Toward Efficient Agents: A Survey of Memory, Tool learning, and Planning
Xiaofang Yang$^{1,2,\dagger}$, Lijun Li$^{1,\dagger,✉}$, Heng Zhou$^{1,3,\dagger}$, Tong Zhu$^{1,\dagger}$, Xiaoye Qu$^{1}$, Yuchen Fan$^{1,4}$, Qianshan Wei$^{5}$, Rui Ye$^{4}$, Li Kang$^{1,4}$, Yiran Qin$^{6}$, Zhiqiang Kou$^{7}$, Daizong Liu$^{8}$, Qi Li$^{5}$, Ning Ding$^{9}$, Siheng Chen$^{4}$, Jing Shao$^{1,✉}$
$^{1}$ Shanghai Artificial Intelligence Laboratory
$^{2}$ Fudan University
$^{3}$ University of Science and Technology of China
$^{4}$ Shanghai Jiaotong University
$^{5}$ Institute of Automation, Chinese Academy of Sciences
$^{6}$ The Chinese University of Hong Kong (Shenzhen)
$^{7}$ Hong Kong Polytechnic University
$^{8}$ Wuhan University
$^{9}$ Tsinghua University
Abstract
Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
$^{\dagger}$ Main contributors
$^{✉}$ Corresponding Author
Keywords: Agents, Efficiency, Agent Memory, Tool Learning, Planning
Date: January 20th, 2026
Projects: https://efficient-agents.github.io/
Code Repository: https://github.com/yxf203/Awesome-Efficient-Agents
Contact: [email protected], [email protected], [email protected], [email protected]
1. Introduction
The landscape of Artificial Intelligence has undergone a paradigm shift, evolving from the era of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) to the advent of Large Language Models (LLMs), and the emergence of LLM-based Agents currently [1, 2, 3, 4, 5, 6]. Unlike their predecessors, which primarily focused on perception or static text generation, agentic systems do not merely process information; they actively interact with external environments to execute complex, multi-step workflows across diverse domains, such as autonomous software engineering [7, 8] and accelerated scientific discovery [9, 10, 11].
However, this shift toward autonomous action has introduced a critical bottleneck: efficiency. While the deployment of LLMs is already resource-intensive, this challenge is significantly exacerbated in agentic systems. Unlike a standard LLM that typically operates in a linear, single-turn query-response format, an agent consumes exponentially more resources due to its recursive nature. To automate intricate real-world tasks [12, 13, 14, 8], agents must perform extensive memory management, iterative tool usage, and complex planning over multiple steps. This multi-step execution leads to prohibitive latency, context window saturation, and excessive token consumption, raising profound concerns regarding the long-term sustainability and equitable accessibility of these increasingly capable systems.
To understand the urgency of agent efficiency, one must examine the typical agentic workflow. Upon receiving a user instruction, an agent engages in a recursive loop that heavily uses the following key components: memory, planning, and tool learning to observe output and provide the final solution.
$ \begin{aligned} \mathrm{Input}\rightarrow \Bigl[, \underbrace{\mathrm{Memory}}{Context} \rightarrow \underbrace{\mathrm{Planning}}{Decision} \rightarrow \underbrace{\mathrm{Tool\ Learning}}{Action} \rightarrow \underbrace{\mathrm{Observation}}{Feedback} , \Bigr] _{!n} \rightarrow \mathrm{Solution}. \end{aligned} $
In each iteration $n$, the system must first retrieve relevant context from memory, reason over the current state to formulate a plan, execute a specific tool-incorporated action, and process the resulting observation. This cycle creates a compounding accumulation of tokens, where the output of step $n$ becomes the input cost of step $n+1$, resulting in high inference costs and slow response times. Consequently, mere model compression is insufficient. We therefore define an efficient agent as follows:
**Efficient agent** is not a smaller model, but as an agentic system optimized to maximize task success rates while minimizing resource consumption, including token usage, inference latency, and computational cost across memory, tool usage, and planning modules.
Our survey aims to systematize the numerous efforts in this emerging field. While a large number of existing surveys focus on Efficient LLMs [15, 16, 17], which serve as the backbone of agents, there is a lack of comprehensive literature addressing the efficiency of the agentic system itself. To bridge this gap, we categorize existing works into three strategic directions: 1) Efficient Memory: Techniques for compressing historical context, managing memory storage, and optimizing context retrieval. 2) Efficient Tool Learning: Strategies to minimize the number of tool calls and reduce the latency of external interactions. 3) Efficient Planning: Strategies to reduce the number of executing steps and API calls required to solve a problem.
The remainder of this survey is organized as follows: Section 2 introduces the preliminaries and highlights the efficiency gap between agents and LLMs. Section 3 through Section 5 explore component-level efficiency, with a focus on memory, tool learning, and planning optimizations. Subsequently, Section 6 addresses the quantification of efficiency. The survey concludes with a discussion on open challenges and future research directions.
2. Preliminaries
2.1 Agent Formulation
We model an LLM-based agent interacting with an environment as a partially observable Markov decision process (POMDP) augmented with an external tool interface and an explicit memory component. Formally, we define the overall model as
$ \mathcal{M} = (\mathcal{S}, \mathcal{O}, \mathcal{A}, P, R, \gamma;\ \mathcal{T}, \Psi;\ \mathcal{M}_{mem}, U, \rho). $
Here $\mathcal{S}$ denotes the latent environment state space, $\mathcal{O}$ the observation space, and $\mathcal{A}$ the agent action space. The environment dynamics are given by the transition kernel $P$, the reward function $R$, and the discount factor $\gamma\in[0, 1)$.
The agent is additionally equipped with a set of external tools $\mathcal{T}$ and a tool interface $\Psi$, which specifies how tool calls are executed and what tool outputs are returned to the agent. Finally, we model explicit agent memory with memory state space $\mathcal{M}_{mem}$, an update rule $U$ that maps the current memory and available information to the next memory state, and an initialization distribution $\rho$ over the initial memory.
2.2 From Pure LLMs to Agents
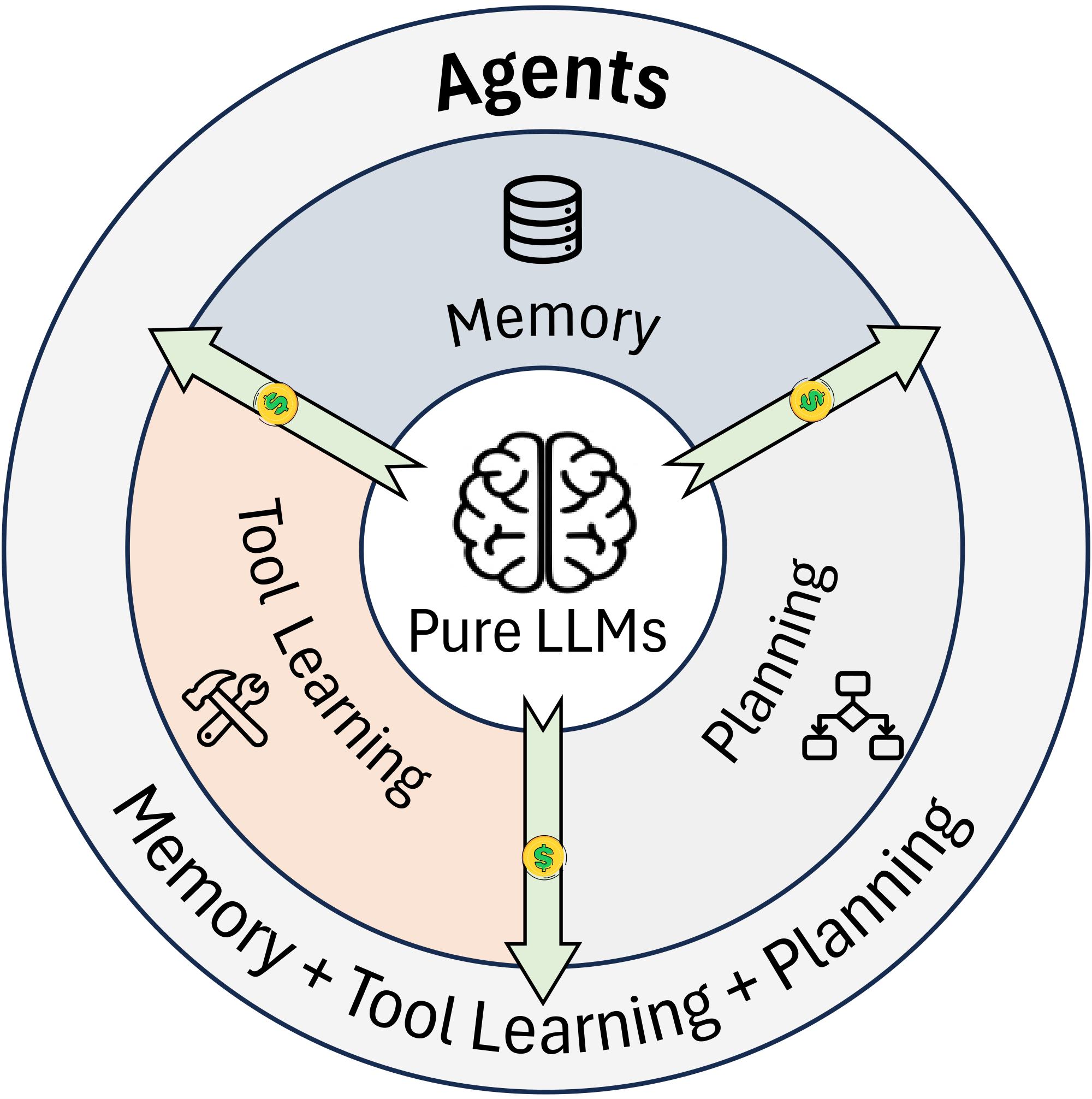
We define efficiency through a cost–performance trade-off: achieving comparable performance with lower cost, or achieving higher performance under a similar cost budget.
We acknowledge that many efficiency techniques used in LLM-based agents overlap with those for standalone LLMs (e.g., model compression and inference acceleration). In agents, however, these techniques mainly serve as foundational enablers rather than addressing the agent-specific sources of inefficiency. As summarized by [18], compared to pure LLMs, LLM-based agents exhibit more human-like decision-making by augmenting a base model with cognitive components such as planning and memory.
Accordingly, in this subsection we focus on what differentiates agent efficiency from LLM efficiency. From a functional perspective, an agent is characterized by its ability to (i) plan and act over multiple steps, (ii) invoke external tools or environment commands to acquire information and execute operations, and (iii) condition subsequent decisions on retrieved or updated memory.
As illustrated in Figure 2, agentic systems introduce additional cost sources beyond generation. For a pure LLM, the inference cost is often dominated by token generation and can be approximated as:
$ \mathrm{Cost}{LLM} \approx \alpha, N{tok}, $
where $N_{\text{tok}}$ is the number of generated reasoning tokens and $\alpha$ captures the per-token cost (e.g., time or monetary cost). In contrast, an agent may incur additional overhead from tools, memory, and retries as needed:
$ \mathrm{Cost}{agent} \approx \alpha, N{tok}
- \mathbb{I}{tool}\cdot \mathrm{Cost}{tool}
- \mathbb{I}{mem}\cdot \mathrm{Cost}{mem}
- \mathbb{I}{retry}\cdot \mathrm{Cost}{retry}, $
where $\mathbb{I}{\text{tool}}, \mathbb{I}{\text{mem}}, \mathbb{I}_{\text{retry}} \in {0, 1}$ are indicator variables that equal $1$ if the agent invokes tools, accesses memory, or performs retries, respectively, and $0$ otherwise. Therefore, improving agent efficiency is not only about reducing language generation, but also about reducing the frequency and improving the selectivity of tool or memory invocations and retries along a trajectory, to achieve a better cost–performance trade-off.
3. Efficient Memory
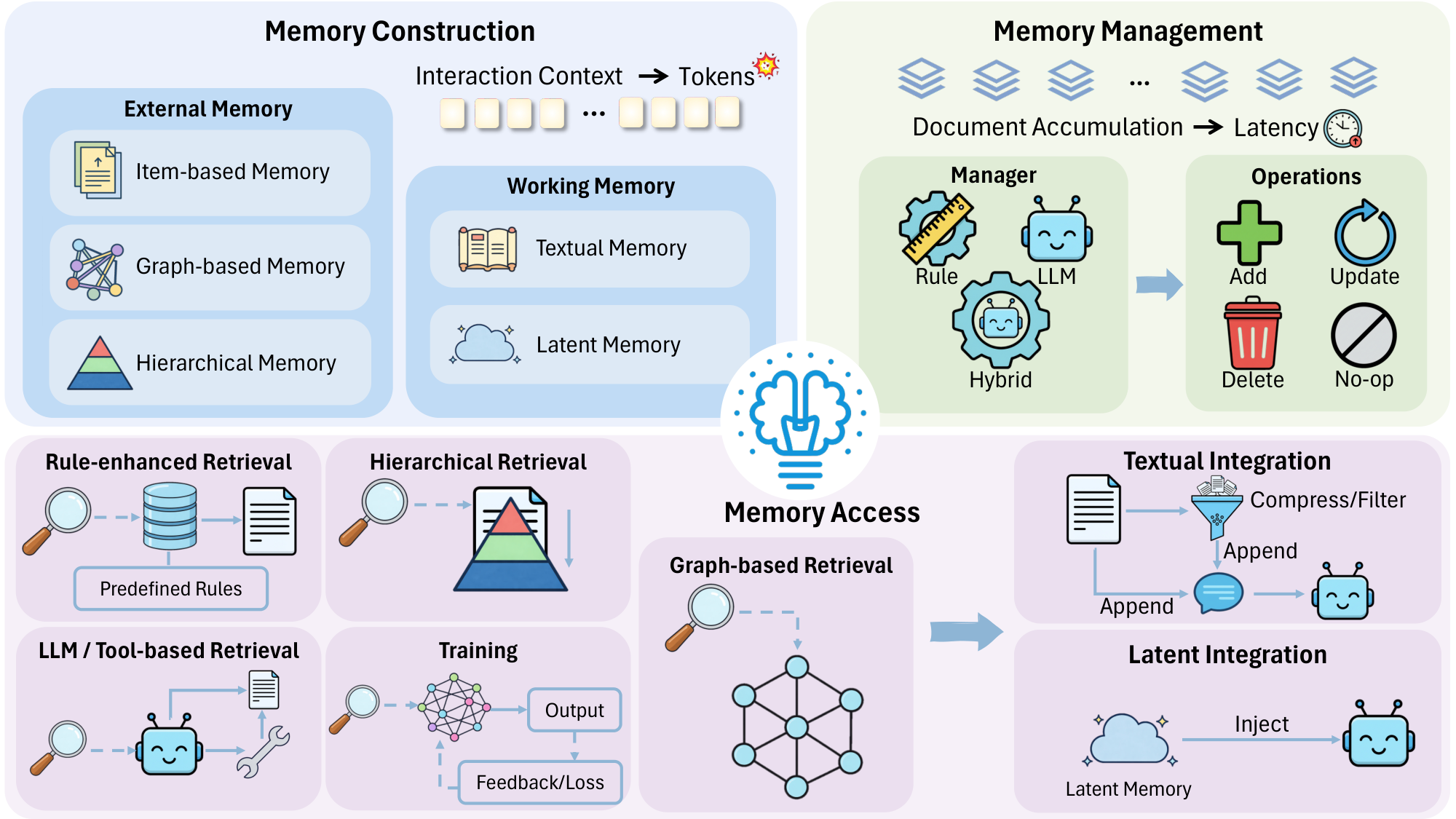
A major efficiency bottleneck for LLM agents is the computational and token overhead induced by long contexts and long-horizon interactions, where agents may repeatedly reprocess large histories to act. Memory-augmented reasoning provides a principled way to alleviate this inefficiency. By storing and reusing past experience, including successes, failures, and interaction traces, agents can avoid redundant computation, make more informed decisions, and reduce costly retries. In this sense, memory is not merely an auxiliary component. It is a key mechanism for improving the overall efficiency-effectiveness trade-off of agent systems.
