Learning Dynamics of LLM Finetuning
Abstract
Learning dynamics, which describes how the learning of specific training examples influences the model's predictions on other examples, gives us a powerful tool for understanding the behavior of deep learning systems. We study the learning dynamics of large language models during different types of finetuning, by analyzing the step-wise decomposition of how influence accumulates among different potential responses. Our framework allows a uniform interpretation of many interesting observations about the training of popular algorithms for both instruction tuning and preference tuning. In particular, we propose a hypothetical explanation of why specific types of hallucination are strengthened after finetuning, e.g., the model might use phrases or facts in the response for question B to answer question A, or the model might keep repeating similar simple phrases when generating responses. We also extend our framework and highlight a unique "squeezing effect" to explain a previously observed phenomenon in off-policy direct preference optimization (DPO), where running DPO for too long makes even the desired outputs less likely. This framework also provides insights into where the benefits of on-policy DPO and other variants come from. The analysis not only provides a novel perspective of understanding LLM's finetuning but also inspires a simple, effective method to improve alignment performance. Code for experiments is available at https://github.com/Joshua-Ren/Learning_dynamics_LLM.
1. Introduction
Deep neural networks usually acquire new knowledge by updating their parameters via gradient descent (GD). This procedure can be described by learning dynamics, which links changes in the model's predictions to the gradients generated by learning specific examples. With the help of learning dynamics, researchers have not only explained many interesting phenomena during training, e.g., the "zig-zag" learning path ([1]) and the formation of compositional concept space ([2]), but used these insights to propose novel, improved algorithms in different problems (e.g. [3,4,5]).
The study of large language models (LLM) is gaining popularity due to their surprising capabilities on various tasks. To ensure the LLMs follow human instructions and align well with human preferences, finetuning has attracted much recent attention. Practitioners often start with instruction tuning, where the model learns extra knowledge necessary for the downstream task, and then preference tuning, where the model aligns its outputs to human preference ([6]). Various finetuning algorithms have been proposed to fit into this pipeline, with differing explanations as to why they improve the model's performance.
Contrary to most existing analyses of LLM finetuning, which use the perspective of their training targets, their status at the end of training, or their relationships to reinforcement learning (e.g. [7,8,9]), this paper tries to understand LLMs' evolution from a dynamical perspective. Specifically, we formalize the learning dynamics of LLM finetuning by decomposing the change of the model's prediction into three terms which play different roles.
This framework can be easily adapted to various finetuning algorithms with different goals, including supervised finetuning (SFT, [10]), direct preference optimization (DPO, [11], and its variants) and even reinforcement learning based methods (e.g., PPO, [12]). This framework helps explain several interesting and counter-intuitive observations during training -- including the "repeater" phenomenon after preference tuning ([13]), hallucination
([14]), the decay in confidence of all responses during off-policy DPO ([8]), and more.
Moreover, we also provide a new perspective on understanding why off-policy DPO and other variants underperform their on-policy counterparts ([15]). Our explanation starts by observing an interesting "squeezing effect, " which we demonstrate is a consequence of gradient ascent (as in DPO and similar algorithms) on models with cross-entropy loss following a softmax layer.
In short, for each token's prediction, the negative gradient will push down the model's predictions on (almost) all possible output labels, moving this probability mass to the most-likely labels. This can be detrimental to the alignment we are trying to achieve. This effect is most serious when the negative gradient is imposed on an already-unlikely label, which is why the confidence of almost all responses decreases during off-policy DPO. Inspired by this, we propose a simple but very effective method to further improve alignment performance.
2. Definition of Learning Dynamics and an MNIST Example
Learning dynamics is usually an umbrella term describing how the change of a specific factor influences the model's prediction. In this paper, we narrow down it to describe ``how the change in model's parameter influences the corresponding change in '', i.e., the relationship between and . When the model updates its parameters using gradient descent (GD), we have
where the update of during step is given by one gradient update on the sample pair with learning rate . In short, the learning dynamics in this paper address the question:
After an GD update on , how does the model's prediction on change?
Learning dynamics can shed light on many important problems in deep learning and also help to understand various counterintuitive phenomena. The origin of it might be the "stiffness" ([16]) or "local elasticity" ([17,18]) of neural networks. See Appendix A for more discussions.
As a warm-up, we first consider a standard supervised learning problem, where the model learns to map to predictions , where is the vocabulary of size .
The model usually outputs a probability distribution by first generating a matrix of logits and then takes the of each column. We can track the change in the model's confidence by observing .
2.1.1.1 Per-step influence decomposition.
The learning dynamics of Equation 1 become,
For simplicity, we start from the scenario, where the and can be linked by the following result, a version of a result of [1] proved and further discussed in Appendix B. For multi-label classification (), the updates separate; we can calculate different and stack them together.
Proposition 1
Let and . The one-step learning dynamics decompose as
where , is the empirical neural tangent kernel of the logit network , and .
only depends on the model's current predicted probability.
The matrix is the empirical neural tangent kernel (eNTK, [19]) of the model, the product of the model's gradients with respect to and . The analysis in this paper relies on the following assumption:
During the training, the relative influence of learning on all other different is relatively stable.
The common "lazy eNTK" assumption discussed in [20] is a sufficient but not necessary condition for this paper. Appendix C provides a more detailed discussion and experimental verification for both MNIST and LLM settings. We can then think of as a model-specific similarity measurement between different input samples: larger means the update of likely influences the model's prediction on more. Finally, is determined by the loss function , which provides the energy and direction for the model's adaptation. For example, for cross-entropy loss , we have , a length- vector that points from the model's current predictive distribution to the desired supervisory distribution. For typical "hard" labels, is a one-hot vector .
2.1.1.2 Accumulated influence and a demonstration on MNIST.
Proposition 1 describes how the update of changes the model's prediction on for each learning step. Since a real model updates its parameters for many steps,
it is important to ask about accumulation of these per-step influences over time.
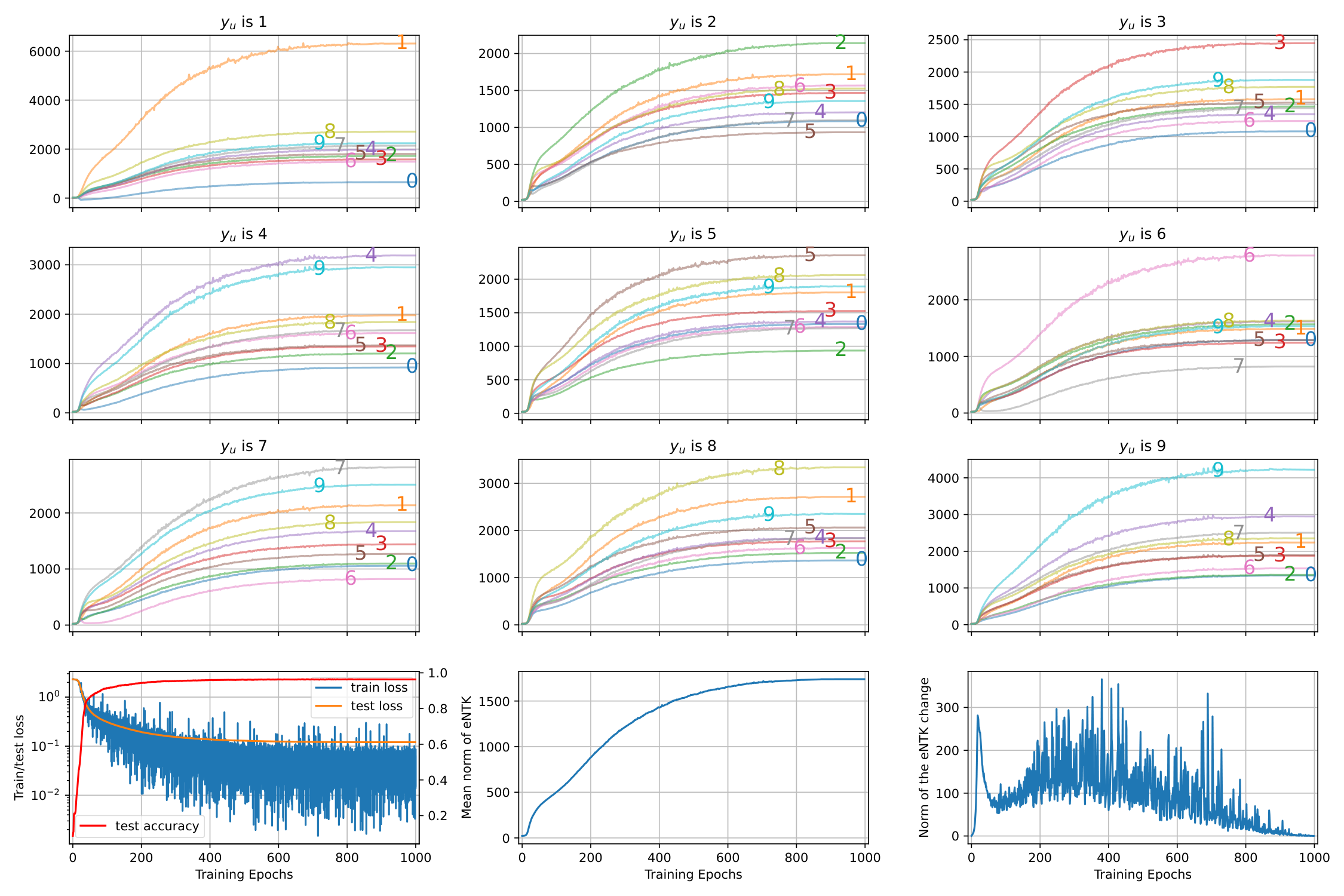
We start by analyzing a simple example of training a LeNet on the MNIST dataset ([21]).
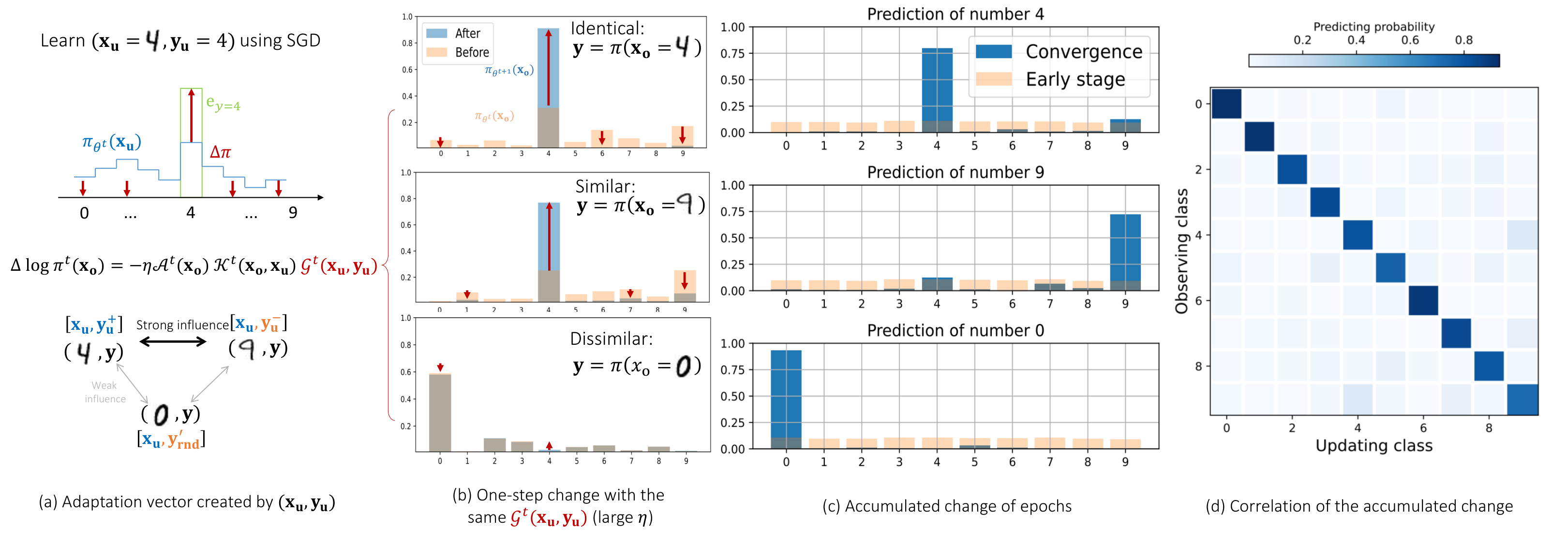
See Figure 1-(a), where the network is updating its parameters using the loss calculated on one training example .
The residual term is then represented by the red arrows, which all start from and point to . We can then ask how the model's predictions on different change after this update. As in Figure 1-(b), for an in the same class with (i.e., the identical case), the predicted probability of this correct label is "pulled up" by this update, as expected.
On the other hand, if this is similar to (i.e., is reasonably large) but comes from another class, then the predicted probability on 's class (not the correct label of ) would be "pulled up, " as in the second panel of Figure 1-(b). Last, for examples that look dissimilar to (small ), this update will not change the model's prediction on much, as in the bottom panel in Figure 1-(b).
💭 Click to ask about this figure
The interactions among the updates of different inputs then form an interesting pattern for the learned predictions. As illustrated in Figure 1-(c), when making predictions on images coming from class
4, the model tends to assign higher confidence on class 9. That is because the examples in class 9 on average look more similar to class 4 than examples in other classes. Hence the update of examples in classes 4 and 9 will reinforce their mutual influence and lead to a bump in their predictions. To verify this, we plot the average of for from each of the classes in Figure 1-(d).The values of some off-diagonal patches are significantly higher than others, which means the examples in those classes look more similar, like
4 and 9, 5 and 3, 8 and 5, etc.3. Learning Dynamics of LLM's Finetuning
Although learning dynamics have been applied to many deep learning systems, extending this framework to LLM finetuning is non-trivial. The first problem is the high dimensionality and the sequence nature of both the input and output signals. The high-dimensional property makes it hard to observe the model's output, and the sequential nature makes the distributions on different tokens mutually dependent, which is more complicated than a standard multi-label classification problem considered by most previous work. Furthermore, as there are many different algorithms for LLM finetuning -- SFT ([10]), RLHF ([6]), DPO ([11]), etc. -- analyzing them under a uniform framework is challenging. Finally, compared with the training-from-scratch scenario, where a roughly uniform distribution over all possible outputs is usually assumed, LLMs' finetuning dynamics heavily rely on the pretrained base model, which could make the analysis harder. For example, the pretrained model usually assigns little probability mass to unlikely tokens, which is good for most applications but leads to risk of the "squeezing effect" we show later.
