Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang$^{\clubsuit}$ ;;; Yeganeh Kordi$^{\diamondsuit}$ ;;; Swaroop Mishra$^{\heartsuit}$ ;;; Alisa Liu$^{\clubsuit}$
Noah A. Smith$^{\clubsuit}$ $^{+}$ ;;; Daniel Khashabi$^{\spadesuit}$ ; ;; Hannaneh Hajishirzi$^{\clubsuit}$ $^{+}$
$^{\clubsuit}$University of Washington ; $^{\diamondsuit}$Tehran Polytechnic ; $^{\heartsuit}$Arizona State University
$^{\spadesuit}$Johns Hopkins University; $^{+}$Allen Institute for AI
[email protected]
Abstract
Large ``instruction-tuned'' language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is often limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We introduce Self-Instruct, a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off their own generations. Our pipeline generates instructions, input, and output samples from a language model, then filters invalid or similar ones before using them to finetune the original model. Applying our method to the vanilla GPT3, we demonstrate a 33% absolute improvement over the original model on Super-NaturalInstructions, on par with the performance of $\text{InstructGPT}{\text{001}}$, which was trained with private user data and human annotations. For further evaluation, we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with Self-Instruct outperforms using existing public instruction datasets by a large margin, leaving only a 5% absolute gap behind $\text{InstructGPT}{\text{001}}$. Self-Instruct provides an almost annotation-free method for aligning pretrained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning.
Executive Summary: Large language models have shown promise in following natural language instructions, enabling versatile applications from writing assistance to task automation. However, training these models relies on human-created instruction datasets, which are expensive to produce and often lack diversity, limiting the models' ability to handle new or creative tasks. This gap is critical now as businesses and developers seek more reliable, general-purpose AI tools that can adapt to real-world needs without constant retraining.
This paper introduces Self-Instruct, a method to enhance a language model's instruction-following skills using data it generates itself, requiring only a small initial set of human-written examples. The goal was to create a scalable, low-cost way to produce diverse training data and test its effectiveness against models trained on human-annotated datasets.
The approach starts with 175 handcrafted seed tasks to prompt a base GPT-3 model—a large language model without prior instruction tuning—to generate new instructions for varied tasks. In an iterative process, the model also creates input-output pairs for these instructions, using tailored prompting to handle different task types like classification or open-ended generation. Low-quality or duplicate items were filtered automatically based on similarity scores and heuristics, yielding about 52,000 instructions and 82,000 instances over several rounds. The same GPT-3 model was then fine-tuned on this synthetic data, using multiple formatting templates to build robustness.
Key findings highlight the method's impact. First, the fine-tuned model, called GPT3_Self-Inst, boosted performance by 33 percentage points on the Super-NaturalInstructions benchmark—a set of 119 diverse natural language processing tasks—surpassing the original GPT-3 and matching InstructGPT-001, a proprietary model trained with human feedback. Second, on a new set of 252 expert-written instructions for user-focused tasks like email drafting or code generation, human evaluators rated GPT3_Self-Inst outputs as valid or acceptable far more often than models trained on public datasets like PromptSource or Super-NaturalInstructions, closing the gap to InstructGPT-001 to just 5 percentage points when counting minor errors as acceptable. Third, the generated data proved diverse, with most instructions showing low overlap (under 70% similarity) to seeds and covering creative areas beyond standard tasks, such as social media analysis. Finally, performance scaled with data size up to around 16,000 instructions before plateauing, and refining outputs via a stronger model improved results by 10 percentage points.
These results mean synthetic data can rival costly human annotation for building instruction-tuned models, cutting development expenses while expanding coverage to novel scenarios. This could speed up AI deployment in areas like productivity tools or customer support, reducing risks from limited training data and improving safety through broader task understanding. Unexpectedly, the method outperformed expectations for public baselines, suggesting self-generation unlocks creativity in models, though it may not fully capture rare or edge-case instructions seen in human data.
Leaders should prioritize Self-Instruct for generating instruction datasets, especially when human labeling budgets are tight, and combine it with existing public data for hybrid training to maximize gains. For next steps, refine the pipeline by adding human review or reward models to cut noise, pilot tests on smaller open-source models to broaden access, and explore bias mitigation to ensure balanced outputs. If stronger decisions require validation, conduct targeted evaluations on domain-specific tasks before full rollout.
While the method succeeds on standard benchmarks with high confidence, limitations include inherited biases from the base model, which could amplify stereotypes in generations, and a reliance on large models like GPT-3 that may limit scalability. Some generated instances contain errors, though most remain useful. Readers should be cautious with low-frequency or sensitive tasks, where further human oversight is advised.
1. Introduction
Section Summary: Recent advances in natural language processing have focused on creating AI models that can follow human instructions, relying on large pretrained models and human-created training data, but gathering this data is expensive and often lacks variety in tasks. To address this, the authors introduce Self-Instruct, an iterative method that starts with a small set of handpicked tasks and uses the AI model itself to generate new instructions and example responses, filtering out low-quality ones to build a diverse dataset. When applied to GPT3, this process creates over 50,000 instructions, and a finetuned version of the model significantly outperforms the original on various benchmarks, nearly matching more advanced instruction-tuned models, with the resulting dataset released for future use.
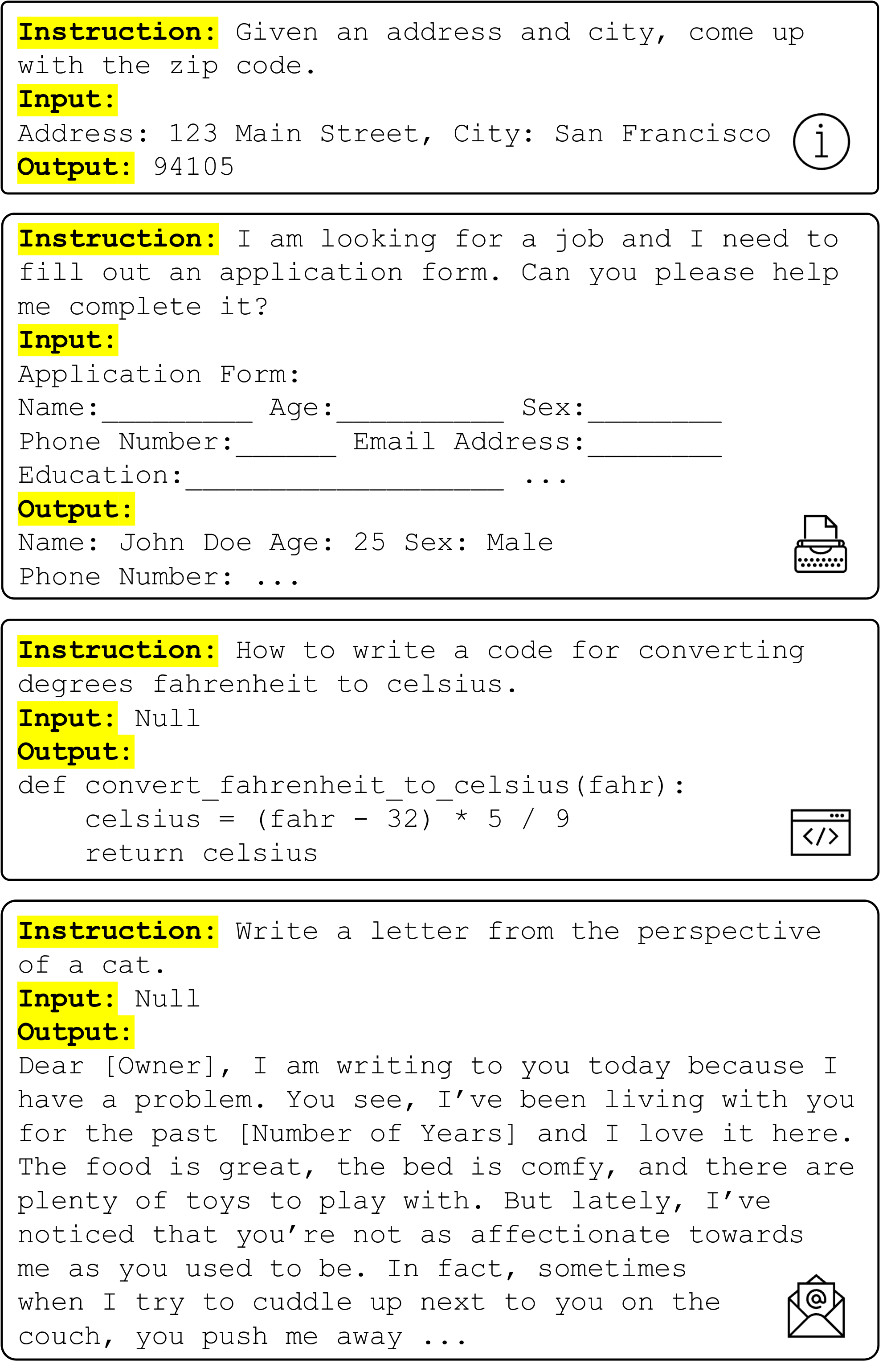
The recent NLP literature has witnessed a tremendous amount of activity in building models that can follow natural language instructions ([1, 2, 3, 4, 5, 6], i.a.). These developments are powered by two key components: large pretrained language models (LM) and human-written instruction data (e.g., $\textsc{PromptSource}$ ([7]) and $\textsc{Super-NaturalInstructions}$ ([4], $\textsc{SuperNI}$ for short)). However, collecting such instruction data is costly and often suffers limited diversity given that most human generations tend to be popular NLP tasks, falling short of covering a true variety of tasks and different ways to describe them. Continuing to improve the quality and coverage of instruction-tuned models necessitates the development of alternative approaches for supervising the instruction tuning process.
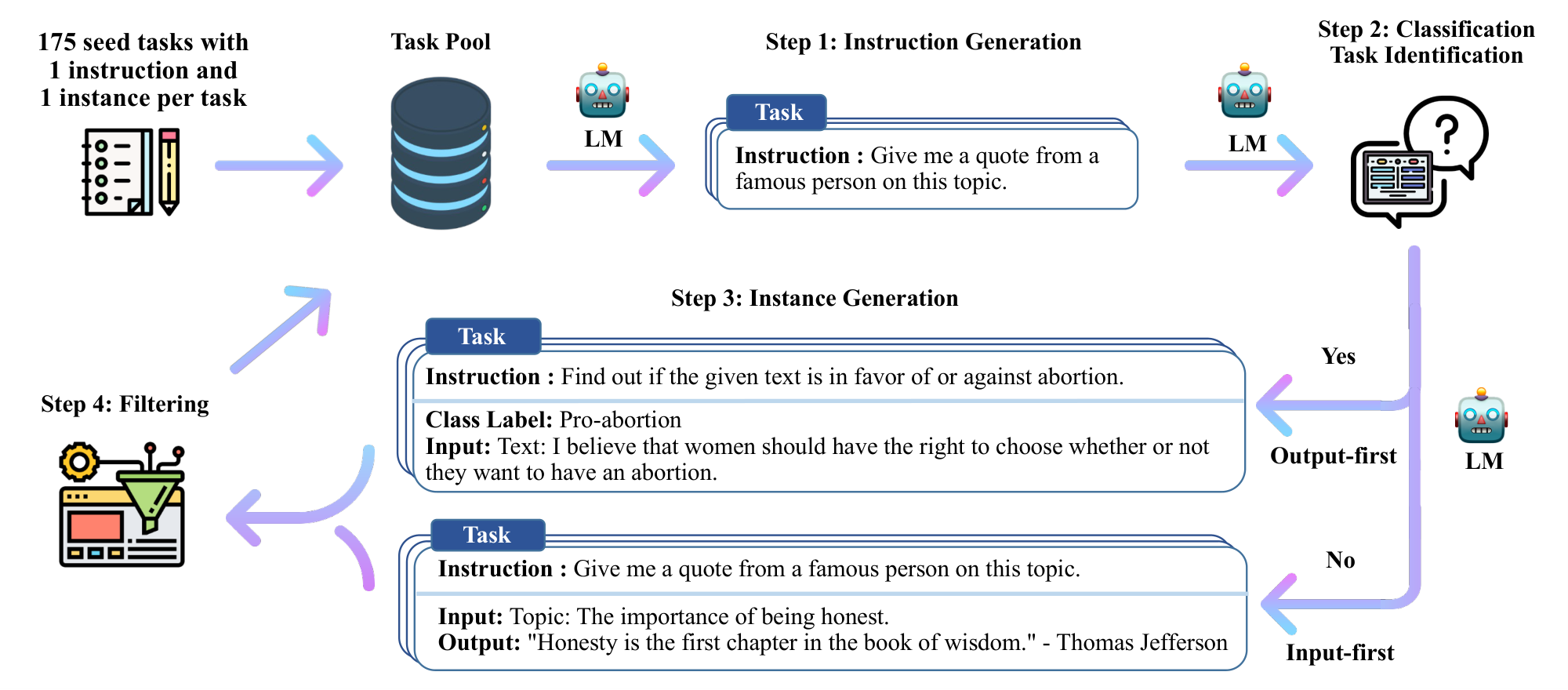
In this work, we introduce $\textsc{Self-Instruct}$, a semi-automated process for instruction-tuning a pretrained LM using instructional signals from the model itself. The overall process is an iterative bootstrapping algorithm (see Figure 2), which starts off with a limited (e.g., 175 in our study) seed set of manually-written tasks that are used to guide the overall generation. In the first phase, the model is prompted to generate instructions for new tasks. This step leverages the existing collection of instructions to create more broad-coverage instructions that define (often new) tasks. Given the newly-generated set of instructions, the framework also creates input-output instances for them, which can be later used for supervising the instruction tuning. Finally, various heuristics are used to automatically filter low-quality or repeated instructions, before adding the remaining valid tasks to the task pool. This process can be repeated for many iterations until reaching a large number of tasks.
