Qwen3.5-Omni Technical Report
Qwen Team
https://huggingface.co/spaces/Qwen/Qwen3.5-Omni-Online-Demo
https://modelscope.cn/studios/Qwen/Qwen3.5-Omni-Online-Demo
Abstract
In this work, we present Qwen3.5-Omni, the latest advancement in the Qwen-Omni model family. Representing a significant evolution over its predecessor, Qwen3.5-Omni scales to hundreds of billions of parameters and supports a 256k context length. By leveraging a massive dataset comprising heterogeneous text-vision pairs and over 100 million hours of audio-visual content, the model demonstrates robust omni-modality capabilities. Qwen3.5-Omni-Plus achieves SOTA results across 215 audio and audio-visual understanding, reasoning, and interaction subtasks and benchmarks, surpassing Gemini-3.1 Pro in key audio tasks and matching it in comprehensive audio-visual understanding. Architecturally, Qwen3.5-Omni employs a Hybrid Attention Mixture-of-Experts (MoE) framework for both Thinker and Talker, enabling efficient long-sequence inference. The model facilitates sophisticated interaction, supporting over 10 hours of audio understanding and 400 seconds of 720P video (at 1 FPS). To address the inherent instability and unnaturalness in streaming speech synthesis—often caused by encoding efficiency discrepancies between text and speech tokenizers—we introduce ARIA (Adaptive Rate Interleave Alignment). ARIA dynamically aligns text and speech units, significantly enhancing the stability and prosody of conversational speech with minimal latency impact. Furthermore, Qwen3.5-Omni expands linguistic boundaries, supporting multilingual understanding and speech generation across 10 languages with human-like emotional nuance. Beyond preset voices, the model enables zero-shot voice customization via user-provided samples. Finally, Qwen3.5-Omni exhibits superior audio-visual grounding capabilities, generating script-level structured captions with precise temporal synchronization and automated scene segmentation. Remarkably, we observed the emergence of a new capability in omnimodal models: directly performing coding based on audio-visual instructions, which we call Audio-Visual Vibe Coding. Qwen3.5-Omni is publicly accessible via API$^{1}$.
$^{1}$ https://www.alibabacloud.com/help/en/model-studio/qwen-omni
Executive Summary: The rapid evolution of artificial intelligence demands models that mimic human-like interaction with the world, integrating text, images, audio, and video seamlessly. Current AI systems often handle these modalities separately, limiting their ability to perceive, reason, and act in real-time like agents in everyday scenarios. This gap hinders practical applications such as voice assistants, multimedia analysis, and autonomous tools, making it urgent to develop unified "omnimodal" systems that process and generate across all senses without performance trade-offs.
This report introduces Qwen3.5-Omni, a large language model designed to unify understanding, reasoning, generation, and action across text, images, audio, and audio-visual inputs. It aims to demonstrate advancements over prior models by enabling efficient long-context handling, natural speech synthesis, and agentic behaviors like tool use and code generation from multimodal cues.
The team built Qwen3.5-Omni using a Thinker-Talker architecture, where the Thinker processes inputs and the Talker generates speech. They pretrained the model on diverse datasets, including over 100 million hours of audio-visual content, image-text pairs, and multilingual text covering 201 languages. Key upgrades include a hybrid mixture-of-experts design for efficient scaling to hundreds of billions of parameters, support for 256,000-token contexts (handling over 10 hours of audio or 400 seconds of video), and a new technique called ARIA to align text and speech for stable streaming output. Post-training involved three stages for the Thinker—specialist distillation, on-policy alignment, and interaction-focused reinforcement learning—and four stages for the Talker to enhance naturalness and multilingual generation in 36 languages and dialects. Evaluations spanned 215 benchmarks without relying on external tools for comparisons.
The model excels on key metrics. First, Qwen3.5-Omni-Plus achieves state-of-the-art results on audio understanding tasks, surpassing Gemini-3.1 Pro by 10-20% on benchmarks like MMAU and SongFormBench for sound effects, music, and dialogue. Second, it matches or exceeds Gemini in comprehensive audio-visual comprehension, scoring comparably on DailyOmni and outperforming by about 15% on real-world interaction tests like Qualcomm IVD. Third, speech generation shows low error rates—under 2% word error in zero-shot English and competitive across 29 languages—outperforming commercial systems like ElevenLabs in 22 languages for content accuracy and voice similarity. Fourth, text and vision performance remains on par with single-modality counterparts, with strengths in video tasks (e.g., 5-10% better on Video-MME). Fifth, an emergent ability allows direct code generation from audio-visual instructions, called Audio-Visual Vibe Coding. The Flash variant offers similar gains with lower resource needs.
These findings mean Qwen3.5-Omni can power more natural, efficient AI agents for real-time applications, reducing latency in conversations to under 200 milliseconds for first audio output and enabling features like voice cloning from samples or controllable captioning with timestamps. It avoids degrading core language skills, unlike some multimodal models, and expands to low-resource languages, cutting risks in global deployments. This outperforms expectations from predecessors, where speech instability or short contexts limited usability, potentially accelerating adoption in education, healthcare, and entertainment by enabling synchronized multimedia responses.
Leaders should prioritize integrating Qwen3.5-Omni via its public API for pilot projects in voice interfaces or multimedia search, focusing on high-impact areas like multilingual support to reach broader users. Trade-offs include choosing the Plus variant for top accuracy (higher compute) versus Flash for speed (slightly lower scores). Further steps could involve real-world testing in agentic workflows, such as combining with robotics, and scaling training data for niche domains like medical video analysis.
While benchmarks confirm high reliability on evaluated tasks, limitations include reliance on controlled datasets, potential gaps in ultra-rare dialects or noisy real-world audio, and assumptions about uniform frame rates in videos. Confidence is strong for core capabilities, backed by diverse tests, but caution is advised for unbenchmarked edge cases like extended multi-turn interactions beyond 10 hours.
1. Introduction
Section Summary: Human interaction with the world combines senses like sight, sound, and language while enabling actions through speech, writing, or tools, but current AI models often fall short in fully integrating these for real-time, agent-like behavior. Qwen3.5-Omni is a new all-in-one AI system from Qwen that understands and generates text, images, audio, and video, trained on vast amounts of data including over 100 million hours of audio-visual content, and it acts autonomously by searching the web, calling functions, producing speech, and handling live interactions. Building on prior versions, it features efficiency boosts, longer context handling, improved speech synthesis, and multilingual support, delivering advanced capabilities like detailed video captions, voice control, and code generation from visuals, while leading in performance on audio and video benchmarks without losing ground in text or image tasks.
Human interaction with the world is inherently omnimodal and agentic, involving the integration of visual, auditory, and linguistic information, and the production of responses through text, speech, and goal-directed tool-mediated actions, facilitating information exchange with other organisms and demonstrating intelligence. Building on the rapid advances in the understanding and reasoning capabilities of large models across text ([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]), vision ([12, 13, 14, 15, 16]), and audio ([17, 18]), natively omnimodal systems that jointly process and generate across all modalities have drawn substantial attention ([19, 20, 21, 22]). However, existing models predominantly operate within passive perception-response paradigms and exhibit limited capacity for scalable agentic behavior, real-time interaction, autonomous tool utilization, and cross-modal reasoning, which are essential prerequisites for practical deployment.
In this report, we present Qwen3.5-Omni, Qwen's latest generation of fully omnimodal LLM, supporting the understanding of text, images, audio, and audio-visual content. Natively pretrained in an omnimodal manner on massive amounts of text, visual data, and more than 100 million hours of audio-visual data, Qwen3.5-Omni is designed as a native omni agent model: it not only perceives and reasons across all modalities, but also acts, autonomously invoking WebSearch, executing complex FunctionCall, generating speech outputs, and engaging in real-time streaming interaction. The model series includes Plus and Flash variants, all of which are instruct models with 256k-token long-context input.
Qwen3.5-Omni builds on the Thinker–Talker architecture introduced in Qwen2.5-Omni ([21]) and introduces five key technical upgrades over Qwen3-Omni ([22]): (1) both the Thinker and Talker adopt Hybrid-Attention Mixture-of-Experts (MoE) designs, enabling highly efficient inference; (2) supporting long-context modeling up to 256k tokens, supporting more than 10 hours of audio and over 400 seconds of 720P audio-visual content at 1 FPS; (3) on the speech generation side, a multi-codebook codec representation enables single-frame, immediate synthesis; (4) the Talker introduces ARIA, a technique that dynamically aligns text and speech units during streaming decoding, significantly improving naturalness and robustness; and (5) multilingual training is substantially expanded, covering 113 languages and dialects for speech recognition and 36 for speech synthesis.
Enabled by these technical advances, Qwen3.5-Omni delivers three major new capabilities over Qwen3-Omni: (1) controllable audio-visual captioning, capable of generating controllable, detailed, and structured captions as well as screenplay-level fine-grained descriptions, including automatic segmentation, timestamp annotation, and detailed descriptions of characters and their relationship to audio; (2) comprehensive real-time interaction, encompassing semantic interruption through native turn-taking intent recognition, end-to-end voice control over volume, speed, and emotion, and voice cloning from user-provided samples; and (3) native omnimodal agentic behavior, including autonomous WebSearch, complex FunctionCall invocation, and Audio-Visual Vibe Coding, an emergent capability wherein the model directly generates executable code from audio-visual instructions, enabling the model to respond to real-time queries without external orchestration.
Critically, Qwen3.5-Omni maintains state-of-the-art performance on text and visual modalities without degradation relative to same-size single-model Qwen counterparts. Across 215 audio and audio-visual understanding, reasoning, and interaction subtasks and benchmarks, covering audio-visual benchmarks, audio benchmarks, ASR benchmarks, language-specific speech-to-text translation tasks, and language-specific ASR tasks, Qwen3.5-Omni-Plus achieves SOTA results, surpassing Gemini-3.1 Pro across general audio understanding, reasoning, recognition, translation, and dialogue, while its overall audio-visual understanding reaches the level of Gemini-3.1 Pro.
2. Architecture
Section Summary: Qwen3.5-Omni uses a Thinker-Talker architecture, where the Thinker processes text, audio, images, and videos into a unified format for understanding and generation, while the Talker creates streaming speech based on the Thinker's outputs to enable real-time conversations. Key upgrades include a hybrid mixture-of-experts design for better efficiency, interleaved handling of audio and video with added timestamps for improved timing in long inputs, and a new Audio Transformer encoder trained on vast multilingual data to capture speech details at a low rate of 6.25Hz. These features support up to 10 hours of audio or 400 seconds of video, with low-latency streaming that aligns text and speech more accurately to avoid errors like skipped words.
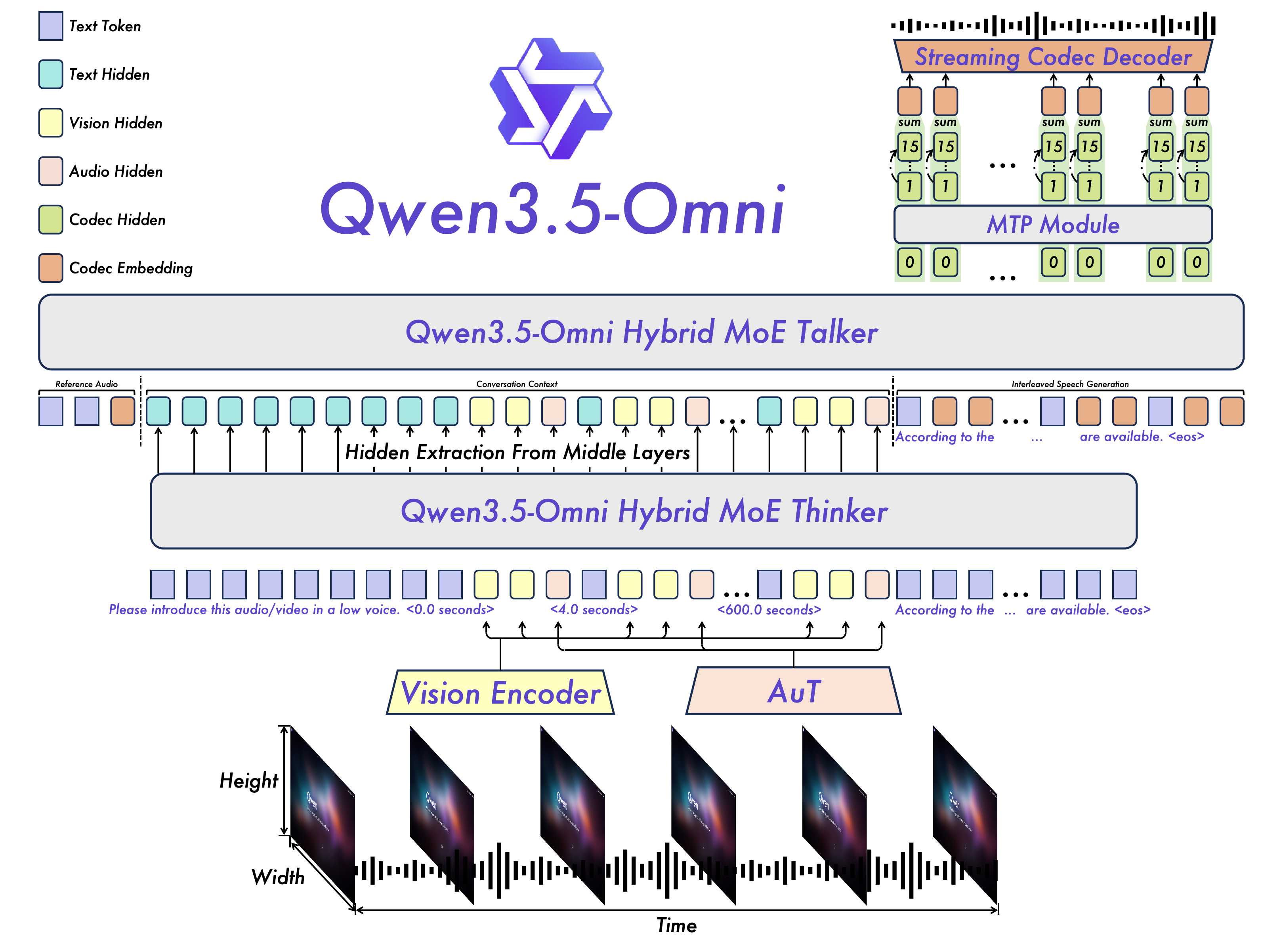
2.1 Overview
As shown in Figure 2, Qwen3.5-Omni continues to adopt the Thinker-Talker architecture ([21]). Compared with Qwen3-Omni ([22]), Qwen3.5-Omni introduces several key improvements in scalability, alignment, and real-time interaction:
- The overall backbone adopts a Hybrid Mixture-of-Experts (MoE) design, improving scalability while better balancing capacity and efficiency across multimodal understanding and generation.
- The Thinker receives visual and audio signals through the Vision Encoder and AuT, respectively. Audio and video inputs are interleaved for unified multimodal modeling, with explicit timestamps inserted to improve temporal perception, especially for long video or audio-video contexts. This design enables the Thinker to handle extended inputs, supporting up to 256k tokens, 10 hours of audio, or 400 seconds of 720P video at 1 FPS.
- The Talker is responsible for contextual speech generation by conditioning on multimodal inputs together with the textual outputs from the Thinker. Qwen3.5-Omni adopts the RVQ-based speech representation introduced in Qwen3-Omni ([22]), which substantially improves inference efficiency.