We organize this section around the lifecycle of agent memory, covering memory construction, memory management, and memory access. Because memory is central to efficiency gains, how to design an efficient memory module becomes an important problem. We therefore discuss efficiency-oriented designs throughout this lifecycle, focusing on how to maximize the benefit of memory while minimizing additional overhead. Figure 3 provides a structured overview of our taxonomy, and Table 1 lists representative works for an at-a-glance summary.
\begin{tabular}{l|l|l|l}
\toprule
\textbf{Method} & \textbf{Category} & \textbf{Core Mechanism} & \textbf{Resource Link} \\
\midrule
\multicolumn{4}{c}{\textbf{\textit{Working Memory}}}\\
\midrule
COMEDY ([19]) & Textual & Two-stage memory distillation & \faIcon{github}\, [GitHub](https://github.com/nuochenpku/COMEDY)\\
MemAgent ([20]) & Textual & Overwrite fixed memory & \faIcon{github}\, [GitHub](https://github.com/BytedTsinghua-SIA/MemAgent)\\
MEM1 ([21]) & Textual & Update a compact shared internal state & \faIcon{github}\, [GitHub](https://github.com/MIT-MI/MEM1)\\
AgentFold ([22]) & Textual & Proactive context folding & N/A \\
DC ([23]) & Textual & Persistent, evolving memory & \faIcon{github}\, [GitHub](https://github.com/suzgunmirac/dynamic-cheatsheet)\\
Activation Beacon ([24]) & Latent & Activation-level beacon for long context & \faIcon{github}\, [GitHub](https://github.com/FlagOpen/FlagEmbedding/)\\
MemoRAG ([25]) & Latent & KV-compressed global memory representation & \faIcon{github}\, [GitHub](https://github.com/qhjqhj00/MemoRAG)\\
MemoryLLM ([26]) & Latent & a fixed-size latent memory pool & \faIcon{github}\, [GitHub](https://github.com/wangyu-ustc/MemoryLLM)\\
M+ ([27]) & Latent & Dual-level latent memory; co-trained retriever & \faIcon{github}\, [GitHub](https://github.com/wangyu-ustc/MemoryLLM)\\
Memory$^3$ ([28]) & Latent & Externalize knowledge into retrievable sparse KV memories & N/A \\
Titans ([29]) & Latent & Sliding-window attention; test-time trainable neural long-term memory & N/A \\
MemGen ([30]) & Latent & On-demand latent memory synthesis & \faIcon{github}\, [GitHub](https://github.com/KANABOON1/MemGen)\\
\midrule
\multicolumn{4}{c}{\textbf{\textit{External Memory}}}\\
\midrule
MemoryBank ([31]) & Item-based & Ebbinghaus forgetting curve–based memory management & \faIcon{github}\, [GitHub](https://github.com/zhongwanjun/MemoryBank-SiliconFriend)\\
RECOMP ([32]) & Item-based & Compress retrieved documents & \faIcon{github}\, [GitHub](https://github.com/carriex/recomp)\\
Expel ([33]) & Item-based & experiential learning; insight distillation and management & \faIcon{github}\, [GitHub](https://github.com/LeapLabTHU/ExpeL)\\
Human-like memory ([34]) & Item-based & Cue-triggered memory recall & N/A \\
SeCom ([35]) & Item-based & Segment-level memory; compression-based denoising for retrieval & \faIcon{github}\, [GitHub](https://github.com/microsoft/SeCom)\\
Memory-R1 ([36]) & Item-based & Adaptive memory CRUD and memory distillation, via two RL-trained agents & N/A \\
Mem0 ([37]) & Item-based & Extract candidate memories; memory CRUD & \faIcon{github}\, [GitHub](https://github.com/mem0ai/mem0)\\
agentic plan caching ([38]) & Item-based & Store plan template; plan cache lookup (hit/miss) and update & N/A \\
LD-Agent ([39]) & Item-based & Separate different memory; topic-based retrieval & \faIcon{github}\, [GitHub](https://github.com/leolee99/LD-Agent)\\
MemoChat ([40]) & Item-based & Structured on-the-fly memos & \faIcon{github}\, [GitHub](https://github.com/LuJunru/MemoChat)\\
RMM ([41]) & Item-based & Topic-based memory organization; consolidation (add/merge); online RL reranker & N/A \\
Memento ([42]) & Item-based & Parametric case retrieval via an online-updated Q-function & \faIcon{github}\, [GitHub](https://github.com/Agent-on-the-Fly/Memento)\\
MemInsight ([43]) & Item-based & Attribute-augmented memory; attribute-guided retrieval & \faIcon{github}\, [GitHub](https://github.com/amazon-science/MemInsight)\\
ReasoningBank ([44]) & Item-based & Distill strategies from failures and successes to cut exploration steps & N/A \\
A-MEM ([45]) & Item-based & Atomic structured notes; link generation and memory evolution & \faIcon{github}\, [GitHub](https://github.com/agiresearch/A-mem)\\
ACE ([46]) & Item-based & Incremental delta updates, lightweight merge and de-dup & \faIcon{github}\, [GitHub](https://github.com/ace-agent/ace)\\
Agent KB ([47]) & Item-based & Cross-framework reusable experience Knowledge Base & \faIcon{github}\, [GitHub](https://github.com/OPPO-PersonalAI/Agent-KB)\\
GraphReader ([48]) & Graph-based & Graph-guided coarse-to-fine exploration & N/A \\
KG-Agent ([49]) & Graph-based & Tool-based hop-local KG processing & N/A \\
Zep ([50]) & Graph-based & Temporal KG memory & \faIcon{github}\, [GitHub](https://github.com/getzep/zep)\\
Mem0$^g$ ([37]) & Graph-based & Extract candidate nodes; graph updation & \faIcon{github}\, [GitHub](https://github.com/mem0ai/mem0)\\
AriGraph ([51]) & Graph-based & Memory graph; semantic-to-episodic cascading retrieval & \faIcon{github}\, [GitHub](https://github.com/AIRI-Institute/AriGraph)\\
D-SMART ([52]) & Graph-based & Structured OWL-compliant KG & N/A \\
MemGPT ([53]) & Hierarchical & OS-style virtual memory paging for context & \faIcon{globe}\, [Website](https://research.memgpt.ai)\\
MemoryOS ([54]) & Hierarchical & OS-inspired three-tier memory hierarchy with policy-based inter-tier updates & \faIcon{github}\, [GitHub](https://github.com/BAI-LAB/MemoryOS)\\
MemOS ([55]) & Hierarchical & Policy-guided type transformation of MemCubes across three memory forms & \faIcon{github}\, [GitHub](https://github.com/MemTensor/MemOS)\\
ReadAgent ([56]) & Hierarchical & Gist memory compression; on-demand lookup & \faIcon{github}\, [GitHub](https://github.com/read-agent/read-agent.github.io/blob/main/assets/read_agent_demo.ipynb)\\
HiAgent ([57]) & Hierarchical & Subgoals as memory chunks; on-demand trajectory retrieval & \faIcon{github}\, [GitHub](https://github.com/HiAgent2024/HiAgent)\\
H-MEM ([58]) & Hierarchical & Layer-by-layer retrieval & N/A \\
LightMem ([59]) & Hierarchical & Pre-compression; soft update (test-time); sleep-time update (offline) & \faIcon{github}\, [GitHub](https://github.com/zjunlp/LightMem)\\
\midrule
\multicolumn{4}{c}{\textbf{\textit{Multi-Agent Memory}}}\\
\midrule
MS ([60]) & Shared & Shared memory pool; selective addition; continual retriever training & \faIcon{github}\, [GitHub](https://github.com/GHupppp/InteractiveMemorySharingLLM)\\
G-Memory ([61]) & Shared & three-tier graph memory with bi-directional coarse-to-fine retrieval & \faIcon{github}\, [GitHub](https://github.com/bingreeky/GMemory)\\
RCR-Router ([62]) & Shared & Feedback-refined iterative router under a token budget & N/A \\
MemIndex ([63]) & Shared & Intent-indexed bipartite graphs; semantic slicing and dynamic indexing & N/A \\
MIRIX ([64]) & Shared & Six-module hierarchical memory with staged retrieval and parallel updates & \faIcon{github}\, [GitHub](https://github.com/Mirix-AI/MIRIX)\\
Intrinsic Memory Agents ([65]) & Local & Role-aligned templates; intrinsic iterative updates & N/A \\
AgentNet ([66]) & Local & Fixed-size memory modules for routing/execution; dynamic pruning & \faIcon{github}\, [GitHub](https://github.com/zoe-yyx/AgentNet)\\
DAMCS ([67]) & Local & Decentralized per-agent STWM/LTM with goal-oriented hierarchical knowledge graph & \faIcon{globe}\, [Website](https://happyeureka.github.io/damcs/)\\
SRMT ([68]) & Mixed & Personal latent memory and globally broadcast shared recurrent memory & \faIcon{github}\, [GitHub](https://github.com/Aloriosa/srmt)\\
Collaborative Memory ([69]) & Mixed & Policy-based filtering/transformation of memory fragments; shared-memory reuse & N/A \\
LEGOMem ([70]) & Mixed & Role-aware memory routing; runtime-efficient retrieval scheduling & N/A \\
\bottomrule
\end{tabular}
3.1 Memory Construction
No matter whether we target long-context tasks or long-term interactions, the core challenge is handling extensive context or interaction history. Naively appending raw history into the prompt is often impractical: token usage grows rapidly, and performance can even degrade when relevant information is buried in long sequences, as observed in the “lost in the middle” phenomenon ([71]). In addition, an LLM's context window is finite, whereas the amount of potentially relevant information is effectively unbounded. These constraints motivate memory construction, which compresses and organizes past information into more manageable representations. Many existing works build memory through summarization, reducing token consumption and improving efficiency.
3.1.1 Working Memory
Working memory is the information directly available at inference time that conditions generation. Here, the term is broader than the common definition that limits working memory to context tokens. It includes the text currently present in the prompt or context window, and latent memory in the form of continuous signals that influence the forward computation without being represented as tokens, such as soft prompts, KV cache, and hidden states. Latent memory can arise inside the model or be stored externally and injected as continuous conditioning. Embeddings count as latent memory only when they are provided to the model as such conditioning signals; embeddings used only to support retrieval are treated separately in Section 3.1.2.
Textual Memory.
In LLM-based agents, textual memory is a common instantiation of working memory. To address the long-context challenge, many methods aim to keep the working memory in the prompt at a roughly constant size. In practice, this is often achieved by frequently rewriting or compressing the memory as the process evolves.
COMEDY ([19]) uses an LLM to generate and compress memory: it extracts session-specific memories from past conversations and then condenses them into a compact representation of key events, the user profile, and relationship changes. MemAgent ([20]) and MEM1 ([21]) both process long inputs sequentially by rewriting and updating a compact memory state at each step: MemAgent updates a summarized memory after each chunk, while MEM1 uses reinforcement learning [72] to maintain a fixed-length internal state tagged by
By retaining a compact memory in the prompt rather than the full history, these methods reduce the effective context length the LLM needs to attend to, thereby improving long-context performance while decreasing computational cost and increasing efficiency.
Latent Memory.
Besides textual working memory, recent work also lets an agent keep its state in latent form, such as hidden activations or KV caches. This kind of memory is not shown as text, but it can be read and updated by the model. In many cases it is much cheaper than storing and re-reading the full interaction history, and thus is attractive for efficient agents.
One group of methods builds compact latent memory by compressing long contexts into a small set of activations in KV space. Activation Beacon ([24]) partitions the context into chunks and fine-grained units, interleaves beacon tokens by a compression ratio, and uses progressive compression to distill layer-wise KV activations into the beacons, which are accumulated as latent memory while raw-token activations are discarded. MemoRAG ([25]) performs memory formation by inserting memory tokens after each window as information carriers of global memory in KV space, and updating a memory-token KV cache across windows with separate weight matrices; the compact global memory can later be reused (e.g., as retrieval clues).
A second group maintains an external pool of latent memory and integrates it into the backbone LLM via attention at inference time, enabling reuse of stored information across steps and episodes. MemoryLLM ([26]) maintains a fixed-size memory pool of memory tokens updated via self-update, enabling reuse of stored latent knowledge without lengthening the prompt. M+ ([27]) adds a GPU/CPU two-tier long-term memory with a co-trained retriever that fetches only a few relevant memory tokens per layer, and Memory$^3$ ([28]) encodes a KB as sparse explicit key–value memory injected into attention at decoding time to avoid repeated document reading.
A third group lets latent memory be a separate neural module that can learn online together with the agent. Titans ([29]) builds latent memory by updating a neural memory module at test time, writing only when prediction error is high and skipping updates otherwise. MemGen ([30]) constructs latent memories via an RL-trained memory trigger and a memory weaver that produces compact latent memory tokens as the stored representation.
Strictly speaking, some of the methods above are proposed as general memory modules for LLMs rather than full agent frameworks. However, from the view of efficient agent memory, they play the same role: they compress long interaction histories into compact latent states, update these states only when needed, and expose them to the policy through attention or simple interfaces. This allows an agent to keep and reuse long-horizon information without replaying the entire textual trajectory at each step.
- **Advantages**: The working memory is directly conditioned upon during generation, eliminating the latency and overhead associated with external retrieval or repeated encoding.
- **Disadvantages**: Expanding the working set leads to computational growth for textual memory or increased memory footprint for latent states, and risks performance degradation due to information dilution in long contexts.
- **Applicable Scenarios**: Textual memory is best for logic-heavy tasks within moderate context limits, while latent memory suits efficiency-critical applications requiring the reuse of historical states without re-processing.
3.1.2 External Memory
External memory refers to information stored outside the model in token-level form, including document collections, knowledge graphs, and retrieval systems such as RAG. It does not condition generation directly. Instead, it is accessed through retrieval and then expressed as tokens placed into the prompt or context window.
Item-based Memory.
Early agent-memory systems often store full trajectories or experiences, sometimes alongside summaries, which leads to long context and inefficiency. MemoryBank ([31]) stores daily conversation records and summarizes past events and user profiles from these conversations, but it incurs high token costs. Similarly, Expel ([33]) suffers from a similar limitation, as it accumulates experiences through trial and error and distills them into natural-language insights.
To be more efficient, some works adopt methods such as memory extraction, compress or summarization to directly reduce context length. This way thereby lowers input token consumption while yielding a shorter but more informative context.
Human-like memory ([34]) extracts episodic memories from users dialogues, encapsulating content and temporal context into database structure. SeCom ([35]) uses segmentation model to divide long-term conversations into topic-coherent segmentation, and applies the compress model to denoise the segmentation, which further promotes efficient retrieval.
Memory-R1 ([36]) and Mem0 ([37]) both extract and summarize ongoing dialogue into candidate memories for downstream updating; Memory-R1 does so at each turn, while Mem0 forms candidate memories from the new message pair, using a conversation summary and recent messages as context. Agentic plan caching ([38]) turns a successful run into a reusable cache entry by rule-based filtering the execution log and then using a lightweight LLM to remove context-specific details, storing the result as a (keyword, plan template) pair. LD-Agent ([39]) separates event and persona memory, using short-term and long-term banks for timestamped dialogue context and embedded event summaries, and a persona extractor to store user and agent traits in long-term persona banks.
Beyond the extraction and compression strategies discussed above, another way to improve efficiency is to design more structured memory systems. Organizing memory more systematically can enable faster retrieval, better utilization of stored information, and improved overall performance. And one type of the structured memory system is topic-indexed memories, which organizes interactions into topic-level groups and stores each topic summary together with its corresponding dialogue segment for efficient retrieval. MemoChat ([40]) and RMM ([41]) both build topic-indexed memories. MemoChat records topic–summary–dialogue entries on the fly, while RMM groups each session by topic and stores each topic summary with its corresponding dialogue segment. Then, some system constructs the attribute-annotated memory items by enriching each interaction with structured attributes such as LLM-mined attribute value pairs, contextual descriptions, keywords, and tags to support fine-grained retrieval. MemInsight ([43]) and A-MEM ([45]) both enrich raw interactions with structured attributes for retrieval: MemInsight annotates memories with LLM-mined attribute–value pairs, while A-MEM converts each interaction into an atomic note with LLM-generated contextual descriptions, keywords, and tags. Besides, a typical way is to distill experience libraries for reusable decision by summarizing trajectories or execution logs into standardized experience entries that capture reusable strategies, domain concepts, and common failure modes for retrieval and reuse. ReasoningBank ([44]) summarizes successful and failed trajectories into structured memory items with a title, brief description, and content, and stores them with the task query and trajectory for embedding-based retrieval. ACE ([46]) represents context as structured, itemized bullets, each with a unique identifier, counters tracking how often it was marked helpful or harmful, and content such as a reusable strategy, domain concept, or common failure mode. Agent KB ([47]) turns execution logs into structured experience entries through human-guided abstraction, using few-shot prompting and a standardized cross-framework action vocabulary.
Graph-based Memory.
It's obvious that graph-based memory is also a structured memory form. Some methods focus on constructing graph-structured representations from long inputs or KG interactions, so multi-hop evidence can be organized and accessed efficiently.
Targeted at the long context task, GraphReader ([48]) segments long text into chunks, compresses them into key elements and atomic facts, and uses these to construct a graph that captures long-range dependencies and multi-hop relations. KG-Agent ([49]) constructs a task-specific subgraph by tool calls and records the retrieved entities and relations as knowledge memory.
Another line of work constructs long-term memory directly as a dynamic knowledge graph, turning interactions into entities, relations, and time-aware facts that can be incrementally updated.
Zep ([50]) builds memory as a temporally-aware knowledge graph by ingesting time-stamped episodes, extracting/aligning entities and relations, storing fact edges with periods of validity and additionally constructs a community subgraph that clusters strongly connected entities and stores high-level community summaries. Mem0$^g$ ([37]) represents memory as a directed labeled graph, where an LLM converts new messages into entities and relation triplets that form candidate nodes or edges for graph updates. D-SMART ([52]) incrementally constructs an OWL-compliant dialogue KG by first distilling each turn into an assertion-like statement, then converting it into a KG fragment for integration. AriGraph ([51]) updates a unified semantic–episodic memory graph online by adding an episodic node for each observation and extracting triplets to update the semantic graph, linking the two via episodic edges.
Graph-based memory represents entities and their relations as a structured graph. Building the graph already compresses and normalizes the history by merging repeated content about the same entity into a single node and keeping only relevant relations as edges. This makes construction more efficient by producing a compact structure that avoids unbounded prompt growth and supports fast retrieval later.
Hierarchical Memory.
Hierarchical memory organizes information into multiple linked levels, enabling coarse-to-fine, on-demand access. Most hierarchical memory methods consider both structure and content, but with different emphases. Accordingly, related work can be grouped by whether it places more weight on structural organization and management or on content abstraction and indexing.
