DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
Makoto Shing$^1$, Masanori Koyama$^2$, Takuya Akiba$^1$
$^1$Sakana AI, $^2$The University of Tokyo
{mkshing, takiba}@sakana.ai, [email protected]
Abstract
End-to-end backpropagation requires storing activations throughout all layers, creating memory bottlenecks that limit model scalability. Existing block-wise training methods offer means to alleviate this problem, but they rely on ad-hoc local objectives and remain largely unexplored beyond classification tasks. We propose DiffusionBlocks, a principled framework for transforming transformer-based networks into genuinely independent trainable blocks that maintain competitive performance with end-to-end training. Our key insight leverages the fact that residual connections naturally correspond to updates in a dynamical system. With minimal modifications to this system, we can convert the updates to those of a denoising process, where each block can be learned independently by leveraging the score matching objective. This independence enables training with gradients for only one block at a time, thereby reducing memory requirements in proportion to the number of blocks. Our experiments on a range of transformer architectures (vision, diffusion, autoregressive, recurrent-depth, and masked diffusion) demonstrate that DiffusionBlocks training matches the performance of end-to-end training while enabling scalable block-wise training on practical tasks beyond small-scale classification. DiffusionBlocks provides a theoretically grounded approach that successfully scales to modern generative tasks across diverse architectures.
Code is available at: https://github.com/SakanaAI/DiffusionBlocks.
Executive Summary: Modern large generative models rely on end-to-end backpropagation, which stores activations across every layer during training. This requirement drives memory use up linearly with depth and creates practical bottlenecks that constrain model scale and research speed.
The document introduces DiffusionBlocks, a framework that converts residual transformer networks into independently trainable blocks. The approach rests on a diffusion-model interpretation of residual connections: each block learns to denoise within a distinct noise-level range, and blocks are trained one at a time using the standard denoising objective. Experiments applied the method, with minimal architectural changes, to vision transformers, diffusion transformers, autoregressive language models, masked diffusion models, and recurrent-depth networks.
Across these architectures, block-wise training matched or slightly exceeded the performance of standard end-to-end training while cutting training memory by a factor equal to the number of blocks. Inference in diffusion models also became cheaper, because only the relevant block runs at each denoising step. Recurrent-depth models gained further savings by replacing dozens of recurrent iterations with a single forward pass during training. Equi-probability partitioning of noise ranges proved essential to these results.
These outcomes matter because they remove a major memory barrier without sacrificing capability on current generative tasks. Organizations can therefore train deeper or wider models on existing hardware, or reduce the cost of each training run.
The authors recommend exploring fine-tuning of already-trained large models, testing alternative diffusion samplers inside blocks, and determining task-specific block counts that balance quality and speed. They note that the method currently assumes matching input and output dimensions per block and has been evaluated mainly on models trained from scratch.
Overall the work provides a coherent, empirically validated route to scalable block-wise training for modern transformers.
1. Introduction
Section Summary: Modern AI models rely on end-to-end backpropagation during training, which stores intermediate results across all layers and quickly creates prohibitive memory demands as networks grow deeper. Existing block-wise training methods try to ease this by breaking networks into independently trainable pieces, but they typically underperform and lack solid theoretical grounding or easy extension to complex modern architectures. DiffusionBlocks addresses these gaps by reinterpreting residual layers in transformers as steps in a continuous diffusion process, allowing each block to be trained separately on its own noise range while preserving overall performance and cutting memory use dramatically.
The memory bottleneck in neural network training.
Modern AI led by generative models ([1, 2, 3, 4]) has become integral to everyday life. These models rely on end-to-end backpropagation, which requires storing intermediate activations across network layers during training. This fundamental requirement causes memory consumption to grow linearly with network depth, creating computational bottlenecks that limit both research flexibility and practical deployment.
Block-wise training: promises and limitations.
Block-wise training methods[^1] partition networks into smaller components that can be trained independently, promising dramatic memory savings. Despite this potential, existing approaches ([5, 6, 7, 8, 9]) consistently underperform end-to-end training. The core challenge is twofold: (1) lack of theoretical grounding: existing methods rely on ad-hoc local objectives without principled coordination between blocks, (2) limited applicability, where they require paradigm-specific designs, task-specific objectives that do not naturally extend beyond classification. Their results are typically demonstrated only on custom architectures without providing systematic procedures to be applied to modern architectures such as Transformers ([10]) (Section 4), leaving their applicability to modern generative AI largely unexplored. Without a systematic framework grounded in theory, block-wise training remains an unfulfilled promise.
[^1]: We use block-wise training to encompass all approaches that partition networks into independently trainable components. This includes layer-wise training as the special case where each block contains one layer.
Diffusion models: a mathematical foundation for decomposition.
Score-based diffusion models ([11, 12]) model the data distribution through a continuous-time process that gradually adds noise, then learns to reverse this process by estimating the score function at each noise level. Crucially, the denoising step at each noise level can be optimized independently from other noise levels. This independence property provides the theoretical foundation that has been missing from block-wise training approaches: it allows us to partition networks into blocks, each responsible for a specific noise level range, without compromising global coherence.
Our approach: interpreting networks as diffusion processes.
We propose DiffusionBlocks, a framework that enables principled block-wise training by interpreting sequential layer updates in transformer-based networks as discretized steps of a continuous-time diffusion process. Building on the established connection between residual networks and differential equations ([13, 14]), we leverage the fact that residual connections naturally correspond to Euler discretization of the probability flow ODE in diffusion models. This correspondence allows us to partition networks with residual connections, particularly transformer-based networks, into blocks that each handle specific noise-level ranges. These blocks can be trained completely independently, requiring gradients for only one block at a time. Figure 1 illustrates the core concept of DiffusionBlocks. Unlike previous block-wise methods with ad-hoc objectives, our framework derives each block's training objective from score matching theory. As a result, consistent local optimization at each noise level collectively yields a faithful approximation of the global reverse process, while also allowing practitioners to seamlessly adopt techniques such as those of [15] to further enhance training.
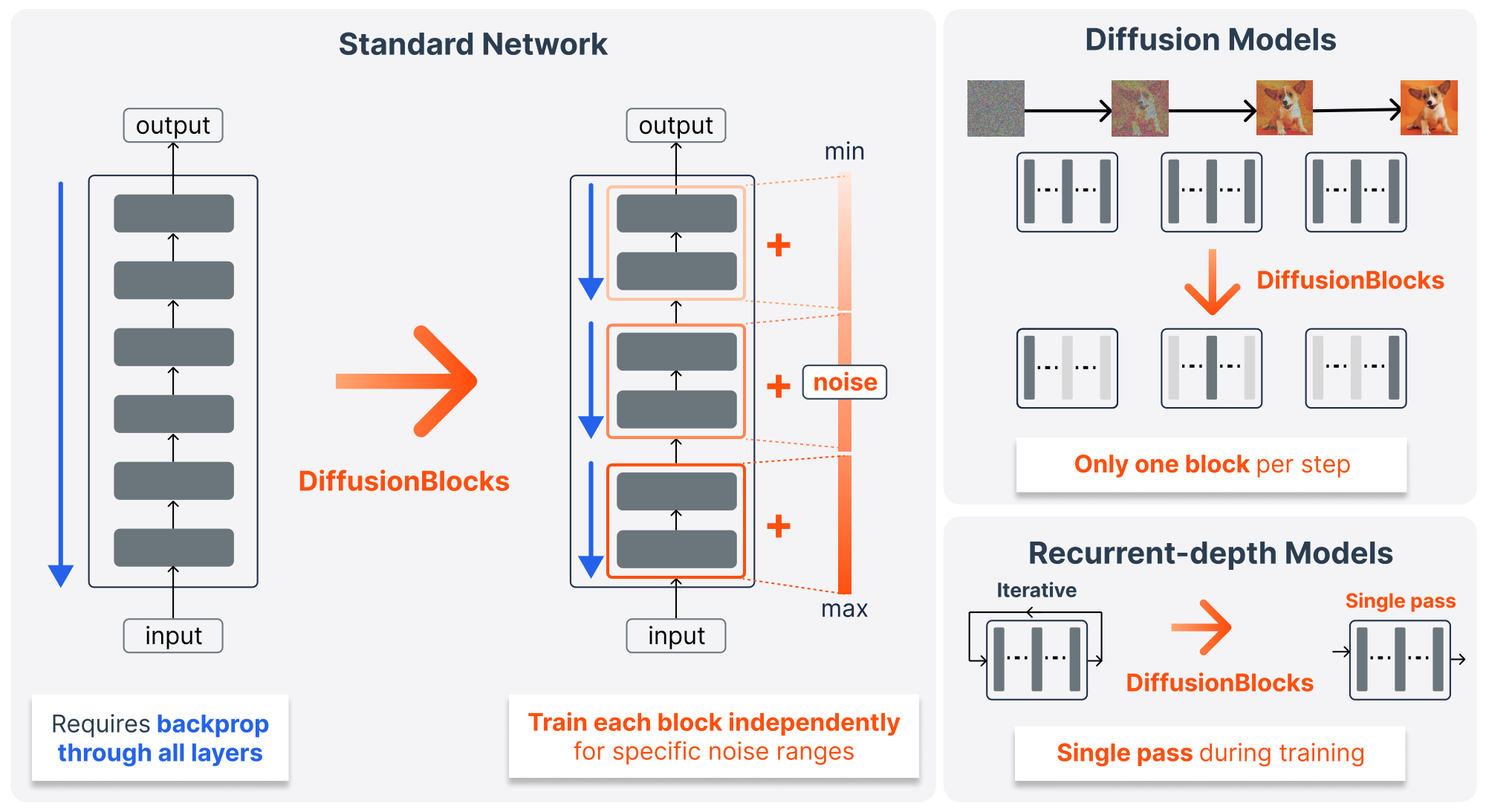
Our main contributions are:
- Block-wise training via continuous-time diffusion interpretation: We show that transformer-based networks can be interpreted as implementing discretized steps of continuous-time diffusion processes (Section 2.2), enabling genuinely independent block training. Each block learns to denoise within its assigned noise level range, requiring gradients for only one block at a time during training (Section 3.1).
- Equi-probability partitioning for balanced learning: We propose a principled, diffusion theoretic strategy that partitions noise levels based on equal cumulative probability mass, ensuring balanced parameter utilization across blocks (Section 3.3).
- Broad applicability with maintained performance: We conduct extensive experiments (Section 5), demonstrating that DiffusionBlocks successfully applies to diverse architectures (vision, diffusion, autoregressive, recurrent-depth, and masked diffusion), achieving competitive performance to end-to-end backpropagation while requiring gradients for only one block at a time. Additionally, our framework naturally extends to recurrent-depth models, transforming their multiple-iteration training into single-pass training (Section 5.5).
- Significant efficiency gains: During training, only one block requires gradient computation, reducing memory requirements proportionally to the number of blocks. For diffusion models, inference requires only one relevant block per denoising step (Section 5.2). For recurrent-depth models, our framework eliminates $K$ iterations during training, demonstrating up to $K$-fold reduction in training computation (Section 5.5).
2. Preliminaries
Section Summary: The section introduces variance-exploding diffusion models, in which clean data is gradually corrupted by Gaussian noise at varying scales and a neural network is trained to reverse this process by learning to predict the original data from its noisy version. It then shows that the deterministic differential equation used for reversal can be discretized with the Euler method, yielding an update rule that precisely matches the residual or skip connections found in common architectures such as ResNets and Transformers. This perspective lets the same network block be applied repeatedly like a diffusion trajectory, while the diffusion-style training objective supplies an efficient way to optimize the resulting dynamical system without back-propagation through many layers.