To evaluate $\textsc{Self-Instruct}$ empirically, we run this framework on $\textsc{GPT3}$ [8], which is a vanilla LM (§ 3). The iterative $\textsc{Self-Instruct}$ process on this model leads to about 52k instructions, paired with about 82K instance inputs and target outputs. We observe that the resulting data provides a diverse range of creative tasks, as is demonstrated by examples in Figure 1. These generated tasks deviate from the distribution of typical NLP tasks, and also have fairly small overlap with the seed tasks (§ 3.2). On this resulting data, we build $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ by finetuning $\textsc{GPT3}$ (i.e., the same model used for generating the instruction data). We evaluate $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ in comparison to various other models on both typical NLP tasks included in $\textsc{SuperNI}$ [4], and a set of new instructions that are created for novel usage of instruction-following models (§ 4). The results indicate that $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ outperforms $\textsc{GPT3}$ (the original model) by a large margin (+33.1%) and nearly matches the performance of $\text{InstructGPT}{\text{001}}$. Moreover, our human evaluation on the newly-created instruction set shows that $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ demonstrates a broad range of instruction following ability, outperforming models trained on other publicly available instruction datasets and leaving only a 5% gap behind $\text{InstructGPT}{\text{001}}$.
In summary, our contributions are: (1) we introduce $\textsc{Self-Instruct}$, a method for inducing instruction following capabilities with minimal human-labeled data; (2) we demonstrate its effectiveness via extensive instruction-tuning experiments; and (3) we release a large synthetic dataset of 52K instructions and a set of manually-written novel tasks for building and evaluating future instruction-following models.
2. Method
Section Summary: Creating large-scale instruction data for training language models is difficult because it demands human creativity and expertise, so the Self-Instruct method uses a basic pretrained language model to generate tasks automatically. The process starts with a small set of 175 human-written seed tasks and bootstraps new instructions by prompting the model with examples, then classifies them as needing inputs or not, generates input-output pairs using tailored approaches to avoid biases, and filters out low-quality or duplicate items. Finally, the generated data trains the model to better follow instructions by fine-tuning it on prompts that combine instructions and inputs with varied formats.
Annotating large-scale instruction data can be challenging for humans because it requires 1) creativity to come up with novel tasks and 2) expertise for writing the solutions to each task. Here, we detail our process for $\textsc{Self-Instruct}$, which refers to the pipeline of generating tasks with a vanilla pretrained language model itself, filtering the generated data, and then conducting instruction tuning with this generated data in order to align the LM to follow instructions better. This pipeline is depicted in Figure 2.
2.1 Defining Instruction Data
The instruction data we want to generate contains a set of instructions ${I_t}$, each of which defines a task $t$ in natural language. Task $t$ has $n_t \ge 1$ input-output instances ${(X_{t, i}, Y_{t, i})}{i=1}^{n_t}$. A model $M$ is expected to produce the output, given the task instruction and the corresponding input: $M(I_t, X{t, i}) = Y_{t, i}$, for $i \in {1, \ldots, n_t}$. Note that the instruction and instance input does not have a strict boundary in many cases. For example, "write an essay about school safety" can be a valid instruction that we expect models to respond to directly, while it can also be formulated as "write an essay about the following topic" as the instruction, and "school safety" as an instance input. To encourage the diversity of the data format, we allow such instructions that do not require additional input (i.e., $X$ is empty).
2.2 Automatic Instruction Data Generation
Our pipeline for data generation consists of four steps: 1) generating task instructions, 2) determining if the instruction represents a classification task, 3) instance generation with either an input-first or output-first approach, and 4) filtering low-quality data.
Instruction Generation.
At the first step, $\textsc{Self-Instruct}$ generates new instructions from a small set of seed human-written instructions in a bootstrapping fashion. We initiate the task pool with 175 tasks (1 instruction and 1 instance for each task).[^1] For every step, we sample 8 task instructions from this pool as in-context examples. Of the 8 instructions, 6 are from the human-written tasks, and 2 are from the model-generated tasks in previous steps to promote diversity. The prompting template is shown in Table 5.
[^1]: These tasks were newly written by the authors and their labmates at UW, without reference to existing datasets or the test set used in this work. We provide more details about these tasks and analyze their similarity to the test tasks in Appendix § A.1.
Classification Task Identification.
Because we need two different approaches for classification and non-classification tasks, we next identify whether the generated instruction represents a classification task or not.[^2] We prompt the LM in a few-shot way to determine this, using 12 classification instructions and 19 non-classification instructions from the seed tasks. The prompting template is shown in Table 6.
[^2]: More concretely, we regard tasks that have a small limited output label space as classification tasks.
Instance Generation.