System-oriented hierarchical memory designs define explicit storage tiers and read/write interfaces to manage long interaction history. MemGPT ([53]) constructs a hierarchical memory by partitioning the in-context prompt into system instructions, a writable working context, and a FIFO message buffer, and storing the remaining history and documents in external recall and archival memory. MemoryOS ([54]) adopts an OS-inspired hierarchical memory design with three storage tiers: short-term memory stores recent dialogue pages, mid-term memory groups pages into topic segments with summaries, and long-term personal memory maintains user and agent persona information. MemOS ([55]) standardizes memory as MemCubes, each composed of a structured metadata header and a memory payload that can encapsulate plaintext, activation states, or parameter deltas. New interactions are incrementally turned into MemCubes and organized in a hierarchical structure.
Content-oriented approaches build hierarchical indices by segmenting and compressing documents or trajectories into multi-granularity summaries. ReadAgent ([56]) splits a long document into pages and summarizes each page into a page-linked gist memory, forming a simple hierarchical index. HiAgent ([57]) compresses working memory into subgoals and observations, and stores full trajectories in external memory indexed by these summaries. H-MEM ([58]) constructs a hierarchical structure, with four memory layers: Domain Layer, Category Layer, Memory Trace Layer, and Episode Layer. It designs prompts to guide model to parse the interactions into these layers, which forms a progressively optimized index. LightMem ([59]) uses a sensory–STM–LTM pipeline that first pre-compresses inputs by the sensory module, then groups turns into topic segments for STM and periodically summarizes these segments into compact LTM entries.
- **Advantages**: Effectively unbounded long-term storage outside the model, reducing context overflow via targeted retrieval.
- **Disadvantages**: Adds system overhead and retrieval latency, with potential retrieval noise.
- **Applicable scenarios**: Item-based memory suits general long-trajectory agents, graph-based memory suits entity–relation and multi-hop reasoning tasks, while hierarchical memory suits ultra-long histories or large corpora needing coarse-to-fine retrieval.
3.2 Memory Management
Some methods, like Human-like memory ([34]), continually insert new memories into memory module, without any operation like updating, removing or merging, leading to memory space explosion. Therefore, the speed of the memory retrieval or recall will significantly decrease, which indicates that memory management is a highly important part for efficiency.
3.2.1 Rule-based Management
Rule-based management refers to predefined rules for updating, removing, and merging existing memories. Because these rules are static, this approach is inexpensive and prevents the overall memory size from growing uncontrollably.
MemoryBank ([31]) introduces an Ebbinghaus-inspired memory update rule that decays memories over time while reinforcing important ones. Building on this idea, H-MEM ([58]) retains forgetting-curve-based decay and further adds feedback-driven regulation to dynamically adjust memory according to user feedback. Experimental results in A-MEM ([45]) suggest that forgetting-curve-based memory management effectively controls memory size and reduces retrieval time. However, it also leads to a substantial drop in task performance.
Apart from forgetting-curve-based policies, a common rule-based strategy is trigger-driven memory maintenance, such as evicting or migrating items when a fixed-size buffer reaches capacity (e.g., FIFO replacement) ([53, 54]). In practice, these simple rules are often intertwined with LLM-based management, where the model summarizes or saves key information before items are removed or moved; more details are discussed in Section 3.2.3.
- **Advantages**: Fast, predictable, and low-cost memory management without extra LLM calls.
- **Disadvantages**: Static and task-agnostic rules can blindly prune or decay memory, causing critical information loss and hurting accuracy when retention matters.
3.2.2 LLM-based Management
LLM-based memory management can be broadly categorized by its decision form: selecting from a discrete set of operations versus generating open-ended updates.
A common formulation is operation selection, where the model picks an action from a predefined set (e.g., ADD/DELETE) and applies it to retrieved memories. Both Memory-R1 ([36]) and Mem0 ([37]) update an external memory by retrieving similar entries and choosing among ADD, UPDATE, DELETE, NOOP. Memory-R1 learns the choice via reinforcement learning, while Mem0 lets an LLM select the operation after vector-based retrieval. RMM ([41]) follows the same retrieve-then-update pattern: for each newly extracted topic memory, it retrieves the top- $k$ most similar entries from the memory bank and prompts an LLM to decide whether to merge or add. Separately, ExpeL ([33]) maintains an insights list through direct list editing, applying operations such as ADD, EDIT, UPVOTE, and DOWNVOTE to correct or gradually suppress erroneous and outdated insights.
A different formulation casts memory management as open-ended generation, where the model produces the update itself and implicitly performs the update operation rather than picking from a fixed action set. A-MEM ([45]) uses generative updates: it retrieves top- $k$ similar notes with a fixed encoder, then an LLM creates links and rewrites related notes via memory evolution.
- **Advantages**: Adaptive, task-aware decisions that keep the most relevant information while enabling effective compression or merging for a concise context.
- **Disadvantages**: Requires extra LLM calls during management, increasing compute cost and latency.
3.2.3 Hybrid Management
Hybrid memory management typically combines lightweight rule-based control with selective LLM-based operations to balance efficiency and effectiveness.
Typical designs include tier-specific management, where rule-based triggers promote or consolidate information across tiers and costly LLM updates are invoked only when necessary. MemoryOS ([54]) and LightMem ([59]) both adopt tier-specific, trigger-driven updates for hierarchical memory. MemoryOS manages STM as FIFO pages with overflow migrated to MTM, uses segment Heat scores in MTM for eviction and promotion, and updates LPM via an LLM, whereas LightMem triggers topic segmentation when the sensory buffer is full, summarizes topics into LTM when STM exceeds a token budget, and combines online soft updates with offline sleep-time consolidation. LD-Agent ([39]) uses a time-gap threshold as the trigger, summarizing the short-term cache into a long-term event record and clearing the cache to mark session boundaries. MemGPT ([53]) uses a hierarchical memory with main context and external context. A Queue Manager enforces token limits via memory pressure warnings, eviction, and recursive summarization, while a Function Executor turns model outputs into function calls to read and write across tiers.
Another management is item-level selection and pruning, using rules or heuristics for fast de-duplication and removal while relying on LLMs for semantic keep-or-drop decisions. Agent KB ([47]) and ACE ([46]) exemplify item-level selection and pruning for hybrid memory management. Agent KB reduces redundancy by thresholding embedding similarity and using an LLM ranker to keep the better experience, then evicts low-utility entries based on a learned utility score. ACE maintains a bulletized context through incremental delta updates and applies embedding-based grow-and-refine to merge, prune, and de-duplicate bullets, keeping the context compact.
Besides, some management also considers lifecycle policies that use lightweight metrics to schedule costly maintenance beyond tier transfer, such as consolidation, deduplication, and archiving. MemOS ([55]) manages MemCubes with explicit lifecycle and version tracking, using policy- and metric-driven modules such as MemScheduler and MemVault for deduplication, conflict handling, and archiving. Crucially, it supports type-aware transformation across Plaintext Memory, Activation Memory, and Parameter Memory, including promotion and demotion between types.
For graph-structured memory, hybrid management applies rule-based graph updates, while using LLMs to retrieve relevant subgraphs and verify contradictions or outdated content before updating relations. Zep ([50]), Mem0$^{g}$ ([37]), and AriGraph ([51]) follow a similar pattern for graph memory maintenance: an LLM judges semantic conflicts or staleness against retrieved related edges, while the graph is updated through rule-based operations such as edge invalidation or removal and insertion of new relations to preserve temporal or world-model consistency. Additionally, D-SMART ([52]) maintains an OWL-compliant Dynamic Structured Memory and performs two-stage conflict resolution by letting an LLM identify contradicted or superseded triples, pruning them before merging the new fragment, with an optional OWL reasoner for logical consistency checking.
- **Advantages**: Balances low-cost, predictable rule control with task-aware LLM decisions, invoking the LLM only when needed to keep memory both efficient and relevant.
- **Disadvantages**: Increases system complexity across tiers, and can suffer from suboptimal policy interactions, while LLM calls still add cost and latency when invoked.
3.3 Memory Access
Memory access retrieves and uses only the small subset of a large memory bank that matters for a query, balancing retrieval latency and token cost against downstream generation quality.
3.3.1 Memory Selection
Memory selection determines what to retrieve and how to retrieve it. Most methods follow vanilla retrieval, i.e., encoding the query and its context into embeddings and selecting relevant information via similarity search, while others employ improved retrieval mechanisms to enhance retrieval quality and efficiency.
Rule-enhanced Retrieval.
Some methods enhance retrieval by incorporating additional rule-based scoring factors and applying preprocessing steps before retrieval. Generative Agents ([73]) and Human-like memory ([34]) take time into consideration, namely recency and elapsed time in these works. Apart from this, Generative Agents adds importance, a score generated by LLM based on the semantic importance, and Human-like memory adds recall frequency, computed according to the mathematical model. Agent KB ([47]) employs a hybrid retrieval strategy that integrates lexical matching with semantic ranking by task similarity, combining both signals into a unified retrieval score. For long-term event retrieval, LD-Agent ([39]) combines semantic relevance, noun-based topic overlap, and an exponential time-decay factor into an overall score, and only retrieves memories whose semantic similarity exceeds a threshold.
While the aforementioned methods improve retrieval by adding additional scoring factors while keeping the computational cost comparable to vanilla retrieval, MemInsight ([43]) augments memories with LLM generated attribute value annotations and leverages these augmentations for retrieval, either by filtering memories via attribute matching or by embedding the aggregated augmentations for vector similarity search.
Graph-based Retrieval.
For graph-based memory, retrieval naturally follows the graph structure, enabling efficient neighbor expansion and more precise localization of relevant facts, especially when queries target entity- and relation-centric information. Given a textual query, Both AriGraph ([51]) and Mem0$^g$ ([37]) retrieve from a memory graph by anchoring on query-relevant facts and expanding neighbors into a local subgraph. AriGraph retrieves semantic triplets and then ranks episodic vertices via episodic search, whereas Mem0$^g$ pairs entity-centric subgraph construction with semantic triplet retrieval over relationship triplets.
LLM or Tool-based Retrieval.
Furthermore, there are methods that do not depend on a retriever, but instead leverage LLMs or external tools for obtaining relevant information.
For LLM-based retrieval, MemGPT ([53]) uses hierarchical memory without a fixed retrieval pipeline: memory tiers are exposed as tools, and the LLM selects the tier and operation under token budgets enforced by the system. MemoChat ([40]) exploits its memo structure by retrieving only the topic and summary, rather than the full topic–summary–dialogue, to reduce input length. ReadAgent ([56]) similarly delegates page lookup to the LLM, which decides when and which page(s) to consult.
However, while using a strong LLM can improve retrieval accuracy, it often incurs substantial overhead in both token consumption and inference latency, making it more suitable for low-frequency, high-stakes queries where correctness outweighs cost.
Besides, some methods rely on tool use for retrieval. GraphReader ([48]) predefines various tools, and employs the tools to read the memory step by step, from coarse-grained to fine-grained. D-SMART ([52]) lets the LLM select graph-operations such as Expand Entity and Find Path to retrieve n-hop neighbors from the global DSM and incrementally grow a task-specific subgraph, which serves as grounded context for answering.
Hierarchical Retrieval.
In line with the hierarchical memory structure, retrieval can likewise be organized hierarchically. Some retrieval methods can be considered as a simple way of hierarchical retrieval, such as the conceptually two-layer design. HiAgent ([57]) can recall the trajectories by a retrieval module, when the agent needs to obtain the details of the previous subgoal. Beyond such a two-layer setup, hierarchical retrieval can be made explicit through multi-layer indexing. In H-MEM ([58]), each memory embedding points to relevant sub-memories in the next layer, recursively indexing down to the last layer to retrieve relevant information, thereby accelerating retrieval. At a more system level, MemoryOS ([54]) uses tier-specific retrieval: STM returns the most recent dialogue pages, MTM retrieves top- $m$ candidate segments and selects top- $k$ relevant pages within them, and LPM performs semantic search over long-term user and agent memories.
Training.
As the memory bank grows, a fixed retriever can drift from what is truly useful, so recent work trains adaptive retrieval that prioritizes high-utility memories for better relevance and efficiency. RMM ([41]) adds a learnable reranker over a dense retriever and updates it online via RL using binary useful memory signals from Retrospective Reflection. Memento ([42]) learns a parametric Q-function over state–case pairs to rank and select Top-K cases, favoring historically high-reward cases over nearest neighbors.
- **Applicable scenarios**: Rule-enhanced retrieval fits settings with clear heuristics or constraints and tight budgets; graph-based retrieval fits entity–relation queries and multi-hop evidence chaining; LLM/tool-based retrieval fits low-frequency, high-stakes queries where correctness outweighs latency; hierarchical retrieval fits very large memory banks requiring coarse-to-fine lookup; training-based retrieval fits long-running systems where the memory distribution drifts over time.
3.3.2 Memory Integration
Memory integration determines how to use retrieved content efficiently. It can leverage techniques such as filtering, compression, and structured insertion to make the retrieved information easier and cheaper to use during generation.
Textual Integration.
When memory is stored as natural language, integration mainly means deciding which small set of text to show to the backbone model and in what format. DC-RS ([23]) integrates persistent memory by keeping a cheatsheet store, doing similarity-based retrieval, then synthesizing a compact cheatsheet that is inserted into the prompt.
Several agent-oriented systems follow the same idea but build on structured memory stores. In Mem0 ([37]), each memory item is a short natural language record with metadata (time, type, source, etc.). At inference time, the system retrieves the most relevant items and formats them as a compact memory block that is appended to the dialogue context, keeping only a handful of focused sentences in the prompt. Taking a more structured approach, A-MEM ([45]) organizes interaction history as Zettelkasten-style notes and uses a two-stage retrieval pipeline to select only a few high-utility notes; these notes are linearized into a small "working set" section inside the agent prompt, while the rest of the note graph remains offline. ACE ([46]) goes one step further and treats the agent context as an evolving playbook: it maintains a library of fine-grained strategy bullets with usage statistics, and before each episode it selects and injects only the most helpful bullets into the system instructions and memory prompts. Similarly, for execution efficiency, agentic plan caching ([38]) caches high-level plan templates distilled from successful past executions; at serving time, a cheap keyword-based matcher looks up a matching template and a small planner LLM adapts it to the new query, replacing a fresh planning phase with a short plan-adaptation prompt. Finally, apart from structured storage, general compression techniques are also employed to fit external information into the prompt. RECOMP ([32]) uses Retrieve–Compress–Prepend: an extractive compressor selects sentences and an abstractive compressor writes a short summary, which is prepended to the query; selective augmentation allows returning an empty string when retrieval is unhelpful.
Across these methods, textual memory integration improves efficiency by compressing long histories into task-specific snippets that fit into the prompt while retaining the main signals that drive agent behavior.
Latent Integration.
Latent memory integration stores long-term information as compact hidden states or key–value pairs and reuses them within the model’s internal computation, avoiding re-encoding the original text.
One approach to latent integration is to scale latent memory capacity while keeping the GPU KV cache roughly constant. MemoryLLM ([26]) inserts a trainable pool of memory tokens into every transformer layer. During inference these tokens are processed together with the normal sequence tokens, so information stored in the memory pool can influence the hidden states at each step without extending the visible context. Based on MemoryLLM, M+ ([27]) adds a CPU-resident long-term memory and a co-trained retriever that fetches a small set of relevant hidden-state memory tokens per layer during generation, enabling long-range recall with similar GPU memory overhead.
Alternatively, some latent integration methods maintain external knowledge or long context directly as compressed KV-level states, which are then integrated into the generation process via attention. Memory$^3$ ([28]) stores a KB as explicit key–value memory and, during decoding, retrieves a few entries per token block and adds their KVs to the attention KV cache, avoiding long prompts. MemoRAG ([25]) compresses long context into a KV-cache global memory over inserted memory tokens; a lightweight memory model generates a draft answer as a retrieval clue, This design reduces the query-time long-context cost by running full long-context inference on only a few selected passages, while the rest of the corpus is accessed through compressed KV-level memory.
Compared with purely textual integration, these latent mechanisms push most long-term information into fixed-size neural states and expose them through attention, so that the cost of using long-horizon experience grows much more slowly than the length of the raw interaction history.
3.4 Multi-Agent Memory
In LLM-based multi-agent systems (MAS), many early studies, such as CAMEL ([74]), mainly focus on textual communication protocols, where memory can typically be regarded as implicit and implemented in a simple form. More recent research has begun to explicitly focus on the notion of memory in MAS. These memory-oriented works still fit into the taxonomy proposed in our framework, but in this section we adopt a MAS-centered perspective and provide a more focused discussion of memory within multi-agent systems.
Shared Memory.
Shared memory centralizes reusable information across agents to mitigate redundancy, as duplicating multi-agent interaction histories in individual prompts is costly in both token budget and inference time.
MS ([60]) stores agent steps as Prompt–Answer pairs and filters them with an LLM evaluator before adding them to a shared pool, then uses accepted memories to continually refine the retriever. However, the frequent LLM-based scoring introduces substantial token and latency overhead.
To improve efficiency, recent work explores structured shared textual memory that supports lightweight retrieval and reduces redundant context replay.
