Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems$
Xuying Ning $^{1}$ $^{\dagger}$, Katherine Tieu $^{1}$ $^{\dagger}$, Dongqi Fu $^{2}$ $^{\dagger}$, Tianxin Wei $^{1}$ $^{\dagger}$, Zihao Li $^{1}$ $^{\dagger}$, Yuanchen Bei $^{1}$ $^{\dagger}$
Jiaru Zou $^{3}$, Mengting Ai $^{1}$, Zhining Liu $^{1}$, Ting-Wei Li $^{1}$, Lingjie Chen $^{1}$, Yanjun Zhao $^{1}$, Ke Yang $^{1}$
Bingxuan Li $^{1}$, Cheng Qian $^{1}$, Gaotang Li $^{1}$, Xiao Lin $^{1}$, Zhichen Zeng $^{1}$, Ruizhong Qiu $^{1}$, Sirui Chen $^{1}$
Yifan Sun $^{1}$, Xiyuan Yang $^{1}$, Ruida Wang $^{1}$, Rui Pan $^{1}$, Chenyuan Yang $^{1}$, Dylan Zhang $^{1}$, Liri Fang $^{1}$
Zikun Cui $^{2}$, Yang Cao $^{2}$, Pan Chen $^{2}$, Dorothy Sun $^{2}$, Ren Chen $^{2}$
Mahesh Srinivasan $^{2}$, Nipun Mathur $^{2}$, Yinglong Xia $^{2}$, Hong Li $^{2}$, Hong Yan $^{2}$
Pan Lu $^{3}$, Lingming Zhang $^{1}$, Tong Zhang $^{1}$, Hanghang Tong $^{1}$ $^{\text{✉}}$, Jingrui He $^{1}$ $^{\text{✉}}$
$^{1}$ University of Illinois Urbana-Champaign, $^{2}$ Meta, $^{3}$ Stanford University
$^{\dagger}$ Core Contributor,
$^{\text{✉}}$ Corresponding Author
Abstract
Abstract: Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
Executive Summary: Recent advances in large language models have greatly improved code understanding and generation, yet agentic systems still struggle to achieve reliable, long-horizon performance. The core difficulty lies in turning stateless model outputs into persistent, verifiable, and adaptive behavior across complex tasks such as repository-level engineering, GUI automation, scientific workflows, and embodied control. Without a robust connecting layer, agents cannot consistently track state, verify intermediate results, or recover from errors.
This survey introduces and systematically examines the concept of “code as agent harness”—the use of executable code not merely as a generated product but as the central substrate for reasoning, action, environment modeling, memory, planning, and coordination. The authors organize existing literature into three interconnected layers: the harness interface that grounds models in executable structures; harness mechanisms that sustain reliable execution through planning, memory, tool use, and feedback-driven control; and scaling strategies that extend these capabilities to multi-agent collaboration over shared code artifacts. The review draws on representative methods across coding assistants, robotics, scientific discovery, and enterprise workflows, while highlighting open engineering challenges.
Key findings show that code-based interfaces improve reasoning reliability by delegating computation to interpreters and symbolic checkers, enable grounded action through programmatic policies and reusable skills, and provide inspectable environment representations via repositories, traces, and tests. At the mechanism layer, structure-grounded planning, experiential memory, verification-driven tool use, and Plan-Execute-Verify control loops demonstrably increase robustness over single-pass generation. In multi-agent settings, shared code artifacts and execution feedback support role specialization and collective verification, reducing individual agent limitations in context and error detection. These patterns appear consistently across domains and outperform purely language-based approaches on long-horizon tasks.
The results indicate that treating code as an operational harness can meaningfully reduce brittleness, improve auditability, and support safer human oversight in production agent systems. Organizations building or deploying autonomous coding or workflow agents may therefore benefit from prioritizing executable interfaces, sandboxed execution with permission tiers, deterministic verification sensors, and telemetry for harness refinement rather than relying solely on prompt engineering or larger base models.
Practical next steps include piloting harness components—such as structured planning artifacts, execution-grounded memory, and multi-agent review workflows—on representative internal tasks while measuring not only final success but also intermediate verification rates, regression incidence, and human review effort. Further investment is warranted in evaluation methods beyond task completion, consistent shared-state mechanisms for multi-agent systems, and safety gates for high-risk actions.
The survey synthesizes a rapidly evolving body of work and therefore reflects the state of published methods up to its coverage date; empirical gains remain sensitive to benchmark quality, sandbox fidelity, and feedback richness, so results should be validated in each target environment before large-scale adoption.
1. Introduction
Section Summary: Recent large language models go beyond simply generating code as a finished product; instead, they increasingly use programs as an active medium for agents to reason step by step, carry out actions in simulated or physical settings, and represent ongoing task states through executable feedback. This perspective, called “code as agent harness,” frames code as the central interface that links a model’s internal abilities with surrounding system tools, memory, validators, and execution loops, enabling reliable long-running behavior. The survey organizes these ideas into connected layers that show how code first supports basic reasoning and environment modeling, then supplies mechanisms for planning and repair, and finally serves as a shared artifact for multiple agents to coordinate.
Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code [1, 2, 3], achieving strong performance in tasks ranging from competitive programming [4] to repository-level software engineering [5]. Building on these capabilities, the role of code in agentic systems is expanding beyond a target artifact to be generated. Programs are increasingly used as the medium through which LLM agents reason, act, and model their environments. Program-aided reasoning methods externalize intermediate computation into executable code [6, 7, 8]; robotic and embodied agents use generated programs as executable policies for interacting with physical or simulated worlds [9, 10]; and software-engineering or interactive environments use codebases, execution traces, tests, and runtime feedback as structured representations of environment state and dynamics, in which agents plan, act, and revise their behavior [11, 5, 12]. Taken together, these developments suggest a broader view: code is not only an artifact generated by LLMs, but also an executable, inspectable, and stateful medium through which agents reason, act, observe feedback, and verify progress. We refer to this view as code as agent harness.
Recent discussions on agent harnesses [13, 14, 15, 16] provide a useful system-level lens for understanding this shift. An agent harness refers to the software layer that surrounds an LLM with tools, APIs, sandboxes, memory, validators, permission boundaries, execution loops, and feedback channels, thereby turning a stateless model into a functional agent capable of long-running task execution [17, 18, 19, 20, 21, 22, 23]. In this view, the bottleneck of autonomy is not only the reasoning ability of the base model, but also the reliability of the system that connects model outputs to long-horizon actions and persistent states.
To clarify the role of code in this broader harness view, we distinguish three coupled elements of long-running agentic systems: model-internal capabilities, system-provided harness infrastructure, and agent-initiated code artifacts. Model-internal capabilities refer to the model's reasoning, perception, planning, simulation, and evaluation abilities. System-provided harness infrastructure refers to the predefined tools, APIs, sandboxes, memory systems, validators, permission boundaries, telemetry, and workflows that connect model outputs to external actions and feedback, and forms the main focus of harness engineering [24, 25]. In contrast, agent-initiated code artifacts, which remain relatively underexplored, are interactive code objects that agents create, execute, observe, revise, persist, and share within the task execution loop. Through execution feedback, these artifacts help agents reason, act, verify progress, store state, and coordinate with other agents. Examples include regression tests, temporary tools, DSL programs, executable workflows, reusable skills, and intermediate program states. Representative systems such as Claude Code [26], Codex [27], LangChain [28], and enterprise agent platforms show how these elements jointly enable adaptation in long-running agent systems.
With this distinction in mind, we revisit the role of code in agentic systems. Existing surveys typically either treat code as the end product of LLMs. In contrast, we focus on agent-initiated code artifacts and how model capabilities construct and evolve them through interaction with harness infrastructure, with code serving as the organizing center for the interface, agent capabilities, and multi-agent coordination. Across diverse agentic systems, code is used not only to produce solutions, but also to execute reasoning, ground actions, maintain state, and expose feedback. We term this view code as agent harness: code as the executable and inspectable medium through which agents reason, act, and adapt. This shifts the scope from producing correct programs to understanding how code supports reliable closed-loop agentic behavior.
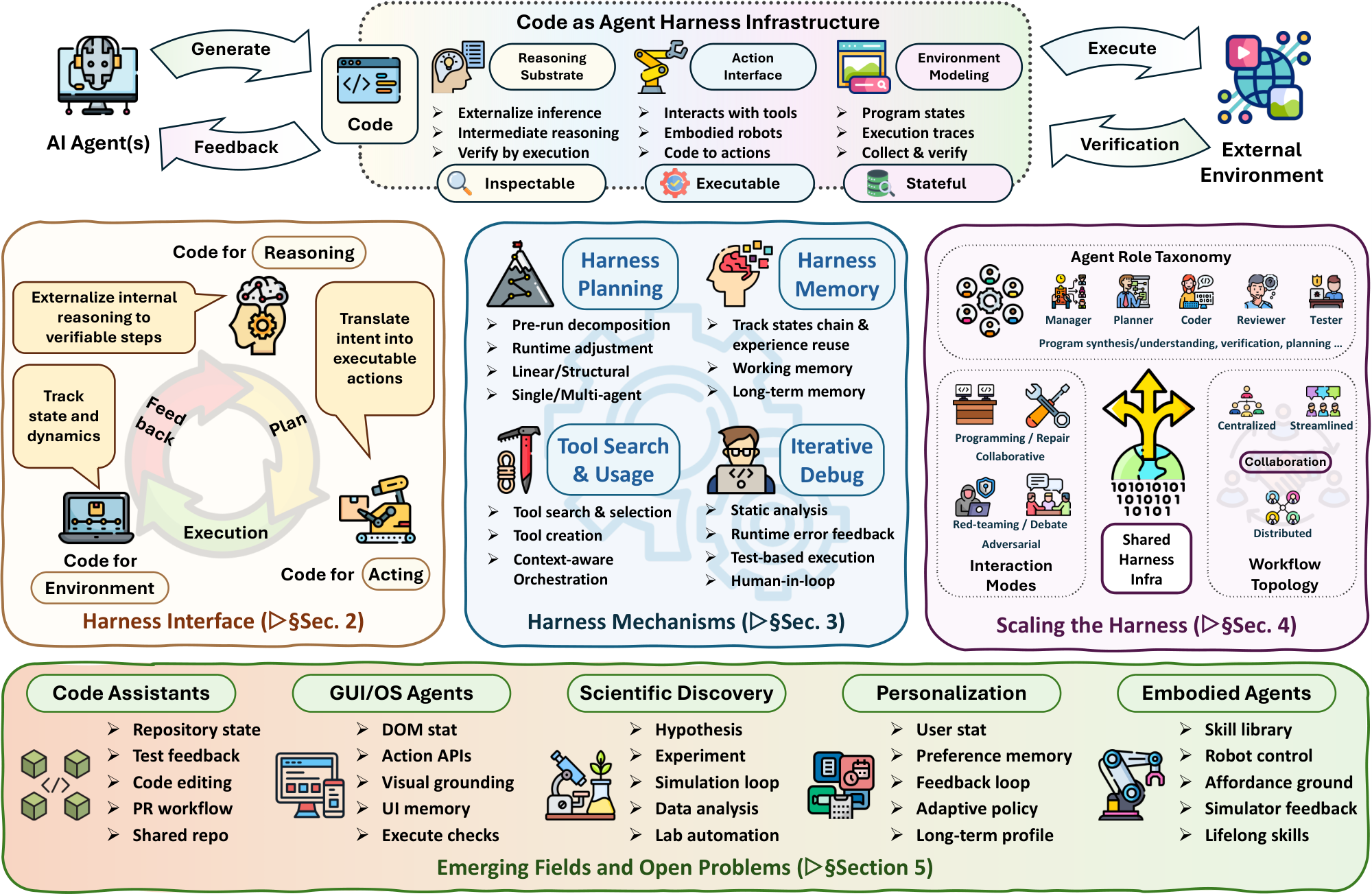
To systematically characterize code as agent harness, we organize the survey into three connected layers, as shown in Figure 1. This organization follows how code becomes an operational medium inside the agent loop: it first enters as a harness interface for reasoning, acting, and environment representation; it then supports harness mechanisms that manage planning, memory, tool use, execution, and repair over time; and it finally becomes a shared artifact through which multiple agents coordinate over repositories, tests, traces, workflows, and execution states.
First, Harness Interface: Code for Reasoning, Acting, and Environment Modeling (§ 2) studies how code forms the basic interface between a model and its task environment. At this layer, code is the medium that converts model outputs into executable and inspectable structures. We review code for reasoning, where programs externalize intermediate computation and allow interpreters, symbolic solvers, execution traces, or process rewards to check and refine reasoning [7, 6, 8, 29, 30, 31]. We then review code for acting, where generated programs serve as policies, tool calls, behavior trees, or reusable skills for embodied, GUI, and software environments [9, 10, 32, 33, 34, 35]. Finally, we examine code for environment modeling, where program states, repositories, traces, simulators, and tests represent state, dynamics, and feedback signals for agent interaction [36, 37, 38, 5, 12, 39]. This layer establishes the core harness interface: code is how the agent makes reasoning executable, action programmable, and environment state inspectable.
Building on this interface, Harness Mechanisms: Planning, Memory, Tool Use, Control, and Optimization (§ 3) studies how code-harnessed agents remain reliable beyond a single generation step. Once code is placed inside the agent loop, the harness must decide what to execute next, preserve useful state, expose the right tools, and convert failures into corrective actions. We therefore review planning methods that organize long-horizon software tasks through decomposition, structural grounding, trajectory search, or workflow orchestration [40, 41, 42, 43, 44]; memory methods that maintain working state, retrieve repository evidence, store reusable experience, and support shared interaction histories [45, 46, 47, 48]; tool-use methods that connect agents to APIs, repositories, execution environments, and verification tools [19, 49]; and feedback-driven control and harness optimization methods that use static analysis, runtime errors, tests, and human feedback to revise code through repeated execution [50, 51, 52, 53]. This layer turns the interface in § 2 into an operational harness: planning controls the execution trajectory, memory preserves state, tools expand the action space, and feedback-driven adaptation closes the loop between failure and revision.
Finally, Scaling the Harness: Multi-Agent Orchestration over Code (§ 4) extends the harness from a single agent to collaborative ecosystems. When multiple agents operate over code, the harness must not only support individual reasoning and execution, but also coordinate roles, share intermediate artifacts, maintain common state, and verify collective progress. We review multi-agent code-centric systems through agent roles such as manager, planner, coder, reviewer, and tester; collaboration modes such as programming, repair, debate, red-teaming, and adversarial interaction; and workflow topologies ranging from centralized coordination to distributed or streaming collaboration [54, 55, 56]. This layer shows how code becomes a shared harness for orchestrated autonomy: repositories, tests, traces, and structured artifacts provide the common workspace through which agents coordinate, inspect, and improve each other's behavior.
This survey studies *code as agent harness*: code-centered agent systems where reasoning, action, state, feedback,
and verification are organized around executable, inspectable, and
stateful programs.
We organize the literature up to 2026 into three connected layers:
- **Harness Interface**: code enters the agent loop as a reasoning substrate, an action interface, and an environment representation.
- **Harness Mechanisms**: planning, memory, tool use, control, and harness optimization sustain code-centric agents over long-horizon execution and revision.
- **Scaling the Harness**: shared code artifacts, execution states, repositories, and structured workflows support coordination, review, and collective verification in multi-agent systems.
Beyond the taxonomy, we examine how agent-initiated code interaction appears across five application domains. In coding assistance, agents author patches, tests, and issue-resolution workflows over live repositories [5, 57, 58]. In GUI and OS automation, agents synthesize and execute interface commands grounded in DOM trees, accessibility APIs, and executable evaluators [59, 60]. In scientific discovery, agents dynamically compose and execute hypothesis-testing pipelines spanning simulations, lab protocols, and data analysis [61, 62, 63, 64]. In personalization and embodied control, agents author and revise executable policies, simulators, and skill libraries in response to environment feedback [9, 10, 32]. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight, and extensions to multimodal environments. This survey provides a roadmap for studying code not only as something agents generate, but as the runtime medium through which they execute, adapt, and coordinate reliable behavior.
- **Conceptual framing**: We formalize *code as agent harness*, reframing code from a generated artifact into the operational substrate of executable, verifiable, and stateful AI agent systems.
- **Taxonomy and synthesis**: We organize code as agent harness into three connected layers: harness interfaces, harness mechanisms, and scaling harness, and synthesize representative methods.
- **Applications and future agenda**:We connect the taxonomy to real-world applications and outline key challenges in evaluation, verification, safety, and coordination.
2. Harness Interface: Code for Reasoning, Acting, and Environment Modeling
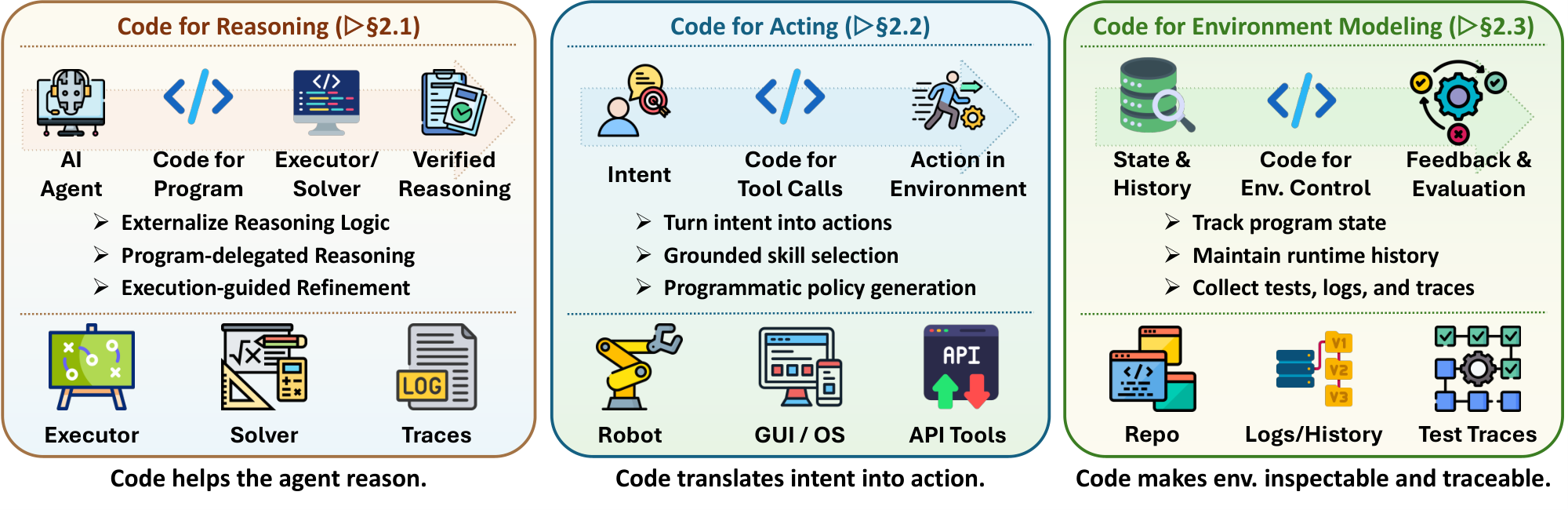
Section Summary: A harness converts a language model into a working agent by linking its outputs to external tools, ongoing memory, and reliable feedback, with code serving as the connecting medium. Code is useful here because it is executable, allowing outside systems to run and check what the model produces; inspectable, so the system can examine intermediate steps and correct errors; and stateful, preserving progress across actions in a modifiable form. The section defines code broadly to include programs, tests, simulators, and logs, while distinguishing it from raw perception or internal thoughts, and organizes its use into three supporting roles: turning reasoning into verifiable computation, turning intentions into grounded actions, and representing the environment’s state and dynamics.
A harness turns a stateless language model into a functional agent by grounding its outputs in external execution, persistent state, and verifiable feedback. The most fundamental design question for any harness is therefore: what medium connects the model to its task environment?
We argue that code is the answer. Unlike natural language, code is executable, meaning model outputs become operations with formally verifiable outcomes; inspectable, meaning intermediate computation is exposed as structured traces that the harness can read, store, and act upon; and stateful, meaning the evolving program represents task progress in a persistent, modifiable form across steps. Crucially, these are not merely properties of code as a notation; they are properties that make code functional as a harness interface. Executability means the harness can verify what the model intended. Inspectability means failures can be diagnosed and fed back. Statefulness means the agent's interaction history is not lost between steps.
Scope boundary.
We use code broadly, but not metaphorically. In this survey, code refers to executable or machine-checkable artifacts, including programs, scripts, formal specifications, proof scripts, API schemas, tool definitions, tests, repositories, simulators, configuration files, and code-adjacent execution artifacts such as traces and logs when they are produced by or consumed by executable systems. By contrast, raw perception, physical state, human intent, and model-internal latent reasoning are not themselves code. They may be sensed, estimated, serialized, verified, or acted upon through code, but they should not be conflated with the code interface. This boundary is important because code as a harness interface does not replace perception, embodiment, human goals, or model reasoning; rather, it makes selected aspects of them executable, inspectable, and stateful within the agent loop.
We organize this interface around three roles that code assumes in agentic systems. Code for reasoning externalizes internal logic into verifiable computation, allowing external interpreters, symbolic solvers, execution traces, or process rewards to check and refine reasoning (§ 2.1). Code for acting translates high-level intent into executable operations grounded in embodied, GUI, software, or tool-use environments (§ 2.2). Code for environment modeling represents world state, transition dynamics, and feedback signals through program states, repositories, simulators, tests, and logs that agents can execute, edit, and query (§ 2.3). Overall, these roles define the harness interface: code makes reasoning executable, action programmable, and environment state inspectable.
2.1 Code for Reasoning
A central role of the agent harness is to transform model reasoning from transient text generation into executable and verifiable computation. Early prompting techniques such as pure chain-of-thought (CoT) [65] perform reasoning and computation entirely in natural language, forcing the model to both decompose problems and execute intermediate operations within a single latent textual process. While language models are often effective at proposing reasoning steps, they remain unreliable at faithfully carrying out symbolic, logical, or arithmetic computation [7]. More importantly, purely textual reasoning provides the agent harness with little ability to verify intermediate states, inspect execution behavior, or persist computational progress across steps.
Code-for-reasoning thus introduces code as the execution interface between the model and the harness, moving beyond purely text-based reasoning. The model generates executable programs that external runtimes, interpreters, symbolic solvers, or verification modules can execute and evaluate. This separates high-level reasoning from low-level computation: the model proposes procedures, while the harness executes them, observes runtime behavior, stores intermediate states, and feeds execution results into future reasoning.
Recent work further broadens this interface from program execution as an external calculator to execution artifacts as reusable reasoning signals. Inputs and outputs, execution traces, variable states, control-flow structures, and function-level tests can all serve as intermediate states that the harness verifies, scores, and feeds back into subsequent reasoning. Existing work can therefore be organized into three paradigms: program-delegated reasoning, formal verification and symbolic reasoning, and iterative code-grounded reasoning. We detail each of them in the following subsections.
2.1.1 Program-Delegated Reasoning
Program-delegated reasoning uses executable programs as the primary interface between problem decomposition and computation. Instead of relying solely on natural language reasoning, the model generates code that external interpreters execute to produce formally grounded outputs. Early works [66, 7] demonstrate that delegating computation to programs substantially improves reliability by moving intermediate reasoning into structured, verifiable execution traces. Program-of-Thoughts (PoT) prompting [6] further systematizes this paradigm by explicitly decomposing reasoning into executable programs, followed by extensions such as POET [67] and MathCoder [68], which improve execution fidelity and domain specialization. Subsequent work investigates the conditions under which program delegation is effective, including the role of execution correctness, task structure, and runtime interaction. For example, Chain of Code (CoC) [8] and CIRS [69] analyze how executable reasoning changes failure modes relative to pure language-based reasoning. Later directions extend this interface beyond isolated task execution. Cross-lingual reasoning frameworks [70] demonstrate that program-based reasoning can generalize across linguistic environments through shared executable structure, while method-based reasoning [71] introduces reusable programmatic procedures that persist across tasks. More recent systems such as CodeAdapt [72] further suggest that tightly coupling language models with executable reasoning interfaces can surpass specialized reasoning-oriented models. Additionally, CodeI/O [73] transforms contextually grounded programs into code input-output prediction tasks, exposing reasoning primitives such as logic-flow planning, state-space search, decision-tree traversal, and modular decomposition while preserving procedural rigor through executable verification.
2.1.2 Formal Verification and Symbolic Reasoning Interfaces
Hybrid neural-symbolic methods combine flexible language-based inference with structured symbolic computation, using code and symbolic artifacts as persistent intermediate representations rather than treating programs as mere generated text. Early formulations such as Graph-of-Thoughts [74] generalize chain-of-thought reasoning into graph-structured trajectories, enabling intermediate states to branch, merge, and be reused. Building on this direction, self-verifying reflection [75], MA-LoT [76], and Socratic self-refine [77] introduce iterative verification loops in which symbolic consistency checks guide the refinement of generated solution paths.
Recent work further tightens the coupling between neural generation and symbolic execution through code-based interfaces. CodeSteer [78] and Code-as-Symbolic-Planner [79] explicitly coordinate free-form language reasoning with executable symbolic operations, treating programs as structured substrates that the harness can inspect, transform, and execute across multiple stages. VisualCoder [80] extends this idea by making program behavior visible through control-flow representations. By aligning generated reasoning with visual control-flow graphs and execution paths, it turns dynamic program behavior into an inspectable artifact for program-behavior prediction. Together, these methods broaden the neural-symbolic interface from textual code to multimodal execution artifacts that a harness can reference, validate, and reuse.
A complementary line of work uses machine-verifiable formal languages as the reasoning interface itself. Proof assistants such as Lean [81], Isabelle [82], and Coq [83] provide formal proof languages based on rigorous logical foundations, enabling each derivation step to be checked by a verifier. Early LLM-based theorem-proving systems, including ReProver [84], DeepSeek-Prover [85], and TheoremLlama [86], establish practical recipes for combining language models with proof-assistant feedback in mathematical reasoning. More recent systems, such as DeepSeek-Prover-V2 [87], Kimina-Prover [88], MA-LoT [76], and Goedel-Prover-V2 [89], improve this process through deliberative proof search, self-correction, and repeated proof generation and verification. Formal verification interfaces are also expanding beyond theorem proving in mathematics. HybridReasoning [90] applies formal provers to support natural-language reasoning; Lean4Physics [91] and PhysLib [92] extend Lean-based verification to physics; and VERINA [93] and Goedel-Code-Prover [94] adapt formal methods to code verification. Lean4Agent [95] further extends this trajectory to agentic systems by using Lean4 to model and verify agent workflows and trajectories. From the harness perspective, these systems show how formal languages can serve not only as reasoning tools, but also as executable contracts that constrain, certify, and audit agent behavior.
2.1.3 Iterative Code-Grounded Reasoning
Iterative code-grounded reasoning focuses on closed-loop interaction between generation, execution, and feedback. In these systems, reasoning is not a single-pass process, but an iterative computational trajectory grounded in executable state transitions. Early work such as NExT [30] trains models to anticipate execution behavior by reasoning over program traces, thereby grounding intermediate reasoning in runtime semantics. Related efforts [96] similarly emphasize that executable traces provide a richer supervision signal than final textual outputs alone. Building on this foundation, subsequent approaches introduce explicit generate–execute–verify–refine loops. Methods such as CodePRM [31] and ORPS [97] use execution outcomes to evaluate and refine intermediate reasoning trajectories, enabling the harness to guide reasoning through runtime feedback rather than pure next-token prediction. Along the same direction, systems such as CYCLE [98] and Self-Edit [99] iteratively revise generated solutions using execution-aware correction signals. Reinforcement learning further strengthens this paradigm by treating execution feedback as an optimization signal over reasoning trajectories. Methods such as CodeRL [100], CodeRL+ [101], and RLTF [102] optimize functional correctness through unit-test-based rewards, while approaches such as StepCoder [103] incorporate fine-grained compiler and runtime feedback during optimization. RLEF [104] formalizes this interaction as policy optimization grounded in multi-step execution feedback, allowing reasoning policies to adapt through iterative runtime interaction. More recent approaches move toward fully interactive reasoning environments. For example, EG-CFG [21] injects execution signals directly during generation to support step-level correction, while systems such as R1-Code-Interpreter [105] interleave reasoning and multiple rounds of code execution within persistent interactive sessions.
\begin{tabularx}{\ccccccccc}{p{2.8cm}p{2.2cm}p{3.1cm}X}
\toprule
\textbf{Method} & \textbf{Mechanism} & \textbf{Reasoning Paradigm} & \textbf{Key Innovation} \\
\midrule
PoT [6] & Delegated & Hybrid comments & Merges code with natural language CoT \\
PAL [7] & Delegated & Program-aided & Decouples logic from computation \\
CodeAdapt [72] & Delegated & Generalizable logic & Code-enabled LLMs outperforming reasoning models \\
CodeI/O [73] & Delegated & I/O prediction & Converts code into verifiable input-output reasoning tasks \\
SATLM [29] & Formal & SAT/SMT solving & Uses symbolic solvers as machine-checkable reasoning backends \\
ReProver [84] & Formal & Lean proof search & Combines LLM generation with proof-assistant feedback \\
Dpsk-Prover [85] & Formal & Lean theorem proving & Trains LLMs for formal mathematical proof generation \\
Dpsk-Prover-V2 [87] & Formal & Deliberative proving & Lean proof search through decomposition and self-correction \\
Goedel-Code-Prover [94] & Formal & Lean code proof & Searches hierarchical Lean proofs for code verification \\
Lean4Agent [95] & Formal & Agent verification & Models and verifies agent workflows and trajectories in Lean4 \\
Chain of Code [8] & Hybrid & LMulator & Simulates non-executable semantic code \\
SATLM [29] & Hybrid & Formal Logic & Uses SAT/SMT solvers as reasoning backend \\
CodeSteer [78] & Hybrid & Symbolic control & Explicitly transitions between symbolic code and neural text \\
VisualCoder [80] & Hybrid & CFG-grounded & Aligns code reasoning with visual control-flow artifacts. \\
NExT [30] & Iterative & Trace-grounded & Anticipates execution behavior via program traces \\
MathCoder [68] & Iterative & Feedback-driven SFT & Interleaves code, output, and reflection \\
CodePRM [31] & Iterative & Process rewards & Learns reward functions over reasoning-execution trajectories \\
RLEF [104] & Iterative & Multi-step RL & Optimizes policy directly using execution feedback \\
EG-CFG [21] & Iterative & Execution-guided & Integrates execution signals directly during generation \\
R1-Code-Int. [105] & Iterative & Fully interactive & Autonomously interleaves reasoning and multiple executions \\
ExecVerify [106] & Iterative & Stepwise RL & Uses statement- and variable-level execution rewards. \\
FunPRM [107] & Iterative & Function-step PRM & Treats functions as verifiable process-reward units. \\
ReCode [108] & Iterative & Process RL & Reinforces code generation with reasoning-process rewards \\
\bottomrule
\end{tabularx}
2.2 Code for Acting
Beyond reasoning, the agent must also connect the model to external environments where decisions produce real executable effects. At this stage, code no longer serves primarily as a medium for computation, but as an action interface that converts model outputs into grounded operations such as tool invocations, robot-control policies, GUI actions, or software commands. Through this interface, the harness translates high-level intent into executable behaviors that can interact with embodied, digital, and interactive environments. The central challenge is therefore grounding: the harness must map abstract language outputs into executable behaviors that respect the constraints of the target environment, including embodiment limits, interface APIs, environment dynamics, and safety requirements. Unlike code-for-reasoning, where interpreters can often directly verify correctness, action execution occurs in partially observed and dynamically evolving environments, where failures may emerge through invalid state transitions, delayed feedback, or silent execution errors. For example, a robot may attempt to grasp an object outside its reachable workspace without producing an explicit runtime exception.
Importantly, executable action code is an interface to these components, not a replacement for them. In embodied settings, perception modules provide observations, affordance or feasibility models estimate which actions are possible, motion planners and controllers connect symbolic commands to sensors and actuators, and safety layers constrain dangerous or invalid behavior. In GUI and software settings, the analogous components include screen parsers, DOM or accessibility trees, backend APIs, user-intent models, permission systems, and programmatic validators. Code sits between the model and these components: it serializes observations, calls grounding and planning modules, invokes executable actions, and exposes validation results back to the harness.
Code-for-acting therefore introduces structured executable programs as the control interface between the model and the environment, allowing the harness to execute, monitor, validate, reuse, and refine actions through interaction feedback. This interface can be realized in different forms: a predefined skill library, a generated control policy, a persistent skill memory, a GUI/API tool protocol, or an explicit action-validation harness. AutoHarness [109] makes the last form explicit by automatically synthesizing a code harness that mediates between the LLM and the environment, filtering invalid actions before execution. This highlights the core harness view of code-for-acting: code is not only the action to be executed, but also the executable boundary that connects model intent to perception, grounding, affordance estimates, controllers, APIs, actuators, and safety constraints.
\begin{tabularx}{\ccccccccc}{p{2.7cm}p{1.7cm}p{3.0cm}X}
\toprule
\textbf{Method} & \textbf{Mechanism} & \textbf{Action Paradigm} & \textbf{Key Innovation} \\
\midrule
AutoHarness [109] & Harness Gen. & Action validation & Synthesizes code harnesses that mediate model actions and filter invalid environment interactions \\
SayCan [9] & Skill Selec. & Affordance-based & Links LLM plans to physical feasibility \\
KnowNo [110] & Skill Selec. & Conformal prediction & Calibrates planner uncertainty for ambiguous instructions \\
SkillVLA [111] & Skill Selec. & Bimanual grounding & Extends grounding to combinatorial skill reuse \\
BOSS [112] & Skill Selec. & Skill bootstrapping & Synthesizes new executable skill chains via guided practice \\
LLM-Guided Traj. [113] & Skill Selec. & Trajectory generation & Generates diverse manipulation trajectories and executable success conditions \\
LRLL [114] & Skill Selec. & Lifelong grounding & Evolving skill interface via memory and self-exploration \\
CaP [10] & Policy Gen. & Hierarchical Python & Generates reactive robot control policies \\
RoboCodeX [33] & Policy Gen. & Multimodal tree & Synthesizes tree-structured code across navigation \\
Code-BT [34] & Policy Gen. & Behavior-tree & Imposes rule constraints via code-to-behavior-tree planning \\
ALRM [115] & Policy Gen. & Closed-loop control & Integrates programmatic generation with ReAct execution \\
CP-Agent [116] & Policy Gen. & Constraint solving & Uses persistent execution loops for formal constraint-model repair \\
Robot-Code Sim. [117] & Policy Gen. & Static simulation & Uses LLMs as static simulators for robot code evaluation \\
GenSwarm [118] & Policy Gen. & Multi-robot control & Coordinates policy generation and deployment across robotic agents \\
NormCode [119] & Policy Gen. & Governed interface & Enforces auditability and data isolation through semi-formal code \\
RACAS [120] & Policy Gen. & Cooperative control & Robot-agnostic architecture for closed-loop cooperative agents \\
Voyager [32] & Lifelong & Skill Library & Autonomous curriculum for open-ended tasks \\
LYRA [121] & Lifelong & Human-in-loop & Encodes human corrections into reusable structured skills \\
ViReSkill [122] & Lifelong & Vision-grounded & Replanning on failure using a skill-memory cache \\
UI-Voyager [35] & Lifelong & Self-evolving & Rejection fine-tuning and self-distillation for mobile GUI agents \\
SkillsCrafter [123] & Lifelong & Continual skills & Mitigates forgetting as executable manipulation skills accumulate \\
\bottomrule
\end{tabularx}
2.2.1 Grounded Skill Selection
Grounded skill selection studies how the agent maps high-level language intent into executable behaviors through reusable skill interfaces. Rather than generating low-level actions directly, these systems treat the environment as a collection of executable capabilities that the agent harness can invoke, compose, and refine under environmental constraints. SayCan [9] establishes the core paradigm by coupling language planning with grounded skill execution, allowing the agent to select actions based not only on semantic relevance but also embodiment feasibility. Subsequent work extends this execution interface in several directions. KnowNo [110] introduces uncertainty-aware control through conformal prediction, enabling the harness to detect ambiguous states and trigger clarification before unsafe execution. BOSS [112] addresses the rigidity of fixed skill libraries by using language-guided practice to synthesize new executable skill chains, allowing the harness to expand its action space over time. Similarly, [113] tackles the data bottleneck of grounded interaction by using LLM-guided generation to construct diverse manipulation trajectories and executable success conditions for automatic retry and relabeling. Beyond static execution, LRLL [114] introduces memory and self-guided exploration to maintain a persistent and evolving skill interface across tasks. Finally, SkillVLA [111] extends this paradigm to combinatorial bimanual interaction, emphasizing that grounded action interfaces must support structured skill reuse and recomposition under increasingly complex embodiment settings.