Given the instructions and their task type, we generate instances for each instruction independently. This is challenging because it requires the model to understand what the target task is, based on the instruction, figure out what additional input fields are needed and generate them, and finally complete the task by producing the output. We found that pretrained LMs can achieve this to a large extent when prompted with instruction-input-output in-context examples from other tasks. A natural way to do this is the Input-first Approach, where we can ask an LM to come up with the input fields first based on the instruction, and then produce the corresponding output. This generation order is similar to how models are used to respond to instruction and input, but here with in-context examples from other tasks. The prompting template is shown in Table 7.
However, we found that this approach can generate inputs biased toward one label, especially for classification tasks (e.g., for grammar error detection, it usually generates grammatical input). Therefore, we additionally propose an Output-first Approach for classification tasks, where we first generate the possible class labels, and then condition the input generation on each class label. The prompting template is shown in Table 8.[^3] We apply the output-first approach to the classification tasks identified in the former step, and the input-first approach to the remaining non-classification tasks.
[^3]: In this work, we use a fixed set of seed tasks for prompting the instance generation, and thus only generate a small number of instances per task in one round. Future work can use randomly sampled tasks to prompt the model to generate a larger number of instances in multiple rounds.
Filtering and Postprocessing.
To encourage diversity, a new instruction is added to the task pool only when its ROUGE-L similarity with any existing instruction is less than 0.7. We also exclude instructions that contain some specific keywords (e.g., image, picture, graph) that usually can not be processed by LMs. When generating new instances for each instruction, we filter out instances that are exactly the same or those with the same input but different outputs. Invalid generations are identified and filtered out based on heuristics (e.g., instruction is too long or too short, instance output is a repetition of the input).
2.3 Finetuning the LM to Follow Instructions
After creating large-scale instruction data, we use it to finetune the original LM (i.e., $\textsc{Self-Instruct}$). To do this, we concatenate the instruction and instance input as a prompt and train the model to generate the instance output in a standard supervised way. To make the model robust to different formats, we use multiple templates to encode the instruction and instance input together. For example, the instruction can be prefixed with "Task:" or not, the input can be prefixed with "Input:" or not, "Output:" can be appended at the end of the prompt or not, and different numbers of break lines can be put in the middle, etc.
::::
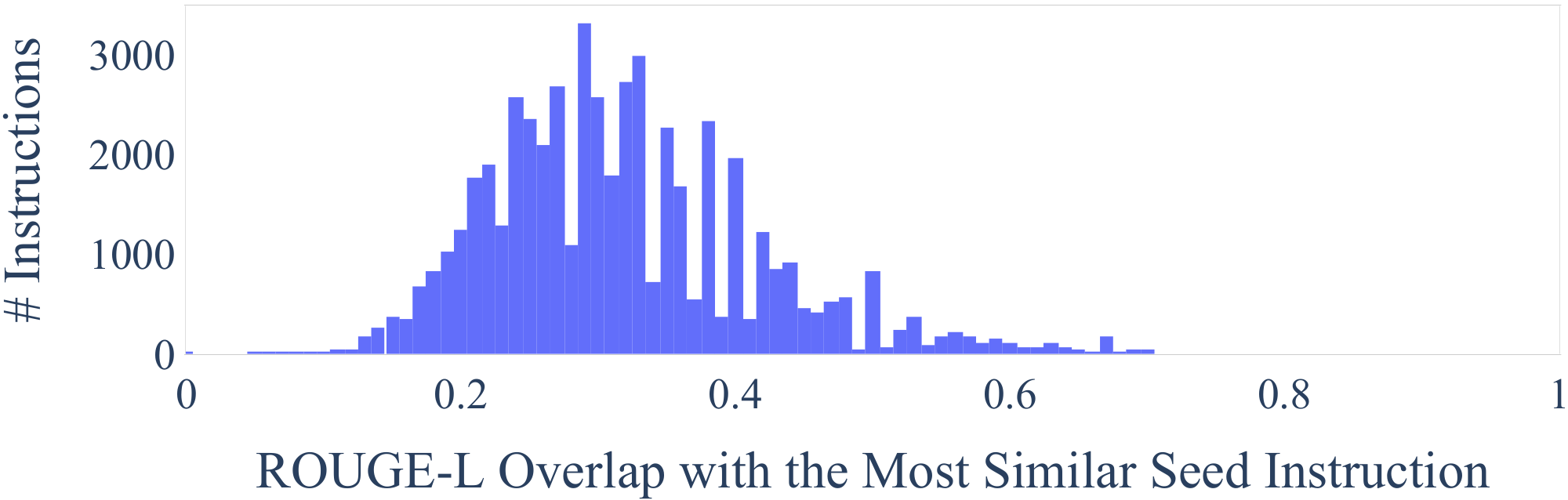
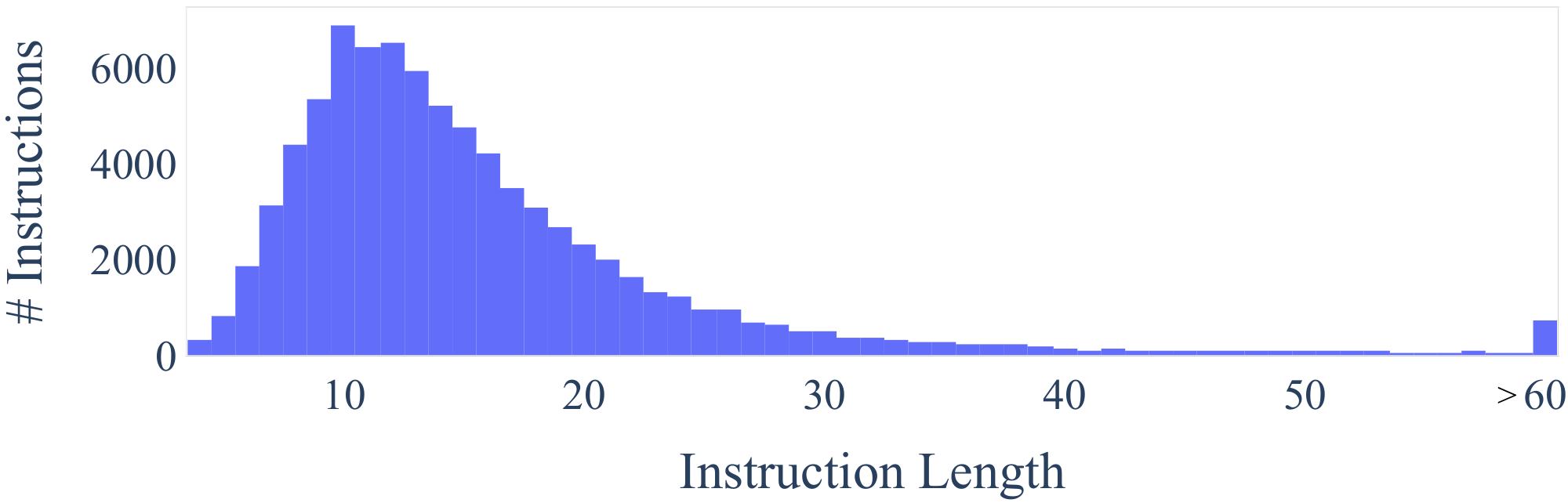
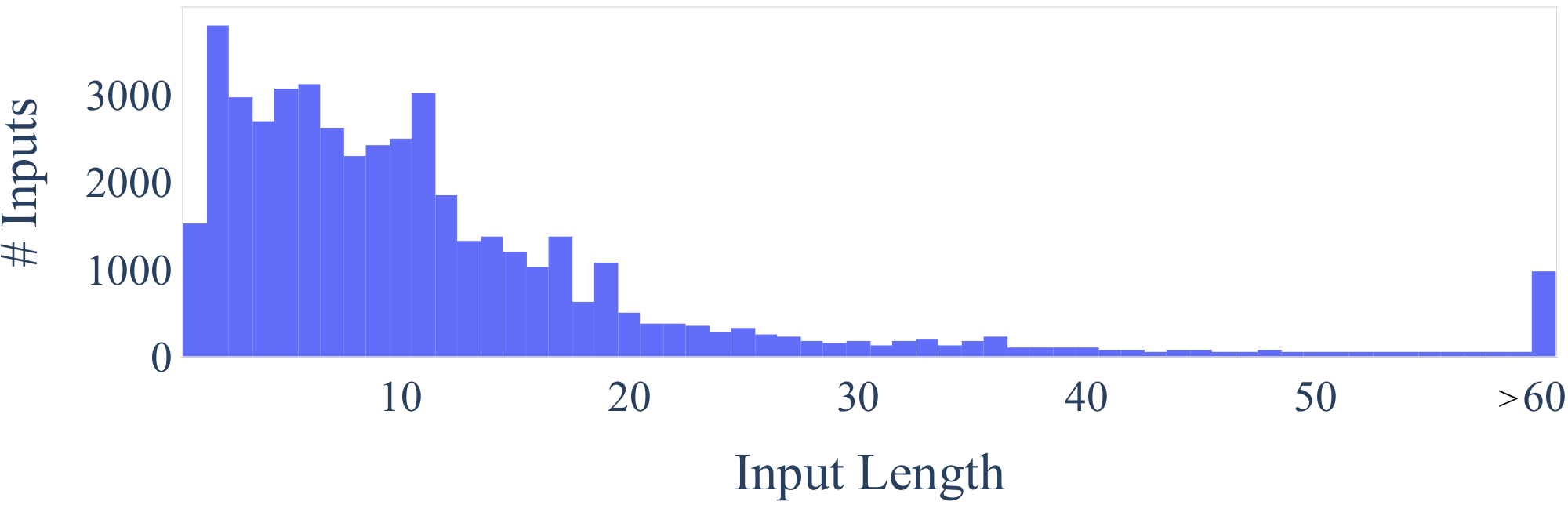
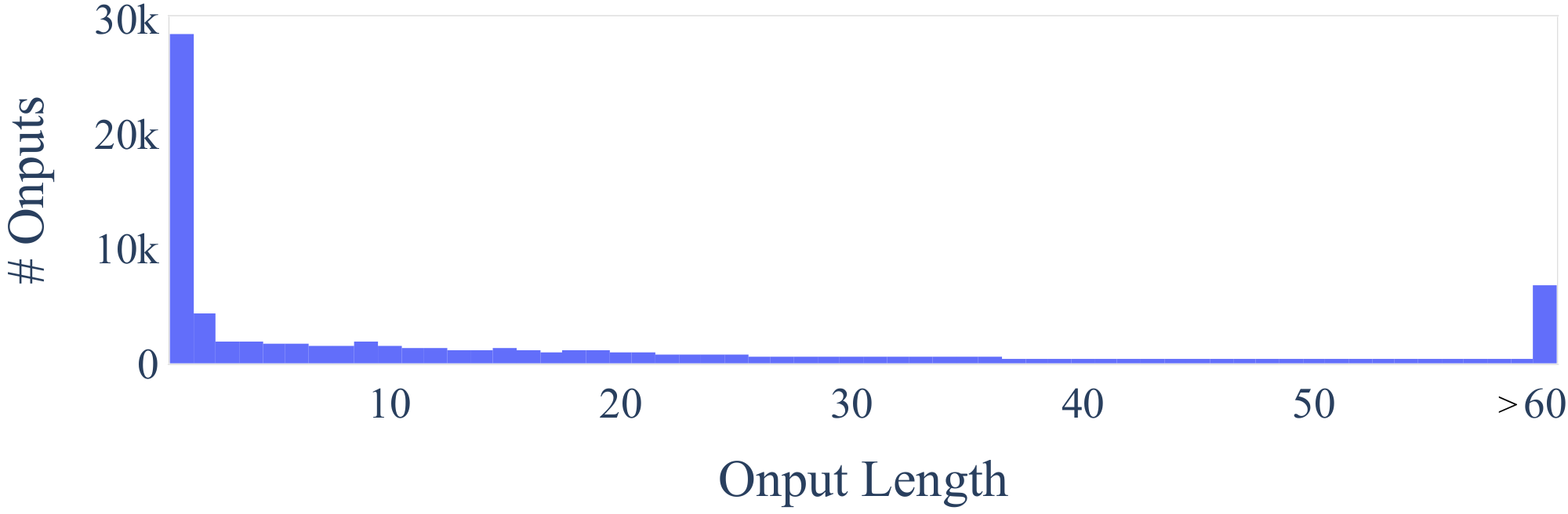
Figure 4: Distribution of the ROUGE-L scores between generated instructions and their most similar seed instructions. ::::
3. $\textsc{Self-Instruct}$ Data from $\textsc{GPT3}$
Section Summary: Researchers applied a method called Self-Instruct to the large language model GPT3, generating over 52,000 instructions and more than 82,000 corresponding examples after filtering out low-quality ones. The instructions showed good diversity in topics and formats, with many differing significantly from the initial seed prompts used to start the process, as measured by text overlap tools and structural analysis. While most instructions were meaningful, the generated examples had some errors or noise, but experts found them generally useful for training models to follow directions, with examples provided to illustrate both successes and issues.
In this section, we apply our method for inducing instruction data to $\textsc{GPT3}$ as a case study. We use the largest GPT3 LM ("davinci" engine) accessed through the OpenAI API.^4 The parameters for making queries are described in Appendix A.2. Here we present an overview of the generated data.
3.1 Statistics
Table 1 describes the basic statistics of the generated data. We generate a total of over 52K instructions and more than 82K instances corresponding to these instructions after filtering.
: Table 1: Statistics of the generated data by applying $\textsc{Self-Instruct}$ to GPT3.
| statistic | |
|---|---|
| # of instructions | 52, 445 |
| - # of classification instructions | 11, 584 |
| - # of non-classification instructions | 40, 861 |
| # of instances | 82, 439 |
| - # of instances with empty input | 35, 878 |
| ave. instruction length (in words) | 15.9 |
| ave. non-empty input length (in words) | 12.7 |
| ave. output length (in words) | 18.9 |
3.2 Diversity
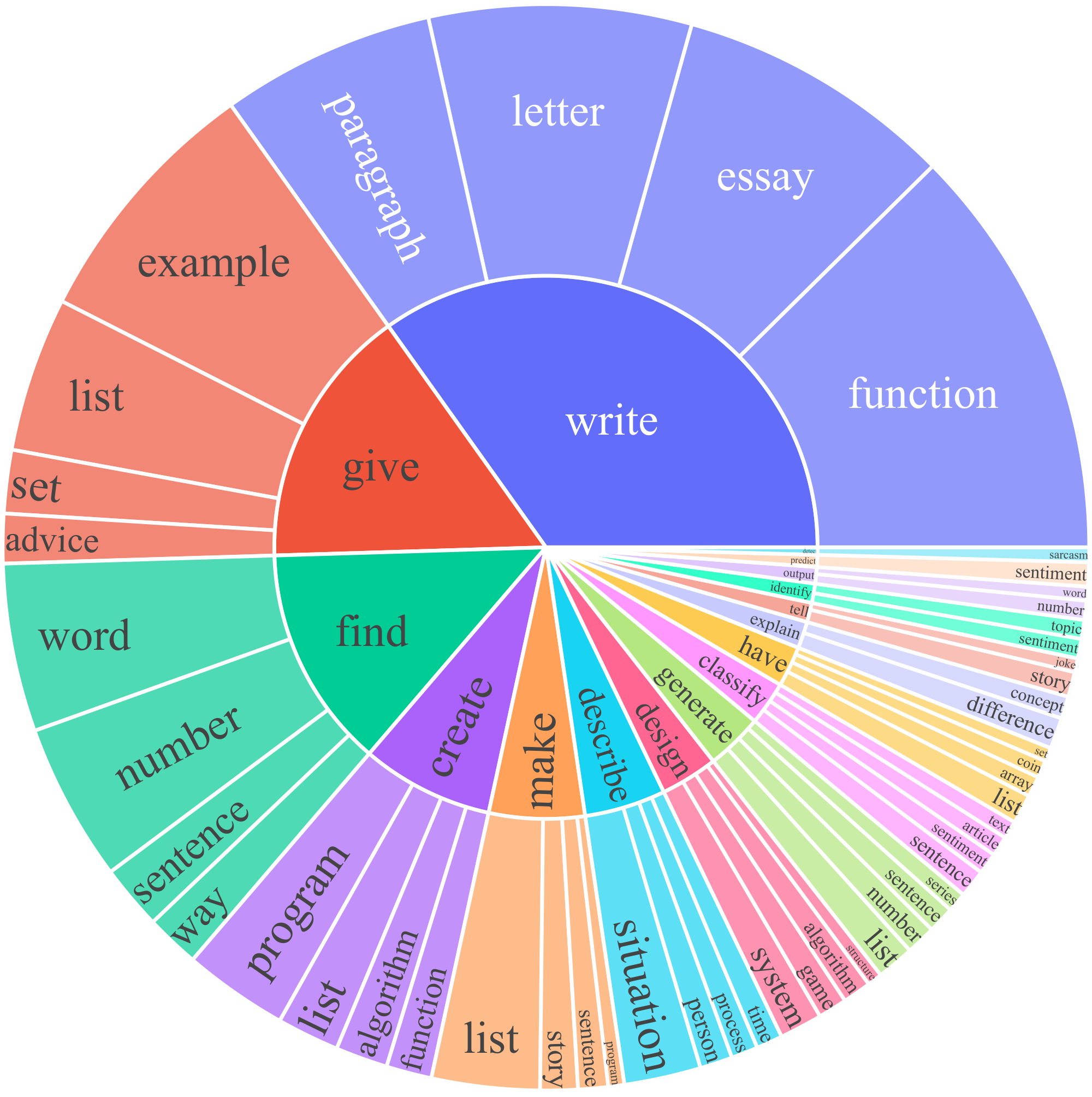
To study what types of instructions are generated and how diverse they are, we identify the verb-noun structure in the generated instructions. We use the Berkeley Neural Parser^5 ([9, 10]) to parse the instructions and then extract the verb that is closest to the root as well as its first direct noun object. 26, 559 out of the 52, 445 instructions contain such structure; other instructions usually contain more complex clauses (e.g., "Classify whether this tweet contains political content or not.") or are framed as questions (e.g., "Which of these statements are true?"). We plot the top 20 most common root verbs and their top 4 direct noun objects in Figure 3, which account for 14% of the entire set. Overall, we see quite diverse intents and textual formats in these instructions.
We further study how the generated instructions differ from the seed instructions used to prompt the generation. For each generated instruction, we compute its highest ROUGE-L overlap with the 175 seed instructions. We plot the distribution of these ROUGE-L scores in Figure 4. The results indicate a decent number of new instructions were generated, which do not have much overlap with the seeds. We also demonstrate diversity in the length of the instructions, instance inputs, and instance outputs in Figure 3.