G-Memory ([61]) models multi-agent experience as a three-tier graph hierarchy of insight, query, and interaction graphs; at inference, it performs bi-directional traversal to retrieve high-level, generalizable insights together with fine-grained, condensed interaction trajectories for agent-specific working memory. RCR-Router ([62]) maintains a Shared Memory Store of interaction history, task-relevant knowledge, and structured state representations, and performs round-wise context routing with an Importance Scorer, a Semantic Filter, and a Token Budget Allocator to minimize redundant context and token usage. MemIndex ([63]) adopts an intent-indexed bipartite graph architecture for memory operations in LM-based multi-agent pub/sub systems, improving storage, retrieval, update, and deletion efficiency and reporting lower elapsed time, CPU utilization, and memory usage. Different from typical shared-memory MAS that mainly consume retrieved context, MIRIX ([64]) adopts a modular multi-agent architecture governed by a Meta Memory Manager and six Memory Managers, and uses Active Retrieval to generate a topic and inject retrieved memories into the system prompt without explicit memory-search prompts.
Beyond textual shared memory, latent shared memory enables agents to exchange compact internal states, reducing redundant token-level replay. LatentMAS ([75]) implements latent shared memory by having each agent perform auto-regressive latent thinking from last-layer hidden states and consolidating the resulting layer-wise KV caches into a shared latent working memory for persistent read–write sharing across agents. KVComm ([76]) enables training-free online KV-cache communication by maintaining an anchor pool of shared segments and their KV offsets, then matching anchors and approximating offsets to safely reuse KV caches across new prefixes, avoiding repeated prefilling.
- **Advantages**: Enables cross-agent reuse of verified facts and decisions, improving coordination and efficiency by reducing redundant work and retries.
- **Disadvantages**: Prone to inconsistency from concurrent writes, and can become noisy and costly to retrieve without consolidation and access control.
Local Memory.
For local memory, redundancy accumulates within each agent as its personal store grows, so retrieval and updates should remain agent-local; meanwhile, local memory management can borrow ideas from single-agent methods such as selective writing, consolidation, and capacity control. Intrinsic Memory Agents ([65]) equips each agent with a role-aligned structured memory template and updates it every turn by folding the agent’s latest output back into the same template until consensus is reached. AgentNet ([66]) maintains fixed-size memory modules for the router and executor, and uses dynamic memory management with signals like frequency, recency, and uniqueness to prune low-utility trajectories at capacity. DAMCS ([67]) introduces A-KGMS, consolidating experiences into a goal-oriented hierarchical knowledge graph and planning via neighborhood queries around the most recent goal node to avoid full-history sharing and reduce overhead.
- **Advantages**: Lightweight, low-noise per-agent workspace that supports efficient retrieval and role-specific prompting.
- **Disadvantages**: Not shared across agents, so useful results may not propagate and work can be duplicated.
Mixed Memory.
Mixed memory combines shared and local memory, and its efficiency often benefits from coordination between the two, including what to write to each, when to retrieve from which, and how to control redundancy. SRMT ([68]) couples each agent’s personal memory vector with a shared recurrent memory by pooling all agents’ memory vectors and letting agents cross-attend to this shared sequence, then updating their personal vectors via a memory head. Collaborative Memory ([69]) uses dynamic bipartite access graphs with private/shared tiers, storing fragments with immutable provenance and enforcing sharing through configurable read/write policies. LEGOMem ([70]) builds modular procedural memory with full-task memories for the orchestrator and subtask memories for task agents, comparing vanilla retrieval with Dynamic and QueryRewrite variants for finer-grained subtask memory access.
- **Advantages**: Combines efficient per-agent local state with cross-agent knowledge reuse via shared memory, improving both specialization and coordination.
- **Disadvantages**: Adds synchronization and routing complexity, and can still suffer from inconsistency or noise in the shared store.
3.5 Discussion
Trade-off Between Memory Compression and Performance.
Although we have repeatedly emphasized that memory extraction can reduce costs such as input token usage, an unavoidable issue is that extraction may lead to the loss of critical information, which can directly degrade the agent's performance. This problem has also been noted in prior work such as AgentFold ([22]). LightMem ([59]), for instance, explicitly takes the compression rate into account. Its experimental results clearly show that excessive compression leads to poorer accuracy, whereas milder compression better preserves performance but incurs relatively higher cost. Therefore, how to strike an appropriate balance between compression and performance remains an open question, and there may also be alternative approaches that aim to retain as much salient information as possible during the extraction or compression process.
Online vs Offline Memory Management.
Regarding memory management strategies, A-MEM([45]) exemplifies a purely online system where memory updates occur synchronously during interaction. As demonstrated by MemoryOS([54]), such real-time updates incur frequent LLM calls per response, leading to higher latency and financial costs. By contrast, LightMem ([59]) adopts a hybrid architecture combining a lightweight online cache with offline consolidation. This design offloads expensive computations to asynchronous offline processes, significantly reducing inference time while maintaining similar overall computational costs. This comparison highlights a fundamental trade-off: online updates ensure immediate adaptation but increase latency and cost, whereas offline updates minimize inference overhead but suffer from slower adaptation. Consequently, this comparison suggests that an optimal memory system design should likely strike a balance between these two paradigms.
4. Efficient Tool Learning
\begin{tabular}{l|l|l|l}
\toprule
\textbf{Method} & \textbf{Category} & \textbf{Core Mechanism} & \textbf{Resource Link} \\
\midrule
\multicolumn{4}{c}{\textit{Efficient Tool Selection}}\\
\midrule
ProTIP [77] & External Retriever & Contrastive learning to correlate queries with tools & N/A \\
TinyAgent [78] & Multi-Label Classification & Implement a small model to select appropriate tools & \faIcon{github}\, [GitHub](https://github.com/SqueezeAILab/TinyAgent) \\
Tool2Vec [79] & Multi-Label Classification & Align tools with synthetic usage examples & \faIcon{github}\, [GitHub](https://github.com/SqueezeAILab/Tool2Vec) \\
ToolkenGPT [80] & Vocabulary-based Retrieval & Train tools as a special token & \faIcon{github}\, [GitHub](https://github.com/Ber666/ToolkenGPT) \\
Toolken+ [81] & Vocabulary-based Retrieval & Rerank top-k tools and reject if no one is selected & N/A \\
Chain-of-Tools [82] & Vocabulary-based Retrieval & Leverage CoT with a huge tool pool & \faIcon{github}\, [GitHub](https://github.com/fairyshine/Chain-of-Tools)\\
ToolGen [83] & Vocabulary-based Retrieval & Encode each tool as a separate token & \faIcon{github}\, [GitHub](https://github.com/Reason-Wang/ToolGen) \\
\midrule
\multicolumn{4}{c}{\textit{Efficient Tool Calling}}\\
\midrule
Toolformer [84] & In-Place Parameter Filling & Leverage CoT to invoke tool calls & N/A \\
CoA [85] & In-Place Parameter Filling & Uses symbolic abstractions for intermediate steps & N/A \\
LLMCompiler [86] & Parallel Tool Calling & A compiler-inspired framework enabling parallel tooling & \faIcon{github}\, [GitHub](https://github.com/SqueezeAILab/LLMCompiler)\\
LLM-Tool Compiler [87] & Parallel Tool Calling & Fusing similar tools and parallel tooling & N/A \\
CATP-LLM [88] & Parallel Tool Calling & Include cost-awareness into planning & \faIcon{github}\, [GitHub](https://github.com/duowuyms/OpenCATP-LLM) \\
BTP [89] & Cost-Aware Tool Calling & Formulates tool calling as a knapsack problem & \faIcon{github}\, [GitHub](https://github.com/THUNLP-MT/BTP) \\
TROVE [90] & Cost-Aware Tool Calling & Introduce compact reusable tools. & \faIcon{github}\, [GitHub](https://github.com/zorazrw/trove) \\
ToolCoder [91] & Cost-Aware Tool Calling & Treat tool as code generation & \faIcon{github}\, [GitHub](https://github.com/dhx20150812/ToolCoder) \\
ToolChain* [92] & Test-Time Scaling & Utilizes A* search to prune unproductive branches & N/A \\
OTC-PO [93] & Post-training / RL & Integrates tool-use penalty into RL objective & N/A \\
ToolOrchestra [94] & Post-training / RL & Efficiency-aware rewards for specialized orchestrators & \faIcon{github}\, [GitHub](https://github.com/NVlabs/ToolOrchestra/) \\
\midrule
\multicolumn{4}{c}{\textit{Tool-Integrated Reasoning (TIR)}}\\
\midrule
TableMind [95] & Adaptive Search & Plan-action-reflect loop with Rank-Aware Optimization & \faIcon{github}\, [GitHub](https://github.com/lennendd/TableMind) \\
SMART [96] & Boundary Awareness & CoT-based dataset to decide parametric vs. tool use & \faIcon{github}\, [GitHub](https://github.com/qiancheng0/Open-SMARTAgent) \\
ARTIST [97] & Policy Optimization & Unified agentic reasoning with outcome-based RL & N/A \\
AutoTIR [98] & Policy Optimization & Hybrid reward for correctness and format adherence & \faIcon{github}\, [GitHub](https://github.com/weiyifan1023/AutoTIR) \\
ReTool [99] & Code-Integrated Reasoning & Dynamic NL-code interleaving with verifiable rewards & \faIcon{github}\, [GitHub](https://github.com/ReTool-RL/ReTool) \\
ToolRL [100] & Structured Rewards & Combines format reward with tool parameter correctness & \faIcon{github}\, [GitHub](https://github.com/qiancheng0/ToolRL) \\
PORTool [101] & Step-wise Planning & Uses fork-relative advantages and decay factors & N/A \\
Agent-FLAN [102] & Data Efficiency & Decomposes agent data into capability-specific subsets & \faIcon{github}\, [GitHub](https://github.com/InternLM/Agent-FLAN) \\
\bottomrule
\end{tabular}
Tool learning provides an interface for LLMs to interact with the physical world and virtual environment. In general, tools refer to search, code sandbox (interpreter), and many other general API endpoints. To call these tools, a basic solution is to provide several candidates to the prompt, and let the LLM think and select the most suitable one with parameters filled [103]. However, as the task become more complex, there would be much more tool calls. For example, LLMs may call the search API for 600 times to resolve a deep research problem [104]. Such long trajectories extremely challenge the models' long context comprehension ability and brings enormous costs. To this end, it is crucial to explore efficient tool learning strategies.
Overall, there are two types of efficiency in tool learning: (1) Tool learning itself is efficient for solving complex problems. Comparing with a task with very long CoT, tool learning could efficiently optimize the length of trajectories and show the efficient reasoning process. (2) Tool learning could be optimized to call fewer tools, which reduces the cost of tool learning itself. For a complex task with hundreds of tool calls, an optimal method could significantly reduces the number of tool calls. So the overall process would be even more efficient.
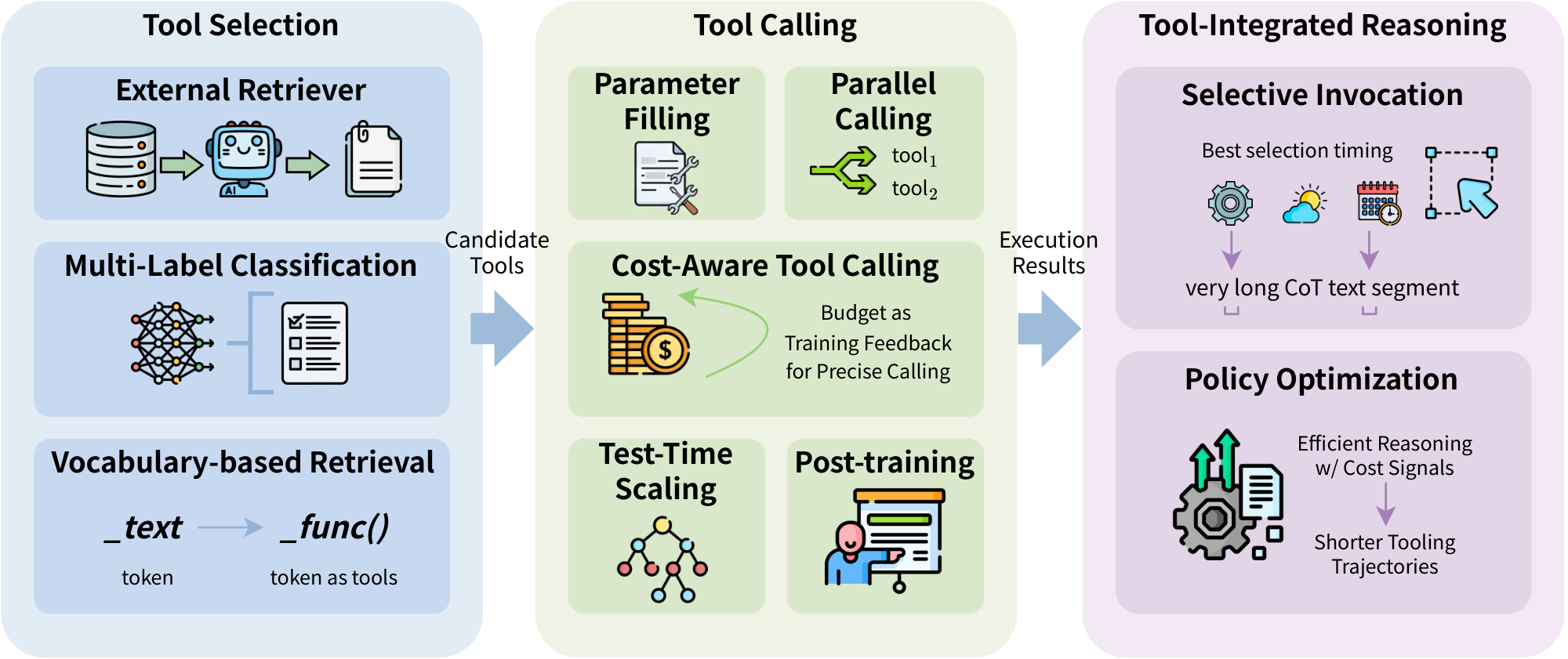
As shown in Figure 4, we introduce efficient tool learning in three main categories, including Tool Selection, Tool Calling, and Tool-Integrated Reasoning. Candidate tools are first selected to let LLM judge when and what to call, then the tool call's results would be embeded into the response and the reasoning trajectories.
4.1 Tool Selection
For massive tool candidates from a very large pool, it is nearly impossible to stuff the prompt with thousands of tool descriptions. To this end, it is crucial to efficiently select the most relevant tools for user queries. We organize current tool retrieval literature into three categories: (1) External Retriever: a independent retriever model which embeds user queries and tool descriptions and calculates the affinity scores (e.g. cosine similarity) to select top- $k$ relevant tools as candidates; (2) Multi-Label Classification: for a fixed size of tool sets, the tool selection process could be formulated as a multi-label classification problem, which directly predicts relevant tools; and (3) Vocabulary-based Retrieval: tools are embedded as special tokens into the model's vocabulary, and the model would enter a tool call mode when generating such tool tokens. We introduce the above three categories of tool selection strategies in this section as below.
External Retriever.
Instead of including the entire tool set, many approaches rely on an external retriever for tool selection. External tool retrieval can be improved from retriever-side advances that redesign the retrieval pipeline or strengthen retrievers and rerankers, and from tool-side enhancements that refine tool descriptions and documentation to make the retrieval corpus easier to match, boosting both accuracy and efficiency.
On the retriever side, ProTIP [77] utilizes a contrastive learning-based method to embed user queries and tool descriptions into the semantic space. After a tool is selected, ProTIP subtracts the query embedding by the selected tool's representation and selects tools on other subtasks. Such a progressive design makes ProTIP efficient to avoid explicit task decomposition overhead. In AnyTool ([105]), retrieval is organized hierarchically and inspired by a divide-and-conquer strategy, narrowing the search space and thereby improving retrieval efficiency.
On the tool side, DRAFT ([106]) refines tool documents via self-driven interactions to improve external tool retrieval, while boosting efficiency by reducing token overhead and stopping refinement at convergence.
In addition, some recent systems combine both directions. Toolshed ([107]) stores enriched tool representations in a tool knowledge base and uses RAG-tool fusion before, during, and after retrieval to scale external tool selection, while controlling top-k to curb token growth and improve efficiency. Similarly, ToolScope ([108]) uses ToolScopeMerger with Auto-Correction to compress tool descriptions and reduce input tokens, and ToolScopeRetriever to hybrid-retrieve top-k tools that fit the LLM context window, improving tool-use quality while boosting efficiency and scalability.
Multi-Label Classification (MLC).
Instead of ranking-based retrieval, MLC-based methods treat tool selection as a classification task. TinyAgent [78] is designed to conduct tool calling on edge devices which pursue extreme efficiency, and it formulates the tool selection task as a multi-label classification problem. For a user query, TinyAgent applies the DeBERTa-v3 small model as the encoder and output the probability distribution for all available tools. Tools with a probability higher than 50% are recognized as relevant ones and will be selected accordingly. Since only a small fraction of tool descriptions are put into the prompt, it efficiently reduces nearly half of the prompt size. Similar to TinyAgent, [79] find MLC-based tool retrieval efficient, but such a task formulation could not handle the growing number of tools, and any updates would require a model re-training. Therefore, they propose Tool2Vec, a two-stage retrieval with a reranker for analyzing fine-grained tool-query interactions. To fill in the semantic gap where natural user queries may not directly align with tool descriptions, the authors generate tool embeddings based on synthetic usage examples rather than static description.
Vocabulary-based Retrieval.
Besides direct retrieving from candidates by external retriever and MLC, tool selection could also be formulated as a token prediction task, where tools are stored in the vocabulary as special tokens.
