ELF: Embedded Language Flows
Keya Hu$^{}$ Linlu Qiu$^{}$ Yiyang Lu Hanhong Zhao Tianhong Li Yoon Kim Jacob Andreas Kaiming He
MIT
$^{*}$ Equal contribution; order decided by a coin flip.
Code: https://github.com/lillian039/ELF
Abstract
Diffusion and flow-based models have become the de facto approaches for generating continuous data, e.g., in domains such as images and videos. Their success has attracted growing interest in applying them to language modeling. Unlike their image-domain counterparts, today's leading diffusion language models (DLMs) primarily operate over discrete tokens. In this paper, we show that continuous DLMs can be made effective with minimal adaptation to the discrete domain. We propose Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching. Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, where it maps to discrete tokens using a shared-weight network. This formulation makes it straightforward to adapt established techniques from image-domain diffusion models, e.g., classifier-free guidance (CFG). Experiments show that ELF substantially outperforms leading discrete and continuous DLMs, achieving better generation quality with fewer sampling steps. These results suggest that ELF offers a promising path toward effective continuous DLMs.
Executive Summary: The rapid growth of AI-driven language generation has highlighted limitations in traditional autoregressive models, such as slow inference and challenges in controlling output diversity. Diffusion and flow-based models, proven effective for images and videos, offer potential for text but have underperformed in language tasks due to text's discrete nature. This gap raises questions about whether continuous diffusion approaches can match or exceed discrete methods, especially as demands for efficient, high-quality text synthesis grow in applications like chatbots, translation, and content creation.
This document introduces Embedded Language Flows (ELF), a new type of continuous diffusion language model designed to generate text by operating mostly in a continuous embedding space before final conversion to discrete words. The goal is to demonstrate that minimal adaptations from image-domain techniques can make continuous models competitive with leading discrete ones, addressing why prior continuous models lagged behind.
The authors developed ELF using Flow Matching, a continuous-time method that denoises noisy embeddings—continuous representations of words derived from a pretrained encoder like T5—toward clean text. They trained models of varying sizes (105 million to 652 million parameters) on datasets including OpenWebText (9 billion tokens for unconditional generation) and smaller sets for tasks like German-to-English translation (144 million tokens) and summarization (6 million tokens). Key aspects include shared network weights for denoising and decoding, self-conditioning for guidance, and samplers like ordinary differential equations (ODE) or stochastic variants. Training spanned 3–5 epochs, emphasizing 80% focus on denoising to build robust flows, with evaluations using metrics like generative perplexity (a quality measure) and task-specific scores.
ELF's strongest results show it achieves generative perplexity of about 24 on OpenWebText using just 32 sampling steps—roughly twice as efficient as top discrete models like MDLM or Duo, which need 64+ steps for similar quality—while using 10 times fewer training tokens (45 billion versus 500+ billion). On translation, ELF scored 26.4 BLEU, outperforming baselines by 1–3 points; for summarization, it led in ROUGE metrics by 2–5 points. Larger ELF models scaled well, improving quality-diversity trade-offs, and stochastic sampling boosted performance in low-step regimes. Unlike expectations that discrete models would dominate, ELF's continuous design excelled without distillation or extra decoders.
These findings mean continuous diffusion can deliver faster, more controllable text generation with lower computational costs, reducing inference time for real-time applications and easing scalability for resource-constrained environments. By borrowing proven image techniques like classifier-free guidance, ELF bridges domains, potentially lowering risks of repetitive or low-diversity outputs in policy-sensitive uses like automated reporting. This challenges prior views favoring discrete methods and highlights untapped potential in continuous flows for safer, higher-performance language AI.
Next, organizations should pilot ELF integration into existing pipelines for tasks like summarization or translation, starting with the base model to test efficiency gains. Trade-offs include balancing guidance strength for quality versus diversity—higher scales improve coherence but may reduce variety. Further work is needed, such as training on multilingual datasets or combining with larger encoders for broader applicability; a pilot on domain-specific data could validate this before full deployment.
Limitations include dependence on pretrained encoders, which may limit adaptability to new languages, and evaluations on standard datasets that might not capture edge cases like rare vocabularies. Confidence in core results is high, backed by consistent ablations across seeds and samplers, though caution is advised for very long sequences or low-resource scenarios where discrete methods might still edge out.
1. Introduction
Section Summary: Diffusion models and related flow-based techniques have gained popularity for creating continuous data like images and videos, sparking interest in adapting them for language tasks through diffusion language models, or DLMs, which come in continuous versions that work in smoothed-out token representations or discrete ones that handle raw words directly. This paper introduces Embedded Language Flows (ELF), a new continuous DLM that operates entirely in a continuous embedding space created by encoding discrete tokens, using a flow-matching approach with continuous time and requiring no separate decoder since it only converts back to words at the very end. ELF delivers superior text generation quality compared to top discrete and continuous rivals, using far fewer training examples and steps, and it also excels in tasks like translation and summarization, suggesting continuous methods hold great promise for language modeling with simple designs.
Diffusion models [1, 2, 3] and flow-based models [4, 5, 6] have become prominent paradigms for generating continuous data, demonstrating strong performance at synthesizing images, videos, and data in other continuous domains. These advances have driven growing interest in extending diffusion methods to language modeling, leading to extensive work on diffusion language models (DLMs). DLMs are commonly formulated in one of two ways: continuous or discrete. Continuous DLMs map discrete tokens into continuous representations and perform denoising in the resulting continuous space ([7, 8, 9]). Discrete DLMs, in contrast, operate directly in token space and formulate a probabilistic diffusion model over discrete random variables ([10, 11, 12, 13, 14]). Recent progress in DLMs has been mostly in the discrete regime, in large part due to the stronger empirical performance of discrete DLMs ([15, 16, 17, 18]). But it remains an open question whether the current performance gap of continuous DLMs is due to the inherently discrete nature of language modeling or to underexplored algorithmic design choices.
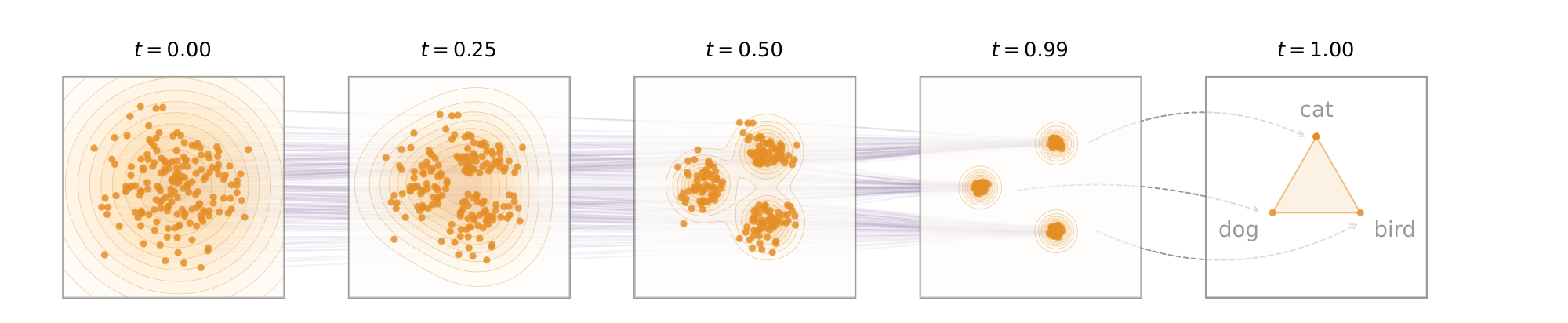
In this work, we introduce Embedded Language Flows (ELF), a class of continuous DLMs based on Flow Matching ([4, 5, 6]). ELF is continuous in two senses. First, it operates in continuous embedding space by directly denoising continuous representations throughout the flowing process, with discretization considered only at the final time step. Second, it is formulated with continuous time, following Flow Matching ([4, 5, 6]), which allows us to define the velocity field via the time derivative. This formulation enables ELF to benefit from advances in Flow Matching, which is now widely used to instantiate diffusion models in image and video generation [19, 20, 21, 22].
Following Latent Diffusion Models (LDM) [23], ELF constructs the continuous embedding space by applying an encoder model to the input discrete tokens. The encoder can be pretrained, jointly trained, or frozen with random weights. Unlike latent diffusion, ELF does not require a separate decoder and thus introduces no additional component at inference time. This design is based on the observation that the final time step in Flow Matching can be naturally repurposed to map continuous embeddings back to discrete tokens, eliminating the need for an explicit decoder. As such, a shared-weight network is trained to perform denoising at all but the final step, and decoding (i.e. discretization) at the final step (see Figure 2).
ELF builds on prior continuous DLMs, but aims for a minimalist design that addresses the interface between continuous and discrete spaces. In contrast to pioneering works on continuous DLMs [7, 8, 9] and many others that employ a per-step discretization loss (e.g., cross-entropy), ELF performs denoising in continuous embedding space at nearly all steps, thereby offering maximal flexibility for the flow dynamics. And unlike latent diffusion methods [24, 25, 26], which typically operate in a compressed latent space and rely on a separate decoder, ELF directly operates in a high-dimensional latent space [27] and requires no extra decoder.
Empirically, we show that ELF outperforms leading methods on discrete DLMs and existing continuous DLMs (Figure 1), following the evaluation protocols established in those works. ELF achieves better generation quality with fewer sampling steps than leading discrete DLMs (e.g., MDLM [13] and Duo [14]) and concurrent continuous DLMs (e.g., FLM [28] and LangFlow [29]). Moreover, ELF achieves this performance using $10\times$ fewer training tokens and without any distillation. We further show that ELF performs strongly on machine translation [30] and summarization [31]. Overall, these results suggest that continuous DLMs can be highly competitive while requiring only minimal treatment of discretization, offering a promising direction for diffusion-based language modeling.
2. Background & Related Work
Section Summary: Diffusion and flow-based models generate data, like language, by gradually transforming random noise into structured outputs using mathematical equations, either in discrete steps or continuous flows; recent advances like Flow Matching allow smoother, velocity-guided paths in continuous spaces. Continuous diffusion language models embed discrete words into a noise-prone continuous realm for denoising, with some tying back to tokens throughout and others, like ELF, staying fully continuous until the final output without needing extra decoders, setting it apart from concurrent flow-based methods that add token checks along the way. Discrete diffusion models work directly on token sequences, using techniques like masking or uniform noise to iteratively build or revise text, and they currently lead in language applications despite the rise of continuous alternatives.
Diffusion-/Flow-based models.
Diffusion models ([1, 3, 2]) and flow-based models ([4, 5, 32]) transform noise into data through ordinary or stochastic differential equations (ODEs/SDEs). In DDPM-style formulations, generation is defined by transitions between successive states ([1, 3, 33]), which may be discrete or continuous. Discrete states require categorical transition distributions, as in discrete DLMs ([10, 13]); continuous states are commonly modeled through score or noise prediction under Gaussian corruption ([2, 3, 20]). Flow Matching extends this view to continuous time by learning the velocity field along a continuous path ([4, 5, 32]), where noise, data, and velocity predictions can be reparameterized into one another ([20, 27]). Our method adopts Flow Matching to formulate language generation in continuous embedding space and continuous time.
Continuous diffusion language models.
Continuous DLMs map discrete tokens to a continuous space to perform denoising. Embedding-space methods, such as Diffusion-LM ([7]), CDCD ([8]), and DiffuSeq ([9]), add Gaussian noise directly to token embeddings ([34, 35, 36, 37, 38, 39, 40, 41]). A complementary direction studies simplex-based representations, including SSD-LM ([42]) and TESS ([43, 44]), as well as related manifold-based formulations ([45]). Although these methods provide continuous relaxations of discrete tokens, their trajectories often remain tied to the discrete token space through mechanisms such as rounding losses, simplex constraints, and token-level cross-entropy objectives. In contrast, ELF denoises entirely in continuous embedding space without per-step token-level supervision and discretizes only at the final step.
Another line applies latent diffusion to frozen encoder representations, represented by LD4LG ([24]) and follow-up work ([46, 47, 48, 25, 26]). Like many diffusion methods described above, these approaches typically follow DDPM-style or score-based formulations with DDPM noise schedules ([3, 33]), and additionally rely on a separately trained decoder to recover tokens. In contrast, ELF uses a continuous-time Flow Matching formulation with a linear (rectified-flow) interpolant ([4, 5, 32]), and does not require a separate decoder. This brings flow-based training and sampling into language diffusion, allowing ELF to benefit from recent advances in Flow Matching.
Several concurrent works also revisit continuous flow-based language modeling. DFM ([49]), CFM ([50]), FLM/FMLM ([28]), and LangFlow ([29]) all incorporate token-level cross-entropy supervision along the flow trajectory, though they differ in the continuous state space, including simplex space, one-hot token encodings, and embedding space. Some of these methods further introduce distillation for few-step generation, such as distilled DFM/CFM and FMLM. In contrast, ELF keeps the denoising trajectory entirely in an unrestricted continuous embedding space, applying token-level supervision only at the final decoding step. A more comprehensive survey is provided in Appendix A.
Discrete diffusion language models.
Due to the discrete nature of language, another line of work applies diffusion directly in token space. D3PMs ([10]) define general discrete corruption processes, including absorbing and uniform transitions. Masked diffusion models, such as MDLMs ([13]), use a special [MASK] absorbing state and generate samples through iterative unmasking ([11, 16, 17]). Subsequent work improves sampling and efficiency through remasking, adaptive inference ([51, 52]), and semi-autoregressive block diffusion, including E2D2 ([53]). Uniform-state diffusion models, such as Duo ([14]), instead diffuse tokens toward a uniform categorical distribution, enabling repeated token revision during inference ([14, 54, 18]). Recent studies further scale discrete DLMs and extend them to code and multimodal generation ([55, 56, 57, 58, 59]). Overall, discrete diffusion models currently remain the dominant paradigm in diffusion-based language modeling ([15]).
3. Embedded Language Flows
Section Summary: ELF, or Embedded Language Flows, is a method for generating text by transforming discrete words into continuous numerical representations called embeddings, then using a flow-based process to gradually remove noise from these embeddings during training. It trains a neural network to predict clean embeddings from corrupted ones using a mean squared error loss, and at the final step, converts those embeddings back into discrete words using a cross-entropy loss for accuracy. During generation, the system begins with random noise and iteratively refines it into meaningful embeddings, decoding them into words only at the end to produce coherent text.
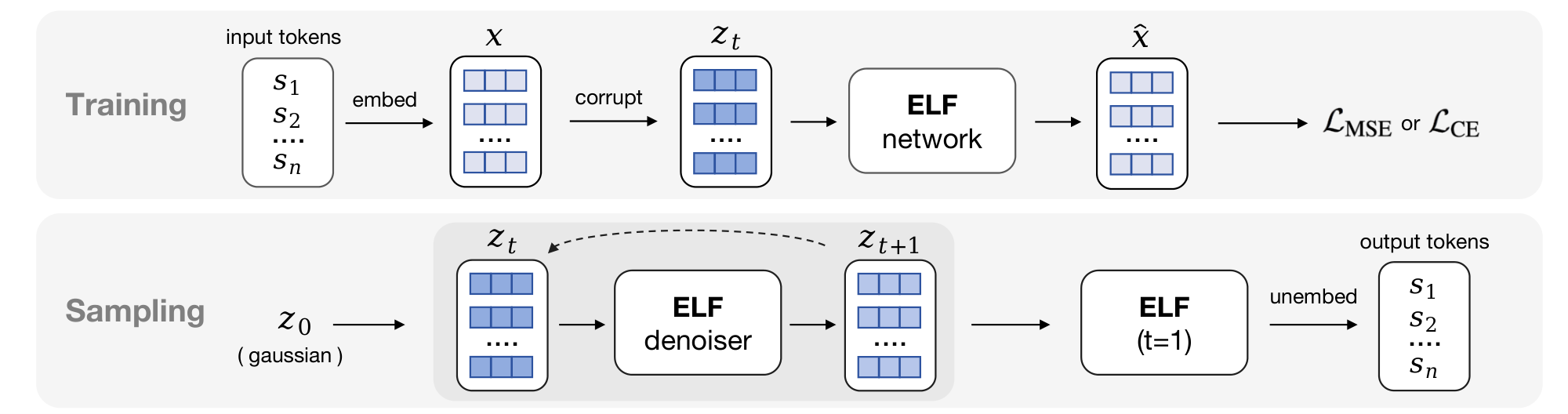
In this section, we present our flow-based formulation for language modeling (Figure 3). Our method leverages the iterative nature of flow models to perform denoising primarily in continuous embedding space, converting clean embeddings back to discrete tokens only at the final step. Following prior work ([13, 14, 28, 29]), we describe our method in the simpler setting of unconditional generation. The framework can be extended to conditional generation, as discussed in Section 3.3.
3.1 The ELF Framework
From discrete tokens to continuous embeddings.
To apply continuous diffusion to language, we first map discrete tokens to continuous representations. Given a sentence, we tokenize it into a sequence of tokens $\bm{s} = [s_1, \ldots, s_L] \in V^L$, where each $s_i$ is drawn from the vocabulary $V$ and $L$ denotes the sequence length. We then map the discrete token sequence into a continuous embedding space. The choice of the embedding method is flexible. By default, we use a pretrained T5 encoder ([60]) for bidirectional contextual embeddings. We also explore other jointly trained and randomized embeddings (see Section 4.1). The encoder is only used during training, which does not incur additional modules at inference.
Flow Matching on continuous embeddings.
