Sparser, Faster, Lighter Transformer Language Models
Edoardo Cetin$^{}$ $^{1}$, Stefano Peluchetti$^{}$ $^{1}$, Emilio Castillo$^{}$ $^{2}$, Akira Naruse$^{2}$, Mana Murakami$^{2}$ and Llion Jones$^{1}$
$^{1}$Sakana AI, $^{2}$NVIDIA, $^{}$Core contributors
Abstract
Scaling autoregressive large language models (LLMs) has driven unprecedented progress but comes with vast computational costs. In this work, we tackle these costs by leveraging unstructured sparsity within an LLM's feedforward layers, the components accounting for most of the model parameters and execution FLOPs. To achieve this, we introduce a new sparse packing format and a set of CUDA kernels designed to seamlessly integrate with the optimized execution pipelines of modern GPUs, enabling efficient sparse computation during LLM inference and training. To substantiate our gains, we provide a quantitative study of LLM sparsity, demonstrating that simple L1 regularization can induce over 99% sparsity with negligible impact on downstream performance. When paired with our kernels, we show that these sparsity levels translate into substantial throughput, energy efficiency, and memory usage benefits that increase with model scale. We will release all code and kernels under an open-source license to promote adoption and accelerate research toward establishing sparsity as a practical axis for improving the efficiency and scalability of modern foundation models.
Corresponding author(s): Edoardo Cetin ([email protected]), Emilio Castillo ([email protected])
Executive Summary: Large language models (LLMs) have transformed fields like text generation and reasoning, but their massive scale—often hundreds of billions of parameters—drives enormous computational demands during training and use. This raises pressing concerns about energy consumption, hardware costs, and sustainability, as models grow larger without proportional efficiency gains. With AI adoption accelerating across industries, finding ways to cut these costs without sacrificing performance is critical to making LLMs more accessible and environmentally viable.
This document evaluates whether inducing sparsity—where most model computations are skipped by activating only a small fraction of parameters—can make LLMs faster and lighter. The authors aimed to demonstrate that high sparsity levels can be achieved in the feedforward layers (which dominate model size and operations) using simple techniques, while quantifying real-world efficiency benefits.
The team developed custom software components, called CUDA kernels, optimized for NVIDIA GPUs to handle sparse computations efficiently during both model training and inference. They trained LLMs from scratch on a large web-text dataset (FineWeb), incorporating a mild penalty (L1 regularization) to promote sparsity in activations, alongside the standard ReLU activation function. Experiments covered models from 0.5 billion to 2 billion parameters, trained on 10 to 40 billion tokens over several weeks on eight H100 GPUs. Performance was assessed via cross-entropy loss and seven reasoning benchmarks, while efficiency metrics included speed, memory use, and energy on the same hardware.
Key results show that sparsity exceeds 99% on average, with only 24 to 39 active "neurons" per layer in larger models, using minimal regularization that keeps performance within 2% of dense baselines on reasoning tasks. This sparsity yields up to 20.5% faster inference and 21.9% faster training for a 2-billion-parameter model, alongside 24% less peak memory during training. Benefits scale with model size: smaller models gain about 10-15% speedups, while larger ones see double that. Energy savings reach 30% in inference due to lower power draw, and sparsity naturally concentrates computations on informative input tokens (like key nouns or early sequence positions), aligning with how LLMs process language.
These findings mean LLMs can run on less powerful hardware, cut training costs by enabling bigger batches, and reduce environmental impact—vital as AI scales amid energy constraints. Unlike denser activations (e.g., SiLU), sparsity exploits inherent model patterns for gains that grow with size, challenging the status quo of brute-force scaling and offering a practical alternative to complex architectures like mixture-of-experts.
Adopt mild L1 regularization (coefficient around 2×10⁻⁵) with ReLU in new LLM training, integrating the open-source kernels for immediate 15-20% efficiency boosts on modern GPUs. For existing models, fine-tune with sparsity techniques to apply these benefits broadly. Trade-offs include slight risks of inactive neurons at higher sparsity; test dead-neuron fixes like gradual regularization warmup or targeted reinitialization in pilots. Next, expand to larger models (beyond 2B parameters), diverse datasets, and older hardware like RTX 6000 GPUs, where gains hit 30% or more; validate on production inference pipelines.
Confidence is high for models up to 2B parameters on H100 GPUs, backed by rigorous benchmarks showing consistent performance parity. Caution applies to non-gated architectures (slightly lower gains) or very high sparsity (potential 5-10% performance dips), where more targeted refinements could help; results assume standard Transformer setups, so adaptations may be needed for variants.
1. Introduction
Section Summary: Large language models have transformed natural language processing with their impressive abilities in generating text, reasoning, and retrieving knowledge, but their massive size demands enormous computing power for training and use, raising concerns about sustainability. While sparsity—where models activate only a fraction of their components—naturally occurs in these models and could cut computation significantly, especially in their largest layers, it often runs slower on modern GPUs due to hardware optimized for dense operations rather than sparse ones. This work introduces efficient new software tools using a format called TwELL for faster, lighter inference and a hybrid approach for training, achieving up to 20% speedups and major energy savings in large models, while showing that simple tweaks can induce high sparsity without harming performance.
Large Language Models (LLMs) have revolutionized natural language processing, demonstrating unprecedented capabilities in text generation, reasoning, and knowledge retrieval ([1, 2]). The core component driving these advancements has been massive computational investments into scaling the seminal Transformer architecture, with current LLMs reaching hundreds of billions of parameters [3, 4, 5]. However, with increasingly larger models requiring vast computational resources for both inference and training, there is a growing need for fundamental efficiency improvements to ensure the present and future sustainability of the field ([6, 7]).
One seminal avenue for improving the efficiency of machine learning models is sparsity ([8, 9, 10]). For modern overparameterized LLMs, recent investigations have even documented that sparsity arises naturally in their feed-forward layers, with only a small fraction of hidden neurons activated for any given token ([11, 12]). Thus, with feed-forward computation accounting for over two-thirds of the parameters and over 80% of the total FLOPs in larger models ([13]), sparsity seemingly offers a natural opportunity for concrete computational savings.
However, a frustrating paradox has blocked progress: despite performing far less theoretical computation, official kernels implementing sparse operations can often run slower than dense operations on modern GPUs. The culprit is a fundamental mismatch between unstructured sparsity and GPU architectures, whose hardware and software stacks have been heavily optimized for dense computation patterns ([14, 15, 16, 17]). In contrast, heterogeneous workloads together with the overheads from materializing and managing sparse indices have been critical challenges preventing generalized computational savings. Due to these challenges, previous attempts to realize efficiency gains have relied on considerable deviations from modern training recipes and have yet to see practical adoption ([18, 19]).
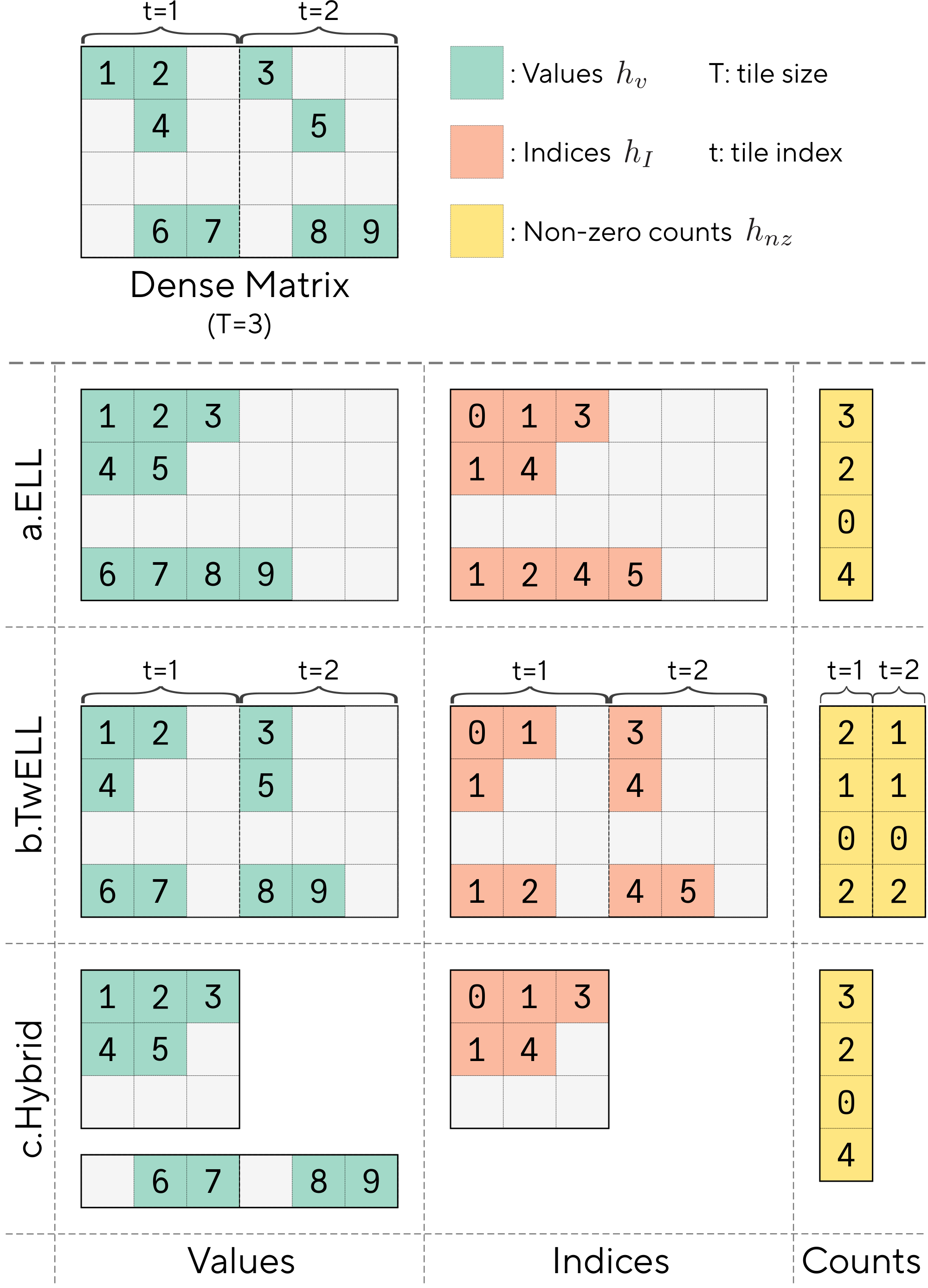
In this work, we introduce new kernels designed for modern NVIDIA GPUs to bridge this gap and leverage unstructured sparsity to deliver substantial speedups while reducing memory requirements and energy consumption during both LLM inference and training. Our kernels build on Tile-wise ELLPACK (TwELL), a new packing format for sparse data that can be naturally materialized in the epilogue of highly-optimized matrix multiplication kernels, removing a canonical bottleneck of prior packing schemes. Starting from TwELL, our inference kernels fuse multiple matrix-multiplications into a single optimized pipeline that minimizes computation, while our training kernels further reduce the sparse representation to a hybrid format that trivializes storage costs of intermediate activations.
To substantiate our gains, we provide a quantitative study of LLM sparsity across model scales, demonstrating that mild levels of L1 regularization can achieve over 99% sparsity with negligible impact on downstream performance. Through our new kernels, we show these sparsity levels translate into increasing benefits with larger parameter counts in terms of processing throughput, energy savings, and memory requirements – delivering up to 20.5% and 21.9% speedups in forward execution and training for models with billions of parameters. We analyze how these benefits specifically come from the computational unevenness across network layers and natural language data, which can be inherently leveraged in sparse models. By providing a clear demonstration of its practical benefits, we hope this work will help establish sparsity as a new axis for improving the scalability and performance of modern foundation models.
In summary, our main contributions are threefold:
- We introduce and share new CUDA kernels for inference and training, with several key innovations to make sparse LLMs cheaper, faster, and lighter on modern GPUs.
- We provide a quantitative analysis showing that high levels of unstructured sparsity can be achieved using mild L1 regularization with negligible compromises on performance.
- We demonstrate and analyze how our kernels leverage such sparsity with substantial and increasing benefits at larger scales for LLMs with billions of parameters.
2. Large Language Models, Feedforward Blocks, and Sparsity
Section Summary: Large language models rely on feedforward blocks, which process information in transformer architectures and have evolved from simple two-layer designs to more effective three-layer gated versions that dominate modern models. These blocks expand input data through projections and activations, combining them to create hidden representations before shrinking them back, and they can be thought of as efficient, dynamic memory stores where the model retrieves relevant knowledge based on the input. To make these blocks sparser and more efficient, the approach uses the ReLU activation function and adds a penalty term to the training loss that encourages many activations to become zero, while noting that alternatives like smoother functions can work with tweaks.
While the original transformer used a simple 2-layer feedforward block, this module has seen considerable evolution since its conception ([3]). The most recent architectures have largely converged to a 3-layer gated design that has consistently proven empirical superiority when evaluated at large scale ([20]). While in this work we release kernels for both the original and gated blocks, we focus our main text on the newer design and defer to Appendix C for further discussions, results, and comparisons with the older variant.
2.1 Feed-forward Modules as Sparse Knowledge Stores
A modern gated feed-forward block ([20]) is parameterized by three weight matrices $W_g\in \mathbb{R}^{K\times N}$, $W_u\in \mathbb{R}^{K\times N}$, and $W_d\in \mathbb{R}^{N\times K}$ representing the gate, up, and down projection matrices, respectively. In our notation, we use $M$ to denote the feed-forward block’s effective batch size over all batched sequences and positions, $K$ to denote its input/output dimensions, and $N$ to denote its hidden expanded dimension. The gate and up projection matrices both process the block's input batch $x\in \mathbb{R}^{M\times K}$ and produce the up and gate activations $h_g$ and $h_u \in \mathbb{R}^{M\times N}$, where the symmetry between the two is broken with a non-linear activation function $\sigma$. These projections are then combined with elementwise multiplication into a unified hidden representation $h\in \mathbb{R}^{M \times N}$, before being projected back to their original dimensionality using the down projection weights $W_d$, to compute the block's outputs $y\in \mathbb{R}^{M \times K}$:
$ h_u = x W_u, \quad h_g = \sigma(x W_g), \quad h = h_u \odot h_g, \quad y = h W_d.\tag{1} $
Since the hidden dimension $N$ is typically much larger than $K$, feed-forward blocks can often account for most of the model’s parameters and FLOPs. We note that a common conceptualization of these architectural components is that of a dynamic key-value memory ([21, 22]). In this mental model, the inner products between $x$ and the columns of $W_g$ and $W_u$ induce keys $h$, while the rows of $W_d$ are seen as values acting as memory slots that can be dynamically retrieved based on the input.
2.2 Simple Ingredients for Training Sparse LLMs
We employ a simple recipe to induce varying levels of sparsity in the feed-forward activations, making minimal deviations from established architectures and training objectives. First, we use the ReLU as the activation function of choice following the gate projections. Second, we add a simple L1 loss to the standard cross-entropy with a tunable coefficient $L_1$ to promote sparsity across the model's $L$ layers:
$ L_1\times\frac{1}{L}\sum_{l=1}^L \frac{1}{MN}\sum_{m=1}^M\sum_{n=1}^N \lvert h^{l}[m, n] \rvert.\tag{2} $
We note that many recent LLM architectures have deviated from using ReLUs in favor of smoother activation functions such as SiLU, with minor but consistent benefits ([20, 23, 24]). In Appendix C, we provide direct empirical comparisons between these choices and also refer to orthogonal studies in the recent literature showing that domain-specific performance differences can be bridged with targeted training techniques ([25, 26]).
3. Making Sparse LLMs Fast
Section Summary: This section explains how to make large language models that use sparse data much faster by developing new computing tools for graphics cards, focusing on the feed-forward parts of these models. It introduces TwELL, a clever data storage method that breaks sparse matrices into small tiles, allowing operations to be combined efficiently without extra delays or memory waste from handling zeros. Building on established formats like ELLPACK, these tools enable seamless integration into model pipelines for quicker training and predictions.
We introduce new CUDA kernels for inference and training that leverage unstructured sparsity to efficiently rework the computation in the feed-forward blocks of an LLM. The algorithms underlying our kernels build on TwELL, a new sparse format specifically designed for seamless kernel fusion to realize the inherent throughput and memory benefits of sparsity with minimal overheads. In this section, we describe the core components and advantages of our new kernels with algorithmic descriptions that summarize their logic at the level of individual cooperative thread arrays (CTAs). We refer to Appendix A for code listings and more detailed design discussions of the thread-level CUDA implementations for H100 GPUs.

3.1 Sparse Formats and Kernels
The ELLPACK format (ELL) is considered the state-of-the-art for fast and efficient sparse matmuls ([27]). This format was leveraged in some of the earliest GPU implementations of sparse algebra ([28]), with more recent work focused on developing packing and sorting variants for better performance ([29, 30]). As shown in part a. of Figure 1, an $M\times N$ matrix $h$ in the ELL format is stored as two padded matrices $h_v$ and $h_I$ of size $M\times N_{nz}$ with the non-zero values of $x$ and their column indices packed at the beginning of each row. This format prioritizes downstream usability over storage, padding the rows up to the maximum number of nonzero elements $N_{nz}$ for efficient retrieval.
The main logic in most matmul kernels to perform $y=hW$ with ELL, is to launch different parallel accumulations for each row $m=0, \dots, M-1$ of the sparse matrix $h$ using a set number of threads. In each accumulation, the kernel iterates for $n=0, ..., N_{nz}-1$ times, loading each column index $i=h_I[i, j]$ and value $v=h_v[i, j]$ of $h$, and multiplying it with the $K-$ dimensional row of the dense weight $W[i, :]$. The key advantage of this format is that only a fraction of the weight columns and input values need to be processed, skipping the remaining zeros. To further reduce data access and computation, some later extensions like ELLPACK-R ([31]) also store the number of non-zeros in each row in a separate vector $h_{nz}$.
3.2 TwELL, a Sparse Data Format for Kernel Fusion
An effective predominant design for modern kernel pipelines is to maximize operator fusion and avoid unnecessary global memory accesses in order to best leverage the high compute throughput of modern NVIDIA GPUs. To this end, in a gated feed-forward block where sparsity patterns are determined by the gate activations $h_g$, prior sparse formats such as ELL suffer a major drawback. In essence, representing $h_g$ with ELL requires first accessing all elements in every row to count, compare, and align the non-zero values and indices. However, existing matmul kernels for dense inputs rely on parallelizing computation across small 2D tiles $T_{m}\times T_{n}$ of the outputs, computed independently in separate CTAs. Thus, obtaining the gate activations directly in the ELL format from the non-sparse inputs cannot be done in the same kernel of $h_g= \operatorname{ReLU}(xW)$ without introducing expensive synchronization among different CTAs. In contrast, launching a separate kernel to do the conversion inherently introduces non-trivial overheads that concretely limit attainable throughput gains of the whole computation.