- To support real-time interaction, Qwen3.5-Omni adopts both chunk-wise streaming input processing in the Thinker and a streaming Talker design, enabling low-latency end-to-end multimodal conversation.
- Different from the dual-track Talker input design in Qwen3-Omni ([22]), the Talker in Qwen3.5-Omni adopts ARIA to dynamically align text and speech units before interleaving them. This design mitigates the instability caused by mismatched tokenization rates between text and speech, thereby reducing issues such as skipped words, incorrect pronunciations, and ambiguous rendering of numbers.
In the following sections, we first introduce with the AuT encoder, including its training methodology. Then, describe how Thinker processes various inputs. We then detail Talker’s multi-codebook streaming speech generation. Finally, we highlight a series of improvements on both the understanding and generation modules aimed at achieving ultra–low-latency, end-to-end streaming audio inference.
2.2 Audio Transformer (AuT)
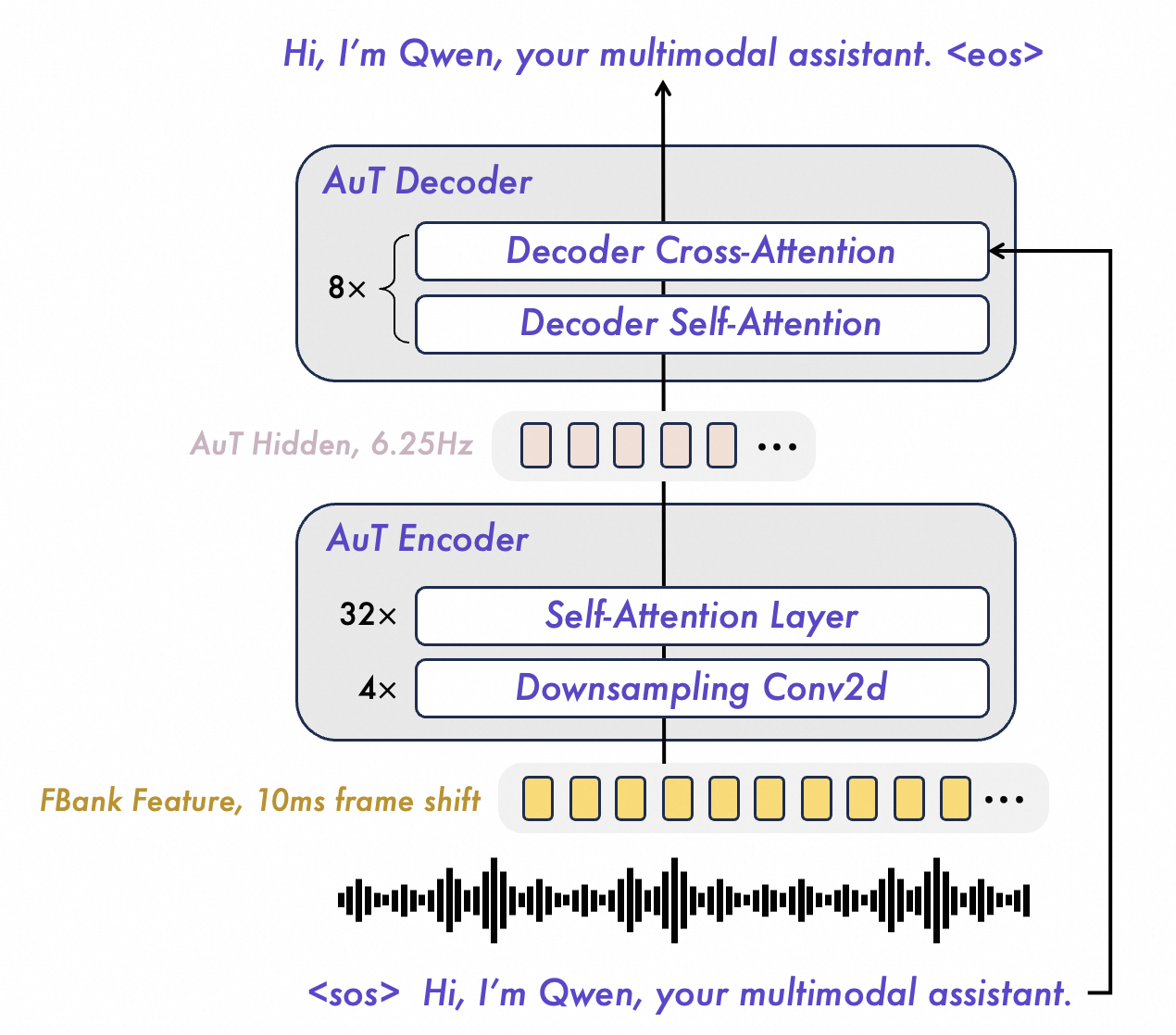
We use transformer based audio encoder trained from scratch in attention-encoder-decoder model AuT, as is shown in Figure 3. The training of Qwen3.5-Omni encoder consumed 40 million hours of audio-text pair data generated by Qwen3-ASR. The filter bank features of the audio are downsampled 16 times using 4 Conv2D blocks and then fed into self-attention layers to obtain audio tokens in 6.25Hz token rate. Comparing to the training process of Qwen3-Omni encoder, the encoder of Qwen3.5-Omni adapts more multilingual data of more than 20 languages, and the proportion of Chinese, English and multilingual data comes to 3.5 : 3.5 : 3. The dynamic attention window size training mechanism is adopted for guaranting balance performance of inference under real-time prefill caching and for the offline audio understanding tasks.
2.3 Perceivation
Text, Audio, Image and Video (w/o Audio).
The Thinker converts text, audio, image, and silent video inputs into a unified sequence of representations. For text, we use the Qwen3.5 tokenizer ([23]), which adopts byte-level byte-pair encoding with a vocabulary size of 250k (up from 150k), improving encoding and decoding efficiency by 10–60% across most languages. For audio inputs, including audio extracted from video, we resample the waveform to 16 kHz and convert it into a 128-channel mel-spectrogram using a 25 ms window and a 10 ms hop size. We use AuT as the audio encoder, trained from scratch on 40 million hours of audio data, where each output frame corresponds to approximately 160 ms of the original signal. For visual inputs, we adopt the vision encoder from Qwen3.5 ([23]) to process both images and videos. Trained on a mixture of image and video data, this encoder provides strong capabilities in both image understanding and video comprehension. To preserve video information as much as possible while maintaining alignment with the audio stream, we sample video frames at a dynamic frame rate.
Audio-visual Timestamp.
Following Qwen3-Omni ([22]), we apply TM-RoPE to endow the model with temporal awareness for audio-video synchronization. However, we find that directly encoding absolute time through temporal position IDs can lead to excessively sparse indices for visual patches from long video with audio inputs, which weakens long-range temporal modeling. In addition, such a design often requires large-scale and uniformly distributed training samples across different frame rates, increasing data construction cost. To address these issues, we prepend each video or audio-video temporal patch with an explicit timestamp represented as a formatted text string in seconds, allowing the model to learn timecode representations more naturally. For audio sequences, we further insert timestamps at random intervals to improve temporal alignment across modalities. Although this strategy slightly increases the context length, it enables more precise and robust temporal perception, especially when extrapolating long-context multimodal inputs.
In the context of multimodal audio-visual streams, the audio component is encoded with a temporal ID for every 160 ms. The video is treated as a sequence of frames with monotonically increasing temporal IDs that are dynamically adjusted based on their actual timestamps to ensure a consistent temporal resolution of 160 ms per ID. The height and width IDs for video frames are assigned in the same manner as for still images. To prevent positional conflicts when processing multiple modalities, the position numbering is made contiguous, with each subsequent modality commencing from one plus the maximum position ID of the preceding modality. This refined approach to positional encoding enables the model to effectively integrate and jointly model information from diverse modalities. Qwen3.5-Omni aligns these representations using their temporal IDs, which are explicitly anchored to absolute time. This design choice affords the model the flexibility to support streaming inputs of arbitrary duration.
2.4 Speech Generation
Talker operates directly on the RVQ tokens produced by Qwen3.5-Omni-Audio-Tokenizer. To model the residual codebooks, it employs a multi-token prediction (MTP) module, which enables fine-grained modeling and control of acoustic details. Coupled with a causal ConvNet for waveform reconstruction, Talker delivers high-fidelity speech synthesis with low inference latency and modest computational overhead.
In multi-turn spoken dialogue, Talker is conditioned on the rich contextual information provided by the Thinker component, including historical text tokens, multimodal representations, and the streamed text of the current turn. Such conditioning allows Talker to dynamically modulate acoustic attributes—such as prosody, loudness, and emotion—in accordance with the evolving conversational context.
Architecturally, our approach differs from Qwen3-Omni ([22]) in two key respects. First, we introduce a dedicated system prompt for Talker that specifies target voice characteristics, thereby enabling both zero-shot voice cloning and controllable speech generation. Compared with conventional speaker embeddings, this prompt can encode richer multimodal cues, including textual descriptions and codec sequences, providing substantially finer-grained control over acoustic realization. Second, we propose ARIA (Adaptive Rate Interleave Alignment), which unifies the conventional dual-channel generation paradigm into a single-channel formulation. Rather than relying on MFA-derived alignments or fixed interleaving rates, ARIA enforces an adaptive rate constraint: for any prefix of the generated sequence, the cumulative speech-to-text token ratio must not exceed the corresponding item-level global ratio. Despite its simplicity, this design affords flexible text-speech alignment across languages, including those with relatively low encoding efficiency, and naturally supports arbitrary text-token prefixes followed by coherent speech-token continuation.
2.5 Designs for Streaming and Concurrency
In streaming audio-visual interaction scenarios, the first-packet latency is a critical factor affecting user experience, and the model's concurrency capability is key to reducing service costs and improving response speed. This section discusses how Qwen3.5-Omni enhances concurrency and reduces first-packet latency through algorithmic and architectural optimizations. Table 1 provides an overview of the relevant architecture of the Qwen3.5-Omni and its associated latency.
::: {caption="Table 1: Architecture of Qwen3.5-Omni and end-to-end first-packet latency under audio/video settings (ms)."}
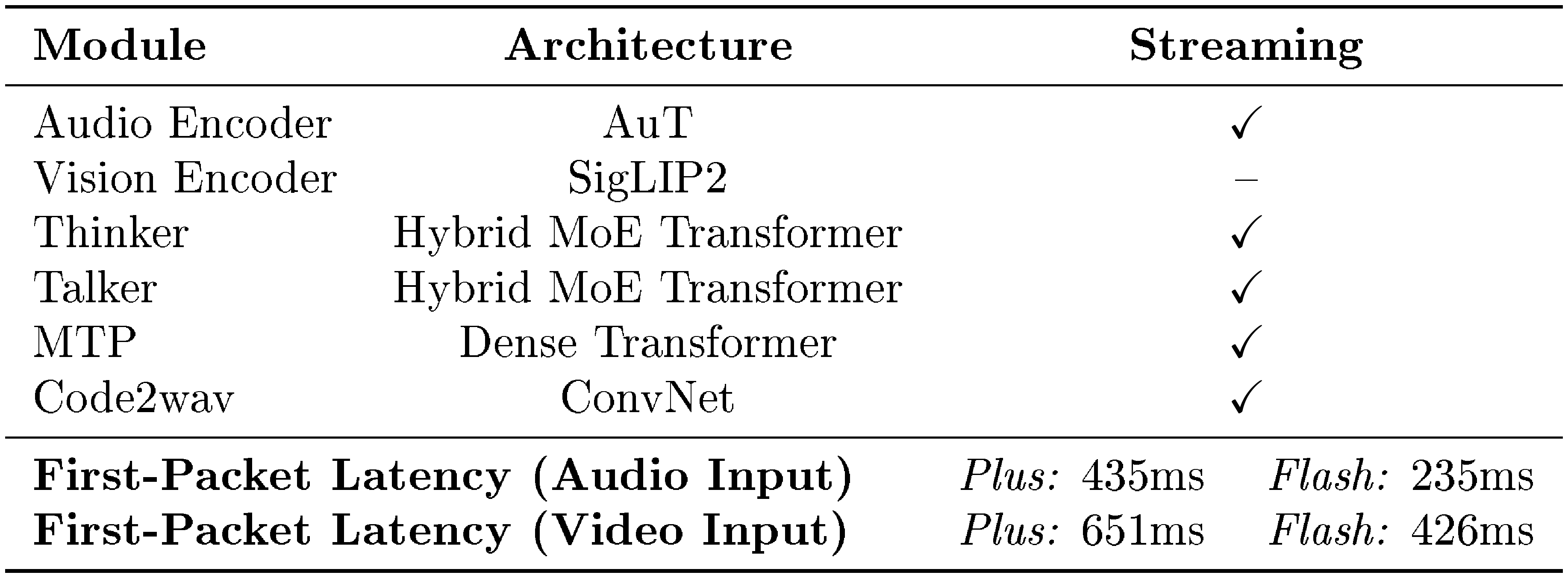
:::
Chunked Prefilling and Hybrid MoE Architecture.
In Qwen3.5-Omni, we retain the chunked-prefilling mechanism as implemented in Qwen3-Omni and Qwen2.5-Omni, whose audio and vision encoders are capable of outputting chunks along the temporal dimension. This approach significantly reduces the Time-To-First-Token (TTFT) for both the Thinker and the Talker. Architecturally, both the Thinker and the Talker in Qwen3.5-Omni are built upon the Hybrid MoE architecture introduced in Qwen3.5. Beyond the general efficiency advantage of Hybrid MoE, this architecture includes the Gated Delta Net (GDN) module, which is particularly effective for accelerating the modeling of long audio-video sequences. As a result, it significantly reduces KV-cache I/O overhead in long-context inference, improving generation throughput and enabling higher serving concurrency.
Streaming Generation with ARIA.
For streaming speech generation and high-concurrency serving, Qwen3.5-Omni largely inherits the efficient design of Qwen3-Omni: Talker predicts RVQ codec tokens with a lightweight MTP module, and the generated multi-codebook tokens are converted to waveform by a causal and streaming ConvNet codec decoder. These components remain computationally lightweight, batch-friendly, and well-suited for low-latency deployment. Built on this shared foundation, the previously introduced ARIA further reformulates the dual-channel generation pattern in Qwen3-Omni into a unified interleaved single-stream formulation over text and speech tokens. By organizing text and speech generation under a monotonic interleaving constraint, ARIA reduces the synchronization overhead between separate generation tracks, enables more efficient token scheduling during decoding, and better matches the naturally incremental regime of streaming interaction.
In Table 2, we report the theoretical first-packet latency of Qwen3.5-Omni under different concurrency levels for audio and video input, evaluated on internal vLLM with torch.compile and CUDA Graph acceleration enabled for the MTP module and codec decoder. Here, Thinker TTFT (Time-To-First-Token) denotes the time from receiving the input stream to the first text token generated by Thinker, while Talker TTFC (Time-To-First-Chunk) measures the time until Talker produces the first audio chunk. TPOP (Time-Per-Output-Token) represents the per-output-token latency during steady-state decoding, where Talker TPOP includes the combined latency of the Talker backbone and the MTP module. TPS (Tokens Per Second) denotes generation throughput. Since ARIA organizes text and speech generation in a unified interleaved stream, Overall Latency cannot be obtained by simply summing several row values, but instead reflects the end-to-end critical path to the first playable audio packet. We also note that, due to the substantial scale difference between Qwen3.5-Omni-Flash and Qwen3.5-Omni-Plus, the two variants adopt different deployment-time resource allocation and parallelization strategies; therefore, their latency and throughput numbers are not intended for strict horizontal comparison. As shown in the table, Qwen3.5-Omni maintains stable latency and decoding efficiency as concurrency increases, while the low Generation RTF provides sufficient margin for smooth streaming audio generation.
