Neural Computers
Mingchen Zhuge$^{1, 2, +}$, Changsheng Zhao$^{1, +}$, Haozhe Liu$^{1, 2, +}$, Zijian Zhou$^{1, +}$, Shuming Liu$^{1, 2, +}$, Wenyi Wang$^{2}$, Ernie Chang$^{1}$, Gael Le Lan$^{1}$, Junjie Fei$^{1, 2}$, Wenxuan Zhang$^{1, 2}$, Yasheng Sun$^{2}$, Zhipeng Cai$^{1}$, Zechun Liu$^{1}$, Yunyang Xiong$^{1}$, Yining Yang$^{1}$, Yuandong Tian$^{1}$, Yangyang Shi$^{1}$, Vikas Chandra$^{1}$, Jürgen Schmidhuber$^{2}$
$^{1}$ Meta AI
$^{2}$ KAUST
$^{+}$ Core Contributors
Abstract
We propose a new frontier: Neural Computers (NCs)—an emerging machine form that unifies computation, memory, and I/O in a learned runtime state. Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. Our long-term goal is the Completely Neural Computer (CNC): the mature, general-purpose realization of this emerging machine form, with stable execution, explicit reprogramming, and durable capability reuse. As an initial step, we study whether early NC primitives can be learned solely from collected I/O traces, without instrumented program state. Concretely, we instantiate NCs as video models that roll out screen frames from instructions, pixels, and user actions (when available) in CLI and GUI settings. These implementations show that learned runtimes can acquire early interface primitives, especially I/O alignment and short-horizon control, while routine reuse, controlled updates, and symbolic stability remain open. We outline a roadmap toward CNCs around these challenges. If overcome, CNCs could establish a new computing paradigm beyond today’s agents, world models, and conventional computers.
Blogpost: https://metauto.ai/neuralcomputer
Correspondence: [email protected], [email protected]
Executive Summary: The rapid evolution of AI agents and world models has exposed a key limitation in current computing: systems still separate learned intelligence from the actual execution environment, relying on external hardware, operating systems, or simulators to handle computation, memory, and input/output. This fragmentation hinders seamless integration, especially for tasks involving dynamic interfaces like command lines or graphical desktops. As AI capabilities grow, there is an urgent need to explore whether a neural model can internalize these roles into a single learned state, potentially creating a new machine paradigm that unifies AI with computing infrastructure.
This document proposes neural computers (NCs)—neural systems where a single set of learned weights acts as the running computer, blending computation, memory, and interfaces in a dynamic runtime state. It evaluates whether basic NC features, such as aligning inputs/outputs and short-term control, can emerge solely from raw interaction traces like screen frames and user actions, without access to underlying program details.
Researchers built NC prototypes as video generation models, trained to predict interface evolution from initial frames, text prompts, or action streams. For command-line interfaces (CLI), they used two datasets: one with 1,100 hours of diverse public terminal recordings and another with 128,000 scripted, clean sessions in controlled environments. For graphical user interfaces (GUI), they collected 1,500 hours of desktop interactions in a standardized Ubuntu setup, including random mouse/keyboard actions and 110 hours of goal-directed traces from AI agents. Training involved fine-tuning a state-of-the-art video model over thousands of GPU hours, focusing on synchronized data to ensure temporal accuracy. Evaluations measured rendering quality, text fidelity via optical character recognition, and control precision through metrics like structural similarity and video distance, without real-time feedback loops.
The most critical finding is that NCs can achieve strong interface fidelity: in CLI setups, generated terminals show readable text at practical font sizes, with character accuracy reaching 54% and exact line matches at 31% after training. In GUI, explicit visual cues for cursor position yield 98.7% accuracy, enabling coherent short responses to actions like clicks or hovers. Second, data quality trumps scale—a small set of purposeful interactions outperformed ten times more random data by improving post-action consistency up to 16% in visual metrics. Third, detailed prompts boost control: CLI arithmetic tasks jumped from 4% to 83% accuracy with better conditioning, though native symbolic reasoning stayed weak at under 5% without aids. Fourth, deeper integration of actions into the model enhances responsiveness, cutting temporal distortion by about 50% compared to surface-level methods. Finally, prototypes handle short workflows well but falter on longer chains, with limited reuse of learned routines.
These results suggest NCs mark an early shift toward self-contained neural runtimes, capable of basic interface simulation without external execution layers. This could reduce costs and risks in AI-driven systems by embedding control directly in models, improving robustness for uncertain tasks like user interactions—areas where traditional computers struggle with noise or adaptation. Unlike prior world models, which predict but do not execute, or agents that rely on separate tools, NCs begin to close this gap, though weaker-than-expected symbolic performance underscores that scaling alone won't suffice; holistic numerical processing favors perceptual tasks over precise math.
To advance, prioritize engineering for stable reuse—such as installing routines that persist across sessions without retraining—and explicit updates to govern changes, avoiding unintended drifts. Test deeper architectures for long-term reasoning, perhaps combining video models with symbolic modules, and run pilots on real-world tasks like error recovery in desktops. Options include heavy reliance on high-quality curated data (lower risk, slower scaling) versus automated collection with filters (faster but higher noise). Further work needs richer datasets for edge cases and closed-loop evaluations to validate interactivity before committing resources.
Confidence in early primitives like rendering and short control is high, backed by consistent metrics across prototypes. However, uncertainties remain in symbolic stability and long-horizon behavior due to video substrates' bias toward visuals over logic, and assumptions of clean data may not hold in diverse real environments—stakeholders should approach full deployment cautiously, focusing first on controlled proofs of concept.
1. Introduction
Section Summary: The introduction proposes the concept of a Neural Computer, a neural network system that combines computing, memory, and input-output functions within a single learned state, aiming to make the AI itself function like a running computer rather than relying on separate external tools. To test this, the authors create practical prototypes using video models that simulate interactions with command-line terminals and graphical desktop interfaces, drawing on advances in world modeling and video generation. Early experiments show promise in rendering basic workflows and handling short actions, but highlight ongoing challenges toward a fully mature version called a Completely Neural Computer, with contributions including new data tools and a roadmap for future development.
Can a single set of weights act as a "computer"? We term this abstraction a Neural Computer (NC): a neural system that unifies computation, memory, and I/O in a learned runtime state. This usage is distinct from the Neural Turing Machine / Differentiable Neural Computer line ([1, 2]): our concern is not differentiable external memory, but whether a learning machine can begin to assume the role of the running computer itself.
To implement this idea, we instantiate NCs as video models. At this stage, video models are the most practical substrate for this prototype, though we expect the long-term solution to require a fundamentally new neural architecture (Section 4). This implementation draws on several technical lines. World models ([3]) show that neural networks can internalize environment dynamics and support predictive imagination, while high-capacity video generators such as Veo 3.1 ([4]) and Sora 2 ([5]) show that such learned dynamics can be rendered into coherent frame sequences. Frontier interactive video models such as Genie 3 ([6]) further extend this trajectory toward action-controllable generative environments. These lines provide practical machinery for current NC prototypes, but do not by themselves define the NC abstraction. In parallel, LLM-driven UI systems such as Imagine with Claude^1 map natural-language inputs to structured interface updates. Yet these capabilities remain split across different systems objects: conventional computers execute explicit programs, agents act through external execution environments, and world models render or predict environment dynamics, while executable state still resides outside the model. NCs are motivated by this gap: they are not a smarter layer on top of the existing stack, but a proposal to make the model itself the running computer. The immediate question in this paper is whether early runtime primitives can be learned directly from raw interface I/O without privileged access to program state.
Throughout this paper, NC denotes this proposed machine form, while CNC denotes its mature, general-purpose realization. We study two interface-specific prototypes of this NC formulation (see Section 2). NC $\text{CLIGen}$ models terminal interaction from text (natural language or command lines) and an initial frame, while NC $\text{GUIWorld}$ models desktop interaction from recent pixels and synchronized mouse/keyboard actions (Section 3.1 and Section 3.2).
**Neural Computer (NC) abstraction (Teaser).**
A neural system $(F, G)$ parameterized by $\theta$ that models an interactive computer interface through a single latent runtime state $h_t$ that carries executable interface state and also acts as working memory (see Equation 1).
In the NC $_\text{CLIGen}$ experiments, the NC can render and execute basic command-line workflows. It often stays aligned with the terminal buffer and captures common "physics" of everyday CLI use (e.g., fast scrollback, prompt wrapping, window resizing). On carefully scripted data, rollouts can be visually and structurally close to real sessions, and the model can execute short command chains and render their outputs. Arithmetic-probe scores improve substantially with stronger system-level conditioning, though symbolic stability remains limited.
In the NC $_\text{GUIWorld}$ experiments, we evaluate standard world-model designs across action injection, action encoding, and data quality. Figure 1 summarizes this template across two interface-specific NCs trained separately without shared parameters. Qualitatively, the model learns coherent pointer dynamics and short-horizon action responses (e.g., hover/click feedback and window/menu transitions), suggesting that local GUI control primitives are learnable in controlled settings.
Our experimental insights indicate that current NCs already realize early runtime primitives, most notably I/O alignment and short-horizon control. The long-term target is a Completely Neural Computer (CNC), the mature, general-purpose realization of this machine form: a fully learned computer whose compute, memory, and interfaces are unified in a single learned runtime substrate rather than engineered as separate modules. These prototypes are an early step toward that CNC vision. Substantial challenges remain in robust long-horizon reasoning, reliable symbolic processing, stable capability reuse, and explicit runtime governance. Section 4 outlines these open challenges and a roadmap toward CNCs.
**Completely Neural Computer (CNC) abstraction (Section 4.2).**
A Neural Computer instance is *complete* (i.e., a CNC) if it is
(i) *Turing complete*,
(ii) *universally programmable*,
(iii) *behavior-consistent* unless explicitly reprogrammed, and
(iv) realizes the architectural and programming-language advantages of NCs relative to conventional computers.
Concretely, this work makes the following contributions:
- Define neural computers (NCs) and build video-based prototypes for both CLI and GUI interfaces.
- Provide a data engine and alignment recipe that synchronize text, actions, and frames for the CLI and GUI environments used in this paper.
- Identify practical design choices for NCs through extensive ablation studies.
- Outline an engineering roadmap toward completely neural computers (CNCs), centered on acceptance challenges such as reuse, consistency, and runtime governance.
2. Preliminaries
Section Summary: This section introduces conventional digital computers as traditional machines that separate processing, memory, and input/output functions, often relying on operating systems to manage them. It poses a key question: can a single neural network's internal state handle all these roles without external support, using a "neural computer" prototype that simulates video interfaces through an update-and-render process? The neural computer updates a hidden internal state based on current screen views and user actions to predict the next frame, drawing from related research in neural memory systems, world models, and advanced video generators to enable interactive simulations like command-line or desktop environments.
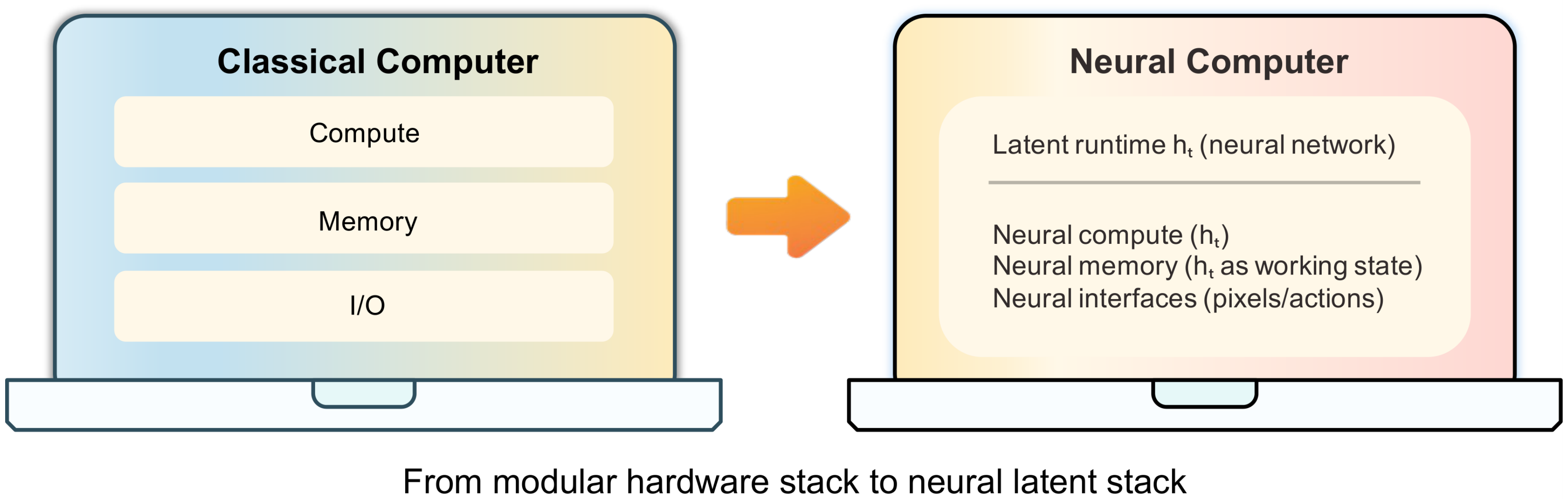
Throughout this paper, we use conventional digital computers as an umbrella term for stored-program machines (e.g., von Neumann-style architectures): at the theory level they are commonly abstracted as random-access machines with an instruction set architecture, and at the systems level they are typically realized through layered operating-system/application stacks. Such systems separate computation, memory, and I/O. Our motivating question is whether a single set of weights can internalize these roles inside one latent runtime state, rather than relying on an external execution environment (e.g., OS/simulator) to carry executable state. We model a video-based neural computer (NC) prototype as a learned latent-state system that folds these roles into an update-and-render loop.
Specifically, an NC updates a latent runtime state from the current observation and conditioning input, and then predicts (or samples) the next observation. In this paper, we treat screen frames as observables and define actions as time-indexed conditions. More broadly, the NC framework can accommodate various other modalities and structural representations for both observables and actions. Given an initial screen frame $x_0$ and conditioned on user action $u_t$ at iteration $t$, an NC updates its runtime state and samples the next frame $x_{t+1}$. Formally, an NC defined by an initial runtime state $h_0$, an update function $F_\theta$, and a decoder $G_\theta$ operates as follows, where $G_\theta$ parameterizes a distribution over next frames:
$ \begin{align} h_t &= F_\theta(h_{t-1}, x_t, u_t), \qquad x_{t+1} \sim G_\theta(h_t). \end{align}\tag{1} $
In this formulation, $h_t$ provides the persistent runtime memory, $F_\theta$ carries the state-update computation, and $(x_t, u_t, G_\theta)$ define the I/O pathway from observations and actions to the next observable state.
Notation. We use $h_t$ for the NC latent runtime state and reserve $z$ for VAE/video latents used in diffusion-style video models (e.g., Section 3.2).
This update-and-render loop can be described using world-model terminology, where $x_t$ are observations and $u_t$ provides conditioning. In that terminology, the input sequence ${u_t}$ is referred to as a conditioning stream. This view supplies practical machinery for the current prototype, but an NC is not merely a predictor of interface dynamics: it is a learned runtime mechanism in which the latent state $h_t$ carries executable context, $F_\theta$ integrates new observations and inputs, and $G_\theta$ renders the next frame. Auxiliary heads can encode and decode prompts, buffers, or action traces, shifting functionality that would traditionally live in OS queues, device drivers, and UI toolkits into latent-state dynamics.
2.1 Related Work
Early neuromorphic designs ([7]) explored neural computation as a physical substrate. Differentiable memory and program-execution architectures, including fast weight programmers ([8, 9, 10]), Neural Turing Machines ([1]), Differentiable Neural Computers ([2]), and Neural Programmer-Interpreters ([11]), showed that neural controllers with memory can execute structured procedures. Differentiable world models ([12, 13]) learn neural representations of environment dynamics, and inspire our update-and-render formulation. Latent video and world models ([3, 14, 15, 6]) apply these ideas to embodied control and interactive environments. Genie 3 ([6]), in particular, frames such models as agent-training substrates with improved physical consistency. More recently, high-capacity generators such as Veo 3 ([4]) and Sora 2 ([5]) emphasize open-ended, photorealistic simulation. In parallel, systems such as NeuralOS ([16]) and Imagine with Claude ([17]) bring model-based conditioning to desktop and DOM-style interfaces. Building on this trajectory, we study two NC instantiations for CLI and GUI with interface-specific conditioning, supported by a shared data engine and a staged roadmap toward the CNC vision.
3. Implementation of Neural Computers
Section Summary: Researchers have developed neural computers, or NCs, by enhancing an advanced video generation model called Wan2.1 to simulate computer interfaces like command-line terminals and graphical user interfaces. These NCs use prompts or recorded action sequences to predict and generate future frames of the interface in an open-loop setup, meaning they don't interact live with real software but replay logged behaviors. For the command-line version, called CLIGen, they created two datasets: one from diverse real-world terminal recordings using public tools like asciinema, and another from controlled, scripted sessions in isolated environments to ensure clean and repeatable data for training.
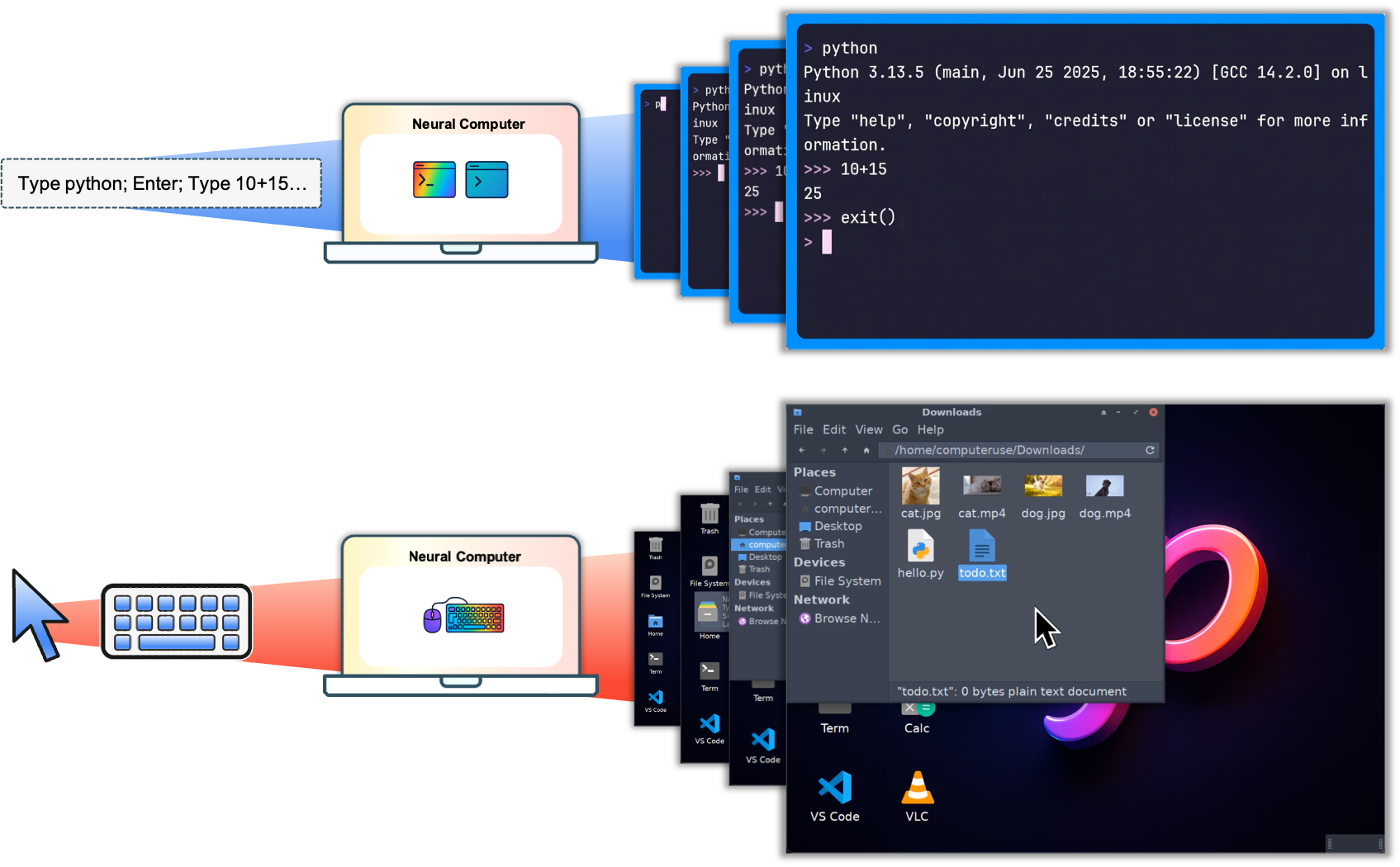
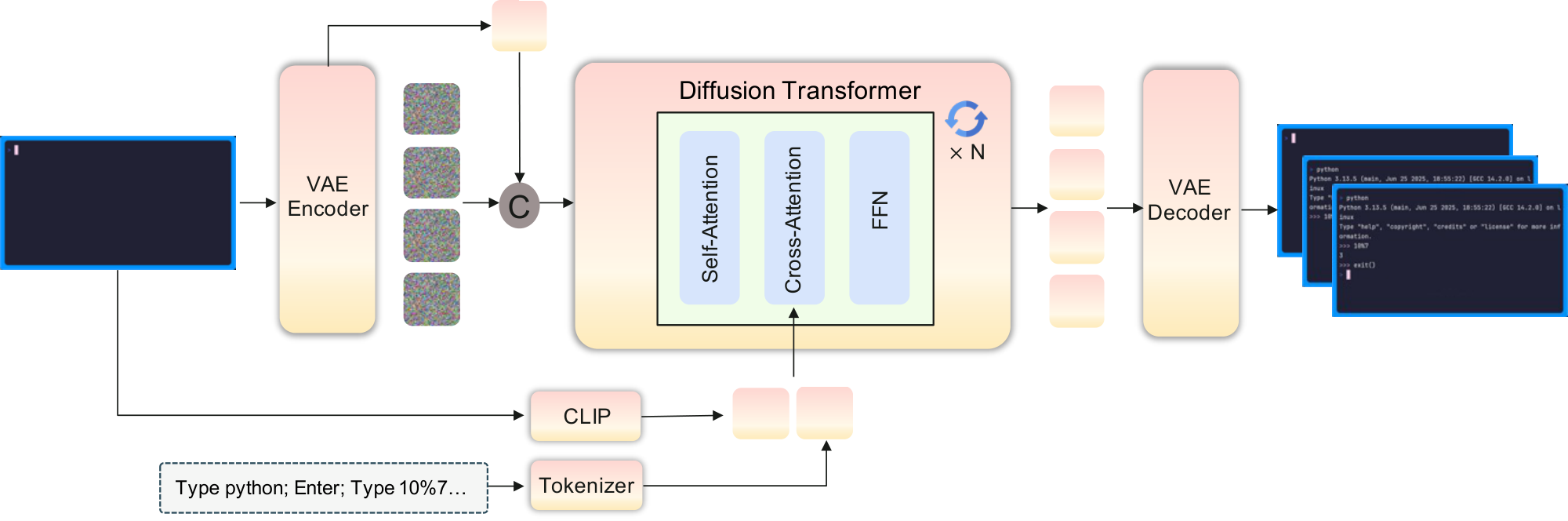
We build on the Wan2.1 model ([18]), which was a state-of-the-art video generation model at the time of our experiments. We add NC-specific conditioning and action modules, together with interface-specific training recipes. Figure 1 illustrates this setup: NCs take a prompt or action stream as input and generate future interface frames in both CLI and GUI settings. In the present prototypes, these prompts and actions are logged conditioning streams, so evaluation remains open-loop rather than closed-loop interaction with a live environment. We refer to these two instantiations as CLIGen (CLI; Section 3.1) and GUIWorld (GUI; Section 3.2).
In this video-based instantiation, the NC latent runtime state $h_t$ is realized by the model’s time-indexed video latents $z_t$. Under this abstraction, the diffusion transformer acts as the state-update map: it consumes prior latents together with the current observation and conditioning inputs, and produces the updated state $h_t$ (realized as $z_t$). The decoder $G_\theta$ parameterizes a distribution over the next frame $x_{t+1}$. Auxiliary heads encode and decode conditioning streams $u_t$, including text prompts and action traces. Structured logs such as terminal buffers are used for alignment and evaluation where available, not as privileged model-state inputs.
3.1 cligenGeneralLogo / cligenCleanLogo The CLI Video Generators
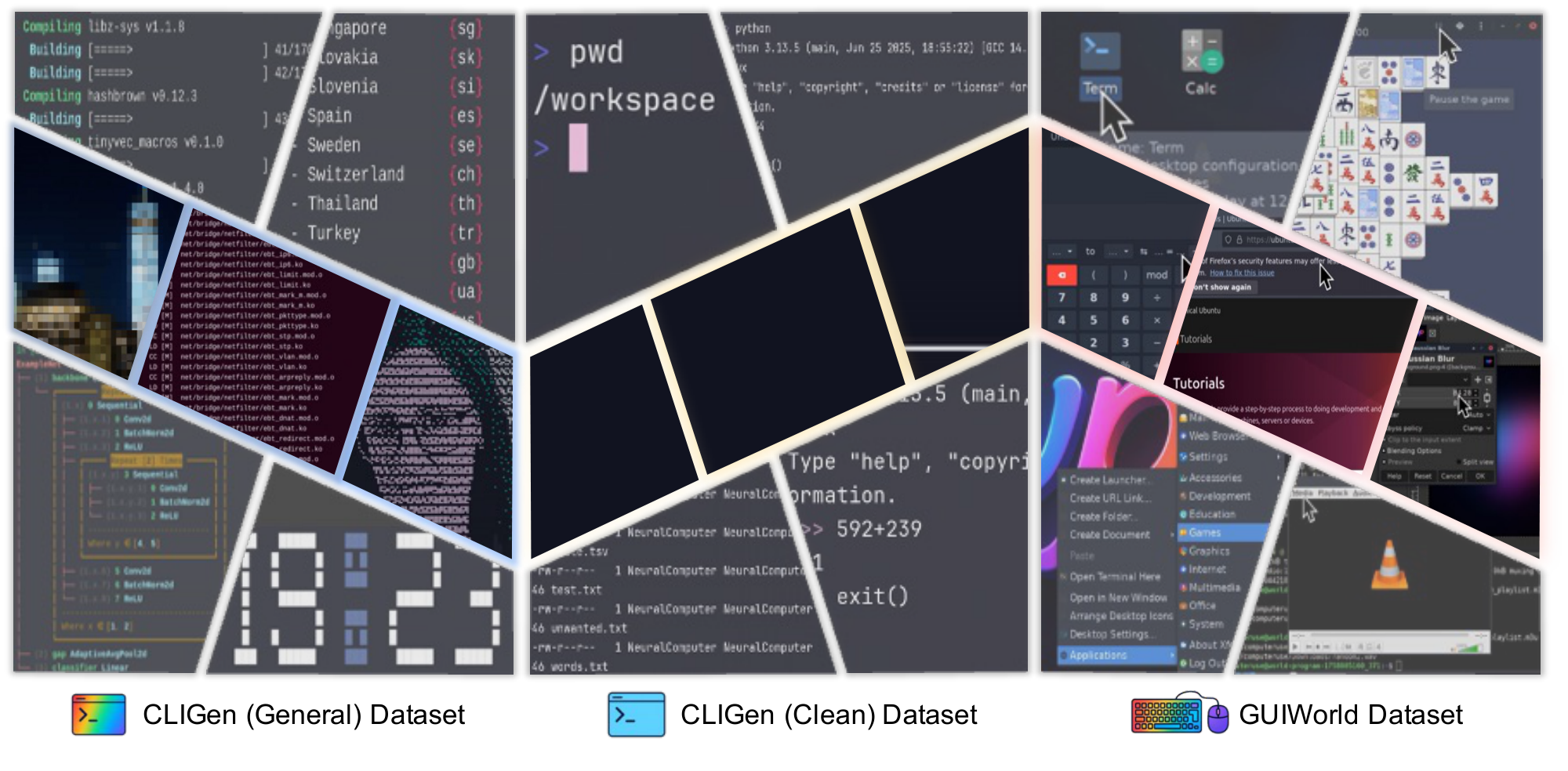
CLIGen instantiates the NC abstraction in command-line interfaces. Observations $x_t$ are terminal frames rendered from the underlying text buffer. The conditioning stream $u_t$ carries a user prompt and optional metadata, and the video latent state $z_t$ implements the latent runtime state $h_t$ by tracking CLI context across frames. At inference time, the model rolls out from the prompt and first frame, updates $z_t$, and predicts future terminal frames (Figure 3). We use two CLI datasets: cligenGeneralLogo CLIGen (General), which contains diverse, open-ended terminal traces, and cligenCleanLogo CLIGen (Clean), which contains deterministic Dockerized traces. We train one NC $_\text{CLIGen}$ model per dataset under the same architecture.
::: {caption="Table 1"}