2.1 Score-based diffusion models
We adopt the Variance Exploding (VE) formulation ([12, 15]) where a clean data $\mathbf{y} \sim p_{\text{data}}$ is perturbed with Gaussian noise at noise level $\sigma$: $\mathbf{z}_{\sigma} = \mathbf{y} + \sigma \boldsymbol{\epsilon}$ where $\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})$. For generations, we use the deterministic probability flow ODE that reverses the noising process:
$ \frac{d\mathbf{z}{\sigma}}{d\sigma} = -\sigma \nabla{\mathbf{z}} \log p_{\sigma}(\mathbf{z}_{\sigma}),\tag{1} $
where $\nabla_{\mathbf{z}} \log p_\sigma(\mathbf{z}\sigma)$ is the score function. Using Tweedie's formula, the score is approximated via a denoiser $D{\boldsymbol{\theta}}(\mathbf{z}{\sigma}, \sigma)$ that predicts clean data from noisy input: $\nabla{\mathbf{z}} \log p_{\sigma}(\mathbf{z}{\sigma}) \approx \frac{D{\boldsymbol{\theta}}(\mathbf{z}{\sigma}, \sigma) - \mathbf{z}{\sigma}}{\sigma^2}$ ([16, 17, 18]). The denoiser is trained by minimizing:
$ \mathcal{L}(\boldsymbol{\theta}) := \mathbb{E}{\mathbf{z}0 \sim p{\text{data}}, \sigma \sim p{\text{noise}}, \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})} \left[w(\sigma) |D_{\boldsymbol{\theta}}(\mathbf{y} + \sigma\boldsymbol{\epsilon}, \sigma) - \mathbf{y}|_2^2 \right],\tag{2} $
where $w(\sigma)$ weights different noise levels and $p_{\text{noise}}$ is the noise level distribution used during training. The choice of $p_{\text{noise}}$ determines which noise levels are emphasized during training. [15] uses a log-normal distribution to concentrate training on perceptually important intermediate noise levels where image structure emerges. The weighting $w(\sigma)$ is designed to counteract the sampling bias from $p_{\text{noise}}$, ensuring balanced gradient magnitudes across all noise levels ([15]).
2.2 Residual connections as Euler steps of the reverse diffusion process
The connection between residual networks and differential equations has been established in prior works ([13, 14]). We extend this perspective to show that residual networks naturally implement discretized steps of the reverse diffusion process. Applying Euler discretization to Eq. (1) with noise levels $\sigma_0 > \sigma_1 > \cdot s > \sigma_T$, we define $\Delta\sigma_\ell := \sigma_{\ell-1} - \sigma_\ell > 0$ and obtain:
$ \begin{aligned} \mathbf{z}{\sigma_l} &= \mathbf{z}{\sigma_{l-1}} - \Delta\sigma_\ell \cdot \sigma_{\ell-1} \nabla_{\mathbf{z}}\log p_{\sigma_{\ell-1}}(\mathbf{z}{\sigma{\ell-1}})\ &= \mathbf{z}{\sigma{\ell-1}} + \frac{\Delta\sigma_\ell}{\sigma_{\ell-1}} \left(\mathbf{z}{\sigma{\ell-1}} - D_{\boldsymbol{\theta}}(\mathbf{z}{\sigma{\ell-1}}, \sigma_{\ell-1})\right). \end{aligned}\tag{3} $
As has historically been utilized in the development of the networks with sequential updates, this update rule has an affinity with skip connections. In fact, modern architectures such as Transformers ([10]) employ residual connections where each block updates its input through an additive transformation: $\mathbf{z}{\ell} = \mathbf{z}{\ell-1} + f_{\theta_\ell}(\mathbf{z}{\ell-1})$ where $\mathbf{z}{\ell} \in \mathbb{R}^d$ denotes the intermediate output of the block $\ell$, and $f_{\theta_\ell}$ is the block transformation parameterized by $\theta_\ell$. This structure appears in ResNets ([19]), Transformers, and other modern architectures ([4, 3, 20]). This scheme is also used in the recent development of recurrent-depth models ([21, 22, 23]), which apply the same network parameters $\boldsymbol{\theta}$ recursively $K$ times: $\mathbf{z}{k} = \mathbf{z}{k-1} + f_{\boldsymbol{\theta}}(\mathbf{z}{k-1})$ for $k \in [K]$. However, these methods suffer from the expensive backpropagation through time (BPTT), and various measures have been taken to reduce its computational burden, for example, by gradient truncation ([24, 25, 23]). That being said, the critical observation is that, in the setting of the diffusion introduced in the previous section, $D{\boldsymbol{\theta}}$ itself in Eq. (3) can be trained with Eq. (2) without BPTT, thereby providing a theoretically sound optimization method of a dynamical system through an ensemble of local optimization. In the next section, we provide a recipe for converting networks with skip connections into diffusion, thereby replacing the backpropagation through layers with the optimization scheme analogous to Eq. (2).
3. Method
Section Summary: The method transforms a standard feedforward neural network into a stack of DiffusionBlocks that emulate the iterative denoising process of diffusion models. Layers are first partitioned into B blocks, each assigned its own interval of noise levels drawn from a distribution such as log-normal. Each block is then augmented with noise conditioning and trained independently to map noisy inputs toward the target output, so that at inference the blocks progressively refine pure noise into a clean prediction without requiring end-to-end backpropagation through the full network.
![**Figure 2:** **3-step conversion of a standard neural network to DiffusionBlocks at training phase.** **Step 1:** Partition $L$ layers into $B$ blocks. **Step 2:** Define noise distribution $p_\sigma$ (e.g., log-normal) and partition the range $[\sigma_{\min}, \sigma_{\max}]$ into $B$ intervals $\{[\sigma_{b}, \sigma_{b-1}]\}_{b=1}^B$, assigning each block a specific noise range (Section 3.3). **Step 3:** Augment blocks with noise conditioning: extend input to $\tilde{\mathbf{x}} = (\mathbf{x}, \mathbf{z}_\sigma)$ where $\mathbf{z}_\sigma = \mathbf{y} + \sigma\boldsymbol{\epsilon}$, and incorporate noise-level conditioning (e.g., via AdaLN). Then, each block is trained independently from other blocks to predict target $\mathbf{y}$ within its assigned noise range.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/n8avgdmg/meta-algo.png)
![**Figure 3:** **Training and inference algorithms for standard residual networks (left) versus DiffusionBlocks (right).** Given: A $L$-layer network partitioned into $B$ blocks with noise ranges $\{[\sigma_{b}, \sigma_{b-1}]\}_{b=1}^B$, noise distribution $p_\sigma$, and training data $\{(\mathbf{x}_n, \mathbf{y}_n)\}_{n=1}^N$. The function $w(\sigma)$ denotes the loss weighting, and $\bar{f}_{\boldsymbol{\theta}_b \mid \cdot}$ represents the noised-conditioned block with parameters $\boldsymbol{\theta}_b$.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/n8avgdmg/complex_fig_9c7d2cd13d26.png)
3.1 Converting a neural network to DiffusionBlocks
Our goal in this section is to transform a given feedforward system into a discretized version of the recursive denoising steps in the diffusion model. Throughout this paper, we denote by $(\mathbf{x}, \mathbf{y})$ the input-output pairs where $\mathbf{x}$ represents the network input (e.g., images for classification) and $\mathbf{y}$ is the target output (e.g., class label for classification). Figure 1 provides an overview: instead of backpropagating through all layers, we partition networks into blocks that independently learn to denoise within assigned noise level ranges. Consider a neural network in a form of a stack of set-to-set maps (e.g. transformer-based networks) $\mathcal{F} = {f_{\theta_\ell} \mid \ell \in [L] }$ with the same output and input dimensions, so that $f_{\theta_\ell}$ maps a variable set of tokens in $\mathbb{R}^d$ to the same number of tokens in $\mathbb{R}^d$. The original network therefore processes the input with $f_{\theta_{L}} \circ \cdot s \circ f_{\theta_{0}}$, followed possibly by a readout module. Or, in more conventional formulation with the presence of residual, the original network may update the $\ell$-th layer input $\mathbf{z}\ell$ to the next layer via the rule $\textbf{z}{\ell+1} = \textbf{z}\ell + f{\theta_\ell}(\textbf{z}_\ell)$. We transform this network into a stack of Diffusion Blocks through the following three steps (Figure 2).
Step 1: Block partitioning.
We partition $\mathcal{F}$ into $B$ blocks $\mathcal{F} = \uplus_{b=1}^B \mathcal{F}b$, where $\mathcal{F}b$ contains layers indexed by ${\ell{b-1}+1, \ldots, \ell_b}$. Let $\bar{f}{\boldsymbol{\theta}b} := f{\theta_{\ell_b}} \circ \cdot s \circ f_{\theta_{\ell_{b-1}+1}}$ be the composition of layers in $\mathcal{F}_b$.
Step 2: Noise range assignment.
We define a noise distribution $p_{\text{noise}}$ and define a noise range $[\sigma_{\min}, \sigma_{\max}]$. We partition the range into $B$ intervals ${[\sigma_{b}, \sigma_{b-1}]}{b=1}^B$. We recommend the choice of log-normal for $p{\text{noise}}$, following [15], along with the partitioning strategy in Section 3.3.
Step 3: Augmenting blocks with noise conditioning.
Finally, we suit ${\bar{f}_{\theta_b} }b $ to the update rule in Eq. (3) by letting $\bar{f}{\boldsymbol{\theta}b}$ play the role of $D{\boldsymbol{\theta}b}$. Leveraging the assumption that $\bar{f}{\boldsymbol{\theta}b}$ is a map from a set of tokens to a set of tokens, we alter the input $\bar{f}{\boldsymbol{\theta}b}$ from $\mathbf{x}$ to $\tilde{\mathbf{x}} = (\mathbf{x}, \mathbf{z})$. Additionally, we extend each block $f{\boldsymbol{\theta}b}$ to incorporate noise-level conditioning through, for example, via normalization (AdaLN) ([4]). We denote this noise-conditioned version as $\bar{f}{\boldsymbol{\theta}_b \mid \sigma}$. Altogether, the update of the diffusion block constructed from $\mathcal{F}$ is given by:
$ \mathbf{z}b = \mathbf{z}{b-1} + \frac{\Delta\sigma_b}{\sigma_{b-1}} \left(\mathbf{z}{b-1} - [\bar{f}{\boldsymbol{\theta}b \mid \sigma{b-1}}(\textbf{x}, \mathbf{z}_{b-1})] _\mathbf{z} \right),\tag{4} $
where $[\bar{f}(\cdot)] \mathbf{z}$ is the set of tokens corresponding to $\mathbf{z}$ (i.e. $\bar{f}(\cdot) = ([\bar{f}(\cdot)] {\textbf{x}}, [\bar{f}(\cdot)] \mathbf{z})$). More abstractly put, our modified update rule Eq. (4) can be rewritten as $\mathbf{z}b = \alpha \mathbf{z}{b-1} + \beta \bar{f}{\boldsymbol{\theta}b \mid \sigma{b-1}}(\textbf{x}, \mathbf{z}{b-1})$ where $\alpha$ and $\beta$ are constants dependent on $\sigma$ ratio. We note that our modification of the network into the stack of diffusion blocks maintains most of the structure of the original, particularly in the presence of skip connection, so that $\mathbf{z}\ell = \mathbf{z}{\ell-1} + f{\theta_\ell}(\mathbf{z}_{\ell-1})$ is the original update rule. At the time of inference, $\mathbf{z}_b$ serves as the intermediate estimator of the target variable, with $\mathbf{z}0 = \sigma{\max} \boldsymbol{\epsilon}$ being the pure noise. Please see Figure 6 in Appendix B for the conversion of this inference process.