To address these limitations, we introduce Tile-wise ELLPACK (TwELL). As illustrated in part b. of Figure 1, rather than focusing on whole rows, TwELL divides the columns of $h_g$ in groups of horizontal 1D tiles of size $T$. Within each group of columns, TwELL stores the non-zero values present and their indices in a local ELL-based packing format, with the data of each row aligned at the beginning of each horizontal tile. This results in two matrices containing locally aligned values $h_v \in R^{M\times N/C}$ and indices $h_I \in R^{M\times N/C}$, where $C$ is a compression factor set such that $T/C$ is higher than the maximum number of non-zeros in any tile to avoid storage overflow. In our implementation of TwELL, we also store an additional matrix with the number of non-zero elements $h_{nz}\in R^{M\times N_T}$ to facilitate further computations, with as many columns as total tiles $N_T=\lceil N/T \rceil$. While inherently less expensive to derive, the main advantage of TwELL over ELL is actually ease of materialization following a modern tiled matmul: by setting the horizontal tiling dimensions to match, $T=T_n$, the TwELL format can be recovered in the same kernel performing $h_g= \operatorname{ReLU}(xW)$ before storing the outputs to DRAM. Fusing the two operations removes the requirement of performing additional kernel spawns, memory reads, or synchronization steps, leading to a natural integration into existing LLM pipelines.
3.3 Kernels for TwELL Construction and Fast, Fused Inference
In Algorithm 1, we provide pseudocode to summarize the logic of our CUDA matmul kernel storing the sparse outputs in the TwELL format (lines 6-18). Given the output distribution patterns of tensor core operations, we obtain the memory addresses to store the packed non-zero values $h_v$ and their indices $h_I$ by keeping a local non-zero count that only requires warp-level synchronization. While not an inherent requirement of TwELL, storing the number of non-zeros in each tile, $h_{nz}$, allows us to forego the overhead from initializing $h_I$ with any "padding" value and from the additional control logic of checking validity in future usages. While omitted from Algorithm 1, we leverage fast asynchronous TMA reads and writes by first caching the dense inputs and sparse TwELL outputs to shared memory. We also pipeline computation and global memory accesses with a persistent cooperative design similar to the one in CUTLASS ([17]).
For inference, we introduce a single additional kernel to perform the rest of the computation in the feedforward block, leveraging the gate activations stored in the TwELL format to efficiently fuse the up and down projections together. This kernel, summarized in Algorithm 2, is launched on a grid made of single warp CTAs each processing a different row $m$ of the input activations $x$. Minimizing the size of each CTA serves the purpose of maximizing concurrency and L2-hits across the grid, as non-zero activations tend to have high correlation within input sequences. The fused matmuls are executed by traversing over the sparsified activations with two nested for loops: the first one statically-unrolled over the number of column tiles (line 6) and the second one dynamically iterating over the corresponding number of non-zeros in each tile (line 8). For each non-zero activation at index $n$, the CTA collectively loads the $n^{th}$ row of $W_u$ and column of $W_d$ to perform a dot product, followed by a scalar-vector product and accumulating its results (lines 9-13) – corresponding to the following computation:
$ y[m, :]!=! \sum_{t=0}^{\scriptscriptstyle N_T!-!1} \sum_{c=0}^{\scriptscriptstyle h_{nz}[m, t]!-!1} \underbrace{ h_v[m, , t\times T_n/C!+!c] }{h_v \text{ non-zero value}} \underbrace{\left(x[m, :]\cdot W_u[:, n] \right) }{h_u \text{ element}} \underbrace{ W_d[n, :] }{W_d\text{ row}}, \text{ where } n = \underbrace{ h_I[m, , t\times T_n/C!+!c] }{h_I \text{ non-zero index}}.\tag{3} $
Implicitly materializing the $h_u$ values only inside the kernel serves to further reduce DRAM access to maximize throughput. Together, the kernels in our inference pipeline align the core principles of tiling and operator fusion into a single execution flow, harnessing the computational advantages of sparsity while minimizing its canonical overheads.
3.4 Hybrid Conversion for Efficient Storage
During training, memory becomes a key bottleneck for throughput as large intermediate activations and optimizer states are needed for backpropagation. Here, sparsity provides a natural opportunity to tackle these bottlenecks by trivializing intermediate storage costs and accelerating gradient computations. However, directly using TwELL with a high compression ratio or other ELL-based formats for this purpose inherently relies on the maximum number of non-zeros $N_{nz}$ to be known ahead of time and strictly small. However, as we will illustrate in Section 4, we find that these conditions are practically never met during LLM training as sparsity patterns exhibit significant non-uniformity across different tokens, with the maximum number of non-zeros often orders of magnitude larger than the average.
We overcome these limitations by first converting the TwELL activations to a hybrid sparse format and introducing a new set of custom kernels designed specifically for memory-efficient training. As illustrated part c. of Figure 1, our format dynamically partitions and stores the rows of $h_g$ either in an aggressively compact ELL matrix $h^{s}g\in R^{M^s\times N{\hat{nz}}}$ or a dense backup $h^{d}g\in R^{M^d\times N}$. The partitioning logic simply routes the rows of $h_g$ based on their non-zero counts, which are cheaply computed from the locally aligned TwELL tiles. Our hybrid format also maintains a lightweight array of column indices $h_I\in R^{M^s\times N{\hat{nz}}}$ matching the size of the sparsified ELL matrix, and a simple binary vector indicating the storage location of each row $h_b\in R^{M}$. In practice, we find that we can set $N_{\hat{nz}}$ over an order-of-magnitude lower than $N$ with minimal overflow into $h^{d}_g$, avoiding stringent ELL requirements while still trivializing memory and computation during the rest of the training step.
3.5 Kernels for Lightweight Efficient Training
After materializing $h_g$ in our hybrid format from the pre-activations $xW_g$, we design custom kernels to perform efficient hybrid-to-dense and dense-to-hybrid matmuls. We directly use these kernels to execute the rest of the forward pass, computing $h_u=xW_u$ and $y=hW_d$. Unlike inference, during training we execute the up and down projections in separate steps, allowing us to efficiently store the sparsified hidden states and minimize recomputation in the backward pass. In Algorithm 3, we outline the logic of the hybrid-to-dense matmul for a generic input $h$ and weight $W$, with the dense-to-hybrid variant also following the same general structure. Our approach combines a typical ELL kernel, with each CTA processing individual rows of the output $y$ (lines 4-13), and a traditional tiled kernel using Tensor cores for the dense backup rows (lines 14-17). During the sparse portion of the matmul computation, we opt to statically-unroll the accumulation up to the maximum number of non-zeros $N_{\hat{nz}}$ for each row. Moreover, we also statically pre-allocate the dense backup portions of all the activations based on the sparsity statistics observed during training. We note that these design choices introduce minimal extra computation and storage costs, which are largely offset by avoiding dynamic overheads.
During the backward pass, we retrieve the sparsified activations together with the L1 and output gradients $\nabla y$, allowing us to backpropagate without performing any expensive dense computation. This is achieved using two additional kernels that support efficient injection of L1 gradients into a given sparsity pattern and efficient transposition of our hybrid format for future coalesced accesses. We first use the stored sparsity pattern of $h$ to obtain its gradients via our efficient dense-to-hybrid matmul $\nabla y W^T_d$, followed by the L1 injection. With $\nabla h$ available, we recover the rest of the input and weight gradients with direct applications of our hybrid-to-dense and transposed kernels:
$ \begin{aligned} \nabla h_u& = \nabla h \odot h_g, \quad \nabla h_g = \nabla h \odot h_u, \ \nabla W_u = x^\top \nabla &h_u, \quad \nabla W_g = x^\top \nabla h_g, \quad \nabla W_d = h^\top \nabla y, \quad \ &\nabla x = \nabla h_u, W_u^\top
- \nabla h_g, W_g^\top. \end{aligned}\tag{4} $
Crucially, our execution logic reflects a deliberate design choice: rather than aggressively fusing individual operators, the training kernel pipeline is structured around the training step in its entirety. In this setting, the hybrid format minimizes backward computation and memory overheads, allowing us to avoid dense calculations while remaining robust to the highly non-uniform sparsity patterns that make ELL-based approaches traditionally brittle.
4. Experimental Results
Section Summary: Researchers trained large language models with varying levels of L1 regularization to create sparsity, meaning fewer active parts in the model's neural networks, using a common architecture and dataset while keeping training settings similar across models. Their 1.5-billion-parameter model showed natural sparsity even without regularization, and adding mild regularization increased sparsity dramatically—up to over 99%—without significantly harming performance on logic and reasoning tasks until sparsity became extreme. This sparsity led to practical benefits, including up to 30% faster inference, reduced energy use by about 3%, quicker training by 24%, and over 24% less memory needed during training.
4.1 Training and Evaluation Settings
We provide quantitative results evaluating the performance and efficiency of LLMs at different sparsity levels and scales. Our models are based on the "Transformer++" architecture, common to recent LLMs such as Qwen and Llama ([23, 24]) with the gated feedforward blocks described in Section 2. We train our models just above the chinchilla-optimal number of tokens for each model size ([32]), using the fineweb dataset ([33]). We default to a context length of 2048, a batch size of 1M tokens, and the AdamW optimizer with a weight decay of 0.1 and a cosine schedule ([34]). Other hyperparameters, such as the hidden size and total number of layers, are based on the model size and chosen based on modern practices ([32]). We note that our sparse models use the same training hyperparameters as our non-sparse baselines, as the addition of L1 regularization in the feedforward blocks did not seem to affect other choices.
To measure model performance, we use cross-entropy scores and seven different common downstream tasks assessing logic and reasoning capabilities after pretraining ([35, 36, 37, 38, 39, 40]). In this Section, we focus on aggregated performance metrics for conciseness, and we refer to Appendix D for the full per-task breakdowns. To measure efficiency, we analyze the throughput gains at different sparsity levels when integrating our training and inference kernels by recording execution times, memory requirements, and energy consumption at each stage. Across our experiments, we keep a fixed sequence length of 2048 and vary the micro batch size based on the available memory. Unless otherwise specified, we train and collect our results on a single node of eight H100 PCIe GPUs, a commonly available infrastructure in current listings of cloud providers and scientific clusters. We refer to Appendix B for further details on our training and evaluation settings, together with full hyperparameters specific to each of the considered model sizes.
4.2 More Efficient LLMs with Unstructured Sparsity
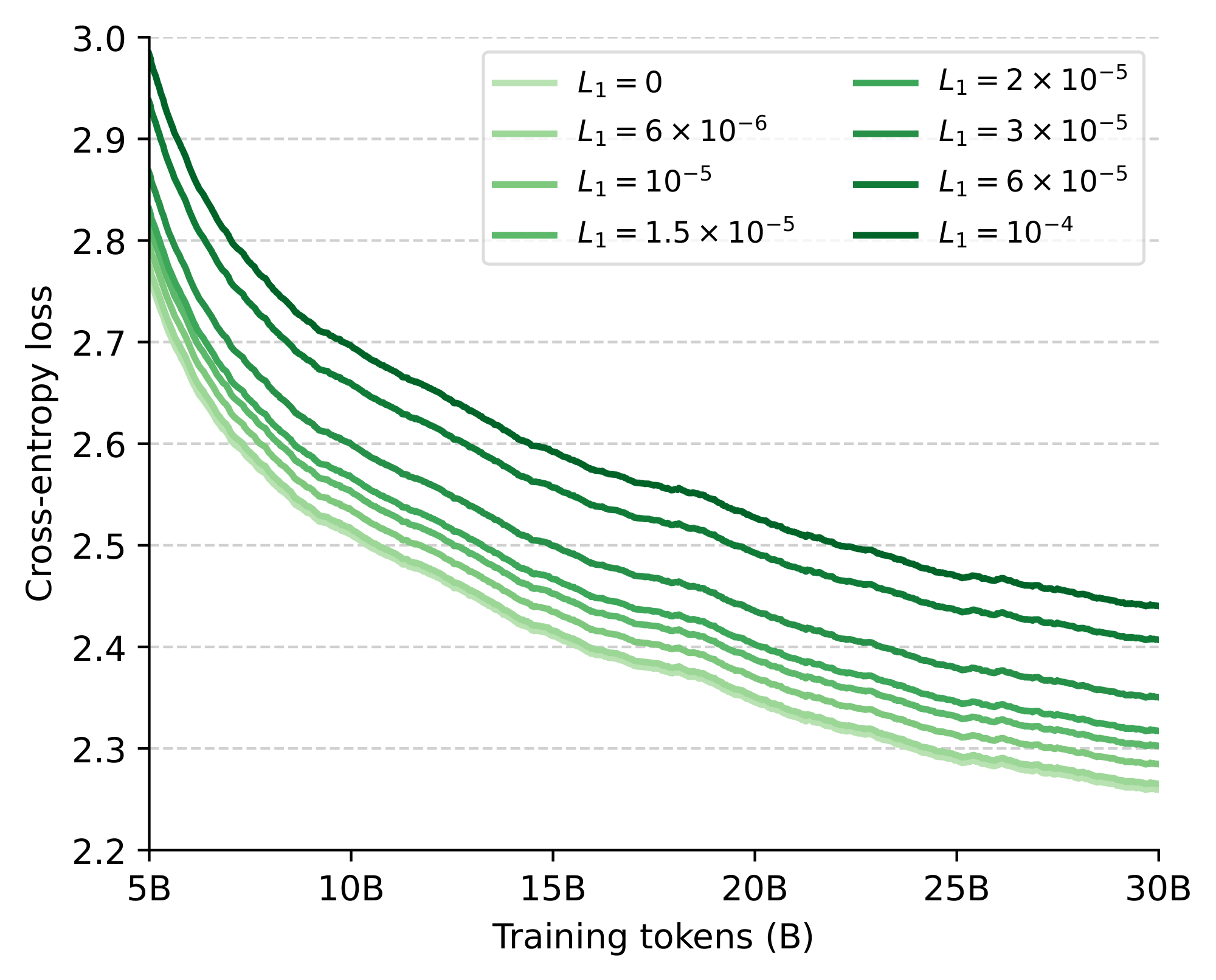
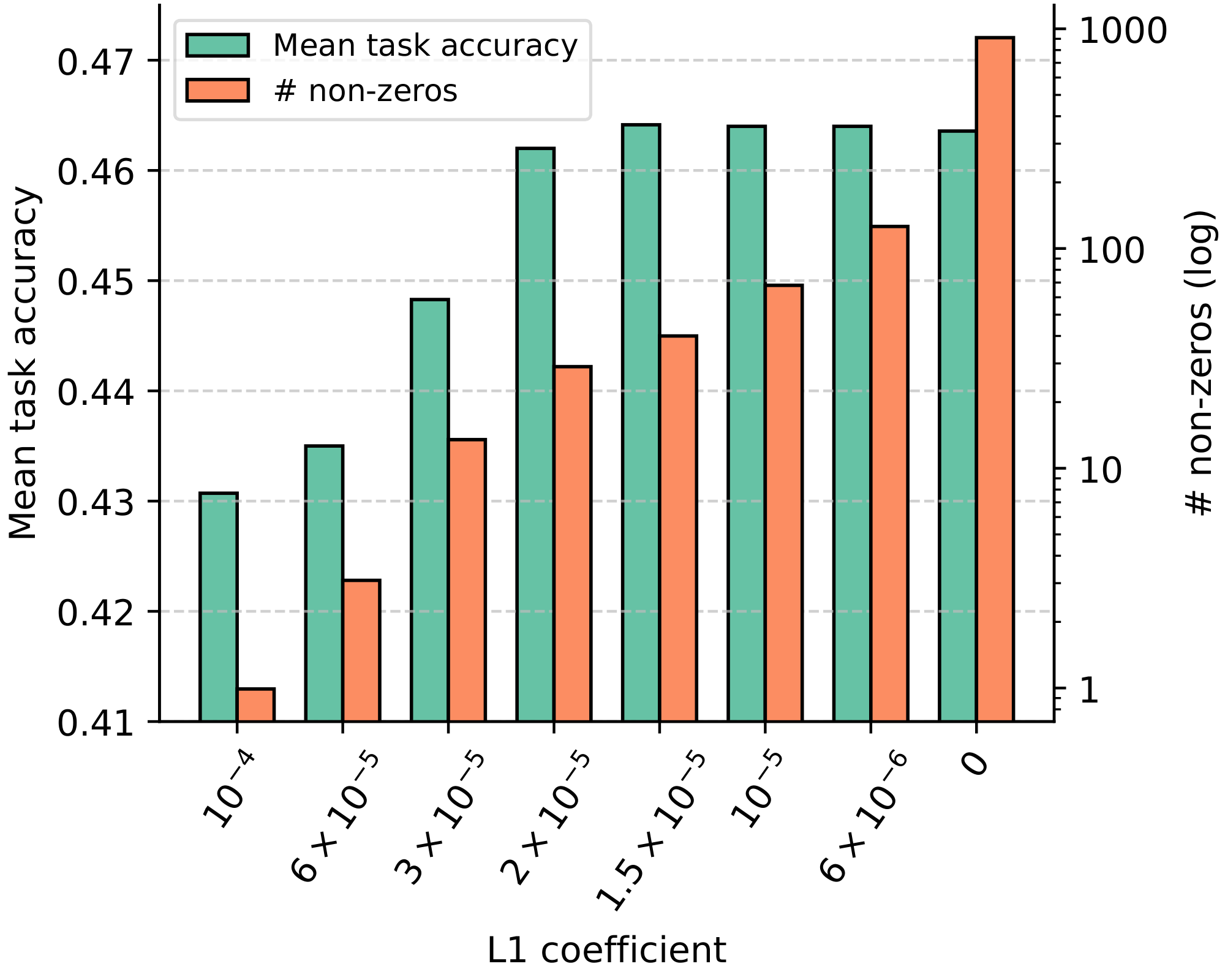
Performance across sparsity levels. We start by evaluating the effect of introducing different levels of L1 regularization on the performance and sparsity of a 1.5B parameter model. In particular, we consider eight values for the $L_1$ coefficient, ranging from no regularization ($L_1=0$) to the point where less than a single neuron on average remains activated after training ($L_1=1\times10^{-4}$). In Figure 2, we show the training curves of the different models, while in Figure 3 we report downstream task performance together with the final number of non-zero activations averaged across the feed-forward blocks. While our 1.5B model has a hidden feedforward dimensionality of 5632, we find that the non-regularized model already attains more than 20% sparsity with only 911 neurons activated. Moreover, consistently with [25], we find that introducing small levels of regularization already pushes the average number of non-zeros orders of magnitude lower but with high variations across different tokens and layers. In particular, even at the highest regularization point, we find that a small fraction of tokens still excite several hundred neurons, indicating a reallocation of capacity. Despite this adaptivity, performance-wise, we do start seeing some performance degradation below 0.5% of activated neurons. Nonetheless, our results suggest that smaller levels of regularization do not visibly hinder capacity beyond the weight decay already induced by the AdamW optimizer: up until $L_1=3\times 10^{-5}$, we record essentially no drop in task performance and a negligible increase of final cross-entropy within 2% of the unregularized baseline.