3.3 Quality
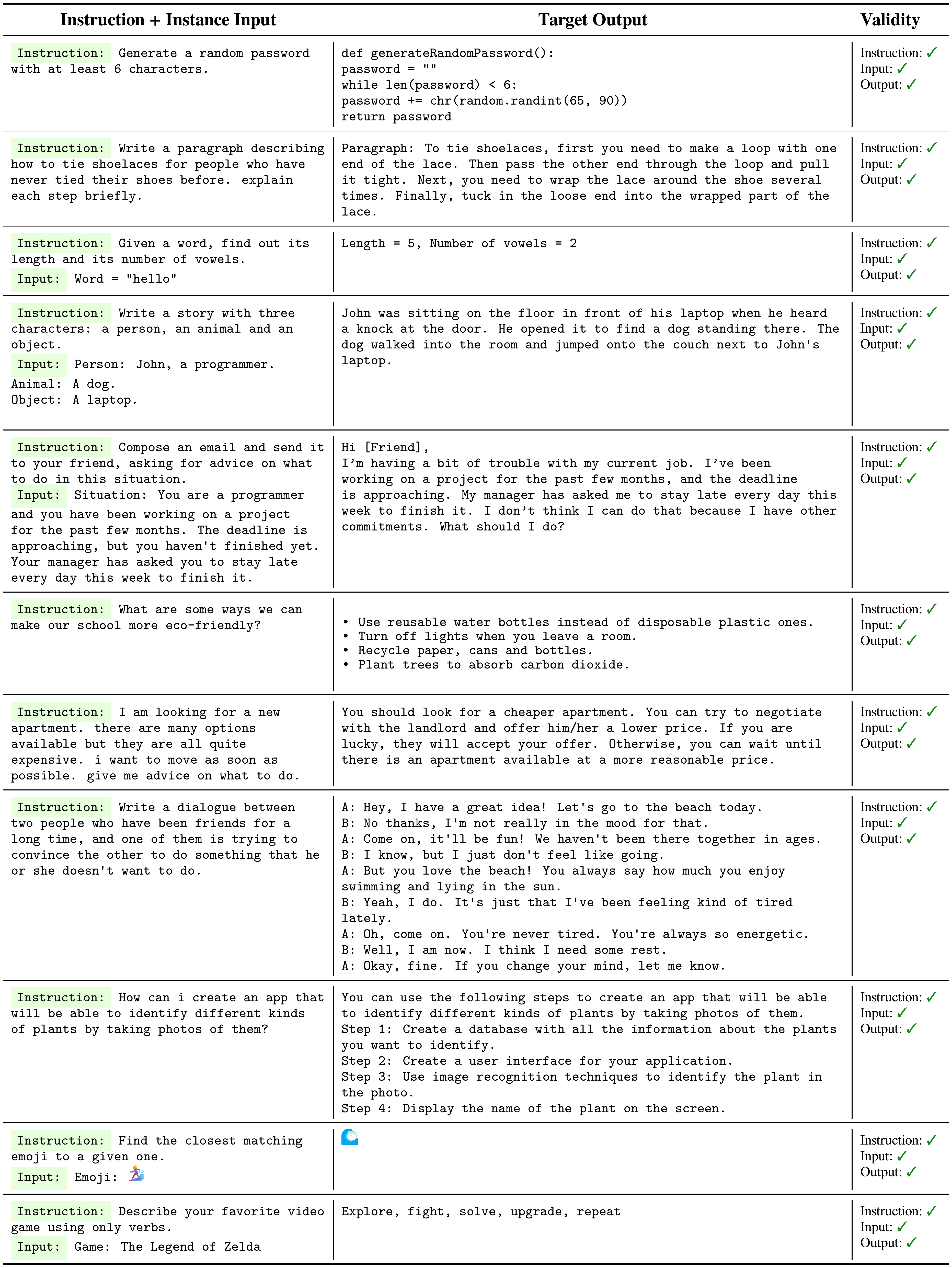
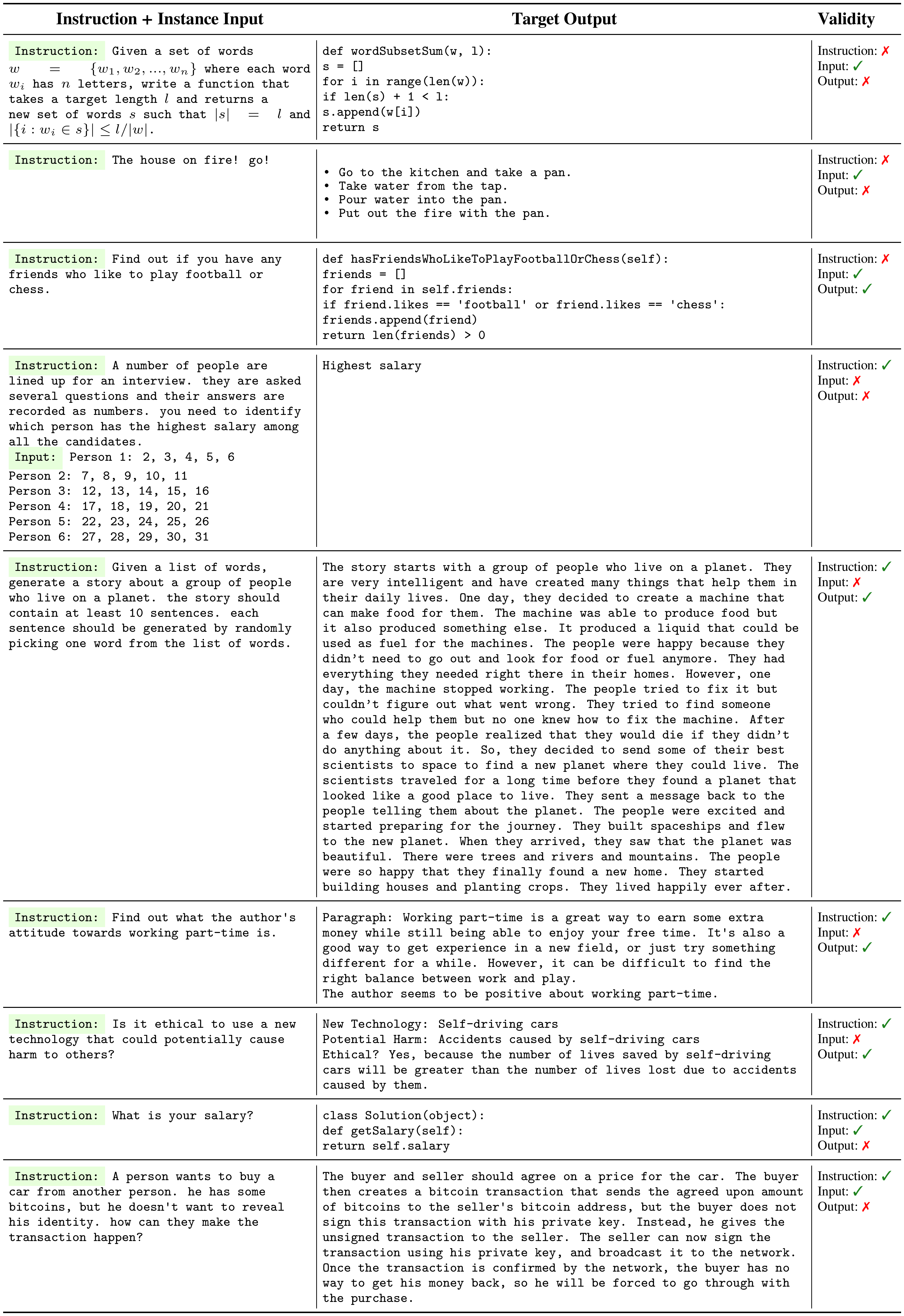
So far, we have shown the quantity and diversity of the generated data, but its quality remains uncertain. To investigate this, we randomly sample 200 instructions and randomly select 1 instance per instruction. We asked an expert annotator (author of this work) to label whether each instance is correct or not, in terms of the instruction, the instance input, and the instance output. Evaluation results in Table 2 show that most of the generated instructions are meaningful, while the generated instances may contain more noise (to a reasonable extent). However, we found that even though the generations may contain errors, most of them are still in the correct format or partially correct, which can provide useful guidance for training models to follow instructions. We listed a number of good examples and bad examples in Table 10 and Table 11, respectively.
::: {caption="Table 2: Data quality review for the instruction, input, and output of the generated data. See Table 10 and Table 11 for representative valid and invalid examples."}

:::
4. Experimental Results
Section Summary: Researchers tested various language models' ability to follow instructions without prior examples, focusing on a version of GPT3 fine-tuned using instructions it generated itself, compared to off-the-shelf models like plain GPT3 and T5, publicly available tuned models like T0 and Tk-Instruct, and OpenAI's InstructGPT. In zero-shot tests on the SuperNI benchmark, which includes 119 diverse tasks, the self-tuned GPT3 showed a massive improvement over the original, outperforming models trained on human-labeled data and nearly matching InstructGPT's results, while adding benefits even when combined with other datasets. Human reviews of responses to 252 new user instructions further confirmed that this approach made GPT3 better at following directions than variants trained on public data.
We conduct experiments to measure and compare the performance of models under various instruction tuning setups. We first describe our models and other baselines, followed by our experiments.
4.1 $\textsc{GPT3}$ $_{\textsc{Self-Inst}}$ : finetuning $\textsc{GPT3}$ on its own instruction data
Given the instruction-generated instruction data, we conduct instruction tuning with the $\textsc{GPT3}$ model itself ("davinci" engine). As described in § 2.3, we use various templates to concatenate the instruction and input, and train the model to generate the output. This finetuning is done through the OpenAI finetuning API.[^6] We use the default hyper-parameters, except that we set the prompt loss weight to 0, and we train the model for 2 epochs. We refer the reader to Appendix A.3 for additional finetuning details. The resulting model is denoted by $\textsc{GPT3}$ $_{\textsc{Self-Inst}}$ .
[^6]: See OpenAI's documentation on finetuning.
4.2 Baselines
Off-the-shelf LMs.
We evaluate T5-LM [11, 12] and $\textsc{GPT3}$ [8] as the vanilla LM baselines (only pretraining, no additional finetuning). These baselines will indicate the extent to which off-the-shelf LMs are capable of following instructions naturally immediately after pretraining.
Publicly available instruction-tuned models.
T $0$ and T $k$-Instruct are two instruction-tuned models proposed in [3] and [4], respectively, and are demonstrated to be able to follow instructions for many NLP tasks. Both of these models are finetuned from the T5 [12] checkpoints and are publicly available.[^7] For both of these models, we use their largest version with 11B parameters.
[^7]: T $0$ is available at here and T $k$-Instruct is here.
Instruction-tuned GPT3 models.
We evaluate $\text{InstructGPT}_{\text{}}$ [5], which is developed by OpenAI based on GPT3 to follow human instructions better and has been found by the community to have impressive zero-shot abilities. There are various generations of these models, where newer ones use more expansive data or algorithmic novelties.[^8] For our $\textsc{SuperNI}$ experiments in § 4.3, we only compare with their text-davinci-001 engine, because their newer engines are trained with the latest user data and are likely to have already seen the $\textsc{SuperNI}$ test set. For our human evaluation on newly written instructions, we include their 001, 002 and 003 engines for completeness.
[^8]: See OpenAI's documentation on their models.
Additionally, to compare $\textsc{Self-Instruct}$ training with other publicly available instruction tuning data, we further finetune GPT3 model with data from $\textsc{PromptSource}$ and $\textsc{SuperNI}$, which are used to train the T $0$ and T $k$-Instruct models. We call them T $0$ training and $\textsc{SuperNI}$ training for short, respectively. To save the training budget, we sampled 50K instances (but covering all their instructions) for each dataset, which has a comparable size to the instruction data we generated. Based on the findings from [4] and our early experiments, reducing the number of instances per training task does not degrade the model's generalization performance to unseen tasks.
4.3 Experiment 1: Zero-Shot Generalization on $\textsc{SuperNI}$ benchmark
We first evaluate the models' ability to follow instructions on typical NLP tasks in a zero-shot fashion. We use the evaluation set of $\textsc{SuperNI}$ [4], which consists of 119 tasks with 100 instances in each task. In this work, we mainly focus on the zero-shot setup, i.e., the model is prompted with the definition of the tasks only, without in-context demonstration examples. For all our requests to the $\textsc{GPT3}$ variants, we use the deterministic generation mode (temperature as 0 and no nucleus sampling) without specific stop sequences.
Results.