3.2 Block-independent training of the diffusion blocks
By the network modification recipe in the previous section, we transform the original feedforward map to the recursive denoising map in a diffusion process. The advantage of this modification is the fact that the objective in Eq. (2) can be optimized at any noise level $\sigma$ independently without knowledge of other noise levels. This allows us to define a training objective for each block $b$:
$ \mathcal{L}b(\boldsymbol{\theta}b) := \mathbb{E}{(\mathbf{x}, \mathbf{y}) \sim p{\text{data}}, \sigma \sim p_{\text{noise}}^{(b)}, \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})} \left[w(\sigma)\cdot \text{Loss}(\bar{f}_{\boldsymbol{\theta}_b | \sigma}(\mathbf{x}, \mathbf{y} + \sigma \boldsymbol{\epsilon}), \mathbf{y})\right],\tag{5} $
where $p_{\text{noise}}^{(b)}$ is the noise distribution $p_{\text{noise}}$ with the support of $[\sigma_{b}, \sigma_{b-1}]$ and renormalized, and $\text{Loss}(\cdot, \cdot)$ is the inner loss function, typically L2 loss as in Eq. (2). Each block independently learns to denoise within its assigned range, with training samples drawn according to the original distribution $p_{\text{noise}}$. Collectively, the $B$ blocks cover the entire noise distribution: $\bigcup_{b=1}^B [\sigma_{b}, \sigma_{b-1}] = [\sigma_{\min}, \sigma_{\max}]$, ensuring that the complete network can denoise at any noise level while each block specializes in its designated range. This independence enables training with memory requirements for only $L/B$ layers, storing activations only for the active block, compared to all $L$ layers required by standard training. More succinctly in comparison to the original network, we gain this block-wise independence from the fact that $ \bar{f}_{\boldsymbol{\theta}_b \mid \sigma}(\mathbf{x}, \mathbf{y} + \sigma \boldsymbol{\epsilon})$ is now modified to predict $\mathbf{y}$ for each $b$. This way, training for each block can be carried out without waiting to receive the output of the previous layer. Please see Figure 5 in Appendix B for the training process in the specific adaptations for different architectures. Figure 3 provides an algorithmic procedure of training and inference. This approach achieves a $B\times$ memory reduction during training, as gradients are computed for only one block at a time.
3.3 Block partitioning strategy
A critical design choice in DiffusionBlocks is how to partition the noise level range $[\sigma_{\min}, \sigma_{\max}]$ into $B$ intervals. A naive approach would divide the range uniformly: $\sigma_b = \sigma_{\min} + b \cdot (\sigma_{\max} - \sigma_{\min})/B$. However, this fails to account for the varying difficulty of denoising at different noise levels. Following [15], we adopt a log-normal distribution for sampling noise levels during training: $\log \sigma \sim \mathcal{N}(P_{\text{mean}}, P_{\text{std}}^2)$. This distribution concentrates probability mass at intermediate noise levels, which empirically contribute most to generation quality.
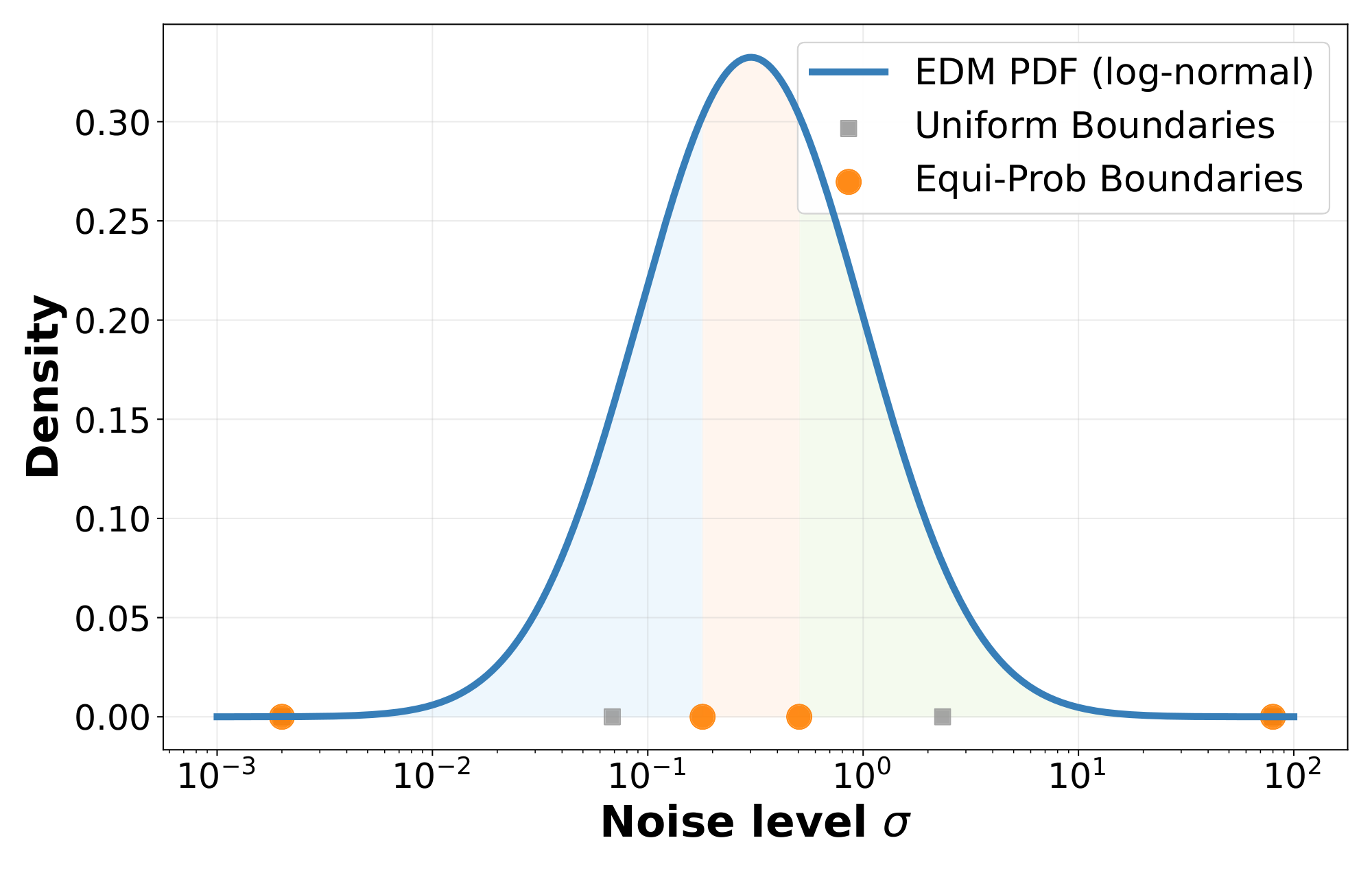
To preserve this distribution across the entire network while ensuring each block handles equal denoising difficulty, we partition based on cumulative probability mass. Specifically, we choose boundaries ${\sigma_b}{b=1}^B$ such that each block handles exactly $1/B$ of the total probability mass: $\int{\sigma_{b-1}}^{\sigma_b} p_{\text{noise}}(\sigma) d\sigma = 1/B$. The block boundaries are computed as $\sigma_b = \exp(P_{\text{mean}} + P_{\text{std}} \cdot \Phi^{-1}(q_b))$, where $\Phi^{-1}$ is the inverse standard normal CDF and $q_b = q_{\min} + \frac{b}{B} (q_{\max} - q_{\min})$, with $q_{\min/\max} = \Phi\left(\frac{\log \sigma_{\min/\max} - P_{\text{mean}}}{P_{\text{std}}}\right)$. This equi-probability partitioning ensures that each block handles an equal amount of the training distribution's probability mass, leading to balanced parameter utilization. As shown in Figure 4, blocks assigned to intermediate noise levels, where denoising is most challenging, receive narrower intervals, while blocks handling very high or low noise levels receive wider intervals. This strategy optimizes learning efficiency across all blocks. In Section 5.6, we demonstrate that this strategy contributes significantly to the training of DiffusionBlocks. Also, see Appendix C for implementation details.
4. Related works
Section Summary: Existing block-wise training methods split networks into separately trained parts using heuristic rules that offer no guarantee of strong overall performance, and approaches like the Forward-Forward algorithm are largely restricted to classification. A concurrent technique called NoProp shares a similar philosophy yet remains tied to a specific CNN architecture and classification tasks, whereas DiffusionBlocks offers a general way to convert standard residual networks and transformers into independently trainable blocks that support both generation and classification. In contrast to earlier diffusion models that train specialized networks for different noise levels through joint optimization or shared parameters, DiffusionBlocks achieves full independence by training each block in isolation with no fine-tuning or parameter sharing.
Block-wise training methods.
Various block-wise training approaches ([5, 6, 7, 8, 9]) partition networks into independently trainable components but lack theoretical grounding, relying on heuristic objectives that fail to guarantee global performance when optimized locally. Approaches like Forward-Forward algorithm ([5]) rely on contrastive objectives, which fundamentally limit them to classification tasks and make adaptation to generation non-trivial. In contrast, DiffusionBlocks leverages denoising score matching theory, which naturally decomposes into independent local objectives without task-specific constructs, enabling application to both classification and generative tasks.
Comparison with NoProp.
Concurrently with our submission, [26] has also released a backpropagation-free strategy in close relation to our philosophy. However, they present their technique together with the custom CNN-based architecture in one package and evaluate only on classification tasks, making it unclear how to apply their approach to modern architectures or tasks other than the classification they showcase in their work. In contrast, DiffusionBlocks provides a systematic procedure for converting any residual networks, particularly modern transformers, into block-wise trainable models with minimal modifications. We partition the continuous noise range using equi-probability partitioning and demonstrate success on both generative tasks and classification tasks. In Section 5.6.1, we apply DiffusionBlocks to their architecture, and demonstrate that our continuous-time block-wise training with equi-probability partitioning is more effective.
Stage-specific diffusion models.
Several works train specialized models for different noise levels in diffusion ([27, 28, 29, 30]). However, these approaches train models jointly or fine-tune from shared parameters. DiffusionBlocks trains blocks independently, with no shared parameters or joint fine-tuning, achieving complete isolation.
5. Experimental results
Section Summary: DiffusionBlocks was tested on multiple neural network architectures for both classification and generation tasks, including vision transformers on CIFAR-100, diffusion transformers for image synthesis on CIFAR-10 and ImageNet, and various language models for text. In each case, the approach preserved or improved task performance metrics such as accuracy, FID scores, and bits-per-character while cutting training memory by factors of three or four, since gradients were needed only for a subset of layers. It also outperformed alternative block-wise methods like Forward-Forward and extended successfully to both continuous and discrete diffusion processes.
We evaluate DiffusionBlocks across diverse architectures and tasks to demonstrate its generality and effectiveness. Detailed experimental configurations are provided in Appendix E. For each architecture, we report task performance alongside the memory reduction factor $B$, where only $L/B$ layers require gradients during training.
Baselines.
Because DiffusionBlocks is a framework for transforming networks into block-wise trainable models, we evaluate its efficacy by comparing the modified network (trained block-wise) against the original network (trained with end-to-end backpropagation). Other block-wise training methods in practice today also include Forward-Forward (FF) ([5]) and the concurrent NoProp ([26]). Fair comparison against these methods warrants careful experimental design. Firstly, we compare against FF only on classification tasks (Section 5.1) since its contrastive objective does not naturally extend to generation. Also, because NoProp is proposed together with a custom architectural design rather than with a principled transformation procedure to be applied to a vanilla network, the adaptation of NoProp to other architectures involves nontrivial design choices and freedom. To enable fair comparison with NoProp, we therefore use their specific architecture as the base diffusion model on which to apply our DiffusionBlocks (Section 5.6.1).