We now tackle these problems and propose a unified framework for different finetuning methods.
3.1 Per-step Decomposition of the SFT Loss
The typical loss function used during supervised finetuning is the negative log-likelihood (NLL) of a given completion , conditioned on the prompt :
Note that compared with the multi-label classification problem discussed before, where the joint distribution of all labels can be factorized as , the sequential nature of language modeling makes the analysis more complicated, because we must have .
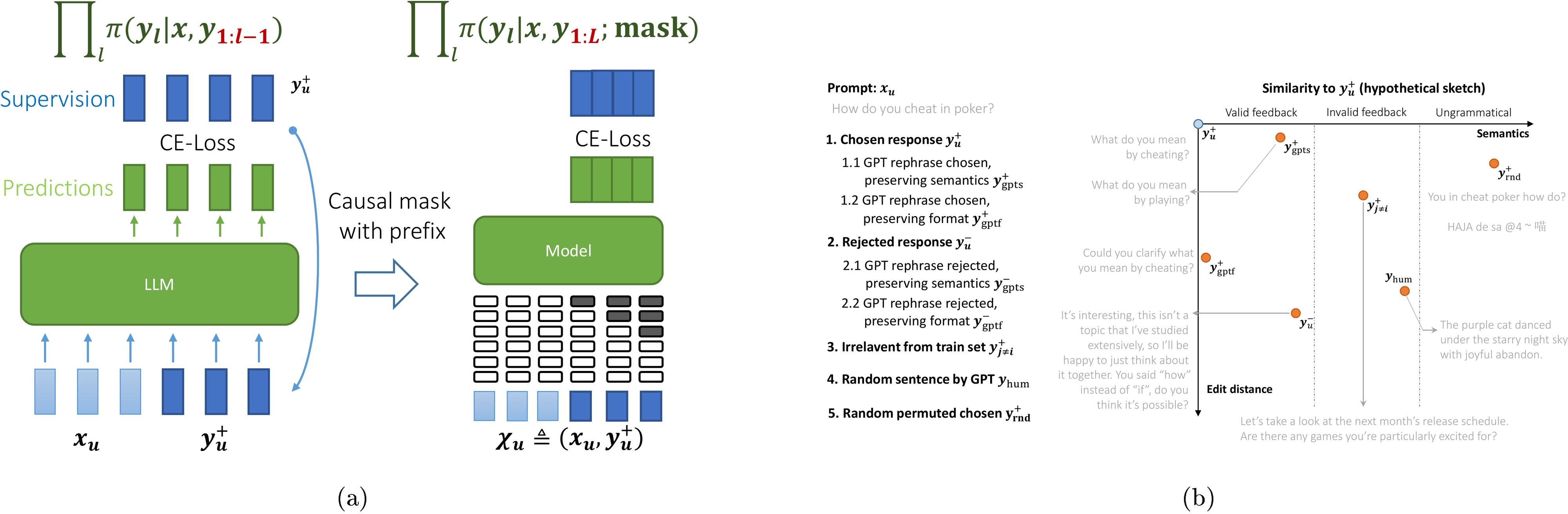
To solve this problem, we can merge this factorization into the definition of the backbone while keeping the format of Proposition 1. Specifically, letting be the concatenation of and , the prediction of all tokens of is
Here is a matrix where each column contains the logits of the prediction of the th token. Our , even though it takes the entire sequence as its input, will force the model not to refer to the future tokens when making predictions on the -th token, commonly implemented via "causal masking" (proposed in [22], details in Figure 10a of Appendix D). Then, we can calculate on each column of and stack them to form a tensor . The calculation of and follows a similar procedure. Thanks to the causal mask implemented in , the resulting decomposition is almost identical to that in a multi-label classification problem. Assuming have a response of length associated with , stacked into , and of length associated with , stacked into . The change of the model's prediction on the -th token of can be represented as, when gradients have bounded norm,
where . Compared with Proposition 1, the main difference is that the eNTK term also depends on the responses and , which allows us to answer questions like
For a prompt , how does learning the response influence the model's belief about a response ?
When tracking the model's confidence on different responses given the question , learning from will impose a strong "upwards" pressure on , as illustrated in the first panel of Figure 2. At the same time, the confidence of "similar responses" will also be slightly pulled up, like how learning a
4 influences the prediction on 9 in the MNIST example. We will discuss how to understand the "similarity" between two sequences of responses in the next section.3.2 Per-step Decomposition of the DPO Loss
Preference finetuning, which teaches the model to provide responses that align better with human preferences, is also an important phase in LLM finetuning pipelines. Different from the SFT stage above, where the training tells the model "what to do", many preference finetuning methods also teach the model "what not to do, " which makes the learning dynamics more complex. For intuition, we start by analyzing a typical method, i.e., DPO (direct preference optimization, an RL-free method), under a similar framework. Following [11], the loss function of off-policy DPO is
where and are pre-generated responses, and is the reference model, typically the result of SFT. and share the same but different . In the loss function, the terms are also calculated using teacher forcing. Hence we can decompose the learning dynamics for DPO similarly to Equation 5,
where is the margin (i.e., the value) for the -th token, which represents how well the current policy separates and compared with the reference policy. Due to the monotonicity of , a larger margin leads to larger , which in turn restrains the strength of . In other words, automatically provides less energy on the examples that are already well separated. We then check the role of , which controls the regularizing effect on the KL distance between and in the original RL loss ([11]). When the margin is negative, larger leads to a smaller and hence provides stronger for the model to "catch up" the separating ability of the reference model faster. But when the model is better and has a positive margin, increasing will increase and hence create a negative influence on , which makes the model update less. This aligns well with the claims of [11]: the stronger regularizing effect tends to "drag back towards " when its predictions deviate from too much. The derivation and the functions for other RL-free methods are given in Appendix B.2.2.
These analyses make no assumptions on where and come from. Hence our framework can be directly extended to on-policy RL-free methods, which often perform better than their off-policy counterparts ([9,15]). The main difference between these algorithms is how the supervisory responses are generated. Off-policy methods typically use a fixed pre-collected dataset, with and are generated by another LLM or humans. In other words, it is likely that both the chosen and rejected responses come from the "less likely" region of the model's prediction. On-policy responses, though, are more likely to have higher predicted probabilities under this model, as they were sampled from it. We will show next that imposing large negative pressure on an unlikely prediction will lead to unexpected behavior, giving a new explanation for why on-policy sampling is important for algorithms with large negative gradients.
![**Figure 2:** The updating vector provided by the residual term $\mathcal{G}^t$ of different algorithms. The \textcolor{gray}{gray $ \bm{\mathsf{y}}$} are responses *sampled* from $\pi$ in an on-policy way. In the second panel, we demonstrate the "squeezing effect" caused by imposing a big negative gradient on a "valley" region of a distribution. For more details about this counter-intuitive effect, please refer to Section 3.3 and Appendix E. Other panels demonstrate on-policy DPO (and IPO), SPIN ([23]), SPPO ([24]), and SLiC ([25]).](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/63899d29/compare_sft_dpo_etc_big.png)
💭 Click to ask about this figure
3.3 The Squeezing Effect Caused by Negative Gradient
As demonstrated by the first two panels in Figure 2, the use of large negative gradients is the main difference between the learning dynamics of SFT and DPO. We will show later that this difference is the key to understanding why the learning curves of SFT and DPO behave so differently. For example, [8,9,26] (and our Figure 4) reported that the confidence of both and gradually decreases when conducting DPO, while the confidence of rarely drops during SFT. This trend becomes more serious if is finetuned for longer before conducting DPO (reported in Figure 3 of [8] and verified by our Figure 17). Furthermore, we also find that for all the we track (various responses similar to or ; details in the next section), none of them increase during the DPO phase. This is different from SFT and quite counter-intuitive:
If everything we observe is becoming less confident, where has the probability mass gone?
To answer this question, we first identify a phenomenon we call the squeezing effect, which occurs when using negative gradients from any model outputting a distribution with output heads, even in a simple multi-class logistic regression task. Specifically, in the case when we impose a negative gradient on label , we can describe the changing of model's predictive distribution as follows:
- Guarantee: the confidence of , i.e., will decrease.
- Guarantee: the decreased probability mass is largely "squeezed" into the output which was most confident before the update: if , then will increase.
- Trend: the rich get richer and the poor get poorer: generally, dimensions with high tend to increase, and those with low tend to decrease.
- Trend: peakier squeezes more. If the probability mass concentrates on few dimensions in , which is common for a pretrained model, all decrease (only is "rich").
- Trend: smaller exacerbate the squeezing effect: if is unlikely under , the probability mass of all other will be more seriously decreased, and the increases more.
Appendix E illustrates the squeezing effect and analytically proves its existence for logistic regression models, by directly computing in different situations. Section 4.2 also experimentally verifies the analysis above in real LLM experiments.
Note that in practical settings, where both positive and negative pressures and the auto-regressive nature are strictly considered, the squeezing effect can become more complicated. The differences between the two eNTK terms in Equation 7 also influence the relative strength and direction of these two pressures. [27] analyze a similar problem in a token-level setting, and their conclusions align with ours well. We left a more detailed analysis to our future work.
We can now get a high-level overview of the learning dynamics of a typical off-policy DPO algorithm. Since both and are not sampled from the model's distribution, sometimes can be dissimilar to , and the are likely located in a valley region of the model's prediction. Then its learning dynamics would look like the sketch in the second panel of Figure 2: the confidence on almost all are pushed down. At the same time, all the decreased probability mass is squeezed to , which might make the model keep generating repeated phrases, as reported by [13]. Variants of DPO algorithms often unintentionally mitigate this squeezing effect by constraining the strength of the negative gradient or the positions of , which partially explains their benefits. The last four panels in Figure 2 and Appendix B.2.2 have more details.
4. Experimental Verifications
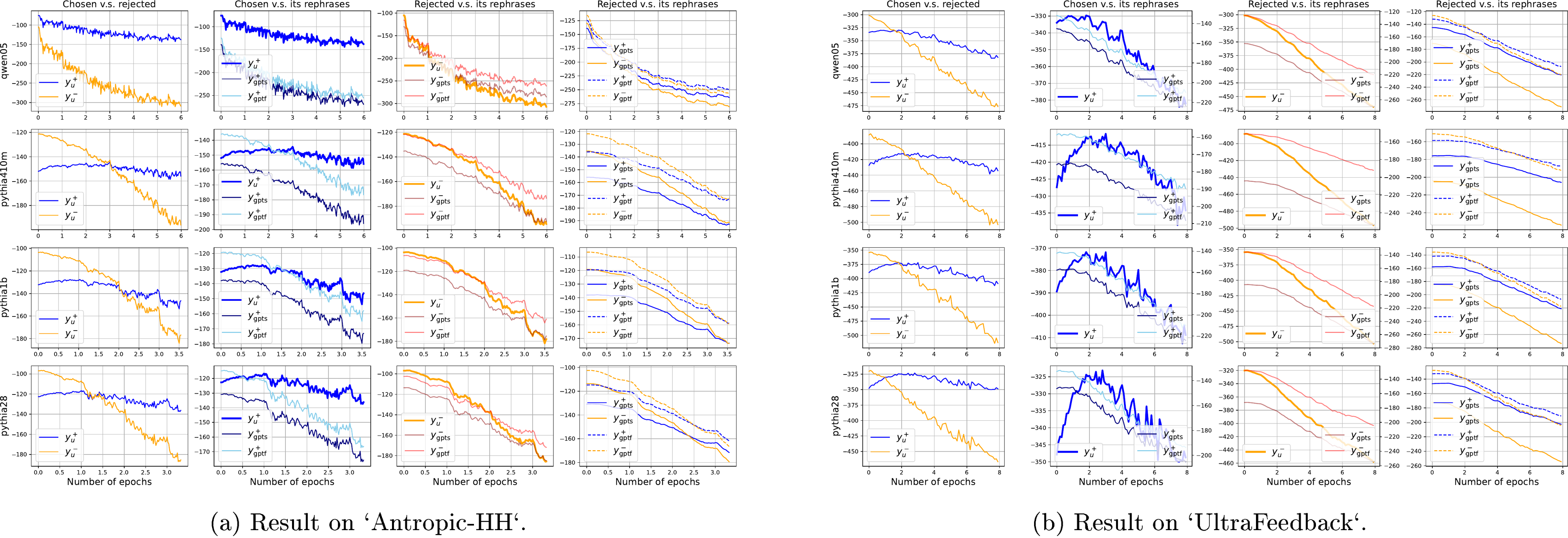
We now verify our analysis in practical settings. We first create the training set by randomly selecting 5000 examples from the training split of the dataset. We consider two common datasets,
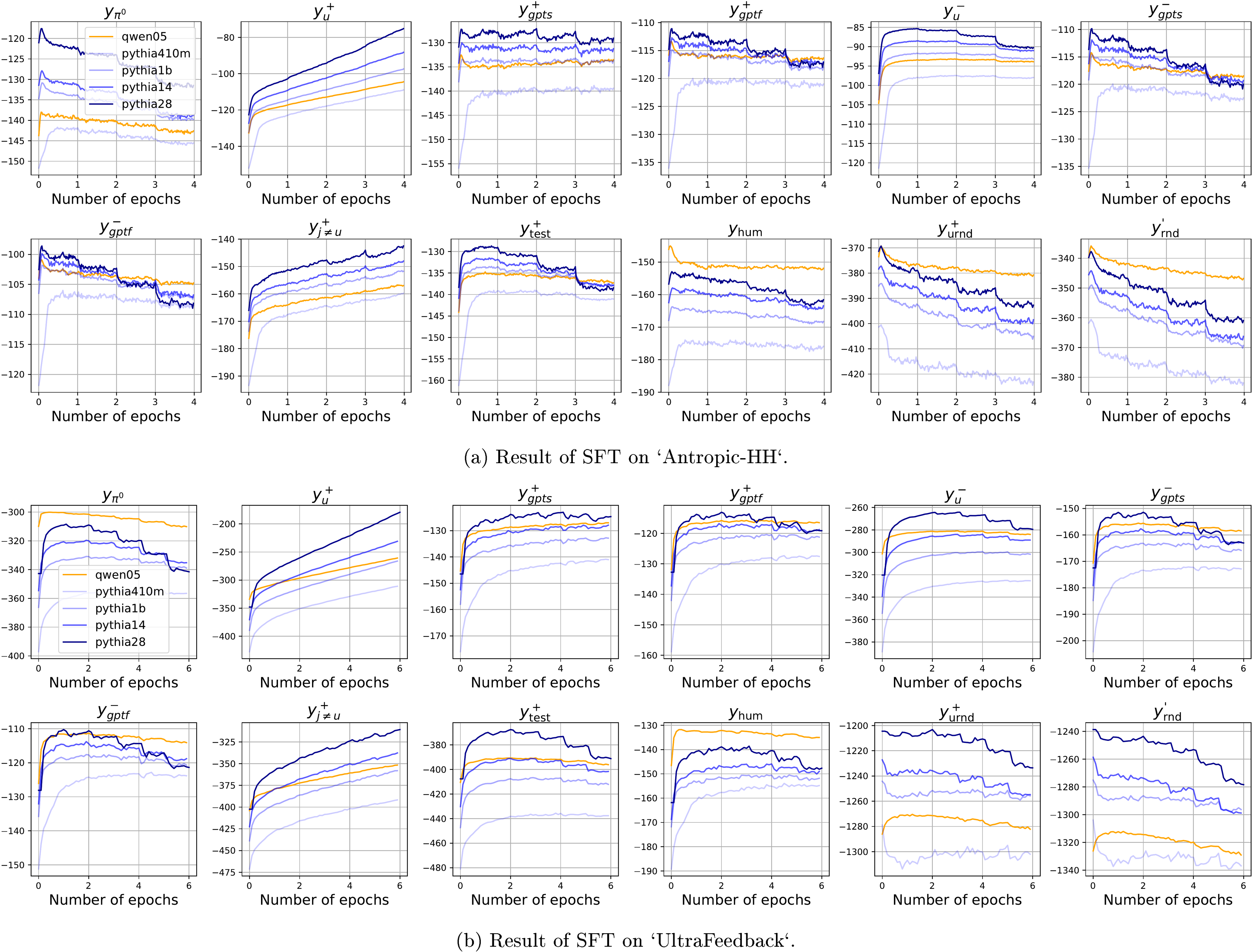
Antropic-HH ([28]) and UltraFeedback ([29]), in all experiments. Each example in contains three components: the prompt (or question) , the preferred response , and the less preferred response . SFT finetunes with and , while DPO uses all three (subscripts of and are removed for conciseness). We repeat the experiments on two series of models: pythia-410M/1B/1.4B/2.8B ([30]) and Qwen1.5-0.5B/1.8B ([31]).To get a more detailed observation of the learning dynamics, we further create a probing dataset by randomly selecting 500 examples from , and generate several typical responses based on the corresponding , , or . (We also study another probing dataset where all come from the test set in an ablation study in the appendix.) Then for each in , we can observe how gradually changes on different types of . For example, one extended response type can be a rephrase of , an irrelevant response answering another question , or just a randomly generated English sentence with the same number of words with . We explain why we need these extended responses and how they are generated in detail in Appendix D.1. In short, helps us to get a more fine-grained inspection of the learning dynamics, which can not only support our analysis above, but also shed more light on how the model's prediction evolves on the entire , a very sparse and huge space.
