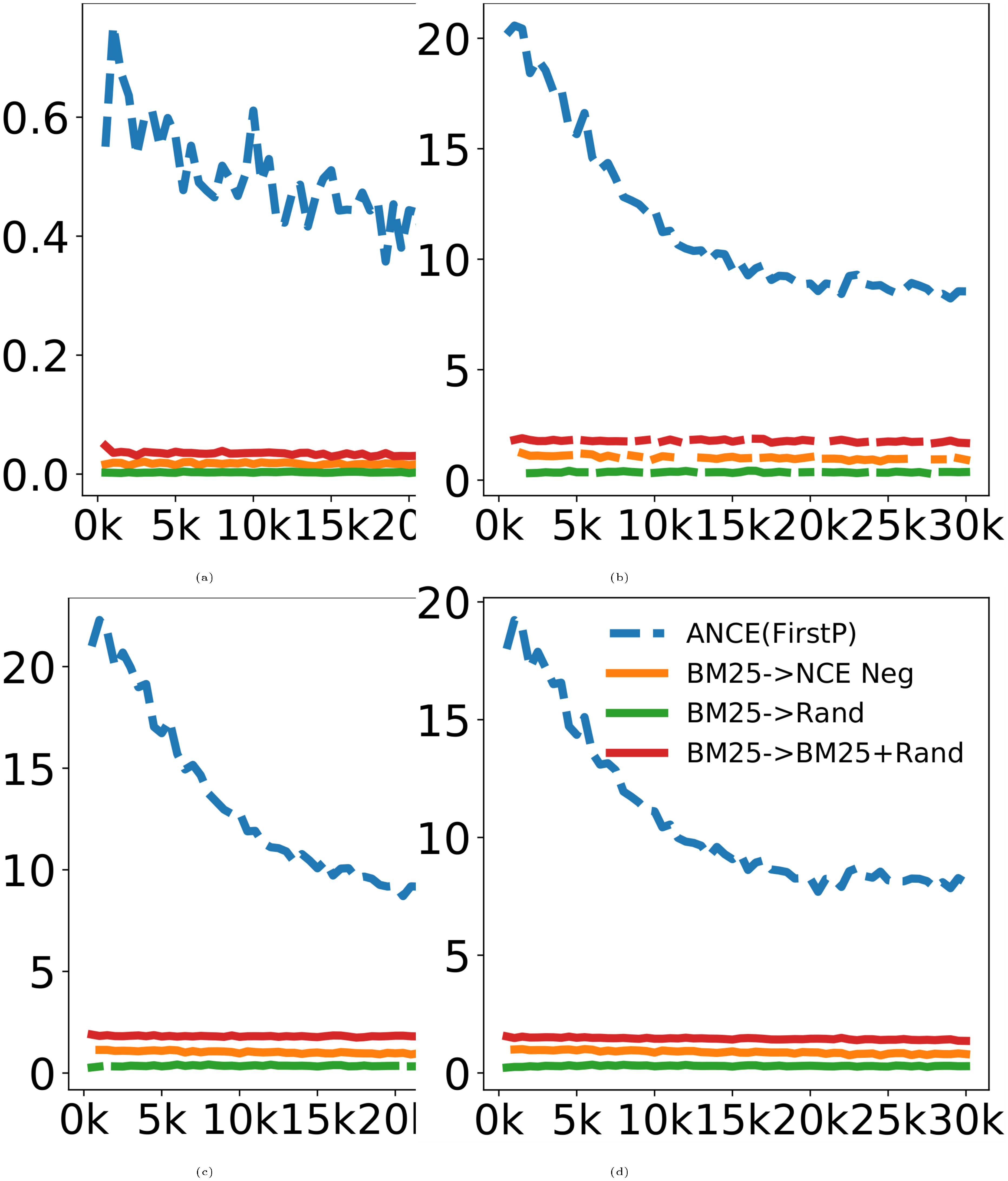
We first show the long tail distribution of search relevance in dense retrieval. As plotted in Figure 3, there are a few instances per query with significant higher retrieval scores, while the majority form a long tail. In retrieval/ranking, the key challenge is to distinguish the relevant ones among those highest scored ones; the rest is trivially irrelevant. We also empirically measure the probability of local in-batch negatives including informative negatives ($D^{-*}$), by their overlap with top 100 highest scored negatives. This probability, either using NCE Neg or Rand Neg, is zero, the same as our theory assumes. In comparison, the overlap between BM25 Neg with top DR retrieved negatives is 15%, while that of ANCE negatives starts at 63% and converges to 100% by design.
Then we empirically validate our theory that local negatives lead to lower loss, bounded gradient norm, and thus slow convergence. The training loss and pre-clip gradient norms during DR training are plotted in Figure 4. As expected, the uninformative local negatives are trivial to separate, yielding near-zero training loss, while ANCE global negatives are much harder and maintain a high training loss. The same with our theoretical assumption, the gradient norms of local negatives are indeed restricted closely to zero. In comparison, the gradient norms on ANCE global negatives are bigger by orders of magnitude. This confirms ANCE better approximates the oracle importance sampling distribution $ p^*_{d^-} \propto ||\nabla_{\theta_t} l(d^+, d^-)||_2$ and improves learning convergence.