5.1 Vision transformers for image classification
We first validate DiffusionBlocks on classification tasks using Vision Transformer (ViT) ([31]) on CIFAR-100 ([32]). A 12-layer ViT is partitioned into $B$ =3 blocks, with noise added to class label embeddings during training. We compare against the Forward-Forward algorithm, a representative block-wise training method that uses contrastive objectives. Table 1 maintains baseline accuracy while requiring gradients for only $4$ layers. Notably, Forward-Forward achieves only 7.85% accuracy, highlighting the importance of principled denoising objectives over ad-hoc contrastive approaches.
5.2 Diffusion models for image generation
\begin{tabular}{lr}
\toprule
\textbf{Method} & \textbf{Accuracy ($\uparrow$)} \\
\midrule
ViT & 60.25 \\
+ Forward-Forward & 7.85 \\
\rowcolor{lightgray}
\textbf{+ DiffusionBlocks} & \textbf{59.30} \\
\bottomrule
\end{tabular}
\begin{tabular}{llr}
\toprule
\textbf{Dataset} & \textbf{Method} & \textbf{FID ($\downarrow$)} \\
\midrule
\multirow{2}{*}{CIFAR-10} & DiT & 32.84 / 39.83 \\
& \cellcolor{lightgray} + \textbf{DiffusionBlocks} & \cellcolor{lightgray} \textbf{30.59 / 37.20} \\
\midrule
\multirow{2}{*}{ImageNet} & DiT & 9.01 / 12.09 \\
& \cellcolor{lightgray} + \textbf{DiffusionBlocks} & \cellcolor{lightgray} \textbf{9.00 / 10.63} \\
\bottomrule
\end{tabular}
\begin{tabular}{lr}
\toprule
\textbf{Method} & \textbf{BPC ($\downarrow$)} \\
\midrule
MDM & 1.56 \\
\rowcolor{lightgray}
+ \textbf{DiffusionBlocks} & \textbf{1.45} \\
\bottomrule
\end{tabular}
Having established its effectiveness on classification tasks, we now turn to generative models. We begin with image generation, where DiffusionBlocks provides both training and inference efficiency benefits. We apply DiffusionBlocks to DiT ([4]) within the EDM ([15]) framework. We evaluate 12-layer DiT (DiT-S/2) on CIFAR-10 ([32]) and 24-layer DiT (DiT-L/2) on ImageNet at $256\times256$ resolution ([33]), both with $B$ =3 blocks. During inference, we use Euler sampling with 50 steps and classifier-free guidance (scale 2.0) ([34]). Table 2 shows that DiffusionBlocks achieves comparable FID scores with 3 $\times$ memory reduction. Additionally, inference requires only one block per denoising step, providing computational savings proportional to the number of steps.
5.3 Masked diffusion models for text generation
We extend DiffusionBlocks to masked diffusion language models using MD4 ([35]) on the text8 dataset ([36]). While continuous diffusion models naturally map to our framework through noise levels $\sigma$, extending DiffusionBlocks to discrete masked diffusion requires careful adaptation. Specifically, we partition the masking schedule rather than continuous noise levels, ensuring each block handles an equal share of the demasking work (details in Appendix D). We use a 12-layer DiT-based transformer ([37, 38]) partitioned into $B$ =3 blocks. Table 3 shows that DiffusionBlocks achieves 1.45 bits-per-character (BPC) compared to MD4's 1.56, while using 3 $\times$ less memory. This improvement confirms that our principled noise-level partitioning effectively extends to discrete diffusion processes.
5.4 Autoregressive models for text generation
::: {caption="Table 4: Autoregressive (AR) transformer results for text generation. DiffusionBlocks maintains generation quality with 4 × memory reduction on both LM1B and Openwebtext (OWT) datasets."}

:::
::: {caption="Table 5: Recurrent-depth model results for text generation. DiffusionBlocks eliminates 32 training iterations, achieving better performance with single-pass training."}

:::
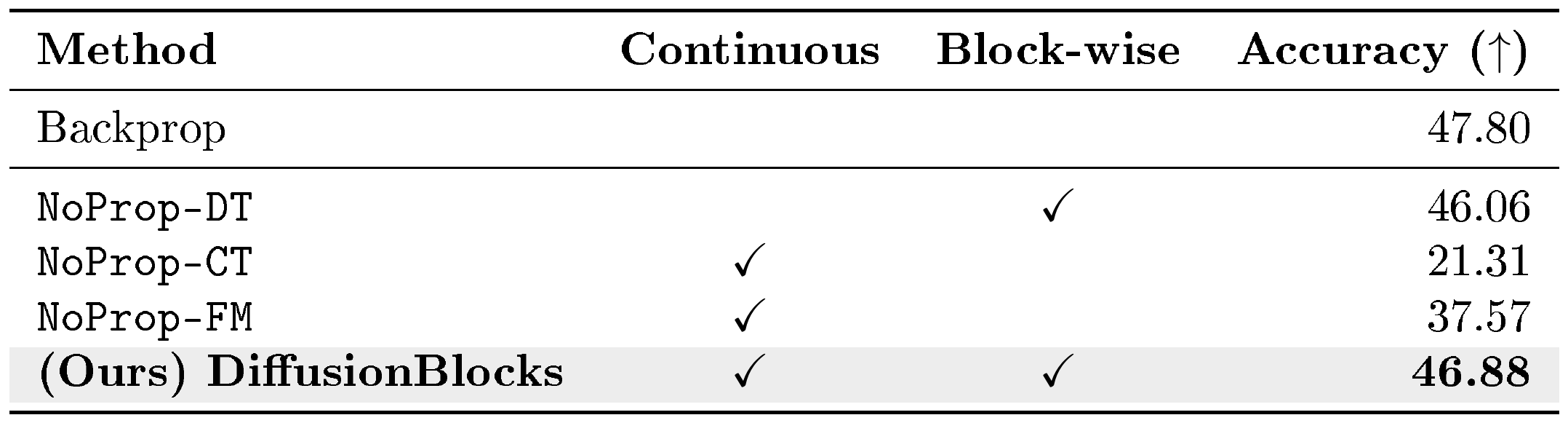
::: {caption="Table 6: Comparison with NoProp on CIFAR-100. DiffusionBlocks achieves both continuous-time formulation and layer-wise training. All scores except DiffusionBlocks are taken from NoProp ([26]). Note that the Backprop in this table is the result of applying BPTT to the sampled paths of a specific form of SDE that equationally resembles the process used in NoProp-DT. See [26] for the details."}
:::
We demonstrate that DiffusionBlocks successfully transforms standard autoregressive (AR) models, which are architectures originally designed for next-token prediction, not denoising. Using 12-layer Llama-2-style transformers ([3]) with $B$ =4 blocks, we evaluate on 1 Billion Words Dataset (LM1B) ([39]) and OpenWebText (OWT) ([40]). While AR models are typically evaluated using perplexity, computing traditional perplexity is non-trivial for our diffusion framework as it is not derived from ELBO. Instead, we evaluate using MAUVE ([41]) scores following SEDD ([37]) to measure similarity between generated and real text. We also report generative perplexity from two teacher models, Llama-2-7B and GPT2-XL ([42]), following [37, 38]. Table 4 shows that DiffusionBlocks achieves comparable performance despite training only 3 layers at a time, demonstrating the framework's broad applicability beyond diffusion-native architectures.
5.5 Recurrent-depth models for text generation
We now showcase a different application of DiffusionBlocks beyond block-wise training. As noted in Section 2.2, the updates in recurrent-depth models naturally correspond to diffusion steps. Following Section 3.1, we apply DiffusionBlocks to Huginn ([23]), a recurrent-depth model that applies the same network multiple times, starting from noise. While Huginn uses 8-step truncated BPTT to avoid the full BPTT over 32 iterations, DiffusionBlocks makes this optimization even more efficient, because it only requires a single forward pass per training step. Table 5 shows better performance on LM1B for text generation while eliminating 32 iterations. This demonstrates that our framework enables fundamental training transformations beyond block-wise training.
5.6 Analysis
5.6.1 Comparison with NoProp
We compare DiffusionBlocks with NoProp as an ablation study, applying to their custom CNN-based architecture to isolate the effect of our continuous-time block-wise training using equi-probability partitioning. Table 6 shows results on CIFAR-100 classification (details in Appendix E.6.1). DiffusionBlocks outperforms all NoProp variants. Notably, while maintaining comparable performance to the backpropagation, DiffusionBlocks is the only method that successfully combines continuous-time formulation with block-wise training. This demonstrates that our equi-probability partitioning with independent denoisers per block is crucial for continuous-time block-wise training.
5.6.2 Ablation Studies on Design Choices
We conduct ablation studies to analyze key design choices in DiffusionBlocks. All experiments follow the configurations described ectiveness of each component.[^2]
[^2]: These ablations disable block overlap in Appendix C to isolate the effectiveness of each component, resulting in the FID difference from Table 2.
\begin{tabular}{lcr}
\toprule
\textbf{Partitioning Strategy} & \textbf{Layer Distribution} & \textbf{FID} ($\downarrow$) \\
\midrule
Uniform & [4, 4, 4] & 43.53 \\
Uniform & [3, 6, 3] & 43.59 \\
Uniform & [6, 4, 2] & 47.49 \\
Uniform & [2, 4, 6] & 42.37 \\
\rowcolor{lightgray}
Equi-Probability & [4, 4, 4] & \textbf{38.03} \\
Equi-Probability & [3, 6, 3] & 41.64 \\
Equi-Probability & [6, 4, 2] & 45.42 \\
Equi-Probability & [2, 4, 6] & 40.40 \\
\bottomrule
\end{tabular}
\begin{tabular}{lrrr}
\toprule
\textbf{Number of Blocks} & \textbf{FID} ($\downarrow$) & \textbf{L/B} ($\downarrow$) & \textbf{Relative Speed} \\
\midrule
$B=1$ & 12.09 & 24 & 1.0 $\times$ \\
\midrule
\rowcolor{lightgray}
$B=2$ & \textbf{9.90} & 12 & 2.0 $\times$ \\
\rowcolor{lightgray}
$B=3$ & \textbf{11.11} & 8 & 3.0 $\times$ \\
\rowcolor{lightgray}
$B=4$ & \textbf{11.90} & 6 & 4.0 $\times$ \\
$B=6$ & 14.43 & 4 & 6.0 $\times$ \\
\bottomrule
\end{tabular}
Block partitioning strategy.
Table 7 compares our equi-probability partitioning with uniform partitioning on CIFAR-10. Equi-probability partitioning achieves significantly better FID across all layer distributions. The improvement stems from allocating computational resources based on denoising difficulty: equi-probability assigns more blocks to challenging intermediate noise levels where most learning occurs, while uniform partitioning wastes capacity on trivial very high/low noise regions. Notably, within equi-probability partitioning, uniform layer distribution (4-4-4) achieves the best FID, demonstrating that practitioners can simply divide layers equally without tuning since the noise-based partitioning automatically balances learning difficulty across blocks.
Number of blocks $B$.
Table 8 summarizes the effect of varying the number of blocks on ImageNet (see Appendix F.2 for the results on CIFAR-10). It reveals the trade-off between generation quality and efficiency on ImageNet. Notably, moderate block counts ($B$ =2 or $B$ =3) achieve better FID than end-to-end training ($B$ =1), suggesting that moderate block partitioning can actually improve performance through specialization. As $B$ increases further, quality gradually declines due to reduced capacity per block, though inference speed improves linearly. The optimal $B$ varies across tasks (see Appendix F.3 for language modeling results).