::: {caption="Table 1: Comparison of performance and efficiency statistics of sparse LLMs leveraging our kernels with traditional models."}

:::
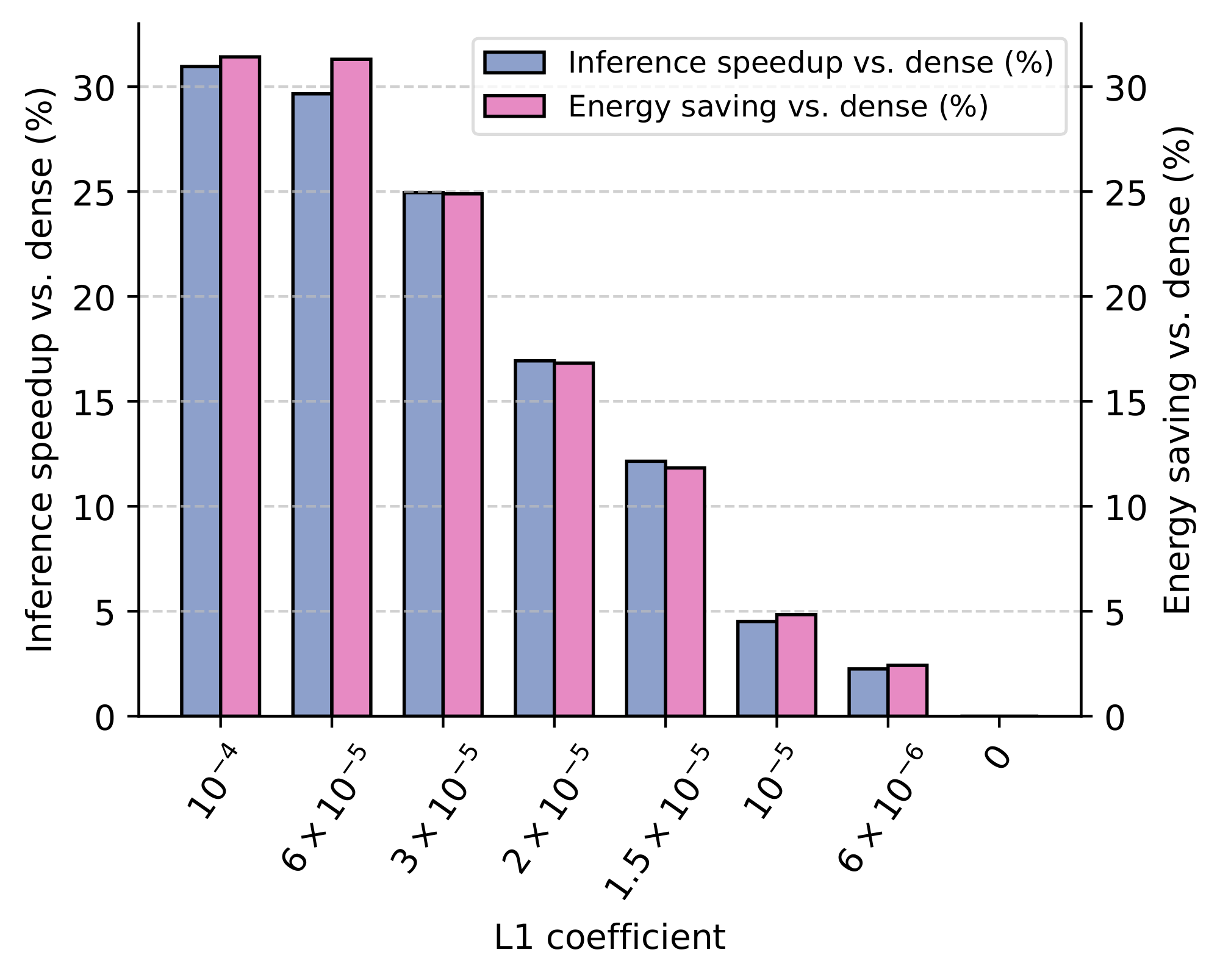
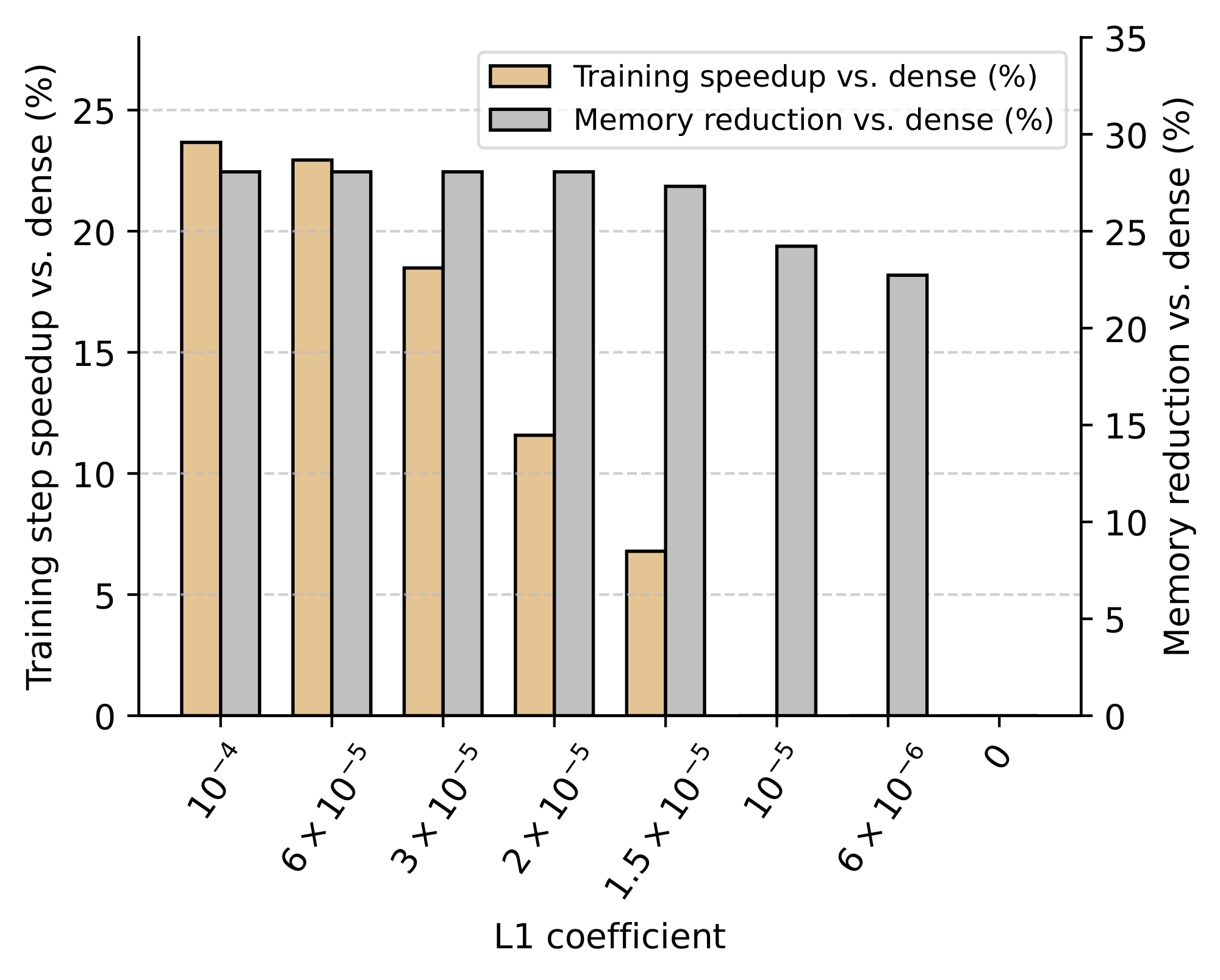
Leveraging sparsity for faster and lighter LLMs. We contrast our performance results by analyzing the efficiency improvements from integrating our kernels at different sparsity levels. In Figure 4, we provide the average relative speedups and total energy savings recorded during forward execution through our LLMs. Across all considered sparsity levels above $L_1=0$, we find that our inference kernels lead to visible throughput gains ranging up to 30%. These throughput gains are compounded by nearly 3% less GPU power draw above $L_1=3\times 10^{-5}$, resulting in even higher energy savings. In Figure 5, we also show the average relative speedups and peak memory reduction with our training kernel. In line with our inference kernels, the speedups recorded throughout training significantly increase up to 24% with sparser models. Furthermore, the peak GPU memory required for training decreases by more than 24% even for the lowest considered sparsity level, reducing hardware barriers for efficient training at billion-parameter scales (we refer to Appendix D for results on an RTX6000). Taken together, we believe our results provide compelling evidence that specialized targeted kernels can make sparsity a new viable axis for the design of modern LLMs, leading to significant efficiency improvements across their full lifecycle.
Sparsity across model scales. We analyze how model scale affects the performance and efficiency of sparse LLMs. For this analysis, we set $L_1=2\times 10^{-5}$ based on our earlier results on the 1.5B model, which we recommend as a conservative threshold to avoid any significant performance degradation. In Table 1, we compare the performance and efficiency of sparse and non-sparse LLMs at the chinchilla-optimality boundary – ranging from a 0.5B model trained on 10B tokens to a 2B model trained on 40B tokens. Consistent with our earlier results, we find no performance drops beyond random deviations for all scales when mild L1 regularization is introduced. Furthermore, we find that LLMs become increasingly effective at supporting sparsity at larger scales, resulting in a lower number of average non-zero elements (from 39 to 24, going from the 0.5B to the 2B model). In turn, this makes all the aforementioned throughput and memory benefits of our kernels grow: the 2B sparse model processes tokens 20.5% faster during inference and trains 21.9% more efficiently with a larger micro-batch size. These findings suggest that sparsity aligns well with recently prevailing scaling trends, highlighting its growing potential relevance for future model development.
4.3 The Properties of Sparse Large Language Models
We analyze how LLMs effectively allocate sparsity across their layers and batched samples. For our analysis, we collect the activations from $2^{20}$ input tokens using our 1.5B model trained with the suggested performance-preserving $L_1=2\times 10^{-5}$. We complement this subsection with additional results in Appendix D, looking at additional levels of L1 regularization together with how sparsity evolves throughout training and its effects on dead neurons.
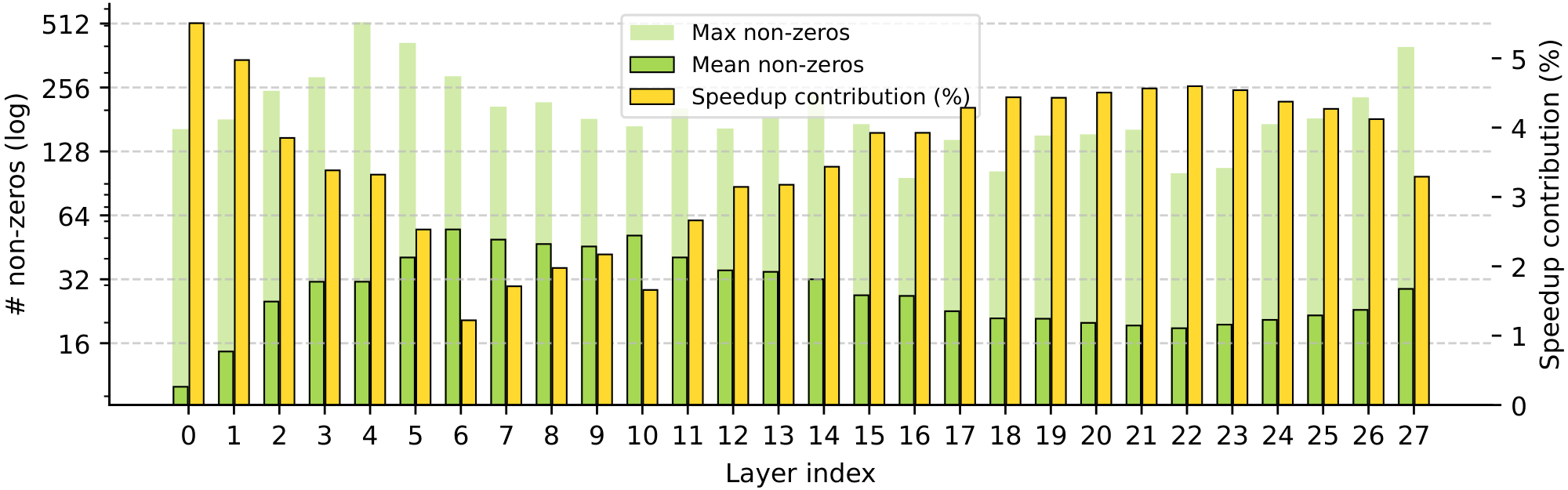
Sparsity and model depth. Figure 6 examines activations across model depth, relating the non-zero statistics of each layer to its respective contribution to inference speed-ups. While the average non-zeros across all layers is less than 30, the figure highlights clear variations in sparsity both across and within individual layers. In particular, the first two layers are the least active, followed by a pronounced hump in the average number of non-zeros across the first half of the network. This sparsity pattern, peaking during early-middle layers, appears consistent with prior work suggesting that a substantial portion of an LLM’s reasoning and knowledge retrieval occurs precisely at these depths ([41]). Furthermore, within each layer, the maximum number of non-zeros often exceeds the layer’s mean by more than an order of magnitude and shows no consistent pattern across the architecture. We also observe an intuitive and pronounced inverse correlation between each layer's average non-zeros and its relative speed-up, with a Pearson coefficient of over -0.996. In contrast, the maximum activation counts have a more limited effect on inference speedups, only noticeably in layer 8. This robustness is due to our kernel design, which hides the latency of highly activated tokens through maximally parallelized execution.

Sparsity and input properties. Given the high level of unevenness across activations, we analyze what inputs spur the peaks and troughs in non-zero activation counts. In part a. of Figure 7, we identify common tokens with the six lowest and highest average number of non-zeros, filtering out outliers occurring at a lower frequency than $1/2^{14}$. We find that the tokens with the lowest non-zero activity often represent parts of common web links (doi, nlm, gov, nih) or contractions (doesn, couldn) that precede predictable next tokens in crawled web corpora. In contrast, tokens providing important contextual information about a passage have the highest activity, including particular verbs (loud, enduring) or nouns representing specific locations or substances (Vermont, Greeks, formaldehyde, ACH"). In part b. of Figure 7, we then plot how the average non-zeros vary with token position in the input sequence on a log-log scale. Interestingly, we find that the LLM allocates a much greater number of non-zeros to the very first tokens in a sequence, with an exponential decrease thereafter. Intuitively, these results indicate that LLMs appear to effectively focus their computational efforts on tokens with high information content and sequence positions where contextual cues from prior tokens are missing. Here, introducing sparsity not only provides an interpretable lens on model behavior, but also enables our kernels to leverage this inherent information unevenness for significant training and inference speedups.
5. Related Work
Section Summary: Previous studies have explored how sparsity—essentially, many zeros in the computations of large language models—naturally arises with certain activation functions and offers efficiency gains. More recent approaches have built on this by modifying modern model designs to increase sparsity, such as repeating activation steps or selectively keeping only the most important signals, often focusing on speeding up isolated parts on older hardware or pruning activations after training. In contrast, this paper proposes versatile tools to exploit unstructured sparsity across the entire model, showing practical speed improvements for both running the models and training them, with more details on earlier architectural changes in the appendix.
The emergence of sparsity in LLMs with ReLU activations and its theoretical benefits have been repeatedly documented in earlier work ([12, 25]). Since then, more recent methods have been proposed to enhance sparsity by altering modern gated architectures, claiming speedups running sparse feed-forward layers in isolation on older generations of devices. TurboSparse ([42]) studies boosting sparsity via repeated ReLU non-linearities, while ProSparse ([43]) finetunes pretrained models by manually thresholding activations. Q-Sparse ([19]) further deviates from standard models by using a straight-through estimator and retaining only top-K activations. Other work instead focused on introducing structured sparsity post-training, such as by predicting ([18]) and pruning activations to accelerate computation ([44, 45]). Unlike these efforts, our paper introduces general-purpose kernels to leverage unstructured sparsity, demonstrating empirical efficiency benefits during both LLM inference and training. We refer to Appendix E for an extended overview of prior work that more fundamentally reshapes architecture design.
6. Discussion and Future Work
Section Summary: This research uses a technique called unstructured sparsity to make large language models run more efficiently by cutting down on computing power needed. For running models, they created a new data format and combined operations that speed up key parts of the process with fewer memory uses, while for training, a smart scheduling method balances different hardware parts and saves space for calculations. The approach shows big improvements in speed, energy use, and memory without hurting performance, and future plans include fixing inactive model parts, adapting existing models, and sharing tools to encourage sparsity as a way to lower the high costs of these AI systems.
In this work, we leverage unstructured sparsity to lessen the computational burdens of modern LLMs. For inference, we design a new sparse format and fused operations to efficiently execute the whole gated feed-forward blocks in only two kernel launches, minimizing global memory accesses and computation. For training, we introduce a new hybrid algorithm that dynamically schedules computation on both CUDA and Tensor cores, while trivializing storage costs of intermediate activations for backpropagation. We demonstrate that mild L1 regularization induces considerable levels of sparsity with negligible impact on downstream performance – which our kernels translate into significant gains in throughput, energy efficiency, and memory footprint at billion-parameter scales. While our work serves to provide a concrete demonstration of the benefits of sparse LLMs, there are numerous exciting avenues for future extensions. For instance, in Appendix C, we provide preliminary results indicating that the performance of highly sparse LLMs can be further improved with strategies targeted at dead-neuron mitigation. Moreover, fine-tuning existing dense models via recent sparsification approaches ([25, 43]) would allow bringing the benefits of our kernels to the vast library of pretrained LLMs available in the wild. By sharing our kernels, we hope our work will help promote sparsity as a new design axis to leverage for efficiency, ultimately reducing the growing energy and hardware costs of large-scale foundation models.
Author contribution
Section Summary: Edoardo Cetin spearheaded the development of the TwELL format and led the creation and testing of specialized computing components, along with training and evaluating models, while also helping with the writing. Emilio Castillo co-developed the hybrid format, collaborated on those computing components, and designed ways to adapt training processes, contributing to benchmarks and the manuscript as well. Other team members, including Stefano Peluchetti, Akira Naruse, Mana Murakami, and Llion Jones, provided early research, advice, discussions, and initial work on sparse training techniques to support the project.
Edoardo Cetin conceived the TwELL format, led the implementation and design of the CUDA kernels using TwELL, led model training and benchmarking, and made contributions to writing.
Stefano Peluchetti did early work on sparse model training, advised the project, and made contributions to writing.
Emilio Castillo conceived the hybrid format, co-led the implementation of the CUDA kernels and designed the training extensions, made contributions to kernel benchmarking, and made contributions to writing.
Akira Naruse advised the project, was involved in early discussions about method design, and worked on early implementations of the sparse kernels.
Mana Murakami was involved in early discussions about method design.
Llion Jones did initial explorations of sparse model training, advised the project, was involved in early discussions about method design, and made contributions to writing.
Appendix
Section Summary: This appendix provides technical details on implementing efficient GPU kernels for matrix multiplication, a key operation in AI inference tasks. It focuses on selecting and optimizing inference kernels using specialized hardware features to load and process data tiles from input matrices A and B into fast shared memory, while coordinating multiple processor units through barriers and queues for smooth synchronization. The code example demonstrates a template-based kernel that supports clustered execution, ensuring high performance by handling data packing, scheduling, and overflow storage.