ToolkenGPT [80] regards massive external tools as learnable token embeddings (aka. "toolken"), so that the target tool could be selected as a normal next token prediction process. Compared with Toolformer [84] that selects tools by predicting a whole trajectory with special characters, this approach is highly efficient since it only trains the added tool embeddings and keeps other model parameters frozen. Furthermore, it bypasses the window constraint of in-context tool selection and retains a shorter prompt. Building on this foundation, Toolken+ [81] enhances ToolkenGPT by introducing an extra reranking step and a rejection toolken, which improves the overall performance and reduces the hallucination rate. Toolken+ also demonstrates a tradeoff between efficiency and efficacy, which could be simply tuned from the number of reranking candidates. Although "toolkens" are efficient for massive tool selection, it requires constructing data samples for supervised fine-tuning and suffers from generalization problems on unseen tools. Similarly, ToolGen ([83]) assigns each tool a unique tool token and trains the model to turn tool retrieval and calling into a unified generation task. By representing a tool with a single token, it is claimed to shorten generation and potentially reduce inference overhead but may be costly at training phase. From a different perspective on efficiency, [109] proposes selective compression and block compression for tool use: they preserve key information (e.g., tool and parameter names) as raw text while compressing the remaining documentation into fixed-length soft tokens per block. The soft tokens can be precomputed and cached offline, reducing prompt length and improving token efficiency at inference. To tackle the generalization problem, CoTools [82] shrinks the number of toolkens to only one and applies a retriever to calculate the similarities between current toolken's representation and all the candidates.
From these literature, we find vocabulary-based methods are an efficient option for tool selection. However, it may suffer from inaccurate invocation timing and poor generalization to unseen new tools, which is less functional for extensive tool updating scenarios.
- **Advantages**: External retriever, MLC, and vocab-based methods are very efficient especially for retrieval from massive candidates. External retriever could be a plug-and-play module with a good generalization ability to unseen tools.
- **Disadvantages**: The external retriever may be a large model with more computational overhead than MLC and vocab-based tool tokens, while MLC and vocab-based tool retrieval may need fine-tuning to adapt models on new tools.
- **Applicable scenarios**: According to the types of candidate tools, if the candidate pool changes a lot over time, it would be better to use external retrievers. However, if the candidate tool set is relatively fixed, MLC and vocab-based methods are good options for better efficiency.
4.2 Tool Calling
Once candidates are selected, the efficiency of the invocation process becomes critical for real-time agentic interactions.
In-Place Parameter Filling.
In-place tool calling is a paradigm where the model directly fills the tool's parameters during the response generation process. Toolformer [84] incorporates tool calling within the CoT path, and fills parameters during the response generation process. It is efficient to obtain the final results once the closure of the tool call is reached. [85] proposes CoA, which shares the similar idea but reduces the response time by providing more accurate tool call results. Instead of directly calculating the final results, CoA introduces symbolic abstractions to represent the intermediate steps, which are later substituted with the actual results during the response generation process. From the experimental results, CoA performs better while reducing more than 30% inference time than Toolformer.
Parallel Tool Calling.
For a complex tasks that incorporates multiple tools, traditional sequential style calling may hurt efficiency since LLMs have to wait for the latest tool call's response. However, there are multiple tasks that could be done in parallel [110]. For example, to get the weather information of a province, we do not have to call the get_weather API one-by-one for each city. Instead, a more practical way is to make parallel tool calls, which would significantly reduce the overall task solving time. LLMCompiler [86] introduces a compiler-inspired framework that formulates execution plans, dispatches tasks, and executes functions in parallel. This achieves improvements in latency, cost, and overall accuracy against the traditional sequential tool execution approach. Building on this parallelization paradigm, LLM-Tool Compiler [87] further optimizes efficiency by selectively fusing similar tool operations at runtime, which increases parallel tool calls while reducing token consumption and latency. Complementing with the above methods, CATP-LLM [88] addresses the execution cost by incorporating cost-awareness into the planning process. It designs a multi-branch planning language and employs cost-aware offline reinforcement learning to fine-tune models, enabling high-quality generation with economic constraints.
Cost-Aware Tool Calling.
Like we have introduced about CATP-LLM in the above paragraph, cost could be a special reward for training efficient tool calling models. Budget-Constrained Tool Learning with Planning (BTP) [89] first formulates tool calling as a knapsack problem, which utilizes dynamic programming to pre-compute how often each tool would be invoked under a hard budget, thereby turning cost control into a forward-looking plan. Building on this planning strategy, [111] estimates LLM confidence via consistency-based sampling strategy to let the model trigger a tool under a certainty-cost optimal condition. This method could reduces the number of tool calls, thereby boosting the overall improvements. From a broader system perspective, [112] reduces redundant calls by jointly updating prompt strategy and tool documentations. It complements the above cost-aware planning and confidence-based gating with context-level efficiency.
Beyond directly constraining invocation budgets, recent research also explores improving efficiency through alternative paradigms, such as function induction, code generation, and model distillation. TROVE [90] introduces a training-free paradigm that incrementally builds and trims a compact toolbox of reusable functions, showing that online induction can improves the accuracy without extra training data. ToolCoder [91] extends this idea by formulating tool learning as an end-to-end code generation task, which converts tasks in natural languages into Python code. This method boosts the success rates while keeping small API usage cost. Focusing on the deployment cost, [113] proposes to distill LLM's knowledge into small language models with retrieval and code interpreter tools, which enables small models competitive with larger ones.
Efficient Test-Time Scaling.
For effective tool calling, a viable solution is tree search-based strategies, where the model may plan a tree of tool calls and select the most promising path [114].
However, such methods are computationally expensive since they may need trail-and-error to explore the entire tree. Instead of extensive tree traversal, ToolChain* [92] utilizes the A* search strategy to efficiently navigate complex action spaces. This method boosts the efficiency by employing task-specific cost functions to prune wrong branches earlier and only requires single-step node expansions. Therefore, it allows the agent to prioritize the most promising paths and avoids exhaustive searches, leading to high success rates.
Efficient Tool Calling with Post-training.
To mitigate the high latency and computational overhead with multi-step tool interactions, recent research has increasingly focused on optimizing tool-calling efficiency through post-training. Specifically, reinforcement learning has emerged as a primary mechanism for teaching models to strategically balance task success with resource parsimony. OTC-PO [93] promotes action-level efficiency by integrating a tool-use penalty into the reinforcement learning objective, which effectively trains models to minimize redundant tool calls without sacrificing answer correctness. Building on the optimization of agentic workflows, ToolOrchestra [94] leverages efficiency-aware rewards within an RL framework to train specialized orchestrators that achieve superior task performance at a fraction of the computational cost of general-purpose large language models. Complementing these strategy-driven approaches, ToolRM [115] addresses the challenge of precise evaluation by utilizing specialized outcome-based reward models to facilitate data-efficient fine-tuning and inference-time scaling, ensuring that models learn to prioritize the most effective and concise tool-calling trajectories.
- **Advantages**: The above tool calling methods focus on different aspects and could be applied simultaneously for better efficiency. Overall, for one trajectory, in-place parameter filling, cost-aware tool calling, test-time scaling, and post training with cost rewards are effective to improve the efficiency, while parallel tool calling could split one trajectory into different branches and finish calling in parallel.
- **Disadvantages**: Although test-time scaling could improve the tool calling accuracy and reduce the length of trajectories, it is still a trade-off between efficacy and efficiency. Besides, parallel tool calling may result in iterative refinement if the parallel task planner fails to find the task dependencies.
- **Applicable scenarios**: If the agent is in a plan-act-reflection mode that plans the whole tool calling trajectory instead of iterative refinement, parallel tool calling is a suitable option to split branches in advance. Besides, cost-aware tool calling and post-training methods are good strategies to reduce the number of tool calls. Efficient test-time scaling is a good way to increase the task accomplishment accuracy, therefore reducing the tool calling trajectories. While it may generate more tokens to try more branches, it is an applicable strategy to generate accurate trajectories for distillation.
4.3 Tool-Integrated Reasoning
The emergence of agents marks a crucial shift from reliance on static internal knowledge toward adaptive, multi-turn reasoning, which is necessary for achieving both high accuracy and computational efficiency in complex problem-solving [116, 117, 118]. Traditional, rigid programmatic workflows or purely text-based methods often fail on tasks requiring numerical precision or dynamic adaptation, thereby constraining the development of truly autonomous reasoning capabilities.
Selective Invocation.
The quest for efficient agents begins with establishing a robust capability to invoke tools only when strictly necessary, thereby minimizing redundant computations. Traditional rigid workflows often lead to excessive interactions. The TableMind framework [95] addresses this by presenting an autonomous programmatic agent specifically tailored for tool-augmented table reasoning. Architecturally, TableMind utilizes an iterative plan-action-reflect loop, where the agent first decomposes a problem, then generates and executes precise code within a secure sandbox environment.
TableMind employs a two-stage training paradigm: Supervised Fine-Tuning (SFT) serves as a vital warm-up phase to establish foundational tool usage patterns and master the necessary syntax for the iterative cycle, thereby mitigating the instability associated with starting subsequent Reinforcement Learning from a cold policy. To further refine the efficiency of tool invocation, [96] first constructs a dataset called SMART with CoT detailing the necessity of each tool call, and they use the dataset to fine-tune a model that efficiently decides whether to use their parametric knowledge or external tools.
Agent-FLAN ([102]) separates format-following agent data from general reasoning data and further decomposes agent data into capability-specific subsets, which improves performance with fewer training tokens.
Cost-Aware Policy Optimization.
Beyond supervised warm-up, Reinforcement Learning (RL) is pivotal for optimizing complex multi-step policies to ensure high reasoning quality and strict adherence to formatting constraints. To prioritize high-quality trajectories, TableMind [95] employs the Rank-Aware Policy Optimization (RAPO) algorithm. RAPO identifies misaligned trajectories and applies rank-aware advantage weighting to guide the model toward consistent answers. In terms of strategic autonomy, the ARTIST framework [97] tightly couples agentic reasoning with outcome-based RL, enabling models to learn optimal tool-use strategies without restrictive step-level supervision. Similarly, ReTool [99] integrates a code interpreter directly into the reasoning loop, allowing the model to dynamically interleave natural language with executable code and discover strategies via verifiable reward signals. To further ensure the validity of these actions, ToolRL ([100]) designs a reward function that combines a format reward with a correctness reward, matching tool parameters against ground truth to improve success rates per call.
Concurrently, another research aspect focuses on making agents faster and more cost-effective by minimizing unnecessary tool invocations and reducing trajectories. Methods like A$^2$ FM ([119]) and IKEA ([120]) aim to balance internal knowledge with external retrieval. A$^2$ FM utilizes Adaptive Policy Optimization (APO) with a self-adaptive router to decide whether to answer instantly or invoke tools, while IKEA trains an adaptive search agent to rely on internal knowledge first and call search APIs only when necessary. To explicitly penalize redundancy, [98] introduce AutoTIR, which discourages unnecessary tool usage through specific reward penalties. Similarly, [93] leverage the OTC-PO algorithm to encourage trajectories with correct answers and fewer tool calls. Other approaches optimize the trajectory generation process itself. SWiRL ([121]) filters redundant actions during parallel trajectory generation, and PORTool ([101]) employs a decay factor $\gamma$ to emphasize steps closer to the final outcome, favoring solutions that solve problems in fewer tool-call steps.
- **Advantages**: Tool-integrated reasoning strategies incorporate tool calls into the long reasoning path, which boosts the task accuracy. By invoking tools at suitable timings, TIR is very data-efficient to reduce the overall training samples.
- **Disadvantages**: Specific tools need special environments, which increases the system design. For example, coding agents needs sandbox environments to verify the generated code, which brings significant development complexity.
- **Applicable scenarios**: For a complex task that should invoke external resources (e.g. browsers, search APIs, and code interpreters), TIR is a good choice to interact with a real environment to accomplish tasks with multi-hop reasoning. For simple tasks that mainly depend on model's internal knowledge, TIR may be less efficient and brings additional tool calling costs.
4.4 Discussion
The evolution of efficient tooling reflects a fundamental shift from merely "enabling" tool use to "optimizing" the interaction loop. While efficient selection and calling techniques (e.g., retrieval and parallelism) address the structural bottlenecks of large toolsets and sequential latency, Tool-Integrated Reasoning targets the strategic overhead of the agent’s decision-making process. The frontier of this field is moving toward a Pareto optimization of performance and cost: rather than maximizing tool usage for accuracy, modern agents are increasingly trained via RL to minimize redundant interactions. This transition suggests that future efficiency gains will likely stem from a tighter coupling between the model’s internal reasoning and the external tool environment, where "acting" is no longer a separate step but an integrated, cost-aware component of the model’s cognitive architecture.
5. Efficient Planning
- **Core Philosophy**: Frames deliberation as a resource-constrained control problem rather than unbounded reasoning.
- **Mechanism**: Optimizes the *depth* of single-agent reasoning (via search and learning) and the *breadth* of multi-agent collaboration (via topology and protocol).
- **Objectives**: Maximizes task success constraints on latency, token consumption, and communication overhead.
This perspective represents a distinct shift from classical planning, which assumes abundant computational resources, and contemporary approaches that conflate planning with direct text generation. Instead, efficient planning conceptualizes reasoning as operational control, where an agent must continuously balance the marginal utility of a refined plan against its computational cost. Within a broader architecture, the planner acts as the central engine for online compute allocation, synergizing with memory components to amortize costs and tools to externalize execution. In this section, we survey the landscape of efficient planning through two primary paradigms: Single-Agent Planning, which optimizes individual deliberation trajectories, and Multi-Agent Collaborative Planning, which minimizes the coordination overhead in distributed systems.