2.2.2 Programmatic Policy Generation
Programmatic policy generation treats code itself as the control interface between the model and the environment. Instead of selecting from predefined skills, the harness directly materializes executable policies as programs that specify control logic, perception-conditioned branching, feedback loops, and API interaction. CaP [10] crystallizes this paradigm by framing LLM-generated Python programs as executable robot policies. Building on this idea, RoboCodeX [33] introduces multimodal and tree-structured code generation to support more complex manipulation and navigation behaviors. Subsequent work focuses on scaling the interaction substrate. RoboPro [124] synthesizes executable policy code from large-scale in-the-wild videos, while Code-BT [34] compiles generated programs into behavior-tree controllers that support constrained execution and iterative runtime feedback. Beyond robotics, CP-Agent [116] demonstrates that persistent execution loops can support formal constraint-solving agents through iterative execution and repair. To reduce dependence on expensive physical environments, [117] configures language models as static execution simulators for robot code evaluation. GenSwarm [118] further extends programmatic control to multi-agent robotic systems, where the harness must coordinate policy generation, constraint analysis, and deployment across multiple embodied agents. At the systems level, NormCode [119] emphasizes governance and auditability by introducing a semi-formal programming interface with enforced data isolation, allowing execution traces and control logic to remain inspectable and constrained. Finally, ALRM [115] and RACAS [120] consolidate these ideas into persistent closed-loop control architectures that integrate code generation, execution, monitoring, and iterative interaction within unified agent harnesses.
2.2.3 Lifelong Code-Based Agents
Lifelong code-based agents study how executable interaction interfaces can persist, evolve, and accumulate capabilities over long-horizon interaction. In these systems, code is not only an execution mechanism, but also a persistent memory substrate through which the harness stores reusable behaviors, interaction traces, and environment knowledge. Voyager [32] establishes this paradigm through an automatic curriculum and continually expanding executable skill library for open-ended interaction in Minecraft. Extending this idea to embodied environments, LRLL [114] introduces persistent memory, self-guided task exploration, and skill abstraction to overcome the limitations of fixed policy libraries without requiring gradient updates. A central challenge in lifelong harnesses is that interaction feedback and corrections are often transient and difficult to reuse. LYRA [121] addresses this issue by converting human corrections into reusable executable skills and retrieval-augmented memory structures. Similarly, ViReSkill [122] combines vision-grounded replanning with skill-memory caching to maintain stable interaction under environmental failures and output variability. Recent work further focuses on continual adaptation and self-evolution under persistent deployment. SkillsCrafter [123] introduces continual language-conditioned manipulation structures to mitigate catastrophic forgetting as executable capabilities accumulate, while UI-Voyager [35] generalizes the self-evolving interaction paradigm to GUI agents through failure-driven adaptation and self-distillation. Together, these systems move beyond one-shot execution toward persistent agent harnesses that continuously expand, refine, and reuse executable interaction interfaces over time.
2.3 Code for Environment
The agent must also maintain an explicit representation of the environment with which the agent interacts. Without such a representation, the environment is exposed to the agent only indirectly through textual observations, API returns, or sparse feedback signals. As a result, environment state often remains implicit, transient, and difficult to verify, making it challenging to track state transitions, evaluate interaction outcomes, or reuse past interaction history across long-horizon tasks. This limitation becomes particularly severe in complex software, robotic, and multi-step interactive environments, where successful interaction depends on maintaining consistent world state and grounded feedback over time.
Code-for-environment addresses this limitation by introducing executable programs as the environment interface itself. Instead of treating the environment as an opaque external process, these systems materialize environment structure and dynamics through computational artifacts such as simulators, repositories, tests, execution traces, logs, and state-transition programs. This allows the agent to explicitly store, inspect, execute, and modify environment state throughout interaction. Representing environments through executable code provides two major advantages. First, executable environments expose verifiable state transitions, allowing the agent to evaluate interaction outcomes through execution rather than ambiguous natural-language judgment. Second, code-based environments are persistent and modifiable that agents can query, simulate, edit, and refine during interaction. Rather than interacting with an opaque world solely through language, agent harness can ground reasoning and action in explicit computational state and runtime dynamics. Existing work in this direction can be organized into four paradigms: structured world representations, execution-trace world modeling, code-grounded evaluation environments, and verifiable environment construction.
\begin{tabularx}{\ccccccccc}{p{2.8cm}p{2.0cm}p{3.1cm}X}
\toprule
\textbf{Method} & \textbf{Mechanism} & \textbf{Environment Paradigm} & \textbf{Key Innovation} \\
\midrule
ViStruct [125] & Structured & Class/object hierarchy & Encodes visual scenes as data structures \\
FactoredScenes [126] & Structured & Room programs & Composes object/relation functions for 3D layout generation \\
PoE-World [127] & Structured & Programmatic experts & Scales symbolic world models beyond simple grid-worlds \\
Code2World [38] & Structured & Render-aware RL & Re-frames GUI state prediction as renderable HTML generation \\
SemCoder [128] & Trace-based & Semantic alignment & Pairs code with detailed execution traces \\
WorldCoder [36] & Trace-based & Model-based RL & Synthesizes transition and reward models \\
CWM [37] & Trace-based & Open-weights trace & Trains large LLMs natively on program execution traces \\
RWML [129] & Trace-based & Self-supervised RL & Aligns simulated next states with realized environment states \\
AWM [130] & Trace-based & World-modeling & Aligns multiple executable world models across tasks \\
WorldMind [131] & Trace-based & Model fusion & Coordinates executable world models from knowledge sources \\
SWE-bench [5] & Evaluation & Repo-level testing & Uses unit tests as objective world states \\
AgentBench [12] & Evaluation & Multi-env interaction & Benchmarks across OS, databases, and games \\
CRUXEval [132] & Evaluation & Execution tasks & Benchmarks functional input and output prediction \\
End Terms. [39] & Evaluation & Procedural RL envs & Automates generation of terminal-use evaluation tasks \\
InterCode [11] & Evaluation & Interactive execution & Frames coding tasks as actions with sandbox feedback \\
LiveCodeBench [133] & Evaluation & Live coding eval & Continuously updates execution-based evaluation pipelines \\
CRUXEval-X [134] & Evaluation & Multilingual execution & Extends input-output execution evaluation across languages \\
CoRe [135] & Evaluation & Runtime reasoning & Evaluates code reasoning through execution-centered tasks \\
CodeGlance [136] & Evaluation & Multimodal code eval & Evaluates code understanding under visual and structural settings \\
SWE-smith [137] & Construction & Synthetic SWE envs & Generates repository-level tasks and execution environments \\
EnvScaler [138] & Construction & Tool-interactive envs & Synthesizes tool-use environments with programmatic validators \\
\bottomrule
\end{tabularx}
2.3.1 Structured World Representations
Structured world representations model environments through explicit programmatic structures that the agent can execute, inspect, and manipulate. Rather than representing the environment solely through latent embeddings or textual descriptions, these approaches encode world state, object relations, spatial layouts, and interaction dynamics as structured computational artifacts. For example, ViStruct [125] uses programming-language structure as an explicit interface for visual structural knowledge extraction, enabling multi-granular visual events to be represented through consistent executable structures. FactoredScenes [126] similarly models indoor environments as compositional "room programs, " where reusable object and relation functions define physically consistent scene layouts. Extending this idea to scalable symbolic world modeling, PoE-World [127] introduces a compositional framework that combines many small programmatic experts to represent increasingly complex environment dynamics. More recent systems broaden structured environment interfaces to high-fidelity interactive worlds. Code2World [38] reframes GUI state prediction as renderable HTML generation, allowing environment transitions to be represented and evaluated through executable rendering code. Code2Worlds [139] further extends this paradigm to 4D simulated environments through language-to-simulation program generation, where physics-aware execution loops reduce semantic-physical inconsistencies during environment construction and interaction.
2.3.2 Execution-Trace World Modeling
Execution-trace world modeling studies how the agent can learn environment dynamics directly from executable interaction traces. Instead of treating execution merely as a final evaluation step, these approaches model runtime transitions themselves as the primary representation of environment behavior. SemCoder [128] bridges static programs and runtime semantics by training language models to reason about functional behavior, statement-level execution effects, and input-output transitions. Building on this perspective, Code World Model (CWM) [37] learns predictive world models directly from program traces, enabling the agent to anticipate future environment states through executable dynamics. WorldCoder [36] further introduces a model-based interaction framework in which the agent explicitly writes and updates executable world models represented as Python programs. Rather than storing environment knowledge implicitly in model parameters alone, the agent maintains editable computational representations that can be executed, revised, and reused during planning and interaction. Subsequent work extends this paradigm toward continual and interactive world-model adaptation. RWML [129] combines execution traces with reinforcement learning to refine environment dynamics through runtime interaction, while AWM [130] and WorldMind [131] study how multiple executable world models can be aligned, fused, and coordinated across tasks and knowledge sources.
2.3.3 Code-Grounded Evaluation Environments
Code-grounded evaluation environments use executable systems as the interface for measuring agent behavior and interaction quality. Unlike static benchmarks based solely on textual outputs, these environments expose explicit runtime state transitions, execution feedback, and verifiable interaction outcomes that the agent can directly observe and evaluate. InterCode [11] establishes this paradigm by reframing coding tasks as interactive execution environments, where code acts as actions, execution feedback serves as observations, and sandboxed runtimes provide grounded interaction. CRUXEval [132] further evaluates program understanding through executable input-output prediction tasks, while LiveCodeBench [133] introduces continuously updated evaluation pipelines that assess execution, self-repair, and runtime reasoning capabilities under evolving problem distributions. SWE-bench [5] extends executable evaluation to real-world software repositories, where agents must modify large-scale codebases and are evaluated through repository-level unit-test execution rather than textual correctness alone. More broadly, AgentBench [12] demonstrates that executable interaction environments can evaluate reasoning and decision-making across diverse embodied and digital tasks. Subsequent benchmarks such as CRUXEval-X [134], CoRe [135], GeoGramBench [140], CodeGlance [136], and Endless Terminals [39] further expand this paradigm toward multilingual, multimodal, and continuously interactive evaluation settings, where runtime interaction rather than static answer matching becomes the primary evaluation interface.
2.3.4 Verifiable Environment Construction
A newer direction treats executable environments not only as benchmarks to evaluate agents, but as harness artifacts that can be synthesized, scaled, and validated programmatically. This is especially important for long-horizon agents, where the harness must provide not only a task prompt, but also a runnable state, transition dynamics, feedback channels, and verification oracles. SWE-smith [137] scales software-engineering agent data by constructing repository-level tasks and execution environments from existing codebases, turning software repositories into reproducible program worlds for agent training and evaluation. EnvScaler [138] extends this idea beyond software engineering by programmatically synthesizing tool-interactive environments together with scenarios and rule-based trajectory validators. From the harness perspective, these methods make the environment interface itself an object of construction: code specifies not only what the agent edits or executes, but also the state transitions, tool affordances, and verifiers that determine whether an interaction has succeeded.
3. Harness Mechanisms: Planning, Memory, Tool Use, Control, and Optimization
Section Summary: Harness mechanisms serve as the overarching control layer that turns an AI model's decisions into reliable, revisable actions within a software environment. They coordinate the model's judgment for breaking down tasks with persistent state that tracks context and results, plus human-designed infrastructure that supplies tools, enforces policies, runs verifications, and maintains safeguards like sandboxes and review gates. This section outlines five core interacting elements—planning for long-term task organization, memory management for retaining context, governed tool use, plan-execute-verify loops for controlled iteration, and ongoing harness optimization—to improve agent performance on complex coding jobs beyond simple one-step generation.
Harness mechanisms form the central systems layer that makes code-harnessed agents reliable beyond a single generation step. Once code enters the agent loop, software generation is no longer only a problem of producing correct programs from a prompt. It becomes an interaction among the model, mutable task state, and human-designed harness infrastructure. The model provides judgment: it decomposes goals, selects actions, interprets feedback, and decides when to revise. Mutable state records repository evidence, working context, execution traces, validation results, memories, and intermediate beliefs about the task. The harness infrastructure exposes tools and execution substrates, persists and compacts state, constrains actions through policies and permission tiers, routes feedback, and verifies whether each state transition is acceptable. From this perspective, harness mechanisms are not isolated add-on modules, but coordinated control surfaces that turn model decisions into bounded, observable, and revisable changes in an executable environment. In its basic form, code allows the agent to call existing executable interfaces. Further, the agent can dynamically author task-specific executable interfaces. These agent-authored artifacts make the harness more adaptive because they allow the execution environment to be reshaped around the current task. However, dynamically authored code does not replace the broader human-designed harness infrastructure. Reliability still depends on model-side judgment together with human-designed policies, sandbox boundaries, permission tiers, verification oracles, audit logs, and human-review gates. Code therefore serves as an executable medium inside the harness, while the harness remains the larger policy-governed system that decides what code may be executed, trusted, persisted, reused, or promoted into future workflows.
In this section, we review five interacting categories of harness mechanisms for code agents. Planning (§ 3.1) organizes long-horizon task execution by externalizing goals into decompositions, structural constraints, search trajectories, or workflow-level orchestration. Memory and context engineering (§ 3.2) manage mutable state across long interactions by preserving working context, retrieving repository evidence, storing reusable experience, supporting shared histories, and offloading state beyond the active context window. Tool usage (§ 3.3) connects the agent to governed executable interfaces, including APIs, repositories, terminals, sandboxes, verification tools, and workflow orchestrators. Harness control through the Plan-Execute-Verify loop (§ 3.4) reframes feedback-guided debugging as a broader control process: plans form contracts over intended changes, execution applies them inside sandboxed and permissioned environments, and verification uses deterministic sensors and human-review gates to decide whether the state should be accepted, revised, escalated, or rolled back. Finally, agentic harness engineering (§ 3.5) studies how the harness itself can be measured and improved through deep telemetry, evolution agents, replay-based evaluation, and governed harness mutation.
3.1 Planning for Agent Harness
Planning plays a central role in agentic harness because real-world software engineering tasks rarely admit a direct one-shot mapping from natural language intent to correct implementation. From the harness perspective, planning is not merely an internal reasoning capability of the LLM, but a form of harness control: it structures how the agent externalizes intent into executable steps, schedules interactions with code artifacts and tools, and regulates the trajectory of reasoning, execution, and revision over time. Beyond generating code tokens, an effective agent harness must organize long-horizon problem solving into a coherent course of action, deciding what intermediate goals to pursue, in what order to execute them, what artifacts to inspect or modify, and how to revise the trajectory when execution feedback reveals errors, missing dependencies, or violated constraints. This need becomes especially pronounced in repository-level editing, web interaction, competitive programming, and hardware design, where the agent must operate over large action spaces, sparse feedback, and deeply interdependent subproblems. In such settings, a fundamental challenge arises between the complexity of the target task and the limited reliability of unconstrained agent execution: without an explicit planning mechanism as harness control, the agent may commit too early to brittle solution paths, overlook latent dependencies, or fail to coordinate reasoning, retrieval, execution, and revision into a stable workflow.
Early planning-oriented systems mainly treated planning as a linear decomposition step, where the model first produced a natural-language solution outline and then translated it into code. As code agents were applied to more complex environments, however, planning gradually evolved from a simple pre-generation scaffold into a richer harness-level control mechanism. It can be grounded in repository structure or external knowledge to constrain the agent's action space, expanded through explicit search over multiple candidate trajectories to improve robustness, or distributed across specialized agent roles and feedback loops to coordinate execution at the system level. Based on the primary locus where harness control is realized, we categorize existing planning methods in code agents into four types: linear decomposition planning, structure-grounded planning, search-based planning, and orchestration-based planning.
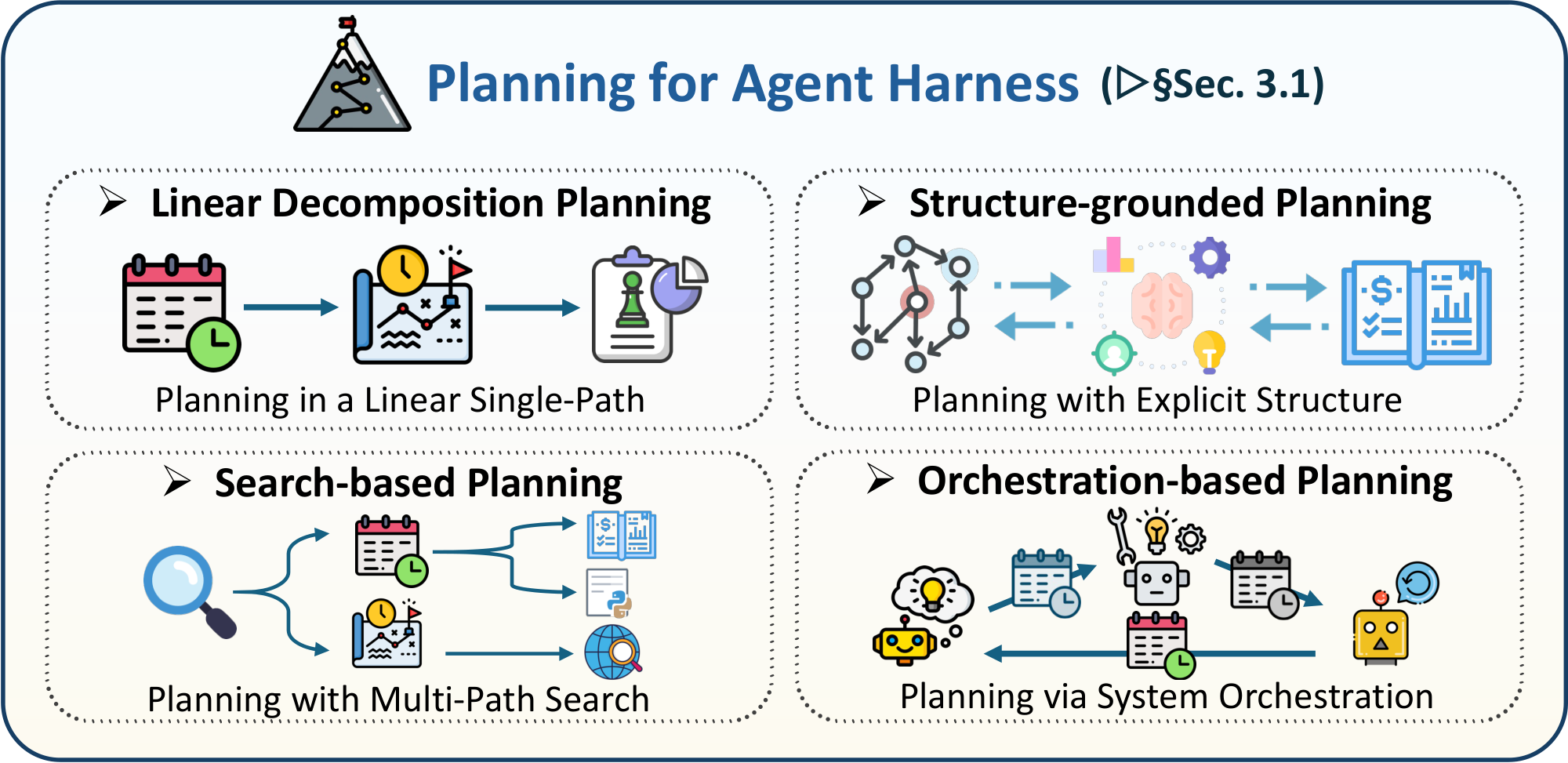
3.1.1 Linear Decomposition Planning
In this planning paradigm, the agent first produces a single explicit, executable sequence of steps, and then carries out generation by following this decomposition [141, 40, 41, 142, 143]. A lightweight precursor of this pattern is ReAct [144], where the agent interleaves thoughts, actions, and observations in a serial trajectory. In this framework, each reasoning step externalizes the current subgoal and constrains the next action, turning the trajectory itself into a stepwise harness for control. This pattern is most directly instantiated in Self-Planning [40]: the model first decomposes the intent into concise, high-level numbered steps, and then generates code step by step under the guidance of this plan. Plan-And-Act [145] further makes this harness explicit by separating a planner, which produces structured high-level plans: the planner repeatedly refreshes the linear scaffold as new observations arrive, allowing the planning strategy to preserve task-level control while adapting to environmental feedback. WebAgent [41] extends this idea to web automation: it decomposes a user instruction into successive sub-instructions, summarizes task-relevant HTML conditioned on the current subgoal, and then synthesizes executable Python actions from that linear sub-instruction sequence. KareCoder [141] follows a similar template in a knowledge-augmented setting, where the model first constructs a knowledge-aware, step-by-step prompt from an external knowledge library and then uses this prompt to generate code, making planning a structured intermediate layer between problem understanding and implementation. Recent industrial practice shows that this linear scaffold can be lifted from an ephemeral prompt artifact to a persistent harness object. In long-horizon coding workflows, files such as PLAN.md, Implement.md, and status logs record milestones, acceptance criteria, validation commands, and recovery rules, allowing the agent to reload, update, verify, and document progress across context resets or multi-session execution [146, 147]. In this view, planning is no longer merely an internal reasoning trace, but a filesystem-backed control object: it can be reviewed by humans, versioned with Git, consumed by subagents, and used as the source of truth for implementation. The main limitation remains that these methods typically commit to a single decomposition trajectory: when the initial plan is incomplete or misaligned, the harness can improve persistence and auditability, but it still provides limited exploration beyond the chosen path.
3.1.2 Structure-grounded Planning
In this line of work, the agent does not derive its action sequence solely from a free-form natural language prompt, but instead grounds planning in an explicit structured representation of the task environment, such as dependency graphs, repository graphs, circuit graphs, or knowledge graphs. These structures act as natural harness scaffolds: they expose relevant entities, encode dependency relations, and guide the order in which subtasks should be generated, revised, or verified. For example, CodePlan [42] constructs a plan graph over edit obligations and derives new steps through dependency analysis and change-impact propagation. Meanwhile, repository understanding methods [148, 149, 150, 148] convert codebases into heterogeneous graphs or text-rich code graphs, then use graph-integrated reasoning to localize relevant entities and condition downstream generation on structural dependencies rather than flat text context. GraphCodeAgent [151] extends this idea with a dual-graph harness, where a Requirement Graph captures relations among natural-language requirements and a Structural-Semantic Code Graph captures repository dependencies. The same principle also appears in recent agent-native repository practices. Files such as architecture notes, API specifications, and testing guides turn project knowledge into persistent, inspectable, and version-controlled artifacts that the agent can consult before acting [152, 153, 154]. This broadens structure-grounded planning beyond graph construction: the relevant structure determines explicit rules, build commands, directory boundaries, coding conventions, and design constraints, thereby promoting a coherent and stable harness control over the programs. Specialized domains follow the same pattern [155, 156]. VerilogCoder [156] grounds subtask planning in a Task and Circuit Relation Graph so that each subtask is enriched with signals, transitions, and examples, while DomAgent [155] uses knowledge graphs to combine top-down structured knowledge with bottom-up examples for domain-specific code generation. Overall, these works show that structure-grounded planning improves coherence, dependency awareness, and long-horizon consistency by turning project or domain knowledge into explicit and inspectable harness objects that guide the agent's behavior over time.
3.1.3 Search-based Planning
Search-Based Planning allocates inference-time compute to systematically explore, evaluate, and select among multiple candidate solution paths. Rather than committing the agent to a single plan, the key idea is to expand the decision space and use feedback to control which alternatives should be pursued, revised, or discarded. A first group of methods [157, 158] instantiates this harness in the thought space. Instead of directly writing code, they first branch over high-level observations, strategies, or reasoning traces, with the goal of increasing conceptual diversity before implementation. In this view, better planning comes from covering a broader idea space and using feedback to refine reasoning itself, rather than merely repairing final code. A second group [43, 159, 160, 161] performs search in the trajectory space of coding actions: these methods model coding as a branching process over strategy choice, implementation, debugging, and revision, and rely on execution signals or learned critics to decide which nodes to expand. Therefore, long-horizon coding quality improves when the agent can backtrack from suboptimal decisions and compare partial trajectories. Another line of these works, such as ReLoc [162] and SFS [163], treats planning as search in code space. Here the methods iteratively explore neighboring programs through mutation, revision, or local optimization, guided by validation feedback or fine-grained scoring signals. Beyond the above methods, recent systems increasingly treat candidate plans, patches, logs, tests, and execution traces as persistent artifacts rather than transient generations. SWE-Search [164] combines Monte Carlo Tree Search with software-engineering agents to explore alternative repair trajectories, while CodeTree [43] organizes strategy exploration, solution generation, and refinement within a unified tree. More broadly, Meta-Harness [13] pushes this idea to the harness level itself: it searches over harness code by giving an agent access to prior source code, scores, and execution traces through a filesystem. These developments suggest that search-based planning is not only a model-side sampling strategy, but also a harness-level state management problem: the runtime must preserve candidates, expose evidence, run validators, and decide which branch deserves further computation.
\begin{tabularx}{\ccccccccc}{@llllX@}
\toprule
\textbf{Method} & \textbf{Category} & \textbf{Core Mechanism} & \textbf{Interface} & \textbf{Feedback} \\
\midrule
Self-Planning [40]
& Linear decomposition
& Stepwise decomposition
& Shared prompt
& None \\
WebAgent [41]
& Linear decomposition
& Sub-instruction sequencing
& APIs
& Runtime exception \\
CodePlan [42]
& Structure-grounded
& Plan graph
& Repo graph
& Critique \\
VerilogCoder [156]
& Structure-grounded
& Task-circuit relation graph
& Repo graph
& Test pass/fail \\
Tree-of-Code [159]
& Search-based
& Trajectory tree search
& Execution env
& Test pass/fail \\
ReThinkMCTS [158]
& Search-based
& MCTS over reasoning paths
& Execution env
& Critique, tests \\
MapCoder [44]
& Orchestration-based
& Role orchestration
& APIs
& Critique, tests \\
Blueprint2Code [165]
& Orchestration-based
& Blueprint-to-code
& Repo interface
& Critique \\
\bottomrule
\end{tabularx}
3.1.4 Orchestration-based Planning
Orchestration-Based Planning refers to a planning paradigm in which the core planning function is realized through a harness design for system-level coordination. In this paradigm, the harness governs how agents or modules specialize roles, execute stages, route feedback, and trigger verification loops, thereby determining what actions should be taken next in long-horizon code generation workflows. A first common pattern [50, 51, 52] is feedback-centered orchestration, where the system distributes coding, testing, analysis, and repair across different modules, so that progress is driven by repeated execution-grounded feedback and adaptive escalation. In this group, planning is not an up-front artifact, but an emergent property of how failures are detected, interpreted, and routed back into subsequent actions. A second pattern [44, 166, 165] is staged workflow orchestration, which casts code generation as a structured software-process pipeline, such as comprehension, retrieval or preview, planning or blueprinting, coding, debugging, and repair. The main advantage of this group lies in decomposing complex generation into interpretable stages with explicit handoff rules, and the actual planning power comes from cross-stage control, candidate pruning, and iterative refinement. A third pattern [167, 168, 169, 170] is controller-centric orchestration, where planning is embedded in the transformation of intermediate artifacts and in the routing substrate itself. Here, systems organize decision-making through mechanisms such as formal-specification pipelines, suggestion stages between localization and repair, typed intermediate representations, shared blackboards, or specialized planner–coder coordination, so that the next plan is determined by the scaffold’s control logic rather than by a single textual prompt.
Recent harness systems make this orchestration view especially explicit. Anthropic's long-running harnesses separate planning, generation, and evaluation into distinct roles, using structured artifacts and independent evaluation to maintain progress across long sessions [15, 171]. Cursor's large-scale autonomous coding experiments similarly highlight planner–worker coordination as a way to scale from focused single-agent tasks to many parallel agents working on a shared project [172]. The most general formulation appears in Natural-Language Agent Harnesses, where high-level harness logic (such as roles, stages, contracts, adapters, state conventions, and failure taxonomies) is written as editable natural language and executed by an Intelligent Harness Runtime [173]. The IHR interprets these high-level natural-language instructions at runtime and converts them into constrained execution steps under explicit contracts, budgets, tool interfaces, and environment state. This reframes orchestration-based planning as a runtime interpretation problem: the plan is not merely a document, but an executable harness specification that mediates between model outputs, filesystem state, tools, validators, and multi-agent delegation.
Discussion: Planning for code generation can be understood as a core form of agentic harness: a control layer that organizes how an LLM agent decomposes tasks, grounds decisions in program structure, explores alternatives at inference time, and coordinates multi-stage software engineering workflows. From this perspective, planning is a set of harness mechanisms centered on one essential question: how to decide what the agent should do next, and how to keep that decision process constrained, inspectable, and coherent across long-horizon coding tasks. Notably, planning in code generation cannot be cleanly separated from the evaluation problem. Many current conclusions about the benefits of planning depend heavily on the surrounding execution conditions, including execution environments, feedback quality, tool access, trajectory budgets, and whether the benchmark truly stresses long-range dependency management rather than localized patch generation. If execution signals are weak, revision budgets are unrealistic, or benchmarks fail to expose multi-step coordination errors, then reported planning gains may not reflect genuine improvements in agent-level problem solving. Therefore, planning is not only a method design problem, but also a harness problem between the agent and the environment. Looking forward, the central challenge is not merely to build larger planners or longer reasoning traces, but to design more reliable agentic harnesses for planning: adaptive commitment mechanisms that decide when to follow, revise, or abandon a plan; structurally meaningful planning states that expose dependencies and progress; efficient exploration-and-revision strategies that use feedback without excessive computation; and rigorous long-horizon evaluation paradigms that can faithfully measure planning quality beyond final-pass accuracy.
3.2 Memory and Context Engineering for Agent Harness
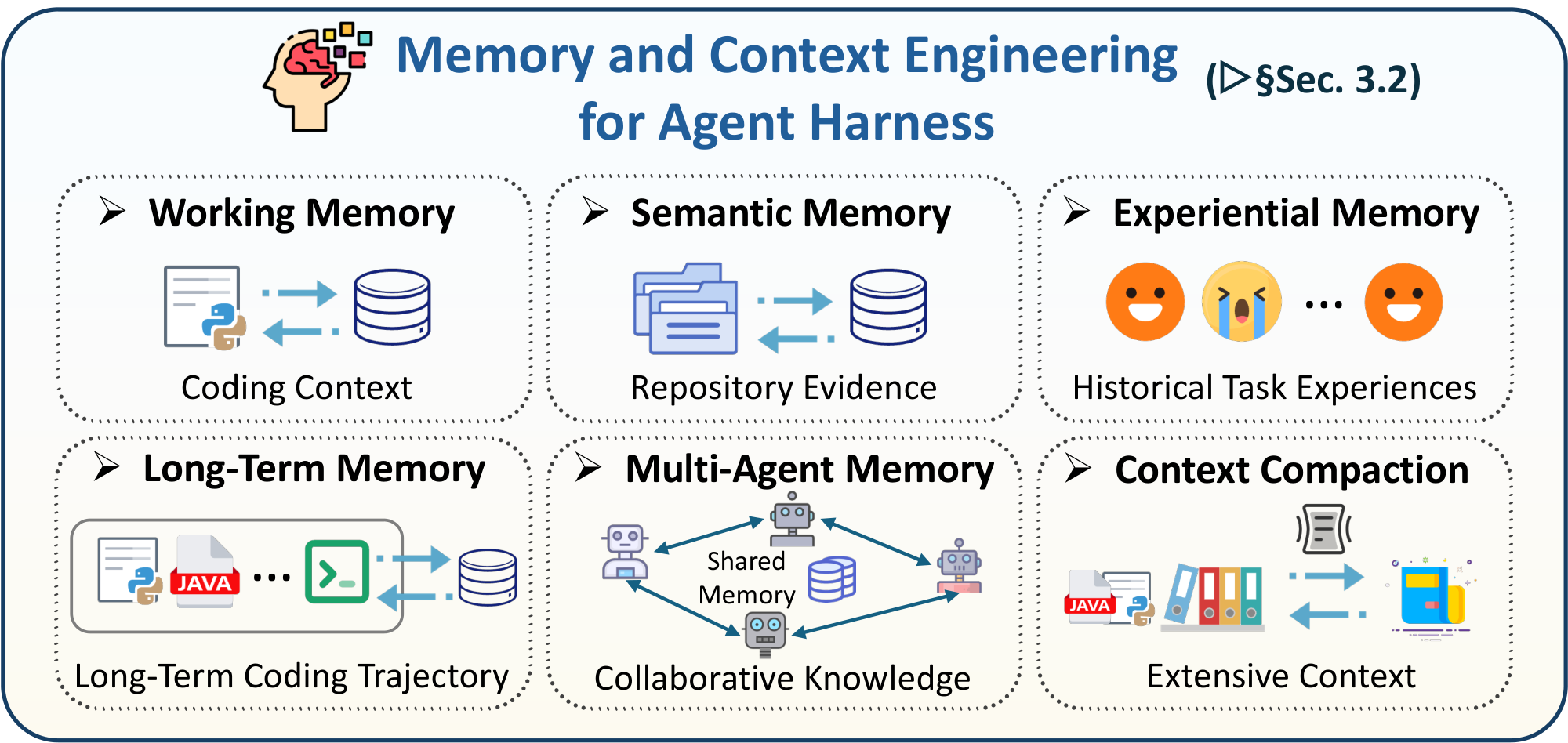
Memory has become a core infrastructure for code agents, largely because real-world software engineering tasks are inherently long-horizon and state-intensive [174, 175]. Unlike single-turn code completion, practical coding scenarios require an agent to sustain a sequence of interdependent steps across many rounds of interaction, such as requirement understanding, code localization, evidence retrieval, multi-file editing, test execution, bug fixing, and regression verification [176, 177]. This introduces a fundamental tension between the limited context window of the model and the continuously expanding intermediate state of the task. From a harness perspective, memory is not simply a larger context window or a vector database. It is a state-management layer that decides which information should remain in the active model context, which information should be compacted into summaries, and which information should be offloaded to durable external storage [178]. Without an effective memory mechanism and context management, an agent can easily lose critical clues during long-range reasoning, repeat searches and analyses that were already completed, or break local consistency established in earlier steps during later modifications [179, 175].
Early systems largely relied on prompts to preserve historical information, treating memory as little more than conversation history or an unstructured scratchpad. However, with the emergence of repository-level repair and other long-horizon coding tasks, it has become increasingly clear that simply accumulating natural language history cannot reliably support complex software engineering loops [180]. As a result, memory is now increasingly externalized as a system component that is retrievable, governable, and traceable. In this subsection, we categorize memory in code agents according to their primary functional role in the software engineering loop. Under this view, existing approaches can be broadly organized into five types: working memory, semantic memory, experiential memory, long-term memory, and multi-agent memory. In addition, we discuss context compaction and state offloading as cross-cutting context-engineering mechanisms that determine how large execution artifacts move between the active model context and durable task state. Representative works are illustrated in Table 5.