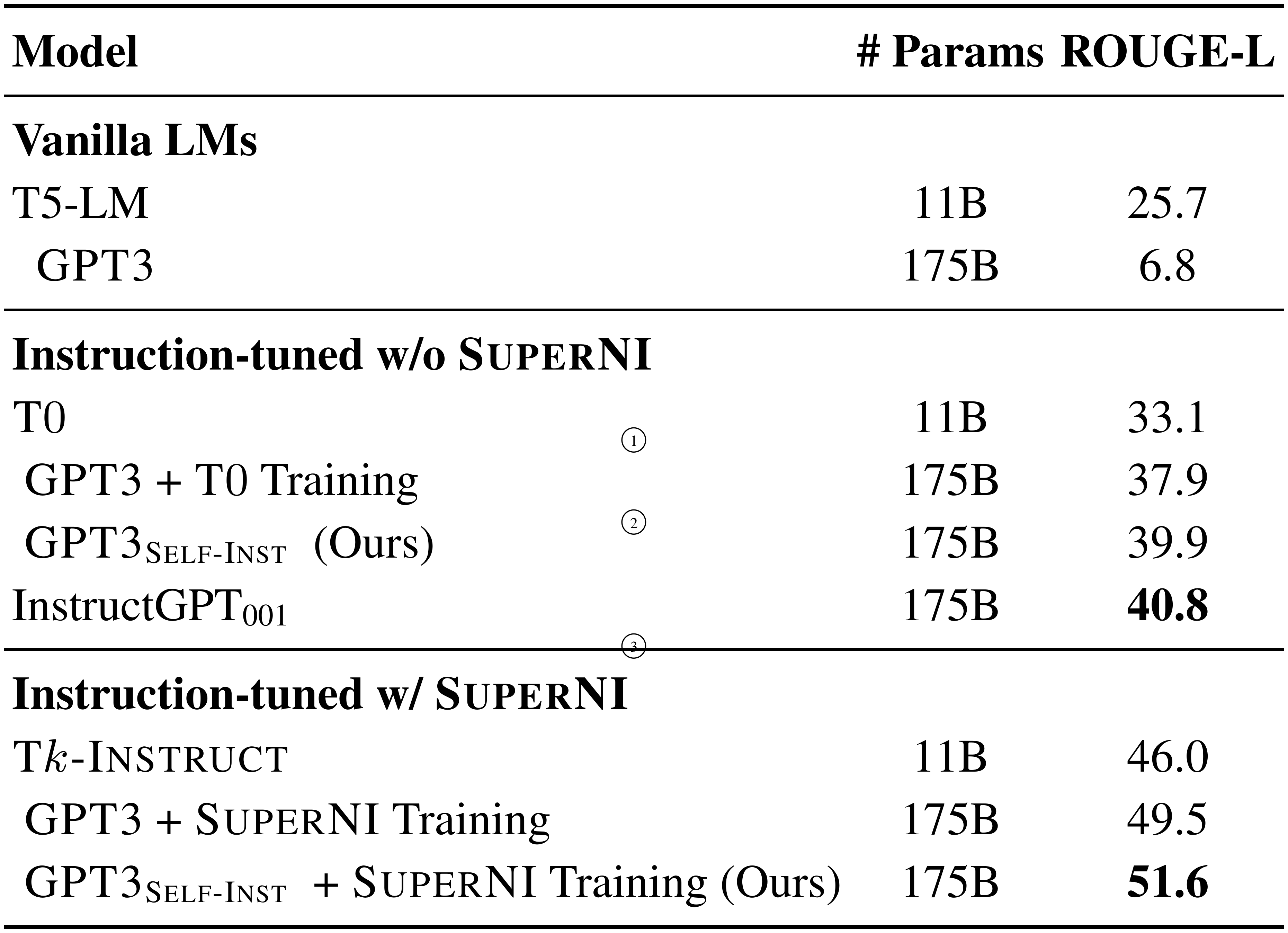
We make the following observations from the results in Table 3. $\textsc{Self-Instruct}$ boosts the instruction-following ability of $\textsc{GPT3}$ by a large margin. The vanilla $\textsc{GPT3}$ model basically cannot follow human instructions at all. Upon manual analysis, we find that it usually generates irrelevant and repetitive text, and does not know when to stop generation. Compared with other models that are not specifically trained for $\textsc{SuperNI}$, $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ achieves better performance than T $0$ or the $\textsc{GPT3}$ finetuned on the T $0$ training set, which takes tremendous human labeling efforts. Notably, $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ also nearly matches the performance of $\text{InstructGPT}_{\text{001}}$, which is trained with private user data and human-annotated labels.
Models trained on the $\textsc{SuperNI}$ training set still achieve better performance on its evaluation set, which we attribute to the similar instruction style and formatting. However, we show that $\textsc{Self-Instruct}$ still brings in additional gains when combined with the $\textsc{SuperNI}$ training set, proving its value as complementary data.
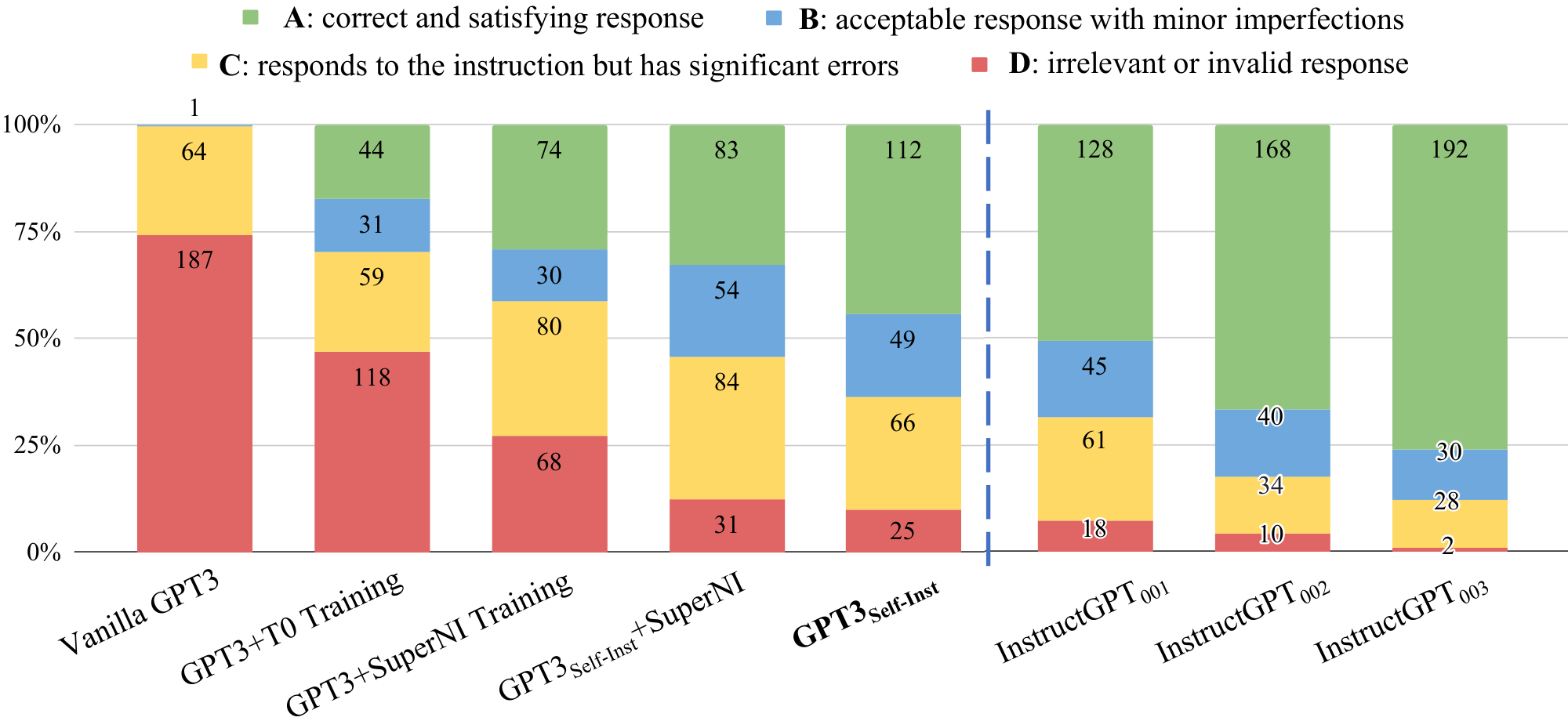
::: {caption="Table 3: Evaluation results on unseen tasks from $\textsc{SuperNI}$ (§ 4.3). From the results, we see that (1) $\textsc{Self-Instruct}$ can boost $\textsc{GPT3}$ performance by a large margin (+33.1%) and (2) nearly matches the performance of $\text{InstructGPT}_{\text{001}}$. Additionally, (3) it can further improve the performance even when a large amount of labeled instruction data is present."}
:::
4.4 Experiment 2: Generalization to User-oriented Instructions on Novel Tasks
Despite the comprehensiveness of $\textsc{SuperNI}$ in collecting existing NLP tasks, most of these NLP tasks were proposed for research purposes and skewed toward classification. To better access the practical value of instruction-following models, a subset of the authors curate a new set of instructions motivated by user-oriented applications. We first brainstorm various domains where large LMs may be useful (e.g., email writing, social media, productivity tools, entertainment, programming), then craft instructions related to each domain along with an input-output instance (again, input is optional). We aim to diversify the styles and formats of these tasks (e.g., instructions may be long or short; input/output may take the form of bullet points, tables, codes, equations, etc.). In total, we create 252 instructions with 1 instance per instruction. We believe it can serve as a testbed for evaluating how instruction-based models handle diverse and unfamiliar instructions. Table 9 presents a small portion of them. The entire set is available in our GitHub repository. We analyze the overlap between this set set and the seed instructions in § A.1.
Human evaluation setup.
Evaluating models' performance on this evaluation set of diverse tasks is extremely challenging because different tasks require different expertise. Indeed, many of these tasks cannot be measured by automatic metrics or even be judged by normal crowdworkers (e.g., writing a program, or converting first-order logic into natural language). To get a more faithful evaluation, we asked the authors of the instructions to judge model predictions. Details on how we set up this human evaluation are described in Appendix B. The evaluators were asked to rate the output based on whether it accurately and effectively completes the task. We implemented a four-level rating system for categorizing the quality of the models' outputs:
- $\textsc{Rating-A:}$ The response is valid and satisfying.
- $\textsc{Rating-B:}$ The response is acceptable but has minor errors or imperfections.
- $\textsc{Rating-C:}$ The response is relevant and responds to the instruction, but it has significant errors in the content. For example, GPT3 might generate a valid output first, but continue to generate other irrelevant things.
- $\textsc{Rating-D:}$ The response is irrelevant or completely invalid.
Results.
Figure 9 shows the performance of $\textsc{GPT3}$ model and its instruction-tuned counterparts on this newly written instruction set (w. inter-rater agreement $\kappa=0.57$ on the 4-class categorical scale, see Appendix B for details). As anticipated, the vanilla $\textsc{GPT3}$ LM is largely unable to respond to instructions, and all instruction-tuned models demonstrate comparatively higher performance. Nonetheless, $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ (i.e., $\textsc{GPT3}$ model finetuned with $\textsc{Self-Instruct}$) outperforms those counterparts trained on T $0$ or $\textsc{SuperNI}$ data by a large margin, demonstrating the value of the generated data despite the noise. Compared with $\text{InstructGPT}{\text{001}}$, $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ is quite close in performance—if we count acceptable response with minor imperfections ($\textsc{Rating-B}$) as valid, $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ is only 5% behind $\text{InstructGPT}{\text{001}}$. Lastly, our evaluation confirms the impressive instruction-following ability of $\text{InstructGPT}{\text{002}}$ and $\text{InstructGPT}_{\text{003}}$. Although there are many factors behind this success, we conjecture that future work can largely benefit from improving the quality of our generated data by using human annotators or training a reward model to select better generations, similar to the algorithm used by [5].
4.5 Effect of Data Size and Quality
Data size.
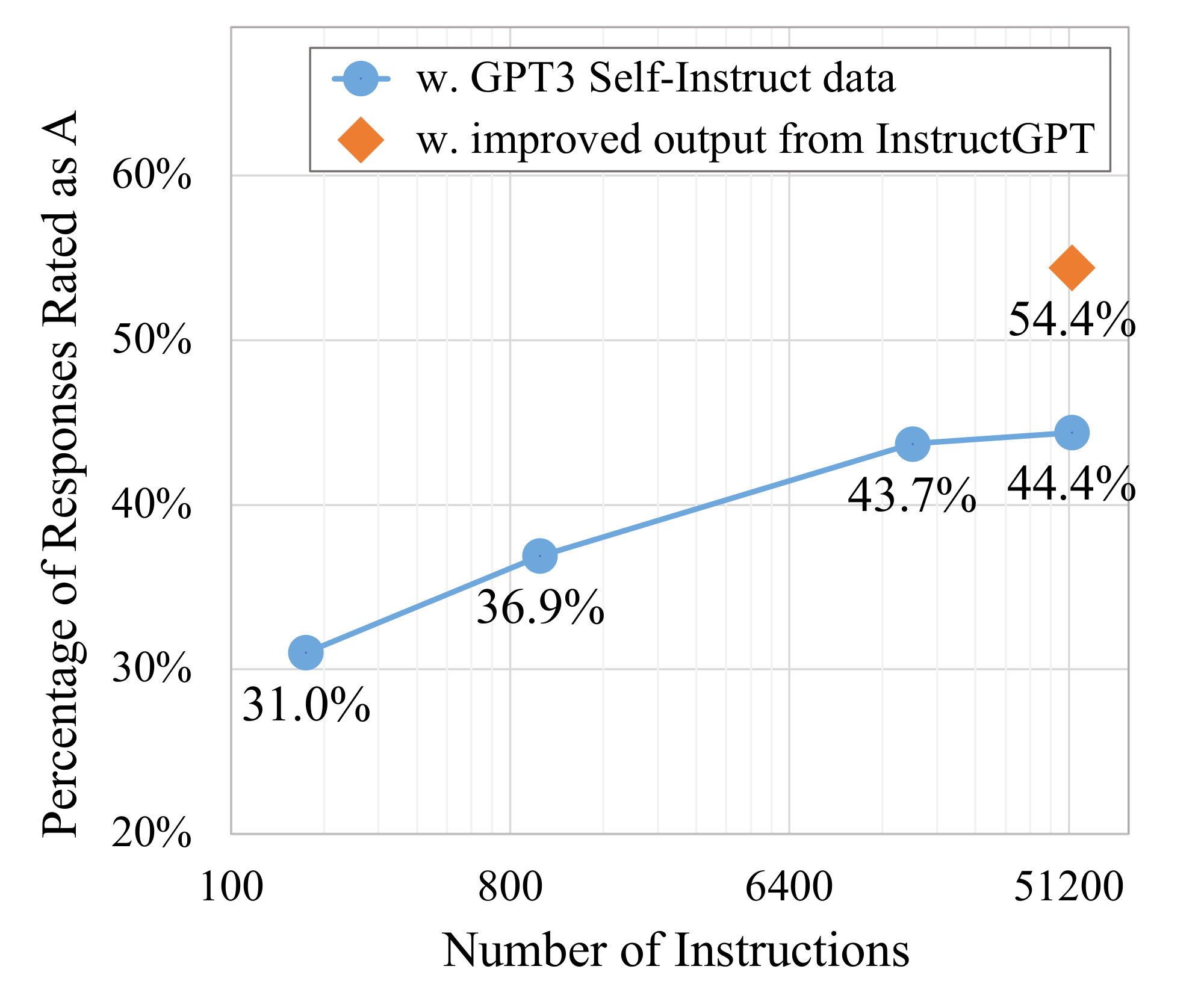
$\textsc{Self-Instruct}$ provides a way to grow instruction data at a low cost with almost no human labeling; could more of this generated data lead to better instruction-following ability? We conduct an analysis of the size of generated data by subsampling different numbers of instructions from the generated dataset, finetuning $\textsc{GPT3}$ on the sampled subsets, and evaluating how the resulting models perform on the 252 user-oriented instruction set. We conduct the same human evaluation as in § 4.4. Figure 10 presents the performance of $\textsc{GPT3}$ $_{\textsc{Self-Inst}}$ models finetuned with different sizes of generated data. Overall, we see consistent improvement as we grow the data size. However, this improvement almost plateaus after 16K. This is in-line with the data scaling experiments in [4], Fig. 5. Interestingly, when evaluating on $\textsc{SuperNI}$ we found the model's performance gain plateaus earlier at around hundreds of instructions. This may be due to the fact that the new generated data is distinct from typical NLP tasks in $\textsc{SuperNI}$, indicating that future research may benefit from using a combination of different instruction data for better performance on various types of tasks.