After obtaining continuous language representations, we formulate the denoising process in the resulting embedding space using Flow Matching ([4, 5, 6]). Flow Matching defines a continuous flow path from noise to data in this space. Let $\times \sim p_\text{data}(\times)$ denote the embedding distribution and $\bm{\epsilon} \sim p_\text{noise}(\bm{\epsilon})$ denote the noise distribution (e.g., $\bm{\epsilon}\sim\mathcal{N}(0, \mathbf{I})$). The noisy latent variable is defined by linear interpolation ("rectified flows"): $\bm{z}_t = t \times + (1 - t)\bm{\epsilon}$, where $t \in [0, 1]$, and $\bm{z}0 \sim p\text{noise} $ and $\bm{z}1 \sim p\text{data}$. In continuous time, the flow velocity $\bm{v}$ is defined as the time derivative of $\bm{z}$, that is, $\bm{v} = d \bm{z}/dt = \times - \bm{\epsilon}.$
While standard Flow Matching directly parameterizes $\bm{v}$ via a neural network, ELF follows recent advances on image generation and instead parameterizes $\times$ [27] ($\times$-prediction). Specifically, let $\times_\theta = \text{\texttt{net}}_\theta(\bm{z}_t, t)$ denote the network's immediate output. We train the model by minimizing the mean squared error (MSE) between the predicted velocity and the target velocity:
$ {\mathcal{L}{\textrm{MSE}}} = \mathbb{E}{t, \times, \bm{\epsilon}} | \bm{v}_\theta(\bm{z}t, t) - \bm{v} |^2 = \mathbb{E}{t, \times, \bm{\epsilon}} \frac{1}{(1-t)^2}| \times _\theta(\bm{z}_t, t) - \times |^2,\tag{1} $
where we leverage the relation $\bm{v}(\bm{z}_t, t) = (\times - \bm{z}_t) / (1 - t)$ [27].
The $\times$-prediction parameterization is important for ELF. First, it enables Flow Matching to perform effectively on high-dimensional representations (e.g., 768-d per-token embeddings), consistent with observations in ([27]) (see Appendix C.1 for ELF's ablations on prediction targets). Second, predicting clean embeddings (i.e., $\times$) aligns naturally with the objective of predicting clean discrete tokens at the final step (discussed next), whereas the standard $\bm{v}$-prediction in Flow Matching does not. Although $\bm{v}$ can be predicted by a network and transformed into $\times$, the weight sharing that ties the denoising (MSE loss) and decoding (cross-entropy loss) objectives is compromised. Empirically, we observe that $\bm{v}$-prediction works poorly when weights are shared with the final discretization step.
Back to discrete tokens.
As the generation output consists of discrete tokens, we convert the clean embeddings back into tokens at the final time step (i.e., at $t=1$). By considering the final time step of ELF naturally as continuous-to-discrete decoding, our method does not require a separate decoder (or equivalently, it can be thought of as a decoder sharing weights with the denoiser).
The network input at this time step should be $\bm{z}t$ in the limit $t \to 1$. But because $\bm{z}t \to \times$ as $t \to 1$, we introduce a token-level corruption process at this final step to create a nontrivial training input, denoted as $\tilde{\bm{z}}$ (detailed in Appendix B.1). The same network $\text{\texttt{net}}\theta$ maps $\tilde{\bm{z}}$ to a clean embedding ${\times}\theta(\tilde{\bm{z}})$, which is subsequently projected by a learnable "unembedding" matrix $W$ to obtain logits. We minimize a per-token cross-entropy (CE) loss against the ground-truth token $\bm{s}$:
$ {\mathcal{L}{\textrm{CE}}} = \mathbb{E}{\tilde{\bm{z}}}\left[\text{CrossEnt}(W{\times }_\theta(\tilde{\bm{z}}), \bm{s})\right],\tag{2} $
The network $\times_\theta$ shares weights with that in Eq. (1) and is conditioned on a binary "mode" token (denoise or decode) in addition to the time condition $t = 1$. At inference time, we evaluate $W {\times}_\theta(\bm{z}_t)$ only at the final step $t = 1$, and apply $\operatorname{argmax}$ to obtain a discrete token.
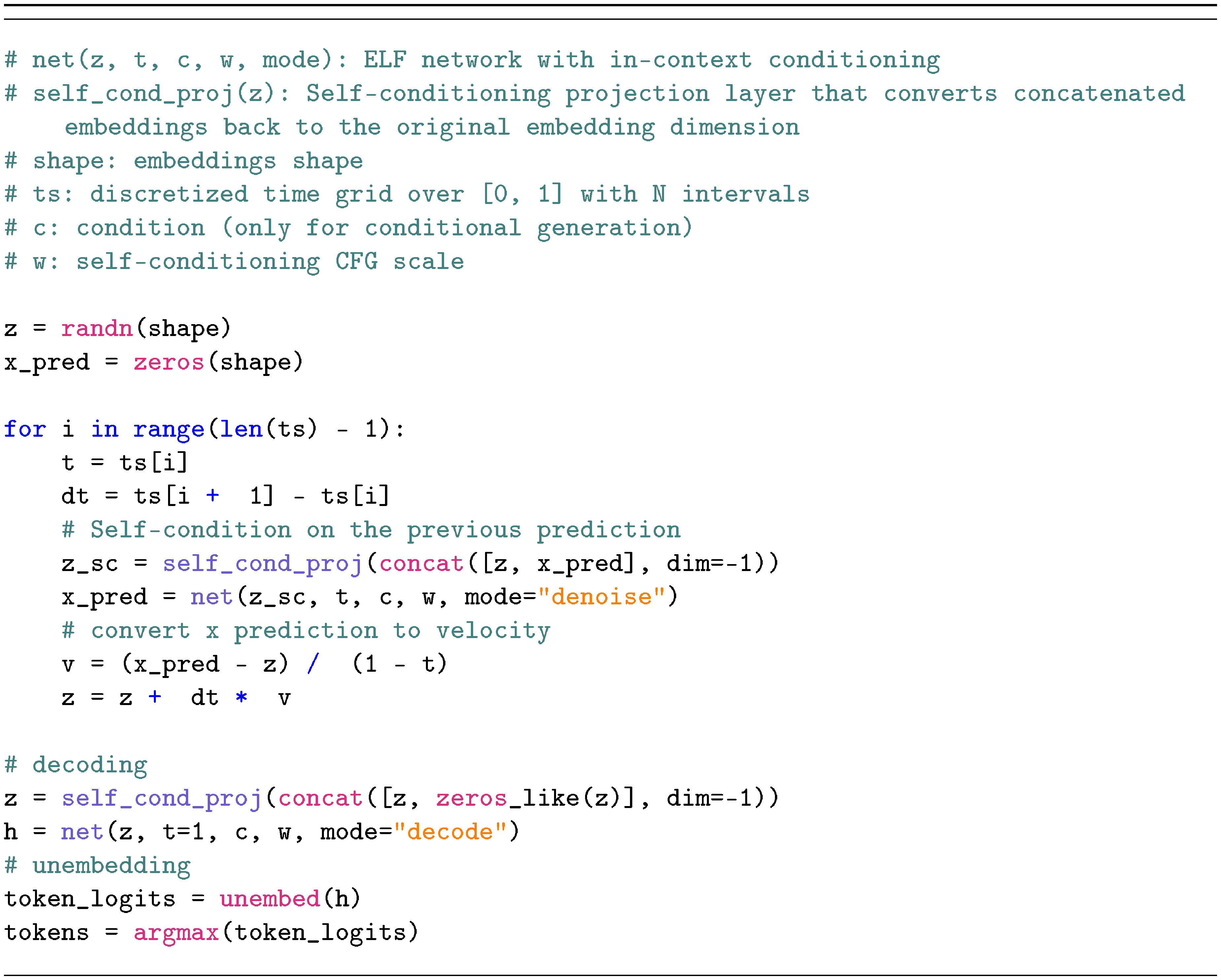
3.2 Pseudocode

The core concepts of ELF are summarized in Algorithm 1 and Algorithm 2 (detailed in Figure 9 in Appendix).
Training.
As in standard Flow Matching, ELF employs a single network $\text{\texttt{net}}_\theta$ to model all time steps, conditioned on $t$. This includes the final time step $t = 1$, which uses different pre-processing (corruption) and post-processing (loss computation). For clarity, we illustrate this distinction using an explicit "if" branch in Algorithm 1. In practice, samples from both branches are processed within a single batch, and masking is used to selectively apply the appropriate corruption and unembedding operations as well as the corresponding loss terms. The network is further conditioned on a binary "mode" token that indicates whether the operation is "denoise" or "decode".
Inference.
During inference, ELF iteratively transforms noisy samples into clean embeddings. Starting from $\bm{z}_0 \sim \mathcal{N}(0, \mathbf{I})$, ELF solves the ODE: ${d \bm{z}t}/{dt} = \bm{v}\theta(\bm{z}_t, t)$, which is approximated with a numerical (e.g., Euler) solver. At the final time step $t=1$, we apply the network under the "decode" mode and perform unembedding and discretization.
Besides the ODE formulation, our method also supports an SDE-inspired sampler. The underlying SDE associated with Flow Matching can be derived following [19], where the dynamics can be interpreted as injecting infinitesimal noise at each step. In practice, we adopt a simpler approximation to emulate this behavior: we inject small noise at each step while correspondingly shifting the time variable $t$ toward the noise regime (detailed in Appendix, Algorithm 4). For brevity, we refer to the resulting SDE-inspired sampler as the "SDE" variant, while noting that it primarily captures the per-step stochastic behavior. We experimentally compare the ODE formulation with this SDE variant.
3.3 Conditioning and Guidance
Controlling model generation is an important aspect of generative modeling. In image diffusion models, classifier-free guidance (CFG) ([61]) has been established as a highly effective technique for steering the generated output. CFG also enables a trade-off between generation quality and diversity. Because CFG was originally formulated for continuous quantities (e.g., score functions or velocity fields), it is naturally applicable to ELF. This stands in contrast to discrete counterparts, where CFG remains largely unexplored and has been shown less effective ([28, 49]).
In the absence of class labels, we employ self-conditioning ([62]) to construct the conditioning signals required for CFG. Given that self-conditioning is already a standard component in DLMs ([35, 8, 34, 24, 43, 47, 63]), incorporating CFG introduces only marginal computational overhead. In what follows, we first describe the self-conditioning used in ELF and then introduce CFG.
Self-conditioning.
In a standard Flow Matching model (i.e., without self-conditioning), a forward pass at a given time step yields a single prediction. We denote this prediction by $\hat{\times}'$ in our case, indicating that it corresponds to a prediction of the clean embedding $\times$. During training, self-conditioning ([62]) performs a second forward pass, conditioned on $\hat{\times}'$, which serves as an intermediate prediction. The output of the second pass, denoted as $\hat{\times}$, can be written as $\hat{\times}= \text{\texttt{net}}_\theta(\bm{z}_t \mid \hat{\times}', t)$. This is implemented by concatenating $[\bm{z}_t, \hat{\times}']$ as the network input ([62]). During training, the model is conditioned on $\hat{\times}'$ with probability 50%, and uses a null condition $\mathbf{0}$ otherwise (see Appendix, Figure 9 for details). During inference, the model conditions on the prediction from the previous time step, thus introducing no extra forward passes for inference.
The intermediate prediction $\hat{\times}'$ serves as a condition for the network. As such, it can be treated as the conditioning signal $\bm{c}$ in the application of CFG, introduced next.
CFG with self-conditioning.
CFG ([61]) combines the unconditional and conditional predictions through a linear extrapolation. Formally, given a conditioning signal $\bm{c}$, CFG in Flow Matching defines a velocity field as $\bm{v}_{\textrm{cfg}}(\bm{z}_t \mid \bm{c}) = \omega \bm{v}(\bm{z}_t \mid \bm{c}) + (1 - \omega)\bm{v}(\bm{z}_t \mid \varnothing)$, where $\varnothing$ denotes the unconditional counterpart and $\omega$ is the guidance scale. As discussed, our conditioning signal $\bm{c}$ is obtained from self-conditioning. In its original form ([61]), CFG is applied at inference time, requiring two forward passes per step.
To avoid inference-time overhead, we adopt training-time CFG techniques ([64, 65, 66, 67]) previously developed for image generation. These methods use a single network pass to model $\bm{v}{\textrm{cfg}}$ instead of $\bm{v}$ (in our case, $\times{\textrm{cfg}}$ instead of $\times$). Because ELF is formulated similarly to its image-generation counterpart, adapting it to training-time CFG is straightforward, further illustrating the advantages of our continuous-based formulation. The implementation details, following the form in ([66, 67]), are in Appendix (Algorithm 1, Algorithm 2, & Algorithm 3).
Extension to conditional generation.
Thus far, we have presented our method in the setting of unconditional generation, as in prior work ([13, 14, 28, 29]). Our method can be naturally extended to conditional generation, in which outputs are conditioned on an input sequence (e.g., a prompt). In this setting, we prepend the clean embeddings of the conditioning sequence to the model input and preserve them without corruption during both training and inference. The model can then condition on them through self-attention.
CFG remains applicable in the conditional setting. The conditioning $\bm{c}$ now consists of both the self-conditioning and the prefix clean embeddings; the unconditional counterpart is obtained by zeroing out $\bm{c}$. Analogous to text-to-image generation [20], CFG is effective in controlling generation quality in our scenario, which can be viewed as "text-to-text" generation.
4. Experiments
Section Summary: The experiments evaluate the model's performance on unconditional text generation using the large OpenWebText dataset, measuring quality through perplexity scores from a pretrained language model and diversity via word variety, while conditional tasks like German-to-English translation and news summarization use standard metrics such as BLEU and ROUGE scores. The models, built on frozen pretrained embeddings from a small T5 encoder and scaled in three sizes, are trained with a mix of loss functions over several epochs and generate text using specialized sampling methods like ODE or SDE. Ablation tests on unconditional generation reveal that classifier-free guidance balances quality and diversity, pretrained contextual embeddings outperform simpler alternatives, shared-weight decoding enables better results than two-stage approaches, and SDE samplers achieve superior efficiency.
Dataset and evaluation.
For unconditional generation, we follow the experimental design used in past work ([13, 14, 28, 29]). We train on the OpenWebText (OWT) dataset ([68]), which has around 9B tokens, and pack sequences to length $L=1024$. For evaluation, we generate 1, 000 samples and report generative perplexity (Gen. PPL), i.e., the perplexity of generated samples under a pretrained GPT-2 Large model ([69]); together with average unigram entropy as a measure of sample diversity.[^1]
[^1]: We do not use validation perplexity, since likelihood evaluation for flow-based models can require additional likelihood-specific training ([70]).
For conditional generation, we consider machine translation and summarization. For machine translation, we use the WMT14 German-to-English (De-En) dataset ([30]) with sequence length $L=128$ (condition length 64, target length 64; 144M total target tokens), and evaluate using BLEU ([71]). For summarization, we use the XSum dataset ([31]) with sequence length $L=1088$ (condition length 1024, target length 64; 6M total target tokens), and report ROUGE-1 (R1), ROUGE-2 (R2), and ROUGE-L (R-L) ([72]). We treat both as sequence-to-sequence tasks and do not use sequence packing for conditional generation.
Model.
We use contextual embeddings from a frozen pretrained T5-small encoder ([60]) (35M) with embedding dimension 512. We use a bottleneck design that linearly projects embeddings into a lower-dimensional space of size 128, and then projects them back to the hidden size of the model ([27]). We consider three model sizes: ELF-B (105M), ELF-M (342M), and ELF-L (652M), and use ELF-B as the default for ablations. Detailed configurations are shown in Table 3 in Appendix.
Training and inference.
We train our model using the Muon optimizer ([73]) with a learning rate of $0.002$ and a batch size of 512. The model is trained for 5 epochs on OWT (around 95K steps), and for 100 epochs on WMT14 and XSum (around 880K and 40K steps, respectively). Depending on the selected model mode, the network is trained with either the MSE loss in Equation 1 (80%) or the CE loss in Equation 2 (20%). During inference, we use the ODE or SDE sampler to generate samples.
4.1 Ablations
We begin by ablating several key design choices of our model on the simpler setting of unconditional generation on OWT, using the default ELF-B model and a 64-step ODE Euler sampler unless otherwise specified. More ablation studies are shown in Appendix C.
Classifier-free guidance (CFG).