6.3 Discussions
We use BERT-Siamese and NLL loss to be consistent with recent research. We have experimented with cosine similarity and BCE/hinge loss, where we observe even smaller gradient norms on local negatives. But the retrieval accuracy is not much better. We include additional experiments in Appendix. Appendix A.2 discusses the surprisingly small overlap (<25%) between dense retrieval results and sparse retrieval results. DR is a fundamentally different approach and more studies are required to understand its behavior. Appendix A.3 and Appendix A.4 study the asynchronous gaps and hyperparameters. Appendix A.5 includes case studies that the irrelevant documents from ANCE are often still "semantically related" and very different from those made by sparse retrieval.
7. Related Work
Section Summary: Early neural retrieval research assumed that expensive interaction-based models, which directly compare query and document terms, would outperform simpler representation-based approaches that embed texts separately, leading to various efficiency tricks like distillation. ANCE demonstrates that a well-trained BERT-based dual-encoder can match those interaction models in accuracy while also outperforming classic sparse retrieval through pure embedding-space search, and it further improves training by selecting challenging negatives from across the entire corpus using an asynchronously updated index. These advances in representation learning are complementary to the use of dense retrieval inside downstream tasks such as question answering and fact verification.
In early research on neural information retrieval (Neu-IR) ([38]), a common belief was that the interaction models, those that specifically handle term level matches, are more effective though more expensive ([39, 36, 1]). Many techniques are developed to reduce their cost, for example, distillation ([40]) and caching ([41, 42, 43]). ANCE shows that a properly trained representation-based BERT-Siamese is in fact as effective as the interaction-based BERT ranker. This finding will motivate many new research explorations in Neu-IR.
Deep learning has been used to improve various components of sparse retrieval, for example, term weighting ([33]), query expansion ([44]), and document expansion ([45]). Dense Retrieval chooses a different path and conducts retrieval purely in the embedding space via ANN search ([8, 46, 9, 6]). This work demonstrates that a simple dense retrieval system can achieve SOTA accuracy, while also behaves dramatically different from classic retrieval. The recent advancement in dense retrieval may raise a new generation of search systems.
Recent research in contrastive representation learning also shows the benefits of sampling negatives from a larger candidate pool. In computer vision, [15] decouple the negative sampling pool size with training batch size, by maintaining a negative candidate pool of recent batches and updating their representation with momentum. This enlarged negative pool significantly improves unsupervised visual representation learning ([47]). A parallel work ([48]) improves DPR by sampling negatives from a memory bank ([49]) — in which the representations of negative candidates are frozen so more candidates can be stored. Instead of a bigger local pool, ANCE goes all the way along this trajectory and constructs negatives globally from the entire corpus, using an asynchronously updated ANN index.
Besides being a real world application itself, dense retrieval is also a core component in many other language systems, for example, to retrieval relevant information for grounded language models ([50, 21]), extractive/generative QA ([9, 29]), and fact verification ([48]), or to find paraphrase pairs for pretraining ([51]). There dense retrieval models are either frozen or optimized indirectly by signals from their end tasks. ANCE is orthogonal with those lines of research and focuses on the representation learning for dense retrieval. Its better retrieval accuracy can benefit many language systems.
8. Conclusion
Section Summary: This paper analyzes why standard training methods for dense retrieval models often fail to converge effectively, showing that locally sampled negative examples tend to be uninformative and produce weak learning signals. To address this, the authors introduce ANCE, which selects more useful negative examples from across the entire corpus during training. Experiments across web search, question answering, and a live commercial system confirm that the approach yields stronger gradient signals, more stable training, and better overall performance.
In this paper, we first provide theoretical analyses on the convergence of representation learning in dense retrieval. We show that under common conditions in text retrieval, the local negatives used in DR training are uninformative, yield low gradient norms, and contribute little to the learning convergence. We then propose ANCE to eliminate this bottleneck by constructing training negatives globally from the entire corpus. Our experiments demonstrate the advantage of ANCE in web search, OpenQA, and the production system of a commercial search engine. Our studies empirically validate our theory that ANCE negatives have much bigger gradient norms, reduce the stochastic gradient variance, and improve training convergence.
Appendix
Section Summary: The appendix provides extra details on the TREC Deep Learning Track benchmarks, including how training data came from MS MARCO with later NIST labeling of top results, the chosen metrics, and various quirks like missing documents from a time gap in data collection. It also covers the exact setups used for dense retrieval experiments, OpenQA baselines such as BM25 and BERT rerankers, model configurations, and training procedures. Finally, it discusses how dense retrieval runs differ sharply from the sparse methods that contributed to the original judgment pools, resulting in high rates of unlabeled results that make some evaluation measures less reliable.
A.1 More Experimental Details
More Details on TREC DL Benchmarks: There are two tasks in the TREC DL 2019 Track: document retrieval and passage retrieval. The training and development sets are from MS MARCO, which includes passage level relevance labels for one million Bing queries ([52]). The document corpus was post-constructed by back-filling the body texts of the passage's URLs and their labels were inherited from its passages ([22]). The testing sets are labeled by NIST accessors on the top 10 ranked results from past Track participants ([22]).
TREC DL official metrics include NDCG@10 on test and MRR@10 on MARCO Passage Dev. MARCO Document Dev is noisy and the recall on the DL Track testing is less meaningful due to low label coverage on DR results. There is a two-year gap between the construction of the passage training data and the back-filling of their full document content. Some original documents were no longer available. There is also a decent amount of content changes in those documents during the two-year gap, and many no longer contain the passages. This back-filling perhaps is the reason why many Track participants found the passage training data is more effective than the inherited document labels. Note that the TREC testing labels are not influenced as the annotators were provided the same document contents when judging.