4.1 Learning dynamics of SFT
The main lesson we learn from the analysis in Section 3.1 is that learning from not only increases the model's confidence on , but also indirectly "pulls up" responses similar to with a smaller strength (scaled roughly by ), similar to how learning a '
4`'' influences the prediction of a '9`'' in the MNIST example. At the same time, the increase of naturally "pushes down" all , because the model's predicted probability to all responses in -space must sum to one. The model's behavior on different is mostly a trade-off among these pressures. To verify this claim, we finetune the model for several epochs and evaluate the model's prediction on all responses in every 25 updates (with a training batch size of 4, the probing occurs every 100 examples). For each type of response, we average the model's confidence on all 500 examples and report the mean value of their log-likelihood.As demonstrated in the first panel of Figure 3, the model's confidence on keeps increasing throughout the whole learning process, which is straightforward because the main "pull-up" pressure is imposed directly on . However, the behavior of some responses similar to is non-trivial. For example, we draw the following types of responses in the same panel, i.e., the less preferred response for the same question (), two types of rephrases of generated by
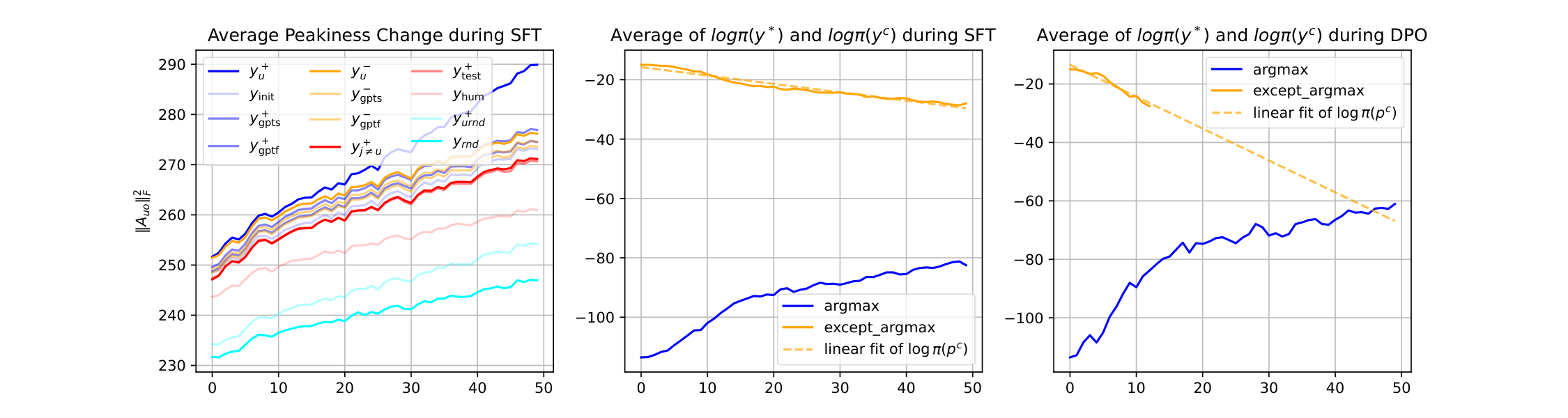
ChatGPT ( and ), another preferred response randomly selected from the test set (), or even a randomly generated English sentence (). The model's confidence in these responses are all slightly increased at the beginning of training, and then gradually decrease as the training goes on, even though the model never sees them during SFT. This counter-intuitive behavior can be well explained by the learning dynamics we discussed before. Since all these examples are "similar" to to some extent (at least, they are all common "standard English" sentences), their are reasonably large. Then learning will indirectly increase the model's confidence of these similar . That is why the corresponding are slightly increased at the beginning of training. However, as the training goes on, the model's confidence on keeps increasing and the update energy, the norm of in Equation 5, gradually decreases. That means the indirect "pull-up" pressures are also diminished accordingly. Then, the "push-down" pressure on all becomes dominant and all the related curves start going down.To verify the existence of this global "push-down" pressure, we observe two types of responses; both have the same number of words as their . One is a purely random English word sequence . Another is a random permutation of all the words in , which is called . Since both are not natural language, we expect the between them and to be very small, which means learning from imposes almost no "pull-up" pressure on them; thus the "push-down" pressure will dominate through the whole training procedure. These analyses are well supported by the second panel in Figure 3, in which we see these all start from a very small value, and keep decreasing throughout the training.
Another interesting type of responses is , a preferred response for another question in the training set. For these responses, the model's prediction on will be kept influenced by two "pull-up" pressures: one is from learning , another is from learning , where the latter might be even stronger as the gradient is directly calculated by observing . That explains why we see the confidence on keeps increasing with a smaller rate compared with in the third panel. Because the "pull-up" pressure is always strong enough to counter the "push-down" one. These observations provide us with a unique explanation of why specific types of hallucinations are amplified after SFT. Specifically, the increase of means if we ask the model to answer a question , it might provide a response from (or partially from) another unrelated question in the training set.

💭 Click to ask about this figure
Last, to further explore the "similarity" between different responses from the model's perspective. we SFT the model using more types of responses and observe how changes accordingly. The results are demonstrated in Figure 3, where the blue and orange colors represent the positive and negative influence respectively. The x-axis is the updating response while the y-axis denotes the observing response. Hence the first column resembles how different changes when we SFT the model using . One interesting finding is that all responses generated by
ChatGPT are considered very similar to each other, regardless of how semantically different they are. Probably, LLM has its preferred idioms or phrases, which could be considered as a type of "fingerprint". We left this interesting problem for our future work.4.2 Learning dynamics of off-policy DPO
💭 Click to ask about this figure
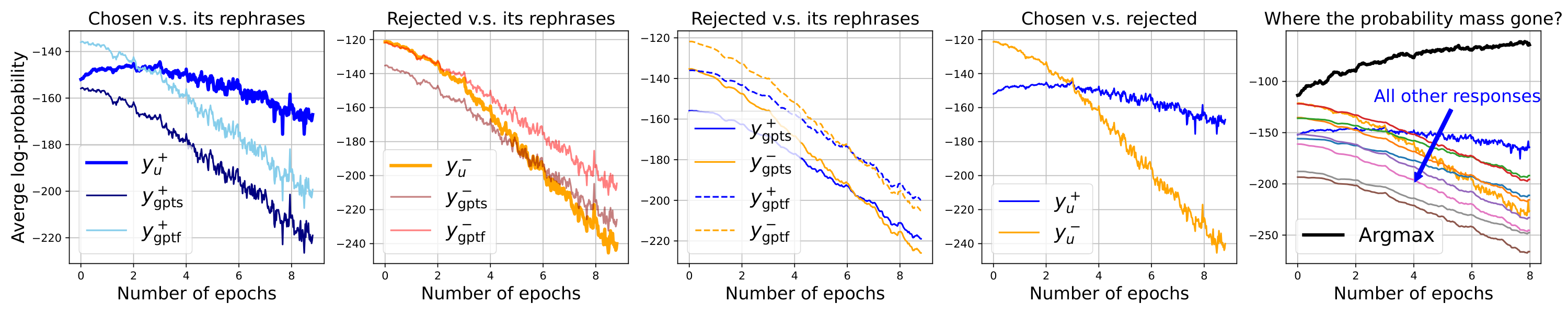
To verify our framework also explains the model's behavior in preference tuning, we conduct similar experiments for DPO. Recall the residual term introduces a pair of arrows on both and , with different directions. To show how these two pressures influence the model, we check two types of rephrases of or (, , , and , used in the previous experiment). See the three curves in the first panel in Figure 4, where the two rephrases decrease at a similar speed, faster than the decay of . That is because the upward pressure is directly imposed on rather than these rephrases. Similarly, in the second panel, we observe that decays faster than its rephrases, because directly imposes a negative pressure on . Then in the third panel, we find the rephrases of consistently decay slower than those of , although none of them ever occur during training. That is because these responses are close to or in , which means their is relatively large. Hence the pressures imposed on and also introduce a non-negligible influence on them. Last, in the fourth panel, the margin keeps increasing, which means the model is gaining the ability to separate and as the training goes on.
Although directly imposes a "pull-up" pressure on , the value of does not increase a lot as it does in SFT. The downward arrow on indeed introduces a "push-down" pressure on responses that are similar to , but the influence is unlikely to be that strong (it will be weakened by ) to make the confidence on almost every observing responses decrease so fast, as demonstrated in the last panel of Figure 3 where we use similar for both SFT and DPO. Then, where has the probability mass gone during DPO? The key to answering this question is the squeezing effect discussed in Section 3.3: since the big negative gradient is imposed on , which is at this point probably in a region of low , the confidence of most will be decreased and will increase very fast.
To verify this, we report the log-likelihood of chosen by greedy decoding: each token is chosen by maximizing the conditional probability given in real-time, where is a sub-sequence of . As illustrated by the last panel of Figure 4, the confidence of this "teacher forcing" greedy increases very fast (from -113 to -63), which is even faster than the increase of during SFT (from -130 to -90), within 8 epochs. However, the tokens with the highest confidence do not necessarily form a preferred response: it will reinforce the prior bias in . This could be a reasonable explanation of the "degeneration" reported in recent work (e.g. [13]): as becomes more peaky at its most confident predictions, it is easier to sample sequences with repeated phrases. Note that such behavior could also be understood as a special type of self-bias amplifying ([32]), which would bring more serious consequences if it is combined with a multiple-generation self-improving algorithm, e.g., self-reward ([33]), iterative DPO ([34]), etc.
In summary, the behaviors of different types of responses all match our analyses well. More subtle trends of different responses support our story well (both for SFT and DPO). Due to space constraints, we explain these (and the full results on other models and datasets) in Appendix D.
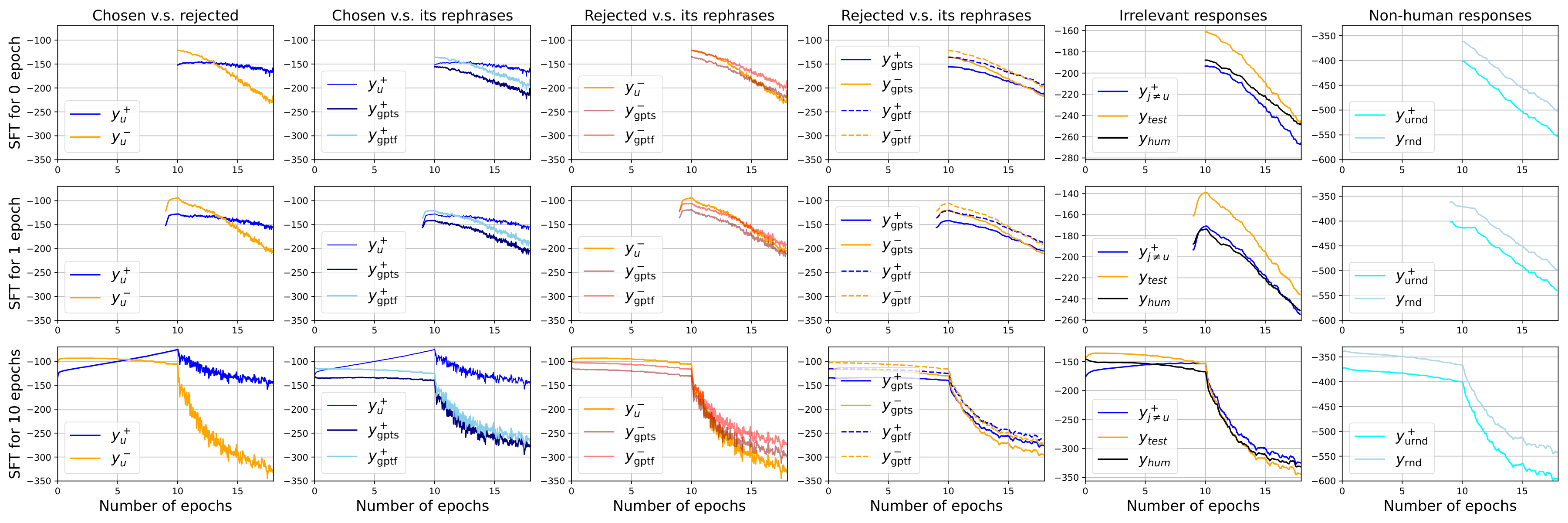
4.3 Mitigating the squeezing effect by augmenting the training set for SFT
Since the "squeezing effect" caused by the big negative gradient on unlikely predictions can damage the model's performance during DPO, we can first train the model on both and during the SFT stage (making the negative response more likely), and then run the usual DPO. Following the analysis above, we can expect during this new SFT stage, the region of those responses similar to or will be "pulled up" simultaneously. This is what we want because in many cases, both and are reasonably good responses for the question ; the new SFT design hence helps to pull up a larger region that contains more suitable responses compared with the baseline SFT. After that, the "push-down" pressure imposed during DPO can efficiently decrease the model's confidence on and its similar responses. Since is no longer so unlikely before DPO, the squeezing effect should not be as strong as in the baseline procedure.