A. Kernels Implementation Details
A.1 Inference Kernels Selection
template <const int $T_m$, const int $T_n$, const int $T_k>$
struct Tiles
alignas(128) __nv_bfloat16 a[$T_m][T_k]$;
alignas(128) __nv_bfloat16 b[$T_n][T_k]$;;
template <
const int $T_m$,
const int $T_n$,
const int $T_k$,
const int QUEUE_SIZE,
const int $T_n_c$ ompressed,
int PADDING = 4
>
struct SmemStorage
Tiles< $T_m, T_n, T_k>$ queue[QUEUE_SIZE];
alignas(128) uint3 $2_t c_p$ acked[$T_m][T_n_c$ ompressed + PADDING];;
template <
const int $T_m$,
const int $T_n$,
const int $T_k$,
const int CLUSTER_DIM_m,
const int CLUSTER_DIM_n,
const int QUEUE_SIZE,
const int NUM_ACTIVE_SMs,
const int $T_n_c$ ompressed,
const bool LOOP_OVERFLOW_STORAGE
>
__global__ __launch_bounds__(NUM_THREADS_PER_BLOCK)
__cluster_dims__(CLUSTER_DIM_m * CLUSTER_DIM_n, 1, 1)
void mm_wgmma_nt_kernel(
const CUtensorMap __grid_constant__ $A_tm$,
const CUtensorMap __grid_constant__ $B_tm$,
const CUtensorMap __grid_constant__ $C_p$ acked_tm,
const int* schedule_gmem_ptr,
const int schedule_size_per_sm,
const int K
)
static_assert(
($T_m == 64$ * 2),
"Only $T_m == 128$ supported"
);
constexpr int CLUSTER_SIZE = CLUSTER_DIM_m * CLUSTER_DIM_n;
extern __shared__ __align__(1024) unsigned char dynamic_smem[];
int cluster_idx;
asm ("mov.u32
int cluster_lane_m;
asm volatile("mov.u32
int cluster_lane_n = cluster_lane_m
cluster_lane_m /= CLUSTER_DIM_n;
auto& tiles_s =
*reinterpret_cast<
SmemStorage< $T_m, T_n, T_k$, QUEUE_SIZE, $T_n_c$ ompressed>*
>(dynamic_smem);
int* schedule_s = reinterpret_cast<int*>(
dynamic_smem
+ sizeof(SmemStorage< $T_m, T_n, T_k$, QUEUE_SIZE, $T_n_c$ ompressed>)
);
schedule_gmem_ptr += cluster_idx * schedule_size_per_sm;
if (threadIdx.x < schedule_size_per_sm) schedule_s[threadIdx.x] = schedule_gmem_ptr[threadIdx.x];
__syncthreads();
__shared__ __align__(8) uint6 $4_t$ queue_full[QUEUE_SIZE];
__shared__ __align__(8) uint6 $4_t$ queue_empty[QUEUE_SIZE];
if (threadIdx.x == 0) {
#pragma unroll
for (int queue_idx = 0; queue_idx < QUEUE_SIZE; ++queue_idx) ptx_init_smem_barrier(&queue_full[queue_idx], 1);
ptx_init_smem_barrier(&queue_empty[queue_idx], 2 * CLUSTER_SIZE);
asm volatile("barrier.cluster.arrive;\n" : :);
asm volatile("barrier.cluster.wait;\n" : :);
if (threadIdx.x < WARP_GROUP_SIZE) {
asm volatile("setmaxnreg.dec.sync.aligned.u32
if (threadIdx.x == 0) {
int queue_idx = 0;
int queue_phase = 0;
uint1 $6_t$ mask_multicast_m = 0;
if constexpr (CLUSTER_DIM_m > 1) {
for (int i = 0; i < CLUSTER_DIM_m; ++i) mask_multicast_m |= (1u << (i * CLUSTER_DIM_n));
mask_multicast_m <<= cluster_lane_n;
uint1 $6_t$ mask_multicast_n;
if constexpr (CLUSTER_DIM_n > 1) mask_multicast_n =
((1u << CLUSTER_DIM_n) - 1)
<< (cluster_lane_m * CLUSTER_DIM_n);
for (int schedule_it = 0;
schedule_it < schedule_size_per_sm;
++schedule_it) {
const int packed_tile = schedule_s[schedule_it];
if (packed_tile == -1) break;
int tile_coord_m = packed_tile >> 16;
int tile_coord_n = packed_tile & 0xFFFF;
if constexpr (CLUSTER_DIM_n > 1) tile_coord_n *= CLUSTER_DIM_n;
tile_coord_n += cluster_lane_n;
if constexpr (CLUSTER_DIM_m > 1) tile_coord_m *= CLUSTER_DIM_m;
tile_coord_m += cluster_lane_m;
for (int tile_start_k = 0;
tile_start_k < K;
tile_start_k += $T_k$, ++queue_idx) {
if (queue_idx == QUEUE_SIZE) queue_idx = 0;
queue_phase ^= 1;
ptx_wait_barrier(&queue_empty[queue_idx], queue_phase);
ptx_arrive_tx_smem_barrier(
&queue_full[queue_idx],
sizeof(tiles_s.queue[queue_idx].a)
+ sizeof(tiles_s.queue[queue_idx].b)
);
if constexpr (CLUSTER_DIM_n > 1) if (cluster_lane_n == 0) ptx_load_tile_tma_multicast_2d(
&tiles_s.queue[queue_idx].a[0][0],
& $A_tm$,
tile_coord_m * $T_m$,
tile_start_k,
mask_multicast_n,
&queue_full[queue_idx]
); else ptx_load_tile_tma_2d(
&tiles_s.queue[queue_idx].a[0][0],
& $A_tm$,
tile_coord_m * $T_m$,
tile_start_k,
&queue_full[queue_idx]
);
if constexpr (CLUSTER_DIM_m > 1) if (cluster_lane_m == 0) ptx_load_tile_tma_multicast_2d(
&tiles_s.queue[queue_idx].b[0][0],
& $B_tm$,
tile_coord_n * $T_n$,
tile_start_k,
mask_multicast_m,
&queue_full[queue_idx]
); else ptx_load_tile_tma_2d(
&tiles_s.queue[queue_idx].b[0][0],
& $B_tm$,
tile_coord_n * $T_n$,
tile_start_k,
&queue_full[queue_idx]
);
} else {
asm volatile("setmaxnreg.inc.sync.aligned.u32
int queue_idx = 0;
int queue_phase = 0;
const int consumer_warpgroup_id =
(threadIdx.x - WARP_GROUP_SIZE) / WARP_GROUP_SIZE;
const int tile_start_m = consumer_warpgroup_id * WGMMA_m;
const int consumer_thread_id = threadIdx.x
const uint thread_lane_idx_n = (consumer_thread_id
const int thread_store_offset_m = (
tile_start_m
+ consumer_thread_id / 32 * 16
+ (consumer_thread_id
);
const int thread_store_offset_n =
((consumer_thread_id
if (consumer_thread_id < CLUSTER_SIZE) {
for (int queue_idx = 0; queue_idx < QUEUE_SIZE; ++queue_idx) ptx_arrive_barrier_across_cluster(
&queue_empty[queue_idx],
consumer_thread_id,
1
);
float $C_a$ ccum[$T_n/16][8]$;
for (int schedule_it = 0;
schedule_it < schedule_size_per_sm;
++schedule_it) {
const int packed_tile = schedule_s[schedule_it];
if (packed_tile == -1) break;
int tile_coord_m = packed_tile >> 16;
int tile_coord_n = packed_tile & 0xFFFF;
if constexpr (CLUSTER_DIM_n > 1) tile_coord_n *= CLUSTER_DIM_n;
tile_coord_n += cluster_lane_n;
if constexpr (CLUSTER_DIM_m > 1) tile_coord_m *= CLUSTER_DIM_m;
tile_coord_m += cluster_lane_m;
if (queue_idx == QUEUE_SIZE) queue_idx = 0;
queue_phase ^= 1;
ptx_wait_barrier(&queue_full[queue_idx], queue_phase);
asm volatile("wgmma.fence.sync.aligned;" ::: "memory");
wgmma< $T_n, 0, 1, 1, 0, 0>($
$C_a$ ccum,
&tiles_s.queue[queue_idx].a[tile_start_m][0],
&tiles_s.queue[queue_idx].b[0][0]
);
#pragma unroll
for (int wgmma_start_k = WGMMA_k;
wgmma_start_k < $T_k$;
wgmma_start_k += WGMMA_k) wgmma< $T_n, 1, 1, 1, 0, 0>($
$C_a$ ccum,
&tiles_s.queue[queue_idx].a[tile_start_m][wgmma_start_k],
&tiles_s.queue[queue_idx].b[0][wgmma_start_k]
);
asm volatile("wgmma.commit_group.sync.aligned;" ::: "memory");
asm volatile("wgmma.wait_group.sync.aligned
if (consumer_thread_id < CLUSTER_SIZE) ptx_arrive_barrier_across_cluster(
&queue_empty[queue_idx],
consumer_thread_id,
1
);
queue_idx++;
for (int tile_idx_k = 1;
tile_idx_k < K / $T_k$;
++tile_idx_k, ++queue_idx) {
if (queue_idx == QUEUE_SIZE) queue_idx = 0;
queue_phase ^= 1;
ptx_wait_barrier(&queue_full[queue_idx], queue_phase);
asm volatile("wgmma.fence.sync.aligned;" ::: "memory");
#pragma unroll
for (int wgmma_start_k = 0;
wgmma_start_k < $T_k$;
wgmma_start_k += WGMMA_k) wgmma< $T_n, 1, 1, 1, 0, 0>($
$C_a$ ccum,
&tiles_s.queue[queue_idx].a[tile_start_m][wgmma_start_k],
&tiles_s.queue[queue_idx].b[0][wgmma_start_k]
);
asm volatile("wgmma.commit_group.sync.aligned;" ::: "memory");
asm volatile("wgmma.wait_group.sync.aligned
if (consumer_thread_id < CLUSTER_SIZE) ptx_arrive_barrier_across_cluster(
&queue_empty[queue_idx],
consumer_thread_id,
1
);
asm volatile("cp.async.bulk.wait_group.read 0;\n");
if (thread_lane_idx_n <= 1) tiles_s. $c_p$ acked[
thread_store_offset_m + 8 * thread_lane_idx_n
][0] = 0;
__syncwarp();
#pragma unroll
for (int quadrant_slice_m = 0;
quadrant_slice_m < 4;
quadrant_slice_m += 2) {
int quadrant_store_offset_m =
thread_store_offset_m + quadrant_slice_m * 4;
#pragma unroll
for (int wgmma_slice_n = 0;
wgmma_slice_n < $T_n / 16$;
++wgmma_slice_n) {
int quadrant_store_offset_n =
thread_store_offset_n + wgmma_slice_n * 16;
#pragma unroll
for (int quadrant_slice_n = 0;
quadrant_slice_n < 8;
quadrant_slice_n += 4) {
#pragma unroll
for (int element_n = 0;
element_n < 2;
++element_n) {
if (
$C_a$ ccum[wgmma_slice_n][
quadrant_slice_m
+ quadrant_slice_n
+ element_n
] > 0
) {
uint current_store_idx = __nv_atomic_fetch_add(
&tiles_s. $c_p$ acked[quadrant_store_offset_m][0],
1u,
__NV_ATOMIC_RELAXED,
__NV_THREAD_SCOPE_BLOCK
);
const uint3 $2_t$ packed_value =
tile_coord_n * $T_n$
+ quadrant_store_offset_n
+ quadrant_slice_n * 2
+ element_n
| (
static_cast<uint3 $2_t>($
__bfloat1 $6_as_u$ short(
__float2bfloat16(
$C_a$ ccum[wgmma_slice_n][
quadrant_slice_m
+ quadrant_slice_n
+ element_n
]
)
)
) << 16
);
if constexpr (LOOP_OVERFLOW_STORAGE) tiles_s. $c_p$ acked[quadrant_store_offset_m][
(current_store_idx & ($T_n_c$ ompressed - 1)) + 1
] = packed_value; else tiles_s. $c_p$ acked[quadrant_store_offset_m][
current_store_idx + 1
] = packed_value;
asm volatile("fence.proxy.async.shared::cta;\n");
asm volatile("bar.sync 10, 256;\n");
if (threadIdx.x == 128) ptx_store_transposed_tile_tma_3d<uint3 $2_t, T_n_c$ ompressed>(
& $C_p$ acked_tm,
&tiles_s. $c_p$ acked[0][0],
tile_coord_m * $T_m$,
tile_coord_n * $T_n_c$ ompressed
);
asm volatile("cp.async.bulk.commit_group;\n");
In Algorithm 1, we provide code listings with the device code for our kernel implementing a custom matmul with our new TwELL storage, which we use to run the gate projection in our model. We omit device functions wrapping longer PTX injections for readability. As explained in Section 3 in the main text, this kernel executes an efficient tiled matrix multiplication, loading the dense input and the dense weight matrix and storing the output values using the Tensor Memory Accelerator (TMA) introduced with Hopper GPUs, while storing the output in the TwELL format during the kernel's epilogue. The base kernel follows a persistent design with pipelined computation based on persistent cooperative kernels in CUTLASS ([17]) and open-source CUDA reproductions ([46]). Unlike CUTLASS, the tile scheduler follows a pre-constructed ordering based on a Hilbert curve to maximize the reuse of the L2 cache ([47, 46]). In practice, we opt to pack the TwELL values $h$, indices $h_I$, and number of non-zeros $h_{nz}$ in a single 32-bit matrix in $\mathbb{R}^{M\times N/C}$. This is done by placing the number of non-zeros for each tile row in the first column and fitting the 16-bit TwELL value and index in the remaining entries. This design ensures strong locality and allows storing and loading the number of non-zeros together with the first 31 TwELL indices and values in a single coalesced access. While this loses a storage position, we set TwELL compression factors very conservatively for each sparsity level, making the occurrence of overflow practically impossible. For instance, we set the compression factor to 8 for our recommended sparsity regularization studied in our main results, with models ranging from 39-24 average non-zeros and an expected chance of overflow of the order of $10^{-34}$. The TwELL conversion occurs when mapping the partial outputs of the asynchronous warpgroup level matmul instructions (WGMMA) from registers to shared memory via a fast CTA-scoped atomic operation with relaxed semantics. To avoid bank conflicts when resetting the number of non-zeros, we minimally pad the TwELL output with four extra elements in the last dimension. In this instance, we found our padding approach to work significantly better than swizzling, due to the lower register pressure introduced in the kernel's epilogue. In an alternative implementation, we also explored a different packing layout, placing the number of non-zeros across the diagonal of the first 32-dimensional subtile to cover all memory banks, an approach we found brought minimal throughput improvements at the cost of extra complexity. We note that for the non-gated variant of our models, we use this same kernel to perform the up projection, as this layer is the one determining the overall sparsity pattern of the tile.
template <
const int T_n,
const int T_n_compressed,
const int NUM_T_n,
const int OUT_DIM
>
__global__ __launch_bounds__(WARP_SIZE)
void mm_t2d_kernel(
const __nv_bfloat16* IN_d,
const uint32_t* GATE_OUT_twell_packed_d,
const __nv_bfloat16* UP_transposed_d,
const __nv_bfloat16* DOWN_d,
__nv_bfloat16* OUT_d
)
static_assert(
(OUT_DIM
"OUT_DIM must be divisible by WARP_SIZE."