6. Conclusion
Section Summary: DiffusionBlocks is a new approach that reinterprets residual neural networks as a series of independent blocks, each trained separately by linking them to a continuous diffusion process. This requires only minor changes to existing models, preserves competitive accuracy, and reduces training memory needs by a factor of B. The authors highlight several avenues for future work and note that the method could help make large-scale AI training more practical and widely accessible.
We introduced DiffusionBlocks, a theoretically grounded framework that transforms residual networks into independently trainable blocks through continuous-time diffusion interpretation. By recognizing that residual connections naturally implement discretized diffusion steps, we provide a systematic recipe requiring minimal modifications that maintains competitive performance across diverse architectures while achieving $B\times$ memory reduction during training.
Future works.
Our work opens several important directions for future research. First, while we consistently used Euler discretization to match residual connections, other diffusion samplers ([43, 44, 45]) could be employed within blocks with modified inter-block connections. Second, DiffusionBlocks currently requires matching input-output dimensions, which limits its application to architectures like U-Net ([46]). Third, while we demonstrate DiffusionBlocks' effectiveness on models trained from scratch, scaling to even larger models would further demonstrate its practical impact. Particularly, a promising direction is to convert pre-trained large models to DiffusionBlocks through fine-tuning rather than training from scratch. Fourth, determining the optimal granularity of block partitioning presents an interesting theoretical and practical challenge. While our experiments demonstrate that treating entire architectural blocks (e.g., complete ViT blocks) as single denoising units works well, a principled method for selecting the ideal partitioning granularity based on architecture and task characteristics could further enhance the framework's applicability. Finally, understanding why moderate block partitioning sometimes outperforms end-to-end training warrants theoretical investigation. We hypothesize two contributing factors: (1) DiffusionBlocks employs a different optimization structure in which each block is directly linked to the target through a denoising objective in Eq. (7), creating a learning signal that differs from standard end-to-end training; and (2) assigning different noise ranges to different blocks may induce beneficial specialization effects. Combined with equi-probability partitioning, this introduces a natural form of curriculum learning ([47]) by allocating balanced difficulty across blocks. Developing a formal theory and analysis for these effects could reveal new principles for scalable and structured neural network optimization beyond memory efficiency.
DiffusionBlocks represents a step toward democratizing large-scale model training by reducing computational requirements without sacrificing performance, making advanced AI capabilities more accessible.
Author contributions
Section Summary: Makoto Shing led the work by creating the DiffusionBlocks idea, building its mathematical link between residual networks and diffusion processes, carrying out the coding and tests, and drafting the paper. Masanori Koyama supplied key theoretical perspectives and helped sharpen both the writing and the overall framing of the study, while Takuya Akiba guided the project and offered technical advice at every stage. Together the three authors reviewed the results and polished the final manuscript.
Makoto Shing conceptualized the DiffusionBlocks framework, developed its diffusion-theoretic formulation connecting residual networks and continuous-time diffusion processes, implemented the method, conducted all experiments, and wrote the manuscript. Masanori Koyama provided theoretical insights into the diffusion-based interpretation and contributed to refining both the manuscript and the conceptual positioning of the work. Takuya Akiba supervised the research and provided technical guidance and feedback throughout the project. All authors contributed to the interpretation of results and manuscript revision.
Acknowledgement
The authors would like to thank Stefano Peluchetti for helpful feedback on an earlier version of the draft.
Appendix
Section Summary: The appendix begins by defining key mathematical notations for inputs, targets, noise levels, and network components used throughout the paper's formulations, along with task-specific examples such as image classification or text generation. It then explains how the DiffusionBlocks framework can be adapted to a range of architectures, including Vision Transformers, standard diffusion models, language models operating in embedding space, and recurrent-depth networks, with adjustments for training via independent block denoising and sequential inference from high to low noise. Finally, it outlines practical implementation choices, such as overlapping noise ranges between blocks to ensure smooth transitions during processing.
A. Notations
In this section, we provide the notations that we will be using in the ensuing mathematical formulations and statements.
\begin{tabular}{ll}
\toprule
\textbf{Notation} & \textbf{Description} \\
\midrule
$x \sim \mathcal{X}$ & Conditioning/Input to the network (task-dependent: see below) \\
$y \in \mathcal{Y}$ & Clean target data (task-dependent: see below) \\
$\sigma \in \mathbb{R}$ & Noise level in continuous diffusion. \\
$z_\sigma \in \mathbb{R}^d$ & Noisy data at noise level $\sigma$: $z_\sigma = y + \sigma\epsilon$, where $\epsilon \sim \mathcal{N}(0, 1)$ \\
$z_\ell \in \mathbb{R}^d$ & Intermediate activation at layer/block $\ell$ \\
$D_\theta: \mathbb{R}^d \times \mathbb{R} \to \mathcal{Y}$ & Denoiser network with parameters $\theta$ \\
$f_{\theta_\ell}: \mathbb{R}^d \to \mathbb{R}^d$ & Layer/block transformation with parameters $\theta_\ell$ \\
$B$ & Number of blocks \\
$L$ & Total number of layers \\
\midrule
\multicolumn{2}{l}{\textbf{Examples of $(x, y)$ on a task:}} \\
Image classification & $x$: input image, $y$: class label \\
Image generation & $x$: noisy image (optionally, and class label), $y$: clean image \\
Text Generation (AR) & $x$: previous tokens, $y$: next token \\
Text Generation (AR) & $x$: sequence with mask tokens, $y$: unmasked sequence \\
\bottomrule
\end{tabular}
B. Extension to diverse architectures
While we have described DiffusionBlocks for standard residual networks where inputs and outputs naturally live in the same $d$-dimensional space, the framework extends to specialized architectures. Figure 5 and Figure 6 illustrate how different model types can be converted to DiffusionBlocks for training and inference, respectively.
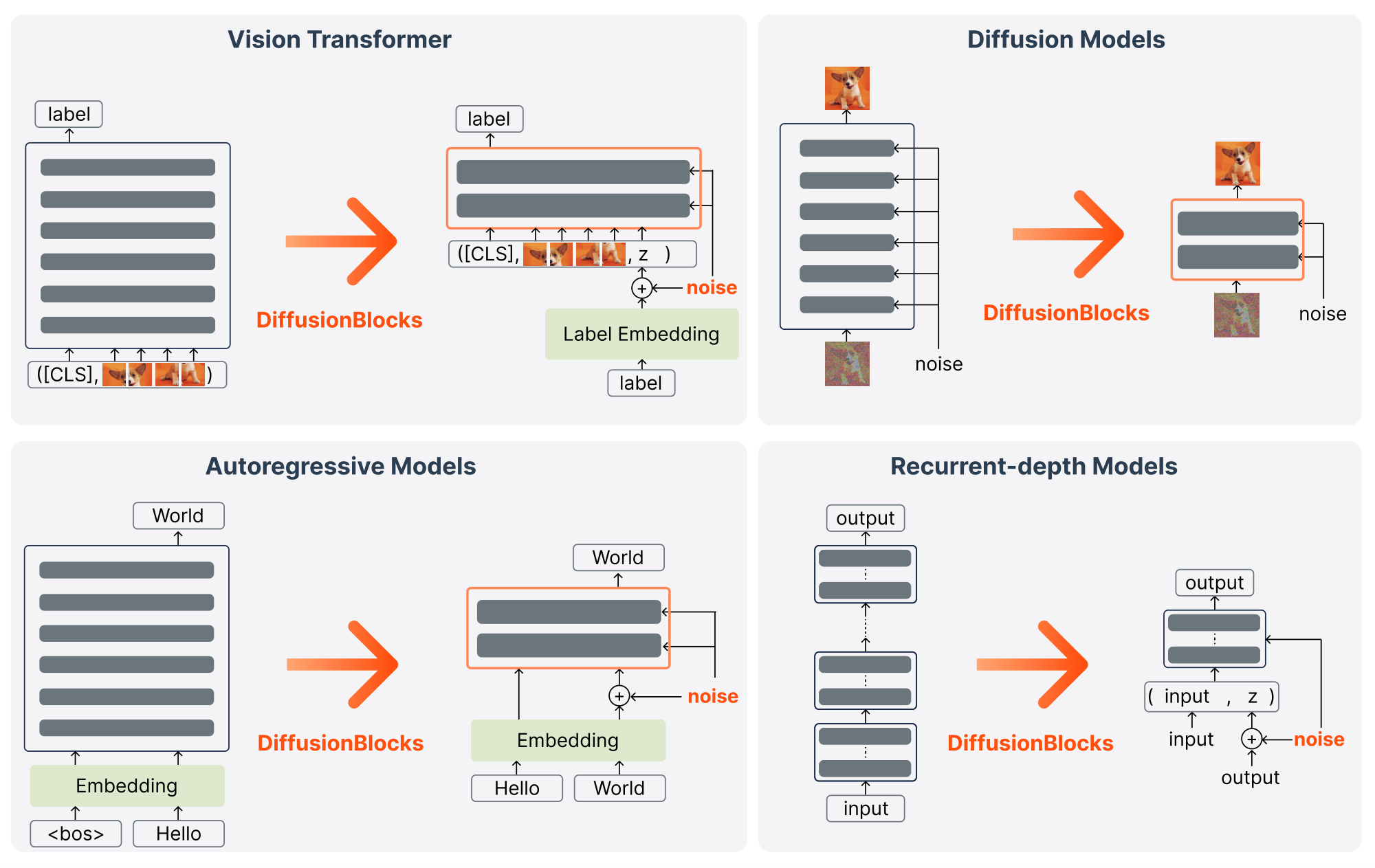
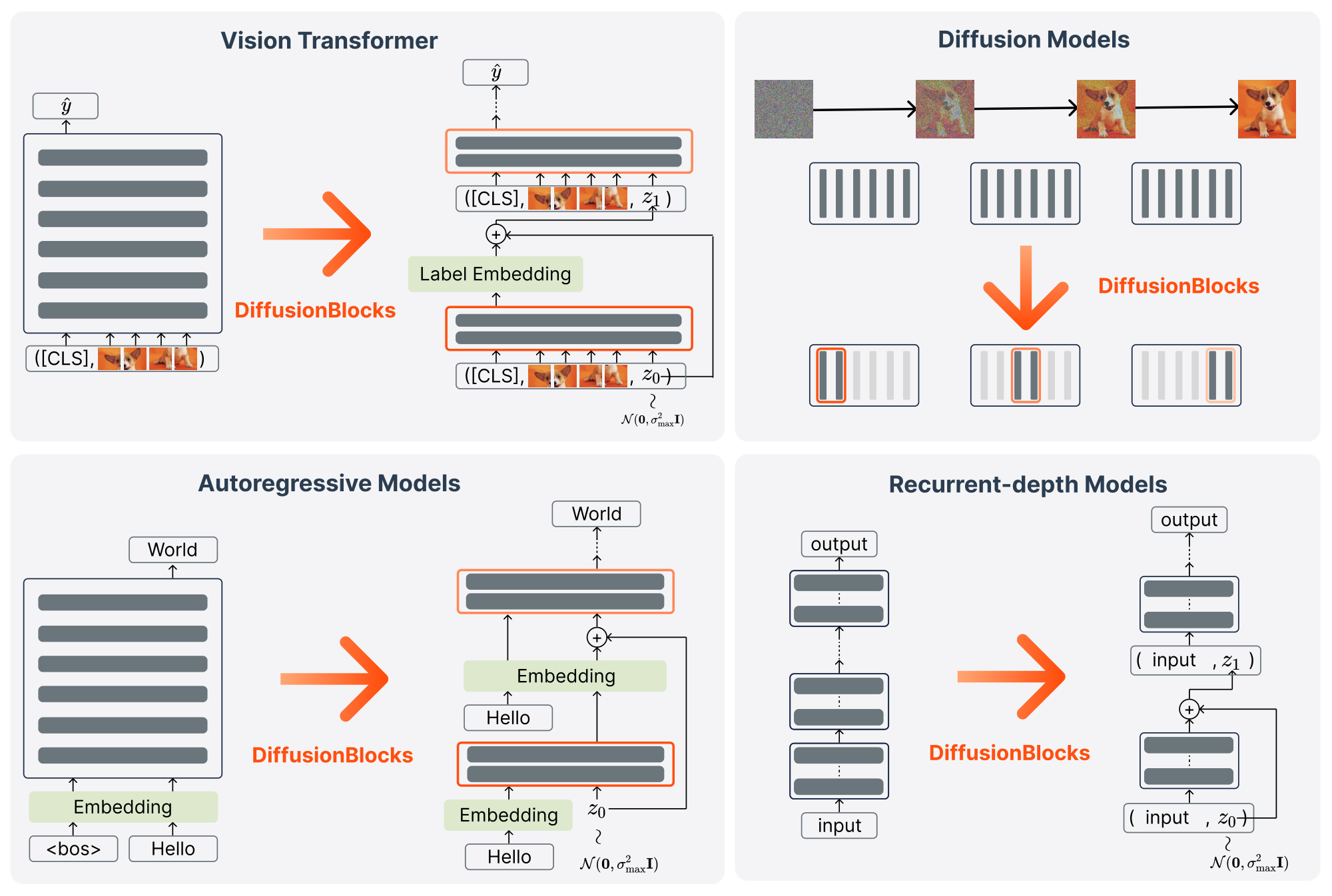
For Vision Transformers (ViT) ([31]) in classification tasks (top left), we adapt DiffusionBlocks by adding noise to the class label embeddings while maintaining the standard ViT architecture. Specifically, we create the input sequence by concatenating the [CLS] token, patch embeddings $\mathbf{x}$, and the noisy label embedding $\mathbf{z}\sigma$, where $\mathbf{z}\sigma = \mathbf{y}{\text{emb}} + \sigma\boldsymbol{\epsilon}$ and $\mathbf{y}{\text{emb}} \in \mathbb{R^d}$ is the learnable continuous embeddings for the class label $y$. Each block $b$ learns to denoise this label representation conditioned on the patch embeddings $\mathbf{x}$. The training loss is the standard cross-entropy between the classification head's output logits (applied to the [CLS] token) and the true class labels, following the conventional ViT training procedure.