:::
% caption, label
::: {caption="Table 2: Data samples for cligenGeneralLogo CLIGen (General) and cligenCleanLogo CLIGen (Clean)."}
:::
3.1.1 Data pipeline
The cligenGeneralLogo CLIGen (General) dataset is built from publicly available asciinema .cast trajectories^2. The asciinema stack records and replays terminal sessions with synchronized timing and ANSI-faithful decoding. We replay each session with the official tools and render it into terminal frames, preserving palette transitions, cursor state, and terminal geometry. Frames, text buffers, and keyboard-event logs share a single monotonic clock. At render time, we normalize resolution and aspect ratio and apply a filter to remove sensitive strings. We render sessions to GIF using and convert them to video with .
We segment each recording into roughly five-second clips using content-aware splits. We temporally normalize each clip to a fixed length: shorter clips repeat the final frame, and longer clips are uniformly subsampled. The resulting 823,989 video streams (approximately 1,100 hours) are resampled to 15 FPS. Underlying buffers and logs are used to generate aligned textual descriptions with Llama 3.1 70B ([19]) in three styles (semantic, regular, and detailed), which serve as prompts. As shown in Figure 2 (left), this split spans diverse real-world terminal use cases[^3].
[^3]: Additional preprocessing details and a .cast example are in Appendix B and Appendix C.1, with a sample overview in Table 2.
The cligenCleanLogo CLIGen (Clean) dataset is collected using the open-source toolkit. It enables repeatable terminal demonstrations and integration tests through scripted execution. Deterministic scripts drive Dockerized environments to capture cleaner, better-paced traces. We authored roughly $250$ k scripts. After filtering (51.21% retained), we keep two subsets. The first contains approximately $78$ k regular traces (package installation, log filtering, interactive REPL usage, etc.). The second contains approximately $50$ k Python math validation traces. Captions are derived directly from the raw vhs scripts for clarity. We standardize frame rendering by fixing one monospace font/size, using a consistent palette for success and error highlights, and locking resolution and theme to remove typography-related confounds. Each episode records its caption type and font settings for later slicing. Clips longer than five seconds are uniformly subsampled for training, while shorter clips repeat the final frame to normalize length[^4].
[^4]: Additional details are provided in Appendix B and Appendix C.2, with a representative data sample in Table 2.
3.1.2 Model architecture
We treat CLI generation as text-and-image-to-video: a caption and the first terminal frame condition the rollout. The first frame is encoded by a VAE into a conditioning latent. In parallel, a CLIP image encoder ([20]) extracts visual features from the same frame, and a text encoder (e.g., T5 ([21])) embeds the caption. Following the Wan2.1 image-to-video (I2V) design, these conditioning features are concatenated with diffusion noise, projected through a zero-initialized linear layer, and processed by a DiT stack. Decoupled cross-attention injects the joint caption and first-frame context derived from the CLIP and text features. The VAE encodes and decodes terminal frames. During generation, the diffusion transformer advances the latent state $z_t$ under the original Wan2.1 I2V sampling schedule, without additional binary masks or periodic reseeding.
3.1.3 Implementation Details
Training uses gradient checkpointing and applies dropout 0.1 to the prompt encoder, CLIP, and VAE modules. Optimization uses AdamW (learning rate $5\times10^{-5}$, weight decay $10^{-2}$), bfloat16 precision, and gradient clipping at 1.0. Training NC $_\text{CLIGen}$ on CLIGen (General) requires $\sim$ 15,000 H100 GPU hours at batch size 1. Training on CLIGen (Clean) across both subsets requires $\sim$ 7,000 H100 GPU hours.
3.1.4 Evaluations
Unless otherwise noted, NC in this section refers to the current video-based CLI prototype. We report six practical takeaways:
1. The NC maintains high-fidelity terminal rendering at practical font sizes (e.g., 13 px), preserving readable interface state.
2. Prompt specificity is an effective control channel: detailed, literal captions improve text-to-pixel alignment.
3. On clean but domain-specific data, global PSNR/ $\textsc{SSIM}$ plateau around 25k steps (Figure 5), indicating early saturation in reconstruction metrics rather than a complete halt in learning.
4. The NC reproduces complex terminal appearances while sustaining coherent short-horizon command rollouts under fixed conditioning.
5. Symbolic computation remains the main bottleneck: structured arithmetic reveals reliability limits, motivating stronger symbolic or system-level conditioning.
6. In our setting, without changing the NC backbone or adding RL, reprompting improves symbolic probes (4% $\rightarrow$ 83%; Figure 6), reinforcing the view that current models are strong renderers and conditionable interfaces rather than native reasoners (Table 7).
cligenGeneralLogo Experiment 1: The NC stays readable at practical font sizes
::: {caption="Table 3: Reconstruction quality."}

:::
Concurrent work ([16]) argues that generic natural-image VAEs can perform poorly on structured computer screenshots. We test this claim directly by applying the Wan2.1 VAE ([18]) to terminal content. In our setting, reconstruction quality is primarily governed by font size. At 13 px, it is high (40.77 dB $\textsc{PSNR}$, 0.989 $\textsc{SSIM}$). At 6 px, text exhibits noticeable blurring even when global $\textsc{PSNR}$ / $\textsc{SSIM}$ remain strong, because background regions dominate these metrics.
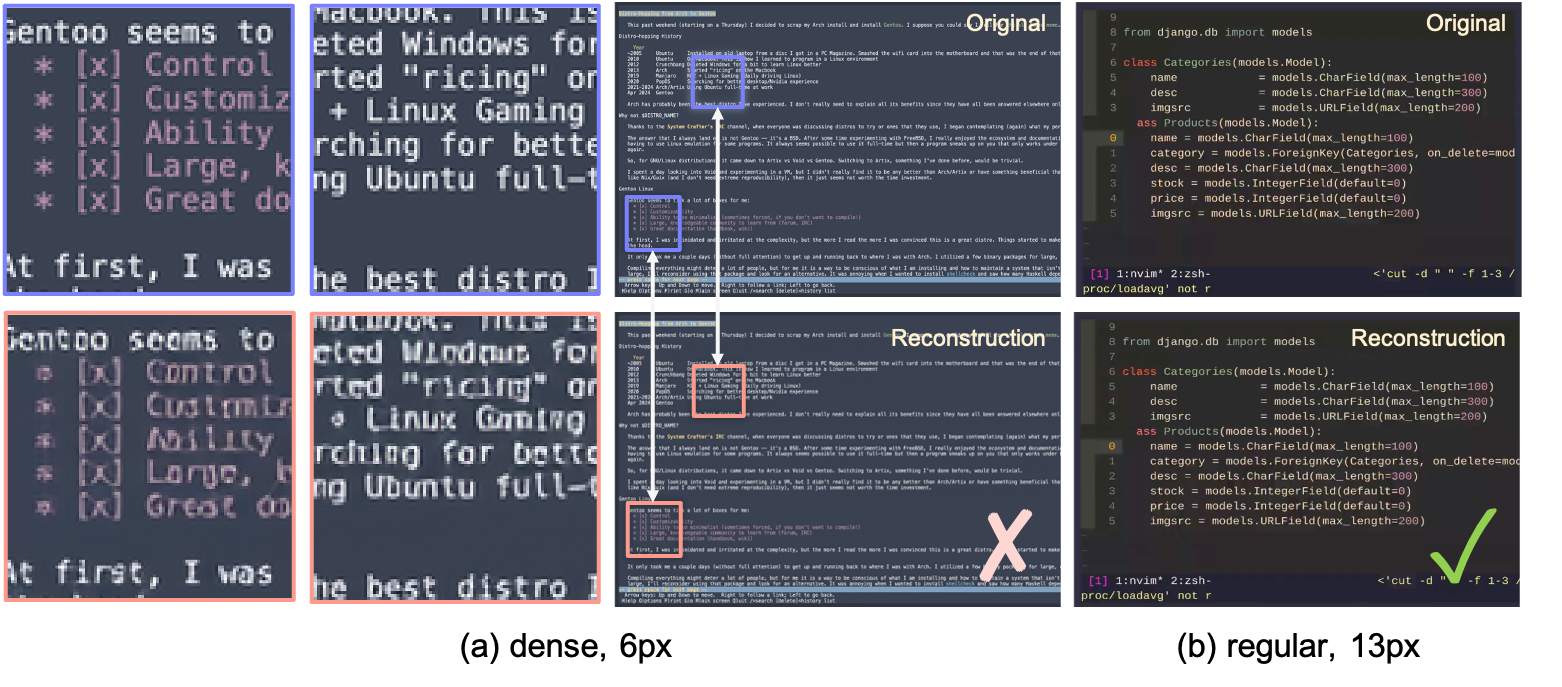
However, a sweep over CLIGen (General) frames shows that this effect is confined to extreme cases (Figure 4). Very small 6 px fonts and ultra-dense text exhibit localized blurring despite high global $\textsc{PSNR}$. In contrast, the 13 px terminal font used in CLIGen remains visually sharp across panes and commands. These results indicate that the VAE is adequate for regular CLIGen usage and highlight that sensible font choices help ensure stable NC training.
cligenCleanLogo Experiment 2: Performance plateaus early and can degrade with prolonged training
On clean but domain-specific structured interfaces, global reconstruction metrics improve rapidly early and then show limited additional gains under the current training objective. In CLIGen (Clean), $\textsc{PSNR}$ / $\textsc{SSIM}$ plateau quickly, suggesting that further optimization becomes bottlenecked less by model capacity than by the quality and pacing of the available supervision. After the early gains, the remaining errors are often tied to artifact-prone signals (e.g., rendering glitches or rapid screen changes that disrupt temporal alignment), so additional training on the same objective can yield diminishing or even slightly unstable returns in these perceptual metrics.
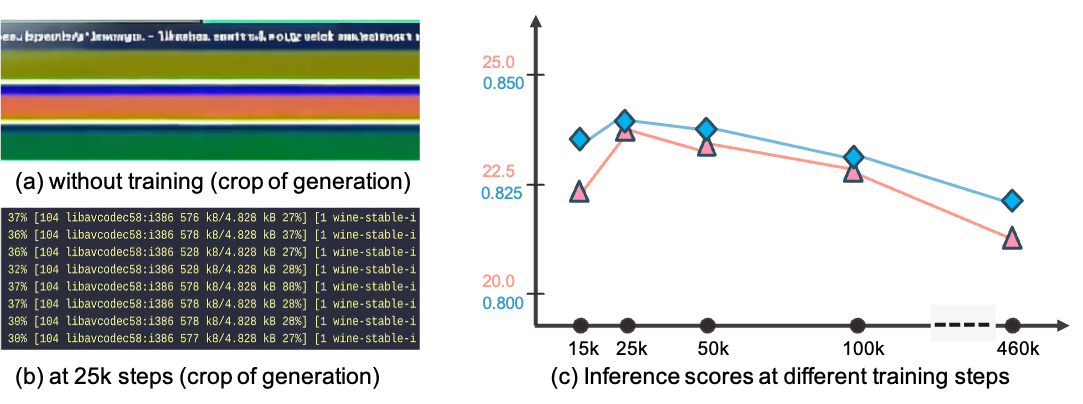
Panels (a–b) illustrate the effect of training on CLIGen data. Without CLIGen fine-tuning, Wan2.1 produces garbled terminal outputs (a). After 25k steps, the model generates readable text with consistent formatting and color cues (b).
Figure 5 plots the corresponding $\textsc{PSNR}$ / $\textsc{SSIM}$ curves and shows that these global perceptual metrics flatten around 25k steps. They improve little with further training up to 460k steps, and extended optimization can even slightly reduce them. One plausible explanation is that most learnable structured patterns are acquired early, and further gains require higher-quality, better-paced, or more informative supervision.
cligenGeneralLogo Experiment 3: Literal captions drive rendering accuracy
Caption specificity has a strong effect on terminal rendering quality. As shown in Table 4, detailed, literal descriptions improve reconstruction fidelity. $\textsc{PSNR}$ increases from 21.90 dB (semantic) to 26.89 dB (detailed), a gain of nearly 5 dB, compared to less specific, high-level semantic descriptions.
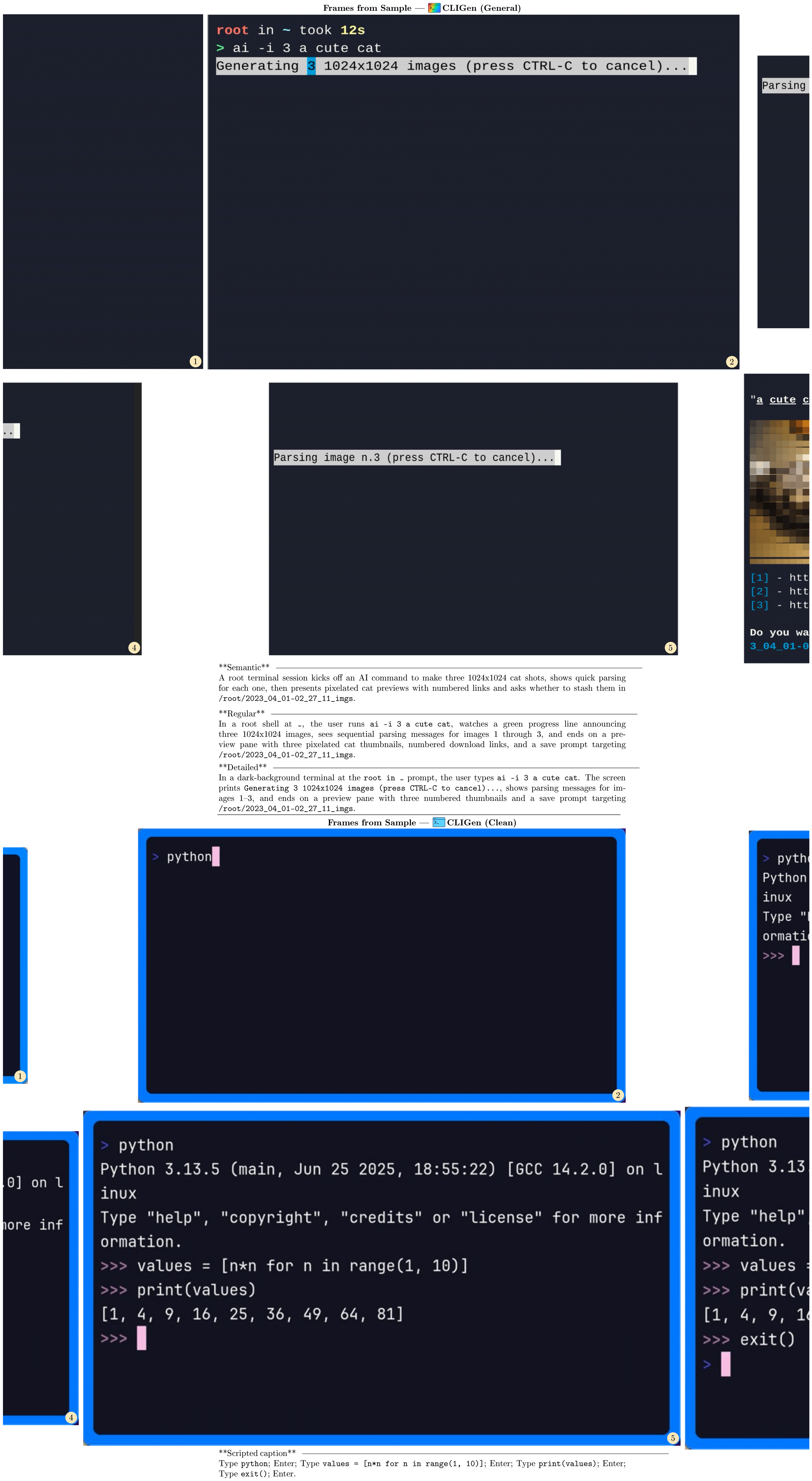
The three caption tiers correspond to the same underlying terminal sequence but differ in length and granularity. Semantic captions (average 55 words) provide high-level summaries (e.g., "a terminal session generates three cat images"). Regular captions (average 52 words) include key commands and outputs (e.g., ai -i 3 a cute cat, status messages). Detailed captions (average 76 words) transcribe screen content more exhaustively, including exact text, colors, and formatting.
::: {caption="Table 4: Caption styles versus TI2V fidelity."}

:::
This progression helps explain why literal descriptions are particularly effective for terminal rendering. Unlike natural images, which are dominated by global style patterns, terminal frames are governed primarily by text placement. Detailed captions act as scaffolding—explicitly specifying which tokens appear where—thereby enabling precise text-to-pixel alignment.
cligenCleanLogo Experiment 4: Neural computers achieve accurate character-level text generation
::: {caption="Table 5: OCR accuracy versus training."}
:::
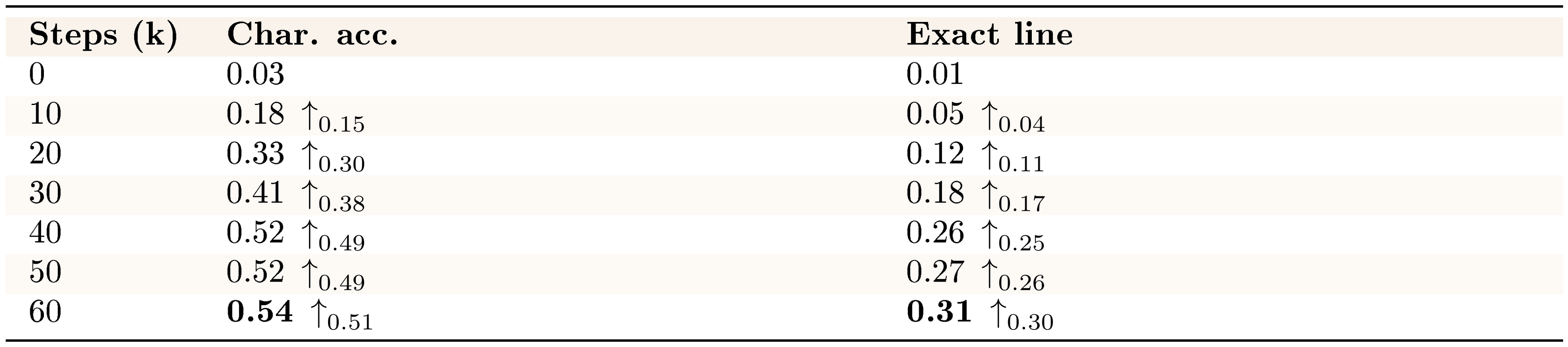
Beyond PSNR and SSIM, character-level accuracy is a more direct metric for terminal rendering. Character-level accuracy requires explicit pixel-to-text correspondence. For CLIGen (Clean), we apply Tesseract to five uniformly sampled (ground-truth, generated) frame pairs per video and normalize whitespace. We then compute two metrics (full protocol in Appendix B). Character accuracy uses the Levenshtein distance between concatenated ground-truth and generated texts. Exact-line accuracy measures the fraction of ground-truth lines whose normalized content exactly matches the prediction at the same line index.
Table 5 shows that our models achieve substantial text rendering accuracy under this protocol. Character accuracy increases from 0.03 at initialization to 0.54 at 60k steps, with exact-line matches reaching 0.31 (0.26 by 40k). Most gains occur within the first 40k steps, followed by smaller refinements thereafter. These OCR-based metrics capture properties beyond perceptual similarity. Accurately generating terminal characters requires modeling text structure, font rendering, and spatial relationships. These are core competencies for interactive neural computer systems. This level of character-level precision is a step toward usable, not just plausible, terminal interfaces. At the same time, we interpret this result primarily as evidence of interface fidelity, while routine reuse and native symbolic computation remain separate questions.
cligenCleanLogo Experiment 5: Does this NC instantiation show native CLI reasoning?
::: {caption="Table 6: Arithmetic probe accuracy (100 problems sampled from a 1,000-problem held-out pool)."}

:::
We also probe symbolic computation with CLI arithmetic tasks. These tasks are a sharp stress test for symbolic reliability: humans answer them instantly, yet current NC instantiations often fail on seemingly simple symbolic operations.
Our arithmetic probe presents basic mathematical operations through terminal interactions. We reserve a held-out pool of 1,000 math problems and randomly sample 100 problems as the final evaluation set. Table 6 shows that current video models, including this NC instantiation, struggle on these symbolic tasks. Wan2.1 achieves 0% accuracy, our NC $_\text{CLIGen}$ model reaches 4%, and Veo3.1 manages 2%—all far below human-level performance on these fundamental tasks. These results contrast with common claims of strong symbolic reasoning in current video models. Sora2's 71% accuracy is a notable outlier and may reflect system-level advantages or additional training beyond our current setup. Overall, native symbolic reasoning remains an open challenge for current video-based NC instantiations. Accordingly, arithmetic probes in this paper serve as a targeted test of symbolic stability under the current prototype substrate.
The poor arithmetic-probe performance in Table 6 raises a key question. Does this prototype require specialized reinforcement learning to achieve reliable symbolic computation, or can stronger conditioning substantially narrow this gap?
cligenCleanLogo Experiment 6: Does this NC instantiation require RL for symbolic probes?
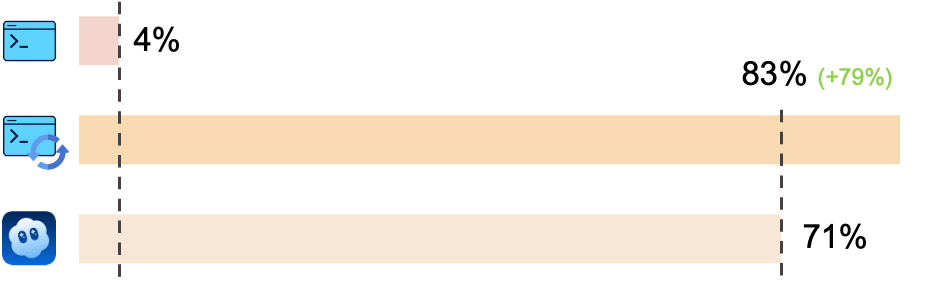
As shown in Figure 6, NC $_\text{CLIGen}$ accuracy on CLIGen (Clean) arithmetic tasks rises from 4% to 83% under reprompting. This suggests that system-level conditioning can be an effective first lever for improving performance on symbolic probes. It is complementary to (rather than strictly requiring) RL-based training pipelines. More generally, the success of reprompting highlights how sensitive symbolic-probe outcomes are to the conditioning interface. Much of the apparent "reasoning" gain can come from better specification and instruction-following rather than new native computation. For the arithmetic subset, we include the correct answer explicitly in roughly half of the training captions to encourage reliable rendering of the output string. Because reprompting can similarly provide stronger hints (or even outsource computation to an external text system), we interpret the gain primarily as evidence of steerability. It also shows faithful rendering of conditioned symbolic content. We do not treat it as a clean demonstration that the NC backbone performs arithmetic internally.
::: {caption="Table 7: Hypotheses for Sora2's advantage."}

:::
The evidence supports system-level conditioning as a practical path forward for this NC instantiation. Among the three hypotheses for improving arithmetic-probe performance—stronger base models, reinforcement learning, or enhanced conditioning—our results most strongly favor the third approach. The gain from reprompting (4% $\rightarrow$ 83%), achieved without modifying the underlying NC backbone, is substantial. It shows that measured "reasoning" on these probes is highly sensitive to specification and conditioning. We therefore do not treat it as direct evidence of native arithmetic inside the NC backbone.
In our setting, strategic conditioning yields larger symbolic-probe gains than the RL pipeline we tested. Evaluations should therefore distinguish native computation from conditioning-assisted performance when assessing reasoning capabilities in current video-based NC instantiations.
3.1.5 Visualizations
(1) CLIGen (General) visualizations. Qualitative samples highlight the breadth of real-world terminal dynamics captured in CLIGen (General): ANSI escape sequences that repaint regions with changing foreground/background colors, incremental command entry with syntax highlighting and cursor edits, classic shell prompts and system outputs, long-running jobs with rapidly scrolling and color-coded package logs, full-screen TUIs such as partition editors, and progress dashboards with updating bars, counts, and ETAs. These traces emphasize that "looking correct" requires maintaining terminal geometry, palette transitions, and cursor state frame-by-frame.
(2) CLIGen (Clean) REPL visualizations. In contrast to open-world traces, CLIGen (Clean) REPL samples are scripted and temporally well-paced (Figure 20–Figure 26; additional examples are in Appendix C). Each sample includes an explicit action trace (e.g., Sleep, Type, Enter, arrow keys, Hide) alongside rendered terminal frames, making the action-to-pixel link visually unambiguous. The key insight is that these scripted traces isolate rendering-and-control errors from semantic ambiguity: with explicit actions, failures are dominated by low-level mechanics (cursor placement, character edits, monospace alignment, line breaks, temporal consistency).
(3) CLIGen (Clean) math visualizations. Figure 28–Figure 32 compare math REPL rollouts, and Figure 34–Figure 38 show reprompting cases. Together they highlight why arithmetic probes should separate native computation from answer-conditioned rendering. All full-resolution pages are in Appendix E; below we keep clickable thumbnails at the original location for quick navigation.
CLIGen Visualization Thumbnails
Click any thumbnail to jump to its full-resolution page in Appendix
::: {caption="Table 8"}

:::
CLIGen Visualization Thumbnails
Click any thumbnail to jump to its full-resolution page in Appendix
::: {caption="Table 9"}

:::
3.2 guiworldLogo The GUI World Models
We also instantiate the NC abstraction in interactive desktop environments with NC $_\text{GUIWorld}$ . In this setting, fine-grained action control is essential: GUI interaction requires precise cursor tracking, timely click feedback, and robustness to rapidly changing interface states. We model each interaction as a synchronized sequence of RGB frames $x_t$ and input events $u_t$ (mouse and keyboard). The latent video state maintains interface context across frames, while temporally aligned action inputs provide control signals designed to preserve pixel-level correspondence between user actions and visual changes.
3.2.1 Data pipeline
::: {caption="Table 10: Cursor/action statistics."}