::: {caption="Table 2: Theoretical first-packet latency of Qwen3.5-Omni under different concurrency levels. A/V denotes audio/video input."}
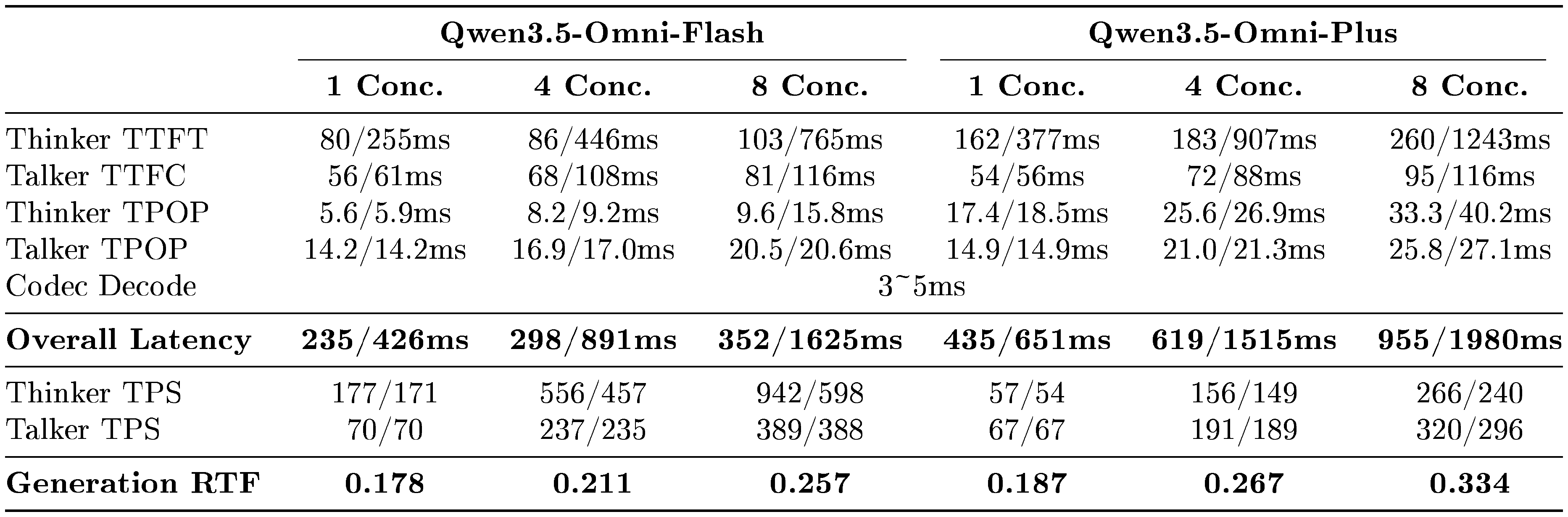
:::
3. Pretraining
Section Summary: Qwen3.5-Omni-Plus supports a wide array of languages and dialects across text, speech input, and speech output, as detailed in Table 3, and is pre-trained on a diverse mix of data including text, images, videos, and audio to handle multiple modalities effectively. The model uses natural language prompts to improve its ability to follow instructions and generalize across different inputs, while addressing previous limitations in time awareness by embedding timestamps in text form for better handling of audio and video sequences. Pre-training occurs in three stages: first locking the language model to train vision and audio components with paired data, then unfreezing everything for broader multimodal training at a medium sequence length, and finally extending to very long sequences for complex content.
: Table 3: Supported languages and dialects in Qwen3.5-Omni-Plus.
| Modality | # Varieties | Supported languages and dialects |
|---|---|---|
| Text | 201 | See Qwen3.5 for the complete list of supported languages. |
| Speech Input | 113 | 74 languages: Afrikaans, Arabic, Asturian, Azerbaijani, Basque, Belarusian, Bengali, Bosnian, Bulgarian, Cantonese, Catalan, Cebuano, Chinese, Croatian, Czech, Danish, Dutch, English, Esperanto, Estonian, Filipino, Finnish, French, Galician, Georgian, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Interlingua, Italian, Japanese, Javanese, Kannada, Kazakh, Korean, Kyrgyz, Lingala, Latvian, Lithuanian, Macedonian, Malay, Malayalam, Maltese, Maori, Marathi, Mongolian, Norwegian Bokmål, Norwegian Nynorsk, Oriya, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tajiki, Tamil, Telugu, Thai, Turkish, Ukrainian, Urdu, Uyghur, and Vietnamese. 39 Chinese dialects: Northeastern Mandarin, Guizhou dialect, Guangdong Cantonese, Henan dialect, Hong Kong Cantonese, Shanghainese, Shaanxi dialect, Tianjin dialect, Taiwanese Mandarin, Yunnan dialect, Anhui dialect, Fujian dialect, Gansu dialect, Guangdong Mandarin, Hubei dialect, Hunan dialect, Jiangxi dialect, Shandong dialect, Shanxi dialect, Sichuanese, Guangxi dialect, Hainan dialect, Chongqing dialect, Changsha dialect, Hangzhou dialect, Hefei dialect, Yinchuan dialect, Zhengzhou dialect, Shenyang dialect, Wenzhou dialect, Wuhan dialect, Kunming dialect, Taiyuan dialect, Nanchang dialect, Jinan dialect, Lanzhou dialect, Nanjing dialect, Hakka, and Southern Min. |
| Speech Output | 36 | 29 languages: Chinese, English, German, Italian, Portuguese, Spanish, Japanese, Korean, French, Russian, Thai, Indonesian, Arabic, Vietnamese, Turkish, Finnish, Polish, Hindi, Dutch, Czech, Urdu, Tagalog, Swedish, Danish, Hebrew, Icelandic, Malay, Norwegian, and Persian. 7 Chinese dialects: Sichuanese, Beijing dialect, Tianjin dialect, Nanjing dialect, Shaanxi dialect, Cantonese, and Southern Min. |
Qwen3.5-Omni is pre-trained on a diverse dataset that encompasses multiple languages and dialects as shown in Table 3 and modalities, including image-text, video-text, audio-text, video-audio, video-audio-text, and pure text corpora. Following Qwen3-Omni ([22]), we employ a wider range of natural language prompts to enhance both the generalization ability and instruction-following capabilities. To achieve robust performance across all modalities, our training strategy incorporates both unimodal and cross-modal data from the early pretraining stage.
In Qwen3-Omni ([22]), we employ TMRoPE to endow the model with temporal awareness. However, we identify two key limitations of this approach: (1) By directly tying temporal position IDs to absolute time, it produces excessively large and sparse temporal position IDs for long audio-video or video inputs, which undermines the model’s ability to capture long-range temporal contexts. (2) Effective learning under this scheme typically requires large-scale and uniformly distributed sampling across different frame rates (fps), significantly increasing the cost of training data construction. To address these issues, we prepend each video or audio-video temporal patch with a timestamp represented as a formatted text string in seconds, enabling the model to better learn and interpret timecode representations. In addition, for audio sequences, we insert timestamps at random intervals to better align training across different modalities. Although this approach introduces a modest increase in context length, it allows the model to perceive temporal information more effectively and precisely.
The pre-training of Qwen3.5-Omni is structured into three distinct stages. In the first stage, we lock the LLM parameters and focus on training the vision and audio encoders, utilizing a vast corpus of audio-text and image-text pairs to enhance semantic understanding within the LLM. In the second stage, we unfreeze all parameters and train with a wider range of multimodal data for more comprehensive learning with a sequence length of 32, 768. In the final stage, we use data with a sequence length of 262, 144 to enhance the model's ability to understand complex long-sequence data:

4. Post-training
Section Summary: The post-training phase for the Thinker component uses a three-stage process to maintain the AI model's abilities across text, visuals, audio, and mixed inputs while improving response quality, especially for audio queries. It starts with specialist distillation to combine knowledge from focused teacher models into one unified system, followed by on-policy distillation to make audio responses as strong and consistent as text-based ones, and ends with interaction-aligned reinforcement learning to fix issues like language switching or inconsistency in long conversations. For the Talker component, a four-stage pipeline trains the model to produce natural spoken replies alongside text, using a consistent format that supports voice cloning for seamless audio output.
4.1 Thinker
The post-training phase employs a three-stage strategy for the Thinker, designed to preserve the model's capabilities across all modalities without degradation, ensure high response quality under audio queries, and optimize the overall interaction experience. The training corpus, structured in the ChatML ([24]) format, encompasses pure text, visual, audio, and mixed-modality conversational data. Specifically, the process consists of the following stages:
- Stage 1: Specialist Distillation To establish a strong foundation for omnimodal capabilities, we first train a suite of domain-specialized teacher models via independent Supervised Fine-Tuning (SFT) and reinforcement learning (RL). All teacher models are fine-tuned from the pre-trained Qwen-3.5 base checkpoint. Beyond text-related tasks, including agentic, coding, and foundational reasoning tasks, we also train specialized teacher models for vision and audio. These teacher models are used to generate domain-specific data, enabling the specialized capabilities learned in each domain to be distilled into a single unified model.
- Stage 2: On-Policy Distillation Through the specialist distillation described above, the model already achieves strong performance in domains such as multimodal understanding and reasoning, as well as text-based dialogue, reasoning, coding, and agentic tasks. Nevertheless, a substantial gap remains between the quality of responses conditioned on audio queries and that of responses conditioned on text queries, particularly in speech dialogue. To reduce this gap, we introduce a second-stage training procedure based on on-policy distillation (OPD), with the goal of distilling the model’s stronger response capabilities under text inputs into the audio-input setting. Concretely, for each audio-text paired query, we first obtain a response generated under the text condition, which typically exhibits higher quality in terms of fluency, reasoning, and task completion. We then use this response as the distillation target for the corresponding audio-conditioned query. By training on such on-policy targets, the model gradually aligns its audio-conditioned outputs with its text-conditioned behavior, thereby improving response quality under audio inputs and promoting modality-consistent generation.
- Stage 3: Interaction-Aligned Reinforcement Learning Although the previous two stages substantially improve the model’s domain capabilities and cross-modal response quality, they are not sufficient to fully optimize the model for real-world interactive use. In multi-turn conversations, we observe several interaction-specific issues, including unintended language code-switching, persona inconsistency, and degraded instruction-following over extended contexts. To mitigate these issues, we introduce Interaction-Aligned RL, a third-stage reinforcement learning procedure aimed at optimizing the model for interaction quality. We construct multi-turn interaction trajectories and design reward signals around these user experience objectives, enabling the model to learn behaviors that are more stable, consistent, and aligned in prolonged interactions. By explicitly optimizing for interaction quality, this stage improves the model’s overall usability in practical conversational scenarios.
4.2 Talker
We employ a four-stage training pipeline for Talker, enabling Qwen3.5-Omni to generate natural and contextually appropriate spoken responses jointly with text. All training data is organized in the ChatML format to maintain consistency with Thinker and to facilitate voice cloning.

5. Evaluation
Section Summary: The evaluation section assesses two versions of the Qwen3.5-Omni AI models—Flash and Plus—focusing on their ability to understand different types of inputs like text, audio, images, and videos, and then produce text outputs. It tests skills in areas such as general knowledge, instruction following, speech recognition, visual question answering, and audio-visual comprehension, using a wide range of benchmarks to compare performance against other models like Qwen3.5-Plus-Instruct and Gemini-3.1 Pro. Overall, the Qwen3.5-Omni models show strong results, often matching or surpassing competitors in text processing, audio understanding, and multimodal tasks, while the section also covers speech generation capabilities.
A comprehensive evaluation was performed on two variants of models, including Qwen3.5-Omni-Flash and Qwen3.5-Omni-Plus. The evaluation results are divided into two main categories: understanding (X $\to$ Text) and speech generation (X $\to$ Speech).
5.1 Evaluation of X $\to$ Text
In this section, we evaluate Qwen3.5-Omni's ability to comprehend various multimodal inputs (text, audio, vision, and audio-visual video) and generate textual responses.
Text $\to$ Text
Our evaluation of Qwen3.5-Omni on text $\to$ text primarily focuses on general knowledge tasks, instruction following, long context tasks, STEM tasks, reasoning tasks and general agent ability. Specifically, we utilize MMLU-Pro ([27]), MMLU-Redux ([28]), SuperGPQA ([29]) and C-Eval ([30]) for general knowledge tasks, IFEval ([31]) and IFBench ([32]) for instruction following, AA-LCR ([33]) and LongBench v2 ([34]) for long context tasks, GPQA ([35]) for STEM tasks, LiveCodeBench v6 ([36]), HMMT Nov 25 ([37]) and IMOAnswerBench ([38]) for reasoning tasks, BFCL-V4 ([39]) and TAU2Bench ([40]) for general agent ability.
Audio $\to$ Text
To evaluate audio-to-text capabilities, we employ benchmarks across four domains: audio understanding, end-to-end speech dialogue, speech-to-text translation (S2TT), and automatic speech recognition (ASR). For audio understanding, we utilize MMAU ([41]), MMAR ([42]), MMSU ([43]), RUL-MuchoMusic ([44]), and SongFormBench ([45]) to assess comprehension of sound effects, speech, and music. Dialogue performance is evaluated via VoiceBench ([46]), URO-Bench-pro ([47]), SpeechRole ([48]), and WildSpeech-Bench ([49]). For S2TT, we focus on the translation of the top 59 languages in Fleurs ([50]) into English and Chinese. Finally, ASR performance is measured using Fleurs ([50]), Common Voice ([51]), LibriSpeech ([52]), WenetSpeech ([53]), KeSpeech ([54]), Opencpop-test ([55]), and MIR-1K (vocal) ([56]), covering multilingual speech, Chinese dialects, and singing voice transcription.
Vision $\to$ Text
The evaluation of the model's vision-to-text capabilities encompasses a suite of benchmarks targeting diverse and challenging tasks. To assess performance in specialized domain of mathematical and STEM reasoning, we utilize MMMU ([57]), MMMU-Pro ([58]), MathVista ([59]), MathVision ([60]), DynaMath ([61]), ZEROBench ([62]). For the general visual question answering, the model is evaluated on RealWorldQA ([63]), MMStar ([64]), HallusionBench ([65]), and SimpleVQA ([66]). The model's proficiency in document understanding is measured using the CharXiv ([67]), CC-OCR ([68]), AI2D ([69]), MMLongBench-Doc ([70]), and OCRBench ([71]). Furthermore, the model's spatial intelligence is specifically tested on ERQA ([72]), CountBench ([73]), RefCOCO ([74]), ODInW13 ([75]), and EmbSpatialBench ([76]). To evaluate performance on dynamic visual data, we report results on six video understanding benchmarks: Video-MME ([77]), MLVU ([78]), MVBench ([79]), LVBench ([80]), MMVU ([81]) and MME-VideoOCR ([82]). Specifically, we evaluate the model’s performance on medical VQA across three established benchmarks: SLAKE ([83]), PMC-VQA ([84]), and MedXpertQA-MM ([85]). This assessment is designed to demonstrate the model’s comprehensive clinical reasoning capabilities and its potential utility as a reliable healthcare AI assistant.
