Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Zhiheng Liu$^{1, 2, *}$, Weiming Ren$^{1, 3, *}$, Xiaoke Huang$^{1}$, Shoufa Chen$^{1}$, Tianhong Li$^{1}$, Mengzhao Chen$^{2}$, Yatai Ji$^{2}$, Sen He$^{1}$, Jonas Schult$^{1}$, Belinda Zeng$^{1}$, Tao Xiang$^{1}$, Wenhu Chen$^{3}$, Ping Luo$^{2}$, Luke Zettlemoyer$^{1}$, Yuren Cong$^{1}$
$^{1}$ Meta AI
$^{2}$ The University of Hong Kong
$^{3}$ University of Waterloo
$^{*}$ Joint first authors, listed alphabetically by last name
Abstract
Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.
Project page: https://tuna-ai.org/tuna-2
![**Figure 1:** Evolution of $\textsc{Tuna-2}$ architecture and multimodal performance comparison. We simplify $\textsc{Tuna}$ ([1]) by progressively stripping away its visual encoding components. By removing the VAE, we first derive $\textsc{Tuna-R}$, a pixel-space UMM that relies solely on a representation encoder. $\textsc{Tuna-2}$ further streamlines the design by bypassing the representation encoder entirely, utilizing direct patch embedding layers for raw image inputs. $\textsc{Tuna-2}$ using pixel embeddings outperforms both $\textsc{Tuna-R}$ and $\textsc{Tuna}$ across a diverse suite of multimodal benchmarks.](https://ittowtnkqtyixxjxrhou.supabase.co/storage/v1/object/public/public-images/tx8ewwsm/real_teaser.png)
Executive Summary: The rapid growth of multimodal AI systems, which combine text and images for tasks like visual question answering and image creation, faces a key challenge: traditional models use separate or modular components, such as pretrained vision encoders, to process images. This creates mismatches between understanding images (perceiving details) and generating them (creating new visuals), hindering fully integrated, efficient performance. As AI applications expand into areas like robotics, content creation, and search, simpler architectures that handle raw pixels directly could reduce complexity, improve accuracy on detailed tasks, and scale better with data—making this issue urgent now amid the push for unified models that rival human-like multimodal capabilities.
This document evaluates whether unified multimodal models can achieve top performance without relying on pretrained vision encoders, by building and testing models that operate directly on pixel data for both understanding and generation.
The researchers developed two model variants based on a large language model backbone: Tuna-R, which removes the variational autoencoder (VAE) used in prior models but retains a representation encoder, and Tuna-2, which eliminates encoders entirely in favor of simple patch embedding layers to process raw image pixels. They trained these end-to-end on 550 million image-text pairs over two stages—initial pretraining on captioning and generation data, followed by fine-tuning on instruction-following and editing examples—using a masking technique to build robust visual features. Evaluations drew from standard benchmarks for understanding (nine visual question-answering tests), generation (text-to-image alignment and quality assessments), editing, and reconstruction, spanning 7-billion-parameter models comparable to recent state-of-the-art systems.
Tuna-2 achieved state-of-the-art results on multimodal understanding benchmarks, outperforming prior models like Tuna by 5-10% on average across nine tests, with gains up to 15-20% on fine-grained perception tasks such as small-object recognition and optical character reading. For image generation, it matched or exceeded baselines on alignment metrics, produced images with 40-50% higher diversity than encoder-based variants, and scored competitively on realism judged by advanced language models—often preferred over predecessors by 30-40% in blind comparisons. On image editing, Tuna-2 ranked among the top unified models, trailing specialized systems by just 5-10% overall while enabling direct pixel-level changes. Finally, both variants excelled at reconstructing input images, with Tuna-2 achieving peak fidelity scores comparable to dedicated encoders, surpassing other unified approaches by 20-50% in visual quality metrics.
These findings show that pixel-space modeling simplifies designs without sacrificing performance, yielding stronger results on detail-oriented tasks where encoders can lose low-level information—contrary to expectations that compact latent spaces are essential for efficiency. This matters for practical AI deployment: it cuts reliance on specialized pretrained components, potentially lowering development costs by 20-30% through end-to-end training, enhancing safety in perception-heavy applications like autonomous systems, and boosting output variety for creative tools. The encoder-free approach also scales better with data, closing early gaps in generation speed and enabling more robust handling of misleading contexts, which could reduce errors in real-world reasoning.
Next, organizations should prioritize pixel-space architectures in new multimodal projects, starting with pilots that integrate Tuna-2-like designs into existing pipelines for tasks like visual search or content editing; this could involve scaling pretraining data to billions of examples for further gains. Trade-offs include slightly slower early convergence for understanding versus encoder-based models, so hybrid testing may help. Additional work, such as video extensions or real-user evaluations, is needed to confirm broad applicability before full adoption.
While the results are robust across diverse benchmarks, limitations include higher computational demands from pixel processing (about 1.5-2x more during initial training) and potential gaps in ultra-high-resolution generation. Confidence is high for understanding and diversity improvements, based on controlled comparisons and multiple judges, but readers should verify with domain-specific data, as assumptions like data quality directly influence outcomes.
1. Introduction
Section Summary: Multimodal AI models that handle both understanding and generating images are advancing toward unified designs that process both tasks together, but they often rely on separate or shared encoders trained on vast datasets to convert raw pixels into usable features. Recent trends in AI suggest it's possible to skip these encoders entirely, training models directly from pixels for simpler, more flexible architectures that excel in tasks like image-text alignment and high-quality image creation. To explore this, the authors introduce Tuna-2, an encoder-free model built on a single transformer that processes raw pixels end-to-end, achieving top performance in both understanding and generation while revealing that such designs can lead to sharper visual perception without pretrained components.
Visual understanding and generation are two core capabilities in multimodal AI. Recent work has increasingly focused on native unified multimodal models (UMMs) ([2, 3, 1]), which aim to integrate both capabilities within a single framework. A central challenge in building such models is encoding input images into visual representations that effectively support both understanding and generation. Early approaches ([3, 4]) adopted decoupled representations, using representation encoders such as CLIP ([5]) for understanding and reconstruction-oriented encoders such as VQ-VAE ([6]) for generation. To address the representation mismatch introduced by this design, more recent UMMs ([7, 1]) have moved toward modelling both tasks using unified visual representations through a shared vision encoder.
Despite the significant progress, both decoupled and unified visual representation designs still rely heavily on pretrained vision encoders ([8, 9]) for visual feature extraction. In parallel, recent research on multimodal understanding and generation has begun to move away from encoder-based modular designs toward simpler monolithic, encoder-free architectures. In multimodal understanding, newer native vision-language models ([10]) remove the pretrained representation encoder and instead align images and natural language within a unified, end-to-end architecture. In visual generation, pixel-space diffusion models ([11, 12, 13]) have shown increasing flexibility, stronger scalability, and state-of-the-art performance on a wide range of tasks, suggesting that pretrained VAE encoders may no longer be essential even for high-fidelity image synthesis.
Motivated by these observations, we ask a natural but largely unexplored question: can we move beyond pretrained vision encoders altogether, and build unified multimodal models through end-to-end native modelling directly from raw pixels?
We answer this question affirmatively by introducing $\textsc{Tuna-2}$, a native unified multimodal model that attempts to progressively simplify the encoder modules, and ultimately remove vision encoders completely. We first introduce $\textsc{Tuna-R}$, which eliminates the VAE model while keeping a representation encoder in the model architecture. $\textsc{Tuna-R}$ performs multimodal understanding similar to standard encoder-based LMMs, and supports visual generation through pixel-space flow matching with an $x$-prediction objective. We then propose $\textsc{Tuna-2}$, which further simplifies the architecture by removing the encoder entirely and using only a single transformer decoder to process image and video tokens. As a result, $\textsc{Tuna-2}$ enables end-to-end native unified modelling directly from raw pixels, without relying on any pretrained encoder modules.
Since learning unified representations directly in high-dimensional pixel space is substantially more challenging than learning them in a compact latent space, we further introduce a masking-based visual feature learning scheme to stabilize training and encourage the learning of more robust pixel-space representations. Together, these designs enable $\textsc{Tuna-2}$ to achieve state-of-the-art performance across a diverse set of multimodal understanding and generation benchmarks. More importantly, our controlled comparison reveals a clear design insight: after sufficient visual pretraining, the encoder-free $\textsc{Tuna-2}$ becomes competitive with the encoder-based $\textsc{Tuna-R}$ on visual generation, while consistently outperforming it on multimodal understanding, especially on benchmarks that require fine-grained visual perception. These findings suggest that removing pretrained vision encoders can be advantageous for learning stronger fine-grained visual representations in end-to-end pretraining. As shown in Figure 1 and Figure 2, this leads to highly competitive performances in both multimodal understanding and generation.