For diffusion models (top right), DiffusionBlocks provides a natural fit: these models already operate by denoising, so partitioning simply assigns different noise ranges to different blocks without architectural modifications. The standard denoiser $D_{\boldsymbol{\theta}}(\mathbf{z}\sigma, \sigma)$ becomes $D{\boldsymbol{\theta}b}(\mathbf{z}\sigma, \sigma)$ for block $b$.
For discrete output spaces like language modeling (bottom left), we operate in the embedding space following prior works ([48, 49, 50, 51]). Noise is added after the embedding layer: given input tokens $\mathbf{x}$, we compute $\mathbf{z} = f_{\text{in}}(\mathbf{x})$, then add noise $\mathbf{z}\sigma = \mathbf{z} + \sigma\boldsymbol{\epsilon}$. For autoregressive models, the denoiser $D{\boldsymbol{\theta}b}(\mathbf{z}{i, \sigma}, \mathbf{z}{<i}, \sigma)$ recovers the clean embedding of token $i$ from its noisy version, conditioned on previous clean token embeddings $\mathbf{z}{<i}$. We minimize cross-entropy loss instead of L2 loss.
For recurrent-depth architectures that apply the same network $K$ times (bottom right), we interpret the entire recurrence as a diffusion process. Instead of training with $K$ forward passes through recurrent iterations, we train the network as a denoiser $D_\theta(\mathbf{z}\sigma, \textbf{x}, \sigma)$ by sampling $\sigma \sim p\sigma$ and performing a single forward pass to map noisy input to clean output, reducing computational cost by factor $K$ while maintaining the original $K$-iteration inference procedure.
Beyond these adaptations, DiffusionBlocks also applies to diffusion language models ([52, 37, 38, 35]), where the framework provides additional benefits for text generation. We provide a detailed treatment of this application in Appendix D. These diverse applications demonstrate that DiffusionBlocks provides a general recipe for transforming various architectures into memory-efficient, independently trainable components.
C. Implementation details in DiffusionBlocks
We introduce several practical considerations for effective training and inference.
Overlap between blocks.
To smooth transitions across block boundaries, we slightly extend each block's noise interval in log- $\sigma$ space. For a block $b$ responsible for $[\sigma_b, \sigma_{b-1}]$ with $\sigma_{b-1}>\sigma_b$, we define $\alpha_b := \left(\sigma_{b-1}/\sigma_b\right)^{\gamma}$, where $\gamma \ge 0$, and train over the expanded range $\left[\sigma_b/\alpha_b, \alpha_b \sigma_{b-1}\right]$. Here $\gamma$ controls the degree of overlap: $\gamma$ =0 recovers non-overlapping intervals, while $\gamma>0$ yields smoother transitions between blocks. In practice, we found $\gamma\in[0.0, 0.1]$ effective, and we use $0.05$ by default and $0.1$ for text generation.
Weighting and preconditioning.
Following the EDM framework ([15]), we use the weighting function: $w(\sigma) = (\sigma^2 + \sigma_{\text{data}}^2)/(\sigma \cdot \sigma_{\text{data}})^2$ where $\sigma_{\text{data}} = 0.5$ for all experiments. The weighting is crucial for equi-probability partitioning to work effectively, as it counteracts the sampling bias introduced by the log-normal distribution $p_\sigma$. We also adopt EDM's preconditioning scheme, which involves input scaling to ensure stable training dynamics across all noise levels. See [15] for more details.
Normalizing embeddings.
For tasks where the target variables are discrete (e.g. class labels in image classification or token ids in text generation), DiffusionBlocks operates the diffusion process in the continuous embedding space (see Appendix B). A known issue in continuous relaxation of discrete variables is embedding collapse, where all learned embeddings correspond to the same vector ([48]). To prevent this, we follow the regularization strategy introduced [48] and apply L2 normalization to the embeddings.
Training and inference details.
For training efficiency, blocks are randomly sampled per iteration, requiring memory for only $L/B$ layers. Blocks can alternatively be trained in parallel across multiple GPUs when available. During inference, we generate samples by sequentially applying blocks from $\sigma_{\max}$ to $\sigma_{\min}$. While we use Euler steps in our experiments due to the natural correspondence between residual connections and Euler discretization (Section 2.2), our framework is not limited to this choice. By modifying the inter-block connections to match the discretization scheme of other solvers, any diffusion sampling methods ([43, 44, 45]) can be employed. We leave this exploration for future work.
D. Masked diffusion language models as DiffusionBlocks
D.1 Continuous-time formulation
We first recall the continuous-time formulation of masked diffusion language models ([38, 35]). Let $\mathbf{x}0 = (x{01}, \dots, x_{0n})$ denote a sequence of tokens and let $\alpha(t) : [0, 1] \rightarrow [1, 0]$ denote the masking schedule at continuous time $t \in [0, 1]$, where $\alpha(t)$ represents the probability of remaining unmasked. The forward process progressively masks tokens as:
$ q(\mathbf{x}t \mid \mathbf{x}0) = \prod{i=1}^n q(x{ti} \mid x_{0i}) \quad\text{where}\quad x_{ti} = \begin{cases} x_{0i}, & \text{with prob. } \alpha(t), \ \texttt{[MASK]}, & \text{with prob. } 1-\alpha(t). \end{cases} $
The training objective in continuous form is:
$ \mathcal{L}(\boldsymbol{\theta}) = \mathbb{E}_{\mathbf{x}0} \int_0^1 \frac{-\alpha'(t)}{1-\alpha(t)} \mathbb{E}{\mathbf{x}t \sim q(\mathbf{x}t\mid \mathbf{x}0)} \left[\sum{i : x{ti}=\texttt{[MASK]}} \text{CE}!\left(f\theta(\mathbf{x}_t, t)i, x{0i}\right) \right] dt,\tag{6} $
where $\alpha'(t) = d\alpha/dt < 0$ and CE denotes cross-entropy loss. This form is equivalent to the continuous-time NELBO ([35, 38]), but expressed with a nonnegative weight multiplying $\text{CE}$, which avoids sign ambiguity.
D.2 Partitioning into DiffusionBlocks
To enable block-wise training, we partition the objective in Eq. (6) into $B$ disjoint intervals in $t$. The expected number of masked positions at time $t$ is $n(1-\alpha(t))$, so the effective density of contributions is
$ \frac{-\alpha'(t)}{1-\alpha(t)} \cdot (1-\alpha(t)) ;=; -\alpha'(t). $
Hence, the contribution of interval $[t_a, t_b]$ is
$ \int_{t_a}^{t_b} -\alpha'(t), dt = \alpha(t_a)-\alpha(t_b). $
This shows that the training mass is distributed uniformly in $\alpha$, not in $t$.
Therefore, the natural partition boundaries are defined by equal decrements of $\alpha$:
$ \alpha_b = 1 - \tfrac{b}{B}, \quad b=0, \dots, B, $
with corresponding time boundaries obtained by inversion:
$ t_b = \alpha^{-1}!\left(1 - \tfrac{b}{B}\right). $
For a linear schedule $\alpha(t)=1-t$, this simply yields $t_b=b/B$. Each block $b$ is then trained independently on its assigned interval:
$ \mathcal{L}b(\boldsymbol{\theta}b) = \mathbb{E}{\mathbf{x}0} \int{t{b-1}}^{t_b} \frac{-\alpha'(t)}{1-\alpha(t)} \mathbb{E}_{\mathbf{x}t\sim q(\mathbf{x}t\mid \mathbf{x}0)} \left[\sum{i:, x{ti}=\texttt{[MASK]}} \text{CE} \left(D{\boldsymbol{\theta}_b}(\mathbf{x}_t, t)i, , x{0i}\right)\right] dt,\tag{7} $
where $D_{\boldsymbol{\theta}b}$ denotes the denoiser assigned to block $b$. The global loss decomposes as $\mathcal{L}=\sum{b=1}^B \mathcal{L}_b$.
This derivation shows that DiffusionBlocks in masked diffusion models amounts to partitioning the masking schedule $\alpha(t)$ rather than time. Each block is responsible for an equal decrement in $\alpha(t)$, i.e. an equal share of the total "demasking work", which ensures balanced parameter utilization and true independence across blocks. This construction is directly analogous to the equi-probability partitioning in continuous diffusion models described in Section 3.3.
E. Experimental details
Unless otherwise specified, all experiments use the following settings. For DiffusionBlocks, we adopt the EDM framework ([15]) with default parameters: log-normal noise distribution with $P_{\text{mean}} = -1.2$ and $P_{\text{std}} = 1.2$, noise range $[\sigma_{\min}, \sigma_{\max}] = [0.002, 80]$, and preconditioning following the recommended configuration. Inference uses Euler sampling with 50 steps unless stated otherwise. During training, blocks are sampled uniformly at random for each iteration.
E.1 Vision transformers for image classification
For image classification experiments in Section 5.1, we use a 12-layer ViT with patch size 4, 128 hidden dimensions, 4 attention heads, and 0.1 dropout, partitioned into $B$ =3 blocks (4 layers each). We train for 500 epochs with batch size 128 and AdamW optimizer with learning rate 5 x 10^-4. We employ a cosine learning rate scheduler with a 10-epoch linear warmup. As data augmentation, we apply random horizontal flipping ($p=0.5$) and RandAugment ([53]) as data augmentation.