);
static_assert(T_n_compressed == WARP_SIZE,
"Warp-sync TwELL-to-dense assumes a 32-wide compressed tile.");
constexpr int NUM_LOAD_ITERS = OUT_DIM / STRIDE_8xWARP;
float OUT_accum[NUM_LOAD_ITERS][8] = 0.0f;
__nv_bfloat162 IN_cached[NUM_LOAD_ITERS][4];
IN_d += blockIdx.x * OUT_DIM + threadIdx.x * 8;
GATE_OUT_twell_packed_d += (
blockIdx.x * T_n_compressed * NUM_T_n + threadIdx.x
);
UP_transposed_d += threadIdx.x * 8;
DOWN_d += threadIdx.x * 8;
OUT_d += blockIdx.x * OUT_DIM + threadIdx.x * 8;
#pragma unroll
for (int iter_idx = 0; iter_idx < NUM_LOAD_ITERS; ++iter_idx) {
*reinterpret_cast<uint4*>(&IN_cached[iter_idx][0]) =
*reinterpret_cast<const uint4*>(
IN_d + iter_idx * STRIDE_8xWARP
);
#pragma unroll 1
for (int tile_idx = 0; tile_idx < NUM_T_n; ++tile_idx) {
const int lane_tile_register =
GATE_OUT_twell_packed_d[tile_idx * T_n_compressed];
const int num_nonzeros =
__shfl_sync(0xFFFFFFFFu, lane_tile_register, 0);
#pragma unroll 1
for (int idx = 1; idx < num_nonzeros + 1; ++idx) {
const uint32_t compressed_idx_bf16 =
__shfl_sync(0xFFFFFFFFu, lane_tile_register, idx);
const uint32_t nonzero_idx = compressed_idx_bf16 & 0xFFFFu;
float UP_OUT_accum = 0.0f;
#pragma unroll
for (int iter_idx = 0; iter_idx < NUM_LOAD_ITERS; ++iter_idx) {
const uint4 packed_bfloats_x8 =
*reinterpret_cast<const uint4*>(
UP_transposed_d
+ nonzero_idx * OUT_DIM
+ iter_idx * STRIDE_8xWARP
);
const __nv_bfloat162 packed_bfloats_1 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.x
);
__nv_bfloat162 scaled_bfloats_1 =
__hmul2(IN_cached[iter_idx][0], packed_bfloats_1);
float2 scaled_floats_1 = __bfloat1622float2(scaled_bfloats_1);
UP_OUT_accum += scaled_floats_1.x + scaled_floats_1.y;
const __nv_bfloat162 packed_bfloats_2 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.y
);
__nv_bfloat162 scaled_bfloats_2 =
__hmul2(IN_cached[iter_idx][1], packed_bfloats_2);
float2 scaled_floats_2 = __bfloat1622float2(scaled_bfloats_2);
UP_OUT_accum += scaled_floats_2.x + scaled_floats_2.y;
const __nv_bfloat162 packed_bfloats_3 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.z
);
__nv_bfloat162 scaled_bfloats_3 =
__hmul2(IN_cached[iter_idx][2], packed_bfloats_3);
float2 scaled_floats_3 = __bfloat1622float2(scaled_bfloats_3);
UP_OUT_accum += scaled_floats_3.x + scaled_floats_3.y;
const __nv_bfloat162 packed_bfloats_4 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.w
);
__nv_bfloat162 scaled_bfloats_4 =
__hmul2(IN_cached[iter_idx][3], packed_bfloats_4);
float2 scaled_floats_4 = __bfloat1622float2(scaled_bfloats_4);
UP_OUT_accum += scaled_floats_4.x + scaled_floats_4.y;
#pragma unroll
for (int butterfly_stride = WARP_SIZE / 2;
butterfly_stride > 0;
butterfly_stride /= 2) {
UP_OUT_accum += __shfl_xor_sync(
0xFFFFFFFFu,
UP_OUT_accum,
butterfly_stride
);
const __nv_bfloat162 nonzero_feature =
__bfloat162bfloat162(
__hmul(
reinterpret_cast<const __nv_bfloat16*>(
&compressed_idx_bf16
)[1],
__float2bfloat16_rn(UP_OUT_accum)
)
);
#pragma unroll
for (int iter_idx = 0; iter_idx < NUM_LOAD_ITERS; ++iter_idx) {
const uint4 packed_bfloats_x8 =
*reinterpret_cast<const uint4*>(
DOWN_d
+ nonzero_idx * OUT_DIM
+ iter_idx * STRIDE_8xWARP
);
const __nv_bfloat162 packed_bfloats_1 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.x
);
__nv_bfloat162 scaled_bfloats_1 =
__hmul2(nonzero_feature, packed_bfloats_1);
float2 scaled_floats_1 = __bfloat1622float2(scaled_bfloats_1);
OUT_accum[iter_idx][0] += scaled_floats_1.x;
OUT_accum[iter_idx][1] += scaled_floats_1.y;
const __nv_bfloat162 packed_bfloats_2 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.y
);
__nv_bfloat162 scaled_bfloats_2 =
__hmul2(nonzero_feature, packed_bfloats_2);
float2 scaled_floats_2 = __bfloat1622float2(scaled_bfloats_2);
OUT_accum[iter_idx][2] += scaled_floats_2.x;
OUT_accum[iter_idx][3] += scaled_floats_2.y;
const __nv_bfloat162 packed_bfloats_3 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.z
);
__nv_bfloat162 scaled_bfloats_3 =
__hmul2(nonzero_feature, packed_bfloats_3);
float2 scaled_floats_3 = __bfloat1622float2(scaled_bfloats_3);
OUT_accum[iter_idx][4] += scaled_floats_3.x;
OUT_accum[iter_idx][5] += scaled_floats_3.y;
const __nv_bfloat162 packed_bfloats_4 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.w
);
__nv_bfloat162 scaled_bfloats_4 =
__hmul2(nonzero_feature, packed_bfloats_4);
float2 scaled_floats_4 = __bfloat1622float2(scaled_bfloats_4);
OUT_accum[iter_idx][6] += scaled_floats_4.x;
OUT_accum[iter_idx][7] += scaled_floats_4.y;
#pragma unroll
for (int iter_idx = 0; iter_idx < NUM_LOAD_ITERS; ++iter_idx) {
__nv_bfloat162 __align__(8) packed_bfloats_x8[4];
packed_bfloats_x8[0] = __floats2bfloat162_rn(
OUT_accum[iter_idx][0], OUT_accum[iter_idx][1]
);
packed_bfloats_x8[1] = __floats2bfloat162_rn(
OUT_accum[iter_idx][2], OUT_accum[iter_idx][3]
);
packed_bfloats_x8[2] = __floats2bfloat162_rn(
OUT_accum[iter_idx][4], OUT_accum[iter_idx][5]
);
packed_bfloats_x8[3] = __floats2bfloat162_rn(
OUT_accum[iter_idx][6], OUT_accum[iter_idx][7]
);
*reinterpret_cast<uint4*>(OUT_d + iter_idx * STRIDE_8xWARP) =
*reinterpret_cast<uint4*>(packed_bfloats_x8);
In Algorithm 2, we provide code listings with the device code for our kernel implementing the custom fused up and down projection kernel that leverages the gate projections stored in the TwELL format. As explained in Section 3 in the main text, this kernel is launched on a grid of warp-sized CTAs and fuses the two operations by keeping in memory the input dense feature row and an accumulator. Then, iterating first statically through the TwELL tiles and then dynamically through the number of non-zeros in each tile, it loads the corresponding gate index, which directly maps to a unique column of the up projection and row of the down projection weight matrices. The kernel computes the up-projected feature from a dot product between the input dense feature row and the up projection weight column, multiplies it by the gate value, and finally uses it to scale the down projection weight row before accumulating the output. To ensure coalesced access, we note that the up projection weight matrix is stored in transposed format. This version of the kernel is specialized to handle the case where $T_n=256$ and the compression ratio is 8, leading to a total of 32 elements for each packed TwELL tile. In this specific instance, we load both the number of non-zeros and all the indices and values for the tile in a single fully coalesced access over the CTA's warp, which later allows loading the full TwELL tile information via minimal warp register shuffle operations without incurring any shared memory overheads. In preliminary experiments, we also found that re-ordering the kernel calls in descending order of non-zeros can further accelerate performance with low batch sizes. However, we note that we did not find this optimization necessary with large batches and omitted it for simplicity.
template <
const int $T_n$,
const int $T_n_c$ ompressed,
const int NUM_T_n,
const int OUT_DIM,
const int SPLIT_OUT_DIM
>
__global__ __launch_bounds__(32)
void mm_t2 $d_k$ ernel(
const uint3 $2_t$* IN_twell_packed_d,
const __nv_bfloat16* DOWN_d,
__nv_bfloat16* OUT_d
)
static_assert(
(SPLIT_OUT_DIM
"OUT_DIM must be divisible by WARP_SIZE."
);
static_assert(
(OUT_DIM
"OUT_DIM must be divisible by SPLIT_OUT_DIM."
);
static_assert($T_n_c$ ompressed == WARP_SIZE,
"Warp-sync TwELL-to-dense assumes a 32-wide compressed tile.");
float OUT_accum[OUT_DIM / STRIDE_8xWARP][8] = 0.0f;
constexpr int NUM_LOAD_ITERS = SPLIT_OUT_DIM / STRIDE_8xWARP;
IN_twell_packed_d += blockIdx.x * $T_n_c$ ompressed * NUM_T_n + threadIdx.x;
DOWN_d += threadIdx.x * 8 + blockIdx.y * SPLIT_OUT_DIM;
OUT_d += blockIdx.x * OUT_DIM + threadIdx.x * 8 + blockIdx.y * SPLIT_OUT_DIM;
#pragma unroll 1
for (int tile_idx = 0; tile_idx < NUM_T_n; ++tile_idx) {
const int lane_tile_register =
IN_twell_packed_d[tile_idx * $T_n_c$ ompressed];
const int num_nonzeros =
__shfl_sync(0xFFFFFFFFu, lane_tile_register, 0);
#pragma unroll 1
for (int idx = 1; idx < num_nonzeros + 1; ++idx) {
const uint3 $2_t$ compressed_idx_bf16 =
__shfl_sync(0xFFFFFFFFu, lane_tile_register, idx);
const uint3 $2_t$ nonzero_idx = compressed_idx_bf16 & 0xFFFFu;
const __nv_bfloat162 nonzero_feature =
__bfloat162bfloat162(
reinterpret_cast<const __nv_bfloat16*>(
&compressed_idx_bf16
)[1]
);
#pragma unroll
for (int iter_idx = 0; iter_idx < NUM_LOAD_ITERS; ++iter_idx) const uint4 packed_bfloats_x8 =
*reinterpret_cast<const uint4*>(
DOWN_d
+ nonzero_idx * OUT_DIM
+ iter_idx * STRIDE_8xWARP
);
const __nv_bfloat162 packed_bfloats_1 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.x
);
__nv_bfloat162 scaled_bfloats_1 =
__hmul2(nonzero_feature, packed_bfloats_1);
float2 scaled_floats_1 = __bfloat1622float2(scaled_bfloats_1);
OUT_accum[iter_idx][0] += scaled_floats_1.x;
OUT_accum[iter_idx][1] += scaled_floats_1.y;
const __nv_bfloat162 packed_bfloats_2 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.y
);
__nv_bfloat162 scaled_bfloats_2 =
__hmul2(nonzero_feature, packed_bfloats_2);
float2 scaled_floats_2 = __bfloat1622float2(scaled_bfloats_2);
OUT_accum[iter_idx][2] += scaled_floats_2.x;
OUT_accum[iter_idx][3] += scaled_floats_2.y;
const __nv_bfloat162 packed_bfloats_3 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.z
);
__nv_bfloat162 scaled_bfloats_3 =
__hmul2(nonzero_feature, packed_bfloats_3);
float2 scaled_floats_3 = __bfloat1622float2(scaled_bfloats_3);
OUT_accum[iter_idx][4] += scaled_floats_3.x;
OUT_accum[iter_idx][5] += scaled_floats_3.y;
const __nv_bfloat162 packed_bfloats_4 =
*reinterpret_cast<const __nv_bfloat162*>(
&packed_bfloats_x8.w
);
__nv_bfloat162 scaled_bfloats_4 =
__hmul2(nonzero_feature, packed_bfloats_4);
float2 scaled_floats_4 = __bfloat1622float2(scaled_bfloats_4);
OUT_accum[iter_idx][6] += scaled_floats_4.x;
OUT_accum[iter_idx][7] += scaled_floats_4.y;
#pragma unroll
for (int iter_idx = 0; iter_idx < NUM_LOAD_ITERS; ++iter_idx) __nv_bfloat162 __align__(8) packed_bfloats_x8[4];
packed_bfloats_x8[0] = __floats2bfloat16 $2_rn($
OUT_accum[iter_idx][0], OUT_accum[iter_idx][1]
);
packed_bfloats_x8[1] = __floats2bfloat16 $2_rn($
OUT_accum[iter_idx][2], OUT_accum[iter_idx][3]
);
packed_bfloats_x8[2] = __floats2bfloat16 $2_rn($
OUT_accum[iter_idx][4], OUT_accum[iter_idx][5]
);
packed_bfloats_x8[3] = __floats2bfloat16 $2_rn($
OUT_accum[iter_idx][6], OUT_accum[iter_idx][7]
);
*reinterpret_cast<uint4*>(OUT_d + iter_idx * STRIDE_8xWARP) =
*reinterpret_cast<uint4*>(packed_bfloats_x8);
As mentioned in Section 2 of the main text, together with modern gated LLMs, we also provide specific kernels that support older non-gated variants, which we empirically evaluate in Appendix C. In Algorithm 3, we provide code listings with the device code for our kernel implementing the custom down projection kernel that leverages up projection activations stored in the TwELL format for these experiments. Similarly to the fused kernel explained in Section 3 and examined above, this kernel is launched on a grid of warp-sized CTAs and reads the sparsity pattern, this time from the up projection activations stored in the TwELL format. This time, the kernel maintains in memory the out projection and a float32 accumulator for a small output segment. Then, it first statically iterates through the TwELL tile and then dynamically iterates over the number of non-zeros in each tile. At each iteration, it loads the non-zero index and the corresponding activation down projection column segment, before multiplying the two and accumulating the result. In contrast to our fused kernel, where we have to consider full rows on the input and output to perform dot products between the input features and the up projection weights, introducing the split formulation in this kernel is a deliberate and purposeful choice: by introducing trivial duplication of the non-zero reads we can further increase parallelism, reduce register pressure, increase occupancy, and hide longer latencies from uneven sparsity. In practice, we note that using a split dimension of half the base output dimension, leading to two CTAs per output row, appears optimal on our Hopper GPUs.
A.2 Training Kernels Selection
__global__ void twell_to_ell_kernel(
const __nv_bfloat16* __restrict__ $C_v$ als,
const uint8_t* __restrict__ $C_i$ dx,
const uint3 $2_t$* __restrict__ $C_n$ nz,
__nv_bfloat16* __restrict__ ell_val,
int1 $6_t$* __restrict__ ell_col,
int3 $2_t$* __restrict__ row_nnz,
float* __restrict__ l0_out,
float* __restrict__ l1_out,
int M,
int $N_T$ ILES,
int BW,
int ELL_W,
int $T_n$
)
const int row = blockIdx.x * blockDim.y + threadIdx.y;
if (row >= M) return;
const int tid = threadIdx.x;
int cnt = (tid < $N_T$ ILES) ? $C_n$ nz[(size_t)tid * M + row] : 0;
cnt = min(cnt, BW);
int offset = cnt;
for (int delta = 1; delta < WARP_SIZE; delta <<= 1) {
const int recv = __shfl_up_sync(0xFFFFFFFFu, offset, delta);
if (tid >= delta) offset += recv;
const int start = offset - cnt;
const int total =
__shfl_sync(0xFFFFFFFFu, offset, min($N_T$ ILES - 1, WARP_SIZE - 1));
const __nv_bfloat16* sv =
$C_v$ als + (size_t)row * $N_T$ ILES * BW + (size_t)tid * BW;
const uint8_t* si =
$C_i$ dx + (size_t)row * $N_T$ ILES * BW + (size_t)tid * BW;
float l0_acc = 0.0f;
float l1_acc = 0.0f;
if (l0_out) {
const float inv_M = 1.0f / (float)M;
l0_acc = (float)cnt * inv_M;
for (int i = 0; i < cnt; ++i) l1_acc += __bfloat162float(sv[i]) * inv_M;
if (cnt > 0 && start < ELL_W) {
const int copy_n = min(cnt, ELL_W - start);
__nv_bfloat16* dv = ell_val + (size_t)row * ELL_W + start;
int1 $6_t$* dc = ell_col + (size_t)row * ELL_W + start;
for (int i = 0; i < copy_n; ++i) dv[i] = sv[i];
dc[i] = (int1 $6_t)($ si[i]) + (int1 $6_t)($ tid * $T_n)$;
if (tid == 0) row_nnz[row] = total;
if (l0_out) {
for (int s = 16; s > 0; s >>= 1) l0_acc += __shfl_down_sync(0xFFFFFFFFu, l0_acc, s);
l1_acc += __shfl_down_sync(0xFFFFFFFFu, l1_acc, s);
if (tid == 0) {
atomicAdd(l0_out, l0_acc);
if (l1_out) atomicAdd(l1_out, l1_acc);
In Algorithm 4, we provide code listings with the device code for our training kernel used to convert gate activations stored in the TwELL format into the compact ELL component of our hybrid training representation while accumulating $L_0$ and $L_1$ statistics. As discussed in Section 3, the conversion dynamically partitions the rows based on the non-zero counts. We allocate a warp to each row, and let each thread read the number of active entries in a single tile. We then use warp register shuffles to obtain an inclusive prefix scan and determine the starting offset of that tile within the destination ELL row. This design allows for directly compacting the tiled representation into contiguous row-wise ELL storage without requiring any synchronization beyond warp-level or shared memory accesses. The kernel writes the true row occupancy to $row_nnz$ even when the row exceeds the configured ELL width $ELL_W$, allowing overflow rows to be detected and promoted to the dense tail of the hybrid format. During training, each warp also reduces simple $L_0$ and $L_1$ sparsity statistics to compute the sparsity levels and L1 loss before issuing a single atomic update.
__global__ void matmul_save_sparse_like_ell(
bfloat16* A,
bfloat16* B_T,
ELL* out,
int M,
int K,
int N
)
const int row = blockIdx.x;
const int ell_n = out->row_counts[row];
if (ell_n == 0 || ell_n > ELL_WIDTH) {
return;
bfloat16* A_row_ptr = A + row * K;
const int lane_id = threadIdx.x & 31;
const int warp_id = threadIdx.x >> 5;
const int num_warps = blockDim.x >> 5;
const int num_chunks = K / 8;
for (int out_idx = warp_id; out_idx < ell_n; out_idx += num_warps) {
const int col = out->cols[row * ELL_WIDTH + out_idx];
bfloat16* B_row_ptr = B_T + col * K;
float acc = 0.0f;
for (int chunk_base = 0; chunk_base < num_chunks; chunk_base += 32) {
const int chunk = chunk_base + lane_id;
if (chunk >= num_chunks) {
break;
int4 a_raw = *(int4*)(A_row_ptr + chunk * 8);
int4 b_raw = *(int4*)(B_row_ptr + chunk * 8);
bfloat16_2* a_vec = (bfloat16_2*)&a_raw;
bfloat16_2* b_vec = (bfloat16_2*)&b_raw;
for (int t = 0; t < 4; ++t) {
float2 af = bfloat1622float2(a_vec[t]);
float2 bf = bfloat1622float2(b_vec[t]);
acc = fmaf(af.x, bf.x, acc);
acc = fmaf(af.y, bf.y, acc);
for (int offset = 16; offset > 0; offset >>= 1) {
acc += __shfl_xor_sync(0xFFFFFFFFu, acc, offset);
if (lane_id == 0) {
out->vals[row * ELL_WIDTH + out_idx] = float2bfloat16(acc);
In Algorithm 5, we provide code listings of our custom kernel used to perform the efficient dense-to-hybrid matmuls used during training, focusing on the sparse component. This kernel shows the logic of the dynamic hybrid partitioning, skipping the sparse operation in the non-zeros is recognized to exceed the size of the aggressively compact ELL format. The kernel takes two dense matrices, $A$ and $B$ (provided as $B_T$), and a pre-allocated ELL output "out" of shape $M \times N$, whose column indices encode the sparsity pattern to be evaluated. Rather than computing all $MN$ outputs, each thread block processes a single output row and iterates only over the column indices stored for that row in out. For each selected column, the kernel computes the dot product between $A[row, :]$ and $B_T[col, :]$. To maximize coalescing and enable vectorized memory accesses, $B$ is stored transposed so that rows of $B_T$ are contiguous in memory. To maximize throughput with bfloat16, threads load $A$ and $B_T$ in 128-bit transactions (8 bfloat16 values at a time) and accumulate in float32 using fused multiply-adds. Each warp reduces partial sums using shuffle-based reduction, and the final value is written to the corresponding slot in the ELL value array. This design aligns with ELL’s row-oriented storage: the sparsity pattern is known up front, so the kernel avoids both dense materialization and irregular gathers beyond the indexed rows of $B_T$. In the forward pass, we use this kernel to compute only the entries of the up projection operation $xW_u$ that will survive the subsequent gating, by copying the sparsity pattern from $h_g$ into out and filling its values with the corresponding dot products. In the backward pass, the same kernel is reused for masked gradient matmuls that share a known sparsity pattern. For instance, we use it to compute $\nabla h = \nabla y, W_d^T$. Rows that exceed the ELL capacity are handled by routing the overflow to the dense backup matrix and computing that portion with Tensor Core–optimized kernels, as described in Algorithm 3, and they are multiplied by a binary mask containing the sparsity pattern to be applied.