3.2.1 Working Memory
Working memory supports state maintenance along the current coding-task trajectory [181]. Its central concern is not how much history to retain, but which pieces of information are most useful for the next action under a limited context budget. In code agents, working memory often appears as structured prompt regions, state summaries, failed-test records, file lists, or critical stack information. Its purpose is to mitigate context explosion, reduce repeated localization, and preserve the local consistency of an ongoing repair or editing trajectory [57, 182, 183, 45]. From a harness perspective, working memory is the active control surface between the model and the code environment: it determines what the agent observes before choosing the next tool call, edit, or verification step. Representative systems such as SWE-agent [57] and RepairAgent [183] show that, even with the same underlying model, repository-level repair performance can vary substantially depending on how interaction state and execution feedback are organized. CodeMem [45] similarly treats context as a managed resource, using budgeted memory slots to stabilize multi-step edits.
3.2.2 Semantic Memory
Semantic memory provides task-relevant external evidence for the current coding process [184, 175]. In code-agent settings, such evidence is usually repository-specific and program-structured, including class definitions, function implementations, call relations, configuration files, documentation, issue descriptions, dependency metadata, and historical implementation patterns. Semantic memory therefore transforms the external codebase into a queryable evidence space that the harness can retrieve from and inject into the active context [46, 185, 186, 187, 188]. Representative works such as AutoCodeRover [46] and RepoCoder [47] show that repository-level coding tasks benefit not simply from retrieving more content, but from retrieving evidence aligned with program structure. Mechanisms such as AST-based structured chunking, iterative query rewriting, and retrieval strategies conditioned on current localization clues can substantially improve the utility of retrieved context for downstream generation. In this sense, semantic memory turns the codebase into a structured evidence layer for the current decision process.
\begin{tabularx}{\ccccccccc}{p{2.35cm}p{2.5cm}p{3.2cm}p{2.8cm}X}
\toprule
\textbf{Method} & \textbf{Role} & \textbf{Managed State} & \textbf{Harness Operation} & \textbf{Primary Use} \\
\midrule
SWE-agent [57]
& Working Memory
& Repair trajectory; runtime state
& Structured state tracking
& Grounds repo repair in files, commands, and tests \\
CodeMem [45]
& Working Memory
& Context slots; edit state
& Budgeted slot management
& Stabilizes multi-step edits under context limits \\
RepairAgent [183]
& Working Memory
& Bug evidence; tool outputs
& Dynamic prompt-state updates
& Carries evidence across autonomous cycles \\
\midrule
AutoCodeRover [46]
& Semantic Memory
& Repo structure; code evidence
& Structure-aware retrieval
& Grounds localization and patching in repo structure \\
RepoCoder [47]
& Semantic Memory
& Retrieved repo context; snippets
& Iterative repo retrieval
& Expands evidence for context-aware generation \\
CodeRAG [187]
& Semantic Memory
& Repo knowledge; code paths
& Querying; multi-path retrieval; reranking
& Selects repo knowledge for long-context completion \\
\midrule
MemGovern [48]
& Experiential Memory
& Trajectories; reflections; critiques
& Governed experience replay
& Reuses quality experience while filtering noise \\
ExpeL [189]
& Experiential Memory
& Reflection traces; learned lessons
& Reflection replay
& Reuses reflections as task-solving strategies \\
\midrule
MemCoder [190]
& Long-term Memory
& Commits; root causes; validated fixes
& Structured memory; self-internalization
& Learns repo-specific intent-to-code mappings \\
TALM [191]
& Long-term Memory
& Task histories; reasoning traces; validated code
& Vector retrieval; consolidation
& Reuses past episodes for tree-structured generation \\
\midrule
MIRIX [192]
& Multi-agent Memory
& Cross-agent state; interaction history
& Cross-agent memory routing
& Routes shared memory across specialized roles \\
ChatDev [193]
& Multi-agent Memory
& Dialogue history; software artifacts
& Phase-level context passing
& Maintains context across role-based phases \\
\midrule
LongCodeZip [194]
& Context Compaction
& Long code context; repo snippets
& Coarse-to-fine compression
& Compresses code while preserving reasoning cues \\
SWE-Pruner [195]
& Context Compaction
& Interaction context; surrounding code
& Task-aware pruning
& Removes irrelevant context before agent decisions \\
SWEZZE [196]
& Context Compaction
& Issue context; fix ingredients
& Lightweight learned compression
& Distills compact, fix-relevant evidence \\
\bottomrule
\end{tabularx}
3.2.3 Experiential Memory
As code agents move from single-task completion toward continual repair and cross-project generalization, increasing attention has been paid to experiential or episodic memory [197, 198]. Unlike working memory, which maintains the current trajectory, or semantic memory, which retrieves repository evidence, experiential memory captures reusable experience accumulated across tasks, such as repair trajectories, failure cases, debugging records, and higher-level strategy patterns [189, 199, 200]. Its main value lies in enabling cross-task transfer. Through mechanisms such as experience cards, reflection buffers, and record-and-replay pipelines, a system can convert past successful or failed debugging processes into reusable units for future problem solving [199, 48, 201]. Works such as MemGovern [48] further suggest that the quality of stored experience matters more than its scale. Ungoverned historical records can introduce semantic noise, error propagation, and false retrievals, whereas curated and quality-controlled experiential memory is more likely to become a useful asset for repository-level repair.
3.2.4 Long-Term Memory
When coding trajectories become longer, working memory and semantic memory alone are insufficient, because the system must also cope with memory growth, compression-induced evidence distortion, and long-term drift. This makes long-term retrieval planning and memory control an increasingly important research direction [202, 203, 204, 205, 206]. The focus therefore shifts from memory capacity to memory governance. Representative systems such as MemGPT [207] and MemoryOS [208] move the discussion from what to store toward when to write, when to compress, when to retrieve, and how to avoid contamination. Recent code-centric studies further ground this line of work in software engineering workflows. MemCoder [190] leverages structured historical commits and human-validated solutions as persistent memory, enabling repository-specific experience accumulation over time. TALM [191] incorporates long-term memory into multi-agent code generation, retrieving prior problem–solution traces and consolidating overlapping memories to control redundancy. These works suggest that, for code agents, long-term memory should not simply accumulate more history, but preserve validated and reusable experience in a compact and controllable form. Otherwise, memory may shift from a resource for long-horizon software engineering into a burden that amplifies noise, staleness, and error.
3.2.5 Multi-Agent Memory
Multi-agent memory extends state management from an individual agent to a shared harness. From a systems perspective, memory in code generation has a strong collaborative dimension [209, 210]. In multi-agent frameworks, memory is not only a container for individual state, but also a medium for information sharing, intention passing, and consistency maintenance across specialized roles [211]. Representative works such as AgentCoder [50], MapCoder [44], MIRIX [192], ChatDev [193], and G-Memory [211] illustrate how memory supports multi-agent planning, testing, reviewing, and trajectory coordination. In this setting, the central challenge is no longer only retrieving relevant content, but controlling the granularity of sharing, preventing information flooding, and supporting bidirectional access between high-level decisions and fine-grained execution traces [210]. Accordingly, memory in multi-agent code generation increasingly resembles a shared blackboard or collaborative state graph rather than a purely individual storage unit [212, 213].
3.2.6 Context Compaction and State Offloading
Context compaction and state offloading are cross-cutting context-engineering mechanisms for memory in code-agent harnesses [214]. Their goal is not to define another memory category, but to control the boundary between active model context and durable task state. Long-horizon software engineering workflows continuously generate high-volume artifacts, such as build logs, execution traces, repository diffs, test outputs, and intermediate plans. Directly placing these artifacts into the prompt can quickly overload the context window, amplify noise, and obscure decision-relevant evidence. A harness must therefore decide which observations should remain in the active context, which should be compacted into concise summaries, and which should be offloaded to external storage with retrievable handles [178]. Context compaction compresses long interaction histories and massive tool outputs into structured, provenance-preserving summaries. For example, a failing-test report can be reduced to the failing test name, key stack frames, suspected files, and links to the full log [196, 215, 194, 195]. State offloading complements this process by preserving full-fidelity artifacts outside the active window, such as in files, databases, trace stores, or protocol-style resource interfaces such as MCP-style servers. The agent then receives compact summaries and resource identifiers rather than raw logs or traces. By separating decision-relevant context from durable evidence, context compaction and state offloading make memory more scalable, auditable, and compatible with execution-time verification.
Discussion: Memory in code-as-agent-harness systems can be understood as a unified state-management layer that connects context management, repository evidence retrieval, experiential transfer, long-term control, and multi-agent synchronization. Rather than being a single data structure, an enlarged context window, or simply a vector database, memory coordinates where task-relevant state should reside and how it should be reused throughout long-horizon software engineering workflows. Working memory keeps the next action grounded; semantic memory exposes repository evidence; experiential memory supports cross-task transfer; long-term memory preserves validated knowledge; and multi-agent memory synchronizes shared state across roles. Context compaction and state offloading further extend this layer by separating decision-relevant active context from durable full-fidelity artifacts, making memory more scalable, auditable, and compatible with execution-time verification. Importantly, memory research in code agents cannot be separated from evaluation reliability. Many conclusions about memory gains depend on the quality of evaluation pipelines [216, 217]: if tests are insufficient, log parsing is flawed, or benchmarks suffer from memorization and contamination, then reported improvements may not reflect robust long-horizon behavior. Looking forward, the key challenge is not merely to enlarge memory capacity, but to build higher-quality write gates, structurally aligned retrieval keys, provenance-preserving compaction mechanisms, reliable state offloading protocols, and rigorous evaluation paradigms that measure whether memory truly helps agents remain grounded, consistent, and verifiable over extended trajectories.
3.3 Tool Use for Agent Harness
Tool usage is the action and observation layer of the code-agent harness. Once code is placed inside the agent loop, the model must not only generate text, but also search repositories, edit code, execute tests, call APIs, query documentation, and verify intermediate results [218, 219]. Tools therefore expand the agent's action space while also exposing external feedback signals that make the harness executable and inspectable. From the perspective of code as agent harness, tool use is not merely an auxiliary capability for code generation. It is a governed interface between model intent and external systems. A reliable harness must decide which tools are available, how their schemas are exposed, what permissions each tool receives, where execution happens, how results are sanitized or compacted, and when risky actions require human approval. Recent agent SDKs and software-agent platforms make this shift explicit by packaging tools, sessions, guardrails, handoffs, workspaces, and execution environments into reusable harness components [58, 220, 221]. In parallel, sandboxed execution environments, including containerized or microVM-based workspaces, isolate agent actions from the host system and make code execution more reproducible and auditable [22, 222, 223]. This harness-level view also highlights the importance of tool lifecycle control. Before a tool is executed, the harness may apply permission checks, policy rules, argument validation, or human-in-the-loop gates. After execution, the harness may sanitize outputs, summarize large logs, offload traces to durable storage, update memory, or trigger verification tools. Lifecycle hooks make these control points explicit. They turn tool use from a raw model-selected action into a monitored transition in the agent's execution loop.
Existing work on tool usage for code agents can therefore be organized according to the primary harness function that tools serve: (1) function-oriented tool use, (2) environment-interaction tool use, (3) verification-driven tool use, and (4) workflow-orchestration tool use. Function-oriented tools ground the agent in APIs, libraries, and external documentation. Environment-interaction tools allow the agent to act inside repositories, terminals, IDEs, browsers, and sandboxes. Verification-driven tools provide deterministic feedback through tests, linters, type checkers, static analyzers, and runtime errors. Workflow-orchestration tools coordinate multiple tools, roles, memory updates, and lifecycle policies into a reliable long-horizon execution process. Representative works are illustrated in Table 6.
\begin{tabularx}{\ccccccccc}{@
>{\raggedright\arraybackslash}p{2.6cm}
>{\raggedright\arraybackslash}p{3.1cm}
>{\raggedright\arraybackslash}p{3.0cm}
>{\raggedright\arraybackslash}p{3.8cm}
>{\raggedright\arraybackslash}X@}
\toprule
\textbf{Method} & \textbf{Role} & \textbf{Tool Boundary} & \textbf{Harness Operation} & \textbf{Primary Use} \\
\midrule
ToolCoder [19]
& Function-oriented
& API search tools
& API selection via trigger prediction
& Grounds generation in retrieved APIs \\
CodeQA [224]
& Function-oriented
& API/doc query tools
& Tool-augmented API QA
& Retrieves API evidence for coding \\
RAG-for-Code [225]
& Function-oriented
& Repo, docs, API
& Retrieval-augmented context
& Knowledge for long-tail libraries \\
\midrule
CodeAgent [185]
& Environment-interaction
& Repo files, tests
& Repo navigation, editing, validation
& Repo-level coding via environment interaction \\
SWE-agent [57]
& Environment-interaction
& Shell, editor, repo, tests
& Agent--computer interface loop
& Resolves GitHub issues via shell commands \\
\midrule
AgentCoder [50]
& Verification-driven
& Test generation
& Programmer--tester--executor loop
& Refines code via generated tests \\
VeriGuard [226]
& Verification-driven
& Execution, tests, verifier
& Verifier-guided tool loop
& Gates and repairs code via verification \\
\midrule
ToolNet [49]
& Workflow-orchestration
& APIs, tools, execution
& Learned multi-tool policy routing
& Routes tool invocations across workflows \\
MapCoder [44]
& Workflow-orchestration
& Coding agents
& Multi-agent tool-supported workflow
& Coordinates planning, generation, debugging \\
OpenHands [58]
& Workflow-orchestration
& Workspace, terminal, browser, files, runtime
& Unified software-agent workspace
& Long-horizon tasks via reusable interfaces \\
\bottomrule
\end{tabularx}
3.3.1 Function-Oriented Tool Use
This line of work uses tools primarily to fill gaps in the model's programming knowledge, especially APIs, libraries, documentation, and external coding utilities [19, 224, 225, 227, 228, 229]. ToolCoder [19], for example, starts from a clear bottleneck: code models often hallucinate APIs, choose inappropriate functions, or fail on public and private libraries with sparse training coverage. To address this problem, it integrates API search tools into the code generation process and trains models to decide when to query the tool and how to select APIs from retrieved results. The key contribution is therefore not better syntax generation alone, but better knowledge acquisition and API grounding. More broadly, retrieval-oriented methods reduce dependence on parametric memory and make code generation more adaptable to long-tail APIs, private libraries, and continuously evolving software ecosystems [225, 230]. They are most effective when the main bottleneck is that the model lacks reliable knowledge of which function, API, or library construct should be used. Accordingly, the core design challenges lie in query formulation, result selection, evidence compression, and robust injection of retrieved knowledge into downstream generation. These agentic methods are particularly suitable for API-oriented generation, library migration, and private SDK usage, but retrieval alone is often insufficient when tasks require cross-file understanding and reasoning, runtime debugging, or repository-wide dependency analysis.
3.3.2 Environment-Interaction Tool Use
Unlike function-oriented tools, environment-interaction approaches treat tools as the interface through which an agent acts inside the software engineering environment [231, 232, 233, 234]. Their central problem is no longer only to obtain missing functions, but to operate effectively over repositories, development artifacts, and execution environments. CodeAgent [185] shows that real-world repository-level code generation is not simply about completing a single function from a prompt. Instead, the model must locate relevant files, understand dependencies, inspect documentation, implement modifications, and validate outcomes through testing. To support this process, CodeAgent integrates programming tools and agent strategies for information retrieval, code-symbol navigation, code implementation, and test interaction over real repositories. SWE-agent [57] pushes this idea further by formalizing the agent-computer interface, where shell commands, file editing, and test execution become the primary interaction channel. RepairAgent [183] similarly equips the agent with repair-specific tools for reading code, searching repair ingredients, applying patches, and running tests. Together, these methods define the core trajectory of environment-interaction tool use, which is especially relevant for repository-level generation, issue resolution, and open-ended software engineering tasks.
3.3.3 Verification-Driven Tool Use
A third line of work uses tools primarily for post-generation verification and iterative improvement. Verification-driven tool use treats external tools as deterministic sensors for the harness. Compared with function-oriented and environment-interaction tools, these approaches do not necessarily emphasize external retrieval or broad repository navigation. Instead, they use tests, execution results, compiler errors, runtime traces, type checkers, static analyzers, and verifier feedback as the main signals for improving code quality [226, 235, 236, 237]. AgentCoder [50], for example, uses a programmer agent, a test designer agent, and a test executor agent to form a closed loop of code generation, test construction, execution, and refinement. In this paradigm, the central role of tools is verification rather than retrieval. From the code-as-agent-harness view, verification tools make agent progress inspectable: test failures, stack traces, coverage gaps, type errors, and static-analysis warnings become structured observations that update working memory and guide the next action. The key design issue is how to route these observations back into the loop [226]. Since raw logs may be too long or noisy for the active context, the harness should parse, summarize, and offload verification traces while preserving full-fidelity artifacts for audit and replay.
3.3.4 Workflow-Orchestration Tool Use
Workflow-orchestration tool use focuses on how multiple tools, roles, and control policies are organized into a coherent agent workflow [238, 239, 240, 241]. In long-horizon software tasks, the agent may need to retrieve evidence, localize bugs, modify files, run tests, inspect failures, update memory, ask for approval, and repeat this cycle several times. The challenge is not simply adding more tools, but deciding when each tool should be invoked, with what permissions, under which context, and how its result should update the harness state [49]. Recent agent SDKs and software-agent platforms make this orchestration layer explicit by packaging typed tool schemas, session state, workspaces, guardrails, handoffs, tracing, and human-review mechanisms into reusable harness components. Lifecycle hooks further refine this boundary: pre-use hooks can validate arguments, enforce permission policies, or block risky commands, while post-use hooks can sanitize outputs, compact logs, update memory, or trigger follow-up verification. Representative systems such as MapCoder [44] exemplify workflow orchestration by assigning agents to example recall, planning, code generation, and debugging, thereby decomposing a difficult coding problem into coordinated subproblems. CodeAgent [185] also studies how tool calls should be scheduled and structured in repository-level workflows. This class is particularly important for long-horizon code agents, where realistic software tasks require demand decomposition, context selection, candidate exploration, execution-based verification, and final repair under explicit control policies [49, 242].
Discussion: Tool usage in code agents has evolved from isolated API retrieval to a full harness mechanism for action, observation, verification, and governance. Function-oriented tools ground implementation choices in external knowledge; environment-interaction tools allow agents to act over repositories and execution environments; verification-driven tools provide deterministic feedback; and workflow-orchestration tools coordinate these capabilities through SDKs, sandboxes, guardrails, and lifecycle hooks. The core challenge is no longer whether a model can call a tool, but whether the harness can make tool use safe, auditable, and useful for long-horizon execution. Future code-agent harnesses should support typed tool schemas, permission-aware invocation, sandboxed execution, lifecycle hooks, result sanitization, context compaction, state offloading, and reproducible traces. These mechanisms ensure that tools expand the agent's action space without sacrificing reliability, safety, or verifiability.
3.4 Harness Control through the Plan, Execute, and Verify Loop
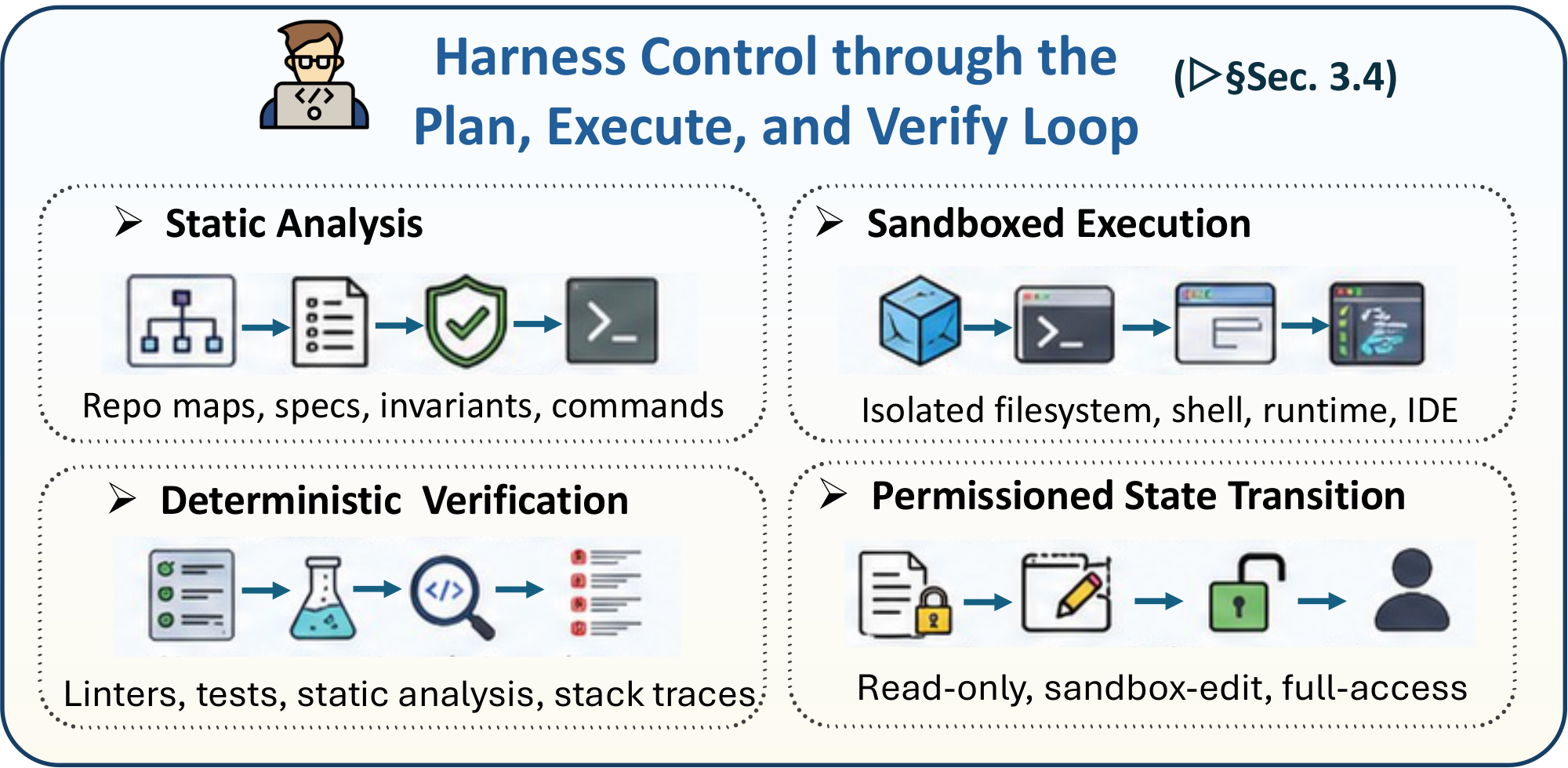
Code-as-harness systems require a control loop that turns model intentions into bounded, observable, and revisable state transitions. This subsection frames that loop as Plan–Execute–Verify (PEV): the harness first externalizes an intended change and its validation criteria, then executes the change inside a sandboxed and permissioned environment, and finally verifies the resulting state through deterministic sensors and human-review gates. This framing unifies planning, execution, debugging, verification, and escalation as parts of a single harness-level control process.
3.4.1 From Debugging to Harness-Level Control
The preceding subsections describe planning as trajectory control, memory as state management, and tool use as a governed action interface. Feedback-guided debugging connects these mechanisms into a closed loop: plans specify intended changes, memory preserves relevant evidence, tools execute and inspect actions, and validation signals determine whether the agent should continue, revise, or stop. As code-centric agents move from single-turn generation to repository-level software work, debugging is therefore better understood as control over executable program state rather than as a post hoc correction stage. Generated programs can fail through syntax errors, runtime exceptions, incorrect outputs, incomplete edge-case handling, unsafe operations, or violations of project-specific conventions, making one-pass generation insufficient [243]. Recent systems revise code through feedback from compilers, runtimes, tests, static analyzers, humans, and auxiliary agents [244, 245, 246, 23]. From the harness perspective, this process can be reframed as a Plan–Execute–Verify (PEV) loop: the agent externalizes an intended trajectory, executes bounded actions inside a controlled environment, and verifies the resulting state before the next transition. The growing engineering ecosystem around agent harnesses reinforces this view: recent curated resources distinguish orchestration, working state, execution substrates, evaluation harnesses, observability, and governance as separable harness layers rather than incidental implementation details [247, 248, 249, 25].
In this view, the harness acts as a cybernetic governor: a control layer that observes the effects of agent actions and regulates subsequent state transitions. Rather than merely forwarding error messages to the model, it observes the repository and execution environment through deterministic sensors such as linters, parsers, compilers, type checkers, unit tests, integration tests, static analyzers, fuzzers, runtime monitors, and CI pipelines. These sensors turn a coding trajectory into inspectable signals, including pass/fail outcomes, diagnostics, failing traces, coverage gaps, security warnings, resource limits, and policy violations. The harness can then decide whether to continue execution, revise a patch, request more context, route the task to another module, reduce permissions, or escalate to a human reviewer. Table 7 summarizes this control surface; the remainder of this subsection follows the loop from contract formation, through sandboxed state transition, to deterministic verification and evidence-grounded repair.
: Table 7: Representative methods and systems for PEV-loop harness control.
| Method | PEV Role | Core Mechanism | Signals and Gates |
|---|---|---|---|
| CodePlan [42] | Plan, structural | Dependency plan graph | Repo links, critiques |
| MapCoder [44] | Plan, orchestration | Map-code-test stages | Handoffs, tests, failures |
| Open-Hands [250] | Full PEV harness | Stateful edit-exec workspace | Diffs, logs, tests, approvals |
| SWE-agent [57] | Execute, CLI | Replayable shell interface | Commands, patches, tests |
| Daytona [251] | Execute, cloud sandbox | Isolated dev workspace | Files, limits, snapshots |
| E2B [252] | Execute, code-browser sandbox | Cloud code-browser sandbox | Stdout, limits, UI state |
| Self-Debugging [243] | Verify, self-debug | Explanation-guided repair | Errors, tests |
| Reflexion [244] | Verify, reflection memory | Verbal feedback memory | Outcomes, critiques |
| Debug Like a Human [245] | Verify, stepwise debug | Runtime-step checks | Traces, variables, asserts |
| Iterative Refinement [246] | Plan–Verify feedback | Project-context repair | Compiler diagnostics |
| Quality-Flow [253] | Verify, quality gate | Quality feedback routing | Tests, success, stopping |
| AgentCoder [50] | Verify, multi-agent repair | Coder-tester-executor loop | Tests, failures, critique |
| Auto-SafeCoder [52] | Verify, safety sensors | Static checks, fuzzing | Alerts, traces, tests |
| VeriGuard [226] | Verify, verified gen. | Verifier guard layer | Proofs, tests, alerts |
| LiteLLM [254] | Permission gateway | Proxy policy routing | Approvals, denials, cost logs |
3.4.2 Planning as Contract Formation
The planning phase turns a user request into an explicit contract over the next state transition. A robust plan does more than decompose the request into implementation steps; it also identifies relevant files, expected invariants, validation commands, rollback points, and risky operations. This makes planning a harness artifact rather than an unobserved reasoning trace. In repository-level tasks, such artifacts constrain the subsequent action space by specifying which components may be read, which files may be edited, and which verification criteria must be satisfied before completion [40, 42, 44]. Repository-local instructions and tool protocols strengthen this contract layer: AGENTS.md-style guidance, MCP server registries, typed tool schemas, adapters, and protocol gateways make the available actions inspectable before execution rather than discovered opportunistically during execution [255, 256, 257, 258, 259, 260, 261, 262]. The PEV framing also clarifies why planning and debugging should not be separated: failed verification updates the plan, while the plan determines which verification evidence is meaningful.
3.4.3 Sandboxed Execution and Permissioned State Transition
The execution phase realizes the plan as a bounded and observable state transition. The sandboxed environment is the operational substrate of the loop: it provides an isolated filesystem, dependency state, shell, language runtime, browser or IDE interface, and resource boundary in which agent-generated actions can be run without directly compromising the host system [263, 22]. Contemporary execution-substrate work is best read as functional clusters rather than as an undifferentiated catalog. Coding sandboxes expose filesystems, Git operations, shells, package managers, and code-execution backends [251, 252, 264, 265, 266, 250]; computer-use substrates add browser, desktop, LSP, or IDE state [267, 268, 269, 270, 271]; and durable runtimes emphasize microVM or WASM isolation, snapshots, warm pools, resumable sessions, benchmark environments, and always-on operating contexts [272, 273, 274, 275, 276, 277, 278]. Sandboxes also improve reproducibility because the harness can replay the same patch, command, seed, dependency lockfile, or test configuration under comparable conditions. Without this stable substrate, verification signals become difficult to interpret, and failures may reflect environment drift rather than program defects [250, 217, 279].
Execution must also be permissioned. A multi-tier model separates low-risk observation from high-risk action: a read-only tier supports repository browsing, retrieval, static inspection, and log analysis; a sandbox-edit tier supports local patching, test execution, and temporary dependency installation inside an isolated workspace; and a full-access tier covers network access, credentials, deployment commands, package publishing, destructive filesystem operations, or Git history mutation. Actions in the final tier should be guarded by mandatory human-in-the-loop (HITL) gates because their consequences can extend beyond the sandbox. Recent software-agent systems and harness engineering work increasingly expose these control points through explicit tools, sessions, policies, approval prompts, and audit logs [280, 250, 281, 178, 282, 283]. Gateway and policy layers then provide the production counterpart: systems for model routing, tool registration, proxy-level logging, centralized guardrails, security automation, and falsifiable approval evidence keep governance outside the prompt alone [254, 284, 285, 262, 286, 287, 288, 289, 290, 291].
3.4.4 Verification through Deterministic Sensors
The verification phase closes and, when necessary, reopens the loop by comparing the new state against explicit constraints. Compilation and static-analysis feedback provide low-cost sensors before full execution, including parser diagnostics, type errors, lint warnings, and security alerts [246, 292, 293]. Runtime signals expose failures that only arise along concrete execution paths, such as exceptions, assertion breaks, invalid API usage, resource exhaustion, and timeouts [294, 295, 245]. Test-based feedback then evaluates whether the observed behavior satisfies the intended specification, using unit tests, integration tests, regression tests, fuzzing, or benchmark-specific evaluators [243, 296, 297, 298]. Evaluation harnesses broaden this idea from a single test command to repeatable task distributions: they encode evaluator logic, simulation hooks, red-team cases, or RL-style environments that can compare harness variants under controlled conditions [299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309]. Compared with natural-language critique, these sensors are deterministic or at least reproducible enough to serve as control signals. Human or agentic critiques remain useful when failure evidence is sparse, but in a governed PEV loop they should interpret sensor outputs rather than replace them [244, 310, 54].
Verification also supplies the evidence for repair, reflection, and termination, so these activities are treated as consequences of the Verify phase rather than as an independent stage. When a check fails, the same sensor evidence can determine whether the harness should ask the model to diagnose the failure, retrieve missing context, regenerate a localized patch, route the task to a testing or security agent, or abandon the current branch. Self-reflection mechanisms help transform raw diagnostics into actionable hypotheses, such as whether the failure comes from incorrect control flow, missing edge cases, misunderstood APIs, or inadequate tests [311, 166]. However, reflection is reliable only when it remains grounded in executable evidence. Systems such as AgentCoder, AutoSafeCoder, and QualityFlow illustrate this principle by combining agentic critique with independent execution, static analysis, fuzzing, or test-quality gates [50, 52, 253]. Termination should likewise be governed by verification rather than by model confidence: a loop can stop when required checks pass, when additional attempts no longer improve the state, when the risk tier changes, or when human review is required.
Discussion: Recasting iterative debugging as the PEV loop emphasizes that reliability comes from governed state transitions, not simply from better repair prompts. Planning externalizes intended changes and risk assumptions; execution applies them inside sandboxed and permissioned environments; verification uses deterministic sensors to decide whether the state is acceptable; and HITL gates preserve accountability when the action space crosses a safety boundary. This framing unifies static analysis, runtime errors, tests, critique, self-reflection, and human review as components of a cybernetic harness that regulates the agent's trajectory over executable program state.
3.5 Agentic Harness Engineering for Adaptive Harness Optimization
Agentic Harness Engineering (AHE) names a harness-level design problem: how to measure and revise the software substrate that turns a language model into a coding agent. Whereas prompt engineering changes instructions and context engineering changes what evidence is presented to the model, AHE treats the operating environment itself as the object of analysis, including tool schemas, planning artifacts, memory policies, retrieval strategies, sandbox configuration, verification sensors, permission tiers, routing rules, multi-agent workflows, and human-review gates [281, 178]. This perspective is useful because many observed failures in code agents arise from missing repository context, brittle tool interfaces, weak validators, excessive token cost, poor retry policies, or mismatched permission boundaries rather than from model generation.
Existing work can be read as three complementary strands. AutoHarness studies automatic synthesis of code harnesses [14]; Meta-Harness formulates harness design as an optimization problem over model-facing infrastructure [13]; and observability-driven AHE emphasizes telemetry-rich diagnosis of where the agent loop fails and which harness component should change [281]. Related work on reflective prompt evolution, self-evolving workflows, and live software-engineering agents supports the same systems view: changing the scaffold around the model can change agent behavior without retraining the base model [18, 312, 182]. Engineering guides from OpenAI, Anthropic, and LangChain converge on the same practical lesson: reliable agents require explicit harness loops, tool contracts, trace replay, evaluation suites, context budgets, and controlled execution boundaries [248, 249, 313, 314, 28].
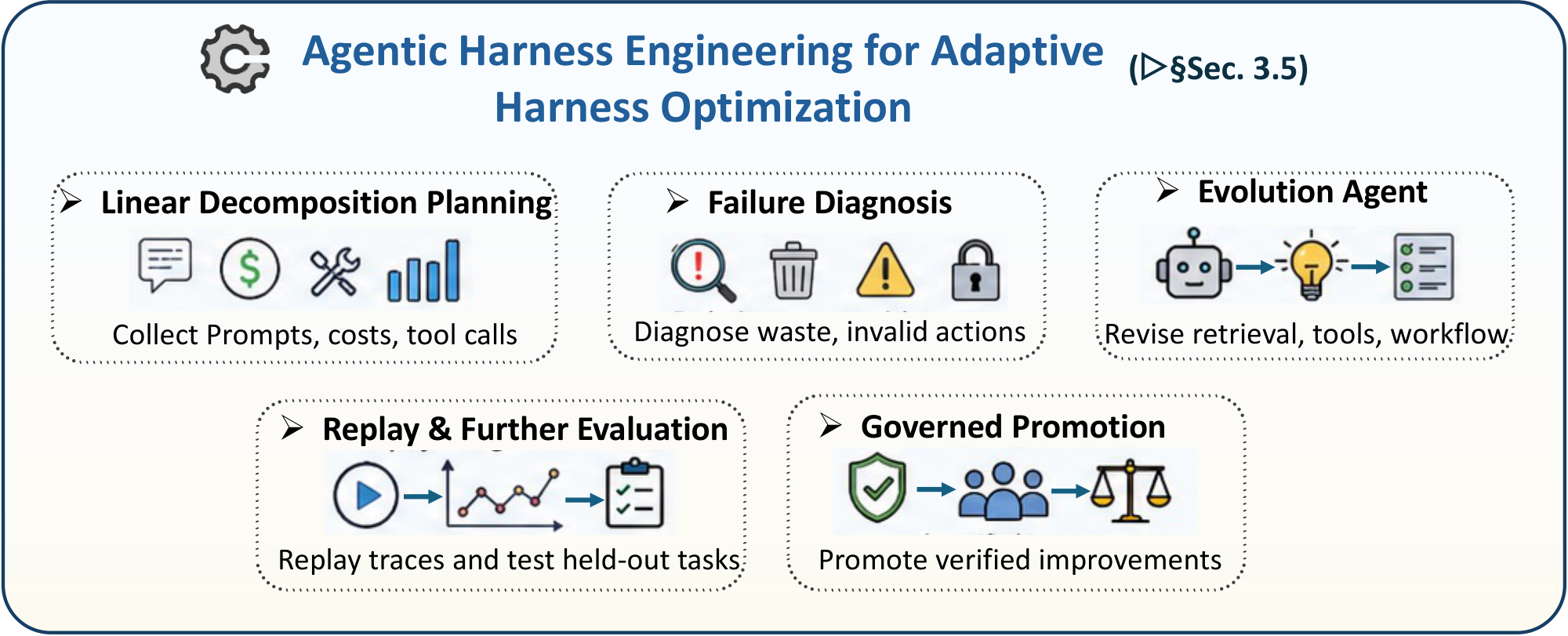
3.5.1 Deep Telemetry as the Optimization Substrate
The central substrate of AHE is deep telemetry: structured traces that connect model decisions, harness actions, environment states, and outcomes. A shallow log may record only the final answer or pass/fail result. Deep telemetry records the decision process in greater detail: prompts and retrieved context, token usage and cost, model/tool latency, tool arguments, permission requests, edited files, sandbox snapshots, command outputs, test results, stack traces, lint warnings, branch decisions, rejected alternatives, human interventions, and final task outcome. In code-centric settings, these traces are especially valuable because program execution already exposes state transitions through logs, tests, diffs, and runtime behavior [128, 96, 37]. In production systems, this role is increasingly served by observability and reliability stacks that record traces, metrics, prompts, model traffic, eval results, and cost signals [315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327]. Evaluation, observability, and governance systems therefore provide complementary telemetry channels: evaluators expose task-level regressions, tracing stacks expose trajectory-level causes, and policy gateways expose boundary violations that an Evolution Agent can turn into harness revisions.