:::
The dataset includes two styles of random interaction: "Random Slow" and "Random Fast", plus a smaller set of supervised trajectories collected by Claude CUA ([22]). Random Slow (approximately 1,000 hours) contains longer pauses, idle gaps, and deliberate cursor movements, which can expose cursor drift after extended inactivity. Random Fast (approximately 400 hours) features denser cursor motion and typing bursts, stressing acceleration dynamics and hover timing. The supervised trajectories are approximately 110 hours. These goal-directed traces provide higher-signal action–response pairs without overwhelming the exploration data. Table 10 summarizes cursor and action statistics across splits; in the collected CUA trajectories, action density is lower due to latency introduced by Claude’s tool API between successive steps.
All GUI data is collected inside an Ubuntu 22.04 container running XFCE4 (Arc-Dark theme, Papirus icons) on a fixed 1024 $\times$ 768 virtual display at 15 FPS. We render the display with Xvfb and interact through a VNC/noVNC stack. The desktop pins a small open-source app set to launchers. It includes Firefox ESR, GIMP, VLC, VS Code, Calculator, Terminal, the file manager, and the Mahjongg game, matching the environment shown in our recordings. Screen capture uses mss and ffmpeg with cursor overlays, and actions are replayed and logged via xdotool. We keep the recorded discontinuities and interface latency intact rather than smoothing them. In dataset packaging, we store both raw-action and meta-action views for modeling. This lets us train either the raw-action or meta-action encoder under the same loss stack[^5].
[^5]: Conversion details and alignment quality appear in Appendix D.
3.2.2 Model architecture
The GUIWorld architecture builds on the Wan2.1 ([18]) by incorporating explicit action-conditioning modules. The central challenge is to align time-stamped user actions with generated frames and inject this information at the appropriate depth within the transformer.
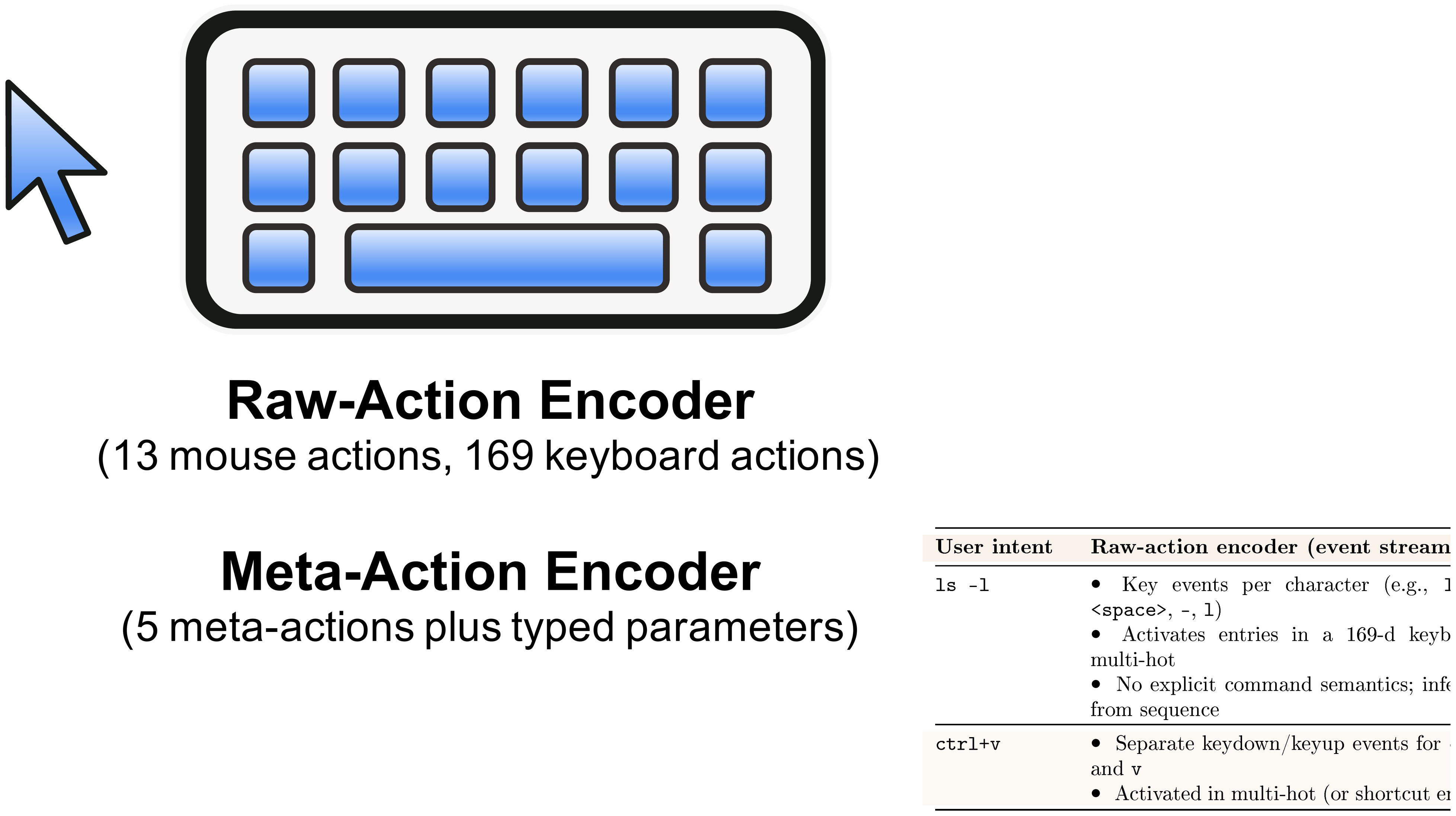
Action features are encoded on-the-fly from frame-aligned mouse and keyboard signals (Section 3.2.1). We aggregate them into latent-aligned embeddings that summarize recent action history at each diffusion step. We evaluate two action encoders. The raw-action encoder (v1) preserves fine-grained mouse/keyboard event streams. The meta-action encoder (v2) abstracts interactions into coarse API-style categories (clicks, drags, scrolls, typing, shortcuts). Both encoders use the same temporal alignment and are evaluated as separate ablations. In our experiments, their differences in rendering fidelity and control behavior are modest[^6].
[^6]: Appendix Table 22 summarizes the representational differences.
We inject action embeddings into the diffusion backbone in four ways (Figure 7). We study external, contextual, residual, and internal conditioning. For the injection-scheme ablation, all four modes share the same meta-action encoder and temporal alignment. They differ only in where the latent action features interact with the video latents and transformer blocks. We compare raw-action vs. meta-action encoders separately in Table 14.
External conditioning. In the external mode, action information modulates the latent video sequence before the diffusion transformer. Action features are applied as a pre-conditioning step at the model input, without introducing explicit action tokens or cross-attention inside the diffusion backbone. As a result, action information enters only through the modified input latents; the diffusion backbone never attends directly to action tokens, so any action signal must be carried implicitly in $z'_{1:T}$.
Formally, given VAE latents $z_{1:T}$ and temporally aligned action features $u_{1:T}$, an external action module applies a small stack of temporal self-attention and action cross-attention layers. This produces a residual update $\Delta z_{1:T}(u_{1:T})$. The modified latents are
$ z'{1:T} = z{1:T} + \Delta z_{1:T}(u_{1:T}), $
and the diffusion transformer operates solely on $z'_{1:T}$. The diffusion backbone remains unchanged, and action features are not exposed as explicit tokens within the transformer.
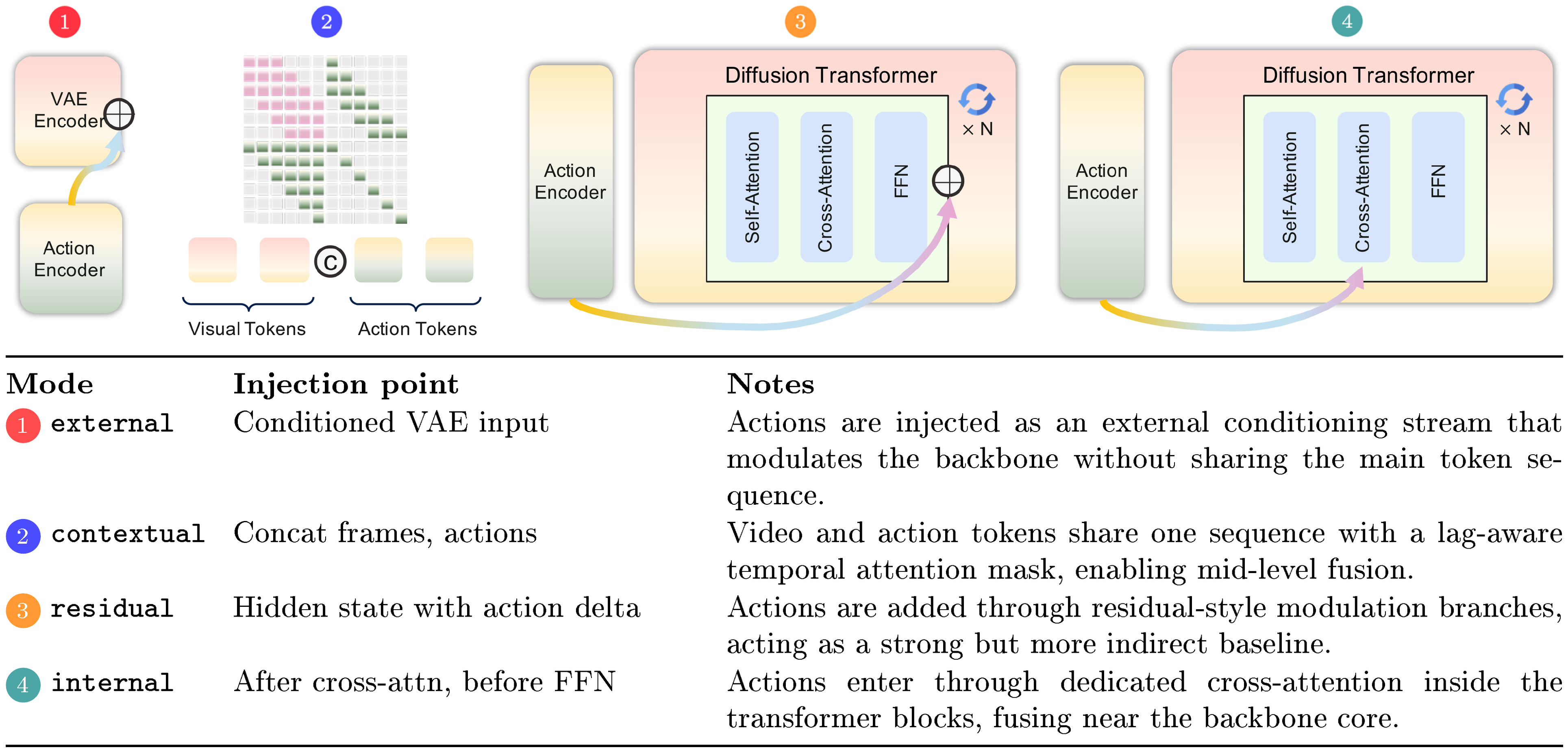
Contextual conditioning. In the contextual mode, actions are represented as additional tokens and integrated directly into the transformer’s self-attention. Similar token-based action representations have been explored in prior world models, including Gato ([23]) and World and Human Action Models ([24]).
The meta-action encoder produces latent-aligned action tokens $A \in \mathbb{R}^{L_a \times D}$. We concatenate them with visual tokens $V \in \mathbb{R}^{L_v \times D}$ to form a joint sequence $[V; A]$. Each transformer block applies self-attention over this combined sequence using a structured temporal mask (Appendix Figure 12). The mask enforces causal alignment: each frame token attends only to actions within a short past window, and each action token attends only to frames after a fixed temporal lag. Through this masked joint attention, contextual conditioning fuses action and visual information within the transformer blocks.
Residual conditioning. In the residual mode, the transformer block structure remains unchanged. A lightweight action module attaches to a subset of layers as an external residual branch. This follows the residual conditioning paradigm introduced by ControlNet ([25]), while remaining modular and additive to the base diffusion backbone.
At each selected layer $l$, the transformer applies its standard sequence of self-attention, text or reference cross-attention, and feed-forward operations to produce hidden states $h^{(l)}$. A separate action module then takes $h^{(l)}$ together with a local temporal window of latent action features and mouse trajectories. It outputs a residual update $\Delta h^{(l)}(a, \text{mouse})$. The updated hidden states are given by
$ \tilde{h}^{(l)} = h^{(l)} + \Delta h^{(l)}(a, \text{mouse}), $
which are passed to the subsequent transformer block. In this formulation, residual conditioning injects action information through block-external residual branches. It does not modify the internal computations of the transformer blocks themselves.
Internal conditioning. In the internal mode, action conditioning is incorporated directly within the transformer blocks. Related multi-stream world models have explored similar designs, including Matrix-Game-2 ([26]). Each selected block augments the standard attention stack with an additional action cross-attention sub-layer. Specifically, the block applies self-attention, followed by cross-attention over text and reference features, and then a dedicated action cross-attention layer. Keys and values are derived from latent action features (and, optionally, mouse inputs).
Given block input $h$, text or reference context $c$, and action latents $a$, the internal block computes
$ h' = \mathrm{FFN}\Big(h + \mathrm{CA}_{\text{text}}\big(\mathrm{SA}(h), c\big)
- \mathrm{CA}_{\text{action}}(h, a) \Big), $
where $\mathrm{SA}$ denotes self-attention and $\mathrm{CA}{\text{text}}$ and $\mathrm{CA}{\text{action}}$ denote the text and action cross-attention modules applied in sequence. As illustrated in Figure 7, action features are injected directly into the block’s cross-attention stage.
In contrast to residual conditioning, internal conditioning integrates action information through a block-internal attention mechanism rather than an external residual branch. This design mirrors the multi-stream injection strategy used in Matrix-Game-2 ([26]) and yields the best SSIM/FVD trade-off for fine-grained GUI interaction in our ablations. In this setting, precise temporal alignment and spatial locality are critical. Each conditioning mode (external, contextual, residual, and internal) is trained as a separate ablation, and no combinations are used.
3.2.3 Implementation Details
We train one model per injection mode (external, contextual, residual, internal), keeping the backbone and all non-action components fixed. Each run lasts about 64k steps. We tune only the action encoder and learning-rate schedule. Training optimizes the diffusion loss together with a small temporal contrastive loss that aligns frame features with action and mouse embeddings (Appendix D). Runs use 64 GPUs for about 15 days, totaling about 23k GPU-hours per full pass.
Preprocessing is implemented in the data loader in two stages. First, we normalize each recording to a fixed resolution and frame rate. This produces tensors for RGB video, per-frame cursor coordinates, and mouse/keyboard event traces (in both raw-action and meta-action views). Second, we render an SVG cursor at each logged position to produce per-frame masks and cursor-only reference frames. The first reference frame contains the full desktop with a unit mask. Later references paste only the cursor over a neutral background, with a mask restricted to arrow pixels. After VAE encoding, these references become latent slots that pin down the static GUI layout at $t{=}0$. For $t{>}0$, they supervise only a small patch around the cursor and leave the rest of the frame unconstrained. We drop clips without valid cursor or action traces to keep supervision consistent.
3.2.4 Evaluation setup
Our ablations target three capabilities: global fidelity, post-action responsiveness, and cursor-control precision. We use the $\textsc{FVD}$ / $\textsc{LPIPS}$ / $\textsc{SSIM}$ suite as the core metrics. We also add action-driven metrics that focus on post-interaction frames after clicks, scrolls, and key/type events. For example, we compute $\textsc{SSIM}$ / $\textsc{LPIPS}$ averaged over the $k$ frames after each logged action, and action-driven $\textsc{FVD}$ on post-action clips. Ablations vary conditioning design and action encoding to measure how these choices affect perceptual quality and responsiveness when rolled out against ground-truth interfaces[^7].
[^7]: Full metric definitions and implementation details are provided in Appendix B.3.
1. In GUIWorld, a small amount of goal-directed data outperforms much larger random exploration, showing that alignment quality matters more than nominal scale for action–response learning.
2. Precise cursor control requires explicit visual supervision: SVG mask/reference conditioning raises cursor accuracy to 98.7%, indicating that local GUI control primitives are learnable in controlled settings.
3. Action injection depth matters: relative to shallow `external` conditioning, `contextual`, `residual`, and especially `internal` fusion improve post-action responsiveness and visual consistency.
4. Action representation also matters: under the same injection mode, API-like meta-actions consistently outperform raw event-stream encoding.
guiworldLogo Experiment 7: Data quality dominates performance
Interactive GUI modeling shows that data quality matters more than dataset size for action-driven performance. We compare slow exploration, fast interaction, and supervised trajectories under contextual conditioning. This isolates which behaviors best support neural computer training.
::: {caption="Table 11: Overall performance across data sources."}

:::
Despite approximately 1,400 hours of random exploration across the slow and fast settings, these datasets are noisy. They are comparatively sample-inefficient for learning stable action–response mappings. They substantially improve global perceptual metrics over a baseline (Table 11). However, high-frequency cursor jitter and irregular, non-goal-directed action bursts make consistent control difficult under dense, stochastic input streams.
In contrast, the substantially smaller high-quality dataset (110 hours from Claude CUA) yields markedly stronger performance across all metrics. Goal-directed trajectories provide clearer action semantics and more predictable state transitions. This enables robust action conditioning even with limited data volume. These results indicate that neural computer development should prioritize curated, purposeful interactions over large-scale passive data collection. At the current stage, this result primarily indicates that alignment quality matters more than nominal scale for learning action–response structure in NC prototypes.
guiworldLogo Experiment 8: Precise cursor control requires explicit visual supervision

::: {caption="Table 12: Cursor conditioning losses versus accuracy."}

:::
We examine whether the NC internalizes cursor dynamics. A natural baseline is to condition on normalized cursor-coordinate sequences $\texttt{mouse_trajectories}\subset[0, 1]^{T\times 2}$ (details in Appendix D.4). To strengthen this signal, we further encode the normalized trajectories using a Fourier mouse encoder. We map coordinates to $[-1, 1]^2$ and project them through a fixed Gaussian matrix to obtain random Fourier features. A small MLP produces per-frame embeddings, which we aggregate into lag-aware windows aligned with the VAE stride. The resulting latent action sequence conditions the action modules and participates in the temporal contrastive loss.
However, Table 12 shows that coordinate-based supervision remains insufficient for precise interaction. Position-only supervision achieves 8.7% accuracy, and even enhanced position features reach only 13.5%. This suggests that richer coordinate encodings alone do not resolve cursor drift and jitter.
Motivated by the importance of precise cursor placement, we introduce explicit visual cursor supervision. We render an SVG cursor at each $(x_t, y_t)$ to produce per-frame cursor masks $m_t$ and cursor-only foregrounds $f_t$ (right panel of Figure 8). Following Figure 8, we construct a reference stream. The first frame contains the full desktop image, while subsequent frames contain only the cursor foreground over a neutral background, masked to the cursor region. We encode both the video and reference streams with the shared VAE, yielding video latents $z_{1:T}$, reference latents $z^{\text{ref}}{1:T}$, and mask tags $\tau{1:T}$. The diffusion transformer receives the concatenated tensor
$ \mathrm{concat}\bigl(z_{1:T}, , \tau_{1:T}, , z^{\text{ref}}_{1:T}\bigr), $
which anchors the static GUI layout at $t{=}0$ and provides localized supervision around the cursor for $t{>}0$.
Under this explicit visual conditioning, cursor accuracy improves to 98.7%. This suggests that neural computers benefit from learning the cursor state as a visual object rather than relying solely on abstract coordinates. Explicit pixel-level supervision helps model cursor acceleration, hover states, and click feedback, which are essential for reliable GUI interaction. At the same time, this result is best viewed as evidence that local GUI control primitives are learnable under explicit supervision in controlled settings.
guiworldLogo Experiment 9: Action injection under different schemes
::: {caption="Table 13: Action-driven metrics across injection schemes (15 frames after action)."}
:::
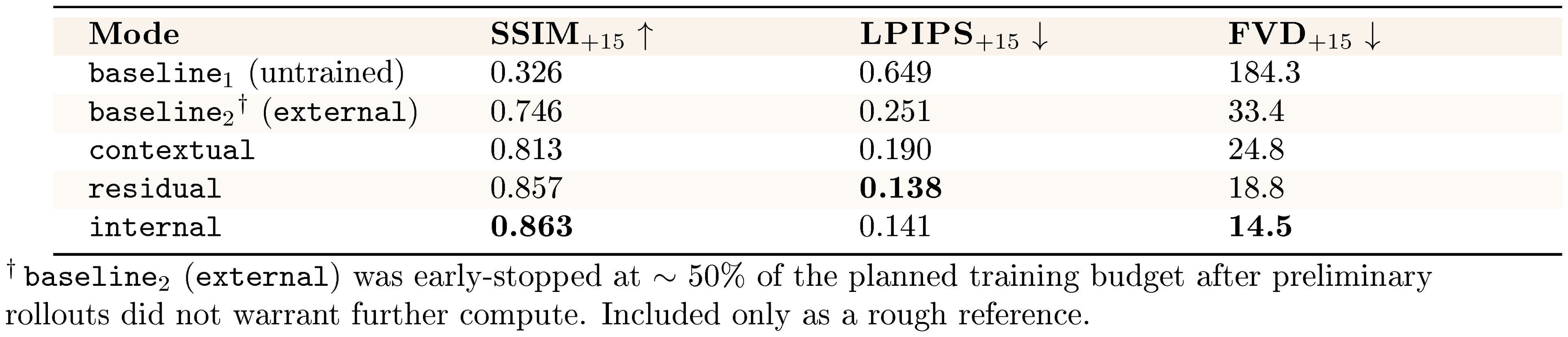
Holding data and the action encoder fixed, we compare injection schemes on clean runs (Table 13). We compute action-driven metrics over the 15 frames following each click, scroll, or key event. Relative to both baselines (untrained and external), mid- and deep-level fusion yields consistent improvements in post-action quality. This includes contextual, residual, and internal injection.
Specifically, moving from input-level conditioning (external) to token-level fusion (contextual) improves SSIM from 0.746 to 0.813 and reduces FVD from 33.4 to 24.8. Deeper injection sharpens these gains. internal achieves the highest structural consistency (SSIM 0.863) and the lowest temporal distortion (FVD 14.5), while residual attains the lowest perceptual distance (LPIPS 0.138). Together, these trends associate deeper action injection with improved tracking of fine-grained cursor motion and layout changes. [^8]
[^8]: Appendix D summarizes the corresponding injection schemes and alignment details.
guiworldLogo Experiment 10: Do action encodings matter?
::: {caption="Table 14: Raw-action vs. API-like action encoding under the same injection mode (15 frames after action)."}

:::
We compare two action encodings under the same injection mode to isolate the effect of representation choice (Table 14). Under internal conditioning, the meta-action (API-like) encoding yields small but consistent improvements over the raw-action representation. SSIM increases from 0.847 to 0.863, LPIPS drops from 0.144 to 0.141, and FVD drops from 16.6 to 14.5. However, these gains are modest compared to the substantially larger improvements observed when varying the action injection scheme itself (Table 13). This suggests that encoding granularity is not the dominant factor governing GUI interaction fidelity.
::: {caption="Table 15: Encoding examples for raw-action and meta-action encoders."}
:::
Table 15 contrasts how short commands and shortcuts (e.g., ls -l, ctrl+v) are represented under the two encodings. The raw-action encoder treats typing as a stream of individual key events, leaving command or shortcut semantics to be inferred from the sequence. In contrast, the meta-action encoder collapses each interaction into a single typed action with associated text or a shortcut identifier. This design aims to model user actions as structured, tool-like operations rather than fragmented event streams.
In practice, this more structured abstraction does not translate into clear qualitative gains. Rendered text remains similarly smeared under both encodings, and robustness under theme changes and timing noise is largely unchanged. Task-level failures such as re-centering, re-acquisition, and multi-step interactions persist across both representations. We adopt the meta-action encoder as the default for its simplicity and semantic alignment with system-level conditioning. These results suggest that encoding granularity is secondary to alignment quality and injection strategy.
3.2.5 Visualizations
Across GUIWorld interactive rollouts, failure modes are dominated by data quality and by where action information enters the backbone. Goal-directed supervision produces smooth, target-aligned cursor paths and consistent post-click UI transitions, whereas random exploration yields bursty jitter and spurious actions that degrade visual coherence (Table 11; Figure 40–Figure 48). Consistent with the action-driven metrics in Table 13, deeper token-level injection (contextual/internal) yields more reliable post-action updates in interactive elements (hover states, dropdowns, modals) and maintains cursor alignment under rapid motion.
Figure 50–Figure 54 emphasize how small low-level deviations compound. Figure 56–Figure 60 focus on numeric/UI fidelity and interaction semantics. Figure 62–Figure 66 add stress cases where correctness hinges on precise field edits and page state. All full-resolution pages are in Appendix E; below we keep clickable thumbnails at the original location for quick navigation.
GUIWorld Visualization Thumbnails
Click any thumbnail to jump to its full-resolution page in Appendix
::: {caption="Table 16"}

:::
GUIWorld Visualization Thumbnails
Click any thumbnail to jump to its full-resolution page in Appendix
::: {caption="Table 17"}

:::
4. Position: Toward Completely Neural Computers
Section Summary: This section explores the current prototypes of neural computers, which demonstrate basic input-output handling and short-term task control but fall short of being reliable, general-purpose systems due to issues like inconsistent reuse and lack of long-term stability. Unlike traditional computers that rely on precise, human-designed symbols and instructions, neural computers use distributed, data-learned patterns for more flexible handling of complex, uncertain tasks like perception and planning. It defines completely neural computers as the ideal mature version—fully programmable, consistent in behavior unless updated, and capable of universal computation—and sketches a path forward while distinguishing them from AI agents and world models.
Section Overview
In this section, we ask what current Neural Computer (NC) prototypes have already shown, what still prevents them from becoming usable or general-purpose runtimes, and why neither current world models ([3, 27, 28, 29]) nor AI agents ([30, 22, 31]) yet amount to this emerging machine form. We then contrast NCs with conventional computers, clarifying that they are not a smarter layer on top of the existing stack, and define their mature general-purpose form, namely Completely Neural Computers (CNCs). Finally, we outline a roadmap toward CNCs, relate NCs to other system objects, and close with several remarks on NCs.
4.1 From Neural Computers to Completely Neural Computers
Current Status of NCs
Our CLI and GUI-based neural computers already show that early runtime primitives can be learned with measurable interface fidelity. In terminal environments, OCR-based text fidelity is already measurable (Table 5); in GUI settings, explicit visual supervision yields strong local cursor control (Table 12); and in GUIWorld, aligned goal-directed data clearly outperforms much larger random exploration (Table 11). Taken together, these results suggest that current NCs already support early runtime primitives, especially I/O alignment and short-horizon control, while stable reuse and general-purpose execution remain out of reach. This does not mean that current prototypes are already close to CNCs; it means that the outline of a distinct machine form has begun to emerge at prototype scale.
However, the current video-based prototypes are only early NC instantiations: if NCs are to mature into general-purpose runtimes, they must go well beyond basic I/O and short-term execution. At the formal level, this ultimately requires Turing completeness ([32, 33, 34, 35]), universal programmability ([36, 37]), and behavior consistency unless explicitly reprogrammed ([38]). Before those conditions are met in full, progress is better read through practical acceptance lenses: routine reuse, execution consistency, and explicit update governance. These lenses matter because the immediate question is not whether CNCs have already been achieved, but whether NCs are beginning to behave more like usable runtimes than isolated demonstrations. For example, once an incident-response routine has been installed, the system should reuse it on later alerts rather than rediscovering the procedure from scratch each time; and if its behavior changes, that change should be attributable to an explicit update rather than ordinary execution. In practice, this reduces to three acceptance lenses: install–reuse, execution consistency, and update governance, which together offer a more useful view of current NC progress than the full CNC definition alone.
While certain sequential neural architectures are Turing complete ([35, 39]) in principle, turning a trained instance into a reliably programmable runtime remains challenging. Preliminary attempts, including Neural Virtual Machine ([40]) and NeuroLISP ([41]), have been explored. Furthermore, ensuring stable behavior over long temporal horizons remains an open problem in neural systems ([42, 43]). Section 4.2 provides a more detailed discussion of these requirements. To the best of our knowledge, existing works on world models lack an analysis of the computability class of the learned models. See Figure 9 for more discussion between NCs and other system objects, including world models and AI agents.
::: {caption="Table 18: Four system objects compared at a common systems level."}