__global__ void hybrid_to_dense_mamtul(
ELL* A,
bfloat16* B,
bfloat16* C,
int M,
int N,
int K
)
const int row = blockIdx.x;
const int ell_n = A->row_counts[row];
if (ell_n == 0 || ell_n > ELL_WIDTH) return;
bfloat16* $A_r$ ow_vals = A->vals + row * ELL_WIDTH;
uint1 $6_t$* $A_r$ ow_idxs = A->cols + row * ELL_WIDTH;
for (int $n_o$ ut = threadIdx.x * 8; $n_o$ ut < N; $n_o$ ut += 8 * blockDim.x) {
float2 acc[4];
for (int i = 0; i < 4; ++i) acc[i] = make_float2(0.f, 0.f);
for (int k = 0; k < ELL_WIDTH; ++k) {
if (k >= ell_n) break;
const bfloat16 $a_v$ al = $A_r$ ow_vals[k];
const uint1 $6_t$ col_idx = $A_r$ ow_idxs[k];
bfloat16* $B_r$ ow_ptr = B + col_idx * N + $n_o$ ut;
int4 $b_v$ ec_raw = *(int4*)($B_r$ ow_ptr);
bfloat162* $b_v$ ec = (bfloat162*)(& $b_v$ ec_raw);
const float a = bfloat162float($a_v$ al);
for (int t = 0; t < 4; ++t) float2 $b_f32 =$ bfloat1622float2($b_v$ ec[t]);
acc[t].x = fmaf(a, $b_f32$.x, acc[t].x);
acc[t].y = fmaf(a, $b_f32$.y, acc[t].y);
bfloat162* $C_p$ tr = (bfloat162*)(C + row * N + $n_o$ ut);
for (int i = 0; i < 4; ++i) $C_p$ tr[i] = float22bfloat162(acc[i]);
In Algorithm 6, we provide code listings of our custom kernel used to perform the efficient hybrid-to-dense used during training, focusing on the sparse component. Again, this kernel implements the same dynamic hybrid partitioning logic, skipping the sparse operation in the non-zeros is recognized to exceed the size of the aggressively compact ELL format. In particular, the kernel computes a sparse–dense matrix multiplication $C = AB$, where $A$ is stored in ELL format and $B$ and $C$ are dense row-major matrices. The kernel maps one CTA per output row of $C$, which aligns naturally with ELL’s row-wise storage and lets the CTA reuse the same sparse row metadata while sweeping across the output columns. Within a CTA, threads partition the output row into contiguous column tiles. For each tile, they iterate over the non-zeros in the corresponding ELL row of $A$ and accumulate contributions of the form $a \cdot B[col_idx, :]$ into $C[row, :]$. To maximize memory throughput for bfloat16, the kernel accesses $B$ using 128-bit SIMD loads, so that each thread processes 8 output elements at a time. Accumulation is performed in float32, and the results are written back in vectorized form, providing a simple and efficient SpMM for the fixed-width ELL layout. Rows that exceed the ELL capacity are handled by routing the overflow to the dense backup matrix and computing that portion with Tensor Core–optimized kernels, as described in Algorithm 3. This kernel is used in the forward pass to compute the feedforward layer output. In the backward pass, it is also used to compute gradients with respect to the layer parameters as well as the input activations.
__global__ void hybrid_transpose(
ELL* A,
ELL* A_T,
bfloat16* tail_A,
bfloat16_t* tail_A_T,
int M,
int N
)
for (int row = blockIdx.x; row < M; row += gridDim.x) {
const int nnz_row = A->row_counts[row];
if (nnz_row == 0 || nnz_row > ELL_WIDTH) {
continue;
for (int k = threadIdx.x; k < nnz_row; k += blockDim.x) {
const uint16_t col = A->cols[row * ELL_WIDTH + k];
const bfloat16 val = A->vals[row * ELL_WIDTH + k];
const int out_row = col;
const int out_col = row;
const int pos = atomicAdd(A_T->row_counts[out_row], 1);
if (pos < ELL_WIDTH) const size_t addr = out_row * ELL_WIDTH + pos;
A_T->cols[addr] = out_col;
A_T->vals[addr] = val; else {
const int d_row =
get_or_allocate_dense_row(out_row, A_T->tail_map);
tail_A_T[d_row * M + out_col] = val;
for (int d_row = blockIdx.x; d_row < A->tail_rows; d_row += gridDim.x) {
const int src_row = A->tail_map_reverse[d_row];
bfloat16_t* src = tail_A + d_row * N;
for (int col0 = threadIdx.x * 8; col0 < N; col0 += blockDim.x * 8) {
int4 raw = *(int4*)(src + col0);
if ((raw.x | raw.y | raw.z | raw.w) == 0) {
continue;
for (int i = 0; i < 8; ++i) {
const bfloat16_t val = unpack_element(&raw, i);
if (val == 0.0f) {
continue;
const int out_row = col0 + i;
const int out_col = src_row;
const int pos = atomicAdd(A_T->row_counts[out_row], 1);
if (pos < ELL_WIDTH) const size_t addr = out_row * ELL_WIDTH + pos;
A_T->cols[addr] = out_col;
A_T->vals[addr] = val; else {
const int dense_row =
get_or_allocate_dense_row(out_row, A_T->tail_map);
tail_A_T[dense_row * M + out_col] = val;
In Algorithm 7, we provide code listings of our custom kernel used to perform efficient transposition of a matrix stored in our hybrid training format. The kernel takes as input a matrix $A$ and produces $A_T$ in the same representation: an ELL matrix, plus a dense backup for rows that overflow the maximum number of non-zeros. It operates in two parts. First, it transposes the non-overflow rows stored in the ELL structure by iterating over each row’s non-zeros and inserting them into the corresponding row of $A_T$ (since a non-zero at $(\texttt{row}, \texttt{col})$ becomes an entry in row $\texttt{col}$ of the transpose). Because many source rows may map to the same destination row, the kernel uses atomic increments to reserve an insertion slot. If the destination row still has capacity, the entry is written into the ELL arrays of $A_T$; otherwise, it is routed to the dense backup, using a per-row mapping that allocates a dense-tail row on demand. Second, it handles the overflow rows that are materialized in the dense tail of $A$. These rows are scanned in vectorized chunks (128-bit loads, i.e., 8 bfloat16 values at a time) with a fast zero check to skip all-zero vectors. Only non-zero elements are emitted into $A_T$ using the same hybrid partitioning logic. This approach keeps transposition efficient while preserving the hybrid format and avoiding expensive conversions to more general sparse layouts. After this kernel completes, we launch a small helper kernel to copy the entries stored in the ELL arrays for rows that overflowed into the corresponding dense-backup rows. We note that the necessity of this final small step comes from the fact that dense rows are only allocated and populated after the ELL slots for a given output row have been exhausted.
B. Hyperparameters and Datasets
B.1 Training Details
::: {caption="Table 2: Default Hyperparameters for Pretraining Sparse and Non-Sparse LLMs."}
:::
As explained in Section 4 of the main text, our sparse models and dense baselines in the main text implement a "Transformer++" architecture with gated feedforward blocks, as common in recent LLMs such as Qwen and Llama ([23, 24]). Moreover, in Appendix C, we also collect results on a non-gated variant of the same architecture, more similar to the traditional architecture, more similar to the original transformer design ([3]). We train all models using the fineweb ([33]). In particular, we consider a deduplicated version of the fineweb-edu split, obtained by from an open corpus used to pretrain the SmolLM family of models ([48]). We note that all our models are trained with the chinchilla-optimal number of tokens ([32]): around 10B tokens for our 0.5B models, 20B tokens for our 1B models, 30B tokens for our 1.5B models, and 40B tokens for our 2B models.
We provide a full list of hyperparameters and training specifications for our training settings and models in Table 2. For all models, we use context lengths of 2048 tokens, with batches of 512 sequences, resulting in a global batch size of 1M tokens. For our gated variant, we use a dimensionality of 2048 and a hidden dimension of 5632 in the feedforward blocks, roughly eight-thirds of the hidden size. The main difference with the non-gated variant is that we use a much larger intermediate size of 8192, four times the hidden size, leading to the same total number of parameters. We note that both these choices are considered optimal in the current literature with larger model design practices. When varying model sizes, we modify the number of layers to achieve the target parameter counts. In practice, modern small models have also considered shifting even more of the parameters and flops to the feedforward blocks: for instance, the 1B model of the llama 3 family has a feedforward size of 4x the hidden size even while implementing the gated design ([49]). While the gains from our sparse kernels could be even greater in these settings, we opted for a more conservative design to avoid biasing our results toward smaller models.
To optimize our models, we use the AdamW optimizer ([34]) with a weight decay of 0.1 and a cosine learning rate schedule starting from a peak learning rate of $1.0\times10^{-3}$, after a small warmup of 600 steps. We use the default Adam parameters of $(\beta_1, \beta_2, \epsilon)=(0.9, 0.95, 1\times10^{-8})$ and clip gradients at a maximum norm of 1.0. Our vocabulary of tokens comes from a GPT2 tokenizer ([4]). We train using standard mixed precision with the bfloat16 format, with our optimizer states stored in full precision.
B.2 Task Evaluation Details
We evaluate our models using cloze-formulation scores on seven standard downstream multiple-choice benchmarks that probe logical and commonsense reasoning after pretraining. In particular, we consider ARC (Easy and Hard versions) ([35]), a grade-school science question answering benchmark comprising both Easy and Challenge subsets, with the latter designed to defeat simple retrieval- and co-occurrence-based baselines; HellaSwag ([36]), a commonsense sentence completion task that was designed for counterintuitive LLM challenge; OpenBookQA ([37]), focused on probing curated sets of science-based and commonsense knowledge; PIQA ([38]), a benchmark benchmark focused on physical commonsense reasoning; WinoGrande ([39]), a Winograd-style large-scale conference benchmark; and CommonsenseQA ([40]), evaluating broader commonsense reasoning. We follow standard evaluation protocols and hyperparameters for formatting the input questions.
B.2.1 Sparse data structures sizing
We note that the hybrid training format proposed in this paper introduces two core hyperparameters necessary to fulfill its targeted static allocation design: the ELL maximum number of elements per row, and the number of rows in the dense matrix that stores overflowing elements. Both hyperparameters effectively control a trade-off between performance and memory savings, making their value partially dependent on the sparsity level. Moreover, because sparsity can change abruptly during training, we evaluate a set of sizes that can tolerate sudden decreases in sparsity while remaining performant. In practice, we find that setting the maximum number of elements to 128, and the maximum number of backup rows to one-eighth of the token batch size, to be a robust choice for all sparsity levels above $1.5 \times 10^{-5}$. Moreover, below this point, simply doubling the ELL non-zeros prevents other instabilities. However, we note that with prior knowledge of the sparsity evolution, these structures can often be made smaller within training itself. For example, for $L_1=1 \times 10^{-4}$, we observe that after training stabilizes, we can reduce the number of rows in the dense overflow matrix to 512, enabling higher speedups and additional memory savings. Moreover, the requirements on these two limits differ between the forward and backward passes due to the sparse-matrix transposition used in backpropagation. We note that relevant future extensions could characterize these requirements and develop online tuning of these hyperparameters to improve performance and memory savings further. Finally, when the number of elements exceeds the capacity of our data structures, we currently discard the excess values to avoid a hard failure and set a flag that is reported to the CPU at the next GPU synchronization point. This allows the training system to adaptively increase the structure sizes and repeat the latest training optimization step to avoid any deterioration in the learning dynamics.
C. Parameter Studies and Ablations
C.1 Performance and Efficiency Across Activation Functions
::: {caption="Table 3: Comparison of performance and efficiency statistics of sparse LLMs leveraging our kernels with traditional gated models using both ReLU and SiLU activations ([50, 51, 20])."}

:::
As noted in Section 2, many recent LLM architectures have deviated from using ReLUs in favor of smoother activation functions such as SiLU ([50, 51]). To provide a direct comparison between the two activations, we collect additional training runs on 30B tokens with our 1.5B model and collect efficiency and performance results. In Table 3, we find that, while final cross-entropy appears equivalent, SiLU activations indeed yield slightly higher task accuracy in our evaluation set. However, we note that SiLU LLMs are already marginally slower than non-sparse ReLU LLMs by 0.5%, and due to their inherent non-sparse nature, they cannot support integration with sparsity and, therefore, the benefits of our kernels. Overall, we find these results are consistent with the ones from [25] using larger OPT models ([52]) – appearing to indicate that the advantages of smooth activation functions are minor and could potentially be offset by efficiency considerations.
C.2 Non-gated Sparse LLMs
::: {caption="Table 4: Comparison of performance and efficiency statistics of sparse LLMs leveraging our kernels with traditional baselines, considering both gated models ([20]), and their original non-gated counterparts used in the original transformer ([3])."}
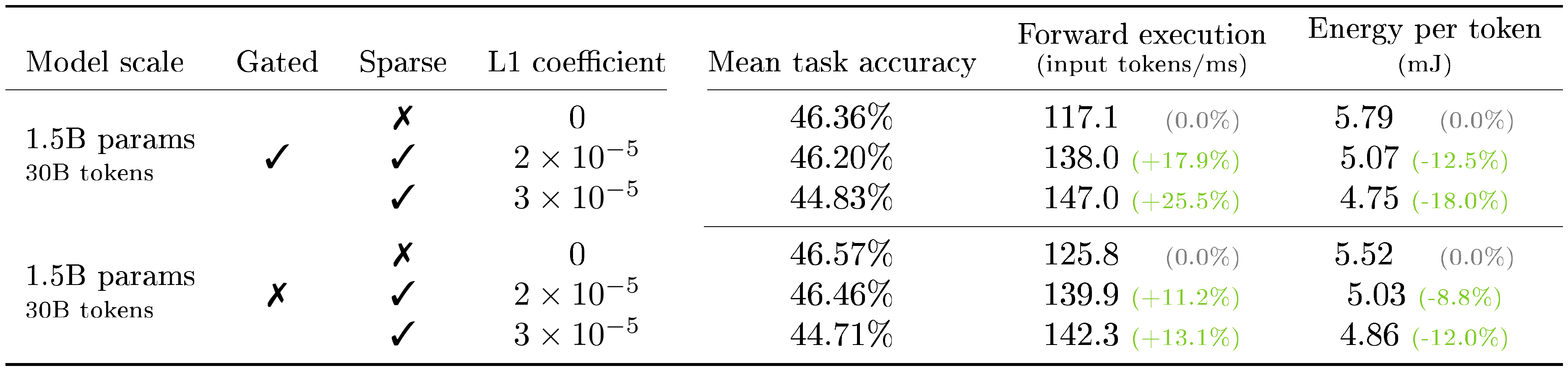
:::
As explained in Section 2, from the simple 2-layer feed-forward block used in the original transformer, there has been a notable shift, with modern models adopting a gated variant due to small but consistent superior empirical results. Nonetheless, in our work, we introduce training and inference kernels for both variants. In contrast to the gated variant, computing the output activations following Equation 1, for the non-gated variant, the computation simplifies to:
$ h = \phi(x W_u), y = h W_d,\tag{5} $
where $\phi$ is, once again, the non-linear activation function. Thus, when $\phi$ is a ReLU activation, the sparsity pattern is determined by the up-projection rather than the gate projection. For inference kernels, we note this implies that a difference between the two variants is that the non-gated version performs the up projection rather than the gate projection with our matrix multiplication kernel with TwELL storage introduced in Section 3. Moreover, as detailed in Appendix A, we designed an additional kernel optimized to perform the down projection alone starting from the TwELL format.
Thus, to provide a direct comparison between the two variants and the relative effects of sparsity and our custom kernels, we collect additional training runs on 30B tokens with our 1.5B model implementing the non-gated parameterization. In particular, we consider two sparsity levels in addition to a non-sparse baseline ($L_1=0$): our recommended conservative regularization of $L_1=2\times 10^{-5}$ and a more aggressive regularization of $L_1=3\times 10^{-5}$. In Table 4, we report the collected relative performance and efficiency results for both variants and all three sparsity levels. As shown, we find only minor performance differences between the two variants, which are likely not significant and attributable to random variations. However, we do note that such differences might become visible only when training with token budgets beyond chinchilla optimality ([32]). Efficiency-wise, while both our variants benefit significantly from our sparse kernels, we find such benefits to be larger for the gated variant. The inference speedup of the non-gated variant is 11.2% at $L_1=2\times 10^{-5}$ compared to 17.9% for the gated variant at the same sparsity level. At larger sparsity levels, this divide is more pronounced, with the gated variant achieving a 25.5% speedup at $L_1=3\times 10^{-5}$ compared to only 13.1% for the non-gated variant. These results are intuitively based on the nature of both models, as the gated variant allows our new inference kernels to leverage the opportunity of efficient fast fusion of both up and down projections. Nonetheless, they also demonstrate that the benefits of our kernels extend beyond a single architectural choice.