\begin{tabular}{l|l|l|l}
\toprule
\textbf{Method} & \textbf{Category} & \textbf{Core Mechanism} & \textbf{Resource Link} \\
\midrule
\multicolumn{4}{c}{\textbf{\textit{Single-Agent: Inference-Time Strategy (Search \& Control)}}}\\
\midrule
SwiftSage [122] & Adaptive Control & Fast/Slow Dual-process (System 1 + 2) & \faIcon{github}\, [GitHub](https://github.com/SwiftSage/SwiftSage)\\
Budget-Aware [123] & Adaptive Control & Budget-constrained tool policy allocation & N/A \\
Reflexion [124] & Adaptive Control & Verbal reinforcement from prior failures & \faIcon{github}\, [GitHub](https://github.com/noahshinn/reflexion) \\
LATS [125] & Tree Search & MCTS with self-reflection & \faIcon{github}\, [GitHub](https://github.com/lapisrocks/LanguageAgentTreeSearch) \\
ToolChain* [92] & Tree Search & A* search with learned cost pruning & N/A \\
CATS [126] & Tree Search & Cost-aware pruning in tree search & N/A \\
ReWOO [127] & Decomposition & Planner-Worker-Solver separation & \faIcon{github}\, [GitHub](https://github.com/billxbf/ReWOO) \\
HuggingGPT [128] & Decomposition & Routing tasks to specialized models & \faIcon{github}\, [GitHub](https://github.com/microsoft/JARVIS) \\
Alita [129] & Decomposition & MCP brainstorming \& subtasking & \faIcon{github}\, [GitHub](https://github.com/CharlesQ9/Alita) \\
\midrule
\multicolumn{4}{c}{\textbf{\textit{Single-Agent: Learning-based Evolution (Policy \& Memory)}}}\\
\midrule
QLASS [130] & Policy Optimization & Q-Value critic for search guidance & N/A \\
ETO [131] & Policy Optimization & Trial-and-error preference learning (DPO) & \faIcon{github}\, [GitHub](https://github.com/Rafa-zy/QLASS) \\
VOYAGER [132] & Memory \& Skill & Iterative skill library construction & \faIcon{github}\, [GitHub](https://github.com/MineDojo/Voyager) \\
GAP [133] & Memory \& Skill & Graph-based decomposition \& parallelism & \faIcon{github}\, [GitHub](https://github.com/WJQ7777/Graph-Agent-Planning) \\
RLTR [134] & Policy Optimization & Process-level reward training & N/A \\
Planning w/o Search [135] & Policy Optimization & Offline goal-conditioned critic & \faIcon{globe}\, [Website](https://jxihong.github.io/pnlc_website/) \\
\midrule
\multicolumn{4}{c}{\textbf{\textit{Multi-Agent: Collaborative Efficiency}}}\\
\midrule
Chain-of-Agents [136] & Topology & Sequential context passing (Linear complexity) & \faIcon{github}\, [GitHub](https://github.com/AdamCodd/Chain-of-agents) \\
MacNet [137] & Topology & DAG-based topological ordering & \faIcon{github}\, [GitHub](https://github.com/OpenBMB/ChatDev/tree/macnet) \\
AgentPrune [138] & Topology & Learned pruning of communication edges & \faIcon{github}\, [GitHub](https://github.com/yanweiyue/AgentPrune) \\
MARS [139] & Topology & Reviewer-Meta-Reviewer pipeline (No debate) & \faIcon{github}\, [GitHub](https://github.com/xwang97/MARS) \\
CodeAgents [140] & Protocol & Structured pseudocode interaction & \faIcon{github}\, [GitHub](https://anonymous.4open.science/r/CodifyingAgent-5A86) \\
Free-MAD [141] & Protocol & Prompt-optimized critical reasoning & N/A \\
MAGDI [142] & Distillation & Distilling interaction graphs into student & \faIcon{github}\, [GitHub](https://github.com/dinobby/MAGDi) \\
D\&R [143] & Distillation & Distilling debate traces via DPO & N/A \\
\bottomrule
\end{tabular}
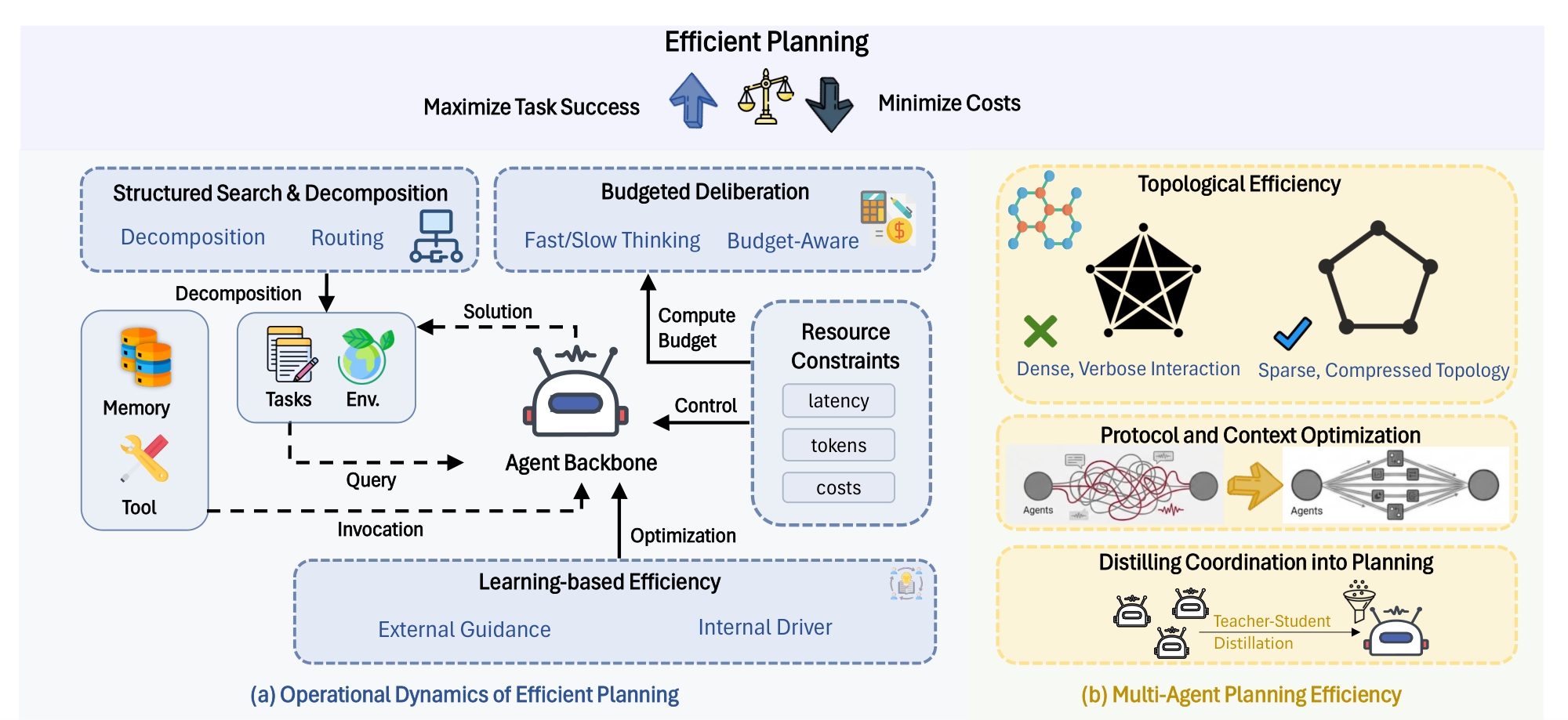
5.1 Single-Agent Planning Efficiency
Single-agent efficiency focuses on minimizing the computational cost, measured in tokens, latency, or search steps, required to reach a valid solution. We categorize these methods into inference-time strategies, which optimize the planning process on-the-fly, and learning-based evolution, which improves the agent's intrinsic planning capabilities.
Inference Strategy I: Adaptive Budgeting and Control.
A key strategy is selective deliberation, allocating computational effort non-uniformly. Architectures like SwiftSage [122] separate fast behaviors from slower planning, defaulting to heuristics unless structured reasoning is required. This can be framed as learning when to invoke a costly planner versus a reactive policy [144], or dynamically adjusting tool strategies based on budget constraints [123]. Efficiency is also gained by preventing redundant failures; methods like Reflexion [124] and ReST [145] use verbal reinforcement or iterative refinement to amortize failure analysis, lowering cumulative interaction costs.
Inference Strategy II: Structured Search.
The combinatorial explosion of action spaces presents a significant bottleneck. To address this, methods adapt formal search algorithms to prune feasible trajectories. Language Agent Tree Search (LATS) [125] reframes agent rollouts as Monte Carlo Tree Search, enabling self-reflection to guide exploration. Building on this, CATS [126] integrates cost-awareness directly into the search tree, pruning expensive branches early. In tool-rich environments, ToolChain* [92] applies A* search to navigate the action space, while retrieval-based approaches like ProTIP [77] reduce decision complexity by only surfacing relevant tools during the planning phase.
Inference Strategy III: Task Decomposition.
Explicitly breaking down complex tasks reduces context overhead. ReWOO [127] and Alita [129] decouple planning from execution, generating blueprints to avoid step-by-step token redundancy. This decomposition facilitates routing: HuggingGPT [128] and ReSo [146] dispatch sub-tasks to specialized models, while BudgetMLAgent [147] optimizes agent routing for cost. In embodied settings, AutoGPT+P [148] grounds this planning in environmental affordances to ensure feasibility.
Learning-Based Evolution: Policy Optimization.
Agents can learn to internalize planning logic. This is driven by external critics, such as QLASS [130] or offline value functions [135], that guide the planner toward high-value actions. Alternatively, learning acts as an internal driver: ETO [131] refines policies via trial-and-error preference learning (DPO). To improve sample efficiency, methods like RLTR [134] and Planner-R1 [149] utilize process-level rewards, providing feedback on the reasoning sequence rather than just the final outcome.
Learning-Based Evolution: Memory and Skill Acquisition.
Efficiency can be amortized by externalizing successful plans. VOYAGER [132] builds a library of reusable skills to avoid re-planning. Graph-based representations also support this: GraphReader [48] and other graph-enhanced models [150] leverage structured memory for long-context retrieval, while GAP [133] identifies parallelizable actions. Ultimately, frameworks like Sibyl [151] demonstrate that efficiency is an emergent property, where improved memory structure directly reduces the cognitive load of future planning.
- **Advantages**: Adaptive control lowers inference cost, structured search improves exploration efficiency, task decomposition reduces step-by-step redundancy and context overhead, and learning-based evolution amortizes planning cost over time.
- **Disadvantages**: Adaptive control can misfire, structured search introduces overhead, task decomposition risks error propagation, and learning and memory add training and maintenance cost.
5.2 Multi-Agent Collaborative Efficiency
Multi-agent systems (MAS) offer enhanced reasoning but often incur quadratic communication costs. Efficient MAS planning therefore focuses on optimizing the topology of interaction and the content of protocols.
Topological Efficiency and Sparsification.
Topological efficiency optimizes the communication graph, mitigating quadratic message costs and reducing message complexity from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$ through structured topologies (e.g., chains, DAGs).
Structured topologies like Chain-of-Agents [136] and MacNet [137] restrict context growth to near-linear complexity, while GroupDebate [152] alternates between dense debate and sparse summaries. Selective interaction protocols further filter turns; MARS [139] and S²-MAD [153] eliminate direct peer-to-peer noise by only triggering debates when viewpoints diverge. More advanced methods, such as AgentPrune [138], AgentDropout [154], and SafeSieve [155], dynamically learn to prune low-utility edges or progressively sparsify the graph during inference.
Protocol and Context Optimization.
Protocol optimization improves efficiency by compressing what is communicated, using concise representations such as pseudocode and prompt-driven constraints to reduce interaction context.
CodeAgents [140] encodes reasoning in concise pseudocode, while Smurfs [156] discards failed search branches to prevent context bloat. In parallel, prompt-level control accelerates convergence; Free-MAD [141] and ConsensAgent [157] engineer prompts to encourage critical reasoning, while supervisors like SMAS [158] terminate redundant loops early.
Distilling Coordination into Planning.
The most radical approach internalizes coordination by distilling collective intelligence into a single-agent model, bypassing runtime coordination costs.
Methods like MAGDI [142] and SMAGDi [159] distill complex interaction graphs or "Socratic" decomposition into a single student model. Similarly, D&R [143] uses a teacher-student debate to generate preference trees for DPO. These approaches retain the quality benefits of diverse perspectives while reverting to the lower inference cost of a single agent.
- **Advantages**: Topology sparsification reduces communication cost, protocol compression prevents context bloat, and coordination distillation keeps quality while lowering inference cost.
- **Disadvantages**: Pruning may drop useful signals, compression may lose key details, and distillation adds training cost and can weaken diversity at inference time.
5.3 Discussion
Efficient agent planning reframes reasoning from an unbounded generation process into a budget-aware control problem. In the single-agent regime, we observe a clear taxonomy of inference-time strategies, ranging from adaptive budgeting to structured search, and learning-based evolution that amortizes cost via policy refinement and skill memory. In the multi-agent regime, the focus shifts to topological pruning and the distillation of collective intelligence. Across both, the unifying trend is the migration of computation from online search to offline learning or structured retrieval, enabling agents to achieve complex goals within strict resource constraints.
6. Benchmarks
Although this survey focuses on efficiency, we adopt an effectiveness-first view: a method that is cheap but fails to solve tasks or substantially harms solution quality is not meaningfully efficient. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, or comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. We provide a high-level overview of benchmarks for memory, tool learning, and planning.
6.1 Memory
Effectiveness Benchmarks.
Agent memory effectiveness is commonly evaluated either indirectly via downstream end-to-end task success or directly via memory-targeted tasks ([160]). For indirect end-to-end evaluation, agent-memory research typically measures downstream task outcomes, using both QA datasets like HotpotQA ([161]) and Natural Questions ([162]) and interactive agent benchmarks where success requires multi-step interaction and tool use, such as GAIA ([163]). In addition, a growing body of work has proposed benchmarks that directly evaluate agent memory abilities, such as LoCoMo ([164]) and LongMemEval ([165]).
Efficiency Benchmarks.
Beyond effectiveness, Some memory benchmarks additionally report efficiency-related signals. Evo-Memory ([166]) introduces step efficiency, measuring how many environment steps are required to reach a goal; fewer steps indicate that the memory mechanism supports more concise and scalable reasoning. StoryBench ([167]) reports two auxiliary efficiency metrics: Runtime Cost, capturing the total time required to run the memory-augmented agent on long-horizon tasks, and Token Consumption, which serves as a proxy for how much contextual information the model processes. MemBench ([168]) explicitly incorporates temporal efficiency into its evaluation, reporting read time and write time (seconds per memory operation) to approximate the overhead introduced by different memory designs and to highlight configurations whose processing time may be prohibitive in practical deployments.
Efficiency Metrics in Memory Methods.
At the methods level, we summarize efficiency metrics reported by existing memory mechanisms, grouped into four categories. Existing work adopts various metrics to quantify the efficiency of memory mechanisms in LLM-based agents. Overall, these metrics can be summarized into four categories.
Token consumption and API cost are among the most frequently used signals. Many studies report efficiency in terms of token consumption ([32, 48, 57, 35, 37, 45, 54, 21]). Beyond raw token counts, some approaches further translate token usage into monetary cost (USD), such as Agentic Plan Caching ([38]) and ACE ([46]).
Time-based metrics focus on latency and runtime overhead. HiAgent ([57]) reports overall runtime, while SeCom ([35]), Mem0 ([37]), and MemOS ([55]) measure end-to-end latency that combines search time and LLM reasoning but explicitly excludes construction time. MEM1 ([21]) reports inference time. Other work targets finer-grained retrieval overhead, e.g., A-MEM ([45]), H-MEM ([58]), and Agent KB ([47]) measure retrieval time or search latency. MemoRAG ([25]) further distinguishes index latency from retrieval latency, which denotes the time taken to fetch evidence for a query.
Resource-based metrics quantify hardware consumption. For example, A-MEM ([45]) and MemoRAG ([25]) report GPU memory usage, and MemoRAG additionally analyzes GPU memory consumption under different context lengths.
Finally, interaction-based metrics capture how intensively the agent interacts with the LLM or a reasoning process. MemoryOS ([54]) reports the average number of LLM calls per response, while benchmarks such as ReasoningBank ([44]) track the number of reasoning steps as an interaction-level efficiency indicator.
6.2 Tool Learning
Tool learning still lacks unified efficiency benchmarks, and most evaluations prioritize effectiveness. Yet it is crucial for LLM agents because tool use often dominates interaction cost and drives end-to-end success. We summarize three benchmark families: selection and parameter infilling, tool learning under model context protocols, and agentic tool learning. These testbeds also support efficiency measurement using tokens, latency, and tool-call turns.
Benchmarks for Selection & Parameter Infilling.
Tool construction is an important dimension to assess, since the availability and quality of tools can fundamentally shape downstream tool-use behavior. Seal-Tools [169] applies LLMs to efficiently generate large scale tools and use cases. While it includes multi-tool instances (with some nested tool callings), more complex compositions can still be under-represented compared to benchmarks that center multi-tool orchestration. UltraTool [170] starts from user queries in real scenarios and evaluate models on tool creation tasks.
Once tools are available, an agent must learn whether to use tools and which tools to select. MetaTool [171] specifically focuses on the decision-making process of whether to employ a tool and which tool to select from a candidate set. The study assess models across diverse scenarios, including reliability issues and multi-tool requirements.
After selecting tools, parameter infilling and schema adherence become the next challenge for reliable execution. Berkeley Function-Calling Leaderboard (BFCL) [172] is a series of benchmarks for tool learning evaluation, which includes tools for real applications with multi-turn and multi-step dialogues. API-Bank [173] provides a manually annotated benchmark with 73 tools, which is more natural for common dialogues.
Beyond single-tool usage, many realistic tasks require multi-tool composition, including sequential and nested tool calls, making long-horizon coordination an essential capability to evaluate. NesTools [174] categorizes multi-tool calling problem and provides comprehensive taxonomy for nested tool learning. $\tau$-Bench ([175]) is a simple tool learning benchmark for retail and airline domains, and $\tau^2$-Bench ([176]) further extends it with the telecom domain, which incorporates tool calls from the users. ToolBench [177] is a large scale dataset which collects more than 16, 000 APIs from RapidAPI^1 . However, the online API service is not always stable and there are reproducibility issues in ToolBench. To address this gap between training instructions and real-user queries, [114] proposes MGToolBench, where they manually curated the ToolBench dataset with multiple granularities.
However, end-to-end success metrics alone often make it difficult to localize where and why failures occur within the tool-use process. T-Eval ([178]) introduces a fine-grained benchmark for evaluating tool utilization by decomposing the process into six constituent capabilities, including planning, reasoning, and retrieval, to enable step-by-step assessment rather than relying solely on holistic outcome metrics.
Finally, from a system-level perspective, some methods focus on the reproducibility and efficiency of evaluation, which is particularly important when benchmarks depend on real-world online APIs. [179] introduce StableToolBench, a benchmark that ensures consistent assessment through a virtual API server employing caching and LLM-based simulation alongside a robust GPT-4 evaluation framework.
Tool Learning with Model Context Protocol.
As tool learning becomes a common practice for LLM agent development, Anthropic proposes Model Context Protocol (MCP) ^2 to provide a standard for tool definitions and calling. Based on this protocol, several benchmarks are proposed. MCP-RADAR ([180]) explicitly evaluates efficiency via metrics such as tool selection efficiency, computational resource efficiency, and execution speed, alongside accuracy-related dimensions. MCP-Bench ([181]) evaluates agent efficiency with an LLM-as-a-Judge rubric, where the parallelism and efficiency criterion scores whether the agent minimizes redundant tool calls and exploits opportunities for parallel execution.
Agentic Tool Learning.
With the growing capabilities of tool learning, modern LLMs gradually saturate on general tool learning benchmarks, and the community requires new evaluation criteria. To this end, instead of tool selection and parameter infilling, modern agentic tool learning tasks mainly focus on how to answer a very complex or unpopular question with iteratively calling search APIs. SimpleQA [182] is designed to evaluate the ability of LLMs to provide factually correct short answers. The benchmark is challenging for frontier models with high correctness and covers a diverse range of topics. BrowseComp [183] largely follows SimpleQA to let human trainers create challenging questions with short and verifiable answers. Since these questions are hard to answer by models' internal knowledge, they would heavily rely on the browsing ability, which correlated to the search tool. SealQA [184] is another benchmark that evaluates search-augmented LLMs on fact-seeking questions where web search results are likely to be conflicting, noisy, and unhelpful. The most challenging 111 questions are composed to be a subset of SEAL-0, where even frontier models consistently achieve near-zero accuracy.
6.3 Planning
Effectiveness Benchmarks.