Audio-Visual Video $\to$ Text
We evaluate our model's audio-visual understanding capabilities from multiple perspectives. For text-query evaluation, we use DailyOmni ([86]), WorldSense ([87]), AVUT ([88]), AV-SpeakerBench ([89]), and VideoMME ([90]). To assess the model's ability in real-world audio-visual interactive scenarios, we use Qualcomm IVD ([91]) as the benchmark for audio-query-based evaluation. Beyond understanding, we also evaluate the model's captioning capability on OmniCloze ([92]) and its tool-use ability on OmniGAIA ([93]).
5.1.1 Performance of Text $\to$ Text
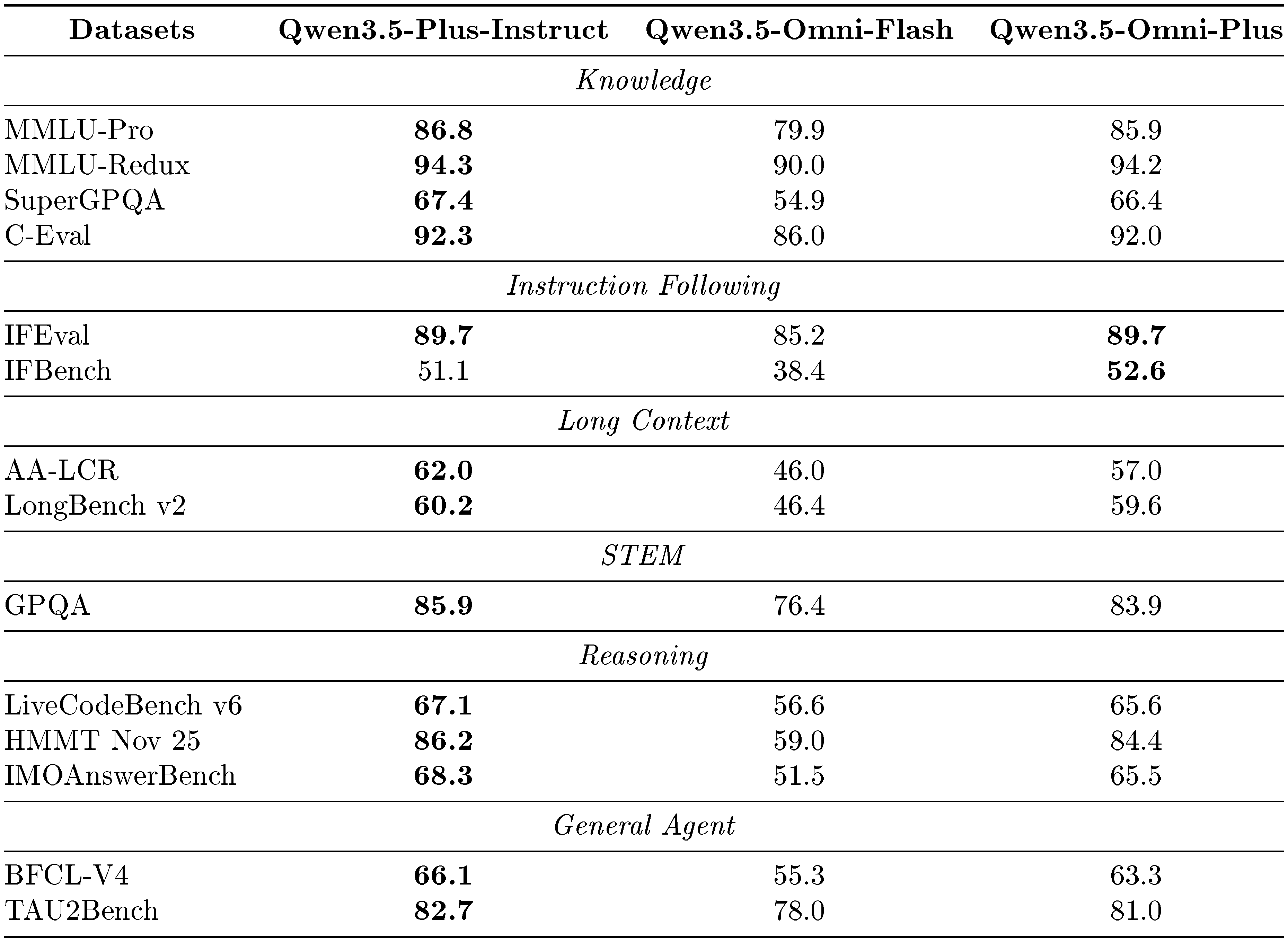
We compare Qwen3.5-Omni-Plus and Qwen3.5-Omni-Flash with Qwen3.5-Plus-Instruct. As shown in Table 4, Qwen3.5-Omni-Plus demonstrates text capabilities that are on par with its text-only counterpart across multiple dimensions, including knowledge, instruction following, long-context understanding, STEM, reasoning, and general agent tasks, highlighting its strong language ability. In particular, Qwen3.5-Omni’s instruction-following performance is slightly better than the baseline. We believe that OPD and interaction-aligned RL have a positive effect on improving the instruction-following capabilities of an omni-model LLM.
::: {caption="Table 4: Text $\to$ Text performance of Qwen3.5-Omni and Qwen3.5-Plus-Instruct. The highest scores are shown in bold."}
:::
5.1.2 Performance of Audio $\to$ Text
::: {caption="Table 5: Audio benchmark comparison across Gemini-3.1 Pro, Qwen3.5-Omni-Flash, and Qwen3.5-Omni-Plus. For most benchmarks, higher is better. For ASR benchmarks, lower WER is better. Best results are shown in bold."}
:::
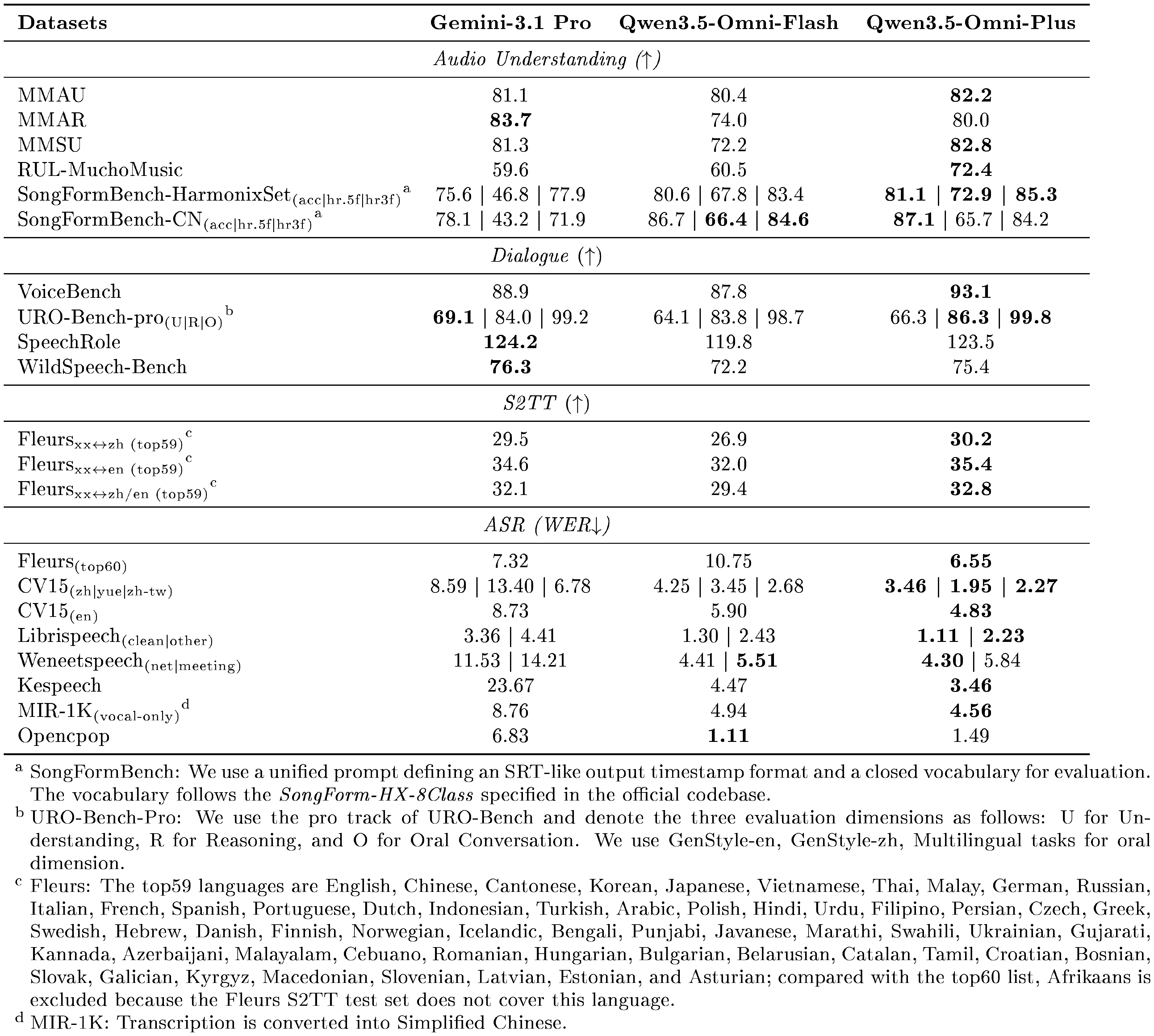
In Table 5, we compare Qwen3.5-Omni with Gemini-3.1 Pro in terms of audio-to-text performance. Compared to Gemini-3.1 Pro, Qwen3.5-Omni exhibits superior performance on MMAU, MMSU, RUL-MuchoMusic, and SongFormBench, while achieving comparable results on MMAR, demonstrating its strong comprehension capabilities across multiple audio domains. Regarding end-to-end speech dialogue, Qwen3.5-Omni significantly outperforms Gemini-3.1 Pro on VoiceBench and matches its performance on other benchmarks, further validating Qwen3.5-Omni’s robust capabilities in end-to-end voice interaction. For S2TT and ASR, Qwen3.5-Omni consistently outperforms Gemini-3.1 Pro, underscoring its superior translation and speech recognition performance across diverse languages, dialects, and domains.
5.1.3 Performance of Vision $\to$ Text
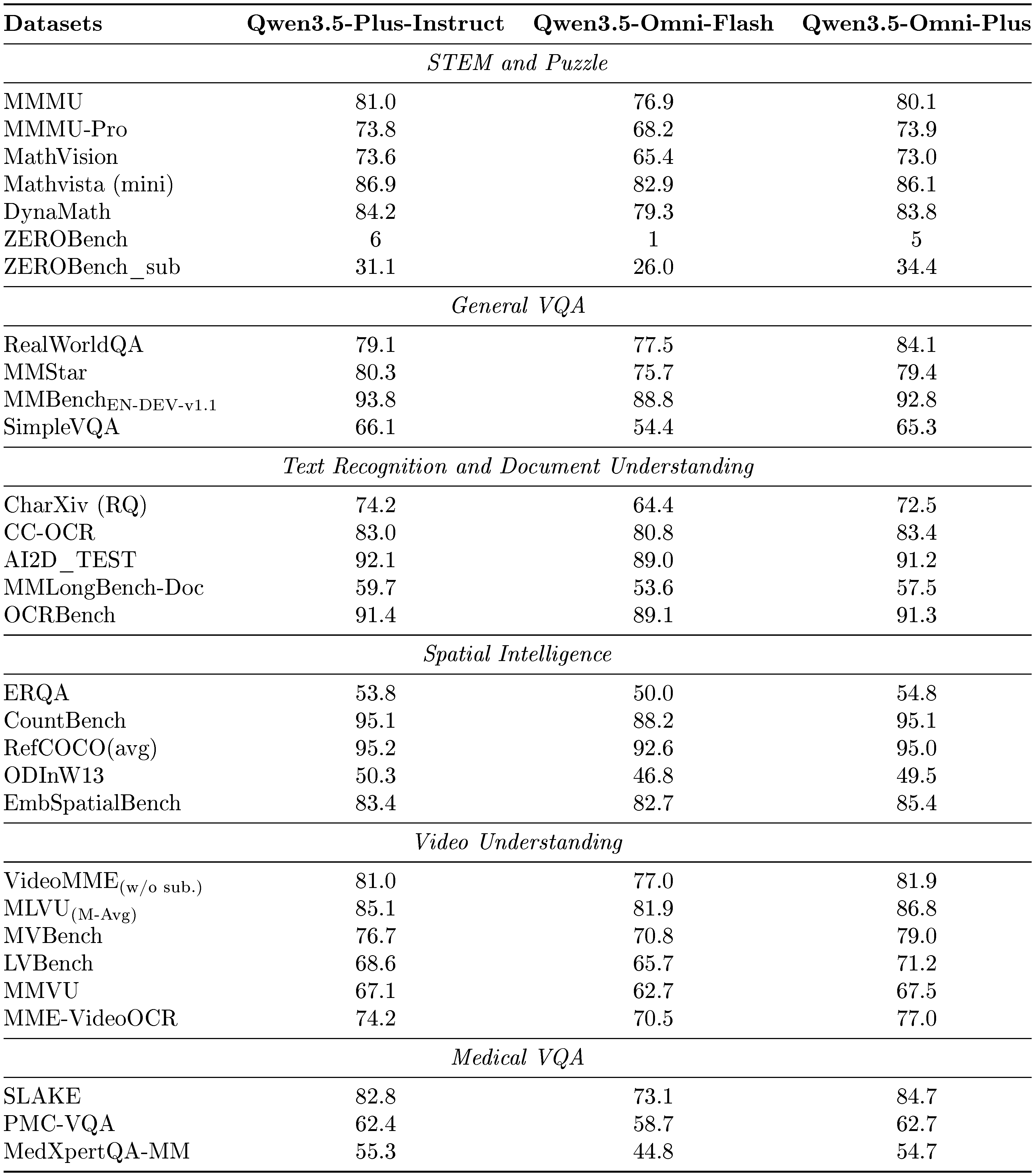
To comprehensively evaluate vision-to-text capabilities, we compare Qwen3.5-Omni-Flash and Qwen3.5-Omni-Plus with Qwen3.5-Plus-Instruct. As shown in Table 6, Qwen3.5-Omni-Plus achieves performance comparable to that of Qwen3.5-Plus-Instruct, while demonstrating stronger results on video understanding tasks involving both short and long videos. These findings highlight the strong dynamic visual perception ability of our model in real-world scenarios and suggest the effectiveness of joint video-audio training paradigms. Furthermore, we posit that audio-visual streams constitute the most naturalistic representation of real-world phenomena, wherein visual and auditory modalities are intrinsically coupled rather than independently processed.