:::
Fundamental differences between NCs and conventional computers
We compare NCs and conventional computers. Here, conventional computers denote random-access machines with instruction set architecture ([44, 45]) and layered OS/application stacks programmed via human-designed high-level languages ([46, 47]). NCs differ fundamentally from conventional computers in their architectural and programming-language semantics.
At the architectural level, random-access machines instantiate local, compositional symbolic semantics ([48]), yielding exactness and interpretability, but brittleness under noise and model mismatch ([49]). Neural computers, by contrast, realize holistic, distributed numerical semantics, trading precise local semantics for robustness and generalization ([50, 51, 52, 53, 54, 55]). Empirical evidence indicates that such holistic numerical representations are particularly well suited to domains characterized by high-dimensional representations ([56]), soft or statistical constraints ([57]), and globally coupled structures ([58, 59]), including perception, natural language, planning under uncertainty, and approximate reasoning. Although conventional computers can, in principle, emulate NCs, doing so often introduces unnecessary conceptual and engineering complexity when the target tasks are already well matched to neural architectures.
At the programming-language level, NCs differ from conventional computers because their "language semantics" are the meanings of user input sequences learned from data rather than explicitly designed by humans. For example, LLMs can be viewed as programmable computers in which prompts act as programs ([60]). In this case, the programming language is a natural language, which no non-neural system has historically been able to interpret robustly at scale ([61]). More broadly, learned programming-language semantics are not constrained by a human-specified syntax/semantics boundary and can, therefore, encode task-relevant conventions implicitly ([62]).
Definition of Completely Neural Computers
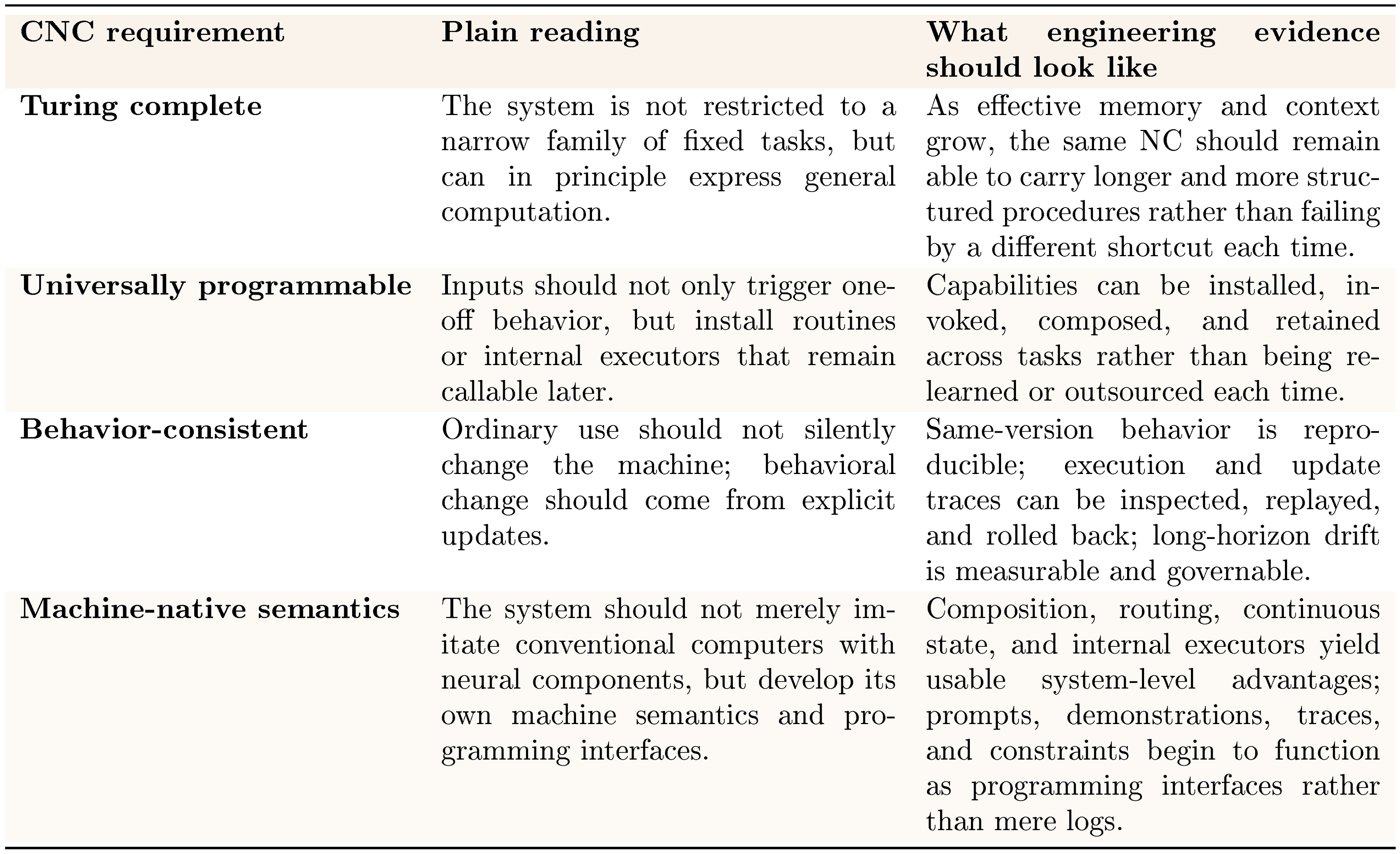
We use CNC to denote the mature form of an NC. Formally, a Neural Computer instance is complete if it is (1) Turing complete, (2) universally programmable, (3) behavior-consistent unless explicitly reprogrammed, and (4) realizes the architectural and programming-language advantages of NCs relative to conventional computers. The following section unpacks these conditions in operational terms.
::: {caption="Table 19: Operational reading of the four CNC requirements."}
:::
4.2 A Roadmap Towards CNC
We frame the path toward CNCs through a set of formal requirements together with the practical challenges that must be resolved before those requirements become engineerable.
Turing completeness
A Neural Computer (NC) instance (a specific architecture with fixed learned weights) defines a class of computational models in which each model corresponds to at least one memory state instance. In the formal computability discussion below, "memory state" is used in the classical state-machine sense; operationally, it corresponds to the NC runtime state introduced earlier. An NC instance is Turing complete if, for any given Turing machine, there exists an initial memory state that allows the NC to emulate that machine exactly. Notice that although Recurrent Neural Networks (RNNs), Neural Turing Machines (NTM) ([1]), and Differentiable Neural Computers (DNC) ([2]) are Turing complete in the asymptotic sense, a particular RNN, NTM, or DNC instance with finite precision cannot be Turing complete due to their fixed finite memory size. For an NC instance to achieve universality, unbounded effective memory is necessary. An NC instance has unbounded effective memory if there are infinitely many possible memory state instances. Existing works approach such unboundedness by progressively growing model parameters ([63]) or context ([59]).
Universal programmability
An NC is universally programmable if, for each given Turing machine, there exists an input sequence such that the NC taking this input realizes a new memory state representing the given machine. Most existing universal programmability results for neural networks are established by constructing computational primitives and proving that their composition can simulate a universal computational model ([11]). Likewise, we believe that universal programmability in NCs can be achieved through compositional neural programs ([64]).
Behavior consistency
A CNC must preserve its function unless explicitly reprogrammed. For each memory state, there must be a non-empty set of inputs that executes the CNC without changing its pure function. Operationally, this requires a separation between run and update: ordinary inputs should execute installed capability without silently modifying it, while behavior-changing updates should occur explicitly through a programming interface. This in turn motivates training and architectural mechanisms that disentangle function use from function update, so that routines can be installed, executed, and composed without accidental functional drift. We hypothesize that gating mechanisms, such as those in LSTM ([65]), are effective in achieving this conditional invariance. In practice, making this separation reliable requires clear boundaries around what state persists across tasks, what counts as an explicit update, and what execution evidence can be replayed, compared, or rolled back.
**Run / update contract.**
- **Run:** invoke installed capability without silently changing persistent behavior.
- **Update:** any behavior-changing modification should occur explicitly through a programming interface.
- **Required boundaries:** state (what persists), update (what counts as reprogramming), and evidence (what can be replayed, compared, or rolled back).
Architectural semantics
Since NC behavior is governed by real-valued parameters, learning can produce input–output mappings that generalize across variations within the training distribution ([66]). For example, after observing many instances of how the visual state of a spreadsheet interface changes when values are typed into cells, a model may learn the underlying transformation and correctly predict the screen updates for previously unseen spreadsheets that follow the same interaction rules. Such in-distribution generalization arises from the smooth function approximation properties of neural networks and their ability to interpolate across previously observed patterns. Furthermore, learning can also produce novel input–output mappings that are not explicitly represented in the training data, potentially introducing new computational primitives ([67]). The combination of such newly formed primitives could enable qualitatively new functions, yielding out-of-distribution functional generalization ([68]).
Beyond emulating conventional computers, NCs can natively support functions whose semantics are ill-suited to symbolic APIs ([69]), including probabilistic inference over high-dimensional latent states ([70]), representation learning ([56]), retrieval over dense memories ([2]), and end-to-end differentiable pipelines that couple perception and control ([58]). These functions are first-class at the architectural level and operate directly on distributed states. This enables capabilities such as learned heuristics ([58]), uncertainty-aware decision-making ([71]), and continual adaptation ([72]).
Because the memory state of an NC/CNC is numerical, computer configuration and design emerge as alternatives to application-level programming: the computer itself is configured by optimizing its internal state to achieve desired computational behaviors under task-defined objectives. Depending on the differentiability of the loss, methods such as Adam ([73]) and natural evolution strategies([74]) apply. In a CNC, the memory constitutes a continuous manifold, so realizing a target capability amounts to synthesizing a machine configuration (a memory state) that minimizes a user-specified loss (e.g., “minimize proof error”) via direct numerical updates to the computer’s state. This reframes system construction from discrete code authoring to differentiable configuration of the computer itself ([75]), with progress evaluated by solver convergence, stability, and reliability relative to combinatorial program search (e.g., LLM-based code generation ([30])).
Programming-language semantics
The learned programming-language semantics of NCs enable a shift from rigid coding to learned specifications, in which user inputs themselves function as programs ([76, 77]). Rather than centering development on explicitly authored code, NCs expose a learned language whose syntax and semantics are acquired from data ([78, 79]), so natural-language instructions, examples, and constraints serve as executable specifications ([80]). Consequently, brief user inputs can replace long sequences of low-level actions. Development, therefore, moves from code authoring to curating, specifying, and verifying inputs under a learned programming-language semantics, aligning system behavior with human intent via in-context specification rather than forcing users to conform to rigid, brittle interfaces ([81]). This does not imply that code disappears, but rather that code becomes one installation medium among several, alongside prompts, demonstrations, trajectories, and constraints.
Since NCs are programmed via users' input sequences under learned programming-language semantics, the training data for programming NCs, i.e., paired user I/O traces ([82]), is far more abundant and continuously generated than high-quality, human-written code. Every interaction with digital systems produces structured streams of inputs, interface states, and effects that can be logged at scale (e.g., keystrokes, cursor trajectories, screen transitions), yielding orders-of-magnitude more supervision than curated program corpora ([83]). These I/O traces constitute executable specifications, revealing user intentions and computer behavior ([84]). This enables end-to-end learning of interface conventions, control policies, and task semantics without requiring explicit program text ([85]). This asymmetry in data availability favors NC training regimes that leverage ubiquitous interaction logs and, by supporting broader task coverage, reduces dependence on brittle, sparsely available code datasets.
4.3 Relations to Other System Objects
Figure 9 summarizes the systems-level shift: conventional computers are used directly, AI agents mediate existing computers, world models act as a parallel predictive layer, and NCs aim to make the learned runtime itself the machine.
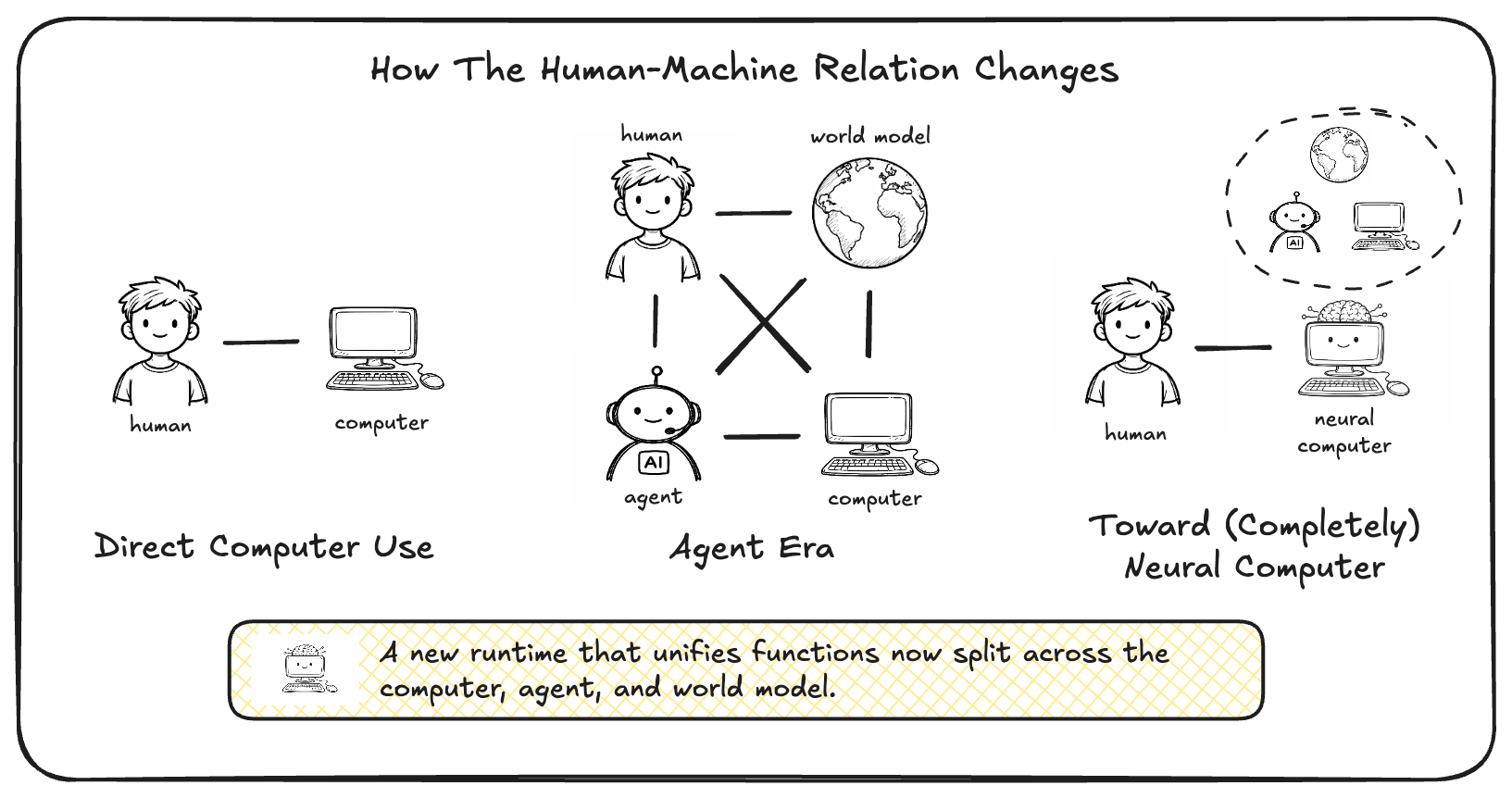
The comparisons below unpack this shift relative to conventional computers, world models, and AI agents. Conventional Computers
Conventional computers remain the reference system object for reliable execution, explicit programmability, and mature governance. NCs differ not by adding a smarter application layer on top of this substrate, but by shifting computation, memory, and I/O into a learned runtime state. In this sense, NCs are best viewed as a different candidate machine form and computing substrate rather than as a direct extension of the conventional software stack. This framing does not imply that conventional computers will disappear soon, but rather that future systems may be built from a different underlying runtime substrate.
World Models
World models learn environment dynamics by predicting action-conditioned transitions ([3]). Such target environments range from the most ambitious, where all sensory inputs form the real world ([12]), to much narrower scopes, such as a few control parameters of a robot arm ([86]). They provide one technical perspective on current NC prototypes, since interactive computers are an important class of action-conditioned environments, but they do not by themselves define the NC abstraction. Many current approaches to modeling computational environments, such as the physical world, also rely heavily on computer-generated data ([87, 88, 89, 90]), potentially leading to models that share characteristics with neural computers.
AI Agents
Another important comparison point is AI agents built on top of modern AI models and external software substrates, including computer-use agents, coding and multi-agent systems ([91, 22, 30, 92, 93]), and recursive self-improvement loops ([94]). These systems place a learned agent between the user and an external execution substrate, whether that substrate is a GUI, a codebase, or a broader software toolchain. This provides strong leverage from existing computers and software stacks, but it also preserves a strict separation between the learned model and the runtime that actually stores executable state, applies updates, and enforces system contracts. Computer-use agents operate through low-bandwidth I/O; coding agents typically emit symbolic artifacts that must be executed elsewhere; and RSI-style loops improve the agent by iterating over external tools, prompts, or code rather than by turning the runtime itself into the computer. Such systems also increasingly rely on automated evaluators, including agent-as-a-judge schemes, to rank outputs, validate task completion, and close iterative improvement loops ([95]). We hypothesize that a sufficiently capable NC can internalize many of these agentic functions within one persistent neural runtime.
4.4 Additional Thoughts
The remarks in this section are intended as hypotheses and design directions motivated by the present results, rather than as empirical conclusions established by the current prototypes.
ONE
ONE ([96]) proposed a single neural substrate that incrementally absorbs and reuses diverse learned skills. While ONE was not instantiated as a computer-like runtime with explicit I/O, programmability, and update governance, a mature CNC can be viewed as a plausible systems-level realization of this idea. In this sense, many specialized world-model-like components may ultimately appear not as separate external systems, but as installable capabilities within one persistent neural runtime.
Video models as a pragmatic prototype substrate
We build our prototypes on state-of-the-art video models because they currently provide the simplest path to an end-to-end learned latent runtime state that jointly models pixels, dynamics, and action-conditioned control. This choice is pragmatic rather than fundamental. In our experiments, symbolic and algorithmic reasoning in terminal settings remains inconsistent for most strong video models, and even simple arithmetic can fail (Table 6). Sora2 is a notable exception in our probe, achieving $71%$ arithmetic accuracy, suggesting that some terminal symbolic reasoning is already possible in modern video generators. At the same time, we do not claim that video models cannot reason more broadly: recent work reports that video models can act as zero-shot learners and reasoners in naturalistic settings ([97]). We expect reasoning capabilities to improve quickly with continued progress in video modeling, but our results suggest that CNC-level reliability will likely require additional architectural and training ingredients beyond scaling today's video generators.
A hypothesis: machine-native neural architectures
We emphasize that the following is a conjecture rather than a conclusion drawn from our experiments. Closing the reasoning gap may not require designing neural networks that more closely mimic animal cognition or the human brain. Many influential architectures, including convolutional networks ([98]) and linear/quadratic Transformers ([8, 59]), are highly engineered systems, but their core inductive biases remain strongly influenced by biological perception and attention. These models primarily rely on continuous, distributed representations, in which reasoning behavior emerges implicitly from large-scale training. We hypothesize that CNCs may instead benefit from designs that are explicitly machine-native. Developing discrete operations, compositional structures, and verifiable computation that are harmonious in neural systems may play an essential role in designing such systems. This approach follows more closely the construction of conventional computers from well-defined computational primitives and stands in contrast to relying on emergent reasoning in generic video generation models.
Neural networks generation via NC interaction
Neural network generation can be viewed as a form of programming, i.e., the synthesis of a neural architecture and its corresponding weights. Because NCs' architectural semantics are already neural and numerical, neural components are first-class, and generation directly manipulates the memory state rather than translating it into symbolic code. Moreover, NCs can be programmed through I/O interaction: sequences of inputs, observations, and outcomes act as executable specifications that shape the internal state and routines of the system ([84, 99]). This suggests a path in which users generate and refine neural modules within NCs through interactive traces, treating interaction logs as programs that configure and compose neural computation.
Unified hardware requirements and data representation
In NCs, tensors and tensor-to-tensor transformations act as primary computational primitives, replacing the heterogeneous mix of data structures and subsystem-specific abstractions common in conventional computers. Traditional systems span many distinct domains—scalars, pointers, linked structures, files, sockets, and processes—each with its own memory layout, invariants, APIs, and failure modes, coordinated by operating systems through largely disjoint subsystems (virtual memory, filesystems, networking, scheduling, and drivers) ([100, 101]). Although this heterogeneity supports broad generality, it also fragments optimization and tooling because compilers, profilers, and debuggers must reason across incompatible abstractions ([102]). By contrast, a tensor-uniform pipeline concentrates representation and execution into a compact set of composable primitives, such as linear algebra and elementwise operations, allowing tooling to target a shared intermediate representation ([103]). As a result, optimizations such as operator fusion, memory planning, and computational-graph rewriting can be applied system-wide ([104]); profiling can focus on throughput and memory bandwidth; and accelerators such as GPUs can be targeted through common tensor runtimes ([105]). This shared numerical representation also naturally supports multimodal computation: vision (pixel tensors), language (sequence embeddings), audio (waveforms or spectrograms), control (state-action tensors), and planning (latent trajectory tensors) all reside in one representational space and can be jointly reasoned over and optimized in a single graph ([106]), without repeated type bridging or subsystem translation—steps that are substantially harder in traditional heterogeneous stacks.
5. Conclusion
Section Summary: Neural computers envision a future where a single underlying state runs the entire machine, controlling displays, text, and actions without traditional operating systems or interfaces. While early versions show promising basics like input-output coordination and short-term decision-making, they still struggle with reliable reuse, consistent symbol handling, and overall control, leaving a big gap between prototypes and practical use. A detailed capability roadmap highlights progress in areas like efficiency and reasoning, but closing these gaps will require not just better models but sustained improvements in stability and governance to make neural computers a viable next-generation option.
Neural computers point toward a machine form in which a single latent runtime state acts as the computer itself, driving pixels, text, and actions while subsuming what operating systems and interfaces handle today. In this paper, the main result is that NCs have begun to exhibit early runtime primitives—most notably I/O alignment and short-horizon control—while stable reuse, symbolic reliability, and runtime governance remain unresolved. Our CNC capability map remains useful as a longer-horizon view, spanning efficiency, computation & reasoning, memory & storage, I/O & control, tool bridges, condition-driven generalization, programmability, and artifact generation. The map is staged and dependency-informed, but the more immediate gap is still the gap from prototype behavior to usable runtime behavior. Progress toward CNCs will therefore depend not only on stronger models, but also on whether reuse, consistency, and governance become sustained and testable. If these gaps continue to close, neural computers will look less like isolated demonstrations and more like a plausible candidate machine form for next-generation computers.
Acknowledgements
Section Summary: The authors thank Yasheng Sun for his early contributions to collecting GUI data. They also acknowledge Deyao Zhu and Firas Laakom for providing helpful feedback on the manuscript. Several researchers, including Mingchen Zhuge, Haozhe Liu, Shuming Liu, Wenyi Wang, Wenxuan Zhang, Junjie Fei, and Jürgen Schmidhuber, were funded by the King Abdullah University of Science and Technology's centers for generative AI and data science and artificial intelligence.
The authors sincerely thank Yasheng Sun for his early input of the GUI data collection. The authors thank Deyao Zhu and Firas Laakom for their feedback on the manuscript. Mingchen Zhuge, Haozhe Liu, Shuming Liu, Wenyi Wang, Wenxuan Zhang, Junjie Fei, and Jürgen Schmidhuber were supported by funding from the King Abdullah University of Science and Technology (KAUST) Center of Excellence for Generative AI (award number 5940) and the SDAIA-KAUST Center of Excellence in Data Science and Artificial Intelligence.
Appendix
Section Summary: Researchers explored alternative ways to gather data for training neural systems to interact with computers, focusing on web videos and live online simulations, though these methods weren't used in the final project due to practical challenges. Extracting videos from the web proved difficult because of privacy and copyright issues, plus the need for extensive cleaning to handle messy content like varying screen setups, low-quality footage, and unrelated distractions that messed up text recognition and timing. They also tested a setup where AI agents interacted in a secure, isolated environment to generate real-time data, which could help build better learning experiences and catch errors, but it ran into delays in communication and complex debugging, leading them to stick with simpler, high-quality data for now while seeing promise for scaling up later.
A. Explorations: Alternative Data Sources and Online Interaction
Beyond the data collection pipelines used in the main text and Appendix B, we explored alternative data sources for neural-computer prototyping. These routes were not incorporated into the final pipeline, but the trials yielded useful insights and suggest directions for future work as tooling matures and data-collection infrastructure scales.
A.1 Web video extraction
We initially tested crawling computer-use videos from the web. We used OCR and layout detectors to locate terminal regions, estimate text content and timestamps, and extract related clips. We did not adopt this route for two main reasons:
- **Data governance constraints:** privacy and copyright risks are difficult to manage at web scale.
- **Data quality burden:** heavy filtering and sanitization are required before the data can support reliable OCR and temporal alignment.
Screen recordings can contain personal identifiers (usernames, emails, file paths, chat content) and may come with licensing constraints that are difficult to verify at scale. Cleaning the resulting data is substantially more complex than it appears (Figure 10). Typical failure modes include (i) uncontrolled content such as faces/hands, picture-in-picture overlays, and unrelated desktop activity; (ii) domain shift across operating systems, themes, fonts, resolutions, and window managers; and (iii) quality factors such as compression artifacts, variable frame rates, zoom/crop edits, and inconsistent capture pipelines. These factors degrade OCR and temporal alignment.
Despite these challenges, web videos remain a potential long-term scaling axis for interface experience. In this work, however, the cost–quality trade-off was unfavorable. Our setting benefits disproportionately from clean, temporally aligned text and interaction signals. Building a high-precision web filter also requires substantial upfront investment. This includes rights-cleared sourcing or licensing, privacy review and redaction, and large-scale multimodal filtering/OCR pipelines that often rely on paid APIs. Given these constraints and our emphasis on high-quality supervision, we prioritized curated, rights-cleared interface trajectories. Future efforts that invest in rights-respecting acquisition and stronger automated filtering could unlock web-scale data as a complementary scaling axis.
A.2 Online environment interaction
We prototyped an agentic interaction pipeline that separates a control plane from an execution environment plane (Figure 11). In the environment plane, a sandboxed container runs a live shell together with LLM agents (planner/controller) and a recorder exposed via a narrow port-based interface. The agents issue commands and control actions. The recorder captures synchronized terminal renders, structured terminal state when available (e.g., buffer/text), and action traces. Structured terminal state is logged for diagnostics/alignment and is not fed to video models as privileged state input. Trajectories are streamed to the control plane for storage and video-model updates.
Concretely, the environment plane exposes a minimal "step/reset" interface over a port. It returns multimodal observations that can be logged deterministically (rendered screenshots plus structured state when available). The agent emits structured actions (typed command text, key/mouse events when applicable, and timing). This separation makes rollouts auditable and lets the control plane scale rollout collection and model updates with decoupled throughput. From the perspective of Toward CNC, this design also makes the evidence boundary more explicit by preserving replayable execution traces with clear provenance across collection and training.
We explored this setup because closed-loop interaction can induce a natural curriculum by continually sampling the boundary of current video-model behavior. It can also surface rare and safety-critical failure modes that do not appear in offline logs. It supports targeted data collection (e.g., focusing on specific tools, error recovery, or long-horizon tasks). In principle, it also offers a direct path to scaling experience rather than only scaling static demonstrations.
Early trials showed promise, but the dominant bottlenecks in the end-to-end system were systems-level: cross-cluster communication latency between rollout workers and training nodes, and high debugging complexity in asynchronous distributed execution. Safety controls (e.g., isolation of untrusted code execution, monitoring and abuse prevention, and deterministic resets and environment control) remained necessary constraints, but they were not the primary bottleneck. The setup also requires robust recording and serialization across heterogeneous environments. Under time and cost constraints, we therefore prioritized controlled video data for the main experiments. Despite not being used in the final pipeline, we consider this design a useful systems template for future work. It supports scalable multi-environment rollout collection and consistent provenance and storage of trajectories. It can support multiple downstream learning algorithms (e.g., behavior cloning or preference-based learning). Execution remains sandboxed and auditable.
B. Datasets: Collection and Evaluation Protocols
This appendix summarizes collection, preprocessing, and evaluation details for the datasets used in the paper. For concrete examples of raw trajectory formats (asciinema .cast and vhs scripts), see Appendix C. Data collection uses a three-stage pipeline to maintain synchronized timing, privacy controls, and consistent, well-documented artifacts across CLIGen and GUIWorld.
Sourcing. We construct our datasets from three complementary sources—public terminal recordings, scripted terminal replays, and a controlled desktop-capture rig. Across all sources, we emphasize rights-respecting acquisition, privacy filtering, and temporally aligned interface signals (frames, actions, and text when available):
- `cligenGeneralLogo` **CLIGen (General)**: public `asciinema` `.cast` archives; traces are replayed with official tools to preserve recorded terminal appearance (color schemes, cursor visibility, window geometry).
- `cligenCleanLogo` **CLIGen (Clean)**: deterministic `vhs` scripts (e.g., package installs, REPLs, log filters) executed in isolated environments.
- `guiworldLogo` **GUIWorld**: footage captured with the rig in Section 3.2, pairing RGB video with low-latency pointer/key logs and optional accessibility cues (logged for analysis; not used as model inputs).
Alignment and sanitization. All modalities share a common clock. We align pointer/key events to the nearest frame, apply drift correction when needed, and drop clips with residual misalignment. Privacy filters remove terminal sessions with sensitive strings and redact GUI regions likely to contain private content. Frozen or repeated-frame recordings (capture artifacts) are discarded.
Episode packaging. Runs are windowed into fixed-length, overlapping episodes (window sizes and strides are specified in the released configs). Each shard stores RGB frames, terminal buffers or GUI metadata, serialized actions, the source tool (asciinema/vhs/GUI capture), and environment metadata. Structured fields (buffers/metadata) are used for alignment and evaluation, but are not provided to the video models as state inputs. Downstream dataloaders reconstruct batches directly. Released configs specify preprocessing and windowing so external users can rebuild the corpus. This packaging turns each episode into a replayable artifact with provenance, which is useful not only for evaluation reproducibility but also for the broader evidence and governance requirements discussed in Toward CNC.
B.1 Caption fields and metadata (CLIGen General)
For CLIGen (General), each replayed .cast fragment (example shown in Appendix C.1) is paired with three aligned descriptions and a compact metadata record. Table 20 summarizes the fields for clip 7****_0001.
% caption, label
::: {caption="Table 20: Caption tiers and metadata for CLIGen (General) clip 7****_0001."}
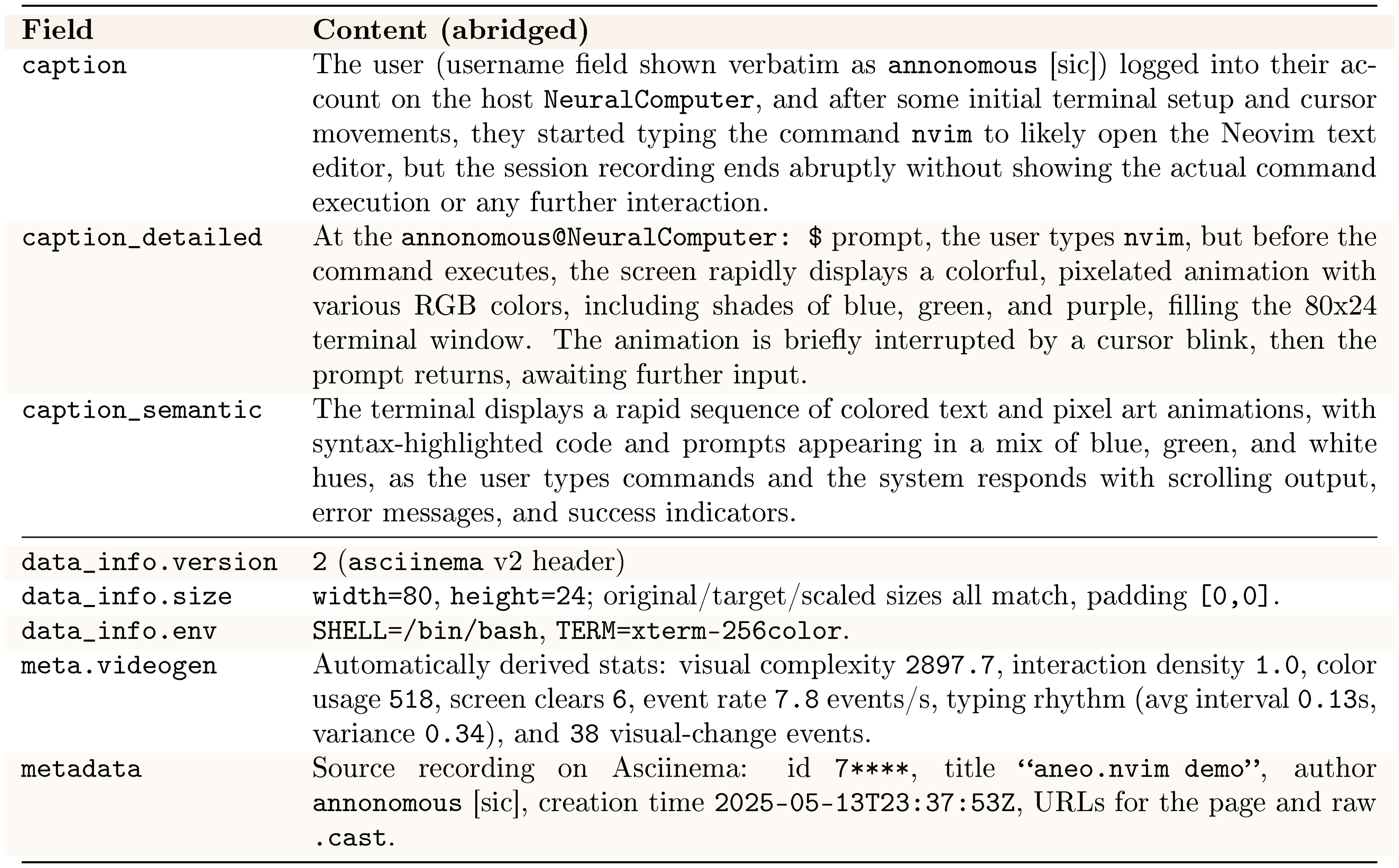
:::
These fields make each CLIGen (General) clip self-contained. The three caption tiers provide prompts at different levels of detail. data_info and metadata preserve the structure needed to rebuild terminal geometry, environment, and source from the raw .cast.
B.2 OCR evaluation protocol (CLIGen Clean)
For CLIGen (Clean), OCR-based metrics evaluate how closely generated terminal videos match reference renderings derived from the ground-truth buffers in text space rather than pixels. Each sample consists of a generated video and its paired reference video (matched by clip ID). We keep only IDs where both videos are present. From each paired video we use at most $K{=}5$ frames. Let $T_\text{gen}$ and $T_\text{gt}$ be the frame counts of the generated and reference videos. We set $T=\min(T_\text{gen}, T_\text{gt})$. If $T \le K$, we use all indices in $[0, T{-}1]$; otherwise, we select $K$ evenly spaced indices by deterministic rounding, then deduplicate and sort them so evaluation frames are spread across the trajectory. For every selected index we read the corresponding frame from both videos.
Each frame is converted to RGB and passed to Tesseract OCR. The resulting string is split into lines, leading and trailing whitespace is stripped, and internal whitespace is normalized by collapsing runs of spaces. Empty lines are dropped. We keep case and punctuation intact so that commands, paths, and symbols remain visible. This gives an ordered list of normalized lines for the ground-truth frame ($g_1, \dots, g_{N_g}$) and the generated frame ($p_1, \dots, p_{N_p}$).
We summarize the OCR text-space metrics used per sampled frame as follows:
**Character accuracy.** This metric pools all lines into a single multi-line string for each side and measures normalized edit distance.
Let $s$ and $t$ be the concatenated ground-truth and generated texts and $d(s, t)$ their Levenshtein distance (insert/delete/replace cost $1$).
If both $s$ and $t$ are empty we set $\text{char\_acc}=1$; if only $s$ is empty we set $\text{char\_acc}=0$.
Otherwise,
$
\text{char\_acc} = \max\Bigl(0, \ 1 - \frac{d(s, t)}{\max(|s|, 1)}\Bigr),
$
Extra or missing characters are normalized by the reference length through the denominator $\max(|s|, 1)$.
Frame-level scores are averaged over the selected frame pairs (up to $K{=}5$) to yield a per-video character accuracy, and group-level scores report the mean over videos.
**Exact-line accuracy.** This metric treats lines as position-sensitive units and reports a recall over ground-truth lines.
For a given frame, we compare line $g_i$ to $p_i$ at the same index.
A line is counted as correct only if $i\le N_p$ and $p_i=g_i$; lines that appear in the wrong position do not count.
If both lists are empty we set $\text{exact\_line\_acc}=1$; if the ground-truth list is empty but the generated list is not, we set $\text{exact\_line\_acc}=0$.
Otherwise,
$
\text{exact\_line\_acc} = \frac{1}{N_g}\sum_{i=1}^{N_g} \mathbf{1}[i \le N_p \land p_i = g_i].
$
As with character accuracy, frame scores are averaged over the $K$ sampled frames to obtain a per-video score and then averaged over videos for the reported aggregate.
Together, these two metrics stress both fine-grained text fidelity and line-ordered terminal state reconstruction.
B.3 Evaluation metrics and protocol (GUIWorld)
We report both global video metrics and action-driven metrics that focus on post-interaction frames. We compute these metrics using our GUIWorld evaluation suite. We summarize the GUIWorld protocol at a glance as follows:
- **Global metrics** ($\textsc{FVD}$ $_\text{all}$, $\textsc{SSIM}$ $_\text{all}$, $\textsc{LPIPS}$ $_\text{all}$): computed over paired generated/ground-truth videos after standardized decoding, subsampling, and resizing.
- **Action-driven metrics** ($\textsc{SSIM}_{+15}$, $\textsc{LPIPS}_{+15}$, $\textsc{FVD}_{+15}$): computed on post-action windows to measure interface fidelity after interaction events.
Global $\textsc{FVD}$ $\text{all}$ / $\textsc{SSIM}$ $\text{all}$ / $\textsc{LPIPS}$ $_\text{all}$ We decode paired generated/ground-truth videos into RGB frames with temporal subsampling and resizing (fps=3, size=256, and max_seconds=5 by default). $\textsc{SSIM}$ $\text{all}$ is computed using torchmetrics on frame tensors normalized to $[0, 1]$ and averaged over frames. $\textsc{LPIPS}$ $\text{all}$ uses the AlexNet backbone on frames normalized to $[-1, 1]$ and is averaged over frames. $\textsc{FVD}$ $_\text{all}$ is computed in an r3d18 embedding space (prelogits by default). We extract features from fixed-length clips (16 frames at 112 $\times$ 112 after uniform subsampling/padding). We compute the Fréchet distance between the generated and reference feature distributions.
Action-driven metrics ($\textsc{SSIM}{+15}$, $\textsc{LPIPS}{+15}$, $\textsc{FVD}_{+15}$) For each paired rollout, we load recorded action timestamps (from JSON/CSV logs), map each timestamp $\tau$ to a frame index $f=\mathrm{round}(\tau \cdot \mathrm{fps})$, and clamp to the valid frame range. We skip the action frame itself (action_start_offset=1) and evaluate the next $k{=}15$ frames after each action. Concretely, for each action frame index $f$, we form the post-action set ${f+1, \dots, f+k}$ and clip it to valid frame indices. We then take the deduplicated union over actions in the clip and keep frame indices in chronological order. Clips with zero logged actions, or with empty valid post-action windows after clipping, are excluded from $+15$ metrics. For $\textsc{SSIM}{+15}$ / $\textsc{LPIPS}{+15}$, we compute per-clip means over selected frame pairs and then average across clips. For action-driven $\textsc{FVD}_{+15}$, we build an after-action clip per video by concatenating the same selected post-action frames, then uniformly subsample/pad to 16 frames and compute the Fréchet distance in the same r3d18 feature space.
C. CLIGen: CLI Trajectory Formats
This appendix provides concrete format examples for the two CLI sources referenced throughout the data pipeline (Appendix B). We show asciinema .cast trajectories for CLIGen (General) and vhs scripts for CLIGen (Clean).
C.1 Asciinema (.cast) example
The header line stores the recording config (version, terminal size, timestamp, env). In this excerpt, output rows follow [time, "o", "payload"], where "o" indicates screen output. The payload contains the terminal text with color codes at that timestamp.
"version": 2, "width": 80, "height": 24,
"timestamp": 1747177906,
"env": {"SHELL": "/bin/bash", "TERM": "xterm-256color"}
[0.082492, "o", "\u001b[H\u001b[2J\u001b[3J"]
[0.950038, "o", "\u001b[38;2;16;131;236m\u001b[39m\r\n..."]
[0.950733, "o", "\u001b[38;2;6;156;220m ... \u001b[38;2;1;195;187m█"]
C.2 VHS script example
## —- VHS documentation start (DO NOT CHANGE) —-
## Require:
## Require <string>
## Sleep:
## Sleep <time>
## Type:
## Type[@<time>] "<characters>"
## Keys:
## Escape[@<time>] [number]
## Backspace[@<time>] [number]
## Delete[@<time>] [number]
## Insert[@<time>] [number]
## Down[@<time>] [number]
## Enter[@<time>] [number]
## Space[@<time>] [number]
## Tab[@<time>] [number]
## Left[@<time>] [number]
## Right[@<time>] [number]
## Up[@<time>] [number]
## PageUp[@<time>] [number]
## PageDown[@<time>] [number]
## ctrl+<key>
## Display:
## Hide
## Show
## —- VHS documentation end (DO NOT CHANGE) —-
## ID: vhs_example
## INSTRUCTION: Runs `uname -s` repeatedly as a basic shell exercise, then hides the prompt.
## LEVEL: 1
## EVENTS: 23
## VISUAL_COMPLEXITY: 45
## —- Theme setting start (DO NOT CHANGE) —-
> **Section Summary**: This section configures the settings for generating a video file named vhs_example.mp4 using a bash shell interface. It applies the Catppuccin Mocha theme with a dark background, white text, and colorful accents like red, green, and pink for elements such as the cursor, while specifying bright variants for emphasis. Additional options set the video dimensions to 1600 by 900 pixels, a large 40-point font size, a typing speed of 300 milliseconds, and styling details like margins, padding, line height, and a rounded border for a polished look.
Output vhs_example.mp4
Set Shell "bash"
Set Theme {
"name": "Catppuccin Mocha (Pure White, Warm Pink Cursor)",
"background": "#1e1e2e",
"foreground": "#ffffff",
"black": "#45475a",
"red": "#f38ba8",
"green": "#a6e3a1",
"yellow": "#f9e2af",
"blue": "#89b4fa",
"purple": "#cba6f7",
"cyan": "#94e2d5",
"white": "#ffffff",
"brightBlack": "#585b70",
"brightRed": "#f38ba8",
"brightGreen": "#a6e3a1",
"brightYellow": "#f9e2af",
"brightBlue": "#89b4fa",
"brightPurple": "#cba6f7",
"brightCyan": "#89dceb",
"brightWhite": "#ffffff",
"cursor": "#f5c2e7",
"cursorAccent": "#1e1e2e",
"selectionBackground": "#585b70"
Set FontSize 40
Set Width 1600
Set Height 900
Set TypingSpeed 300ms
Set PlaybackSpeed 1
Set Margin 28
Set MarginFill "#0091FF"
Set BorderRadius 25
Set Padding 18
Set LineHeight 1.2
Set LetterSpacing 0.8
## —- Theme setting end (DO NOT CHANGE) —-
> **Section Summary**: This section details the technical underpinnings of GUIWorld, a simulated environment for GUI interactions, focusing on how actions like mouse clicks, drags, scrolls, and keyboard inputs are represented, encoded, and aligned with video frames. It describes two encoder types—a raw one for detailed events and a meta one for compressed schemas—and four injection modes to integrate these actions into a model's processing, such as fusing them externally or adding them as residuals inside neural network layers. Temporal alignment ensures actions are synchronized with visual changes by windowing and lagging features to account for delays, enabling more accurate simulation of user interactions.
Sleep 800ms
Sleep 180ms
Type "uname -s"
Sleep 120ms
Enter
Sleep 400ms
Type "uname -s"
Sleep 120ms
Enter
Sleep 400ms
Type "uname -s"
Sleep 120ms
Enter
Sleep 400ms
Type "uname -s"
Sleep 120ms
Enter
Sleep 400ms
Type "uname -s"
Sleep 120ms
Enter
Sleep 400ms
Sleep 400ms
Sleep 600ms
Hide
D. GUIWorld: Action Representation, Temporal Alignment, and Conditioning
This appendix provides additional technical details on GUIWorld action representation, temporal alignment, and conditioning used in Section 3.2. Additional visualization pages are collected in Appendix E; evaluation metrics and protocols are summarized in Appendix B.3.
D.1 Action schema
NC $_\text{GUIWorld}$ represents actions as a structured stream, enabling the NC to condition on both cursor movements and key presses.
At each timestep, we log absolute cursor coordinates, button up/down transitions, scroll deltas, and keyboard events. Keyboard inputs are split into two types: typed characters (e.g., ls -l) and shortcut-style chords (e.g., ctrl+v). We also track state flags such as whether a drag is currently active. This lets us represent extended interactions like click-drag or press-hold as short labeled segments rather than isolated spikes. The meta-action encoder described in Section 3.2 compresses this stream into a small typed schema. In all reported v2 experiments, we use $S{=}2$ action slots per frame; empty slots are padded with type 0. Each action has a type (e.g., mouse click or keyboard type) plus parameters. Table 21 summarizes the types and fields. Type 0 corresponds to the absence of an action. Type 1 encodes mouse clicks and drags via button identity, click count, and a drag flag. Type 2 captures scrolls with a direction and scalar amount. Type 3 packages free-form keyboard text (such as ls -l) embedded by the shared text encoder. Type 4 records shortcuts such as ctrl+v via a small shortcut vocabulary. This representation resembles a tool API while remaining recoverable from raw logs.
::: {caption="Table 21: Meta-action schema for GUIWorld (per action slot)."}