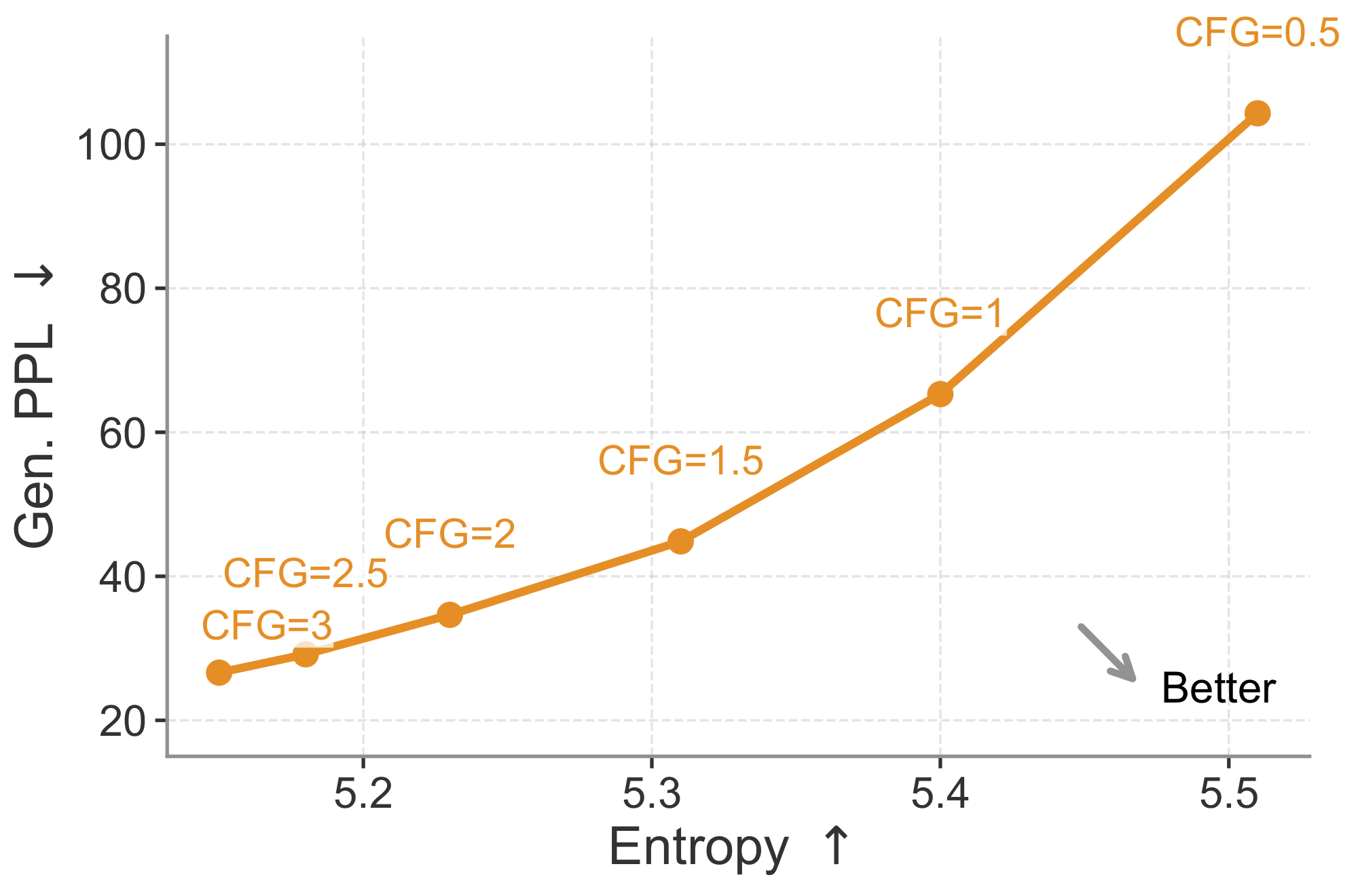
Our flow-based continuous formulation is naturally compatible with CFG, a highly effective technique in standard diffusion models. Therefore, we first study the effect of the CFG scale. As shown in Figure 4, increasing the CFG scale lowers generative perplexity but also reduces entropy, reflecting a quality–diversity trade-off. The preferred direction is toward the lower-right region of the plot, corresponding to lower generative perplexity and higher entropy. For most of the remaining ablations, we evaluate this quality–diversity trade-off by sweeping the CFG scale. Each point on the curve is computed from 1, 000 generated samples at a specific CFG scale.
Embedding choices.
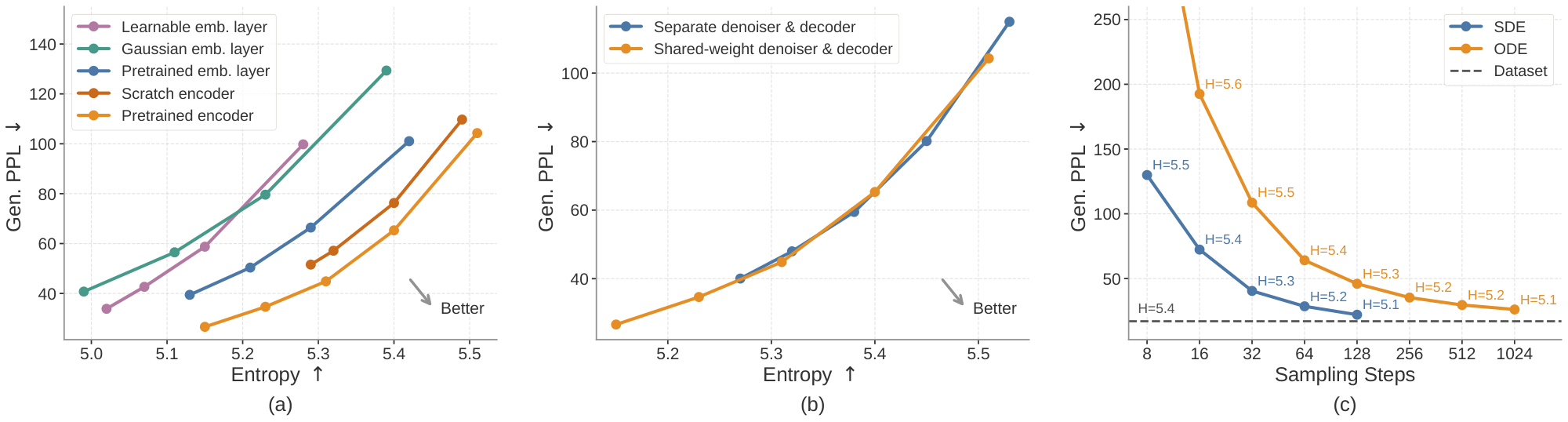
Since ELF operates in a continuous embedding space, we next study how the choice of embeddings affects performance. We ablate the continuous embeddings along two axes: whether the embeddings are contextual (i.e., from an encoder) or non-contextual (i.e., from a single embedding layer), and whether they are fixed or learnable. For contextual embeddings, we evaluate those from an off-the-shelf T5 encoder ([60]) and embeddings from an encoder trained from scratch on OWT using the original T5 objective. For non-contextual embeddings, we consider token embeddings from the pretrained T5 model, frozen Gaussian embeddings, and learnable embeddings. See Appendix D.3 for detailed setup. We show the results in Figure 5 a. Contextual embeddings achieve a better generative perplexity–entropy trade-off. Embeddings from an encoder trained from scratch on OWT perform well, but slightly lag behind those from a pretrained encoder. Among the non-contextual variants, pretrained token embeddings outperform frozen Gaussian embeddings. Learnable embeddings perform the worst, likely due to the difficulty of jointly optimizing the embeddings and the denoiser. Overall, these results suggest that pretrained contextual embeddings are favorable representations of language for ELF.
Decoding strategies.
Since we use contextual embeddings as our continuous representations, we need to decode them back into discrete tokens. We use a shared-weight network, with training interleaving ${\mathcal{L}{\textrm{MSE}}}$ and ${\mathcal{L}{\textrm{CE}}}$. Alternatively, we explore a two-stage strategy. In the first stage, we train a decoder from scratch with a frozen pretrained T5 encoder to reconstruct tokens from masked and noisy embeddings using ${\mathcal{L}{\textrm{CE}}}$. In the second stage, we freeze both the encoder and decoder, and train a separate denoiser using ${\mathcal{L}{\textrm{MSE}}}$ (see Appendix D.3 for details). As shown in Figure 5 b, both strategies achieve a similar trade-off, but the shared-weight variant extends further toward the regime of low generative perplexity, while also simplifying the pipeline by avoiding an extra training stage.
Samplers.
Since ELF is formulated in continuous time and continuous space, it naturally supports both deterministic ODE sampling and stochastic SDE-like sampling; see Algorithm 4 in Appendix for details. We compare ODE and SDE samplers across different sampling budgets with a self-conditioning CFG scale of 1. As shown in Figure 5 c, SDE sampling achieves substantially lower generative perplexity than ODE sampling in the few-step regime. These results suggest that introducing stochasticity during sampling can effectively reduce error accumulation and provide a better quality–efficiency trade-off.
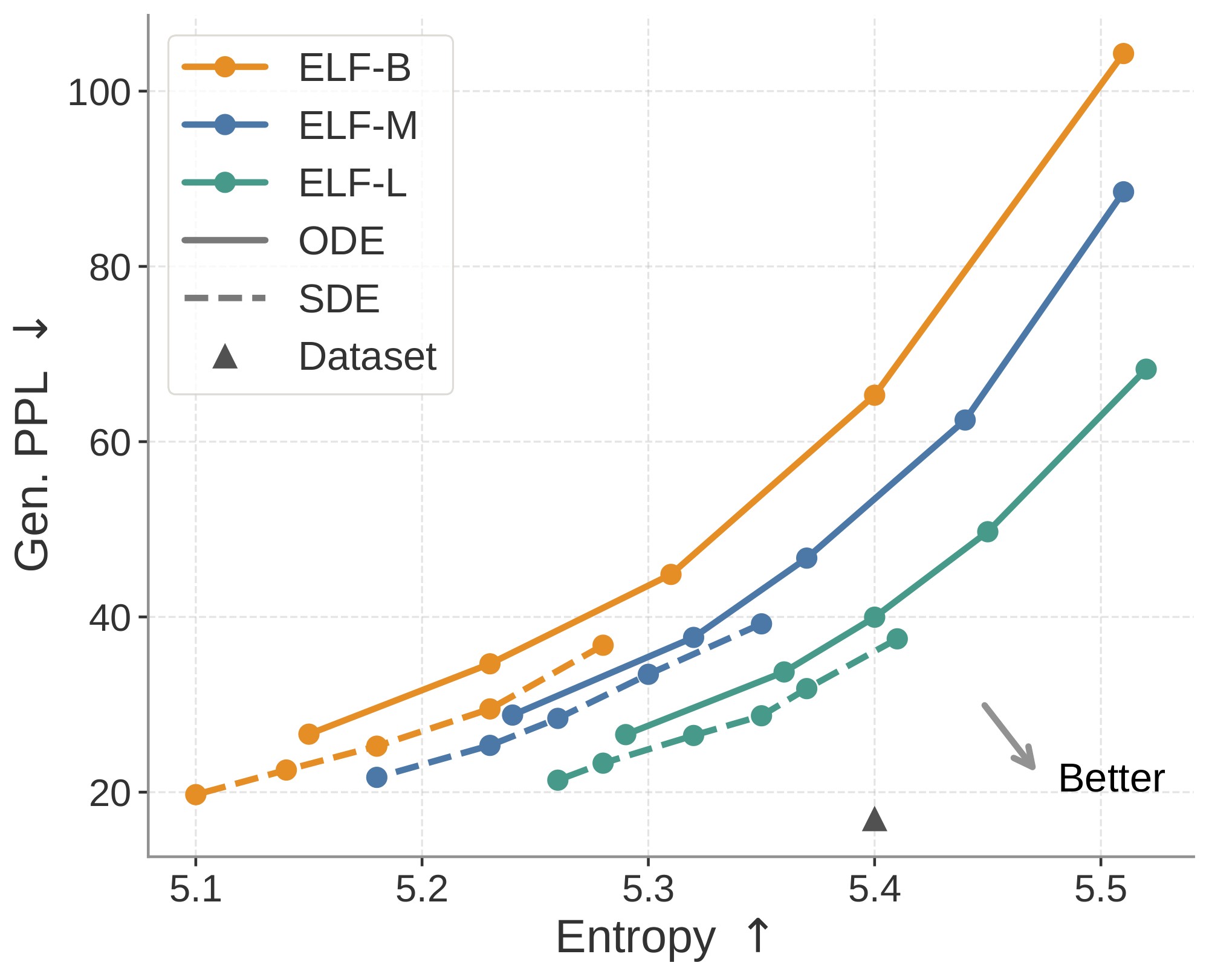
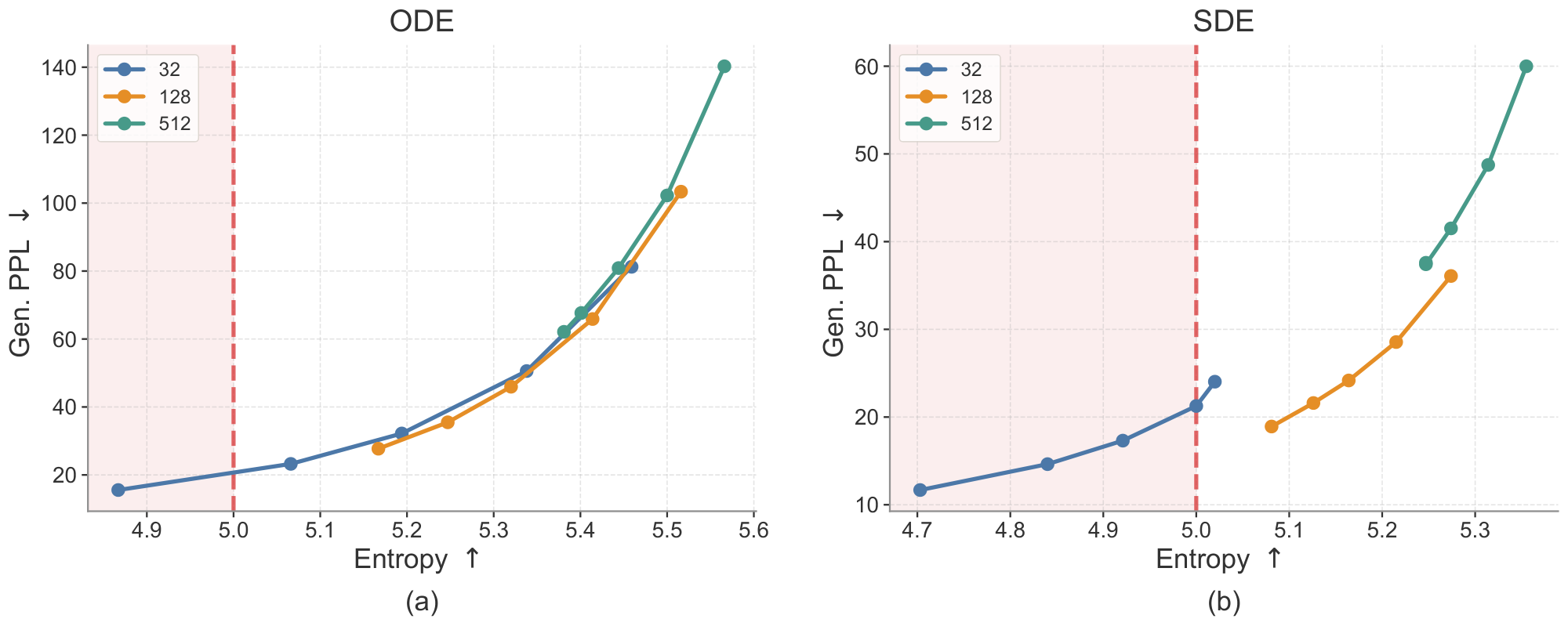
Model scales.
We study the scaling behavior of ELF across three model sizes: ELF-B (105M), ELF-M (342M), and ELF-L (652M) (detailed in Table 3 in Appendix). We evaluate each model using both ODE and SDE sampling. As shown in Figure 6, scaling consistently improves the generative perplexity–entropy frontier. In particular, at matched entropy, larger models achieve lower generative perplexity, indicating higher sample quality with comparable diversity. Conversely, at similar generative perplexity, larger models maintain higher entropy. The effect of the sampler is consistent across model sizes: SDE sampling improves over ODE sampling by pushing the frontier in a more optimal direction. These results suggest that ELF scales effectively, demonstrating the potential of model scaling. See Table 7 in Appendix for the detailed numbers.
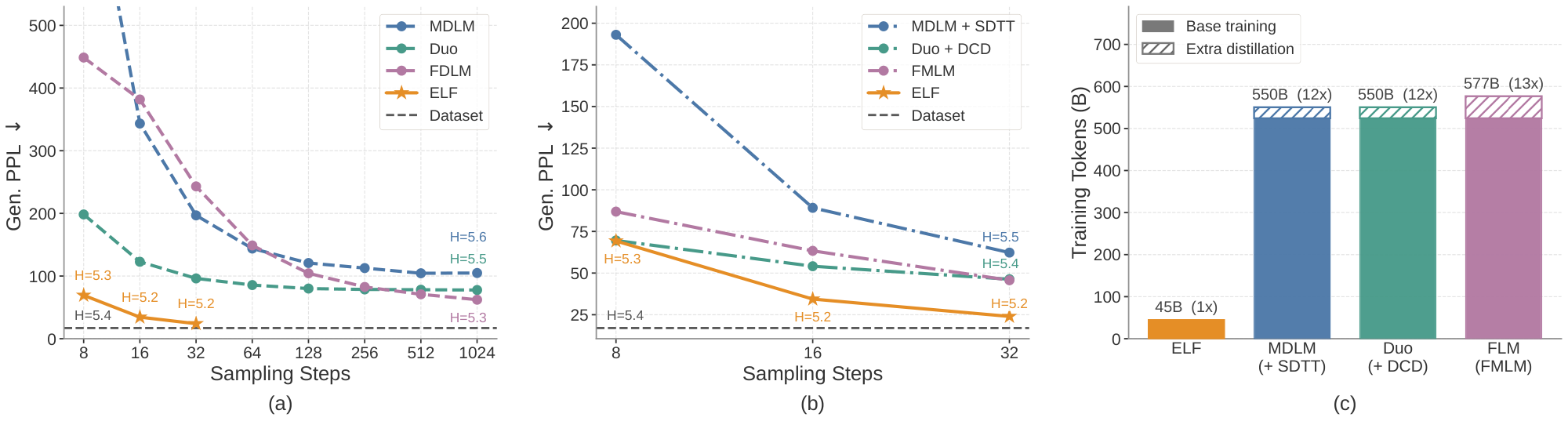
4.2 System-Level Comparison on Unconditional Generation
We first compare ELF-B against both discrete DLMs, including MDLM ([13]) and Duo ([14]), and continuous DLMs, including FLM ([28]) and LangFlow ([29]), under a comparable setting. All models are trained on the OWT dataset. ELF has 105M parameters, while the compared baselines have around 170M parameters. For ELF, we use our best configuration: SDE sampling with self-conditioning CFG scale of 3 (see Appendix D.2 for details). We show results in Figure 7 a. ELF achieves a generative perplexity of 24 using only 32 sampling steps, requiring substantially less inference-time compute than prior methods. ELF remains strong even compared with distilled models, which require extra training to distill a student model for few-step generation. As shown in Figure 7 b, in the few-step regime, ELF outperforms distilled models, including MDLM+SDTT ([13, 74]), Duo+DCD ([14]), and FMLM ([28]), even without any additional distillation.