::: {caption="Table 6: Vision $\to$ Text performance of Qwen3.5-Omni and Qwen3.5-Plus-Instruct. The highest scores are shown in bold."}
:::
5.1.4 Performance of Audio-Visual Video $\to$ Text
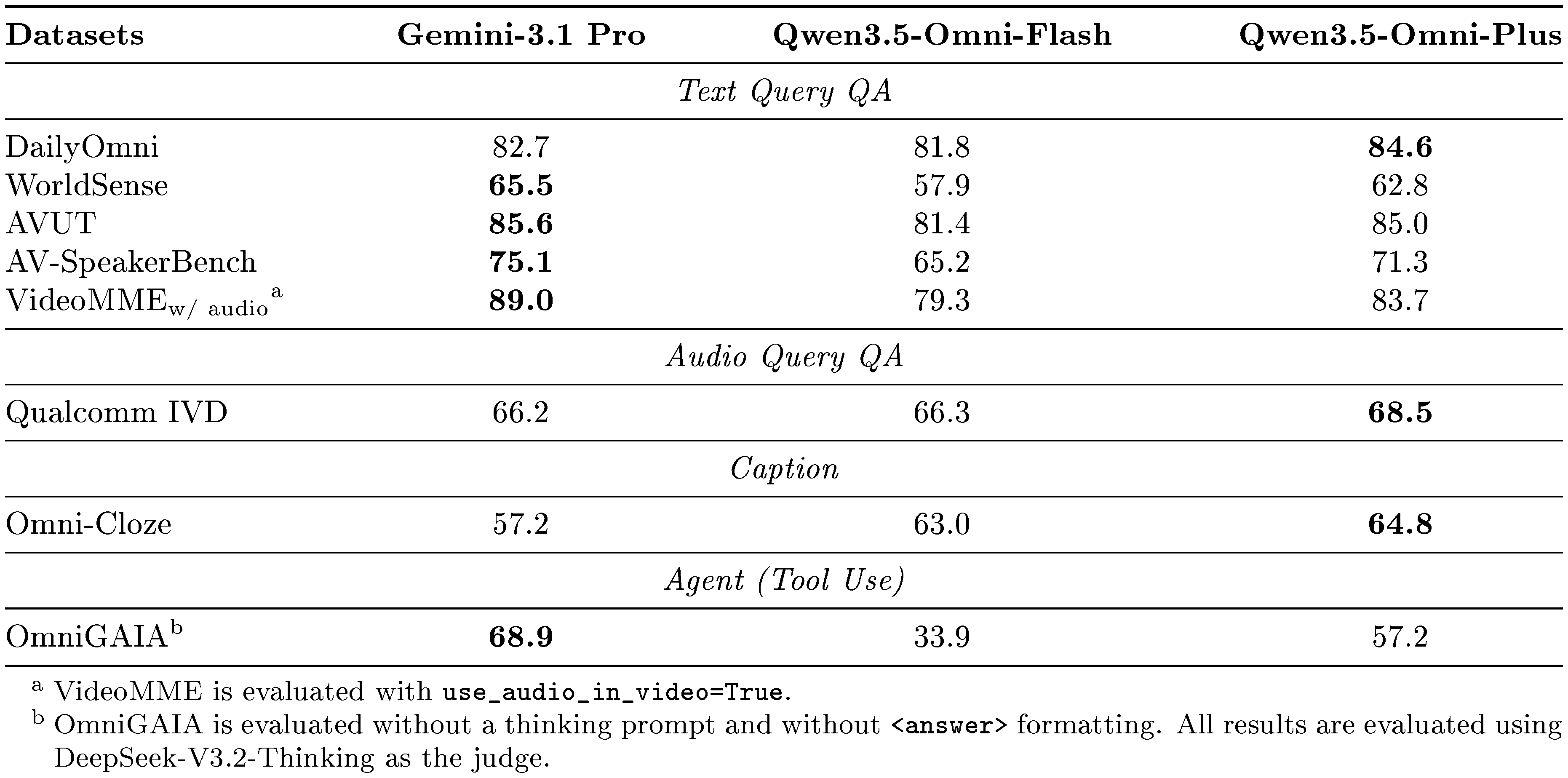
We compare Qwen3.5-Omni and Gemini-3.1 Pro across a diverse range of audio-visual tasks, as shown in Table 7. For general understanding, Qwen3.5-Omni achieves state-of-the-art performance on DailyOmni and obtains comparable results on AVUT. Our model also surpasses Gemini-3.1-Pro by a substantial margin on Qualcomm IVD, demonstrating its effectiveness in real-world audio-visual interactive scenarios. Moreover, our model shows strong performance on captioning tasks. It can provide detailed audio, visual, and audio-visual captions. In this version, we also enhance the model's tool-use capability, achieving 57.2% on OmniGAIA.
::: {caption="Table 7: Audio-Visual $\to$ Text performance of Qwen3.5-Omni and Gemini-3.1-Pro. The highest scores are shown in bold."}
:::
5.2 Evaluation of X $\to$ Speech
In this section, we evaluate the speech generation capability of Qwen3.5-Omni. Our evaluation mainly focuses on speech generation conditioned on text and prompt speech, following a zero-shot text-to-speech (TTS) setting. We study the model from four perspectives:
- Zero-Shot Speech Generation: We evaluate content consistency, measured by WER, on SEED ([94]).
- Multilingual Speech Generation: We evaluate both content consistency and speaker similarity in zero-shot multilingual speech generation on the TTS multilingual test set ([95]) and an internal multilingual test set built on FLEURS ([50]).
- Cross-Lingual Speech Generation: We evaluate content consistency in zero-shot cross-lingual speech generation on CV3-Eval ([96]).
- Custom-Voice Speech Generation: We evaluate the stability of our speaker fine-tuned model on the TTS multilingual test set ([95]) and our internal multilingual test set.
5.2.1 Evaluation of Zero-Shot Speech Generation
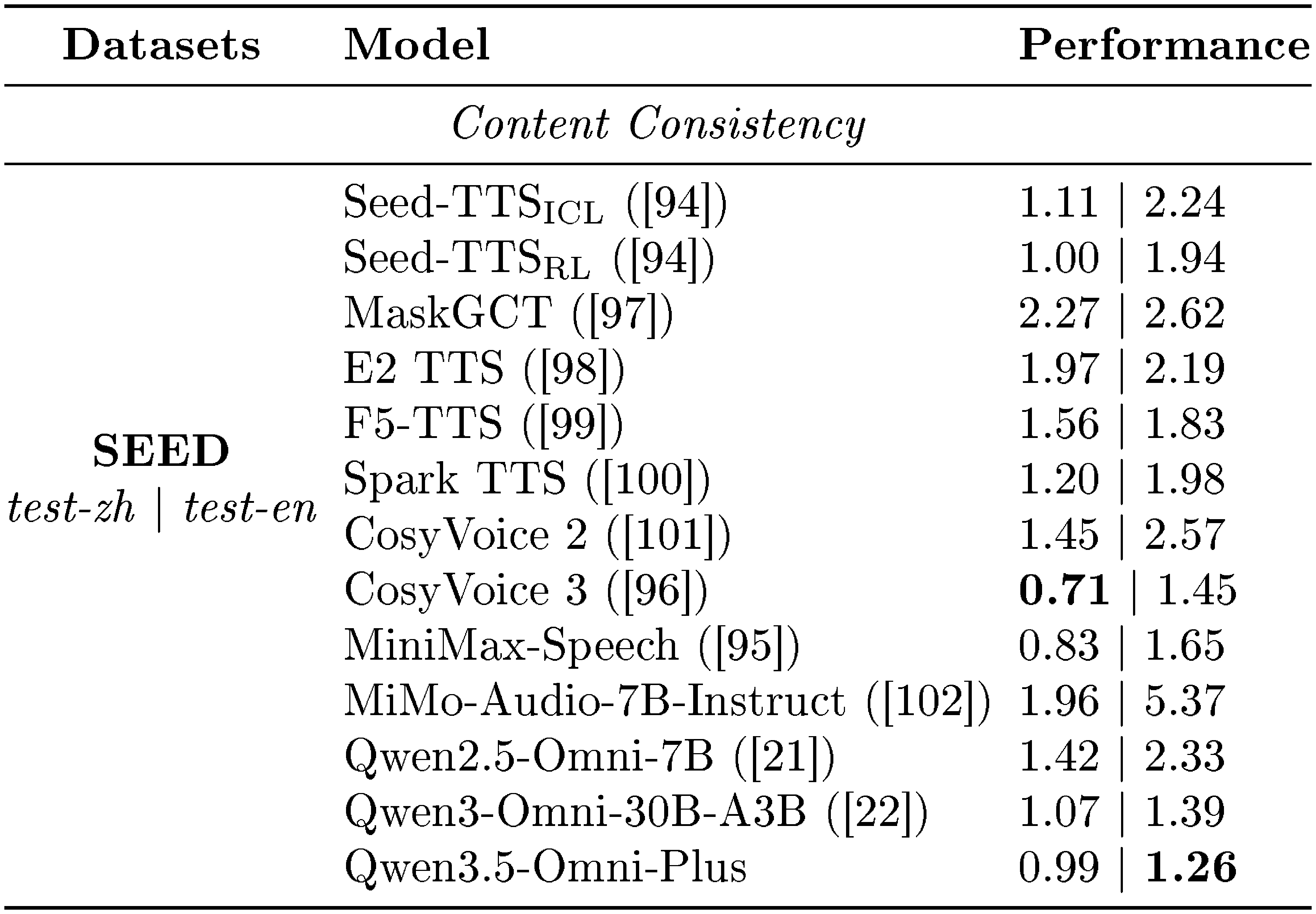
We compare Qwen3.5-Omni with state-of-the-art zero-shot TTS systems. As shown in Table 8, Qwen3.5-Omni achieves highly competitive performance on the SEED-TTS benchmark, demonstrating strong content fidelity in zero-shot speech generation. These results reflect the effectiveness of our pretraining and continual pretraining pipeline in building robust speech generation and context modeling capabilities. Moreover, after RLHF optimization, Qwen3.5-Omni further improves generation stability and naturalness, achieving the best performance on the test-en split with a WER of 1.26.
::: {caption="Table 8: Zero-shot speech generation on the SEED-TTS test set. Performance is measured by Word Error Rate (WER, $\downarrow$), where lower is better. The best results are highlighted in bold."}
:::
5.2.2 Evaluation of Multilingual Speech Generation
Qwen3.5-Omni supports speech generation in 29 languages. We compare its multilingual speech generation performance with two strong commercial systems, MiniMax-Speech and ElevenLabs. For the internal multilingual test set, we use GPT-4o-transcribe-2025-03-20 for automatic speech recognition.
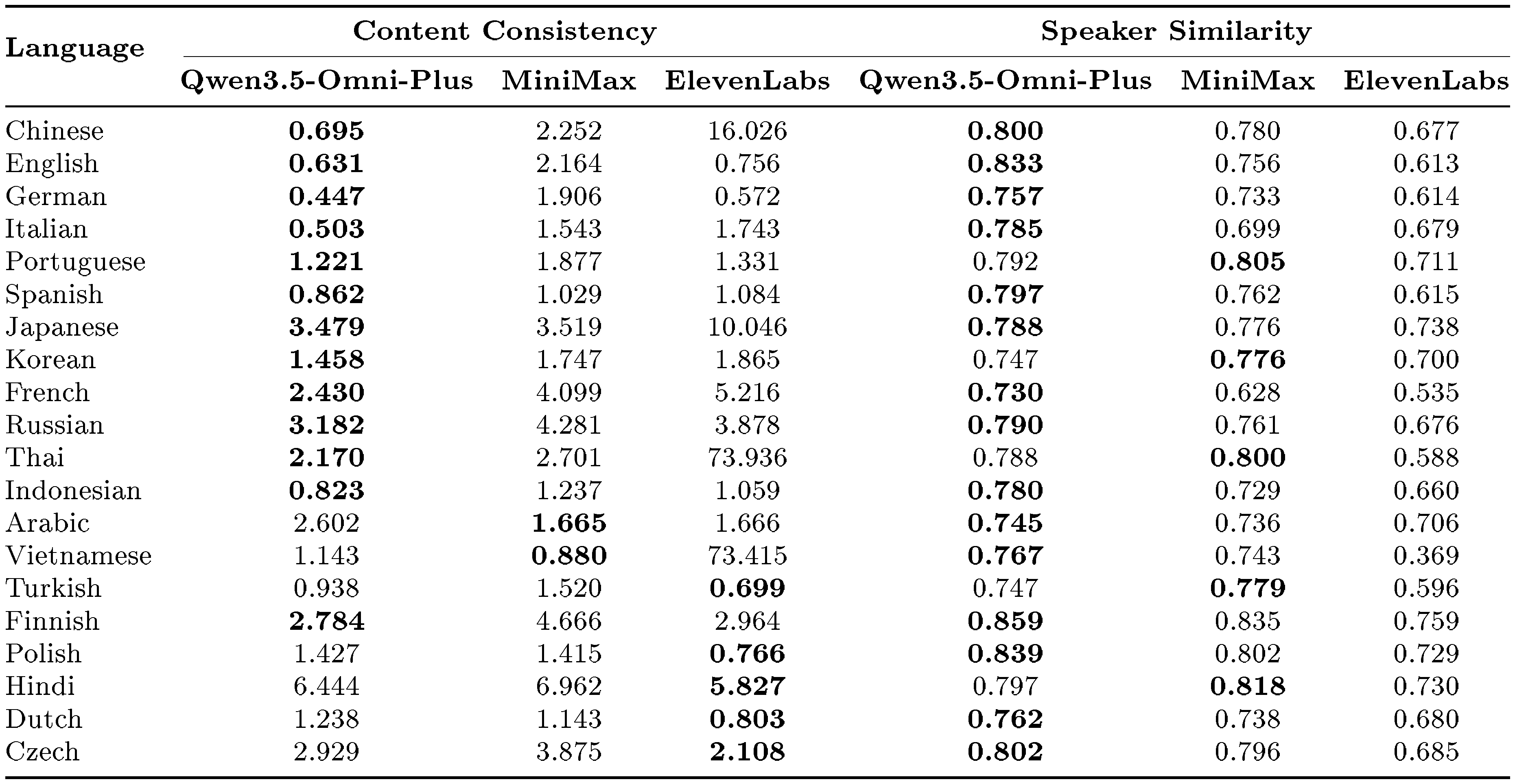
As shown in Table 9 and Table 10, Qwen3.5-Omni achieves the lowest WER in 22 out of 29 evaluated languages on the multilingual test sets, outperforming the comparison systems by a clear margin in most cases. On the remaining languages, Qwen3.5-Omni remains competitive with state-of-the-art systems. In addition to content consistency, Qwen3.5-Omni also shows strong voice cloning fidelity. It obtains the highest speaker similarity scores in the majority of evaluated languages and consistently outperforms both MiniMax-Speech and ElevenLabs overall. These results suggest that Qwen3.5-Omni effectively preserves speaker characteristics, such as timbre and prosodic style, while maintaining robust multilingual speech generation quality.