:::
D.2 Conditioning: encoders and injection
The main text considers two encoders for this stream. A raw-action encoder (v1) keeps fine-grained mouse and key events in a multi-hot representation that closely mirrors real cursor and typing behavior. A complementary meta-action encoder (v2) compresses events into a small typed schema (Table 21) and embeds any free-form text with a shared text encoder. Both encoders produce per-frame action features that undergo temporal windowing and alignment (described below). These embeddings support four injection modes, summarized below:
- `external`: fuse actions at the VAE input.
- `contextual`: mix actions and frames as tokens in one sequence.
- `internal`: inject actions inside transformer blocks.
- `residual`: add lightweight action deltas to hidden states.
Injection-mode definitions (schematic)
Below we give compact schematic definitions for the three formula-based modes (external, residual, internal); contextual is specified by the structured attention mask in Figure 12.
External. Given VAE latents $z_{1:T}$ and temporally aligned action features $u_{1:T}$, an external action module produces a residual update $\Delta z_{1:T}(u_{1:T})$ and forms modified latents
$ z'{1:T} = z{1:T} + \Delta z_{1:T}(u_{1:T}). $
The diffusion backbone then operates on $z'_{1:T}$ (actions do not appear as explicit tokens inside the transformer).
Residual. At selected transformer layers $l$, an auxiliary action module takes block hidden states $h^{(l)}$ together with local action/mouse features and outputs a residual update $\Delta h^{(l)}(a, \text{mouse})$. The updated hidden states are
$ \tilde{h}^{(l)} = h^{(l)} + \Delta h^{(l)}(a, \text{mouse}), $
which are passed to the next block.
Internal. At selected blocks, action conditioning is inserted as an additional cross-attention sub-layer inside the standard attention stack. With self-attention $\mathrm{SA}$, text/reference cross-attention $\mathrm{CA}{\text{text}}$, and action cross-attention $\mathrm{CA}{\text{action}}$, a schematic update is
$ h' = \mathrm{FFN}\Big(h + \mathrm{CA}_{\text{text}}\big(\mathrm{SA}(h), c\big)
- \mathrm{CA}_{\text{action}}(h, a) \Big). $
D.3 Temporal alignment and attention
Temporal alignment and windows. The GUI backbone processes a compressed latent video at stride $c$ (every $c$ pixel frames correspond to one latent frame). For a pixel sequence of length $F$ and latent sequence of length $T$, we approximately have $F \approx (T-1)c + 1$ under uniform sampling. Exact indexing follows the dataloader timestamp mapping and boundary handling. Anchor frame $a_t = t \cdot c$ marks the pixel frame corresponding to latent step $t$.
Mouse and keyboard logs start as per-frame features $r_f \in \mathbb{R}^D$ at the pixel rate. A windowed encoder aggregates them around each anchor over $p = c \cdot w$ frames. Here $w$ controls the window width, and a lag $\ell$ accounts for GUI response delay (actions precede their visual effects). We use zero-padding outside the valid range, i.e., $\tilde{r}_f=r_f$ for $0\le f<F$ and $\tilde{r}_f=0$ otherwise, and form a lag-shifted window that ends at $a_t-\ell$:
$ W_{t, k} = \tilde{r}{, a_t - (p-1+\ell) + k}, \quad k\in{0, \dots, p-1}, \quad a^{\text{act}}t = \frac{1}{p} \sum{k=0}^{p-1} W{t, k}. $
This shared action encoder yields one latent-aligned action embedding $a^{\text{act}}_t$ per step. It summarizes a short, lagged history of cursor motion and key events and is reused across all injection modes.
Contextual attention mask. In the contextual mode, video and action tokens are concatenated into a single sequence and processed under a structured lag-aware local attention mask. Appendix Figure 12 can be read as a query–key matrix: rows are queries and columns are keys.
The upper-left block (V2V) restricts each frame $V_i$ to attend only to neighboring frames within a window of $\pm w$ steps, so very distant frames cannot interfere. The upper-right block (V2A) lets frame $V_i$ see only recent actions in a lag-bounded recent-action range. In implementation, this window is $j \in [\max(0, i-\ell), \min(i, A-1)]$, where $\ell$ is the action lag and $A$ is the action-token length. This way, frame conditioning stays focused on recent operations and excludes future actions. In the lower-left block (A2V), an action $A_i$ can attend to frames $V_t$ that occur after it has had time to take effect ($t \ge i+\ell$, with boundary clipping), but not to earlier frames. This path is representation-only and does not expose future frame information to frame prediction. The lower-right block (A2A) is strict diagonal: each action token attends to itself.
In practice $(w, \ell)$ act as fixed hyperparameters that trade off temporal coverage and cost. Together, these choices implement a structured lag-aware temporal prior: actions do not explain past frames, and each frame conditions on recent operations that could plausibly have shaped its pixels.
Design insights. Two insights from the GUI experiments motivate this schema. First, raw action streams are bursty and high-dimensional. Cursor and key events arrive in short spikes, and simple smoothing or full-history attention can cause false interpolated motion and underestimated typing speed. Using short, lagged windows and local attention bands makes credit assignment more intuitive: each frame connects to the few operations that could have produced it. Second, in our experiments, with the visual backbone fixed, control fidelity improved more from conditioning design than from encoder choice. Clean, well-paced supervision and mid- or deep-level action injection improve cursor accuracy and hover timing, while different encodings of the same stream perform similarly. This action schema and mask implement these principles: keep pixels and actions aligned in time, prioritize recent operations over distant ones, and use attention structure rather than capacity alone.
D.4 Cursor rendering and supervision
Cursor rendering and reference construction. The cursor pipeline applies the same design principles on the visual side. Instead of relying on the global diffusion loss to recover a small, high-frequency visual target, we render the cursor explicitly. We treat it as a first-class conditioning signal.
From logs to normalized trajectories.
Desktop logs provide per-frame cursor positions in screen coordinates $(x_\text{screen}, y_\text{screen})$ at the native GUI resolution. We align these with sampled video frames using the same letterbox mapping as the RGB stream. Given source and target resolutions $(w_\text{src}, h_\text{src})$ and $(w_\text{dst}, h_\text{dst})$, we compute a uniform scale $s$ and padding offsets $(p_x, p_y)$. Each coordinate is then mapped to normalized positions $(x_t, y_t)\in[0, 1]^2$ as
$ x_t = \frac{s, x_{\text{screen}, t} + p_x}{w_\text{dst}-1}, \qquad y_t = \frac{s, y_{\text{screen}, t} + p_y}{h_\text{dst}-1}. $
Stacking these over time yields the trajectory tensor mouse_trajectories used across rendering and action encoding.
::: {caption="Table 22: Raw-action versus meta-action encoders in GUIWorld."}
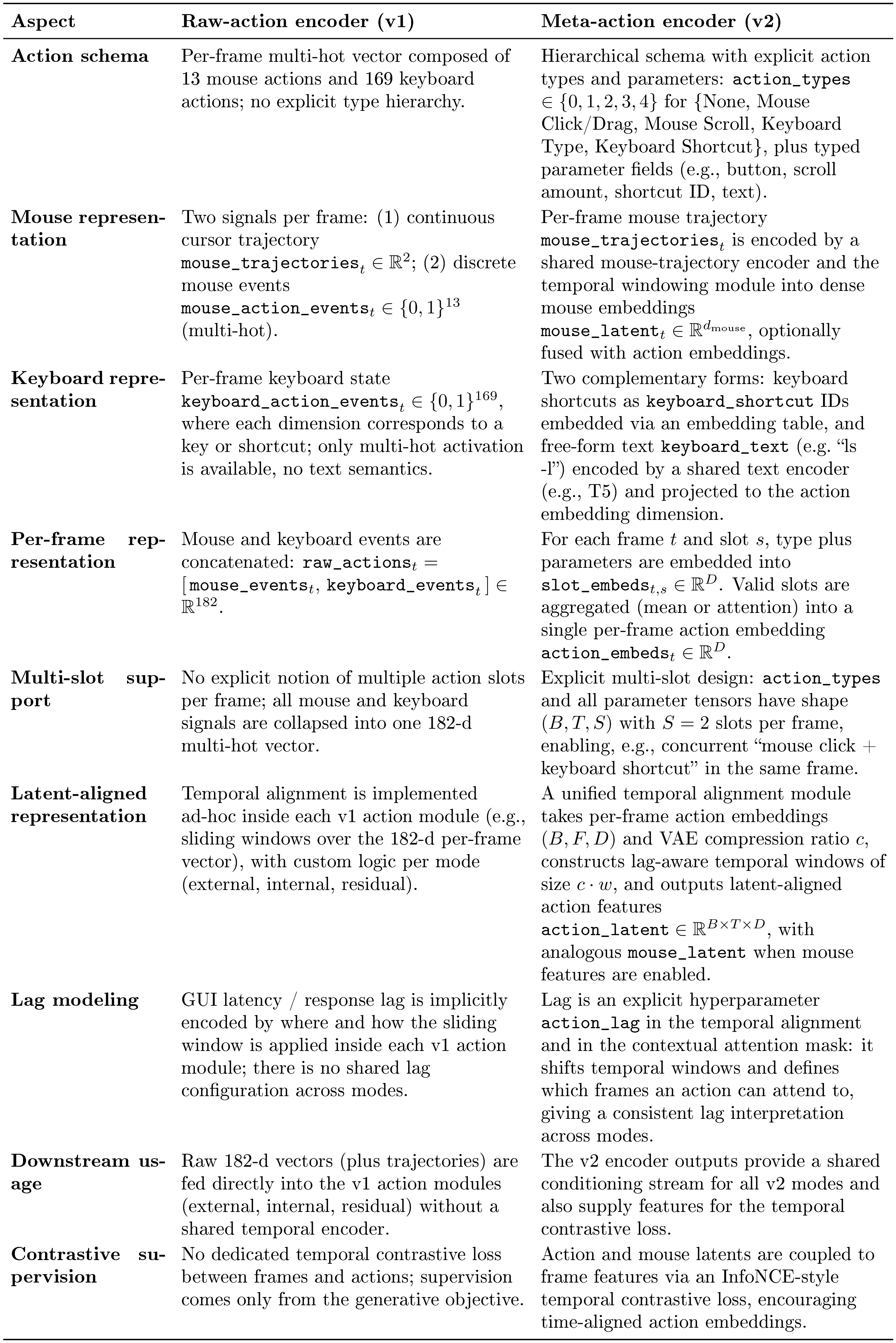
:::
D.5 Training signals and encoder design
From trajectories to cursor layers. Starting from normalized $(x_t, y_t)$ coordinates, a cursor-layer module renders a fixed SVG arrow template into RGB and alpha channels. The template is reused across frames. For each timestep $t$, it is positioned so the hotspot (arrow tip) aligns with $(x_t, y_t)$, clipped to screen bounds, and alpha-blended over a neutral background. This produces two tensors at video frame rate: a cursor-only foreground image $f_t \in [-1, 1]^{3\times H \times W}$ and a soft mask $m_t \in [0, 1]^{1\times H \times W}$ isolating the arrow pixels. Invalid or missing coordinates zero the mask and leave the foreground unchanged, so frames without visible cursors do not add spurious supervision.
Reference images and masks. These cursor layers become reference conditions for the image-to-video (I2V) model. For each clip we form reference images $\mathrm{ref_img}{0:T-1}$ and masks $\mathrm{ref_mask}{0:T-1}$:
- At $t{=}0$, $\mathrm{ref_img}_0$ is the full desktop frame and $\mathrm{ref_mask}_0$ is all ones, anchoring the static layout and theme;
- For $t{>}0$, $\mathrm{ref_img}_t$ is the cursor foreground $f_t$ and $\mathrm{ref_mask}_t$ is the cursor mask $m_t$, so only the arrow region is supervised while the background remains free.
The model encodes these references with the same VAE as target frames and concatenates their latents and masks into the diffusion input. It enforces masked, reference-consistent reconstruction inside the cursor region while relying on learned dynamics elsewhere. This makes cursor supervision a pixel-level constraint rather than a side effect of the global loss.
Fourier mouse encoding. The same $(x_t, y_t)$ trajectories serve as a continuous control signal. We apply a Fourier position module: clamp coordinates to $[0, 1]^2$, map them to $[-1, 1]^2$, and compute random Fourier features via a fixed Gaussian projection followed by sine/cosine. A small MLP maps these features to per-frame mouse embeddings. The GUIWorld action encoder then aggregates them with lag-aware, stride-aligned windows to produce latent-aligned mouse features. These features condition the external/contextual/residual/internal modes and participate in the temporal contrastive loss.
Cursor-aware losses. Section 3.2 introduces cursor-aware losses that use this construction. A basic variant penalizes position error only in $(x, y)$. Richer variants add Fourier features of the trajectory and, most importantly, an $\ell_2$ loss on the reconstructed cursor patch under $\mathrm{ref_mask}_t$. Table 12 shows that position-only objectives yield low cursor hit rate and visibly jittery arrows even when videos look plausible. Adding the explicit cursor reference stream together with the masked patch loss substantially improves control, reaching 98.7% cursor accuracy. This confirms that explicit cursor rendering plus localized supervision effectively separates "where the arrow is" from "what the rest of the frame should look like".
Temporal contrastive alignment. To strengthen learning signals for the action pathway, we add a lightweight temporal contrastive loss that operates on the same latent timeline as the diffusion model. For each sequence we take per-step frame features $F_{t} \in \mathbb{R}^{d_f}$ pooled from the latent video. We also take per-step action features $A_{t} \in \mathbb{R}^{d_a}$ and (optionally) mouse features $M_{t} \in \mathbb{R}^{d_m}$ produced by the action encoder. Linear projections map these into a common space and the resulting vectors are $\ell_2$-normalized. An InfoNCE-style objective brings matching pairs $(F_t, A_t)$ (and, when present, $(F_t, M_t)$) from the same timestep together. In implementation, matching is lag-aware: frame $t$ is aligned with action/mouse features at $t-\ell$, where $\ell$ is the configured action_lag. Similarities are scaled by a temperature $\tau$. It pushes matched pairs away from other timesteps of the same sequence. We use frame and action masks to ignore positions without actions. A symmetric variant averages frame-to-action and action-to-frame directions.
When enabled, a small future-prediction head adds a second term. Action features at time $t$ are mapped to a prediction of the frame feature at a slightly later step $t+\ell$. A mean-squared error encourages consistency between the prediction and the projected future frame. Together, these terms give the action encoder direct gradients tied to specific frames rather than relying solely on the pixel diffusion loss. The contrastive term enforces tight temporal alignment between actions and the frames they co-occur with. The future head encourages actions to anticipate the visual consequences that appear shortly after they are issued.
Encoder comparison. Table 22 contrasts the two encoders used in GUIWorld. The key theme is moving from a high-dimensional, bursty event vector toward a typed, API-like schema with explicit lag handling. This makes the action stream easier to align with the latent video timeline and to reuse across injection modes.
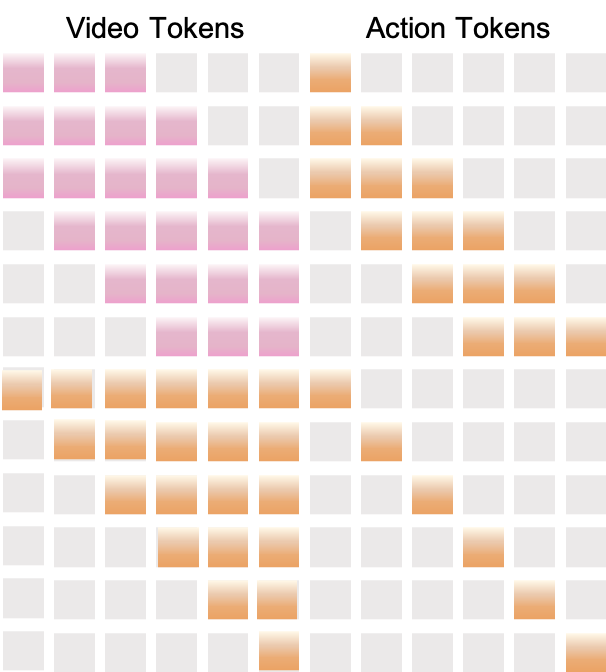
Injection schemes. The GUI experiments explore four conditioning schemes built on this encoder: external, contextual, internal, and residual (Figure 7). Representative action-driven metrics comparing these modes are reported in Table 13. Full metric definitions and the evaluation protocol are provided in Appendix B.3.
E. Additional Visualizations
E.1 CLIGen Visualizations
This subsection consolidates all CLIGen visualization pages referenced in the paper. The main text keeps section-local thumbnail panels at the end of each visualization subsection, while full-size pages are collected here.
(1) CLIGen (General) visualizations. Qualitative samples highlight the breadth of real-world terminal dynamics captured in CLIGen (General): ANSI escape sequences that repaint regions with changing foreground/background colors, incremental command entry with syntax highlighting and cursor edits, classic shell prompts and system outputs, long-running jobs with rapidly scrolling and color-coded package logs, full-screen TUIs, and progress dashboards.
(2) CLIGen (Clean) REPL visualizations. In contrast to open-world traces, CLIGen (Clean) REPL samples are scripted and temporally well-paced (Figure 20–Figure 26; additional format examples are in Appendix C). Each sample includes an explicit action trace (e.g., Sleep, Type, Enter, arrow keys, Hide) alongside rendered terminal frames, making action-to-pixel causality easy to inspect.
(3) CLIGen (Clean) math visualizations. Figure 28–Figure 32 compare model rollouts on CLIGen (Clean) math REPL prompts. Figure 34–Figure 38 show reprompting cases and highlight why these probes should separate native computation from answer-conditioned rendering.
E.2 GUIWorld Visualizations
This subsection consolidates all GUIWorld rollout visualizations (Figure 40–Figure 66). CUA-based pages overlay the CUA trace (natural-language rationale when available, e.g., in a thinking field, plus structured action fields such as left_click, double_click, left_click_drag, and type). It contrasts the Ground Truth trajectory (top) with a Generation conditioned on the first frame and the action sequence (bottom), making state drift easy to spot.
Figure 50–Figure 54 emphasize compounding low-level deviations; Figure 56–Figure 60 focus on numeric/UI fidelity and interaction semantics; and Figure 62–Figure 66 provide additional stress cases where correctness hinges on precise field edits and page state.
Back to Main Thumbnails