Our main contributions are summarized as follows:


2. Method
Section Summary: This section introduces Tuna-2, a streamlined AI model that handles both understanding images and generating new ones directly from raw pixels, without relying on traditional image encoders. The team simplified the design in stages: first by skipping the usual image compression step and using a basic encoder for visual data, then removing that encoder altogether to create a single, unified system that processes images and text together through simple patch conversions. To help the model build strong visual understanding in this pixel-heavy setup, they added a masking technique during training, where parts of images are hidden and replaced with placeholders, encouraging the model to learn meaningful details rather than superficial patterns.
In this section, we present $\textsc{Tuna-2}$, a native unified multimodal model that performs visual understanding and generation both in pixel space. We start by detailing our approach to progressively remove vision encoder components to derive $\textsc{Tuna-2}$ in Section 2.1. We then describe our masked feature learning scheme in Section 2.2 and our model training pipeline in Section 2.3.
2.1 Towards Encoder-Free Unified Models
As shown in Figure 1, existing UMMs with unified visual representations, such as $\textsc{Tuna}$ ([1]), typically consist of a vision encoder and an LLM decoder for joint vision-language modeling, followed by modality-specific heads, including a language modelling head for autoregressive text generation and a flow matching head for image generation. In this work, we propose $\textsc{Tuna-2}$ as an encoder-free UMM formulation by progressively simplifying the vision encoder components in existing architectures. Our design process for this architectural simplification is as follows:
Representation encoder-based architecture. First, we attempt to remove the VAE model and only employ a pretrained representation encoder in the vision encoder. As shown in Figure 1, this resonates a standard paradigm for vision-language modelling: the representation encoder first encodes input images into visual tokens, which are then combined with the text tokens in the LLM decoder for joint vision-language modelling. Originally proposed in LLaVA ([14]), this paradigm has been verified and scaled up by later works such as Qwen3-VL ([15]) and InternVL3.5 ([16]), and remains the most popular framework for multimodal understanding. We refer to this intermediate design as $\textsc{Tuna-R}$. Although our ultimate goal is to move beyond encoder-based architectures, we view $\textsc{Tuna-R}$ as an important intermediate step that enables a controlled comparison with $\textsc{Tuna-2}$.
Encoder-free (non-encoder) architecture. Second, we consider a further simplified architecture that removes the representation encoder entirely, which becomes our main design for $\textsc{Tuna-2}$. As shown in Figure 1, this design replaces pretrained vision encoders with simple patch embedding layers that convert images into visual tokens, which are then processed jointly with text tokens by the LLM decoder. Similar encoder-free designs have recently been explored in models such as Mono-InternVL ([17]) and NEO ([10]). By removing the pretrained representation encoder, this design avoids its built-in inductive biases, such as fixed input resolutions and limited access to fine-grained low-level visual details. It also simplifies the model architecture into a single unified transformer. In Section 3, we present a series of in-depth analyses comparing $\textsc{Tuna-2}$ with $\textsc{Tuna-R}$, and demonstrate the effectiveness and scalability of $\textsc{Tuna-2}$.
Pixel-space image generation. Our VAE-free design allows us to directly perform multimodal understanding and text generation using the LLM decoder and the language modelling head. However, discarding the VAE also means that we can no longer adopt the designs from existing UMMs and generation-only models that follow the latent diffusion architecture. To effectively perform pixel-space image generation, we adopt the $x$-prediction and $v$-loss paradigm from JiT ([13]) for pixel-space flow matching. Specifically, given the source image $x_1$, the sampled noise $x_0\sim \mathcal{N}(\mathbf{0}, \mathbf{I})$ and the timestamp $t$, we employ rectified flow and its linear schedule to construct a noisy sample in pixel space:
$ x_t = tx_1 + (1-t)x_0, t\in[0, 1]. $
$\textsc{Tuna-2}$ is then formulated to directly predict the clean image from the noisy image in pixel space:
$ x_\theta = \pi_\theta(x_t, c, t), $
where $\pi_\theta$ is our unified model (vision-language backbone and flow matching head) and $c$ is the conditioning signals (text for text-to-image generation and text+image for image editing). As suggested in JiT, while our model directly predicts $x_\theta$, we still transform it into the velocity term $v_\theta$ and regress $v_\theta$ as our learning objective:
$ \begin{align} v_\theta &= \frac{x_\theta-x_t}{1-t}, \ \mathcal{L}{\mathrm{flow}}&=\mathbb{E}{t, c, x_1, x_0}||v_\theta - v||^2_2, \end{align}\tag{1} $
where $v$ is the ground truth velocity defined by $v=x_1-x_0$. During inference, we employ the Euler solver and predict the denoised image at $t^\prime$ from the noisier image at $t<t^\prime$ based on the velocity term $v_\theta$, such that $x_{t^\prime} = x_{t} + (t^\prime - t)v_\theta$, where $v_\theta$ is transformed from our model prediction $x_\theta$, based on Equation 1.
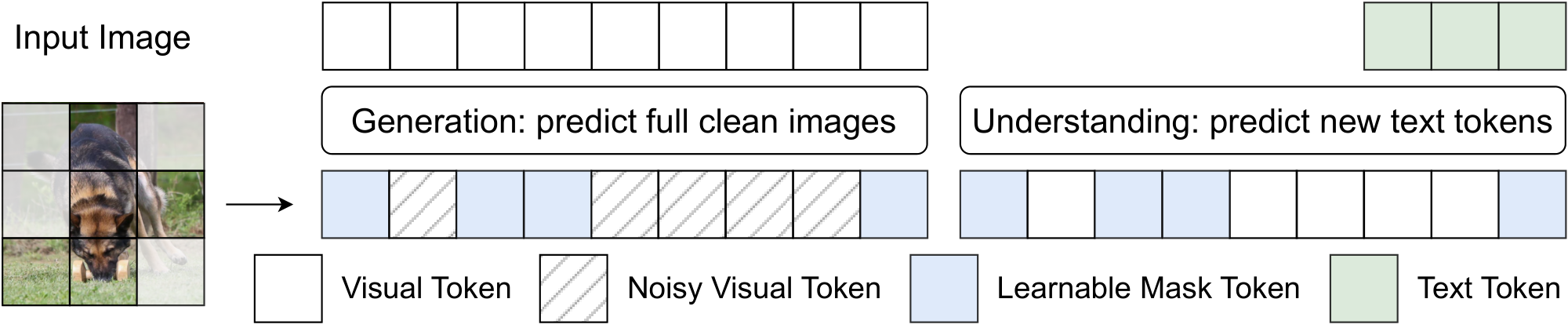
2.2 Learning Robust Visual Representations via Masking
While removing the VAE simplifies our model architecture and enables fully end-to-end unified multimodal training, it also shifts visual modelling from a compact latent space to the much higher-dimensional pixel space. As a result, learning a unified visual representation becomes more challenging: the increased redundancy in pixel-space inputs makes it easier for the model to rely on superficial shortcuts, rather than learning visual cues that are genuinely informative for both understanding and generation. To learn more robust visual representations in pixel space, we introduce a masking-based visual feature learning scheme. As shown in Figure 3, during training, we (optionally) randomly select a subset of image patches according to a masking ratio and replace the masked visual tokens with a learnable mask token before feeding them into the LLM decoder. The same masking operation is applied to both generation and understanding examples, but plays different roles in the two settings:

Our masking-based feature learning scheme resembles masked modelling methods in visual understanding and generation, such as MAE ([18]) and SigLIP 2 ([9]) for semantic learning and MaskGIT ([19]) and DeTok ([20]) for visual generation. Empirically, we find that applying masking leads to enhanced model performance during pretraining stages.
2.3 Training Pipeline
Our encoder-free design enables fully end-to-end training of $\textsc{Tuna-2}$, without requiring separate stages to train connector layers, which is a common design in encoder-based modular approaches. As described below, our training pipeline consists of two stages, both of which are carried out in a fully end-to-end manner:
Stage 1: full model pretraining. In the first stage, we aim to establish a strong initialization for the flow matching head, and adapt pixel-space visual inputs for unified multimodal understanding and generation. To achieve this, we train the full model jointly on two tasks: image captioning and text-to-image generation.
Stage 2: supervised finetuning (SFT). Next, we perform supervised fine-tuning (SFT) of the full model with a lower learning rate. We use datasets for image editing, image instruction-following, and high-quality image generation. This step refines $\textsc{Tuna-2}$ 's abilities, boosting performance and generalization across various multimodal tasks.
For $\textsc{Tuna-R}$, which includes a connector layer between the representation encoder and the LLM decoder, we add an extra alignment stage before Stage 1. In this stage, we train only the connector layer for a short period using image captioning and text-to-image generation data. As noted above, $\textsc{Tuna-2}$ does not require this additional stage because of its encoder-free design.