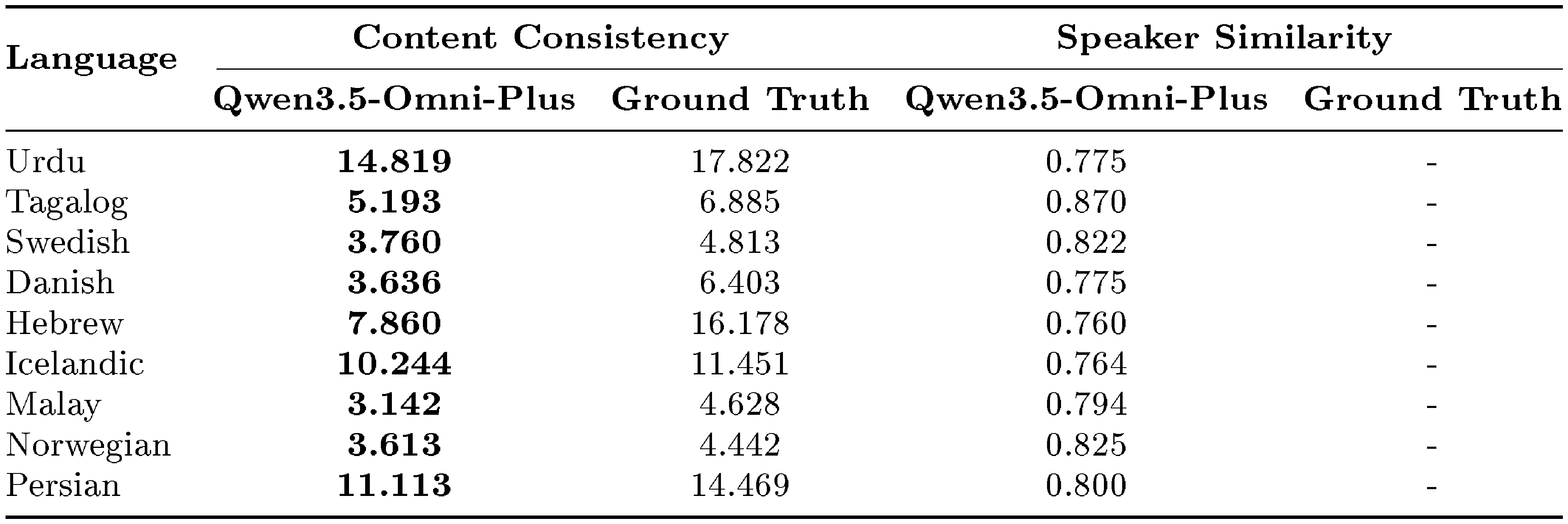
Furthermore, in Table 10, we report results on our internal multilingual test set, covering an additional 9 languages. Qwen3.5-Omni continues to achieve strong performance across all evaluated languages, indicating that its multilingual speech generation ability generalizes well beyond the public benchmark languages.
::: {caption="Table 9: Multilingual speech generation on the TTS multilingual test set. Performance is measured by Word Error Rate (WER, $\downarrow$) for content consistency and cosine similarity (SIM, $\uparrow$) for speaker similarity. The best results are highlighted in bold."}
:::
::: {caption="Table 10: Multilingual speech generation on the internal multilingual test set. Performance is measured by Word Error Rate (WER, $\downarrow$) for content consistency and cosine similarity (SIM, $\uparrow$) for speaker similarity. The best results are highlighted in bold."}
:::
5.2.3 Evaluation of Cross-Lingual Speech Generation
Beyond multilingual voice cloning, Qwen3.5-Omni also supports cross-lingual voice cloning, where the model is required to preserve speaker identity while generating speech in a different target language. We evaluate this capability on the Cross-Lingual benchmark and compare against the CosyVoice series as well as Qwen3-Omni-30B-A3B.
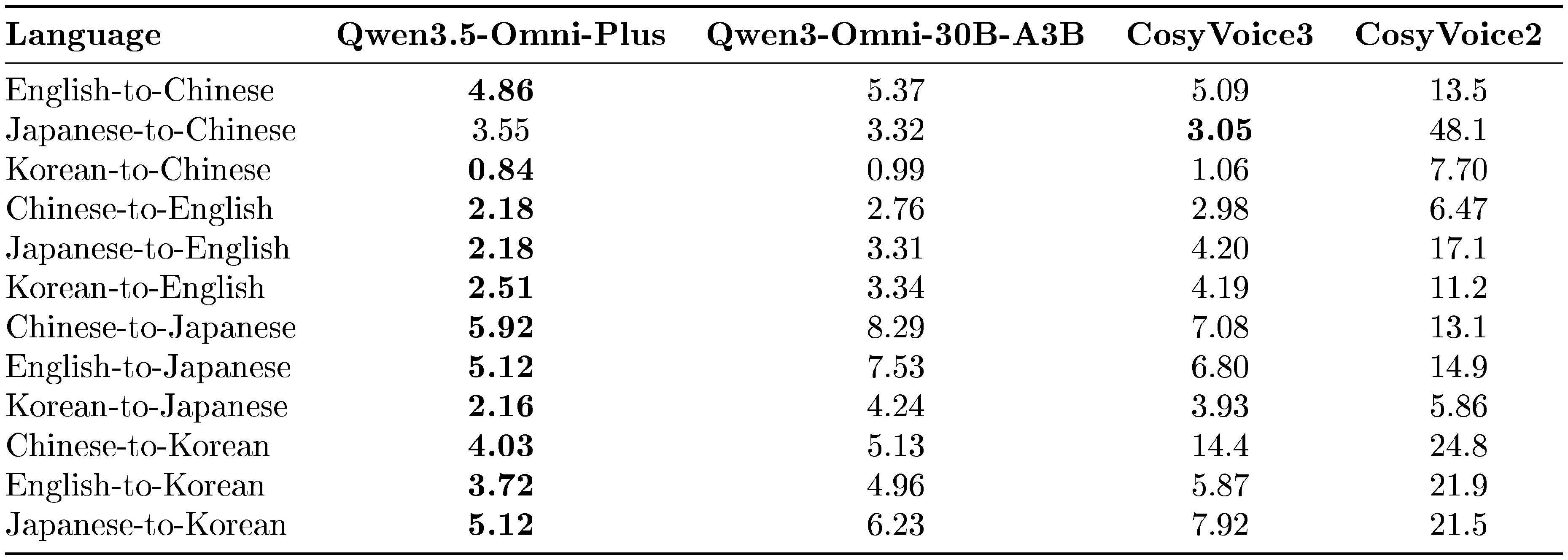
In Table 11, we report the mixed error rate (WER for English and CER for the other languages) across different source–target language pairs. Overall, Qwen3.5-Omni achieves the best performance in 10 out of 12 evaluated directions and sets a new state of the art on most English-, Japanese-, and Korean-targeted pairs. In particular, for zh-to-ko, Qwen3.5-Omni reduces the error rate from 14.4 to 4.03 compared with CosyVoice3, corresponding to an approximately 72% relative reduction. Qwen3.5-Omni also performs strongly on commonly used language pairs such as zh-to-en and en-to-zh, indicating better content consistency under cross-lingual generation. These results demonstrate that Qwen3.5-Omni generalizes effectively across language boundaries while preserving target linguistic accuracy.
::: {caption="Table 11: Cross-lingual speech generation on the Cross-Lingual benchmark. Performance is measured by mixed error rate (WER for English and CER for the other languages, $\downarrow$). The best results are highlighted in bold."}
:::
5.2.4 Evaluation of Custom-Voice Speech Generation
We evaluate the custom-voice speech generation capability of Qwen3.5-Omni in multilingual settings. We compare Qwen3.5-Omni with several strong commercial systems accessed through their official APIs in March 2026, including ElevenLabs Multilingual v2 (9YHcvj6GT2YYXdXww), Gemini-2.5 Pro-Preview-TTS (Achernar), GPT-Audio-2025-08-28 (Alloy), and MiniMax-Speech-2.8-HD (English_expressive_narrator).
: Table 12: Custom-voice multilingual speech generation on the multilingual test set. Performance is measured by Word Error Rate (WER, $\downarrow$). The best results are highlighted in bold.
| Language | Qwen3.5-Omni-Plus | ElevenLabs | Gemini-2.5 Pro | GPT-Audio | MiniMax |
|---|---|---|---|---|---|
| Chinese | 0.785 | 3.801 | 1.890 | 0.829 | 0.786 |
| English | 0.839 | 1.126 | 0.953 | 1.050 | 1.429 |
| German | 0.182 | 0.500 | 0.509 | 0.558 | 1.581 |
| Italian | 0.458 | 0.513 | 0.991 | 0.769 | 1.063 |
| Portuguese | 1.581 | 1.109 | 2.050 | 1.506 | 1.240 |
| Spanish | 0.768 | 0.520 | 0.891 | 0.936 | 0.691 |
| Japanese | 3.306 | 11.685 | 4.420 | 4.317 | 4.254 |
| Korean | 1.309 | 3.981 | 4.110 | 3.999 | 3.635 |
| French | 2.724 | 2.574 | 3.284 | 2.809 | 3.439 |
| Russian | 4.723 | 4.324 | 3.858 | 4.346 | 3.529 |
| Thai | 1.653 | 114.813 | 2.539 | 4.430 | 1.811 |
| Indonesian | 1.596 | 6.094 | 1.498 | 2.362 | 1.585 |
| Arabic | 3.183 | 5.400 | 5.525 | 5.326 | 3.309 |
| Vietnamese | 1.320 | 82.849 | 1.699 | 1.854 | 1.058 |
| Turkish | 1.309 | 0.551 | 2.237 | 1.389 | 0.652 |
| Finnish | 4.039 | 2.522 | 5.331 | 3.270 | 2.939 |
| Polish | 1.462 | 0.733 | 1.622 | 1.737 | 0.833 |
| Hindi | 6.776 | 6.388 | 6.596 | 7.191 | 6.146 |
| Dutch | 1.135 | 1.005 | 0.973 | 1.561 | 1.406 |
| Czech | 3.769 | 1.916 | 3.380 | 2.859 | 1.766 |
| Urdu | 14.916 | 12.970 | 14.141 | 13.362 | 24.151 |
| Tagalog | 5.090 | 5.473 | 6.784 | 5.352 | 5.674 |
| Swedish | 3.588 | 3.132 | 3.196 | 2.898 | 2.833 |
| Danish | 7.183 | 2.604 | 3.876 | 3.846 | 4.951 |
| Hebrew | 7.680 | 102.018 | 4.459 | 5.328 | 8.161 |
| Icelandic | 10.322 | 25.110 | 6.348 | 9.648 | 33.431 |
| Malay | 3.738 | 6.448 | 3.731 | 3.406 | 3.955 |
| Norwegian | 5.576 | 7.351 | 4.304 | 3.400 | 9.492 |
| Persian | 12.140 | 20.564 | 12.620 | 13.202 | 12.722 |
As shown in Table 12, although Qwen3.5-Omni is fine-tuned only on monolingual data, it demonstrates strong cross-lingual generalization in custom-voice speech generation. The model is able to transfer the target speaker characteristics to all 29 evaluated languages while maintaining stable generation quality. Overall, Qwen3.5-Omni achieves the best WER in 10 languages and remains competitive in many others. In particular, it shows clear advantages in several challenging languages, including Japanese (3.306) and Korean (1.309), indicating strong intelligibility under cross-lingual voice transfer. These results suggest that Qwen3.5-Omni can generate custom-voice speech with robust linguistic fidelity across a wide range of languages.
6. Conclusion
Section Summary: This paper introduces Qwen3.5-Omni, a versatile AI model that processes and responds to text, images, audio, and video all in one system, using a smart framework to handle understanding, thinking, creating, and acting across these formats. It features efficient designs for long conversations, better real-time speech generation, and support for many languages, enabling things like describing videos on demand, live interactions, and AI agents that use tools or generate code from sight and sound. The model performs at the top level on audio and video tests while keeping strong skills in text and images, showing that training AI on multiple inputs can lead to systems that sense, reason, and act seamlessly in real time, paving the way for more advanced all-purpose AI agents.
In this work, we present Qwen3.5-Omni, a fully omnimodal large language model that unifies understanding, reasoning, generation, and action across text, images, audio, and audio-visual inputs. Built on the Thinker–Talker framework, Qwen3.5-Omni introduces efficient Hybrid-Attention MoE architectures, 256k long-context modeling, improved streaming speech generation with multi-codebook codec prediction and ARIA, and substantially expanded multilingual speech support. These advances enable three key capabilities: controllable audio-visual captioning, comprehensive real-time interaction, and native omnimodal agentic behavior through autonomous tool use and audio-visual code generation. Empirically, Qwen3.5-Omni achieves state-of-the-art or highly competitive performance across a broad range of audio and audio-visual benchmarks, while maintaining the strong text and vision capabilities of same-scale Qwen models. These results suggest that scaling native omnimodal training can produce unified systems that not only perceive and reason across modalities, but also interact and act in real time. We hope Qwen3.5-Omni provides a strong foundation for future research on general-purpose omnimodal agents.
7. Authors
Section Summary: The section titled "7. Authors" lists the individuals who contributed to the work, starting with a group of core contributors—around 40 people with names like Bing Han, Baosong Yang, and Zhifang Guo—who likely played primary roles. It then expands to a much larger group of additional contributors, exceeding 100 names such as Andong Chen, Fei Huang, and Zhengyang Zhuge, recognizing their supporting efforts in the project. This acknowledgment highlights the collaborative nature of the endeavor, involving a diverse team primarily with Chinese names.
Core Contributors
Bing Han
Baosong Yang
Bin Zhang
Bo Zheng
Dayiheng Liu
Fan Zhou
Hongkun Hao
Hangrui Hu
Jin Xu$^*$
Jianxin Yang
Jingren Zhou
Keqin Chen
Le Yu
Mingkun Yang
Peng Wang
Pei Zhang
Qize Yang
Rui Men
Ruiyang Xu
Shuai Bai
Sibo Song
Ting He
Xize Cheng
Xuejing Liu
Xingzhang Ren
Xian Shi
Xiong Wang
Xinyu Zhang
Xinfa Zhu
Yunfei Chu
Yuanjun Lv
Yuchong Sun
Yongqi Wang
Yuxuan Wang
Yang Zhang
Zhifang Guo
Zishan Guo
Ziyang Ma
Contributors
Andong Chen
Anfeng Li
An Yang
Bei Chen
Bin Lin
Bingshen Mu
Bohan Wang
Buxiao Wu
Bowen Xu
Beichen Zhang
Cheng Chen
Chang Gao
Chengen Huang
Chenyang Le
Chenhao Li
Chenglong Liu
Chenxu Lv
Chen Qiang
Chenfei Wu
Chenhan Yuan
Chengruidong Zhang
Chujie Zheng
Daren Chen
Dake Guo
Fei Huang
Gaoji Liu
Guangdong Zhou
Hao Ge
Huiqiang Jiang
Haoran Lian
Hongjian Tu
Hao Yu
Hang Zhang
Hao Zhou
Haiquan Zhao
Humen Zhong
Jiawei Chen
Jian Guan
Jiayi Leng
Jiahao Li
Junrong Lin
Jiawei Liu
Jialong Tang
Jun Tang
Jianhong Tu
Jianqiang Wan
Jinxi Wei
Jianwei Zhang
Jing Zhou
Kai Dang
Kangxiang Xia
Kun Yan
Kexin Yang
Lianghao Deng
Lulu Hu
Linhan Ma
Lingchen Meng
Lei Xie
Laiwen Zheng
Miao Hong
Mei Li
Mingcheng Li
Mingze Li
Minsheng Li
Minghao Wu
Mingfeng Xue
Na Ni
Peng Liu
Peng Wang
Pengfei Wang
Peiyang Zhang
Qidong Huang
Qingfeng Lan
Qintong Li
Que Shen
Qiuyue Wang
Qin Zhu
Ruisheng Cao
Rongyao Fang
Rui Hu
Ruibin Yuan
Song Chen
Su Hao
Shen Li
Shixuan Liu
Shurui Li
Siqi Zhang
Tianyi Tang
Tingyu Xia
Wei Ding
Wenbin Ge
Weizhou Shen
Wei Wang
Wentao Yao
Xi Chen
Xiaotong Chen
Xionghui Chen
Xiaodong Deng
Xudong Guo
Xin Le
Xiao Li
Xie Chen
Xinyao Niu
Xuancheng Ren
Xuechun Wang
Xuwu Wang
Xingzhe Wu
Xipin Wei
Xiao Xu
Xian Yang
Yuxuan Cai
Yizhong Cao
Yilei Chen
Yuxiang Chen
Yiming Dong
Yang Fan
Yanpeng Li
Yucheng Li
Yang Liu
Yantao Liu
Yuqiong Liu
Yuxuan Liu
Yuyan Luo
Yubo Ma
Yang Su
Yuezhang Wang
Yuhao Wang
Yi Wu
Yunbao Wu
Yu Xi
Yi Zhang
Yichang Zhang
Yinger Zhang
Yuxiang Zheng
Zeyu Cui
Ziwei Ji
Ziyue Jiang
Zhaohai Li
Zheng Li
Zhi Li
Zihan Qiu
Zekun Wang
Zhihai Wang
Zhenghao Xing
Zhibo Yang
Zhuorui Ye
Zhenru Zhang
Zhipeng Zhou
Zhengyang Zhuge
8. Appendix
Section Summary: The appendix provides detailed results showing that the Qwen3.5-Omni models outperform leading competitors like Gemini and GPT-4o in multilingual speech recognition and translation tasks tested on the FLEURS dataset. In speech recognition, the top version achieves the lowest word error rate of 6.6%, with especially strong results in tricky Asian languages such as Cantonese, Thai, and Vietnamese, while a faster variant remains competitive and efficient. For translation, it delivers higher quality scores on average, particularly excelling in directions involving Asian languages like Cantonese, Korean, and Japanese, highlighting its optimization for complex regional linguistics.