cligenGeneralLogo CLIGen (General) visualization samples (A).
Back to Main Thumbnails
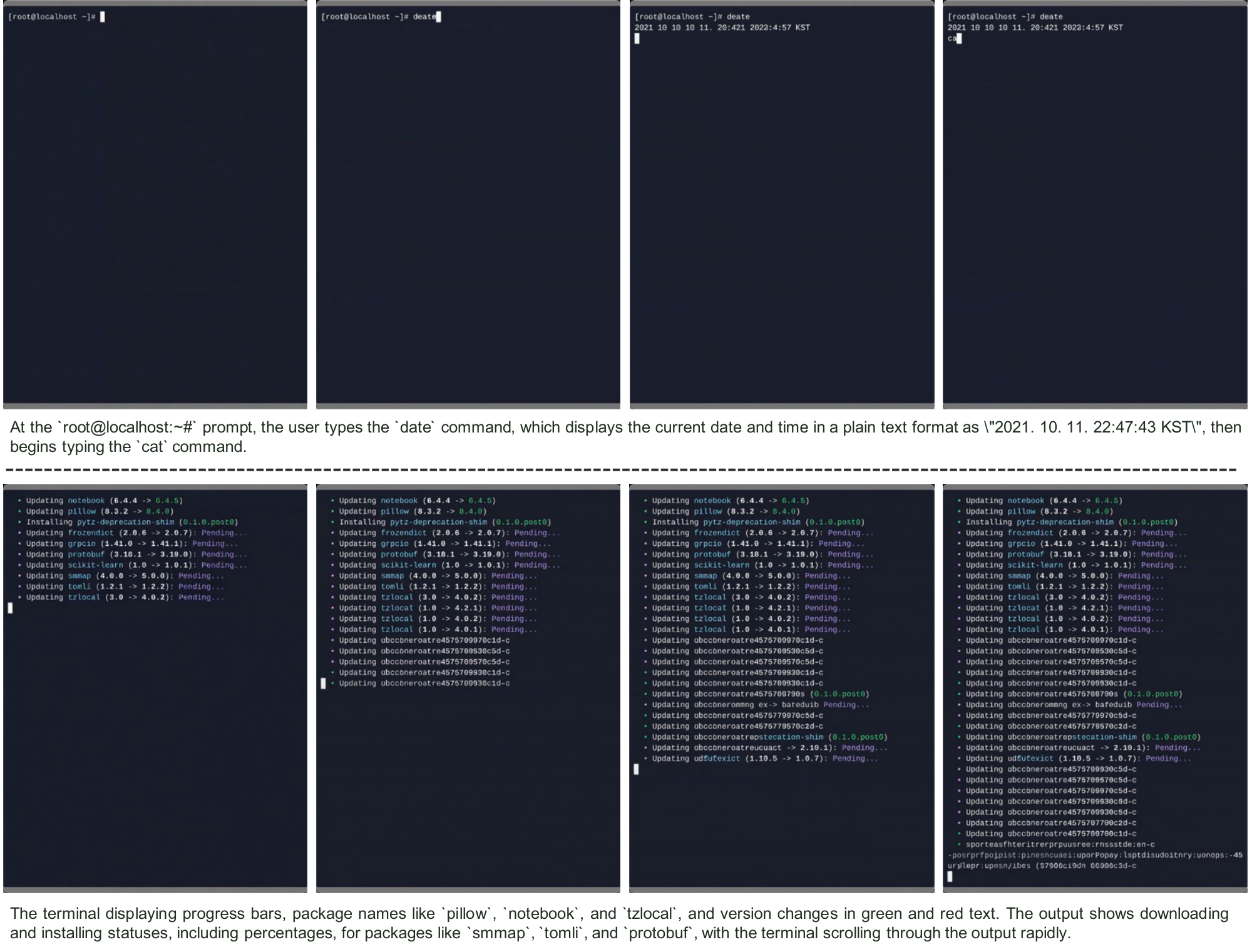
cligenGeneralLogo CLIGen (General) visualization samples (B).
Back to Main Thumbnails
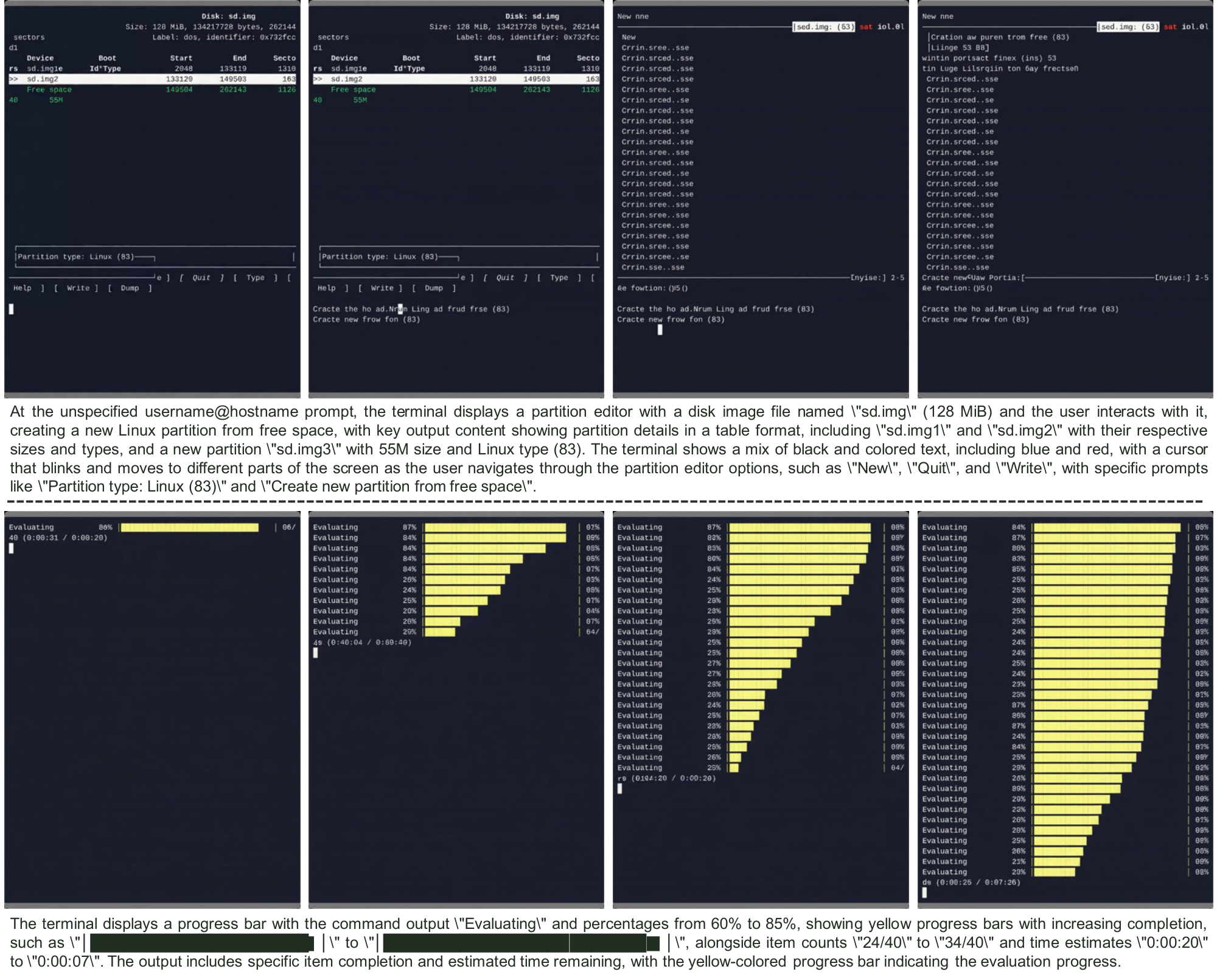
cligenGeneralLogo CLIGen (General) visualization samples (C).
Back to Main Thumbnails
cligenCleanLogo CLIGen (Clean) REPL visualization samples (A).
Back to Main Thumbnails
cligenCleanLogo CLIGen (Clean) REPL visualization samples (B).
Back to Main Thumbnails
cligenCleanLogo CLIGen (Clean) REPL visualization samples (C).
Back to Main Thumbnails
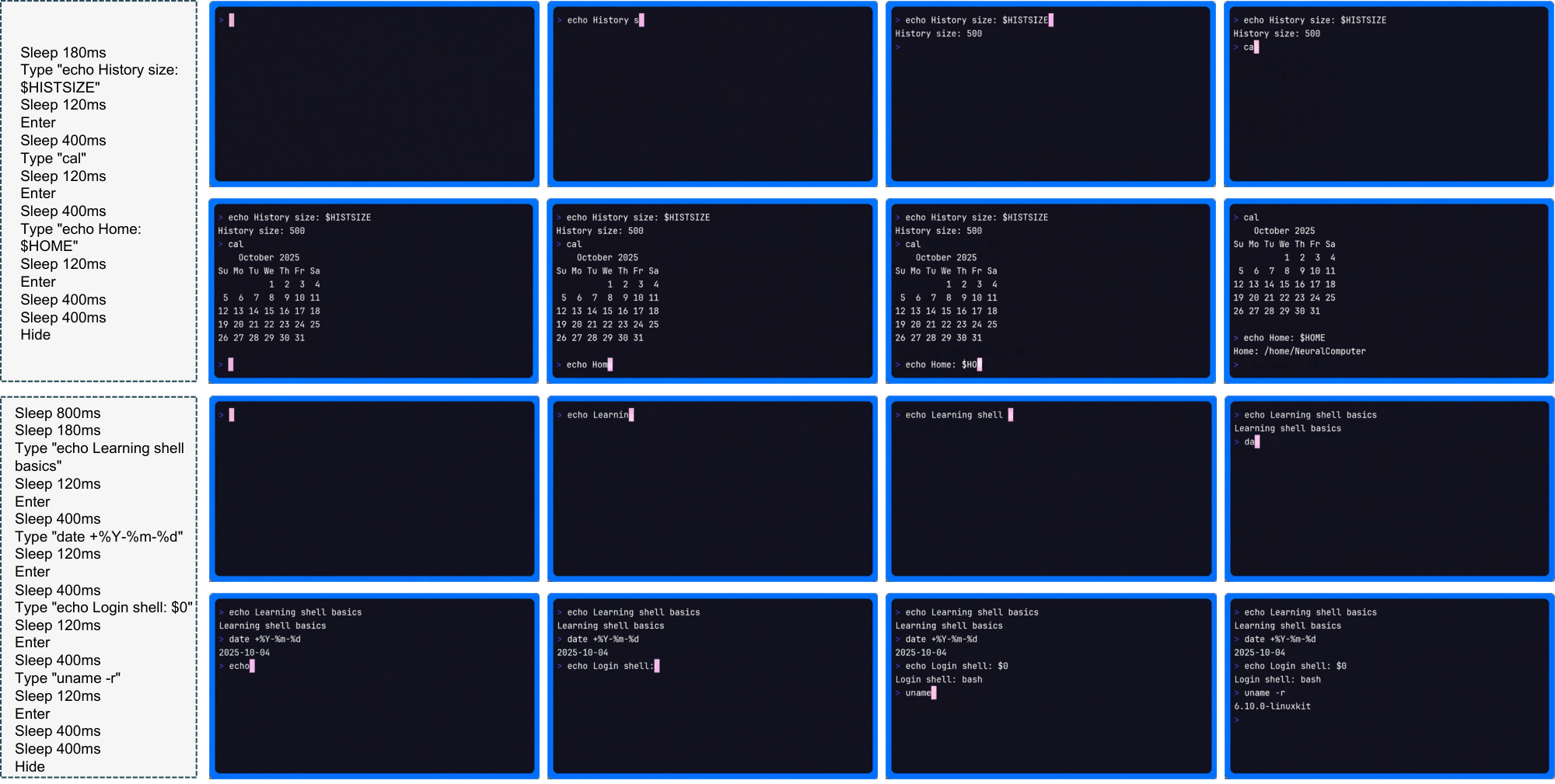
cligenCleanLogo CLIGen (Clean) REPL visualization samples (D).
Back to Main Thumbnails
cligenCleanLogo CLIGen (Clean) math comparison samples (A).
Back to Main Thumbnails
cligenCleanLogo CLIGen (Clean) math comparison samples (B).
Back to Main Thumbnails
cligenCleanLogo CLIGen (Clean) math comparison samples (C).
Back to Main Thumbnails
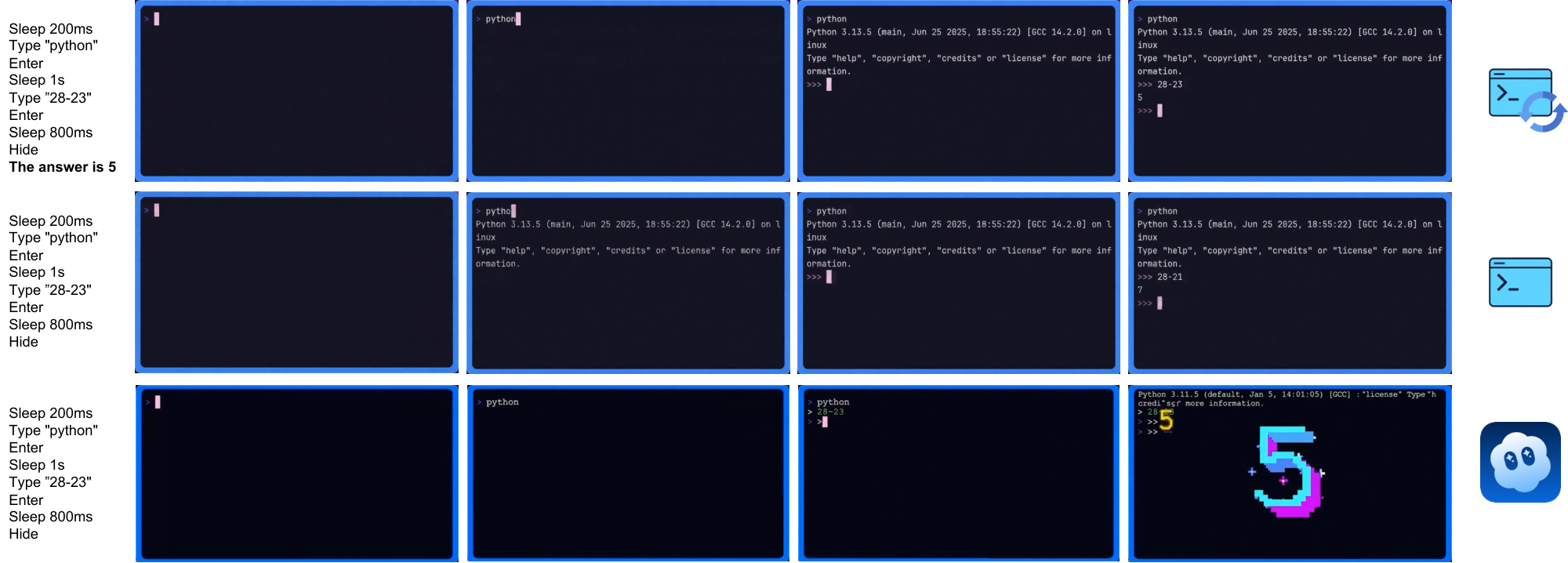
cligenCleanLogo CLIGen (Clean) math reprompting samples (A).
Back to Main Thumbnails
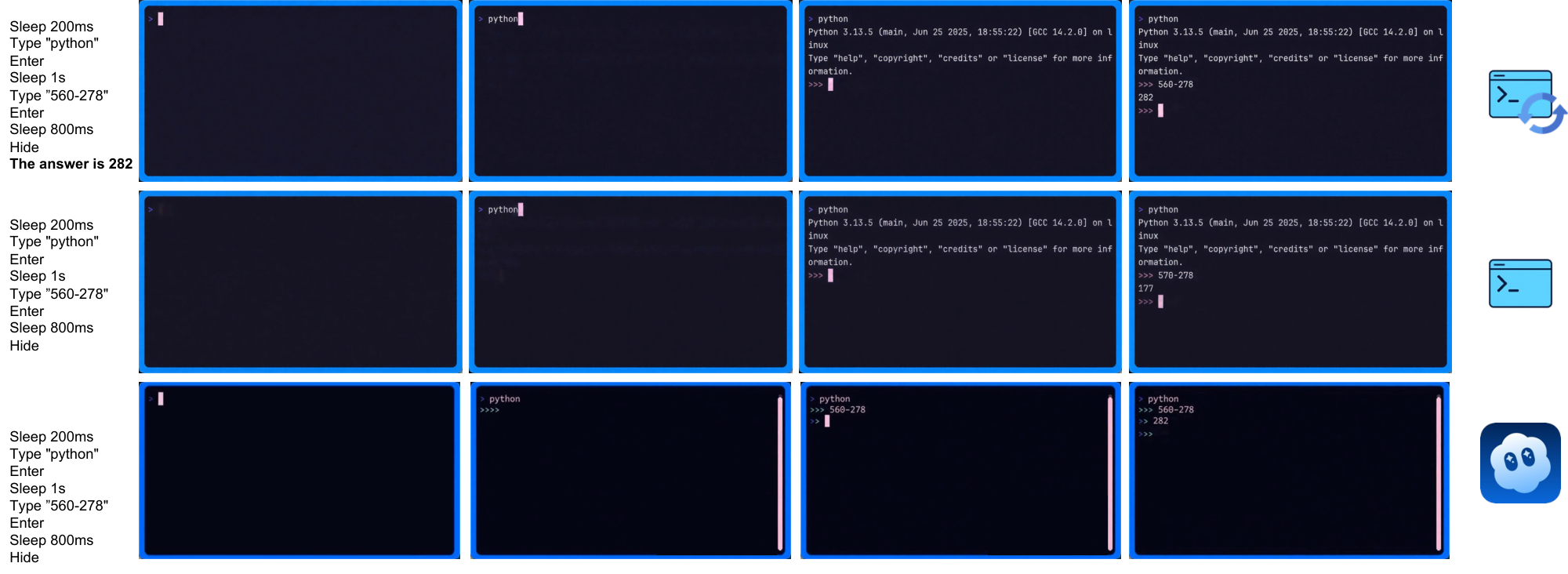