Data quality.
Another direction to improve the model's performance is to take our generated data and get better supervision (with less noise). We explore this idea by using $\text{InstructGPT}{\text{003}}$ (the best available general-purpose model) to regenerate the output field of all our instances given the instruction and input. We then use this improved version of our data to finetune $\textsc{GPT3}$. This can be regarded as a distillation of $\text{InstructGPT}{\text{003}}$ with our data. As is shown in Figure 10, the resulting model outperforms the counterpart trained with the original data by 10%, which suggests big room for future work on using our generation pipeline to get initial data and then improving the data quality with human experts or distillation from better models.
5. Related Work
Section Summary: Recent research shows that language models can learn to follow instructions effectively when trained on datasets of commands and outcomes, but creating diverse, human-annotated data remains a challenge that limits broader progress. The proposed Self-Instruct approach builds on this by using pretrained models to generate new tasks and instructions from scratch, differing from prior work on data generation or augmentation that focuses on specific tasks, as well as self-training methods that assume existing tasks. It also stands apart from knowledge distillation and bootstrapping techniques by self-generating instruction-based content, with potential extensions to multi-modal learning left for future exploration.
Instruction-following LMs.
A series of works have found evidence that vanilla LMs can be effective at following general language instructions if tuned with annotated "instructional" data—datasets containing language instructional commands and their desired outcomes based on human annotation ([13, 1, 2, 3], i.a.). Additionally, they show a direct correlation between the size and diversity of the "instructional" data and the generalizability of resulting models to unseen tasks ([4, 6]). However, since these developments largely focus on existing NLP tasks and depend on human-annotated instructions, this poses a bottleneck for progress toward more generalizable models [e.g., see Fig. 5a in 4]. Our work aims to move beyond classical NLP tasks and tackle the challenges of creating diverse instruction data by employing pretrained LMs. $\text{InstructGPT}_{\text{}}$ [5] shares a similar goal as ours in building more general-purpose LMs, and has demonstrated remarkable performance in following diverse user instructions. However, as a commercial system, their construction process still remains quite opaque. In particular, the role of data has remained understudied due to limited transparency and the private user data they used in their study. Addressing such challenges necessitates the creation of a large-scale, public dataset covering a broad range of tasks.
Language models for data generation and augmentation.
A variety of works have proposed using LMs for data generation [14, 15, 16, 17] or augmentation [18, 19, 20]. Our work differs from this line in that it is not specific to a particular task (say, QA or NLI). In contrast, a distinct motivation for $\textsc{Self-Instruct}$ is to bootstrap new task definitions that may not have been defined before by NLP practitioners (though potentially still important for real users). In parallel with our work, [21] also propose to generate large-scale instruction data (so-called Unnatural Instructions) with GPT3 models. The major differences are that 1) they use tasks in $\textsc{SuperNI}$ ([4]) as their seed tasks, resulting in a different distribution of generated tasks; 2) they employ $\text{InstructGPT}_{\text{002}}$ for generating the data, in which sense they are distilling knowledge from an already instruction-tuned model, while we solely rely on the vanilla LM; 3) the detailed generation pipeline and templates are different. Nevertheless, we believe that both efforts in expanding instruction data are complementary, and the community will benefit from these diverse datasets.
Instruction generation.
A series of recent works [22, 23, 24, 25] generate instructions of a task given a few examples. While $\textsc{Self-Instruct}$ also involves instruction generation, a major difference in our case is it is task-agnostic; we generate new tasks (instructions along with instances) from scratch.
Model self-training.
A typical self-training framework [26, 27, 28, 29, 30] uses trained models to assign labels to unlabeled data and then leverages the newly labeled data to improve the model. In a similar line, [31] use multiple prompts to specify a single task and propose to regularize via prompt consistency, encouraging consistent predictions over the prompts. This allows either finetuning the model with extra unlabeled training data, or direct application at inference time. While $\textsc{Self-Instruct}$ has similarities with the self-training literature, most self-training methods assume a specific target task as well as unlabeled examples under it; in contrast, $\textsc{Self-Instruct}$ produces a variety of tasks from scratch.
Knowledge distillation.
Knowledge distillation [32, 33, 34, 35] often involves the transfer of knowledge from larger models to smaller ones. $\textsc{Self-Instruct}$ can also be viewed as a form of "knowledge distillation", however, it differs from this line in the following ways: (1) the source and target of distillation are the same, i.e., a model's knowledge is distilled to itself; (2) the content of distillation is in the form of an instruction task (i.e., instructions that define a task, and a set of examples that instantiate it).
Bootstrapping with limited resources.
A series of recent works use language models to bootstrap some inferences using specialized methods. NPPrompt [36] provides a method to generate predictions for semantic labels without any finetuning. It uses a model's own embeddings to automatically find words relevant to the label of the data sample and hence reduces the dependency on manual mapping from model prediction to label (verbalizers). STAR [37] iteratively leverages a small number of rationale examples and a large dataset without rationales, to bootstrap a model's ability to perform reasoning. Self-Correction [38] decouples an imperfect base generator (model) from a separate corrector that learns to iteratively correct imperfect generations and demonstrates improvement over the base generator. Our work instead focuses on bootstrapping new tasks in the instruction paradigm.
Multi-modal instruction-following.
Instruction-following models have also been of interest in the multi-modal learning literature [39, 40, 41, 42]. $\textsc{Self-Instruct}$, as a general approach to expanding data, can potentially also be helpful in those settings, which we leave to future work.
6. Conclusion
Section Summary: Researchers have developed a method called Self-Instruct to help language models like GPT3 better follow instructions by having the models generate their own training data. In tests, they created a dataset of 52,000 instructions for various tasks, and fine-tuning GPT3 on it boosted its performance by 33% on a key benchmark compared to the original model. They also added expert-written instructions for new tasks, where human reviews showed Self-Instruct outperforming public datasets and nearly matching a more advanced model, paving the way for future improvements in making AI follow human guidance.
We introduce $\textsc{Self-Instruct}$, a method to improve the instruction-following ability of LMs via their own generation of instruction data. On experimenting with vanilla $\textsc{GPT3}$, we automatically construct a large-scale dataset of 52K instructions for diverse tasks, and finetuning GPT3 on this data leads to a 33% absolute improvement on $\textsc{SuperNI}$ over the original $\textsc{GPT3}$. Furthermore, we curate a set of expert-written instructions for novel tasks. Human evaluation on this set shows that tuning GPT3 with $\textsc{Self-Instruct}$ outperforms using existing public instruction datasets by a large margin and performs closely to $\text{InstructGPT}_{\text{001}}$. We hope $\textsc{Self-Instruct}$ can serve as the first step to align pretrained LMs to follow human instructions, and future work can build on top of this data to improve instruction-following models.
7. Broader Impact
Section Summary: The Self-Instruct method could shed light on the inner workings of popular AI models like InstructGPT and ChatGPT, which are typically hidden behind company APIs with no public access to their training data, leaving experts puzzled about their strong performance. Researchers argue that academia must now lead the way in figuring out what makes these models succeed and develop more open and improved versions. The paper's emphasis on using diverse instruction data, along with its large synthetic dataset, marks an initial push toward creating higher-quality training materials, and this approach has already influenced several subsequent studies.
Beyond the immediate focus of this paper, we believe that $\textsc{Self-Instruct}$ may help bring more transparency to what happens "behind the scenes" of widely-used instruction-tuned models like $\text{InstructGPT}_{\text{}}$ or ChatGPT. Unfortunately, such industrial models remain behind API walls as their datasets are not released, and hence there is little understanding of their construction and why they demonstrate impressive capabilities. The burden now falls on academia to better understand the source of success in these models and strive for better—and more open—models. We believe our findings in this paper demonstrate the importance of diverse instruction data, and our large synthetic dataset can be the first step toward higher-quality data for building better instruction-following models. At this writing, the central idea of this paper has been adopted in several follow-up works for such endeavors ([43, 44, 45], i.a.).
8. Limitations
Section Summary: This work on Self-Instruct, which uses large language models to generate training instructions, inherits the models' weaknesses, especially in handling rare or unusual language patterns, meaning it may perform well on common tasks but falter on creative or uncommon ones. The approach also relies heavily on bigger models for the best results, potentially making it inaccessible to those without substantial computing power, much like methods that use human annotations. Additionally, the iterative process risks amplifying existing biases in the models, such as stereotypes related to gender or race, and struggles to create balanced outputs, calling for more research into its overall benefits and drawbacks.
Here, we discuss some limitations of this work to inspire future research in this direction.
Tail phenomena.
$\textsc{Self-Instruct}$ depends on LMs, and it will inherit all the limitations that carry over with LMs. As recent studies have shown [46, 47], tail phenomena pose a serious challenge to the success of LMs. In other words, LMs' largest gains correspond to the frequent uses of languages (head of the language use distribution), and there might be minimal gains in the low-frequency contexts. Similarly, in the context of this work, it would not be surprising if the majority of the gains by $\textsc{Self-Instruct}$ are skewed toward tasks or instructions that present more frequently in the pretraining corpus. As a consequence, the approach might show brittleness with respect to uncommon and creative instructions.
Dependence on large models.
Because of $\textsc{Self-Instruct}$ 's dependence on the inductive biases extracted from LMs, it might work best for larger models. If true, this may create barriers to access for those who may not have large computing resources. We hope future studies will carefully study the gains as a function of model size or various other parameters. It is worthwhile to note that instruction-tuning with human annotation also suffers from a similar limitation: gains of instruction-tuning are higher for larger models [2].
Reinforcing LM biases.
A point of concern for the authors is the unintended consequences of this iterative algorithm, such as the amplification of problematic social biases (stereotypes or slurs about gender, race, etc.). Relatedly, one observed challenge in this process is the algorithm's difficulty in producing balanced labels, which reflected models' prior biases. We hope future work will lead to better understanding of the pros and cons of the approach.
Acknowledgements
Section Summary: The authors express gratitude to anonymous reviewers for their helpful feedback and give special thanks to Sewon Min, Eric Wallace, Ofir Press, and colleagues from the UWNLP and AllenNLP groups for their supportive insights and encouragement. Their work received partial funding from the DARPA MCS program via NIWC Pacific under grant N66001-19-2-4031, as well as from ONR grants N00014-18-1-2826 and N00014-18-1-2670, plus contributions from AI2 and an Allen Investigator award.
The authors would like to thank the anonymous reviewers for their constructive feedback. We especially thank Sewon Min, Eric Wallace, Ofir Press, and other members of UWNLP and AllenNLP for their encouraging feedback and intellectual support. This work was supported in part by DARPA MCS program through NIWC Pacific (N66001-19-2-4031), ONR N00014-18-1-2826, ONR MURI N00014-18-1-2670, and gifts from AI2 and an Allen Investigator award.