We call our training pipeline "extend" and compare its learning dynamics with the baseline setting in Figure 5. It is clear that the squeezing effect is mitigated, because the confidence of other responses all decays slower during DPO, and we also observe a big drop in the greedy-decoding response when DPO starts. To further show that mitigating the squeezing effect indeed brings benefits, we compare the responses generated by models trained using different methods by feeding them to
ChatGPT and Claude3. Specifically, we first SFT the model for two epochs using two methods discussed above and call the resulting policy network and . Then, we conduct identical DPO training on both and for several epochs. The win rate of the proposed method against the baseline one is provided in Table 1. It is clear that before DPO, is better, because is explicitly trained on those . However, the performs better after DPO several epochs since the squeezing effect is efficiently mitigated. Please refer to Appendix F for more details. In the future, this simple method inspired by our analysis could be further improved by introducing more responses, e.g., rephrases of , etc., during both stages, and also by combining with many existing RL-free methods we mentioned before.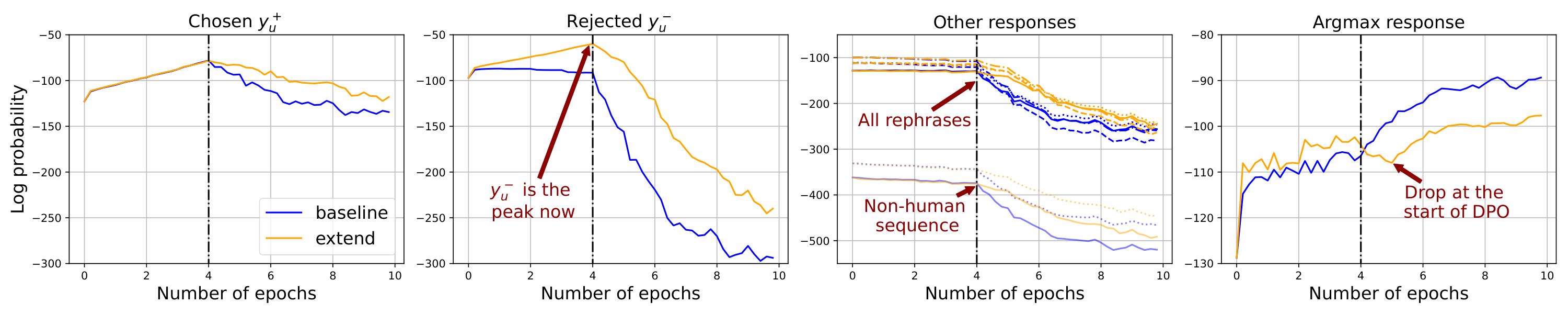
💭 Click to ask about this figure
5. Conclusion
Learning dynamics, which depict how the model's prediction changes when it learns new examples, provide a powerful tool to analyze the behavior of models trained with gradient descent. To better utilize this tool in the context of LLM finetuning, we first derive the step-wise decomposition of LLM finetuning for various common algorithms. Then, we propose a unified framework for understanding LLM predictions' behaviors across different finetuning methods. The proposed analysis successfully explains various phenomena during LLM's instruction tuning and preference tuning, some of them are quite counter-intuitive. We also shed light on how specific hallucinations are introduced in the SFT stage, as previously observed ([35]), and where the improvements of some new RL-free algorithms come from compared with the vanilla off-policy DPO. The analysis of the squeezing effect also has the potential to be applied to other deep learning systems which apply big negative gradients to already-unlikely outcomes. Finally, inspired by this analysis, we propose a simple (but counter-intuitive) method that is effective in improving the alignment of models.
Acknowledgements
This research was enabled in part by support provided by the Canada CIFAR AI Chairs program, WestGrid, and Compute Canada. We thank Shangmin Guo, Noam Razin, Wonho Bae, and Hamed Shirzad for their valuable discussions and feedback. We also appreciate the constructive comments from the anonymous reviewers, which helped improve this work.
Appendix
A. More Related Works
A.1 More about learning dynamics
Beyond their application to LLMs, learning dynamics are widely utilized in analyzing various machine learning problems. For example, if we consider from the training set, and from the test set, this form of learning dynamics provides a new perspective on generalization: the model generalizes better if the loss of keeps decreasing when it learns from . By studying the influence of different at different stages during supervised learning, [1] explain a "zigzag" pattern of the learning path,
which sheds light on why the model can spontaneously pursue better supervisory signals and correct noisy labels in the early stage of training (see also [36]). [37,3] apply learning dynamics to explain why directly finetuning a well-trained backbone with a randomly initialized task head might harm the out-of-distribution generalization ability. [38,39,40] also explains where the simplicity bias favoring compositional representations comes from during knowledge distillation ([41]), providing a new perspective of understanding why successive knowledge transferring can improve the model's systematic generalization ability.
The network's local elasticity ([17]) and stiffness ([16]) are also correlated with this topic. It reveals that neural networks operate like adaptive local learners, influencing only nearby points in feature space during training. This gives them a unique edge over linear models in terms of memorization, stability, and the emergence of meaningful internal structure—all without explicit regularization. The authors of [18] further link this behavior to the model's generalization ability. Extending their theoretical framework to more complicated settings like LLMs' finetuning might be a promising direction.
Besides explaining the model's behavior, learning dynamics is also helpful for evaluating the quality or the effectiveness of different training samples. For example, [4] propose a quantitative metric called
TracIn to compute the influence of a training example on the predictions made by the model. This metric is then applied by [5] to search for the most influential examples in LLM instruction finetuning. By expanding Equation 1 in the neural tangent kernel (NTK) regime, [42] propose a metric called lpNTK to measure the relative difficulty among different training samples. These metrics and analyses inspired by learning dynamics are expected to be helpful in many related fields, like coreset selection ([43]), active learning ([44]) (see, e.g., [45]), and dataset distillation ([46]).A.2 More about LLM's finetuning
In this paper, we broadly define finetuning as any in-weight learning on top of a pretrained base model, including supervised finetuning (SFT), direct policy optimization (DPO, [11]) and its variants, etc. Since the analysis throughout this paper relies on the "teacher forcing" mechanism and the relatively stable eNTK assumption, our framework cannot be directly applied to algorithms with token-wise supervision like reinforcement learning with human feedback (RLHF, [6]) and proximal policy optimization (PPO, [12]). We leave the study of the token-wise learning dynamics, which aligns better with the "squeezing effect" in real settings, to future work.
We also identify several related works that report similar observations on the phenomena discussed in this paper. For example, [47,35] mentioned that learning new facts during SFT tends to make the model hallucinate more, which aligns with our finding that the model tends to use when answering question . [13] related the peakiness of the model's distribution to LLM's "repeater phenomena", which also indirectly supports our claims well: more DPO leads to a more serious squeezing effect, hence the model's prediction becomes peakier on most tokens, which makes the aforementioned phenomena more common.
Furthermore, the "confidence decaying on " attracts more attention in the community, because it is quite counter-intuitive and the vanilla off-policy DPO algorithm works reasonably well in most cases. Many related works study this phenomenon by analyzing the major discrepancy between off-policy DPO and PPO, i.e., where the samples used to train the model comes from, e.g., [8,48,15]. They showed that when the responses are off-policy sampled, the learning process may fail to benefit from the contrastive information in the data. In other words, we should be more careful when working on the "valley" region of the model's distribution. Other works try to analyze this problem by inspecting the token-level influence between responses. For example, [26] assumes and are identical expect one token. Under this assumption, the model's confidence of after the identical token is guaranteed to decrease. They propose a solution by significantly enhancing the learning rate (roughly x50 larger when their ) of the positive part when detecting located in a low-confidence region. [27] takes the similarity between the hidden embeddings and the geometry of the readout layer of different responses into account. Most of the conclusions of their paper align with ours well. The main discrepancy lies in the squeezing effect part, which we will discuss in our future work (they do not contradict each other, but need a more detailed analysis to understand the whole story).
A.3 Benign and harmful negative gradient
The "squeezing effect" can negatively impact our analysis when it is strongly imposed in a valley region of the model. However, a well-regulated negative gradient is both beneficial and commonly observed in many deep-learning systems. For example, it is common in many "machine unlearning" algorithms, e.g., in [49]. Moreover, even in the field of LLM finetuning, we can find many mechanisms in different popular algorithms that can mitigate this effect. For example, the typical learning rate of DPO is usually smaller than that used in SFT, which unintentionally mitigates the harmful squeezing effect. The on-policy counterpart of the DPO-like algorithms is shown to perform better than their off-policy counterparts, which also supports our claims. Furthermore, we find the PPO loss automatically avoids imposing a big negative gradient (when its is negative) on the valley region (when its is small).
On the other hand, the effect that negative gradients make the model's distribution peakier is independently reported in many related works. For example, Equation 1 in [50] shows that we are minimizing a negative thing in a standard GAN loss, which might explain why peakiness occurs. Furthermore, in Table 1 and Table 2 of [51], we see the peakiness (measured by ) of the “PG-average” method is stronger than the standard PG method. Note that the “PG-average” method will map a reward ranging from 0 to 1 to a centered one ranging from -0.5 to 0.5. Since the negative reward can introduce a negative gradient, the peakiness increases.
B. Proof of Propositions and Residual Term for Different Losses
B.1 Proof of Proposition 1
Proof: 1 Suppose we want to observe the model's prediction on an "observing example" . Starting from Equation 2, we first approximate using first-order Taylor expansion (we use to represent interchangeably for notation conciseness):
Then, assuming the model updates its parameters using SGD calculated by an "updating example" , we can rearrange the terms in the above equation to get the following expression:
where is the number of parameters of the model. To evaluate the leading term, we plug in the definition of SGD and repeatedly use the chain rule:
Note that this proposition assumes . For case, we will have multiple task heads which leads to different Equation 3. The matrix can then be achieved by stacking them.
For the higher-order term, using as above that
and noting that, since the residual term is usually bounded (and the practical algorithms will also use gradient clip to avoid too large gradient), we have that
In the decomposition, using to represent the model's prediction on different dimensions, we can write our as:
The second term in this decomposition, , is the product of gradients at and . Intuitively, if their gradients have similar directions, the Frobenius norm of this matrix is large, and vice versa. This matrix is known as the empirical neural tangent kernel, and it can change through the course of training as the network's notion of "similarity" evolves. For appropriately initialized very wide networks trained with very small learning rates, remains almost constant during the course of training, the kernel it converges to is known as the neural tangent kernel ([19,20]). Note that the assumption that is unchanged (usually used in theoretical analysis) might be too strong in the LLM's finetuning. Hence as stated in the main context, our qualitative analysis only assumes that "during the training, the relative influence of learning on all other different is relatively stable". We will validate this assumption using experiments in Appendix C.
B.2 Residual Term for Different LLM Finetuning Algorithms
As stated in Section 3, one of the conundrums of decomposing the learning dynamics of LLM is its auto-regression nature of the output sequence. Different from the multi-label classification problem, where for different is independently generated as long as the shared network is fixed, the for the LLM's output depends on , which is usually sampled from the model's prediction iteratively. However, in most of the finetuning cases where the supervisory signal is given, the model will apply the so-called "teacher forcing" mechanism when calculating the predicting probabilities. In other words, when generating the output of each , the is given rather than sampled on-policy. This mechanism makes it possible for us to define and hence merge the auto-regressive nature of the sequence prediction into the shared . After this step, the decomposition of LLM's finetuning learning dynamics then becomes similar to a multi-label classification task.
B.2.1 Instruction finetuning using auto-regression loss (SFT)
Here we derive the residual term, i.e., for different algorithms in LLM's finetuning. We first rewrite Equation 5 here:
where , , and is a matrix. As the auto-regression nature of the SFT loss is already encoded in the causal mask used in , as demonstrated in Figure 10a. the columns in are independent of each other, which can be separately calculated. Plus, the summation over can also be achieved by left-multiplying a length- all-one vector . Specifically, the SFT loss for each is:
where is for the -th dimension of . The gradient of on can be then calculated as:
where is element-wise division.
To calculate the equation above, we first recall the NLL loss of the -th token is , where . Then, . For each dimension of , we have if and if . By writing it in vector form, we have . For , we have:
Combining this matrix and the vector , where the only non-zero term is at the position. So, left multiplying by this vector is actually first selecting the -th row of , and then multiplying to it. In summary, we have:
By stacking the terms with different , we can get
B.2.2 Different preference finetuning algorithms
Direct Preference Optimization (DPO, [11]) is usually considered the first RL-free alignment algorithm for preference finetuning. Different from the standard RLHF (reinforcement learning with human feedback ([52])), the training of off-policy DPO is more similar to SFT, where the model keeps learning from a pre-generated preference dataset. Hence, we start from DPO to analyze the learning dynamics of different preference finetuning algorithms (the on-policy versions of these algorithms could also be explained using the proposed framework).