All the TREC DL runs are trained using these training data. Their inference results on the testing queries of the document and the passage retrieval tasks were evaluated by NIST assessors in the standard TREC-style pooling technique ([53]). The pooling depth is set to 10, that is, the top 10 ranked results from all participated runs are evaluated, and these evaluated labels are released as the official TREC DL benchmarks for passage and document retrieval tasks.
More Details on OpenQA Experiments: All the DPR related experimental settings, baseline systems, and DPR Reader are based on their open source libarary^1. The RAG-Token reader uses their open-source release in huggingface^2. The RAG-Seq release in huggingface is not yet stable by the time we did our experiment, thus we choose the RAG-Token in our OpenQA experiment. RAG only releases the NQ models thus we use DPR reader on TriviaQA. We feed top 20 passages from ANCE to RAG-Token on NQ and top 100 passages to DPR's BERT Reader, following the guideline in their open-source codes.
More Details on Baselines: The most representative sparse retrieval baselines in TREC DL include the standard BM25 ("bm25base" or "bm25base_p"), Best TREC Sparse Retrieval ("bm25tuned_rm3" or "bm25tuned_prf_p") with tuned query expansion ([54]), and Best DeepCT ("dct_tp_bm25e2", doc only), which uses BERT to estimate the term importance for BM25 ([55]). These three runs represent the standard sparse retrieval, best classical sparse retrieval, and the recent progress of using BERT to improve sparse retrieval. We also include the standard cascade retrieval-and-reranking systems BERT Reranker ("bm25exp_marcomb" or "p_exp_rm3_bert"), which is the best run using standard BERT on top of query/doc expansion, from the groups with multiple top MARCO runs ([1, 45]).
BERT-Siamese Configurations: We follow the network configurations in [6] in all Dense Retrieval methods, which we found provides the most stable results. More specifically, we initialize the BERT-Siamese model with RoBERTa base ([32]) and add a $768\times768$ projection layer on top of the last layer's "[CLS]" token, followed by a layer norm.
Implementation Details: The training often takes about 1-2 hours per ANCE epoch, which is whenever new ANCE negative is ready, it immediately replaces existing negatives in training, without waiting. It converges in about 10 epochs, similar to other DR baselines. The optimization uses LAMB optimizer, learning rate 5e-6 for document and 1e-6 for passage retrieval, and linear warm-up and decay after 5000 steps. More detailed hyperparameter settings can be found in our code release.
::: {caption="Table 6: Coverage of TREC 2019 DL Track labels on Dense Retrieval methods. Overlap with BM25 is calculated on top 100 retrieved documents."}

:::
A.2 Overlap with Sparse Retrieval in TREC 2019 DL Track
As a nature of TREC-style pooling evaluation, only those ranked in the top 10 by the 2019 TREC participating systems were labeled. As a result, documents not in the pool and thus not labeled are all considered irrelevant, even though there may be relevant ones among them. When reusing TREC style relevance labels, it is very important to keep track of the "hole rate" on the evaluated systems, i.e., the fraction of the top K ranked results without TREC labels (not in the pool). A larger hole rate shows that the evaluated methods are very different from those systems that participated in the Track and contributed to the pool, thus the evaluation results are not perfect. Note that the hole rate does not necessarily reflect the accuracy of the system, only the difference of it.
In TREC 2019 Deep Learning Track, all the participating systems are based on sparse retrieval. Dense retrieval methods often differ considerably from sparse retrievals and in general will retrieve many new documents. This is confirmed in Table 6. All DR methods have very low overlap with the official BM25 in their top 100 retrieved documents. At most, only 25% of documents retrieved by DR are also retrieved by BM25. This makes the hole rate quite high and the recall metric not very informative. It also suggests that DR methods might benefit more in this year's TREC 2020 Deep Learning Track if participants are contributing DR based systems.
The MS MARCO ranking labels were not constructed based on pooling the sparse retrieval results. They were from Bing ([52]), which uses many signals beyond term overlap. This makes the recall metric in MS MARCO more robust as it reflects how a single model can recover a complex online system.