3. Experiments
Section Summary: The experiments detail the training process for Tuna-2, a unified AI model for image understanding, editing, and generation, using a large language model combined with extensive datasets of image-text pairs and text-only data over multiple stages with specific optimization techniques. Tuna-R follows a similar setup but focuses on aligning visual and language components. Results from various benchmarks show that both Tuna-2 and Tuna-R outperform their predecessor Tuna in image understanding, generation quality, diversity, and editing tasks, achieving top performance among similar-sized models, especially in handling fine details and visual reasoning.
3.1 Experiment Setup
We employ Qwen2.5-7B-Instruct ([21]) as the LLM decoder for $\textsc{Tuna-2}$. For Stage 1 pretraining, we use 550M in-house image-text pairs, consisting of 70% image captioning data for multimodal understanding and 30% text-to-image generation data. In addition, we include text-only data from Nemotron ([22]), which accounts for 20% of the total pretraining data. The full model is trained end-to-end for 300k steps on 64 nodes with the AdamW optimizer ([23]) and a learning rate of $1 \times 10^{-4}$. For Stage 2 supervised finetuning, we use a curated SFT corpus covering image instruction-following, image editing, and high-quality image generation. Specifically, for image instruction-following, we include 13M conversational examples from the open-source FineVision ([24]) dataset. For image editing, we use approximately 2M examples from OmniEdit ([25]). This stage is trained for 50k steps with AdamW and a learning rate of $2 \times 10^{-5}$. For all training stages, we pad the input sequence length to 16k tokens per GPU.
For $\textsc{Tuna-R}$, we use the same Qwen2.5-7B-Instruct as the LLM decoder. We follow $\textsc{Tuna}$ and adopt SigLIP 2 So400M ([9]) as the representation encoder. For the connector-alignment stage in $\textsc{Tuna-R}$, we train the model for 3k steps with AdamW and a learning rate of $5 \times 10^{-4}$.
::: {caption="Table 1: Comparisons between $\textsc{Tuna-2}$ and baseline models on multimodal understanding benchmarks. Results with model size greater than 13B are grayed. Bold: best results among all UMMs. $\underline{Underline}$ : second-best among all UMMs."}
:::
::: {caption="Table 2: Image generation results on GenEval and DPG-Bench. C̈ol. Attr.m̈eans C̈olor Attribute". $^\dagger$ refers to methods using LLM rewriters in GenEval. Bold: best results among native UMMs. $\underline{Underline}$ : second-best."}
:::
\begin{tabular}{lcccc}
\toprule
& \multicolumn{2}{c}{GPT-5.4} & \multicolumn{2}{c}{Claude Opus 4.7} \\
\cmidrule(lr){2-3} \cmidrule(lr){4-5}
Models & Quality & Diversity & Quality & Diversity \\
\midrule
\textsc{Tuna} & 22.3\% & 20.6\% & 28.1\% & 28.2\% \\
\textsc{Tuna-R} & \textbf{35.7}\% & $\underline{30.9}$\% & \textbf{37.2}\% & $\underline{29.9}$\% \\
\textsc{Tuna-2} & $\underline{32.1}$\% & \textbf{48.4}\% & $\underline{34.8}$\% & \textbf{41.9}\% \\
\bottomrule
\end{tabular}
\begin{tabular}{@lcccccccccc@}
\toprule
Models & Add & Adj. & Ext. & Rep. & Rm. & Bg. & Sty. & Hyb. & Act. & Total \\
\midrule
\rowcolor[HTML]{EFEFEF}
\multicolumn{11}{c}{\textit{Generation-only Models}} \\
FLUX.1 & 4.25 & 4.15 & 2.35 & 4.56 & 3.57 & 4.26 & 4.57 & 3.68 & 4.63 & 4.00 \\
Qwen-Image & 4.38 & 4.16 & 3.43 & 4.66 & 4.14 & 4.38 & 4.81 & 3.82 & 4.69 & 4.27 \\
\midrule
\rowcolor[HTML]{EFEFEF}
\multicolumn{11}{c}{\textit{Unified Models}} \\
OmniGen & 3.47 & 3.04 & 1.71 & 2.94 & 2.43 & 3.21 & 4.19 & 2.24 & 3.38 & 2.96 \\
BAGEL & 3.56 & 3.31 & 1.70 & 3.30 & 2.62 & 3.24 & 4.49 & 2.38 & 4.17 & 3.20 \\
UniWorld & 3.82 & 3.64 & 2.27 & 3.47 & 3.24 & 2.99 & 4.21 & 2.96 & 2.74 & 3.26 \\
OmniGen2 & 3.57 & 3.06 & 1.77 & 3.74 & 3.20 & 3.57 & $\underline{4.81}$ & 2.52 & 4.68 & 3.44 \\
GPT-Image & \textbf{4.61} & $\underline{4.33}$ & \textbf{2.90} & $\underline{4.35}$ & $\underline{3.66}$ & \textbf{4.57} & \textbf{4.93} & $\underline{3.96}$ & \textbf{4.89} & $\underline{4.20}$ \\
\textsc{Tuna} & $\underline{4.43}$ & \textbf{4.48} & $\underline{2.46}$ & \textbf{4.65} & \textbf{4.55} & $\underline{4.52}$ & 4.69 & \textbf{4.22} & $\underline{4.76}$ & \textbf{4.31} \\
\rowcolor[HTML]{ECF4FF}
\textsc{Tuna-R} & 4.46 & 4.27 & 2.38& 4.61 &4.48 & 4.44 & 4.54 & 4.06 & 4.43 & 4.18 \\
\rowcolor[HTML]{ECF4FF}
\textsc{Tuna-2} & 4.34 & 4.13 & 2.22 & 4.53 & 4.42 & 4.36 & 4.58 & 3.91 &4.28 & 4.09 \\
\bottomrule
\end{tabular}
3.2 Main Results
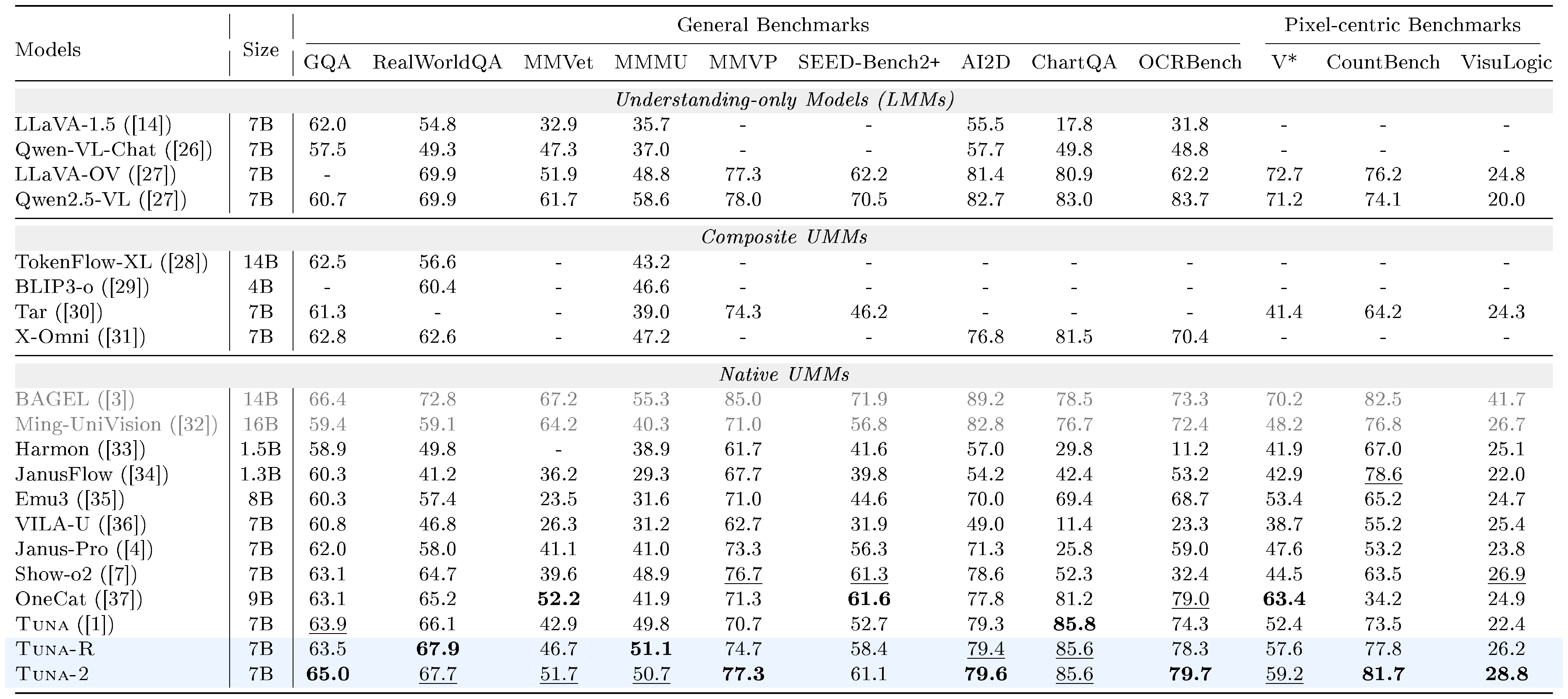
Image understanding. We employ a comprehensive evaluation suite consisting of nine VQA benchmarks, including GQA ([49]), RealWorldQA ([50]), MMVet ([51]), MMMU ([52]), MMVP ([53]), SEED-Bench2+ ([54]), AI2D ([55]), ChartQA ([56]) and OCRBench ([57]), to evaluate the image understanding capabilities for $\textsc{Tuna-2}$. As shown in Table 1, after removing the VAE model, both $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ outperform $\textsc{Tuna}$ and achieve state-of-the-art results among all 7B-scale native UMMs, demonstrating the effectiveness of our pixel-space unified representations. Notably, $\textsc{Tuna-2}$ outperforms $\textsc{Tuna-R}$ even after replacing the representation encoder with the simple patchify layer. This may indicate that large-scale joint training of a unified, monolithic architecture achieves better understanding performance than relying on the inductive bias in the pretrained representation encoders in the modular setting. We show more analysis comparing $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ in Section 3.5.