ELF is also substantially more data-efficient in terms of estimated training tokens, as shown in Figure 7 c. While prior DLMs typically use over 500B tokens, ELF uses only 45B.[^2] Together, these results show that, when combined with proper sampling and guidance, ELF achieves strong system-level performance. It not only improves inference efficiency, but also achieves strong performance with a much smaller training budget, demonstrating the potential of our flow-based language model. See Figure 8 for qualitative examples of ELF-B's generations.
[^2]: A per-method breakdown of training token counts is provided in Table 5 in Appendix. We also experimented with training on more tokens, but did not observe further performance improvement.
4.3 System-Level Comparison on Conditional Generation
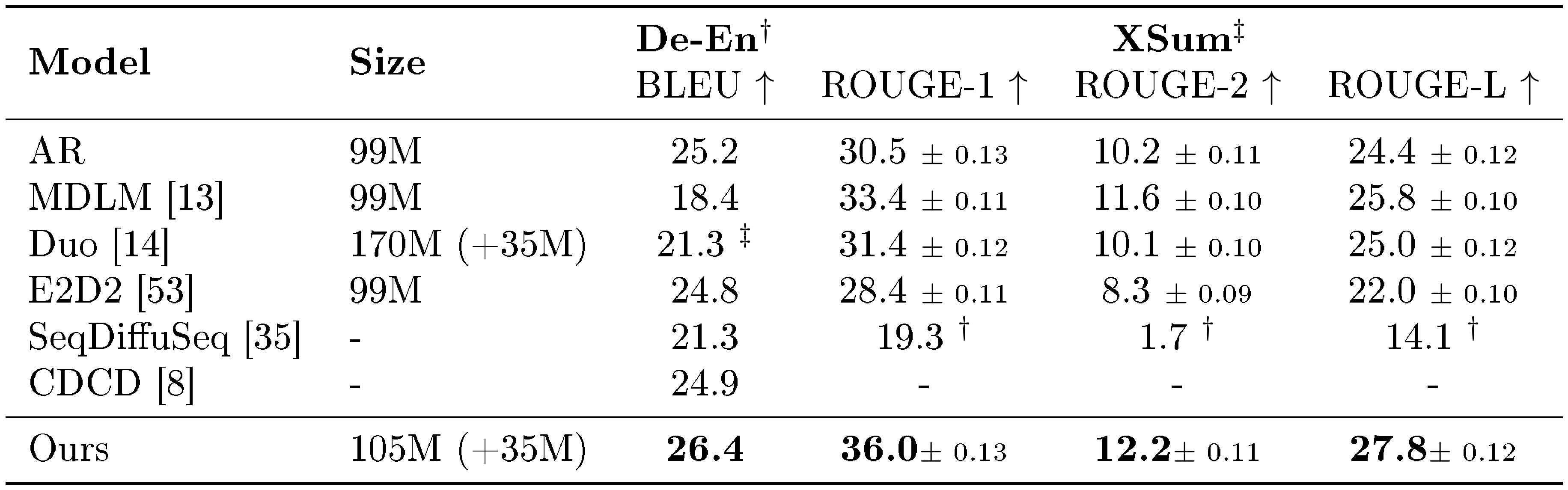
::: {caption="Table 1: Results on machine translation and summarization. We evaluate ELF-B on WMT14 German-to-English (De-En) translation and XSum summarization, comparing against baselines of similar parameter scale. $^{\dagger}$ denotes results taken directly from prior work and is the default source for De-En, while $^{\ddagger}$ denotes results we reproduced using public codebases and is the default source for XSum. For XSum, we additionally report the standard error across evaluation examples when available. ELF achieves the best performance on both settings."}
:::
We compare ELF-B with autoregressive and diffusion-based baselines at a similar model scale. These include discrete DLMs (MDLM ([13]), Duo ([14]), and E2D2 ([53])) and continuous DLMs (SeqDiffuSeq ([35]) and CDCD ([8])). Some results are taken from the literature and others are reproduced from public codebases. See Table 8 in Appendix for a summary. We use the best sampling configuration selected on the validation set: a 64-step ODE sampler with the self-conditioning CFG scale set to 1 and the input-condition CFG scale set to 2.
We show the results in Table 1. On WMT14 De–En, ELF-B achieves a BLEU score of 26.4, outperforming all compared baselines. On XSum, ELF-B also outperforms all compared baselines across all ROUGE metrics. These results demonstrate the effectiveness of ELF on conditional generation tasks. Qualitative examples in Figure 8 show that ELF-B generally follows the input context and produces outputs that semantically align with the ground-truth references.

5. Conclusion
Section Summary: Researchers have introduced Embedded Language Flows (ELF), a new type of language model that generates text in a smooth, continuous space using a technique called flow matching, rather than jumping between discrete words like older models. Unlike those predecessors, ELF maintains a fluid process until the very end, when it converts the output to readable text, allowing it to borrow efficient methods from image-generating AI. In tests, ELF delivered higher-quality results with fewer steps and less training data than competitors, pointing to continuous models as a promising future for language generation.
We introduced Embedded Language Flows (ELF), a continuous diffusion language model that formulates language generation in continuous embedding space using continuous-time Flow Matching. In contrast to prior DLMs, ELF keeps the denoising trajectory continuous and applies discretization only at the final step, enabling straightforward adaptation of techniques from continuous diffusion models. Empirically, compared with leading discrete DLMs and existing continuous DLMs, ELF achieves a strong quality–efficiency trade-off across language generation tasks, attaining lower generative perplexity with fewer sampling steps and fewer training tokens. These results suggest that continuous DLMs remain a promising direction for diffusion-based language modeling.
Acknowledgments
We thank Mingyang Deng, Belinda Li, Itamar Pres, and Laura Ruis, for their helpful feedback and insightful discussions. We thank Google TPU Research Cloud (TRC) for granting us access to TPUs.
Appendix
Section Summary: The appendix provides a survey of continuous diffusion and flow-based language models, outlining key design features like whether they use continuous or discrete time processes, how they handle noisy data during training and generation, and if they need extra components to convert outputs back to readable text. It highlights how the ELF model stands out by using a smooth, continuous approach in a pre-trained embedding space and relying on a single network for both cleaning data and producing final text, without separate decoders. The section also details ELF's training process, which involves adding noise to text embeddings, applying conditioning techniques, and using two types of supervision—one for predicting clean embeddings and another for directly matching tokens—to refine the model.
A. Continuous Diffusion Language Model Survey
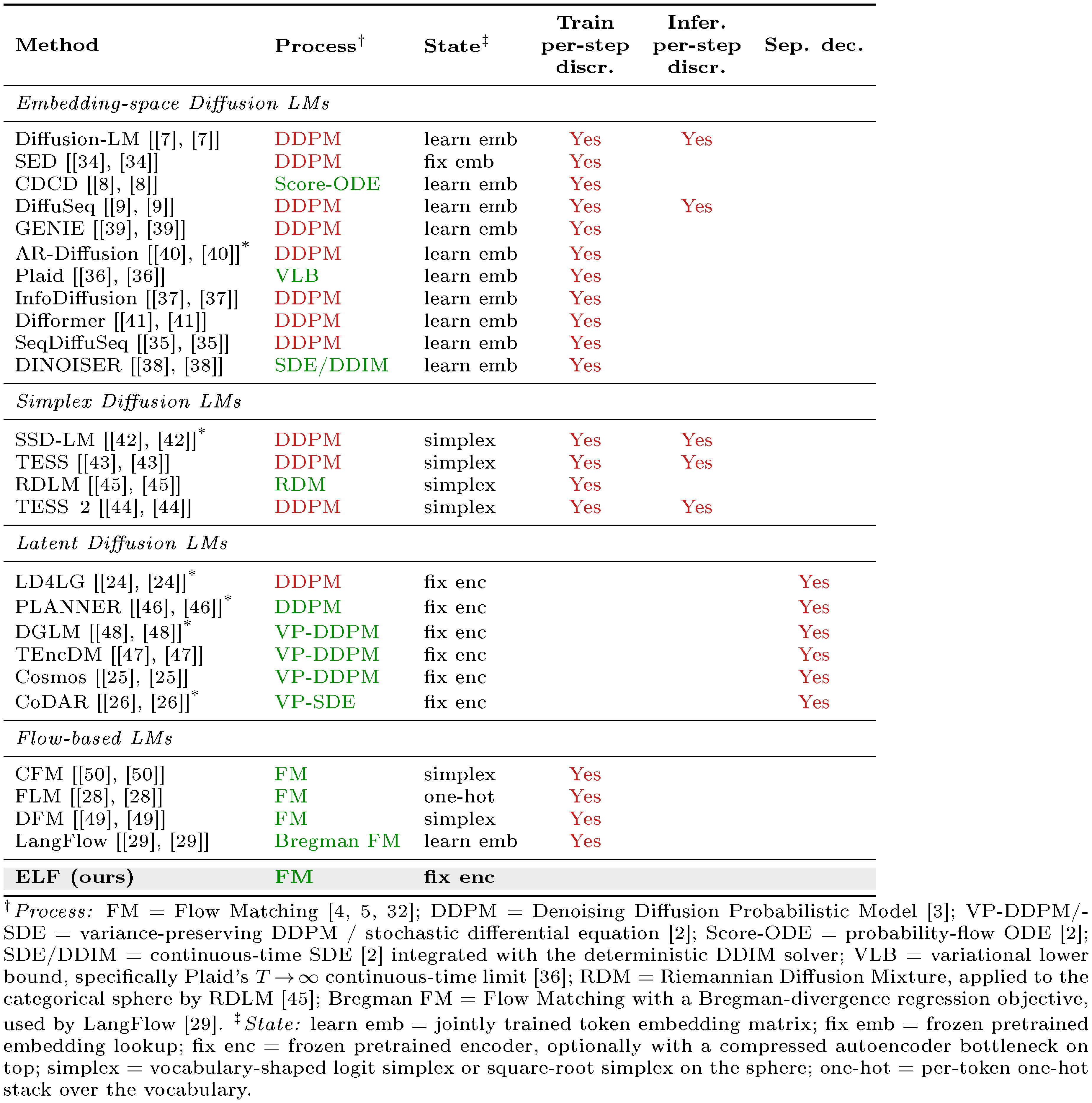
::: {caption="Table 2: Survey of continuous diffusion and flow-based language models. We summarize representative continuous diffusion and flow-based language models along several design axes. Process denotes the diffusion or flow process, with green indicating continuous-time formulations and red indicating discrete-time formulations. State denotes the continuous state in which denoising is performed. Train per-step discr. marks methods that convert intermediate denoising states to token predictions during training and apply token-level supervision such as cross-entropy loss at intermediate steps. Infer. per-step discr. marks methods that project intermediate sampling states back to token-aligned states during generation. Sep. dec. marks methods that require a separately trained decoder to map latent representations back to text. Blank entries indicate absence. $^{\text{*}}$ denotes autoregressive or block-autoregressive generation."}
:::
Survey details.
We provide a detailed survey in Table 2. The survey summarizes representative continuous diffusion and flow-based language models along several design axes, including the underlying diffusion or flow process, the continuous state in which denoising is performed, whether intermediate denoising states are discretized during training or inference, and whether a separately trained decoder is required to map latent states back to text.
In particular, the Train per-step discr. and Infer. per-step discr. columns distinguish two different uses of intermediate discretization. Train per-step discr. indicates that intermediate denoising states are mapped to token predictions during training and supervised with token-level objectives such as cross-entropy loss. This provides direct vocabulary-level guidance, but also couples intermediate denoising states to categorical predictions. Infer. per-step discr. indicates that intermediate sampling states are explicitly projected back to token-aligned representations during generation, such as nearest-neighbor rounding in embedding space or argmax projection on a simplex. Methods without inference-time per-step discretization keep the sampling trajectory continuous and discretize only at the final step. The Sep. dec. column indicates whether a method requires a separately trained decoder to map continuous latent representations back to discrete text.
Positioning of ELF.
Table 2 shows that existing continuous DLMs differ substantially in where the denoising process is defined and how continuous states are mapped back to text. Many embedding-space and simplex-based methods use training-time per-step discretization through token-level objectives, commonly cross-entropy, at intermediate denoising steps. These objectives provide direct token-level guidance, while making the denoising trajectory more tightly coupled to vocabulary-level prediction. Latent Diffusion LMs often avoid such per-step vocabulary supervision, but typically rely on DDPM-style or score-based formulations with DDPM noise schedules ([3, 33]) and require a separately trained latent-to-text decoder, such as an autoregressive decoder, non-autoregressive decoder, or latent decompressor, to recover discrete tokens.
ELF occupies a different design point. It formulates language generation as continuous-time Flow Matching in a frozen contextual embedding space and keeps the sampling trajectory continuous, applying discretization only at the final decoding step. Unlike prior latent Diffusion LMs, ELF does not require a separately trained decoder: a single shared-weight network performs intermediate denoising and recovers tokens at the final step through the unembedding layer.
B. Method Details
![**Figure 9:** **Illustration of our training pipeline.** Starting from the clean embeddings $\times$, we apply different noise schedules in the two modes to obtain corrupted embeddings $\bm{z}_t$. We then apply self-conditioning by concatenating either $\mathbf{0}$ or the previous prediction $\hat{\times}'$ along the channel dimension, and project the concatenated embeddings back to the original dimension to form $\hat{\bm{z}}_t$. Next, we prepend control tokens to the embedding sequence, including time tokens in $[0, 1]$, CFG scale tokens in $[0.5, 5]$, and model-mode tokens indicating either denoising or decoding. The resulting sequence is fed into ELF to produce the final prediction $\hat{\times}$, which is supervised using either a denoising loss ${\mathcal{L}_{\textrm{MSE}}}$ or a token-wise cross-entropy loss ${\mathcal{L}_{\textrm{CE}}}$.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/nwuumch2/training_pipeline_details.png)
B.1 Training
We show the full training pipeline in Figure 9. The input tokens are first encoded into clean embeddings $\times$, which then go through three key steps before being fed into the ELF model: corruption, self-conditioning, and adding control tokens for conditioning and guidance. In the denoising branch, the model predicts clean embeddings $\hat{\times}$ and is supervised with ${\mathcal{L}{\textrm{MSE}}}$. In the decoding branch, the same shared-weight network predicts embeddings that are then passed through an unembedding layer and supervised with ${\mathcal{L}{\textrm{CE}}}$. The full training algorithm is shown in Algorithm 1 and Algorithm 2.
Embedding corruption.
First, we corrupt the clean embeddings $\times$ by adding noise. Specifically, we use $\bm{z}_t = t \times + (1 - t)\bm{\epsilon}$ to obtain noisy embeddings $\bm{z}_t$, where $\bm{\epsilon}$ is Gaussian noise and $t$ is the time step. Before corruption, we first normalize the clean embeddings using the estimated mean and standard deviation from the OWT dataset. We use different noise schedules for different modes.


For the denoising branch, we sample the time step $t$ from a logit-normal distribution for each sequence. Specifically, we draw $t' \sim \mathcal{N}(P_{\text{mean}}, P_{\text{std}}^2)$ and map it to the unit interval via $t = \sigma(t')$, where $\sigma(\cdot)$ denotes the sigmoid function. In all experiments, we use $P_{\text{mean}}=-1.5$ and $P_{\text{std}}=0.8$. We rescale the Gaussian noise by a factor of 2.
For the decoding branch, we train final-step discretization by conditioning the model on the decoder mode, i.e., $t=1$. At this time step, $\bm{z}t$ corresponds to clean embeddings. Therefore, to make the final-step input nontrivial, we corrupt the clean embeddings with a per-token corruption level $p$ sampled from a different noise schedule. Specifically, we draw $p$ from a logit-normal distribution with $P{\text{mean}}=0.8$ and $P_{\text{std}}=0.8$, and form $\tilde{\bm{z}}=p \times+(1-p)\bm{\epsilon}$, multiplying $\bm{\epsilon}$ by a noise scale. We use noise scales of 5 and 1 for OWT and conditional generation tasks, respectively. As a result, the corruption level varies across tokens within the same sequence. This design encourages the shared-weight decoder mode to recover corrupted embeddings from their surrounding context, making final-step discretization more robust to imperfect embeddings produced by the denoiser at inference time.
Self-conditioning.
We apply self-conditioning following prior work ([62]). During training, with a certain probability, we perform an additional forward pass to obtain the predicted embeddings $\hat{\times}'$, which are concatenated with the noisy embeddings $\bm{z}_t$ along the channel dimension. We stop the gradient through the predicted embeddings $\hat{\times}'$. For the remaining examples, we concatenate $\bm{z}_t$ with all-zero embeddings $\mathbf{0}$ instead. Since this concatenation doubles the channel dimension, we project it back to the original dimension using a linear layer. We apply self-conditioning with $\hat{\times}'$ in the denoising branch with 50% probability. For the decoding branch, we always use $\mathbf{0}$ as the self-conditioning input, as shown in Algorithm 2.