A.3 Impact of Asynchronous Gap
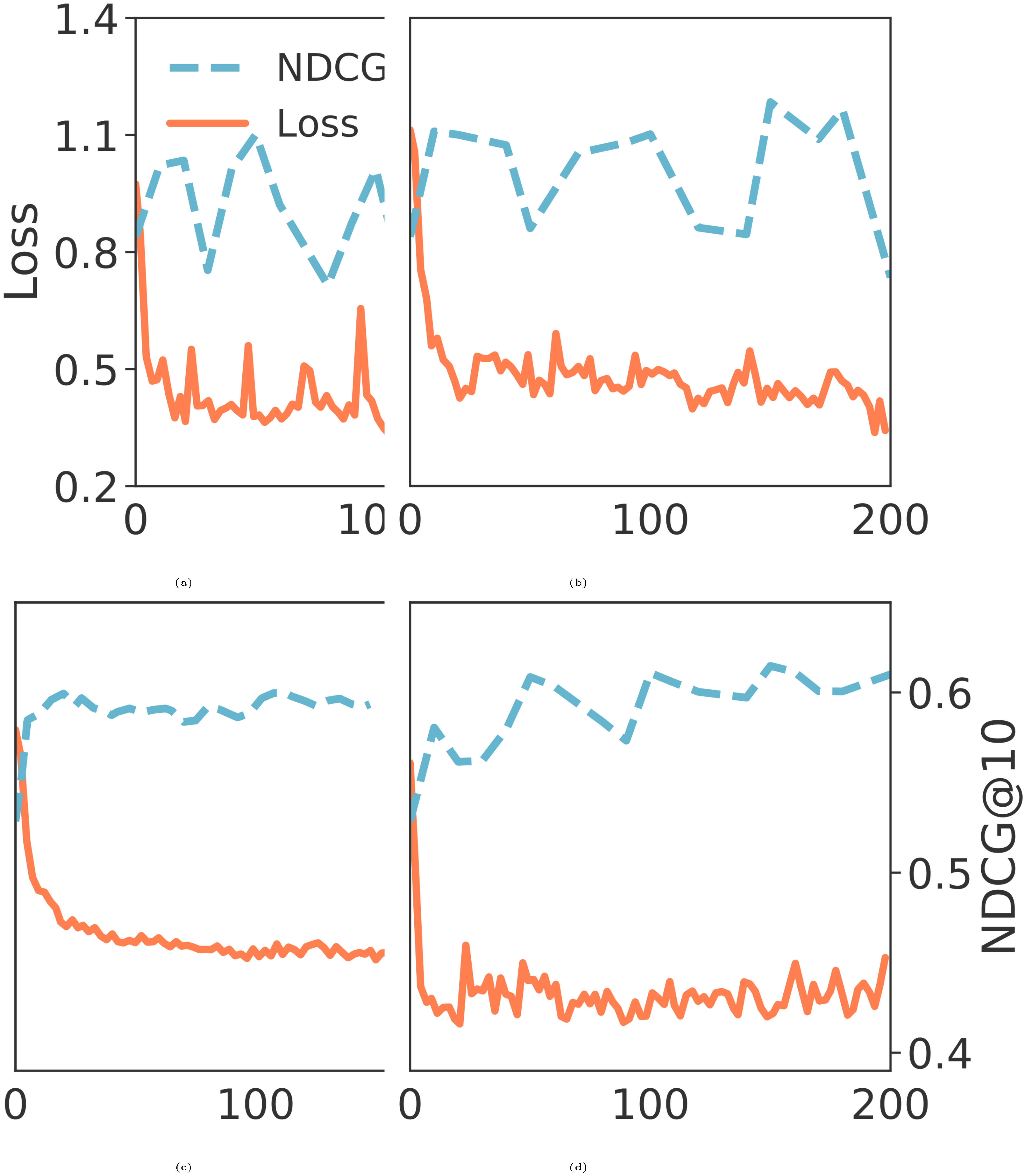
Figure 5 illustrates the behavior of asynchronous learning with different configurations. A large learning rate or a low refreshing rate (Figure 5 and Figure 5) leads to fluctuations as the async gap of the ANN index may drive the representation learning to undesired local optima. Refreshing as often as every 5k Batches yields a smooth convergence (Figure 5), but requires twice as many GPU allocated to the Inferencer. A 1:1 GPUs allocation of Trainer and Inference with appropriate learning rates is adequate to minimize the impact of async gap.
A.4 Hyperparameter Studies
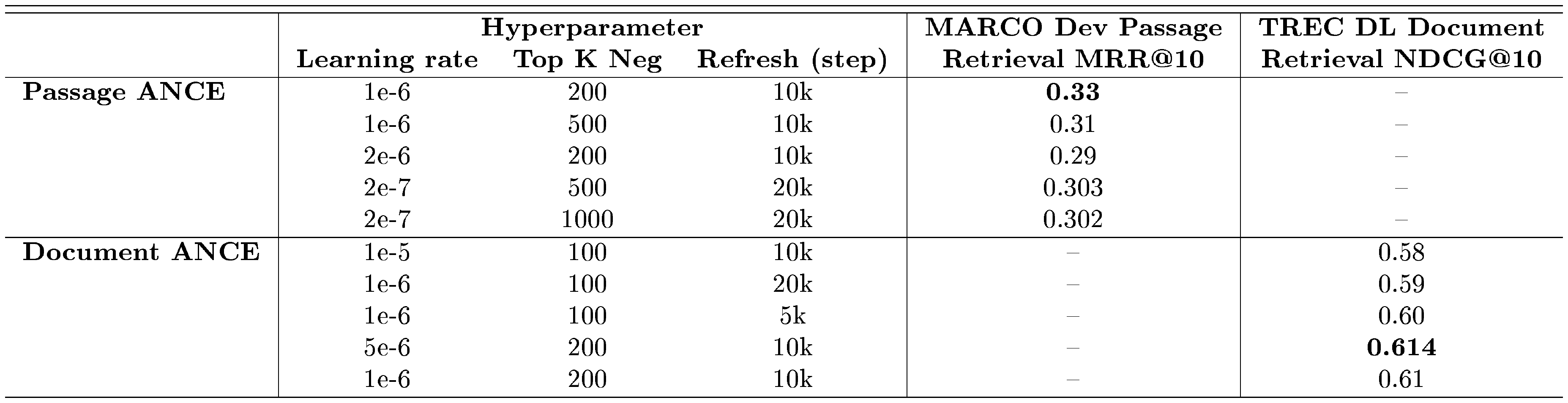
::: {caption="Table 7: Results of several different hyperparameter configurations. "Top K Neg" lists the top k ANN retrieved candidates from which we sampled the ANCE negatives from."}
:::
We show the results of some hyperparameter configurations in Table 7. The cost of training with BERT makes it difficult to conduct a lot hyperparameter exploration. Often a failed configuration leads to divergence early in training. We barely explore other configurations due to the time-consuming nature of working with pretrained language models. Our DR model architecture is kept consistent with recent parallel work and the learning configurations in Table 7 are about all the explorations we did. Most of the hyperparameter choices are decided solely using the training loss curve and otherwise by the loss in the MARCO Dev set. We found the training loss, validation NDCG, and testing performance align well in our (limited) hyperparameter explorations.