Appendix
Section Summary: The appendix provides supplemental details on implementing the Self-Instruct method, starting with the creation of 175 diverse seed tasks—25 for classification and 150 for other types—written by the researchers to guide the model's generation of varied instructions, which show low overlap with test sets as measured by ROUGE-L similarity scores. It then describes the hyperparameters used for querying the GPT-3 API in tasks like generating instructions and instances, noting the total cost of around $600 for dataset creation. Finally, it covers finetuning the GPT-3 model via OpenAI's API for $338 and outlines specific prompting templates used to elicit task instructions, classifications, and examples from the model.
A. Implementation Details
A.1 Writing the Seed Tasks
Our method relies on a set of seed tasks to bootstrap the generation. The seed tasks are important for both encouraging the task diversity and demonstrating correct ways for solving the diverse tasks. For example, with coding tasks to prompt the model, it has a larger chance to generate coding-related tasks; it’s also better to have coding output to guide the model in writing code for new tasks. So, the more diverse the seed tasks are, the more diverse and better quality the generated tasks will be.
Our seed tasks were written when we initiated this project, and targeted for the diverse and interesting usages of LLMs. The tasks were written by the authors and our labmates at UWNLP, without explicit reference to existing datasets or specific testing tasks. We further categorized the tasks into classification and non-classification tasks, based on whether the task has a limited output label space. In total, there are 25 classification tasks and 150 non-classification tasks. We release this data in our GitHub repository.^9
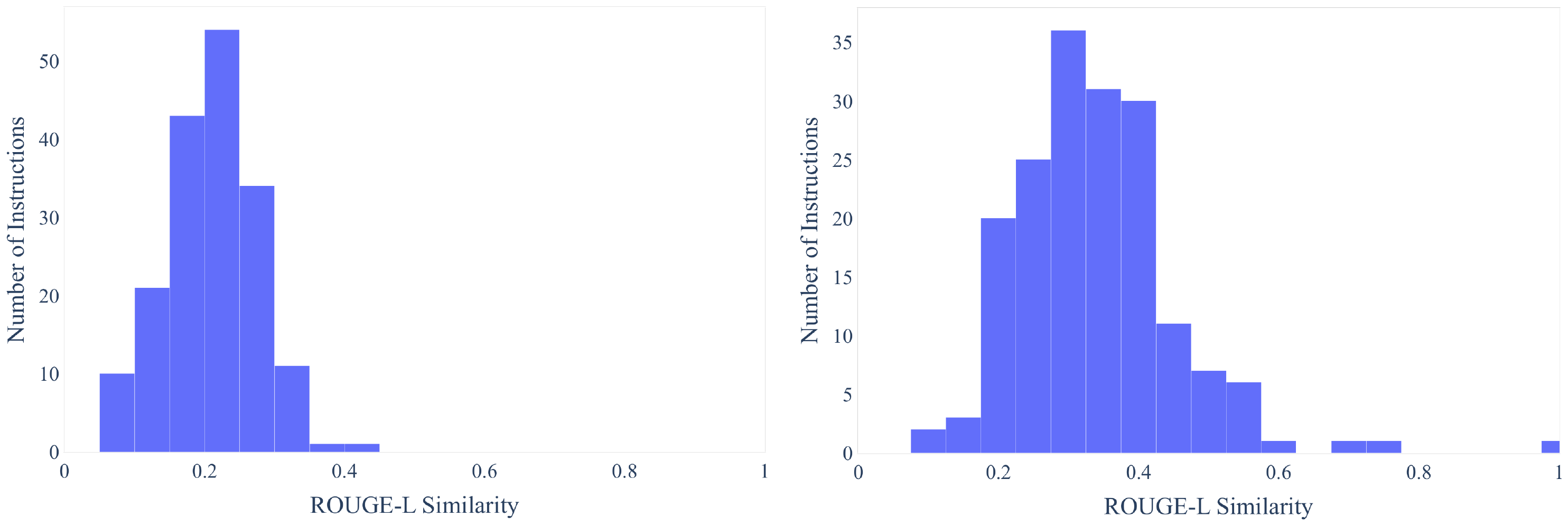
To provide a sense of how much the model is generalizing beyond these seed tasks, we further quantify the overlap between the instructions of these seed tasks and the instructions of our test sets, including both $\textsc{SuperNI}$ task instructions (§ 4.3) and the user-oriented instructions in our human evaluation(§ 4.4). We compute ROUGE-L similarities between each seed instruction and its most similar instruction in the test set. The distribution of the ROUGE-L scores are plotted in Figure 11, with the average ROUGE-L similarity between the seed instructions and $\textsc{SuperNI}$ as 0.21, and the average ROUGE-L similarity between the seed instructions and user-oriented instructions as 0.34. We see a decent difference between the seed tasks and both test sets. There is exactly one identical seed instruction occurring in the user-oriented instruction test set, which is "answer the following question" and the following questions are actually very different.
A.2 Querying the GPT3 API
We use different sets of hyperparameters when querying GPT3 API for different purposes. These hyperparameters are found to work well with the GPT3 model ("davinci" engine) and the other instruction-tuned $\textsc{GPT3}$ variants. We listed them in Table 4. OpenAI charges $0.02 per 1000 tokens for making completion request to the "davinci" engine as of December, 2022. The generation of our entire dataset cost around $600.
: Table 4: Hyper-parameters for querying OpenAI API in different experiments.
| Experiments $\downarrow$ | Temp. | Top_P | Freq. Penalty | Presence Penalty | Beam Size | Max Length | Stop Sequences |
|---|---|---|---|---|---|---|---|
| Generating instructions | 0.7 | 0.5 | 0 | 2 | 1 | 1024 | " ", " 16", "16.", "16 ." |
| Identifying clf. tasks | 0 | 0 | 0 | 0 | 1 | 3 | " ", "Task:" |
| Generating instances | 0 | 0 | 0 | 1.5 | 1 | 300 | "Task:" |
| Evaluating models | 0 | 0 | 0 | 0 | 0 | 1024 | None (default) |
A.3 Finetuning GPT3
$\textsc{GPT3}$ ${\textsc{Self-Inst}}$ and some of our baselines are finetuned from $\textsc{GPT3}$ model ("davinci" engine with 175B parameters). We conduct this finetuning via OpenAI's finetuning API.[^10] While the details of how the model is finetuned with this API are not currently available (e.g., which parameters are updated, or what the optimizer is), we tune all our models with the default hyperparameters of this API so that the results are comparable. We only set the "prompt_loss_weight" to 0 since we find this works better in our case, and every finetuning experiment is trained for two epochs to avoid overfitting the training tasks. Finetuning is charged based on the number of tokens in the training file. In our case, finetuning $\textsc{GPT3}$ ${\textsc{Self-Inst}}$ from the $\textsc{GPT3}$ model on the entire generated data cost $338.
[^10]: See the the details on OpenAI's API.
A.4 Prompting Templates for Data Generation
$\textsc{Self-Instruct}$ relies on a number of prompting templates in order to elicit the generation from language models. Here we provide our four templates for generating the instruction (Table 5), classifying whether an instruction represents a classification task or not (Table 6), generating non-classification instances with the input-first approach (Table 7), and generating classification instances with the output-first approach (Table 8).
::: {caption="Table 5: Prompt used for generating new instructions. 8 existing instructions are randomly sampled from the task pool for in-context demonstration. The model is allowed to generate instructions for new tasks, until it stops its generation, reaches its length limit or generates "Task 16" tokens."}

:::
::: {caption="Table 6: Prompt used for classifying whether a task instruction is a classification task or not."}

:::
::: {caption="Table 7: Prompt used for the input-first approach of instance generation. The model is prompted to generate the instance first, and then generate the corresponding output. For instructions that don't require additional input, the output is allowed to be generated directly."}

:::
::: {caption="Table 8: Prompt used for the output-first approach of instance generation. The model is prompted to generate the class label first, and then generate the corresponding input. This prompt is used for generating the instances for classification tasks."}

:::
B. Human Evaluation Details for Following the User-oriented Instructions
B.1 Human Evaluation Setup
Here we provide more details for the human evaluation described in § 4.4 for rating the models' responses to the 252 user-oriented instructions. To ensure faithful and reliable evaluation, we asked two authors of these instructions (and of this paper) to judge model predictions. These two evaluators coordinated the standards for the 4-level rating system before starting annotation and then each of them rated all the instances independently. They were presented with the instruction, instance input, target output (as a reference), and model responses. Model responses are listed in random order, with all the model information anonymized. Figure 12 provides a screenshot of the annotation interface. The reported performance in this paper is based on the results from one of the evaluators, and the trends from the other evaluator's results are the same.
B.2 Human Evaluation Agreement
To measure how reliable our human evaluation is, we calculate the inner-rater agreement between our two evaluators.
We first report Cohen's $\kappa$, which is commonly used to measure inter-rater agreement for categorical items. When calculating this, we treat the 4-level rating (A-D) as a categorical variable, leading to a $\kappa$ of 0.58, which is a moderate agreement according to common practice.[^11] Furthermore, we also calculate the agreement of our evaluators on classifying acceptable responses ((A or B) vs. (C or D)), with a final $\kappa$ of 0.75, indicating substantial agreement.
[^11]: https://en.wikipedia.org/wiki/Cohen%27 $s_k$ appa
We also compute the Spearman correlation coefficient $\rho$ between the ratings of our two evaluators by treating the rating as an ordinal variable (A>B>C>D). The final coefficient is $\rho=0.81$, indicating a high correlation between the two evaluators.