Training-time CFG.
As discussed in Section 3.3, our model performs training-time CFG ([66, 67, 64, 65]) with self-conditioning. In training-time CFG, the network is designed to model the post-combination quantity $\bm{v}^\textrm{cfg}\theta$, rather than the pre-combination quantity $\bm{v}\theta$. Following ([66, 67]), the regression target $\bm{v}_{\textrm{target}}$ is now:
$ \bm{v}{\textrm{target}} = \times - \bm{\epsilon} + \left(1 - \frac{1}{\omega}\right) \bigl(\bm{v}^\textrm{cfg}\theta(\bm{z}t \mid t, \bm{c}, \omega) - \bm{v}^\textrm{cfg}\theta(\bm{z}_t \mid t, \varnothing, \omega)\bigr),\tag{3} $
where $\omega$ is the guidance scale. When $\omega=1$, this reduces to the case without training-time CFG. In this case, the loss becomes $| \bm{v}^\textrm{cfg}\theta(\cdot) - \bm{v}{\textrm{target}} |^2$ ([66, 67]). See Algorithm 1. For each training example, we randomly sample a self-conditioning CFG scale $w \in [0.5, 5.0]$ from a power distribution biased toward smaller values ([66, 67]). Since ELF uses $\times$-prediction, the quantity $\bm{v}$ is always converted from its $\times$ prediction counterpart (conditional or unconditional).
Our model uses a diverse set of conditions. Standard diffusion models typically implement conditioning through adaLN-Zero ([75]), which combines all conditioning signals through summation. This design becomes less effective when many heterogeneous conditions are present. Therefore, we adopt in-context conditioning ([67]) by prepending a set of control tokens that encode the conditioning information. Each control-token embedding has the same dimensionality as a standard language-token embedding. We prepend three types of control tokens: 4 time tokens with values in $[0, 1]$, 4 CFG-scale tokens sampled from $[0.5, 5]$, and 4 model-mode tokens indicating either denoising or decoding. These tokens are jointly trained with the model. All continuous values, i.e., time and CFG scale, are encoded with positional embeddings.
For conditional generation, we place the clean embeddings of the conditioning sequence immediately after the control tokens and before the target sequence to be generated. The model then performs bidirectional self-attention over the concatenated sequence of conditioning and target tokens. The conditioning embeddings are kept uncorrupted during training. To enable CFG for conditional generation, we randomly drop the condition with 10% probability by zeroing out the embeddings of the conditioning sequence. This allows the model to learn both conditional and unconditional generation under the same framework.
B.2 Inference
We show the full inference algorithm in Algorithm 3. Since the self-conditioning CFG scale is provided through in-context conditioning, changing $w$ does not require an additional inference pass. By modifying $w$ as a model input, we can flexibly control the trade-off between generation quality and diversity.

Time schedule.
We discretize the continuous time interval $t \in [0, 1]$ into $T$ intervals using a logit-normal time schedule. Specifically, we sample $T-1$ time steps from the same logit-normal distribution used for the denoising branch during training and sort them to form the intermediate points. We use $P_{\text{mean}}=-1.5$ and $P_{\text{std}}=0.8$ to match the training-time logit-normal distribution. We ensure that the first interval starts at $t=0$ and the last interval ends at $t=1$. This schedule produces smaller intervals when $t$ is close to 0 and larger intervals as $t$ approaches 1. It shows strong empirical performance, likely because the noisier regime requires finer discretization and the schedule better matches the noise distribution used during training.
Samplers.
Our method supports both deterministic ODE sampling and an SDE-inspired stochastic sampler. The main algorithm in Algorithm 2 uses the ODE sampler for simplicity, while Algorithm 4 summarizes one-step updates for both samplers.
The SDE variant is motivated by the SDE associated with Flow Matching ([19]), whose dynamics can be interpreted as injecting infinitesimal noise at each step. In practice, we adopt a simple approximation that re-injects Gaussian noise at each sampling step while shifting the time variable slightly toward the noise regime. We introduce a noise re-injection scale $\gamma$ to control the amount of stochasticity added at each step. The denoiser is then evaluated on this perturbed state, and its clean-embedding prediction is used to update the original state. When $\gamma=0$, no stochastic perturbation is applied, and the update reduces to deterministic ODE sampling.
CFG for conditional generation.
We apply standard CFG by combining the conditional and unconditional predictions. Similarly, we use the CFG scale to control the guidance strength.
C. Additional Ablations
In this section, we present additional ablations of our design choices. Unless otherwise specified, all experiments use time schedule with either a 64-step ODE sampler or a 64-step SDE sampler with $\gamma=1$. As before, we evaluate the generative perplexity–entropy trade-off by varying the self-conditioning CFG scale. We use red to indicate regions with poor generation quality, i.e., entropy below 5.0, which often corresponds to repetitive or degenerate sentences, or generative perplexity above 300, which often corresponds to semantically meaningless or ungrammatical sentences. All models are trained for the same number of steps, with all other configurations kept the same as the default setting.
C.1 Prediction Targets
![**Figure 10:** **Effects of prediction targets.** We vary the input dimension from 512 to 768 and 1024 by using T5-small, T5-base, and T5-large encoders, respectively. Across all input dimensions, $\times$-prediction remains stable and performs well. In contrast, $\bm{v}$-prediction performs well at 512 dimensions but degrades at higher dimensions, while $\bm{\epsilon}$-prediction collapses across all dimensions from 512 to 1024. The red region indicates poor-quality generations, where entropy falls below 5 (*e.g.*, repetitive sentences) or generative perplexity exceeds 300 (*e.g.*, meaningless or ungrammatical sentences). This aligns with the hypothesis from prior work that high-dimensional clean data often lies on a low-dimensional manifold ([27]).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/nwuumch2/prediction_target.png)
Our model directly predicts the clean embeddings $\times$ ($\times$-prediction). This allows us to use a unified denoiser and decoder through weight sharing and jointly optimize the model with both the denoising objective ${\mathcal{L}{\textrm{MSE}}}$ and the token-level objective ${\mathcal{L}{\textrm{CE}}}$. Prior work has also suggested that $\times$-prediction is essential, as high-dimensional clean data tends to lie on a low-dimensional manifold ([27]).
Here, we further study the effect of prediction targets. Specifically, since there are three quantities and two constraints: linear interpolation $\bm{z}_t = t , \times + (1 - t), \bm{\epsilon}$ and flow velocity $\bm{v} = \times - \bm{\epsilon}$, the network can be trained to predict one of these quantities, i.e., $\times$-, $\bm{v}$-, or $\bm{\epsilon}$-prediction. To study this in a controlled setting, we use a two-stage pretrained encoder-decoder setup: a pretrained T5 encoder maps tokens into continuous embeddings, and a decoder is trained to reconstruct masked and noisy embeddings (See Appendix D.3 for details). We train only the denoising model while keeping both the encoder and decoder fixed. We use adaLN-Zero conditioning and a 64-step ODE sampler to plot the generative perplexity–entropy trade-off curve.
To study how prediction targets behave as the embedding dimension increases, we consider T5-small, T5-base, and T5-large encoders, corresponding to embedding dimensions of 512, 768, and 1024, respectively. We set the bottleneck dimension equal to the corresponding input embedding dimension. As shown in Figure 10, $\times$-prediction remains the most stable across all dimensions, maintaining a reasonable generative perplexity–entropy trade-off even at 1024 dimensions. In contrast, $\bm{v}$-prediction is competitive at 512 dimensions but degrades as the dimension increases, with substantially higher generative perplexity at 768 and 1024 dimensions. $\bm{\epsilon}$-prediction collapses across all dimensions, either achieving extremely low entropy or high generative perplexity, indicating repetitive, degenerate, or ungrammatical generations. These results support the hypothesis that clean-data prediction is better suited to high-dimensional language representations, consistent with findings from prior work ([27]).
C.2 Bottleneck
Our model uses a bottleneck design that projects encoder representations into a lower-dimensional space before mapping them back to the model hidden size. This design is motivated by the hypothesis that natural data may lie on a low-dimensional manifold within the high-dimensional embedding space. We compare bottleneck dimensions of 32, 128, and 512, and show the results in Figure 11. The bottleneck dimension has a clear effect on the generative perplexity–entropy trade-off. Under ODE sampling, all three bottleneck sizes follow a similar frontier, but smaller bottlenecks tend to reach lower generative perplexity at the cost of lower entropy. Under SDE sampling, the differences become more significant: the 32-dimensional bottleneck achieves the lowest generative perplexity but often lies in the low-entropy region, indicating reduced diversity, whereas the 512-dimensional bottleneck maintains higher entropy but suffers from substantially worse generative perplexity. The 128-dimensional bottleneck provides the best overall balance, achieving strong generative perplexity while preserving reasonable entropy. We therefore use a bottleneck dimension of 128 as the default setting. This finding is also consistent with prior work ([27]), which observes that an appropriate bottleneck can improve performance.
C.3 Denoising Mode Probability
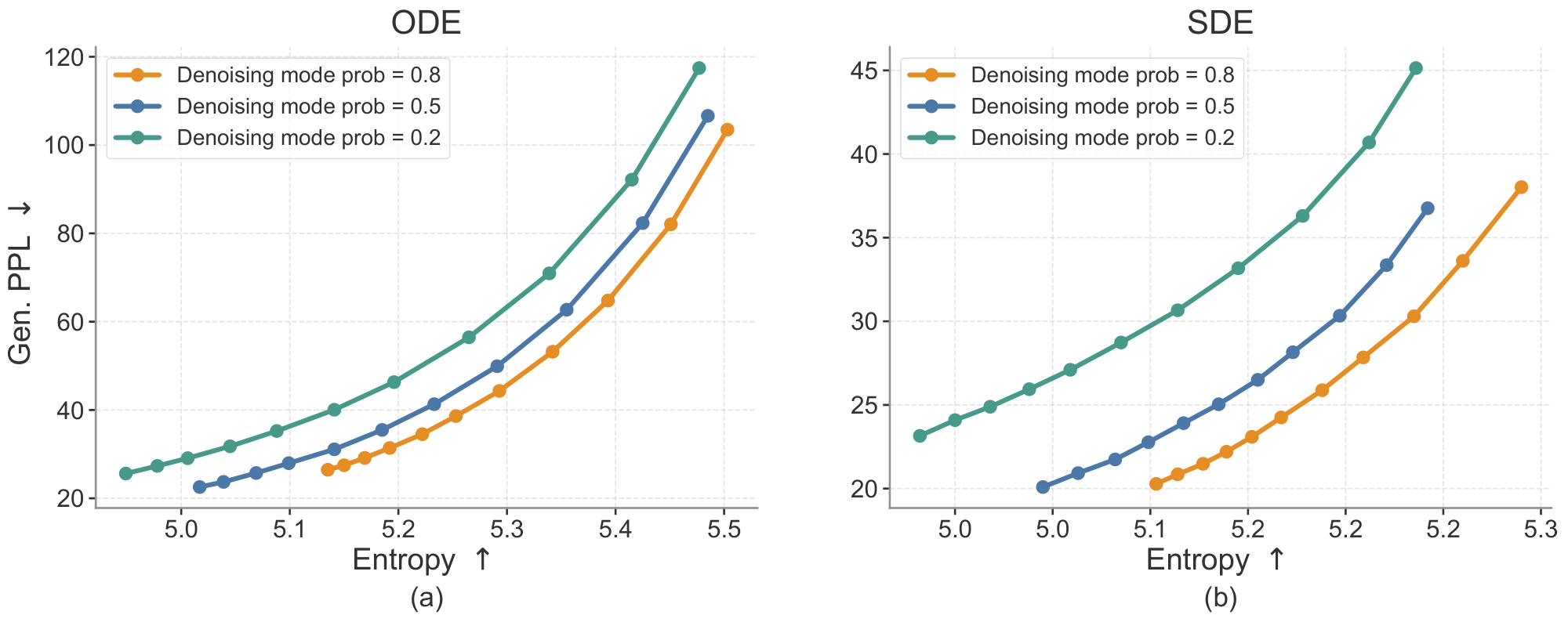
Since ELF is trained with both MSE and CE losses through a shared-weight denoiser-decoder, each training step is assigned to either denoising mode or decoding mode. The denoising-mode probability controls this allocation: a higher probability emphasizes learning the continuous denoising dynamics, while a lower probability provides more supervision for mapping embeddings back to tokens. We study this trade-off by varying the denoising-mode probability during training.
As shown in Figure 12, assigning a low probability to the denoising mode consistently degrades the generative perplexity–entropy trade-off, especially under SDE sampling. This suggests that the model requires sufficient training on the denoising process. Among the configurations tested, a denoising mode probability of $0.8$ achieves the best overall trade-off across both ODE and SDE samplers. We therefore use $0.8$ as the default denoising mode probability in our main experiments.
C.4 Conditioning Strategies
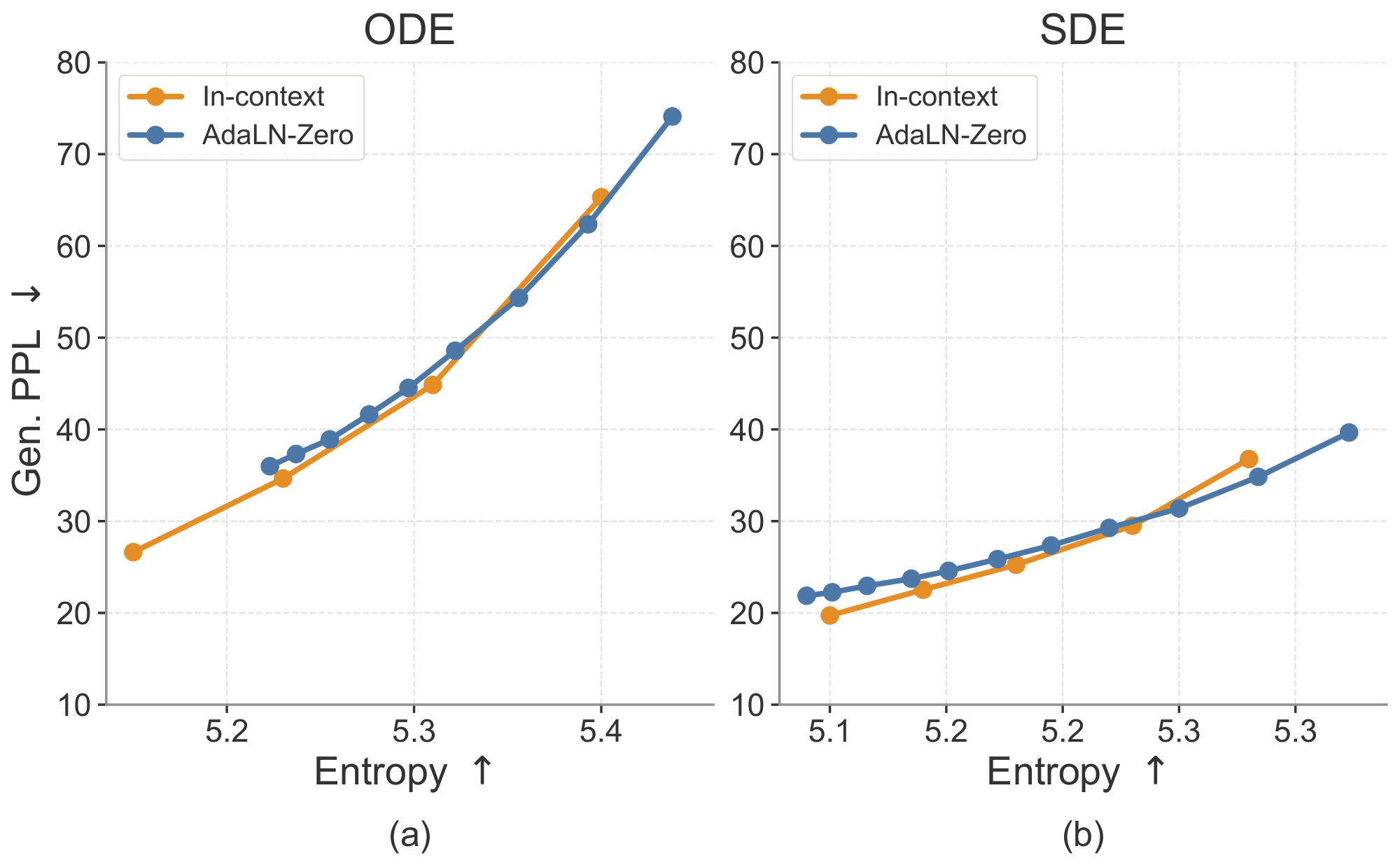
As discussed in Section 3.3, our model is conditioned on the time step, CFG scale, and model mode. We use in-context conditioning for these signals by prepending them as condition tokens to the input sequence, allowing the model to attend to them through full attention. This differs from the conventional adaLN-Zero conditioning design, which typically introduces additional model components to process the conditioning inputs. We compare these two designs in Figure 13. In-context conditioning performs slightly better while avoiding the substantial parameter overhead introduced by adaLN-Zero (ELF-B's parameter count is reduced from 148M to 105M). Therefore, we use in-context conditioning as our default setting.