Telemetry turns harness revision from anecdotal debugging into comparative diagnosis. Token-cost traces reveal when retrieval or reflection stages consume budget without improving verification outcomes. Decision-tree traces show where the agent repeatedly chooses unproductive tools, edits irrelevant files, or loops between failed strategies. Failure traces cluster recurring patterns such as missing dependencies, weak tests, hallucinated APIs, flaky sandboxes, over-permissive tool calls, or premature termination. Because these signals are linked to concrete artifacts, they can be replayed and compared across harness versions, making it possible to evaluate whether a change improves reliability rather than merely changing surface behavior [216, 217].
3.5.2 The Evolution Agent
An Evolution Agent is a meta-level agent that uses deep telemetry to propose, evaluate, and promote revisions to harness components. Unlike a task agent, which edits the target repository, the Evolution Agent edits the operating conditions under which later task agents work. Its input is a corpus of trajectories; its output may be a revised prompt template, a retrieval policy, a more precise tool schema, an added validator, a changed permission rule, a workflow-topology adjustment, or a new regression test. This role is closely related to self-evolving multi-agent systems in which specialized agents inspect execution logs, attribute failures to workflow components, and update collaboration structures [328, 329]. In the harness setting, the same idea is generalized from multi-agent topology to the control surface of the agent runtime.
A typical Evolution-Agent loop contains five stages. First, it observes trajectories by collecting telemetry from PEV executions. Second, it diagnoses failure modes by attributing cost, latency, invalid actions, test failures, or permission denials to specific harness components. Third, it proposes candidate revisions, such as rewriting tool descriptions, changing context packing rules, adding a linter, modifying retry limits, or inserting a HITL gate before risky commands. Fourth, it evaluates the revised harness on held-out tasks or replayed traces using deterministic sensors and regression tests. Finally, it promotes only changes that improve reliability, cost, or safety without regressing previously solved cases. This keeps AHE within the same engineering discipline as the PEV loop: proposed changes must be executed, verified, and made auditable before adoption.
: Table 8: Representative methods for Agentic Harness Engineering with telemetry-driven revision targets.
| Method | Category | Telemetry | Revision Target |
|---|---|---|---|
| AutoHarness [14] | Harness synthesis | Failures, fixtures, assertions | Harness code and tests |
| Meta-Harness [13] | Harness search | Code, scores, traces | Prompts, tools, scripts |
| AHE [281] | Telemetry-driven optimization | Cost, decisions, latency, failures | Context, tools, validators |
| GEPA [18] | Reflective prompt evolution | Scores, feedback, critiques | Prompts and instructions |
| EvoMAC [328] | Workflow topology evolution | Handoffs, idle roles, loops | Agent roles and graph |
| SEW [312] | Self-evolving workflow | Workflow scores, failures | Stage order and roles |
| Live-SWE [182] | Online agent evolution | Live issue trajectories | Policies, tools, memory |
| GroundedTTA [232] | Test-time adaptation | State-action evidence | Adaptation rules |
| RLEF [104] | Execution-feedback learning | Execution rewards, failures | Feedback reward signal |
| DeepEval [300] | Evaluation harness | Scenario and metric traces | Regression suites, gates |
| FeedbackEval [23] | Repair evaluation benchmark | Feedback-task scores | Failure taxonomy and eval set |
| Langfuse [315] | Observability platform | Spans, cost, latency, evals | Dashboards and replay |
| OpenLLMetry [321] | Trace instrumentation | OpenTelemetry spans, calls | Harness instrumentation |
| Promptfoo [299] | Evaluation harness | Scores, regressions, failures | Eval gates and red tests |
| LiteLLM [254] | Gateway governance | Routing, budgets, failures | Budgets, fallbacks, tiers |
3.5.3 Governed Harness Mutation
AHE should not be confused with unconstrained self-modification. Because the Evolution Agent changes the harness that controls later task agents, its actions require stronger governance than ordinary code repair. Candidate harness changes should be evaluated inside sandboxes, compared against fixed regression suites, and recorded with auditable rationales. Changes that alter permission boundaries, network access, credential handling, deployment behavior, or human-review requirements should require HITL approval before activation. In this sense, the Evolution Agent is itself subject to the PEV loop: it plans a harness mutation, executes it in an isolated evaluation environment, verifies the result through telemetry and regression tests, and escalates risky changes to humans.
Discussion: Agentic Harness Engineering extends the code-as-harness view from operating agents to analyzing the infrastructure that operates them. Deep telemetry provides evidence for locating failures across prompts, tools, memory, sandboxes, validators, permissions, and workflows. Evolution Agents use this evidence to propose and evaluate harness mutations, turning harness design into an iterative and measurable engineering process governed by verification and human approval.
4. Scaling the Harness: Multi-Agent Orchestration over Code
Section Summary: As AI coding tools tackle bigger projects, a single agent often cannot hold an entire codebase in memory, perform every step from planning to testing, or reliably catch its own mistakes. Multi-agent systems solve this by assigning different roles to separate agents that coordinate through shared code artifacts and feedback, turning the overall process into a more modular and inspectable workflow. The section surveys current approaches to these role-specialized teams and argues for building common code-centered platforms that let such agents plan, verify, and improve together.
As AI systems tackle increasingly complex problems from function-level code synthesis to repository-level system engineering, fundamental limitations for single-agent emerge: (1) context window constraints prevent a single agent from holding an entire codebase, long interaction history, and execution trace in working memory; (2) specialization requirements make it inefficient to use one generalist agent for planning, synthesis, testing, review, and debugging simultaneously; and (3) the absence of independent coordination and verification channels prevents the agent from reliably detecting and correcting its own errors during long-horizon execution. Multi-agent systems introduce a powerful principle: once these responsibilities are distributed across specialized roles, the agent harness itself becomes more modular, inspectable, and adaptable. Early systems such as ChatDev [330], MetaGPT [55], and AgentCoder [50] demonstrate this shift by dividing software-development responsibilities among distinct agents such as architect, programmer, tester, reviewer, and executor. Coordinated through structured communication protocols and shared code artifacts, these role-specialized agents turn code from a mere output target into the shared substrate through which the overall harness plans, acts, verifies, and improves itself.
In this section, we systematically survey the rapidly growing direction on using MAS to scale coding harnesses, and we propose a new position on building shared code-centric harness substrates for AI agents.
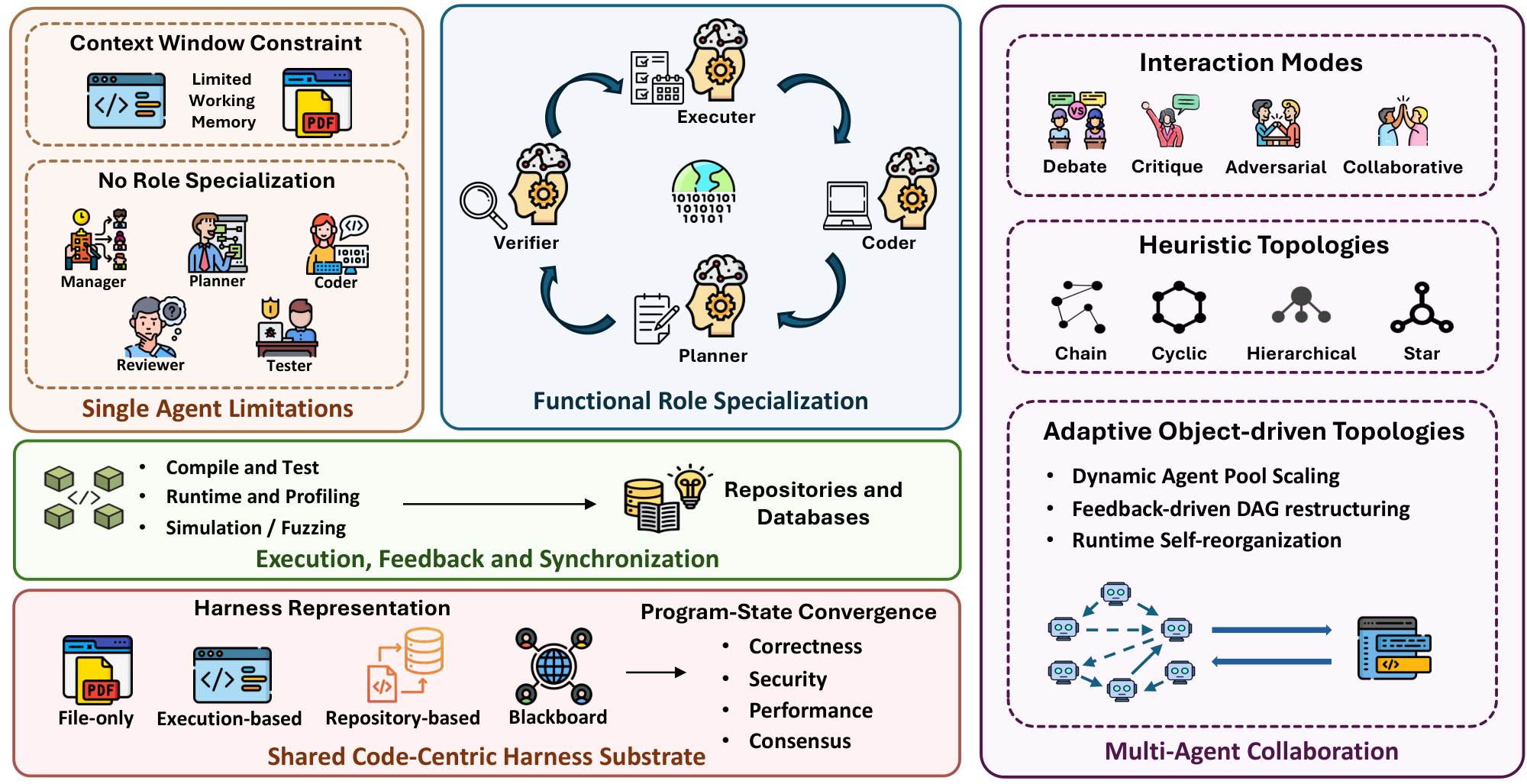
4.1 Improved Coding Support through Multi-agent Collaboration
The most immediate contribution of multi-agent systems is that they improve coding support by decomposing the harness into specialized but coordinated components. Instead of integrating planning, synthesis, execution, and verification into a single agent loop, these systems distribute responsibility across roles that interact through shared code artifacts and feedback signals. This division of labor makes the overall harness more capable of handling complex software tasks, while also making its internal workflow more inspectable and controllable. In practice, this improvement is realized through three closely related design dimensions: how roles are specialized, how agents interact over shared program artifacts, and how the workflow topology organizes their collaboration.
\begin{tabularx}{\ccccccccc}{@
>{\raggedright\arraybackslash}p{2.55cm}
>{\raggedright\arraybackslash}p{2.85cm}
>{\raggedright\arraybackslash}p{3.05cm}
>{\raggedright\arraybackslash}p{3.05cm}
>{\raggedright\arraybackslash}X@}
\toprule
\textbf{System}
& \textbf{Harness Substrate}
& \textbf{Agent Roles}
& \textbf{Interaction Mode}
& \textbf{Topology} \\
\midrule
Self-Collaboration [56]
& Blackboard, implicit
& Plan, Synth., Verif. (simulated)
& Critique-repair
& Pre-defined cyclic \\ \midrule
CodePori [331]
& Implicit
& Plan, Synth., Verif.
& Collab-Synth., critique-repair
& Pre-defined chain, cyclic \\ \midrule
MAGIS [332]
& Repository, evolution memory
& Plan, Understand, Synth., Verif.
& Critique-repair, debate, delegation
& Hierarchical, cyclic, dynamic pool \\ \midrule
HyperAgent [333]
& Repository, execution
& Plan, Understand, Synth., Exec
& Critique-repair
& Pre-defined hierarchical, cyclic \\ \midrule
PairCoder [334]
& Execution
& Plan-Understand, Synth-Exec
& Collab-Synth., critique-repair
& Pre-defined cyclic with conditional branch \\ \midrule
FlowGen [335]
& Execution, implicit
& Plan, Understand, Synth., Verif.
& Critique-repair, debate
& Pre-defined chain, cyclic (Scrum) \\ \midrule
Trae Agent [336]
& Repository, execution
& Generate, Prune, Select
& Collab-Synth., search (selection)
& Pre-defined search pipeline \\ \midrule
BOAD [337]
& Repository, execution
& Orchestrate, Localize, Edit, Validate
& Delegation, adaptive selection
& Adaptive hierarchical \\ \midrule
FlowReasoner [338]
& Execution, implicit
& Meta-design, Solve
& Runtime workflow generation
& Objective-driven adaptive \\ \midrule
ChatDev [330]
& Implicit, borderline exec
& Plan, Synth., Verif., Exec
& Critique-repair, debate
& Pre-defined chain (waterfall) \\ \midrule
MetaGPT [55]
& Implicit, partial blackboard
& Plan$\times$3, Synth., Verif.
& Critique-repair, pub-sub scheduling
& Pre-defined chain (waterfall) \\ \midrule
GameGPT [210]
& Blackboard (dual collaboration)
& Plan, Synth., Verif.
& Critique-repair, collaborative
& Pre-defined \\
\bottomrule
\end{tabularx}
4.1.1 Functional Role Specialization and Human-Guided Planning
In human software development, different roles specialize in different aspects of the development process. Many MAS naturally mirror this division of labor by assigning distinct functional roles to different agents. This specialization allows each agent to focus on a specific slice of the shared code harness, leveraging its unique capabilities and perspectives to contribute to the overall task. Here, we elaborate on the most common functional roles identified across the surveyed literature, noting that many systems implement multiple roles and that the boundaries between them can be fluid.
Program synthesis agents
Program synthesis agents are responsible for generating or transforming code. They consume specifications, plans, or feedback signals and produce or revise code artifacts. This is the most common role across surveyed systems. Representative instances include the Coder in Self-Collaboration [56], the Programmer in AgentCoder [50], the Engineer in MetaGPT [55], the Developer in ChatDev [330], and the RTL Generation Agent in MAGE [339].
Program understanding agents
Program understanding agents analyze existing code or specifications to produce higher-level representations. They own the interpretation of what the code means rather than what it does. This category includes the Repository Custodian in MAGIS [332], the Navigator in HyperAgent [333], the RepoUer in Lingma SWE-GPT [340], and the Column-type Annotator in CleanAgent [341].
Verification agents
Verification agents evaluate code quality, typically by generating test cases, running static analysis, or simulating execution. The Test Designer in AgentCoder [50] generates test cases independently of the code to avoid circular reasoning, a design principle against the mode-collapse problem where an agent's biased tests pass its own buggy code. The Test Quality Checker in QualityFlow [253] addresses this at a meta-level, filtering synthesized tests before they are used as feedback. The Static Analyzer and Fuzzing Agent in AutoSafeCoder [52] provide security-oriented verification through static CWE analysis and dynamic crash detection, respectively. The Panelists in CANDOR [342] independently audit oracle correctness against natural language specifications rather than against the code itself, deliberately avoiding contamination by faulty implementations.
Execution agents
Execution agents interface directly with the program runtime. Critically, the Test Executor in AgentCoder [50] is a deterministic Python script (not an LLM) which cleanly separates reasoning from execution and grounds the feedback signal in objective program behavior. The Executor in HyperAgent [333] runs unit and integration tests via an interactive bash shell. The Judge Agent in MAGE [339] interfaces with RTL simulation tools to produce per-clock-edge waveform snapshots.
Planning agents
Planning agents decompose the overall software-development task into subtasks and assign them to synthesis agents. The Architect and Project Manager in MetaGPT [55], the Manager in MAGIS [332], the Scrum Master in FlowGen [335], and the Mother agents in SoA [212] all perform task decomposition. The Mother agents in SoA [212] are particularly notable: they dynamically spawn Child agents at runtime based on the inferred complexity of each subfunction, making planning and agent initialization interdependent.
A distinctive feature of EvoMAC [328] is the introduction of two novel meta-roles not present in any other surveyed system: the Gradient Agent, which reads execution logs to identify which agents caused failures, and the Updating Agent, which revises agent prompts and restructures the workflow DAG accordingly. These roles operate at the level of the MAS itself rather than the program, enabling the system to adapt its own structure in response to execution feedback.
4.1.2 Diverse Interaction Modes Grounded in Shared Program State
Unlike general MAS where agent interaction is primarily message-passing, code-centric interaction is characterized by artifact-mediated communication: agents observe and modify shared code artifacts, and their interaction is grounded in the objective state exposed by those artifacts and their execution results. These coordination channels are broader than source code alone: agents communicate through APIs, files, diffs, tests, logs, schemas, blackboards, and explicit workflow states. In most systems, these channels are part of the human-designed harness, while agents dynamically write to or modify the artifacts circulating within them. We identify four interaction modes.
Collaborative synthesis
Collaborative synthesis occurs when two agents jointly construct a program component, analogous to pair programming [343]. The Navigator–Driver pairing in PairCoder [334] is the most direct instantiation: the Navigator generates and selects solution plans while the Driver implements them, with bidirectional information flow. CodePori [331] implements collaborative synthesis between Dev_01 and Dev_02, who exchange code drafts across three rounds. This mode is relatively rare among the surveyed system, as most systems prefer a sequential handoff rather than true co-construction.
Critique and repair
Critique and repair is the dominant interaction mode across the surveyed literature. A verification or evaluation agent inspects a code artifact and produces structured feedback; a synthesis agent then revises the artifact in response. This pattern appears in some form in virtually every surveyed system. Its key design decisions are: (a) whether the critique is LLM-simulated or execution-grounded (Self-Collaboration [56] uses a simulated LLM tester, while AgentCoder [50] uses a real Python executor); (b) the richness of the feedback signal (ranging from binary pass/fail in SEW [312] to structured execution logs enumerating satisfied requirements, function errors, and unmet requirements in EvoMAC [328]); and (c) the number of repair iterations permitted before fallback.
Adversarial validation
Adversarial validation is a more active form of verification in which one agent attempts to break the code through adversarial inputs, rather than passively reviewing it. AutoSafeCoder [52] implements this via its Fuzzing Agent, which generates crash-inducing input seeds using type-aware mutation and executes the code to produce crash traces. This mode has a fundamentally different character from critique-and-repair: the fuzzer does not explain what is wrong, but demonstrates a concrete execution failure, a counterexample that the coding agent must address. MAGE [339] similarly uses simulation mismatch as an adversarial signal: the Debug Agent receives the exact waveform window around the first clock-edge failure, enabling targeted repair.
Reasoning debate
Reasoning debate involves agents arguing over the correctness of a decision or the interpretation of a specification, before arriving at a consensus. ChatDev [330] introduces communicative de-hallucination, a mechanism in which the assistant agent reverses roles to ask clarifying questions before committing to a response. The Scrum sprint meetings in FlowGen [335] enable disordered multi-agent discussion around a shared context buffer before the Scrum Master synthesizes a decision. CANDOR [342] implements the most structured debate mechanism: three independent Panelists evaluate oracle correctness, and a Curator aggregates their verdicts via majority vote. The kick-off meeting in MAGIS [332] involves a circular speech among the Manager and all Developer agents to negotiate task dependencies and prevent conflicts.
4.1.3 Optimized Workflow Topology for Agentic Coordination
The topology of agent interaction, who communicates with whom, in what order, and how many times, is one of the most consequential design decisions in a MAS for code generation. We organize topologies along two primary axes.
Pre-defined Heuristic Topologies
The majority of surveyed systems use topologies that mirror established software development life cycle (SDLC) models. These topologies are fixed at design time and do not change in response to task complexity or system performance.
Chain (Waterfall) topologies sequence agents in a strict linear order, with artifacts flowing unidirectionally from planning to synthesis to verification. ChatDev [330] and MetaGPT [55] are canonical examples, explicitly modeling the waterfall SDLC: design $\rightarrow$ coding $\rightarrow$ testing. FlowGen [335] operationalizes three SDLC models as distinct topologies: FlowWater (strict waterfall chain), FlowTDD (requirement $\rightarrow$ design $\rightarrow$ test $\rightarrow$ implementation $\rightarrow$ fix, a test-driven reordering), and FlowScrum (cyclic iterative sprints). This paper is unique in directly comparing the implications of different SDLC-mirroring topologies for code quality. L2MAC [344] also follows a chain topology but with a novel twist: each step in the instruction plan is executed by a fresh-context agent, making the chain a sequence of independent LLM invocations sharing only the external file store.
Cyclic (Agile/Iterative) topologies introduce back-edges that allow code to be revised in response to verification feedback. AgentCoder [50] implements a programmer $\rightarrow$ test executor $\rightarrow$ (if fail) $\rightarrow$ programmer cycle, bounded at 5 iterations. Self-Collaboration [56] embeds a coder $\leftrightarrow$ tester back-edge within its waterfall chain, max 4 iterations. PairCoder [334] enhances the cyclic pattern with multi-plan exploration: a pool of $n$ solution plans is pre-generated via k-means++ clustering for diversity, and the cycle can switch to the next candidate plan when dead-end is detected through history-based loop analysis. MAGE [339] combines a linear initialization chain with a cyclic debug-judge loop, and introduces high-temperature candidate sampling to explore multiple program variants simultaneously.
Hierarchical topologies place one or more manager agents above a pool of worker agents, enabling decomposition-and-delegation patterns. MAGIS [332] has a Manager that dynamically instantiates one Developer agent per candidate file at runtime; each Developer edits its assigned file and reports back to the manager-review layer. HyperAgent [333] uses a planner above multiple repository navigation and editing workers, combining top-down decomposition with bottom-up repository evidence. SoA [212] pushes this hierarchy further by allowing Mother agents to spawn Child agents recursively according to inferred subtask complexity. These systems treat harness orchestration itself as a resource-allocation problem.
Star topologies center on a hub agent that coordinates multiple parallel worker agents. The CANDOR [342] Stage 3 panel is an example: a Requirement Engineer fans out to three independent Panelist+Interpreter pipelines, and the Curator aggregates their outputs. MetaGPT [55]'s publish-subscribe message pool creates a de facto star topology where the shared pool serves as the hub.
Objective-driven and Adaptive Topologies
A smaller but rapidly growing class of systems treats the topology itself as a design variable to be optimized toward a code quality signal. Recent systems such as FlowReasoner [338] and BOAD [337] further reinforce this trend by treating multi-agent organization itself as an adaptive object to be generated, searched, or optimized per task.
Dynamic agent pool scaling is the simplest form of adaptivity: the number of agents scales with task complexity, but the topology type is fixed. SoA [212] implements this via a hierarchical tree of Mother and Child agents, where Mother agents decide at runtime how many subfunctions to decompose into, spawning corresponding Child agents. The key insight is that each agent's context window remains bounded, as complexity is handled by growing the agent pool rather than growing individual context windows. MAGIS [332] similarly instantiates Developer agents dynamically based on the number of candidate files identified during repository analysis. BOAD [337] extends this line of thought from dynamic scaling to hierarchy discovery: instead of manually fixing the specialized sub-agent structure, it formulates the selection of helpful localization, editing, and validation sub-agents as a bandit-optimization problem, showing that automatically discovered hierarchical teams can outperform manually designed ones.
Feedback-driven DAG restructuring is best represented by EvoMAC [328]. Its workflow is a DAG whose nodes correspond to agents and whose edges define information flow. After each iteration, a Gradient Agent reads execution logs to attribute failures to agents, and an Updating Agent modifies the prompts and graph structure. This is the only system in the survey where the harness topology is structurally modified in response to execution feedback.
Runtime self-reorganization is SEW [312]'s approach: the system generates and mutates entire workflow specifications using Direct Evolution (DE) and Hyper Evolution (HE) operators applied to LLM-generated workflow descriptions in structured formats (BPMN, CoRE, Python, YAML). Rather than optimizing agent parameters, SEW [312] optimizes the workflow structure including the sequence of agent calls, the routing logic, and the feedback paths. The two canonical topologies it discovers (a linear chain and a feedback loop) emerge from optimization rather than being hand-designed. FlowReasoner [338] pushes this adaptive view further by training a query-level meta-agent that generates a tailored multi-agent system for each input problem under external execution feedback, making topology selection itself part of the deliberative inference process rather than a fixed system design.
4.2 Execution Feedback and Shared-Harness Synchronization
We discuss how a group of agents can exploit the executability of code, and how they maintain a consistent shared view of the program state. This dimension is the defining one for code-centric MAS: the shared harness is uniquely executable and produces objective oracle signals. We address two sub-questions: what types of execution feedback are used, and how is shared state synchronized across agents.
\begin{tabularx}{\ccccccccc}{@
>{\raggedright\arraybackslash}p{2.6cm}
>{\raggedright\arraybackslash}p{3.8cm}
>{\raggedright\arraybackslash}p{2.3cm}
>{\raggedright\arraybackslash}p{3.3cm}
>{\raggedright\arraybackslash}X@}
\toprule
\textbf{System} & \textbf{Harness Substrate} & \textbf{Topology} & \textbf{Execution Feedback} & \textbf{Convergence} \\
\midrule
\multicolumn{5}{@l}{\textit{Pre-defined topology}} \\
\addlinespace[2pt]
AgentCoder [50] & Execution & Cyclic & Test pass/fail & Correctness (test-gated) \\
MAGE [339] & Execution (waveform) & Chain-cyclic & Checkpoint waveform & Score-based correctness \\
MapCoder [44] & Execution, implicit & Cyclic & Test pass/fail & Correctness \\
AutoSafeCoder [52] & Execution (static, fuzzer) & Cyclic & CWE warnings, crashes & Security convergence \\
QualityFlow [253] & Execution (real, imagined) & Gated cyclic & Pass/fail, imagined exec & Correctness (quality-gated) \\
CodeCoR [166] & Execution, implicit & Cyclic & Syntax, test pass/fail & Score-based soft correctness \\
MARCO [345] & Execution (performance) & 2-node Cyclic & Time, memory, FLOPS & Performance, correctness \\
\midrule
\multicolumn{5}{@l}{\textit{Adaptive topology}} \\
\addlinespace[2pt]
SoA [212] & Execution, implicit gap & Hierarchical tree & Test pass/fail & Correctness (implicit fallback) \\
SEW [312] & Implicit & Evolution & Test pass/fail & Implicit \\
EvoMAC [328] & Execution & Text DAG & Compiler, execution logs & Correctness (fixed-iteration) \\
FlowReasoner [338] & Execution, implicit & Query workflow & Execution feedback & Objective-driven adaptive \\
Trae Agent [336] & Repository, execution & Search pipeline & Test, pruning signals & Score-/selection-based \\
\bottomrule
\end{tabularx}
4.2.1 Execution Feedback Integration
Compiler and syntax feedback
Compiler and syntax feedback catch structural errors before runtime and are used by many systems. ChatDev [330] feeds compiler errors from the testing phase back to the programmer, though only as one-off corrections within a single phase. L2MAC [344] runs syntax checks via its evaluator module $E(D)$ after every file write, treating them as blocking conditions that prevent the instruction pipeline from advancing.
Test pass/fail signals
Test pass/fail signals are the most commonly used execution-feedback type. AgentCoder [50] centers its entire loop on whether independently generated test cases pass; the iteration terminates on full pass or at the 5-iteration budget. QualityFlow [253] introduces a notable variant: Imagined Execution, in which an LLM simulates the Python interpreter step-by-step and predicts test outcomes without actually running the code, achieving 98%+ precision and recall on MBPP while avoiding label leakage from visible test cases. The near-identical performance of Self-Collaboration [56]'s simulated LLM tester and its real-compiler ablation raises a provocative empirical question: when is actual execution necessary, and when can linguistic simulation of execution suffice?
Fuzzer crash traces
Fuzzer crash traces represent a qualitatively different type of feedback: rather than a pass/fail outcome, they provide a concrete failing input. AutoSafeCoder [52] uses type-aware mutation to generate crash-inducing input seeds and passes the crashing input plus exit code to the Coding Agent. This adversarial feedback is more informative than a generic failure signal because it localizes the bug to a specific input category.
Static analysis warnings
Static analysis warnings provide feedback about code structure and security properties without execution. AutoSafeCoder [52] uses CWE-mapped static analysis against the MITRE vulnerability database, enabling the Static Analyzer Agent to suggest remediation strategies keyed to specific vulnerability classes.
Performance profiling results
Performance profiling results are uniquely exploited by MACRO [345], which treats code optimization as the primary task rather than correctness. The Performance Evaluator Agent measures execution time, memory usage, and FLOPS, and MACRO [345] uniquely augments this with real-time web search to retrieve relevant optimization techniques from the research literature.
Fine-grained simulation feedback
MAGE [339]'s distinctive contribution is the finest-grained execution feedback in the surveyed literature. Rather than reporting only whether a testbench passes or fails, the State Checkpoint mechanism records signal values at every clock edge and delivers to the Debug Agent a waveform window around the first failing clock cycle. This enables targeted repair at sub-test granularity.
4.2.2 Shared-Harness Synchronization
Sequential handoff is the most common synchronization mechanism: each agent receives the output of its predecessor and passes its own output to its successor. The program state exists only in the form of the most recent artifact in the pipeline. This is sufficient for simple linear pipelines but creates invisible state divergence in multi-agent settings where multiple agents modify the codebase in parallel or iteratively. It is also where the limits of code-mediated coordination become clear. Even when agents share executable artifacts, the harness still imposes information-theoretic constraints: channels have finite bandwidth, summaries introduce compression loss, logs become noisy, cached views go stale, and parallel branches raise unresolved questions of authority and consistency. Code provides a richer substrate for coordination, but it does not remove these distributed-systems constraints.
Shared blackboard
Shared blackboard provides a globally accessible program state that all agents can read and update. L2MAC [344] implements this most cleanly: the file store $D$ is an external, persistent structure that is never overwritten but extended and revised. The Control Unit manages all reads and writes, ensuring that each agent invocation receives a precisely controlled context window. MAGIS [332]'s repository evolution memory $M$ is a persistent key-value store mapping file versions to LLM-generated summaries, updated incrementally via a specialized blackboard for repository-level reasoning. Self-Collaboration [56] is among the first systems to explicitly name and invoke the blackboard architecture, establishing a shared memory from which all three roles read and write.
Parallel branches with merge
Parallel branches with merge arise when multiple agents modify independent components simultaneously, with their changes integrated at a later stage. MAGIS [332] instantiates one Developer per candidate file; each modifies its assigned file independently, and all changes are merged into the final repository diff. HyperAgent [333] runs multiple Navigator and Editor instances in parallel via Redis queues, with results merged at the Planner level.
Structured context scheduling
Structured context scheduling is the explicit management of what each agent sees and when. It is the primary innovation of L2MAC [344]. The Control Unit resets the context window between instruction steps, providing each new invocation with a targeted summary of prior progress $(M_{rs})$ rather than the full conversation history. When the context window approaches capacity, the Control Unit stores partial results to $D$ and re-initializes with a compressed view, explicitly instructing the LLM which files to read or skip given the remaining context margin. This mechanism solves the context-window problem not by expanding the window but by carefully controlling its contents. MetaGPT [55] implements a lighter form of context scheduling via a publish-subscribe message pool: each agent subscribes only to the document types relevant to its role, receiving a filtered view of the shared state.
Hierarchical memory
Hierarchical memory combines short-term working context with longer-term accumulated knowledge. ChatDev [330] explicitly separates short-term memory (full dialogue within a phase) from long-term memory (extracted solutions carried across phases). Cogito [346] implements hierarchical memory, drawing on neurobiological architecture: short-term memory for immediate task state, a long-term knowledge base for accumulated expertise, and growth units for evolving abstractions that improve over time. HyperAgent [333] uses a lightweight LLaMA-3.1-8B summarizer to condense execution logs before storing them in hierarchical memory, preventing context bloat.
Agent pool scaling
Agent pool scaling addresses the context-management problem orthogonally: rather than managing what a single agent sees, it distributes the context load across more agents. SoA [212] is the canonical example: by spawning more agents as task complexity grows, each agent's context remains bounded. This is a structural solution to the harness-state problem: instead of building a shared representation that all agents can query, SoA [212] partitions the task state across agents, each holding a bounded slice. The limitation is that global consistency is sacrificed: agents cannot reason about the full program, only their assigned sub-function.
Other
QualityFlow [253]'s revert mechanism represents a synchronization pattern: the initial code artifact is never overwritten, enabling the system to roll back to a prior shared harness state if the debugging trajectory degrades quality. This is the only work among the surveyed system that explicitly manages state history rather than always moving forward.
4.3 Position: The Shared Code-Centric Harness Substrate
We propose a new position for the next generation of multi-agent intelligence: the shared code-centric harness substrate. This position is motivated by the central gap identified in the literature: the lack of formal, persistent representations of the shared code state that agents can query and update across iterations. We argue that building such a harness substrate is both feasible and necessary for achieving robust, scalable multi-agent intelligence.
\begin{tabularx}{\ccccccccc}{@
>{\raggedright\arraybackslash}p{2.55cm}
>{\raggedright\arraybackslash}p{3.05cm}
>{\raggedright\arraybackslash}p{3.15cm}
>{\raggedright\arraybackslash}p{3.05cm}
>{\raggedright\arraybackslash}X@}
\toprule
\textbf{System}
& \textbf{Harness Substrate}
& \textbf{Agent Roles}
& \textbf{Execution Feedback}
& \textbf{Convergence / Synchronization} \\
\midrule
L2MAC [344]
& Blackboard, repository, execution
& Plan, Synth, Verif (evaluator)
& Syntax, test pass/fail
& Correctness per instruction step \\ \midrule
Cogito [346]
& Blackboard (3-tier memory)
& Neurobiological model
& NA
& Hierarchical memory synchronization \\ \midrule
CleanAgent [341]
& Execution (weak), implicit
& Plan, Understand, Synth, Exec
& Runtime errors
& Correctness through execution success \\ \midrule
Lingma SWE-GPT [340]
& Repository, execution
& Understand, Synth-Verif
& Syntax, git apply, tests
& Fixed-limit implicit convergence \\ \midrule
SyncMind [347]
& Repository, execution (formal $S_k/B_k$)
& Synth-Understand, oracle Understand
& Test pass/fail, runtime errors
& Correctness, resource-constrained synchronization \\ \midrule
BOAD [337]
& Repository, execution
& Orchestrator with specialized sub-agents
& Test pass/fail, validation reward
& Hierarchy discovery, coordination \\ \midrule
CANDOR [342]
& Execution (Java, JaCoCo)
& Plan, Synth, Verif, Understand, Debate
& Compiler, coverage, tests
& Correctness, coverage, consensus \\
\bottomrule
\end{tabularx}
4.3.1 Shared Harness Representation
A foundational question for any MAS is: what is the substrate these agents inhabit? In code as agent harness, the natural answer is the shared program environment, namely the collection of artifacts, execution contexts, and quality signals that agents collectively act upon and that evolve as agents produce, revise, and evaluate code. We call this the shared harness substrate, and we distinguish four levels of formalization with which existing systems represent it.