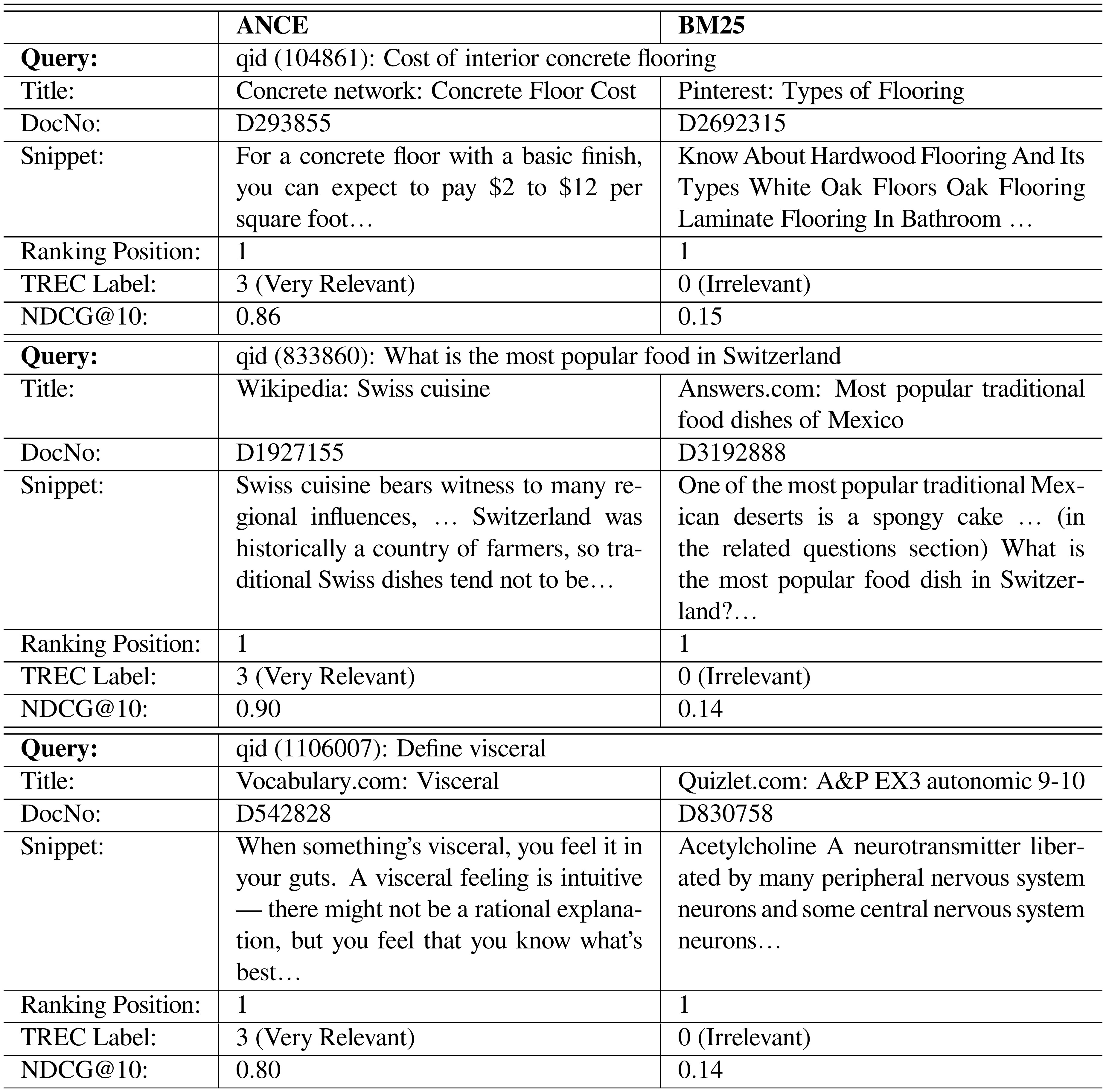
::: {caption="Table 8: Queries in the TREC 2019 DL Track Document Ranking Tasks where ANCE performs better than BM25. Snippets are manually extracted. The documents in the first disagreed ranking position are shown, where on all examples ANCE won. The NDCG@10 of ANCE and BM25 in the corresponding query is listed."}
:::
::: {caption="Table 9: Queries in the TREC 2019 DL Track Document Ranking Tasks where ANCE performs worse than BM25. Snippets are manually extracted. The documents in the first position where BM25 wins are shown. The NDCG@10 of ANCE and BM25 in the corresponding query is listed. Typos in the query are from the real web search queries in TREC."}
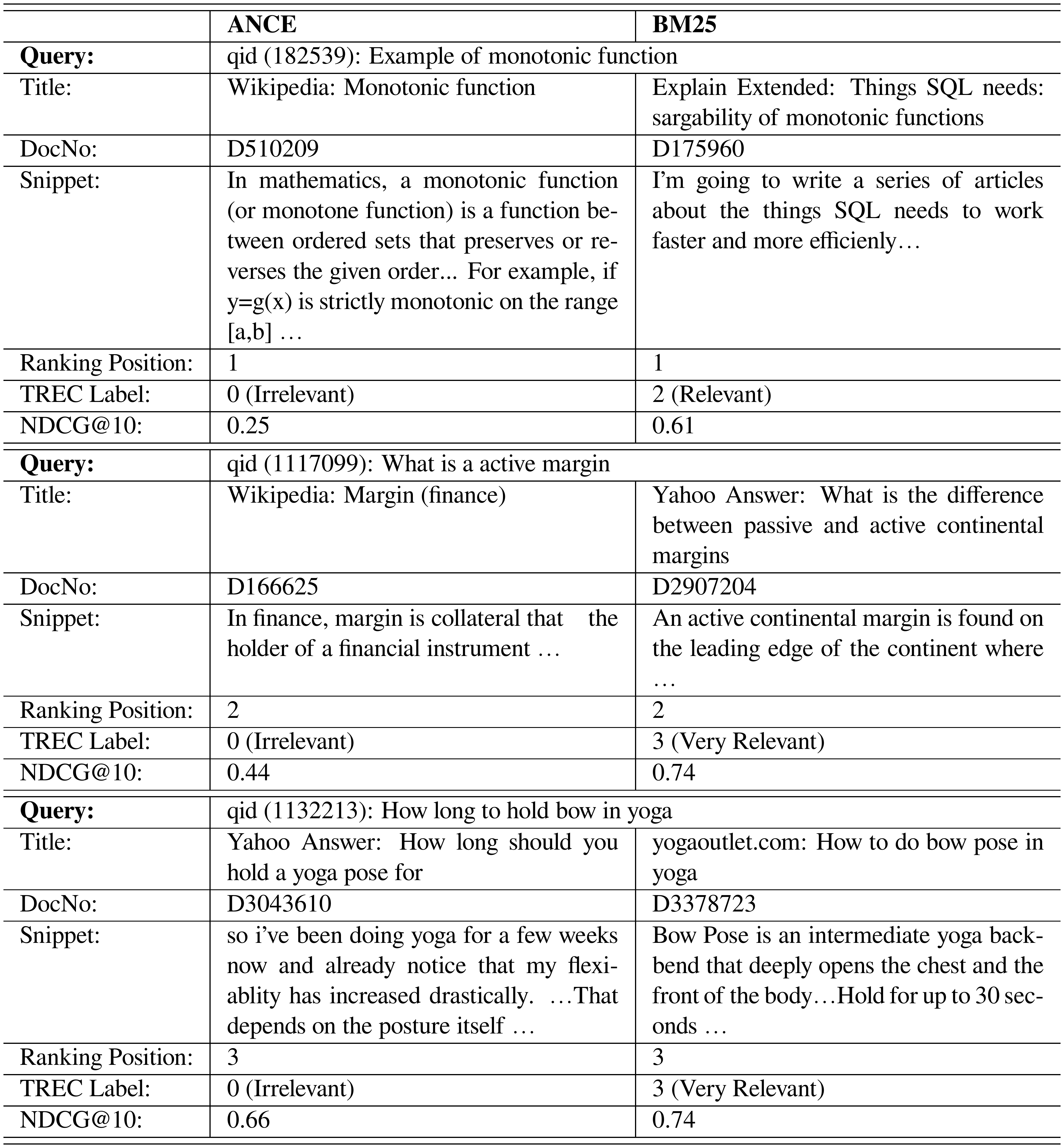
:::
A.5 Case Studies
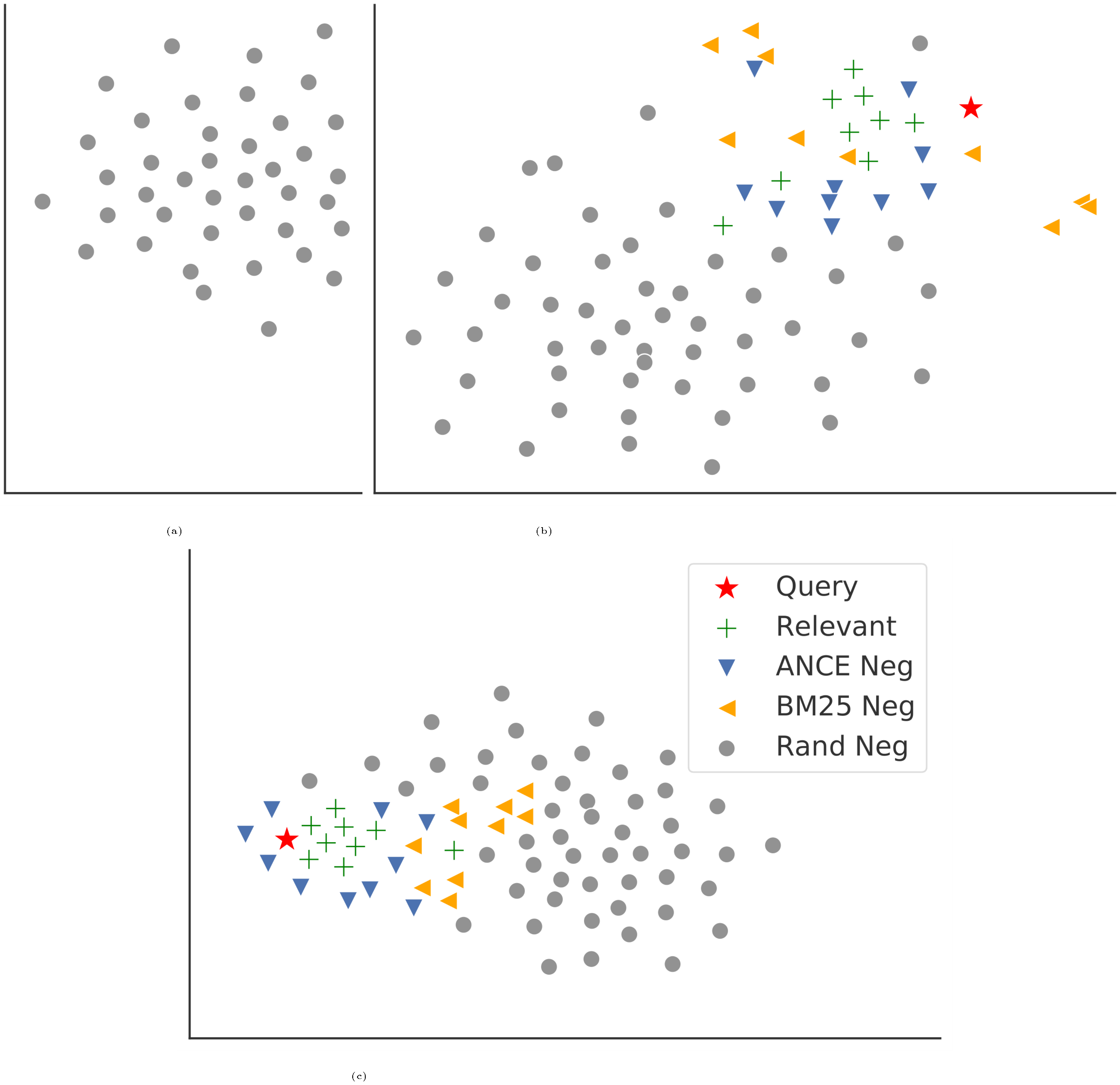
In this section, we show Win/Loss case studies between ANCE and BM25. Among the 43 TREC 2019 DL Track evaluation queries in the document task, ANCE outperforms BM25 on 29 queries, loses on 13 queries, and ties on the rest 1 query. The winning examples are shown in Table 8 and the losing ones are in Table 9. Their corresponding ANCE-learned (FirstP) representations are illustrated by t-SNE in Figure 6 and Figure 7.
In general, we found ANCE better captures the semantics in the documents and their relevance to the query. The winning cases show the intrinsic limitations of sparse retrieval. For example, BM25 exact matches the "most popular food" in the query "what is the most popular food in Switzerland" but using the document is about Mexico. The term "Switzerland" only appears in the related question section of the web page.