Based on tool learning benchmarks, many benchmarks further consider planning into consideration. Planning effectiveness is often assessed indirectly via downstream task success in agent benchmarks, such as SWE-Bench ([185]), WebArena ([186]), and WebShop ([187]). While prior work like PlanBench ([188]) has introduced evaluations of planning efficiency, most existing planning benchmarks focus on pure LLM settings, which limits their direct applicability to LLM-based agents. In agentic systems, efficiency depends not only on LLM-side compute (e.g., token usage), but also on closed-loop interaction costs (e.g., environment steps and tool calls). Therefore, alongside the rapid progress in agent effectiveness, planning efficiency has become an equally important evaluation dimension; in what follows, we summarize the benchmarks and metrics used to quantify it.
Efficiency Benchmarks.
Several recent works have begun to emerge in this direction. Based on Blocksworld domain ([189]), [190] proposes a structured benchmark to evaluate an agent’s planning and execution. From an efficiency perspective, it reports end-to-end execution time, the number of planning attempts, token consumption, and the corresponding monetary cost. TPS-Bench ([191]) evaluates not only effectiveness but also planning and tooling efficiency using token usage, end-to-end time, and tool-call turns. It further proposes cost-of-pass, the expected monetary cost per successful completion, linking token-based cost with completion rate for cost-effectiveness comparison across models. CostBench ([192]) benchmarks cost-optimal tool-use planning under dynamic changes. It models tools with explicit costs and evaluates efficiency via Cost Gap and path deviation from the ground-truth trajectory, while also accounting for invalid tool calls as tooling inefficiency.
Efficiency Metrics in Planning Methods.
Apart from benchmarks, many agent planning methods also evaluate the efficiency of their approaches. Consistent with the metrics discussed earlier, they also consider token consumption ([122, 125, 127, 146]) and runtime ([92]).
From the perspective of search depth and breadth, SwiftSage ([122]) considers time steps, Reflexion ([124]) counts the number of trials, LATS computes the lowest average number of nodes/states required for success, and CATS ([126]) reports the average number of iterations needed to find a valid solution. This aspect is strongly related to planning efficiency.
In addition, cost-of-pass style metrics ([193]) have also been adopted, as seen in TPS-Bench ([191]) and subsequent work ([194, 133]). Beyond directly using cost-of-pass, many methods further operationalize it in evaluation. A common practice is to keep the budget the same and compare performance, such as ([123, 130, 131]).
7. Challenges and Future Directions
Towards a unified efficiency evaluation framework for agent memory.
Although these methods and benchmarks all attempt to quantify memory efficiency, they do so using different subsets of the above dimensions and heterogeneous terminology. Some works only report token consumption or API cost, while others focus on runtime, latency, inference time, retrieval time, or step efficiency, often without clearly specifying which stages of the pipeline are included. Even token-based metrics may be defined per query, per memory operation, per episode, or for constructing the memory store. As a result, existing efficiency numbers are not directly comparable across papers, which makes it difficult to systematically analyze the cost–performance trade-offs of different memory designs.
Agentic Latent Reasoning.
Recent months have seen growing interest in latent-space reasoning for LLM([195, 196, 197]) , where intermediate computations are carried out in continuous hidden representations rather than being fully externalized as natural-language tokens. Compared with token-level “decode-and-read” reasoning, latent reasoning can reduce token overhead and may preserve richer, high-dimensional information during multi-step computation. However, existing work has largely focused on standalone LLM settings, while agentic latent reasoning remains relatively underexplored. This gap is important because agentic scenarios introduce additional requirements, such as tool use, long-horizon planning, memory management, and action verification, that differ from pure text-only reasoning and may demand new training objectives, interfaces, and evaluation protocols. Investigating latent reasoning mechanisms tailored for agents could therefore be a promising future direction.
Deployment-Aware Agentic Design.
Inspired by MemAgent ([20]) and Chain-of-Agents ([136]), which address long-context reasoning by chunking context and processing it sequentially, we argue that agentic systems should be more deployment-aware. In practice, multi-agent designs can be realized either as true multi-model deployments or as single-model role-play pipelines, and these implementations differ substantially in orchestration overhead, latency, and reliability. Future work should compare these alternatives under matched resource budgets and report end-to-end cost–benefit metrics, clarifying whether the performance gains from adding more agents justify the additional complexity.
Efficiency Challenges and Directions for MLLM-based Agents.
There has been a rapid emergence of MLLM-based agent methods, including agents equipped with multimodal memory ([198, 199, 200]), approaches that explicitly enhance planning and decision-making for MLLM-based agents ([201]), and multi-agent systems built upon LLM and MLLM backbones ([67, 64]), among others. However, efficiency in MLLM-based agents is relatively under-explored, which is also emphasized in ([202]). In realistic deployments, efficiency is crucial due to the need for rapid responses under strict latency and compute budgets. In this regard, we observe that several efficiency techniques in LLM-based agents may inspire MLLM-based agents. For example, SwiftSage ([122]) adopts fast–slow mode switching to allocate computation adaptively, and FAST-GRPO ([203]) explores a similar fast–slow thinking mechanism for MLLM agents. Nevertheless, transferring text-centric efficiency strategies to multimodal agents remains challenging. Compared with language-only settings, MLLM-based agents often operate in different action spaces and task structures, such as GUI-based or embodied interactions, while multimodal perception and grounding can introduce additional latency and compound errors over long-horizon interactions [204]. Notably, long-horizon multimodal tasks require maintaining a visual history. The cumulative computational burden of re-encoding visual context for every step creates a trade-off between memory retention and inference speed that is far more severe than in LLM-based agents. As a future direction, we advocate efficiency-aware agent design and evaluation for MLLM-based agents by jointly considering performance and cost, including latency, interaction steps, and tool-call overhead.
8. Conclusion
In conclusion, this survey summarizes the evolution from LLMs to LLM-based agents, highlighting the shift toward increasingly complex settings that motivates our discussion. We review three core components, memory, tool learning, and planning, with an emphasis on efficiency, and find that many seemingly different methods converge on shared high-level ideas. We also summarize efficiency-oriented benchmarks and commonly used metrics across both benchmark and methodological studies. Finally, we outline key challenges and future directions. Overall, our survey consolidates the design space and evaluation practices for agent efficiency, while underscoring the need for more standardized and transparent reporting to enable fair comparison and reproducibility. We hope this survey offers useful guidance for designing and evaluating efficient agents, and helps encourage further progress in this direction.
References
[1] LeCun, Yann and Bengio, Yoshua (1998). Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks.
[2] Gers et al. (2000). Learning to forget: Continual prediction with LSTM. Neural computation. 12(10). pp. 2451–2471.
[3] Schuster, Mike and Paliwal, Kuldip K (1997). Bidirectional recurrent neural networks. IEEE transactions on Signal Processing. 45(11). pp. 2673–2681.
[4] Hurst et al. (2024). Gpt-4o system card. arXiv preprint arXiv:2410.21276.
[5] Yao et al. (2022). React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations.
[6] Hong et al. (2023). MetaGPT: Meta programming for a multi-agent collaborative framework. In The Twelfth International Conference on Learning Representations.
[7] Zhang et al. (2024). CodeAgent: Enhancing Code Generation with Tool-Integrated Agent Systems for Real-World Repo-level Coding Challenges. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13643–13658. doi:10.18653/v1/2024.acl-long.737. https://aclanthology.org/2024.acl-long.737/.
[8] Yang et al. (2024). Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems. 37. pp. 50528–50652.
[9] Yamada et al. (2025). The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066.
[10] Lu et al. (2024). The ai scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292.
[11] Gottweis et al. (2025). Towards an AI co-scientist: A multi-agent system for scientific discovery. arXiv preprint arXiv:2502.18864. pp. 3.
[12] Hong et al. (2024). Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14281–14290.
[13] He et al. (2024). WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 6864–6890. doi:10.18653/v1/2024.acl-long.371. https://aclanthology.org/2024.acl-long.371/.
[14] Novikov et al. (2025). AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131.
[15] Xu et al. (2024). A survey of resource-efficient llm and multimodal foundation models. arXiv preprint arXiv:2401.08092.
[16] Zhou et al. (2024). A survey on efficient inference for large language models. arXiv preprint arXiv:2404.14294.
[17] Wan et al. (2023). Efficient large language models: A survey. arXiv preprint arXiv:2312.03863.
[18] Wang et al. (2024). A survey on large language model based autonomous agents. Frontiers of Computer Science. 18(6). pp. 186345.
[19] Chen et al. (2025). Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations. In Proceedings of the 31st International Conference on Computational Linguistics. pp. 755–773. https://aclanthology.org/2025.coling-main.51/.
[20] Yu et al. (2025). MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent. arXiv preprint arXiv:2507.02259.
[21] Zijian Zhou et al. (2025). MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents. https://arxiv.org/abs/2506.15841.
[22] Ye et al. (2025). AgentFold: Long-Horizon Web Agents with Proactive Context Management. arXiv preprint arXiv:2510.24699.
[23] Suzgun et al. (2025). Dynamic cheatsheet: Test-time learning with adaptive memory. arXiv preprint arXiv:2504.07952.
[24] Zhang et al. (2024). Long context compression with activation beacon. arXiv preprint arXiv:2401.03462.
[25] Hongjin Qian et al. (2025). MemoRAG: Boosting Long Context Processing with Global Memory-Enhanced Retrieval Augmentation. In Proceedings of the ACM Web Conference 2025 (TheWebConf 2025). https://arxiv.org/abs/2409.05591.
[26] Wang et al. (2024). MEMORYLLM: towards self-updatable large language models. In Proceedings of the 41st International Conference on Machine Learning. pp. 50453–50466.
[27] Yu Wang et al. (2025). M+: Extending MemoryLLM with Scalable Long-Term Memory. In Forty-second International Conference on Machine Learning.
[28] Yang et al. (2024). Memory3: Language modeling with explicit memory. arXiv preprint arXiv:2407.01178.
[29] Behrouz et al. (2024). Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663.
[30] Zhang et al. (2025). MemGen: Weaving Generative Latent Memory for Self-Evolving Agents. arXiv preprint arXiv:2509.24704.
[31] Zhong et al. (2024). Memorybank: Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence. pp. 19724–19731.
[32] Xu et al. (2023). Recomp: Improving retrieval-augmented lms with compression and selective augmentation. arXiv preprint arXiv:2310.04408.
[33] Zhao et al. (2024). Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence. pp. 19632–19642.
[34] Hou et al. (2024). " my agent understands me better": Integrating dynamic human-like memory recall and consolidation in llm-based agents. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems. pp. 1–7.
[35] Pan et al. (2025). Secom: On memory construction and retrieval for personalized conversational agents. In The Thirteenth International Conference on Learning Representations.
[36] Yan et al. (2025). Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning. arXiv preprint arXiv:2508.19828.
[37] Chhikara et al. (2025). Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413.
[38] Qizheng Zhang et al. (2025). Cost-Efficient Serving of LLM Agents via Test-Time Plan Caching. https://arxiv.org/abs/2506.14852.
[39] Li et al. (2025). Hello again! llm-powered personalized agent for long-term dialogue. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 5259–5276.
[40] Lu et al. (2023). Memochat: Tuning llms to use memos for consistent long-range open-domain conversation. arXiv preprint arXiv:2308.08239.
[41] Tan et al. (2025). In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 8416–8439.
[42] Zhou et al. (2025). Memento: Fine-tuning llm agents without fine-tuning llms. arXiv preprint arXiv:2508.16153.
[43] Salama et al. (2025). MemInsight: Autonomous Memory Augmentation for LLM Agents. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 33136–33152. doi:10.18653/v1/2025.emnlp-main.1683. https://aclanthology.org/2025.emnlp-main.1683/.
[44] Ouyang et al. (2025). Reasoningbank: Scaling agent self-evolving with reasoning memory. arXiv preprint arXiv:2509.25140.
[45] Xu et al. (2025). A-mem: Agentic memory for llm agents. In Advances in Neural Information Processing Systems.
[46] Zhang et al. (2025). Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618.
[47] Tang et al. (2025). Agent kb: Leveraging cross-domain experience for agentic problem solving. arXiv preprint arXiv:2507.06229.
[48] Li et al. (2024). GraphReader: Building Graph-based Agent to Enhance Long-Context Abilities of Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 12758–12786. doi:10.18653/v1/2024.findings-emnlp.746. https://aclanthology.org/2024.findings-emnlp.746/.
[49] Jiang et al. (2025). KG-Agent: An Efficient Autonomous Agent Framework for Complex Reasoning over Knowledge Graph. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9505–9523. doi:10.18653/v1/2025.acl-long.468. https://aclanthology.org/2025.acl-long.468/.
[50] Rasmussen et al. (2025). Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956.
[51] Anokhin et al. (2024). Arigraph: Learning knowledge graph world models with episodic memory for llm agents. arXiv preprint arXiv:2407.04363.
[52] Lei et al. (2025). D-SMART: Enhancing LLM Dialogue Consistency via Dynamic Structured Memory And Reasoning Tree. arXiv preprint arXiv:2510.13363.
[53] Packer et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv preprint arXiv:2310.08560.
[54] Kang et al. (2025). Memory OS of AI Agent. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 25961–25970. doi:10.18653/v1/2025.emnlp-main.1318. https://aclanthology.org/2025.emnlp-main.1318/.
[55] Li et al. (2025). Memos: A memory os for ai system. arXiv preprint arXiv:2507.03724.
[56] Lee et al. (2024). A human-inspired reading agent with gist memory of very long contexts. In Proceedings of the 41st International Conference on Machine Learning. pp. 26396–26415.
[57] Hu et al. (2025). Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 32779–32798.
[58] Sun, Haoran and Zeng, Shaoning (2025). Hierarchical memory for high-efficiency long-term reasoning in llm agents. arXiv preprint arXiv:2507.22925.
[59] Fang et al. (2025). Lightmem: Lightweight and efficient memory-augmented generation. arXiv preprint arXiv:2510.18866.
[60] Gao, Hang and Zhang, Yongfeng (2024). Memory sharing for large language model based agents. arXiv preprint arXiv:2404.09982.
[61] Guibin Zhang et al. (2025). G-Memory: Tracing Hierarchical Memory for Multi-Agent Systems. In The Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=mmIAp3cVS0.
[62] Liu et al. (2025). RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory. arXiv preprint arXiv:2508.04903.
[63] Saleh et al. (2025). MemIndex: Agentic Event-based Distributed Memory Management for Multi-agent Systems. ACM Transactions on Autonomous and Adaptive Systems.
[64] Wang, Yu and Chen, Xi (2025). Mirix: Multi-agent memory system for llm-based agents. arXiv preprint arXiv:2507.07957.
[65] Yuen et al. (2025). Intrinsic Memory Agents: Heterogeneous Multi-Agent LLM Systems through Structured Contextual Memory. arXiv preprint arXiv:2508.08997.
[66] Yang et al. (2025). Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems. arXiv preprint arXiv:2504.00587.
[67] Yang et al. (2025). Llm-powered decentralized generative agents with adaptive hierarchical knowledge graph for cooperative planning. arXiv preprint arXiv:2502.05453.
[68] Sagirova et al. (2025). SRMT: shared memory for multi-agent lifelong pathfinding. arXiv preprint arXiv:2501.13200.
[69] Rezazadeh et al. (2025). Collaborative Memory: Multi-User Memory Sharing in LLM Agents with Dynamic Access Control. arXiv preprint arXiv:2505.18279.
[70] Han et al. (2025). LEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation. arXiv preprint arXiv:2510.04851.
[71] Liu et al. (2024). Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics. 12. pp. 157–173.
[72] Zhang et al. (2025). A survey of reinforcement learning for large reasoning models. arXiv preprint arXiv:2509.08827.
[73] Park et al. (2023). Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology. pp. 1–22.
[74] Li et al. (2023). Camel: Communicative agents for" mind" exploration of large language model society. Advances in Neural Information Processing Systems. 36. pp. 51991–52008.
[75] Zou et al. (2025). Latent Collaboration in Multi-Agent Systems. arXiv preprint arXiv:2511.20639.
[76] Ye et al. (2025). Kvcomm: Online cross-context kv-cache communication for efficient llm-based multi-agent systems. arXiv preprint arXiv:2510.12872.
[77] Raviteja Anantha et al. (2023). ProTIP: Progressive Tool Retrieval Improves Planning. https://arxiv.org/abs/2312.10332.
[78] Erdogan et al. (2024). Tinyagent: Function calling at the edge. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. pp. 80–88.
[79] Moon et al. (2024). Efficient and scalable estimation of tool representations in vector space. arXiv preprint arXiv:2409.02141.
[80] Hao et al. (2023). ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings. In Advances in Neural Information Processing Systems. pp. 45870–45894.
[81] Yakovlev et al. (2024). Toolken+: Improving LLM Tool Usage with Reranking and a Reject Option. In Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 5967–5974. doi:10.18653/v1/2024.findings-emnlp.345. https://aclanthology.org/2024.findings-emnlp.345/.
[82] Wu et al. (2025). Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models. arXiv preprint arXiv:2503.16779.
[83] Wang et al. (2024). Toolgen: Unified tool retrieval and calling via generation. arXiv preprint arXiv:2410.03439.
[84] Schick et al. (2023). Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems. 36. pp. 68539–68551.
[85] Silin Gao et al. (2025). Efficient Tool Use with Chain-of-Abstraction Reasoning. https://arxiv.org/abs/2401.17464.
[86] Kim et al. (2024). An llm compiler for parallel function calling. In Forty-first International Conference on Machine Learning.