Implicit / File-only Representation
The most common and least formalized category treats the shared harness as simply the current code file or set of code files. Agents receive the latest code artifact as part of their input context and produce a modified or evaluated version. There is no persistent, queryable representation: the shared state is reconstructed implicitly at each agent invocation from the conversational history. This category encompasses many foundational systems: ChatDev [330], MetaGPT [55], FlowGen [335], MapCoder [44], CodeCoR [166], SEW [312], and CodePori [331]. While this representation is simple to implement, it entails a fundamental limitation: agents cannot reason about the shared substrate except through the narrow lens of their most recent context window. State divergence [347], in which an agent's internal belief about the code state diverges from the true state, is invisible to the system and cannot be detected or corrected.
Repository-based Representation
A richer class of systems represents the shared harness as a navigable repository: a file system with directory structure, inter-file dependency graphs, call hierarchies, and version history. This representation supports agents that reason about where in the codebase a change needs to be made, what other components depend on the changed function, and how the codebase has evolved over time. MAGIS [332] introduces a repository evolution memory that caches file-level summaries and incrementally updates them via git diff as files change across issue-resolution episodes. HyperAgent [333] provides agents with repository navigation tools (get_tree_structure, go_to_definition, code_search, get_all_references), treating the repository as a structured knowledge base. Lingma SWE-GPT [340] compresses the repository view via abstract syntax tree (AST) skeletons, preserving function signatures and class definitions to enable efficient navigation. SyncMind [347] is the only work to formally define the repository substrate as a ground-truth state $S_k$ and measure the divergence between $S_k$ and an agent's belief state $B_k$.
Execution-based Representation
Execution-based representation is the most distinctive category for code generation. It has no direct parallel in general MAS and represents the shared substrate through execution behavior. The state is not what the code looks like but what the code does: whether it compiles, which tests it passes, what vulnerabilities a fuzzer uncovers, how fast it runs, and whether its runtime behavior matches its specification. This execution-based representation provides an objective oracle signal, a ground truth that is not subject to the hallucination or bias that affects purely linguistic agent evaluations. Systems that exploit this representation include AgentCoder [50], AutoSafeCoder [52], QualityFlow [253], MACRO [345], EvoMAC [328], CANDOR [342], and MAGE [339]. Notably, MAGE [339] achieves the finest-grained execution feedback in the literature, operating at clock-edge granularity via State Checkpoint waveform snapshots.
Blackboard / Shared-State Representation
A fourth category introduces an explicit, globally accessible data structure that all agents can read from and write to (akin to the classical blackboard architecture in AI [348]). This shared state is the closest approximation in the literature to a formal harness substrate: it persists across agent invocations, can be queried and updated, and provides a consistent view of the program state to all agents. Self-Collaboration [56] is among the first systems to explicitly invoke the blackboard metaphor, establishing a shared memory from which all three roles (Analyst, Coder, Tester) read and write. L2MAC [344] implements the most principled blackboard in the literature: a persistent file store $D$ with semantically meaningful paths, accessed through a Control Unit that explicitly manages which slice of state each agent invocation sees. GameGPT [210] uses a shared context buffer to reduce redundant information retransmission in multi-round game development. Cogito [346] draws on neurobiological architecture to implement a three-tier memory: short-term working state, long-term knowledge base, and growth units for evolving abstractions, as a structured harness representation.
The Central Gap
The distribution of systems across these four categories reveals a striking pattern: the majority of the literature resides in the implicit/file-only category, lacking any formal model of the shared harness substrate. This is the central gap that motivates the code as agent harness framing. The program, uniquely among multi-agent domains, is an artifact that executes. It produces objective, non-linguistic signals that could in principle anchor a formal shared substrate. Yet most systems fail to exploit this property at the architectural level, instead relying on agents to reason about code quality through natural language alone.
4.3.2 Harness-State Convergence
Convergence determines when a multi-agent coding harness should stop iterating and accept its current program state as a satisfactory outcome. In many existing MAS, convergence is still defined implicitly, either by consensus among agents or by an external iteration budget. However, code as agent harness has a distinctive advantage: because the shared substrate is executable, convergence can be grounded in objective behavioral signals rather than in conversational agreement alone. We identify six convergence patterns, ranging from widely used test-gated and implicit convergence to less common security-, performance-, and consensus-based criteria.
Correctness convergence
Correctness convergence (test-gated) is the most principled and widely used objective criterion: the system terminates successfully when all test cases pass. AgentCoder [50], L2MAC [344], SyncMind [347], and CANDOR [342] implement test-gated convergence. PairCoder [334] augments this with dead-end detection: if the same buggy code or feedback appears in the iteration history, the system switches to the next candidate plan rather than looping. FlowGen [335] uses test-gated convergence but on LLM-generated tests rather than ground-truth tests, introducing a potential quality concern: a system can converge on code that passes its own biased tests but fails on external evaluation.
Security convergence
Security convergence is uniquely implemented by AutoSafeCoder [52]: the system terminates successfully when no CWE vulnerabilities are flagged by static analysis and no crashes are induced by the fuzzer. This multi-criteria convergence is a strong argument for the execution-based harness framing. Both convergence criteria are grounded in objective program behavior, not agent opinions.
Performance convergence
Performance convergence is the focus of MACRO [345]: the optimization loop terminates when user-defined runtime and memory thresholds are satisfied, as measured by the Performance Evaluator against actual execution benchmarks. This is the only system that treats performance as the primary convergence criterion rather than correctness.
Score-based convergence
Score-based convergence uses quantitative quality scores computed by agents evaluating intermediate outputs to determine when to stop. MAGE [339] ranks candidate programs by their simulation mismatch score $s(r) = 1 - m(r) / tc(r)$ and continues iterating until the maximum score reaches 1.0. CodeCoR [166] uses a four-criteria binary score (clarity, relevance, conciseness, context) to prune intermediate outputs at each agent stage and selects the highest-ranked code in its Ranked Code Set as the final output. It sets a soft correctness convergence that submits the best available result rather than waiting for a perfect solution. Trae Agent [336] introduces a closely related search-and-selection view at repository scale: it formulates issue resolution as an optimal solution search problem and uses modular generation, pruning, and selection agents to navigate a large ensemble space of candidate patches. In this setting, convergence is not only a matter of repeated repair, but also of ranking, filtering, and selecting among competing solutions under repository-aware evidence.
Consensus convergence
Consensus convergence aggregates judgments from multiple reviewer agents. CANDOR [342] implements majority voting among three Panelists on oracle correctness. MAGIS [332] uses LLM-judgment from the QA Engineer as the acceptance signal, though this is a single-agent consensus rather than a multi-agent vote. QualityFlow [253] uses its Code Quality Checker as the single gating signal. It is an efficient design where the quality checker serves as both a convergence oracle and the system controller, enabling early exit (75–84% of problems converge after the first generator call).
Implicit convergence
Pipeline termination after a fixed number of stages or iterations with no objective quality criterion is the most prevalent convergence pattern in the literature and represents the most significant gap in the field. ChatDev [330] terminates after a fixed number of phases, or when two consecutive rounds produce identical code, or after 10 rounds, none of which is an objective quality signal. MetaGPT [55] terminates after completing the fixed SOP stages. Self-Collaboration [56] falls back to implicit convergence after $n = 4$ iterations if the tester never approves. EvoMAC [328] runs a fixed $K$ iterations of the textual backpropagation loop. The prevalence of implicit convergence is a direct consequence of the lack of formal shared substrates: without an objective representation of the program state, systems have no principled criterion for convergence.
4.4 Patterns and Trends
Across systems, differences in role specialization, shared-state representation, execution grounding, and workflow topology are not independent engineering choices; they interact to determine how reliably a group of agents can maintain coherence over long-horizon coding tasks. In this subsection, we distill the main trends that emerge from the surveyed systems, highlighting both the common structural bottlenecks of current systems and the design principles that point toward more robust shared harnesses.
The implicit-harness-state constraint
The majority of surveyed systems (ChatDev [330], MetaGPT [55], FlowGen [335], CodePori [331], SEW [312], MapCoder [44], CodeCoR [166]) operate without explicit representations of the shared code harness. These systems rely on agents to reconstruct state implicitly from conversational history at each invocation. This design choice works for function-level tasks where the program state is simple and does not fragment across agents. However, this implicit approach creates a fundamental vulnerability: without a formal shared substrate, agents cannot reliably detect when their internal understanding diverges from the true program state [347]. From the code as agent harness perspective, the reliance on implicit state representations is the technical root of system brittleness rather than a scalability convenience.
Code-mediated channels do not eliminate coordination bottlenecks
The shift from free-form dialogue to code-mediated coordination is a genuine architectural advance, but it should not be overstated. Files, APIs, diffs, tests, logs, schemas, blackboards, and workflow states are all partial channels through which task state is encoded, transmitted, and reconstructed. Each channel trades off fidelity, latency, and scope: tests compress semantics into pass/fail, summaries save context at the cost of detail, logs are grounded but noisy, and shared blackboards improve persistence while creating authority and consistency problems. The central design question is therefore not merely whether code is present, but which artifacts are authoritative, how they are compressed, and how conflicts across channels are resolved.
Execution feedback as the bridge between linguistic and formal reasoning
The deepest divide in the literature is between systems that use execution as ground truth and those that rely on linguistic model judgments. Systems that ground shared state in execution (AgentCoder [50], AutoSafeCoder [52], QualityFlow [253], EvoMAC [328], MAGE [339]) have access to objective oracle signals, signals that cannot hallucinate. Yet a surprising finding complicates this picture: Self-Collaboration [56] and QualityFlow [253] demonstrate that LLM-simulated execution can achieve 98%+ precision and recall in predicting actual outcomes without running code. This suggests that execution feedback's value is not uniform across all failure modes. It excels at detecting the corner cases that linguistic simulation structurally cannot imagine (runtime crashes, resource exhaustion, boundary condition errors, performance regressions), but for many correctable bugs, simulated reasoning may suffice. A mature harness would integrate both: using linguistic reasoning as the fast path and delegating to execution as the verification oracle only for the failure modes that require it.
Two complementary representations of the shared harness
The surveyed systems reveals two conceptually orthogonal views: repository-based representation (structure: what functions call what, where does data flow, what are the dependencies) and execution-based representation (behavior: what does the code do when run, how does state evolve at runtime, what emergent failures occur under different inputs). MAGIS [332] and HyperAgent [333] operate primarily in the repository view, enabling agents to reason about codebase architecture. AgentCoder [50] and MAGE [339] operate primarily in the execution view, grounding shared state in runtime signals. Yet none of the surveyed systems fully unifies both views into a single harness substrate where agents can reason across both the static structure of code and its dynamic behavior. The deepest harness would integrate these two perspectives, answering questions like "which components are slow" (requires both call graphs and profiling data) or "does this refactoring break APIs that external code depends on" (requires both static analysis and dynamic testing).
Topology complexity inversely correlates with harness-state formality
Systems with explicit, formal shared substrates use simpler topologies, while systems lacking formal shared state employ increasingly complex topology patterns as a structural workaround. L2MAC [344], which has the clearest formal harness substrate (a persistent file store with explicit context scheduling), uses a simple sequential chain with sophisticated state management. By contrast, implicit-state systems like EvoMAC [328] and SEW [312] develop elaborate adaptive topologies (dynamic DAGs, workflow mutation, agent pool scaling) that attempt to optimize the collaboration structure in the absence of a principled shared representation. This suggests that topology complexity is partially a symptom: when the substrate is formally represented and queryable, agents can coordinate through simple, transparent protocols. When the substrate is implicit, agents require richer interaction patterns to compensate for missing state information.
Context management is the tax of implicit shared state
A striking pattern is that many systems have developed sophisticated context-management mechanisms precisely because they lack a formal shared substrate. L2MAC [344]'s Control Unit, MetaGPT [55]'s publish-subscribe pool, SoA [212]'s agent-pool scaling, and Cogito [346]'s three-tier memory are all responses to the same underlying problem: how to give agents a coherent view of a code harness that is too large to fit in any one context window. A mature harness substrate could unify these disparate solutions by providing a principled, queryable representation of task state that agents access on demand, rather than forcing the system to carefully manage what each agent sees at every step.
Agent specialization increases the criticality of shared state metrics
As agent role diversity increases, from basic coder-tester pairs to systems with Architect, Manager, Navigator, Executor, and Verifier roles, the need for a unified shared substrate becomes urgent. Without shared understanding of code state, the Planning Agent may decompose tasks based on an outdated codebase snapshot, the Execution Agent may run tests against a different version than the Synthesis Agent intended, and the Verification Agent's feedback may misfire. EvoMAC [328] addresses this through its Gradient and Updating agents that explicitly monitor failure attribution at the MAS level. SyncMind [347] formalizes the problem as agent belief divergence $|B_k - S_k|$, proposing explicit synchronization protocols. The proliferation of agent roles is thus not merely an engineering choice. It is a forcing function for developing more mature shared harnesses. Multi-agent systems with rich role repertoires cannot function robustly without them.
5. Emerging Fields and Open Problems
Section Summary: The section explores how code functions as a central control system for AI agents across practical areas such as coding assistants, GUI and operating-system agents, scientific research tools, personalized recommendation systems, and physically embodied robots. In each case, code does more than produce answers; it manages ongoing states, executes actions, stores memory, incorporates feedback, and enforces rules to support extended, reliable operation. At the same time, these emerging uses expose shared unsolved problems around evaluation, safety, verification, coordination, and adapting the surrounding control structures themselves.
Having characterized code as an agent harness through its interfaces, mechanisms, and orchestration patterns, we now examine how this paradigm materializes in concrete application domains and what open problems it exposes. Across coding assistants, GUI/OS agents, scientific discovery, personalization, and embodied agents, code serves not only as a model output, but also as the operational substrate for state representation, action execution, memory, feedback, and governance. These domains make the promise of code-centric agentic systems tangible, while revealing a common set of unresolved challenges around evaluation, verification, safety, coordination, multimodal grounding, and harness evolution.
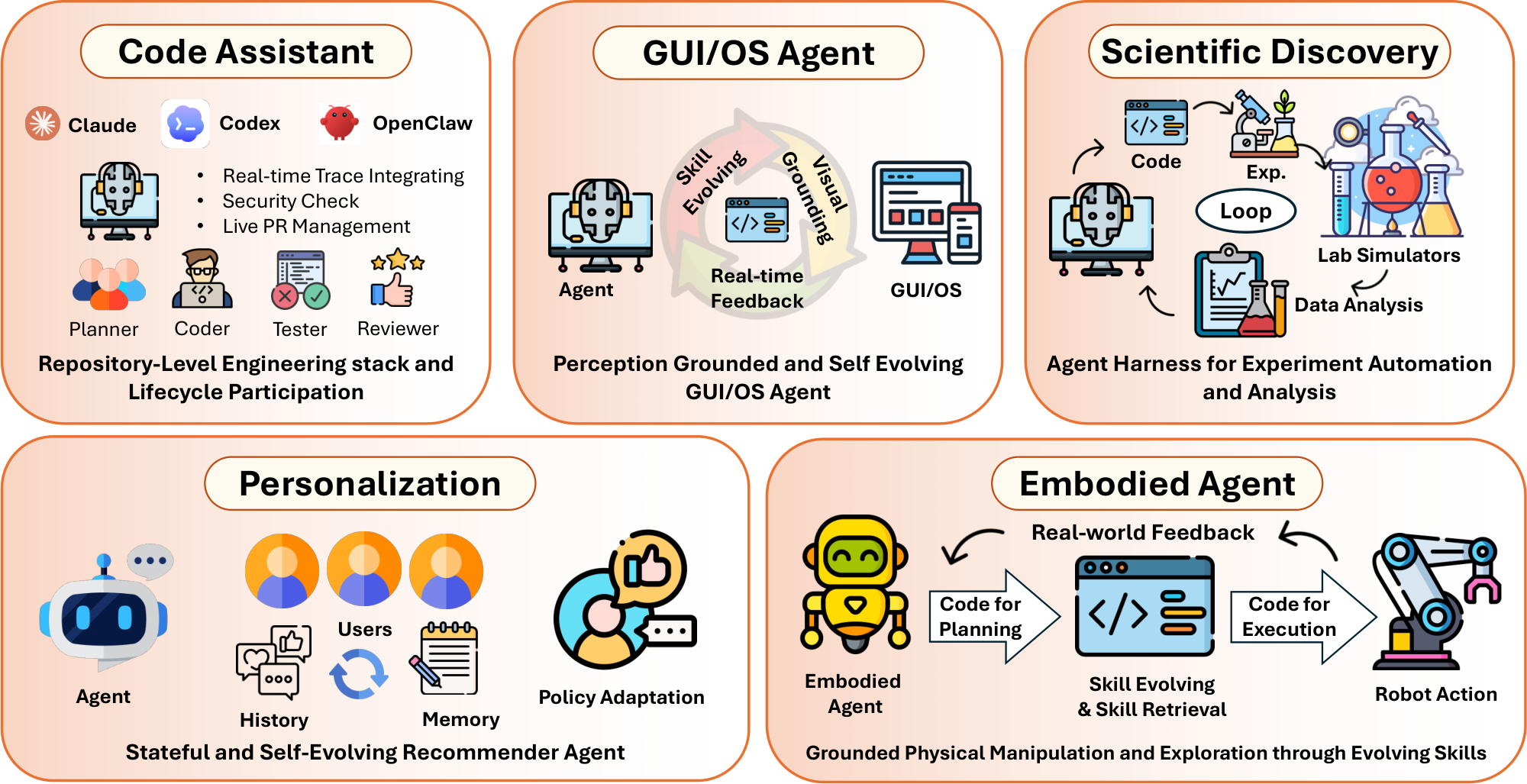
5.1 Emerging Fields and Tangible Applications
This subsection surveys five application domains where code-as-harness systems have become especially visible. Code assistants operate over repositories, tests, development tools, and collaborative workflows; GUI and OS agents manipulate rendered interfaces through executable actions and programmatic checkers; scientific agents organize hypotheses, experiments, analyses, and laboratory protocols as executable pipelines; personalization agents adapt recommendation policies through structured user feedback and editable preference states; and embodied agents ground high-level intent in executable skills subject to physical constraints. Together, these domains show how code connects model outputs to real-world systems, and how the design of the surrounding harness shapes reliability, controllability, and long-horizon autonomy.
5.1.1 Code Assistants
Code assistants provide one of the clearest application domains where code-centric agentic systems become operational. Early systems mainly supported localized completion or single-turn code generation. Recent assistants instead operate across repository-level workflows, where editing, tool use, validation, and pull-request interaction form a closed-loop agent process. This shift is reflected in research systems such as SWE-agent ([57]) and OpenHands ([58]), as well as production-oriented platforms such as Claude Code ([26]), Codex ([27]), GitHub Copilot coding agents ([349]), and DeepAgents ([350]). In these systems, the assistant is no longer a standalone code generator. It is embedded in a development environment where repository state, tools, validation routines, and collaboration workflows provide the operational context for action and feedback.
Repository-centered Workspace
Modern code assistants operate over repositories rather than isolated code snippets. Source files, tests, build scripts, dependency metadata, issues, branches, and pull requests form a persistent workspace that the agent can inspect, modify, and validate over multiple steps. This makes repository-level assistance less a matter of placing relevant files in the prompt, and more a matter of constructing a task-specific working view over a large and evolving codebase. Systems such as RepoCoder [47], CodexGraph [351], and AutoCodeRover [46] address this problem through repository indexing, dependency-aware retrieval, graph-based code representations, and agentic localization before editing. In this sense, the repository becomes the operational substrate on which code assistants plan, act, and receive feedback.
Executable Development Harnesses.
Executable development harnesses are becoming the runtime and control plane of code assistants. Rather than exposing the model to a flat list of tools, recent systems wrap it in a managed development loop that controls repository access, file edits, command execution, approval boundaries, context isolation, logging, and validation. This trend is visible in production systems: Claude Code packages local terminal/IDE/browser coding into a tool-mediated loop with editing, command execution, permissions, hooks, memory, and subagents; Codex and GitHub Copilot coding agents move similar loops into managed cloud or GitHub-native workspaces with sandboxes, branches, approvals, and auditable pull-request outputs; and DeepAgents exposes planning, filesystem-backed state, context management, code execution, and subagent delegation as reusable harness components ([26, 27, 350, 349]). Such loops are increasingly mediated by open protocols such as the Model Context Protocol ([352, 260]), which standardize how harnesses expose tools, context, and resources to the model and enable cross-system tool reuse. In parallel, recent research treats the harness itself as an object of optimization rather than a fixed wrapper: AutoHarness ([14]) synthesizes code harnesses from environment feedback, Meta-Harness ([13]) searches over harness code using prior candidates and execution traces, Agentic Harness Engineering ([281]) evolves coding-agent harnesses through observability, and Natural-Language Agent Harnesses ([353]) externalize roles, contracts, adapters, and state conventions into editable harness specifications. Together, these developments suggest that practical progress in code assistants is increasingly shaped not only by improvements in the base model, but also by the surrounding execution runtime, including its sandbox, permissions, context plumbing, telemetry, and verification hooks.
Execution Feedback as Grounded Verification
A distinguishing property of code assistants is the availability of machine-checkable feedback: compiler diagnostics, test outcomes, linter warnings, and runtime traces. Agentless [354] shows that a fault-localization and patch-generation pipeline guided by test execution achieves competitive results on SWE-bench [216] without elaborate agentic control. RepairAgent [183] and Live-SWE-agent [182] extend this loop into autonomous program repair driven by test results, while AlphaCodium [355] demonstrates that test-driven flow engineering substantially improves competitive programming performance over single-shot prompting. Execution thus converts each candidate edit from a textual hypothesis into a verifiable transformation of the program world.
Memory and Context Management at Repository Scale
Repositories routinely exceed any plausible context window, forcing code assistants to maintain explicit, structured memory. Retrieval-augmented completion [47], graph-based code indexing [351], documentation-oriented agents such as RepoAgent [356], and recent context-retrieval benchmarks such as ContextBench [357] instantiate the memory abstractions of § 3.2 with a code-specific twist: stored items such as functions, tests, traces, and retrieved issue contexts are themselves executable or directly tied to executable states, and can be re-run, checked, or localized rather than merely re-read. Recent memory systems further extend this view by storing reusable agent procedures or repository experience as procedural and experiential memory [45, 48]. This narrows the gap between memory and environment found in conventional agent architectures, and makes abstraction management particularly acute, since the assistant must select the right scale of code and experience to surface for a given subtask.
Developer Intent and Project Conventions as Latent State
Beyond explicit repository state, practical coding assistants must reason about latent developer intent and project conventions. A useful patch should not only pass visible tests, but also align with the repository's architecture, coding style, and internal API reuse, properties that recent work describes as the organicity of generated code [358]. Agents that ignore these constraints can produce technically correct patches that maintainers still reject [358, 359], while benchmark analyses show that some seemingly solved SWE-bench issues rely on solution leakage in the issue text rather than genuine intent inference [360]. Coding assistance is therefore a partially observable program world problem: files, tests, and tool outputs provide observable state, while design rationales, implicit constraints, and team conventions must be inferred from issue threads, prior commits, code reviews, and accumulated interaction history. This extends the belief state divergence studied in SyncMind from shared multi agent state to individual agent and user alignment [347]. Modeling this latent state is essential for moving from functional code generation toward trustworthy developer collaboration.
From Inline Completion to Autonomous SWE Agents
The evolution of code assistants can be viewed as an expansion of the development harness around the model. Early systems such as Codex-based completion [1] and commercial assistants such as Copilot [361] rely on a lightweight IDE harness, where local context is surfaced, an inline suggestion is generated, and the developer remains the primary executor, verifier, and state manager. Productivity [361] and usability [362, 363] studies show that even this lightweight harness matters, since the value of a suggestion depends on its alignment with the developer's evolving program state and intent. At the autonomous end, systems such as SWE-agent, OpenHands, AutoCodeRover, and Agentless operate within a repository-level harness, shifting from isolated code generation to stateful inspection, editing, execution, and revision.
From Patch Generation to Software Lifecycle Participation
Code assistants are also moving from isolated patch generation toward broader software lifecycle participation. SWE-bench framed repository-level assistance as an issue-to-patch task ([5]), while newer benchmarks such as SWE-Lancer ([364]) and SWE-Bench Pro ([365]) evaluate longer-horizon, economically meaningful software deliverables that span multiple files and require professional engineering effort. Related benchmarks such as Terminal-Bench ([366]) and AppWorld ([367]) further reflect the same shift toward interactive environments where agents must operate through commands, tools, and executable application states ([368, 369]). In deployment, this trend appears as agents that work inside persistent engineering workflows rather than static repository snapshots, including pull-request review, CI/CD feedback, and production issue resolution ([370, 371]). At production scale, LingmaAgent reports that an autonomously deployed issue-resolution agent at Alibaba Cloud resolves 16.9% of in-house issues fully autonomously and 43.3% with manual intervention ([372, 373]). This suggests that code assistants are becoming workflow participants, not merely patch generators.
Multi-Agent Code Assistance and Shared Repositories
At the upper end of the spectrum, code assistance increasingly takes a multi-agent form, with planner, coder, tester, and reviewer roles operating over a shared repository. ChatDev [330], MetaGPT [55], CodeAgent [185], and METAL [374] show how role specialization combined with a shared executable artifact enables coordination patterns that single agents struggle to sustain over long horizons. The repository, together with its tests and execution traces, becomes both the medium of communication and the convergence target, directly instantiating the shared program world of § 4. Concurrent edits, however, can silently invalidate assumptions held by other agents, exposing the world-state synchronization challenges discussed in the same section.
The Harness as a Distillation Surface
A defining 2026 development is that production harnesses are no longer only deployment infrastructure; they are becoming a dominant source of training data for the next generation of code-assistant models. Cursor's Composer is trained with continuous online reinforcement learning on real Cursor usage traces, tightening the loop between deployed agent behavior and model updates ([375, 376]). OpenAI's codex-1 (an o3 derivative) ([27]), GPT-5-Codex ([377]), and GPT-5.1-Codex-Max ([378]) are explicitly trained on long-horizon, multi-turn coding interactions that mirror the Codex harness loop, while Anthropic's internal Claude Code dogfooding contributes a similar feedback channel documented in their teams-using-Claude-Code whitepaper ([379]). At the same time, the harness itself is becoming an explicit optimization object: AutoHarness ([14]) synthesizes harness code with a smaller LLM that filters illegal actions, Agentic Harness Engineering ([281]) closes an observability-driven evolution loop over harness components, Meta-Harness ([13]) formalizes joint model–harness optimization, and Live-SWE-agent ([182]) edits its own scaffolding at runtime—together suggesting that the boundary between "the agent" and "the harness around the agent" is becoming a learnable surface in its own right.
Open Challenges for Code-Assistant Harnesses
The maturation of production harnesses surfaces several coding-specific open problems that complement the cross-domain agenda discussed in the next subsection. First, verification beyond unit tests remains largely unsolved: the oracle-adequacy crisis exposed by PatchDiff ([380]) and SWE-Bench++ ([381]), the security-correctness gap addressed by Aardvark ([382]) and Codex Security ([383]), and the organicity gap between functional and accepted patches ([358, 359]) all point to a verifier surface that current harnesses underspecify. Second, failure attribution in long-horizon agent loops is still immature: empirical studies such as "Why do multi-agent systems fail?" ([384]), the Who&When attribution dataset ([385]), AgenTracer ([386]), and AgentDebug ([387]) report best step-level attribution accuracies in the 14–53% range, suggesting that production harnesses lack the structured traces needed for principled debugging. Third, safety governance of autonomous code execution requires capability-based primitives that remain rare in practice: Aethelgard's learned capability governor ([388]), fault-tolerant transactional sandboxing ([389]), and Microsoft's Agent Governance Toolkit ([390]) represent early steps toward enforcing least privilege under concurrent agent action. Fourth, harness self-evolution at production scale—demonstrated only in narrow settings by AutoHarness, AHE, and Live-SWE-agent—raises stability and rollback questions absent from non-self-modifying harnesses. Fifth, multi-agent state synchronization on live repositories generalizes the SyncMind belief-state divergence problem ([347]) to settings where humans, autonomous agents, and CI systems concurrently mutate shared program state. Finally, trust calibration in pair programming user experience remains an under studied human factors problem, including decisions about when to interrupt, when to checkpoint, when to delegate, and when to defer, despite its centrality to whether harness driven autonomy can be safely scaled to enterprise workflows.
Code assistants are thus the clearest production instantiation of code-centric agentic systems and the most demanding testbed for the harness-engineering discipline now emerging across industry and academia.
5.1.2 GUI/OS Agents as a Program World
Graphical user interfaces and operating systems constitute, perhaps more than any other tangible application of foundation-model agents, a program world in the most literal sense: every observation an agent receives is the rendered output of executable code (HTML, CSS, layout XML, accessibility APIs, framebuffers driven by window managers), and every action it takes is a call into another piece of code (a DOM event, an adb shell command, a keystroke captured by the OS event loop, a Playwright script). For this reason, GUI/OS agents have become the canonical testbed for the central thesis that code is the unifying substrate through which perception, action, environment dynamics, and memory can be represented, executed, and verified. Below we develop this view systematically.
GUI/OS as a Partially Observable Program World
We model a GUI/OS environment as a Partially Observable Markov Decision Process $\langle \mathcal{S}, \mathcal{A}, \mathcal{O}, T, R\rangle$ in which the latent state s $\in \mathcal{S}$ is the full program state of one or more processes (a browser's full DOM and JavaScript heap, an Android emulator's Activity stack and content providers, a Linux VM's filesystem and window tree). The agent never observes s directly; it observes o $\in \mathcal{O}$, which in modern systems takes one of four code-defined forms: (i) a serialized DOM or HTML subtree as in WebArena and Mind2Web ([60, 59]); (ii) an accessibility tree (AXTree) exposed by Android's UIAutomator or by macOS/Windows accessibility APIs as in AndroidWorld and WindowsAgentArena, for example, adopted by AgentOccam ([391, 392, 393]); (iii) a screenshot annotated with bounding-box or Set-of-Mark coordinates, the representation adopted by SeeAct, WebVoyager, OSWorld, and most recent native models ([394, 395, 396, 397]); or (iv) hybrid representations that interleave pixels, accessibility metadata and HTML, as in WebArena's BrowserGym observation space and in CogAgent's dual-resolution encoder ([398, 399]). The action space $\mathcal{A}$ is likewise code: a tuple $\langle action_type, target, value\rangle$ that compiles either to a DOM/accessibility call (element.click(), $\texttt{setText(node_id, ``...'')}$) or to OS-level keyboard/mouse primitives (pyautogui.click(x, y), xdotool key). Crucially, the transition function $T$ is not learned but executed: the browser engine, the Android runtime, or the host OS deterministically produces the next observation. Agents are commonly framed as human-like computer users: they perceive the visual interface, reason over the user instruction, and execute actions through the same graphical channel available to humans. The agent's policy $\pi(a|h)$ is therefore best thought of as a program synthesizer that, conditioned on a history h, emits the next snippet of executable code; the environment is the interpreter.
Code as a Bridge Between User Interfaces and GUI Agents
Recent works treat code as an intermediate interface between high-level model reasoning and low-level UI execution ([396, 400, 401]). This interface provides two main advantages: First, it abstracts away noisy visual details, and creates a natural boundary between the model's semantic planning and the system's executable control layer. Second, it fuses the perception, action, and evaluation in to a single code-as-harness pipeline.
On the action side, this is the GUI specialization of the broader CodeAct paradigm ([402]): rather than emitting JSON tool calls, agents emit Python or JavaScript snippets that compose primitives such as click(x, y), type(text), scroll(dx, dy), $\texttt{key(``Enter'')}$, and arbitrary library calls (e.g., requests, subprocess, selenium). Cradle makes this explicit by having an LMM output executable Python that drives keyboard and mouse for any application, including AAA games, achieving generalization across previously unseen software through skill curation and self-reflection rather than task-specific APIs ([403]). WebArena, BrowserGym, and TheAgentCompany similarly expose Playwright-style code actions whose execution is the ground truth of progress ([60, 398, 404]).
On the perception side, recent native GUI models such as SeeClick, CogAgent, Ferret-UI, OS-Atlas, ShowUI, Aria-UI, UGround, UI-TARS, and GUI-Libra treat grounding as a function from pixels to executable coordinates, training large vision-language models to emit $(x, y)$ or bbox tokens that can be directly piped into an action API ([405, 399, 406, 407, 408, 409, 410, 411, 412]). By collapsing the planner→grounder→executor pipeline into a single VLA model whose output token stream is itself runnable code, these systems eliminate the brittle string-matching layer that historically separated language plans from grounded actions, as documented in SeeAct's analysis showing that grounding, rather than planning, is the dominant bottleneck on Mind2Web ([394]).
On the evaluation side, code-defined environments enable executable feedback: success is determined not by a learned reward model but by running an evaluator script over the post-action system state. WebArena's URL/string assertions, OSWorld's per-task Python checkers operating over OS file I/O and application state, AndroidWorld's adb-based state inspection, and Spider2-V's enterprise-tool checks all share the same pattern, an evaluator is itself a piece of code that interrogates the program world after the agent has finished ([60, 396, 391, 413]). This closes the loop: code generates the environment, code is the agent's action, and code adjudicates the result.
Memory as Persistent Programmatic State
For code-grounded GUI agents, memory is best understood as a persistent programmatic state layer: structured artifacts that outlive the current UI state and can be retrieved, composed, or executed in later interactions. Recent works explore different line of memory: (i) Working memory of UI state compresses the current observation to a task-relevant abstraction: Synapse's state-abstraction module filters HTML to a few task-relevant elements, allowing trajectory-as-exemplar prompting and an exemplar memory that retrieves prior trajectories by similarity ([414]). (ii) Long-term cross-app/session memory is implemented as structured documents and skill libraries: AppAgent compiles an exploration document per application that records the learned function of each UI element, which is then consulted on subsequent tasks ([415]); Mobile-Agent-v2 introduces a dedicated planning agent whose memory tracks long-horizon progress across sub-tasks ([416]); Cradle maintains an explicit skill-curation module that promotes successful code snippets to a reusable library ([403]). Whereas these designs are tightly coupled to the host application's UI ontology, PlugMem proposes a task-agnostic plugin memory module that distils raw interaction traces into a compact knowledge-centric memory graph of propositional and prescriptive knowledge, transferring unchanged from web agents to long-horizon dialogue and multi-hop retrieval ([417]). (iii) Self-evolving GUI agents (already cited in this survey as UI-Voyager ([418])) and AutoGLM extend this idea with online curriculum reinforcement learning that continuously grows a library of grounded behaviors, while OS-Genesis and UI-TARS use reflective trace collection on hundreds of virtual machines as a form of distilled memory ([419, 420, 411]). In all three regimes the memory is itself a code artifact, for example, a JSON document, a Python skill module, or a vector index of code-formatted trajectories, directly executable or directly composable into the agent's next action.