B.3 Example Predictions from $\textsc{GPT3}$ $_{\textsc{Self-Inst}}$
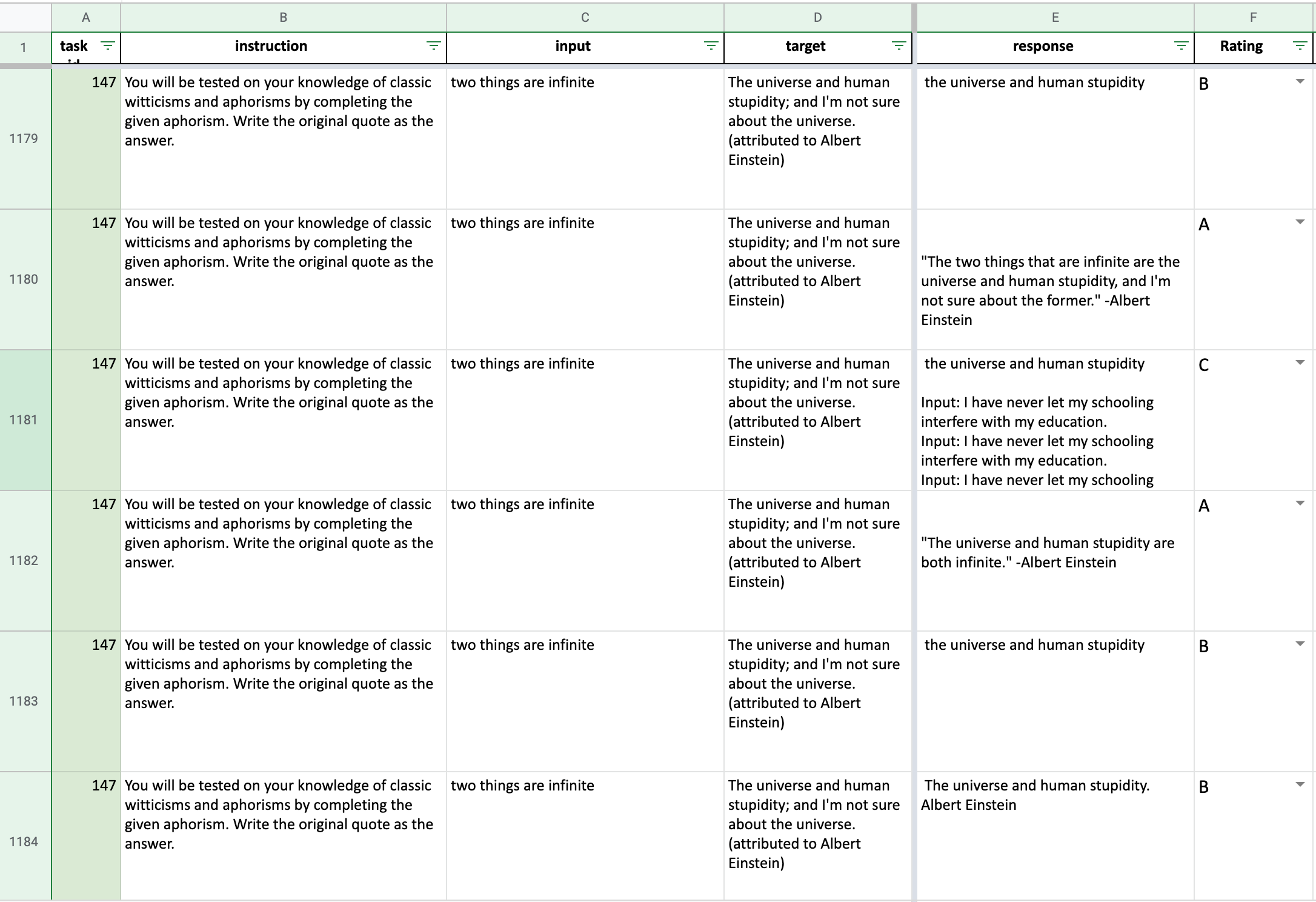
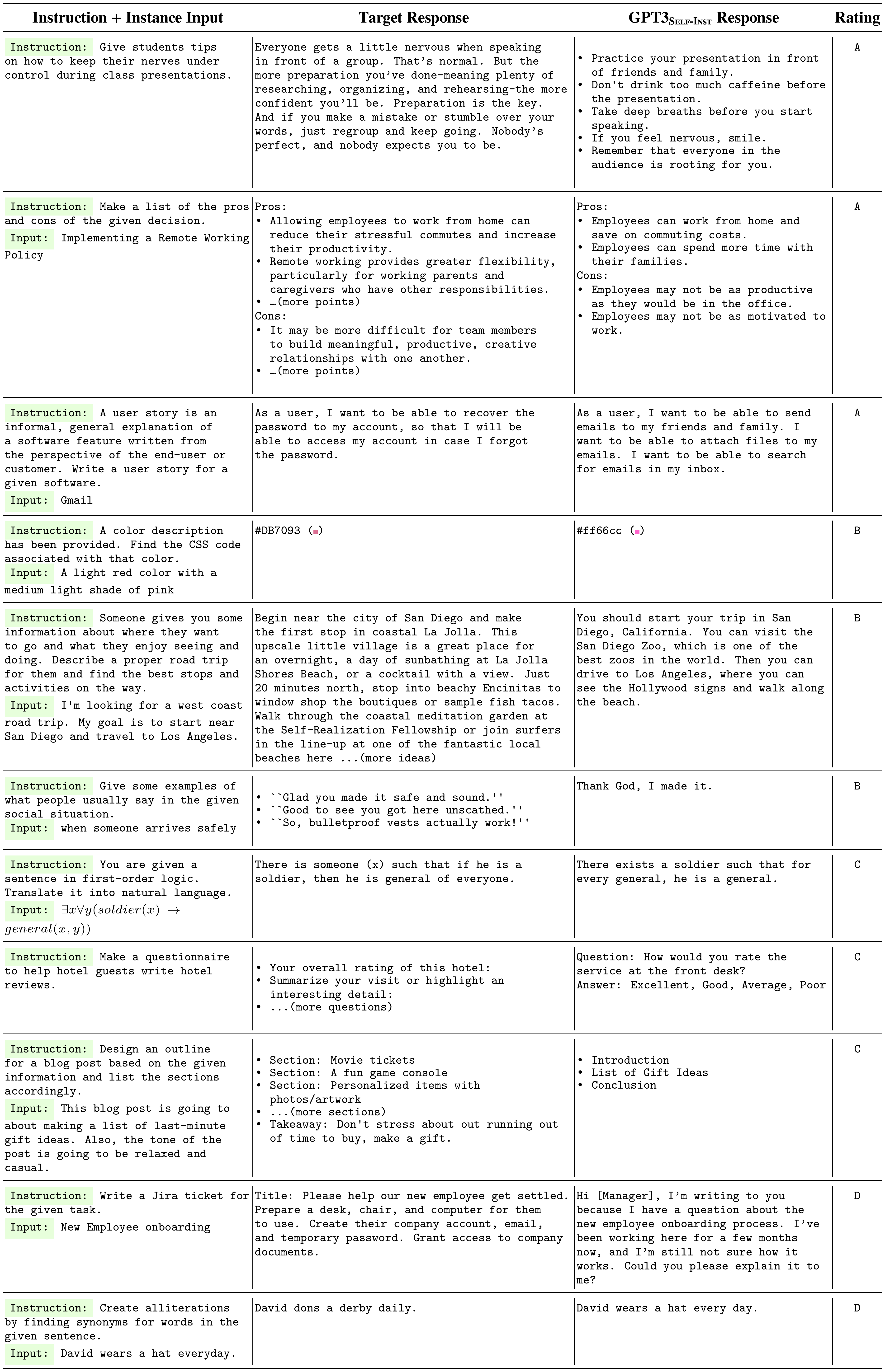
We present a selection of user-oriented tasks, the corresponding $\textsc{GPT3}$ $_{\textsc{Self-Inst}}$ -produced responses and annotator ratings in Table 9. We see that even for responses rated as level C, the model demonstrates extensive steps in solving the task, even though its final output is incorrect.
::: {caption="Table 9: Examples in the user-oriented instructions dataset (§ 4.4) and predictions from $\textsc{GPT3}$ $_{\textsc{Self-Inst}}$ . The right column indicates one of the four quality ratings assigned to the model's response, with "A" indicating "valid and satisfying" responses (highest) and "D" indicating "irrelevant or invalid response" (lowest)."}
:::
C. Task and Instance Examples from the Generated Instruction Data
::: {caption="Table 10: Representative valid tasks generated by GPT3. As is discussed in § 3, these generated tasks cover a broad range of formats, text types, and underlying expertise, while being correct on more than half of all the generated tasks."}
:::
::: {caption="Table 11: Representative invalid tasks generated by $\textsc{GPT3}$. The problematic fields are indicated in the validity column. As discussed in § 3.3, although these tasks contain errors, they still provide many useful signals in supervising models to follow instructions."}
:::
References
[1] Mishra et al. (2022). Cross-Task Generalization via Natural Language Crowdsourcing Instructions. In acl. https://arxiv.org/abs/2104.08773.
[2] Jason Wei et al. (2022). Finetuned Language Models are Zero-Shot Learners. In iclr. https://arxiv.org/abs/2109.01652.
[3] Victor Sanh et al. (2022). Multitask Prompted Training Enables Zero-Shot Task Generalization. In iclr. https://arxiv.org/abs/2110.08207.
[4] Wang et al. (2022). Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ Tasks. In emnlp. https://arxiv.org/abs/2204.07705.
[5] Ouyang et al. (2022). Training Language Models to Follow Instructions with Human Feedback. In nips. https://arxiv.org/abs/2203.02155.
[6] Chung et al. (2022). Scaling Instruction-Finetuned Language Models. arXiv preprint arXiv:2210.11416. https://arxiv.org/abs/2210.11416.
[7] Bach et al. (2022). PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts. In acl # - System Demonstrations. https://arxiv.org/abs/2202.01279.
[8] Brown et al. (2020). Language models are few-shot learners. In nips. https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
[9] Kitaev, Nikita and Klein, Dan (2018). Constituency Parsing with a Self-Attentive Encoder. In acl. pp. 2676–2686. doi:10.18653/v1/P18-1249. https://www.aclweb.org/anthology/P18-1249.
[10] Kitaev et al. (2019). Multilingual Constituency Parsing with Self-Attention and Pre-Training. In acl. pp. 3499–3505. doi:10.18653/v1/P19-1340. https://www.aclweb.org/anthology/P19-1340.
[11] Lester et al. (2021). The power of scale for parameter-efficient prompt tuning. In emnlp. https://arxiv.org/abs/2104.08691.
[12] Raffel et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. jmlr. https://arxiv.org/abs/1910.10683.
[13] Weller et al. (2020). Learning from Task Descriptions. In emnlp. https://aclanthology.org/2020.emnlp-main.105/.
[14] Schick, Timo and Schütze, Hinrich (2021). Generating Datasets with Pretrained Language Models. In emnlp. https://aclanthology.org/2021.emnlp-main.555/.
[15] Wang et al. (2021). Towards zero-label language learning. arXiv preprint arXiv:2109.09193. https://arxiv.org/abs/2109.09193.
[16] Liu et al. (2022). WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation. In emnlp # - Findings. https://preview.aclanthology.org/emnlp-22-ingestion/2022.findings-emnlp.508/.
[17] Meng et al. (2023). Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning. In icml. https://arxiv.org/abs/2211.03044.
[18] Feng et al. (2021). A Survey of Data Augmentation Approaches for NLP. In acl # ACL-IJCNLP - Findings. pp. 968–988. https://aclanthology.org/2021.findings-acl.84/.
[19] Yang et al. (2020). Generative data augmentation for commonsense reasoning. In emnlp # - Findings. https://aclanthology.org/2020.findings-emnlp.90.
[20] Mekala et al. (2022). Leveraging QA Datasets to Improve Generative Data Augmentation. arXiv preprint arXiv:2205.12604. https://arxiv.org/abs/2205.12604.
[21] Honovich et al. (2022). Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor. arXiv preprint arXiv:2212.09689. https://arxiv.org/abs/2212.09689.
[22] Zhou et al. (2022). Large Language Models Are Human-Level Prompt Engineers. arXiv preprint arXiv:2211.01910. https://arxiv.org/abs/2211.01910.
[23] Ye et al. (2022). Guess the Instruction! Making Language Models Stronger Zero-Shot Learners. arXiv preprint arXiv:2210.02969. https://arxiv.org/abs/2210.02969.
[24] Singh et al. (2022). Explaining Patterns in Data with Language Models via Interpretable Autoprompting. arXiv preprint arXiv:2210.01848. https://arxiv.org/abs/2210.01848.
[25] Honovich et al. (2022). Instruction Induction: From Few Examples to Natural Language Task Descriptions. arXiv preprint arXiv:2205.10782. https://arxiv.org/abs/2205.10782.
[26] He et al. (2019). Revisiting Self-Training for Neural Sequence Generation. In iclr. https://arxiv.org/abs/1909.13788.
[27] Xie et al. (2020). Self-training with noisy student improves imagenet classification. In cvpr. pp. 10687–10698. https://arxiv.org/abs/1911.04252.
[28] Du et al. (2021). Self-training Improves Pre-training for Natural Language Understanding. In naacl #: Human Language Technologies. pp. 5408–5418. https://aclanthology.org/2021.naacl-main.426.
[29] Amini et al. (2022). Self-Training: A Survey. arXiv preprint arXiv:2202.12040. https://arxiv.org/abs/2202.12040.
[30] Huang et al. (2022). Large Language Models Can Self-Improve. arXiv preprint arXiv:2210.11610. https://arxiv.org/abs/2205.10782.
[31] Zhou et al. (2022). Prompt Consistency for Zero-Shot Task Generalization. In emnlp # - Findings. https://arxiv.org/abs/2205.00049.
[32] Hinton et al. (2015). Distilling the knowledge in a neural network. In nips # Workshop on Deep Learning. https://arxiv.org/abs/1503.02531.
[33] Victor Sanh et al. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. In nips # Workshop on Energy Efficient Machine Learning and Cognitive Computing. https://arxiv.org/abs/1910.01108.
[34] West et al. (2021). Symbolic knowledge distillation: from general language models to commonsense models. In naacl. https://aclanthology.org/2022.naacl-main.341/.
[35] Magister et al. (2022). Teaching Small Language Models to Reason. arXiv preprint arXiv:2212.08410. https://arxiv.org/abs/2212.08410.
[36] Zhao et al. (2022). Pre-trained Language Models can be Fully Zero-Shot Learners. arXiv preprint arXiv:2212.06950. https://arxiv.org/abs/2212.06950.
[37] Zelikman et al. (2022). STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning. In nips. https://arxiv.org/abs/2203.14465.
[38] Welleck et al. (2023). Generating Sequences by Learning to Self-Correct. In iclr. https://arxiv.org/abs/2211.00053.
[39] Fried et al. (2018). Speaker-follower models for vision-and-language navigation. In nips. https://arxiv.org/abs/1806.02724.
[40] Shridhar et al. (2020). ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. In cvpr. https://arxiv.org/abs/1912.01734.
[41] Min et al. (2022). FILM: Following Instructions in Language with Modular Methods. In iclr. https://arxiv.org/abs/2110.07342.
[42] Weir et al. (2022). One-Shot Learning from a Demonstration with Hierarchical Latent Language. arXiv preprint arXiv:2203.04806. https://arxiv.org/abs/2203.04806.
[43] Rohan Taori et al. (2023). Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
[44] Xu et al. (2023). Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data. arXiv preprint arXiv:2304.01196. https://arxiv.org/abs/2304.01196.
[45] Sun et al. (2023). Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision. arXiv preprint arXiv:2305.03047. https://arxiv.org/abs/2305.03047.
[46] Razeghi et al. (2022). Impact of pretraining term frequencies on few-shot reasoning. arXiv preprint arXiv:2202.07206. https://arxiv.org/abs/2202.07206.
[47] Kandpal et al. (2022). Large language models struggle to learn long-tail knowledge. arXiv preprint arXiv:2211.08411. https://arxiv.org/abs/2211.08411.