Following [11], the training loss of DPO is:
Before calculating the residual term , we need to re-calculate the learning dynamics decomposition, because the loss term now depends on both and , which involves two different terms. Specifically, we define and , where and respectively ( and ). Then, starting from , the decomposition for the DPO loss (similar to Equation 8 for SFT) could be written as:
where are concatenation of two vectors or matrices, , and . To calculate the residual terms, we decompose the loss into:
where is not a function of . Using the chain rule, the -th column of the residual term can be calculated as (the calculate of is similar):
By stacking values with different , we can get the residual term of DPO as
Similarly, we can calculate the residual terms for other off-policy preference optimization methods, like Identity-preference Optimization (IPO ([53])):
For the Sequence Likelihood Calibration (SLiC ([25])), we have:
In summary, these RL-free algorithms all relate to the SFT loss to some extent. For the DPO and IPO loss, the directions of the updating signals are identical. A scalar controls the strength of this update, which usually correlated with the confidence gap between the model's current confidence on and , i.e., . Generally, larger this value leads to a bigger , making the norm of smaller. In other words, we see a "regularizing" effect in this term, where the model should not make too large. The SLiC loss can be considered as a combination of SFT adaptation and preference adaptation. Similarly, we can also see a hard version of the regularization effect mentioned above. If , the indicator function will become zero, and the model stops pushing and away when it already separates and well.
Recently, authors of ([24]) propose another interesting self-play alignment algorithm called SPPO, which further improves the alignment performance on top of many on-policy DPO methods. Our framework could also give an interesting explanation of why this method works so well. Specifically, the loss function of SPPO can be written as:
This loss looks similar to the IPO one, but the main difference between SPPO and other methods (e.g., DPO, KTO, IPO, SPIN, etc.) is that there is no negative sign in front of or . From its residual term , it is more convenient to understand this algorithm as imposing two positive vectors on both and , but the former has a longer norm, as illustrated in Figure 2. By doing so, the big negative gradient no longer exists, and so does the squeezing effect. That is partly why this method is more stable and performs better.
C. The "Relative Stable" eNTK Assumption
We use this appendix to verify the core assumption of our analysis -- during the training, the relative influence of learning on all other different is relatively stable -- on both MNIST and LLM finetuning settings. To make the notation concise, we use to represent , and other related variants.
💭 Click to ask about this figure
💭 Click to ask about this figure
C.1 Relative Stable eNTK Assumption - MNIST Experiments
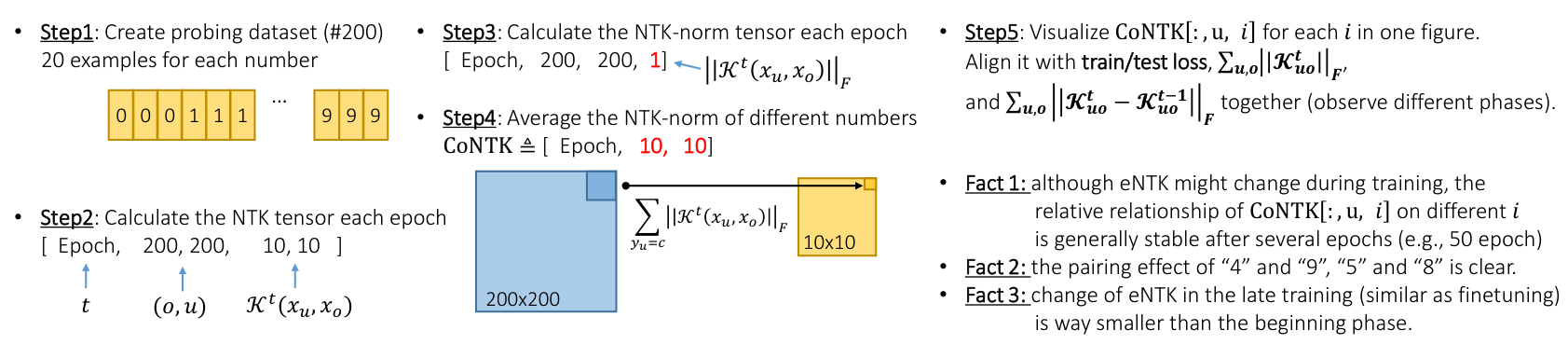
For the MNIST example, we directly calculate the eNTK term using a pipeline demonstrated in Figure 6. The results are showed in Figure 7, where the key findings are:
- 1. The last three panels roughly indicate different phases throughout the training, where the first several epochs () are a bit messy, and the last several epochs () behave similarly to the finetuning stage;
- 2. Although the norm of eNTK () and the norm of eNTK's adaptation () changes a lot after 30 epochs, the ranking between on different are relatively stable, as demonstrated by the upper 9 panels;
- 3. The pairing effect between the "similar" inputs is clear, e.g., "4" and "9", "5" and "8", etc;
- 4. The pairing effect between the "dis-similar" inputs are also clear, e.g., "6" and "7", "2" and "5", etc.
- 5. The pairing effect mentioned previously is not strictly symmetry, which is because the inconsistent and terms;
- 6. The accumulated influence demonstrated in the third panel of Figure 1 is strongly correlated to the integral of all these curves.
C.2 Relative Stable eNTK Assumption - LLM Experiments
Directly calculating for the LLM experiment requires huge amount of computation, because for each token in each example, we need to multiply a matrix to a one, where is the number of parameters of the LLM. However, since we only care about the relative relationship between on different , where is fixed, based on the basic decomposition in Proposition 1, we can get a lower-bound as follows (ignoring superscript for conciseness, ignoring the influence of ):
We hence define two quantitive measurements to have a better understanding of , they are:
where the subscript here represent the -th token and -th dimension for the prediction. In later experiments, we will observe both and to have a better understanding of the strength (norm) and the direction (sign) of the relative influence imposed via .
💭 Click to ask about this figure
Regarding the calculation of , is easy to track because, in the main context, we already showed for different responses. , where is defined as a stacking of one-hot vectors. The is a bit complex. Recall the definition that , we can have:
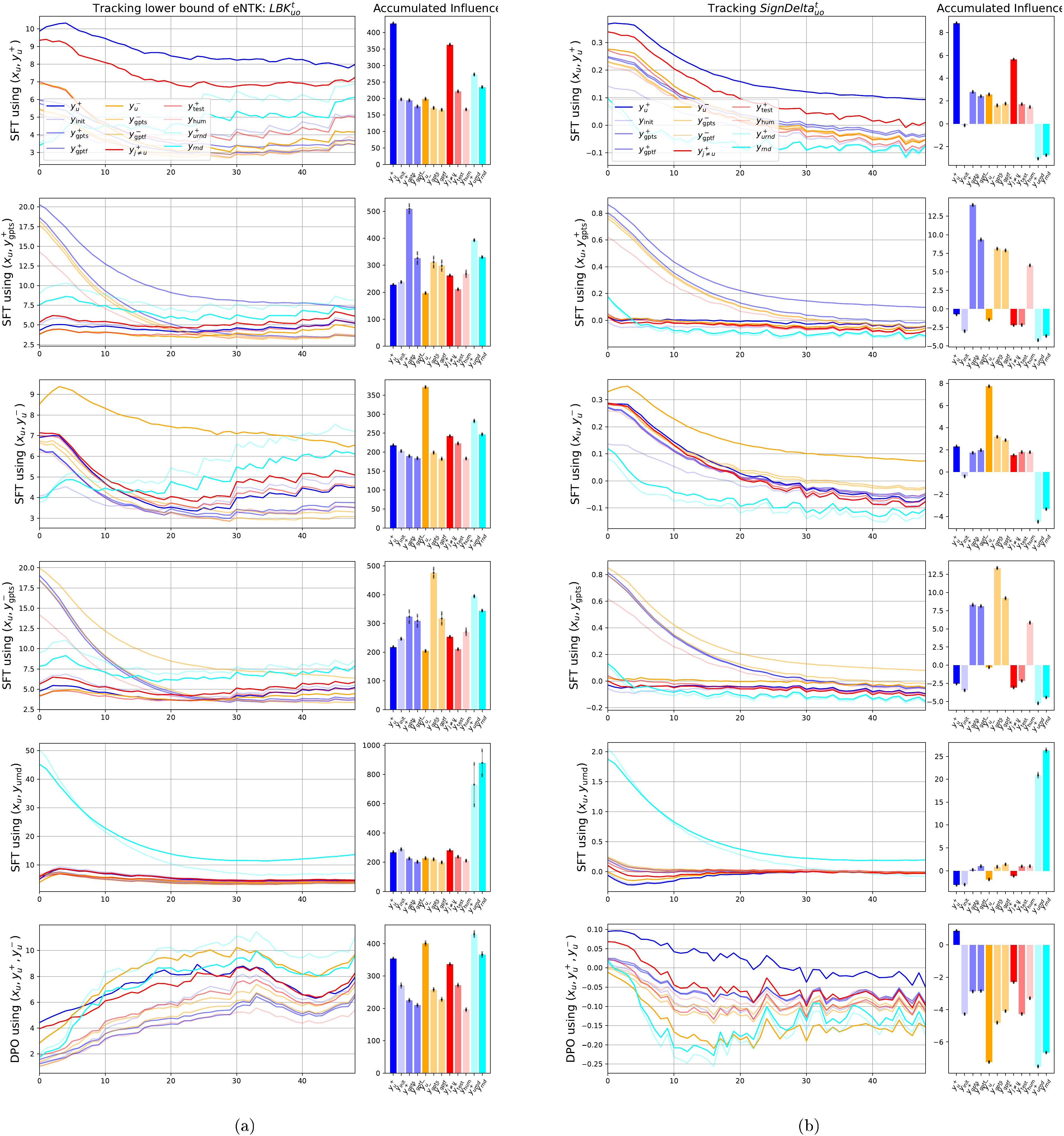
which is also trackable in our setting. Note that intuitively, the value of is inversely correlated to the Shannon entropy of the distribution : if is one-hot; if is uniform. Hence we can also interoperate as the peakiness of . In the following experiment, we track the value of for different types of responses during SFT and DPO to show that the relative influence between different response types is relatively stable. We show the experimental results in Figure 8, in which the key findings are:
- 1. In both SFT and DPO under different supervisory signals, the change of these two metrics are relatively stable, similar to those in Figure 7;
- 2. The clear pairing effect between (blue curve) and (red curve) exist;
- 3. In , learning any natural language sequences (i.e., ) influence the non-language sequence () a lot, especially at the end of finetuning. However, from we know such an influence is negative, which is caused by the pushing down pressure;
- 4. An interesting "similarity pattern" occurs: by observing , we see SFT using or imposes more influence on the sequence generated using
ChatGPTother than their original response (i.e., or ), which might be an interesting phenomenon to explore further; - 5. By observing the last row, where the model is trained using DPO, it is clear that the push-down pressure is dominant. Because almost all terms have big negative values, and the only positive one is (roughly 0.5, much smaller than other positive values in the SFT cases).
We also provide some intermediate quantities in Figure 9 to further validate our analysis. The key trends are provided in its caption for ease of reading.
💭 Click to ask about this figure
D. More About Experiments
This section provides more experimental details and results about the learning dynamics to support our claim. We will first discuss how different types of responses are selected in our probing dataset . These responses can fit into a 2-D space where one dimension is semantical relevance of the response to . We then provide more results and discussions on different models and settings. The subtle differences between the responses all support our story well.
💭 Click to ask about this figure
D.1 The Selection of Response Types for the Probing Dataset
Besides the sequential nature of the loss function, another conundrum in analyzing LLM learning dynamics is the huge response space : the number of possible is , but the vast majority of possible sequences look nothing like natural language, and we expect the model to generate only a subset of natural language-like responses. These properties prevent us from observing the changes of all possible like what we did for MNIST. Instead, we define several interesting regions of , and select corresponding typical responses to observe. Intuitively, we can use the semantic relevance between and as a heuristic. Such a measurement can be understood as "how suitable this is as a response to , compared to ." Then, starting from the structure of common preference optimization datasets such as
Antropic-HH ([28]) and UltraFeedback ([29]), we can divide into three sub-spaces and evaluate the following types of responses (as in Figure 10b). The prompt templates used to generate them are illustrated in Figure 11. We also provide examples of all 14 types of responses in Figure 12.-
: reasonable responses following the instruction :
-
0. , the initial response generated by feeding to LLM before finetuning;
-
1. , the chosen (i.e., the preferred) response to .
-
1.1 , rephrase using , algorithm from [54];
-
1.2 , rephrase using
ChatGPT, keep the semantics while changing the format; -
1.3 , rephrase using
ChatGPT, keep the format while changing the semantics; -
2. , the rejected (i.e., the less preferred, but still reasonable) response to .
-
2.1 , rephrase using , algorithm from [54];
-
2.2 , rephrase using
ChatGPT, keep the semantics while changing the format; -
2.3 , rephrase using
ChatGPT, keep the format while changing the semantics;
-
-
: irrelevant responses to that are still recognizably human language (in these datasets, roughly "internet-standard" English):
- 3. , the chosen response for a different question selected from the training set.
- 4. , the chosen response of a question selected from the test set.
- 5. , a "random" English sentence generated by
ChatGPTwith as many words as .
-
: token sequences that do not form meaningful human language:
- 6. , a random permutation of the words (space-separated strings) of .
- 7. , a random permutation of the words of a generated sentence as in .