Figure 5 (top left) illustrates the DiffusionBlocks adaptation for ViT. We add noise to the class label embeddings and concatenate them with the patch embeddings. Each block learns to denoise the label embedding conditioned on the patch embeddings. We use an overlap ratio $\gamma = 0.05$ and perform 4 denoising steps during inference (matching $L/B$ = 12/3). The classification head is applied after the final denoising step to produce class predictions. We minimize cross-entropy loss between predicted and true class labels during training. For the Forward-Forward baseline, we adapt the Contrastive Forward-Forward (FF) ([54]) implementation to ViT ^3.
E.2 Diffusion models for image generation
For image generation experiments in Section 5.2, we use DiT-S/2 (12 layers) for CIFAR-10 and DiT-L/2 (24 layers) for ImageNet-256. Both models are partitioned into $B=3$ blocks. Training follows the EDM framework with classifier-free guidance ([34]) (10% label dropout). For CIFAR-10, we train for 100 epochs with batch size 512 and AdamW optimizer with learning rate $10^{-4}$. For ImageNet, we resize to 256 $\times$ 256 and encode images by a pre-trained VAE ([4])^4. We also train 100 epochs with batch size 512 and AdamW optimizer with learning rate 5 x 10^-5. Overlap ratio is set to $\gamma=0.05$.
In evaluation, we apply Euler sampling with 50 steps and classifier-free guidance (scale 2.0) on both CIFAR-10 and ImageNet experiments. FID is computed using 50, 000 generated samples against the training and test sets, with the minimum of three evaluations reported following [15]. For the training set, we use the official ADM ([55]) evaluation suite, which computes FID against the entire training set as the reference distribution. For the test split, we compute FID using clean-fid ([56]).
E.3 Masked diffusion models for text generation
In Section 5.3, we follow MD4's training protocol with 256 sequence length, AdamW optimizer with learning rate 3 x 10^-4, weight decay 0.03, and 2, 000 linear warmup steps. Training runs for 100 epochs with batch size 256. The 12-layer DiT-based transformer ([37, 38]) uses 768 hidden dimensions and 12 attention heads, partitioned into $B$ =3 blocks with overlap ratio $\gamma=0.05$. Masking schedule follows MD4's linear schedule. For block partitioning in discrete diffusion, we apply equi-probability partitioning to the masking ratio distribution rather than continuous noise levels in Appendix D. Bits-per-character (BPC) is evaluated on the text8 test set following [35].
E.4 Autoregressive models for text generation
In Section 5.4, we use a 12-layer Llama-2-style transformer ([3]) augmented with time conditioning as in DiT ([4]) with 768 hidden dimensions, 12 attention heads, and the Llama-2 tokenizer with 32K vocabulary size. The model is partitioned into $B$ =4 blocks with an overlap ratio $\gamma$ =0.1. Training uses sequence length 256 for LM1B and 3072 for OWT, batch size 256, AdamW with learning rate 3 x 10^-4, and 2500 warmup steps for 10 epochs.
Since DiffusionBlocks is not derived from ELBO-based objectives, computing traditional perplexity is non-trivial. Instead, we evaluate using MAUVE scores following SEDD ([37]), which measures the similarity between generated and real text distributions. For each test sample, we generate 5 continuations of 50 tokens from 1K prompts and compute MAUVE against 1K reference samples with the scaling factor 0.2. Additionally, we report generative perplexity, commonly used in diffusion language models ([37, 38]), by computing the perplexity of generated text using teacher models (Llama-2-7B^5 and GPT2-XL ([42])^6). For generations, we use top-p sampling (0.95) for the baseline and 4 diffusion steps with greedy sampling for DiffusionBlocks. The OWT test set is created by splitting 10% of the data since no official test set exists.
Applying DiffusionBlocks to autoregressive models requires maintaining causal consistency during training. When denoising future tokens, the model must condition on clean past tokens rather than noisy ones to preserve the autoregressive property. Following Block Diffusion ([57]), we implement this using sequence concatenation: noisy and clean sequences are concatenated with a modified causal attention mask that allows noisy tokens to attend to their corresponding clean past tokens while preventing information leakage. This approach doubles sequence memory but maintains single forward pass efficiency. An alternative implementation computes key-value pairs separately for clean and noisy sequences, combining them during attention computation. This requires two forward passes but uses standard sequence memory. We adopt the concatenation approach for computational efficiency.
E.5 Recurrent-depth models
For Huginn ([23]) described in Section 5.5, we use the default configuration: 2 prelude layers, 4-layer recurrent block, and 2 coda layers following Pythia-70M ([58])^7 architecture with 512 hidden dimensions and 8 attention heads. Unlike other architectures, recurrent-depth models do not require block partitioning since the entire network is applied recurrently. Instead, we train the full network as a denoiser by sampling different noise levels $\sigma$ at each training step. While baseline Huginn uses stochastic recurrence depth (average 32 iterations) with truncated BPTT (8 steps), DiffusionBlocks trains with single-pass diffusion. We train on LM1B for 15 epochs compared to Huginn's 5 epochs. Despite this, our approach uses approximately 10 $\times$ less total computation since we avoid the 32 $\times$ recurrent iterations during training.
E.6 Ablation studies
E.6.1 Comparison with NoProp
We follow the experimental protocol of NoProp ([26]). In the absence of publicly available code, we implemented their NoProp-DT architecture augmented with time conditioning from NoProp-CT, following their specifications (Figure 5 in their paper). Training follows NoProp-CT's hyperparameters with AdamW optimizer, learning rate $10^{-4}$, batch size 128, and 1000 epochs on CIFAR-100. For DiffusionBlocks, we use $B$ =3 blocks with overlap ratio $\gamma = 0.1$. Following NoProp-CT's evaluation protocol, we use 1000 Euler sampling steps instead of our default 50.
We attempted to adapt Forward-Forward (FF) algorithm ([5]) as an additional baseline to NoProp's architecture for Table 6. However, without publicly available code and with no specified adaptation procedure, the implementation requires numerous design decisions. Our attempts achieved only 1% accuracy, highlighting the fundamental incompatibility: NoProp's architecture is specifically designed for their method (type (e) in their Figure 2), while FF requires contrastive positive/negative samples (type (d)). Successfully bridging these paradigms may require innovations beyond straightforward adaptation. This highlights a key distinction between approaches. NoProp does not provide guidance for adapting to other methods or architectures. DiffusionBlocks instead offers a systematic procedure for converting existing Transformer-based networks into block-wise trainable models. This recipe enabled successful application to modern architectures with minimal modifications, demonstrating the generality of our framework.
E.6.2 Design choice analysis
All ablation studies follow the configurations described in Appendix E.2. We report FID scores on the test splits. For partitioning experiments, we test both uniform partitioning (equal intervals in log-space) and our equi-probability method. Layer distribution indicates the number of layers in each block. For block count experiments, we vary $B$ from 2 to 6 while keeping total layers fixed at 12. We disabled the block overlap ($\gamma=0.0$) in Appendix C to isolate the effectiveness of each component.
F. Additional experiments
F.1 Image Classification Experiment on Tiny ImageNet
\begin{tabular}{lc}
\toprule
\textbf{Method} & \textbf{Accuracy ($\uparrow$)} \\
\midrule
ViT & 35.32 \\
\rowcolor{lightgray}
\textbf{+ DiffusionBlocks} & \textbf{36.16} \\
\bottomrule
\end{tabular}
To further evaluate the effectiveness of DiffusionBlocks on classification tasks beyond CIFAR-100, we conducted an additional experiment on the Tiny ImageNet dataset ([59]). This dataset consists of 200 classes, 100, 000 training images with each image resized to 64 $\times$ 64 resolution. Tiny-ImageNet provides a more challenging and higher-resolution benchmark than CIFAR-100.
We trained a 12-layer Vision Transformer (ViT) with patch size 4, hidden size 768, and 12 attention heads. Both the baseline ViT and DiffusionBlocks models were trained for 100 epochs using a batch size of 256 and the AdamW optimizer with a learning rate of $10^{-4}$. For DiffusionBlocks, we used $B=2$ blocks (each containing 6 layers).
Table 9 demonstrates that DiffusionBlocks maintains competitive performance relative to the baseline ViT, consistent with our findings on CIFAR-100 as well as our large-scale classification experiments in language modeling (LM1B and OpenWebText in Table 3, Table 4, Table 5). These results further indicate that DiffusionBlocks remains effective as a classifier across different data modalities, resolutions, and dataset scales.
F.2 Effect of block count on CIFAR-10
To examine whether the design trends observed on ImageNet in Table 8 generalize to different datasets, we additionally evaluate the effect of the number of blocks on CIFAR-10. This experiment allows us to assess whether the behavior of DiffusionBlocks remains consistent across datasets of different scales and complexities. We use the same DiT-S/2 architecture described in Section 5.2, training under the EDM framework while varying the number of blocks $B \in {1, 2, 3, 4, 6}$ and disabling block overlap ($\gamma=0.0$) to isolate the effectivenss of the number of blocks $B$.
\begin{tabular}{lrrr}
\toprule
Number of Blocks & FID ($\downarrow$) & L/B ($\downarrow$) & Relative Speed \\
\midrule
$B=1$ & 39.83 & 12 & 1.0 $\times$ \\
\midrule
\rowcolor{lightgray}
$B=2$ & \textbf{35.47} & 6 & 2.0 $\times$ \\
\rowcolor{lightgray}
$B=3$ & \textbf{38.03} & 4 & 3.0 $\times$ \\
$B=4$ & 45.43 & 3 & 4.0 $\times$ \\
$B=6$ & 53.32 & 2 & 6.0 $\times$ \\
\bottomrule
\end{tabular}
\begin{tabular}{lrrr}
\toprule
Number of Blocks & MAUVE ($\uparrow$) & Layers per Block ($\downarrow$) & Relative Speed \\
\midrule
$B=2$ & 0.61 & 6 & 2.0 $\times$ \\
$B=3$ & 0.65 & 4 & 3.0 $\times$ \\
\rowcolor{lightgray}
$B=4$ & \textbf{0.67} & 3 & 4.0 $\times$ \\
$B=6$ & 0.62 & 2 & 6.0 $\times$ \\
\bottomrule
\end{tabular}
As shown in Table 10, smaller block counts tend to achieve better FID scores, and $B=2$ or $B=3$ provides strong performance. This trend matches the observations in Table 8. These results indicate that the effectiveness of using a moderate number of blocks is consistent across datasets of varying scale, supporting the validity of the design choices analyzed in Section 5.6.
F.3 Effect of block count on text generation
Table 11 shows the effect of varying the number of blocks for autoregressive language modeling on LM1B with overlap ratio $\gamma=0.0$.
The optimal number of blocks differs between tasks: image generation achieves best FID with $B$ =2 or $B$ =3 (Table 8), while language modeling achieves best MAUVE with $B$ =4. This motivated our choice of $B$ =4 for language modeling experiments in the main paper.
G. Comparison with Activation Checkpointing
DiffusionBlocks and activation checkpointing (also known as activation recomputation, gradient checkpointing, or rematerialization) offer fundamentally different trade-offs and can be powerfully combined.
The key distinction lies in what each method reduces. Activation checkpointing reduces only activation memory, leaving parameters, gradients, and optimizer states unchanged. In contrast, DiffusionBlocks reduces all memory components by a factor of $B$. This distinction becomes increasingly critical as modern models grow larger.