To further understand the benefit of our pixel-space unified models, we include several pixel-centric benchmarks that focus heavily on visual reasoning over fine-grained visual details (e.g. recognizing very small objects in high-resolution images). These benchmarks include V* ([58]), CountBench ([59]) and VisuLogic ([60]). As shown in Table 1, both $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ outperform latent-space UMMs (e.g. Show-o2, $\textsc{Tuna}$, etc.) across all benchmarks, indicating the necessity of pixel-space visual representations when reasoning over fine-grained visual details.
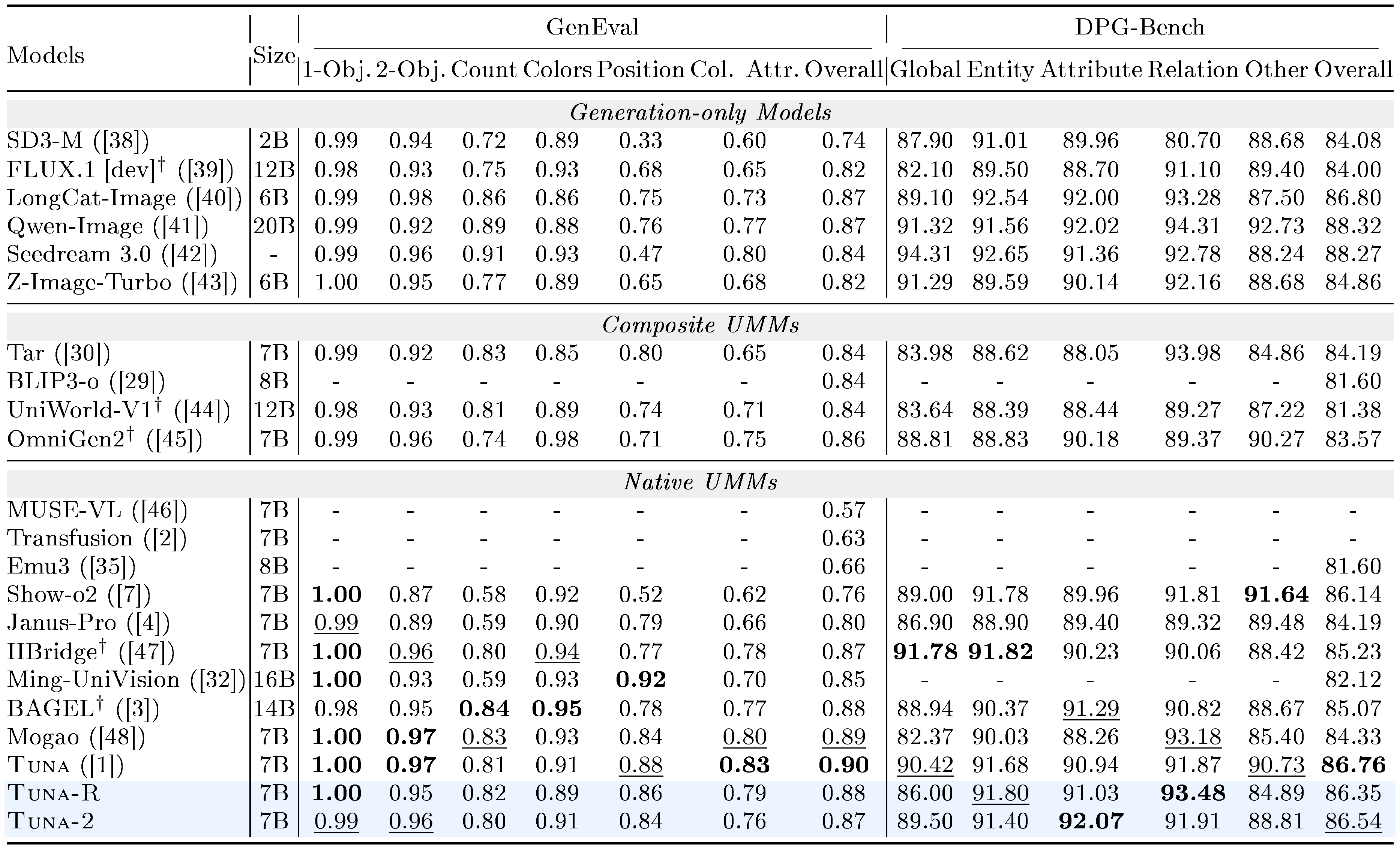
Image generation. We evaluate the image generation performance of $\textsc{Tuna-2}$ on GenEval ([61]) and DPG-Bench ([62]). As shown in Table 2, both $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ achieve state-of-the-art results on these benchmarks and perform competitively with contemporary approaches such as BAGEL, Mogao, and $\textsc{Tuna}$. Between the two variants, $\textsc{Tuna-R}$ consistently performs slightly better than $\textsc{Tuna-2}$, suggesting that the semantic prior introduced by the representation encoder helps our method learn a stronger image generation model. Overall, these results show that even without a VAE and while performing image generation entirely in pixel space, $\textsc{Tuna-2}$ remains competitive with recent state-of-the-art unified models, highlighting the effectiveness and scalability of our pixel-space generation design.
Since existing image generation benchmarks such as GenEval mainly evaluate text-image alignment and the model's world knowledge, we further adopt an LLM-judge-based evaluation to assess the quality and diversity of images generated by $\textsc{Tuna-2}$, $\textsc{Tuna-R}$, and $\textsc{Tuna}$. Specifically, we sample 1.5K text prompts and ask each model to generate four images per prompt. We then use GPT-5.4 ([63]) and Claude Opus 4.7 ([64]) as judges to select the best model among the three for each prompt based on the quality and diversity of the generated images, where quality mainly refers to realism and fine-grained detail and texture fidelity, while diversity measures the extent to which the four generated images exhibit distinct visual variations under the same prompt. The results are reported in Table 3. We find that under both LLM judges, $\textsc{Tuna-2}$ achieves competitive image generation quality, performing comparably to $\textsc{Tuna-R}$ and better than $\textsc{Tuna}$, while being significantly preferred in terms of diversity. These results demonstrate that our encoder-free design is highly effective and enables $\textsc{Tuna-2}$ to generate both high quality and diverse images.
\begin{tabular}{lcccc}
\toprule
\textbf{Tokenizer} & \textbf{Res.} & \textbf{rFID $\downarrow$} & \textbf{PSNR $\uparrow$} & \textbf{SSIM $\uparrow$} \\
\midrule
\multicolumn{5}{l}{\textit{Specialized tokenizers}} \\
SD-VAE & 256 & 1.06 & 28.62 & 0.86 \\
GigaTok & 256 & 0.51 & 21.32 & 0.69 \\
VA-VAE & 256 & 0.26 & 28.59 & 0.80 \\
DC-AE & 512 & 0.22 & 26.15 & 0.71 \\
MAE-Tok & 512 & 0.62 & -- & -- \\
TexTok & 512 & 0.73 & 24.45 & 0.66 \\
FLUX.1[dev]-VAE$^{\dagger}$ & 512 & 0.06 & 33.65 & 0.93 \\
\midrule
\multicolumn{5}{l}{\textit{Unified tokenizers}} \\
UniTok & 256 & 0.38 & -- & -- \\
TokenFlow & 384 & 0.63 & 22.77 & 0.73 \\
X-Omni$^{\dagger}$ & 512 & 8.30 & 15.66 & 0.38 \\
MingTok$^{\dagger}$ & 512 & 0.53 & 23.49 & 0.61 \\
RAE & 256 & 0.61 & 19.20 & 0.44 \\
PS-VAE & 256 & 0.20 & 28.79 & 0.82 \\
\textbf{\textsc{Tuna-R}} & 512 & \textbf{0.12} & 32.22 & \textbf{0.93} \\
\textbf{\textsc{Tuna-2}} & 512 & 0.15 & \textbf{32.80} & \textbf{0.93} \\
\bottomrule
\end{tabular}

Image editing. We further evaluate the image editing capability of $\textsc{Tuna-2}$ on ImgEdit ([65]). As shown in Table 4, $\textsc{Tuna-2}$ achieves strong editing performance among unified models, outperforming earlier baselines such as OmniGen ([66]), BAGEL ([3]), UniWorld ([44]), and OmniGen2 ([45]). While being slightly behind $\textsc{Tuna}$ and $\textsc{Tuna-R}$, $\textsc{Tuna-2}$ remains competitive with strong generation-only and unified editing systems, despite performing editing directly in pixel space without relying on vision encoders. These results suggest that our pixel-space unified modelling framework can effectively support instruction-guided image editing, while the small gap between $\textsc{Tuna-2}$ and encoder-based variants indicates that pretrained visual priors may still provide benefits for fine-grained editing fidelity.