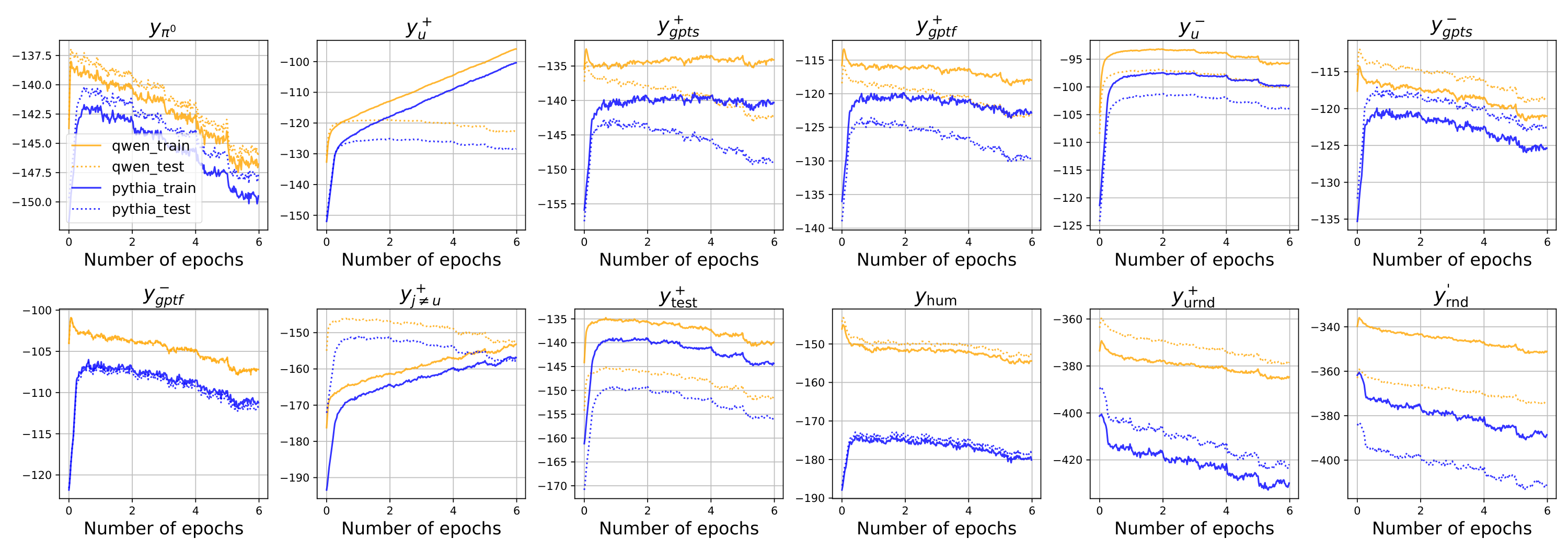
Furthermore, we also create another probing dataset (named ) where all comes from the test set. Compared with that we used in the main context, all the prompts and responses in are never exposed to the model during finetuning. By comparing the learning curves of these two probing datasets, we can figure out the difference between the model's prediction of those directly influenced responses ( appears during training) and the indirectly influenced ones ( that the model never sees during training). Finally, we believe the level of the "on-policy" property (which is very important for the preference finetuning, as discussed in [9]) could also be introduced as the second axis in our 2-D plane. We left the exploration of this interesting direction in our future work.
![**Figure 11:** The prompts used to generate $ \bm{\mathsf{y}}_\text{selfr}^+$, $ \bm{\mathsf{y}}_\text{gpts}^+$, and $ \bm{\mathsf{y}}_\text{gptf}^+$. The rephrases of rejected samples are generated similarly. The self-rephrase template comes from [54].](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/63899d29/app_prompt_design.png)
💭 Click to ask about this figure

💭 Click to ask about this figure
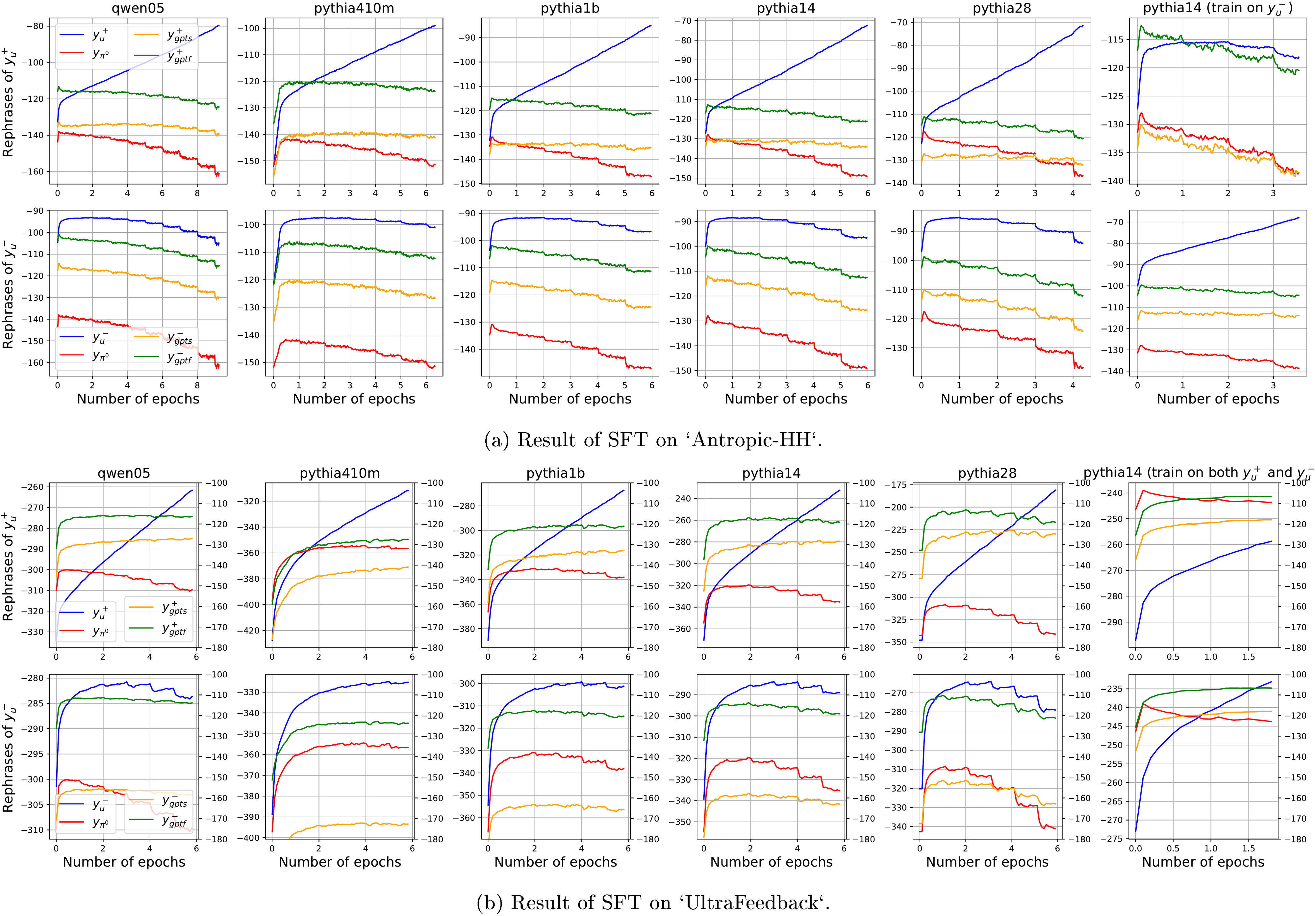
D.2 More results on different settings: SFT case
Consistent learning dynamics for different models. In this subsection, we provide more results to support our analysis on SFT in Section 4.1. The first thing to verify is the consistency of the trends of learning dynamics across different settings. As illustrated in Figure 14, we conduct SFT on five models with different sizes pretrained using different recipes. Note that
Pythia-410M/1B/1.4B/2.8B are pretrained using exactly the same dataset and pipeline ([30]), while Qwen1.5-0.5B are pretrained differently. Hence we can observe a slight difference between the curves from Pythia series and Qwen series, e.g., those in . However, the trends demonstrated in Figure 3 consistently hold for all models.Compare the rephrases of and . See Figure 15, where we put the rephrases of the same response into the same figure. We can treat the red curve, i.e., the one of generated by , as a baseline, whose decaying suggests the policy model is deviating from the initial point. The first observation is that after several updates, is the only one that keeps increasing fast, which means the "pull up" pressure generated by do not have that strong influence on these rephrases compared to , even though these are good rephrases of (recall the curve always increase in Figure 14). Furthermore, by carefully comparing the decreasing speed of and other curves, we find those rephrases decays slower than in the chosen case, but not the case for the rejected responses. This phenomenon also supports our analysis well: because we train the model using , their rephrases are "pulled up" more than the rephrases of . Such a claim is also verified by the experiment in the last column of this figure, where we train the model using rather than . In these two panels, we see the decaying speed of rephrases of is now identical to that of while the decaying speed of rephrases for is slightly slower. Last, compare the green and orange curves (i.e., the format-keeping and semantics-keeping
GPT rephrases), we find the predicting probabilities of those format-keeping curves are usually larger than their semantic-keeping counterparts. This is a sign that the model during SFT might care more about the format rather than the semantics of one sentence. We will delve into this interesting phenomenon in our future work.Compare and . To isolate the influence of the "pull up" pressure introduced by the training updates, we also create another probing dataset using the same pipeline as . The only difference between them is that all in comes from the test set, and hence neither the prompts nor the responses ever occur during training. See Figure 16, where the solid curves and dotted curves represent the learning dynamics of responses in and respectively. The color of the curves represents the model we are finetuning. By qualitatively comparing the trend difference between curves coming from and , we roughly observe that
trend_diff > trend_diff() > trend_diff() > trend_diff(), which aligns well with our hypothesis about how strong the "pull up" pressure influence different responses.![**Figure 13:** The learning dynamics of responses in different groups in the proposed probing dataset. Trends to observe: 1.) $ \bm{\mathsf{y}}_u^+$ increase and $ \bm{\mathsf{y}}_u^-$ first increase then decrease; 2.) both $ \bm{\mathsf{y}}_\text{urnd}^+$ and $ \bm{\mathsf{y}}_\text{rnd}'$ decrease and very small; 3.) $ \bm{\mathsf{y}}_{j\neq u}^+$ increases with a smaller rate than $ \bm{\mathsf{y}}_u^+$, although the $[\bm{\mathsf{x}}_u; \bm{\mathsf{y}}_{j\neq u}^+]$ never occurs during training; 4.) both $ \bm{\mathsf{y}}_\text{test}^+$ and $ \bm{\mathsf{y}}_\text{hum}$ has a bell-shape curve; 5.) the inflection of $ \bm{\mathsf{y}}_\text{hum}$ is earlier. Because we find that most sentences in $ \bm{\mathsf{y}}_\text{hum}$ are descriptive ones while those in $ \bm{\mathsf{y}}_\text{test}^+$ are question-answer style sentences. This suggest that the $ \bm{\mathsf{y}}_\text{test}^+$ are semantically more similar to $ \bm{\mathsf{y}}_u^+$ than $ \bm{\mathsf{y}}_\text{hum}$ (i.e., larger $\|\mathcal{K}^t\|_F$). Hence in general, the "pull-up" pressure on $ \bm{\mathsf{y}}_\text{test}^+$ is larger, and hence its inflection point is later than $ \bm{\mathsf{y}}_\text{hum}$.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/63899d29/complex_fig_33e650da94b4.png)
💭 Click to ask about this figure
💭 Click to ask about this figure
💭 Click to ask about this figure
💭 Click to ask about this figure
D.3 More results on different settings: off-policy DPO case
Similar to Appendix D.2, we also provide extra experiments for DPO in this part using the same probing dataset. Note that as the responses of on-policy DPO change generation-by-generation, it is hard to observe the dynamics of a pre-collected probing dataset. We left the exploration of how to effectively probe other DPO variants in our future work.
Consistent learning dynamics for different models. Compare Figure 4 in the main context and Figure 18, where we provide the results on many different models (
Pythia-410M/1B/2.8B and Qwen1.5-0.5B). Their trends on different are quite consistent:- 1.) in the first column, the margin keeps increasing. The first increase and then decrease, always with a smaller decay speed than that of ;
- 2.) in the second column, decreases slower than the other rephrases, verifying the "pull up" pressure and the influence on other responses via ;
- 3.) in the third column, decreases faster than the other rephrases, verifying the "push down" pressure and the influence on other ;
- 4.) in the fourth column, the rephrases of decay slower than those of , supporting the claims that the rephrases near the chosen responses are influenced by the "pull up" pressure while the rephrases of the rejected ones are influenced by the "push down" pressure.
Learning dynamics of conducting SFT first, then DPO. As stated in ([6]), conducting SFT before DPO is a common pipeline for alignment. Using as the SFT dataset is also a common practice in many existing works. Hence in this part, we plot the curves of different in both two stages to demonstrate their differences. See Figure 17, where the difference between the experiments in these three rows is how long the model is trained using SFT before DPO. The learning rate of both SFT and DPO are controlled to be the same (i.e., , the default value in ([9])). All the curves are aligned by the 10th epoch on the x-axis (i.e., the starting time for the DPO training) for the convenience of comparing the trends across different settings.
We first check the curves of SFT and DPO parts separately and find that all the above relative trends still hold in these experiments. We then compare the model's behavior in these two phases respectively. In the last two rows of Figure 17, where the epoch for SFT is non-zero, it is clear that the decaying speed of most observing is much larger in DPO than those in SFT. The main reason for this is the existence of a big negative gradient introduced in DPO. This gradient, especially conducted on a "valley" region of the model's prediction, will "push down" the whole curve significantly, except the one with the highest confidence before updating. This non-trivial trend is named "squeezing effect", which is elaborated on in Appendix E. Furthermore, a more peaky and a smaller will lead to a stronger "squeezing effect", which can be verified by comparing the curves of the last two panels: longer SFT makes the model's prediction peakier when DPO is conducted, which leads to a larger decay on all during DPO.
💭 Click to ask about this figure
💭 Click to ask about this figure
E. The Squeezing Effect Introduced by Big Negative Gradient
In DPO, the model gradually learns how to separate the chosen and rejected responses by imposing one positive and one negative adaptation vector centered at and respectively, as illustrated in the second panel in Figure 2. These two opposite pressures ensure the margin reward keep increasing, which makes the model align better with human preferences. However, if we go deeper and consider and separately (actually we should, because their are usually different), a very interesting phenomenon occurs. See the first column of Figure 18, we find although DPO also contains a strong positive adaptation vector, the curve of all goes down after several updates, which is very different from in the SFT case. Such an observation is also reported in many related works ([8,9,26,27]), but a clear-cut explanation of it is still missing. Furthermore, although the relative behaviors of various rephrases matches our analysis of learning dynamics well, merely the two pressures on and cannot explain why all these observed keeps decreasing during training. So, it is natural to ask:
Where has the probability mass gone?
E.1 The Squeezing Effect and Why it Exists
To answer the above question, we can start from the properties of the basic function by analyzing a simple multi-class logistic regression problem. Because no matter how complex the LLM is, its predictions are made by converting the logits into probabilities using heads. Note that the analysis here only considers the negative gradient, i.e., the one imposed by in LLM's finetuning. As also pointed by [27], the pull up pressure imposed by will cancel the influence imposed by when their are identical. However, when and are dissimilar, the squeezing effect discussed in this paper still dominates. We left analyzing this intricate interaction between these two pressures is left to our future work.