The losing cases in Table 9 are also quite interesting. Many times we found that it is not that DR fails completely and retrieves documents not related to the query's information needs at all, which was a big concern when we started research in DR. The errors ANCE made include retrieving documents that are related just not exactly relevant to the query, for example, "yoga pose" for "bow in yoga". In other cases, ANCE retrieved wrong documents due to the lack of the domain knowledge: the pretrained language model may not know "active margin" is a geographical terminology, not a financial one (which we did not know ourselves and took some time to figure out when conducting this case study). There are also some cases where the dense retrieved documents make sense to us but were labeled irrelevant.
The t-SNE plots in Figure 6 and Figure 7 show many interesting patterns of the learned representation space. The ANCE winning cases often correspond to clear separations of different document groups. For losing cases the representation space is more mixed, or there is too few relevant documents which may cause the variances in model performances. There are also many different interesting patterns in the ANCE-learned representation space. We include the t-SNE plots for all 43 TREC DL Track queries in the supplementary material. More future analyses of the learned patterns in the representation space may help provide more insights on dense retrieval.
References
[1] Nogueira, Rodrigo and Cho, Kyunghyun (2019). Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085.
[2] Chen et al. (2017). Reading wikipedia to answer open-oomain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. pp. 1870–1879.
[3] Thorne et al. (2018). The fact extraction and verification (FEVER) shared task. In Proceedings of the 1st Workshop on Fact Extraction and VERification (FEVER). pp. 1–9.
[4] Rajpurkar et al. (2016). SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. pp. 2383–2392.
[5] Wang et al. (2018). Glue: a multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.
[6] Luan et al. (2020). Sparse, dense, and attentional representations for text retrieval. arXiv preprint arXiv:2005.00181.
[7] Chen Zhao et al. (2020). Transformer-XH: multi-evidence reasoning with extra hop attention. In International Conference on Learning Representations.
[8] Lee et al. (2019). Latent retrieval for weakly supervised open domain question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 6086–6096.
[9] Karpukhin et al. (2020). Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
[10] Johnson et al. (2019). Billion-scale similarity search with GPUs. IEEE Transactions on Big Data.
[11] Croft et al. (2010). Search engines: information retrieval in practice. Addison-Wesley Reading.
[12] Huang et al. (2020). Embedding-based Retrieval in Facebook Search. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. pp. 2553–2561.
[13] Faghri et al. (2017). Vse++: Improving visual-semantic embeddings with hard negatives. arXiv preprint arXiv:1707.05612.