[87] Simranjit Singh et al. (2024). An LLM-Tool Compiler for Fused Parallel Function Calling. https://arxiv.org/abs/2405.17438.
[88] Wu et al. (2025). Catp-llm: Empowering large language models for cost-aware tool planning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8699–8709.
[89] Zheng et al. (2024). Budget-Constrained Tool Learning with Planning. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 9039–9052. doi:10.18653/v1/2024.findings-acl.536. https://aclanthology.org/2024.findings-acl.536/.
[90] Zhiruo Wang et al. (2024). TroVE: Inducing Verifiable and Efficient Toolboxes for Solving Programmatic Tasks. https://arxiv.org/abs/2401.12869.
[91] Hanxing Ding et al. (2025). ToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models. https://arxiv.org/abs/2502.11404.
[92] Yuchen Zhuang et al. (2023). ToolChain: Efficient Action Space Navigation in Large Language Models with A* Search*. https://arxiv.org/abs/2310.13227.
[93] Hongru Wang et al. (2025). Acting Less is Reasoning More! Teaching Model to Act Efficiently. https://arxiv.org/abs/2504.14870.
[94] Hongjin Su et al. (2025). ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration. https://arxiv.org/abs/2511.21689.
[95] Jiang et al. (2025). TableMind: An Autonomous Programmatic Agent for Tool-Augmented Table Reasoning. arXiv preprint arXiv:2509.06278.
[96] Qian et al. (2025). SMART: Self-aware agent for tool overuse mitigation. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 4604–4621.
[97] Singh et al. (2025). Agentic reasoning and tool integration for llms via reinforcement learning. arXiv preprint arXiv:2505.01441.
[98] Wei et al. (2025). Autotir: Autonomous tools integrated reasoning via reinforcement learning. arXiv preprint arXiv:2507.21836.
[99] Jiazhan Feng et al. (2025). ReTool: Reinforcement Learning for Strategic Tool Use in LLMs. https://arxiv.org/abs/2504.11536.
[100] Qian et al. (2025). Toolrl: Reward is all tool learning needs. arXiv preprint arXiv:2504.13958.
[101] Wu et al. (2025). PORTool: Tool-Use LLM Training with Rewarded Tree. arXiv preprint arXiv:2510.26020.
[102] Zehui Chen et al. (2024). Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models. https://arxiv.org/abs/2403.12881.
[103] Shunyu Yao et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. https://arxiv.org/abs/2210.03629.
[104] Team et al. (2025). MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling. arXiv preprint arXiv:2511.11793.
[105] Du et al. (2024). AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls. In Proceedings of the 41st International Conference on Machine Learning. pp. 11812–11829. https://proceedings.mlr.press/v235/du24h.html.
[106] Qu et al. (2025). From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=QKBu1BOAwd.
[107] Lumer et al. (2024). Toolshed: Scale tool-equipped agents with advanced rag-tool fusion and tool knowledge bases. arXiv preprint arXiv:2410.14594.
[108] Marianne Menglin Liu et al. (2025). ToolScope: Enhancing LLM Agent Tool Use through Tool Merging and Context-Aware Filtering. https://arxiv.org/abs/2510.20036.
[109] Xu et al. (2024). Concise and Precise Context Compression for Tool-Using Language Models. In Findings of the Association for Computational Linguistics: ACL 2024. pp. 16430–16441. doi:10.18653/v1/2024.findings-acl.974. https://aclanthology.org/2024.findings-acl.974/.
[110] Zhang et al. (2025). Parallel Task Planning via Model Collaboration. In Natural Language Processing and Chinese Computing. pp. 79–91.
[111] Xu et al. (2025). Alignment for Efficient Tool Calling of Large Language Models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 17787–17803. doi:10.18653/v1/2025.emnlp-main.898. https://aclanthology.org/2025.emnlp-main.898/.
[112] Wu et al. (2025). A Joint Optimization Framework for Enhancing Efficiency of Tool Utilization in LLM Agents. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 22361–22373. doi:10.18653/v1/2025.findings-acl.1149. https://aclanthology.org/2025.findings-acl.1149/.
[113] Minki Kang et al. (2025). Distilling LLM Agent into Small Models with Retrieval and Code Tools. https://arxiv.org/abs/2505.17612.
[114] Wu et al. (2024). ToolPlanner: A Tool Augmented LLM for Multi Granularity Instructions with Path Planning and Feedback. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 18315–18339. doi:10.18653/v1/2024.emnlp-main.1018. https://aclanthology.org/2024.emnlp-main.1018/.
[115] Mayank Agarwal et al. (2025). ToolRM: Outcome Reward Models for Tool-Calling Large Language Models. https://arxiv.org/abs/2509.11963.
[116] Ma et al. (2024). Sciagent: Tool-augmented language models for scientific reasoning. arXiv preprint arXiv:2402.11451.
[117] Ruan et al. (2023). TPTU: large language model-based AI agents for task planning and tool usage. arXiv preprint arXiv:2308.03427.
[118] Qu et al. (2025). A survey of efficient reasoning for large reasoning models: Language, multimodality, and beyond. arXiv preprint arXiv:2503.21614.
[119] Qianben Chen et al. (2025). A$^2$FM: An Adaptive Agent Foundation Model for Tool-Aware Hybrid Reasoning. https://arxiv.org/abs/2510.12838.
[120] Huang et al. (2025). Reinforced Internal-External Knowledge Synergistic Reasoning for Efficient Adaptive Search Agent. arXiv preprint arXiv:2505.07596.
[121] Anna Goldie et al. (2025). Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use. https://arxiv.org/abs/2504.04736.
[122] Bill Yuchen Lin et al. (2023). SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks. https://arxiv.org/abs/2305.17390.
[123] Tengxiao Liu et al. (2025). Budget-Aware Tool-Use Enables Effective Agent Scaling. https://arxiv.org/abs/2511.17006.
[124] Noah Shinn et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. https://arxiv.org/abs/2303.11366.
[125] Andy Zhou et al. (2024). Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models. https://arxiv.org/abs/2310.04406.
[126] Zhang, Zihao and Liu, Fei (2025). Cost-Augmented Monte Carlo Tree Search for LLM-Assisted Planning. arXiv preprint arXiv:2505.14656.
[127] Xu et al. (2023). Rewoo: Decoupling reasoning from observations for efficient augmented language models. arXiv preprint arXiv:2305.18323.
[128] Yongliang Shen et al. (2023). HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face. https://arxiv.org/abs/2303.17580.
[129] Qiu et al. (2025). Alita: Generalist agent enabling scalable agentic reasoning with minimal predefinition and maximal self-evolution. arXiv preprint arXiv:2505.20286.
[130] Lin et al. (2025). Qlass: Boosting language agent inference via q-guided stepwise search. arXiv preprint arXiv:2502.02584.
[131] Song et al. (2024). Trial and Error: Exploration-Based Trajectory Optimization of LLM Agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 7584–7600. doi:10.18653/v1/2024.acl-long.409. https://aclanthology.org/2024.acl-long.409/.
[132] Guanzhi Wang et al. (2024). Voyager: An Open-Ended Embodied Agent with Large Language Models. Transactions on Machine Learning Research. https://openreview.net/forum?id=ehfRiF0R3a.
[133] Wu et al. (2025). GAP: Graph-Based Agent Planning with Parallel Tool Use and Reinforcement Learning. arXiv preprint arXiv:2510.25320.
[134] Zhiwei Li et al. (2025). Encouraging Good Processes Without the Need for Good Answers: Reinforcement Learning for LLM Agent Planning. https://arxiv.org/abs/2508.19598.
[135] Joey Hong et al. (2025). Planning without Search: Refining Frontier LLMs with Offline Goal-Conditioned RL. https://arxiv.org/abs/2505.18098.
[136] Zhang et al. (2024). Chain of agents: Large language models collaborating on long-context tasks. Advances in Neural Information Processing Systems. 37. pp. 132208–132237.
[137] Qian et al. (2024). Scaling large language model-based multi-agent collaboration. arXiv preprint arXiv:2406.07155.
[138] Zhang et al. (2024). Cut the crap: An economical communication pipeline for llm-based multi-agent systems. arXiv preprint arXiv:2410.02506.
[139] Wang et al. (2025). MARS: toward more efficient multi-agent collaboration for LLM reasoning. arXiv preprint arXiv:2509.20502.
[140] Yang et al. (2025). CodeAgents: A Token-Efficient Framework for Codified Multi-Agent Reasoning in LLMs. arXiv preprint arXiv:2507.03254.
[141] Cui et al. (2025). Free-mad: Consensus-free multi-agent debate. arXiv preprint arXiv:2509.11035.
[142] Chen et al. (2024). MAGDi: Structured Distillation of Multi-Agent Interaction Graphs Improves Reasoning in Smaller Language Models. arXiv preprint arXiv:2402.01620.
[143] Zhou et al. (2025). Debate, reflect, and distill: Multi-agent feedback with tree-structured preference optimization for efficient language model enhancement. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 9122–9137.
[144] Davide Paglieri et al. (2025). Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents. https://arxiv.org/abs/2509.03581.
[145] Renat Aksitov et al. (2023). ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent. https://arxiv.org/abs/2312.10003.
[146] Heng Zhou et al. (2025). ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks. https://arxiv.org/abs/2503.02390.
[147] Shubham Gandhi et al. (2025). BudgetMLAgent: A Cost-Effective LLM Multi-Agent system for Automating Machine Learning Tasks. https://arxiv.org/abs/2411.07464.
[148] Timo Birr et al. (2024). AutoGPT+P: Affordance-based Task Planning with Large Language Models. doi:https://doi.org/10.15607/RSS.2024.XX.112. https://arxiv.org/abs/2402.10778.
[149] Siyu Zhu et al. (2025). Planner-R1: Reward Shaping Enables Efficient Agentic RL with Smaller LLMs. https://arxiv.org/abs/2509.25779.
[150] Fangru Lin et al. (2024). Graph-enhanced Large Language Models in Asynchronous Plan Reasoning. https://arxiv.org/abs/2402.02805.
[151] Yulong Wang et al. (2024). Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning. https://arxiv.org/abs/2407.10718.
[152] Liu et al. (2024). Groupdebate: Enhancing the efficiency of multi-agent debate using group discussion. arXiv preprint arXiv:2409.14051.
[153] Yuting Zeng et al. (2025). S$^2$-MAD: Breaking the Token Barrier to Enhance Multi-Agent Debate Efficiency. https://arxiv.org/abs/2502.04790.
[154] Wang et al. (2025). AgentDropout: Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 24013–24035. doi:10.18653/v1/2025.acl-long.1170. https://aclanthology.org/2025.acl-long.1170/.
[155] Zhang et al. (2025). SafeSieve: From Heuristics to Experience in Progressive Pruning for LLM-based Multi-Agent Communication. arXiv preprint arXiv:2508.11733.
[156] Chen et al. (2025). Smurfs: Multi-agent system using context-efficient dfsdt for tool planning. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 3281–3298.
[157] Pitre et al. (2025). Consensagent: Towards efficient and effective consensus in multi-agent llm interactions through sycophancy mitigation. In Findings of the Association for Computational Linguistics: ACL 2025. pp. 22112–22133.
[158] Lin et al. (2025). Stop Wasting Your Tokens: Towards Efficient Runtime Multi-Agent Systems. arXiv preprint arXiv:2510.26585.
[159] Aluru et al. (2025). SMAGDi: Socratic Multi Agent Interaction Graph Distillation for Efficient High Accuracy Reasoning. arXiv preprint arXiv:2511.05528.
[160] Zhang et al. (2025). A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems. 43(6). pp. 1–47.
[161] Yang et al. (2018). HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing. pp. 2369–2380.
[162] Kwiatkowski et al. (2019). Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics. 7. pp. 452–466. doi:10.1162/tacl_a_00276. https://aclanthology.org/Q19-1026/.
[163] Mialon et al. (2023). Gaia: a benchmark for general ai assistants. In The Twelfth International Conference on Learning Representations.
[164] Maharana et al. (2024). Evaluating Very Long-Term Conversational Memory of LLM Agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13851–13870. doi:10.18653/v1/2024.acl-long.747. https://aclanthology.org/2024.acl-long.747/.
[165] Wu et al. (2024). Longmemeval: Benchmarking chat assistants on long-term interactive memory. arXiv preprint arXiv:2410.10813.
[166] Wei et al. (2025). Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory. arXiv preprint arXiv:2511.20857.
[167] Wan, Luanbo and Ma, Weizhi (2025). StoryBench: A Dynamic Benchmark for Evaluating Long-Term Memory with Multi Turns. arXiv preprint arXiv:2506.13356.
[168] Tan et al. (2025). MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents. arXiv preprint arXiv:2506.21605.
[169] Mengsong Wu et al. (2024). Seal-Tools: Self-Instruct Tool Learning Dataset for Agent Tuning and Detailed Benchmark. https://arxiv.org/abs/2405.08355.
[170] Shijue Huang et al. (2024). Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios. https://arxiv.org/abs/2401.17167.
[171] Yue Huang et al. (2024). MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use. https://arxiv.org/abs/2310.03128.
[172] Patil et al. (2025). The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models. In Forty-second International Conference on Machine Learning.
[173] Li et al. (2023). API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 3102–3116. doi:10.18653/v1/2023.emnlp-main.187. https://aclanthology.org/2023.emnlp-main.187/.
[174] Han Han et al. (2025). NesTools: A Dataset for Evaluating Nested Tool Learning Abilities of Large Language Models. https://arxiv.org/abs/2410.11805.
[175] Shunyu Yao et al. (2024). $\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. https://arxiv.org/abs/2406.12045.
[176] Victor Barres et al. (2025). $\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment. https://arxiv.org/abs/2506.07982.
[177] Yujia Qin et al. (2024). ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. In The Twelfth International Conference on Learning Representations.
[178] Chen et al. (2024). T-eval: Evaluating the tool utilization capability of large language models step by step. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9510–9529.
[179] Zhicheng Guo et al. (2025). StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models. https://arxiv.org/abs/2403.07714.
[180] Xuanqi Gao et al. (2025). MCP-RADAR: A Multi-Dimensional Benchmark for Evaluating Tool Use Capabilities in Large Language Models. https://arxiv.org/abs/2505.16700.
[181] Wang et al. (2025). Mcp-bench: Benchmarking tool-using llm agents with complex real-world tasks via mcp servers. arXiv preprint arXiv:2508.20453.
[182] Wei et al. (2024). Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368.
[183] Wei et al. (2025). Browsecomp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516.
[184] Pham et al. (2025). SealQA: Raising the Bar for Reasoning in Search-Augmented Language Models. arXiv preprint arXiv:2506.01062.
[185] Carlos E Jimenez et al. (2024). SWE-bench: Can Language Models Resolve Real-world Github Issues?. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66.
[186] Zhou et al. (2023). WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv preprint arXiv:2307.13854. https://webarena.dev.
[187] Yao et al. (2022). Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems. 35. pp. 20744–20757.
[188] Valmeekam et al. (2023). Planbench: An extensible benchmark for evaluating large language models on planning and reasoning about change. Advances in Neural Information Processing Systems. 36. pp. 38975–38987.
[189] Slaney, John and Thiébaux, Sylvie (2001). Blocks world revisited. Artificial Intelligence. 125(1-2). pp. 119–153.
[190] Jobs et al. (2025). Benchmark for Planning and Control with Large Language Model Agents: Blocksworld with Model Context Protocol. arXiv preprint arXiv:2512.03955.
[191] Xu et al. (2025). TPS-Bench: Evaluating AI Agents' Tool Planning$\backslashamp; Scheduling Abilities in Compounding Tasks. arXiv preprint arXiv:2511.01527.
[192] Liu et al. (2025). CostBench: Evaluating Multi-Turn Cost-Optimal Planning and Adaptation in Dynamic Environments for LLM Tool-Use Agents. arXiv preprint arXiv:2511.02734.
[193] Erol et al. (2025). Cost-of-Pass: An Economic Framework for Evaluating Language Models. arXiv preprint arXiv:2504.13359.
[194] Wang et al. (2025). Efficient agents: Building effective agents while reducing cost. arXiv preprint arXiv:2508.02694.
[195] Wang et al. (2025). System-1.5 Reasoning: Traversal in Language and Latent Spaces with Dynamic Shortcuts. arXiv preprint arXiv:2505.18962.
[196] Hengli Li et al. (2025). Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space. https://arxiv.org/abs/2505.13308.
[197] Yige Xu et al. (2025). SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs. https://arxiv.org/abs/2502.12134.
[198] Li et al. (2024). Optimus-1: Hybrid multimodal memory empowered agents excel in long-horizon tasks. Advances in neural information processing systems. 37. pp. 49881–49913.
[199] Wang et al. (2024). Videoagent: Long-form video understanding with large language model as agent. In European Conference on Computer Vision. pp. 58–76.
[200] Sarch et al. (2024). Vlm agents generate their own memories: Distilling experience into embodied programs of thought. Advances in Neural Information Processing Systems. 37. pp. 75942–75985.
[201] Yuhang Liu et al. (2025). InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection. https://arxiv.org/abs/2501.04575.
[202] Yao et al. (2025). A survey on agentic multimodal large language models. arXiv preprint arXiv:2510.10991.
[203] Xiao, Wenyi and Gan, Leilei (2025). Fast-Slow Thinking GRPO for Large Vision-Language Model Reasoning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems.
[204] He et al. (2025). DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models. arXiv preprint arXiv:2512.24165.