UI Simulators and Sandboxes as Executable Dynamics
The simulator stack for GUI/OS agents is perhaps the clearest demonstration that environment dynamics in this domain is code. Early benchmarks such as MiniWoB++ defined each task as a self-contained HTML/JavaScript page with a programmatic reward function ([421]); WebShop scaled this to 1.18M real Amazon products inside a self-hosted shopping site ([422]). Mind2Web cached real-world traces for offline evaluation, while WebArena and VisualWebArena fork four full-stack open-source sites into Docker containers with deterministic resets and per-task functional checkers ([59, 60, 423]). OSWorld pushes this further to 369 real Ubuntu/Windows/macOS tasks in disposable VMs whose initial state, golden actions, and Python evaluation scripts are all version-controlled artifacts ([396]); WindowsAgentArena specializes the same architecture for Windows 11 with Azure-parallel execution ([392]); and Spider2-V extends OSWorld to professional data-engineering pipelines spanning BigQuery, dbt, and Airbyte ([413]). On mobile, AndroidWorld provides 116 programmatic tasks dynamically parameterized from natural-language templates with reward signals derived from device system state, while AndroidArena and AndroidLab supply complementary cross-app evaluations ([391, 424, 401]). BrowserGym and WorkArena unify many of these under a common Gym-style API and add 23, 150 enterprise ServiceNow task instances ([398]), while AgentBench's OS and web tracks and the OpenHands-driven TheAgentCompany benchmark situate GUI control inside broader knowledge-work simulations ([425, 404]). Most recently, Code2World makes the program-world stance explicit at the model level by training a vision-language coder that predicts the next GUI state as renderable HTML, turning the world model itself into an executable artifact and using rendered outcomes as reinforcement signals ([426]). Together, these sandboxes embody the survey's claim that environment dynamics in agentic systems are increasingly authored as code: they are forkable, diffable, version-controlled, and reproducible in ways that no learned simulator can match.
From Simulation to Production: Executable Feedback Loops
The same code-as-harness interface that makes simulators tractable has enabled an unusually rapid jump to production deployment, because the agent's input/output contract: screenshots in, code (or coordinate-typed function calls) out, is identical in both settings. Anthropic's Claude Computer Use exposes a public-beta API in which the model takes screenshots of a sandboxed desktop and emits keyboard/mouse actions as structured tool calls ([427]). OpenAI's Operator and the underlying Computer-Using Agent (CUA) followed, combining GPT-4o's vision with reinforcement-learned reasoning over a unified click/scroll/type action space ([428]). Google DeepMind's Project Mariner ships a Gemini-powered Chrome extension that observes the rendered DOM, plans, and executes browser actions on behalf of the user, and is being integrated into Search's AI Mode and the Gemini app ([429]). ByteDance's UI-TARS-1.5/2 and the associated UI-TARS-desktop product, Zhipu's AutoGLM (web browser plug-in and Android app), and Tencent's AppAgent lineage demonstrate that the same architecture transfers from the lab to consumer devices ([411, 419, 415]). AutoWebGLM, the production sibling of CogAgent, exemplifies the route from arXiv preprint to deployed browser agent through an "intermediate interface" that decouples planning from grounding ([430]). Earlier industrial efforts, like Adept's ACT-1/ACT-2 and Rabbit's Large Action Model, anticipated this trajectory but predated the executable-feedback infrastructure that has since made the loop reliable enough for deployment.
Looking forward, the literature converges on three frontiers, all expressed in code-as-harness terms. First, native end-to-end agents that internalize perception, planning, grounding, and action into a single VLA model are displacing the modular planner+grounder pipeline. Second, executable world models promise to give agents human-like foresight by predicting the next UI state as renderable code rather than as pixels or unstructured text. Third, embodied, instruction-following GUI agents treat the entire device (e.g., terminal, browser, native apps, and peripherals) as a unified program world. The common thread is that code is the lingua franca: it defines observations, actions, evaluation, memory, and increasingly the world model itself.
5.1.3 Autonomous Embodied Agents
Embodied agent operates in the physical world or its simulation, perceiving the environment through structured outputs from vision and force sensors, and acting through motor commands subject to physical constraints such as reachability, collision, and dynamics.
Code as the Control Boundary that Connecting Agents and the World
Unlike purely reasoning agents, embodied agents operate under physical constraints that may fail silently when violated: a robot may attempt to grasp an object outside its workspace without producing any explicit failure signal ([431]). This shifts the burden of correctness from runtime to action-generation time, where the agent's output must already be expressive enough to compose verified operation intents before reaching the actuator. Code naturally satisfies the requirements by serving both as the grounding interface and as the safety boundary. As a grounding interface, it translates high-level intent from LLMs into embodiment-respecting commands through primitive skill calls ([9, 110, 111, 112]), synthesized Python control policies ([10, 33, 124, 117, 118]), and structured behavior-tree programs ([34]). As a safety boundary, it constrains admissible actions at execution time ([119, 116, 226]).
Layered Harness for Grounded and Verifiable Embodied Actions
Embodied agents require a layered harness that separates semantic reasoning from executable, physically grounded, and human-governed control ([432]). Foundation models handle the semantic layer of embodied agency: interpreting goals, decomposing tasks, inferring affordances, selecting skills, proposing actions, and replanning under changing observations ([433, 32]). Code and classical robotics software define the admissibility boundary by exposing typed robot APIs, parameterizing primitive skills, calling geometric libraries, invoking motion planners, and supporting inspection, replay, versioning, and verification ([124, 10, 434, 435]). Perception models and state estimators convert raw sensor streams into structured state that planners and controllers can use ([436, 437]). Physical systems and low-level controllers then enforce embodiment-specific constraints such as kinematics, dynamics, collision avoidance, workspace limits, contact forces, timing, and stability.
Reusable Skills as Embodied Memory
While code grounds a single action in physical feasibility, embodied agents operating over long horizons must also accumulate experience across tasks. In this regime, code takes on a second role: the same executable form that makes an action verifiable also makes it storable and reusable. Memory therefore naturally takes the form of a skill library, a collection of code artifacts that record past behavior and can be called as actions in future tasks. This dual identity distinguishes embodied memory from other memory abstractions in § 3.2: a skill is not merely something the agent reads, but something the agent re-executes. Voyager pioneered this paradigm with an growing skill library for open-ended tasks in Minecraft ([32]), and other work extends the same idea along several directions: tabletop manipulation ([114]), human correction ([121]), vision-grounded replanning ([122]), and continual learning ([123]). The principle has even crossed into the GUI domain ([418]). Across these systems, the challenge has shifted from generating skills to governing the library: handling forgetting, abstraction, and grounding alignment.
Coordinated and Auditable Real-World Deployment
Moving from simulation to real-world deployment introduces challenges that go beyond a single agent: multiple robots must coordinate, behaviors must be auditable, and skills must transfer across embodiments. Code naturally extends to address all three. For coordination, it provides the substrate for multi-robot policy synthesis ([118]) and robot-agnostic cooperative architectures ([120]). For auditability, it supports governance mechanisms for industrial safety ([119, 235]) and verified closed-loop control ([115]). For cross-embodiment transfer, the same code-based skill abstraction enables combinatorial reuse on dual-arm systems ([111]). Open challenges remain in reducing the sim-to-real gap, scaling multi-agent coordination, and maintaining safety as environments evolve.
5.1.4 Agents for Scientific Discovery as Program Worlds
Scientific research is among the most natural testbeds for code as an agent harness: the scientific method is itself a closed loop of hypothesize → design → execute → observe → revise, in which each transition is mediated by an artifact that is, increasingly, a program. Modern science can already be digital end-to-end, for example, hypotheses are encoded as differential equations or generative models, experimental protocols are written as XDL or Opentrons scripts, instruments are driven through Python APIs, and analyses live in Jupyter notebooks whose cells form a verifiable trace of reasoning. This makes scientific discovery an ideal domain to instantiate the three-fold role of code: code as the medium of reasoning (e.g., symbolic derivations, formal proofs, hypothesis-as-program), code as the substrate of acting (e.g., calls to wet-lab robots, simulators, statistical pipelines), and code as the executable environment itself (e.g., molecular-dynamics engines, autonomous laboratories, virtual research teams). Recent systems, like AI Scientist v1/v2, ([63, 438]) AI co-scientist ([439]), Virtual Lab ([440]) and Biomni ([64]), make this code-as-harness framing concrete by elevating the entire research workflow to a single, executable program graph.
Scientific Discovery as a Partially Observable Program World
We treat a research project as a partially observable program world $\langle \mathcal{S}, \mathcal{A}, T, \mathcal{O}, R\rangle$. The state $\mathcal{S}$ is a structured program memory containing the current best hypotheses, accumulated literature, code artifacts, intermediate datasets, and experimental observations. Actions $\mathcal{A}$ are typed code expressions: literature-search queries, calls to symbolic or numerical solvers, generation of new experimental scripts, modifications to a training pipeline, or robot-control commands. The transition function $T$ is realized by a Python interpreter, a Lean kernel, a quantum-chemistry package, a robotic synthesizer, or, in fully end-to-end systems such as the AI Scientist v2 ([438]), by a tree-search experiment manager that orchestrates all of these. Observations $\mathcal{O}$ correspond to execution outputs (numerical results, plots, error messages, peer-review scores), and the latent reward $R$ encodes desiderata such as novelty, reproducibility, and statistical significance. Crucially, the policy of a scientific agent is itself a program: ChemCrow ([61]) composes 18 expert-designed chemistry tools through structured tool calls; Coscientist ([62]) interleaves Python execution, web search, and robotic-API actions; and AlphaProof ([441]) expresses each "reasoning step" as a Lean tactic that the proof assistant verifies before transitioning the state. This view recasts traditionally informal categories (e.g., hypothesis, protocol, claim) as concrete program objects whose execution traces can be logged, replayed, and audited.
Unifying Ideation, Experimentation, Analysis, and Communication
Traditional accounts of science separate ideation, experiment design, data analysis, and dissemination into distinct workflows with distinct tools. Code-centric agents collapse these into a single executable pipeline. ResearchAgent ([442]) and SciAgents-style systems iteratively refine hypotheses by traversing entity graphs over the literature, with each candidate idea materialized as a structured object that can be passed to downstream planners. BioPlanner ([443]) formalizes wet-lab protocols as pseudocode whose admissible functions can be type-checked, retrieved, and composed, providing the same compositional substrate for biology that XDL provides for chemistry ([444]). Agent Laboratory ([445]) and its preprint-sharing extension AgentRxiv ([446]) explicitly factor research into three program-level phases: literature review, experimentation, report writing, orchestrated by specialized PhD, postdoc, and engineer agents that exchange Python files, LaTeX, and arXiv records. The AI Scientist ([63, 438]) goes further by representing an entire ML paper as a single executable trace: the system writes the experimental code with a coding assistant, executes it, reads the figures with a vision-language model, and emits a LaTeX manuscript that includes the very plots it generated. In all of these systems, what used to be a heterogeneous pipeline of natural-language artifacts becomes a homogeneous flow of typed code objects, enabling end-to-end optimization and automatic verification at every stage ([447, 402]).
Memory as Persistent Program State
Long-horizon research depends on memory: prior experiments, failed attempts, citation graphs, and tacit lab know-how. Code-centric agents externalize this memory as persistent program state. At the working-memory level, agents maintain executable scratchpads, typically a Jupyter kernel or a CodeAct-style Python REPL ([448]), whose live variables, dataframes, and figures form the immediate context for reasoning. El Agente Q ([449]) and Biomni ([64]) exemplify hierarchical memory: short-lived tool outputs are cached in an episodic buffer, while structured artifacts (plasmid maps, optimized geometries, fitted models) are written to durable file stores that subsequent agent steps can re-load. At the long-term level, PaperQA / PaperQA2 ([450]) and Google's AI co-scientist ([439]) treat the scientific literature itself as an indexed knowledge base, accessed through tool calls that retrieve passages, expand citations, and detect contradictions; this enables hypothesis evaluation against millions of prior results without inflating the prompt. AgentRxiv ([446]) takes the idea one step further by giving autonomous research agents a shared preprint server: hypotheses, code, and findings produced by one run are uploaded as durable program artifacts that future runs can build on, instantiating cumulative scientific progress as a globally shared, version-controlled program state. Biomni's action-discovery agent ([64]) mines tens of thousands of bioRxiv papers to populate a unified tool registry across 25 biomedical subfields, so that "remembering how to clone a plasmid" becomes the concrete act of importing a verified, code-level protocol from persistent storage.
Simulators as Executable Dynamics
Scientific agents rely on simulators of physical and computational reality, and the code-as-harness view treats these uniformly as executable transition models. In computational chemistry, El Agente Q ([449]) wraps DFT engines, geometry optimizers, and thermochemistry tools as callable functions that the LLM invokes to roll out alternative reaction trajectories; on six university-level benchmarks it exceeds 87% task success while emitting a transparent action-trace log of every simulation. ChemCrow ([61]) similarly integrates RDKit, retrosynthesis engines, and reaction predictors so that an agent can "execute" a candidate synthesis virtually before committing to a wet-lab run. In structural and systems biology, the Virtual Lab ([440]) composes ESM, AlphaFold-Multimer, and Rosetta into a Python pipeline through which an LLM Principal-Investigator agent and its subordinate scientist agents jointly designed 92 SARS-CoV-2 nanobodies, two of which showed validated binding to JN.1 and KP.3 variants, all in a few days of simulated meetings. For algorithmic and mathematical science, AlphaProof ([441]) uses the Lean theorem prover as the executable environment, formally verifying every candidate proof step before reinforcing the language model, and AlphaEvolve ([451]) orchestrates an evolutionary loop in which Gemini-generated code edits are executed and scored by automated evaluators, yielding new matrix-multiplication algorithms and mathematical constructions. In each case the simulator is the world: program states evolve only through verified executions, eliminating much of the hallucination that plagues purely textual scientific reasoning ([447]).
From Simulation to Production: Self-Driving Labs as Executable Feedback Loops
The decisive test of a scientific agent is whether its closed loop crosses the boundary into physical reality. Self-driving laboratories (SDLs) are the production systems of this domain: they expose real instruments, like liquid handlers, XRD scanners, spectrometers, robotic arms, through code APIs, and accept agent-generated programs as their primary input. Berkeley's A-Lab ([452]) combines machine-learned synthesis recipes with autonomous robotics to synthesize 41 novel inorganic compounds from a target list of 58 in 17 days of continuous operation, while early thin-film SDLs ([453]) established that Bayesian optimization loops can be wrapped as Python services and run unattended. Coscientist ([62]) crossed this threshold for organic chemistry by autonomously planning, executing, and analyzing palladium-catalyzed Suzuki and Sonogashira couplings on the Emerald Cloud Lab and an in-house liquid-handling platform from a single English prompt. The Cronin group's Chemputer and its XDL chemical-description language ([444]) formalize this contract: any synthesis published in the literature can be parsed into hardware-independent XDL code that compiles, like LLVM IR for chemistry, onto any compliant robotic platform. In biology, Biomni ([64]) generates end-to-end molecular-cloning protocols that human reviewers rated comparable to a senior Stanford postdoc, while Google's AI co-scientist's drug-repurposing and antimicrobial-resistance hypotheses were experimentally validated in collaborator wet labs at Imperial College and Stanford ([439]). MatPilot ([454]) explicitly couples a hypothesis-generation cognition module to an autonomous experimental-verification module driving physical synthesis robots, instantiating a complete generate–execute–feedback loop for materials. These systems make the survey's central thesis tangible: in a self-driving lab, the agent's policy is the code, the lab is the runtime, and the publication record is the log.
Toward Agentic and Instruction-Following Science
A final dimension of code-as-harness scientific agents is controllability: the ability to steer them with high-level scientific intent while preserving rigorous execution semantics. Benchmarks have rapidly emerged to measure this capability. MLAgentBench ([455]) evaluates language agents on 13 open-ended ML research tasks, requiring agents to read code, run experiments, and improve metrics. MLE-bench ([456]) scales this to 75 Kaggle ML-engineering competitions; the best-performing scaffold at release (OpenAI o1-preview with the Weco AIDE tree-search agent ([457])) reaches Kaggle bronze-medal level on 16.9% of competitions, and AIDE achieves roughly three times the medal rate of the next agent. ScienceAgentBench ([458]) compiles 102 tasks adapted from peer-reviewed publications across bioinformatics, computational chemistry, GIS, and cognitive neuroscience, unifying every target output as a self-contained Python program, which is an explicit endorsement of code as the universal interface to data-driven science. DiscoveryBench ([459]) complements this with 264 multi-step hypothesis-search tasks across six domains, exposing failure modes of current agents (best system score $\sim$ 25%). On the controllability side, instruction-following progress is visible in systems such as the AI co-scientist ([439]), where scientists steer the multi-agent debate via natural-language research goals and constraints, in Biomni ([64]), whose graphical interface accepts natural-language queries and returns auditable code execution, and in the Virtual Lab ([440]), where a human PI specifies high-level objectives and the AI PI dynamically configures a team of expertise-specific agents. AlphaEvolve ([451]) and AlphaProof ([441]) represent the goal-conditioned extreme: the agent is given only an objective function or a theorem statement, and the closed code-execution loop searches for any program that satisfies the verifier. Across these systems, instruction-following is realized by translating user goals into typed program specifications that the runtime can rigorously enforce.
Taken together, recent work on agents for scientific discovery exemplifies the survey's central shift: from static prediction toward interactive, stateful, and executable decision making. Hypotheses cease to be free-floating sentences and become parameterized programs; experiments cease to be lab notebooks and become version-controlled code; analyses cease to be one-off scripts and become reproducible artifacts that downstream agents can re-execute; and laboratories cease to be opaque physical sites and become production runtimes addressable through documented APIs. The result is a closed generate–execute–feedback loop in which a single substrate, code, carries scientific reasoning, scientific action, and the scientific environment itself, providing a unified foundation on which agents like the AI Scientist ([63, 438]), AI co-scientist ([439]), Virtual Lab ([440]), Biomni ([64]), Coscientist ([62]), and AlphaEvolve ([451]) can be compared, composed, and progressively improved. As benchmarks such as MLAgentBench ([455]), MLE-bench ([456]), ScienceAgentBench ([458]), and DiscoveryBench ([459]) make precise, the open challenge is not whether code-as-harness agents can imitate isolated scientific tasks, but whether they can be trusted to drive the full loop autonomously, which is a challenge for which the program-world abstraction provides both the right ontology and the right experimental harness.
5.1.5 Agent Personalization
Personalization and recommender systems offer a distinctive setting for code-centric agentic systems. Unlike coding, GUI control, or scientific discovery, the environment here is not only a software system but also a human user whose intent, satisfaction, and long-term goals are only partially observed. As recommendation moves from static ranking toward interactive agents, the central challenge becomes how to maintain, update, and govern a user model through repeated interaction. Code is useful in this setting not simply because it executes recommendation policies, but because it provides an inspectable substrate for preference representation, feedback processing, constraint enforcement, and policy adaptation.
From Static Recommendation to Interactive Personalization
Traditional recommender systems usually treat personalization as a prediction problem: given historical interactions, the system scores candidate items and returns a ranked list ([460, 461]). LLM-based recommenders broaden this view by enabling conversational preference elicitation, explanation, and multi-step refinement. Early prompting-based approaches query an LLM with user history and ask it to produce recommendations directly ([462, 463]). More agentic systems instead decompose recommendation into candidate retrieval, filtering, re-ranking, explanation, and feedback collection. The emerging agentic recommendation ([464, 465, 466]) instantiate this direction by using LLMs to coordinate recommendation sub-tasks through tool calls and structured intermediate states. Agent4Rec ([467]) and iAgent [468] further simulates recommendation sessions with synthetic users, enabling offline evaluation of interactive policies. These systems mark a shift from recommendation as one-shot scoring to an adaptive process, where each interaction may revise the system's belief about the user.
Preference State as an Editable Artifact
A key difference between personalization agents and other agentic systems is that the most important state is not fully observable. User preferences are latent, contextual, and often unstable. A user may click an item for convenience rather than genuine interest, skip an item because of timing rather than dislike, or change goals across sessions. Therefore, personalization agents need explicit preference states that can absorb noisy behavioral signals while remaining interpretable and correctable. Code-centric representations provide a practical way to structure this state. Short-term interests can be stored as recent interaction logs, contextual summaries, or session-level preference vectors. Long-term preferences can be maintained as structured memory objects that record stable interests, constraints, and user-provided corrections. AMem ([469]) and related memory-based systems ([199, 470]) show how long-term user information can be maintained as editable documents or structured records. MemRec ([471]) further studies how collaborative signals can support memory management for personalized recommendation. Compared with opaque embedding-only memory, structured preference memory is easier to inspect, revise, and reuse. A user can correct a stored preference in natural language, and the system can update the corresponding state before generating future recommendations.
Feedback as Policy Adaptation
Personalization agents are driven by feedback, but the feedback is often sparse, delayed, and ambiguous. Clicks, dwell time, ratings, purchases, skips, and conversational corrections all provide partial evidence about user satisfaction. Production recommender systems already rely on code-defined feedback pipelines that log interactions, compute metrics, run A/B tests, and trigger model or policy updates. In an agentic setting, these pipelines become part of the personalization harness: they determine what signals are recorded, how they are interpreted, and when the agent should adapt. User simulators ([472, 473, 464]) provide an offline way to study such adaptation. They allow recommendation policies to be tested under controlled behavioral assumptions before real deployment. Recent LLM-based simulators extend this idea by generating richer synthetic user profiles and interaction traces. However, the central difficulty remains that simulated feedback may not match real user behavior, especially when recommendations themselves influence future preferences.
Controllable and Instruction-Following Personalization
A major opportunity for agentic personalization is to move beyond optimizing implicit engagement signals toward following explicit user instructions. Users may want recommendations that satisfy constraints such as avoiding certain sources, limiting repeated categories, balancing exploration and familiarity, or prioritizing long-term goals over short-term engagement. These requirements are hard to express through a single learned score but can be represented as structured constraints, filters, or reward functions. LLM-based conversational recommenders can elicit such preferences in natural language and translate them into policy specifications ([462]). Constraint-based recommendation further shows how fairness, diversity, and exposure requirements can be enforced at serving time rather than hidden inside model parameters ([474]). Explanation-based systems provide another path toward controllability: if a system explains why an item was recommended, the user can correct the rationale, and the corrected explanation can update the preference state. This makes personalization more interactive and auditable, since the user can shape not only outputs but also the logic behind future outputs.
Open Challenges for Personalization Harnesses
Personalization raises several challenges that are sharper than in other domains. First, preference grounding remains unresolved. Unlike code assistants, which can rely on tests, or GUI agents, which can check interface states, personalization agents lack a reliable oracle for true user satisfaction. Proxy metrics such as clicks and engagement can be misleading or even harmful when optimized too aggressively. Second, preference memory introduces privacy and governance risks. Long-term user models may contain sensitive behavioral patterns, so the harness must specify what is stored, where it is stored, how it is updated, and how users can inspect or delete it. Third, personalization is inherently multi-stakeholder. A platform may optimize engagement, a creator may seek exposure, and a user may value welfare or autonomy. Reducing these objectives to a single reward function can obscure conflicts of interest.
5.2 Open Problems
Code-as-harness systems shift the central challenge of agentic AI from isolated model generation to the reliability of the complete execution loop. Once agents act through tools, memory, code execution, shared state, and environment feedback, failures may arise from weak verifiers, stale context, unsafe tool access, inconsistent multi-agent state, insufficient multimodal grounding, or poorly governed self-improvement. These issues cannot be diagnosed by final task success alone. This section outlines the key open problems that emerge when the harness is treated as a first-class system component, with the goal of building agentic systems that are executable, inspectable, stateful, verifiable, and governed in long-horizon real-world environments.
5.2.1 Harness-Level Evaluation and Oracle Adequacy
Evaluation becomes difficult once an LLM is embedded in a code-agent harness. In this setting, performance is no longer determined by the base model alone, but also by the surrounding runtime: which repository files are retrieved, which tools are exposed, how many retries are allowed, whether the agent can execute tests, how failures are summarized, and what verifier decides success. However, most existing evaluations measure end-task success: whether a generated solution passes tests, solves an issue, or completes an interactive task. Such metrics conflate the capabilities of the base model, the quality of the harness, the reliability of tools, the informativeness of feedback, and the difficulty of the environment. This is especially visible in repository-level software engineering, where an agent may pass visible tests while exploiting weak or incomplete test suites; in GUI/OS tasks, where a scripted checker may miss unsafe or undesirable intermediate actions; and in scientific or embodied settings, where successful execution in a simulator may not imply that the result is scientifically valid or physically safe ([216, 365, 364, 366, 133, 458]).
A key open problem is therefore to define harness-level metrics that evaluate the operational substrate itself. These metrics should complement final task accuracy with measurements of execution reliability, feedback quality, context sustainability, safety, coordination, and reproducibility. Useful dimensions include: (i) trajectory efficiency, such as number of tool calls, tokens, edits, executions, and wall-clock time; (ii) verification strength, such as test coverage, oracle diversity, and rate of false acceptance; (iii) recovery ability, such as whether the agent can diagnose and repair failures after invalid actions; (iv) state consistency, such as whether memory, repository state, execution traces, and agent beliefs remain synchronized; (v) safety compliance, such as whether permissions, sandboxes, and human-approval gates are respected; and (vi) replayability, such as whether the full trajectory can be reconstructed and audited from logs and artifacts ([475]). A central bottleneck in this agenda is oracle adequacy: whether the evaluator captures the intended task rather than only a narrow executable proxy. The open problem is not merely to build harder benchmarks, but to evaluate the code-agent harness as an executable runtime system.
5.2.2 Semantic Verification Beyond Executable Feedback
Oracle adequacy becomes especially challenging because execution feedback, while central to code-centric agents, can create a false sense of correctness: code can be run, traces can be inspected, tests can be checked, and failures can be fed back into revision. However, execution is only as reliable as the oracle attached to it. Unit tests may be incomplete, static analyzers may over-approximate, GUI checkers may miss unacceptable intermediate actions, scientific scripts may encode invalid assumptions, and robot simulators may hide physical risks. As a result, a harness can become overconfident precisely because it has executable feedback: the agent sees a green test, but the green test is not the full specification.
The central missing abstraction is a verification stack with explicit scope. Instead of treating pass/fail as a single terminal signal, future harnesses should compose multiple verification artifacts: unit tests, integration tests, property-based tests, fuzzers, static analyzers, type checkers, security scanners, runtime monitors, coverage reports, formal specifications, model-based critiques, and human review. Each artifact should declare what it verifies, what it cannot verify, and what confidence it provides. This is especially important for self-repair and self-evolving harnesses: if the verifier is weak, the agent will learn to optimize against the wrong signal. A useful direction is to make every accepted action carry an evidence bundle containing the checks run, the assumptions preserved, the untested regions, and the remaining risks. In this view, verification is not a final gate; it is an evolving, inspectable contract between the agent, the harness, and the environment.
Other promising directions include feedback calibration, independent verification, metamorphic testing, differential testing, property-based test generation, execution-trace summarization, and uncertainty-aware critics ([476, 477, 478]). Reliable feedback should also be routed differently depending on its type: compiler errors may trigger local syntax repair, test failures may trigger behavioral diagnosis, coverage gaps may trigger test generation, and inconsistent reviewer comments may trigger arbitration. The broader goal is to build feedback loops that are not merely reactive, but epistemically aware: the harness should know when a signal is strong enough to act on, when it is weak, and when additional evidence is required.
5.2.3 Self-Evolving Harnesses without Regression
Most current harnesses are manually designed: developers choose the planning loop, memory format, tool set, permission rules, debugging procedure, and agent topology. However, as tasks become longer and more diverse, fixed harnesses may be suboptimal. A harness that works well for competitive programming may fail for repository repair; a harness tuned for GUI navigation may be inefficient for scientific workflows; and a multi-agent topology that succeeds on one task distribution may waste computation on another. This suggests that future systems should treat the harness itself as a programmable component that can adapt to new environments, rather than a fixed wrapper around the base model.
Automatic harness evolution is already underway. AutoHarness synthesizes code harnesses that constrain invalid actions ([14]), MetaHarness searches over harness code ([13]), Agentic Harness Engineering evolves harness components from observability signals ([281]), and related methods optimize prompts, contexts, and workflows through reflection, search, or execution feedback ([18, 312, 17]). These systems point toward a broader paradigm in which an overarching optimization process analyzes runtime feedback, such as computational cost, decision paths, tool-use traces, memory pressure, and specific failure cases, and proposes modifications to the harness itself. Such modifications may reorganize communication among sub-agents, adjust memory allocation, revise retrieval or verification policies, or change how execution feedback is routed through the system. Therefore, "automated harness evolution" is not itself the open problem. The harder problem is whether a harness can improve itself without overfitting, weakening safety, increasing cost, hiding failures, or regressing on rare but important tasks.
The central insight is that a harness mutation should be treated like a code change to a safety-critical runtime. Every proposed edit should carry a change contract: which component is modified, which failure mode it targets, what improvement it predicts, which invariants it must preserve, which evaluation can falsify it, and how it can be rolled back. This is especially important because harness changes affect the future distribution of agent behavior. A new retrieval policy may improve benchmark accuracy while increasing hallucinated evidence; a new tool schema may reduce token cost while weakening permission boundaries; a new verifier may improve pass rate by accepting underspecified solutions. Future work should develop evidence-carrying harness evolution, held-out regression suites, safety invariants, canary deployment, rollback semantics, and causal evidence for why a harness edit helped. The goal is not a harness that changes often, but one that changes only when it can justify the change. A practical research agenda includes: defining mutation operators for harness components; building telemetry standards; evaluating evolved harnesses across diverse tasks; enforcing safety invariants during evolution; and separating improvements in the harness from improvements in the base model.
5.2.4 Transactional Shared Program State and Semantic Conflict Resolution
Scaling from single agents to multi-agent systems turns the codebase into a shared harness substrate. Planners, coders, testers, reviewers, security agents, and humans may all read and modify overlapping artifacts. Prior sections show that many systems still rely on sequential handoff, shared logs, or file-only state, while newer systems introduce blackboards, repository memories, execution feedback, and explicit belief-state synchronization ([330, 55, 50, 250, 347]). The open problem is that synchronization alone does not provide transactional semantics or assumption-level consistency: these mechanisms often synchronize artifacts but not assumptions. One agent may plan from an old repository snapshot, another may test a newer patch, a third may remember an obsolete invariant, and a human reviewer may introduce a new constraint that is not propagated to the rest of the system.
The missing abstraction is transactional shared program state. Agents should not merely append messages to a common log; each action should declare its read set, write set, assumptions, version dependencies, verifier obligations, and conflict policy. Conflicts should be detected not only at the level of file diffs, but also at the level of plans, tests, retrieved evidence, permissions, memory entries, and latent user requirements. Future harnesses need conflict-resolution mechanisms that are semantic rather than purely textual, including semantic merge, rollback, dependency-aware locking, belief-state reconciliation, conflict explanation, and re-verification after merge. Classical version control, databases, CRDTs, and build systems provide useful analogies, but agentic systems add conflicts that conventional tools do not see: incompatible plans, stale memories, duplicated subtasks, inconsistent tool authority, and divergent interpretations of the user's goal. A key research challenge is to determine when a conflict can be resolved automatically and when it requires external judgment. Such mechanisms also require metrics beyond merge correctness, including merge success, semantic regression rate, rollback frequency, conflict recurrence, and the cost of human intervention.
5.2.5 Human-in-the-Loop Safety and Accountability as Harness State
As code-as-agent-harness systems are used in increasingly consequential settings, safety cannot be delegated to the base model or encoded only as a natural-language instruction. In critical domains such as software deployment, cybersecurity, finance, healthcare, scientific experimentation, enterprise automation, and embodied control, agent actions may affect production systems, private data, external users, physical devices, or institutional compliance. A harness therefore needs to function not only as a context manager or tool executor, but also as a safety governor between model intent and real-world consequence. It should classify proposed actions by risk, enforce permission tiers, deny actions that violate hard constraints, and require human approval for irreversible or externally consequential transitions. For example, when an agent requests credentials, modifies security-critical code, accesses user data, deploys a service, issues financial or medical recommendations, or controls physical equipment, the harness should be able to override the base model and suspend autonomy until a human decision is made ([52, 263, 119]).
Future harnesses need explicit governance mechanisms that mediate between model intent and environmental action. A useful design pattern is a multi-tier permission model. At the lowest tier, agents may read files, inspect logs, and run static analysis. At higher tiers, they may edit local files, execute sandboxed code, access the network, call external APIs, modify shared repositories, or affect production systems. Each tier should specify its allowed actions, constraints, audit logs, rollback mechanisms, and human-in-the-loop gates for high-risk operations. Such governance must also be context-sensitive. The same command may be safe in a disposable sandbox but unsafe in a production repository, and the same network request may be benign during documentation retrieval but risky when it transmits local state. Therefore, permissions should depend not only on tool identity, but also on arguments, environment state, data sensitivity, and expected side effects. Open problems include policy specification, side-effect prediction, sandbox escape prevention, secret handling, secure tool schemas, reversible execution, and measuring the tradeoff between autonomy and safety.
This safety role also changes how human feedback should be represented. Human-in-the-loop control should not appear only as an occasional prompt interruption; it should become durable harness state. Each approval, rejection, policy exception, or reviewer correction should update the harness's permission rules, escalation policy, verification criteria, and future memory retrieval. Likewise, high-stakes approvals should be auditable state transitions: what action was proposed, what evidence was shown, what risks were surfaced, who approved or rejected it, and what responsibility boundary changed afterward. The open problem is to design harnesses that can decide when autonomy is appropriate and when human judgment is mandatory. In this view, reliable code-as-agent-harness systems require not only executable code and verifiable feedback, but also executable accountability: a safety layer that filters, vetoes, escalates, and records agent actions before they reach the real world.
5.2.6 Multimodal Code-Harness Systems
Most code-agent harnesses are still designed around textual state: prompts, files, logs, tool outputs, tests, and execution traces. However, many emerging agentic systems operate in environments where the critical state is multimodal. GUI agents observe screenshots, accessibility trees, and rendered interface states; embodied agents rely on egocentric images, depth, force, tactile signals, object poses, and simulator or robot states; scientific agents inspect plots, microscope images, molecular structures, and experimental readouts. In these settings, the harness can no longer treat perception as a passive input to the model. It must manage multimodal observations as persistent, queryable, and verifiable state.
A central challenge is multimodal context compression. Visual observations are large, redundant, and often only partially relevant to the task. A GUI screenshot may contain hundreds of elements, while only one button matters; an embodied trajectory may contain thousands of frames, while only a few reveal task-critical object relations, contact events, or failure causes. Future harnesses need compression mechanisms that preserve task-relevant visual evidence rather than merely reduce token cost. This suggests a multi-level memory design: raw images or frames are stored as immutable evidence; object-, region-, element-, and pose-level annotations provide structured intermediate state; and compact textual or symbolic summaries expose only the information needed for skill retrieval and planning. The open problem is to decide what multimodal information should be retained, abstracted, forgotten, or promoted into long-term memory, especially when later failures reveal that an earlier visual or physical detail was important.
Visual grounding introduces a second challenge: aligning observations with actions. In text-centric harnesses, an action can often be checked against a file, command, or test result. In visual environments, the agent must map language goals to image regions, interface elements, objects, coordinates, poses, and executable actions. A GUI agent must know that a planned click corresponds to the correct rendered button; an embodied agent must know that a grasp command targets the intended object under the current camera view and physical configuration. This requires harness-level grounding contracts that connect perception, action, and verification. Each action should carry not only a natural-language rationale, but also a grounded reference to the evidence it depends on, such as a bounding box, object identifier, UI element, frame index, region feature, object position, or orientation. After execution, the harness should verify whether the intended grounded state changed as expected, rather than relying only on the model's self-report.