[14] Oord et al. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.
[15] He et al. (2019). Momentum contrast for unsupervised visual representation learning. arXiv preprint arXiv:1911.05722.
[16] Chen et al. (2020). A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709.
[17] Gao et al. (2020). Complementing lexical retrieval with semantic residual embedding. arXiv preprint arXiv:2004.13969.
[18] Maaten, Laurens van der and Hinton, Geoffrey (2008). Visualizing data using t-SNE. Journal of Machine Learning Research. 9(Nov). pp. 2579–2605.
[19] Alain et al. (2015). Variance reduction in sgd by distributed importance sampling. arXiv preprint arXiv:1511.06481.
[20] Katharopoulos, Angelos and Fleuret, François (2018). Not all samples are created equal: Deep learning with importance sampling. arXiv preprint arXiv:1803.00942.
[21] Guu et al. (2020). Realm: retrieval-augmented language model pre-training. arXiv preprint arXiv:2002.08909.
[22] Craswell et al. (2020). Overview of the TREC 2019 deep learning track. In Text REtrieval Conference (TREC).
[23] Kwiatkowski et al. (2019). Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics. 7. pp. 453–466.
[24] Guo et al. (2020). Accelerating Large-Scale Inference with Anisotropic Vector Quantization. arXiv preprint arXiv:1908.10396.
[25] Liu, Tie-Yan (2009). Learning to rank for information retrieval. Foundations and trends in information retrieval. 3(3). pp. 225–331.
[26] Johnson, Tyler B and Guestrin, Carlos (2018). Training deep models faster with robust, approximate importance sampling. In Advances in Neural Information Processing Systems. pp. 7265–7275.
[27] Mosbach et al. (2020). On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines. arXiv preprint arXiv:2006.04884.
[28] Joshi et al. (2017). TriviaQA: a large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. pp. 1601–1611.
[29] Lewis et al. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. arXiv preprint arXiv:2005.11401.
[30] Gutmann, Michael and Hyvärinen, Aapo (2010). Noise-contrastive estimation: a new estimation principle for unnormalized statistical models. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. pp. 297–304.
[31] Yan et al. (2019). IDST at TREC 2019 Deep Learning Track: Deep Cascade Ranking with Generation-based Document Expansion and Pre-trained Language Modeling. In Text REtrieval Conference.
[32] Liu et al. (2019). RoBERTa: a robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692.
[33] Dai, Zhuyun and Callan, Jamie (2019). Deeper text understanding for IR with contextual neural language modeling. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 985–988.
[34] Dai et al. (2019). Transformer-XL: attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 2978–2988.
[35] Roberts et al. (2020). How Much Knowledge Can You Pack Into the Parameters of a Language Model?. arXiv preprint arXiv:2002.08910.
[36] Chenyan Xiong et al. (2017). End-to-end neural ad-hoc ranking with kernel pooling. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 55–64.
[37] Qiao et al. (2019). Understanding the Behaviors of BERT in Ranking. arXiv preprint arXiv:1904.07531.
[38] Mitra et al. (2018). An introduction to neural information retrieval. Foundations and Trends® in Information Retrieval. 13(1). pp. 1–126.
[39] Guo et al. (2016). A deep relevance matching model for ad-hoc retrieval. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. pp. 55–64.
[40] Gao et al. (2020). Understanding BERT Rankers Under Distillation. In Proceedings of the 2020 ACM SIGIR on International Conference on Theory of Information Retrieval. pp. 149–152.
[41] Humeau et al. (2020). Poly-encoders: architectures and pre-training strategies for fast and accurate multi-sentence scoring. In International Conference on Learning Representations.
[42] Khattab, Omar and Zaharia, Matei (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. arXiv preprint arXiv:2004.12832.
[43] MacAvaney et al. (2020). Efficient document re-ranking for transformers by precomputing term representations. arXiv preprint arXiv:2004.14255.
[44] Zheng et al. (2020). BERT-QE: Contextualized Query Expansion for Document Re-ranking. arXiv preprint arXiv:2009.07258.
[45] Nogueira et al. (2019). Document expansion by query prediction. arXiv preprint arXiv:1904.08375.
[46] Chang et al. (2020). Pre-training tasks for embedding-based large-scale retrieval. arXiv preprint arXiv:2002.03932.
[47] Chen et al. (2020). Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297.
[48] Xiong et al. (2020). Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval. arXiv preprint arXiv:2009.12756.
[49] Wu et al. (2018). Unsupervised feature learning via non-parametric instance-level discrimination. arXiv preprint arXiv:1805.01978.
[50] Khandelwal et al. (2019). Generalization through memorization: Nearest neighbor language models. arXiv preprint arXiv:1911.00172.
[51] Lewis et al. (2020). Pre-training via paraphrasing. arXiv preprint arXiv:2006.15020.
[52] Bajaj et al. (2016). Ms marco: A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268.
[53] Voorhees, Ellen M (2000). Variations in relevance judgments and the measurement of retrieval effectiveness. Information Processing & Management. 36(5). pp. 697–716.
[54] Lavrenko, Victor and Croft, W Bruce (2017). Relevance-based language models. In Association for Computing Machinery (ACM) Special Interest Group on Information Retrieval (SIGIR) Forum. pp. 260–267.
[55] Dai, Zhuyun and Callan, Jamie (2019). Context-aware sentence/passage term importance estimation for first stage retrieval. arXiv preprint arXiv:1910.10687.