Consider a simple -class logistic regression problem where each high-dimensional input data is converted to a length- feature vector via a deep neural network . In other words, we have . The model uses a linear read-out layer to convert the feature vector to logits and then generate the probability prediction vector using a head. We consider a common cross-entropy loss function for each input pair . In summary, we have:
where is the index of the step during training and is a length- one-hot vector determined by the ground truth label . To simplify our analysis, we assume a fixed and only update the parameters of the read-out layer using stochastic gradient descent:
where is the learning rate which can be negative if we consider a negative gradient during training. With Equation 18 and (Equation 19), we can write down each dimension of and after some calculations. To quantitatively analyze how the model's confidence in each class changes, we define a ratio and use the following lemma to describe its behavior:
Lemma 2
The ratio of confidence change for each can be represented as:
Note that the values of also depends on whether equals , hence for Case 1 () and Case 2 (), we have ( is the equivalent learning rate):
Proof: To derive Equation 20, we need to have the analytical expression of each and . As , we need to link and first. With Equation 18 and (Equation 19), can be recursively written down as:
where is the equivalent learning rate that depends on the norm of feature representation. Note that , and are all length- vectors and is an integer ranging from 1 to . Then we can write down each as:
Then, we can combine the definition of function and write down different case-by-case. For Case 1 where , we have:
combining the fact that , we can derive and as the left part of Equation 21. Similarly, when , we have:
which leads to the right part of Equation 21.
We can now better understand how each changes after this update. Specifically, if , the corresponding increases, and vice versa. To determine the value of , we can treat any as contributing to the conclusion that while any against it. The value of the corresponding and controls how strong the contribution is. With the preparations above, we derive the following observations on how the confidence evolves when a gradient ascent (i.e., ) is imposed on class .
Claim 1: The value of is guaranteed to decrease, i.e., .
We start from the value of in Case 1 as illustrated in Equation 21. It is clear that for any , we have , because . Combining with , it is straightforward to have Claim 1.
Claim 2: The value of where is guaranteed to increase, i.e., .
We now use the value of in Case 2, since cannot equal by definition. When , we have for all possible , because is the largest among all of . Hence all must be smaller than one. Combining with the fact that (because must be negative), we can prove that .
The two claims above demonstrate that the parameter update can be imagined as taking the probability mass from and redistributing that to other dimensions. From Claim 2, we know some of the mass is guaranteed to be "squeezed" into the dimension with the highest (if is the highest value, then is the second highest in ). But how other changes is still not clear yet. Will the probability mass from is also split into other (i.e., other increases)? Or will absorb the mass not only from but also from other dimensions (i.e., other decreases)? To get a clearer picture, we need to track the adaptations of each . To achieve this, we now must scrutinize the distribution of , because it controls the value of for different . We chose three typical scenarios where is strictly uniform, slightly non-uniform, and extremely peaky, and leads to the following claims.
Claim 3A: When is a uniform distribution, the probability mass decreased from class is uniformly distributed to all other , i.e., all increase the same value.
With the uniform assumption, Equation 20 can be simplified to . Note that the first two claims hold for any distribution , hence we only check the values of here to verify the "uniformly distributed mass" hypothesis. Substituting the values of to this new leads to for all . Since and , we must have . Combined with the fact that all are the same, this claim can be proved.
Claim 3B: When is slightly non-uniform, with smaller tend to decrease, and vice versa.
This claim is a general trend and might not have any guarantees. However, analyzing such a scenario helps us to understand the influence of better. Assume we are observing where is not nor . We consider two subsets of , i.e., , which contains all with and that contains all with . Now consider Case 2 in Equation 21, we have:
Note that we misuse the notation to highlight the fact that would be much smaller than , because there is a negative one term in the exponential. With the above expression, we can imagine that if is relatively small, the size of would be large, which means there will be more contributing to the conclusion that . If the influence of is strong enough to override the influence of other (especially which is way smaller than other ), would be smaller than one and hence decreases. On the contrary, for those with relatively large , the terms becomes dominant and hence lead to , i.e., increases.
In the analysis above, we assume is only slightly non-uniform (i.e., not so peaky), which means the values of different are relatively comparable. However, in practical machine learning systems like LLM's finetuning, the distribution would be very non-uniform, which means most of the probability mass is obtained by a few dimensions. That is because the LLM's vocabulary size is usually very large and the reasonable choice of the next word is only a small portion of the whole vocabulary. Thus we have the following claim to describe this practical scenario.
Claim 3C: When is very peaky, which means most of the probability mass is obtained by , then all other will decrease. In other words, the probability mass of all other is squeezed to .
We continue the analysis in Claim 3B but consider a more extreme influence on . For this peaky , we might have an very large that dominates . In other words, . Then for any we want to observe, the . In other words, the model's predictions on all dimensions other than the one with the highest confidence in will decrease.
Last, we analyze the influence of to explain why "imposing a large negative gradient on the valley region" makes the squeezing effect more serious.
Claim 4: Smaller makes those non-max easier to decay, i.e., a stronger squeezing effect.
This is also a general trend that is observed in the experiments in Figure 20. Intuitively, since the model is already confident that cannot be the correct label (i.e., is very small), letting the model further decrease the prediction on does not make sense. We can also use the analysis above to understand how it happens. As illustrated in Equation 23, where the value of is decomposed into three subgroups. Recall the definition of , we know all contribute to the hypothesis that increases after this update, where the strength of this contribution is controlled by . Since a small means a small , the influence of is significantly weakened under this scenario. In other words, is more likely to occur for all possible , which means the squeezing effect (all decreases) becomes more serious.
Claim 5: The learning rate with a larger absolute value and a larger feature norm will amplify all the trends, maybe more serious than our expectation.
Throughout our analysis, the equivalent learning rate is a shared scalar in all . Hence larger can amplify all the trends aforementioned. Furthermore, recall the shape of an exponential function , where a small change of (especially when ) will make changes a lot. Then the terms in Case 1 and in Case 2 will play a stronger role if we use a larger learning rate or the norm of features is larger.
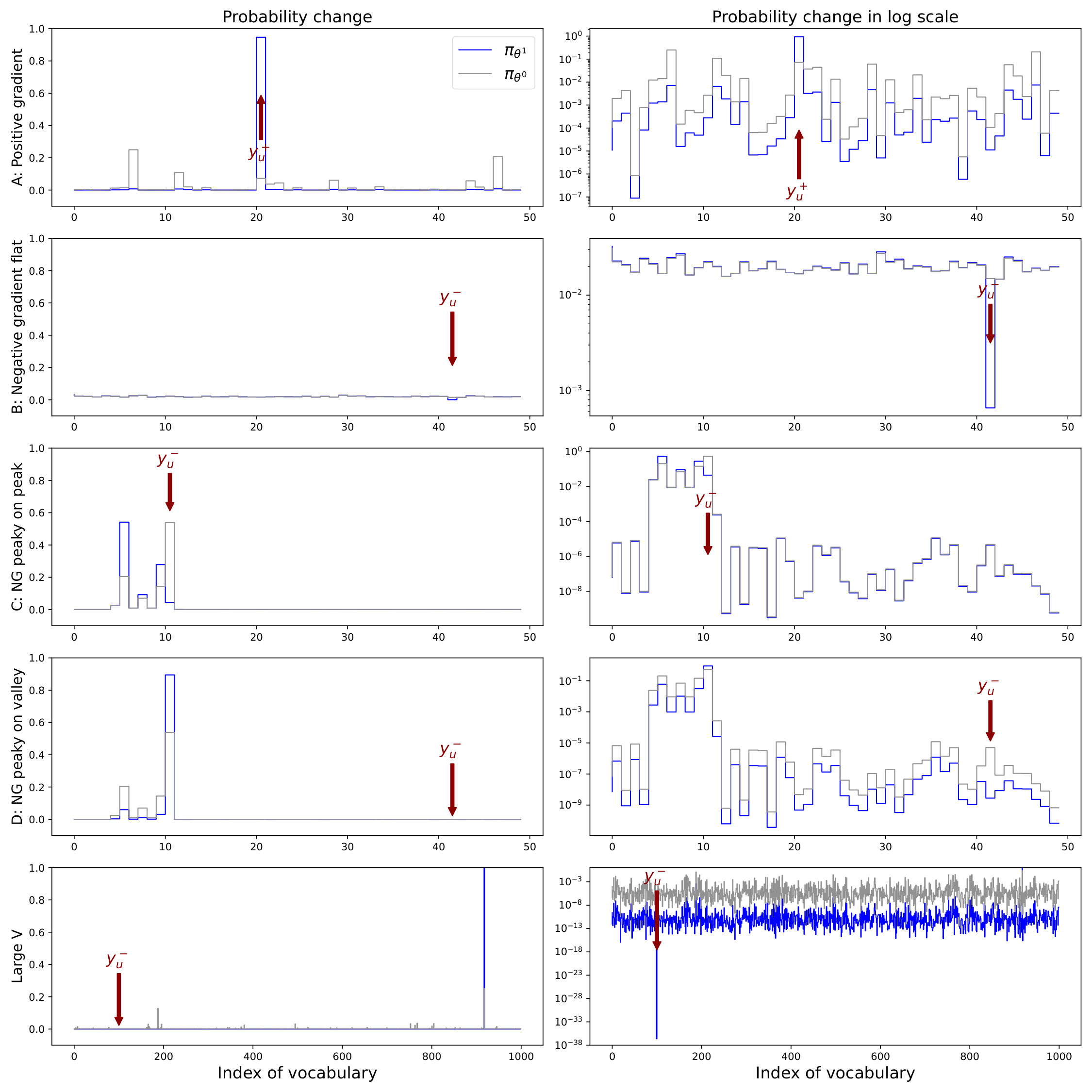
E.2 Verify the Squeezing Effect using a Simple Experiment

💭 Click to ask about this figure
💭 Click to ask about this figure
Let us analyze a simple example to get an intuition. We set , , , and a randomly generated . In the first row of Figure 20, we consider the model updates its parameters using standard SGD assuming the label of this is 21. Specifically, we randomly generate by sampling each parameter from a standard Gaussian distribution and calculate using Equation 19. The two curves in each panel demonstrate the model's predicted distribution before and after this update. As we expected, the positive vector on the 21st class "pull up" and "push down" all other at the same time. This trend is quite consistent under different settings (i.e., different choices of , etc.), which can be depicted by the first panel in Figure 19.
We then set to simulate the negative gradient in DPO and consider three different settings. First, we assume the model's prediction on is relatively flat, as demonstrated in the second row of Figure 20, where the predicting probability of every class is around 0.02. The negative gradient is imposed on , a randomly selected number. We see the negative adaptation vector "push down" heavily and re-assign those decreased probability mass evenly to all other classes, as illustrated in the second panel in Figure 19.
Although the behavior described above follows our intuitions well, a flat is not common in LLM's finetuning. Because finetuning usually starts from a pre-trained , where the model's prediction would likely be non-uniform. So in the third row of Figure 20, we consider a more practical that leads to a multi-mode . In this example, the model has relatively high confidence in classes 5 to 11 and low confidence in all other dimensions. We set the target label as 11 (i.e., the one in the model has the highest confidence) and use to "push down" the model's prediction on this class. As demonstrated by the blue curve, decreases a lot as we expected. However, different from the flat case, where the model evenly assigns the reduced probability mass to all other , the model in this example "squeezes" the mass to those confident predictions, i.e., classes 6, 9, and 10, leaving the confidence of other classes almost unchanged. Such a trend is consistent when the negative gradient is imposed on the "peaky" region of a non-uniform distribution, as illustrated in the third panel in Figure 19.
The previous setting simulates the on-policy DPO well, where the rejected examples are sampled from the high confidence region of the model's predictions. Then, what will happen if we conduct off-policy DPO and impose a big negative gradient on those classes that already have very low confidence? See the fourth row of Figure 20, where we use the same and as in the previous case. The only difference is that we change the label of to 42, where is very small (roughly ) before training. The behavior in this setting is quite interesting: we first observe a big increase on , which means the model "squeezes" the probability mass to the most confident one in , similar to the previous setting. More interesting, the predictions on all other are heavily "pushed down", even including classes 6, 9, and 10, whose confidence is relatively high before training. In the last two panels of Figure 20, we set and find this trend is more obvious (that might be because the absolute value of the efficient learning rate, which depends on , becomes larger). Since the vocabulary size of a common LLM is usually more than 50k, the squeezing effect in real systems would be non-negligible even if the learning rate is small. Such a trend is also quite consistent as long as we impose a big negative gradient on the "valley" region of the model's prediction, as illustrated in the last panel in Figure 19. Now we can answer the question of why all observing decreases and where the probability mass has gone:
For each token, the probability mass is squeezed to the one with the highest confidence.
Note that the tokens with the highest confidence do not necessarily form a preferred response: it just reinforces the prior knowledge contained in , which could be a drawback for off-policy DPO.
The hypothesis above is not only supported by this simple logistic regression problem but also by many consistent trends in LLM's finetuning experiments. First, by comparing the average decaying speed of the when the model SFT different epochs before DPO (in Figure 17), we notice that longer SFT leads to a more peaky and hence leads to a faster decaying speed of all non-argmax responses. That is because the longer SFT stage will eventually push down more. Hence in the DPO stage, the big negative gradient is imposed on a deeper valley region, which makes the squeezing effect stronger. Second, to directly verify this hypothesis, we track the sum of the log-likelihood of the tokens with the largest confidence and call it "argmax confidence", i.e., . As illustrated in the last panel in Figure 4, the argmax confidence keeps increasing while all other decreases: the missing probability mass is found! Last, in the dataset-extension method we proposed in Section 4.3 and Appendix F, we train the model using both and during SFT to also "pull up" the region before conducting DPO. Then, we observe compared with the standard training flow, i.e., SFT using first and then DPO, the proposed flow has a lower "argmax confidence" during DPO. That is because we pulled up during the modified SFT stage, the big negative gradient is then imposed on the peaky region rather than the valley region of the model's prediction. Such a change in turn weakens the squeezing effect, as illustrated in Figure 5.
F. A Simple Method to Improve Alignment
F.1 Pinpointing the drawback of off-policy DPO
Based on our observations and analysis above, we speculate that "imposing big negative gradients on the valley region" is one of the bottlenecks of off-policy RL-free methods. Starting from this hypothesis, we believe introducing on-policy sampling has the potential to mitigate this problem, as demonstrated in SPIN ([23]) and other online algorithms ([15]). However, we also speculate that these methods improve the model's performance not only by mitigating the squeezing effect. Hence to figure out to what extent the squeezing effect can harm the model's performance, we propose a simple yet effective method to isolate its influence. As this method can directly mitigate this effect, it can also be considered as an ablation study of this interesting phenomenon.