Image reconstruction. To further investigate the image generation capability of $\textsc{Tuna-2}$, we examine whether the model can faithfully reconstruct an input image from its corresponding pixel-space visual representations. To this end, we perform lightweight finetuning on an image reconstruction task and evaluate reconstruction quality on the ImageNet validation set ([67]). As shown in Table 5, both $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ achieve strong reconstruction performance, ranking first among unified tokenizers and approaching specialized image tokenizers such as the VAE model in FLUX.1 [dev] ([39]). Figure 4 further shows that our models produce substantially better reconstructions than other non-KL-regularized VAE approaches such as RAE ([68]). These results indicate that our pixel-space unified visual representation can support strong image reconstruction and generation quality even without relying on VAE models.
3.3 Ablation: Model Training Dynamics
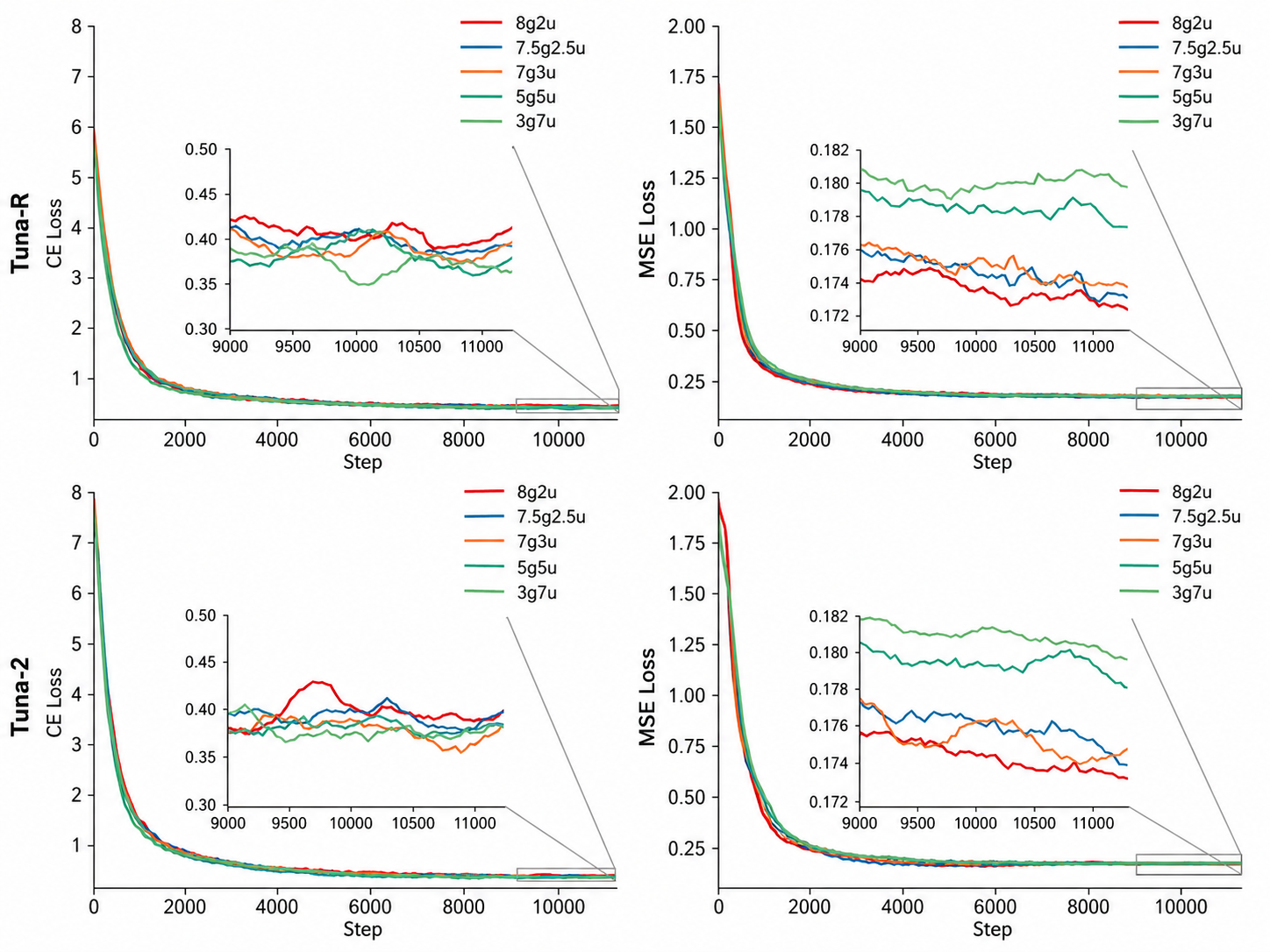
To better understand the learning dynamics of our joint multimodal training paradigm, we conduct a series of pretraining ablation studies on both $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ by varying the sampling ratio between generation and understanding data. We use the notation xgyu (e.g., 8g2u) to represent a generation-to-understanding sampling ratio of $x:y$. As shown in Figure 5, increasing the proportion of either generation or understanding data consistently reduces its corresponding training loss, namely MSE for flow matching and cross entropy loss (CE) for language modelling. Notably, the MSE loss is more sensitive to changes in the sampling ratio, while the CE loss varies within a relatively smaller range across different ratios. This suggests that both tasks benefit from scaling up the amount of their corresponding training data, with the generation objective being more affected by the data mixture. We also observe that a generation-to-understanding ratio of $7:3$ (7g3u) achieves the best trade-off between the two objectives, yielding a strong balance between generation and understanding performance. We therefore adopt this data sampling ratio in all experiments.
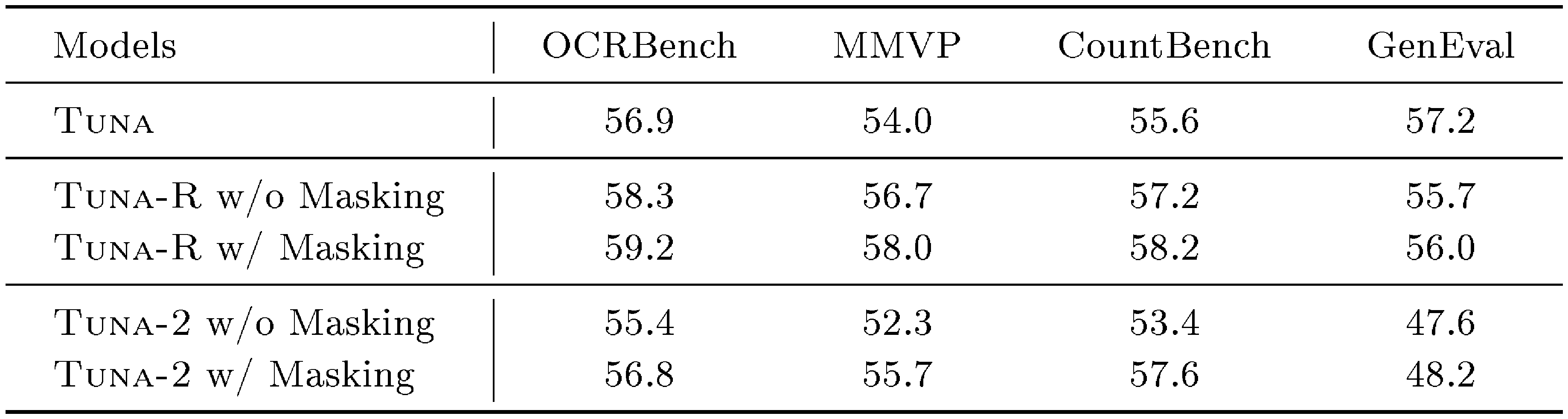
::: {caption="Table 6: Ablation study results for $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$, with or without our proposed masking-based feature learning scheme during pretraining."}
:::
3.4 Ablation: Masking-based Feature Learning
To verify the effectiveness of our proposed masking-based feature learning strategy, we conduct controlled experiments on both $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ using the smaller Qwen-2.5-Instruct-1.5B backbone. Since we expect this strategy to serve as a representation enhancement strategy after the model has acquired basic multimodal knowledge, we do not apply this objective from the beginning of pretraining. Instead, we first train all models for 50k steps; We then split each model variant into two groups: one continues standard pretraining, while the other continues pretraining with the masking-based feature learning objective applied with a probability of 50%. Both groups are further trained for another 50k steps. As shown in Table 6, this strategy consistently improves performance on both understanding and generation benchmarks for both model variants. We further observe that $\textsc{Tuna-2}$ benefits more from masked training than $\textsc{Tuna-R}$. We hypothesize that this difference is related to the SigLIP 2 representation encoder used in $\textsc{Tuna-R}$, since SigLIP 2 itself is pretrained with a similar masked prediction objective. In addition, the results suggest that compressing images into the VAE latent space before visual encoding ($\textsc{Tuna}$) can introduce certain information loss for visual understanding, compared with directly encoding pixel-level inputs through the vision encoder ($\textsc{Tuna-R}$). Based on these findings, we apply the masking-based feature learning strategy during the final 40% of pretraining, encouraging more robust visual representation learning for both multimodal understanding and generation.