Reliable feedback is also harder in multimodal settings. A textual error message or unit-test failure provides an explicit signal, but visual and physical feedback is often implicit, delayed, or ambiguous. A button may look clicked without triggering the right state transition; a robot may appear to hold an object while the grasp is unstable; a chart may seem to support a conclusion while its axis scale changes the interpretation. Future harnesses therefore need multimodal verification stacks that combine visual state checks, object tracking, OCR or UI-tree inspection, simulator state, physical sensors, tactile feedback, and task-specific validators. More importantly, each feedback signal should expose its scope and uncertainty. For example, a bounding-box detector verifies localization but not task completion; a simulator state verifies object position but not physical robustness; an OCR result verifies visible text but not semantic correctness. This also calls for tighter integration between world modeling and action modeling: the harness should predict how the visual or physical world is expected to change after an action, compare that prediction with the observed outcome, and use the mismatch to diagnose failures. In embodied and robotic settings, such prediction-error signals are especially important for recovery, since failures may arise from occlusion, slippage, collision, unreachable poses, or violated preconditions rather than from an explicit error message. Treating multimodal feedback as calibrated evidence, rather than as a binary success signal, is essential for safe long-horizon autonomy.
Multimodal memory should also support skill evolution. In visual-centric domains such as GUI control and embodied manipulation, reusable skills cannot be represented only as text or code snippets. A useful skill often couples a multimodal precondition, an executable action pattern, and an expected postcondition: what the agent should see or sense before acting, what program, UI command, or motor primitive it should execute, and what visual, physical, or state change should follow. For example, a GUI skill may encode how to locate a settings menu from a screenshot, click the correct region, and verify that a new panel appears. An embodied skill may encode how to identify a graspable object, choose an approach pose, execute a primitive controller, and confirm through vision, force, or tactile feedback that the object has moved into the gripper. Such skills should evolve from successful trajectories, failed attempts, and human corrections, while retaining their grounding evidence. The harness must therefore decide when a visual-action pattern is reusable, how abstractly it should be stored, and how to adapt it across layouts, viewpoints, embodiments, sensors, or tasks.
5.2.7 Toward a Science of Harness Engineering
Taken together, these open problems suggest that code-as-harness research is moving toward a broader science of harness engineering. The central object of study is no longer only the model or the generated program, but the complete closed-loop system: context, memory, tools, execution, feedback, safety, coordination, and evaluation. Progress will require benchmarks that expose long-horizon failures, telemetry that makes trajectories auditable, metrics that isolate harness components, and design principles that allow agents to operate safely in persistent program worlds.
The most important future systems will likely be those that combine four properties. First, they will be executable, grounding decisions in code, tools, tests, and environments. Second, they will be inspectable, exposing plans, state, provenance, and failure causes. Third, they will be stateful, preserving task-relevant information across long trajectories and multiple agents. Fourth, they will be governed, ensuring that autonomy is constrained by permissions, verification, and accountability. These properties define the next frontier for reliable, long-horizon agentic AI.
References
Section Summary: This section catalogs academic papers and industry blog posts focused on large language models for code generation, program synthesis, and agent-based systems. The citations cover benchmarks for evaluating coding agents, methods that combine language models with code execution or external tools for better reasoning, and emerging work on “harness” engineering to manage and improve long-running AI agents. They span foundational research on models like Codex and AlphaCode through to recent advances in embodied robotics, feedback-driven repair, and self-improving agent frameworks.
[1] Chen et al. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
[2] Austin et al. (2021). Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
[3] Nijkamp et al. (2022). Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474.
[4] Li et al. (2022). Competition-level code generation with alphacode. Science. 378(6624). pp. 1092–1097.
[5] Jimenez et al. (2023). Swe-bench: Can language models resolve real-world github issues?. arXiv preprint arXiv:2310.06770.
[6] Chen et al. (2022). Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588.
[7] Gao et al. (2023). Pal: Program-aided language models. In International conference on machine learning. pp. 10764–10799.
[8] Li et al. (2023). Chain of code: Reasoning with a language model-augmented code emulator. arXiv preprint arXiv:2312.04474.
[9] Ahn et al. (2022). Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691.
[10] Liang et al. (2023). Code as policies: Language model programs for embodied control. In 2023 IEEE International conference on robotics and automation (ICRA). pp. 9493–9500.
[11] Yang et al. (2023). Intercode: Standardizing and benchmarking interactive coding with execution feedback. Advances in Neural Information Processing Systems. 36. pp. 23826–23854.
[12] Liu et al. (2023). Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688.
[13] Lee et al. (2026). Meta-Harness: End-to-End Optimization of Model Harnesses. arXiv preprint arXiv:2603.28052.
[14] Lou et al. (2026). AutoHarness: improving LLM agents by automatically synthesizing a code harness. arXiv preprint arXiv:2603.03329.
[15] Justin Young (2025). Effective Harnesses for Long-Running Agents. Anthropic Engineering Blog. Accessed: 2026-05-11. https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents.
[16] Lopopolo, Ryan (2026). Harness Engineering: Leveraging Codex in an Agent-First World. https://openai.com/index/harness-engineering/. OpenAI Engineering Blog, February 11, 2026. Accessed: 2026-05-10.
[17] Zhang et al. (2025). Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618.
[18] Agrawal et al. (2025). Gepa: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457.
[19] Zhang et al. (2023). Toolcoder: Teach code generation models to use api search tools. arXiv preprint arXiv:2305.04032.
[20] Wang et al. (2025). Teaching code llms to use autocompletion tools in repository-level code generation. ACM Transactions on Software Engineering and Methodology. 34(7). pp. 1–27.
[21] Lavon et al. (2025). Execution guided line-by-line code generation. arXiv preprint arXiv:2506.10948.
[22] Cheng et al. (2026). Computer Environments Elicit General Agentic Intelligence in LLMs. arXiv preprint arXiv:2601.16206.
[23] Dai et al. (2025). Feedbackeval: A benchmark for evaluating large language models in feedback-driven code repair tasks. arXiv preprint arXiv:2504.06939.
[24] Ryan Lopopolo (2026). Harness Engineering: Leveraging Codex in an Agent-First World. OpenAI Engineering Blog. Accessed: 2026-05-11. https://openai.com/index/harness-engineering/.
[25] Trivedy, Vivek (2026). The Anatomy of an Agent Harness. https://www.langchain.com/blog/the-anatomy-of-an-agent-harness. LangChain blog. Accessed: 2026-05-10.
[26] Anthropic. Claude Code. https://www.anthropic.com/product/claude-code. Accessed: 2026-05-09.
[27] OpenAI (2025). Introducing Codex. https://openai.com/index/introducing-codex/. OpenAI announcement.
[28] Trivedy, Vivek (2026). Improving Deep Agents with Harness Engineering. https://www.langchain.com/blog/improving-deep-agents-with-harness-engineering. LangChain blog. Accessed: 2026-05-10.
[29] Ye et al. (2023). Satlm: Satisfiability-aided language models using declarative prompting. Advances in Neural Information Processing Systems. 36. pp. 45548–45580.
[30] Ni et al. (2024). Next: Teaching large language models to reason about code execution. arXiv preprint arXiv:2404.14662.
[31] Li et al. (2025). Codeprm: Execution feedback-enhanced process reward model for code generation. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 8169–8182.
[32] Wang et al. (2023). Voyager: An open-ended embodied agent with large language models, 2023. URL https://arxiv. org/abs/2305.16291. 2(11).
[33] Mu et al. (2024). Robocodex: Multimodal code generation for robotic behavior synthesis. arXiv preprint arXiv:2402.16117.
[34] Zhang et al. (2025). Code-BT: A Code-Driven Approach to Behavior Tree Generation for Robot Tasks Planning with Large Language Models. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence. pp. 8814–8822.
[35] Lin et al. (2026). UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience. arXiv preprint arXiv:2603.24533.
[36] Tang et al. (2024). Worldcoder, a model-based llm agent: Building world models by writing code and interacting with the environment. Advances in Neural Information Processing Systems. 37. pp. 70148–70212.
[37] Copet et al. (2025). Cwm: An open-weights llm for research on code generation with world models. arXiv preprint arXiv:2510.02387.
[38] Zheng et al. (2026). Code2world: A gui world model via renderable code generation. arXiv preprint arXiv:2602.09856.
[39] Gandhi et al. (2026). Endless Terminals: Scaling RL Environments for Terminal Agents. arXiv preprint arXiv:2601.16443.
[40] Jiang et al. (2024). Self-planning code generation with large language models. ACM Transactions on Software Engineering and Methodology. 33(7). pp. 1–30.
[41] Gur et al. (2023). A real-world webagent with planning, long context understanding, and program synthesis. arXiv preprint arXiv:2307.12856.
[42] Bairi et al. (2024). Codeplan: Repository-level coding using llms and planning. Proceedings of the ACM on Software Engineering. 1(FSE). pp. 675–698.
[43] Li et al. (2025). Codetree: Agent-guided tree search for code generation with large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 3711–3726.
[44] Islam et al. (2024). Mapcoder: Multi-agent code generation for competitive problem solving. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 4912–4944.
[45] Gaurav et al. (2025). CodeMem: Architecting Reproducible Agents via Dynamic MCP and Procedural Memory. arXiv preprint arXiv:2512.15813.
[46] Zhang et al. (2024). Autocoderover: Autonomous program improvement. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. pp. 1592–1604.
[47] Zhang et al. (2023). Repocoder: Repository-level code completion through iterative retrieval and generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 2471–2484.
[48] Wang et al. (2026). MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences. arXiv preprint arXiv:2601.06789.
[49] Liu et al. (2024). Toolnet: Connecting large language models with massive tools via tool graph. arXiv preprint arXiv:2403.00839.
[50] Huang et al. (2023). Agentcoder: Multi-agent-based code generation with iterative testing and optimisation. arXiv preprint arXiv:2312.13010.
[51] Ukai et al. (2024). Adacoder: Adaptive prompt compression for programmatic visual question answering. In Proceedings of the 32nd ACM International Conference on Multimedia. pp. 9234–9243.
[52] Nunez et al. (2024). AutoSafeCoder: A multi-agent framework for securing LLM code generation through static analysis and fuzz testing. arXiv preprint arXiv:2409.10737.
[53] Li et al. (2026). Agent Harness Engineering: A Survey. https://openreview.net/pdf?id=eONq7FdiHa.
[54] Wu et al. (2024). Autogen: Enabling next-gen LLM applications via multi-agent conversations. In First conference on language modeling.
[55] Sirui Hong et al. (2024). MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. https://openreview.net/forum?id=VtmBAGCN7o.
[56] Dong et al. (2024). Self-collaboration code generation via ChatGPT. ACM Transactions on Software Engineering and Methodology. 33(7). pp. 1–38.
[57] Yang et al. (2024). Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems. 37. pp. 50528–50652.
[58] Wang et al. (2025). OpenHands: An Open Platform for AI Software Developers as Generalist Agents. In International Conference on Learning Representations (ICLR).
[59] Xiang Deng et al. (2023). Mind2Web: Towards a Generalist Agent for the Web. https://arxiv.org/abs/2306.06070. arXiv:2306.06070.
[60] Shuyan Zhou et al. (2024). WebArena: A Realistic Web Environment for Building Autonomous Agents. https://arxiv.org/abs/2307.13854. arXiv:2307.13854.
[61] Andres M Bran et al. (2023). ChemCrow: Augmenting large-language models with chemistry tools. https://arxiv.org/abs/2304.05376. arXiv:2304.05376.
[62] Boiko et al. (2023). Autonomous chemical research with large language models. Nature. 624(7992). pp. 570–578.
[63] Chris Lu et al. (2024). The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. https://arxiv.org/abs/2408.06292. arXiv:2408.06292.
[64] Huang et al. (2025). Biomni: A general-purpose biomedical ai agent. biorxiv.
[65] Wei et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems. 35. pp. 24824–24837.
[66] Nye et al. (2021). Show your work: Scratchpads for intermediate computation with language models.
[67] Pi et al. (2022). Reasoning like program executors. In Proceedings of the 2022 conference on empirical methods in natural language processing. pp. 761–779.
[68] Wang et al. (2023). Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning. arXiv preprint arXiv:2310.03731.
[69] Bi et al. (2024). When do program-of-thought works for reasoning?. In Proceedings of the AAAI conference on artificial intelligence. pp. 17691–17699.
[70] Payoungkhamdee et al. (2025). Towards better understanding of program-of-thought reasoning in cross-lingual and multilingual environments. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 15810–15828.
[71] Su, Hong (2025). Method-based reasoning for large language models: Extraction, reuse, and continuous improvement. arXiv preprint arXiv:2508.04289.
[72] Zhang et al. (2025). Code-enabled language models can outperform reasoning models on diverse tasks. arXiv preprint arXiv:2510.20909.
[73] Li et al. (2025). CodeIO: Condensing Reasoning Patterns via Code Input-Output Prediction. In Proceedings of the 42nd International Conference on Machine Learning. pp. 34471–34489. https://proceedings.mlr.press/v267/li25t.html.
[74] Besta et al. (2024). Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI conference on artificial intelligence. pp. 17682–17690.
[75] Yu et al. (2025). Self-Verifying Reflection Helps Transformers with CoT Reasoning. arXiv preprint arXiv:2510.12157.
[76] Wang et al. (2025). MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought Reasoning enhances Formal Theorem Proving. arXiv e-prints. pp. arXiv–2503.
[77] Shi et al. (2025). SSR: Socratic Self-Refine for Large Language Model Reasoning. arXiv preprint arXiv:2511.10621.
[78] Chen et al. (2025). CodeSteer: Symbolic-Augmented Language Models via Code/Text Guidance. arXiv preprint arXiv:2502.04350.
[79] Chen et al. (2025). Code-as-symbolic-planner: Foundation model-based robot planning via symbolic code generation. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 19248–19254.
[80] Chi et al. (2025). VisualCoder: Guiding Large Language Models in Code Execution with Fine-grained Multimodal Chain-of-Thought Reasoning. In Findings of the Association for Computational Linguistics: NAACL 2025. pp. 6643–6660. doi:10.18653/v1/2025.findings-naacl.370. https://aclanthology.org/2025.findings-naacl.370/.
[81] Moura, Leonardo de and Ullrich, Sebastian (2021). The lean 4 theorem prover and programming language. In International Conference on Automated Deduction. pp. 625–635.
[82] Nipkow et al. (2002). Isabelle/HOL: a proof assistant for higher-order logic. Springer.
[83] Barras et al. (1999). The Coq proof assistant reference manual. INRIA, version. 6(11). pp. 17–21.
[84] Yang et al. (2023). Leandojo: Theorem proving with retrieval-augmented language models. Advances in Neural Information Processing Systems. 36. pp. 21573–21612.
[85] Xin et al. (2025). Deepseek-prover-v1. 5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search. In International Conference on Learning Representations. pp. 72274–72303.
[86] Wang et al. (2024). Theoremllama: Transforming general-purpose llms into lean4 experts. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 11953–11974.
[87] Ren et al. (2025). Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition. arXiv preprint arXiv:2504.21801.
[88] Wang et al. (2025). Kimina-prover preview: Towards large formal reasoning models with reinforcement learning. arXiv preprint arXiv:2504.11354.
[89] Lin et al. (2025). Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction. arXiv preprint arXiv:2508.03613.
[90] Wang et al. (2025). Let’s reason formally: Natural-formal hybrid reasoning enhances llm’s math capability. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 16794–16820.
[91] Li et al. (2025). Lean4Physics: Comprehensive Reasoning Framework for College-level Physics in Lean4. arXiv preprint arXiv:2510.26094.
[92] The Physlib community (2024). Physlib: The Lean Physics Library. https://github.com/leanprover-community/physlib.
[93] Ye et al. (2025). Verina: Benchmarking verifiable code generation. arXiv preprint arXiv:2505.23135.
[94] Li et al. (2026). Goedel-Code-Prover: Hierarchical Proof Search for Open State-of-the-Art Code Verification. arXiv preprint arXiv:2603.19329.
[95] Wang et al. (2026). Lean4Agent: Formal Modeling and Verification for Agent Workflow and Trajectory. Preprint.
[96] Armengol-Estapé et al. (2025). What I cannot execute, I do not understand: Training and Evaluating LLMs on Program Execution Traces. arXiv preprint arXiv:2503.05703.
[97] Yu et al. (2024). Reasoning through execution: Unifying process and outcome rewards for code generation. arXiv preprint arXiv:2412.15118.
[98] Ding et al. (2024). Cycle: Learning to self-refine the code generation. Proceedings of the ACM on Programming Languages. 8(OOPSLA1). pp. 392–418.
[99] Zhang et al. (2023). Self-edit: Fault-aware code editor for code generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 769–787.
[100] Le et al. (2022). Coderl: Mastering code generation through pretrained models and deep reinforcement learning. Advances in Neural Information Processing Systems. 35. pp. 21314–21328.
[101] Jiang et al. (2025). CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment. arXiv preprint arXiv:2510.18471.
[102] Liu et al. (2023). Rltf: Reinforcement learning from unit test feedback. arXiv preprint arXiv:2307.04349.
[103] Dou et al. (2024). Stepcoder: improving code generation with reinforcement learning from compiler feedback. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 4571–4585.
[104] Gehring et al. (2024). Rlef: Grounding code llms in execution feedback with reinforcement learning. arXiv preprint arXiv:2410.02089.
[105] Chen et al. (2025). R1-code-interpreter: Training llms to reason with code via supervised and reinforcement learning. arXiv e-prints. pp. arXiv–2505.
[106] Lingxiao Tang et al. (2026). ExecVerify: White-Box RL with Verifiable Stepwise Rewards for Code Execution Reasoning. https://arxiv.org/abs/2603.11226. arXiv:2603.11226.
[107] Ruiyi Zhang et al. (2026). FunPRM: Function-as-Step Process Reward Model with Meta Reward Correction for Code Generation. https://arxiv.org/abs/2601.22249. arXiv:2601.22249.
[108] Lishui Fan et al. (2026). ReCode: Reinforcing Code Generation with Reasoning-Process Rewards. https://arxiv.org/abs/2508.05170. arXiv:2508.05170.
[109] Xinghua Lou et al. (2026). AutoHarness: improving LLM agents by automatically synthesizing a code harness. https://arxiv.org/abs/2603.03329. arXiv:2603.03329.
[110] Ren et al. (2023). Robots that ask for help: Uncertainty alignment for large language model planners. arXiv preprint arXiv:2307.01928.
[111] Zhai et al. (2026). SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse. arXiv preprint arXiv:2603.03836.
[112] Zhang et al. (2023). Bootstrap your own skills: Learning to solve new tasks with large language model guidance. arXiv preprint arXiv:2310.10021.
[113] Ha et al. (2023). Scaling up and distilling down: Language-guided robot skill acquisition. In Conference on Robot Learning. pp. 3766–3777.
[114] Tziafas, Georgios and Kasaei, Hamidreza (2024). Lifelong robot library learning: Bootstrapping composable and generalizable skills for embodied control with language models. In 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 515–522.
[115] Santos et al. (2026). ALRM: Agentic LLM for Robotic Manipulation. arXiv preprint arXiv:2601.19510.
[116] Szeider, Stefan (2025). Cp-agent: Agentic constraint programming. arXiv preprint arXiv:2508.07468.
[117] Wang et al. (2025). LLM-Driven Corrective Robot Operation Code Generation with Static Text-Based Simulation. arXiv preprint arXiv:2512.02002.
[118] Ji et al. (2026). Genswarm: Scalable multi-robot code-policy generation and deployment via language models. npj Robotics. 4(1). pp. 5.
[119] Guan et al. (2025). NormCode: A Semi-Formal Language for Auditable AI Planning. arXiv preprint arXiv:2512.10563.
[120] Ashley et al. (2026). RACAS: Controlling Diverse Robots With a Single Agentic System. arXiv preprint arXiv:2603.05621.
[121] Meng et al. (2025). Growing with your embodied agent: A human-in-the-loop lifelong code generation framework for long-horizon manipulation skills. arXiv preprint arXiv:2509.18597.
[122] Kagaya et al. (2025). Vireskill: Vision-grounded replanning with skill memory for llm-based planning in lifelong robot learning. arXiv preprint arXiv:2509.24219.
[123] Wang et al. (2026). Lifelong Language-Conditioned Robotic Manipulation Learning. In Proceedings of the AAAI Conference on Artificial Intelligence. pp. 18629–18637.
[124] Xie et al. (2025). Robotic programmer: Video instructed policy code generation for robotic manipulation. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 14923–14930.
[125] Chen et al. (2023). Vistruct: Visual structural knowledge extraction via curriculum guided code-vision representation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 13342–13357.
[126] Hsu et al. (2025). From Programs to Poses: Factored Real-World Scene Generation via Learned Program Libraries. arXiv preprint arXiv:2510.10292.
[127] Piriyakulkij et al. (2025). Poe-world: Compositional world modeling with products of programmatic experts. arXiv preprint arXiv:2505.10819.
[128] Ding et al. (2024). Semcoder: Training code language models with comprehensive semantics. arXiv preprint arXiv:2406.01006. 47.
[129] Yu et al. (2026). Reinforcement World Model Learning for LLM-based Agents. arXiv preprint arXiv:2602.05842.
[130] Wang et al. (2026). Agent world model: Infinity synthetic environments for agentic reinforcement learning. arXiv preprint arXiv:2602.10090.
[131] Ren et al. (2026). Aligning Agentic World Models via Knowledgeable Experience Learning. arXiv preprint arXiv:2601.13247.
[132] Gu et al. (2024). Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065.
[133] Jain et al. (2024). Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974.
[134] Xu et al. (2025). Cruxeval-x: A benchmark for multilingual code reasoning, understanding and execution. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 23762–23779.
[135] Xie et al. (2025). Core: Benchmarking llms code reasoning capabilities through static analysis tasks. arXiv preprint arXiv:2507.05269.
[136] Wang et al. (2026). CodeGlance: Understanding Code Reasoning Challenges in LLMs through Multi-Dimensional Feature Analysis. arXiv preprint arXiv:2602.13962.
[137] John Yang et al. (2025). SWE-smith: Scaling Data for Software Engineering Agents. https://arxiv.org/abs/2504.21798. arXiv:2504.21798.
[138] Xiaoshuai Song et al. (2026). EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis. https://arxiv.org/abs/2601.05808. arXiv:2601.05808.
[139] Zhang et al. (2026). Code2Worlds: Empowering Coding LLMs for 4D World Generation. arXiv preprint arXiv:2602.11757.
[140] Luo et al. (2025). Geogrambench: Benchmarking the geometric program reasoning in modern llms. arXiv preprint arXiv:2505.17653.
[141] Huang et al. (2024). Knowledge-aware code generation with large language models. In Proceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. pp. 52–63.
[142] Yoon et al.. PaT: Planning-after-Trial for Efficient Code Generation.
[143] Zhang et al. (2025). A Little Help Goes a Long Way: Tutoring LLMs in Solving Competitive Programming through Hints. IEEE Transactions on Software Engineering.
[144] Shunyu Yao et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. https://arxiv.org/abs/2210.03629. arXiv:2210.03629.
[145] Erdogan et al. (2025). Plan-and-act: Improving planning of agents for long-horizon tasks. arXiv preprint arXiv:2503.09572.
[146] Aaron Friel (2025). Using PLANS.md for Multi-Hour Problem Solving. OpenAI Cookbook. Accessed: 2026-05-11. https://developers.openai.com/cookbook/articles/codex_exec_plans.
[147] Derrick Choi (2026). Run Long Horizon Tasks with Codex. OpenAI Developers Blog. Accessed: 2026-05-11. https://developers.openai.com/blog/run-long-horizon-tasks-with-codex.
[148] Luo et al. (2025). RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation. arXiv preprint arXiv:2509.16198.
[149] Chen et al. (2025). Locagent: Graph-guided llm agents for code localization. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 8697–8727.
[150] Tao et al. (2025). Code graph model (cgm): A graph-integrated large language model for repository-level software engineering tasks. arXiv preprint arXiv:2505.16901.
[151] Li et al. (2025). GraphCodeAgent: Dual Graph-Guided LLM Agent for Retrieval-Augmented Repo-Level Code Generation. arXiv preprint arXiv:2504.10046.
[152] AGENTS.md Contributors (2025). AGENTS.md: A Simple, Open Format for Guiding Coding Agents. Project Website. Accessed: 2026-05-11. https://agents.md/.
[153] OpenAI (2026). Custom Instructions with AGENTS.md. OpenAI Codex Documentation. Accessed: 2026-05-11. https://developers.openai.com/codex/guides/agents-md.
[154] Anthropic (2025). Best Practices for Claude Code. Claude Code Documentation. Accessed: 2026-05-11. https://code.claude.com/docs/en/best-practices.
[155] Wang et al. (2026). DomAgent: Leveraging Knowledge Graphs and Case-Based Reasoning for Domain-Specific Code Generation. arXiv preprint arXiv:2603.21430.
[156] Ho et al. (2025). Verilogcoder: Autonomous verilog coding agents with graph-based planning and abstract syntax tree (ast)-based waveform tracing tool. In Proceedings of the AAAI Conference on Artificial Intelligence. pp. 300–307.
[157] Wang et al. (2024). Planning in natural language improves llm search for code generation. arXiv preprint arXiv:2409.03733.
[158] Li et al. (2025). Rethinkmcts: Refining erroneous thoughts in monte carlo tree search for code generation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 8103–8121.
[159] Ni et al. (2024). Tree-of-code: A tree-structured exploring framework for end-to-end code generation and execution in complex task handling. arXiv preprint arXiv:2412.15305.
[160] Dainese et al. (2024). Generating code world models with large language models guided by monte carlo tree search. Advances in Neural Information Processing Systems. 37. pp. 60429–60474.
[161] Aggarwal et al. (2025). Dars: Dynamic action re-sampling to enhance coding agent performance by adaptive tree traversal. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 19808–19855.
[162] Lyu et al. (2025). Let's Revise Step-by-Step: A Unified Local Search Framework for Code Generation with LLMs. arXiv preprint arXiv:2508.07434.
[163] Light et al. (2025). SFS: Smarter code space search improves LLM inference scaling. In The Thirteenth International Conference on Learning Representations.
[164] Antonis Antoniades et al. (2024). SWE-Search: Enhancing Software Agents with Monte Carlo Tree Search and Iterative Refinement. Revised Apr. 2, 2025. doi:10.48550/arXiv.2410.20285. https://arxiv.org/abs/2410.20285. arXiv:2410.20285.
[165] Mao et al. (2025). Blueprint2Code: a multi-agent pipeline for reliable code generation via blueprint planning and repair. Frontiers in Artificial Intelligence. 8. pp. 1660912.
[166] Pan et al. (2025). CodeCoR: An LLM-based self-reflective multi-agent framework for code generation. arXiv preprint arXiv:2501.07811.
[167] Khan et al. (2025). Multi-Agent Code-Orchestrated Generation for Reliable Infrastructure-as-Code. arXiv preprint arXiv:2510.03902.
[168] Dou et al.. AlgoForge: Specializing Code Generation Agents through Collaborative Reinforcement Learning.
[169] Zhang et al. (2026). SGAgent: Suggestion-Guided LLM-Based Multi-Agent Framework for Repository-Level Software Repair. arXiv preprint arXiv:2602.23647.
[170] Lu et al. (2025). Requirements Development and Formalization for Reliable Code Generation: A Multi-Agent Vision. arXiv preprint arXiv:2508.18675.
[171] Prithvi Rajasekaran (2026). Harness Design for Long-Running Application Development. Anthropic Engineering Blog. Accessed: 2026-05-11. https://www.anthropic.com/engineering/harness-design-long-running-apps.
[172] Wilson Lin (2026). Scaling Long-Running Autonomous Coding. Cursor Blog. Accessed: 2026-05-11. https://cursor.com/blog/scaling-agents.
[173] Linyue Pan et al. (2026). Natural-Language Agent Harnesses. doi:10.48550/arXiv.2603.25723. https://arxiv.org/abs/2603.25723. arXiv:2603.25723.
[174] Dong et al. (2025). A survey on code generation with llm-based agents. arXiv preprint arXiv:2508.00083.
[175] Huang et al. (2026). Rethinking Memory Mechanisms of Foundation Agents in the Second Half. arXiv preprint arXiv:2602.06052.
[176] Xia et al. (2025). Demystifying llm-based software engineering agents. Proceedings of the ACM on Software Engineering. 2(FSE). pp. 801–824.
[177] Zhang et al. (2025). A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems. 43(6). pp. 1–47.
[178] Zhou et al. (2026). Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering. arXiv preprint arXiv:2604.08224.
[179] Zhang et al. (2025). A survey of graph retrieval-augmented generation for customized large language models. arXiv preprint arXiv:2501.13958.
[180] Jiang et al. (2026). A survey on large language models for code generation. ACM Transactions on Software Engineering and Methodology. 35(2). pp. 1–72.
[181] Huang et al. (2025). On the Failure of Latent State Persistence in Large Language Models. arXiv preprint arXiv:2505.10571.
[182] Xia et al. (2025). Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?. arXiv preprint arXiv:2511.13646.
[183] Bouzenia et al. (2025). Repairagent: An autonomous, llm-based agent for program repair. In 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). pp. 2188–2200.
[184] Wu et al. (2025). From human memory to ai memory: A survey on memory mechanisms in the era of llms. arXiv preprint arXiv:2504.15965.
[185] Zhang et al. (2024). Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13643–13658.
[186] Biswal et al. (2026). AgentSM: Semantic Memory for Agentic Text-to-SQL. arXiv preprint arXiv:2601.15709.
[187] Zhang et al. (2025). CodeRAG: Finding Relevant and Necessary Knowledge for Retrieval-Augmented Repository-Level Code Completion. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 23289–23299.
[188] Phan et al. (2025). Repohyper: Search-expand-refine on semantic graphs for repository-level code completion. In 2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). pp. 14–25.
[189] Zhao et al. (2024). Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence. pp. 19632–19642.
[190] Deng et al. (2026). Your Code Agent Can Grow Alongside You with Structured Memory. arXiv preprint arXiv:2603.13258.
[191] Shen, Ming-Tung and Joung, Yuh-Jzer (2025). TALM: Dynamic Tree-Structured Multi-Agent Framework with Long-Term Memory for Scalable Code Generation. arXiv preprint arXiv:2510.23010.
[192] Wang, Yu and Chen, Xi (2025). Mirix: Multi-agent memory system for llm-based agents. arXiv preprint arXiv:2507.07957.
[193] Qian et al. (2024). Chatdev: Communicative agents for software development. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). pp. 15174–15186.
[194] Shi et al. (2025). LongCodeZip: Compress Long Context for Code Language Models. In 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). pp. 141–153.
[195] Wang et al. (2026). SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents. arXiv preprint arXiv:2601.16746.
[196] Jia et al. (2026). Compressing Code Context for LLM-based Issue Resolution. arXiv preprint arXiv:2603.28119.
[197] Dong et al. (2025). Towards large language models with human-like episodic memory. Trends in Cognitive Sciences.
[198] Alexis Huet et al. (2025). Episodic Memories Generation and Evaluation Benchmark for Large Language Models. In The Thirteenth International Conference on Learning Representations.
[199] Wei et al. (2025). Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory. arXiv preprint arXiv:2511.20857.
[200] Liang et al. (2026). Generalizable Self-Evolving Memory for Automatic Prompt Optimization. arXiv preprint arXiv:2603.21520.
[201] Chu et al. (2024). Leveraging prior experience: An expandable auxiliary knowledge base for text-to-sql. arXiv preprint arXiv:2411.13244.
[202] Maharana et al. (2024). Evaluating very long-term conversational memory of llm agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13851–13870.
[203] Wang et al. (2026). Memex (RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory. arXiv preprint arXiv:2603.04257.
[204] Bei et al. (2026). Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents. arXiv preprint arXiv:2601.03515.
[205] Yanjun Zhao et al. (2026). PaperMind: Benchmarking Agentic Reasoning and Critique over Scientific Papers in Multimodal LLMs. https://arxiv.org/abs/2604.21304. arXiv:2604.21304.
[206] Xuying Ning et al. (2026). MC-Search: Evaluating and Enhancing Multimodal Agentic Search with Structured Long Reasoning Chains. In The Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=JEGDp1E4OH.
[207] Packer et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv preprint arXiv:2310.08560.
[208] Kang et al. (2025). Memory os of ai agent. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 25972–25981.
[209] Li et al. (2025). Swe-debate: Competitive multi-agent debate for software issue resolution. arXiv preprint arXiv:2507.23348.
[210] Chen et al. (2023). Gamegpt: Multi-agent collaborative framework for game development. arXiv preprint arXiv:2310.08067.
[211] Guibin Zhang et al. (2025). G-Memory: Tracing Hierarchical Memory for Multi-Agent Systems. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.
[212] Ishibashi, Y. and Nishimura, Y. (2024). Self-organized agents: A LLM multi-agent framework toward ultra large-scale code generation and optimization. arXiv preprint arXiv:2404.02183.
[213] Bei et al. (2025). Graphs meet ai agents: Taxonomy, progress, and future opportunities. arXiv preprint arXiv:2506.18019.
[214] Liu et al. (2026). Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems. arXiv preprint arXiv:2604.14228.
[215] Sun et al. (2025). Scaling long-horizon llm agent via context-folding. arXiv preprint arXiv:2510.11967.
[216] Carlos E Jimenez et al. (2024). SWE-bench: Can Language Models Resolve Real-world Github Issues?. In The Twelfth International Conference on Learning Representations.
[217] Feng et al. (2026). LongCLI-Bench: A Preliminary Benchmark and Study for Long-horizon Agentic Programming in Command-Line Interfaces. arXiv preprint arXiv:2602.14337.
[218] Watanabe et al. (2025). On the use of agentic coding: An empirical study of pull requests on github. ACM Transactions on Software Engineering and Methodology.
[219] Sapkota et al. (2025). Vibe coding vs. agentic coding: Fundamentals and practical implications of agentic ai. arXiv preprint arXiv:2505.19443.
[220] Meng et al. (2026). Agent Harness for Large Language Model Agents: A Survey.
[221] Xi et al. (2025). Agentgym: Evaluating and training large language model-based agents across diverse environments. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 27914–27961.
[222] Wang et al. (2024). Executable code actions elicit better LLM agents. In Proceedings of the 41st International Conference on Machine Learning. pp. 50208–50232.
[223] Wang et al. (2025). Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning. arXiv preprint arXiv:2509.02544.
[224] Ahmed et al. (2024). CodeQA: Advanced programming question-answering using LLM agent and RAG. In 2024 6th Novel Intelligent and Leading Emerging Sciences Conference (NILES). pp. 494–499.
[225] Zhao et al. (2025). RAG-Based AI Agents for Enterprise Software Development: Implementation Patterns and Production Deployment. Frontiers in Artificial Intelligence Research. 2(3). pp. 501–520.
[226] Miculicich et al. (2025). Veriguard: Enhancing llm agent safety via verified code generation. arXiv preprint arXiv:2510.05156.
[227] Li et al. (2025). A Survey of RAG-Reasoning Systems in Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 12120–12145.
[228] Yuan et al. (2025). Easytool: Enhancing llm-based agents with concise tool instruction. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 951–972.
[229] Jiaru Zou et al. (2025). AutoTool: Dynamic Tool Selection and Integration for Agentic Reasoning. https://arxiv.org/abs/2512.13278. arXiv:2512.13278.
[230] Zhou et al. (2023). The devil is in the tails: How long-tailed code distributions impact large language models. In 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). pp. 40–52.
[231] Li et al. (2026). Environment-in-the-Loop: Rethinking Code Migration with LLM-based Agents. arXiv preprint arXiv:2602.09944.
[232] Arthur Chen et al. (2026). Grounded Test-Time Adaptation for LLM Agents. In The Fourteenth International Conference on Learning Representations.
[233] Song et al. (2026). Envscaler: Scaling tool-interactive environments for llm agent via programmatic synthesis. arXiv preprint arXiv:2601.05808.
[234] Gao et al. (2026). Teaching LLMs to Learn Tool Trialing and Execution through Environment Interaction. arXiv preprint arXiv:2601.12762.
[235] Liu et al. (2026). Agents4plc: Automating closed-loop plc code generation and verification in industrial control systems using llm-based agents. IEEE Transactions on Software Engineering.