cligenCleanLogo CLIGen (Clean) math reprompting samples (B).
Back to Main Thumbnails
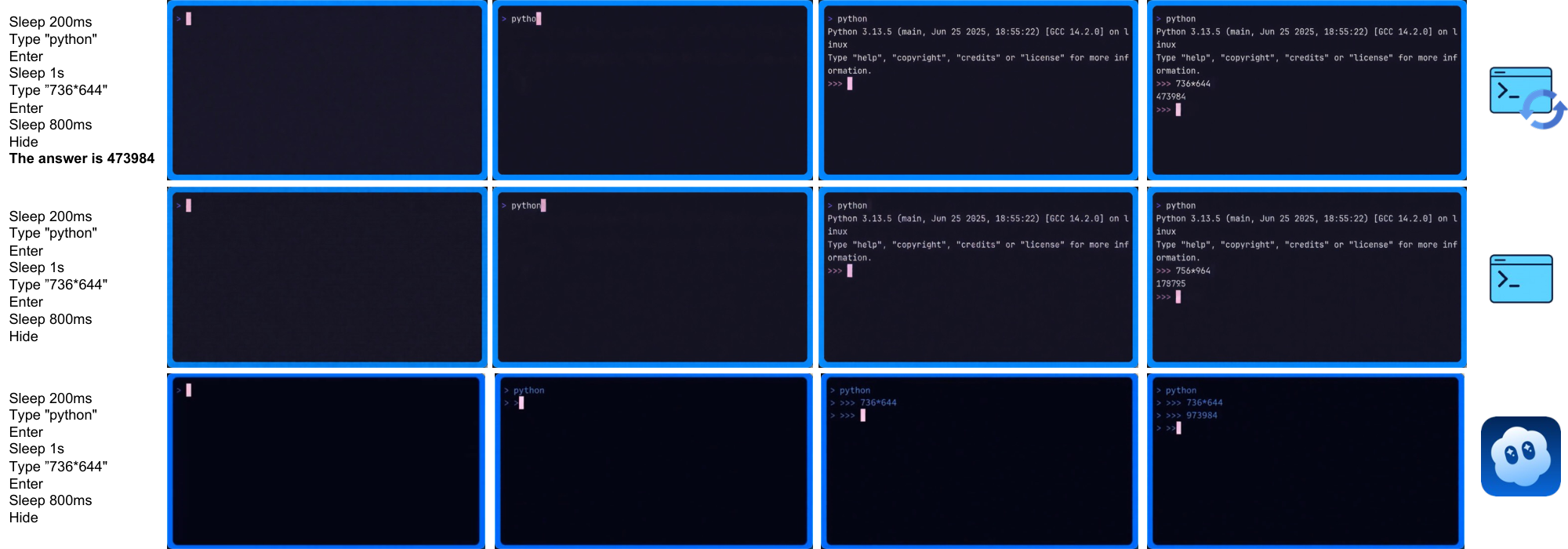
cligenCleanLogo CLIGen (Clean) math reprompting samples (C).
Back to Main Thumbnails
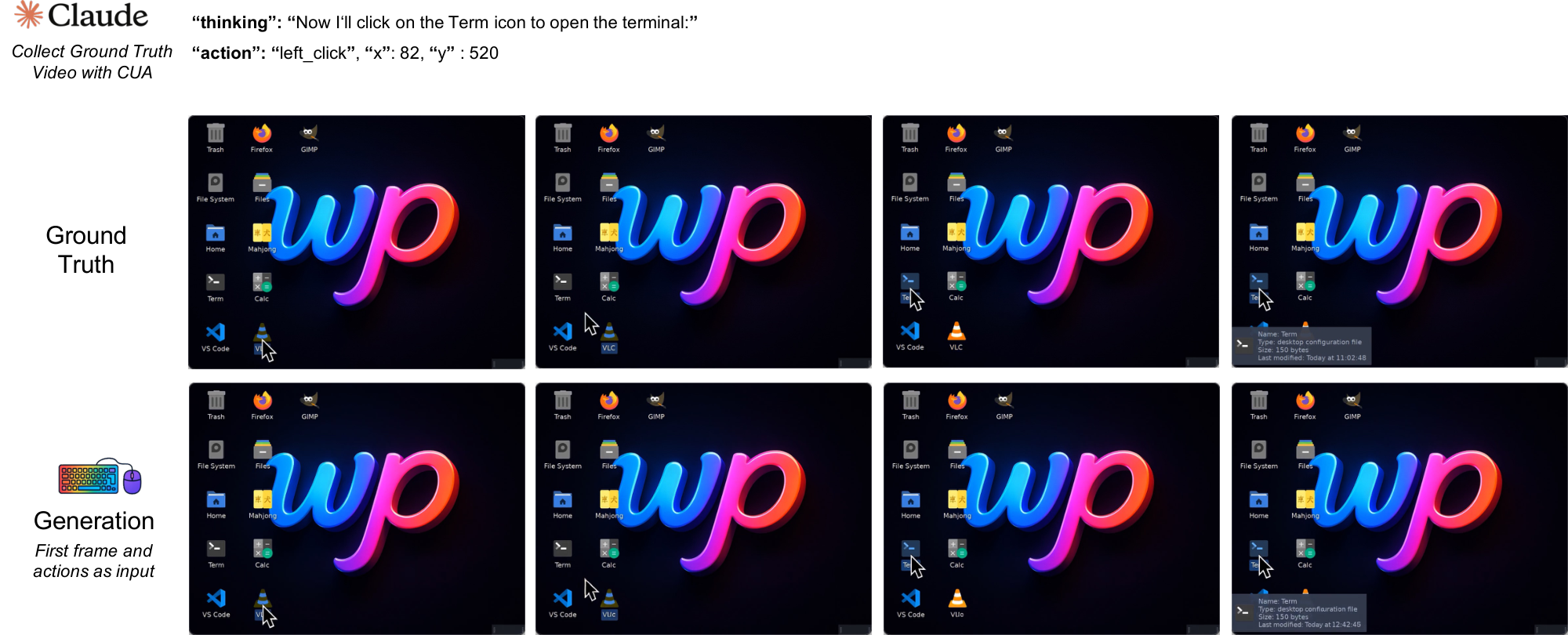
guiworldLogo GUIWorld visualization sample (1).
Back to Main Thumbnails
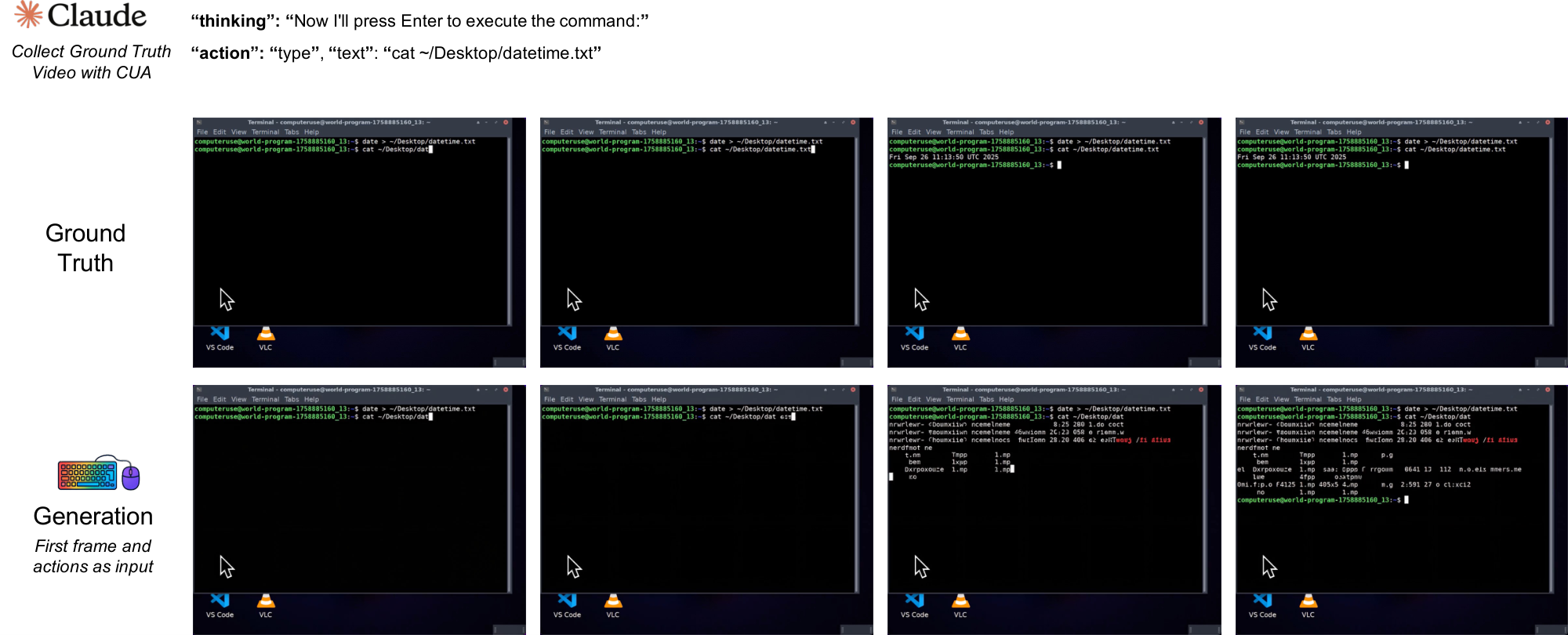
guiworldLogo GUIWorld visualization sample (2).
Back to Main Thumbnails
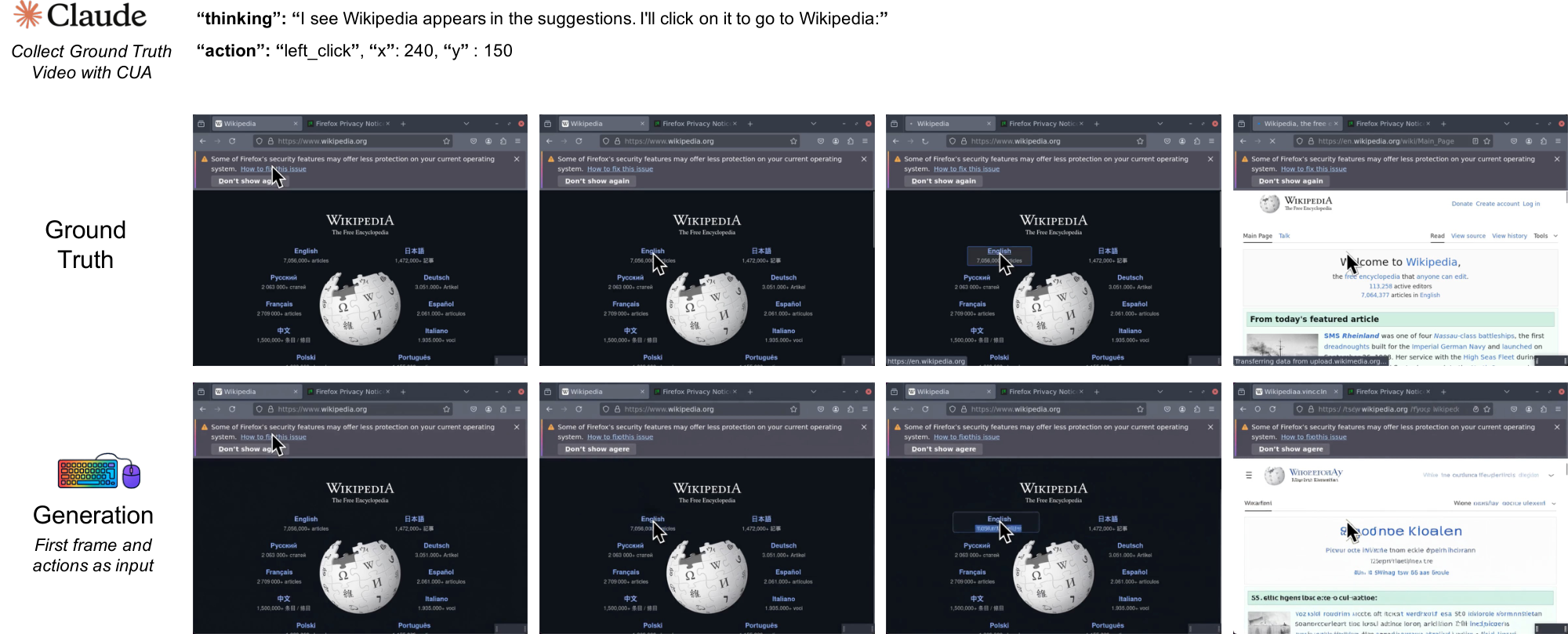
guiworldLogo GUIWorld visualization sample (3).
Back to Main Thumbnails
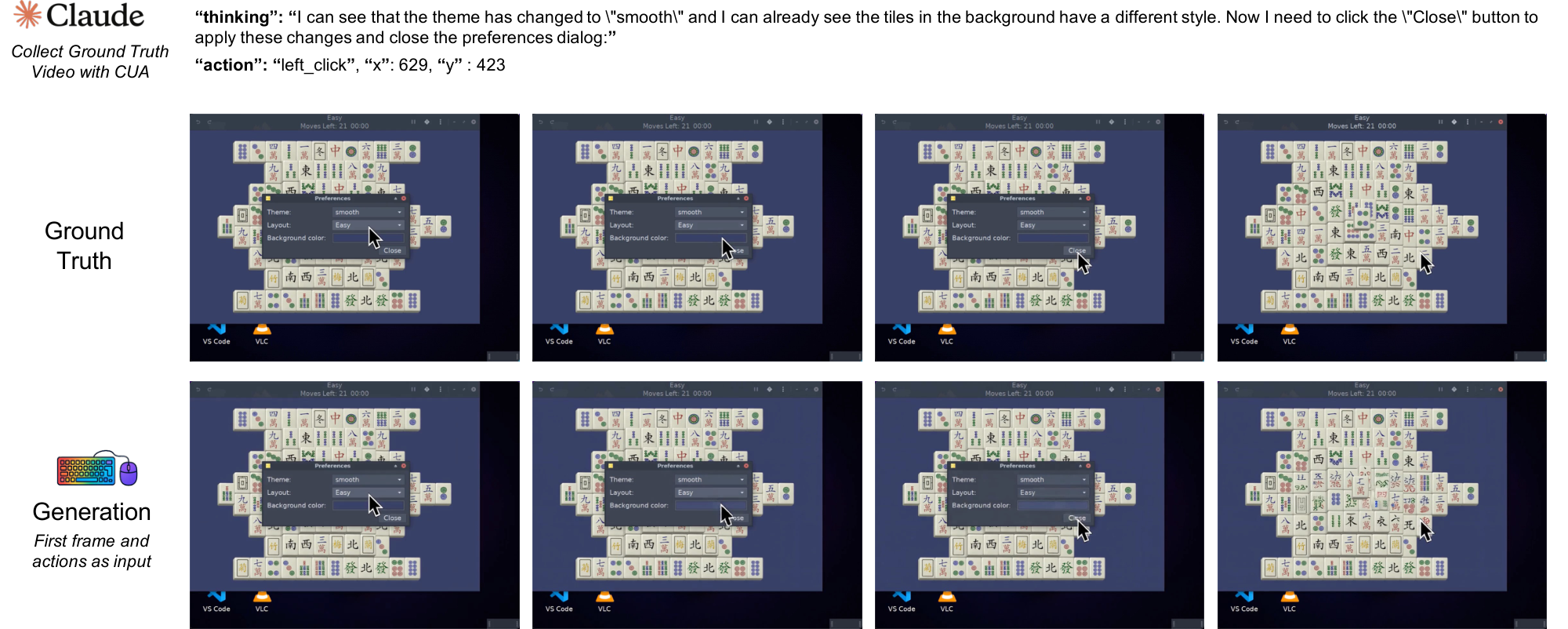
guiworldLogo GUIWorld visualization sample (4).
Back to Main Thumbnails
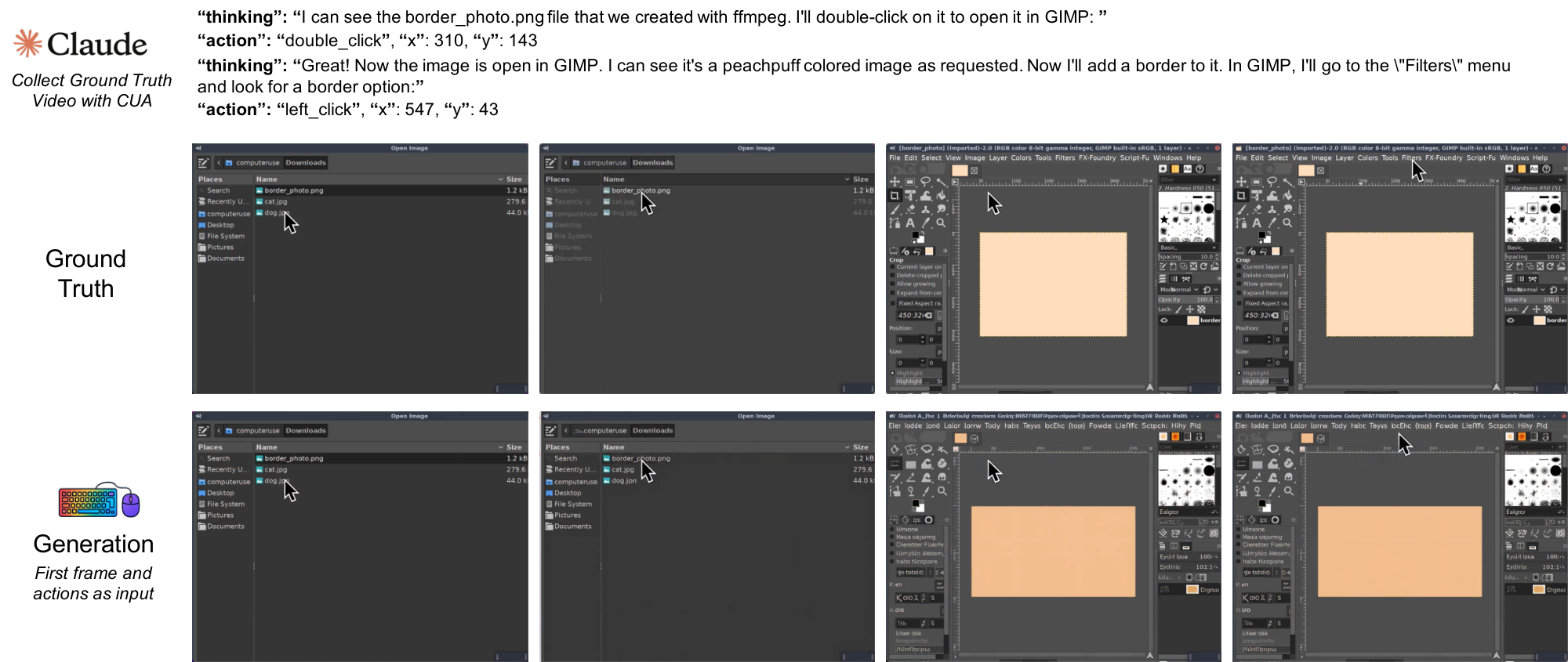
guiworldLogo GUIWorld visualization sample (5).
Back to Main Thumbnails
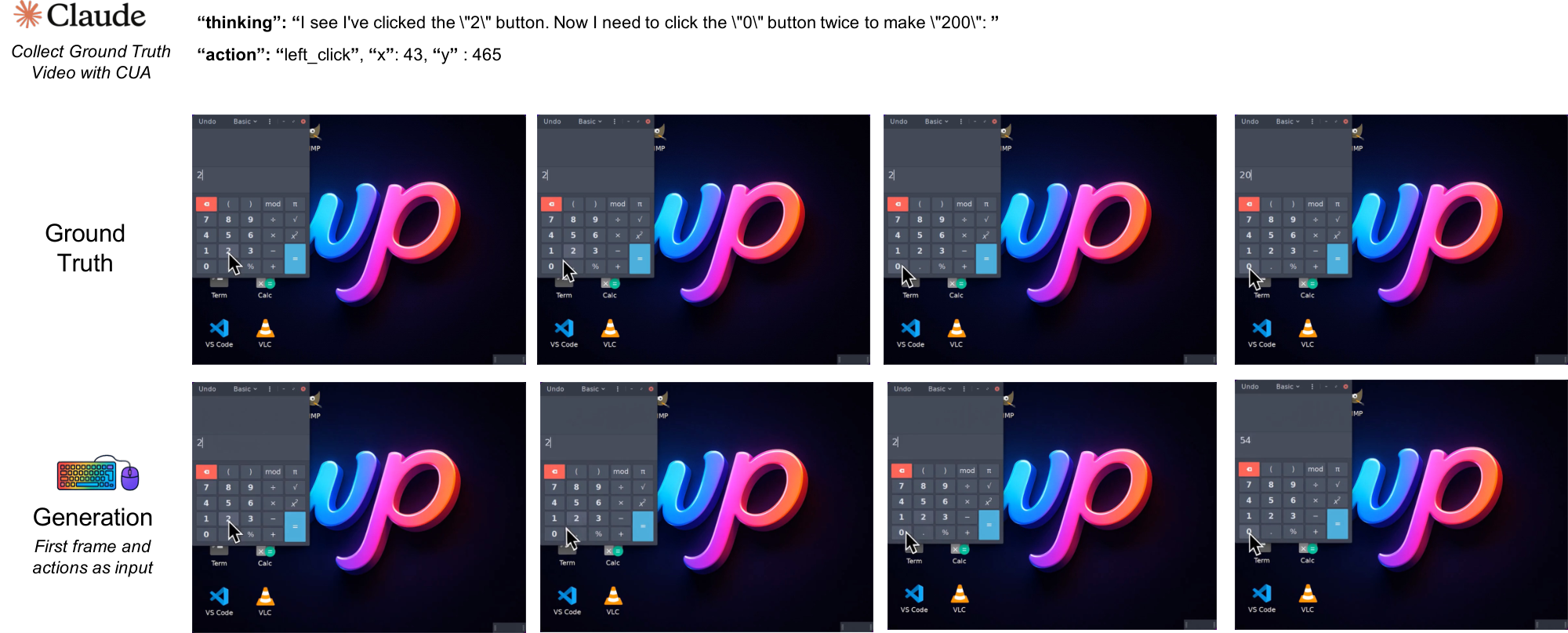
guiworldLogo GUIWorld visualization sample (6).
Back to Main Thumbnails
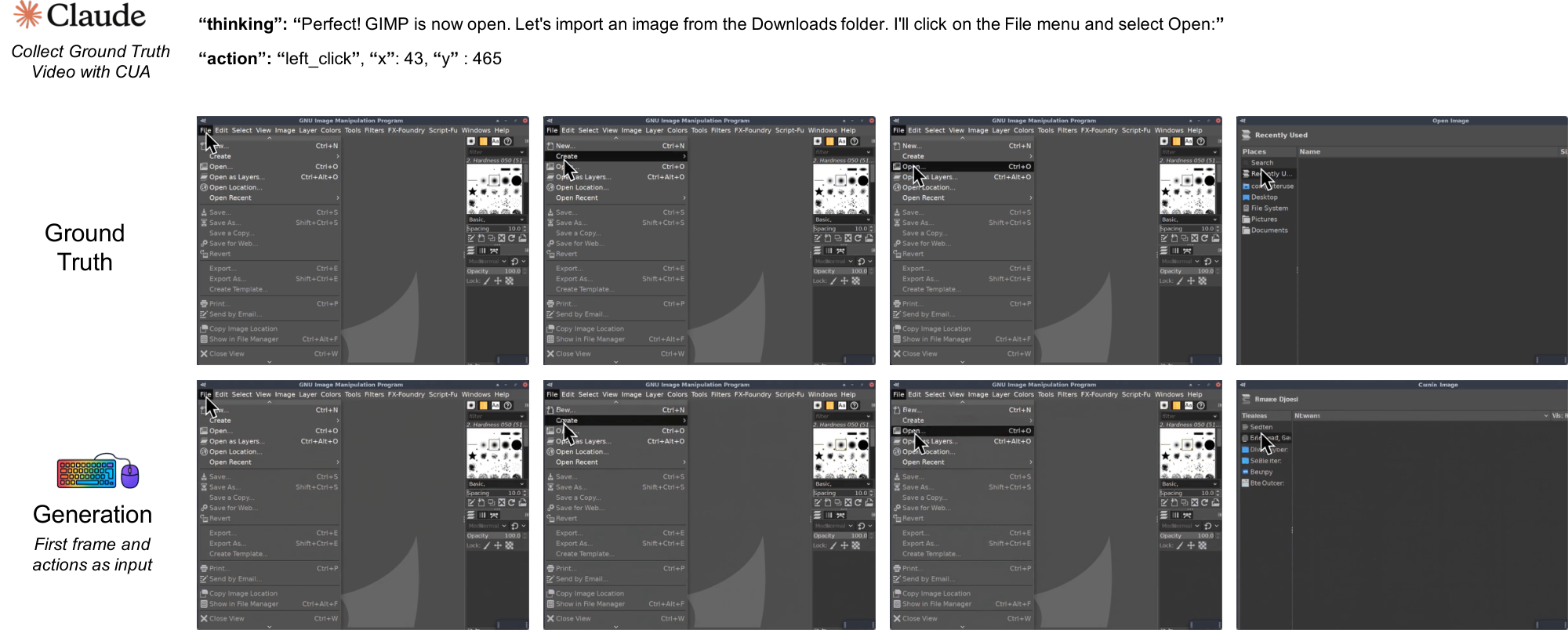
guiworldLogo GUIWorld visualization sample (7).
Back to Main Thumbnails
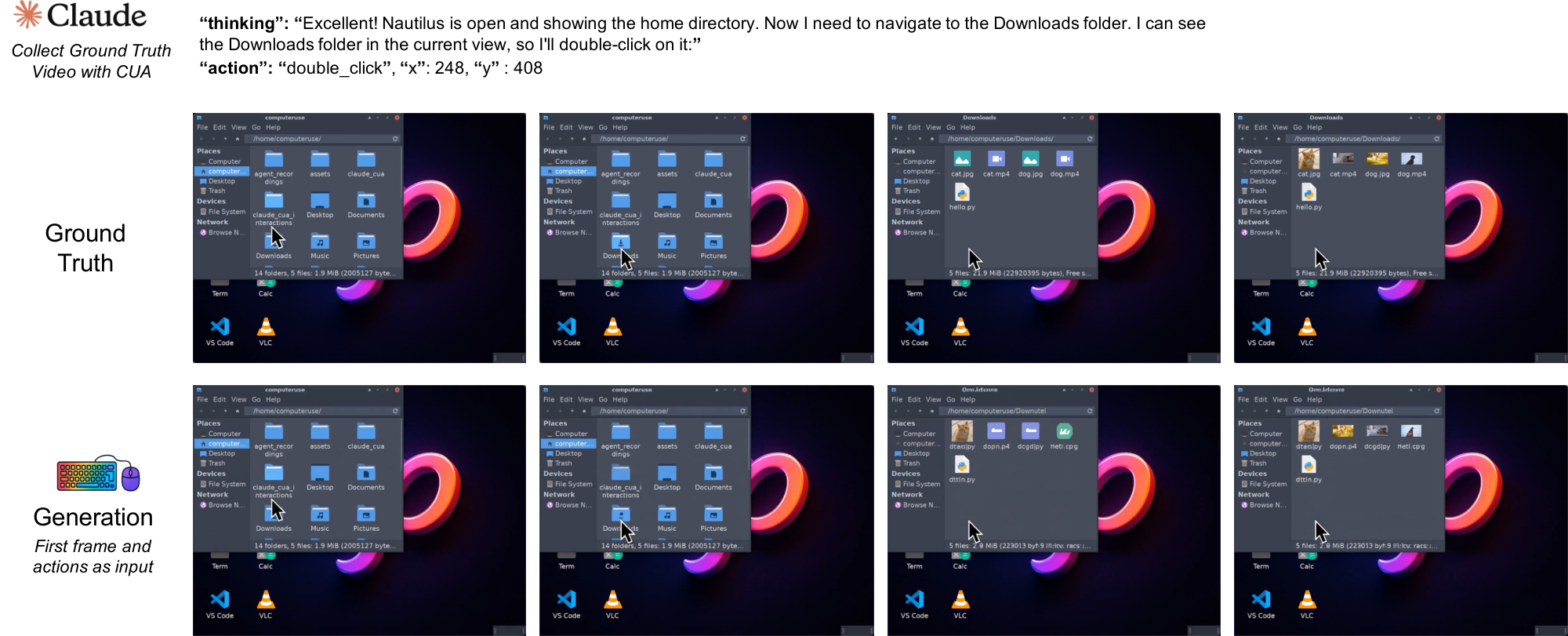
guiworldLogo GUIWorld visualization sample (8).
Back to Main Thumbnails