8.1 Detailed Multilingual Evaluation Results
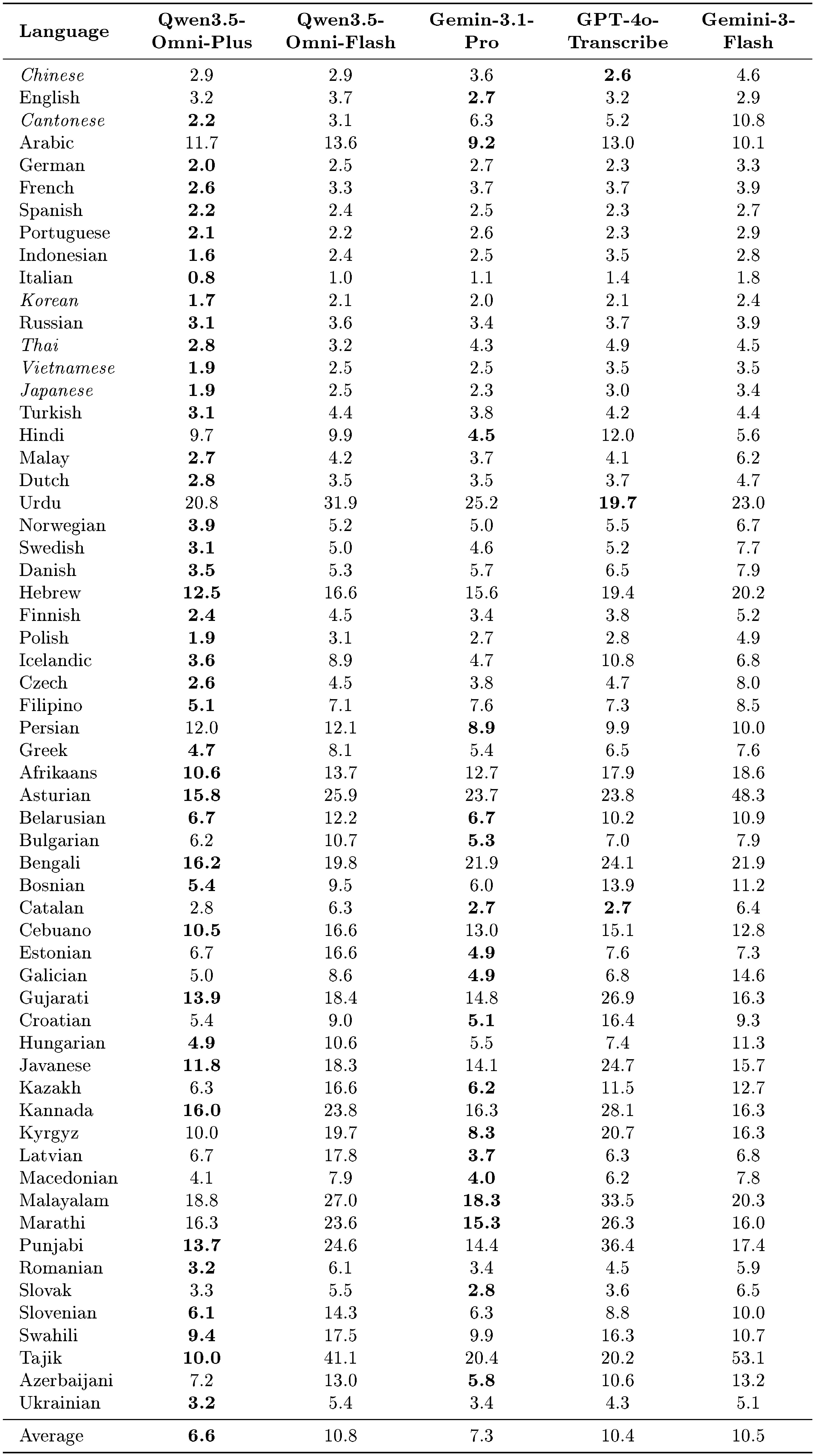
Multilingual ASR.
As presented in Table 13, Qwen3.5-Omni demonstrates superior speech recognition capabilities compared to state-of-the-art competitors on the FLEURS test set. Qwen3.5-Omni-Plus achieves the lowest average WER of 6.6%, outperforming both Gemini-3.1-Pro (7.3%) and GPT-4o-Transcribe (10.4%). It secures the best performance in the majority of languages, with particularly significant margins in complex tonal and low-resource languages such as Cantonese (2.2% vs. 6.3% for Gemini-3.1-Pro), Thai, and Vietnamese. Meanwhile, Qwen3.5-Omni-Flash offers a highly efficient alternative, achieving an average WER of 10.8% that remains competitive against Gemini-3-Flash (10.5%). Notably, Qwen3.5-Omni-Flash exhibits exceptional robustness in challenging scenarios, drastically reducing errors in Cantonese (3.1% vs. 10.8% for Gemini-3-Flash) and maintaining strong performance in Japanese and Korean, thereby highlighting its advantage for high-value Asian language pairs.
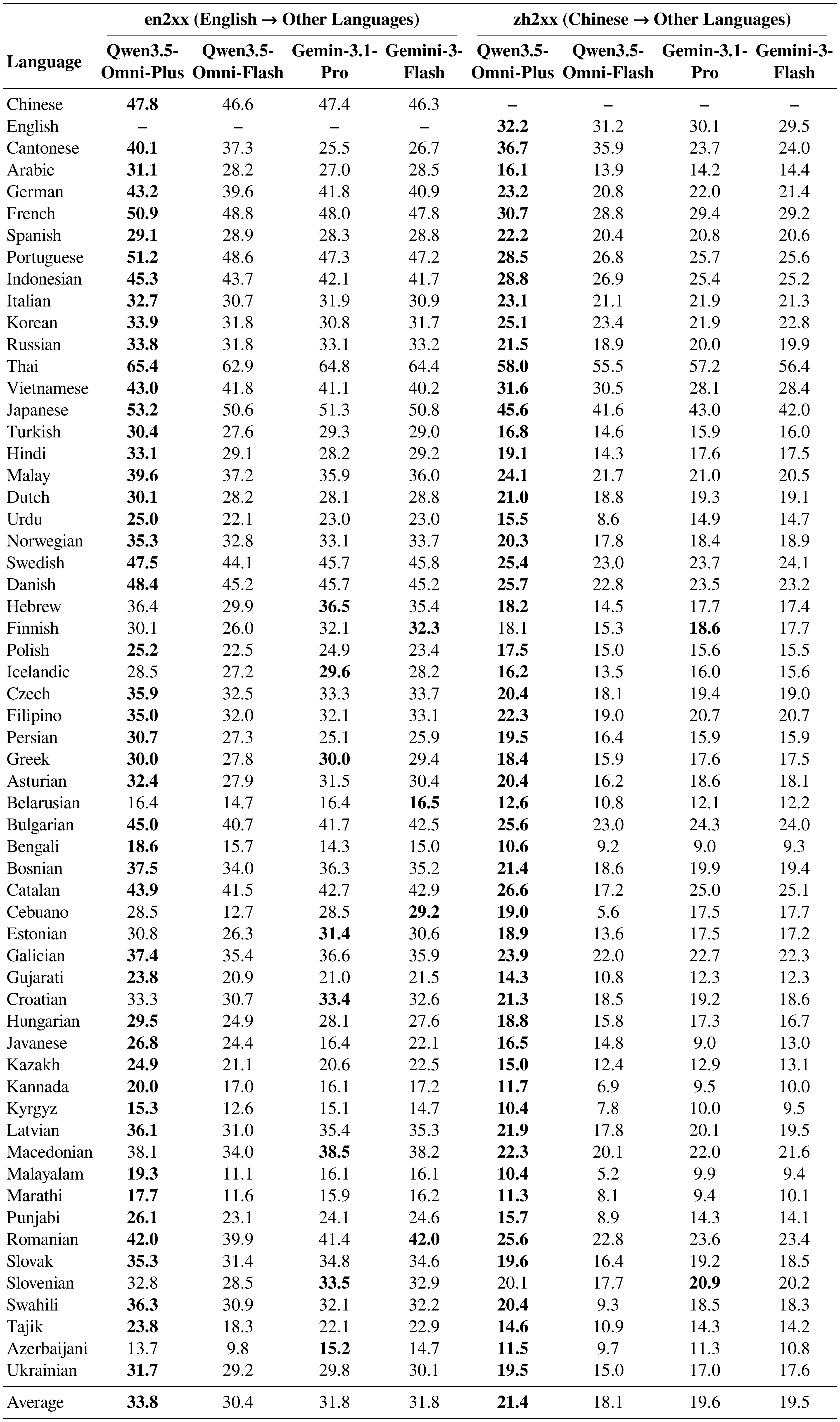
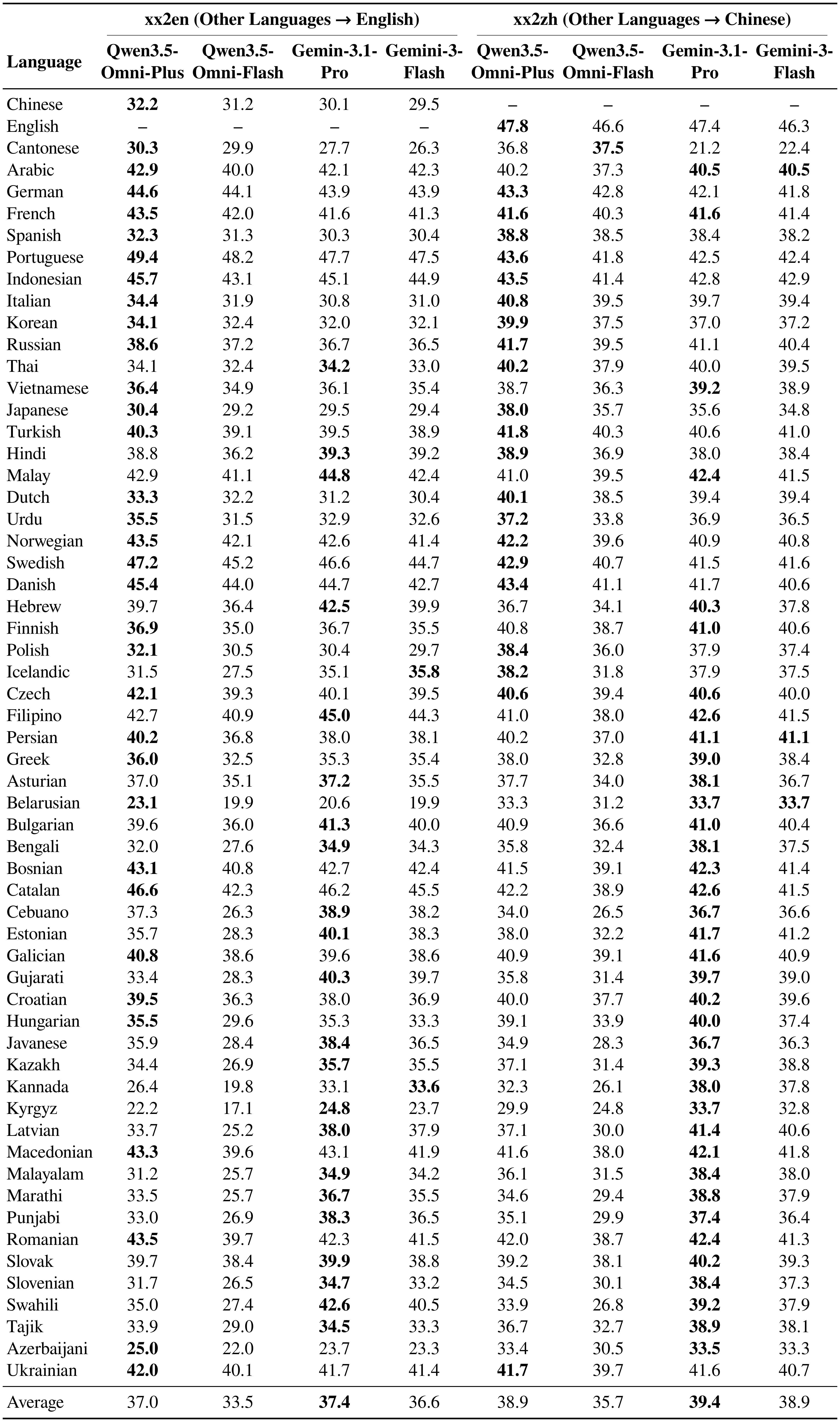
Multilingual Translation.
As shown in Table 14 and Table 15, the Qwen3.5-Omni series demonstrates distinct advantages over state-of-the-art competitors on the FLEURS test set, particularly in Asian languages and specific high-resource pairs. Qwen3.5-Omni-Plus exhibits comprehensive superiority over Gemini-3.1-Pro in the many-to-many directions (en2xx/zh2xx), achieving higher average BLEU scores in both English-to-XX (33.8 vs. 31.8) and Chinese-to-XX (21.4 vs. 19.6). It also leads in key xx2en pairs such as Portuguese (49.4 vs. 47.7) and Indonesian (45.7 vs. 45.1). Although Gemini-3.1-Pro holds a slight edge in overall xx2zh averages, Qwen3.5-Omni-Plus significantly outperforms it in critical Asian languages, including Cantonese (+15.6 BLEU), Korean, and Japanese. Similarly, Qwen3.5-Omni-Flash shows targeted strengths against Gemini-3-Flash. While maintaining competitive general performance, it vastly surpasses Gemini in Cantonese translation across all directions (e.g., 37.5 vs. 22.4 in xx2zh and 37.3 vs. 26.7 in en2xx) and delivers better results in Japanese and Korean xx2zh tasks. These results underscore Qwen3.5-Omni’s robust optimization for complex Asian linguistic structures and key regional languages.