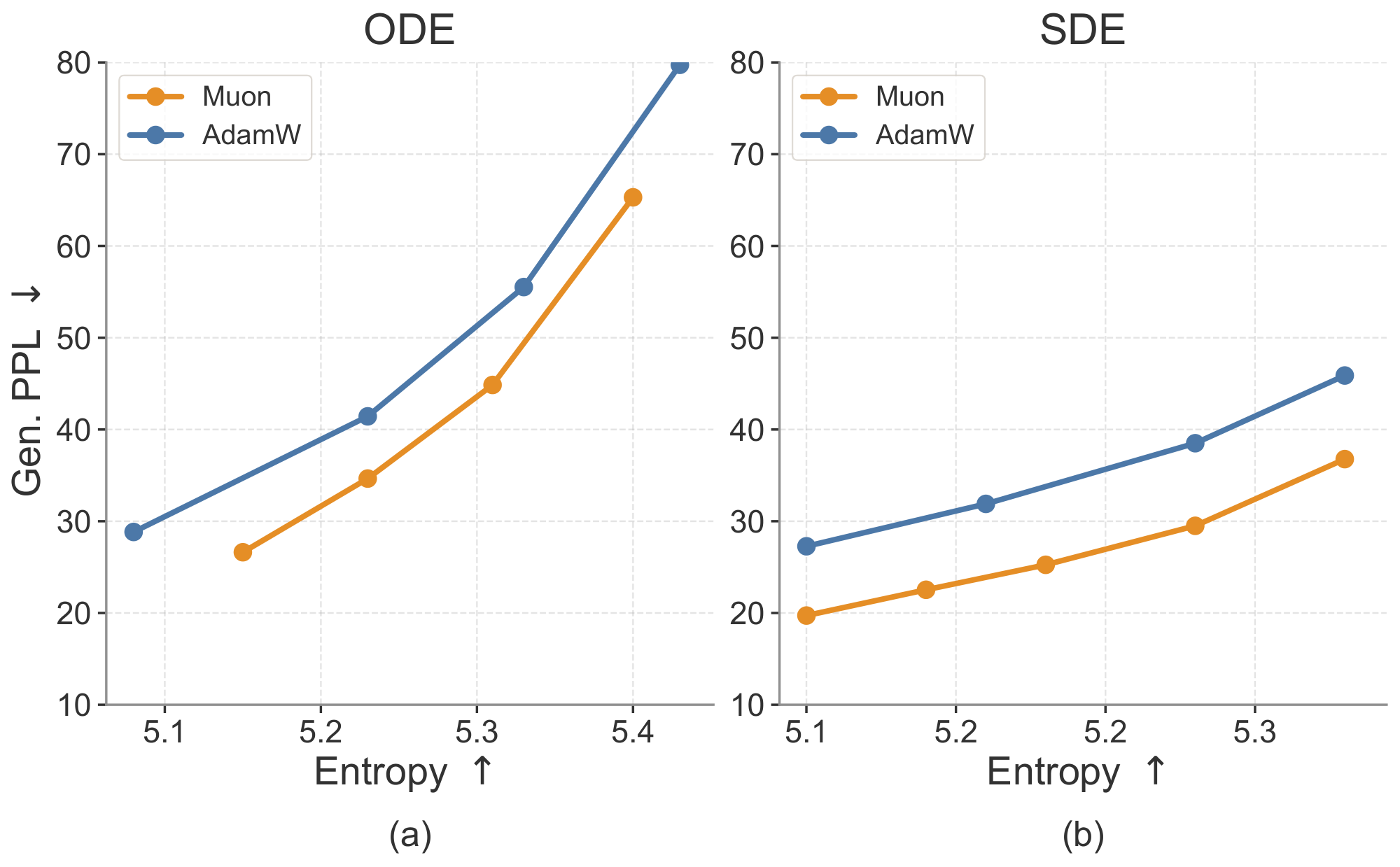
C.5 Optimizers
We evaluate the impact of optimizer choice, comparing Muon ([73]) and AdamW ([76]), and show the results in Figure 14. We tune the hyperparameters for both optimizers to obtain their best performance: for Muon, we use a learning rate of $2\times10^{-3}$; for AdamW, we use a learning rate of $1\times10^{-4}$ with $\beta_1=0.9$ and $\beta_2=0.95$. During training, Muon achieves lower loss within the same number of steps. During inference, models trained with Muon consistently achieve a better generative perplexity–entropy trade-off than those trained with AdamW under both samplers. The improvement is especially significant under SDE sampling, where Muon achieves lower generative perplexity at the same entropy level. These results highlight the importance of optimizer choice. Nevertheless, models trained with both optimizers still outperform other baselines, suggesting that the strong performance of ELF cannot be attributed to the optimizer alone.
C.6 Sampling Methods
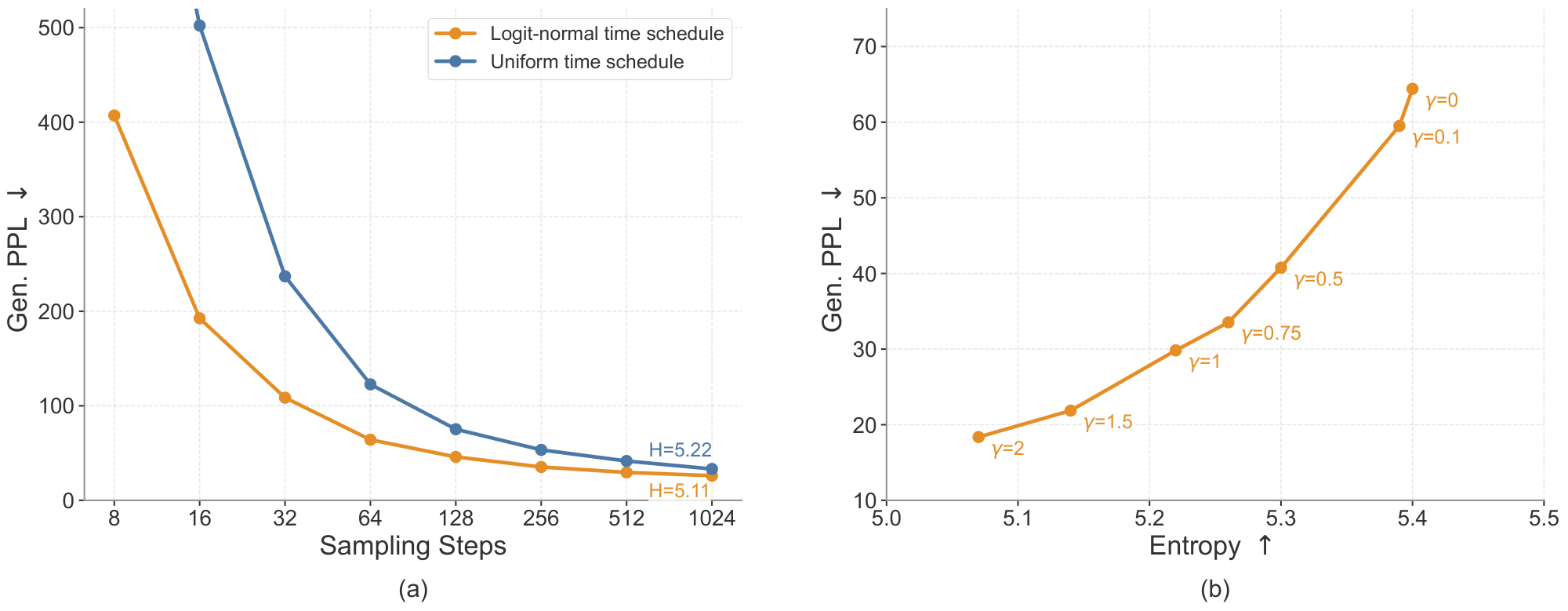
We study two sampling design choices that improve inference efficiency and generation quality: sampling time schedule and stochastic SDE-inspired sampling. The logit-normal time schedule improves sampling efficiency by reducing the required number of denoising steps, while the SDE noise re-injection scale provides additional control over the generative perplexity–entropy trade-off.
Time schedules.
By default, we use a logit-normal time schedule during inference ([77]). We also evaluate an alternative uniform schedule. Figure 15 a shows the effect of the time schedule on ODE sampling across different numbers of sampling steps. Across all step counts, the logit-normal schedule consistently reduces generative perplexity compared with the uniform schedule. This improvement is especially significant in the few-step regime. These results suggest that the logit-normal time schedule improves sampling efficiency and final sample quality, likely because it better aligns the inference-time trajectory with the training-time schedule and allocates more sampling steps to noisier time steps.
SDE noise re-injection scale.
For SDE sampling, we introduce a noise re-injection scale hyperparameter $\gamma$ that controls the amount of stochasticity injected at each sampling step, as discussed in Appendix B.2. Intuitively, increasing $\gamma$ introduces more stochasticity, while $\gamma=0$ reduces to deterministic ODE sampling. As shown in Figure 15 b, $\gamma$ controls the generative perplexity–entropy trade-off: within a moderate range, larger $\gamma$ leads to lower generative perplexity while slightly reducing entropy. We hypothesize that the noise re-injection process helps correct early denoising errors, rather than deterministically amplifying imperfect trajectories as in ODE sampling. We therefore choose $\gamma=1.0$ as our default setting, which provides a strong balance between generative perplexity and entropy.
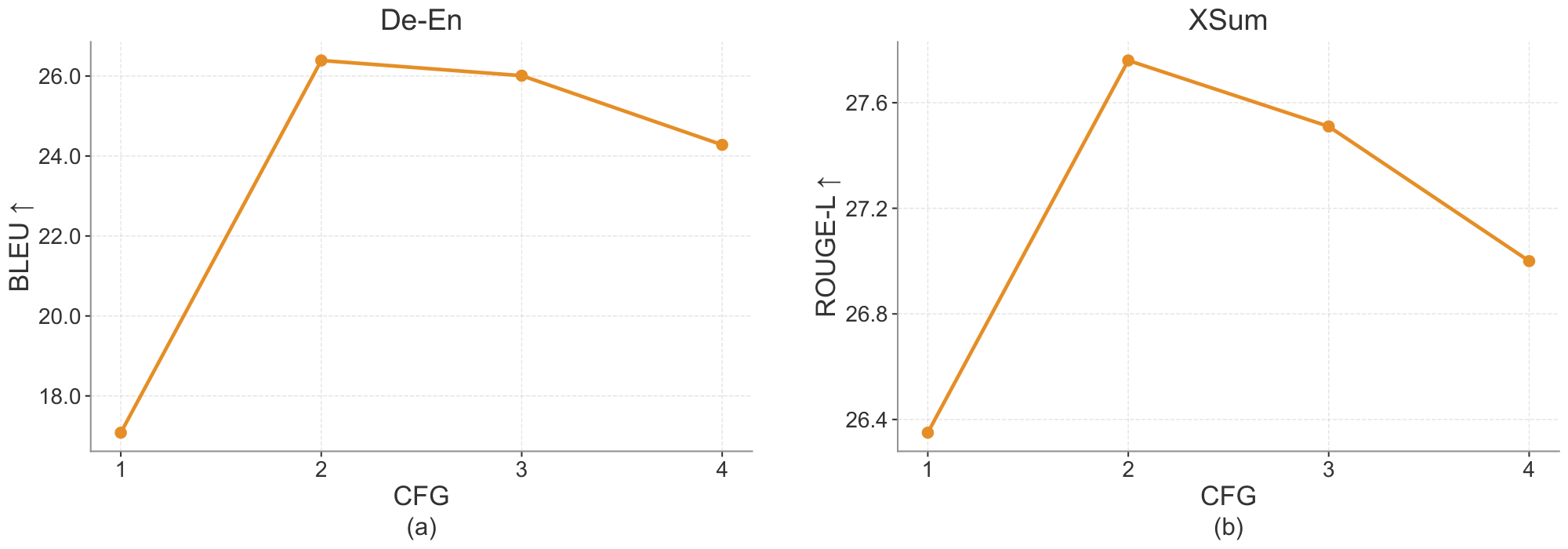
C.7 CFG on Conditional Generation
We further study the effect of CFG scale on conditional generation tasks. As shown in Figure 16, increasing the CFG scale from 1 to 2 substantially improves performance on both WMT14 De-En and XSum, suggesting that stronger conditioning helps the model better follow the source input. However, further increasing the scale leads to a gradual decline in performance, indicating that overly strong guidance can hurt generation quality. Based on this trend, we use CFG scale 2 as the default setting for conditional generation.
D. Experimental Details
D.1 Model Architecture
Our model uses a standard Diffusion Transformer architecture ([75]). We also incorporate popular general-purpose improvements, including SwiGLU ([78]), RMSNorm ([79]), RoPE ([80]), and qk-norm ([81]). We use in-context conditioning instead of adaLN-Zero ([75]) conditioning, which allows us to significantly reduce the number of parameters; for example, the ELF-B model size is reduced from 148M to 105M parameters. Table 3 summarizes the configurations of ELF across different model sizes. We report the Transformer depth, hidden size, number of attention heads, and parameter count. We also report the number of training epochs used on the OWT dataset for each variant. Larger models tend to learn faster in our setup, and therefore require fewer training epochs.
: Table 3: ELF Model configurations across different scales.
| Model | Depth | Hidden size | # Heads | Params | Training epochs |
|---|---|---|---|---|---|
| ELF-B | 12 | 768 | 12 | 105M | 5 |
| ELF-M | 24 | 1056 | 16 | 342M | 4 |
| ELF-L | 32 | 1280 | 16 | 652M | 3 |
D.2 Hyperparameters
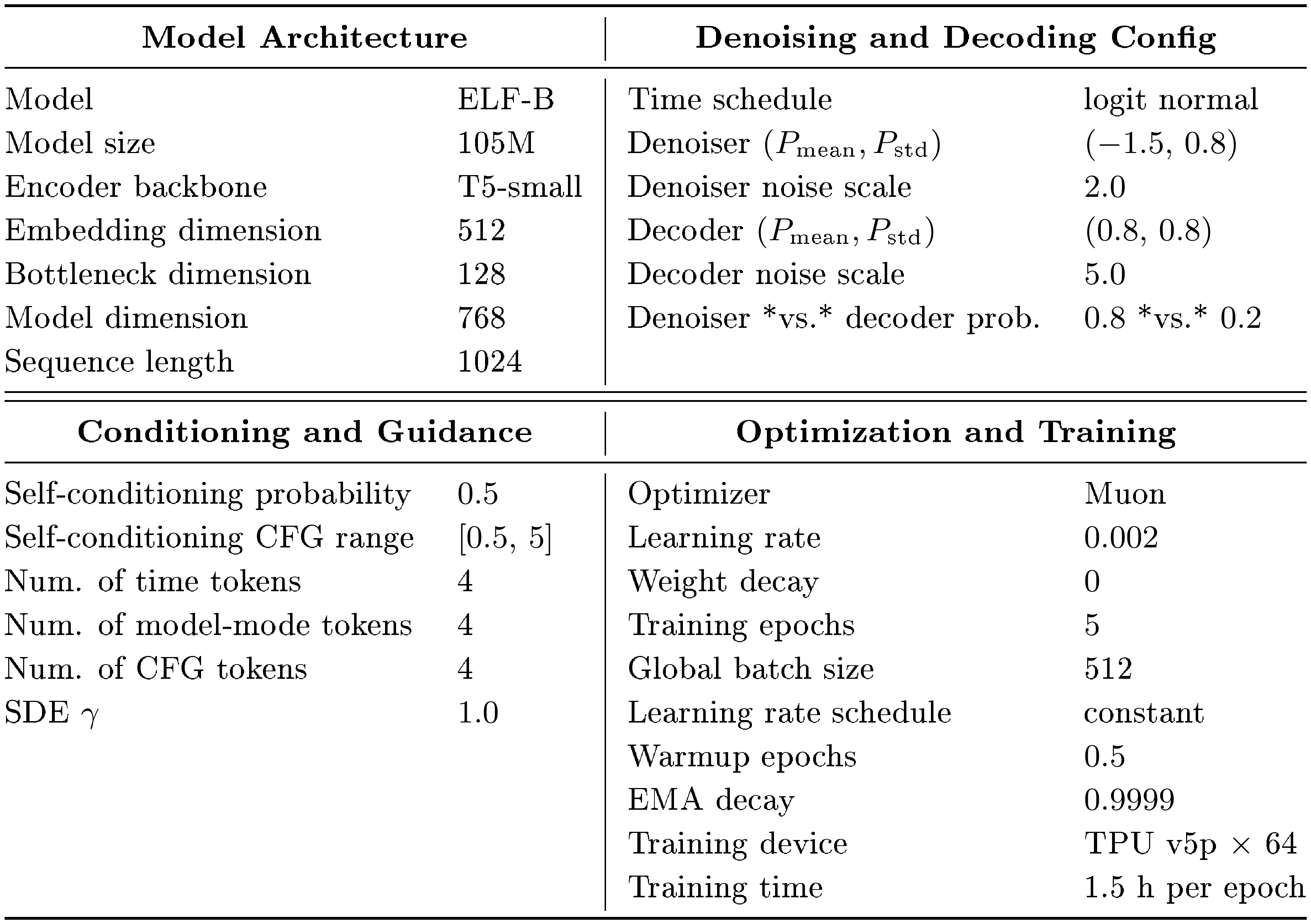
::: {caption="Table 4: Default training hyperparameters and setup for ELF-B on the OpenWebText dataset. Unless noted otherwise, all experiments in the paper follow this default configuration."}
:::
ELF pipeline hyperparameters.
Table 4 summarizes the main hyperparameters used in the ELF pipeline, covering model architecture, diffusion settings, conditioning and guidance, and optimization details. Unless noted otherwise, all experiments in the paper follow this default configuration. We include these settings for completeness and to facilitate reproducibility.