3.5 Analysis: $\textsc{Tuna-R}$ vs. $\textsc{Tuna-2}$
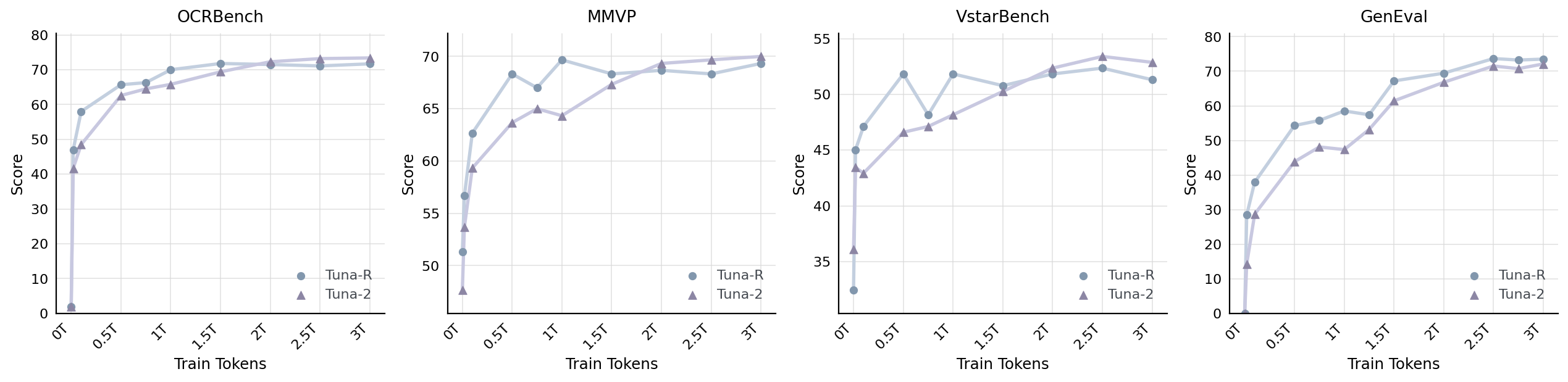
Our experimental results in Section 3.2 reveal two interesting findings: First, without vision encoders, $\textsc{Tuna-2}$ outperforms $\textsc{Tuna-R}$ on most image understanding benchmarks. Second, $\textsc{Tuna-R}$ achieves similar or slightly stronger performance than $\textsc{Tuna-2}$ on generation tasks. To better understand these trends, we plot the performance curves of both models on understanding and generation benchmarks as the training data scale increases. As shown in Figure 6, on the three understanding benchmarks (OCRBench ([57]), MMVP ([53]) and V* ([58])), $\textsc{Tuna-R}$ actually outperforms $\textsc{Tuna-2}$ during the early stage of the training. We believe this advantage comes from the pretrained representation encoder in $\textsc{Tuna-R}$, whose rich semantic priors help the model acquire multimodal understanding capabilities more quickly at the beginning of training. Nevertheless, $\textsc{Tuna-2}$ later catches up and eventually surpasses $\textsc{Tuna-R}$. This suggests that the monolithic, encoder-free design of $\textsc{Tuna-2}$ may be better suited to benefit from large-scale unified multimodal pretraining, enabling it to develop stronger multimodal understanding capabilities.
For generation evaluation on GenEval ([61]), we observe that $\textsc{Tuna-R}$ consistently outperforms $\textsc{Tuna-2}$ throughout the entire training process. This suggests that the semantic priors provided by the representation encoder play an important role in improving generation performance, which is consistent with prior findings from REPA ([69]) and $\textsc{Tuna}$ ([1]). However, this trend gradually weakens as the training data scale increases. As shown in the figure, the two model variants achieve nearly identical performance after SFT. Overall, compared with latent-space generation, both $\textsc{Tuna-R}$ and $\textsc{Tuna-2}$ 's pixel-space generation paradigm achieves competitive performances.

3.6 Analysis: Attention Map Visualizations
To qualitatively analyze and compare the cross-modal alignment capabilities learned by different models, we visualize the attention maps of selected keywords in the input prompt with respect to the input image. We focus on the $\textsc{Tuna}$ model family, including $\textsc{Tuna}$, $\textsc{Tuna-R}$, and $\textsc{Tuna-2}$, and compare them with representative encoder-based open-source LMMs, including models with ViT-based encoders, such as LLaVA-OneVision-1.5 ([70]) and Qwen2.5-VL ([71]), as well as models with LLM-based encoders, such as Penguin-VL ([72]). The results are shown in Figure 7.
Our first observation is that $\textsc{Tuna-2}$ exhibits more accurate vision-language alignment in basic perception scenarios. For example, in the "shining window" case, $\textsc{Tuna-2}$ consistently highlights the regions that are semantically associated with "shining", while other models tend to provide only coarse or incomplete localization. In the "purple object" case, the attention activations of $\textsc{Tuna-2}$ are well aligned with the target object, whereas other methods often show dispersed attention or spurious activations in irrelevant regions.
We further construct examples with misleading linguistic contexts to evaluate whether models overly rely on language priors. For example, in the "dog cafe" case, the prompt suggests a cat cafe scenario, whereas the actual animals in the image are dogs. Some models tend to rely on textual cues within the image (e.g. "dog cafe" sign) instead of the actual visual subjects. In contrast, $\textsc{Tuna-2}$ places its attention on the truly relevant visual regions, demonstrating more robust cross-modal alignment under misleading linguistic contexts.
In the more challenging counterintuitive "football match" case, we introduce both strong linguistic priors and salient visual distractors. Specifically, the prompt contains strong football-related cues, such as "football match", "players", and "kicking". The image also includes a large and visually salient football as a distractor. However, the actual object being kicked by the player is a glass cup. Most models are easily misled by either the textual prior or the salient distractor and therefore attend to incorrect regions. In contrast, $\textsc{Tuna-2}$ accurately localizes the key object that is consistent with the question semantics, showing stronger robustness in such counterintuitive settings.
Overall, as an encoder-free native multimodal architecture, $\textsc{Tuna-2}$ produces more accurate and stable attention distributions across all cases. These results suggest that $\textsc{Tuna-2}$ learns more reliable visual representations, leading to more consistent cross-modal alignment and better robustness to misleading language priors and visual distractors.
4. Related Works
Section Summary: Unified multimodal models aim to combine the understanding and creation of text, images, and other data types into a single system, often blending text-generating language models with visual tools like diffusion models, though challenges like mismatched representations persist; recent efforts use shared tokenizers or encoders to improve efficiency and perception. For multimodal understanding, traditional large models pair image encoders with language decoders, but newer designs employ a single transformer to process raw pixels and text together without separate encoders, enabling strong performance across tasks. In visual generation, while most models work in compressed latent spaces, emerging pixel-space techniques show promise for high-quality results, and this work demonstrates scaling them for large-scale text-to-image creation and editing.
4.1 Unified Multimodal Models
Unified multimodal models (UMMs) ([73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 40, 90, 91, 92]) seek to integrate multimodal understanding and generation within a single framework. A prevalent approach for UMMs combines autoregressive (AR) language models for text generation ([93, 26]) with diffusion or flow-matching models for visual generation ([94, 95]). While AR models excel at understanding, their integration with high-fidelity generation typically relies on decoupled encoders ([4, 48, 3]), leading to representation mismatches and inefficiencies. To address this problem, recent works such as UniTok ([96]), TokLip ([97]), UniLip ([98]), UniFlow ([99]), UAE ([100]) and OpenVision 3 ([101]) pretrain unified vision tokenizers for both semantic understanding and visual reconstruction. Meanwhile, native UMMs like the Show-o series ([102, 7]), $\textsc{Tuna}$ ([1]), Ming-UniVision ([103]), and Transfusion-RAE ([76]) build unified representations using pretrained VAE ([8]) and representation encoders ([68]). Despite the significant progress, recent native UMMs still predominantly rely on VAE latents to build their unified representations, which hinders the model's performance on fine-grained visual perception and reasoning.