To illustrate this difference, consider an $L$-layer network where each layer has parameter size $P$ and activation size $A$. With Adam optimizer (requiring $2P$ for momentum and variance), each layer needs $4P$ memory for parameters, gradients, and optimizer states. Standard training thus requires $(4P + A)L$ total memory. Activation checkpointing reduces this to $4PL + A$ by rematerializing activations only when needed (though this is an optimistic estimate that ignores the memory cost of the checkpoints). DiffusionBlocks, by training $B$ independent blocks, requires $(4P + A)(L/B)$. Since $L > B$, combining DiffusionBlocks and activation checkpointing uses the least memory among these four patterns.
Regarding computational costs, it is empirically known that activation checkpointing increases the training time by a factor of approximately 4/3, and this holds true when combined with the proposed method. This is justified as follows. With a forward pass computation cost of $F$, a backward pass requires approximately $2F$ (computing Jacobians and weight gradients). Standard training uses $3F$ cost per iteration, while activation checkpointing increases this to $4F$ due to recomputation. DiffusionBlocks maintains this ratio when combined with checkpointing.
Beyond memory reduction, DiffusionBlocks offers unique advantages regarding training time: each block can be trained in an embarrassingly parallel manner. This means each block can be trained in parallel with absolutely no communication overhead. This provides an additional advantage over activation checkpointing, especially when computational resources are abundant.
H. Training and inference efficiency
This section provides a detailed analysis of the computational efficiency and wall-time characteristics of DiffusionBlocks.
Training efficiency.
Consider an $L$-layer network trained for $K$ iterations. Standard end-to-end backpropagation performs $K \times L$ layer evaluations. DiffusionBlocks trains only $L/B$ layers at a time; training all $B$ blocks for $K$ iterations each performs $(L/B) \times B \times K = L \times K$ layer evaluations. Thus, DiffusionBlocks requires the same total amount of computation as standard training, while reducing memory usage by a factor of $B$.
: Table 12: Wall-time comparison on ViT. The aggregated DiffusionBlocks time is computed by multiplying the measured per-block iteration time by $B=3$.
| Method | Wall time (sec/iter) |
|---|---|
| ViT | 0.0507 |
| DiffusionBlocks: per-block time (4 layers) | 0.0181 |
| DiffusionBlocks: aggregated time (0.0181 × 3) | 0.0543 |
To validate this theoretical equivalence, we measured the per-iteration wall time using a 12-layer ViT on a single H100 80GB GPU, averaging over 100 iterations. As summarized in Table 12, standard training requires 0.0507 seconds per iteration for all 12 layers. Under DiffusionBlocks with $B=3$, each block (4 layers) takes 0.0181 seconds per iteration (measured). The total per-iteration wall time for DiffusionBlocks is therefore obtained by summing the independently trained blocks, computed as $0.0181 \times 3 = 0.0543$ seconds. The resulting end-to-end wall time is thus comparable to standard training, with the small difference attributable to the noise-level conditioning introduced during the DiffusionBlocks conversion (Section 3.1).
Inference efficiency.
For inference, we ensure that the total amount of computation matches that of the baseline model. For a 12-layer network, the baseline performs a single forward pass through all 12 layers. Under DiffusionBlocks with $B=3$, we perform three denoising steps, each invoking the corresponding 4-layer block once. The total compute therefore corresponds to the same 12 layer evaluations as in standard inference.
For diffusion models used in image generation, the computational benefit is even more pronounced. Standard diffusion models must apply the full network for every denoising step. With 50 denoising steps, a 12-layer DiT requires $12 \times 50$ layer evaluations. In DiffusionBlocks, each denoising step applies only the block responsible for that noise level, which contains 4 layers when $B=3$. This reduces the total compute to $4 \times 50$, achieving a $B$-fold reduction in inference cost. The 50 denoising steps are assigned to blocks according to the equi-probability partitioning in Section 3.3, so that each block is used approximately the same number of times during inference. Euler sampling is used for simplicity, and, as shown in Section 2.2, it is computationally equivalent to a residual update, requiring no additional overhead.
References
Section Summary: This section lists dozens of academic papers, preprints and technical reports that the work draws upon, covering foundational advances in large language models, diffusion-based image and data generation, alternative neural network training methods, and transformer architectures. The citations come mainly from major AI conferences such as NeurIPS, CVPR, ICML and ICLR, along with a few arXiv preprints and benchmark datasets. Most entries date from 2016 onward, with several very recent papers from 2024–2025, indicating the authors are building on the latest developments in generative modeling and efficient learning.
[1] Brown et al. (2020). Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems. pp. 1877–1901.
[2] Rombach et al. (2022). High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684-10695.
[3] Touvron et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288.
[4] Peebles, William and Xie, Saining (2023). Scalable Diffusion Models with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4195-4205.
[5] Hinton, Geoffrey (2022). The Forward-Forward Algorithm: Some Preliminary Investigations. arXiv preprint arXiv:2212.13345.
[6] Bengio et al. (2006). Greedy Layer-Wise Training of Deep Networks. In Advances in Neural Information Processing Systems.
[7] Nøkland, Arild and Eidnes, Lars Hiller (2019). Training Neural Networks with Local Error Signals. In International Conference on Machine Learning. pp. 4839–4850.
[8] Belilovsky et al. (2019). Greedy Layerwise Learning Can Scale To ImageNet. In International Conference on Machine Learning. pp. 583–593.
[9] Siddiqui et al. (2024). Blockwise Self-Supervised Learning at Scale. Transactions on Machine Learning Research.
[10] Vaswani et al. (2017). Attention is All you Need. In Advances in Neural Information Processing Systems. pp. .
[11] Song, Yang and Ermon, Stefano (2019). Generative Modeling by Estimating Gradients of the Data Distribution. In Advances in Neural Information Processing Systems. pp. .
[12] Song et al. (2021). Score-Based Generative Modeling through Stochastic Differential Equations. In International Conference on Learning Representations.
[13] Haber, Eldad and Ruthotto, Lars (2017). Stable architectures for deep neural networks. Inverse Problems. 34(1). pp. 014004.
[14] Chen et al. (2018). Neural Ordinary Differential Equations. In Advances in Neural Information Processing Systems. pp. .
[15] Karras et al. (2022). Elucidating the Design Space of Diffusion-Based Generative Models. In Advances in Neural Information Processing Systems. pp. 26565–26577.
[16] Robbins, Herbert E. (1992). An Empirical Bayes Approach to Statistics.
[17] Aapo Hyvärinen (2005). Estimation of Non-Normalized Statistical Models by Score Matching. Journal of Machine Learning Research. 6(24). pp. 695–709.
[18] Vincent, Pascal (2011). A Connection Between Score Matching and Denoising Autoencoders. Neural Computation. 23(7). pp. 1661-1674.
[19] He et al. (2016). Deep Residual Learning for Image Recognition. In IEEE Conference on Computer Vision and Pattern Recognition. pp. 770-778.
[20] DeepSeek-AI et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948.
[21] Mostafa Dehghani et al. (2019). Universal Transformers. In International Conference on Learning Representations.
[22] Ying Fan et al. (2025). Looped Transformers for Length Generalization. In The Thirteenth International Conference on Learning Representations.
[23] Geiping et al. (2025). Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach. arXiv preprint arXiv:2502.05171.
[24] Williams, Ronald J. and Zipser, David (1995). Gradient-based learning algorithms for recurrent networks and their computational complexity.
[25] Mikolov et al. (2010). Recurrent neural network based language model. In Interspeech 2010. pp. 1045–1048.
[26] Li et al. (2025). NoProp: Training Neural Networks without Back-propagation or Forward-propagation. In 4th Conference on Lifelong Learning Agents.
[27] Balaji et al. (2023). eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers. arXiv preprint arXiv:2211.01324.
[28] Fang et al. (2024). Remix-DiT: Mixing Diffusion Transformers for Multi-Expert Denoising. In Advances in Neural Information Processing Systems. pp. 107494–107512.
[29] Park et al. (2024). Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts. arXiv preprint arXiv:2403.09176.
[30] Moritz Reuss et al. (2025). Efficient Diffusion Transformer Policies with Mixture of Expert Denoisers for Multitask Learning. In The Thirteenth International Conference on Learning Representations.
[31] Alexey Dosovitskiy et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations.
[32] Krizhevsky, Alex (2009). Learning multiple layers of features from tiny images.
[33] Deng et al. (2009). ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 248-255.
[34] Ho, Jonathan and Salimans, Tim (2021). Classifier-Free Diffusion Guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications.
[35] Shi et al. (2024). Simplified and Generalized Masked Diffusion for Discrete Data. In Advances in Neural Information Processing Systems. pp. 103131–103167.
[36] Mahoney, Matt (2011). About the Test Data. https://mattmahoney.net/dc/textdata.html.
[37] Aaron Lou et al. (2024). Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution. arXiv preprint arXiv:2310.1683.
[38] Sahoo et al. (2024). Simple and Effective Masked Diffusion Language Models. In Advances in Neural Information Processing Systems. pp. 130136–130184.
[39] Chelba et al. (2014). One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling. arXiv preprint arXiv:1312.3005.
[40] Aaron Gokaslan and Vanya Cohen (2019). OpenWebText Corpus. http://Skylion007.github.io/OpenWebTextCorpus.
[41] Pillutla et al. (2021). MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers. In Advances in Neural Information Processing Systems. pp. 4816–4828.
[42] Radford et al. (2019). Language models are unsupervised multitask learners. OpenAI blog. 1(8). pp. 9.
[43] Jiaming Song et al. (2021). Denoising Diffusion Implicit Models. In International Conference on Learning Representations.
[44] Lu et al. (2023). DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models. arXiv preprint arXiv:2211.01095.
[45] Zhao et al. (2023). UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models. In Advances in Neural Information Processing Systems. pp. 49842–49869.
[46] Ronneberger et al. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. pp. 234–241.
[47] Bengio et al. (2009). Curriculum learning. In International Conference on Machine Learning. pp. 41–48.
[48] Dieleman et al. (2022). Continuous diffusion for categorical data. arXiv preprint arXiv:2211.15089.
[49] Li et al. (2022). Diffusion-LM Improves Controllable Text Generation. In Advances in Neural Information Processing Systems. pp. 4328–4343.
[50] Gulrajani, Ishaan and Hashimoto, Tatsunori B (2023). Likelihood-Based Diffusion Language Models. In Advances in Neural Information Processing Systems. pp. 16693–16715.
[51] Lovelace et al. (2023). Latent Diffusion for Language Generation. In Advances in Neural Information Processing Systems. pp. 56998–57025.
[52] Austin et al. (2021). Structured Denoising Diffusion Models in Discrete State-Spaces. In Advances in Neural Information Processing Systems. pp. 17981–17993.
[53] Cubuk et al. (2020). RandAugment: Practical Automated Data Augmentation with a Reduced Search Space. In Advances in Neural Information Processing Systems. pp. 18613–18624.
[54] Aghagolzadeh, Hossein and Ezoji, Mehdi (2025). Contrastive Forward-Forward: A training algorithm of vision transformer. Neural Networks. 192. pp. 107867.
[55] Dhariwal, Prafulla and Nichol, Alexander (2021). Diffusion Models Beat GANs on Image Synthesis. In Advances in Neural Information Processing Systems. pp. 8780–8794.
[56] Parmar et al. (2022). On Aliased Resizing and Surprising Subtleties in GAN Evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11410-11420.
[57] Marianne Arriola et al. (2025). Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models. In International Conference on Learning Representations.
[58] Biderman et al. (2023). Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. In International Conference on Machine Learning. pp. 2397–2430.
[59] Le, Ya and Yang, Xuan (2015). Tiny ImageNet Visual Recognition Challenge. http://vision.stanford.edu/teaching/cs231n/reports/2015/pdfs/yle_project.pdf.