[236] Liu et al. (2026). LLM-Assisted Circuit Verification: A Comprehensive Survey. In 2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC). pp. 439–446.
[237] Jin et al. (2025). ReVeal: Self-Evolving Code Agents via Reliable Self-Verification. arXiv preprint arXiv:2506.11442.
[238] Xiong et al. (2025). Self-organizing agent network for llm-based workflow automation. arXiv preprint arXiv:2508.13732.
[239] Shi et al. (2025). FlowXpert: Expertizing Troubleshooting Workflow Orchestration with Knowledge Base and Multi-Agent Coevolution. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. pp. 4839–4850.
[240] Lumer et al. (2025). Tool-to-agent retrieval: Bridging tools and agents for scalable llm multi-agent systems. arXiv preprint arXiv:2511.01854.
[241] Hongjin Su et al. (2025). ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration. https://arxiv.org/abs/2511.21689. arXiv:2511.21689.
[242] Liu et al. (2024). Controlllm: Augment language models with tools by searching on graphs. In European Conference on Computer Vision. pp. 89–105.
[243] Chen et al. (2023). Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128.
[244] Shinn et al. (2023). Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems. 36. pp. 8634–8652.
[245] Zhong et al. (2024). Debug like a human: A large language model debugger via verifying runtime execution step by step. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 851–870.
[246] Bi et al. (2024). Iterative refinement of project-level code context for precise code generation with compiler feedback. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 2336–2353.
[247] Picrew (2026). Awesome Agent Harness. https://github.com/Picrew/awesome-agent-harness. Curated catalog. Accessed: 2026-05-10.
[248] OpenAI (2026). Harness Engineering: Leveraging Codex in an Agent-First World. https://openai.com/index/harness-engineering/. Engineering article. Accessed: 2026-05-10.
[249] Bolin, Michael (2026). Unrolling the Codex Agent Loop. https://openai.com/index/unrolling-the-codex-agent-loop/. OpenAI engineering article. Accessed: 2026-05-10.
[250] Wang et al. (2025). The openhands software agent sdk: A composable and extensible foundation for production agents. arXiv preprint arXiv:2511.03690.
[251] Daytona (2026). Daytona: Secure and Elastic Infrastructure for Running AI-Generated Code. https://github.com/daytonaio/daytona. GitHub repository. Accessed: 2026-05-10.
[252] E2B (2026). E2B: Secure Cloud Environments for AI Agents. https://github.com/e2b-dev/E2B. GitHub repository. Accessed: 2026-05-10.
[253] Hu et al. (2025). QualityFlow: An agentic workflow for program synthesis controlled by LLM quality checks. arXiv preprint arXiv:2501.17167.
[254] BerriAI (2026). LiteLLM. https://github.com/BerriAI/litellm. GitHub repository. Accessed: 2026-05-10.
[255] AGENTS.md contributors (2026). AGENTS.md. https://github.com/agentsmd/agents.md. GitHub repository. Accessed: 2026-05-10.
[256] Model Context Protocol (2026). MCP Servers. https://github.com/modelcontextprotocol/servers. GitHub repository. Accessed: 2026-05-10.
[257] Model Context Protocol (2026). Model Context Protocol. https://github.com/modelcontextprotocol/modelcontextprotocol. GitHub repository. Accessed: 2026-05-10.
[258] LangChain (2026). LangChain MCP Adapters. https://github.com/langchain-ai/langchain-mcp-adapters. GitHub repository. Accessed: 2026-05-10.
[259] Partha Pratim Ray. A Survey on Model Context Protocol: Architecture, State-of-the-art, Challenges and Future Directions. https://api.semanticscholar.org/CorpusID:281419186.
[260] Hou et al. (2025). Model context protocol (mcp): Landscape, security threats, and future research directions. ACM Transactions on Software Engineering and Methodology.
[261] Li, Qiaomu and Xie, Ying (2025). From glue-code to protocols: A critical analysis of a2a and mcp integration for scalable agent systems. arXiv preprint arXiv:2505.03864.
[262] IBM (2026). ContextForge. https://github.com/IBM/mcp-context-forge. GitHub repository. Accessed: 2026-05-10.
[263] Vijayvargiya et al. (2025). Openagentsafety: A comprehensive framework for evaluating real-world ai agent safety. arXiv preprint arXiv:2507.06134.
[264] Alibaba (2026). OpenSandbox. https://github.com/alibaba/OpenSandbox. GitHub repository. Accessed: 2026-05-10.
[265] Judge0 (2026). Judge0: Scalable Sandbox Code Execution. https://github.com/judge0/judge0. GitHub repository. Accessed: 2026-05-10.
[266] SWE-agent (2026). SWE-ReX. https://github.com/SWE-agent/SWE-ReX. GitHub repository. Accessed: 2026-05-10.
[267] CUA (2026). CUA: Infrastructure for Computer-Use Agents. https://github.com/trycua/cua. GitHub repository. Accessed: 2026-05-10.
[268] browser-use (2026). Browser Harness. https://github.com/browser-use/browser-harness. GitHub repository. Accessed: 2026-05-10.
[269] E2B (2026). E2B Desktop Sandbox. https://github.com/e2b-dev/desktop. GitHub repository. Accessed: 2026-05-10.
[270] agent-infra (2026). agent-infra sandbox. https://github.com/agent-infra/sandbox. GitHub repository. Accessed: 2026-05-10.
[271] AgentScope (2026). AgentScope Runtime: A Production-grade Runtime for Agent Applications. https://github.com/agentscope-ai/agentscope-runtime. GitHub repository. Accessed: 2026-05-10.
[272] Tensorlake (2026). Tensorlake. https://github.com/tensorlakeai/tensorlake. GitHub repository. Accessed: 2026-05-10.
[273] Arrakis (2025). Arrakis. https://github.com/abshkbh/arrakis. GitHub repository. Accessed: 2026-05-10.
[274] Capsule (2026). Capsule. https://github.com/capsulerun/capsule. GitHub repository. Accessed: 2026-05-10.
[275] Kubernetes SIGs (2026). Agent Sandbox. https://github.com/kubernetes-sigs/agent-sandbox. GitHub repository. Accessed: 2026-05-10.
[276] Th0rgal (2026). sandboxed.sh. https://github.com/Th0rgal/sandboxed.sh. GitHub repository. Accessed: 2026-05-10.
[277] UCSB ML Security (2026). terminal-bench-env. https://github.com/ucsb-mlsec/terminal-bench-env. GitHub repository. Accessed: 2026-05-10.
[278] stakpak (2026). stakpak/agent. https://github.com/stakpak/agent. GitHub repository. Accessed: 2026-05-10.
[279] Anthropic (2026). Quantifying Infrastructure Noise in Agentic Coding Evals. https://www.anthropic.com/engineering/infrastructure-noise. Engineering article. Accessed: 2026-05-10.
[280] Sergeyuk et al. (2026). Human-AI experience in integrated development environments: a systematic literature review. Empirical Software Engineering. 31(3). pp. 55.
[281] Lin et al. (2026). Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses. arXiv preprint arXiv:2604.25850.
[282] Anthropic (2026). Claude Code Auto Mode: A Safer Way to Skip Permissions. https://www.anthropic.com/engineering/claude-code-auto-mode. Engineering article. Accessed: 2026-05-10.
[283] Anthropic (2025). Beyond Permission Prompts: Making Claude Code More Secure and Autonomous. https://www.anthropic.com/engineering/claude-code-sandboxing. Engineering article. Accessed: 2026-05-10.
[284] Kong (2026). Kong Gateway. https://github.com/Kong/kong. GitHub repository. Accessed: 2026-05-10.
[285] Portkey (2026). Portkey Gateway. https://github.com/Portkey-AI/gateway. GitHub repository. Accessed: 2026-05-10.
[286] AgentGateway (2026). AgentGateway. https://github.com/agentgateway/agentgateway. GitHub repository. Accessed: 2026-05-10.
[287] OpenAI (2026). OpenAI Realtime Agents. https://github.com/openai/openai-realtime-agents. GitHub repository. Accessed: 2026-05-10.
[288] OpenAI (2026). OpenAI CS Agents Demo. https://github.com/openai/openai-cs-agents-demo. GitHub repository. Accessed: 2026-05-10.
[289] Tracecat (2026). Tracecat. https://github.com/TracecatHQ/tracecat. GitHub repository. Accessed: 2026-05-10.
[290] Archestra AI (2026). Archestra. https://github.com/archestra-ai/archestra. GitHub repository. Accessed: 2026-05-10.
[291] Haft contributors (2026). Haft. https://github.com/m0n0x41d/haft. GitHub repository. Accessed: 2026-05-10.
[292] Adnan, Muntasir and Kuhn, Carlos CN (2025). The Debugging Decay Index: Rethinking Debugging Strategies for Code LLMs. arXiv preprint arXiv:2506.18403.
[293] Blyth et al. (2025). Static analysis as a feedback loop: Enhancing llm-generated code beyond correctness. In 2025 IEEE International Conference on Source Code Analysis & Manipulation (SCAM). pp. 100–109.
[294] Sun et al. (2024). Llm as runtime error handler: A promising pathway to adaptive self-healing of software systems. arXiv preprint arXiv:2408.01055.
[295] Huang et al. (2025). Mldebugging: Towards benchmarking code debugging across multi-library scenarios. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 5866–5879.
[296] Fakhoury et al. (2024). Llm-based test-driven interactive code generation: User study and empirical evaluation. IEEE Transactions on Software Engineering. 50(9). pp. 2254–2268.
[297] Gu et al. (2024). Testart: Improving llm-based unit testing via co-evolution of automated generation and repair iteration. arXiv preprint arXiv:2408.03095.
[298] Yuling Shi et al. (2025). From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging. https://openreview.net/forum?id=dwQIVcW1du.
[299] Promptfoo (2026). Promptfoo. https://github.com/promptfoo/promptfoo. GitHub repository. Accessed: 2026-05-10.
[300] Confident AI (2026). DeepEval. https://github.com/confident-ai/deepeval. GitHub repository. Accessed: 2026-05-10.
[301] RAGAS (2026). RAGAS. https://github.com/vibrantlabsai/ragas. GitHub repository. Accessed: 2026-05-10.
[302] EleutherAI (2026). lm-evaluation-harness. https://github.com/EleutherAI/lm-evaluation-harness. GitHub repository. Accessed: 2026-05-10.
[303] LangWatch (2026). LangWatch. https://github.com/langwatch/langwatch. GitHub repository. Accessed: 2026-05-10.
[304] ModelScope (2026). EvalScope. https://github.com/modelscope/evalscope. GitHub repository. Accessed: 2026-05-10.
[305] Harbor Framework (2026). Harbor. https://github.com/harbor-framework/harbor. GitHub repository. Accessed: 2026-05-10.
[306] Sierra Research (2026). tau2-bench. https://github.com/sierra-research/tau2-bench. GitHub repository. Accessed: 2026-05-10.
[307] NVIDIA NeMo (2026). NeMo Gym. https://github.com/NVIDIA-NeMo/Gym. GitHub repository. Accessed: 2026-05-10.
[308] AWS Labs (2026). Agent Evaluation. https://github.com/awslabs/agent-evaluation. GitHub repository. Accessed: 2026-05-10.
[309] UK AI Security Institute (2026). Inspect Evals. https://github.com/UKGovernmentBEIS/inspect_evals. GitHub repository. Accessed: 2026-05-10.
[310] Ross et al. (2023). The programmer’s assistant: Conversational interaction with a large language model for software development. In Proceedings of the 28th international conference on intelligent user interfaces. pp. 491–514.
[311] Jie Wu et al. (2025). IterPref: Focal Preference Learning for Code Generation via Iterative Debugging. ArXiv. abs/2503.02783. https://api.semanticscholar.org/CorpusID:282402257.
[312] Liu et al. (2025). SEW: Self-evolving agentic workflows for automated code generation. arXiv preprint arXiv:2505.18646.
[313] Anthropic (2026). Scaling Managed Agents: Decoupling the Brain from the Hands. https://www.anthropic.com/engineering/managed-agents. Engineering article. Accessed: 2026-05-10.
[314] Anthropic (2025). Code Execution with MCP: Building More Efficient Agents. https://www.anthropic.com/engineering/code-execution-with-mcp. Engineering article. Accessed: 2026-05-10.
[315] Langfuse (2026). Langfuse. https://github.com/langfuse/langfuse. GitHub repository. Accessed: 2026-05-10.
[316] MLflow (2026). MLflow. https://github.com/mlflow/mlflow. GitHub repository. Accessed: 2026-05-10.
[317] Comet (2026). Opik. https://github.com/comet-ml/opik. GitHub repository. Accessed: 2026-05-10.
[318] RagaAI (2026). RagaAI Catalyst. https://github.com/raga-ai-hub/RagaAI-Catalyst. GitHub repository. Accessed: 2026-05-10.
[319] TensorZero (2026). TensorZero. https://github.com/tensorzero/tensorzero. GitHub repository. Accessed: 2026-05-10.
[320] Arize AI (2026). Arize Phoenix. https://github.com/Arize-ai/phoenix. GitHub repository. Accessed: 2026-05-10.
[321] Traceloop (2026). OpenLLMetry. https://github.com/traceloop/openllmetry. GitHub repository. Accessed: 2026-05-10.
[322] Helicone (2026). Helicone. https://github.com/Helicone/helicone. GitHub repository. Accessed: 2026-05-10.
[323] AgentOps (2026). AgentOps SDK. https://github.com/AgentOps-AI/agentops. GitHub repository. Accessed: 2026-05-10.
[324] Latitude (2026). Latitude. https://github.com/latitude-dev/latitude-llm. GitHub repository. Accessed: 2026-05-10.
[325] Laminar (2026). Laminar. https://github.com/lmnr-ai/lmnr. GitHub repository. Accessed: 2026-05-10.
[326] Arize AI (2026). OpenInference. https://github.com/Arize-ai/openinference. GitHub repository. Accessed: 2026-05-10.
[327] Future AGI (2026). Future AGI. https://github.com/future-agi/future-agi. GitHub repository. Accessed: 2026-05-10.
[328] Hu et al. (2025). Self-evolving multi-agent collaboration networks for software development. In International Conference on Learning Representations (ICLR).
[329] Jiaru Zou et al. (2025). Latent Collaboration in Multi-Agent Systems. https://arxiv.org/abs/2511.20639. arXiv:2511.20639.
[330] Chen Qian et al. (2024). ChatDev: Communicative Agents for Software Development. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024. pp. 15174–15186. doi:10.18653/V1/2024.ACL-LONG.810. https://doi.org/10.18653/v1/2024.acl-long.810.
[331] Rasheed et al. (2024). Codepori: Large-scale system for autonomous software development using multi-agent technology. arXiv preprint arXiv:2402.01411.
[332] Tao et al. (2024). Magis: LLM-based multi-agent framework for GitHub issue resolution. In Advances in Neural Information Processing Systems (NeurIPS). pp. 51963–51993.
[333] Phan et al. (2024). HyperAgent: Generalist software engineering agents to solve coding tasks at scale. arXiv preprint arXiv:2409.16299.
[334] Zhang et al. (2024). A pair programming framework for code generation via multi-plan exploration and feedback-driven refinement. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE). pp. 1319–1331.
[335] Lin et al. (2025). Soen-101: Code generation by emulating software process models using large language model agents. In Proceedings of the 47th International Conference on Software Engineering (ICSE). pp. 1527–1539.
[336] Gao et al. (2025). Trae Agent: An LLM-based Agent for Software Engineering with Test-time Scaling. arXiv preprint arXiv:2507.23370.
[337] Xu et al. (2025). BOAD: Discovering Hierarchical Software Engineering Agents via Bandit Optimization. arXiv preprint arXiv:2512.23631.
[338] Gao et al. (2025). FlowReasoner: Reinforcing Query-Level Meta-Agents. arXiv preprint arXiv:2504.15257.
[339] Zhao et al. (2024). MAGE: A multi-agent engine for automated RTL code generation. arXiv preprint arXiv:2412.07822.
[340] Yingwei Ma et al. (2024). Lingma SWE-GPT: An Open Development-Process-Centric Language Model for Automated Software Improvement. CoRR. abs/2411.00622. doi:10.48550/ARXIV.2411.00622. https://doi.org/10.48550/arXiv.2411.00622.
[341] Qi et al. (2024). CleanAgent: Automating data standardization with LLM-based agents. arXiv preprint arXiv:2403.08291.
[342] Xu et al. (2025). Hallucination to Consensus: Multi-Agent LLMs for End-to-End JUnit Test Generation. arXiv preprint arXiv:2506.02943.
[343] Jiaru Zou et al. (2026). Recursive Multi-Agent Systems. https://arxiv.org/abs/2604.25917. arXiv:2604.25917.
[344] Holt et al. (2023). L2MAC: Large language model automatic computer for extensive code generation. arXiv preprint arXiv:2310.02003.
[345] Asif Rahman et al. (2025). MARCO: Multi-Agent Code Optimization with Real-Time Knowledge Integration for High-Performance Computing. https://arxiv.org/abs/2505.03906. arXiv:2505.03906.
[346] Li et al. (2025). Cogito, ergo sum: A neurobiologically-inspired cognition-memory-growth system for code generation. arXiv preprint arXiv:2501.18653.
[347] Guo et al. (2025). SyncMind: Measuring agent out-of-sync recovery in collaborative software engineering. In International Conference on Machine Learning (ICML).
[348] Erman et al. (1980). The Hearsay-II Speech-Understanding System: Integrating Knowledge to Resolve Uncertainty. ACM Computing Surveys (CSUR). 12(2). pp. 213–253. doi:10.1145/356810.356816.
[349] GitHub. About GitHub Copilot Cloud Agent. https://docs.github.com/copilot/concepts/agents/coding-agent/about-coding-agent. Accessed: 2026-05-09.
[350] LangChain. DeepAgents. https://github.com/langchain-ai/deepagents. GitHub repository. Accessed: 2026-05-09.
[351] Xiangyan Liu et al. (2024). CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases. https://arxiv.org/abs/2408.03910. arXiv:2408.03910.
[352] Anthropic (2024). Model Context Protocol. https://docs.anthropic.com/en/docs/agents-and-tools/mcp.
[353] Pan et al. (2026). Natural-language agent harnesses. arXiv preprint arXiv:2603.25723.
[354] Xia et al. (2024). Agentless: Demystifying LLM-based Software Engineering Agents. arXiv preprint arXiv:2407.01489.
[355] Ridnik et al. (2024). Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering. arXiv preprint arXiv:2401.08500.
[356] Luo et al. (2024). RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. pp. 436–464. doi:10.18653/v1/2024.emnlp-demo.46. https://aclanthology.org/2024.emnlp-demo.46/.
[357] Li et al. (2026). ContextBench: A Benchmark for Context Retrieval in Coding Agents. arXiv preprint arXiv:2602.05892.
[358] Li et al. (2026). Learning to Commit: Generating Organic Pull Requests via Online Repository Memory. arXiv preprint arXiv:2603.26664.
[359] Thillen et al. (2026). CodeTaste: Can LLMs Generate Human-Level Code Refactorings?. arXiv preprint arXiv:2603.04177.
[360] Aleithan et al. (2024). Swe-bench+: Enhanced coding benchmark for llms. arXiv preprint arXiv:2410.06992.
[361] Peng et al. (2023). The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. arXiv preprint arXiv:2302.06590.
[362] Vaithilingam et al. (2022). Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models. In Extended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems (CHI EA). doi:10.1145/3491101.3519665.
[363] Mozannar et al. (2022). Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming. arXiv preprint arXiv:2210.14306.
[364] Miserendino et al. (2025). SWE-lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering?. arXiv preprint arXiv:2502.12115.
[365] Deng et al. (2025). Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?. arXiv preprint arXiv:2509.16941.
[366] Merrill et al. (2026). Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces. arXiv preprint arXiv:2601.11868.
[367] Trivedi et al. (2024). Appworld: A controllable world of apps and people for benchmarking interactive coding agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 16022–16076.
[368] Xie et al. (2024). Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems. 37. pp. 52040–52094.
[369] Shunyu Yao et al. (2025). ${\backslash}tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=roNSXZpUDN.
[370] Tang et al. (2024). Codeagent: Autonomous communicative agents for code review. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 11279–11313.
[371] Baqar et al. (2025). AI Augmented CI/CD Pipelines: From Code Commit to Production with Autonomous Decisions. In 2025 3rd International Conference on Foundation and Large Language Models (FLLM). pp. 1041–1048. doi:10.1109/fllm67465.2025.11391007. http://dx.doi.org/10.1109/FLLM67465.2025.11391007.
[372] Ma et al. (2025). Alibaba lingmaagent: Improving automated issue resolution via comprehensive repository exploration. In Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. pp. 238–249.
[373] Li et al. (2026). Advances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey. arXiv preprint arXiv:2601.11655.
[374] Li et al. (2025). Metal: A multi-agent framework for chart generation with test-time scaling. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 30054–30069.
[375] Cursor Team (2025). Composer: Building a fast frontier model with reinforcement learning. https://cursor.com/blog/composer. Cursor blog.
[376] Cursor Team (2025). Improving Composer through real-time reinforcement learning. https://cursor.com/blog/real-time-rl-for-composer. Cursor blog.
[377] OpenAI (2025). Addendum to GPT-5 system card: GPT-5-Codex.
[378] OpenAI (2025). Building more with GPT-5.1-Codex-Max. https://openai.com/index/gpt-5-1-codex-max/. OpenAI announcement.
[379] Anthropic (2025). How Anthropic teams use Claude Code.
[380] Wang et al. (2025). Are" solved issues" in swe-bench really solved correctly? an empirical study. arXiv preprint arXiv:2503.15223.
[381] Wang et al. (2025). SWE-Bench++: A Framework for the Scalable Generation of Software Engineering Benchmarks from Open-Source Repositories. arXiv preprint arXiv:2512.17419.
[382] OpenAI (2025). Introducing Aardvark: OpenAI's agentic security researcher. https://openai.com/index/introducing-aardvark/.
[383] OpenAI (2026). Codex Security: now in research preview. https://openai.com/index/codex-security-now-in-research-preview/.
[384] Cemri et al. (2025). Why Do Multi-Agent LLM Systems Fail?. arXiv preprint arXiv:2503.13657.
[385] Zhang et al. (2025). Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems. arXiv preprint arXiv:2505.00212.
[386] Zhang et al. (2025). AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?. arXiv preprint arXiv:2509.03312.
[387] Zhu et al. (2025). Where llm agents fail and how they can learn from failures. arXiv preprint arXiv:2509.25370.
[388] Sidik, Bronislav and Rokach, Lior (2026). Beyond static sandboxing: Learned capability governance for autonomous ai agents. arXiv preprint arXiv:2604.11839.
[389] Boyang Yan (2025). Fault-Tolerant Sandboxing for AI Coding Agents: A Transactional Approach to Safe Autonomous Execution. arXiv preprint arXiv:2512.12806.
[390] Microsoft (2026). Introducing the Agent Governance Toolkit: open-source runtime security for AI agents. https://opensource.microsoft.com/blog/2026/04/02/introducing-the-agent-governance-toolkit-open-source-runtime-security-for-ai-agents/.
[391] Christopher Rawles et al. (2025). AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. https://arxiv.org/abs/2405.14573. arXiv:2405.14573.
[392] Rogerio Bonatti et al. (2024). Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale. https://arxiv.org/abs/2409.08264. arXiv:2409.08264.
[393] Yang et al. (2024). Agentoccam: A simple yet strong baseline for llm-based web agents. arXiv preprint arXiv:2410.13825.
[394] Boyuan Zheng et al. (2024). GPT-4V(ision) is a Generalist Web Agent, if Grounded. https://arxiv.org/abs/2401.01614. arXiv:2401.01614.
[395] Hongliang He et al. (2024). WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. https://arxiv.org/abs/2401.13919. arXiv:2401.13919.
[396] Tianbao Xie et al. (2024). OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. https://arxiv.org/abs/2404.07972. arXiv:2404.07972.
[397] Jianwei Yang et al. (2023). Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V. https://arxiv.org/abs/2310.11441. arXiv:2310.11441.
[398] Alexandre Drouin et al. (2024). WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?. https://arxiv.org/abs/2403.07718. arXiv:2403.07718.
[399] Wenyi Hong et al. (2024). CogAgent: A Visual Language Model for GUI Agents. https://arxiv.org/abs/2312.08914. arXiv:2312.08914.
[400] Shuai Wang et al. (2025). GUI Agents with Foundation Models: A Comprehensive Survey. https://arxiv.org/abs/2411.04890. arXiv:2411.04890.
[401] Yifan Xu et al. (2024). AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents. https://arxiv.org/abs/2410.24024. arXiv:2410.24024.
[402] Xingyao Wang et al. (2024). Executable Code Actions Elicit Better LLM Agents. https://arxiv.org/abs/2402.01030. arXiv:2402.01030.
[403] Weihao Tan et al. (2024). Cradle: Empowering Foundation Agents Towards General Computer Control. https://arxiv.org/abs/2403.03186. arXiv:2403.03186.
[404] Frank F. Xu et al. (2025). TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks. https://arxiv.org/abs/2412.14161. arXiv:2412.14161.
[405] Kanzhi Cheng et al. (2024). SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. https://arxiv.org/abs/2401.10935. arXiv:2401.10935.
[406] Keen You et al. (2024). Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs. https://arxiv.org/abs/2404.05719. arXiv:2404.05719.
[407] Zhiyong Wu et al. (2024). OS-ATLAS: A Foundation Action Model for Generalist GUI Agents. https://arxiv.org/abs/2410.23218. arXiv:2410.23218.
[408] Kevin Qinghong Lin et al. (2024). ShowUI: One Vision-Language-Action Model for GUI Visual Agent. https://arxiv.org/abs/2411.17465. arXiv:2411.17465.
[409] Yuhao Yang et al. (2025). Aria-UI: Visual Grounding for GUI Instructions. https://arxiv.org/abs/2412.16256. arXiv:2412.16256.
[410] Boyu Gou et al. (2025). Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents. https://arxiv.org/abs/2410.05243. arXiv:2410.05243.
[411] Yujia Qin et al. (2025). UI-TARS: Pioneering Automated GUI Interaction with Native Agents. https://arxiv.org/abs/2501.12326. arXiv:2501.12326.
[412] Rui Yang et al. (2026). GUI-Libra: Training Native GUI Agents to Reason and Act with Action-aware Supervision and Partially Verifiable RL. https://arxiv.org/abs/2602.22190. arXiv:2602.22190.
[413] Ruisheng Cao et al. (2024). Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?. https://arxiv.org/abs/2407.10956. arXiv:2407.10956.
[414] Longtao Zheng et al. (2024). Synapse: Trajectory-as-Exemplar Prompting with Memory for Computer Control. https://arxiv.org/abs/2306.07863. arXiv:2306.07863.
[415] Chi Zhang et al. (2023). AppAgent: Multimodal Agents as Smartphone Users. https://arxiv.org/abs/2312.13771. arXiv:2312.13771.
[416] Junyang Wang et al. (2024). Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration. https://arxiv.org/abs/2406.01014. arXiv:2406.01014.
[417] Ke Yang et al. (2026). PlugMem: A Task-Agnostic Plugin Memory Module for LLM Agents. https://arxiv.org/abs/2603.03296. arXiv:2603.03296.
[418] Zichuan Lin et al. (2026). UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience. https://arxiv.org/abs/2603.24533. arXiv:2603.24533.
[419] Xiao Liu et al. (2024). AutoGLM: Autonomous Foundation Agents for GUIs. https://arxiv.org/abs/2411.00820. arXiv:2411.00820.
[420] Qiushi Sun et al. (2025). OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis. https://arxiv.org/abs/2412.19723. arXiv:2412.19723.
[421] Evan Zheran Liu et al. (2018). Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration. https://arxiv.org/abs/1802.08802. arXiv:1802.08802.
[422] Shunyu Yao et al. (2023). WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. https://arxiv.org/abs/2207.01206. arXiv:2207.01206.
[423] Jing Yu Koh et al. (2024). VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. https://arxiv.org/abs/2401.13649. arXiv:2401.13649.
[424] Mingzhe Xing et al. (2024). Understanding the Weakness of Large Language Model Agents within a Complex Android Environment. https://arxiv.org/abs/2402.06596. arXiv:2402.06596.
[425] Xiao Liu et al. (2025). AgentBench: Evaluating LLMs as Agents. https://arxiv.org/abs/2308.03688. arXiv:2308.03688.
[426] Yuhao Zheng et al. (2026). Code2World: A GUI World Model via Renderable Code Generation. https://arxiv.org/abs/2602.09856. arXiv:2602.09856.
[427] Anthropic (2024). Introducing computer use, a new Claude 3.5 Sonnet, and a new Claude 3.5 Haiku. https://www.anthropic.com/news/3-5-models-and-computer-use.
[428] OpenAI (2025). Introducing Operator. https://openai.com/index/introducing-operator/.
[429] Google DeepMind (2025). Project Mariner. https://deepmind.google/models/project-mariner/.
[430] Hanyu Lai et al. (2024). AutoWebGLM: A Large Language Model-based Web Navigating Agent. https://arxiv.org/abs/2404.03648. arXiv:2404.03648.
[431] Jacky Liang et al. (2023). Code as Policies: Language Model Programs for Embodied Control. https://arxiv.org/abs/2209.07753. arXiv:2209.07753.
[432] Vemprala et al. (2024). Chatgpt for robotics: Design principles and model abilities. Ieee Access. 12. pp. 55682–55696.
[433] Huang et al. (2022). Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608.
[434] Huang et al. (2023). Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973.
[435] Macenski et al. (2020). The Marathon 2: A Navigation System. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. https://arxiv.org/abs/2003.00368.
[436] Driess et al. (2023). Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378.
[437] Team et al. (2025). Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer. arXiv preprint arXiv:2510.03342.
[438] Yutaro Yamada et al. (2025). The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search. https://arxiv.org/abs/2504.08066. arXiv:2504.08066.
[439] Juraj Gottweis et al. (2025). Towards an AI co-scientist. https://arxiv.org/abs/2502.18864. arXiv:2502.18864.
[440] Swanson et al. (2025). The Virtual Lab of AI agents designs new SARS-CoV-2 nanobodies. Nature. 646(8085). pp. 716–723.
[441] Hubert et al. (2025). Olympiad-level formal mathematical reasoning with reinforcement learning. Nature. pp. 1–3.
[442] Jinheon Baek et al. (2025). ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models. https://arxiv.org/abs/2404.07738. arXiv:2404.07738.
[443] Odhran O'Donoghue et al. (2023). BioPlanner: Automatic Evaluation of LLMs on Protocol Planning in Biology. https://arxiv.org/abs/2310.10632. arXiv:2310.10632.
[444] Mehr et al. (2020). A universal system for digitization and automatic execution of the chemical synthesis literature. Science. 370(6512). pp. 101–108.
[445] Samuel Schmidgall et al. (2025). Agent Laboratory: Using LLM Agents as Research Assistants. https://arxiv.org/abs/2501.04227. arXiv:2501.04227.
[446] Samuel Schmidgall and Michael Moor (2025). AgentRxiv: Towards Collaborative Autonomous Research. https://arxiv.org/abs/2503.18102. arXiv:2503.18102.
[447] Shuo Ren et al. (2026). Towards Scientific Intelligence: A Survey of LLM-based Scientific Agents. https://arxiv.org/abs/2503.24047. arXiv:2503.24047.
[448] Zhengyao Jiang et al. (2025). AIDE: AI-Driven Exploration in the Space of Code. https://arxiv.org/abs/2502.13138. arXiv:2502.13138.
[449] Zou et al. (2025). El Agente: An autonomous agent for quantum chemistry. Matter. 8(7). pp. 102263. doi:10.1016/j.matt.2025.102263. http://dx.doi.org/10.1016/j.matt.2025.102263.
[450] Jakub Lála et al. (2023). PaperQA: Retrieval-Augmented Generative Agent for Scientific Research. https://arxiv.org/abs/2312.07559. arXiv:2312.07559.
[451] Alexander Novikov et al. (2025). AlphaEvolve: A coding agent for scientific and algorithmic discovery. https://arxiv.org/abs/2506.13131. arXiv:2506.13131.
[452] Szymanski et al. (2023). An autonomous laboratory for the accelerated synthesis of inorganic materials. Nature. 624(7990). pp. 86.
[453] Benjamin P. MacLeod et al. (2020). Self-driving laboratory for accelerated discovery of thin-film materials. https://arxiv.org/abs/1906.05398. arXiv:1906.05398.
[454] Ziqi Ni et al. (2024). MatPilot: an LLM-enabled AI Materials Scientist under the Framework of Human-Machine Collaboration. https://arxiv.org/abs/2411.08063. arXiv:2411.08063.
[455] Qian Huang et al. (2024). MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation. https://arxiv.org/abs/2310.03302. arXiv:2310.03302.
[456] Jun Shern Chan et al. (2025). MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. https://arxiv.org/abs/2410.07095. arXiv:2410.07095.
[457] Ming Hu et al. (2025). A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers. https://arxiv.org/abs/2508.21148. arXiv:2508.21148.
[458] Ziru Chen et al. (2025). ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery. https://arxiv.org/abs/2410.05080. arXiv:2410.05080.
[459] Bodhisattwa Prasad Majumder et al. (2024). DiscoveryBench: Towards Data-Driven Discovery with Large Language Models. https://arxiv.org/abs/2407.01725. arXiv:2407.01725.
[460] He et al. (2020). Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. pp. 639–648.
[461] Guo et al. (2017). DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247.
[462] Hou et al. (2024). Large language models are zero-shot rankers for recommender systems. In European conference on information retrieval. pp. 364–381.
[463] Dai et al. (2023). Uncovering chatgpt’s capabilities in recommender systems. In Proceedings of the 17th ACM conference on recommender systems. pp. 1126–1132.
[464] Liu et al. (2025). Recoworld: Building simulated environments for agentic recommender systems. arXiv preprint arXiv:2509.10397.
[465] Wang et al. (2024). Recmind: Large language model powered agent for recommendation. In Findings of the Association for Computational Linguistics: NAACL 2024. pp. 4351–4364.
[466] Huang et al. (2025). Recommender ai agent: Integrating large language models for interactive recommendations. ACM Transactions on Information Systems. 43(4). pp. 1–33.
[467] Zhang et al. (2024). On generative agents in recommendation. In Proceedings of the 47th international ACM SIGIR conference on research and development in Information Retrieval. pp. 1807–1817.
[468] Xu et al. (2025). iagent: Llm agent as a shield between user and recommender systems. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 18056–18084.
[469] Xu et al. (2026). A-mem: Agentic memory for llm agents. Advances in Neural Information Processing Systems. 38. pp. 17577–17604.
[470] Chhikara et al. (2025). Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413.
[471] Chen et al. (2026). MemRec: Collaborative Memory-Augmented Agentic Recommender System. arXiv preprint arXiv:2601.08816.
[472] Zhang et al. (2025). Llm-powered user simulator for recommender system. In Proceedings of the AAAI Conference on Artificial Intelligence. pp. 13339–13347.
[473] Wang et al. (2025). User behavior simulation with large language model-based agents. ACM Transactions on Information Systems. 43(2). pp. 1–37.
[474] Lei et al. (2020). Conversational recommendation: Formulation, methods, and evaluation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2425–2428.
[475] Anthropic (2026). Demystifying evals for AI agents. https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents. Accessed: 2026-05-10.
[476] Ni et al. (2023). Lever: Learning to verify language-to-code generation with execution. In International Conference on Machine Learning. pp. 26106–26128.
[477] Jung et al. (2025). Code Execution as Grounded Supervision for LLM Reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 24811–24822. doi:10.18653/v1/2025.emnlp-main.1260. https://aclanthology.org/2025.emnlp-main.1260/.
[478] Tang et al. (2026). ExecVerify: White-Box RL with Verifiable Stepwise Rewards for Code Execution Reasoning. arXiv preprint arXiv:2603.11226.