guiworldLogo GUIWorld visualization sample (9).
Back to Main Thumbnails
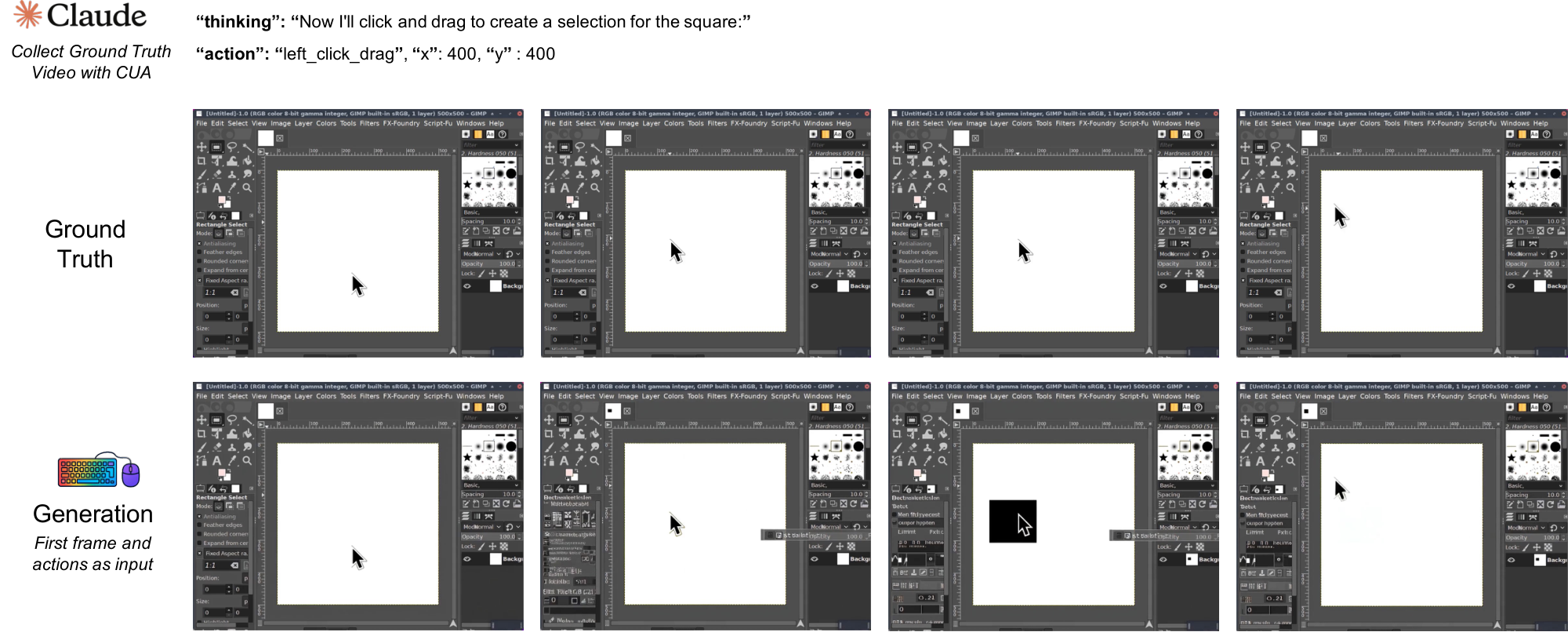
guiworldLogo GUIWorld visualization sample (10).
Back to Main Thumbnails
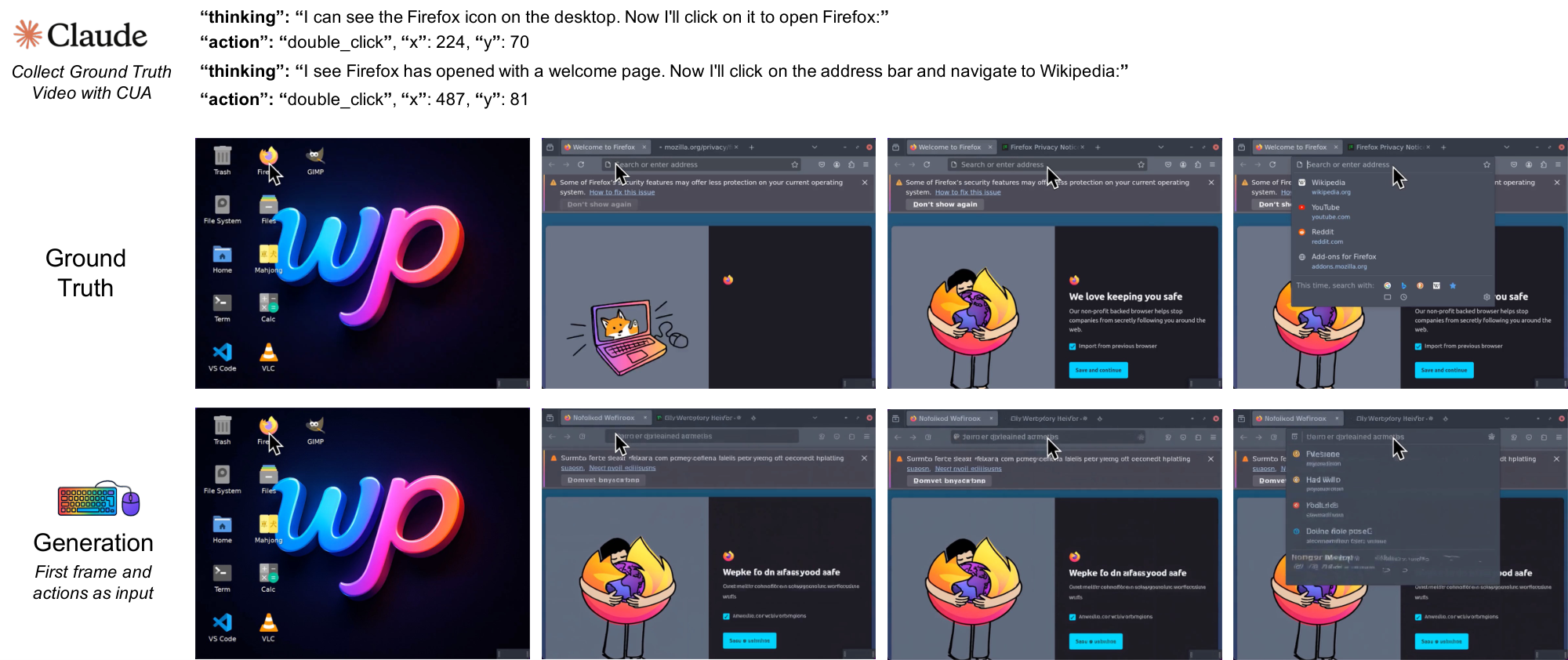
guiworldLogo GUIWorld visualization sample (11).
Back to Main Thumbnails
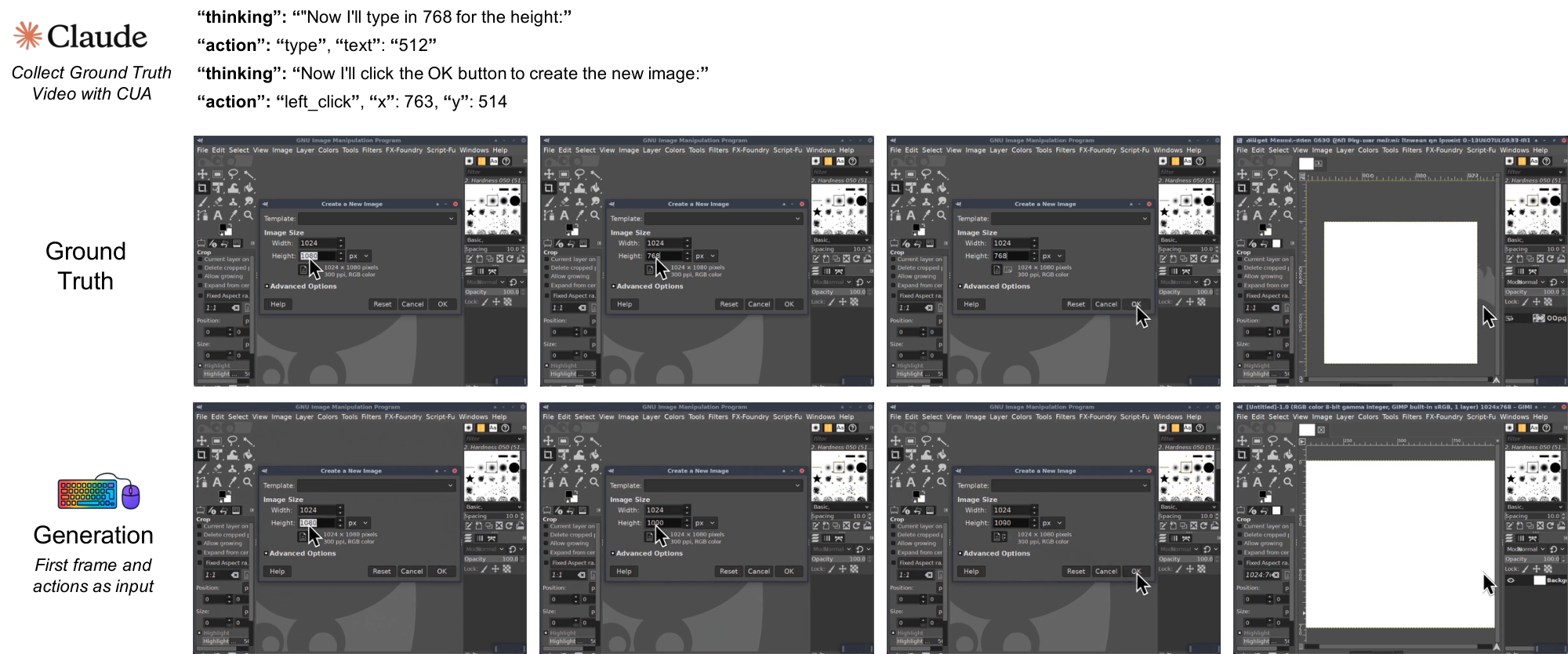
guiworldLogo GUIWorld visualization sample (12).
Back to Main Thumbnails
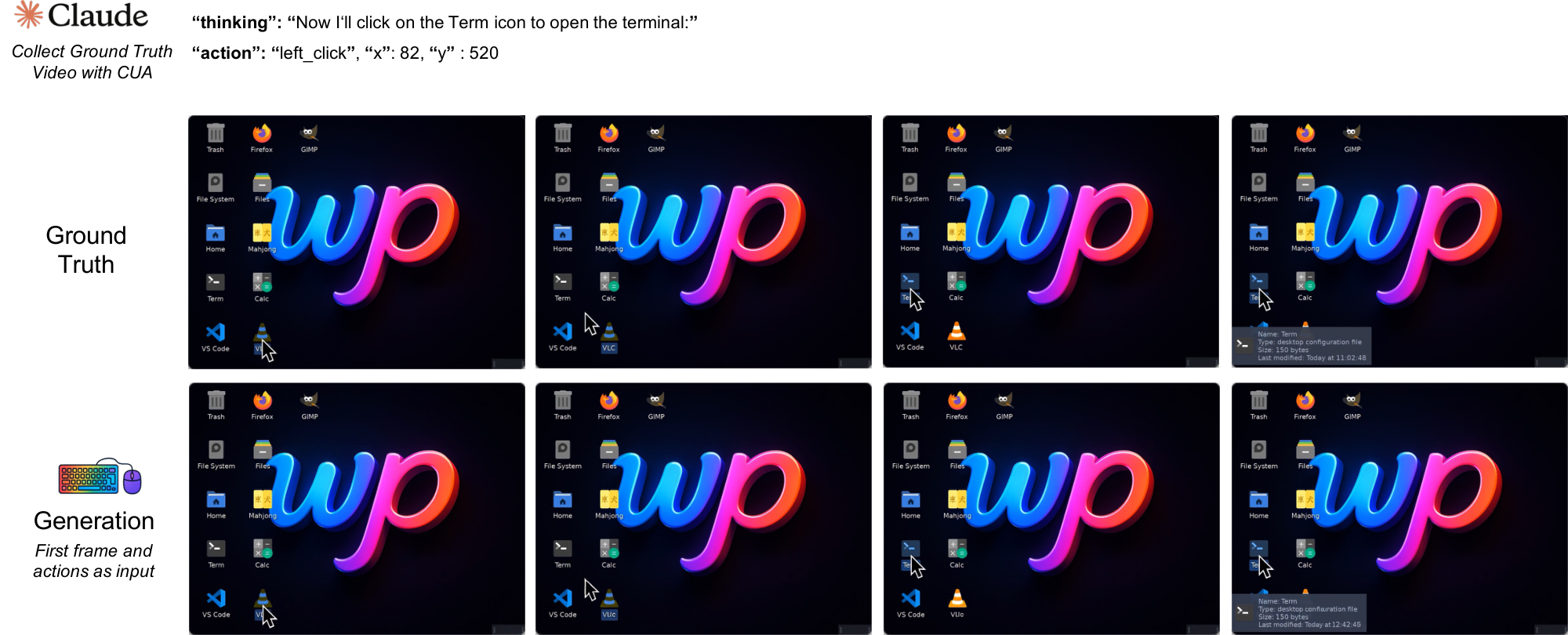
guiworldLogo GUIWorld visualization sample (13).
Back to Main Thumbnails
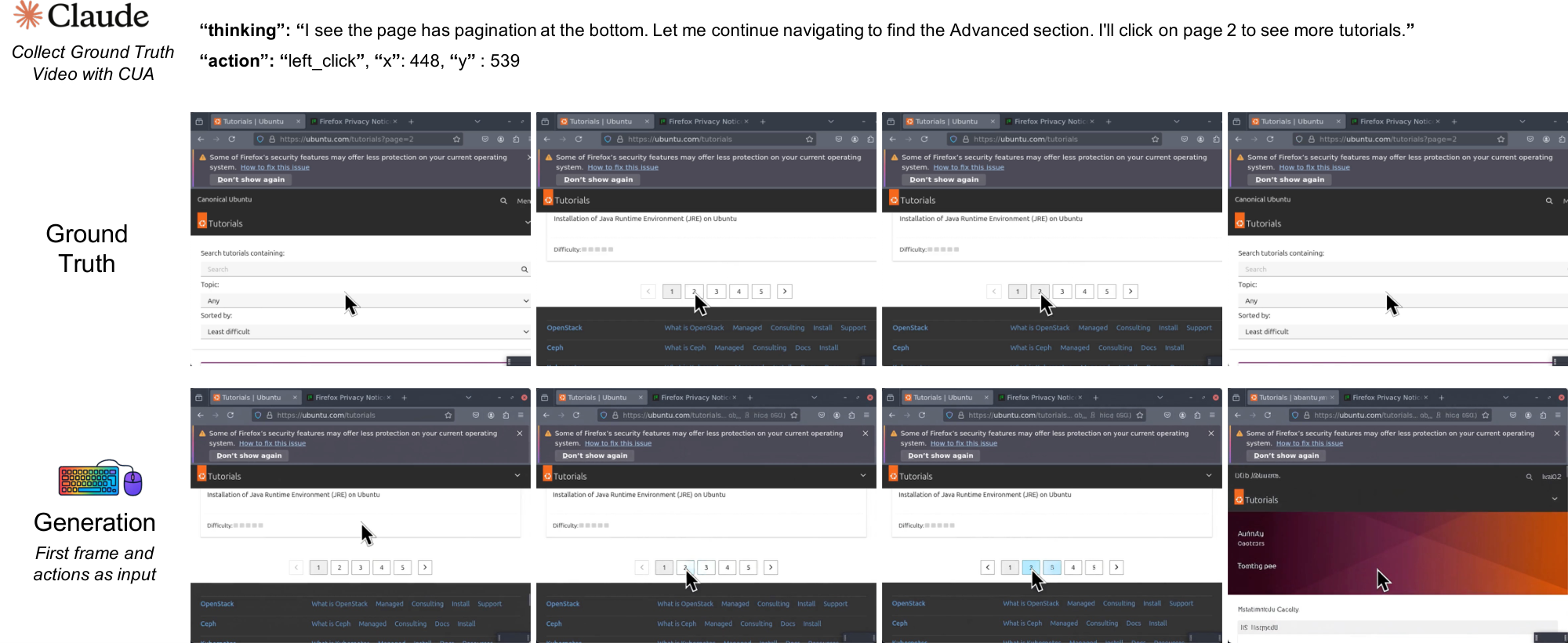
guiworldLogo GUIWorld visualization sample (14).
References
[1] Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014.
[2] Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, et al. Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626):471–476, 2016.
[3] David Ha and Jürgen Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2018.
[4] Google. Break the silence with veo 3.1. https://gemini.google/overview/video-generation/, November 2025.
[5] OpenAI. Sora 2 is here. https://openai.com/index/sora-2/, September 2025.
[6] Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In Forty-first International Conference on Machine Learning, 2024.
[7] Carver Mead and Mohammed Ismail. Analog VLSI implementation of neural systems, volume 80. Springer Science & Business Media, 2012.
[8] J. Schmidhuber. Learning to control fast-weight memories: An alternative to recurrent nets. Neural Computation, 4(1):131–139, 1992.
[9] J. Schmidhuber. A self-referential weight matrix. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 446–451. Springer, 1993b.
[10] J. Schmidhuber. On decreasing the ratio between learning complexity and number of time-varying variables in fully recurrent nets. In Proceedings of the International Conference on Artificial Neural Networks, Amsterdam, pages 460–463. Springer, 1993a.
[11] Scott Reed and Nando De Freitas. Neural programmer-interpreters. arXiv preprint arXiv:1511.06279, 2015.
[12] Jürgen Schmidhuber. Making the world differentiable: on using self supervised fully recurrent neural networks for dynamic reinforcement learning and planning in non-stationary environments, volume 126. Inst. für Informatik, 1990.
[13] Jürgen Schmidhuber. On learning to think: Algorithmic information theory for novel combinations of reinforcement learning controllers and recurrent neural world models. arXiv preprint arXiv:1511.09249, 2015.
[14] Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. In International conference on machine learning, pages 2555–2565. PMLR, 2019b.
[15] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019a.
[16] Luke Rivard, Sun Sun, Hongyu Guo, Wenhu Chen, and Yuntian Deng. Neuralos: Towards simulating operating systems via neural generative models. arXiv preprint arXiv:2507.08800, 2025.
[17] Anthropic. Introducing claude sonnet 4.5. https://www.anthropic.com/news/claude-sonnet-4-5, September 2025.
[18] Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025.
[19] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
[20] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PmLR, 2021.
[21] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
[22] Anthropic. Computer use tool — platform.claude.com. https://platform.claude.com/docs/en/agents-and-tools/tool-use/computer-use-tool. [Accessed 02-02-2026].
[23] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A generalist agent. arXiv preprint arXiv:2205.06175, 2022.
[24] Anssi Kanervisto, Dave Bignell, Linda Yilin Wen, Martin Grayson, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Tabish Rashid, Tim Pearce, Yuhan Cao, et al. World and human action models towards gameplay ideation. Nature, 638(8051):656–663, 2025.
[25] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023.
[26] Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source, real-time, and streaming interactive world model. arXiv preprint arXiv:2508.13009, 2025.
[27] OpenAI. Sora by openai. https://openai.com/sora/, 2024. Accessed: 2025-07-14.
[28] Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024.
[29] Google DeepMind. Veo. https://deepmind.google/models/veo/, May 2025.
[30] Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. In The Twelfth International Conference on Learning Representations, 2023.
[31] Mingchen Zhuge, Ailing Zeng, Deyao Zhu, Sherry Yang, Vikas Chandra, and Jürgen Schmidhuber. Ai with recursive self-improvement. In ICLR 2026 Workshop Proposals, 2026a.
[32] K. Gödel. Über formal unentscheidbare Sätze der Principia Mathematica und verwandter Systeme I. Monatshefte für Mathematik und Physik, 38:173–198, 1931.
[33] A. Church. An unsolvable problem of elementary number theory. Bulletin of the American Mathematical Society, 41:332–333, 1935.
[34] Alan Mathison Turing et al. On computable numbers, with an application to the entscheidungsproblem. J. of Math, 58(345-363):5, 1936.
[35] Hava T Siegelmann and Eduardo D Sontag. On the computational power of neural nets. In Proceedings of the fifth annual workshop on Computational learning theory, pages 440–449, 1992.
[36] John Von Neumann. First draft of a report on the edvac. IEEE Annals of the History of Computing, 15(4):27–75, 1993.
[37] Maurice Wilkes. The best way to design an automatic calculating machine. 1981.
[38] Matthieu Queloz. Explainability through systematicity: The hard systematicity challenge for artificial intelligence. Minds and machines, 35(3):35, 2025.
[39] Jorge Pérez, Pablo Barceló, and Javier Marinkovic. Attention is turing-complete. Journal of Machine Learning Research, 22(75):1–35, 2021.
[40] Garrett E Katz, Gregory P Davis, Rodolphe J Gentili, and James A Reggia. A programmable neural virtual machine based on a fast store-erase learning rule. Neural Networks, 119:10–30, 2019.
[41] Gregory P Davis, Garrett E Katz, Rodolphe J Gentili, and James A Reggia. Neurolisp: High-level symbolic programming with attractor neural networks. Neural Networks, 146:200–219, 2022.
[42] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
[43] Diego Calanzone, Stefano Teso, and Antonio Vergari. Logically consistent language models via neuro-symbolic integration. In The Thirteenth International Conference on Learning Representations, 2025.
[44] Juris Hartmanis and Janos Simon. On the power of multiplication in random access machines. In 15th Annual Symposium on Switching and Automata Theory (swat 1974), pages 13–23. IEEE, 1974.
[45] Paul Constantine Anagnostopoulos, MJ Michel, Gary H Sockut, George M Stabler, and Andries van Dam. Computer architecture and instruction set design. In Proceedings of the June 4-8, 1973, national computer conference and exposition, pages 519–527, 1973.
[46] John W Backus, Robert J Beeber, Sheldon Best, Richard Goldberg, Lois M Haibt, Harlan L Herrick, Robert A Nelson, David Sayre, Peter B Sheridan, Harold Stern, et al. The fortran automatic coding system. In Papers presented at the February 26-28, 1957, western joint computer conference: Techniques for reliability, pages 188–198, 1957.
[47] John W Backus, Friedrich L Bauer, Julien Green, Charles Katz, John McCarthy, Alan J Perlis, Heinz Rutishauser, Klaus Samelson, Bernard Vauquois, Joseph Henry Wegstein, et al. Revised report on the algorithmic language algol 60. Communications of the ACM, 6(1):1–17, 1963.
[48] Allen Newell and Herbert A. Simon. Computer science as empirical inquiry: symbols and search. Commun. ACM, 19(3):113–126, March 1976. ISSN 0001-0782. doi:10.1145/360018.360022. https://doi.org/10.1145/360018.360022.
[49] Rodney A. Brooks. Intelligence without representation. Artificial Intelligence, 47(1):139–159, 1991. ISSN 0004-3702. doi:https://doi.org/10.1016/0004-3702(91)90053-M. https://www.sciencedirect.com/science/article/pii/000437029190053M.
[50] Alekseĭ Grigorʹevich Ivakhnenko and Valentin Grigorévich Lapa. Cybernetic Predicting Devices. CCM Information Corporation, 1965.
[51] Aleksey Grigorievitch Ivakhnenko, Valentin Grigorievitch Lapa, and Robert N McDonough. Cybernetics and forecasting techniques. American Elsevier, NY, 1967.
[52] Aleksey Grigorievitch Ivakhnenko. The group method of data handling – a rival of the method of stochastic approximation. Soviet Automatic Control, 13(3):43–55, 1968.
[53] Aleksey Grigorievitch Ivakhnenko. Polynomial theory of complex systems. IEEE Transactions on Systems, Man and Cybernetics, (4):364–378, 1971.
[54] G. E. Hinton, J. L. McClelland, and D. E. Rumelhart. Distributed representations, page 77–109. MIT Press, Cambridge, MA, USA, 1986. ISBN 026268053X.
[55] Christopher M Bishop. Pattern Recognition and Machine Learning, volume 4 of Information science and statistics. Springer, 2006. ISBN 9780387310732. doi:10.1117/1.2819119. http://www.library.wisc.edu/selectedtocs/bg0137.pdf.
[56] Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8):1798–1828, 2013.
[57] Paul Smolensky. On the proper treatment of connectionism. Behavioral and Brain Sciences, 11(1):1–23, 1988. doi:10.1017/s0140525x00052432.
[58] David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017.
[59] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
[60] Laria Reynolds and Kyle McDonell. Prompt programming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, CHI EA '21, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450380959. doi:10.1145/3411763.3451760. https://doi.org/10.1145/3411763.3451760.
[61] Daniel Jurafsky and James H. Martin. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, with Language Models. 3rd edition, 2026. https://web.stanford.edu/~jurafsky/slp3/. Online manuscript released January 6, 2026.
[62] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. https://arxiv.org/abs/2201.11903.
[63] Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks. arXiv preprint arXiv:1606.04671, 2016.
[64] Thomas Pierrot, Guillaume Ligner, Scott E Reed, Olivier Sigaud, Nicolas Perrin, Alexandre Laterre, David Kas, Karim Beguir, and Nando de Freitas. Learning compositional neural programs with recursive tree search and planning. Advances in Neural Information Processing Systems, 32, 2019.
[65] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[66] Tomaso Poggio, Andrzej Banburski, and Qianli Liao. Theoretical issues in deep networks: Approximation. Optimization and Generalization, 2019.
[67] David Ha, Andrew Dai, and Quoc V Le. Hypernetworks. arXiv preprint arXiv:1609.09106, 2016.
[68] Brenden Lake and Marco Baroni. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. In International conference on machine learning, pages 2873–2882. PMLR, 2018.
[69] Gary Marcus. Deep learning: A critical appraisal. arXiv preprint arXiv:1801.00631, 2018.
[70] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[71] William R Clements, Bastien Van Delft, Beno^ıt-Marie Robaglia, Reda Bahi Slaoui, and Sébastien Toth. Estimating risk and uncertainty in deep reinforcement learning. arXiv preprint arXiv:1905.09638, 2019.
[72] German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review. Neural networks, 113:54–71, 2019.
[73] Kingma DP Ba J Adam et al. A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 1412(6), 2014.
[74] Daan Wierstra, Tom Schaul, Tobias Glasmachers, Yi Sun, Jan Peters, and Jürgen Schmidhuber. Natural evolution strategies. The Journal of Machine Learning Research, 15(1):949–980, 2014.
[75] Mike Innes, Alan Edelman, Keno Fischer, Chris Rackauckas, Elliot Saba, Viral B Shah, and Will Tebbutt. A differentiable programming system to bridge machine learning and scientific computing. arXiv preprint arXiv:1907.07587, 2019.
[76] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[77] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
[78] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[79] Rishi Bommasani. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
[80] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
[81] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
[82] Pierre Flener and Ute Schmid. An introduction to inductive programming. Artificial Intelligence Review, 29(1):45–62, 2008.
[83] Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems, 35:20744–20757, 2022a.
[84] Allen Cypher and Daniel Conrad Halbert. Watch what I do: programming by demonstration. MIT press, 1993.
[85] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations, 2022b.
[86] Yunhai Feng, Nicklas Hansen, Ziyan Xiong, Chandramouli Rajagopalan, and Xiaolong Wang. Finetuning offline world models in the real world. arXiv preprint arXiv:2310.16029, 2023.
[87] Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In European conference on computer vision, pages 102–118. Springer, 2016.
[88] Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017.
[89] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. In Conference on robot learning, pages 1–16. PMLR, 2017.
[90] Ricardo Garcia, Robin Strudel, Shizhe Chen, Etienne Arlaud, Ivan Laptev, and Cordelia Schmid. Robust visual sim-to-real transfer for robotic manipulation. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 992–999. ieee, 2023.
[91] OpenAI. Computer-Using Agent — openai.com. https://openai.com/index/computer-using-agent/, 2023. [Accessed 07-02-2026].
[92] Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. In Forty-first International Conference on Machine Learning, 2024a.
[93] Pascal J. Sager, Benjamin Meyer, Peng Yan, Rebekka von Wartburg-Kottler, Layan Etaiwi, Aref Enayati, Gabriel Nobel, Ahmed Abdulkadir, Benjamin F. Grewe, and Thilo Stadelmann. A comprehensive survey of agents for computer use: Foundations, challenges, and future directions, 2025. https://arxiv.org/abs/2501.16150.
[94] Mingchen Zhuge, Ailing Zeng, Deyao Zhu, Sherry Yang, Vikas Chandra, and Jürgen Schmidhuber. Ai with recursive self-improvement. In ICLR 2026 Workshop Proposals, 2026b.
[95] Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. Agent-as-a-judge: Evaluate agents with agents. arXiv preprint arXiv:2410.10934, 2024b.
[96] Jürgen Schmidhuber. One big net for everything. arXiv preprint arXiv:1802.08864, 2018.
[97] Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328, 2025.
[98] Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological cybernetics, 36(4):193–202, 1980.
[99] Brad A Myers. Demonstrational interfaces: A step beyond direct manipulation. Computer, 25(8):61–73, 2002.
[100] A.S. Tanenbaum and T. Austin. Structured Computer Organization. Pearson, 2013. ISBN 9780132916523. https://books.google.com.sa/books?id=m0HHygAACAAJ.
[101] Abraham Silberschatz, Peter B Galvin, and Greg Gagne. Operating system concepts. John Wiley & Sons, 2019.
[102] Brendan Gregg. Systems performance: enterprise and the cloud. Pearson Education, 2014.
[103] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
[104] Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. Tensor comprehensions: Framework-agnostic high-performance machine learning abstractions. arXiv preprint arXiv:1802.04730, 2018.
[105] Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S Emer. Efficient processing of deep neural networks: A tutorial and survey. Proceedings of the IEEE, 105(12):2295–2329, 2017.
[106] Dhanesh Ramachandram and Graham W Taylor. Deep multimodal learning: A survey on recent advances and trends. IEEE signal processing magazine, 34(6):96–108, 2017.