4.2 Encoder-Free Multimodal Understanding and Generation
Large multimodal models (LMMs) have traditionally adopted a modular design, combining pixel-space representation encoders with LLM decoders. Early work on LMMs explored integration strategies between representation encoders and LLM decoders, such as using cross-attention in Flamingo ([104]) and MLP connectors in LLaVA ([14]). Subsequent research largely followed LLaVA and scaled this paradigm to larger models ([105, 71, 16, 106]), datasets ([107, 24, 70]), and diverse understanding tasks ([108, 109, 110]). More recently, an alternative design of employing a monolithic, encoder-free transformer to natively process vision and language has emerged ([111, 112, 113]). Fuyu ([114]), EVE ([115]), Chameleon ([116]), Mono-InternVL ([17]) and NEO ([10]) employ simple MLP or patch embedding layers to tokenize raw image pixels into patches, and jointly process these image patches with language tokens using a single transformer. In this work, we show that both the representation encoder-based design and the monolithic design can be integrated into pixel-space UMMs and achieve high performance on multimodal understanding.
Recent visual generation models ([117, 118, 119, 120, 121, 122]) typically operate in a compressed latent space using KL- or VQ-regularized VAEs ([95, 38, 41, 6, 123]). Although pixel-space diffusion or flow matching is often considered more challenging, recent work such as PixelFlow ([12]), DiP ([124]), PixelDiT ([125]) and JiT ([13]) increasingly suggests that pixel-space flow matching has the potential to match or surpass latent diffusion models. However, these studies are usually limited to small-scale settings (e.g., class-conditioned generation on ImageNet ([126])). We demonstrate in $\textsc{Tuna-2}$ that pixel-space flow matching can be scaled up to large-scale unified multimodal pretraining and support free-form text-to-image generation and image editing.
5. Conclusion
Section Summary: Tuna-2 is a new set of AI models that handle both understanding images and creating new ones directly from raw pixels, without using the usual compression tools or hidden data layers found in older systems. It combines a shared base for vision and language processing with a special tool for generating visuals, allowing it to understand images, turn text into pictures, and edit photos all in one setup, and it comes in two versions that both perform well on standard tests. The results show Tuna-2 outperforming earlier models on detailed image analysis while keeping up with the best on picture creation, pointing to a bright future for this direct pixel-based approach in AI.
We introduced $\textsc{Tuna-2}$, a family of native unified multimodal models that perform multimodal understanding and visual generation directly in pixel space, without relying on VAE encoders or latent diffusion. By combining a unified vision-language backbone with a pixel-space flow matching head, $\textsc{Tuna-2}$ supports image understanding, text-to-image generation, and image editing within a single framework. We further instantiated $\textsc{Tuna-2}$ with both a representation encoder-based variant and an encoder-free monolithic variant, and showed that both designs achieve strong performance across multimodal understanding and generation benchmarks. Our experiments demonstrate that $\textsc{Tuna-2}$ surpasses prior latent-space unified models such as $\textsc{Tuna}$ and Show-o2 on fine-grained visual understanding benchmarks while remaining competitive with state-of-the-art unified models on image generation. Overall, these results highlight the effectiveness and scalability of pixel-space unified multimodal modelling and suggest a promising direction for future native UMMs.
References
Section Summary: This section is a bibliography listing over 40 research papers and conference proceedings, mostly from 2023 to 2025, that explore advancements in artificial intelligence for handling images, videos, and text together. The references focus on developing unified models that can both understand visual content—like interpreting photos or videos—and generate new ones, using techniques such as diffusion processes and transformers. Many are preprints from arXiv, covering topics from scalable vision learners to efficient multimodal systems like Qwen and InternVL, building on foundational works in machine learning.
[1] Liu et al. (2025). Tuna: Taming unified visual representations for native unified multimodal models. arXiv preprint arXiv:2512.02014.
[2] Zhou et al. (2024). Transfusion: Predict the next token and diffuse images with one multi-modal model. arXiv preprint arXiv:2408.11039.
[3] Deng et al. (2025). Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683.
[4] Chen et al. (2025). Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811.
[5] Radford et al. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning. pp. 8748–8763.
[6] Esser et al. (2021). Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883.
[7] Xie et al. (2025). Show-o2: Improved Native Unified Multimodal Models. arXiv preprint arXiv:2506.15564.
[8] Wan et al. (2025). Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314.
[9] Tschannen et al. (2025). Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786.
[10] Diao et al. (2025). From Pixels to Words–Towards Native Vision-Language Primitives at Scale. arXiv preprint arXiv:2510.14979.
[11] Hoogeboom et al. (2023). simple diffusion: End-to-end diffusion for high resolution images. In International Conference on Machine Learning. pp. 13213–13232.
[12] Chen et al. (2025). Pixelflow: Pixel-space generative models with flow. arXiv preprint arXiv:2504.07963.
[13] Li, Tianhong and He, Kaiming (2025). Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720.
[14] Liu et al. (2023). Visual instruction tuning. Advances in neural information processing systems. 36. pp. 34892–34916.
[15] Bai et al. (2025). Qwen3-vl technical report. arXiv preprint arXiv:2511.21631.
[16] Wang et al. (2025). Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265.
[17] Luo et al. (2025). Mono-internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24960–24971.
[18] He et al. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009.
[19] Chang et al. (2022). Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11315–11325.
[20] Yang et al. (2025). Latent Denoising Makes Good Tokenizers. In The Fourteenth International Conference on Learning Representations.
[21] Qwen et al. (2024). Qwen2. 5 technical report. arXiv preprint.
[22] Bercovich et al. (2025). Llama-nemotron: Efficient reasoning models. arXiv preprint arXiv:2505.00949.
[23] Loshchilov, Ilya and Hutter, Frank (2017). Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
[24] Wiedmann et al. (2025). Finevision: Open data is all you need. arXiv preprint arXiv:2510.17269.
[25] Wei et al. (2024). Omniedit: Building image editing generalist models through specialist supervision. In The Thirteenth International Conference on Learning Representations.
[26] Bai et al. (2023). Qwen technical report. arXiv preprint arXiv:2309.16609.
[27] Li et al. (2024). Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326.
[28] Qu et al. (2025). Tokenflow: Unified image tokenizer for multimodal understanding and generation. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2545–2555.
[29] Chen et al. (2025). Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568.
[30] Han et al. (2025). Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations. arXiv preprint arXiv:2506.18898.
[31] Geng et al. (2025). X-omni: Reinforcement learning makes discrete autoregressive image generative models great again. arXiv preprint arXiv:2507.22058.
[32] Huang et al. (2025). Ming-UniVision: Joint Image Understanding and Generation with a Unified Continuous Tokenizer. arXiv preprint arXiv:2510.06590.
[33] Wu et al. (2025). Harmonizing visual representations for unified multimodal understanding and generation. arXiv preprint arXiv:2503.21979.
[34] Ma et al. (2025). Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7739–7751.
[35] Wang et al. (2024). Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869.
[36] Wu et al. (2024). Vila-u: a unified foundation model integrating visual understanding and generation. arXiv preprint arXiv:2409.04429.
[37] Li et al. (2025). Onecat: Decoder-only auto-regressive model for unified understanding and generation. arXiv preprint arXiv:2509.03498.
[38] Esser et al. (2024). Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning.
[39] Batifol et al. (2025). FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space. arXiv e-prints. pp. arXiv–2506.
[40] Team et al. (2025). Longcat-image technical report. arXiv preprint arXiv:2512.07584.
[41] Wu et al. (2025). Qwen-image technical report. arXiv preprint arXiv:2508.02324.
[42] Gao et al. (2025). Seedream 3.0 technical report. arXiv preprint arXiv:2504.11346.
[43] Cai et al. (2025). Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699.
[44] Lin et al. (2025). Uniworld: High-resolution semantic encoders for unified visual understanding and generation. arXiv preprint arXiv:2506.03147.
[45] Wu et al. (2025). OmniGen2: Exploration to Advanced Multimodal Generation. arXiv preprint arXiv:2506.18871.
[46] Xie et al. (2025). Muse-vl: Modeling unified vlm through semantic discrete encoding. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24135–24146.
[47] Wang et al. (2025). HBridge: H-Shape Bridging of Heterogeneous Experts for Unified Multimodal Understanding and Generation. arXiv preprint arXiv:2511.20520.
[48] Liao et al. (2025). Mogao: An omni foundation model for interleaved multi-modal generation. arXiv preprint arXiv:2505.05472.