::: {caption="Table 13: Multilingual ASR performance on the FLEURS test set. Results are reported using Word Error Rate (WER, ↓), where lower values indicate better performance. For italicized languages, Character Error Rate (CER, ↓) is reported instead. Compared with competing models, Qwen3.5-Omni-Plus achieves the best results on the majority of languages. The best results are highlighted in bold."}
:::
::: {caption="Table 14: Multilingual translation performance on the FLEURS en2xx and zh2xx test sets. Results are reported using BLEU (↑). Compared with competing models, Qwen3.5-Omni-Plus outperforms them on the majority of language pairs. The best results are highlighted in bold."}
:::
::: {caption="Table 15: Multilingual translation performance on the FLEURS xx2en and xx2zh test sets. Results are reported using BLEU (↑). The best results are highlighted in bold."}
:::
References
Section Summary: This references section compiles a wide array of academic papers, technical reports, and online announcements about cutting-edge AI language models from major developers like OpenAI, Anthropic, Google, and Alibaba, covering advancements in text-based systems like GPT, Claude, and Qwen, as well as multimodal versions that handle images, audio, and long contexts. It also includes works on training methods, such as few-shot learning and preference optimization, and various benchmarks to test AI performance in areas like reasoning, math, coding, and instruction-following. These sources, dated from 2020 to 2026, provide foundational and recent insights into the evolution of versatile AI agents.
[1] Brown et al. (2020). Language models are few-shot learners. In NeurIPS.
[2] OpenAI (2023). GPT4 technical report. CoRR. abs/2303.08774.
[3] Gemini Team (2024). Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf.
[4] Anthropic (2023). Introducing Claude. https://www.anthropic.com/index/introducing-claude.
[5] Anthropic (2023). Claude 2. https://www-files.anthropic.com/production/images/Model-Card-Claude-2.pdf.
[6] Anthropic (2024). The Claude 3 model family: Opus, Sonnet, Haiku. https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf.
[7] Jinze Bai et al. (2023). Qwen Technical Report. CoRR. abs/2309.16609.
[8] Yang et al. (2024). Qwen2 technical report. arXiv:2407.10671.
[9] Yang et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388.
[10] Touvron et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288.
[11] Abhimanyu Dubey et al. (2024). The Llama 3 Herd of Models. CoRR. abs/2407.21783.
[12] Li et al. (2023). Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv:2301.12597.
[13] Liu et al. (2023). Visual instruction tuning. arXiv:2304.08485.
[14] Zhu et al. (2023). Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv:2304.10592.
[15] Jinze Bai et al. (2023). Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities. CoRR. abs/2308.12966.
[16] Bai et al. (2025). Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923.
[17] Yunfei Chu et al. (2023). Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models. CoRR. abs/2311.07919.
[18] Chu et al. (2024). Qwen2-audio technical report. arXiv preprint arXiv:2407.10759.
[19] OpenAI (2024). Hello GPT-4o. https://openai.com/index/hello-gpt-4o/.
[20] Comanici et al. (2025). Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261.
[21] Xu et al. (2025). Qwen2. 5-omni technical report. arXiv preprint arXiv:2503.20215.
[22] Jin Xu et al. (2025). Qwen3-Omni Technical Report. ArXiv. abs/2509.17765.
[23] Qwen Team (2026). Qwen3.5: Accelerating Productivity with Native Multimodal Agents. https://qwen.ai/blog?id=qwen3.5.
[24] OpenAI (2022). ChatML. https://github.com/openai/openai-python/blob/e389823ba013a24b4c32ce38fa0bd87e6bccae94/chatml.md.
[25] Rafael Rafailov et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. In NeurIPS.
[26] Zheng et al. (2025). Group sequence policy optimization. arXiv preprint arXiv:2507.18071.
[27] Yubo Wang et al. (2024). MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. CoRR. abs/2406.01574.
[28] Gema et al. (2024). Are We Done with MMLU?. CoRR. abs/2406.04127.
[29] M.-A-P. Team et al. (2025). SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines. CoRR. abs/2502.14739. doi:10.48550/ARXIV.2502.14739. https://doi.org/10.48550/arXiv.2502.14739.
[30] Yuzhen Huang et al. (2023). C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. In NeurIPS.
[31] Jeffrey Zhou et al. (2023). Instruction-Following Evaluation for Large Language Models. CoRR. abs/2311.07911.
[32] Valentina Pyatkin et al. (2025). Generalizing Verifiable Instruction Following. CoRR. abs/2507.02833. doi:10.48550/ARXIV.2507.02833. https://doi.org/10.48550/arXiv.2507.02833.
[33] Artificial Analysis Team (2025). Artificial Analysis Long Context Reasoning Benchmark (LCR). Artificial Analysis, Inc.. Dataset.
[34] Yushi Bai et al. (2025). LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025. pp. 3639–3664. https://aclanthology.org/2025.acl-long.183/.
[35] David Rein et al. (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark. CoRR. abs/2311.12022.
[36] Naman Jain et al. (2024). LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. CoRR. abs/2403.07974.
[37] Mislav Balunović et al. (2025). MathArena: Evaluating LLMs on Uncontaminated Math Competitions. https://matharena.ai/.
[38] Thang Luong et al. (2025). Towards Robust Mathematical Reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. https://aclanthology.org/2025.emnlp-main.1794/.
[39] Fanjia Yan et al. (2024). Berkeley Function Calling Leaderboard. https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html.
[40] Victor Barres et al. (2025). $\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment. https://arxiv.org/abs/2506.07982. arXiv:2506.07982.
[41] S Sakshi et al. (2024). MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark. https://arxiv.org/abs/2410.19168. arXiv:2410.19168.
[42] Ziyang Ma et al. (2025). MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix. CoRR. abs/2505.13032. doi:10.48550/ARXIV.2505.13032. https://doi.org/10.48550/arXiv.2505.13032.
[43] Dingdong Wang et al. (2025). MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark. CoRR. abs/2506.04779. doi:10.48550/ARXIV.2506.04779. https://doi.org/10.48550/arXiv.2506.04779.
[44] Zang et al. (2025). Are you really listening? boosting perceptual awareness in music-qa benchmarks. arXiv preprint arXiv:2504.00369.
[45] Chunbo Hao et al. (2025). SongFormer: Scaling Music Structure Analysis with Heterogeneous Supervision. https://arxiv.org/abs/2510.02797. arXiv:2510.02797.
[46] Chen et al. (2024). Voicebench: Benchmarking llm-based voice assistants. arXiv preprint arXiv:2410.17196.
[47] Yan et al. (2025). URO-Bench: A Comprehensive Benchmark for End-to-End Spoken Dialogue Models. arXiv preprint arXiv:2502.17810.
[48] Jiang et al. (2025). SpeechRole: A Large-Scale Dataset and Benchmark for Evaluating Speech Role-Playing Agents. arXiv preprint arXiv:2508.02013.
[49] Linhao Zhang et al. (2025). WildSpeech-Bench: Benchmarking End-to-End SpeechLLMs in the Wild. arXiv:2506.21875.
[50] Alexis Conneau et al. (2022). FLEURS: FEW-Shot Learning Evaluation of Universal Representations of Speech. 2022 IEEE Spoken Language Technology Workshop (SLT). pp. 798-805. https://api.semanticscholar.org/CorpusID:249062909.
[51] Rosana Ardila et al. (2020). Common Voice: A Massively-Multilingual Speech Corpus. In Proceedings of The 12th Language Resources and Evaluation Conference, LREC 2020, Marseille, France, May 11-16, 2020. pp. 4218–4222. https://aclanthology.org/2020.lrec-1.520/.
[52] Vassil Panayotov et al. (2015). Librispeech: An ASR corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015.
[53] Binbin Zhang et al. (2022). WENETSPEECH: A 10000+ Hours Multi-Domain Mandarin Corpus for Speech Recognition. In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022, Virtual and Singapore, 23-27 May 2022. pp. 6182–6186. doi:10.1109/ICASSP43922.2022.9746682. https://doi.org/10.1109/ICASSP43922.2022.9746682.
[54] Zhiyuan Tang et al. (2021). KeSpeech: An Open Source Speech Dataset of Mandarin and Its Eight Subdialects. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual. https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/0336dcbab05b9d5ad24f4333c7658a0e-Abstract-round2.html.
[55] Yu Wang et al. (2022). Opencpop: A High-Quality Open Source Chinese Popular Song Corpus for Singing Voice Synthesis. In 23rd Annual Conference of the International Speech Communication Association, Interspeech 2022, Incheon, Korea, September 18-22, 2022. pp. 4242–4246. doi:10.21437/INTERSPEECH.2022-48. https://doi.org/10.21437/Interspeech.2022-48.
[56] Chao-Ling Hsu and Jyh-Shing Roger Jang (2010). On the Improvement of Singing Voice Separation for Monaural Recordings Using the MIR-1K Dataset. IEEE Trans. Speech Audio Process.. 18(2). pp. 310–319. doi:10.1109/TASL.2009.2026503. https://doi.org/10.1109/TASL.2009.2026503.
[57] Yue et al. (2023). Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. arXiv:2311.16502.
[58] Yue et al. (2024). MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark. arXiv preprint arXiv:2409.02813.
[59] Pan Lu et al. (2024). MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts. In ICLR.
[60] Ke Wang et al. (2024). Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset. arXiv:2402.14804.
[61] Chengke Zou et al. (2025). DynaMath: A Dynamic Visual Benchmark for Evaluating Mathematical Reasoning Robustness of Vision Language Models. In ICLR.
[62] Jonathan Roberts et al. (2025). ZeroBench: An Impossible Visual Benchmark for Contemporary Large Multimodal Models. CoRR. abs/2502.09696.
[63] Zhang et al. (2024). MME-RealWorld: Could Your Multimodal LLM Challenge High-Resolution Real-World Scenarios that are Difficult for Humans?. arXiv preprint arXiv:2408.13257.
[64] Chen et al. (2024). Are We on the Right Way for Evaluating Large Vision-Language Models?. arXiv:2403.20330.
[65] Tianrui Guan et al. (2024). Hallusionbench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 14375–14385.
[66] Xianfu Cheng et al. (2025). SimpleVQA: Multimodal Factuality Evaluation for Multimodal Large Language Models. CoRR. abs/2502.13059.
[67] Wang et al. (2024). CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs. arXiv preprint arXiv:2406.18521.
[68] Zhibo Yang et al. (2024). CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy. CoRR. abs/2412.02210.
[69] Kembhavi et al. (2016). A diagram is worth a dozen images. In ECCV.
[70] Yubo Ma et al. (2024). MMLONGBENCH-DOC: Benchmarking Long-context Document Understanding with Visualizations. In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024.
[71] Liu et al. (2024). OCRBench: on the hidden mystery of OCR in large multimodal models. Science China Information Sciences. 67(12). doi:10.1007/s11432-024-4235-6. http://dx.doi.org/10.1007/s11432-024-4235-6.
[72] Gemini Robotics Team (2025). Gemini Robotics: Bringing AI into the Physical World. CoRR. abs/2503.20020.
[73] Roni Paiss et al. (2023). Teaching CLIP to Count to Ten. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 3147–3157.
[74] Kazemzadeh et al. (2014). Referitgame: Referring to objects in photographs of natural scenes. In EMNLP.
[75] Liunian Harold Li et al. (2022). Grounded Language-Image Pre-training. In CVPR. pp. 10955–10965.
[76] Mengfei Du et al. (2024). EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024. pp. 346–355.
[77] Fu et al. (2024). Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. arXiv:2405.21075.
[78] Junjie Zhou et al. (2025). MLVU: Benchmarking Multi-task Long Video Understanding. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 13691–13701.
[79] Li et al. (2024). Mvbench: A comprehensive multi-modal video understanding benchmark. In CVPR.
[80] Weihan Wang et al. (2024). LVBench: An Extreme Long Video Understanding Benchmark. CoRR. abs/2406.08035.
[81] Yilun Zhao et al. (2025). MMVU: Measuring Expert-Level Multi-Discipline Video Understanding. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 8475–8489.
[82] Yang Shi et al. (2025). MME-VideoOCR: Evaluating OCR-Based Capabilities of Multimodal LLMs in Video Scenarios. CoRR. abs/2505.21333.
[83] Bo Liu et al. (2021). Slake: A Semantically-Labeled Knowledge-Enhanced Dataset For Medical Visual Question Answering. In 18th IEEE International Symposium on Biomedical Imaging, ISBI 2021, Nice, France, April 13-16, 2021. pp. 1650–1654.
[84] Xiaoman Zhang et al. (2023). PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering. CoRR. abs/2305.10415.
[85] Yuxin Zuo et al. (2025). MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding. In ICML.
[86] Ziwei Zhou et al. (2025). Daily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities. CoRR. abs/2505.17862.
[87] Jack Hong et al. (2025). WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs. CoRR. abs/2502.04326.
[88] Yang et al. (2025). Audio-centric video understanding benchmark without text shortcut. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 6580–6598.
[89] Nguyen et al. (2025). See, Hear, and Understand: Benchmarking Audiovisual Human Speech Understanding in Multimodal Large Language Models. arXiv preprint arXiv:2512.02231.
[90] Fu et al. (2025). Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118.
[91] Pourreza et al. (2025). Can Vision-Language Models Answer Face to Face Questions in the Real-World?. arXiv preprint arXiv:2503.19356.
[92] Ma et al. (2025). Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception. arXiv preprint arXiv:2510.12720.
[93] Li et al. (2026). OmniGAIA: Towards Native Omni-Modal AI Agents. arXiv preprint arXiv:2602.22897.
[94] Anastassiou et al. (2024). Seed-TTS: A Family of High-Quality Versatile Speech Generation Models. arXiv preprint arXiv:2406.02430.
[95] Bowen Zhang et al. (2025). MiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder. CoRR. abs/2505.07916.
[96] Zhihao Du et al. (2025). CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training. CoRR. abs/2505.17589.
[97] Wang et al. (2024). Maskgct: Zero-shot text-to-speech with masked generative codec transformer. arXiv preprint arXiv:2409.00750.
[98] Eskimez et al. (2024). E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts. In 2024 IEEE Spoken Language Technology Workshop (SLT). pp. 682–689.
[99] Chen et al. (2024). F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching. arXiv preprint arXiv:2410.06885.
[100] Xinsheng Wang et al. (2025). Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens. CoRR. abs/2503.01710.
[101] Du et al. (2024). CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models. arXiv preprint arXiv:2412.10117.
[102] Xiaomi LLM-Core Team Dong Zhang et al. (2025). MiMo-Audio: Audio Language Models are Few-Shot Learners. ArXiv. abs/2512.23808. https://api.semanticscholar.org/CorpusID:284351195.