💭 Click to ask about this figure
F.2 A simple method inspired by learning dynamics
As illustrated in Figure 21, where the baseline method is a standard SFT-then-DPO pipeline. The proposed method is very simple. We only need to augment the dataset used in SFT by adding pairs for each sample into it. All other settings are unchanged. The motivation for this method is also quite simple: as SFT can pull up the region of supervised and we don't want the model to impose big negative gradients on a valley region, we can just pull up those before DPO. Furthermore, as demonstrated in the third panel in Figure 19 and Equation 11, the negative gradient in DPO would be strong enough to push down , because the gradient will be large if the model cannot separate and well. In other words, under DPO's loss, there is no need to worry about the model overfitting those during SFT.
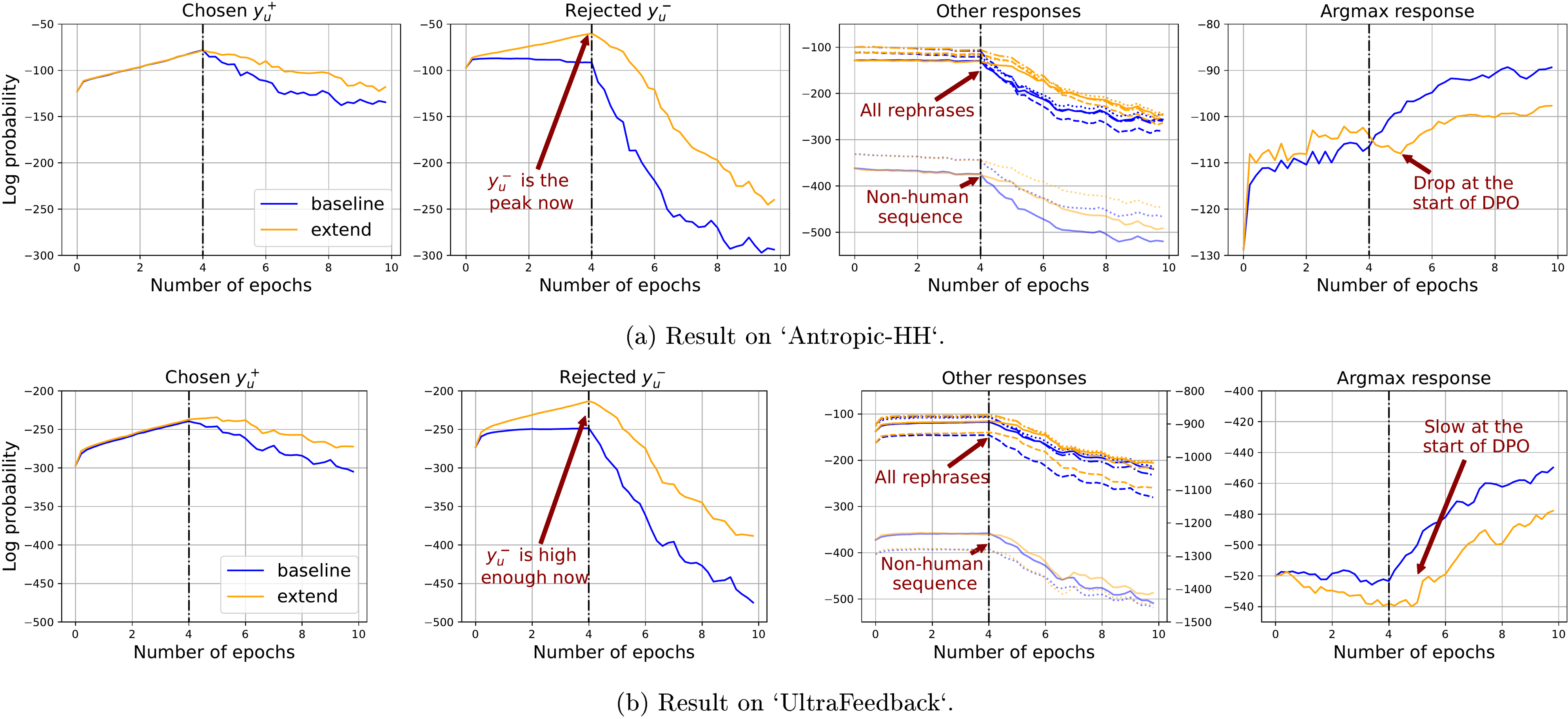
💭 Click to ask about this figure
F.3 Experimental verification
To verify our analysis, we conduct experiments by finetuning a pretrained
Qwen1.5-1.8B ([31]) model using Antropic-HH dataset ([28]) (we use a subset containing 5000 random examples from the training split). The pipelines of different methods are demonstrated in Figure 21. In this experiment, we call the pretrained model (and , which is identical to ), which is an official checkpoint pretrained by [31]. Model and are the ones after SFT, which are different for these two methods. Model and are the models finetuned using DPO for 2/4/6 epochs. All the settings (except the starting model) of the DPO stage are the same for these two methods.We first observe the learning dynamics of these two methods in Figure 5, where all the trends support our analysis quite well. See the first two panels that compare and respectively. It is clear that these two methods have an almost identical curve on in the SFT stage but behave quite differently on : because we directly train the model using in the proposed method. Then, after the SFT stage, we conduct DPO using identical settings for these two methods. From the first three panels, we can observe the decay speed of all curves of the proposed method is smaller than its counterpart in the baseline. That is the benefit introduced by "pulling up" the region before conducting DPO. With this specific design, the big negative gradients in DPO are imposed on the peaky region (the behavior is like the third panel in Figure 19) rather than the valley region (see the fourth panel), hence the squeezing effect is successfully restrained. The results in the last panel of Figure 5 are also a strong verification of the whole picture. During the SFT stage, the observed "argmax-probability" of the proposed method is higher than the baseline, because we impose twice "pull up" pressure, i.e., those for , compared with the baseline. However, at the beginning of DPO, we observe a clear drop in the orange curve. That is because the negative gradients are exactly imposed on those (in the second panel of Figure 5, is already very high). Furthermore, at the end of DPO, we see the "argmax-probability" of the proposed method is significantly lower than the baseline setting, which implies that the squeezing effect is restrained in our setting.
In order to figure out whether the model trained using the proposed flow, which successfully restrains the squeezing effect, indeed does alignment better, we conduct pair-wise comparisons of these models' responses and report their win rate as in ([11]). Specifically, we first randomly select 1000 test questions from the test split of
Antropic-HH and generate 1000 responses by feeding the prompts to each of these models (we use the default sampling setting provided in ([11])). Then, with the prompt template provided in Figure 23, we evaluate the win rate of the responses pairs using GPT3.5-Turbo and Claude3-Haiku. Here we report the average win rate of different comparisons (the degenerated responses are not compared, so the number of compared examples is slightly smaller than 1000). Note that a win rate greater than 0.5 means the method that comes first is preferred by the evaluator.-
1. Compare models after SFT: v.s. , win rate is 0.4729 and 0.4679;
-
2. Demonstrate benefits of DPO:
- a. v.s. , win rate is 0.6727 and 0.6411;
- b. v.s. , win rate is 0.6898 and 0.7321;
-
3. Compare the proposed method and baseline after DPO for different epochs:
- a. v.s. , win rate is 0.6518 and 0.5151;
- b. v.s. , win rate is 0.6928 and 0.6045;
- c. v.s. , win rate is 0.6667 and 0.5432;
-
4. Compare the best with other 2 checkpoints:
- a. v.s. , win rate is 0.6853 and 0.5517;
- b. v.s. , win rate is 0.6324 and 0.5316;
In the first comparison, we find the model trained using both and loses more (win rate is smaller than 0.5), which makes sense because assigns higher probabilities on those less preferred responses. In the second comparison, the model fine-tuned using DPO indeed aligns with human value better. The win rate of the proposed method is slightly higher, which might also be explained as leaving more space for improvement. Hence we then directly compare the models after DPO in these two methods in the third group. In this group, all models in the proposed method win the baseline counterparts by a large margin, which demonstrates the effectiveness of our proposed method. Furthermore, we find the evaluation made by
Claude is more reserved compared with GPT (the numbers are smaller). However, the trends among the comparisons in this group are consistent: brings the largest improvement, which is potentially the best model. This fact is verified in the fourth group comparison, where we evaluate against and . The results demonstrate that both a too-long or too-short finetuning stage using DPO is not the best choice.![**Figure 23:** Prompt used for evaluating model's response (from ([11])), an example feedback from `GPT3.5-turbo`, and two examples of the "degenerate" effect described in [13]. Although both $B_2$ and $E_2$ inevitably generate such degenerate responses, we find this phenomenon is less common in the proposed method.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/63899d29/app_proposed_method_prompts.png)
💭 Click to ask about this figure
References
[1] Ren et al. (2022). Better Supervisory Signals by Observing Learning Paths. In ICLR.
[2] Park et al. (2024). Emergence of Hidden Capabilities: Exploring Learning Dynamics in Concept Space. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
[3] Ren et al. (2023). How to prepare your task head for finetuning. In ICLR.
[4] Pruthi et al. (2020). Estimating training data influence by tracing gradient descent. NeurIPS.
[5] Xia et al. (2024). Less: Selecting influential data for targeted instruction tuning. arXiv:2402.04333.
[6] Ouyang et al. (2022). Training language models to follow instructions with human feedback. NeurIPS. pp. 27730– 27744.
[7] Ji et al. (2024). Towards Efficient and Exact Optimization of Language Model Alignment. arXiv:2402.00856.
[8] Rafailov et al. (2024). From to : Your Language Model is Secretly a Q-Function. arXiv:2404.12358.
[9] Tajwar et al. (2024). Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data. arXiv:2404.14367.
[10] Wei et al. (2022). Finetuned Language Models are Zero-Shot Learners. In ICLR.
[11] Rafailov et al. (2023). Direct preference optimization: Your language model is secretly a reward model. NeurIPS.
[12] Schulman et al. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
[13] Holtzman et al. (2020). The Curious Case of Neural Text Degeneration. In ICLR.
[14] Huang et al. (2023). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv:2311.05232.
[15] Guo et al. (2024). Direct language model alignment from online AI feedback. arXiv:2402.04792.
[16] Fort et al. (2019). Stiffness: A new perspective on generalization in neural networks. arXiv preprint arXiv:1901.09491.
[17] Hangfeng He and Weijie Su (2020). The Local Elasticity of Neural Networks. In International Conference on Learning Representations.
[18] Deng et al. (2021). Toward better generalization bounds with locally elastic stability. In International Conference on Machine Learning. pp. 2590– 2600.
[19] Jacot et al. (2018). Neural tangent kernel: Convergence and generalization in neural networks. In NeurIPS.
[20] Arora et al. (2019). On Exact Computation with an Infinitely Wide Neural Net. In NeurIPS. arXiv:1904.11955.
[21] LeCun et al. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE. 86(11). pp. 2278– 2324.
[22] Vaswani et al. (2017). Attention Is All You Need. In NeurIPS. arXiv:1706.03762.
[23] Chen et al. (2024). Self-play fine-tuning converts weak language models to strong language models. arXiv:2401.01335.
[24] Wu et al. (2024). Self-play preference optimization for language model alignment. arXiv:2405.00675.
[25] Zhao et al. (2023). Slic-hf: Sequence likelihood calibration with human feedback. arXiv:2305.10425.
[26] Pal et al. (2024). Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive. arXiv:2402.13228.
[27] Razin et al. (2025). Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization. In The Thirteenth International Conference on Learning Representations.
[28] Bai et al. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv:2204.05862.
[29] Cui et al. (2023). UltraFeedback: Boosting Language Models with High-quality Feedback. arXiv:2310.01377.
[30] Biderman et al. (2023). Pythia: A suite for analyzing large language models across training and scaling. In ICML. pp. 2397– 2430.
[31] Jinze Bai and Shuai Bai (2023). Qwen Technical Report. arXiv:2309.16609.
[32] Ren et al. (2024). Bias Amplification in Language Model Evolution: An Iterated Learning Perspective. NeurIPS.
[33] Yuan et al. (2024). Self-rewarding language models. arXiv:2401.10020.
[34] Xiong et al. (2024). Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-constraint. In ICML.
[35] Gekhman et al. (2024). Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?. arXiv:2405.05904.
[36] Liu et al. (2020). Early-learning regularization prevents memorization of noisy labels. NeurIPS.
[37] Kumar et al. (2022). Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution. In ICLR.
[38] Ren et al. (2020). Compositional languages emerge in a neural iterated learning model. In ICLR.
[39] Ren et al. (2023). Improving compositional generalization using iterated learning and simplicial embeddings. NeurIPS.
[40] Yi Ren and Danica J. Sutherland (2024). Understanding Simplicity Bias towards Compositional Mappings via Learning Dynamics. In NeurIPS 2024 Workshop on Compositional Learning: Perspectives, Methods, and Paths Forward.
[41] Hinton et al. (2015). Distilling the knowledge in a neural network. arXiv:1503.02531.
[42] Guo et al. (2024). lpNTK: Better Generalisation with Less Data via Sample Interaction During Learning. In ICLR.
[43] Dan Feldman (2020). Introduction to core-sets: an updated survey. arXiv:2011.09384.
[44] Burr Settles (2009). Active learning literature survey.
[45] Mohamadi et al. (2022). Making Look-Ahead Active Learning Strategies Feasible with Neural Tangent Kernels. In NeurIPS. arXiv:2206.12569.
[46] Wang et al. (2018). Dataset distillation. arXiv:1811.10959.
[47] Zhang et al. (2023). Siren's song in the AI ocean: a survey on hallucination in large language models. arXiv preprint arXiv:2309.01219.
[48] Tang et al. (2024). Understanding the performance gap between online and offline alignment algorithms. arXiv preprint arXiv:2405.08448.
[49] Zhang et al. (2024). Negative preference optimization: From catastrophic collapse to effective unlearning. arXiv preprint arXiv:2404.05868.
[50] Caccia et al. (2020). Language GANs Falling Short. In International Conference on Learning Representations.
[51] Choshen et al. (2020). On the Weaknesses of Reinforcement Learning for Neural Machine Translation. In International Conference on Learning Representations.
[52] Christiano et al. (2017). Deep reinforcement learning from human preferences. NeurIPS.
[53] Azar et al. (2024). A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics. pp. 4447– 4455.
[54] Yang et al. (2024). Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning. arXiv:2402.13669.