C.3 Strategies for Dead Neuron Mitigation
::: {caption="Table 5: Comparison of performance and efficiency statistics of sparse LLMs leveraging our kernels with traditional baselines trained using our standard recipe, or with dead neuron mitigation strategies such as warming up the coefficient of the L1 loss and applying targeted reinitialization to the gate projection's weights."}

:::
:::: {cols="2"}
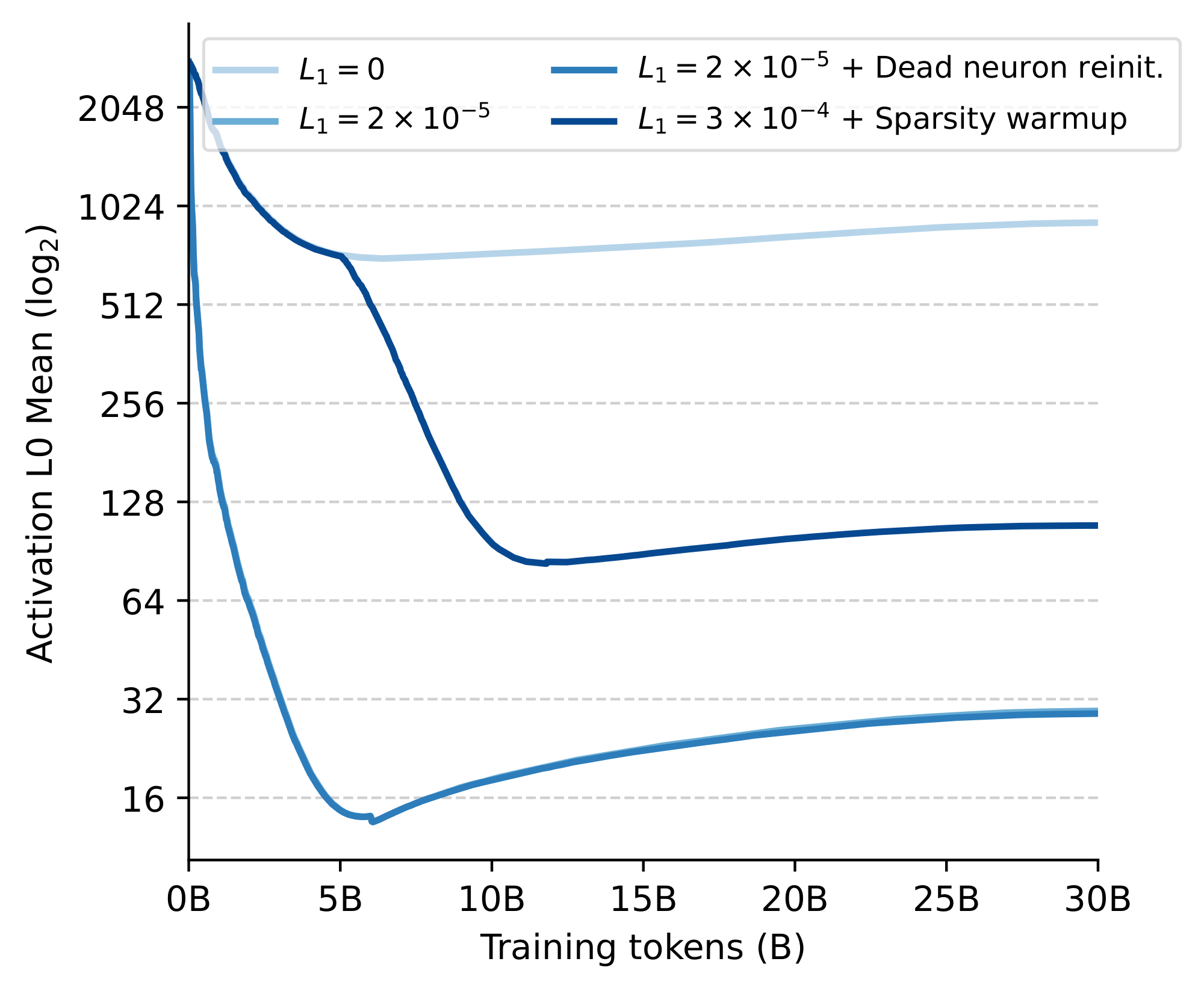
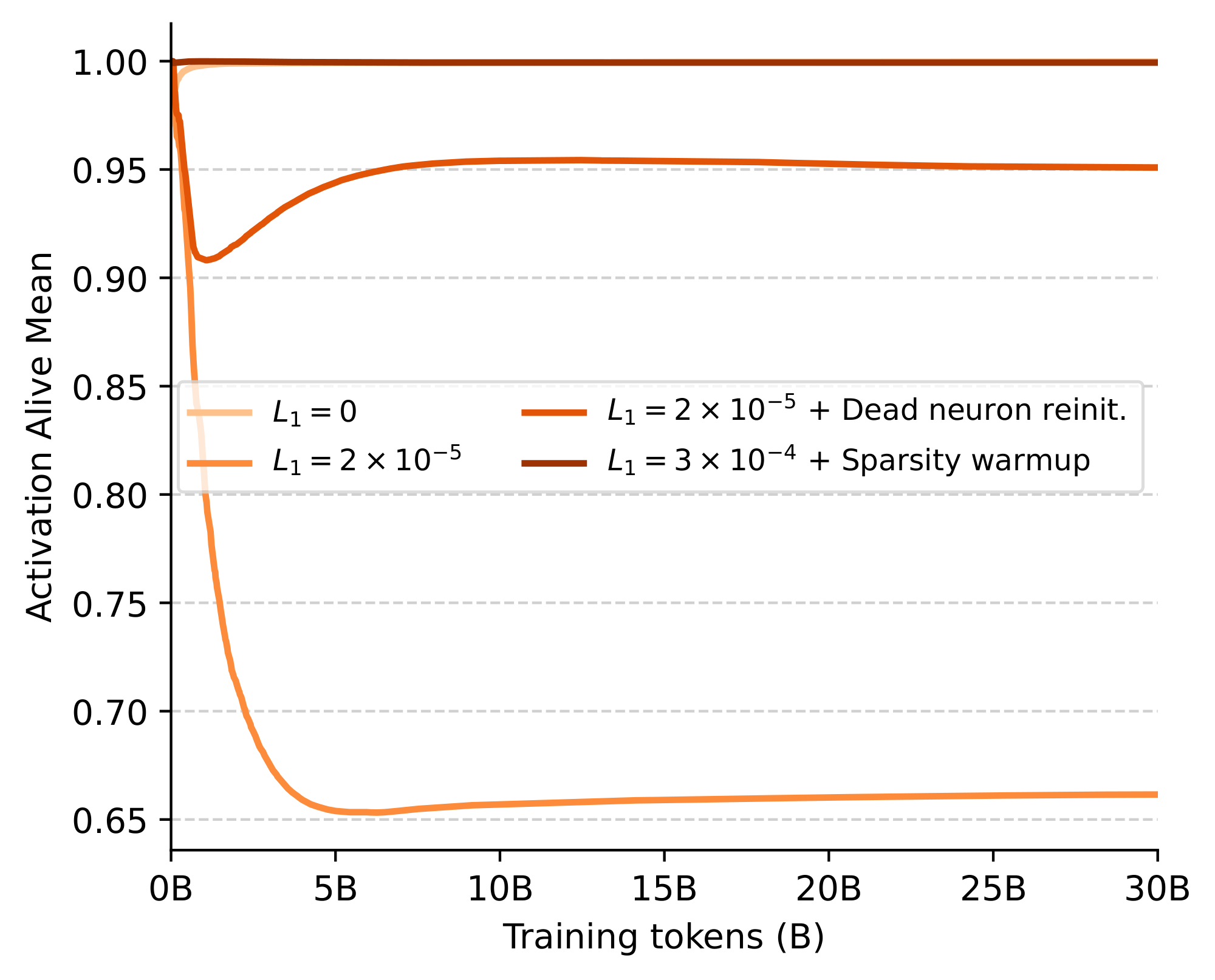
Figure 8: Number of non-zeros and fraction of dead neurons of LLMs with different strategies for dead neuron mitigation throughout training. ::::
While we find that using an L1 coefficient of $L_1=2\times 10^{-5}$ provides a relevant boost in efficiency without any noticeable downstream performance degradation, we explore preliminary directions to mitigate the potential downsides of sparse training. In particular, as detailed in Appendix D, when examining the number of active neurons throughout training, we see that over 30% of the neurons become permanently inactive on average across layers when using our recommended L1 coefficient, with this metric considerably rising for higher regularizations. While for our recommended coefficient, this symptom does not seem to evidently reflect on downstream performance, reducing such an effect could potentially allow supporting even higher sparsity before incurring performance degradation.
Based on these considerations, we explore two preliminary extensions to our simple L1-regularized training recipe explained in Section 2. First, we consider simply scheduling the L1 regularization, motivated by our findings that dead neurons appear to arise very early during training. Concretely, we first train our models for 5000 steps without any L1 regularization, followed by a further 5000 steps of linear increase of the L1 coefficient. We make the training setting artificially similar to prior work that focuses on finetuning and continued-pretraining ([43, 19]). Second, we consider implementing a target reinitialization strategy to lower the magnitude and reinject random noise only in the columns of the gate projection that lead to always negative outputs (which then, after ReLU, lead to dead neurons). Given the model's initialization standard deviation $\sigma=0.02$, we noised and rescaled to regress the weights to their initial state, essentially interpolating with a coefficient $\lambda$:
$ W_g[:, j] \leftarrow (1-\lambda) W_g[:, j] + \lambda \mathcal{N}(0, \sigma^2), $
We apply this targeted reinitialization after every training step, which we find does not significantly affect training time. In preliminary experiments, We found $\lambda=0.1$ to be a good choice that avoids affecting training dynamics while injecting sufficient noise to revive dead neurons. We note this strategy is similar to older techniques for reinjecting plasticity into architectures in continual learning and other non-stationary settings ([53]).
In Table 5, we report the performance and efficiency results of our two strategies compared to our standard recipe and the non-sparse baseline, while in Figure 8 we analyze the number of non-zero activations and dead neurons throughout training. When looking at the dead neuron statistics, we find that both strategies almost entirely mitigate the emergence of dead neurons. However, we immediately see a concerning pattern with the sparsity-warmup strategy, as the number of non-zeros considerably increases throughout training. In particular, the considered coefficient of $L_1=3\times 10^{-4}$, which is ten times larger than our recommended value, leads to over 100 non-zeros on average across layers at the end of training, compared to only 29 non-zeros when using our standard recipe with $L_1=2\times 10^{-5}$. We note that, in early experiments, we found that increasing the L1 coefficient further led to training instabilities and loss spikes. In contrast, using the targeted dead neuron reinitialization, we find similar non-zero statistics to our standard recipe while still effectively mitigating dead neurons. Furthermore, as reported in Table 5, we find that this latter strategy provides a small boost in both downstream performance and efficiency, processing tokens 19.1% faster than the non-sparse baseline with our default L1 coefficient of $L_1=2\times 10^{-5}$. We believe these preliminary results suggest that further research in examining optimal sparse training would potentially further increase the relevance and efficiency upsides of sparse LLMs.
D. Extended Results
D.1 Sparsity and Dead Neurons During Training
:::: {cols="2"}
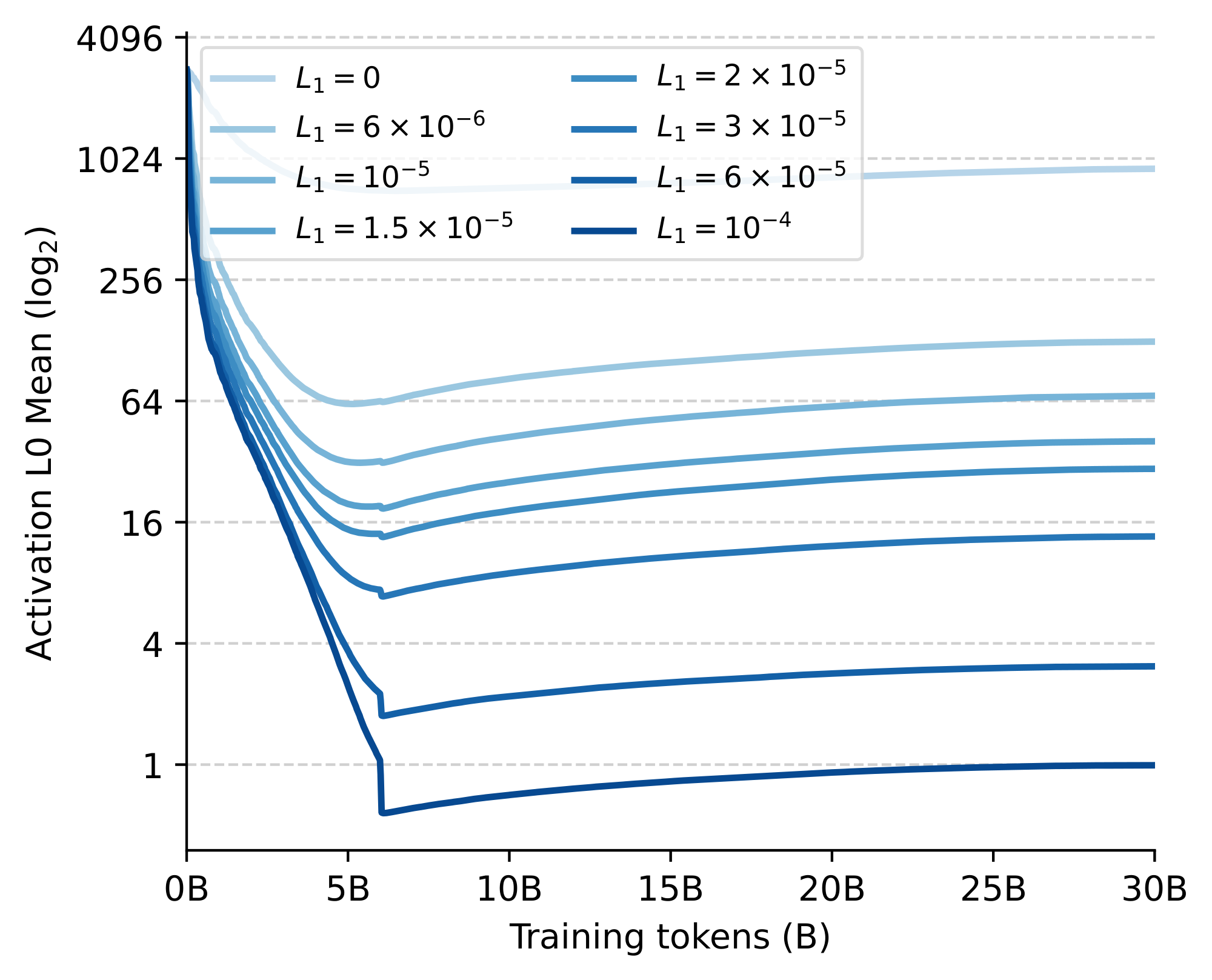
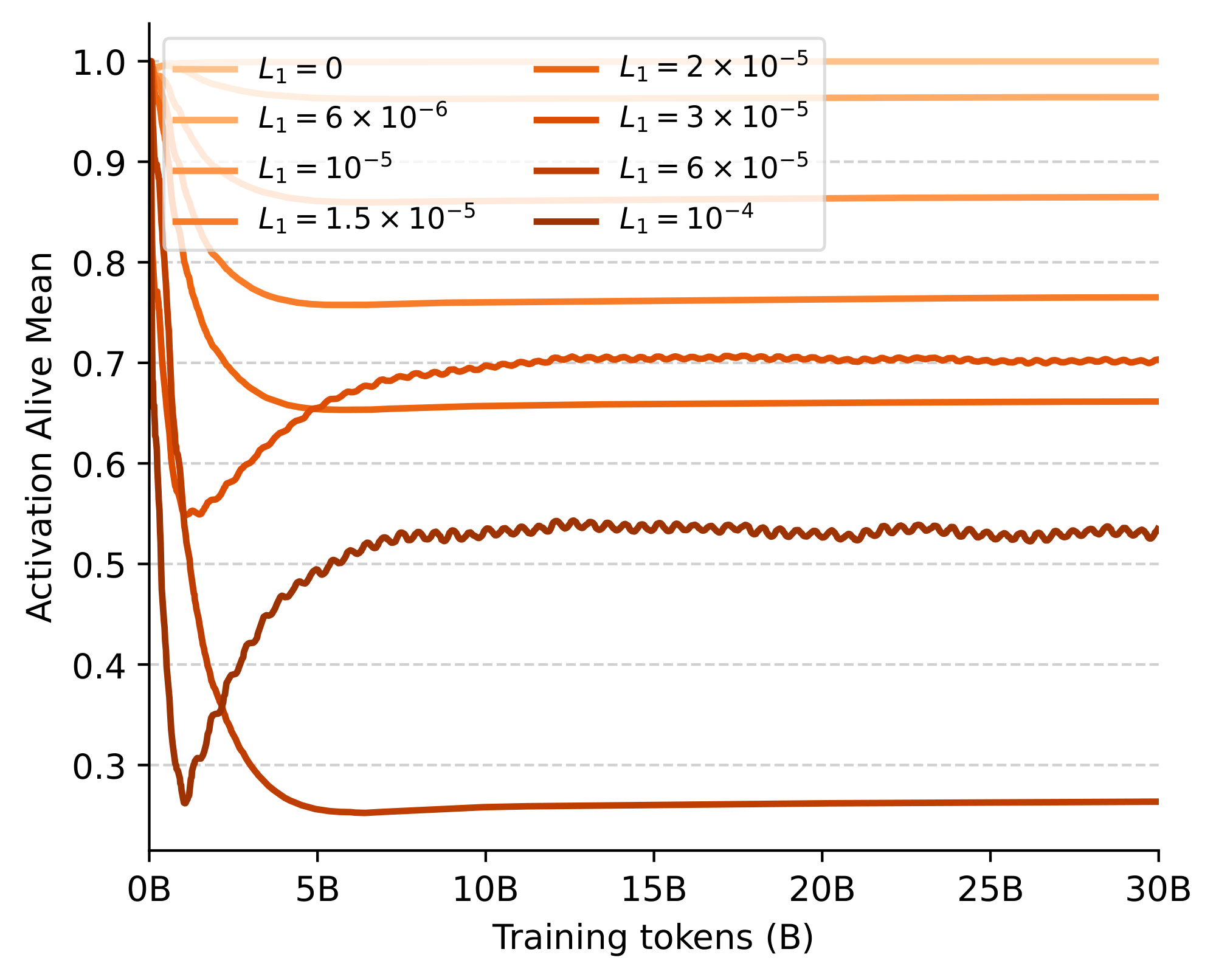
Figure 12: Number of non-zeros and fraction of dead neurons of LLMs across L1 regularization levels throughout training. ::::
In Figure 12, we provide detailed results about how activation sparsity and dead neuron occurrence evolve during training for all our different L1 regularization levels. In particular, we record dead neurons at the end of each training step by keeping track, for each hidden feedforward activation of each layer, the last time it was non-zero. If a neuron was never active for a whole training step (just above 1M tokens), we consider it dead for that step.
We make two immediate observations from these results. First, we find that the sparsity levels settle early on to low values after only around 1000 training steps (around 1B tokens). Due to this property, we note that the throughput and memory advantages of our training kernels become relevant almost at the inception of our training runs. Second, we observe that the same trend applies to the number of dead neurons: our recommended $L_1=2\times 10^{-5}$ already exceeds 30% inactivity, which further monotonically increases with higher regularization levels. While for our recommended coefficient, this symptom does not seem to evidently reflect on downstream performance, reducing such an effect could potentially allow supporting even higher sparsity before incurring performance degradation. To this end, we note that in Appendix C we provide preliminary results indicating that the performance of sparse LLMs could be further improved with strategies targeted at dead-neuron mitigation.
D.2 Task Performance Details
::: {caption="Table 6: Granular comparison of per-task downstream performance across model scales to complement Table 1."}
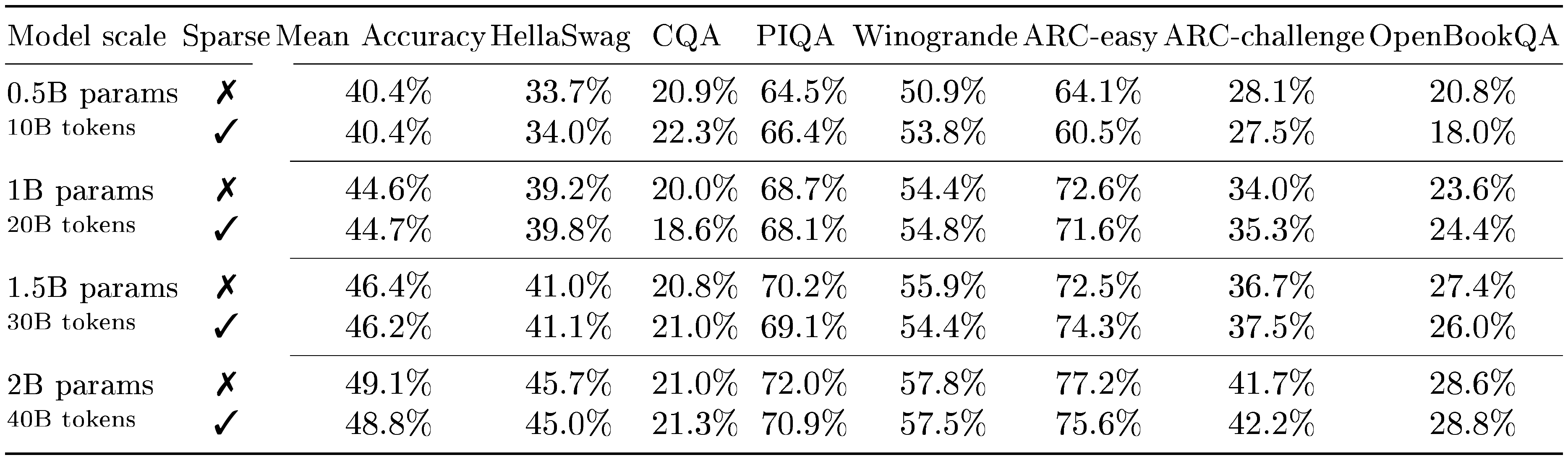
:::
To complement the results in Section 4 in the main text, we provide the detailed granular results of downstream task performance across the seven downstream tasks considered, targeting logic and reasoning capabilities after pretraining ([35, 36, 37, 38, 39, 40]). In particular, we report the per-task accuracies for both sparse models, using our recommended conservative L1 regularization of $2\times 10^{-5}$, and their non-sparse counterparts across all the examined model scales. As shown in Table 6 and consistently with our main text analysis, we do not find significant performance differences between sparse and non-sparse models for our regularization level and all considered tasks. We do, indeed, observe an expected performance rise with larger models across the great majority of tasks.