Inference-time settings for system-level comparison.
For system-level comparison in Figure 7, we use SDE sampling with time schedule enabled for all step budgets. We set the CFG scale to 3 for 8-, 16-, and 32-step generation. For SDE sampling, we use a stronger noise injection scale of $\gamma=2$ in the very few-step regimes of 8 and 16 steps, and reduce it to $\gamma=1.5$ for 32 steps, as longer denoising trajectories require less stochastic correction. For the system-level comparison in Table 1, we use 64-step ODE sampling with time schedule. We set the self-conditioning CFG scale to 1 and the input-condition CFG scale to 2.
Training-token budget for system-level comparison.
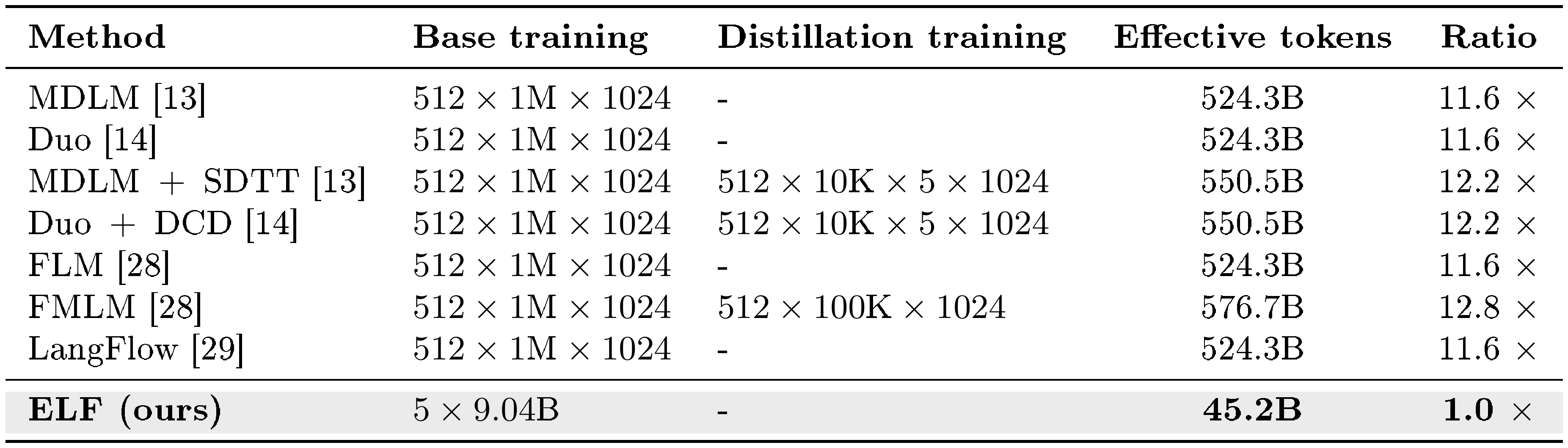
Table 5 reports the estimated effective training tokens used by ELF and each baseline in Figure 7 c. We estimate base-training tokens as $\text{batch size}\times\text{steps}\times\text{sequence length}$ and add distillation or flow-map stages on top where applicable. The OWT dataset contains roughly 9.04B tokens. With our default training schedule of 5 epochs, ELF therefore uses 45.2B effective training tokens. Thus, ELF requires roughly an order of magnitude fewer effective training tokens than the compared DLMs.
::: {caption="Table 5: Estimated effective training tokens for ELF and the prior DLM baselines used in our system-level comparison (Figure 7 c). We estimate base-training tokens as $\text{batch size}\times\text{steps}\times\text{sequence length}$; distillation / flow-map stages are added on top where applicable."}
:::
D.3 Ablation Studies Setting
We evaluate several choices of embedding representations for ELF, and report the implementation details as below. We also try two-stage training with a separate decoder. Unless specified, we keep other settings the same as the default ELF configuration.
Scratch encoder.
We train an encoder from scratch on OpenWebText ([68]) by following the original T5-small training pipeline ([60]). The encoder is trained for 5 epochs with a learning rate of $1\times10^{-3}$, cosine learning rate schedule, 0.4 epoch warmup, and a batch size of 512. During ELF training, we apply channel-wise normalization to the encoder outputs.
Pretrained embedding layer.
We use the frozen embedding table from the T5-small encoder as the token embedding layer. The embedding layer matrix is normalized, and the unembedding layer is trained separately.
Gaussian embedding layer.
We randomly initialize and freeze an embedding layer from a Gaussian distribution, with token-wise embedding mean 0 and standard deviation 1. The unembedding layer is trained separately using the decoder mode.
Learnable embedding layer.
We jointly train the embedding layer together with the denoiser and decoder modes. The unembedding layer is tied with the embedding layer: denoiser-mode updates affect the embedding layer, while decoder-mode updates affect the unembedding layer. To stabilize training, we apply normalization directly on the unembedding layer matrix at every step.
Separate decoder.
For the separate-decoder setting, we use a randomly initialized decoder architecture obtained by mirroring the T5-small encoder. We keep the encoder fixed, mask 20% of the input tokens, and add logit-normal noise to the latent representations with $P_{\mathrm{mean}}=0.5$ and $P_{\mathrm{std}}=1.0$. The model is trained for 3 epochs with a learning rate of $3\times10^{-4}$ and a cosine learning-rate schedule. The relative noise scale with respect to the normalized latent representations is set to $5.0$.
D.4 Reported Numbers
: Table 6: System-level ELF performance reported as mean $\pm$ standard error (SE) over 6 independent evaluation runs (seeds 0–5; $n=6$).
| Steps | SC CFG | $\gamma$ | Gen. PPL $\downarrow$ | Entropy $\uparrow$ |
|---|---|---|---|---|
| 8 | 3 | 2.0 | $67.32 \pm 2.25$ | $5.14 \pm 0.085$ |
| 16 | 3 | 2.0 | $33.66 \pm 1.09$ | $5.16 \pm 0.026$ |
| 32 | 3 | 1.5 | $24.08 \pm 0.16$ | $5.15 \pm 0.002$ |
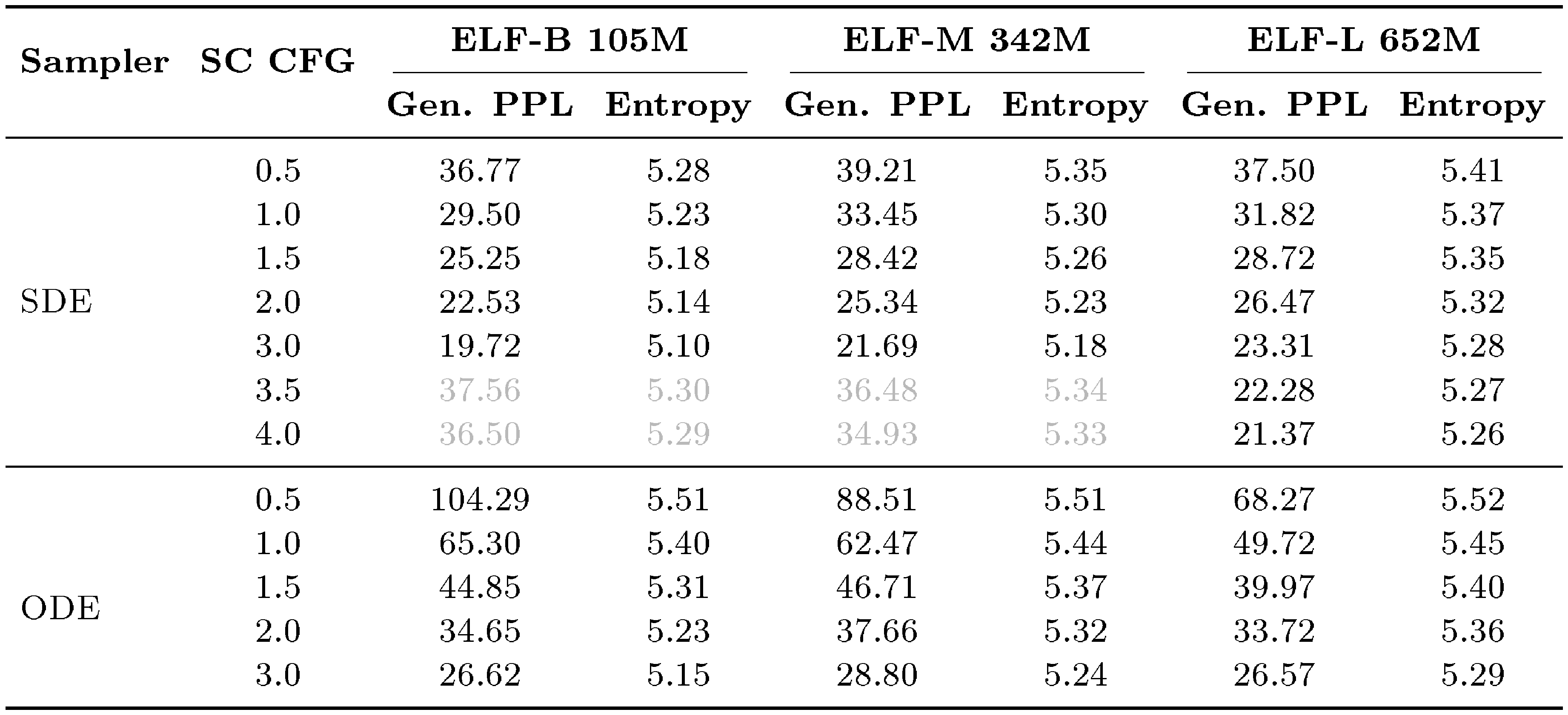
::: {caption="Table 7: Scaling performance of generative perplexity (Gen. PPL) and unigram entropy for ELF models of different sizes under SDE and ODE samplers with 64 sampling steps. The effect of self-conditioning (SC) CFG scaling diminishes beyond 3."}
:::
System level comparison.
Across 6 independent evaluation seeds, ELF shows highly consistent system-level behavior, as shown in Table 6. As the number of sampling steps increases from 8 to 32, the standard error (SE) decreases. The small standard errors—especially at 32 steps—suggest that these gains are robust to random seed variation and that the overall trend is reliable across runs. See Table 6 for detailed numbers.
Scaling behavior with CFG scales.
The default setting for both sampling methods uses 64 sampling steps with time schedule. For the SDE sampler, we set $\gamma=1.0$. The exact numbers are reported in Table 7. Larger CFG scales improve generation quality by reducing Gen. PPL within a certain range. The effect of CFG scaling reverses beyond 3. Only ELF-L benefits from increasing the CFG scale from 3 to 4. Thus, in most default ablation studies, we only consider CFG scales from 0.5 to 3.
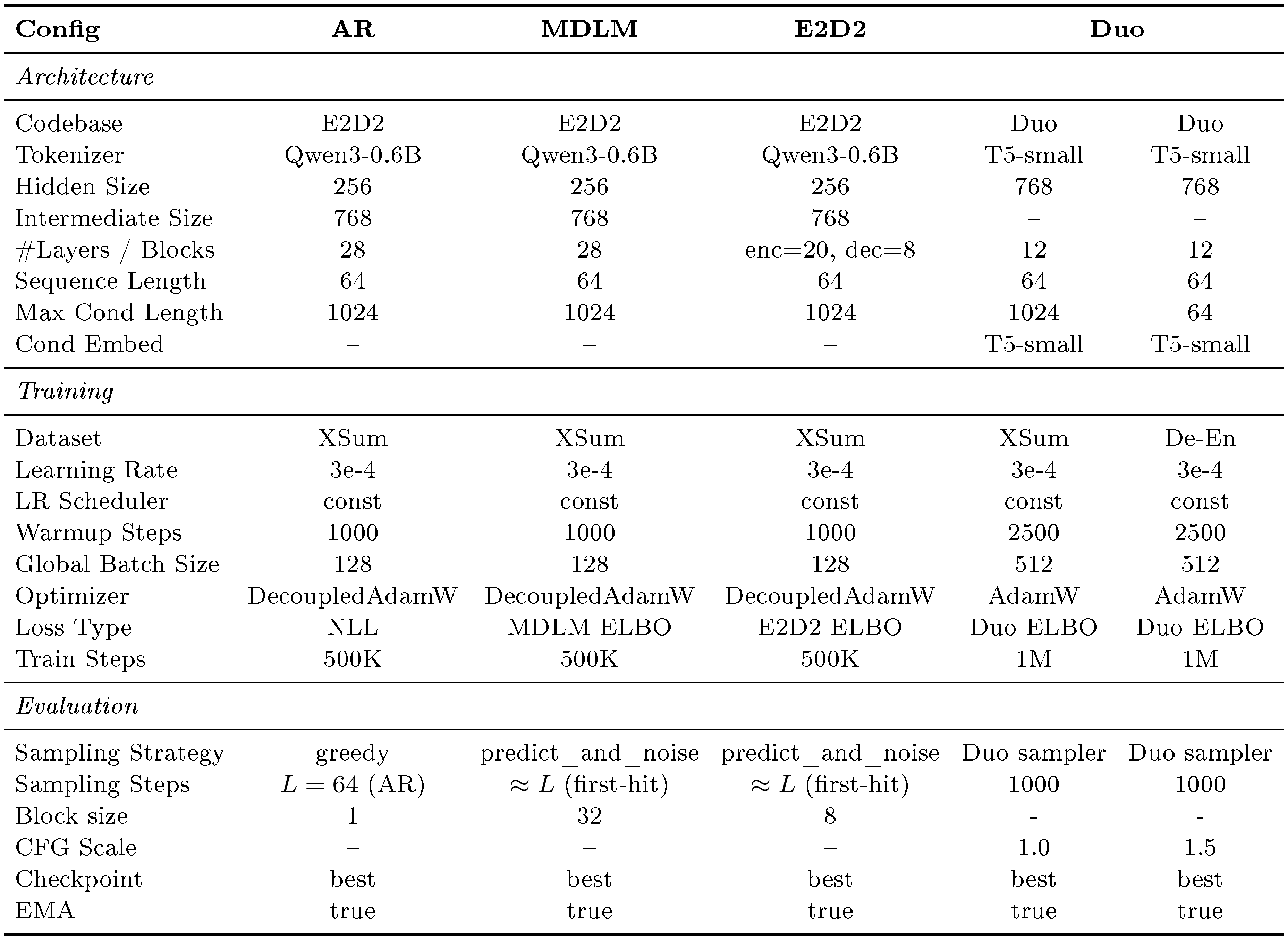
::: {caption="Table 8: Detailed training and evaluation configurations for conditional generation tasks of our reproduced AR, MDLM, E2D2, and Duo baselines. AR, MDLM, and E2D2 are reproduced on XSum using the E2D2 [53] codebase and follow the configurations reported in the E2D2 paper. For Duo, we build on the original Duo [14] repository, add cross-attention conditioning and CFG, adapt the T5-small encoder to match our setting, and tune the hyperparameters to obtain the strongest reproduced results."}
:::
D.5 Conditional Generation
Specifically, the WMT14 results for AR, MDLM, and E2D2 are taken from the E2D2 [53] paper, the SeqDiffuSeq result is taken from the LD4LG [24] paper, and the CDCD result is taken from the original CDCD [8] paper. For reproduced results, Duo [14] is implemented using the Duo codebase^3, while AR, MDLM, and E2D2 are reproduced using the E2D2 codebase^4.
For a fair comparison, we reproduce all baselines using settings that are as close as possible to their original implementations, as summarized in Table 8. For AR, MDLM, and E2D2, we use the E2D2 codebase and follow the training and evaluation configurations reported in the E2D2 paper on XSum. Note that although E2D2 is primarily designed for semi-autoregressive generation, we find that MDLM also achieves its best performance under a semi-autoregressive setting (i.e., block size 32 with two-block generation); using single-block diffusion without semi-autoregressive generation degrades performance. For Duo, we start from the official Duo repository and adapt it to our conditional generation setting by adding cross-attention conditioning and classifier-free guidance, and by using a T5-small encoder for the conditioning input. During inference, we generate without semi-autoregressive decoding. We tune the main sampling and guidance hyperparameters and report the best reproduced results we obtain.
E. Qualitative Examples

E.1 Denoising Trajectory
Figure 17 visualizes the intermediate predictions along ELF's denoising process. Starting from repetitive tokens at $t=0$, the model gradually forms semantically meaningful phrases, improves grammar, and refines word choices as $t$ approaches 1. This trajectory illustrates how continuous diffusion generation progressively transforms noisy embeddings that decode to gibberish text into clean embeddings that decode to grammatical sentences.