[49] Hudson, Drew A and Manning, Christopher D (2019). Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6700–6709.
[50] xAI. Grok-1.5 Vision Preview. https://x.ai/news/grok-1.5v.
[51] Yu et al. (2023). Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490.
[52] Yue et al. (2024). Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9556–9567.
[53] Tong et al. (2024). Eyes wide shut? exploring the visual shortcomings of multimodal llms. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9568–9578.
[54] Li et al. (2024). Seed-bench-2-plus: Benchmarking multimodal large language models with text-rich visual comprehension. arXiv preprint arXiv:2404.16790.
[55] Kembhavi et al. (2016). A diagram is worth a dozen images. In European conference on computer vision. pp. 235–251.
[56] Masry et al. (2022). Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In Findings of the association for computational linguistics: ACL 2022. pp. 2263–2279.
[57] Liu et al. (2024). Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences. 67(12). pp. 220102.
[58] Wu, Penghao and Xie, Saining (2024). V?: Guided visual search as a core mechanism in multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13084–13094.
[59] Paiss et al. (2023). Teaching clip to count to ten. In Proceedings of the IEEE/CVF international conference on computer vision. pp. 3170–3180.
[60] Xu et al. (2025). Visulogic: A benchmark for evaluating visual reasoning in multi-modal large language models. arXiv preprint arXiv:2504.15279.
[61] Ghosh et al. (2023). Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems. 36. pp. 52132–52152.
[62] Hu et al. (2024). Ella: Equip diffusion models with llm for enhanced semantic alignment. arXiv preprint arXiv:2403.05135.
[63] OpenAI (2026). Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/. Accessed: 2026-04-24.
[64] Anthropic (2026). Introducing Claude Opus 4.7. https://www.anthropic.com/news/claude-opus-4-7. Accessed: 2026-04-24.
[65] Ye et al. (2025). Imgedit: A unified image editing dataset and benchmark. arXiv preprint arXiv:2505.20275.
[66] Xiao et al. (2025). Omnigen: Unified image generation. In Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13294–13304.
[67] Deng et al. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255.
[68] Zheng et al. (2025). Diffusion Transformers with Representation Autoencoders. arXiv preprint arXiv:2510.11690.
[69] Yu et al. (2024). Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940.
[70] An et al. (2025). Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661.
[71] Bai et al. (2025). Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923.
[72] Zhang et al. (2026). Penguin-VL: Exploring the Efficiency Limits of VLM with LLM-based Vision Encoders. arXiv preprint arXiv:2603.06569.
[73] Xin et al. (2025). Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding. arXiv preprint arXiv:2510.06308.
[74] You et al. (2026). LLaDA-o: An Effective and Length-Adaptive Omni Diffusion Model. arXiv preprint arXiv:2603.01068.
[75] Tian et al. (2026). Internvl-u: Democratizing unified multimodal models for understanding, reasoning, generation and editing. arXiv preprint arXiv:2603.09877.
[76] Tong et al. (2026). Beyond language modeling: An exploration of multimodal pretraining. arXiv preprint arXiv:2603.03276.
[77] Zhang et al. (2026). NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation. arXiv preprint arXiv:2601.02204.
[78] Yang et al. (2025). Mmada: Multimodal large diffusion language models. arXiv preprint arXiv:2505.15809.
[79] Shi et al. (2025). Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model. arXiv preprint arXiv:2505.23606.
[80] Shen et al. (2025). MammothModa2: A Unified AR-Diffusion Framework for Multimodal Understanding and Generation. arXiv preprint arXiv:2511.18262.
[81] Xie et al. (2025). Reconstruction alignment improves unified multimodal models. arXiv preprint arXiv:2509.07295.
[82] Niu et al. (2025). Does Understanding Inform Generation in Unified Multimodal Models? From Analysis to Path Forward. arXiv preprint arXiv:2511.20561.
[83] Wei et al. (2025). Univideo: Unified understanding, generation, and editing for videos. arXiv preprint arXiv:2510.08377.
[84] Wang et al. (2025). LightFusion: A Light-weighted, Double Fusion Framework for Unified Multimodal Understanding and Generation. arXiv preprint arXiv:2510.22946.
[85] Wei et al. (2025). Skywork unipic 2.0: Building kontext model with online rl for unified multimodal model. arXiv preprint arXiv:2509.04548.
[86] Cui et al. (2025). Emu3. 5: Native multimodal models are world learners. arXiv preprint arXiv:2510.26583.
[87] He et al. (2025). Emma: Efficient multimodal understanding, generation, and editing with a unified architecture. arXiv preprint arXiv:2512.04810.
[88] Wang et al. (2025). Ovis-u1 technical report. arXiv preprint arXiv:2506.23044.
[89] Hao et al. (2025). Uni-X: Mitigating Modality Conflict with a Two-End-Separated Architecture for Unified Multimodal Models. arXiv preprint arXiv:2509.24365.
[90] AI et al. (2025). Ming-flash-omni: A sparse, unified architecture for multimodal perception and generation. arXiv preprint arXiv:2510.24821.
[91] Wu et al. (2025). Openuni: A simple baseline for unified multimodal understanding and generation. arXiv preprint arXiv:2505.23661.
[92] Fan et al. (2025). Unified autoregressive visual generation and understanding with continuous tokens. arXiv preprint arXiv:2503.13436.
[93] Grattafiori et al. (2024). The llama 3 herd of models. arXiv preprint arXiv:2407.21783.
[94] Ho et al. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems. 33. pp. 6840–6851.
[95] Rombach et al. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695.
[96] Ma et al. (2025). Unitok: A unified tokenizer for visual generation and understanding. arXiv preprint arXiv:2502.20321.
[97] Haokun Lin et al. (2025). TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation. https://arxiv.org/abs/2505.05422. arXiv:2505.05422.
[98] Tang et al. (2025). Unilip: Adapting clip for unified multimodal understanding, generation and editing. arXiv preprint arXiv:2507.23278.
[99] Yue et al. (2025). UniFlow: A Unified Pixel Flow Tokenizer for Visual Understanding and Generation. arXiv preprint arXiv:2510.10575.
[100] Fan et al. (2025). The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding. arXiv preprint arXiv:2512.19693.
[101] Zhang et al. (2026). OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation. arXiv preprint arXiv:2601.15369.
[102] Xie et al. (2024). Show-o: One single transformer to unify multimodal understanding and generation. arXiv preprint arXiv:2408.12528.
[103] Huang et al. (2025). Ming-univision: Joint image understanding and generation with a unified continuous tokenizer. arXiv preprint arXiv:2510.06590.
[104] Alayrac et al. (2022). Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems. 35. pp. 23716–23736.
[105] Wang et al. (2024). Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191.
[106] An et al. (2026). Video Understanding: From Geometry and Semantics to Unified Models. Machine Intelligence Research.
[107] Zhang et al. (2024). Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713.
[108] Cheng et al. (2024). Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476.
[109] Li et al. (2024). Videochat-flash: Hierarchical compression for long-context video modeling. arXiv preprint arXiv:2501.00574.
[110] Ren et al. (2025). Vamba: Understanding hour-long videos with hybrid mamba-transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21197–21208.
[111] Wang et al. (2025). Vision as lora. arXiv preprint arXiv:2503.20680.
[112] Li et al. (2026). BREEN: bridge data-efficient encoder-free multimodal learning with learnable queries. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5384–5395.
[113] Lei et al. (2025). The scalability of simplicity: Empirical analysis of vision-language learning with a single transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20758–20769.
[114] Bavishi et al. (2023). Fuyu-8B: A Multimodal Architecture for AI Agents. https://www.adept.ai/blog/fuyu-8b/.
[115] Diao et al. (2024). Unveiling encoder-free vision-language models. Advances in Neural Information Processing Systems. 37. pp. 52545–52567.
[116] Team, Chameleon (2024). Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818.
[117] Yang et al. (2026). Gloria: Consistent Character Video Generation via Content Anchors. arXiv preprint arXiv:2603.29931.
[118] Chen et al. (2024). Pixart-$\sigma$: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. In European Conference on Computer Vision. pp. 74–91.
[119] An et al. (2026). OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory. CVPR.
[120] An et al. (2026). VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward. arXiv preprint arXiv:2603.26599.
[121] Zhou et al. (2025). Scaling Zero-Shot Reference-to-Video Generation. arXiv preprint arXiv:2512.06905.
[122] Qiu et al. (2025). HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming. arXiv preprint arXiv:2512.21338.
[123] Sun et al. (2024). Autoregressive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525.
[124] Chen et al. (2025). Dip: Taming diffusion models in pixel space. arXiv preprint arXiv:2511.18822.
[125] Yu et al. (2025). Pixeldit: Pixel diffusion transformers for image generation. arXiv preprint arXiv:2511.20645.
[126] Russakovsky et al. (2015). Imagenet large scale visual recognition challenge. International journal of computer vision. 115(3). pp. 211–252.