D.3 Activation Sparsity at High and Low Levels
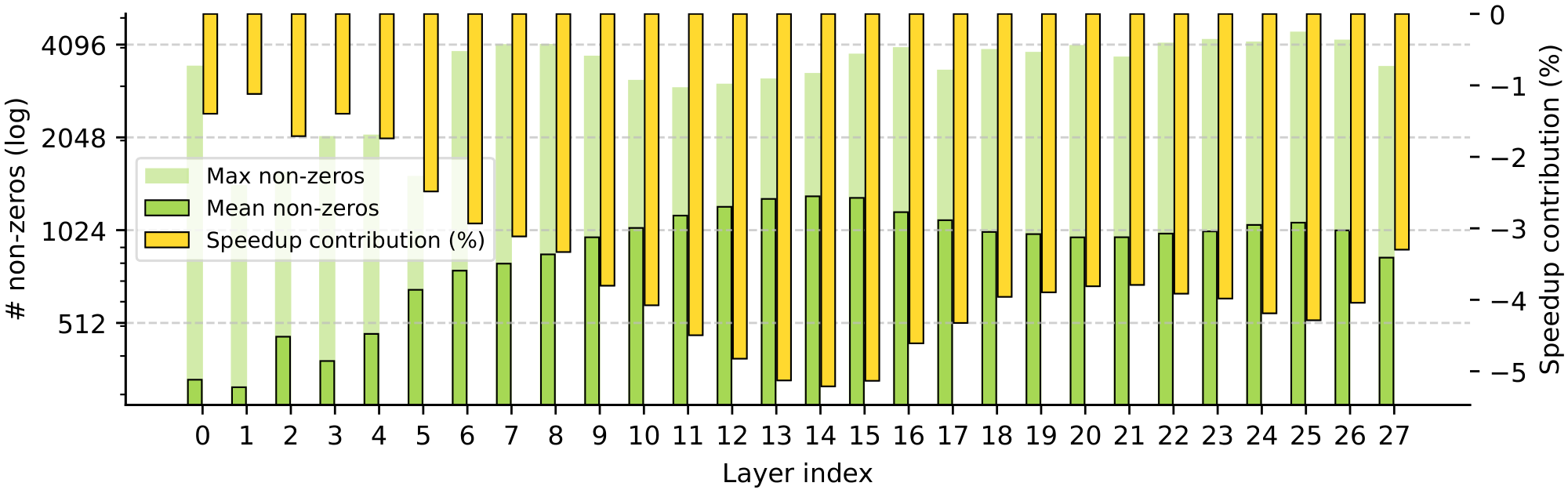
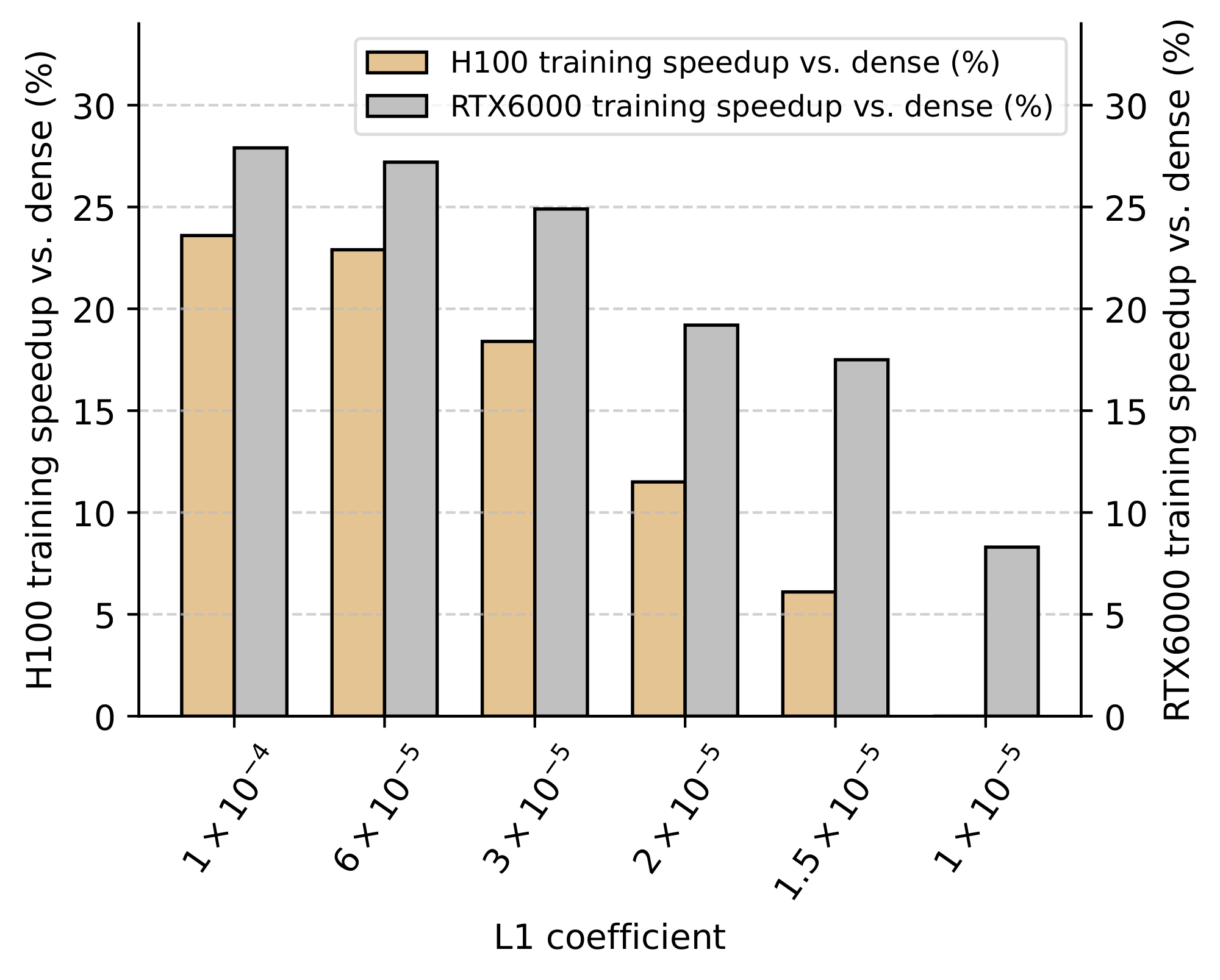
To complement the analysis results provided in Section 4 of the main text, we examine how sparsity regularization affects the distribution of non-zero activations across model depth and relate these metrics to the corresponding speed-up contributions from our kernels during inference. While in our main analysis we reported and analyzed the LLM trained with our recommended conservative L1 regularization of $2\times 10^{-5}$, in Figure 16 we provide analogous results for a non-sparse LLM while in Figure 17 we analyze an LLM trained with the highest regularization regularization level considered ($1\times 10^{-4}$). We note that for non-sparse models, due to the high number of non-zeros, the contributions of applying our kernel are actually detrimental – and as such, we report the speed-up contributions as negative percentages. A first observation from the sparsity statistics is that the average number of non-zeros also follows a noticeable trend in the non-sparse model, with the first few layers being the least active, followed by a hump with a peak in activations. However, a key difference comes with the location of the hump: while in our recommended sparse model the peak occurs around layer 6, in the non-sparse LLM the peak still occurs within the first half of the network but is shifted visibly deeper into the architecture around layer 13. Interestingly, in the high-regularization LLM, we actually observe that while the very first layer is again the least active, there are two different peaks – one very early around the second layer and another one in the last layer of the model. Once again, we find that maximum activation counts can easily be well over an order of magnitude higher than the average, with no clear pattern across layers. For the non-sparse model, we again observe a strong inverse correlation between each layer's average non-zeros and its relative speed-up. In contrast to the high-regularization LLM, this correlation is much less visible, as given the high sparsity encountered, the speedups of our kernels are already at their achievable maximum for almost all layers, essentially making executing the up and down projection negligible in the overall computation time.
D.4 Improving Efficiency of other Devices
As mentioned in Section 4, given that our kernels consistently reduce memory requirements during training, and as a side benefit, reduce reliance on newer tensor core units, they immediately have higher potential relevance for less capable hardware. Thus, to empirically validate these considerations, we provide additional results comparing the performance speedups of our kernels during training on NVIDIA's RTX PRO 6000 GPUs against the H100 PCIe GPUs used throughout our main paper and other experiments. Some of the other crucial differences of this GPU come from the memory side, with a considerably reduced memory bandwidth (1.59 TB/s vs. 2.0 TB/s). In contrast, the RTX PRO 6000 can benefit from a larger number of Streaming Multiprocessors than the H100 (188 vs. 114), potentially allowing for greater occupancy for sparse workloads.
As shown in Figure 18, and in line with our considerations, we find significantly higher speedups on the RTX 6000 GPU across all L1 regularization levels considered. These speedup differences are even more pronounced at higher regularization levels, extending the practical range of L1 coefficients make sparsity provide meaningful efficiency improvements. When dissecting what causes these greater speedups, we first find that thanks to the specific H100 features, such as the higher tensor cores throughput, the runtime of the dense GEMM operations increases from around 400 to 800 microseconds on the RTX 6000. Similarly, kernels that are memory bandwidth bound, including the dense to hybrid matrix multiplication, are also slightly slower by 19% on the RTX 6000 than on the H100. However, once in our hybrid sparse format, due to the larger Streaming Multiprocessors count of the RTX 6000 GPU, the sparse operations run faster than on the H100, with speedups of 1.34 $\times$ and 2.1 $\times$ for sparse-to-dense and transposition operations, respectively. We find these results indicate that leveraging sparsity with targeted kernels could significantly improve the performance of cheaper devices, which do not implement the latest hardware innovations of higher-end units such as the H100, lowering the field's canonical hardware barriers.
E. Further Related Work
E.1 Activation Sparsity in Transformers
Expanding on the findings of [11], [12] documents that Transformer MLP layers with ReLU activations exhibit inherent activation sparsity across architectures, depths, and data distributions. Building on this observation, [25] shows that replacing GELU with ReLU in non-gated feed-forward layers yields negligible performance degradation while enabling up to three times theoretical inference speedup with less computation. However, they focus on older architectures (OPT models) with non-gated feed-forward blocks and leave efficient kernel implementation to future work.
More recent methods have also been proposed to enhance sparsity after altering modern gated architectures and have claimed speedups when running sparse feedforward layers in isolation on older generations of devices. TurboSparse ([42]) proposes a modification to the feed-forward block itself, introducing dReLU, which applies ReLU to both gate and up projections: $h = \mathrm{ReLU}(xW_g) \odot \mathrm{ReLU}(xW_u)$. ProSparse ([43]) proposes finetuning pretrained models and artificial thresholding of the activations to increase sparsity. Q-Sparse ([19]), further deviates from standard architectures via maintaining only the top-K activations and applying a straight-through estimator. We also note that additional works proposed introducing structured sparsity post-training, such as by predicting ([18]) and pruning activation to set sparsity levels ([44, 45]). Unlike these works, our paper introduces general-purpose kernels to leverage unstructured sparsity, demonstrating empirical efficiency benefits during LLM training and inference.
E.2 Architectural Approaches to Sparsity
Mixture-of-Experts (MoE) architectures ([54, 55, 56]) partition feed-forward layers into separately routed experts, decoupling model capacity from per-token computation. However, MoE requires predetermining the number of experts and sparsity level before training, limiting adaptability to input complexity.
Product key memory ([57]) maintains fixed sparsity patterns through $O(\log n)$ key retrieval. PEER ([58]) extends this approach to over one million single-neuron experts with 99.99% architectural sparsity. UltraMem ([59]) improves PKM and scales to 20 million memory slots, showing that it can outperform MoE with the same parameter and computation budgets. Fast Feedforward Networks ([60]) use differentiable binary trees to achieve 99% sparsity.
While these architectural approaches achieve extreme sparsity, they require substantial modifications to standard Transformer training pipelines. Our approach instead works with conventional architectures, requiring only a change of activation function and optional regularization, making it readily applicable to existing models and training infrastructure.
References
[1] OpenAI (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
[2] Team et al. (2023). Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
[3] Vaswani et al. (2017). Attention is all you need. Advances in neural information processing systems. 30.
[4] Radford et al. (2019). Language models are unsupervised multitask learners. OpenAI blog. 1(8). pp. 9.
[5] Brown et al. (2020). Language models are few-shot learners. Advances in neural information processing systems. 33. pp. 1877–1901.
[6] Schwartz et al. (2020). Green AI. Communications of the ACM. 63(12). pp. 54–63.
[7] Luccioni et al. (2023). Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model. Journal of Machine Learning Research. 24(253). pp. 1–15.
[8] LeCun et al. (1989). Optimal brain damage. Advances in neural information processing systems. 2.
[9] Han et al. (2015). Learning both weights and connections for efficient neural network. Advances in neural information processing systems. 28.
[10] Hoefler et al. (2021). Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. Journal of Machine Learning Research. 22(241). pp. 1–124.
[11] Zhang et al. (2022). Moefication: Transformer feed-forward layers are mixtures of experts. In Findings of the Association for Computational Linguistics: ACL 2022. pp. 877–890.
[12] Zonglin Li et al. (2023). The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers. https://arxiv.org/abs/2210.06313. arXiv:2210.06313.
[13] Pope et al. (2023). Efficiently scaling transformer inference. Proceedings of machine learning and systems. 5. pp. 606–624.
[14] Lawson et al. (1979). Basic linear algebra subprograms for Fortran usage. ACM Transactions on Mathematical Software (TOMS). 5(3). pp. 308–323.
[15] NVIDIA (2025). cuBLAS Library. https://docs.nvidia.com/cuda/cublas/index.html.
[16] NVIDIA (2025). NVIDIA cuBLASDx Documentation. https://docs.nvidia.com/cuda/cublasdx/.
[17] NVIDIA (2025). CUTLASS: CUDA Templates and Python DSLs for High-Performance Linear Algebra. https://github.com/NVIDIA/cutlass.
[18] Liu et al. (2023). Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning. pp. 22137–22176.
[19] Wang et al. (2024). Q-sparse: All large language models can be fully sparsely-activated. arXiv preprint arXiv:2407.10969.
[20] Shazeer, Noam (2020). Glu variants improve transformer. arXiv preprint arXiv:2002.05202.
[21] Geva et al. (2021). Transformer Feed-Forward Layers Are Key-Value Memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. pp. 5484–5495. doi:10.18653/v1/2021.emnlp-main.446.
[22] Dai et al. (2022). Knowledge Neurons in Pretrained Transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 8493–8502. doi:10.18653/v1/2022.acl-long.581.
[23] Touvron et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
[24] Yang et al. (2024). Qwen2 technical report, 2024. URL https://arxiv. org/abs/2407.10671. 7. pp. 8.
[25] Mirzadeh et al. (2023). ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models. In The Twelfth International Conference on Learning Representations.
[26] Maria Lomeli et al. (2025). Stochastic activations. arXiv:2509.22358.
[27] Kincaid et al. (1989). ITPACKV 2D user's guide.
[28] Bell, Nathan and Garland, Michael (2009). Implementing sparse matrix-vector multiplication on throughput-oriented processors. In Proceedings of the conference on high performance computing networking, storage and analysis. pp. 1–11.
[29] Kreutzer et al. (2014). A unified sparse matrix data format for efficient general sparse matrix-vector multiplication on modern processors with wide SIMD units. SIAM Journal on Scientific Computing. 36(5). pp. C401–C423.
[30] Anzt et al. (2014). Implementing a Sparse Matrix Vector Product for the SELL-C/SELL-C-$\sigma$ formats on NVIDIA GPUs. University of Tennessee, Tech. Rep. ut-eecs-14-727.
[31] Vazquez et al. (2010). Improving the performance of the sparse matrix vector product with GPUs. In 2010 10th IEEE International Conference on Computer and Information Technology. pp. 1146–1151.
[32] Hoffmann et al. (2022). Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
[33] Penedo et al. (2024). The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems. 37. pp. 30811–30849.
[34] Loshchilov, Ilya and Hutter, Frank (2017). Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
[35] Clark et al. (2018). Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
[36] Zellers et al. (2019). Hellaswag: Can a machine really finish your sentence?. arXiv preprint arXiv:1905.07830.
[37] Mihaylov et al. (2018). Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789.
[38] Bisk et al. (2020). Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence. pp. 7432–7439.
[39] Sakaguchi et al. (2021). Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM. 64(9). pp. 99–106.
[40] Talmor et al. (2019). Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 4149–4158.
[41] Wendler et al. (2024). Do llamas work in english? on the latent language of multilingual transformers. arXiv preprint arXiv:2402.10588.
[42] Song et al. (2024). Turbo sparse: Achieving llm sota performance with minimal activated parameters.
[43] Song et al. (2025). Prosparse: Introducing and enhancing intrinsic activation sparsity within large language models. In Proceedings of the 31st International Conference on Computational Linguistics. pp. 2626–2644.
[44] Lee et al. (2024). Cats: Contextually-aware thresholding for sparsity in large language models. arXiv preprint arXiv:2404.08763.
[45] Liu et al. (2024). Training-free activation sparsity in large language models. arXiv preprint arXiv:2408.14690.
[46] Pranjal Shankhdhar (2024). Outperforming cuBLAS on H100: a Worklog. https://cudaforfun.substack.com/p/outperforming-cublas-on-h100-a-worklog.
[47] Chatterjee et al. (1999). Recursive array layouts and fast parallel matrix multiplication. In Proceedings of the eleventh annual ACM symposium on Parallel algorithms and architectures. pp. 222–231.
[48] Loubna Ben Allal et al. (2024). SmolLM - blazingly fast and remarkably powerful.
[49] Grattafiori et al. (2024). The llama 3 herd of models. arXiv preprint arXiv:2407.21783.
[50] Hendrycks, D (2016). Gaussian Error Linear Units (Gelus). arXiv preprint arXiv:1606.08415.
[51] Ramachandran et al. (2017). Searching for activation functions. arXiv preprint arXiv:1710.05941.
[52] Zhang et al. (2022). Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
[53] Ash, Jordan and Adams, Ryan P (2020). On warm-starting neural network training. Advances in neural information processing systems. 33. pp. 3884–3894.
[54] Noam Shazeer et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. CoRR. abs/1701.06538. http://arxiv.org/abs/1701.06538.
[55] Lepikhin et al. (2020). Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668.
[56] Fedus et al. (2022). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research. 23(120). pp. 1–39.
[57] Guillaume Lample et al. (2019). Large Memory Layers with Product Keys. https://arxiv.org/abs/1907.05242. arXiv:1907.05242.
[58] Xu Owen He (2024). Mixture of A Million Experts. https://arxiv.org/abs/2407.04153. arXiv:2407.04153.
[59] Zihao Huang et al. (2025). Ultra-Sparse Memory Network. https://arxiv.org/abs/2411.12364. arXiv:2411.12364.
[60] Peter Belcak and Roger Wattenhofer (2023). Fast Feedforward Networks. https://arxiv.org/abs/2308.14711. arXiv:2308.14711.