E.2 Unconditional Generation Examples on OpenWebText
We provide three unconditional samples generated by ELF-B on OpenWebText, reported with their entropy and generative perplexity (Gen. PPL). The examples illustrate that ELF produces fluent, syntactically coherent, and topically consistent long-form text across diverse domains.
entropy: 5.36 Gen. PPL: 21.04
The company has been developing a virtual sleep mode for its iPhone and iPad for years. This means that users can improve their quality of life without turningping off their fingers thanks to Google's new virtual sleep technology. To make the experience a reality, virtual sleep mode was developed for Google, using a new built-in technology that includes real-time photography and shadow monitoring. This technology enables users to have a safe, comfortable look at where they sleep, even if you place the keyboard or a button under your fingers. Some sources point to the iPhone 6 and iPhone 6 as yet another example of the importance of virtual sleep mode in our everyday lives. This technology has been shown to be useful when staying busy on tight days, during difficult times or lying asleep on a hot night. This technology could also be used to improve sleep quality and help users improve quality of life. Editor's note: This post has been updated to answer to relevant questions. Google says it will add virtual sleep mode to its iPhone and iPad in coming week. Google announced some good news Thursday morning, including instructions on when to eat, checking out, where to sleep and the rules surrounding what to eat. The company reported a revenue of \$957 billion – more than a third of the total revenue during the same period. But the company doesn't seem to have a slew of other good news yet, like the first one ...
entropy: 5.27 Gen. PPL: 21.29
Balin said the potential cost of starting there is very low, and he told USA2 Network in an interview that he is not only interested in expanding the capacity of the university, but is also interested in expanding other services, including student assistance, community assistance, youth assistance, youth assistance, and social justice assistance. Balin said, \"One of the things about this is that it's difficult to start, because if you're underfunded, you're going to need all the services that you need, and that's what you have to pay for. And it's going to difficult, if nothing, for you to get the funding you need to start right there.\" The UDU has not made such promise. \"We have a lot of the guys in the department that are doing well, a lot of the guys that aren't doing well at the university and they're currently underfunded, \" Balin said. \"Most of the other LHS universities across the country are currently underfunded. So, what do you want them to do? You know, right now, the cost is very low and there are no great universities in the rest of the country. It's not going to be easy.\" In the meantime, Balin said, the UDU isn't looking to attract high-quality...
entropy: 5.17 Gen. PPL: 21.80
Hey, I grew up in Lyndon in the early ’90s and, after my father’s death, began writing a book about himself called The Life of Steve O’Malse. After his second year at the University of Chicago O’Malse decided to write a biobio about his father. He finished his study at the University of Chicago in the fall of 1999. In 2009 he published a biobio called “My Dad And Daughter While he Was Home, ” a successful biobio written by a former military officer, Lt. Gen. David Wilde. Steve O’Malse has had great national security experience. Throughout his career as a high-level national security adviser, he has served as an adviser to George H.W. Bush and an adviser to two top FBI officials, John J. Tillerson and Michael E. Comey, both of whom have been involved in the investigations that led to the resignation of Attorney General Rex Tillerson. He played a key role throughout the administration as a national security adviser, then as a special adviser to former President George W. Bush, then as secretary of Homeland Security under Bush and former presidential candidate Ronald Clinton. In 2008, O’Malse was named by President Ronald Reagan as a new national security adviser. In a speech last year, he detailed his experience in the Reagan administration, as a new national security adviser. O’Malse said he was surprised by his ability to express his concerns about national security, but added that he would be speaking more for years to come...
E.3 Conditional Generation Examples
WMT14 De-En qualitative examples.
We show qualitative examples on WMT14 De-En to complement the corpus-level BLEU results. ELF generally produces fluent and globally coherent translations.
<Original text>
Dieses Phänomen hat nach den Wahlen vom November 2010 an Bedeutung gewonnen, bei denen 675 neue republikanische Vertreter in 26 Staaten verzeichnet werden konnten.
<Reference translation>
This phenomenon gained momentum following the November 2010 elections, which saw 675 new Republican representatives added in 26 States.
<Our translation>
This phenomenon has increased in significance after the elections in November 2010, in which 675 new Republicanan representatives have been recorded in 26 countries.
<Original text>
Im Gegensatz zu Kanada sind die US-Bundesstaaten für die Durchführung der Wahlen in den einzelnen Staaten verantwortlich.
<Reference translation>
Unlike in Canada, the American States are responsible for the organisation of federal elections in the United States.
<Our translation>
Unlike Canada, the United States are states responsible for holding elections in each country.
XSum qualitative examples.
We show qualitative examples on XSum to complement the ROUGE results. ELF generally produces fluent and concise summaries that capture the main content of the source document.
<Original text>
Voges was forced to retire hurt on 86 after suffering the injury while batting during the County Championship draw with Somerset on 4 June.
Middlesex hope to have the Australian back for their T20 Blast game against Hampshire at Lord's on 3 August.
The 37-year-old has scored 230 runs in four first-class games this season at an average of 57.50.
"Losing Adam is naturally a blow as he contributes significantly to everything we do, " director of cricket Angus Fraser said.
"His absence, however, does give opportunities to other players who are desperate to play in the first XI.
"In the past we have coped well without an overseas player and I expect us to do so now."
Defending county champions Middlesex are sixth in the Division One table, having drawn all four of their matches this season.
Voges retired from international cricket in February with a Test batting average of 61.87 from 31 innings, second only to Australian great Sir Donald Bradman's career average of 99.94 from 52 Tests.
<Reference summarization>
Middlesex batsman Adam Voges will be out until August after suffering a torn calf muscle in his right leg.
<Our summarization>
Middlesex captain Adam Voges will not miss the rest of the season as he struggles with a bone injury.
<Original text>
Ms Kendall told the BBC Labour risked sending a "resignation letter to the British people as a serious party of government" by electing Mr Corbyn.
Separately, Ms Cooper warned there was a "serious risk the party will split" if the left-winger becomes its leader.
It comes as Labour begins sending out the first ballot papers to voters.
The result of the contest will be announced at a special conference on 12 September.
More than 600, 000 people have signed up to vote in the four-way contest but Labour has said applications are still being verified.
610, 753
total electorate, though this may fall as party removes those not entitled to vote
Of which, full party members: 299, 755
Affiliated to a trade union: 189, 703
Registered to vote by paying £3: 121, 295
Meanwhile voting in the election for the new Scottish Labour leader ended at midday.
Mr Corbyn is due to unveil a 10-point policy plan while in Glasgow later.
The popularity of the left-wing Islington North MP, who is promising "a new kind of politics", has sparked a row about the future direction of the Labour party.
Another leadership contender, Andy Burnham, told the BBC Mr Corbyn's policies "lack credibility".
"It's not possible to promise free university education, re-nationalising the utilities, without that coming at a great cost and if you can't explain how that is going to be paid for then I don't think we'll win back the trust of voters on the economy, " he said.
BBC political correspondent Ross Hawkins said there had been "frustration" in rival camps who accused Mr Burnham of being reluctant to take on Mr Corbyn. This appeared to be his most direct attack yet, he added.
But in an interview with Jeremy Vine on BBC Radio 2, Mr Burnham declined to follow Ms Kendall and Ms Cooper and advise his supporters not to back Mr Corbyn with their second and third preferences.
He added: "People will say if they hear things like that, 'hang on, what do you believe?'"
In an interview with The Independent, Ms Kendall called for voters to mark Ms Cooper or Mr Burnham as second and third preferences, and avoid giving votes to Mr Corbyn.
"I have set out very clearly where I differ with all the candidates but our differences with Jeremy's kind of politics are far greater, " said Ms Kendall.
Speaking on BBC Radio 4's Today programme she said she "can't pretend to be agnostic" about a victory for Mr Corbyn, saying of the voting process: "It is an alternative vote system and I want to urge party members to use all of their different preferences.
"I will be using my second and third preferences and I would urge others to do the same because I don't want to see our party go back to the politics of the '80s, just being a party of protest."
The Leicester West MP also said she did not see the party splitting, as it did in the 1980s when Labour members formed the Social Democratic Party.
However, Ms Cooper told BBC 2's Newsnight: "I think there is a serious risk that the party will split, will polarise and I cannot bear to see that happen because there is too much at stake."
Asked in an interview with grassroots Labour website Labourlist whether voters should use their votes to try to prevent Mr Corbyn winning, she said: "I think people should use all of their preferences.
"And I think the focus has to be how do we make sure we can win that election, and that's the most important thing - and I don't think Jeremy can do that."
Mr Corbyn has warned against "personal abuse" in the campaign, saying he wants to focus on policy.
His policy programme includes a commitment to "growth not austerity", nationalising the railways and energy sector, and a plan for nuclear disarmament.
In an essay for the Fabian Society he also suggested Labour's new increased following should be more involved in the party and proposed a review of membership fees to make the party more "inclusive".
Former Prime Minister Gordon Brown is expected to join the debate over the leadership contest with a speech on Sunday, called "power for a purpose - the future of the Labour Party".
Lance Price, former director of communications for Labour, told the BBC the contest had been an "unedifying mess" and had "done nothing to reengage the labour party with those millions of people who deserted it".
The Guardian newspaper has endorsed Ms Cooper for the leadership while the Daily Mirror has given its backing to Mr Burnham, although the paper urged him to "find a role" in his team for Mr Corbyn, who it says has "lit up the election campaign".
Labour leadership hopefuls Liz Kendall and Yvette Cooper have said their supporters should back anyone other than Jeremy Corbyn in the contest.
<Reference summarization>
Labour leadership hopefuls Liz Kendall and Yvette Cooper have said their supporters should back anyone other than Jeremy Corbyn in the contest.
<Our summarization>
Labour leadership contender Kendall Kendall has warned she does not avoid an threat of using Jeremy Corbyn with second and third preferences.
References
[1] Sohl-Dickstein et al. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. In ICML.
[2] Song et al. (2021). Score-based Generative Modeling through Stochastic Differential Equations. In ICLR.
[3] Ho et al. (2020). Denoising diffusion probabilistic models. In NeurIPS.
[4] Lipman et al. (2023). Flow matching for generative modeling. In ICLR.
[5] Liu et al. (2023). Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. In ICLR.
[6] Albergo, Michael Samuel and Vanden-Eijnden, Eric (2023). Building Normalizing Flows with Stochastic Interpolants. In ICLR.
[7] Li et al. (2022). Diffusion-LM improves controllable text generation. In NeurIPS.
[8] Dieleman et al. (2022). Continuous diffusion for categorical data. arXiv preprint arXiv:2211.15089.
[9] Gong et al. (2023). Diffuseq: Sequence to sequence text generation with diffusion models. In ICLR.
[10] Austin et al. (2021). Structured denoising diffusion models in discrete state-spaces. In NeurIPS.
[11] He et al. (2023). Diffusionbert: Improving generative masked language models with diffusion models. In ACL.
[12] Lou et al. (2024). Discrete diffusion modeling by estimating the ratios of the data distribution. In ICML.
[13] Sahoo et al. (2024). Simple and effective masked diffusion language models. In NeurIPS.
[14] Sahoo et al. (2025). The diffusion duality. In ICML.
[15] Li et al. (2025). A survey on diffusion language models. arXiv preprint arXiv:2508.10875.
[16] Nie et al. (2025). Large Language Diffusion Models. In NeurIPS.
[17] Ye et al. (2025). Dream 7B: Diffusion Large Language Models. arXiv preprint arXiv:2508.15487.
[18] Sahoo et al. (2026). Scaling Beyond Masked Diffusion Language Models. arXiv preprint arXiv:2602.15014.
[19] Ma et al. (2024). SiT: Exploring flow and diffusion-based generative models with scalable interpolant Transformers. In ECCV.
[20] Esser et al. (2024). Scaling rectified flow Transformers for high-resolution image synthesis. In ICML.
[21] Black Forest Labs et al. (2025). FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space. arXiv preprint arXiv:2506.15742.
[22] Wan Team et al. (2025). Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314.
[23] Rombach et al. (2022). High-resolution image synthesis with latent diffusion models. In CVPR.
[24] Lovelace et al. (2023). Latent diffusion for language generation. In NeurIPS.
[25] Meshchaninov et al. (2025). Cosmos: Compressed and Smooth Latent Space for Text Diffusion Modeling. In NeurIPS.
[26] Shen et al. (2026). CoDAR: Continuous Diffusion Language Models are More Powerful Than You Think. arXiv preprint arXiv:2603.02547.
[27] Li, Tianhong and He, Kaiming (2025). Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720.
[28] Lee et al. (2026). Flow Map Language Models: One-step Language Modeling via Continuous Denoising. arXiv preprint arXiv:2602.16813.
[29] Chen et al. (2026). LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling. arXiv preprint arXiv:2604.11748.
[30] Bojar et al. (2014). Findings of the 2014 Workshop on Statistical Machine Translation. In ACL # Workshop on Statistical Machine Translation.
[31] Narayan et al. (2018). Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In EMNLP.
[32] Albergo et al. (2025). Stochastic interpolants: A unifying framework for flows and diffusions. JMLR.
[33] Nichol, Alexander Quinn and Dhariwal, Prafulla (2021). Improved denoising diffusion probabilistic models. In ICML.
[34] Strudel et al. (2022). Self-conditioned embedding diffusion for text generation. arXiv preprint arXiv:2211.04236.
[35] Yuan et al. (2024). Seqdiffuseq: Text diffusion with encoder-decoder transformers. In NAACL.
[36] Gulrajani, Ishaan and Hashimoto, Tatsunori B (2023). Likelihood-based diffusion language models. In NeurIPS.
[37] Wang et al. (2023). InfoDiffusion: Information Entropy Aware Diffusion Process for Non-Autoregressive Text Generation. In Findings of.
[38] Ye et al. (2024). DINOISER: Diffused Conditional Sequence Learning by Manipulating Noises. Transactions of the Association for Computational Linguistics.
[39] Lin et al. (2023). Text generation with diffusion language models: A pre-training approach with continuous paragraph denoise. In ICML.
[40] Wu et al. (2023). AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation. In NeurIPS.
[41] Gao et al. (2024). Empowering Diffusion Models on the Embedding Space for Text Generation. In NAACL.
[42] Han et al. (2023). SSD-LM: Semi-autoregressive simplex-based diffusion language model for text generation and modular control. In ACL.
[43] Mahabadi et al. (2024). Tess: Text-to-text self-conditioned simplex diffusion. In EACL.
[44] Tae et al. (2025). Tess 2: A large-scale generalist diffusion language model. In ACL.
[45] Jo, Jaehyeong and Hwang, Sung Ju (2025). Continuous Diffusion Model for Language Modeling. In NeurIPS.
[46] Zhang et al. (2023). PLANNER: Generating Diversified Paragraphs via Latent Language Diffusion Model. In NeurIPS.
[47] Shabalin et al. (2025). TEncDM: Understanding the properties of the diffusion model in the space of language model encodings. In AAAI.
[48] Lovelace et al. (2024). Diffusion Guided Language Modeling. In Findings of.
[49] Potaptchik et al. (2026). Discrete Flow Maps. arXiv preprint arXiv:2604.09784.
[50] Roos et al. (2026). Categorical flow maps. arXiv preprint arXiv:2602.12233.
[51] Wang et al. (2025). Remasking Discrete Diffusion Models with Inference-Time Scaling. In NeurIPS.
[52] Wu et al. (2026). Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding. In ICLR.
[53] Arriola et al. (2025). Encoder-decoder diffusion language models for efficient training and inference. In NeurIPS.
[54] Deschenaux et al. (2026). The Diffusion Duality, Chapter II: $\Psi$-Samplers and Efficient Curriculum. In ICLR.
[55] Gong et al. (2026). Diffucoder: Understanding and improving masked diffusion models for code generation. In ICLR.
[56] Song et al. (2025). Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference. arXiv preprint arXiv:2508.02193.
[57] Yang et al. (2025). MMaDA: Multimodal Large Diffusion Language Models. In NeurIPS.
[58] You et al. (2025). LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning. arXiv preprint arXiv:2505.16933.
[59] Li et al. (2026). Omni-Diffusion: Unified Multimodal Understanding and Generation with Masked Discrete Diffusion. arXiv preprint arXiv:2603.06577.
[60] Raffel et al. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR.
[61] Ho, Jonathan and Salimans, Tim (2021). Classifier-Free Diffusion Guidance. In NeurIPS # Workshops.
[62] Chen et al. (2023). Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning. In ICLR.
[63] Shabalin et al. (2026). Why Gaussian Diffusion Models Fail on Discrete Data?. arXiv preprint arXiv:2604.02028.
[64] Chen et al. (2025). Visual Generation Without Guidance. In ICML.
[65] Tang et al. (2025). Diffusion models without classifier-free guidance. arXiv preprint arXiv:2502.12154.
[66] Geng et al. (2025). Mean Flows for One-step Generative Modeling. In NeurIPS.
[67] Geng et al. (2025). Improved mean flows: On the challenges of fastforward generative models. arXiv preprint arXiv:2512.02012.
[68] Gokaslan, Aaron and Cohen, Vanya (2019). OpenWebText Corpus.
[69] Radford et al. (2019). Language models are unsupervised multitask learners. OpenAI blog.
[70] Ai et al. (2026). Joint Distillation for Fast Likelihood Evaluation and Sampling in Flow-based Models. In ICLR.
[71] Papineni et al. (2002). BLEU: a method for automatic evaluation of machine translation. In ACL.
[72] Lin, Chin-Yew (2004). ROUGE: A package for automatic evaluation of summaries. In ACL # Workshop on Text Summarization Branches Out.
[73] Jordan et al. (2024). Muon: An optimizer for hidden layers in neural networks. Technical report, Keller Jordan blog.
[74] Deschenaux, Justin and Gulcehre, Caglar (2025). Beyond Autoregression: Fast LLMs via Self-Distillation Through Time. In ICLR.
[75] Peebles, William and Xie, Saining (2023). Scalable diffusion models with Transformers. In ICCV.
[76] Loshchilov, Ilya and Hutter, Frank (2019). Decoupled weight decay regularization. In ICLR.
[77] Tero Karras et al. (2022). Elucidating the Design Space of Diffusion-Based Generative Models. In NIPS.
[78] Shazeer, Noam (2020). GLU variants improve Transformer. arXiv preprint arXiv:2002.05202.
[79] Zhang, Biao and Sennrich, Rico (2019). Root mean square layer normalization. In NeurIPS.
[80] Su et al. (2024). Roformer: Enhanced transformer with rotary position embedding. Neurocomputing. 568. pp. 127063.
[81] Henry et al. (2020). Query-Key Normalization for Transformers. In Findings of.